Embed Size (px)
Citation preview

BCC402 Algoritmos e Programação Avançada Prof. Marco Antonio M. Carvalho Prof. Túlio Toffolo 2012/1

¡ Strings § Estrutura § Leitura § Impressão § Processamento § Problemas Ad Hoc § Trie, Árvore e Vetor de Sufixos ▪ Aplicações
§ Casos especiais de busca em texto


¡ Em C § Vetor do tipo char, terminado pelo caractere ‘\0’; § Temos que saber o tamanho da string, ou pelo menos, um limite máximo a princípio.
!char str[1000];
¡ Em C++ § Classe string.
#include <string>!string str; !

¡ C #include <stdio.h> !!scanf("%s", &str); !//& opcional
¡ C++ !#include <iostream> !using namespace std; !!cin >> str;

¡ C gets(str); !// versão alternativa/segura!fgets(str, 10000, stdin); !// mas adiciona o !// ‘\n‘ ao final !
¡ C++ getline(cin, str); !getline(str, 'A'); !

¡ C printf("s = %s, l = %d\n",str, strlen(str)); !
¡ C++ cout << "s = " << str <<", l = " << str.length();

¡ C printf(strcmp(str, "teste") ? "diferente\n" : "igual\n"); !
¡ C++ cout << (str2 == "teste" ? "igual" : "diferente") << endl;

¡ C strcpy(str, "hello"); !strcat(str, " world"); !printf("%s\n", str); !
¡ C++ str2 = "hello"; !str2.append(" world"); !cout << str2 << endl; ! !str3+="hello "; !str3+="world"; !cout << str2 << endl;

¡ C char *p; !for (p=strtok(str, " "); p; p = strtok(NULL, " ")) ! printf("%s\n", p);
¡ C++ #include <sstream> !string token; !istringstream iss(str2); ! !while (getline(iss, token, ' ')) ! cout << token << endl;

¡ C ! char *p=strstr(str, substr); ! if (p) ! printf("%d\n", p-str-1); !!C++ ! int pos = str2.find(substr2); ! //npos= final de string! if (pos != string::npos) ! cout << pos - 1 << endl;

¡ C char str[1000] = "quinze de maio de 1984", numeros[11] = "0123456789"; !cout<<strcspn(str, numeros)<<endl; !!
¡ C++ string str2 = "quinze de maio de 1984"; !cout<<str2.find_first_of("0123456789")<<endl;

¡ C char *ch=strrchr(str, 'd'); !cout<<ch-str<<endl; !!
¡ C++ //procura por uma string, ao inves de um caractere!cout<<str2.find_last_of("d")<<endl;

¡ C e C++ #include <cctype> ! ! for (int i = 0; str[i]; i++) ! str[i] = toupper(str[i]); ! // ou tolower(ch),! // isalpha(ch), isdigit(ch)...! ! cout<<str;

¡ C e C++
#include <algorithm>! !//usando vetores de caracteres! sort(str, str + (int)strlen(str)); ! !//usando objetos string!sort(str2.begin(), str2.end());

¡ C++ #include <algorithm>!#include <string>!#include <vector>!!vector<string> S; !// assumindo que S não é vazio!sort(S.begin(), S.end()); !

¡ Encontrar a primeira ocorrência de um caractere que não pertença a uma string § find_first_not_of();
¡ Encontrar a última ocorrência de um caractere que não pertença a uma string § find_last_not_of();
¡ Encontrar a quantidade de caracteres de uma string que ocorram contiguamente no início de outra string § strspn().

¡ toupper: converte um caractere para maiúsculas; ¡ tolower : converte um caractere para minúsculas; ¡ isupper: testa se um caractere é maiúsculo; ¡ islower: testa se um caractere é minúsculo; ¡ isalnum: testa se um caractere é alfanumérico; ¡ isalpha: testa se um caractere é uma letra; ¡ isdigit: testa se um caractere é um dígito decimal; ¡ isxdigit: testa se um caractere é um dígito em hexa; ¡ iscntrl: testa se um caractere é de controle; ¡ ispunct: testa se um caractere é de pontuação; ¡ isprint: testa se um caractere é imprimível; ¡ Retornos: 0 se falso, não-‐zero se verdadeiro.


¡ Cifra (codificar/decodificar) § Transformar uma string dado um mecanismo de codificação/decodificação;
§ Normalmente, segue-‐se a descrição do problema; § Em alguns casos, temos que descobrir um padrão § Uva 10878 – Decode the Tape.

¡ Contagem de Frequência § Conferir quantas vezes certos caracteres/palavras ocorrem em uma string;
§ Usar a estrutura de dados certos (hashing?); § Uva 902 – Password Search.

¡ Análise da Entrada § Dada uma gramática, verificar se uma string é válida ou não de acordo com a gramática;
§ Java sai na frente ▪ Classe Pattern (RegEX).
§ Uva 662 – Grammar Evaluation.

¡ Formatação da Saída § Formatar strings na saída de acordo com uma regra específica;
§ Uva 10894 – Save Hridoy.

¡ Comparação entre strings § Dadas duas strings, elas são iguais, de acordo com algum critério?
§ Case sensitive? § Apenas substring? § Outros critérios… § Uva 11233 – Deli Deli.

¡ Outros § Problemas sem uma estrutura comum; § No entanto, ainda podem ser resolvidos por processamento básico de strings.


¡ Dada uma string padrão P, ela pode ser encontrada na string maior T? § Não codifiquem a versão gulosa (ingênua).
¡ Solução mais fácil: bibliotecas de string § C++: string.find; § C: strstr.
¡ Ou ainda, algoritmos avançados § KMP (Knuth, Morris, Pratt) ▪ Código no Moodle;
§ Vetor de sufixos.


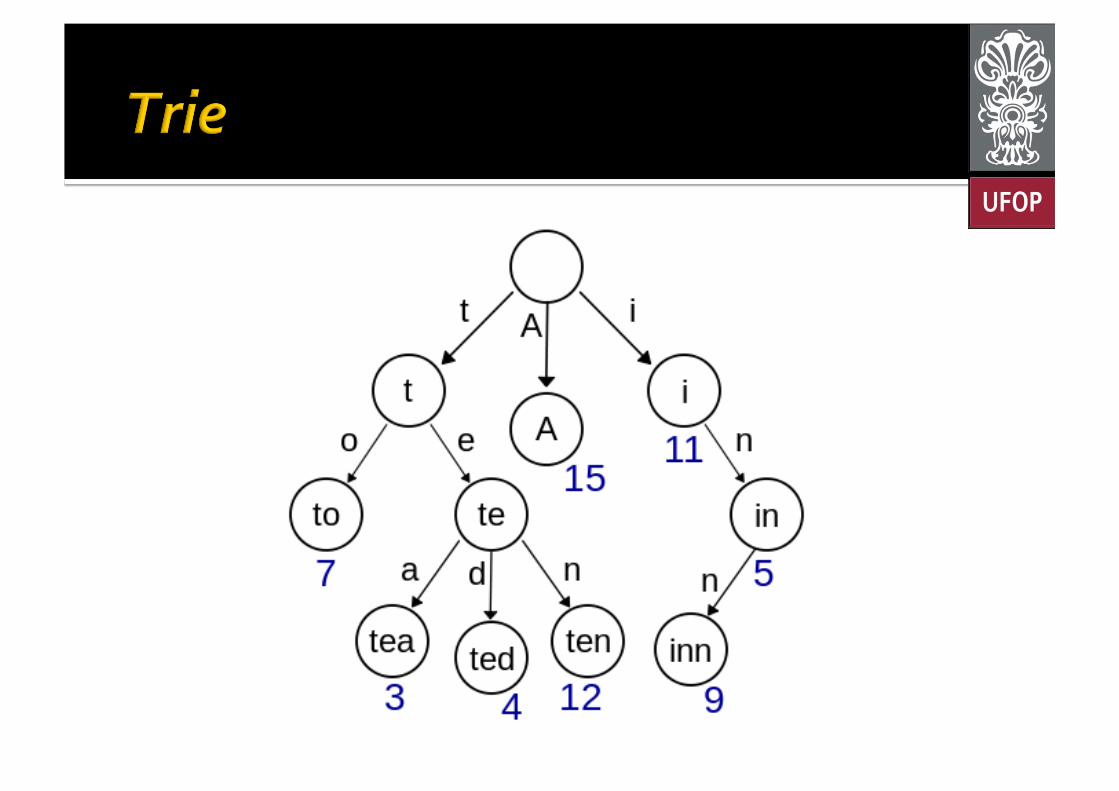
¡ Uma trie é uma estrutura de dados do tipo árvore ordenada § Pode ser utilizada para armazenar um dicionário (ou mapa);
§ Normalmente, as chaves são strings; § Usada basicamente na recuperação de dados ▪ Mais rápida que árvores binárias.

¡ Há tipo especial de trie, chamada de árvore de sufixos § Pode ser utilizada para indexar todos os sufixos de um texto;
§ Torna a busca em texto/casamento de padrões mais rápida.
¡ Dada uma string S, sua árvore de sufixos é uma árvore cujas arestas são rotuladas com strings § Tal que cada sufixo de S corresponde a exatamente um caminho da raiz até uma folha.
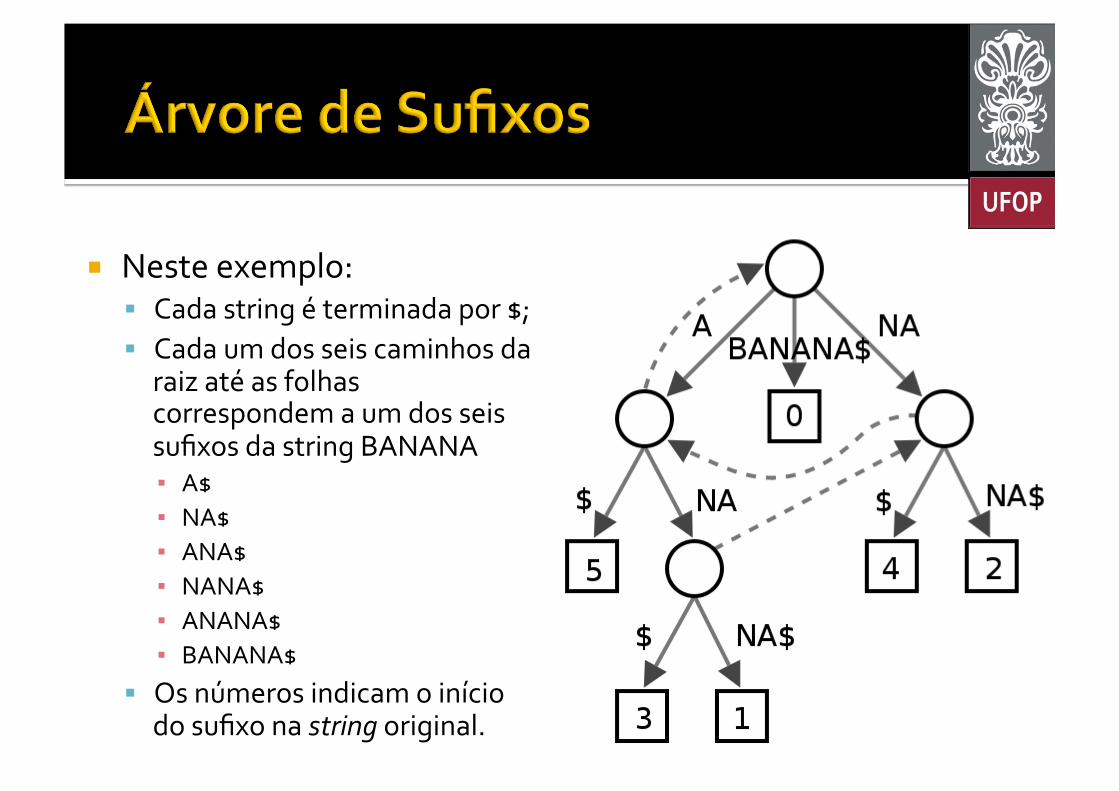
¡ Neste exemplo: § Cada string é terminada por $; § Cada um dos seis caminhos da
raiz até as folhas correspondem a um dos seis sufixos da string BANANA ▪ A$ ▪ NA$ ▪ ANA$ ▪ NANA$ ▪ ANANA$ ▪ BANANA$
§ Os números indicam o início do sufixo na string original.
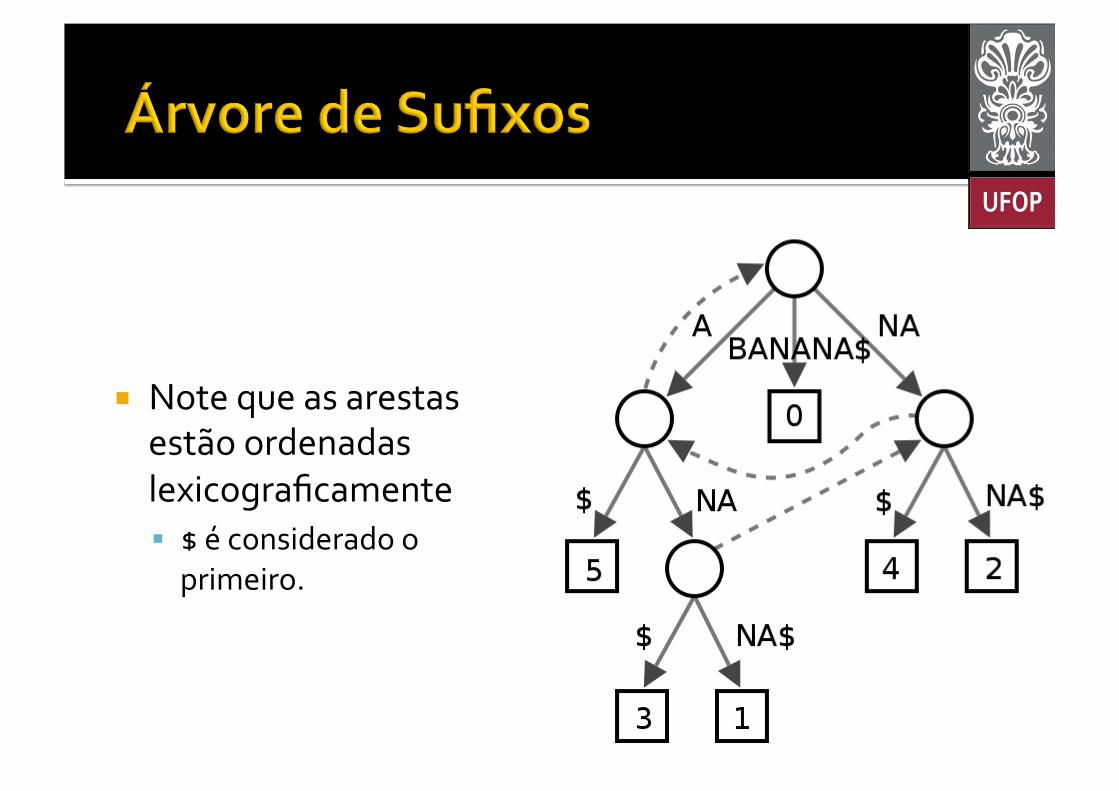
¡ Note que as arestas estão ordenadas lexicograficamente § $ é considerado o primeiro.


¡ Casamento de Padrões § Encontrar todas as ocorrências de da substring P na string T.
¡ Procure pelo vértice da árvore de sufixos que represente P § Todas as folhas na subárvore iniciada neste vértice são ocorrências de P.
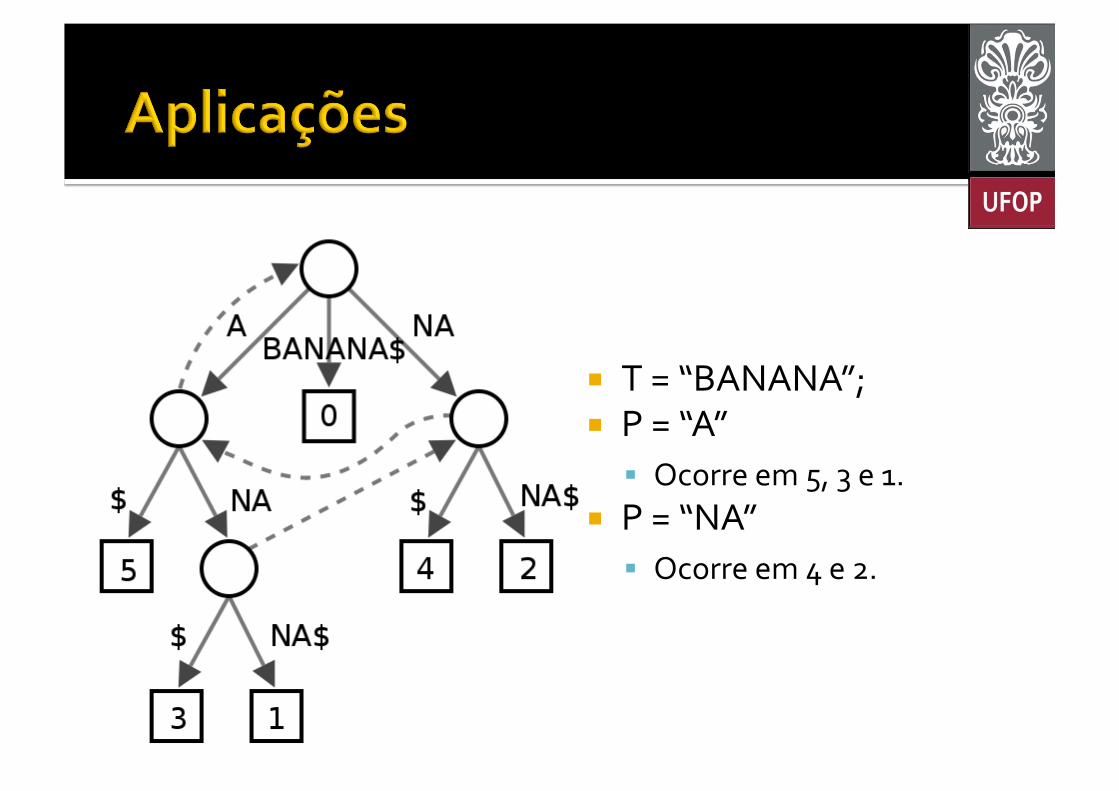
¡ T = “BANANA”; ¡ P = “A”
§ Ocorre em 5, 3 e 1. ¡ P = “NA”
§ Ocorre em 4 e 2.

¡ Maior Substring Repetida § Encontrar a substring de maior comprimento que se repete na string original.
¡ Encontre o vértice interno mais profundo § Ou seja, o vértice mais distante da raiz que não seja uma folha.
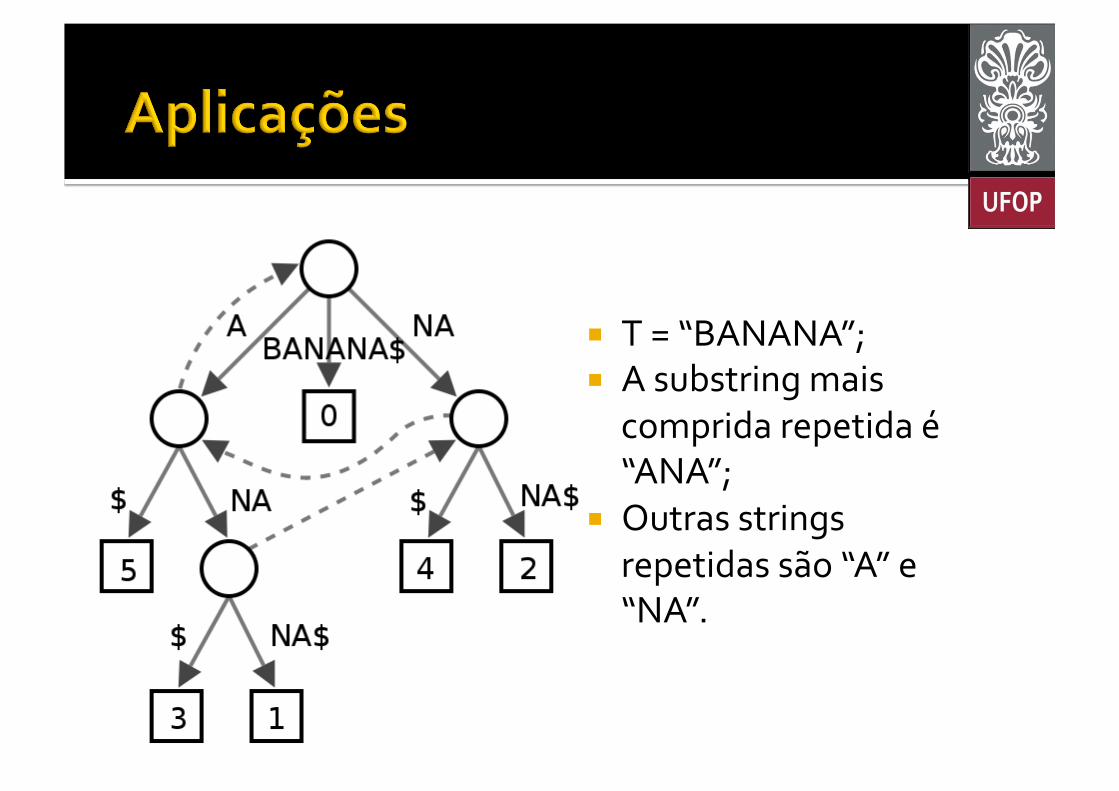
¡ T = “BANANA”; ¡ A substring mais comprida repetida é “ANA”;
¡ Outras strings repetidas são “A” e “NA”.

¡ Maior Substring Comum § Encontrar o maior trecho em comum entre duas ou mais strings;
¡ Crie uma árvore de sufixos que seja a união das árvores de sufixos de cada uma das strings do problema § Marque os vértices internos cujas folhas sejam sufixos de todas as strings;
§ Retorne o vértice marcado mais profundo.

¡ Exemplo no quadro: § “BANANA” e “MANA”.


¡ Um vetor de sufixos possui a mesma funcionalidade de uma árvore de sufixos § Porém, mais eficiente em termos de uso de memória;
§ Mais simples de ser codificado. ¡ É um vetor que armazena:
§ Sufixos ordenados lexicograficamente; § Índices dos sufixos.
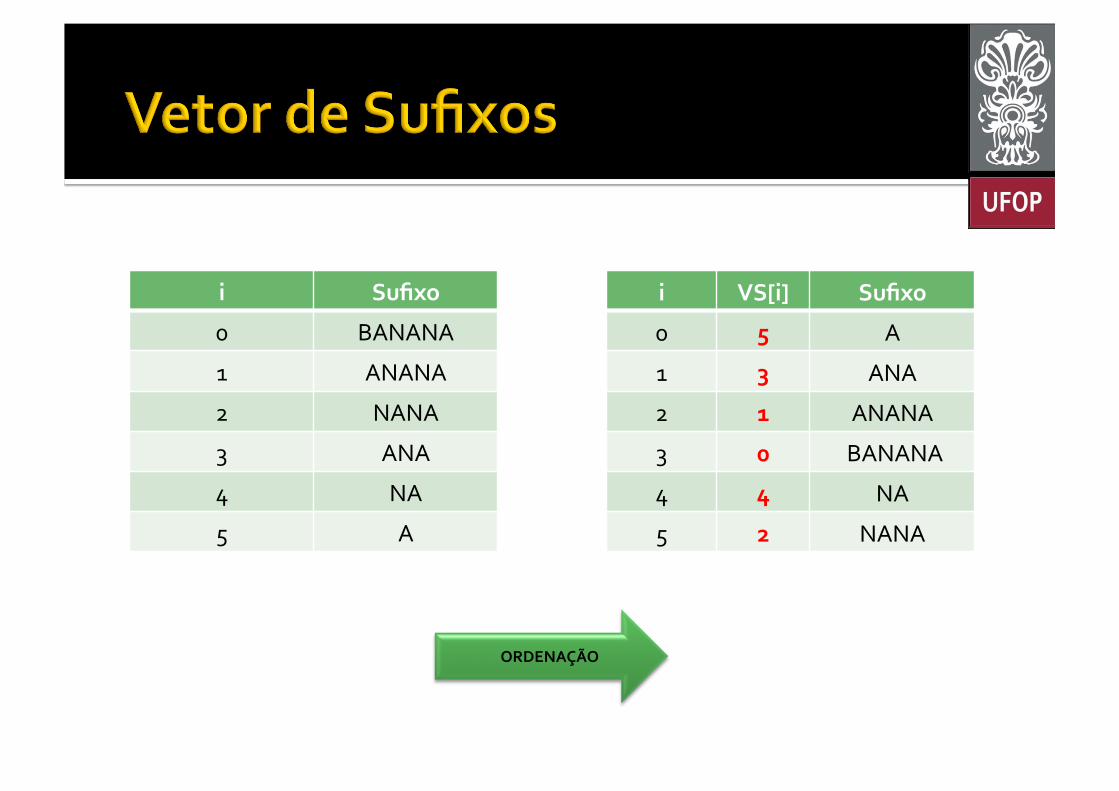
i Sufixo
0 BANANA
1 ANANA
2 NANA
3 ANA
4 NA
5 A
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA
ORDENAÇÃO
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA

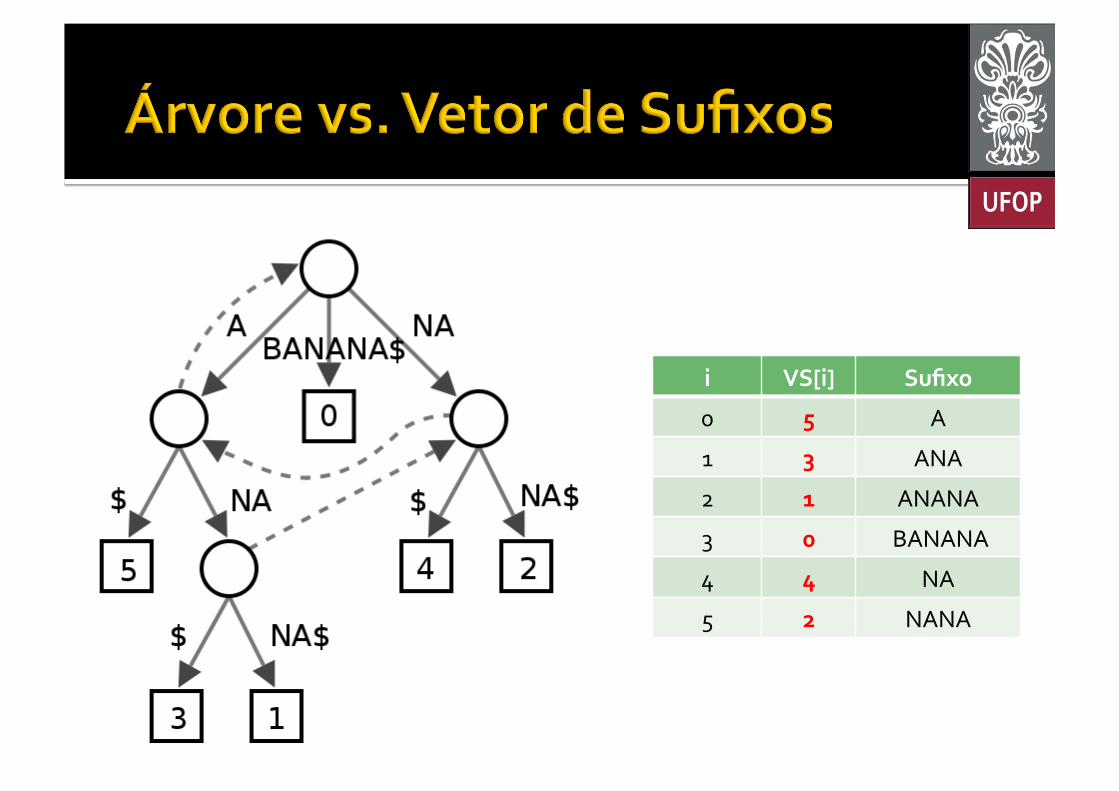
¡ Percorrer os sufixos em ordem lexicográfica § Árvore: Percurso em pré-‐ordem (DFS da esquerda para a direita);
§ Vetor: Percorrer o vetor do início ao final. ¡ Encontrar um sufixo
§ Árvore: Percorrer até uma folha; § Vetor: Acessar um único índice.
¡ Percorrer os sufixos que começam com uma mesma letra § Árvore: Explorar a subárvore de um nó interno; § Vetor: Percorrer um intervalo do vetor.
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA


#include <algorithm>!#include <cstdio> !#include <cstring> !using namespace std; !char T[MAX_N]; int SA[MAX_N]; !!bool cmp(int a, int b) !{ ! return strcmp(T + a, T + b) < 0; !} !!int main() !{ ! int n = (int) strlen(gets(T)); ! ! for (int i = 0; i < n; i++) ! SA[i] = i; ! ! sort(SA, SA + n, cmp); !} !


¡ Casamento de Padrões § Encontrar todas as ocorrências de da substring P na string T.
¡ Solução: Busca binária! § Duas vezes: ▪ Uma para obter um limitante inferior; ▪ Outra para obter um limitante superior.
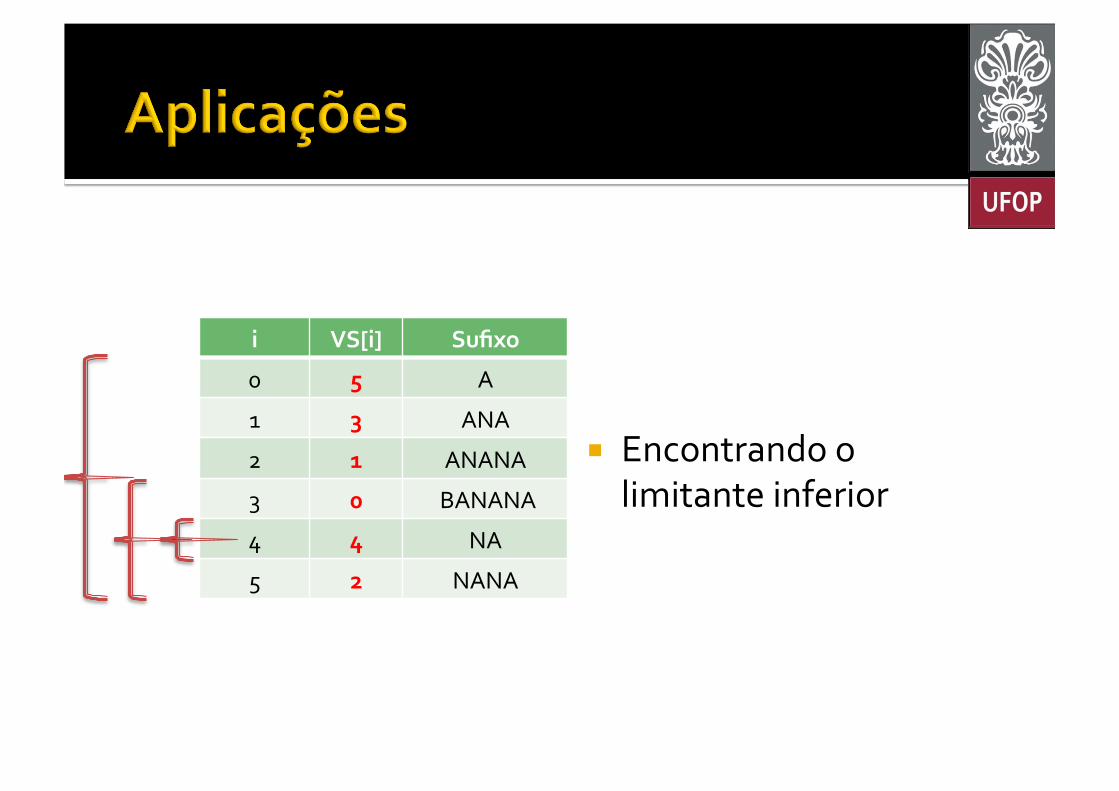
¡ Encontrando o limitante inferior
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA
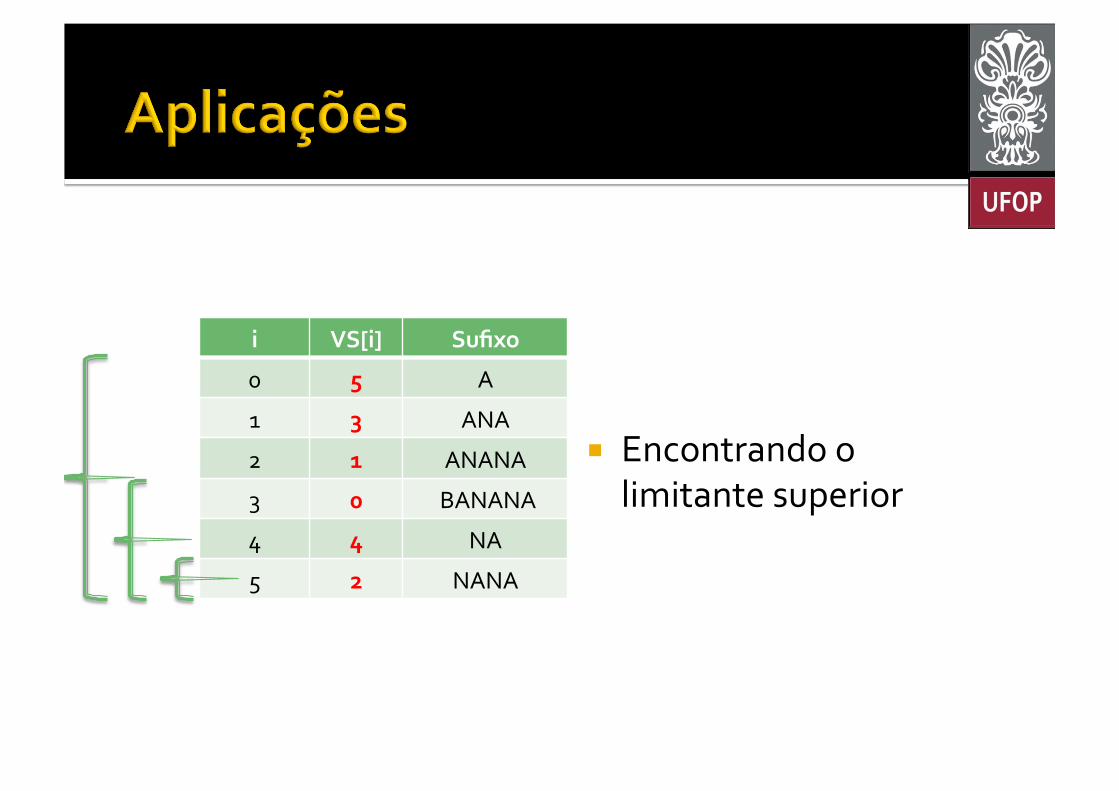
¡ Encontrando o limitante superior
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA
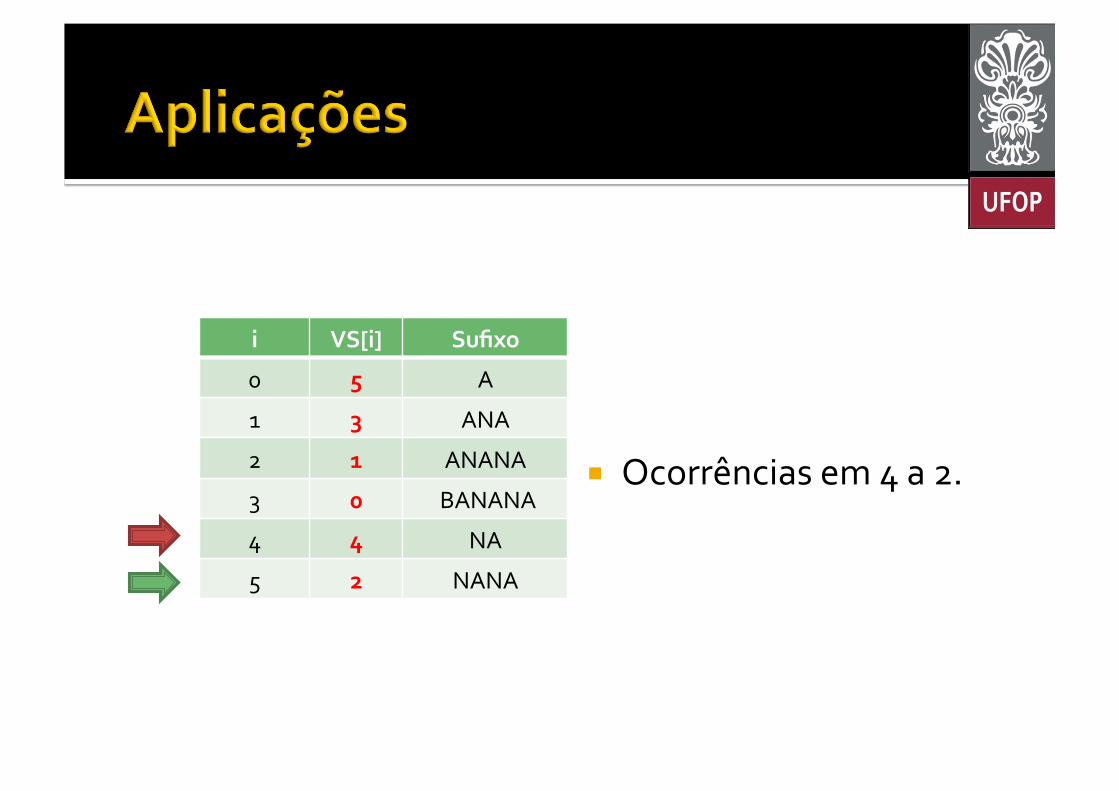
¡ Ocorrências em 4 a 2.
i VS[i] Sufixo
0 5 A
1 3 ANA
2 1 ANANA
3 0 BANANA
4 4 NA
5 2 NANA

¡ Maior Substring Repetida § Encontrar a substring de maior comprimento que se repete na string original.
¡ É necessário incluir o campo “Maior Prefixo Comum” (MPC, ou Longest Common Prefix -‐ LCP) no vetor de Sufixos § Calculado a cada par de sufixos consecutivos no vetor;
§ A posição de maior MPC é a maior substring repetida.
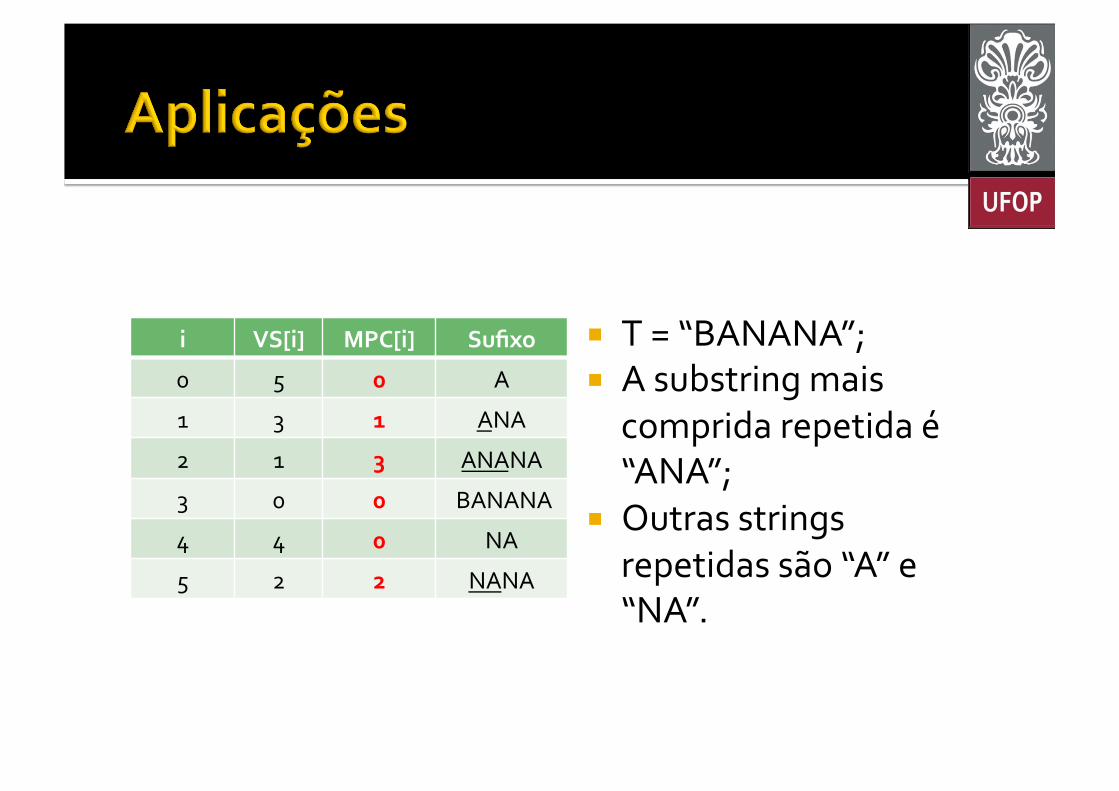
¡ T = “BANANA”; ¡ A substring mais comprida repetida é “ANA”;
¡ Outras strings repetidas são “A” e “NA”.
i VS[i] MPC[i] Sufixo
0 5 0 A
1 3 1 ANA
2 1 3 ANANA
3 0 0 BANANA
4 4 0 NA
5 2 2 NANA

¡ Maior Substring Comum § Encontrar o maior trecho em comum entre duas ou mais strings;
¡ Crie uma string a partir da concatenação das strings do problema § Crie o vetor de sufixos desta nova string; § Calcule os MPCs; § Marque qual string é a origem de cada sufixo; § Retorne o maior valor de MPC cujo sufixo tenha origem em todas as strings do problema.
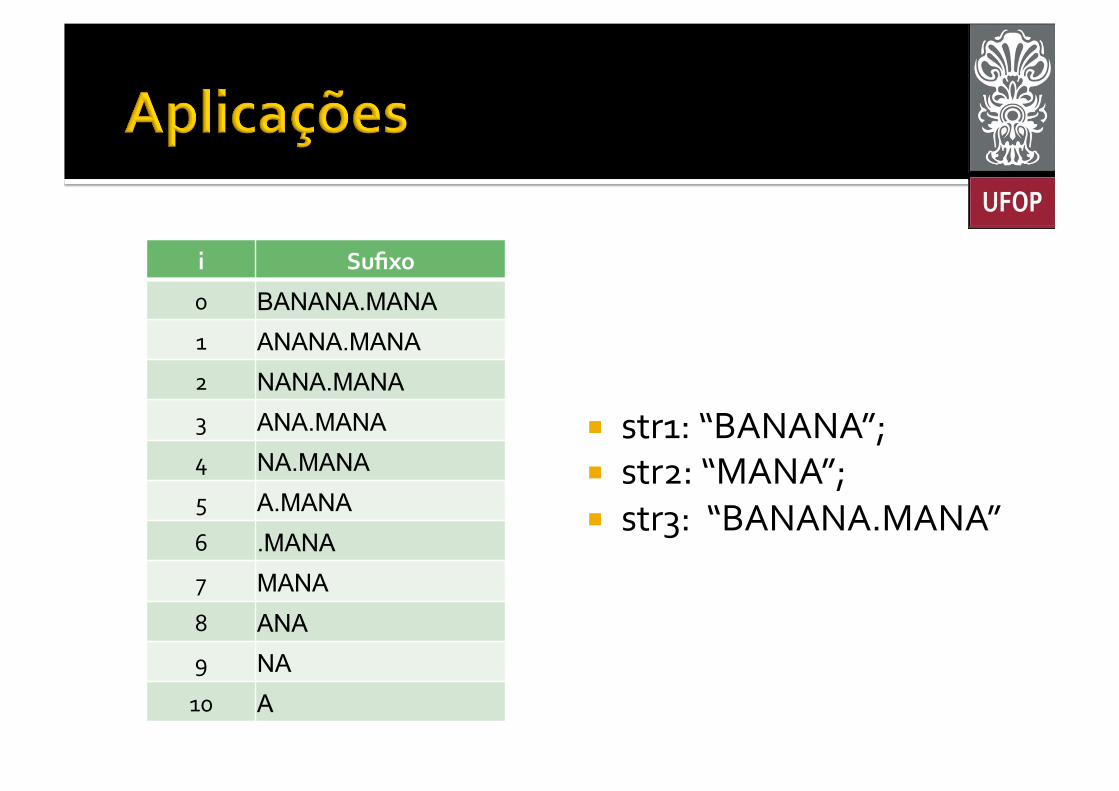
¡ str1: “BANANA”; ¡ str2: “MANA”; ¡ str3: “BANANA.MANA”
i Sufixo
0 BANANA.MANA 1 ANANA.MANA 2 NANA.MANA 3 ANA.MANA 4 NA.MANA 5 A.MANA 6 .MANA 7 MANA 8 ANA 9 NA 10 A
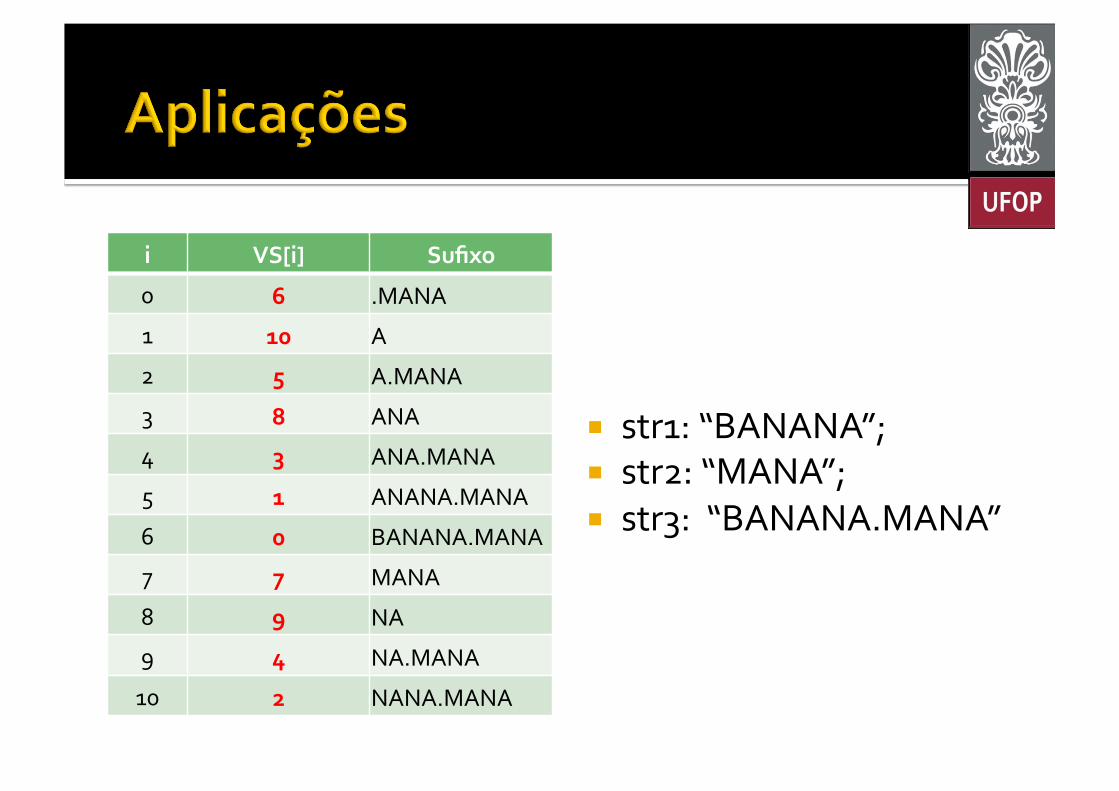
¡ str1: “BANANA”; ¡ str2: “MANA”; ¡ str3: “BANANA.MANA”
i VS[i] Sufixo
0 6 .MANA
1 10 A
2 5 A.MANA
3 8 ANA
4 3 ANA.MANA
5 1 ANANA.MANA
6 0 BANANA.MANA
7 7 MANA
8 9 NA
9 4 NA.MANA
10 2 NANA.MANA
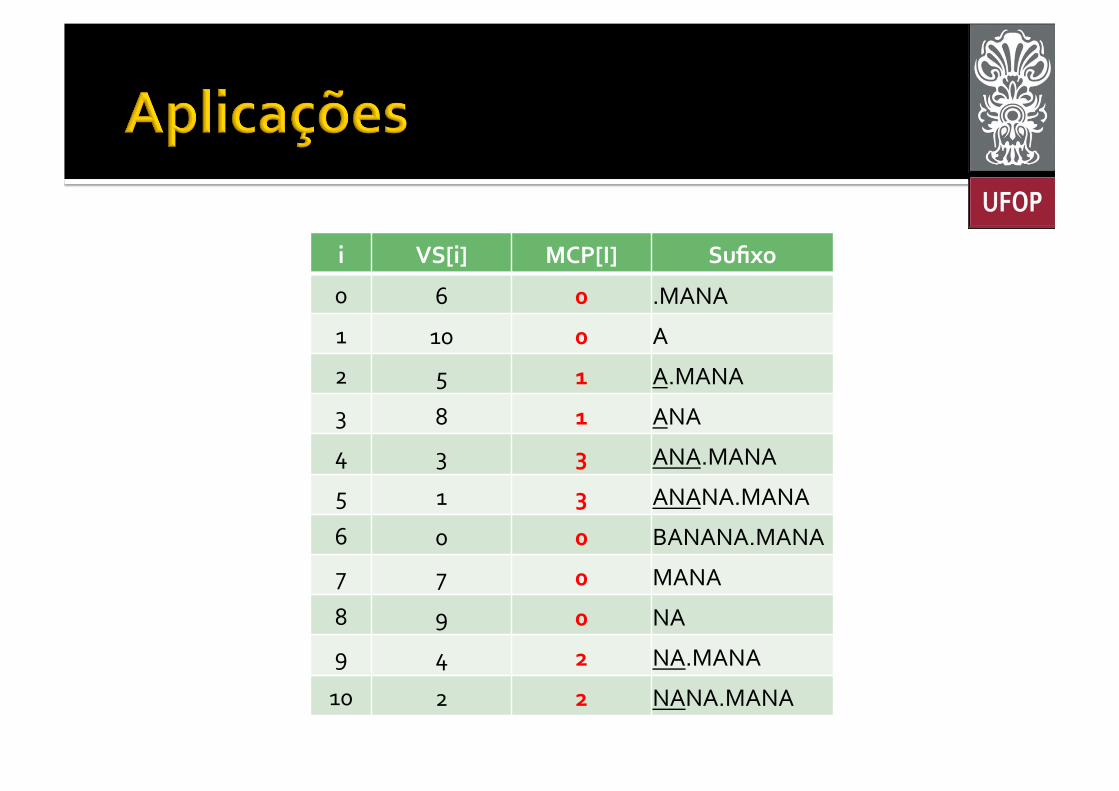
i VS[i] MCP[I] Sufixo
0 6 0 .MANA
1 10 0 A
2 5 1 A.MANA
3 8 1 ANA
4 3 3 ANA.MANA
5 1 3 ANANA.MANA
6 0 0 BANANA.MANA
7 7 0 MANA
8 9 0 NA
9 4 2 NA.MANA
10 2 2 NANA.MANA
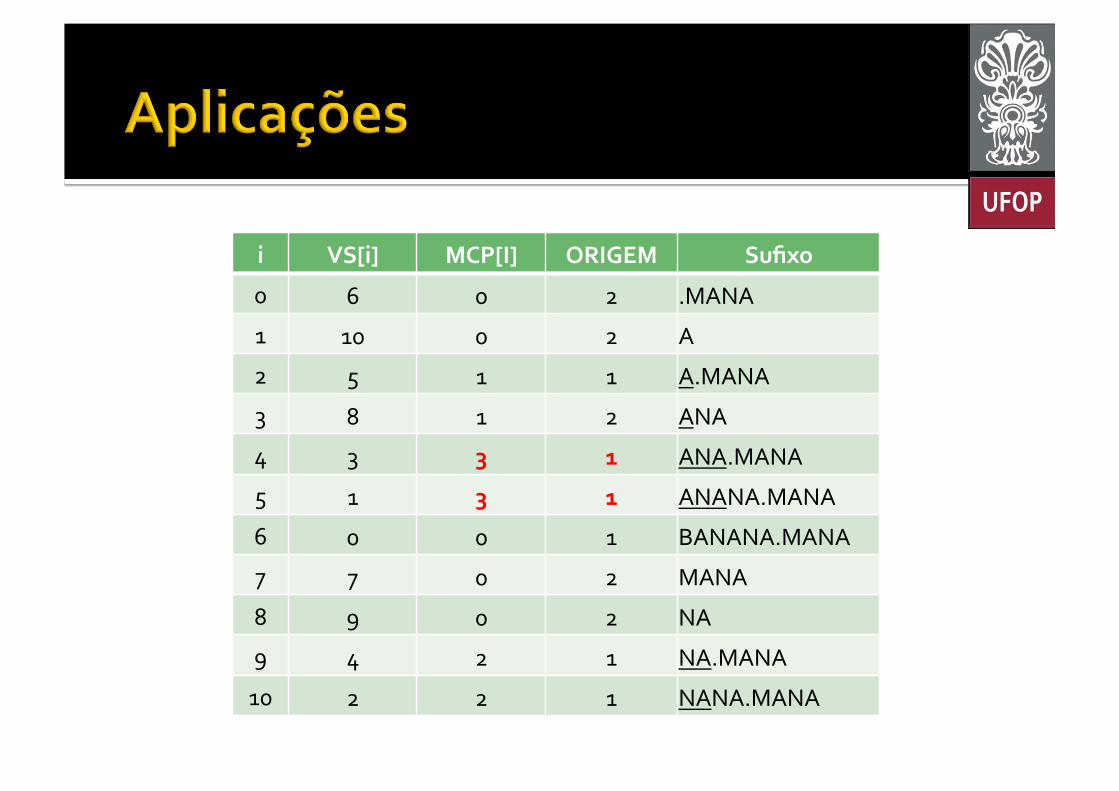
i VS[i] MCP[I] ORIGEM Sufixo
0 6 0 2 .MANA
1 10 0 2 A
2 5 1 1 A.MANA
3 8 1 2 ANA
4 3 3 1 ANA.MANA
5 1 3 1 ANANA.MANA
6 0 0 1 BANANA.MANA
7 7 0 2 MANA
8 9 0 2 NA
9 4 2 1 NA.MANA
10 2 2 1 NANA.MANA


Suponha um problema em que você é contratado para analisar o arquivo de
documentos de uma empresa que mudou de nome. Nesta análise, você deve substituir as ocorrências exatas do nome anterior pelo
novo nome.

4 "Anderson Consulting" to "Accenture" "Enron" to "Dynegy" "DEC" to "Compaq" "TWA" to "American" 5 Anderson Accounting begat Anderson Consulting, which offered advice to Enron before it DECLARED bankruptcy, which made Anderson Consulting quite happy it changed its name in the first place!

Anderson Accounting begat Anderson Consulting, which offered advice to Enron before it DECLARED bankruptcy, which made Anderson Consulting quite happy it changed its name in the first place! Anderson Accounting begat Accenture, which offered advice to Dynegy before it CompaqLARED bankruptcy, which made Anderson Consulting quite happy it changed its name in the first place!

¡ O enunciado não menciona nada sobre a necessidade de espaços em branco após o nome § Logo, DECLARED poderia ser substituído por CompaqLARED ?
¡ O casamento de padrões é case-‐sensitive? ¡ Como tratar casos em que o nome a ser substituído está dividido em mais de uma linha?
¡ São permitidos caracteres coringa?

¡ O casamento inexato de padrões será abordado na aula de programação dinâmica, porém alguns pontos devem ser mencionados: § Casamento inexato de substrings ▪ Ex.: Skiena e Skinna, Skienna, Skena.
§ Maior subsequência comum ▪ Ex.: democrata e republicano.
§ Maior subsequência monotônica, ou seja, uma sequência em que o i-‐ésimo elemento é no minimamente maior ou igual ao elemento i-‐1 ▪ Ex.: “243517698” produz “23568”.


¡ ch6_01_kmp.cpp § Algoritmo KMP (algoritmo baseado em backtracking para busca em texto);
§ Algoritmo ingênuo de busca em texto (guloso).

¡ ch6_03_sa.cpp § Implementação de vetores de sufixos (duas versões, complexidades diferentes);
§ Funções para computar: ▪ Maior substring repetida; ▪ Maior substring comum.

Perguntas?
FIM



























