Embed Size (px)
Citation preview

A Análise Multivariada no Tratamento da Informação Espacial
Uma Abordagem Matemático-Computacional em
Análise de Agrupamentos e Análise de Componentes Principais
Bernardo Jeunon de Alencar
Belo Horizonte
2009

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

Bernardo Jeunon de Alencar
A Análise Multivariada no Tratamento da Informação Espacial
Uma Abordagem Matemático-Computacional em
Análise de Agrupamentos e Análise de Componentes Principais
Tese apresentada ao Programa de Pós-Graduação em
Geografia – Tratamento da Informação Espacial – da
Pontifícia Universidade Católica de Minas Gerais como
requisito parcial à obtenção do Título de Doutor
Área de Concentração: Análise Espacial
Orientador: Prof. Dr. Leônidas Conceição Barroso
Co-Orientador: Prof. Dr. João Francisco de Abreu
Belo Horizonte
2009

FICHA CATALOGRÁFICA
Elaborada pela biblioteca da Pontifícia Universidade Católica de Minas Gerais
Alencar, Bernardo Jeunon
A368a A análise multivariada aplicada ao tratamento da informação
espacial: uma abordagem matemático-computacional em
análise de agrupamentos e análise de componentes principais /
Bernardo Jeunon de Alencar. Belo Horizonte, 2009.
200f.
Orientador: Leônidas Conceição Barroso
Co-orientador: João Francisco de Abreu
Tese (Doutorado) – Pontifícia Universidade Católica de
Minas Gerais. Programa de Pós-Graduação em Tratamento da
Informação
Espacial.
Bibliografia
1. Geografia. 2. Análise Espacial. 3. Análise de Agrupamentos. 4.
Análise de Componentes Principais. I. Barroso, Leônidas
Conceição. II. Abreu, João Francisco. III. Pontifícia Universidade
Católica de Minas Gerais. Programa de Pós-Graduação em
Tratamento da Informção Espacial. IV. Título.
CDU: 91:681.3

Título: A Análise Multivariada no Tratamento da Informação Espacial
Uma Abordagem Matemático-Computacional em
Análise de Agrupamentos e Análise de Componentes Principais
Autor: Bernardo Jeunon de Alencar
Data da Defesa: 17 de Agosto de 2009
Comissão :
Leônidas Conceição Barroso
João Francisco de Abreu
Aurélio Muzzarelli
José Irineu Rangel Rigotti
Marco Túlio Oliveira Valente

À minha família.

Para Carlito - Carlos Alencar Filho.

Agradecimentos
À minha família. Ao meu pai, Carlos Alencar Filho – Carlito – e à minha mãe,
Anna Maria Jeunon de Alencar – Ninna – sempre em meu coração e em minhas
boas lembranças. Às minhas irmãs Patrícia, Ângela e Denise, sempre especiais, por
acreditarem e se dedicarem tanto a mim, em todos os momentos.
À Beth, Elizabeth Coutinho de Moraes Alencar, minha esposa, companheira
querida, pelo incentivo e pelo carinho, por acreditar em minha capacidade e em meu
esforço, pela paciência e tolerância nos momentos de estudo e dedicação.
Obrigado. Sua presença em minha vida faz isso tudo ter mais sentido.
À Pontifícia Universidade Católica de Minas Gerais, pelo incentivo que dá à
capacitação de seu corpo docente, do qual participo, com muito orgulho.
Ao Programa de Pós-Graduação em Geografia – Tratamento da Informação
Espacial da PUC Minas, pela responsabilidade, carinho e orientação para com todos
os seus alunos. Ser membro dessa querida e grande família de pesquisadores é
uma grande honra para mim.
Ao prof. Dr. Leônidas Conceição Barroso, meu amigo e meu orientador, pela
simplicidade e segurança em todas as suas ações, pela confiança que sempre
depositou em minha capacidade e pelo estímulo que me deu em todos os momentos
dessa pesquisa. Obrigado pelo seu exemplo, professor. Obrigado por sua dedicação
para comigo. Eu nunca conseguirei expressar a minha gratidão por tudo que fez por
mim. Eu agradeço a Deus por ter tido a oportunidade de cruzar o seu caminho,
conhecer o tamanho de seu coração e por torná-lo participante de minha história. O
senhor será sempre meu professor. Vamos continuar juntos.

Ao prof. Dr. João Francisco de Abreu, meu co-orientador, pela amizade, pela
generosidade. Obrigado por ser um exemplo de competência técnica e acadêmica.
Obrigado pela segurança que transmite, pelo zelo e pela confiança que demonstra
em minhas habilidades. É um privilégio tê-lo como professor. Obrigado por sempre
somar em minha vida. Eu desejo muito que continuemos juntos em outros projetos.
Ao prof. Dr. Oswaldo Bueno Amorim Filho, meu primeiro professor no
programa, pela amizade sincera que desenvolvemos, pelo exemplo de caráter,
simplicidade, competência, pelas palavras de incentivo e pelas várias contribuições
diretas e indiretas em todos os momentos desta pesquisa.
Ao prof. Dr. José Irineu Rangel Rigotti, coordenador do PPGTIE, e, em sua
pessoa, a todos os demais professores do programa. Obrigado pelo incentivo, pelas
palavras amigas. Tenho grande admiração por todos.
Às secretárias e aos funcionários do PPGTIE, pela ajuda silenciosa, paciente
e competente, sempre. E também aos meus colegas mestrandos e doutorandos,
pesquisadores, companheiros de trabalhos e discussões.
Ao prof. Aluísio Eustáquio da Silva, sempre com seu coração de pai, de
irmão. Obrigado. O senhor é o responsável por tudo isso. Nunca vou esquecê-lo.
Obrigado por ter me dado a oportunidade de ingresso na vida acadêmica. Obrigado
pelo estímulo, pela amizade.
Aos meus colegas professores da PUCMinas pela presença sempre amiga.
Não é possível, aqui, nomear cada um dos que estiveram comigo nessa jornada.
E aos meus alunos da PUC Minas. Em especial quero agradecer ao aluno
Fabrício Maciel Sales, pela ajuda na codificação e nos testes das muitas rotinas que
compõe os softwares NinnaPCA e NinnaCluster, pela competência técnica e pela
responsabilidade que assumiu nos trabalhos.

Resumo
A organização e a análise de dados é um tema de grande importância na
Geografia porque pode possibilitar uma maior facilidade no exame conjunto de
informações que possam oferecer subsídios para a explicação de fenômenos
geográficos de maneira a auxiliar o homem no planejamento de suas atividades, nos
seus processos de tomada de decisões e em suas ações estratégicas.
A Análise Multivariada tem ganhado um significado cada vez mais amplo na
Geografia por possibilitar uma maior facilidade no exame de grandes conjuntos de
informações, tão necessários para a explicação de fenômenos geográficos, o estudo
de tendências e padrões espaciais, a formulação de modelos e a elaboração de
previsões. A Análise de Agrupamentos e a Análise de Componentes Principais são
duas técnicas multivariadas muito utilizadas na Geografia.
Esse trabalho reúne diversos fundamentos matemáticos, estatísticos e
computacionais que amparam a utilização dessas duas técnicas no tratamento de
dados espaciais. Ele faz um estudo de suas aplicações na Geografia, revela os
algoritmos que tornam viáveis a sua computação e fornece artefatos de software que
servem como instrumentos para os cálculos envolvidos nos processos. Ele também
apresenta um exemplo de uso das técnicas na Geografia utilizando dados sócio-
econômicos de 23 municípios pertencentes à Mesorregião do Vale do Mucuri, em
Minas Gerais.
Palavras-chave: Geografia; Análise Espacial; Análise de Componentes Principais;
Análise de Agrupamentos.

Abstract
Data analysis and organization is a theme of great importance in Geography
because it can enable easiness to integrated information examination, which may
offer subsidies to the explanation of geographic phenomena in a way that helps
people in activities planning, decision making processes and strategic actions.
Multivariate Analysis is getting a broad meaning in Geography because it
enables an easier examination of wide information sets which are needed to the
explanation of geographic phenomena, trends studies and spatial standards,
formulation of models and preparation of forecasts. Cluster Analysis and Principal
Components Analysis are two multivariate techniques widely used in Geography.
This work gathers a lot of mathematical, statistical and computational
foundations that support the utilization of these two techniques on spatial data
handling. Through a study of their application in Geography, this work reveals the
algorithms that make available their computation and supplies software artifacts that
are instruments to the calculation processes. It also presents an example of use case
of these techniques in Geography using socio-economic data from twenty three cities
from the region denominated “Mesorregião do Vale do Mucuri” in the state of Minas
Gerais.
Key-words: Geography; Spatial Analysis; Principal Component Analysis; Cluster
Analysis.

Sumário
Capítulo 1 - Introdução ....................................................................................... 15
1.1 - Considerações Iniciais .............................................................................................. 15
1.2 - Objetivos .................................................................................................................. 18
Capítulo 2 - Algumas Considerações Teóricas na Geografia .......................... 19
2.1 - O Surgimento da Geografia Teorético-Quantitativa ................................................... 19
2.2 - A Geografia Teorético-Quantitativa e a Análise Multivariada ...................................... 23
2.3 - Revisão Bibliográfica
2.3.1 - Aplicações em Análise de Agrupamentos ................................................. 27
2.3.2 - Aplicações em Componentes Principais .................................................... 31
Capítulo 3 - Fundamentos Matemáticos .............................................................. 37
3.1 - Conceitos Iniciais – Par Ordenado ............................................................................. 40
3.2 - Produto Cartesiano .................................................................................................... 46
3.3 - Relação Binária ......................................................................................................... 51
3.4 - Relação Recíproca e Imagem de um Conjunto por uma Relação ............................... 60
3.5 - Relação Composta .................................................................................................... 63
3.6 - Relações Reflexivas .................................................................................................. 66
3.7 - Relação de Equivalência e Classe de Equivalência .................................................... 73
3.8 - Partição de um Conjunto ............................................................................................ 76
Capítulo 4 - A Análise de Agrupamentos ........................................................... 83
4.1 - Exemplo de Cálculo de Agrupamentos....................................................................... 86
4.2 - Coeficientes de Similaridade e de Dissimilaridade...................................................... 97
4.3 - Coeficientes Utilizados para Variáveis Quantitativas .................................................. 99
4.4 - Coeficientes Utilizados para Variáveis Qualitativas .................................................. 103
4.5 - Técnicas de Formação de Agrupamentos ................................................................ 110
4.6 - Técnicas Hierárquicas e de Partição para Análise de Agrupamentos ....................... 111
4.6.1 - Método das Médias das Distâncias (Average Linkage).............................. 112
4.6.2 - Método da Ligação Simples (Single Linkage) ........................................... 113
4.6.3 - Método da Ligação Completa (Complete Linkage) ................................... 114
4.6.4 - Método do Centróide (Centroid Distance) ................................................. 116
4.6.5 - Método K-Médias .................................................................................... 117

Capítulo 5 - A Análise de Componentes Principais......................................... 123
5.1 - A Matemática nas Componentes Principais ............................................................ 126
5.2 - Etapas de Cálculo .................................................................................................... 130
5.3 - Metodologia ............................................................................................................. 138
Capítulo 6 - O Software NinnaCluster e o Software NinnaPCA ..................... 144
6.1 - NinnaCluster ............................................................................................................ 148
6.2 - NinnaPCA ................................................................................................................ 154
Capítulo 7 - Estudo de Caso ............................................................................. 164
Capítulo 8 - Considerações Finais ................................................................... 183
Referências ........................................................................................................ 189

Lista de Figuras
Figura 1 – Exemplo de Formação de Classes de Equivalência ............................................. 79
Figura 2 – Problema Exemplo – Gráfico de Dispersão .......................................................... 89
Figura 3 – Problema Exemplo – Dendograma ...................................................................... 94
Figura 4 – Processo de Formação de Agrupamentos ......................................................... 111
Figura 5 – Método das Médias das Distâncias .................................................................... 112
Figura 6 – Método da Ligação Simples ou do Vizinho mais Próximo ................................... 114
Figura 7 – Método da Ligação Completa ou do Vizinho mais Distante ................................ 115
Figura 8 – Método do Centróide ......................................................................................... 116
Figura 9 – Processo de Divisão de um Conjunto através das Técnicas de Partição ............ 118
Figura 10 – Ilustração do Método K-Médias – Agrupamento de cores em padrão RGB ....... 121
Figura 11 – Rotação de Eixos efetuada pelas Componentes Principais .............................. 125
Figura 12 – Etapas da Análise de Componentes Principais ................................................ 130

Lista de Mapas
Mapa 1 – Vale do Mucuri – Localização Geográfica ........................................................... 165
Mapa 2 – Vale do Mucuri – Escores – Componente Principal I ........................................... 175
Mapa 3 – Vale do Mucuri – Escores – Componente Principal II .......................................... 176

Lista de Telas dos Sistemas NinnaPCA e NinnaCluster
Tela 1 – Ícones do Software NinnaCluster – Executável e Bibliotecas ................................ 148
Tela 2 – Ícone de Execução do NinnaCluster ..................................................................... 148
Tela 3 – Fragmento de Tela – Tela Principal do NinnaCluster ............................................. 149
Tela 4 – Fragmento de Tela – Abertura da Fonte de Dados no NinnaCluster ...................... 150
Tela 5 – Caixa de Seleção de Cultura do NinnaCluster ....................................................... 151
Tela 6 – Escolha do Método de Agrupamento no NinnaCluster .......................................... 151
Tela 7 – Botão “Iniciar Análise” do NinnaCluster ................................................................. 151
Tela 8 – Construção de Dendograma através do NinnaCluster ........................................... 152
Tela 9 – Botão “Salvar Imagem” do NinnaCluster ............................................................... 153
Tela 10 – Formação de Agrupamentos através do NinnaCluster......................................... 153
Tela 11 – Ícones do Software NinnaPCA – Executável e Bibliotecas .................................. 154
Tela 12 – Ícone de Execução do NinnaPCA ....................................................................... 155
Tela 13 – Fragmento de Tela – Tela Principal do NinnaPCA............................................... 155
Tela 14 – Fragmento de Tela – Dados Importados para o NinnaPCA ................................. 156
Tela 15 – Fragmento de Tela – Área Mapa do NinnaPCA ................................................... 157
Tela 16 – Caixa de Seleção de Cultura do NinnaPCA......................................................... 158
Tela 17 – Botão “Iniciar Análise” do NinnaPCA ................................................................... 158
Tela 18 – Fragmento de Tela – Resultados da Análise de Componentes Principais ............ 158
Tela 19 – Fragmento de Tela – Matriz de Autovalores e Autovetores .................................. 160
Tela 20 – Mudança de Sentido dos Autovetores ................................................................. 160
Tela 21 – Seleção das Variáveis Agrupadas pela Componente Principal ............................ 161
Tela 22 – Elaboração de Mapas Temáticos no NinnaPCA .................................................. 162
Tela 23 – Exemplo de Mapa Temático feito no NinnaPCA .................................................. 163
Tela 24 – Fragmento de Tela – Dados de Trabalho – Vale do Mucuri – NinnaPCA ............. 167
Tela 25 – Fragmento de Tela – Médias e Desvios Padrão de Variáveis .............................. 168
Tela 26 – Fragmento de Tela – Dados Padronizados ......................................................... 169
Tela 27 – Fragmento de Tela – Matriz de Correlação ......................................................... 170
Tela 28 – Fragmento de Tela – Autovalores e Autovetores ................................................. 171
Tela 29 – Fragmento de Tela – Componentes Principais .................................................... 173
Tela 30 – Fragmento de Tela – Escores ............................................................................. 173
Tela 31 – Fragmento de Tela – Ordenação de Escores ...................................................... 174
Tela 32 – Fragmento de Tela – Dados de Trabalho – Vale do Mucuri – NinnaCluster ......... 178
Tela 33 – Dendograma – Método das Médias das Distâncias ............................................. 179
Tela 34 – Dendograma – Método da Ligação Simples ........................................................ 180
Tela 35 – Dendograma – Método da Ligação Completa ..................................................... 181
Tela 36 – Formação de Agrupamentos pelo Método de Partição K-Means ......................... 182

Página 15
Capítulo 1
Introdução
1.1 - Considerações Iniciais
Uma característica comum a muitos trabalhos científicos é a observação de
fatos e o registro de informações. Isso é importante porque possibilita avaliações,
aperfeiçoa as generalizações indutivas e contribui para o estabelecimento de
modelos e teorias.
O volume de dados envolvidos nesse processo pode ser muito grande, muito
diversificado e até redundante, o que pode dificultar a análise, a identificação de
ocorrências e de padrões, a classificação das informações e as conclusões corretas
e bem fundamentadas sobre o que se estuda. Pode tornar-se necessário que esses
dados sejam sistematicamente organizados de maneira a facilitar o seu acesso e a
sua manipulação.
Particularmente na Geografia, essa organização é importante porque pode
promover avaliações, de caráter geral ou local, mais precisas, aprimorando
predições e facilitando as ações de cunho estratégico.
Segundo Barroso (2003), a Análise Multivariada de dados tem um significado
cada vez mais amplo na Geografia porque possibilita uma maior facilidade no exame
conjunto de informações necessárias ao fornecimento de subsídios que permitam a
explicação de fenômenos geográficos, o estudo de tendências e padrões espaciais,
a formulação de modelos e a elaboração de previsões. É necessário, disponibilizar,
de forma rápida, precisa e organizada, informações que venham a auxiliar o homem
no planejamento de suas atividades.

Página 16
A organização, a classificação e a análise de dados na Geografia podem ser
feitas através de várias técnicas multivariadas. Esse trabalho discute duas delas. A
primeira, Análise de Agrupamentos, corresponde ao conjunto de diversas técnicas e
algoritmos que objetivam identificar e agrupar objetos segundo alguma similaridade
existente entre eles e é muito utilizada para uma melhoria na análise de dados e na
identificação de padrões de comportamento. A segunda, Análise de Componentes
Principais, pode ter aplicação quando existe, por exemplo, a necessidade de se
agrupar um grande número de variáveis relacionadas a um determinado conjunto de
observações. Seu uso simplifica a análise e a visualização das informações contidas
nos dados originais.
Estas técnicas vêm sendo aplicadas em vários ramos do conhecimento
humano com o objetivo de facilitar a explicação de fenômenos das mais variadas
naturezas, possibilitando a identificação de padrões e o estudo de tendências.
Nesse trabalho são mostrados alguns fundamentos matemáticos, estatísticos
e computacionais que sustentam a aplicação dessas duas técnicas na Geografia
como instrumento de análise de dados espaciais.
Primeiramente se torna necessário contextualizar o momento em que a
Geografia viu surgir um novo ambiente de desenvolvimento que abria caminho para
a aplicação em larga escala dos métodos quantitativos dentro da Geografia.
Uma não menos necessária revisão bibliográfica também é feita e mostra
algumas aplicações relevantes da Análise de Agrupamentos e da Análise de
Componentes Principais dentro e fora da Ciência Geográfica.
Os fundamentos matemáticos e um estudo mais detalhado dessas duas
técnicas também são mostrados, incluindo seus algoritmos. As etapas de cálculo
estão detalhadas e são importantes para a codificação das técnicas em nível

Página 17
computacional. Um artefato de software capaz de suportar o uso das duas técnicas
também é mostrado e disponibilizado.
Por fim, um exemplo detalhado da aplicação das duas técnicas é apresentado
utilizando-se dados sócio-econômicos de 23 municípios da mesorregião do Vale do
Mucuri, localizada na porção nordeste de Minas Gerais.

Página 18
1.2 - Objetivos
Esse trabalho tem como objetivos:
Abordar os fundamentos matemáticos que orientam a aplicação das
Técnicas Multivariadas da Análise de Agrupamentos e da Análise de
Componentes Principais;
Mostrar as respectivas formulações teóricas e princípios matemáticos e
estatísticos presentes nessas técnicas;
Exibir os algoritmos para os cálculos envolvidos nos processos;
Mostrar a utilização dessas técnicas na Geografia através de um
exemplo prático;
Disponibilizar um software aplicativo para a computação de cada uma
dessas técnicas que possa ser executado em ambiente local e também
através da internet.

Página 19
Capítulo 2
Algumas Considerações Teóricas na Geografia
Nessa parte do trabalho é feita uma pequena abordagem sobre o surgimento
da Geografia Teorético-Quantitativa. A Geografia Tradicional, representada
principalmente, na ocasião, pela escola francesa de Geografia, passou a sofrer
muitas críticas quanto a sua eficiência e outra forma de se trabalhar a Geografia
surgiu com o objetivo de responder a necessidades mais imediatas. O caminho se
abria para os sistemas de quantificação.
2.1 - O Surgimento da Geografia Teorético-Quantitativa
Depois da Segunda Guerra Mundial, as ciências sociais começaram a ser
solicitadas a responder a novos tipos de problemas, de uma forma mais rápida e
eficaz. Era necessário, por exemplo, superar a crise econômica capitalista, o que fez
surgir a econometria e a economia positiva. Tornaram necessários, também, novos
instrumentos de controle social, o que trouxe o desenvolvimento da sociologia e da
psicologia social. A exigência de planificação regional e urbana, originada pela crise
econômica do pós-guerra, também trouxe a necessidade de reconstrução das áreas
devastadas, com conseqüências diretas e imediatas para a Geografia.
O fato é que a pesquisa científica teve um grande desenvolvimento no
período de reconstrução neste período. A Geografia sentiu esses reflexos e alguns
fenômenos delinearam na comunidade geográfica uma crise em sua ciência. O que
se ressalta, segundo Amorim Filho (2003), é que com os instrumentos conceituais e

Página 20
metodológicos disponíveis na época, não se conseguia resolver problemas que,
acreditava-se, poderiam ser solucionados pela Geografia. Além disso, os contatos
com trabalhos produzidos por membros de outras comunidades científicas
mostravam que a organização e os resultados das pesquisas geográficas ficavam
aquém das demais ciências, contribuindo para o sentimento de inferioridade e
isolamento dos geógrafos em relação às ciências mais dinâmicas. Ainda assim, a
Geografia, diante desse impasse epistemológico, viu fortalecer ramos científicos
antes colocados sob seu nome, como a climatologia e a geomorfologia, por
exemplo.
Ainda segundo Amorim Filho (2003), a partir desse momento, para se buscar
um enquadramento maior da Geografia no contexto científico global, seria
necessário:
Um rigor maior na aplicação da metodologia científica. Na Geografia a
pesquisa contribui para a compreensão da ordem e da estrutura existente
nas organizações espaciais e, portanto, não só deve explicar o fenômeno
existente e o acontecido como também propor predições, com base nas
teorias e nas leis. O resultado do trabalho geográfico deveria, também, ser
capaz de prever o estado futuro dos sistemas de organização espacial e
contribuir de modo efetivo para suprir as necessidades humanas;
O uso de técnicas estatísticas e matemáticas, com o objetivo de analisar os
dados coletados. A denominação “Geografia Quantitativa” ou “Revolução
Quantitativa” é dada justamente pelo uso das ferramentas matemáticas e
estatísticas no tratamento desses dados;

Página 21
O desenvolvimento de teorias. A Geografia deveria procurar estimular o
desenvolvimento de teorias relacionadas com as características da
distribuição e arranjo espacial dos fenômenos;
Uma abordagem sistêmica. A aplicação da teoria dos sistemas aos estudos
geográficos deveria servir para focalizar melhor a pesquisa e para delinear
com maior exatidão o foco holístico da ciência geográfica;
O uso de modelos, que permitiria estruturar o funcionamento do sistema a
fim de torná-lo compreensível e expressar as relações entre os seus
diversos componentes.
O que se observa é que esse novo paradigma fez uma abordagem que
utilizava o método científico para identificar regularidades nos fenômenos espaciais
e alcançar níveis de generalização e de explicação elevados, com vista à criação de
modelos, leis e teorias e sua possível predição. De fato, era esse o objetivo primeiro
da Geografia Quantitativa. Além disso, é uma Geografia que prioriza a importância
das técnicas quantitativas, a formulação de modelos e teorias ou o uso delas oriundo
de outras áreas do conhecimento. Pode-se dizer que ela tinha um grande potencial
de aplicação nas questões sobre planejamento e organização dos espaços urbanos
e regionais.
A Geografia Teorético-Quantitativa surgiu como uma alternativa à abordagem
ideográfica, que assumia um lugar como sendo único, como era o caso de algumas
tendências de trabalho da escola francesa. A abordagem passou a ser nomotética,

Página 22
mais genérica, o que veio a estabelecer uma nova perspectiva para os geógrafos
deste período, constituindo-se em um novo paradigma.
Essa nova visão trouxe consigo a necessidade de se abrirem novos
horizontes e, buscando uma reorientação em seus estudos, promoveu a coleta de
dados, sua quantificação para a pesquisa geográfica e o desenvolvimento de um
raciocínio lógico com o uso de uma teorização adequada para embasá-la. A
cartografia, nesse momento, foi muito beneficiada.
Segundo Abreu (2003), uma nova cartografia surgiu como um dos principais
legados dessa Geografia. E esse desenvolvimento atingiu não somente os
geógrafos, que começaram a participar desse processo, mas também outras
ciências, que começaram a dar importância à questão do espaço. A Cartografia
Analítica, que, em síntese, transforma números em mapas, tomou grande impulso e
está contida na sistemática de todo GIS, ou SIG, Sistemas de Informações
Geográficas.

Página 23
2.2 - A Geografia Teorético-Quantitativa e a Análise Multivariada
A Geografia Teorético-Quantitativa promoveu uma intensiva coleta de dados
para a pesquisa geográfica. Esses dados precisavam ser organizados. A aplicação
de métodos e técnicas da Análise Multivariada ganhou com isso um novo impulso na
Geografia, como cita Amorim Filho (2003).
Segundo Johnson e Wichern (1988), a Análise Multivariada se utiliza de
métodos estatísticos com a finalidade de descrever e analisar dados de muitas
variáveis simultaneamente. Entender o relacionamento entre essas diversas
variáveis faz desse conjunto de técnicas uma metodologia de grande potencial de
aplicação, principalmente com a computação, veloz e acessível como se observa
atualmente. Para os autores, a Análise Multivariada pode ser usada, principalmente,
para a redução ou simplificação de dados, para a distribuição e para o agrupamento
de dados, para a investigação sobre a interdependência entre variáveis, para
predição e para testes de hipóteses.
Para Hair et al (2005), a Análise Multivariada é um conjunto de técnicas
voltadas para a análise de dados e é uma área em constante expansão. Dentre
tantas já bastante estabelecidas, pode-se citar, por exemplo, a Análise de
Componentes Principais e a Análise dos Fatores Comuns, a Análise de
Agrupamentos, a Regressão Múltipla e a Correlação Múltipla, a Análise de
Discriminante Múltipla, a Análise Multivariada de Variância e Covariância e a
Correlação Canônica. Outras técnicas ainda emergentes podem ser citadas, por
exemplo, a Análise de Correspondência, Modelos Lineares de Probabilidade e a
Modelagem de Equações Simultâneas e Estruturais. A Área de Sistemas
Multivariados, que envolve trabalhos em Mineração de Dados e Redes Neurais é

Página 24
outra em grande desenvolvimento.
A Análise de Agrupamentos é uma técnica analítica para criar grupos
significativos de indivíduos ou objetos. Especificamente, o que se faz com essa
técnica é classificar uma amostra de objetos em um número de grupos mutuamente
excludentes com base nas similaridades entre seus atributos.
A Análise de Componentes Principais, técnica incluída na Análise Fatorial, é
uma abordagem estatística que pode ser usada para analisar as inter-relações entre
um grande número de variáveis de maneira a condensar a informação contida nelas
em um conjunto menor de variáveis estatísticas, observando uma perda mínima de
informação.
Muitas das técnicas multivariadas envolvem conceitos sobre classificação de
dados. Classificar, em termos muito simplistas, é impor algum tipo de organização
aos dados através da criação de grupos que tenham uma determinada característica
semelhante. Esse conceito é antigo. Desde tempos imemoriais o homem faz isso.
Ele observa seu lugar e as coisas desse lugar. Descreve e define seu espaço
agrupando semelhanças que ele simplesmente observa.
A partir de 1960, a introdução das metodologias que utilizavam algoritmos e
computadores para a construção de sistemas de classificação deu origem ao termo
Taxonomia Numérica (Sneath e Sokal, 1973).
A Taxonomia Numérica pode ser definida como a formação de grupos
baseados no estudo das características dos dados em análise e em suas
semelhanças. Ela é feita através de processos numéricos, geralmente baseados em
uma Matriz de Semelhanças que é reduzida à medida que grupos similares de
objetos são construídos (Sneath e Sokal, 1973). A Análise de Agrupamentos é um
exemplo de um processo numérico, baseado na Estatística Multivariada, que faz

Página 25
exatamente isso.
Existem muitas vantagens da Taxonomia Numérica. Sneath e Sokal (1973)
apontam diversas delas, algumas a seguir descritas:
A Taxonomia Numérica tem o poder de integrar dados de uma
variedade de fontes, coisa difícil de ser feita por meio da Taxonomia
Convencional;
A possibilidade de automatização de processos taxonômicos propicia
um aumento da eficiência na análise dos dados, exigindo menos
trabalho e um número menor de pessoas envolvidas;
Os dados trabalhados, como estão na forma numérica, podem ser
integrados com sistemas de processamento de dados e utilizados na
elaboração de descrições, gráficos, mapas e outros documentos;
Sendo quantitativos, os métodos fornecem maior discriminação ao
longo do espectro de diferenças taxonômicas e são mais sensíveis na
delimitação de grupos, fornecendo conseqüentemente melhores
agrupamentos;
A criação de tabelas de dados, feitas de maneira explícita na
Taxonomia Numérica, força seus usuários a utilizarem informações
mais bem descritas, melhorando a qualidade dos resultados como um
todo;

Página 26
Como metodologia a Taxonomia Numérica não produz novos dados. Trata-se
na verdade de outra forma de organizar esses dados e obter, a partir deles, outra
forma de apresentação, segundo as necessidades de um pesquisador.
O aumento na disponibilização de dados e os recentes avanços nas técnicas
metodológicas exigem formas de organização cada vez melhores. A Estatística
Multivariada fornece um meio para isso. E ela tem ganhado um significado cada vez
mais amplo na Geografia por poder possibilitar um aumento considerável na
facilidade de se examinar grandes conjuntos de informações, tão necessários no
fornecimento de elementos que permitam a explicação de fenômenos geográficos, o
estudo de tendências e padrões espaciais, a formulação de modelos e a elaboração
de previsões. É importante disponibilizar, de forma rápida, organizada e precisa
informações que venham a auxiliar o homem na tomada de decisões, em suas
ações estratégicas e no planejamento de suas atividades.
A Análise de Agrupamentos e a Análise de Componentes Principais são
técnicas que são tratadas nesse trabalho nos próximos capítulos. Antes, porém, é
feita uma pequena revisão bibliográfica mostrando algumas aplicações das duas
técnicas na Geografia e também em outras ciências.

Página 27
2.3 - Revisão Bibliográfica
2.3.1 - Aplicações em Análise de Agrupamentos
A Análise de Agrupamentos é muito utilizada na Geografia e em diversas
outras áreas do conhecimento humano. Ela corresponde a um conjunto amplo e
variado de técnicas e algoritmos que objetivam identificar e agrupar objetos segundo
a similaridade sobre algum atributo ou característica particular que possuem,
possibilitando uma melhor análise dos dados e a identificação de padrões de
comportamento. Na Geografia, ela possibilita uma melhor organização dos dados
através da divisão desses dados em grupos ou classes, auxiliando a compreensão
de um fenômeno e facilitando sua interpretação.
Reis et al (2004), no artigo “Determinação das Áreas de Potencial de Riscos
de Precipitações Intensas em Belo Horizonte”, buscou coletar dados durante e
estação chuvosa de 2003/2004 na Região Metropolitana de Belo Horizonte para
fazer uma Análise Espacial das precipitações, uma regionalização dos dados e um
mapeamento de regiões com alto potencial para chuvas intensas. A classificação
das estações de medição em grupos similares foi feita pela Análise de
Agrupamentos usando a métrica da distância euclidiana e o método de ligações
completas. A consistência dos grupos formados foi feita através de outra técnica
multivariada, a Análise de Discriminantes.
Chiguti (2005), em sua dissertação de mestrado intitulada “Aplicação da
Análise Multivariada na Caracterização dos Municípios Paranaenses segundo suas

Página 28
Produções Agrícolas”, fez um estudo sobre a produtividade média de algumas
culturas nos municípios do estado do Paraná nas últimas safras. Depois de se
utilizar da técnica da Análise de Componentes Principais para estabelecer uma
hierarquia das melhores mesorregiões do Paraná em termos de produtividade para
cada cultura analisada, foi utilizada a Análise de Agrupamentos para agrupar
aquelas mesorregiões semelhantes. Isso permitiu classificar e agrupar os municípios
que obtiveram as melhores médias de produtividade.
GURGEL et al. (2003), no artigo intitulado “Estudo da Variabilidade do NDVI
sobre o Brasil utilizando-se a Análise de Agrupamentos”, analisam a variabilidade do
Índice de Vegetação por Diferença Normalizada sobre o Brasil. A Análise de
Agrupamentos foi utilizada no conjunto de dados de NDVI coletados para identificar
regiões semelhantes quanto a esse índice. A Distância Euclidiana foi utilizada como
medida de proximidade. O volume de dados, em grande quantidade, foi classificado
por meio da técnica em nove grupos quando então as análises foram feitas.
Meira-Neto e Martins (2006), no trabalho “Composição Florística de uma
Floresta Estacional Semidecidual Montana no Município de Viçosa – MG” , procuram
investigar a composição florística arbórea da Mata da Silvicultura, município de
Viçosa, Zona da Mata de Minas Gerais, com o objetivo de avaliar sua similaridade
com outras florestas. A Análise de Agrupamentos foi utilizada para se fazer a
comparação florística, quando a métrica das médias aritméticas não ponderadas foi
utilizada a partir dos índices binários de similaridade de Sørensen entre as florestas
comparadas.

Página 29
Foram relacionadas 154 espécies de 47 famílias botânicas para a Mata da
Silvicultura, que se mostrou mais similar às florestas semideciduais de altitude de
Lavras (MG) e de Atibaia (SP) e menos similar às florestas submontanas e
litorâneas. Estes resultados evidenciam uma importante influência das temperaturas
na determinação do tipo florístico das florestas do Sudeste e Sul brasileiros.
Em outras disciplinas a Análise de Agrupamentos também é bastante
utilizada. Azambuja (2005), por exemplo, em sua dissertação de mestrado chamada
“Estudo e Implementação da Análise de Agrupamento em Ambientes Virtuais de
Aprendizagem”, faz um amplo estudo sobre a Análise de Agrupamentos e propõe
seu uso na análise de informações relativas à participação de alunos em um
Ambiente Virtual de Aprendizagem, como método de identificação e geração de
grupos homogêneos em tarefas e cenários pedagógicos. De acordo com os critérios
pertinentes ao cenário pedagógico escolhido uma classificação é gerada
identificando os alunos semelhantes. Com os grupos formados o aumento das
interações nesses ambientes pode proporcionar melhores condições de
aprendizagem.
Metz e Monard (2006), no artigo “Projeto e Implementação do Módulo de
Clustering Hierárquico do Discover”, fazem um importante trabalho sobre processo
de extração de conhecimento em bases de dados em aplicações de Mineração de
Dados. Nesse trabalho é apresentado o projeto de um módulo de clustering
hierárquico integrado ao ambiente computacional Discover, que dispões de muitas
ferramentas que podem ser utilizadas nas etapas do processo de Mineração de
Dados.

Página 30
Gimenes et al. (2003), no artigo “Os Processos de Integração Econômica sob
a Ótica da Análise Estatística de Agrupamento” procuram identificar o nível de
similaridade existente entre blocos econômicos e utilizam para isso a Análise de
Agrupamentos. Foram considerados no estudo 33 nações, de diferentes continentes
agrupadas nos blocos econômicos Mercosul, Comunidade Andina, Acordo Livre de
Comércio da América do Norte (Nafta), União Européia e Associação das Nações do
Sudeste Asiático, além de um suposto bloco constituído pela China e pelo Japão.
Os trabalhos mostrados ilustram algumas das aplicações da Análise de
Agrupamentos dentro e fora da Geografia. É uma técnica que se mostra muito
conveniente para agrupar objetos ou indivíduos que possuam características
similares, simplificando a análise do que se pretende estudar.

Página 31
2.3.2 - Aplicações em Análise Componentes Principais
A Análise de Componentes Principais vem sendo utilizada para inúmeras
finalidades na Geografia e em outras disciplinas, geralmente quando existe a
necessidade de se agrupar um grande número de variáveis relacionadas a um
conjunto de observações simplifica a análise do que se pretende estudar. Nesse
momento serão mostradas algumas aplicações e estudos feitos na Geografia que se
utilizaram desta técnica.
Uma ampla revisão bibliográfica pode ser encontrada em Abreu e Barroso
(1980), Marques e Najar (1998), Najar et al. (2002), entre outros, que a partir de
agora são explicitados.
Paiva (2003), em seu trabalho “Mapeando a Qualidade de Vida em Minas
Gerais Utilizando Dados de 1991 e 2000”, buscou caracterizar a situação da
qualidade de vida em Minas Gerais na perspectiva do desenvolvimento humano
sustentável nos anos de 1991 e 2000 e sua evolução nesse período. As
classificações necessárias ao trabalho de análise das 64 variáveis foram feitas
utilizando a Análise de Componentes Principais e resultou em um conjunto de
componentes altamente explicativas das situações nos dois momentos, o que
facilitou a análise do Índice de Desenvolvimento Humano do Estado, objeto da tese.
A Análise de Componentes Principais foi adotada, no caso, em virtude da
facilidade de sua utilização em larga escala para a identificação de fatores que
caracterizam uma determinada situação em particular.
Em 1991, por exemplo, a análise dos resultados foi composta por um conjunto
de três componentes que responderam por mais de 82% da variância total contida

Página 32
nos dados originais. Apenas a primeira componente conseguiu agrupar 36 variáveis,
ou 52% da variância total. Em 2000, os resultados também foram compostos por um
conjunto de três componentes que responderam por 79% da variância total dos
dados.
Depois dos levantamentos seguiram-se a geração cartográfica e as
caracterizações e análises.
Silva (2002) fez um trabalho cujo objetivo inicial era criar uma tipologia e
hierarquização dos municípios pertencentes à Mesorregião 10 – Sul/Sudoeste de
Minas Gerais, região conhecida como Sul de Minas. Em seu trabalho elaborou-se
uma análise comparativa visando a caracterização da dinâmica espaço-temporal da
região, por meio da análise de 24 variáveis sócio-econômicas correspondentes aos
períodos de 1970, 1980, 1990 e 2000 de seus 146 municípios.
A opção por se usar dados destes períodos exigiu que se procedesse a uma
tipologia de cada ano de forma isolada, complementada depois por meio de uma
análise comparativa.
A aplicação da Análise de Componentes Principais resultou na criação de
componentes que, em cada um dos quatro períodos, representaram um percentual
de variância maior que 60%. Em outras palavras, das 24 variáveis de trabalho 14 já
expressavam um percentual de variância considerado suficiente para a
representação cartográfica e para uma análise comparativa e evolutiva bem
fundamentada. O estabelecimento de classes e a hierarquização promovida pelo
uso da técnica permitiram maior riqueza nesta análise.
Na conclusão deste trabalho é evidenciado que “a facilidade da técnica
permite o uso de grande volume de variáveis e municípios, e busca relatar, com

Página 33
precisão, a realidade dos mesmos”.
Castro (2000) faz uma proposta metodológica voltada para a caracterização
espacial do Sul de Minas e “Entorno”, nos anos de 1970, 1980, 1991, 1992 e 1999.
Em seu roteiro, a Análise de Componentes Principais foi empregada para a criação
de bancos de dados cartográficos e alfanuméricos, georeferenciados, contendo
indicadores sócio-econômicos e de volume de carga transportada na rede rodoviária
da região.
Como fonte de informação para o trabalho, selecionou-se, em princípio, 22
variáveis sócio-econômicas que integram o banco de dados do IPEA/FJP (1998),
organizadas na forma de indicadores por blocos (demográficos, econômicos, de
saúde, educação, infância e habitação).
Uma análise preliminar revelou redundâncias entre variáveis de um mesmo
bloco e a Análise de Componentes Principais serviu para evidenciar a necessidade
de que as informações passassem por um processo de seleção mais elaborado.
A partir da análise da matriz de correlação entre variáveis e sucessivas
intervenções nos dados originais feitas com a aplicação de Componentes Principais
em diversos arranjos de variáveis, obteve-se 12 variáveis que apresentavam um
percentual de variância em torno de 70%, e foram apontadas como aquelas que
melhor expressavam e sintetizavam a Infra-Estrutura Sócio-Econômica da região.
Essas variáveis foram, então, reduzidas a componentes ou factor scores que,
por sua vez, foram classificados e representados em cartogramas coropléticos,
permitindo estabelecer a hierarquia e a tipologia dos municípios da região.

Página 34
Simão (1999) fez um estudo exploratório utilizando a Análise Espacial e a
Estatística Multivariada para facilitar análise da evolução espacial da cultura cafeeira
em Minas Gerais. A Análise de Componentes Principais, neste trabalho, foi utilizada
para classificar os municípios mineiros com relação a esta atividade.
Em seu trabalho foram utilizados os dados censitários em nível de municípios
nos períodos relativos aos anos de 1985 e 1995/1996. Foram selecionadas 30
variáveis de análise.
Neste primeiro período, a aplicação da técnica permitiu gerar uma primeira
componente que sintetizava 54% da variância dos dados, correspondente a 16 das
30 variáveis. Com a segunda componente essa variância subiu para 70%,
agrupando quatro variáveis.
Para o período de 1995/1996, a primeira componente mostrou um percentual
da variância total acima de 55%, agrupando 16 variáveis. A segunda componente
sintetizou mais 14% da variância total, agrupando outras quatro variáveis.
A Análise de Componentes Principais possibilitou classificar a região não
mais com base nos dados univariados, mas com base em grupos de variáveis que
se destacam em termos de sua representatividade. Como mencionado no trabalho,
as componentes são consideradas “em ordem de importância, segundo o percentual
de variabilidade explicado para cada uma delas”.
Pires (2007), fez uma análise da rede de serviços básicos de saúde do
município de Teófilo Otoni – MG – tendo como foco as áreas de abrangência das
unidades de saúde inseridas no PSF (Programa de Saúde da Família) e no PACS
(Programa de Agentes Comunitários de Saúde). Depois de um cuidadoso estudo
sobre as variáveis e dados de estudo, obtidos no IBGE e no Ministério da Saúde, a

Página 35
técnica da Análise de Componentes Principais foi utilizada para a construção de um
diagnóstico sócio-econômico dos territórios intra-urbanos
Batella (2008), em seu trabalho “Análise Espacial dos Condicionantes da
Criminalidade Violenta no Estado de Minas Gerais – 2005: Contribuições da
Geografia do Crime” faz um estudo que investiga a relação entre a criminalidade
violenta contra o patrimônio e contra a pessoa e seus condicionantes. Os dados de
trabalho foram organizados em sete temas e os temas que apresentavam mais de
uma variável foram submetidos à Análise de Componentes Principais. Com o uso da
técnica foi possível o agrupamento de variáveis e uma apresentação final muito
expressiva.
Em outras disciplinas, a aplicação de Componentes Principais se mostra
também muito interessante. Komatsu (2003), por exemplo, fez um trabalho que une
aspectos das Ciências Biológicas e da Geografia na análise biogeográfica de lagoas.
Seu estudo, “Lagoas da Planície Aluvial do Rio Ivinheima – Morfologia e
Comunidade Bêntica”, analisa quatro lagoas aluviais do baixo curso do rio Ivinheima
(MG) e se utiliza da Análise de Componentes Principais para ordenar pontos de
coletas de dados físicos e químicos de interesse do estudo.
Na Engenharia Agrícola, Bueno (2001) fez um estudo na área de
Planejamento e Desenvolvimento Rural Sustentável e estudou a aplicação de
técnicas multivariadas em mapeamento e interpretação de parâmetros de solo. O
objetivo do seu trabalho foi investigar uma metodologia que permitisse a análise da
variabilidade espacial de um conjunto de parâmetros coletados em uma área

Página 36
experimental em Piracicaba (SP). A Análise de Componentes Principais foi utilizada
para a identificação de variáveis que possuíam maior poder de explicação da
variabilidade contida no conjunto de parâmetros avaliados e serviu para a
determinação de modelos de semivariogramas e interpolação. A interpretação dos
dados foi facilitada por meio da elaboração de mapas destas componentes.
Os trabalhos mostrados ilustram algumas das aplicações da Análise de
Componentes Principais na Geografia. É uma técnica que deve ser utilizada para a
criação de novas variáveis que sintetizam, agrupam informações de outras. Sua
aplicação permite análises mais ricas porque agregam uma maior quantidade de
informação. Particularmente na Geografia, quando existe a necessidade de alguma
representação por meio de mapas, estes se revelam muito mais representativos.

Página 37
Capítulo 3
Fundamentos Matemáticos
No Capítulo 4 e no Capítulo 5 dois métodos importantes e muito utilizados na
Geografia são apresentados. Em uma visão bastante simplista os dois métodos
buscam transformar um conjunto de dados de observações, de maneira tal que suas
representações se tornem mais significativas dentro de um contexto de estudo.
A Análise de Agrupamentos, por exemplo, trabalhada no Capítulo 4, pode
criar subconjuntos de um conjunto segundo a similaridade entre seus elementos.
Pode também criar grupos onde suas semelhanças internas são maximizadas ao
mesmo tempo em que, entre grupos, são minimizadas. A Análise de Componentes
Principais, por sua vez, trabalhada no Capítulo 5, toma um grupo de variáveis e,
segundo o critério da máxima variância, cria uma componente que fornece o
significado de várias outras em conjunto. Ela gera como resultado uma ordenação
de observações segundo essas componentes que serve, inclusive, como ponto de
partida para a formação de classes e até para aplicação de outras técnicas.
Todas elas são técnicas que podem ser aplicadas em várias áreas do
conhecimento. Particularmente na Geografia, são técnicas que simplificam muito a
análise das inúmeras informações inerentes ao estudo de um fenômeno geográfico.
Mas uma questão é importante que seja registrada: será que todos esses resultados
numéricos, representados por tabelas, gráficos, diagramas, mapas, dentre outras
representações possíveis, servem para a realidade do que um geógrafo busca
explicar?
Se o objetivo é o estudo de um fenômeno geográfico então a presença de um
geógrafo passa a ser fundamental, mesmo que os recursos matemáticos e

Página 38
computacionais simplifiquem o entendimento do problema ou que um computador
facilite os cálculos envolvidos nos processos. Isso vale em outras áreas do
conhecimento.
A análise de dados possui grande importância para a Geografia. Ela
possibilita uma maior facilidade no exame conjunto de informações e nas suas inter-
relações e isso auxilia a explicação de fenômenos geográficos. Conseqüentemente
ela pode auxiliar o homem na tomada de decisões e em suas ações estratégicas.
Números sem significado e explicação não fazem isso.
Os resultados da aplicação dessas técnicas são, então, apresentados.
Obviamente, em se tratando da Geografia, preferencialmente sob forma cartográfica.
O geógrafo então se utiliza desses agrupamentos, visualiza dados segundo um
determinado critério, filtra informações de interesse. O que está por trás disso?
Segundo Barroso (2003), a base teórica reside na Matemática, particularmente na
Teoria de Conjuntos e nas Relações de Equivalência.
Intuitivamente, a noção de conjunto é tão primitiva quanto a noção de número.
Como cita Castrucci (1969), uma criança quando se refere ao número três, por
exemplo, ao mesmo tempo associa esse número a uma coleção de três objetos.
Com bastante freqüência é necessária a comparação entre vários elementos
de um conjunto, quer seja para reuni-los de acordo com uma determinada
característica comum, quer seja para agrupá-los segundo a semelhança existente
entre eles.
Essa idéia de conjunto, embora existente na Ciência Matemática e também
no pensamento comum, só começou a ser tratada formalmente no final do século
XIX quando o matemático alemão Georg Cantor (1845 – 1918) formalizou a teoria.

Página 39
Hoje a Teoria de Conjuntos é linguagem de ampla utilização em várias partes da
Matemática, como a Geometria e a Álgebra (Barroso, 2003).
Para se fazer essa abordagem é apresentada nesse momento uma linha
elementar de conceitos matemáticos inseridos na Teoria de Conjuntos. Inicialmente
é importante a definição de Par Ordenado e de Produto Cartesiano entre conjuntos.
Essa será a base para o entendimento das Relações Binárias e de suas
propriedades, que precisam também de uma abordagem detalhada. As Relações de
Equivalência e as Classes de Equivalência decorrem, naturalmente, da exploração
das propriedades das Relações Binárias.

Página 40
3.1 - Conceitos Iniciais - Par Ordenado
Dados dois elementos quaisquer, a1 e a2, pode-se formar com eles um
conjunto A = { a1 , a2 } no qual é irrelevante a ordem em que se apresentam, ou seja,
A = { a1 , a2 } = { a2 , a1 }
No conceito de Par Ordenado, no entanto, deve-se definir outro conjunto que
dependa não somente dos elementos a1 e a2 como também da ordem em que são
considerados no conjunto A definido anteriormente. Esse conjunto é chamado de par
ordenado a1a2 e é indicado por ( a1 , a2 ). Nesse caso a definição deve ser tal que
resulte em um conjunto binário tal que ( a1 , a2 ) ( a2 , a1 ) para a1 a2.
Segundo Alencar Filho (1984), é clássica a definição dada por K. Kuratowski
em 1921. Segundo ele, chama-se par ordenado ( a1 , a2 ) ao conjunto binário cujos
elementos são { a1 } e { a1 , a2 }. O par ordenado ( a1 , a1 ) e ( a2 , a2 ), cujos
elementos são iguais, é um conjunto unitário { a1 } e { a2 } respectivamente.
Temos então:
( a1 , a2 ) = { { a1 }, { a1 , a2 } }
e
( a2 , a1 ) = { { a2 }, { a2 , a1 } }

Página 41
Os pares ordenados ( a1 , a2 ) e ( a2 , a1 ) são, portanto, diferentes.
Na notação ( a1 , a2 ) dizemos que a1 é o primeiro elemento e a2 é o segundo
elemento.
Pode-se dizer que ( a2 , a1 ) é o par ordenado recíproco de ( a1 , a2 ). Um par
ordenado cujos elementos são iguais, como ( a1 , a1 ) é chamado de par ordenado
idêntico.
Dois pares ordenados ( a1 , a2 ) e ( b1 , b2 ) são chamados de pares
ordenados iguais se e somente se a1 = b1 e a2 = b2, ou seja:
{ { a1 }, { a1 , a2 } } = { { b1 }, { b1 , b2 } } a1 = b1 e a2 = b2
Qualquer par ordenado pode se representado graficamente por meio de uma
flecha que tem por origem o primeiro elemento do par ordenado e por extremidade o
segundo elemento do par ordenado. A esse tipo de representação dá-se o nome de
diagrama sagital do par ordenado. Alguns exemplos:
a2
a1
a1

Página 42
Um par ordenado é dito consecutivo quando o primeiro elemento de um deles
é igual ao segundo elemento do outro. Em outras palavras, como exemplo, tem-se:
O par ordenado ( a1 , a2 ) tem por consecutivo ( a2 , b1 )
O par ordenado ( a1 , a1 ) tem por consecutivo ( a1 , a2 )
O par ordenado ( a1 , a2 ) tem por consecutivo ( a2 , a2 )
O par ordenado ( a1 , a2 ) tem por consecutivo ( a2 , a1 )
a2
a1
b1
a1
a2
a2
a1
a2 a1

Página 43
Dados dois pares ordenados consecutivos u = ( a1 , a2 ) e v = ( a2 , b1 ), diz-se
que o par ordenado w = ( a1 , b1 ) é o par ordenado composto de u e de v.
Outros exemplos:
O par ordenado composto de u = ( a1 , a1 ) e de v = ( a1 , a2 ) é
w = ( a1 , a2 )
a1
a2
b1
w
v u
a1
a2
w
v
u

Página 44
O par ordenado composto de u = ( a1 , a2 ) e de v = ( a2 , a2 ) é
w = ( a1 , a2 )
Em uma perspectiva geográfica, diversas análises podem ser feitas com
relação às definições mostradas:
Um par ordenado pode representar, por exemplo, uma coordenada
geográfica de longitude x e latitude y. Nesse caso a ordem dos elementos
precisa ser considerada, uma vez que um ponto de coordenadas ( x ,y ) é
diferente de outro de coordenadas ( y , x ), se x for diferente de y. Em um
par ordenado é relevante a ordem em que os elementos se apresentam;
Se um par ordenado é igual a outro par ordenado e cada um deles
contém uma coordenada geográfica, os dois pares ordenados se referem
à mesma posição do espaço;
Pares ordenados consecutivos podem mostrar caminhos, ou rotas, entre
pontos do espaço geográfico. O conceito de adjacência, utilizado nos
Sistemas de Informações Geográficas também leva isso em consideração
na Análise Espacial;
a1 a2
w v
u

Página 45
Pares ordenados compostos representam bem o conceito de grafos
quando tomados cada um deles como vértices e a ligação entre eles
como arestas;
De forma complementar, um par ordenado composto pode representar
alternativas de trajetórias entre pontos, se esse par ordenado não for
idêntico.

Página 46
3.2 - Produto Cartesiano
O Produto Cartesiano de dois conjuntos, A e B, não vazios, é definido como o
conjunto formado por todos os pares ordenados ( x , y ) em que o primeiro elemento
x pertença a A e o segundo elemento y pertença a B. A representação desse
conjunto é A x B, que se lê “A por B”, “A vezes B” ou “A cartesiano B”.
Os conjuntos A e B que participam do produto cartesiano são chamados de
fatores do produto cartesiano A x B. Em notação matemática pode-se representar:
A x B = { ( x , y) / x ϵ A ˄ y ϵ B }
Se os conjuntos A e B são finitos, formados respectivamente por uma
quantidade m e n de elementos, o produto cartesiano também será finito com uma
quantidade total de mn elementos.
Por exemplo, sendo A = { a1 , a2 , a3 } e B = { b1 , b2 },
A x B = { ( a1 , b1 ) , ( a1 , b2 ) , ( a2 , b1 ) , ( a2 , b2 ) , ( a3 , b1 ) , ( a3 , b2 ) }
É muito importante notar que, por ser formado por pares ordenados de dois
conjuntos, o produto cartesiano não goza de propriedade comutativa. Em outras
palavras, o par ordenado ( a1 , b1 ) é diferente do par ordenado ( b1 , a1 ), de maneira
que o conjunto { ( a1 , b1 ) } é diferente de { ( b1 , a1 ) }.

Página 47
No caso particular em que o conjunto A é igual ao conjunto B, o produto
cartesiano de A por B é chamado de Quadrado Cartesiano do conjunto A (ou B), e é
indicado por A2 (ou B2). Os elementos de A2 são pares ordenados cujos
componentes são pertencentes a A:
A x A = A2 = { ( x , y) / x , y ϵ A }
O conjunto de todos os pares ordenados idênticos ( x , y ) pertencentes a A2 é
chamado de Diagonal do Quadrado Cartesiano de A2, podendo ser indicado por dA.
Em notação matemática, dA = { ( x , x ) / ( x , x ) ϵ A2 ˄ x ϵ A }.
Se A é um conjunto finito com m elementos, dA também é finito e possui m
elementos.
Por exemplo, sendo A = { ( 1 , 2 ) },
A2 = { ( 1 , 1 ) , ( 1 , 2 ) , ( 2 , 1 ) , ( 2 , 2 ) } e
dA = { ( 1 , 1 ) , ( 2 , 2 ) }
As representações do produto cartesiano podem ser feitas de diversas
formas, algumas descritas a seguir.

Página 48
Considerando, como exemplo, A = { 1 , 2 , 3 } e B = { 4 , 5 } , o produto
cartesiano A x B será:
A x B = { ( 1 , 4 ) , ( 1 , 5 ) , ( 2 , 4 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 3 , 5 ) }
Diagrama Cartesiano
Tabela de Dupla Entrada
Elementos 4 5
1 ( 1 , 4 ) ( 1 , 5 )
2 ( 2 , 4 ) ( 2 , 5 )
3 ( 3 , 4 ) ( 3 , 5 )

Página 49
Diagrama Sagital
O produto cartesiano entre dois conjuntos pode representar, na Geografia, as
inúmeras relações ou as relações possíveis entre dois pontos geográficos,
considerando estes dois conjuntos com elementos formados por coordenadas
geográficas, por exemplo.
Algumas propriedades devem ser consideradas com relação ao Produto
Cartesiano:
A x B = Ф se e somente se A = Ф ou B = Ф;
A x B = B x A se e somente se A = Ф , B = Ф ou A = B;
Se A = Ф, A x B A x C e B x A C x A, o que demonstra que B C;
Se A B então A x C B x C e C x A C x B;
Se A C e se B D então A x B C x D;
A x ( B C ) = ( A x B ) ( A x C ) e ( A B ) x C = ( A x C ) ( B x C ) –
Propriedade Distributiva em relação à interseção;
A B
1
2
3
4
5

Página 50
A x ( B C ) = ( A x B ) ( A x C ) e ( A B ) x C = ( A x C ) ( B x C ) –
Propriedade Distributiva em relação à união;
A x ( B - C ) = ( A x B ) - ( A x C ) e ( A - B ) x C = ( A x C ) - ( B x C ) –
Propriedade Distributiva em relação à diferença;
A x ( B C ) = ( A x B ) ( A x C ) e ( A B ) x C = ( A x C ) ( B x C ) –
Propriedade Distributiva em relação à diferença simétrica;
( A x B ) x C A x ( B x C ) – Não existe a propriedade associativa no
Produto Cartesiano;

Página 51
3.3 - Relação Binária
Chama-se Relação Binária R de um conjunto A em um conjunto B a todo
subconjunto do Produto Cartesiano A x B. Nesse caso o conjunto A é chamado de
Conjunto de Partida de R e B é chamado de Conjunto de Chegada de R. Se um
dado par ordenado ( x , y ) pertence a R é usual indicar essa relação por xRy. No
entanto, se ( x , y ) não pertence a R é usual indicar essa relação por xRy. Um
conjunto S também pode ser uma relação de A em B se S está contido em R, ou
seja, S R.
Da mesma forma chama-se Relação Binária R em um conjunto A todo
subconjunto do Produto Cartesiano A x A = A2.
O conjunto vazio ( Ф ) é uma relação de A em B e também é relação em A
uma vez que o conjunto vazio está contido em A x B, ou seja, Ф ( A x B ) e em A,
ou seja, (Ф ( A2 ) ) respectivamente.
Como exemplo, sejam A = { 1 , 2 , 3 } e B = { 1 , 3 }. São relações binárias de
A em B:
R1 = { ( 2 , 3 ) }
R2 = { ( 1 , 3 ) , ( 2 , 1 ) }
R3 = { ( 1 , 1 ) , ( 1 , 3 ) , ( 2 , 3 ) , ( 3 , 3 )
R4 = { ( 1 , 1 ) , ( 1 , 3 ) , ( 2 , 1 ) , ( 2 , 3 ) , ( 3 , 1 ) , ( 3 , 3 ) } = A x B
R5 = Ф

Página 52
Em uma relação binária pode-se criar uma “regra” para a seleção dos
subconjuntos contidos no produto cartesiano de dois conjuntos. Por exemplo, para
os mesmos conjuntos A e B apresentados anteriormente, pode-se estabelecer a
seguinte relação binária:
R = { ( x , y ) ϵ A x B / x < y }
Que resulta no seguinte subconjunto R A x B:
R = { ( 1 , 3 ) , ( 2 , 3 ) }
Seja agora o conjunto A = { 1 , 2 , 3 , ... } dos inteiros positivos maiores ou
iguais a 1. O conjunto:
R = { ( x , y ) ϵ A2 / mdc ( x , y ) = 1 }
é uma relação em A porque R A2 ou seja, um inteiro positivo está
relacionado com todos os inteiros positivos que são primos com ele. Nesse caso os
pares ( 3 , 7 ) , ( 9 , 35 ) e ( 12 , 39 ) são exemplos de elementos do conjunto R.

Página 53
A representação de uma relação binária também pode ser feita através do
diagrama cartesiano, do diagrama sagital ou da tabela de dupla entrada.
Como exemplo de uma representação, sejam os conjuntos A = { -2 , 0 , 1 , 2 }
e B = { -1 , 0 , 3 } e a relação binária R = { ( x , y ) ϵ A x B / x + y < 1 }. Tem-se:
R = { ( -2 , -1 ) , ( -2 , 0 ) , ( 0 , -1 ) , ( 0 , 0 ) , ( 1 , -1 ) }
A tabela de dupla entrada dessa relação assinala a célula formada pelo
encontro de uma linha com uma coluna:
-1 0 3
-2 x x
0 x x
1 x
2
As operações com relações, como, por exemplo, interseção, união e
diferença, podem ser feitas com relações que possuem o mesmo conjunto de partida
e o mesmo conjunto de chegada. Esse conceito também está inserido nos Sistemas
de Informações Geográficas e são aplicados à Análise Espacial e à Cartografia, por
exemplo.
A B

Página 54
De fato, se R e S são relações de A em B, ou seja, R A x B e S A x B ,
os conjuntos R S , R S , R – S e R S são todos subconjuntos de A x B e,
portanto, são também relações de A em B.
Para exemplificar, sejam as relações de A = { 1 , 2 , 3 } e B = { 3 , 4 } :
R = { ( 1 , 3 ) , ( 1 , 4 ) , ( 2 , 4 ) }
S = { ( 1 , 3 ) , ( 1 , 4 ) , ( 3 , 3 ) }
R S = { ( 1 , 3 ) , ( 1 , 4 ) } Interseção
R S = { ( 1 , 3 ) , ( 1 , 4 ) , ( 2 , 4 ) , ( 3 , 3 ) } União
CA x B R = { ( 2 , 3 ) , ( 3 , 3 ) , ( 3 , 4 ) } Complementação
R – S = { ( 2 , 4 ) } Diferença
R S = { ( 2 , 4 ) , ( 3 , 3 ) } Diferença Simétrica
O conceito de Domínio e Imagem de uma relação pode ser representado pelo
diagrama abaixo:
R
A B
D ( R ) I ( R )

Página 55
Domínio de uma relação R de A em B é o conjunto formado pelos primeiros
elementos de todos os pares ordenados pertencentes a R.
Para exemplificar, sejam os conjuntos A = { -2 , 0 , 1 , 2 } e B = { -1 , 0 , 3 }. A
relação R = { ( x , y ) ϵ A x B / x + y < 1 } é:
R ={ ( -2 , -1 ) , ( -2 , 0 ) , ( 0 , -1 ) , ( 0 , 0 ) , ( 1 , -1 ) }
Os primeiros elementos de todos os pares ordenados de R representam o
Domínio da relação R, ou seja, D ( R ) = { -2 , 0 , 1 } .
Imagem de uma relação R de A em B é o conjunto dos segundos elementos
de todos os pares ordenados pertencentes a R. Nesse caso, I ( R ) = { -1 , 0 } .
Algumas outras Relações podem ser citadas. Chama-se Relação Identidade
de um conjunto A a relação em A:
IA = { ( x , x ) / x ϵ A }
Por exemplo, seja A = { -1 , 0 , 1 , 2 ). A Relação Identidade em A, chamada
de IA, é:
IA = { ( -1 , -1 ) , ( 0 , 0 ) , ( 1 , 1 ) , ( 2 , 2 ) }

Página 56
Dá-se o nome de Restrição de uma Relação R ao conjunto X, representada
por R | X, aquela formada pelos elementos ( x , y ) de R tais que x ϵ X.
Por exemplo, considerando os conjuntos A = { 1 , 2 , 3 , 4 } e B = { 4 , 5 , 6 }
e a relação R = { ( 1 , 4 ) , ( 1 , 6 ) , ( 3 , 5 ) , ( 3 , 6 ) , ( 4 , 4 ) }, as restrições de R ao
conjunto X = { 1 , 2 , 4 } é:
R | X = { ( 1 , 4 ) , ( 1 , 6 ) , ( 4 , 4 ) }
Seja R é uma Relação de A em B. Diz-se que R é também uma Relação
Funcional de A em B quando existe um elemento y ϵ B tal que ( x , y ) ϵ R para todo
x ϵ D(R)
Como exemplo, sejam os conjuntos A = { -2 , 0 , 1 , 2 } e B = { -1 , 0 , 3 } e a
relação R:
R ={ ( -2 , -1 ) , ( -2 , 0 ) , ( 0 , -1 ) , ( 0 , 0 ) , ( 1 , -1 ) , ( 0 , 0 ) , ( 1 , 3 ) }
Os primeiros elementos de todos os pares ordenados de R representam o
Domínio da relação R, ou seja, D(R) = { -2 , 0 , 1 }. Nesse caso para todo x
pertencente a D(R) existe um e somente um elemento y de B tal que o par ( x , y )
pertença a R, o que faz a relação R ser uma Relação Funcional de A em B.
Quando uma dada Relação Funcional possui como domínio o próprio
conjunto de partida, essa relação é chamada de Função. Em outras palavras, se R é

Página 57
uma Relação Funcional de A em B e o domínio de R é igual a A, ou seja, D(R) = A,
R é uma função de A em B.
Para exemplificar, sejam A = { a , b , c , d } e B = { 1 , 2 , 3 }.
Considerando a Relação de A em B,
R={ ( a , 2 ) , ( b , 1 ) , ( c , 2 ) , ( d , 3 ) }
O domínio da relação R, D(R) = { a , b , c , d }. Nesse caso D(R) = A e R é,
além de uma relação funcional de A em B, uma função de A em B.
A notação para indicar uma função de A em B é:
f : A B
O conjunto B chama-se contradomínio de f. Para cada elemento x
pertencente a A, o único elemento y pertencente a B tal que ( x, y ) pertença a f é
representado por
y = f ( x )
o que indica que y é o valor de f no elemento x.
A imagem da função f : A B é o conjunto formado por todos os elementos
de B que são imagens dos elementos de A.

Página 58
Assim, considerando, por exemplo,
A = { -2 , -1 , 0 , 1 }
e a função f : A B definida por f ( x ) = x3 – 2 , para se determinar I ( f )
cabe a aplicação de cada elemento x a f ( x ):
f ( -2 ) = ( -2 ) 3 – 2 = -10
f ( -1 ) = -3
f ( 0 ) = -2
f ( 1 ) = -1
Portanto, f ( A ) = { -10 , -3 , -2 , -1 } , que é um subconjunto de B
A B
-2
-1
0
1
-10
-3
-2
-1

Página 59
Como se pode observar, as regras que determinam uma relação estabelecem
um meio de seleção de elementos de um conjunto, isto é, uma lei para se criar
subconjuntos do conjunto original.
Nesse ponto de vista, uma seleção geográfica pode surgir da aplicação, a um
conjunto de elementos geográficos, de uma determinada regra de interesse a fim de
se escolher aqueles que satisfazem a um propósito de estudo.
Muitas aplicações dos Sistemas de Informações Geográficas fazem isso para
gerar inúmeras representações, como mapas temáticos, cobertura de áreas ou
interseções de características e propriedades geográficas. O conceito de Relação
Funcional é utilizado, inclusive, em operações matemáticas com pixels no
tratamento de imagens e no sensoriamento remoto para realce de características em
imagens de satélite.

Página 60
3.4 - Relação Recíproca e Imagem de um Conjunto por uma Relação
Se R é uma relação de A em B, chama-se Relação Recíproca de R a relação
R-1 de B em A. Em termos matemáticos, se R é representado por
R = { ( x , y ) ϵ A x B }
R-1 pode ser representado por
R-1 = { ( y , x ) ϵ B x A / ( x , y ) ϵ R }
Por exemplo, se A = { 1 , 2 , 3 } e B = { 4 , 5 }, pode-se dizer que a Relação
R = { ( x , y ) ϵ A x B } é
R = { ( 1 , 4 ) , ( 1 , 5 ) , ( 2 , 4 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 3 , 5 ) }
e a Relação Recíproca de R,
R-1 = { ( 4 , 1 ) , ( 5 , 1 ) , ( 4 , 2 ) , ( 5 , 2 ) , ( 4 , 3 ) , ( 5 , 3 ) }
O conceito de Imagem de um Conjunto por uma Relação pode ser dado
tomando-se como base o exemplo a seguir.

Página 61
Sejam os conjuntos A e B:
A = { 2 , 3 , 5 , 7 , 11 , 19 , 33 }
B = { 1 , 3 , 7 , 10 , 11 , 13 , 17 }
e a Relação R formada pelos elementos ( x , y ) de A x B tal que x divide y:
R = { ( 2 , 10 ) , ( 3 , 3 ) , ( 5 , 10 ) , ( 7 , 7 ) , ( 11 , 11 ) }
Seja agora o subconjunto X de A
X = { 3 , 5 , 7 }
A imagem de X pela Relação R é:
R ( X ) = { 3 , 7 , 10 }
Em outras palavras, a Imagem de um Conjunto por uma Relação é um
conjunto de todos os elementos y de uma Relação cujo elemento x pertença ao
conjunto e, simultaneamente, o par ( x , y ) pertença à Relação. No caso cada
elemento de X possui, na relação um y correspondente. Cada y é parte da Imagem
de X pela Relação R.
De maneira análoga ao apresentado, tem-se a Imagem Recíproca de um
conjunto por uma Relação. Para o exemplo anterior, R-1( X ) = { 3 , 7 }

Página 62
Um Corte de uma Relação R qualquer segundo um elemento a, com a ϵ A, é
um conjunto C ( a ) de todos os elementos y ϵ B tais que o par ( a , y ) ϵ R.
Por exemplo, sejam os conjuntos A = { 1 , 2 , 3 , 4 , 5 } e B = { a , b , c , d } .
Os Cortes da Relação R = { ( 1 , a ) , ( 2 , b ) , ( 2 , c ) , ( 5 , a ), ( 5 , b ) }
segundo os elementos de A e de B são os seguintes conjuntos:
C ( 1 ) = { a } ; C ( 2 ) = { b , c } ; C ( 3 ) = Ф ; C ( 4 ) = Ф ; C ( 5 ) = { a , b }
C ( a ) = { 1 , 5 } ; C ( b ) = { 2 , 5 } ; C ( c ) = { 2 } ; C ( d ) = Ф

Página 63
3.5 - Relação Composta
Sejam os seguintes conjuntos A, B e C com as relações R = A x B e também
S = B x C. Seja também a relação T = A x C.
A Relação T é chamada de Relação Composta das Relações R e S quando
seus pares ordenados ( x , y ) ϵ A x C são tais que existe um elemento z ϵ B também
( x , z ) ϵ R e ( z , y ) ϵ S.
Representa-se a Relação composta das Relações R e S da seguinte forma:
S o R
que se lê “Composta de R e S”.
A B C
x z y
R S
T

Página 64
Conclui-se, portanto que a Composição das Relações R e S, nessa ordem, só
se torna possível quando o conjunto de chegada de R é igual ao conjunto de partida
de S.
O exemplo a seguir representa uma Relação Composta de R e S a partir dos
conjuntos A = { 1 , 2 , 3 , 4 } , B = { m , n , p , q } e C = { 5 , 6 , 7 , 8 }.
Assumindo a Relação R = { ( 1 , m ) , ( 1 , n ) , ( 2 , m ) , ( 3 , q ) , ( 4 , q ) } e
também a Relação S = { ( n , 5 ) , ( n , 6 ) , ( p , 8 ) , ( q , 7 ) } , tem-se a
representação:
A Relação Composta de R e S é:
S o R = { ( 1 , 5 ) , ( 1 , 6 ) , ( 3 , 7 ) , ( 4 , 7 ) }
Outro exemplo toma uma relação formada por uma equação. Se a Relação
xRy é definida por y = x2 e a Relação ySz é definida por y = 2z, a relação composta
de R e S é encontrada eliminando-se o y das duas equações.
A B C
1
2
3
4
R S
m
n
p
q
5
6
7
8

Página 65
Portanto:
S o R = { ( x , y ) ϵ A x C / x2 = 2z }
A Relação Recíproca da Relação Composta de R e S, como definida
anteriormente, é a Relação Composta das Relações Recíprocas de S e R.
Em outras palavras:
( S o R ) -1 = R -1 o S -1
A regra de Associatividade da Composição de Relações também pode ser
definida da seguinte forma:
( T o S ) o R = T o ( S o R )
Nesse caso podem-se representar as composições acima por T o S o R.

Página 66
3.6 - Relações Reflexivas
Uma relação R em um conjunto dado A pode possuir as propriedades
reflexiva, não reflexiva, simétrica, assimétrica, anti-simétrica, transitiva e intransitiva.
Nesse tópico desse trabalho serão exemplificadas essas propriedades.
Propriedade Reflexiva
Uma relação R em A é reflexiva quanto para todo elemento x de A (x ϵ A)
tem-se o par ( x , x ) ϵ R. Em outras palavras, R é reflexiva quando todo
elemento x de A está relacionado consigo mesmo (xRx).
Por exemplo, a relação R em A = { a , b , c }:
R = { ( a , a ) , ( a , c ) , ( b , b ) , ( b , c ) , ( c , c ) }
é reflexiva porque temos em R o par ( x , x ) para cada elemento de A, ou
seja, todo elemento de A está relacionado consigo mesmo.
Já a relação R = { ( a , a ) , ( a , b ), ( b , b ) , ( b , c ) } nesse mesmo
conjunto A não é reflexiva porque c ϵ A e não existe um par ( c , c ) em R
(cRc).

Página 67
Propriedade Irreflexiva e não Reflexiva
Uma relação R em A é chamada de irreflexiva quando, para todo
elemento x de A ( x ϵ A), não se encontram pares ( x , x ) ϵ R. Em outras
palavras, R é irreflexiva quando nenhum elemento x de A está
relacionado consigo mesmo.
Por exemplo, a relação R em A = { a , b , c }:
R = { ( a, b ) , (a , c ) , ( b , c ) , ( c , a ) }
é irreflexiva porque não se tem em R um par ( x , x ) para cada elemento
de A.
Já a relação R = { ( a , a ) , ( a , b ), ( a , c ) , ( c , c ) } não é irreflexiva
uma vez que a ϵ A e aRa, ou seja, o elemento a de A está relacionado
consigo mesmo, da mesma forma que o elemento c.
Essa relação também não é reflexiva uma vez que se tem b ϵ A e não se
tem o par ( b, b ) ϵ R.
Propriedade Simétrica
Uma relação R em A é chamada de Simétrica quando para quaisquer
elementos x e y de A tem-se um par ( x , y ) ϵ R e, simultaneamente,
também um par recíproco ( y , x ) ϵ R.

Página 68
Por exemplo, sejam as relações em A = { 1 , 2 , 3 , 4 }:
R = { ( 1 , 1 ) , ( 1 , 2 ) , (1 , 3 ) , ( 2 , 1 ) , ( 2 , 2 ) , ( 3 , 1 ) }
S = { ( 1 , 1 ) , ( 2 , 3 ) , ( 3 , 2 ) , ( 3 , 4 ) , ( 4 , 4 ) }
Como se pode observar, a relação R é simétrica uma vez que temos
pares ordenados de R recíprocos na mesma relação. S, no entanto, não é
simétrica uma vez que possui o par ordenado ( 3 , 4 ) e não possui o
correspondente par recíproco ( 4 , 3 ).
Propriedade Assimétrica
Uma relação R em A é chamada de Assimétrica quando para quaisquer
elementos x e y de A não se tem em R um par ordenado recíproco ( y , x )
de todo par ordenado ( x , y ) ϵ R.
Por exemplo, sejam as relações de A = { a , b , c }:
R = { ( a , b ) , ( a , c ) , ( b , c ) }
S = { ( a , a ) , ( a , b ) , ( a , c ) , ( b , a ) }

Página 69
A relação R é assimétrica porque não existem pares ordenados de
elementos de A em R, cada um deles com seu correspondente par
ordenado recíproco. Já a relação S não é assimétrica uma vez que existe
pares recíprocos ( a , b ) e ( b , a ), além de ( a , a ).
Propriedade Anti-Simétrica
Uma relação R em A é Anti-Simétrica se e somente se quaisquer que
sejam os elementos x e y pertencentes a A, se os pares ( x , y ) e o par
recíproco ( y , x ) pertencem a R, então, obrigatoriamente x = y.
Por exemplo, sejam as seguintes relações em A = { 1 , 2 , 3 }:
R = { ( 1 , 1 ) , ( 1 , 2 ) , ( 1 , 3 ) , ( 2 , 2 ) , ( 2 , 3 ) }
S = { ( 1 , 1 ) , ( 1 , 2 ) , ( 2 , 1 ) , ( 2 , 2 ) , ( 2 , 3 ) }
R é anti-simétrica e S não é anti-simétrica uma vez que são encontrados
os pares ( 1 , 2 ) e ( 2 , 1 ) e 1 ≠ 2.

Página 70
Propriedade Transitiva
Uma relação R em A é Transitiva quando quaisquer que sejam os
elementos x , y e z de A, se ( x , y ) ϵ R e ( y , z ) ϵ R então ( x , z ) ϵ R.
Em outras palavras, se os pares consecutivos ( x , y ) e ( y , z ) pertencem
a R e o par ordenado composto ( x , z ) também pertence a R, a relação R
é chamada de Transitiva.
Por exemplo, seja a relação em A = { a , b , c , d }:
R = { ( a , b ) , ( a , c ) , ( a , d ) , ( b , c ) , ( b , d ) , ( c , d ) }
O diagrama sagital dessa relação pode ser representado:
b
a
c
d

Página 71
Como se observa R é uma relação Transitiva. A relação S definida como:
S = { ( a , b ) , ( b , a ) , ( b , b ) , ( c , a ) , ( c , b ) , ( d , c ) }
não é transitiva, como se pode comprovar:
Nesse caso temos o par ( d , c ) e ( c , a ) e não temos o par ( d , a ).
Propriedade Intransitiva
Uma relação R em A é Intransitiva se, para quaisquer elementos x , y e z
de A, se o par ( x , y ) ϵ R e o par consecutivo ( y , z ) ϵ R, não se tem o
par ordenado composto ( x , z ) ϵ R.
Por exemplo, sejam as relações em A = { a , b , c , d }:
R = { ( a , b ) , ( a , d ) , ( b , c ) , ( c , d ) }
S = { ( a , d ) , ( b , b ) , ( b , c ) , ( c , b ) }
b
a
c
d

Página 72
Pode-se dizer claramente que a relação R é intransitiva uma vez que se
tem os pares consecutivos ( a , b ) e ( b , c ) e não se tem o par ordenado
composto ( a , c ) e se tem os pares consecutivos ( b , c ) e ( c , d ) e não
se tem o par ordenado composto ( b , c ). A relação S, no entanto, não é
intransitiva, porque se tem os pares consecutivos ( c , b ) e ( b , c ) e não
se tem ( c , c ).

Página 73
3.7 - Relação de Equivalência e Classe de Equivalência
Quando uma relação R em um conjunto A possui as propriedades Reflexiva,
Simétrica e Transitiva, simultaneamente, dá-lhe o nome de Relação de Equivalência.
Em outras palavras, uma relação R em A é uma Relação de Equivalência quando,
simultaneamente:
Todo elemento x de A está relacionado consigo mesmo (xRx);
Para quaisquer elementos x e y de A tem-se um par ( x , y ) ϵ R e,
simultaneamente, também um par recíproco ( y , x ) ϵ R;
Os pares consecutivos ( x , y ) e ( y , z ) pertencem a R e o par ordenado
composto ( x , z ) também pertence a R.
Um exemplo pode ser citado. Seja a relação em A = { 1 , 2 , 3 }:
R = { ( 1 , 1 ) , ( 1 , 2 ) , ( 2, 1 ) , ( 2 , 2 ) , ( 3 , 3 ) }
Como se observa,
Todo elemento de A está relacionado consigo mesmo, indicando que R é
Reflexiva.
Quaisquer que sejam os elementos de A, sempre existe em R um par de
elementos ( x , y ) e outro ( y , x ), mostrando que R é Simétrica.

Página 74
Quando, em R, são encontrados pares consecutivos ( x , y ) e ( y , z ),
encontra-se também o par ordenado composto ( x , z ), ou seja, R é
também Transitiva.
Essa Relação R é, portanto, uma Relação de Equivalência em A.
O diagrama sagital a seguir mostra também uma Relação de Equivalência no
conjunto A = { a , b , c , d , e , f }:
Classe de Equivalência segundo uma Relação de Equivalência R dos
elementos de um conjunto A é definida como sendo um conjunto formado por todos
os elementos de A que estão na relação R com xRa.
Por exemplo, seja o conjunto A = { 0 , 1 , 2 , 3 } e a Relação de Equivalência:
R = { ( 0 , 0 ) , ( 0 , 2 ) , ( 1 , 1 ) , ( 1 , 3 ) , ( 2 , 0) , ( 2 , 2 ) , ( 3 , 1 ) , ( 3 , 3 ) }
b
a
c
d
f
e
A

Página 75
As Classes de Equivalência segundo R dos elementos de A, representadas
por ClR(a), são:
ClR(0) = { 0 , 2 } ; ClR(1) = { 1 , 3 } ; ClR(2) = { 2 , 0 } ; ClR(3) = { 3 , 1 }
Nesse caso específico, ClR(0) = ClR(2) e ClR(1) = ClR(3).
Ao conjunto de todas as Classes de Equivalência segundo uma Relação de
Equivalência R dos elementos de um conjunto A dá-se o nome de Conjunto-
Quociente. No exemplo dado, seguindo a notação matemática, tem-se:
A / R = { ClR(0) , ClR(1) }

Página 76
3.8 - Partição de um Conjunto
Tudo que foi mostrado até o momento nesse trabalho serviram como
embasamento para o que agora é apresentado. O conceito de Partição de um
Conjunto está intimamente ligado, pelo lado matemático, ao conceito da
Classificação em Geografia. Como se demonstrou, a base matemática conceitual da
Classificação reside na Teoria de Conjuntos, particularmente nos temas relativos às
Relações Binárias.
Dado um conjunto A não vazio, uma partição P de A é também um conjunto
cujos elementos são subconjuntos de A de forma que:
Cada um dos subconjuntos não é vazio;
Os elementos de um subconjunto não estão presentes em outro
subconjunto;
A reunião de todos os subconjuntos é o próprio conjunto A.
Cada elemento da partição criada é chamado de cela da partição P. Todo
elemento do conjunto A pertence unicamente a uma cela de P.
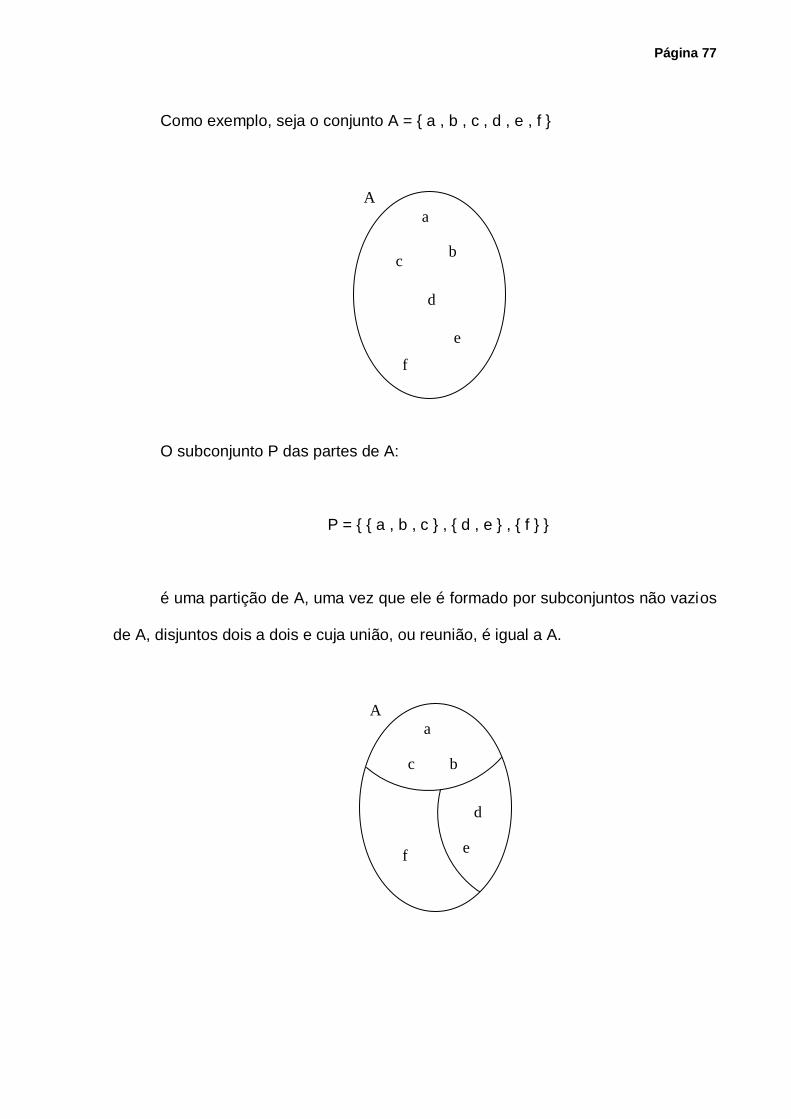
Página 77
Como exemplo, seja o conjunto A = { a , b , c , d , e , f }
O subconjunto P das partes de A:
P = { { a , b , c } , { d , e } , { f } }
é uma partição de A, uma vez que ele é formado por subconjuntos não vazios
de A, disjuntos dois a dois e cuja união, ou reunião, é igual a A.
A
a
b c
d
e
f
A
f
d
e
a
b c

Página 78
Partes de A:
Como outro exemplo, seja A o conjunto formado por elementos inteiros
positivos e definido por:
A = { x ϵ N / 1 ≤ x ≤ 100 }
Sejam também os subconjuntos de A:
P1 = { x ϵ N / 1 ≤ x ≤ 30 }
P2 = { x ϵ N / 30 < x ≤ 60 }
P3 = { x ϵ N / 60 < x ≤ 100 }
O conjunto P = { P1 , P2 , P3 } é uma partição de A porque P1, P2 e P3 não
são vazios, nenhum elemento x de qualquer subconjunto está presente em outro
subconjunto e ( P1 U P2 U P3 ) = A.
a
b c d
e
f
P1 P2 P3
P
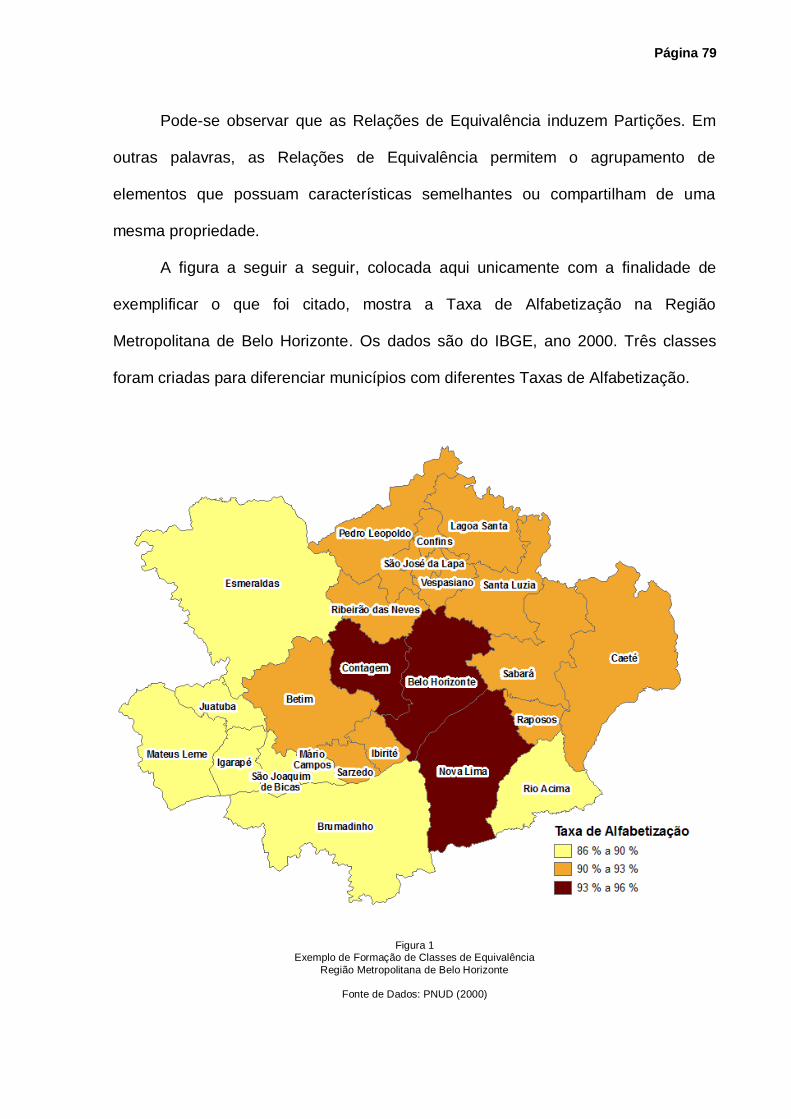
Página 79
Pode-se observar que as Relações de Equivalência induzem Partições. Em
outras palavras, as Relações de Equivalência permitem o agrupamento de
elementos que possuam características semelhantes ou compartilham de uma
mesma propriedade.
A figura a seguir a seguir, colocada aqui unicamente com a finalidade de
exemplificar o que foi citado, mostra a Taxa de Alfabetização na Região
Metropolitana de Belo Horizonte. Os dados são do IBGE, ano 2000. Três classes
foram criadas para diferenciar municípios com diferentes Taxas de Alfabetização.
Figura 1
Exemplo de Formação de Classes de Equivalência
Região Metropolitana de Belo Horizonte
Fonte de Dados: PNUD (2000)

Página 80
Em uma definição matemática, sendo M o conjunto formado por todos os
municípios ( m ) da Região Metropolitana de Belo Horizonte (RMBH) e a Taxa de
Alfabetização de cada município, tem-se:
M = { m ϵ RMBH }
Os subconjuntos de M podem ser definidos por meio das Partições P1, P2 e
P3, definidas como:
P1 = { m ϵ RMBH / 86 ≤ Taxa de Alfabetização ≤ 90 }
P2 = { m ϵ RMBH / 90 < Taxa de Alfabetização ≤ 93 }
P3 = { m ϵ RMBH / 93 < Taxa de Alfabetização ≤ 96 }
Como se observa, P1, P2 e P3 são partições de M porque P1, P2 e P3 não
são vazios, nenhum elemento m de qualquer subconjunto está presente em outro
subconjunto e ( P1 U P2 U P3 ) = M.
O conjunto P, formado pelas Partições P1, P2 e P3, são classes de
Equivalência do Conjunto M. Cada uma delas possui um atributo, ou característica,
no caso a Taxa de Alfabetização, que são próprias, que a tornam distinguível.

Página 81
A formação de partições é a base da classificação e, nesse caso,
representam uma hierarquia de classes. Uma Classe, por sua vez, é base para a
formação (ou definição) de uma região ou uma tipologia. Se existe uma continuidade
de espaço, tem-se uma região, se não, uma tipologia, entendidas aqui como um
estudo de um determinado tipo de atributo encontrado em um espaço que pode ser
encontrado em outro espaço, constituindo-se em um padrão.
O cerne é a Relação de Equivalência, mas ela não se estabelece de forma
aleatória. Existem muitas formas de se criar uma partição, de se estabelecer as
regras da Relação de Equivalência que induzirão à partição. No caso da figura
mostrada, apenas por conveniência, ela foi feita manualmente, em intervalos iguais,
já que não se trabalhou uma aplicação específica.
Existem inúmeras técnicas que podem ser aplicadas para a formação de
partições e, portanto, de classes. As classes são baseadas em agrupamentos
inerentes aos dados. O objetivo, de maneira geral, é maximizar as semelhanças
dentro de cada classe e maximizar as diferenças entre as classes. O recurso se
baseia, em princípio, em estabelecer intervalos, segundo limites estabelecidos, onde
existam relativamente grandes saltos nos valores dos dados. Muitas vezes critérios
estatísticos são estabelecidos, como análise do espectro de freqüência dos dados,
entre outros.
Vale repetir que o número de classes e a escolha da técnica utilizada para o
estabelecimento das classes é critério específico do pesquisador e da área, do
objeto em estudo.
Existem também outras técnicas matemáticas e estatísticas que servem ao
propósito de se estabelecer o conjunto de partida para a classificação. No exemplo
dado utilizou-se somente uma variável, a Taxa de Alfabetização. A estatística

Página 82
multivariada, por exemplo, pode fornecer elementos capazes de analisar mais de
uma variável ao mesmo tempo, como já se disse. A Análise de Componentes
Principais e a Análise de Agrupamentos são exemplos de técnicas multivariadas e
são tratadas a partir de agora.

Página 83
Capítulo 4
A Análise de Agrupamentos
A Análise de Agrupamentos é um conjunto variado de técnicas e algoritmos
que objetivam identificar e agrupar objetos segundo a similaridade sobre algum
atributo ou característica particular que possuem. Ela vem sendo utilizada em muitas
áreas do conhecimento humano, principalmente para identificação de padrões de
comportamento nos dados de observações. Também na Geografia, uma
organização feita através da divisão desses dados em grupos ou classes pode
possibilitar uma melhor compreensão de um fenômeno, facilitando sua interpretação
e, mais tarde, sua representação.
Separar objetos em grupos similares, principalmente considerando apenas
uma característica em particular, é uma atividade comum e intuitiva, e está presente
no cotidiano do homem em qualquer coisa que faça e que requeira algum tipo de
organização. No entanto, quando existe a necessidade de se analisar mais de uma
característica simultaneamente, identificar grupos de objetos passa a ser trabalhoso,
exigindo conceitos mais sofisticados de semelhança e procedimentos mais
“científicos” para se criar os agrupamentos (Bassab et al., 1990). A Análise de
Agrupamentos trabalha essa necessidade.
Segundo Everitt (1974), o problema básico que a Análise de Agrupamentos
pretende resolver é, “dada uma amostra de “n” objetos (ou indivíduos), cada um
deles segundo “p” variáveis, procurar um esquema de classificação que agrupe os
objetos em “g” grupos. Devem ser determinados também o número e as
características desses grupos”.

Página 84
Hair et al. (2005), de forma análoga, dizem que a Análise de Agrupamentos é
uma técnica analítica para a criação de grupos de indivíduos que objetiva classificar
uma amostra de objetos em um pequeno número de grupos mutuamente
excludentes, com base nas similaridades entre eles.
De fato, os algoritmos voltados para a Análise de Agrupamentos buscam
particionar um conjunto de dados formando subconjuntos, ou grupos, de tal forma
que os indivíduos, ou observações, presentes em um grupo, tenham alto grau de
similaridade entre eles, enquanto que indivíduos pertencentes a diferentes grupos
tenham alto grau de dissimilaridade.
Existem diversas etapas que precisam ser seguidas na realização da Análise
de Agrupamentos sobre um conjunto de dados. Sneath (1967) apontou essa
necessidade. Bassab et al. (1990) também propõem uma estrutura apropriada para
a aplicação das técnicas de agrupamento, podendo ser decomposta nas etapas
seguintes:
1. Definição de objetivos, critérios, escolha de variáveis e objetos;
2. Obtenção dos dados;
3. Tratamento dos dados;
4. Escolha dos critérios de similaridade ou dissimilaridade;
5. Adoção e execução de um algoritmo para o agrupamento;
6. Apresentação dos resultados;
7. Avaliação e interpretação dos resultados.
Nessa estrutura, as etapas não são independentes. Ao contrário, pode ser
necessário voltar a etapas anteriores para se corrigir ou aprimorar etapas

Página 85
posteriores.
Nas primeiras etapas são definidos os objetivos que se pretendem alcançar
com a utilização da Análise de Agrupamentos. Aqui também são conhecidas as
variáveis de análise e suas características no contexto do estudo. As variáveis
também são consideradas quanto à escala em que se encontram e se são variáveis
quantitativas ou qualitativas, derivadas, compostas, discretas ou contínuas, nominais
ou ordinais. Se necessário as variáveis podem ser padronizadas para que se tornem
adimensionais.
Na quarta etapa são feitas as principais opções da Análise de Agrupamentos.
Se não for um dos objetivos a criação de um número já determinado de
agrupamentos, opta-se, na maioria das vezes, pelas Técnicas Hierárquicas. Em
contrapartida, se um determinado número de agrupamentos se faz necessário, opta-
se pelo uso das Técnicas de Partição.
Uma vez escolhida qual técnica de partição que será utilizada é necessário
definir a medida de distância, ou seja, o Coeficiente de Similaridade ou de
Dissimilaridade.
Na quinta etapa aplicam-se diferentes algoritmos com o objetivo de se criarem
agrupamentos preliminares. Diversos algoritmos podem ser utilizados até que se
defina qual o mais adequado. Nesses casos, a experiência do pesquisador influi na
definição da técnica a ser utilizada e isso é muito comum. Na criação dos
agrupamentos, é importante que se diga, o que se quer garantir é que elementos
pertencentes a um mesmo grupo apresentem comportamentos semelhantes e que
elementos pertencentes a grupos diferentes apresentem comportamentos distintos.
Para se avaliar os agrupamentos, as demais etapas se utilizam de
Dendogramas, Matrizes Cofenéticas e Gráficos, por exemplo.

Página 86
4.1 - Exemplo de Cálculo de Agrupamentos
Com o objetivo de proporcionar um exemplo da aplicação da Análise de
Agrupamentos, será definida uma situação problema que pretende investigar a
estrutura de educação nos estados da região sudeste do Brasil. A situação tem
caráter ilustrativo, embora trabalhe com dados censitários do ano 2000, obtidos no
Atlas do Desenvolvimento Humano no Brasil (PNUD - Programa das Nações Unidas
para o Desenvolvimento). O que se quer nesse momento é exemplificar a aplicação
de uma técnica para o agrupamento das observações, ou registros, sobre os
estados da região.
Um pesquisador poderia definir dois indicadores próximos das características
do tema de estudo, por exemplo, a Renda Per Capita e a Taxa de Alfabetização de
Adultos, como mostra a tabela a seguir:
Renda Per Capita Taxa de Alfabetização
Espírito Santo 289,593 88,334
Minas Gerais 276,557 88,036
Rio de Janeiro 413,94 93,362
São Paulo 442,673 93,365
A Renda Per Capita é medida em Reais e a Taxa de Alfabetização em valores
percentuais.
Os dados trabalhados podem apresentar grandezas e unidades de medida
muito diversificadas e isso pode induzir imprecisões nos resultados. Um bom
procedimento, portanto, é padronizar esses dados, tornando-os adimensionais.

Página 87
Para isso pode-se fazer uso da média aritmética e do desvio padrão das
variáveis. As propriedades dessa transformação são muito conhecidas na
Estatística.
A padronização de cada variável pode ser calculada, por meio da equação:
xS
mXxZ
(4.1)
onde:
Z é o valor da variável padronizada,
x é o valor da variável a ser padronizada,
xS é o desvio padrão da variável considerada e
mX é a média aritmética da variável considerada.
A média aritmética é uma medida de tendência central cuja fórmula é:
n
x
mX
n
i
i 1 (4.2)
onde:
mX é a média da variável considerada,
ix é o valor de cada observação da variável considerada e
n é o número total de observações.

Página 88
O desvio padrão de cada variável é obtido calculando-se a raiz quadrada da
sua variância, que mede a dispersão dos dados observados para uma variável com
relação à sua média aritmética. A variância é igual à soma dos quadrados dos
desvios dividida pelo número de observações (considerando a população total de
dados e não uma amostra desses dados).
A fórmula para o cálculo do desvio padrão é a seguinte:
n
i
i
xn
mXxS
1
2)( (4.3)
onde:
xS é o desvio padrão da variável considerada,
mX é a média aritmética da variável considerada,
ix é o valor de cada observação da variável considerada e
n é o número total de observações.
Para os dados do problema, tem-se, então a matriz de dados padronizada:
Renda Per Capita Taxa de Alfabetização ZRenda Per Capita ZTaxa Alfabetização
Espírito Santo 289,59 88,334 -0,779 -0,816
Minas Gerais 276,55 88,036 -0,933 -0,915
Rio de Janeiro 413,94 93,362 0,687 0,865
São Paulo 442,67 93,365 1,025 0,866
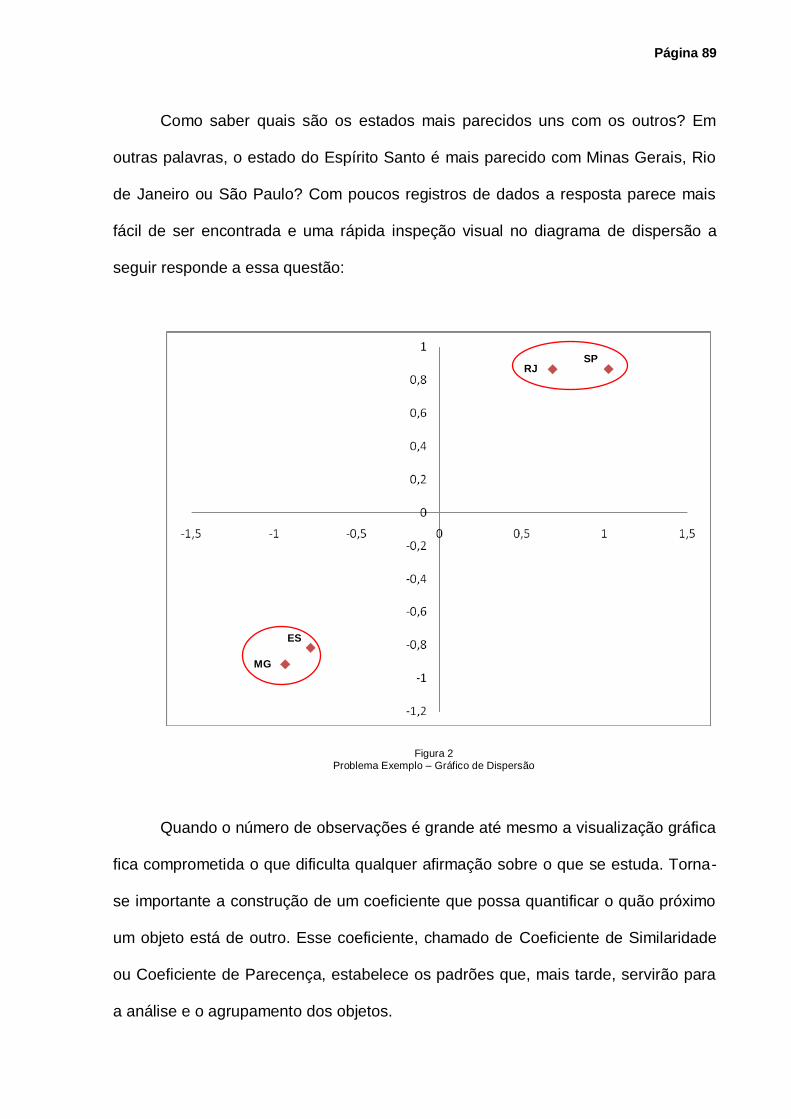
Página 89
Como saber quais são os estados mais parecidos uns com os outros? Em
outras palavras, o estado do Espírito Santo é mais parecido com Minas Gerais, Rio
de Janeiro ou São Paulo? Com poucos registros de dados a resposta parece mais
fácil de ser encontrada e uma rápida inspeção visual no diagrama de dispersão a
seguir responde a essa questão:
Quando o número de observações é grande até mesmo a visualização gráfica
fica comprometida o que dificulta qualquer afirmação sobre o que se estuda. Torna-
se importante a construção de um coeficiente que possa quantificar o quão próximo
um objeto está de outro. Esse coeficiente, chamado de Coeficiente de Similaridade
ou Coeficiente de Parecença, estabelece os padrões que, mais tarde, servirão para
a análise e o agrupamento dos objetos.
MG
ES
RJ SP
Figura 2 Problema Exemplo – Gráfico de Dispersão

Página 90
Considera-se Coeficiente de Similaridade aquele cujo maior valor observado
representa a maior proximidade. Em contrapartida, o Coeficiente de Dissimilaridade
indica que quanto maior for o valor observado menor é a proximidade e menos
parecidos são aqueles objetos.
O Coeficiente de Correlação, por exemplo, é uma medida quantitativa que
representa o Coeficiente de Similaridade. A Distância Euclidiana já representa o
Coeficiente de Dissimilaridade. Segundo Bassab et al. (1990), em geral os
Coeficientes de Dissimilaridade são mais adequados para as variáveis quantitativas.
A Distância Euclidiana será utilizada nesse momento para quantificar a
distância entre os objetos. A Distância Euclidiana entre dois pontos, A e B, de
coordenadas respectivas ),( 11 yx e ),( 22 yx é definida como:
2
)(2)(1
2
)(2)(1))(( )()( BABABA yyxxd (4.4)
Dessa forma, a distância entre o estado do Espírito Santo e Minas Gerais é:
183,0)036,88334,88()55,27659,289( 22 d

Página 91
Aplicando-se essa forma para todos os pares da matriz de dados obtêm-se a
matriz de distâncias a seguir, também chamada de Matriz de Similaridade ou Matriz
de Parecença:
ES MG RJ SP
ES 0
MG 0,183 0
RJ 2,230 2,406 0
SP 2,466 2,647 0,339 0
Por se tratar de uma matriz simétrica, os elementos acima da diagonal
principal foram omitidos.
A distância entre o Espírito Santo e Minas Gerais, expressa pelo valor 0,183 ,
é a menor distância entre todas as calculadas. Isso significa que os dois estados
devem ser agrupados. O Nível desse agrupamento é de 0,183 .
A partir desse momento apenas três objetos participam da análise. O
primeiro, RJ, o segundo, SP e o terceiro, o grupo formado por ES e MG.
É necessário reconstruir a Matriz de Similaridade. Como os objetos RJ e SP
não sofreram alterações, as distâncias entre eles permanecem as mesmas. É
necessário calcular a distância de RJ e SP para o grupo ES – MG. A distância entre
dois grupos deve ser calculada por meio da média entre os valores das distâncias
dos objetos de um dos grupos com os do outro.

Página 92
Assim, a distância entre RJ, por exemplo, e o grupo ES – MG pode ser
calculada como:
2
))(())((
))((
MGRJESRJ
MGESRJ
ddd
Portanto,
318,22
406,2230,2))((
MGESRJd
A Matriz de Similaridade, depois de recalculada, é mostrada:
RJ SP ES - MG
RJ 0
SP 0,339 0
ES – MG 2,318 2,557 0
Observa-se que, nesse momento, o menor valor encontrado nessa matriz,
0,339 , corresponde à distância entre RJ e SP, indicando que os dois estados devem
formar um novo grupo, no nível 0,339 .
Seguindo o mesmo princípio mostrado anteriormente, o cálculo da distância
entre os dois grupos mostrados será baseado na média das distâncias:
4
))(())(())(())((
))((
MGSPESSPMGRJESRJ
MGESSPRJ
ddddd

Página 93
Isso finaliza a construção da Matriz de Similaridade, quando os dois grupos,
RJ – SP e ES – MG são agrupados no nível 2,437 :
RJ – SP ES – MG
RJ – SP 0
ES – MG 2,437 0
A escolha de um determinado algoritmo de agrupamento exige o
conhecimento de suas propriedades frente aos objetivos do que se estuda (Bassab
et al., 1990). No exemplo dado, a Distância Euclidiana foi utilizada como coeficiente
de similaridade, mas muitos outros poderiam ter sido trabalhados.
Esse processo é dito Hierárquico. Em cada passo a Matriz de Similaridade
diminui uma dimensão através da reunião de pares semelhantes até que todos os
pontos sejam reunidos em um único grupo.
Uma representação gráfica muito útil e muito utilizada em Análise de
Agrupamentos é o “Dendograma”. Trata-se de uma estrutura gráfica em forma de
uma árvore que mostra os agrupamentos obtidos e o nível de similaridade entre os
grupos. Essas estruturas, como afirmam Johnson e Wichern (1998), são utilizadas
para representar as junções (métodos hierárquicos) ou divisões (métodos de
partição) que ocorreram a partir de valores provenientes da Matriz de Distâncias.
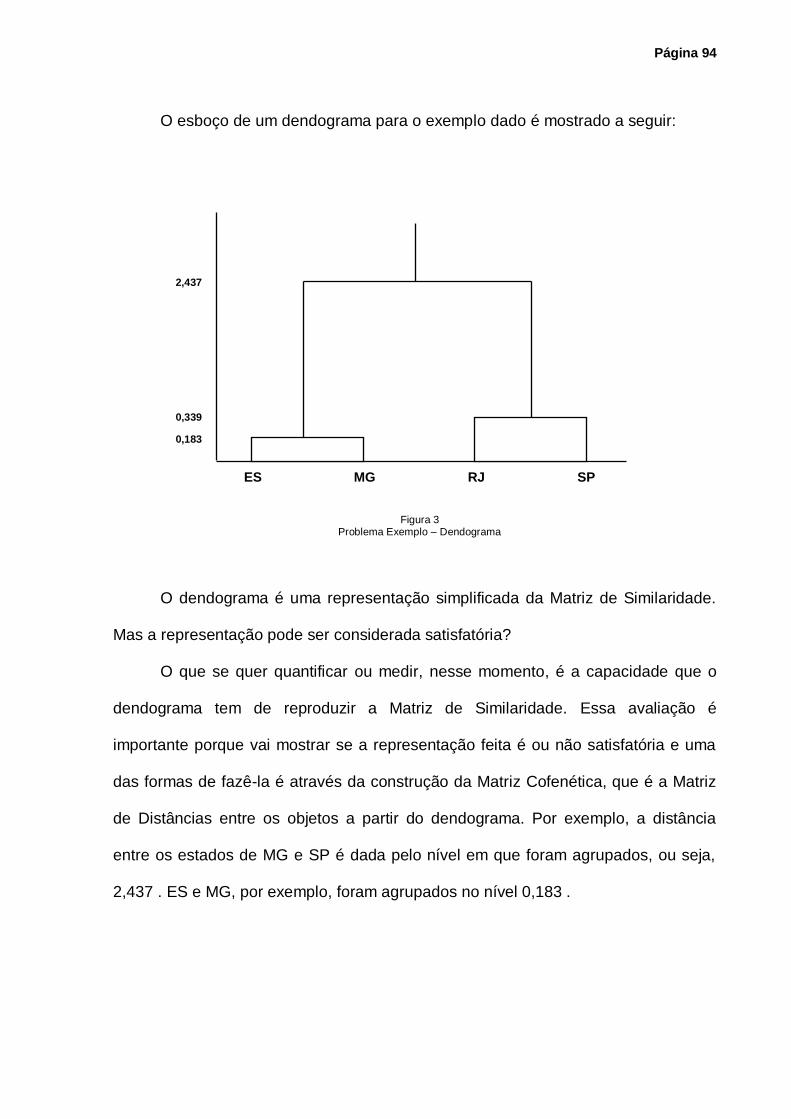
Página 94
O esboço de um dendograma para o exemplo dado é mostrado a seguir:
O dendograma é uma representação simplificada da Matriz de Similaridade.
Mas a representação pode ser considerada satisfatória?
O que se quer quantificar ou medir, nesse momento, é a capacidade que o
dendograma tem de reproduzir a Matriz de Similaridade. Essa avaliação é
importante porque vai mostrar se a representação feita é ou não satisfatória e uma
das formas de fazê-la é através da construção da Matriz Cofenética, que é a Matriz
de Distâncias entre os objetos a partir do dendograma. Por exemplo, a distância
entre os estados de MG e SP é dada pelo nível em que foram agrupados, ou seja,
2,437 . ES e MG, por exemplo, foram agrupados no nível 0,183 .
ES MG RJ SP
0,183
0,339
2,437
Figura 3 Problema Exemplo – Dendograma

Página 95
Para o problema apresentado, a Matriz Cofenética é, portanto:
ES MG RJ SP
ES 0
MG 0,183 0
RJ 2,437 2,437 0
SP 2,437 2,437 0,339 0
A proximidade da Matriz Cofenética com a Matriz de Similaridade pode ser
medida por meio do cálculo do Coeficiente de Correlação Cofenética, que pode ser
expresso como:
n
i
i
n
i
i
n
i
ii
mYymXx
mYymXx
Ccof
1
2
1
2
1
)(.)(
))((
(4.5)
onde:
cofC é o Coeficiente de Correlação Cofenética,
ix é o valor da variável na Matriz de Similaridade em cada observação,
iy é o valor da variável na Matriz Cofenética em cada observação,
mX e mY são as médias aritméticas das variáveis consideradas;
n é a dimensão da matriz.

Página 96
Quanto mais próximo da unidade estiver o valor do Coeficiente de Correlação
Cofenético, mais próximas estarão as duas matrizes, ou seja, melhor será a
representação fornecida pelo Dendograma e, por conseqüência, melhor também
será o resultado da Análise de Agrupamentos feita sobre os dados originais.
Segundo Bassab et al. (1990), é conveniente aceitar Coeficientes de
Correlação Cofenéticos acima de 0,80 . Dependendo da matriz de dados esse valor
pode ser revisto. No exemplo dado esse coeficiente foi de 0,98 , revelando uma
ótima representação.
Existem outras formas de avaliação que podem ser utilizadas. Cormack
(1971), apud Bassab et al. (1990), enumera outras medidas de distorção entre
agrupamentos, como a de Sokal e Rohlf (1962), Guttman (1968), Gower (1966 e
1970), Jardine (1967), Hartigan (1967), Anderson (1971), Shepard (1962) e Sammon
(1969).

Página 97
4.2 - Coeficientes de Similaridade e de Dissimilaridade
Um conceito fundamental na Análise de Agrupamento reside na escolha de
um critério para medir a distância entre objetos ou quantificar sua similaridade.
Segundo Sneath e Sokal (1973), agrupar é constatar uma distância mínima ou de
alta correlação dentro de um padrão. Como afirma Azambuja (2005), para se
construir um simples grupo a partir de um conjunto de elementos é necessário
utilizar algum critério de proximidade ou tipo de medida que possibilite a comparação
entre os componentes desse conjunto, tornando possível verificar se um dado
elemento A é mais parecido com B do que com C.
É necessária a definição de um coeficiente de mensuração que quantifique a
distância entre os objetos da análise e mostre o quanto dois elementos de um
conjunto são similares.
Essa medida é chamada, como já citado anteriormente, de Coeficiente de
Similaridade ou Coeficiente de Parecença. É importante observar que é possível se
estabelecer também o conceito e o termo Coeficiente de Dissimilaridade. O
Coeficiente de Similaridade é aquele cujo maior valor observado represente a maior
proximidade, como é o caso do Coeficiente de Correlação. O Coeficiente de
Dissimilaridade indica que quanto maior for o valor observado menor é a
proximidade e menos parecidos são aqueles objetos, como é o caso da Distância
Euclidiana.
Alguns coeficientes se adaptam melhor a determinadas situações de estudo e
análise. Também, como já citado anteriormente, os Coeficientes de Dissimilaridade
são mais adequados para as variáveis quantitativas, e os de Similaridade para as

Página 98
variáveis qualitativas. Escolhido o coeficiente, torna-se possível construir a Matriz de
Distâncias, que é de onde surgirão os grupos.
Toda característica, ou evento da natureza que apresente mais de uma
realização possível, poderá ser representado através de uma variável, a qual se
refere convencionalmente, ao conjunto de resultados possíveis de um fenômeno
(Azambuja, 2005). As variáveis são classificadas, dicotomicamente, em Qualitativas
ou Quantitativas.
Uma variável Quantitativa é aquela que apresenta como possíveis realizações
números oriundos de uma contagem, de uma medição ou de uma apuração. As
variáveis quantitativas podem ser discretas, se o conjunto de valores que ela pode
assumir for um conjunto finito ou infinito enumerável, ou podem ser contínuas, se o
conjunto de valores que ela pode assumir for um conjunto infinito não enumerável
(Bussab e Morettin, 2003, apud Azambuja, 2005).

Página 99
4.3 - Coeficientes Utilizados para Variáveis Quantitativas
A Distância Euclidiana é o Coeficiente de Dissimilaridade mais conhecido e
mais utilizado para indicar a distância entre objetos de análise. Trata-se,
objetivamente, da distância geométrica entre dois pontos no espaço. Cada
observação é tomada como sendo um ponto e o cálculo do coeficiente representa a
distância física entre cada uma delas.
Em termos matemáticos, tem-se:
2
)(2)(1
2
)(2)(1))(( )()( BABABA yyxxd (4.6)
Onde:
))(( BAd é a Distância Euclidiana entre duas observações, A e B,
)(1 Ax , )(1 Ay são as coordenadas do ponto A e
)(2 Bx , )(2 By são as coordenadas do ponto B.

Página 100
Generalizando, tem-se:
p
i
BiAiBA xxd1
2
)()())(( )( (4.7)
Onde:
))(( BAd , é a distância euclidiana e
)( Aix e )(Bix são os pontos considerados
A Distância Euclidiana apresenta simplicidade de cálculo e a distância entre
quaisquer dois objetos não é afetada pela inserção de outros objetos ao conjunto de
dados de análise. No entanto é conveniente que os dados sejam padronizados para
que se evitem erros provocados pelas diferenças de escala associadas a
dimensões.
Algumas medidas derivadas da Distância Euclidiana podem ser definidas.
A Distância Euclidiana Média ))(( BAdDEM , também muito utilizada na Análise
de Agrupamentos é definida como:
p
xx
dDEM
p
i
BA
BA
1
2
)(2)(1
))((
)(
(4.8)
Onde p é o número de pontos considerados, como também nas demais
fórmulas dessa seção.

Página 101
A Distância Euclidiana Quadrática ))( BAdDEQ é definida por:
p
xx
dDEQ
p
i
BA
BA
1
2
)(2)(1
))((
)(
(4.9)
Essa distância é o quadrado da Distância Euclidiana, como o próprio nome
diz, e é mais influenciada por aqueles objetos localizados a uma distância maior.
A Distância Manhattan ))(( BAdMAN , também chamada de Métrica Quarteirão, é
outra medida utilizada na Análise de Agrupamentos. Ela é calculada através da
soma do valor absolutos das diferenças entre as observações. Ela é definida como:
|| )()(
1
))(( BiAi
p
i
iBA xxwdMAN
(4.10)
Onde:
iw é uma ponderação que pode ser aplicado a cada dupla de variáveis.
O Coeficiente de Gower, ))(( BAdGOW , é baseado na proporção da variação em
relação à maior discrepância possível entre as observações:
p
i MiniMaxi
BiAi
BAxx
xx
pdGOW
1
)()(
10))((
||11log (4.11)

Página 102
O Coeficiente de Cattel, ))(( BAdCAT , utiliza a Distância Euclidiana com
variáveis padronizadas:
))((
))((
))((
)3
2(2
)3
2(2
BA
BA
BA
dp
dp
dCAT
(4.12)
Alguns coeficientes são baseados no fato do critério de similaridade assumir
valores estritamente positivos. É o caso do Coeficiente de Canberra, do Coeficiente
de Bray-Curtis e do Coeficiente de Sokal e Sneath, respectivamente definidos como:
p
i BiAi
BiAi
BAxx
xx
pdCanberra
1 )()(
)()(
))((
||1 , (4.13)
p
i BiAi
BiAi
BAxx
xxCurtisdBray
1 )()(
)()(
))((
||, (4.14)
2
1
2
1 )()(
)()(
))((
1
p
i BiAi
BiAi
BAxx
xx
pSneathdSokal (4.15)
Existem diversos coeficientes também trabalhados na Análise de
Agrupamentos. Alguns ainda poderiam ser citados como a Distância de Minkowsky,
a Distância de Chebyshev, dentre outros. Referencias sobre os coeficientes citados
e outros aqui não citados podem ser encontrados em Bassab et al. (1990) e Sneath
e Sokal (1973).

Página 103
4.4 - Coeficientes Utilizados para Variáveis Qualitativas
Uma variável é considerada qualitativa quando seu valor se apresenta como
uma qualidade ou atributo. Segundo Bassab et al. (1990), é freqüente o uso de
critérios qualitativos na procura de elementos semelhantes, daí a necessidade de se
definir coeficientes capazes de estabelecer o grau de similaridade entre objetos de
análise. Azambuja (2005), de forma análoga, diz que na área das Ciências Sociais, é
freqüente a utilização de técnicas estatísticas para a análise de variáveis
qualitativas. A Análise de Agrupamento também aplica as técnicas nos dados
qualitativos para gerar outros dados, ou seja, ela utiliza as variáveis qualitativas, e
também as quantitativas, para subsidiar seus objetivos que se apresentam
focalizados na identificação daqueles elementos que possuem uma mesma
categoria de comportamento no conjunto das observações analisadas.
As variáveis dicotômicas são aquelas que podem assumir somente um valor
(nominal ou ordinal), dentre dois valores possíveis. O fator RH do sangue, por
exemplo, ou é positivo ou é negativo. O sexo, masculino ou feminino, também é
outro exemplo. No entanto os valores dessas variáveis podem ser substituídos pelos
números 1 e 0 para facilitar análises e representações gráficas, comuns na
estatística. Quando isso ocorre essas variáveis ganham o nome de binárias.
Para as variáveis binárias os coeficientes de similaridade são baseados na
contagem das concordâncias positivas e negativas existentes entre os elementos da
análise. Embora seja possível tomar-se como medida o número de discordâncias,
isso é pouco usual, como aponta Bassab et al. (1990). Os autores também afirmam
que os coeficientes que existem para as variáveis qualitativas surgiram das tabelas
de contingência ou de dupla entrada.
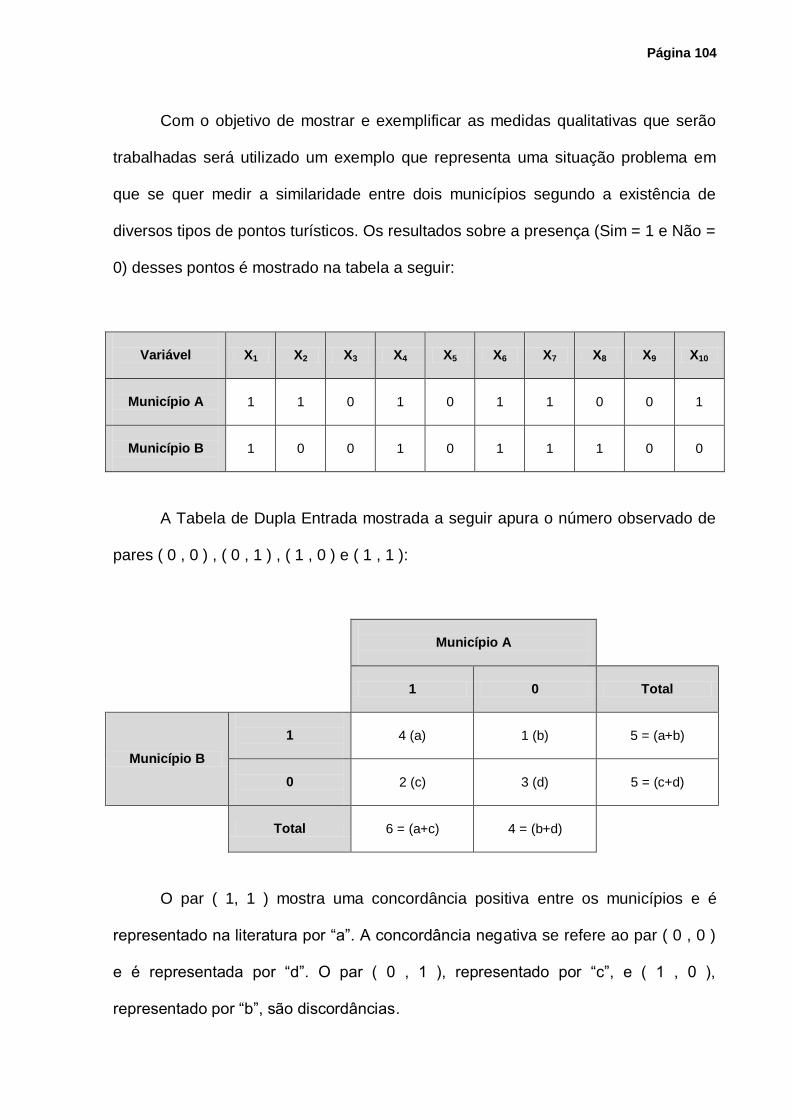
Página 104
Com o objetivo de mostrar e exemplificar as medidas qualitativas que serão
trabalhadas será utilizado um exemplo que representa uma situação problema em
que se quer medir a similaridade entre dois municípios segundo a existência de
diversos tipos de pontos turísticos. Os resultados sobre a presença (Sim = 1 e Não =
0) desses pontos é mostrado na tabela a seguir:
Variável
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
Município A
1 1 0 1 0 1 1 0 0 1
Município B
1 0 0 1 0 1 1 1 0 0
A Tabela de Dupla Entrada mostrada a seguir apura o número observado de
pares ( 0 , 0 ) , ( 0 , 1 ) , ( 1 , 0 ) e ( 1 , 1 ):
Município A
1 0 Total
Município B
1
4 (a) 1 (b) 5 = (a+b)
0
2 (c) 3 (d) 5 = (c+d)
Total 6 = (a+c) 4 = (b+d)
O par ( 1, 1 ) mostra uma concordância positiva entre os municípios e é
representado na literatura por “a”. A concordância negativa se refere ao par ( 0 , 0 )
e é representada por “d”. O par ( 0 , 1 ), representado por “c”, e ( 1 , 0 ),
representado por “b”, são discordâncias.
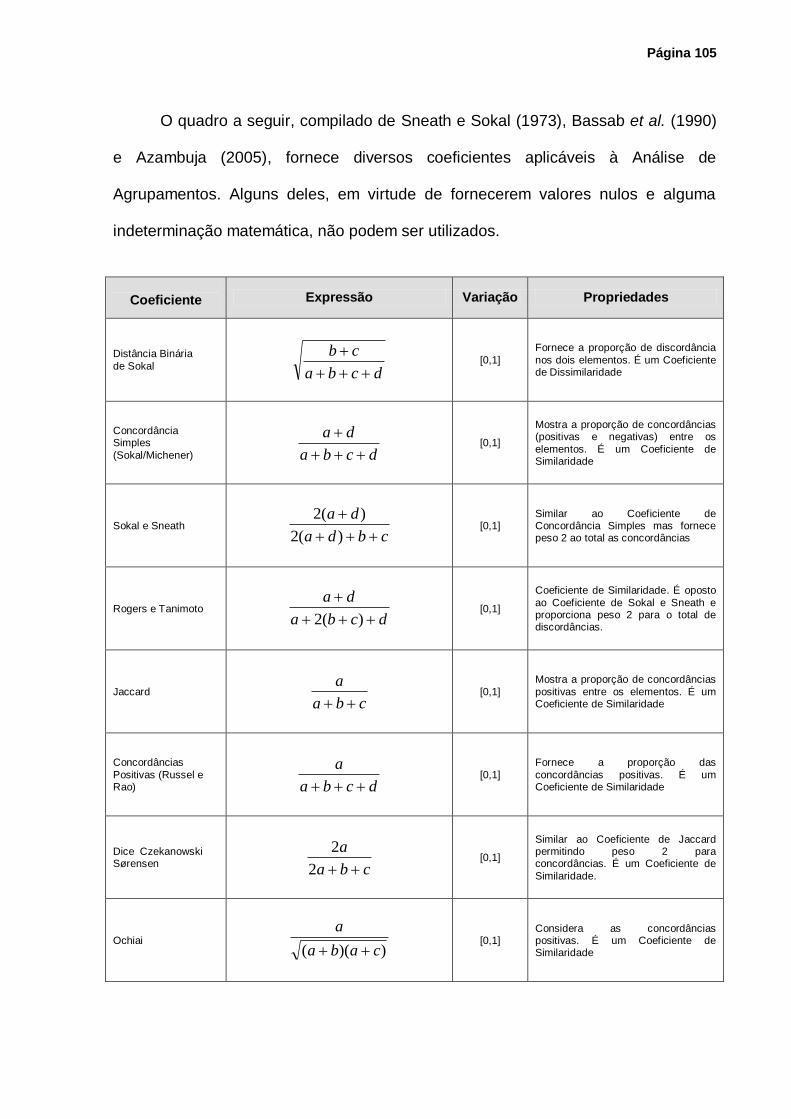
Página 105
O quadro a seguir, compilado de Sneath e Sokal (1973), Bassab et al. (1990)
e Azambuja (2005), fornece diversos coeficientes aplicáveis à Análise de
Agrupamentos. Alguns deles, em virtude de fornecerem valores nulos e alguma
indeterminação matemática, não podem ser utilizados.
Coeficiente
Expressão Variação Propriedades
Distância Binária
de Sokal dcba
cb
[0,1]
Fornece a proporção de discordância
nos dois elementos. É um Coeficiente de Dissimilaridade
Concordância Simples
(Sokal/Michener) dcba
da
[0,1]
Mostra a proporção de concordâncias (positivas e negativas) entre os
elementos. É um Coeficiente de Similaridade
Sokal e Sneath cbda
da
)(2
)(2 [0,1]
Similar ao Coeficiente de Concordância Simples mas fornece peso 2 ao total as concordâncias
Rogers e Tanimoto dcba
da
)(2 [0,1]
Coeficiente de Similaridade. É oposto
ao Coeficiente de Sokal e Sneath e proporciona peso 2 para o total de discordâncias.
Jaccard
cba
a
[0,1]
Mostra a proporção de concordâncias
positivas entre os elementos. É um Coeficiente de Similaridade
Concordâncias
Positivas (Russel e Rao) dcba
a
[0,1]
Fornece a proporção das
concordâncias positivas. É um Coeficiente de Similaridade
Dice Czekanowski Sørensen
cba
a
2
2 [0,1]
Similar ao Coeficiente de Jaccard permitindo peso 2 para concordâncias. É um Coeficiente de
Similaridade.
Ochiai ))(( caba
a
[0,1]
Considera as concordâncias positivas. É um Coeficiente de Similaridade
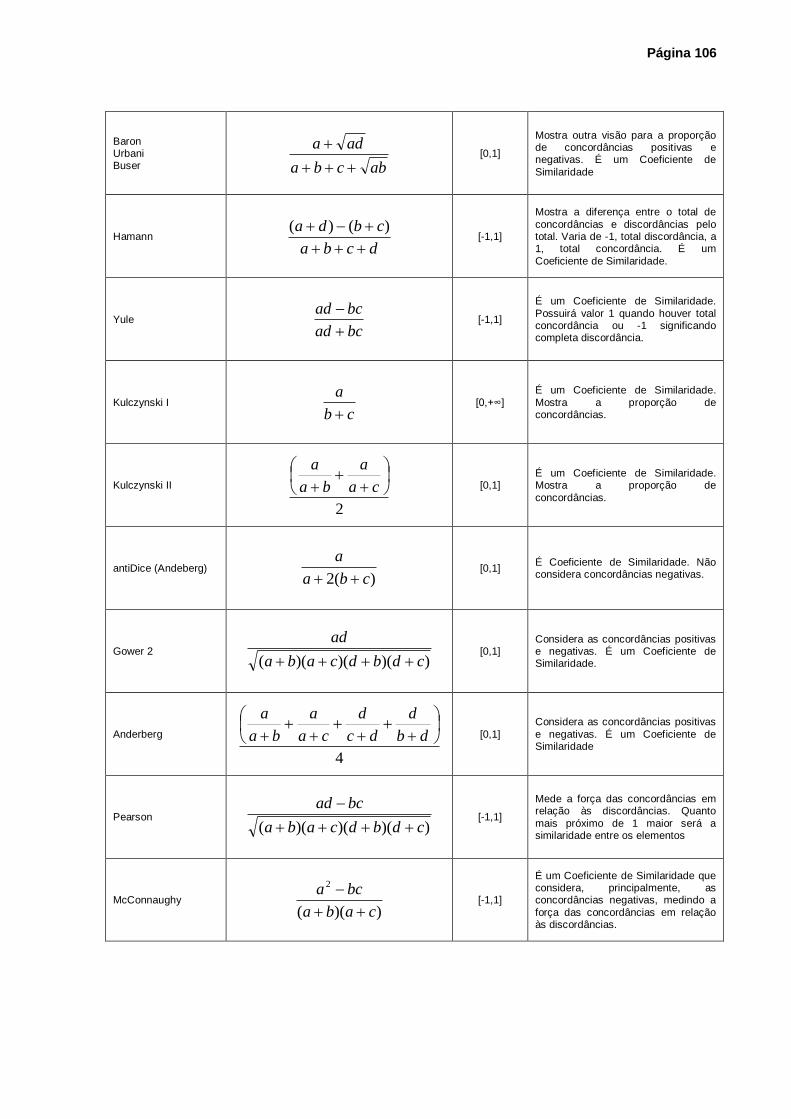
Página 106
Baron Urbani Buser abcba
ada
[0,1]
Mostra outra visão para a proporção de concordâncias positivas e negativas. É um Coeficiente de
Similaridade
Hamann
dcba
cbda
)()( [-1,1]
Mostra a diferença entre o total de
concordâncias e discordâncias pelo total. Varia de -1, total discordância, a 1, total concordância. É um
Coeficiente de Similaridade.
Yule
bcad
bcad
[-1,1]
É um Coeficiente de Similaridade.
Possuirá valor 1 quando houver total concordância ou -1 significando completa discordância.
Kulczynski I
cb
a
[0,+∞]
É um Coeficiente de Similaridade.
Mostra a proporção de concordâncias.
Kulczynski II
2
ca
a
ba
a
[0,1]
É um Coeficiente de Similaridade. Mostra a proporção de
concordâncias.
antiDice (Andeberg) )(2 cba
a
[0,1]
É Coeficiente de Similaridade. Não considera concordâncias negativas.
Gower 2 ))()()(( cdbdcaba
ad
[0,1]
Considera as concordâncias positivas e negativas. É um Coeficiente de Similaridade.
Anderberg
4
db
d
dc
d
ca
a
ba
a
[0,1]
Considera as concordâncias positivas
e negativas. É um Coeficiente de Similaridade
Pearson ))()()(( cdbdcaba
bcad
[-1,1]
Mede a força das concordâncias em relação às discordâncias. Quanto
mais próximo de 1 maior será a similaridade entre os elementos
McConnaughy
))((
2
caba
bca
[-1,1]
É um Coeficiente de Similaridade que considera, principalmente, as concordâncias negativas, medindo a
força das concordâncias em relação às discordâncias.

Página 107
Considerando o exemplo dado, o Coeficiente de Jacard seria:
571,0214
4))((
cba
ad BA
O Coeficiente de Jacard avalia as concordâncias positivas, ou seja, o
resultado obtido indica que os dois municípios apresentam semelhanças quanto à
presença de um tipo de recurso turístico
Até o presente momento consideraram-se variáveis qualitativas dicotômicas,
ou seja, variáveis que poderiam conter um dentre dois valores disponíveis.
Quando a variável qualitativa possui mais de dois níveis o artifício usual é a
sua transformação em variáveis binárias através da criação de variáveis fictícias.
Seja 'y uma variável qualitativa, formada por um vetor de variáveis
qualitativas nominais:
),...,,,(' 321 iyyyyy
O i-ésimo componente assume il níveis codificados de maneira que jy '
com ilj ,...,2,1 .
Supondo que pli , ao transformar essa variável em uma variável binária,
cada componente contribuirá para a geração de il variáveis binárias )(ixk tal que
ky
kyix
i
i
k0
1)(

Página 108
Assim, o vetor y de dimensão l é transformado no vetor x de dimensão p , e
é formado apenas por componentes binários.
Por exemplo, deseja-se medir a semelhança entre dois objetos segundo 4
variáveis nominais com 3, 4, 5 e 6 níveis cada uma. Se as características de dois
objetos, A e B são, respectivamente )5,3,1,2()(' Ay e )3,3,3,3()(' By , tem-se:
)0,1,0,0,0,0;0,0,1,0,0;0,0,0,1;0,1,0()(' Ax
)0,0,0,1,0,0;0,0;1,0,0;0,1,0,0;1,0,0()(' Bx
Em outras palavras, se )5,3,1,2()(' Ay , )(' Ax será um vetor cujo primeiro
elemento conterá 3 elementos (níveis), sendo o segundo (2) igual a 1, seguido de
outros 4 elementos com o primeiro (1) igual a 1, seguido de outros 5 elementos com
o terceiro igual a 1, seguido de outros 6 elementos sendo o quinto igual a 1.
A tabela de dupla entrada será:
A
1 0 Total
B
1
1 3 4
0
3 11 14
Total 4 14

Página 109
Nesse momento o Coeficiente Jacard fornece:
14,0331
1))((
cba
ad BA
A escolha do Coeficiente de Similaridade se mostra muito importante. No
exemplo anterior, por exemplo, a coincidência de zeros deve orientar a escolha de
uma família particular de coeficientes. Além disso, o número de níveis escolhidos de
cada variável pode ser fator de preocupação.
Outra análise se faz necessária nesse momento quando os critérios de
semelhança são estabelecidos por variáveis qualitativas do tipo ordinal. Nesse caso,
uma solução simples, como aponta Bassab et al. (1990), é considerá-la
simplesmente como variáveis qualitativas e aplicar qualquer um dos coeficientes
definidos anteriormente. Esse procedimento deixa de considerar a importante
propriedade da ordem, no entanto.
Para se introduzir a questão da ordem, um artifício se faz necessário. Se uma
variável ordinal, por exemplo, nível de escolaridade, pode assumir os valores 1
(Analfabeto), 2 (Primário), 3 (Secundário) e 4 (Superior), pode-se criar quatro
variáveis binárias, ou seja ),,,( 4321 xxxxy .
Uma pessoa com nível secundário, ou seja, 13 x é considerada, em virtude
da categoria de ordem, portadora das características anteriores 1x e 2x , de forma
que:
Analfabeto Primário Secundário Superior
1 – 0 – 0 – 0 1 – 1 – 0 – 0 1 – 1 – 1 – 0 1 – 1 – 1 – 1
A partir daí a aplicação do processo para variáveis binárias é o mesmo.

Página 110
4.5 - Técnicas de Formação de Agrupamentos
O número de técnicas e algoritmos para a formação de agrupamentos é
grande e diversificado. Um tipo de proposta de organização dessas técnicas é citada
em Everitt (1974) e Cormack (1971), apud Bassab et al. (1990). Segundo os autores,
pode-se dizer que existem três grandes famílias de técnicas voltadas para a
formação de agrupamentos:
Técnicas Hierárquicas, nas quais os objetos, ou observações, são
classificados em grupos em diferentes etapas produzindo uma árvore
de classificação;
Técnicas de Partição, nos quais os grupos obtidos produzem uma
partição no conjunto de objetos;
Técnicas de Cobertura, nos quais os grupos formados recobrem o
conjunto de objetos embora possam também se sobrepor.
Esse trabalho se detém nas duas primeiras técnicas. Na verdade elas se
diferem, basicamente, pela metodologia utilizada para se construir os agrupamentos.
Escolher uma técnica em particular exige não somente o conhecimento de suas
propriedades particulares como também sua adequação aos objetivos do
pesquisador (Bassab et al., 1990).
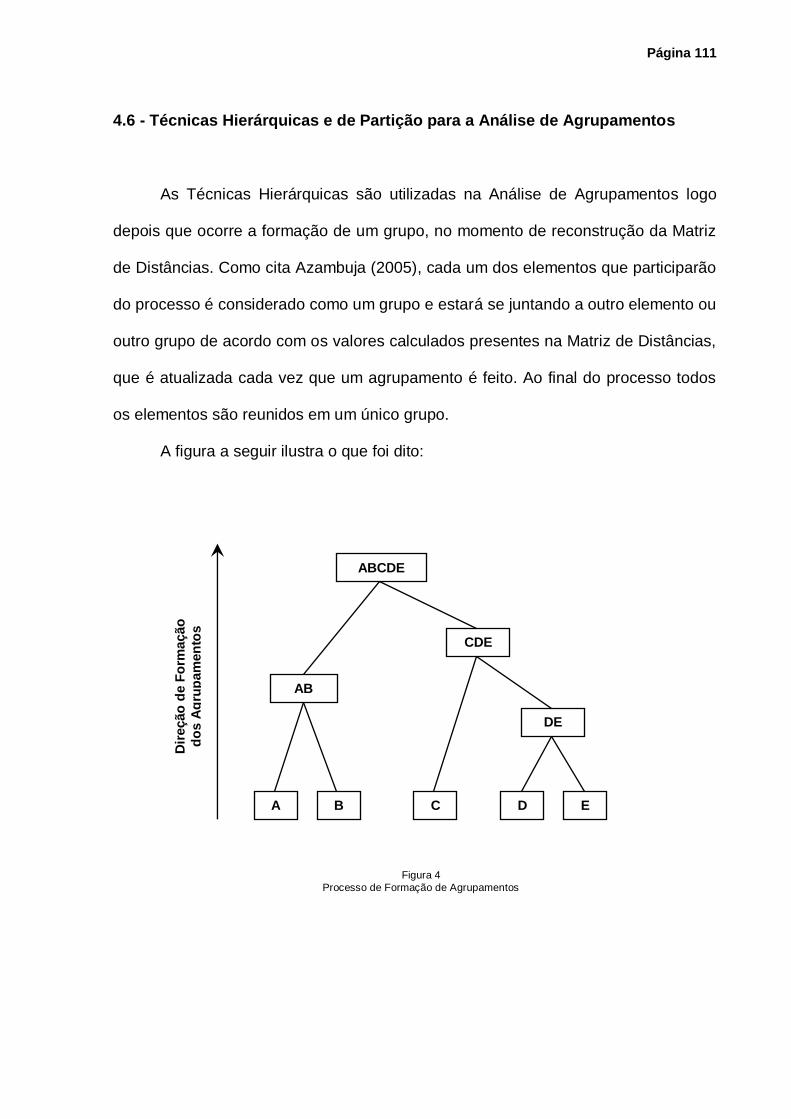
Página 111
4.6 - Técnicas Hierárquicas e de Partição para a Análise de Agrupamentos
As Técnicas Hierárquicas são utilizadas na Análise de Agrupamentos logo
depois que ocorre a formação de um grupo, no momento de reconstrução da Matriz
de Distâncias. Como cita Azambuja (2005), cada um dos elementos que participarão
do processo é considerado como um grupo e estará se juntando a outro elemento ou
outro grupo de acordo com os valores calculados presentes na Matriz de Distâncias,
que é atualizada cada vez que um agrupamento é feito. Ao final do processo todos
os elementos são reunidos em um único grupo.
A figura a seguir ilustra o que foi dito:
A B
AB
D C E
DE
CDE
ABCDE
Figura 4
Processo de Formação de Agrupamentos
Dir
eção
de F
orm
ação
do
s A
gru
pam
en
tos

Página 112
Nas técnicas hierárquicas não se sabe, preliminarmente, a quantidade de
grupos que serão formados. Diferentes técnicas podem formar diferentes
quantidades de grupos. Isso pode ser útil como levantamento preliminar, feito na
fase exploratória da análise.
No contexto desse estudo serão trabalhas as seguintes técnicas, também
chamadas na literatura de métodos hierárquicos:
Método das Médias das Distâncias (Average Linkage)
Método da Ligação Simples (Single Linkage)
Método da Ligação Completa (Complete Linkage)
Método do Centróide (Centroid Distance)
4.6.1 - Método das Médias das Distâncias (Average Linkage)
Esse método foi apresentado no exemplo feito no início desse estudo com a
finalidade de ilustrar a formação de agrupamentos. É uma técnica que possui
facilidade e rapidez de cálculo, principalmente se comparada às outras técnicas.
A figura a seguir ilustra o método aplicado a dois grupos com três elementos
cada um:
Figura 5
Método das Médias das Distâncias
d

Página 113
Como já visto, o Average Linkage utiliza a média das distâncias entre todos
os pares de objetos da matriz de dados para se criar a matriz de distâncias.
Baseando-se nela um grupo é formado e a matriz de distâncias é recalculada
tomando-se esse grupo como novo elemento. Um novo agrupamento é formado e o
processo continua até que apenas um grupo, contendo todos os elementos do
conjunto de dados, seja criado.
Segundo Johnson e Wichern (1998), esse método pode ser afetado se
ocorrer mudança no coeficiente utilizado para os cálculos da matriz de distâncias,
ainda que esse novo coeficiente mantenha a ordem dessas distâncias.
4.6.2 - Método da Ligação Simples (Single Linkage)
Esse método também é conhecido como o Método do Vizinho mais Próximo
ou Método da Distância Mínima. Ele define como similaridade entre dois grupos
aquela formada pelos elementos mais parecidos. Em outras palavras, quando ele é
aplicado para fornecer a distância entre conjuntos de elementos, ele seleciona a
distância que corresponde à maior semelhança entre os elementos de grupos
distintos.
Para exemplificar, sejam os conjuntos A e B de objetos de análise. A distância
entre eles será definida como:
},,min{))(( BjAidd ijBA

Página 114
A figura a seguir representa esse método:
Se o coeficiente utilizado para o cálculo da matriz de distâncias for um
coeficiente de similaridade, a maior semelhança será representada pela maior
distância entre os elementos. Analogamente, se o coeficiente utilizado for de
dissimilaridade a maior semelhança será a menor distância.
Como esse método une grupos segundo uma distância mínima entre eles, os
grupos formados tendem a ser menos homogêneos se comparados ao Método das
Médias das Distâncias. Isso significa que em um mesmo grupo podem ser
encontrados elementos bem distintos. Esse método tende a formar grupos com
vários elementos enquanto isola outros elementos ainda não anexados (Azambuja,
2005).
4.6.3 - Método da Ligação Completa (Complete Linkage)
Esse método é também conhecido como o Método do Vizinho mais Distante.
Nesse caso a similaridade é definida pelos objetos de cada grupo que menos se
d
Figura 6
Método da Ligação Simples ou do Vizinho mais Próximo

Página 115
parecem. Em outras palavras, quando ele é aplicado para fornecer a distância entre
conjuntos de elementos, ele seleciona a distância que corresponde à maior
diferença entre os elementos de grupos distintos.
Para exemplificar, assim como foi feito no método anterior, sejam os
conjuntos A e B de objetos de análise. A distância entre eles será definida como:
},,{))(( BjAidmáxd ijBA
É importante ressaltar que a fusão ainda é feita com os grupos mais similares,
ou seja, que estão a uma menor distância. A figura a seguir ilustra esse método:
Cada vez que um novo elemento é adicionado a um grupo esse se torna mais
distinto em relação aos outros. Esse método, como cita Azambuja (2005), apud
Krzanowski e Marriot (1995), é indicado para a formação de grupos com tamanhos
semelhantes. Ele assegura que as distâncias calculadas, dentre todos os
componentes do grupo, estarão inseridos na distância utilizada em sua formação
(Johnson e Wichern, 1998).
d
Figura 7
Método da Ligação Completa ou do Vizinho mais Distante

Página 116
Esse método forma grupos mais homogêneos que os formados por meio do
Método das Médias das Distâncias e do Método da Ligação Simples. Além disso,
como ressalta Johnson e Wichern (1998), é um método que produz grupos que não
se modificam mesmo quando outro coeficiente é adotado para o cálculo das
distâncias, ou seja, ele mantém a ordenação das distâncias. O Método da Ligação
Simples também possui essa característica.
4.6.4 - Método do Centróide (Centroid Distance)
Esse método é o mais direto no cálculo da distância entre um elemento de um
grupo ou entre dois grupos. Para cada novo grupo formado uma nova distância é
calculada e representa o centro médio dos elementos do grupo. Em outras palavras,
em cada etapa procura-se criar grupos que tenham a menor distância entre si,
sendo essa distância definida entre os centros de cada grupo. A figura a seguir
mostra isso:
d
Figura 8
Método do Centróide

Página 117
Esse método é similar ao Método das Médias das Distâncias. Seus
resultados, em virtude disso, também são similares. A maior dificuldade do método,
no entanto, como ressalta Bassab et al. (1990), é a necessidade de se recuperar os
dados originais, a cada grupo criado, para que seja possível recalcular o valor das
distâncias. Quando muitas variáveis e objetos estão presentes o processo pode se
tornar muito demorado.
Outro problema, em nível computacional, também merece atenção. Os
cálculos feitos a cada iteração podem trazer junções no dendograma com valores
inferiores ao de alguma junção calculada em outra iteração anterior. A junção, que
deveria ser simultânea, não ocorre e o algoritmo precisa supor o mesmo nível da
junção anterior. Na prática, principalmente na presença de muitas variáveis, isso não
é muito comum.
4.6.5 - Método K-Médias
As Técnicas de Partição, como o próprio nome diz, buscam produzir
agrupamentos através de partições do conjunto original de elementos de análise. A
figura a seguir, já utilizada quando se mostrou as técnicas de agrupamento, possui
uma seta vertical em sentido contrário, mostrando a direção de formação de
subconjuntos, ou partições, a partir de um conjunto de dados.

Página 118
Cada partição deve mostrar coesão interna dentro de um mesmo grupo e
isolamento entre os demais grupos. Além disso, as técnicas de partição já precisam
definir o número total de grupos que serão criados antes de sua aplicação.
Um método de partição bastante conhecido e talvez o mais usado em Análise
de Agrupamentos quando se tem muitos objetos (Bassab et al., 1990) é o K-Médias.
O K-Médias é uma técnica de partição que procura alocar os elementos de
dados em K grupos previamente definidos. É um método que minimiza a soma dos
quadrados residuais dentro de cada grupo formado, aumentando a homogeneidade
dentro dele ao mesmo tempo em que aumenta a diferença entre eles. Segundo
Johnson e Wichern (1998), esse método foi introduzido por J. B. MacQueen em
1967.
Figura 9
Processo de Divisão de um Conjunto através das Técnicas de Partição
Dir
eção
de F
orm
ação
das P
art
içõ
es
A B
AB
D C E
DE
CDE
ABCDE

Página 119
O processo algorítmico do método é relativamente simples. Inicialmente é
distribuído um elemento do conjunto de dados para cada grupo definido. Essa
distribuição pode ser feita aleatoriamente ou através dos elementos que apresentem
valores mais distantes de uma variável escolhida (como a média, por exemplo). Essa
última opção é a mais utilizada e mais adequada.
Cada um desses K elementos se torna, então, o elemento central do grupo a
que pertence e representam as sementes dos agrupamentos no momento inicial do
processo. Quando, no decorrer do processo, novos elementos entrarem no grupo, o
elemento central passa a ser a média entre eles. O processo segue designando
cada novo elemento para um determinado grupo, especificamente aquele que
apresente o elemento central mais próximo deste. Ao final da distribuição de todos
os elementos do conjunto de dados nos K grupos a soma dos quadrados residuais
de cada grupo é calculada.
Isso pode ser feito por meio da equação:
2
1
)()(Re
n
i
i mXxksSQ (4.16)
Onde,
k é a quantidade de grupos previamente definida,
)(Re ksSQ é a soma dos quadrados residuais de cada grupo k ,
n é a quantidade de elementos de cada grupo k ,
ix é o i-ésimo elemento de cada grupo k e
mX é a média dos elementos de cada grupo k .

Página 120
Depois que todos os cálculos forem feitos para cada grupo, calcula-se:
.
k
i
ksSQsSQ1
)(ReRe (4.17)
Onde,
k é a quantidade de grupos,
sSQRe é a soma dos quadrados residuais e
)(Re ksSQ é a soma dos quadrados residuais de cada grupo k .
Quanto menor o valor de sSQRe mais homogêneo são os grupos formados.
Nesse momento do processo os elementos de um grupo serão movidos para
outros grupos buscando a formação de grupos os mais homogêneos possíveis.
Cada movimentação implica no recalculo da média do grupo, da soma dos
quadrados residuais de cada grupo, )(Re ksSQ , e a soma dos quadrados gerais para
todos os grupos, sSQRe .
Se sSQRe diminui, indicando aumento da homogeneidade, a movimentação é
mantida e caso contrário ela é desfeita e o objeto movido retorna ao seu grupo
original ou é movido para algum outro grupo, quando o ciclo se inicia novamente.
Quando sSQRe não diminui mais ao longo das iterações (que podem, inclusive, ter
um número determinado), o processo termina. Os grupos são apresentados.
Um exemplo bastante interessante mostrado por Azambuja (2005) ilustra o
método para separar as cores semelhantes em um padrão RGB.
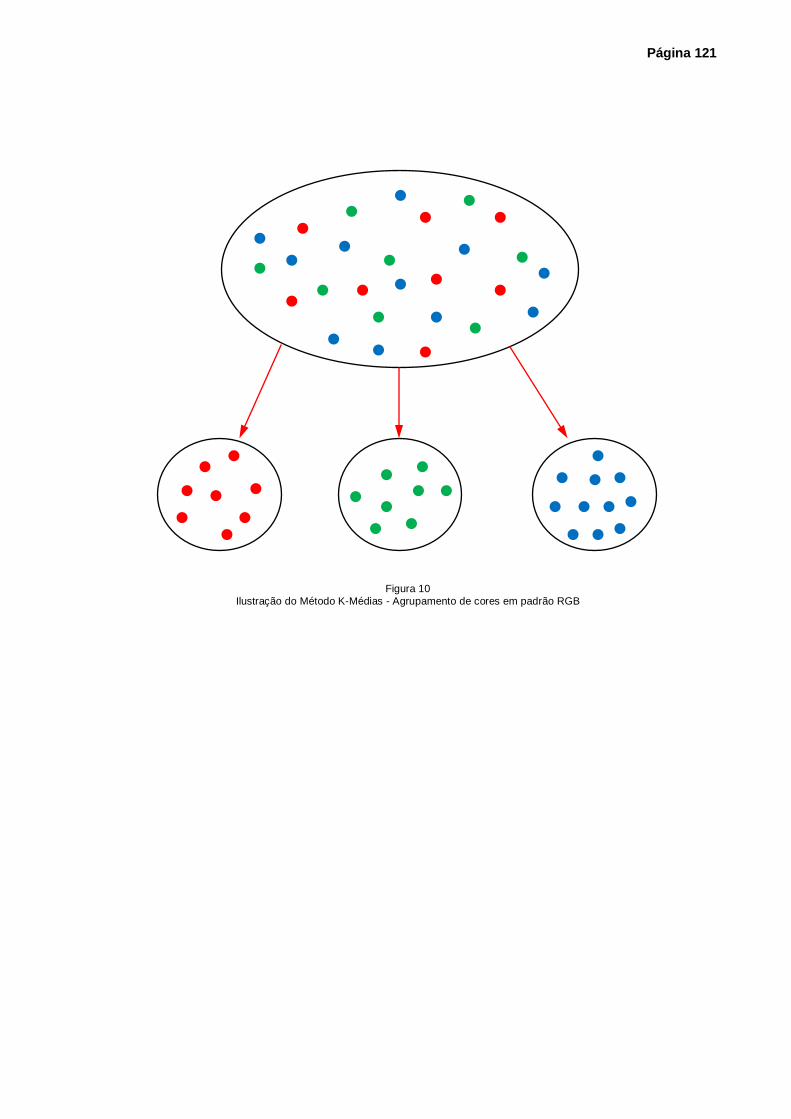
Página 121
Figura 10
Ilustração do Método K-Médias - Agrupamento de cores em padrão RGB

Página 122
Algumas comparações entre os Métodos de Agrupamento podem ser feitas.
Os métodos hierárquicos não mudam elementos de um grupo para outro. Quando
um elemento entra em um grupo ele permanece nele até a finalização do processo
quando então todo o agrupamento feito poderá ser avaliado.
Johnson e Wichern (1998), afirmam que quando a quantidade de
observações em análise é grande, o uso do K-Médias pode ser melhor que o uso
das outras técnicas hierárquicas. Os resultados representados na forma de árvores,
binárias ou n-áreas, são difíceis de análise quando se tem muitos objetos.
No K-Médias os agrupamentos são feitos em domínios numéricos através de
partições realizadas em grupos disjuntos. Como o número de agrupamentos é
definido antecipadamente, esse método deve ser direcionado para se criar poucos
agrupamentos.
É importante que se diga, também, que os processos de partições como o K-
Médias, podem não revelar similaridades entre objetos individuais e isso precisa ser
considerado.
O que se conclui é que a escolha de um tipo particular de algoritmo para se
realizar a Análise de Agrupamentos, deve ser função dos objetivos de um
pesquisador frente aos dados de trabalho que ele possui. A utilização de
computadores para tornar mais ágil os processos de cálculo envolvidos pode ser
muito útil para o teste de diferentes métodos. A escolha de um que seja eficaz diante
da necessidade de explicação de uma realidade deve ser critério desse pesquisador.

Página 123
Capítulo 5
A Análise de Componentes Principais
A Análise de Componentes Principais, também conhecida como a
Transformação de Karhunen-Loéve ou de Hotelling (Simão, 1999), é uma técnica
matemático-estatística que objetiva reduzir um conjunto de dados criando
componentes, chamados de principais.
Em termos muito reduzidos, a Análise de Componentes Principais é uma
técnica Matemático-Estatística que busca eliminar a redundância existente entre um
grupo de variáveis criando outras, por meio de uma combinação linear entre elas.
Essas novas variáveis criadas sintetizam a maior variabilidade dos dados originais,
não são correlacionadas entre si e são ordenadas segundo a proporção da variância
que podem explicar.
Segundo Barroso (2003), algumas afirmações podem ser feitas sobre essa
técnica:
Ela busca eliminar a redundância existente entre as variáveis por meio de
uma combinação linear entre elas, de tal modo que as novas variáveis criadas, ou
componentes, não sejam correlacionadas entre si e sejam ordenadas em termos da
proporção da variância que podem explicar;
Ela busca sintetizar a maior variabilidade dos dados, o que sugere a
qualificação de principal. Pela inspeção dessas componentes, pode-se encontrar um
modelo para classificar ou detectar relações entre pontos.

Página 124
Os objetivos dessa técnica, em síntese, são:
Gerar novas variáveis em um número reduzido, mas que consigam
expressar de modo satisfatório a informação contida no conjunto original
de dados;
Reduzir a dimensão do problema que está sendo estudado, como passo
prévio para futuras análises;
Eliminar, quando for possível, algumas variáveis originais, caso elas
contribuam com pouca informação.
De fato, como cita Rogerson (2001), os geógrafos freqüentemente se utilizam
de variáveis de censo em suas análises e o conjunto dessas variáveis pode
facilmente conter um subconjunto composto de outras variáveis que significam,
essencialmente, o mesmo fenômeno.
Segundo Abreu e Barroso (1980), a Análise de Componentes Principais
procura fazer p combinações lineares das p variáveis 1X , 2X , 3X , ..., pX tais que
cada uma delas capte o máximo possível da variação da matriz de dados X e,
simultaneamente, cada componente permaneça linearmente independente dos
demais.
De acordo com Johnson e Wichern (1998), geometricamente, essas
combinações lineares representam a seleção de um novo sistema de coordenadas,
obtido através da rotação de eixos do sistema de coordenadas original. Esses novos
eixos representam as direções com o máximo de variabilidade.

Página 125
A combinação linear entre variáveis permite a redução de muitos problemas
multivariados. Dentre as inúmeras possibilidades de escolha de uma combinação
linear, deve-se optar por aquelas que sejam adequadas ao problema que se procura
resolver.
Em outras palavras, tem-se na equação nn xaxaxaxay ...332211
diversos sna ' capazes de satisfazê-la. É necessário, então, impor condições para
esses coeficientes sna ' .
Nesse trabalho, escolheu-se esse método por se tratar de uma técnica
matemática que permite a estruturação dos dados sem a necessidade de se
conhecer um modelo estatístico que explique a sua distribuição de probabilidade.
Figura 11 Rotação de Eixos efetuada
pelas Componentes Principais
O segmento “a” revela uma menor variabilidade dos
dados quando comparado ao segmento “b”
por causa da rotação de eixos.
(Adaptado pelo autor de Barroso, 2003)
Q
P
a
b
x
y
x’
y’

Página 126
5.1 - A Matemática nas Componentes Principais
Uma combinação linear possui a seguinte forma:
nn xaxaxaxay ...332211 (5.1)
As incógnitas naaaa ,...,,, 321 são denominados coeficientes da combinação
linear. Os valores nxxxx ,...,,, 321 são dados e, portanto, possuem médias e
variâncias.
Pode-se calcular, então, a média da combinação linear mostrada acima:
nn xaxaxaxay ...332211 (5.2)
onde y é média da combinação linear e ix é a média das variáveis ix .
A variância de y é dada pela seguinte equação:
n
j
n
j
n
jk
jkkjjjy SaaSaS1
1
1 1
222 2 (5.3)
onde ))(( kkjjjk xxxxS é a co-variância entre as variáveis jx e kx e 2
yS é
a variância da variável jx .

Página 127
A Componente Principal é uma combinação linear
nn xaxaxay ...2211 ou
n
j
jj Xay1
(5.4)
cuja variância 2
yS deve ser maximizada e está sujeita a
n
j
ja1
2 1
Para ilustrar sua obtenção pode-se considerar a seguinte combinação linear
de duas variáveis:
2211 xaxay (5.5)
O que se procura, então,
1221
2
2
2
2
2
1
2
1
2 2 SaaSaSaS y (5.6)
sujeita a 12
2
2
1 aa .
Para maximizar 2
yS deve-se derivar a equação acima em relação a a :
2
2
1
2
2
a
S
a
S
a
S
y
y
y (5.7)

Página 128
Pode-se fazer:
02 1221
2
2
2
2
2
1
2
1 SaaSaSaM (5.8)
ou
)1(2 2
2
2
11221
2
2
2
2
2
1
2
1 aaSaaSaSaM (5.9)
onde é um escalar qualquer, admitindo 12
2
2
1 aa , o que se obtém:
1122
2
11
1
222 aSaSaa
M
e 2121
2
22
2
222 aSaSaa
M
(5.10)
Do Cálculo, M possui seu valor máximo quando 0
a
M,
o que conduz a se buscar uma solução para o sistema:
0222
0222
2121
2
22
1122
2
11
aSaSa
aSaSa
(5.11)
Em notação matricial, pode-se escrever:
02
1
2
212
12
2
1
a
a
SS
SS
(5.12)
ou
010
01
2
1
2
212
12
2
1
a
a
SS
SS (5.13)

Página 129
o que dá a equação do tipo 0)( aIA onde I é a Matriz Identidade.
Como 0a , uma vez que 12
2
2
1 aa , e como se busca uma solução não
trivial, deve-se ter o determinante 0)det( IA , que é uma equação algébrica de
segundo grau cujas raízes são os autovalores de S .
Para cada autovalor têm-se os respectivos autovetores.
Assim, para uma Matriz nxnA , um vetor 0v e um escalar qualquer, o
vetor v é um autovetor de A relativo ao autovalor quando vAv .
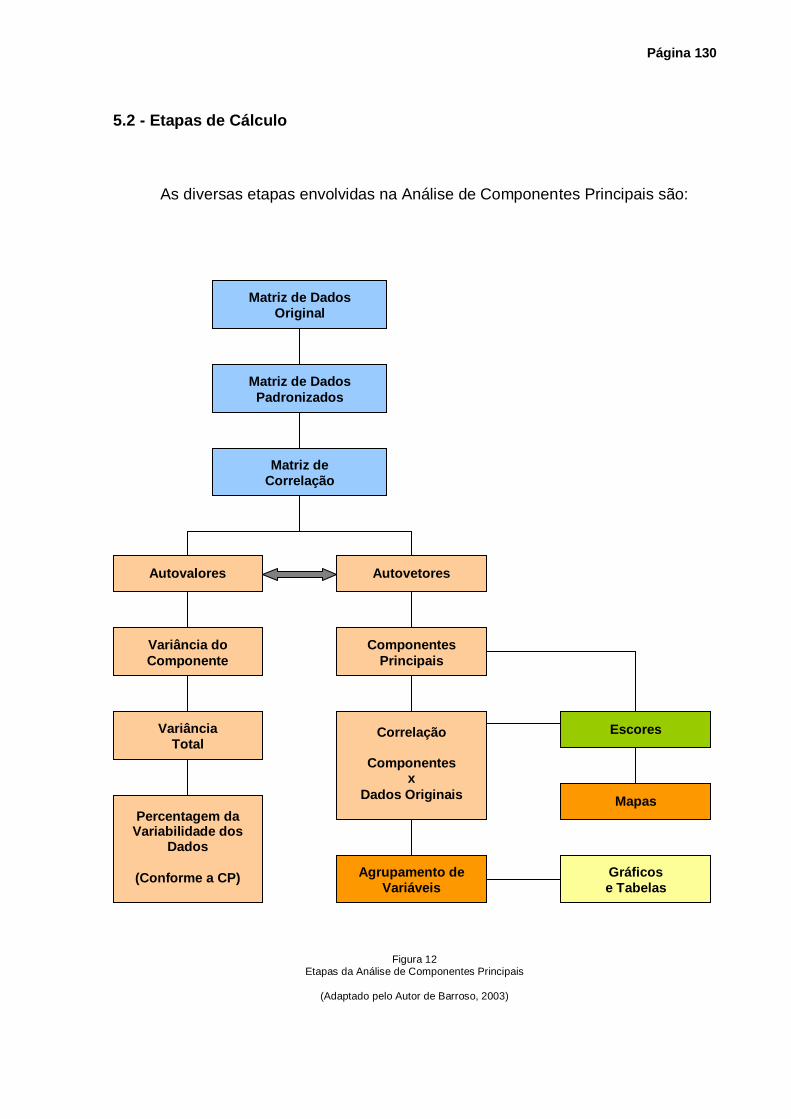
Página 130
5.2 - Etapas de Cálculo
As diversas etapas envolvidas na Análise de Componentes Principais são:
Figura 12 Etapas da Análise de Componentes Principais
(Adaptado pelo Autor de Barroso, 2003)
Matriz de Dados Original
Matriz de Dados
Padronizados
Matriz de Correlação
Autovalores Autovetores
Variância do
Componente
Componentes
Principais
Variância Total
Percentagem da Variabilidade dos
Dados
(Conforme a CP)
Correlação
Componentes x
Dados Originais
Agrupamento de Variáveis
Gráficos e Tabelas
Mapas
Escores

Página 131
A Matriz de Dados contém os dados coletados com coordenadas geográficas.
É importante observar que esses dados originais podem apresentar grandezas e
unidades de medida muito diversificadas. Para contornar este obstáculo devem-se
padronizar esses dados, tornando-os adimensionais. Para isso pode-se fazer uso da
média aritmética e do desvio padrão das variáveis.
A média aritmética de uma variável é obtida somando-se todos os seus
valores e dividindo esse resultado pelo número total de observações. É uma medida
de tendência central, como é definida na Estatística.
Em termos matemáticos, ela pode ser equacionada da seguinte maneira:
n
i
i
n
xmX
1
(5.14)
onde:
mX é a média da variável considerada,
ix é o valor de cada observação da variável considerada e
n é o número total de observações.
O desvio padrão de cada variável é obtido calculando-se a raiz quadrada da
sua variância, que por sua vez mede a dispersão dos dados observados para uma
variável com relação à sua média aritmética.
A variância é igual à soma dos quadrados dos desvios dividida pelo número
de observações (considerando a população total de dados e não uma amostra
desses dados).

Página 132
A equação matemática que mostra o desvio padrão é a seguinte:
n
i
i
xn
mXxS
1
2)( (5.15)
onde:
xS é o desvio padrão da variável considerada,
mX é a média aritmética da variável considerada,
ix é o valor de cada observação da variável considerada e
n é o número total de observações.
A padronização de cada variável é calculada, então, por meio da equação:
xS
mXxZ
(5.16)
onde:
Z é o valor da variável padronizada,
x é o valor da variável a ser padronizada,
xS é o desvio padrão da variável considerada e
mX é a média aritmética da variável considerada.

Página 133
Com os dados padronizados pode-se construir a matriz de correlação. Ela
pode ser calculada por meio de uma operação de multiplicação de matrizes.
n
ZZR
T . (5.17)
onde:
R é a matriz de correlação;
Z é a matriz padronizada;
TZ é a matriz transposta de Z e
n é o número de observações consideradas.
A matriz de correlação é uma matriz quadrada, ou seja, o número de linhas é
igual ao número de colunas, e é simétrica, ou seja, o elemento, por exemplo, da
linha 3 e coluna 5 tem o mesmo valor do elemento da linha 5 e coluna 3. Além
disso,os elementos de sua diagonal principal possuem valor 1, uma vez que mostra
a correlação de uma variável com ela mesma.
Pode-se observar que esse coeficiente sempre varia entre os valores -1 e 1.
Quando esse valor está próximo de 1 tem-se uma forte correlação positiva e quando
está próximo de -1 é porque existe uma forte correlação negativa. Um valor próximo
de 0 indica ausência de correlação.
O Traço da Matriz de Correlação é a soma dos elementos da sua diagonal
principal e expressa a variância total dos dados considerados. É o mesmo que dizer
que o número de variáveis em análise é a variância total.
É importante dizer que seria possível o cálculo da matriz de correlação
utilizando a própria matriz de dados original, ao invés da matriz padronizada.

Página 134
Depois disso é possível calcular os autovalores e os seus respectivos
autovetores da matriz de correlação. É bom relembrar que um vetor 0v é
autovetor de uma matriz R relativo a um autovalor quando a relação vRv é
verdadeira.
Com o auxílio da matriz identidade I , monta-se seguinte equação linear:
0)( vIR (5.18)
Para que se tenha 0v , 0)det( IR , isto é, impõe-se a condição para que
o determinante de R seja igual a zero, para que se tenha uma solução
indeterminada.
Desta forma, a solução dessa equação (polinomial) fornece diversos valores
possíveis para e cada é um autovalor de R . Substituindo em 0)( vIR
será encontrado o autovetor de R relativo à .
Aqui, as coordenadas dos autovetores v da matriz de correlação equivalem
aos coeficientes ou pesos das componentes principais e os autovalores equivalem
às variâncias dessas componentes principais.
O autovalor representa o percentual da quantidade de variância total que está
associado ao componente. Encontra-se também o respectivo autovetor associado
ao autovalor calculado, o peso, que corresponde à correlação entre as componentes
principais e as variáveis, e a variância de cada elemento individual do autovetor.
A soma dos autovalores fornece a variância total que corresponde ao número
de variáveis consideradas (Barroso, 2003).
O primeiro autovalor corresponde ao maior percentual da variabilidade
máxima. O segundo autovalor corresponde ao segundo maior percentual de

Página 135
variabilidade máxima e assim por diante.
Uma vez calculados os autovalores e autovetores pode-se calcular as
componentes principais. Uma componente principal é uma combinação linear que
possui uma equação da forma:
nn xaxaxaxay ...332211
onde:
naaaa ,...,,, 321 são os coeficientes e
nxxxx ,...,,, 321 são as variáveis.
A primeira componente principal 1Y deve satisfazer às seguintes condições:
Os naaaa ,...,,, 321 são tais que 1aaT ou 1... 22
3
2
2
2
1 naaaa ;
A variância de 1Y é máxima.
Uma vez calculada a primeira componente principal impõem-se as mesmas
condições para a segunda componente com mais uma exigência, a de que ela
deverá ser ortogonal à primeira, e assim sucessivamente para todas as outras
componentes principais nYYY ,...,, 32 que participarem do processo.

Página 136
Pode-se expressar, por exemplo, a equação das duas primeiras componentes
principais em uma notação matricial:
18)1,18(3)1,3(2)1,2(1)1,1(1 ... ZvZvZvZvY (5.19)
18)2,18(3)2,3(2)2,2(1)2,1(2 ... ZvZvZvZvY (5.20)
onde:
1Y é a primeira componente;
),( mnv correspondem aos índices dos autovetores e
nZ são as colunas da matriz padronizada.
A próxima etapa é a do cálculo dos escores. Eles são utilizados para o
agrupamento e classificação das observações no âmbito de cada componente
principal, para a finalidade de mapeamento.
O que se faz agora é tomar a matriz padronizada dos dados e multiplicá-la
pelo vetor que expressa a correlação entre as componentes principais e as
variáveis. Isso já foi calculado anteriormente quando se trabalhou os autovetores. Na
ocasião chamou-se de Peso a essa informação.

Página 137
Em uma notação matemática pode-se fazer:
cvZEscore . (5.21)
onde:
Z é a matriz de dados padronizada e
cv é a correlação entre as componentes principais e as variáveis.
Essa correlação cv é expressa matematicamente por meio da equação:
vcv . (5.22)
onde (variância da componente principal) é o autovalor da matriz de
correlação R relativo a v , e v (coeficientes da componente principal) é o autovetor
da matriz de correlação R . Na verdade, o que se faz é aplicar o desvio padrão do
autovalor sobre os coeficientes dos autovetores.

Página 138
5.3 - Metodologia
Um aspecto computacional importante envolvido na Análise de Componentes
Principais consiste no cálculo dos Autovalores e Autovetores da Matriz de
Correlação. Alguns algoritmos numéricos para essa finalidade são bastante
conhecidos, como o Método da Potência, o Método Iterativo QR, o Método da
Iteração Inversa, entre outros, como cita Sperandio et al. (2003). Geralmente são
técnicas matemáticas e computacionais baseadas em equações iterativas que, por
meio de repetições sucessivas buscam decompor ou transformar a Matriz de
Correlação, ou em uma forma mais tratável ou que tenha uma estrutura que permita
o cálculo de Autovalores e Autovetores de modo mais fácil.
O software NinnaPCA utiliza o Método de Jacobi para a determinação dos
Autovalores e Autovetores da Matriz de Correlação. Segundo Sperandio et al.
(2003), o Método de Jacobi é uma técnica utilizada em matrizes simétricas que, por
meio de transformações de similaridade buscam aproximar os elementos de sua
diagonal principal aos seus Autovalores, enquanto aproxima os seus demais
elementos a zero. Os Autovetores são calculados também de maneira semelhante,
transformando sucessivamente os elementos da Matriz Identidade.
No Método de Jacobi, em cada iteração os elementos na porção triangular
superior da matriz de dados são anulados, linha por linha, na ordem
;...,...,,;,..., 2242311312 nn rrrrrr , onde n é o número de variáveis. Se algum elemento ijr se
torna suficientemente menor em magnitude que uma tolerância determinada
previamente, ele não será anulado e o processo continua sua execução.
Um número máximo de iterações é definido previamente, como limite caso
não ocorra convergência, quando todos os elementos de fora da diagonal principal

Página 139
da matriz estarão anulados. Outro critério para término das iterações é também
estabelecido, por meio da soma dos quadrados dos elementos da diagonal da
matriz, que é calculado antes e depois de cada iteração e armazenado em 1 e 2
respectivamente. Nesse caso, o critério de parada é:
2
11 (5.23)
onde é um valor de tolerância definido previamente
Ao final das iterações a diagonal da matriz de correlação conterá os
Autovalores e a Matriz Identidade conterá os respectivos Autovetores.
O Método de Jacobi toma uma Matriz de Correlação R com p e q colunas.
Em cada passo da iteração k será tomado o elemento pqr e definido um
determinado ângulo de tal modo que reduza esse elemento a zero, ou seja,
011 k
qp
k
pq rr .
Os elementos transformados podem ser calculados por meio de diversas
equações a seguir definidas. Inicialmente, seja:
k
k
pp
pq
rr
rtg
2 , (5.24)
k
pq
k
k
pp
k
k
pp
rrr
rrcos
4)(2
2
, (5.25)

Página 140
2
21)_(
costgSinalsen
, (5.26)
e 21 sencos . (5.27)
Define-se também:
cosc , (5.28)
sens , (5.29)
c
sh
1, (5.30
e c
st . (5.31)
Depois de efetivados os cálculos, os elementos transformados são:
k
pq
k
pp
k
pp trrr 1 e k
pq
k
k
qq trrr 1 , (5.32)
e, para qipi , ,
).(1 k
pi
k
iq
k
ip
k
pi
k
ip rhrsrrr e ).(1 k
qi
k
ip
k
iq
k
qi
k
iq rhrsrrr (5.33)
Os demais elementos permanecerão inalterados.

Página 141
Os Autovetores são transformações sucessivas efetuadas na Matriz
Identidade. Para cada uma das variáveis, dispostas em v colunas, têm-se, em cada
iteração k , os seguintes elementos:
senIcosII k
vq
k
vp
k
vp 1 , (5.34)
senIcosII k
vq
k
vp
k
vq 1 (5.35)
Para exemplificar numericamente o que foi mostrado, seja a seguinte matriz
simétrica de ordem 3:
19501,09213,0
9501,018706,0
9213,08706,01
R
Seja também a Matriz Identidade de ordem 3:
100
010
001
I
Para 1k , 1p e 1q tem-se:
sen cos c s h t
-0,7071 0,7071 0,7071 -0,7071 -0,4142 -1

Página 142
As matrizes transformadas são:
10204,03233,0
0204,01294,00
3233,108706,1
1R e
100
07071,07071,0
07071,07071,0
1I
Para a segunda iteração, 2k , 1p e 3q tem-se:
sen cos c s h t
-0,5863 0,8100 0,8100 -0,5863 -0,3239 -0,7237
0423,00165,00
0165,01294,00119,0
00119,08283,2
2R e
8100,005863,0
4145,07071,05728,0
4145,07071,05728,0
2I
É conveniente notar que um determinado elemento anulado pode se tornar
não nulo novamente. O processo continuará até que todos os elementos de fora da
diagonal principal da matriz tenham um valor menor que uma determinada tolerância
estabelecida previamente, como já foi dito. No software NinnaPCA foi estabelecido
como condição de término das iterações um valor da ordem de 10-8.
Ao término das iterações a diagonal principal da matriz R conterá os
Autovalores e cada coluna da matriz I conterá os Autovetores respectivos:
0392,000
01324,00
008284,2
kR e
7972,01433,05863,0
5346,06183,05759,0
2800,07726,05696,0
kI

Página 143
Como afirma Sperandio et al. (2003), sendo n o número de variáveis da
Matriz de Correlação, se a anulação for feita em ordem cíclica, ou seja, fornecida
pelos índices ),1);...(,2),...(4,2(),3,2();,1),...(3,1(),2,1( nnnn , o método de Jacobi
converge quadraticamente. É, portanto, um método que apresenta grande eficiência
para matrizes de grande porte uma vez que nem sempre a redução da matriz dada à
forma diagonal é possível em um número finito de transformações similares.
Os demais cálculos envolvidos na Análise de Componentes Principais
envolvem as operações normais de multiplicação de matrizes, cujas equações já
foram mostradas anteriormente.

Página 144
Capítulo 6
O Software NinnaCluster e o Software NinnaPCA
Os softwares NinnaCluster e NinnaPCA são aplicativos desenvolvidos para
realizar os cálculos envolvidos nas técnicas da Análise de Agrupamentos e na da
Análise de Componentes Principais, respectivamente. São produtos deste trabalho e
estão disponibilizados na Home Page do Programa de Pós-Gradução em Geografia
– Tratamento da Informação Espacial – da PUCMinas.
Trata-se de uma atualização do software Ninna, desenvolvido pelo autor em
sua dissertação de mestrado intitulada “Análise Multivariada de Dados no
Tratamento da Informação Espacial – Um Aplicativo em Componentes Principais”.
Dentre outras, as diferenças básicas mais importantes das duas versões são as
seguintes:
O software Ninna era um aplicativo para se realizar os cálculos
envolvidos na Análise de Componentes Principais. Ele foi ampliado
para que realize também os cálculos envolvidos em muitos métodos da
Análise de Agrupamentos. Ele também foi separado em dois
aplicativos distintos, o NinnaPCA e o NinnaCluster;
O Ninna não representava os resultados da análise sob a forma
cartográfica. Um protótipo foi disponibilizado na ocasião, mas não
possuía os recursos atuais do NinnaPCA. Um novo módulo de
elaboração de mapas, bem mais completo, foi desenvolvido e
apresenta muitas funcionalidades adicionais;

Página 145
Tanto o NinnaPCA quanto o NinnaCluster podem ler dados em formato
texto CSV, cujos valores são separados por vírgula, ou diretamente de
uma planilha do Microsoft® Excel ou outras compatíveis, inclusive
gratuitas, como as geradas através do StarOffice, OpenOffice,
BROffice, entre outras. Isso facilita muito a entrada de dados;
Da mesma forma, os resultados obtidos pelo NinnaPCA são
disponibilizados também na forma de planilhas compatíveis com as do
Microsoft® Excel;
O software agora possui um tamanho bastante reduzido,
principalmente em virtude de sua forma de estruturação em nível de
plataforma e pode ser executado diretamente a partir de qualquer meio
de armazenamento sem a necessidade de uma instalação prévia;
O software também pode ser acessado através da internet, o que
fornece maior independência e portabilidade;
A possibilidade de múltiplas análises de dados em uma mesma seção
de cálculo foi também desenvolvida. Através do recurso de seleção das
variáveis que participarão dos processos de cálculo, o software agora
pode criar cenários variados de análise;

Página 146
Como os dados de análise podem vir de várias fontes de dados o
software é dotado de “globalização de cultura”, que permite a leitura de
dados de planilhas cuja formatação numérica ou de data seja diferente;
A arquitetura interna do software é aberta e desenvolvida para
funcionar como um serviço. Em outras palavras, incorporar novas
funcionalidades e recursos aos softwares ficou mais rápido e mais fácil
de ser feita e disponibilizada para outros desenvolvedores.
A primeira versão, a qual se deu o nome de Desktop, foi desenvolvida para
ser instalada e utilizada em qualquer equipamento que possua o sistema
operacional Microsoft Windows® 2000, 2003, XP e Vista, com memória RAM mínima
de 32 MBytes. É possível sua execução sob outras versões do Windows®, desde
que o computador possua instalado o Framework .NET (versão 2.0 ou superior), um
conjunto de bibliotecas que formam uma plataforma única de desenvolvimento e
execução de sistemas e aplicações desenvolvidas no ambiente .NET . Essa
plataforma foi feita também pela empresa Microsoft®. O arquivo para a instalação
desse Framework está disponível na mídia ótica anexa a essa trabalho. O processo
pode ser realizado automaticamente quando se instala o Windows®, principalmente
nas versões mais atuais.
A segunda versão foi desenvolvida para utilização através da internet, com o
objetivo fornecer portabilidade. Qualquer portal ou site na internet poderá instalar um
hiperlink para a utilização do software desde que esteja devidamente autorizado pelo
Programa de Mestrado e Doutorado em Geografia – Tratamento da Informação
Espacial – da PUCMinas.

Página 147
Os softwares permitem a leitura de dados por meio de arquivos do tipo
planilha, desenvolvidas através do software Microsoft Excel® ou outro compatível
com ele. Também permite a leitura de arquivos texto do tipo CSV, um padrão de
transferência de informações cujos dados são separados um do outro por meio de
um caractere neutro, normalmente o ponto e vírgula (;). Para permitir maior
facilidade na leitura de dados diretamente nas tabelas associadas de mapas
vetoriais, o sistema também é capaz de ler dados e informações diretamente dos
formatos SHP (Shapes) compatíveis com o ArcGIS e ArcInfo. Formatos vetoriais de
outros aplicativos podem ser convertidos para o formato SHP por meio de outro
software específico de conversão, também disponibilizado.
Na mídia ótica anexa a esse trabalho está disponível a planilha de dados do
exemplo que será trabalhado, em formato compatível com o software Microsoft
Excel®. Os dados de trabalho podem ou não estar georeferenciados. No caso do
NinnaCluster os resultados obtidos (dendogramas) ficam disponíveis na forma de
imagem e podem ser armazenados em diversos formatos. E no caso do NinnaPCA
os resultados obtidos ficam disponíveis através de um arquivo do Microsoft Excel®.

Página 148
6.1 - NinnaCluster
O NinnaCluster é um software específico para a Análise de Agrupamentos.
Ele é formado por um módulo executável que se utiliza de diversas rotinas, funções
e controles, armazenados em cinco bibliotecas.
A execução do software pode ser feita diretamente através da mídia
magnética anexa a esse trabalho. No entanto, uma cópia dos arquivos para o disco
rígido de um computador pode fornecer maior independência no seu uso.
O arquivo executável do software é o seguinte:
Tela 1
Ícones do Software NinnaCluster Executável e Bibliotecas
Tela 2
Ícone de Execução do NinnaCluster

Página 149
A imagem a seguir é uma parte, ou fragmento, da tela principal do
NinnaCluster. Apenas as opções Arquivo, Janela e Ajuda são disponibilizadas nesse
momento.
O menu “Arquivo” fornece a opção para abertura da fonte de dados e para a
escolha da linguagem de operação do software, português ou inglês. O menu
“Janela” tem finalidades apenas organizacionais, uma vez que diversas análises
podem ser feitas de maneira comparativa. O menu “Ajuda” mostra o roteiro de
operação do software.
Os tipos de dados disponíveis para leitura pelo NinnaCluster são os do tipo
planilha, do Microsoft Excel® ou algum outro compatível com ele, CSV (padrão de
transferência de informações cujos dados são separados um do outro por meio de
um caractere neutro, como o ponto e vírgula (;)),ou do tipo vetorial (SHP).
Tela 3 Fragmento de Tela – Tela Principal do NinnaCluster
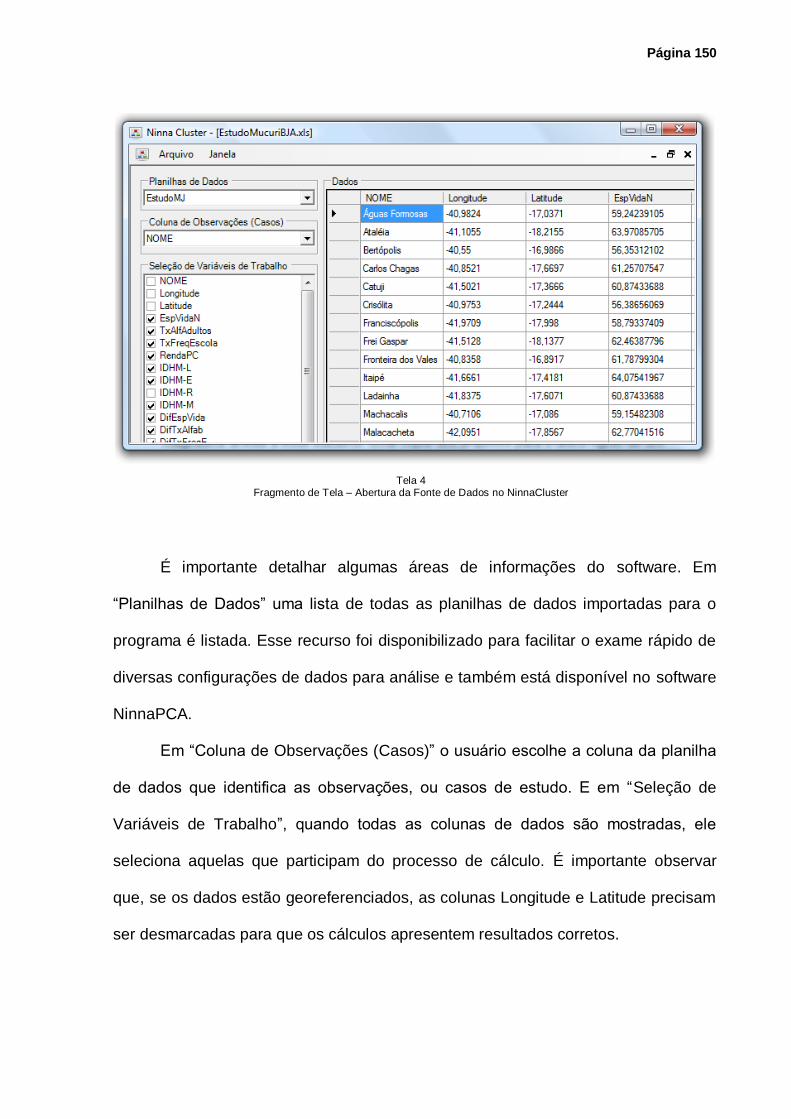
Página 150
É importante detalhar algumas áreas de informações do software. Em
“Planilhas de Dados” uma lista de todas as planilhas de dados importadas para o
programa é listada. Esse recurso foi disponibilizado para facilitar o exame rápido de
diversas configurações de dados para análise e também está disponível no software
NinnaPCA.
Em “Coluna de Observações (Casos)” o usuário escolhe a coluna da planilha
de dados que identifica as observações, ou casos de estudo. E em “Seleção de
Variáveis de Trabalho”, quando todas as colunas de dados são mostradas, ele
seleciona aquelas que participam do processo de cálculo. É importante observar
que, se os dados estão georeferenciados, as colunas Longitude e Latitude precisam
ser desmarcadas para que os cálculos apresentem resultados corretos.
Tela 4 Fragmento de Tela – Abertura da Fonte de Dados no NinnaCluster

Página 151
A área de “Dados” representa a planilha de dados propriamente dita, lida pelo
sistema. No processo de abertura e importação dos dados o sistema detecta
automaticamente as colunas e as observações presentes na planilha, de maneira
que é dispensável informar o número de observações e o número de variáveis de
análise.
Em virtude da diferença que os dados de uma planilha podem apresentar
quanto à representação numérica (separador de milhares ou separador de casas
decimais) um recurso adicional foi disponibilizado e pode ser acessado por meio da
caixa de combinação mostrada na figura a seguir:
O usuário deverá escolher previamente o método de agrupamento que deseja
utilizar. Para o método KMeans o usuário deverá também escolher o número de
agrupamentos que deseja criar.
O botão “Iniciar Análise” executa as rotinas do sistema responsáveis pelos
cálculos envolvidos na Análise de Agrupamentos:
Tela 6 Escolha do Método de Agrupamento no NinnaCluster
Tela 5 Caixa de Seleção de Cultura do NinnaCluster
Tela 7 Botão “Iniciar Análise” do NinnaCluster

Página 152
Uma vez clicado o botão “Iniciar Análise”, o sistema alimenta três “abas” no
formulário. Em “Dados Coletados” pode-se observar o resultado da importação dos
dados feita pelo sistema.
De maneira geral, os dados originais apresentam grandezas e unidades de
medida muito diversificadas e por isso a padronização dos dados torna-se
importante no processo. O NinnaCluster padroniza os dados de análise.
Em “Matriz de Distâncias” fica disponibilizada a matriz simétrica contendo as
distâncias entre os objetos da análise.
Em “Dendograma” a representação gráfica dos agrupamentos é mostrada. Se
o número de observações for muito elevado o diagrama poderá ficar muito grande,
excedendo o limite da tela. Nesse caso o usuário poderá se utilizar dos recursos de
Zoom IN e Zoom OUT do mouse para se aproximar ou se afastar da imagem.
Recursos de movimentação de imagem também estão disponíveis.
A imagem a seguir foi gerada pelo software NinnaCluster:
Tela 8
Construção de Dendograma através do NinnaCluster

Página 153
A imagem do Dendograma poderá ser salva em formato PNG, JPG, GIF e
BMP por meio do botão “Salvar Imagem”:
No caso da escolha do método de agrupamento KMeans, o resultado será
mostrado em forma de tabela contendo a composição de cada cluster desenvolvido:
No Capítulo VII um estudo de caso é feito para exemplificar a utilização do
software NinnaCluster em uma aplicação na Geografia.
Nesse momento é feita uma pequena abordagem sobre o software
NinnaPCA, mostrando seus principais recursos.
Tela 9 Botão “Salvar Imagem” do NinnaCluster
Tela 10
Formação de Agrupamentos através do NinnaCluster

Página 154
6.2 - NinnaPCA
O NinnaPCA é um software específico para a Análise de Componentes
Principais. Como mencionado anteriormente, o software permite a leitura de dados
de qualquer fonte por meio de arquivos do tipo planilha, do Microsoft Excel®, de
texto, do tipo CSV (padrão de transferência de informações cujos dados são
separados um do outro por meio de um caractere neutro, normalmente o ponto e
vírgula (;)), ou Shape (SHP). Geralmente todos os programas e aplicativos
disponibilizam algum meio para fornecer seus dados em algum desses formatos. Os
dados de trabalho podem ou não estar georeferenciados.
Os resultados obtidos podem também ser enviados para qualquer outro
aplicativo que leia o formato planilha do Microsoft Excel®.
O NinnaPCA pode ser executado diretamente do CD anexo a esse trabalho.
Ele é composto de um arquivo executável e outros quatro arquivos, com a extensão
.dll, que possuem as rotinas, funções e controles utilizados.
Tela 11 Ícones do Software NinnaPCA
Executável e Bibliotecas
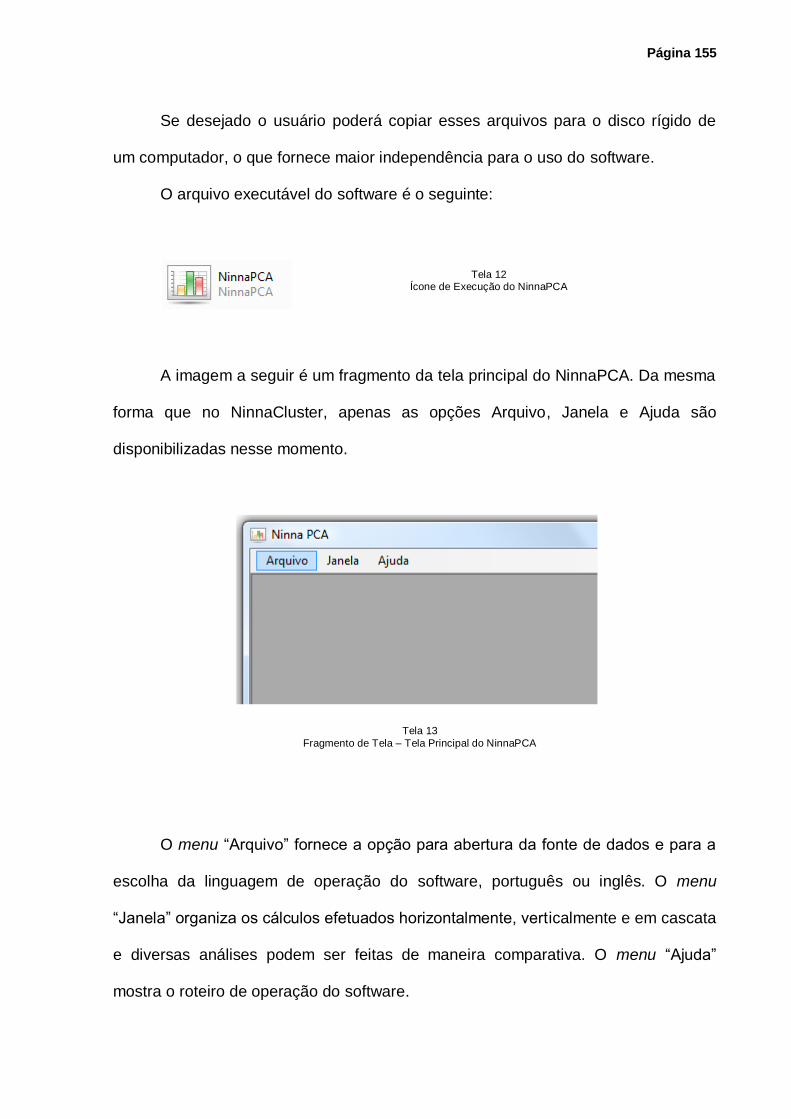
Página 155
Se desejado o usuário poderá copiar esses arquivos para o disco rígido de
um computador, o que fornece maior independência para o uso do software.
O arquivo executável do software é o seguinte:
A imagem a seguir é um fragmento da tela principal do NinnaPCA. Da mesma
forma que no NinnaCluster, apenas as opções Arquivo, Janela e Ajuda são
disponibilizadas nesse momento.
O menu “Arquivo” fornece a opção para abertura da fonte de dados e para a
escolha da linguagem de operação do software, português ou inglês. O menu
“Janela” organiza os cálculos efetuados horizontalmente, verticalmente e em cascata
e diversas análises podem ser feitas de maneira comparativa. O menu “Ajuda”
mostra o roteiro de operação do software.
Tela 12 Ícone de Execução do NinnaPCA
Tela 13
Fragmento de Tela – Tela Principal do NinnaPCA
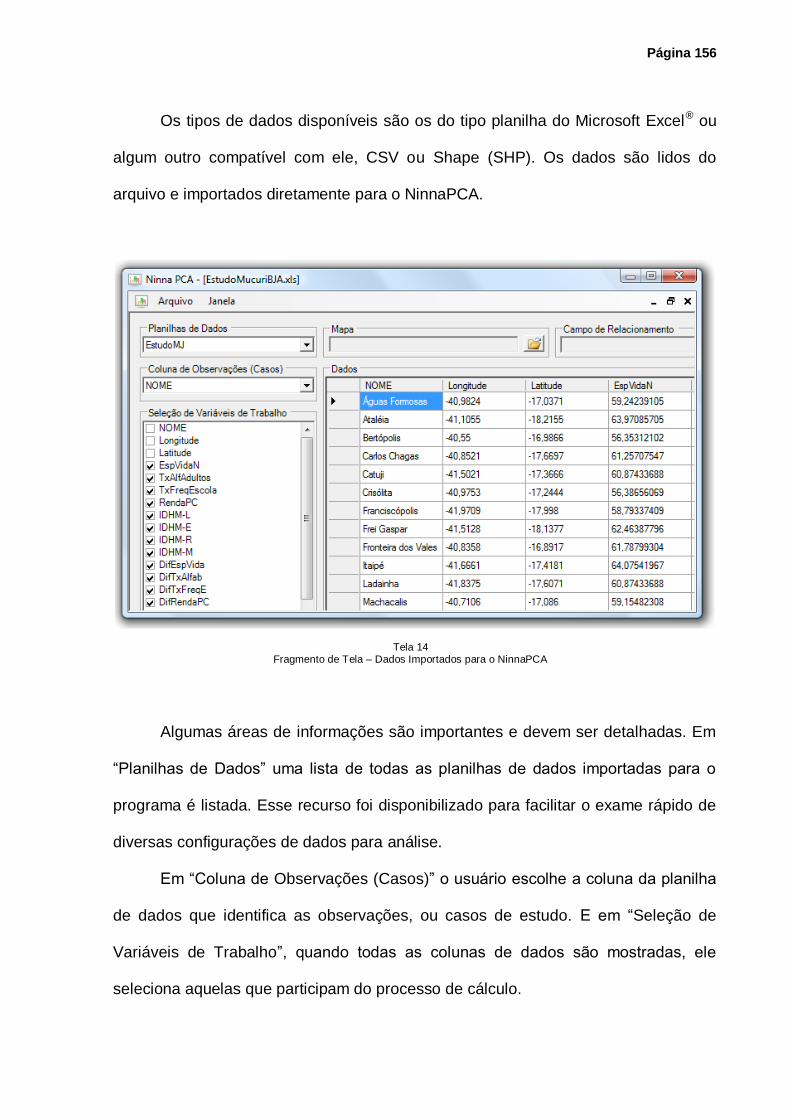
Página 156
Os tipos de dados disponíveis são os do tipo planilha do Microsoft Excel® ou
algum outro compatível com ele, CSV ou Shape (SHP). Os dados são lidos do
arquivo e importados diretamente para o NinnaPCA.
Algumas áreas de informações são importantes e devem ser detalhadas. Em
“Planilhas de Dados” uma lista de todas as planilhas de dados importadas para o
programa é listada. Esse recurso foi disponibilizado para facilitar o exame rápido de
diversas configurações de dados para análise.
Em “Coluna de Observações (Casos)” o usuário escolhe a coluna da planilha
de dados que identifica as observações, ou casos de estudo. E em “Seleção de
Variáveis de Trabalho”, quando todas as colunas de dados são mostradas, ele
seleciona aquelas que participam do processo de cálculo.
Tela 14 Fragmento de Tela – Dados Importados para o NinnaPCA

Página 157
É importante observar que, se os dados estão georeferenciados, as colunas
Longitude e Latitude precisam ser desmarcadas para que os cálculos apresentem
resultados corretos.
Na área “Mapa”, cujos fragmentos de tela são mostrados a seguir, um arquivo
em formato SHP (ESRI) pode ser carregado. Se esse arquivo possuir uma tabela de
dados associada aos vetores eles irão compor a análise. No caso de uma planilha
de dados já ter sido carregada o arquivo SHP servirá para a elaboração de mapas
depois que os cálculos tiverem sido concluídos.
.
A área “Campo de Relacionamento” serve para informar ao sistema qual
campo da tabela de dados associada aos vetores deverá ser utilizada para se
estabelecer uma união com a planilha de dados. Sem essa informação não será
possível se construir os mapas temáticos.
A área de “Dados” representa a planilha de dados propriamente dita, lida pelo
sistema. No processo de abertura e importação dos dados o sistema detecta
automaticamente as colunas e as observações presentes na planilha, de maneira
que é dispensável informar o número de observações e o número de variáveis de
análise.
Tela 15
Fragmento de Tela – Área Mapa do NinnaPCA

Página 158
Em virtude da diferença que alguns softwares apresentam quanto à
representação numérica (separador de milhares ou separador de casas decimais) e
para compatibilizar o software aos dados desses softwares, um recurso adicional foi
disponibilizado e pode ser acessado por meio da caixa de combinação mostrada na
figura a seguir:
O botão “Iniciar Análise” executa as rotinas do sistema responsáveis pelos
cálculos envolvidos na Análise de Componentes Principais.
Uma vez clicado o botão “Iniciar Análise”, o sistema alimenta diversas “abas”
com os resultados de cada etapa do algoritmo. Todas as fases do cálculo também
são mostradas de forma descritiva nesse formulário.
Tela 17 Botão “Iniciar Análise” do NinnaPCA
Tela 16 Caixa Seleção de Cultura do NinnaPCA
Tela 18 Fragmento de Tela - Resultados da Análise de Componentes Principais

Página 159
Em “Dados Coletados” pode-se observar o resultado da importação dos
dados feita pelo sistema. Se eles estiverem georeferenciados, embora não
apareçam nessa matriz, estão gravados no sistema e podem ser exportados
normalmente para qualquer aplicativo que necessite dessas informações.
De maneira geral, os dados originais apresentam grandezas e unidades de
medida muito diversificadas e por isso a padronização dos dados torna-se
importante no processo. Para tornar os dados adimensionais, o software faz uso da
Média e do Desvio Padrão das variáveis. Com isso ele pode montar a Matriz
Padronizada. Os resultados estão disponibilizados nas “abas” respectivas.
Em “Matriz de Correlação” pode-se ver a correlação entre as variáveis. Os
elementos da diagonal principal dessa matriz possuem valor igual a 1. A soma de
todos os elementos dessa diagonal é igual à variância total dos dados.
Em “Autovalores e Autovetores” têm-se algumas informações importantes
dispostas em colunas. Quando o sistema calcula um autovalor, ele mostra também o
percentual de variância que ele está captando. Na coluna Total essa informação é
acumulada para cada autovalor calculado.
Cada autovalor possui o seu autovetor correspondente que está disposto na
coluna respectiva. Cada elemento de um autovetor possui um peso e um percentual
relativo à variância total, que é o Coeficiente de Determinação.
Essas informações foram disponibilizadas para facilitar a identificação
daquelas variáveis que possuem maior representatividade de variância no autovetor
correspondente.

Página 160
Esta “aba” ainda mostra dois botões de comando que possuem finalidades
específicas. O primeiro, que se destaca, é o que Muda o Sentido do Autovetor.
Os métodos numéricos iterativos que podem ser utilizados para o cálculo de
autovalores e autovetores de uma matriz são diferentes. Além disso, dependendo
também do condicionamento da matriz utilizada, os cálculos feitos com diferentes
métodos podem fazer com que os autovetores calculados mostrem sentidos
contrários. Para a Matemática, particularmente em uma de suas áreas de estudo, a
Álgebra Linear, isso pode ser explicado pela maneira que a iteração se faz e pela
Tela 19 Fragmento de Tela – Matriz de Autovalores e Autovetores
Nesta “Caixa de Texto” seleciona-se o Autovetor
Clicando o Mouse sobre esse Botão muda-se o sentido do Autovetor selecionado
Tela 20
Mudança de Sentido de Autovetores
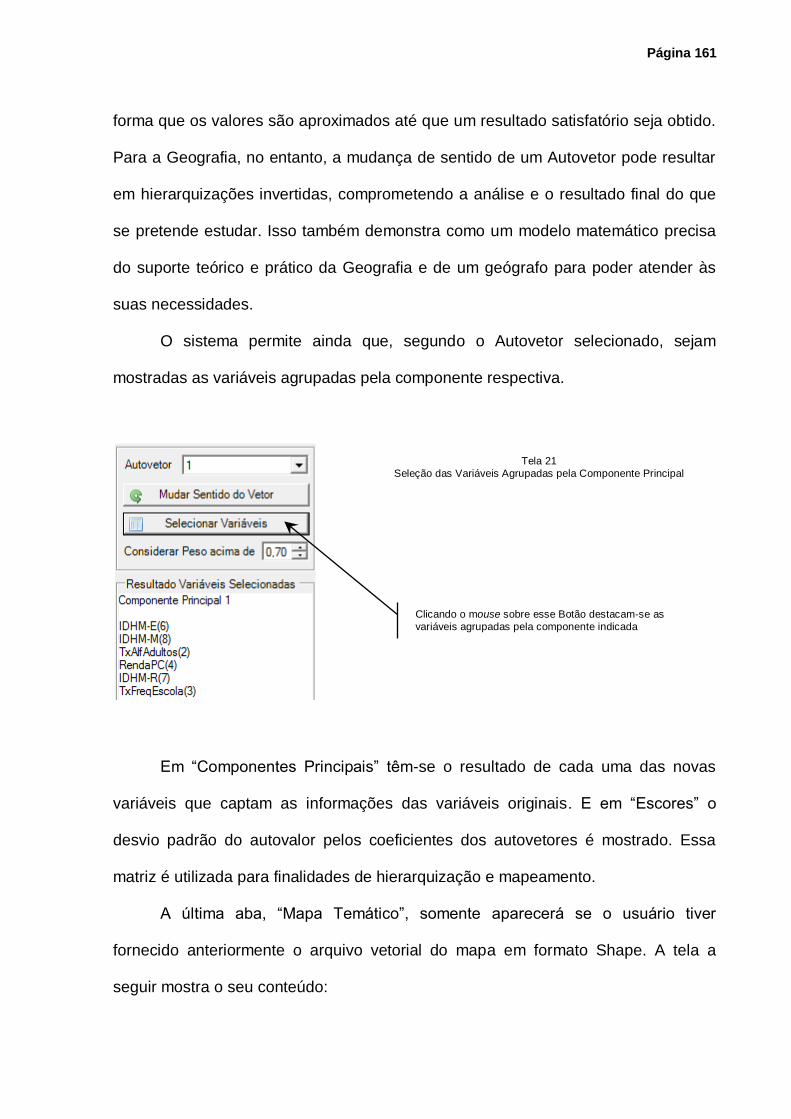
Página 161
forma que os valores são aproximados até que um resultado satisfatório seja obtido.
Para a Geografia, no entanto, a mudança de sentido de um Autovetor pode resultar
em hierarquizações invertidas, comprometendo a análise e o resultado final do que
se pretende estudar. Isso também demonstra como um modelo matemático precisa
do suporte teórico e prático da Geografia e de um geógrafo para poder atender às
suas necessidades.
O sistema permite ainda que, segundo o Autovetor selecionado, sejam
mostradas as variáveis agrupadas pela componente respectiva.
Em “Componentes Principais” têm-se o resultado de cada uma das novas
variáveis que captam as informações das variáveis originais. E em “Escores” o
desvio padrão do autovalor pelos coeficientes dos autovetores é mostrado. Essa
matriz é utilizada para finalidades de hierarquização e mapeamento.
A última aba, “Mapa Temático”, somente aparecerá se o usuário tiver
fornecido anteriormente o arquivo vetorial do mapa em formato Shape. A tela a
seguir mostra o seu conteúdo:
Clicando o mouse sobre esse Botão destacam-se as
variáveis agrupadas pela componente indicada
Tela 21
Seleção das Variáveis Agrupadas pela Componente Principal

Página 162
Na área “Escore” o usuário seleciona o escore segundo uma determinada
Componente Principal. Ele seleciona também quais descrições dos casos devem ser
mostradas no mapa e o número de classes desejadas. O botão “Gerar Mapa” mostra
o resultado dos cálculos sob a forma cartográfica, que podem ser salvos através do
botão “Salvar Imagem” nos formatos PNG, JPG, GIF ou BMP. Recursos de Zoom e
de movimento estão disponíveis na janela de mapa.
Tela 22 Elaboração de Mapas Temáticos no NinnaPCA
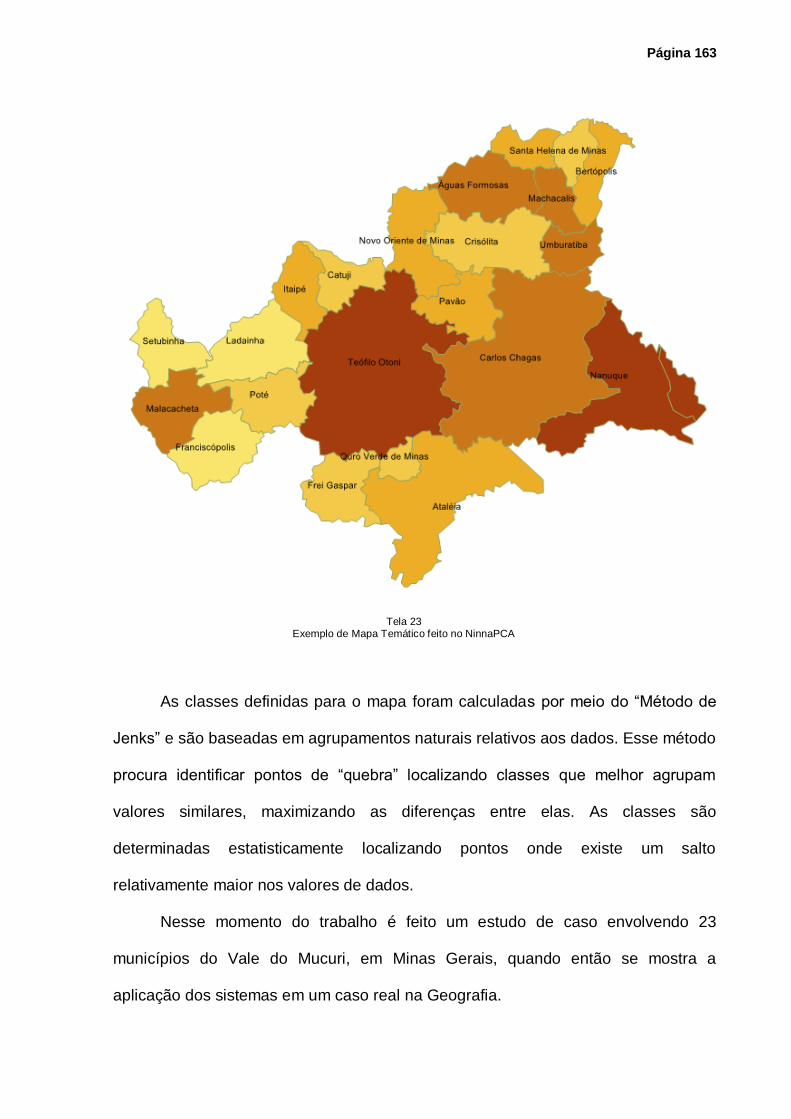
Página 163
As classes definidas para o mapa foram calculadas por meio do “Método de
Jenks” e são baseadas em agrupamentos naturais relativos aos dados. Esse método
procura identificar pontos de “quebra” localizando classes que melhor agrupam
valores similares, maximizando as diferenças entre elas. As classes são
determinadas estatisticamente localizando pontos onde existe um salto
relativamente maior nos valores de dados.
Nesse momento do trabalho é feito um estudo de caso envolvendo 23
municípios do Vale do Mucuri, em Minas Gerais, quando então se mostra a
aplicação dos sistemas em um caso real na Geografia.
Tela 23 Exemplo de Mapa Temático feito no NinnaPCA

Página 164
Capítulo 7
Estudo de Caso
Essa parte do trabalho tem como objetivo explicitar todas as etapas e
procedimentos envolvidos na Análise de Agrupamentos e na Análise de
Componentes Principais.
Para o exemplo, serão considerados alguns dados sócio-econômicos de 23
municípios pertencentes ao Vale do Mucuri, em Minas Gerais. Essa região vem
sendo estudada pelo Programa de Mestrado e Doutorado em Geografia –
Tratamento da Informação Espacial – da PUCMinas, através do projeto TOR –
Teófilo Otoni e Região – coordenado pelo Prof. Dr. Leônidas Conceição Barroso. A
planilha de dados trabalhados se encontra no CD anexo a esse trabalho.
O Vale do Mucuri é uma região que se encontra, em termos de
desenvolvimento nas áreas social, cultural, econômica, de meio ambiente, dentre
outras, no grupo das mais deprimidas de Minas Gerais. Existem atualmente diversas
iniciativas, inclusive governamentais, no sentido de minimizar esse quadro. Muito já
foi feito nos últimos anos, mas seus índices de desenvolvimento ainda colocam a
região dentre as mais desprovidas e carentes de recursos e de assistência social do
estado, embora tenham um rico patrimônio cultural, artístico e arquitetônico.
A região foi colonizada a partir das primeiras décadas do século XVIII em
virtude da descoberta de jazidas de ouro e diamante. A atividade mineradora logo se
expandiu, fazendo surgir os primeiros núcleos urbanos que tinham como principal
objetivo a fiscalização da exploração das jazidas.
A maior parte do solo é árido, castigado, ora por intermináveis secas, ora por
violentas enchentes. Grande parte de sua população vive na área rural e exercita, de
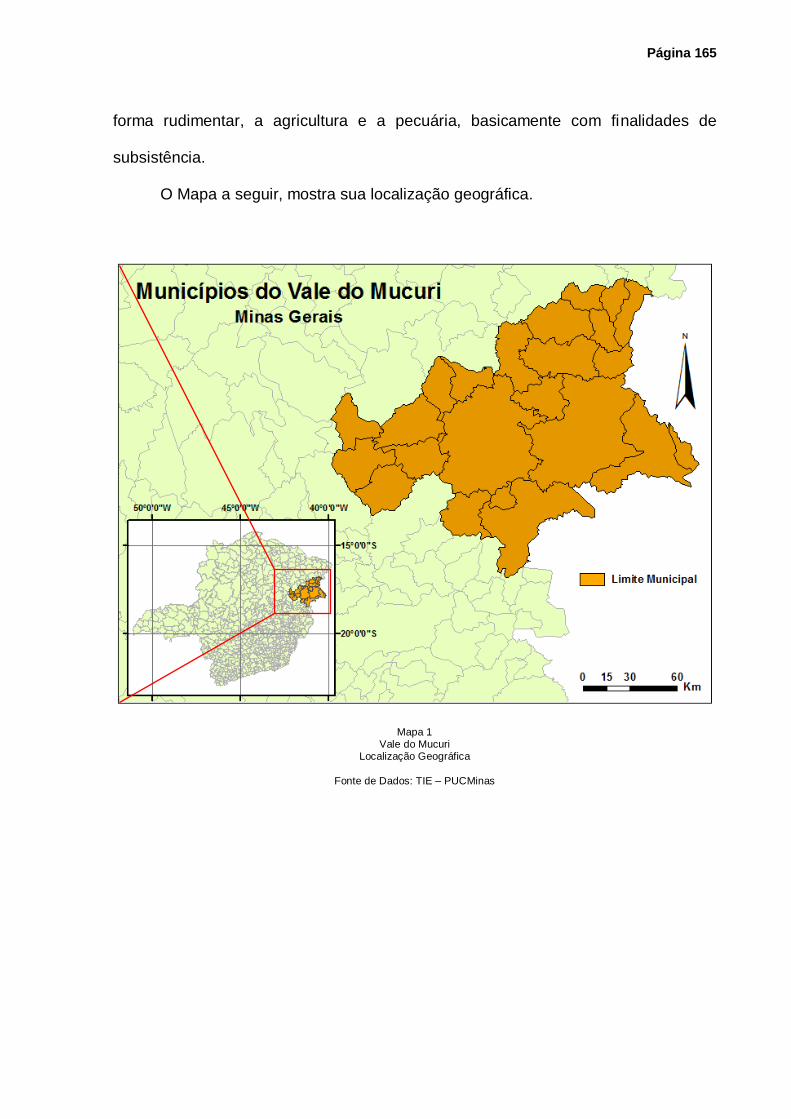
Página 165
forma rudimentar, a agricultura e a pecuária, basicamente com finalidades de
subsistência.
O Mapa a seguir, mostra sua localização geográfica.
Mapa 1 Vale do Mucuri
Localização Geográfica
Fonte de Dados: TIE – PUCMinas
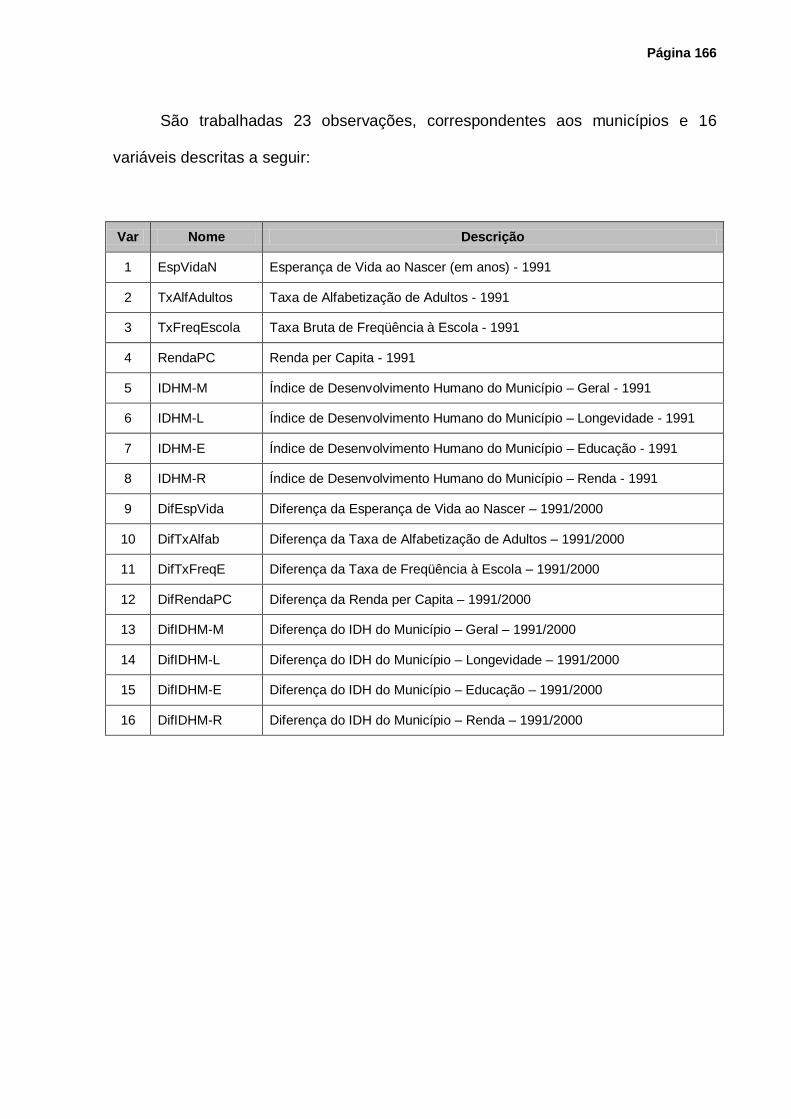
Página 166
São trabalhadas 23 observações, correspondentes aos municípios e 16
variáveis descritas a seguir:
Var Nome Descrição
1 EspVidaN Esperança de Vida ao Nascer (em anos) - 1991
2 TxAlfAdultos Taxa de Alfabetização de Adultos - 1991
3 TxFreqEscola Taxa Bruta de Freqüência à Escola - 1991
4 RendaPC Renda per Capita - 1991
5 IDHM-M Índice de Desenvolvimento Humano do Município – Geral - 1991
6 IDHM-L Índice de Desenvolvimento Humano do Município – Longevidade - 1991
7 IDHM-E Índice de Desenvolvimento Humano do Município – Educação - 1991
8 IDHM-R Índice de Desenvolvimento Humano do Município – Renda - 1991
9 DifEspVida Diferença da Esperança de Vida ao Nascer – 1991/2000
10 DifTxAlfab Diferença da Taxa de Alfabetização de Adultos – 1991/2000
11 DifTxFreqE Diferença da Taxa de Freqüência à Escola – 1991/2000
12 DifRendaPC Diferença da Renda per Capita – 1991/2000
13 DifIDHM-M Diferença do IDH do Município – Geral – 1991/2000
14 DifIDHM-L Diferença do IDH do Município – Longevidade – 1991/2000
15 DifIDHM-E Diferença do IDH do Município – Educação – 1991/2000
16 DifIDHM-R Diferença do IDH do Município – Renda – 1991/2000

Página 167
Os softwares utilizados são o NinnaCluster, na Análise de Agrupamentos, e o
software NinnaPCA, na Análise de Componentes Principais. A versão utilizada é a
Desktop e o funcionamento de ambos já foi mostrado no capítulo VI.
Os dados que participam da análise são organizados em uma matriz. As
observações são dispostas em cada linha e as variáveis nas colunas. Estabeleceu-
se que o número de observações deva sempre ser maior ou igual ao número de
variáveis. Os dados estão espacializados.
Apenas por conveniência na explicação desse estudo de caso, será feita,
primeiramente a análise de dados através das componentes principais. Os
agrupamentos serão alvo de uma análise posterior quando então os resultados das
duas técnicas serão analisados. As telas mostradas são todas capturadas
diretamente dos dois softwares mostrados.
Os dados de trabalho são inicialmente carregados como mostrado, em parte,
na figura a seguir extraída do NinnaPCA:
Tela 24
Fragmento de Tela – Dados de Trabalho – Vale do Mucuri - NinnaPCA

Página 168
Os dados originais mostrados na matriz de dados apresentam grandezas e
unidades de medida muito diversificadas. A variável “Esperança de Vida ao Nascer”,
por exemplo, tem como unidade de medida o número de anos. A “Renda Per Capita”
já é um valor do tipo moeda. O IDH, por sua vez, é um índice absoluto que varia de
0 a 1. Trabalhar com dados dispostos dessa maneira não é a forma mais correta e
pode produzir resultados não significativos e propagar erros em cálculos iterativos
(Barroso, 2003). Uma boa medida para se evitar esses problemas é padronizar os
dados de análise.
Para padronizar os dados de trabalho, tornando-os adimensionais, o software
faz uso da Média e do Desvio Padrão das variáveis:
Tela 25 Fragmento de Tela – Médias e Desvios Padrão de Variáveis
Página 169
A Matriz Padronizada de Dados é mostrada no fragmento de tela:
A Matriz de Correlação mostra como as variáveis estão correlacionadas umas
com as outras. A variável IDHM-L, por exemplo, que mostra o Índice de
Desenvolvimento Humano Municipal no aspecto Longevidade, possui altíssima
correlação com a variável EspVidaN, que mostra a Esperança de Vida ao Nascer.
Essa mesma variável já possui baixíssima correlação com relação à variável
RendaPC, que mostra a Renda Per Capita da População.
A variável IDHM-E mostra o Índice de Desenvolvimento Humano Municipal,
segundo o aspecto Educação. Sua correlação com a variável TxAlfAdultos, que
mostra a Taxa de Alfabetização de Adultos, ou com a variável TxFreqEscola, que
mostra a Taxa Bruta de Freqüência à escola é muito elevada.
Tela 26
Fragmento de Tela – Dados Padronizados

Página 170
A figura a seguir mostra uma parte da Matriz de Correlação calculada pelo
NinnaPCA:
Os Autovalores e os Autovetores são muito importantes na Análise de
Componentes Principais. Os Autovalores representam o percentual da quantidade
de variância total que está associado a um determinado componente. Encontra-se
também o respectivo autovetor associado ao autovalor calculado, o peso, que
corresponde à correlação entre as componentes principais e as variáveis, e a
variância de cada elemento individual do autovetor.
A soma dos autovalores fornece a variância total que corresponde ao número
de variáveis consideradas (Barroso, 2003).
O primeiro autovalor corresponde ao maior percentual da variabilidade
máxima. O segundo autovalor corresponde ao segundo maior percentual de
variabilidade máxima e assim por diante.
Tela 27 Fragmento de Tela – Matriz de Correlação
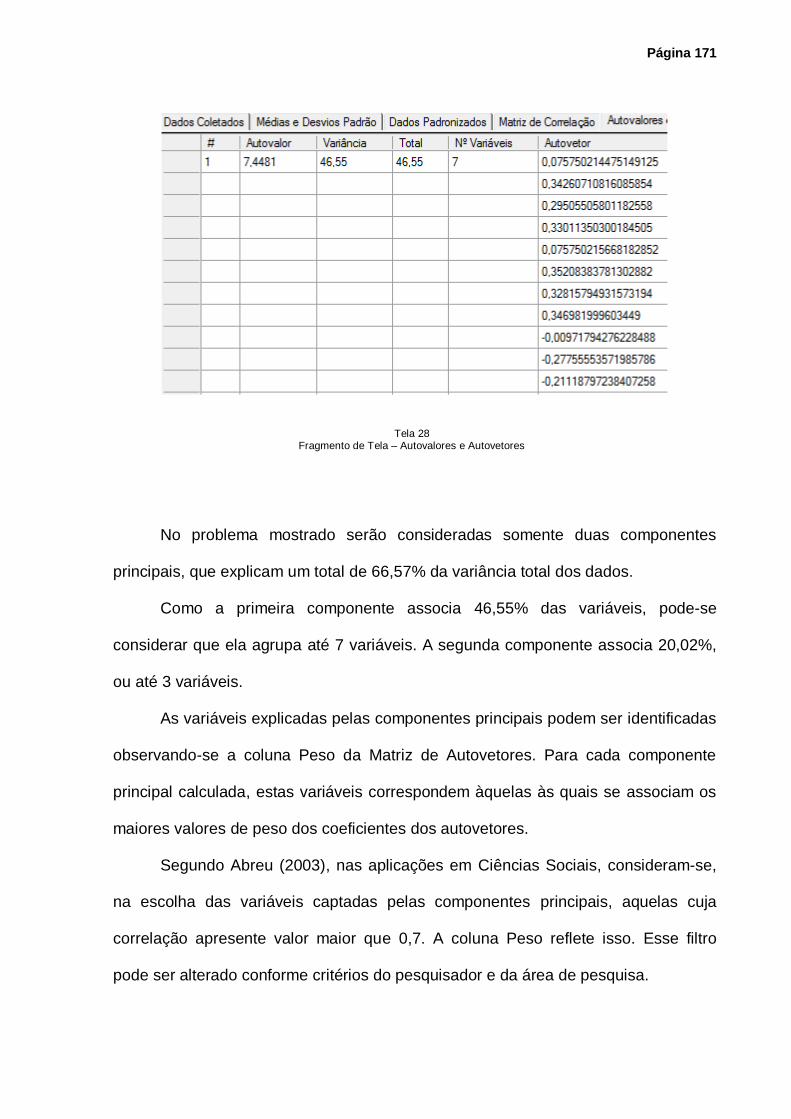
Página 171
No problema mostrado serão consideradas somente duas componentes
principais, que explicam um total de 66,57% da variância total dos dados.
Como a primeira componente associa 46,55% das variáveis, pode-se
considerar que ela agrupa até 7 variáveis. A segunda componente associa 20,02%,
ou até 3 variáveis.
As variáveis explicadas pelas componentes principais podem ser identificadas
observando-se a coluna Peso da Matriz de Autovetores. Para cada componente
principal calculada, estas variáveis correspondem àquelas às quais se associam os
maiores valores de peso dos coeficientes dos autovetores.
Segundo Abreu (2003), nas aplicações em Ciências Sociais, consideram-se,
na escolha das variáveis captadas pelas componentes principais, aquelas cuja
correlação apresente valor maior que 0,7. A coluna Peso reflete isso. Esse filtro
pode ser alterado conforme critérios do pesquisador e da área de pesquisa.
Tela 28 Fragmento de Tela – Autovalores e Autovetores

Página 172
A tabela abaixo mostra as variáveis captadas pela primeira componente:
2 Taxa de Alfabetização de Adultos (TxAlfAdultos)
3 Taxa Bruta de Frequência à Escola (TxFreqEscola)
4 Renda Per Capita (RendaPC)
6 Índice de Desenvolvimento Humano – Educação (IDHM-E)
7 Índice de Desenvolvimento Humano – Renda (IDHM-R)
8 Índice de Desenvolvimento Humano – Municipal (IDHM-M)
A segunda componente agrupa outras duas variáveis:
1 Esperança de Vida ao Nascer (EspVidaN)
5 Índice de Desenvolvimento Humano – Longevidade (IDHM-L)
É importante firmar o conceito de que a primeira componente registra, na
verdade, seis variáveis conjuntas, que dizem respeito, basicamente, àquelas que
representam valores sobre a renda e a educação dos municípios.
Da mesma forma, a segunda componente agrupa mais duas variáveis, que
dizem respeito à esperança de vida ao nascer e à longevidade.
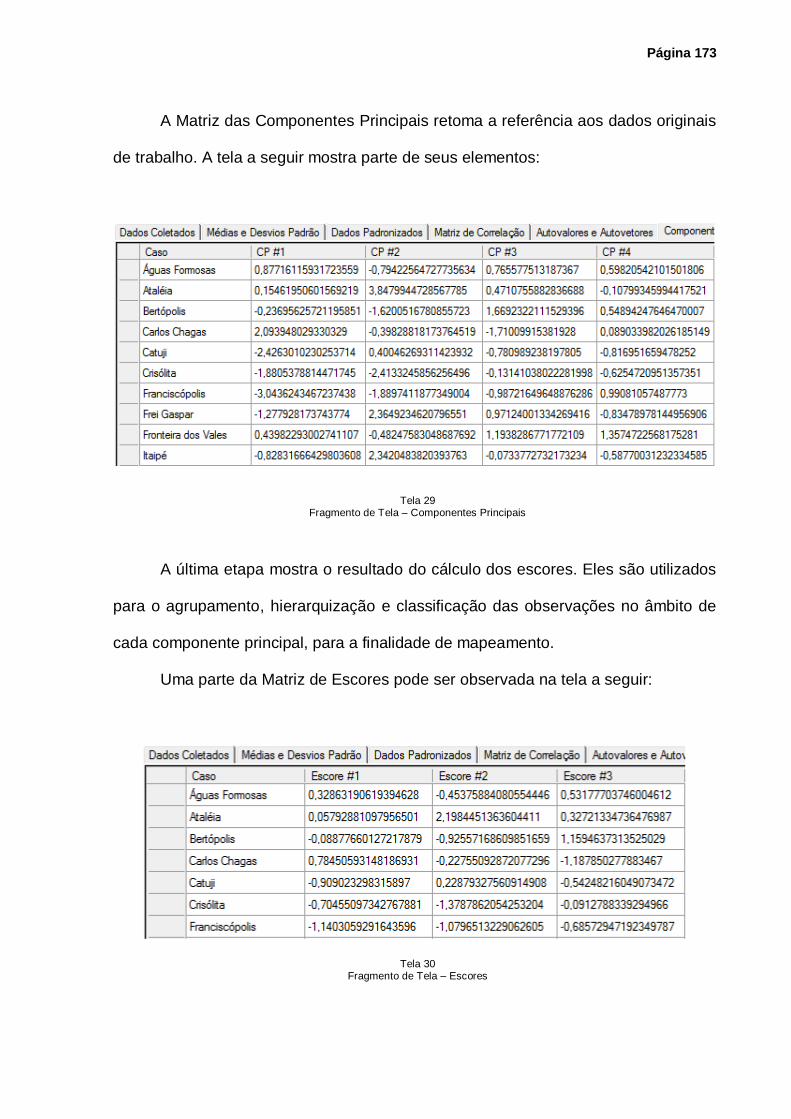
Página 173
A Matriz das Componentes Principais retoma a referência aos dados originais
de trabalho. A tela a seguir mostra parte de seus elementos:
A última etapa mostra o resultado do cálculo dos escores. Eles são utilizados
para o agrupamento, hierarquização e classificação das observações no âmbito de
cada componente principal, para a finalidade de mapeamento.
Uma parte da Matriz de Escores pode ser observada na tela a seguir:
Tela 29 Fragmento de Tela – Componentes Principais
Tela 30 Fragmento de Tela – Escores

Página 174
Nessa Matriz de Escores, ao se clicar no cabeçalho da coluna, ordena-se a
mesma em ordem crescente ou decrescente. A tela a seguir revela uma hierarquia
interessante no que diz respeito às variáveis agrupadas pela primeira componente:
Nesse momento alguns mapas podem ser feitos para representar uma visão
de conjunto de diversas variáveis. Isso pode ser importante em alguma análise que
se queira fazer.
O mapa a seguir representa a primeira componente principal. Ela associa
variáveis ligadas à taxa de alfabetização de adultos e freqüência à escola, muito
determinantes para o IDH sobre o critério Educação e variáveis ligadas à renda per
capita, que influencia o IDH municipal. Pode-se dizer que essa componente associa
valores ligados à infra-estrutura dos municípios da região.
Tela 31
Fragmento de Tela – Ordenação de Escores
A ordem decrescente mostra uma hierarquia, do
maior para o menor escore, dos dados relativos à Componente Principal 1.
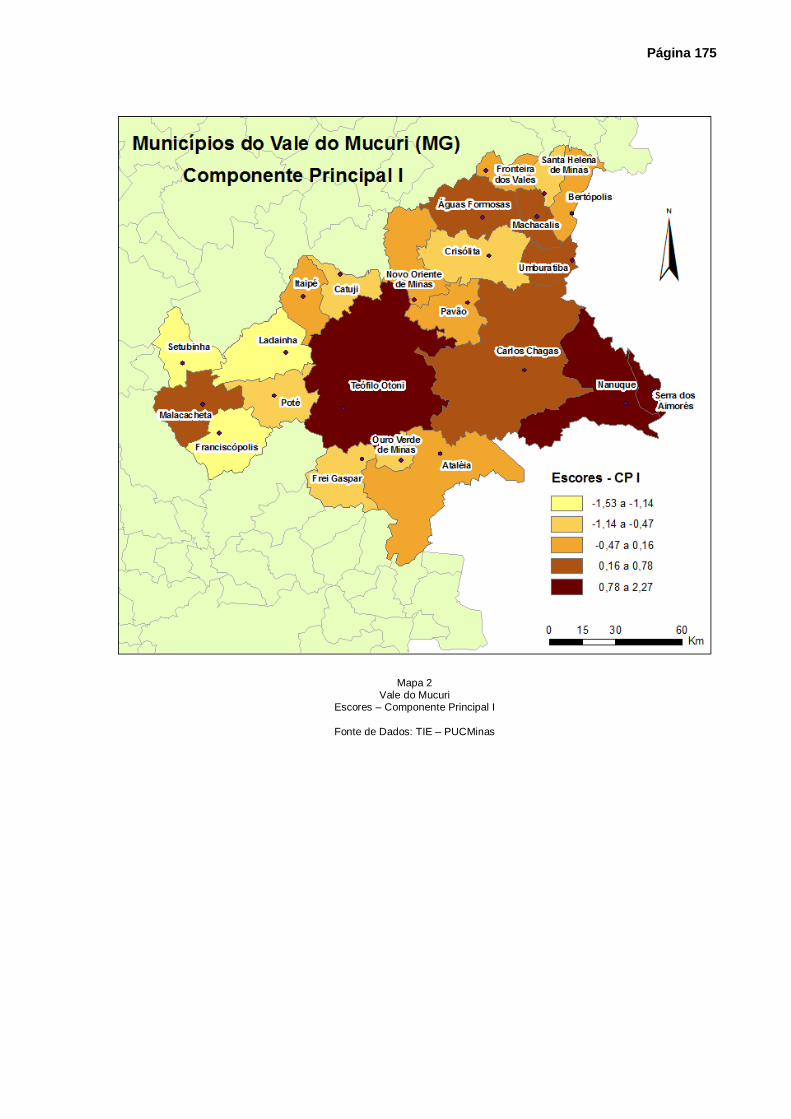
Página 175
Mapa 2 Vale do Mucuri
Escores – Componente Principal I
Fonte de Dados: TIE – PUCMinas
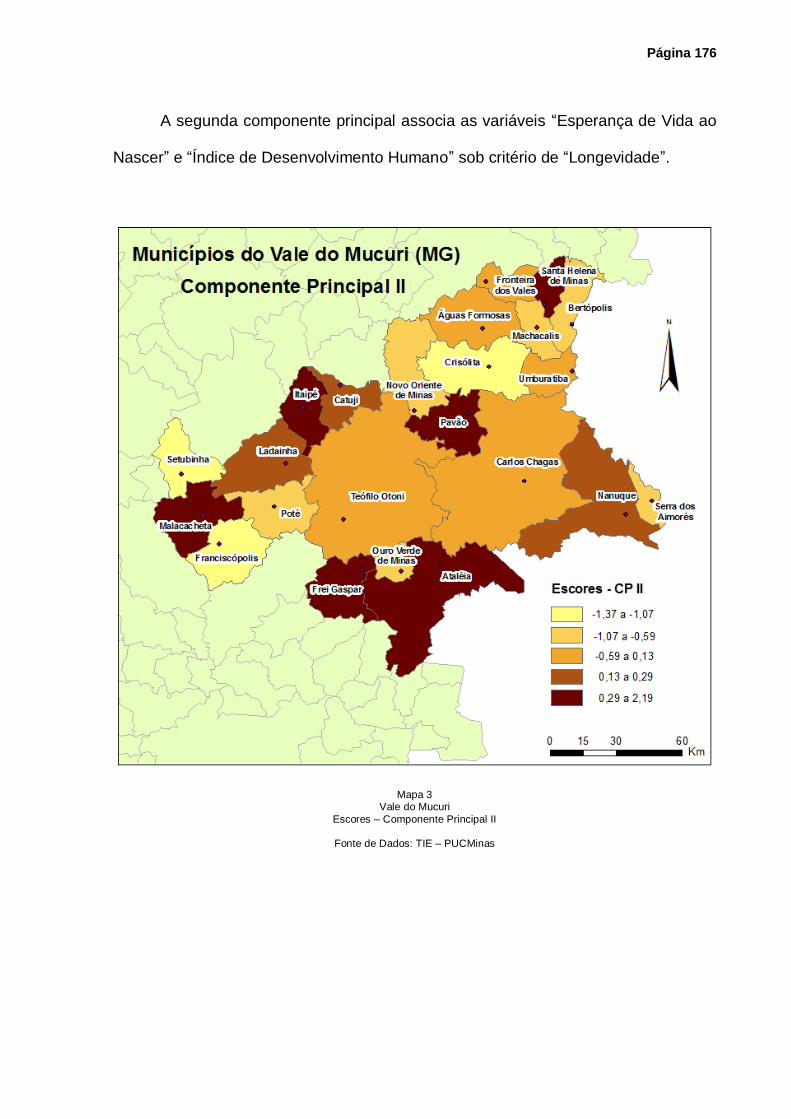
Página 176
A segunda componente principal associa as variáveis “Esperança de Vida ao
Nascer” e “Índice de Desenvolvimento Humano” sob critério de “Longevidade”.
Mapa 3 Vale do Mucuri
Escores – Componente Principal II
Fonte de Dados: TIE – PUCMinas

Página 177
É importante observar que a análise que se faz por meio das Componentes
Principais pode ou não atender às necessidades do geógrafo para a explicação ou
entendimento de um fenômeno geográfico. Ainda que matematicamente uma
solução tenha sido encontrada, ela pode não servir às necessidades da Geografia.
Sem dúvida essa técnica é muito adequada para a expressão de um conjunto
de variáveis. Mas essa expressão é válida? O modelo proposto é válido?
Segundo Barroso (2003), esses questionamentos revelam a necessidade de
se voltar ao problema geográfico e de se verificar se o modelo matemático-
estatístico utilizado promove alguma facilidade em sua explicação. Muitas vezes
serão necessários outros instrumentos da matemática e da estatística para a
formulação de um modelo mais adequado à realidade.
A Análise de Agrupamentos pode também auxiliar a explicação de um
problema na Geografia. A partir de agora, ela é trabalhada. Os dados são os
mesmos utilizados na Análise de Componentes Principais.
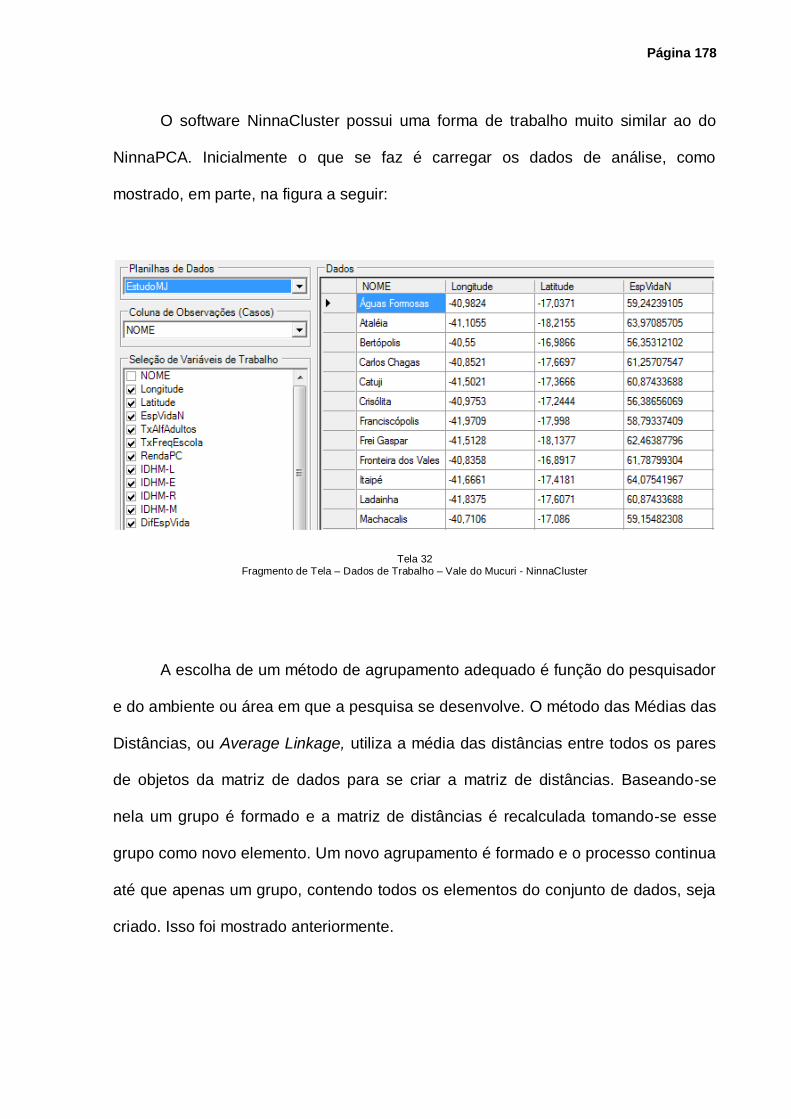
Página 178
O software NinnaCluster possui uma forma de trabalho muito similar ao do
NinnaPCA. Inicialmente o que se faz é carregar os dados de análise, como
mostrado, em parte, na figura a seguir:
A escolha de um método de agrupamento adequado é função do pesquisador
e do ambiente ou área em que a pesquisa se desenvolve. O método das Médias das
Distâncias, ou Average Linkage, utiliza a média das distâncias entre todos os pares
de objetos da matriz de dados para se criar a matriz de distâncias. Baseando-se
nela um grupo é formado e a matriz de distâncias é recalculada tomando-se esse
grupo como novo elemento. Um novo agrupamento é formado e o processo continua
até que apenas um grupo, contendo todos os elementos do conjunto de dados, seja
criado. Isso foi mostrado anteriormente.
Tela 32 Fragmento de Tela – Dados de Trabalho – Vale do Mucuri - NinnaCluster
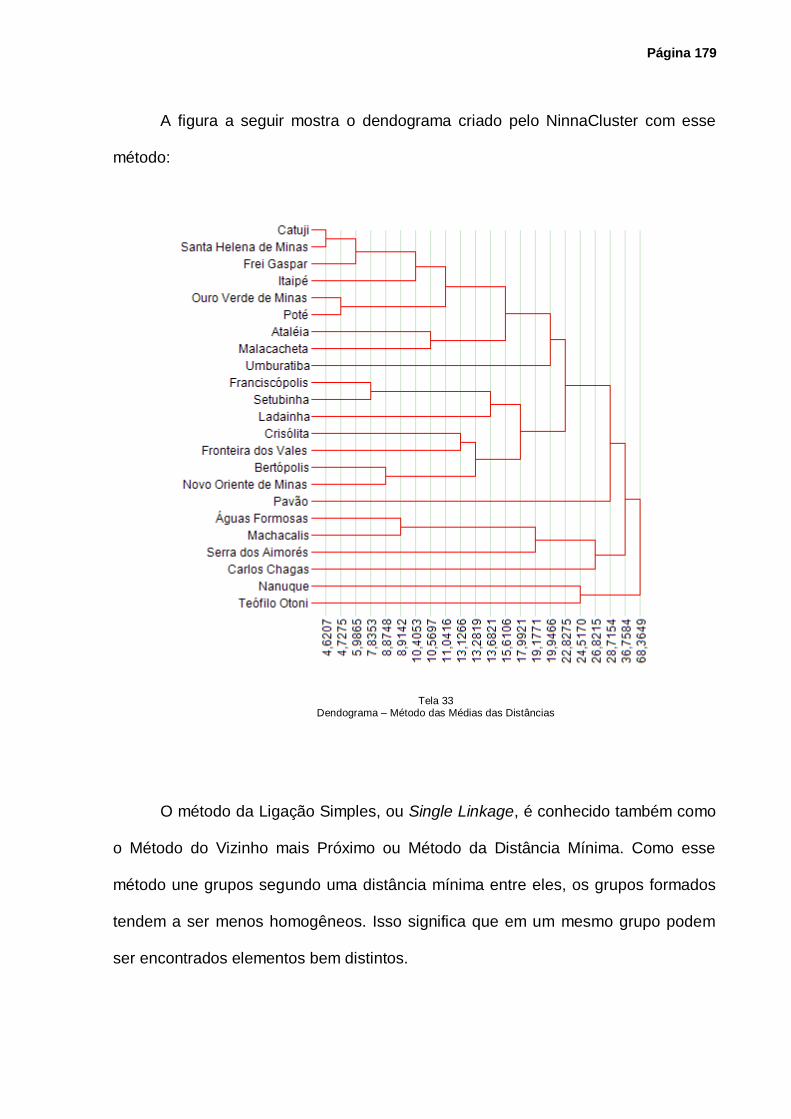
Página 179
A figura a seguir mostra o dendograma criado pelo NinnaCluster com esse
método:
O método da Ligação Simples, ou Single Linkage, é conhecido também como
o Método do Vizinho mais Próximo ou Método da Distância Mínima. Como esse
método une grupos segundo uma distância mínima entre eles, os grupos formados
tendem a ser menos homogêneos. Isso significa que em um mesmo grupo podem
ser encontrados elementos bem distintos.
Tela 33 Dendograma – Método das Médias das Distâncias
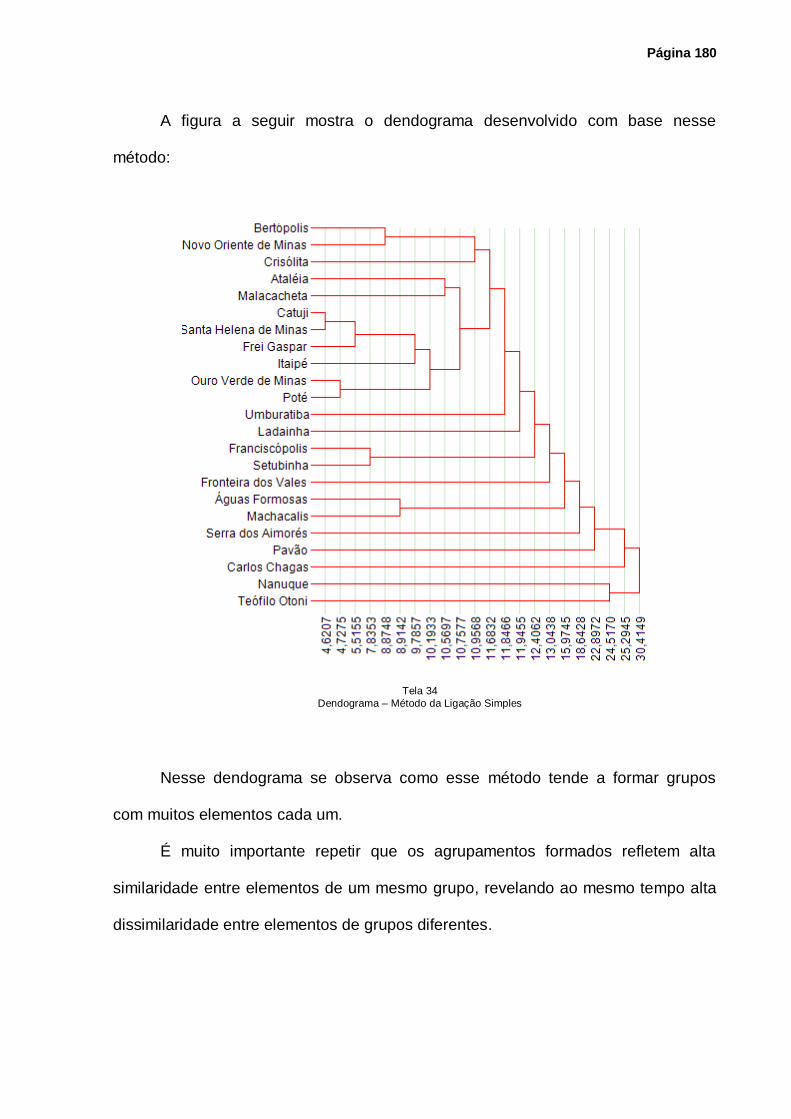
Página 180
A figura a seguir mostra o dendograma desenvolvido com base nesse
método:
Nesse dendograma se observa como esse método tende a formar grupos
com muitos elementos cada um.
É muito importante repetir que os agrupamentos formados refletem alta
similaridade entre elementos de um mesmo grupo, revelando ao mesmo tempo alta
dissimilaridade entre elementos de grupos diferentes.
Tela 34
Dendograma – Método da Ligação Simples

Página 181
O método da Ligação Completa, ou Complete Linkage, também é conhecido
como o Método do Vizinho mais Distante. Ao longo do processo, cada vez que um
novo elemento é adicionado a um grupo, esse se torna mais distinto em relação aos
outros, formando, ao final, grupos mais homogêneos que os formados por meio do
Método da Ligação Simples. Esse método é particularmente indicado para a
formação de grupos com tamanhos mais semelhantes.
Tela 35 Dendograma – Método da Ligação Completa

Página 182
Um método de partição muito conhecido e muito utilizado na Análise de
Agrupamentos é o K-Médias, ou K-Means. É um método muito útil para a formação
de agrupamentos quando se tem muitos objetos. É um método que procura
aumentar a homogeneidade dentro de cada grupo aumentando também a diferença
entre eles.
A figura a seguir mostra a aplicação do K-Means para a formação de cinco
grupos, ou clusters.
Na Geografia, as conclusões que podem ser elaboradas com o uso dos
métodos mostrados são muitas e cada uma delas deve ser feita segundo a ótica de
quem pesquisa o fenômeno. Cabe a ele analisar e verificar se os resultados
encontrados se adaptam à realidade do problema geográfico e servem para compor
uma nova e mais rica representação ou explicação do fenômeno que se estuda.
Isso termina o estudo de caso.
Tela 36 Formação de Agrupamentos pelo Método de Partição K-Means

Página 183
Capítulo 8 – Considerações Finais
A Geografia é uma ciência que trabalha com uma grande variedade de
informações que precisa ser organizada para que possibilite avaliações de caráter
geral ou local, promova um aperfeiçoamento de generalizações e predições e
permita a validação e o estabelecimento de modelos e teorias.
Uma das formas de se organizar melhor esses dados de análise é através da
Análise Multivariada. Ela tem ocupado um espaço cada vez maior na Geografia por
possibilitar um tratamento mais sistemático das informações inerentes ao estudo de
uma determinada ocorrência geográfica, fornecendo meios que facilitam a
explicação de fenômenos geográficos, sua representação, o estudo de tendências e
padrões espaciais, a validação e a formulação de modelos e a elaboração de
previsões. São recursos importantes que podem ser utilizados em processos
estratégicos e de tomada de decisão.
A organização, a classificação e a análise de dados na Geografia podem ser
feitas através de inúmeras técnicas multivariadas, algumas bastante estabelecidas,
como a Análise Fatorial, a Regressão Múltipla e a Correlação Múltipla, a Análise de
Discriminante Múltipla, a Análise Multivariada de Variância e Covariância e a
Correlação Canônica, entre outras. A Análise de Correspondência, os Modelos
Lineares de Probabilidade e a Modelagem de Equações Simultâneas / Estruturais
são técnicas ainda emergentes. A Área de Sistemas Multivariados, que envolve
trabalhos em Mineração de Dados e Redes Neurais é outra em grande
desenvolvimento.
Esse trabalho aborda duas dessas técnicas multivariadas: a Análise de
Agrupamentos e a Análise de Componentes Principais.

Página 184
A Análise de Agrupamentos e a Análise de Componentes Principais são
técnicas multivariadas que possibilitam essa organização e estão sendo aplicadas
em vários ramos do conhecimento humano com o objetivo de facilitar a explicação
de fenômenos das mais variadas naturezas, possibilitando o estudo de tendências e
a formulação de modelos.
A Análise de Agrupamentos corresponde a um conjunto amplo de técnicas e
algoritmos que objetivam identificar e agrupar objetos segundo alguma similaridade
existente entre eles. É uma técnica analítica que pode ser utilizada para criar e
classificar grupos de indivíduos mutuamente excludentes com base nas
similaridades entre seus atributos. Ela é muito utilizada para a identificação de
padrões de comportamento.
A Análise de Componentes Principais, técnica incluída na Análise Fatorial, é
uma abordagem estatística que pode ser usada para analisar as inter-relações
existentes entre um grande número de variáveis, condensando a informação contida
nelas em um conjunto menor de variáveis estatísticas, observando uma perda
mínima de informação. Ela é utilizada quando se tem necessidade de se agrupar um
grande número de variáveis relacionadas a um determinado conjunto de
observações. Seu uso simplifica a análise e a visualização das informações contidas
nos dados originais.
As duas técnicas vêm sendo aplicadas em vários ramos do conhecimento
humano com o objetivo de facilitar a explicação de fenômenos das mais variadas
naturezas, possibilitando a identificação de padrões e o estudo de tendências.
Esse trabalho procurou, primeiramente, contextualizar o momento do
surgimento da Geografia Teorético-Quantitativa, que trouxe como conseqüência a
aplicação em larga escala dos métodos quantitativos dentro da Geografia. O estudo

Página 185
realizado sobre a evolução do pensamento geográfico foi muito importante, uma vez
que, tendo esse trabalho uma característica tão técnica, computacional e aplicativa,
resgata, dentre outras coisas, a forte preocupação do autor com a manutenção do
vínculo teórico que sustenta tantas práticas da Geografia atual.
Uma revisão bibliográfica também foi feita com o objetivo de mostrar algumas
aplicações relevantes da Análise de Agrupamentos e da Análise de Componentes
Principais dentro da Geografia e também em outras ciências.
Foram mostrados também alguns fundamentos matemáticos, estatísticos e
computacionais que sustentam a aplicação dessas duas técnicas na Geografia como
instrumento de análise de dados espaciais. A abordagem, extraída da Teoria de
Conjuntos, procurou, matematicamente, detalhar os conceitos inerentes às Relações
de Equivalência e à Partição de Conjuntos. Esses fundamentos, como se
demonstrou, estão presentes nos bastidores dos processos de classificação e
hierarquização contidos nas técnicas trabalhadas.
Além dos fundamentos matemáticos, um estudo mais detalhado dessas duas
técnicas também foi feito, revelando os algoritmos e passos metodológicos contidos
nos processos. Para as duas abordagens todas as etapas de cálculo foram
detalhadas por serem importantes para a codificação das técnicas em nível
computacional.
Dois artefatos de software foram desenvolvidos e são disponibilizados com
esse trabalho, em duas versões, incluindo a portabilidade de uso através da internet.
Eles são capazes de suportar o uso das duas técnicas trabalhadas na Geografia de
forma profissional ou acadêmica e incluem funcionalidades gráficas e de
mapeamento temático.
Um exemplo da aplicação das duas técnicas na Geografia foi apresentado

Página 186
utilizando-se dados sócio-econômicos de 23 municípios da Mesorregião do Vale do
Mucuri, localizada na porção nordeste de Minas Gerais. Os resultados alcançados,
primeiramente através da Análise de Componentes Principais e, depois, através da
Análise de Agrupamentos, se mostraram complementares.
A aplicação da técnica da Análise de Componentes Principais permitiu o
exame dos dados de trabalho através de mapas temáticos altamente expressivos
que possuíam maior conteúdo de informação, já que reuniam diversos atributos de
forma simultânea. Ela se mostra uma técnica matemática e estatística muito eficiente
quando existe a necessidade de se comparar, de maneira conjunta, um grande
número de variáveis relacionadas a um determinado conjunto de observações.
Efetivamente ela possibilita uma simplificação no processo de análise.
A Análise de Agrupamentos, por sua vez, criou grupos de dados através de
diversas técnicas. Esses grupos, altamente similares entre si, mostraram coerência
com a análise feita através das Componentes Principais.
Essas técnicas podem ser aplicadas em pesquisas nas mais diversas áreas
do conhecimento humano. Em especial na Geografia elas simplificam muito a
análise das inúmeras informações inerentes ao estudo de um fenômeno geográfico.
No entanto, em mais de uma ocasião nesse trabalho, refletiu-se sobre a importância
da presença de um geógrafo na análise e na validação dos resultados encontrados
por meio da aplicação dessas e de outras técnicas matemáticas e estatísticas. O uso
puro e simples de um método não assegura, por si só, melhoria na explicação de um
fenômeno espacial.
A análise de dados e a coleta de informações sempre foram de grande
importância para a Geografia. E ela constantemente tem buscado ajustar-se frente
às necessidades do homem, e isso exige, sobretudo, uma aplicação rigorosa de

Página 187
metodologias que garantam sua contribuição efetiva na solução de seus problemas.
As técnicas apresentadas são exemplos disso.
As pesquisas realizadas durante o desenvolvimento desse trabalho
fomentaram algumas idéias quanto a trabalhos futuros que poderiam ser feitos.
O prosseguimento nos estudos sobre a Mesorregião do Vale do Mucuri sem
dúvida faz parte de um importante esforço conjunto que efetivamente procura
promover o desenvolvimento sustentável para a região e é possível também
contribuir com isso.
As diversas técnicas presentes na Análise Multivariada podem demonstrar um
uso importante para a Geografia e o estudo mais detalhado de algumas delas pode
trazer visões muito interessantes na análise de dados. A Análise de Discriminantes e
os trabalhos que envolvem a Mineração de Dados e as Redes Neurais são
exemplos de técnicas emergentes que poderiam ser estudadas e avaliadas quanto à
sua aplicação na Geografia.
Uma idéia que desde já se procurou colocar em prática é o estabelecimento
de uma mesma interface ou ambiente de trabalho para os dois softwares
disponibilizados. Outros desenvolvimentos poderiam utilizar o mesmo padrão, de
maneira a facilitar sua integração e sua utilização.
No estudo sobre a Análise de Agrupamentos, observou-se certa dificuldade
quanto ao acesso à literatura sobre os coeficientes utilizados para variáveis
qualitativas. Esse tema poderia ser aprofundado porque, entre outras coisas, pode
abrir bastante as possibilidades de acesso a dados e informações importantes
dentro da Geografia no estudo de um fenômeno.
Outros métodos de agrupamento hierárquico e de partição poderiam ser
desenvolvidos e disponibilizados para aumentar as opções do usuário na criação de

Página 188
dendogramas e agrupamentos.
O NinnaPCA trouxe muitos novos recursos nessa versão. Um deles foi a
possibilidade de se criar mapas diretamente a partir dos resultados da análise. Muito
pode ser feito nesse módulo. O método para a criação das classes nos mapas é o
Método de Jenks. Outros métodos poderiam ser agregados, utilizando-se de
intervalos iguais, manuais, do desvio padrão, percentil, entre outras técnicas. Além
disso, opções de mudança de cores e padrões de cores para os mapas gerados
podem ser disponibilizados, o que amplia a utilização desse recurso em outras áreas
científicas.
A colocação de rotinas responsáveis por dar ao módulo de mapas a
possibilidade de se trabalhar com projeções é outra idéia que pode ser levada em
conta em desenvolvimentos futuros. Essa importante funcionalidade está presente
no ambiente dos Sistemas de Informações Geográficas e permitiria ao módulo a
geração completa de mapas temáticos, com barra de escala, norte e outros
elementos.
Esse trabalho está disponível em meio ótico e, como já mencionado, contém
os aplicativos desenvolvidos e os dados trabalhados no estudo de caso.

Página 189
Referências
ABREU, J. F.; BARROSO, L. C. (Org), Geografia, Modelos de Análise Espacial e
GIS. PUCMinas. Belo Horizonte, MG, 2003, 232p.
ABREU, J. F.; BARROSO, L. C., Relatório Nº 1 – Análise de Componentes
Principais (PRINCO). UFMG, Instituto de Geociências, Belo Horizonte, MG,1980.
ABREU, J. F., Análise Espacial – Notas de Aula – Programa de Pós Graduação
em Geografia – Tratamento da Informação Espacial. Pontifícia Universidade
Católica de Minas Gerais, Belo Horizonte, MG, 2003.
ABREU, J. F. e MUZZARELLI, A., Introduzione ai Sistemi Informativi Geografici.
Franco Angeli, Forum per la Tecnologia della Informazione. Università di Bologna,
Dipartimento di Architetura e Pianificazione Territoriale e Pontifícia Universidade
Católica de Minas Gerais, Programma di Post-Laurea in Tratamento da Informação
Espacial, Milano, Italy, 2003.
AFREIXO, V. M. A., Análise Estatística da Linguagem Genética. 2002.
Dissertação (Mestrado em Matemática). Orientadora: Adelaide de Fátima Baptista
Valente Freitas. Universidade de Aveiro, Portugal.
ALENCAR, B. J., Análise Multivariada de Dados no Tratamento da Informação
Espacial – Um Aplicativo em Componentes Principais. 2005, 90p. Dissertação
(Mestrado em Geografia). Orientadores: Leônidas Conceição Barroso e João
Francisco de Abreu. PUCMinas, Belo Horizonte, MG.

Página 190
ALENCAR FILHO, E., Relações Binárias. São Paulo, SP - Nobel, 1984, 303p.
AMORIM FILHO, O. B., Reflexões sobre as Tendências Teórico-Metodológicas
da Geografia. ICG/UFMG, Departamento de Geografia, Publicação Especial nº 2,
Belo Horizonte, MG, 1985, 155 p.
AMORIM FILHO, O. B.: A Evolução do Pensamento Geográfico. In: Revista
Geografia e Ensino. Ano I, nr. 1, Belo Horizonte, IGC/UFMG, Mar/1982;
AMORIM FILHO, O. B., Evolução do Pensamento Geográfico – Notas de Aula –
Programa de Pós Graduação em Geografia – Tratamento da Informação
Espacial. Pontifícia Universidade Católica de Minas Gerais, Belo Horizonte, MG,
2003.
ANDRADE, L. P., Procedimento Interativo de Agrupamento de dados – 2004,
193p. (Tese de Doutorado) – COPPE – Engenharia Civil – Orientador: Nelson
Francisco Favilla Ebecken - Universidade Federal do Rio de Janeiro – Rio de
Janeiro, RJ..
Atlas do Desenvolvimento Humano no Brasil – V. 1.0.0 – Software © 2003 ESM
Consultoria. Dados © 2003 PNUD.

Página 191
AZAMBUJA, S., Estudo e Implementação da Análise de Agrupamento em
Ambientes Virtuais de Aprendizagem – 2005. Dissertação (Mestrado em
Informática). UFRJ. Orientadores: Cláudia Lage Rebello da Motta e Marcos da
Fonseca Elia. Rio de Janeiro, RJ.
BARROSO, L. C., Métodos Quantitativos – Notas de Aula – Programa de Pós
Graduação em Geografia – Tratamento da Informação Espacial. Pontifícia
Universidade Católica de Minas Gerais, Belo Horizonte, MG, 2003.
BARROSO, L. C., BARROSO, M. M. A., FILHO, F. F. C., CARVALHO, M. L. B.
MAIA, M. L., Cálculo Numérico (com Aplicações), 2ª Edição, Editora Harbra Ltda.
São Paulo, SP, 1987, 366p.
BASSAB, W. O., MIAZAKI, É. S. e ANDRADE, D. F., Introdução à Análise de
Agrupamentos. Associação Brasileira de Estatística – ABE. 9º Simpósio Nacional
de Probabilidade e Estatística. São Paulo – Julho de 1990.
BATELLA, W. B., Análise Espacial dos Condicionantes da Criminalidade
Violenta no Estado de Minas Gerais – 2005: Contribuições da Geografia do
Crime – 2008, 142p. – Dissertação (Mestrado em Geografia) – Pontifícia
Universidade Católica de Minas Gerais – Orientador: Alexandre Magno Alves Diniz –
Belo Horizonte, MG .
BATTISTI, J., ASP .NET – Uma Nova Revolução na Construção de Sites e
Aplicações Web. Axcel Books do Brasil Editora – Rio de Janeiro, RJ, 2001. 728p.

Página 192
BERRY, B. J. L. e MARBLE, D. F., Spatial Analysis – A Reader in Statistical
Geography. Prentice Hall, New Jersey, 1968.
BROEK, J. O. M., Iniciação ao Estudo da Geografia. Zahar Editores, Rio de
Janeiro, 1972.
BUENO, B. F., Aplicação de técnicas multivariadas em mapeamento e
interpretação de parâmetros do solo – Unicamp (São Paulo).
http://libdigi.unicamp.br/document/?code=vtls000228710, 2001.
BURTON, I., A Revolução Quantitativa e a Geografia Teorética. In: Boletim de
Geografia Teorética, Vol. 7, nº 13. Ageteo, Rio Claro, São Paulo, 1977, 137p.
CAMPOS FILHO, F. F., Algoritmos Numéricos. LTC, Rio de Janeiro, 2000, 383p.
CAPEL, H. e URTEAGA, L., Las Nuevas Geografias. Salvat Editores S. A.,
Barcelona, 1984.
CASTRO, J. F. M., Caracterização espacial do sul de Minas e “entorno”
utilizando-se o modelo potencial e a análise de fluxos em sistemas digitais:
uma proposta metodológica. 2000, 157p. - Tese (Doutorado em Geografia) –
Universidade Estadual Paulista/Instituto de Geociências e Ciências Exatas –
Orientador: João Francisco de Abreu. Rio Claro, SP.

Página 193
CASTRUCCI, B., Elementos de Teoria dos Conjuntos. 3ª Edição. Livraria Nobel.
São Paulo, 1969, 131p.
CARNAHAN, B., LUTHER, H. A, e WILKES, J. O., Applied Numerical Methods.
John Wiley & Sons, Inc., USA, 1969, 604p.
COLE, J. P., Geografia Quantitativa. Instituto Brasileiro de Geografia, Rio de
Janeiro, 1972, 120p.
CHIGUTI, M., Aplicação da Análise Multivariada na Caracterização dos
Municípios Paranaenses segundo suas Produções Agrícolas. 2005. Dissertação
(Mestrado em Métodos Numéricos em Engenharia). Orientador: Jair Mendes
Marques. Curitiba, PR.
CHRISTOFOLETTI, A. (Org.), Perspectivas da Geografia. Tradução de Jaci Silva
Fonseca ... et al. 2ª Edição, Difel, São Paulo, 1982, 318p.
CLAVAL, P.: Histoire de la Géographie. – Tradução: Oswaldo Bueno Amorim Filho.
Paris, PUF, 1995, 127 p.
DECANINI, M. M. S., Cartografia Temática: Métodos de Classificação dos Dados
Geográficos Quantitativos – Departamento de Cartografia – FCT – UNESP –
Presidente Prudente - 2003

Página 194
DEITEL, P. J. e DEITEL, H. M., Ajax, Rich Internet Applications e
Desenvolvimento Web para Programadores. Pearson - Prentice Hall – São Paulo,
SP, 2008 – 747p.
DEITEL, P. J., DEITEL, H. M., LISTFIELD, J., NIETO, T. R., YAEGER, C.
ZLATKINA, M., C# - Como Programar. Pearson Education – São Paulo, SP, 2008 –
1153p.
EVERITT, B., Cluster Analysis. Heinemann Educational Books, London, 1974.
FERREIRA, A. B. de H., Novo Aurélio Século XXI: o Dicionário da Língua
Portuguesa, 3ª Edição, Nova Fronteira, Rio de Janeiro, RJ, 1999.
FERREIRA, C. C.; SIMÕES, N. N., A evolução do pensamento geográfico.
Lisboa: Gradiva, 1986.
FLANAGAN, D., JavaScript – O Guia definitivo. Tradução de Edson
Furmankiewicz – 4ª Edição – Porto Alegre, PR - O’Reilly – Bookman – 2004 – 818p.
GERARDI, L. H. O. e SILVA, B. C. N., Quantificação em Geografia. Difel, São
Paulo, SP, 1981, 161p.
GIMENES, F. M. P., GIMENES, R. M. T. e OPAZO, M. A. U., Os Processos de
Integração Econômica sob a Ótica da Análise Estatística de Agrupamento.
Revista da FAE, Curitiba, V. 7, Nr. 2, p. 19-32, julho/dezembro de 2004.

Página 195
GOULD, P., Becoming a Geographer. Syracuse University Press. Tradução e
Adaptação de AMORIM FILHO, O. B.
GURGEL, H. C., FERREIRA, N. J. e LUIZ, A. J. B., Estudo da Variabilidade do
NDVI sobre o Brasil utilizando-se a Análise de Agrupamentos. Revista Brasileira
de Engenharia Agrícola e Ambiental, V. 7, Nr. 1, p.85-90, 2003. Campina Grande,
PB, DEAg/UFCG.
GRIGG, D., Regiões, Modelos e Classes. In: CHORLEY, R. J. e HAGGETT, P.
(Org.), Modelos Integrados em Geografia. Livros Técnicos e Científicos Editora S.
A. , Rio de Janeiro, 1974, 222p.
HAIR JR., J. F.; ANDERSON, R.; TATHAM, R. L.; BLACK, W. C., Análise
Multivariada de Dados – 5ª Edição – Bookman – 2005 – 593p.
JENKS, G. F., Generalization in Statistical Mapping – University of Kansas – USA
– March, 1963, 15-26
JENKS, G. F.; KNOS, D. S., The Use of Shading Patterns in Graded Series –
University of Kansas – USA – September, 1961, 316-334
JOHNSON, R. A.; WICHERN, D. W., Applied Multivariate Statistical Analysis.
Prentice Hall, New Jersey, USA, 1998, 816p.
JOHNSTON, R.J. Geografia e Geógrafos. São Paulo: Editora Difel, 1986.

Página 196
KHOSRAVI, S., ASP .NET 2.0 – Server Control and Component Developtment.
Wiley Publishing, Inc., Indianapolis, Indiana, USA, 2006
KOMATSU, E. H., Lagoas da Planície Aluvial do Rio Ivinheima – Morfologia e
Comunidade Bêntica. 2003 - Dissertação (Mestrado em Geografia) – Universidade
Estadual de Maringá, Maringá, SP
LEON, S. J., Álgebra Linear com Aplicações. LTC, Rio de Janeiro, 1998, 390p.
LONGLEY, P. A., et al. Geographic Information Systems and Science. John Wiley
& Sons, Ltd., City University, London, UK, 2001, 454p.
MANLY, B. J. F., Métodos Estatísticos Multivariados – Uma Introdução. Western
EcoSystems Technology, Inc. Laramie, Wyoming, USA. 3ª Edição. Tradução de Sara
Ianda Correa Carmona – Artmed e Bookman. 229p.
MARCONI, Marina de Andrade; LAKATOS, Eva Maria., Fundamentos de
Metodologia Científica. 6ª ed. São Paulo: Atlas, 2005.
MARQUES, E. C.; NAJAR A. L., Saúde e Espaço; Estudos Metodológicos e
Técnicas de Análise. Rio de Janeiro, Ed. Fiocruz, 1998, 167-197.
MARTINS, G. A., Estatística Geral e Aplicada. 2ª Edição, Editora Atlas, São Paulo,
2002, 412p.

Página 197
MEIRA-NETO, J. A. A., e MARTINS, F. R., Composição Florística de uma
Floresta Estacional Semidecidual Montana no Município de Viçosa – MG.
Revista Árvore, V. 26, Nr. 4. Viçosa, Julho/Agosto de 2002.
METZ, J. , MONARD, M. C., Projeto e Implementação do Módulo de Clustering
Hierárquico do Discover. Relatório do ICMC – Nr. 278 – São Carlos, SP, Agosto
de 2006
MORRIL, R. L., A Theoretical Imperative. University of Washington, p. 535 – 541.
NAJAR, A. L. et al. Desigualdades Sociais no Município do Rio de Janeiro: uma
comparação entre os censos 1991 e 1996 in Cad. Saúde Pública, Rio de Janeiro,
18 (Suplemento), 89 – 102, 2002.
O’BRIAN, L., Introducing Quantitative Geography – Measurement, methods ans
generalised linear models. Routledge, New York, 1992, 356p.
PAIVA, J. E. M., Mapeando a Qualidade de Vida em Minas Gerais Utilizando
Dados de 1991 e 2000. 2003. Tese (Doutorado em Geografia) – Universidade
Estadual Paulista/Instituto de Geociências e Ciências Exatas – Orientador: João
Francisco de Abreu - Rio Claro, SP.
PATTISON, W. D., As quatro tradições da Geografia. In: Boletim de Geografia
Teorética, Vol. 7, nº 13. Ageteo, Rio Claro, São Paulo, 1977, 137p.

Página 198
PETROUTSOS, E., Visual Basic 6 – A Bíblia. Makron Books, São Paulo, SP, 1999,
1126p.
PINHEIRO, L. C., Método de Representação Espacial de Clustering. 2006 -
Dissertação (Mestrado em Informática) – Orientadora: Maria Salete Marcon Gomes
Vaz. Curitiba, PR
PIRES, M. M., Agrupamento incremental e hierárquico de documentos – 2008,
80p. - Dissertação (Mestrado em Engenharia Civil) - COPPE – Engenharia Civil –
Orientador: Alexandre Gonçalves Evsukoff - Universidade Federal do Rio de
Janeiro– RJ
PIRES, C. A. A. – Estratégias de Saúde da Família na Cidade de Teófilo Otoni –
MG: Perspectivas Geográficas de uma Rede de Saúde no Espaço Intra-Urbano.
2007, 126p. - Dissertação (Mestrado em Geografia) – Pontifícia Universidade
Católica de Minas Gerais – Orientador: Prof. Leônidas Conceição Barroso – Belo
Horizonte – MG – 2007 – 126p.
REIS, R. J., GUIMARÃES, D. P., COELHO, C. W. G. A., PAIXÃO, G. M.,
NASCIMENTO, J. S. e SIMÕES, T. K. DE S. L., Determinação das Áreas de
Potencial de Riscos de Precipitações Intensas em Belo Horizonte. Caderno de
Geografia, Belo Horizonte, V. 14, Nr. 23, p. 127-134 – 2º Semestre de 2004.
ROGERSON, P. A., Statistical Methods for Geography. SAGE Publications Ltd,
London, 2001, 236p.

Página 199
ROHLF, F. J., SOKAL, R. R., Comparing Numerical Taxonomic Studies.
Systematic Zoology, Vol. 30, Nr. 4 – 1981 – pp 459 - 490. Taylor & Francis, Ltd. For
the Society of Systematic Biologists.
SEYMOR, L., Álgebra Linear – Teoria e Problemas. 3ª Edição, Makron Books do
Brasil Editora Ltda., São Paulo, 1994, 646p.
SCHAEFER, F. K., O excepcionalismo na Geografia: um estudo metodológico.
In: Boletim de Geografia Teorética, Vol. 7, nº 13. Ageteo, Rio Claro, São Paulo,
1977, 137p.
SHARP, J., Microsoft Visual C# 2005 – Passo a Passo. Microsoft Corporation –
2007 – Tradução de Altair Dias Caldas de Moraes
SILVA, L. V. D., Tipologia e hierarquização no sul de Minas utilizando métodos
e técnicas de estatística multivariada, análise de componentes principais –
ACP e sistemas de informações geográficas – GIS. 2002 - Dissertação (Mestrado
em Geografial) – PUCMinas – Belo Horizonte, MG
SIMÃO, M. L. R., Caracterização espacial da produção cafeeira de Minas Gerais:
um estudo exploratório utilizando técnicas de análise espacial e de estatística
multivariada. 1999 - Dissertação (Mestrado em Geografia) – PUCMinas – Belo
Horizonte, MG

Página 200
SNEATH, P. H. A, Some Statistical Problems in Numerical Taxonomy. The
Statistician, Vol. 17, Nr. 1 – 1967 – pp 1 – 12 – Blackwell Publishing for the Royal
Statistical Society
SNEATH, P. H. A. e SOKAL, R. R., Numerical Taxonomy – The Principles and
Practice of Numerical Classification. W. H. Freeman and Company – 1973 – 573p.
SPERANDIO, D.; MENDES, J. T. e SILVA, L. H. M., Cálculo Numérico –
Características Matemáticas e Computacionais dos Métodos Numéricos.
Prentice Hall, São Paulo, 2003, 354p.
Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas
Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo





























