Embed Size (px)
Citation preview

Comparador de Preços Inteligente
Jhonny Alexander Aldeia de Jesus
Dissertação para obtenção do Grau de Mestre em
Engenharia Informática e de Computadores
Orientador: Professor José Alberto Rodrigues Pereira Sardinha
Júri
Presidente: Professor Alberto Manuel Rodrigues da SilvaOrientador: Professor José Alberto Rodrigues Pereira Sardinha
Vogal: Professor Bruno Emanuel da Graça Martins
Junho 2015


Agradecimentos
É com muita satisfação que expresso o meu mais profundo agradecimento a todos aqueles que torna-
ram possível a realização deste trabalho, e também aos diversos professores que me acompanharam
durante estes anos, que muito contribuíram para o enriquecimento da minha formação académica e
científica. Ao Professor Alberto Sardinha, o meu mais profundo Obrigado, pela orientação, ajuda, ami-
zade, disponibilidade e apoio, foi imprescindível para a conclusão desta dissertação.
Aos meus amigos e colegas, em especial a Nuno Marcos, queria expressar a minha mais sincera grati-
dão, obrigado pelo apoio, companheirismo, ajuda e motivação nas alturas de desânimo.
Á minha namorada, o meu mais sincero obrigado, pelo apoio, paciência, disponibilidade e ajuda, que
sempre me demostraste nas horas de maior aflição, com as tuas palavras de motivação fizeste-me
acreditar que seria capaz.
Quero agradecer à minha família, em especial aos meus pais e aos meus irmãos, por todo o apoio que
me deram, pela paciência, e por sempre acreditarem em mim, pois sem eles, não teria atingido esta
meta. O meu muito Obrigado.
i


Abstract
Price Comparators are tools that help users on the Internet to identify product prices obtained by
different e-commerce stores. These comparators help perform your shopping, finding the best deals
and offers.
Thus, we intend to implement a Intelligent Price Comparator using a Data Mining (DM) technique, that
searches for products in various e-commerce stores and finds results of similar products.
This project aims to evaluate existing technological capabilities, integrating internet information extrac-
tion and data analysis with DM techniques in price comparators, creating mechanisms that allow us to
perform different approaches. The evaluation will be made based on a comparison where we highlight
the differences, advantages and disadvantages of the intelligent price comparator and current market
price comparators with existing methodologies that support the veracity of the results of the techniques
applied.
Keywords
Web Crawler, Web Spider, Web Scraping, Data Mining, K-means, Incremental K-means, Internet,
Price comparators, Services search.

iv

Resumo
Os Comparadores de Preços são ferramentas que auxiliam os utilizadores na internet para identifi-
car preços de produtos dados por diferentes lojas e-commerce. Estes comparadores ajudam a realizar
as suas compras, localizando as melhores oportunidades e ofertas.
Assim, pretende-se implementar um Comparador de Preços Inteligente utilizando uma técnica de (Data
Mining) (DM), que pesquise produtos em diversas lojas e-commerce, e encontre resultados de produtos
semelhantes.
Este projeto pretende avaliar as potencialidades tecnológicas existentes, integrando a extração de in-
formação da internet e a análise dos dados com técnicas de DM num Comparador de Preços, criando
assim mecanismos que nos permitam realizar abordagens diferentes. A avaliação será efetuada com
base numa comparação onde realçamos as diferenças, vantagens e desvantagens do Comparador
de Preços Inteligente e os Comparadores de Preços do mercado, com metodologias existentes que
suportem a veracidade dos resultados das técnicas aplicadas.
Palavras Chave
Web Crawler, Web Spider, Web Scraping, Data Mining, K-means, Incremental K-means, Internet,
Comparador de preços, Serviços de pesquisa.
v


Índice
1 Introdução 1
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Comparadores de Preços . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Secções do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Trabalho Relacionado 5
2.1 Comparadores de Preços . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 PriceGrabber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1.A Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1.B Data Feed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2 Buscapé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2.A Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2.B Data Feed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.2.C Application Programming Interface (API) . . . . . . . . . . . . . . . . . . 10
2.1.3 Kuanto Kusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.3.A Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.3.B Data Feed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.1.3.C API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Extração de Dados em Páginas de Internet . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.1 Web Crawlers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.2 Web Spider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3 Web Scraping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.4 Ferramentas para Web Scrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.4.A Jsoup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Análise de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.1 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.2 K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3.2.A Incremental K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3.2.B Escolha do K ideal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
vii

3 Arquitetura 25
3.1 Arquitetura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 PC Core . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.1 Modo 1 - WebScrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2 Modo 2 - Configuração e Execução . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.2.A Configuração . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.2.B Execução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3 PC Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4 Base de Dados (BD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.5 Comunicação entre PC Core e PC Interface é Interação com o Utilizador . . . . . . . . . 39
4 Caso de Estudo 45
4.1 Variáveis em Estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2 Extração de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Pré-processamento dos Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4 Análises de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.5 Resultados Experimentais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.1 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.2 Vantagens e Desvantagens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Conclusões e Trabalho Futuro 59
5.1 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2 Trabalho Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
Bibliography 63
Apêndice A Anexos A-1
A.1 Página principal do PriceGrabber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-2
A.2 Página principal do KuantoKusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-3
A.3 Estrutura HyperText Markup Language (HTML) do Título e Preço das televisões na WortenA-4
A.4 Estrutura HTML das características das televisões na Worten . . . . . . . . . . . . . . . . A-5
A.5 Apresentação da execução de /PCInterface/fk.php . . . . . . . . . . . . . . . . . . . . . . A-6
A.6 Exemplos de execução de F(k) na população de dados em estudo . . . . . . . . . . . . . A-7
A.7 PC Core Packages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-8
A.8 Package db . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-9
A.9 Package product . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-10
A.10 Package ws . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-11
A.11 Package dm.clustering.kmeans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-12
A.12 Package pc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-13
viii

Lista de Figuras
2.1 PriceGrabber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Formatação de dados para os ficheiros Text File (TXT) e Comma Separated Values (CSV)
para DataFeed do PriceGrabber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Buscapé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Resultados de uma pesquisa no Buscapé . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5 XML Data Feed do Buscapé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.6 Kuanto Kusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.7 Resultados de uma pesquisa no KuantoKusta . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.8 TXT Data Feed do KuantoKusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.9 Formato resposta em Extensible Markup Language (XML) de um pedido GET KuantoKusta 13
2.10 Google Crawling[1] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.11 Clusters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.12 Pseudocódigo do k-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.13 Iterações do K-Means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.14 Incremental K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.15 Função F(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.16 Funções complementares para o cálculo de F(k) . . . . . . . . . . . . . . . . . . . . . . . 21
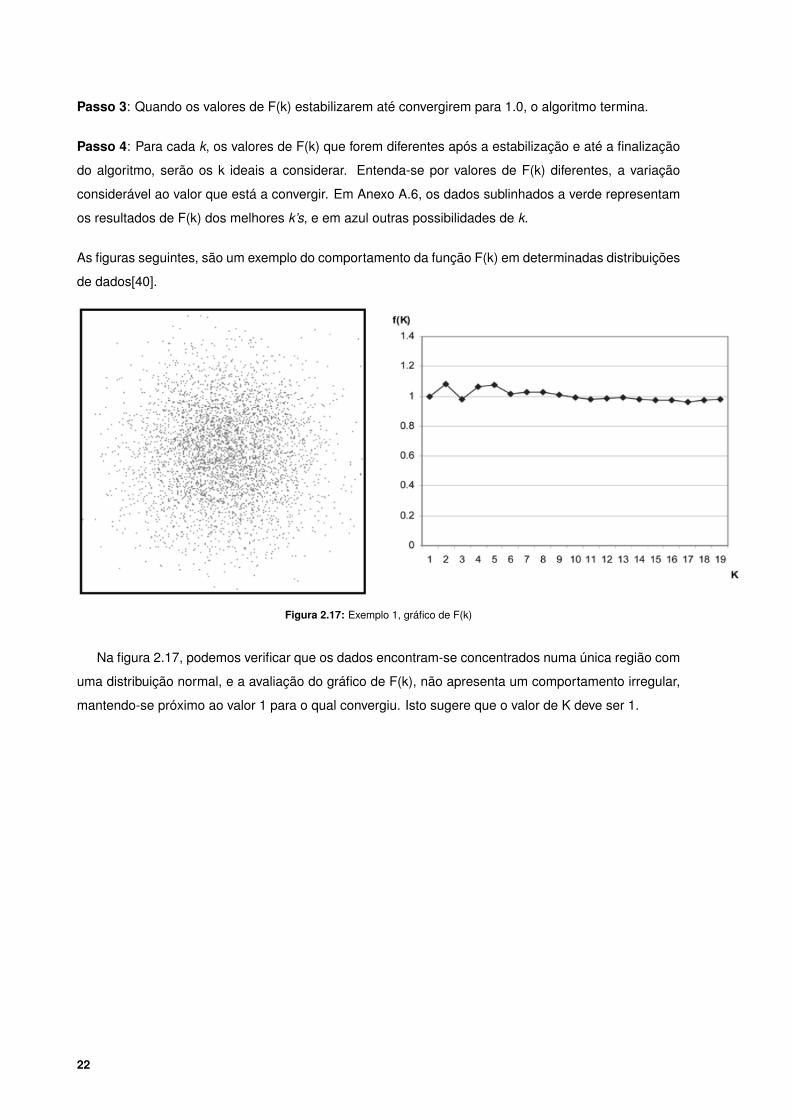
2.17 Exemplo 1, gráfico de F(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.18 Exemplo 2, gráfico de F(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.19 Exemplo 3, gráfico de F(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1 Comparador de Preços Inteligente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
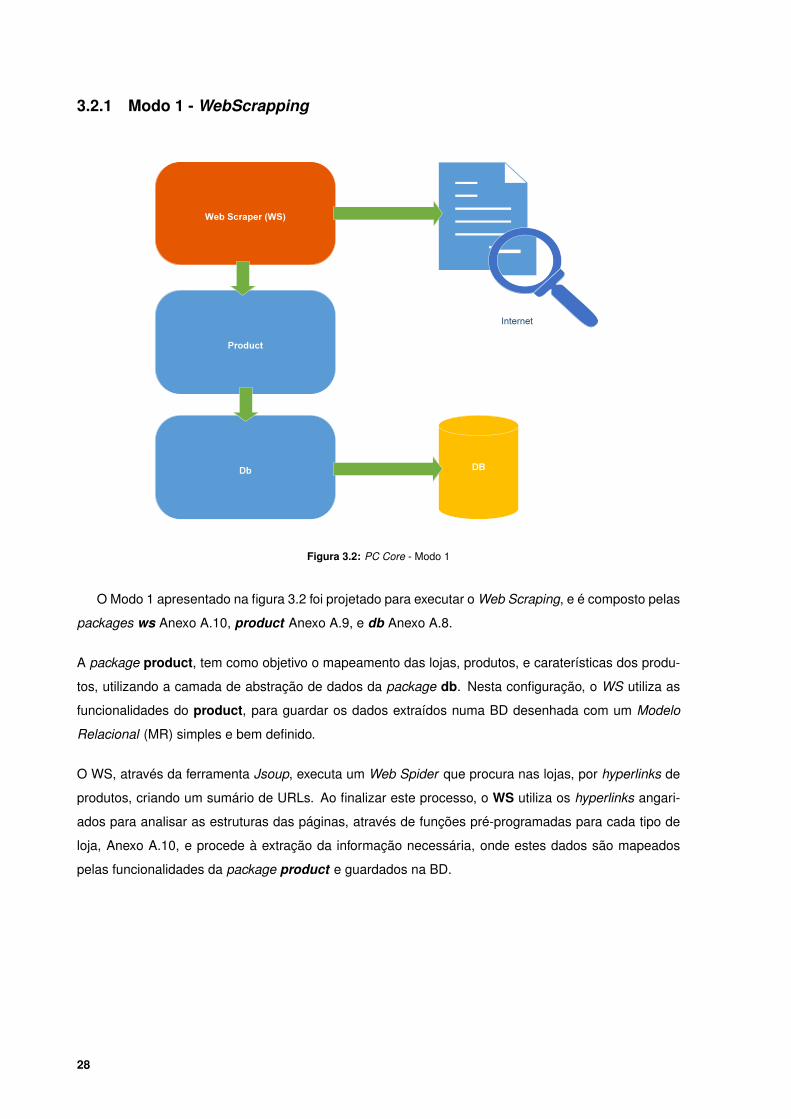
3.2 PC Core - Modo 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 Diagrama de sequência do PC Core Modo 1 (Web Scraping) . . . . . . . . . . . . . . . . 29
3.4 Iniciação do Web WebScraper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
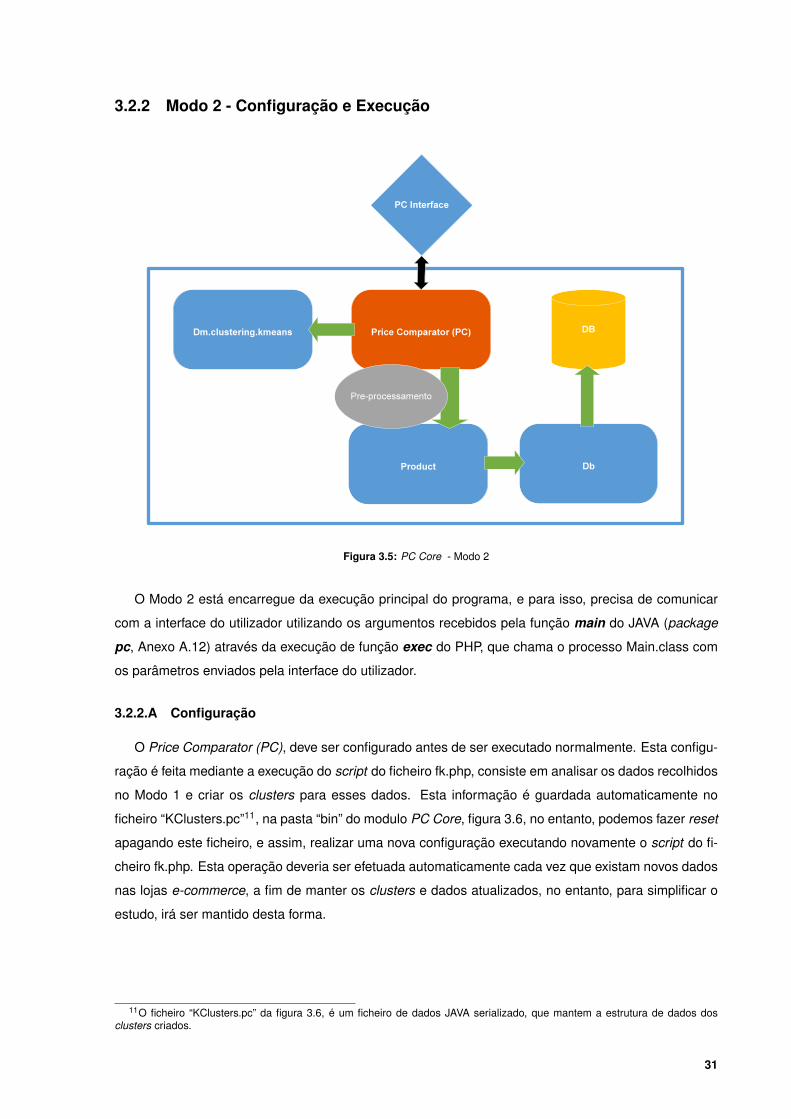
3.5 PC Core - Modo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.6 Ficheiro KClusters.pc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.7 Ficheiro fk.php . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.8 Diagrama de sequência do PC Core Modo 2 . . . . . . . . . . . . . . . . . . . . . . . . . 33
ix

3.9 Geração dos Cluster e Avaliação de possíveis K’s, com base na população de televisões
em estudo. Código é executado no método detailedClusteringKMeans da Classe Pri-
ceComparator e Corresponde a Envia Dados para o Gera clustering no Diagrama de
Sequencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.10 Configuração e compilação dos dados. Executado no método main da package pc . . . 35
3.11 Screenshot PC Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.12 Modelo Relacional (MR) da Base de Dados (BD) . . . . . . . . . . . . . . . . . . . . . . . 37
3.13 Diagrama de sequência do PC Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.14 Pedido efetuado pelo PC Interface ao PC Core (Linguagem: PHP - Ficheiro index.php no
Modulo PC Interface). Corresponde a seta "Envia dados"do processo PC Interface no
diagrama de Sequencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.15 Interpretação e Apresentação da resposta ao utilizador pelo PC Interface (Linguagem:
PHP, HTML - Ficheiro index.php no Modulo PC Interface). Corresponde a seta "Dados
dos produtos"do processo PC Interface no diagrama de Sequencia. . . . . . . . . . . . . 40
3.16 Ficheiro de avaliação fk.php do PC Interface (Linguagem: PHP) . . . . . . . . . . . . . . 41
3.17 Resposta gerada pelo PC Core (Linguagem: JAVA). Executado no método detailedClus-
teringKMeans da Classe PriceComparator . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.18 Interface "Pesquisa por Parâmetros", correspondente ao modulo PC Interface . . . . . . . 43
4.1 Método que obtém o Nome / Titulo do produto - Worten[2] . . . . . . . . . . . . . . . . . . 47
4.2 Método que obtém o Nome / Titulo do produto - Fnac[3] . . . . . . . . . . . . . . . . . . . 47
4.3 Método o Preço do produto - Worten[2] . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.4 Método o Preço do produto - Fnac[3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.5 Método para obter a Uniform Resource Locator (URL) da imagem do produto do lojista -
Worten[2] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.6 Método para obter a URL da imagem do produto do lojista - Fnac[3] . . . . . . . . . . . . 49
4.7 Método que obtem a listagem das caracteristicas de um produto - Worten[2] . . . . . . . 49
4.8 Método que obtem a listagem das caracteristicas de um produto - Fnac[3] . . . . . . . . . 49
4.9 Pré-processamento da população de dados (Linguagem: JAVA) . . . . . . . . . . . . . . 51
4.10 Pré-processamento da população de dados (Linguagem: JAVA) . . . . . . . . . . . . . . 52
4.11 Normalização da população de dados (Linguagem: PHP) . . . . . . . . . . . . . . . . . . 53
4.12 Resultado 1, Anexo A.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.13 Resultado 2, Anexo A.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.14 Resultado 3, Anexo A.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
x

Abreviações
API Application Programming Interface
BD Base de Dados
CPC Custo-por-clique
CSS Cascading Style Sheets
CSV Comma Separated Values
DAO Direct Access Object
DOM Document Object Model
DM Data Mining
DBMS Data Base Management System
EAN European Article Number
HDMI High-Definition Multimedia Interface
HTML HyperText Markup Language
HTML5 HyperText Markup Language v5
HTTP Hypertext Transfer Protocol
HTTPS Hypertext Transfer Protocol Secure
ISBN International Standard Book Number
ID Identifier
IPv6 Internet Protocol version 6
JSON JavaScript Object Notation
LN Língua Natural
MR Modelo Relacional
PHP Hypertext Pre Processor
xi

SKU Stock Keeping Unit
SQL Structured Query Language
SSL Secure Socket Layer
TXT Text File
UPC Universal Product Code
UML Unified Modeling Language
URL Uniform Resource Locator
WS Web Services
WWW World Wide Web
W3C World Wide Web Consortium
XML Extensible Markup Language
xii

1Introdução
Contents1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Comparadores de Preços . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Secções do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1

1.1 Motivação
Os Comparadores de Preços (Price Comparison Website) são ferramentas para comparar preços
de produtos, também conhecidas como Price Comparison Service, ou Price Engine, estes, apresentam
listas de diferentes preços para produtos do mesmo género. Os Comparadores de Preços não são
locais de venda de produtos, como as lojas online (também conhecidas como lojas e-commerce), mas
sim agregadores dos produtos desses locais.
Atualmente existe uma grande variedade de mecanismos que facilitam estas tarefas, como por exem-
plo, os motores de busca integrados nas proprias lojas online: Fnac[3], Worten[2], os quais ajudam e
fornecem informação sobre os produtos pretendidos pelo cliente. Estes também podem procurar por
produtos extraídos das próprias lojas e-commerce, para posteriormente comparar o preço, e/ou filtrar
outras caraterísticas, como por exemplo: num televisor temos a dimensão diagonal do ecrã, o consumo
elétrico em Wats, entre outros.
Existem diferentes formas, dos Comparadores de Preços executarem as suas pesquisas:
• Online - A pesquisa é feita diretamente nas páginas de internet nesse mesmo instante;
• Offline - Os dados ou meta dados sobre os produtos que os utilizadores pretendem pesquisar já
se encontram numa Base de Dados (BD) local ao programa;
• Metasearch - Envia pedidos dos utilizadores para outros motores de pesquisa e/ou BD e agrega
os resultados em uma única lista ou exibe-os de acordo com sua fonte[4].
A tecnologia utilizada na internet está em constante evolução e sempre a melhorar, por isso, os
Comparadores de Preço seriam ferramentas interessantes para estudo junto com abordagens tecnoló-
gicas aplicadas a estes, utilizando métodos estáticos e matemáticos que poderiam ajudar a fazer uma
procura mais personalizada.
1.2 Comparadores de Preços
Os Comparadores de Preços existentes no mercado são diferentes entre eles, alguns com capaci-
dade de oferecer maior diversidade de produtos do que outros, interfaces alternativas, inclusive, apre-
sentações diferentes para os produtos comparados. O critério mais importante para o consumidor na
seleção de um produto, é o preço face as caraterísticas e marcas.
É importante referir que conceitos como: a extração de dados de internet, a análise de dados, e a apre-
sentação dos resultados, são componentes dos Comparadores de Preços que os tornam ferramentas
interessantes de estudo, não apenas pelas diversas possibilidades de implementação, arquiteturas e
modelos de negócio, mas também, para outras possíveis soluções a adotar, onde será introduzido o
caso de estudo de este trabalho.
2

1.3 Objetivos
Pretende-se desenvolver um Comparador de Preços Inteligente que utilize uma técnica de Data Mi-
ning (DM)1, que pesquise produtos em diversas lojas e-commerce2, de forma a agrupar produtos com
caraterísticas semelhantes.
O Comparador de Preços Inteligente, será semelhante aos comparadores de preços existentes:
PriceGrabber[5], Buscapé[6], e KuantoKusta[7]. A diferença encontra-se no funcionamento e na apre-
sentação dos resultados, face às caraterísticas escolhidas, num processo de procura de um produto do
mesmo género.
Os Comparadores de Preços, normalmente, funcionam com consultas Structured Query Language
(SQL) à BD e podem utilizar ficheiros de formatos e estruturas diferentes e/ou disponibilizar Web Servi-
ces (WS) para fazer o carregamento da informação. O nome atribuído a este processo é Data Feed.
Nestes Comparadores de Preços, o utilizador escolhe um produto pesquisando através de um campo
de texto ou pela seleção de categorias, até atingir o género de produto pretendido, podendo posterior-
mente restringir as caraterísticas disponibilizadas.
Por sua vez, o Comparador de Preços Inteligente utiliza diferentes abordagens, inclui técnicas de Web
Scraping para extrair informação das lojas e-commerce, e Clustering como técnica de DM escolhida
para a análise dos dados. Assim, o utilizador escolhe diretamente as caraterísticas do produto pre-
tendido, sendo-lhe apresentados como resultado, produtos semelhantes ou iguais às caraterísticas
indicadas.
1.4 Secções do Documento
O Caso de Estudo está organizado da seguinte forma:
No Capitulo 2 são apresentados conceitos básicos, introduzindo alguns Comparadores de Preços com
a sua respetiva arquitetura e funcionamento, para além dos algoritmos utilizados na implementação e
avaliação do programa a implementar.
O Capitulo 3 contem a Arquitetura do Comparador de Preços inteligente, assim como os passos para
o desenvolvimento e execução, código e diagramas de sequências dos módulos que fazem parte da
arquitetura.
No Capitulo 4 temos o caso de estudo, que aborda as variáveis em estudo, o processo de extração de
dados necessários para construir a população de dados a utilizar, o seu pré-processamento, a análise
1DM é o processo de análise de grandes quantidades de dados à procura de padrões consistentes, e envolve métodos queintersetam Inteligência artificial, Aprendizagem máquina e estatística.
2Lojas e-commerce também será denominado ao longo do texto por lojas online.
3

destes, e por fim mostro os resultados do estudo, finalizando com o Capitulo 5 correspondente as
conclusões.
4

2Trabalho Relacionado
Contents2.1 Comparadores de Preços . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 PriceGrabber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Buscapé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 Kuanto Kusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Extração de Dados em Páginas de Internet . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.1 Web Crawlers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.2 Web Spider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3 Web Scraping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.4 Ferramentas para Web Scrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Análise de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.1 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.2 K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5

Nesta secção será apresentado o estado da arte correspondente às técnicas e ferramentas exis-
tentes na atualidade que se pretendem utilizar no estudo, assim como alguns comparadores de preços
existentes no mercado. Desta forma, este capítulo será dividido em três partes, onde são apresentados
alguns Comparadores de Preços, técnicas e ferramentas para Extração de Dados Web, e a Análise de
Dados que compreendem técnicas de DM.
2.1 Comparadores de Preços
Com base em diversas pesquisas feitas na internet, entre elas artigos que avaliam a popularidade
dos diversos Comparadores de Preços [8][9][10][11][12], foi escolhido para estudo os comparadores de
preços PriceGrabber[5], Buscapé[6] e KuantoKusta[7], pela sua popularidade internacional e na comu-
nidade lusófona (Buscapé e KuantoKusta).
Estes serão utilizados como base de exemplo para este caso de estudo. Para o utilizador, são seme-
lhantes quanto à utilização e apresentação dos resultados de uma pesquisa, no entanto, apesar das
semelhanças, são diferentes no funcionamento e apresentação da informação.
Os Comparadores de Preços podem disponibilizar Application Programming Interface (API)s que per-
mitem consultar informações para desenvolvimento de aplicações externas, e/ou pontos de acesso
para WS, além disso, oferecem meios para o carregamento da informação das lojas e-commerce. Este
processo é chamado de Data Feed.
2.1.1 PriceGrabber
Figura 2.1: PriceGrabber
6

O PriceGrabber é um Comparador de Preços que opera na América do Norte e no Reino Unido,
comparando milhares de produtos e serviços exclusivos em mais de 26 categorias. O site oferece aos
clientes, a possibilidade de comparar preços e caraterísticas dos produtos e/ou serviços, em diversas
lojas online, permitindo assim aos utilizadores, encontrarem o artigo desejado. Ele inclui também:
cálculos Bottom Line Price3, classificações e opiniões de comerciantes, comentários detalhados sobre
o produto, comparações de produtos lado a lado, e, notificações de e-mail com os melhores preços e
disponibilidade na Internet.
Este apresenta na página principal numa abordagem de cima para baixo (Anexo A.1): uma barra no
topo com pequenos menus de informação auxiliar a todo o site, uma barra de pesquisa, as categorias
dos produtos e serviços, dois banners publicitários, categorias mais populares e, no fim, informações
de contacto, suporte entre outros.
2.1.1.A Funcionamento
O utilizador pode começar a procura de um produto pela barra de pesquisa, categorias, ou também
utilizar os banners publicitários que o levem diretamente ao lojista do produto, sem oportunidade de fa-
zer qualquer tipo de comparação. Porém, se a pesquisa é feita pelos meios normais, isto é, através da
barra de pesquisa ou pelas categorias, ser-lhe-á apresentada a interface com uma listagem de produtos
possíveis a comparar. A diferença do PriceGrabber em relação aos comparadores que falarei adiante,
está em que este acrescenta uma forma de comparação, onde o utilizador pode escolher até quatro
produtos da lista apresentada para compará-los lado a lado. Além disso na listagem dos produtos,
cada produto da lista apresenta um botão para ver o produto diretamente na loja, ou compara-lo direta-
mente com outros produtos iguais de diversas lojas e-commerce, e por sua vez, todo este processo é
acompanhado por uma barra lateral com opções de filtragem das caraterísticas dos produtos, como: o
preço, marca entre outros.
2.1.1.B Data Feed
O Data Feed é um processo de carregamento de informação que serve para apresentar os dados
das lojas e-commerce e no PriceGrabber é feito através da submissão de um ficheiro em formato Text
File (TXT), Comma Separated Values (CSV) ou Extensible Markup Language (XML). (Esta informação
pode ser encontrada na documentação do PriceGrabber[13]).
Os ficheiros em formatos TXT e CSV, devem respeitar um conjunto de requerimentos mínimos, com
uma formatação que consta de um cabeçalho na primeira linha e cada uma das linhas seguintes des-
creve um produto, como apresentado na figura 2.2. O ficheiro em formato XML, pode ser gerado
automaticamente por lojas e-commerce que funcionem nas plataformas da Yahoo! Store ou pode ser
criado manualmente.
3Impostos e transporte incluído no preço.
7

Figura 2.2: Formatação de dados para os ficheiros TXT e CSV para DataFeed do PriceGrabber
2.1.2 Buscapé
Figura 2.3: Buscapé
O BuscaPé é um Comparador de Preços, brasileiro, líder na decisão de compra, na América Latina.
Este disponibiliza na sua página principal, uma barra de pesquisa geral, uma coluna com as diversas
categorias de produtos, um banner de apresentação dos seus serviços, uma secção com os produtos
mais populares, e as suas principais lojas, como se pode ver na figura 2.3. Alem disso, disponibiliza
um meio para a integração dos produtos das lojas e-commerce, e uma API para oferecer serviços
publicitários.
2.1.2.A Funcionamento
Quando um utilizador pesquisa por um determinado produto, tem de o fazer pela barra de pesquisa
ou através das categorias de produtos apresentadas na coluna lateral. Posterior a esse processo de
escolha, será apresentada a interface dos resultados com uma listagem de produtos do mesmo género,
8

que inclui o preço, um nome, marca, caraterísticas, e um campo de texto para filtrar as caraterísticas
dos produtos, como apresentado na figura 2.4.
Figura 2.4: Resultados de uma pesquisa no Buscapé
2.1.2.B Data Feed
O Data Feed no BuscaPé é feito através de um ficheiro que o lojista irá fornecer em formato XML,
como apresentado na figura 2.5, o qual possui informações relacionadas ao produto que ele quer pu-
blicar no site. O Uniform Resource Locator (URL) que aponta para o ficheiro XML é fornecido aos
servidores do Buscapé. Um robô denominado Spider, acesa e extrai todas as informações necessárias
contidas no XML automaticamente. Mais informações podem ser consultadas na documentação do
Buscapé[14].
9

Figura 2.5: XML Data Feed do Buscapé
As informações mínimas que devem ser fornecidas para que o XML seja válido são as seguintes:
1. Valor e hyperlink do produto para cada canal (Buscapé ou Lomadee4)
2. Título do produto (tamanho máximo: 250 caracteres)
3. URLs das imagens (maior tamanho disponível)
4. Categoria na qual o produto pertence (endereço completo, exemplo: "Moda / Camisa Masculina /
Polo")
5. International Standard Book Number (ISBN) (poderá ser ISBN-10 ou ISBN-13)
6. ID da oferta (Stock Keeping Unit (SKU))
7. Código de barras (deverão ser Universal Product Code (UPC) ou European Article Number (EAN))
2.1.2.C API
O Buscapé utiliza um modelo de negócio Custo-por-clique (CPC) em que qualquer pessoa se pode
registar como programador no portal de desenvolvimento do BuscaPé e é recompensado por cada
clique que utilizadores façam num hyperlink a partir da sua aplicação. A API do Buscapé fornece
pontos de acesso aos WS, para poder apresentar serviços publicitários da sua base de produtos em
aplicações, sites, lojas, banners e plugins.
4A Lomadee é uma plataforma que tem como objetivo procurar as melhores oportunidades de negócio[15].
10
Para o programador utilizar a API[16], o primeiro passo é o registo no portal de desenvolvimento do
BuscaPé de modo a obter um Identifier (ID). Este ID será utilizado para identificar o programador em
todo o processo de comunicação entre a aplicação desenvolvida e os WS do BuscaPé.
Esta comunicação é feita através da construção de uma Uniform Resource Locator (URL) para fazer o
pedido ao WS, que responde em formato XML sendo este o formato de resposta padrão, podendo ser
utilizado como opção JavaScript Object Notation (JSON).
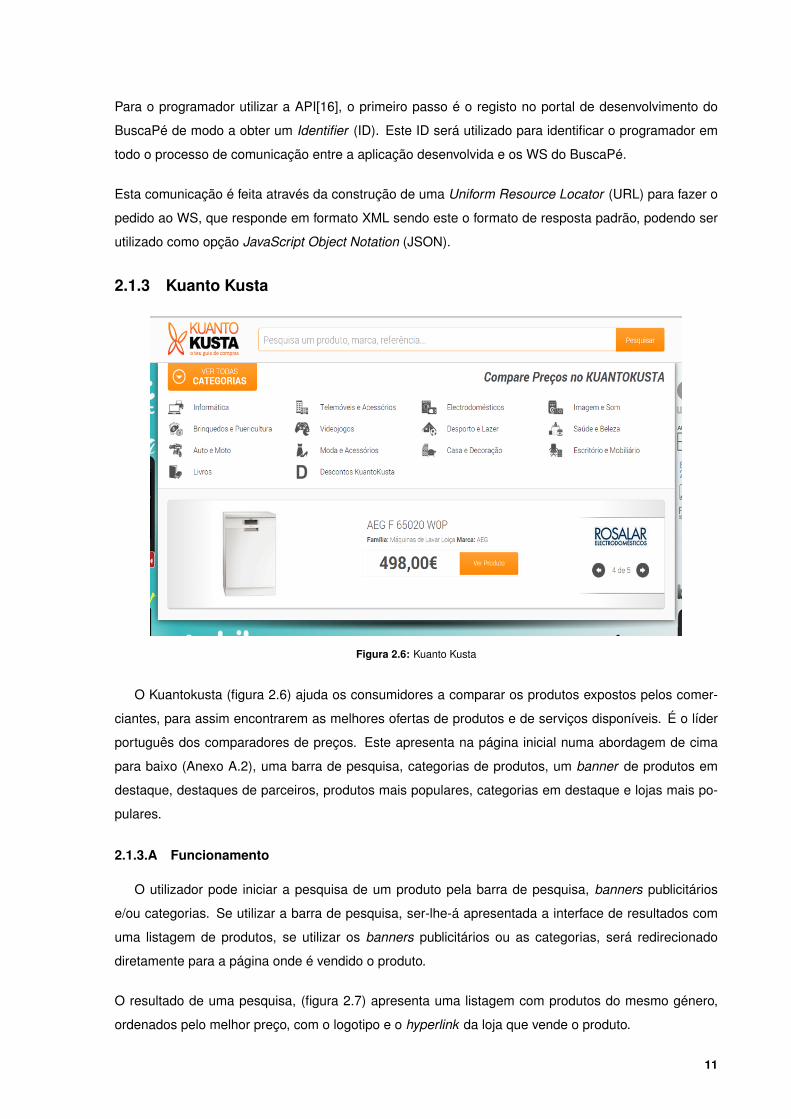
2.1.3 Kuanto Kusta
Figura 2.6: Kuanto Kusta
O Kuantokusta (figura 2.6) ajuda os consumidores a comparar os produtos expostos pelos comer-
ciantes, para assim encontrarem as melhores ofertas de produtos e de serviços disponíveis. É o líder
português dos comparadores de preços. Este apresenta na página inicial numa abordagem de cima
para baixo (Anexo A.2), uma barra de pesquisa, categorias de produtos, um banner de produtos em
destaque, destaques de parceiros, produtos mais populares, categorias em destaque e lojas mais po-
pulares.
2.1.3.A Funcionamento
O utilizador pode iniciar a pesquisa de um produto pela barra de pesquisa, banners publicitários
e/ou categorias. Se utilizar a barra de pesquisa, ser-lhe-á apresentada a interface de resultados com
uma listagem de produtos, se utilizar os banners publicitários ou as categorias, será redirecionado
diretamente para a página onde é vendido o produto.
O resultado de uma pesquisa, (figura 2.7) apresenta uma listagem com produtos do mesmo género,
ordenados pelo melhor preço, com o logotipo e o hyperlink da loja que vende o produto.
11
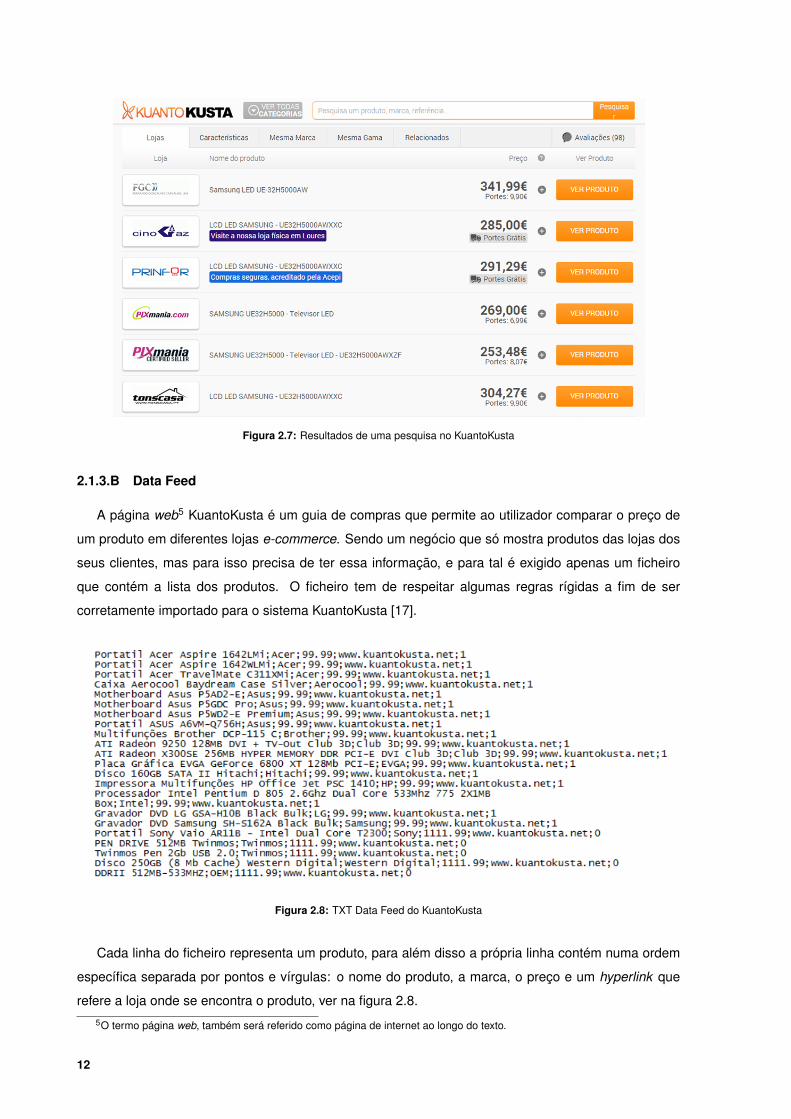
Figura 2.7: Resultados de uma pesquisa no KuantoKusta
2.1.3.B Data Feed
A página web5 KuantoKusta é um guia de compras que permite ao utilizador comparar o preço de
um produto em diferentes lojas e-commerce. Sendo um negócio que só mostra produtos das lojas dos
seus clientes, mas para isso precisa de ter essa informação, e para tal é exigido apenas um ficheiro
que contém a lista dos produtos. O ficheiro tem de respeitar algumas regras rígidas a fim de ser
corretamente importado para o sistema KuantoKusta [17].
Figura 2.8: TXT Data Feed do KuantoKusta
Cada linha do ficheiro representa um produto, para além disso a própria linha contém numa ordem
específica separada por pontos e vírgulas: o nome do produto, a marca, o preço e um hyperlink que
refere a loja onde se encontra o produto, ver na figura 2.8.5O termo página web, também será referido como página de internet ao longo do texto.
12

2.1.3.C API
O KuantoKusta também disponibiliza pontos de acesso para WS, distribuídos em três tipos de
acesso: Private (para logistas), Public(livre acesso), Enterprise (ainda não se encontra devidamente
implementado). Estes são acedidos pelos métodos Hypertext Transfer Protocol (HTTP) POST ou GET,
sendo GET utilizado por todos os pedidos feitos via URL. Os métodos de acesso disponibilizados pela
API são os seguintes[18]:
KKPrivate
• UpdateProducts - Atualiza o preço dos produtos pelo código de barras;
• InfoPrice - Apresenta informações sobre um preço por ID;
KKPublic
• ListBestPrice - Listagem de todos os produtos ou de um produto especifico pelo melhor preço;
• ListStorePrices - Listagem de todos os preços de um produto de uma loja especifica;
• ListProducts - Listagem de todos os produtos ou preços de produtos específicos;
• ListStores - Listagem de todas as lojas;
KKEnterprise
• UpdateProducts - Atualiza o preço dos produtos pelo código de barra de uma determinada data.
Á exceção do serviço UpdateProducts, todos os pedidos dos restantes são feitos através de URL, tendo
como formato de resposta XML. O UpdateProducts funciona com o formato XML, tanto para os pedidos,
como para as respostas.
Exemplo do funcionamento para o serviço InfoPrice:
Pedido via URL:
http://kuantokusta-api.appspot.com/kkprivate/infoprice/8001
Resposta ao pedido:
Figura 2.9: Formato resposta em XML de um pedido GET KuantoKusta
13

2.2 Extração de Dados em Páginas de Internet
Para extrair os dados, existem alguns passos que deverão ser tidos em conta, começando por um
conjunto de URLs, que servem de ponto de partida para atingir as páginas web6 desejadas. Se dese-
jarmos procurar por mais informação, continuamos explorando de hyperlinks em hyperlinks, avançando
em profundidade pela World Wide Web (WWW) até obter o que pretendemos retirar.
2.2.1 Web Crawlers
Web Crawlers [19] [20] é um Bot7 que navega, sistematicamente a WWW. O Crawler inicia-se com
uma listagem de URLs também chamadas de Seeds. À medida que o crawler visita essas URLs, este
identifica todos os hyperlinks na página, e acrescenta-os à lista8 de URLs, e esta por sua vez, será
visitada recursivamente.
Figura 2.10: Google Crawling[1]
Na figura 2.10 é apresentado um exemplo de crawling da Google[21]. Existem diversos programas
para Crawlers, que já estão desenvolvidos, tais como: Wget [22], Methabot [23], Googlebot [24], Msn-
bot [25]. Cada um destes, faz a sua função de crawlers otimizados e especializados em trabalhos
diferentes, por exemplo: O GoogleBot é especializado em indexar páginas e hyperlinks da internet no
seu motor de pesquisa, o Msnbot é utilizado particularmente no motor de pesquisa do MSN, Wget
e o Methabot são ferramentas Open Source que executam um crawler otimizado para procurar texto
de forma mais rápida e simplificada, evitando preocupações com protocolos HTTP, Hypertext Transfer
Protocol Secure (HTTPS), Secure Socket Layer (SSL), e Internet Protocol version 6 (IPv6); O Methabot
tem a particularidade de poder converter HyperText Markup Language (HTML) para XML.
6Páginas web também será referido como sites ou páginas de internet ao longo do texto.7Diminutivo de robot, também conhecido como internet bot ou web robot, esta é uma aplicação de software concebida para
simular ações humanas repetidas vezes.8Chamada de fronteira de rastreamento.
14

2.2.2 Web Spider
Web Spider [26][27] é um crawler que visita URLs nas páginas web, afim de criar uma lista de URLs
das mesmas, sendo este processo feito em simultâneo até visitar todos os URLs, de forma a criar uma
teia de todos estes.
2.2.3 Web Scraping
Web Scraping[28] é uma técnica de extração de informação das páginas de internet (sendo está
adotada pela maioria dos motores de pesquisa), que através da utilização de um web crawler trans-
forma dados não estruturados na web, (tipicamente páginas em formato HTML), em dados estruturados
que podem ser guardados numa BD.
2.2.4 Ferramentas para Web Scrapping
Após a realização de uma pesquisa, a extração de dados Web, será efetuada com uma das seguin-
tes ferramentas: Link Web Extractor [29], Web-Harvest [30] e Jsoup[31]. É relevante explicar que o Link
Web Extrator não se adequa, pois limita-se a extrair dados em formato XML, e é necessário para este
caso de estudo, ter a flexibilidade de poder extrair dados de outras formas, por exemplo: diretamente de
texto simples das páginas Web, para posteriormente guarda-los numa BD. No entanto, o Web-Harvest
e Jsoup podem extrair informação de documentos HTML, que é o pretendido, assim, optou-se ferra-
menta Jsoup, porque apresenta semânticas semelhantes à biblioteca jQuery e dos seletores Cascading
Style Sheets (CSS), com os quais nos encontramos familiarizados, enquanto que o Web-Harvest tem
uma própria sintaxe.
2.2.4.A Jsoup
Jsoup[31] é uma biblioteca Java para trabalhar com HTML, que fornece uma API para a extração e
manipulação de dados, usando o melhor do Document Object Model (DOM), CSS e métodos jQuery-
like.
• DOM - É uma especificação da World Wide Web Consortium (W3C)[32] é uma interface que per-
mite programas e scripts acederem e atualizarem dinamicamente o conteúdo, estrutura e estilo
de um documento. Este pode ser processado e os resultados desse processamento são incorpo-
rados novamente na página apresentada.
• CSS - É uma linguagem utilizada para definir a apresentação de documentos como HTML ou
XML.
Jsoup implementa a especificação WHATWG[33] HyperText Markup Language v5 (HTML5), e ana-
lisa HTML para o mesmo DOM como navegadores modernos.
• Faz scraping e parsing de: documento HTML desde uma URL, arquivo ou string.
15

• Encontra e extrai dados, utilizando DOM traversal9 ou seletores CSS
• Manipula os elementos, os atributos e o texto do HTML
Jsoup é projetado para lidar com todas as variedades de HTML encontradas e por sua vez cria uma
árvore de análise.
2.3 Análise de Dados
A técnica de DM escolhida para a análise e agrupamento de dados dos produtos é o Clustering, e o
algoritmo para este é o Incremental k-means, uma variante do k-means que tem como tarefa apresentar
o melhor agrupamento de dados, ou seja, o melhor cluster. A utilização desta variante deve-se à
aplicação de uma função de avaliação denominada F(k). A função F(k) avalia qual o melhor número de
clusters num determinado agrupamento de dados, ou seja, a escolha de um valor de K ótimo.
2.3.1 Clustering
O Clustering (em português "Segmentação"[34]) é uma técnica que consiste em encontrar uma
coleção de dados, que de alguma forma são semelhantes, sendo um cluster uma coleção de objetos
que são semelhantes entre si, mas distintos de outros objetos de outro cluste[35].
O objetivo de criar um cluster é determinar um conjunto de objetos (dados) que ainda não têm uma
caraterística definida que os assemelha. Não existe qualquer critério para definir o que constitui um
bom agrupamento, sendo este definido pelo utilizador face às suas necessidades[35]. Os algoritmos de
Clustering podem ser aplicados em Biologia, Biblioteconomia, Urbanismo, Sismologia, Marketing entre
outros.
Figura 2.11: Clusters
9São seletores próprios do DOM que servem para navegar através dos seus nós
16

Na figura 2.11 A, podemos identificar três conjuntos se o critério de similaridade for a distância, pois,
conseguimos ver cada um de estes objetos (pontos) mais próximos entre si do que aos objetos dos ou-
tros conjuntos. Assim podemos agrupa-los criando três grupos (clusters) como mostrado em 2.11 B.
Estes algoritmos devem principalmente satisfazer os seguintes requisitos: escalabilidade, alta dimensi-
onalidade, capacidade de interpretação, usabilidade, lidar com diferentes tipos de atributos, capacidade
de lidar com o ruído e descobrir clusters com forma arbitrária, ou seja, para podermos criar um cluster
devemos saber como lidar com os dados e as suas caraterísticas.
Por outro lado existem diversos problemas com este tipo de técnica [35]: As técnicas atuais não con-
templam todos os requisitos de forma adequada, o resultado do algoritmo de agrupamento pode ser
interpretado de diferentes maneiras, lidar com grande número de dimensões e objetos de dados pode
ser problemático por causa da complexidade de tempo e a eficácia do método depende da definição de
distancia (isto para o agrupamento com base na distância).
2.3.2 K-means
O termo K-means foi usado pela primeira vez por James MacQueen em 1967 [36] sendo um algo-
ritmo de aprendizagem não supervisionada que resolve o problema de agrupamento, sendo um dos
mais simples que existe atualmente [37]. O objetivo deste algoritmo é agrupar um conjunto de dados
(ou instâncias) num certo número de clusters definindo K centróides, um para cada cluster [34][38], em
que o K será calculado mediante a utilização de uma função F(k) que será abordado mais adiante. Os
centróides representam o centro de cada conjunto de dados (o centro de cada cluster).
Existem várias formas de inicializar os centróides, sendo a inicialização aleatória utilizada neste estudo[34].
Passos da Inicialização aleatória utilizada[34]:
• Primeiro passo - consiste em inicializar os centróides, atribuindo-lhes um valor aleatório;
• Segundo passo - temos que levar cada ponto que pertence a um determinado conjunto de dados
e associá-la ao centróide mais próximo, até associar os pontos todos e assim concluímos este
passo;
• Terceiro passo - Voltamos a recalcular os novos K centróides como baricentro dos clusters resul-
tantes da etapa anterior;
• Quarto passo - Agora temos novos K centróides, onde uma ligação tem de ser feita entre os
mesmos dados e o novo centróide mais próximo, e assim sucessivamente até que não seja pos-
sível fazer mais mudanças, isto é, até os K centróides estabilizarem e não mudarem mais a sua
posição.
17

O K-means é representando pela seguinte fórmula:
J =
k∑j=1
n∑i=1
‖x(j)i − cj‖2 (2.1)
1 k-means(Dataset D, int k)
2 // Escolha de uma instancia representante para cada grupo
3 for each for each for each cluster Gi c {G1...Gk} do
4 Gi.c <- x: x c Dom(D)
5 ok <- true
6 do
7 // x passa a pertencer ao grupo com representante mais semelhante
8 for each for each for each instance x c D do
9 Gi <- G:G.c = arg min(f(x, ci))
10 if x c Gi then
11 Gi <- Gi U {x}
12 ok <- false
13 // O representante de um grupo torna-se a media das instancias do grupo
14 for each for each for each cluster Gi c {G1...Gk} do
15 Gi.c <- mean {x: x c Gi}
16 while not ok()
17 return {G return i}
Figura 2.12: Pseudocódigo do k-means
onde ‖x(j)i − cj‖2 é uma medida de distância escolhida entre uma instancia x
(j)i e o centro de cluster
cj , que a sua vez é um indicador da distância entre as "n"instancias e os seus respetivos centros dos
clusters [37].
Para uma melhor compreensão, será explicado os passos do k-means com a ilustração seguinte 2.13:
Figura 2.13: Iterações do K-Means
Na figura 2.13 os pontos azuis representam as instâncias (dados) e o ponto vermelho e verde (bolas
maiores) são os centróides que representam os grupos de instâncias (clusters).
Passo 1: Como podemos ver na figura 2.13, em "A", foram colocados os pontos K que representam o
grupo de centróides inicial, e calculamos as distâncias dos centróides para todas as instâncias existen-
tes (pontos azuis).
18

Passo 2: Tendo as distâncias calculadas, agrupamos as instâncias com as distâncias mais perto dos
centróides como podemos ver em "B".
Passo 3: Quando todas as instâncias foram finalmente assignadas ao grupo correspondente, recalcula-
mos novamente a posição dos centróides, isto é feito com base na média das distâncias das instâncias
de cada agrupamento provisório do passo 2, e assim obtemos "C".
Passo 4: Por último temos de repetir o passo 2 e 3 até os centróides estabilizarem e não haver mais
mudanças, para obtermos os respetivos clusters.
A Aleatoriedade do K-means pode ser um problema em situações que os agrupamentos devem conter
dados semelhantes entre eles, isto acontece porque a inicialização do k-means é feita aleatoriamente,
podendo escolher centróides que criem agrupamentos com dados semelhantes, muito distanciados
entre eles. A inicialização dos centróides e a escolha de um bom K (número de clusters) pode aju-
dar a resolver esse problema. Existem abordagens possíveis que resolvem esse problema, como por
exemplo Incremental K-means.
2.3.2.A Incremental K-means
Uma das maiores deficiências do K-means é a dependência da aleatoriedade, isto faz com que
exista a possibilidade de serem criados agrupamentos de dados menos desejados. O Incremental K-
means é uma variante do K-means que resolve esse problema, criando resultados mais consistentes,
tendo como objetivo uniformizar a distribuição dos dados pelos clusters, reduzindo o erro de distor-
ção2.14a.
(a) Distorção do Erro (b) Cálculo do novo centróide wk
(c) Número de objetos do cluster k
Figura 2.14: Incremental K-means
A diferença do Incremental k-means para o k-means, está na inicialização e na criação de clusters
incrementalmente. O Incremental k-means é iniciado atribuindo-lhe um valor K, este inicia com k=1 e
vai incrementando por 1 valor em cada iteração até atingir o valor de K atribuído inicialmente. Enquanto
k < 2, os primeiros centróides são escolhidos aleatoriamente, quando k > 1, é criado 1 centróide em
cada iteração mas não aleatoriamente, este centróide é calculado com base na distribuição dos clusters
e dados existentes, de forma a manter uma distribuição uniforme pelos dados.
O Incremental k-means inclui uma operação de salto durante o processo de aprendizagem, para corrigir
a posição do cluster pior colocado. A operação lida com o problema removendo o centróide de um
19

cluster duma inadequada posição, e cria um novo centróide 2.14b que é inserido no pior cluster (o
que tem pior distorção do erro) em cada iteração, inserindo-a para uma posição mais promissora. A
Distorção do Erro 2.14a serve para apresentar as irregularidades na distribuição de dados avaliando se
o cluster está numa má posição, ou seja, em quanto a distorção do erro não convergir para um valor,
esta correção será feita até o algoritmo estabilizar.
Na figura acima 2.14, o N representa o numero de objetos de um cluster, S é a soma das distorções
dos clusters, Wk corresponde ao centróide do cluster k, e x0 é o centro do espaço euclidiano, que
representa a media das distâncias de todos os objetos. Os índices i e j representam o índice do pior
cluster e do cluster mais próximo ao pior, respetivamente.
O algoritmo segue os seguintes passos[39]:
Atribuir K = 1.
Fase 1 (Treinamento normal
1. Se K = 1, escolher um ponto arbitrário para o centróide do cluster. Se K > 1, inserir o centróide do
novo cluster, no cluster com a maior distorção;
2. Atribuir cada objeto do conjunto de dados ao cluster mais próximo e atualiza o seu centróide
(similar ao k-means);
3. Se o centróide do cluster não se mover, ir a Fase 2. Caso contrario, ir a Fase 1, passo 2;
Fase 2 (Aumento dos clusters)
1. Se K é mais pequeno que um valor específico, aumentar K por 1 e ir a Fase 1, passo 1. Caso
contrário, parar.
2.3.2.B Escolha do K ideal
O valor K, serve para indicar o número de clusters num determinado conjunto de dados, e a escolha
deste é muito importante devido a qualidade dos resultados. Se para uma determinada população o K
for muito pequeno, a distribuição dos dados face às suas características podem não ser corretos, pois
formar-se-ão poucos clusters, que contêm dados que poderão não ser semelhantes entre si. No caso
do K ser muito grande, estaríamos a criar demasiados clusters com dados semelhante distribuídos por
diversos clusters, o que não faz muito sentido, uma vez que o objetivo é separar os dados semelhantes
o mais próximo possível por clusters. Exemplo:
Considerando um caso em que existe dados que tem como característica a cor: amarelo, azul, verde
e vermelho, o K ideal seria 4, uma cor para cada clusters. Se o K for menor que 4, haveria mistura de
cores nos clusters. Se o K for superior a 4 haverá repetição de cores nos diferentes clusters.
20

Tendo em conta este problema, a abordagem utilizada para encontrar o K ideal, seria a implementação
da função F(k)[40], que testa diversos valores de k, de modo a determinar o melhor número de clusters.
A função F(k), pode revelar mais do que um K válido. O algoritmo desta função deve começar em k
= 2 e incrementar por 1, até o resultado de F(k) convergir para um valor mais próximo de 1.0, e ai o
algoritmo termina. Se k fosse 1, o valor de F(k) seria 1.0. Se os valores iniciais de F(k) para cada k
forem muito diferentes, o algoritmo tem de incrementar o k até que ele comece a convergir. Quando os
resultados da função F(k) comecem a estabilizar (a convergir para 1.0) e aparecerem valores diferentes
ao valor que se está a convergir, esse será um possível K ideal.
F(k) toma em conta a distorção do cluster, figura 2.16a, que são as irregularidades na distribuição dos
dados num cluster, para perceber se os clusters estão bem distribuídos. A função F(k) rege-se pela
seguinte fórmula:
Figura 2.15: Função F(k)
Na utilização da função F(k), é importante que o resultado varie o menos possível quando o K
permanece inalterado. Por isso, o algoritmo k-means deverá obter resultados consistentes para que
o desempenho da função de avaliação F(k) tenha bons resultados. E é por este motivo que introduzi
anteriormente a variante Incremental K-means que resolve esse problema, pois a principal deficiência
do k-means é a dependência da aleatoriedade. As figuras abaixo 2.16, representam as fórmulas que
complementam a receita da função F(k)2.15.
(a) Distorção do cluster (b) Soma das distorções dos clusters(c) Factor de peso da distribuição dos
dados
Figura 2.16: Funções complementares para o cálculo de F(k)
A inicialização do algoritmo F(k) pode variar dependo da forma como queremos que termine, pode-
mos optar por ele terminar num valor fixo, ou deter o algoritmo quando estabilize ao convergir para 1.0.
Resumidamente, o algoritmo F(k) segue os seguintes passos[40]:
Passo 1: Inicializar k = 2, e incrementar por 1 valor, até o algoritmo finalizar.
Passo 2: No arranque do algoritmo, se os valores de F(k) não estabilizarem em quanto convergem para
1.0, ignorar os resultados de F(k).
21
Passo 3: Quando os valores de F(k) estabilizarem até convergirem para 1.0, o algoritmo termina.
Passo 4: Para cada k, os valores de F(k) que forem diferentes após a estabilização e até a finalização
do algoritmo, serão os k ideais a considerar. Entenda-se por valores de F(k) diferentes, a variação
considerável ao valor que está a convergir. Em Anexo A.6, os dados sublinhados a verde representam
os resultados de F(k) dos melhores k’s, e em azul outras possibilidades de k.
As figuras seguintes, são um exemplo do comportamento da função F(k) em determinadas distribuições
de dados[40].
Figura 2.17: Exemplo 1, gráfico de F(k)
Na figura 2.17, podemos verificar que os dados encontram-se concentrados numa única região com
uma distribuição normal, e a avaliação do gráfico de F(k), não apresenta um comportamento irregular,
mantendo-se próximo ao valor 1 para o qual convergiu. Isto sugere que o valor de K deve ser 1.
22

Figura 2.18: Exemplo 2, gráfico de F(k)
No conjunto de dados apresentado na figura acima 2.18, podemos visualizar duas regiões bem
separadas, e como podemos notar, a avaliação do gráfico F(k) tem uma forte irregularidade nos seus
valores quando K = 2, mantendo os restantes convergindo para 1. Isto sugere que K = 2 deve ser o
valor tomado.
Figura 2.19: Exemplo 3, gráfico de F(k)
No exemplo acima 2.19, o conjunto de dados apresentado, apresenta 3 conjuntos de dados bem
separados, isto significa que os dados são fortemente semelhantes em cada conjunto. A avaliação feita
pelo gráfico de F(k) mostra esse comportamento, indicando uma forte tendência quando K = 3, logo
esse é o valor que deve ser utilizado.
Em síntese uma tendência ou comportamento irregular significa que o valor da função F(k) é muito
23

elevado ou muito baixo do valor para o qual está a convergir, é assim que se escolhe o valor de K.
Nos exemplos indicados acima, percebemos como F(k) com base no gráfico de tendências, consegue
indicar-nos possíveis valores que o K deve tomar. Evidentemente, se existir uma distribuição com re-
giões de dados que se sobreponham, podem existir mais do que um valor de K.
A versão normal do k-means pode ser um problema na utilização do F(k), porque pode induzir-nos em
erro, uma vez que esta função, avalia a distribuição dos clusters pela distribuição dos dados, e o Incre-
mental k-means tem isso em consideração, conseguindo melhorar as escolhas dos novos centróides
incrementalmente, mantendo assim resultados mais consistentes, evitando agrupamentos com dados
de regiões muito diferentes.
24

3Arquitetura
Contents3.1 Arquitetura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 PC Core . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.1 Modo 1 - WebScrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2 Modo 2 - Configuração e Execução . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.3 PC Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4 Base de Dados (BD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.5 Comunicação entre PC Core e PC Interface é Interação com o Utilizador . . . . . . . 39
25

3.1 Arquitetura
O Comparador de Preços Inteligente é composto por dois módulos principais: PC Core (desenvol-
vido em JAVA) e PC Interface (desenvolvido em Hypertext Pre Processor (PHP) e HTML), tal como
representado na figura 3.1.
DB
PC Interface
pc
PC Core
product ws
dm.clusterin
g.kmeansdb
Pedido
Resposta
DAO
Internet
Resposta
Pedido
Comunicação
Figura 3.1: Comparador de Preços Inteligente
O PC Interface (Price Comparator Interface) é o módulo que trata da interação com o utilizador, tendo
como principais funcionalidades a comunicação com o PC Core (Price Comparator Core) e a Internet.
O PC Interface processa os dados inseridos pelo utilizador, comunica-os ao PC Core, e recebe como
resposta uma listagem dos produtos.
A comunicação com a Internet acontece, quando o utilizador seleciona um dos produtos listados, onde
será redirecionado para a loja do produto específico, como podemos verificar na figura 3.1, onde está
represetanda a comunicação entre o PC Core e a Internet.
PC Core, Anexo A.7, é composto pelas seguintes packages:
• db (Data Base) Anexo A.8;
• product (Produto) Anexo A.9;
• ws (Web Scraper ) Anexo A.10;
• dm.clustering.kmeans (Algoritmo Incremental K-means e função F(k)) Anexo A.11;
26

• pc (Price Comparator ) Anexo A.12.
Package pc contém a função Main do processo PC Core, funções auxiliares para o pré-processamento
dos dados extraídos da Internet, e oferece a comunicação para a transação dos dados entre o PC In-
terface e o PC Core, através do processo exec do PHP.
Package product é encarregado pela organização dos dados dos produtos e a comunicação com a BD
através da Package db.
Package ws é composto pelas funcionalidades responsáveis para o Web Scraping das lojas e-commerce.
Package dm.clustering.kmeans aglomera todas as funcionalidades para o cálculo do clustering com
o algoritmo k-means.
Package db apresenta uma camada de abstração de dados Direct Access Object (DAO)10 para lidar
com a BD, executando os pedidos em SQL e representando os resultados em objetos.
O PC Core apresenta dois tipos de comportamentos: O Modo 1 (Web Scraping), e o Modo 2 (Configu-
ração e Execução). O Modo 1 serve para procurar e extrair os dados das lojas e-commerce na internet,
e o Modo 2, para a configuração e execução dos dados do programa. O Modo 1 precisa ser executado
pelo menos uma vez, com o fim de recolher dados e criar uma população dos produtos das lojas online,
se quisermos atualizar a BD, podemos executar novamente o Modo 1.
3.2 PC Core
O PC Core contém as funcionalidades principais do Comparador de Preços Inteligente, o processo
para extrair dados das lojas online, pré-processamento dos dados obtidos, consultas à BD, execução
do clustering, e a comunicação com a interface. Como referido anteriormente, este consta de duas
funcionalidades fundamentais, uma para a extração dos dados das lojas (Modo 1), e outra para a con-
figuração e execução normal do programa (Modo 2).
A implementação foi desenvolvida em JAVA, pois, as ferramentas utilizadas, disponibilizam APIs para
esta linguagem, da mesma forma que o k-means adquirido[41], com base nos artigos[34][37], e adap-
tado para a variante Incremental K-means[39].
10Camada de abstração que mapeia os dados da BD em objetos.
27
3.2.1 Modo 1 - WebScrapping
DB
Product
Web Scraper (WS)
Internet
Db
Figura 3.2: PC Core - Modo 1
O Modo 1 apresentado na figura 3.2 foi projetado para executar o Web Scraping, e é composto pelas
packages ws Anexo A.10, product Anexo A.9, e db Anexo A.8.
A package product, tem como objetivo o mapeamento das lojas, produtos, e caraterísticas dos produ-
tos, utilizando a camada de abstração de dados da package db. Nesta configuração, o WS utiliza as
funcionalidades do product, para guardar os dados extraídos numa BD desenhada com um Modelo
Relacional (MR) simples e bem definido.
O WS, através da ferramenta Jsoup, executa um Web Spider que procura nas lojas, por hyperlinks de
produtos, criando um sumário de URLs. Ao finalizar este processo, o WS utiliza os hyperlinks angari-
ados para analisar as estruturas das páginas, através de funções pré-programadas para cada tipo de
loja, Anexo A.10, e procede à extração da informação necessária, onde estes dados são mapeados
pelas funcionalidades da package product e guardados na BD.
28

Lojas A, B, C... Product Db
Mapeia dados
dos produtos e lojas Guarda dados
dos produtos e lojas
Web Scraper
Consulta e
Scraping de A
Retorna dados
dos produtos
Mapeia dados
dos produtos e lojas Guarda dados
dos produtos e lojas
Consulta e
Scraping de B
Retorna dados
dos produtos
C ...
Figura 3.3: Diagrama de sequência do PC Core Modo 1 (Web Scraping)
O diagrama apresentado acima 3.3, mostra a interação desde o momento que o módulo PC Core
em Modo 1, inicia a atividade de extração, até à sua finalização. Este processo é lançado pela apli-
cação PC Core, e o modo em que opera, é configurado na Classe Main encontrada na package pc,
como podemos ver nó código da aplicação 3.10 da secção 4.4, assim, este será executado por um
conjunto de métodos: execute, spideringURL, scrapingURL, getProductName, getProductPrice,
getProductImgURL, e getProductFeature, pertencentes à Clase WebScraper fornecidos pela pac-
kage ws, Anexo A.10.
Quando o PC Core inicia em Modo 1, é invocado o método execute, que faz duas operações, a primeira,
invoca o Web Spider (metodo spideringURL) que constrói um sumário de hyperlinks guardados numa
ArrayList<String>. A segunda, invoca o processo de Web Scraping através do método scrapingURL,
figura 3.4, para cada URL recolhida pelo Web Spider.
29

1 @Override
2 public void execute() {
3 try {
4 System.out.println("\nSHOP: "+_shopName);
5
6 //downloadUrlIntoFile();
7 for (String u1 : _url) {
8 for(int i=1; ; i++){
9 System.out.println("\nPRODUCT VIEW: "+i);
10 String url = u1+"?p="+i;
11
12 _hasContent = false;
13
14 ArrayList<String> urls = spideringURL(url);
15 System.out.println("SCRAPING URL: "+url);
16 for(String u2 : urls){
17 scrapingURL(u2);
18 }
19
20 if(!hasContent())
21 break;
22 }
23 }
24 } catch (Exception e) {
25 e.printStackTrace();
26 }
27 }
Figura 3.4: Iniciação do Web WebScraper
A extração de dados não foi desenhada para ser automática, assim, o desenho do sistema foi feito
para se adaptar facilmente a cada loja, sendo necessário reescrever os métodos: getProductName,
getProductPrice, getProductImgURL, e getProductFeature, utilizando Jsoup, para a estrutura de
cada loja. Os métodos descritos anteriormente, são utilizados pelo método scrapingURL.
30
3.2.2 Modo 2 - Configuração e Execução
DB
Product
Price Comparator (PC)Dm.clustering.kmeans
PC Interface
Db
Pre-processamento
Figura 3.5: PC Core - Modo 2
O Modo 2 está encarregue da execução principal do programa, e para isso, precisa de comunicar
com a interface do utilizador utilizando os argumentos recebidos pela função main do JAVA (package
pc, Anexo A.12) através da execução de função exec do PHP, que chama o processo Main.class com
os parâmetros enviados pela interface do utilizador.
3.2.2.A Configuração
O Price Comparator (PC), deve ser configurado antes de ser executado normalmente. Esta configu-
ração é feita mediante a execução do script do ficheiro fk.php, consiste em analisar os dados recolhidos
no Modo 1 e criar os clusters para esses dados. Esta informação é guardada automaticamente no
ficheiro “KClusters.pc”11, na pasta “bin” do modulo PC Core, figura 3.6, no entanto, podemos fazer reset
apagando este ficheiro, e assim, realizar uma nova configuração executando novamente o script do fi-
cheiro fk.php. Esta operação deveria ser efetuada automaticamente cada vez que existam novos dados
nas lojas e-commerce, a fim de manter os clusters e dados atualizados, no entanto, para simplificar o
estudo, irá ser mantido desta forma.
11O ficheiro “KClusters.pc” da figura 3.6, é um ficheiro de dados JAVA serializado, que mantem a estrutura de dados dosclusters criados.
31

Figura 3.6: Ficheiro KClusters.pc
O ficheiro “fk.php” encontra-se no módulo PC Interface figura 3.7, e pode ser executado da se-
guinte forma, por exemplo: "http://localhost/PCInterface/fk.php", que informa ao PC Core que pre-
tende fazer a configuração, o Price Comparator (PC) interpreta o comando recebido para indicar a
package product que faça o mapeamento dos dados encontrados na BD, o pré-processamento e nor-
malização destes. Após o tratamento dos dados, executa o algoritmo Incremental K-means(package
dm.clustering.kmeans) descrito na secção 2.3.2.A e depois executa o algoritmo F(k) descrito na sec-
ção 2.3.2.B, que apresentará uma listagem dos valores K avaliados, como em Anexo A.5. De seguida,
configurámos manualmente a variável K encontrada na função main da package pc e compilamos
novamente o modulo PC Core.
Figura 3.7: Ficheiro fk.php
Feita esta configuração, o Price Comparator (PC) encontra-se preparado para execução normal
do programa, assim, quando um utilizador fizer uma pesquisa, o Price Comparator (PC) interpreta os
dados recebidos por parte da interface, cria um novo ponto com valores normalizados, e procura o
centróide do cluster mais próximo a esse ponto, obtendo como resultado o cluster que identifica os
produtos semelhantes associados.
3.2.2.B Execução
Após a configuração, a execução principal do programa passa pelo pré-processamento e a análise
dos dados. O pré-processamento descrito na seção 4.3, consiste em limpar os dados extraídos para
poder utilizá-los.
A análise de dados abrange a criação dos clusters e é executada depois do pré-processamento, no
mesmo método detailedClusteringKMeans da Classe PriceComparator, package pc. A package
32

dm.clustering.kmeans, Anexo A.11, contém implementado todo o algoritmo, incluindo a função de
avaliação F(k). Quando o PC Core encontra-se em Modo 2, e o programa nunca foi iniciado, tem de se
criar os clusters para os dados da população, entrando aqui em ação o seguinte diagrama de sequência
3.8.
Produto DbClustering
Kmeans
Envia
dadosExecuta
queries SQL
Retorna
Ids e atributos
dos produtos
Envia dados
Devolve
clusters
Price Comparator
Recebe
dados
Interpreta
dados
Preparação e
pre-processamento
dos dados
Gera
clustering
Produtos
mapeados
Escolhe
Cluster
Envia Ids dos produtos
pertencentes ao cluster
Executa
queries SQL
Retorna dados
dos produtosRetorna
produtosEnvia
dados
Figura 3.8: Diagrama de sequência do PC Core Modo 2
No Instante em que o processo do PriceComparator envia os dados preparados para o processo
"Clustering Kmeans", o seguinte código 3.9 é executado. Podemos notar que ele tenta ler dados do
ficheiro "KClusters.pc", este ficheiro é muito importante, pois contém a informação dos clusters criados
para cada K, caso este não exista, procede a execução do Incremental k-means e apresenta a avaliação
de F(k).
33

1 List<List<Cluster>> clustersListBestK = new ArrayList<List<Cluster>>();
2 try {
3 FileInputStream fin = new FileInputStream("KClusters.pc");
4 ObjectInputStream oin = new ObjectInputStream (fin);
5 clustersListBestK = (List<List<Cluster>>) oin.readObject();
6
7 oin.close();
8 } catch (Exception e) {
9
10 for (int k = 1; k <= 100; k++){
11 IncrementalKMeans kMeans = new IncrementalKMeans(points, k);
12 List<Cluster> pointsClusters = kMeans.getPointsClusters();
13 clustersListBestK.add(pointsClusters);
14
15 Double currentFactor = new Fk(pointsClusters, k).execute();
16 System.out.println("K " + k + " Factor: " + currentFactor);
17 }
18
19 try {
20 FileOutputStream fout = new FileOutputStream("KClusters.pc");
21 ObjectOutputStream oout = new ObjectOutputStream(fout);
22 oout.writeObject(clustersListBestK);
23 } catch (Exception e1) {
24 e1.printStackTrace();
25 }
26 }
Figura 3.9: Geração dos Cluster e Avaliação de possíveis K’s, com base na população de televisões em estudo. Código éexecutado no método detailedClusteringKMeans da Classe PriceComparator e Corresponde a Envia Dados para o Gera
clustering no Diagrama de Sequencia.
O diagrama de sequência 3.8, inicia-se quando o "fk.php"do PC Interface for executado. Este di-
agrama, também pode ser o mesmo para a execução normal do programa, mas, sem o processo
"ClusteringKmeans"ativo. Se o ficheiro "KClusters.pc"não existir, o processo "ClusteringKmeans"fica
ativo.
Com base nos clusters criados e avaliações apresentadas na interface, Anexo A.5, procedemos a es-
colher o valor K que mais se adequa. De seguida configurámos as variáveis no código da Classe
Main 3.10, e compilamos com o K definido. Para além disto, no código apresentado abaixo, podemos
configurar também, a variável que controla o Modo em que opera o PC Core.
34

1 /**
2 * Modo 1 (Web Scraping)
3 * Modo 2 (PCInterface)
4 **/
5 static int MODE = 2;
6 static int K = 39;
7
8 public static void main(String[] args){
9
10 try {
11 DataBase db = new DataBase("localhost:3306", "comparador_precos", "root", "");
12 db.debugMode(false);
13
14 if(MODE == 1){
15 WebScraperWorten wsw = new WebScraperWorten(db);
16 wsw.execute();
17
18 WebScraperFnac wsf = new WebScraperFnac(db);
19 wsf.execute();
20 }else if(MODE == 2){
21 PriceComparator pc = new PriceComparator(db, args);
22 pc.executeSearch();
23 }
24
25 db.closseConnection();
26
27 } catch (Exception e) {
28 e.printStackTrace();
29 }
30 }
Figura 3.10: Configuração e compilação dos dados. Executado no método main da package pc
Em Anexo A.11, apresenta o modelo Unified Modeling Language (UML) da implementação do algo-
ritmo Incremental k-means, o qual é constituído por cinco classes: Point, Cluster, Clusters, Incremen-
talKmeans e Fk.
• Classe Point, corresponde ao ponto que representa um objeto no cluster, este ponto é de N
dimensões, onde N é o número de características dos produtos, para além de esta informação,
também identifica os produtos pelo seu respetivo ID.
• Classe Cluster, guarda uma lista dos pontos List<Point> points, o seu centróide (Point), métodos
para, atualizar o centróide, obter a lista de pontos e centróide.
• Classe Clusters corresponde a uma ArrayList da Classe Cluster : Clusters extends ArrayList<Cluster>.
Contem métodos para, atualizar os clusters, atribuir pontos aos clusters, e saber o cluster mais
próximo a um ponto.
• Classe IncrementalKmeans executa o algoritmo utilizando todas as funcionalidades das classes
das alíneas anteriores.
• Classe Fk executa a função de avaliação, e recebe como argumento no construtor uma lista de
clusters: List<Cluster> clusters, e o valor de K que foi utilizado para a lista de clusters criada.
35

3.3 PC Interface
O programa, comporta dois tipos de interfaces, uma será meramente exploratória, denominada
por "Pesquisa Absoluta", que serve para simular os mesmos comportamentos dos Comparadores de
Preços existentes. A outra interface, "Pesquisa por Parâmetros"é a que corresponde ao Comparador
de Preços Inteligente, nesta, a procura do produto é feita através da escolha de características do
produto de um único género para o estudo que abordarei adiante. A Interface (modulo PC Interface) é
implementada em PHP e HTML com suporte da biblioteca jQuery Mobile.
Figura 3.11: Screenshot PC Interface
A interface da figura acima 3.11, é composta pela seguinte estrutura:
• Selecionador de interface serve para fazer a seleção entre a interface de teste "Pesquisa Abso-
luta", e a do Comparador Inteligente "Pesquisa por Parâmetros".
• Filtro de ordenação apresenta os produtos ordenados da seguinte forma: mais semelhante,
ordem alfabética, mais barato e mais caro.
• Filtros de características representa os filtros das características, onde cada uma de estas é
associada a um valor numérico. O utilizador poderá ajustar cada uma destas, através de um
slider com limites de intervalo.
• Botão de Pesquisa Ao ser pressionado, inicia a operação de pesquisa que comunica com o
modulo PC Core, e presentara uma listam de produtos.
36

• Apresentação de resultados é a secção que apresenta a listagem dos resultados. A apresen-
tação é feita em blocos, onde cada um representa um produto composto por um título, imagem,
preço, e a loja de onde provém. Nestes blocos é incluído o hyperlink que reencaminha o utilizador
para o produto na loja respetiva.
3.4 Base de Dados (BD)
Figura 3.12: Modelo Relacional (MR) da BD
A Base de Dados (BD) é construída em MySQL, que é um Data Base Management System (DBMS)12.
Esta foi concebida num Modelo Relacional (MR) apresentado na figura 3.12, composta por três tabelas,
onde será armazenado os dados estraídos das lojas online, que correspondem à população em estudo.
As tabelas foram organizadas em três tipos: shop, product e features.
• shop esta tabela corresponde as listas de lojas e-commerce a serem estudadas neste projeto. É
composto por três campos: um identificador que relaciona a loja aos produtos, o nome e a URL
da respetiva loja.
• product a tabela é composta por um identificador para associar as características dos produtos
extraídos na tabela features, um nome que faz parte do titulo apresentado pelo lojista na página12Conjunto de programas, responsáveis pela gestão da BD
37

web onde se encontra o produto, o preço, e os URLs, onde um deles é para a imagem, e o outro
reencaminha o produto a ser visualizado na interface do Comparador Inteligente para a respetiva
loja.
• features é a tabela que representa o tipo de característica e o valor associado a este, seja ele
numérico ou texto, embora para este estudo só iremos considerar valores numéricos. É importante
notar, que os dados armazenados no momento da extração, ainda não passaram por uma fase de
limpeza (pré-processamento), com exceção do preço (inserido na tabela product). Isto acontece,
porque no momento do desenho deste modelo, os preços foram assumidos como numéricos, mas
nos sites das lojas, estes vem acompanhado do símbolo da moeda euro (e), vírgulas e/ou pontos
das casas decimais. Para os restantes casos, como referi anteriormente, as características como
contêm grande diversidade de informação textual e numérica, a limpeza é feita posteriormente,
na configuração do clustering (fase de pré-processamento, secção 4.3).
38

3.5 Comunicação entre PC Core e PC Interface é Interação com oUtilizador
A comunicação entre PC Core e PC Interface só deverá ser realizada quando o PC Core se encon-
trar em Modo 2, com o código configurado e compilado como indicado na secção do capitulo anterior
3.2.2. Se tentar qualquer interação com a interface, e o modulo PC Core não estiver compilado, ou está
compilado em Modo 1, não obterá qualquer tipo de resposta.
Assim, todo o processo de comunicação só poderá ser feito com o PC Core em Modo 2. O diagrama de
sequência apresentado 3.13, é um exemplo de um funcionamento completo, onde o modulo PC Core
já se encontra configurado e preparado para o utilizador poder fazer as suas pesquisas. No entanto, a
sequência de comunicação é a mesma omitindo só o processo "Loja Online", quando fazemos a confi-
guração do agrupamento de dados (clustering) através da execução "fk.php"do modulo PC Interface.
Utilizador PC Interface PC Core Loja Online
Escolhe
atributos Envia
dados
Dados
dos produtos
Processa
dadosListagem
dos produtos
Escolhe
produto
Vai
a Loja
Dados
do produtoApresenta
produto
Figura 3.13: Diagrama de sequência do PC Interface
Quando se deseja efetuar um pedido de pesquisa desde o PC Interface, e o PC Core está preparado
para execução, uma sequência de código PHP como indicado em 3.14 é executado.
39

1 if(isset($_POST["submit-page2"])){
2 $params = "1";
3 $params .= " ".(isset($_POST["clust"])? $_POST["clust"] : "0");
4 $params .= " ".(isset($_POST["typesearch"])? $_POST["typesearch"] : "0");
5 $params .= " ".(isset($_POST["order"])? $_POST["order"] : "0");
6 $params .= " ".(isset($_POST["price-min"])? $_POST["price-min"] : "0");
7 $params .= " ".(isset($_POST["price-max"])? $_POST["price-max"] : "0");
8 $params .= " ".(isset($_POST["diagonal"])? $_POST["diagonal"] : "0");
9 $params .= " ".(isset($_POST["standby"])? $_POST["standby"] : "0");
10 $params .= " ".(isset($_POST["hdmi"])? $_POST["hdmi"] : "0");
11
12 exec('java -cp ../libs/mysql-connector-java-5.1.26/mysql-connector-java-5.1.26-bin.jar; pc
.Main '.$params, $output);
13 }
Figura 3.14: Pedido efetuado pelo PC Interface ao PC Core (Linguagem: PHP - Ficheiro index.php no Modulo PC Interface).Corresponde a seta "Envia dados"do processo PC Interface no diagrama de Sequencia.
Quando um pedido é recebido pelo PC Core, este avalia os dados, e gera uma resposta numa string
parametrizada da seguinte forma:
1 System.out.println(obj.get("shop_name")+"#$#"+obj.get("price")+"#$#"+obj.get("product_name")+"#$
#"+obj.get("url")+"#$#"+obj.get("url_img"));
Onde "#$#"corresponde aos separadores dos dados. Esta string será interpretada pelo PC Interface,
recebendo-a na variável $output, e apresenta o resultado como indicado no seguinte troço de código
3.15.
1 <?php
2 if(isset($_POST["submit-page2"])){
3 foreach($output as $value){
4 list($shop, $price, $title, $url, $url_img) = explode("#$#", $value);
5 if(strtolower($shop) == "worten")
6 $shopUrlImg = $shopImgUrl["worten"];
7 elseif(strtolower($shop) == "fnac")
8 $shopUrlImg = $shopImgUrl["fnac"];
9 ?>
10 <div class="ui-block-b ui-shadow" style="text-align:center;margin-bottom:2%;" >
11 <div title="title" class="ui-bar ui-bar-a" style="text-align:left;"><?php echo $title;
?></div>
12 <a href="<?php echo $url; ?>" target="_blank"><img alt="portrait" src="<?php echo $url_img
; ?>" /></a>
13 <div class="ui-bar" style="text-align:left;">
14 <span title="price" style="position:relative;float:left;"><br><b>PRE\c{C}O: <?php
echo str_replace(".", ",", $price); ?>\euro</b></span>
15 <img alt="brand" style="position:relative;float:right;" src="<?php echo $shopUrlImg; ?>"
/>
16 </div>
17 </div>
18 <?php
19 }
20 }
21 ?>
Figura 3.15: Interpretação e Apresentação da resposta ao utilizador pelo PC Interface (Linguagem: PHP, HTML - Ficheiroindex.php no Modulo PC Interface). Corresponde a seta "Dados dos produtos"do processo PC Interface no diagrama de
Sequencia.
40

Se executamos o script do ficheiro "fk.php"do Modulo PC Interface para configurar o sistema, será
executado o código 3.16, que apresentará mediante a impressão da variável $output, uma listagem de
avaliações F(k) para diferentes K clusters analisados, Anexo A.5.
1 <?php
2 $output = array ();
3 chdir ( "../PCCore/bin" );
4
5 $params = "1 1 1 2 0 500 50 3 2";
6
7 echo exec ( 'java -cp ../libs/mysql-connector-java-5.1.26/mysql-connector-java-5.1.26-bin
.jar; pc.Main '.$params, $output);
8
9 echo '<pre>';
10 print_r ( $output );
11 echo '</pre>';
12 ?>
Figura 3.16: Ficheiro de avaliação fk.php do PC Interface (Linguagem: PHP)
O seguinte código 3.17, é parte da elaboração de uma resposta para o PC Interface por parte do PC
Core, nesta é executada uma query em SQL que contém informação referente aos produtos listados.
Esta amostra de código, faz parte do método detailedClusteringKMeans pertencente a Classe Price-
Comparator da package pc, Anexo A.12. A query inclui, informação da ordem em que de devem ser
listados os produtos, e todos os IDs referentes aos produtos associados a pontos do cluster escolhido
como o melhor, com base no cálculo da distância mais próxima aos dados enviados pelo utilizador.
41

1 for (String pId : pointsId.values()){
2 if(executeOne){
3 cond += "(product.id='"+pId+"'";
4 }else{
5 cond += " OR product.id='"+pId+"'";
6 }
7 executeOne = false;
8 }
9 cond += ")";
10
11 query =
12 "SELECT product.id AS product_id, shop.name AS shop_name, product.name AS product_name,
price, product.url, url_img"
13 + " FROM shop, product"
14 + " WHERE shop.id = product.shop_id"
15 + " AND " + cond;
16
17 if(_sortType.equals("1")) query += " ORDER BY product.name ASC";
18 else if(_sortType.equals("2")) query += " ORDER BY price ASC";
19 else if(_sortType.equals("3")) query += " ORDER BY price DESC";
20 result = p.getBySQL(query);
21 it = result.iterator();
22
23 //Send response to PCInterface
24 while(it.hasNext()){
25 HashMap<String, String> obj = it.next();
26 System.out.println(obj.get("shop_name")+"#$#"+obj.get("price")+"#$#"+obj.get("product_name
")+"#$#"
27 +obj.get("url")+"#$#"+obj.get("url_img"));
28 }
Figura 3.17: Resposta gerada pelo PC Core (Linguagem: JAVA). Executado no método detailedClusteringKMeans da ClassePriceComparator
A interação do utilizador com o Comparador de Preços Inteligente, é feita através da interface apre-
sentada na figura 3.18. Ressalto que o valor correspondente a característica "Consumo em Standby"é
apresentado na interface como um número inteiro, que vai desde 1 até 5. No entanto esse valor é
decimal, e significa na verdade 0,1 até 0,5. Por agilizar o processo de estudo, mantém-se o valor inteiro
na interface, no entanto, o programa avalia corretamente esse valor, considerando-o como decimal.
42

Figura 3.18: Interface "Pesquisa por Parâmetros", correspondente ao modulo PC Interface
1. Selecionador de interface serve para fazer a seleção entre a interface de teste "Pesquisa Abso-
luta", e a do Comparador Inteligente "Pesquisa por Parâmetros".
2. • Filtro de ordenação apresenta os produtos ordenados da seguinte forma: mais semelhante,
ordem alfabética, mais barato e mais caro.
• Filtros de características representa os filtros das características, onde cada uma de estas
é associada a um valor numérico. O utilizador poderá ajustar cada uma destas, através de
um slider com limites de intervalo.
3. Botão de Pesquisa ao ser pressionado, inicia a operação de pesquisa que comunica com o
modulo PC Core, e presentara uma listam de produtos.
4. Apresentação de resultados é a secção que apresenta a listagem dos resultados. A apresen-
tação é feita em blocos, onde cada um representa um produto composto por um título, imagem,
preço, e a loja de onde provém. Nestes blocos é incluído o hyperlink que reencaminha o utilizador
para o produto na loja respetiva.
43

44

4Caso de Estudo
Contents4.1 Variáveis em Estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2 Extração de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Pré-processamento dos Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4 Análises de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.5 Resultados Experimentais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.1 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.2 Vantagens e Desvantagens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
45

O caso em estudo irá incidir na discussão entre os Comparadores de Preços existentes no mercado
e o Comparador de Preços Inteligente. Com base nisto, o ponto de partida foi a análise do funciona-
mento dos comparadores de preço existentes, ou seja, como apresentam os produtos ao cliente, como
obtêm informação das lojas e-comerce, a seleção e apresentação da pesquisa de um produto, tendo
em conta as características desejadas.
Devido à grande variedade de produtos com diversificadas características no mercado online, decidiu-
se que a população mais adequada para o estudo seriam as televisões (TV’s), pois, são um produto
de fácil acesso, e que se encontra em qualquer loja e-commerce. Estas apresentam caraterísticas com
denominações semelhantes, nas diferentes lojas escolhidas, o que facilita o tratamento da informa-
ção. As lojas e-commerce em estudo são a Worten[2] e a Fnac[3], pois apresentam uma estrutura do
documento HTML bem organizada, que facilita a extração dos dados.
4.1 Variáveis em Estudo
Em análise feita ao projeto, tendo em conta as televisões como o produto eleito, escolheram-se
como variáveis de estudo, as seguintes características: o preço, dimensão diagonal do ecrã, con-
sumo de energia em modo de espera (standby), e o número de portas High-Definition Multimedia
Interface (HDMI), pois são comuns à população em estudo, estas caraterísticas foram escolhidas por
ser mais fácil aplicar o clustering em variáveis numéricas.
O clustering é um método matemático e estatístico para agrupar dados num espaço euclidiano por pon-
tos de N dimensões, dos quais têm de se calcular distâncias entre elas para obter os agrupamentos de
dados (clusters) desejados, e estas dimensões são respetivamente as características escolhidas dos
produtos, ou seja, neste caso N têm o valor de 4, isto quer dizer que a configuração dos dados, serão
representados num espaço multidimensional de 4 dimensões.
Se utilizarmos caraterísticas com base a texto, teríamos de abordar paradigmas de Língua Natural (LN),
que possivelmente, implicaria adaptar texto a valores numéricos, e assim, para simplificar o problema,
consideramos então as caraterísticas do tipo numérico.
Para este caso de estudo, gerou-se uma população com aproximadamente 500 indivíduos, extraídos
das lojas online referidas anteriormente. Os dados extraídos foram diretamente guardados na BD, o que
poderá implicar situações onde os dados podem precisar de passar por um processo de limpeza, pois,
em algumas circunstâncias as caraterísticas numéricas estão acompanhados por algum texto ou sím-
bolos que precisam de ser removidos. Este processo de limpeza e/ou tratamento (pré-processamento),
será feito posteriormente à extração de dados, ao realizar a configuração do programa para escolher o
agrupamento de dados adequado a população.
46

4.2 Extração de Dados
O processo de extração de dados compreende duas fases, Web Spidering, e Web Scraping. Antes
de iniciar o processo, foi necessário fazer uma análise da estrutura interna do documento HTML de cada
loja, para saber como se encontra formulado, efetuando-se através do debugger do browser Google
Chrome. Notar que este processo não é totalmente automático, pois, isso teria de abordar paradigmas
de LN que nos levaria a outro trabalho.
Posteriormente a esta análise, foi necessário compreender a forma como os dados se encontravam
estruturados e os seus respetivos hyperlinks. Para esta tarefa utilizaremos Jsoup[31] que realizara o
trabalho de Web Spidering e Web Scraping, tendo como ponto de partida os URLs de cada loja online,
e assim, explorar o documento HTML destas, criando um sumário de hyperlinks dos produtos, que de
seguida serão percorridos um a um aplicando a técnica de Web Scrapping. Este procedimento é lento,
o que impede a atualização dos dados em tempo real na BD, e implica fazermos um pesquisa do tipo
offline, pois, cada iteração do utilizador, envolveria efetuar novas operações de ajustamento do agrupa-
mento de dados(clustering) incluindo a espera da própria extração dos dados.
Para o caso de estudo em questão, não é requerido que os dados sejam constantemente atualizados.
No entanto, podem-se atualizar executando o Modo 1, e posteriormente, executar o Modo 2 para recon-
figurar o programa se desejarmos obter os resultados corretamente, pois, o clustering é um processo
à parte, que precisa de recalcular os seus novos dados e manter guardada essa informação que deve
permanecer imutável, como já referido no capítulo anterior, na secção 3.2.2.
O seguinte troço de código, 4.1 e 4.2, corresponde ao método getProductName, que tem como função
extrair o título do produto, de uma determinada estrutura HTML da loja Worten[2] e Fnac[3] respetiva-
mente, Anexo(Worten) A.3.
1 @Override
2 protected String getProductName(Document doc) {
3 Elements name = doc.select("div[class=product-name]");
4 System.out.println("NAME: "+name.text());
5 return name.text();
6 }
Figura 4.1: Método que obtém o Nome / Titulo do produto - Worten[2]
1 @Override
2 protected String getProductName(Document doc) {
3 Elements name = doc.select("strong.titre");
4 System.out.println("NAME: "+name.text());
5 return name.text();
6 }
Figura 4.2: Método que obtém o Nome / Titulo do produto - Fnac[3]
47

O seguinte código 4.3 e 4.4, corresponde ao método getProductPrice, que está encarregue de
extrair o preço do produto, e fazer um pequeno pré-processamento, que limpa caracteres da moeda, e
substitui as vírgulas por pontos, sendo as vírgulas o sistemas decimal utilizado em Portugal, e o ponto
corresponde ao sistema decimal em linguagem de programação (vírgula flutuante). Isto pode servir
como exemplo de um pormenor de LN. Estrutura HTML Anexo(Worten) A.3.
1 @Override
2 protected String getProductPrice(Document doc) {
3 Elements price1 = doc.select("div.product-essential");
4 price1 = price1.select("div.price-box");
5 Elements price2 = price1.select("p[class=special-price]");
6 if(!price2.hasText()) price2 = price1.select("p[class=regular-price]");
7 price2 = price2.select("span[class=price]");
8 System.out.println("PRICE: "+price2.text());
9 return price2.text().replace("\euro", "").replace(",", ".");
10 }
Figura 4.3: Método o Preço do produto - Worten[2]
1 @Override
2 protected String getProductPrice(Document doc) {
3 Elements price = doc.select("div.blk_inside.filled.pdg_v.txt_c");
4 price = price.select("span.price");
5 String priceText = price.text().replace("\euro", "").replace(".", "").replace(",", ".");
6 priceText = Jsoup.clean(priceText, Whitelist.basic());
7 priceText = priceText.replace(" ", "");
8 System.out.println("PRICE: "+priceText);
9 return priceText;
10 }
Figura 4.4: Método o Preço do produto - Fnac[3]
O código seguinte, 4.5 e 4.6, corresponde ao método getProductImgURL, que serve para extrair a
URL da imagem do produto. Este é o hyperlink que apresenta as imagens dos produtos na interface.
1 @Override
2 protected String getProductImgURL(Document doc){
3 Elements img1 = doc.select("#main-image");
4 img1 = img1.select("img");
5 System.out.println("IMG_SRC: "+img1.attr("src"));
6 return img1.attr("src");
7 }
Figura 4.5: Método para obter a URL da imagem do produto do lojista - Worten[2]
48

1 @Override
2 protected String getProductImgURL(Document doc) {
3 Elements img1 = doc.select("#headMenu");
4 img1 = img1.select("img");
5 System.out.println("IMG_SRC: "+img1.attr("src"));
6 return img1.attr("src");
7 }
Figura 4.6: Método para obter a URL da imagem do produto do lojista - Fnac[3]
Por último, o método getProductFeatures, 4.7 e 4.8, tem como objetivo obter as tabelas das ca-
racterísticas para cada produto, sendo o attributeName o tipo de característica, e attributeValue o valor
associado a essa característica. Estrutura HTML em Anexo(Worten) A.4.
1 @Override
2 protected HashMap<String, String> getProductFeatures(Document doc) {
3 HashMap<String, String> f = new HashMap<String, String>();
4 Elements attributes = doc.select("table.data-table");
5 for(Element node : attributes.select("tr")){
6 Elements attributeName = node.select(".label");
7 Elements attributeValue = node.select(".data");
8 f.put(Functions.removeSpecialCharacters(Functions.deAccent(attributeName.text())),
attributeValue.text());
9 }
10 return f;
11 }
Figura 4.7: Método que obtem a listagem das caracteristicas de um produto - Worten[2]
1 @Override
2 protected HashMap<String, String> getProductFeatures(Document doc) {
3 HashMap<String, String> f = new HashMap<String, String>();
4 Elements attributes = doc.select("div.blk_content.pdg_l_lg.pdg_t_15");
5 for(Element node : attributes.select("tr")){
6 Elements attributeName = node.select("th");
7 Elements attributeValue = node.select("td");
8 f.put(Functions.removeSpecialCharacters(Functions.deAccent(attributeName.text())),
attributeValue.text());
9 }
10 return f;
11 }
Figura 4.8: Método que obtem a listagem das caracteristicas de um produto - Fnac[3]
Em síntese, cada segmento de dados extraídos, são mapeados em cada iteração do método scra-
pingURL como um produto. As funcionalidades para o mapeamento são disponibilizadas pela package
product, em Anexo A.9, que por sua vez, guardam os dados utilizando a camada de abstração DAO
da package db, Anexo A.8.
49

4.3 Pré-processamento dos Dados
O Pré-processamento, consiste em fazer um tratamento nos dados recolhidos, e prepara-los para
poderem ser manipulados, neste caso, limpeza de texto indesejado e normalização dos valores. A
eleição de características com valores de origem numérico tem como objetivo agilizar o processo de
estudo, no entanto, não é suficiente pensar que os dados extraídos estão em boas condições, para
serem utilizados em avaliações de cálculo matemático e estatístico.
Também foram encontrados alguns obstaculos na população de dados, que podem ser resolvidas, mas
em contrapartida podem influenciar os resultados. Adiante, explico como foi abordado e resolvido este
problema.
O pré-processamento é sempre iniciado quando é executado o método detailedClusteringKMeans da
Classe PriceComparator, package pc Anexo A.12, e pela inexistência do ficheiro "KClusters.pc". Isto
acontece quando o PC Core opera em Modo 2, e se encontra na fase de configuração 3.2.2. Re-
cordamos que esta fase, acontece na primeira execução do programa ou pela remoção do ficheiro
"KClusters.pc", e serve para criar um agrupamento de dados, criando os clusters com um devido K ava-
liado, armazenando esta informação no ficheiro "KClusters.pc", que será sempre utilizado na execução
de uma pesquisa feita no Comparador de Preços Inteligente.
A primeira depuração efetuada nos dados, foi associar nomes iguais para características do mesmo
género, que continham palavras ou letras diferentes. Esta solução serve para identificar uma caracte-
rística com designações diferentes e associar-lhe uma única designação, por exemplo: existe "Diagonal
de Ecra", "Tamanho (ecra visivel)"entre outros, que significam o mesmo, e neste caso, classifiquei-os
como "Diagonal".
Como apresentado no código 4.9 (executado no método detailedClusteringKMeans da Classe Price-
Comparator ), esta abordagem é feita logo na query inicial (SQL), que servirá para facilitar a normaliza-
ção e avaliação dos dados, que posteriormente serão mapeados em pontos de espaço multidimensio-
nal, para serem analisados com o algoritmo Incremental K-means.
50

1 String replaceDiagonal = "REPLACE(specification_type, 'Diagonal Ecra', 'Diagonal')";
2 replaceDiagonal = "REPLACE("+replaceDiagonal+", 'Diagonal do ecra', 'Diagonal')";
3 replaceDiagonal = "REPLACE("+replaceDiagonal+", 'DIAGONAL DE ECRA', 'Diagonal')";
4 replaceDiagonal = "REPLACE("+replaceDiagonal+", 'Tamanho (ecra visivel)', 'Diagonal')";
5 String replaceStandby = "REPLACE("+replaceDiagonal+", 'Consumo Modo de Espera', 'Consumo
em standby')";
6 String replaceHdmi = "REPLACE("+replaceStandby+", 'N de Entradas HDMI', 'Portas HDMI')";
7 replaceHdmi = "REPLACE("+replaceHdmi+", 'Entradas HDMI', 'Portas HDMI')";
8
9 String query =
10 "SELECT product_id, price, "+replaceHdmi+" AS specification_type2, specification_value"
11 + " FROM features, product"
12 + " WHERE features.product_id = product.id AND"
13 + " (specification_type LIKE '%Diagonal ecra%' OR specification_type LIKE '%Diagonal do
ecra%'"
14 + " OR specification_type LIKE '%DIAGONAL DE ECRA%' OR specification_type LIKE '%
Tamanho (ecra visivel)%'"
15 + " OR specification_type LIKE '%Entradas HDMI%' OR specification_type LIKE '%Portas
HDMI%'"
16 + " OR specification_type LIKE '%Consumo em standby%' OR specification_type LIKE '%
Consumo Modo de Espera%')"
17 + " ORDER BY specification_type ASC";
Figura 4.9: Pré-processamento da população de dados (Linguagem: JAVA)
51

Após a primeira depuração, constatamos no código 4.10 (executado no método detailedCluste-
ringKMeans da Classe PriceComparator ), uma segunda abordagem, que efetua a limpeza dos dados
correspondentes aos valores das características, de forma a obter só a parte numérica, e remover o
texto desnecessário, que pode ter sido acrescentado pelo lojista como referências. Por exemplo: a
diagonal do ecrã é um numero acompanhado pelo símbolo das polegadas ”, o consumo em standby é
acompanhado de um W (Watts).
1 while(it.hasNext()){
2 ...
3 if(obj.get("specification_type2").toLowerCase().equals("diagonal")){ //Diagonal
4 diagonal.put(obj.get("product_id"), ""+Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
5 diagonalMaxValue = Math.max(diagonalMaxValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
6 diagonalMinValue = Math.min(diagonalMinValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
7 }else //StandBy
8 if(obj.get("specification_type2").toLowerCase().equals("consumo em standby")){
9 standby.put(obj.get("product_id"), ""+Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
10 standbyMaxValue = Math.max(standbyMaxValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
11 standbyMinValue = Math.min(standbyMinValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
12 }else //HDMI Ports
13 if(obj.get("specification_type2").toLowerCase().equals("portas hdmi")){
14 hdmi.put(obj.get("product_id"), ""+Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
15 hdmiMaxValue = Math.max(hdmiMaxValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
16 hdmiMinValue = Math.min(hdmiMinValue, Functions.extractNumber(obj.get("
specification_value").toLowerCase()));
17 }
18 }
Figura 4.10: Pré-processamento da população de dados (Linguagem: JAVA)
Existem determinados casos em que as características dos produtos não são visíveis, gerando
valores a null, isto pode significar que estas realmente não existam, o valor delas é zero, ou não foram
acrescentadas pelo lojista, embora sejam poucos casos, eles acontecem. A solução encontrada pode
interferir com os resultados, e por isso, alguns cuidados foram considerados.
Omissões aplicadas para resolver casos com valores a null :
• Nas portas HDMI, para além do lojista poder esquecer-se de acrescentar, pode significar princi-
palmente que não existem portas HDMI. Então para este o valor a considerar é 0.
• Em Consumo em standby sempre existe algum tipo de consumo, logo não podemos dizer que
é zero. Nesta situação considerou-se o valor médio de toda a população existente: 0,3.
• A Diagonal do Ecrã sempre existe! Logo como na alínea anterior temos o mesmo problema. Não
pode ser considerado zero. Sendo utilizado, o valor medio a toda a população de dados: 40.
52

Para finalizar o pré-processamento, temos de normalizar os dados. A normalização é importante e
necessária para as operações do clustering, pois os valores, têm de estar coerentes. O seguinte có-
digo 4.11 (executado no método detailedClusteringKMeans da Classe PriceComparator ), é realizado
posteriormente ao código acima, este, efetua a normalização e considera as omissões descritas acima,
caso aconteçam.
1 List<Point> points = new ArrayList<Point>();
2 for(String pId : productsId){
3
4 ArrayList<Double> dimensions = new ArrayList<Double>();
5 dimensions.add(Functions.parameterNormalization(priceMaxValue, priceMinValue, Double.
parseDouble(price.get(pId))));
6
7 if(diagonal.get(pId) == null) dimensions.add(Functions.parameterNormalization(
diagonalMaxValue, diagonalMinValue, 40));
8 else dimensions.add(Functions.parameterNormalization(diagonalMaxValue, diagonalMinValue,
Double.parseDouble(diagonal.get(pId))));
9
10 //Quando null, ponho o valor 0.3 que corresponde a media entre os valores mais comuns
11 //entre 0.1 a 0.5
12 if(standby.get(pId) == null) dimensions.add(Functions.parameterNormalization(
standbyMaxValue, standbyMinValue, 0.3));
13 else dimensions.add(Functions.parameterNormalization(standbyMaxValue, standbyMinValue,
Double.parseDouble(standby.get(pId))));
14
15 if(hdmi.get(pId) == null) dimensions.add(Functions.parameterNormalization(hdmiMaxValue,
hdmiMinValue, 0));
16 else dimensions.add(Functions.parameterNormalization(hdmiMaxValue, hdmiMinValue, Double.
parseDouble(hdmi.get(pId))));
17
18 points.add(new Point(pId, dimensions));
19 }
Figura 4.11: Normalização da população de dados (Linguagem: PHP)
53

4.4 Análises de Dados
Esta é a abordagem mais importante para o Comparador de Preços Inteligente, pois depende desta
para escolher os produtos a serem apresentados. É preciso obter resultados coerentes, mas acima de
tudo, resultados que sejam próximos ou iguais a pesquisa.
Decidiu-se aplicar Clustering neste caso de estudo, escolhendo clustering como a técnica para anali-
sar e agrupar os produtos, sendo o algoritmo k-means escolhido por ser simples, computacionalmente
leve, e satisfaz os requisitos para a elaboração de este estudo. O k-means, é dependente da escolha
de um valor K que determina quantos agrupamentos de dados iremos construir. O problema deste
algoritmo é a dependência de aleatoriedade, e devido a esse motivo, utilizaremos a variante Incremen-
tal k-means[39]. A utilização desta variante deve-se a metodologia que iremos utilizar para avaliar a
escolha do nosso K, que é feita pela função F(k)[40] descrita na secção 2.3.2.B.
A função F(k) avalia possíveis agrupamentos que melhor se adequem a população de dados, e in-
dica possíveis K’s. Na utilização da função F(k), é importante que o resultado varie o menos possível.
Por isso, o algoritmo deverá obter resultados consistentes, desta forma, utilizaremos o Incremental
K-means. O Incremental K-means, tenta maximizar a uniformidade na distribuição dos clusters, e o k-
means não se preocupa com isso. Por exemplo, se tivéssemos uma população de dados, onde temos
agrupamentos de dados bem separados, o k-means, não lhe garante a escolha de um centróide para
cada um desses agrupamentos, mas o Incremental k-means, consegue em cada iteração melhorar a
escolha dos centróides na medida que o K aumenta, de maneira a conseguir levar os centróides para
esses agrupamentos.
54

4.5 Resultados Experimentais
4.5.1 Resultados
Os seguintes gráficos 4.12, 4.13, 4.14, são semelhantes aos descritos na secção 2.3.2.B, e re-
presentam os resultados obtidos de três execuções sobre a população de dados do caso de estudo,
utilizando a variante Incremental k-means secção 2.3.2.A e a função de avaliação F(k) explicada na sec-
ção 2.3.2.B. A população compreende um tamanho aproximado de 500 televisões e 4 características
que são as 4 dimensões dos dados no clustering.
Figura 4.12: Resultado 1, Anexo A.6
Neste primeiro resultado 4.12, podemos notar a convergência de F(k) para 1.0 (linha cor laranja).
Seguindo as tendências do gráfico e tendo em conta que o algoritmo começou a estabilizar em K=15,
podemos observar nos seguintes K’s algumas oscilações no gráfico. Estas oscilações indica-nos quais
os melhores valores de K, que são: K=30 (cor verde), sendo também possível, como segunda opção,
os valores K=33 e K=44 (cor azul). A cor verde são os melhores, porque depois do algoritmo estabilizar,
foram os valores de F(k) que apresentaram maiores oscilações.
55
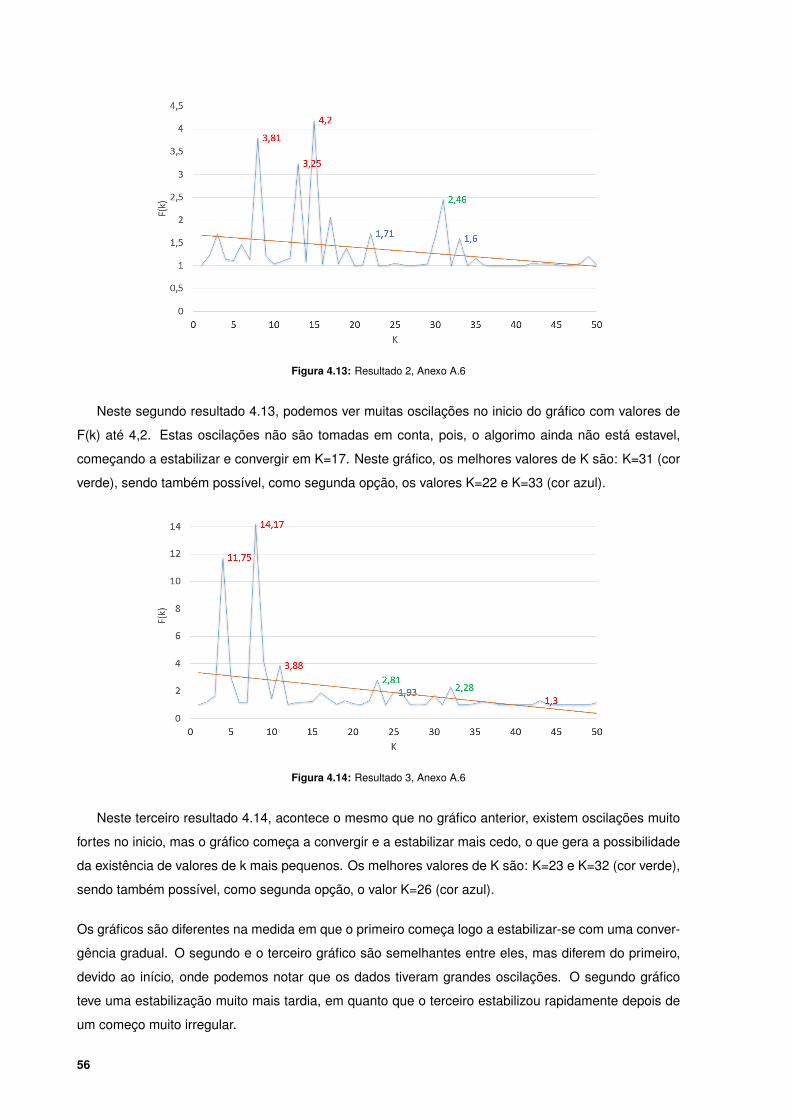
Figura 4.13: Resultado 2, Anexo A.6
Neste segundo resultado 4.13, podemos ver muitas oscilações no inicio do gráfico com valores de
F(k) até 4,2. Estas oscilações não são tomadas em conta, pois, o algorimo ainda não está estavel,
começando a estabilizar e convergir em K=17. Neste gráfico, os melhores valores de K são: K=31 (cor
verde), sendo também possível, como segunda opção, os valores K=22 e K=33 (cor azul).
Figura 4.14: Resultado 3, Anexo A.6
Neste terceiro resultado 4.14, acontece o mesmo que no gráfico anterior, existem oscilações muito
fortes no inicio, mas o gráfico começa a convergir e a estabilizar mais cedo, o que gera a possibilidade
da existência de valores de k mais pequenos. Os melhores valores de K são: K=23 e K=32 (cor verde),
sendo também possível, como segunda opção, o valor K=26 (cor azul).
Os gráficos são diferentes na medida em que o primeiro começa logo a estabilizar-se com uma conver-
gência gradual. O segundo e o terceiro gráfico são semelhantes entre eles, mas diferem do primeiro,
devido ao início, onde podemos notar que os dados tiveram grandes oscilações. O segundo gráfico
teve uma estabilização muito mais tardia, em quanto que o terceiro estabilizou rapidamente depois de
um começo muito irregular.
56

Estas oscilações mostram a aleatoriedade na inicialização do k-means, e por sua vez, mostra a recupe-
ração que o Incremental K-means faz, ao distribuir os clusters uniformemente, o que podemos verificar
no momento em que o gráfico começa a estabilizar.
Neste caso de estudo, os valores de K poderam variar entre K=15 e K=35, onde o K utilizado poderia
ser qualquer um dos apresentados nos gráficos acima 4.12, 4.13, 4.14, a variação destes valores de
K sobre a mesma população deve-se aos clusters criados em diferentes casos, como numa atualiza-
ção dos dados, ou mesmo na execução do Incremental K-means sobre a mesma população de dados
diversas vezes (o valor de K sempre tenderá varia porque o inicio do algoritmo é aleatório).
4.5.2 Vantagens e Desvantagens
Tendo em conta todo o caso de estudo, e os resultados obtidos, abaixo explico as diferenças do
Comparador de Preços Inteligente face aos Comparadores existentes.
Vantagens do Comparador de Preço Inteligente face aos Comparadores existentes:
• É rápido para o utilizador pesquisar produtos semelhantes, pois a pesquisa torna-se direta;
• A pesquisa é feita em busca do que o utilizador quere, e não limitada a opções apresentadas;
• Não é necessário o carregamento de dados via ficheiros, como os processos de Data Feed feitos
por outros comparadores, evitando pedir ao lojista, os dados da sua loja;
• Os produtos podem manter-se atualizados facilmente, pois não é necessário pedir aos lojistas
qualquer tipo de ficheiros ou BD para atualizar, sendo estas atualizações feitas diretamente das
lojas online.
Desvantagens do Comparador de Preço Inteligente face aos Comparadores existentes:
• É necessário fazer cálculos matemáticos e estatísticos, criando funções matemáticas, o que pode
fazer o processo tedioso, transformando uma coisa simples em algo complexo;
• A interface não deixa de estar dependente de filtragens;
• Computacionalmente pode tornar-se pesado, com populações de dados muito grandes;
• Muito dependente de pré-processamento dos dados. Exemplo: um número extraído pode vir
acompanhado de um símbolo da moeda, ou com vírgula como separador das casas decimais
(computacionalmente o ponto é o separador das casas decimais);
• A Extração de dados não é fácil de implementar, principalmente se desejamos total automati-
zação, estando muito dependentes da estrutura HTML, que pode estar sujeitas a modificações
constantes, tendo que abordar paradigmas de LN. Exemplo: não podemos saber se um número
é um preço ou outro tipo de valor, ao menos que tenhamos uma gramática que identifique o que
pode ser (no contexto do HTML).
57

58

5Conclusões e Trabalho Futuro
Contents5.1 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2 Trabalho Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
59

5.1 Conclusões
A implementação do Comparador de Preços Inteligente passou por diferentes abordagens, foram: a
Extração de Dados da Internet, Pré-processamento e a Análise de Dados. A população escolhida para
estudo foram as televisões, com aproximadamente 500 produtos, tendo sido escolhidas as seguinte
variáveis : o preço, numero de portas HDMI, diagonal do ecrã, e consumo em stanby
De entre as diferentes abordagens, o pré-processamento foi a mais difícil, devido às irregularidades nos
dados extraídos. Os casos de limpeza mais comuns, como texto acrescentado num valor numérico, fo-
ram resolvidos sem qualquer inconveniente, no entanto, existe outra situação, em que os produtos, com
características idênticas, surgem com denominações diferentes, o que exige um cuidado redobrado no
tratamento da informação. Outra contrariedade, foi deparar-me com valores nulos, sendo estes de difícil
resolução, pois o produto poderá não apresentar uma determinada caraterística, ou o lojista esqueceu-
se de coloca-la na apresentação do produto. A solução encontrada foi atribuir-lhes valores intermédios
ou zero, consoante a situação.
Para a extração de dados, utilizou-se Web Spidering que visita URLs nas páginas web, afim de criar
um sumário de URLs das mesmas, e assim atingir as páginas dos produtos desejados. Posteriormente
a este processo utiliza-se Web Scraping, para extrair os dados das páginas. O Web Spidering e o Web
Scraping, foram executados através da ferramenta Jsoup que tem uma sintaxe bastante familiar ao Ja-
vaScript, CSS e Jquery, e agilizou o processo de implementação.
A análise de dados foi a mais importante, já que o Comparador de Preços Inteligente, depende total-
mente desta para a apresentação dos dados (produtos). Esta foi feita com a técnica de agrupar dados
(Clustering), e utilizou-se o algoritmo Incremental k-means. A escolha do número de clusters, isto é, o
número de agrupamentos possíveis para os dados, foi feita através de uma função F(k) que avalia um
conjunto de clusters já criados numa distribuição de dados.
Concluindo, o Comparador de Preços Inteligente, apesar de ser ágil na procura de um determinado
produto, pode pecar no seu desempenho na medida em que os dados dos produtos aumentem, este
está muito dependente de pré-processamento dos dados e de implementações matemáticas. Porém,
tem a vantagem de não ser necessário o carregamento de dados, e as atualizações destes, são feitas
diretamente das lojas online.
5.2 Trabalho Futuro
Com base neste estudo e face às dificuldades ao longo das implementações, foi possível obter co-
nhecimentos de múltiplas situações, que foram omissas para simplificar este estudo mas no entanto,
podem dar origem a outros trabalhos. Ao longo do estudo referi frequentemente problemas onde é
necessário abordagens de Língua Natural, principalmente quando extraímos informação diretamente
de documentos HTML. Outro problema, foi a limitação em automatizar a recolha de dados das lojas
60

online.
Dito isto, podemos considerar os seguintes casos para estudos ou implementações futuras.
Desenvolver uma aplicação que automatize a extração de dados, com reconhecimento de padrões,
numa determinada língua. Por exemplo, reconhecer produtos, identificar o nome, preço, e as carac-
terísticas. Isto implica abordagens de Língua Natural, e torna a extração de dado escalável para um
Comparador de preços.
Desenvolver um programa que adapte o texto utilizando Data Mining. No caso de estudo do Compa-
rador Inteligente, só optamos por valores numéricos. Podia-se fazer outra abordagem incluindo texto,
evidentemente teríamos de abordar Língua Natural.
61

62

Bibliografia
[1] T. W. Blog, “Google crawler figure,” 2014, http://www.wpromote.com/blog/seo/helping-web-
crawlers-help-you-how-to-create-an-xml-sitemap/attachment/google-crawling-sitemaps-2/.
[2] S. WORTEN EQUIPAMENTOS PARA O LAR, “Worten,” 2014, http://www.worten.pt/store.
[3] L. FNAC PORTUGAL ACDLDMPT, “Fnac,” 2014, http://www.fnac.pt.
[4] M. M and E. Jacob, “Article: Design and development of a programmable meta search engine,”
International Journal of Computer Applications, vol. 74, no. 5, pp. 6–11, July 2013, published by
Foundation of Computer Science, New York, USA.
[5] I. PriceGrabber.com, “Pricegrabber,” 2014, http://www.pricegrabber.com.
[6] B. Company, “Buscapé,” 2014, http://www.buscape.pt.
[7] K. Kusta, “Kuanto kusta,” 2014, http://www.kuantokusta.pt.
[8] S. Inc, “Ecommerce marketing blog,” 2014, http://www.shopify.com/blog/7068398-10-best-
comparison-shopping-engines-to-increase-ecommerce-sales.
[9] I. I. M. LLC, “Search engine watch,” 2014, http://searchenginewatch.com/article/2097413/The-10-
Best-Shopping-Engines.
[10] digitalks, “Digitalks - comparadores de preços,” 2014, http://digitalks.com.br/guia-de-empresas-
categoria/comparadores-de-precos/.
[11] e commercebrasil, “E-commercebrasil - comparadores de preços,” 2014,
http://www.ecommercebrasil.com.br/fornecedores-categoria/comparadores-de-precos/.
[12] eBizMBA Inc, “ebizmba,” 2014, http://www.ebizmba.com/articles/shopping-websites.
[13] I. PriceGrabber.com, “Pricegrabber documentation,” 2014, https://partner.pricegrabber.com/mss_main.php?sec=2.
[14] B. Company, “Buscapé documentação,” 2014, http://developer.buscape.com/pt/product/buscape/.
[15] ——, “Lomadee,” 2014, http://br.lomadee.com/.
[16] ——, “Buscapé api,” 2014, http://developer.buscape.com/pt/product/buscape/manual-api.html.
63

[17] R. Alves, “Declarative approach to data extraction of web pages,” pp. 90–91, universidade Nova de
Lisboa, Faculdade de Ciências e Tecnologia, Department of Computer Science. November 2009.
http://run.unl.pt/bitstream/10362/5822/1/Alves_2009.pdf.
[18] K. Kusta, “Kuanto kusta api,” 2014, http://kuantokusta-api.appspot.com/.
[19] P. Gupta and K. Johari, “Implementation of web crawler,” in Emerging Trends in Engineering and
Technology (ICETET), 2009 2nd International Conference on, Dec 2009, pp. 838–843.
[20] G. Jawaheer and P. Kostkova, “Web crawlers on a health related portal: Detection, characterisation
and implications,” in Developments in E-systems Engineering (DeSE), 2011, Dec 2011, pp. 24–29.
[21] G. Inc, “Google,” 2014, https://www.google.com.
[22] G. O. System, “Wget,” 2010, http://www.gnu.org/software/wget.
[23] E. Romanus, “Methabot,” http://sourceforge.net/projects/methabot/.
[24] G. Inc., “Googlebot,” http://support.google.com/webmasters/bin/answer.py?hl=pt-
BR&answer=182072.
[25] M. Corporation, “Msnbot,” http://en.wikipedia.org/wiki/Msnbot.
[26] L. Jiang and H. Zhang, “Multi-agent based individual web spider system,” in World Automation
Congress (WAC), 2010, Sept 2010, pp. 177–181.
[27] X. Han, X. Li, and Q. Zheng, “Research on web information extraction based on spider algorithm
and dom thinking,” in Information Networking and Automation (ICINA), 2010 International Confe-
rence on, vol. 2, Oct 2010, pp. V2–182–V2–185.
[28] S. Malik and S. A. M. Rizvi, “Information extraction using web usage mining, web scrapping and
semantic annotation,” in Computational Intelligence and Communication Networks (CICN), 2011
International Conference on, Oct 2011, pp. 465–469.
[29] L. W. Extractor, “Link web extractor,” http://www.linkws.com/br/marketing/extractor_apres.htm.
[30] W. Harvest, “Web harvest,” http://web-harvest.sourceforge.net/.
[31] J. Hedley, “Jsoup,” http://jsoup.org/.
[32] W3C, “World wide web consortium,” 2014, http://www.w3.org/.
[33] Whatwg, “Whatwg,” http://www.whatwg.org/specs/web-apps/current-work/multipage/.
[34] C. Antunes, Data Mining e Data Warehousing, 2nd ed., Departamento de Engenharia Informática,
Instituto Superior Técnico, Março, 2008, pp. 87–97.
[35] http://home.deib.polimi.it, “Clustering: An introduction,” http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/index.html.
64

[36] J. B. MacQueen, “Some methods for classification and analysis of multivariate observations,” in
Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley,
University of California Press, 1967, pp. 1:281–297.
[37] K.-M. Clustering, http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/kmeans.html.
[38] P. K. Agarwal and D. Hou, “Lecture 18: Clustering and classification,” October 30, 2003,
https://www.cs.duke.edu/courses/fall03/cps260/notes/lecture18.pdf.
[39] D. Pham, S. Dimov, and C. Nguyen, “An incremental k-means algorithm,” Proceedings of the Insti-
tution of Mechanical Engineers, Part C: Journal of Mechanical Engineering Science, vol. 218, no. 7,
pp. 783–795, 2004.
[40] D. T. Pham, S. S. Dimov, and C. Nguyen, “Selection of k in k-means clustering,” Proceedings of the
Institution of Mechanical Engineers, Part C: Journal of Mechanical Engineering Science, vol. 219,
no. 1, pp. 103–119, 2005.
[41] https://www.blogger.com/profile/17797460307331045438, “A java implementation of k-means,”
2014, http://moderntone.blogspot.pt/2013/04/a-java-implementation-of-k-means.html.
[42] Y. Inc, “Yahoo,” 2014, http://www.yahoo.com/.
[43] ——, “Yahoo! store,” 2014, https://smallbusiness.yahoo.com/.
[44] T. Bruggemann and M. Breitner, “Mobile price comparison services,” in Mobile Commerce and
Services, 2005. WMCS ’05. The Second IEEE International Workshop on, July 2005, pp. 193–201.
[45] LinkWS, “Linkws,” http://www.linkws.com/.
[46] J. C. Dunn, “A fuzzy relative of the isodata process and its use in detecting compact well-separated
clusters,” Journal of Cybernetics, pp. 3: 32–57, 1973.
[47] J. B. MacQueen, “Pattern recognition with fuzzy objective function algoritms,” Plenum Press, New
York, 1981.
[48] S. C. Johnson, “Hierarchical clustering schemes,” Psychometrika, pp. 2:241–254, 1967.
[49] C. Abar, “O conceito ’fuzzy’,” 2004, http://www.pucsp.br/ logica/Fuzzy.htm.
[50] O. do Nascimento Souza, “Introdução à teoria dos conjuntos fuzzy,” Março 8, 2010,
http://www.ime.unicamp.br/ valle/PDFfiles/osmar10.pdf.
[51] F. C.-M. Clustering, http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/cmeans.html.
[52] G. H. B. P. P. R. I. H. W. . T. W. D. M. S. A. U. S. E. V. . I. . Mark Hall, Eibe Frank,
http://www.cs.waikato.ac.nz/ml/weka/index.html.
[53] G. G. P. License, http://www.gnu.org/licenses/gpl.html.
65

66

AAnexos
A-1
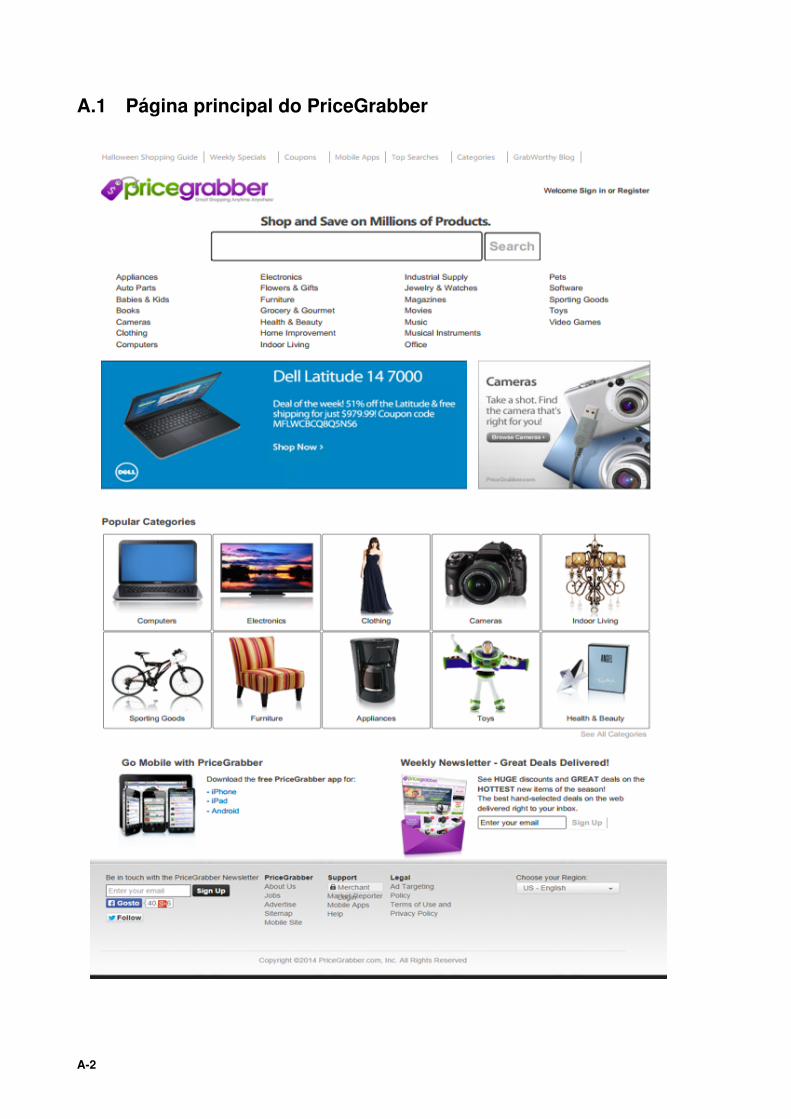
A.1 Página principal do PriceGrabber
A-2
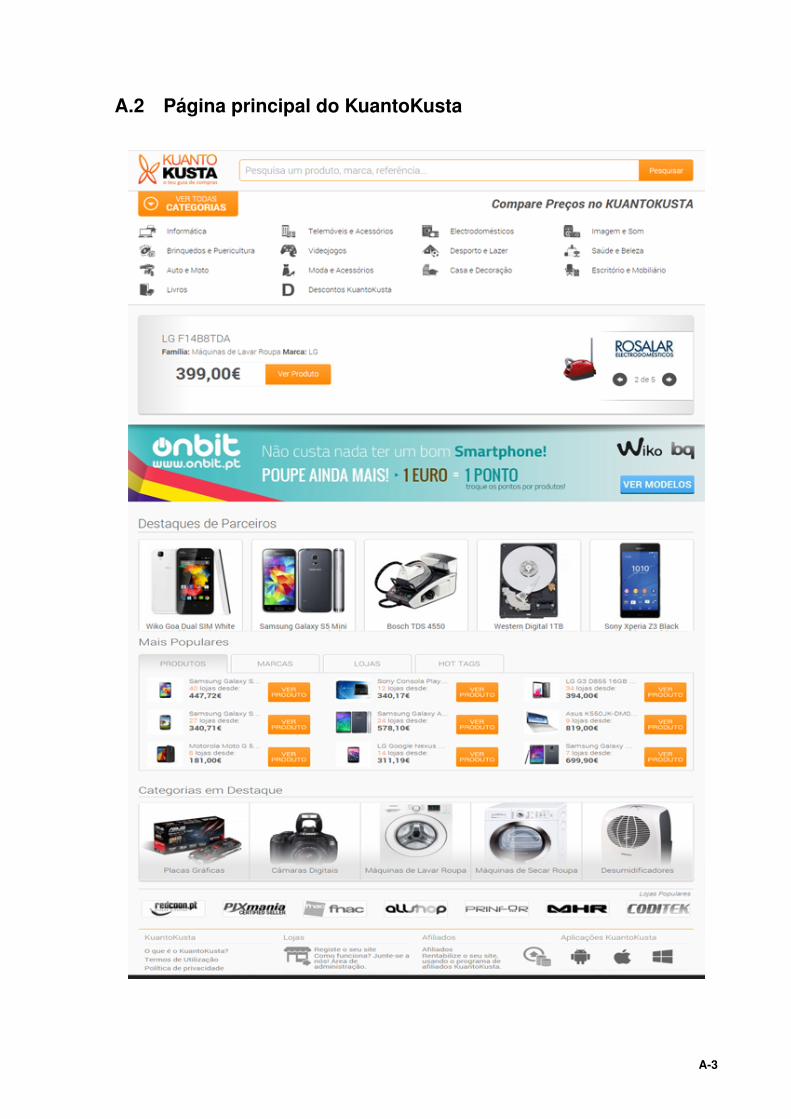
A.2 Página principal do KuantoKusta
A-3

A.3 Estrutura HTML do Título e Preço das televisões na Worten
A-4
A.4 Estrutura HTML das características das televisões na Worten
A-5

A.5 Apresentação da execução de /PCInterface/fk.php
A-6

A.6 Exemplos de execução de F(k) na população de dados emestudo
A-7

A.7 PC Core Packages
A-8

A.8 Package db
A-9

A.9 Package product
A-10
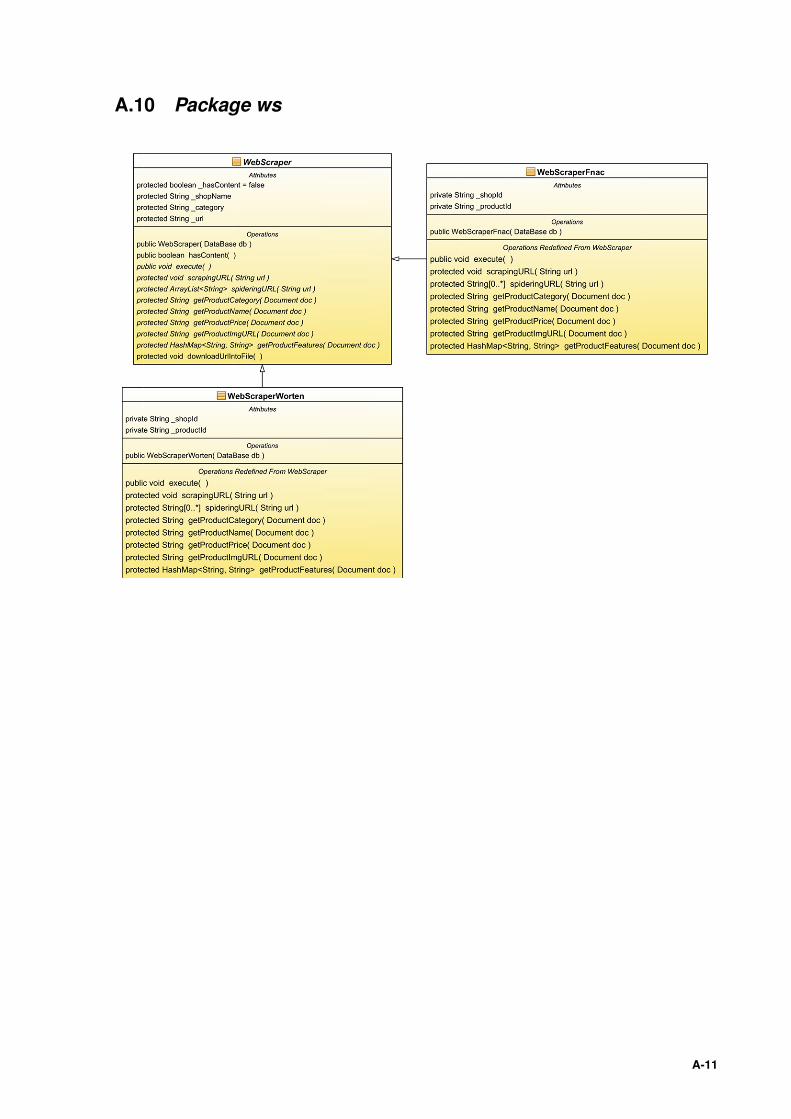
A.10 Package ws
A-11

A.11 Package dm.clustering.kmeans
A-12

A.12 Package pc
A-13

A-14