Embed Size (px)
Citation preview

Universidade Federal de Pernambuco
Centro de Ciências Exatas e da Natureza
Centro de Informática
Pós-graduação em Ciência da Computação
Busca Meta-Heurística para Resolução deCSP em Teste de Software
Mitsuo Takaki
Recife
Setembro de 2009

Universidade Federal de Pernambuco
Centro de Ciências Exatas e da Natureza
Centro de Informática
Mitsuo Takaki
Busca Meta-Heurística para Resolução de CSP em Teste deSoftware
Trabalho apresentado ao Programa de Pós-graduação em
Ciência da Computação do Centro de Informática da Uni-
versidade Federal de Pernambuco como requisito parcial
para obtenção do grau de Mestre em Ciência da Computa-
ção.
Orientador: Prof. Dr. Ricardo Bastos Cavalcante Prudêncio
Co-orientador: Prof. Dr. Marcelo Bezerra d’Amorim
Recife
Setembro de 2009

Takaki, Mitsuo Busca meta-heurística para resolução de CSP em teste de software / Mitsuo Takaki. - Recife: O autor, 2009. xi, 105 folhas : il., fig., tab.. Dissertação (mestrado) - Universidade Federal de Pernambuco. CIN. Ciência da Computação, 2009. Inclui bibliografia e apêndice. 1.Inteligência artificial. I. Título. 006.3 CDD (22.ed.) MEI-2009-137

Dedico esta dissertação à minha mãe, minha fonte de
inspiração durante este mestrado.

Agradecimentos
Agradeço à minha mãe, pela constante dedicação e apoio e por ter me mostrado o que é ser
pesquisador. Seu esforço para alcançar o que sonhava me serviu de inspiração neste mestrado.
À minha noiva Roberta, por estar sempre ao meu lado, me apoiando nos momentos mais
difíceis, e por me motivar e ajudar a concluir este trabalho.
Aos meu orientadores Ricardo Prudêncio e Marcelo d’Amorim, por terem me orientado e
ajudado em diversas situações, além do mestrado. Sou grato pelas orientações durante as difi-
culdades que surgiram no desenvolvimento deste trabalho. Obrigado por acreditarem na minha
capacidade e pelas oportunidades que obtive durante este período que trabalhamos juntos.
À professora Flávia Barros, que me orientou inicialmente, e que sem o seu apoio não estaria
onde estou agora. Obrigado pela oportunidade e pela confiança no meu trabalho.
Ao meu amigo Márcio Ribeiro, que, graças aos conhecimentos que me passou, pude con-
cluir este trabalho. Aos meus amigos Edeilson, Edilson, Eduardo, Leopoldo, Mário, Paulo e
Ivan pela convivência e apoio durante este mestrado.
iv

Resumo
Os algoritmos de busca meta-heurística vêm sendo pesquisados em inúmeros domínios, in-
clusive na resolução de restrições. Devido à sua capacidadede atuação em problemas que a
solução é desconhecida, são utilizados em diversas situações. Os algoritmos evolutivos são uma
família dos algoritmos de busca, que simulam o comportamento da natureza. Os problemas de
satisfação de restrição (CSP) são compostos por um conjunto de conjunções de variáveis, ca-
racterizando uma restrição. Valores são associados às variáveis, os quais devem satisfazer a
restrição, caso contrário, são considerados inválidos. Problemas de resolução de restrição estão
associados a diversos contextos, desde problemas de alocação de recursos a design de circuitos
integrados. Algoritmos de busca meta-heurística vêm sendoutilizados para a solução de CSP,
resolvendo o problema da limitação dos provadores de teoremas, que necessitam modelar uma
teoria para serem capazes de encontrar uma solução. Neste trabalho, investigamos o uso do
algoritmo de busca meta heurística em um tipo de teste de software (execução concólica) que
é tratado como um problema de CSP. A execução concólica se baseia no teste simbólico, o
qual extrai as decisões internas de um programa que formam uma restrição, também conheci-
das como Path Condition (PC). Estas restrições são formadas a partir das variáveis de entrada,
portanto, a solução de uma restrição determina as entradas necessárias para percorrer um deter-
minado caminho no software. As técnicas clássicas utilizamprovadores de teoremas, os quais
são limitados a teoria suportada, e métodos de randomização, que geram valores aleatórios
para as variáveis, reduzindo a complexidade da restrição. Apresente dissertação teve como
objetivo criar e analisar o desempenho de solucionadores baseados em algoritmos de busca
meta-heurística, sendo comparados às técnicas clássicas utilizadas neste contexto. Os resulta-
dos mostraram que o uso de heurísticas de busca pode permitira criação de novas técnicas de
resolução de restrição, no contexto de teste simbólico.
Palavras-chave: Problema de Satisfação de Restrição, Execução Concólica, Algoritmos de
Busca Meta-Heurística
v

Abstract
The meta-heuristic search algorithms have been researchedin several domains, including in
constraint satisfaction problem. Due to its good adaptability to be used in problems where the
actual solution is unknown, they are applied in innumerous contexts. The evolutive algorithms
are a search algorithm family that simulates the nature behavior. The constraint satisfaction
problem (CSP) is a set of variables conjunction, compoundinga constraint. Values are associ-
ated to the variables, which should satisfy the constraint;otherwise, it violates the restriction.
CSP are related to innumerous domains, from resource allocation to integrated circuits design.
Meta-heuristic search algorithms have been used for solving CSP, surpassing the theorem pro-
ver limitation problem that needs a theory modeling in orderto be able to find a solution. This
work, we investigated the usage of meta-heuristic search algorithms in a kind of software test
(concolic execution) that is dealt as a constraint satisfaction problem. The concolic execution is
based on the symbolic test, which is a technique used to gather internal decisions of software,
which compound a restriction also called as Path Condition (PC). These restrictions are formed
by the input variables, thus, the solution of them is used as input data to traverse a specific
path in the software. The classical techniques use theorem prover, which are constrained by the
theory supported, and randomization methods, that generates random values for the variables,
reducing the constraint complexity. The current dissertation had as main objective to create and
analyze the performance of meta-heuristic search based solvers, being compared to the classi-
cal techniques used in this context. The results have shown that the usage of search heuristics
may allow the creation of new constraint satisfaction techniques in the symbolic test domain.
Keywords: Constraint Satisfaction Problem, Concolic Execution, Meta-Heuristic Search Al-
gorithms
vi

Sumário
1 Introdução 1
1.1 Objetivos 3
1.2 Organização da Dissertação 5
2 Busca Meta-Heurística 7
2.1 Algoritmos de Busca e Otimização 7
2.2 Busca Local e Global 10
2.3 Algoritmos Evolutivos 11
2.3.1 Algoritmos Genéticos (AG) 11
2.3.2 Otimização por Enxame de Partículas (PSO) 11
2.3.3 Influência da Dimensionalidade e Tamanho da População 15
2.4 Problema de Satisfação de Restrições (CSP) 16
2.4.1 Algoritmos Completos 16
2.4.2 Algoritmos Incompletos 17
2.4.3 Algoritmos Evolutivos em CSP 17
2.5 Considerações Finais 18
3 Teste de Software 20
3.1 Teste de Software 20
3.2 Técnicas de Teste 21
3.3 Fases de Teste 23
3.4 Testes de Caixa Preta 25
3.5 Testes de Caixa Branca 28
3.6 Critérios de Adequação e Métricas 29
3.7 Criação de Casos de Teste 31
3.8 Teste Simbólico 32
3.8.1 Problema de Resolução de Restrições no Contexto de Teste Simbólico 33
vii

SUMÁRIO viii
3.9 Execução Concólica 34
3.10 Teste Randômico 35
3.11 Considerações Finais 36
4 Metodologia 38
4.1 Framework 38
4.1.1 Biblioteca Simbólica e Instrumentador 40
4.1.2 Driver 41
4.1.3 Solvers 41
4.1.4 SolversHíbridos 44
4.2 Representação do Problema 45
5 Experimentos 49
5.1 Descrição dos Experimentos 49
5.2 Resultados Gerais 52
5.2.1 Impacto dotimeout 55
5.2.2 Impacto dos Parâmetros dos Algoritmos de Busca 62
5.3 Discussão dos Resultados 66
5.4 Considerações Finais 70
6 Conclusões 71
6.1 Contribuições 71
6.2 Limitações e Trabalhos Futuros 72
6.3 Considerações Finais 74
A Gráficos 75
B Tabelas 79
C Códigos Fonte 89

Lista de Figuras
1.1 Conjunto de decisões internas. 3
2.1 Mínimo local e global. 8
2.2 Exemplo de um vale. 10
2.3 Operadores decross-overe mutação. 12
2.4 Algoritmo genético. 13
2.5 Algoritmo do PSO. 14
2.6 Exemplos de topologias. 15
3.1 Processo de Testes. 21
3.2 Processo de Testes. 23
3.3 Fases de Teste e Seus Requisitos. 24
3.4 Teste de Unidade. 25
3.5 Exemplo de um grafo de causa e efeito. 27
3.6 Exemplo de código fonte com umbranch. 30
3.7 Exemplo de código fonte com umloop. 30
3.8 Gráfico do custo relativo de correção de um defeito. 33
3.9 Conjunto de decisões internas (Path Condition). 34
3.10 Exemplo de um PC. 35
4.1 Arquitetura utilizada. 39
4.2 Exemplo de uma árvore semântica. 40
4.3 Código fonte de BST original e instrumentado. 42
4.4 Driver do programa BST. 43
4.5 Arquitetura utilizada pelossolvers. 44
4.6 Representação no plano cartesiano dos espaço de busca. 47
4.7 Operação de transposição da representação do problema para a árvore semântica. 48
ix

LISTA DE FIGURAS x
5.1 Diagrama de Venn do desempenho dossolversaleatórios. 56
5.2 Diagrama de Venn do desempenho dossolvershíbridos GCF. 57
5.3 Diagrama de Venn do desempenho dossolvershíbridos BCF. 58
5.4 Diagrama de Venn do desempenho dossolvershíbridos. 59
5.5 Comportamento da função MaxSAT. 60
5.6 Comportamento da função SAW. 61
5.7 Cobertura dossolversnos programasSwitcheColt 63
5.8 Influência dos parâmetros de AG. 64
5.9 Influência dos parâmetros de AG. 65
5.10 Influência dos parâmetros de PSO. 67
5.11 Influência dos parâmetros de PSO. 68
A.1 Cobertura dossolversutilizando gráfico de barras empilhadas no experimento
BST. 75
A.2 Cobertura dossolversutilizando gráfico de barras empilhadas nos experimen-
tosFileSystemeTreeMap. 76
A.3 Cobertura dossolversutilizando gráfico de barras empilhadas nos experimen-
tosRatPolyeRationalScalar. 77
A.4 Cobertura dossolversutilizando gráfico de barras empilhadas nos experimen-
tosNewtoneHashMap. 78

Lista de Tabelas
4.1 Exemplo de uma representação através de um código genético. 46
5.1 Comparação dos Experimentos. 52
5.2 Tabela da cobertura média dos pares: experimento (linha) esolver(coluna). 53
5.3 Desvio padrão da tabela 5.2. 54
B.1 Comparação dos resultados dossolversno experimentoBST. 80
B.2 Comparação dos resultados dossolversno experimentoFileSystem. 81
B.3 Comparação dos resultados dossolversno experimentoTreeMap. 82
B.4 Comparação dos resultados dossolversno experimentoSwitch. 83
B.5 Comparação dos resultados dossolversno experimentoRatPoly. 84
B.6 Comparação dos resultados dossolversno experimentoRationalScalar. 85
B.7 Comparação dos resultados dossolversno experimentoNewton. 86
B.8 Comparação dos resultados dossolversno experimentoHashMap. 87
B.9 Comparação dos resultados dossolversno experimentoColt. 88
xi

CAPÍTULO 1
Introdução
Os algoritmos de busca meta-heurística constituem uma família de algoritmos utilizados na
solução de diversos problemas percorrendo um espaço de busca. O termo meta-heurística foi
inicialmente utilizado por Glover (1986), onde é descrito oalgoritmoTabu Searchcomo uma
meta-heurística sobreposta em outra heurística. Podem seraplicados em diversos contextos,
desde o design de circuitos integrados à teste de técnicas decriptografia (Silva e Sakallah;
1996).
O algoritmo de força bruta, ou busca cega, é o mais simples exemplo de um método de
busca, percorrendo todo o espaço de busca até que uma soluçãoseja encontrada. Este método
é capaz de garantir que, se existir, uma solução será encontrada, porém o tempo de busca
pode se tornar extremamente grande. Neste sentido, métodosque criam uma solução aleatória
e, iterativamente, melhoram até encontrar uma solução aceitável tornam possível encontrar
soluções em um espaço de tempo mais aceitável. Porém, estes métodos são algoritmos de
busca local, ou seja, não são capazes de transpor áreas de mínimos ou máximos locais, portanto
nescessitam de diferentes inicializações para buscar a melhor solução (mínimo ou máximo
global). Um exemplo de um método iterativo de melhoria de solução é o algoritmo de subida
da encosta (hill climbing), que simula a subida de uma colina e pára sua execução quando
chega ao topo. Para resolver o problema da transposição de áreas de mínimos ou máximos
locais, foram propostos diferentes algoritmos, como exemplo a têmpera simulada (simulated
annealing) (Kirkpatrick et al.; 1983). O algoritmo inicia realizandograndes passos e o tamanho
dos passos é reduzido gradativamente, permitindo percorrer grandes espaços no inicio e realizar
pequenos incrementos no final (Russell e Norvig; 2003, p. 94-131).
O algoritmo genético (AG) (Holland; 1975) e a otimização porenxame de partículas (Par-
ticle Swarm Optimization– PSO) (Kennedy e Eberhart; 1995) fazem parte dos algoritmosde
busca, mais especificamente dos algoritmos evolutivos, e sebaseiam em comportamentos ob-
servados na natureza. AG foi proposto para introduzir o comportamento de adaptação aos siste-
mas. PSO foi criado por Kennedy e Eberhart (1995) a partir da observação do comportamento
1

CAPÍTULO 1 INTRODUÇÃO 2
de grupos, o qual mimetiza a criação de estruturas sociais, onde indivíduos podem influenciar
o grupo e, ao mesmo tempo, os indivíduos são influenciados pelo grupo. Eles são métodos
de busca global, ou seja, são capazes de transpor áreas de mínimos, ou máximos, locais. Os
mínimos, ou máximos, locais são soluções do espaço de busca,porém não são as melhores
soluções de um problema. Em problemas de otimização, o algoritmo busca pelo mínimo ou
máximo global. A função objetivo, ou função defitness, direciona o algoritmo, avaliando a
qualidade das soluções candidatas. O algoritmo de subida daencosta, têmpera simulada, AG e
PSO podem ser denominados, de uma forma geral, de métodos de busca meta-heurística. Por
outro lado, o algoritmo de força bruta não é considerado uma meta-heurística por não utilizar
nenhuma heurística na busca da solução, pois o algoritmo percorre exaustivamente o espaço de
busca.
Algoritmos de busca meta-heurística têm sido usados com freqüência em problemas de
resolução de restrições (ouconstraint satisfaction problem, CSP). O problema de resolução de
restrições é a determinação de valores para variáveis que compõem uma restrição. Este tipo
de problema está relacionado a diversos contextos, desde o problema clássico de coloração de
grafos à problemas de alocação. O uso de algoritmos de busca neste contexto é bem conhecido
pelo comunidade (Zhou et al.; 2009; Lin; 2005; Rossi et al.; 2000; Marchiori e Rossi; 1999;
Folino et al.; 1998). Um exemplo de CSP é atribuir valores às variáveis (x e y) de forma a
satisfazer todas as cláusulas da seguinte sentença:(x = y2)∧ (x < 10)∧ (y≥ 0), onde uma
possível solução para esta restrição é:x = 4 ey = 2.
Diversas soluções foram propostas no desenvolvimento de funções defitness, mais especifi-
camenteMaxSAT (Folino et al.; 1998; Rossi et al.; 2000; Marchiori e Rossi; 1999) eStep-Wise
Adaptation of Weigths (SAW) (Bäck et al.; 1998; Eiben e van der Hauw; 1997). MaxSAT ape-
nas conta o número de cláusulas satisfeitas, o que permite identificar quando uma solução
candidata satisfaz a restrição. Entretanto, MaxSAT não é capaz de direcionar corretamente o
algoritmo, pois nem sempre encontrar uma solução candidataque resolve a maior parte das
cláusulas significa estar na direção correta. SAW utiliza ummétodo de identificar cláusulas
“difíceis” de resolver, atribuindo pesos as mesmas. Desta forma, a solução candidata que re-
solve uma cláusula difícil, deve ser recompensada por isto –através de um valor defitnessmais
alto.
O foco da presente dissertação é a resolução de CSP no contextode teste desoftware, mais
especificamente com teste simbólico. O teste simbólico é umatécnica de extração do conjunto

1.1 OBJETIVOS 3
Figura 1.1: Um exemplo de um conjunto de decisões internas.
de decisões internas de um sistema – também chamado dePath Condition(PC) –, as quais
caracterizam uma restrição e o conjunto de dados de entrada são as variáveis destas restrições.
Na figura 1.1 está um exemplo de um programa, onde as seguintesrestrições são geradas:
(x> y)∧(x%2= 0), (x> y)∧(x%2 6= 0), (x≤ y)∧(y % 2= 0) e(x≤ y)∧(y % 2 6= 0). Existem
soluções clássicas para resolver estes restrições, as quais envolvem o uso de provadores de
teorema. Os provadores de teorema possuem um poder de atuação limitado à teoria suportada.
Facilmente programas simples geram restrições não-lineares, como no exemplo da figura 1.1
que possui operador de resto de divisão (%). Ossolversaleatórios são capazes de resolver
restrições, independente do tipo de operador utilizado. Esta característica permite que estes
sejam aplicados na resolução de CSP, onde apresentam resultados motivantes (Godefroid et al.;
2005; Majumdar e Sen; 2007).
1.1 Objetivos
As soluções propostas por Godefroid et al. (2005) e Majumdare Sen (2007) não utilizam ne-
nhum tipo de heurística na geração de valores para a resolução de restrições ou para reduzir
a complexidade das restrições. Os resultados obtidos por estas técnicas produziram resultados

1.1 OBJETIVOS 4
motivantes e o uso de meta-heurísticas de busca pode produzir melhores resultados. O principal
objetivo deste trabalho é a aplicação de meta-heurísticas de busca emsolverspara resolver res-
trições provenientes de uma execução concólica, além de analisar o desempenho destessolvers
emsoftwarescom diferentes características.
O trabalho de Lakhotia et al. (2008) utilizou o algoritmo de subida da encosta para resolução
de restrições da execução concólica, porém o uso de algoritmos evolutivos, neste contexto, não
havia sido proposto anteriormente. O uso destes algoritmospara a resolução de restrições é a
principal contribuição deste trabalho.
Ossolversbaseados em algoritmos de busca foram propostos de duas formas: usados dire-
tamente e combinados aosolversimbólico (symSOL). Ossolvershíbridos utilizam três estra-
tégias: restrições “boas” primeiro (Good Constraints First– GCF), restrições “ruins” primeiro
(Bad Constraints First– BCF) e variáveis “ruins” primeiro (Bad Variables First– BVF). GCF
e BCF separa as restrições em partes “boas” e “ruins”. São chamadas de “boas” as restrições
que estão dentro do escopo da teoria suportada por symSOL e, conseqüentemente, “ruins” as
que estão fora do escopo. GCF resolve primeiro as restrições “boas” no symSOL e passa o
restante para osolverrandômico (puramente aleatório, AG ou PSO). Isto permite que a restri-
ção seja simplificada, gerando uma nova restrição reduzida.De forma contrária, BCF resolve
as restrições “ruins” primeiro, passando para symSOL uma restrição com complexidade redu-
zida, permitindo que este a resolva. BVF, se baseia no DART Godefroid et al. (2005), gerando
valores aleatórios para as variáveis que compõem as cláusulas não satisfatíveis por symSOL.
Nesta dissertação, foram avaliadas quatro abordagens clássicas, umsolversimbólico e três
híbridos. Trêssolversaleatórios foram comparados, utilizando um algoritmo puramente ale-
atório, AG e PSO. Às estratégias de hibridação, exceto BVF, foram combinados ossolvers
baseados em AG e PSO, substituindo osolverpuramente aleatório mais comumente utilizado.
Nesta avaliação foram utilizados nove experimentos, algumas implementações de estruturas
conhecidas, como árvore binária de busca e tabela de hash, e bibliotecas de uso matemático.
A partir da análise do desempenho dossolversnos experimentos escolhidos, foi possível
observar que o uso de meta-heurísticas de busca produz bons resultados, especialmente em
situações que o uso de umsolver simbólico não é possível ou sua capacidade de atuação é
limitada. Problemas em que o espaço de busca se torna muito grande, ossolversque utilizam
geração de valores puramente aleatória não são capazes de resolver a maior parte das restrições
geradas. Entretanto, em espaços de busca reduzidos o uso de heurísticas não se justifica devido

1.2 ORGANIZAÇÃO DA DISSERTAÇÃO 5
seu maior custo computacional.
1.2 Organização da Dissertação
Este trabalho está organizado da seguinte forma:
Capítulo 2 Introdução aos algoritmos de busca, passando pelo principais métodos de busca
iterativa e introdução aos algoritmos evolutivos. O problema de satisfação de restrições (CSP)
é apresentado e como estes algoritmos podem ser aplicados neste contexto. Considerando o
objetivo deste trabalho ser uma aplicação de algoritmos evolutivos em CSP, é dado uma maior
ênfase nestes algoritmos e suas aplicações em CSP, sendo apresentada uma proposta de repre-
sentação do problema e a determinação o espaço de busca de acordo com esta representação.
Capítulo 3 Introdução ao teste desoftware, separando em dois grupos: funcionais e estruturais.
Em cada grupo estão definidos os tipos de testes e seus critérios de adequação. O problema
da automação da geração de casos de teste é apresentado com a solução abordada no presente
trabalho:teste simbólico. O teste simbólico possui deficiências que são supridas com oadvento
da execução concólica. Esta solução determina a capacidadede suprir as lacunas deixadas pelo
teste simbólico. São apresentados ospath conditions(PC) e como estes podem ser vistos como
um CSP. O uso de provadores de teoremas (solverssimbólicos – symSOL) para a resolução
destes PCs, abordando que esta solução não é aplicável, pois freqüentemente uma aplicação
simples pode gerar restrições que estão fora do escopo do provador. No caso em que symSOL
é capaz de resolver problemas de aritmética inteira linear,estes PCs podem ser simplificados à
uma forma satisfatível. Esta solução é apresentada, contudo, suas deficiências são identificadas.
Capítulo 4 A metodologia utilizada é apresentada, com a arquitetura proposta para o desenvol-
vimento doframework, onde cada componente doframeworké apresentado. A representação
do problema escolhida é apresentada com suas possíveis implicações na definição do espaço de
busca.
Capítulo 5 A solução proposta para prover uma heurística aos métodos derandomização de
restrições é apresentada. São identificadas deficiências nos algoritmos escolhidos e como seu
desempenho é afetado pelo tempo de execução (timeout). Os experimentos escolhidos são

1.2 ORGANIZAÇÃO DA DISSERTAÇÃO 6
detalhados e caracterizados pelo tipo de restrição que sua execução gera. Os resultados obtidos
são apresentados, comparando o desempenho de cadasolverem nove experimentos. Os efeitos
do timeoute variação doseeddo número aleatório são analisados. Além disso, uma discussão
sobre as características dos algoritmos de busca de acordo com o experimento é realizada e
demonstradas as conclusões extraídas dos resultados.
Capítulo 6 As conclusões deste trabalho são apresentadas, como também, as contribuições,
limitações e perspectivas para os pontos de melhoria que poderão gerar mais investigação.

CAPÍTULO 2
Busca Meta-Heurística
Este capítulo apresenta uma introdução aos algoritmos de busca meta-heurística e o problema
de satisfação de restrições (Constraint Satisfaction Problem - CSP), dando uma ênfase maior
aos algoritmos evolutivos e suas aplicações em CSP. Ossolversde CSP estão sendo apresen-
tados, separados, em dois grupos: completos e incompletos.Os algoritmos incompletos se
referem ao tema principal nesta seção, visto que o objetivo deste trabalho é a aplicação de
algoritmos de busca meta-heurística na resolução de restrições.
2.1 Algoritmos de Busca e Otimização
A inteligência artificial vem sendo utilizada na resolução de problemas e, mais especifica-
mente, em problemas de otimização. A resolução automática érealizada através de métodos
inteligentes, onde a aquisição de conhecimento pode ocorrer durante a execução ou previa-
mente. Existem diversas técnicas, sendo que cada uma possuicaracterísticas que a tornam apta
a resolver problemas específicos. Contudo, não existe um método capaz de resolver qualquer
problema, este deve ser escolhido de acordo com o contexto.
São chamados de problemas de otimização os problemas que requerem que seus dados
sejam modificados para que atinjam um certo grau de qualidade. Vão desde problemas de rota
(e.g., problema do caixeiro viajante) até problemas complexos de otimização de funções. Os
problemas podem ser definidos por quatro componentes, segundo Russell e Norvig (2003, cap.
3): o estado inicial, as ações possíveis, o teste de objetivoe uma função de custo. Para resolver
os problemas, os algoritmos de otimização realizam uma busca de soluções em um espaço de
estados.
Máximo global (ou mínimo global) é a melhor solução em todo espaço de busca, a qual é
o objetivo de todos os problemas de otimização. Máximo local(ou mínimo local) é a melhor
solução em um subespaço de busca. Um exemplo de uma função e seu mínimo global e local
7

2.1 ALGORITMOS DE BUSCA E OTIMIZAÇÃO 8
Figura 2.1: Uma função de exemplo com seu mínimo global (círculo vermelho) e seu mínimo
local (triângulo azul).
é apresentada na figura 2.1. Algoritmos de busca que melhoramseus resultados sem guardar
estados anteriores tendem a ficarem presos em máximos locais.
Os algoritmos de busca procuram por soluções para um problema específico, em um grande
espaço de possíveis soluções. Uma função defitness, também chamada de função objetivo,
é utilizada para validar estes candidatos e medir a qualidade desta solução. Os algoritmos
de busca podem ser utilizados quando não há um conhecimento sobre a solução real para o
problema, entretanto, a função defitnessdeve ser capaz de identificar quando a solução foi
encontrada. Muitas pesquisas vem sendo realizadas nesta área e várias novas técnicas foram
propostas, cada uma aplicável a um determinado domínio. Dentre essas técnicas citamos inici-
almente:
• Busca por força-bruta
Também conhecido como busca cega, é o mais simples. Utiliza um método simples, o
qual precisa percorrer todo o espaço de busca, que, dependendo do problema, pode de-
mandar um esforço imenso. Toda possível solução deve ser analisada e nenhum conhe-
cimento é adquirido durante este processo. O uso de algoritmos baseados em heurísticas
pode reduzir o tempo gasto nesta operação. Entretanto, o algoritmo de força-bruta é ca-

2.1 ALGORITMOS DE BUSCA E OTIMIZAÇÃO 9
paz de garantir a existência, ou a ausência, de soluções parao problema, apesar de o
tempo aumentar consideravelmente quando o número de estados aumenta. Mas, eventu-
almente, a melhor solução será encontrada. Quando não há umalimitação de tempo, esta
torna-se a melhor escolha para um problema de otimização.
• Subida da encosta (Hill-Climbing)
Algoritmo iterativo de melhoria, em outras palavras, ele melhora sua solução inicial passo
a passo. A solução inicial é escolhida aleatoriamente e, então, é melhorada até atingir um
resultado aceitável. Esta técnica não armazena estados anteriores, move-se no espaço de
busca enxergando apenas o estado atual (Russell e Norvig; 2003, p. 94-131). Portanto,
não é capaz de atingir resultados ótimos, apesar de eventualmente poder atingir, mas
fornece soluções aceitáveis, as quais necessitariam de um longo período de tempo para
serem encontradas pelo algoritmo de força bruta. Devido a sua inicialização estocástica,
este algoritmo torna-se sensível à sua inicialização, ou seja, depende fortemente de um
bom estado inicial para encontrar o máximo global.
• Têmpera Simulada (Simulated Annealing)
O algoritmo de subida da encosta não é capaz de realizar movimentos de “descida” da
encosta para que possa sair de um máximo local. Introduzir uma certa aleatoriedade à
subida da encosta, pode trazer melhorias ao seu desempenho,permitindo que este saia
de picos e encontre novos máximos locais – podendo eventualmente encontrar o má-
ximo global. Criado por Kirkpatrick et al. (1983), foi inspirado na metalurgia, a têmpera
é o processo utilizado para temperar ou endurecer metais e vidros, aquecendo-os a al-
tas temperaturas e depois resfriando-os gradualmente. Um comportamento análogo é
reproduzido no algoritmo da têmpera simulada, que inicia sua busca com um grau de
exploração do espaço de estados alto e gradativamente reduzessa exploração.
• Algoritmos Evolutivos
É uma família de algoritmos baseados em comportamentos da natureza. Dentre estes
algoritmos, se destacam o algoritmo genético (Holland; 1975) e a otimização por enxame
de partículas (Kennedy e Eberhart; 1995). Estes algoritmosserão detalhados na seção
2.3.
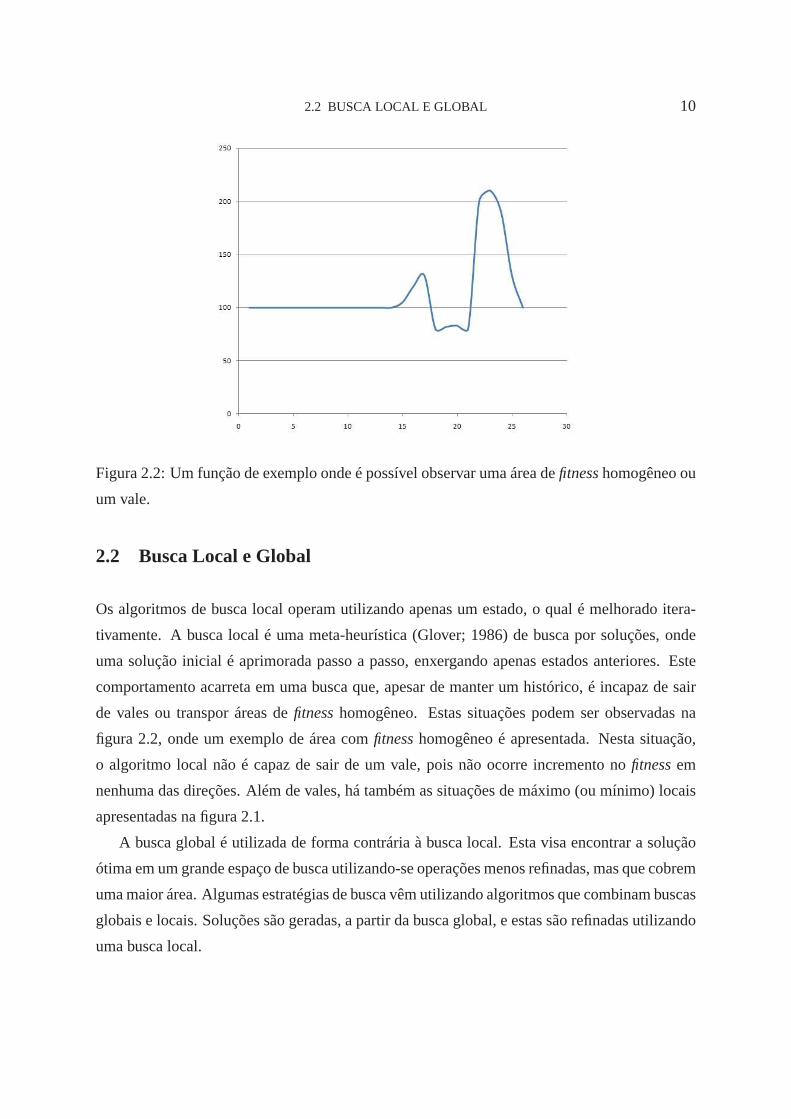
2.2 BUSCA LOCAL E GLOBAL 10
Figura 2.2: Um função de exemplo onde é possível observar umaárea defitnesshomogêneo ou
um vale.
2.2 Busca Local e Global
Os algoritmos de busca local operam utilizando apenas um estado, o qual é melhorado itera-
tivamente. A busca local é uma meta-heurística (Glover; 1986) de busca por soluções, onde
uma solução inicial é aprimorada passo a passo, enxergando apenas estados anteriores. Este
comportamento acarreta em uma busca que, apesar de manter umhistórico, é incapaz de sair
de vales ou transpor áreas defitnesshomogêneo. Estas situações podem ser observadas na
figura 2.2, onde um exemplo de área comfitnesshomogêneo é apresentada. Nesta situação,
o algoritmo local não é capaz de sair de um vale, pois não ocorre incremento nofitnessem
nenhuma das direções. Além de vales, há também as situações de máximo (ou mínimo) locais
apresentadas na figura 2.1.
A busca global é utilizada de forma contrária à busca local. Esta visa encontrar a solução
ótima em um grande espaço de busca utilizando-se operações menos refinadas, mas que cobrem
uma maior área. Algumas estratégias de busca vêm utilizandoalgoritmos que combinam buscas
globais e locais. Soluções são geradas, a partir da busca global, e estas são refinadas utilizando
uma busca local.

2.3 ALGORITMOS EVOLUTIVOS 11
2.3 Algoritmos Evolutivos
Os algoritmos evolutivos são algoritmos de busca que utilizam operadores baseados em fenô-
menos da natureza. São chamados de evolutivos devido a esta característica de mimetizar estes
fenômenos naturais. Dentre os algoritmos mais populares, podemos citar os:Algoritmos Ge-
néticoseOtimização por Enxame de Partículas.
2.3.1 Algoritmos Genéticos (AG)
Algoritmos genéticos foram propostos por Holland (1975) para introduzir uma capacidade de
adaptação aos programas. Pesquisas na área de reprodução decomportamentos da natureza
produziram novas técnicas, como algoritmos baseados em inteligência de grupos (swarm intel-
ligence). Diferentemente de outras estratégias evolutivas, Holland (1975) analisou o fenômeno
de adaptação, como acontece na natureza, e como aplicá-lo aos sistemas de computadores.
AG é baseado na teoria evolutiva das espécies, que evoluem para melhorar suas capacida-
des de adaptação, de acordo com o ambiente. Cada solução candidata, chamada de indivíduo,
é modelada em uma estrutura de cromossomos e aplicada operações de recombinação a essas
estruturas, onde a preservação de informações criticas é o objetivo. Esta operação de recom-
binação é chamada decross-overe pode ser observada na figura 2.3a. Operadores de mutação
também são utilizados para modificar, levemente, as soluções (Whitley; 2002). A figura 2.3b
apresenta um exemplo de operação de mutação. Estas operações são realizadas entre a popula-
ção de soluções até que um certo grau de qualidade é atingido,de acordo com a funçãofitness
onde cada população de uma iteração é chamada degeração.
O algoritmo genético provê soluções viáveis em diversas áreas, onde variações do algoritmo
básico são utilizadas. Estas áreas vão desde problemas científicos a problemas de engenharia
(Mitchell; 1998). Alguns sistemas devem ser capazes de se adaptar a um ambiente em cons-
tante mudança, comportamento análogo ao fenômeno da natureza em que indivíduos devem se
adaptar para continuarem sua existência. O algoritmo básico do AG está na figura 2.4.
2.3.2 Otimização por Enxame de Partículas (PSO)
Kennedy e Eberhart (1995) propuseram a otimização por enxame de partículas, inspirado pelo
comportamento descentralizado de grupos. Cada partícula é um protótipo de solução e cada

2.3 ALGORITMOS EVOLUTIVOS 12
(a)Cross-Over
(b) Mutação
Figura 2.3: Operadores decross-overe mutação.
uma possui um grau de confiança em si mesma e um grau de confiançano grupo. As partículas
movem-se através do espaço de busca visando um resultado ótimo, enquanto informações são
adquiridas do problema para melhorar seu desempenho. O grupo armazena a melhor partícula
e cada partícula armazena sua melhor solução, até o momento.Estes dados influenciam a pró-
xima posição de cada partícula. As equações (2.1) e (2.2) mostram como a velocidade e a nova
posição são calculadas.r1 e r2 são números aleatórios entre 0 e 1, definidos durante a criação
de cada partícula, para criar uma distribuição homogênea dediferentes comportamentos, onde
existirão indivíduos com maior confiança em si mesmo, indivíduos com maior confiança no
grupo e indivíduos com um comportamento mais balanceado. Ser1 tende a zero, a confiança
da partícula em si mesma tende a zero e quandor2 tende a zero, a partícula tende a não confiar
no grupo. ω é chamado de inércia e é a proporção da velocidade anterior que será usado na
próxima velocidade, proporciona uma mudança gradativa na direção do movimento da partí-
cula. Diferentemente de outros algoritmos evolutivos, PSOnão usa operadores decross-over
e mutação. O espaço de busca é percorrido pelo PSO através dasmudanças de posição das
partículas.
O grupo exerce uma influência em cada indivíduo, fazendo com que este siga a direção do
grupo. Entretanto, os indivíduos também exercem influênciano grupo, pois um indivíduo pode

2.3 ALGORITMOS EVOLUTIVOS 13
Algoritmo Algoritmo Genético
Entrada
n: Tamanho da população.
c: Taxa de cruzamento.
m: Taxa de mutação.
g: Número de gerações.
Saída
p: Conjunto de soluções candidatas.
1 init (p) { Inicializando a população.}
2 enquanto iteration< g||solutionFoundfaça
3 para i← 0. . .n faça
4 f itness(p[i])
5 order(p) { Ordena a população de acordo com o fitness de cada um.}
6 para i← 0. . .n faça{ Sorteia dois indivíduos para o cruzamento.}
7 indexFather← random(n)
8 indexMother← random(n)
9 shouldBreed← random()
10 shouldMutate← random()
11 seshouldBreed≥ c então
12 newSub jects← breed(p[indexFather], p[indexMother])
13 add(p,newSub jects)
14 seshouldMutate≥mentão
15 mutate(newSub jects)
16 para i← 0. . .n faça
17 seeval(p[1]) então
18 solutionFound← true
19 iteration← iteration+1
Figura 2.4: Algoritmo genético.

2.3 ALGORITMOS EVOLUTIVOS 14
vt+1 = ω ∗vt + r1∗c1∗ (bestsolutionparticle−xi)+ r2∗c2∗ (bestsolutiongroup−xi) (2.1)
xt+1 = xt +vt+1 (2.2)
Algoritmo PSO
Entrada
n: Tamanho da população.
ω: Inércia.
c1: Grau de confiança na própria partícula.
c2: Grau de confiança na população.
g: Número de gerações.
Saída
p: Conjunto de soluções candidatas.
1 init (p) { Inicializando a população.}
2 enquanto iteration< g||solutionFoundfaça
3 para i← 0. . .n faça
4 f itness(p[i])
5 para i← 0. . .n faça{ Atualiza velocidade e posição.}
6 updateVelocity(p[i])
7 updatePosition(p[i])
Figura 2.5: Algoritmo do PSO.
tornar-se, em um determinado momento, a melhor solução do grupo (Li e Engelbrecht; 2007).
PSO é capaz de atingir bons resultados em, relativamente, poucos passos – se comparado ao
algoritmo genético. É bastante útil em problemas que utilizam dados de ponto flutuante e alta
dimensionalidade. Dimensionalidade é o número de dimensões do espaço de busca. Também
possui uma implementação bastante simples, o que o torna um algoritmo eficiente. Na figura
2.5, é possível observar o algoritmo básico do PSO.
As partículas podem ser organizadas através de uma topologia que determina como estas
irão se comportar e interagir uma com as outras. Partículas são influenciadas pelos vizinhos e
estas influenciam sua vizinhança. Na formação destas vizinhanças não se deve levar em conta a

2.3 ALGORITMOS EVOLUTIVOS 15
(a) Anel (b) Estrela
Figura 2.6: Exemplos de topologias utilizadas para determinar vizinhanças.
distância física, geralmente são utilizados seus rótulos (label) para determinar quais partículas
fazem parte do mesmo grupo.
As vizinhanças criam estruturas sociais que indicam com quais partículas um indivíduo
deve interagir (Lin; 2005). Esta estrutura é determinante no desempenho do algoritmo. Estas
estruturas podem utilizar formas já conhecidas, como estrela, anel, entre outros, como pode
ser visto na figura 2.6. Como esta determina a interação entre as partículas, vai determinar o
comportamento das mesmas no espaço de busca.
2.3.3 Influência da Dimensionalidade e Tamanho da População
O desempenho de algoritmos de busca é diretamente afetado com o aumento da dimensionali-
dade. Para problemas com um alto número de dimensões, ou seja, um vasto espaço de busca,
um número maior de partículas/indivíduos é necessário. Porém, com o aumento do tamanho
da população, o desempenho é degradado. A. Carlisle (2001) realizou diversos experimentos
e identificou, empiricamente, que uma população de 30 partículas é suficiente para resolver
muitos problemas de baixa dimensionalidade. Parsopoulos (2009) fez uma análise do desem-
penho do PSO em problemas com uma alta dimensionalidade (n≥ 100, onden é o número de
dimensões) e percebeu que PSO começa a perder desempenho devido ao tamanho do espaço
de busca. Parsopoulos (2009) propõe um novo algoritmo, chamado de (µPSO), para problemas
de alta dimensionalidade.µPSO mantém um baixo custo computacional, enquanto minimizao

2.4 PROBLEMA DE SATISFAÇÃO DE RESTRIÇÕES (CSP) 16
impacto do aumento do número de dimensões.
2.4 Problema de Satisfação de Restrições (CSP)
O problema de satisfação de restrições (CSP) está relacionado à determinação de valores para
variáveis que satisfaçam ou atendam a um dado conjunto de restrições. Segundo Russell e
Norvig (2003, cap. 5), CSP é definido por um conjunto de variáveis x1,x2, . . . ,xn e por um
conjunto de cláusulasC1,C2, . . . ,Cn. Cada cláusulaCi envolve um subconjunto de variáveis e
valores atribuídos. Cada variávelxi possui um domínioDi, não-vazio, de valores possíveis. E
um estado do problema é uma atribuição a um conjunto de variáveis{xi = vi,x j = v j}, onde
vi ∈ Di . Quando uma atribuição não viola nenhuma restrição, então échamada de consistente
ou válida. CSP vem sendo pesquisado em vários contextos, desde design de circuitos integrados
através de computador a testes de criptografia (Eibach et al.; 2008). Um problema clássico de
CSP é o problema de coloração mapas, um caso específico do problema de coloração de grafo.
Neste caso, a cada região do mapa deve ser atribuída uma cor, sem que haja regiões vizinhas
com a mesma cor.
A criação desolversautomáticos vem evoluindo devido à crescente necessidade da comu-
nidade. Um dos ramos de pesquisa nesta área utilizasolversaleatórios, que geram valores para
satisfazer a restrição. Alguns resultados foram motivantes e aumentaram a pesquisa no uso de
solversaleatórios e sua aplicação em outras áreas. Existem vários algoritmos propostos para
resolver CSP, alguns são completos e outros incompletos.
2.4.1 Algoritmos Completos
Alguns algoritmos completos foram desenvolvidos para resolver o problema de satisfação de
restrições. Estes algoritmos são capazes de garantir que uma restrição é satisfatível ou insatis-
fatível de acordo com seu suporte de teoremas interno.
Provadores de teorema vêm sendo utilizados para este propósito, ou seja, resolver pro-
blemas de resolução de restrição. Porém estes apresentam uma desvantagem: possuem uma
capacidade de atuação limitada, pois necessitam que um teorema seja modelado e introduzido
ao mesmo. Devido esta limitação, não existe umsolvercompleto disponível para todo tipo de
teorema. Um exemplo é o CVC3 (CVC3 web page; s.d.). O solucionador CVC3 é um provador

2.4 PROBLEMA DE SATISFAÇÃO DE RESTRIÇÕES (CSP) 17
de teorema automático que suporta apenas aritmética linearde número inteiros e alguns casos
especiais de aritmética não linear. Para restrições dentrodeste escopo, o CVC3 é osolvermais
apropriado.
2.4.2 Algoritmos Incompletos
Algoritmos incompletos são baseados em solução aleatória.Esses algoritmos atribuem valores
aleatórios as variáveis do problema e verifica se eventualmente os valores satisfazem as res-
trições. Esses algoritmos não são capazes de afirmar que uma restrição é insatisfatível, sendo
apenas capazes de garantir que é satisfatível, quando a solução é encontrada. É classificado
como desconhecido quando não é capaz de encontrar uma solução. Vários algoritmos incom-
pletos foram propostos para CSP e, posteriormente, algoritmos de busca foram utilizados para
este propósito.
2.4.3 Algoritmos Evolutivos em CSP
A utilização de algoritmos evolutivos para resolver problemas de restrição já é bastante conhe-
cida na comunidade (Bäck et al.; 1998; Jong e Kosters; 1998; Lie Engelbrecht; 2007; Zhou
et al.; 2009; Eiben e van der Hauw; 1997). Nesse uso, cada solução do espaço de busca é
uma atribuição de valores para as variáveis do problema CSP. Os algoritmos evolutivos pos-
suem uma capacidade de percorrer os espaços de busca rapidamente e utilizam uma forma de
busca global, isto permite que sejam aplicados a este contexto com sucesso. A aquisição de
conhecimento do problema é realizada através de funções defitness, que avaliam a qualidade
da solução candidata e medem a distância da solução final.
Duas funções defitnesssão bastante usadas neste contexto de resolução de restrição, Max-
SAT(Folino et al.; 1998; Rossi et al.; 2000; Marchiori e Rossi; 1999) eStep-wise Adaptation
of Weights(SAW) (Bäck et al.; 1998; Eiben e van der Hauw; 1997). MaxSAT é uma função
simples que conta o número de cláusulas que são satisfeitas pela solução candidata. Apesar de
sua simplicidade, esta função é capaz de fornecer uma forma de avaliar a qualidade da solução,
pois a solução final deve satisfazer todas as cláusulas. Quanto mais próximo da solução final,
maior a quantidade de cláusulas satisfeitas. Porém, MaxSATnão é capaz de prover um direci-
onamento adequado ao algoritmo de busca. Este último deve ser capaz de tomar decisões onde
uma solução “ruim” pode se tornar uma solução “boa”, posteriormente.

2.5 CONSIDERAÇÕES FINAIS 18
Bäck et al. (1998) propuseram oStep-wise Adaptation of Weights(SAW) para reduzir o
impacto do problema encontrado pela função MaxSAT durante abusca por uma solução ótima.
SAW associa pesos a cada cláusula em uma restrição. Cada peso éatualizado a cada iteração
que a sua cláusula não é satisfeita. Através do uso de SAW, é possível identificar cláusulas que
são mais difíceis de serem resolvidas, com o passar das iterações. Osolversusa esta informação
para favorecer os indivíduos que estão resolvendo as cláusulas mais difíceis.
Problemas simples podem possuir vastos espaços de busca, com poucas soluções. Nem
sempre resolver uma cláusula significa estar no caminho correto. Este tipo de decisão é re-
alizada pela função SAW. Utilizando a função MaxSAT, o algoritmo poderia ficar preso em
uma das linhas azuis, que possuem um valor defitnessrelativamente alto. Em um algoritmo
completo, de força-bruta, para encontrar uma solução nesteespaço de busca, seria necessário
um grande esforço computacional, onde todos os estados seriam testados até que uma solução
fosse encontrada.
Algumas observações devem ser feitas sobre a resolução de CSPcom PSO. A representa-
ção do problema é realizada de acordo com o domínio do tipo dasvariáveis. Para restrições
com variáveis inteiras, apenas número inteiros serão utilizados na representação. Esta modifi-
cação permite que o PSO seja capaz de percorrer o espaço de busca de acordo com o tipo de
dados. PSO originalmente utiliza valores ponto-flutuante eesta característica dificulta a busca
por soluções em um domínio de valores inteiros. Esta soluçãofoi proposta por Kennedy e
Eberhart (1997), chamado de PSO discreto, ou binário. Permite aplicar PSO em outros con-
textos, além de otimização de funções matemáticas contínuas não-lineares. A adaptação do
algoritmo genético à resolução de CSP é realizada de forma simples, pois este não possui a
mesma dependência de números ponto-flutuante.
2.5 Considerações Finais
Os algoritmos de busca meta-heurística podem ser aplicadosem muitos contextos, incluindo
resolução de restrições. Estas pesquisas trouxeram muitassoluções práticas, com resultados
motivantes (Folino et al.; 1998; Silva e Sakallah; 1996; Takaki et al.; 2009;?; Zhou et al.;
2009), apesar de algoritmos incompletos não serem capazes de garantir que uma solução será
encontrada. Esta escolha, usar algoritmos incompletos devido a seu ganho de desempenho, é

2.5 CONSIDERAÇÕES FINAIS 19
aceitável quando existe uma limitação de tempo. Essa limitação de tempo é importante em pro-
blemas que necessitam obter um resultado em curtos espaços de tempo. O algoritmo utilizado
atualmente, CVC3, não é capaz de resolver restrições que estãofora do escopo de sua teoria
suportada, o que acontece freqüentemente.
Os algoritmos de busca são afetados com o aumento da dimensionalidade. Uma expressão
com vários literais acarreta em um vasto espaço de busca, devido à representação do problema
escolhida. O tamanho da população influencia diretamente nacapacidade de percorrer vas-
tos espaços de buscas, porém o tamanho da população está diretamente relacionado ao custo
computacional de cada iteração.
A função defitnessdeve ser bem escolhida para prover o devido direcionamento ao al-
goritmo para que este seja capaz de encontrar o máximo global. Atualmente, a função mais
apropriada para o CSP é a função SAW, proposta por Bäck et al. (1998). Esta é capaz de favo-
recer os indivíduos que são capazes de resolver as cláusulasmais difíceis. Isto é feito através
de pesos, associados a cada cláusula, que são incrementadosa cada iteração que as cláusulas
não são resolvidas.

CAPÍTULO 3
Teste de Software
Neste capítulo será apresentado o atual estado da arte do teste de software, enfocando em testes
de caixa branca, mais especificamente teste simbólico e concólico. As soluções conhecidas e
utilizadas são abordadas com suas principais lacunas. Serão apresentadas as diversas técnicas
de teste de software, além de métricas e critérios de adequação. A visão dospath condition
como problemas de resolução de restriçãoConstraint Satisfaction Problem(CSP) é apresentada
e como isto permitiu automatizar o teste simbólico.
3.1 Teste de Software
Com o aumento da importância dos softwares, testá-los se tornou uma tarefa essencial para
a garantia da sua qualidade. Devido a sua alta complexidade eseus grandes times de desen-
volvimento, o teste de software vem se tornando uma tarefa árdua. A comunidade de teste de
software vem buscando novos métodos que forneçam um alto nível de garantia de qualidade.
O teste não é capaz de garantir a ausência de erros, apenas é capaz de garantir a presença
de erros. Esta é a causa para que se invista em, cada vez melhores, novos métodos de teste de
software. Visando um aumento da qualidade do produto, os testes são executados exaustiva-
mente até que uma quantidade mínima de defeitos seja encontrada. Na figura 3.1 é possível
observar que a quantidade de defeitos encontrados é diretamente proporcional a probabilidade
de existirem novos defeitos.
Ao se utilizar um processo bem definido de desenvolvimento e testes, o controle de qua-
lidade de um produto pode ser automatizado e os erros minimizados. Porém, com o aumento
do esforço no controle de qualidade, o custo do produto é aumentado. A decisão da escolha
de um processo de testes deve ser feito de acordo com o tipo e necessidades do produto. Um
produto amador, que visa prover um serviço de baixa qualidade, não necessita de um processo
de testes detalhado e com várias fases. Isto acarretaria em um aumento no custo e no tempo de
20
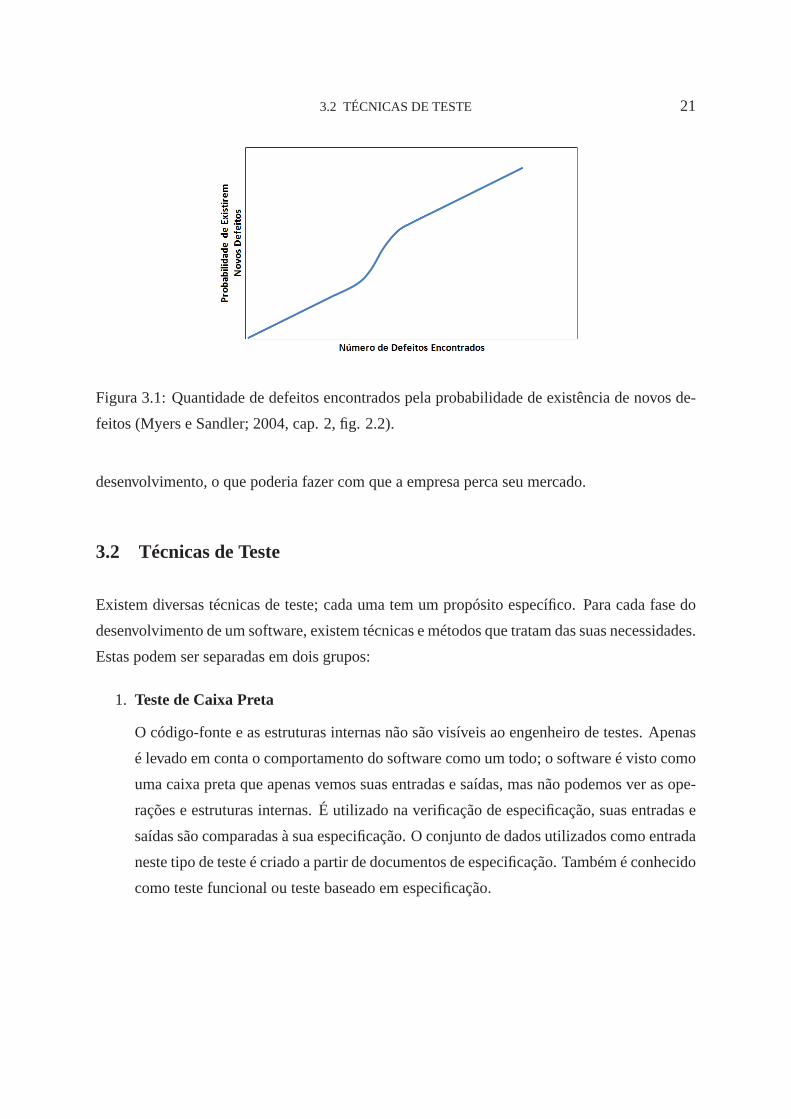
3.2 TÉCNICAS DE TESTE 21
Figura 3.1: Quantidade de defeitos encontrados pela probabilidade de existência de novos de-
feitos (Myers e Sandler; 2004, cap. 2, fig. 2.2).
desenvolvimento, o que poderia fazer com que a empresa percaseu mercado.
3.2 Técnicas de Teste
Existem diversas técnicas de teste; cada uma tem um propósito específico. Para cada fase do
desenvolvimento de um software, existem técnicas e métodosque tratam das suas necessidades.
Estas podem ser separadas em dois grupos:
1. Teste de Caixa Preta
O código-fonte e as estruturas internas não são visíveis ao engenheiro de testes. Apenas
é levado em conta o comportamento do software como um todo; o software é visto como
uma caixa preta que apenas vemos suas entradas e saídas, mas não podemos ver as ope-
rações e estruturas internas. É utilizado na verificação de especificação, suas entradas e
saídas são comparadas à sua especificação. O conjunto de dados utilizados como entrada
neste tipo de teste é criado a partir de documentos de especificação. Também é conhecido
como teste funcional ou teste baseado em especificação.

3.2 TÉCNICAS DE TESTE 22
2. Teste de Caixa Branca
As operações e estruturas internas são visíveis e são o principal foco deste tipo de teste.
O conjunto de dados de entrada é criado visando testar estruturas específicas do soft-
ware. Uma das métricas utilizadas é a medição da cobertura doteste. A cobertura mede
o quanto do código está sendo coberto por um teste. Esta cobertura pode ser medida
utilizandostatements, blocos,branches, caminhos, métodos ou classes, em um desenvol-
vimento orientado a objeto.
O termostatementse refere à menor e indivisível instrução utilizada em código fonte (Stan-
dard glossary of terms used in Software Testing; 2007). Poderia ser chamado delinha, porém,
em algumas linguagens de programação, um comando pode ocupar mais de uma linha.State-
mentprovê o significado necessário neste contexto de teste de software.
O teste de caixa branca, a principio, parece ser a melhor opção para realizar testes que
garantam a ausência de erros. Porém, para testes de caminhos, um teste minucioso pode ser
tornar impraticável. Em um simples programa, a quantidade de caminhos possíveis pode ser
extremamente grande. O teste exaustivo não é possível em grandes sistemas (Pressman; 2001).
Testes de caixa branca não são impossíveis de serem criados,os principais caminhos podem
ser escolhidos e exercitados através de técnicas de geraçãode dados de entrada, que forçam o
fluxo de controle a percorrer o caminho a ser exercitado. Alémda forma tradicional, este pode
ser combinado ao teste de caixa preta para prover uma abordagem que verifica a interface e o
funcionamento interno.
Pressman (2001) questiona por que utilizar testes de caixa branca, quando poderíamos ape-
nas verificar se os requisitos estão sendo cumpridos. Entretanto, os testes de caixa preta, por
mais minuciosos que sejam, não são capazes de realizar verificações que evitam os seguintes
tipos de defeitos:
• Os caminhos com as menores probabilidades de serem executados, possuem as maiores
chances de conter um erro. Processos mais comuns tendem a serem bem entendidos, por
isso possuem menor probabilidade de conterem um erro.
• Algumas conclusões sobre o fluxo do programa levam a cometererros e estes só podem
ser descobertos através de testes de caminho.
• Erros de digitação podem ser detectados pelo compilador, mas alguns destes erros só
podem ser encontrados através de testes.

3.3 FASES DE TESTE 23
3.3 Fases de Teste
O desenvolvimento de um software segue uma seqüencia de fases, onde cada uma tem um
objetivo e uma abordagem específica. Segundo Pressman (2001), o processo de testes é visto
como um espiral como pode ser visto na figura 3.2. Na figura 3.3 podem ser observadas as
fases e seus requisitos.
Figura 3.2: Processo de testes, com suas fases, utilizando uma representação de espiral (Press-
man; 2001, cap. 18, fig. 18.1).
1. Teste de Unidade
Foca na menor unidade do desenvolvimento de software – um componente ou módulo.
Os limites do teste são determinados pelo módulo a ser testado, o teste não deve ultra-
passar este limite. Utiliza a abordagem de caixa branca. Para cada teste, é desenvolvido
um driver e umstub, como pode ser visto na figura 3.4. Odriver é basicamente um
programa que aceita dados de entrada e repassa para o componente a ser testado. Ostub
é um subprograma que substitui os componentes necessários para executar o teste e que
não estão sendo testados. Este é constituído de uma interface simplificada, construída
apenas para permitir a execução do componente, suprindo suas dependências de outros
módulos.
2. Teste de Integração
Na fase anterior, os módulos são testados individualmente,porém, ao serem integrados,
problemas podem ocorrer na interface que os conecta. Módulos, ao serem integrados,
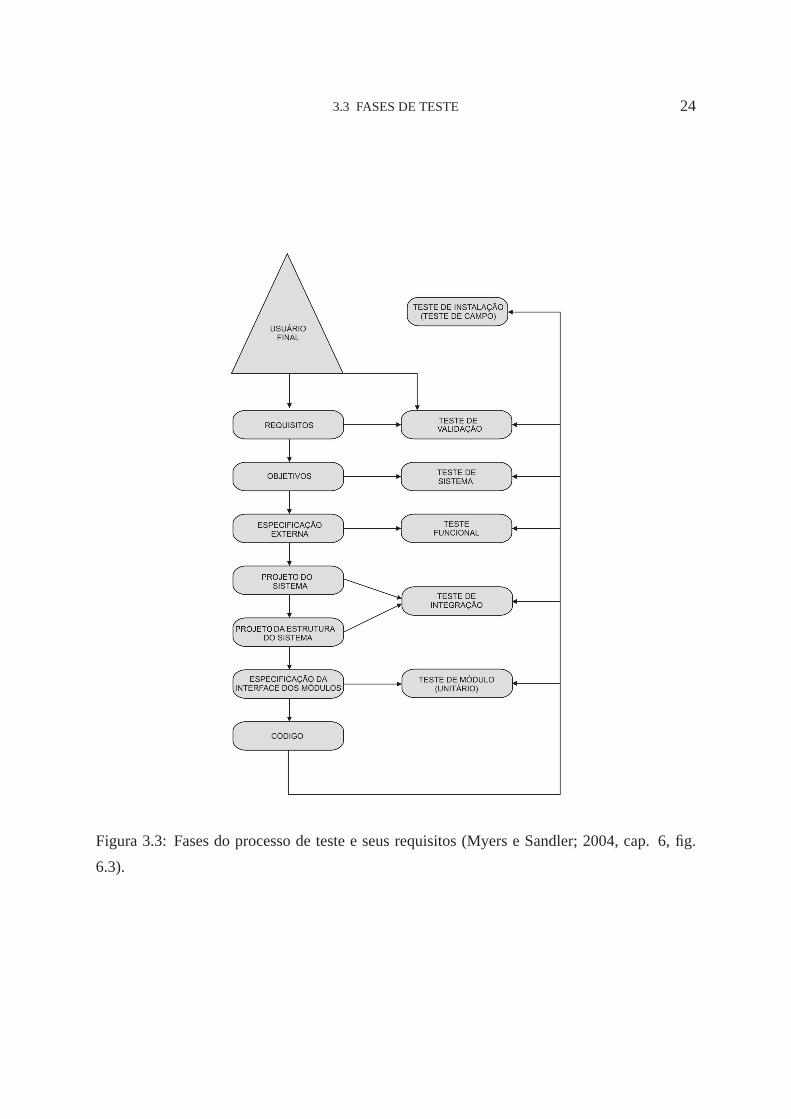
3.3 FASES DE TESTE 24
Figura 3.3: Fases do processo de teste e seus requisitos (Myers e Sandler; 2004, cap. 6, fig.
6.3).

3.4 TESTES DE CAIXA PRETA 25
podem gerar resultados inválidos e não produzir o comportamento esperado. O objetivo
é obter os módulos testados, providos da fase anterior, e criar uma estrutura de acordo
com a especificação.
3. Teste de Validação
Após a correção dos erros de integração, o software passa a ser validado de acordo com
as especificações do software. É realizado utilizando a abordagem de caixa preta para
garantir a conformidade com os requisitos.
4. Teste de Sistema
O software, ao final do desenvolvimento, deve ser testado no ambiente do cliente. Estes
testes estão fora do escopo do processo de testes, pois não são realizados apenas por
engenheiros de software.
Figura 3.4: Teste de unidade com seus principais componentes: caso de teste,driver e stub.
(Pressman; 2001, cap. 18, fig. 18.5).
3.4 Testes de Caixa Preta
Os testes de caixa preta, ou funcionais, visam garantir a conformidade do software com seus
requisitos. Os casos de teste são criados de acordo com as especificações, sem se preocupar
com as estruturas ou design internos. Nem sempre podem ser automatizados, pois podem exigir

3.4 TESTES DE CAIXA PRETA 26
intervenção humana. A base da criação de testes funcionais éparticionar os possíveis compor-
tamentos do programa em um número finito de classes, onde espera-se que cada classe estaja
funcionalmente correta. Um erro ocorre quando um programa não funciona como o esperado,
ou seja, um defeito não é apenas causado por erros de programação, a não conformidade com
requisitos também é caracterizada como um erro. Segundo Myers e Sandler (2004), existem os
seguintes tipos de teste que se enquadram nesta abordagem:
Particionamento de Equivalência. Um bom caso de teste é aquele que possui uma grande
chance de encontrar um defeito. Quando um software está sendo testado através de um teste
de caixa preta, este é visto como um módulo que possui entradas e defeito, conforme visto na
seção 3.2. Um teste exaustivo com todas as possíveis entradas é impossível de ser realizado.
Então o subconjunto de entradas que possua a maior probabilidade de encontrar defeitos deve
ser encontrado. Duas propriedades devem ser consideradas neste caso: cada caso de teste deve
conter o máximo possível de diferentes entradas para minimizar a quantidade de testes necessá-
rias e o domínio dos dados de entrada devem ser particionadosem um número finito declasses
de equivalência. Esta segunda propriedade garante que, se um caso de teste deuma determi-
nada classe de equivalência encontra um erro, outro caso de teste, da mesma classe, também
deve encontrar o mesmo erro. Estas classes são divididas em dois grupos: dados válidos e
inválidos. Em um módulo que possui como entrada apenas valores entre 1 e 999, existe uma
classe de equivalência válida: 1≤ n≤ 999 e existem duas classes de valores inválidos:n < 1 e
999< n.
Análise de Valores de Limite (boundary-value analysis). Exercita os limites do tipo de dados
de entrada. Difere do particionamento de equivalência em duas propriedades: 1. ao invés de
escolher valores qualquer dentro da classe de equivalênciacomo representante, um ou mais
valores devem ser selecionados que representam os extremosda classe. 2. ao invés de se preo-
cupar apenas com valores de entrada, os valores de saída também são verificados. É necessário
um bom conhecimento do problema para criar testes deboundary. Se o domínio dos valores
de entrada de um módulo é[−1.0,+1.0], devem ser criados testes que utilizam valores como
−1.0, 1.0,−1.001 e 1.001.
Grafo de Causa e Efeito. Explora uma das deficiências da análise de valores de limite eo
particionamento de equivalência, que é a combinação de valores de entrada. Uma situação
de erro pode ocorrer após uma seqüencia de valores de entrada. Esta situação poderia não

3.4 TESTES DE CAIXA PRETA 27
ser detectada pelas outras técnicas. As possíveis combinações podem tender a infinito e ao se
escolher um subconjunto de condições, que podem acarretar em um teste ineficaz. Utiliza uma
uma notação similar a lógica Booleana de circuitos digitais para representar o grafo. Este grafo
é utilizado para a escolha da seqüencia de valores de entrada. Um exemplo deste grafo pode
ser observado na figura 3.5.
Métodos de Estimativa de Erro (Error-guessing methods). É um processoad hoce intuitivo
de escrita de casos de teste, onde a experiência previa do engenheiro de testes é utilizada. A
idéia básica é identificar e listar os possíveis erros, ou possíveis situações de erro, e escrever
casos de teste baseado nesta lista.
Figura 3.5: Exemplo de um grafo de causa e efeito (Myers e Sandler; 2004, cap. 4, fig. 4.14).

3.5 TESTES DE CAIXA BRANCA 28
3.5 Testes de Caixa Branca
Os testes de caixa branca, ou estruturais, verificam o funcionamento interno de um software.
Estes não são capazes de garantir a ausência de defeitos, pois um defeito pode não se manifestar
mesmo executando a região de código que contenha o defeito. Para que este se manifeste, pode
ser necessário que o software esteja em um estado específico eapenas executar, sem criar este
estado, não fará com que o defeito se manifeste.
Existem diversas técnicas que seguem a abordagem de caixa branca. As técnicas de teste
são complementares, ou seja, não existe uma técnica que consiga encontrar todos os defeitos.
Estas devem ser utilizadas em conjunto ou em momentos diferentes, pois uma técnica não
substitui a outra. Segue, abaixo, uma lista das principais técnicas de testes de caixa branca,
segundo Young e Pezze (2005).
• Teste deStatement
É a forma mais básica e intuitiva de testar o fluxo de controle de um software. Cada
statementdeve ser executado pelo menos uma vez, seguindo a idéia de queum defeito
é revelado quando a região de código, que contém o defeito, é executada. Como visto
anteriormente, não é capaz de revelar todos os defeitos sem criar o estado específico em
que manifesta o defeito.
• Teste deBranch
Teste destatement, mesmo com uma cobertura total, pode não cobrir todos osbranches.
Cadabranchdeve ser executado pelo menos uma vez. Os testes cobrem, pelomenos, uma
ramificação do grafo de fluxo de controle do software. Em situações que uma ramificação
nunca é executada – por realmente ser inalcançável – o teste não satisfaz o critério de
adequação deste teste.
• Teste de Condição
Exercita as condições lógicas contidas em um módulo de um software. Teste debranch
enxerga apenas as ramificações, enquanto que teste de condição enxerga as estruturas
lógicas que compõem as condições dosbranches. Por essa característica, alguns defeitos
podem escapar, pois o teste debranchpoderá irá exercitar apenas as ramificações, sem
levar em conta que a condição pode conter um defeito. Na figura3.7, existem dois

3.6 CRITÉRIOS DE ADEQUAÇÃO E MÉTRICAS 29
caminhos possíveis –if eelse. Entretanto, se a condição contiver um erro como(x == 1
||y ==−1), o teste debranchnão irá identificar este erro.
• Teste de Caminho
Visa cobrir os possíveis caminhos de um software. É realizado criando-se entradas que
resultem em um determinado caminho. Alguns defeitos podem se manifestar após uma
seqüencia de decisões, ou seja, um caminho específico do software. Programas que con-
tenhamloopspodem gerar um número infinito de caminhos, o que torna este critério
difícil de ser totalmente coberto. É importante observar que um aumento na cobertura de
caminhos, não necessariamente acarreta em um aumento na cobertura destatements.
– Teste de Loop
Variação do teste de caminho, onde o principal objetivo é testar osloops. Para que
isto seja realizado, é estabelecido um critério de parada para que exista um número
finito de possíveis caminhos. O teste de caminho não é capaz deverificar todos os
caminhos em situações descritas na figura 3.6, pois poderá gerar infinitos possíveis
caminhos.
• Teste de Chamada de Procedimento/Método
Visa cobrir o fluxo de controle entre procedimentos ou métodos, útil em testes de inte-
gração ou testes de sistemas. Se o teste unitário foi bem sucedido, os defeitos que restam
serão de interface. Esta é a principal razão para se utilizaresta técnica na fase de inte-
gração. Nesta fase de teste, o principal foco deve ser a interface entre módulos, tornando
fundamental o uso de testes de chamada de procedimento.
3.6 Critérios de Adequação e Métricas
Critérios de adequação é um conjunto de obrigações que o par [Programa, Suite de Testes]
deve satisfazer. Uma suite de testes é dita que satisfaz o critério de adequação quando todas as
obrigações do critério são satisfeitas por, pelo menos, um caso de teste, segundo Young e Pezze
(2005).

3.6 CRITÉRIOS DE ADEQUAÇÃO E MÉTRICAS 30
1 pub l i c c l a s s ClassUnderTes t {
2 pub l i c vo id foo ( i n t x , i n t y ) {
3 i f ( x == −1 | | y == −1) {
4 . . .
5 } e l s e {
6 . . .
7 }
8 }
9 }
Figura 3.6: Exemplo de código fonte com umbranch.
1 pub l i c c l a s s PathWithLoop {
2 pub l i c vo id foo ( i n t x ) {
3 boolean s t o p = t rue ;
4
5 whi le ( s t o p ) {
6 . . .
7 }
8 }
9 }
Figura 3.7: Exemplo de código fonte com umloop, situação em que o teste de caminho pode
se tornar impraticável.
Algumas métricas são extraídas das suites de testes para prover uma medida quantitativa
da qualidade das suites de testes. Existem diversas medidase critérios de adequação. Cada
técnica de teste possui seu critério específico, como no teste destatement, cadastatementdeve
ser executado pelo menos uma vez. Caso esta exigência não sejacumprida, a suite de testes
falha neste critério. Estas informações também são utilizadas para medir o progresso do de-
senvolvimento dos testes, porém estas métricas podem ocultar e desviar do objetivo principal:
garantir a qualidade do software.
Métricas são utilizadas para analisar um software. Acomplexidade ciclomáticaé uma mé-
trica de software que fornece uma medida quantitativa da complexidade lógica de um sistema.
No contexto de teste de caminho, esta métrica define o número de caminhos independentes

3.7 CRIAÇÃO DE CASOS DE TESTE 31
e provê um limite máximo de testes necessários para garantirque todos osstatementssejam
executados, pelo menos uma vez (Pressman; 2001). Para extração de métricas, são utilizados
métodos estáticos, que analisam estaticamente osoftware, e métodos dinâmicos, que obtém as
métricas a partir da execução. Técnicas como a proposta por Buse e Weimer (2009), utilizam
um método estático para predizer osbranchesexistentes em um sistema.
Os critérios de adequação também fornecem informações úteis no desenvolvimento de um
software. Se o critério destatementnão é capaz de ser cumprido, isto significa que algum
trecho de código não é atingível, o que pode ser causado por algum erro de programação. Por
outro lado, alguns critérios não pode ser totalmente cumpridos. Critérios baseados em especi-
ficação pode exigir combinações de diferentes módulos, porém nem todas as combinações são
possíveis (Young e Pezze; 2005).
Dentre os diversos critérios, a principal questão é decidirqual destes critérios melhor se
enquadra na situação do desenvolvimento de um software. A definição de um critério como
mais “forte” ou mais “fraco” é extremamente subjetiva e específica para cada projeto. Alguns
critérios podem sobrepor outros, como no caso de um critérioestrutural que exige a cobertura
debranchessobrepõe a cobertura destatements.
3.7 Criação de Casos de Teste
O grau de esforço e complexidade na criação de casos de teste pode ser comparado ao esforço
relativo ao desenvolvimento de umsoftware. Estes testes devem ser desenvolvidos para encon-
trar a maior quantidade de erros possíveis em um mínimo tempoe esforço (Pressman; 2001).
Os testes de caixa preta são utilizados para testar a interface do software. Estes são utilizados
para garantir que o objeto a ser testado (pode ser um módulo, uma classe ou até o sistema
inteiro) está seguindo as especificações e que seu funcionamento básico está operacional. A
especificação funcional é a principal fonte de informação para a criação de casos de teste. Já
o teste de caixa branca, visa garantir o funcionamento das estruturas internas do produto e se
baseia nas estruturas internas e no desenvolvimento do software para criar seus testes.
Nestas abordagens, a geração de dados para a criação de testes produzem resultados dife-
rentes. Devido a diferença de propósitos, estes dados devemser gerados de formas diferentes.
Conforme visto na seção 3.4, testes de caixa preta podem utilizar dados de entrada para verifi-

3.8 TESTE SIMBÓLICO 32
cação de limites (boundaries), porém verificando apenas conformidade com os requisitos.No
teste de caixa branca, estes dados são gerados visando exercitar as estruturas de dados internas,
pois estas não estão visíveis no teste funcional. Existem diversas técnicas de geração de casos
de teste, como a execução concólica, vista adiante.
A automação de testes se tornou necessária devido a necessidade de identificar a presença
de defeitos sem intervenção humana. A verificação de softwares é uma árdua tarefa que exige
um grande esforço. Quanto mais tarde um defeito é encontrado, mais custoso se torna sua
correção. Na figura 3.8, o gráfico mostra o custo relativo de correção de um defeito de acordo
com a fase em que é encontrado. Como é possível observar, se um defeito é encontrado na
fase de levantamento de requisitos, o custo é de ordem 1. Porém se encontrado na fase final,
esta correção tem um custo de quase mil vezes maior, se comparado a fase inicial. Por causa
disto, inúmeros métodos foram criados para encontrar os defeitos o mais cedo possível, mais
próximo do instante em que o desenvolvedor introduz o erro. Uma das técnicas propostas para
geração automática de testes é a execução simbólica, utilizada em testes de caixa branca e de
caminho. Pode ser utilizado em testes unitários e de integração.
Existem diversas técnicas de geração automática de casos detestes ou de dados de entrada,
para serem utilizados por um teste já existente. Algumas técnicas utilizam um método aleató-
rio de geração de dados, os quais são modificados sem seguir nenhum critério sobre o tipo das
estruturas utilizadas nosoftware, como a técnica defuzzingcriada por Miller et al. (1990). A
técnica defuzzingse enquadra no tipo de teste de caixa-preta, pois não leva em consideração
nenhuma das estruturas internas e é utilizada unicamente com o intuito de verificar a confor-
midade das funcionalidades. Existe um aprimoramento destatécnica, chamado dewhite box
fuzzing. Ganesh et al. (2009) apresenta uma ferramenta que utiliza este método, chamada de
Buzz Fuzz, que analisa a estrutura do código dosoftwarena geração dos dados.
3.8 Teste Simbólico
Teste simbólico é uma técnica proposta por King (1976) para prover uma melhoria na auto-
mação de testes. Esta técnica é capaz de extrair as tomadas dedecisões internas, chamadas de
Path Condition(PC). Esta extração é feita usando os valores simbólicos ao invés dos valores
concretos. Com esta mudança, o programa é executado usando todo domínio do tipo da variá-

3.8 TESTE SIMBÓLICO 33
Figura 3.8: Gráfico de custo relativo de correção de um defeito de acordo com a fase em que é
encontrado (Pressman; 2001, cap. 8, fig. 8.1).
vel. O teste simbólico fornece uma forma prática de verificara corretude do software. A figura
3.9 mostra um exemplo de um conjunto de decisões internas de um exemplo de código. A va-
lidação de um programa utilizando uma análise formal é capazde prover melhores resultados,
mas sem resultados práticos devido sua alta complexidade.
3.8.1 Problema de Resolução de Restrições no Contexto de Teste Simbólico
A técnica proposta por King (1976) não fornecia um processo automático de resolver as res-
trições encontradas e, assim, fornecer dados de entrada. Clarke (1976) combinou a execução
simbólica com umsolverde restrições automático. Se o conjunto de restrições for linear, téc-
nicas de programação linear são utilizadas para obter uma solução. Apesar desta melhoria, a
intervenção humana ainda era necessária para resolver as restrições que não fossem lineares,
utilizando o método do gradiente conjugado.
Cadapath conditionpode ser visto como um problema de resolução de restrição e ossolvers

3.9 EXECUÇÃO CONCÓLICA 34
Figura 3.9: Um exemplo de um conjunto de decisões internas (Path Condition).
podem ser utilizados para gerar dados de entrada que satisfazem a restrição. Estes dados de
entrada são usados pelo software que está sendo testado e cada restrição satisfeita é um caminho
da árvore de fluxo de controle. Mas a capacidade dossolvers, usados para gerar estes dados de
entrada, limita que a técnica seja eficaz.
3.9 Execução Concólica
Ao método de execução simbólica faltava um valor concreto, oqual é necessário em casos de
indexação de vetores e conversão de tipos. Uma nova técnica foi proposta para preencher as
lacunas do teste simbólico. O software é executado usando dados concretos, mas os valores
simbólicos são armazenados em cada tomada de decisão durante a execução. Esta técnica é
chamada de execução concólica (Godefroid et al.; 2005), visto que combina execução concreta
e simbólica. A figura 3.10 representa umpath conditionextraído de uma execução concólica,
usando o mesmo código da figura 3.9, porém com dados concretos. Na figura, é possível
observar que a partir daquelas entradas, apenas um caminho éconhecido. Existem outros
caminhos a serem percorridos, porém estão ocultos ao algoritmo de execução.
É importante ter em mente que na execução concólica, é levadoem conta o critério de

3.10 TESTE RANDÔMICO 35
Figura 3.10: Um exemplo de umpath conditionextraído usando execução concólica.
adequação de caminhos. Apesar desta técnica ser capaz de satisfazer o critério destatements,
este não é seu objetivo. Encontrar soluções para novos caminhos nem sempre acarreta em um
aumento na cobertura de código. Porém, conforme visto na seção 3.5, esta técnica é capaz
de encontrar defeitos não descobertos pela técnica de cobertura destatements, pois apenas
executar uma região de código nem sempre é suficiente para queum erro se manifeste.
3.10 Teste Randômico
Teste randômico é uma técnica de geração de dados de entrada para a criação de casos de
teste para cobertura de código. As principais ferramentas são DART (Godefroid et al.; 2005) e
Randoop (Pacheco e Ernst; 2007).
DART provê uma execução simbólica com umsolverde restrições aleatório. A ferramenta
armazena o caminho que um determinado dado de entrada produziu, e seus valores simbólicos.
Sempre que uma expressão sai do escopo da teoria suportada pelo solver, um valor aleatório

3.11 CONSIDERAÇÕES FINAIS 36
é gerado até que um limite de tempo seja excedido ou uma solução seja encontrada. Quando
uma solução é encontrada, uma nova execução é realizada com estes novos dados e, assim,
novos PCS são gerados. Este método propõe duas soluções: (1) utiliza dados concretos quando
é necessário; (2) geração de dados aleatórios quando a expressão está fora do escopo suportado
pelosolver. DART é reduzido a um simplessolverrandômico quando a expressão está fora do
escopo da teoria suportada.
3.11 Considerações Finais
Com o crescimento da complexidade dos softwares desenvolvidos, o processo de testes se
tornou uma árdua tarefa. O processo de testes deve ser realizado de forma incremental, o qual
se assemelha a um espiral (Pressman; 2001). Cada fase possui seus objetivos e suas técnicas de
testes. Estas técnicas podem ser separadas em dois grupos:teste de caixa pretaeteste de caixa
branca. Os testes de caixa branca, mais especificamente ostestes de caminhopossuem uma
necessidade de um método de geração de dados de entrada para cobrir os possíveis caminhos
de um software. Os testes de caminho possuem um importante problema, osloopspodem gerar
uma grande quantidade de possíveis caminhos.
As técnicas de teste, seus critérios de adequação e métricaspermitem obter informações
sobre a qualidade dos testes criados e sobre o próprio software sob teste. Métricas, como
a complexidade ciclomática, auxiliam também no desenvolvimento e planejamento de testes,
pois esta permite obter uma estimativa da quantidade de testes necessários para prover uma
adequação destatements.
O teste simbólico possibilita a geração de dados para testesde caminhos, porém não é
capaz de resolver o problema deloops, além de outros problemas, como indexação de vetores
com valores simbólicos. A execução concólica resolve este problema combinando execução
simbólica, guardando as restrições criadas, e execução concreta, utilizando o valor concreto
para realizar ações de indexação e decisões deloops. Para a resolução das restrições de forma
automática, são utilizados provadores de teoremas que não são capazes de resolver restrições
que estão fora do escopo da teoria suportada pelo mesmo. Paraisto, DART (Godefroid et al.;
2005) e Randoop (Pacheco e Ernst; 2007) utilizam geração aleatória de valores. Apesar de sua
simplicidade, este método é capaz de resolver boa parte das restrições. A execução concólica

3.11 CONSIDERAÇÕES FINAIS 37
vem sendo aplicada no teste de diversos softwares, inclusive em linguagem de scripts como
PHP (Wassermann et al.; 2008).
Ossolversque são utilizados atualmente são restritos à teoria suportada. Esta limitação é
atualmente contornada utilizando-se uma randomização dasrestrições que estão fora do escopo
da teoria suportada pelosolver. Apesar de esta solução ser eficiente, esta randomização neces-
sita de pequenos intervalos para guiar o algoritmo, caso contrário, a probabilidade de encontrar
uma solução diminui à medida que o intervalo aumenta.
Soluções híbridas, ou até puramente aleatórias, têm apresentado resultados que poderiam
ser melhorados através de algoritmos baseados em heurística, os quais seriam capazes de intro-
duzir um melhor direcionamento, ao invés de percorrer aleatoriamente o espaço de busca.
Uma outra solução adotada para complementar a efetividade dossolvershíbridos é a rando-
mização das variáveis que compõem cláusulas que contém operações que estão fora da teoria
suportada pelosolver.

CAPÍTULO 4
Metodologia
Este capítulo apresenta a metodologia utilizada no desenvolvimento deste trabalho, onde será
detalhado oframeworkutilizado, com seus principais componentes, e a representação do pro-
blema utilizada pelos algoritmos de busca meta-heurística.
4.1 Framework
Foi definido umframeworkpara a realização das experimentações utilizando a arquitetura de-
finida na figura 4.1. A utilização doframeworksegue o seguinte fluxo: (1) umsoftwarea ser
testado é passado para o instrumentador, que introduz a bibilioteca simbólica; após a instru-
mentação, dá-se início à execução concólica (2) que é iniciada com um valor pré-definido e
nesta primeira execução são gerados PCs, que são armazenadose passados para ossolvers(3)
que tentam resolver as restrições; as soluções encontradasservem de entrada para odriver (4)
que reinicia a execução concólica com estes novos dados de entradas. Ao final deste ciclo, são
produzidos um conjunto de PCs e um conjunto de dados de entradaque permitem percorrer o
caminho determinado por um PC.
Os principais componentes destaframeworksão:
• Biblioteca Simbólica
Tipos simbólicos, que representam os tipos primitivos, sãoutilizados para guardar os
valores simbólicos gerados durante a execução, além de conter valores concretos, para
permitir a execução concreta.
• Instrumentador
Ferramenta desenvolvida para introduzir a biblioteca simbólica em umsoftware. Permite
reduzir drástricamente o tempo de preparação de umsoftware, realizando a instrumenta-
ção de forma automática.
38

4.1 FRAMEWORK 39
Figura 4.1: Arquitetura utilizada para acoplar ossolversaoframeworkde execução concólica.
• Execução Concólica
Frameworkcriado para realizar a execução concólica, onde os os PCs são armazenados
a medida que osoftwareé executado.
• Driver
Test driverque inicia a execução do programa. Recebe um conjunto de dadosde entradas,
os quais são passados para osoftwarea ser testado. Cada execução gera um conjunto de
PCs, que representam os caminhos que não foram executados. Alguns destes PCs podem
não ser satisfeitos, o que caracteriza em um trecho de códigoinatingível.
• Solver
Conjunto desolversque são utilizados para resolver as restrições e gerar dadosde entrada
para odriver executar o programa e percorrer o caminho relativo a este PC.

4.1 FRAMEWORK 40
Figura 4.2: Exemplo de uma árvore semântica.
4.1.1 Biblioteca Simbólica e Instrumentador
A biblioteca simbólica possui tipos simbólicos que representam os tipos primitivos da lingua-
gem Java. Para cada tipo primitivo, foi criado seu tipo simbólico correspondente. As classes
simbólicas armazenam um valor concreto e um valor simbólico, onde o valor simbólico apenas
é associado ao se criar uma expressão, comox> y. Foi utilizada uma árvore semântica que gera
a expressão, onde as variáveis e as constantes estão sempre nas folhas da árvore. Na figura 4.2
é possível observar um exemplo de árvore semântica. Os quadrados representam expressões
(como soma, comparação) e as folhas são as variáveis (branco) ou constantes (cinza).
O instrumentador foi desenvolvido utilizando as bibliotecas de manipulação debyte code
Java, ASM (ASM webpage; s.d.) e BCEL (Byte Code Engineering Library) (BCEL webpage;
s.d.). O uso destas bibliotecas permite a manipulação desoftwaresJava, sem a necessidade de
haver um código fonte. O instrumentador é utilizado para introduzir a biblioteca simbólica no
programa a ser testado, ou seja, substituir todos os tipos primitivos por tipos simbólicos. A
transformação exibida nas figuras 4.3 e 4.3b é realizada de forma automática, sem modificar a
semântica do programa. Esta transformação é também chamadade instrumentação.
Um exemplo de umsoftwareantes de ser instrumentado pode ser observado na figura 4.3a,
onde o código fonte do nó de uma árvore binária de busca é apresentado. Na figura 4.3b é

4.1 FRAMEWORK 41
apresentado o mesmo código após a instrumentação. Como pode-se observar, o atributoinfo
é do tipoint e, após a instrumentação, este torna-se em um tipo simbólico, SymInt. O tipo
SymInt é uma representação simbólico do tipoint, onde este armazena o valor concreto
inteiro e o seu valor simbólico.
4.1.2 Driver
O driver é utilizado para dar início à execução dosoftware. Deve ser criado umdriver espe-
cífico para cada programa a ser testado. Odriver utilizado nesteframeworkpossui o mesmo
papel de umtest driverdescrito pela literatura de testes (Pressman; 2001, cap. 18).
Na figura 4.4, é possível observar o código fonte de umdriver para o programa BST. São
realizadas chamadas aos métodos do programa que serão testados. Os métodos que não são
chamados, direta ou indiretamente, não serão testados pelaexecução concólica, pois o trecho
de código nunca será atingido pelo teste. É possível observar, também, que valores inicias são
definidos para iniciar a primeira execução, pois, sem estes valores, não seria possível gerar os
primeiros PCs.
4.1.3 Solvers
Como visto no capítulo anterior, existem técnicas já conhecidas que utilizam randomização
para prover uma simplificação nas restrições (Godefroid et al.; 2005). Apesar de seus resultados
promissores, existe espaço para uma melhoria no processo degeração de dados. O uso de meta-
heurísticas busca introduzir uma forma de resolver problemas, caminhando-se no espaço de
busca de possíveis soluções. Este se guia através de funçõesdefitnessque avaliam cada solução
candidata e identificam o quão perto, da solução final, estão.Lakhotia et al. (2008) propôs
uma solução que utiliza algoritmos de busca na geração de dados, porém com o propósito de
cobertura debranches. Além disso, a solução de Lakhotia et al. (2008) utilizou o algoritmo de
subida da encosta, ao invés de algoritmos evolutivos, apesar do algoritmo de subida da encosta
realizar apenas uma busca local.
Foram escolhidos os algoritmos de busca Algoritmo Genético(AG) e Otimização por En-
xame de Partículas (PSO) devido suas capacidade de percorrer grandes espaços de buscas –
os quais podem ter inúmeras dimensões – e, ainda assim, encontrar soluções ótimas. PSO
também possui uma qualidade de grande importância neste tipo de problema:baixo custo

4.1 FRAMEWORK 42
1 package benchmark . b s t ;
2
3 pub l i c c l a s s Node {
4 pub l i c Node l e f t ; / / l e f t c h i l d
5 pub l i c Node r i g h t ; / / r i g h t c h i l d
6 pub l i c i n t i n f o ; / / da ta
7
8 Node ( i n t i n f o ) {
9 t h i s . i n f o = i n f o ;
10 }
11
12 Node ( Node l e f t , Node r i g h t , i n t i n f o ) {
13 t h i s . l e f t = l e f t ;
14 t h i s . r i g h t = r i g h t ;
15 t h i s . i n f o = i n f o ;
16 }
17 }
(a) Original
1 package benchmark . b s t . i n s t r u m e n t e d ;
2
3 pub l i c c l a s s Node {
4 pub l i c Node l e f t ; / / l e f t c h i l d
5 pub l i c Node r i g h t ; / / r i g h t c h i l d
6 pub l i c SymInt i n f o = new SymIn tCons tan t ( 0 ) ; / / da ta
7
8 Node ( SymInt i n f o ) {
9 t h i s . i n f o = i n f o ;
10 }
11
12 Node ( Node l e f t , Node r i g h t , SymInt i n f o ) {
13 t h i s . l e f t = l e f t ;
14 t h i s . r i g h t = r i g h t ;
15 t h i s . i n f o = i n f o ;
16 }
17 }
(b) Instrumentado
Figura 4.3: Código fonte de BST original e instrumentado.

4.1 FRAMEWORK 43
1 package benchmark . d r i v e r s . c o n c o l i c ;
2
3 pub l i c c l a s s BST_Driver implements D r i v e r {
4 S y m I n t L i t e r a l [ ] l i t s = new S y m I n t L i t e r a l [ ] { new S y m I n t L i t e r a l ( 3 ) ,
5 new S y m I n t L i t e r a l ( 5 ) , new S y m I n t L i t e r a l ( 1 ) , } ;
6
7 pub l i c vo id t e s t ( SymL i t e ra l [ ] l i t e r a l s ) {
8 BST b s t = new BST ( ) ;
9
10 f o r ( SymL i t e ra l s y m L i t e r a l : l i t e r a l s ) {
11 b s t . add ( ( SymInt ) s y m L i t e r a l ) ;
12 }
13 f o r ( SymL i t e ra l s y m L i t e r a l : l i t e r a l s ) {
14 b s t . remove ( ( SymInt ) s y m L i t e r a l ) ;
15 }
16 }
17 }
Figura 4.4:Driver do programa BST.

4.1 FRAMEWORK 44
Figura 4.5: Arquitetura utilizada pelossolvers.
computacional. É comum neste tipo de problema que ossolversutilizem um critério de pa-
rada extremamente rígido:tempo de execução. Este critério é utilizado devido à sua aplicação
prática não se tornar viável, caso o tempo de execução se torne longo. Em problemas que, em
média, 100 restrições são geradas, não seria útil utilizar um solverque exigisse uma quantidade
indefinida de tempo em cada uma das restrições.
Ossolversforam implementados seguindo a estrutura definida na figura 4.5, a qual repre-
senta umsolverque utiliza algoritmo genético. Esta arquitetura permite implementar novos
solversde forma rápida, onde é necessário apenas trocar o gerador dedados – neste caso, AG
– e o funcionamento será mantido.
4.1.4 Solvers Híbridos
Solverssimbólicos de restrições são limitados a um conjunto de teorias decidíveis. CVC3 (CVC3
web page; s.d.), por exemplo, suporta aritmética linear de inteirose racionais (entre outros), mas
provê um suporte bastante limitado a aritmética não-linear, divisão de inteiros e módulo.
Godefroid et al. (2005) propuseram uma técnica que combina provadores de teorema clás-
sicos a um algoritmo aleatório, que tentar diminuir a complexidade da restrição. Esta técnica,
apesar de bastante eficiente, não utiliza nenhuma heurística na geração de valores. Ossolvers
que utilizam algum algoritmo estocástico, serão chamados de solvers aleatórios, nesta disser-
tação.
Os solvershíbridos combinamsolverssimbólicos e aleatórios. Existem alguns métodos
bem conhecidos de realizar esta interface. O algoritmo chamado deBads-First(BCF) identifica
as restrições “ruins”, restrições que não podem ser solucionadas pelosolverbaseado em teoria

4.2 REPRESENTAÇÃO DO PROBLEMA 45
(geralmente teoria de inteiros não linear e ponto flutuante), e tentam resolvê-las usando um
solveraleatório. Este gera dados aleatórios até a restrição ser satisfeita ou o limite de tempo é
excedido. O algoritmoGoods-First(GCF) é exatamente o oposto, tenta identificar as restrições
“boas” e as envia aosolverbaseado em teoria e, somente após isto, tenta resolvê-las através
de randomização. OsolverhíbridoBad Variables First(BVF) é baseado no algoritmoDART
(Godefroid et al.; 2005). BVF gera valores aleatórios para resolver variáveis que compõem
restrições “ruins”. Desta forma, a complexidade da restrição é reduzida e osolversimbólico
pode ser capaz de resolvê-la.
Dentre as técnicas de hibridação desolvers, apenas um destes não pode utilizar algoritmos
de meta-heurística: variáveis “ruins” primeiro (Bad Variables First– BVF). Este não pôde ser
combinado aossolversbaseados em busca, pois os algoritmos de busca utilizam uma função
objetivo que avalia a qualidade dos resultados gerados e a utiliza para guiar a geração de novos
valores.
Foi possível combinar ossolvershíbridos (GCF, BCF) aossolversque utilizam algoritmos
de busca (AG e PSO). Desta forma, foram criados os seguintessolvers: GCF+AG, BCF+AG,
GCF+PSO e BCF+PSO.
4.2 Representação do Problema
Para representar o problema de resolução de restrições, cada dimensão de uma solução repre-
senta um valor de uma variável. Do problema CSP, como ilustração, a restrição, no formato
CNF, a seguir será usada: (x= y) AND (y= z) AND (x= z). A tabela 4.1 mostra quatro exem-
plos de soluções candidatas, entretanto, apenas a quarta solução é capaz de resolver a restrição.
Pode-se observar o valor defitnessde cada indivíduo, utilizando-se a função MaxSAT. Neste
exemplo, o espaço de busca é relativamente pequeno, pois o domínio das variáveis é apenas
números inteiros (D ∈ Z), e possui apenas 3 variáveis, ou seja, 3 dimensões. Supondoque o
domínio do espaço de busca deste exemplo seja[−10,10], na figura 4.6 é possível observar
uma representação onde a reta vermelha representa as soluções deste problema (f itness= 3), a
reta azul representa locais em que ofitnessé igual a 1 e no restante do espaço ofitnessé igual
a 0. Pode-se observar que neste cubo, que representa o espaçode busca, existe apenas uma
reta vermelha, onde as soluções do problema estão localizadas, e seis retas azuis, onde estão

4.2 REPRESENTAÇÃO DO PROBLEMA 46
Tabela 4.1: Exemplo de um código genético representando umasolução de uma restrição e
seus respectivos valores defitnessutilizando função MaxSAT.
id x y z Fitness
1 2 10 1 0
2 -5 7 7 1
3 3 0 3 1
4 -10 -10 -10 3
(x = y)∧ (y = z)∧ (x = z)
as soluções parciais. As três cláusulas são resolvidas na reta vermelha, apenas uma cláusula é
resolvida em qualquer ponto das retas azuis, e no restante doespaço estão soluções inválidas.
Para avaliar cada solução candidata, é necessário transpordessa representação – vetor de
variáveis – para a árvore semântica, descrita na figura 4.2. Existe um custo computacional as-
sociada a essa operação de tranposição, o qual não deve ser alto, pois esta avaliação é realizada
a cada iteração. A figura 4.7 mostra a representação da expressão: (x > y)∧ (x 6= y%2). Os
valores da solução candidata (x = 4 ey = 2) devem ser modificados na árvore semântica, que
deve ser percorrida até encontrar uma variável (x ouy) e modificar o seu valor concreto.

4.2 REPRESENTAÇÃO DO PROBLEMA 47
Figura 4.6: Representação no plano cartesiano do espaço de busca do exemplo da tabela 4.1,
onde a reta vermelha representa as soluções do problema (f itness= 3), as retas azuis soluções
parciais (f itness= 1) e o restante do espaço não é uma solução válida (f itness= 0).
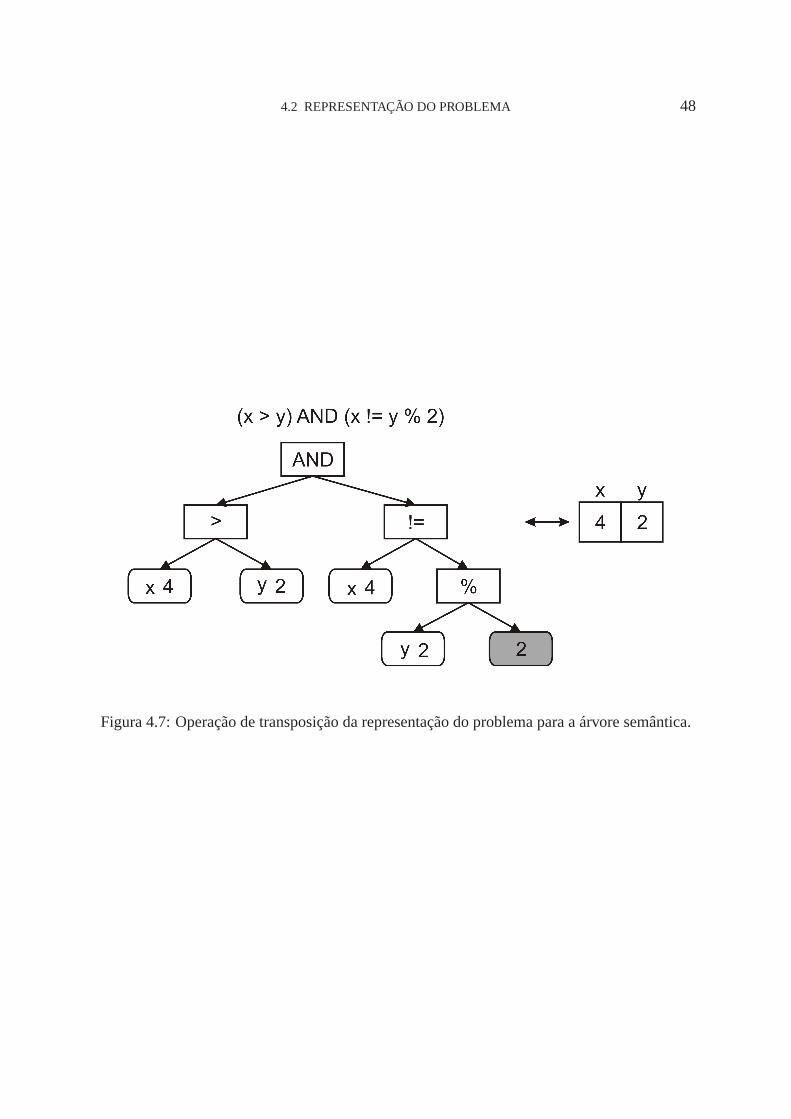
4.2 REPRESENTAÇÃO DO PROBLEMA 48
Figura 4.7: Operação de transposição da representação do problema para a árvore semântica.

CAPÍTULO 5
Experimentos
Neste capítulo, será apresentada uma solução para o problema de resolução de restrições através
do uso de solucionadores baseados em algoritmos de busca. Também será apresentada uma
proposta de algoritmo híbrido, onde a combinação de umsolversimbólico e um baseado em
algoritmos de busca é realizada. Esta combinação visa combinar as características de ambos os
algoritmos e, assim, prover um melhor desempenho.
5.1 Descrição dos Experimentos
Ossolversanalisados foram: puramente randômico – ranSOL, algoritmogenético – GA, oti-
mização por enxame de partículas – PSO, CVC3 – symSOL,Good Constraints First– GCF,
Bad Constraints First– BCF, Bad Variables First(BVF), GCF+AG, BCF+AG, GCF+PSO,
BCF+PSO. O desempenho destessolversforam analisados de acordo com um conjunto de
programas conhecidos, os quais, de acordo com o tipo de restrições produzidas, podem ser se-
parados em dois grupos: lineares e não-lineares. As restrições lineares satisfatíveis devem ser
100% resolvidas pelosolversimbólico.
Os programas selecionados podem ser classificados, além de lineares e não-lineares, de
acordo com o tipo das variáveis que podem ser inteiras ou ponto-flutuante. Desta forma, é pos-
sível identificar os pontos fortes e fracos de cada algoritmode acordo com estas informações.
Os programas escolhidos foram:
1. Árvore Binária de Busca (BST)
Algoritmo de inserção e remoção de elementos em uma estrutura em forma de árvore
binária, onde os elementos estão organizados de forma ordenada, de acordo com o valor
de seus elementos. Implementação de Boyapati et al. (2002).
2. FileSystem
49

5.1 DESCRIÇÃO DOS EXPERIMENTOS 50
Simulação de um sistema de arquivos, com arquivos, diretórios e i-nodes. Simula as
principais operações em um sistema de arquivos deste tipo, como criação e remoção de
diretórios e arquivos e busca do i-node de um arquivo. Utiliza apenas aritmética linear
inteira. Simplificação do sistema de arquivos Daisy (Qadeer; s.d.).
3. TreeMap
Estrutura de armazenamento de dados que utiliza uma forma deárvore para indexar os
dados. Utiliza uma chave de indexação, calculada de acordo com o próprio dado. Similar
à árvore binária de busca, produz restrições lineares. Implementação do jdk1.4 da classe
java.util.TreeMap de árvores red-black.
4. Switch
Programa de exemplo da distribuição do jCUTE (Sen e Agha; 2006).
5. Polinomiais Racionais (RatPoly)
Método de criação de polinomiais racionais que utiliza um coeficiente arbitrário de pre-
cisão racional. Utiliza apenas valores inteiros e restrições não-lineares. Implementação
disponível na distribuição do Randoop (Pacheco et al.; 2007).
6. RationalScalar
Algoritmo que simula um número racional, extraído da bibliotecaojAlgo (ojAlgo web-
page; s.d.) de métodos matemáticos, álgebra linear e otimizações. Assim comoRatPoly,
produz restrições inteiras não-lineares.
7. Método de Newton
Método iterativo para determinar a raiz quadrada de um número através de aproxima-
çõesNewton’s square root webpage(s.d.). Produz restrições longas e não-lineares, porém
utiliza apenas dois operadores aritméticos.
8. Tabela de Hash (HashMap)
Estrutura de armazenamento de dados, os quais são indexadosatravés de uma chave cal-
culada de acordo com o valor do próprio dado. Utiliza operadores de deslocamento de
bits, que produzem restrições extremamente complexas e de difícil resolução. Implemen-
tação da classejava.util.HashMap do jdk1.4.

5.1 DESCRIÇÃO DOS EXPERIMENTOS 51
9. Mersenne Twister (Colt)
O Colt é uma biblioteca de operações matemáticas, da qual foi escolhido o algoritmo
Mersenne Twisterpara ser instrumentado.Mersenne Twisteré um algoritmo de gera-
ção de números aleatórios proposto por Matsumoto e Nishimura (1998), capaz de gerar
números aleatórios, seguindo uma distribuição normal. Foiescolhido devido sua capaci-
dade de gerar restrições não-lineares e de grande complexidade.
Para realizar os experimentos, os programas foram instrumentados manualmente e um
(Colt) foi instrumentado automaticamente através da ferramentade instrumentação debyte
codeJava descrita na seção sobre oframework. Os programas foram instrumentados e, em pa-
ralelo, a ferramenta foi desenvolvida, o que acarretou na utilização em apenas um dos progra-
mas. Entretanto, a ferramenta de instrumentação automática poderia ser utilizada para estender
o conjunto de programas utilizados para experimentação. Esta ferramenta foi de extrema im-
portância, pois possibilitou introduzir o código de suporte à execução concólica rapidamente,
sem intervenção do usuário.
Os programas são comparados na tabela 5.1. Os operadores≪,≫, >>>, &, | eˆequivalem
aos operadores de deslocamento a esquerda, deslocamento a direita, deslocamento a direita sem
sinal, “e”, “ou” e “ou” exclusivo, respectivamente. Apesarde não ser capaz de inferir a comple-
xidade do problema, estas informações são úteis para entender o desempenho e funcionamento
dossolvers. Na tabela é possível observar que, nos programas não-lineares, há uma baixa di-
mensionalidade, exceto emHashMap. Como a representação do problema utiliza cada variável
como uma dimensão, os experimentos não-lineares apresentaram uma média de 5.52 variáveis
por restrição. O tamanho e o número médio de cláusulas por restrição determina o tamanho das
expressões. Quanto maior o tamanho, maior o custo computacional para avaliar as soluções
candidatas. Os operadores utilizados determinam o tipo de restrição (linear ou não-linear).
Na tabela 5.2 é apresentado o desempenho de cadasolverde acordo com o programa. A
métrica de desempenho utilizada é a porcentagem de restrições satisfeitas, dentre as restrições
satisfatíveis. O primeiro grupo de experimentos produz apenas restrições lineares, as quais
CVC3 é capaz de resolver 100%. Enquanto que o segundo grupo produz apenas restrições
não-lineares, as quais CVC3 é capaz de resolver apenas alguns casos específicos.
Foi utilizada uma execução concólica, conforme visto na seção 3.9, para a extração dos
Path Conditionsdos programas selecionados. Foram realizadas duas formas de execução para
comparação dos resultados dossolvers: 10 execuções variando a semente do número aleatório
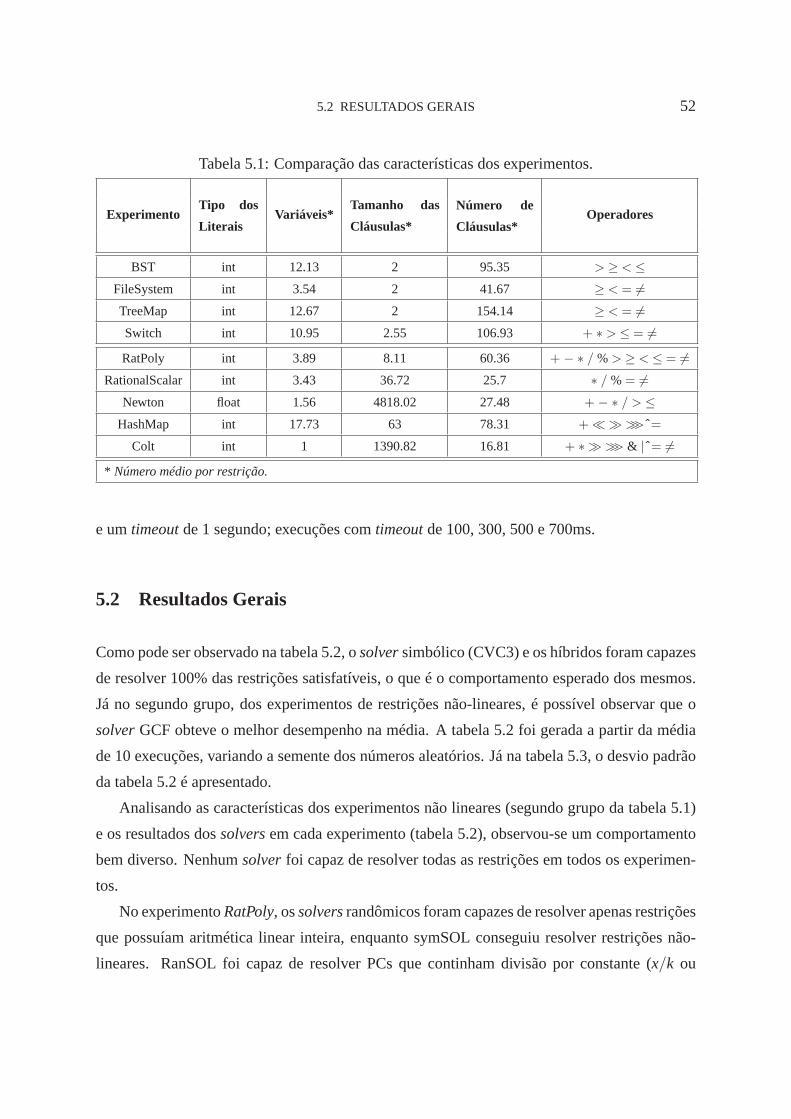
5.2 RESULTADOS GERAIS 52
Tabela 5.1: Comparação das características dos experimentos.
ExperimentoTipo dos
LiteraisVariáveis*
Tamanho das
Cláusulas*
Número de
Cláusulas*Operadores
BST int 12.13 2 95.35 > ≥ < ≤
FileSystem int 3.54 2 41.67 ≥ < = 6=
TreeMap int 12.67 2 154.14 ≥ < = 6=
Switch int 10.95 2.55 106.93 + ∗ > ≤ = 6=
RatPoly int 3.89 8.11 60.36 + − ∗ / % > ≥ < ≤ = 6=
RationalScalar int 3.43 36.72 25.7 ∗ / % = 6=
Newton float 1.56 4818.02 27.48 + − ∗ / > ≤
HashMap int 17.73 63 78.31 +≪≫ >>>ˆ=
Colt int 1 1390.82 16.81 + ∗ ≫ >>> & |ˆ= 6=
* Número médio por restrição.
e umtimeoutde 1 segundo; execuções comtimeoutde 100, 300, 500 e 700ms.
5.2 Resultados Gerais
Como pode ser observado na tabela 5.2, osolversimbólico (CVC3) e os híbridos foram capazes
de resolver 100% das restrições satisfatíveis, o que é o comportamento esperado dos mesmos.
Já no segundo grupo, dos experimentos de restrições não-lineares, é possível observar que o
solverGCF obteve o melhor desempenho na média. A tabela 5.2 foi gerada a partir da média
de 10 execuções, variando a semente dos números aleatórios.Já na tabela 5.3, o desvio padrão
da tabela 5.2 é apresentado.
Analisando as características dos experimentos não lineares (segundo grupo da tabela 5.1)
e os resultados dossolversem cada experimento (tabela 5.2), observou-se um comportamento
bem diverso. Nenhumsolverfoi capaz de resolver todas as restrições em todos os experimen-
tos.
No experimentoRatPoly, ossolversrandômicos foram capazes de resolver apenas restrições
que possuíam aritmética linear inteira, enquanto symSOL conseguiu resolver restrições não-
lineares. RanSOL foi capaz de resolver PCs que continham divisão por constante (x/k ou

5.2 RESULTADOS GERAIS 53
Tabela 5.2: Tabela da cobertura média dos pares: experimento (linha) esolver(coluna).
ranSol AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
BST 0.02 0.01 0.02 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
FileSystem 0.06 0 0.06 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
TreeMap 0.02 0.01 0.02 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
Switch 0.48 0 0.35 0.99 1.00 1.00 1.00 0.08 0.99 0.07 0.99
média 0.15 0.01 0.11 1.00 1.00 1.00 1.00 0.77 1.00 0.77 1.00
RatPoly 0.12 0.01 0.10 0.09 0.86 0.27 0.17 0.86 0.13 0.86 0.19
RationalScalar 0.44 0.01 0.37 0.04 0.43 0.18 0.10 0.22 0.04 0.50 0.14
Newton 0.74 0.14 0.57 0 0.49 0.31 0 0.14 0 0.29 0.17
HashMap 0.02 0 0.63 0 0.02 0.02 0 0 0 0.64 0.65
Colt 0.86 0.32 0.35 0 0.93 0.93 0 0.32 0.32 0.36 0.37
média 0.44 0.10 0.41 0.03 0.54 0.34 0.05 0.31 0.10 0.53 0.31
k/x, ondex é um literal ek uma constante) e operador de “maior que” (>) e PSO não foi
capaz de resolvê-los. SymSOL também obteve êxito em resolver o produto de duas variáveis
(x× y), apesar de symSOL ser apenas capaz de resolver alguns casosespeciais de restrições
não-lineares.
Na execução doRationalScalar, o desempenho de GCF+PSO sobrepôs GCF, ou seja, não
houve nenhuma restrição resolvida por GCF que GCF+PSO não fosse capaz de resolver. Os
outrossolversapresentaram um comportamento complementar, ranSOL e PSO resolveram res-
trições que GCF e GCF+PSO não foram capazes de resolver e vice-versa.
Em Newton, ranSOL foi capaz de resolver a maior parte das restrições e não está claro a
razão deste resultado. Pode ter sido causado pelo baixo número de literais, que reduz consi-
deravelmente o espaço de busca, ou o tipo de dados das variáveis serem ponto-flutuante, que
aumenta o espaço de busca. Outro experimento que use variáveis ponto-flutuante seria neces-
sário para identificar a real razão para este comportamento.
Já o experimentoHashMapilustra a capacidade do algoritmo PSO de resolver restrições
complexas. É possível observar na tabela 5.1 queHashMapproduz restrições com o maior
número de literais, ou seja,HashMapé o experimento com o maior número de dimensões.
Visto que a quantidade de dimensões está diretamente relacionada com o tamanho do espaço
de busca,HashMappossui o maior espaço de busca. RanSOL não demonstrou complementa-
ridade com PSO e PSO foi capaz de resolver todas as restriçõesresolvidas por ranSOL. O alto

5.2 RESULTADOS GERAIS 54
Tabela 5.3: Desvio padrão da tabela 5.2.
ranSol AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
BST 0 0 0 0 0 0 0 0 0 0 0
FileSystem 0 0 0 0 0 0 0 0 0 0 0
TreeMap 0 0 0 0 0 0 0 0 0 0 0
Switch 0 0 0.03 0.01 0 0.01 0.01 0.05 0.01 0.03 0.01
média 0 0 0.01 0 0 0 0 0.01 0 0.01 0
RatPoly 0.01 0.01 0 0 0 0.12 0.08 0 0.02 0 0.01
RationalScalar 0.03 0.02 0.01 0 0.05 0.02 0 0 0 0 0.01
Newton 0.06 0 0 0 0.10 0.26 0 0 0 0 0.15
HashMap 0 0 0.15 0 0 0 0 0 0 0.20 0.18
Colt 0.02 0.02 0.02 0 0.01 0.01 0 0.02 0.02 0.03 0.02
média 0.03 0.01 0.05 0 0.04 0.07 0 0 0.01 0.06 0.09
número de literais pode ter afetado a capacidade de busca do algoritmo randômico.
Em Colt, ranSOL obteve um melhor resultado, comparado com GA e PSO. Aprincipal ra-
zão para isto é o baixo número de literais, que resulta em um pequeno espaço de busca. O custo
computacional associado à busca heurística não é capaz de sobrepor o algoritmo puramente
aleatório, que possui um custo computacional mínimo. Entretanto, sem limite de tempo, todos
devem obter o mesmo resultado.
Podemos observar os efeitos de uma alta e baixa dimensionalidade do espaço de busca na
métrica de cobertura dossolversnos experimentosHashMape Colt, respectivamente. Estes
resultados confirmam nossas expectativas de que ossolverssão complementares, não há uma
sobreposição dos resultados. Nas tabelas B.2, B.4, B.6, B.8 e B.9 estão os resultados compa-
rativo do desempenho de cadasolver. Pode-se observar o desempenho médio de cadasolver
nos 9softwaresescolhidos para experimentação. A linha representa a quantidade de restrições
resolvidas pelo solver da coluna. Desta forma é possível observar um comportamento comple-
mentar dos mesmos, além de permitir identificar os programasque geram restrições lineares,
as quais são facilmente resolvidas pelosolversimbólico.
Dentre ossolversaleatórios, destacou-se o ranSol com o melhor desempenho namédia e
na maior parte dos experimentos. Já nossolvershíbridos, GCF obteve o melhor desempenho
na média. Apesar destessolversse destacarem na média, estes não foram capazes de obter o
melhor desempenho em todos os experimentos, como pode ser observado na tabela 5.2.

5.2 RESULTADOS GERAIS 55
Além das tabelas de comparação do desempenho dossolvers, foram criadas as figuras 5.1,
5.2, 5.3 e 5.4 que apresentam um conjunto de diagramas de Venn, utilizado na representa-
ção de conjuntos, onde é possível observar a complementaridade dossolvers, apresentando a
quantidade de restrições satisfeitas de uma execução. Nas figuras 5.1, 5.2, 5.3 e 5.4, a compa-
ração entre ossolversaleatórios, híbridos (GCF e BCF) e os híbridos puramente aleatórios é
realizada, respectivamente.
Na figura 5.1e, que representa o desempenho dossolversrandômicos no experimentoRat-
Poly, pode-se observar que ranSol foi capaz de resolver 5 restrições que AG e PSO não foram
capazes de resolver. AG e PSO não foram capazes de resolver restrições únicas – que somente
eles resolveram – e o seu conjunto de restrições satisfeitasestá contido no conjunto das restri-
ções satisfeitas por ranSol. Figura 5.1i apresentou o melhor caso de complementaridade, onde
cadasolverfoi capaz de resolver restrições únicas, além de resolver restrições do conjunto do
outrossolvers. No programaHashMap, foram comparados ossolvershíbridos baseados no
algoritmo PSO na figura 5.4h, pois os híbridos baseados no algoritmo puramente aleatório não
obtiveram um bom resultado.
A figura 5.5 mostra o comportamento da função MaxSAT no experimento BST. Está cla-
ramente visível que o valor da função acompanha o número de cláusulas satisfeitas, visto que
o calculo da função é exatamente isto – a contagem dos númerosde cláusulas satisfeitas. Este
comportamento prejudica as tomadas de decisões e faz com queo algoritmo fique preso em
vales de máximos locais. A figura 5.6 mostra a função SAW. É possível observar quando o
algoritmo decide escolher uma solução candidata que resolve uma cláusula difícil de resolver,
mesmo que isto signifique reduzir o número de cláusulas satisfeitas. Estas soluções são favo-
recidas com um valor defitnessmais alto. As figuras 5.5 e 5.6 ilustram o comportamento da
função, independente do algoritmo utilizado.
5.2.1 Impacto dotimeout
Para observar o impacto dotimeout, os experimentos foram executados utilizandotimeoutde
100, 300, 500 e 700ms. A figura 5.7 apresenta os resultados dasexecuções utilizando gráficos
de barras empilhadas (Stacked Bars). Esta representação foi escolhida pois o resultado de um
timeoute a diferença do subseqüente é exibida claramente. Neste caso, os resultados de 300ms
engloba os resultados de 100ms. Os gráficos dos outros experimentos foram omitidos pois

5.2 RESULTADOS GERAIS 56
(a) BST (b) FileSystem (c) TreeMap
(d) Switch (e) RatPoly (f) RationalScalar
(g) Newton (h) HashMap (i) Colt
Figura 5.1: Diagrama de Venn do desempenho dossolversaleatórios.

5.2 RESULTADOS GERAIS 57
(a) BST (b) FileSystem (c) TreeMap
(d) Switch (e) RatPoly (f) RationalScalar
(g) Newton (h) HashMap (i) Colt
Figura 5.2: Diagrama de Venn do desempenho dossolvershíbridos GCF.

5.2 RESULTADOS GERAIS 58
(a) BST (b) FileSystem (c) TreeMap
(d) Switch (e) RatPoly (f) RationalScalar
(g) Newton (h) HashMap (i) Colt
Figura 5.3: Diagrama de Venn do desempenho dossolvershíbridos BCF.

5.2 RESULTADOS GERAIS 59
(a) BST (b) FileSystem (c) TreeMap
(d) Switch (e) RatPoly (f) RationalScalar
(g) Newton (h) HashMap (i) Colt
Figura 5.4: Diagrama de Venn do desempenho dossolvershíbridos.
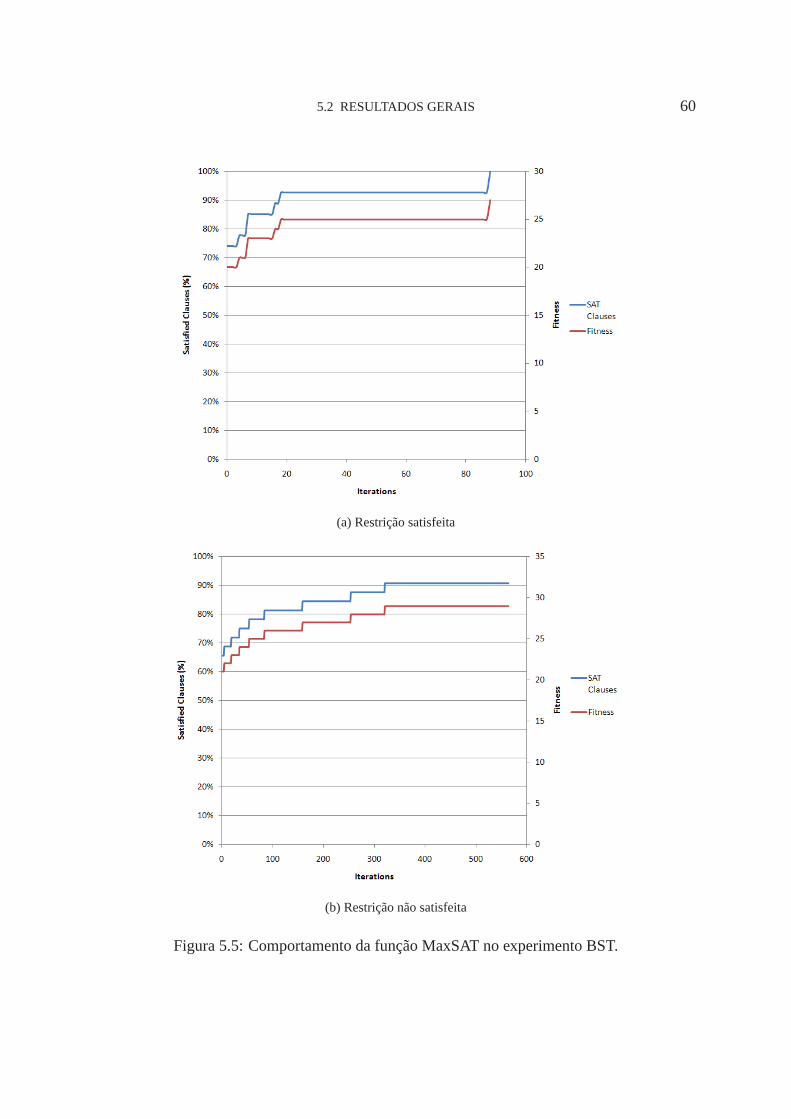
5.2 RESULTADOS GERAIS 60
(a) Restrição satisfeita
(b) Restrição não satisfeita
Figura 5.5: Comportamento da função MaxSAT no experimento BST.

5.2 RESULTADOS GERAIS 61
(a) Restrição satisfeita
(b) Restrição não satisfeita
Figura 5.6: Comportamento da função SAW no experimento BST.

5.2 RESULTADOS GERAIS 62
não houve nenhum comportamento fora do esperado ou não houveganhos com o aumento do
timeout. Os gráficos restantes estão no apêndice, nas figuras A.1, A.2, A.3 e A.4.
Os experimentos que geram restrições lineares, puderam serresolvidas por symSOL e ne-
nhum ganho de desempenho pôde ser observado com o incrementodo timeout. Entretanto, em
Switche HashMapa métrica de cobertura dossolversobteve um ganho com o acréscimo de
tempo.
Switchdemonstrou um comportamento diferente do esperado. Por gerar apenas restrições
satisfatíveis, ossolverssimbólicos deveriam ser capazes de resolver 100% das restrições em
um tempo extremamente baixo, porém foi observado que para resolver as restrições deSwitch,
symSOL demandou um tempo maior do que o esperado. Este comportamento pode ser ex-
plicado pelo custo computacional para transpor da representação de árvore semântica (repre-
sentação das restrições) para uma entrada válida para o CVC3. Oframeworkdesenvolvido de
execução concólica deve ser revisto de modo que esta operação não seja tão custosa e, assim, a
execução de symSOL seja menos afetada pela variação dotimeout.
5.2.2 Impacto dos Parâmetros dos Algoritmos de Busca
O desempenho dossolversbaseados em busca e seus parâmetros foram analisado nos diversos
experimentos. No algoritmo genético foram definidos valores para os parâmetros:tamanho
da populaçãoe taxa de mutação. Como visto no capítulo 2, o tamanho da população deve
ser escolhido de acordo com a dimensionalidade do problema.Este parâmetro está presente
nos algoritmos evolutivos, portanto, também existe no PSO.A taxa de mutação, determina a
probabilidade de novos indivíduos sofrerem mutação. Nas figuras 5.8 e 5.9, são apresentados
os gráficos da influência dos parâmetros no desempenho dosolverbaseado em AG. No expe-
rimentoColt, AG necessitou uma população relativamente grande, já no experimentoRatPoly,
AG foi capaz de atingir seu melhor resultado utilizando uma população pequena. O valor de
mutação baixo é determinando para um bom desempenho emColt devido sua baixa dimensio-
nalidade. EmRatPoly, a variação no parâmetro de mutação não resultou em nenhuma mudança
de desempenho.
No algoritmo PSO, foram analisados os impactos dos parâmetros: tamanho da popula-
ção, incremento global e inércia (ω). O incremento global determina o tamanho do passo
realizado pelo algoritmo, ou seja, quanto menor for este parâmetro, menor será o passo. Passos
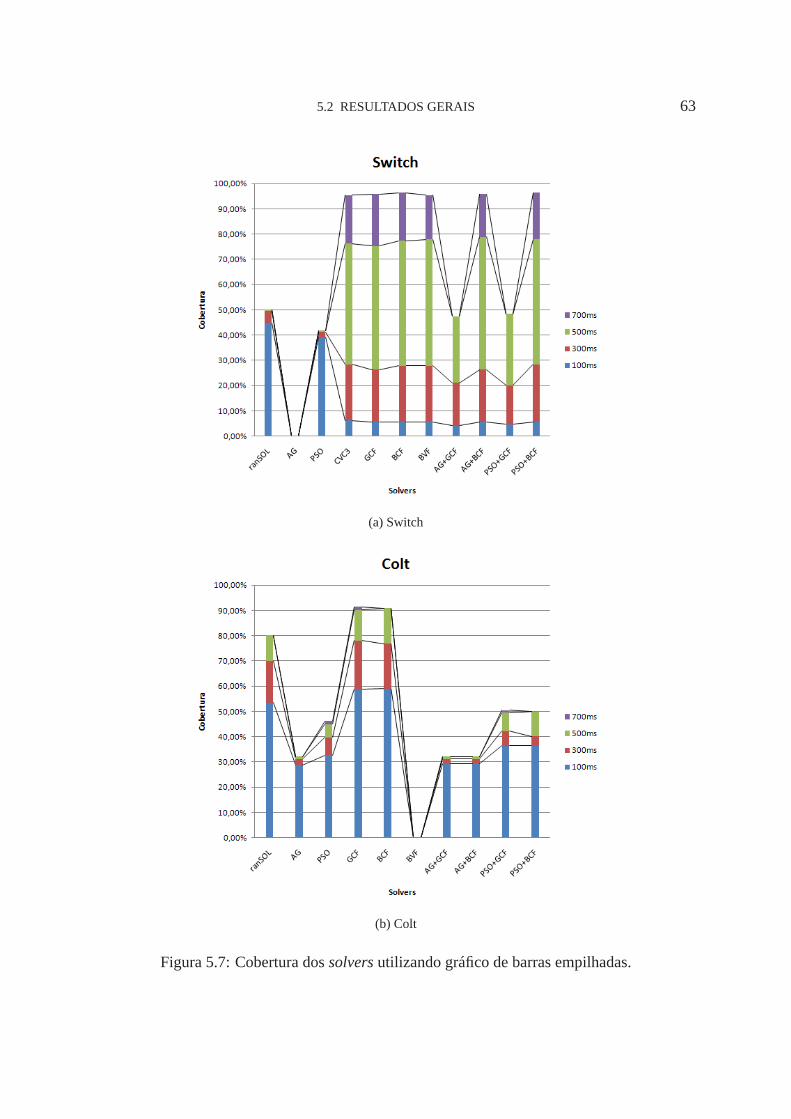
5.2 RESULTADOS GERAIS 63
(a) Switch
(b) Colt
Figura 5.7: Cobertura dossolversutilizando gráfico de barras empilhadas.
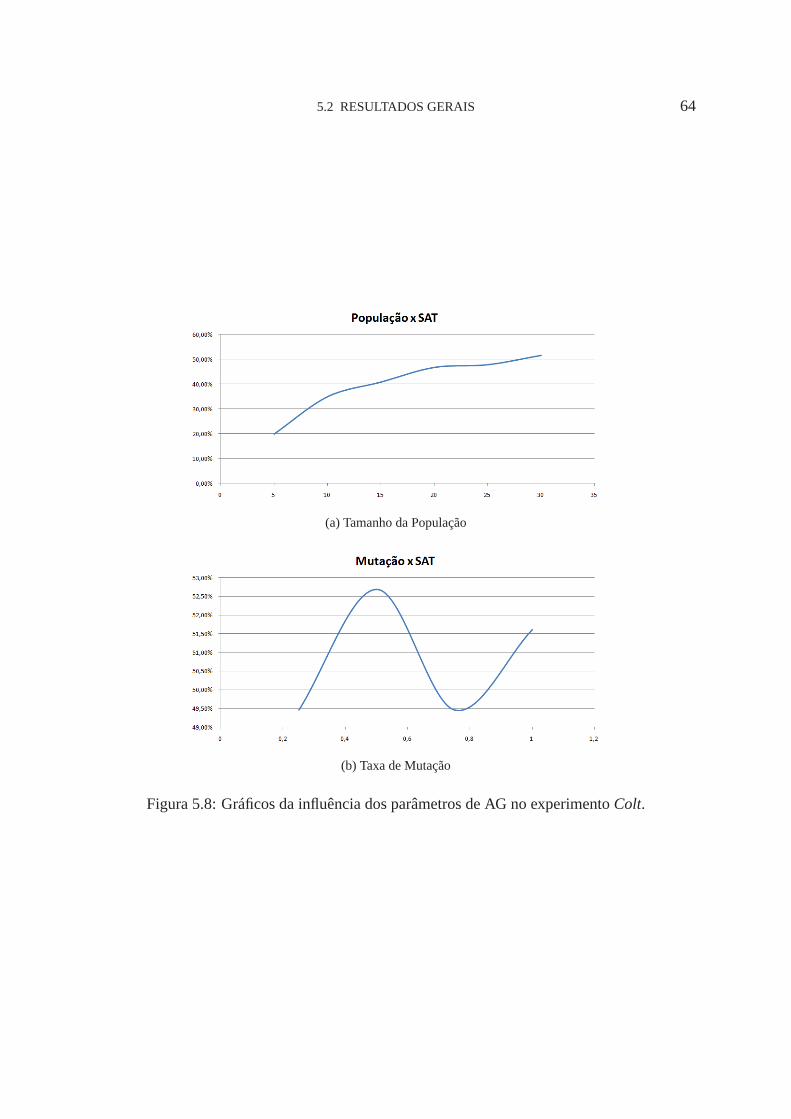
5.2 RESULTADOS GERAIS 64
(a) Tamanho da População
(b) Taxa de Mutação
Figura 5.8: Gráficos da influência dos parâmetros de AG no experimentoColt.

5.2 RESULTADOS GERAIS 65
(a) Tamanho da População
(b) Taxa de Mutação
Figura 5.9: Gráficos da influência dos parâmetros de AG no experimentoRatPoly.

5.3 DISCUSSÃO DOS RESULTADOS 66
menores permitem percorrer de forma refinada, com pequeno incrementos. Porém, em vastos
espaços de busca, um passo maior permite que o algoritmo o percorra rapidamente. A inércia,
conforme visto no capítulo 2, na equação (2.1), determina o quanto da velocidade anterior será
considerado na velocidade atual. Os resultados da influência destes parâmetros podem ser ob-
servados nas figuras 5.10 e 5.11. Como pode ser observado nas figuras, no experimentoColt,
não é necessária uma população grande e o incremento global deve ser pequeno, pois o espaço
de busca é relativamente pequeno, devido a baixa dimensionalidade. Já no experimentoHash-
Map, há um vasto espaço de busca, portanto, é necessário um número maior de partículas com
um alto valor do incremento global, para permitir que o espaço seja percorrido rapidamente.
5.3 Discussão dos Resultados
O uso de algoritmos de busca já é bem conhecido no contexto de problemas de resolução de
restrições e teste de software (Windisch et al.; 2007; Lin; 2005; Rossi et al.; 2000; Eiben e
van der Hauw; 1997). A utilização destes para resolução de restrições geradas a partir de
uma execução concólica foram propostas por Lakhotia et al. (2008), porém este utilizou um
algoritmo de busca incremental. Os resultados obtidos por outros autores não utilizavam heu-
rísticas de busca (Majumdar e Sen; 2007; Sen; 2007; Godefroid et al.; 2005; Visser et al.; 2004)
ou não utilizaram algoritmos evolutivos (Lakhotia et al.; 2008). Uma solução, proposta nesta
dissertação, para suprir a deficiência na execução concólica é criarsolversque utilizam busca
meta-heurística para resolver ospath conditionsgerados durante esta execução. Além de criar
uma arquitetura que permitiu realizar experimentações de forma rápida e possibilitou a intro-
dução de novossolversà mesma. Pasareanu et al. (2008) propõe uma arquitetura similar de
execução, utilizando a ferramentaJava Path Finder(JPF) para prover uma execução simbólica
e uma extensão que provê valores concretos. Se assemelha ao utilizar estruturas que represen-
tam os tipos baseados no formato dobyte codeJava, pois o instrumentador desenvolvido para
as experimentações utilizabyte codeJava.
Os efeitos de uma baixa dimensionalidade podem ser observados nos resultados deColt,
que apresenta um baixo número de literais (apenas um). Cada literal é mapeado como um eixo
do plano do espaço de busca, por exemplo: em uma restrição comdois literais, o espaço de
busca possui duas dimensões (x e y). A eficiência do algoritmo PSO é degradada com o au-

5.3 DISCUSSÃO DOS RESULTADOS 67
(a) Tamanho da População
(b) Incremento Global
(c) Inércia (ω)
Figura 5.10: Gráficos da influência dos parâmetros de PSO no experimentoColt.

5.3 DISCUSSÃO DOS RESULTADOS 68
(a) Tamanho da População
(b) Incremento Global
(c) Inércia (ω)
Figura 5.11: Gráficos da influência dos parâmetros de PSO no experimentoHashMap.

5.3 DISCUSSÃO DOS RESULTADOS 69
mento da dimensionalidade. Portanto, quanto maior o númerode literais do experimento, mais
degradado será o desempenho de PSO. Todos ossolversrandômicos são sensíveis ao aumento
da dimensionalidade. O aumento do tamanho das cláusulas também afeta o desempenho, porém
isto é causado pela implementação doframeworkde execução concólica, pois a capacidade de
transposição da forma de árvore semântica para a representação interna do problema não está
relacionada com o algoritmo de meta-heurística. Os algoritmos de busca são mais afetados
que o ranSOL, pois esta operação é realizada diversas vezes em cada iteração. O tamanho da
população determina o número de vezes que esta operação é realizada, conforme visto na seção
2.3.3.
Em experimentos que geram restrições lineares, excetoSwitch, o comportamento esperado
foi observado: osolversimbólico (symSOL) é o mais apropriado, pois este é capaz de resolver
todas as restrições satisfatíveis. No experimentoSwitch, symSOL também é o mais apropriado,
porém não foi possível obter o comportamento esperado. No segundo grupo de experimentos,
nenhumsolverpôde ser apontado como o mais apropriado. Cada um demonstrou ser capaz de
resolver as restrições geradas, dependendo da situação.
Na média, GCF obteve o melhor resultado, com a maior cobertura. BVF se mostrou como
a solução menos capaz de resolver restrições não-lineares.GA e seus híbridos (GCF+GA e
BCF+GA) não demonstraram resultados promissores. Isto pode ser explicado pelo alta com-
plexidade do seu algoritmo, em comparação com PSO. Seus operadores, comocross-overe
mutação, têm um custo computacional que o torna inapropriado para o teste simbólico, entre-
tanto, em outros contextos de resolução de restrições poderia ser aplicado. Apesar disto, um
algoritmo híbrido que combina GA e PSO poderia ser criado para produzir um novo algoritmo
mais capaz de percorrer o espaço de busca (Ru e Jianhua; 2008),visto que GA foi capaz de
resolver restrições que PSO não conseguiu em alguns dossoftwaresescolhidos na experimen-
tação. RanSOL apresentou uma boa capacidade de resolução de restrições, o que o torna útil
neste contexto. Seu baixo custo computacional permite percorrer vastos espaços de busca sem
exceder o tempo determinado.
Os resultados indicam quesolversrandômicos e híbridos são eficazes para resolver restri-
ções indecidíveis. Entretanto, não é possível determinar osolverque melhor se adapta a uma
aplicação específica, especialmente porque ossolversresolvem diferentes restrições. Os re-
sultados sugerem que o uso combinado ou alternado dossolversobtém melhor desempenho à
utilizar unicamente umsolver.

5.4 CONSIDERAÇÕES FINAIS 70
5.4 Considerações Finais
Os solucionadores de restrição híbridos apresentaram um bom desempenho em experimentos
não lineares, onde CVC3 (symSOL) não é capaz de resolver as restrições. Ossolversrandô-
micos também apresentaram um bom desempenho, apesar de relativamente pior. Na média, os
híbridos obtiveram a melhor cobertura e foram capazes de resolver 54% (GCF) das restrições
dos programas não lineares. Nos experimentos lineares, symSOL é osolvermais apropriado,
como já era esperado.
A complexidade do AG prejudicou o seu desempenho, pois, neste contexto de execução
concólica, o tempo de execução é essencial que seja baixo. PSO, com seu simples algoritmo,
foi capaz de obter resultados promissores. Ossolvershíbridos, por combinar as características
de symSOL com solucionadores randômicos, obtiveram bons resultados, sendo capazes de
obter resultados melhores que suas versões originais.
Experimentos comoHashMape Colt representam experimentos com uma alta e baixa di-
mensionalidade, respectivamente. Seus resultados demonstraram claramente que PSO é capaz
de resolver restrições em vastos espaços de busca, onde a dimensionalidade é alta. Nesta si-
tuação, ranSOL não é capaz de encontrar soluções, apesar do seu baixo custo computacional
permitir que este percorra rapidamente o espaço de busca. EmColt, devido sua dimensionali-
dade baixa (apenas um literal), PSO não foi capaz de obter um bom resultado, se comparado
à ranSOL – umsolverpuramente randômico. Isto indica que o custo de se utilizar uma meta-
heurística não se justifica em problemas que possuem um pequeno espaço de busca, soluções
mais simples podem obter melhores resultados.
Melhorias nos métodos de transposição da representação do problema para a árvore se-
mântica são visivelmente necessárias. Este custo computacional para a realização desta tarefa
prejudicou o desempenho do symSOL emSwitch, onde era esperado que este obtivesse 100%
de cobertura. Porém, a medida que otimeouté incrementado, este obtém seu comportamento
esperado.

CAPÍTULO 6
Conclusões
Foram apresentados soluções para o problema de geração de casos de teste, mais especifi-
camente através do uso de execução concólica. Foi apresentada a metodologia utilizada e a
arquitetura doframework. Foram escolhidos algoritmos evolutivos (AG e PSO) para a criação
desolverse uma representação do problema foi apresentada.
As contribuições, limitações e trabalhos futuros deste trabalhos serão apresentadas neste
capítulo, nas seções 6.1 e 6.2, respectivamente.
6.1 Contribuições
Foi desenvolvido umframeworkde execução concólica, o qual permite extrair ospath conditi-
onsde uma execução, além de uma biblioteca de tipos simbólicos.Para permitir a introdução
desta biblioteca em aplicações fechadas, foi utilizado uminstrumentador. Este instrumentador
foi criado com este intuito, introduzir a biblioteca de tipos simbólicos em uma aplicação. Além
disto, o instrumentador é uma ferramenta que possibilita reduzir o tempo de experimentação,
pois seu uso é automático. Porém, apesar de realizar esta tarefa de forma automática, a aplica-
ção deve ser auto-contida. Tornar uma aplicação em auto-contida significa remover qualquer
dependência de bibliotecas externas, ou seja, é necessárioa criação destubs. Para permitir a
execução concólica, é necessário também a criação de umdriver, o qual passa os dados de
entrada para o programa em teste. No capítulo 3, a figura 3.4 mostra um teste unitário com
seus principais componentes. Nesta figura é possível observar a utilização dodriver na execu-
ção de um teste. Entretanto, o instrumentador pode ser usado, independente dossolverse da
biblioteca simbólica, para outros fins, como extração de métricas (complexidade ciclomática,
por exemplo). A biblioteca simbólica também pode ser utilizada independente deste projeto.
Solversde restrição baseado em algoritmos de meta-heurística de busca foram criados,
mais especificamente algoritmo genético (AG) e otimização por enxame de partículas (PSO).
71

6.2 LIMITAÇÕES E TRABALHOS FUTUROS 72
Eles foram desenvolvidos e integrados aoframeworkde execução concólica. A criação desta
arquitetura permite que novossolverssejam integrados à mesma sem que haja retrabalho.
Através da utilização destes novossolversfoi possível percorrer caminhos que não eram sa-
tisfeitos pelas técnicas de vários autores: Majumdar e Sen (2007); Sen (2007); Godefroid et al.
(2005). Foi provado que o uso de meta-heurísticas de busca é capaz de introduzir melhorias
nas técnicas já utilizadas.
Os resultados parciais desta dissertação foram apresentados na conferência1st NASA For-
mal Methods Symposium(Takaki et al.; 2009) e a versão estendida deste artigo está sendo
submetida para publicação no journalInnovations in Systems and Software Engineering: A
NASA Journal.
6.2 Limitações e Trabalhos Futuros
Foi observado que o método de transposição da árvore semântica das restrições para a forma
utilizada para representar os dados nos algoritmos de busca, possui um custo computacional
relativamente alto. Este alto custo computacional acarretou em comportamentos não esperados,
como pôde ser observado nos resultados do experimentoSwitch. O solversimbólico deveria
ser capaz de resolver todas as restrições, porém este necessitou de um aumento notimeoutpara
que seu comportamento esperado pudesse ser observado.
Apenas um experimento que utiliza variáveis ponto flutuantefoi escolhido. Não foi possível
encontrar resultados determinantes para este domínio. A escolha de outros experimentos neste
domínio seriam importantes para observar o comportamento dossolverse confirmar os resul-
tados obtidos nesta pesquisa. Experimentos mais complexossão necessários para determinar
a aplicabilidade desta técnica em situações reais. O experimentoColt, que foi instrumentado
automaticamente através do instrumentador, é uma estrutura simples e foi utilizada em um
ambiente controlado, através de um simplesdriver que monta as estruturas internas do mesmo.
Outros algoritmos de busca podem ser utilizados juntamentecom a arquitetura criada, pois
com o uso desta arquitetura é possível introduzir novossolversfacilmente. O algoritmoµPSO,
proposto por Parsopoulos (2009), não foi utilizado. Neste contexto em que os intervalos de
tempo são reduzidos, um algoritmo que atinja uma rápida convergência, à um custo computa-
cional reduzido, pode obter resultados melhores que os apresentados neste trabalho.

6.2 LIMITAÇÕES E TRABALHOS FUTUROS 73
Não foi realizada uma análise dos efeitos do uso de diferentes topologias no algoritmo PSO.
Diferentes topologias podem acarretar em diferentes convergências. A partir desta análise, será
possível determinar a melhor topologia para este contexto de resolução de restrições de teste
de software. Melhores resultados podem ser encontrados como uso de diferentes topologias.
Um estudo preliminar com os diferentes parâmetros dos algoritmos AG e PSO foi realizado
e foram escolhidos empiricamente. Entretanto, uma análisemais detalhada pode determinar,
ou confirmar, os parâmetros utilizados no presente trabalho.
Os resultados indicam que é possível e interessante o desenvolvimento de um algoritmo hí-
brido, que utiliza AG e PSO, corroborando com a solução proposta por Ru e Jianhua (2008). O
solverbaseado em algoritmo genético, apesar de ter obtido piores resultados, foi capaz de en-
contrar soluções que PSO não foi capaz. O uso deste algoritmohíbrido poderá trazer resultados
que combine comportamento de ambos ossolvers.
O frameworkde execução concólica desenvolvido suporta apenas tipos primitivos de Java,
como inteiros, ponto flutuante, entre outros. O desenvolvimento de uma extensão no suporte
de tipos, para tipos complexos, poderá prover um maior impacto na geração automática de
testes. O instrumentador desenvolvido possui limitações na capacidade de substituir instruções
originais de Java, como instruções nativas. Além da necessidade de modificar os experimentos
para que sejam autocontidos, o que limita o uso do instrumentador. Kiezun et al. (2009) propõe
uma solução baseada nesta arquitetura:frameworkde execução concólica com umsolverpara
resolver as restrições. Porém, este utiliza para resolver este problema de usar apenas tipos
primitivos. Kiezun et al. (2009) apresenta uma ferramenta chamadaHampi, um solver para
restrições de strings. Esta ferramenta é de grande importância no teste desoftwarepois existem
poucas capazes de resolver restrições de strings e é utilizada, inclusive, para testar casos de
vunerabilidade deSQL injection. Ihantola (2006) utiliza a ferramentaJava Path Finder(JPF)
de execução simbólica para a geração de dados utilizandolazy initialization, o que permite
criar dados complexos como objetos. A arquitetura propostano presente trabalho necessita
executar osoftwarede acordo com odriver do teste, entretanto, Pasareanu et al. (2008) utiliza
um frameworkcapaz de executar um programa a partir de qualquer ponto.

6.3 CONSIDERAÇÕES FINAIS 74
6.3 Considerações Finais
O presente trabalho apresentou bons resultados na aplicação de algoritmos de busca meta-
heurística no contexto de resolução de restrições extraídas de uma execução concólica. Os
resultados já conhecidos pela comunidade utilizam técnicas de randomização sem heurística,
porém com resultados promissores. Um estudo mais detalhadona escolha dos parâmetros dos
algoritmos e o uso de diferentes topologias poderá produzirnovos resultados corroborando com
as conclusões obtidas neste trabalho. Uma análise comparativa com outros algoritmos de busca
pode obter melhores resultados, como o uso do algoritmoµPSO (Parsopoulos; 2009).
Os algoritmos de busca escolhidos obtiveram bons resultados, se comparados aosolver
puramente randômico. Na criação desolvershíbridos, PSO não obteve o melhor resultado na
média, porém foi capaz de se destacar em diversos experimentos. Estes resultados podem ser
explicados pelo baixo custo computacional das operações decaminhamento no espaço de busca
do algoritmo, comparado ao AG, que não obteve um bom resultado.
A presente pesquisa obteve resultados e pontos de melhoriasque poderão ser estendidos e
implementados, podendo obter resultados mais promissores. O frameworkdesenvolvido para
permitir as experimentações poderá ser utilizado independente do uso dossolversdesenvolvi-
dos nesta pesquisa. Além de poder ser utilizado para outros fins, como extração de métricas de
softwares.

APÊNDICE A
Gráficos
Figura A.1: Cobertura dossolversutilizando gráfico de barras empilhadas no experimentoBST.
75

APÊNDICE A GRÁFICOS 76
(a) FileSystem
(b) TreeMap
Figura A.2: Cobertura dossolversutilizando gráfico de barras empilhadas nos experimentos
FileSystemeTreeMap.

APÊNDICE A GRÁFICOS 77
(a) RatPoly
(b) RationalScalar
Figura A.3: Cobertura dossolversutilizando gráfico de barras empilhadas nos experimentos
RatPolyeRationalScalar.

APÊNDICE A GRÁFICOS 78
(a) Newton
(b) HashMap
Figura A.4: Cobertura dossolversutilizando gráfico de barras empilhadas nos experimentos
NewtoneHashMap.

APÊNDICE B
Tabelas
79

AP
ÊN
DIC
EB
TAB
ELA
S80
BST
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 1 0 0 0 0 0 0 0 0 0
AG 0 - 0 0 0 0 0 0 0 0 0
PSO 1.3 2.3 - 0 0 0 0 0 0 0 0
CVC3 196 197 194.7 - 0 0 0 0 0 0 0
GCF 196 197 194.7 0 - 0 0 0 0 0 0
BCF 196 197 194.7 0 0 - 0 0 0 0 0
BVF 196 197 194.7 0 0 0 - 0 0 0 0
GCF+AG 196 197 194.7 0 0 0 - 0 0 0
BCF+AG 196 197 194.7 0 0 0 0 0 - 0 0
GCF+PSO 196 197 194.7 0 0 0 0 0 0 - 0
BCF+PSO 196 197 194.7 0 0 0 0 0 0 0 -
Summary: 199 SAT, 508 UNK.
ranSOL:3, AG:2, PSO:4.3, CVC3:199, GCF:199, BCF:199
BVF:199, GCF+AG:199, BCF+AG:199, GCF+PSO:199, BCF+PSO:199
Tabela B.1: Resultados dossolversno experimentoBST. Cada célula representa o número médio de restrições resolvida pelosolver
(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S81
FileSystem
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 12 0 0 0 0 0 0 0 0 0
AG 0 - 0 0 0 0 0 0 0 0 0
PSO 0 12 - 0 0 0 0 0 0 0 0
CVC3 186.8 198.8 186.8 - 0.2 0.2 0 0 0 0.2 0
GCF 186.8 198.8 186.8 0.2 - 0 0 0.2 0 0 0
BCF 186.8 198.8 186.8 0.2 0 - 0 0.2 0 0 0
BVF 187 199 187 0.2 0.2 0.2 - 0.2 0 0.2 0
GCF+AG 186.8 198.8 186.8 0 0.2 0.2 - 0 0.2 0
BCF+AG 187 199 187 0.2 0.2 0.2 0 0.2 - 0.2 0
GCF+PSO 186.8 198.8 186.8 0.2 0 0 0 0.2 0 - 0
BCF+PSO 187 199 187 0.2 0.2 0.2 0 0.2 0 0.2 -
Summary: 199 SAT, 407 UNK.
ranSOL:12, AG:0, PSO:12, CVC3:198.8, GCF:198.8, BCF:198.8
BVF:199, GCF+AG:198.8, BCF+AG:199, GCF+PSO:198.8, BCF+PSO:199
Tabela B.2: Resultados dossolversno experimentoFileSystem. Cada célula representa o número médio de restrições resolvida pelo
solver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S82
TreeMap
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 1.2 0.2 0 0 0 0 0 0 0 0
AG 0 - 0 0 0 0 0 0 0 0 0
PSO 0 1 - 0 0 0 0 0 0 0 0
CVC3 137 138.2 137.2 - 0 0 0 0 0 0 0
GCF 137 138.2 137.2 0 - 0 0 0 0 0 0
BCF 137 138.2 137.2 0 0 - 0 0 0 0 0
BVF 137 138.2 137.2 0 0 0 - 0 0 0 0
GCF+AG 137 138.2 137.2 0 0 0 - 0 0 0
BCF+AG 137 138.2 137.2 0 0 0 0 0 - 0 0
GCF+PSO 137 138.2 137.2 0 0 0 0 0 0 - 0
BCF+PSO 137 138.2 137.2 0 0 0 0 0 0 0 -
Summary: 140 SAT, 1070 UNK.
ranSOL:3, AG:1.8, PSO:2.8, CVC3:140, GCF:140, BCF:140
BVF:140, GCF+AG:140, BCF+AG:140, GCF+PSO:140, BCF+PSO:140
Tabela B.3: Resultados dossolversno experimentoTreeMap. Cada célula representa o número médio de restrições resolvida pelo
solver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S83
Switch
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 96.4 27 0.4 0.1 0.5 0.3 89.9 0.7 90.5 0.5
AG 0 - 0 0 0 0 0 0 0 0 0
PSO 0 69.4 - 0.1 0 0.1 0 66.6 0.2 67.6 0.3
CVC3 101.9 197.9 128.6 - 0.5 0.7 0.6 182.9 0.7 183.8 1.1
GCF 102.2 198.5 129.1 1.1 - 0.7 0.8 183.2 1.1 184 1.2
BCF 102.2 198.1 128.8 0.9 0.3 - 0.5 183.1 0.8 184 1.2
BVF 102.1 198.2 128.8 0.9 0.5 0.6 - 183 0.8 183.8 1.2
GCF+AG 9.3 15.8 13 0.8 0.5 0.8 - 0.7 5.6 1.1
BCF+AG 102.2 197.9 128.7 0.7 0.5 0.6 0.5 182.8 - 183.9 1
GCF+PSO 8.8 14.7 12.9 0.6 0.2 0.6 0.3 4.5 0.7 - 0.8
BCF+PSO 101.8 197.7 128.6 0.9 0.4 0.8 0.7 183 0.8 183.8 -
Summary: 199 SAT, 367 UNK.
ranSOL:96.4, AG:0, PSO:69.4, CVC3:197.9, GCF:198.5, BCF:198.1
BVF:198.2, GCF+AG:15.8, BCF+AG:197.9, GCF+PSO:14.7, BCF+PSO:197.7
Tabela B.4: Resultados dossolversno experimentoSwitch. Cada célula representa o número médio de restrições resolvida pelosolver
(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S84
RatPoly
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 22.1 3.6 16.4 6 9.1 12.6 6 15.9 6 10.9
AG 0 - 0.1 2.3 1.8 0.7 1.1 1.8 1.8 1.8 1.1
PSO 0 18.6 - 12.8 5.8 6.5 9.5 5.8 12.3 5.8 7.4
CVC3 11 19 11 - 0 0 0 0 0 0 0
GCF 158.6 176.5 162 158 - 137.6 147.1 0 157.5 0 153
BCF 40.6 54.3 41.6 36.9 16.5 - 21 16.5 32.6 16.5 20.3
BVF 23.1 33.7 23.6 15.9 5 0 - 5 14.5 5 10.6
GCF+AG 158.6 176.5 162 158 0 137.6 - 157.5 0 153
BCF+AG 18.4 26.4 18.4 7.9 7.4 3.6 6.5 7.4 - 7.4 4.5
GCF+PSO 158.6 176.5 162 158 0 137.6 147.1 0 157.5 - 153
BCF+PSO 26 38.3 26.1 20.5 15.5 3.9 15.2 15.5 17.1 15.5 -
Summary: 207 SAT, 1403 UNK.
ranSOL:24.7, AG:2.3, PSO:20.8, CVC3:19, GCF:177, BCF:56.2
BVF:35.9, GCF+AG:177, BCF+AG:26.8, GCF+PSO:177, BCF+PSO:39.8
Tabela B.5: Resultados dossolversno experimentoRatPoly. Cada célula representa o número médio de restrições resolvida pelo
solver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S85
RationalScalar
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 21.8 6.7 20.1 16.1 13.6 17.1 20.1 20.1 16.1 16.9
AG 0.2 - 0.2 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5
PSO 3.1 18.2 - 16.5 9.5 13.3 13.5 16.5 16.5 9.5 11.3
CVC3 0 2 0 - 0 0 0 0 0 0 0
GCF 15.4 21.4 12.4 19.4 - 19.4 19.4 10.4 19.4 3.4 17.4
BCF 0.5 9 3.8 7 7 - 4 7 7 7 3.8
BVF 0 5 0 3 3 0 - 3 3 3 0
GCF+AG 9 11 9 9 0 9 - 9 0 9
BCF+AG 0 2 0 0 0 0 0 0 - 0 0
GCF+PSO 19 25 16 23 7 23 23 14 23 - 21
BCF+PSO 2 7.2 0 5.2 3.2 2 2.2 5.2 5.2 3.2 -
Summary: 50 SAT, 225 UNK.
ranSOL:22.1, AG:0.5, PSO:18.5, CVC3:2, GCF:21.4, BCF:9
BVF:5, GCF+AG:11, BCF+AG:2, GCF+PSO:25, BCF+PSO:7.2
Tabela B.6: Resultados dossolversno experimentoRationalScalar. Cada célula representa o número médio de restrições resolvida
pelosolver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S86
Newton
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 4.2 1.2 5.2 2 3.2 5.2 4.2 5.2 3.2 4
AG 0 - 0 1 0 0.4 1 0 1 0 0.4
PSO 0 3 - 4 2 2.8 4 3 4 2 2.8
CVC3 0 0 0 - 0 0 0 0 0 0 0
GCF 0.2 2.4 1.4 3.4 - 1.2 3.4 2.4 3.4 1.4 2.2
BCF 0.2 1.6 1 2.2 0 - 2.2 1.6 2.2 1 1
BVF 0 0 0 0 0 0 - 0 0 0 0
GCF+AG 0 0 0 1 0 0.4 - 1 0 0.4
BCF+AG 0 0 0 0 0 0 0 0 - 0 0
GCF+PSO 0 1 0 2 0 0.8 2 1 2 - 0.8
BCF+PSO 0 0.6 0 1.2 0 0 1.2 0.6 1.2 0 -
Summary: 7 SAT, 80 UNK.
ranSOL:5.2, AG:1, PSO:4, CVC3:0, GCF:3.4, BCF:2.2
BVF:0, GCF+AG:1, BCF+AG:0, GCF+PSO:2, BCF+PSO:1.2
Tabela B.7: Resultados dossolversno experimentoNewton. Cada célula representa o número médio de restrições resolvida pelo
solver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

AP
ÊN
DIC
EB
TAB
ELA
S87
HashMap
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 1 0 1 0 0 1 1 1 0 0
AG 0 - 0 0 0 0 0 0 0 0 0
PSO 26.8 27.8 - 27.8 26.8 26.8 27.8 27.8 27.8 3.7 3.5
CVC3 0 0 0 - 0 0 0 0 0 0 0
GCF 0 1 0 1 - 0 1 1 1 0 0
BCF 0 1 0 1 0 - 1 1 1 0 0
BVF 0 0 0 0 0 0 - 0 0 0 0
GCF+AG 0 0 0 0 0 0 - 0 0 0
BCF+AG 0 0 0 0 0 0 0 0 - 0 0
GCF+PSO 27.3 28.3 4.2 28.3 27.3 27.3 28.3 28.3 28.3 - 3.1
BCF+PSO 27.7 28.7 4.4 28.7 27.7 27.7 28.7 28.7 28.7 3.5 -
Summary: 44 SAT, 1281 UNK.
ranSOL:1, AG:0, PSO:27.8, CVC3:0, GCF:1, GCF:1
BVF:0, GCF+AG:0, BCF+AG:0, GCF+PSO:28.3, BCF+PSO:28.7
Tabela B.8: Resultados dossolversno experimentoHashMap. Cada célula representa o número médio de restrições resolvida pelo
solver(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.
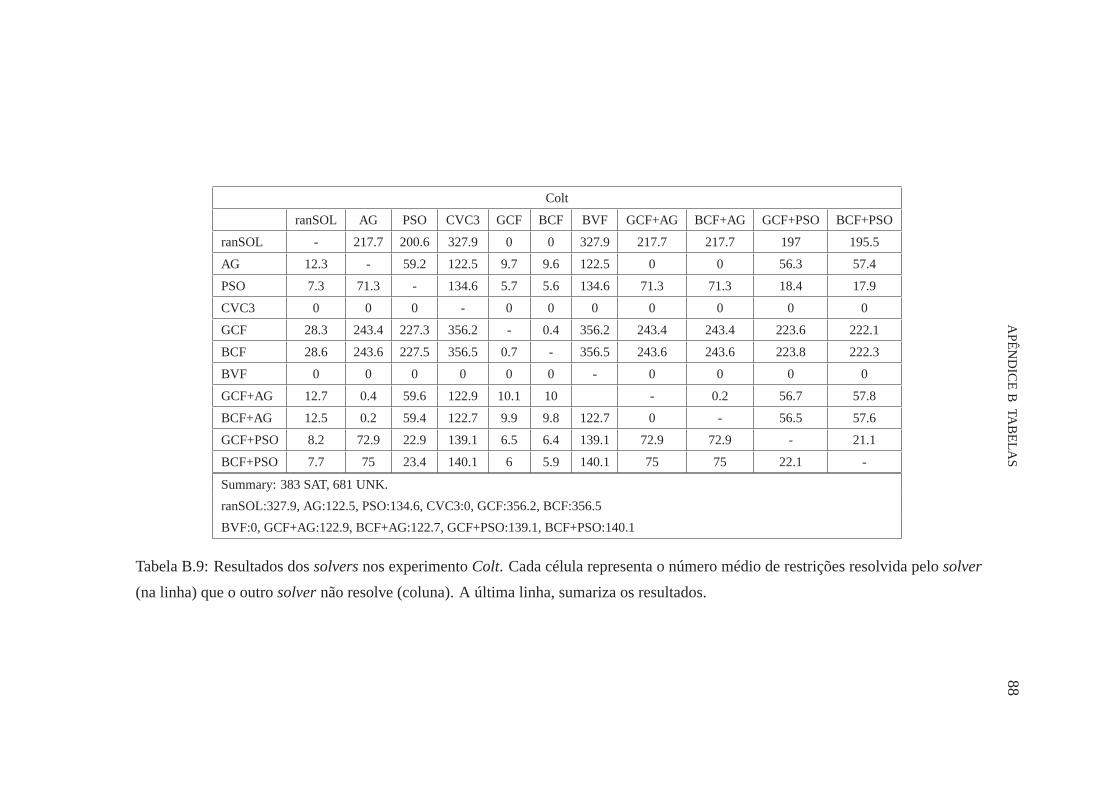
AP
ÊN
DIC
EB
TAB
ELA
S88
Colt
ranSOL AG PSO CVC3 GCF BCF BVF GCF+AG BCF+AG GCF+PSO BCF+PSO
ranSOL - 217.7 200.6 327.9 0 0 327.9 217.7 217.7 197 195.5
AG 12.3 - 59.2 122.5 9.7 9.6 122.5 0 0 56.3 57.4
PSO 7.3 71.3 - 134.6 5.7 5.6 134.6 71.3 71.3 18.4 17.9
CVC3 0 0 0 - 0 0 0 0 0 0 0
GCF 28.3 243.4 227.3 356.2 - 0.4 356.2 243.4 243.4 223.6 222.1
BCF 28.6 243.6 227.5 356.5 0.7 - 356.5 243.6 243.6 223.8 222.3
BVF 0 0 0 0 0 0 - 0 0 0 0
GCF+AG 12.7 0.4 59.6 122.9 10.1 10 - 0.2 56.7 57.8
BCF+AG 12.5 0.2 59.4 122.7 9.9 9.8 122.7 0 - 56.5 57.6
GCF+PSO 8.2 72.9 22.9 139.1 6.5 6.4 139.1 72.9 72.9 - 21.1
BCF+PSO 7.7 75 23.4 140.1 6 5.9 140.1 75 75 22.1 -
Summary: 383 SAT, 681 UNK.
ranSOL:327.9, AG:122.5, PSO:134.6, CVC3:0, GCF:356.2, BCF:356.5
BVF:0, GCF+AG:122.9, BCF+AG:122.7, GCF+PSO:139.1, BCF+PSO:140.1
Tabela B.9: Resultados dossolversnos experimentoColt. Cada célula representa o número médio de restrições resolvida pelosolver
(na linha) que o outrosolvernão resolve (coluna). A última linha, sumariza os resultados.

APÊNDICE C
Códigos Fonte
Código Fonte C.1: HashMap Original
1 / *
2 * @( # ) HashMap . j ava 1 .59 04 /12 /09
3 *
4 * Copy r i gh t 2005 Sun Microsys tems , Inc . A l l r i g h t s r e s e r v e d .
5 * SUN PROPRIETARY / CONFIDENTIAL . Use i s s u b j e c t t o l i c e n s e terms .
6 * /
7
8 package benchmark . hashmap . simp ;
9
10
11
12 pub l i c c l a s s HashMap {
13 s t a t i c i n t DEFAULT_INITIAL_CAPACITY = 3 ;
14 s t a t i c i n t MAXIMUM_CAPACITY = 1 << 30 ;
15 s t a t i c f l o a t DEFAULT_LOAD_FACTOR = 0.75 f ;
16
17 Ent ry [ ] t a b l e ;
18 i n t s i z e = 0 ;
19 i n t t h r e s h o l d ;
20 f l o a t l o a d F a c t o r ;
21 i n t modCount = 0 ;
22
23 pub l i c HashMap ( ) {
24 t h i s . l o a d F a c t o r = DEFAULT_LOAD_FACTOR;
25 t h r e s h o l d = (i n t ) ( DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR) ;
26 t a b l e = new Ent ry [ DEFAULT_INITIAL_CAPACITY ] ;
27 i n i t ( ) ;
28 }
29
30 void i n i t ( ) {
89

APÊNDICE C CÓDIGOS FONTE 90
31 }
32
33 s t a t i c Objec t NULL_KEY = new Objec t ( ) ;
34
35 s t a t i c Objec t maskNul l ( Ob jec t key ) {
36 re turn ( key == n u l l ? NULL_KEY : key ) ;
37 }
38
39 s t a t i c Objec t unmaskNul l ( Ob jec t key ) {
40 re turn ( key == NULL_KEY ? n u l l : key ) ;
41 }
42
43 s t a t i c i n t hash ( Ob jec t x ) {
44 i f ( ! ( x i n s t a n c e o f I n t e g e r ) ) {
45 throw new Runt imeExcept ion ("Unsupported type." ) ;
46 }
47
48 i n t h = ( ( I n t e g e r ) x ) . hashCode_ ( ) ;
49 h += ~( h << 9) ;
50 h ^= ( h >>> 14) ;
51 h += ( h << 4) ;
52 h ^= ( h >>> 10) ;
53 re turn h ;
54 }
55
56 s t a t i c boolean eq ( Ob jec t x , Ob jec t y ) {
57 re turn x == y | | x . e q u a l s ( y ) ;
58 }
59
60 s t a t i c i n t i ndexFor (i n t h , i n t l e n g t h ) {
61 re turn h & ( l eng th−1) ;
62 }
63
64 pub l i c Objec t g e t ( Ob jec t key ) {
65 Objec t k = maskNul l ( key ) ;
66 i n t hash = hash ( k ) ;
67 i n t i = i ndexFor ( hash , t a b l e . l e n g t h ) ;
68 Ent ry e = t a b l e [ i ] ;
69 whi le ( t rue ) {

APÊNDICE C CÓDIGOS FONTE 91
70 i f ( e == n u l l )
71 re turn e ;
72 i f ( e . hash == hash && eq ( k , e . key ) )
73 re turn e . va l ue ;
74 e = e . nex t ;
75 }
76 }
77
78 pub l i c Objec t pu t ( Ob jec t key , Ob jec t va l ue ) {
79 Objec t k = maskNul l ( key ) ;
80 i n t hash = hash ( k ) ;
81 i n t i = i ndexFor ( hash , t a b l e . l e n g t h ) ;
82
83 f o r ( En t r y e = t a b l e [ i ] ; e != n u l l ; e = e . nex t ) {
84 i f ( e . hash == hash && eq ( k , e . key ) ) {
85 Objec t o ldVa lue = e . va l ue ;
86 e . va l ue = va l ue ;
87 e . r eco r dAcces s (t h i s ) ;
88 re turn o ldVa lue ;
89 }
90 }
91
92 modCount ++;
93 addEnt ry ( hash , k , va lue , i ) ;
94 re turn n u l l ;
95 }
96
97 void r e s i z e (i n t newCapac i ty ) {
98 Ent ry [ ] o l dTab le = t a b l e ;
99 i n t o l d C a p a c i t y = o ldTab le . l e n g t h ;
100 i f ( o l d C a p a c i t y == MAXIMUM_CAPACITY) {
101 t h r e s h o l d = I n t e g e r .MAX_VALUE;
102 re turn ;
103 }
104
105 Ent ry [ ] newTable = new Ent ry [ newCapac i ty ] ;
106 t r a n s f e r ( newTable ) ;
107 t a b l e = newTable ;
108 t h r e s h o l d = (i n t ) ( newCapac i ty * l o a d F a c t o r ) ;

APÊNDICE C CÓDIGOS FONTE 92
109 }
110
111 void t r a n s f e r ( En t ry [ ] newTable ) {
112 Ent ry [ ] s r c = t a b l e ;
113 i n t newCapac i ty = newTable . l e n g t h ;
114 f o r ( i n t j = 0 ; j < s r c . l e n g t h ; j ++) {
115 Ent ry e = s r c [ j ] ;
116 i f ( e != n u l l ) {
117 s r c [ j ] = n u l l ;
118 do {
119 Ent ry nex t = e . nex t ;
120 i n t i = i ndexFor ( e . hash , newCapac i ty ) ;
121 e . nex t = newTable [ i ] ;
122 newTable [ i ] = e ;
123 e = nex t ;
124 } whi le ( e != n u l l ) ;
125 }
126 }
127 }
128
129 pub l i c Objec t remove ( Ob jec t key ) {
130 Ent ry e = removeEntryForKey ( key ) ;
131 re turn ( e == n u l l ? e : e . va l ue ) ;
132 }
133
134 Ent ry removeEntryForKey ( Ob jec t key ) {
135 Objec t k = maskNul l ( key ) ;
136 i n t hash = hash ( k ) ;
137 i n t i = i ndexFor ( hash , t a b l e . l e n g t h ) ;
138 Ent ry prev = t a b l e [ i ] ;
139 Ent ry e = prev ;
140
141 whi le ( e != n u l l ) {
142 Ent ry nex t = e . nex t ;
143 i f ( e . hash == hash && eq ( k , e . key ) ) {
144 modCount ++;
145 s i z e−−;
146 i f ( p rev == e )
147 t a b l e [ i ] = nex t ;

APÊNDICE C CÓDIGOS FONTE 93
148 e l s e
149 prev . nex t = nex t ;
150 e . recordRemoval (t h i s ) ;
151 re turn e ;
152 }
153 prev = e ;
154 e = nex t ;
155 }
156
157 re turn e ;
158 }
159
160 s t a t i c c l a s s Ent ry {
161 Objec t key ;
162 Objec t va l ue ;
163 i n t hash ;
164 Ent ry nex t ;
165
166 Ent ry ( i n t h , Ob jec t k , Ob jec t v , En t r y n ) {
167 va l ue = v ;
168 nex t = n ;
169 key = k ;
170 hash = h ;
171 }
172
173 void r eco r dAcces s ( HashMap m) {
174 }
175
176 void recordRemoval ( HashMap m) {
177 }
178 }
179
180 void addEnt ry (i n t hash , Ob jec t key , Ob jec t va lue ,i n t bucke t I ndex ) {
181 t a b l e [ bucke t I ndex ] =new Ent ry ( hash , key , va lue , t a b l e [ bucke t I ndex ] ) ;
182
183 i f ( s i z e ++ >= t h r e s h o l d )
184 r e s i z e (2 * t a b l e . l e n g t h ) ;
185 }
186 }

APÊNDICE C CÓDIGOS FONTE 94
Código Fonte C.2: HashMap Instrumentado
1 / *
2 *
3 * Copy r i gh t 2005 Sun Microsys tems , Inc . A l l r i g h t s r e s e r v e d .
4 * SUN PROPRIETARY / CONFIDENTIAL . Use i s s u b j e c t t o l i c e n s e terms .
5 * /
6
7 package benchmark . hashmap . i n s t r u m e n t e d ;
8
9 pub l i c c l a s s HashMap {
10 s t a t i c f i n a l SymInt DEFAULT_INITIAL_CAPACITY = c o n c o l i c . l i b . U t i l
11 . c r e a t e C o n s t a n t (3/ * 16 * / ) ;
12 s t a t i c f i n a l SymInt MAXIMUM_CAPACITY = c o n c o l i c . l i b . U t i l
13 . a r i t h m e t i c S h i f t L e f t ( c o n c o l i c . l i b . U t i l . c r e a t e C o n s t an t ( 1 ) ,
14 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( 3 0 ) ) ;
15 s t a t i c f i n a l SymFloat DEFAULT_LOAD_FACTOR = c o n c o l i c . l i b . U t i l
16 . c r e a t e C o n s t a n t ( 0 . 7 5 f ) ;
17
18 t r a n s i e n t Ent ry [ ] t a b l e ;
19
20 t r a n s i e n t SymInt s i z e = c o n c o l i c . l i b . U t i l .ZERO;
21
22 SymInt t h r e s h o l d = c o n c o l i c . l i b . U t i l .ZERO;
23
24 f i n a l SymFloat l o a d F a c t o r ;
25
26 t r a n s i e n t v o l a t i l e SymInt modCount = c o n c o l i c . l i b . U t i l . ZERO;
27
28 pub l i c HashMap ( ) {
29 t h i s . l o a d F a c t o r = DEFAULT_LOAD_FACTOR;
30 t h r e s h o l d = c o n c o l i c . l i b . U t i l
31 . c r e a t e C o n s t a n t (
32 ( i n t ) c o n c o l i c . l i b . U t i l . mul (
33 DEFAULT_LOAD_FACTOR,
34 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t (
35 ( f l o a t ) DEFAULT_INITIAL_CAPACITY . e v a l ( ) ) ) . e v a l ( ) ) ;
36 t a b l e = new Ent ry [ DEFAULT_INITIAL_CAPACITY . e v a l ( ) ] ;
37 i n i t ( ) ;
38 }

APÊNDICE C CÓDIGOS FONTE 95
39
40 void i n i t ( ) {
41 }
42
43 s t a t i c f i n a l I n t e g e r NULL_KEY = new I n t e g e r ( c o n c o l i c . l i b . U t i l . ZERO) ;
44
45 s t a t i c I n t e g e r maskNul l ( I n t e g e r key ) {
46 re turn key ;
47 }
48
49 s t a t i c SymInt hash ( I n t e g e r x ) {
50 SymInt h = x . hashCode_ ( ) ;
51 h = c o n c o l i c . l i b . U t i l . add ( h , c o n c o l i c . l i b . U t i l . cmp ( c o nc o l i c . l i b . U t i l
52 . a r i t h m e t i c S h i f t L e f t ( h , c o n c o l i c . l i b . U t i l . c r e a t e C o n st a n t ( 9 ) ) ) ) ;
53 h = c o n c o l i c . l i b . U t i l . xor ( h , c o n c o l i c . l i b . U t i l . l o g i c a lS h i f t R i g h t ( h ,
54 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( 1 4 ) ) ) ;
55 h = c o n c o l i c . l i b . U t i l . add ( h , c o n c o l i c . l i b . U t i l . a r i t h m et i c S h i f t L e f t ( h ,
56 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( 4 ) ) ) ;
57 h = c o n c o l i c . l i b . U t i l . xor ( h , c o n c o l i c . l i b . U t i l . a r i t h m et i c S h i f t R i g h t ( h ,
58 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( 1 0 ) ) ) ;
59 re turn h ;
60 }
61
62 s t a t i c SymBool eq ( I n t e g e r x , I n t e g e r y ) {
63 re turn c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( x == y
64 | | x . e q u a l s _ ( y ) . eva lBoo l ( ) ) ;
65 }
66
67 s t a t i c SymInt i ndexFor ( SymInt h , SymInt l e n g t h ) {
68 re turn c o n c o l i c . l i b . U t i l . and ( h , ( c o n c o l i c . l i b . U t i l . sub ( l ength ,
69 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( 1 ) ) ) ) ;
70 }
71
72 pub l i c Objec t pu t ( I n t e g e r key , Ob jec t va l ue ) {
73 I n t e g e r k = maskNul l ( key ) ;
74 SymInt hash = hash ( k ) ;
75 SymInt i = indexFor ( hash , c o n c o l i c . l i b . U t i l
76 . c r e a t e C o n s t a n t ( t a b l e . l e n g t h ) ) ;
77

APÊNDICE C CÓDIGOS FONTE 96
78 i n t s t o p = 0 ;
79 f o r ( En t r y e = t a b l e [ i . e v a l ( ) ] ; e != n u l l ; e = e . nex t ) {
80 i f ( s t o p ++ > ConcolicDemo . LOOP_UNFOLDING_LIMIT ) {
81 throw new TooLongPathExcept ion ( ) ;
82 }
83
84 i f ( U t i l . choose ( c o n c o l i c . l i b . U t i l . and ( c o n c o l i c . l i b . U t il . eq ( e . hash ,
85 hash ) , eq ( k , e . key ) ) ) ) {
86 Objec t o ldVa lue = e . va l ue ;
87 e . va l ue = va l ue ;
88 e . r eco r dAcces s (t h i s ) ;
89 re turn o ldVa lue ;
90 }
91 }
92 modCount = c o n c o l i c . l i b . U t i l . add ( modCount , c o n c o l i c . l ib . U t i l .ONE) ;
93 addEnt ry ( hash , k , va lue , i ) ;
94 re turn n u l l ;
95 }
96
97 void r e s i z e ( SymInt newCapac i ty ) {
98 Ent ry [ ] o l dTab le = t a b l e ;
99 SymInt o l d C a p a c i t y = c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t (o l dTab le . l e n g t h ) ;
100 i f ( U t i l . choose ( c o n c o l i c . l i b . U t i l . eq ( o ldCapac i t y , MAXIMUM_CAPACITY) ) ) {
101 t h r e s h o l d = I n t e g e r .MAX_VALUE;
102 re turn ;
103 }
104 Ent ry [ ] newTable = new Ent ry [ newCapac i ty . e v a l ( ) ] ;
105 t r a n s f e r ( newTable ) ;
106 t a b l e = newTable ;
107 t h r e s h o l d = c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( (i n t ) c o n c o l i c . l i b . U t i l
108 . mul (
109 l o a d F a c t o r ,
110 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( (f l o a t ) newCapac i ty
111 . e v a l ( ) ) ) . e v a l ( ) ) ;
112 }
113
114 void t r a n s f e r ( En t ry [ ] newTable ) {
115 Ent ry [ ] s r c = t a b l e ;
116 SymInt newCapac i ty = c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t (newTable . l e n g t h ) ;

APÊNDICE C CÓDIGOS FONTE 97
117
118 i n t s t o p = 0 ;
119 f o r ( SymInt j = c o n c o l i c . l i b . U t i l . ZERO; U t i l . choose ( c o n c o l ic . l i b . U t i l
120 . l t ( j , c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( s r c . l e n g t h ) )) ; j = c o n c o l i c
. l i b . U t i l
121 . add ( j , c o n c o l i c . l i b . U t i l .ONE) ) {
122 i f ( s t o p ++ > ConcolicDemo . LOOP_UNFOLDING_LIMIT ) {
123 throw new TooLongPathExcept ion ( ) ;
124 }
125
126 Ent ry e = s r c [ j . e v a l ( ) ] ;
127 i f ( e != n u l l ) {
128 s r c [ j . e v a l ( ) ] = n u l l ;
129
130 i n t s t op2 = 0 ;
131 do {
132 i f ( s t op2 ++ > ConcolicDemo . LOOP_UNFOLDING_LIMIT ) {
133 throw new TooLongPathExcept ion ( ) ;
134 }
135
136 Ent ry nex t = e . nex t ;
137 SymInt i = indexFor ( e . hash , newCapac i ty ) ;
138 e . nex t = newTable [ i . e v a l ( ) ] ;
139 newTable [ i . e v a l ( ) ] = e ;
140 e = nex t ;
141 } whi le ( e != n u l l ) ;
142 }
143 }
144 }
145
146 s t a t i c c l a s s Ent ry / * imp lemen ts Map . En t ry* / {
147 f i n a l I n t e g e r key ;
148 Objec t va l ue ;
149 f i n a l SymInt hash ;
150 Ent ry nex t ;
151
152 Ent ry ( SymInt h , I n t e g e r k , Ob jec t v , En t r y n ) {
153 va l ue = v ;
154 nex t = n ;

APÊNDICE C CÓDIGOS FONTE 98
155 key = k ;
156 hash = h ;
157 }
158
159 void r eco r dAcces s ( HashMap m) {
160 }
161
162 void recordRemoval ( HashMap m) {
163 }
164 }
165
166 void addEnt ry ( SymInt hash , I n t e g e r key , Ob jec t va lue , SymInt bucke t I ndex )
{
167 t a b l e [ bucke t I ndex . e v a l ( ) ] =new Ent ry ( hash , key , va lue ,
168 t a b l e [ bucke t I ndex . e v a l ( ) ] ) ;
169 i f ( U t i l . choose ( c o n c o l i c . l i b . U t i l . ge ( c o n c o l i c . l i b . U t i l. add ( s i z e ,
170 c o n c o l i c . l i b . U t i l .ONE) , t h r e s h o l d ) ) )
171 r e s i z e ( c o n c o l i c . l i b . U t i l . mul ( c o n c o l i c . l i b . U t i l . c r e at e C o n s t a n t ( 2 ) ,
172 c o n c o l i c . l i b . U t i l . c r e a t e C o n s t a n t ( t a b l e . l e n g t h ) ) ) ;
173 }
174 }

APÊNDICE C CÓDIGOS FONTE 99
Código Fonte C.3:Driver de HashMap
1 package benchmark . d r i v e r s . c o n c o l i c ;
2
3 import benchmark . hashmap . i n s t r u m e n t e d . HashMap ;
4 import c o n c o l i c . l i b . SymInt ;
5 import c o n c o l i c . l i b . S y m I n t L i t e r a l ;
6 import c o n c o l i c . l i b . SymL i t e ra l ;
7
8 pub l i c c l a s s HashMap_Driver implements D r i v e r {
9 i n t [ ] c t e s = new i n t [ ] {
10 3 , 5 , 6 ,
11 5 , 6 , 7 ,
12 9 , 5 , −10,
13 2 , 1 , 20 ,
14 1 , 10 , 0 ,
15 11 , 8 , 9 ,
16 30 , 25 , 16 ,
17 15 , 36 , 27 ,
18 19 , 35 , 715 ,
19 12 , 21 , 22 ,
20 117 , 150 , 40 ,
21 23 , 18 , 29 ,
22 120 , 32 , 33 ,
23 111 , 123 , 42
24 } ;
25
26 S y m I n t L i t e r a l [ ] l i t s = new S y m I n t L i t e r a l [ c t e s . l e n g t h ] ;
27
28 pub l i c vo id t e s t ( SymL i t e ra l [ ] l i t e r a l s ) {
29 HashMap hash =new HashMap ( ) ;
30
31 f o r ( i n t i = 0 ; i < l i t e r a l s . l e n g t h ; i ++) {
32 hash . pu t (new benchmark . hashmap . i n s t r u m e n t e d . I n t e g e r ( ( SymInt ) l i t er a l s
[ i ] ) , i ) ;
33 }
34 }
35
36 @Override
37 pub l i c S t r i n g getExper imentName ( ) {

APÊNDICE C CÓDIGOS FONTE 100
38 re turn "HashMap" ;
39 }
40
41 @Override
42 pub l i c SymL i t e ra l [ ] g e t L i t e r a l s ( ) {
43 re turn l i t s ;
44 }
45
46 @Override
47 pub l i c vo id s e t I n i t i a l V a l u e s ( ) {
48 f o r ( i n t i = 0 ; i < l i t s . l e n g t h ; i ++) {
49 l i t s [ i ] = new S y m I n t L i t e r a l ( c t e s [ i ] ) ;
50 }
51 }
52
53 @Override
54 pub l i c i n t ge tLoopUn fo ld ingL im i t ( ) {
55 re turn 7 ;
56 }
57 }

Referências Bibliográficas
A. Carlisle, G. D. (2001). An off-the-shelf pso,Proc. Workshop Particle Swarm Optimization.
ASM webpage(s.d.).
URL: http://asm.ow2.org/
Bäck, T., Eiben, A. E. e Vink, M. E. (1998). A superior evolutionary algorithm for 3-sat,EP
’98: Proceedings of the 7th International Conference on Evolutionary Programming VII,
Springer-Verlag, London, UK, pp. 125–136.
BCEL webpage(s.d.).
URL: http://jakarta.apache.org/bcel/
Boyapati, C., Khurshid, S. e Marinov, D. (2002). Korat: Automated testing based on Java
predicates,International Symposium on Software Testing and Analysis (ISSTA), pp. 123–
133.
Buse, R. P. L. e Weimer, W. (2009). The road not taken: Estimating path execution frequency
statically,ICSE ’09: Proceedings of the 2009 IEEE 31st International Conference on Soft-
ware Engineering, IEEE Computer Society, Washington, DC, USA, pp. 144–154.
Clarke, L. (1976). A system to generate test data and symbolically execute programs,Software
Engineering, IEEE Transactions onSE-2(3): 215–222.
CVC3 web page(s.d.).
URL: http://www.cs.nyu.edu/acsys/cvc3/
Eibach, T., Pilz, E. e Völkel, G. (2008). Attacking bivium using sat solvers.,in H. K. Büning e
X. Zhao (eds),SAT, Vol. 4996 ofLecture Notes in Computer Science, Springer, pp. 63–76.
Eiben, A. e van der Hauw, J. (1997). Solving 3-sat by gas adapting constraint weights,Evolu-
tionary Computation, 1997., IEEE International Conference on pp. 81–86.
101

REFERÊNCIAS BIBLIOGRÁFICAS 102
Folino, G., Pizzuti, C. e Spezzano, O. (1998). Combining cellular genetic algorithms and
local search for solving satisfiability problems,IEEE Conference on Tools with Artificial
Intelligence, pp. 192–198.
Ganesh, V., Leek, T. e Rinard, M. (2009). Taint-based directed whitebox fuzzing,ICSE ’09:
Proceedings of the 2009 IEEE 31st International Conference on Software Engineering, IEEE
Computer Society, Washington, DC, USA, pp. 474–484.
Glover, F. (1986). Future paths for integer programming andlinks to artificial intelligence,
Comput. Oper. Res.13(5): 533–549.
Godefroid, P., Klarlund, N. e Sen, K. (2005). Dart: directedautomated random testing.,in
V. Sarkar e M. W. Hall (eds),PLDI, ACM, pp. 213–223.
Holland, J. H. (1975).Adaptation in natural and artificial systems, MIT Press, Cambridge,
MA, USA.
Ihantola, P. (2006). Test data generation for programming exercises with symbolic execution in
Java PathFinder,Baltic Sea ’06: Proceedings of the 6th Baltic Sea conferenceon Computing
education research, ACM, New York, NY, USA, pp. 87–94.
Jong, M. B. D. e Kosters, W. A. (1998). Solving 3-sat using adaptive sampling,Proceedings of
the Tenth Dutch/Belgian Artificial Intelligence Conference, Springer-Verlag, pp. 221–228.
Kennedy, J. e Eberhart, R. C. (1995).Swarm intelligence, Morgan Kaufmann Publishers Inc.,
San Francisco, CA, USA.
Kennedy, J. e Eberhart, R. C. (1997). A discrete binary versionof the particle swarm algorithm,
Systems, Man, and Cybernetics, 1997. ’Computational Cybernetics and Simulation’., 1997
IEEE International Conference on, Vol. 5, pp. 4104–4108 vol.5.
Kiezun, A., Ganesh, V., Guo, P. J., Hooimeijer, P. e Ernst, M.D. (2009). Hampi: a solver
for string constraints,ISSTA ’09: Proceedings of the eighteenth international symposium on
Software testing and analysis, ACM, New York, NY, USA, pp. 105–116.
King, J. C. (1976). Symbolic execution and program testing,Commun. ACM19(7): 385–394.

REFERÊNCIAS BIBLIOGRÁFICAS 103
Kirkpatrick, S., Gelatt, C. D., Jr. e Vecchi, M. P. (1983). Optimization by simulated annealing,
Science220: 671–680.
Lakhotia, K., Harman, M. e McMinn, P. (2008). Handling dynamic data structures in search
based testing,GECCO ’08: Proceedings of the 10th annual conference on Genetic and
evolutionary computation, ACM, New York, NY, USA, pp. 1759–1766.
Li, X. e Engelbrecht, A. P. (2007). Particle swarm optimization: an introduction and its recent
developments.,in D. Thierens (ed.),GECCO (Companion), ACM, pp. 3391–3414.
Lin, I.-L. (2005). Particle swarm optimization for solving constraint satisfaction problems,
Master’s thesis, Simon Fraser University, Burnaby, BC, Canada.
Majumdar, R. e Sen, K. (2007). Hybrid concolic testing,ICSE ’07: Proceedings of the 29th
international conference on Software Engineering, IEEE Computer Society, Washington,
DC, USA, pp. 416–426.
Marchiori, E. e Rossi, C. (1999). A flipping genetic algorithm for hard 3-SAT problems,Gene-
tic and Evolutionary Computation Conference, Vol. 1, Morgan Kaufmann, Orlando, Florida,
USA, pp. 393–400.
Matsumoto, M. e Nishimura, T. (1998). Mersenne twister: a 623-dimensionally equidistributed
uniform pseudo-random number generator,ACM Trans. Model. Comput. Simul.8(1): 3–30.
Miller, B. P., Fredriksen, L. e So, B. (1990). An empirical study of the reliability of unix
utilities, Commun. ACM33(12): 32–44.
Mitchell, M. (1998). An Introduction to Genetic Algorithms, MIT Press, Cambridge, MA,
USA.
Myers, G. J. e Sandler, C. (2004).The Art of Software Testing, John Wiley & Sons.
Newton’s square root webpage(s.d.).
URL: https://trac.videolan.org/skin-designer/browser/trunk/src
ojAlgo webpage(s.d.).
URL: http://ojalgo.org

REFERÊNCIAS BIBLIOGRÁFICAS 104
Pacheco, C. e Ernst, M. D. (2007). Randoop: feedback-directedrandom testing for Java.,in
R. P. Gabriel, D. F. Bacon, C. V. Lopes e G. L. S. Jr. (eds),OOPSLA Companion, ACM,
pp. 815–816.
Pacheco, C., Lahiri, S., Ernst, M. e Ball, T. (2007). Feedback-directed random test generation,
International Conference on Software Engineering, pp. 75–84.
Parsopoulos, K. E. (2009). Cooperative micro-differentialevolution for high-dimensional pro-
blems,GECCO ’09: Proceedings of the 11th Annual conference on Genetic and evolutionary
computation, ACM, New York, NY, USA, pp. 531–538.
Pressman, R. S. (2001).Software engineering: a practitioner’s approach, 5 edn, McGraw-Hill,
New York, NY.
Pasareanu, C. S., Mehlitz, P. C., Bushnell, D. H., Gundy-Burlet, K.,Lowry, M., Person, S. e
Pape, M. (2008). Combining unit-level symbolic execution and system-level concrete execu-
tion for testing nasa software,ISSTA ’08: Proceedings of the 2008 international symposium
on Software testing and analysis, ACM, New York, NY, USA, pp. 15–26.
Qadeer, S. (s.d.). Daisy File System. Joint CAV/ISSTA Special Event on Specification, Verifi-
cation, and Testing of Concurrent Software. 2004.
URL: http://research.microsoft.com/ qadeer/cav-issta.htm
Rossi, C., Marchiori, E. e Kok, J. N. (2000). An adaptive evolutionary algorithm for the satis-
fiability problem.,SAC (1), pp. 463–469.
Ru, N. e Jianhua, Y. (2008). A GA and particle swarm optimization based hybrid algorithm,
IEEE World Congress on Computational Intelligence, Hong Kong.
Russell, S. e Norvig, P. (2003).Artificial Intelligence: A Modern Approach, 2nd edition edn,
Prentice-Hall, Englewood Cliffs, NJ, chapter Informed Search and Exploration, pp. 94–131.
Sen, K. (2007). Concolic testing,ASE ’07: Proceedings of the twenty-second IEEE/ACM
international conference on Automated software engineering, ACM, New York, NY, USA,
pp. 571–572.
Sen, K. e Agha, G. (2006). CUTE and jCUTE: Concolic unit testing and explicit path model-
checking tools,CAV, pp. 419–423.

REFERÊNCIAS BIBLIOGRÁFICAS 105
Silva, J. P. M. e Sakallah, K. A. (1996). Grasp—a new search algorithm for satisfiability,
ICCAD ’96: Proceedings of the 1996 IEEE/ACM international conference on Computer-
aided design, IEEE Computer Society, Washington, DC, USA, pp. 220–227.
Standard glossary of terms used in Software Testing(2007).
URL: http://www.istqb.org/downloads/glossary-current.pdf
Takaki, M., Cavalcanti, D., Gheyi, R., Iyoda, J., D’Amorim, M.e Prudêncio, R. (2009). A
comparative study of randomized constraint solver for random-symbolic testing,1st NASA
Formal Methods Symposium (NFM).
Visser, W., Pasareanu, C. S. e Khurshid, S. (2004). Test input generation with Java PathFinder,
ISSTA ’04: Proceedings of the 2004 ACM SIGSOFT internationalsymposium on Software
testing and analysis, ACM, New York, NY, USA, pp. 97–107.
Wassermann, G., Yu, D., Chander, A., Dhurjati, D., Inamura, H. e Su, Z. (2008). Dynamic
test input generation for web applications,ISSTA ’08: Proceedings of the 2008 international
symposium on Software testing and analysis, ACM, New York, NY, USA, pp. 249–260.
Whitley, D. (2002). Genetic algorithm and evolutionary computing, Van Nostrand’s Scientific
Encyclopedia, Wiley-Interscience.
Windisch, A., Wappler, S. e Wegener, J. (2007). Applying particle swarm optimization to
software testing,GECCO ’07: Proceedings of the 9th annual conference on Geneticand
evolutionary computation, ACM, New York, NY, USA, pp. 1121–1128.
Young, M. e Pezze, M. (2005).Software Testing and Analysis: Process, Principles and Tech-
niques, John Wiley & Sons.
Zhou, Y., He, J. e Nie, Q. (2009). A comparative runtime analysis of heuristic algorithms for
satisfiability problems,Artif. Intell. 173(2): 240–257.