Embed Size (px)
Citation preview

Extensões SIMD
J. Miguel Leitão

J. Miguel Leitão Extensões SIMD
2
Índice
Introdução _________________________________________________________ 4 Pré-requisitos ............................................................................................................................. 4 Sumário ...................................................................................................................................... 4
Arquitecturas SIMD - Single Instruction Multiple Data ____________________ 5
Características dos Dados Multimédia ___________________________________ 7
MMX _____________________________________________________________ 8
Registos MMX __________________________________________________________ 8
Tipos de dados __________________________________________________________ 9
Saturação _____________________________________________________________ 10
Instruções MMX _______________________________________________________ 12 Operandos ................................................................................................................................ 13 Instruções Aritméticas ............................................................................................................. 13 Instruções de Comparação ....................................................................................................... 16 Instruções de Conversão (Pack e Unpack) ............................................................................... 16 Instruções Lógicas ................................................................................................................... 17 Instruções de Deslocamento .................................................................................................... 17 Instruções de transferência de dados ........................................................................................ 18 Instrução EMMS ...................................................................................................................... 18 Instruções MMX e Vírgula flutuante ....................................................................................... 18
Alinhamento dos dados ________________________________________________________ 18 Alinhamento da Stack .............................................................................................................. 19
Exemplos de Aplicação ______________________________________________ 21
Selecção Condicional ____________________________________________________ 21
Soma de Produtos ______________________________________________________ 23
Produto de matrizes ____________________________________________________ 24
Junção de Imagens _____________________________________________________ 25
SSE - Streaming SIMD Extensions ____________________________________ 28
Instrução Shuffle _______________________________________________________ 30
Exemplo de aplicação de SSE_____________________________________________ 31
Exemplo - Braço de robot ________________________________________________ 33
SSE2 _________________________________________________________________ 34
SSE3 _________________________________________________________________ 34
SSSE3 ________________________________________________________________ 36
SSE4 _________________________________________________________________ 36
AVX _________________________________________________________________ 37

J. Miguel Leitão Extensões SIMD
3
AVX2 _____________________________________________________________________ 37
AVX512 ___________________________________________________________________ 37
Desenvolvimento ___________________________________________________ 38
Biblioteca intrínseca ____________________________________________________ 38
Exemplo de utilização _________________________________________________________ 39
Classes C++ ___________________________________________________________ 39 SIMD Vector Classes .............................................................................................................. 40
Exemplo de utilização _________________________________________________________ 41
AltiVec ___________________________________________________________ 42
3DNow! _______________________________________________________________ 42
MAX - Multimedia Acceleration eXtensions ________________________________ 43
MDMX - Mips Digital Media eXtensions ___________________________________ 43
VIS - Visual Instruction Set ______________________________________________ 43
DSPs com capacidades SIMD ________________________________________ 44
Conclusões ________________________________________________________ 45
Anexo 1. Tabela cronológica de microprocessadores _________________________ 46

J. Miguel Leitão Extensões SIMD
4
Introdução
Pré-requisitos
Conhecimentos básicos de arquitectura de processadores, família Intel x86 e
programação assembly.
Sumário
Introdução às extensões de microprocessadores com tecnologias Single Instruction
Multiple Data (SIMD) mais comuns, tais como o MMX, o SSE e o SSE2.
Aplicação destas extensões na implementação de algoritmos típicos de
computação 3D e de comunicação em tempo real, com demonstrações
exemplificativas das vantagens associadas.
Breves referências a outras arquitecturas de extensões SIMD como o AltiVec e o
3DNow.

J. Miguel Leitão Extensões SIMD
5
Arquitecturas SIMD - Single Instruction Multiple Data
Classifica-se como SIMD (Single Instruction Multiple Data) uma máquina que opera
muitos itens de dados simultaneamente, utilizando os mesmos processos de
manipulação para cada item de dados.
ALU
Figura 1. – Soma dos vectores de amostras A e B
A filosofia SIMD serviu de base às primeiras implementações de computadores com
um número de processadores realmente grande. Muitos dos primeiros sistemas
capazes de disponibilizar capacidade computacional da ordem dos GFLOPs foram
também implementados segundo o conceito SIMD.
Esta classificação genérica pode ser atribuída a uma grande variedade de
sistemas, desde supercomputadores a máquinas de processamento numérico

J. Miguel Leitão Extensões SIMD
6
massivo e mais recentemente, extensões destinadas ao processamento de dados
multimédia integradas em microprocessadores.
Como se pode constar da tabela cronológica apresentada no Anexo 1, durante a
segunda metade da década de 90, diversos fabricantes incorporaram nos seus
microprocessadores extensões computacionais baseadas no conceito SIMD, com o
objectivo de melhorar o desempenho de aplicações multimédia. Neste grupo de
extensões incluem-se:
MMX, o SEE e o SEE2 da Intel.
AltiVec integrado no PowerPC.
3D-Now da AMD.
O VIS integrado na família SPARC
O MAX (Multimedia Acceleration eXtensions) da HP
O MDMX dos processadores Mips

J. Miguel Leitão Extensões SIMD
7
Características dos Dados Multimédia
Tipos de dados de dimensão reduzida:
o 8 bits / amostra som baixa qualidade
o 16 bits / amostra som de alta qualidade
o 8 bits / pixel imagem monocromática
o 8 bits / componente de cor / pixel imagem alta qualidade
Pequenos ciclos com grande número de repetições
Multiplicações e acumulações frequentes
Algoritmos de elevado peso computacional
Operações facilmente paralelizáveis
O grande número de dados que tipicamente é necessário tratar de forma
independente, a sua dimensão reduzida e a simplicidade dos processos a que cada
item é sujeito, apontam claramente para adequação de estratégias do tipo SIMD.

J. Miguel Leitão Extensões SIMD
8
MMX
A tecnologia MMX da Intel apareceu no processador Pentium MMX e consiste num
conjunto de extensões à arquitectura dos processadores Intel de 32 bits projectadas
para maximizar o desempenho de aplicações multimédia. Estas extensões
oferecem um modelo de execução SIMD simples, capaz de efectuar
processamentos de 64 bits sobre dados inteiros empacotados.
As extensões associadas à tecnologia MMX podem ser resumidas em:
8 Registos MMX (MM0- MM7)
47 Novas instruções MMX
Estas novas instruções permitem o tratamento em paralelo de diversos itens de
dados do tipo inteiro, empacotados de acordo com os tipos de dados definidos para
o efeito. Para além desta possibilidade de processamento em paralelo, a tecnologia
MMX disponibiliza funcionalidades orientadas para o processamento de dados
multimédia, como por exemplo a aritmética com saturação.
Registos MMX
O novo conjunto de registos MMX é constituído por 8 registos de 64 bits.
Apesar destes registos MMX serem apresentados como um melhoramento
associado à tecnologia MMX, na realidade eles são apenas nomes alternativos para
designar os 64 bits menos significativos dos registos da Unidade de Vírgula
Flutuante (R0-R7), como se mostra na figura 1.
Os registos MMX podem ser acedidos nos modos de 64 bits e de 32 bits. O modo
de acesso de 64 bits é utilizado nas transferências de 64 bits de ou para memória,
nas transferências e dados entre registos MMX, por todas as instruções lógicas,
aritméticas, de empacotamento e por algumas instruções de desempacotamento. O
modo de acesso de 32 bits é utilizado nas transferências de 32 bits de ou para
memória, na transferência de dados com os registos de uso geral e em algumas
instruções de desempacotamento.

J. Miguel Leitão Extensões SIMD
9
mm0
mm1
mm2
mm3
mm4
mm6
mm5
mm7
80 bits
Registos FPU
64 bits
Registos MMX
Figura 2. - Registos MMX
Tipos de dados
Para permitir o processamento paralelo de diversos itens de dados em blocos de 64
bits, foram definidos 4 tipos de dados empacotados, como se apresenta na figura
seguinte.

J. Miguel Leitão Extensões SIMD
10
Quadword (64 bits)
Packed Doublewords (2 x 32 bits)
Packed Words (4 x 16 bits)
Packed Bytes (8 x 8 bits)
063
Figura 3. – Tipos de dados utilizados pela tecnologia MMX
Cada elemento representa uma quantidade inteira, com ou sem sinal.
Saturação
Quando se realizam operações aritméticas de inteiros podem ser obtidos resultados
fora dos limites representáveis para o tipo de dados utilizado. A metodologia de
tratamento destes excessos na maioria dos processadores aritméticos, consiste em
truncar os bits mais significativos e sinalizar, através de flags, a aplicação de nível
superior que se deve encarregar de agir em conformidade.
À semelhança do que acontece na maioria dos processadores vocacionados para o
processamento digital de sinais (DSPs), a tecnologia MMX disponibiliza 3 soluções
aritméticas para tratar estes casos de resultados fora dos limites representáveis:
Wraparound.
Saturação com sinal.
Saturação sem sinal.
A aritmética wraparound corresponde ao que acontece na maioria dos
processadores de uso genérico. Com aritmética deste tipo, os bits do resultado que
não são comportáveis pelo registo de destino são eliminados. Apenas os bits
menos significativos do resultado são colocados no registo de destino. Isto significa
ignorar os bits de carry ou overflow que possam resultar da operação realizada.
J. Miguel Leitão Extensões SIMD
11
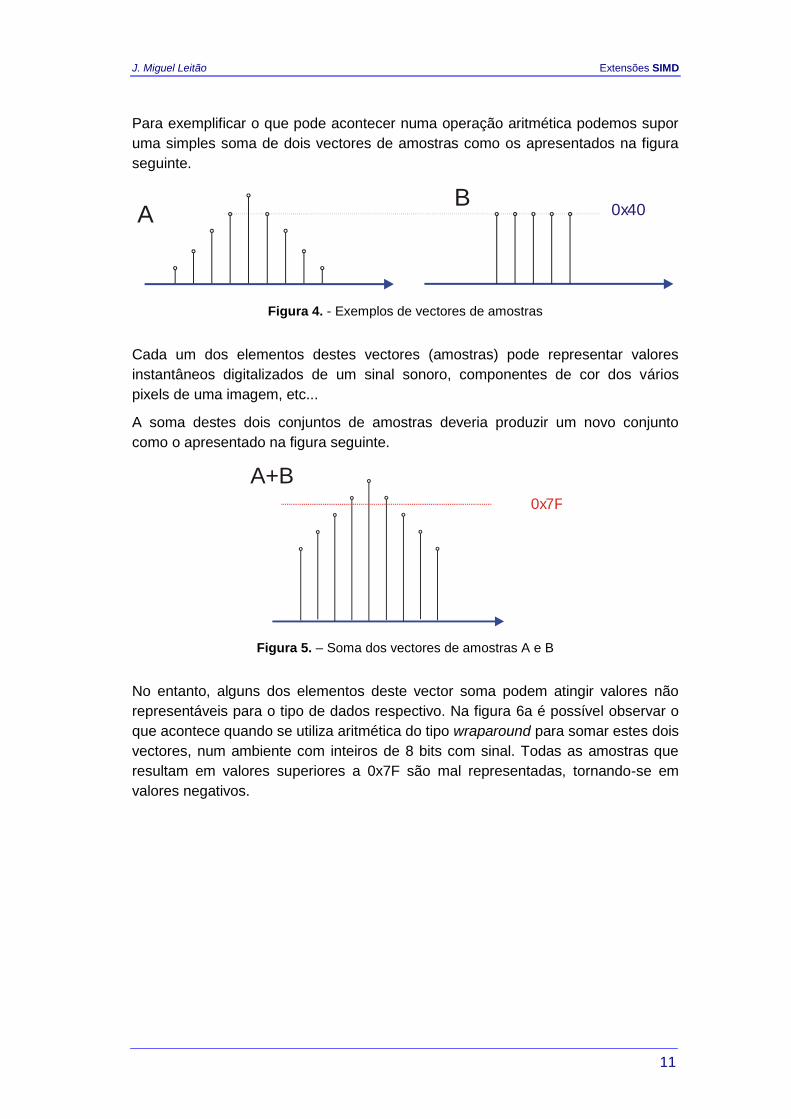
Para exemplificar o que pode acontecer numa operação aritmética podemos supor
uma simples soma de dois vectores de amostras como os apresentados na figura
seguinte.
A 0x40B
Figura 4. - Exemplos de vectores de amostras
Cada um dos elementos destes vectores (amostras) pode representar valores
instantâneos digitalizados de um sinal sonoro, componentes de cor dos vários
pixels de uma imagem, etc...
A soma destes dois conjuntos de amostras deveria produzir um novo conjunto
como o apresentado na figura seguinte.
0x7F
A+B
Figura 5. – Soma dos vectores de amostras A e B
No entanto, alguns dos elementos deste vector soma podem atingir valores não
representáveis para o tipo de dados respectivo. Na figura 6a é possível observar o
que acontece quando se utiliza aritmética do tipo wraparound para somar estes dois
vectores, num ambiente com inteiros de 8 bits com sinal. Todas as amostras que
resultam em valores superiores a 0x7F são mal representadas, tornando-se em
valores negativos.

J. Miguel Leitão Extensões SIMD
12
a b
Figura 6. – Resultado sujeito a: (a) wraparound; (b) saturação
Utilizando aritmética com saturação, os resultados que não são comportáveis pelo
registo de destino são limitados aos limites representáveis para o tipo de dados
respectivo.
Quando numa operação ocorre um resultado com excesso, este é automaticamente
saturado para o valor máximo representável. A figura 6b apresenta o resultado da
soma dos vectores (A e B) saturada dentro limites representáveis com 8 bits com
sinal.
Instruções MMX
As 47 novas instruções MMX podem ser agrupadas nas categorias:
Instruções Aritméticas
Instruções de Comparação
Instruções de Conversão
Instruções Lógicas
Instruções de Deslocamento
Instruções de Transferência de Dados
Instrução de Inicialização (EMMS)
Todas as mnemónicas de instruções MMX (excepto a instrução EMMS) começam
pela letra P que indica processamento de dados empacotados. Seguem-se
caracteres que identificam a operação, o tipo de saturação e o tipo de dados
utilizado, como se indica na figura seguinte.

J. Miguel Leitão Extensões SIMD
13
Packed
POperação
XXX [ S]
com Saturação
[U]
Unsigned
[tipo] Tipo de dados: “B” - Byte
“W” - Word “D” - Doubleword “Q” - Quadword
(8)
(16)
(32)
(64)
Figura 7. - Formato de uma instrução MMX
Operandos
Todas as instruções MMX, excepto a instrução EMMS, esperam dois operandos. O
operando da direita é o operando fonte (SRC) e o da esquerda é o destino (DEST).
Dependendo da operação, este operando de destino pode também ser utilizado
como segunda fonte.
Por exemplo, uma instrução do tipo:
OP DEST(operando esquerdo) SRC(operando direito)
Pode ser descodificada como:
DEST(operando esquerdo) = DEST OP SRC(operando direito)
O operando fonte pode residir num registo MMX ou pode ser lido directamente da
memória.
O operando de destino é normalmente um registo MMX. O conteúdo deste registo é
sobreposto com o resultado da operação.
Para as instruções de transferência de dados os operandos fonte ou destino podem
ser registos de inteiros (instrução MOVD) ou posições de memória (instruções
MOVD e MOVQ).
Instruções Aritméticas
Adição e Subtracção
As instruções PADD (Packed Add) e PSUB (Packed Subtract) somam ou subtraem
os dados, com ou sem sinal, dos operandos fonte e destino, no modo wrap-around.
Estas instruções suportam dados empacotados do tipo byte, word ou doubleword.
As instruções PADDS (Packed Add with Saturation) e PSUBS (Packed Subtract
with Saturation) somam ou subtraem os dados, com sinal, dos operandos fonte e
destino, saturando o resultado dentro dos limites do tipo de dados com sinal
utilizado. Estas instruções aritméticas suportam dados empacotados do tipo byte ou
word.

J. Miguel Leitão Extensões SIMD
14
As instruções PADDUS (Packed Add Unsigned with Saturation) e PSUBUS (Packed
Subtract Unsigned with Saturation) somam ou subtraem os dados, sem sinal, dos
operandos fonte e destino, saturando o resultado dentro dos limites do tipo de
dados sem sinal utilizado. Estas instruções aritméticas suportam dados
empacotados do tipo byte ou word.
A figura seguinte mostra um exemplo da instrução PADDW MM3, MM4, que soma
as 4 words de 16 bits do registo MM3 com as 4 words de igual dimensão do registo
MM4. Os 4 resultados de 16 bits são colocados no registo MM3.
MM3
MM3
MM4
a3 a2 a1 FFFFh
b3 b2 b1 8000h
a3+b3 a2+b2 a1+b1 7FFFh
+ + + +
Figura 8. - Exemplo da instrução PADDW
Como se pode constatar pela coluna da direita, esta operação utiliza aritmética
wraparound: ao resultado da soma (FFFFh+8000h=17FFFh) é truncado o bit mais
significativo de forma a poder ser representado em 16 bits.
A figura seguinte mostra um exemplo da instrução PADDUSW MM3, [myBuffer],
que soma as 4 words de 16 bits do registo MM3 com as 4 words de igual dimensão
lidas da posição myBuffer da memória. Os 4 resultados de 16 bits são colocados no
registo MM3.
MM3
MM3
myBuffer
a3 a2 a1 FFFFh
b3 b2 b1 8000h
a3+b3 a2+b2 a1+b1 FFFFh
+ + + +
Figura 9. - Exemplo da instrução PADDUSW
Como se pode constatar pela coluna da direita, esta operação utiliza aritmética com
saturação sem sinal: como o resultado da soma (FFFFh+8000h=17FFFh) é superior
ao valor máximo sem sinal representável com 16 bits (FFFFh), é utilizado este limite
para representar a soma.

J. Miguel Leitão Extensões SIMD
15
Multiplicação
As instruções de multiplicação empacotada realizam 4 multiplicações em pares de
operandos de 16 bit, produzindo resultados intermédios de 32 bit. O programador
pode optar pelo armazenamento das partes mais significativas ou menos
significativas de cada resultado de 32 bit.
A instrução PMULHW (Packed Multiply High) multiplica as words com sinal dos
operandos fonte e destino e escreve os 16 bits mais significativos do resultado no
operando de destino. A figura seguinte mostra um exemplo da instrução PMULHW
MM3, MM4
MM3
MM3
MM4
0002h 0100h 5622h 1000h
0030h 3A65h 0200h 8000h
0000h 003Ah 00ACh 0800h
* * * *
Figura 10. - Exemplo da instrução PMULHW
A instrução PMULLW (Packed Multiply Low) multiplica as words com sinal dos
operandos fonte e destino e escreve os 16 bits menos significativos do resultado no
operando de destino. A figura seguinte mostra um exemplo da instrução PMULLW
MM3, MM4
MM3
MM3
MM4
0002h 0100h 5622h 1000h
0030h 3A65h 0200h 8000h
0060h 6500h 4400h 0000h
* * * *
Figura 11. - Exemplo da instrução PMULLW
Soma de produtos
A instrução PMADDWD (Packed Multiply and Add) calcula os produtos das words
com sinal dos operandos fonte e destino. Os quatro resultados (doublewords de 32-
bit) são somados em pares, produzindo dois resultados de 32 bit.
A figura seguinte mostra um exemplo da instrução PMADDSW MM3, MM4.

J. Miguel Leitão Extensões SIMD
16
MM3
MM3
MM4
a3 a2 a1 a0
b3 b2 b1 b0
a3*b3+a2*b2 a1*b1+a0*b0
* * * *
Figura 12. - Exemplo da instrução PMADDSW
Instruções de Comparação
As instruções PCMPEQ (Packed Compare for Equal) e PCMPGT (Packed Compare
for Greater Than) comparam os elementos do operando fonte com os elementos
respectivos do operando de destino. Ambas geram uma máscara de zeros ou uns
que é escrita no operando de destino, correspondente ao valor Booleano da
comparação efectuada.
As operações lógicas podem depois utilizar esta máscara para seleccionar
elementos a tratar. Isto pode ser utilizado para implementar processamentos
condicionais sem necessidade de instruções de salto. Ao contrário do que acontece
vulgarmente nas instruções que tratam dados únicos, estas instruções de
comparação não afectam flags internas.
Estas instruções de comparação empacotada podem ser aplicadas a bytes, a words
e a doublewords.
A figura seguinte mostra um exemplo da instrução PCMPGTW MM3, MM4.
MM3
MM3
MM4
21 56 88 76
34 12 92 76
0000h 0000h 0000h
>? >? >? >?
FFFFh
Figura 13. - Exemplo da instrução PCMPGTW
Instruções de Conversão (Pack e Unpack)
As instruções de empacotamento e desempacotamento realizam conversões entre
tipos de dados empacotados.

J. Miguel Leitão Extensões SIMD
17
A instrução PACKSS (Pack with Signed Saturation) converte words com sinal em
bytes com sinal ou doublewords com sinal em words com sinal, utilizando o modo
de saturação com sinal.
A instrução PACKUS (Pack with Unsigned Saturation) converte words com sinal em
bytes sem sinal, utilizando o modo de saturação sem sinal.
As instruções PUNPCKH (Unpack High Packed Data) e PUNPCKL (Unpack Low
Packed Data) convertem bytes em words, words em doublewords, ou doublewords
em quadwords.
MM3
MM3
MM4
B4A4B5A5B6A6B7A7
B0B1B2B3B4B5B6B7A0A1A2A3A4A5A6A7
Instruções Lógicas
As instruções PAND (Packed Bitwise Logical And), PANDN (Packed Bitwise Logical
And Not), POR (Packed Bitwise Logical OR), e PXOR (Packed Bitwise Logical
Exclusive OR) realizam operações lógicas bit a bit em operandos de 64 bits.
Instruções de Deslocamento
As instruções de deslocamento permitem deslocar, individualmente, cada elemento
no sentido e número de bits especificados.
A instrução PSLL (Packed Shift Left Logical) realiza um deslocamento lógico para a
esquerda, preenchendo os bits menos significativos que surgem à direita com
zeros.
A instrução PSRL (Packed Shift Right Logical) realiza um deslocamento lógico para
a direita, preenchendo os bits mais significativos que surgem à esquerda com
zeros.
Estas instruções de deslocamento lógico podem ser aplicadas a dados
empacotados de 8, 16, 32 e 64 bits.
A instrução PSRA (Packed Shift Right Arithmetic) realiza um deslocamento
aritmético para a direita, preenchendo os bits mais significativos que surgem à
esquerda com o bit de sinal. Esta instrução de deslocamento aritmético pode ser
aplicada a dados empacotados de 8, 16 e 32 bits.

J. Miguel Leitão Extensões SIMD
18
Instruções de transferência de dados
A instrução MOVD (Move Doubleword) transfere 32 bits de dados empacotados da
memória para um registo MMX e vice versa, ou de um registo uso geral para um
registo MMX e vice versa.
A instrução MOVQ (Move Quadword) transfere 64 bits de dados empacotados da
memória para um registo MMX e vice versa, ou efectua transferências entre
registos MMX.
Instrução EMMS
A instrução EMMS (Empty MMX State) limpa os registos de estado MMX. Esta
instrução deve ser utilizada para limpar as variáveis MMX no final de uma rotina
MMX antes da execução de qualquer instrução de vírgula flutuante.
Instruções MMX e Vírgula flutuante
Sempre que um programador decide utilizar a tecnologia MMX é necessário ter em
atenção que os registos MMX são mapeados sobre os registos da Unidade de
Vírgula Flutuante (FPU). Passar de um contexto de programação MMX para um
contexto de programação FPU pode provocar um atraso de 5 ciclos de clock. É
portanto conveniente minimizar as alterações entre contextos de programação
destes dois tipos.
As aplicações que necessitam de utilizar secções de instruções MMX e secções de
instruções FPU, não devem confiar no conteúdo dos registos (MMX e FPU) quando
iniciam uma secção de instruções de um destes tipos.
Como se apresenta no esqueleto de programa seguinte, as secções de programa
que utilizem instruções MMX devem ser concluídas com a instrução EMMS. As
secções de programa que utilizem instruções de vírgula flutuante devem deixar a
stack limpa.
FP_code:
..
.. (* deixa a stack FP limpa *)
MMX_code:
..
EMMS (* limpa a contexto MMX *)
FP_code 1:
..
.. (* deixa a stack FP limpa *)
Alinhamento dos dados
Os problemas de alinhamento dos dados são já conhecidos das arquitecturas de 16
e de 32 bits. Um alinhamento deficiente dos dados na memória implica
normalmente prejuízos de desempenho devidos à multiplicação dos ciclos de

J. Miguel Leitão Extensões SIMD
19
acesso à memória. Estes problemas são ainda mais delicados quando se passam a
utilizar dados de 64 bits.
A maioria dos compiladores permite especificar o alinhamento das variáveis através
de directivas de controlo. De uma maneira geral, isto permite resolver de forma
simples os problemas de alinhamento das variáveis declaradas. No entanto, se esta
funcionalidade não estiver disponível ou se for ineficaz, é possível impor o
alinhamento utilizando um algoritmo como o exemplificado a seguir:
new_ptr = malloc(new_value * sizeof (var_struct) + 8);
mem_tmp = new_ptr;
mem_tmp /= 8;
new_tmp_ptr = (var_struct*) ((mem_tmp+1) * 8);
Este exemplo aloca um vector de new_value elementos do tipo var_struct
alinhado para acessos de 64 bits. Este alinhamento pode permitir um ganho de 3
ciclos de clock em cada acesso a elementos deste vector.
Em casos de acessos muito frequentes pode até tornar-se vantajoso realizar um
alinhamento pela cópia dos dados para uma zona alinhada da memória, antes de
iniciar o processamento.
Alinhamento da Stack
Normalmente, os compiladores utilizam a stack para alocar todas as variáveis que
não sejam declaradas como estáticas. Sempre que seja necessário utilizar
quantidades de 64 bits colocadas na stack torna-se importante garantir que a stack
esteja também alinhada nas fronteiras de 64 bits.
Os blocos código seguintes, colocados respectivamente no prólogo e no epílogo de
uma função permitem garantir o alinhamento da stack dentro da função.
Prologue:
push ebp ; preserva ebp
mov ebp, esp ; stack ptr
sub ebp, 4 ; aloca espaço para
; stack ptr
and ebp, 0FFFFFFFC ; alinha a 64 bits
mov [ebp], esp ; preserva stack ptr
mov esp, ebp ; alinha esp
…
epilogue:
…
mov esp, [ebp] ; recupera esp
pop ebp ; recupera ebp
ret
É também possível copiar previamente os dados desalinhados da stack para uma
zona alinhada da memória.

J. Miguel Leitão Extensões SIMD
20
Alinhamento
Há no entanto aplicações em que os padrões de acessos aos dados são
inerentemente desalinhados. Isto significa que pode não ser possível encontrar uma
localização dos dados na memória que elimine completamente os acessos
desalinhados. Um exemplo simples de um destes casos é o filtro FIR. Um filtro FIR
é obtido, para cada amostra do sinal a filtrar, pela soma das amostras vizinhas
pesadas pelos coeficientes respectivos. Assim, se a operação de filtragem para o
elemento i dos dados for obtida pela soma pesada dos elementos j e seguintes,
então, para o elemento i+1 dos dados esta soma deverá utilizar os elementos j+1 e
seguintes.
n
p
pcoefpjdataifir0
*
n
p
pcoefpjdataifir0
*11
Uma vez que as transferências de dados da memória são realizadas em 64 bits, e
admitindo que as amostras do sinal são representadas com palavras de
comprimento menor, os acessos aos dados a partir de duas posições consecutivas
da memória nunca poderão ser alinhados em simultâneo. Se os dados forem
colocados de forma a permitir um acesso alinhado aos elementos j e seguintes,
então o acesso aos elementos da posição j+1 e seguintes será desalinhado.

J. Miguel Leitão Extensões SIMD
21
Exemplos de Aplicação
Nesta secção apresentam-se algumas aplicações exemplificativas da utilização da
tecnologia MMX.
Selecção Condicional
Neste exemplo utiliza-se uma imagem de uma borboleta sobre um fundo verde
(imagem X) para realizar uma sobreposição condicional sobre a paisagem da
imagem Y. O resultado deve ser a imagem sobreposta (S) apresentada na figura
seguinte.
+ =
X + Y = S
Figura 14. – Soma condicional de duas imagens
Assumindo que utilizamos representações de 16 bits por pixel, o processamento
pode ser efectuado, em paralelo, a cada grupo de 4 pixels, devidamente
empacotados em registos MMX.
X1!=green
green
X2=green
green
X3!=green
green
X4=green
green
0000h FFFFh 0000h FFFFh
=? =? =? =?
Figura 15. - Obtenção da imagem de máscara

J. Miguel Leitão Extensões SIMD
22
A instrução de comparação PCMPEQW permite criar uma máscara identificadora
da presença ou não do fundo verde na primeira imagem. Esta máscara é uma
sequência de valores com os bits todos a um ou os bits todos a zero, representando
os valores Booleanos Verdadeiro e Falso. Esta máscara corresponde à imagem
sombra da figura 15.
Esta máscara é depois usada nos mesmos pixels da imagem da borboleta e nos
pixels equivalentes da imagem florida. As instruções PANDN e PAND utilizam a
máscara para identificar quais os pixels que devem ser aproveitados de cada uma
das imagens. Os pixels não necessários são colocados a zero (preto). Em seguida,
a instrução POR soma as duas imagens mascaradas para produzir a imagem final.
X1 X2 X3 X4
0000h FFFFh 0000h FFFFh
X1 0000h X3 0000h
pandn pandn pandn pandn
Y1 Y2 Y3 Y4
0000h FFFFh 0000h FFFFh
0000h Y2 0000h Y4
pand pand pand pand
X1 Y2 X3 Y4
POR
Figura 16. - Junção de duas imagens através de uma máscara
Apenas quatro instruções MMX são suficientes para produzir quatro pixels da
imagem final, sem a inclusão de qualquer salto ou instrução condicional.

J. Miguel Leitão Extensões SIMD
23
Neste exemplo as imagens foram tratadas utilizando 16 bits para representar cada
pixel. É também possível utilizar instruções MMX para aplicar o mesmo tratamento
a imagens representadas em 8 bits por pixel, duplicando o número de pixels
processados com o mesmo número de instruções.
Soma de Produtos
As somas de produtos são operações muito frequentes no processamento de
dados multimédia digitalizados. Os filtros e as transformações geométricas, por
exemplo, são operações normalmente implementadas através de somas de
produtos.
Como se pode observar pela figura seguinte, a implementação de uma soma de
produtos de quantidades inteiras de 16 bits pode ser efectuado pela instrução
PMADDWD, seguida da soma dos resultados parciais com a instrução PADDD.
)()(7
0
iciaxi
a0 a1 a2 a3
c0 c1 c2 c3
paddd
paddd
pshfr 32
pmaddwd* * * *
a4 a5 a6 a7
c4
…
c5
x
c6 c7
a0*c0 + a1*c1 a2*c2 + a3*c3 a4*c4 + a5*c5 a6*c6 + a7*c7
* * * *
a0*c0 + a1*c1 ++ a4*c4 + a5*c5
0
a2*c2 + a3*c3 ++ a6*c6 + a7*c7
a2*c2 + a3*c3 ++ a6*c6 + a7*c7
Figura 17. - Exemplo de implementação de uma soma de produtos
A tabela seguinte permite comparar o número de instruções necessárias para
realizar esta soma de produtos, com e sem a utilização da tecnologia MMX.

J. Miguel Leitão Extensões SIMD
24
Número de instruções
sem tecnologia MMX
Número de
instruções MMX
Load 16 4
Multiply 8 2
Shift 0 1
Add 7 2
Store 1 1
Total 32 10
Produto de matrizes
O produto de 2 matrizes é um caso de utilização sistemática de somas de produtos.
O exemplo ilustrado na figura seguinte corresponde à aplicação de uma
transformação geométrica a um ponto tridimensional definido em coordenadas
homogéneas.
13210
3210
3210
3210
z
y
x
dddd
cccc
bbbb
aaaa
w
z
y
x
Perspectiva
TranslacçãoRotação eescalamento
Figura 18. - Transformação geométrica de um ponto 3D
A tabela seguinte permite comparar o número de instruções necessárias para
realizar este produto de matrizes, com e sem a utilização da tecnologia MMX.

J. Miguel Leitão Extensões SIMD
25
Número de instruções
sem tecnologia MMX
Número de
instruções MMX
Load 32 6
Multiply 16 4
Add 12 2
Miscellaneous 8 12
Store 4 4
Total 72 28
Junção de Imagens
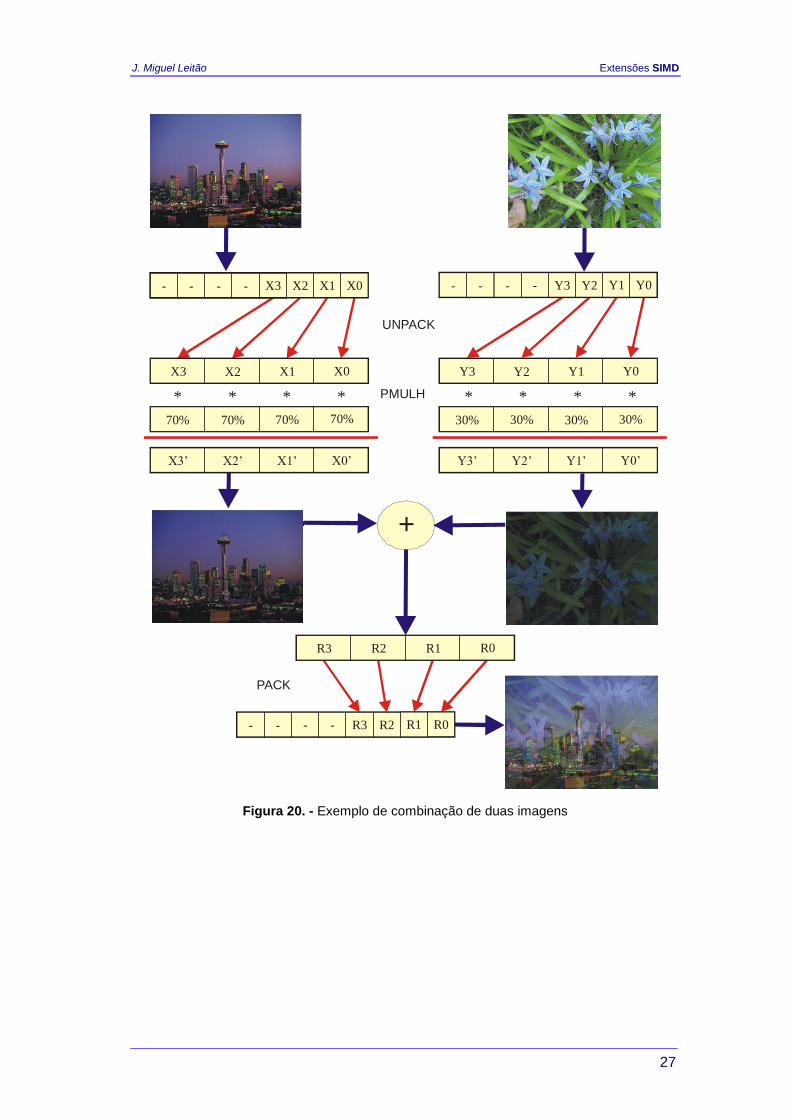
Neste exemplo pretende-se combinar duas imagens em função de parâmetro de
transparência (alfa), como se representa na figura seguinte.
70% + 30% =
Figura 19. – Junção de duas imagens
Considera-se que as imagens se encontram representadas por conjuntos de bytes
que podem ser carregados para registos MMX, empacotados em grupos de 8. O
escalamento das imagens pode ser efectuado em simultâneo para 4 pixels da
imagem através da instrução PMUL que apenas está disponível para dados de 16
bits. Existe portanto a necessidade de desempacotar previamente cada grupo de 4
bytes, que podem corresponder a 4 pixels de um plano de cor da imagem ou a 4
componentes de cor de um pixel, para words de 16 bits. No final, os pixels são
novamente empacotados para bytes. A figura 20 ilustra a aplicação deste processo
a um conjunto de 4 bytes. Este processo pode ser duplicado para cada grupo de 8
bytes, resultando no programa seguinte:
; mm0 contém 0
; mm7 contem 4CCC 4CCC 4CCC 4CCC h (30% 30% 30% 30%)
; mm6 contém B333 B333 B333 B333 h (70% 70% 70% 70%)
; mm1 contém 8 pixels da imagem X
; mm2 contém 8 pixels da imagem Y
; preserva pixels
movq mm3, mm1
movq mm4, mm2
; trata 4 pixels menos significativos
punpcklbw mm1, mm0
punpcklbw mm2, mm0

J. Miguel Leitão Extensões SIMD
26
pmulhw mm1, mm6 ; escala imagem X
pmulhw mm2, mm7 ; escala imagem Y
paddw mm1, mm2
; trata 4 pixels mais significativos
punpckhbw mm3, mm0
punpckhbw mm4, mm0
pmulhw mm3, mm6 ; escala imagem X
pmulhw mm4, mm7 ; escala imagem Y
paddw mm3, mm4
; empacota 8 pixels da imagem final para mm1
packuswb mm1, mm2
J. Miguel Leitão Extensões SIMD
27
X3 X2 X1 X0
X0 Y0X1 Y1X2 Y2X3 Y3- -- -- -- -
70% 70% 70% 70%
X3’ X2’ X1’ X0’
* * * *
Y3 Y2 Y1 Y0
30% 30% 30% 30%
Y3’ Y1’ Y0’
R3
PACK
UNPACK
PMULH
R2 R1 R0
+
* * * *
R0R1R2R3----
Figura 20. - Exemplo de combinação de duas imagens

J. Miguel Leitão Extensões SIMD
28
SSE - Streaming SIMD Extensions
A tecnologia MMX introduziu capacidades SIMD na arquitectura Intel de 32 bits
através da utilização de registos de 64 bits e de novas instruções que permitem
tratar dados inteiros empacotados.
As extensões SSE, introduzidas no processador Pentium III, ampliam ainda mais
este modelo de execução SIMD pela adição de novas funcionalidades de
processamento empacotado ou escalar de valores representados em vírgula
flutuante de precisão simples, contidos em registos de 128 bits.
4 x Floating Foint (4 x 32 bits)
Figura 21. – Registo com 4 valores representados em vírgula flutuante de 32 bits.
As extensões SSE mantêm a compatibilidade com toda a arquitectura de 32 bits da
Intel, incluindo as extensões MMX. As principais adições associadas a esta
tecnologia são:
8 novos registos de 128 bits (XMM0 – XMM7), como se apresenta na figura
22.
Novo registo de 32 bits (MXCSR). Este registo contém bits de controlo e de
status das operações realizadas nos registos XMM.
Novo tipo de dados: 4 valores representados em vírgula flutuante de
precisão simples (32 bits) empacotados em registos de 128 bits (figura 21).
Novas instruções SIMD para suportar operações de 128 bits sobre valores
representados em vírgula flutuante de precisão simples empacotados nos
registos XMM (XMM0-XMM7).
Novas instruções SIMD de 64 bits para suportar operações adicionais sobre
inteiros empacotados nos registos MMX (MM0-MM7).
Instruções para controlo da cache de dados.

J. Miguel Leitão Extensões SIMD
29
xmm0
xmm1
xmm2
xmm3
xmm4
xmm6
xmm5
xmm7
128 bits
Figura 22. – Registos SSE (xmm0-xmm7)
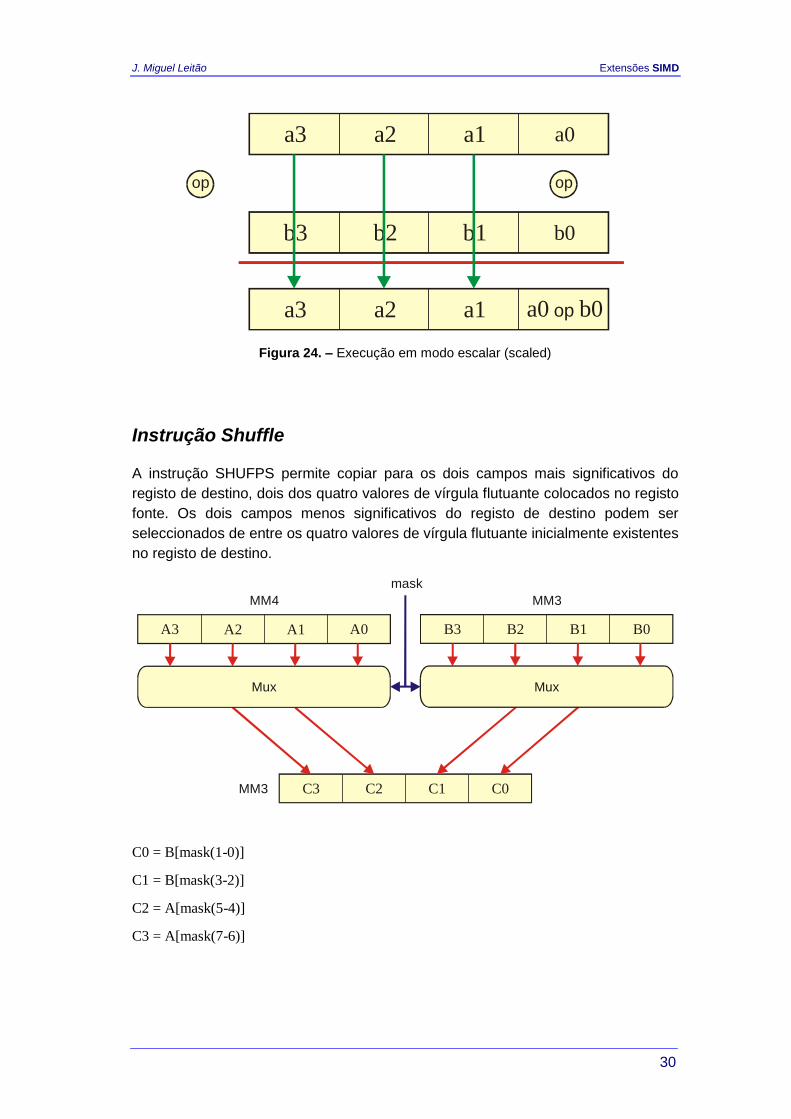
Para além do processamento em modo empacotado (figura 23) já aplicado na
tecnologia MMX, foi agora introduzido o modo escalar que permite afectar apenas
um dos elementos empacotados, como se representa na figura 24.
a3 a2 a1 a0
b3 b2 b1 b0
a3 b3 op a2 b2 op a1 b1 op a0 b0 op
op op op op op
Figura 23. – Execução em modo empacotado (packed)
O modo de execução é seleccionado pelo programador através do sufixo da
instrução:
PS – para processamento empacotado.
SS – para processamento escalar.
J. Miguel Leitão Extensões SIMD
30
a3 a2 a1 a0
b3 b2 b1 b0
a3 a2 a1 a0 b0 op
op op
Figura 24. – Execução em modo escalar (scaled)
Instrução Shuffle
A instrução SHUFPS permite copiar para os dois campos mais significativos do
registo de destino, dois dos quatro valores de vírgula flutuante colocados no registo
fonte. Os dois campos menos significativos do registo de destino podem ser
seleccionados de entre os quatro valores de vírgula flutuante inicialmente existentes
no registo de destino.
C0C1C2C3MM3
B0B1B2B3
MM3
A0A1A2A3
MM4
mask
Mux Mux
C0 = B[mask(1-0)]
C1 = B[mask(3-2)]
C2 = A[mask(5-4)]
C3 = A[mask(7-6)]

J. Miguel Leitão Extensões SIMD
31
Exemplo de aplicação de SSE
Para comparar, elemento a elemento, dois vectores (a[ ] e b[ ]) de 4 números
representados em virgula flutuante, poderia ser utilizado o seguinte programa em C:
float a[4], b[4]
int i, c[4];
// a[] contém 4.9 6.3 3.1 25.6
// b[] contém 9.4 1.8 3.5 12.7
for (i = 0;i < 4; i++ )
c[i] = a[i] < b[i];
O vector c[ ] fica com uma máscara correspondente aos valores booleanos da
comparação efectuada.
O mesmo resultado pode ser obtido utilizando as funcionalidades disponibilizadas
pela tecnologia SSE, como se apresenta no seguinte excerto de programa:
; xmm3 contém 4.9 6.3 3.1 25.6
; xmm4 contém 9.4 1.8 3.5 12.7
; compara xmm3 com xmm4
cmpps xmm3, xmm4, 1;
; coloca o resultado em eax, na forma de máscara
movmskps eax, xmm3;
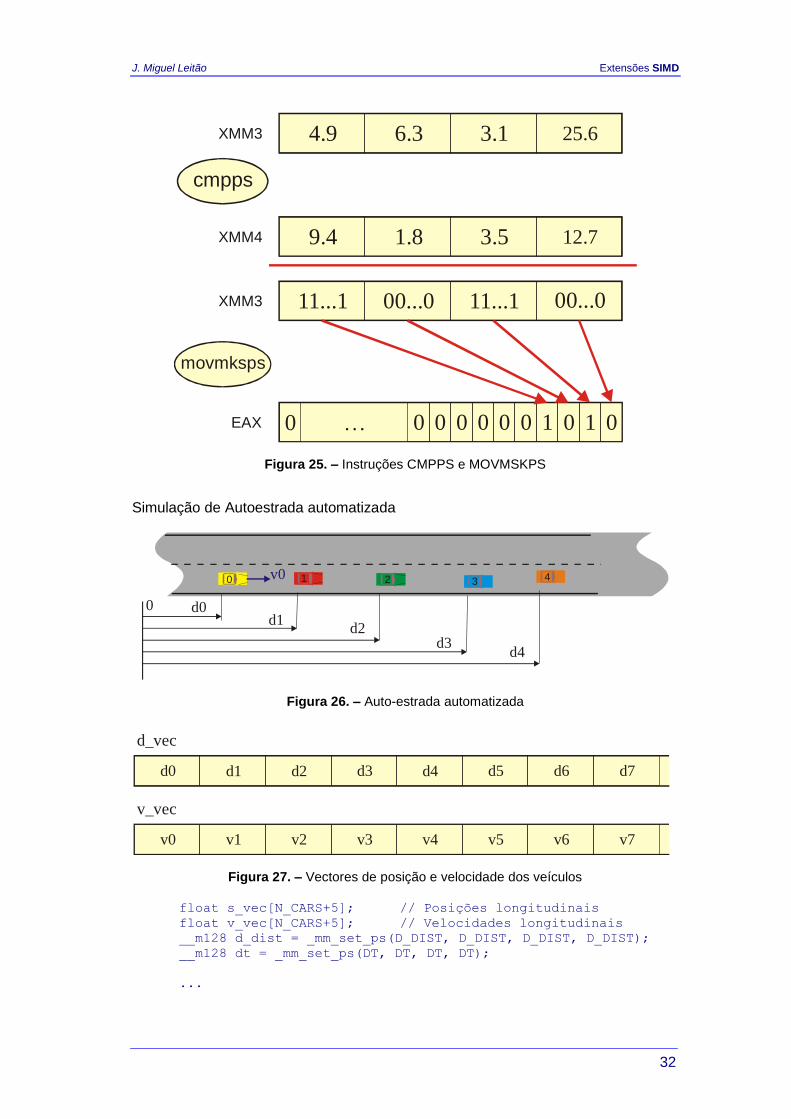
A figura seguinte ilustra a execução destas instruções. A instrução CMPPS
compara os 2 conjuntos de valores localizados nos operandos (XMM3 e XMM4) e
coloca o resultado no primeiro operando (XMM3). O terceiro operando indica o tipo
de comparação a efectuar. Neste caso foi utilizada uma comparação do tipo menor
que, de forma a colocar no registo de saída (XMM3) o valor FFFFFFFFh quando o
elemento do primeiro operando é superior ao elemento respectivo do segundo
operando. No caso inverso é colocado o valor 00000000h no registo de saída.
Este resultado é depois mapeado para uma máscara de um bit por elemento e
colocado num registo de uso genérico através da instrução MOVMSKPS.
J. Miguel Leitão Extensões SIMD
32
4.9 6.3 3.1 25.6
9.4 1.8 3.5 12.7
11...1 00...0 11...1 00...0
0101000000…0
cmpps
XMM3
XMM3
XMM4
EAX
movmksps
Figura 25. – Instruções CMPPS e MOVMSKPS
Simulação de Autoestrada automatizada
d00d1
d2d3
d4
0 1 2 3 4v0
Figura 26. – Auto-estrada automatizada
d0
d_vec
d1 d2 d3 d4 d5 d6 d7
v0
v_vec
v1 v2 v3 v4 v5 v6 v7
Figura 27. – Vectores de posição e velocidade dos veículos
float s_vec[N_CARS+5]; // Posições longitudinais
float v_vec[N_CARS+5]; // Velocidades longitudinais
__m128 d_dist = _mm_set_ps(D_DIST, D_DIST, D_DIST, D_DIST);
__m128 dt = _mm_set_ps(DT, DT, DT, DT);
...
J. Miguel Leitão Extensões SIMD
33
for( int i=0 ; i<N_CARS ; i+=4 ) {
__m128 s, s_frt, d_ftr, dt;
s = _mm_load_ps(s_vec+i); // Posição de 4 carros
s_ftr = _mm_loadu_ps(s_vec+i+1); // carros da frente
d_ftr = _mm_sub_ps(s_frt, s); // distância frente
d_ftr = _mm_sub_ps(d_ftr, d_dist); // erro de posição
a = ... // aceleração
v = _mm_load_ps(v_vec+i);
v = _mm_add_ps(v, _mm_mul_ps(a, dt)); // v = v + a.dt
_mm_store_ps(v_vec+i, v); // guarda velocidade
s = _mm_add_ps(s, _mm_mul_ps(v, dt)); // s = s + v.dt
_mm_store_ps(s_vec+i, s); // guarda posição
}
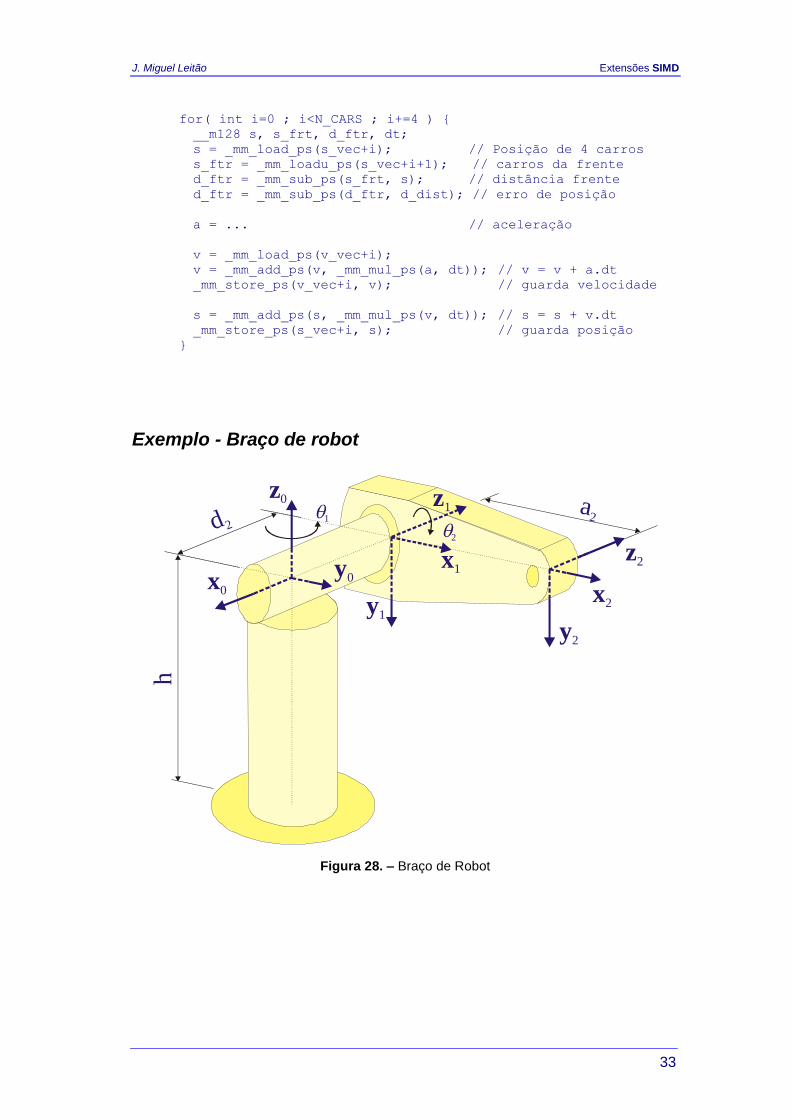
Exemplo - Braço de robot
z0 z1
z2
a2d 2
h
x1
x2y1
y2
1
2
x0
y0
Figura 28. – Braço de Robot

J. Miguel Leitão Extensões SIMD
34
1000
0010
00
00
11
11
1
0CS
SC
A
1000
100
0
0
2
2222
2222
2
1
d
SaCS
CaSC
A
iiii SC sencos
1000
0 2222
1221212121
1221212121
2
1
1
0
2
0
SaCS
CdCSaCSSCS
SdCCaSSCCC
AAT
SSE2
As extensões SSE2 foram introduzidas no processador Intel Pentium 4, lançado em
Novembro de 2000. Apresentam 144 novas instruções destinadas ao
processamento de dados empacotados nos registos XMM. As novas instruções
incluem funcionalidades para tratamento de novos tipos de dados como os números
de vírgula flutuante de dupla precisão e os inteiros (doubleword ou quadword). As
funcionalidades de tratamento de inteiros introduzidas na tecnologia MMX foram
agora estendidas a dados empacotados de 128 bits, duplicando portanto a
capacidade de processamento de dados deste tipo.
SSE3
As extensões SSE3 (Streaming SIMD Extensions 3) permitem um alargamento das
capacidades SIMD disponibilizadas pelas extensões SSE e SSE2. Oferecem um
aumento do desempenho no processamento de dados em diversas áreas como por
exemplo a aritmética de números complexos e na descodificação de video.
A maioria das instruções SSE e SSE2 que implementam operações aritméticas são
vocacionadas para o processamento paralelo de dados num modelo vertical. Neste
modelo, todos os elementos dos operandos de entrada são tratados uniformemente
pela mesma operação. A utilização eficiente destas instruções vocacionadas para o
processamento vertical obriga à organização dos dados em conjuntos
perfeitamente homogéneos o que por vezes implica um esforço adicional de
organização.

J. Miguel Leitão Extensões SIMD
35
A tecnologia SSE3 apresenta algumas novas instruções que permitem um
processamento mais rápido de conjuntos de dados que têm de ser operados de
forma assimétrica ou não homogénia. Dois exemplos de instruções deste tipo são
as novas instruções ADDSUBPS e HADDPD.
A instrução ADDSUBPS permite efectuar operações aritméticas assimétricas. Dois
pares de valores de vírgula flutuante de precisão simples são adicionados e dois
pares de valores do mesmo tipo são subtraídos simultaneamente. Esta
funcionalidade permite implementações mais directas de algumas operações
básicas da álgebra de números complexos.
Figura 29. – Operação ADDSUBPS
A instrução HADDPD é um exemplo de uma instrução que permite efectuar
operações aritméticas em conjuntos de elementos que se encontram organizados
de forma não compatível com o modelo de computação vertical. Esta instrução
realiza uma soma horizontal de elementos adjacentes do mesmo operando. As
somas e subtrações horizontais podem ser úteis para a determinação de produtos
escalares e produtos vectoriais.
Figura 30. – Operação HADDPD

J. Miguel Leitão Extensões SIMD
36
SSSE3
As extensões SSSE3 (Supplemental Streaming SIMD Extensions 3) correspondem
a uma actualização das extensões SSE3 que permite alargar as possibilidades de
processamento horizontal de dados empacotados nos registos XMM. Esta
tecnologia está disponível nos processadores Intel CORE e Intel CORE Duo.
SSE4
A versão 4 das extensões SSE disponibiliza 54 novas instruções e começou a ser
incorporada nos processadores da Intel em 2008. Um subconjunto de 47 destas
instruções foi disponibilizado nos processadores da micro-arquitectura Penryn,
sendo normalmente referido como SSE4.1. O conjunto completo das instruções
SSE4.1 com as sete instruções adicionais é por vezes referido como SSE4.2 e está
disponível em todos os processadores com a micro-arquitectura Nehalem (Core I3,
I5 e I7).
As extensões SSE4.1 são vocacionadas para o desempenho de tarefas envolvendo
dados multimédia, 3D e imagens. As suas 47 novas instruções incluem:
• Duas instruções para multiplicação de DoubleWords empacotadas.
• Duas instruções para produto escalar de vectores
• Uma instrução para leitura de dados em fluxo (streaming).
• Seis instruções para cópia e junção condicional de dados empacotados.
• Oito instruções para determinação de máximo e mínimo.
• Quatro instruções para arredondamento de valores de vírgula flutuante
• Sete instruções de transferência de dados de e para os registos XMM.
• Doze instruções para conversões de formatos de inteiros empacotados.
• Uma instrução para cálculo da soma de diferenças absolutas (SAD).
• Uma instrução de pesquisa horizontal.
• Uma instrução para implementação de comparações com máscara.
As sete instruções disponibilizadas adicionalmente nas unidades SSE4.2 incluem
instruções vocacionadas para o processamento texto e de cadeias de caracteres e
instruções que facilitam o processamento SIMD de dados localizados nos registos
de uso geral.
Mais informação: http://software.intel.com/file/18187

J. Miguel Leitão Extensões SIMD
37
AVX
As extensões AVX (Advanced Vector Extensions) são implementadas por novas
unidades computacionais SIMD apresentadas em 2008 e incorporadas nos
processadores Intel e AMD desde 2011. Apresentam um conjunto de 16 novos
registos de 256 bits designados YMM0-YMM15.
Disponibilizam novas operações com 3 operandos que evitam a sobreposição dos
operandos de entrada pelos resultados das operações. As novas instruções são
identificáveis pelo prefixo VEX e vocacionadas para o tratamento de dados de
vírgula flutuante empacotados nos novos registos.
AVX2
As extensões AVX2 encontram-se integradas em alguns processadores desde
2013 e alargam também as capacidades de processamento SIMD a dados do tipo
inteiro empacotados nos registos YMM de 256 bits.
Uma nova instrução FMA (Fused Multiply and Add) foi introduzida com o objectivo
de agilizar o cálculo de somas de produtos.
AVX512
As extensões de AVX de 512 bits foram apresentadas pela Intel em 2013.
Disponibilizam um conjunto de 32 registos de 512 bits designados ZMM0-ZMM31,
sobre o qual são mapeados os registos das unidades SIMD anteriores (YMM e
XMM).
As novas instruções são organizadas num conjunto base (AVX512 Foundation) que
será comum ao todos os processadores com esta tecnologia e conjuntos adicionais
que serão incorporados pontualmente apenas em algumas versões.

J. Miguel Leitão Extensões SIMD
38
Desenvolvimento
Biblioteca intrínseca
A biblioteca intrínseca de extensões SIMD da Intel é uma ferramenta adicional de
desenvolvimento que oferece um acesso directo às funcionalidades MMX ou SSE a
partir de programação em linguagem C. Todas as instruções MMX ou SSE
possuem uma função C correspondente na biblioteca intrínseca.
A mnemónica de linguagem assembly para somar os valores de vírgula flutuante
empacotados em dois registos XMM é addps. A biblioteca intrínseca define uma
função correspondente com o nome _mm_add_ps.
Para além de definir funções para todas as instruções, a biblioteca intrínseca define
também um tipo de dados (__m128) de 128 bits. Numa variável deste tipo é possível
armazenar 4 quantidades do tipo float. Estas variáveis podem ser inicializadas
através das funções:
__m128 _mm_load_ps(float*)
ou
__m128 _mm_set_ps(float,float,float,float);
Exemplo:
float a[4] = { 1.0, 2.0, 3.0, 4.0 };
__m128 t = _mm_load_ps(a);
Produz o mesmo efeito que:
__m128 t = _mm_set_ps(4.0, 3.0, 2.0, 1.0);
Ou seja,
t = [ 4.0, 3.0, 2.0, 1.0 ]
Para utilizar a biblioteca intrínseca é necessário incluir o ficheiro xmmintrin.h.
#include <xmmintrin.h>
...
__m64 ai, bi, ci;
char av[8] = { 1, 2, 3, 4, 5, 6, 7, 8};
char bv[8] = { 1, 2, 3, 4, 5, 6, 7, 8};
char cv[8];
ai = _mm_load_q(av);

J. Miguel Leitão Extensões SIMD
39
Exemplo de utilização
Neste exemplo vai ser utilizada a funcionalidade SSE de multiplicação de números
de vírgula flutuante empacotados, acessível através da mnemónica assembly
mulps ou da função C _mm_mul_ps().
As variáveis a, b e c são declaradas com o tipo __m128, que permite representar 4
quantidades de vírgula flutuante de 32 bits.
As variáveis a e b são inicializadas com os valores a multiplicar, através da função
_mm_set_ps. Esta função utiliza o primeiro parâmetro para definir o valor mais
significativo e o último parâmetro para o valor menos significativo.
Por fim, é utilizada a função _mm_mul_ps para obter os 4 produtos que ficam
empacotados na variável c.
#include <xmmintrin.h>
...
__m128 a, b, c;
a = _mm_set_ps(4.0, 5.0, 1.0, 2.0);
b = _mm_set_ps(3.0, 2.0, 6.0, 8.0);
c = _mm_set_ps(0., 0., 0., 0.);
c = _mm_mul_ps(a, b);
...
float s_vec[N_CARS+5]; // Posições longitudinais
float v_vec[N_CARS+5]; // Velocidades longitudinais
__m128 d_dist = _mm_set_ps(D_DIST, D_DIST, D_DIST, D_DIST);
__m128 dt = _mm_set_ps(DT, DT, DT, DT);
for( int i=0 ; i<N_CARS ; i+=4 )
{
__m128 s, s_frt, d_ftr, dt;
s = _mm_load_ps(s_vec+i); // Posição de 4 carros
s_ftr = _mm_load_ps(s_vec+i+1); // carros da frente
d_ftr = _mm_sub_ps(s_frt, s); // distância frente
d_ftr = _mm_sub_ps(d_ftr, d_dist); // erro de posição
a = ... // aceleração máxima
v = _mm_load_ps(v_vec+i);
v = _mm_add_ps(v, _mm_mul_ps(a, dt)); // v = v + a.dt
_mm_store_ps(v_vec+i, v); // guarda velocidade
s = _mm_add_ps(s, _mm_mul_ps(v, dt)); // s = s + v.dt
_mm_store_ps(s_vec+i, s); // guarda posição
}
Classes C++
Outra ferramenta adicional disponível para o desenvolvimento de aplicações com
acesso às funcionalidades MMX ou SSE, são as classes C++ das famílias Ivec,
J. Miguel Leitão Extensões SIMD
40
Fvec, e Dvec, disponibilizadas pelo sistema de desenvolvimento da Intel. Todas as
operações possíveis para cada tipo de dados empacotados são encapsuladas pela
classe respectiva.
Internamente, estas classes utilizam as funções da biblioteca intrínseca.
Para utilizar a classe F32vec4 é necessário incluir o ficheiro fvec.h.
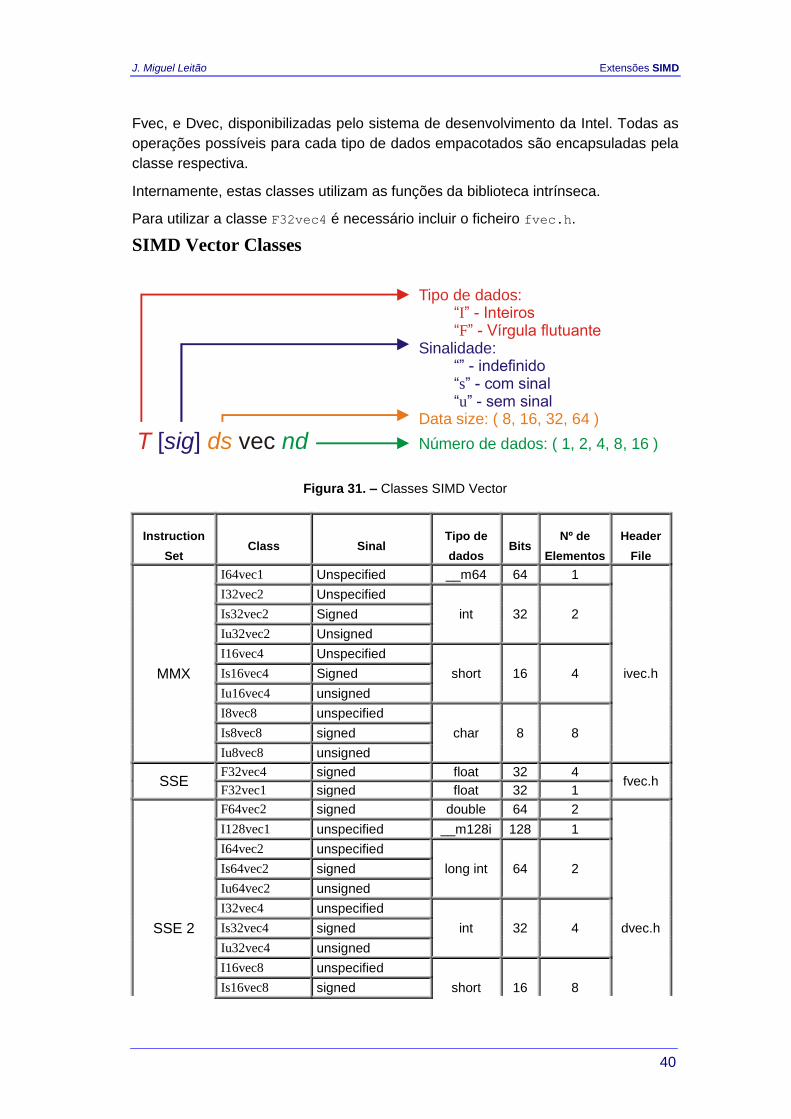
SIMD Vector Classes
Tipo de dados:“ ” - Inteiros“ ” - Vírgula flutuanteIF
T
Sinalidade: “” - indefinido“ ” - com sinal“ ” - sem sinalsu
[ ] sigData size: ( 8, 16, 32, 64 )
ds vec nd Número de dados: ( 1, 2, 4, 8, 16 )
Figura 31. – Classes SIMD Vector
Instruction
Set Class Sinal
Tipo de
dados Bits
Nº de
Elementos
Header
File
I64vec1 Unspecified __m64 64 1
I32vec2 Unspecified
Is32vec2 Signed int 32 2
Iu32vec2 Unsigned
I16vec4 Unspecified
MMX Is16vec4 Signed short 16 4 ivec.h
Iu16vec4 unsigned
I8vec8 unspecified
Is8vec8 signed char 8 8
Iu8vec8 unsigned
SSE F32vec4 signed float 32 4
fvec.h F32vec1 signed float 32 1
F64vec2 signed double 64 2
I128vec1 unspecified __m128i 128 1
I64vec2 unspecified
Is64vec2 signed long int 64 2
Iu64vec2 unsigned
I32vec4 unspecified
SSE 2 Is32vec4 signed int 32 4 dvec.h
Iu32vec4 unsigned
I16vec8 unspecified
Is16vec8 signed short 16 8

J. Miguel Leitão Extensões SIMD
41
Iu16vec8 unsigned
I8vec16 unspecified
Is8vec16 signed char 8 16
Iu8vec16 unsigned
Exemplo de utilização
Again, assume a and b are two 128-bit numbers. The result of the computation will
be stored in another 128-bit number, c.
Neste caso utilizam-se objectos da classe F32vec4. A ordem dos parâmetros do
construtor F32vec4 é a mesma utilizada pela função _mm_set_ps.
#include <dvec.h>
...
F32vec4 a(6.0, 4.4, 37.8, 1.0);
F32vec4 b(3.0, 2.0, 1.0, 53.2);
F32vec4 c;
...
c = a * b;
...
Resultado: c = ( 18.0, 8.8, 37.8, 53.2 );

J. Miguel Leitão Extensões SIMD
42
AltiVec
O AltiVec é uma extensão SIMD do Processador PowerPC destinada a melhorar o
desempenho de qualquer aplicação que permita o processamento em paralelo de
dados.
Utiliza um conjunto distinto de 32 registos de 128 bits que podem conter vários itens
de dados de diversos formatos, incluindo representações de inteiros e de vírgula
flutuante. Estes dados são utilizados por instruções que permitem tratar de uma só
vez:
16 caracteres ou inteiros de 8 bits, com ou sem sinal.
8 inteiros de 16 bits, com ou sem sinal.
4 inteiros de 32 bits, com ou sem sinal.
4 números representados em vírgula flutuante de 32 bits.
3DNow!
O 3DNow! é um conjunto de instruções SIMD desenvolvido pela Advanced Micro
Devices (AMD) para o seu processador K6-2. Constitui uma extensão à tecnologia
MMX, já disponível nos processadores desta família, para permitir o tratamento de
dados de vírgula flutuante de precisão simples (32 bits). As instruções 3DNow!
utilizam os registos MMX e permitem efectuar operações, simultaneamente, sobre
dois itens de dados.
2 x Floating Foint (4 x 32 bits)
063 32 31
As operações adicionais disponibilizadas pela tecnologia 3DNow! são, por exemplo,
comparações, somas, subtracções, multiplicações e inversos (utilizados para a
implementação de divisões) de dados de vírgula flutuante empacotados nos
registos MMX.
Com o processador Athlon, a AMD apresentou o Enhanced 3DNow! (ou
Extendended 3DNow!) que inclui extensões aos conjuntos de instruções 3DNow! e
MMX. Ao conjunto de instruções 3DNow! foram adicionas 5 novas instruções que
incluem conversões entre inteiros e números de vírgula flutuante, trocas e
acumulações. O conjunto de instruções MMX foi estendido com 19 instruções que
incluem cálculo de médias, determinação de máximos e mínimos, multiplicação
sem sinal, controlo de cache, e manipulação selectiva de dados empacotados.

J. Miguel Leitão Extensões SIMD
43
MAX - Multimedia Acceleration eXtensions
O MAX-1 foi introduzido pela HP no seu processador PA-RISC 7100LC em 1994. É vulgarmente apontado como o primeiro conjunto de extensões SIMD a ser integrado num processador. Seguiu-se o MAX-2 que apareceu no processador PA-8000.
Estas extensões correspondem a conjuntos de instruções SIMD para tratamento de inteiros de 16 bits empacotados nos registos de uso geral. Disponibilizam funcionalidades SIMD para a implementação de somas, subtracções e deslocamentos.
MDMX - Mips Digital Media eXtensions
As extensões MDMX foram introduzidas pela SGI em 1999 nos seus processadores
da família MIPS.
Incluí um acumulador de produtos de 192 bits.
Utiliza os registos da unidade de vírgula flutuante.
VIS - Visual Instruction Set O VIS é um conjunto de instruções SIMD preparado pela SUN para o seu
processador UltraSparc. Utiliza os registos de uso geral, tirando assim partido do
elevado número de registos disponíveis nestes processadores.
Incluí instruções de complexidade elevada, pensadas para a implementação de
algoritmos de descodificação de MPEG. Uma destas instruções é soma das
diferenças acumuladas (pdist).
Esta extensão inclui ainda funcionalidades para transferências de blocos de 64
Bytes da memória para grupos de registos ou de grupos de registos para memória.
J. Miguel Leitão Extensões SIMD
44
DSPs com capacidades SIMD
Alguns fabricantes de DSPs têm também aderido às extensões SIMD como
estratégia de melhoramento dos seus processadores. A Analog Devices, por
exemplo, para criar o ADSP-2116x, duplicou o conjunto executivo do seu DSP
convencional com capacidades de cálculo de vírgula flutuante ADSP-2106x. Cada
um destes conjuntos executivos incluí uma unidade lógica e aritmética (ALU) um
multiplicador / acumulador (MAC), uma unidade de deslocamento (Shifter) e um
conjunto de registos próprios. Esta arquitectura duplicada pode executar a mesma
instrução em ambos os conjuntos executivos, cada um com o seu conjunto de
dados. Desta forma, o desempenho é efectivamente duplicado em algumas
aplicações.
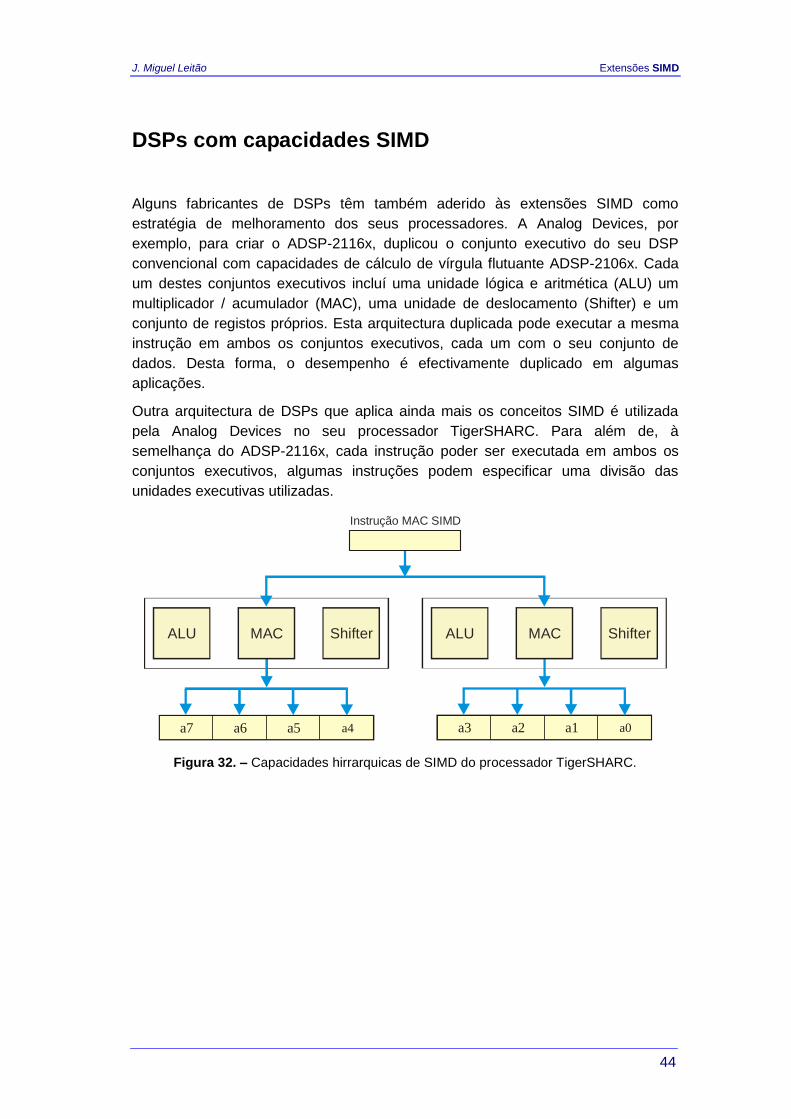
Outra arquitectura de DSPs que aplica ainda mais os conceitos SIMD é utilizada
pela Analog Devices no seu processador TigerSHARC. Para além de, à
semelhança do ADSP-2116x, cada instrução poder ser executada em ambos os
conjuntos executivos, algumas instruções podem especificar uma divisão das
unidades executivas utilizadas.
ALU ALUMAC MACShifter Shifter
Instrução MAC SIMD
a7 a3a6 a2a5 a1a4 a0
Figura 32. – Capacidades hirrarquicas de SIMD do processador TigerSHARC.

J. Miguel Leitão Extensões SIMD
45
Conclusões
O número de soluções disponíveis para o processamento digital de sinal tem
crescido muito nos últimos anos.
A modificação mais significativa é a integração de extensões SIMD. Esta
abordagem adapta-se bem aos processadores que possuem registos, barramentos
e unidades computacionais largas e que podem facilmente ser adaptadas para
processar simultaneamente vários itens de dados de dimensão reduzida.
Utilizando estas extensões, os processadores de uso genérico podem, em
determinados casos, realizar tarefas de processamento digital de sinal com
desempenhos superiores aos DSPs mais rápidos. Este resultado que pode parecer
surpreendente é devido, em grande parte, às elevadas frequências de trabalho a
que os processadores de uso genérico actuais podem operar. Face a esta
vantagem em termos de velocidade e à grande flexibilidade oferecida surge
naturalmente a questão:
- Porquê usar DSPs ?
Existem, no entanto várias razões que continuam a justificar a utilização de DSPs
para muitas aplicações. Apesar dos processadores de uso genérico poderem
apresentar desempenho comparáveis ou até superiores no número de dados
processados no mesmo intervalo de tempo, muitas vezes são os processadores
específicos que apresentam a melhor combinação de desempenho, preço, potência
consumida, etc... Há também que ter em conta as vantagens associadas à
facilidade de projecto que um sistema baseado num processador DSP pode
oferecer graças à superior disponibilidade de componentes associados de hardware
e de software vocacionados para o processamento digital de sinal.

J. Miguel Leitão Extensões SIMD
46
Anexo 1. Tabela cronológica de microprocessadores
Z80
Z8000
Z80
000
6800
Pow
erP
C 6
01
Pow
erP
C A
35 A
pache
S/3
70
R2000
T800
T900
Sta
nfo
rd M
IPS
R4000
R3000
R8000
R10
000
R12
000
R14
000
6800
0320
32
6x86
PA
-Ris
c
2900
0
29
01
8x300
AR
M
K5
K6
K7
6802
0
6803
0
68040
68060
801
RIS
C 1
88000
PIC
16x/1
7x
Sparc
SuperS
parc
Ultra
Sp
arc
Sparc
64
Alp
ha 2
1064
Alp
ha 2
1364
Alp
ha 2
1264
Mic
roV
AX
VA
X
PD
P-1
1
2000
1995
1990
1985
1980
1975
80
86
8085
80
88
8080
Inte
lZ
ilog
Moto
rola
IBM
MIP
SIN
MO
SD
EC
HP
AM
DN
S/C
yrix
Outr
os
80286
80386
80486
MM
XA
ltiV
ec
MA
X-1
3D
-No
w
VIS
MD
MX
Pe
ntium
Pentium
Pro
Pentium
II
Pentium
III
Pentium
4It
aniu
m
Alp
ha 2
116
4
Pow
er
1
Po
wer
2
Po
wer
3
T414
Pow
erP
C 6
04





























