Embed Size (px)
Citation preview

ARQUITETURA DE COMPUTADORES
Aula 10: UCP – Evolução - II
Prof. Benito Piropo Da-Rin

Unidade Central de Processamento
• Evolução dos processadores - II
– Arquitetura superescalar (ou multiescalar);
– Exec. fora de ordem / Renomeamento de regs.
– Tecnologias SIMD / SSE
– Tecnologia HTT (Hyperthreading)
– Stepping / No eXecute Bit
– Controlador de memória integrado à UCP
(do Pentium ao Core)
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P5x (Pentium) março 1993: (P5: 03/93; P54: 10/94; P54C: 03/95)
Por que não i586? Arquitetura superescalar (ou multiescalar), duas pipelines; Cache 16 KB (2 x 8 KB, instruções e dados); Registradores: 64 bits (2 de 32 bits justapostos) FSB dados: 64 bits; endereços: 32 bits; Freq: 60/66 MHz Memória RAM endereçável: 4 GB; Virtual: 64 TB; Frequência: P5: 60/66 (P54: 75 a 120; P54C: 120 a 200) MHz; P5: 3,1 milhões de transistores (P54: 3,2 ; P54C: 3,3) Camada de Si: P5: 0,8 micron (P54: 0,6 ; P54C: 0,35) Dissipador de calor ativo (com ventoinha)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Pentium – P5
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Arquitetura superescalar: Nem todas as instruções precisam ser
executadas na sequência original (por exemplo: a parte inicial do cálculo da área das paredes de uma sala pode ser distribuída por duas rotinas paralelas)
Quando há mais de uma pipeline, as rotinas podem ser simultaneamente executadas, uma em cada pipeline.
A “arquitetura superescalar” é um recurso típico de processadores RISC incorporado à linha Pentium. Com o Pentium começou a migração da arquitetura CISC para a RISC nas UCPs da Intel (compatibilidade retroativa -> pré-processamento )
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Execução fora de ordem: A distribuição de tarefas entre
pipelines raramente é equilibrada, o que faz com que uma pipeline fique ociosa quando termina antes.
Neste caso o processador a ocupa com rotinas cuja execução não dependem de resultados intermediários, mesmo que tenha que alterar sua ordem de execução (execução fora de ordem).
Os resultados são “guardados” até o momento em que são necessários.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Renomeamento de registradores: Registradores são designados por
nomes, não por endereços. No caso da execução fora de ordem, é
comum que uma rotina executada “antes da hora” precise usar o mesmo registrador em uso por outra que está sendo executada na ordem correta.
SOLUÇÃO: Implementar maior número de registradores que os nominalmente existentes e “renomear” dinamicamente os registradores “reserva”, se necessário.
Isto se denomina “Renomeamento Dinâmico de Registradores”.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P55 (Pentium MMX) (Pentium P55C (MMX): outubro de 1996) Incorporou tecnologia SIMD (Intel “batizou” de
MMX); Mesmas características básicas dos P5x; Primeiro a usar o “Socket 7” de 321 pinos; Frequências: 166 / 200 / 233 / 266 / 300 MHz; FSB: 66 MHz; 4,5 milhões de transistores; Camada de Si: 0,35 micron; Cache interno aumentado para 32 KB.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Single Instruction, Multiple Data (SIMD) No final dos anos 90 a multimídia (som, imagem, vídeo)
passou a ser importante para a linha PC. O que caracteriza as instruções usadas em programas
voltados para multimídia é o fato delas executarem a mesma operação, repetidamente, com os mesmos dados (por exemplo: mudar a cor do fundo de uma imagem).
Para melhorar o desempenho de programas multimídia, a Intel incorporou ao conjunto de instruções do Pentium 55C algumas capazes de lidar, de uma só vez, com grandes blocos de dados – uma instrução, muitos dados = SIMD
Intel batizou esta extensão do conjunto de instruções de “MMX”, significando originalmente “MultiMidia eXtension”.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P5/P55:
CONCEITOS:
• Arquitetura Superescalar (ou multiescalar): Execução fora de ordem, Renomeamento de Registradores.
• Tecnologia SIMD (Single Instruction, Multiple Data).
• Início do uso do dissipador de calor ativo (com ventoinha) nas UCP Intel.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6 (Pentium Pro)
(Pentium Pro: novembro de 1995) Criado para servidores (alto desempenho; núcleo
RISC, instruções CISC “traduzidas” em micro ops);
Caches: L1=8+8KB; L2 Integrado (interno): 256 KB / 1 MB funcionando na mesma frequência que UCP;
Freqüência: 166/ 180/ 200 MHz; FSB: 60 / 66 MHz;
5,5 milhões de transistores (na UCP);
Camada de Si: 0,6 micron;
Socket 8 (387 contatos).
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6 (Pentium II)
(Pentium II: maio de 1997) Mesmo núcleo P6 (era um PPro com L2 externo);
Em vez de soquete, “Slot 1” (242 contatos);
Cache Interno (L1): 32 KB, Externo (L2): 512 KB
Cache L2:
• Fora do encapsulamento, mas no mesmo módulo
• Operando com metade da freqüência do L1
Frequência: 233 / 266 / 300 / 333 / 350 / 450 MHz;
FSB: 66 MHz (até 333 MHz) / 100 MHz (até 450 MHz);
7,5 milhões de transistores
Camada de Si: 0,35 micron (até 300 MHz); 0.25 micron.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6 (Pentium II)
(Pentium II e seu “Slot 1”) Módulo e proteção com ventoinha.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6 (Pentium III/Xeon)
(Pentium III: 02/1999; Xeon: 06/1998) Pentium III: “desktops”; Xeon: servidores
SSE (Streaming SIMD Extensions) com 70 novas instruções;
Cache: L1 = 32 KB / L2: 256 KB-2MB
9,5 a 28 milhões de transistores; 450 MHz a 1,4 GHz;
Diversas versões (a Tualatin com pipeline de 10 estágios):
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin
Codinome Camada de Si (μ) Encaixe FSB (MHz) Freq. (MHz)
Katmai 0,25 Slot 1 100/133 450 a 600
Coppermine 0,18 Slot 1/ Socket 370 100/133 500 a 1000
Tualatin 0,13 Socket 370 133 1133 a 1400

Microarquitetura P6 (Pentium III)
(Versões para Slot 1 e Soquete 370)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6 (Pentium III)
(SSE: Streaming SIMD Extensions) SSE: aperfeiçoamento da tecnologia SIMD
SIMD só funcionava para dados do tipo “inteiro” porque suas instruções usavam os registradores da unidade de ponto flutuante como registradores auxiliares.
SSE: adicionou 8 novos registradores (Regs XMM 0 a 7) de 128 bits cada; Cada um deles pode armazenar 4 dados numéricos de ponto flutuante de 32 bits.
A melhora no desempenho multimídia, sobretudo em atividades tipo transmissão de áudio e vídeo pela Internet (“streaming” de áudio e vídeo) foi significativa.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura P6:
CONCEITOS:
• SSE: Streaming SIMD Extensions.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Netburst (Pentium 4) (Pentium 4: novembro de 2000) Nova geração Pentium (P7), microarquitetura NetBurst;
• Hyper Pipelined Technology: pipeline com 20 estágios, chegando a 31 estágios na versão Prescott (“press hot”);
• Rapid Execution Engine: ULA opera com o dobro da frequência nominal do microprocessador para compensar perdas dos erros frequentes da pipeline demasiadamente longa;
• SSE2/SSE3: Extensão da SSE: 144/+13 novas instruções. • Execution Trace Cache: micro-ops ficam armazenadas no cache
L2; evita decodificar se for invocada novamente;
42 / 55 milhões de transistores; Camada de Si: 0,18 / 0,13 micron Frequência: 1,4-2,8 GHz; FSB 400/533 MHz; Cache:256/512 MB Consumo de potência elevadíssimo (P4 EE: 130 W)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Netburst (Pentium 4)
Pentium 4 HT (HyperThreading)/EE
Pentium 4 HT: Novembro de 2002
• Incorporou a HTT (Hyper Threading Technology), marca registrada Intel para “Simultaneous Multithreading”;
• Frequência: 3/3,73 GHz; FSB: 400/1066 MHz (4 x 266)
• 55 / 169 milhões de transistores (Extreme Edition)
• Camada de silício: 0,13 a 0,09 micron (90 nm)
• Cache L2: 512 MB / 2 GB (Extreme Edition)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Netburst (Pentium 4HT)
(HTT: Hyper Threading Technology) HTT: marca registrada Intel para sua implementação de
“simultaneous multithreading”.
Esta tecnologia faz com que, em determinadas situações, cada “pipeline” de um Pentium 4 HT apareça para o sistema como uma linha de processamento independente simulando dois processadores “lógicos” (antecipação dos núcleos múltiplos). Estas situações são tipicamente: erros de cache, erro na predição de ramo, execução de rotina dependente de dados.
Como estas ocorrências são relativamente comuns, a liberação de uma pipeline para o HT é relativamente frequente. A Intel alega um ganho de 30% no desempenho.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Netburst:
CONCEITOS:
• Hyper Pipelined Technology (chegou a 31 estágios; foi um erro: dissipava muito calor e consumia muita potência justamente na época em que os dispositivos portáteis ganhavam mercado);
• Rapid Execution Engine (ULA: dobro da frequência da CPU);
• Execution Trace Cache (cache para micro-ops):
• “Simultaneous Multithreading” (para Intel: HTT);
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

O problema do calor… A energia dissipada sob a forma de calor em uma UCP
depende de três fatores: tensão, frequência de operação e resistência interna (todos na razão direta);
Os processadores antigos eram alimentados com tensão de 5 V. Os mais modernos (Core) chegaram a 1,035 V. Não dá para baixar mais.
PORTANTO: para aumentar o desempenho aumentando a frequência é preciso baixar a resistência
E para baixar a resistência é preciso reduzir a espessura da camada de Silício…
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Reduzindo a camada de Si O processo de fabricação dos microprocessadores
consiste na gravação por processo fotográfico do circuito dos núcleos em uma placa circular de Silício
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Reduzindo a camada de Si Cada transistor é gerado pela deposição de impurezas
microscópicas sobre o silício. Em camadas de silício de 30 nm de espessura a largura da “porta” chega a 15 nm (microfotografia 5); atualmente as menores espessuras fabricadas são de 32 nm (Intel Core i7-900 EE)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Reduzindo a camada de Si Estudos indicam que se a espessura da porta (base) se
reduzir até cerca de 5 nm (o que, mantido o ritmo atual de evolução da tecnologia de fabricação, deverá ocorrer em menos de dez anos), fonte e dreno (coletor e emissor) ficarão tão próximas que o silício entre elas não conseguirá funcionar como isolante e a corrente fluirá mesmo que não haja tensão na porta (fenômeno denominado “tunneling”).
PORTANTO: o aumento do desempenho pelo aumento da frequência está próximo do limite.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Reduzindo a camada de Si Estudos indicam que se a espessura da porta (base) se
reduzir até cerca de 5 nm (o que, mantido o ritmo atual de evolução da tecnologia de fabricação, deverá ocorrer em menos de dez anos), fonte e dreno (coletor e emissor) ficarão tão próximas que o silício entre elas não conseguirá funcionar como isolante e a corrente fluirá mesmo que não haja tensão na porta (fenômeno denominado “tunneling”).
PORTANTO: o aumento do desempenho pelo aumento da frequência está próximo do limite.
SOLUÇÃO: processamento paralelo (núcleos múltiplos)
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Processadores multinucleares;
Primeira tentativa: Pentium D (maio de 2005)
• Ainda usando a microarquitetura Netburst, variantes Smithfield e Presler, sem HT;
• Dois núcleos independentes (na verdade, duas UCPs) no mesmo encapsulamento;
• Freq: 2,8 a 3,6 GHz ; FSB: 800 MHz
• Nr. transistores: 230 (Smithfield)/ 376 milhões (Presler);
• Camada de Si: 90 nm (Smithfield) / 65 nm (Presler)
• Cache L2: 2 MB
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Core (Core 2 Duo: 06/2006) Núcleos múltiplos (no início: 2 ou 4) integrados e interagindo.
Baseada revisão Yonah da P6, usada no Pentium M, devido ao menor consumo de energia (“performance per watt”).
Uso de patamares (“steppings”) de consumo de potência.
Frequência: 1,33 a 3,2 GHz; FSB: 800 / 1066 MHz
Cache L2 (2MB-4MB)compartilhado pelos núcleos.
Cache L1: 64 KB por núcleo.
Pipeline de 14 estágios por núcleo;
Nr. de transistores: 167 a 586 milhões
Camada de Si: 65 nm/45nm.
Execute Disable Bit.
Suporte a virtualização.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Core Execute Disable Bit ou NX bit • Na arquitetura de Von Neumann, dados e instruções compartilham
o mesmo espaço de memória; • Isto pode ser inconveniente se por acaso ou por malícia um dado for
confundido com uma instrução (e “executado”); • A tecnologia NX bit segrega dados de instruções e impede que
qualquer código armazenado no trecho dedicado a dados possa ser executado;
• O bit NX (não executável) é o de ordem 63 (o mais significativo) de cada entrada em uma tabela de páginas (“table page”). UCPs que usam esta tecnologia armazenam código em páginas cujas entradas têm o bit 63 valendo zero. Se ponteiro de instruções apontar para um endereço começando em “um”, o sistema recusa.
• Esta tecnologia já era adotada comumente em máquinas de grande porte e processadores como Power PC e Itanium. Nos micros de mesa, foi adotada antes pela AMD.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Core Suporte a Virtualização (Intel VT-x); • Virtualização é a capacidade de permitir que diferentes
sistemas operacionais rodem simultaneamente em um mesmo computador de forma segura e eficiente;
• Ela usa o modo protegido para criar uma ou mais máquina(s) virtual(is) para instalar o(s) novo(s) sistema(s);
• Para funcionar, os dispositivos de E/S precisam ser emulados por software e algumas instruções têm que ser “traduzidas”;
• A Intel e AMD implementaram “extensões” (Intel VT-x e AMD-V) que facilitam esta “tradução”.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Core:
CONCEITOS: • Mais de um núcleo;
independentes porém interagindo entre si;
• Desempenho referido à potência consumida (“performance per watt”);
• Consumo de potência em patamares (“steppings”);
• Execute Disable Bit ou NX bit (No eXecute bit);
• Suporte a Virtualização.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Nehalem (Core iX: 12/2008) Nehalem: concebida desde o início para núcleos
múltiplos (Core i7 “Gulftown”: março 2010, 6 núcleos).
Substituição do Barramento Frontal (FSB) pela conexão direta com memória (QPI de “Quick Path Interconect”).
Núcleos mútiplos (2/4/6/...) integrados e interagindo.
Cache L2 (4MB-12MB)compartilhado pelos núcleos. Cache L1: 256 KB por núcleo. HyperThreading (não usada desde Netburst); Frequências: 1,07 a 3,33GHz; QPI: 800 / 1333 MHz; Nr. de transistores: 781 milhões e mais; Camada de Si: 45 nm/32nm. Ajuste dinâmico da frequência (“TurboBoost”).
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Conexão Convencional entre UCP e Memória (FSB) Processadores se comunicam
através de um barramento (o FSB ou “Barramento Frontal”) com um CI auxiliar (“North bridge”) que abriga o controlador da memória e se comunica com um segundo CI (“South bridge”) que controla todos os dispositivos de E/S, inclusive memória secundária.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin
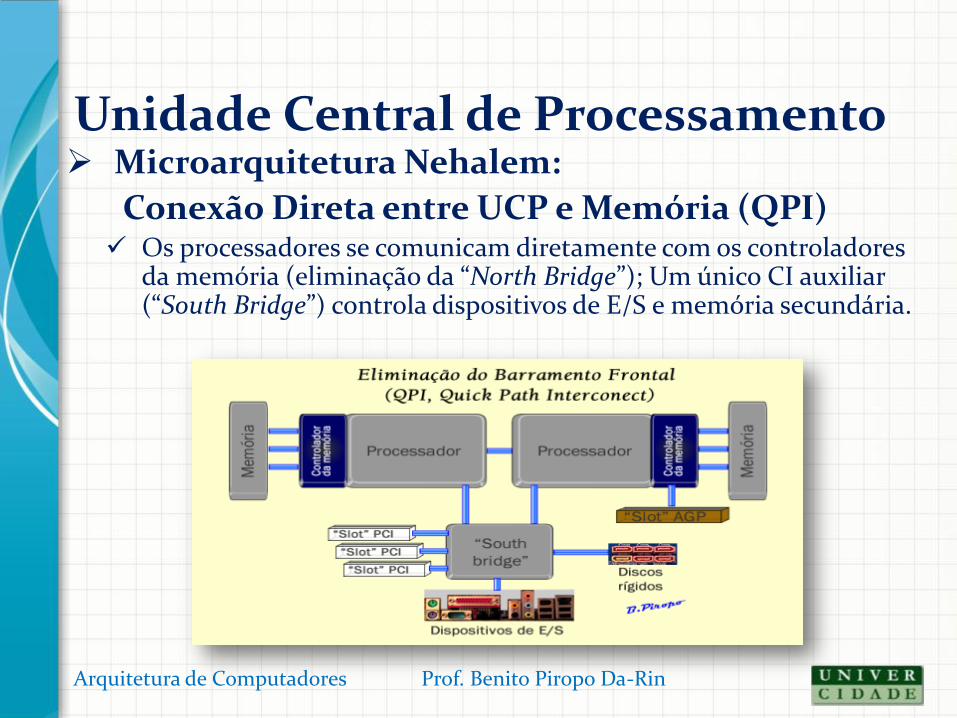
Microarquitetura Nehalem:
Conexão Direta entre UCP e Memória (QPI) Os processadores se comunicam diretamente com os controladores
da memória (eliminação da “North Bridge”); Um único CI auxiliar (“South Bridge”) controla dispositivos de E/S e memória secundária.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Nehalem: Ajuste dinâmico da frequência (TurboBoost) Em um processador multinuclear a demanda sobre os diversos
núcleos não é equilibrada. Por vezes um dos núcleos recebe uma carga de processamento muito maior que os demais;
Nestas ocasiões a UCP opera globalmente muito abaixo de seus limites térmicos e elétricos (baixa demanda sobre muitos núcleos, alta apenas sobre poucos);
Quando isso ocorre, a tecnologia TurboBoost aumenta a frequência de operação do núcleo que recebe maior carga em incrementos de 133 MHz em rápidos intervalos até que os limites globais da UCP sejam alcançados. E, se ultrapassados, reduz na mesma proporção até que voltem a se equilibrar.
O “TurboBoost” funciona como se fosse um “overclock” consentido apenas do núcleo que suporta demanda máxima.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Microarquitetura Nehalem:
CONCEITOS: • Controlador da memória incorporado aos
processadores (Intel QPI / AMD Direct Connect Architecture);
• Ajust dinâmico da frequência dos núcleos (“Turbo Boost”);
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Integração do processamento gráfico à UCP (Arquiteturas Intel SandyBridge / AMD Fusion)
O coprocessador gráfico (GPU, de “Graphics Processing Unit”) se integra à UCP (como o i486 integrou um coprocessador matemático até então fornecido separadamente);.
No processamento gráfico predominam operações sobre vetores (dados em posições contiguas da MP); no processamento geral não [Processamento Gráfico: vetorial (SIMD) / Geral: escalar (SISD)].
Porém: cada vez se usa mais processamento vetorial nas tarefas comuns (reconhecimento de fisionomia, impressões digitais, etc.);
Resultado: em processadores de núcleos múltiplos, alguns são otimizados para processamento escalar, outros para processamento vetorial (são processadores gráficos incorporados à UCP).
Intel: Clarkdale; Arandale / AMD: Brazos; Llano.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Arquitetura ARM (Advanced Risc Machine) Baixos consumo de energia e capacidade de processamento;
Processadores “de 32 bits”, RISC, instruções de tamanho fixo;
Embora simples, usam recursos avançados como “pipeline”, SIMD, virtualização, núcleos múltiplos.
6 modelos, básicos, duas famílias: Classic e Cortex (2 núcleos);
Usados em telefones espertos (“smartphones”), tabletes, micros portáteis de baixo desempenho, automação, “consumer electronics” (TVs, DVD/MP3 players, agendas, calculadoras...)
Licenciados pela ARM Holdings para empresas que podem agregar partes opcionais e usar sua marca: Nvidia, TI, Sharp...
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

Algumas observações… ... à margem da disciplina, apenas para evitar confusões;
• Não confundir marca (Pentium, Core, Xeon) com microarquitetura (P6, Netburst, Core, Nehalem) ou com suas variantes (Tualatin, Yonah.../ Willamettte, Foster... /Merom, Conroe... / Clarksfield, Arrandale...). No conjunto, formam um emaranhado de denominações sem qualquer lógica ou sentido que só interessa a quem pretende se especializar em microprocessadores ou aos vendedores de produtos Intel. Mais informações em Nova Estrutura da Marca Intel I: Arquitetura e Plataforma
• O Core Duo (núcleo duplo) lançado em janeiro de 2006, assim como o Core Solo (núcleo único), de fevereiro de 2006, não usavam microarquitetura Core, mas a variante Yonah da P6. O primeiro membro da microarquitetura Core foi o Core 2 duo lançado em junho de 2006.
• Centrino e VPro não são UCPs, mas plataformas.
• Alguns modelos, como Celeron, Pentium M, Itanium, Atom e outros, não foram mencionados por não implicarem alterações conceituais na microarquitetura.
Unidade Central de Processamento
Arquitetura de Computadores Prof. Benito Piropo Da-Rin

ARQUITETURA DE COMPUTADORES
Aula 10: UCP – Evolução - II
Prof. Benito Piropo Da-Rin