Embed Size (px)
Citation preview

16-05-11 7.1
ESTATÍSTICA MULTIVARIADA
2º SEMESTRE 2010 / 11
EXERCÍCIOS PRÁTICOS - CADERNO 7 Análise de Clusters

16-05-11 7.2
7.1 (A1) Considere a seguinte matriz de distâncias :
0436
025
01
0
4
3
2
1
4321
Determine os clusters para estes 4 objectos assumindo:
a) Um modelo hierárquico "single linkage". b) Um modelo hierárquico "complete linkage". c) Um modelo hierárquico "average linkage". d) Desenhe os dendrogramas e compare os resultados dos três modelos. 7.2. (T) Considere agora a matriz de distâncias:
08536
01072
096
04
0
5
4
3
2
1
54321
Repita as alíneas a) a d) do exercício anterior. 7.3. (A1) Uma amostra para as cotações das acções de 5 empresas transaccionadas na NYSE permitiu calcular a
seguinte matriz de correlações entre as cotações dos títulos (arredondadas a 2 casas decimais):
152.43.32.46.
144.39.39.
160.51.
158.
1
Texaco
Exxon
CarbideUnion
PontDu
ChemicalAllied
TexacoExxonCarbide
UnionPontDu
Chemical
Allied
Usando as correlações como medida de semelhança entre os títulos construa os clusters das acções
usando os modelos de "single linkage" e "complete linkage".

16-05-11 7.3
7.4. (A1) Para quatro indivíduos (A … D) foram medidas as variáveis X1 e X2 obtendo-se:
Indiv. X1 X2
A 5 4 B 1 -2 C -1 1 D 3 1
Use o algoritmo das K-médias para dividir os indivíduos em K=2 grupos.
a) Comece com os grupos (AB) e (CD).
b) Repita começando com os grupos (AC) e (BD).
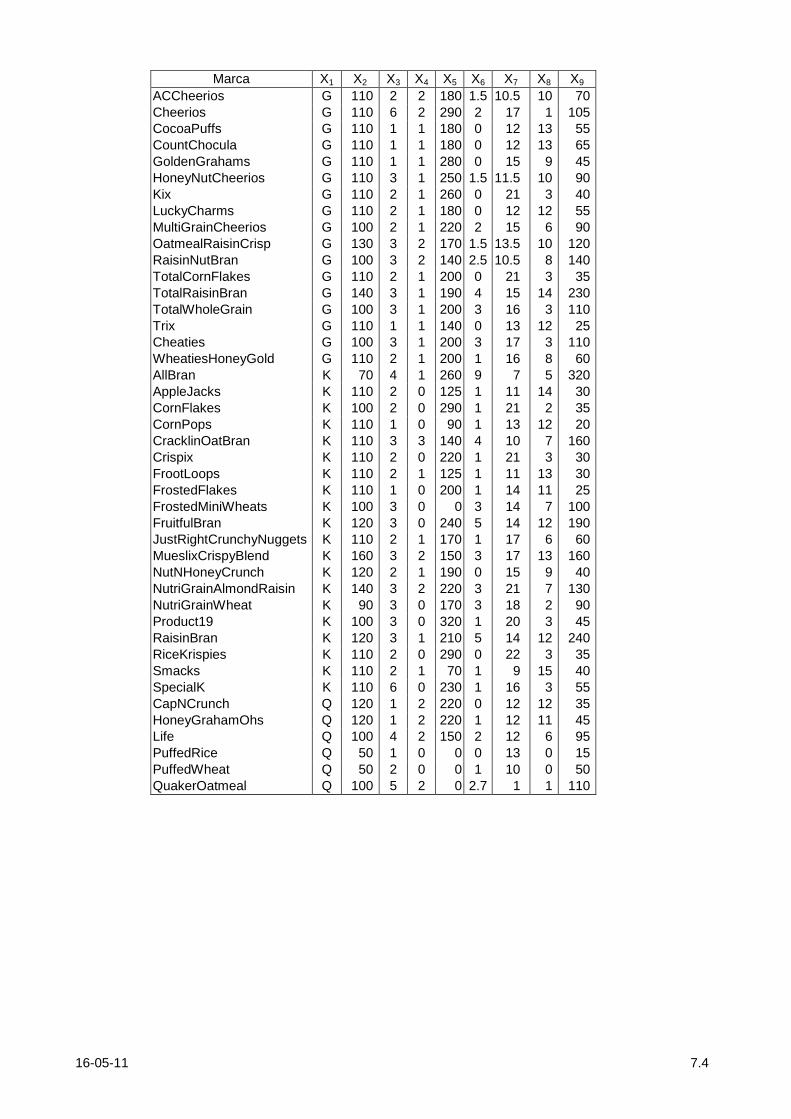
7.5. (A2) O quadro seguinte apresenta dados sobre 43 marcas comerciais de cereais de pequeno almoço para os quais se mediram 9 variáveis (dispõe destes dados no ficheiro CEREAIS.SAV)
X1 - Fabricante X2 - teor de calorias X3 - " proteínas X4 - " gordura X5 - " sódio X6 - " fibras X7 - " hidratos de carbono X8 - " açúcar X9 - " potássi0
Utilize o SPSS para a) Calcular a distância euclideana entre cada par de marcas de cereais. b) Utilizando essas distâncias agrupar as marcas de cereais usando os métodos de "single linkage" e
"complete linkage". Compare os dendrogramas.
c) Utilize os algoritmo das K-médias para agrupar as marcas de cereais. Use K=2 , 3 e 4 e compare os
resultados.
16-05-11 7.4
Marca X1 X2 X3 X4 X5 X6 X7 X8 X9
ACCheerios G 110 2 2 180 1.5 10.5 10 70
Cheerios G 110 6 2 290 2 17 1 105
CocoaPuffs G 110 1 1 180 0 12 13 55
CountChocula G 110 1 1 180 0 12 13 65
GoldenGrahams G 110 1 1 280 0 15 9 45
HoneyNutCheerios G 110 3 1 250 1.5 11.5 10 90
Kix G 110 2 1 260 0 21 3 40
LuckyCharms G 110 2 1 180 0 12 12 55
MultiGrainCheerios G 100 2 1 220 2 15 6 90
OatmealRaisinCrisp G 130 3 2 170 1.5 13.5 10 120
RaisinNutBran G 100 3 2 140 2.5 10.5 8 140
TotalCornFlakes G 110 2 1 200 0 21 3 35
TotalRaisinBran G 140 3 1 190 4 15 14 230
TotalWholeGrain G 100 3 1 200 3 16 3 110
Trix G 110 1 1 140 0 13 12 25
Cheaties G 100 3 1 200 3 17 3 110
WheatiesHoneyGold G 110 2 1 200 1 16 8 60
AllBran K 70 4 1 260 9 7 5 320
AppleJacks K 110 2 0 125 1 11 14 30
CornFlakes K 100 2 0 290 1 21 2 35
CornPops K 110 1 0 90 1 13 12 20
CracklinOatBran K 110 3 3 140 4 10 7 160
Crispix K 110 2 0 220 1 21 3 30
FrootLoops K 110 2 1 125 1 11 13 30
FrostedFlakes K 110 1 0 200 1 14 11 25
FrostedMiniWheats K 100 3 0 0 3 14 7 100
FruitfulBran K 120 3 0 240 5 14 12 190
JustRightCrunchyNuggets K 110 2 1 170 1 17 6 60
MueslixCrispyBlend K 160 3 2 150 3 17 13 160
NutNHoneyCrunch K 120 2 1 190 0 15 9 40
NutriGrainAlmondRaisin K 140 3 2 220 3 21 7 130
NutriGrainWheat K 90 3 0 170 3 18 2 90
Product19 K 100 3 0 320 1 20 3 45
RaisinBran K 120 3 1 210 5 14 12 240
RiceKrispies K 110 2 0 290 0 22 3 35
Smacks K 110 2 1 70 1 9 15 40
SpecialK K 110 6 0 230 1 16 3 55
CapNCrunch Q 120 1 2 220 0 12 12 35
HoneyGrahamOhs Q 120 1 2 220 1 12 11 45
Life Q 100 4 2 150 2 12 6 95
PuffedRice Q 50 1 0 0 0 13 0 15
PuffedWheat Q 50 2 0 0 1 10 0 50
QuakerOatmeal Q 100 5 2 0 2.7 1 1 110
16-05-11 7.5
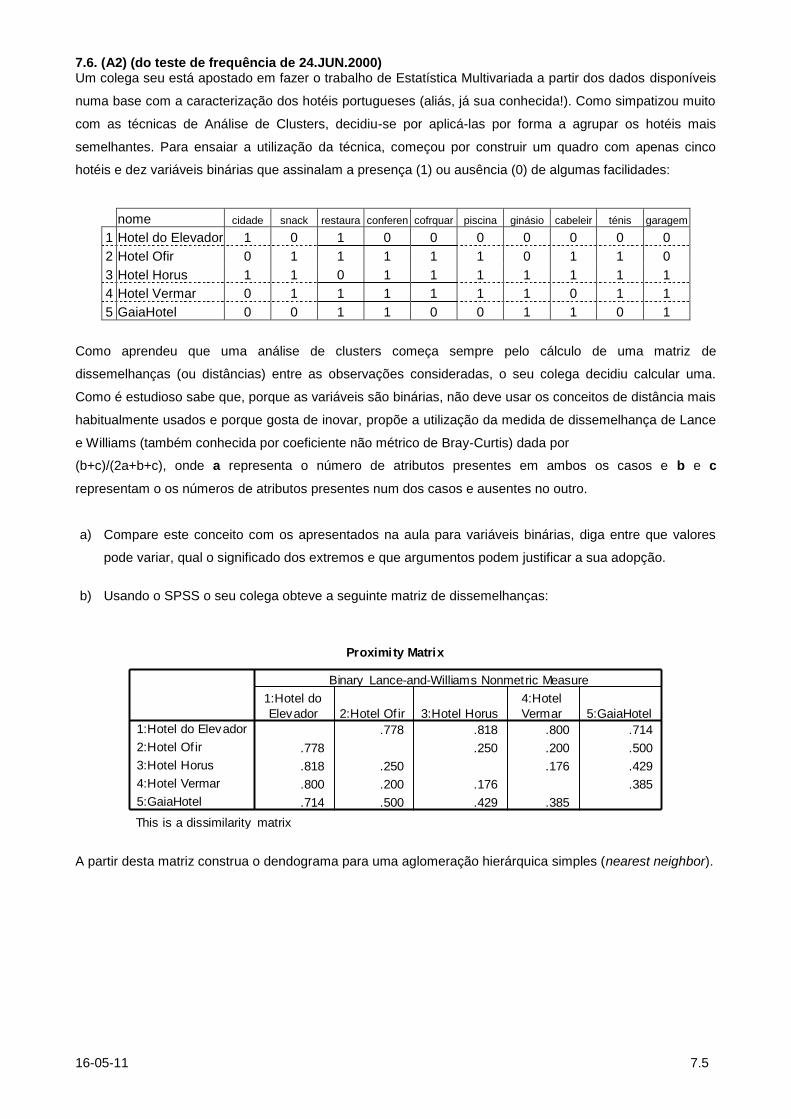
7.6. (A2) (do teste de frequência de 24.JUN.2000) Um colega seu está apostado em fazer o trabalho de Estatística Multivariada a partir dos dados disponíveis
numa base com a caracterização dos hotéis portugueses (aliás, já sua conhecida!). Como simpatizou muito
com as técnicas de Análise de Clusters, decidiu-se por aplicá-las por forma a agrupar os hotéis mais
semelhantes. Para ensaiar a utilização da técnica, começou por construir um quadro com apenas cinco
hotéis e dez variáveis binárias que assinalam a presença (1) ou ausência (0) de algumas facilidades:
nome cidade snack restaura conferen cofrquar piscina ginásio cabeleir ténis garagem
1 Hotel do Elevador 1 0 1 0 0 0 0 0 0 0
2 Hotel Ofir 0 1 1 1 1 1 0 1 1 0
3 Hotel Horus 1 1 0 1 1 1 1 1 1 1
4 Hotel Vermar 0 1 1 1 1 1 1 0 1 1
5 GaiaHotel 0 0 1 1 0 0 1 1 0 1
Como aprendeu que uma análise de clusters começa sempre pelo cálculo de uma matriz de
dissemelhanças (ou distâncias) entre as observações consideradas, o seu colega decidiu calcular uma.
Como é estudioso sabe que, porque as variáveis são binárias, não deve usar os conceitos de distância mais
habitualmente usados e porque gosta de inovar, propõe a utilização da medida de dissemelhança de Lance
e Williams (também conhecida por coeficiente não métrico de Bray-Curtis) dada por
(b+c)/(2a+b+c), onde a representa o número de atributos presentes em ambos os casos e b e c
representam o os números de atributos presentes num dos casos e ausentes no outro.
a) Compare este conceito com os apresentados na aula para variáveis binárias, diga entre que valores
pode variar, qual o significado dos extremos e que argumentos podem justificar a sua adopção.
b) Usando o SPSS o seu colega obteve a seguinte matriz de dissemelhanças:
Proximity Matrix
.778 .818 .800 .714
.778 .250 .200 .500
.818 .250 .176 .429
.800 .200 .176 .385
.714 .500 .429 .385
1:Hotel do Elevador
2:Hotel Of ir
3:Hotel Horus
4:Hotel Vermar
5:GaiaHotel
1:Hotel do
Elevador 2:Hotel Of ir 3:Hotel Horus
4:Hotel
Vermar 5:GaiaHotel
Binary Lance-and-Williams Nonmetric Measure
This is a dissimilarity matrix
A partir desta matriz construa o dendograma para uma aglomeração hierárquica simples (nearest neighbor).

16-05-11 7.6
7.7. (A2) (usando os dados do teste de freq. de 27.JAN.2004) O ficheiro Ex7-7.xls apresenta os dados do consumo médio de proteínas em diversos tipos de alimentos
para 25 países europeus (São dados de 1973 citados em Manly, 1994). Os valores são consumos médios
diários em gr. por pessoa e as variáveis referem-se a nove grupos de alimentos:
redmeat - carnes vermelhas;
whitemea - carnes brancas;
eggs - ovos;
milk - leite;
fish - peixe;
cereals - cereias;
starchyf - féculas (batata e outras)
pulsenut - leguminosas e oleaginosas;
fruveget - frutas e vegetais.
Pretende-se agora agrupar os países com hábitos alimentares semelhantes (no que toca a quantidades e
fontes de proteínas) recorrendo à Análise de Clusters.
a) Faz sentido a utilização desta técnica?
b) Proponha um conceito de distância e um método de agregação e use o SPSS para constituir os
grupos.
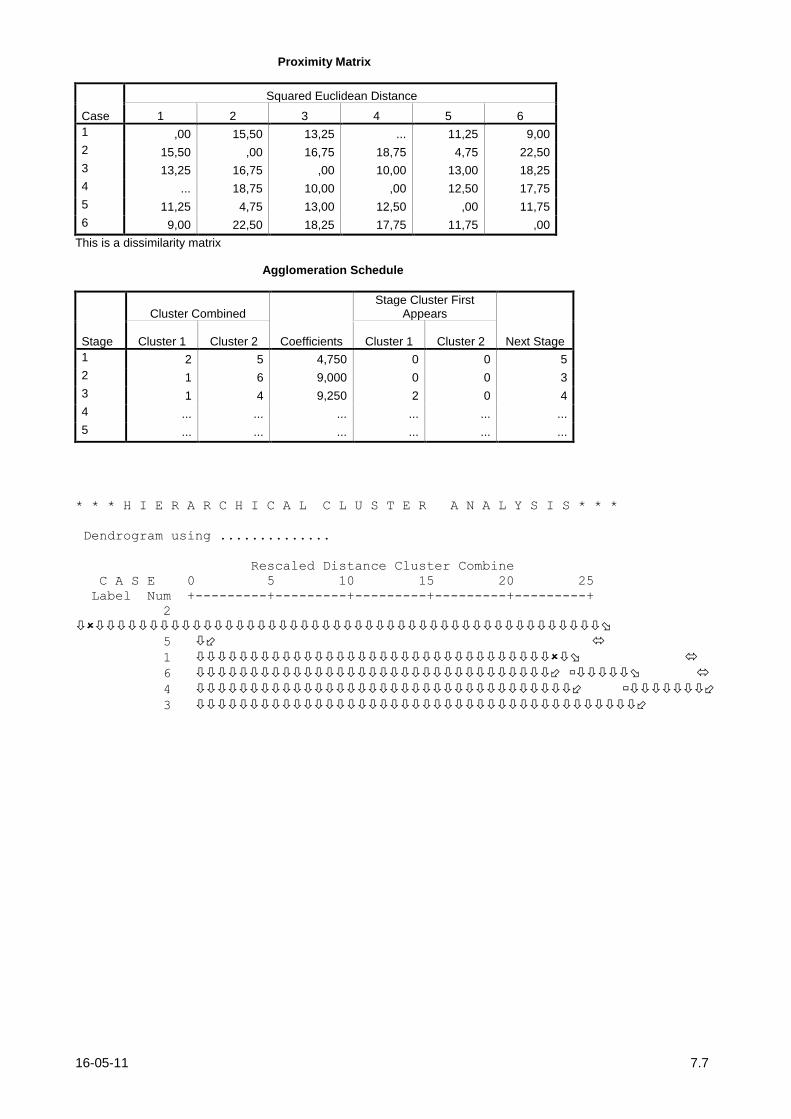
7.8. (T) (do teste de frequência de 6.JAN.2006) Um colega seu está a experimentar a utilização da Análise de Clusters. Trabalhando com o conjunto de
dados no Quadro 7.8.1, obteve o output do SPSS para a utilização dum método hierárquico de clustering
que consta abaixo.
Indivíduo X1 X2 X3 X4 X5
A 3.0 4.0 2.5 1.5 5.0
B 2.0 5.0 1.5 2.0 1.5
C 4.5 3.5 4.0 3.0 2.5
D 4.0 2.5 1.5 3.5 4.0
E 2.0 3.0 2.0 1.5 2.0
F 1.0 2.5 4.0 2.0 4.5
Quadro 7.8.1
a) Diga, justificando, qual o método hierárquico utilizado.
b) Complete o aglomeration schedule e acrescente ao dendrograma uma escala para as distâncias
apropriada ao problema.
c) Como ficam divididas as observações se decidir formar dois clusters? Trata-se duma solução possível
no caso de utilizar o algoritmo das K-médias (com k=2)?
OUTPUT:
16-05-11 7.7
Proximity Matrix
Case
Squared Euclidean Distance
1 2 3 4 5 6
1 ,00 15,50 13,25 ... 11,25 9,00
2 15,50 ,00 16,75 18,75 4,75 22,50
3 13,25 16,75 ,00 10,00 13,00 18,25
4 ... 18,75 10,00 ,00 12,50 17,75
5 11,25 4,75 13,00 12,50 ,00 11,75
6 9,00 22,50 18,25 17,75 11,75 ,00
This is a dissimilarity matrix Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 2 5 4,750 0 0 5
2 1 6 9,000 0 0 3
3 1 4 9,250 2 0 4
4 ... ... ... ... ... ...
5 ... ... ... ... ... ...
* * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * *
Dendrogram using ..............
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
2
5
1
6
4
3

16-05-11 7.8
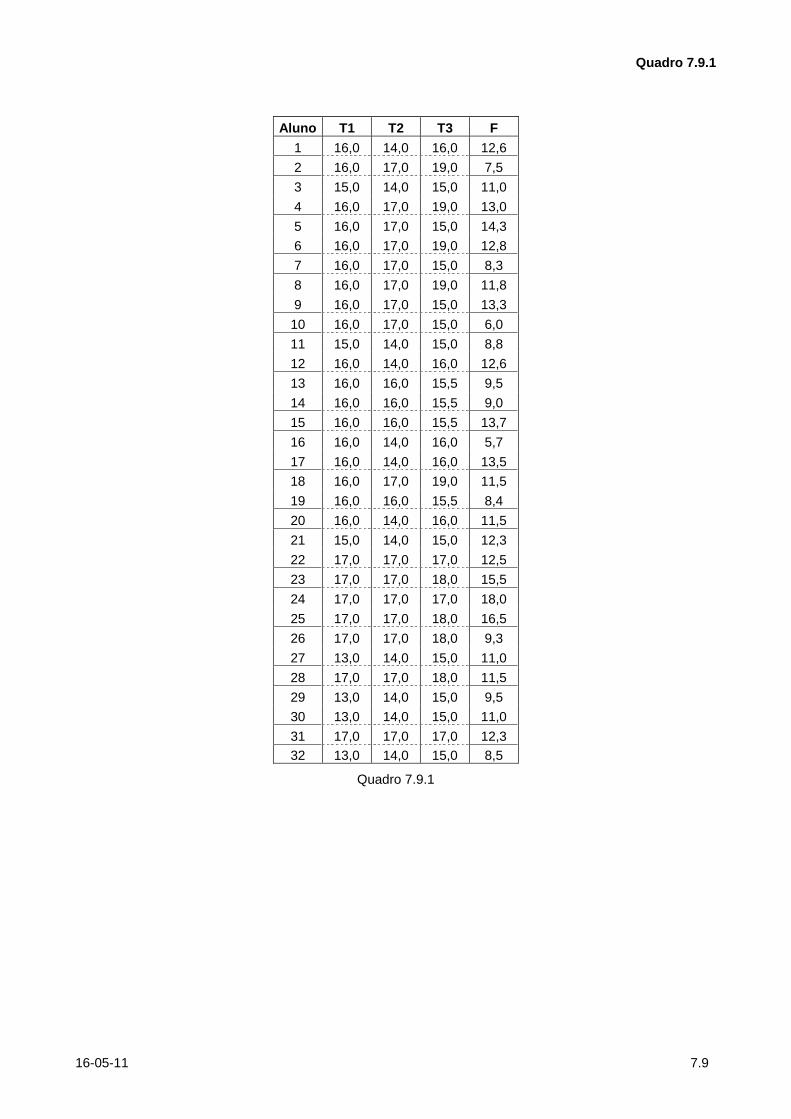
7.9. (Do exame de 26.JUN.2007) No Quadro 7.9.1 tem as notas de três testes e da prova final numa disciplina da nossa Universidade.
Utilizou-se esta informação para fazer uma análise de clusters dos alunos considerando, primeiro a "block
distance" (isto é distância de Minkovski com m=1) e depois a distância euclideana. Os resultados obtidos
para o método hierárquico com ligações médias apresentam-se no Output 7.9.2.
a) Compare os resultados, referindo-se especialmente aos objectivos do clustering no que toca à
variabilidade intra e inter clusters. (Seja sucinto na resposta.)
b) Repare agora que, nesta análise, os trabalhos (que são de grupo) têm um peso tão grande que quase
se podem identificar os grupos de trabalho nos dendogramas. Um seu colega sugeriu então que se
padronizassem as variáveis. Outro sugeriu que se fizesse o clustering com base na nota de fim de
semestre. Que comentários lhe merecem estas sugestões?
c) Eu preferi construir uma nova variável, que é a média aritmética das notas dos três trabalhos. Fiz então
o clustering usando esta média e a nota do teste de frequência. O resultado desta minha análise
apresenta-se no Output 7.9.3. Que comentários lhe suscita?
16-05-11 7.9
Quadro 7.9.1
Aluno T1 T2 T3 F
1 16,0 14,0 16,0 12,6
2 16,0 17,0 19,0 7,5
3 15,0 14,0 15,0 11,0
4 16,0 17,0 19,0 13,0
5 16,0 17,0 15,0 14,3
6 16,0 17,0 19,0 12,8
7 16,0 17,0 15,0 8,3
8 16,0 17,0 19,0 11,8
9 16,0 17,0 15,0 13,3
10 16,0 17,0 15,0 6,0
11 15,0 14,0 15,0 8,8
12 16,0 14,0 16,0 12,6
13 16,0 16,0 15,5 9,5
14 16,0 16,0 15,5 9,0
15 16,0 16,0 15,5 13,7
16 16,0 14,0 16,0 5,7
17 16,0 14,0 16,0 13,5
18 16,0 17,0 19,0 11,5
19 16,0 16,0 15,5 8,4
20 16,0 14,0 16,0 11,5
21 15,0 14,0 15,0 12,3
22 17,0 17,0 17,0 12,5
23 17,0 17,0 18,0 15,5
24 17,0 17,0 17,0 18,0
25 17,0 17,0 18,0 16,5
26 17,0 17,0 18,0 9,3
27 13,0 14,0 15,0 11,0
28 17,0 17,0 18,0 11,5
29 13,0 14,0 15,0 9,5
30 13,0 14,0 15,0 11,0
31 17,0 17,0 17,0 12,3
32 13,0 14,0 15,0 8,5
Quadro 7.9.1
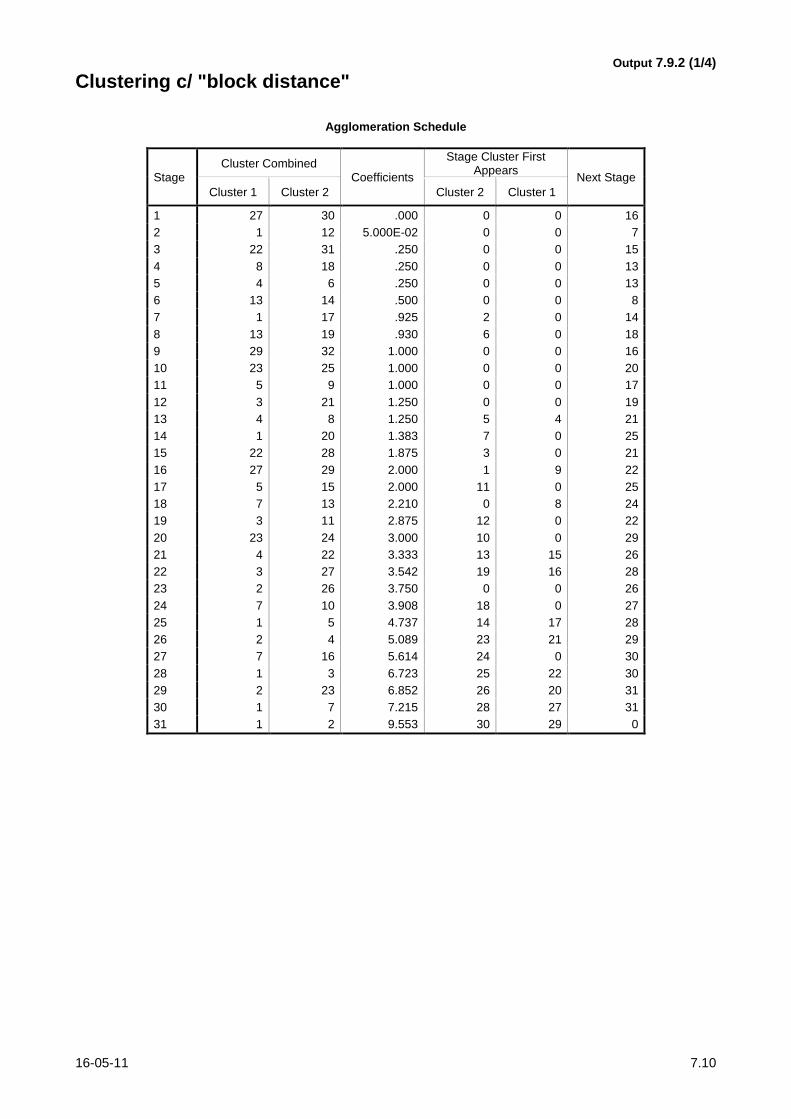
16-05-11 7.10
Output 7.9.2 (1/4)
Clustering c/ "block distance"
Agglomeration Schedule
Stage Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 2 Cluster 1
1 27 30 .000 0 0 16
2 1 12 5.000E-02 0 0 7
3 22 31 .250 0 0 15
4 8 18 .250 0 0 13
5 4 6 .250 0 0 13
6 13 14 .500 0 0 8
7 1 17 .925 2 0 14
8 13 19 .930 6 0 18
9 29 32 1.000 0 0 16
10 23 25 1.000 0 0 20
11 5 9 1.000 0 0 17
12 3 21 1.250 0 0 19
13 4 8 1.250 5 4 21
14 1 20 1.383 7 0 25
15 22 28 1.875 3 0 21
16 27 29 2.000 1 9 22
17 5 15 2.000 11 0 25
18 7 13 2.210 0 8 24
19 3 11 2.875 12 0 22
20 23 24 3.000 10 0 29
21 4 22 3.333 13 15 26
22 3 27 3.542 19 16 28
23 2 26 3.750 0 0 26
24 7 10 3.908 18 0 27
25 1 5 4.737 14 17 28
26 2 4 5.089 23 21 29
27 7 16 5.614 24 0 30
28 1 3 6.723 25 22 30
29 2 23 6.852 26 20 31
30 1 7 7.215 28 27 31
31 1 2 9.553 30 29 0

16-05-11 7.11
Output 7.9.2 (2/4)
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
27 -+---------+
30 -+ +-------+
29 -----+-----+ I
32 -----+ +---------------+
3 -------+-------+ I I
21 -------+ +---+ I
11 ---------------+ +-+
1 -+---+ I I
12 -+ +-+ I I
17 -----+ +-----------------+ I I
20 -------+ +---------+ I
5 -----+-----+ I I
9 -----+ +-------------+ +-----------+
15 -----------+ I I
13 ---+-+ I I
14 ---+ +-----+ I I
19 -----+ +---------+ I I
7 -----------+ +-------+ I I
10 ---------------------+ +-------+ I
16 -----------------------------+ I
23 -----+---------+ I
25 -----+ +-------------------+ I
24 ---------------+ I I
8 -+-----+ I I
18 -+ +---------+ +-------------+
4 -+-----+ I I
6 -+ +---------+ I
22 -+-------+ I I I
31 -+ +-------+ +-------+
28 ---------+ I
2 -------------------+-------+
26 -------------------+
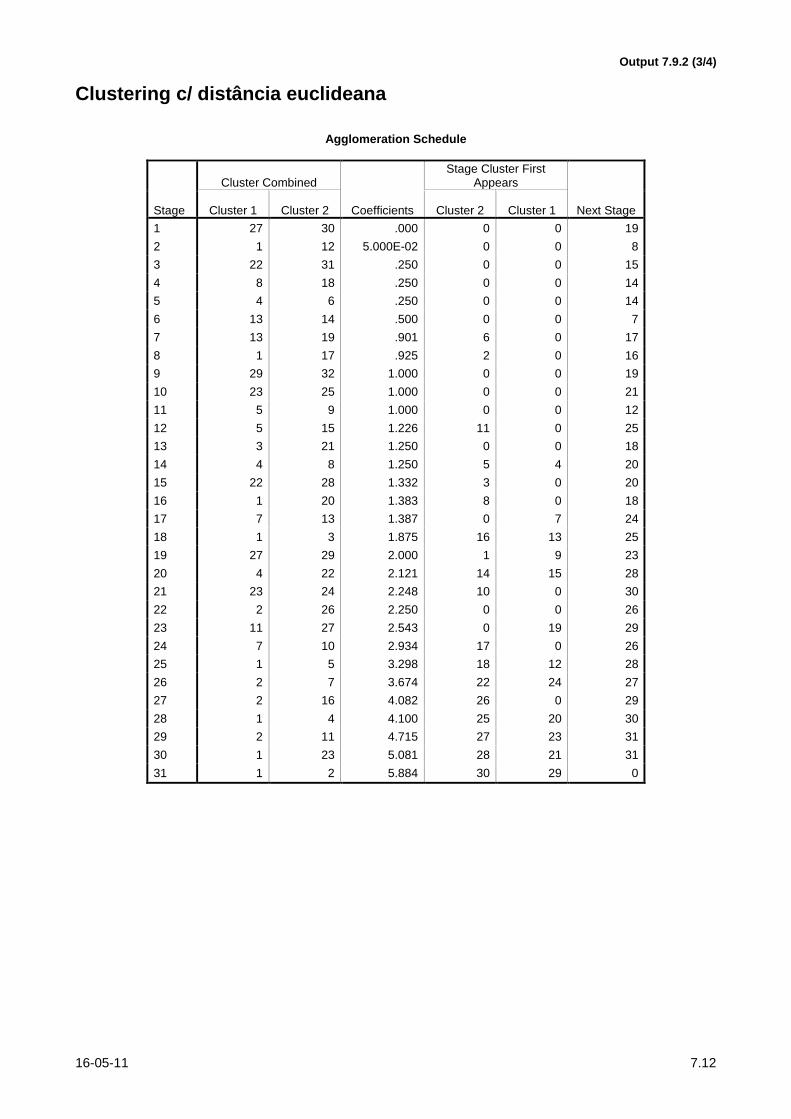
16-05-11 7.12
Output 7.9.2 (3/4)
Clustering c/ distância euclideana
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 2 Cluster 1
1 27 30 .000 0 0 19
2 1 12 5.000E-02 0 0 8
3 22 31 .250 0 0 15
4 8 18 .250 0 0 14
5 4 6 .250 0 0 14
6 13 14 .500 0 0 7
7 13 19 .901 6 0 17
8 1 17 .925 2 0 16
9 29 32 1.000 0 0 19
10 23 25 1.000 0 0 21
11 5 9 1.000 0 0 12
12 5 15 1.226 11 0 25
13 3 21 1.250 0 0 18
14 4 8 1.250 5 4 20
15 22 28 1.332 3 0 20
16 1 20 1.383 8 0 18
17 7 13 1.387 0 7 24
18 1 3 1.875 16 13 25
19 27 29 2.000 1 9 23
20 4 22 2.121 14 15 28
21 23 24 2.248 10 0 30
22 2 26 2.250 0 0 26
23 11 27 2.543 0 19 29
24 7 10 2.934 17 0 26
25 1 5 3.298 18 12 28
26 2 7 3.674 22 24 27
27 2 16 4.082 26 0 29
28 1 4 4.100 25 20 30
29 2 11 4.715 27 23 31
30 1 23 5.081 28 21 31
31 1 2 5.884 30 29 0

16-05-11 7.13
Output 7.9.2 (4/4)
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
27 -+---------------+
30 -+ +---+
29 ---------+-------+ +-------------------+
32 ---------+ I I
11 ---------------------+ I
2 -------------------+-----------+ +-------+
26 -------------------+ I I I
13 -----+-+ +---+ I I
14 -----+ +---+ I I I I
19 -------+ +-------------+ I +-----+ I
7 -----------+ +-----+ I I
10 -------------------------+ I I
16 -----------------------------------+ I
23 ---------+---------+ I
25 ---------+ +-----------------------+ I
24 -------------------+ I I
8 ---+-------+ I I
18 ---+ +-------+ I I
4 ---+-------+ I +-----+
6 ---+ +---------------+ I
22 ---+-------+ I I I
31 ---+ +-------+ I I
28 -----------+ +-------+
5 ---------+-+ I
9 ---------+ +-----------------+ I
15 -----------+ I I
3 -----------+---+ +-----+
21 -----------+ I I
1 -+-----+ +-------------+
12 -+ +---+ I
17 -------+ +---+
20 -----------+
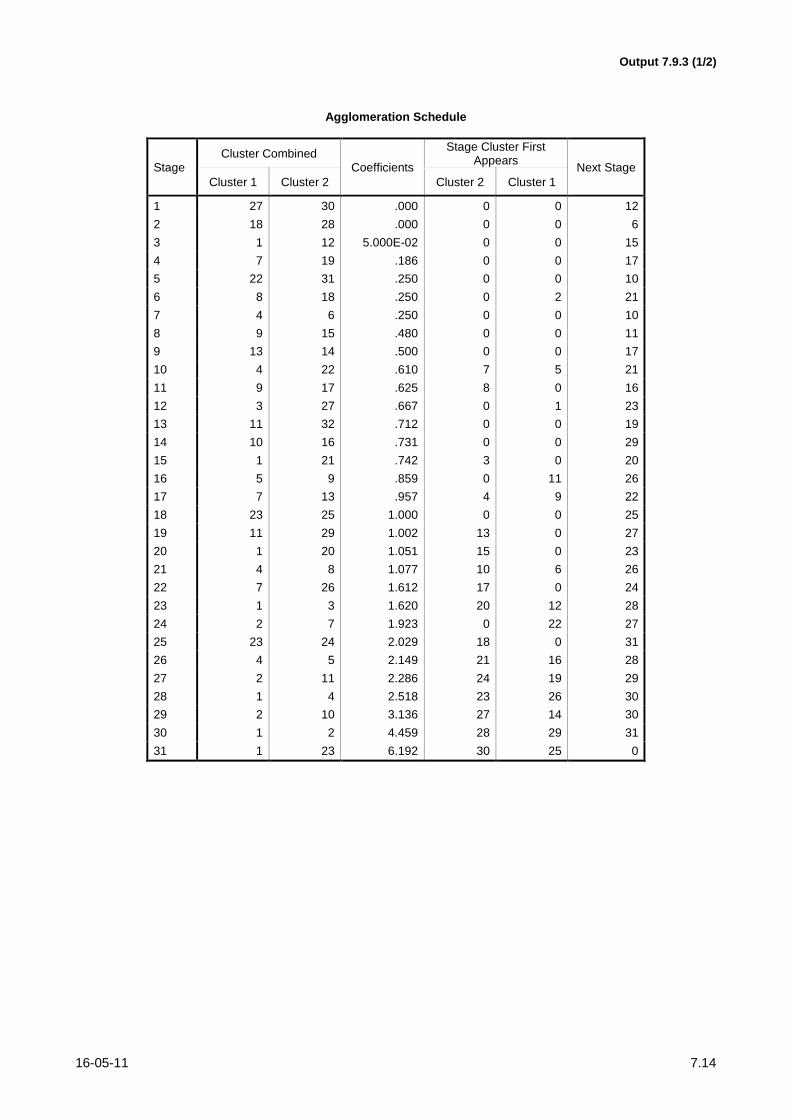
16-05-11 7.14
Output 7.9.3 (1/2)
Agglomeration Schedule
Stage Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 2 Cluster 1
1 27 30 .000 0 0 12
2 18 28 .000 0 0 6
3 1 12 5.000E-02 0 0 15
4 7 19 .186 0 0 17
5 22 31 .250 0 0 10
6 8 18 .250 0 2 21
7 4 6 .250 0 0 10
8 9 15 .480 0 0 11
9 13 14 .500 0 0 17
10 4 22 .610 7 5 21
11 9 17 .625 8 0 16
12 3 27 .667 0 1 23
13 11 32 .712 0 0 19
14 10 16 .731 0 0 29
15 1 21 .742 3 0 20
16 5 9 .859 0 11 26
17 7 13 .957 4 9 22
18 23 25 1.000 0 0 25
19 11 29 1.002 13 0 27
20 1 20 1.051 15 0 23
21 4 8 1.077 10 6 26
22 7 26 1.612 17 0 24
23 1 3 1.620 20 12 28
24 2 7 1.923 0 22 27
25 23 24 2.029 18 0 31
26 4 5 2.149 21 16 28
27 2 11 2.286 24 19 29
28 1 4 2.518 23 26 30
29 2 10 3.136 27 14 30
30 1 2 4.459 28 29 31
31 1 23 6.192 30 25 0

16-05-11 7.15
Output 7.9.3 (2/2)
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
27 -+---+
30 -+ +-------+
3 -----+ I
1 -+---+ +-------+
12 -+ +---+ I I
21 -----+ +---+ I
20 ---------+ I
9 ---+-+ +---------------+
15 ---+ +-+ I I
17 -----+ +---------+ I I
5 -------+ I I I
18 -+-+ +---+ I
28 -+ +-----+ I I
8 ---+ +-------+ +-----------+
22 ---+-+ I I I
31 ---+ +---+ I I
4 ---+-+ I I
6 ---+ I I
10 -----+-------------------+ I I
16 -----+ I I I
11 -----+---+ +-----------+ I
32 -----+ +---------+ I I
29 ---------+ I I I
7 -+-----+ +-----+ I
19 -+ +-----+ I I
13 -----+-+ +-+ I I
14 -----+ I +---+ I
26 -------------+ I I
2 ---------------+ I
23 ---------+-------+ I
25 ---------+ +-------------------------------+
24 -----------------+





























