Embed Size (px)
Citation preview

Universidade Federal do Pará Instituto de Ciências Exatas e Naturais
Faculdade de Estatística Estatística Aplicada
ANÁLISE DISCRIMINANTE (MÓDULO I)
Franciely Farias da Cunha (201007840014), aluna do curso de bacharelado em Estatística pela Universidade Federal do Pará.
Belém 2014

1. O que é a Análise Discriminante?
É uma técnica multivariada utilizada quando a variável dependente é categórica, ou seja, qualitativa (não métrica) e as variáveis independentes são quantitativas (métricas).
1.1 Qual seu objetivo? O objetivo principal da AD é identificar as variáveis que discriminam os grupos e, assim, elaborar previsões a respeito de uma nova observação, identificando o grupo mais adequado a que ela deverá pertencer, em função de suas características. Para alcançar esse objetivo, a AD gera funções discriminantes (combinações lineares das variáveis) que ampliam a discriminação dos grupos descritos pelas variáveis dependentes (FÁVERO et al., 2009).
2. Tipos de Análise Discriminante
Quando o pesquisador estiver interessado em estudar somente dois grupos de variáveis dependentes, a técnica é chamada de Análise Discriminante Simples. No entanto, em muitos casos, há o interesse na discriminação entre mais de dois grupos, sendo a técnica, assim, denominada de Análise Discriminante Múltipla (MDA).
2.1 Objetivos
Os objetivos principais desses dois tipos de análises são parecidos: (i) identificar as variáveis que melhor discriminam dois ou mais grupos; (ii) utilizar estas variáveis para desenvolver funções discriminantes que representem as diferenças entre os grupos; (iii) fazer uso das funções discriminantes para o desenvolvimento de regras de classificação de futuras observações nos grupos.
3. Modelagem da Análise Discriminante
Antes de iniciar a modelagem da AD propriamente dita, é pertinente esclarecer os pressupostos inerentes a está técnica. As suposiçoes em AD, de acordo Hair et al. (2005) e Fávero et al. (2009), são:
Normalidade multivariada das variáveis explicativas: a violação
desse pressuposto poderá causar distorções nas avaliações do pesquisador;

Homogeneidade das Matrizes de variância e covariância: este pressuposto é verificado por meio da estatística Box’s M, que pode ser sensível ao tamanho da amostra;
Inexistência de outliers; Presença de linearidade das relações; Ausência de problemas relacionados à multicolinearidade das
variáveis explicativas.
4. Tamanho da Amostra
Hair et al. (2005), destaca que é essencial definir o tamanho correto da amostra que será estudada, já que esta técnica é muito sensível à proporção do tamanho da amostra em relação ao número de variáveis preditoras. Assim, como regra geral, utiliza-se no mínimo 20 observações para cada variável explicativa, mesmo que o número final das variáveis preditoras a serem incluídas no modelo seja reduzido (método stepwise).
5. Composições das Funções Discriminantes Apresentados os pressupostos, pode-se começar os passos para a composição das funções discriminantes. Portanto, esta etapa consiste na seleção da varável dependente (categórica) e das variáveis explicativas (métricas). A AD permite o conhecimento das variáveis que mais se destacam na discriminação dos grupos, a partir de testes estatísticos, como o lambda de Wilks, a correlação canônica, o qui-quadrado e o eigenvalue. O lambda de Wilks, que varia de 0 a 1, propicia a avaliação da existência de diferenças de médias entre os grupos para cada variável. Os valores elevados desta estatística indicam ausência de diferenças entre os grupos, e sua expressão é dada por
,
em que SQdg representa a soma dos erros (dentro dos grupos) e SQT, a soma dos quadrados total. Com a seleção das variáveis discriminantes (explicativas) para formação dos grupos, o próximo passo é a identificação das funções discriminantes. Desta forma, a função geral discriminante pode ser representada pela seguinte equação linear, ,
em que Z é a variável dependente, α é o intercepto, Xi são as variáveis explicativas e β1 são os coeficientes discriminantes para cada variável explicativa.
SQT
SQ
dg
n2211 X...XX nnZ

Fávero et al. (2009), afirmam que é importante ressaltar que esta função discriminante é diferente da função discriminante linear de Fisher, uma vez que, enquanto a primeira é utilizada como um meio de facilitar a interpretação dos parâmetros das variáveis explicativas, a função discriminante linear de Fisher é utilizada para classificar as observações nos grupos, assim os valores das variáveis explicativas de uma observação são inseridos nas funções de classificação e, consequentemente, um escore de classificação é calculado para cada grupo, para aquela observação. Dadas as p variáveis e g grupos, é possível estabelecer m = min(g - 1; p) funções discriminantes que são combinações lineares das p variáveis, de modo que a função linear de Fisher seja dada por ,
em que Wi representa o vetor de pesos das variáveis para as funções discriminantes e são estimados de modo que a variabilidade dos escores da função discriminante seja máxima entre os grupos e mínima dentro dos grupos (MAROCO, 2007). Em termos matriciais, Sharma (1996) apresenta a função discriminante como, , Em que X’(px1) e a transposta da matriz com p variáveis e representa o vetor de pesos das variáveis. A soma dos quadrados totais dos escores pode ser
definido como ' Sendo a matriz da soma dos
quadrados e produtos cruzados totais da matriz X com p variáveis. Fazendo T = B + W, em que B e W representam, respectivamente, as
matrizes das somas dos quadrados entre os grupos e dentro dos grupos, a soma dos quadrados totais para a função discriminante pode agora ser escrita como (MAROCO, 2007),
Uma vez que ’ B e ’ W são respectivamente a soma dos quadrados entre
os grupos e dentro dos grupos para a função , a obtenção da função
discriminante resume-se, segundo Maroco (2007), a encontrar o vetor , de
modo que Seja máximo. 6. Escore de Corte
Após a função discrimante ser definida, será calculado o escore discriminante da variável dependente (Z) para cada observação. Segundo Hair
n2211 XW...XWXW nnZ
'X
''''' )X()X( XX T'XX
WBWBT '')(''''
,'
B'
W

et al. (2005), o escore de corte é o critério em relação ao qual o escore discriminante de cada objeto é comparado para determinar em qual grupo o objeto deve ser classificado. Para os grupos de mesma dimensão amostral (tamanho), o cálculo do escore de corte é
em que 1d e 2d representam as médias das funções discriminantes
(centróides) nos grupos 1 e 2, respectivamente. Já para o grupos de tamanhos diferentes, têm-se
em que n1 e n2 são os tamanhos dos grupos 1 e 2, respectivamente. Sharma (1996) destaca que o valor do corte selecionado é aquele que minimiza o número de classificação incorreta.
7. Métodos: Simultâneo e Stepwise Simultâneo: considera a inclusão de todas as variáveis explicativas conjuntamente no modelo, mesmo quando 1 ou mais delas não forem significativas. Stepwise: considera a inclusão passo a passo apenas das variáveis significantes. O procedimento de stepwise oferece diversos métodos de inclusão ou exclusão de variáveis discriminantes na função discriminante. Dentre eles podemos citar: Método de lambda de Wilks D2 de Mahalanobis Razão F entre os grupos V de Rao Método Unexplained Variance 8. Aplicação EXEMPLO: Um agrônomo deseja estudar a qualidade do solo de uma área particular de plantio de Açaí. Porém, neste momento, para cada amostra de solo foi atribuído um índice e, então a amostra de solo foi classificada
2
dd 21 f
21
2211 dd
nn
nnf

(categorizada) de acordo com esse índice, sendo estabelecido o seguinte critério: valor do índice igual ou superior a 0,70 é considerados bom; valor situado de 0,35 e 0,69 é regular; valor inferior a 0,35 é considerado ruim. As variáveis explicativas que poderão formar a função discriminante, a fim de que as amostras sejam distribuídas nos grupos corretos são: potencial hidrogeniônico (pH), matéria orgânica (MO), fósforo (P), potássio (K), cálcio (Ca), magnésio (Mg), alumínio, (Al), acidez potencial (H+Al) e saturação por base (V).
Para aplicar a técnica podemos utilizar o software SPSS, após abrir o banco de dados, é necessário clicar em Analisar Classificar Discriminante.
Insira a variável Grupo na caixa Variável de Agrupamento e defina a amplitude dos grupos, clicando em Definir faixa. Digite 1 e 3 em Mínimo e Máximo, respectivamente, a fim de que todas as categorias da variável dependente sejam selecionados para a formação dos grupos (3 grupos). Posteriormente clique em Continuar.
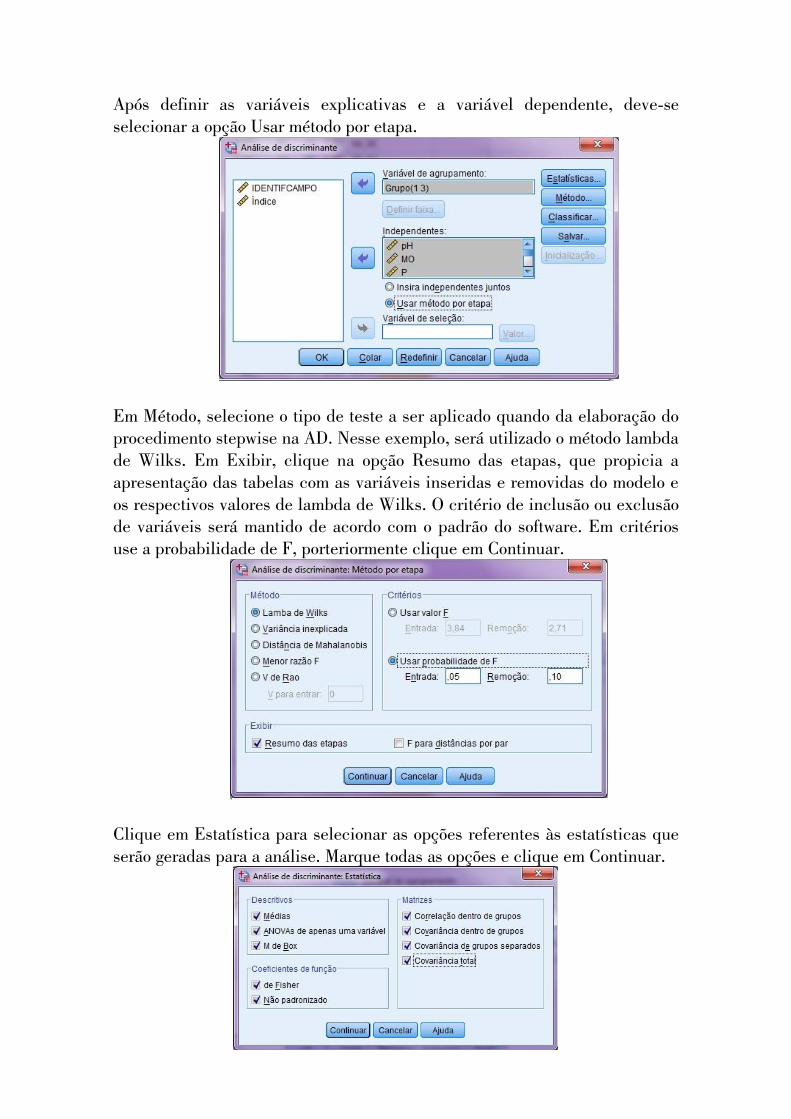
Após definir as variáveis explicativas e a variável dependente, deve-se selecionar a opção Usar método por etapa.
Em Método, selecione o tipo de teste a ser aplicado quando da elaboração do procedimento stepwise na AD. Nesse exemplo, será utilizado o método lambda de Wilks. Em Exibir, clique na opção Resumo das etapas, que propicia a apresentação das tabelas com as variáveis inseridas e removidas do modelo e os respectivos valores de lambda de Wilks. O critério de inclusão ou exclusão de variáveis será mantido de acordo com o padrão do software. Em critérios use a probabilidade de F, porteriormente clique em Continuar.
Clique em Estatística para selecionar as opções referentes às estatísticas que serão geradas para a análise. Marque todas as opções e clique em Continuar.

Em Classificação, selecione a opção Calcular a partir de tamanhos de grupo e clique na opção Tabela de resumo em exibir. Selecione a opção Dentro dos grupos em Usar Matriz de Covariância. Por fim, em Diagramas, selecione grupos combinados e Territorial Map, depois clique em Continuar e em OK.
A Figura a seguir apresenta a análise descritiva das variáveis, em que pode-se ver as médias, os desvio padrão e o número de observações em cada grupo, com o total de 45 observações.
Group Statistics
Grupo Mean Std. Deviation Valid N (listwise)
Unweighted Weighted
Ruim
pH 4,7267 ,27140 18 18,000
MO ,9416 ,43841 18 18,000
P 1,0841 ,14661 18 18,000
K -,8594 ,19642 18 18,000
Ca ,4747 ,28416 18 18,000
Mg -,4135 ,33270 18 18,000
Al ,9972 ,19887 18 18,000
HeAl 5,2593 ,68255 18 18,000
V 17,4638 5,93469 18 18,000
Regular
pH 5,5305 ,37357 21 21,000
MO ,8844 ,42866 21 21,000
P 1,1743 ,19628 21 21,000
K -,7500 ,21901 21 21,000
Ca 1,5406 ,46088 21 21,000
Mg -,2425 ,32455 21 21,000
Al ,5024 ,34441 21 21,000
HeAl 3,6032 1,58243 21 21,000
V 42,4932 11,55820 21 21,000
Bom
pH 6,4850 ,34887 6 6,000
MO ,8534 ,24989 6 6,000
P 1,3490 ,17963 6 6,000
K -,5811 ,16541 6 6,000
Ca 2,5437 ,60984 6 6,000
Mg -,2139 ,26732 6 6,000
Al ,1250 ,02739 6 6,000
HeAl 1,5741 ,44119 6 6,000
V 68,8069 9,17182 6 6,000
Total
pH 5,3362 ,67505 45 45,000
MO ,9031 ,40741 45 45,000
P 1,1615 ,19185 45 45,000
K -,7713 ,21942 45 45,000
Ca 1,2480 ,82731 45 45,000
Mg -,3071 ,32646 45 45,000
Al ,6500 ,40816 45 45,000
HeAl 3,9951 1,69313 45 45,000
V 35,9899 19,78231 45 45,000
O teste de igualdade de médias dos grupos para cada variável explicativa é apresentado na próxima Figura, que mostra a ANOVA One Way das variáveis em estudo. Nela, também pode-se identificar as variáveis que são as melhores discriminantes dos níveis de qualidade (bom, regular e ruim). O lambda de Wilks, que varia de 0 a 1, testa a existência de diferenças de médias entre os grupos para cada variável. É importante lembrar que valores elevados desta estatística indicam ausência de diferenças entre os grupos. Pode-se perceber por meio dessa mesma Figura que as variáveis Saturação por Base (V), Potencial Hidrogeniônico (pH) e Cálcio (Ca) são as que mais discriminam os grupos, ou seja, seu poder de diferenciação dos grupos é superior, se comparado com as outras variáveis. Por outro lado, as variáveis Matéria Orgânica (MO) e Magésio (Mg) apresentam os valores mais elevados, demonstrando serem a pior em termos de discriminação dos grupos. O sig. F expressa as diferenças entre as médias, sendo que os valores mais próximos de 0 indicam médias mais distintas. Assim, pode-se assumir, que para a maioria das variáveis explicativas em análise, existe pelo menos um grupo em que as médias são diferentes.
Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
pH ,232 69,515 2 42 ,000
MO ,993 ,141 2 42 ,869
P ,801 5,216 2 42 ,009
K ,827 4,391 2 42 ,019
Ca ,248 63,544 2 42 ,000
Mg ,927 1,660 2 42 ,202
Al ,416 29,494 2 42 ,000
HeAl ,468 23,914 2 42 ,000
V ,214 76,962 2 42 ,000
As próximas Figuras apresentam as matrizes de covariância e de correlações. Estas figuras contribuem para a avaliação da relação entre as variáveis, e é a partir delas que pode-se notar a presença de multicolinearidade entre os elementos. Caso ocorram correlações muito elevadas entre duas variáveis, recomenda-se a exclusão de uma delas.

Pooled Within-Groups Matricesa
pH MO P K Ca Mg Al HeAl V
Covariance
pH ,111 ,006 ,015 ,014 ,082 -,003 -,022 -,104 1,624
MO ,006 ,173 ,017 ,003 ,006 ,004 ,021 -,049 ,305
P ,015 ,017 ,031 ,016 ,031 -,008 ,007 ,037 ,197
K ,014 ,003 ,016 ,042 ,009 -,010 ,002 ,078 -,211
Ca ,082 ,006 ,031 ,009 ,178 -,016 -,015 -,037 2,020
Mg -,003 ,004 -,008 -,010 -,016 ,103 ,027 ,021 ,899
Al -,022 ,021 ,007 ,002 -,015 ,027 ,073 ,079 -,416
HeAl -,104 -,049 ,037 ,078 -,037 ,021 ,079 1,404 -7,888
V 1,624 ,305 ,197 -,211 2,020 ,899 -,416 -7,888 87,886
Correlation
pH 1,000 ,042 ,263 ,208 ,582 -,033 -,250 -,264 ,521
MO ,042 1,000 ,226 ,040 ,037 ,031 ,189 -,100 ,078
P ,263 ,226 1,000 ,441 ,424 -,138 ,140 ,180 ,120
K ,208 ,040 ,441 1,000 ,100 -,153 ,033 ,323 -,110
Ca ,582 ,037 ,424 ,100 1,000 -,120 -,131 -,073 ,510
Mg -,033 ,031 -,138 -,153 -,120 1,000 ,308 ,056 ,298
Al -,250 ,189 ,140 ,033 -,131 ,308 1,000 ,247 -,165
HeAl -,264 -,100 ,180 ,323 -,073 ,056 ,247 1,000 -,710
V ,521 ,078 ,120 -,110 ,510 ,298 -,165 -,710 1,000
a. The covariance matrix has 42 degrees of freedom.
A seguir mostra-se a matriz de covariância para cada um dos grupos auxilia quanto à percepção de homogeneidade de covariância. É importante lembrar que a presença de homogeneidade das matrizes de covariância é um dos pressupostos da AD. Entretanto é a partir da estatística Box’M que será verificado se as diferentes dispersões observadas são ou não estatisticamente significativas. Este teste tem como hipótese nula que não há diferenças significativas entre os grupos, ou seja, que há homogeneidade das matrizes de covariância para os grupos em análise.
Covariance Matricesa
Grupo pH MO P K Ca Mg Al HeAl V
Ruim
pH ,074 ,005 -,001 ,018 ,018 -,004 -,040 ,008 ,321
MO ,005 ,192 ,003 ,005 -,016 ,017 -,012 -,050 ,045
P -,001 ,003 ,021 ,004 ,008 -,003 -,002 ,027 ,094
K ,018 ,005 ,004 ,039 ,013 -,025 -,012 ,028 ,073
Ca ,018 -,016 ,008 ,013 ,081 -,025 -,028 -,040 1,117
Mg -,004 ,017 -,003 -,025 -,025 ,111 ,000 -,004 ,892
Al -,040 -,012 -,002 -,012 -,028 ,000 ,040 ,031 -,554
HeAl ,008 -,050 ,027 ,028 -,040 -,004 ,031 ,466 -1,566
V ,321 ,045 ,094 ,073 1,117 ,892 -,554 -1,566 35,221
Regular
pH ,140 ,008 ,034 ,024 ,108 -,014 -,013 -,214 2,643
MO ,008 ,184 ,024 ,001 ,011 -,005 ,054 -,059 ,515
P ,034 ,024 ,039 ,026 ,054 -,008 ,015 ,045 ,510
K ,024 ,001 ,026 ,048 ,020 ,005 ,014 ,131 -,282
Ca ,108 ,011 ,054 ,020 ,212 -,030 -,008 -,021 2,378
Mg -,014 -,005 -,008 ,005 -,030 ,105 ,056 ,063 ,647
Al -,013 ,054 ,015 ,014 -,008 ,056 ,119 ,141 -,419
HeAl -,214 -,059 ,045 ,131 -,021 ,063 ,141 2,504 -14,354
V 2,643 ,515 ,510 -,282 2,378 ,647 -,419 -14,354 133,592
Bom
pH ,122 ,001 -,003 -,035 ,193 ,040 -,001 -,047 1,983
MO ,001 ,062 ,032 ,009 ,065 -,003 ,005 -,008 ,352
P -,003 ,032 ,032 ,018 ,021 -,026 ,002 ,042 -,702
K -,035 ,009 ,018 ,027 -,050 -,019 ,000 ,040 -,888
Ca ,193 ,065 ,021 -,050 ,372 ,070 ,002 -,087 3,654
Mg ,040 -,003 -,026 -,019 ,070 ,071 -,002 -,060 1,929
Al -,001 ,005 ,002 ,000 ,002 -,002 ,001 -,006 ,064
HeAl -,047 -,008 ,042 ,040 -,087 -,060 -,006 ,195 -3,519
V 1,983 ,352 -,702 -,888 3,654 1,929 ,064 -3,519 84,122
Total
pH ,456 -,014 ,065 ,067 ,501 ,044 -,204 -,830 11,914
MO -,014 ,166 ,013 ,000 -,017 ,001 ,031 -,007 -,281
P ,065 ,013 ,037 ,023 ,089 -,001 -,019 -,069 1,654
K ,067 ,000 ,023 ,048 ,073 -,003 -,026 -,038 1,384
Ca ,501 -,017 ,089 ,073 ,684 ,044 -,237 -,917 14,495
Mg ,044 ,001 -,001 -,003 ,044 ,107 -,001 -,078 2,282
Al -,204 ,031 -,019 -,026 -,237 -,001 ,167 ,456 -5,836
HeAl -,830 -,007 -,069 -,038 -,917 -,078 ,456 2,867 -29,161
V 11,914 -,281 1,654 1,384 14,495 2,282 -5,836 -29,161 391,340
a. The total covariance matrix has 44 degrees of freedom.
Resultado do teste Box’M
Test Results
Box's M 8,450
F
Approx. 1,259
df1 6
df2 1762,804
Sig. ,273
Tests null hypothesis of equal population
covariance matrices.
A Figura a seguir fornece as variáveis discriminantes em cada passo da análise. Pode-se perceber que apenas a variável V é incluída no modelo no passo 1. Já no passo 2, são incluídas as variáveis V e pH. Por mais que as variáveis P, K, Ca, Al e H + Al tenham se mostrado significante, isto é,

apresentam diferenças significativas nos três grupos, eles não foram incluídos na análise. Como pode ser observado por meio da matriz de correlações totais, obtida por meio do procedimento Analisar Correlação Bivariada, essas variáveis apresentam altas correlações com as variáveis V e pH selecionados na análise. Portanto, ficaram no modelo apenas os atributos com menores valores de lambdas de Wilks.
Variables Entered/Removeda,b,c,d
Step Entered Wilks' Lambda
Statistic df1 df2 df3 Exact F
Statistic df1 df2 Sig.
1 V ,214 1 2 42,000 76,962 2 42,000 ,000
2 pH ,178 2 2 42,000 28,134 4 82,000 ,000
At each step, the variable that minimizes the overall Wilks' Lambda is entered.
a. Maximum number of steps is 18.
b. Maximum significance of F to enter is .05.
c. Minimum significance of F to remove is .10.
d. F level, tolerance, or VIN insufficient for further computation.
Variáveis discriminantes em cada passo (stepwise)
Variables in the Analysis
Step Tolerance Sig. of F to Remove Wilks' Lambda
1 V 1,000 ,000
2
V ,729 ,004 ,232
pH ,729 ,021 ,214

Após a definição das variáveis discriminantes, procedeu-se a determinação das funções discriminantes importantes na análise das contribuições desses atributos. Neste estudo, como há três grupos, duas funções discriminantes são definidas para representar 100% da variância total, conforme apresenta a Figura a seguir, nela nota-se que houve grande predominância da primeira função discriminante, que representa 99,9% da variância total explicada. Além disso, o valor alto do coeficiente de correlação canônica da primeira função indica alto grau de associação entre a primeira função discriminante e os grupos.
Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical
Correlation
1 4,591a 99,9 99,9 ,906
2 ,007a ,1 100,0 ,081
a. First 2 canonical discriminant functions were used in the analysis.
Na Figura a seguir, inicialmente na primeira linha, são testadas as duas funções em conjunto, podendo-se concluir que pelo menos a primeira função discriminante é altamente significativa. A linha seguinte é referente à segunda função discriminante, sendo que não é possível rejeitar H0 de que as médias dos grupos nesta função são iguais. Além disso, há um decréscimo no poder discriminatório por conta do aumento no valor do lambda de Wilks.
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 through 2 ,178 71,704 4 ,000
2 ,993 ,272 1 ,602
A Figura a seguir apresenta os coeficientes não padronizados das funções discriminantes para cada uma das variáveis explicativas.
Canonical Discriminant Function
Coefficients
Function
1 2
pH 1,582 3,144
V ,066 -,106
(Constant) -10,819 -12,958
Unstandardized coefficients
Os coeficientes padronizados das funções discriminantes são obtidos pela multiplicação dos coeficientes não padronizados pelas respectivas raízes de covariâncias para cada variável. Os valores dos coeficientes padronizados das funções discriminantes, são apresentados na Figura abaixo. Segundo Maroco (2007), esses coeficientes, que também são chamados de pesos

discriminantes, podem ser utilizados para avaliar a importância relativa de cada variável explicativa para a função discriminante. Assim, variáveis explicativas com grande poder discriminante geralmente apresentam grandes pesos, porém a presença de multicolinearidade pode gerar certa igualdade na magnitude dos pesos discriminantes. A matriz de estrutura apresentada abaixo auxilia na interpretação da contribuição que cada variável forneceu para cada função discriminante, uma vez que apresenta as correlações entre as variáveis explicativas e as funções discriminantes canônicas padronizadas. As variáveis cujos valores apresentam-se com o asterico são as mais relevantes para a determinação de cada função discriminante, uma vez que oferecem maiores correlações com essas funções. Porém, apenas as variáveis com maior correlação com cada função canônica serão incluídos no modelo final, ou seja, V e pH na primeira função discriminante.
A definição do ponto de corte auxilia na classificação de novos elementos. A Figura abaixo apresenta os coeficientes das funções de classificação, que servem apenas para classificar observações e não têm qualquer interpretação discriminante.
Classification Function Coefficients
Grupo
Ruim Regular Bom
pH 54,545 58,771 64,570
V -,809 -,603 -,410
(Constant) -122,756 -150,473 -197,263
Fisher's linear discriminant functions
Standardized Canonical Discriminant
Function Coefficients
Function
1 2
pH ,527 1,046
V ,619 -,994
Structure Matrix
Function
1 2
V ,893* -,450
pH ,849* ,529
Cab ,622* ,101
HeAlb -,579* ,429
Alb -,234* -,098
Pb ,212* ,156
MOb ,071* -,034
Mgb ,167 -,330*
Kb ,041 ,327*

Como exemplo, considere uma amostra de solo com o grau de reação do potencial hidrogeniônico (pH) igual a 6,57 e percentual de saturação por bases (V) igual a 75,18%. Qual o possível grupo que pertenceria essa amostra de solo?
Bom = 64; 57 x 6; 57 – 0,41 x 75,18 – 197,26 = 196,11; Regular = 58; 77 x 6; 57 – 0,60 x 75,18 – 150,47 = 190,34;
Ruim = 54; 54 x 6, 57 – 0,81 x 75,18 – 122,76 = 174,75.
Dessa forma, essa nova amostra de solo, com as características mencionadas, pertenceria ao grupo bom do índice de qualidade do solo, visto que é neste grupo que se observa o maior valor das funções de classificação. A Figura abaixo mostra o resultado da classificação das amostras de solo pelo procedimento stepwise. Observa-se que 91,11% das amostras de solo foram classificadas corretamente e que apenas 4 amostras foram classificadas de forma errada.
Classification Resultsa
Grupo Predicted Group Membership Total
Ruim Regular Bom
Original
Count
Ruim 18 0 0 18
Regular 1 18 2 21
Bom 0 1 5 6
%
Ruim 100,0 ,0 ,0 100,0
Regular 4,8 85,7 9,5 100,0
Bom ,0 16,7 83,3 100,0
a. 91,1% of original grouped cases correctly classified.
No menu Analisar Classificar Discriminante, clique em Salvar e
selecione a opção Associação de grupo prevista, clique em continuar e em
OK.

Esta opção faz com que uma nova variável seja incluída no banco de dados, com os resultados dos grupos preditos. Este procedimento, realizado para cada observação, foi elaborado da mesma forma que o desenvolvido anteriormente quando do cálculo dos escores das funções de classificação para definição do grupo da nova amostra de solo. A Figura abaixo apresenta este novo banco de dados, por meio do qual é possível verificar quais foram as quatro observações classificadas de modo errado.
REFERÊNCIAS
[1] FÁVERO, L. P.; BELFIORE, P.; SILVA, F. L.; CHAN, B. L. Análise de
dados: modelagem multivariada para tomada de decisões. Rio de Janeiro:
Elsevier, 2009.
[2] HAIR, J. F.; ANDERSON, R. E.; TATHAM, R. L.; BLACK, W. C. Análise
multivariada de dados. Porto Alegre: Bookman, 2005.
[3] MAROCO, J. Análise estatística com utilização do SPSS. 3. ed. Lisboa:
Edições Sílabo, 2007.
[4] SHARMA, S. Applied multivariate techniques. New York: John Wiley &
Sons, 1996.





























