Embed Size (px)
Citation preview

Unioeste - Universidade Estadual do Oeste do ParanáCENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICASColegiado de InformáticaCurso de Bacharelado em Informática
DATA WAREHOUSE
Rafael Ervin HassRaphael Laércio Zago
CASCAVEL2005

Rafael Ervin HassRaphael Laércio Zago
DATA WAREHOUSE
Monografia apresentada como requisito parcialpara aprovação na disciplina de Banco de Dados IIdo curso de Bacharelado em Informática, do Cen-tro de Ciências Exatas e Tecnológicas da Univer-sidade Estadual do Oeste do Paraná - Campus deCascavel
Professor: Carlos José Maria Olguín
CASCAVEL2005

Lista de Figuras
2.1 Arquitetura de data warehouse . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.1 Modelo de cubo de dados tridimensional . . . . . . . . . . . . . . . . . . . . . 10
3.2 Versão com rotação do cubo de dados da figura 3.1 . . . . . . . . . . . . . . . 11
3.3 Esquema estrela com tabelas de fatos e de dimensões . . . . . . . . . . . . . . 12
3.4 Esquema snowflake . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
iii

Lista de Abreviaturas e Siglas
OLAP On Line Analytical ProcessingDW Data WarehouseDWA Data Warehouse ArchitureSQL Structured Query LanguageSGDB Sistema Gerenciador de Banco de Dados
iv

Sumário
Lista de Figuras iii
Lista de Abreviaturas e Siglas iv
Sumário v
Resumo vi
1 Introdução 1
2 Data Warehouse 3
2.1 Uma arquitetura de data warehouse . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Bancos de Dados Operacionais / Camada de Banco de Dados Externo . 4
2.1.2 Camada de Acesso à Informação . . . . . . . . . . . . . . . . . . . . . 5
2.1.3 Camada de Acesso de Dados . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.4 Diretório de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.5 Camada de Gerenciamento de Processos . . . . . . . . . . . . . . . . . 6
2.1.6 Camada de Mensagens de Aplicação . . . . . . . . . . . . . . . . . . . 6
2.1.7 Camada de Data Warehouse . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.8 Camada de Plataforma de Dados . . . . . . . . . . . . . . . . . . . . . 7
2.2 Características de Data Warehouses . . . . . . . . . . . . . . . . . . . . . . . 7
3 Desenvolvimento de Data Warehouse 9
3.1 Modelagem do Data Warehouse . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Construção de um Data Warehouse . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Estudo de Caso 16
5 Conclusão 18
Glossário 19
Referências Bibliográficas 20
v

Resumo
Será definido o conceito de data warehouse, bem como sua arquitetura e os mecanismos de
modelagem e implentação necessários. Discutiremos aplicações do data warehouse e apresen-
taremos um estudo de caso para demonstrar as vantagens da tecnologia de data warehousing no
ambiente de auxílio à tomada de decisões.
Palavras-chave: data warehouse, OLAP, sistemas de apoio á decisão
vi

Capítulo 1
Introdução
Podemos encontrar reconhecidamente dois tipos fundamentalmente diferentes de sistemas
de informação nas organizações: os sistemas operacionais e os sistemas informacionais.
Sistemas operacionais são exatamente o que seu nome implica, isto é, sistemas utilizados na
operação diária das organizações. Eles são a espinha dorsal de qualquer organização, e devido
à sua importância, foram em geral as primeiras partes a serem informatizadas.
Sistemas informacionais lidam com com a análise de dados e a tomada de decisões, fre-
quentemente decisões de alto nível, sobre como a organização vai operar, agora e no futuro.
Além disso possuem um foco diferente dos sistemas operacionais, e frequentemente um es-
copo diferente. Enquanto dados operacionais são geralmente focados em uma única área, dados
informacionais podem frequentemente se extender por um número diferente de áreas.
O conceito de "data warehousing"data da metade da década de 1980. Em essência, ele
pretendia prover um modelo arquitetural para o fluxo de dados dos sistemas operacionais para
ambientes de suporte à decisão. Ele tentava lidar com os diversos problemas associados com
esse fluxo, e com os altos custos associados a ele. Na inexistência de tal arquitetura, existia uma
enorme quantidade de redundância na entrega de informações de gerenciamento. Em grandes
corporações era comum multiplos sistemas de suporte à decisão operarem independentemente,
cada um servindo diferentes usuários porém requerendo muitos dos mesmos dados. O processo
de capturar, limpar e integrar dados de várias fontes, não raro sistemas legados, era tipicamente
replicado para cada projeto. Além disso, sistemas legados eram frequentemente revisitados à
medida que novos requerimentos emergiam, cada vez requerendo visões levemente diferentes
dos dados legados.
Baseado em analogias com armazéns da vida real (warehouses), data warehouses preten-

diam ser áreas de armazenamento em larga escala para dados legados. De onde estes poderiam
ser distribuídos para "lojas de varejo"onde eles poderiam ser preparados para acesso dos usuá-
rios de suporte à decisão. Enquanto os data warehouses foram designados para gerenciar o
suprimento de dados dos fornecedores, e manipular a organização e armazanamento desses da-
dos, as "lojas de varejo"poderiam estar focadas no empacotamento e apresentação de dados
selecionados aos usuários finais, comumente para atender necessidades específicas [1].
Atualmente data warehouses são utilizadas nas seguintes áreas:
• On-Line Analytic Processing (OLAP) para suporte a tomada de decisões;
• Data mining, que usa o data warehouse como fonte de informações para sistemas de
descoberta de dados através de técnicas estatísticas e inteligência artificial para encontrar
associações, seqüências, classificações, conjuntos e previsões;
• Database marketing, que utiliza o data warehouse para prover serviços personalizados
para compradores específicos.
Data warehouses não são baratos, o custo gira em torno de milhões de dólares, ou seja, pou-
cas organizações tem condições de adquirir um DW. A implementação consome muito tempo e
exige requisitos criteriosos da organização. Como é desenvolvido para grandes empresas e
A área de data warehouse teve um grande crescimento ao longo da década de 1990. DW
proveram uma vantagem estratégica para muitas empresas que as adotaram previamente. Na
atual situação do mercado os data warehouse se tornaram uma necessidade estratégica para as
organizações, pois seus competidores usam essa tecnologia. Os web browsers se tornaram o
grande veiculo para o acesso aos dados do warehouse, atualmente também se utilizam tecnolo-
gias como Java, CORBA e Active X.
2

Capítulo 2
Data Warehouse
Uma das razões para que o data warehouse levou tanto tempo para se desenvolver é que ele
é atualmente uma tecnologia muito abrangente. De fato, data warehouse pode ser representado
como um framework para gerenciamento informacional de dados da organização. De modo
à entender como todos os componentes envolvidos em uma estratégia de data warehouse são
relacionados, é necessário ter uma arquitetura do mesmo.
2.1 Uma arquitetura de data warehouse
Uma arquitetura de data warehouse (data warehouse architeture ou DWA) é um meio de re-
presentar a estrutura de geral de dados, comunicação, processamento e apresentação que existe
para a computação de usuário final que ocorre na organização. Essa arquitetura é composta de
vários componentes interconectados [3]:
• Bancos de Dados Operacionais / Camada de Banco de Dados Externo
• Camada de Acesso à Informação
• Camada de Acesso de Dados
• Diretório de Dados
• Camada de Gerenciamento de Processos
• Camada de Mensagens de Aplicação
• Camada de Data Warehouse

• Camada de Plataforma de Dados
Figura 2.1: Arquitetura de data warehouse
2.1.1 Bancos de Dados Operacionais / Camada de Banco de Dados Ex-terno
Sistemas operacionais processam dados para suportar necessidades operacionais críticas.
Para isso, estes devem ser criados históricamente para prover uma estrutura de processamento
eficiente para um número relativamente pequeno de transações de negócios bem definidas. En-
tretanto, devido ao foco limitado de sistemas operacionais, o banco de dados é designado para
suportar sitemas operacionais que tem dificuldade em acessar dados para outros gerenciamen-
tos ou propósitos informacionais. Essa dificuldade em acessar dados operacionais é amplificada
pelo fato de que muitos sistemas operacionais são frequentemente de dez ou quinze anos atrás.
A idade de alguns desses sistemas significa que a tecnologia de accesso aos dados disponível
para obter dados operacionais é ela mesma antiga.
Claramente, a meta do data warehousing é libertar a informação que está travada no banco
de dados operacional e misturar ela com a informação de outras fontes de dados, possivelmente
externas. Cada vez mais, grandes organizações estão adquirindo dados adicionais de bancos de
dados externos. Esses incluem dados demográficos, econométricos, tendências competitivas e
4

de compras. A chamada "supervia da informação"está provendo acesso à mais fontes de dados
a cada dia.
2.1.2 Camada de Acesso à Informação
A camada de acesso à informação da arquitetura de data warehouse é aquela com a qual o
usuário final lida diretamente. Em particular, ela representa as ferramentas que o usuário final
normalmente usa no dia a dia. Essa camada também inclui o hardware e software envolvido na
visualização e impressão de relatórios, planilhas, grafos e gráficos para análise e apresentação.
A camada de acesso à informação se expandiu fortemente, devido especialmente à migração de
usurários finais para PCs e PC/LANs.
Hoje existem ferramentas cada vez mais sofisticadas em desktops para manipular, analisar e
apresentar dados, entretanto, existem problemas relevantes na criação de dados "crus"contidos
em sistemas operacionais disponíveis facilmente e perfeitamente para usuários finais. Uma das
chaves para isso é encontrar linguagens de dados comuns que podem ser usadas na organização
inteira.
2.1.3 Camada de Acesso de Dados
A camada de acesso de dados da arquitetura de data warehouse é envolvida com a permissão
da camada de acesso à informação para "conversar"com a camada operacional. Nas redes mun-
diais de hoje, a linguagem de dados comum que emergiu é o SQL. Originalmente desenvolvida
pela IBM como uma linguaguem de consultas, mas acabou se tornando um padrão de fato para
o intercâmbio de dados.
Uma das descobertas chave dos últimos anos foi o desenvolvimento de uma série de fil-
tros de acesso aos dados, tais como EDA/SQL, que possibilitam ao SQL acessar praticamente
qualquer SGDB e sistema de arquivos de dados, seja relacional ou não relacional. Esses filtros
tornaram possível para as ferramentas de acesso à informações no estado da arte acessar dados
armazenados em sistemas de gerenciamento de banco de dados que datam de muitos anos atrás.
A camada de acesso de dados não somente extende diferentes SGDBs e sistemas de arquivos
no mesmo hardware, ele exptende fabricantes e protocolos de rede também. Uma das chaves
para uma estratégia de data warehouse é prover os usuários finais com "acesso de dados univer-
5

sal", isto é, pelo menos teoricamente usuários finais, independentemente de sua localização ou
ferramenta de acesso à informação, devem ser capazes de acessar qualquer ou todos os dados
na organização que são necessãrios para ele realizar seu trabalho.
Essa camada é então responsável pelo interfaceamento entre ferramentas de acesso à infor-
mação e bancos de dados operacionais. Em muitos casos, isso é tudo que certos usuários finais
necessitam. Entretanto, em gera, organizações estão desenvolvendo esquemas muito mais so-
fisticados para suportar data warehouse [3].
2.1.4 Diretório de Dados
De modo a prover acesso a dados universal, é absolutamente necessário manter alguma
forma de diretório de dados ou repositório de informações de metadados. Metadados são os
dados sobre os dados internos à organização. Para termos um armazém de dados completamente
funcional, é necessário ter uma variedade de metadados disponível, dados sobre as visões de
dados dos usuário finais e sobre bancos de dados operacionais. Idealmente, usuários finais
devem ser capazes de acessar dados do data warehouse, sem ter de conhecer onde os dados
residem ou a forma na qual ele é armazenado.
2.1.5 Camada de Gerenciamento de Processos
A camada de gerenciamento de processos é envolvida no escalonamento das várias tarefas
que devem ser realizadas para gerar e manter as informações do data warehouse e do diretório de
dados. Ela pode ser vista como o controlador de alto nível das tarefas para os muitos processos
(procedimentos) que devem ocorrer para manter o data warehouse atualizado.
2.1.6 Camada de Mensagens de Aplicação
A camada de mensagens de aplicação lida com o transporte de informação pela rede de com-
putação organizacional. As mensagens de aplicação são também chamadas de "middleware",
mas ele pode envolver mais do que simplesmente protocolos de rede. Elas podem ser usadas,
por exemplo, para isolar aplicações, operacionais ou informacionais, do formato exato dos da-
dos no outro lado. Mensagens de aplicação podem também ser usados para coletar transações
ou mensagens e entregá-las em um certo local em um certo tempo.
6

2.1.7 Camada de Data Warehouse
O núcleo do data warehouse é onde os dados são primariamente usados para uso informacio-
nal. Em alguns casos, podemos pensar no data warehouse simplesmente como uma visão lógica
ou virtual dos dados. Em muitas instâncias, o data warehouse pode atualmente não envolver o
armazenamento de dados.
No data warehouse físico, cópias de dados operacionais ou externos são armazenados em um
formato de fácil acesso e altamente flexível. Cada vez mais os data warehouses são armazenados
em plataformas cliente/servidor, mas são frequentemente armazenados em quadros principais
também.
2.1.8 Camada de Plataforma de Dados
O componente final da arquitetura de um data warehouse é a plataforma de dados. A pla-
taforma de dados também é chamada de gerenciamento de cópia ou gerenciamento de replica-
ção, mas de fato, ela inclui todos os processos necessários para selecionar, editar, sumarizar,
combinar e carregar data warehouses e dados de informações de acesso de bancos de dados
operacionais ou externos.
A plataforma de dados frequentemente envolve programação complexa, mas ferramentas
de data warehouse estão sendo criadas para ajudar nesse processo. Ela também pode envolver
programas de análise da qualidade de dados e filtros que identificam padrões e estruturas de
dados em dados operacionais existentes.
2.2 Características de Data WarehousesOrientado à Assunto
A informação é apresentada de acordo com assuntos específicos ou áreas de interesse, não
simplismente como arquivos de computador. Os dados são manipulados para prover informa-
ções sobre um assunto em particular. Por exemplo, o SGDB não é simplesmente tornado acessí-
vel aos usuários finais, mas são providas estruturas e organizações de acordo com necessidades
específicas.
7

Integrados
Uma fonte única de informações para e sobre a compreensão de múltiplas áreas de interesse.
O data warehouse contém informações sobre uma variedade de assuntos.
Não-Volátil
Informações estáveis que não mudam cada vez que um processo operacional é executado.
As informações são consistentes à despeito de quando o data warehouse é acessado.
Variável no Tempo
Contendo um histórico de um assunto, assim como informações atualizadas. Informação
histórica é um importante componente de um data warehouse.
Accessivel
O principal propósito de um data warehouse é prover informações acessíveis prontamente
aos usuários finais.
Orientado à Processo
É importante visualizar o data warehouse como um processo para a entrega de informações.
A manutenção de um data warehouse é contínua e iterativa por natureza [4].
8

Capítulo 3
Desenvolvimento de Data Warehouse
O modelo de dados multidimensional se encaixa bem com o OLAP e com as tecnologias
de apóio a decisão. Geralmente um data warehouse é um deposito de dados integrados oriun-
dos de fontes múltiplas, processados para armazenamento em um modelo multidimensional. Se
comparado com um banco de dados transacionais podemos dizer que um data warehouse é não
volátil, ou seja, a informação no DW muda muito menos freqüentemente e pode ser conside-
rada como não sendo de tempo real e com atualização periódica. Os sistemas transacionais, as
transações são a unidade e o agente de mudança no banco de dados. Em um data warehouse a
granularidade dos dados é muito mais espessa e sua atualização depende de uma política apro-
priada previamente definida. Em um DW existe um componente responsável pela aquisição
e pré-processamento dos dados, e é esse o componente responsável pela atualização. Como
abrangem grandes volumes de dados, os data warehouses geralmente são uma ordem de mag-
nitude maior que os banco de dados fontes, o volume absoluto de dados, que gira em torno de
terabytes, é uma questão a ser tratada com data warehouses que abrangem toda a organização
[2].
3.1 Modelagem do Data Warehouse
Os modelos multidimensionais tiram proveito de relações inerentes aos dados para gerar
dados em matrizes multidimensionais chamadas cubos de dados. Também podem ser chama-
dos de hipercubos, se tiverem mais que três dimensões. Para dados que seguem à formatação
dimensional, o desempenho de consultas em matrizes multidimensionais pode ser muito melhor
do que no modelo de dados relacional. Na figura 3.1 há um cubo de dados tridimensional que

Figura 3.1: Modelo de cubo de dados tridimensional
organiza os dados de vendas dos produtos por trimestres fiscais e regiões de vendas. Outras
dimensões poderiam ser acrescentadas, caracterizando um hipercubo, porém objetos com mais
de três dimensões não são facilmente apresentados graficamente. Os dados podem ser consul-
tados diretamente em qualquer combinação das dimensões, o que evita consultas complexas ao
bando de dados. A mudança de uma hierarquia, também chamada de orientação dimensional,
para outra é facilmente realizada em um cubo de dados por uma técnica chamada pivoteamento,
ou rotação. Nessa técnica o cubo de dados pode ser pensado como se tivesse uma rotação para
mostrar uma orientação diferente dos eixos. Por exemplo, poderia ser provocada uma rotação no
cubo de dados para mostrar as receitas das vendas regionais como linhas, os totais das receitas
dos trimestres fiscais como colunas e os produtos da empresa na terceira dimensão, como está
representado na figura 3.2. Conseqüentemente, essa técnica é equivalente a ter uma tabela de
vendas regionais separadamente para cada produto, em que cada tabela mostra as vendas trimes-
trais para aquele produto por região. Os modelos multidimensionais podem ser perfeitamente
utilizados para visões hierárquicas no que é conhecido como apresentação roll-up e apresen-
tação drill-down. Apresentações roll-up seguem na direção de baixo para cima na hierarquia,
agrupando segundo unidades maiores ao longo de uma dimensão. Por exemplo, sumarizando
dados semanais por trimestre. A apresentação drill-down proporciona a capacidade oposta, for-
necendo uma visão de granularidade mais fina. O modelo de armazenamento multidimensional
10

Figura 3.2: Versão com rotação do cubo de dados da figura 3.1
utiliza as tabelas de dimensão e as tabelas de fatos. Uma tabela de dimensão possui atributos de
dimensões, enquanto que as tabelas de fatos podem ser imaginadas como possuindo tuplas, uma
por fato registrado. Esse fato contém algumas variáveis medidas ou observadas e as identificam
com ponteiros para tabelas de dimensão, ou seja, as tabelas de fatos contém os dados, e as di-
mensões identificam cada tupla naqueles dados. Na figura 3.3 é representada uma tabela de fato
que pode ser vista a partir da perspectiva de tabelas de dimensão. Os esquemas multidimensio-
nais mais comuns são o estrela e o snowflake. No esquema estrela uma tabela de fato possui uma
única tabela para cada dimensão como podemos ver na figura 3.3. O esquema snowflake é uma
variação do esquema estrela, onde as tabelas dimensionais do esquema estrela são organizadas
segundo uma hierarquia definida por meio da sua normalização. A figura 3.4 representa um
esquema snowflake. Para poder dar suporte ao acesso de alto desempenho o armazenamento em
data warehouse utiliza técnicas de indexação. Em um esquema estrela, pode ser utilizada uma
indexação de junção para indexar os dados dimensionais as tuplas na tabela de fatos. Os índices
de junção são índices tradicionais para a manutenção de relacionamentos entre os valores da
chave primária e da chave estrangeira. Eles relacionam os valores de dimensão de um esquema
estrela às linhas na tabela de fato. Por exemplo, considere uma tabela de fato de vendas que
possua cidade e trimestre fiscal como dimensões. Se existir um índice de junção para cidade,
11
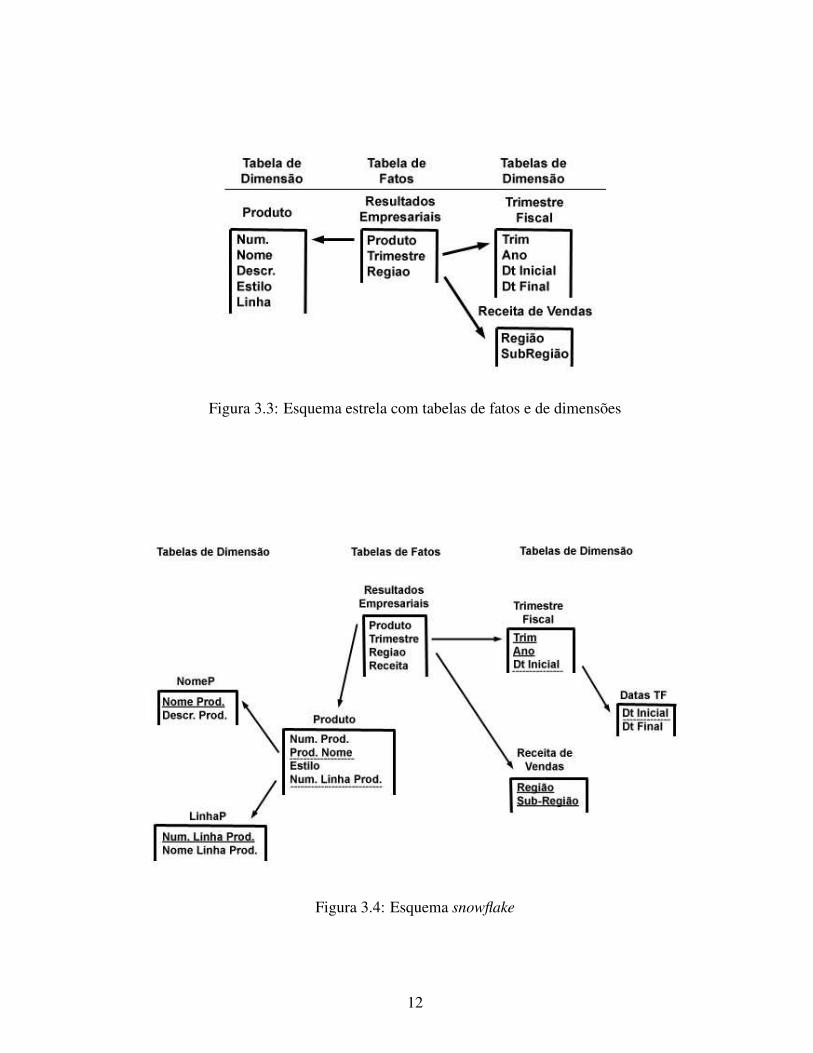
Figura 3.3: Esquema estrela com tabelas de fatos e de dimensões
Figura 3.4: Esquema snowflake
12

para cada cidade o índice de junção manterá os identificadores de tuplas que contenham aquela
cidade. Os índices de junção podem envolver dimensões múltiplas. O armazenamento em data
warehouses pode facilitar o acesso a dados sumários tirando maior vantagem da persistência dos
data warehouses e do grau de previsibilidade das análises que serão executadas utilizando-os.
Duas abordagens têm sido usadas. Uma utiliza tabelas menores que contém dados sumários, e
a outra utiliza codificação de nível dentro das tabelas existentes.
3.2 Construção de um Data Warehouse
Para a construção de um DW, os desenvolvedores devem, antecipadamente, obter uma ampla
visão do uso do warehouse. É impossível antecipar todas as possíveis consultas ou análises
durante a fase de projeto, por esta razão o projeto deve dar suporte às consultas ad hoc, ou
seja, o acesso aos dados em qualquer combinação significativa dos valores para os atributos nas
tabelas de dimensão ou de fato. Inicialmente deve ser definido como os dados serão adquiridos.
A aquisição de dados para o warehouse envolve alguns passos, sejam eles:
• Os dados precisam ser extraídos de fontes múltiplas e heterogêneas;
• Os dados precisam ser formatados visando à consistência dentro do warehouse;
• Os dados precisam ser limpos para assegurar a validade;
• Os dados precisam ser carregados no DW.
Os banco de dados precisam atingir um equilíbrio entre a eficiência no processamento de transa-
ções e o suporte aos requisitos de consultas, porém um data warehouse é tipicamente otimizado
para o acesso a partir das necessidades de um tomador de decisão. O armazenamento de dados
em um data warehouse reflete essa especialização e envolve os seguintes processos:
• Armazenamento dos dados de acordo com modelo de dados do warehouse;
• Criação e manutenção das estruturas de dados necessárias;
• Criação e manutenção de caminhos de acesso adequados;
• Fornecimento de dados que variam no tempo conforme novos dados são acrescentados;
13

• Suporte a atualização dos dados do warehouse;
• Atualização dos dados;
• Eliminação dos dados.
Pelo volume de dados presente no data warehouse a sua total recarga geralmente se mostra
impossível. Por isso é utilizada a atualização seletiva e versões de warehouse separadas do
warehouse. Alguns warehouses utilizam um mecanismo incremental de atualização dos dados,
onde dados antigos são eliminados periodicamente. O ambiente onde o DW residirá também
merece total consideração durante a elaboração do projeto. Segundo [2] as mais importantes
são as seguintes:
• Projeções de uso;
• O ajuste ao modelo de dados;
• Características das fontes disponíveis
• Projeto do componente de metadados;
• Projeto modular de componente;
• Projeto da capacidade de gerenciamento e de alterações;
• Considerações de arquitetura distribuída e paralela.
O projeto do DW é inicialmente dirigido pelas projeções de uso, ou seja, baseado nas expecta-
tivas de quem usará o warehouse e como o fará. Inicialmente um dos pontos chave é a escolha
de um modelo de dados adequado. As características das fontes de dados disponíveis devem
ser analisadas, para validar sua usabilidade. O projeto modular permite que o warehouse possa
evoluir junto com a organização e seu ambiente de informação. Um data warehouse, para ser
considerado bem construído, deve ser projetado para possibilitar a manutenção, durante o pleno
funcionamento do warehouse, sem a interrupção ou queda na qualidade, do serviço prestado
aos usuários. Um componente-chave de um data warehouse é o repositório de metadados. Esse
repositório deve conter o metadado técnico e empresarial. O metadado técnico cobre detalhes
14

do processo de aquisição, estruturas de armazenamento, descrições de dados, operações e ma-
nutenção do warehouse e funcionalidade de suporte ao acesso. O metadado empresarial possui
as regras empresariais e os detalhes organizacionais relevantes que dão suporte ao warehouse.
A arquitetura de computação distribuída da organização é um ponto extremamente importante
para o projeto do DW. Existem duas arquiteturas distribuídas básicas: o warehouse distribuído
e o warehouse federado. Em um data warehouse distribuído, todas as questões de banco de da-
dos distribuídos são relevantes, como, replicação, partição, comunicação e preocupações com
a consistência. Contudo as vantagens de um banco de dados distribuídos também são herda-
das, como, balanceamento de carga, escalabilidade de desempenho e maior disponibilidade. Na
abordagem distribuída existe apenas um repositório de metadados, replicado em cada unidade
do sistema distribuído. O warehouse federado utiliza a idéia de banco de dados federado, ou
seja, um conjunto descentralizado de data warehouses autônomos, cada um com seu próprio
repositório de metadados. Geralmente na abordagem federada os data warehouses que compõe
o sistema possuem uma menor escala, como os data marts [2].
15

Capítulo 4
Estudo de Caso
A Fingerhut Corp., sediada em Minnetonka, Minn., EUA, é um négocio de US$2 bilhões
cuja sobrevivência depende de seu enorme data warehouse. O grupo de pesquisa de mercado
conta com duzentos analistas de mercado, trezentos designers e quarenta cientistas estatísticos,
que usam o banco de dados para a introspecção que ajuda a organização a se diferenciar dos seus
competidores. O departamento de marketing da Fingerhut usa centenas de intrincadas fórmulas
matemáticas proprietárias para separar o mercado em nichos e tomar decisões em tudo, desde o
preço até descrições de produtos.
A maior parte das organizações que se aventuram no database marketing o fazem para
vender para uma miríade de consumidores, um por vez. O sucesso da Fingerhut se deve a isso,
as vendas cresceram constantemente desde o final da década de 1980, só em 1995 foram 23%.
Isso é o resultado do esforço em tornar o departamento de marketing um grupo de usuários com
alto grau de especialização tecnológica.
É aqui que entra a divisão de TI da Fingerhut, com quinhentos e cinquenta membros, de-
zesseis deles dedicados ao data warehouse. Ajudando o marketing a evoluir em perfeita sinto-
nia com a tecnologia, a divisão de TI faz uma contribuição direta para a base da organização:
Quanto mais rápido os marketeiros puderem identificar novos nichos demográficos significati-
vos e nuances no comportamento, mais rapidamente a Fingerhut poderá alcançar seus consumi-
dores com as ofertas certas no momento certo.
Se você comprasse um item ou dois através de catálogos, especialmente itens que a Fin-
gerhut vende, provavelmente a organização entenderia melhor que você seus hábitos de con-
sumo. O objetivo é agrupar todos os seus próprios consumidores e aqueles cujas informações
foram compradas de outras organizações, de venda por catálogos, em grupos grandes o sufici-

ente para justificar o custo de impressão, produção e envio dos catálogos. Considerando que
cada consumidor do grupo interage com o marketing direto da mesma maneira, a Fingerhut
pode direcionar seus esforços para incrementar os negócios com esse grupo como um todo. O
data mining auxilia a Fingerhut a competir com organizações baseadas em lojas "físicas".
Como um exemplo, podemos citar o caso em que o departamento de marketing da Fingerhut
descobriu que consumidores que mudam de residência triplicam suas compras nas doze sema-
nas após a mudança, com um pico de compras nas quatro primeiras semanas. Suas escolhas
seguem um padrão de compras, seguindo a ordem: ferragens, telecomunicações, equipamentos
e decorações. Porém evitam a compra de produtos de joalheria e de eletrodomésticos. Não é
uma descoberta revolucionária, mas é uma descoberta chave para a Fingerhut. A organização
usou a descoberta para não somente criar um novo catálogo para pessoas que se mudaram, mas
também para economizar dinheiro não enviando certos catálogos durante esse períodod de doze
semanas. A lição é de que se um subconjunto de consumidores existe, não importa o quão
geográficamente dispersos eles estejam, o departamento de marketing precisa descobri-los.
Estudo de caso encontrado em [1].
17

Capítulo 5
Conclusão
Um data warehouse serve como um foco para a análise e apoio à decisão através de consultas
e relatórios. Análise e apois à decisão podem significar sistemas de informação executivos
com estruturas de dados altamente sumarizadas; análise gerencial sumarizando departamentos
e linhas de produção; análise em estações de trabalho com mais detalhes do que em análise
gerencial mas ainda agregado para tendências e outros tipos de análises.
Data warehouses são desenvolvidos iterativamente, isto é, cada área de atuação é desenvol-
vida como um projeto separado. A performance extremamente baixa de planos de projeto que
requerem desenvolvimento altamente distribuído de todas as áreas de atuação sugere fortemente
que uma abordagem iterativa seja usada.
Uma arquitetura de data warehouse irá prover muitos beneficios para as organizações. Van-
tagens competitivas, conhecimento aprimorado de relacionamentos entre produtos e serviços e
suas performances, além de ganhos de análise e apoio à decisão que podem ser alcançados pela
integração do data warehouse em um ambiente de informações

Glossário
Data Mart Um repositório de dados que serve uma comunidade de usuários em particular.Data Mining A prática de extair dados de um data warehouse com o objetivo de analisar padrões, tendências e relacionamentos.OLAP Análise de dados complexos a partir do data warehouse.

Referências Bibliográficas
[1] Data warehouse. Darwin Executive Guides, 2005. Website:
http://guide.darwinmag.com/technology/enterprise/data/index.html.
[2] ELMASRI, R.; NAVATHE, S. B. Sistemas de Bancos de Dados. 4. ed. Addison-
Wesley, 2005.
[3] ORR, K. Data warehousing technology. Ken Orr Institute, 2000. Website:
http://www.kenorrinst.com/dwpaper.html.
[4] VASSILIADIS, P. et al. Data warehouse process management. Information Sys-
tems, [S.l.], v.26, n.3, p.205–236, 2001.





![ADEMAR CÉZAR FEIL ALESSANDRO QUIROLLIolguin/4463-semin/g1... · 2020. 10. 3. · comparação. Por exemplo, o artigo de Tsichritzis e Lochovsky [1982] classificou os modelos como](https://img.document.onl/doc/110x75/60e9ffb47ab22036d949a48a/ademar-czar-feil-alessandro-quirolli-olguin4463-seming1-2020-10-3.jpg)