Embed Size (px)
Citation preview

FILLIPE GUSTAVO BRANDÃO
ESTIMATIVA DA ALTURA TOTAL DE EUCALYPTUS SP.UTILIZANDO LÓGICA FUZZY E NEURO FUZZY
Monografia de graduação apresentada aoDepartamento de Ciência da Computação daUniversidade Federal de Lavras como parte dasexigências do curso de Ciência da Computaçãopara obtenção do título de Bacharel em Ciênciada Computação.
LAVRASMINAS GERAIS – BRASIL
2007

FILLIPE GUSTAVO BRANDÃO
ESTIMATIVA DA ALTURA TOTAL DE EUCALYPTUS SP.UTILIZANDO LÓGICA FUZZY E NEURO FUZZY
Monografia de graduação apresentada aoDepartamento de Ciência da Computação daUniversidade Federal de Lavras como parte dasexigências do curso de Ciência da Computaçãopara obtenção do título de Bacharel em Ciênciada Computação.
Área de Concentração:
Inteligência Artificial / Otimização
Orientador / Co-orientador:
Prof. Dr. Ricardo Martins de Abreu SilvaMsc. Adriano Ribeiro de Mendonça
LAVRASMINAS GERAIS – BRASIL
2007

Ficha Catalográfica
Brandão, FillipeGustavo
Estimativa da altura total de Eucalyptus sp. utilizando Lógica Fuzzy e NeuroFuzzy / Fillipe Gustavo Brandão. Lavras – Minas Gerais, 2007. 62p : il.
Monografia de Graduação – Universidade Federal de Lavras. Departamento de Ciência da Computação.
1.Inteligência Artificial 2.Lógica fuzzy 3.Neuro fuzzy. I. BRANDÃO,F.G. II. Universidade Federal de Lavras. III. Título.

FILLIPE GUSTAVO BRANDÃO
ESTIMATIVA DA ALTURA TOTAL DE EUCALYPTUS SP.UTILIZANDO LÓGICA FUZZY E NEURO FUZZY
Monografia de graduação apresentada ao Departamentode Ciência da Computação da Universidade Federal deLavras como parte das exigências do curso de Ciênciada Computação para obtenção do título de Bacharel emCiência da Computação.
Aprovada em (6 de Agosto de 2007)
_______________________________________Prof. Dr. Thiago de Souza Rodrigues
_______________________________________Prof. Dr. Claudio Fabiano Motta Toledo
_______________________________________Prof. Dr. Ricardo Martins de Abreu Silva
(Orientador)
_______________________________________Msc. Adriano Ribeiro de Mendonça
(Co-orientador)
LAVRASMINAS GERAIS – BRASIL

"A coisa mais bela que o homem pode experimentar eh o mistério. É esta a emoção que está na raiz de toda ciência e arte. O homem que desconhece esse encanto, incapaz de
sentir admiração e estupefação, esse já está, por assim dizer,morto, e tem os olhos extintos." Albert Einstein

Agradecimentos
A Deus pela fé e perseverança concedidos em todos os momentos da vida. Aos meus pais, Francisco Antônio Brandão e Gilma Lopes Brandão, que não pouparam
esforços para minha formação, seja de caráter ou profissional, a quem devo tudo e expresso meu eterno amor e gratidão.
Às minhas irmãs, Fernanda e Flávia, pelo carinho, amizade, força, confiança e incentivo para a realização deste curso.
À Aline por ter me acolhido com muito amor e carinho a todo instante e a quem devo muitos dos melhores momentos da minha vida.
Aos meus avós que nem cheguei a conhecer mas que lhes agradeço pela vida.Em especial minha vovó Cacilda a quem amo muito e devo minha gratidão e respeito por
tudo que representa.Ao Tio Zé, Dudu e Thiago que tiveram passagens importantes na minha vida e que agora
estão em um lugar melhor. Aos meus orientadores, Ricardo e Adriano, pela amizade, orientação, paciência e atenção
dedicada durante todo o transcorrer do desenvolvimento deste trabalho. Aos meus companheiros de república pela convivência e amizade.
Ao pessoal da TecnoLivre que me ensinaram muito, e que se tornaram pessoas especiais para mim.
Aos membros da equipe Danilo, Gleimar (baiano), Felipe, Alexandre que me ajudaram na construção deste trabalho
A todos os professores do DCC, que me ajudarem ao longo do curso. Enfim, a todos aqueles que tenham contribuído, direta ou indiretamente, para a realização
deste trabalho, deixo registrado os meus sinceros agradecimentos.


ESTIMATIVA DA ALTURA TOTAL DE EUCALYPTUS sp. UTILIZANDO LÓGICA FUZZY E NEURO-FUZZY
RESUMO
A importância do Eucalipto se mostra diante de seu uso múltiplo em vários segmentos, destacando-
se papel, celulose e energia . Estimar sua altura total colabora para o manejo florestal e
estimativa da produção. Portanto, o objetivo desse presente trabalho será estudar os efeitos
do DAP (diâmetro na altura do peito) e da idade da árvore na sua altura total e depois com
base neste estudo desenvolver um sistema de decisão baseado em Lógica fuzzy e outro em
Neuro-fuzzy . Em seguida, uma comparação será realizada com os principais modelos
clássicos da literatura.
Palavras-Chave: Eucalyptus sp., Lógica fuzzy, Neuro-fuzzy
ESTIMATE OF THE TOTAL HEIGHT OF EUCALYPTUS sp. USING LOGICAL FUZZY AND NEURO-FUZZY
ABSTRACT
The importance of the Eucalipto if ahead shows of its multiple use in some segments,
being distinguished paper, cellulose and energy. Esteem its total height collaborates for the
forest and estimative handling of the production. Therefore, the objective of this present
work will be to study the effect of the DBH (diameter at breast height) and the age of the
tree in its total height and later on the basis of this study to develop a system of decision
based on fuzzy Logic and another one in Neuro-fuzzy. After that, a comparison will be
carried through with the main classic models of literature.
Key-words: Eucalyptus sp., fuzzy Logic, Neuro-fuzzy
vii

SUMÁRIO
Lista de Figuras................................................................................................................... ix
Lista de Tabelas...................................................................................................................xi
1 Introdução..........................................................................................................................1
2 Referencial Teórico........................................................................................................... 32.1 Setor Florestal..............................................................................................................32.2 O gênero Eucalyptus....................................................................................................42.3 Altura........................................................................................................................... 4
2.3.1 Relações Hipsométricas....................................................................................... 52.3.1.1 Fatores que afetam a relação hipsométrica.................................................. 7
2.4 Lógica Fuzzy............................................................................................................... 72.4.1 Conjuntos fuzzy................................................................................................... 92.4.2 Sistema de Inferência fuzzy............................................................................... 14
2.5 Redes Neurais............................................................................................................ 172.5.1 Treinamento da Rede......................................................................................... 192.5.2 Neuro fuzzy........................................................................................................20
3 Proposta............................................................................................................................233.1 Modelo baseado em Lógica fuzzy............................................................................. 233.2 Modelo Neuro fuzzy.................................................................................................. 26
4 Metodologia......................................................................................................................294.1 Tipo de Pesquisa........................................................................................................ 294.2 Obtenção dos Dados.................................................................................................. 294.3 Procedimentos Metodológicos.................................................................................. 314.4 Modelos comparados................................................................................................. 324.5 Avaliação dos modelos.............................................................................................. 33
5 Resultados e Discussão....................................................................................................355.1 Avaliação com o conjunto de treino.......................................................................... 355.2 Avaliação do conjunto de checagem ........................................................................ 40
6 Conclusões e Propostas futuras......................................................................................466.1 Conclusões.................................................................................................................466.2 Trabalhos Futuros...................................................................................................... 46
Bibliografia..........................................................................................................................47
ix

LISTA DE FIGURAS
Figura 2.1: Exemplo da operação de União......................................................................... 10Figura 2.2: Exemplo da operação de interseção...................................................................10Figura 2.3: Exemplo da operação de Complemento............................................................ 11Figura 2.4: Principais padrões de Funções de Pertinência................................................... 13Figura 2.5: Diagrama de processo de inferência fuzzy........................................................ 14Figura 2.6: Exemplo de fuzzificação....................................................................................15Figura 2.7: Exemplo de aplicação do operador de implicação.............................................16Figura 2.8: Agregação de todas as saídas.............................................................................16Figura 2.9: Diagrama esquemático de um sistema neuro fuzzy...........................................22Figura 2.10: Estrutura de um sistema Neuro fuzzy.............................................................. 22Figura 3.1: Conjuntos fuzzy com suas respectivas funções membro para o DAP...............24Figura 3.2: Conjuntos fuzzy com suas respectivas funções membro para a altura total......24Figura 3.3: Diagrama de inferência ‘fuzzy’ utilizado para estimar a altura total do eucalipto para um DAP de 11 cm........................................................................................................ 25Figura 3.4: Sistema de inferência fuzzy............................................................................... 26Figura 3.5: Conjuntos fuzzy para a Idade.............................................................................27Figura 3.6: Conjuntos fuzzy para o DAP............................................................................. 28Figura 4.1: Distribuição de freqüência das idades das árvores-amostra para o treinamento .............................................................................................................................................. 30Figura 4.2: Distribuição de freqüência das idades das árvores-amostra para validação dos modelos................................................................................................................................ 30Figura 5.1: Distribuição Residual para o modelo de Curtis com conjunto de treino........... 36Figura 5.2: Distribuição Residual para o modelo de Curtis com Idade com conjunto de treino.....................................................................................................................................36Figura 5.3: Distribuição Residual para o modelo Parabólico com conjunto de treino.........37Figura 5.4: Distribuição residual para modelo logístico com conjunto de treino................ 37Figura 5.5: Distribuição residual para o modelo de Prodan com conjunto de treino........... 37Figura 5.6: Distribuição Residual do modelo fuzzy com conjunto de treino.......................38Figura 5.7: Distribuição Residual do modelo Neuro-fuzzy com conjunto de treino........... 38Figura 5.8: Distribuição residual da altura total para Curtis com o conjunto de checagem.41Figura 5.9: Distribuição residual da altura total para Curtis com idade com o conjunto de checagem.............................................................................................................................. 42Figura 5.10: Distribuição residual da altura total para o modelo Parabólico com o conjunto de checagem......................................................................................................................... 42Figura 5.11: Distribuição residual da altura total para o modelo Logístico com conjunto de checagem.............................................................................................................................. 42Figura 5.12: Distribuição residual da altura total para o modelo de Prodan com conjunto de checagem.............................................................................................................................. 43Figura 5.13: Distribuição residual da altura total para o modelo fuzzy com o conjunto de
x

checagem.............................................................................................................................. 43Figura 5.14: Distribuição residual da altura total para o modelo Neuro-fuzzy com o conjunto de checagem.......................................................................................................... 43
xi

LISTA DE TABELAS
Tabela 2.1: Principais modelos hipsometricas tradicionais ...................................................6Tabela 3.1: Tabela com as regras geradas............................................................................25Tabela 4.1: Critérios para avaliação do ajuste e validação dos modelos............................. 34Tabela 5.1: Medidas de precisão para o conjunto de treino ............................................... 36Tabela 5.2: Estatística da Bias, média das diferenças absolutas (MD) e desvio padrão das diferenças (DPD) para estimativa a altura total....................................................................39Tabela 5.3: Notas atribuídas, a partir das estatísticas da Tabela 5.2, para as estimativas de altura total.............................................................................................................................40Tabela 5.4: Medidas de precisão para o cojunto de checagem............................................ 41Tabela 5.5: Estatística da Bias, média das diferenças absolutas (MD) e desvio padrão das diferenças (DPD) para a altura total com conjunto de checagem........................................ 43Tabela 5.6: Notas atribuídas, a partir das estatísticas da Tabela 5.5, para as estimativas de altura total com o conjunto de checagem............................................................................. 43
xii

1 INTRODUÇÃO
O setor florestal brasileiro contribui com uma parcela importante para a economia
brasileira, gerando produtos para consumo direto ou para exportação, gerando impostos e
empregos para a população e, ainda, atuando na conservação e preservação dos recursos
naturais. De acordo com a classificação do Programa Nacional de Florestas (PNF) do
Ministério do Meio Ambiente, oito cadeias produtivas exploram o patrimônio florestal:
chapas e compensados, óleos e resinas; fármacos; cosméticos; alimentos; carvão, lenha e
energia; papel e celulose; madeira e móveis. Segundo Embrapa (2003) no setor florestal
brasileiro no que diz respeito às áreas plantadas, destacam-se as espécies do gênero Pinus e
Eucalyptus que hoje no Brasil, ocupam uma área de cerca de 4,8 milhões de hectares,
sendo 64% de Eucalyptus e 36% de Pinus. As maiores áreas plantadas estão nos estados de
Minas Gerais, São Paulo e Paraná, destacando-se, também, Santa Catarina e Bahia.
Por ser uma madeira que pode ser aproveitada no segmento de indústria de celulose,
siderurgia a carvão vegetal, lenha, serrado, compensados e lâminas, o Eucalyptus tem uma
grande influência na economia nacional. Para Medrado (2003) a produção brasileira está
aquém do desejado e acredita-se, que com base nas expectativas de crescimento de deman-
da, haverá uma necessidade de plantio em torno de 630 mil hectares ao ano, ao invés dos
200 mil hectares atuais. A Sociedade Brasileira de Silvicultura - SBS distribui essa necessi-
dade de plantio como sendo: 170 mil ha / ano para celulose, 130 mil ha / ano para madeira
sólida, 250 mil ha / ano para carvão vegetal e 80 mil ha / ano para energia.
Com base nesses dados observa-se a importância do Eucalyptus por ser uma espécie
de uso múltiplo com possibilidade de atender a todos os segmentos acima descritos, princi-
palmente para papel, celulose e energia onde historicamente tem contribuição especial.
Sendo assim com este aumento de demanda surge a necessidade de uma estimativa mais
precisa da altura total do Eucalipto, consequentemente auxiliando no controle e manejo das
plantações no intuito de aumentar a produção do mesmo.
Vários estudos já foram feitos para tentar estimar a altura total do gênero Eucalyp-
tus sp. Em sua maioria modelos matemáticos complexos que utilizam tanto regressão line-
ar quanto não-linear, entre os quais pode-se citar Assman (1952), Herinksen (1950),
Stofells(1953), Curtis(1967) , Scolforo (1993), Soares et al (2004).

Devido a importância de estimar a altura total de Eucalyptus e na tentiva de melho-
rar tal estimativa, o objetivo do presente trabalho foi a proposição de dois modelos, um
baseado em lógica fuzzy e outro em neuro-fuzzy, para estimar a altura de Eucalyptus sp.
diante das variáveis idade e DAP. No caso do primeiro modelo utilizar-se-á o Método
Direto de Mandani. Quanto ao segundo modelo, será aplicado no desenvolvimento a técni-
ca Neuro-fuzzy a partir dos dados obtidos. Tal técnica realiza o ajuste dos parâmetros de
um sistema de lógica fuzzy do tipo Sugeno, que utiliza funções lineares nas regras de infe-
rência.
Após toda a abordagem teórica, a proposta para a resolução do problema será expla-
nada em detalhes referente a construção tanto do modelo em Lógica fuzzy quanto do mode-
lo Neuro-fuzzy. Posteriormente os resultados obtidos serão explicitados e analisados de
forma a se ter uma conclusão concreta sobre quais os modelos obtiveram maior desempe-
nho.
2

2 REFERENCIAL TEÓRICO
2.1 Setor Florestal
De acordo com Embrapa(2005) o Setor Florestal Brasileiro conta com, aproximada-
mente, 530 milhões de hectares de florestas nativas, 43,5 milhões de hectares em Unidades
de Conservação Federal e 4,8 milhões de hectares de florestas plantadas com Pinus,
Eucalyptus e acácia-negra. Com a exploração de áreas de florestas nativas e florestas plan-
tadas gera-se mais de 2 milhões de empregos, contribui com mais de US$ 20 bilhões para o
PIB, exporta mais de US$ 4 bilhões (8% do agronegócio) e contribui com US$ 3 bilhões
em impostos, ao ano, arrecadados de 60.000 empresas. As florestas plantadas estão distri-
buídas estrategicamente, em sua maioria, nos estados do Paraná, Rio Grande do Sul, Santa
Catarina, São Paulo, Minas Gerais e Espírito Santo.
Há uma plena convicção particularmente nos meios técnico-científicos e acadêmi-
cos de que as atividades floresto-industriais e os produtos extraídos das florestas para os
mais diversos usos (bebidas, fármacos, resinas, etc...) fazem do recurso florestal no Brasil,
se gerido de forma sustentável, importante e imprescindível fator para o desenvolvimento
rural. Além disso constitui um suporte para uma indústria transformadora próspera, moder-
na e competitiva, num contexto de ampla inserção e aceitação social, além de proporcionar
importante melhoria dos recursos naturais fundamentais como a água, o solo, o ar a biodi-
versidade. (TONELLO et al, 2000)
Graças ao domínio tecnológico da silvicultura e às vantagens ambientais, as flores-
tas plantadas alcançam tamanho de corte entre 12 e 14 anos, onde a idade de corte para o
eucalipto chega a ser de 5 a 7 anos, para algumas regiões contra períodos em torno de 50
anos em clima temperado. Logo o eucalipto se mostra um importante segmento do agrone-
gocio colaborando em uma grande fatia para a economia nacional.
“Estamos plenamente convencidos de que Floresta com tecnologia é Investimento
econômico, social e ambiental; promove a segurança social e alimentar, apóia as ações de
conservação do meio ambiente e promove a sustentabilidade do agronegócio brasileiro”
(HOEFLICH, 1998).

2.2 O gênero Eucalyptus
O gênero Eucalyptus, pertencente a família Myrtacea, é uma planta originária da
Austrália, onde existem mais de 600 espécies. A partir do início do século XX, o Eucalyp-
tus teve seu plantio intensificado no Brasil, sendo usado durante algum tempo nas ferrovi-
as, como dormentes e lenha para as mariafumaças e mais tarde como poste para eletrifica-
ção das linhas. (ForestBrazil,2007).
A importância econômica que assume a cultura do Eucalyptus em nosso país decor-
re tanto da inerente multiplicidade de seus usos e empregos de suas diferentes espécies,
como da expressiva área de florestas implantadas existentes. Atualmente, do eucalipto,
muito se aproveita. Extraem-se óleos essenciais das folhas empregados em produtos de
limpeza e alimentícios, em perfumes e em remédios. A casca oferece tanino, usado no
curtimento do couro. O tronco fornece madeira para sarrafos, lambris, ripas, vigas, postes,
varas, esteios para minas, mastros para barco, tábuas para embalagens e móveis. Sua fibra
é utilizada como matéria-prima para a fabricação de papel e celulose.
“O eucalipto tem o dobro da produtividade de espécies coníferas plantadas no Brasil
e da maioria das árvores nativas. O eucalipto é uma árvore bastante versátil e com inúme-
ras aplicações industriais”(Aracruz,2007).
Com base no que foi dito anteriormente observa-se a importância do eucalipto por
ser uma espécie de uso múltiplo com possibilidade de atender a todos os segmentos acima
descritos, principalmente para papel e celulose e energia onde historicamente deu contri-
buição especial.
2.3 Altura
A altura da árvore é uma importante variável dendrométrica, necessária para esti-
mar, junto com o diâmetro, fundamentalmente o volume de madeira da árvore e seus
componentes. Torna-se também necessária conhecer a medida de altura para a interpreta-
ção do processo de crescimento e incremento volumétrico, e fornece importante subsídio à
classificação de sítios. A variável altura adquire também importância fundamental no estu-
do de sítios (CAMPOS, 1983 e FINGER, 1992), ou seja, quando se deseja conhecer o
4

comportamento de uma espécie em um determinado local, ao longo do tempo. Para o
manejo florestal, é importante o conhecimento desta variável, pois traduz as respostas em
crescimento das árvores segundo os fatores do meio em que vegetam.
Os pontos de mensurações da altura da árvore podem distinguir-se da seguinte
forma:
● Altura total (H): distancia vertical considerada desde o chão até o ápice da
copa.
● Altura do fuste: distância vertical que corresponde desde o chão até a base
da copa.
● Altura comercial: parte do fuste economicamente aproveitável que
corresponde a distância desde a altura do corte até a altura do diâmetro
mínimo comercial.
● Altura do toco: parte que fica no terreno após o corte aproveitável da árvore,
que corresponde normalmente a distância desde o chão até uma altura de
aproximadamente 30 cm.
● Altura da copa: É a distância ao longo do eixo da árvore, entre o ponto de
inserção e a extremidade superior da copa.
2.3.1 Relações Hipsométricas
Segundo Campos (1983), a relação hipsométrica pode ser definida como a relação
matemática entre as variáveis dendrométricas altura e diâmetro de uma árvore. A determi-
nação da altura de uma árvore em função de seu DAP, em várias circunstâncias é a única
possibilidade viável de poder definir a correspondente estrutura vertical do povoamento.
A determinação das alturas das árvores por meio de instrumentos é uma operação
onerosa e sujeita a erros. Com as alturas estimadas das árvores, juntamente com seus
respectivos diâmetros, é possível, empregando-se equações de volume, estimar o volume
de cada árvore e consequentemente o volume da parcela e do povoamento.
A partir de uma amostra de dados de diâmetro e altura, é possível estabelecer uma
relação matemática que permite estimar as alturas restantes da amostra e em consequência
5

da população, significando um grande ganho prático na realização de inventários florestais.
Campos (1983) e Scolforo (1993) citam que em populações com árvores de grande porte
como de eucaliptos, a variável altura é de difícil mensuração, elevando muito o tempo e o
custo da coleta dos dados do inventário, podendo também aumentar a margem de erro na
coleta dessa informação.
“É importante ressaltar que o uso da relação hipsométrica torna o inventário flores-
tal mais operacional e com menor custo” (CAMPOS,1983). Com o intuito de reduzir
custos durante a coleta de dados no inventário florestal, vários pesquisadores têm estudado
a relação existente entre o diâmetro e a altura das árvores (BARROS, 2002).
De acordo com Campos (1993), a literatura registra uma série bastante complexa de
modelos matemáticos para interpretar a relação hipsométrica. Dependendo da espécie e do
sítio será escolhida uma equação matemática mais apropriada. Entre os melhores modelos
e mais utilizados estão os seguintes citados na Tabela 2.1:
Os modelos citados acima são ditos tradicionais pois descrevem as alturas das árvo-
res em função apenas dos diâmetros medidos a 1,30 m do solo (DAP).
Em populações florestais onde se conhecem o índice de sítio, suas estruturas diamé-
trica e de altura, a densidade e a idade, podem-se obter estimativas da altura média através
dos modelos hipsométricos, os quais são denominados genéricos (SCOLFORO,1993).
6
Tabela 2.1: Principais modelos hipsometricas tradicionais

2.3.1.1 Fatores que afetam a relação hipsométrica
Existem vários fatores que afetam diretamente a relação hipsométrica. Estes fatores
têm sido estudados ao longo do tempo e são tratados em diversas literaturas, dentre as
quais pode-se citar Loestch et al. (1973), Finger (1992), Scolforo (1993). A seguir são
apresentados os principais fatores e como eles afetam a relação hipsométrica.
● Idade: Em idades mais jovens, o crescimento em altura das árvores é mais
acentuado, o que não ocorre quando as árvores atingem a fase adulta. Baseado
nisso não é difícil perceber a influência da idade nas relações hipsométricas.
● Sítio: Assim como a idade, o sítio também influencia as relações de crescimento,
principalmente em locais menos produtivos. Portanto, povoamentos jovens em
sítios bons mostram uma curva de altura íngreme, enquanto que em situação
contrária as curvas são mais achatadas.
● Densidade: Este é um outro ponto que influencia a relação hipsométrica e ela vai
ser maior ou menor dependendo a qual estrato da floresta pertence à árvore. Nas
árvores dominantes a altura é pouco afetada pelo espaçamento, já nas dominadas a
influência no desenvolvimento da altura é bastante acentuada.
● Posição Sociológica: Para árvores dominantes, a razão altura/DAP é menor do que
para árvores dominadas.
2.4 Lógica Fuzzy
Aristóteles, filósofo grego (384 - 322 a.C.), foi o fundador da ciência da lógica, e
estabeleceu um conjunto de regras rígidas para que conclusões pudessem ser aceitas logi-
camente válidas. O emprego da lógica de Aristóteles levava a uma linha de raciocínio lógi-
co baseado em premissas e conclusões. Como por exemplo: se é observado que "todo ser
vivo é mortal" (premissa 1), a seguir é constatado que "João é um ser vivo" (premissa 2),
como conclusão tem-se que "João é mortal". Desde então, a lógica Ocidental, assim
chamada, tem sido binária, isto é, uma declaração é falsa ou verdadeira, não podendo ser
ao mesmo tempo parcialmente verdadeira e parcialmente falsa. Esta suposição e a lei da
7

não contradição, que coloca que "U ou não U" cobre todas as possibilidades, formam a
base do pensamento lógico Ocidental.
A lógica fuzzy viola estas suposições. O conceito de dualidade, estabelecendo que
algo possa e deva coexistir com o seu oposto, faz a lógica difusa parecer natural, até
mesmo inevitável. A lógica de Aristóteles trata com valores "verdade" das afirmações,
classificando-as como verdadeiras ou falsas. Não obstante, muitas das experiências huma-
nas não podem ser classificadas simplesmente como verdadeiras ou falsas, sim ou não,
branco ou preto. Por exemplo, é aquele homem alto ou baixo? A taxa de risco para aquele
empreendimento é grande ou pequena? Um sim ou um não como resposta a estas questões
é, na maioria das vezes, incompleta.
A lógica fuzzy nasceu em 1965. Neste ano Lotfi A. Zadeh, que então era professor
do departamento de engenharia elétrica da Universidade da Califórnia em Berkeley, publi-
cou um artigo titulado “fuzzy Sets” (ZADEH, 1965) no journal Information and Control.
Ele propôs graduar a pertinência de elementos nos conjuntos. Esta nova teoria foi vista
naquela época, por uma parte da comunidade científica, como um escândalo matemático e
uma forma de pensamento impreciso.
Segundo Oliveira (2006), técnicas da área da Inteligência Artificial (IA) têm sido
amplamente utilizadas na construção de sistemas que necessitam manipular conhecimento
humano especializado. Um dos grandes gargalos na construção de sistemas que envolvem
conhecimento especialista é a dificuldade na obtenção e modelagem desse conhecimento.
Particularmente, a lógica fuzzy tem sido apresentada na literatura como uma das tecnologi-
as de IA que efetivamente resolve com sucesso certa classe de problemas.
De acordo com Zanon et al (2004) a lógica fuzzy expressa exatamente os valores
com que lida. Com lógica fuzzy, não trata-se uma variável como tendo apenas um estado
atual, mas sim com 'n' estados, cada um com um grau de associação. Em outras palavras,
não afirmarmos que uma casa é grande, mas sim que ela é 0.8 grande, 0.2 média e 0.0
pequena. Isto faz com que defina-se conjuntos em que um dado valor pode ser enquadrado.
Neste exemplo da casa tem-se três conjuntos: casas grandes, médias e pequenas. Mas nada
impede que tenha cinco conjuntos: casas enormes, grandes, médias, pequenas e minúscu-
las. O número de conjuntos nos diz quão precisamente estamos lidando com uma variável.
Segundo Lenke (2005) a força da Lógica fuzzy deriva da sua habilidade em inferir
conclusões e gerar respostas baseadas em informações vagas, ambíguas e qualitativamente
8

incompletas e imprecisas. Neste aspecto, os sistemas de base fuzzy têm habilidade de racio-
cinar de forma semelhante à dos humanos. Seu comportamento é representado de maneira
muito simples e natural, levando à construção de sistemas compreensíveis e de fácil manu-
tenção.
Tibiriçá (2005) cita como exemplo a aprovação ou reprovação de um aluno em uma
disciplina que pode ser tratada como uma medida fuzzy, pois os conjuntos “aprovado” e
“reprovado” são bem delimitados (clássico) entretanto pode existir algumas incertezas com
relação aos trabalhos realizados pelo aluno ou seu comportamento em sala de aula os quais
podem lhe atribuir um “grau de evidência” para cada um dos dois conjuntos.
2.4.1 Conjuntos fuzzy
A teoria de conjuntos fuzzy tem sido estendida a diversas abordagens, sendo o termo
lógica fuzzy usado em dois sentidos distintos: um sentido mais restrito que se refere a um
sistema lógico que generaliza a lógica clássica para uma mais flexível (teoria de conjuntos,
implicações lógicas, verdades parciais, etc.) e um sentido mais amplo, que engloba o senti-
do mais restrito, que se refere a todas as teorias e tecnologias onde se aplicam conjuntos
fuzzy (processos de decisão fuzzy, fuzzy clustering, relações fuzzy, modelos híbridos, etc.).
Todavia, a grande maioria das teorias e técnicas abrangidas pelo sentido mais amplo da
lógica fuzzy estão baseadas em quatro conceitos básicos: conjuntos fuzzy, variáveis linguís-
ticas, distribuição de possibilidades e regras Se-Então fuzzy
Os conjuntos fuzzy são conjuntos que não possuem fronteiras bem definidas e que
foram introduzidos devido ao fato de que os conjuntos clássicos apresentarem limitações
para lidar com problemas onde as transições de uma classe para outra acontecem de forma
suave. Sua definição, propriedades e operações são obtidas da generalização da teoria de
conjuntos clássicos, recaindo esta em um caso particular da teoria de conjuntos fuzzy.
A teoria de conjuntos clássicos está baseada na função característica clássica, dada
por
9

onde U é o conjunto Universo, A é um subconjunto de U e x é um elemento de U, ou seja,
a função característica é um mapeamento do conjunto universo no conjunto [0, 1] . Essa
função característica discrimina entre todos os elementos de U aqueles que, segundo algum
critério, pertence ou não ao subconjunto A, dividindo o conjunto universo em duas partes
com fronteira bem definida. As operações básicas dos conjuntos clássicos são a união, a
intersecção e o complemento e eles podem ser expressos através da função característica.
Seja A e B subconjuntos de U, então, temos respectivamente:
a) União
A∪Bx =maxAx ,Bx
b) Interseção
A∩Bx =minAx ,Bx
10
Figura 2.2: Exemplo da operação de interseção
Figura 2.1: Exemplo da operação de União
A B

c) Complemento
−A x=1−A x
Note que a escolha dos operadores união e intersecção é arbitrária. A única proprie-
dade que a operação interseção deve satisfazer é retornar 1 quando ambos os argumentos
são 1 e zero quando algum dos argumentos é 0. Da mesma forma, a operação união exige
apenas que o operador retorne 1 se pelo menos um dos argumentos é 1 e zero caso contrá-
rio. Para obtermos os conjuntos fuzzy e suas operações basta generalizarmos a função
característica da lógica clássica para o intervalo [0, 1], ou seja, Ax :U[0,1] , o que
implica em considerarmos um contínuo de valores de pertinência e não apenas pertence e
não-pertence. O elemento x pertencerá ao subconjunto A com um grau de pertinência que é
um valor no intervalo [0, 1].
De acordo com Tanaka (1991) um conjunto fuzzy é caracterizado por uma função de
pertinência, e o grau de pertinência pode ser considerado como uma medida que expressa a
possibilidade de que um dado elemento seja membro de um conjunto fuzzy. Os métodos de
expressão para conjuntos fuzzy podem ser divididos aproximadamente em dois:
● Expressão Discreta (quando o universo é finito): Na representação de um conjunto
fuzzy temos que, se ele é discreto podemos simplesmente enumerar os seus
elementos juntamente com seus graus de pertinência, peguemos o universo X sendo
X={x1 , x2 , ... , xn}.
Então, o conjunto A em X pode ser representado como a seguir:
A=A x1/ x1Ax2/ x2...A xn/ xn=∑ Ax i/ x i
11
Figura 2.3: Exemplo da operação de Complemento
A

● Expressão Contínua (quando o universo é infinito): Quando o universo X é um
conjunto infinito, o conjunto fuzzy A em X pode ser representado como a seguir:
A=∫x xi/ x i
Quando os conjuntos fuzzy são contínuos sua representação é a própria função de
pertinência. As formas para as funções de pertinência são totalmente arbitrárias. Todavia,
as funções mais utilizadas são:
● Função Triangular:
● Função-Γ:
● Função-S:
12

● Função Trapezoidal:
● Função Gaussiana:
● Função Exponencial:
A figura 2.4 exemplificada as formas das funções de pertinência citadas acima:
13
Figura 2.4: Principais padrões de Funções de Pertinência

2.4.2 Sistema de Inferência fuzzy
Os conceitos estabelecidos pela teoria de conjuntos fuzzy e da lógica fuzzy são utili-
zados na geração de programas de computador aplicados à solução de problemas como
controle e automação, classificação de dados, análise de decisões, sistemas especialistas e
robótica entre outras. Tais programas são conhecidos como sistemas de inferência fuzzy.
Os principais elementos de um sistema de inferência são:
(1) A base de regras, que contém o conjunto de regras se-então;
(2) Um dicionário de funções de pertinência utilizadas pelas regras;
(3) O procedimento de inferência, também denominado agregador;
(4) Caso a saída necessite ser numérica, um processo para conversão de fuzzy para
número, denominado “defuzzificação”.
A figura 2.5 mostra um diagrama básico de um sistema de inferência fuzzy.
14
Figura 2.5: Diagrama de processo de inferência fuzzy

Para Tanaka (1991) a inferência fuzzy é o processo de mapear uma dada entrada
para uma saída, utilizando-se para isto a lógica fuzzy. Neste processo, tem-se: funções de
pertinência, operadores lógicos fuzzy e regras do tipo Se-Então.
De acordo com Domingos et al (2005), para estabelecer um processo de inferência
fuzzy, é necessário estabelecer um conjunto de regras, as quais são sentenças com uma
estrutura do tipo Se-Então, que são interpretadas pelo sistema. Convém ressaltar que há um
paralelismo natural das regras, na forma em que são avaliadas, sendo este um dos aspectos
mais importantes dos sistemas de lógica fuzzy. As regras são muito úteis, pois fazem refe-
rência as variáveis, aos termos e aos adjetivos que as descrevem. Para cada caso de variá-
vel analisada é estabelecida uma faixa de valores na qual ela é esperada variar, como
também qual é o significado de cada termo lingüístico.
Em um Sistema de Inferência fuzzy, consideram-se entradas não-fuzzy, ou precisas –
resultantes de medições ou observações (conjuntos de dados, por exemplo) –, que é o caso
da grande maioria das aplicações práticas. Em virtude disto, é necessário efetuar um mape-
amento destes dados precisos para os conjuntos fuzzy (de entrada) relevantes, o que é reali-
zado no estágio de fuzzificação. Neste estágio ocorre também a ativação das regras rele-
vantes para uma dada situação. A figura 2.6 apresenta um exemplo de “fuzzyficação” da
qualidade do serviço de um garçom.
As regras podem ser fornecidas por especialistas, em forma de sentenças linguísti-
cas, e se constituem em um aspecto fundamental no desempenho de um sistema de inferên-
cia fuzzy. Novamente tomando o exemplo de um controlador fuzzy, este só terá um bom
desempenho se as regras que definem a estratégia de controle forem consistentes. Extrair
regras de especialistas na forma de sentenças do tipo se ... então pode não ser uma tarefa
fácil, por mais conhecedores que eles sejam do problema em questão. Alternativamente ao
uso de especialistas para a definição da base de regras, existem métodos de extração de
15
Figura 2.6: Exemplo de fuzzificação

regras de dados numéricos. Este métodos são particularmente úteis em problemas de clas-
sificação e previsão de séries temporais.
No estágio de inferência ocorrem as operações com conjuntos fuzzy propriamente
ditas: combinação dos antecedentes das regras, implicação e modus ponens generalizado.
Os conjuntos fuzzy de entrada, relativos aos antecedentes das regras, e o de saída, referente
ao consequente, podem ser definidos previamente ou, alternativamente, gerados automati-
camente a partir dos dados.
A Figura 2.7 mostra um exemplo de implicação do serviço do garçom e qualidade
da comida no valor da gorjeta. Neste caso se o serviço do garçom foi excelente ou se a
comida for deliciosa então a gorjeta dada ao garçom será generosa.
A Figura 2.8 apresenta a agregação de todas as saídas, ainda seguindo o exemplo do
garçom. Todas as saídas são combinadas em um único conjunto fuzzy onde as entradas são
as funções retornadas pela implicação e a saída é um conjunto fuzzy para cada variável de
saída.
16
Figura 2.7: Exemplo de aplicação do operador de implicação
Figura 2.8: Agregação de todas as saídas

Uma vez obtido o conjunto fuzzy de saída por meio do processo de inferência
(modus ponens generalizado), no estágio de defuzzificação é efetuada uma interpretação
dessa informação. Isto se faz necessário, pois em aplicações práticas, geralmente são
requeridas saídas precisas. No caso de um sistema de controle, por exemplo, em que o
controle é efetuado por um sistema de inferência fuzzy (ou controlador fuzzy), este deve
fornecer à planta dados ou sinais precisos, já que a "apresentação" de um conjunto fuzzy à
entrada da planta não teria significado algum. Existem vários métodos de defuzzificação na
literatura; dois dos mais empregados é o centro de gravidade e a média dos máximos.
Neste, a saída precisa é obtida tomando-se a média entre os dois elementos extremos no
universo que correspondem aos maiores valores da função de pertinência do consequente.
Com o centro de gravidade, a saída é o valor no universo que divide a área sob a curva da
função de pertinência em duas partes iguais.
Em resumo, o desempenho de um sistema de inferência fuzzy depende da escolha de
uma base de regras adequada e do número e forma dos conjuntos atribuídos a cada variá-
vel. Pode-se inserir também a escolha do operador de implicação e do método de defuzzifi-
cação.
2.5 Redes Neurais
As redes neurais artificiais surgiram na década de 40, como uma tentativa de emular
a estrutura e o funcionamento do cérebro biológico. Não se trata de uma abordagem de
natureza algorítmica, ou seja, baseada em procedimentos que descrevem a solução de
problemas. É um modelo inteligente, paralelo e dinâmico que adquire conhecimento e
experiência paulatinamente. Devido a estas características, a computação neural é uma
alternativa a métodos clássicos para resolver problemas mais complexos.
Jang(1993) cita que as redes neurais artificiais são sistemas paralelos e distribuídos
formados por elementos de processamento simples que calculam funções, geralmente
funções não-lineares. Esses elementos estão dispostos em camadas, interconectados por
ligações geralmente unidirecionais, as quais estão associadas a um peso. Esses pesos arma-
zenam o conhecimento da rede e servem para ponderar a entrada recebida por cada
elemento.
17

O paradigma neural não faz uso dos conceitos que até então caracterizam os demais
algoritmos e sistemas computacionais. Uma rede neural pode ser integralmente implemen-
tada em Hardware, os chips neurais são objeto de intenso estudo em grandes centros de
pesquisa e muito em breve serão realidade em muitas aplicações e produtos comerciais. No
Japão é comum encontrar-se hoje eletrodomésticos sendo lançados com recursos de auto-
controle, por eles chamados neuro-fuzzy (Sistemas híbridos combinando redes neurais e
lógica fuzzy).
Os modelos neurais foram concebidos com base na estrutura do sistema nervoso,
mais especificamente na estrutura do cérebro humano e, assim, sua principal característica
está na capacidade de aprender com base na exposição a exemplos. A construção de uma
rede neural se constitui portanto, na configuração da sua arquitetura interna (uma rede
interligada de neurônios) e no treinamento desta rede com base em exemplos, até que ela
própria consiga aprender como resolver o problema.
Na sua tarefa de emular a estrutura e o funcionamento básico do cérebro, as redes
neurais fazem uso de um modelo abstrato (matemático) do neurônio cerebral. No modelo
de neurônio artificial, a intensidade das ligações entre neurônios (sinapses) são emuladas
através de pesos, que são ajustáveis durante o processo de evolução do treinamento e
aprendizado da rede. O corpo celular é emulado pela composição de duas funções, chama-
das geralmente na literatura de funções de ativação e de propagação. Estas funções reali-
zam o mapeamento, ou seja a transferência dos sinais de entrada em um único sinal de
saída. Este sinal de saída é então, propagado para os neurônios seguintes da rede, como no
modelo biológico.
Diversos são os modelos de rede propostos na literatura, cada qual advindo de uma
linha de pesquisa diferente e visando um melhor desempenho na solução de um tipo espe-
cífico de problema. Basicamente, os modelos neurais podem ser classificados segundo:
(a) A estratégia de treinamento : em supervisionados (quando a rede dispõe de um
instrutor apontando erros e acertos) ou não-supervisionados (caso contrário).
(b) A forma de treinamento: em incremental (quando o conhecimento da rede se
ajusta após a apresentação de cada padrão de entrada (estímulo)) ou lote (onde o
ajuste do conhecimento só é realizado após “visão” de todos os estímulos).
18

(c) A forma de operação: em unidirecional (os sinais internos se propagam apenas na
direção entrada/saída - feedforward) e recorrente (quando há realimentação –
recurrent).
As RNAs para resolver um problema, antes devem passar por um processo de
aprendizagem, durante o qual os seus pesos são ajustados. Para treinar uma rede, é neces-
sário apresentar a ela um conjunto de exemplos de entradas, chamado de conjunto de trei-
namento. Desta forma, a rede consegue extrair informações importantes sobre as caracte-
rísticas das entradas. Após a aprendizagem, a rede é capaz de fazer generalizações, ou seja,
fornecer respostas coerentes para dados de entrada nunca vistos, baseada em características
de exemplos já aprendidos.(OLIVEIRA,2002).
2.5.1 Treinamento da Rede
É na fase de treinamento que a rede neural aprende o problema e tenta resolvê-lo
auto ajustando seus parâmetros internos. Uma vez que a rede tenha aprendido, isto é, ela
tenha chegado a uma condição de erro considerada satisfatória, seus parâmetros são conge-
lados e ela, a partir de então, está pronta para ser usada com dados da situação corrente.
Segundo Thome (2005) existem várias arquiteturas e várias técnicas de treinamento
de rede neural propostas na literatura. Cada uma com vantagens e desvantagens, dependen-
do do problema e da aplicação específica a que se destinam. Na etapa do treinamento é
escolhido o algoritmo de aprendizado juntamente com os parâmetros de aprendizado. O
aprendizado é o processo pelo qual a rede adapta seus parâmetros (em geral os pesos das
conexões entre os neurônios) de forma a satisfazer os requisitos de mapeamento estabeleci-
dos. A dinâmica de treinamento representa a freqüência com que estes parâmetros (pesos)
são atualizados.
A taxa de aprendizado é um valor positivo, geralmente menor do que 1, que regula
a intensidade com que as atualizações dos parâmetros (pesos) serão efetuadas. Taxas muito
baixas, próximas de zero, tendem a fazer com que o aprendizado seja bastante lento, porém
taxas muito altas, próximas de 1, podem fazer com que a rede oscile, como se estivesse
aprendendo e desaprendendo, e às vezes nem consiga chegar a um patamar aceitável de
aprendizado. O valor da taxa de aprendizado não precisa permanecer fixo durante todo o
19

treinamento. Em algumas implementações ela pode ser adaptativa e controlada pela própria
rede.
A taxa de momento é um parâmetro de uso opcional, de valor também positivo e
menor do que 1, cuja utilização visa imprimir uma dinâmica no treinamento tal que, even-
tualmente, possibilite o algoritmo livrar-se de mínimos locais durante o processo de busca
pelo mínimo global (ponto de menor erro). Fazendo um paralelo com o mundo real, a taxa
de momento aplica um fator de inércia no processo de evolução do treinamento, que se
mantém acelerando enquanto o permanecer diminuindo e, assim, eventualmente faz com
que o processo adquira velocidade suficiente para livrar-se de pequenos buracos (mínimos
locais) que possam ser encontrados pelo caminho.
A condição de parada é geralmente estipulada com base na ocorrência de dois even-
tos: erro mínimo e número de ciclos. A parada pelo erro mínimo ocorre se e quando o algo-
ritmo de treinamento levar a rede a convergir para um erro menor que o mínimo estipulado
como critério de término. A parada pelo número de ciclos de treinamento encerra o proces-
so independentemente do nível de aprendizado alcançado pela rede. A parada por este
critério deve sempre ser utilizada em conjunto com qualquer outro, com vistas a evitar
processos de treino intermináveis.
2.5.2 Neuro fuzzy
Cada técnica de inteligência artificial possui características que a torna adequada a
determinadas aplicações. Por causa do alto paralelismo na sua estrutura, as redes neurais
têm respostas mais rápida e com melhor desempenho do que os computadores seqüênciais
na emulação do cérebro humano (KWAN e CAI, 1994). Assim processamentos de grandes
quantidades de dados tornam-se fáceis mediante hardware adequado.
De outro lado, a lógica fuzzy é uma poderosa ferramenta para modelar o pensamento
e a percepção humana (KWAN e CAI, 1994). O raciocínio humano é de alguma forma
nebuloso, pois é capaz de trabalhar com dados incertos, incompletos e ambígüos. As
imagens na vida real, frequentemente contém dados que são incompletos ou ambígüos
(LAW, ITOH e SEKI, 1994). A utilidade da lógica “fuzzy” está na sua habilidade de tratar
esses dados que são encontrados frequentemente na prática (PAL e MITRA, 1992).
20

Os sistemas híbridos combinam duas ou mais técnicas de maneira a aproveitar suas
vantagens, e também superar algumas limitações que as técnicas individuais possuírem.
Assim, para habilitar um sistema a manipular situações da vida real de uma forma mais
parecida com a do ser humano, uma forma é incorporar os conceitos dos conjuntos fuzzy
dentro de redes neurais (PAL e MITRA, 1992).
As redes neuro-fuzzy podem ser divididas em duas categorias. Um grupo de redes
neurais para o raciocínio fuzzy utilizam pesos fuzzy nas conexões entre nós. No segundo
grupo, os dados são “fuzzificados” na primeira ou segunda camada, mas os pesos da rede
não são fuzzy , sendo este o grupo mais utilizado na prática.
Um neurônio não fuzzy convencional possui N entradas, N pesos e uma saída. O
neurônio soma o produto das N entradas com seus pesos correspondentes e através de uma
função de ativação é calculada a saída.
Segundo Kwan & Cai (1994) um neurônio fuzzy possui N entradas com seus N
pesos, e M saídas. Todas as entradas e pesos são valores reais e as saídas são valores reais
no intervalo [0, 1]. Cada saída expressa o grau com que um dado modelo pertence ao
conjunto fuzzy.
Um sistema neuro-fuzzy pode ser representado através das seguintes camadas
(HIGGINS e GOODMAN, 1989):
● Camada de entrada (“fuzzificação”): esta camada implementa a função de
pertinência gerando valores entre 0 e 1 para um dado na entrada.
● Camada de regras (AND/OR ou MIN/MAX): esta camada contém um nó para cada
regra, aplicando as operações “fuzzy” de AND e OR. As regras AND/OR podem
ser implementadas em camadas diferentes (LEE, KWAK & KWANG, 1996) ou na
mesma camada . As operações AND e OR podem, também, ser implementadas na
mesma regra (HIGGINS & GOODMAN, 1989).
● Camada de saída (“defuzzificação”): esta camada transforma o sinal nebuloso em
sua entrada em um sinal definido utilizando algumas das estratégias de
“defuzzificação”.
21

Uma possível arquitetura de um sistema híbrido neuro-fuzzy é mostrada na Figura
2.9 O sistema contém três diferentes camadas, sendo elas:
• Camada de Fuzzificação;
• Camada de Inferência (Regras fuzzy);
• Camada de Defuzzificação.
Na Camada de Fuzzificação cada neurônio representa uma função "membro" de
entrada do antecedente de uma regra fuzzy (ver Figura 2.10) . Na Camada de Inferência as
regras são ativadas e os valores ao final de cada regra representam o peso inicial da regra, e
serão ajustados ao seu próprio nível ao final do treinamento. Na Camada de Defuzzifica-
ção cada neurônio representa uma proposição conseqüente e suas funções "membros"
podem ser implementadas combinando uma ou duas funções "sigmoid" e lineares. O peso
de cada saída representa aqui o centro de gravidade de cada saída da função "membro".
Após adquirir a saída correspondente o ajuste é feito na conexão do peso e nas funções
"membro" visando compensar o erro e produzir um novo controle de sinal.
22
Figura 2.9: Diagrama esquemático de um sistema neuro fuzzy
Figura 2.10: Estrutura de um sistema Neuro fuzzy

3 PROPOSTA
3.1 Modelo baseado em Lógica fuzzy
Para o desenvolvimento do modelo em lógica fuzzy foi usado o modelo direto de
Mandani. Foram construídas funções de pertinência, diferentes conjuntos fuzzy para cada
variável, e regras de inferência, do tipo ‘se-então’. Para essa construção foi requerida a
ajuda de especialistas, de informações da literatura da área e de dados cuja interpretação
possa ajudar nesse trabalho.
O modelo contem uma entrada e uma saída. Como entrada foi usado o DAP e para
ela foram criados 9 conjuntos fuzzy (Figura 3.1). A altura total foi utilizada como saída e
neste caso foram criados 7 conjuntos fuzzy (Figura 3.2). Posteriormente especificou-se um
conjunto de regras de inferência para relacionar as variáveis e seus conjuntos de forma a
constituir o mecanismo de inferência (Tanaka, 1997). O sistema utilizou o operador de
implicação “Minimo” de Mamdani por ser intuitivo, amplamente aceito e por traduzir
melhor a experiência humana (Driankov et al., 1993), para composição foi usado o opera-
dor 'MAX' que considera apenas o valor de pertinência máximo.
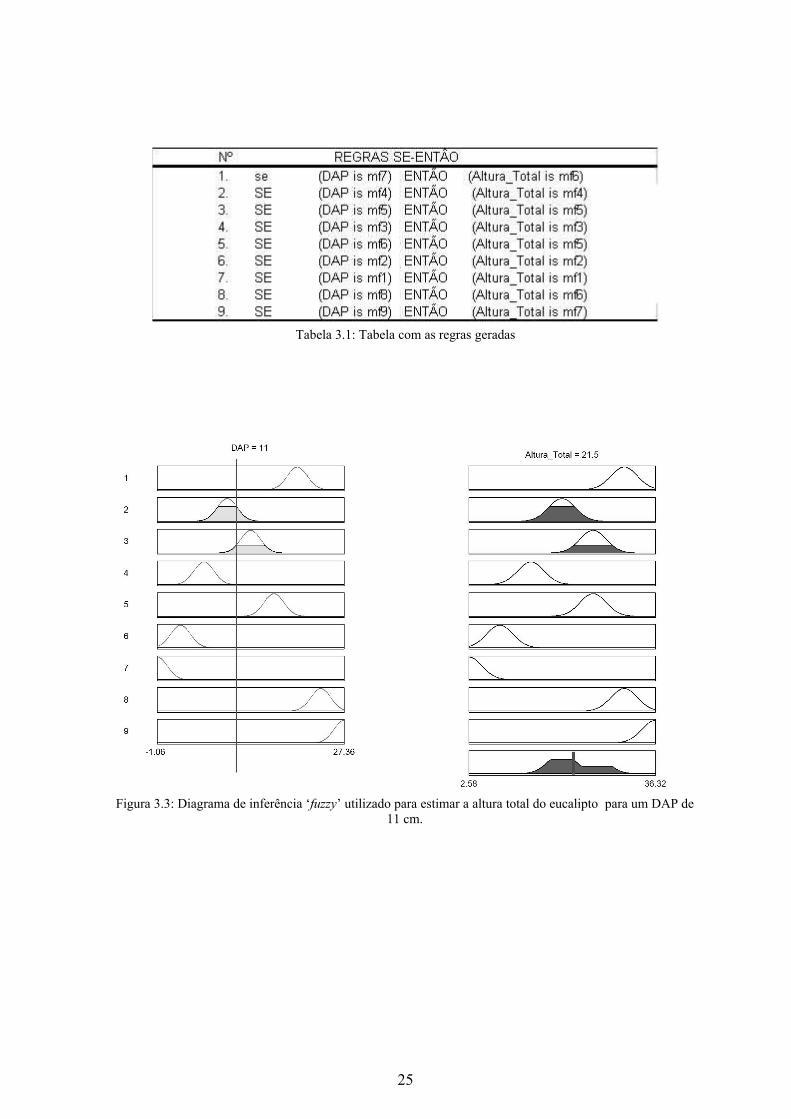
Foram geradas nove regras de inferência (Tabela 3.1), de acordo com informações
do especialista e análise da base de dados. O esquema que mostra as regras criadas operan-
do sobre os conjuntos e suas funções de pertinência para determinados valores de entrada é
o diagrama de inferência (Figura 3.3).

24
Figura 3.1: Conjuntos fuzzy com suas respectivas funções membro para o DAP
Figura 3.2: Conjuntos fuzzy com suas respectivas funções membro para a altura total
25
Tabela 3.1: Tabela com as regras geradas
Figura 3.3: Diagrama de inferência ‘fuzzy’ utilizado para estimar a altura total do eucalipto para um DAP de 11 cm.

3.2 Modelo Neuro fuzzy
O modelo proposto utiliza o sistema híbrido neuro-fuzzy idealizado por Roger Jang
(JANG, 1993). Para desenvolver o sistema Neuro-fuzzy foi necessário um conjunto de
dados, representados na forma de matriz, onde os dados referentes à variável de saída esta-
vam na última coluna. Foram utilizados dados obtidos nos experimentos descritos. Nesse
caso, definiram-se as funções de pertinência ou funções membro e base de regras por meio
de uma rede neuronal (Jang, 1993; Jang & Sun, 1995; Almeida, 2004)
A matriz de dados possui duas entradas e uma saída. A primeira entrada é a idade
do Eucalyptus, a segunda o DAP da árvore e a saída é a altura total. Como o treinamento
foi supervisionado, esta saída é a valor real da base de dados, pois é necessário calcular o
erro para o aprendizado. Esta matriz de dados então foi carregada para a rede.
Após o carregamento foi gerado o FIS (fuzzy Inference System). Neste trabalho
escolheu-se o método Grid Partition, com 7 funções de pertinência para a primeira variá-
vel (idade), 7 funções de pertinência para a segunda (DAP). A Figura 3.4 mostra o FIS do
problema abordado.
26
Figura 3.4: Sistema de inferência fuzzy
Como parâmetro para o treinamento, foi escolhido o método de treinamento híbri-
do, que consiste pela combinação do método de backpropagation e o dos mínimos quadra-
dos, sendo o primeiro associado às estimativas dos parâmetros das funções de pertinência
de entrada, e o segundo, associado às estimativas dos parâmetros de saída das funções de
pertinência. Outros parâmetros usados foram o erro igual a zero e o número de épocas
igual a 50.
Neste método de treinamento o aprendizado ocorre em duas etapas:
● ETAPA 1: Os parâmetros dos antecedentes ficam fixos e os conseqüentes
são ajustados pelo método MQD- estimação por Mínimos Quadrados
Ordinários.
● ETAPA 2: Os parâmetros dos conseqüentes ficam fixos e os antecedentes
são ajustados pelo algoritmo Gradiente Descendente.
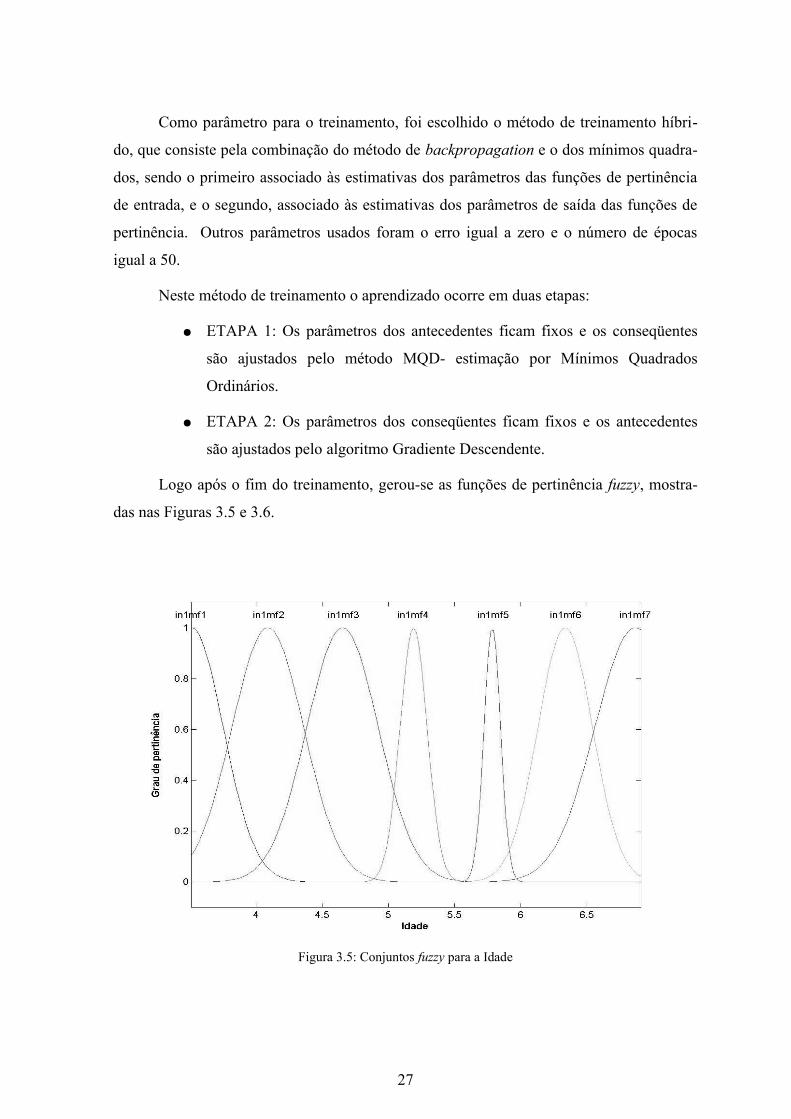
Logo após o fim do treinamento, gerou-se as funções de pertinência fuzzy, mostra-
das nas Figuras 3.5 e 3.6.
27
Figura 3.5: Conjuntos fuzzy para a Idade

28
Figura 3.6: Conjuntos fuzzy para o DAP

4 METODOLOGIAPara desenvolver um sistema de lógica fuzzy e neuro fuzzy foram necessários dados
sobre o problema abordado. Estes ajudarão a interpretar e construir a intuição sobre o
problema utilizando o método direto de Mandani ou de Sugeno.
4.1 Tipo de Pesquisa
Pesquisa é o mesmo que busca ou procura. Pesquisar, portanto, é buscar ou procurar
respostas para alguma coisa. Em se tratando de Ciência a pesquisa é a busca de solução a
um problema em que alguém queira saber a resposta. Não é certo dizer que se faz ciência,
mas que se produz ciência através de uma pesquisa. Pesquisa é portanto o caminho para se
chegar à ciência, ao conhecimento.
É na pesquisa que utilizaremos diferentes instrumentos para se chegar a uma respos-
ta mais precisa. O instrumento ideal deverá ser estipulado pelo pesquisador para se atingir
os resultados ideais.
Segundo Jung (2004), tem-se que a presente pequisa será de natureza aplicada ou
tecnológica pois pode ser utilizada para prever o crescimento e consequentemente a produ-
ção do Eucalyptus, com características de pesquisa exploratória porque visa conhecer os
fatos e fenômenos relacionados ao tema e recuperar as informações disponíveis sobre o
problema, seguindo os procedimentos de pesquisa operacional, fundamentados em referên-
cias bibliográficas e documental, classificada quanto ao local como pesquisa laboratorial e
quanto ao tempo como estudo longitudinal.
4.2 Obtenção dos Dados
A base de dados utilizada é proveniente da empresa International Paper. É originada
de povoamentos comerciais clonais de Eucalyptus sp., situados em Mogi das Cruzes, São
Paulo - Brasil. Os dados foram coletados a partir do processo de inventário florestal com a
medição do diâmetro a 1,30 m do solo (DAP) e altura total de árvores de Eucalyptus sp.
com idades variando de 3,51 a 6,90 anos. Foram selecionadas 131 árvores-amostra de um
mesmo clone, totalizando 131 árvores.

Destas foram selecionadas 91 árvores da amostra para o treinamento e para o ajuste
dos modelos que utilizam regressão. Já para a validação dos modelos utilizou-se 40 árvo-
res-amostra. As figuras 4.1 e 4.2 mostram respectivamente a distribuição de freqüência dos
conjuntos de árvores-amostra usados no treinamento e validação dos modelos utilizados.
30
Figura 4.1: Distribuição de freqüência das idades das árvores-amostra para o treinamento
Figura 4.2: Distribuição de freqüência das idades das árvores-amostra para validação dos modelos

4.3 Procedimentos Metodológicos
A pesquisa foi desenvolvida no período de janeiro a junho de 2007.
Inicialmente foi feita uma revisão bibliográfica sobre a predição da altura utilizando
o DAP, teorias e técnicas relativas a lógica fuzzy, redes neurais, sistemas híbridos e neuro-
fuzzy. Para tal foram utilizados livros, teses e artigos e materiais disponíveis na internet.
Em paralelo foi realizado o estudo e análise da base de dados disponibilizada para o traba-
lho.
Posteriormente foram criados os modelos de lógica fuzzy e neuro fuzzy para a reso-
lução do problema e ambos comparados a outros 5 modelos. Foram escolhidos para a
comparação os modelos de Curtis, Curtis com idade, Parabólico, Logístico e de Prodan
pois como já foi dito antes estes são uns dos melhores e mais utilizados na predição de
altura utilizando o DAP.
O utilitário usado para o desenvolvimento da parte relacionada a lógica fuzzy foi o
fuzzy Logic Toolbox versão 2.2 que faz parte do software MATLAB R2006b v.7.3.0.267® .
Para o desenvolvimento do modelo neuro fuzzy utilizou-se o módulo denominado ANFIS
parte integrante do toolbox citado acima.
Os sistemas operacionais utilizados tanto para a modelagem e desenvolvimento
quanto para a revisão de literatura foram o Microsoft Windows XP® Professional versão
2002 Service Pack 2 e o Kurumin 7. A criação e simulação do modelo foi feita em um
computador AMD Athlon 3800+ com 1GB de memória RAM.
31

4.4 Modelos comparados
Existem vários modelos para a predição da altura total das árvores. Para este traba-
lho foram comparados cinco modelos hipsométricos que são bem difundidos no meio
florestal. Esses modelos são descritos abaixo:
● Curtis: ln H=01 DAP−1
● Curtis com idade: ln H=01 DAP−12 I−13DAP.I −1
onde I : idade
● Parabólico: H=01 DAP2 DAP 2
● Prodan: ln H=01 ln DAP
● Logístico: H=0
1exp1−DAP /2
Estes modelos citados acima foram comparados tanto com o modelo de lógica fuzzy
quanto com o neuro-fuzzy.
32

4.5 Avaliação dos modelos
Foram utilizadas 91 árvores para o ajuste dos modelos e 40 árvores para realizar a
validação. As equações foram comparadas tomando em conta o coeficiente de correlação
(r) entre os valores observados e estimados pelas equações ajustadas e o erro padrão relati-
vo (SYX (%)).
S yx= Y−A2
n−p
S yx %=S yx
Y. 100
onde,
S yx = erro padrão da estimativa (m);
S yx (%) = erro padrão relativo;
Y = altura total (m) estimada;
Y = altura total (m) observada;
Y = media das alturas totais;
n = número de observações;
p = número de parâmetros (considerada zero (0) para Fuzzy e Neuro-Fuzzy).
Foram feitas as análises gráficas dos resíduos. Os valores residuais utilizados na
construção dos gráficos são expressos por:
Erro (%) = Y− YY
.100
Realizou-se também testes complementares, por meio das seguintes estatísticas:
bias (B); média das diferenças absolutas (MD); e desvio padrão das diferenças (DPD). Foi
considerado o modelo mais preciso, aquele que resulta em menor somatório nas notas para
a altura total (Lima, 1986 e Mendonça et al., 2007). A Tabela 4.1 apresenta os critérios e
respectivos estimadores para avaliação do ajuste e validação dos modelos.
33

Para a estatística Bias os valores negativos e positivos indicam um subestimativa e
superestimativa respectivamente. Os menores valores das três estatísticas testadas indicam
que a equação apresenta maior precisão quanto a estimativa da altura total da árvore.
34
Tabela 4.1: Critérios para avaliação do ajuste e validação dos modelos
Critério Estimador
Bias (B)
Media das diferenças absolutas (MD)
Desvio padrão das diferenças (DPD)
B=∑
1
n
Y i−∑1
nY i
n
MD=∑i=1
n
∣Y i− Y i∣n
DPD=∑i=1
n
d i2−∑
i=1
n
d i2/n

5 RESULTADOS E DISCUSSÃONa avaliação dos modelos, foi usado um conjunto de dados para treinar o modelo
Neuro-Fuzzy e estimar os betas dos modelos de Curtis, Curtis com idade, Parabólico,
Logístico e Prodan. No subtópico 5.1 será apresentado os resultados para o conjunto de
dados de treinamento e no subtópico 5.2 será apresentando os resultados para o conjunto
de checagem/validação, conjunto este que não é conhecido por nenhum dos modelos.
5.1 Avaliação com o conjunto de treinoAs equações estimadas para os modelos tradicionais com o conjunto de 91 árvores
que foram para a obtenção dos parâmetros são apresentadas logo abaixo:
● Curtis: ln H=3,534882−5,44553 . 1DAP
● Curtis com idade:
ln H=3,461818−5,06878. 1DAP
0,419402 . 1I−2,18368 . 1
DAP.I
● Parabólico: H=−0,09882,552543. DAP−0,06052 . DAP2
● Prodan: ln H=0,6270450,635641 . ln DAP
● Logístico: H= 27,33941exp6,49695−DAP /3,83406
Através das medidas de precisão das equações testadas apresentadas na Tabela 5.1,
observa-se que os modelos Neuro-fuzzy e fuzzy apresentam um melhor grau de ajuste, pois
apresentaram valores de r superiores (mais próximos de 1) e de erro padrão relativo (SY.X
(%)) mais baixo, seguido dos modelos Parabólico, Logístico, Prodan, Curtis e Curtis com
idade.
Tabela 5.1: Medidas de precisão para o conjunto de treino
Modelos r Syx(%)Curtis 0,964471 7,237039Curtis com idade 0,96436 7,285877Parabólico 0,969668 6,467256Logístico 0,969548 6,480282Prodan 0,967808 6,553775Lógica Fuzzy 0,97022 6,335519Neuro-Fuzzy 0,988495 3,965766

As Figuras 5.1 a 5.7 apresentam graficamente a distribuição residual da estimativa
da altura total para os modelos avaliados.
36
Figura 5.1: Distribuição Residual para o modelo de Curtis com conjunto de treino
Curtis
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total es tim ada (m )
Erro
(%)
Figura 5.2: Distribuição Residual para o modelo de Curtis com Idade com conjunto de treino
Curtis com idade
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total es tim ada (m )
Erro
(%)
37
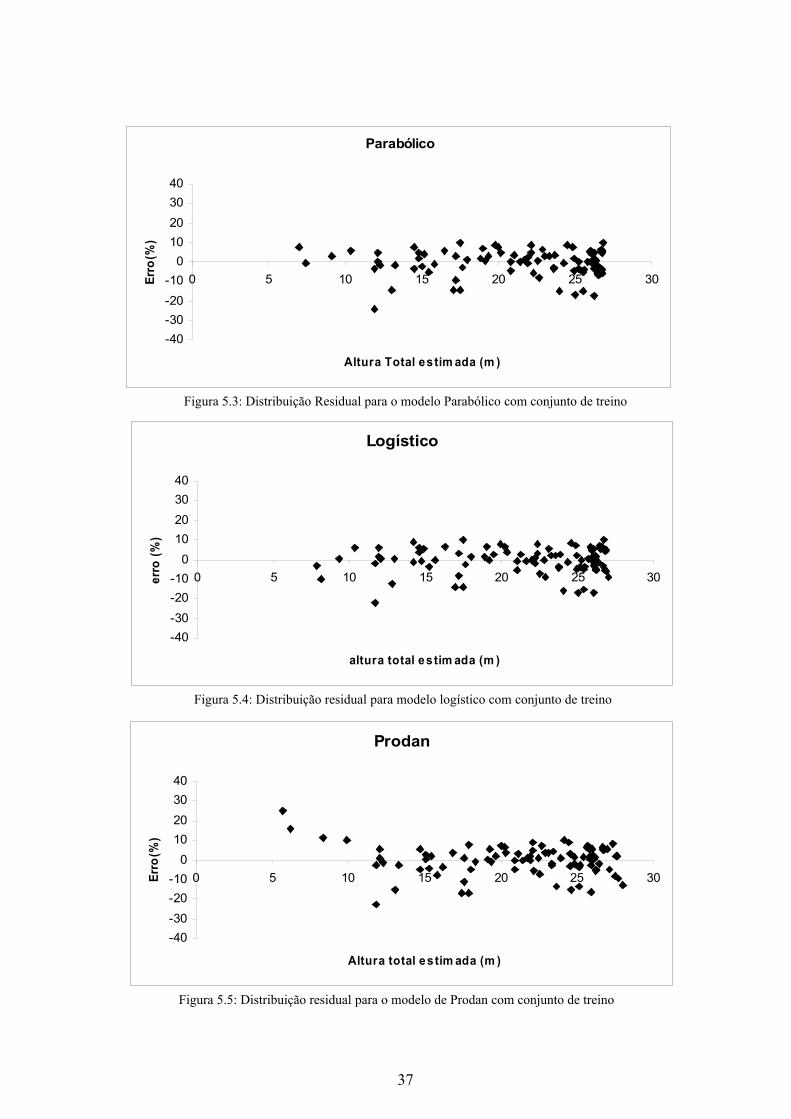
Figura 5.3: Distribuição Residual para o modelo Parabólico com conjunto de treino
Parabólico
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total estim ada (m )
Erro
(%)
Figura 5.4: Distribuição residual para modelo logístico com conjunto de treino
Logístico
-40-30-20-10
010203040
0 5 10 15 20 25 30
altura total estim ada (m )
erro
(%)
Figura 5.5: Distribuição residual para o modelo de Prodan com conjunto de treino
Prodan
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura total estim ada (m )
Erro
(%)

38
Figura 5.7: Distribuição Residual do modelo Neuro-fuzzy com conjunto de treino
Neuro-Fuzzy
-40-30-20-10
010203040
0 5 10 15 20 25 30 35
Altura Total estim ada
Erro
(%)
Figura 5.6: Distribuição Residual do modelo fuzzy com conjunto de treino
Lógica Fuzzy
-40-30-20-10
010203040
0 5 10 15 20 25 30 35
Altura Total estim ada (m )
Erro
(%)

Ao analisar as Figuras observa-se uma melhor distribuição residual referente ao
modelo Neuro-fuzzy pois obteve uma variação menor, que ficou entre -13% a +10%. Os
modelos fuzzy, Logístico e Parabólico também apresentaram distribuições semelhantes a
do Neuro-fuzzy.Já os modelos de Curtis e Curtis com idade apresentaram a maior variação,
entre -30% e +30%.
Os modelos de Curtis, Curtis com idade e Prodan apresentaram tendência em errar a
estimativa para as árvores com alturas menores. Diferentemente dos outros modelos que
não apresentaram tal tendência.
A Tabela 5.2 apresenta as estatísticas “bias” (B), média das diferenças absolutas
(MD) e desvio padrão das diferenças (DPD) para estimativa da altura total.
A Tabela 5.3 mostra as notas atribuídas para as estimativas da altura total, baseadas
nas estatísticas da Tabela 5.2. Os valores positivos e negativos da estatística Bias indicam
subestimativa e superestimativa, respectivamente. Os menores valores das três estatísticas
testadas indicam que a equação apresenta maior precisão para o objetivo em pauta. Como
exemplo, o modelo Neuro-fuzzy, para a altura, tem para a estatística média das diferenças
absolutas (MD) o valor 0,566755 (Tabela 5.2). Quando este valor é comparado com o MD
das equações associadas aos outros modelos, a nota atribuída a ele foi 1 (Tabela 5.3). Esse
valor significa que, considerando o MD, o modelo neuro-fuzzy obteve a melhor estimativa
em relação as outras equações avaliadas, seguida, pela ordem, pelos modelos lógica fuzzy
(Nota 2), Logístico (Nota 3), Parabólico (Nota 4), Prodan (Nota 5) Curtis (Nota 6) e Curtis
com idade (Nota 7).
39
Tabela 5.2: Estatística da Bias, média das diferenças absolutas (MD) e desvio padrão das diferenças (DPD) para estimativa a altura total
Modelos Bias MD DPD
Curtis 0,108491 1,21048 1,51382Curtis com idade 0,108013 1,214452 1,541301Parabólico -0,00018 1,043621 1,371634Logístico -0,003968 1,039649 1,374391Prodan 0,013375 1,088737 1,413413Lógica Fuzzy 0,085066 1,004396 1,34626Neuro-Fuzzy -0,093676 0,566755 0,835863

Seguindo o raciocínio apresentado e analisando os dados das Tabelas 5.2 e 5.3, veri-
fica-se que os modelos Neuro-fuzzy, fuzzy e Parabólico apresentaram os melhores resulta-
dos para estimativa da altura total, seguidos dos modelos Logístico, Prodan, Curtis e Curtis
com idade.
Estes resultados, de maneira geral, corroboram os anteriormente encontrados, ou
seja, comprovam o que foi mostrado nos gráficos de resíduos (Figuras 5.1 a 5.7) e através
do Syx e do r da Tabela 5.1 que os modelos Neuro-fuzzy e fuzzy apresentaram maior preci-
são na predição da altura total dos eucaliptos utilizando o conjunto de treino.
5.2 Avaliação do conjunto de checagem
É na avaliação com o conjunto de checagem que os modelos mostram sua capacida-
de de generalização, ou seja, através de uma amostra conseguir estimar os valores de todo
o inventário. Então nesta avaliação é feita a validação dos dados.
O conjunto de checagem contém como foi dito anteriormente 40 árvores-amostra,
ou seja, aproximadamente 30,5% do total da base de dados. Nesta parte não há obtenção
dos parâmetros (modelos tradicionais) e treino (Neuro-fuzzy), apenas tem-se o teste deste
conjunto em cima do que já foi obtido no tópico anterior.
A Tabela 5.4 mostra as medidas de precisão r e Syx (%) para o conjunto de checa-
gem.
40
Tabela 5.3: Notas atribuídas, a partir das estatísticas da Tabela 5.2, para as estimativas de altura total
Modelos Bias MD DPDCurtis 7 6 6 19Curtis com idade 6 7 7 20Parabólico 1 4 3 8Logístico 2 3 4 9Prodan 3 5 5 13Lógica Fuzzy 4 2 2 8Neuro-Fuzzy 5 1 1 7
Total

Através das medidas de precisão das equações testadas apresentadas na Tabela 5.4,
observa-se que os modelos Neuro-Fuzzy e Fuzzy apresentam um melhor grau de ajuste,
pois apresentaram valores de r superiores (mais próximos de 1) e de erro padrão relativo
(SY.X (%)) mais baixo, seguido dos modelos Logístico, Parabólico, Prodan, Curtis e por
último Curtis com idade.
As Figuras 5.8 a 5.14 mostram a distribuição residual para os modelos testados com
o conjunto de checagem para a predição da altura total.
41
Tabela 5.4: Medidas de precisão para o cojunto de checagem
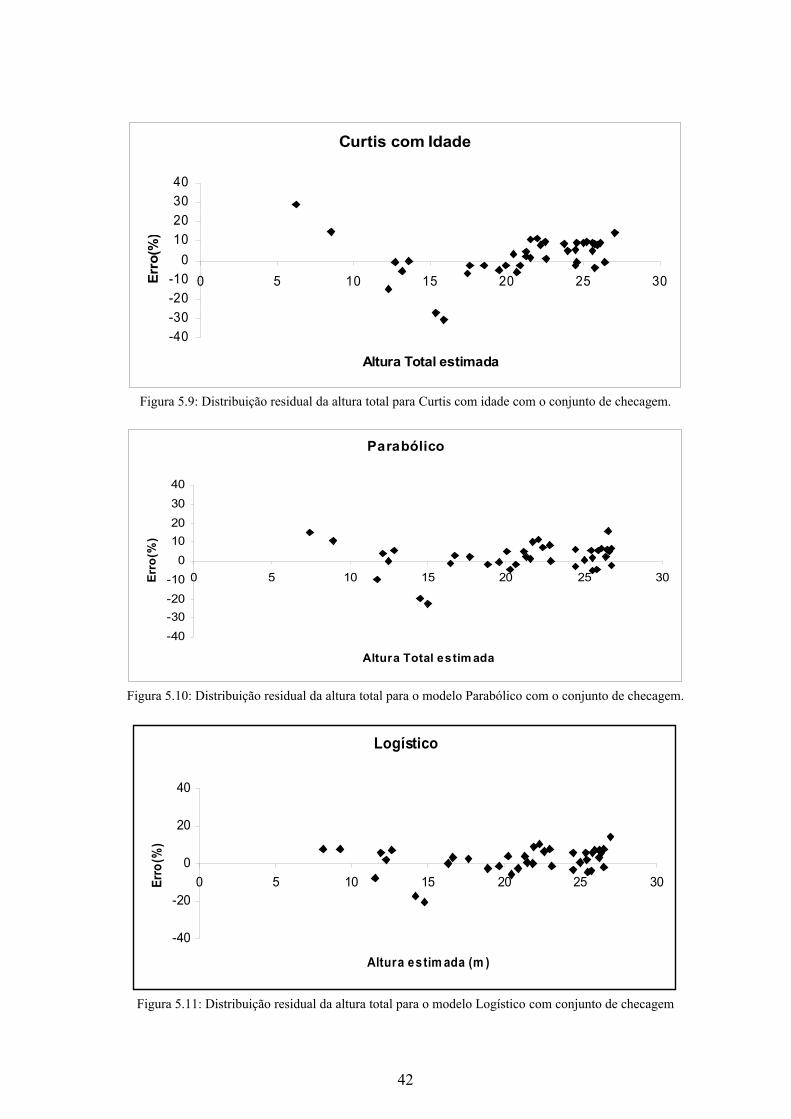
Figura 5.8: Distribuição residual da altura total para Curtis com o conjunto de checagem.
Curtis
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total estim ada (m )
Erro
(%)
Modelos r Syx(%)Curtis 0,966003 8,931018Curtis com idade 0,963527 9,015184Parabólico 0,974691 7,361681Logístico 0,978041 7,095013Prodan 0,973367 7,315504Lógica Fuzzy 0,981727 6,141636Neuro-Fuzzy 0,997969 1,860791
42
Figura 5.9: Distribuição residual da altura total para Curtis com idade com o conjunto de checagem.
Curtis com Idade
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total estimada
Erro
(%)
Figura 5.10: Distribuição residual da altura total para o modelo Parabólico com o conjunto de checagem.
Parabólico
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura Total estim ada
Erro
(%)
Figura 5.11: Distribuição residual da altura total para o modelo Logístico com conjunto de checagem
Logístico
-40
-20
0
20
40
0 5 10 15 20 25 30
Altura estim ada (m )
Erro
(%)

43
Figura 5.13: Distribuição residual da altura total para o modelo fuzzy com o conjunto de checagem.
Lógica Fuzzy
-40-30-20-10
010203040
0 5 10 15 20 25 30 35
Altura Total es tim ada
Erro
(%)
Figura 5.14: Distribuição residual da altura total para o modelo Neuro-fuzzy com o conjunto de checagem
Neuro-Fuzzy
-40-30-20-10
010203040
0 5 10 15 20 25 30 35
Altura Total estimada
Erro
(%)
Figura 5.12: Distribuição residual da altura total para o modelo de Prodan com conjunto de checagem
Prodan
-40-30-20-10
010203040
0 5 10 15 20 25 30
Altura total estim ada (m )
Erro
(%)

Ao analisar as Figuras observa-se uma melhor distribuição residual referente ao
modelo Neuro-fuzzy pois obteve uma variação menor, que ficou entre 0% a +10%. Os
modelos fuzzy, Logístico e Parabólico apresentaram distribuições semelhantes. Já os mode-
los de Curtis e Curtis com idade apresentaram a maior variação, entre -30% e +30%, igual
à alcançada com o conjunto de treino.
Como no conjunto de treino, os modelos de Curtis, Curtis com idade e Prodan apre-
sentaram tendência em errar a estimativa para as árvores com alturas menores.
A Tabela 5.5 apresenta as estatísticas Bias (B), média das diferenças absolutas
(MD) e desvio padrão das diferenças (DPD) para estimativa da altura total com o conjunto
de checagem
A Tabela 5.6 mostra as notas atribuídas para as estimativas de altura total referentes
ao conjunto de checagem, baseadas nas estatísticas da Tabela 5.5 mostrada acima.
44
Tabela 5.5: Estatística da Bias, média das diferenças absolutas (MD) e desvio padrão das diferenças (DPD) para a altura total com conjunto de checagem
Tabela 5.6: Notas atribuídas, a partir das estatísticas da Tabela 5.5, para as estimativas de altura total com o conjunto de checagem
Modelos Bias MD DPDCurtis 0,723793 1,486494 1,769552Curtis com Idade 0,693856 1,535251 1,850958Parabolico 0,611 1,19386 1,471821Logístico 0,583762 1,161884 1,398505Prodan 0,657192 1,270315 1,484707Fuzzy 0,48225 1,01225 1,192444Neuro Fuzzy 0,070022 0,179633 0,383371
Modelos Bias MD DPD TotalCurtis 7 6 6 19Curtis com Idade 6 7 7 20Parabolico 4 4 4 12Logístico 3 3 3 9Prodan 5 5 5 15Fuzzy 2 2 2 6Neuro Fuzzy 1 1 1 3

O modelo Neuro-fuzzy assim como no conjunto de treinamento obteve o melhor
resultado com uma pontuação maior. Em seguida tem-se o modelo fuzzy, Logístico, Para-
bólico, Prodan, Curtis e Curtis com idade.
Estes resultados, de maneira geral, confirmam com os resultados anteriormente
encontrados que os modelos Neuro-fuzzy e fuzzy obtiveram melhor desempenho que os
outros modelos usados. Esta verificação pode ser obtida analisando os gráficos residuais
(Figuras 5.8 a 5.14) e os valores de Syx e r dados na tabela 5.4. Comparando os dados do
conjunto de treinamento, percebe-se que os melhores modelos são também os melhores
modelos para os dados de validação. Com isso percebe-se que os modelos propostos forne-
cem boas estimativas tanto para a base de dados utilizadas para o treinamento quanto para
uma generalização para o restante dos dados.
45

6 CONCLUSÕES E PROPOSTAS FUTURAS
6.1 Conclusões
Após as avaliações tanto do conjunto de treino quanto o de checagem conclui-se
que os sitemas baseados em inteligência artificial, que no caso são os modelos em lógica
fuzzy e neuro-fuzzy, obtiveram melhores resultados que os modelos baseados em regres-
são. Vale ressaltar que o conjunto de treino foi usado para ajuste dos modelos matemáticos
e para treinamento da rede neural. Já o de checagem foi utilizado para validar o resultado
encontrado.
Estes modelos têm grande aplicação prática, já que tanto o modelo Neuro-fuzzy
quanto o fuzzy mostraram-se melhores que os modelos utilizados no cotidiano das empre-
sas que cultivam Eucalyptus pois apresentaram maior capacidade de generalização quando
foi aplicado o teste com o conjunto de checagem.
6.2 Trabalhos Futuros
Como foi dito no tópico 6.1, os modelos baseados em inteligênia artificial se
mostram com grande aplicabilidade, então futuramente eles poderão ser usados em um
ambient real. Para isso deve ser desenvolvido um sistema com interface gráfica para facili-
tar ainda mais o trabalho.
Outro trabalho futuro seria por meio da estimativa da altura, conseguir também esti-
mar o volume total com uma precisão grande. Isto também poderia estar sendo acoplado ao
sistema citado acima.
46

BIBLIOGRAFIA
ALMEIDA, M. R. A. Sistema híbrido Neuro-fuzzy-genético para mineração automática de dados. Rio de Janeiro : PUC. Departamento de Engenharia Elétrica, 2004. 112 p.
ANDRADE, V. C. L.; MARTINS, S. V.; CALEGARIO, N; CHICHORRO, J. F. Influência de três sistemas de amostragem na estimativa da relação hipsométrica e do volume de árvores em um fragmento de Mata Atlântica, Scientia Florestalis - n. 70, p. 31-37, abril 2006
BARROS L.C. 1992. “Modelos determinísticos com parâmetros subjetivos”. Dissertação de Mestrado, Instituto de Matemática, Estatística e Ciência da Computação, Universidade de Campinas, Brasil.
CAMARGOS, F. L. Lógica Nebulosa: uma abordagem filosófica e aplicada, Santa Catarina, Brasil - Universidade Federal de Santa Catarina (UFSC), 2002.
CAMPOS, J. C. Ch. Dendrometria, I parte. Viçosa: Universidade Federal de Viçosa, Escola Superior de Florestas, 1983. 43p.
COSTA, J. C. Aplicação da Lógica Fuzzy na Construção de um Modelo de Cadeia Ising; Lavras, Brasil, 2006. 34 p. COX, E. The fuzzy systems: handbook a practitioner's guide to building, using, and maintaining fuzzy systems. London: Academic Press, 1994. 625 p.
DOMINGOS, V. F., VALENÇA, M. J. S., LUDERMIR, T. B., SILVA, G. P. F. Uma Proposta fuzzy na Avaliação de Desempenho de Bibliotecas Universitárias Brasileiras. Pernambuco, Brasil. 2005.
DRIANKOV, D.; HELLENDOORN, H.; REINFRANK, M. An introduction to Fuzzy control. New York: Springer-Verlag, 1993. 316 p.
FINGER, C. A. G. Fundamentos de Biometria Florestal. Santa Maria. Universidade Federal de Santa Maria CEPEF – FATEC, 1992. 481p.
FINGER, C. A G. Ein Beitrag zur Ertragskunde von Eucalyptus grandis und Eucalyptus saligna in Sudbrasilien. Wien: Universität für Bodenkultur, 1991. 137p. Tese Doutorado
FOREST BRAZIL – Viveiro Florestal..Disponível em: <http://www.forestbrazil.com.br/eucalipto.htm>. Acesso em: 21 jun. 2007.
47

GOODMAN, R., HIGGINS, A. Neuronal misconnections and psychiatric disorder. Is there a link? Br J Psychiatry 1989;154:292-9.
HEILPERN S. 1993. “fuzzy subsets of the space of probability measures and expectedvalue of fuzzy variable”. fuzzy Sets and Systems 54, 301-309.
HOEFLICH, V. A. Planejamento estratégico para o desenvolvimento florestal brasileiro: 504 anos de espera, até quando? . Paraná, Brasil. Embrapa, 1998.
JANG, J. S. R. ANFIS: Adaptive-Network-Based fuzzy Inference System. IEEE Transactions on Systems, Man, and Cybernetics, New York, v. 23, n. 3, p. 665-685, May 1993.
JANG, J. S. R.; SUN, C. T. Neuro-fuzzy modeling and control. Proceedings of the IEEE, New York, v. 83, n. 3, p. 378-406, Mar. 1995.
KLIR, G. J.; YUAN, B. fuzzy sets and fuzzy logic: theory and applications. New Jersey: Prentice Hall, 1995. 574 p.
KWAN, H. K.; Cai,Y. A fuzzy neural network and its application to pattern recognition. fuzzy Systems, IEEE Transactions, v. 2, n. 3, p. 185 – 193, Agosto 1994.
T. Law, H. Itoh, H. Seki, "Filtering Images for Edge Detection Using fuzzy Reasoning," Proc. Third Int'l Conf. Automation, Robotics, and Computer Vision, Singapura, 1994.
LEE, K. M., KWAK, D. H., KWANG, L. H. fuzzy Inference Neural Network for fuzzy model tuning, IEEE Transactions Systems Man Cyberneticas, vol. 26, n° 4B
LENKE, A. P. Solução Computacional Para um Sistema de Avaliação da Qualidade dos Serviços em Instituições de Ensino Superior, Baseado nos Parâmetros do PQSP. Pelotas, Brasil. Universidade Federal de Pelotas, 2005.
LIMA, F. Análise de funções de “taper” destinadas à avaliação demultiprodutos de árvores de Pinus elliottii. 1986. 79f. Dissertação (Mestrado emCiência Florestal) - Universidade Federal de Viçosa, Viçosa,1986.
LOETSCH, F., ZOEHRER, F., HALLER, K. E. Forest Inventory. München: BLV, 1973. v.2, 469p.
MAMDANI, E. H. 1974. Applications of fuzzy algorithms for control of a simple dynamic plant. Prodeedings IEEE, 121, 12; 1585-1588.
MARSEGUERRA, M., ZIO, E. Model-free fuzzy tracking control of a nuclear reactor; Annals of Nuclear Energy; n.30; 2003; p.953–981
48

MEDRADO,M. Embrapa. O cultivo do Eucalipto em: http://sistemasdeproducao.cnptia.embrapa.br/FontesHTML/Eucalipto/CultivodoEucalipto/01_Importancia_economica.htm. acessado em 29/01/2007.
MENDONÇA, A. R., SILVA, F. G., OLIVEIRA, S. T., NOGUEIRA, S. G., ASSIS, A. L. Avaliação de funções de afilamento visando a otimização de fustes de Eucalyptus sp para multiprodutos, Cerne, Lavras, v. 13, n. 1, p. 71-82, jan./mar. 2007
MOUZOURIS, G. C.; MENDEL, J. M. Dynamic Non-Singleton fuzzy Logic Systems for Nonlinear Modeling. IEEE Transactions on fuzzy Systems, New York, v. 5, n. 2, p. 199-208, May 1997.
OLIVEIRA, A. A. S. Modelagem Fuzzy e Neuro-Fuzzy do Processo Monocíclico da Ferrugem Asiática da Soja,Universidade Federal de Lavras, Lavras – Minas Gerais, 2007. 29p
OLIVEIRA, A. G. Implementação de um Sistema de Tratamento e Reconhecimento de Padrões para uma Microbalança de Quartzo Utilizando Redes Neurais Artificiais; Lavras – Minas Gerais, 2002
PAL, S., MITRA, P. Case Generation: A Rough-fuzzy Approach, Workshop em Soft Computing in Case-Based Reasoning, International Conference on Case-Based Reasoning, ICCBR'01 Vancouver, British Columbia, Canada. 1992
PEDRYCZ W. & GOMIDE F. 1998. An Introduction to fuzzy Sets: Analysis andDesign. editora MIT Press, USA.
REZNIK L. fuzzy Controllers. Newnes, Reino Unido, 1997.
SCOLFORO, J. R. S. Apostila de Dendrometria. Lavras, DCF – ESAL, 1992. 320p.
SCOLFORO, J. R. S. Mensuração Florestal 3. Lavras, Brasil. 1993. 292p.
SUGENO M. 1974. “Theory of fuzzy integrals and its applications”. Tese de doutorado, Instituto de Tecnologia de Tokio, Tokio, Japão.
SUGENO, M. Industrial applications of fuzzy control. New York: Elsevier Science, 1985.
TANAKA, K. An Introduction to fuzzy Logic for Practical Applications. Kanazawa, Japão. Kanazawa University, 1991.
TIBIRIÇÁ, G. Uma Abordagem Híbrida fuzzy-Bayesiana para Modelagem de Incertezas. Florianópolis, Brasil. Universidade Federal de Santa Catarina, 2005.
49

THOMÉ, A. C. G. Redes Neurais - uma Ferramenta para KDD E DATA MINING. 2005
TONELLO, C. T.; COTTA, M. K.; ALVES, R. R.; CARMELITA, C. A. O Destaque Econômico Do Setor Florestal Brasileiro. Campinas, Brasil. UNICAMP, 2000.
WU C. & MA M. 1990. “fuzzy norms, probabilistic norms and fuzzy metrics”. fuzzy Sets and Systems 36, 137-144.
YEN J. & LANGARI R. 1999. fuzzy Logic: Intelligence, Control, and Information.Prentice Hall, EUA.
ZADEH, L. A. 1965. fuzzy sets. Information And Control 8; 338-353
ZADEH L.A. 1978. “fuzzy sets as a basis for a theory of possibility”. fuzzy Sets and Systems 1 (1); 3-28
ZADEH L. A. 1973.“Outline of a New Approach to the Analysis of Complex Systems and Decision Processes”. IEEE Transactions on systems, man and cybernetics S1C-3 (1), 28-44.
ZANON, D. ; DEUS, A. M. ; PAULO, A. R. G. S. ; ALMEIDA, K. A. A Comparative Analysis of Neural and Fuzzy Cluster Techniques Applied to the Characterization of Electric Load in Substations. In: T&D IEEE Congress, 2004, São Paulo, 2004.
50





























