Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULESCOLA DE ENGENHARIA
DEPARTAMENTO DE ENGENHARIA ELÉTRICACURSO DE GRADUAÇÃO EM ENGENHARIA DE COMPUTAÇÃO
OSVALDO MARTINELLO JUNIOR
ESTABILIZAÇÃO DE IMAGENSAPLICADA A UM ROBÔ PARA
INSPEÇÃO DE LINHAS DETRANSMISSÃO
Porto Alegre2006


OSVALDO MARTINELLO JUNIOR
ESTABILIZAÇÃO DE IMAGENSAPLICADA A UM ROBÔ PARA
INSPEÇÃO DE LINHAS DETRANSMISSÃO
Trabalho de Diplomação apresentado ao Departa-mento de Engenharia Elétrica da Universidade Fe-deral do Rio Grande do Sul como parte dos requi-sitos para a obtenção do título de Engenheiro deComputação.
ORIENTADOR: Prof. Dr. Walter Fetter Lages
Porto Alegre2006


OSVALDO MARTINELLO JUNIOR
ESTABILIZAÇÃO DE IMAGENSAPLICADA A UM ROBÔ PARA
INSPEÇÃO DE LINHAS DETRANSMISSÃO
Este Trabalho foi julgado adequado para a obten-ção dos créditos da Disciplina Trabalho de Diplo-mação do Departamento de Engenharia Elétrica eaprovado em sua forma final pelo Orientador e pelaBanca Examinadora.
Orientador:Prof. Dr. Walter Fetter Lages, UFRGSDoutor pelo Instituto Tecnológico de Aeronáutica – São Josédos Campos, Brasil
Banca Examinadora:
Profa. Dra. Letícia Vieira Guimarães, UFRGSDoutora pelo Muroran Institute of Technology – Muroran, Japão
Prof. Dr. Jacob Scharcanski, UFRGSDoutor pela University of Waterloo – Waterloo, Canadá
Chefe do DELET:Prof. Dr. Romeu Reginatto
Porto Alegre, dezembro de 2006.


AGRADECIMENTOS
Gostaria de agradecer à minha família pelo apoio que me deu, não somente durante aminha vida universitária, que culmina agora com a minha conclusão do curso, mas durantetodos os meus momentos de escolha que me fizeram chegar onde estou hoje.
Queria agradecer também a todos os meus amigos, pois acredito que a formação docaráter de uma pessoa está intimamente ligada com as pessoas que a rodeiam, logo, o queeu sou hoje é, em grande parte, conseqüência das amizades que cultivei durante toda aminha vida.
E finalmente, agradecer a todos da UFRGS que estiveram envolvidos direta ou indi-retamente na minha formação. Em especial ao corpo docente que, salvo raras exceções,não medem esforços para transferir o máximo de conhecimento aos seus discípulos.


RESUMO
O objetivo deste documento é o de apresentar um algoritmo de estabilização de ví-deo que devido à sua modularidade e à sua parametrização é aplicável aos mais diversosfins. Porém, ele deve ser utilizado num projeto que visa a construção de um robô para ainspeção de cabos e isoladores da rede de transmissão de energia elétrica. Constam nesteuma visão geral do algoritmo implementado, um exemplo de execução, bem como umaanálise de desempenho.
Palavras-chave: Processamento de imagens, visão computacional, estabilização deimagens, robótica.


ABSTRACT
The objective of this document is to present an algorithm of video stabilization, wichdue to its modularity and parameterization is usable into the most various applications.However, it is going to serve to a project of a construction of an examiner robot, to in-spect the cables and isolators of electric power lines. In this document there is a globalvision of the implemented algorithm, an execution example, as well as a benchmark ofthe program.
Keywords: image processing, computational vision, image stabilization, robotics.


SUMÁRIO
LISTA DE ILUSTRAÇÕES . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
LISTA DE TABELAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 O PROJETO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 O ALGORITMO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.1 Definição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Implementação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Filtragem dos vetores globais de movimento . . . . . . . . . . . . . . . . 283.4 Aperfeiçoamentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.4.1 Interpolação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.4.2 Paralelização de código . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4 RESULTADOS EXPERIMENTAIS . . . . . . . . . . . . . . . . . . . . . 314.1 Execução passo a passo da implementação . . . . . . . . . . . . . . . . . 314.2 Resultados utilizando o robô Janus . . . . . . . . . . . . . . . . . . . . . 36
5 ANÁLISE DE DESEMPENHO . . . . . . . . . . . . . . . . . . . . . . . 39
6 CONCLUSÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
APÊNDICE A CÓDIGO DA IMPLEMENTAÇÃO DO ALGORITMO . . . . 47A.1 libstab.h . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47A.2 libstab.cpp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47A.3 stab.cpp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55


LISTA DE ILUSTRAÇÕES
Figura 1: Fluxogramado algoritmo. . . . . . . . . . . . . . . . . . . . . . . . . 22Figura 2: Fluxograma da implementação do algoritmo. . . . . . . . . . . . . . 26Figura 3: Alguns dos parâmetros modificáveis. . . . . . . . . . . . . . . . . . 27Figura 4: Parâmetros de definição da janela de busca. . . . . . . . . . . . . . . 28Figura 5: Cálculo dos pixels na interpolação. . . . . . . . . . . . . . . . . . . 29
Figura 6: Quadros originais antes da execução do programa. . . . . . . . . . . 32Figura 7: Quadro de referência dividido. . . . . . . . . . . . . . . . . . . . . . 32Figura 8: Mapa de filtragem passa-altas do quadro de referência. . . . . . . . . 33Figura 9: Quadro de referência com os blocos escolhidos para os vetores de
movimento locais. . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Figura 10: Detalhe da interpolação. . . . . . . . . . . . . . . . . . . . . . . . . 35Figura 11: Quadro atual corrigido. . . . . . . . . . . . . . . . . . . . . . . . . . 35Figura 12: Sequência estabilizada. . . . . . . . . . . . . . . . . . . . . . . . . . 36Figura 13: Robô Janus. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Figura 14: Quadros adquiridos pelas câmeras do Janus. . . . . . . . . . . . . . . 37Figura 15: Quadros adquiridos pelas câmeras do Janus estabilizados. . . . . . . 38
Figura 16: Tamanho de bloco versus taxa de quadros em execução monothread. . 40Figura 17: Tamanho de janela de busca versus taxa de quadros em execução mo-
nothread. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40Figura 18: Tamanho de bloco versus taxa de quadros em execução multithread. . 41Figura 19: Tamanho de janela de busca versus taxa de quadros em execução mul-
tithread. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42


LISTA DE TABELAS
Tabela 1: Vetores de movimento locais calculados. . . . . . . . . . . . . . . . 34
Tabela 2: Análise de desempenho monothread. . . . . . . . . . . . . . . . . . 39Tabela 3: Análise de desempenho multithread. . . . . . . . . . . . . . . . . . . 41


17
1 INTRODUÇÃO
A robótica vem conquistando mais e mais adeptos, seja pelo aumento de produtivi-dade proporcionado para o ramo industrial, seja pelo conforto ou entretenimento no focodoméstico. Até algum tempo atrás o que se poderia esperar de robôs era um serviço rá-pido e bem feito, porém pouco versátil, mas com o aumento do poder de processamentoe com o desenvolvimento de técnicas de visão computacional esses bens passaram a serutilizados em uma infindável variedade de aplicações, que vai desde a pintura de auto-móveis até um simpático bichinho de estimação. Áreas como a segurança e a saúde nãoforam deixadas de lado, o que ressalta a importância da robótica na sociedade.
É nesse contexto que se desenvolve a visão computacional aplicada à robótica, emáreas onde seria praticamente impossível (ou simplesmente inviável) a operação via sen-sores, por exemplo, para a operação de câmeras em cirurgias vídeo-laparoscópicas, ou oreconhecimento do rosto do dono feito pela sua câmera de segurança.
O presente documento ilustrará um algoritmo de estabilização de imagens, definidopor alinhar os quadros entre si, de forma com que eles sejam espacialmente correspon-dentes. O algoritmo de propõe a estabilizar seqüências de vídeo compostas basicamentepor objetos estáticos e rígidos, e constituído de quadros fortemente correlatos. Neste tra-balho, encontra-se a descrição de como o algoritmo foi implementado, alguns resultadosexperimentais, bem como uma análise de desempenho.

18

19
2 O PROJETO
O projeto, que é uma parceria com a CEEE, visa o estudo e a criação de um sistemaautomatizado para a inspeção de cabos e isoladores de linhas de transmissão.
O objetivo é o de chegar a um sistema autônomo que seja capaz de se locomoveratravés das linhas de transmissão, identificar um defeito, localizá-lo geograficamente earmazenar em vídeo a inspeção, permitindo assim a validação do processo e o rápidoreparo do problema.
Em se tratando de um dispositivo móvel, a imagem capturada pelas câmeras será pro-vavelmente oscilante, e para isso existem algumas alternativas de como será efetuado oposterior tratamento da imagem. Poderia se tentar atacar o problema de reconhecimentode defeitos diretamente, sem que haja qualquer estabilização de vídeo, porém isto acar-retaria principalmente na falta de coerência entre os quadros adquiridos; Pode-se utilizaruma correção mecânica para as oscilações, o que permite resultados eficientes, porémnão muito versáteis; Ou pode-se optar pela estabilização digital, que é mais facilmenteparametrizável, porém exige um poder de processamento significante.
A opção tomada foi pela última alternativa, e é sobre esse tipo de estabilização devídeo que versa este trabalho.

20

21
3 O ALGORITMO
O objetivo do algoritmo desenvolvido é o de criar uma seqüência de vídeo estável.Estabilizar um vídeo, neste contexto, significa fazer com que cada quadro do vídeo estejaalinhado com o quadro antecessor, de forma a corresponder espacialmente ao quadro dereferência. Para tanto, o programa deve comparar dois quadros consecutivos, identificarpartes coincidentes entre as imagens, identificar a transformação linear que leva o quadroatual ao quadro de referência, e, ainda levando em consideração os quadros passados,transformar o quadro corrente em um que se ajuste aos quadros anteriores.
É importante ressaltar que o presente algoritmo se propõe a estabilizar seqüências dequadros que sejam fortemente correlatos, que tenham grande parte das imagens coinci-dentes, e que os objetos enquadrados nas regiões onde serão definidos os blocos sejamestáticos e rígidos.
É um algoritmo que foi concebido de forma a equilibrar a qualidade de resposta como tempo de processamento, e para tanto leva em consideração somente determinadas re-giões da imagem, segundo critérios geográficos bem como de características da imagem,e realiza a busca da posição ideal dentro de uma janela limitada, reduzindo assim o custocomputacional da tarefa, e consequentemente diminuindo o tempo de processamento.
3.1 Definição
A estrutura do algoritmo pode ser vista através do seu diagrama de fluxo, que é mos-trado na figura 1.
Inicialmente, o algoritmo recebe dois quadros consecutivos, o quadro de referência eo quadro atual, respectivamente. Devem-se definir n pontos, para que, baseados nesses,o algoritmo possa decidir uma transformação linear a ser aplicada ao quadro atual, paraque esse corresponda ao bloco de referência.
Agora, para cada um dos pontos definidos anteriormente, deve-se localizar o seu cor-respondente no quadro de referência, e denomina-se vetor de movimento local a diferençaentre as posições do ponto no quadro atual e no quadro de referência.
De posse dos vetores locais de movimento, deve-se encontrar o vetor de movimentoglobal a ser aplicado ao quadro atual.
Considerando as coordenadas (Xc, Yc) como sendo a coordenada de um ponto doquadro corrente correspondente ponto (Xr, Yr) do quadro de referência, pode-se modelaruma transformação linear, como proposto em (MORIMOTO; CHELLAPPA, 1996), quepermita rotação θ, uma escala S e um deslocamento (∆X, ∆Y ) da seguinte forma:
[Xc
Yc
]= S
[cos θ − sin θsin θ cos θ
] [Xr
Yr
]+
[∆X∆Y
]
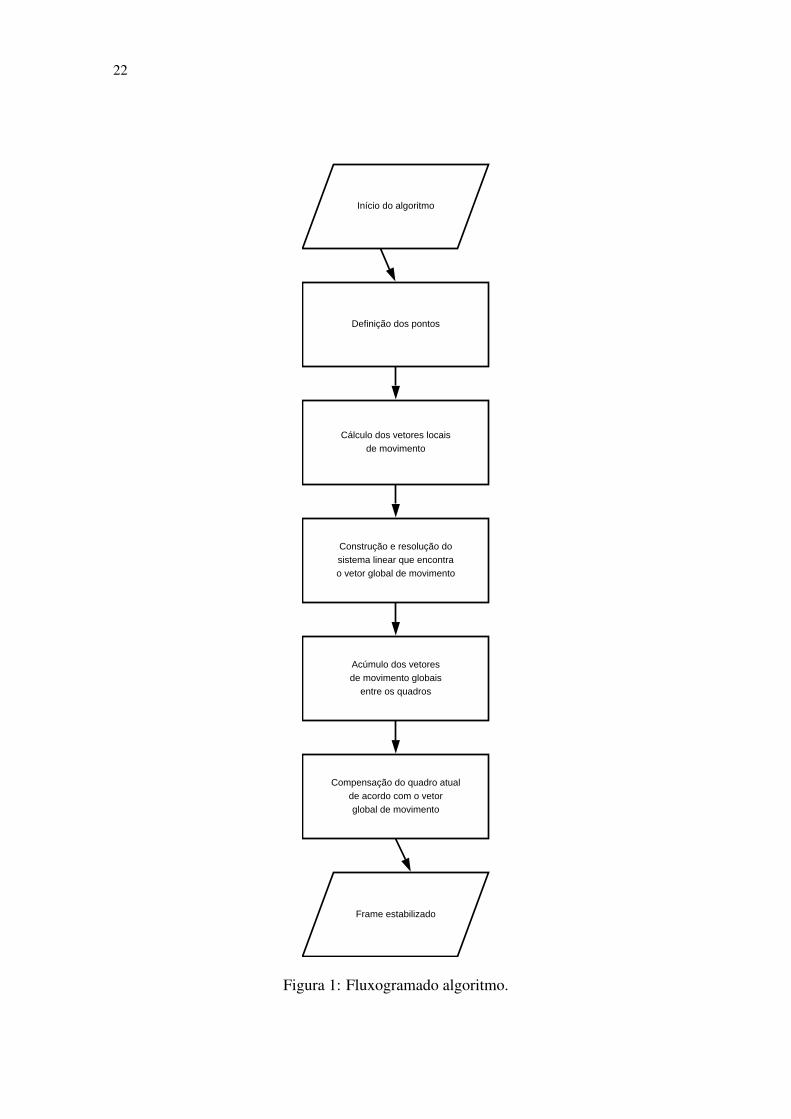
22
Início do algoritmo
Definição dos pontos
Cálculo dos vetores locaisde movimento
Construção e resolução dosistema linear que encontrao vetor global de movimento
Acúmulo dos vetoresde movimento globais
entre os quadros
Compensação do quadro atualde acordo com o vetorglobal de movimento
Frame estabilizado
Figura 1: Fluxogramado algoritmo.

23
Transformando-se as variáveis, onde
a = S. sin θ
b = S. cos θ
c = ∆X
d = ∆Y
Obtém-se: [Xc
Yc
]=
[a −bb a
] [Xr
Yr
]+
[cd
]
O que implica em:
a.Xr − b.Yr + c−Xc = 0
b.Xr + a.Yr + d− Yc = 0
Logo, para n vetores de movimento, chega-se ao seguinte sistema:
Xr1 −Yr1 1 0...
......
...Xrn −Yrn 1 0Yr1 Xr1 0 1
......
......
Yrn Xrn 0 1
abcd
=
Xc1...
Xcn
Yc1...
Ycn
Como se pode observar, para um n maior do que dois, o sistema pode não ter umasolução definida, por ter mais equações do que variáveis. Para contornar isso, procura-sea solução que minimize a soma dos quadrados das diferenças entre os valores calculadose os reais.
Tem-se um vetor genérico (Xri, Yri) que equivale à (Xci, Yci). Logo, busca-se o mí-nimo de:
S =n∑
i=1
[(Xci_calc −Xci)
2 + (Yci_calc − Yci)2]
S =n∑
i=1
[(a.Xri − b.Yri + c−Xci)
2 + (a.Yri + b.Xri + d− Yci)2]
Como se deve minimizar a equação acima, e como todas as quatro variáveis em ques-tão (a, b, c, d) têm ordem dois com coeficiente positivo, o mínimo está exatamente ondetodas as derivadas são iguais à zero, ou seja:
∂S
∂a= 0
∂S
∂b= 0
∂S
∂c= 0
∂S
∂d= 0

24
Derivando:
∂S
∂a=
n∑i=1
[2 (a.Xri − b.Yri + c−Xci) Xri + 2 (a.Yri + b.Xri + d− Yci) Yri]
=n∑
i=1
[(2X2
ri + 2Y 2ri
)a + 2.c.Xri + 2.d.Yri − 2XriXci − 2YriYci
]
∂S
∂b=
n∑i=1
[−2 (a.Xri − b.Yri + c−Xci) Yri + 2 (a.Yri + b.Xri + d− Yci) Xri]
=n∑
i=1
[(2X2
ri + 2Y 2ri
)b− 2.c.Yri + 2.d.Xri + 2YriXci − 2XriYci
]
∂S
∂c=
n∑i=1
[2 (a.Xri − b.Yri + c−Xci)]
∂S
∂d=
n∑i=1
[2 (a.Yri + b.Xri + d− Yci)]
De onde se obtém o sistema:
n∑i=1
X2ri + Y 2
ri 0 Xri Yri
0 X2ri + Y 2
ri −Yri Xri
Xri −Yri 1 0Yri Xri 0 1
abcd
=
n∑i=1
XriXci + YriYci
XriYci − YriXci
Xci
Yci
Logo, após a resolução do sistema, tem-se o vetor global de movimento, definido pelovetor (a, b, c, d), e a partir dele se pode fazer com que o quadro atual corresponda aoquadro de referência.
Todavia, para todas as iterações sucessivas devem-se levar em conta o movimento acu-mulado pelos quadros anteriores. Precisa-se, então, acumular o movimento dos quadrosanteriores. Sejam (X0, Y0), (X1, Y1) e (X2, Y2) as coordenadas de um mesmo ponto nosquadros 0, 1 e 2 sucessivamente.
[X1
Y1
]=
[a′ −b′
b′ a′
] [X0
Y0
]+
[c′
d′
]
[X2
Y2
]=
[a′′ −b′′
b′′ a′′
] [X1
Y1
]+
[c′′
d′′
]
⇒[
X2
Y2
]=
[a′′ −b′′
b′′ a′′
]([a′ −b′
b′ a′
] [X0
Y0
]+
[c′
d′
])+
[c′′
d′′
]
⇒[
X2
Y2
]=
[a′a′′ − b′b′′ −a′′b′ − a′b′′
a′b′′ + a′′b′ a′a′′ − b′b′′
] [X0
Y0
]+
[a′′c′ − b′′d′ + c′′
b′′c′ + a′′d′ + d′′
]

25
Logo, devem-se acumular os fatores usando o seguinte critério:
aacc = a′a′′ − b′b′′
bacc = a′b′′ + a′′b′
cacc = a′′c′ − b′′d′ + c′′
dacc = b′′c′ + a′′d′ + d′′
O valor do vetor de movimento global (a, b, c, d) no início da execução do algoritmodeve ser (1, 0, 0, 0).
Finalmente, utilizando estes fatores, pode-se correlacionar cada pixel do quadro es-tabilizado com o quadro corrente simplesmente realizando o inverso da transformaçãolinear, ou seja, para cada ponto (Xci, Yci) se encontra a coordenada correspondente por:
Xri =−bd− ca + b.Yci + a.Xci
a2 + b2
Yri =bc− ad + a.Yci − b.Xci
a2 + b2
3.2 Implementação
A implementação foi feita em linguagem C++, da maneira mais parametrizada possí-vel, permitindo assim que com o mesmo algoritmo se possam obter diversos resultadoscom variados tempos de processamento, possibilitando uma maior liberdade na escolhado hardware. A sua modularidade visa também promover a evolução do projeto, já quefacilita uma posterior modificação de uma determinada função dentro do algoritmo.
O fluxograma da implementação do algoritmo é ilustrado na figura 2O algoritmo recebe dois quadros, o primeiro chamado de quadro de referência e o
imediatamente posterior a esse chamado de quadro atual. Inicialmente, o quadro atualé dividido em diversos blocos, segundo os parâmetros definidos em libstab.h, comoilustra a figura 3.
Os parâmetros em questão são:
xRes e yRes: indica a resolução dos quadros [pixels];
xBlockSize e yBlockSize: indica as dimensões de cada bloco [pixels];
xThickness e yThickness: indica o numero de linhas/colunas de blocos [blocos];
xTolerance e yTolerance: indica a área a ser deixada de fora [pixels];
Os blocos são organizados sempre nas extremidades da imagem para evitar o seu cen-tro, pois normalmente é lá onde se encontra o objeto em foco, que por sua vez apresentamovimentos alheios aos movimentos da câmera. Logo, tenta-se atingir áreas onde a únicamovimentação presente entre os quadros seja o da câmera. Porém, devem-se evitar blocosmuito próximos às bordas, pois se corre o risco de que a imagem do bloco não esteja maispresente no quadro atual.
Conforme (OKUDA et al., 2006) e (OKUDA et al., 2003), utilizando-se apenas al-guns blocos dentre os descritos anteriormente, obtém-se um resultado muito semelhante,porém de processamento muito mais rápido. Deve-se então escolher quais serão os blocosrealmente utilizados. Para se obter um parâmetro de escolha é feita uma filtragem do tipo

26
Chamada da rotinastabilizeFrame
Filtragem passa altasdo quadro atual
Definição dos blocose cálculo dos índices de freqüência
Ordenamento decrescentedos blocos de acordo comos índices de freqüência
Cálculo dos vetores locaisde movimento
Construção e resolução dosistema linear que encontrao vetor global de movimento
Acúmulo dos vetoresde movimento globais
entre os quadros
Interpolação doquadro atual
Compensação do quadro atualde acordo com o vetorglobal de movimento
Frame estabilizado
Figura 2: Fluxograma da implementação do algoritmo.

27
xRes
xTolerance xThickness
xBlockSize
yRes
yTolerance
yThickness
yBlockSize
Figura 3: Alguns dos parâmetros modificáveis.
passa alta no quadro atual, fazendo a convolução pixel a pixel da imagem com a matriz aseguir:
Filtro =
−1 −1 −1 −1 −1−1 −1 −1 −1 −1−1 −1 24 −1 −1−1 −1 −1 −1 −1−1 −1 −1 −1 −1
O valor da convolução de cada pixel é armazenado no mapa de freqüência criado, noseu valor absoluto e truncado em 255. Observando a matriz de filtragem, percebe-se queo resultado da convolução é tanto maior quanto for a diferença do pixel em questão comrelação os pixels vizinhos, o que confirma a idéia de um filtro passa alta.
Tendo o mapa de freqüência do quadro, computa-se a soma dos pixels dentro de cadabloco definido anteriormente, de forma com que se tenha um valor indicativo de compo-nentes de alta freqüência no bloco: o índice de freqüência. Em seguida, os blocos sãoordenados de forma decrescente de acordo com o índice de freqüência. Os blocos em queo índice é mais alto são os utilizados, pois é menos provável que destes se resulte um vetorde movimento falso. Imaginando, por exemplo, um bloco que corresponda a uma paredelisa, é fácil compreender que a probabilidade de erros no caso de baixas freqüências émais alta.
A próxima etapa é calcular os vetores locais de movimento dos blocos que possuemíndices de freqüência mais elevados. O número de blocos é definido em libstab.h,pela variável nbrChosenBlocks.
Cada bloco é considerado como um ponto, logo, o seu vetor de movimento é compostoapenas de um deslocamento espacial. Para decidir o vetor local de deslocamento, é feitauma varredura do bloco dentro da janela de busca, e opta-se pelo deslocamento que gera

28
a menor soma dos quadrados das diferenças entre os pixels do bloco do quadro originalcom relação ao quadro de referência.
xWindowSize
yWindowSize
Figura 4: Parâmetros de definição da janela de busca.
O tamanho da janela de busca é definido pelas variáveis xWindowSize e yWindowSizeem libstab.h, como ilustra a figura 4. É a janela de busca quem limita o deslocamentopontual máximo que o programa será capaz de reconhecer.
Neste ponto, temos uma lista de vetores de deslocamento locais. Com base nissodeve-se encontrar uma transformação linear que permita estabilizar o quadro corrente deacordo com esses vetores locais, ou seja, encontrar um vetor global de movimento, comoporposto em (VELLA et al., 2002). Para tanto, basta construir e resolver o sistema lineardescrito na seção anterior:
n∑i=1
X2ri + Y 2
ri 0 Xri Yri
0 X2ri + Y 2
ri −Yri Xri
Xri −Yri 1 0Yri Xri 0 1
abcd
=
n∑i=1
XriXci + YriYci
XriYci − YriXci
Xci
Yci
De posse do vetor global, deve-se atualizar o vetor global de movimento acumulado,conforme rege o algoritmo:
aacc = a′a′′ − b′b′′
bacc = a′b′′ + a′′b′
cacc = a′′c′ − b′′d′ + c′′
dacc = b′′c′ + a′′d′ + d′′
Finalmente, pode-se correlacionar cada pixel do quadro estabilizado com o quadrocorrente da seguinte forma:
Xri =−bd− ca + b.Yci + a.Xci
a2 + b2
Yri =bc− ad + a.Yci − b.Xci
a2 + b2
3.3 Filtragem dos vetores globais de movimento
O presente algoritmo tenta anular o movimento da câmera realizando a movimenta-ção inversa da imagem, o que resulta em uma imagem estática na tela. Fica evidente queao movermos uma imagem, as bordas que não foram filmadas acabam por ser cortadas.Dependendo da aplicação pode-se desejar que sejam filtradas somente as vibrações dacâmera, mas que o seu curso seja preservado, ou seja, uma filtragem passa baixa, comoproposto em (XU; LIN, 2006). Por exemplo, em uma seqüência de quadros em que se

29
tenha um grande curso horizontal, a imagem estabilizada vai se estreitando até que, even-tualmente, termina por desaparecer (vide figura 15). Para tentar minimizar esse efeito, foicriado um parâmetro chamado filterFactor em libstab.h.
O elemento neutro da transformação linear é:
a = 1
b = 0
c = 0
d = 0
Pois: [1 00 1
] [XY
]+
[00
]=
[XY
]
Então, para que a imagem tenda a se alinhar com a câmera, a acumulação do vetorglobal de movimento se dá por:
aacc =a′a′′ − b′b′′ + Ff − 1
Ff
bacc =a′b′′ + a′′b′
Ff
cacc =a′′c′ − b′′d′ + c′′
Ff
dacc =b′′c′ + a′′d′ + d′′
Ff
Onde Ff é o fator filterFactor definido em libstab.h.Para um filterFactor igual a 1 não existe filtragem nenhuma, e para um filterFactor
tendendo ao infinito, não existe estabilização nenhuma. Logo, filterFactor permiteuma solução intermediária entre a estabilização da imagem, e o ajuste entre imagem esta-bilizada com a posição de câmera.
3.4 Aperfeiçoamentos
3.4.1 Interpolação
Para melhorar a precisão na transformação de imagem, no momento da aplicação datransformação linear encontrada, foi utilizado um processo de interpolação de imagem,no qual se obtém uma imagem duas vezes mais larga e duas vezes mais alta, fazendo comque se possa virtualmente ter uma resolução de meio pixel. Os novos pixels criados sãocalculados pela média dos pixels que os cercam, como mostra a figura 5.
papa+pb
2pb
pa+pc
2pa+pb+pc+pd
2pb+pd
2
pcpc+pd
2pd
Figura 5: Cálculo dos pixels na interpolação.

30
3.4.2 Paralelização de código
Para que um hardware possa executar um código mais rapidamente pode-se optar poralgumas modificações, como por exemplo, trocar um processador por um de freqüênciamais alta, por um de arquitetura diferente, ou ainda recorrer ao multiprocessamento.
O código implementado neste trabalho foi escrito voltado à última opção, multipro-cessamento. O programa foi desenvolvido de forma que seja possível escolher o númerode threads concorrentes que realizarão as partes mais críticas do processo:
• Filtragem passa-altas da imagem;
• Cálculos dos índices de freqüência;
• Cálculos dos vetores individuais de movimento;
• Interpolação;
• Transformação linear.
Dos quais, o mais significativo é, sem dúvidas, o cálculo de vetores individuais demovimento.
O algoritmo poderia ter sido mais facilmente paralelizado simplesmente chamando afunção de estabilização para vários quadros ao mesmo tempo, porém esse método pecariapor consumir memória proporcionalmente ao número de threads em execução. Com asolução proposta, a tarefa é dividida entre as threads em execução, que trabalham sempresobre o mesmo conjunto de variáveis em memória.
A escolha do número de threads concorrentes é feita através da variável maxThreadsem libstab.h.

31
4 RESULTADOS EXPERIMENTAIS
4.1 Execução passo a passo da implementação
Para melhor ilustrar o processo, o passo a passo da execução do algoritmo é descritoa seguir.
O exemplo foi executado usando os seguintes parâmetros:
xRes 640; (imagem de resolução 640x480 pixels)
yRes 480;
xBlockSize 32; (blocos de 32x32 pixels)
yBlockSize 32;
xWindowSize 30; (janela de busca de ±30x±30 pixels)
yWindowSize 30;
xTolerance 40; (bordas horizontais ignoradas de tamanho 40 pixels)
yTolerance 40; (bordas verticais ignoradas de tamanho 40 pixels)
xThickness 3; (3 linhas de blocos)
yThickness 3; (3 colunas de blocos)
nbrChosenBlocks 16; (16 blocos escolhidos)

32
O algoritmo é executado aqui com apenas dois quadros (figura 6).
(a) Quadro de referência. (b) Quadro atual.
Figura 6: Quadros originais antes da execução do programa.
Inicialmente, o quadro de referência é dividido nos diversos blocos (figura 7).
Figura 7: Quadro de referência dividido.

33
Para que se possam escolher quais serão os blocos que resultarão em vetores de mo-vimento mais eficientes, o quadro de referência passa por um filtro passa alta (figura 8).
Figura 8: Mapa de filtragem passa-altas do quadro de referência.
Nesse ponto o programa escolhe os blocos mais significativos segundo o índice defreqüência de cada bloco (figura 9).
Figura 9: Quadro de referência com os blocos escolhidos para os vetores de movimentolocais.

34
Agora o programa encontra os vetores locais de deslocamento para cada bloco esco-lhido. Como cada bloco é considerado pontual o vetor de movimento é constituído apenasde um deslocamento, sem rotação ou escala. Os vetores individuais podem ser vistos natabela 1.
Tabela 1: Vetores de movimento locais calculados.Coordenadas do bloco Vetor de movimento local
(X,Y ) (∆X, ∆Y )(201, 329) (−19,−3)(233, 329) (−19, 2)(329, 329) (−19, 14)(137, 105) (10,−13)(41, 329) (−22,−24)(41, 297) (−17,−24)(201, 393) (−27,−3)(73, 329) (−21,−20)(41, 265) (−13,−24)(105, 329) (−21,−16)(201, 361) (−23,−2)(137, 361) (−2,−16)(233, 361) (−24, 2)(169, 329) (−20,−6)(169, 361) (−23,−6)(265, 361) (−23, 6)
De posse dos vetores locais de movimento, o programa monta o sistema linear a serresolvido para encontrar o vetor global de movimento deste quadro.
2, 2575× 106 0 2576 51680 2, 2575× 106 −5168 2576
2576 −5168 16 05168 2576 0 16
abcd
=
2, 16998× 106
9216622935035
Resolvendo, encontra-se o vetor global de movimento:
(S cos θ, S sin θ, ∆X, ∆Y ) = (1, 00578; 0, 127778; 22, 655;−30, 7501)
⇒ (S, θ, ∆X, ∆Y ) = (1, 013864205; 7, 240280414◦; 22, 655;−30, 7501)

35
Antes de realizar as transformações lineares na imagem, a resolução da imagem éaumentada por interpolação de forma a poder nos referir aos pixels com uma precisão demeio pixel. Pode-se ver em detalhe na figura 10.
(a) Zoom no quadro atual original (640x480) (b) Zoom no quadro atual interpolado (1280x960)
Figura 10: Detalhe da interpolação.
E finalmente, uma vez com a imagem interpolada e com o vetor global de movimento,pode-se transformar o quadro atual de forma com que ele corresponda ao quadro de refe-rência (figura 11).
Figura 11: Quadro atual corrigido.

36
Enfim, os quadros estão estabilizados (figura 12).
Figura 12: Sequência estabilizada.
4.2 Resultados utilizando o robô Janus
Janus é um robô antropomórfico, dotado de dois braços com oito articulações cada, ede uma cabeça com duas articulações e duas câmeras CCD SONY coloridas, que por suavez são ligadas à duas placas de captura de víideo BT878 (figura 13).
Figura 13: Robô Janus.
A captura de imagens foi implementada a partir de códigos já existentes no projeto,com as devidas modificações, e utiliza o padrão Video4Linux. O processo de capturainicia-se abrindo o dispositivo. Em seguida selecionam-se as diversas configurações, porioctl(), como o modo de vídeo, resolução, profundidade e paleta de cores. Feito isso, seordena a captura do quadro e espera que ele termine com o comando de sincronia.
Os testes mostrados nas figuras 14 e 15 foram efetuados utilizando apenas uma dassuas câmeras, uma vez que o algoritmo prevê visão mono, em sistema PAL, em escala decinza, a uma resolução de 320 por 240 pixels cada quadro.

37
Figura 14: Quadros adquiridos pelas câmeras do Janus.

38
Figura 15: Quadros adquiridos pelas câmeras do Janus estabilizados.

39
5 ANÁLISE DE DESEMPENHO
A análise aqui presente serve como base para que se possa compreender o peso emprocessamento que cada parâmetro escolhido em libstab.h causa na execução doprograma. Ou seja, mais importante que o valor absoluto de taxa de quadros é a suarelação variando-se os diversos parâmetros. Também se poderá observar os benefícioscausados pela programação voltada ao multiprocessamento.
Os testes a seguir foram executados em um micro-computador utilizando um pro-cessador Intel Centrino Duo T2300 @ 1.66 GHz, com 1GB de memória RAM, e umaseqüência de 50 quadros de resolução igual a 640 por 480 pixels.
A primeira seqüência foi executada em apenas uma linha de execução, ou seja, mo-nothread (tabela 2 e figuras 16 e 17).
Tabela 2: Análise de desempenho monothread.Tamanho Tamanho Blocos Tempo de Taxa dede bloco de janela escolhidos execução quadros[pixels] [pixels] [] [segundos] [quadros por segundo]
16 20 16 5,77 8,6716 20 32 6,81 7,3416 30 16 7,02 7,1216 30 32 9,31 5,3716 40 16 9,19 5,4416 40 32 12,77 3,9124 20 16 7,23 6,9224 20 32 9,74 5,1324 30 16 10,69 4,6824 30 32 15,75 3,1824 40 16 14,41 3,4724 40 32 24,15 2,0732 20 16 9,34 5,3532 20 32 13,42 3,7232 30 16 14,32 3,4932 30 32 23,95 2,0932 40 16 21,61 2,3132 40 32 38,58 1,30

40
Figura 16: Tamanho de bloco versus taxa de quadros em execução monothread.
Figura 17: Tamanho de janela de busca versus taxa de quadros em execução monothread.

41
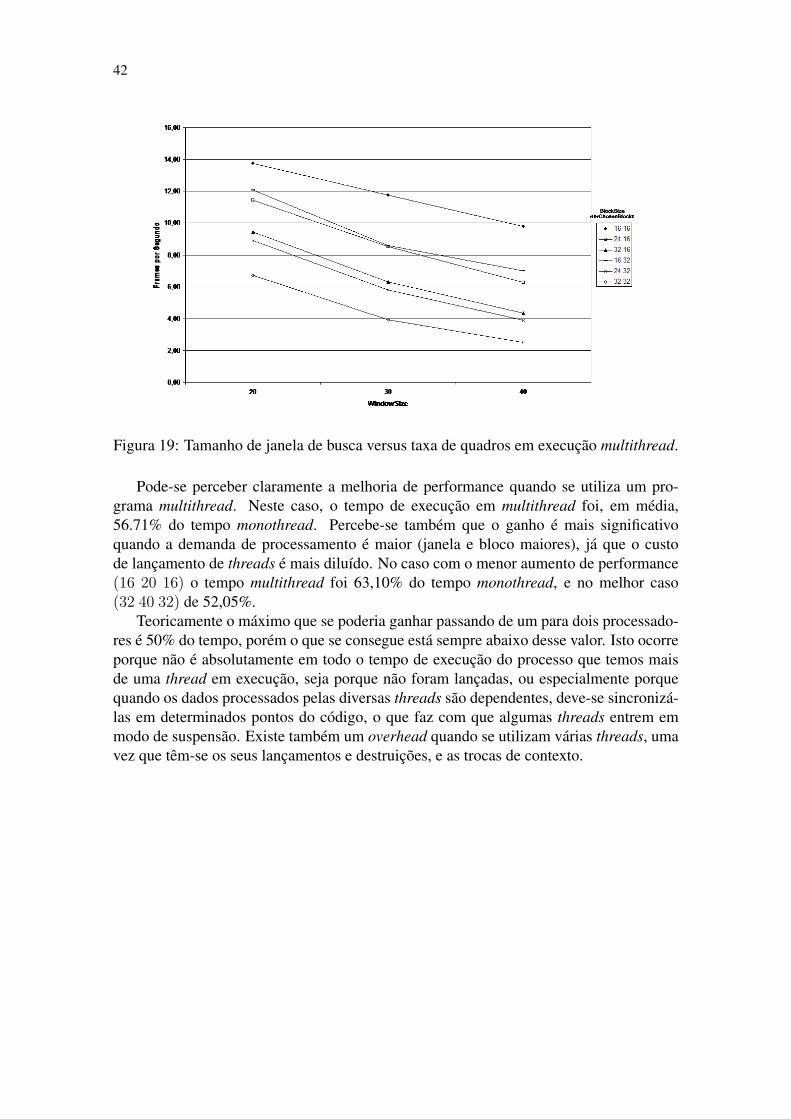
E em seguida os dados obtidos com a execução do mesmo conjunto de dados, porémdesta vez aproveitando-se do fato de o computador possuir dois processadores, ou seja,execução multithread (tabela 3 e figuras 18 e 19).
Tabela 3: Análise de desempenho multithread.Tamanho Tamanho Blocos Tempo de Taxa dede bloco de janela escolhidos execução quadros[pixels] [pixels] [] [segundos] [quadros por segundo]
16 20 16 3,64 13,7416 20 32 4,14 12,0816 30 16 4,25 11,7716 30 32 5,82 8,6016 40 16 5,11 9,7816 40 32 7,13 7,0224 20 16 4,37 11,4524 20 32 5,62 8,9024 30 16 5,87 8,5224 30 32 8,65 5,7824 40 16 7,95 6,2924 40 32 12,83 3,9032 20 16 5,30 9,4332 20 32 7,46 6,7032 30 16 7,93 6,3132 30 32 12,73 3,9332 40 16 11,55 4,3332 40 32 20,08 2,49
Figura 18: Tamanho de bloco versus taxa de quadros em execução multithread.
42
Figura 19: Tamanho de janela de busca versus taxa de quadros em execução multithread.
Pode-se perceber claramente a melhoria de performance quando se utiliza um pro-grama multithread. Neste caso, o tempo de execução em multithread foi, em média,56.71% do tempo monothread. Percebe-se também que o ganho é mais significativoquando a demanda de processamento é maior (janela e bloco maiores), já que o custode lançamento de threads é mais diluído. No caso com o menor aumento de performance(16 20 16) o tempo multithread foi 63,10% do tempo monothread, e no melhor caso(32 40 32) de 52,05%.
Teoricamente o máximo que se poderia ganhar passando de um para dois processado-res é 50% do tempo, porém o que se consegue está sempre abaixo desse valor. Isto ocorreporque não é absolutamente em todo o tempo de execução do processo que temos maisde uma thread em execução, seja porque não foram lançadas, ou especialmente porquequando os dados processados pelas diversas threads são dependentes, deve-se sincronizá-las em determinados pontos do código, o que faz com que algumas threads entrem emmodo de suspensão. Existe também um overhead quando se utilizam várias threads, umavez que têm-se os seus lançamentos e destruições, e as trocas de contexto.

43
6 CONCLUSÃO
Existem muitas variantes de como implementar uma forma de estabilização de ima-gem, bem como variados conceitos sobre o assunto. Este trabalho foi centrado apenasuma, que ainda assim foi concebida da forma mais customizável possível, para que possaser útil a diversos cenários.
Alguns pontos na implementação do algoritmo poderiam ainda sofrer alguns ajustes.Para obter melhores resultados: instituir uma política de zonas dentro da imagem, paragarantir que os blocos sejam escolhidos de maneira distribuída dentro do quadro. Paraa validação dos blocos escolhidos: eliminar os vetores locais de movimento falsos queeventualmente existam, utilizando métodos de estatística, por exemplo. E para a melhoriade desempenho: modificar a implementação para que se utilizem alguns conjuntos deinstruções estendidos SIMD (single instruction multiple data), como o MMX, 3DNow!,SSE, etc.
Pode-se perceber claramente que os resultados e o desempenho estão intimamenteligados, logo, deve-se estabelecer um contrato levando em conta os objetivos e o po-der de processamento disponível. É notável também que o ganho de desempenho pormultiprocessamento para esta tarefa é significativo, pois existem inúmeros cálculos nãorelacionados a serem efetuados, o que favorece o paralelismo.
Vale ressaltar também que muitas das funções aqui implementadas para a estabili-zação de imagens são de utilização ampla, podendo facilmente ser reaproveitadas comoutros fins. Por exemplo, sem muitas modificações de código pode-se implementar umrastreador de objetos, ou ainda um montador de fotos para somar fotografias e criar umaimagem panorâmica, visto que os processos são fortemente relacionados.
Enfim, foi abordada neste documento uma fração do que pode ser feito na área deprocessamento de imagens, algumas aplicações e alguns métodos de otimização.

44

45
REFERÊNCIAS
MORIMOTO, C.; CHELLAPPA, R. Fast Electronic Digital Image Stabilization. IEEE,[S.l.], 1996.
OKUDA, H.; HASHIMOTO, M.; SUMI, K.; KANEKO, S. Optimum Motion Estima-tion Algorithm for Fast and Robust Digital Image Stabilization. IEEE Transactions onConsumer Electronics, [S.l.], v.52, n.1, Feb. 2006.
OKUDA, H.; HASHIMOTO, M.; SUMI, K.; SASAKI, K. Optimum Selection Algorithmof Motion Estimation Blocks for Fast and Robust Digital Image Stabilization. IEEE,[S.l.], 2003.
VELLA, F.; CASTORINA, A.; MANCUSO, M.; MESSINA, G. Robust Digital ImageStabilization Algorithm Using Block Motion Vectors. IEEE, [S.l.], 2002.
XU, L.; LIN, X. Digital Image Stabilization Based on Circular Block Matching. IEEETransactions on Consumer Electronics, [S.l.], v.52, n.2, May 2006.

46

47
APÊNDICE A CÓDIGO DA IMPLEMENTAÇÃO DO ALGO-RITMO
A.1 libstab.h
Segue o código do arquivo header, onde são configurados todos os parâmetros doalgoritmo.
#ifndef LIBSTAB_H_#define LIBSTAB_H_
#define xRes 640#define yRes 480#define xBlockSize 32#define yBlockSize 32#define xWindowSize 40#define yWindowSize 40#define xTolerance 40 // >= xWindowSize#define yTolerance 40 // >= yWindowSize#define xThickness 3#define yThickness 3#define nbrChosenBlocks 32 // >= 2#define filterFactor 1#define maxThreads 2 // ideal = nro de processadores#define imageType 0 // 0 = BMP, 1 = PNM
#define xNbrBlocks (int)((xRes-2*xTolerance)/xBlockSize)#define yNbrBlocks (int)((yRes-2*yTolerance)/yBlockSize)#define nbrBlocks xNbrBlocks*2*xThickness + yNbrBlocks*2*yThickness - 4*xThickness*yThickness#define size_header (imageType == 0) ? 1078 /*BMP*/: ((imageType == 1) ? 15 /*PNG*/: 0)#define size_image xRes * yRes
void stabilizeFrame(unsigned char *, unsigned char *, unsigned char *, double *);
#endif /*LIBSTAB_H_*/
A.2 libstab.cpp
Segue o código da biblioteca, onde estão implementadas as diversas funções.
#include <iostream>#include <pthread.h>
using namespace std;#include "libstab.h"
struct me_block {// estrutura para identificar um bloco de pixels// que inicia em xyCorner de tamanho xyBlockSize// xyShift sera o vetor de movimento do bloco

48
int xCorner, yCorner, count, xShift, yShift;};
// estruturas thr_t_* sao para a passagem de parametros// para as threads thr_f_*
struct thr_t_motVector {unsigned char * ref_image;unsigned char * cur_image;me_block * block;int thr_id;
};
struct thr_t_hpFilter {unsigned char * original;unsigned char * filtered;int thr_id;
};
struct thr_t_initBlocks {me_block * blocks;unsigned char * filtered_image;int thr_id;int * count;pthread_mutex_t * mutex1;
};
struct thr_t_interpolate {unsigned char * orig_image;unsigned char * doub_image;int thr_id;pthread_mutex_t * mutex1;pthread_mutex_t * mutex2;pthread_cond_t * cond1;int * count;
};
struct thr_t_compensateImage {unsigned char * doub_image;unsigned char * comp_image;double * x_mat;int thr_id;
};
int pixToInt (int xPix, int yPix, int xResol, int yResol) {// converte uma coordenada xy em uma posicao do array de char// de (1, 1) até (xRes, yRes)
if (imageType == 1)return (yPix - 1) * xResol + xPix - 1; // pnm
elsereturn (yResol - yPix) * xResol + xPix - 1; // bmp
};
unsigned char sumFilter ( unsigned char * image, int matrix [5][5], int xPos, int yPos) {// realiza a convolucao do filro para um pixel
int sum = 0;char ret;
for (int i = -2; i <= 2; i++)for (int j = -2; j <= 2; j++)
if ((xPos + i >= 1)&&(xPos + i <= xRes)&&(yPos + j >= 1)&&(yPos + j <= yRes))sum += matrix[i+2][j+2] * image[pixToInt(xPos + i, yPos + j, xRes, yRes)];
sum = min(abs(sum),255);
ret = (unsigned char) sum;return ret;
}

49
void * thr_f_hpFilter (void * params_void) {// filtra uma imagem fazendo a convolucao de uma matriz// com os pixels de uma imagem
thr_t_hpFilter * params;params = (thr_t_hpFilter *) params_void;
int filter_matrix[5][5] = {{-1, -1, -1, -1, -1},{-1, -1, -1, -1, -1},{-1, -1, 24, -1, -1},{-1, -1, -1, -1, -1},{-1, -1, -1, -1, -1}
};
for (int i = params->thr_id+1; i <= xRes; i = i + maxThreads)for (int j = 1; j <= yRes; j++)
params->filtered[pixToInt(i, j, xRes, yRes)] =(char) sumFilter(params->original, filter_matrix, i, j);
return NULL;
}
int squares (unsigned char * ref_image, unsigned char * cur_image, int xStart, int yStart,int xShift, int yShift) {// faz a soma dos quadrados das diferencas entre os pixels// de dois blocos de imagens
int sum;int sub;sum = 0;
// i e j definem o tamanho do blocofor ( int i = 0; i < xBlockSize; i++ ) {
for ( int j = 0; j < yBlockSize; j++ ) {sub = cur_image[pixToInt(xStart + xShift + i, yStart + yShift + j, xRes,
yRes)] - ref_image[pixToInt(xStart + i, yStart + j, xRes, yRes)];sum += sub*sub;
}}
return sum;
}
void * thr_f_motVector (void * params_void) {// encontra o vetor de movimento de um bloco, encontrando// o deslocamento que resulta no minimo das somas dos// quadrados das diferencas
thr_t_motVector * params;params = (thr_t_motVector *) params_void;
for (int k = params->thr_id; k < nbrChosenBlocks; k = k + maxThreads) {int minDif;int curDif;params->block[k].xShift = 0;params->block[k].yShift = 0;minDif = 100000000;
// i e j definem a janela de buscafor ( int i = -1*xWindowSize; i <= xWindowSize; i++ ) {
for ( int j = -1*yWindowSize; j <= yWindowSize; j++ ) {curDif = squares(params->ref_image, params->cur_image,
params->block[k].xCorner, params->block[k].yCorner, i, j);if (curDif < minDif) {
minDif = curDif;params->block[k].xShift = -i;params->block[k].yShift = -j;
}}

50
}}
return NULL;
}
int blockSum ( unsigned char * image, int xPos, int yPos) {// faz a soma dos pixels de um bloco
int sum = 0;
for (int i = 0; i < xBlockSize; i++)for (int j = 0; j < yBlockSize; j++)
sum += image[pixToInt(xPos + i, yPos + j, xRes, yRes)];
return sum;
}
void sortBlocks (me_block * blocks, int begin, int end) {// ordena os blocos de acordo com um indicador// de alta frequencia de uma imagem
if (end - begin > 1) {me_block pivot = blocks[begin];int l = begin + 1;int r = end;while(l < r) {
if (blocks[l].count >= pivot.count) {l++;
} else {r--;swap(blocks[l], blocks[r]);
}}l--;swap(blocks[begin], blocks[l]);sortBlocks(blocks, begin, l);sortBlocks(blocks, r, end);
}}
void * thr_f_initBlocks (void * params_void) {// constroi um array de blocos, inicializa suas coordenadas,// e cria um indice de alta frequencia
thr_t_initBlocks * params;params = (thr_t_initBlocks *) params_void;int localCount;
for (int i = params->thr_id; i < xNbrBlocks; i = i + maxThreads)for (int j = 0; j < yNbrBlocks; j++)
if (!((i > xThickness-1)&&(i < xNbrBlocks-xThickness)&&(j > yThickness-1)&&(j < yNbrBlocks-yThickness))) { // se bloco valido
pthread_mutex_lock(params->mutex1);
*(params->count) = *(params->count) + 1;localCount = *(params->count);pthread_mutex_unlock(params->mutex1);
params->blocks[localCount].xCorner = i * xBlockSize + xTolerance + 1;params->blocks[localCount].yCorner = j * yBlockSize + yTolerance + 1;params->blocks[localCount].count = blockSum(params->filtered_image,
params->blocks[localCount].xCorner,params->blocks[localCount].yCorner);
}
return NULL;}
void solveLinSystem (double a_mat[4][4], double * x_mat, double b_mat[4]) {// resolve um sistema 4x4

51
// 1ra colunadouble fact;fact = a_mat[1][0] / a_mat[0][0];b_mat[1] -= b_mat[0] * fact;a_mat[1][3] -= a_mat[0][3] * fact;a_mat[1][2] -= a_mat[0][2] * fact;a_mat[1][1] -= a_mat[0][1] * fact;a_mat[1][0] = 0;fact = a_mat[2][0] / a_mat[0][0];b_mat[2] -= b_mat[0] * fact;a_mat[2][3] -= a_mat[0][3] * fact;a_mat[2][2] -= a_mat[0][2] * fact;a_mat[2][1] -= a_mat[0][1] * fact;a_mat[2][0] = 0;fact = a_mat[3][0] / a_mat[0][0];b_mat[3] -= b_mat[0] * fact;a_mat[3][3] -= a_mat[0][3] * fact;a_mat[3][2] -= a_mat[0][2] * fact;a_mat[3][1] -= a_mat[0][1] * fact;a_mat[3][0] = 0;
// 2da colunafact = a_mat[2][1] / a_mat[1][1];b_mat[2] -= b_mat[1] * fact;a_mat[2][3] -= a_mat[1][3] * fact;a_mat[2][2] -= a_mat[1][2] * fact;a_mat[2][1] = 0;fact = a_mat[3][1] / a_mat[1][1];b_mat[3] -= b_mat[1] * fact;a_mat[3][3] -= a_mat[1][3] * fact;a_mat[3][2] -= a_mat[1][2] * fact;a_mat[3][1] = 0;
// 3a colunafact = a_mat[3][2] / a_mat[2][2];b_mat[3] -= b_mat[2] * fact;a_mat[3][3] -= a_mat[2][3] * fact;a_mat[3][2] = 0;
// solucao:x_mat[3] = b_mat[3] / a_mat[3][3];x_mat[2] = (b_mat[2] - x_mat[3]*a_mat[2][3]) / a_mat[2][2];x_mat[1] = (b_mat[1] - x_mat[2]*a_mat[1][2] - x_mat[3]*a_mat[1][3]) / a_mat[1][1];x_mat[0] = (b_mat[0] - x_mat[1]*a_mat[0][1] - x_mat[2]*a_mat[0][2] -
x_mat[3]*a_mat[0][3]) / a_mat[0][0];
}
void * thr_f_interpolate (void * params_void) {// realisa a interpolacao da imagem params->orig_image// devolvendo-a em params->doub_image
thr_t_interpolate * params;params = (thr_t_interpolate *) params_void;
for (int i = params->thr_id+1; i <= xRes; i = i + maxThreads) {for (int j = 1; j <= yRes; j ++)
params->doub_image[pixToInt(2*i-1, 2*j-1, 2*xRes, 2*yRes)] =params->orig_image[pixToInt(i, j, xRes, yRes)];
for (int j = 1; j < yRes; j ++)params->doub_image[pixToInt(2*i-1, 2*j, 2*xRes, 2*yRes)] =
(params->doub_image[pixToInt(2*i-1, 2*j-1, 2*xRes, 2*yRes)] +params->doub_image[pixToInt(2*i-1, 2*j+1, 2*xRes, 2*yRes)]) / 2;
params->doub_image[pixToInt(2*i-1, 2*yRes, 2*xRes, 2*yRes)] =params->doub_image[pixToInt(2*i-1, 2*yRes-1, 2*xRes, 2*yRes)];
};
// espera todas as threads acabarem a primeira parte da interpolacaopthread_mutex_lock(params->mutex1);
*(params->count) = *(params->count) + 1;pthread_mutex_unlock(params->mutex1);

52
pthread_mutex_lock(params->mutex2);if (*(params->count) < maxThreads) {
pthread_cond_wait(params->cond1, params->mutex2);} else {
pthread_cond_broadcast(params->cond1);}pthread_mutex_unlock(params->mutex2);
for (int i = params->thr_id+1; i < xRes; i = i + maxThreads)for (int j = 1; j <= 2*yRes; j ++)
params->doub_image[pixToInt(2*i, j, 2*xRes, 2*yRes)] =(params->doub_image[pixToInt(2*i-1, j, 2*xRes, 2*yRes)] +params->doub_image[pixToInt(2*i+1, j, 2*xRes, 2*yRes)]) / 2;
if ((xRes % maxThreads) == params->thr_id)for (int j = 1; j <= 2*yRes; j++)
params->doub_image[pixToInt(2*xRes, j, 2*xRes, 2*yRes)] =params->doub_image[pixToInt(2*xRes-1, j, 2*xRes, 2*yRes)];
return NULL;
}
void * thr_f_compensateImage (void * params_void) {// aplica a transformacao linear em uma imagem de acordo// com a matriz x
thr_t_compensateImage * params;params = (thr_t_compensateImage *) params_void;
double xOrig, yOrig;int x_int, y_int;
// encontra cada pixel na figura originalfor (int i = params->thr_id+1; i <= xRes; i++)
for (int j = 1; j <= yRes; j++) {xOrig = (-params->x_mat[0]*params->x_mat[2] -
params->x_mat[1]*params->x_mat[3] + params->x_mat[0]*i +params->x_mat[1]*j)/(params->x_mat[0]*params->x_mat[0] +params->x_mat[1]*params->x_mat[1]);
yOrig = (-params->x_mat[0]*params->x_mat[3] +params->x_mat[1]*params->x_mat[2] - params->x_mat[1]*i +params->x_mat[0]*j)/(params->x_mat[0]*params->x_mat[0] +params->x_mat[1]*params->x_mat[1]);
x_int = int(xOrig*2-0.5);y_int = int(yOrig*2-0.5);if ((x_int > 0) && (x_int <= 2*xRes) && (y_int > 0) && (y_int <= 2*yRes))
params->comp_image[pixToInt(i, j, xRes, yRes)] =params->doub_image[pixToInt(x_int, y_int, 2*xRes, 2*yRes)];
elseparams->comp_image[pixToInt(i, j, xRes, yRes)] = 0;
}
return NULL;
}
void acumulateMotionVectors (double * x_mat, double * x_mat_acc) {// acumula o vetor global de movimento// ao mesmo tempo que executa a filtragem
double a_acc, b_acc, c_acc, d_acc;
a_acc = x_mat_acc[0]*x_mat[0] - x_mat_acc[1]*x_mat[1];b_acc = x_mat_acc[0]*x_mat[1] + x_mat_acc[1]*x_mat[0];c_acc = x_mat_acc[2]*x_mat[0] - x_mat_acc[3]*x_mat[1] + x_mat[2];d_acc = x_mat_acc[2]*x_mat[1] + x_mat_acc[3]*x_mat[0] + x_mat[3];
// filtragem que objetiva atrair a imagem para a camerax_mat_acc[0] = (a_acc+filterFactor-1)/filterFactor;x_mat_acc[1] = b_acc/filterFactor;x_mat_acc[2] = c_acc/filterFactor;x_mat_acc[3] = d_acc/filterFactor;

53
}
void stabilizeFrame (unsigned char * ref_image, unsigned char * cur_image,unsigned char * stab_image, double * x_mat_acc) {// é a funcao usada externamente// recebe o frame de referencia, o frame corrente, o vetor// global de deslocamento e faz a transformacao linear// necesaria para que o frame corrente esteja "estabilizado"
// passa alta no frame de referenciaunsigned char * hp_image;hp_image = new unsigned char [size_image];
pthread_t thr_hpFilter[maxThreads];thr_t_hpFilter params_hpFilter[maxThreads];for (int i = 0; i < maxThreads; i++) {
params_hpFilter[i].original = ref_image;params_hpFilter[i].filtered = hp_image;params_hpFilter[i].thr_id = i;pthread_create(&thr_hpFilter[i], NULL, thr_f_hpFilter, ¶ms_hpFilter[i]);
}for (int i = 0; i < maxThreads; i++)
pthread_join(thr_hpFilter[i], NULL);
// aloca os blocosme_block * blocks;blocks = new me_block [nbrBlocks];
// inicializa os blocosint count_initBlocks = -1;pthread_mutex_t mutex1_initBlocks = PTHREAD_MUTEX_INITIALIZER;
pthread_t thr_initBlocks[maxThreads];thr_t_initBlocks params_initBlocks[maxThreads];for (int i = 0; i < maxThreads; i++) {
params_initBlocks[i].blocks = blocks;params_initBlocks[i].filtered_image = hp_image;params_initBlocks[i].thr_id = i;params_initBlocks[i].count = &count_initBlocks;params_initBlocks[i].mutex1 = &mutex1_initBlocks;pthread_create(&thr_initBlocks[i], NULL, thr_f_initBlocks, ¶ms_initBlocks[i]);
}for (int i = 0; i < maxThreads; i++)
pthread_join(thr_initBlocks[i], NULL);
// ordena os blocos de acordo com o indice de frequenciasortBlocks(blocks, 0, nbrBlocks);
// calcula os vetores locais de deslocamentopthread_t thr_motVector[maxThreads];thr_t_motVector params_motVector[maxThreads];for (int i = 0; i < maxThreads; i++) {
params_motVector[i].ref_image = ref_image;params_motVector[i].cur_image = cur_image;params_motVector[i].block = blocks;params_motVector[i].thr_id = i;pthread_create(&thr_motVector[i], NULL, thr_f_motVector, ¶ms_motVector[i]);
}for (int i = 0; i < maxThreads; i++)
pthread_join(thr_motVector[i], NULL);
// constroi o sistema linearint s_xci, s_yci, s_xri, s_yri, s_xri2, s_yri2, s_xrixci, s_yriyci, s_xriyci, s_xciyri;s_xci = 0;s_yci = 0;s_xri = 0;s_yri = 0;s_xri2 = 0;s_yri2 = 0;s_xrixci = 0;s_yriyci = 0;s_xriyci = 0;s_xciyri = 0;

54
for (int i = 0; i < nbrChosenBlocks; i++) {s_xci += (blocks[i].xCorner+xBlockSize/2) + blocks[i].xShift;s_yci += (blocks[i].yCorner+yBlockSize/2) + blocks[i].yShift;s_xri += (blocks[i].xCorner+xBlockSize/2);s_yri += (blocks[i].yCorner+yBlockSize/2);s_xri2 += (blocks[i].xCorner+xBlockSize/2) * (blocks[i].xCorner+xBlockSize/2);s_yri2 += (blocks[i].yCorner+yBlockSize/2) * (blocks[i].yCorner+yBlockSize/2);s_xrixci += (blocks[i].xCorner+xBlockSize/2) * ((blocks[i].xCorner+xBlockSize/2)
+ blocks[i].xShift);s_yriyci += (blocks[i].yCorner+yBlockSize/2) * ((blocks[i].yCorner+yBlockSize/2)
+ blocks[i].yShift);s_xriyci += (blocks[i].xCorner+xBlockSize/2) * ((blocks[i].yCorner+yBlockSize/2)
+ blocks[i].yShift);s_xciyri += (blocks[i].yCorner+yBlockSize/2) * ((blocks[i].xCorner+xBlockSize/2)
+ blocks[i].xShift);}double a_mat[4][4] = {
{s_xri2 + s_yri2, 0, s_xri, s_yri},{0, s_xri2 + s_yri2, (-1)*s_yri, s_xri},{s_xri, (-1)*s_yri, nbrChosenBlocks, 0},{s_yri, s_xri, 0, nbrChosenBlocks}
};double b_mat[4] = {
s_xrixci + s_yriyci,s_xriyci - s_xciyri,s_xci,s_yci
};
double * x_mat;x_mat = new double [4];
// resolve o sistema linearsolveLinSystem(a_mat, x_mat, b_mat);
// combina o vetor de deslocamento atual com o acumulado// e filtra o movimento acumuladoacumulateMotionVectors(x_mat, x_mat_acc);
// aloca a imagem interpoladaunsigned char * doub_image;doub_image = new unsigned char [4*size_image];
// realiza a interpolacaoint count_interpolate = 0;pthread_mutex_t mutex1_interpolate = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t mutex2_interpolate = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t cond1_interpolate = PTHREAD_COND_INITIALIZER;
pthread_t thr_interpolate[maxThreads];thr_t_interpolate params_interpolate[maxThreads];for (int i = 0; i < maxThreads; i++) {
params_interpolate[i].orig_image = cur_image;params_interpolate[i].doub_image = doub_image;params_interpolate[i].thr_id = i;params_interpolate[i].mutex1 = &mutex1_interpolate;params_interpolate[i].mutex2 = &mutex2_interpolate;params_interpolate[i].cond1 = &cond1_interpolate;params_interpolate[i].count = &count_interpolate;pthread_create(&thr_interpolate[i], NULL, thr_f_interpolate,
¶ms_interpolate[i]);}for (int i = 0; i < maxThreads; i++)
pthread_join(thr_interpolate[i], NULL);
// compensa o frame correntepthread_t thr_compensateImage[maxThreads];thr_t_compensateImage params_compensateImage[maxThreads];for (int i = 0; i < maxThreads; i++) {
params_compensateImage[i].doub_image = doub_image;params_compensateImage[i].comp_image = stab_image;params_compensateImage[i].x_mat = x_mat_acc;

55
params_compensateImage[i].thr_id = i;pthread_create(&thr_compensateImage[i], NULL, thr_f_compensateImage,
¶ms_compensateImage[i]);}for (int i = 0; i < maxThreads; i++)
pthread_join(thr_compensateImage[i], NULL);
// libera memoriadelete[] doub_image;delete[] x_mat;delete[] hp_image;delete[] blocks;
}
A.3 stab.cpp
Segue o código de um exemplo de utilização do algoritmo.
#include <iostream>#include <fstream>#include <sys/time.h>#include "libstab.h"
using namespace std;
int main(int argc, char ** argv){
if ((argc != 4)||(atoi(argv[3]) < 2)) {cout << "Uso:" << endl;cout << "./stab prefixo_entrada prefixo_saida nro_frames" << endl << endl;return -1;
}
char file[20];
fstream ref_file;strcpy(file, argv[1]); strcat(file, "1.bmp");ref_file.open(file, ios::in|ios::out|ios::binary);if (!(ref_file.is_open())) {
cout << file << " NOK" << endl;return -2;
}char * ref_header;ref_header = new char [size_header];ref_file.seekg(0, ios::beg);ref_file.read(ref_header, size_header);char * ref_image;ref_image = new char [size_image];ref_file.read(ref_image, size_image);ref_file.close();
fstream stab_file;strcpy(file, argv[2]); strcat(file, "1.bmp");stab_file.open(file, ios::out|ios::binary);if (!(stab_file.is_open())) {
cout << file << " NOK" << endl;return -2;
}stab_file.seekp(0, ios::beg);stab_file.write(ref_header, size_header);stab_file.write(ref_image,size_image);stab_file.close();
char * cur_image;cur_image = new char [size_image];char * stab_image;stab_image = new char [size_image];

56
double * x_mat_acc; // deslocamento inicial nulox_mat_acc = new double [4];x_mat_acc[0] = 1;x_mat_acc[1] = 0;x_mat_acc[2] = 0;x_mat_acc[3] = 0;
char * num;num = new char[20];
struct timeval time_begin, time_end;gettimeofday(&time_begin, NULL);
for (int i = 2; i <= atoi(argv[3]); i++) {
//cout << "Frame " << i << endl;sprintf(num,"%d",i);
fstream cur_file;strcpy(file, argv[1]); strcat(file, num); strcat(file, ".bmp");cur_file.open(file, ios::in|ios::out|ios::binary);if (!(cur_file.is_open())) {
cout << file << " NOK" << endl;return -2;
}cur_file.seekg(size_header, ios::beg);cur_file.read(cur_image, size_image);cur_file.close();
fstream stab_file;strcpy(file, argv[2]); strcat(file, num); strcat(file, ".bmp");stab_file.open(file, ios::out|ios::binary);if (!(stab_file.is_open())) {
cout << file << " NOK" << endl;return -2;
}stab_file.seekp(0, ios::beg);stab_file.write(ref_header, size_header);
stabilizeFrame((unsigned char *) ref_image, (unsigned char *) cur_image,(unsigned char *) stab_image, x_mat_acc);
stab_file.write(stab_image,size_image);stab_file.close();
swap(ref_image, cur_image); // troca os ponteiros
}
delete[] num;delete[] ref_image;delete[] cur_image;delete[] ref_header;delete[] stab_image;delete[] x_mat_acc;
gettimeofday(&time_end, NULL);
double diff_time = ((time_end.tv_sec + time_end.tv_usec/1000000.0)-(time_begin.tv_sec + time_begin.tv_usec/1000000.0));
cout << "Tempo de execucao = " << diff_time << endl;cout << diff_time / (atoi(argv[3])-1) << " segundos por frame" << endl;
return 0;
}





























