Embed Size (px)
Citation preview

Atualmente a estatística é uma ferramenta indispensável para os profissionais na área dasciências da saúde. Conhecer, interpretar e aplicar a teoria e as técnicas estatísticas é funda-mental para uma boa investigação, estudo e práticas esclarecidas.
Este livro, com evidente cuidado pedagógico, e recorrendo permanentemente a exemplospráticos, apresenta em 21 capítulos e vários anexos todo o instrumental teórico e prático paradotar o leitor de tudo o que necessita para enfrentar os obstáculos que poderá encontrar no seuestudo ou profissão.
Nos primeiros capítulos apresenta os conceitos básicos da Estatística e o ambiente e utili-zação do software SPSS. Depois aborda a noção de probabilidade, as distribuições amostrais eos vários tipos de amostragem. Seguidamente trata da comparação de dados categóricos edados numéricos em duas ou mais amostras independentes, fazendo intervir o teste do qui--quadrado, o teste -Student (também para variáveis emparelhadas) e o teste da análise devariância (ANOVA). Discute o modelo de regressão e a correlação e os diferentes testes nãoparamétricos. Nos capítulos seguintes apresenta as medidas de força da associação ou efeito,através dos , risco relativo e da diferença de risco. Nos capítulos finais apresenta aparte mais complexa constituída pelos modelos de regressão logística, análise de sobrevivên-cia, regressão de Cox e regressão de Poisson e aborda a meta-análise, principalmente no quediz respeito à sua representação gráfica ( ).
Este livro destina-se pois a todos os estudantes e profissionais que, na sua atividade profis-sional ou nos seus estudos necessitem de aprender ou consolidar os conceitos teóricos estatís-ticos e a sua respetiva transposição para a prática.
t F
odds ratio
forest plot
O presente trabalho escrito com a clareza, que só quem viveu explicando consegueimprimir, é um auxílio de extrema utilidade, não só para quem se queira envolver nainvestigação biomédica, mas também para quem necessita de compreender a linguagemda maioria dos trabalhos publicados. (...) O recurso aos exemplos reais é sem sombra dedúvida, mais um dos argumentos que pode justificar a recomendação deste livro aosprofissionais de saúde.
A publicação desta obra teve o apoio:
Prof. Alexandre Castro CaldasProfessor Catedrático
Diretor do Instituto de Ciências da Saúde – Universidade Católica Portuguesa
FRANCISCO MERCÊS DE MELLO • RITA CABRAL GUIMARÃESFrancisco Mercês de Mello
Curso de Engenheiro Agrónomoem 1961 (UTL). Bacharelato emMatemática Aplicada em 1974(ULM). Doutoramento emEngenharia Agrícola em 1987(U. Évora). Professor associado(aposentado) da Universidadede Évora.
Rita Cabral Guimarães
Licenciatura em EngenhariaAgrícola em 1993 (U. Évora).Mestrado em Engenharia do Soloe da Água em 1997 (U. Évora).Doutoramento em Engenharia dosRecursos Hídricos em 2005 (U. Évora).Licenciatura em Engenharia Civilem 2013 (U. Évora). Professora auxiliarna Universidade de Évora.
Métodos Estatísticospara o Ensino e a Investigação nas
Ciências da Saúde
– 1.00 0.00 1.00 2.00 3.00
FavortratamentoFavortratamento
Favorplacebo
Favorplacebo
Com exemplos extraídos de revistase publicações médicas
Apresentação e utilização do SPSS
Méto
do
s Estatístico
sp
ara o E
nsin
o e a Investig
ação n
as
Ciên
cias da S
aúd
e
MERCÊSDE MELLO
•RITA
GUIMARÃES
EDIÇÕES SÍLABO
Prefácio
Prof. Alexandre Castro Caldas
ISBN 978-972-618-805-6
9 188056789726
506



Métodos Estatísticos para o Ensino
e a Investigação nas Ciências da Saúde
Com Utilização do SPSS
FRANCISCO MERCÊS DE MELLO
RITA CABRAL GUIMARÃES
EDIÇÕES SÍLABO

É expressamente proibido reproduzir, no todo ou em parte, sob qualquer
forma ou meio, NOMEADAMENTE FOTOCÓPIA, esta obra. As transgressões serão passíveis das penalizações previstas na legislação em vigor.
Visite a Sílabo na rede
www.si labo.pt
Editor: Manuel Robalo
FICHA TÉCNICA:
Título: Métodos Estatísticos para o Ensino e a Investigação nas Ciências da Saúde – Com utilização do SPSS Autores: Francisco Mercês de Mello, Rita Cabral Guimarães © Edições Sílabo, Lda. Capa: Pedro Mota
1ª Edição – Lisboa, julho de 2015 Impressão e acabamentos: Europress, Lda. Depósito Legal: 395231/15 ISBN: 978-972-618-805-6
EDIÇÕES SÍLABO, LDA.
R. Cidade de Manchester, 2 1170-100 Lisboa Tel.: 218130345 Fax: 218166719 e-mail: [email protected] www.silabo.pt

Índice
Agradecimentos 13 Palavras prévias 15 Prefácios 17 Introdução 19
Capítulo 1 Conceitos básicos da estatística e da análise exploratória dos dados
1.1. Introdução 21 1.2. Conceitos básicos 21 1.3. Medição e escalas de medição 22 1.4. Ordenação dos dados 23 1.5. Dados agrupados: distribuição de frequências 23 1.6. Estatística descritiva 28
1.6.1. Medidas de localização 28 1.6.2. Medidas de dispersão 31 1.6.3. Medidas de forma 33
Capítulo 2 Princípios básicos de utilização do SPSS
2.1. Introdução 37 2.2. Como iniciar o SPSS 37 2.3. Como criar um ficheiro de dados no SPSS 39 2.4. Tratamento e apresentação dos dados 44
2.4.1. Tabela de frequências 44 2.4.2. Estatística descritiva 48

2.5. Como calcular uma nova variável a partir de outra existente 51 2.6. Como calcular variáveis a partir de datas 55
Capítulo 3 Exemplos de aplicação do SPSS a casos concretos de estatística descritiva
3.1. Introdução 61 3.2. Exemplos de aplicação 61
Capítulo 4 Probabilidade
4.1. Introdução 79 4.2. Conceitos de probabilidade 79 4.3. Algumas propriedades e teoremas 80 4.4. Distribuições discretas 82 4.5. Distribuições contínuas 86
Capítulo 5 Distribuições amostrais
5.1. Introdução 93 5.2. Teorema do limite central 94 5.3. Parâmetros de uma população 94
5.3.1. Distribuição amostral da média, x 94 5.3.2. Distribuição amostral de uma proporção 96 5.3.3. Distribuição amostral da variância 97
5.4. Parâmetros de duas populações 97 5.4.1. Distribuição da diferença entre duas médias amostrais 97 5.4.2. Distribuição amostral para a diferença
entre duas proporções populacionais 101 5.4.3. Distribuição amostral para o quociente entre variâncias 102

Capítulo 6 Estimação pontual e intervalar
6.1. Introdução 105 6.2. Estimação pontual 105 6.3. Estimação intervalar 105
Capítulo 7 Testes de hipóteses
7.1. Introdução 115 7.2. Hipóteses estatísticas 115 7.3. Estatística de teste 117 7.4. Nível de significância 117 7.5. Valores críticos e região de rejeição de um teste de hipótese 117 7.6. Erro associado a uma decisão estatística 121 7.7. Probabilidade de significância (p-value) 121 7.8. Cálculo das probabilidades de cometer um erro tipo I e tipo II.
Função potência 126 7.9. Comparação conjunta dos erros tipo II e potência para testes
de hipóteses bilaterais e unilaterais 129 7.10. Testes de hipóteses vs. intervalos de confiança 130 7.11. Como calcular o valor-p com o SPSS 131
Capítulo 8 Amostragem
8.1. Introdução 133 8.2. Dimensão da amostra 133
8.2.1. Nomograma de Altman para cálculo da dimensão da amostra 136 8.2.2. Fórmula rápida de Lehr 137
8.3. Métodos de seleção de amostras 138

Capítulo 9 Comparação de dados categóricos em amostras independentes
9.1. Introdução 141 9.2. Teste do qui-quadrado 141 9.3. Teste de Fisher 146 9.4. Medidas de força da associação/efeito: risco relativo e odds ratio 147
Capítulo 10 Testes para analisar a normalidade dos dados e a homogeneidade das variâncias
10.1. Introdução 167
10.2. Análise da normalidade 167
10.3. Análise da homogeneidade das variâncias 173
Capítulo 11 Testes t-Student
11.1. Teste t-Student para uma amostra 177
11.2. Teste t-Student para comparação de dados numéricos em duas amostras 180 11.2.1. Teste t-Student para duas amostras independentes 180 11.2.2. Teste t-Student para duas amostras emparelhadas 184
Capítulo 12 Comparação de dados numéricos em mais de duas amostras independentes. Análise de variância
12.1. Introdução 189
12.2. Os diferentes tipos de ANOVA 190
12.3. Delineamentos completamente casualizados 190
12.4. Delineamentos em blocos completamente casualizados 197
12.5. Delineamentos com medições repetidas (one way ANOVA) 207
12.6. Experiências fatoriais 213 12.6.1. Classificação dupla cruzada 214

12.6.2. Esquema de dois fatores completamente casualizados 214
12.7. Modelo a dois fatores misto 225
Capítulo 13 Regressão linear. Correlação
13.1. Introdução 233
13.2. O modelo de regressão linear simples 233
13.3. Pressupostos do modelo de regressão linear simples 234
13.4. Correlação paramétrica 234
13.5. Correlação não paramétrica 238
13.6. Coeficiente de correlação bisserial por pontos 240
13.7. O Modelo de regressão linear múltipla 250 13.7.1. Coeficientes de regressão parciais 251
13.7.2. Coeficiente de determinação múltipla 251
13.7.3. Coeficiente de correlação parcial 251
13.7.4. Testes de hipóteses 252
13.7.5. Escolha do processo de seleção de variáveis 253
13.8. Variáveis independentes categóricas 261
Capítulo 14 Testes não paramétricos
14.1. Introdução 263
14.2. Teste de Kolmogorov-Smirnov 263
14.3. Teste binomial 264
14.4. Teste do qui-quadrado 267
14.5. Teste de Fisher 267
14.6. Teste de Mann-Whitney 267
14.7. Teste de Kruskall-Wallis 271
14.8. Teste dos sinais 273
14.9. Teste de Wilcoxon 276 14.10. Teste de McNemar 278 14.11. Teste de Cochran 280 14.12. Teste de Friedman 282

Capítulo 15 Testes de diagnóstico. Curva ROC
15.1. Introdução 285
15.2. Definições. Cálculos 286 15.2.1. Probabilidade condicional e testes de diagnóstico 289
15.3. Curva ROC 291
Capítulo 16 Regressão logística simples e múltipla
16.1. Introdução 299
16.2. Categorização das variáveis independentes 303
16.3. Esquema geral de procedimento para efetuar uma análise de regressão logística com SPSS 306
16.4. Regressão logística politómica 323 16.4.1. Testes de significância 325
16.4.2. Interpretação dos parâmetros 325
16.5. Regressão ordinal 330 16.5.1. Avaliação da qualidade do modelo 331
16.5.2. Classificação com o modelo de regressão ordinal 332
Capítulo 17 Confundimento e modificação de efeitos
17.1. Introdução 339
17.2. Estatísticas de Mantel-Haenszel 339
17.3. Como analisar confundimento e modificação de efeito 342 17.3.1. Inexistência de confundimento e de interação 343
17.3.2. Existência de confundimento sem interação 347
17.3.3. Existência de interação sem confundimento 350
17.3.4. Existência de confundimento e de interação 352
17.4. Comparação da regressão logística com a análise estratificada em tabelas 2 × 2 354

Capítulo 18 Análise de sobrevivência
18.1. Introdução 357
18.2. Método actuarial 357
18.3. Método de Kaplan-Meier 362
18.4. Comparação de curvas de sobrevivência 364 18.4.1. Comparação pontual 364
18.4.2. Comparação global 365
18.5. Taxas de incidência cumulativa 374
Capítulo 19 Análise de regressão de Cox
19.1. Introdução 377
19.2. Coeficientes de regressão parciais 378
19.3. Testes de hipóteses a efetuar 380
19.4. Validação dos pressupostos do modelo 382
19.5. Modelos paramétricos 403
Capítulo 20 Análise de regressão de Poisson
20.1. Introdução 407
20.2. Razão de taxas de incidência 408
Capítulo 21 Meta-análise
21.1. Introdução 425
21.2. Modelos de efeitos fixos e modelos de efeitos aleatórios 426
21.3. Heterogeneidade estatística 426
21.4. Gráfico dos resultados (forest plot) 427

Anexo 1 – Tabelas para a distribuição normal 431
Anexo 2 – Tabelas para a distribuição t-Student 437
Anexo 3 – Tabelas para a distribuição de qui-quadrado 441
Anexo 4 – Tabelas para a distribuição de F-Snedecor 443
Referências bibliográficas 451 Índice remissivo 457

Agradecimentos
Os autores vêm expressar o seu agradecimento ao Sr. Dr. Luís Santos, Chefe de Serviço de Patologia Clínica, Diretor Técnico do Serviço de Patologia Clínica do Hospital de Cascais Dr. José de Almeida, pelo incentivo constante que lhes deu para a concreti-zação deste livro, juntamente com o esclarecimento que lhes foi prestando quanto a variados termos médicos e à revisão final que se dignou a fazer a esta obra.
Ao Professor Doutor Pedro Aguiar, do Instituto Nacional de Saúde Pública, os auto-res agradecem os esclarecimentos que deu às varias questões que lhe apresentaram e à forma amável como para tal se disponibilizou.
Ao Sr. Dr. António Paula Brito Pina, da ARS do Algarve – IP, agradecemos a pronta autorização que nos concedeu para usar os seus textos e dados de obras por si publi-cadas.
Ao Sr. Dr. Frederico do Rosário, do Centro de Saúde de Tondela, agradecemos a forma amável como acolheu as nossas dúvidas, ao ponto de nos deixar utilizar os seus dados e trabalhar connosco no SPSS a regressão de Poisson.
Ao Professor Doutor Paulo Margotto os autores querem agradecer a amabilidade com que nos autorizou a usar os deus dados e os seus textos publicados na World Wide Web.
Não podíamos deixar de agradecer o acolhimento que tivemos na excelente Biblio-teca do Hospital de S. José, na pessoa da sua assistente-técnica Sra. D. Mónica Tei-xeira. Trata-se de uma funcionária sempre disposta a resolver os nossos inúmeros pro-blemas, de uma forma que consideramos exemplar e com um zelo inexcedível.


Palavras prévias
A estatística desempenha um importante papel na pesquisa médica. Odd O. Aalem, da Secção de Estatística Médica da Universidade de Oslo, no ano 2000, escreveu na revista Statistical Methods in Medical Research, um artigo intitulado «Medical Statistics – No Time for Complacency». Neste excelente artigo, para além de chamar a atenção para a incerteza, como essência da estatística, aponta um conjunto de fatores que res-pondem à pergunta do presente capítulo. São eles:
A prática médica e a pesquisa médica geram grande quantidade de dados, cheios de incerteza e variabilidade, impondo uma análise apropriada ao tratamento destes dados – a análise estatística;
Os testes aos tratamentos ou medidas preventivas, na prática apoiam-se na estatís-tica. Isto é verdadeiro para ambos, quer no delineamento, quer na análise. A casualiza-ção foi entusiasticamente implementada nas experiências clínicas e a chamada medi-cina baseada em evidências tem a sua base nos ensaios clínicos e em estudos epide-miológicos.
O panorama médico mundial tem fortes aspetos estatísticos. Medidas estatísticas respondem a questões do tipo: «Quão comum é a doença?»; «Qual o fator responsá-vel?»; «Qual a probabilidade de melhorar a sobrevivência?».
Por outro lado é importante deixar bem expresso que uma diferença entre compor-tamentos, estatisticamente significantes, pode não ser clinicamente «importante». A importância em termos biológicos não deve ser julgada pelos estatísticos, mas sim pelos profissionais da área em que a pesquisa está sendo feita.


Prefácios
Os métodos quantitativos de investigação dominam hoje a literatura biomédica. Ao longo dos anos a metodologia estatística tem vindo a refinar a sua capacidade de valori-zação dos resultados obtidos na experimentação, enriquecendo assim a oferta das opções e das aplicações.
Os cálculos estatísticos deixaram há muito de ser realizados com papel e lápis ou com o recurso à regra de cálculo, passaram a integrar programas complexos de que os utilizadores desconhecem as regras matemáticas que os suportam.
Desta forma, os profissionais não acompanharam a evolução das metodologias estatísticas e recorrem à aparente simplicidade do teclado de um computador para rea-lizar os seus estudos. Nada mais passível de erro do que fazê-lo desta forma. A estatís-tica é um componente da metodologia da investigação que deve ser ponderada com conhecimento das suas regras de utilização, no mesmo momento em que se planeia um estudo. Não é qualquer coisa que se aplica aos resultados para lhes dar uma tonalidade de verdade. Por outro lado, mesmo quando bem utilizada a metodologia, muitos leitores dos trabalhos publicados se confundem na leitura e interpretação dos resultados.
O presente trabalho escrito com a clareza, que só quem viveu explicando consegue imprimir, é um auxílio de extrema utilidade, não só para quem se queira envolver na investigação biomédica, mas também para quem necessita de compreender a lingua-gem da maioria dos trabalhos publicados.
É certo que não é o único livro sobre o assunto disponível nas livrarias mas é, decerto, dos que melhor conjugam o rigor que a metodologia requer, com a simplicidade do texto. O recurso aos exemplos reais é sem sombra de dúvida, mais um dos argu-mentos que pode justificar a recomendação deste livro aos profissionais de saúde.
Prof. Doutor Alexandre Castro Caldas
Professor Catedrático Diretor do Instituto de Ciências da Saúde
Universidade Católica Portuguesa

O trabalho que agora se publica materializa a difícil tarefa de disponibilizar aos investigadores em Ciências da Saúde os indispensáveis instrumentos de análise esta-tística, não ignorando que a maioria dos interessados não possui conhecimentos apro-fundados de métodos de análise matemática, mas sem descurar o rigor teórico exigido a qualquer texto de carácter científico.
Para tanto, os autores começam por apresentar os conceitos fundamentais da aná-lise estatística servindo-se de exemplos retirados de casos clínicos descritos nas princi-pais revistas médicas. Em simultâneo mostram como pode ser utilizado o programa informático SPSS para implementação dos métodos de análise.
Para além dos testes estatísticos mais habitualmente utilizados neste tipo de investi-gação, os autores alargam o seu trabalho aos mais recentes modelos de regressão logística, de Cox e de Poisson e à meta-análise, na sua formulação gráfica «forest plot».
A riquesa e a variedade da centena de casos apresentados no livro fazem dele um singular instrumento de trabalho que merecerá sem dúvida o interesse dos profissionais do sector das Ciências da Saúde.
E para aqueles que quiserem ir mais longe no estudo destas questões, a extensa lista de Referências Bibliográficas e obras consultadas constitui uma preciosa orienta-ção.
Prof. Doutor Fernando Brito Soares
Professor Catedrático da Faculdade de Economia da Universidade Nova de Lisboa

Introdução
Qualquer projeto de investigação em Ciências da Saúde, tem necessariamente de se complementar com estudos bioestatísticos. Os autores possuem uma formação no âmbito da Biologia e da Estatística, tendo até o primeiro autor regido uma disciplina de Bioestatística no Instituto Superior das Ciências da Saúde, a convite do seu Presidente, Professor Manuel Halpern, nos anos letivos de 1994/95 e 1995/96.
Talvez por este facto, e incentivados por médicos amigos, começaram há 3 anos a «construir» este livro, vendo hoje com regozijo, que valeu a pena o trabalho destes anos, já que esta ambição se concretizou.
Para melhor entenderem o largo espectro da aplicação da Estatística na investiga-ção nas Ciências da Saúde e tomarem contacto com a terminologia, testes e modelos mais utilizados, os autores consultaram cerca de uma centena de revistas médicas cientificas (vários volumes e números) que estão identificadas em Anexo, e que lhes permitiram dispor de uma vasta coleção de dados.
O package estatístico utilizado foi o SPSS 21, versão para Windows. Procurou-se não sobrecarregar o leitor com cálculos manuais extensos e matematicamente pesados, nos cerca de 100 exemplos resolvidos, partindo quase sempre de dados reais e recor-rendo ao SPSS. Procurou-se, em síntese, fazer com que o leitor olhe amigavelmente para este programa, que resolve em poucos segundos aquilo que, manualmente, pode-ria levar horas.
O livro contém 21 capítulos e vários anexos. Nos primeiros capítulos, faz-se uma revisão dos conceitos básicos da Estatística, uma descrição do ambiente SPSS e incluem-se exemplos resolvidos neste Software, sobre estatística descritiva. Segue-se depois uma abordagem à noção de probabilidade, às distribuições amostrais e aos tipos de amostragem. Posteriormente, trata-se da comparação de dados categóricos e dados numéricos em duas ou mais amostras independentes, fazendo intervir o teste do qui- -quadrado, o teste t-Student (também para variáveis emparelhadas) e o teste F da aná-lise de variância (ANOVA). Estudaram-se o modelo de regressão e a correlação e os diferentes testes não paramétricos. Tratam-se a seguir as medidas de força da associa-ção ou efeito, através dos odds ratios, risco relativo e da diferença de risco. Nos capítulos finais, aborda-se a parte mais complexa constituída pelos modelos de regressão logís-tica, análise de sobrevivência, de regressão de Cox e regressão de Poisson.
O livro termina com uma referência à meta-análise, principalmente no que toca à sua representação gráfica (forest plot).


Capítulo 1
Conceitos básicos da estatística e da análise exploratória
dos dados
1.1. Introdução
O objetivo deste capítulo é tratar da organização, condensação e apresentação da informação extraída de um conjunto de dados, de forma a caracterizar quantitativamente o objetivo do estudo. Nisto consiste a estatística descritiva, etapa indispensável à infe-rência estatística, que, como veremos adiante, integra um conjunto de técnicas que permitem tirar ilações acerca das características da população.
1.2. Conceitos básicos
Variável, é uma característica que muda de pessoa para pessoa, de local para local,
de instante para instante. Como exemplo, podemos referir a pressão sanguínea diastó-lica.
Variáveis quantitativas, são aquelas que podem ser medidas no sentido usual do termo. Por exemplo, podemos medir as alturas de crianças numa escola, conhecer as idades de doentes numa clínica, avaliar o teor em ácido úrico, etc.
Variáveis qualitativas, são aquelas que são identificadas apenas pela atribuição de um nome que designa uma classe, podendo estas classes ser ou não ordenáveis. Como exemplo podemos referir a cor dos olhos das pessoas, as classificações de muito bom,

22 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
bom, suficiente, medíocre e mau, obtidas por alunos em testes. Evidentemente será depois possível fazer contagens nas diferentes categorias.
Variável aleatória, é aquela que, antecipadamente, não pode ser exatamente pre-dita. É o caso, por exemplo, da altura de um adulto.
Variável aleatória discreta, é aquela que apresenta interrupções nos valores que
pode assumir. Por exemplo, o número de doentes que deram entrada na urgência de um hospital é traduzido por números inteiros como 0, 1, 2, etc., mas nunca poderá ser, por exemplo, 1,2 ou 3,8, etc.
Variável aleatória contínua, é aquela que, ao contrário da anterior, não apresenta
interrupções nos seus valores, podendo assumir qualquer valor dentro de determinado intervalo. É o caso, por exemplo, da altura de um indivíduo, já que podemos teorica-mente encontrar outra pessoa com altura inferior ou superior à dada.
População, é uma coleção de entidades para as quais estamos interessados num
determinado tempo. Por exemplo, a população estudantil que frequentou em 2009 o ensino básico na cidade de Lisboa. As populações podem ser finitas ou infinitas.
Amostra, é um subconjunto de uma população, selecionada com o objetivo de estu-dar propriedades particulares da população de interesse.
1.3. Medição e escalas de medição
Quando dispomos dos valores de uma variável usa-se uma escala de medição apro-priada. A escala de medição permite atribuir números com significado, de acordo com regras específicas, aos elementos em estudo. Deve analisar-se cuidadosamente o tipo de escala a utilizar, pois as operações aritméticas não são válidas para todas as esca-las.
Na Escala nominal, incluem-se as variáveis cujas modalidades ou categorias quan-
titativas são mutuamente exclusivas e não hierarquizáveis. Quando se atribuem núme-ros às diferentes classes, estes são utilizados como se fossem simples nomes, não gozam de qualquer tipo de propriedade aritmética. Apenas se podem fazer contagens dentro do mesmo código da categoria.
Na Escala ordinal, as diferentes modalidades da variável podem ser ordenadas de
acordo com determinado critério. Não é igualmente possível efetuar, com os números de uma escala ordinal, qualquer operação aritmética.
Na Escala intervalar, são válidas relações de ordem e as operações de soma e subtração. Como a origem da escala é arbitrária, não são legítimas as operações de multiplicação e divisão. A temperatura é um exemplo de variável de escala intervalar.

C O N C E I T O S B Á S I C O S D A E S T A T Í S T I C A E D A A N Á L I S E E X P L O R A T Ó R I A D O S D A D O S 23
Na Escala de razão, são possíveis todas as operações aritméticas, já que a origem
é fixa correspondendo sempre ao valor zero, que representa a ausência total da variável medida. São exemplo de escalas de razão, o tempo, o peso, etc.
1.4. Ordenação dos dados
O primeiro passo na organização dos dados é a preparação de um quadro orde-nado, isto é, uma lista de valores da coleção (população ou amostra) ordenados por ordem de grandeza, do mais baixo ao mais elevado, tarefa facilitada pelo uso de um computador.
1.5. Dados agrupados: distribuição de frequências
A principal finalidade de agrupamento dos dados é a sua sumarização, tornando mais fácil determinar a natureza da informação.
Para agrupar um conjunto de observações, devemos selecionar um conjunto de intervalos contíguos e não sobrepostos, de forna a que cada valor do conjunto das observações possa ser colocado apenas num só intervalo. Estes intervalos são desig-nados por intervalos de classe.
O número de intervalos de classe deve, em princípio, oscilar entre 5 e 15. A fórmula de Sturges deve guiar-nos na escolha do número K de classes. Esta fórmula diz-nos
que 101 3, 322 logK n= + × sendo n o número total de valores observados.
Outra grandeza a calcular é a amplitude da classe, que designamos por a, e se aconselha ser constante para todas as classes. A amplitude da classe pode ser deter-
minada dividindo a amplitude total da variação pelo número de classes: R
aK
= , onde
a é a amplitude da classe, R é a amplitude total da variação (diferença entre o maior e o menor valor dos dados) e K o número de classes.

24 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
EXEMPLO 1.1
Suponhamos conhecida a pressão arterial sistólica de 40 indivíduos apresentada no Quadro 1.1. Agrupar os dados em classes e construir a tabela de distribuição de frequências.
Quadro 1.1. Pressão arterial sistólica de 40 indivíduos
Indivíduo Pressão arterial (mmHg)
Indivíduo Pressão arterial (mmHg)
1 122 21 107
2 119 22 112
3 107 23 123
4 118 24 108
5 111 25 102
6 120 26 107
7 133 27 110
8 129 28 118
9 118 29 115
10 121 30 119
11 124 31 118
12 116 32 113
13 119 33 108
14 119 34 105
15 117 35 112
16 111 36 116
17 116 37 109
18 104 38 116
19 122 39 104
20 111 40 113
Resolução
Para termos uma ideia sobre o número de classes a usar, podemos aplicar a regra de Sturges:
101 3, 322 log 6, 3K n= + × = . Como a amplitude total dos dados é 133 102 31− = , temos,
315,17
6a = = . Podemos optar por 7 classes com uma amplitude de classe de 5, como se apre-
senta no Quadro 1.2.

C O N C E I T O S B Á S I C O S D A E S T A T Í S T I C A E D A A N Á L I S E E X P L O R A T Ó R I A D O S D A D O S 25
Quadro 1.2. Distribuição dos indivíduos pelas classes
Número da classe Classe Frequência
1 [100; 105[ 3
2 [105; 110[ 7
3 [110; 115[ 8
4 [115; 120[ 14
5 [120; 125[ 6
6 [125; 130[ 1
7 [130; 135[ 1
Total 40
F I M D E E X E M P L O
Frequência relativa. Por vezes, é útil conhecer, não o número de valores que per-
tencem a cada classe, mas sim a sua proporção. Para tal, dividimos o número de valo-res de cada classe (chamado frequência absoluta) pelo número total de valores. Assim,
para a primeira classe teríamos 3 40 ou seja 0,075 (ou em percentagem 7,5%). Este
valor é designado frequência relativa.
Podemos agora construir a tabela, apresentada no Quadro 1.3, com as frequências absolutas acumuladas, frequências relativas e frequências relativas acumuladas, res-peitantes ao Exemplo 1.1.
Histograma. No caso de variáveis contínuas, as distribuições de frequências são
representadas através de histogramas, que são gráficos constituídos por retângulos adjacentes, cujas bases e áreas representam, respetivamente as amplitudes e as fre-quências das classes.
O centro das classes ou ponto médio da classe determina-se calculando a média
aritmética dos limites das classes, ou seja limite inferior limite superior
2C
+= . Para
a primeira classe teríamos, portanto, 1100 105
102, 52
C+= = .
26 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
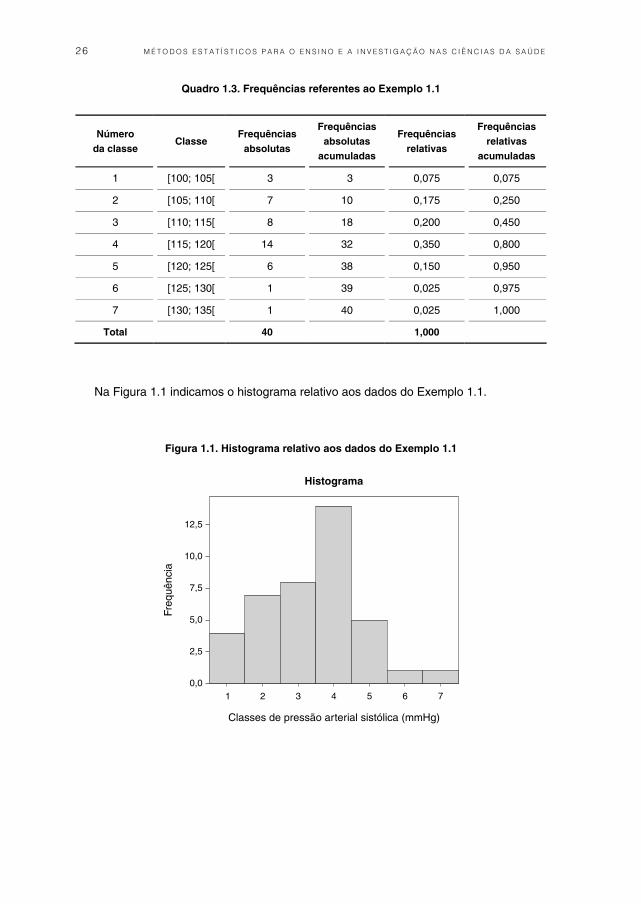
Quadro 1.3. Frequências referentes ao Exemplo 1.1
Número da classe
Classe Frequências
absolutas
Frequências absolutas
acumuladas
Frequências relativas
Frequências relativas
acumuladas
1 [100; 105[ 3 3 0,075 0,075
2 [105; 110[ 7 10 0,175 0,250
3 [110; 115[ 8 18 0,200 0,450
4 [115; 120[ 14 32 0,350 0,800
5 [120; 125[ 6 38 0,150 0,950
6 [125; 130[ 1 39 0,025 0,975
7 [130; 135[ 1 40 0,025 1,000
Total 40 1,000
Na Figura 1.1 indicamos o histograma relativo aos dados do Exemplo 1.1.
Figura 1.1. Histograma relativo aos dados do Exemplo 1.1
Histograma
Freq
uênc
ia
Classes de pressão arterial sistólica (mmHg)
1 2 3 4 5 6 7
12,5
10,0
7,5
5,0
2,5
0,0

C O N C E I T O S B Á S I C O S D A E S T A T Í S T I C A E D A A N Á L I S E E X P L O R A T Ó R I A D O S D A D O S 27
Polígono de Frequências. A distribuição de frequências pode ser representada graficamente dum outro modo, pelo polígono de frequências. Para a sua construção devem criar-se duas classes adicionais com a mesma amplitude e de frequência nula, uma em cada extremo do histograma. O polígono de frequências obtém-se unindo os pontos médios dos topos dos retângulos através de segmentos de reta. Na Figura 1.2 apresenta-se o polígono de frequências relativo aos dados do Exemplo 1.1. A área total sob o polígono de frequências é igual à área total correspondente ao histograma.
Figura 1.2. Polígono de frequências relativo aos dados do Exemplo 1.1
Polígono de frequências
Freq
uênc
ia
Classes de pressão arterial sistólica (mmHg)
15
10
5
095 100 105 110 115 120 125 130 135 140
Diagrama de caule e folhas. É também frequente utilizar-se o diagrama de «caule e folhas» composto por duas colunas designadas por «caule» e «folhas». Normalmente, no caule representam-se os algarismos das unidades de cada observação e, à frente de cada valor, inscrevem-se nas folhas os algarismos representativos da primeira casa decimal de cada observação.
Para os dados do Exemplo 1.1, optámos por tomar para a unidade do caule o número 10 e para a unidade das folhas o número 1. Assim, o 10 que se lê na primeira linha do caule significa 100, o 11 que se lê na segunda linha significa 110, etc.
Uma vantagem do diagrama de «caule e folhas» sobre o histograma consiste no facto de ele preservar a informação contida nas medidas individuais.
Na Figura 1.3 indicamos o diagrama de «caule e folhas» relativo aos dados do Exemplo 1.1.

28 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
Figura 1.3. Diagrama de «caule e folhas» relativo aos dados do Exemplo 1.1
Caule Folhas
10
11
12
13
2 4 4 5 7 7 7 8 8 9
0 1 1 1 2 2 3 3 5 6 6 6 6 7 8 8 8 8 9 9 9 9
0 1 2 2 3 4 9
3
Unidade do caule: 10
Unidade da folha: 1
1.6. Estatística descritiva
1.6.1. Medidas de localização
1.6.1.1. Medidas de Tendência Central
A distribuição de frequências e a sua representação gráfica são, sem dúvida, uma importante etapa na análise de dados. Contudo, situações há em que se requerem outros tipos de sumarização dos dados, por meio de medidas descritivas. Estas medi-das podem ser calculadas a partir dos dados de uma amostra ou de uma população.
Quando a medida descritiva é calculada a partir da amostra chama-se estatística.
Se é calculada a partir dos dados de uma população designa-se parâmetro. As medi-das de localização podem ser medidas de tendência central ou medidas de tendência não central. Vamos estudar as três medidas de tendência central: média, mediana e moda.
Média aritmética ou simplesmente média, representada por X , para a amostra, e
igual a 1
n
ii
X
Xn
==
ou, sendo para a população, representada por 1
N
ii
X
N=μ =
.
O símbolo 1
n
i = indica a soma de todos os valores desde primeiro (1) até ao último
(n), e designa-se por somatório.

C O N C E I T O S B Á S I C O S D A E S T A T Í S T I C A E D A A N Á L I S E E X P L O R A T Ó R I A D O S D A D O S 29
Média harmónica. É o inverso da média aritmética dos inversos dos valores das
observações e é igual a
1
1h n
ii
nX
X=
=
.
Média aparada. É uma média aritmética que é calculada após a eliminação de uma certa percentagem de valores extremos inferiores e superiores. A média aparada a 5% é calculada eliminando 2,5% das observações em cada extremidade da distribuição. É vantajoso utilizá-la quando a distribuição da variável contém valores extremos aberran-tes.
Mediana. Representa-se por Me e é o centro de posição da distribuição. Corres-ponde ao valor abaixo e acima do qual se registaram metade das observações. Após a ordenação das observações por ordem crescente a mediana calcula-se do seguinte modo:
12
12 2
se é impar
se é par2
n
n n
X n
Me X X
n
+
+
= +
Considerando os valores ordenados: 0; 2; 8; 14; 30. Como n = 5 é impar, vem que
5 1 32
Me X X+= = , significando que o valor central é o terceiro e a mediana é 8.
Quando o conjunto tiver um número par de dados, a mediana é a média dos dois valores centrais. É o caso da série de 4 valores: 1; 4; 8; 100, onde a mediana está na
posição
4 41
2 2
2
X X+
+
, ou seja, na posição intermédia entre o 2º e o 3º valores. Cal-
cula-se a média entre estes dois valores e a mediana da série é, portanto, 4 8
62+ = .
Repare-se que a mediana pode ser um valor observado ou não, como neste caso.
Moda. Representa-se por Mo, é o valor que ocorre com mais frequência. Se todos os valores são diferentes não existe moda. Por outro lado, pode também existir mais do que uma moda.
1.6.1.2. Medidas de Tendência Não Central
Quantis. Chamam-se quantis de ordem K aos K – 1 valores que dividem o conjunto
das observações ordenadas em K partes. Se 4K = , tomam o nome de quartis. Se 10K = , temos os decis e se 100K = designam-se percentis, pois dividem o conjunto
de observações em 100 partes iguais. Para variáveis de escala de razão ou intervalar,
define-se o percentil de ordem p, pP , como:

30 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
[ ]
1
1
se é inteiro2 100
se não é inteiro100
K K
p
K
npX XK
Pnp
X K
+
+
+ == =
,
onde p representa a ordem do percentil e [ ]1K + representa a parte inteira de 1K + .
Para variáveis ordinais,
[ ]1
se é inteiro100
se não é inteiro100
K
p
K
npX K
Pnp
X K+
== =
.
Note-se que a mediana é também um quantil de ordem 2.
EXEMPLO 1.2
Suponhamos a seguinte distribuição de frequências das idades (anos) de 90 indivíduos apresenta-
das no Quadro 1.4. Calcule 25P e 70P .
Quadro 1.4. Idades (anos) numa amostra de 90 indivíduos do sexo masculino
Idade Frequência
14 17
15 13
19 20
20 22
30 18
Resolução
Para
25P , 90 25
22, 5100 100np
K×= = = .
Como K não é inteiro, o [ ] [ ]25 231 23,5 15KP X X X+= = = = .
Para 70P ,
90 7063
100 100np
K×= = = .
Como K é inteiro, o 63 6470
22 2222
2 2X X
P+ += = = .
F I M D E E X E M P L O

C O N C E I T O S B Á S I C O S D A E S T A T Í S T I C A E D A A N Á L I S E E X P L O R A T Ó R I A D O S D A D O S 31
Cálculo de quantis para dados contínuos. Se a variável é contínua, estando os
dados agrupados em classes de frequência, podemos determinar o quantil i, iQ , pela
expressão, 1 i ii ci ci
i
n cum FQ l a
F−−= + , onde cil é o limite inferior da classe que
contém o quantil correspondente, in é o número de observações, 1 icum F − são as fre-
quências acumuladas até à classe anterior à do quantil, iF é a frequência da classe do
quantil e cia é a amplitude desta classe.
EXEMPLO 1.3
Calcular o 4º decil e o 70º percentil da seguinte distribuição das 40 observações apresentadas no Quadro 1.5.
Quadro 1.5. Distribuição de frequências de 40 observações
Classe iF 1 icum F −
[5; 10[ 8 8
[10; 15[ 12 20
[15; 20[ 17 37
[20; 25[ 3 40
Resolução
O 4º decil deve corresponder àquele que acumula 4
40 1610
× = observações. A classe que contém o
4º decil é [ [10;15 . Assim o 4º decil é calculado por 416 8
Decil 10 5 13, 3312
− = + × = .
O cálculo do 70º percentil faz-se de modo idêntico. Ele acumula 70
40 28100
× = observações. Ora a
acumulação das 28 observações cai na classe [ [15; 20 , portanto, 70
28 20Percentil 15 5
17− = + × =
17, 35= .
F I M D E E X E M P L O
1.6.2. Medidas de dispersão
As medidas de localização não são suficientes, por si só, para bem caracterizar a distribuição de frequências de uma variável, devendo ser complementadas por medidas que deem uma indicação da dispersão dos valores da variável.

32 M É T O D O S E S T A T Í S T I C O S P A R A O E N S I N O E A I N V E S T I G A Ç Ã O N A S C I Ê N C I A S D A S A Ú D E
Amplitude. Também chamada de intervalo de variação, R, é dada pela diferença entre os valores extremos, isto é, R = Xmáximo – Xmínimo.
Amplitude interquartílica. Uma desvantagem da amplitude, R, é o facto de ser cal-culada apenas com dois valores, o menor e o maior valor observado. Ora a amplitude interquartílica não tendo esta desvantagem reflete a variabilidade das 50% observações centrais e define-se como sendo a diferença entre o terceiro e o primeiro quartil,
3 1AIQ Q Q= − .
Dispondo do conjunto de observações { }9;10;11;18;19; 23; 30 vê-se que 1 10Q = e
3 23Q = , então, 3 1 23 10 13AIQ Q Q= − = − = .
Variância. Representada por 2S , é a soma dos quadrados das diferenças entre os valores observados e a sua média divididos pela dimensão da amostra, ou seja,
( )2
2 1
n
ii
X X
Sn
=−
=
. Esta fórmula só é válida para amostras grandes. Assim, a
variância é usualmente calculada pela expressão,
( )2
2 1
1
n
ii
X X
Sn
=−
′ =−
, designando-
-se por variância corrigida. A (n – 1) chamamos número de graus de liberdade. Se a variância é calculada para uma população finita de N elementos, então é designada por
2σ e o seu valor é dado por,
( )2
2 1
1
N
ii
X
N=
− μσ =
−
.
Desvio padrão. A variância tem o inconveniente de ser expressa no quadrado das unidades respetivas. O desvio padrão, S, pelo contrário, exprime-se na mesma unidade de medida das observações e é dado pela raiz quadrada positiva da variância.
O desvio padrão de uma população finita, σ , é obtido extraindo a raiz quadrada à expressão que fornece
2σ .
Coeficiente de variação. O desvio padrão é uma medida de variação muito útil quando nos limitamos a observar um determinado conjunto de dados. Porém, quando desejamos comparar a dispersão em dois conjuntos de dados, deve-se expressar o desvio padrão em valor relativo à média das observações, numa forma adimensional e
geralmente expresso em percentagem, por, 100S
CVX
= × .

Atualmente a estatística é uma ferramenta indispensável para os profissionais na área dasciências da saúde. Conhecer, interpretar e aplicar a teoria e as técnicas estatísticas é funda-mental para uma boa investigação, estudo e práticas esclarecidas.
Este livro, com evidente cuidado pedagógico, e recorrendo permanentemente a exemplospráticos, apresenta em 21 capítulos e vários anexos todo o instrumental teórico e prático paradotar o leitor de tudo o que necessita para enfrentar os obstáculos que poderá encontrar no seuestudo ou profissão.
Nos primeiros capítulos apresenta os conceitos básicos da Estatística e o ambiente e utili-zação do software SPSS. Depois aborda a noção de probabilidade, as distribuições amostrais eos vários tipos de amostragem. Seguidamente trata da comparação de dados categóricos edados numéricos em duas ou mais amostras independentes, fazendo intervir o teste do qui--quadrado, o teste -Student (também para variáveis emparelhadas) e o teste da análise devariância (ANOVA). Discute o modelo de regressão e a correlação e os diferentes testes nãoparamétricos. Nos capítulos seguintes apresenta as medidas de força da associação ou efeito,através dos , risco relativo e da diferença de risco. Nos capítulos finais apresenta aparte mais complexa constituída pelos modelos de regressão logística, análise de sobrevivên-cia, regressão de Cox e regressão de Poisson e aborda a meta-análise, principalmente no quediz respeito à sua representação gráfica ( ).
Este livro destina-se pois a todos os estudantes e profissionais que, na sua atividade profis-sional ou nos seus estudos necessitem de aprender ou consolidar os conceitos teóricos estatís-ticos e a sua respetiva transposição para a prática.
t F
odds ratio
forest plot
O presente trabalho escrito com a clareza, que só quem viveu explicando consegueimprimir, é um auxílio de extrema utilidade, não só para quem se queira envolver nainvestigação biomédica, mas também para quem necessita de compreender a linguagemda maioria dos trabalhos publicados. (...) O recurso aos exemplos reais é sem sombra dedúvida, mais um dos argumentos que pode justificar a recomendação deste livro aosprofissionais de saúde.
A publicação desta obra teve o apoio:
Prof. Alexandre Castro CaldasProfessor Catedrático
Diretor do Instituto de Ciências da Saúde – Universidade Católica Portuguesa
FRANCISCO MERCÊS DE MELLO • RITA CABRAL GUIMARÃESFrancisco Mercês de Mello
Curso de Engenheiro Agrónomoem 1961 (UTL). Bacharelato emMatemática Aplicada em 1974(ULM). Doutoramento emEngenharia Agrícola em 1987(U. Évora). Professor associado(aposentado) da Universidadede Évora.
Rita Cabral Guimarães
Licenciatura em EngenhariaAgrícola em 1993 (U. Évora).Mestrado em Engenharia do Soloe da Água em 1997 (U. Évora).Doutoramento em Engenharia dosRecursos Hídricos em 2005 (U. Évora).Licenciatura em Engenharia Civilem 2013 (U. Évora). Professora auxiliarna Universidade de Évora.
Métodos Estatísticospara o Ensino e a Investigação nas
Ciências da Saúde
– 1.00 0.00 1.00 2.00 3.00
FavortratamentoFavortratamento
Favorplacebo
Favorplacebo
Com exemplos extraídos de revistase publicações médicas
Apresentação e utilização do SPSS
Méto
do
s Estatístico
sp
ara o E
nsin
o e a Investig
ação n
as
Ciên
cias da S
aúd
eMERCÊS
DE MELLO•
RITAGUIMARÃES
EDIÇÕES SÍLABO
Prefácio
Prof. Alexandre Castro Caldas
ISBN 978-972-618-805-6
9 188056789726
506