Embed Size (px)
Citation preview

Data miningSISTEMAS DE SAÚDE
Equipa 05_02:
Claudia Ferreira
Tomás Rocha
Patrícia Mendes
Moisés Coelho
Rui Morais
Supervisor:
Luís Guimarães
Monitor:
Jorge Ferreira

Sumário
1. Conceito
2. Técnicas
3. Casos de aplicação
4. Softwares de Data Mining
5. Limitações de desafios

Conceito de Data mining
Data mining é uma disciplina que incluiu estatística, tecnologias de
base de dados, reconhecimento de padrões, machine learning, entre
outras áreas.
(Hand, 1998)
1
Data mining – Tomada de decisões eficazes 2

2. Técnicas de Data mining 3
Clustering Regras de associação
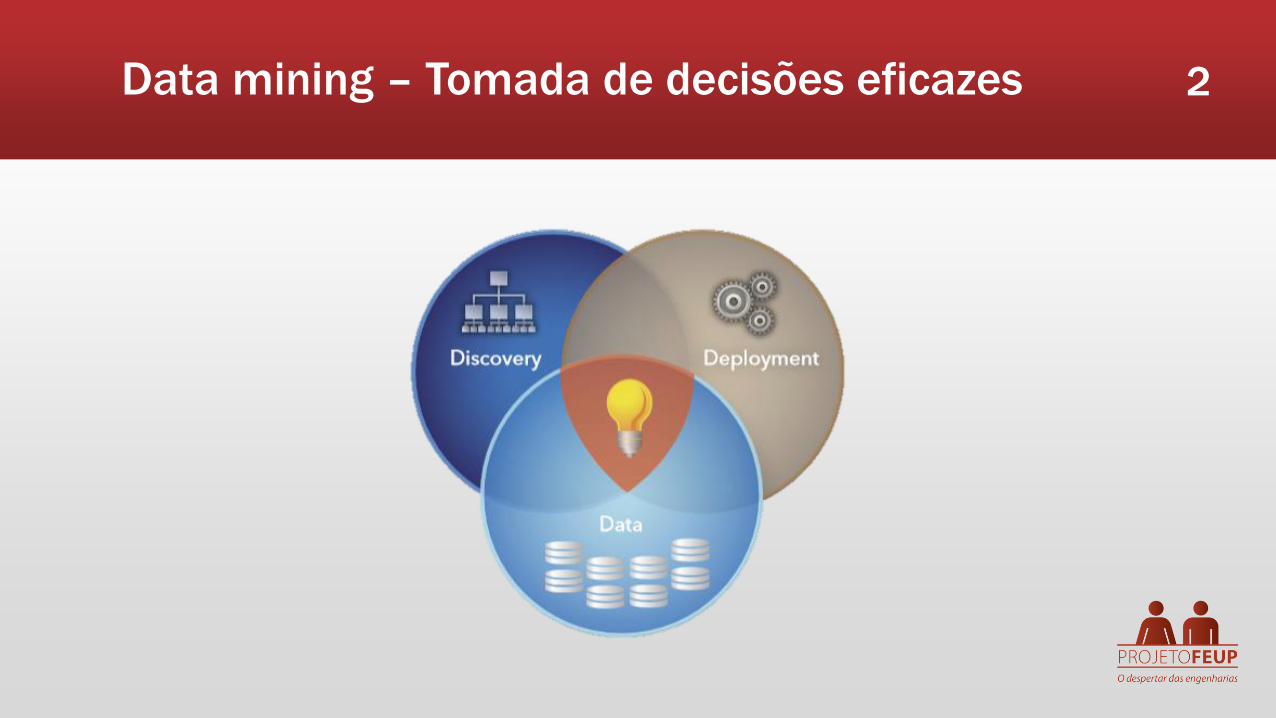
Técnicas de Data mining 4
Árvores de decisão Redes neuronais

Tarefas do Data mining
• Descrição
• Classificação
• Estimação/Regressão
• Previsão
• Sequenciação
5

Data mining associado à hipertensão
Objetivo:
Recolha de informações que facilitem o controlo da hipertensão.
Metodologia:
1. Seleção de registos de pacientes com e sem hipertensão, em igual número. A informação abrange dados biomédicos (altura, peso, etc.) e outros (como a taxa de fumadores).
2. Aplicação das técnicas de regressão, previsão (árvore de decisão) e associação.
6

Data mining associado à hipertensão
Resultados:
Técnica de regressão
Técnica de previsão
Técnica de associação
7

Data mining associado à hipertensão
Conclusão:
Estas metodologias são bastante úteis e eficazes na descoberta de padrões associados à doença da hipertensão, apesar das limitações subjacentes ao conjunto de dados utilizados.
8

Casos fraudulentos e de abuso hospitalar
Objetivo:
Desenvolvimento de um processo para a detenção de casos abusivos ou fraudulentos nos sistemas de saúde.
Metodologia:
1. Seleção de dados de pacientes do Departamento de Ginecologia de Taiwan.
2. Eliminação de registos incoerentes e leitura por especialistas dos restantes casos.
3. Criação de uma base de dados com a mesma quantidade de casos normais e fraudulentos.
9
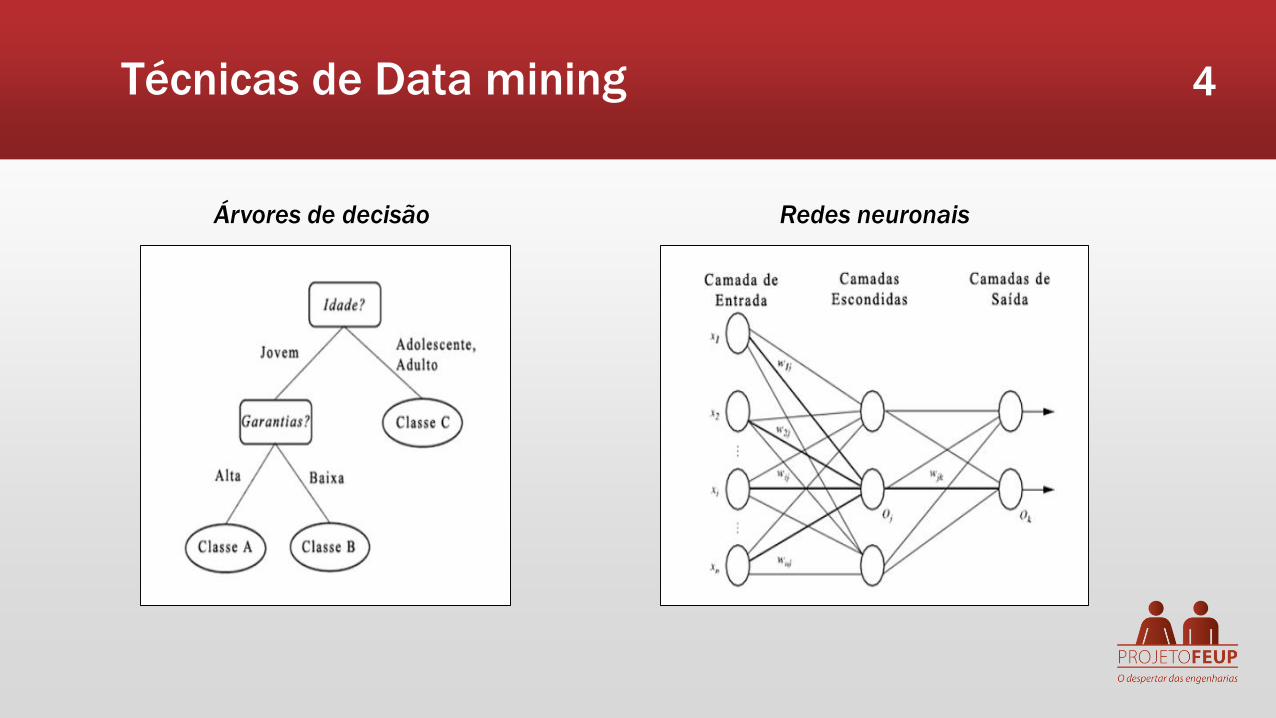
Casos fraudulentos e de abuso hospitalar
Resultados:
Sensitivity- 64% (percentagem de casos fraudulentos detetados mediante o total de casos desse tipo)
Specificity- 67% (percentagem de casos normais identificados no total existente)
10

Casos fraudulentos e de abuso hospitalar
Conclusões:
É uma aplicação diferente de Data Mining.
Foi possível identificar as caraterísticas discriminatórias predominantes em casos fraudulentos.
O software mostrou-se eficiente na deteção de grande parte dos casos abusivos e fraudulentos usados no teste.
11
Sistema WEKA e sistemas CAD 12

Limitações e desafios do Data mining
A nível dos resultados
A nível legal/ético
A nível tecnológico
13

Agradecemos a vossa atenção