Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
DANIEL GOMES DE OLIVEIRA
Avaliação de Ferramentas de GeraçãoAutomática de Dados de Teste para
Programas Java: Um EstudoExploratório
Goiânia
2016


DANIEL GOMES DE OLIVEIRA
Avaliação de Ferramentas de GeraçãoAutomática de Dados de Teste paraProgramas Java: Um Estudo
Exploratório
Dissertação apresentada ao Programa de Pós-Graduação do
Instituto de Informática da Universidade Federal de Goiás,
como requisito parcial para obtenção do título de Mestre em
Ciência da Computação.
Área de concentração: Ciência da Computação.
Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi
Goiânia
2016

Ficha de identificação da obra elaborada pelo autor, através doPrograma de Geração Automática do Sistema de Bibliotecas da UFG.
CDU 004
Gomes de Oliveira, Daniel Avaliação de Ferramentas de Geração Automática de Dados deTeste para Programas Java: Um Estudo Exploratório [manuscrito] /Daniel Gomes de Oliveira. - 2016. LVIII, 58 f.: il.
Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi . Dissertação (Mestrado) - Universidade Federal de Goiás, Institutode Informática (INF), Programa de Pós-Graduação em Ciência daComputação, Goiânia, 2016. Bibliografia. Apêndice. Inclui siglas, abreviaturas, símbolos, gráfico, tabelas, lista defiguras, lista de tabelas.
1. Teste de software. 2. geradores automáticos de dados deteste. 3. cobertura de código. 4. teste de mutação. 5. estudosexperimentais. I. , Auri Marcelo Rizzo Vincenzi, orient. II. Título.


DANIEL GOMES DE OLIVEIRA
Avaliação de Ferramentas de GeraçãoAutomática de Dados de Teste paraProgramas Java: Um Estudo
Exploratório
Dissertação apresentada ao Programa de Pós-Graduação do
Instituto de Informática da Universidade Federal de Goiás,
como requisito parcial para obtenção do título de Mestre em
Ciência da Computação.
Área de concentração: Ciência da Computação.
Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi
Goiânia
2016

DANIEL GOMES DE OLIVEIRA
Avaliação de Ferramentas de GeraçãoAutomática de Dados de Teste para
Programas Java: Um EstudoExploratório
Dissertação defendida no Programa de Pós-Graduação do Instituto deInformática da Universidade Federal de Goiás como requisito parcialpara obtenção do título de Mestre em Ciência da Computação, aprovadaem 15 de Fevereiro de 2016, pela Banca Examinadora constituída pelosprofessores:
Prof. Dr. Auri Marcelo Rizzo Vincenzi
Instituto de Informática – UFGPresidente da Banca
Prof. Dr. Plínio de Sá Leitão Júnior
Instituto de Informática – UFG
Prof. Dr. Arilo Cláudio Dias Neto
Instituto de Computação – UFAM

Todos os direitos reservados. É proibida a reprodução total ou parcial dotrabalho sem autorização da universidade, do autor e do orientador(a).
Daniel Gomes de Oliveira
Graduado em Análise de Sistemas pela Universidade Salgado de Oliveira,Possui o título de Especialista em Desenvolvimento de Software pela insti-tuição Senac. Bolsista pela Coordenação de Aperfeiçoamento de Pessoal doNível Superior (CAPES).

Dedico este trabalho principalmente à minha família e ao meu orientador.

Agradecimentos
A Deus por permitir que diante de todas as dificuldades encontradas no caminho
os objetivos fossem alcançados.
À minha família, Romes Carlos de Oliveira (pai), Orcélia Maria de Oliveira
(mãe), Flávio Gomes de Oliveira (irmão), Raquel Martins de Oliveira (Esposa) e a Giovani
Martins de Oliveira Gomes e Gustavo Martins de Oliveira Gomes (filhos) que além de
apoio, não se opuseram a ausências em alguns eventos familiares.
Ao meu orientador, Dr. Auri Marcelo Rizzo Vincenzi, por todos os momentos em
que esteve disponível para esclarecer minhas dúvidas e passar orientações com clareza.
Agradeço pela dedicação oferecida a mim durante este período de mestrado, mesmo em
momentos de disponibilidade à sua família.
À Coordenação de Aperfeiçoamento de Pessoal do Nível Superior (CAPES),
pela bolsa que contribuiu para que essa pesquisa se tornasse possível.
Ao Professor Dr. Fernando Marques Federson por permitir cumprir meu estágio
de docência em sua disciplina, me passando todas as orientações quanto a como proceder
em um ambiente acadêmico como também orientações que são para toda uma vida.
À toda equipe administrativa da Universidade Federal de Goiás por ceder espaço
para realização dos estudos como insumos necessários para o mesmo.
Aos amigos de mestrado, que me apoiaram em toda essa jornada, Tiago do
Carmo Nogueira, Márcio Dias de Lima, Matheus Rudolfo Diedrich Ullmann, Weder
Cabral Mendes, Flávio de Assis Vilela.

Um bom teste de software é aquele que revela a presença de falhas noproduto com a máxima cobertura de códigos e o mínimo de esforço por partedo testador (BARBOSA; MALDONADO; VINCENZI, 2000).
Barbosa E. F., Maldonado J. C., Vincenzi A. M. R.,ICMC-USP.

Resumo
Oliveira, Daniel G. Avaliação de Ferramentas de Geração Automática de
Dados de Teste para Programas Java: Um Estudo Exploratório. Goiânia,2016. 57p. Dissertação de Mestrado. Instituto de Informática, UniversidadeFederal de Goiás.
Considerando o alto custo e a grande quantidade de tempo demandada pela atividade
de criação de casos de testes dentro do processo de desenvolvimento de software. A
utilização de ferramentas ou procedimentos que tornem o processo de geração de dados
de testes mais ágil, menos oneroso e que atendam demandas por precisão se tornam
fundamentais para que as empresas atuantes no mercado de desenvolvimento de software
possam atingir seus objetivos. Com base nessas informações, surge a dúvida relacionada
a como proceder para adotar um processo de desenvolvimento e teste de software que
tornem possíveis o alcance dos objetivos de forma a atender os resultados mencionados
anteriormente, mesmo com as dificuldades de gerar dados de teste em decorrência dos
domínios de entrada dos programas serem em geral infinitos. O objetivo do presente
trabalho é conduzir uma avaliação experimental de geradores automáticos de dados de
teste visando identificar qual deles apresenta a melhor relação custo/benefício em termos
de eficácia em detectar defeitos, número de dados de teste gerados e cobertura de código
determinada pelos conjuntos de teste. A pesquisa foi dirigida em duas etapas: na primeira,
dois geradores foram avaliados em relação a um conjunto de 32 programas Java e os
resultados obtidos indicam que, de maneira geral, o gerador CodePro foi o que apresentou
a melhor relação custo benefício frente ao Randoop; na segunda, foi inclusa uma terceira
ferramenta, juntamente a testes gerados de forma manual. Foram gerados novos conjuntos
de teste utilizando os três geradores automáticos e incluso ao projeto conjuntos gerados
de forma manual. Ao final, foram apresentados os resultados em termos de eficácia e
eficiência por meio dos comparativos entre os quatro conjuntos de teste.
Palavras–chave
Teste de software, geradores automáticos de dados de teste, cobertura de código,
teste de mutação, estudos experimentais.

Abstract
Oliveira, Daniel G. Automatic Generation Tools Assessment Test Data: Ex-
ploratory Study.. Goiânia, 2016. 57p. MSc. Dissertation. Instituto de Informá-tica, Universidade Federal de Goiás.
Considering the high cost and large amount of time demanded by the activity generation
tests in the software development process, the need a proposal to reduce both the time
spent as the related costs testing activities is necessary. In this context, the use of tools or
processes that make the activities of generation of more agile testing, less costly and meet
demands for precision are key to companies operating in software development market
can achieve their goals. Based on these information comes to questions regarding how to
go about adopting a process that makes possible the achievement of objectives in order to
meet the results mentioned previously, even with the difficulties of generating test data as
a result of of programs input areas are infinite. There are different tools that use various
strategies for generating test data, however, lacks evidence as the quality of these tools.
In this context, the aim of this work is conducting an experimental evaluation of some
automatic test data generators to identify which one offers the best cost / benefit in terms
of effective in detecting defects number of generated test data, code coverage demanded
by test data, and generation time of testing. At second step a third tool was included along
manually generated tests. New test sets using three automatic generators and included the
manually -generated sets project were generated. Finally, results were presented in terms
of effectiveness and efficiency through the comparison between the four test sets .
Keywords
Software testing, automatic test data generators, code coverage, mutation testing,
experimental studies.

Sumário
Lista de Figuras 10
Lista de Tabelas 11
1 Introdução 12
1.1 Motivação 131.2 Objetivo do Trabalho 16
1.2.1 Metodologia 171.3 Organização do Trabalho 18
2 Terminologia e Conceitos Básicos 19
2.1 Considerações Iniciais 192.2 Dado de Teste, Caso de Teste e Conjunto de Teste 192.3 Etapas do Processo de Testes 202.4 Geração de Dados de Teste 212.5 Variáveis 23
3 Revisão Bibliográfica 26
4 Ambiente de Experimentação 31
4.1 Definição de Experimentação 324.2 Metodologia 334.3 Plano de Experimentação 364.4 Validação dos Dados 374.5 Execução do Experimento 384.6 Análise de Dados Coletados 404.7 Ameaças a Validade 504.8 Considerações Finais 51
5 Conclusão 52
5.1 Contribuições 535.2 Trabalhos Futuros 53
Referências Bibliográficas 55

Lista de Figuras
2.1 Domínios de entrada e saída de dado programa. Adaptada de (JORGE,2013). 22
4.1 Conjunto de ferramentas formado com Randoop - fase 1. 344.2 Conjunto de ferramentas formado com CodePro Tools - Fase 1. 354.3 Programas em projetos Maven. 384.4 Estrutura dos programas usando o Maven. 394.5 Forma como são gerados os testes no CodePro Tools. 404.6 Relação Cobertura de Códigos. 434.7 Relação Dados de Teste Gerados. 434.8 Relação Quantidade de Mutantes Gerados. 454.9 Relação Quantidade de Mutantes Mortos. 464.10 Relação Score de Mutação. 47

Lista de Tabelas
2.1 Lista de ferramentas de geração automática de dados de teste. 24
3.1 Trabalhos relacionados a avaliação de ferramentas. 30
4.1 Lista filtrada de ferramentas de geração automática de dados de teste. 324.2 Lista completa de ferramentas, versões e funcionalidades. 324.3 Hipótese. 364.4 Lista de programas utilizados para a geração dos experimentos. 374.5 Tabela com os dados analisados - CodePro Tools. 414.6 Tabela com os dados a serem analisados - Randoop. 424.7 Tabela com os dados analisados CodePro Tools e PIT Test. 444.8 Tabela com os dados analisados Randoop e PIT Test. 454.9 Tabela - Informações Estáticas dos Programas Java. 474.10 Cobertura e Declaração de Mutação - Score por Teste Gerado. 48

CAPÍTULO 1Introdução
O desenvolvimento de software é um processo composto por etapas, e o teste de
software é uma etapa que compõe esse processo.
Teste é uma atividade obrigatória para a garantia da qualidade de software.
Com base nesta etapa do processo, surgem diversos paradigmas e questionamen-
tos relacionados ao assunto (DELAHAYE; BOUSQUET, 2015).
Perguntas como, qual a melhor linguagem para o desenvolvimento, quais fer-
ramentas utilizar para geração de dados de teste, qual a melhor metodologia de testes
utilizar, e outros questionamentos surgem durante todo o projeto.
A presente pesquisa tem o intuito de avaliar eficácia, custo e força de um
conjunto de testes gerados de forma manual e automática em programas Java.
Para cobrir acima de 80% do código o profissional deve conhecer profundamente
as regras de negócio implementadas (BACHIEGA et al., 2016).
Um aspecto interessante pode ser observado em um trabalho reproduzido em
paralelo ao atual, conjuntos de teste gerados de forma automática complementam os
gerados de forma manual (BACHIEGA et al., 2016).
Nesse estudo, quando combinados conjuntos teste manuais com aqueles gerados
automaticamente, a média de cobertura de código e de escore de mutação aumentaram
mais de 10% em relação aos valores obtidos pelos conjuntos de teste individuais, man-
tendo um custo baixo.
Sendo assim, sugere-se que os testes manuais poderiam ser utilizados para testes
em partes essenciais e críticas do software podendo melhorar os resultados adicionando
dados de testes gerados automaticamente.
Ainda em relação a etapa de testes de software, existem vários processos bem
definidos para auxiliar na tarefa árdua, e onerosa que compõem este processo.
Entretanto, testes de software apresenta ainda muito potencial de melhoria e ma-
turação abrindo espaço para que os estudiosos e pesquisadores invistam seus conhecimen-
tos em busca de novas técnicas e procedimentos.
A fase de teste é tida como a etapa mais dispendiosas no processo de desenvolvi-
mento de softwares podendo ultrapassar 50% do custo total do projeto (DELAHAYE;

1.1 Motivação 13
BOUSQUET, 2015; SHARMA; BAJPAI, 2014; KRACHT; PETROVIC; WALCOTT-
JUSTICE, 2014).
O fator tempo impacta de forma direta no custo, sendo que quanto maior o tempo
gasto para o desenvolvimento e testes, maiores serão os gastos com mão de obra entre
outras variáveis que também dependem desta etapa.
De forma geral, a grande maioria dos autores envolvidos nessa linha de pesquisa
concordam que tanto o tempo quando os custos do processo devem ser reduzidos.
Isso pode ocorrer tanto em função de mudanças nas metodologias já existentes
quanto na automatização de atividades repetitivas, e muito onerosas do processo e que
demandem uma quantidade excessiva de tempo.
Existem vários segmentos relacionados a testes de software, dentre eles estão
a geração de dados de teste de forma manual e geração de dados de teste de forma
automática.
Em relação a geradores automáticos, a presente pesquisa está direcionada a
domínios de geração aleatória de dados de teste e geração baseada em heurísticas e
técnicas de otimização.
Quanto antes uma falha é identificada, menor será o custo de correção e menor a
possibilidade do projeto fracassar.
Os testes se iniciam em nível de unidade, seguido por testes de integração, e,
finalmente, são realizados os testes de sistema. Este trabalho tem foco nos testes unitários.
A seleção dos casos de teste tem fundamental importância para o processo, tendo
em vista que, idealmente, todas as unidades a serem testadas devem ser cobertas pelos
casos de teste.
Esse processo pode ocorrer de forma manual ou automatizada.
As entradas são geradas, mas o gerador não conhece as regras de negócio do
produto.
As regras não podem ser geradas de forma automática, mas uma vez definidas,
elas são a base para a identificação das saídas esperadas que cada unidade em teste deve
produzir.
1.1 Motivação
O fator predominantemente motivador para a elaboração dessa pesquisa está
relacionado às ferramentas e metodologias utilizadas no processo de testes e em como a
utilização de um determinado conjunto pode impactar nos resultados e custos do processo
como um todo.

1.1 Motivação 14
Alguns problemas identificados durante o andamento do projeto foram conside-
rados como potenciais oportunidades de melhorias a serem empregadas na fase de testes
de software.
Durante a elaboração da pesquisa, em uma pré-apresentação do trabalho aos
alunos de graduação ocorrida no estágio docência, na disciplina de Gerenciamento de
Projetos da Universidade Federal de Goiás, foi feita uma pergunta aos alunos, quais
atuavam do mercado como testadores. Na ocasião, 5 de aproximadamente 40 alunos
informaram serem atuantes em empresas distintas na cidade de Goiânia.
Esses alunos foram questionados quanto a quais estariam utilizando ferramentas
para geração de dados de teste de forma automatizada e nenhum deles estava utilizando
tais ferramentas em suas posições de trabalho até a ocasião (06/2015).
Dados obtidos através de 5 testadores somente e em um ambiente especifico, não
são indicadores conclusivos para saber se o problema abordado é realmente relevante, mas
agrega valor aos demais aspectos levantados no decorrer da pesquisa.
Por meio do relato acima mencionado e pela carência ainda presente no ambiente
de desenvolvimento direcionado ao estado de Goiás, podemos ter uma pequena amostra
quanto a como o mercado em questão apresenta potencial para estudo direcionado às
novas ferramentas, conjuntos e metodologias voltadas a teste de software.
Os 5 testadores mencionados na citação foram questionados quanto à relevância
de um estudo direcionado à geração de dados de teste de forma automatizada e todos
concordaram que o tema temmuita relevância para evitar a geração de dados tendenciosos
e a cobertura de domínios de entrada mais variados.
Conforme Fraser et al. (2014) relatam em seu artigo, sistemas geradores de dados
de testes de forma automatizada conseguem cobrir até 300% a mais do código fonte do
que conjuntos de teste gerados de forma manual e com base em seus estudos podemos
ter uma percepção maior quanto a relevância de dar continuidade a essa pesquisa e
desenvolver projetos que inovem a forma como o setor de desenvolvimento pode optar
por uma ferramenta ou metodologia que mais se adeque às suas necessidades.
Fraser et al. (2014) comentam ainda em sua pesquisa que a cobertura de código
não está diretamente associada a qualidade dos testes.
Boa parte dos dados de teste gerados são desnecessários por revelarem os mes-
mos defeitos, outros podem ser gerados de forma duplicada, e outros serem redundantes
por exercitarem as mesmas funcionalidades e explorarem os mesmos domínios de entrada.
Maiores detalhes quanto ao comparativo realizado por Fraser et al. (2014) serão
relatados no Capítulo 3.
Outros autores já avaliaram testes manuais e automáticos em contextos diferen-
tes. Por exemplo, Ma, Offutt e Kwon. (2005) defendem o fato de testes manuais e auto-

1.1 Motivação 15
matizados serem complementares. Eles também desenvolveram uma ferramenta chamada
auto teste, que combinam as melhores práticas relacionadas às duas técnicas.
A mesma conclusão foi obtida por Bachiega et al. (2016) utilizando metodologia
diferente e conjuntos de ferramentas também diferentes. A pesquisa de Bachiega et
al. (2016) foi gerara em paralelo a presente pesquisa, sendo de fundamental importância
para a obtenção de dados e elaboração deste texto.
Solingen V. Basili e Rombach. (2002) avaliaram a qualidade dos testes unitários
gerados de forma manual e os conjuntos de teste gerados de forma automática por meio
de dois geradores de dados, Randoop e JWalk. Smeets e Simons. (2011) aplicam testes de
mutação gerados pela MuJava (PACHECO; ERNST., 2007).
Randoop também foi objeto de estudos na presente pesquisa conforme veremos
de uma forma mais detalhada no Capítulo 4. Solingen V. Basili e Rombach. (2002)
defendem a ideia que geradores de teste automatizados são melhores em geral que
a geração de forma manual, considerando que os testes gerados de forma automática
garantem a integridade em áreas onde os testes são tendenciosos ou quando o teste é para
uma parte específica do código. Nesse estudo, tanto a pontuação obtida em relação a morte
de mutantes por meio de testes manuais quanto de testes gerados de forma automatizada
são baixas, inferior a 70%, e todos os conjuntos de testes podem ser considerados
incompletos em alcançarem uma boa cobertura de código e morte de mutantes ou score
de mutação.
Kracht, Petrovic e Walcott-Justice (2014) realizaram uma avaliação empírica
entre testes automatizados e testes manuais, com o objetivo de ajudar os desenvolvedores
na redução do custo do processo de testes.
Foram utilizados 10 programas disponíveis a partir de um repositório de soft-
ware (FRASER; ARCURI., 2016).
Foram selecionados programas com base no seu tamanho e disponibilidade para
geração de conjuntos de testes unitários de forma manual. Os geradores automáticos de
dados de teste utilizados na comparação foram EvoSuite e CodePro. A qualidade dos
conjuntos de teste foi baseada na cobertura de código e score de mutação ou morte de
mutantes.
Os resultados mostram que EvoSuite apresenta valores mais satisfatórios que
CodePro em termos de cobertura de código e score de mutação, entre tanto, os conjuntos
de testes gerados de forma manual apresentammaior cobertura que as ferramentas citadas.
(SIMONS., 2007) Relata o motivo pela qual foram selecionados os programas
testados em sua pesquisa. Apresenta o motivo que teve para selecionar programas de
tamanho que variavam de 18 mil à 783 linhas de código, ou seja, programas relativamente
grandes.

1.2 Objetivo do Trabalho 16
Apesar da presente pesquisa utilizar programas menores em relação a quantidade
de linhas de código, os resultados obtidos em relação a quantidade de linhas de código
foram bem próximos conforme veremos no Capítulo 4.
1.2 Objetivo do Trabalho
O objetivo da pesquisa é obter dados a partir de experimentações que possam
demonstrar as vantagens na utilização de ferramentas e metodologias já existentes dentro
de um ambiente controlado.
Por meio dos dados obtidos, responder a questionamentos como por exemplo
como selecionar uma ferramenta de geração automática de dados de testes que mais se
adeque às necessidades de uma equipe voltada a esta atividade?
Quais as melhores ferramentas e como utilizá-las em conjunto para que se tenha
os melhores resultados quanto à eficácia e eficiência?
Qual a ferramenta ou conjunto de ferramentas trabalha melhor para cobrir a
maior quantidade de cobertura de códigos possível?
Outro aspecto abordado será como os mesmos conjuntos de programas se
comportam por meio de testes gerados de forma manual e comparar esses dados aos testes
gerados de forma automatizada.
A utilização de ferramentas geradoras de dados de testes de forma automática
ainda apresenta potencial muito elevado de melhorias que levem a uma aceitação maior
por parte das empesas do ramos de desenvolvimento.
Além da dúvida relacionada a qual ferramenta adotar, outros questionamentos
também relacionados a essa mudança são levantados quando se fala no assunto.
A forma como a ferramenta geradora de dados de testes atua (aleatória ou ba-
seada em heurísticas de otimização), cobertura de código, número de defeitos revelados,
tempo gasto para percorrer o código, quantidade de falhas identificadas durante a execu-
ção, são critérios de qualidade importantes ao se considerar quando se deseja selecionar
ferramentas que gerem dados de teste automaticamente.
Como a ferramenta irá se comportar em relação a cobertura de código?
Como a ferramenta atua em relação ao tempo gasto em sua execução?
Os testes executados pela ferramenta são realmente confiáveis?
A ferramenta que será adotada é suficiente para atender as demandas da equipe
de testes ou será necessária a combinação de ferramentas para a obtenção de testes de
melhor qualidade?
Como base nesses questionamentos, surge a necessidade de avaliações que
justifiquem a escolha de uma ferramenta ou um conjunto específico de ferramentas que

1.2 Objetivo do Trabalho 17
se adequem mais às características de uma empresa que atenda da melhor forma às
necessidades dessa empresa.
1.2.1 Metodologia
O objetivo dessas avaliações consiste em realizar experimentos em ambiente
controlado com intuito de levantar dados que comprovem a qualidade do conjunto de
ferramentas de testes fundamentada em experimentos científicos.
Os experimentos foram executados em duas etapas e foram feitos em três
ferramentas geradoras de dados de teste de forma automática, um conjunto de testes
gerados de forma manual.
Para motivos de comparação, a presente pesquisa utiliza os mesmos programas
e os conjuntos de teste gerados manualmente na pesquisa de Souza et al. (2012).
Os conjuntos de teste gerados de forma automática foram obtidos a partir da
execução de três diferentes ferramentas:
• EvoSuite (FRASER; ARCURI., 2016): Estado da arte entre os geradores de dados
de teste.
• Randoop (PACHECO; ERNST., 2007): Gerador de dados de teste aleatório.
• CodePro (GOOGLE, 2010): Essa ferramenta foi descontinuada durante a pesquisa,
mas foi mantida pelo fato de já possuirmos os dados gerados por ela e em decor-
rência de estar ainda funcional e o plugin ainda poder ser instalado conforme será
apresentado no decorrer na pesquisa.
Ambas as técnicas foram somadas um conjunto com um gerador de relatórios
em formato JUnit que posteriormente foi alterado adequado às necessidades encontradas
na segunda parte do projeto conforme detalhado no 4.
A primeira ferramenta apresenta relatórios contendo dados sobre cobertura de
linhas de códigos e quantidade de dados de testes gerados.
A segunda ferramenta foi utilizada com o intuito de apresentar dados referentes
à quantidade de mutantes mortos pelo conjunto de teste gerado.
A ideia é utilizar o teste de mutação como modelo de defeitos que possam ser
detectados pelos testes e, desse modo, ter um parâmetro para comparar a eficácia dos
conjuntos de teste em detectar defeitos.
Esse método foi o mesmo nas duas fases do projeto.
A eficiência é mensurada considerando os resultados obtidos com o mínimo de
recursos possíveis, como por exemplo, a relação cobertura de código e quantidade de
dados gerados.
A eficiência é evidenciada em um gerador que apresente baixa quantidade de
dados gerados e uma boa cobertura de código.

1.3 Organização do Trabalho 18
O cálculo é realizado da seguinte forma:
Conjunto "A" atuando no programa "1" cobriu "X%" de código e gerou "Y" da-
dos de teste.
O mesmo é feito com os demais conjuntos e posteriormente são comparados os
valores de forma a chegar a um resultado que possibilite identificar quais os conjuntos
com melhor ou pior resultados em relação as métricas propostas.
A eficácia é mensurada pelo fato de conseguir atingir o resultado. Isso é visível
quando os dois conjuntos de software funcionam como esperado e sem apresentar falhas.
Além da comparação entre os conjuntos de teste gerados de forma automática,
foi realizado um comparativo entre um conjunto de testes gerados de forma manual
considerando aspectos que equiparem os conjuntos de teste de forma geral. Souza e
Prado (2011).
Uma descrição mais detalhada está disponível no Capítulo 4.
1.3 Organização do Trabalho
Este capítulo apresenta o contexto no qual este trabalho se insere, as motivações
para a sua realização e seus objetivos.
No Capítulo 2 são apresentadas, terminologias adotadas pela área de testes,
as fases e etapas que envolvem o processo de testes de software e dados referentes a
automação de testes de software com ênfase em técnicas de automação e tipos de testes
existentes.
O Capítulo 3 descreve os trabalhos relacionados a este e como os mesmos
contribuíram para o desenvolvimento desta pesquisa.
No Capítulo 4 é descrito como o ambiente de experimentação foi preparado,
como o plano de experimentação foi conduzido, e quais dados e resultados foram obtidos.
Finalmente no Capítulo 5 são apresentadas a conclusão e perspectivas de traba-
lhos futuros.

CAPÍTULO 2Terminologia e Conceitos Básicos
2.1 Considerações Iniciais
Dentro do segmento teste de software existem algumas divisões de conheci-
mento que vão desde etapas e fases de aplicação dos testes, técnicas e critérios e até
ferramentas e funcionalidades que envolvem essas ferramentas. Neste capítulo são apre-
sentadas as fases do teste e as principais técnicas e critérios que podem ser utilizadas em
cada uma delas.
2.2 Dado de Teste, Caso de Teste e Conjunto de Teste
Os casos de teste são representados da seguinte forma <I;Eo> onde I é uma
entrada, também chamada de dado de teste e Eo é a saída esperada em relação a unidade
específica.
Quando uma unidade é executada com I, produz uma saída resultante Ro.
Quando Ro for igual a Eo, a unidade em teste se comportou como especificado,
caso contrário, uma falha foi revelada pelo caso de teste e pode-se dar início ao processo
de depuração para descobrir qual(is) defeito(s) originou(aram) a falha.
A identificação do Eo não é uma tarefa fácil e, em geral, requer intervenção
humana aumentando assim o custo da criação de conjuntos de teste para um grande
número de unidades, uma vez que o testador irá gastar muito tempo na seleção de entradas
e determinar a saída esperada para cada uma dessas entradas.
Os geradores automatizados geram os dados de teste (a entrada), ou seja, eles não
são capazes, em geral, de gerar automaticamente as saídas esperadas para cada entrada.
No caso dos geradores utilizados neste estudo, geram os chamados casos de teste de
regressão.
Eles geram e executam determinada unidade com I e a saída resultante Ro é
considerada a saída esperada Eo. Desse modo, o par <I;Ro> consiste em um caso de teste
de regressão criado pelos geradores de teste automatizados empregados no estudo.

2.3 Etapas do Processo de Testes 20
No restante deste texto, quando citados casos de teste gerados por geradores
automatizados, esses casos de teste são casos de teste de regressão.
É possível verificar que todos os casos de teste de regressão passam sem falhas
na versão atual da unidade em teste. Esses casos de teste são úteis quando uma unidade
passa por alguma alteração e precisa ser reavaliada.
Em seguida, os mesmos casos de teste criados a partir da versão anterior são
utilizados para verificar se a nova versão da unidade está se comportando da mesma forma
de acordo com os casos de teste anteriores.
Qualquer discrepância deve ser variada, uma vez que pode ser devido a uma
falha na versão da nova unidade, ou pode ser um problema em assumir a saída resultante
anterior como a saída esperada.
Finalmente, um conjunto de teste é um conjunto formado por nenhum ou mais
casos de teste, ou seja, o conjunto de teste pode, inicialmente, ser vazio e, com o passar
do tempo, casos de teste são construídos (de forma manual ou automática) e adicionados
ao conjunto de teste.
2.3 Etapas do Processo de Testes
Por mais que uma equipe de testes seja competente e adote critérios de testes
bem definidos, a erradicação total de defeitos no produto de software não é total e alguma
falha acaba ocorrendo posterior a conclusão do projeto.
Os defeitos não estão diretamente relacionados somente à competência ou falta
de atenção das equipes de desenvolvimento e testes. Eles podem surgir por exemplo
em decorrência de atualizações em softwares ou incompatibilidade com hardwares, em
caso de comunicação com os mesmos, ou seja, os defeitos não ocorrem somente em
decorrência de fatores internos ao processo de desenvolvimento mas também podem
ocorrer por questões externas ao processo.
O intuito da atividade de testes em softwares é identificar a presença de defeitos
para que os mesmos possam ser localizados e corrigidos. E esse processo segue as
seguintes fases:
1. Identificar dos dados de teste que será utilizado de entrada para o teste;
2. Identificar a saída esperada para cada dado de teste definido;
3. Criar casos de teste, o qual é formado pelo dado de teste e pela saída esperada;
4. Executar os casos de teste no produto em testes;
5. Comparar a saída obtida com a saída esperada para cada caso de teste;
6. Analisar os resultados obtidos e, se falhas foram detectadas, localizar e corrigir o(s)
defeito(s) que a originou.

2.4 Geração de Dados de Teste 21
A atividade de teste pode ser executada em uma sequência de três fases.
A primeira delas é o teste de unidade, no qual cada unidade do software é
testada individualmente, buscando-se evidências de que ela funciona adequadamente. A
próxima fase, o teste de integração, é uma atividade sistemática para integrar as unidades
componentes da estrutura do software, visando identificar a presença de defeitos de
interação e comunicação entre as unidades. Finalizando, no teste de sistema é verificado
se todos os elementos do sistema combinam-se adequadamente e se a função/desempenho
global do sistema é atingida (PRESSMAN; MAXIM, 2014).
Conforme comentado anteriormente, a ênfase deste trabalho é avaliar geradores
de dados de teste automáticos para a execução da fase de teste de unidade.
Dada a grande importância do teste de software, esforços vêm sendo feitos
para padronizar algumas terminologias comumente utilizadas. O padrão ISO/IEC/IEEE
24765:2010 (ISO/IEC/IEEE, 2010) consiste de um glossário de termos de engenharia
de software e, os termos abaixo, também relacionados ao tema desta pesquisa, foram
extraídos dessa referência:
1. Cobertura de Código (Test Covarage): a porcentagem que determinados elementos
do código são executados em relação ao total de elementos existente no código.
Um dos elementos mais utilizados são instruções ou linhas de código. Nesse caso,
por exemplo, quanto mais instruções são executadas pelo conjunto de teste, maior
a cobertura de código obtida;
2. Teste deMutação (Mutation Testing): É uma técnica que consiste em inserir defeitos
de forma proposital no código com intuito de checar se os dados de teste são bons a
ponto de identificar tais defeitos. Muito utilizado em experimentação para se avaliar
ou comparar a eficácia de conjuntos de teste (ANDREWS; BRIAND; LABICHE,
2005);
3. Teste aleatório (Random testing): consiste em uma técnica de teste de software
cujos programas são testados por meio da geração de entradas escolhidas ao acaso
e independentes. Os resultados da produção são comparados com as especificações
de software para verificar se a saída obtida é aprovada ou reprovada em relação
a saída esperada. Em caso de ausência de especificações, as exceções lançadas são
usadas o que significa que, se surgir uma exceção durante a execução do teste, então
é possível concluir que existe uma falha no programa.
2.4 Geração de Dados de Teste
Quando se trata de geração de dados de testes, o ideal é que todas as possibi-
lidades de domínios e subdomínios de entrada possam ser executadas. Isso, em geral, é
impraticável tendo em vista que os domínios de entrada podem ser infinitos.

2.4 Geração de Dados de Teste 22
Figura 2.1: Domínios de entrada e saída de dado programa. Adap-
tada de (JORGE, 2013).
A automação da atividade de geração de dados de teste é extremamente desejá-
vel, entretanto, existem restrições associadas a atividade de testes que impossibilitam a
automatização da atividade por completo. As restrições encontradas na literatura são:
• Correção coincidente: ocorre quando o programa apresenta, coincidentemente,
um resultado correto para uma entrada particular, mesmo a entrada executando
comandos com defeitos. Isso ocorre pois um defeito pode corrigir o erro causado
por outro e a saída obtida corresponde à esperada;
• Caminho ausente: ocorre quando uma determinada funcionalidade requerida pelo
programa deixa de ser implementada por engano e o caminho não leva a essa
funcionalidade;
• Caminho não-executável: consiste em um caminho que está presente em um grafo
e pode ser requerido por algum critério mas, em função das restrições impostas,
não existe um dado de entrada que possibilite que a sequências de comandos do
caminho seja executada;
• Mutante equivalentes: ocorre quando o mutante sempre apresenta uma saída idên-
tica à do programa original, para todo e qualquer item de dado do domínio de en-
trada.
Existem diferentes técnicas já abordadas pela literatura com a finalidade de
satisfazer esses critérios. As técnicas mais conhecidas são geração aleatória de dados,
geração com execução simbólica, geração com execução dinâmica, geração utilizando
técnicas de computação evolutiva e geração de dados sensíveis a defeitos.
No contexto da presente pesquisa, são apresentadas duas ferramentas de geração
de dados de testes de forma automática. Uma trabalha com a técnica de geração aleatória e
a outra com funcionalidades de envolvem técnicas de heurísticas de otimização dos dados.
A proposta da presente pesquisa está ligada à geração de dados de teste de forma
automática, mas a compreensão da geração de dados de teste de forma manual é de
fundamental importância para a compreensão do processo como um todo.

2.5 Variáveis 23
No mercado, ainda é uma realidade a geração de dados de testes de forma
manual. Isso ocorre quando o testador não utiliza ferramentas para a obtenção dos dados
de teste. Os dados de entrada são gerados baseados nas saídas esperadas e inseridos com
intuito de analisar o comportamento dos programas o que acaba sendo uma forma muitas
vezes tendenciosa, considerando que o produto final será executado de forma a percorrer
o caminho esperado pela equipe de desenvolvimento, ou visando a satisfazer determinado
requisito de teste.
Em geral, a geração de dados de teste de forma manual é utilizada nas seguintes
situações:
• Testes que envolvam tarefas mais intelectuais e que exijam análise e pensamento
lógico;
• Testes de usabilidade;
• Tarefas dinâmicas;
• Em sistemas que apresentam ciclo de vida curto.
A geração automatizada de dados de testes, consiste na utilização de ferramentas
que executem os testes na aplicação, por meio da implementação de scripts. Dessa forma,
a ferramenta simula uma utilização do software testado e verifica os resultados esperados.
Em geral é utilizada nas seguintes situações:
• Quando envolver tarefas repetitivas;
• Aplicações com ciclos de vida longos;
• Testes que devem ser feitos com maior frequência.
A Tabela 2.1, extraída de Micskei (2013), apresenta uma lista de geradores auto-
máticos de dados de teste para diferentes linguagens de programação. A grande maioria se
concentra na geração de testes unitários. No contexto deste trabalho, a avaliação realizada
até o momento envolveu as ferramentas Randoop e CodePro, ambas para a linguagens
Java.
2.5 Variáveis
Com base nas hipóteses foram definidas as variáveis dependentes e independen-
tes do experimento.
Variável Independente: É qualquer variável que pode ser manipulada ou contro-
lada no processo de experimentação (MAHMOOD, 2007).
As principais variáveis independentes dessa pesquisa são:
* As ferramentas de teste adotadas;

2.5 Variáveis 24
Tabela 2.1: Lista de ferramentas de geração automática de dados
de teste.
Relação de Ferramentas
Ferramenta Linguagem
AutoTest EiffelCATG JavaCAUT CCREST CEvoSuite JavaGUITAR GUI application (JFC, Web)Jalangi JavaScriptKLEE C (LLVM bitcode)LCT Java
MergePoint/Mayhem binary (32bit, Linux)PathCrawler C
Palus JavaPET, jPET Java
Pex .NET codeRandoop JavaSAGE x86 binary
Symbolic PathFinder JavaCodePro Analytix JavaCUTE, jCUTE C, Java
DART CDOTgEAr Java
DSD-Crasher JavaEuclide CEXE C
Jcrashe JavaJET Java annotated with JMLjFuzz JavaKorrat JavaTAO C
* Os critérios de teste utilizados;
*A habilidade do testador em testar adequadamente os programas;
* O tamanho e complexidade dos programas a serem testados; e
* O conjunto de testes final;
Esse fator tem dois tratamentos: manual e automatizado. As outras variáveis
foram definidas para não interferir nos resultados.
A habilidade do testador é a mesma para os 32 programas, gerando um conjunto
de testes manuais de forma a possibilitar a formulação da hipótese.
Variáveis Dependentes: São aquelas em que o resultado da manipulação das
variáveis independentes podem ser observados (MAHMOOD, 2007).
Na presente pesquisa, as variáveis dependentes foram utilizadas para definirem
a eficácia do conjunto de testes e o score de mutação por programa.
Conforme mencionada na primeira fase do projeto, e mantida na segunda fase,
o teste de mutação foi utilizado como um modelo de falha para avaliar a capacidade dos
conjuntos de teste dos conjuntos de teste sobre a detecção de um conjunto bem conhecido
de defeitos representados pelos mutantes (DELAHAYE; BOUSQUET, 2015).

2.5 Variáveis 25
Quanto maior o número de mutantes mortos em um conjunto de testes, maior a
eficácia na detecção de falhas.
As variáveis dependentes servem para descrever o custo do conjunto de testes e
o número de casos de teste por conjunto de teste.
As variáveis dependentes para descrever a força para um conjunto de teste são:
* A cobertura em um conjunto de teste por programa;
* O Score de mutação de um conjunto de testes por programa;

CAPÍTULO 3Revisão Bibliográfica
Para a obtenção dos dados necessários para a realização da pesquisa, de uma
forma geral, foram considerados artigos científicos escritos em Português ou Inglês, que
continham informações relevantes tanto em aspectos de procedimentos para a realização
dos experimentos quanto relacionados à problemática abordada.
No trabalho de Delahaye e Bousquet (2015), é proposta uma metodologia para
seleção de ferramentas que apoiam o testes de mutação. Conceitua o teste de mutação
como uma injeção de defeitos nos códigos fonte com intuito de avaliar a eficácia de um
dado conjunto de teste.
O autor realiza seus experimentos comparando diversas ferramentas de mutação
para a linguagem Java: Bacterio; Javalanche; Jester; Judy; Jumble; MAJOR; MuJava;
MuClipse; e PIT.
O autor conclui que apesar de analisar esse conjunto de ferramentas, a escolha de
uma ferramenta de testes de mutação é um desafio. Para a obtenção dos dados referentes
a presente pesquisa a ferramenta adotada foi a PIT uma vez que, segundo Delahaye e
Bousquet (2015), foi a que apresentou melhor resultado e apresenta usabilidade melhor
que das demais avaliadas.
As ferramentas se diferem em relação a determinadas características o que
dificulta a geração de critérios que sejam relevantes no momento da avaliação do conjunto
de ferramentas.
Para cobrir essas dificuldades, Delahaye e Bousquet (2015) propõe critérios
avaliativos que satisfaçam as diferenças de características tendo assim dados suficientes
para uma conclusão em relação a sua avaliação de ferramentas.
Sharma e Bajpai (2014) falam das dificuldades encontradas pelos testadores de
gerarem os testes de forma manual dando ênfase em programas grandes. Um estímulo
para um estudo mais aprofundado em relação a ferramentas geradoras de dados de testes
de forma automatizada.
Oladejo e Ogunbiyi (2014) conduziram os experimentos são voltados à avaliação
de duas técnicas de teste de software: Concolic e Combinatória. Os autores concluíram
que em vários aspectos a técnica Combinatória supera a Concolic. Parte do protocolo

27
de experimentação foi utilizado como um guia para a obtenção dos dados analisados na
presente pesquisa.
O protocolo de experimentação empregado por Kracht, Petrovic e Walcott-
Justice (2014) também serviu como guia para a obtenção dos dados analisados e os dados
da obtidos são de fundamental importância para obtenção de uma comparação entre as
ferramentas CodePro, Randoop e geração de forma manual.
Por meio desses dados foi possível a obtenção de uma conclusão mais abrangente
da presente pesquisa em relação à cobertura de códigos usando estatística por amostra-
gem.
Fraser et al. (2014) realizaram testes com 97 pessoas comparando relação a
testes manuais e testes gerados por ferramentas de geração automática. As ferramentas
de geração de dados de teste de forma automática geram até 300% mais dados em relação
a geração manual.
Em outra pesquisa realizada por (FRASER; ARCURI, 2014) foi feita uma
avaliação da ferramenta EvoSuite. Os experimentos são realizados em uma seleção
aleatória de 100 programas de código aberto ou open source. Após extrair os relatórios
de dados gerados, concluiu-se que a cobertura média de código foi de 71%. A forma com
que os autores obtêm os dados de cobertura contribuíram para a elaboração do protocolos
de experimentação, obtenção de dados e cálculos estatísticos.
Chhillar e Bala (2014) focam seus esforços em obter métodos para a geração
de dados de teste que atendam requisitos de eficácia e eficiência. Para seus estudos
são utilizados algoritmos genéticos. Apesar do conjunto de ferramentas utilizado pelos
autores não ter relação com o conjunto de ferramentas da presente pesquisa, a forma
como ele trabalha com determinadas ferramentas para evitar que os dados extraídos sejam
tendenciosos serviram para auxiliar na forma de trabalho da presente pesquisa.
Gheyi et al. (2010) realizaram uma análise de ferramentas destinadas a diversas
tarefas. São reunidos diferentes conjuntos de ferramentas e aplicados seus recursos
em 3 softwares diferentes com intuito de analisar seu comportamento. As ferramentas
estudadas foram as seguintes: Findbugs; MuClipse; Randoop; EclEmma; Cobertura;
Clover; e Metrics.
Essas ferramentas foram estruturadas formando 4 diferentes conjuntos que são
os seguintes:
1. Randoop + EclEmma + (Clover, Cobertura);
2. Findbugs + Randoop;
3. MuClipse;
4. Metrics + (Findbugs + EclEmma + [Clover, Cobertura]);
A forma como Gheyi et al. (2010) trabalharam com ferramentas em conjunto
teve impacto direto em como seriam utilizados os conjuntos de ferramentas adotados

28
na presente pesquisa no qual as ferramentas Randoop, CodePro, EclEmma e PIT foram
adotadas como foco de estudo.
No trabalho de Fraser e Arcuri (2013) foram gerados dados de teste utilizando
as abordagens da EvoSuite e de SBST, aplicados a um conjunto de 100 programas
Open Sourse escolhidos de forma aleatória. Tanto o fato do autor utilizar um conjunto
de ferramentas a fim de obter dados de forma amostral para uma avaliação quanto a
forma como foram obtidos os dados de teste foram de fundamental importância para a
elaboração da presente pesquisa.
Singh, Causevic e Punnekkat (2014) realizaram um filtro tanto no que se refere
a material bibliográfico quanto aos tipos de ferramentas disponíveis para geração de
dados de teste de forma automática. Em seu trabalho são apresentadas as strings de busca
utilizadas para a obtenção dos materiais que foram utilizados para a elaboração de uma
revisão bibliográfica.
Os autores apresentam em uma tabela a fonte onde realizou a consulta, a string
utilizada, a quantidade de materiais encontrados e a data de realização da busca.
Por fim criou-se uma planilha contendo as ferramentas e descrevendo as carac-
terísticas de cada uma, a quantidade de material bibliográfico que encontrou de cada e
citações.
A lista de ferramentas influenciou na adoção de ferramentas para a obtenção de
dados da presente pesquisa em especial Randoop que é mencionada na pesquisa.
O paradigma de linguagens de programação estruturadas e orientadas a objetos
também são levados em consideração quando se trada de testes de software e, no trabalho
de Souza e Prado (2011), esses paradigmas são tratados de forma experimental com base
em testes de software.
Souza e Prado (2011) utilizaram 32 programas do domínio de estrutura de dados
em linguagem Java Orientada a Objetos (ZIVIANI, 2011a) e versões dos mesmo 32
programas são compilados em linguagem C estruturada (ZIVIANI, 2011b).
São gerados dados de teste de forma manual para cada o conjunto de programas e
os resultados obtidos são confrontados. A adequação dos conjuntos de teste desenvolvidos
para os programas procedimentais é avaliada em relação às implementações orientadas a
objetos e vice-versa.
Os autores informam que foi possível concluir que em relação a custo e a força
dos critérios de teste entre programas procedurais e Orientados a Objetos não apresentam
diferenças significativas suficientes para afirmar que uma metodologia é melhor que a
outra em relação a esses indicadores.
O estudo dos autores foi de fundamental importância em relação a presente
pesquisa tendo em vista que os mesmos 32 programas são utilizados no experimento,

29
viabilizando a comparação dos conjuntos de teste gerados automaticamente em relação
aqueles gerados manualmente no trabalho de Souza e Prado (2011).
Smeets e Simons (2010) conduziram experimentos comparando testes gerados
de forma manual com um conjunto de 3 ferramentas para a geração de dados de teste de
forma automática. O conjunto é composto pelas ferramentas Randoop, JWalk e µJava.
Em relação a todas as pesquisas mencionadas, várias foram as contribuições con-
forme foi pontuado anteriormente. Alguns domínios de estudo foram guias importantes
para a realização da pesquisa principalmente no que está relacionado a protocolo de ex-
perimentação e embasamentos teóricos.
As características de pesquisa que mais auxiliaram na elaboração da presente
pesquisa foram:
• Comparativo entre ferramentas;
• Comparativo entre procedimentos manuais e automatizados;
• Paradigmas relacionado ao setores de TI de forma geral;
• Abordagens para trabalhar com ferramentas geradoras de dados que atuem de
maneiras diferentes;
• Elaboração e aplicação de um protocolo de experimentação.
Todo o material citado foi utilizado como base para direcionar a elaboração da
presente pesquisa, entretanto, o trabalho de (SOUZA; PRADO, 2011) foi de fundamental
importância pois o mesmo conjunto de programas foi utilizado para a elaboração dos
experimentos.
Kracht, Petrovic e Walcott-Justice (2014) realizaram os experimentos são volta-
dos à comparação de testes gerados de forma manual e testes gerados utilizando automa-
ção na geração dos dados. Em sua conclusão os autores mencionam que utilizaram duas
ferramentas de geração de dados de teste: EvoSuite e CodePro. CodePro cobre 5% mais
de código que EvoSuite que por sua vez cobre 16,4% mais código que a geração manual.
Os dados apresentados por (KRACHT; PETROVIC; WALCOTT-JUSTICE, 2014), por
serem resultados de um experimento semelhante ao desenvolvido neste trabalho, serão
apresentados ao término confrontando os dados obtidos na presente pesquisa.
A Tabela 3.1 sintetiza a metodologia e as ferramentas empregadas em cada um
dos estudos mencionados acima.

30
Tabela 3.1: Trabalhos relacionados a avaliação de ferramentas.
Principais Trabalhos RelacionadosAtigo Metodologia Ferramentas
Bacterio;Javalanche;Jesper;Judy;
Delahaye e Bousquet (2015) Este artigo propõe uma metodologia paracomparar ferramentas de mutação. Jumble;MAJOR;MuJava;MuClipse; ePIT.
Fraser et al. (2014) Avaliação da ferramenta EvoSuite em realizada de formas diferentes. EvoSuite(FRASER; ARCURI, 2014)
Findbugs;MuClipse;Randoop;
Gheyi et al. (2010) Avaliação de conjuntos de ferramentas. EclEmma;Cobertura;Clover; eMetrics.Randoop;
Smeets e Simons (2010) Comparação de testes manuais e automatizados. Jwalk; eµJava.
Kracht, Petrovic e Walcott-Justice (2014) Comparação de testes manuais e automatizados. EvoSuit; eCodePro Tools.

CAPÍTULO 4Ambiente de Experimentação
Para a realização dos experimentos, foram levados em consideração alguns
elementos tais como:
A configuração do computador utilizado para a experimentação.
Conforme informando anteriormente, o experimento foi executado em duas
partes e levando em consideração itens que podem impactar nos experimentos como por
exemplo a configuração dos computadores.
O computador utilizado para rodar os experimentos na primeira parte possuía as
seguintes configurações:
• Sistema Operacional: Windows 8.1 Pro 64 bits;
• Processador: Core I5-3337U CPU @ 1.80 GHz; e
• Memória instalada (RAM): 6,00 GB (utilizável 5,87 GHz).
Os mesmos experimentos da primeira parte foram refeitos em um computador
diferente com as seguintes configurações:
• Sistema Operacional: Linux Ubuntu, 16.04 LTS64 bits;
• HD: 1TB; e
• Memória instalada (RAM): 8GB.
Para a experimentação, o escopo foi reduzido a ferramentas que trabalhem com
a linguagem Java, tenham saída de dados no formado JUnit, permitam a utilização de
testes de mutação em conjunto, que gerem dados de testes de forma automática e que são
Sistemas Open Source.
Versão do JDK: 1.7.0. Versão do eclipse: eclipse-jee-luna-SR2-win32-x86_64.
Após filtrar a tabela inicial de acordo com as características visadas para a
experimentação restaram as ferramentas ilustradas na Tabela 4.1:
Algumas dessas ferramentas estão descontinuadas ou são incompatíveis com as
características de plataforma, versão do Eclipse ou o projeto parou de ser atualizado e em
determinados casos as informações se perderam com links quebrados.

4.1 Definição de Experimentação 32
Tabela 4.1: Lista filtrada de ferramentas de geração automática de
dados de teste.
Relação de Ferramentas
Ferramenta Linguagem
EvoSuite JavaCodePro Tools JavaPET, jPET JavaRandoop Java
Symbolic PathFinder Java
Em decorrência desses problemas, na primeira fase do experimento os geradores
adotados foram os seguintes:
• CodePro;
• Randoop;
Na segunda fase, o experimento foi incrementado com testes gerados de forma
manual e testes gerados por EvoSuite, finalizando o experimento com a seguinte lista de
ferramentas e funcionalidades:
Tabela 4.2: Lista completa de ferramentas, versões e funcionalida-
des.
Ferramenta Versão PropósitoJavaNCSS 32.53 Gerador de Métricas EstáticasEvoSuite 1.0.3 Gerador de TesteCodePro Tools 7.1.0 Gerador de TesteRandoop 3.0.1 Gerador de TestePitest 1.1.10 Teste de Mutação e de CoberturaEclipse 4.5 Ambiente de Desenvolvimento IntegradoMaven 3.3.3 Construtor de AplicaçõesJUnit 4.12 Framework para Testes UnitáriosPython 2.7,11 Linguagem de Scripts
Essas ferramentas trabalharam em conjunto seguindo uma metodologia para a
obtenção dos dados que foram analisados.
Os conjuntos de ferramentas e forma de trabalho adotados estão detalhados na
Seção 4.1.
4.1 Definição de Experimentação
Aspectos tais como o tempo gasto pela ferramenta para a cobertura do código
foram cogitados, entretanto, o tempo é uma variante relativa pelo fato das ferramentas

4.2 Metodologia 33
não fornecerem o tempo gasto de forma precisa e também pelo fado das ferramentas não
trabalham da mesma forma.
Os conjuntos foram formados da seguinte maneira:
Na primeira faze do experimento, a ferramenta EclEmma foi adotada com intuito
de realizar a mensuração de cobertura de código dos conjuntos de teste gerados pela
Randoop e CodePro.
PIT teve a finalidade de geração de mutantes nos programas utilizados no
experimento visando avaliar a capacidade dos conjuntos de teste da Randoop e da
CodePro detectar os defeitos modelados pelos operadores da PIT.
Na segunda fase, a partir da lista de programas P, foram criadas especificações
Sp para um conjunto de testes manuais M, foram usados os geradores automáticos de
dados de teste, EvoSuite(it E), CodePro Tools(C) e Randoop(R), três conjuntos de testes
forma gerados para cada programa P. Com relação a Randoop, foi fixado um número
máximo de casos de teste equivalente a quantidade de casos de teste manuais usando
técnicas de otimização. A geração aleatória foi repetida 30 vezes e as médias forma
calculadas referente aos números de casos de teste gerados. Da mesma forma foi feito com
relação ao Score de Mutação. Em relação aos testes de mutação, foi utilizada a ferramenta
Pitest(PIT) (SOUZA et al., 2012), o que possibilitou calcular a pontuação das mutações
e também a cobertura após a execução de cada conjunto de teste. Após todos os ajustes
e configurações, forma escritos scripts Python para chamar o Maven executando todo o
processo de testes e obtendo os relatórios esperados por essa execução.
Com intuito de manter um histórico que possibilite uma futura reprodução
dos experimentos foi criado um blog onde está descrito um passo a passo de como
instalar o Randoop e o CodePro no Eclipse. Este blog está acessível pelo endereço:
http://quebrandoacabecati.blogspot.com.br/
Entre a primeira e a segunda fases do projeto, a ferramenta CodePro foi descon-
tinuada pela desenvolvedora Google, mas por meio dos dados contidos no blog acima
informado a mesma pode ser utilizada para fins de comparação.
Na segunda fase, decidimos manter os dados de CodePro pelo fato de ainda ser
uma ferramenta totalmente funcional e estar disponível para o uso da comunidade.
A instalação de CodePro no Eclipse foi verificada pela última vez em
(03/09/2016) e todos os recursos para a utilização encontram-se disponíveis.
4.2 Metodologia
Na primeira fase do experimento, a comprovação de vantagens em adotar uma
determinada ferramenta, foi levada em consideração tendo como base três características
fundamentais conforme segue:

4.2 Metodologia 34
• Tamanho do conjunto de teste gerado;
• Cobertura de código; e
• Score de mutação.
O ideal seria que a ferramenta gerasse um conjunto de teste com poucos elemen-
tos, que fossem capazes de executar grande parte do código fonte e, além disso, determinar
um alto score de mutação. Quanto mais próximo ela chegar desses objetivos melhor, será
a ferramenta de geração de dado de teste.
Para a obtenção de dados estatísticos relacionados aos geradores, outras ferra-
mentas foram utilizadas em conjunto com a finalidade de gerarem relatórios.
O experimento em questão foi executado em duas fases, sendo que na primeira
fase foram utilizadas as ferramentas a seguir:
{Randoop ou CodePro} + EclEmma + PIT Test Mutation, conforme Figu-
ras 4.1e 4.2:
Figura 4.1: Conjunto de ferramentas formado com Randoop - fase
1.
O conjunto de ferramentas completo que contemplou a segunda fase dos experi-
mentos encontra-se disponível na Tabela 4.2, informando as versões e funções.
A escolha de CodePro e Randoop se deu principalmente pelo fato de trabalharem
no Eclipse de uma forma bem similar, ambas têm plugin para o Eclipse, a forma de
instalação é similar e a forma como elas apresentam os resultados em testes unitários
é similar.
Outras ferramentas com similaridade no funcionamento foram cogitadas para
fazerem parte da pesquisa mas não funcionaram. Em contato o os desenvolvedores a
resposta é que o sistema fora descontinuado e não estaria funcionando mesmo.

4.2 Metodologia 35
Figura 4.2: Conjunto de ferramentas formado com CodePro Tools
- Fase 1.
Desta forma os geradores (Randoop e CodePro) foram utilizados nos experimen-
tos da primeira fase e na segunda fase os mesmo tornaram a ser utilizados em conjunto
com EvoSuite e dados gerados de forma manual, a PIT, foi a ferramenta responsável pela
geração dos mutantes que foram utilizados para representar possíveis falhas que os produ-
tos em teste pudessem ter. E a ferramenta EclEmma que foi utilizada para mensurar qual
a porcentagem de código fonte foi efetivamente executada pelos teste gerados na primeira
fase, sendo substituída por um script Phyton na segunda fase do experimento.
Os dados foram coletados em relação a um conjunto de 32 programas do
domínio de estrutura de dados totalizando 64 compilações responsáveis pela geração dos
dados que serão utilizados para a elaboração de um relatório estatístico. Os programas
foram extraídos do livro “Projeto de Algoritmos com Implementações em Java e C++”
de Ziviani (2011a) e já foram utilizados em experimentos anteriores (SOUZA; PRADO,
2011).
Os programas utilizados para a obtenção dos resultados são utilizados em geral
em um ambiente acadêmico e os dados gerados podem não condizerem com dados
obtidos em um ambiente real de desenvolvimento, entre tanto a forma de condução de
experimentos será a mesma. Apesar disso, a complexidade dos programas em nível de
método é semelhante à complexidade de aplicações reais em sua grande maioria.
A formulação da hipótese se deu com base no objetivo do trabalho de avaliar
conjuntos de testes gerados de forma automática e complementando essa avaliação com
conjuntos de testes gerados de forma manual.
Assume-se que efetivamente um conjunto de testes pode ser avaliado em temos
de score de mutação, determinando o custo, levando em consideração o tamanho do

4.3 Plano de Experimentação 36
conjunto de testes gerado e a força que pode ser medida por meio de cobertura dos testes
de mutação. As medidas podem ser influenciadas por alguns aspectos.
Na segunda fase, foram formuladas hipóteses conforme Tabela 4.3 a seguir:
Tabela 4.3: Hipótese.
Hipotese Nula Hipotese AlternativaNão ha diferença de Eficácia entre os testes Manuais (M) Ha diferença de Eficácia entre os testes Manuais (M)e conjuntos de teste Automatizados (A). e conjuntos de teste Automatizados (A).
H10: Eficácia (M) = Eficácia (A) H11: Eficácia (M) = Eficácia (A)Não ha diferença de Custo entre os testes Manuais (M) Ha diferença de Custo entre os testes Manuais (M)e conjuntos de teste Automatizados (A). e conjuntos de teste Automatizados (A).
H20: Custo (M) = Custo (A) H21: Custo (M) = Custo (A)Não ha diferença de Strength entre os testes Manuais (M) Ha diferença de Strength entre os testes Manuais (M)e conjuntos de teste Automatizados (A). e conjuntos de teste Automatizados (A).
H30: Strength (M) = Strength (A) H31: Strength (M) = Strength (A)
4.3 Plano de Experimentação
É composto por preparação de artefatos e ferramentas, a execução das atividades
definidas na Definição de Experimentação e a validação dos dados coletados durante a
execução.
O plano de experimentação ficou estruturado da seguinte forma. Um conjunto de
32 softwares em Java que implementam estruturas de dados (ZIVIANI, 2011a).
Os softwares utilizados para a obtenção desses resultados são os mesmos que
foram aplicados por Souza e Prado (2011) em seus experimentos, mesmo se tratando
de um teste diferente do que foi realizado no artigo. Como no experimento de Souza e
Prado (2011) os conjuntos de teste foram gerados manualmente.
Na primeira fase da presente pesquisa, o comparativo contemplou somente as
ferramentas Randoop e CodePro, evoluindo na segunda fase para um comparativo entre
as ferramentas já citadas juntamente com EvoSuite e testes gerados de forma manual.
Para facilitar a execução das ferramentas e manter a organização do experimento,
para cada um desses programas foi criado um projeto Maven (Apache Software Founda-
tion, 2002) correspondente, totalizando 32 projetos.
Esse procedimento foi adotado tanto para a primeira quanto para a segunda etapa
do projeto.
Na segunda fase do experimento, o primeiro passo na execução do programa é o
cálculo de métricas estáticas em relação a cada programa. Tabela 4.4.
Para cada programa, foram calculados o número de linhas de código fonte,
excluindo-se os comentários (NCSS), o número ciclomático de complexidade (CCN), o
número de casos de teste para cada programa, Manuais(M), EvoSuite(E), CodePro(C), e
o número máximo de casos de teste a partir de M, E ou C que foram usados para fixar

4.4 Validação dos Dados 37
Tabela 4.4: Lista de programas utilizados para a geração dos ex-
perimentos.
Id Nome Descrição1 Max Programa para obter o valor máximo de um conjunto.2 MaxMin1 Programa para obter os valores máximos e mínimos de um conjunto, de uma forma não-efiente.3 MaxMin2 Programa para obter os valores máximos e mínimos de um conjunto, de uma forma mais eficiente que MaxMin1.4 MaxMin3 Programa para obter os valores máximos e mínimos de um conjunto, de uma forma mais eficiente que MaxMin2.5 Sort1 Programa para ordenar um vetor de valores inteiros.6 FibRec Programa para calcular a seqüência de Fibonacci (recursivo).7 FibIte Programa para calcular a seqüência de Fibonacci (iterativo).8 MaxMinRec Programa para obter os valores máximos e mínimos de um conjunto maxmin de forma recursiva.9 Mergesort Classificando programa pelo método mergesort.10 MultMatrixCost Programa para obter o custo minimo para multiplicar n matrizes.11 ListArray Programa para manipular uma estrutura de dados lista, desenvolvidas através de acordos.12 ListAutoRef Programa para manipular uma estrutura de dados lista, implementado através de estruturas de auto-referência.13 StackArray Programa para manipular uma estrutura de dados pilha, desenvolvidas através de acordos.14 StackAutoRef Programa para manipular uma estrutura de dados pilha, implementado através de estruturas de auto-referência.15 QueueArray Programa para manipular uma estrutura de dados fila, desenvolvidas através de acordos.16 QueueAutoRef Programa para manipular uma estrutura de dados fila, implementado através da estrutura de auto-referência.17 Sort2 Classificando programa pelos métodos de seleção, inserção, Shell Sort, quicksort e heapsort.18 HeapSort Programa para manipular filas de prioridade, implementado através de acordos.19 PartialSorting Programa de triagem para obter os elementos k primeiro de um conjunto ordenado de tamanho n.20 BinarySearch Programa que implementa os métodos de busca seqüencial e binário para recuperação de informações.21 BinaryTree Programa que implementa árvore binária e suas operações.22 Hashing1 Programa que implementa o método de hash, usando listas ligadas para resolver colisões.23 Hashing2 Programa que implementa o método de hash, usando endereçamento aberto para resolver colisões.24 GraphMatAdj Programa para Manipular Uma Estrutura de Dados do Gráfico, implementado atraves de MATRIZes de adjacência.25 GraphListAdj1 Programa para manipular uma estrutura de dados do gráfico, implementado através de listas de adjacência usando estruturas auto-referência.26 GraphListAdj2 Programa para manipular uma estrutura de dados do gráfico, implementado através de listas de adjacência usando arranjos.27 DepthFirstSearch Programa que implementa uma busca primeiro depth- num gráfico.28 BreadthFirstSearch Programa que implementa uma busca primeiro breadth- num gráfico.29 Graph Programa para obter componentes fortemente conectados de um gráfico.30 PrimAlg Programa que implementa o algoritmo de Prim para a descoberta da árvore de cobertura mínima num gráfico ponderada.31 ExactMatch Programa que implementa o algoritmo de correspondência exata para pesquisar em strings.32 AproximateMatch Programa que implementa o algoritmo aproximado de correspondência para procurar em strings.
o número máximo de casos de teste gerados por Randoop (R), o número de requisitos
exigidos para cobrir os mutantes gerados considerando todos os operadores de mutação
disponíveis na ferramenta PIT.
Os testes manuais foram obtidos por meio de (FRASER; ARCURI, 2014).
O tempo de execução para este experimento corresponde ao tempo para executar
cada gerador de teste em cada programa, bem como o tempo para executar os scripts para
coletar os relatórios de cada métrica obtida no experimento.
Os geradores de teste exceto Randoop usaram a configuração padrão.
Para Randoop foram gerados 30 conjuntos de teste diferentes para cada programa
para evitar qualquer viés, que fixa o número máximo de casos de teste gerados pela outra
ferramenta.
Assim, Randoop leva mais tempo para gerar conjuntos de teste e gerar os
relatórios dos experimentos.
4.4 Validação dos Dados
Antes de executar os scripts para a geração automática de dados, todas as fer-
ramentas foram executadas manualmente em dois programas diferentes para certificar de
que iriam obter as informações necessárias. Posteriormente, foram comparados os dados
gerados de forma manual aos gerados pelos scripts e como não apresentaram diferenças,
aumentou a confiança no roteiro iniciando assim a geração para os 32 programas.

4.5 Execução do Experimento 38
4.5 Execução do Experimento
Após levantamento de como seriam estruturados os conjuntos de ferramentas a
serem utilizadas nos experimentos, o próximo passo foi a criação dos projetos Maven para
cada software que seria testado pelas ferramentas conforme Figura 4.4.
Figura 4.3: Programas em projetos Maven.
Dentro de cada Maven Project, os programas foram inseridos na pasta
src/main/java e as classes testadas organizadas em src/test/java conforme vemos na Fi-
gura 4.5:
O próximo passo foi a realização da geração de dados de teste utilizando a
ferramenta CodePro. A ferramenta gera abaixo do programa uma nova pasta com amesma

4.5 Execução do Experimento 39
Figura 4.4: Estrutura dos programas usando o Maven.
nomenclatura do programa testado seguida pela palavra Test conforme marcação 1 da
Figura 4.5. Também mostra a quantidades de dados de teste que foram gerados para a
classe testada conforme marcação 2 da Figura 4.5.
Nesse caso foi preciso fazer algumas configurações para que os testes fossem
possíveis. Os testes contidos no projeto Test são copiados para src/test/java do projeto
origem e o Java Build Path é configurado com as seguintes bibliotecas:
• JRE System Library [jre7];
• JUnit 4;
• Maven Dependencies;
Após toda estruturação dos conjuntos de ferramentas e dos softwares gerados
é possível coletar os dados de saída dos JUnits gerados por ambas as ferramentas e
alimentar algumas planilhas que serão detalhadas na seção a seguir.

4.6 Análise de Dados Coletados 40
Figura 4.5: Forma como são gerados os testes no CodePro Tools.
4.6 Análise de Dados Coletados
A obtenção dos dados analisados foi realizada por meio de uma tabela que foi
alimentada de acordo com a execução dos experimentos.
Os primeiros dados coletados foram da ferramenta CodePro conforme Ta-
bela 4.5:
O CodePro é uma ferramenta da Google que gera os dados de teste de forma
automática por meio de uma inteligência artificial. O desenvolvedor menciona que a
ferramenta utiliza heurísticas de otimização mas não detalha como essa tecnologia é
implementada e a forma com a qual ela trabalha. O que difere essa ferramenta das demais
é o fato dela conseguir alta cobertura do código com baixa quantidade de dados de teste.
Não é necessário entrar com a quantidade de tempo que a ferramenta irá gerar os dados
de teste ou a quantidade de dados de teste a ferramenta deve gerar, ou seja, o critério
de parada de CodePro, está em gerar dados de teste até que determinada cobertura seja
atingida ou até que um certo número de iterações seja alcançado.
A segunda ferramenta analisada foi a Randoop, e os dados obtidos alimentaram
a Tabela 4.6.

4.6 Análise de Dados Coletados 41
Tabela 4.5: Tabela com os dados analisados - CodePro Tools.
Dados CodePro ToolsIdentificador Programa Cobertura (%) Qtd Casos de Teste
1 Max 45,8 62 MaxMin1 97,5 43 MaxMin2 76 44 MaxMin3 89,5 65 Sort1 19,1 46 FibRec 95 57 FibIte 87,5 28 MaxMinRec 98,3 59 Mergesor 3,8 210 MultMatrixCost 0 1611 ListArray 95,1 3912 ListAutoRef 95,1 1613 StackArray 94,3 1614 StackAutoRef 93 715 QueueArray 93,6 1616 QueueAutoRef 71,6 817 Sort2 33,3 2618 HeapSort 88,8 1119 PartialSorting 31,8 1220 BinarySearch 69,3 1121 BinaryTree 69,3 1122 Hashing1 69,3 1123 Hashing2 69,3 1124 GraphMatAdj 69,3 2225 GraphListAdj1 40,7 2426 GraphListAdj2 58,4 2227 DepthFirstSearch 58,3 2528 BreadthFirstSearch 56,9 1329 Graph 35,1 2230 PrimAlg 35,1 2231 ExactMatch 96,3 5332 AproximateMatch 100 53
Médias 66,7 15,6
Essa ferramenta gera dados de teste de forma randômica e tem a necessidade que
o usuário informe alguns dados a ela. O que difere o Randoop do CodePro tools é que o
segundo não tem necessidade de nenhuma informação nesse sentido pois a forma com a
qual trabalha é diferente.
Para que os dados obtidos entre as duas ferramentas pudessem ser comparados,
foi observado o tempo gasto aproximado pela ferramenta CodePro para gerar os dados de
teste e informado ao Randoop que gerasse os dados de teste em tempo aproximado. Para
cada programa foi dado o tempo de 1 segundo. Para que o mesmo pudesse gerar dados
realmente de forma aleatória, foram geradas chaves de números pseudo aleatórios obtidos
a partir do relógio do computador.
A seguir apresenta-se a Tabela 4.6 com os dados a serem analisados, extraídos
da Randoop:

4.6 Análise de Dados Coletados 42
Tabela 4.6: Tabela com os dados a serem analisados - Randoop.
Dados RandoopIdentificador Programa Chave Aleatória Cobertura (%) Qtd Casos de Teste
1 Max 45 52,1 4462 MaxMin1 43 37,8 1363 MaxMin2 86 100 1194 MaxMin3 70 34,2 975 Sort1 36 68,1 3356 FibRec 62 60 57 FibIte 5 100 88 MaxMinRec 3 53,1 879 Mergesor 81 91,5 5410 MultMatrixCost 75 1,6 211 ListArray 81 1,8 212 ListAutoRef 42 1,8 213 StackArray 64 2,1 214 StackAutoRef 44 100 3715 QueueArray 19 2,4 216 QueueAutoRef 0 100 5017 Sort2 32 22,7 6418 HeapSort 86 27,1 8819 PartialSorting 57 19,5 1320 BinarySearch 54 4 621 BinaryTree 67 27,1 2522 Hashing1 73 27,1 8823 Hashing2 91 88,7 5724 GraphMatAdj 38 71,9 8425 GraphListAdj1 3 65,2 5626 GraphListAdj2 60 58,4 2427 DepthFirstSearch 52 71,7 4928 BreadthFirstSearch 47 35,7 2829 Graph 67 63,7 3130 PrimAlg 71 49,8 2131 ExactMatch 44 90,8 3432 AproximateMatch 41 100 126
Médias - 48,1 68,1
As médias dos dados obtidos para a analise já foram inclusas nas tabelas
pertinentes a cada ferramenta.
Para que fosse possível a obtenção uma margem de erro foi gerado um desvio
padrão utilizando a técnica de amostragem. Após a coleta dos dados de cada ferramenta
foram realizadas análises comparativas.
Primeiramente relacionada aos dados de cobertura de ambas as ferramentas:
CodePro Tools apresentou cobertura média de código igual a 66,7% enquanto
Randoop apresentou cobertura média do código igual a 48,1%. CodePro Tools apresentou
18,6% mais cobertura de código que Randoop nos casos avaliados. Figura 4.6
O desvio padrão de cobertura de códigos para CodePro Tools ficou em 29,2%.
Randoop, apresentou desvio padrão igual a 34,4%. Randoop apresentou a diferença de
5,2% a mais de variação na cobertura de códigos o que CodePro Tools.
A segunda comparação foi relacionada a quantidade de dados de testes gerados:
CodePro Tools gerou uma média de 15,6 dados de teste por código analisado
enquanto Randoop gerou uma média de 68,1 dados de teste por programa analisado.

4.6 Análise de Dados Coletados 43
Figura 4.6: Relação Cobertura de Códigos.
Randoop gerou aproximadamente 52,5 mais dados de teste em sua média que CodePro
Tools.
Figura 4.7: Relação Dados de Teste Gerados.
Na análise do desvio padrão, a variação de CodePro Tools foi menor que a do
Randoop. CodePro Tools apresentou 13 de variação e Randoop 94,3. O desvio padrão de
Randoop apresentou 81,3 mais variação que CodePro Tools;
Para coletar dados referentes a testes de mutação, a ferramenta adotada foi o PIT
Mutation Test. O teste de mutação é uma técnica na qual são inseridos erros no código
fonte de forma proposital para que se possa avaliar a eficácia dos dados de teste gerados.
O PIT Mutation Test realiza testes de mutação nos dados de teste gerados pelas
duas ferramentas de geração automática de dados de teste.

4.6 Análise de Dados Coletados 44
O intuito da utilização dessa ferramenta é levantar a quantidade de mutantes
gerados para os dados de teste, obter a informação referente a quantidade de mutantes
mortos pela ferramenta e o score de mutação para ambas as ferramentas demonstrado nas
planilhas a seguir:
Tabela 4.7: Tabela com os dados analisados CodePro Tools e PIT
Test.
Dados CodePro Tools e PIT TestIdentificador Programa Mutantes Gerados Mutantes Mortos Escore de mutação
CodePro CodePro CodePro1 Max 20 5 25%2 MaxMin 10 4 40%3 MaxMin 8 4 50%4 Maxmin 28 8 25%5 Ordenacao 10 3 30%6 Fibonacci 15 10 67%7 Fibonacci 6 4 67%8 MaxMin 15 5 33%9 Ordenacao 31 2 6%10 AvaliaMultMatrizes 41 0 0%11 ListArray 26 3 12%12 Lista 26 3 12%13 Pilha 20 1 5%14 Pilha 8 7 88%15 Fila 20 3 15%16 Fila 8 3 38%17 Ordenacao 41 2 5%18 FPHeapMax 0 0 0%19 FPHeapMin 0 0 0%20 Tabela 0 0 0%21 ArvoreBinaria 41 18 44%22 TabelaHash 41 19 46%23 TabelaHash 41 18 44%24 Grafo 54 19 35%25 Grafo 37 15 41%26 Grafo 41 17 41%27 Grafo 47 23 49%28 CasamentoExato 42 7 17%29 Grafo 34 12 35%30 Grafo 34 12 35%31 CasamentoExato 83 35 42%32 CasamentoAproximado 83 35 42%
Médias 31 7 35%
Neste cenário, ocorreu a obtenção das seguintes métricas:
CodePro Tools apresentou uma média de geração de mutantes igual a 31 en-
quanto Randoop, apresentou a média de geração de mutantes igual a 34, dando uma di-
ferença média igual a 3 mutantes a mais gerados em Randoop conforme consta na Fi-
gura 4.8:
CodePro Tools apresentou desvio padrão por amostragem de 19,8 enquanto
Randoop apresentou desvio padrão por amostragem de 20,3 com diferença de variação
de 0,5 a mais para Randoop.

4.6 Análise de Dados Coletados 45
Tabela 4.8: Tabela com os dados analisados Randoop e PIT Test.
Dados Randoop e PIT TestIdentificador Programa Mutantes Gerados Mutantes Mortos Escore de mutação
Randoop Randoop Randoop1 Max 20 3 15%2 MaxMin 10 3 30%3 MaxMin 8 2 25%4 Maxmin 28 5 18%5 Ordenacao 20 2 20%6 Fibonacci 0 0 0%7 Fibonacci 6 6 100%8 MaxMin 15 5 33%9 Ordenacao 31 13 42%10 AvaliaMultMatrizes 41 0 0%11 ListArray 26 0 0%12 Lista 26 0 0%13 Pilha 20 0 0%14 Pilha 8 7 88%15 Fila 20 0 0%16 Fila 8 6 75%17 Ordenacao 41 0 0%18 FPHeapMax 41 9 22%19 FPHeapMin 41 9 22%20 Tabela 58 2 1%21 ArvoreBinaria 41 7 17%22 TabelaHash 41 9 22%23 TabelaHash 41 0 0%24 Grafo 54 33 61%25 Grafo 37 24 65%26 Grafo 41 18 44%27 Grafo 55 36 65%28 CasamentoExato 42 0 0%29 Grafo 34 0 0%30 Grafo 34 0 0%31 CasamentoExato 83 27 33%32 CasamentoAproximado 83 43 52%
Médias 34 5 22%
Figura 4.8: Relação Quantidade de Mutantes Gerados.

4.6 Análise de Dados Coletados 46
Em relação a mutantes mortos por ambas as ferramentas os resultados foram os
seguintes:
CodePro Tools apresentou média de mutantes mortos igual a 7 enquanto Ran-
doop apresentou a média de 5. CodePro Tools matou uma média de 2 mutantes a mais
que Randoop conforme vemos na Figura 4.9:
Figura 4.9: Relação Quantidade de Mutantes Mortos.
CodePro Tools apresentou desvio padrão por amostragem em relação a mutantes
mortos igual a 9,5 e Randoop apresentou desvio padrão por amostragem igual a 11,8 com
diferença de variação de 2,3 a mais para Randoop.
Em relação aos dados obtidos referentes a Score de Mutação, CodePro Tools
apresentou Score Médio igual a 35% enquanto Randoop apresentou score de mutação
igual a 22%. A diferente foi de 13% a mais para CodePro Tools que para Randoop
conforme vemos na Figura 4.10:
CodePro Tools apresentou desvio padrão por amostragem em relação a score de
mutação igual a 0,2% enquanto Randoop apresentou score de mutação igual a 0,3%.
Na segunda fase do experimento, os dados coletados foram inseridos em duas
tabelas diferentes conforme segue:
Caracterizando os programas utilizados no experimento, a partir da Tabela 4.9,
pode-se ver que são programas de uma forma geral simples, implementados com 1 a
3 classes (1,5 em média), 6,2 métodos em média apresentando cerca de 40,5 linhas de
código.
A coluna CCM representa a complexidade máxima ciclomática encontrada nos
métodos de um programa, e CCA é a complexidade média ciclomática.
CCM varia de 2 (mínimo) a 9(no máximo) de complexidade ciclomática, em
média 4.8.
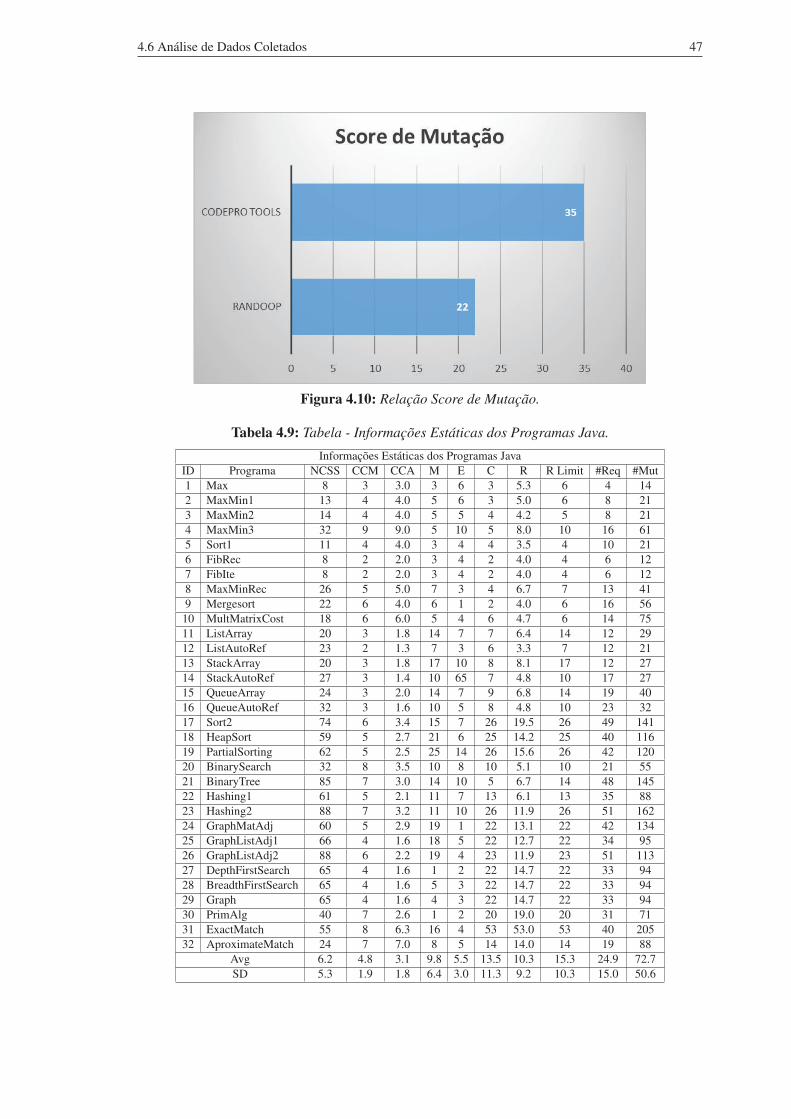
4.6 Análise de Dados Coletados 47
Figura 4.10: Relação Score de Mutação.
Tabela 4.9: Tabela - Informações Estáticas dos Programas Java.
Informações Estáticas dos Programas JavaID Programa NCSS CCM CCA M E C R R Limit #Req #Mut1 Max 8 3 3.0 3 6 3 5.3 6 4 142 MaxMin1 13 4 4.0 5 6 3 5.0 6 8 213 MaxMin2 14 4 4.0 5 5 4 4.2 5 8 214 MaxMin3 32 9 9.0 5 10 5 8.0 10 16 615 Sort1 11 4 4.0 3 4 4 3.5 4 10 216 FibRec 8 2 2.0 3 4 2 4.0 4 6 127 FibIte 8 2 2.0 3 4 2 4.0 4 6 128 MaxMinRec 26 5 5.0 7 3 4 6.7 7 13 419 Mergesort 22 6 4.0 6 1 2 4.0 6 16 5610 MultMatrixCost 18 6 6.0 5 4 6 4.7 6 14 7511 ListArray 20 3 1.8 14 7 7 6.4 14 12 2912 ListAutoRef 23 2 1.3 7 3 6 3.3 7 12 2113 StackArray 20 3 1.8 17 10 8 8.1 17 12 2714 StackAutoRef 27 3 1.4 10 65 7 4.8 10 17 2715 QueueArray 24 3 2.0 14 7 9 6.8 14 19 4016 QueueAutoRef 32 3 1.6 10 5 8 4.8 10 23 3217 Sort2 74 6 3.4 15 7 26 19.5 26 49 14118 HeapSort 59 5 2.7 21 6 25 14.2 25 40 11619 PartialSorting 62 5 2.5 25 14 26 15.6 26 42 12020 BinarySearch 32 8 3.5 10 8 10 5.1 10 21 5521 BinaryTree 85 7 3.0 14 10 5 6.7 14 48 14522 Hashing1 61 5 2.1 11 7 13 6.1 13 35 8823 Hashing2 88 7 3.2 11 10 26 11.9 26 51 16224 GraphMatAdj 60 5 2.9 19 1 22 13.1 22 42 13425 GraphListAdj1 66 4 1.6 18 5 22 12.7 22 34 9526 GraphListAdj2 88 6 2.2 19 4 23 11.9 23 51 11327 DepthFirstSearch 65 4 1.6 1 2 22 14.7 22 33 9428 BreadthFirstSearch 65 4 1.6 5 3 22 14.7 22 33 9429 Graph 65 4 1.6 4 3 22 14.7 22 33 9430 PrimAlg 40 7 2.6 1 2 20 19.0 20 31 7131 ExactMatch 55 8 6.3 16 4 53 53.0 53 40 20532 AproximateMatch 24 7 7.0 8 5 14 14.0 14 19 88
Avg 6.2 4.8 3.1 9.8 5.5 13.5 10.3 15.3 24.9 72.7SD 5.3 1.9 1.8 6.4 3.0 11.3 9.2 10.3 15.0 50.6

4.6 Análise de Dados Coletados 48
Tabela 4.10: Cobertura e Declaração de Mutação - Score por
Teste Gerado.
Cobertura e Declaração de Mutação - Score por Teste GeradoCobertura por Conjunto Teste Score de Mutação por Conjunto de Teste
ID M E C R M E C R1 75.0 100.0 50.0 93.3 85.7 71.4 28.57 38.62 87.5 100.0 87.5 94.2 81.0 66.7 52.38 25.73 87.5 100.0 87.5 91.7 81.0 28.6 52.38 24.94 93.8 100.0 75.0 84.8 72.1 26.2 13.11 11.25 90.0 100.0 50.0 60.7 81.0 81.0 42.86 17.66 83.3 100.0 83.3 98.9 100.0 100.0 83.33 95.87 83.3 100.0 83.3 98.9 100.0 75.0 83.33 95.88 92.3 100.0 23.1 88.5 80.5 19.5 7.32 18.29 93.8 93.8 12.5 66.9 91.1 21.4 5.36 17.910 92.9 92.9 92.9 90.5 38.7 30.7 48.00 27.811 100.0 100.0 75.0 71.7 65.5 69.0 24.14 36.112 100.0 100.0 91.7 95.0 71.4 66.7 52.38 58.313 100.0 100.0 100.0 81.7 74.1 74.1 44.44 61.114 100.0 100.0 94.1 88.4 66.7 77.8 62.96 63.015 78.9 100.0 73.7 68.4 57.5 85.0 22.50 39.616 100.0 100.0 78.3 89.0 68.8 65.6 34.38 64.017 97.9 70.8 64.6 64.0 85.8 35.5 32.62 21.018 97.5 80.0 85.0 56.9 76.7 39.7 43.97 19.919 28.6 97.6 28.6 57.4 29.2 45.8 6.67 22.420 100.0 100.0 71.4 52.5 69.1 67.3 23.64 15.021 81.3 58.3 37.5 46.5 55.9 21.4 8.97 14.322 100.0 100.0 77.1 85.0 59.1 58.0 28.41 45.723 80.8 94.2 82.7 92.4 47.5 51.2 30.86 47.524 100.0 0.0 83.3 83.6 73.1 0.0 52.24 52.925 97.1 64.7 82.4 79.5 68.4 37.9 45.26 43.526 96.1 78.4 68.6 60.5 73.5 30.1 35.40 30.927 60.6 30.3 81.8 74.3 30.9 10.6 30.85 33.4
28 39.4 18.2 81.8 74.3 13.8 11.7 30.85 33.429 84.8 18.2 81.8 74.3 38.3 10.6 30.85 33.430 93.8 43.8 50.0 28.1 38.0 5.6 5.63 1.431 97.5 72.5 100.0 96.1 40.0 21.0 51.22 41.532 94.7 100.0 100.0 92.3 29.5 31.8 37.50 33.0Avg 87.8 81.7 73.0 77.5 63.9 44.9 36.0 37.0SD 16.9 29.1 22.6 17.3 22.0 27.2 20.0 22.1
CCA varia de 1,25 (mínimo) a 9 (máximo) de complexidade ciclomática, em
média 3,1.
As duas últimas colunas apresentam o número de requisitos de teste exigidos
para critério de cobertura e critérios de teste de mutação. No caso de experimento de
mutação, foram usados todos os operadores de mutação implementados no PIT.
As colunas rotuladas M, E e C correspondem ao número de casos de teste gerados
manualmente M, automaticamente por EvoSuite E, e automaticamente por CodePro C.
A coluna Limit R é o valor máximo entre M, E e C e é utilizada para limitar o
número de casos de teste aleatórios do Randoop, permitindo assim gerar o estudo.
A coluna R corresponde ao número médio de testes aleatórios gerados para cada
programa com Randoop. Padrão de 30 testes por programa.
Observou-se que o conjunto de testes manuais teve em média 9,8 casos de teste.

4.6 Análise de Dados Coletados 49
EvoSuite gerou em média 6,5 casos de teste, CodePro gerou 13,5 casos de teste
e Randoop gerou 10,3 casos de teste em média.
Especialmente para EvoSuite e CodePro, considerou-se este conjunto de casos
de teste gerenciáveis no sentido de que se o testador quer verificar se eles estão corretos,
é uma tarefa viável.
Além disso, o desvio padrão do conjunto de testes M e E é menor que os
apresentados por C e R.
Portanto, em relação a custo, devemos aceitar a alternativa H21 da hipótese em
relação a custo de testes gerados de forma manual e automatizada.
A Tabela 4.10 apesenta os dados referentes a declaração de cobertura e o score
de mutação.
A partir da Tabela 4.10, os resultados dos conjuntos de melhor a pior resultado
ficaram na seguinte ordem M, E, R e C.
Em média M obtitda de uma cobertura de 87,8% com um desvio padrão (SD) de
16,9%;
E obtida uma cobertura de 81,7% e (SD) de 29,1%;
R obtida uma cobertura de 77,5% e (SD) de 17,3%; e
C obtida uma cobertura de 73,0% e (SD) de 22,6%.
Mas há situações específicas em que um conjunto de testes apresentam desem-
penho melhor que outros
Em negrito na Tabela 4.10 estão conjuntos de teste que apresentaram melhor
desempenho.
Quando a cobertura foi igual, também foram negritados os valores nas células.
Observando o padrão, E gerou mais conjuntos de teste com 100% de cobertura
seguido por M.
Apenas em 27, 28 e 31, it C obteve melhores resultados. Eles estão entre os
programas mais complexos e ambos os conjuntos de teste M e E não conseguiram superar
C.
EvoSuite não conseguiu gerar casos de teste para o programa 22 e não foi
possível identificar a razão para isso.
No caso de Score de mutação, os valores obtidos não foram muito altos. Mais
uma vez M obteve um melhor resultado médio com score de mutação de 63%, seguido de
E com um resultado de mutação de 44,9%, seguido de R, com 37%, e C com 36%.
A diferença média que representa o score de mutação é significante embora o
desvio padrão para todos os conjuntos de teste é de cerca de 20%.
Uma possível causa dessa diferença é que em caso de score de mutação, para
distinguir o comportamento entre o programa original e seus mutantes, PIT usa as

4.7 Ameaças a Validade 50
afirmações presentes em cada caso de teste. Estas pontuações são realmente muito baixas,
considerando que normalmente é fácil matar 80% dos mutantes.
Quando o testador escreve casos de teste de forma manual, ele tem conhecimento
sobre o programa e seus métodos. Ele verifica se o resultado é correto e avalia o
comportamento de um método ou se o mesmo corresponde a um método vazio.
Por outro lado, geradores automatizados em geral, omitem algumas informações
como por exemplo se um método está vazio. Além disso, PIT mede a cobertura e gera
mutantes de bytecode.
No caso de CodePro, que gera dados de teste a partir do código fonte, quando
uma classe não declarar explicitamente o construtor padrão, nenhum caso de teste é
gerado para testá-lo, mas PIT funciona em bytecode. Ele vai encontrar a construção
padrão no bytecode, e irá gerar requisitos de teste e mutantes para ele.
Considerando as hipóteses estabelecidas, observou-se uma diferença na eficácia
nos conjuntos de teste gerados de forma manual e automatizada. Os resultados referentes a
scores de mutação para os conjuntos de teste gerados de forma manual apresentam melhor
resultado na detecção de falhas modeladas por operadores de mutação. Neste sentido, a
hipótese H11 foi aceita em relação a eficácia. Em termos de força, os conjuntos de teste
apresentaram valores bem próximos e não foi possível confirmar que não há diferença na
força, sendo aceita a hipótese H31 em relação a eficácia.
4.7 Ameaças a Validade
A pesquisa é voltada a avaliar um grupo de ferramentas e extrair dados referente
ao comportamento dessas ferramentas com o intuito de facilitas a escolha de um usuário
por uma ferramenta que atenda melhor as suas necessidade.
Levando em consideração essa informação, desde que se tenham duas ou mais
ferramentas para em funcionamento perfeito os dados podem ser extraídos e comparados
o que reduz a possibilidade de refutar uma provável hipótese.
Mesmo assim, alguns fatores são considerados de rico a validade dos experimen-
tos como por exemplo:
• A falta de conhecimento relacionado as funcionalidades das ferramentas por parte
do testador;
• O fato de uma ferramenta ser totalmente descontinuada no decorrer do projeto
inviabilizando a execução dos experimentos;
• A incompatibilidade de uma ferramenta com uma plataforma específica ou até
mesmo que não se adapte as ferramentas utilizadas na extração dos dados.

4.8 Considerações Finais 51
Algumas ferramentas foram descontinuadas já no início do projetos e outras no
decorrer do mesmo. Quando mantemos as mesmas carateristas do grupo de ferramentas
os dados podem ser obtidos da mesma forma, mas em caso de alguma alteração no grupo
de ferramentas, podemos inviabilizar o uso de uma determinada ferramenta.
4.8 Considerações Finais
De acordo com os dados extraídos dos testes preliminares realizados, CodePro
Tools apresenta maior cobertura de código que Randoop conforme Figura 5.5.
A variação relacionada a cobertura de códigos de CodePro Tools foi inferior a
variação de Randoop.
Randoop gerou uma quantidade de casos de testes muito superior a CodePro
Tools, entretanto, Randoop não permite a inclusão de tempo inferior a 1 segundo o que
pode impactar na quantidade de casos de testes gerados.
Em geral a ferramenta CodePro Tools gera os casos de teste em um prazo inferior
ao mencionado conforme visto na Figura 5.6.
CodePro Tools também apresentou uma variação muito inferior a Randoop em
relação à quantidade de casos de teste.
Mesmo adotando um padrão em relação ao tempo de geração de casos de teste,
Randoop variou mais em relação à quantidade de casos de teste gerados.
Em relação a testes de mutação, foi possível concluir que Randoop gerou mais
mutantes que CodePro Tool conforme Figura 5.8, entretanto, CodePro Tools teve uma
variação menor em relação a quantidade de mutantes gerados que Randoop.
Randoop apresenta uma quantidade maior de mutantes mortos que CodePro
Tools o que é facilmente justificado em relação a quantidade de mutantes gerados
conforme podemos ver na Figura 5.9, onde são apresentadas as quantidades e na figura
5.10 com o score de mutação.
Os dados acima mencionados foram elaborados para uma análise inicial e
utilizados na primeira fase do projeto. Para a segunda fase, alguns dos procedimentos
mudaram com intuito de acrescentar ao comparativo dados de testes gerados de forma
manual juntamente com dados gerados pela ferramenta EvoSuite obtendo assim uma
gama maior de dados foram avaliados.

CAPÍTULO 5Conclusão
Na primeira fase dos experimentos, pode-se concluir que CodePro Tools apre-
senta melhores resultados que Randoop em relação a geração geração de casos de teste
mas quando o fator é testes de mutação Randoop apresentou melhores resultados.
A presente pesquisa apresenta aspectos para avaliar conjuntos de testes gerados
de forma manual e gerados por meio de geradores automáticos em 32 programas de
estrutura de dados.
Foram utilizados três geradores de teste automáticos diferentes. Em geral, exis-
tem algumas diferenças em relação ao número de casos de teste gerados, devido às estra-
tégias de otimização adotadas por cada gerador. Randoop por exemplo limita a quantidade
de casos de teste de acordo com valores inseridos em uma de suas condições de parada.
Nesse caso, foi adotada a condição tempo, rodando o programa 60 segundos por pro-
grama. Em 60 segundos no menor programa ele gerou 30 mil casos de teste. Em termos
de cobertura, analisando as médias, os conjuntos de teste manuais obtiveram melhorem
melhores resultados.
Os conjuntos de teste de EvoSuite tem 100% de cobertura em 17 dos 32
programas, seguido de testes manuais.
Em termos de eficácia, os conjuntos de teste manuais obtiveram melhor score de
mutação em quase todos os programas.
Apenas em 9 programas a pontuação ficou abaixo de conjuntos de teste automa-
tizados, atingindo um score de mutação de 63,9% em média.
O segundo melhor conjunto de testes com melhor score de mutação foi o de
EvoSuite com uma pontuação de 44,9%, em média.
A presente pesquisa abre possibilidades para vários domínios diferentes de novas
pesquisas que poderão ser feitas em um futuro. Tendo em vista que no decorrer desta
pesquisa algumas ferramentas novas surgiram, e ao mesmo tempo algumas deixaram de
ser atualizadas, para trabalhos futuros poderão ser feitos nos comparativos, seguindo os
mesmos critérios em uma quantidade maior de ferramentas e obtendo um conjunto de
possibilidades maior que os apresentados até o momento.

5.1 Contribuições 53
Outra possibilidade seria o fato de trabalhar as ferramentas geradoras em con-
junto com a finalidade de obter valores combinados ou até mesmo uma combinação entre
todos os geradores.
Além das possibilidades já informadas, existem outras possibilidades seguindo o
mesmo contexto de geradores automatizados de dados de teste que podem ser trabalhados
como a adoção de ferramentas descontinuadas para a criação de uma nova ferramenta
que se adeque as características abordadas na atualidade ou até mesmo a criação de uma
ferramenta que contemple o melhor obtido entre as ferramentas já avaliadas.
Finalizando, por meio dos dados obtidos o gerador que apresenta os melhores
resultados é EvoSuite cobrindo 4,2% mais linhas de código que Randoop e 8,7% a mais
que CodePro Tools.
Randoop fica em segunda posição cobrindo 4,5% a mais de linhas de código que
CodePro Tools.
5.1 Contribuições
Outros autores realizaram trabalhos avaliando ferramentas de geração automá-
tica de testes, mas a forma com que conduziram seus experimentos não foi igual a da
presente pesquisa.
A princípio uma das maiores contribuições visíveis no projeto é a formação de
grupos de ferramentas que trabalhem em conjunto formando um conjunto que permita um
estudo mais aprofundado em relação aos aspectos apresentados no mesmo.
Outra contribuição está na montagem do protocolo de experimentação onde
temos dados que foram avaliados e podem servir como referencia para futuras pesquisas.
Dentro do contexto estudado, temos dados que evidenciam a qualidade de
um determinado grupo de ferramentas. Esses dados também podem ser levados em
consideração em relação a contribuições da presente pesquisa.
5.2 Trabalhos Futuros
A presente pesquisa abre ramificações para outras pesquisas como por exemplo a
avaliação de ferramentas de geração de testes de mutação, aprimoramento de ferramentas
já existentes no mercado, criação de uma ferramenta nova composta pelas melhores
características avaliadas até o momento, avaliação de aspectos complementares entre as
ferramentas, a abrangência de uma quantidade maior de linguagens de programação, entre
outros aspectos.

5.2 Trabalhos Futuros 54
Para um trabalho futuro dentro desse mesmo seguimento o mais interessante
seria o uso de uma quantidade maior de ferramentas de geração automática de testes em
uma quantidade maior de programas.

Referências Bibliográficas
ANDREWS, J. H.; BRIAND, L. C.; LABICHE, Y. Is mutation an appropriate tool for testingexperiments. ICSE’05, May 15–21, 2005, St. Louis, Missouri, USA. Copyright 2005 ACM1-58113-963-2/05/0005, 2005.
Apache Software Foundation. Apache Maven Project. 2002. Página Web. Disponível em:https://maven.apache.org/. Acesso em: 10/02/2016.
BACHIEGA, T. et al. Complementary aspects of automatically and manually generatedtest case sets. In: ACM. Workshop on Automated Software Testing – A-TEST’2016.Seattle, WA, EUA: ACM Press, 2016. Aceito para publicação.
BARBOSA, E. F.; MALDONADO, J. C.; VINCENZI, A. M. R. Introdução ao teste desoftware. 2000.
CHHILLAR, R. S.; BALA, A. A review on existing techniques for generating automatic testcase for object oriented software. International Journal of Mathematics and ComputerResearch, 2014.
DELAHAYE, M.; BOUSQUET, L. Selecting a software engineering tool: lessons learntfrom mutation analysis. Software: Practice and Experience, 2015.
FRASER, G.; ARCURI, A. 1600 faults in 100 projects: Automatically finding faults whileachieving high coverage with evosuite. 2013.
FRASER, G.; ARCURI, A. A large-scale evaluation of automated unit test generationusing evosuite. ACM Trans. Softw. Eng. Methodol, 2014.
FRASER, G.; ARCURI., A. Evosuite at the sbst 2016 tool competition. In Proceedings ofthe 9th International Workshop on Search-Based Software Testing, pages 33-36, NewYork, NY, USA, 2016. ACM., 2016.
FRASER, G. et al. Does automated unit test generation really help software testers? acontrolled empirical study. ACM Transactions on Software Engineering and Methodology,2014.
GHEYI, R. et al. Análise conjunta das ferramentas. 2010. Disponível em: <http:/-/engenhariadesoftwareufcg.googlecode.com/svn/trunk/documentosEscritos/PDFs/p17-.pdf>.
GOOGLE. Codepro analytix evaluation guide. Página Web - https://google-web-toolkit.googlecode.com/files/CodePro-EvalGuide.pdf Acesso em: 04/07/2016., 2010.

Referências Bibliográficas 56
ISO/IEC/IEEE. Systems and software engineering – vocabulary. ISO/IEC/IEEE
24765:2010(E), n. 24765:2010(E), p. 1–418, dez. 2010.
JORGE, R. F. Estudo, definição e implementação de técnicas para a geração de dadosde teste a partir de gui. Instituto de Informática - Universidade Federal de Goiás, 2013.,2013.
KRACHT, J. S.; PETROVIC, J. Z.; WALCOTT-JUSTICE, K. R. Empirically evaluatingthe quality of automatically generated and manually written test suites. InternationalConference on Quality Software, 2014.
MA, Y.-S.; OFFUTT, J.; KWON., Y. R. Mujava: an automated class mutation system:Research articles. STVR - Software Testing, Verification and Reliability, 15(2):97-133,2005., 2005.
MAHMOOD, S. A systematic review of automated test data generation techniques. Schoolof Engineering – Blekinge Institute of Technology, Ronneby, Sweden, out. 2007., 2007.
MICSKEI, Z. Code-based test generation. 2013. Página Web. Disponível em:http://mit.bme.hu/~micskeiz/pages/code_based_test_generation.html.Acesso em: 10/02/2016.
OLADEJO, B. F.; OGUNBIYI, D. T. An empirical study on the effectiveness of automatedtest case generation techniques. American Journal of Software Engineering andApplications, 2014.
PACHECO, C.; ERNST., M. D. Randoop: Feedback-directed random testing for java. InCompanion to the 22Nd ACM SIGPLAN Conference on Object-oriented ProgrammingSystems and Applications Companion, OOPSLA ’07, pages 815-816, New York, NY,USA, 2007. ACM., 2007.
PRESSMAN, R. S.; MAXIM, B. Software Engineering – A Practitioner’s Approach. 8. ed.[S.l.]: McGraw-Hill Education, 2014.
SHARMA, P.; BAJPAI, N. Testing approaches to generate automated unit test cases.International Journal of Computer Science and Information Technologies, v. 5 (3), 2014.
SIMONS., A. J. Jwalk: A tool for lazy, systematic testing of java classes by designintrospection and user interaction. Automated Software Engg., 14(4):369-418, Dec. 2007.,2007.
SINGH, I.; CAUSEVIC, A.; PUNNEKKAT, S. A mapping study of automation support toolsfor unit testing. Mälardalen University School of Innovation, Design and Engineering,2014.
SMEETS, N.; SIMONS, A. J. H. Automated unit testing with randoop, jwalk and µjavaversus manual junit testing. 2010.
SMEETS, N.; SIMONS., A. J. H. Automated unit testing with randoop, jwalk and mujavaversus manual junit testing. Research reports, Department of Computer Science,University of Sheffield/University of Antwerp, Sheffield, Antwerp, 2011., 2011.

Referências Bibliográficas 57
SOLINGEN V. BASILI, G. C. R. van; ROMBACH., H. D. Goal question metric (gqm)approach. John Wiley & Sons, Inc., 2002., 2002.
SOUZA, S. R. S.; PRADO, M. P. An experimental study to evaluate the impact of theprogramming paradigm in the testing activity. CLEI ELECTRONIC JOURNAL, XX, 2011.
SOUZA, S. R. S. et al. An experimental study to evaluate the impact of the programmingparadigm in the testing activity. CLEI Electronic Journal, 15(1):1-13, Apr. 2012. Paper 3.,2012.
ZIVIANI, N. Projeto de Algoritmos com Implementações em Java e C++. [S.l.]: CengageLearning, 2011.
ZIVIANI, N. Projeto de Algoritmos com Implementações em Pascal e C. 3. ed. [S.l.]:Cengage Learning, 2011.