Embed Size (px)
Citation preview

A Previsão com o Modelo de Regressão.................................................................................... 1 1. Introdução ao Modelo de Regressão .............................................................................. 1 2. Exemplos de Modelos Lineares ..................................................................................... 2 3. Derivação dos Mínimos Quadrados no Modelo de Regressão ...................................... 6 4. A Natureza Probabilística do Modelo de Regressão...................................................... 9 5. Propriedades Estatísticas dos Estimadores................................................................... 13 6. Critérios de Avaliação dos Estimadores....................................................................... 14 7. Obtenção da Média e o Desvio Padrão dos Melhores Estimadores Lineares Não Tendenciosos ou “Best Linear Unbiased Estimators” (BLUEs) .......................................... 16 8. Aplicação de Testes de Hipóteses e Intervalos de Confiança aos EstimadoresErro! Indicador não definido. 9. O Coeficiente de Ajustamento ou Determinação: Erro! Indicador não definido. 10. Interpretação da Variação em Y em termos da Análise de VariânciaErro! Indicador não definido. 11. O Modelo de Regressão Múltipla......................... Erro! Indicador não definido. 12. Considerações Adicionais: a Correlação Parcial.................................................34 13. Teste de Chow: um Teste para a Estabilidade Estrutural dos Modelos ................36 14. O Modelo de Regressão Múltipla com Variáveis Explanatórias Estocásticas......36 15. Violação dos Pressupostos Básicos do Modelo de Regressão Clássico..............37 16. O Problema da Multicolinearidade .....................................................................38 17. O Problema de Heteroscedasticidade..................................................................40 18. O Problema da Correlação Serial ......................... Erro! Indicador não definido. 19. A Previsão com o Modelo de Regressão.............. Erro! Indicador não definido.
Leituras recomendadas (Pindyck e Rubinfeld(1976)): 1. Variáveis instrumentais e mínimos quadrados em dois estágios (Leitura
recomendada) (Pindyck e Rubinfeld)
2. Tópicos avançados em estimação de uma equação singular (Leitura recomendada)
3. Modelos de escolha qualitativa (Leitura recomendada) (Pindyck e Rubinfeld)
Referências Bibliográficas:
• Kmenta, Jan, “Elementos de Econometria”, Ed. Atlas.
• Thomas, J. J. (1978), “Introdução à Análise Estatística para Economistas”, Zahar Editores.
• Pindyck, R. S. e Rubinfeld, D. L. (1976), “Econometric Models and Economic Forecasts”, McGraw-Hill Kogakusha Ltd., Tokyo.
• Pindyck, R.S. e Rubinfeld, D.L. (1991), “Econometric Models and Economic Forecasts”, Mcgraw-Hill International Editors.
• Bowerman, B.L. e O`Connel, R.T. (1987), “Times Series Forecasting-Unified Concepts and Computer Implementation”, Duxbury Press, Boston.
• Levenbach, H. e Cleary, J.P. (1984), “ The Modern Forecaster: The Forecasting Process Through Data Analysis”, Lifetime Learning Publications, Belmonnt, Califórnia.

1
A Previsão com o Modelo de Regressão
1. Introdução ao Modelo de Regressão
A teoria da Regressão permite que se estabeleçam relações entre variáveis que se
interrelacionam cujas informações estão disponíveis (dados pré-coletados), relações às quais
associam-se os modelos de regressão. Dessa forma, os economistas e os administradores
procuram compreender a natureza e o funcionamento de sistemas econômicos que são
descritos por meio dessas variáveis. Por exemplo, o volume do comércio internacional pode
ser modelado como uma função linear do produto interno bruto dos países. As vendas de um
produto podem ser estimadas por uma relação entre a variável que as representa e variáveis
relativas aos preços desse produto e de seus concorrentes no mercado e aos respectivos gastos
relativos com propaganda. Uma vez estabelecida essa relação pelo modelo de regressão, é
preciso avaliar a confiança que nela se pode colocar, realizando testes estatísticos.
Temos dois tipos básicos de informação a considerar:
(1) • Informação descrevendo as mudanças assumidas por uma variável através
do tempo (dados de séries temporais)
(2) • Informação descrevendo as atividades de pessoas, firmas etc. num dado
instante de tempo (dados de corte transversal)
Para esses dois tipos de informação é possível estabelecer relações que descrevem as
situações observadas por meio de modelos de regressão.
Ou seja, dado um conjunto finito de observações X e Y, por meio do modelo de
regressão é buscado estabelecer relações entre X e Y. Esse conjunto finito de observações
corresponde a uma amostra representativa do universo de informações ou população, a qual
permitiria estabelecer a verdadeira relação entre X e Y (Figura 1).
Amostra População (verdadeira relação entre X e Y)
Figura 1- Relação entre a amostra e a população ou universo de informações

2
Tome-se por hipótese que exista a relação linear li entre X e Y. No diagrama de
dispersão da Figura 2 são representadas as linhas l1 e l2 que se procurou ajustar ao conjunto de
pares ordenados (X, Y) do conjunto amostral, assim como os desvios (positivos e negativos)
em relação a l2 .
Figura 2 - Diagrama de dispersão e desvios em relação à linha ajustada
Definem-se desvios como os valores, segundo Y, das diferenças entre os valores
observados e os valores sobre a linha li ajustada ao conjunto de pares (X, Y). Como regra
estabelece-se que a melhor linha li corresponde àquela cujo somatório dos desvios tende a
zero (é minimizado). A melhor linha ajustada define o modelo de regressão e pode ser obtida
pela derivação de mínimos quadrados ordinários, apresentada mais à frente.
2. Exemplos de Modelos Lineares
(A) Modelagem de Tendência e Sazonalidade através de Funções do Tempo
Seja por exemplo o modelo Yt = St + Tt , onde Tt representa a tendência no período
t. Por outro lado, St representa a sazonalidade no período t, sendo L o comprimento da
sazonalidade. Exemplos de situações onde a tendência é modelada, em que β0, β1 e β2 são os
parâmetros do modelo, são:

3
Modelo
∗ Tendência inexistente, ou constante
horizontal
Tt = β0
∗ Tendência linear Tt = β0 + β1t
∗ Tendência quadrática (Figura 3) Tt = β0 + β1t + β2t2
Tt
t
Tt
t
que se transforma em:
Tt = β0 + β1t + β2v,
fazendo v=t2, o que torna possível transformação do grau da relação.
Tt
t
Tt
t
Figura 3- Gráficos de dados com tendência quadrática
Em algumas situações observa-se sazonalidade ou seja, os valores observados variam
de forma característica por período de tempo t ao longo do comprimento da sazonalidade.
Assim, pode-se escrever que:
St = t1),(L1)(Lt2,2t1,1 SSSSSS Xβ...XβXβ
−−+++
Variáveis “dummies”
Define-se cada variável “dummy” por:
t1,SX =
t2,SX =
t1),-(LSX =
1 se t é o período sazonal 2 0 senão
1 se t é o período sazonal 1 0 senão
1 se t é o período sazonal (L-1) 0 senão

4
Observa-se que o período sazonal L corresponde ao período base da representação de St
(poderia ser outro qualquer, definindo-o a priori).
(B) Exemplos de Transformação Linear
Seja o modelo:
• y = ea+bx ⇒ = (a + bx) ⇒ y = a + bx (transformação
linear).
Substituindo-se x = 1/t, obtém-se a curva S ou curva do aprendizado (Figura 4):
Figura 4- Gráfico da curva do aprendizado
• Modelo recíproco
bxa1Y+
= ⇒ Y1 = a + bx ⇒ y=a+bx (transformação linear)
• Modelo semilogarítmico
Y = a + b log x ⇒ Y = a + bv (transformação linear)
Da mesma forma:
Y = α0 + α1 x12 + α2 log x2 ⇒ Y = α0 + α1 V1 + α2 V2
V1 V2
Seja a equação não linear nas variáveis independentes:
Y = α0 x1α1 x2
α2
Esta equação é não linear nos coeficientes, mas linearizável, por meio de aplicação
de logaritmos.
y logey
1 logee
v
t

5
Seja o exemplo das vendas de um produto introduzido no mercado e com vendas,
posteriormente, em expansão. Esta situação é típica do modelo que representa a curva do
aprendizado do tipo Y = ea – (b/t), pois observa-se o começo lento, crescimento forte e período
de saturação (Figura 5).
Resultados do ajuste do modelo ao
conjunto de observações:
Parâmetros (a) 20.7867
(b) -21.0389
R2 = 0.953, Fteste = 442.6
Dados
tempo(t) vendas(Y) 1/t Loge(vendas) 1 0.023 1 -3.77226 2 0.157 0.5 -1.851151 3 0.329 4 0.48 5 1.205 6 1.748 7 1.996 8 2.509 9 2.366
10 2.94 11 2.8714 12 2.9346 13 3.1346 14 3.24 15 3.148 16 3.522 17 3.54 18 3.31 19 3.547 20 3.374 21 3.3745 22 3.401 23 3.6971 24 3.493
Figura 5- Exemplo de situação típica da curva do aprendizado (vendas de T.V.
a cores, Makridakis e Wheelwright, Forecasting, pág. 203)
(C) Uso do tempo como uma das variáveis explanatórias
Situações-Exemplo:
1) Qt = γ Ltα Kt
β A(t) εt
2) Inclusão da variável tempo em modelo “pouco aderente”
Yt = β1 + β2 x2t + β3t + εt, sendo que o termo β3t modela o efeito líquido de
conjunto de variáveis excluídas. O efeito da inclusão desse termo é estatístico.
Y = e1,478 – (5,786/t)
função de produção
mudança técnica
funcional de tex.: A(t) = eδt

6
3. Derivação dos Mínimos Quadrados no Modelo de Regressão
A derivação dos mínimos quadrados permite testes estatísticos sobre o
ajustamento entre X e Y, da forma Y = a + bX, sendo, por hipótese, Y a variável
dependente e X a variável independente.
Y = a + bX
⇓ ⇓ Variável dependente Variável independente
Figura 6 – Linha de mínimos quadrados ajustada ao conjunto amostral
Define-se o resíduo ou desvio (εi) como εi = iY – iY , onde iY = a + bXi , e N
corresponde ao número de observações amostrais.
Busca-se obter Min ∑ −−=
N
1i
2ii )bXa(Y ou seja, a minimização do somatório dos N
desvios ao quadrado (Figura 6).
Dessa forma, define-se o sistema de equações normais:
0)bXa(Ya
2ii =−−∑
∂∂ ⇒ ... ⇒ ∑ Yi = a N + b∑Xi (I)
0)bXa(Yb
2ii =−−∑
∂∂ ⇒ ... ⇒ ∑ Xi Yi = a ∑Xi + b∑Xi
2 (II)
que multiplicadas, respectivamente, por ∑ Xi e N, são reescritas:
equações normais
εi
-2 ∑iεi = 0
-2 ∑Xiεi = 0

7
(I) ∗ ∑ Xi ⇒ equações ⇒ (∗∑Xi) ∑Yi = (∗∑Xi) (a N + b ∑Xi)
(II) ∗ N normais (∗ N) ∑Xi Yi = (∗ N) (a ∑Xi + b ∑Xi2)
Fazendo (II) – (I), pode-se obter os parâmetros (a e b) do modelo de regressão:
b = 2
i2
i
iiii
)X(XNYXYXN
∑−∑
∑∑−∑
a = NXb
NY ii ∑
−∑
onde se definem as médias amostrais Y e X .
Se Y = X = 0 isto significa a = 0, e
b = 2
2
N)(N)(...
÷÷ ⇒ b =
2i
2i
iiii
/N)X(ΣNX
/N)Y(Σ/N)X(ΣN)/YX(
−∑
−∑ , que pode ser escrito:
b = 2
2i
ii
X-NX
YX/N)YX(∑
−∑
Tomando-se a situação onde X = Y = 0 ⇒ b = /N)X(/N)YX(
2i
ii
∑∑
.
Esses resultados sugerem a conveniência de escrever a estimativa de mínimos
quadrados por meio de variáveis que representam desvios em relação às médias, sejam
essas nulas ou não. Dessa forma, deve-se obter a transformação: xi = Xi - X e yi = Yi - Y ,
pois x = NΣxi = 0 = y (são nulas as médias das variáveis que correspondem à uma
transformação de defasagem em relação às médias das variáveis originais, pois:
0NXN
NX
N)X(Xx ii =−
∑=
−∑= ).
Assim, reescrevem-se as estimativas dos parâmetros de mínimos quadrados da
relação linear ajustada entre X e Y, antes da transformação, como:
X
Y
“inclinação”
“coeficiente linear”
“intercepto”
“constante” Y X
X

8
onde o significado dessas estimativas de a e b é:
b → dXdY razão da variação (marginal) em Y com a variação em X.
a → Y = a, quando Xi = 0 ⇒ tal conclusão em geral não diz muita coisa sobre o
evento observado, sendo apenas um valor para o intercepto da relação linear do ajuste
feito. Para que essa informação tenha significado para a situação modelada, deve-se ter
informação próxima de X = 0.
Na Tabela 1 a seguir exemplifica-se a obtenção dos valores de a e b, sendo os
gráficos da linha ajustada representados na Figura 7.
Tabela 1- Obtenção das estimativas dos parâmetros
(introduzir planilha EXCEL)
Y X 4.0 21.0 3.0 15.0 3.5 15.0 2.0 9.0 3.0 12.0 3.5 18.0 2.5 6.0 2.5 12.0
Calcula-se: X = 13.5 e Y = 3.0
∑xi = 0
∑yi = 0
∑xiyi = 19.50
∑xi2 = 162.00
b = 2i
ii
ΣxyΣx = 0,120
a = 1,375
Y = 1,375 + 0,12 X
(R2 = 0.77; F1,6 = 21.2)
b = 2i
ii
ΣxyΣx
a = XbY −

9
Regressão transformada
Figura 7- Exemplo do ajustamento da linha de regressão e da linha de regressão
transformada
Exercício (casa)
Prove que a linha de regressão estimada passa sobre o ponto de média ( X , Y ).
Sugestão: mostre que X e Y satisfazem à equação Y = a + bX, sendo a e b
definidos como: b = 2
i2
i
iiii
)X(XNYXYXN
∑−∑
∑∑−∑ e a = N
XbNY ii ∑
−∑
4. A Natureza Probabilística do Modelo de Regressão
Para que se possa avaliar a qualidade da relação linear ajustada às informações
amostrais das variáveis, é preciso realizar testes estatísticos no modelo de regressão. Por
exemplo, como realizar esses testes estatísticos no modelo de regressão de mínimos
quadrados com uma variável independente e uma variável dependente? Para isso, é
preciso, em primeiro lugar, reconhecer a natureza probabilística do modelo de regressão.
Seja o exemplo da Figura 8, no qual observa-se que para um mesmo valor de X
(renda) existem vários valores de Y (gastos com alimentação). Isto se explica porque,
embora a renda de grupos de indivíduos esteja, por exemplo, em torno de R$ 60.000/ano, o
meio e fatores aleatórios fazem existir uma significativa oscilação nos gastos com
alimentação nessa faixa de renda.

10
Renda dos Indivíduos
Meio/ Fatores aleatórios
Gastos com alimentação
Figura 8- Relação entre amostra de renda dos indivíduos e seus gastos com
alimentação
Dessa forma, definem-se as variáveis aleatórias Yi e Xi e, por hipótese, a
verdadeira relação linear entre elas, como Yi = α + βXi + εi (Figura 9).
Yi = α + β Xi + εi “TRUE MODEL”
(população) erro aleatório
variável aleatória
“Fixados”
(distribuição de probabilidade)
(omissão de variáveis explicativas) (erro de coleta de dados)
Figura 9- A verdadeira relação linear ou “true model” entre as variáveis aleatórias
O valor esperado E(Yi) = E(α + βXi + εi) = α + βX corresponde ao verdadeiro
modelo, representado na Figura 10 a seguir. Embora Xi ´s tenham seus valores fixados, são
variáveis aleatórias com distribuição de probabilidades.
Figura 10 – Natureza probabilística das variáveis do modelo de regressão
X
observados
Y
εi

11
Assim, são pressupostos básicos do modelo clássico de regressão linear a duas
variáveis:
(i) Relação linear entre Y e X como descrita em Yi = α + βXi + εi
(ii) Xi`s não-estocásticos e fixados (será relaxado mais tarde)
(iii) a) O erro εi tem (zero) e E(εi)2 = σ2 (constante), para
todas as observações.
b) εi`s não correlacionados estatisticamente, de forma que: E (εi εj) = 0,
para i ≠ j.
No caso de (iii), supondo-se E (εi) = α`, sendo α` um valor constante qualquer,
pode-se escrever: Yi = α + βXi + εi + (α` - α`) = (α + α`) + βXi + (εi - α`), definindo-se
assim um novo coeficiente α*.
Obtém-se E (εi*) como: E (εi - α`) = E (εi ) – E (α`) = E (εi ) - α` = 0 (!),
constante α`
ou seja: E (εi*) = 0, mantendo válidas as suposições do modelo de regressão clássico.
As suposições (ii) (a) e (b) tratam de garantir a homocedasticidade (variância do
erro aleatório constante) e a ausência de correlação serial. No caso contrário, tem-se a
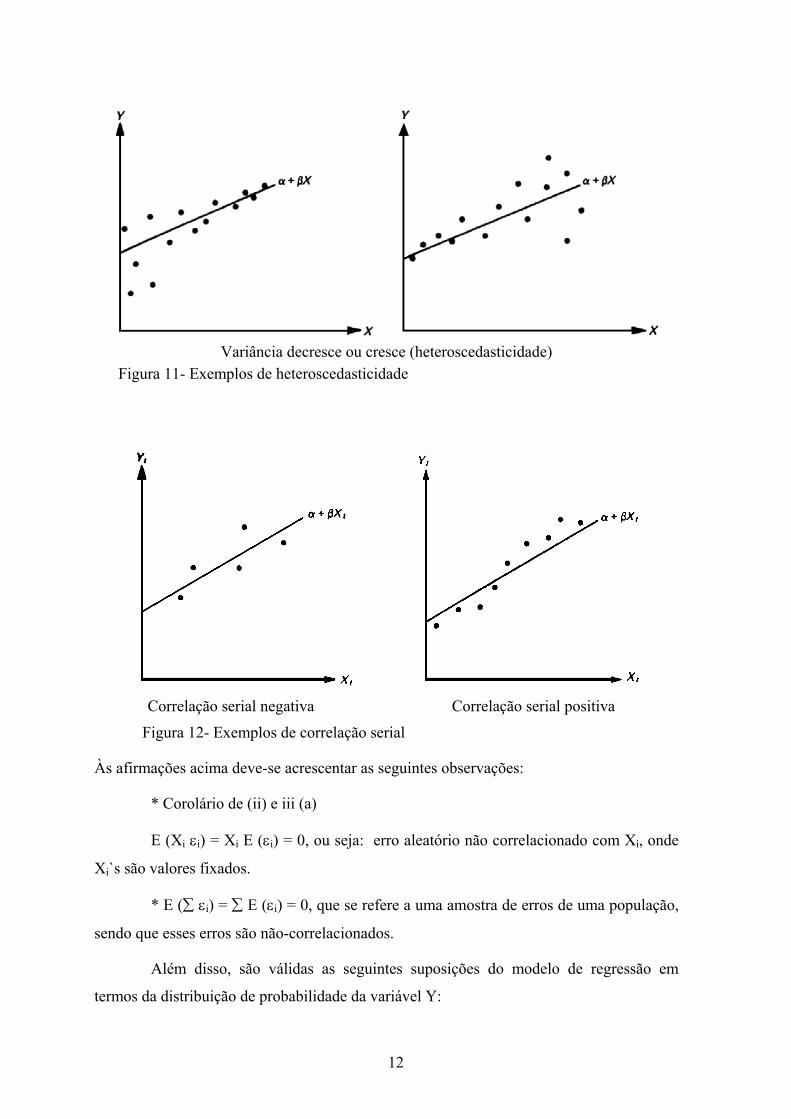
presença de heteroscedasticidade e correlação serial (Figuras 11 e 12):
1) Presença de heteroscedasticidade: E(εi2) não é constante e igual a σ2
2) Erros correlacionados → correlação serial ou autocorrelação,
onde E (εi εj) ≠ 0 (existe um padrão na disposição dos dados em
relação à linha ajustada)
E (εi) = 0
εi* α*
12
Variância decresce ou cresce (heteroscedasticidade) Figura 11- Exemplos de heteroscedasticidade
Correlação serial negativa Correlação serial positiva
Figura 12- Exemplos de correlação serial
Às afirmações acima deve-se acrescentar as seguintes observações:
* Corolário de (ii) e iii (a)
E (Xi εi) = Xi E (εi) = 0, ou seja: erro aleatório não correlacionado com Xi, onde
Xi`s são valores fixados.
* E (∑ εi) = ∑ E (εi) = 0, que se refere a uma amostra de erros de uma população,
sendo que esses erros são não-correlacionados.
Além disso, são válidas as seguintes suposições do modelo de regressão em
termos da distribuição de probabilidade da variável Y:

13
(iii) (a`) Y → E (Yi) = α + βX
VAR (Yi) = σ2 , sendo α, β e σ2 a determinar.
(b`) Yi`s → não correlacionados
5. Propriedades Estatísticas dos Estimadores
Assume-se que:
(iii) c) O termo do erro é normalmente distribuído (erros de medida e omissão
de variáveis pequenos e independentes entre si).
Yi → combinação dos εi`s, normalmente distribuída, sendo: Yi = α + βXi +εi.
Assim, a linha de regressão estimada XβαY += deve estar próxima ao
verdadeiro modelo Y = α + βX, onde as estimativas de α e β, os estimadores βeα , são
variáveis aleatórias ou seja, tem E ( α ), VAR( α ), E ( β ) e VAR ( β ) (Figura 13). Para que
se possa entender melhor este ponto supõe-se que se tenha N valores fixados de Xi, em
uma determinada amostra (A1), de forma que se tenha Yi valores associados a esses N
valores de Xi. Com esses valores de X e Y, estima-se β → )β( .
E )β( e VAR )β( ,
E )α( e VAR )α( .
Figura 13- A natureza probabilística dos estimadores βeα
β / )β(
α / )α(
A1 A2
X1
população Yi
Yi ↔ Xi N

14
Toma-se outra amostra de pares de valores Xi e Yi, obtendo novos N valores de Yi
associados aos N valores de Xi, com os quais estima-se um novo β → )β( . Note-se que os
εi`s são diferentes, sempre. Com esse procedimento, pode-se obter uma distribuição de
estimativas de β )β( , sendo: β = 2i
ii
xyx
∑∑ com respectivos valor esperado e variância, aos
quais aplica-se os testes estatísticos. O mesmo raciocínio se estende ao estimador α .
6. Critérios de Avaliação dos Estimadores
São exemplicados a seguir quatro critérios de avaliação dos estimadores.
1) Ausência de tendenciosidade (viés = 0)
Define-se o viés como: Viés = E )β( - β, onde β é o verdadeiro parâmetro
(Figura 14).
Figura 14- Exemplo de viés
Quando N → número grande, NXi∑ é estimador não-viesado da verdadeira média
da população. Da mesma forma, observa-se que: 1N
)X(X 2i
−∑ − é estimador não-viesado da
verdadeira variância da população, em cujo denominador tem-se N-1, pois X foi fixado
para estabelecer os desvios.
2) Eficiência

15
β é um estimador não-viesado eficiente se a VAR )β( é menor que a variância de
qualquer outro estimador não-viesado.
Maior eficiência implica que são mais fortes as afirmações estatísticas sobre os
estimadores. Quando a variância é igual a zero (0), isto implica que se está tratando do
parâmetro verdadeiro da regressão.
3) Erro Quadrático Médio Mínimo (MSE)
MSE )β( = E 2β)-β( = E [ 2β)]β()β-β( −+ = ... = VAR )β( + [viés )β( ]2, sendo
E )β( = β .
Observa-se uma interrelação (“trade-off”) entre viés e variância para se obter
maior precisão ou seja, o “trade-off” de maior precisão entre o viés e a variância
implicando pequena variância e algum viés.
4) Consistência
Este critério diz respeito a quando o tamanho da amostra N tender a ser grande
(Figura 15) verificar-se propriedades assintóticas, definidas pelo limite em probabilidade
de β ou p lim β :
p lim β ⇔ lim Prob 1 δ) |)β-β| (( =< , de forma que: p lim β = β.
N → ∞
δ > 0, pequeno
Figura 15- Exemplo das propriedades assintóticas com aumento do tamanho amostral
Na prática, o critério de estimação é a consistência ou seja: estimador viesado mas
consistente pode não ser igual ao valor de β na média mas aproxima-se dele para N muito
Prob β
ββ
N muito grande
Pequeno N

16
grande. Como exemplo, usa-se N no denominador para obter estimador da variância
populacional, de forma a ter ∑−N
)X(X 2i como um estimador viesado mas consistente da
variância populacional (base das estimações robustas).
Como alternativa para a consistência pode-se ter por critério:
MSE → 0 quando N → ∞, o que significa que se tem um estimador não-viesado
assintóticamente cuja variância → 0 quando N → ∞.
7. Obtenção da Média e o Desvio Padrão dos Melhores Estimadores Lineares Não Tendenciosos ou “Best Linear Unbiased Estimators” (BLUEs)
Considerando-se que βeα são os estimadores de mínimos quadrados do modelo
de regressão Yi = α + βXi + εi, pelo Teorema de Gauss-Markov se estabelece que “ βeα
são os melhores (mais eficientes) estimadores lineares não tendenciosos de α e β” no
sentido de que esses estimadores tem variância mínima em relação aos estimadores não
tendenciosos de α e β, ou seja: βeα são BLUEs.
O Teorema não se aplica a estimadores não-lineares. É possível que existam
estimadores não-lineares não tendenciosos e com variância menor que a dos estimadores
de mínimos quadrados. Além disso, um estimador tendencioso pode ter variância menor
que os estimadores de mínimos quadrados. Estimadores ditos robustos, não-lineares e
tendenciosos, com mínimos MSE, tem sido estudados e utilizados em aplicações práticas
(embora não sejam objeto do presente estudo).
Como já visto, os estimadores βeα são variáveis aleatórias, com respectivas
média e variância. Considerando-se que XXx ii −= e YYy ii −= , pode-se escrever
E (yi) = βxi e β = ∑ ∑ 2iii x/yx , onde é definida a constante ci =
∑ 2i
ix
x de forma que
β = ∑=
N
1iiiyc .
Assim:
β = ∑ ∑ ∑+∑=+= iiiiiiiii εcβxc)εβx(cyc (I)
Obtém-se:

17
E )β( = )E(εcβxc iiii ∑+∑
* E )β( = βxcββxc iiii =∑=∑ , logo β é estimador não tendencioso,
onde 1xx
xxc i2i
iii =⎥
⎦
⎤⎢⎣
⎡∑
∑=∑ (II)
De modo similar:
VAR )β( = E 2 β) -β(
Substituindo (I) em VAR )β( , tem-se que VAR )β( = E 2iiii ]βεcβxc[ −∑+∑ .
β -β Observa-se que β -β = =−∑+∑ βεcβxc iiii ( iiii εcβ1)xc ∑+−∑
De (II) tem-se que 1xc ii =∑ , logo
β -β = iiεc∑ , sendo ( β -β )2 = ( iiεc∑ )2
∴ VAR )β( = E ( β -β )2 = E [ iiεc∑ ]2
VAR )β( = E [( 11εc )2 + ( 22εc )2 + ...] + E [(2c1c2ε1ε2) + ...]
Ora, E (εiεj) = 0, i ≠ j, assim:
VAR )β( = E ( 11εc )2 + E ( 22εc )2 + ... =
= c12 E (ε1)2 + c2
2 E (ε2)2 + ... =
= c12 σ1
2 + c22 σ2
2 + ... = σ2∑ci2, pois, na presença de
homocedasticidade, E (εi)2 = cte = σi2 = σ2.
Ora, ∑ci2 =
∑=
∑∑
2i
22i
2i
x1
)x(x , logo:
VAR )β( = σ2 / ∑xi2 , xi = Xi - X
De forma similar pode-se obter que:
E )α( = α
0

18
VAR )α( = ⎥⎦
⎤⎢⎣
⎡−∑
∑2
i
2i2
)X(XNX
σ
COV ( β,α ) = 2i
2
xσX
∑−
É preciso remarcar que se β =∑ iiyc é uma combinação linear de variáveis yi e se
yi é normalmente distribuída, β é uma variável aleatória normalmente distribuída, o que
implica que os testes de hipótese são válidos para β . Além disso, observa-se que, de
acordo com o Teorema do Limite Central, se o tamanho da amostra cresce, a distribuição
da média amostral de uma variável independentemente distribuída tende para a
normalidade. Com isso pode-se afirmar que, mesmo no caso dos yi não serem
normalmente distribuídos, a distribuição de β é, ainda assim, assintóticamente normal.
Ou seja, para amostras de grande tamanho:
⎥⎦
⎤⎢⎣
⎡∑ 2
i
2
xσβ,N~β , de onde extrai-se o critério amostral: maior variância na amostra
de Xi leva a menor variância de β .
⎥⎦
⎤⎢⎣
⎡∑
∑2i
2i2
xNX
σα,N~α , cuja variância reduz-se a σ2/N se X = 0 na amostra.
2i
2
xσX )β,α( COV
∑−= , onde se observa que, se X > 0, superestimar α corresponde
a subestimar β e vice-versa.
Observa-se que: 2σ é o verdadeiro valor da variância do erro. Utiliza-se S2 como
estimador não-viesado 2σ de 2σ ou seja: S2 = 2σ = 2N
)Xβα(Y2N
ε 2ii
2i
−−−∑
=−
∑ .
8. Aplicação de Testes de Hipóteses e Intervalos de Confiança aos Estimadores
Define-se o intervalo de confiança como o intervalo de valores que contém, com
uma determinada probabilidade (1-n.s.), ou um nível de significância estatística (n.s.), os
verdadeiros parâmetros da regressão. Nele se baseiam os testes de hipóteses estatísticas.

19
Em geral estabelece-se a hipótese nula ou seja, de que o efeito não está presente. Para o
modelo ser explicativo, a hipótese nula deve ser rejeitada. Ao associar-se ao conjunto
amostral um modelo de regressão, é objetivo analisar os dados de forma a testar o modelo
ajustado e avaliar a adequação de novos modelos. Desta forma, realizam-se os testes de
hipóteses, tendo resultados que podem levar a uma seqüência de testes de modelos. Ou
seja:
(a) Informação inconsistente com o modelo:
Rejeição do modelo; novo modelo é considerado.
(b) Informação consistente com o modelo:
Modelo aceito até que novas hipóteses ou nova informação permitam novos testes.
Os testes são aplicados a um nível de significância (n.s.). Por exemplo, o que
significa: nível de significância de 5%? Significa que, se a hipótese nula for rejeitada neste
nível, é fato que ela estava correta pelo menos 5% das vezes. O nível de significância pode
ser compreendido como o índice de erro aceito ao estabelecer o modelo de regressão (ou
erro Tipo 1).
O teste estatístico para rejeitar a hipótese nula associada ao coeficiente da
regressão baseia-se usualmente na distribuição t de “Students”. Essa distribuição é
relevante pois nela utiliza-se a estimativa amostral da variância do erro, ao invés de seu
valor verdadeiro (na população).
Para compreender a formação dos intervalos de confiança e o procedimento do
teste, inicialmente obtém-se a estatística t com N-2 graus de liberdade (considerando-se o
modelo com dois estimadores) como:
tN-2 = 1/22iβ )xS/(ββ
Sββ
∑−
=− , com a qual se obtém a padronização do valor estimado
β .
Constrói-se em torno de estatística tN-2 um intervalo de confiança tal que:
-tc < tN-2 < tc , que tem (1-n.s.)% de probabilidade de conter o verdadeiro valor do
parâmetro, onde tc corresponde ao valor tabelado da estatística t de “Students” para um
nível de significância (n.s.) ou probabilidade (1-n.s.), com N-2 graus de liberdade (N é o
tamanho da amostra e 2 representa o número de estimadores).

20
Assim, seja por exemplo a probabilidade de 95% de que o valor padronizado
pertença ao intervalo de confiança:
Prob (- tc < tN-2 < tc) = 0,95 por exemplo, onde tc = 1,96, com N – 2 graus de
liberdade, N tendendo a um número grande.
Prob 0,95t)xS/(ββt c1/22i
c =⎥⎥⎦
⎤
⎢⎢⎣
⎡<
∑−
<− significa que há 95% de probabilidade de
que β está contido no intervalo entre β ± tc 1/22i )x(
S∑
= β ± tc S β .
Da mesma forma, estabelece-se o intervalo:
α ± tc S α = α ± tc ∑∑
1/22i
1/22i
)x(N)X(S
O teste de hipótese é definido de forma que:
Ho = hipótese nula β = 0,
Hipótese alternativa β ≠ 0.
Nesse caso, sendo o valor padronizado:
βSββ− , se β = 0 ⇒ c
β
tSβ
≥ , sendo tc = 1,96, por exemplo.
1.96
condição de rejeição de Ho
Como regra prática: a 5% n.s., se 2Sβ
β
> → rejeito Ho.
Deve ser remarcado que não rejeitar Ho não significa aceitá-la. O procedimento
de teste nos fala sobre a situação de rejeitar a hipótese nula (e aceitar a estimativa de β)
quando na verdade a hipótese nula é verdadeira em n.s. % das vezes.
São exemplos de testes de hipóteses para situações com presença de sazonalidade:
Caso 1

21
Ct = β1 + β2 Yt + εt não há variação do tipo sazonal, logo não
há teste de hipótese para avaliar a
presença de sazonalidade.
Caso 2
Ct = β1 + β2 Yt + α Dt + εt , onde Dt representa a variação sazonal.
E (Ct) = β1 + β2 E (Yt)
ou
E (Ct) = (β1 + α) + β2 E (Yt)
Caso 3
Ct = β1 + β2 Yt + γ (Dt Yt) + εt
E (Ct) = β1 + β2 Yt
ou
E (Ct) = β1 + (β2 + γ) Yt
Caso 4
Ct = β1 + β2 Yt + α Dt + γ (Dt Yt) + εt
9. O Coeficiente de Ajustamento ou Determinação:
Os resíduos de uma regressão dão uma medida da qualidade do ajustamento.
Como regra, tem-se que:
0 paz
1 guerra
σ2 constante teste: α=0, verifica se a mudança é significativa entre diferentes períodos.
Os testes para α=0 e para γ=0 avaliam se há mudança significativa entre diferentes períodos sazonais.
teste: γ=0, verifica se a mudança é significativa e altera a taxa de mudança em Ct associada a Yt.

22
Grandes resíduos → ajuste ruim
Pequenos resíduos → bom ajuste
Observe-se que os resíduos têm unidade relativa ao problema. Intuitivamente, ao
obter-se 2y
2
σ)resíduo( tem-se a geração de parâmetros para comparações. É esse raciocínio
que inspira a definição de uma medida de qualidade do ajustamento ou aderência, o
coeficiente de ajustamento R2 (ou coeficiente de determinação).
Seja a Figura 16 a seguir, onde se tem a representação da linha ajustada a um
conjunto de observações de X e Y.
Figura 16- Obtenção dos desvios entre a variável observada, a linha ajustada e o seu valor médio
Analisando o valor Y, pode-se obter a variação total de Y como o somatório do
quadrado dos desvios das observações em relação à média amostral:
Variação (Y) = ∑ − 2i )Y(Y , onde:
)YY()Y(YYY iiii −+−=− ,
De forma que:

23
∑ ∑ ∑ −−+−+−=∑ − )YY()Y(Y2)YY()Y(Y)Y(Y iii2
i2
ii2
i
De forma simbólica, escreve-se:
TSS = ESS + RSS
Regressão Erro Total Dividindo-se os dois lados da equação por TSS (a variação total de Y):
1 = TSSRSS
TSSESS
+
Define-se o coeficiente de ajustamento R2 como a relação entre a variação de Y
explicada pela regressão e a variação total. Assim,
, sem , 0 ≤ R2 ≤ 1.
Observe-se que R2 é função dos parâmetros estimados. Na Figura 17 são
representadas duas situações-limite para o valor de R2: ajustamento perfeito (a), e caso em
que a relação linear não se ajusta aos dados amostrais (b).
Figura 17 – Exemplos de situações-limite do ajustamento
iy
0
⇓
variação residual
de Y (não explicada)
(ESS)
⇓
variação total de
Y (TSS)
⇓
variação explicada
de Y (RSS)
ii xβy =
iiεxβ2∑
iε
R2 = 1 - TSSRSS
TSSESS
=

24
Uma outra maneira de se obter R2 é mostrada a seguir. Seja:
XXx;YYy iiii −=−=
ii xβy =
iii εyy += ∑ ∑ ∑ ∑++= ii2i
2i
2i εy2εyy
⇓
⇓ = 0
(nas equações normais da regressão)
∑ 2iy = + 2
iε∑ + ( 00β2 = ), onde
2i
2 xβ ∑ = ∑ 2iy - 2
iε∑ .
Lembrando que o coeficiente de ajustamento é função de 2i
2i yey , ou seja, as
variações 2i )YY( − e 2
i )Y(Y − , e considerando-se a relação anterior obtida:
R2 = ∑∑=
∑∑
= 2i
2i2
2i
2i
yxβ
yy
TSSRSS => R2 = 1 -
∑∑
2i
2i
yε
10. Interpretação da Variação em Y em termos da Análise de Variância
As medidas relativas a TSS, RSS e ESS devem ser convertidas em variâncias, por
sua divisão pelos graus de liberdade associados ao processo de sua obtenção. Assim,
Variância total em Y = 1N
TSS−
Variância explicada em Y = 1
RSS
(explicado)
(total)
média
Resíduo da regressão
∑ ii εxβ2
∑ ii εxβ2
2i
2 xβ ∑

25
Variância residual em Y = 2N
ESS−
β,Xouβ,α
Define-se a relação de variâncias: explicadanãovariância
explicadavariância−
, como uma boa
medida (complementar ao coeficiente de determinação) da qualidade do ajustamento,
permitindo que se avalie a existência de relação linear em Y e X. Essa medida permite que
se aplique o teste estatístico da equação de regressão. O teste da equação de regressão que
testa a existência de relação linear entre Y e X baseia-se na estatística F de “Snedecor”
associada à essa relação de variâncias.
Assim, obtém-se a estatística F1,N-2, com 1 e N-2 graus de liberdade, como:
F1,N-2 = explicadanãovariância
explicadavariância−
= 2ESS/N
RSS/1−
,
que segue a distribuição F com 1, N-2 graus de liberdade no numerador e no denominador,
respectivamente.
F1, N-2 = 2
2i
2
Sxβ ∑ ⇔ F1, N-2 = 0 → somente quando 0
1RSS
= ,
onde S2 = 2-Nε 2
i∑
Como orientação,
Dessa forma, estabelece-se o teste da equação de regressão onde:
Hipótese Nula (H0): Relação linear não explicada (F1, N-2 = 0)
Xi
S2
F1, N-2 pequenos Relação linear fraca Relação linear forte F1, N-2 grandes

26
Os valores da distribuição F estão tabelados, onde se obtém valores de Fcrítico (Fc).
Dessa forma,
Tabela F1, N-2 → Fc
n.s. %
1, N-2 graus de liberdade
11. O Modelo de Regressão Múltipla
O caso geral de modelo de regressão múltipla significa que existem várias
variáveis Xi explicativas da variação em uma outra (Yi). Assim, escreve-se o modelo de
regressão múltipla a k variáveis ou parâmetros:
Yi = β1 X1i + β2 X2i + ... + βk Xki + εi
onde X1i = 1
i = 1,2,…, N β1, β2, ... βk são os coeficientes parciais da regressão.
São válidas as seguintes suposições para o modelo:
i) A especificação do modelo é linear
ii) X`s não-estocásticos. Não há relação linear exata entre os X`s (senão:
multicolinearidade).
iii) E (εi) = 0
E (εi)2 = σ2
E (εi . εj) = 0, i ≠ j
εi ~ N [0, σ2]
Por simplicidade, considere-se o modelo a 2 variáveis independentes:
Yi = β1 + β2 X2i + β3 X3i + εi ⇒ 3i32i21i XβXββY ++=
E (Yi) = β1 + β2X2i + β3X3i
E (Yi)2 = σ2
Os coeficientes da regressão podem ser obtidos por:
22 Sσ =
se F1, N-2 > Fc rejeito Ho
se F1, N-2 < Fc não posso rejeitar

27
33221 XβXβYβ −−=
∑ ∑ ∑∑ ∑ ∑ ∑
−
−=
23i2i
23i
22i
3i2ii3i2
3ii2i2 )xx()x()x(
)xx()yx()x()yx(β
∑ ∑ ∑∑ ∑ ∑ ∑
−
−=
23i2i
23i
22i
3i2ii2i2
2ii3i3 )xx()x()x(
)xx()yx()x()yx(β
sendo que as estimativas das variâncias podem ser obtidas por:
...S2jβ= =
−
−=−
∑ ∑ ∑∑ ∑ ∑ ∑
223i2i
23i
22i
23i2i
23i
22i
23i
22
22 ])xx(x.x[])xx(xx[xσ
])βE[(b
j = 1, ..., k
k = 3 ∑ ∑ ∑
∑−
= 23i2i
23i
22i
23i
2
)xx(xxxσ
22 bβ = E[(b3 - β3)2] = ... ∑ ∑ ∑
∑−
= 23i2i
23i
22i
22i
2
)xx(xxxσ
33 bβ =
Pode-se demonstrar também que:
,])xx(xx[ N
)XX(XX[σ])βE[(b 2
3i2i23i
22i
23i2i
23i
22i
22
11 ∑−∑∑∑−∑∑
=− sendo .βb 11 =
Cov (b2, b3) = 23i2i
23i
22i
3i2i2
)xx(xxxxσ∑−∑∑
∑−
(a) A Significância dos Coeficientes do Modelo de Regressão Múltipla
A derivação das estatísticas dos estimadores no modelo de regressão múltipla é
obtida através da Álgebra Matricial. Apresenta-se a seguir sumário dos resultados mais
relevantes:
i) Os estimadores de mínimos quadrados de βj, j = 1, ... , k são BLUEs
Quando o erro ~ N (0, σ2), estes estimadores são também os estimadores de
máxima verossimilhança.

28
ii) S2 = kN
ε 2i
−∑
é uma estimativa consistente e não-viesada de σ2.
iii) Quando o erro é normalmente distribuído, testes t podem ser aplicados pois
os valores padronizados dos parâmetros βj seguem essa distribuição de probabilidade de
forma que:
jβ
jj
Sββ −
~ tN-k, j = 1, ..., k
(b) Avaliação da Qualidade do Ajustamento: Teste F, R2 e R2 Corrigido
Seja:
Yi = β1 + β2 X2i + ... + εi, com k variáveis ou k parâmetros
Yi - Y = )YY()Y(Y ii −+−
⇓ Total = Residual + Explicada
∑ 2i
2ii
2i )YY()Y(Y)Y-(Y −∑+−∑= ⇒
O coeficiente de ajustamento:
R2 = )Y(Y
ε1
)Y(Y)YY(
TSSRSS
i
2i
2i
2i
−∑∑
−=−∑−∑
=
mede a qualidade do ajustamento
Algumas questões se impõem ao uso isolado do R2 como medida do ajustamento.
Entre elas:
1) Em sua obtenção parte-se do pressuposto da boa especificação
2) R2 → depende do número de variáveis independentes.
A adição de variável independente pode não ser adequada, mas não
deve baixar R2
Além disso, o uso isolado do R2 tem valor limitado, pois pode ocorrer bom ajustamento
(leia-se aqui: bom R2) do modelo global porque variáveis independentes estão fortemente
correlacionadas entre si, com baixos valores de t e altos desvios padrão individuais.
TSS = ESS + RSS

29
Para avaliar a significância do R2 realiza-se o teste F k-1, N-k , com k-1 e N-k graus
de liberdade no numerador e denominador, respectivamente, representando o número de
variáveis independentes e o grau de variação não explicada. Para realizar o teste de
hipótese Fk-1, N-k, obtém-se:
Define-se medida complementar da qualidade do ajustamento: R2 corrigido ou 2R ,
que é obtido, por definição, em função de variâncias.
kNε
S2i2
−= ∑
2R = 1 - var(Y)
)εvar(
1N)Y(Y 2
i
−∑ −
Note-se que:
Variação não explicada
R2 = 1 - ∑ −
∑2
i
2i
)Y(Yε é igual a 1 -
1)-(N var(Y)k)(NS2 −
Variação total
Assim, pode-se derivar a relação entre R2 e 2R :
2R = 1 – (1 – R2) kN1N
−− (N>k), para a qual:
1. k = 1 ⇔ R2 = 2R
2. k > 1, R2 ≥ 2R , sendo que 2R pode ser negativo.
2R é sensível à informação usada para estimar k parâmetros.
Fk-1, N-k = 1kkN
R1R
2
2
−−
−

30
(c) Comparando Modelos de Regressão
Seja o 2R obtido por:
2R = 1 - Var(Y)
)εVar( -, onde (1 - 2R ) = 2Y
2
SS e S2 = (1 - 2R ) 2
YS .
A equação de S2 permite concluir que S2 decresce se 2R aumenta, pois 2YS
(variância de Y) depende de Yi e Y e independe do modelo formulado.
Neste ponto são necessárias algumas considerações. Por exemplo, R2 ≈ 1 indica
bom modelo explicativo. Mas qual é seu valor na previsão?
Para nortear essa resposta, deve ser destacado que R2 deve aumentar ao adicionar-
se uma variável explicativa pouco importante ao modelo, mas se esse aumento ocorrer com
um decréscimo em 2R e um aumento em S2 (impacta a variância do erro de previsão;
significa perda de precisão do modelo de previsão), essa variável não deve constar da
formulação definitiva do modelo.
Nota-se que a adição de uma variável explicativa (k cresce) irá diminuir a
variação não explicada em Y (ESS = ∑ −=
N
1i
2i ))Y(Y , entretanto a variância S2 =
kNESS−
poderá diminuir ou aumentar (depende da variação do numerador e do denominador).
(d) Construindo Modelos de Regressão com o Método de Máxima Melhoria em
R2 (MAXR)
O Método da Máxima Melhoria em R2 é composto de etapas sucessivas para
ajustar modelo composto de n variáveis explicativas aos dados:
Y ↔ Xi ... Xn
S2
2YS

31
Etapas:
1) Avaliação dos coeficientes de ajustamento dos modelos a 2 variáveis:
11,11 XbaY += → 21R
. . .
21,22 XbaY += → 22R
. . .
nn1,n XbaY += → 2nR
Assim,
t1xbaY += modelo a duas variáveis
2) Modelos a 3 variáveis:
pp2,t1 XbXbaY ++= , novo modelo, onde Xp é a variável associada ao maior R2
(valor abaixo do R2 do modelo escolhido na etapa anterior).
Estratégia:
“Troca-se” cada variável no modelo (Xt e Xp) com cada variável fora do modelo,
de forma a saber se haverá uma troca de variável (entre as dentro e as fora do
modelo) que irá melhorar o R2 do modelo.
Resultado:
Novo modelo a três variáveis.
3) Modelos a 4 variáveis:
Toma-se o melhor modelo a três variáveis e adiciona-se uma nova variável
(aquela associada ao maior R2 na etapa 1, por exemplo). Procede-se à troca entre
as três variáveis de dentro com as de fora do modelo. A composição com maior
R2 ⇒ novo modelo a 4 variáveis.
4) Repete-se o procedimento, até obter o modelo a n variáveis.
Busca do maior R2: t1XbaY +=
t1,1 bb = do modelo com o maior R2

32
Exercício 1 - Regressão
Estabeleça, com suas palavras, um paralelo entre o método MAXR e o processo
de comparação de modelos a partir de R2, R 2 e S2, considerando-se o modelo de vendas
do detergente Fresh (30 observações semanais) (Bowerman e O´Connel, 1987), onde:
Yt ≡ centenas de milhares de embalagens vendidas em cada período de observações t;
xt1 ≡ preço (US$) do detergente Fresh no período t;
xt2 ≡ o preço médio dos detergentes competidores (US$);
xt3 ≡ o gasto em propaganda no período t (em centenas de milhares de US$);
xt4 ≡ xt2 – xt1 ≡ diferença de preços entre a média do mercado e o Fresh;
xt5 ≡ t1
t2
xx
≡ razão entre preços (alternativa a xt4).
O modelo a quatro variáveis independentes (ou a 5 variáveis):
Yt = βo + β1xt4 + β2xt3 + β3 x2t3 + β4 xt4xt3 + εt tem as seguintes estatísticas associadas:
1. ESS = 1,0644
2. Variação Explicada = 12,3942
3. R2 = 9209,04586,133942,12
TotalVariaçãoExplicadaVariação
==
4. S2 = 0426,0250644,1
5300644,1
kNESS
==−
=−
5. =⎥⎦
⎤⎢⎣
⎡−−
⎥⎦
⎤⎢⎣
⎡−−
−=kN1N
1N1kRR 22
= 9083,0530130
130159029,0 =⎥
⎦
⎤⎢⎣
⎡−−
⎥⎦
⎤⎢⎣
⎡−−
−
O mesmo que kN1N)R(11R 22
−−
−−= N > k
Adicionando-se a variável independente xt4 x2t3
v3
v1 (⇒ linearizado) ...)v2

33
Yt = βo + β1xt4 + β2xt3 + β3 x2t3 + β4 xt4xt3 + β5 xt4 x2
t3 + εt
1. ESS decresce para 1,0425
2. Variação explicada pelo modelo cresce para 12,4161
3. R2 (cresce) = 9225,04586,134161,12
=
4. S2 (cresce) = 0,0434630
1,0425npN
ESS=
−=
−
5. 0,8701R 2 =
Embora R2 cresça, S2 cresce e 2R diminui, logo o poder preditivo decresce,
desaconselhando a manter a nova variável independente no modelo.

34
Exemplo: DATA (QUATERLY, 1954-1 até 1971-4, em US$)
Função de con.s.umo (Ct)
Variáveis independentes: yt renda disponível, Ct-1 con.s.umo no período anterior.
Modelo III → St = Yt - Ct ⇒ variável dependente representando renda disponível
após con.s.umo (“savings function”).
St = α3 + β3Yt + ε3t
Coeficientes Valores Estatístico t Modelo
I 1α
1β R2 = 0,9977
14,51
0,88
ESS = 966,50
7,03
173,06
SER = 3,72 Modelo
II 2α
2β
2y R2 = 0,9989
5,52
0,31
0,65
ESS = 440,70
3,06
4,85
8,78
SER = 2,55
Modelo III
3α
3β R2 = 0,8961
-14,51
0,12
ESS = 966,5
-7,03
24,57
SER = 3,72
12. Considerações Adicionais: a Correlação Parcial
As correlações parciais variam no intervalo [-1,1]. Elas são medida de
importância relativa das variáveis independentes no modelo.
Seja: i3i32i21i εXβXββY +++= .
σ
Cresceu pois não
há multicoli-nearidade
disposição ao con.s.umo
Abaixou em relação ao R2 mod. I
)65,01(31,0
− = 0,88
significante
mod I Ct = α1 + β1 yt + ε1t
mod II Ct = α2 + β2 yt + γ2Ct-1 + ε2t

35
O coeficiente de correlação parcial entre Y e X2 mede o efeito de X2 em Y sem
levar em conta outra variável do modelo.
Os passos para sua obtenção são:
1. Regressão Y em X3 321 XααY +=
2. Regressão X2 em X3 3212 XγγX +=
3. Remover influência de X3 em Y e X2
Assim, obtém-se: Y* = Y – Y
X2* = X2 - 2X
4. A correlação parcial entre X2 e Y é a correlação simples entre Y* e X2*.
Conhecendo-se a definição de correlação parcial, pode-se derivar a relação entre a
correlação parcial e a correlação simples (2YXr ,
3YXr , 3YXr ), de forma que:
32 .XYXr
2YXr 32 .XYXr = 1/22
YX1/22
XX
XXYXYX
)r(1)r(1r.rr
332
3232
−−−
, onde:
3YXr 32 .XYXr é o coeficiente de correlação parcial
32 .XXr
É possível também derivar a seguinte relação entre o coeficiente de ajustamento
R2, que mede a múltipla correlação no modelo, e a correlação parcial:
32 X2YX .r =
3
3
YX2
YX22
r1rR
−− ou 1-R2 = )r(1)r(1 323 .XYX
2YX
2 −−
Observa-se uso freqüente do coeficiente de correlação parcial como apoio nas
escolhas do procedimento de composição do modelo de regressão denominado “Stepwise”
(as variáveis adicionadas ao modelo devem maximizar 2R ). Esse coeficiente dá medida do
impacto de cada variável independente sobre a variável dependente, sendo particularmente
útil com grande número de variáveis independentes.

36
13. Teste de Chow: um Teste para a Estabilidade Estrutural dos Modelos
É importante saber se a estabilidade estrutural do modelo se mantém ao longo do
tempo em que se obtém informações de suas variáveis. O teste de Chow é um teste da
estatística F que permite avaliar se um modelo adequado a um conjunto de informações
continua válido para valores mais recentes amostrais.
O procedimento do teste é o seguinte:
• Combinar todas as (N1 + N2) informações e ajustar um modelo de regressão a esse
conjunto amostral. Calcular a soma do quadrado dos resíduos (ESS0) com N1 + N2– k
graus de liberdade, onde k é o número de parâmetros estimados (incluindo o termo
constante).
• Ajustar dois modelos aos N1 e N2 subconjuntos amostrais, que não precisam ser de
mesmo tamanho, calculando as respectivas somas do quadrado dos resíduos (ESS1 e
ESS2), com graus de liberdade N1-k e N2-k.
• Adicionar as somas do quadrado dos resíduos desses dois subconjuntos amostrais e
subtrair essa adição do valor ESS0 inicialmente calculado (modelo ajustado ao conjunto
total de dados).
• Calcular a estatística F:
)2N N/()(/)}({
2121
210
kESSESSkESSESSESS
F−++
+−= , com k e N1 + N2– k graus de liberdade.
• Se o valor da estatística F for significativo a n.s. % , a hipótese de que não existe
significativa diferença entre os modelos deve ser rejeitada e pode-se concluir que o
modelo completo é estruturalmente instável.
Observe-se que: S2 = kN
ESS−
, onde ESS é soma do quadrado dos resíduos e S2 é a
estimativa amostral da variância do erro para amostras de tamanho N.
14. O Modelo de Regressão Múltipla com Variáveis Explanatórias Estocásticas
Suposição: X´s ~ distribuição de probabilidade.
São pressupostos:
1. A distribuição de cada variável explanatória é independente dos verdadeiros
parâmetros de regressão.

37
2. Cada variável explanatória é distribuída independente dos verdadeiros erros no
modelo.
Pode-se afirmar que as propriedades dos estimadores de mínimos quadrados
ordinários (MQO) de consistência e eficiência permanecem para grandes amostras, não
sendo afetadas na condição de que os valores das variáveis independentes e os erros sejam
independentes um do outro. Os parâmetros de regressão estimados são estimados
condicionados a determinados valores de X`s. Sob os pressupostos acima, continuam a ser
estimadores de máxima verossimilhança.
15. Violação dos Pressupostos Básicos do Modelo de Regressão Clássico
É preciso determinar quando os pressupostos são violados e quais os
procedimentos de estimação são adequados nesses casos.
Sejam exemplos de violação:
1) Em relação à forma funcional:
Yi = β1 + β2X2i + ... + βk Xki + εi
erro de especificação
erro de construção do modelo
2) Em relação às variáveis explanatórias:
X`s média e variância finitas não correlacionadas com erros
(variável estocástica)
erros de medida solução através de variáveis instrumentais
não existe relação linear entre X´s
forte relação linear entre variáveis explanatórias (multicolinearidade)
3) Em relação ao pressuposto de normalidade dos resíduos:
εi ~ N (0, σ2) e distribuídos independentemente
E (εi) ≠ 0 muda intercepto (α*)
ausência de normalidade: os estimadores de MQO permanecem não-
viesados e consistentes mas nada se pode dizer sobre a verossimilhança.

38
Nesse caso diz-se que os testes são aproximadamente válidos ou seja, são
válidos quando o tamanho da amostra N → ∞.
Outras violações são os casos de heteroscedasticidade e correlação serial,
discutidos a seguir.
16. O Problema da Multicolinearidade
Uma forma de detectar multicolinearidade é através da porcentagem de variação
explicada (RSS/TSS) associada a alguma variável sendo introduzida no modelo de
regressão. Se a porcentagem RSS/TSS decrescer, a multicolinearidade explica este fato.
Como regra prática, quando o coeficiente de correlação simples entre duas
variáveis aleatórias independentes for ≥ 0,7, isso significa indício de problema de
multicolineariedade.
A multicolinearidade é um problema associado à amostra de dados. A presença
da multicolinearidade implica que há pouca informação na amostra para dar confiança na
interpretação da situação em análise.
Se existe multicolineariedade, os resultados da regressão podem estar errados.
Passos para avaliar a multicolineariedade:
Passo no 1: Testar nova amostra de dados.
Há indicação de multicolineariedade, por exemplo, quando o teste t indica
insignificância estatística dos estimadores e R2 ou estatística F são altos.
Passo no 2: Nessa situação, a matriz de correlação deve ser investigada.
Todas as variáveis independentes altamente correlacionadas devem ser retiradas
exceto uma. Embora essa seja uma solução, há perda de valor dos estimadores dos
parâmetros.
É importante ressaltar que:
1. É possível haver variáveis independentes altamente correlacionadas (altos
coeficientes de correlação) e a regressão não ter problemas de multicolinearidade.
2. Se o teste t indicar significância do estimador, é sinal que a
multicolinearidade não é séria para fins de previsão.

39
Entretanto na presença de multicolinearidade os parâmetros individuais não são
valores satisfatórios.
O exame dos desvios padrão dos coeficientes pode indicar se a multicolinearidade
está causando problemas. Assim, se vários coeficientes tem altos desvios padrão e, ao
retirar-se duas ou mais variáveis do modelo, observa-se baixarem os desvios padrão, a
multicolinearidade é provavelmente a origem disto.
Uma outra regra prática, válida para o caso de duas variáveis independentes:
Se a correlação simples entre duas variáveis independentes for maior que a
correlação de pelo menos uma delas com a variável dependente, a multicolinearidade é um
problema.
A multicolinearidade é um problema computacional que se amplia quando duas
ou mais variáveis independentes estão altamente correlacionadas (nos cálculos aparece a
indeterminação 0/0).
(a) Explicação do Problema
Considere-se o modelo:
i3i32i21i εXβXββY +++= , i = 1, ..., N
No caso extremo, por exemplo, tem-se: 3i2i δXγX += , uma relação exata. Se
essa relação for conhecida: não há problema.
Essa relação pode ser reescrita: 3i2i δxx = , fazendo 22i2i XXx −= e
33i3i XXx −= , por exemplo. Dessa forma,
00
)x(δ)x(δxxyδxxyδ
β 223i
2223i
2
23i3ii
23i3ii
2 =∑−∑
∑∑−∑∑= e
00...β3 == indeterminação.
Var )β( 2 = )r(1x
σ)xx(xx
xσ23
222i
2
23i2i
23i
22i
23i
2
−∑=
∑−∑∑∑
, onde r23 é o coeficiente de
correlação simples entre X2 e X3, de forma que:
r23 = 21
23
22
32
)xx(
xx
∑
∑ (Thomas, (1978), págs. 132, 217).

40
Como r23 → ± 1 (alta correlação), e Var )β( 2 → ∞ e Var )β( 3 → ∞, a aplicação
dos mínimos quadrados falha neste caso.
O problema da multicolinearidade é razoavelmente fácil de reconhecer, mas
difícil de resolver, pois exige soluções como a retirada de variáveis explicativas do
modelo, o que não deve ser feito sob risco de retirar-se importante variável por causa de
seu baixo valor de t. Quando o modelo é projetado para a previsão, muitas vezes é
preferível manter no modelo as variáveis que a teoria indica que explicam a variável
independente e que sejam fáceis de prever. Uma vez que a multicolinearidade tenha sido
resolvida, deve-se verificar se outros pressupostos do modelo clássico foram violados.
17. O Problema de Heteroscedasticidade
A heteroscedasticidade ocorre quando as variâncias são variáveis. Seja por
exemplo os gastos de indivíduos de renda baixa e alta. É esperado que exista uma
impossibilidade de variar no caso de renda baixa e uma grande variabilidade nos gastos de
indivíduos de renda alta, com excedente em relação aos gastos obrigatórios mensais
(Figura 18).
Figura 18- Variabilidade nos gastos de indivíduos de acordo com a renda
Em conjuntos de dados de séries temporais, é raro observar-se a
heteroscedasticidade, pois a relação é com tempo. Entretanto, ela é frequente em conjuntos
de dados de corte transversal, como o exemplo citado acima.
Na presença de heteroscedasticidade, assume-se;
εi ~ N (0, σ2i)
Var(εi) = E(εi2) = σ2
i
Gastos de indivíduos de renda
baixa
alta

41
Em presença de σ2i, o procedimento de MQO dá maior peso, naturalmente, às
observações com maiores variâncias, o que leva a estimadores não-viesados e consistentes,
mas que não são eficientes (variâncias do MQO não são as mínimas).
Na derivação de β , onde ii XβαY += ou, com a transformação de variáveis,
ii xβy = , iii εβxy += , logo iii εyy += ,
2i
ii
xyxβ
∑∑
= ⇒ β + 2i
ii
xεx
∑∑
E )β( = β + βx
)εxE(2i
ii =∑∑ , logo 2
iσ não importa na derivação do valor esperado.
Entretanto, na derivação de Var )β( = 2i
2
xσ∑
, σ2 não pode ser concluído. O uso da
expressão Var )β( = 2i
2
xσ∑
para obtenção da variância do estimador leva a estimativas
tendenciosas das verdadeiras variâncias e a aplicação dos testes a resultados incorretos.
Dessa maneira são definidos procedimentos para a correção e teste da
heteroscedasticidade.
(a) Procedimentos para correção da heteroscedasticidade
Caso 1: Variâncias são conhecidas
Var(εi) = σi2 conhecidas a priori.
Uso dos Mínimos Quadrados Ponderados (caso especial dos mínimos quadrados
generalizados). Seja o modelo a duas variáveis:
ii XβαY +=
min 2
i
ii
σXβαY
⎥⎥⎦
⎤
⎢⎢⎣
⎡ −−∑ ou min
2
i
ii
σxβy
⎥⎥⎦
⎤
⎢⎢⎣
⎡ −∑
∴ β = 2*
i
*i
*i
)(xyx
∑
∑ , i
i*i σ
xx = e i
i*i σ
yy = ,
onde primeiro obtém-se a transformação das variáveis dividindo-as por σi, para
em seguida subtraí-las dos seus valores médios.

42
No caso do modelo de regressão múltipla, obtém-se:
i
i*i σ
YY = , i
ji*ji σ
XX = ,
i
i*i σ
εε = , j = 1, ..., k
*i
*2i2
*1i1
*i ε...XβXβY +++= , onde
i
*1i σ
1X = ou seja, a equação ajustada não tem
intercepto, sendo que: Var(εi*) = Var ⎥
⎦
⎤⎢⎣
⎡
i
i
σε = 1
σσ
σ)Var(ε
2i
2i
2i
i == .
Caso 2: Variâncias desconhecidas mas estimadas nas amostras
Seja a Tabela 2, onde são tabulados os gastos com a casa de indivíduos, agrupados
em grupos de acordo com a variação nesses gastos, com as faixas de renda familiar
variando entre R$ 5.000,00 e R$20.000,00. Após proceder à análise dos dados em que
observa-se que os gastos variam diferentemente por cada uma das faixas de renda, obtém-
se as variâncias desses gastos por grupo, o que é apresentado na Tabela 3.
Tabela 2
Grupos (Yi) gastos com a casa ($1.000)
(Xi) renda familiar ($1.000)
1 1,8 2,0 2,0 2,0 2,1 5,0 2 3,0 3,2 3,5 3,5 3,6 10,0 iii εβXαY ++= 3 4,2 4,2 4,5 4,8 5,0 15,0 4 4,8 5,0 5,7 6,0 6,2 20,0
Yi = 890,0 + 0,237 Xi
(4,4) (15,9)
estimativa de MQO
R2 = 0,93 F = 252,7
Análise do Dados (plotar)
Heteroscedasticidade
As variâncias estimadas por grupo representam uma possibilidade de correção
para o Caso 2. A correção sugerida sege a correção do Caso 1, por exemplo.
Tabela 3-
Variâncias estimadas por grupo 1 9.800 2 50.400 3 102.400 4 302.400
A correção sugerida segue a correção do Caso 1.

43
Caso 3: Variâncias do erro variam diretamente com uma variável
independente
Assume-se: Var(εi) = C Xi2
uma das variáveis independentes
≠ 0
Por exemplo: Var(εi) = 22iXC em ikik2i21i εXβ...XββY ++++=
onde a transformação das variáveis do modelo define o novo intercepto:
22i
2i2 βX
Xβ= .
Aplica-se os mínimos quadrados ponderados com as variáveis:
21
i*i X
YY = 21
ji*ji X
XX =
21
i*i X
εε =
onde: Var(εi*) = Var
2i
i
Xε = C
X)Var(ε
22i
i =
A estimação com dados do exemplo do Caso 2 permite obter:
*i
i
**
i
i εX1αβ
XY
++= ii
i
X1752,90,249
XY
+=
R2 = 0,76 F = 58,7
Houve transformação na variável
dependente (R2 não deve ser comparado
ao anterior).
(b) Testes para Verificar Heteroscedasticidade
Hipótese Nula (Ho): σ12 = σ2
2 = ... = σN2, em N observações (Homocedasticidade)
Hipótese Alternativa: Heteroscedasticidade
Teste 1: Teste de Bartlett (a partir dos dados amostrais).
Passos do teste:

44
1. Estima-se Sg2 =
⎥⎥⎦
⎤
⎢⎢⎣
⎡
gN1 ∑ −
=
Ng
1i
2i )Y(Y para cada grupo de observações, g = 1, 2, ..., G,
onde: Sg2 = 2
gσ
2. Teste S, sendo S = ∑ −−+
∑ ∑−
=
= =G
1gg
G
1g
G
1g
2gg
2gg
(1/N)])(1/N[]1)(G[1/31
SlogN]S/N)(N[logN
3. Na situação de homocedasticidade ⇒ S ~ Qui-quadrado com (G-1) graus de liberdade
Hipótese Nula: Variâncias iguais em todos os grupos
Se S > Scrítico (tabela χ2) ⇒ rejeito Ho
4. Rejeição de Ho ⇒ modificação de MQO
No exemplo do Caso 2: S = 10,7 Scrítico, 3 graus de liberdade = 7,81, 5% n.s.
Teste 2: Teste de Goldfeld-Quandt
Hipótese Nula: Homocedasticidade
Hipótese Alternativa: σi2 = C Xi
2

45
Procedimentos gerais do teste:
Linha de regressão com dados
associados às baixas variâncias
* Cálculo de duas linhas de regressão +
linha de regressão com dados associados
às grandes variâncias
Assim:
1. Ordenação dos dados de acordo com a magnitude de uma das variáveis independentes
(relacionada à magnitude da variância do erro).
2. Omite-se d informações centrais (d ≈ 1/5 N), e ajusta-se 2 regressões aos 2
dN − dados
e k2
d)(N−
− graus de liberdade.
3 Calcula-se ESS1 (menores valores) e ESS2.
4. Pressupõe-se
1
2
ESSESS ⇒ distribuição F[N-d-2k)/2 graus de liberdade no numerador e no denominador]
Se 1
2
ESSESS > Fcrítico ⇒ rejeito Ho
Ao utilizar-se maiores valores de d, melhora-se o teste.
Erros normalmente distribuídos Erros não correlacionados serialmente

46
Seja o mesmo exemplo anterior (em que d = 0):
1. Rendas menores ($5.000 e $10.000)
Yi = 600,00 + 0,276 Xi
(3,1) (11,3)
R2 = 0,94 ESS1 = 3,0 x 105
2. Rendas maiores ($15.000 e $20.000)
Yi = 1.540,0 + 0,20 Xi
(1,4) (3,1)
R2 = 0,55 ESS2 = 20,2 x 105
Teste 3: Teste de White
O procedimento do teste de White determina que, em um primeiro passo, se avalie
o ajustamento entre os resíduos da regressão original estimada e as variáveis explanatórias
formuladas conforme o modelo:
ε 2i = γ+ φ X 2
i + δ Z 2i + θ Xi Zi + νi,
que permite não-linearidades e para o qual se obtém o coeficiente de ajustamento
ou determinação R2,
sendo que Zi e Xi correspondem às variáveis explanatórias da regressão original
das quais se suspeita serem a origem da heteroscedasticidade.
Em seguida é obtida a estatística Qui-quadrado para o teste, em que se calcula o
valor:
χ 2 = N R2, onde N é o tamanho da amostra que ajustou a regressão que deu
origem aos resíduos ε 2i .
Se N R2 for um valor significativo com p graus de liberdade e (1-n.s.)% de
probabilidade significa que o modelo sugerido para relacionar o quadrado dos resíduos e as
p variáveis explanatórias indica heteroscedasticidade (no modelo formulado, p=3).
6,7ESSESS
1
2 =
Fcrítico = 6,03 (8,8) graus de liberdade 6,7 > 6,3, logo, rejeito Ho

47
Por exemplo, se Xi for a única variável da qual se suspeita ser a origem da
heteroscedasticidade, deve-se calcular a estatística χ 2 para o modelo:
a) ε 2i = γ+ φ X 2
i + νi , e avaliar sua significância com 1 grau de liberdade, ou
b) Sugere-se que o modelo inclua as variáveis explanatórias X i e X 2i , e o teste
seja feito com 2 graus de liberdade.

48
Exemplo
Considere-se o modelo de regressão estimado:
1t61t51t41t36t21t PβEβIβISβDIββDS −−−−− +++++= (highly trended time-series).
N = 88 graus de liberdade = 82
S = 263,4 R2 = 0,93 0,92R 2 =
Soma dos (Resíduos2) = 5,7 x 106 F5,82 = 220,6
Coeficiente Valor Desvio Padrão t Média Coeficientes parciais
(de correlação)
1β 12.091,0 2.321,0 5,2 1,0
2β 0,109 0,06 1,8 15.507,9 0,19373
3β -1.690,3 483,6 -3,5 1,96 -0,36010
4β -76,2 65,6 -1,2 5,28 -0,12719
5β 5.585,6 974,4 5,7 2,96 0,53486
6β -175,6 34,4 -5,1 105,1 -049147
(coef. corr. parcial)2 = (0,53)2 = 0,28 da variância da variável dependente SD.
Exercício: Questão 1 escolher uma série sazonal e estimar seus parâmetros, R2,
testes, ...

49
18. O Problema da Correlação Serial
Na análise de dados de séries temporais, principalmente, é freqüente a correlação
entre os termos de erro em períodos de tempo adjacentes. A presença de correlação serial
de 1ª ordem significa que os erros em um período estão correlacionados diretamente aos
erros no período seguinte. Por exemplo, a previsão superestimada de taxa de vendas para
um período provavelmente induz a superestimativas dos períodos seguintes (exemplo de
correlação serial positiva). A correlação serial entre termos de erro é positiva, na maioria
das séries temporais. Isto deve-se, por exemplo, ao efeito de variáveis omitidas ou erros de
medida.
Como regra geral, a presença de correlação serial não afeta a não-tendenciosidade
e a consistência dos estimadores de mínimos quadrados (MQO) mas afeta a eficiência
(variância). No caso de correlação serial positiva a “perda” de eficiência é mascarada pelo
fato de que as estimativas dos desvios padrão obtidas (pelo MQO) são menores que os
verdadeiros desvios padrão (desvio padrão viesado para menos). Com isso os parâmetros
da regressão podem ser considerados mais precisos do que realmente são. Além disso, o
intervalo de confiança é mais estreito, fazendo com que a hipótese nula seja rejeitada
quando ela não deveria sê-lo.
Intuitivamente, as duas situações da Figura 19 ocorrem:
Figura 19- Exemplos de ajustamentos de modelos de regressão a dados
serialmente correlacionados (positivamente)
No caso de correlação serial positiva, R2 é melhor do que deveria ser. Como
representado na Figura 19, são observadas duas situações de ajustamento ao longo do

50
conjunto amostral: (a) β < β e (b) β > β . Na média, entretanto, há ausência de viés (ou
seja, os estimadores estão corretos). Entretanto, a medida do sucesso da estimação estará
super avaliada se a variância estimada for utilizada em testes.
Desta forma, devem ser introduzidas medidas de correção e de teste sobre a
presença da correlação serial dos erros ou autocorrelação.
a) Correção para a autocorrelação:
Assume-se erros ~ N (0, σε2) mas E (εt εt-1) ≠ 0
T...,1,t,εXβ...XββY tktk2t21t =++++=
Assume-se que os erros correlacionem-se serialmente conforme:
1ρ0,vερε t1tt ≤≤+= − Processo autoregressivo de 1ª ordem,
onde 0)vE(v);σN(0,~v 1tt2vt =− e 0)εE(v tt = .
O efeito do erro num determinado instante de tempo sobre os demais períodos
decresce no tempo. Isto é fácil de observar por meio das covariâncias dos erros. Assim,
se:
Var (εt) = E (ε2t) = E [(ρ εt-1 + vt)2] =
= E[ρ2ε2t-1 + v2
t + 2 (ρεt-1 . vt)] = ρ2 Var (εt-1) + Var (vt) = ρ2 Var (εt) + Var (vt)
Var (εt) = σ2ε = 2
v2
ρ1σ−
,
Cov (εt, εt-1) = E (εt, εt-1) =
= E [(ρ εt-1 + vt) . εt-1] = E [ρ ε2t-1 + vt . εt-1] = ρ E (ε2
t-1) = ρ Var(εt) = ρ σ2ε ,
de forma similar obtém-se:
Cov (εt, εt-2) = E (εt, εt-2) = ρ2 σ2ε
Cov (εt, εt-3) = E (εt, εt-3) = ρ3 σ2ε
São válidas as seguintes observações adicionais no estudo de correlação serial:
1. Sobre o termo de erro para o primeiro período: Não há dados sobre valores
anteriores que o influenciaram. Assim, assume-se: ε1 ~ N (0, )ρ1
σ2
v2
−

51
2. Assume-se a seguinte expressão para obtenção de ρ: ρ = ε
21tt
σ)ε,(εCov − ,
sendo 21
1t2
1
tε2 )Var(ε)Var(εσ −=
(I) Correção na hipótese: ρ conhecido a priori
Neste caso, é feito um ajustamento do procedimento de regressão por mínimos
quadrados, aplicando o método das diferenças generalizadas para recálculo das variáveis,
de forma que:
1tt*t YρYY −−=
Assim:
Yt = ....
Yt-1 = β1 + β2 X2t-1 + ... + βk Xkt-1 + εt-1
Essa equação é multiplicada por ρ x (-1), de forma que se obtém:
*tY = β1(1-ρ) + β2 X*2t + ... + βk X*kt + vt , onde vt não são correlacionados entre si, sendo:
Y*t = Yt - ρYt-1, X*
2t = X2t - ρX2t-1, vt = εt - ρεt-1
var(εt) = 2v
2
ρ1σ−
0 ≤ ρ < 1 .
Observa-se que o intercepto do modelo original (β1) deve ser calculado a partir do
intercepto obtido para a equação transformada *tY .
Quando:
ρ = 1 ⇒ “primeira diferença”. Obtém-se. ∑−=k
2ii1 XβYβ , pois nessa situação
o intercepto é nulo. Ou seja: Y*t = β2 X*
2t + ... + βkX*kt + vt
Y*t = Yt – Yt-1, X*
2t = X2t – X2t-1, vt = εt - εt-1
(II) Correção na hipótese: ρ não é conhecido a priori
Neste caso são sugeridos três procedimentos alternativos:
- O Procedimento de Cochrane - Orcutt

52
1º passo: Estimação do modelo original por mínimos quadrados.
Definição de “erros estimados” (resíduos)
2º passo: Utilização dos resíduos como dados de base para a estimação.
t1tt vερε += −
parâmetro estimado )ρ(
3º passo: Uso do parâmetro estimado )ρ( para compor as diferenças
generalizadas.
1tt*t YρYY −−=
1ktkt*kt XρXX −−=
4º passo: Estimar parâmetros da equação transformada
Y*t = β1(1- ρ ) + β2X*
2t + ... + vt
k321 β,...,β,β,β
5º passo: Definir e obter:
ktk2t21tt Xβ...XββYε −−−−=
6º passo: Estimar parâmetro da regressão.
t1tt ερε v+= −
Nova estimativa de ρ
7º passo: Pare o procedimento ou continue até que,
1º, 2º estimativas de ρ foram obtidas
por exemplo:
ρ - ρanterior ≤ 0,01 ou 0,005
Problema: valor obtido pela minimização da soma dos quadrados dos resíduos
pode ser mínimo local (x mínimo global).
- O Procedimento de Hildreth-Lu

53
Os passos do procedimento são os seguintes:
1º passo: Escolha de valores alternativos para ρ ⇒ escolhido em um conjunto
de valores entre 0 e 1.
Por exemplo
ρ= ρ
2º passo: Para cada ρ , estimar Y*t = β1 (1- ρ ) + β2X*
2t + ... + vt e calcular a
soma dos quadrados dos resíduos
3º passo: ρ ótimo ⇒ menor soma dos quadrados dos resíduos.
4º passo: Pare o procedimento (estabelecendo critério de parada) ou continue
estabelecendo nova variação de valores em torno do ρ ótimo, recomeçando no
1º passo.
Esse procedimento pode garantir máxima verossimilhança. Como precaução, no
entanto, deve-se ter atenção na escolha de valores dos coeficientes para definir ρ ótimo de
forma que sejam bem espaçados e deve-se também variar o conjunto inicial.
- O Procedimento de Durbin
1º passo: A partir das diferenças generalizadas do modelo linear:
Yt - ρ Yt-1 = β1 (1-ρ) + β2 (X2t - ρX2t-1) + ... + vt, que permite obter:
Yt = β1 (1-ρ) + ρ Yt-1 + β2X2t - ρβ2X2t-1 +...+ βkXkt - ρβkXkt-1 + vt,
estima-se ρ aplicando a estimação de mínimos quadrados (ρ é o coeficiente
estimado para a variável Yt-1).
2º passo: Substitui-se ρ na equação:
Yt - ρ Yt-1 = β1 (1- ρ ) + β2 (X2t - ρ X2t-1) +...+ βk (Xkt - ρ Xkt-1) + vt
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0

54
Com esse conjunto de variáveis estima-se novo conjunto de parâmetros (mais
eficiente que o anteriormente obtido).
(b) Testes para correlação serial
Hipótese nula ⇒ ρ = 0
Hipótese Alternativa ⇒ ρ ≠ 0 (ou ρ > 0 ou ρ < 0)
O teste mais popular para a correlação serial é o teste de Durbin-Watson.
Existem testes alternativos, como o teste de Durbin, que se aplicam a situações
específicas observados na amostra e modeladas (ver Durbin, J. (1970), “Testing for Serial
Correlation in Least-Squares Regression When Some of the Regressors are Lagged
Variables”, Econometrica, vol. 38, pp.410-421; Siegel, S. (1956), “Nonparametric
Statistics for the Behavioral Sciences”, Mc Graw-Hill e Theil. H. (1965), “The Analysis of
Disturbances in Regression Analysis”, Journal of the American Statistical Association,
Vol. 60, pp. 1067-1079).
(b1) Teste de Durbin-Watson
No teste de Durbin-Watson, é calculada a estatística DW, cujo valor permite
concluir sobre a presença ou não de significativa correlação serial. São procedimentos do
teste:
Sejam 1tt ε,ε − ⇒ resíduos da aplicação de MQO
Calcula-se: DW = ∑
∑ −
=
=−
T
1t
2t
T
2t
21tt
ε
)εε( , situando essa estatística de acordo com valores
tabelados conforme a Figura 20.
O teste não pode ser usado (por definição) quando o modelo de regressão inclui,
como variável explanatória, a variável dependente defasada.
Observa-se que, quando(Figura 20):
tε próximos a 1-tε (autocorrelação positiva) ⇒ baixos DW
Nova Variável Dependente
Nova Variável Independente
Nova Variável Independente

55
tε opostos a 1-tε (autocorrelação negativa) ⇒ altos DW
Caso DW = 2 ⇒ correlação serial de 1ª ordem: ausente.
dL e dU ⇒ obtidos na Tabela DW, a 5% n.s, k’ variáveis, onde k’= k-1
(exclui-se o intercepto) e de acordo com o tamanho (T) da amostra.
4 – dL < DW < 4: rejeito Ho; há correlação serial negativa.
4 – dU < DW < 4 – dL: inconclusivo.
2 < DW < 4 - dU: não há.
dU < DW < 2: não há.
dL < DW < dU: inconclusivo.
0 < DW < dL: há correlação positiva.
Figura 20- Variação de valores para a avaliação da presença de correlação
serial
As regiões de indeterminação do teste devem-se à seqüência de resíduos ser
influenciada pelas variáveis independentes. Por outro lado, a análise do modelo de
regressão a duas variáveis leva à conclusão que DW ≈ 2 (1 - ρ ) podendo este resultado ser
obtido a partir da relação DW = ∑
∑
=
=−−
T
1t
2t
T
2t
21tt
ε
)εε( inicial.
Exemplo:
COAL = 12,262 + 92,34 FIS + 118,57 FEU- 48,90 PCOAL + 118,91 PGAS
(Demanda) (3,51) (6,46) (7,14) (-3,82) (3,18)
R2 = 0,692 F(4,91) = 51,0 DW = 0,95 (DW< dL, logo há correlação positiva)
Hildreth-Lu ⇒ ρ = 0,6

56
COAL* = 16,245 + 75,29 FIS* + 100,26 FEU*- 38,98 PCOAL* + 105,99 PFAS*
(3,3) (4,4) (3,7) (-2,0) (2,0)
DW = 2,07 ⇒ Ho aceita (2<DW< 4-dU) nas condições: 5% n.s., 96 observações e
4 variáveis independentes, para os valores de dL = 1,58 e dU = 1,75 tabelados.
(b2) O teste de Durbin
Este teste aplica-se ao caso em que a variável dependente defasada é variável
independente no modelo.
Para isto calcula-se a estatística h que vai testar a presença de correlação serial no
caso citado. Essa estatística é definida por:
h = ρ { N/(1-N VAR ( β )}1/2 para N VAR ( β ) <1, onde:
ρ = (1-1/2 DW),
VAR ( β ) é a variância estimada do coeficiente da variável defasada Y t-1.
O teste é válido para amostras de grande tamanho (N>30) (embora na prática seja
aplicado também em amostras pequenas). A estatística é testada como um desvio da
distribuição normal. Se h > 1,645, rejeita-se a hipótese nula de que os resíduos não tem
correlação serial a 5 % de nível de significância.
19. A Previsão com o Modelo de Regressão
O modelo de regressão de uma equação (singular) é base para dois tipos de
previsão: (a) as previsões pontuais, às quais associam-se intervalos de confiança, dando
origem a (b) previsões de intervalos de confiança da previsão, construídos de forma a que
se observe uma margem de erro em torno da previsão pontual, definindo bandas de (1-
n.s.)% de confiança (n.s. é o nível de significância).
As previsões são guias para as decisões e dão orientação para a (re)construção do
modelo de regressão, na medida que se tenha informação atual da situação em análise.
Elas se distinguem em ex “post” e ex “ante”, conforme o período previsto se baseie ou
não no conjunto de dados amostrais correntes das variáveis independentes (Figura 21):

57
(a) Período das previsões ex “post”: usado para a avaliação do modelo de
previsão. Essas são previsões ditas incondicionais (valores das variáveis
independentes conhecidos).
(b) Período das previsões ex “ante”: essas previsões podem ser incondicionais ou
condicionais. Seja por exemplo:
Figura 21- Distinção entre previsão ex “post” e ex “ante”
Pode-se definir como sendo a melhor previsão aquela com variância mínima em
seu erro de previsão. Pode-se afirmar que as estimativas de MQO levam às melhores
previsões não tendenciosas com modelos lineares (BLUEs). O erro do procedimento de
previsão está associado aos seguintes pontos:
1. Natureza aleatória do termo aditivo do erro.
2. O processo de estimação envolve erro ao estimar parâmetros que tendem aos
verdadeiros parâmetros, mas diferindo deles.
3. Previsão condicional introduz erros ao calcular valores esperados para as
variáveis independentes ou explanatórias.
4. Erro de especificação do modelo (≠ do modelo real).
O erro de previsão é, aqui, avaliado em três situações: (A) previsão incondicional,
(B) previsão incondicional com erros serialmente correlacionados e (C) previsão
condicional, que traz inerente maior dificuldade.
Períodos de previsão
T1
ex“post” estimação
Período da
Tempo T
ex “ante”
T2 T3 (atual)
S(t) = ao + b1 X(t-3) + b2 Y(t-4) Incondicional até 3 períodos no futuro S(t) = ao t b1 X(t) + b2 Y(t) condicional

58
(A) Previsão Incondicional
Na previsão incondicional os valores assumidos pelas variáveis independentes são
conhecidos no período da previsão. Nesse caso diz-se que os valores são previstos quase
– perfeitamente. Cita-se como exemplo de variáveis explanatórias: mês do ano e
população no mês do ano, em um período de previsão (mensal) total de 1 ano.
Os modelos para previsão incondicional são desejáveis pois removem erros do
processo de previsão, ao serem construídos com base em variáveis explanatórias de
previsão fácil e precisa.
Seja:
Yt = α + β Xt + εt, t = 1, 2, ..., T
εt ~ N (0, σ2), a variável independente XT+1 conhecida.
Pressuposto: α e β conhecidos ∴ Y T+1 = E (YT+1) = α + β XT+1
erro de previsão: êT+1 = Y T+1 – YT+1
Nesse caso, são válidas as seguintes propriedades do erro de previsão:
1. E ( 1Te + ) = E ( 1TY + - 1TY + ) = 0 = E (-εT+1) , ou seja: a previsão de YT+1 é um
valor não-enviesado (isto é: correto na média).
2. A variância do erro de previsão (σp2 )
σp2 = E [( 1Te + )2] = E [( 1Tε + )2] = σ2 ou seja, é a variância de MQO.
Assim: erro de previsão ~ N (0, σ2)
Para a avaliação da significância estatística dos valores previstos deve ser obtido o
erro normalizado: λ = σ
YY 1T1T ++ − , onde λ ~ N (0, 1).
Constrói-se o intervalo de confiança em torno do erro normalizado com 5% de
nível de significância (Figura 22), de forma que:
- λ0,0 5 ≤ σ
YY 1T1T ++ − ≤ λ0,05, onde λ0,05 é o valor de λcrítico que se obtém segundo
a tabela da distribuição normal.

59
Figura 22- A previsão pontual e o intervalo de previsão com bandas de 95 % de confiança para a previsão incondicional
Pode ser feita a avaliação do modelo de previsão após obter-se YT+1 e comparar-se
seu valor com valores previstos para os limites do intervalo de previsão. São possíveis as
situações:
− O valor obtido ∈ intervalo de previsão; com isto, conclui-se que o modelo é
satisfatório.
− Se o valor estiver fora do intervalo, deve ser analisado se trata-se de um
evento extraordinário, ou se o modelo deve ser revisto. Novas observações
devem, neste caso, ser obtidas antes de uma conclusão.
Ao se utilizar os modelos de regressão para a previsão é possível ter:
* Modelos com estatísticas t com valores significativos e bom R2 mas que
podem não explicar mudanças estruturais resultando em previsões pobres.
* Modelos com baixos R2 e algum(s) coeficiente(s) não significativos que
podem fornecer boas previsões pois embora os modelos não sejam muito
explicativos, houve pouca variação em Yt, e a previsão é fácil de ser obtida.
Yt = α + βX σλYYσλY 0,051T1T0,051T +≤≤− +++
* intervalo de previsão

60
No caso de violação do pressuposto: α e β conhecidos, tem-se a situação mais
realista ou seja, supõe-se que α e β são variáveis aleatórias que podem ser estimadas e σ2
desconhecido, podendo ser, também, estimado.
Nesse caso, a previsão de Yt+1 é obtida por procedimento de dois estágios,
apresentado a seguir, sendo que o valor previsto é BLUE. (Johnston, J., “Econometric
Methods”, pp. 38-40, 1972).
O procedimento de 2 estágios:
1. Yt = α + βXt + εt
Com a aplicação dos Mínimos Quadrados Ordinários obtém-se α , β , 2σ .
2. 1TY + = E ( 1TY + ) = α + β XT+1
O erro de previsão é 1Te + = 1TY + - 1TY + = ( α - α) + ( β - β) XT+1 - εT+1
As origens de erro em 1Te + são:
1) Presença de um termo εT+1 aditivo, devido à variância de Y.
2) Natureza aleatória dos coeficientes estimados, sensível aos graus de
liberdade do processo de estimação.
O erro de previsão, combinação linear de variáveis normalmente distribuídas α ,
β e εT+1, também é considerado normalmente distribuído. O valor esperado do erro de
previsão é:
E ( 1Te + ) = E ( α - α) + E [( β - β)XT+1] + E (-εT+1) = E ( α - α) + XT+1 E ( β - β) =
0, pois XT+1 é considerado conhecido e E(εT+1) = 0.
A variância de 1Te + (σp2) pode ser obtida:
σp2 = E [( 1Te + )2] = E [( α - α)2] + E [( β - β)2] . X2
T+1 +
+ E [(εT+1)2] + E [( α - α) ( β - β)] 2XT+1
Observe-se que α , β dependem de ε1, ... , εt mas são independentes de εT+1.
Assim,
σp2 = Var( α ) + 2Xt+1 COV ( α , β ) + X2
T+1 Var( β ) + σ2 ,
sendo:

61
Var( α ) = 2t
2t
2
)X(XTXσ−∑
∑ , Var( β ) = 2
t
2
)X(Xσ−∑
,
Cov( α , β ) = 2t
2
)X(XσX-−∑
e X ≡ média amostral .
∴ σp2 = σ2 ⎥
⎦
⎤⎢⎣
⎡−∑
+−++ ++
2t
1T2
1T2
)X(XXXX2X
T11
ou
σp2 = σ2 ⎥
⎦
⎤⎢⎣
⎡−∑
++ +2
t
21T
)X(X)X-(X
T11
Ou seja, o erro de previsão é sensível a (a), (b) e (c). Dessa forma, (XT+1 - X )
permite ter uma medida da variação que pode-se assumir para o período de previsão. Em
pacotes estatísticos, são gerados valores para a variável hzz , definida para o modelo a 2
variáveis por hzz = ∑ −
−+
t
22t
2
XTX)X(X
T1 z sendo σp
2 = σ2 (1 + hzz), onde z é o período da
previsão.
Para construir o intervalo de confiança em torno dos valores previstos, obtém-se o
valor do erro normalizado λ tal que, se σ for conhecido, λ = p
1t1t
σYY ++ −
~ N (0,1), e se σ2
não é conhecido, utiliza-se S2 ≡ estimativa amostral de σ2 , sendo:
S2 = 2tt )Y(Y
2T1
−∑−
Assim, conhecida Sp2 = S2 ⎥
⎦
⎤⎢⎣
⎡−∑−
++ +2
t
21t
)X(X)X(X
T11 e o valor do erro normalizado λ:
p
1T1T
SYY ++ − , que segue a distribuição da estatística t, com (T-2) graus de liberdade:
“distância” entre Xt+1 e X
Variância na amostra de dados de X
Tamanho da amostra (estimação)
(a)
(b)
(c)

62
p0.051T1Tp0.051T StYYStY +≤≤− +++ é o intervalo de previsão com 95% de
confiança de conter o verdadeiro valor a ser observado da variável independente (Figura
23). Como foi visto, ele varia com o tamanho da amostra, a variância na amostra da
variável independente e com a diferença entre o valor da média amostral da variável
independente e o seu valor no período da previsão.
Figura 23 – Intervalo de previsão com bandas de confiança quando α , β e σ2 são variáveis
aleatórias
Exemplo-
Previsão de padrão médio (Yi) x rendas familiares (Xi)
N = 8, linha de regressão estimada: iY = 1,375 + 0,120 Xi
S2 = 0,111
X = 13,5 ∑ (Xi - X )2 = 162
XN+1 Y N+1 Sf2
Y N+1 – 1,96 Sf Y N+1 + 1,96 Sf
6,5 2,155 0,158 1,375 2,935
10,0 2,575 0,133 1,860 3,415
X 13,5 2,995 0,125 2,303 3,687
17,0 3,315 0,133 2,600 4,030
20,5 3,835 0,158 3,055 4,615
24,00 4,155 0,259 3,677 5,673
menor Sp2
bem fora dos valores observados

63
(B) A Previsão incondicional com erros serialmente correlacionados
É preciso atenção pois o erro da previsão em séries com erros serialmente
correlacionados será menor do que quando a autocorrelação não for levada em conta.
Seja:
Yt = α + β Xt + εt , onde os erros são serialmente correlacionados segundo:
εt = ρ εt-1 + vt
vt ~ N (0, σv2), E (vt vt-1) = 0
|ρ| < 1
Tome-se como pressuposto: α, β e ρ conhecidos a priori
1T1T1T εXβαY +++ ++=
Uma vez que εT+1 = ρ εT + vT , pode-se escrever T1T ερε =+ , logo:
T1T1T ερXβαY ++= ++ .
Observe-se que, quanto mais para o futuro T+s, a informação sobre a correlação
dos erros se torna pouco expressiva:
t2
1t2t ερερε == ++ . .
0ρs,ερε st
sSt →⇒∞→=+
A expressão T1T1T ερXβαY ++= ++ também pode ser derivada do modelo na
forma de diferenças generalizadas em (1) a seguir. Esse é um resultado interessante, pois a
correlação serial é comumente corrigida introduzindo essa modificação nas variáveis do
modelo.
Yt* = α (1 - ρ) + β Xt
* + vt
onde:
Yt* = Yt - ρ Yt-1
Xt* = Xt - ρ Xt-1
(1)

64
Nessa forma, a previsão para o período T+1 pode ser obtida pela equação (2):
*1TY + = α (1 - ρ) + β *
1TX + (2)
onde:
Y *T+1 = Y T+1 - ρ YT (3)
*1TX + = XT+1 - ρ XT (4)
Assim, substituindo-se (2) em (3) pode-se escrever:
Y T+1 = *1TY + + ρ YT = α (1 - ρ) + β X*
T+1 + ρ YT
Sabendo de (4) que *1TX + = XT+1 - ρ XT ,
Y T+1 = α (1 - ρ) + β (XT+1 - ρ XT) + ρYT =
= α (1 - ρ) + β XT+1 + ρ (YT - β XT),
devendo ser lembrado que YT = α + β XT + εt ∴YT - β XT = α + εT ,
logo:
Y T+1 = α (1 - ρ) + β XT+1 + ρ (α + εT) = α + β XT+1 + ρ εT
Além disso:
* e T+1 = Y T+1 – YT+1 = ρ εT - εT+1 = - vT+1 ∴ E ( e T+1) = 0
* σp2 = E [(ρ εT - εT+1)2] =
= ρ2 E (εT2) + E ( 2
1Tε + ) – 2 ρ E (εT εT+1) =
= ρ2 E (εT2) + E (ε2
T+1) – 2 ρ2 E (εT2) =
= ρ2 σ2 + σ2 – 2 ρ2 σ2 = σ2 - ρ2 σ2 = (1 - ρ2) σ2,
onde (1 - ρ2) é o fator de redução no erro de previsão (em relação à situação com ausência
de autocorrelação). Observe-se que (1 - ρ2) σ2 = 2vσ .
Na prática, há violação do pressuposto, pois α, β e ρ não são conhecidos, embora
possam ser estimados (veja: Goldberger, A.S. (1962), “Best Linear Unbiased Prediction in
the Linear Regression Model”, Journal of the American Statistical Association, vol. 57, pp.
369-375).
εT+1 = ρ εT + vT+1

65
Nessa situação, o valor previsto 1TY + pode ser calculado por:
)Xρ(Xβ)ρ(1αYρY T1TT1T −+−+= ++ ou seja, na forma das diferenças
generalizadas. Pode ser provado que E ( e T+1) → 0 quando T → ∞. Na prática assume-se
ρρ = (isto é, que foi estimado com exatidão), para se obter a variância do erro de previsão
(na realidade há correlação entre parâmetros estimados e os resíduos).
A variância do erro de previsão é obtida por:
Sp2 = S2 ⎥
⎦
⎤⎢⎣
⎡−∑−
++ +2**
t
2**1T
)X(X)X(X
T11 , onde o termo do erro é vt ao invés de εt, fazendo
com que se obtenha S2 = Sv2 , pois Sp
2 é obtida a partir do modelo de diferenças
generalizadas (baseado em Pindyck e Rubinfeld (1976), “Economic Models and Economic
Forecasts”, pp. 172).
(C) A Previsão Condicional
Neste caso é reconhecida a natureza estocástica dos Xi`s. Os intervalos de
previsão crescem quando os valores assumidos para as variáveis independentes Xi forem
também previstos. É difícil derivar resultados para o erro de previsão no caso geral. Para
o modelo a duas variáveis, supõe-se:
Yt = α + β Xt + εt , t = 1, 2, ..., T
X T+1 = XT+1 + uT+1
εt ~ N (0, σ2), ut ~ N (0, σu2), εt e ut não correlacionados
E [( X t+1 – Xt+1) ( β - β)] = E [( X t+1 – Xt+1) ( α - α)] = 0
onde α , β são as estimativas de MQO.
Nesse caso, pode-se concluir que:
1T1T XβαY ++ += , sendo a variância do erro de previsão:
σp2 = σ2 2
u2
2t
2u
21T σβ
)X(Xσ)X(X
T11 +
⎥⎥⎦
⎤
⎢⎢⎣
⎡
−∑+−
++ +
1TY + não é normalmente distribuído, envolvendo a soma de produtos de variáveis
normalmente distribuídas.
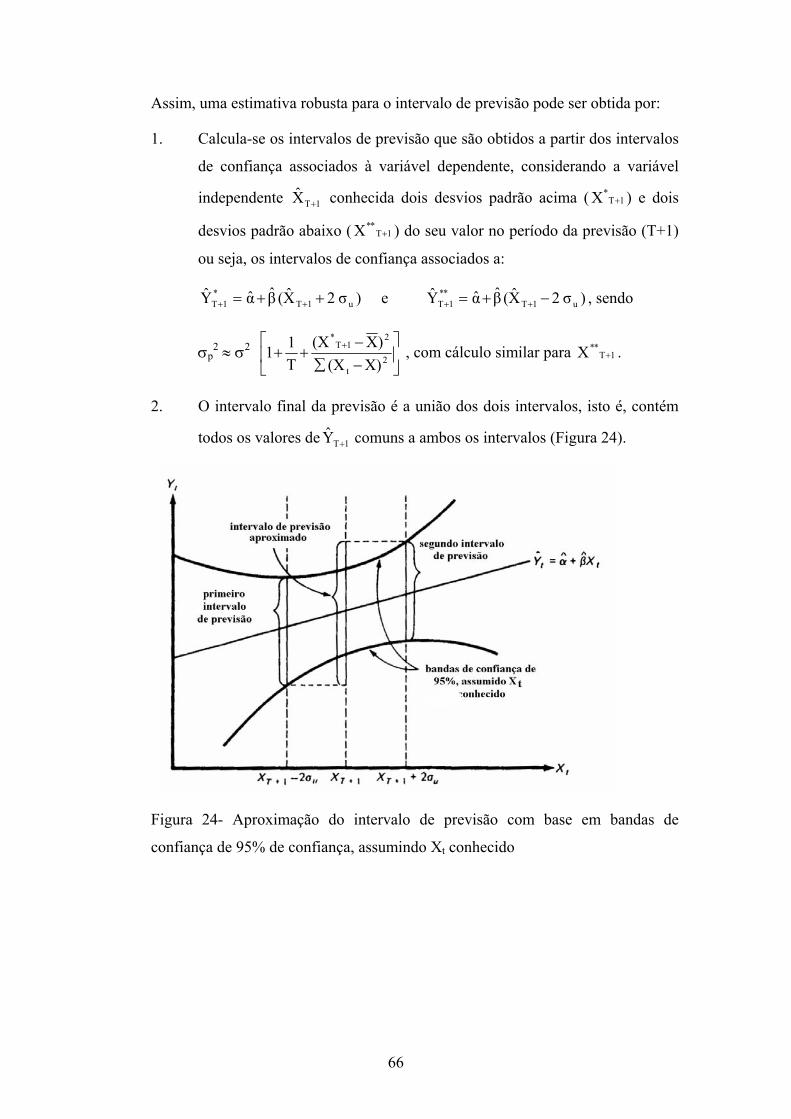
66
Assim, uma estimativa robusta para o intervalo de previsão pode ser obtida por:
1. Calcula-se os intervalos de previsão que são obtidos a partir dos intervalos
de confiança associados à variável dependente, considerando a variável
independente 1TX + conhecida dois desvios padrão acima ( 1T*X + ) e dois
desvios padrão abaixo ( 1T**X + ) do seu valor no período da previsão (T+1)
ou seja, os intervalos de confiança associados a:
)σ2X(βαY u1T*
1T ++= ++ e )σ2X(βαY u1T**
1T −+= ++ , sendo
σp2 ≈ σ2 ⎥
⎦
⎤⎢⎣
⎡−∑−
++ +
2t
21T
*
X)(X)X(X
T11 , com cálculo similar para 1T
**X + .
2. O intervalo final da previsão é a união dos dois intervalos, isto é, contém
todos os valores de 1TY + comuns a ambos os intervalos (Figura 24).
Figura 24- Aproximação do intervalo de previsão com base em bandas de
confiança de 95% de confiança, assumindo Xt conhecido





























