Embed Size (px)
Citation preview

ANÁLISE E PROJETO DE
BANCO DE DADOSESTRUTURAS E
INDEXAÇÃOFELIPE G. TORRES

ARQUIVOS
• Um arquivo é uma sequência de registros. Em
muitos casos do mesmo tipo.
• Se cada registro no arquivo tem exatamente o
mesmo tamanho (em bytes), o arquivo é
considerado composto de registro de tamanho
fixo.
• Caso contrário ele é chamado de arquivo
composto por registro de tamanho variável.

ARQUIVOS
• Os arquivos de registro são utilizados em larga
escala para a integração de sistemas.
• Para determinar os bytes em um registro em
particular em cada campo, podemos usar
caracteres separadores (%, #, @,|).
• Uma opção prática também é atribuir um código
curto de tipo de campo.
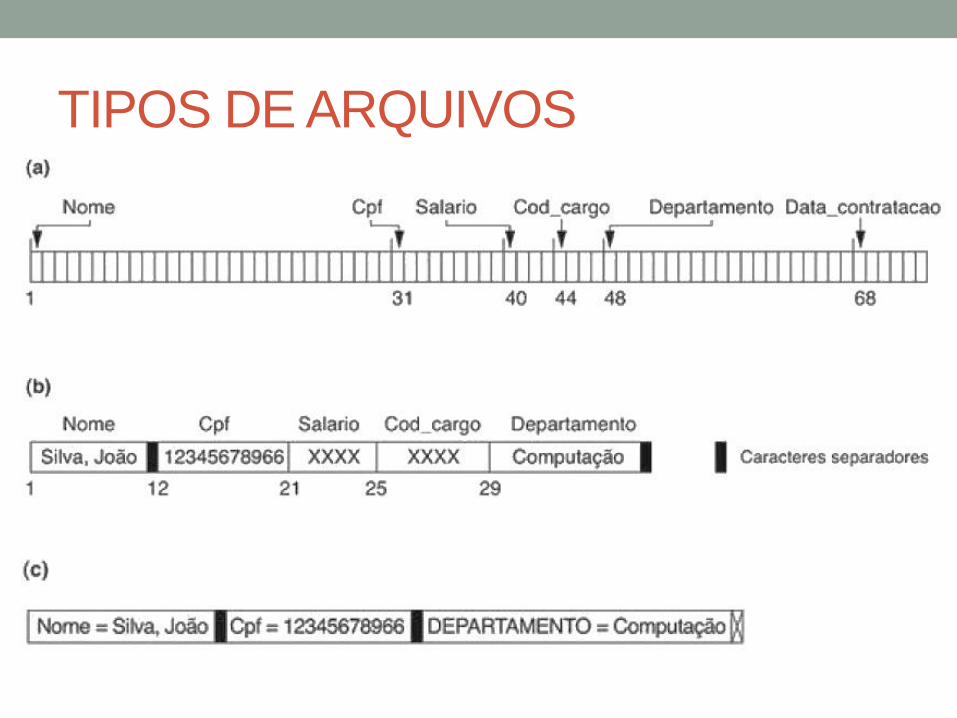
TIPOS DE ARQUIVOS

BLOCAGEM DE REGISTROS
• Os registros de um arquivo precisam ser
alocados a blocos de disco.
• Conceitua-se blocos de disco como uma
unidade de transferência de dados entre o disco
e a memória.
• Se um bloco for maior que um registro, o bloco
poderá ter um ou mais registros, porém pode
ocorrer de um arquivo ter um registro muito
extenso, que não caiba em um bloco.

BLOCAGEM DE REGISTROS
• Para um arquivo de registro de tamanho fixo,
com tamanho de R bytes, sendo:
• Pode-se então estabelecer o fator de blocagem:
tamanho do bloco ≥ R
bfr = [B/R]

BLOCAGEM DE REGISTROS
• Em geral, R pode não dividir B exatamente, de
modo que temos algum espaço não usado em
cada bloco, igual a:
• Para não perder-se esse espaço vago nos
blocos, pode-se armazenar um registro
parcialmente em blocos distintos.
B – (bfr * R) em bytes

BLOCAGEM DE REGISTROS
• Um ponteiro no final do primeiro bloco, aponta para o
bloco que contém o restante. Essa organização é
chamada de espalhada porque os registros podem se
espalhar em mais de um bloco.

BLOCAGEM DE REGISTROS
• Para registros de tamanho variável que usam a
organização espalhada, cada bloco pode
armazenar um número diferente de registros.
• Para calcular o número de blocos b necessários
para um arquivo de r registros:
b = [(r / brf)] em blocos

ALOCAÇÃO DE BLOCOS
• A alocação contígua, os blocos de arquivo são
alocados a blocos de disco consecutivos. Esta
alocação tem a leitura do arquivo inteiro. Este
método dificulta a expansão dos arquivos.
• A alocação ligada, cada bloco de arquivo
contém um ponteiro para o próximo bloco de
arquivo. Isso facilita a expansão do arquivo mas
deixa a leitura mais lenta.

TÉCNICAS DE HASHING
• Um tipo de organização de arquivo principal é
baseado no hashing, que oferece acesso muito
rápido. Ela é chamada de arquivo de hash.
• A condição de pesquisa precisa ser uma
condição de igualdade em um único campo,
chamado campo de hash ou campo-chave
(chave hash).

TÉCNICAS DE HASHING
• A idéia por trás do hashing é oferecer uma
função h, chamada de função de hash ou
função de randomização.
• Esta função é aplicada ao valor do campo de
hash de um regitro e gera o endereço do bloco
de disco em que o registro está armazenado.
• Uma pesquisa pelo registro no bloco pode ser
executada em um buffer da memória principal.

TÉCNICAS DE HASHING• O hashing também é utilizado como uma
estrutura de pesquisa interna em um programa
que um grupo de registro seja acessado por
uma chave.

HASHING INTERNO
• Normalmente o hashing implementado para
arquivos internos é uma tabela hash por meio
do uso de um array de registros.
• Então, temos M slots cujos endereços
correspondem aos índices de array.
• A função hash que regerá a alocação de
valores na tabela deverá normalizar os valores
em inteiros variando entre 0 e M-1. Exemplo a :
h(K) = K mod M

DESDOBRAMENTO
• Os valores de campo de hash não inteiros podem
ser transformados em inteiros antes que a função
mod seja aplicada.
• Uma técnica, chamada desdobramento, envolve
aplicar uma função aritmética, como a adição, ou
uma função lógica, como o or exclusivo.
• Por exemplo, com um hash de 1000 chaves, uma
chave de seis dígitos 235469 pode ser
desdobrada e armazenada no endereço: (235 +
964) mod 1000 = 199.

DESDOBRAMENTO

PROBLEMA DE COLISÕES
• O problema com a maioria das funções de
hashing é que elas não garantem que valores
distintos terão endereços de hash distintos.
• O motivo é que normalmente o número de
valores é muito maior que o número de
endereços.
• Uma colisão ocorre quando o valor do campo
de hash de um registro que está sendo inserido
é calculado como um endereço que contém um
registro ocupando-o.

RESOLUÇÃO DE COLISÕES
• A ação de localizar outra posição é chamado de
resolução de colisão. Existem vários métodos
para resolução de colisão, incluindo:
• Endereçamento aberto. Partindo da posição
ocupada especificada pelo endereço de hash, o
programa verifica as posições subsequentes
em ordem, até que uma posição não usada seja
encontrada.

RESOLUÇÃO DE COLISÕES
• Encadeamento. Para esse método, vários
locais de overflow são mantidos, normalmente
estendendo o array com uma série de posições
de overflow.

RESOLUÇÃO DE COLISÕES
• Hashing múltiplo. O algoritmo aplica uma
segunda função hash se a primeira resultar em
uma colisão.
• Se houver outra colisão, o programa utiliza o
endereçamento aberto ou aplica uma terceira
função hash e, depois, usa o endereçamento
aberto se necessário.

ESTRUTURA DE INDEXAÇÃO
• Além dos hashes existem outras estruturas de
acesso auxiliares, chamadas de índices, que
são utilizadas para agilizar a recuperação de
registros em resposta a pesquisas.
• As estruturas de índices são arquivos adicionais
que oferecem caminhos de acesso
secundários.
• Formas alternativas de acessar registros sem
afetar o posicionamento físico dos arquivos de
dados.

ESTRUTURA DE INDEXAÇÃO
• Além dos hashes existem outras estruturas de
acesso auxiliares, chamadas de índices, que
são utilizadas para agilizar a recuperação de
registros em resposta a pesquisas.
• As estruturas de índices são arquivos adicionais
que oferecem caminhos de acesso
secundários.
• Formas alternativas de acessar registros sem
afetar o posicionamento físico dos arquivos de
dados.





























