Embed Size (px)
Citation preview

Renato Ramalho Costa
FERRAMENTA DE DATA MINING PARA IDENTIFICAÇÃODE POTENCIAIS PROTEÍNAS ALVO PARA TRATAMENTO
DE ESQUISTOSSOMOSE MANSÔNICA
Belo Horizonte
2017

Renato Ramalho Costa
FERRAMENTA DE DATA MINING PARA IDENTIFICAÇÃO DEPOTENCIAIS PROTEÍNAS ALVO PARA TRATAMENTO DE
ESQUISTOSSOMOSE MANSÔNICA
Dissertação apresentada ao programa deMestrado Profissional em Tecnologia daInformação aplicada à Biologia Computacionalda Faculdade Promove de Tecnologia comorequisito parcial para a obtenção do grau deMestre em Tecnologia da Informação aplicadaà Biologia Computacional.
Orientadora: Dra. Rosângela Silqueira HicksonRios
Belo Horizonte
2017

Renato Ramalho Costa
Ferramenta de Data Mining para identificação de potenciaisproteínas alvo para tratamento de esquistossomose mansônica
Dissertação apresentada ao programa de Mestrado Profissional em Tecnologia da Informa-ção aplicada à Biologia Computacional da Faculdade Promove de Tecnologia como requisitoparcial para a obtenção do grau de Mestre em Tecnologia da Informação aplicada à BiologiaComputacional.
Banca examinadora
Dra. Rosângela Silqueira Hickson RiosOrientadora
Dr. Rodrigo Gontijo CunhaMembro Externo
Dra. Maria Helena Rossi VallonMembro Interno
Belo Horizonte, 11 de Setembro de 2017

A minha mãe Ivani e a minha família por todoamor e apoio durante toda minha vida.

AGRADECIMENTOS
Agradeço a minha orientadora, Rosangela, pela paciência, dedicação e ensinamentosque possibilitaram que eu realizasse este trabalho.
Agradeço aos professores que desempenharam com dedicação as aulas ministradas.Em especial a professora Maria Helena pela inestimável ajuda e pelo paciente trabalho narevisão da dissertação.
A professora Helena por toda ajuda na revisão da dissertação.
Agradeço a minha mãe Ivani, meus avós Anésio e Ana, minha irmã Edivânia e todos osmeus familiares, pelo amor, carinho, paciência e ensinamentos.
Aos amigos e colegas, pelo incentivo e apoio constantes.

"A única coisa que interfere com meuaprendizado é a minha educação."
(Albert Einstein)

RESUMO
Esta pesquisa tem como objetivo desenvolver uma ferramenta de data mining para análise dedados de potenciais proteínas alvo para tratamento da esquistossomose mansônica. Trata-se deuma pesquisa do tipo exploratória. São feitas abordagens teóricas tais como, esquistossomosemansônica, data mining e bioinformática. Como técnica utilizou-se o Knowledge Discovery inDatabase (KDD) e pesquisa bibliográfica para obtenção das proteínas, fármacos e demaisinformações relevantes para realização desta pesquisa. Sobressai-se do estudo que com autilização dos indicadores da ferramenta desenvolvida tornam-se facilitadores na identificaçãode potenciais proteínas alvo para tratamento da esquistossomose mansônica. Conclui-se que aferramenta desenvolvida pode ser utilizada em diversas pesquisas e instituições de ensino epesquisa.
Palavras-chave: Data Mining. Esquistossomose mansônica. Proteínas. Fármacos. Bioinformá-tica.

ABSTRACT
This research have objective to develop a data mining tool for data analysis of potential targetproteins for the treatment of schistosomiasis mansoni. This is an exploratory research. Are madetheoretical approaches such as, schistosomiasis mansoni, data mining and bioinformatics. As atechnique, was use knowledge discovery in the database (KDD) and bibliographic search to getthe proteins, drugs and other information relevant to the research. It stands out from the studythat with using the indicators of the developed tool become facilitators in the identification ofpotential target proteins for the treatment of schistosomiasis mansoni. It is concluded that thetool developed can be used in several researches and teaching and research institutions.
Keywords: Data Mining. Schistosomiasis mansoni. Proteins. Drugs. Bioinformatics.

SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 ESQUISTOSSOMOSE MANSÔNICA . . . . . . . . . . . . . . . . . . . . . . . 12
3 DATA MINING: ASPECTOS TEÓRICOS . . . . . . . . . . . . . . . . . . . . . 173.1 Descoberta de conhecimento . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2 Tarefas em Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.3 Algoritmos de Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4 BIOINFORMÁTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 MATERIAIS E MÉTODOS UTILIZADOS NA PESQUISA . . . . . . . . . . . . 275.1 Banco de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275.2 Linguagem de Programação . . . . . . . . . . . . . . . . . . . . . . . . . . . 285.3 Hypertext Markup Language (HTML) . . . . . . . . . . . . . . . . . . . . . . 285.4 Cascading Style Sheets (CSS) . . . . . . . . . . . . . . . . . . . . . . . . . . 285.5 Docking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.6 AutoDock Vina . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.7 AutoDockTools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.8 Highcharts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.9 A “regra de 5” de Lipinski . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6 RESULTADOS DA FERRAMENTA DE DATA MINING DESENVOLVIDA NAPESQUISA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
6.1 Dados para modelagem do banco de dados . . . . . . . . . . . . . . . . . 306.2 Arquivos PHP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7 DISCUSSÃO SOBRE O DESENVOLVIMENTO DA FERRAMENTA DE DATAMINING NA TOMADA DE DECISÕES SOBRE POTENCIAIS PROTEÍNASALVO NO TRATAMENTO DA ESQUISTOSSOMOSE MANSÔNICA . . . . . 39
8 CONCLUSÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
APÊNDICE A – MÉTODOS, TABELAS E DESCRIÇÕES DA CLASSE CO-NEXAODMDB.PHP . . . . . . . . . . . . . . . . . . . . . . . 46
APÊNDICE B – MÉTODOS, MÉTODOS DE CONEXAODMDB E DESCRI-ÇÕES DA CLASSE SISTEMADM.CLASS.PHP . . . . . . . 48

APÊNDICE C – PROTEÍNAS UTILIZADAS NA PESQUISA . . . . . . . . . 50
APÊNDICE D – FÁRMACOS UTILIZADOS NA PESQUISA . . . . . . . . . 55

10
1 INTRODUÇÃO
Constitui-se tema desta pesquisa o desenvolvimento de uma ferramenta de data miningpara descoberta de potenciais proteínas alvo para o tratamento de esquistossomose mansônica.
Trata-se no estudo de desenvolver uma ferramenta que ofereça indicadores que auxiliemna tomada de decisão sobre potenciais proteínas alvo no tratamento da esquistossomosemansônica.
Delimita-se o tema ao desenvolvimento de uma ferramenta de data mining para identifi-cação de potenciais proteínas alvo para o tratamento de esquistossomose mansônica utilizandofármacos previamente selecionados.
A pergunta norteadora do estudo foi no sentido de investigar se o desenvolvimentode uma ferramenta de data mining pode auxiliar na tomada de decisões sobre potenciaisproteínas alvo para tratamento de esquistossomose mansônica. Formulou-se como hipótesebásica orientadora da pesquisa que o desenvolvimento da ferramenta de data mining auxilia aobtenção de informação de potenciais proteínas no tratamento de esquistossomose mansônicaoferecendo indicadores quantitativos e algoritmos de data mining.
O objetivo geral da pesquisa é desenvolver uma ferramenta de data mining para des-coberta de potenciais proteínas alvo para o tratamento de esquistossomose mansônica. Sãoobjetivos específicos: (a) mapear as proteínas no banco de dados biológico National Center forBiotechnology Information (NCBI); (b) obter os dados detalhados das proteínas no banco dedados biológico Protein Data Bank (PDB); (c) criar um banco de dados relacional; (d) analisaros algoritmos de data mining e adequar para a ferramenta; (e) desenvolver indicadores quanti-tativos para tomada de decisão; (f) criar interfaces para que o usuário possa fazer a análise dosindicadores.
Justifica-se este estudo tendo-se em vista que a esquistossomose infecta milhões depessoas em todo mundo e que não existem muitas pesquisas relacionadas ao desenvolvimentode novos fármacos para tratamento da mesma. Segundo informações da World Health Orga-nization (2017) pelo menos 218 milhões de pessoas precisaram de tratamento preventivo nomundo em 2015 e o tratamento preventivo deve continuar ao longo dos anos. No Brasil cercade 1,5 milhões de pessoas vivem e áreas com risco de contrair a esquistossomose (BRASIL,2014a).
Quanto à metodologia utilizada no estudo, trata-se de uma pesquisa do tipo exploratória.Teve-se como técnica a documentação indireta, por meio da pesquisa bibliográfica (fontessecundárias) e a pesquisa documental (fontes primárias).
A pesquisa bibliográfica, fontes secundárias, reúne teorias sobre data mining, bioinfor-mática, banco de dados e sobre os materiais e métodos utilizados na pesquisa.
A pesquisa documental, fontes primárias, compõe-se de dados sobre esquistosso-mose mansônica (BRASIL, 2014b), (SÃO PAULO, 2005), Fundação Oswaldo Cruz (2016),

11
Universidade Estadual Paulista (2015) e World Health Organization (2017) .
Para compreensão deste tema este trabalho foi dividido em oito seções. A seção 1 estaintrodução, contém os elementos indicativos desse estudo; a seção 2 apresenta a abordagemsobre a esquistossomose mansônica; a seção 3 mostra os aspectos teóricos sobre o datamining; a seção 4 aborda sobre bioinformática; a seção 5 apresenta os materiais e métodosutilizados na pesquisa; a seção 6 apresenta os resultados da pesquisa; a seção 7 mostra asdiscussões sobre a ferramenta desenvolvida e técnicas utilizadas; a seção 8 tece as conclusõesdo estudo.

12
2 ESQUISTOSSOMOSE MANSÔNICA
Esta seção tem como objetivo apresentar a esquistossomose mansônica, seu ciclo devida, sintomas e tratamento da doença.
A esquistossomose mansônica é uma doença infecto parasitária que é transmitida porvermes do tipo Schistosoma, os mesmos têm como hospedeiros intermediários os caramujosde água doce do gênero Biomphalaria que vivem em rios e lagos contaminados, conformeinformação do (BRASIL, 2014b).
Figura 1 – Casal de Schistosoma mansoni, mostrando a fêmea do verme no canal ginecóforodo macho
Fonte: CENTER FOR DISEASE CONTROL AND PREVENTION. Schistosomiasis Infection. Atlanta,2016. Dispo-nível em: <https://www.cdc.gov/dpdx/schistosomiasis/index.html>. Acesso em: 11 Jun. 2016.
A esquistossomose foi descoberta no Brasil em 1908 pelo pesquisador Manuel AugustoPirajá da Silva e foi publicada no dia 27 de julho de 1908 na Revista Científica Brazil Médico(PRATA, 2008).

13
O ciclo de vida do Schistosoma mansoni é dividido em várias fases e as mesmas sãodemonstradas na figura 2.
Figura 2 – Ciclo de vida – Modo de transmissão
Fonte: SÃO PAULO. Secretaria de Estado da Saúde de São Paulo. Centro de Vigilância Epidemioló-gica. Manual de doenças transmitidas por água e alimentos. São Paulo, 2005. Disponível em:<ftp://ftp.cve.saude.sp.gov.br/doc_tec/hidrica/if_esqui0405.pdf>. Acesso em: 11 Jun. 2016.
A esquistossomose mansônica pode ser sintomática ou assintomática, sendo assim,a mesma pode não apresentar sintomas, ou na sua forma sintomática pode apresentar-sebasicamente as fases aguda e crônica. O sintomas iniciais na fase aguda, são principalmentecoceira e vermelhidão no local de penetração da cercária. Podendo apresentar outros sintomastais como: "[...] febre, suor frio, dor de cabeça, dores musculares, cansaço, perda de apetite,emagrecimento, tosse, dores de barriga. Algumas pessoas relatam enjôos e vômitos. O fígadofica um pouco aumentado e doloroso a palpação"(FUNDAÇÃO OSWALDO CRUZ, 2016).
Já nos casos com fase crônica a mesma é apresentada em três formas, a intestinal,a hepato-intestinal e a hepato-esplênica, porém podem existir algumas outras formas oucomplicações (FUNDAÇÃO OSWALDO CRUZ, 2016). Como exemplo, a forma neurológicaque “[...] decorrem da presença de ovos e de granulomas esquistossomóticos nesse sistema”conforme informado pelo (BRASIL, 2014b). Na primeira forma a diarreia é mais comum, porémtambém podem ocorrer perda de apetite, cansaço e dor na barriga quando apalpada. Nasegunda forma, tem-se os mesmos sintomas da primeira forma, porém com agravamento doaumento do volume do fígado. Já na terceira forma é mais grave e é apresentada a seguir:
A forma hepato-esplênica tem este nome devido a lesões no fígado e baço.

14
O indivíduo queixa-se de tumor na barriga, já que fígado e baço estão muitoaumentados de volume. A lesão no fígado, com o tempo, leva ao aparecimentode varizes no esôfago, com sangue no vômito e nas fezes. Pode ocorrer aumentodo tamanho da barriga, com presença de líquido (barriga d’água). Esta formaé observada mais frequentemente nas áreas em que ocorrem mais casos noBrasil: Nordeste e Minas Gerais (FUNDAÇÃO OSWALDO CRUZ, 2016).
No tratamento da esquistossomose mansônica utiliza-se atualmente nos casos em quenão há lesões avançadas apenas dois fármacos, o Praziquantel e o Oxamniquina, porém osmesmos possuem contraindicações em pacientes com insuficiência hepática, insuficiência renalou em outras situações de saúde agravadas conforme critério médico. Não se recomenda ouso dos medicamentos em mulheres grávidas e em crianças com menos de dois anos(BRASIL,2014b).
O Ministério da Saúde disponibiliza alguns indicadores da esquistossomose mansônicano Brasil, neste trabalho utilizar-se-á os indicadores de casos de esquistossomose mansônicaem áreas endêmicas e não endêmicas por unidade federativa(tab. 1 e 2).
Destaca-se na tabela 1 o estado de Alagoas que possui o maior número de casos emáreas endêmicas em 2015.
Tabela 1 – Número de casos de esquistossomose mansônica em área endêmica por unidadesda federação - Brasil de 2010 - 2015
Unidades da Federação 2010 2011 2012 2013 2014 2015Rondônia - - - - - -Pará 164 448 167 28 7 15Maranhão 5.083 3.381 2.452 2.857 3.135 2.128Piauí 1 - - - - -Ceará 121 37 44 53 115 118Rio Grande do Norte 2.829 1.073 837 612 727 154Paraíba 2.053 2.411 2.074 2.020 2.410 -Pernambuco 8.186 7.623 5.336 6.509 8.713 7.299Alagoas 13.283 13.003 11.384 12.652 9.767 7.965Sergipe 8.844 8.534 1.767 3.308 2.551 -Bahia 10.437 7.184 4.939 1.739 60 -Minas Gerais 16.331 14.348 8.329 6.445 4.831 3.998Espírito Santo 2.066 1.888 1.356 770 877 757Rio de Janeiro 5 12 - - - -São Paulo - - - - - -Paraná 33 4 - - - -Santa Catarina - - - - - -Goiás - - - - - -Distrito Federal - - - - - -Total 69.436 59.946 38.685 36.994 33.193 22.434
Fonte: BRASIL. Ministério da Saúde. Situação Epidemiológica - Dados. Brasília, DF,2014a. Dispo-nível em: <http://portalsaude.saude.gov.br/index.php/o-ministerio/principal/leia-mais-o-ministerio/656-secretaria-svs/vigilancia-de-a-a-z/esquistossomose/11244-situacao-epidemiologica-dados>. Acesso em: 11 Jun. 2016. (Adap-tado pelo autor)
Nota: Sinal convencional utilizado: - dado numérico igual a zero não resultante de arredondamento.

15
Já na tabela 2 destaca-se o estado de Minas Gerais com o maior número de casos emáreas não endêmicas em 2015.
Tabela 2 – Número de casos de esquistossomose mansônica em área não endêmica porunidades da federação - Brasil de 2010 - 2015
Unidades da Federação 2010 2011 2012 2013 2014 2015Rondônia 73 19 27 23 7 41Acre - - - - - -Amazonas - - - - - 2Roraima - - - - - -Pará 5 26 6 13 4 14Amapá 1 - 1 - - -Tocantins - 1 - 5 5 2Maranhão 79 65 63 10 2 17Piauí 1 6 3 2 - 1Ceará 73 28 23 20 1 38Rio Grande do Norte 49 22 26 31 - 27Paraíba 71 164 169 33 24 87Pernambuco 458 347 288 275 104 391Alagoas 96 67 59 37 5 44Sergipe 61 93 79 95 30 150Bahia 707 754 625 689 259 736Minas Gerais 22.408 11.807 5.187 4.152 1.600 3.713Espírito Santo 1601 744 513 452 141 409Rio de Janeiro 110 71 73 74 44 107São Paulo 1.093 1.144 1.109 842 173 554Paraná 67 41 53 34 9 30Santa Catarina 7 4 6 5 4 10Rio Grande do Sul 3 3 1 1 - 2Mato Grosso do Sul 8 9 4 3 5 13Mato Grosso 10 35 20 53 9 28Goiás 13 11 4 11 6 18Distrito Federal 5 3 5 3 2 6Total 26.999 15.464 8.344 6.863 2.434 6.440
Fonte: BRASIL. Ministério da Saúde. Situação Epidemiológica - Dados. Brasília, DF,2014a. Dispo-nível em: <http://portalsaude.saude.gov.br/index.php/o-ministerio/principal/leia-mais-o-ministerio/656-secretaria-svs/vigilancia-de-a-a-z/esquistossomose/11244-situacao-epidemiologica-dados>. Acesso em: 11 Jun. 2016. (Adap-tado pelo autor)
Nota: Sinal convencional utilizado: - dado numérico igual a zero não resultante de arredondamento.
A esquistossomose "[...] é uma doença de ocorrência tropical, registrada em 54 países,principalmente na África e Leste do Mediterrâneo, atinge as regiões do Delta do Nilo e paísescomo Egito e Sudão"(BRASIL, 2014a).
Estima-se que cerca de 1,5 milhões de pessoas vivem em áreas sob o risco decontrair a doença. Os estados das regiões Nordeste e Sudeste são os mais afe-tados sendo que a ocorrência está diretamente ligada à presença dos moluscostransmissores. Atualmente, a doença é detectada em todas as regiões do país.As áreas endêmicas e focais abrangem 19 Unidades Federadas e compreendemos Estados de Alagoas, Bahia, Pernambuco, Rio Grande do Norte (faixa litorâ-nea), Paraíba, Sergipe, Espírito Santo e Minas Gerais (predominantemente noNorte e Nordeste do Estado). No Pará, Maranhão, Piauí, Ceará, Rio de Janeiro,

16
São Paulo, Santa Catarina, Paraná, Rio Grande do Sul, Goiás e no DistritoFederal, a transmissão é focal, não atingindo grandes áreas (BRASIL, 2014a).
Abordou-se nesta seção aspectos que mostram a gravidade da doença infecto parasitá-ria transmitida pelo Schistosoma mansoni e o tratamento utilizado para a mesma.
A seção 3 discorre sobre Data Mining e descoberta do conhecimento, onde mostram osprocessos, tarefas e algoritmos.

17
3 DATA MINING: ASPECTOS TEÓRICOS
Esta seção tem como objetivo apresentar o Data Mining e o processo de descoberta doconhecimento, onde são detalhadas as suas etapas, tarefas e algoritmos.
Nas últimas décadas houve um enorme crescimento na quantidade de dados produzidospelas diversas áreas de conhecimento, juntamente com isso sugiram diversos termos, um delesé o Data Mining ou Mineração de Dados(em português).
A Mineração de Dados é uma das etapas do Knowledge Discovery in Database (KDD)ou Descoberta de Conhecimento em Bases de Dados (ELMASRI; NAVATHE, 2005, p. 625).Goldschmidt, Passo e Bezerra (2015, p. 2) afirmam que a "[...] expressão Mineração de Dados(Data Mining), mais popular, é, na realidade, uma das etapas da Descoberta de Conhecimentoem Bases de Dados".
Vários autores propõem definições para Data Mining, para esse estudo selecionou-se o trabalho de Han e Kamber (2006, p. 5) os quais conceituam que "[...] a mineração dedados refere-se à extração ou ‘mineração’ de conhecimento de grandes quantidades de dados".(Tradução nossa) 1
Já Berry e Linoff (2004, p. 7) definem que o "Data Mining, como usamos o termo, é aexploração e análise de grandes quantidades de dados para descobrir padrões significativos eregras". (Tradução nossa)2
Existem várias outras definições de Data Mining como etapa do processo de Descobertade Conhecimento em Bases de Dados.
A etapa de Mineração de Dados compreende a busca efetiva por conhecimentosúteis no contexto da aplicação de KDD. É principal etapa do processo de KDD.Tanto que alguns autores se referem à Mineração de Dados e à Descobertade Conhecimento em Base de Dados como sinônimos. Esta etapa envolve aaplicação de algoritmos sobre os dados em busca de conhecimento implícito eútil (GOLDSCHMIDT; PASSO; BEZERRA, 2015, p. 24).
O Data Mining tem aplicação nas mais diversas áreas de conhecimento tais como, com-putação, saúde, vendas, marketing e várias outras. O mesmo também pode ser aplicado paravárias finalidades, como exemplo, verificar padrões de compras realizadas por um determinadoconjunto de clientes de um supermercado.
A mineração de dados tem atraído muita atenção na indústria e na sociedadecomo um todo nos últimos anos, devido à ampla disponibilidade de grandesquantidades de dados, e a iminente necessidade de ajuste de tais dados, deinformação e conhecimento útil. As informações e os conhecimentos adquiridospodem ser utilizados para aplicação que vão desde análise de mercado, detec-
1 [...] data mining refers to extracting or “mining” knowledge from large amounts of data.2 Data Mining, as we use the term, is the exploration and analysis of large quantities of data in order to discover
meaningful patterns and rules.

18
ção de fraude e retenção de clientes, para a produção de controle e exploraçãocientífica (HAN; KAMBER, 2006, p. 1, Tradução nossa)3.
Abordar-se-á a seguir, de forma detalhada sobre KDD e Data Mining, mostrando oprocesso de KDD, tarefas de Data Mining e seus respectivos algoritmos.
3.1 Descoberta de conhecimento
O termo Knowledge Discovery in Database ou simplesmente KDD teve sua formalizaçãona década de 80, e a partir deste momento surgiram muitas definições. Fayyad, Piatetsky-Shapiro e Smyth (1996 apud GOLDSCHMIDT; PASSO; BEZERRA, 2015, p. 6) afirmam que o"KDD é um processo não trivial, interativo e iterativo, para identificação de padrões compreen-síveis, válidos, novos e potencialmente úteis a partir de grandes conjuntos de dados". Outradefinição se apresenta como:
O processo de KDD consiste de uma sequencia de iterações complexas, quese estende sobre um determinado período de tempo, entre um ‘usuário’ e umacoleção de dados, possivelmente auxiliado por um conjunto heterogêneo de fer-ramentas computacionais. (BRACHMAN; ANAND, 1996 apud GOLDSCHMIDT;PASSO; BEZERRA, 2015, p. 10)
O processo de KDD divide-se em fases como: (1a) Seleção; (2a) Pré-processamento;(3a) Transformação; (4a) Mineração de dados e a (5a) Avaliação (fig. 3).
Figura 3 – Processo de Knowledge Discovery in Database(KDD)
Fonte: FERREIRA, A. G. D.; PEREIRA, L. Mineração de dados com Orange. Rio de Janeiro: Devmedia,2016.Disponível em: <http:www.devmedia.com.brmineracao-de-dados-com-orange31678>. Acesso em: 25 jun.2016.
3 Data mining has attracted a great deal of attention in the industry and in society as a whole in recent years, dueto the wide availability of huge amounts of data and the imminent need tuning such data useful information andknowledge. The information and knowledge gained can be used for application ranging from market analysis,fraud detection, and customer retention, to producing control and science exploration.

19
a) Seleção
A etapa de seleção é o momento em que são selecionadas as informações a seremutilizadas no processo KDD.
A seleção é definida como “[...] função que compreende, em essência, a identificação dequais informações dentre as bases de dados existentes, devem ser efetivamente consideradasdurante o processo de KDD”(GOLDSCHMIDT; PASSO; BEZERRA, 2015, p. 38). Já para Fayyad,Piatetsky-Shapiro e Smyth (1996) é quando a "[...] selecionar um conjunto de dados, focar emum subconjunto de variáveis ou amostras de dados, em que a descoberta deve ser executado".(Tradução nossa) 4
b) Pré-processamento
O Pré-processamento é o momento que é realizada a limpeza e a seleção de melhoriasdas informações a serem utilizadas.
Nesse sentido Fayyad, Piatetsky-Shapiro e Smyth (1996) indicam que é a etapa de "[...]limpeza de dados e pré-processamento. As operações básicas incluem a remoção de ruído, seapropriado, a coleta das informações necessárias para modelar ou contabilizar o ruído, decidirsobre estratégias de tratamento de campos de dados ausentes e contabilizar informações desequência de tempo e mudanças conhecidas". (Tradução nossa)5
c) Transformação
A etapa de transformação é o momento em que é realizada melhoria das informaçõesserem utilizadas no processo.
Do ponto de vista de Fayyad, Piatetsky-Shapiro e Smyth (1996) é a etapa de "[...]redução de dimensionalidade ou métodos de transformação, o número efetivo de variáveissob consideração pode ser reduzido, ou representações invariantes para os dados podem serencontradas". (Tradução nossa) 6
d) Data Mining ou Mineração de Dados
A mineração é considerada por vários autores a etapa principal do KDD e a mesma éum dos principais objetivos de estudos deste trabalho. Sendo assim, esta etapa será detalhadanos próximos tópicos.
Goldschmidt, Passo e Bezerra (2015, p. 69) definem como "[...] a principal etapa doprocesso de KDD. Nesta etapa ocorre a busca efetiva por conhecimentos novos e úteis a partir4 selecting a data set, or focusing on a subset of variables or data samples, on which discovery is to be performed.5 data cleaning and preprocessing. Basic operations include removing noise if appropriate, collecting the necessary
information to model or account for noise, deciding on strategies for handling missing data fields, and accountingfor time-sequence information and known changes.
6 dimensionality reduction or transformation methods, the effective number of variables under consideration can bereduced, or invariant representations for the data can be found.

20
dos dados". Já Fayyad, Piatetsky-Shapiro e Smyth (1996) mostram que "[...] está combinandoos objetivos do processo de KDD [...] para um método de mineração de dados particular. Porexemplo, compactação, classificação, regressão, agrupamento, e assim por diante[...]".(Traduçãonossa)7
e) Avaliação
Avaliação é a etapa em que os dados são avaliados e realizados os últimos ajustes ne-cessários para serem utilizados nas tomadas de decisões com base nas informações extraídasnas etapas anteriores.
Fayyad, Piatetsky-Shapiro e Smyth (1996) detalham que trata-se de "[...]agir sobre oconhecimento descoberto: usando o conhecimento diretamente, incorporando o conhecimentoem outro sistema para ações futuras, ou simplesmente documenta-lo e reportar às partesinteressadas". (Traduação nossa) 8
3.2 Tarefas em Data Mining
As tarefas de data mining são definidas por vários autores e alguma destas definiçõesforam selecionadas para esta pesquisa.
a) Classificação
A tarefa de classificação é considerada como uma das principais tarefas de data mining.
A classificação, afirmam Han e Kamber (2006, p. 24) é o processo para encontrarum modelo ou função que é utilizada para distinguir classes de dados ou conceitos, a fim depredizer uma determinada classe de objetos cujo rótulo é desconhecido. Já para Goldschmidt,Passo e Bezerra (2015, p. 88) indicam que a tarefa utiliza aprendizagem supervisionada e amesma é dividida em dois grupos, o primeiro é o atributo-alvo para o qual se deve fazer apredição, já o segundo é o que contém os atributos que são utilizados na predição.
A tarefa de classificação é definida como examinar as características de um objetorecém criado e atribuir a ele uma característica de um conjunto de classes pré-definidasconforme Berry e Linoff (2004, p. 9).
b) Predição
A tarefa de predição é muito parecida com a tarefa de classificação, porém com adiferença de que ela prevê algo com base em um conjunto de dados informado.
A predição, ressaltam Han e Kamber (2006, p. 354) é a tarefa de prever valores contínuospara determinada entrada de dados e para realização da mesma pode ser utilizada a analise7 [...] is matching the goals of the KDD process [...] to a particular data-mining method. For example, summarization,
classification, regression, clustering, and so on [...].8 [...]is acting on the discovered knowledge: using the knowledge directly, incorporating the knowledge into another
system for further action, or simply documenting it and reporting it to interested parties.

21
de regressão. Já Witten, Frank e Hall (2011, p. 42) destacam que a predição numérica é umavariante da tarefa de classificação na qual retorna um valor numérico, em vez de retornar umacategoria.
Para Berry e Linoff (2004, p. 10) a tarefa de predição é como a de classificação, excetoque os registros são classificados por comportamentos ou valores futuros.
c) Regras de associação
A tarefa de regra de associação para Goldschmidt, Passo e Bezerra (2015, p. 81)consiste em encontrar subconjuntos de itens em um conjunto de dados e que esses itensapareçam simultaneamente em uma frequência mínima pré-estabelecida.
Do ponto de vista de Witten, Frank e Hall (2011, p. 72) a regra de associação podeprever qualquer atributo e não apenas classes como é o caso da classificação, sendo assim amesma tem a liberdade de prever atributos também. Já Berry e Linoff (2004, p. 11) afirmamque a tarefa é determinar quais itens andam juntos, como exemplo, um supermercado podeusar a regra de associação para planejar o arranjo de itens nas prateleiras das lojas ou em umcatálogo para que os itens comprados juntos sejam vistos juntos.
A tarefa de regra de associação possui várias utilidades e uma delas é identificarpadrões. Um exemplo de padrão: é identificar que um grupo de clientes sempre compram leitee pão todas as vezes que vão ao supermercado.
d) Agrupamento ou Clustering
A tarefa de agrupamento tem a finalidade de segmentar uma população heterogêneaem subgrupos mais homogêneos e o que distingue a mesma da tarefa de classificação é queela não depende de classes predefinidas conforme Berry e Linoff (2004, p. 11). Já Goldschmidt,Passo e Bezerra (2015, p. 95) definem que tarefa de agrupamento é utilizada para separarregistros de um conjunto em subconjuntos de dados com propriedades em comum e que sejamdistintos dos demais grupos.
De acordo com Witten, Frank e Hall (2011, p. 138) a tarefa de agrupamento deve seraplicada quando não existe uma classe para predizer e as instâncias devem ser divididas emgrupos naturais.
Na tarefa de agrupamento deve ser utilizada para identificar características comuns emelementos de um conjunto de dados e criar subconjuntos com os elementos agrupados com ascaracterísticas similares.
3.3 Algoritmos de Data Mining
Na abordagem dos algoritmos de data mining apresenta-se os algoritmos tradicionaise bioinspirados, dentro dos mesmos foram listados alguns algoritmos, porém existem váriosoutros definidos por outros autores9.9 Neste estudo priorizou-se os algoritmos mais conhecidos e utilizados em pesquisas científicas.

22
a) Tradicionais
Os algoritmos tradicionais selecionados para esta pesquisa são:
- k-Nearest Neighbors (k-NN)
O algoritmo k-NN pode ser utilizado tanto em tarefas de classificação e análise deregressão.
Para Kanj et al. (2016) o algoritmo de k-NN é um procedimento de decisão não paramé-trico para tarefas de aprendizagem de máquina e mineração de dados, e, para essa regra éatribuído um exemplar ainda não classificado a classe da instância de treinamento mais próximade acordo com algumas métricas de distância. Já Witten, Frank e Hall (2011, p. 568) destacamque assim como outras técnicas o k-NN é sensível a ruído nos dados de treinamento.
Do ponto de vista de Han e Kamber (2006, p. 348) quando é dada uma tupla desco-nhecida, o algoritmo de k-NN procura um espaço padrão para k tuplas de treinamento que sãomais próximas da tupla desconhecida.
- Classificador Naïve Bayesian
O algoritmo Classificador Naïve Bayesian como vários outros algoritmos é baseado emteorias da estatística.
O algoritmo Classificador Naïve Bayesian é baseado no Teorema de Bayes, sendoassim, está relacionado com cálculos probabilísticos condicionais conforme mostrado porGoldschmidt, Passo e Bezerra (2015, p. 121). Já Wang et al. (2007) afirmam que o algoritmo ésimples, mas eficiente e que o termo ingênuo refere-se a suposição que o atributos de dadossão independentes.
- k-Means
O algoritmo k-Means é um dos mais populares algoritmos que utiliza a tarefa deagrupamento por ser simples, eficiente, escalável e muito fácil de se modificar conformemostrado por Lei et al. (2016).
O “k” no nome do algoritmo se refere ao fato de que ele procura por um número fixode grupos definidos e que são agrupados pela proximidade entre eles segundo Berry e Linoff(2004, p. 354).
- Apriori
O algoritmo de Apriori é utilizado para mineração de tarefas de regras de associaçãoem banco de dados transacionais conforme informado por Song, Choi e Yoon (2016). Já Han e

23
Kamber (2006, p. 235) acrescentam que o nome do algoritmo se dá por conta que o mesmoutiliza o conhecimento prévio das propriedades dos conjuntos de itens.
O algoritmo segue uma metodologia de gerar e testar para encontrar conjuntos de itensfrequentes e gerando sucessivamente grandes conjuntos de itens candidatos de mais curtosque são conhecidos por serem frequentes (WITTEN; FRANK; HALL, 2011, p. 216).
- C4.5
O algoritmo C4.5 inspirado no algoritmo ID3 é baseado em arvore de decisões, onde seutiliza a abordagem recursiva de particionamento do conjunto de dados e conceitos da teoriada informação conforme Goldschmidt, Passo e Bezerra (2015, p. 131).
Já Ruggieri (2002) mostra que cada nó de uma árvore de decisões está associado comum conjunto de casos e são atribuídos pesos a esses casos para se ter em conta os valores deatributos desconhecidos.
- Máquinas de Vetores Suporte
O algoritmo de Máquinas de Vetores de Suporte é baseado em aprendizagem demáquina e na minimização de risco estrutural conforme mostrado por Mojumder et al. (2016).
Goldschmidt, Passo e Bezerra (2015, p. 131) mostram também que o algoritmo deMáquinas de Vetores de Suporte constrói classificadores lineares que são separados por umhiperplano tridimensional.
b) Bioinspirados
Os algoritmos bioinspirados selecionados para esta pesquisa são:
- Redes Neurais
A técnica de Redes Neurais é baseada no funcionamento do cérebro simulado porcomputador conforme afirmam Goldschmidt, Passo e Bezerra (2015, p. 145).
Para Han e Kamber (2006, p. 433) um Rede Neural é um conjunto de unidades deentrada e saída conectados em que cada ligação possui um peso associado a ela.
- Algoritmos Genéticos
Os Algoritmos Genéticos são baseados em processos biológicos conforme Berry eLinoff (2004, p. 421). Goldschmidt, Passo e Bezerra (2015, p. 151) complementam que osAlgoritmos Genéticos são úteis em problemas complexos que necessitem de otimização.
Já Han e Kamber (2006, p. 351) afirmam que os Algoritmos Genéticos incorporamideias da evolução natural.

24
- Lógica Nebulosa
A Lógica Nebulosa ao invés de utilizar um atalho preciso entre as categorias, a mesmautiliza valores verdadeiros entre 0 e 1 para representar o grau de pertinência que um certo valortem em uma determinada categoria conforme Han e Kamber (2006, p. 353).
Nesta seção buscou-se apresentar o Data Mining que foi utilizado para o desenvolvi-mento desta pesquisa.
A seção 4 discorre sobre Bioinformática, quando mostra-se as áreas desta, comocomputação, biologia, aplicações e uma introdução à ferramenta desenvolvida durante apesquisa.

25
4 BIOINFORMÁTICA
Esta seção tem como objetivo introduzir o termo Bioinformática, sua definição, suasàreas, suas aplicabilidades e a ferramenta desenvolvida no estudo.
A Bioinformática é definida por Gibas e Jambeck (2001, p. 3) como o uso da informaçãopara entendimento da biologia. Já para Keçeci (2015, p. 11) a Bioinformática é o ramo daciência da computação que lida com dados biológicos, principalmente em nível molecular.
Do ponto de vista de Fenstermacher (2005) Bioinformática como uma disciplina mul-tifacetada que combina vários campos científicos, como biologia computacional, estatística,matemática, biologia molecular e genética.
Para Claverie e Notredame (2007, p. 9) a Bioinformática é o ramo computacional dabiologia molecular. Já para Higgs e Attwood (2005) Bioinformática é o desenvolvimento demétodos computacionais para estudo de proteínas, genes ou genomas.
A Bioinformática como área de estudo multidisciplinar é composta por várias áreas deconhecimentos. Neste trabalho abordar-se os campos de computação e biologia.
a) Computação
No dizer de Feijó, Clua e Silva (2010) a computação consiste em encontrar algoritmosque solucionem da melhor forma problemas do dia a dia, a mesma divide-se em campos como:banco de dados, computação gráfica, inteligência artificial, otimização, computação paralela,entretenimento, redes, engenharia de software entre vários outros.
Já para Guzdial e Ericson (2013, p. 3) a computação compreende o estudo do processo:a forma que humanos ou computadores fazem as coisas, como especifica o que faz e o queestá processando.
b) Biologia
A biologia é a ciência que estuda os organismos vivos e seus relacionamentos (BIOLO-GIA, 2015). Outra é que a biologia consiste no estudo dos organismos, estes são divididos emvárias especialidades que cobrem sua morfologia, fisiologia, anatomia, comportamento, origeme distribuição (BIOLOGY, 2009).
Assim como outras áreas do conhecimento, a biologia divide-se em vários campos depesquisa, mas neste trabalho abordar-se-á o campo da biologia molecular.
A Bioinformática possui as mais diversas aplicabilidades e algumas delas serão aborda-das neste trabalho.
Para Keçeci (2015, p. 13) cita alguns campos de aplicação da bioinformática comodescoberta de drogas, desenho de drogas baseado em estrutura, polímeros e fibras, entreoutros vários campos. Já Rastogi, Mendiratta e Rastogi (2013) divide a aplicabilidade em três

26
níveis, sendo que, o primeiro nível é o uso Bioinformática para organizar os dados biológicose ajudar no acesso e adição de novas informações pelos pesquisadores; o segundo nível é odesenvolvimento de ferramentas e recursos que ajuda na analise dos dados; já no terceiro eultimo nível é o uso das ferramentas para analisar dados e interpretar os resultados de umamaneira biologicamente significativa.
No estudo foi desenvolvida uma ferramenta de Data Mining que utiliza dados do Schis-tosoma mansoni obtidos de bancos de dados públicos e de ferramentas de bioinformática paraobter potenciais proteínas alvo que poderão ser utilizadas no desenvolvimento de fármacospara o tratamento de esquistossomose.
Nesta seção destacou-se a aplicabilidade da Bioinformática, onde a mesma pode serutilizada em vários níveis de pesquisas biológicas.
A seção 5 tem como objetivo detalhar os materiais e métodos utilizados durante apesquisa, tais como, banco de dados relacionais e biológicos, linguagens de programação eferramentas.

27
5 MATERIAIS E MÉTODOS UTILIZADOS NA PESQUISA
Esta seção apresenta os recursos utilizados para o desenvolvimento da pesquisa.
5.1 Banco de Dados
Os bancos de dados utilizados neste estudo divide-se em banco de dados relacional ebiológicos.
O modelo relacional representa um banco de dados como se fosse uma coleção derelacionamentos, onde uma relação se assemelha a uma tabela de valores conforme Elmasri eNavathe (2005, p. 90). Já Puga, França e Goya (2013, p. 54) mostram que uma das principaiscaracterísticas do modelo relacional é a possibilidade de se criar relacionamentos entre váriastabelas, desta forma evita-se o armazenamento de dados redundantes no banco de dados.
Para Oikawa (2012), banco de dados biológicos são os bancos de dados que arma-zenam dados biológicos, e não é, como se confunde frequentemente, os sites que acessamsequências e informações biológicas.
Os bancos de dados biológicos utilizados nesse trabalho são os do National Centerfor Biotechnology Information (NCBI), ZINC, Protein Data Bank (PDB) e o banco de dadosrelacional quando utilizar-se-á o MySQL.
a) MySQL
O MySQL é um sistema gerenciador de banco de dados relacional, distribuído pelaOracle Corporation. Ele é o banco de dados de código aberto mais popular e utilizado em váriasempresas principalmente no desenvolvimento de sistemas web (ORACLE CORPORATION,2016).
b) ZINC
O ZINC é uma ferramenta de pesquisa para pesquisadores que procuram matériaquímica para seus alvos biológicos, o mesmo incorpora compostos compráveis de váriosfornecedores e compostos anotados de mais de vinte bases de dados segundo Irwin et al.(2012).
c) NCBI
O NCBI , é uma divisão da National Library of Medicine (NLM) do U.S. National Institutesof Health. O mesmo é líder no campo de bioinformática, estudando abordagens computacionaispara questões fundamentais da biologia e oferece online informações biomédicas e ferramentasde bioinformática. A base de dados e recursos estão divididos em sete áreas e mais três

28
categorias adicionais, as áreas são as de literatura, genomas, variação, saúde, genes e ex-pressão de genes, nucleotídeos, proteínas e pequenas moléculas e ensaios biológicos. Já ascategorias adicionais são as de ferramentas, infraestrutura e metadados (NATIONAL CENTERFOR BIOTECHNOLOGY INFORMATION, 2013)
d) PDB
O PDB é um repositório mundial de informações de estruturas 3D de grandes moléculasbiológicas, incluindo proteínas e ácidos nucleicos conforme Berman et al. (2000).
5.2 Linguagem de Programação
A linguagem de programação é uma forma de comunicar com o dispositivo utilizado eque assemelham muito com a linguagem humana, pois as mesmas são definidas por pessoasde acordo com Feijó, Clua e Silva (2010).
a) Hypertext Preprocessor (PHP)
O PHP ou Pré-processador de hipertexto é uma linguagem de script de código abertoque pode ser utilizada em vários tipos de ambiente, porém é grandemente utilizado no desen-volvimento de páginas web. O PHP é executado do lado do servidor diferente do JavaScript queé executado no navegador do cliente como descrito por Achour et al. (2016).
b) JavaScript
O JavaScript foi originalmente concebido para ser uma interface de script que criauma interação entre uma página web no navegador do cliente e a uma aplicação no servidor(POWERS, 2009). Já Flanagan (2011, p. 1) a define como uma linguagem de programaçãoweb que é utilizada na grande maioria das páginas web e navegadores modernos.
5.3 Hypertext Markup Language (HTML)
O HTML ou linguagem de marcação de hipertexto é a linguagem utilizada para descreveras estruturas das páginas web. A linguagem da suporte para criação de tabelas, listas, textos,links e várias outras funcionalidades (WORLD WIDE WEB CONSORTIUM, 2016).
5.4 Cascading Style Sheets (CSS)
O CSS ou Folhas de estilos cascata é uma linguagem independente do HTML utilizadapara descrever a apresentação das páginas web, que incluem cores, layout e fontes. A linguagemtambém permite o dimensionamento para diversos tipos de dispositivos com telas grandes,pequenas ou impressoras (WORLD WIDE WEB CONSORTIUM, 2016).

29
5.5 Docking
Nesse estudo abordar-se-á o Docking Molecular e Docking Inverso, porém será utilizadoneste trabalho apenas o Docking Molecular.
No dizer de Guido, Andricopulo e Oliva (2010) o Docking Molecular consiste na prediçãoda interação entre uma pequena molécula que é o ligante no sitio de ligação de macromoléculaque é a proteína-alvo, seguindo da pontuação e classificação conforme o modo de ligaçãoproposto.
Para Grinter et al. (2011) o Docking Inverso é uma pequena molécula específica deinteresse para uma biblioteca de estruturas receptoras e que podem ser usadas para identificarnovos potenciais alvos biológicos ou para identificar alvos para compostos dentro de uma famíliade receptores relacionados.
5.6 AutoDock Vina
AutoDock Vina é um software de código aberto para realização de docking molecularconforme Trott e Olson (2010).
5.7 AutoDockTools
O AutoDockTools é uma ferramenta que facilita a formatação de arquivos de moléculasde entrada, com um conjunto de métodos que orientam o usuário através da protonação,calculando as cargas e especificando ligações rotativas no ligando e na proteína. Para simplificara concepção e preparação de experimentos de docking, ele permite ao usuário identificar osite ativo e determinar visualmente o volume de espaço pesquisado na simulação de docking(MORRIS et al., 2009).
5.8 Highcharts
O Highcharts é uma biblioteca de gráficos desenvolvida pela empresa Highsoft, amesma foi escrita em JavaScript puro e disponibiliza vários tipos de gráficos tais como debarras, linha, área, bolha, entre vários outros tipos (HIGHSOFT, 2016).
5.9 A “regra de 5” de Lipinski
Na configuração de descoberta, “a regra de 5” prevê que uma má absorção ou permea-ção é mais provável quando há mais de 5 doadores de ligação de Hidrogênio, 10 aceitadoresde ligação Hidrogênio, o peso molecular é maior que 500 e o Log P calculado é maior que 5conforme Lipinski et al. (2001).
Nesta seção descreveu-se as ferramentas e métodos utilizados no desenvolvimento dapesquisa.
A seção 6 tem como objetivo detalhar os resultados da ferramenta de Data Miningdesenvolvida na pesquisa obtidos durante a realização da pesquisa.

30
6 RESULTADOS DA FERRAMENTA DE DATA MINING DESENVOLVIDA NA PESQUISA
Apresenta-se nesta seção os resultados obtidos com a realização do estudo utilizandoos materiais e métodos descritos na seção 5 bem como as noções teóricas que compõem estapesquisa.
6.1 Dados para modelagem do banco de dados
a) Fármacos
Utilizar-se-á 14 fármacos obtidos do projeto World Community Grid, porém nestapesquisa foram selecionados apenas 9 fármacos dos 14 com base na existência de solventescadastrados no banco de dados da ferramenta como potenciais drogas para tratamento deesquistossomose(apêndice D).
b) Proteínas
No decorrer da pesquisa foram obtidas 95 proteínas através de buscas realizadas noNCBI e PDB. As proteínas obtidas são utilizadas como potenciais alvos nos testes realizadoscom os fármacos, os seus dados também são utilizadas no algoritmo de data mining e nosgráficos gerados pela ferramenta desenvolvida na pesquisa(apêndice C).
c) Docking
Para realização do Docking das proteínas foram utilizadas apenas 91 das 95, poisas proteínas de código PDB 1BDG, 1U3I, 2M7Z e 4AKA apresentaram erro na ferramentaAutoDockTools durante as alterações necessária para criação do arquivo de extensão pdqt paraexecução do docking na ferramenta AutoDock Vina.
Na realização do docking ocorreram erros na execução com as proteínas de códigoPDB 2V1M, 3H4K, 4Q3Q, 4Q3R, 4Q3S, 4Q3V e 5BYK em todos os fármacos e a 3ZLP ocorreuerro apenas com o fármaco de código ZINC ZINC01543873.
Os resultados das execuções de docking das proteínas podem ser visualizados noRelatório de Execução de Docking por Fármaco que será detalhado nos próximos tópicos.
d) Banco de dados desenvolvido
No decorrer deste trabalho foi desenvolvido o banco de dados relacional ferramenta_dataminingem MySQL para armazenar as informações da pesquisa e a estrutura do banco de dados édatalhada na figura 4.

31
Figu
ra4
–D
iagr
ama
das
tabe
las
doba
nco
deda
dos
Font
e:E
labo
rado
pelo
auto
r.

32
As tabelas criadas no banco de dados são utilizadas nos métodos criados na classeConexaoDMBD.php de comunicação com o banco de dados detalhada a seguir na subseçãoarquivos PHP.
6.2 Arquivos PHP
No decorrer da pesquisa foram desenvolvidos arquivos em PHP e esta subseção édestinada para detalhamento dos mesmos.
a) ConexaoDMBD.php
O arquivo ConexaoDMBD.php é a classe que possui os métodos responsáveis porconectar no banco de dados, inserir e recuperar dados nas tabelas do mesmo(apêndice A).
b) SistemaDM.Class.php
O arquivo SistemaDM.Class.php é classe responsável por validar os dados de en-trada dos métodos da classe ConexaoDMBD.php e retornar os dados formatados para seremutilizados nas interfaces(apêndice B).
c) pesquisa-resultados-docking.php
O arquivo pesquisa-resultados-docking.php utiliza os métodos listarFarmacosPesquisae relatorioExecucaoDocking do arquivo SistemaDM.Class.php, para isso é necessário que seinforme o código do projeto para que o sejam exibidos os fármacos para busca do relatório. Afigura 5 a seguir mostra o status inicial da tela.
Figura 5 – Tela inicial do arquivo pesquisa-resultados-docking.php.
Fonte: Elaborado pelo autor.
Ao selecionar o fármaco desejado e clicar no botão pesquisar são retornados osdados de código PDB, Descrição da proteína, Mode, affinity, Dist From e Best Mode com asinformações de docking de cada uma das proteínas executadas para o fármaco selecionado. Afigura 6 detalha a tela.

33
Figura 6 – Tela com dados retornados do arquivo pesquisa-resultados-docking.php.
Fonte: Elaborado pelo autor.
d) indicadores-graficos-pesquisa.php
O arquivo indicadores-graficos-pesquisa.php utiliza os métodos listarFarmacosPesquisa,listarProteinasPDB e indicadoresPesquisa do arquivo SistemaDM.Class.php, para isso é neces-sário que informe o código do projeto para que o sejam exibidos os fármacos e as proteínaspara busca do relatório (fig. 7).
Figura 7 – Tela inicial do arquivo indicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.
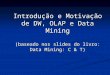
Ao selecionar o fármaco ou fármaco e proteína desejados e clicar no botão pesquisarsão retornados os indicadores gráficos gerais e do fármaco selecionado. A figura 8 mostra oindicador geral de quantidade de fármacos por solvente.
34
Figura 8 – Tela do indicador geral de quantidade de fármacos por solvente do arquivoindicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.
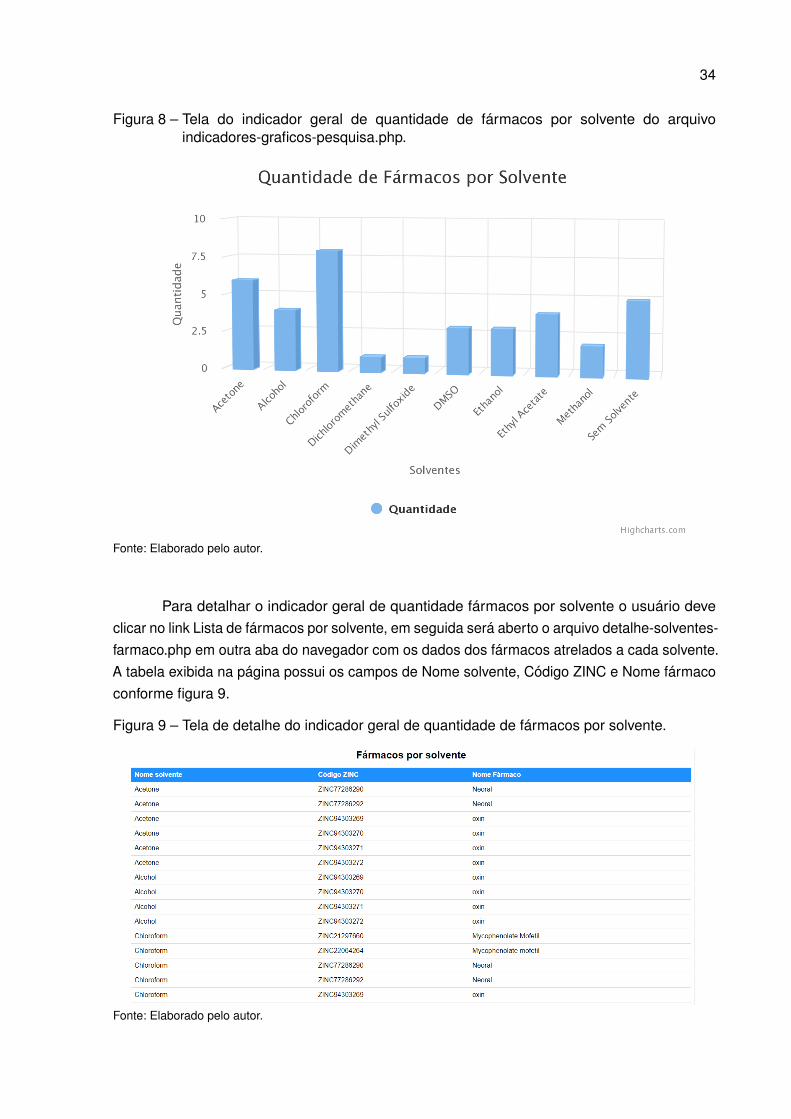
Para detalhar o indicador geral de quantidade fármacos por solvente o usuário deveclicar no link Lista de fármacos por solvente, em seguida será aberto o arquivo detalhe-solventes-farmaco.php em outra aba do navegador com os dados dos fármacos atrelados a cada solvente.A tabela exibida na página possui os campos de Nome solvente, Código ZINC e Nome fármacoconforme figura 9.
Figura 9 – Tela de detalhe do indicador geral de quantidade de fármacos por solvente.
Fonte: Elaborado pelo autor.

35
A figura 10 mostra o indicador geral de percentual de fármacos em conformidade com a“regra de 5” de Lipinski.
Figura 10 – Tela do indicador geral de percentual de fármacos em conformidade com a “regrade 5” de Lipinsk do arquivo indicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.
Ao clicar em um dos percentuais do indicador geral de percentual de fármacos emconformidade com a “regra de 5” de Lipinski é detalhado o percentual dos fármacos utilizadosou não na pesquisa pelo dado selecionado (fig. 11).
Figura 11 – Tela do percentual de fármacos utilizados na pesquisa “regra de 5” de Lipinsk doarquivo indicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.

36
Para detalhar o indicador geral de percentual de fármacos em conformidade com a“regra de 5” de Lipinski o usuário deve clicar no link Lista de fármacos em conformidade coma "Rega de 5"de Lipinski, em seguida será aberto o arquivo detalhe-farmacos-regra5.php emoutra aba do navegador com os dados dos fármacos em conformidade ou não com a “Regra de5” de Lipinski. A tabela exibida na página possui os campos de Código ZINC, Nome fármaco eEm conformidade (fig. 12).
Figura 12 – Tela de detalhe do indicador geral de percentual de fármacos em conformidadecom a “regra de 5” de Lipinsk.
Fonte: Elaborado pelo autor.
Na figura 13 é feito o detalhamento do indicador de afinidade por melhor modo dofármaco e proteína. O indicador exibe o agrupamento das afinidades por melhor modo dasexecuções de docking realizadas para um fármaco e suas respectivas proteínas.

37
Figura 13 – Tela do indicador de afinidade por melhor modo do arquivo indicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.
Ao selecionar uma parte desejada do gráfico é feita a aproximação do conjunto dedados selecionado conforme demonstrado na figura 14.
Figura 14 – Tela do indicador de afinidade por melhor modo do arquivo indicadores-graficos-pesquisa.php.
Fonte: Elaborado pelo autor.

38
No indicador de afinidade por melhor modo é possível realizar o filtro apenas porfármaco ou pelo fármaco e proteína. Sendo que, o indicador também exibe o resultado docálculo para predição de possíveis valores de afinidade, e o mesmo é recalculado com basenos dados retornados da busca.
Para realização da predição dos valores de afinidade utilizar-se-á regressão linearatravés da fórmula y = a − bx, onde os valores de b e a são obtidos através das fórmulas
b =∑
xy−∑
x∑
y
n∑x2−
(∑
x)2
n
e a = y − bx.
A regressão linear foi selecionada por ser uma equação que trabalha com conjuntosde dados numéricos predefinidos para realizar predições de possíveis valores futuros. Sendoassim, possibilitando que o pesquisador utilize um valor de melhor modo de um resultado deexecução Docking para a previsão um possível valor de afinidade utilizando os dados obtidosanteriormente com as execuções de Docking.
Nesta seção mostra-se os indicadores quantitativos disponíveis na ferramenta desenvol-vida.
Na seção 7 apresenta-se a discussão em torno do tema tratado nesse estudo.

39
7 DISCUSSÃO SOBRE O DESENVOLVIMENTO DA FERRAMENTA DE DATA MINING NATOMADA DE DECISÕES SOBRE POTENCIAIS PROTEÍNAS ALVO NO TRATAMENTODA ESQUISTOSSOMOSE MANSÔNICA
A pergunta norteadora do estudo foi no sentido de investigar se o desenvolvimento deuma ferramenta de data mining pode auxiliar na tomada de decisões sobre potenciais proteínasalvo para tratamento de esquistossomose mansônica. A pesquisa permitiu identificar que aoutilizar os indicadores desenvolvidos facilitou a tomada de decisões em relação às proteínasalvo por conta dos agrupamentos das informações contidas nos indicadores.
A integração entre NCBI e PDB é um dos facilitadores desenvolvidos durante a pesquisa,pois o pesquisador não tem a necessidade de se preocupar em procurar as proteínas no NCBI eem seguida ir ao PDB para obter as informações complementares sobre a proteína selecionada.Esse processo de obtenção de proteínas é feito de forma manual pelo pesquisador, porémcom a ferramenta desenvolvida as proteínas são obtidas automaticamente através de buscasrealizadas no NCBI e PDB e cadastradas no banco de dados da ferramenta desenvolvida.
Isto permite afirmar que o tempo ganho com a obtenção automática das proteínas podeser utilizado para obtenção dos demais dados utilizados durante a pesquisa.
Nesta pesquisa utilizar-se-á as ferramentas AutoDock Vina e AutoDockTools, porém asmesma não possuem indicadores como os desenvolvidos na ferramenta durante este estudo.
A ferramenta AutoDock Vina já citada de Trott e Olson (2010) na seção de materiais emétodos desta pesquisa é muito robusta para realização de Docking Molecular, porém a mesmanão possui indicadores nos o pesquisador possa tomar decisões. A ferramenta possibilita que opesquisador salve os resultados das execuções de Docking, mas os dados ficam separadoscada uma das execuções em um arquivo. Sendo assim, é necessário que o pesquisadorvisualize os resultados logo após a execução do Doking ou entre em cada um dos arquivospara fazer a suas respectivas analises dos resultados.
Já a ferramenta AutoDockTools também citada de Morris et al. (2009) na seção demateriais e métodos desta pesquisa, possibilita a formatação dos arquivos de moléculas deentrada para execução de Docking Molecular nela mesma ou em outras ferramentas, comoexemplo, a AutoDock Vina. A ferramenta possui um modulo de analise de dados, porém nãopossui nenhum indicador como os desenvolvidos na ferramenta desenvolvida neste estudo.
Sobressae desse do estudo dois relatórios, o Relatório de Execução de Docking porFármaco e o de Indicadores Gráficos da Pesquisa, ambos com indicadores agrupados parafacilitar a tomada de decisões.
O Relatório de Execução de Docking por Fármaco apresenta os resultado Docking decada uma das execuções do fármaco para cada uma das proteínas utilizando a ferramentaAutoDock Vina abordada na seção de materiais e métodos desta pesquisa. Sendo assim, oindicador exibe os resultados das execuções de Docking agrupadas por fármaco conformefigura 6 da seção de resultados, e com isto, apresentando-se como facilitador na análise dos

40
resultados de execuções Docking pelo pesquisar.
A utilização do Relatório de Execução de Docking por Fármaco permite afirmar qualproteína possui maior chance de ser um alvo para o fármaco selecionado.
Já o relatório de Indicadores Gráficos da Pesquisa apresenta três indicadores, o primeiroé o indicador geral de quantidade de fármacos por solvente e seu detalhamento, o segundo é oindicador geral de percentual de fármacos em conformidade com a “regra de 5” de Lipinski eseu detalhamento, e o terceiro e último dos indicadores é o indicador de afinidade por melhormodo do fármaco e proteína.
Assim, tem-se que o indicador geral de quantidade de fármacos por solvente apresentatodos os fármacos utilizados para a pesquisa em questão agrupados por solvente. Com issopode-se afirmar que os fármacos agrupados por “Sem solvente” não são utilizados na pesquisa,pois essa informação foi utilizada como critério de exclusão dos fármacos que não possuemsolventes dos fármacos utilizados nas execuções de Docking da pesquisa. Este indicadortambém possui o detalhamento de quais fármacos estão atrelados a quais solventes conformedetalhado na figura 9. Assim, facilitando a tomada decisão em relação à inclusão e exclusãodos fármacos a serem utilizados na pesquisa.
No indicador geral de percentual de fármacos em conformidade com a “regra de 5” deLipinski utilizou a “regra de 5” demonstrada na seção de materiais e métodos. Este indicadorpossui o detalhamento de quais fármacos estão em conformidade ou com a “regra de 5” deLipinski conforme figura 12. Com esse indicador é possível prever quais são os melhoresfármacos para utilização no tratamento da esquistossomose mansônica, pois os fármacos queestão em conformidade com a “regra de 5” de Lipinski são considerados melhores do que osque não estão em conformidade.
Já o indicador de afinidade por melhor modo do fármaco e proteína mostra os dadosagrupados por fármaco ou por proteína onde também é exibido o resultado do cálculo deregressão linear apresentado na seção de resultados. Neste indicador é apresentado o gráficoprincipal da ferramenta que utiliza a tarefa de predição do data mining que foi apresentada naseção elementos teóricos sobre data mining.
O indicador de afinidade por melhor modo do fármaco e proteína permite afirmar queao realizar a busca por proteína mostra uma predição com menos disparidade entre o valor daafinidade real e a afinidade calculada através do cálculo de regressão linear. Este indicadortambém mostra que ao utilizar o mesmo é possível realizar uma execução de docking commaior chance de assertividade por conta de o pesquisador poder prever uma afinidade combase no melhor modo da execução do docking.
Acrescenta-se que o estudo teve como limitação a utilização dos fármacos obtidosdo projeto da World Community Grid e as proteínas existentes no NCBI para o Schistosomamansoni, onde foram feitas apenas uma execução de docking do fármaco para cada proteínasem fazer remoções de suas cadeias. Um estudo que realize nestes mesmos moldes novosfármacos e proteinas ou apenas alterando as configurações de execução de docking poderáobter resultados de afinidades muito melhores do que os resultantes das execuções de docking

41
desta pesquisa, possibilitando assim, a identificação de novas proteínas alvo para o tratamentoda esquistossomose mansônica.
A contribuição relevante do estudo foi de colocar em evidência que a ferramenta desen-volvida durante a pesquisa torna-se um facilitador na tomada de decisões sobre quais proteínaspodem ser tratadas como potenciais proteínas alvo no tratamento da esquistossomose mansô-nica.

42
8 CONCLUSÃO
Para compreensão do tema desta pesquisa, buscou-se, inicialmente, reunir aspectosteóricos sobre esquistossomose mansônica com o objetivo de mostrar o quadro dessa doençainfecto parasitária.
Em seguida, apresentou-se fundamentos teóricos de data mining e bioinformática parademonstrar os materiais métodos utilizados para o desenvolvimento da pesquisa.
O estudo empreendido desta base teórica inicial permitiu demonstrar o potencial daferramenta desenvolvida durante a pesquisa, quando apresenta-se os seus indicadores detomada de decisão.
Isto significa que estes indicadores permitem ter a informação agrupada e exposta deuma forma estrutural que facilita decisões sobre potenciais proteínas alvo.
No estudo foram desenvolvidas duas classes que compõem a ferramenta desenvolvidana pesquisa com diversos métodos para alimentação dos dados para utilização nos indicadorespresentes nos relatório da ferramenta.
Ainda como resultados desta pesquisa foram desenvolvidos dois relatórios para tomadade decisões. O primeiro é o Relatório de Execuções de Docking por Fármaco que apresentadode forma agrupada e organizada os resultados das execuções de docking de um fármaco parasuas respectivas proteínas. Já o segundo relatório é o Indicadores Gráficos da Pesquisa quedispõem de três indicadores que são indicador geral de quantidade de fármacos por solvente eo indicador de afinidade por melhor modo.
Desta forma, tem-se que o melhoramento da ferramenta desenvolvida na pesquisapara que a mesma seja utilizada para outros organismos e não somente para o S. mansonie, também, o desenvolvimento de interfaces visuais para a inserção, alteração e exclusão dosdados necessários para a realização da pesquisa.

43
REFERÊNCIAS
ACHOUR, M. et al. Manual do PHP. PHP Group, 2016. Disponível em: <https://secure.php.net/manual/pt_BR/index.php>. Acesso em: 25 dez. 2016.
BERMAN, H. M. et al. The protein data bank. Nucleic Acids Research, Oxford, v. 28, n. 1, p.235–242, 2000. Disponível em: <http://nar.oxfordjournals.org/content/28/1/235.abstract>.
BERRY, M. J. A.; LINOFF, G. S. Data mining Techniques: For marketing, sales and customerrelationship management. 2nd. ed. Indianapolis: Wiley, 2004.
BIOLOGIA. In: MICHAELIS dicionário brasileiro da língua portuguesa. São Paulo:Melhoramentos, 2015. Disponível em: <http://michaelis.uol.com.br/busca?r=0&f=0&t=0&palavra=biologia>. Acesso em: 12 out. 2016.
BIOLOGY. In: OXFORD dictionary of english. 2nd. ed. Oxford: Oxford University, 2009.
BRASIL. Ministério da Saúde. Situação Epidemiológica - Dados. Brasília, DF,2014a. Disponível em: <http://portalsaude.saude.gov.br/index.php/o-ministerio/principal/leia-mais-o-ministerio/656-secretaria-svs/vigilancia-de-a-a-z/esquistossomose/11244-situacao-epidemiologica-dados>. Acesso em: 11 jun. 2016.
BRASIL. Ministério da Saúde. VIGILÂNCIA DA ESQUISTOSSOMOSE MANSONI: Diretrizestécnicas. 4. ed. Brasília, DF: Secretaria de Vigilância em Saúde, 2014b.
CENTER FOR DISEASE CONTROL AND PREVENTION. Schistosomiasis Infection. Atlanta,2016. Disponível em: <https://www.cdc.gov/dpdx/schistosomiasis/index.html>. Acesso em: 11jun. 2016.
CLAVERIE, J.-M.; NOTREDAME, C. Bioinformatics for Dummies. 2nd. ed. Indianapolis: Wiley,2007.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 4. ed. São Paulo: AddisonWesley, 2005.
FAYYAD, U.; PIATETSKY-SHAPIRO, G.; SMYTH, P. From data mining to knowledge discovery indatabases. AI Magazine, Palo Alto, v. 17, n. 3, p. 37–54, 1996.
FEIJÓ, B.; CLUA, E.; SILVA, F. S. C. da. Introdução à ciência da computação com jogos:Aprendendo a programar com entretenimento. Rio de Janeiro: Elsevier, 2010.
FENSTERMACHER, D. Introduction to bioinformatics. Journal of the American Societyfor Information Science and Technology, Wiley, Hoboken, v. 56, n. 5, p. 440–446, 2005.Disponível em: <http://dx.doi.org/10.1002/asi.20133>.
FERREIRA, A. G. D.; PEREIRA, L. Mineração de dados com Orange. Rio de Janeiro: Dev-media, 2016. Disponível em: <http://www.devmedia.com.br/mineracao-de-dados-com-orange/31678>. Acesso em: 25 jun. 2016.
FLANAGAN, D. JavaScript: the definitive guide. 6. ed. Sebastopol: O’Reilly, 2011.
FUNDAÇÃO OSWALDO CRUZ. Esquitossomose Mansônica. Rio de Janeiro, 2016.Disponível em: <http://www.fiocruz.br/bibmang/cgi/cgilua.exe/sys/start.htm?infoid=92&sid=106>.Acesso em: 11.06.2016.

44
FUNDAÇÃO OSWALDO CRUZ. Activity of compounds over Schistosoma mansonischistosomula. Belo Horizonte, 2017.
GIBAS, C.; JAMBECK, P. Desenvolvendo Bioinformática: ferramentas de software paraaplicações em biologia. Rio de Janeiro: Campus, 2001.
GOLDSCHMIDT, R.; PASSO, E.; BEZERRA, E. Data mining: conceitos, técnicas, algortimos,orientações e aplicações. 2. ed. Rio de Janeiro: Elsevier, 2015.
GRINTER, S. Z. et al. An inverse docking approach for identifying new potential anti-cancertargets. Journal of Molecular Graphics and Modelling, Amsterdã, v. 29, n. 6, p. 795–799,2011.
GUIDO, R. V. C.; ANDRICOPULO, A. D.; OLIVA, G. Planejamento de fármacos, biotecnologia equímica medicinal: aplicações em doenças infecciosas. Estudos Avançados, São Paulo, v. 24,n. 70, 2010.
GUZDIAL, M. J.; ERICSON, B. Introducción a la computación y programación con Python.3. ed. México: Pearson Educación, 2013.
HAN, J.; KAMBER, M. Data mining: concepts and techniques. 2nd. ed. San Francisco: Elsevier,2006.
HIGGS, P. G.; ATTWOOD, T. K. Bioinformatics and Molecular Evolution. [S.l.]: Blackwell,2005.
HIGHSOFT. Highsharts. Vik i Sogn, 2016. Disponível em: <http://www.highcharts.com/products/highcharts>. Acesso em: 05 nov.2016.
IRWIN, J. J. et al. Zinc: A free tool to discover chemistry for biology. Journal ofChemical Information and Modeling, v. 52, n. 7, p. 1757–1768, 2012. Disponível em:<http://dx.doi.org/10.1021/ci3001277>. Acesso em: 20 nov. 2016.
KANJ, S. et al. Editing training data for multi-label classification with the k-nearest neighbor rule.Pattern Analysis and Applications, London, v. 19, p. 145–161, 2016.
KEÇECI, M. Bioinformatics1: introduction to Bioinformatics. Istambul: [s.n.], 2015.
LEI, J. et al. Robust k-means algorithm with automatically splitting and merging clusters and itsapplications for surveillance data. Multimedia Tools and Applications, New York, v. 75, p.1–17, 2016.
LIPINSKI, C. A. et al. Experimental and computational approaches to estimatesolubility and permeability in drug discovery and development settings1. AdvancedDrug Delivery Reviews, v. 46, n. 1–3, p. 3 – 26, 2001. Disponível em: <http://www.sciencedirect.com/science/article/pii/S0169409X00001290>. Acesso em: 25 dez. 2016.
MOJUMDER, J. C. et al. Application of support vector machine for prediction of electrical andthermal performance in pv/t system. Energy and Buildings, Amsterdã, v. 111, p. 267 – 277,2016.
MORRIS, G. M. et al. Autodock4 and autodocktools4: Automated docking with selective receptorflexibility. Journal of Computational Chemistry, Wiley, Hoboken, v. 30, n. 16, p. 2785–2791,2009. Disponível em: <http://dx.doi.org/10.1002/jcc.21256>. Acesso em: 25 nov. 2016.
NATIONAL CENTER FOR BIOTECHNOLOGY INFORMATION. The NCBI Handbook. 2nd. ed.Bethesda, 2013. Disponível em: <https://www.ncbi.nlm.nih.gov/books/NBK143764/>. Acessoem: 20 nov. 2016.

45
OIKAWA, M. K. Bancos de Dados Biológicos. São Paulo: [s.n.], 2012. Slide do Curso deVerão 2012 - Bioinformática.
ORACLE CORPORATION. MySQL 5.7 Reference Manual. Redwood City, 2016. Disponívelem: <https://dev.mysql.com/doc/refman/5.7/en/what-is-mysql.html>. Acesso em: 05 nov. 2016.
POWERS, S. Learning JavaScript. 2nd. ed. Sebastopol: O’Reilly, 2009.
PRATA, A. Comemoração do centenário da descoberta do schistosoma mansoni no brasil.Revista da Sociedade Brasileira de Medicina Tropical, Uberaba, v. 41, n. 6, 2008.
PUGA, S.; FRANÇA, E.; GOYA, M. Banco de dados: implementação em SQL, PL/SQL eOracle 11g. São Paulo: Pearson Education do Brasil, 2013.
RASTOGI, S. C.; MENDIRATTA, N.; RASTOGI, P. Bioinformatics: methods and applications.4th. ed. Delhi: PHI Learning Private, 2013.
RUGGIERI, S. Efficient c4.5 [classification algorithm]. IEEE Transactions on Knowledge andData Engineering, Los Alamitos, v. 14, n. 2, p. 438–444, Mar 2002.
SÃO PAULO. Secretaria de Estado da Saúde de São Paulo. Centro de Vigilância Epidemiológica.Manual de doenças transmitidas por água e alimentos. São Paulo, 2005. Disponível em:<ftp://ftp.cve.saude.sp.gov.br/doc_tec/hidrica/if_esqui0405.pdf>. Acesso em: 11 jun. 2016.
SONG, S. H.; CHOI, Y.; YOON, T. Comparison of episodes of mosquito borne disease: Dengue,yellow fever, west nile, and filariasis with decision tree, apriori algorithm. In: InternationalConference on Advanced Communication Technology, 18th, 2016, PyeongChang.PyeongChang: [s.n.], 2016. p. 455–458.
TROTT, O.; OLSON, A. J. Autodock vina: Improving the speed and accuracy ofdocking with a new scoring function, efficient optimization, and multithreading. Journalof Computational Chemistry, Wiley, v. 31, n. 2, p. 455–461, 2010. Disponível em:<http://dx.doi.org/10.1002/jcc.21334>. Acesso em: 03 jun.2016.
UNIVERSIDADE ESTADUAL PAULISTA. Esquistossomose. São Paulo, 2015. Disponível em:<http://www2.ibb.unesp.br/departamentos/Educacao/Trabalhos/obichoquemedeu/helminto_esquistossomose.htm>. Acesso em: 20 jul. 2015.
WANG, Q. et al. Naïve bayesian classifier for rapid assignment of rrna sequences into the newbacterial taxonomy. Applied and environmental microbiology, Washington, v. 73, n. 16, p.5261–5267, 2007.
WITTEN, I. H.; FRANK, E.; HALL, M. A. Data mining: practical machine learning tools andtechniques. 3th. ed. Burlington: Morgan Kaufmann, 2011.
WORLD HEALTH ORGANIZATION. Schistosomiasis Fact sheet N ◦ 115. Geneva, 2017.Disponível em: <http://www.who.int/mediacentre/factsheets/fs115/en/>. Acesso em: 10 jun.2017.
WORLD WIDE WEB CONSORTIUM. HTML & CSS. São Paulo: World Wide Web Consortium,2016. Disponível em: <https://www.w3.org/standards/webdesign/htmlcss>. Acesso em: 03 nov.2016.

46
APÊNDICE A – Métodos, tabelas e descrições da classe ConexaoDMDB.php
Quadro 1 – Métodos da classe ConexaoDMBD.php
(Continua)
Método Tabela Descrição
__construct -Método que realiza co-nexão com o banco dedados MySQL.
cadastrarProjetoPesquisa projetos_pesquisaMétodo para cadastrarum novo projeto de pes-quisa.
listarProjetosPesquisa projetos_pesquisaMétodo para retornar alista de projetos de pes-quisa cadastrados.
cadastrarPoteinaPDB proteinas_pdbMétodo para cadastrarproteínas.
listarProteinasPDB proteinas_pdbMétodo para retornar alista de proteínas doPDB cadastradas.
cadastrarFarmaco farmacosMétodo para cadastrarum novo fármaco.
listarFarmacos farmacosMétodo para retornar alista de fármacos cadas-trados.
cadastrarRepresentacaoFisicaFarmacorespresentacao_fisica_farmaco
Método para cadastrarrepresentação fisica dofármaco.
listarRepresentacaoFisicaFarmacorespresentacao_fisica_farmaco
Método para retornar alista de representaçõesfísicas de um fármaco.
cadastrarSolubilidadeFarmaco solubilidade_farmacoMétodo para cadastraruma nova solubilidadede fármaco.
listarSolubilidadeFarmaco solubilidade_farmacoMétodo para retornar alista de solubilidades defármaco.
cadastrarSolubilidade solubilidadesMétodo para cadastraruma solubilidade.
listarSolubilidades solubilidadesMétodo para retornar alista de solubilidades.
cadastrarResultadoDocking resultados_dockingMétodo para cadastrarresultados de docking.

47
Quadro 1 - Métodos da classe ConexaoDMBD.php
(Conclusão)
Método Tabela Descrição
listarResultadosDocking resultados_dockingMétodo para retornar alista de resultados dedocking.
listarFarmacosPesquisa farmacos
Método para retornar alista de fármacos parapesquisa na tela.
relatorioExecucaoDockingresultados_dockingproteinas_pdb
Método para retornar orelatório de execuçõesde docking.
indicadoresPesquisa
farmacossolubilidade_farmacosolubilidadesrespresentacao_fisica_farmaco
Método para retornaros indicadores da pes-quisa.
Fonte: Elaborada pelo autor.

48
APÊNDICE B – Métodos, métodos de ConexaoDMDB e descrições da classeSistemaDM.Class.php
Quadro 2 – Métodos da classe SistemaDM.Class.php
(Continua)
Método Método ConexaoDMDB Descrição
__construct - Cria a instancia daclasse ConexaoDMBD.
executarRequisicao - Executa a requisição deCURL.
obterDadosNCBI - Obtém as proteínas doNCBI.
obterDadosProteinaPDB - Obtém os dados da pro-teína no PDB.
obterProteinas cadastrarPoteinaPDBObtém as proteínas ecadastra.
cadastrarProjetoPesquisacadastrarProjetoPes-
quisa
Valida os dados e ca-dastra um novo projetode pesquisa.
listarProjetosPesquisa listarProjetosPesquisaLista os projetos de pes-quisa cadastrados.
listarProteinasPDB listarProteinasPDB
Valida os dados e listaas proteínas cadastra-das para o projeto.
cadastrarFarmaco cadastrarFarmacoValida os dados e ca-dastra um novo fár-maco.
listarFarmacos listarFarmacos
Valida os dados e listaos fármacos cadastra-dos para o projeto.
cadastrarRepresentacaoFisicaFarmacocadastrarRepresenta-
caoFisicaFarmaco
Valida os dados e ca-dastra uma nova repre-sentação fisica do fár-maco.
listarRepresentacaoFisicaFarmacolistarRepresentacaoFi-
sicaFarmaco
Valida os dados e listaas representações fisi-cas de um fármacos nobanco de dados.
cadastrarSolubilidadeFarmacocadastrarSolubilidade-
Farmaco
Valida os dados e ca-dastra uma nova solubi-lidade de fármaco.

49
Quadro 2 - Métodos da classe SistemaDM.Class.php
(Conclusão)
Método Método ConexaoDMDB Descrição
listarSolubilidadeFarmacolistarSolubilidadeFar-
maco
Valida os dados e listaas solubilidades de fár-maco cadastradas nobanco de dados para ofármaco.
cadastrarSolubilidade cadastrarSolubilidade
Valida os dados e ca-dastra uma nova solubi-lidade no banco de da-dos.
listarSolubilidades listarSolubilidadesLista as solubilidadescadatrastradas nobanco de dados.
cadastrarResultadoDockingcadastrarResultado-
Docking
Valida os dados e ca-dastra um novo resul-tado de docking.
listarResultadosDockinglistarResultadosDoc-
kingLista resultados de doc-king cadatrastrados.
listarFarmacosPesquisa listarFarmacosPesquisaValida os dados e listaos fármacos para pes-quisa.
relatorioExecucaoDockingrelatorioExecucaoDoc-
king
Valida os dados e listaos resultados do rela-tório de execuções dedocking.
indicadoresPesquisa indicadoresPesquisaValida e lista os dadosde indicadores da pes-quisa.
Fonte: Elaborada pelo autor.

50
APÊNDICE C – Proteínas utilizadas na pesquisa
Quadro 3 – Proteínas utilizadas na pesquisa
(Continua)
Código PDB Proteína
5FUECrystal structure of Schistosoma mansoni HDAC8 comple-xed with 3- benzamido-benzohydroxamate
5CYGCrystal Structure of isoform 2 of uridine phosphorylase fromSchistosoma mansoni APO form
5CYFCrystal structure of isoform 2 of uridine phosphorylase fromSchistosoma mansoni in complex with citrate
4TXNCrystal structure of uridine phosphorylase from Schistosomamansoni in complex with 5-fluorouracil
4TXMCrystal structure of uridine phosphorylase from Schistosomamansoni in complex with thymine
4TXHCrystal structure of uridine phosphorylase from Schistosomamansoni in APO form
4TXLCrystal structure of uridine phosphorylase from Schistosomamansoni in complex with uracil
4TXJCrystal structure of uridine phosphorylase from Schistosomamansoni in complex with thymidine
5BYKSchistosoma mansoni (Blood Fluke) Sulfotransferase/S-oxamniquine Complex
5BYJSchistosoma mansoni (Blood Fluke) Sulfotransferase/R-oxamniquine Complex
3JAXHeavy meromyosin from Schistosoma mansoni muscle thickfilament by negative stain EM
4AKA IPSE alpha-1, an IgE-binding crystallin
4WOEThe duplicated taurocyamine kinase from Schistosoma man-soni with bound transition state analog (TSA) components
4WODThe duplicated taurocyamine kinase from Schistosoma man-soni complexed with arginine
4WO8The substrate-free duplicated taurocyamine kinase fromSchistosoma mansoni
4MDV Crystal structure of calcium-bound annexin (Sm)1
4MDU Crystal structure of apo-Annexin (Sm)1
4I07Structure of mature form of cathepsin B1 from Schistosomamansoni
4L5YMethylthioadenosine phosphorylase from Schistosoma man-soni in APO form
4CQFCrystal structure of Schistosoma mansoni HDAC8 comple-xed with a mercaptoacetamide inhibitor

51
Quadro 3 - Proteínas utilizadas na pesquisa
(Continuação)
Código PDB Proteína
4P27Structure of Schistosoma mansoni venom allergen-like pro-tein 4 (SmVAL4)
4Q42Crystal structure of Schistosoma mansoni arginase in com-plex with L-ornithine
4Q41Crystal structure of Schistosoma mansoni arginase in com-plex with L-lysine
4Q40Crystal structure of Schistosoma mansoni arginase in com-plex with L-valine
4Q3VCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor BEC
4Q3UCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor nor-NOHA
4Q3TCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor NOHA
4Q3SCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor ABHPE
4Q3RCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor ABHDP
4Q3QCrystal structure of Schistosoma mansoni arginase in com-plex with inhibitor ABH
4Q3P Crystal structure of Schistosoma mansoni arginase
4L6IMethylthioadenosine phosphorylase from Schistosoma man-soni in complex with adenine
3ZLPCrystal structure of Schistosoma mansoni Peroxiredoxin 1C48P mutant form with four decamers in the asymmetricunit
3ZL5Crystal structure of Schistosoma mansoni Peroxiredoxin IC48S mutant with one decamer in the ASU
4L5CMethylthioadenosine phosphorylase from Schistosoma man-soni in complex with adenine in space group P212121
4L5AMethylthioadenosine phosphorylase from Schistosoma man-soni in complex with tubercidin
3H4KCrystal structure of the wild type Thioredoxin glutatione re-ductase from Schistosoma mansoni in complex with aurano-fin
4KVAGTPase domain of Septin 10 from Schistosoma mansoni incomplex with GTP
4KV9GTPase domain of Septin 10 from Schistosoma mansoni incomplex with GDP
4I05Structure of intermediate processing form of cathepsin B1from Schistosoma mansoni

52
Quadro 3 - Proteínas utilizadas na pesquisa
(Continuação)
Código PDB Proteína
4I04Structure of zymogen of cathepsin B1 from Schistosomamansoni
2WGRCombining crystallography and molecular dynamics: Thecase of Schistosoma mansoni phospholipid glutathione pe-roxidase
2V1MCrystal structure of Schistosoma mansoni glutathione pero-xidase
2M7Z SmTSP2EC2
4MUBSchistosoma mansoni (Blood Fluke) Sulfotransfe-rase/Oxamniquine Complex
4MUA Schistosoma mansoni (Blood Fluke) Sulfotransferase
4BZ9Crystal structure of Schistosoma mansoni HDAC8 comple-xed with J1075
4BZ8Crystal structure of Schistosoma mansoni HDAC8 comple-xed with J1038
4BZ7Crystal structure of Schistosoma mansoni HDAC8 comple-xed with M344
4BZ6Crystal structure of Schistosoma mansoni HDAC8 comple-xed with SAHA
4BZ5 Crystal structure of Schistosoma mansoni HDAC8
4EL6Crystal structure of IPSE/alpha-1 from Schistosoma man-soni eggs
3VCO Schistosoma mansoni Dihydrofolate reductase
1TCVCrystal Structure of the Purine Nucleoside Phosphorylasefrom Schistosoma mansoni in complex with Non-detergentSulfobetaine 195 and acetate
4DC3Adenosine kinase from Schistosoma mansoni in complexwith 2-fluoroadenosine
3VASAdenosine kinase from Schistosoma mansoni in complexwith adenosine in occluded loop conformation
3VAQAdenosine kinase from Schistosoma mansoni in complexwith adenosine
3UQ9Adenosine kinase from Schistosoma mansoni in complexwith tubercidin
3UQ6Adenosine kinase from Schistosoma mansoni in complexwith adenosine and AMP
1TD1Crystal Structure of the Purine Nucleoside Phosphorylasefrom Schistosoma mansoni in complex with acetate
2V6OSTRUCTURE OF SCHISTOSOMA MANSONITHIOREDOXIN-GLUTATHIONE REDUCTASE (SMTGR)
1TO4 Structure of the cytosolic Cu,Zn SOD from S. mansoni
3UMF Schistosoma mansoni adenylate kinase

53
Quadro 3 - Proteínas utilizadas na pesquisa
(Continuação)
Código PDB Proteína
3ZVJCrystal structure of high molecular weight (HMW) form ofPeroxiredoxin I from Schistosoma mansoni
3ZTLCrystal structure of decameric form of Peroxiredoxin I fromSchistosoma mansoni
3S3RStructure of cathepsin B1 from Schistosoma mansoni incomplex with K11777 inhibitor
3S3QStructure of cathepsin B1 from Schistosoma mansoni incomplex with K11017 inhibitor
3QSDStructure of cathepsin B1 from Schistosoma mansoni incomplex with CA074 inhibitor
2XC2Crystal structure of oxidized Schistosoma mansoni Thiore-doxin pre- protein at 1.6 Angstrom
2XBQCrystal structure of reduced Schistosoma mansoni Thiore-doxin pre- protein at 1.7 Angstrom
2XBICrystal structure of Schistosoma mansoni Thioredoxin at1.6 Angstrom
2X99THIOREDOXIN GLUTATHIONE REDUCTASE FROMSCHISTOSOMA MANSONI IN COMPLEX WITH NADPH
2X8HTHIOREDOXIN GLUTATHIONE REDUCTASE FROMSCHISTOSOMA MANSONI IN COMPLEX WITH GSH
2X8GOXIDIZED THIOREDOXIN GLUTATHIONE REDUCTASEFROM SCHISTOSOMA MANSONI
2X8CTHIOREDOXIN GLUTATHIONE REDUCTASE FROMSCHISTOSOMA MANSONI WITH THE REDUCED C-TERMINAL END
3IEXSchistosoma Purine nucleoside phosphorylase in complexwith guanosine
3FB1Crystal Structure of Purine Nucleoside Phosphorylase inComplex with Ribose-1-Phosphate
3FAZCrystal structure of Schistosoma mansoni purine nucleosidephosphorylase in complex with inosine
3F8WCrystal structure of Schistosoma mansoni purine nucleosidephosphorylase in complex with adenosine
3E9ZCrystal structure of purine nucleoside phosphorylase fromSchistosoma mansoni in complex with 6-chloroguanine
3E9RCrystal structure of purine nucleoside phosphorylase fromSchistosoma mansoni in complex with adenine
3HXICrystal structure of Schistosome eIF4E complexed withm7GpppG and 4E-BP
3HXGCrystal structure of Schistsome eIF4E complexed withm7GpppA and 4E-BP
3E0QCrystal structure of Schistosoma mansoni purine nucleosidephosphorylase complexed with a novel monocyclic inhibitor

54
Quadro 3 - Proteínas utilizadas na pesquisa
(Continuação)
Código PDB Proteína
3DJFCrystal Structure of Schistosoma mansoni Purine Nucleo-side Phosphorylase in a complex with BCX-34
3FNQCrystal structure of schistosoma purine nucleosidephosphorylase in complex with hypoxanthine
2POA
Schistosoma mansoni Sm14 Fatty Acid-Binding Protein: im-provement of protein stability by substitution of the singleCys62 residue
1BDGHEXOKINASE FROM SCHISTOSOMA MANSONI COM-PLEXED WITH GLUCOSE
2CMTTHE STRUCTURE OF REDUCED CYCLOPHILIN A FROMS. MANSONI
2CK1THE STRUCTURE OF OXIDISED CYCLOPHILIN A FROMS. MANSONI
1U3ICrystal structure of glutathione S-tranferase from Schisto-soma mansoni
1VYGSCHISTOSOMA MANSONI FATTY ACID BINDING PRO-TEIN IN COMPLEX WITH ARACHIDONIC ACID
1TO5 Structure of the cytosolic Cu,Zn SOD from S. mansoni
1TCUCrystal Structure of the Purine Nucleoside Phosphorylasefrom Schistosoma mansoni in complex with phosphate andacetate
1VYFSCHISTOSOMA MANSONI FATTY ACID BINDING PRO-TEIN IN COMPLEX WITH OLEIC ACID
Fonte: Elaborada pelo autor.

55
APÊNDICE D – Fármacos utilizados na pesquisa
Quadro 4 – Todos os fármacos obtidos na pesquisa
Código ZINC Fármaco
ZINC01543873 Vorinostat
ZINC03927870 Fludarabine phosphate
ZINC21297660 Mycophenolate Mofetil
ZINC22064264 Mycophenolate mofetil
ZINC95862733 BANZINC94303269 oxin
ZINC94303270 oxin
ZINC94303271 oxin
ZINC94303272 oxin
ZINC77286290 Neoral
ZINC77286292 Neoral
ZINC03780343 Tolrestat
ZINC03812918 Bepridil hydrochloride
ZINC03830283 Bepridil hydrochloride
Fonte: Elaborada pelo autor.
Quadro 5 – Todos os fármacos utilizados na pesquisa
Código ZINC Fármaco
ZINC01543873 Vorinostat
ZINC21297660 Mycophenolate Mofetil
ZINC22064264 Mycophenolate mofetil
ZINC94303269 oxin
ZINC94303270 oxin
ZINC94303271 oxin
ZINC94303272 oxin
ZINC77286290 Neoral
ZINC77286292 Neoral
Fonte: Elaborada pelo autor.