Embed Size (px)
Citation preview

i
ALGORITMOS GENÉTICOS COMO ESTRATÉGIA DE PRÉ-PROCESSAMENTO
EM CONJUNTOS DE DADOS DESBALANCEADOS
Marcelo Beckmann
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Engenharia
Civil, COPPE, da Universidade Federal do Rio
de Janeiro, como parte dos requisitos
necessários à obtenção do título de Mestre em
Engenharia Civil.
Orientadores: Beatriz de Souza Leite Pires de
Lima
Nelson Francisco Favilla
Ebecken
Rio de Janeiro
Setembro de 2010

ii
ALGORITMOS GENÉTICOS COMO ESTRATÉGIA DE
PRÉ-PROCESSAMENTO EM CONJUNTOS DE DADOS DESBALANCEADOS
Marcelo Beckmann
DISSERTAÇÃO SUBMETIDA AO CORPO DOCENTE DO INSTITUTO ALBERTO
LUIZ COIMBRA DE PÓS-GRADUAÇÃO E PESQUISA DE ENGENHARIA
(COPPE) DA UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE
DOS REQUISITOS NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE MESTRE
EM CIÊNCIAS EM ENGENHARIA CIVIL.
Examinada por:
_________________________________________________
Profª. Beatriz de Souza Leite Pires de Lima, D.Sc.
_________________________________________________
Prof. Nelson Francisco Favilla Ebecken, D.Sc.
_________________________________________________
Prof. Alexandre Gonçalves Evsukoff, Dr.
_________________________________________________
Prof. Carlos Cristiano Hasenclever Borges, D.Sc.
RIO DE JANEIRO, RJ, BRASIL
SETEMBRO/2010

iii
Beckmann, Marcelo
Algoritmos Genéticos como Estratégia de Pré-
Processamento em Conjuntos de Dados Desbalanceados
/Marcelo Beckmann. - Rio de Janeiro: UFRJ/COPPE,
2010.
IX, 103 p.: il.; 29,7 cm.
Orientadores: Beatriz de Souza Leite Pires de Lima
Nelson Francisco Favilla Ebecken
Dissertação (mestrado) - UFRJ/COPPE/ Programa de
Engenharia de Civil, 2010.
Referências Bibliográficas: p. 91-103.
1. Classificação. 2. Algoritmo Genético. 3. Dados
Desbalanceados. 4. Mineração de Dados. I Lima, Beatriz
de Souza Leite Pires et al. II. Universidade Federal do Rio
de Janeiro, COPPE, Programa de Engenharia Civil. III.
Título.

iv
Agradecimentos A Deus.
À minha mãe, que me ensinou a amar as pessoas e ao mundo, e a ser quem eu sou.
À minha tia e madrinha, que me ensinou o que é amizade, palavra, honestidade e
respeito.
Ao meu pai, que me ensinou que trabalhando sempre se chega a algum lugar.
Ao meu avô (in memorian), que apesar de sua precária formação acadêmica, me
mostrou que o conhecimento faz diferença.
À minha avó (in memorian), que conseguiu o meu primeiro emprego.
Ao meu tio, que me deu o meu primeiro kit de ciências.
À minha esposa, meu amor, minha vida.
Ao meu filho, minha luz, minha inspiração.
Aos meus colegas e professores da COPPE/UFRJ, que me ensinaram a aprender,
pesquisar e divulgar.

v
Resumo da Dissertação apresentada à COPPE/UFRJ como parte dos requisitos
necessários para a obtenção do grau de Mestre em Ciências (M.Sc.)
ALGORITMOS GENÉTICOS COMO ESTRATÉGIA DE
PRÉ-PROCESSAMENTO EM CONJUNTOS DE DADOS DESBALANCEADOS
Marcelo Beckmann
Setembro/2010
Orientadores: Beatriz de Souza Leite Pires de Lima
Nelson Francisco Favilla Ebecken
Programa: Engenharia Civil
Em mineração de dados, a classificação tem como objetivo rotular eventos e
objetos de acordo com classes pré-estabelecidas. Todavia, os algoritmos tradicionais de
classificação tendem a perder sua capacidade de predição quando aplicados a um
conjunto de dados cuja distribuição de instâncias entre classes é desbalanceada.
Uma das estratégias para solucionar este problema consiste em efetuar um pré-
processamento no conjunto de dados de forma a equalizar a distribuição de exemplos
entre as classes.
Este trabalho tem como objetivo apresentar uma proposta de pré-processamento
utilizando algoritmos genéticos, de forma a se criar instâncias sintéticas da classe com
menor número de exemplos. Os experimentos com o algoritmo proposto apresentaram
melhor desempenho de classificação na maioria dos casos, em comparação aos
resultados de três estudos publicados. Também se verificou que as instâncias sintéticas
foram criadas longe da superfície de decisão, e que a aplicação da técnica de
aprendizado incremental diminuiu o tempo de processamento do mesmo.

vi
Abstract of Dissertation presented to COPPE/UFRJ as partial fulfillment of the
requirements for the degree of Master of Science (M.Sc.)
GENETIC ALGORITMS AS A PRE PROCESSING STRATEGY FOR
IMBALANCED DATASETS
Marcelo Beckmann
September/2010
Advisors:Beatriz de Souza Leite Pires de Lima
Nelson Francisco Favilla Ebecken
Department: Civil Engineering
In data mining, the classification aims to label events and objects according
classes previously established. Nevertheless, the traditional classification algorithms
tend to loose its predictive capacity when applied on a dataset which distribution
between classes is imbalanced.
One of the strategies to resolve this problem is to execute a pre-processing on a
dataset in order to equalize the examples distribution among the classes.
This work aims to present one proposal of pre-processing using genetic
algorithms, in order to create synthetic instances from the class with less number of
instances. The experiments with the proposal algorithm demonstrated a better
classification performance in most of the problems, in comparison with three studies
published. It was also demonstrated the synthetic instances were created far from the
decision surface, and the application of incremental learning technique decreased the
processing time.

vii
Sumário
1 Introdução 1
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Contexto de Pesquisa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Objetivos e Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Organização Deste Trabalho . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Classificação 5
2.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Algoritmos de Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1 Classificador Bayesiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.2 Árvores de Decisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.3 Vizinhos mais Próximos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Aprendizado Incremental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4 Métricas de Avaliação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4.1 Precisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.2 Recall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.3 F-Measure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.4 G-Mean . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.5 Curva ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.6 AUC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 O Problema de Classificação em Conjuntos de Dados Desbalanceados 18
3.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Causas Associadas ao Baixo Desempenho em Conjunto de Dados
Desbalanceados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
3.2.1 Métricas de Avaliação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19

viii
3.2.2 Raridade Relativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2.3 Raridade Absoluta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2.4 Fragmentação de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.5 Bias Inapropriado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.6 Ruídos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Sobreposição de Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.4 Pequenos Disjuntos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Sensibilidade dos Algoritmos de Classificação . . . . . . . . . . . . . . . . . . . . . 26
4 Soluções para o Problema de Classificação em Conjuntos de Dados
Desbalanceados
27
4.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 Notação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3 Ajuste em Nível de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3.1 Amostragem Aleatória de Instâncias . . . . . . . . . . . . . . . . . . . . . . . . 29
4.3.2 Técnicas de Subamostragem Orientada . . . . . . . . . . . . . . . . . . . . . 30
4.3.3 Técnicas de Sobreamostragem Orientada . . . . . . . . . . . . . . . . . . . . 33
4.4 Aprendizado Sensível a Custos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.5 Ajuste em Nível de Algoritmos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Algoritmos Genéticos 41
5.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.2 Componentes do Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.2.1 Cromossomo e Genes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2.2 População Inicial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2.3 Função Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.4 Avaliação e Substituição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.5 Critério de Parada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.6 Seleção . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.7 Processo de Busca Global . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.2.8 Cruzamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.2.9 Mutação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.2.10 Parâmetros do Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

ix
5.3 Funcionamento do Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.4 Aplicações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
6 Algoritmo Genético para Balanceamento de Conjunto de Dados 56
6.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.2 Codificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.3 Operador de Cruzamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6.4 Mutação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.5 Função Aptidão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.6 Implementação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7 Experimentos e Resultados 76
7.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
7.2 Conjunto de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
7.3 Parâmetros do Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
7.4 Execução dos Experimentos e Comparação . . . . . . . . . . . . . . . . . . . . . . . . 80
7.4.1 Comparação com Diversos Métodos de Sobreamostragem . . . . . . 80
7.4.2 Comparação com o Algoritmo Borderline SMOTE . . . . . . . . . . . . 82
7.4.3 Comparação com o Algoritmo ADASYN . . . . . . . . . . . . . . . . . . . . 83
7.4.4 Experimentos com Aprendizado Incremental . . . . . . . . . . . . . . . . 84
8 Conclusões 89
Referências Bibliográficas 91

1
Capitulo 1
Introdução
Atualmente, a quantidade de dados gerada por processos automatizados têm
crescido de forma explosiva, tornando difícil a compreensão desse volume de
informações de maneira correta e em tempo hábil. De forma a automatizar a análise
dessas informações, conta-se com o auxílio de ferramentas computacionais em
mineração de dados, e especificamente para a descoberta do conhecimento,
identificação de padrões, e predição, algoritmos de aprendizado de máquina são
utilizados em atividades de classificação.
Os algoritmos de classificação visam identificar padrões pré-estabelecidos em um
conjunto de dados. Isso é feito através de um treinamento prévio, utilizando-se
algoritmos de aprendizado de máquina, onde é criado um modelo
matemático/computacional conforme o algoritmo utilizado. A partir desse modelo, será
possível rotular novos registros de acordo com seus atributos. Esses algoritmos têm
aplicação em diversas áreas, como por exemplo, medicina, segurança, prospecção
geológica, meteorologia, finanças, automação industrial, controle de qualidade,
comercialização, logística, econometria, etc. Um exemplo prático da aplicação dos
algoritmos de classificação consiste na prospecção e jazidas de petróleo em terra, onde a
presença de determinadas quantidades de hidrocarbonetos no solo determina a
existência de uma jazida petrolífera no subsolo. O algoritmo de classificação efetua o
aprendizado sobre quais amostras determinam ou não uma jazida petrolífera, e na

2
presença de uma nova amostra de solo, é possível predizer se na região onde a mesma
foi coletada existe uma nova jazida (Pramanik et al. 2001).
1.1 Motivação
Na maioria dos algoritmos de classificação tradicionais, dentre eles os algoritmos
de árvore de decisão, vizinhos mais próximos, redes neurais, bayesiano, máquina de
vetor de suporte, assumem que o conjunto de dados terá uma distribuição balanceada de
instâncias entre classes, e que o custo de errar em uma classe será o mesmo que em
outra classe. Todavia, ficou comprovado que na maioria dos casos, sem nenhuma
preparação ou ajuste, os algoritmos tradicionais tendem a rotular as instâncias da classe
com menor número de exemplos, como pertencentes à classe mais numerosa. Contudo,
justamente os objetos e eventos raros, e por conseqüência menos numerosos, são os
mais importantes e valiosos a se buscar. Tomando-se como exemplo o problema de
prospecção petrolífera citado acima, não é em todo o lugar que existe uma jazida de
petróleo, e muito pelo contrário, tal jazida é um objeto raro e valioso. Essa conformação
de objetos e eventos raros existentes no mundo real acaba por se refletir nos conjuntos
de dados do mundo computacional, fazendo com que tal problema ocorra tipicamente
em classificação de dados.
Este tipo de comportamento está presente em problemas como diagnóstico de
câncer de mama (Woods et al. 1993), identificação de clientes não confiáveis em
operações de telefonia (Ezawa et al. 1996), detecção de vazamentos de óleo através de
imagens de radar (Kubat et al., 1998), detecção de chamadas telefônicas fraudulentas
(Fawcett e Provost, 1996), tarefas de recuperação de informações e tarefas de filtragem
(Lewis e Catlett , 1994), não sendo incomuns na literatura problemas com razões de
desbalanceamento de 100:1 e até 10000:1 (He e Shen, 2007, Kubat et al., 1998, Pearson
et al., 2003).
1.2 Contexto de Pesquisa

3
Com o objetivo de solucionar ou mitigar tal problema, existem atualmente
diversas iniciativas de pesquisa e desenvolvimento de estratégias e algoritmos, de forma
a adequar o processo de classificação aos conjuntos de dados desbalanceados. Conforme
citado por (He e Garcia, 2009), de acordo com relatórios do Institute of Electrical and
Electronics Engineers (IEEE) e da Association for Computing Machinery (ACM),
ocorreu um crescimento de 980% na quantidade de publicações anuais sobre o assunto
entre 1997 e 2007. De forma a sistematizar o estudo do problema, (Weiss, 2004,
Japkowicz e Stephen, 2002) identificaram causas e condições associadas ao problema,
onde foi concluído que nem sempre o desbalanceamento entre classes é a causa
principal do problema, podendo o mesmo estar associado a outros problemas existentes
em classificação, como por exemplo, a sobreposição entre classes.
De acordo com (Qiong et al., 2006), existem basicamente três estratégias para
solucionar as causas associadas ao problema: ajuste em nível de dados; aprendizado
sensível a custos; ajuste em nível de algoritmos. Neste trabalho, se concentrou no ajuste
em nível de dados como estratégia para solução do problema de desbalanceamento. Esta
abordagem se resume basicamente em ações de sobreamostragem (oversampling) e
subamostragem (undersampling), o que consiste respectivamente na criação de
instâncias da classe minoritária, por convenção chamada de classe positiva, e remoção
de instâncias da classe majoritária, também conhecida como classe negativa. Conforme
comprovado na literatura, tais ações efetuam o balanceamento do conjunto de dados, de
forma que as classes tenham a mesma quantidade de exemplos, sanando as causas
associadas ao problema de conjuntos de dados desbalanceados.
1.3 Objetivos e Metodologia De forma a propor uma solução de ajuste no conjunto de dados, este trabalho tem
como objetivo apresentar um algoritmo genético (AG) para sobreamostragem, isto é, a
criação de instâncias sintéticas positivas orientadas por um processo evolutivo.
Basicamente o objetivo do AG proposto é otimizar a métrica AUC obtida no processo
de classificação, ajustando o posicionamento e tamanho de regiões, dentro dos limites
mínimos e máximos da classe positiva, de forma que essas regiões sejam pré
enchidas com instâncias sintéticas positivas, balanceando dessa maneira a base
de dados. O algoritmo foi desenvolvido como um plugin de pré-processamento na

4
plataforma de mineração de dados Weka (Witten e Frank, 2005). Conforme será visto
no capítulo 7, o AG proposto neste trabalho demonstrou melhor desempenho de
classificação, se comparado com outros resultados publicados anteriormente na
literatura, e onde foi identificado através da métrica DANGER (Han et al., 2005), que as
instâncias sintéticas foram criadas distantes da superfície de decisão. Este trabalho
também se preocupou em propor soluções para diminuição do tempo de processamento
do AG, o que foi obtido através da utilização de aprendizado incremental, o qual
permite que o conjunto de dados original seja treinado uma vez, e as instâncias
sintéticas geradas são treinadas e adicionadas ao modelo posteriormente.
1.4 Organização Deste Trabalho
Este trabalho foi organizado da seguinte forma: No capítulo 2 foi efetuada uma
revisão bibliográfica sobre a atividade de classificação em mineração de dados, onde os
conceitos de treinamento e teste, principais algoritmos e métricas foram revistos e
detalhados. No capítulo 3, foram descritas de maneira sistemática as principais causas e
condições associadas ao problema de classificação em conjuntos de dados
desbalanceados, e no capítulo 4, foram apresentadas as principais estratégias para
solução do problema. No capítulo 5, descreve-se a heurística de algoritmos genéticos
para otimização combinatória e suas aplicações. No capítulo 6 será apresentado o
algoritmo genético proposto neste trabalho. No capítulo 7 demonstra-se a configuração
e resultados dos experimentos, bem como a comparação e discussão desses resultados
com outros métodos e resultados publicados na literatura. Finalmente no capítulo 8, as
conclusões deste estudo e trabalhos futuros.

5
Capítulo 2
Classificação
Este capítulo tem como objetivo apresentar a atividade de classificação em
mineração de dados, os algoritmos de classificação utilizados neste trabalho, as métricas
de distância e as métricas utilizadas para avaliação do desempenho de classificadores
em aprendizado de máquina.
2.1 Introdução
O grande volume de dados que hoje é produzido por processos automatizados, e o
seu crescimento esperado para os próximos anos são alguns dos principais desafios em
mineração de dados e aplicações de descoberta de conhecimento. Dentro do contexto de
mineração de dados, a classificação é uma atividade que utiliza algoritmos de
aprendizado de máquina, e onde as instâncias de um conjunto de dados são rotuladas de
acordo com suas características. O processo de classificação é dividido em duas etapas:
treinamento e predição.
A classificação nada mais é do que a implementação computacional da capacidade
do ser humano de identificar, predizer e rotular objetos e eventos no mundo em que
vive, e na prática é aplicável em todas as áreas do conhecimento humano, como por
exemplo: medicina, segurança, automação industrial e robótica, mineração e prospecção
petrolífera, meteorologia, finanças, administração, econometria, sociologia, etc.
Para o processo de treinamento, utiliza-se um algoritmo de aprendizado de
máquina sobre um conjunto de dados, entitulado conjunto de treinamento, o qual é
composto de registros ou instâncias. Cada instância é composta de um ou mais

6
atributos, e um atributo específico, que contém o rótulo daquela instância, o qual
associa a mesma a uma classe pré-determinada. Pelo fato de ser necessário um rótulo
pré-definido na etapa de treinamento, a classificação é considerada uma atividade de
aprendizado supervisionado.
De posse das instâncias rotuladas, o algoritmo de treinamento irá gerar um modelo
preditivo baseado na relação entre os valores dos atributos e a respectiva classe a qual a
instância pertence, isto é, o algoritmo induz que determinados valores estão associados a
determinadas classes. Para esta tarefa, existem diversos algoritmos que utilizam técnicas
tais como: árvores de decisão, redes neurais, máquina de vetores de suporte, regra de
Bayes, etc.
A segunda etapa, também conhecida como teste, consiste em rotular novas
instâncias, de classe desconhecida, através do modelo preditivo obtido na etapa de
treinamento, predizendo através dos valores dos seus atributos a qual classe essa
instância pertence, completando dessa maneira o processo de aprendizado de máquina e
classificação. Nesta etapa são aplicadas métricas que avaliam a qualidade do modelo
preditivo obtido na fase de treinamento. Na seção 2.4 serão detalhadas as métricas
utilizadas em classificação.
O processo de treinamento e teste também é conhecido como seleção do modelo
preditivo. Entre os diversos métodos de seleção do modelo, a técnica mais simples
consiste na separação de uma parte do conjunto de dados para treino, e o restante para
teste.
Outro método conhecido é a validação cruzada (Arlot e Celisse, 2010), cujo
objetivo é otimizar a avaliação do modelo preditivo, testando o desempenho do mesmo
em instâncias “nunca vistas” pelo classificador. O funcionamento consiste em
particionar o conjunto de dados em f partes iguais (geralmente f=10), e separar f-1
partes do conjunto de dados para treino, e 1 parte para teste. O processo é repetido f
vezes, sendo que a cada repetição, uma parte diferente do conjunto é separada para
teste, e o restante para treino. Ao final, obtém-se a média das métricas de classificação
obtidas em cada repetição.

7
Nas próximas seções serão descritos os algoritmos de classificação citados neste
trabalho, o processo de aprendizado incremental, e as métricas de avaliação aplicadas
em classificação.
2.2 Algoritmos de Classificação
Atualmente existe um grande número de métodos de classificação e diversas
variações dos mesmos. O objetivo desta seção consiste em descrever os métodos de
classificação citados neste trabalho. Para informações adicionais sobre outros métodos
de classificação e mineração de dados, vide (Wu el al., 2007).
2.2.1 Classificador Bayesiano
Este método de classificação utiliza a regra de Bayes (1) para efetuar classificação
supervisionada, sendo mais indicado para conjuntos de dados que seguem uma
distribuição normal, e classes que tenham uma separabilidade linear, isto é, onde as
mesmas podem ser separadas completamente através de uma reta ou hiperplano, pois a
classificação bayesiana sempre gera um discriminante de ordem 2 (quadrático).
• Estrutura e formulação do modelo
Dada a fórmula da regra de Bayes:
)(
)()|()|(
xp
yPyxpxyP
jj
j = (1)
Onde:
x - Um determinado valor de uma variável
jy - Uma determinada classe
Deduz-se que, em um conjunto de treinamento (em que os dados já estão
classificados, isto é, as classes são conhecidas a priori), a função )|( xyP j , retorna a

8
probabilidade da classe jy ocorrer quando da ocorrência de x. Com isso, obtém-se um
discriminante, de forma que:
Se )|()|( 12 xyPxyP > , então x ∈ 2y ,
Se )|()|( 21 xyPxyP > , então x ∈ 1y ,
Se )|()|( 12 xyPxyP = , então x ∈ classe com maior probabilidade a priori, isto
é, ),max( 12 yy .
O discriminante acima descrito é conhecido como classificador bayesiano simples,
ou ingênuo (naive). O mesmo não leva em conta que, quando existir um maior número
de registros da classe 1y , a probabilidade de instâncias da outra classe 2y serem
classificadas incorretamente como 1y será maior, o que o torna bastante suscetível ao
problema de conjuntos de dados desbalanceados (vide seção 4.4).
2.2.2 Árvores de Decisão
Em classificação supervisionada, uma árvore de decisão permite a criação de
regras de decisão, isto é, conjuntos de entãose ⇒ os quais permitem aprender e
distinguir as classes dos registros de dados.
As regras de decisão geradas pelo classificador de árvore de decisão podem ser
compreendidas e interpretadas por humanos, sendo dessa maneira considerado um
algoritmo de caixa branca. O algoritmo permite classificação em regiões de decisão
muito complexas, gerando bons resultados tanto com valores numéricos ou categóricos,
podendo ser combinado com outros métodos de mineração de dados.
A utilização de árvores de decisão como um método de inteligência artificial foi
proposto inicialmente por (Morgan e Sonquist, 1963) com o método AID (Automatic
Interaction Detection). Posteriormente foram propostas novas implementações baseadas
no conceito de árvore de decisão, como os métodos CART (Breimann et al., 1984), ID3

9
(Quinlan, 1986), C4.5 (Quinlan, 1988), C5.0 (Quinlan, 1996, Kohavi e Quinlan, 2002),
GUIDE (Loh, 2002), entre outros.
• Estrutura e formulação do modelo
Não existe uma formulação, e sim algoritmos. Basicamente esses algoritmos
efetuam uma separação no conjunto de dados baseado em um valor de atributo testado.
O processo é recursivo, e repetido em cada subconjunto de outros atributos. A recursão
é completada quando a separação se tornar impraticável, ou quando uma classificação
singular pode ser aplicada a cada elemento do subconjunto derivado.
Cada nó interior corresponde a uma variável. Um galho para um filho representa
uma possível combinação de valores para aquela variável e a variável pai. Uma folha
representa uma possível combinação de valores desde a folha até a raiz. Como exemplo,
segue abaixo o fluxo do algoritmo ID3:
1. Começar com todos os exemplos de treino;
2. Escolher o teste (atributo) que melhor divide os exemplos, ou seja agrupar
exemplos da mesma classe ou exemplos semelhantes;
3. Para o atributo escolhido, criar um nó filho para cada valor possível do atributo;
4. Transportar os exemplos para cada filho tendo em conta o valor do filho;
5. Repetir o procedimento para cada filho não "puro". Um filho é puro quando cada
atributo X tem o mesmo valor em todos os exemplos.
Nos algoritmos ID3, C4.5 e C5.0, utiliza-se para a escolha do melhor atributo duas
avaliações: entropia e ganho de informação.
A entropia (entropy), também conhecida como entropia de Shannon (Shannon,
1951), quantifica a informação que um conjunto de dados pode representar. Este
conceito define a medida de incerteza ou falta de informação, associada a um atributo.
A entropia E de um atributo X com possíveis valores { }nxx ,...,1 e com probabilidade
)( ixp , é obtida pela equação ∑=
−=n
i
ii xpxpXE1
2 )(log)()( .

10
O ganho de informação (information gain) é um nome alternativo para a
divergência de Kullback-Leibler (Kullback e Leibler, 1951 e define a redução na
entropia. ),( XSIG , que significa a redução esperada na entropia de um atributo S,
condicionado pela ocorrência de um valor v no atributo X. O ganho de informação é
obtido pela fórmula )(.)(),( V
V
VSE
S
SSEXSIG ∑−= , sendo Xv ∈ .
Isto posto, na escolha do melhor atributo, no primeiro passo do algoritmo são
analisados todos os atributos disponíveis, calculando-se o ganho de cada um deles.
Escolhe-se o de maior ganho e continua-se o processo sempre removendo o atributo
utilizado na iteração It-1 da iteração It. O algoritmo termina quando em todos os nós a
entropia for nula.
2.2.3 Vizinhos mais Próximos
O classificador vizinhos mais próximos, também conhecido como KNN (k nearest
neighbors), cria uma superfície de decisão que se adapta à forma de distribuição dos
dados de treinamento de maneira detalhada, possibilitando a obtenção de boas taxas de
acerto quando o conjunto de treinamento é grande ou representativo, não dependendo
que as classes possuam alguma separabilidade linear (Dasarathy, 1991, Hastie, 2003).
• Estrutura e formulação do modelo
Este é um método considerado não paramétrico, pois não utiliza modelo, e a
classificação é realizada conforme o seguinte algoritmo:
1. Inicialmente, calcula-se a distância (geralmente euclidiana) entre uma nova
instância ni e todas as instâncias do conjunto de treinamento T;
2. Verifica-se a quais classes pertencem as k instâncias mais próximas;
3. A classificação é feita rotulando-se ni com a classe que for mais freqüente
entre os k padrões mais próximos de ni.

11
O valor de k pode variar de acordo com os dados disponíveis para treinamento.
Geralmente utiliza-se tentativa e erro para ajustar esse parâmetro, começando por 1NN.
Entretanto, para um conjunto de treinamento numeroso, é esperado que o classificador
3NN permita a obtenção de um desempenho muito próximo do classificador Bayesiano
(Dasarathy, 1991), porém, tipicamente na literatura são encontrados valores de k =5 ou
k=7.
O algoritmo pode utilizar outras métricas de distância, que não a euclidiana. Para
maiores detalhes sobre a distância euclidiana e outras métricas, vide (Wilson e
Martinez, 1997, Boriah, 2008, Argentini e Blanzieri, 2010).
2.3 Aprendizado Incremental
Normalmente nas atividades de classificação, o aprendizado de máquina acontece
de maneira a priori, isto é, o modelo preditivo é construído apenas uma vez, com todos
os registros disponíveis, e não evolui mais. Todavia, existem situações em que nem
sempre todos os registros necessários estão disponíveis para treinamento, e re-treinar
todo o conjunto a cada nova instância pode ser computacionalmente caro e consumir
muito tempo, e dependendo do tamanho do conjunto de treinamento, o mesmo sequer
caberá por inteiro na memória do computador.
Ao contrário do aprendizado a priori, que cria um modelo preditivo estático, o
aprendizado incremental permite que um modelo preditivo possa ser adaptado de
maneira contínua, conforme os registros se tornem disponíveis para treinamento, sem
necessidade de re-processamento de todo o conjunto de treinamento. De acordo com
(Giraud-Carrier, 2000), as principais características de uma atividade de aprendizado
incremental são:
• Os exemplos não estão disponíveis a priori, mas se tornam disponíveis ao longo
do tempo, normalmente um exemplo por vez;
• Na maioria dos casos, o aprendizado precisa ir à frente de maneira indefinida.

12
Algoritmos incrementais são também conhecidos como algoritmos em tempo real
(online) que requerem pouca memória (Anthony e Biggs, 1997). Requerem pouca
memória por que o conjunto de treinamento não é carregado inteiro para a mesma, pois
o treinamento foi feito com poucos registros, à medida que os mesmos se tornam
disponíveis. Obtém-se um grande ganho computacional pelo fato de somente os novos
registros serem treinados, o que torna essa abordagem bastante apropriada para
aplicações online, isto é, onde um usuário deva aguardar por um resultado.
Como exemplo de algoritmos incrementais, pode-se citar o ID5 (Utgoff, 1988), o
qual é a versão incremental do ID3 (Quinlan, 1986), COBWEB (Fischer, 1987), ILA
(Giraud-Carrier e Martinez, 1995). No aplicativo Weka (Witten e Frank, 2005) versão
6.2, estão presentes 12 classificadores, dentre eles pode-se citar o AODE (Webb et. al,
2005), LWL (Frank et. al, 2003) e o NayveBayesUpdateable (John e Langley, 1995).
Em aprendizado incremental, o método de seleção do modelo consiste em separar
o conjunto de dados em treino e teste. Conforme foi verificado no aplicativo Weka
(Witten e Frank, 2005), a técnica de validação cruzada (Arlot e Celisse, 2010) não é
aplicável ao aprendizado incremental, pois a validação cruzada é um método que requer
maior custo computacional, e impõe uma reordenação aleatória de exemplos, a qual é
indesejável em aprendizado incremental, além de introduzir algum grau de instabilidade
no modelo preditivo (MacGregor, 1988, Fischer et al., 1992, Cornúejols, 1993,
Breiman, 1996).
A estratégia de aprendizado incremental, apesar de ser bastante promissora, não se
tornou um consenso na comunidade de mineração de dados, cedendo lugar ao
aprendizado a priori. Recentemente, de forma a prover ferramentas de análise para
grandes conjuntos de dados, foi proposta a plataforma Massive on Line Analisys
(MOA), em português, Análise Massiva em Tempo Real, o qual utiliza técnicas de
aprendizado incremental para criar modelos preditivos através de fluxos de dados (Bifet
et. al, 2010), possuindo ainda integração bi-direcional com o Weka, isto é, o Weka
consegue manipular dados e algoritmos do MOA, e vice-vesa,.
No capítulo 6 será demonstrado como o aprendizado incremental foi aplicado ao
algoritmo genético para balanceamento (AGB) proposto neste trabalho, de forma que o

13
conjunto de dados original seja treinado uma só vez, e as novas instâncias criadas para
balanceamento treinadas incrementalmente.
2.4 Métricas de Avaliação
Em classificação, se faz necessária a utilização de alguma métrica para avaliar os
resultados obtidos. A matriz de confusão (Figura 2.4.1), também denominada matriz de
contingência, é freqüentemente utilizada para tal fim, fornecendo além da contagem de
erros e acertos, as principais variáveis necessárias para o cálculo de outras métricas.
A matriz de confusão pode representar tanto problemas de duas classes, como
problemas multiclasses. Entretanto, a pesquisa e literatura sobre classificação em
conjunto de dados desbalanceados se concentra em problemas com duas classes, onde
se considera uma classe como positiva, e o restante das classes como negativa. A
diagonal principal da matriz de confusão indica os acertos do classificador, enquanto
que a diagonal secundária indica os erros..
Figura 2.4.1 – Matriz de Confusão
Uma das métricas frequentemente utilizadas a partir das informações desta matriz
é a taxa de erro (2), e a acurácia (3). Todavia, estas métricas não são as mais apropriadas
para a avaliação de problemas de classes desbalanceados, pois não leva em conta a
distribuição das mesmas.

14
TNFPFNTP
FNFPErr
+++
+=
(2)
TNFPFNTP
TNTPAcc
+++
+=
(3)
As métricas detalhadas nas próximas seções utilizam as variáveis da matriz de
confusão de forma a compensar a desproporção entre classes. As métricas de Precisão,
Recall e F-Measure são apropriadas quando se está preocupado com o desempenho da
classe positiva. As métricas G-Mean, ROC e AUC se aplicam quando o desempenho de
ambas as classes são importantes.
2.4.1 Precisão
A precisão é uma medida de exatidão, e denota o percentual de acerto em relação
a todos os objetos tidos como positivos. Ao analisar em conjunto a fórmula (4) e a
matriz de confusão da figura 7, nota-se a razão entre os verdadeiros positivos e a soma
da coluna predição positiva. Nota-se ainda que esta métrica é sensível à distribuição,
tendo em vista que o divisor é composto da soma de instâncias positivas e negativas.
FPTP
TPec
+=Pr
(4)
2.4.2 Recall
O Recall, também denominado Sensitividade, é uma medida de completitude, e
denota o percentual de objetos positivos que foram recuperados pelo classificador. Ao
analisar em conjunto a fórmula (5) e a matriz de confusão da figura 7, nota-se uma
razão entre os verdadeiros positivos e a soma da linha classe positiva. Por somente

15
computar instâncias positivas em seu divisor, a métrica de recall não é sensível à
distribuição.
FNTP
TPcall
+=Re
(5)
2.4.3 F- Measure
Utiliza-se a métrica F-Measure (6) com o objetivo de sintetizar as informações das
últimas duas métricas, Precisão e Recall, obtendo dessa maneira uma média harmônica
entre as mesmas, onde β é um coeficiente que ajusta a importância relativa de precisão
versus recall, sendo normalmente 1=β (Van Rijsbergen, 1979).
.
callecisão
callecisãomeasureF
RePr.
Re.Pr).1(
+
+=−
β
β
(6)
2.4.4 G-Mean
De forma a medir o desempenho de ambas as classes levando-se em conta a
distribuição das mesmas, pode se utilizar a métrica G-Mean (7), o qual computa a média
geométrica dos verdadeiros positivos (TP) e verdadeiros negativos (TN).
TNTPMeanG *=− (7)
2.4.5 Curva ROC
O gráfico ROC (do inglês, receiver operating characteristics), também
denominada Curva ROC, vem sendo utilizado desde a segunda guerra mundial em
detecção e análise de sinais, sendo recentemente aplicado em mineração de dados e
classificação. Consiste de um gráfico de duas dimensões onde o eixo y refere-se à

16
Sensitividade ou Recall (5), e o eixo x à (1-Especificidade) (8), conforme pode ser visto
na equação 8.
Espec=TNFP
TN
+
(8)
De acordo com (Fawcett, 2005), existem diversos pontos nesse gráfico que
merecem atenção. Analisando a figura 8, temos os pontos: (0,0), que significa não ter
classificado nenhuma instância positiva; (1,1), que significa não ter classificado
nenhuma instância negativa; e (0,1), também indicado pela letra D, que corresponde à
classificação perfeita. Pode-se considerar que um ponto será melhor que o outro se o
mesmo estiver mais a noroeste.
Quanto mais o ponto estiver próximo do eixo x, no lado esquerdo inferior, mais o
classificador terá um comportamento conservador, isto é, o mesmo só fará predições
positivas se tiver fortes evidências, o que pode acarretar em poucos verdadeiros
positivos. Por outro lado, pontos na parte superior direita também denotam um
classificador mais liberal e/ou agressivo, o que pode acarretar um maior índice de falsos
positivos, por exemplo, na figura 8 temos o ponto A, que é mais conservador que o
ponto B.
A diagonal secundária do gráfico, onde y=x, denota que o classificador possui um
comportamento aleatório. Um ponto (0.5, 0.5) diz que o classificador acertou 50% dos
positivos e 50% dos negativos, sendo que os outros 50% foram preditos de forma
aleatória. O ponto C na figura 8 indica um classificador que tentou adivinhar a classe
positiva 70% das vezes.
Por último, o ponto E, que se localiza no triângulo inferior, e indica um
classificador com desempenho pior que o aleatório. De acordo com (Flach e Wu, 2005),
pode-se dizer que um classificador abaixo da diagonal possui informação útil, mas a
está utilizando incorretamente.

17
Figura 2.4.5 – Exemplo de Gráfico ROC, onde os pontos identificados por
letras representam os principais comportamentos a serem analisados.
2.4.6 AUC
Considera-se neste trabalho ambas as classes (positivas e negativas) como de igual
importância, sendo assim, foi utilizada a métrica AUC, do inglês Area Under Curve, a
qual é insensível a desbalanceamento de classes (Fawcett, 2004, 2005), e a qual sintetiza
como um simples escalar a informação representada pela curva ROC, sendo definida
como (9).
+Φ=
negpos
AUCφφ
δ
(9)
Onde, conforme descrito por (Batista e Monard, 2005), Φ é a distribuição
cumulativa normal padrão,δ é a distância euclidiana entre os centróides das duas
classes, e posφ , e negφ são, respectivamente, o desvio padrão das classes positiva e
negativa.

18
Capítulo 3
O Problema de Classificação em Conjuntos de
Dados Desbalanceados
Este capítulo tem como objetivo apresentar o problema de classificação em
conjuntos de dados desbalanceados, e as causas associadas ao mesmo.
3.1 Introdução
Normalmente no mundo real as informações estão dispostas e agrupadas de
maneira irregular e desbalanceada. Esta irregularidade no mundo real se atribui a
eventos e objetos raros, e tais eventos e objetos não ocorrem a todo o momento e em
todo o lugar. Tal comportamento acaba se refletindo no mundo computacional, onde se
criam conjuntos de dados em que a numerosidade de exemplos para cada classe acaba
sendo desigual e desbalanceada.
Os algoritmos de classificação, na presença desse desbalanceamento entre classes
no conjunto de dados, na maioria dos casos, tendem a classificar a instância da classe
minoritária como sendo da classe majoritária. Todavia, justamente a classe com menor
número de exemplos é a mais interessante e valiosa de se identificar, o que pode
acarretar riscos e prejuízos financeiros e pessoais, caso essa predição esteja errada.
Como exemplo deste problema, podemos citar o diagnóstico de câncer, onde um
pequeno percentual da população o possui. No caso de uma pessoa com câncer ser

19
diagnosticada como saudável, ou seja, um falso negativo, a mesma não será tratada a
tempo (Woods et al. 1993).
É de comum acordo na comunidade científica que este problema necessita de
atenção e soluções, mas para se obter soluções, é preciso entender as causas e condições
que ocasionam tal problema, o que será apresentado nas próximas seções deste capítulo.
3.2 Causas Associadas ao Baixo Desempenho em
Conjunto de Dados Desbalanceados
De acordo com (Weiss, 2004), existem seis causas associadas ao baixo
desempenho de classificação em conjuntos de dados desbalanceados, onde se verifica
que nem sempre a raridade de instâncias positivas é a causa principal do baixo
desempenho na presença de conjunto de dados desbalanceados.
3.2.1 Métricas de Avaliação
A utilização de métricas de avaliação inapropriadas para se mensurar o
desempenho de um classificador em um conjunto de dados desbalanceados acarreta o
entendimento incorreto do problema que se está analisando, pois a acurácia, ou taxa de
verdadeiros positivos (Fawcett, 2004), não é uma métrica apropriada para classes
desbalanceadas. Por exemplo, dado um problema com 99 negativos e 1 positivo, 99%
de acerto na classe negativa, apesar de ser um bom resultado em relação ao conjunto de
dados como um todo, não faz sentido se analisado em relação à classe positiva.
Como foi visto na seção 2.1.1, de acordo com (Weiss, 2004, Qiong et al., 2006,
He e Garcia, 2009), as métricas AUC, F-Measure e G-Mean, são as mais apropriadas
por ponderar a quantidade de instâncias por classe.

20
Outro problema relacionado às métricas inadequadas para conjuntos de dados
desbalanceados está associado à estrutura interna de alguns algoritmos de classificação,
os quais utilizam estratégias de “dividir e conquistar”, como por exemplo, o algoritmo
de árvore de decisão C4.5 (Quinlan, 1988). Esses algoritmos utilizam métricas tais
como ganho de informação (Kullback et Leibler, 1951) e entropia (Shannon, 1951) para
medir o quanto de informação está contida em cada ramificação. Entretanto, em
conjunto de dados desbalanceados, as instâncias positivas não possuem ganho de
informação suficiente para criar uma regra de decisão, sendo necessária a utilização de
métricas menos gananciosas para a formação de uma árvore de decisão que também
leve em conta a classe minoritária.
Na figura 3.2.1.1, é exibido um exemplo de particionamento em um conjunto de
dados, onde regras que contemplam instâncias positivas são podadas (linha horizontal),
por conter pouco ganho de informação, em relação às regras criadas para as instâncias
negativas. Nota-se nesta figura que grande parte das regras da classe positiva (em
vermelho), foram podadas.
Figura 3.2.1.1 – Particionamento de um conjunto de dados, e posterior poda,
representada pela linha horizontal.
3.2.2 Raridade Relativa
Ainda que existam muitos exemplos positivos, os mesmos são ofuscados pela
grande quantidade de exemplos negativos, representando o clássico exemplo de
“Agulha no palheiro”.

21
Figura 3.2.2.1 – Projeção da base de dados Satimage, onde os pontos em
vermelho são as instâncias positivas.
3.2.3 Raridade Absoluta
Ainda que existam muitos exemplos no mundo real, a classe está representada no
conjunto de dados em estudo por poucos exemplos, o que gera dificuldade para o
algoritmo generalizar, pois com poucos dados a superfície de decisão ficará muito
diferente do que existe no mundo real. A figura 3.2.3.1 exemplifica a superfície de
decisão (linhas pontilhadas) criada na presença de poucos exemplos (a) em comparação
com a superfície criada com mais exemplos (b).
Figura 3.2.3.1 – Os exemplos da figura A irão proporcionar uma superfície de
decisão com menor generalização do que os exemplos da figura B.

22
3.2.4 Fragmentação de Dados
Algoritmos que utilizam estratégias de dividir e conquistar, como por exemplo, o
algoritmo de árvore de decisão C4.5 (Quinlan, 1988), podem separar exemplos
positivos em diferentes galhos, os quais separados perdem ainda mais peso e acabam
sendo podados, conforme demonstrado na figura 3.2.4.1.
Figura 3.2.4.1 – Instâncias positivas podem ser separadas por um algoritmo de
árvore de decisão, sendo sua regra de decisão podada subsequentemente
(linha horizontal).
3.2.5 Bias Inapropriado
Classificadores generalizam incorretamente na presença de instâncias positivas, e
com o objetivo de evitar o overfitting, um bias com generalização máxima pode não
levar em conta as instâncias positivas, e as regras contendo classes minoritárias
possuem menor ganho de informação, sendo mais susceptíveis à poda.

23
Figura 3.2.5.1 – Efeito da generalização em maior ou menor grau em uma
superfície de decisão.
3.2.6 Ruídos
Instâncias ruidosas de ambas as classes podem confundir o algoritmo de
classificação (Hulse e Khoshgoftaar, 2009), de forma que o mesmo generalize
incorretamente. Na figura 3.2.6.1, verifica-se que, devido a algumas instâncias
negativas, o classificador moveu a superfície de decisão para dentro da classe positiva,
fazendo com que algumas instâncias positivas sejam classificadas incorretamente.
Figura 3.2.6.1 – Ruídos causam generalização incorreta e baixo desempenho
do classificador.
24
3.3 Sobreposição de Classes
De acordo com os experimentos de (Japkowicz, 2003), (Batista e Monard, 2004),
(Prati et al., 2004), o baixo desempenho de classificação em conjunto de dados
desbalanceados não está associado só à distribuição de classes, mas também à
sobreposição das mesmas (class overlapping).
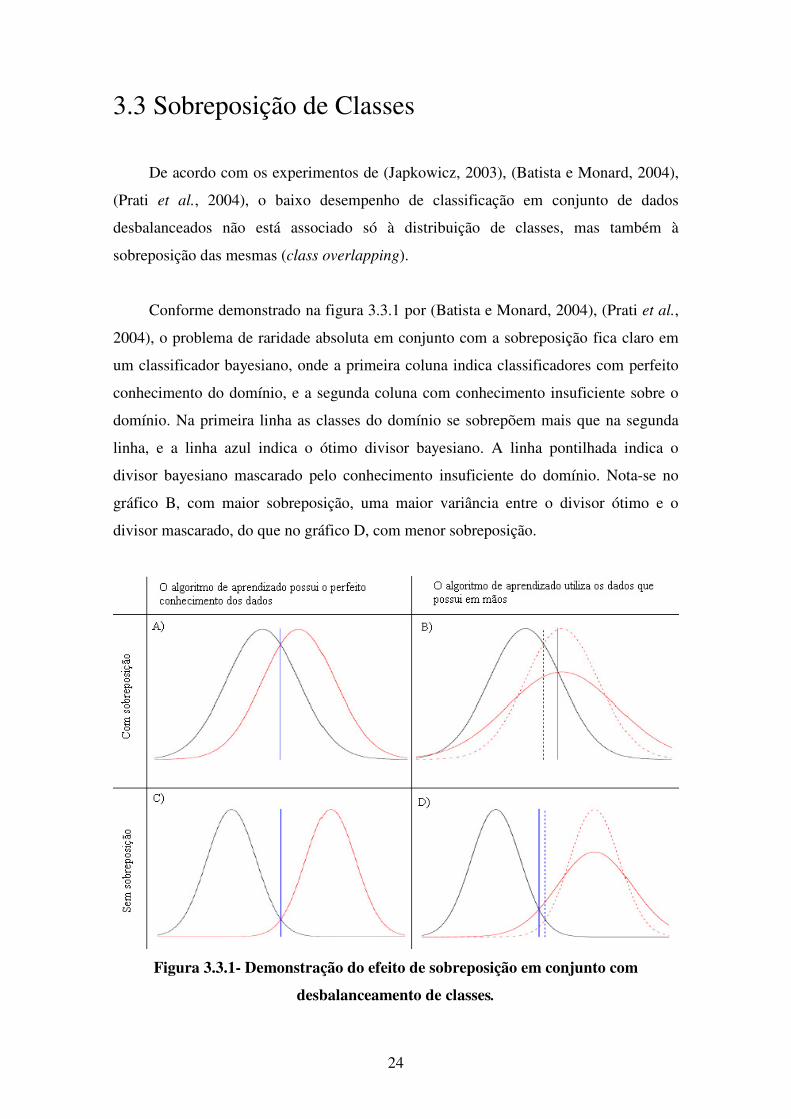
Conforme demonstrado na figura 3.3.1 por (Batista e Monard, 2004), (Prati et al.,
2004), o problema de raridade absoluta em conjunto com a sobreposição fica claro em
um classificador bayesiano, onde a primeira coluna indica classificadores com perfeito
conhecimento do domínio, e a segunda coluna com conhecimento insuficiente sobre o
domínio. Na primeira linha as classes do domínio se sobrepõem mais que na segunda
linha, e a linha azul indica o ótimo divisor bayesiano. A linha pontilhada indica o
divisor bayesiano mascarado pelo conhecimento insuficiente do domínio. Nota-se no
gráfico B, com maior sobreposição, uma maior variância entre o divisor ótimo e o
divisor mascarado, do que no gráfico D, com menor sobreposição.
Figura 3.3.1- Demonstração do efeito de sobreposição em conjunto com
desbalanceamento de classes.

25
3.4 Pequenos Disjuntos
Em condições ideais, os conjuntos de dados deveriam apresentar conceitos em
grandes agrupamentos, também denominados grandes disjuntos. Todavia, em aplicações
do mundo real nem sempre isso é possível, e normalmente os conceitos se subdividem
em pequenos sub-conceitos (Holte el al., 1989), também conhecidos na literatura como
pequenos disjuntos, ou desbalanceamento interno à classe.
O problema de pequenos disjuntos em bases desbalanceadas ocorre quando um
sub-conceito está associado a uma classe minoritária, o que acarretará poucos exemplos
para representar esses sub-conceitos, e um menor desempenho obtido pelo classificador.
Em um estudo efetuado por (Jo e Japkowicz, 2004), foram criados 125 domínios
artificiais, onde foram mensurados: o grau de complexidade (isto é, disjuntos), o
tamanho do conjunto de treinamento e o grau de desbalanceamento entre classes.
Concluiu-se que o problema é agravado por dois fatores: aumento no grau de
desbalanceamento e grau de complexidade, e que o problema de desbalanceamento
pode ser mitigado se o conjunto de treinamento for grande.
De acordo com Weiss (2004), um conjunto de dados se apresenta internamente
desbalanceado quando ocorrem casos raros em comparação com o restante dos dados, e
casos raros não são facilmente identificáveis. Todavia, métodos de aprendizagem não
supervisionada, como agrupamento, ajudam na identificação desses casos, sendo que
eles podem se apresentar como pequenos grupos (em inglês, clusters) dentro de uma
classe. Em classificação, casos raros potencialmente se apresentam como pequenos
disjuntos, que são conceitos aprendidos que cobrem poucos casos do conjunto de
treinamento. Em outras palavras, casos raros ocorrem quando alguns subconjuntos de
uma classe são muito menores do que os outros (Han et. al, 2005). Ocorre que certos
algoritmos classificadores, como o C4.5, tendem a ignorar tais casos por eles não terem
representatividade no conjunto de treinamento (Japkowicz, 2003), tornando-se
problemático quando casos raros ocorrem na classe minoritária.

26
3.5 Sensibilidade dos Algoritmos de Classificação
Conforme os experimentos efetuados por (Japkowicz e Stephen, 2002), o
algoritmo de árvore de decisão (C5.0) é o mais afetado na presença de dados
desbalanceados por trabalhar de forma global, e não prestar atenção em pontos
específicos. Já os algoritmos de redes neurais, como o Multi-Layer Percepton (MLP) é
menos propenso a erros que o C5.0, por causa de sua flexibilidade, pois o mesmo ajusta
o seu modelo tanto no nível de instância quanto no nível global. Por último, a Máquina
de Vetor de Suporte (SVM), a qual é menos propensa a erros que os dois últimos, pois
se concentra nas instâncias próximas da superfície de decisão para a construção do
modelo.
Neste capítulo, enumeramos as principais causas associadas ao problema de
conjunto de dados desbalanceados relatadas na literatura. No próximo capítulo serão
detalhadas as abordagens propostas para solucionar o problema.

27
Capítulo 4
Soluções para o Problema de Classificação em
Conjuntos de Dados Desbalanceados
Este capítulo tem como objetivo efetuar uma revisão bibliográfica a respeito de
soluções para problemas de classificação em conjunto de dados desbalanceados.
4.1 Introdução
Tendo em vista a importância do problema de baixo desempenho na classificação
de conjuntos de dados desbalanceados, ao longo dos últimos anos diversas abordagens
têm sido adotadas pela comunidade de mineração de dados com objetivo de atacar as
causas do problema, as quais foram relacionadas no capítulo 3.
Com o objetivo de agrupar tais iniciativas, (Qiong et al., 2006), identificaram três
principais abordagens:
• Ajuste em nível de dados;
• Aprendizado sensível a custos.
• Ajuste em nível de algoritmos;

28
Neste capítulo serão detalhadas as principais estratégias para ajuste em nível de
dados, as quais são o foco deste trabalho, e abordar de maneira sucinta os principais
métodos das outras abordagens.
4.2 Notação
Com o objetivo de apresentar claramente os conceitos deste trabalho, nesta seção
serão estabelecidas algumas notações que serão doravante utilizadas no mesmo.
Dado o conjunto de treinamento T com m exemplos e n atributos, onde
miyxT ii ,...,1},,{ == , onde Xxi ∈ é uma instância no conjunto de atributos
},...,{ 1 naaX = , e Yyi ∈ é uma instância no conjunto de classes, },...,1{ cY = , existe
um subconjunto com instâncias positivas XP ⊂ , e um subconjunto de instâncias
negativas XN ⊂ , onde NP < . Todo subconjunto de P criado por métodos de
amostragem, será denominado S. As estratégias de pré-processamento no conjunto de
dados têm como objetivo balancear o conjunto de treinamento T, de forma que NP ≅ .
4.3 Ajuste em Nível de Dados
A abordagem em nível de dados consiste em efetuar um ajuste no conjunto de
dados de forma a equalizar a distribuição de exemplos entre classes utilizando
amostragem (em inglês, sampling), seja removendo instâncias da classe majoritária, isto
é, subamostragem (em inglês, undersampling) ou adicionando exemplos da classe
majoritária, isto é, sobreamostragem (em inglês, oversampling). O objetivo final é
efetuar um pré-processamento de forma que o algoritmo de classificação trabalhe em
um conjunto de dados balanceado, onde NP ≅ .
Os estudos de (Estabrooks et. al., 2004, Laurikkala, 2001, Weiss e Provost, 2001),
reportaram que diversos classificadores básicos apresentaram melhor desempenho se
aplicados a conjuntos de dados balanceados. Todavia, também foram reportados

29
problemas como remoção de conceitos importantes relativos à classe negativa, e sobre
ajustamento (overfitting) ao adicionar instâncias positivas (Chawla et al. 2001,
Drummond e Holte, 2003).
Em (Drummond e Holte, 2003) foi argumentado que a sobreamostragem é
ineficiente por duplicar instâncias e não introduzir novos dados, sendo a subamostragem
uma melhor escolha. Todavia, um estudo posterior utilizando domínios artificiais
concluiu o oposto (Japkowicz, 2003), isto é, a sobreamostragem provê melhor
desempenho de classificação que a subamostragem, sendo tais resultados também
obtidos por (Batista e Monard, 2004).
4.3.1. Amostragem Aleatória de Instâncias
Uma das estratégias mais simples para o ajuste de conjuntos de dados
desbalanceados consiste na remoção (subamostragem) e adição (sobreamostragem)
aleatória de instâncias.
Para a sobreamostragem, instâncias do conjunto P são selecionadas
aleatoriamente, duplicadas e adicionadas ao conjunto T. Por outro lado, na remoção de
instâncias, se seleciona aleatoriamente instâncias da classe majoritária do subconjunto
N, para remoção.
Ainda que ambas as estratégias tenham o funcionamento semelhante, e trazem
algum benefício do que simplesmente classificar sem nenhum tipo de pré-
processamento (Weiss e Provost, 2001, Laurikkala, 2001, Estabrooks et al., 2004), elas
também introduzem problemas no aprendizado de máquina. Para a remoção de
instâncias, corre-se o risco de remover conceitos importantes relativos à classe negativa.
No caso da adição de instâncias positivas, ocorre o problema de sobre ajustamento
(overfitting), onde, de acordo com (Batista, 2003): “Um classificador simbólico, por
exemplo, pode construir regras que são aparentemente precisas, mas que na verdade
cobrem um único exemplo replicado”.

30
De forma a se evitar ou mitigar tais efeitos causados pela amostragem aleatória de
exemplos, utiliza-se alguma heurística para orientar tais ações. Esses métodos serão
detalhados nas seções 4.3.2 e 4.3.3.
4.3.2 Técnicas de Subamostragem Orientada
Nesta seção serão apresentadas as técnicas onde se leva em conta alguma
heurística de forma a remover instâncias da classe majoritária do conjunto de
treinamento.
• EasyEnsemble e BalanceCascade
Os métodos EasyEnsemble e BalanceCascade propostos por (Liu et al., 2006a),
tem como objetivo superar a perda de informação relevante introduzida pelo método
tradicional de subamostragem aleatória. Em ambos os métodos, o classificador H
utilizado foi o AdaBoost (Schapire, 1999).
A implementação do EasyEnsemble é bem simples: dado o conjunto de
treinamento minoritário P, e o conjunto de treinamento majoritário N, criam-se t
subconjuntos 'iN , tii == ,...,1 , compostos de exemplos retirados aleatoriamente de N,
onde NN i <' , onde se usa comumente PN i =' . Os subconjuntos ti NN ',...,' são
criados e treinados separadamente, onde um classificador iH é treinado usando 'iN e
todos os exemplos de P. Todos os classificadores gerados são combinados para uma
decisão final.
O EasyEnsemble é considerada uma estratégia não supervisionada, pois explora o
conjunto N através de amostragem aleatória com troca.
Já o método BalanceCascade explora o conjunto N de maneira supervisionada,
sendo um classificador em cascata a conjunção de todos os classificadores iH ,
tii == ,...,1 . Depois que o classificador iH é treinado, se um exemplo Nxi ∈ é
corretamente classificado, é aceitável conjecturar que ix é de alguma maneira
redundante em N, dado que iH já aprendeu a classificar esse exemplo. Então, ao longo

31
do processo, pode-se remover alguns exemplos corretamente classificados do conjunto
N, de forma que NP ≅ .
• Tomek Links
O método de Tomek Links (Tomek, 1976), pode ser aplicado em subamostragem,
pois permite a remoção orientada de instâncias da classe majoritária consideradas como
ruídos e próximas à superfície de decisão. O Tomek Links consiste em um par de
instâncias de classes opostas ),( ji xx , sendo Pi ,...,1= , e Nj ,...,1= , onde Pxi ∈ e
Nx j ∈ , e dada uma função de distância ),( ji xxd , o par ),( ji xx é considerado um
Tomek Link se não existir instância kx de forma que ),(),( jiki xxdxxd < ou
),(),( jikj xxdxxd < , definindo que uma das instâncias ),( ji xx são ruídos ou ambas
encontram-se próximas à superfície de decisão.
A técnica de Tomek Links tem sido aplicada com sucesso em conjunto com outros
métodos de sobreamostragem, como o SMOTE (Batista e Monard, 2004). De forma a
remover as instâncias jx da classe majoritária junto à superfície de decisão, evitando
assim a sobreposição de classes que eventualmente podem já existir no conjunto de
treinamento, bem como criadas pelos métodos de amostragem.
• Condensed Nearest Neighbor Rule (CNN)
O algoritmo CNN, o qual pode ser traduzido como “Regra de vizinhos mais
próximos condensados”, também conhecido como algoritmo de Hart (Hart, 1968), cria
um subconjunto consistente C a partir de um conjunto de treinamento T.
O subconjunto TC ⊆ é considerado consistente quando um classificador 1-NN
(classificador k-NN, sendo k = 1) consegue classificar de forma correta todo o conjunto
T, tendo como conjunto de treinamento o subconjunto C.
Com o objetivo de aplicar o CNN como método de subamostragem em conjuntos
de dados desbalanceados, (Kubat e Matwin, 1997) propõe uma modificação a esse

32
método, de forma a remover instâncias apenas da classe majoritária. Isso é obtido ao se
inicializar o conjunto C somente com todos os casos da classe minoritária e ir
adicionando ao conjunto C apenas os exemplos da classe majoritária do conjunto T onde
o classificador 1-NN conseguiu classificar corretamente. O conjunto balanceado passa a
ser o subconjunto C, com as instâncias menos relevantes da classe majoritária
removidas.
• One Side Selection (OSS)
O método OSS proposto por (Kubat e Matwin, 1997) consiste da aplicação do
método Tomek Links seguido do CNN. O método Tomek Links atua removendo
instâncias pertencentes à classe majoritária consideradas ruidosas ou próximas da
superfície de decisão. De acordo com os autores, exemplos limítrofes são considerados
instáveis, pois uma pequena quantidade de ruído pode fazê-los cair no lado errado do
limiar de decisão. O método CNN atua removendo instâncias da classe majoritária
distantes da superfície de decisão, consideradas irrelevantes para construção do modelo.
• Edited Nearest Neighbor Rule (ENN)
O método ENN proposto por (Wilson, 1972), em português, “Regra editada de
vizinhos mais próximos”, remove instâncias da classe majoritária de maneira oposta ao
método CNN, onde dado um conjunto de treinamento T, retira-se todos os casos Txi ∈ ,
cuja classe for diferente da predita pelo método KNN, onde geralmente k=3.
De acordo com os (Wilson e Martinez, 2000), o método remove tanto os exemplos
ruidosos quanto os exemplos limítrofes, propiciando uma superfície de decisão mais
suave.
• Neighbor Cleaning Rule (NCL)
O método NCL proposto por (Laurikkala, 2001), em português, “Regra de limpeza
de vizinhança”, consiste em ampliar o método ENN, funcionando para um problema de
duas classes da seguinte maneira: para cada exemplo Txi ∈ , encontra-se os seus k=3

33
vizinhos mais próximos. Se ix pertencer à classe majoritária, e ocorrer um erro de
predição relativo aos seus vizinhos mais próximos, ix será removido. Se ix pertencer à
classe minoritária, e ocorrer um erro de predição relativo aos seus vizinhos mais
próximos, os vizinhos mais próximos pertencentes à classe majoritária serão removidos.
4.3.3 Técnicas de Sobreamostragem Orientada
Nesta seção serão apresentadas as técnicas onde se leva em conta alguma
heurística de forma a adicionar instâncias da classe minoritária ao conjunto de
treinamento. Conforme (Batista e Monard, 2004), as técnicas de sobreamostragem
podem ser combinadas com sucesso com as técnicas de subamostragem descritas na
seção anterior.
• Synthetic Minority Over-Sampling Technique (SMOTE)
O algoritmo SMOTE, proposto por (Chawla et al. 2001) é um das mais conhecidas
técnicas de sobreamostragem, tendo obtido sucesso em diversas áreas de aplicação,
servindo também como base para outros algoritmos de sobreamostragem. O SMOTE
efetua o balanceamento do conjunto P de instâncias minoritárias, onde são criadas n
instâncias sintéticas para cada instância ix do conjunto P.
O algoritmo funciona criando instâncias sintéticas baseadas em uma instância
minoritária e seus k vizinhos mais próximos. Uma instância sintética é gerada tendo
como base as instâncias ix e ix̂ , sendo ix̂ selecionada aleatoriamente entre os k
vizinhos de ix , e δ um número aleatório entre 0 e 1, conforme (10). O processo é
repetido n vezes para cada instância ix do conjunto P.
δ).ˆ(sin iiitético xxxx −+= (10)
De acordo com os experimentos efetuados por (Wang e Japkowicz, 2004), um dos
pontos fracos do SMOTE reside no fato de que todas as instâncias positivas servem
como base para a geração de instâncias sintéticas. Todavia, tal estratégia não leva em

34
conta que nem sempre uma distribuição homogênea de instâncias sintéticas é aplicável a
um problema de desbalanceamento, tendo em vista que tal prática pode causar
sobreajustamento e sobreposição de classes. Outro ponto fraco relatado é a variância de
resultados, tendo em vista o caráter aleatório em alguns pontos do algoritmo.
• ADASYN
O algoritmo ADASYN (He et al., 2008) é baseado no algoritmo SMOTE, e tem
como ponto chave adaptar a quantidade de instâncias sintéticas produzidas pelo SMOTE
para cada instância ix no conjunto de instâncias positivas P, sendo Pi ,...,1= . Tal
adaptação é feita levando-se em conta que para cada instância Pxi ∈ , serão criadas
GDg ii .= instâncias sintéticas positivas, sendo iD obtido pelas equações (11) e G (12).
Avaliando-se a equação (11), verifica-se que quanto maior o número de instâncias da
classe majoritária, mas se está próximo da superfície de decisão, e mais instâncias
sintéticas serão criadas.
Z
KD
i
i
∆
=
(11)
Onde ∆ é o número de K vizinhos mais próximos pertencentes à classe
majoritária, e Z é uma constante de normalização de forma que ∑ = 1D .
β).( PNG −= (12)
Onde β é um parâmetro contido entre 0 e 1, e indica o nível de balanceamento
desejado.
• Borderline SMOTE
Com o objetivo de evitar os pontos fracos identificados no SMOTE, (Han et al.,
2005) desenvolveram uma variação do mesmo, o qual tem como objetivo identificar as

35
instâncias próximas à superfície de decisão, identificadas como conjunto DANGER. De
acordo com os experimentos efetuados pelos autores, verificou-se que as instâncias
próximas da superfície de decisão são mais susceptíveis à erros, então, ao contrário do
SMOTE que gera instâncias sintéticas a partir de todos os exemplos do conjunto P de
instâncias minoritárias, o Borderline SMOTE irá aplicar o SMOTE somente às
instâncias do conjunto DANGER.
As instâncias positivas que pertencem ao conjunto DANGER são aquelas que,
possuem mais vizinhos da classe negativa, do que vizinhos da classe positiva, sendo os
vizinhos obtidos com o algoritmo KNN, onde k=5.
• Cluster Based Oversampling (CBO)
O método CBO, em português “Sobreamostragem baseada em agrupamentos”
proposto por (Nickerson et al., 2001), tem como objetivo minimizar o problema de
pequenos disjuntos em todas as classes, sendo aplicável a conjuntos de dados
multiclasses.
Esse balanceamento é obtido partindo do pressuposto de que um conjunto de
dados retém algumas características originais do problema em questão, e usam estas
características para fazer oversampling não somente da classe minoritária, mas também
dos casos raros. O ponto chave do algoritmo consiste agrupar os dados de treinamento e
então, balancear a distribuição de seus exemplos.
Como técnica de agrupamento, utiliza-se o método Principal Direction Divisive
Partitioning (PDDP) (Boley, 1998), que é uma técnica não-supervisionada de
agrupamento para formar os grupos em todas as classes. Com os grupos em mãos,
efetua-se a sobreamostragem a partir dos centróides obtidos. A utilização da técnica
K-Means (MacQueen, 1967) como método de agrupamento aplicado CBO foi proposta
por (Jo e Japkowicz, 2004).

36
Entrada: T
Saída: T balanceado
1. Obtenha os grupos da classe negativa de T com PDDP;
2. max <- número de exemplos do maior grupo;
3. Para cada cluster Ci faça {
4. Replique os casos de Ci até que o tamanho de Ci seja igual a max; }
5. numeroGrupos <- quantidade de grupos da classe negativa;
6. max <- número de exemplos da classe negativa dividido por número de grupos;
7. Obtenha os grupos da classe positiva de T com PDDP;
8. Para cada grupo Ci faça {
9. Replique os casos de Ci até que o tamanho de Ci seja igual a max;
10. }
11. Retorna S
Figura 4.3.3.1 – Pseudocódigo do algoritmo CBO
Ao final do processo, todas as classes do conjunto de treinamento T estarão
balanceadas internamente, isto é, todas as classes e seus grupos terão a mesma
quantidade de exemplos.
• SMOTE Boost
O método SMOTE Boost (Chawla, 2003) consiste da integração do algoritmo
AdaBoost.M2 ao SMOTE, onde a cada iteração são inseridas instâncias sintéticas de
acordo com os erros do classificador.
• DEC
O método DEC (Chen et al., 2010) é um algoritmo híbrido, que efetua
sobreamostragem através de um AG, em conjunto com subamostragem utilizando
técnicas de agrupamento.
Para a sobreamostragem, é utilizado o algoritmo SMOTE, o qual se vale de um
vetor numérico evoluído por um AG baseado em evolução diferencial (Storn, 1997), e
opera basicamente em três passos:

37
1) O processo de mutação é baseado no algoritmo SMOTE (10), onde se obtém valores
aleatórios δ entre [0,1] para a criação de instâncias sintéticas mux .
2) O cruzamento opera de acordo com (13), onde ijx é o j-ésimo atributo do exemplo
ix , a função aleatório(j) retorna a j-ésima seleção de um número aleatório entre [0,1] e
CR é a constante de cruzamento entre [0,1]. A função aleatório(s) permite que ao menos
um atributo seja obtido do s-ésimo exemplo mutante mux .
(13)
3) Dependendo do montante de sobreamostragem requerida, os passos 1) e 2) são
computados circularmente.
O método de subamostragem baseada em agrupamento utiliza o método K-Means
(MacQueen, 1967) para identificar os centróides no conjunto de dados após o
balanceamento e eliminar instâncias ruidosas ou próximas da superfície de decisão.
4.4 Aprendizado Sensível a Custos
Os algoritmos tradicionais de classificação foram desenhados para reduzir os erros
de predição, mas não distinguem, por exemplo, que é mais caro errar quando um
paciente é diagnosticado como saudável, mas na verdade possui alguma doença que
exige tratamento imediato.
Fundamentações sobre abordagem de aprendizado utilizando custos foram
publicadas por (Pazzani, 1994, Elkan, 2001), onde basicamente se utiliza uma matriz de
custos de forma a atribuir pesos a cada classe (13). Estudos práticos mostraram que o
aprendizado sensível a custos aplicado a determinados problemas foi superior às

38
técnicas de ajuste nos dados (Liu e Zhou, 2006b, McCarthy et. al, 2005), e de acordo
com (Chawla et. al, 2004, Maloof, 2003, Weiss, 2004), o aprendizado sensível a custos
possui uma forte conexão com o aprendizado em conjuntos de dados desbalanceados.
Todavia nem sempre é fácil determinar a matriz de custos para todos os problemas
(Chawla, 2003), apesar dos estudos publicados por (Elkan, 2001), o qual propõe um
teorema para definição dos custos. Outro ponto fraco relatado na literatura consiste em
que nem todos os algoritmos suportam aprendizado sensível a custos, mas dentre os que
aceitam, pode se citar as árvores de decisão, redes neurais e o classificador bayesiano.
No caso do classificador bayesiano, também conhecido como classificador
ingênuo (em inglês, Naive Bayes), o mesmo não leva em conta que, quando existir um
maior número de registros da classe 1y , a probabilidade de instâncias da outra classe 2y
serem classificadas incorretamente como 1y será maior, o que o torna bastante suscetível
ao problema de conjunto de dados desbalanceados.
Para eliminar esse efeito, deve-se aplicar uma matriz de custos, com objetivo de
ponderar a probabilidade de classificação incorreta, que no caso de duas classes, pode
ser escrita como (14).
=
021
120
λ
λL
(14)
Onde, aplicada ao problema do diagnóstico de câncer, poderia ser preenchida
como: 12λ = probabilidade de classificar saudável como doente, e 21λ = probabilidade
de classificar doente como saudável. Então, com a aplicação dessa matriz de custos, o
discriminante bayesiano (1) poderia ser reescrito como (15).

39
Se
>
)(
)(
12
21
)/(
)/(
1
2
2
1
yP
yP
yxp
yxp
λ
λ, então x ∈ 1y
Se
<
)(
)(
12
21
)/(
)/(
1
2
2
1
yP
yP
yxp
yxp
λ
λ, então x ∈ 2y
(15)
Com o advento do AdaBoost (Schapire, 1999), diversas estratégias que combinam
métodos adaptativos e atribuição de custos foram implementadas, onde a cada ciclo os
custos são ajustados de acordo com os erros do classificador. Dentre esses métodos,
pode-se citar o Adacost (Fan et al. 1999) e recentemente os métodos AdaC1, AdaC2,
AdaC3 (Sun et al. 2007). Estudos a respeito de custos aplicados às redes neurais foram
efetuados por (Haykin, 1999, Kuzar e Kononenko, 1998, Drummond e Holte, 2000)
exploraram custos aplicados a critérios de divisão em árvores de decisão.
4.5 Ajuste em Nível de Algoritmos
Esta abordagem propõe aplicar ou ajustar os algoritmos de classificação existentes
de maneira que o mesmo trate a classe minoritária de maneira diferenciada, de forma a
diminuir os erros do classificador na presença de conjuntos de dados desbalanceados.
Aplicados ao SVM (Support Vector Machine), são reportadas as pesquisas de (Lin
et al., 2002) os quais propõem que as penalidades da otimização combinatória do SVM
sejam diferenciadas de acordo com o nível de balanceamento de cada classe. Outra
abordagem utilizando o SVM consiste em ajustar o limite das classes através de
modificações no kernel, conforme apresentado por (Wu e Chang, 2003, 2004, 2005,
Hong et al., 2007).
Uma abordagem de aprendizado em uma só classe aplicada a redes neurais e SVM
pode ser vista em (Manevitz, 2001), e de acordo com (Japkowicz, 2001), esta

40
abordagem mostrou ser superior em problemas multiclasses do que a tradicional técnica
de aprendizado em duas classes. Todavia, tal abordagem não se aplica a algoritmos
como árvores de decisão e Naive Bayes, pelo fato de os mesmos necessitarem no
mínimo duas classes para que o treinamento seja efetuado.
Os algoritmos adaptativos, também denominados algoritmos de boosting, como o
AdaBoost (Schapire, 1999), consistem de um algoritmo iterativo onde a cada ciclo são
atribuídos pesos às instâncias classificadas incorretamente, fazendo com que o
algoritmo de classificação, o qual pode ser escolhido, tenha maior foco nessas instâncias
na próxima interação. Tendo em vista que as instâncias pertencentes à classe minoritária
são mais susceptíveis a erros, a cada iteração o algoritmo adaptativo delineia uma
superfície de decisão mais adequada para esses exemplos minoritários, tornando tais
algoritmos aplicáveis ao problema de conjunto de dados desbalanceados, podendo ainda
ser combinado com outros métodos, conforme foi visto neste capítulo.
Estudos mostraram que o problema de bias inapropriado descrito nas seções 3.2.1
e 3.2.5 pode ser resolvido utilizando algoritmos que não levem em conta métricas tidas
como “gananciosas”, como por exemplo, ganho de informação (Kullback e Leibler,
1951), e entropia (Shanon, 1951) para a construção do seu modelo. A aplicação de um
bias apropriado para o problema foi proposto por (Zadrozny e Elkan, 2001), e
recentemente, a métrica CCPDT apresentada por (Liu et al. 2010) foi aplicada à árvores
de decisão, a qual se mostrou robusta e insensível ao tamanho das classes, gerando
regras estatisticamente significantes.
Uma outra abordagem consiste na utilização de algoritmos genéticos (Goldberg,
1989) para a formação de regras de decisão (Freitas, 2002, 2003), pois os mesmos
contam como função de desempenho uma métrica de classificação (vide seção 2.4), ao
invés das métricas tradicionais de árvores de decisão. O algoritmo Timewaver, um AG
preparado para predizer eventos raros foi desenvolvido por (Weiss, 1999), e um
algoritmo genético para descobrir regras em pequenos disjuntos foi desenvolvida por
(Carvalho e Freitas, 2002, 2003). A heurística de algoritmos genéticos será mais bem
detalhada no próximo capítulo.

41
Capítulo 5
Algoritmos Genéticos
Este capítulo tem como objetivo apresentar a heurística de algoritmos genéticos.
5.1 Introdução
Muitos problemas não têm uma fórmula específica para sua solução, pois muitas
vezes os mesmos são muitos complexos, ou levam muito tempo para se calcular a
solução exata. Dessa maneira, a aplicação de uma heurística torna-se uma abordagem
adequada.
A heurística de algoritmos genéticos (AG) é utilizada para encontrar soluções
ótimas ou próximas do ótimo em problemas de busca ou otimização combinatória. O
AG é um método inspirado na natureza, sendo classificado como um algoritmo
evolucionário, e uma heurística de busca global, possuindo uma abordagem
probabilística e não determinística. O AG foi proposto inicialmente por John Holland,
que buscava uma forma de modelar sistemas complexos adaptativos e de estudar a
evolução através de simulação. Holland publicou seu primeiro trabalho preliminar sobre
GA, em 1962. Ele continuou a sua pesquisa e em 1975 estabeleceu o seu método em um
livro (Holland, 1975), sendo o mesmo popularizado por (Goldberg, 1989).
Os problemas de otimização combinatória se baseiam em três principais
características: codificação do problema, função objetivo e o espaço de busca associado
ao problema. O AG endereça essas três características para solução do problema de

42
maneira simples, se comparado a outros algoritmos, (Whitley, 1994), e possui vantagens
em relação a outros métodos em diversos aspectos, dentre eles:
• Não necessita de funções deriváveis e outras informações auxiliares;
• Realiza exploração simultânea em várias regiões do espaço de busca, pois
trabalha com uma população e não com um único ponto;
• São adaptáveis para processamento paralelo;
• Conseguem evitar o mínimo local;
• Pode obter soluções para problemas de otimização multidimensionais
complexos.
Entre as desvantagens do AG, temos:
• São necessários muitos ciclos e avaliações de funções do que outros
métodos, o que acarreta maior tempo de execução;
• Não garante a convergência para o ótimo global;
• Não existe um AG único, sendo necessária a incorporação de informações
específicas do problema em estudo para uma melhor performance.
Nas próximas seções serão detalhados os componentes do AG, o seu
funcionamento e as suas aplicações.

43
5.2 Componentes do Algoritmo
O AG é constituído de componentes que simulam a evolução de indivíduos ao
longo de gerações através de operadores específicos, e por ter sido inspirado na teoria
evolutiva, empresta termos da biologia e ecologia (Tabela 5.2.1). A junção desses
componentes em um fluxo de processamento, conforme exemplificado na figura 5.3.1,
formam o algoritmo genético propriamente dito. Tais componentes serão detalhados nas
próximas seções.
No AG clássico proposto inicialmente por (Holland, 1975), também conhecido
como AG simples, o algoritmo é composto de cromossomos com representação binária,
população de tamanho fixo, reprodução com substituição da população, seleção por
método da roleta, cruzamento simples de 1 ponto, e mutação pontual. Todavia, não
existe um único algoritmo que se adéque a todos os problemas de otimização, ao
contrário, após o advento do AG, diversas implementações e melhorias foram
propostas, de forma a adequar o AG aos problemas e desafios do mundo real.
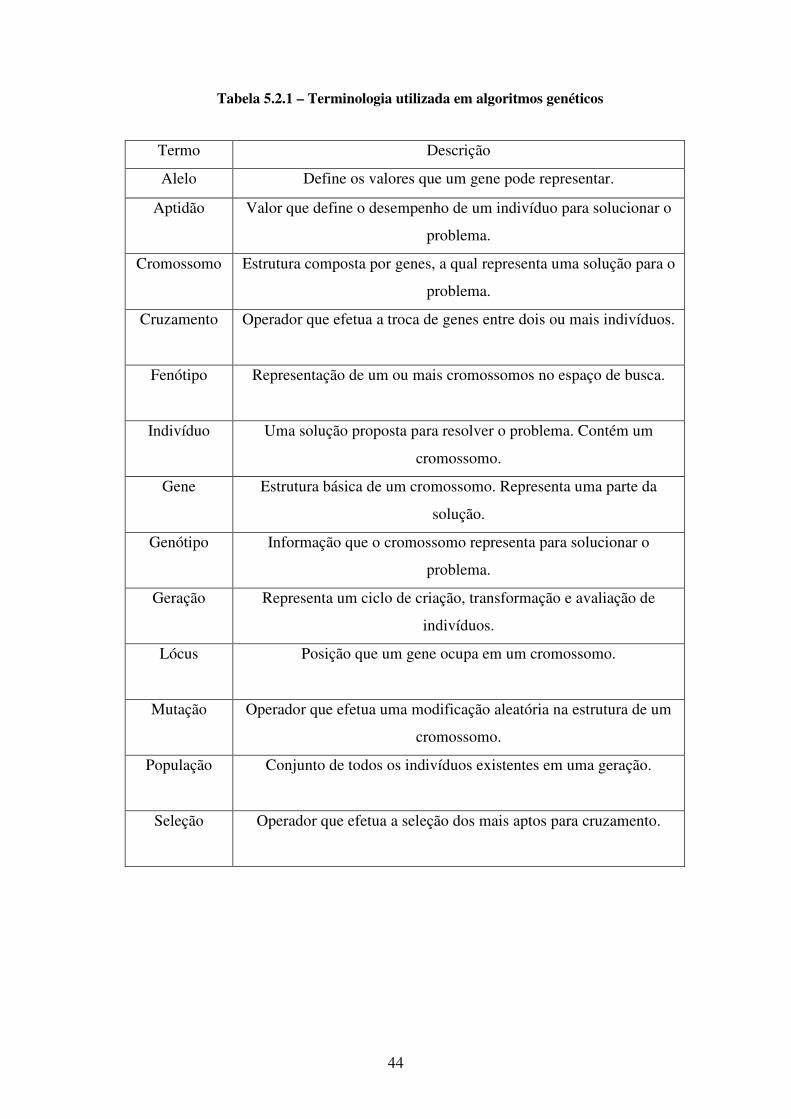
44
Tabela 5.2.1 – Terminologia utilizada em algoritmos genéticos
Termo Descrição
Alelo Define os valores que um gene pode representar.
Aptidão Valor que define o desempenho de um indivíduo para solucionar o
problema.
Cromossomo Estrutura composta por genes, a qual representa uma solução para o
problema.
Cruzamento Operador que efetua a troca de genes entre dois ou mais indivíduos.
Fenótipo
Representação de um ou mais cromossomos no espaço de busca.
Indivíduo Uma solução proposta para resolver o problema. Contém um
cromossomo.
Gene Estrutura básica de um cromossomo. Representa uma parte da
solução.
Genótipo Informação que o cromossomo representa para solucionar o
problema.
Geração Representa um ciclo de criação, transformação e avaliação de
indivíduos.
Lócus Posição que um gene ocupa em um cromossomo.
Mutação Operador que efetua uma modificação aleatória na estrutura de um
cromossomo.
População Conjunto de todos os indivíduos existentes em uma geração.
Seleção Operador que efetua a seleção dos mais aptos para cruzamento.

45
5.2.1 Cromossomo e Genes
Um típico AG requer uma representação genética de forma a codificar uma
solução. Essa solução é representada por um cromossomo em um indivíduo, e um
conjunto de indivíduos constituem uma população. Cada cromossomo codifica uma
solução para o problema a ser otimizado, e é composto por genes, que representam uma
parte da solução. No AG clássico proposto inicialmente por (Holland, 1975), o
cromossomo é codificado de maneira binária e possui tamanho fixo. Posteriormente,
optou-se por codificar os genes com números inteiros ou reais (Srinivas e Patnaik,
1994a, Michalewicz, 1996), e cromossomos com tamanho variável. O mais importante
nesta representação é que um indivíduo represente um ponto no espaço das possíveis
soluções para o problema (Koza, 1995). A figura 5.2.2.1 exemplifica um conjunto de
valores representados respectivamente por um cromossomo binário e inteiro.
Figura 5.2.1 – Exemplo de cromossomos e genes com codificação binária e
inteira.
5.2.2 População Inicial
O algoritmo inicia com a criação da população inicial de indivíduos. Dentre as
abordagens existentes na literatura, pode-se citar: geração aleatória; geração uniforme
através de uma grade; geração de maneira tendenciosa em regiões promissoras do
espaço de busca; iniciar com uma grande população, e depois diminuir o tamanho da
mesma; semeadura (seeding): utilizar a solução de outro método de otimização para
gerar os indivíduos iniciais. O objetivo principal em qualquer dessas abordagens é
explorar soluções no espaço de busca, e aumentar a diversidade da população.

46
5.2.3 Função Objetivo
A função objetivo )(xf , também conhecida como função de desempenho e em
inglês, fitness, é a função que deve ser otimizada pelo AG, pois define o quanto a
solução codificada por aquele indivíduo está apta para resolver o problema em estudo.
A fórmula da função objetivo varia de acordo com o problema.
5.2.4 Avaliação e Substituição
A avaliação ocorre no início do algoritmo, e ao final de cada geração. Neste ponto
é assegurado que todos os indivíduos recém criados tenham a sua função objetivo
calculada. A substituição visa eliminar os indivíduos menos aptos da população,
levando-se em conta que a quantidade de indivíduos não pode ultrapassar uma
população máxima pré-estabelecida. Pode-se citar como estratégias de substituição:
• Geracional
Seja t o tamanho da população, os t pais são substituídos pelos t filhos em
cada geração.
• Geracional com elitismo
Os e<t melhores pais não são substituídos ao final da geração, sendo
tipicamente e=1. O risco de pressão de seleção e convergência prematura
aumenta ao se aumentar e.
• Regime permanente (Steady State)
A cada geração apenas 1 ou 2 filhos são gerados e substituem: os 2 piores
indivíduos da população, os pais, os indivíduos mais velhos.

47
5.2.5 Critério de Parada
De posse da aptidão de cada indivíduo, o algoritmo verifica se o critério de parada
foi atingido. O critério de parada pode ser:
• Um número máximo de gerações;
• O desempenho ótimo, se conhecido;
• Um valor de desempenho não ótimo a ser atingido;
• O grau de convergência da população, que é a diferença do desempenho
entre o indivíduo mais apto e menos apto;
• Pressão de seleção, que consiste de ))((
))(max(
xfmédia
xf.
5.2.6 Seleção
De forma a permitir que os indivíduos compartilhem o seu conteúdo genético com
outros, faz-se uma seleção onde os mais aptos terão maior probabilidade de fazer parte
de uma população intermediária (matting pool), destinada ao cruzamento. Os critérios
de escolha mais conhecidos são a seleção por roda da roleta, torneio e amostragem
estocástica universal.
A figura 5.2.6.1 exibe como indivíduos mais aptos, e por conseqüência com maior
desempenho acumulado, têm maior probabilidade de serem selecionados. Conforme
(Michalewicz, 1996), o cálculo da probabilidade de seleção de um indivíduo ix ,
proporcional à sua aptidão, consiste da razão entre o desempenho )( ixf e o somatório
do desempenho de toda a população, onde pmax=população máxima (16).
∑=
= max
1
)(
)(p
k
k
ii
xf
xfp
(16)
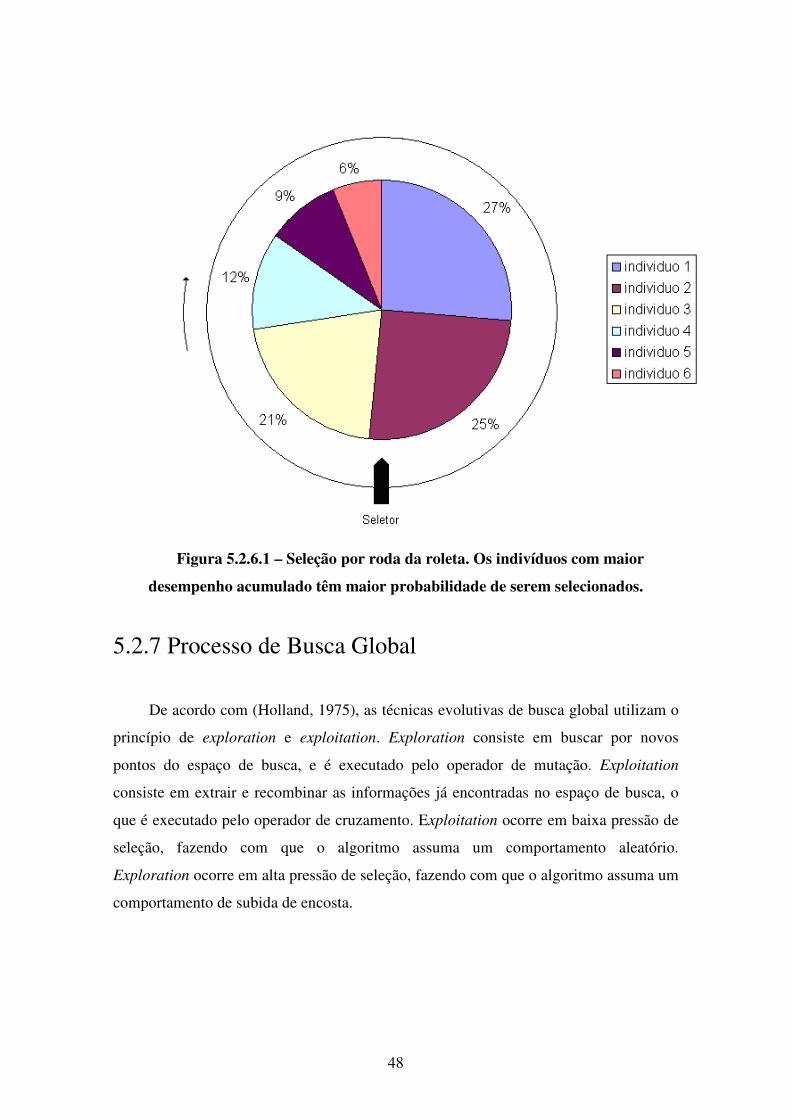
48
Figura 5.2.6.1 – Seleção por roda da roleta. Os indivíduos com maior
desempenho acumulado têm maior probabilidade de serem selecionados.
5.2.7 Processo de Busca Global
De acordo com (Holland, 1975), as técnicas evolutivas de busca global utilizam o
princípio de exploration e exploitation. Exploration consiste em buscar por novos
pontos do espaço de busca, e é executado pelo operador de mutação. Exploitation
consiste em extrair e recombinar as informações já encontradas no espaço de busca, o
que é executado pelo operador de cruzamento. Exploitation ocorre em baixa pressão de
seleção, fazendo com que o algoritmo assuma um comportamento aleatório.
Exploration ocorre em alta pressão de seleção, fazendo com que o algoritmo assuma um
comportamento de subida de encosta.

49
5.2.8 Cruzamento
O cruzamento (crossover) é um dos principais operadores do AG, o qual reproduz
em um ambiente computacional o comportamento evolutivo que ocorre na natureza,
pois permite que os indivíduos, os quais foram inicialmente criados de maneira
aleatória, compartilhem a sua codificação com outros indivíduos, gerando filhos e
criando uma diversidade orientada pela aptidão dos pais. Conforme (Srinivas e Patnaik,
1994b): “O poder do AG vem do operador de cruzamento”. Após o processo de seleção,
é criada uma população intermediária de indivíduos selecionados para o cruzamento. Os
indivíduos dessa população intermediária são selecionados, geralmente em pares, seja
de maneira aleatória ou de maneira em que os pares tenham o mesmo nível de
desempenho (Spears, 2001). Apesar de existirem diversas variações, existem três
estratégias básicas para o cruzamento:
• Simples
Um ponto de corte, escolhido aleatoriamente (Figura 5.2.8.1).
Figura 5.2.8.1 – Cruzamento simples.
• Múltiplo
Mais de um ponto de corte, escolhidos aleatoriamente (Figura 5.2.8.2)

50
Figura 5.2.8.2 – Cruzamento múltiplo.
• Uniforme
Existe uma máscara pré-definida, orientando onde a troca de genes deverá ocorrer
(Figura 5.2.8.3).
Figura 5.2.8.3 – Cruzamento uniforme.
De acordo com a análise de (Spears, 2001), a qual se baseia em uma taxa de
perturbação (disruption rate) na distribuição de amostras, dentre as estratégias de
cruzamento, o cruzamento múltiplo com dois pontos causa menos perturbação, e o
cruzamento uniforme é o que causa mais perturbação. Frequentemente encontra-se na
literatura o percentual de cruzamento (pc) como %100%50 << pc (Srinivas e Patnaik,
1994b).

51
5.2.9 Mutação
O operador de mutação permite que o algoritmo busque por novas soluções no
espaço de busca, pois em problemas práticos o AG tende a gerar indivíduos muito
parecidos, ocasionando perda de diversidade. Conforme (Michalewicz, 1996), “O
intuito por trás do operador de mutação é introduzir alguma variabilidade extra na
população”. De acordo com (Srinivas e Patnaik, 1994a), a mutação é um operador
secundário que pode restaurar o material genético perdido ou inexistente em gerações
anteriores.
Os indivíduos são escolhidos aleatoriamente da população. De acordo com
(Whitley, 1994), a exemplo do que ocorre na natureza, o percentual de indivíduos que
sofrem mutação não deve ultrapassar 1%. Na literatura, constam estudos de caso (Tate e
Smith, 1993) onde se utilizam percentuais maiores, mas o suficiente para assegurar a
diversidade de cromossomos na população, pois, como acontece na natureza, a mutação
também pode danificar a codificação do indivíduo. A mutação pontual modifica um
gene por cromossomo (figura 5.2.9.1), mas existem outras estratégias que modificam
mais de um gene.
De acordo com (Srinivas e Patnaik, 1994b), frequentemente encontra-se na
literatura o percentual de mutação (pm) como %5%1,0 << pm . Ainda neste trabalho,
os autores propõem uma probabilidade adaptativa tanto para mutação quanto para
cruzamento. Em (Tate e Smith, 1993), são citados os benefícios obtidos por altos
percentuais de mutação.
Figura 5.2.9.1 – Operador de mutação pontual.

52
5.2.10 Parâmetros do Algoritmo
De forma a orientar o funcionamento do algoritmo, alguns parâmetros são
necessários. A lista dos principais parâmetros utilizados no AG está relacionada na
tabela 5.2.10.
Tabela 5.2.10 – Típicos parâmetros para funcionamento do AG.
Parâmetro Descrição
População inicial,
população máxima
O tamanho da população irá depender da complexidade do
problema. Assim, quanto maior a população, maior a chance
de encontrar a solução para o problema. Porém, maior será o
tempo de processamento. Caso o tamanho da população
aumente muito, o processo estará se aproximando de uma
busca exaustiva. Geralmente utiliza-se população
inicial>população máxima, pois dessa maneira é possível,
através de uma busca ampla inicial, diversificar as soluções no
espaço de busca (Barreto, 1996).
Percentual de
Cruzamento
Define o percentual da população que será selecionado para
cruzamento.
Percentual de Mutação Define o percentual da população que será selecionado para
mutação.
Percentual ou
quantidade de elitismo
Define um percentual ou quantidade dos melhores indivíduos
da geração anterior que serão mantidos para a próxima
geração.
Número de Gerações Quantidade de ciclos que o algoritmo funcionará.
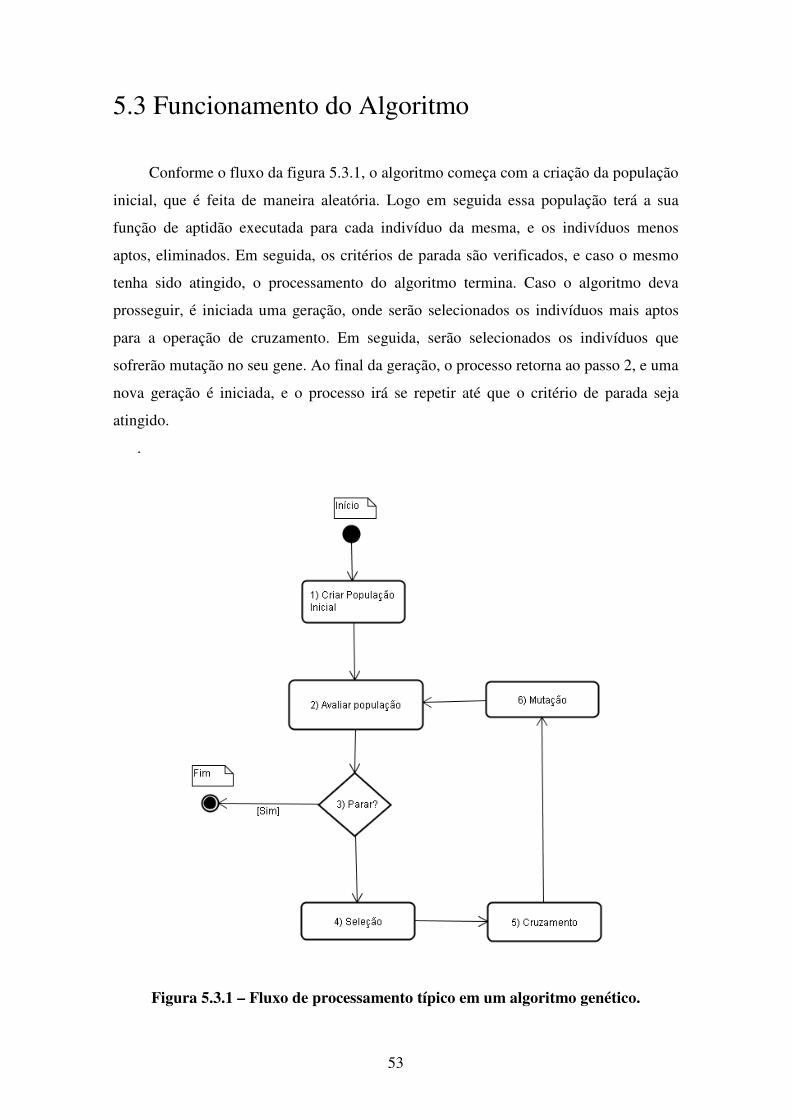
53
5.3 Funcionamento do Algoritmo
Conforme o fluxo da figura 5.3.1, o algoritmo começa com a criação da população
inicial, que é feita de maneira aleatória. Logo em seguida essa população terá a sua
função de aptidão executada para cada indivíduo da mesma, e os indivíduos menos
aptos, eliminados. Em seguida, os critérios de parada são verificados, e caso o mesmo
tenha sido atingido, o processamento do algoritmo termina. Caso o algoritmo deva
prosseguir, é iniciada uma geração, onde serão selecionados os indivíduos mais aptos
para a operação de cruzamento. Em seguida, serão selecionados os indivíduos que
sofrerão mutação no seu gene. Ao final da geração, o processo retorna ao passo 2, e uma
nova geração é iniciada, e o processo irá se repetir até que o critério de parada seja
atingido.
.
Figura 5.3.1 – Fluxo de processamento típico em um algoritmo genético.

54
5.4 Aplicações
As aplicações do AG são bastante abrangentes, sendo indicado em problemas
NP-Difíceis e em casos onde outras técnicas de otimização falham. Dentre suas
inúmeras aplicações, pode-se citar como exemplo:
• Logística: Na solução de problemas de roteamento, também conhecido como o
problema do caixeiro viajante, o qual consiste na minimização da distância de uma
rota, combinando a ordem de visitas em uma lista de localidades. Um repositório de
dados com exemplos desse tipo de problema foi disponibilizado por (Reinelt, 1991);
• Planejamento e controle de produção: na alocação de trabalhos em máquinas de uma
indústria, também conhecido como job shop problem, ou no problema da grade de
turmas, onde o objetivo é maximizar a alocação de professores e salas de aula em
um colégio, combinando a disponibilidade das salas e professores de forma a
preencher uma grade curricular (Petrovic e Fayad, 2005);
• Robótica: Planejamento de trajetórias em robôs (Sariff e Buniyamin, 2009);
• Processamento de sinais: Projeto de filtros para eliminação de ruídos e ajuste de
sinais diversos (White e Flockton, 1994);
• Engenharia: No projeto de esquema de semicondutores, aeronaves, motores, redes
de comunicação, estruturas (Motta e Ebecken, 2007, de Lima et al. 2005);
• Economia e finanças: No desenvolvimento de estratégias para licitações, planos para
mercados emergentes, identificação e mapeamento de eventos (Czarnitzki e Doherr,
2002);
• Medicina e biologia: Análise de modelos simbióticos, análise de genoma, a análise
de viabilidade de mutações (Walker, 1994).

55
• Mineração de Dados: Em atividades de preparação, seleção de atributos,
classificação e predição (Freitas, 2002, 2003, Ebecken et al., 2005).
Na próxima seção será apresentado um AG aplicado ao problema de classificação
em conjuntos de dados desbalanceados.

56
Capítulo 6
Algoritmo Genético para Balanceamento de
Conjuntos de Dados
Este capítulo tem como objetivo apresentar a estrutura e funcionamento do
algoritmo genético para balanceamento desenvolvido neste trabalho.
6.1 Introdução
De forma a buscar soluções para o problema de classificação em conjuntos de
dados desbalanceados, propõe-se neste trabalho uma abordagem de pré-processamento
aplicado a esses conjuntos, com a criação de instâncias sintéticas da classe positiva de
forma a balancear o mesmo, caracterizando-se como uma estratégia de
sobreamostragem (oversampling). Todavia, conforme foi demonstrado no capítulo 4,
não é vantajoso criar tais instâncias sintéticas sem utilizar algum critério que evite o
sobreajustamento.
Para efetuar a sobreamostragem de maneira orientada, foi criado um algoritmo
genético para o balanceamento de conjunto de dados (AGB), o qual busca pelo melhor
posicionamento de regiões dentro dos valores mínimos e máximos do conjunto de
instâncias positiva P, as quais são preenchidas aleatoriamente com instâncias sintéticas.
Dessa maneira efetua-se uma distribuição de instâncias no conjunto de treinamento T,
compensando o desbalanceamento entre as classes.

57
Conforme foi verificado no capítulo 3, existem diversas causas associadas ao
problema de balanceamento, as quais ocorrem separadamente ou em conjunção. O AGB
é uma simples, mas elegante técnica, cujo objetivo não é corrigir somente uma das
causas de desbalanceamento, mas permite que um algoritmo genético possa evoluir para
um subconjunto das instâncias da classe minoritária que venha a sanar todas as causas
existentes no problema em estudo, fornecendo melhores dados para o treinamento do
classificador. Outrossim, a motivação de um AG para sobreamostragem, ao invés de se
utilizar diretamente um AG para criar regras de decisão (vide seção 4.5), reside no fato
de ser possível escolher um algoritmo de classificação mais adequado para o conjunto
de dados.
No AGB, cada indivíduo é representado por um cromossomo contendo r regiões,
cada região contém um conjunto de n genes, sendo n a quantidade de atributos do
conjunto de treinamento T. Cada gene representa um limite mínimo e máximo de um
atributo. Conforme exemplificado nos gráficos das figuras 6.1.1 e 6.1.2, em um
problema desbalanceado de duas dimensões, são criadas r regiões, as quais são
preenchidas aleatoriamente com instâncias sintéticas.
O melhor indivíduo é aquele que possuir a melhor combinação de regiões e
instâncias sintéticas, de forma a obter o melhor balanceamento e por conseqüência o
melhor desempenho de classificação, o qual é calculado pela métrica AUC (9). A seguir,
apresenta-se a estrutura e operadores do algoritmo implementado.
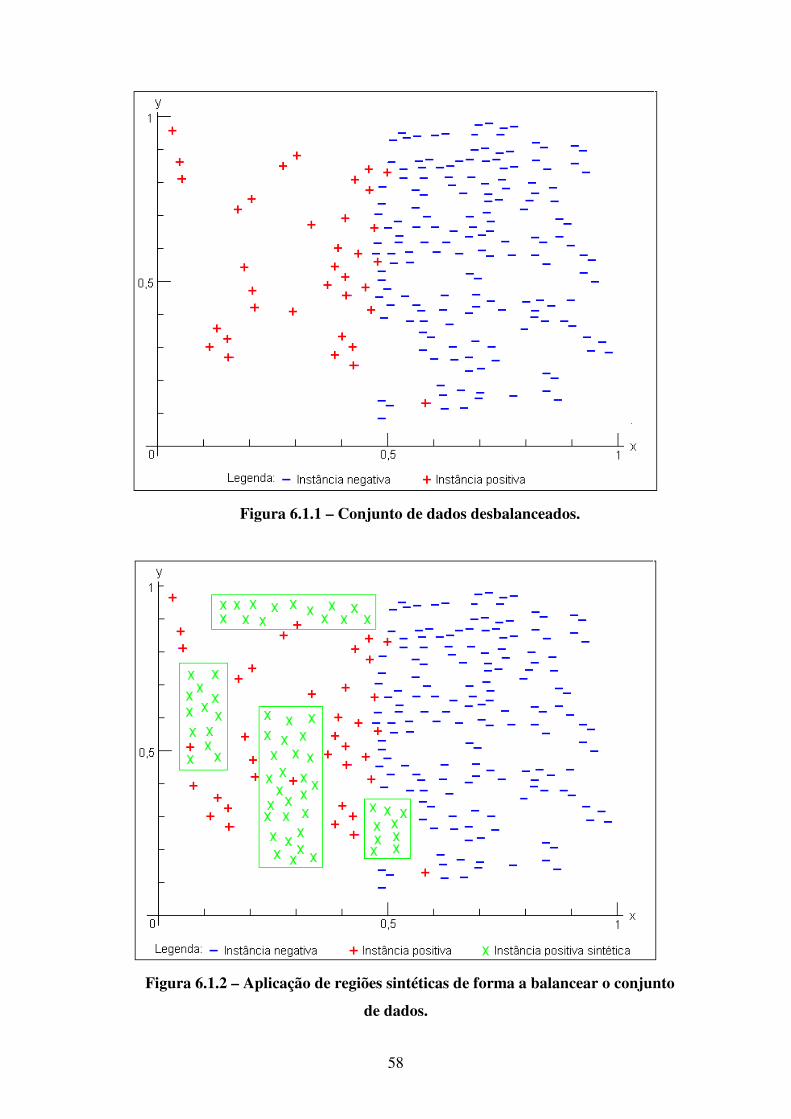
58
Figura 6.1.1 – Conjunto de dados desbalanceados.
Figura 6.1.2 – Aplicação de regiões sintéticas de forma a balancear o conjunto
de dados.

59
6.2 Codificação
O cromossomo C que codifica uma solução no AGB é composto de um conjunto
de t genes, sendo nrt *= , onde r é a quantidade de regiões, e n a quantidade de
atributos, sendo },...,1{},,...,1{)},(),...,({ njrcagagC nrjc === . Cada gene )( jc ag
está associado a uma região c, e a um atributo ja , e é composto de um valor mínimo e
máximo, compreendido entre os valores mínimos e máximos do atributo ja , no
subconjunto P de instâncias positivas (17).
ePagP jjcj ),max())(min()min( ≤≤
)max())(max()min( jjcj PagP ≤≤
(17)
Os cromossomos da população inicial serão inicializados aleatoriamente, dentro
dos valores mínimos e máximos dos atributos do conjunto de classes positivas P.
O problema exibido na figura 6.1.1 contém duas variáveis (x,y) do tipo numérico
contínuo. O cromossomo aplicado a esse problema possui r=4 regiões, cada uma com
n=2 genes, sendo o total de genes t=8, conforme demonstrado na tabela 6.2.1, onde cada
coluna x ou y representa um gene. Os limites mínimos e máximos de cada gene estão
assinalados em amarelo no gráfico da figura 6.2.2.
Tabela 6.2.1 – Codificação de uma solução com 4 regiões e dois atributos
numéricos contínuos.
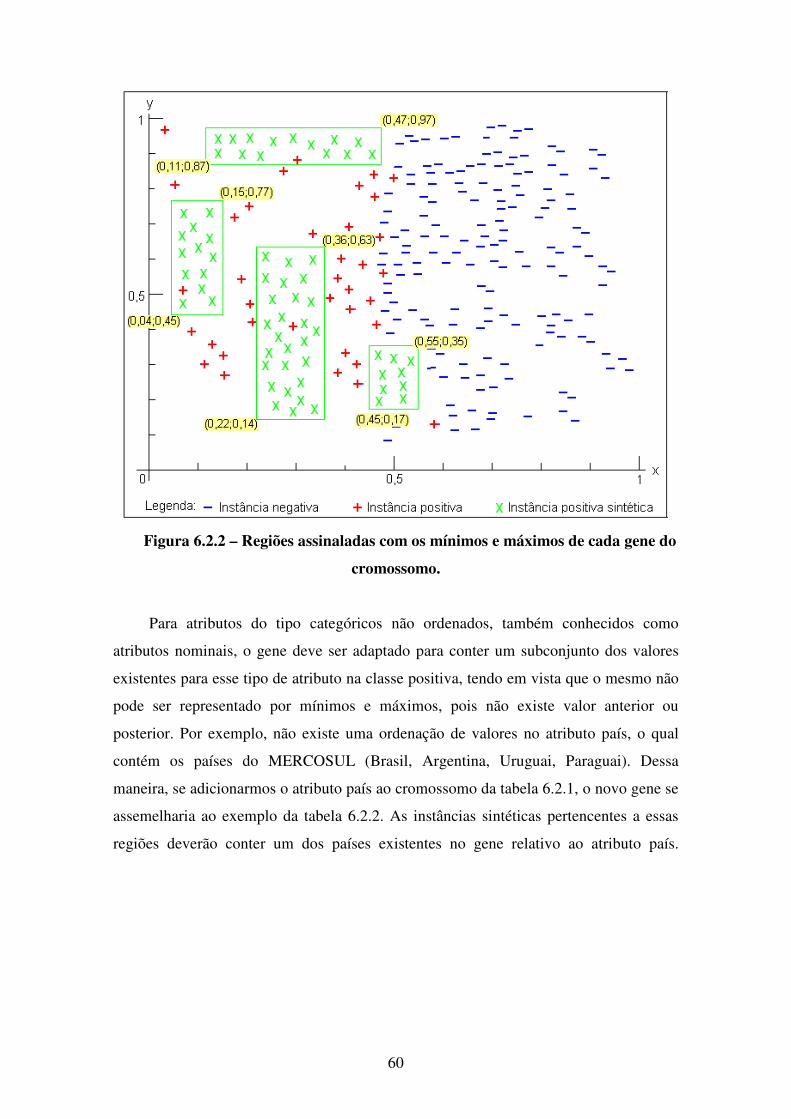
60
Figura 6.2.2 – Regiões assinaladas com os mínimos e máximos de cada gene do
cromossomo.
Para atributos do tipo categóricos não ordenados, também conhecidos como
atributos nominais, o gene deve ser adaptado para conter um subconjunto dos valores
existentes para esse tipo de atributo na classe positiva, tendo em vista que o mesmo não
pode ser representado por mínimos e máximos, pois não existe valor anterior ou
posterior. Por exemplo, não existe uma ordenação de valores no atributo país, o qual
contém os países do MERCOSUL (Brasil, Argentina, Uruguai, Paraguai). Dessa
maneira, se adicionarmos o atributo país ao cromossomo da tabela 6.2.1, o novo gene se
assemelharia ao exemplo da tabela 6.2.2. As instâncias sintéticas pertencentes a essas
regiões deverão conter um dos países existentes no gene relativo ao atributo país.

61
Tabela 6.2.2 – Codificação de um gene para um problema com um atributo do tipo
nominal (país).
Com as regiões definidas, deve-se preencher as mesmas com instâncias sintéticas,
sendo sugerido que o conjunto de instâncias da classe positiva P tenha a mesma
quantidade de instâncias do conjunto da classe negativa N, ou seja, NP ≅ . São
criadas 100
. Pbq = instâncias sintéticas, sendo b o percentual de sobreamostragem a ser
aplicado no conjunto de dados. As q instâncias sintéticas são criadas aleatoriamente
dentro dos limites de cada região, sendo a quantidade de instâncias distribuídas
proporcionalmente à área das mesmas.
Conforme os experimentos iniciais, a criação de instâncias aleatórias que
convergem para uma solução ótima ou próxima do ótimo tendem a criar instâncias
sintéticas semelhantes às instâncias originais e às outras instâncias sintéticas, levando-se
em conta que essa conformação acarreta melhor aptidão dos indivíduos, que é baseada
no desempenho dos classificadores. Todavia, esse desempenho não é verdadeiro, pois o
modelo criado não consegue generalizar com novos dados, o que é chamado
sobreajustamento, ou em inglês, overfitting.
A solução proposta para este problema consiste em, dado o conjunto de instâncias
sintéticas qissS qi ,...,1},,...,{ == , uma instância sintética is , para ser válida, deve
manter uma distância dos seus k=5 vizinhos mais próximos maior ou igual à distância
mínima dm, conforme demonstrado na figura 6.2.3. As instâncias sintéticas não válidas
são descartadas, e outra instância sintética é criada, por v=7 tentativas, até que se
obtenha uma instância válida.
A distância mínima dm consiste na média da distância dos k vizinhos mais
próximos de cada instância ix , pertencente ao conjunto de instâncias positivas P (18),
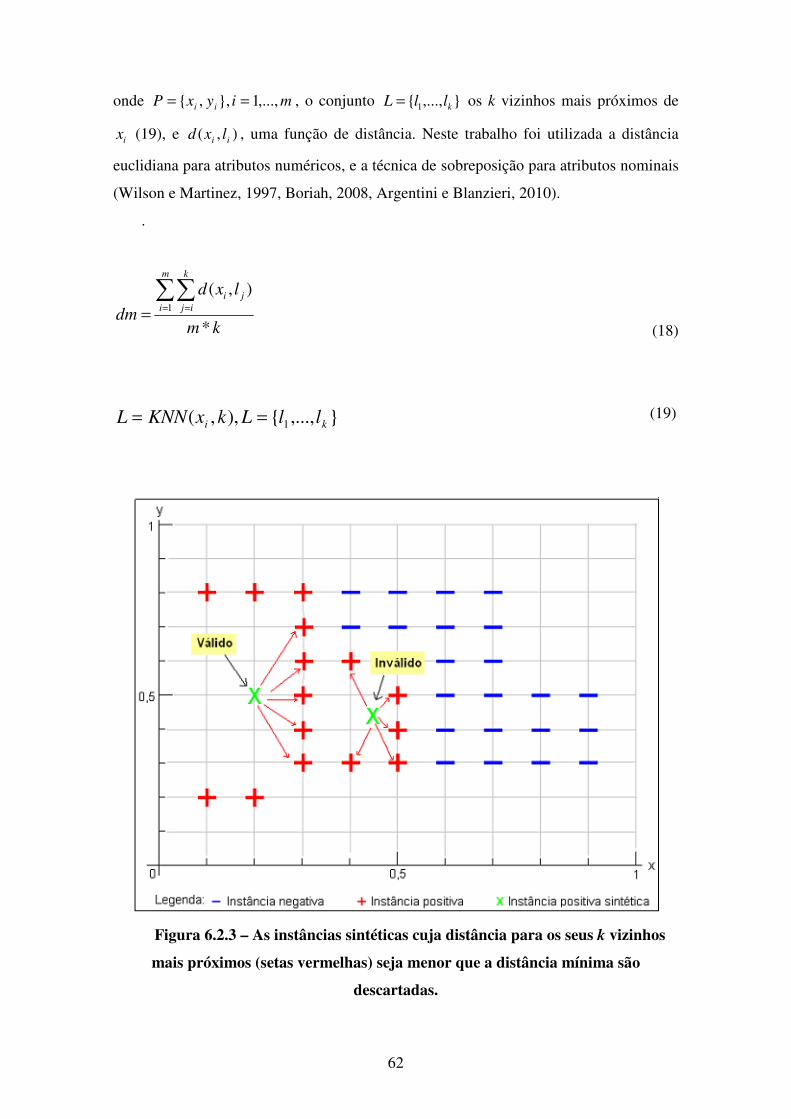
62
onde miyxP ii ,...,1},,{ == , o conjunto },...,{ 1 kllL = os k vizinhos mais próximos de
ix (19), e ),( ii lxd , uma função de distância. Neste trabalho foi utilizada a distância
euclidiana para atributos numéricos, e a técnica de sobreposição para atributos nominais
(Wilson e Martinez, 1997, Boriah, 2008, Argentini e Blanzieri, 2010).
.
km
lxd
dm
m
i
j
k
ij
i
*
),(1∑∑
= ==
(18)
},...,{),,( 1 ki llLkxKNNL == (19)
Figura 6.2.3 – As instâncias sintéticas cuja distância para os seus k vizinhos
mais próximos (setas vermelhas) seja menor que a distância mínima são
descartadas.

63
Ao contrário do algoritmo SMOTE, que efetua o balanceamento do conjunto de
dados sem levar em conta que alguma instância pode ser duplicada, esta solução não
permite instâncias duplicadas ou similares às instâncias já existentes. Com esta solução
também se evita a sobreposição de regiões, o que em ambos os casos traria um
problema de overfitting ao processo de treinamento.
Como pôde ser visto no capítulo 4 com os algoritmos Bordeline SMOTE (Han el
al., 2005) e ADASYN (He et al., 2008), existe uma preocupação no processo de
orientação e ajuste do balanceamento do conjunto de dados, o qual consiste em não se
criar instâncias sintéticas próximas à superfície de decisão, de forma a não se criar
ruídos no treinamento. No caso do AGB, optou-se por deixar que o próprio processo
evolutivo decida onde alocar as instâncias sintéticas, tendo em vista que as piores
alocações podem levar a um pior resultado de AUC. O indicador DANGER, proposto
por (Han et al., 2005), for aplicado ao algoritmo AGB, e permite identificar se as regiões
evoluídas fazem parte da superfície de decisão.
Em um trabalho anterior (Beckmann et al., 2009), cada gene do cromossomo
representava uma instância sintética. No AGB, os experimentos demonstraram que a
utilização de regiões para a codificação torna o AG mais escalável, e menos sensível a
conjuntos de dados com maior número de instâncias e maior nível de
desbalanceamento, pois o cromossomo não irá crescer de acordo com o número de
instâncias que devem ser criadas para balancear o conjunto.
6.3 Operador de Cruzamento
A seleção de indivíduos para cruzamento é feita por roda da roleta (Goldberg,
1989). Optou-se pelo cruzamento múltiplo com dois pontos de corte escolhidos
aleatoriamente por região, com geração de dois indivíduos por operação, conforme
exemplificado na figura 6.3.1, onde cada cromossomo apresenta 2 regiões e 4 atributos.
Para cada novo indivíduo, um novo conjunto de instâncias sintéticas é inserido
dentro dos limites das regiões recém criadas. Com isso é possível evoluir o tamanho e

64
posicionamento das regiões, de forma a prover as instâncias sintéticas que agreguem
ganho de informação à classe minoritária do conjunto de dados.
Não é possível cruzar separadamente os mínimos e máximos entre indivíduos, o
intercâmbio de informações ocorre em nível de genes. Também foram tentadas outras
quantidades de pontos de corte por região, sendo a quantidade de 02 pontos a que
apresentou melhores resultados.
Figura 6.3.1 – Operador de cruzamento múltiplo, com dois pontos de corte por
região.
6.4 Mutação
O operador de mutação seleciona por sorteio alguns genes a serem substituídos
aleatoriamente, de forma a trazer diversidade à população. Para o AGB foi utilizada a
mesma estratégia de mutação demonstrada na seção 5.2.9.
6.5 Função Aptidão
A função de aptidão f do AGB consiste na métrica AUC (9), onde para todo
indivíduo é efetuado um processo de treinamento e teste, onde se junta ao conjunto de
treinamento T as instâncias sintéticas positivas S criadas dentro dos limites das regiões

65
(20), contidas no cromossomo do indivíduo. Ao final do processo de treinamento e
teste, o qual pode ser feito com qualquer algoritmo de classificação presente no
aplicativo de mineração de dados Weka (Witten e Frank, 2005), se obtém a aptidão f do
balanceamento obtido com as instâncias sintéticas do indivíduo.
)( STAUCf ∪= (20)
Conforme verificado nos experimentos do AGB, e também relatado por
(Michalewicz, 1996, Freitas, 2003), os algoritmos genéticos aplicados à classificação
são métodos que demandam mais tempo que outras heurísticas, pois para cada indivíduo
da população, um processo de treinamento e teste deve ser executado, sendo a fase de
treinamento a que mais consome tempo.
De acordo com o que foi detalhado na seção 2.3, e confirmado nos experimentos
da seção 7.4.5, a aplicação de um algoritmo de classificação incremental pode diminuir
o tempo de processamento do AGB, pois o conjunto de treinamento T original é
treinado somente uma vez, e as instâncias sintéticas de cada indivíduo adicionadas e
treinadas a uma cópia do modelo preditivo treinado inicialmente.
A utilização do aprendizado incremental no AGB só é possível com a seleção de
um dos algoritmos listados na tabela 6.5.1. Ao selecionar um algoritmo incremental, o
processo de seleção utilizado será a partição do conjunto de dados para treino e teste.
Para outros algoritmos não incrementais, o processo utilizado será a validação cruzada,
com 10 desdobramentos.
Vale ressaltar que, apesar do AGB demandar maior tempo para o balanceamento
do conjunto de dados em relação a outras estratégias de pré-processamento, depois do
conjunto balanceado, o processo de treinamento e teste fica restrito ao tempo de
processamento do algoritmo de classificação escolhido. Cabe ainda lembrar que a
sobreamostragem obtida serve apenas para a criação do modelo durante o processo de
treinamento, e que durante a avaliação do modelo todas as instâncias sintéticas são
removidas.

66
Nome do Algoritmo
AODE
DMNBText
IB1, IBk
KStar
LWL
NaiveBayesMultinomialUpdateable
NayveBayesUpdateable
NNge
RacedIncrementalLogitBoost
Winnow
Tabela 6.5.1 – Algoritmos de classificação incremental existentes no Weka 3.6.
6.6 Implementação
De forma a distribuir o algoritmo desenvolvido neste trabalho, e facilitar a
reprodução dos experimentos por outros pesquisadores, o AGB foi implementado como
um plugin para pré-processamento no aplicativo de mineração de dados Weka (Witten e
Frank, 2005). O aplicativo Weka foi desenvolvido na linguagem Java (Gosling el al.,
2000), e provê componentes orientados a objeto de código aberto, como estrutura de
dados, avaliadores de métricas e distâncias, menus e telas.
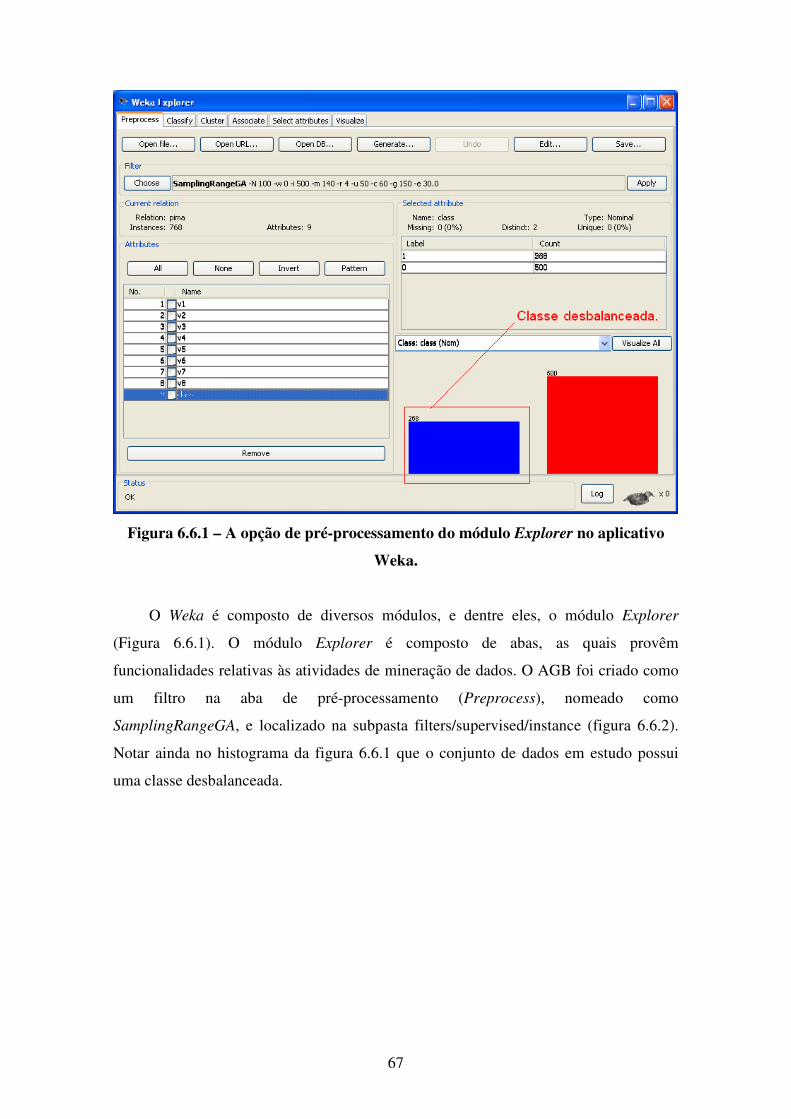
67
Figura 6.6.1 – A opção de pré-processamento do módulo Explorer no aplicativo
Weka.
O Weka é composto de diversos módulos, e dentre eles, o módulo Explorer
(Figura 6.6.1). O módulo Explorer é composto de abas, as quais provêm
funcionalidades relativas às atividades de mineração de dados. O AGB foi criado como
um filtro na aba de pré-processamento (Preprocess), nomeado como
SamplingRangeGA, e localizado na subpasta filters/supervised/instance (figura 6.6.2).
Notar ainda no histograma da figura 6.6.1 que o conjunto de dados em estudo possui
uma classe desbalanceada.
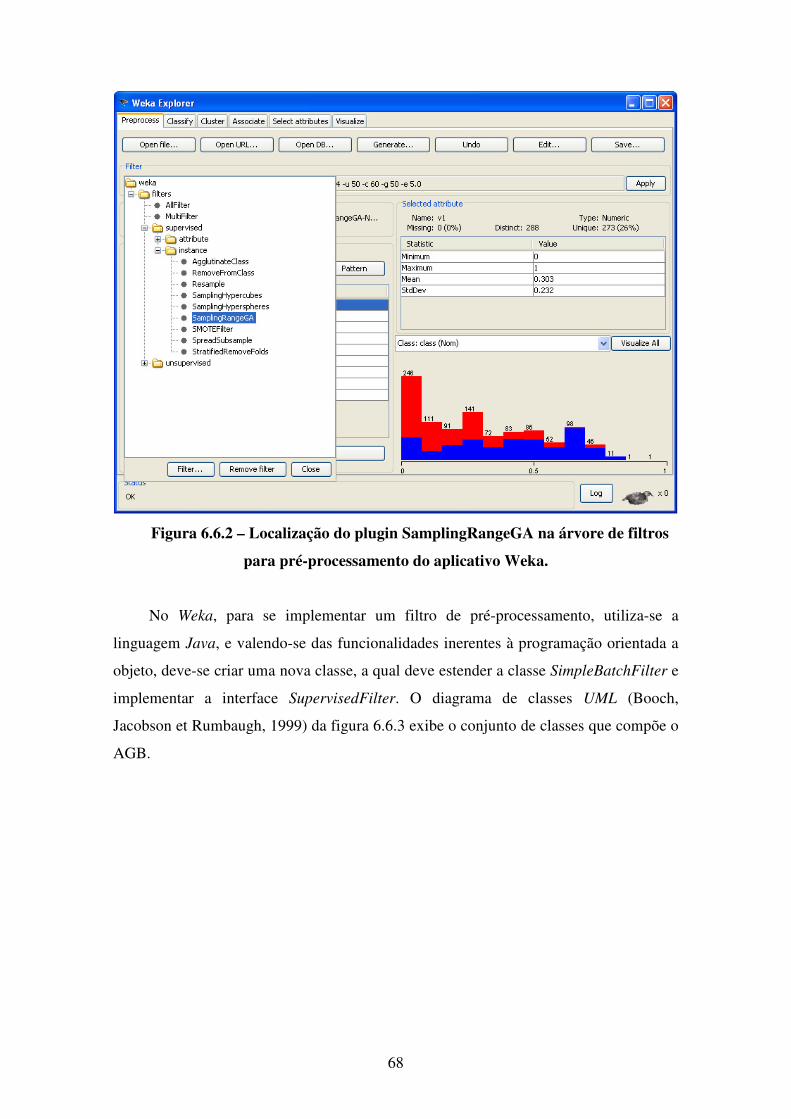
68
Figura 6.6.2 – Localização do plugin SamplingRangeGA na árvore de filtros
para pré-processamento do aplicativo Weka.
No Weka, para se implementar um filtro de pré-processamento, utiliza-se a
linguagem Java, e valendo-se das funcionalidades inerentes à programação orientada a
objeto, deve-se criar uma nova classe, a qual deve estender a classe SimpleBatchFilter e
implementar a interface SupervisedFilter. O diagrama de classes UML (Booch,
Jacobson et Rumbaugh, 1999) da figura 6.6.3 exibe o conjunto de classes que compõe o
AGB.
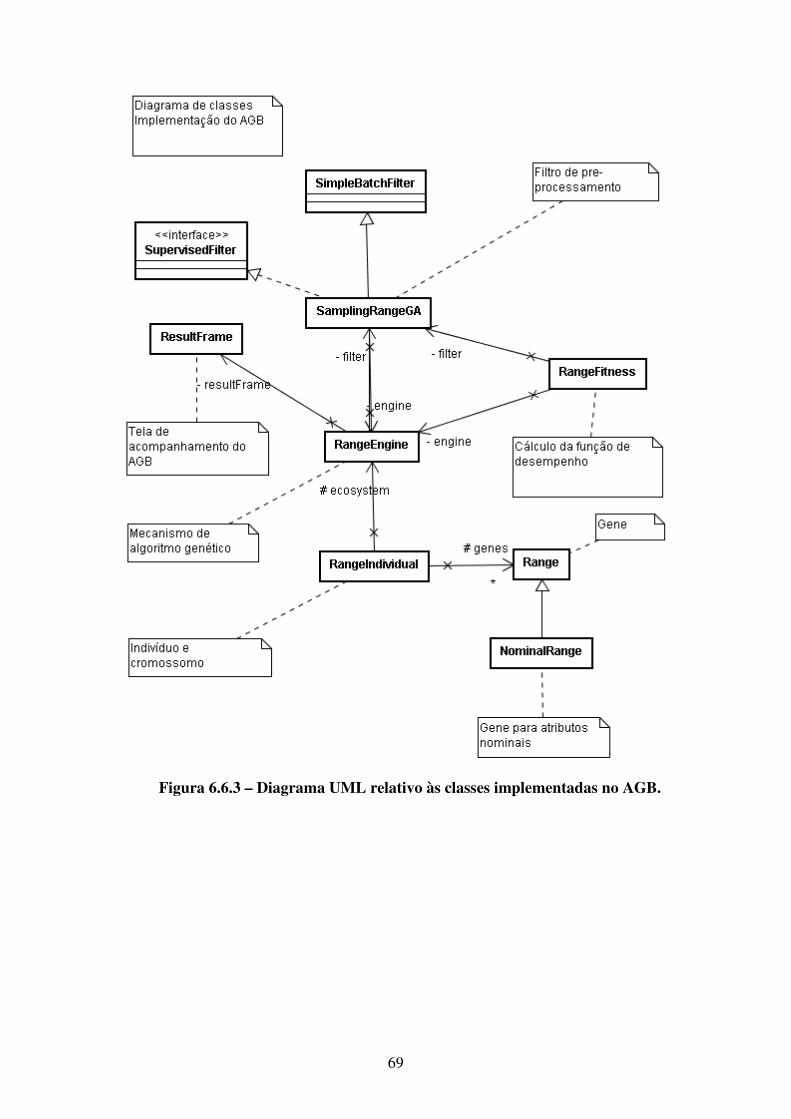
69
Figura 6.6.3 – Diagrama UML relativo às classes implementadas no AGB.
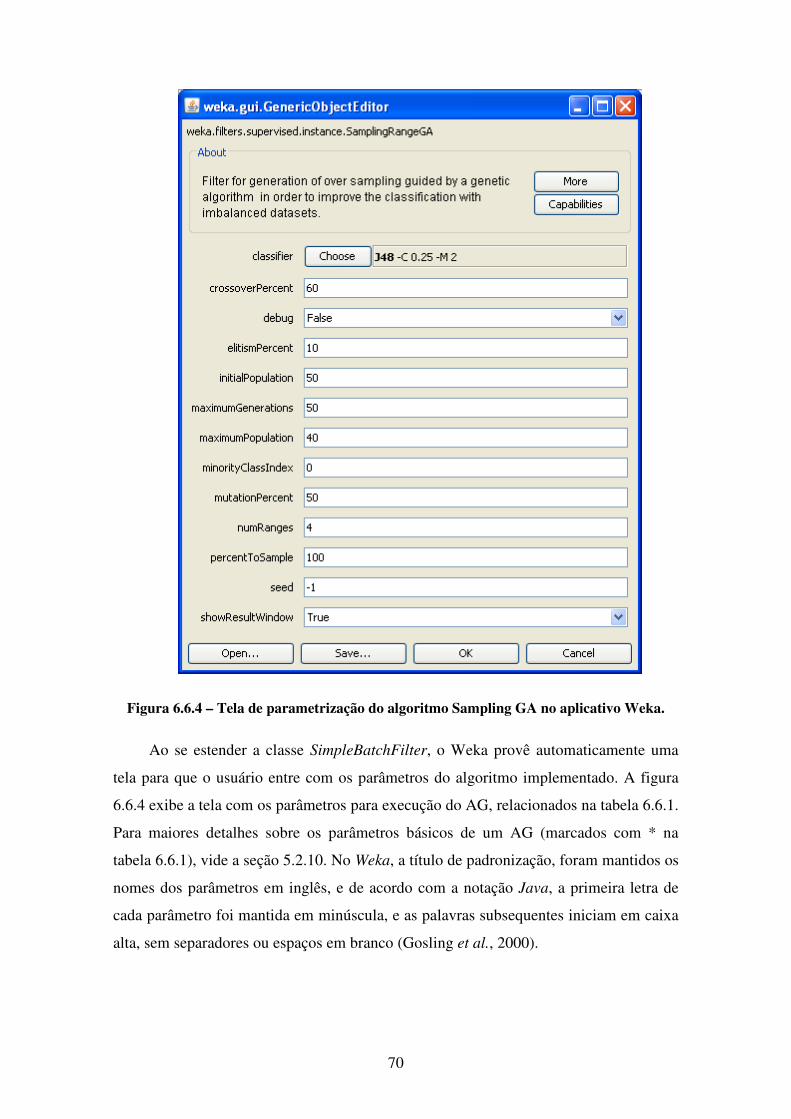
70
Figura 6.6.4 – Tela de parametrização do algoritmo Sampling GA no aplicativo Weka.
Ao se estender a classe SimpleBatchFilter, o Weka provê automaticamente uma
tela para que o usuário entre com os parâmetros do algoritmo implementado. A figura
6.6.4 exibe a tela com os parâmetros para execução do AG, relacionados na tabela 6.6.1.
Para maiores detalhes sobre os parâmetros básicos de um AG (marcados com * na
tabela 6.6.1), vide a seção 5.2.10. No Weka, a título de padronização, foram mantidos os
nomes dos parâmetros em inglês, e de acordo com a notação Java, a primeira letra de
cada parâmetro foi mantida em minúscula, e as palavras subsequentes iniciam em caixa
alta, sem separadores ou espaços em branco (Gosling et al., 2000).

71
Tabela 6.6.1 – Parâmetros do AGB.
Parâmetro Descrição Parâmetro no Weka
Classificador Classificador que irá avaliar os indivíduos.
classifier
* Percentual de cruzamento
Percentual da população que compartilhará a sua codificação com o
operador de cruzamento.
crossoverPercent
Mostrar processamento
interno
Exibe informações internas do algoritmo no console Java.
debug
* Percentual de elitismo
Percentual dos melhores indivíduos da população anterior que será mantido
para a próxima população.
elitismPercent
* População inicial Quantidade de indivíduos que serão criados no início de execução do
algoritmo.
initialPopulation
* Número máximo de gerações
Quantidade de ciclos que o algoritmo irá funcionar.
maximumGenerations
* População máxima Quantidade de indivíduos que permanecerão na população ao final de
cada geração.
maximumPopulation
Índice da classe minoritária
Número inteiro iniciado por 0, indicando qual classe do conjunto de
dados é a classe minoritária.
minorityClassIndex
* Percentual de mutação
Percentual de indivíduos da população os quais sofrerão mutação em seus
genes.
mutationPercent
Número de regiões Número de regiões que serão criadas e evoluídas no algoritmo.
numRanges
Percentual de sobreamostragem
Percentual de instâncias sintéticas que serão criadas e adicionadas ao conjunto
de instâncias positivas.
percentToSample
Semente aleatória Número que irá alimentar o gerador de números pseudo-aleatórios do algoritmo
genético. Deixar -1 para utilizar o número de milisegundos do sistema.
seed
Mostrar janela de resultados
Se verdadeiro, exibe uma janela adicional com detalhes da evolução do
algoritmo (figuras 6.8.3 e 6.8.4).
showResultWindow

72
Figura 6.6.5 – Tela para acompanhamento da evolução do algoritmo AGB.
A figura 6.6.5 mostra a tela para acompanhamento da evolução do algoritmo, onde
o painel do lado esquerdo mostra os detalhes como o conjunto de dados que se está
processando, os parâmetros do algoritmo, melhor e pior indivíduo, e detalhes dos 10
melhores indivíduos na população, conforme detalhado na figura 6.6.6. O painel
superior do lado direito contém um gráfico de projeção de pontos em três dimensões, os
botões na parte inferior permitem intercambiar 3 variáveis do conjunto de dados para
visualização em 3 dimensões. Os pontos azuis são as instâncias da classe negativa, em
amarelo são as instâncias da classe positiva e em lilás são as instâncias positivas
sintéticas criadas pela evolução do algoritmo dentro de regiões. O painel inferior direito
contém a evolução do pior e melhor indivíduo ao longo das gerações.
Relation Name: pima
Num Instances: 768
Average euclidean distance:0,2636 (0,0925)
-N 100 -w 0 -i 50 -m 40 -r 4 -u 25 -c 70 -g 50 -e 5
Generation #50

73
Best individual:
49 0,8096 in 1013797 ms
Worst individual:
49 0,6975
# generation fitnesses
-- ---------- ----------
1 49 AUC:0,8096 Precision:0,6790 Recall:0,6157 F-Measure:0,6458 G-
Mean:0,7209 %DANGER:0.0
2 45 AUC:0,8092 Precision:0,7118 Recall:0,6082 F-Measure:0,6559 G-
Mean:0,7266 %DANGER:0.0
3 44 AUC:0,8091 Precision:0,6667 Recall:0,6418 F-Measure:0,6540 G-
Mean:0,7290 %DANGER:0.0
4 49 AUC:0,7988 Precision:0,6951 Recall:0,5784 F-Measure:0,6314 G-
Mean:0,7069 %DANGER:0.0
5 49 AUC:0,7936 Precision:0,6667 Recall:0,6119 F-Measure:0,6381 G-
Mean:0,7152 %DANGER:0.0
6 49 AUC:0,7816 Precision:0,6418 Recall:0,6418 F-Measure:0,6418 G-
Mean:0,7201 %DANGER:0.0
7 49 AUC:0,7807 Precision:0,6602 Recall:0,6306 F-Measure:0,6450 G-
Mean:0,7217 %DANGER:0.0
8 49 AUC:0,7774 Precision:0,6840 Recall:0,5896 F-Measure:0,6333 G-
Mean:0,7096 %DANGER:0.0
9 49 AUC:0,7768 Precision:0,6371 Recall:0,6157 F-Measure:0,6262 G-
Mean:0,7071 %DANGER:0.0
10 49 AUC:0,7702 Precision:0,6184 Recall:0,6530 F-Measure:0,6352 G-
Mean:0,7155 %DANGER:0.0
Figura 6.6.6 – Detalhes da evolução do algoritmo contido no painel esquerdo da tela de
acompanhamento do AGB.
A figura 6.6.6 mostra os detalhes do painel esquerdo na tela de acompanhamento
do algoritmo, onde pode ser vista a evolução do AGB. Para os 10 melhores indivíduos
da população são exibidas a posição de desempenho, a geração em que o mesmo foi
criado, os valores das métricas AUC, Precisão, Recall, F-Measure e G-Mean, e a
métrica DANGER (Han et al., 2005), aplicada às regiões evoluídas pelo algoritmo.
O objetivo final do AGB é efetuar um pré-processamento no conjunto de dados,
de forma a balancear a quantidade de instâncias entre classes, preparando o conjunto de
dados para o algoritmo de classificação. Isso é alcançado após o AGB ter atingido o
critério de parada, seja pelo número de gerações, ou pelo valor ótimo de AUC, isto é,
100. Após a parada do AGB, o filtro automaticamente seleciona o melhor indivíduo, e
aplica as suas instâncias sintéticas ao conjunto de dados original. Conforme assinalado

74
na figura 6.6.7, o histograma da classe positiva agora tem a quantidade aproximada de
instâncias, em relação à classe negativa.
Figura 6.6.7 – Histograma da classe positiva balanceada após o processamento do
AGB.
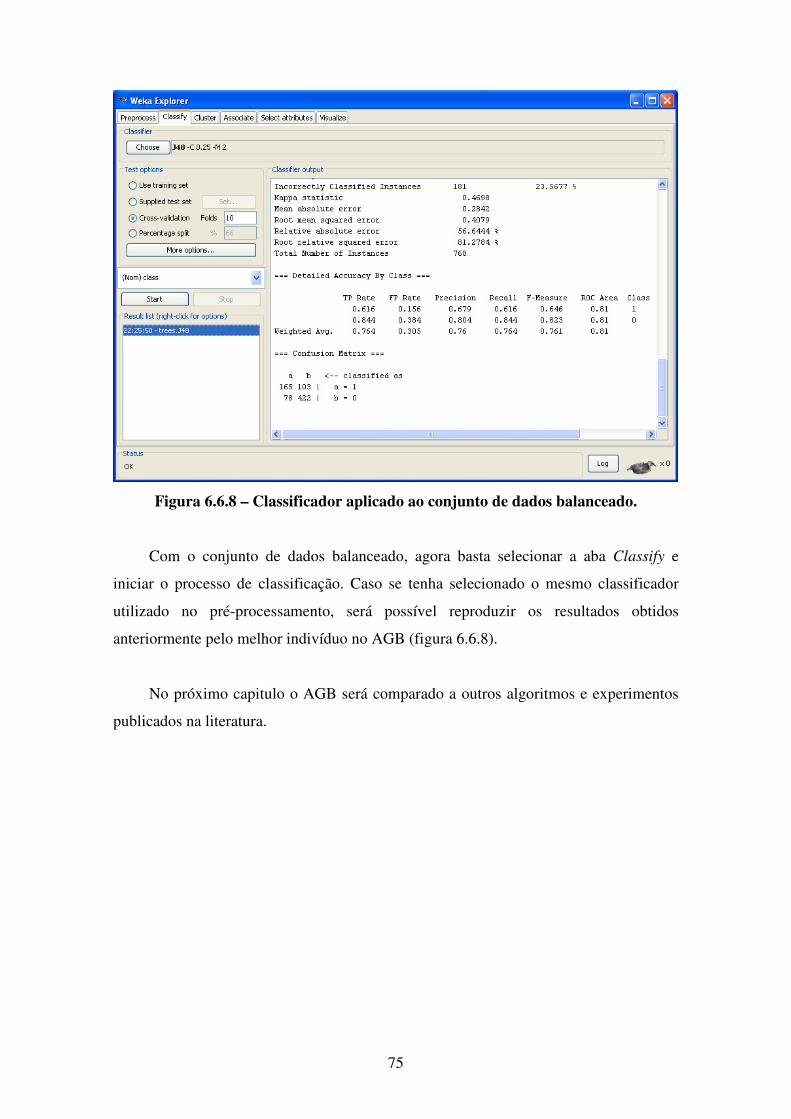
75
Figura 6.6.8 – Classificador aplicado ao conjunto de dados balanceado.
Com o conjunto de dados balanceado, agora basta selecionar a aba Classify e
iniciar o processo de classificação. Caso se tenha selecionado o mesmo classificador
utilizado no pré-processamento, será possível reproduzir os resultados obtidos
anteriormente pelo melhor indivíduo no AGB (figura 6.6.8).
No próximo capitulo o AGB será comparado a outros algoritmos e experimentos
publicados na literatura.

76
Capítulo 7
Experimentos e Resultados
Neste capítulo serão demonstrados e discutidos os experimentos e resultados
obtidos com o AGB.
7.1 Introdução
Com o objetivo de comprovar a aplicabilidade do AGB, neste capítulo serão
demonstrados e comparados os resultados, em termos de AUC, Precision, F-Measure,
Recall e G-Mean, obtidos pelos classificadores C4.5 e Naive Bayes Updateable, após o
balanceamento do conjunto de dados efetuado com o AGB.
Os resultados do AGB em conjunto com o algoritmo C4.5 (Quinlan, 1988) foram
comparados com os resultados dos métodos de sobreamostragem orientada publicados
em (Batista e Monard, 2004) e com os resultados obtidos com os algoritmos Borderline-
SMOTE (Han et al., 2005), e ADASYN (He et al., 2008). Foi utilizado o indicador
DANGER, proposto por (Han el al., 2005), de forma a identificar se as instâncias
sintéticas foram criadas próximas à superfície de decisão.
Também foram efetuados experimentos com aprendizado incremental aplicado a
algoritmos genéticos, onde o AGB, em conjunto com o classificador Naive Bayes
Updateable (George e Pat, 1995) foram comparados com os resultados obtidos pelos
classificadores Naive Bayes, e SMOTE (Chawla et al., 2002) e AdaBoost (Schapire et

77
al., 1999) combinados com o Naive Bayes, todos estes implementados no aplicativo de
mineração de dados Weka versão 3.6 (Witten e Frank, 2005).
7.2 Conjuntos de dados
Para a execução dos experimentos foram utilizadas 16 bases de dados
provenientes do UCI machine learning repository (Blake e Merz, 1998), a partir dos
quais foram preparados dezoito conjuntos de dados onde uma classe foi selecionada, e
as restantes aglutinadas em uma só classe, conforme utilizado nos experimentos de
(Batista e Monard, 2004, He et al., 2008, Han et al., 2005). Dessa maneira é possível
experimentar o AGB em diversas condições, como por exemplo, níveis de
balanceamento diferenciados, sobreposição entre classes, quantidade de instâncias e
tipos de atributos.
A Tabela 7.2.1 demonstra as bases de dados preparadas e ordenadas pela taxa de
desbalanceamento, Imbalance Rate (IR) (Orriols-Puig el al., 2009), que é a razão entre a
quantidade de instâncias negativas e positivas. Também foi adicionado à essa tabela a
distância média (DM), que consiste na distância euclidiana média dos k vizinhos de
todas as instâncias do conjunto S de instâncias positivas, conforme foi descrito no
capítulo 6, sendo o valor entre parênteses o desvio padrão. Todos os conjuntos de dados
tiveram os seus valores numéricos normalizados entre 0 e 1.
Cabe aqui uma ressalva, pois de acordo com (He e Garcia, 2009), apesar da
iniciativa para prover conjuntos de dados pelo UCI machine learning repository (Blake
e Merz, 1998), entre outros, não existe um repositório de dados padronizado para
problemas desbalanceados. Este fato acarreta retrabalho na preparação do conjunto de
dados, e impossibilita uma comparação unificada das pesquisas e inovações nesta área.
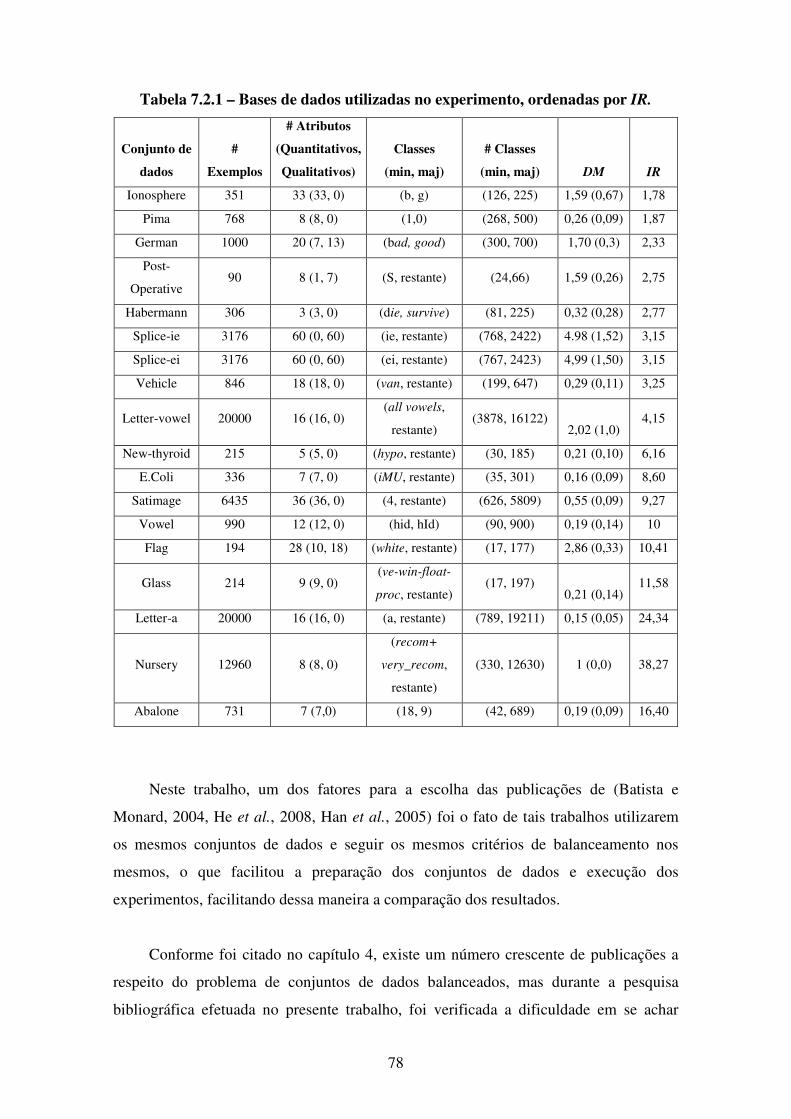
78
Tabela 7.2.1 – Bases de dados utilizadas no experimento, ordenadas por IR.
Conjunto de
dados
#
Exemplos
# Atributos
(Quantitativos,
Qualitativos)
Classes
(min, maj)
# Classes
(min, maj)
DM IR
Ionosphere 351 33 (33, 0) (b, g) (126, 225) 1,59 (0,67) 1,78
Pima 768 8 (8, 0) (1,0) (268, 500) 0,26 (0,09) 1,87
German 1000 20 (7, 13) (bad, good) (300, 700) 1,70 (0,3) 2,33
Post-
Operative 90 8 (1, 7) (S, restante) (24,66) 1,59 (0,26) 2,75
Habermann 306 3 (3, 0) (die, survive) (81, 225) 0,32 (0,28) 2,77
Splice-ie 3176 60 (0, 60) (ie, restante) (768, 2422) 4.98 (1,52) 3,15
Splice-ei 3176 60 (0, 60) (ei, restante) (767, 2423) 4,99 (1,50) 3,15
Vehicle 846 18 (18, 0) (van, restante) (199, 647) 0,29 (0,11) 3,25
Letter-vowel 20000 16 (16, 0) (all vowels,
restante) (3878, 16122)
2,02 (1,0) 4,15
New-thyroid 215 5 (5, 0) (hypo, restante) (30, 185) 0,21 (0,10) 6,16
E.Coli 336 7 (7, 0) (iMU, restante) (35, 301) 0,16 (0,09) 8,60
Satimage 6435 36 (36, 0) (4, restante) (626, 5809) 0,55 (0,09) 9,27
Vowel 990 12 (12, 0) (hid, hId) (90, 900) 0,19 (0,14) 10
Flag 194 28 (10, 18) (white, restante) (17, 177) 2,86 (0,33) 10,41
Glass 214 9 (9, 0) (ve-win-float-
proc, restante) (17, 197)
0,21 (0,14) 11,58
Letter-a 20000 16 (16, 0) (a, restante) (789, 19211) 0,15 (0,05) 24,34
Nursery 12960 8 (8, 0)
(recom+
very_recom,
restante)
(330, 12630) 1 (0,0) 38,27
Abalone 731 7 (7,0) (18, 9) (42, 689) 0,19 (0,09) 16,40
Neste trabalho, um dos fatores para a escolha das publicações de (Batista e
Monard, 2004, He et al., 2008, Han et al., 2005) foi o fato de tais trabalhos utilizarem
os mesmos conjuntos de dados e seguir os mesmos critérios de balanceamento nos
mesmos, o que facilitou a preparação dos conjuntos de dados e execução dos
experimentos, facilitando dessa maneira a comparação dos resultados.
Conforme foi citado no capítulo 4, existe um número crescente de publicações a
respeito do problema de conjuntos de dados balanceados, mas durante a pesquisa
bibliográfica efetuada no presente trabalho, foi verificada a dificuldade em se achar

79
publicações que compartilhem os mesmos conjuntos de dados e configurações de
desbalanceamento. Tal fato impediu que outros algoritmos fossem comparados neste
trabalho, e atestam o que foi constatado por (He e Garcia, 2009).
7.3 Parâmetros do Algoritmo
Em todos os experimentos, foram aplicados para o AGB os parâmetros exibidos
na tabela 7.3.1. O tempo corrente em milissegundos foi utilizado para se iniciar o
gerador de números aleatórios do AGB.
Tabela 7.3.1 – Parâmetros utilizados no AGB.
Parâmetro Parâmetro no Weka
Percentual de cruzamento 60
Percentual de elitismo 5
População inicial 50
Número máximo de gerações 50
População máxima 40
Percentual de mutação 25
Número de regiões 4
Percentual de sobreamostragem 100).int(IRb =
Para o percentual de sobreamostragem b aplicado em cada conjunto de dados, o
mesmo deverá ser o suficiente para que cada um tenha uma distribuição aproximada de
50% de instâncias para cada classe, ou seja, NP ≅ . Dessa forma, optou-se por utilizar
a parte inteira da taxa de desbalanceamento (IR), conforme demonstrado na tabela 7.2.1,
sendo 100).int(IRb = . Vale novamente ressaltar que a sobreamostragem obtida serve
apenas para a criação do modelo durante o processo de treinamento, e que durante a
avaliação do modelo todas as instâncias sintéticas são removidas.
Para o percentual de mutação, muitos autores defendem que este valor não pode
ultrapassar 5% sob o risco de perda de material genético. Todavia, nos experimentos
preliminares não foram obtidos resultados satisfatórios com um baixo percentual de

80
mutação, optando-se dessa maneira a utilização de 25% de mutação, conforme os
benefícios citados por (Tate e Smith, 1993). A utilização de 4 regiões apresentou melhor
desempenho de classificação e estabilidade nos experimentos efetuados.
7.4 Execução dos Experimentos e Comparação
Nesta seção, serão demonstrados e discutidos quatro experimentos efetuados com
o AGB.
7.4.1 Comparação com Diversos Métodos de
Sobreamostragem
Neste experimento, os resultados do AGB foram comparados com os métodos de
sobreamostragem orientada publicados em (Batista e Monard, 2004). Como o foco deste
trabalho consiste em métodos de sobreamostragem orientada, os resultados obtidos com
sobreamostragem aleatória não serão comparados aqui.
Em (Batista e Monard, 2004) os autores efetuaram a comparação de diversos
métodos de amostragem aplicados em quinze conjuntos de dados desbalanceados, e
concluíram que a sobreamostragem apresentou melhor desempenho que a
subamostragem, em especial o método SMOTE combinado com Tomek Links, e SMOTE
combinado com ENN. Também se verificou que os métodos de amostragem aleatória
apresentaram resultados significantes, mas os autores recomendam que tais métodos
sejam aplicados em conjuntos de dados com maior número de exemplos, e por
conseqüência, com maior número de instâncias positivas.
Para a execução deste experimento com o AGB, os quinze conjuntos de dados
utilizados em (Batista e Monard, 2004), foram submetidos ao processo de
balanceamento com o algoritmo AGB, e em seguida classificados com o algoritmo
C4.5. Cada execução consiste em um processo de validação cruzada, com dez
desdobramentos, sendo obtida a média para a métrica AUC desses desdobramentos. De
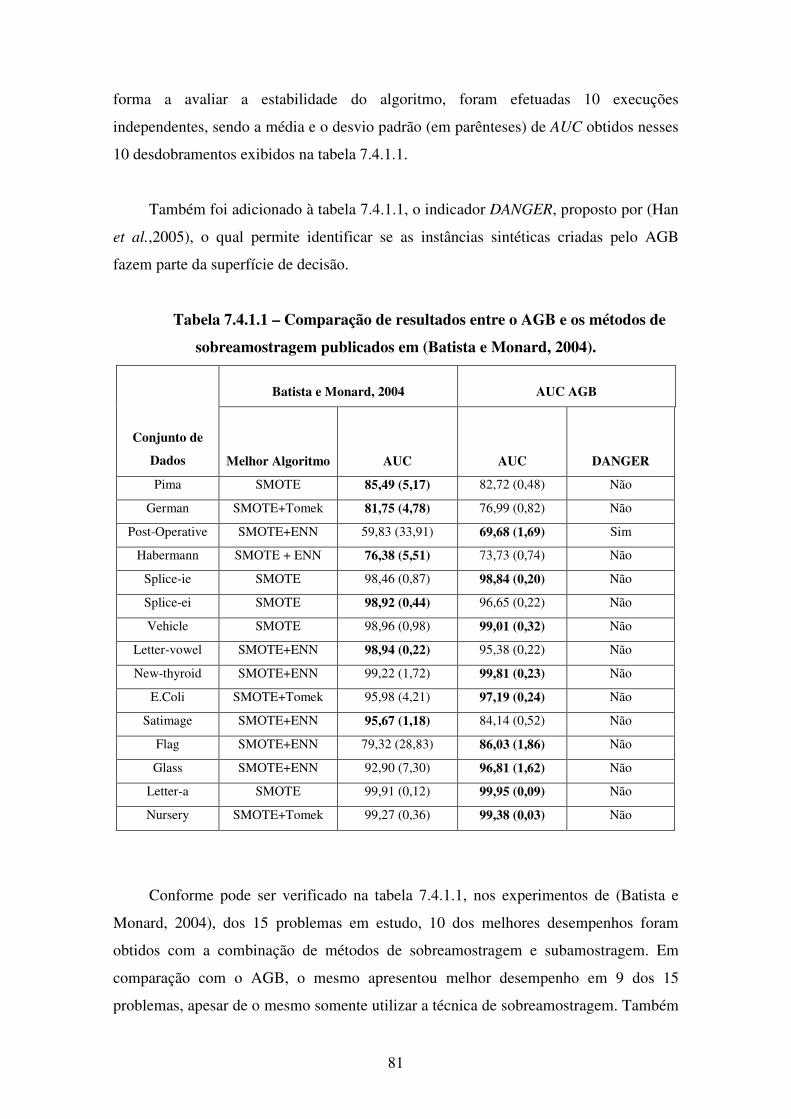
81
forma a avaliar a estabilidade do algoritmo, foram efetuadas 10 execuções
independentes, sendo a média e o desvio padrão (em parênteses) de AUC obtidos nesses
10 desdobramentos exibidos na tabela 7.4.1.1.
Também foi adicionado à tabela 7.4.1.1, o indicador DANGER, proposto por (Han
et al.,2005), o qual permite identificar se as instâncias sintéticas criadas pelo AGB
fazem parte da superfície de decisão.
Tabela 7.4.1.1 – Comparação de resultados entre o AGB e os métodos de
sobreamostragem publicados em (Batista e Monard, 2004).
Batista e Monard, 2004 AUC AGB
Conjunto de
Dados
Melhor Algoritmo
AUC
AUC DANGER
Pima SMOTE 85,49 (5,17) 82,72 (0,48) Não
German SMOTE+Tomek 81,75 (4,78) 76,99 (0,82) Não
Post-Operative SMOTE+ENN 59,83 (33,91) 69,68 (1,69) Sim
Habermann SMOTE + ENN 76,38 (5,51) 73,73 (0,74) Não
Splice-ie SMOTE 98,46 (0,87) 98,84 (0,20) Não
Splice-ei SMOTE 98,92 (0,44) 96,65 (0,22) Não
Vehicle SMOTE 98,96 (0,98) 99,01 (0,32) Não
Letter-vowel SMOTE+ENN 98,94 (0,22) 95,38 (0,22) Não
New-thyroid SMOTE+ENN 99,22 (1,72) 99,81 (0,23) Não
E.Coli SMOTE+Tomek 95,98 (4,21) 97,19 (0,24) Não
Satimage SMOTE+ENN 95,67 (1,18) 84,14 (0,52) Não
Flag SMOTE+ENN 79,32 (28,83) 86,03 (1,86) Não
Glass SMOTE+ENN 92,90 (7,30) 96,81 (1,62) Não
Letter-a SMOTE 99,91 (0,12) 99,95 (0,09) Não
Nursery SMOTE+Tomek 99,27 (0,36) 99,38 (0,03) Não
Conforme pode ser verificado na tabela 7.4.1.1, nos experimentos de (Batista e
Monard, 2004), dos 15 problemas em estudo, 10 dos melhores desempenhos foram
obtidos com a combinação de métodos de sobreamostragem e subamostragem. Em
comparação com o AGB, o mesmo apresentou melhor desempenho em 9 dos 15
problemas, apesar de o mesmo somente utilizar a técnica de sobreamostragem. Também

82
verificou-se que o AGB possui maior estabilidade, pois demonstrou menor desvio
padrão em 14 dos 15 problemas em estudo, e no problema Letter-vowel, o desvio
padrão foi igual.
Com relação ao indicador DANGER, o algoritmo AGB somente apresentou
instâncias sintéticas próximas à superfície de decisão no problema Post-Operative, onde
obteve melhor resultado em relação ao SMOTE+ENN. Nos outros problemas, as
instâncias sintéticas não foram criadas próximas à superfície de decisão, e mesmo
assim, em 8 dos casos o desempenho de classificação foi maior.
7.4.2 Comparação com o Algoritmo Borderline SMOTE
O método Borderline SMOTE, proposto por (Han et al., 2005), o qual foi
detalhado na seção 4.3.3, aplica o algoritmo SMOTE somente a partir de instâncias
pertencentes ao conjunto DANGER, o qual consiste de instâncias próximas à superfície
de decisão. Neste estudo, os autores concluem que as instâncias sintéticas devem ser
criadas próximas à superfície de decisão, pois a mesma é mais susceptível a erros
causados por desbalanceamento entre classes, de acordo com os autores: “Os exemplos
da classe minoritária na borda de decisão são mais facilmente mal classificados do que
aqueles distantes da borda de decisão. Então os nossos métodos somente efetuam
sobreamostragem dos exemplos da classe minoritárias na borda de decisão.”
Para a execução deste experimento com o AGB, os três conjuntos de dados
utilizados em (Han et al., 2005), foram submetidos ao processo de balanceamento com
o algoritmo AGB, e em seguida classificados com o algoritmo C4.5. Cada execução
consiste em um processo de validação cruzada, com dez desdobramentos, sendo obtida
a média para a métrica F-Measure desses desdobramentos. De forma a avaliar a
estabilidade do algoritmo, foram efetuadas 10 execuções independentes, sendo a média
e o desvio padrão (entre parênteses) de F-Measure exibidos na tabela 7.4.2.1.

83
Tabela 7.4.2.1 – Comparação de resultados entre o AGB e o método Borderline
SMOTE 1.
F-Measure
Conjunto de Dados
Borderline SMOTE1 AGB
DANGER
Pima 65,10 67,16 (1,04) Não
Habermann 52,70 53,48 (2,46) Não
Satimage 57,60 58,80 (0,2) Não
Como pode ser visto na tabela 7.4.2.1, em todos os problemas o AGB obteve
melhor desempenho de F-Measure. Não é possível comparar o desvio padrão, pois os
autores não publicaram essa informação.
A métrica DANGER foi aplicada aos experimentos da seção 7.4.1, bem como aos
experimentos desta seção. Na seção 7.4.1, o algoritmo AGB somente apresentou
instâncias sintéticas DANGER em um problema, onde se obteve melhor resultado em
relação ao SMOTE+ENN. Nos outros problemas, as instâncias sintéticas não foram
criadas próximas à superfície de decisão, e mesmo assim, em 8 dos casos o desempenho
de classificação foi maior. Na tabela 7.4.2.1, o AGB não gerou instâncias DANGER em
nenhum dos problemas, mas obteve melhor desempenho de F-Measure, em relação ao
Borderline SMOTE1. Com estes resultados, deduz-se que a criação de instâncias
sintéticas junto à superfície de decisão pode acarretar problemas de ruído e sobreposição
entre classes, o que contradiz os resultados publicados por (Han et al., 2005).
7.4.3 Comparação com o Algoritmo ADASYN
Conforme detalhado na seção 4.3.3, o método ADASYN (He et al., 2008) tem
como ponto chave adaptar a quantidade de instâncias sintéticas produzidas pelo SMOTE
para cada instância ix no conjunto de instâncias positivas P.
Para este experimento, os conjuntos de dados utilizados em (He et al., 2008)
tiveram suas instâncias reordenadas aleatoriamente, e separadas em 50% para treino, e
50% para teste. Cada execução consiste em submeter o conjunto de treinamento ao
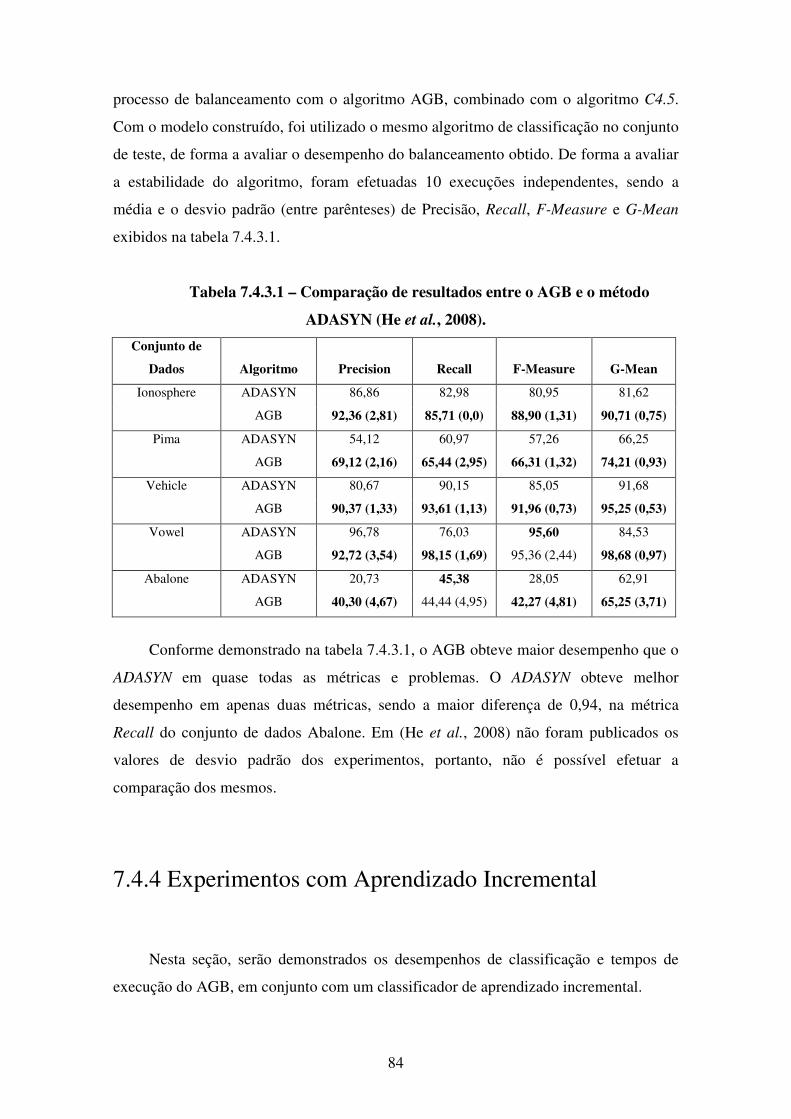
84
processo de balanceamento com o algoritmo AGB, combinado com o algoritmo C4.5.
Com o modelo construído, foi utilizado o mesmo algoritmo de classificação no conjunto
de teste, de forma a avaliar o desempenho do balanceamento obtido. De forma a avaliar
a estabilidade do algoritmo, foram efetuadas 10 execuções independentes, sendo a
média e o desvio padrão (entre parênteses) de Precisão, Recall, F-Measure e G-Mean
exibidos na tabela 7.4.3.1.
Tabela 7.4.3.1 – Comparação de resultados entre o AGB e o método
ADASYN (He et al., 2008).
Conjunto de
Dados Algoritmo Precision Recall F-Measure G-Mean
Ionosphere ADASYN 86,86 82,98 80,95 81,62
AGB 92,36 (2,81) 85,71 (0,0) 88,90 (1,31) 90,71 (0,75)
Pima ADASYN 54,12 60,97 57,26 66,25
AGB 69,12 (2,16) 65,44 (2,95) 66,31 (1,32) 74,21 (0,93)
Vehicle ADASYN 80,67 90,15 85,05 91,68
AGB 90,37 (1,33) 93,61 (1,13) 91,96 (0,73) 95,25 (0,53)
Vowel ADASYN 96,78 76,03 95,60 84,53
AGB 92,72 (3,54) 98,15 (1,69) 95,36 (2,44) 98,68 (0,97)
Abalone ADASYN 20,73 45,38 28,05 62,91
AGB 40,30 (4,67) 44,44 (4,95) 42,27 (4,81) 65,25 (3,71)
Conforme demonstrado na tabela 7.4.3.1, o AGB obteve maior desempenho que o
ADASYN em quase todas as métricas e problemas. O ADASYN obteve melhor
desempenho em apenas duas métricas, sendo a maior diferença de 0,94, na métrica
Recall do conjunto de dados Abalone. Em (He et al., 2008) não foram publicados os
valores de desvio padrão dos experimentos, portanto, não é possível efetuar a
comparação dos mesmos.
7.4.4 Experimentos com Aprendizado Incremental
Nesta seção, serão demonstrados os desempenhos de classificação e tempos de
execução do AGB, em conjunto com um classificador de aprendizado incremental.

85
Nos experimentos anteriores, os autores não publicaram os tempos dos algoritmos,
dessa forma, para que seja possível comparar os tempos de processamento do AGB com
aprendizado incremental, primeiro é necessário comparar o desempenho de
classificação do AGB com essa estratégia de aprendizado. Para tal comparação, foram
utilizados o algoritmo Naive Bayes (NB), e os algoritmos SMOTE e AdaBoost em
conjunto com o Naive Bayes. O AGB foi executado em conjunto com o algoritmo de
aprendizado incremental Naive Bayes Updateable (NBU), o qual foi fundamentado por
(John e Langley, 1995). Vale ressaltar que os algoritmos Naive Bayes e o Naive Bayes
Updateable tratam-se do mesmo algoritmo e compartilham o mesmo desempenho sobre
o mesmo conjunto de dados, a única diferença é que o segundo permite uma atualização
de probabilidades no modelo previamente construído. Todos os algoritmos estão
implementados no Weka versão 3.6.
Para o algoritmo SMOTE, foi utilizado 5=k . A tabela 7.3.1 mostra os parâmetros
utilizados para o AG. Para o AdaBoost, denominado no Weka como AdaBoostM1, foi
utilizado o número de iterações=10, não utilização de amostragem, e peso limite=100.
Em todos os algoritmos, foi utilizado o tempo corrente em milissegundos para se iniciar
o gerador de números aleatórios.
Conforme foi esclarecido nos capítulos 2 e 6, é recomendada a utilização de um
conjunto de treino e outro de teste no aprendizado incremental, portanto, os 18
conjuntos de dados relacionados na seção 7.2 tiveram suas instâncias reordenadas
aleatoriamente, e particionados em 80% para treinamento, e 20% para teste. De forma a
avaliar a estabilidade dos algoritmos SMOTE e AGB, foram efetuadas 10 execuções
independentes, sendo a média e o desvio padrão (entre parênteses) de AUC exibidos
onde aplicáveis na tabela 7.4.4.1.
Na tabela 7.4.4.1, verifica-se que o AGB + NBU obteve maior desempenho de
AUC em 12 problemas, e obtendo classificação perfeita no problema Glass, juntamente
com os algoritmos Naive Bayes e AdaBoost. Em todos os experimentos, o AGB
apresentou desvio padrão abaixo de 1, e foi superior ou igual ao Naive Bayes. Nota-se
ainda que o problema Post-Operative demonstrou mal desempenho de classificação em
todos os algoritmos.

86
Tabela 7.4.4.1 – Comparação de resultados entre o AGB e os algoritmos do Weka.
AUC
Conjunto de Dados
Naive Bayes
(NB)
SMOTE+NB AdaBoost+NB AGB+NBU
Ionosphere 92,50 93,15 (0,49) 88,70 95,32 (0,32)
Pima 80,40 80,00 (0,15) 77,80 82,99 (0,53)
German 75,40 78,60 (0,07) 76,80 77,82 (0,07)
Post-Operative 23,50 41,20 (5,02) 0,05 27,08 (2,2)
Habermann 60,40 64,80 (0,84) 75,90 77,91 (0,84)
Splice-ie 99,10 98,70 (2,12) 98,60 99,13 (0,09)
Splice-ei 99,40 98,50 (1,21) 98,80 99,57 (0,67)
Vehicle 84,00 84,60 (0,68) 82,70 90,69 (0,21)
Letter-vowel 72,90 72,90 (0,52) 73,20 100,00 (0,0)
New-thyroid 99,30 98,75 (0,77) 99,65 99,70 (0,84)
E.Coli 92,20 91,65 (0,35) 93,00 98,66 (0,32)
Satimage 93,40 92,05 (0,21) 91,80 93,67 (0,42)
Vowel 98,20 97,30 (1,15) 99,20 99,89 (0,41)
Flag 62,90 67,50 (0,56) 45,70 67,14 (0,19)
Glass 100,00 97,40 (0,0) 100,00 100,00 (0,0)
Letter-a 95,90 95,70 (1,22) 99,00 98,50 (0,98)
Nursery 99,50 99,10 (2,25) 99,40 99,15 (0,29)
Abalone 67,30 67,42 (0,15) 72,40 81,03 (0,31)
Na tabela 7.4.4.1, verifica-se que o AGB + NBU obteve maior desempenho de
AUC em 12 problemas, e obtendo classificação perfeita no problema Glass, juntamente
com os algoritmos Naive Bayes e AdaBoost. Em todos os experimentos, o AGB
apresentou desvio padrão abaixo de 1, e foi superior ou igual ao Naive Bayes. Nota-se
ainda que o problema Post-Operative demonstrou mal desempenho de classificação em
todos os algoritmos.
Na tabela 7.4.4.2 e nas figuras 7.4.4.1 e 7.4.4.2, estão dispostas as médias do
tempo de processamento dos algoritmos em estudo, após 10 execuções, as quais foram
processadas em um computador Intel Dual Core T7500 com 2.2 Gigahertz de
velocidade de processamento e 2 gigabytes de memória RAM. O desvio padrão não será
demonstrado, pelo fato de ter ocorrido pouca variância de tempo entre as 10 execuções.
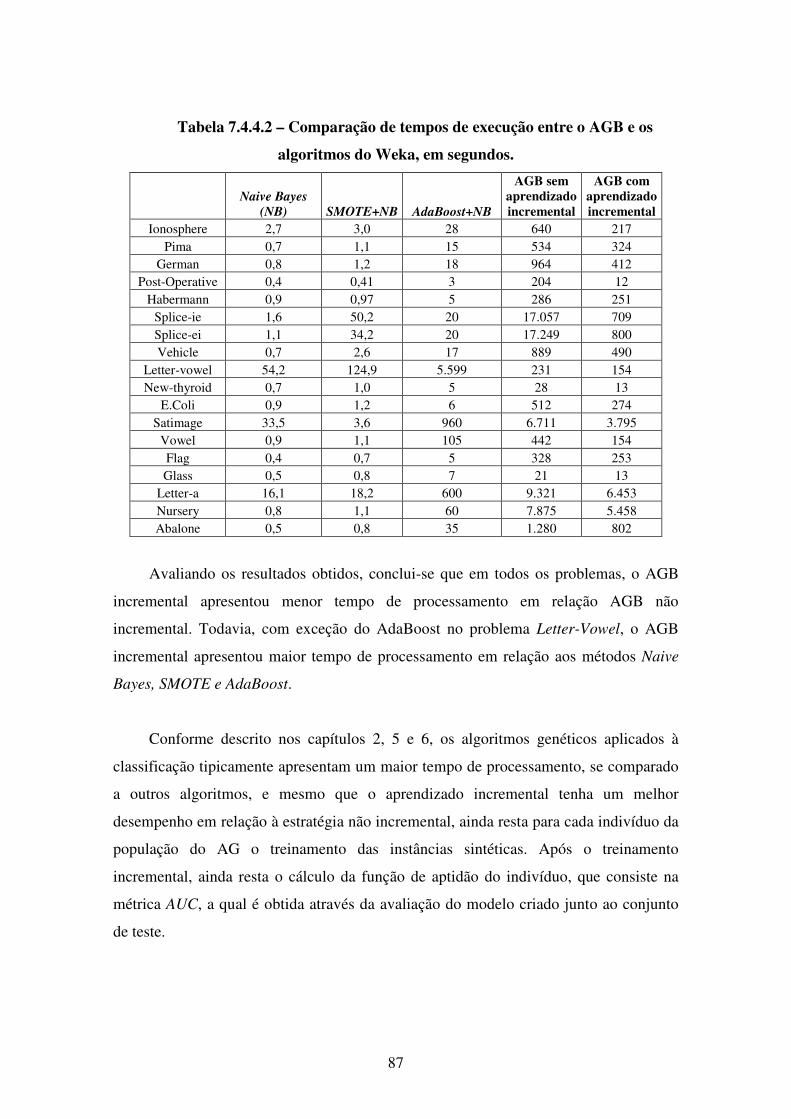
87
Tabela 7.4.4.2 – Comparação de tempos de execução entre o AGB e os
algoritmos do Weka, em segundos.
Naive Bayes
(NB)
SMOTE+NB AdaBoost+NB
AGB sem aprendizado incremental
AGB com aprendizado incremental
Ionosphere 2,7 3,0 28 640 217 Pima 0,7 1,1 15 534 324
German 0,8 1,2 18 964 412 Post-Operative 0,4 0,41 3 204 12
Habermann 0,9 0,97 5 286 251 Splice-ie 1,6 50,2 20 17.057 709 Splice-ei 1,1 34,2 20 17.249 800 Vehicle 0,7 2,6 17 889 490
Letter-vowel 54,2 124,9 5.599 231 154 New-thyroid 0,7 1,0 5 28 13
E.Coli 0,9 1,2 6 512 274 Satimage 33,5 3,6 960 6.711 3.795
Vowel 0,9 1,1 105 442 154 Flag 0,4 0,7 5 328 253 Glass 0,5 0,8 7 21 13
Letter-a 16,1 18,2 600 9.321 6.453 Nursery 0,8 1,1 60 7.875 5.458 Abalone 0,5 0,8 35 1.280 802
Avaliando os resultados obtidos, conclui-se que em todos os problemas, o AGB
incremental apresentou menor tempo de processamento em relação AGB não
incremental. Todavia, com exceção do AdaBoost no problema Letter-Vowel, o AGB
incremental apresentou maior tempo de processamento em relação aos métodos Naive
Bayes, SMOTE e AdaBoost.
Conforme descrito nos capítulos 2, 5 e 6, os algoritmos genéticos aplicados à
classificação tipicamente apresentam um maior tempo de processamento, se comparado
a outros algoritmos, e mesmo que o aprendizado incremental tenha um melhor
desempenho em relação à estratégia não incremental, ainda resta para cada indivíduo da
população do AG o treinamento das instâncias sintéticas. Após o treinamento
incremental, ainda resta o cálculo da função de aptidão do indivíduo, que consiste na
métrica AUC, a qual é obtida através da avaliação do modelo criado junto ao conjunto
de teste.
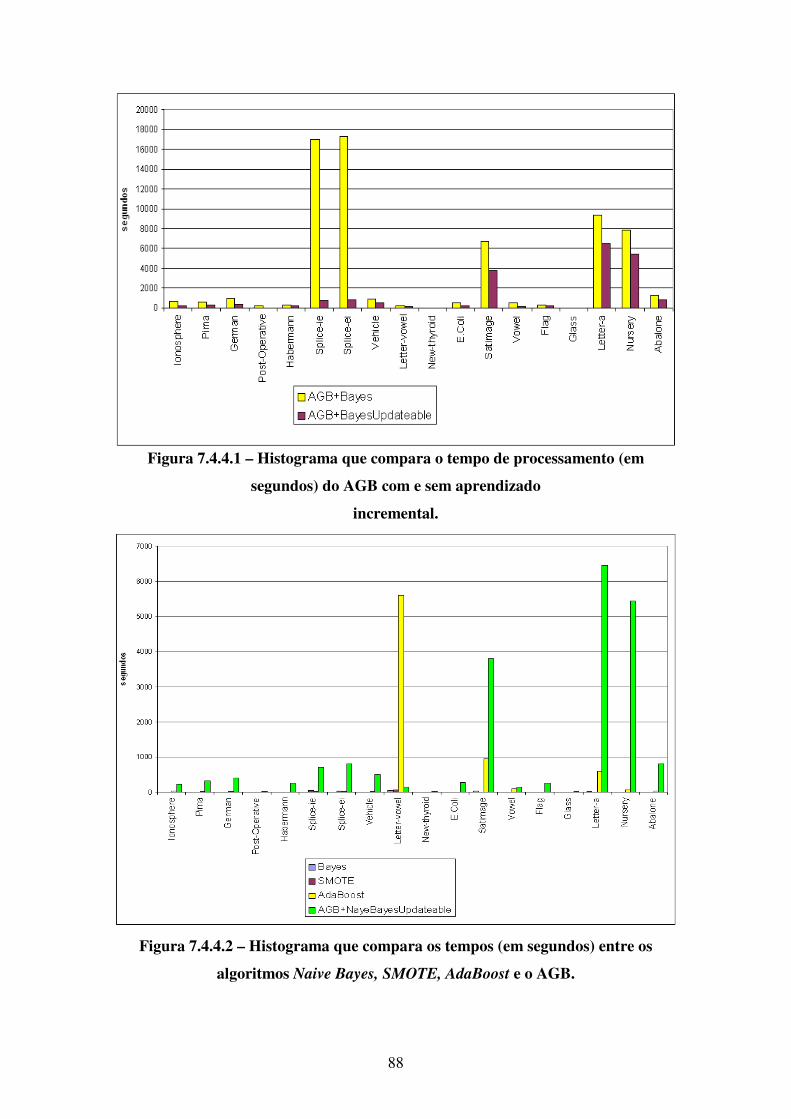
88
Figura 7.4.4.1 – Histograma que compara o tempo de processamento (em
segundos) do AGB com e sem aprendizado
incremental.
Figura 7.4.4.2 – Histograma que compara os tempos (em segundos) entre os
algoritmos Naive Bayes, SMOTE, AdaBoost e o AGB.

89
Capítulo 8
Conclusões
Neste trabalho foi apresentada uma estratégia de sobreamostragem utilizando um
algoritmo genético para balanceamento (AGB), a qual efetua o ajuste do conjunto de
dados através da criação de instâncias sintéticas positivas orientadas por um processo
evolutivo. O algoritmo foi desenvolvido como um plugin de pré-processamento na
plataforma de mineração de dados Weka versão 3.6 (Witten e Frank, 2005), sendo
aplicável a atributos numéricos e nominais, permitindo ainda a utilização de
aprendizado incremental de forma a diminuir o tempo de processamento.
Foram efetuados experimentos com dezoito conjuntos de dados desbalanceados,
provenientes do UCI Machine Learning Repository (Blake e Merz, 1998), de forma a
comprovar a eficácia do algoritmo proposto. Em um dos experimentos, os conjuntos de
dados foram balanceados com o AGB e classificados com o algoritmo C4.5. Os
resultados obtidos foram comparados aos de três estudos publicados na literatura
especializada, e na maioria dos casos, o AGB obteve melhor desempenho de
classificação. Em outro experimento, a métrica DANGER indicou que os melhores
balanceamentos obtidos com o AGB consistiam de instâncias sintéticas distantes da
superfície de decisão, o que contradiz os resultados publicados por (Han et al., 2005).
No terceiro experimento o AGB utilizou uma estratégia de aprendizado incremental
com o algoritmo Naive Bayes Updateable, sendo o desempenho de classificação e
tempo de execução comparados aos dos algoritmos Naive Bayes, e SMOTE e AdaBoost
em conjunto com Naive Bayes. Os resultados demonstraram que o AGB incremental
obteve melhor desempenho de classificação na maioria dos problemas, e um menor
tempo de processamento em relação ao AGB não incremental. Todavia, na maioria dos

90
casos, o AGB apresentou um tempo de processamento maior em relação aos outros
algoritmos avaliados.
Com os resultados apresentados, demonstrou-se que o processo de
sobreamostragem aplicado a conjuntos de dados desbalanceados tem como função o
favorecimento da classe positiva no processo de classificação, e que a criação de
instâncias sintéticas junto à superfície de decisão pode acarretar problemas de ruído e
sobreposição entre classes. Apesar do maior tempo de processamento, o desempenho de
classificação obtido com o algoritmo proposto indica um caminho interessante e
competitivo, em relação aos outros algoritmos aplicados em pré-processamento de
conjuntos de dados desbalanceados.
Em trabalhos futuros pretende-se utilizar o AGB em conjunto com estratégias de
subamostragem, a utilização de outras métricas de distância aplicadas a atributos
nominais, bem como a aplicação do algoritmo em conjuntos de dados com mais de duas
classes.

91
Referências Bibliográficas
Anthony, M., Biggs, N., 1997, Computational Learning Theory, Cambridge University
Press.
Argentini, A., Blanzieri, E., 2010, About Neighborhood Counting Measure Metric and
Minimum Risk Metric, IEEE Transactions on Pattern Analysis and Machine
Intelligence, vol. 32, issue 4, pp. 763-765.
Arlot, S., Celisse, A., 2010, A survey of cross-validation procedures for model
Selection, Statistics Surveys 4, pp 40-79.
Bradley, A.P., 1997, The Use of the Area Under the ROC Curve in the Evaluation of
Machine Learning Algorithms, Pattern Recognition, vol. 30, no. 7, pp.1145-1159.
Barreto, J.M., 1996, Algoritmo genético: inspiração biológica na solução de problemas -
uma introdução. Revista Marítima Brasileira – Suplemento Especial, Pesquisa Naval,
número 11, pp. 105-128.
Batista, G. E. A. P. A., 2003, PhD. Thesis: Pré-processamento de Dados em
Aprendizado de Máquina Supervisionado, Departamento de Ciência da Computação e
Estatística, Universidade de São Paulo, São Paulo, SP, Brasil.
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C., 2004, A Study of the Behavior of
Several Methods for Balancing Machine Learning Training Data, ACM SIGKDD
Explorations Newsletter, vol. 6, no. 1, pp. 20-29.
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C., 2005, Balancing Strategies and Class
Overlapping, In: Proceedings of the VI International Symposium on Intelligent Data
Analysis, Madrid, Springer-Verlag, LNAI 3646, pp. 24-35.

92
Boriah, S., Chandola, V., Kumar, V., 2007, Similarity Measures for Categorical Data: A
Comparative Evaluation, In: Proceedings of the SIAM International Conference on Data
Mining, Minneapolis, Minnesota, USA, pp. 243-254.
Beckmann, M., de Lima, B. S. L. P., Ebecken, N.F.F., 2009, Algoritmos Genéticos
como Estratégia de Pré-Processamento para o Aprendizado de Máquina em Conjuntos
de Dados Desbalanceados, CILAMCE/2009 – Congresso Latino Americano em
Métodos Computacionais em Engenharia, Búzios, Brasil.
Bifet, A., Holmes, G., Kirkby, R., Pfahringer, B., 2010, MOA: Massive Online
Analysis, Journal of Machine Learning Research, vol. 11, pp. 1601-1604.
Blake, C., & Merz, C., 1998, UCI Repository of Machine Learning Databases,
disponível em: http://www.ics.uci.edu/~mlearn/~MLRepository.html, Department of
Information and Computer Sciences, University of California, Irvine.
Booch, G., Jacobson, I., and Rumbaugh, J., 1999, Unified Modeling Language – User’s
Guide, 2 ed., Addison–Wesley.
Boley, D.L., 1998, Principal Direction Divisive Partitioning, Data Mining and
Knowledge Discovery, vol. 2, no. 4, pp. 325-344.
Breiman, L., Friedman, J., Olshen, R., Stone C., 1984, Classification and Regression
Trees, Monterey, CA, USA, Wadsworth and Brooks.
Breiman, L., 1996, Heuristics of Instability and Stabilization in Model Selection, The
Annals of Statistics, vol. 24, no. 6, 2350-2383.
Carvalho, D.R., Freitas, A.A., 2002, A genetic algorithm for discovering small-disjunct
rules in data mining. Applied Soft Computing vol. 2, issue 2, pp. 75-88.
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P., 2002, SMOTE:
SyntheticMinority Over-sampling Technique, JAIR vol. 16, pp. 321-357.

93
Chawla, N.V., Lazarevic, A., Hall, L.O., Bowyer, K.W., 2003, SMOTEBoost:
Improving Prediction of the Minority Class in Boosting, In: Proceeding of Seventh
European Conf. Principles and Practice of Knowledge Discovery in Databases, Cavtat-
Dubrovnik, Croatia, pp. 107-119.
Chawla, N.V., 2003, C4.5 and imbalanced data sets: investigating the effect of sampling
method, probabilistic estimate, and decision tree structure, In: Workshop on Learning
from Imbalanced Datasets II, International Conference on Machine Learning,
Washington DC, USA.
Chen L., Cai Z., Chen, L., Gu Q., 2010, A Novel Differential Evolution-Clustering
Hybrid Resampling Algorithm on Imbalanced Datasets, Third International Conference
on Knowledge Discovery and Data Mining, Phuket, Thailand.
Cornúejols, A., 1993, Getting order independence in incremental learning, In:
Proceedings of the Sixth European Conference on Machine Learning, pp. 196–212,
Vienna, Austria.
Czarnitzki, D., Doherr, T., 2002, Genetic Algorithms: A Tool for Optimization in
Econometrics - Basic Concept and an Example for Empirical Applications, ZEW
Discussion Paper no. 02-41. Available at SSRN: http://ssrn.com/abstract=320987.
Dasarathy, B.V., 1991, Nearest Neighbor Pattern Classification Techniques, IEEE
Computer Society Press.
de Lima, B. S. L. P., Breno, P.J., Ebecken, N.F.F., 2005, A hybrid fuzzy/genetic
algorithm for the design of offshore oil production risers. International Journal for
Numerical Methods in Engineering, v. 64, p. 1459-1482.
Drummond, C., Holte, C., 2003, C4.5, Class Imbalance, and Cost Sensitivity: Why
Under-Sampling beats Over-Sampling, Workshop on Learning from Imbalanced
Datasets II, International Conference on Machine Learning, Washington DC, USA.

94
Drummond, C., Holte, R.C., 2000, Exploiting the Cost (In)Sensitivity of Decision Tree
Splitting Criteria, In: Proc. International Conference on Machine Learning, pp. 239-246,
Stanford, CA, USA.
Ebecken, N.F.F., Hruschka, E.R., Hruschka Jr., E.R., 2005, Missing Values Imputation
for a Clustering Genetic Algorithm, Lecture Notes in Computer Science, SpringerLink,
vol. 1, pp. 245-254.
Elkan, C., 2001, The Foundations of Cost-Sensitive Learning, The Seventeenth
International Joint Conference on Artificial Intelligence, pp. 973-978.
Estabrooks, A, Jo, T., Japkowicz, N., 2004, A Multiple Resampling Method for
Learning from Imbalanced Data Sets, Computational Intelligence, vol. 20, pp. 18-36.
Ezawa, K., Moninder, S., Steven, N., 1996, Learning Goal Oriented Bayesian Networks
for Telecommunications Management, The International Conference on Machine
Learning, Morgan Kaufmann, pp. 139-147.
Fan, W., Stolfo, S.J., Zhang, J., Chan, P.K., 1999, AdaCost: Misclassification Cost-
Sensitive Boosting, In: Proceedings of International Conference of Machine Learning,
pp. 97-105, Bled, Slovenia.
Fawcett, T., Provost, F., 1996, Combining Data Mining and Machine Learning for
Effective User Profile, The 2nd International Conference on Knowledge Discovery and
Data Mining, AAAI Press, pp. 8-13, Portland, Oregon, USA.
Fawcett, T., 2004, ROC Graphs: Notes and Pratical Considerations for Researchers,
Kluwer Academic Publishers.
Fawcett, T., 2005, An introduction to ROC analysis, Pattern Recognition Letters 27(8),
861-874.
Flach, P.A., Wu, S., 2005, Repairing concavities in ROC curves, International Joint
Conference On Artificial Intelligence, Morgan Kaufmann, pp. 702-707, Scotland, UK.

95
Fisher, D., 1987, Knowledge acquisition via incremental conceptual clustering,
Machine Learning vol. 2, no. 2, SpringerLink, pp. 139–172.
Fisher, D., Xu, L., Zard, N., 1992, Ordering effects in clustering, In: Proceedings of the
Eighth International Conference on Machine Learning, Scotland, UK.
Frank, E., Hall, M., Pfahringer, B., 2003, Locally Weighted Naive Bayes, In: 19th
Conference in Uncertainty in Artificial Intelligence, pp. 249-256, Acapulco, MEX.
Freitas, A.A., 2002, Evolutionary computation. Handbook of Data Mining and
Knowledge Discovery, Oxford University Press, pp. 698-706.
Freitas, A.A., 2003, A survey of evolutionary algorithms for data mining and
knowledge Discovery, Advances in evolutionary computing: theory and applications,
Springer-Verlag, pp. 819–845.
Goldberg, D.E., 1989, Genetic Algorithms in Search, Optimization, and Machine
Learning, Addison-Wesley Professional.
Giraud-Carrier, C., Martinez, T., 1995, ILA: Combining inductive learning with prior
knowledge and reasoning, Technical report CSTR-95-03, University of Bristol,
Department of Computer Science.
Giraud-Carrier, C., 2000, A note on the utility of incremental learning, AI
Communications, vol. 13, issue 4, pp. 215-223.
Gosling, J., Joy, B., Steele, G., Bracha, G., 2000, The Java Language Specification.
Addison–Wesley, 2 ed.
Han, H., Wang, W.Y., Mao, B.H., 2005, Borderline-SMOTE: A New Over-Sampling
Method in Imbalanced Data Sets Learning, In: Proceedings of International Conference
of Intelligent Computing, pp. 878-887, Hefei, China.

96
Hart, P. E., 1968, The Condensed Nearest Neighbor Rule, IEEE Transactions on
Information Theory, vol. IT-14. pp. 515–516.
Hastie, T., Tibshirani, R., Friedman, J., 2003, The Elements of Statistical Learning,
Data Mining, Inference and Prediction, Springer Series in Statistics. pp 411-433.
Haykin S., 1999, Neural Networks: A Comprehensive Foundation, 2 ed., Prentice-Hall.
He, H., Shen, X., 2007, A Ranked Subspace Learning Method for Gene Expression
Data Classification, In: Proc. Int’l Conf. Artificial Intelligence, pp. 358-364.
He, H., Bai, Y., Garcia, E.A.., 2008, ADASYN: Adaptive Synthetic Sampling Approach
for Imbalanced Learning, In: Proceedings of International Joint Conference Neural
Networks, pp. 1322-1328.
He, H., Garcia, E.A., 2009, Learning from Imbalanced Data, IEEE Transactions on
Knowledge and Data Enginering, vol. 21, no. 9, pp. 1263-1284.
Holland, J.H., 1975, Adaptation in natural and artificial systems, University of
Michigan Press.
Holte, R.C., Acker, L., Porter, B., 1989, Concept Learning and the Problem with Small
Disjuncts, In: Proceedings of the Eleventh International Joint Conference on Artificial
Intelligence, 813-818, Menlo Park, CA, USA.
Hong, X., Chen, S., Harris, C.J., 2007, A Kernel-Based Two-Class Classifier for
Imbalanced Data Sets, IEEE Trans. Neural Networks, vol. 18, no. 1, pp. 28-41.
Hulse, J.V., Khoshgoftaar, T., 2009, Knowledge discovery from imbalanced and noisy
data, Elsevier, Data & Knowledge Engineering, vol. 68, pp. 513–1542.
Japkowicz, N., 2001, Supervised Versus Unsupervised Binary-Learning by
Feedforward Neural Networks, Machine Learning, vol. 42, no. 1-2, pp. 97-122.

97
Japkowicz, N., Stephen, S., 2002, The class imbalance problem: a systematic study,
Inteligent Data Analysis, vol. 6, no. 5, pp. 429-450.
Japkowicz, N., 2003, Class imbalances. Are we focusing on the right issue?, In:
Proceedings of the ICML’2003 Workshop on Learning from Imbalanced Data Sets II,
Washington DC, USA.
Jo, T., Japkowicz, N., 2004, Class Imbalances Versus Small Disjuncts, Sigkdd
Explorations, vol. 6, issue 1, pp. 40-49.
John, G.H., Langley, P., 1995, Estimating Continuous Distributions in Bayesian
Classifiers, In proceedings of the Eleventh Conference on Uncertainty in Artificial
Intelligence, Morgan Kaufmann Publisher.
Kohavi, R., Quinlan, J.R., 2002, Decision Tree Discovery, Handbook of Data Mining
and Knowledge Discovery, chapter 16.1.3, pages 267-276. Oxford University Press.
Koza, J.R., 1995, Survey of genetic algorithms and genetic programming, In:
Proceedings of Wescon 95, IEEE Press, pp. 589-594.
Kubat, M., Matwin, S., 1997, Addressing the Curse of Imbalanced Training Sets: One-
sided Selection. In Proceedings of ICML. pp.179–86, Nashville, Tenesee, USA.
Kubat, M., Holte, R., Matwin, S., 1998, Machine Learning for the Detection of Oil
Spills in Radar Images, Machine Learning, vol.30, pp.195-215.
Kullback, S., Leibler, R. A., 1951, On Information and Sufficiency, Annals of
Mathematical Statistics, vol. 22, no. 1, pp. 79-86.
Kuzar, M.Z., Kononenko, I., 1998, Cost-Sensitive Learning with Neural Networks, In:
Proceedings of European Conf. Artificial Intelligence, pp. 445-449, Brighton, UK.
Laurikkala, J., 2001, Improving Identification of Difficult Small Classes by Balancing
Class Distribution, Technical Report A-2001-2, University of Tampere.

98
Lewis, D.D., Catlett J., 1994, Heterogeneous Uncertainty Sampling for Supervised
Learning, The 11th International Conference on Machine Learning, Morgan Kaufmann,
pp.148-156.
Lin, Y., Yoonkyung, L., Grace, W., 2002, Support Vector Machines for Classification
in Nonstandard Situations, Machine Learning, vol. 46, no. 1-3, pp.191-202.
Liu, W., Chawla, S., Cieslaky, D.A., Chawla, N.V., 2010, A Robust Decision Tree
Algorithm for Imbalanced Data Sets, In: Proceedings of the SIAM International
Conference on Data Mining, Columbus, Ohio, USA.
Liu, X.Y., Wu, J., Zhou, Z.H., 2006a, Exploratory Under Sampling for Class Imbalance
Learning, In: Proc. Int’l Conf. Data Mining, pp. 965-969.
Liu, X.Y., Zhou, Z.H., 2006b, The Influence of Class Imbalance on Cost-Sensitive
Learning: An Empirical Study, Proc. Int’l Conf. Data Mining, pp. 970-974.
Loh, W.Y., 2002, Regression trees with unbiased variable selection and interaction
detection, Statistica Sinica, vol. 12, pp. 361–386.
MacGregor, J., 1988, The effects of order in learning classifications by example:
Heuristics for finding the optimal order, Artificial Intelligence, no. 34, pp. 361–370.
MacQueen, J.B., 1967, Some Methods for Classification and Analysis of Multivariate
Observations, Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and
Probability, Berkeley, University of California Press, vol.1, pp.281-297.
McCarthy, K., Zabar, B., Weiss, G.M., 2005, Does Cost-Sensitive Learning Beat
Sampling for Classifying Rare Classes?, In: Proc. Int’l Workshop Utility-Based Data
Mining, pp. 69-77.

99
Maloof, M.A., 2003, Learning When Data Sets Are Imbalanced and When Costs Are
Unequal and Unknown, In: Proc. Int’l Conf. Machine Learning, Workshop Learning
from Imbalanced Data Sets II, Washington DC, USA
Manevitz, L.M., Malik, Y., 2001, One-Class Svms for Document Classification,
Machine Learning Research, vol. 2, no. 2, pp.139-154.
Michalewicz, Z., 1996, Genetic algorithm + data structures = evolution programs, 3º
ed., Springer-Verlag.
Motta, A.A., Ebecken, N.F.F., 2007, On the Application of Genetic Algorithms in
Underwater Explosive Charges Optimization, International Journal For Computation
Methods In Engineering Science And Mechanics, vol. 8, pp. 1-9.
Nickerson, A., Japkowicz, N. & Millos, E., 2001, Using Unsupervised Learning to
Guide Resampling in Imbalanced Data Sets, In Proceedings of the 8th International
Workshop on AI and Statistics, pp.261-65, Key West, Florida, USA.
Orriols-Puig, A., Bernadó-Mansilla, E., 2009, Evolutionary rule-based systems for
imbalanced datasets, Soft Computing, vol. 13, no. 3, pp. 213-225.
Pazzani, M., Merz, C., Murphy, P., Ali, K., Hume, T., Brunk, C., 1994, Reducing
misclassification costs, In Proceedings of the Eleventh International Conference on
Machine Learning, pp 217-225.
Pearson, R., Goney, G., Shwaber, J., 2003, Imbalanced Clustering for Microarray Time-
Series, Proc. Int’l Conf. Machine Learning, Workshop Learning from Imbalanced Data
Sets II, , Washington DC, USA
Petrovic, S., Fayad C., 2005, A Genetic Algorithm for Job Shop Scheduling with Load
Balancing, Lecture Notes in Computer Science, Springer Link, vol. 3809, pp. 339-348.

100
Pramanik, A.G., Painuly, P.K., Singh V, Katiyar, Rakesh, 2001, Geophysical
Technology Integration in Hydrocarbon Exploration and Production: An Overview,
Geohorizons, vol.6, no.2.
Prati, R.C., Batista, G.E.A.P.A., Monard, M.C, 2004, Class Imbalances versus Class
Overlapping: an Analysis of a Learning System Behavior, In: MICAI, pp. 312 -321,
Springer-Verlag.
Reinelt, G., 1991, TSPLIB, A Traveling Salesman Problem Library, ORSA Journal on
Computing 3, 376-384.
Disponível em: http://www.iwr.uni-heidelberg.de/groups/comopt/software/TSPLIB95/
Sariff, N.B., Buniyamin, N., 2009, Comparative study of Genetic Algorithm and Ant
Colony Optimization algorithm performances for robot path planning in global static
environments of different complexities, Computational Intelligence in Robotics and
Automation (CIRA), IEEE International Symposium, pp. 132-137.
Spears, William, 2001, Foundations of Genetic Algorithms 6. Morgan Kaufmann.
Srinivas, M., Patnaik, L.M., 1994a, Genetic algorithms: A survey, IEEE.
Srinivas, M., Patnaik, L.M., 1994b, Adaptive probabilities of crossover and mutation in
genetic algorithms, IEEE Transactions on System, Man and Cybernetics, vol.24, no.4,
pp.656–667.
Qiong, G., Cai, Z., Zhu, L., Huang, B., 2008, Data Mining on Imbalanced Data Sets,
International Conference on Advanced Computer Theory and Engineering, Phuket,
Thailand.
Quinlan, J.R, 1986, Machine Learning, Vol. 1, pp. 81-106.
Quinlan, J.R, 1988, C4.5 Programs for Machine Learning, Morgan Kaufmann.

101
Quinlan, J. R., 1996, Bagging, boosting, and c4.5, in: Proceedings of the Thirteenth
National Conference on Arti_cial Intelligence, AAAI Press and the MIT Press, pp. 725-
730, Portland, Oregon, USA.
Schapire, R.E., 1999, A brief introduction to boosting, In Proceedings of the Sixteenth
International Joint Conference on Artificial Intelligence. pp. 1401-1406, Stockholm,
Sweden.
Shannon, C.E., 1951, Prediction and entropy of printed English, The Bell System
Technical Journal, vol. 30, pp. 50-64.
Storn, R., Price K., 1997, Differential Evolution: A Simple and Efficient Adaptive
Scheme for Global Optimization over Continuous Spaces, Journal of Global
Optimization, vol. 11, pp. 341-359.
Sun, Y., Kamel, M.S., Wong, A.K.C., Wang Y., 2007, Cost-Sensitive Boosting for
Classification of Imbalanced Data, Pattern Recognition, vol. 40, no. 12, pp. 3358-3378.
Su, J., Zhang, H., Ling, C.X., Matwin, L.S., 2008, Discriminative Parameter Learning
for Bayesian Networks, In: Proceedings of International Conference of Machine
Learning, Helsinki, Finland.
Tate, D.M., Smith, A.E., 1993, Expected allele coverage and the role of mutation in
genetic algorithms, In. Proc. of the Fifth Int. Conf. on Genetic Algorithms, pp. 31–37,
San Mateo, CA, USA, Morgan Kaufmann
Tomek, I., 1976, Two Modifications of CNN, IEEE Transactions on Systems Man and
Communications, vol.6 , pp. 769–772.
Utgoff, P., 1988, ID5: An incremental ID3, In Proceedings of Fifth International
Workshop on Machine Learning, pp. 107–120, Ann Arbor, Michigan, USA.
Van Rijsbergen, C.J., 1979, Information Retrieval. Butterworths.

102
Walker J.D., File, P.E., Miller, C.J., Samson, W.B., 1994, Building DNA maps, a
genetic algorithm based approach, Advances in molecular bioinformatics. S. Schulze-
Kremer, IOS Press. pp.179-199.
Wang. B.X., Japkowicz, N., 2004, Imbalanced Data Set Learning with Synthetic
Samples, In: Proc. IRIS Machine Learning Workshop, Ottawa, Canada.
Webb, G., Boughton J., Wand, Z., 2005, Not So Naive Bayes: Aggregating One-
Dependence Estimators, Machine Learning. Archives, Vol. 58, Issue 1, pp 5-24.
Weiss, G. M., 1999, Timeweaver: a genetic algorithm for identifying predictive patterns
in sequences of events, In Proceedings of the Genetic and Evolutionary Computation
Conference, pages 718-725, Morgan Kaufmann, Orlando, Florida, USA.
Weiss, G.M., Provost, F., 2001, The Effect of Class Distribution on Classifier Learning:
An Empirical Study, Technical Report MLTR-43, Dept. of Computer Science, Rutgers
Univ.
Weiss, G.M., 2004, Mining with Rarity: A Unifying Framework, ACM SIGKDD
Explorations Newsletter, vol. 6, no. 1, pp. 7-19.
Weiss, G.M., McCarthy, K., Zabar, B., 2007, Cost-Sensitive Learning vs. Sampling:
Which is Best for Handling Unbalanced Classes with Unequal Error Costs?,
Proceedings of the 2007 International Conference on Data Mining, CSREA Press, pp.
35-41.
White, M.S., Flockton, S.J., 1994, Genetic algorithms for digital signal processing,
Lecture Notes in Computer Science, 1994, Vol. 865, pp. 291-303.
Whitley, Darrell, 1994, A Genetic Algorithm Tutorial, Springer Science + Business
Media B.V., pp. 65-85.

103
Wilson, D.R, Martinez, T.R., 1997, Improved Heterogeneous Distance Functions, AI
Access Foundation and Morgan Kaufmann Publishers, Journal of Artificial Intelligence
Research vol. 6, pp.1-34.
Wilson, D. L., 1972, Asymptotic Properties of Nearest Neighbor Rules Using Edited
Data, IEEE Transactions on Systems, Man, and Communications vol. 2, no. 3, pp. 408–
421.
Witten, I.H., Frank, E., 2005, Data Mining: Practical machine learning tools and
techniques, 2nd Edition, San Francisco, CA, USA, Morgan Kaufmann.
Woods, K., Doss, C., Bowyer, K., Solka, J., Priebe, C., Kegelmeyer, W., 1993,
Comparative Evaluation of Pattern Recognition Techniques for Detection of
Microcalcifications in Mammography, In: Proc. Int’l J. Pattern Recognition and
Artificial Intelligence, vol. 7.
Wu, G., Chang, E.Y., 2003, Class-Boundary Alignment for Imbalanced Dataset
Learning, The International Conference of Machine Learning, Workshop on Learning
from Imbalanced Data Sets, pp. 49-56, Washington DC, USA.
Wu, G., Chang, E.Y., 2004, Aligning Boundary in Kernel Space for Learning
Imbalanced Data Set, In: Proc. Int’l Conf. Data Mining, pp. 265-272.
Wu, G., Chang, E.Y., 2005, KBA: Kernel Boundary Alignment Considering
Imbalanced Data Distribution, IEEE Trans. Knowledge and Data Eng., vol. 17, no. 6,
pp. 786-795.
Wu, X., Kumar, V., Quinlan, J.R., 2007, et al., Top 10 algorithms in data mining.
Knowlegdment and Information System, Springer-Verlag, vol. 1, pp. 1-37.
Zadrozny, B., Elkan, C., 2001, Learning and Making Decisions When Costs and
Probabilities Are Both Unknown, In: the Seventh International Conference on
Knowledge Discovery and Data Mining, pp. 204-213, San Francisco, California, USA.





























