Embed Size (px)
Citation preview

GEOESTATÍSTICA EM ESTUDOS DE VARIABILIDADE ESPACIAL DO SOLO1
Sidney R. Vieira2
Resumo Quando uma determinada propriedade varia de um local para outro com algum grau de organização ou continuidade, expresso pela dependência espacial, a estatística clássica deve ser abandonada e dar lugar a uma estatística relativamente nova: a geoestatística. Por estatística clássica entende-se aquela que utiliza parâmetros como média e desvio padrão para representar um fenômeno, e baseia-se na hipótese principal de que as variações de um local para outro são aleatórias. Desse modo, esses dois ramos da estatística têm validade de aplicação em condições perfeitamente distintas. Para se determinar qual das duas deve ser usada em cada caso, utiliza-se o semivariograma que expressa a dependência espacial entre as amostras. Havendo dependência espacial, pode-se estimar valores da propriedade em estudo para os locais não amostrados dentro do campo, sem tendenciosidade e com variância mínima, pelo método denominado krigagem. Além disso, muitas vezes, duas propriedades correlacionam-se entre si e no espaço, e uma é mais difícil ou mais cara para se medir no campo. A dependência espacial entre duas propriedades no espaço pode ser expressa pelo semivariograma cruzado, e se ele existir, o método chamado co-krigagem pode ser utilizado para estimar aquela mais difícil de se medir, utilizando-se os dados de ambas. Estes métodos oferecem a escolha de se medir a propriedade mais difícil com um número mínimo possível. A construção de mapas de contornos (isolinhas), e o delineamento de espaçamento e disposição ótima de amostras no campo são outras aplicações imediatas. Neste trabalho procurou-se dar o maior detalhamento possível nos aspectos teóricos e nos conceitos básicos de geoestatística, numa linguagem simples e compreensível ao leitor. Para ilustrar, utilizaram-se dados da literatura, como exemplo aplicativo para propriedades químicas de solo. Os dados e os programas de geoestatística utilizados estão listados em apêndice no final do trabalho. Termos de indexação: semivariogramas, krigagem, co-krigagem, “jack-knifing” ABSTRACT: GEOSTATISTICS IN SOIL SPATIAL VARIABILITY STUDIES When a given soil property varies from place to place with some degree of continuity, as expressed through its autocorrelation, classical statistical analysis is not valid and a relatively new tool in soil science called geostatistics must be used. Classical statistical is understood as that which uses such parameters as mean and standard deviation, to represent a phenomenon and is based on the principal hypothesis that spatial variation is random. These
1 Recebido para publicação em e aceito em 2 Pesquisador, Centro de Solos e Recursos Agroambientais, Instituto Agronômico, Caixa Postal
28 - 13001-970, Campinas, SP. Email: [email protected]

aspects of statistics are applicable in perfectly distinct circunstances. In order to determine which should be used in which instance, semivariograms are used to show autocorrelation among samples. Autocorrelation allows estimation of values for places not sampled in the field, without bias and with minimum variance, with the kriging method. Furthermore, two properties may have spatial autocorrelation with each other, and one may be more difficult or more expensive to measure in the field. Spatial autocorrelation between two properties can be expressed with cross-semivariograms, and in some cases, the co-kriging method can be used to estimate the property more difficult to measure, thus using both measures. This method allow selection of the most difficult property to measure with the lowest possible number of samples. Immediate applications of these methods are the creation of contour maps and delineation of optimal spacing of field samples. This paper seeks to provide a high level of detail about theoretical aspects and basic concepts of geostatistics in a comprehensible format to the reader. As examples, data available from the literature are used for applications of soil chemical properties. The data and geoestatistics programs used in this paper are listed in appendices at the end of the paper. Index terms: semivariograms, kriging, co-kriging, “jack-knifing”.

ÍNDICE RESUMO ABSTRACT I. INTRODUÇÃO 1. Variabilidade: preocupação antiga 2. Repetição e casualização: Fisher entra em cena 3. Das minas de ouro da África do Sul para Fontainebleau na França: nasce a geoestatística 4. Da mineração à Geologia, Dendrologia, Hidrologia e Ciência do Solo: e a moda pega 5. Os objetivos e as ressalvas II. AS HIPÓTESES 1. Campo de estudo: o domínio e as definições básicas 2. Hipótese de estacionaridade de ordem 2 3. Hipótese intrínseca 4. Hipótese de tendência: krigagem universal III. O SEMIVARIOGRAMA 1. A equação de cálculo 2. As características ideais 3. Os modelos 4. Os exemplos IV. A KRIGAGEM 1. O estimador 2. As condições requeridas 3. A dedução do sistema de equações 4. Sistema matricial 5. Particularidades do sistema e métodos de solução 6. Os exemplos V. O SEMIVARIOGRAMA CRUZADO 1. As definições pertinentes 2. A equação de cálculo 3. As características ideais 4. Os exemplos VI. A CO-KRIGAGEM 1. O estimador 2. As condições requeridas 3. A dedução do sistema de equações 4. Sistema matricial 5. Os exemplos VII. A VARIÂNCIA DA ESTIMATIVA 1. Significado 2. Utilidade

VIII. A VIZINHANÇA USADA NA ESTIMATIVA 1. Vizinhança única 2. Distância constante 3. Número constante de vizinhos 4. Quadrantes IX. A AUTOVALIDAÇÃO: UMA PODEROSA FERRAMENTA 1. O gráfico 1:1 - Medido vs. Estimado 2. O erro absoluto 3. O erro reduzido 4. Os exemplos X. CONCLUSÕES XI. LITERATURA CITADA XII. APÊNDICE 1. Listagem dos dados de Waynick & Sharp (1919)

Lista das figuras 1. Semivariograma típico. 2. Esquema de amostragem, onde os sinais "+" indicam posição onde amostras foram
coletadas. 3. Semivariogramas escalonados médios para C e N, para dados originais, nos dois locais. 4. Semivariogramas escalonados médios para C/N, para dados originais nos dois locais. 5. Semivariogramas mostrando o efeito da tendência: (a) carbono – Davis; (b) carbono –
Oakley; (c) nitrogênio – Davis; (d) nitrogênio - Oakley. 6. Semivariogramas para os resíduos de tendência, para os dois locais: (a) carbono, com
modelo esférico com parâmetros 0,4; 0,6 e 15,0: (b) nitrogênio, com modelo esférico com parâmetros 0,0; 1,0 e 25,0.
7. Semivariograma escalonado médio para C/N - Davis, com modelo esférico com parâmetros 0,3; 0,7 e 25,0.
8. Mapa para carbono (%), Davis. 9. Mapa para carbono (%), Oakley. 10. Mapa para nitrogênio (%), Davis. 11. Mapa para nitrogênio (%), Oakley. 12. Semivariogramas escalonados médios para carbono versus nitrogênio, para Davis e Oakley,
com modelo gaussiano com parâmetros 0,0, 1,0 e 13,0. 13. Mapa para nitrogênio (%), Oakley, obtido por cokrigagem.

I. INTRODUÇÃO 1. Variabilidade: preocupação antiga A variabilidade espacial de propriedades do solo vem sendo uma das preocupações de pesquisadores, praticamente desde o início do século. Smith (1910) estudou a disposição de parcelas no campo em experimentos de rendimento de variedades de milho, numa tentativa de eliminar o efeito de variações no solo. Montgomery (1913), preocupado com o efeito do nitrogênio no rendimento de trigo, fez um experimento com 224 parcelas nas quais mediu o rendimento de grãos. E assim, vários outros, como Robinson e Lloyd (1915) e Pendleton (1919) estudaram erros em amostragem e diferenças em solos do mesmo grupo. Waynick (1918) estudou a variabilidade espacial da nitrificação no solo. Waynick e Sharp (1919) estudaram o nitrogênio total e o carbono no solo, todos com grande intensidade de amostras, nos mais variados esquemas de amostragem, mas sempre com a preocupação de caracterizar ou conhecer a variabilidade. Numa tentativa de encontrar uma maneira única de analisar uma vasta coleção de dados, Harris (1920) utilizou uma equação muito semelhante a que hoje conhecemos como variância de blocos. 2. Repetição e casualização: Fisher entra em cena É lamentável que experimentos como os anteriormente descritos não tenham tido continuidade no tempo, porque é provável que se poderia ter muito mais conhecimento sobre a variabilidade hoje. A maior causa dessa descontinuidade foi a adoção de técnicas como casualização e repetição, e melhor conhecimento de funções de distribuição, que levaram à adoção de amostragem ao acaso, desprezando assim as coordenadas geográficas do ponto amostrado. Esse procedimento, somado à distribuição normal de freqüências era, e ainda é, usado para assumir independência entre as amostras e assim garantir a validade do uso da média e do desvio padrão para representar o fenômeno. Esses conceitos da estatística clássica e seus fundamentos podem ser encontrados em Fisher (1956), ou Snedecor & Cochran (1967). 3. Das minas de ouro da África do Sul para Fontainebleau na França: nasce a geoestatística A distribuição normal não garante, de maneira alguma, a independência entre amostras, a qual pode ser verificada pela autocorrelação. A principal razão para isto é que o cálculo da freqüência de distribuição não leva em conta a distância na qual as amostras foram coletadas no campo. A presença de dependência espacial requer o uso de um tipo de estatística chamada geoestatística, que surgiu na África do Sul, quando Krige (1951), trabalhando com dados de concentração de ouro, concluiu que não conseguia encontrar sentido nas variâncias, se não levasse em conta a distância entre as amostras. Matheron (1963, 1971), baseado nessas observações, desenvolveu uma teoria, a qual ele chamou de Teoria das Variáveis Regionalizadas e que contém os fundamentos da geoestatística. Matheron (1963) define Variável Regionalizada como uma função espacial numérica, que varia de um local para outro, com uma continuidade aparente e cuja variação não pode ser representada por uma função matemática simples. Essa continuidade ou dependência espacial pode ser estimada pelo semivariograma. A geoestatística tem um método de interpolação chamado krigagem (nome dado por Matheron (1963), em homenagem ao matemático sul-africano D. G. Krige), que usa a dependência espacial entre amostras vizinhas, expressa no semivariograma, para estimar valores em qualquer posição dentro do campo, sem tendência e com

variância mínima. Essas duas características fazem da krigagem um interpolador ótimo (Burgess e Webster, 1980a). Quando se tem duas variáveis medidas no mesmo campo, com parte dos pontos de amostragem ou todos, coincidentes, pode-se avaliar o grau de semelhança da variação das duas no espaço, pelo semivariograma cruzado. Um bom exemplo dessas variáveis é o teor de areia e a taxa de infiltração, porque se sabe, de antemão, que elas são correlacionadas, ou seja, espera-se que nos locais onde o teor de areia é alto, a infiltração também seja alta. Se isso for verdade, o que pode ser mostrado pelo semivariograma cruzado, um outro método de interpolação, chamado co-krigagem, pode ser usado. Sabe-se de antemão que o teor de areia é mais fácil de medir do que a infiltração. Assim, seria desejável amostrar-se com menor freqüência o mais difícil, por exemplo a cada 50 m, e com maior freqüência o mais fácil, por exemplo a cada 10 m. E assim, usando-se a correlação cruzada entre as duas variáveis, pode-se estimar valores da infiltração a cada 10 metros ou qualquer outra distância desejável, usando os valores e a correlação cruzada entre ambos, pela co-krigagem. Esses dois métodos de interpolação possibilitam a construção de mapas de contornos (isolinhas) com alta precisão, uma vez que após a interpolação a densidade espacial dos dados será muito maior do que antes, além de oferecer também os limites de confiança para o mapa, pela variância da estimativa. Além disso, conhecendo-se os semivariogramas das variáveis em estudo e os semivariogramas cruzados daquelas correlacionadas, pode-se usar a krigagem ou a co-krigagem para delinear o espaçamento e a disposição de amostras no campo para se obter um valor prefixado de variância da estimativa. 4. Da mineração à Geologia, Dendrologia, Hidrologia e Ciência do Solo: e a moda pega A geoestatística teve suas primeiras aplicações em mineração (Blais e Carlier, 1968; David, 1970; Ugarte, 1972; Journel, 1974; Olea, 1975, 1977), depois em hidrologia (Delhomme, 1976). Já existem vários estudos em ciência do solo (Hajrasuliha et al., 1980; Burgess & Webster, 1980a e 1980b; Webster & Burgess, 1980; Vieira et al., 1981; Vauclin et al., 1982; Vieira et al., 1983; Nielsen et al., 1983; Vieira et al., 1987, Vieira et al., 1991; Vieira et al., 1992) e em sensoriamento remoto (Vauclin et al., 1982; Vieira & Hatfield, 1984). Além disso, existem alguns livros tratando do assunto, dentre os quais destacam-se David (1977) e Journel & Huijbregts (1978). 5. Os objetivos e as ressalvas O objetivo principal deste trabalho é fornecer ao leitor uma bibliografia em português, em linguagem simples e completa, com todos os detalhes teóricos e aplicações da geoestatística. Isto se faz necessário pela importância do problema variabilidade espacial, e de um possível método de solução e conhecimento, a geoestatística. O nível de detalhes teóricos foi mantido propositalmente para auxiliar no acompanhamento e compreensão. A matemática envolvida, embora à primeira vista assustadora pelo tamanho das equações, é na maioria das vezes álgebra elementar, probabilidade e operações com matrizes. O leitor é encorajado a seguir as deduções, passo a passo, o que facilitará grandemente sua compreensão. Um conjunto de dados obtidos da literatura será usado como exemplo, listado no apêndice 1. É importante também salientar que o presente trabalho não tem por finalidade desencorajar o uso de estatística clássica, a qual tem seu espaço, potencialidade e limitações. É justamente nos problemas onde a estatística clássica tem limitações que a geoestatística tem suas maiores aplicações.

II. AS HIPÓTESES Todos os conceitos teóricos de geoestatística têm suas bases em funções e variáveis aleatórias, as quais, por convenção, recebem símbolos maiúsculos. Os valores medidos recebem símbolos minúsculos. É preciso também entender que uma realização em particular de uma função é um valor numérico assumido por esta função dentro de uma dada condição fixa. Por exemplo, Cos(0) = 1, então 1 é uma realização da função coseno para o ângulo 0 (zero) graus. 1. Campos de estudo: o domínio e as definições básicas Para o estabelecimento do problema, considere-se um campo de área S, para o qual se tem um conjunto de valores medidos {z(xi), i=1, n}, onde xi identifica uma posição no espaço ou no tempo, e representa pares de coordenadas (xi, yi). Esse procedimento é usado para simplicidade de representação na dedução das equações. O ponto de referência para o sistema de coordenadas é arbitrário e fixado a critério do interessado. Para uma dada posição fixa xk, cada valor medido da variável em estudo, z(xk), pode ser considerado como uma realização de uma certa variável aleatória, Z(xk). A variável regionalizada Z(xk), para qualquer xi dentro da área S, por sua vez pode ser considerada uma realização do conjunto de variáveis aleatórias {Z(xi), para qualquer xi dentro de S}. Esse conjunto de variáveis aleatórias é chamado uma função aleatória e é simbolizado por Z(xi) (Journel e Huijbregts, 1978). O exposto acima se faz necessário porque, pelo fato de uma função aleatória ser contínua, pode ser submetida a uma grande gama de hipóteses, sem as quais a dedução de equações é impossível. O que se deve esperar é que com pontos discretos de amostragem, se possa satisfazer as hipóteses às quais as funções aleatórias estão sujeitas. Com uma única amostragem, tudo o que se sabe de uma função aleatória Z(ki) é uma única realização. Então, para se estimar valores para os locais não amostrados, ter-se-á que introduzir a restrição de que a variável regionalizada seja, necessariamente, estacionária estatisticamente. Formalmente, uma variável regionalizada é estacionária se os momentos estatísticos da variável aleatória Z(xi+h) forem os mesmos para qualquer vetor h. De acordo com o número k de momentos estatísticos que são constantes, a variável é chamada de estacionária de ordem k. Estacionariedade de ordem 2 é tudo que é requerido em geoestatística (Olea, 1975). Supondo-se que a função aleatória Z(xi) tenha valores esperados E{Z(xi)} = m(xi) e E{Z(xi+h)} = m(xi+h) e variâncias VAR {Z(xi)} e VAR {Z(xi+h)}, respectivamente, para os locais xi e xi+h, e qualquer vetor h, então, a covariância C(xi, xi+h) entre Z(xi) e Z(xi+h) é definida por
C( x ,x + h) = E {Z( x ) Z( x + h)} - m( x ) m( x + h)i i i i i i (1)
e o variograma 2γ(xi, xi+h) é definido por
(2) 2 ( x ,x + h) = E {Z( x ) - Z( x + h) }i i i i2γ
A variância de Z(xi) é
(3)
VAR {Z( x )} = E {Z( x ) Z( x +0) - m( x ) m( x +0)} =
= E {Z ( x )- m ( x )} = C( x ,x )
i i i i i
2i
2i i i

i
e a variância de Z(xi+h) é
(4) VAR {Z( x + h)} = E {Z ( x + h) - m ( x + h)} = C ( x + h, x + h)i2
i2
i i
Assim, existem três hipóteses de estacionaridade de uma função aleatória Z(xi), e pelo menos uma delas deve ser satisfeita antes de se fazer qualquer aplicação de geoestatística. 2. Hipótese de estacionaridade de ordem 2 Uma função aleatória Z(xi) é estacionária de ordem 2 se:
(5) E {Z( x )} = mi
a) O valor esperado E{Z(xi)} existir e não depender da posição x, ou seja para qualquer xi dentro da área S. b) Para cada par de variáveis aleatórias, {Z(xi), Z(xi+h)}, a função covariância, C(h), existir e for função de h:
(6) C(h) = E {Z( x ) Z( x + h)} - mi i2
para qualquer xi dentro da área S. A equação (6), estacionaridade da covariância, implica na estacionaridade da variância e do variograma. Assim, usando a linearidade do operador valor esperado, E, na equação (3), obtém-se:
(7) VAR {Z( x )} = E {Z( x +0)} - E {m ( x )}i i2
i
e aplicando as condições de estacionaridade (5) e (6) obtém-se:
(8) VAR {Z( x )} = E {Z ( x )} - m = C(0)i2
i2
O variograma na equação (2) pode ser desenvolvido em:
h)}+x(Z + h)+xZ()x( Z2 - )x(Z{ E = (h)2 = h)+x,x(2 i2
iii2
ii γγ (9)
Somando e subtraindo 2m2:
(10) 2 (h) = E {Z ( x )- m - 2Z( x ) Z( x + h)+ 2m + Z ( x + h)- m }2i
2i i
2 2i
2γ
Usando a linearidade do operador E, e reconhecendo que o valor esperado de uma constante é a própria constante tem-se:
(11) 2 (h) = E {Z ( x )} - m - 2(E {Z( x )Z( x + h)} - m )+ E {Z ( x + h)} - m2i
2i i
2 2i
2γ
Substituindo as equações (6) e (8) na equação (11), tem-se:
2 (h) = C(0)- 2C(h)+ C(0) = 2 C(0) - 2 C(h)γ (12)
ou simplificando,
γ (h) = C(0) - C(h) (13)
Isolando C(h), tem-se:
C(h) = C(0) - (h)γ (14)

Dividindo ambos os lados por C(0) e reconhecendo que o correlograma ρ(h) = C(h)/C(0):
ργ
ργ
(h) = C(h)C(0)
= C(0)C(0)
- (h)
C(0)
(h) = 1-(h)
C(0)
Portanto, se a hipótese de estacionaridade de ordem 2 puder ser satisfeita, a covariância C(h) e o variograma 2γ(h) são ferramentas equivalentes para caracterizar a dependência espacial. A existência de estacionaridade dá a oportunidade de repetir um experimento mesmo que as amostras devam ser coletadas em pontos diferentes, porque todas são consideradas pertencentes a populações com os mesmos momentos estatísticos. 3. Hipótese intrínseca A hipótese de estacionaridade de ordem 2 implica a existência de uma variância finita dos valores medidos, VAR {Z(x)} = C(0). Esta hipótese pode não ser satisfeita para alguns fenômenos físicos que têm uma capacidade infinita de dispersão. Exemplos incluem a concentração de ouro em minas da África do Sul (Krige, 1951), o movimento browniano (Journel e Huijbregts, 1978) e algumas cadeias de Markov (Bartlett, 1966). Para tais situações, uma hipótese menos restritiva, a hipótese intrínseca, pode ser aplicável. Essa hipótese requer apenas a existência e estacionaridade do variograma, sem nenhuma restrição quanto à existência de variância finita. Uma função aleatória é intrínseca quando, além de satisfazer a condição expressa na equação (5), a estacionaridade do primeiro momento estatístico, também o incremento {Z(xi) - Z(xi+h)} tem variância finita, e não depende de xi para qualquer vetor h.. Matematicamente, isso pode ser escrito:
(16) { } ]h)+x Z(- )xE[Z( =])h+x Z(- )x[Z( VAR 2iiii
para qualquer xi dentro da área S. Substituindo a equação (2) na equação (16), tem-se:
(17) 2 (h) = E[Z( x ) - Z( x + h) ]i i2γ
A função γ (h) é o semivariograma. A razão para o prefixo "semi" é que a equação (17) pode ser escrita na forma:
(18) γ (h) = 1 / 2 E[Z( x ) - Z( x + h) ]i i2
O fator 2 foi introduzido na definição do variograma, 2γ(h), para cancelamento e simplificação da equação (13) e a quantidade mais freqüentemente usada é γ(h) e não 2γ(h). A hipótese intrínseca é, na verdade, a mais freqüentemente usada em geoestatística, principalmente por ser a menos restritiva. 4. Hipótese de tendência - krigagem universal Nesta hipótese, a função aleatória Z(xi), para qualquer posição, xi, consiste de dois

componentes:
(19) )xe(+)xm(=)xZ( iii
onde m(xi) é o "drift" (tendência principal) e e(xi) é o erro residual. Portanto, para se trabalhar sob esta hipótese é preciso, para cada posição xi, determinar o "drift", m(xi), e ter uma expressão para o semivariograma dos resíduos (Webster & Burgess, 1980). Devido à arbitrariedade envolvida na expressão do "drift" e do semivariograma dos resíduos, não será apresentado aqui nenhum desenvolvimento teórico para krigagem universal. Trabalhos sobre este assunto podem ser encontrados em Olea (1975 e 1977) e um exemplo de aplicação pode ser visto em Webster & Burgess (1980). O leitor é encorajado a consultar essas literaturas para maiores informações. Se uma função aleatória é estacionária de ordem k (k>0), ela também será estacionária de todas as ordens menores que k. Consequentemente, se uma função aleatória Z(xi) é estacionária de ordem 2, ela será também intrínseca. Entretanto, o contrário não é necessariamente verdade. Não existe um método fácil para testar em qual tipo de estacionaridade os dados se enquadram. O exame do semivariograma, como será visto a seguir, e um teste conhecido como "jack-knifing", mostrado no capítulo IX deste trabalho, são as principais ferramentas utilizadas para se conhecer indiretamente a estacionaridade dos dados. III. O SEMIVARIOGRAMA Até o início dos anos 60, a análise de dados era feita sob a hipótese de independência estatística ou distribuição espacial aleatória, para permitir o uso de métodos estatísticos como análise de variância e parâmetros como o coeficiente de variação (Harradine, 1949; Ball & Williams, 1968). Entretanto, esse tipo de hipótese não pode simplesmente ser feito antes que se prove a não existência de correlação de amostras com distância. Se provada a correlação espacial, a hipótese de independência fracassa. Um dos métodos mais antigos de se estimar a dependência no espaço ou no tempo de amostras vizinhas é pelo uso da autocorrelação. Esse método tem suas origens em análise de séries temporais e tem sido largamente usado em ciência do solo (Webster, 1973; Webster & Cuanalo, 1975; Vieira et al., 1981), principalmente para medições efetuadas em uma linha reta (transeto). A sua análise pode auxiliar na localização de divisas entre dois tipos de solos, ou na análise de periodicidade nos dados, pela análise espectral (Vauclin et al. 1982). Porém, quando as amostras forem coletadas nas duas dimensões do campo e interpolação entre locais medidos for necessária para a construção de mapas de isolinhas, será preciso usar uma ferramenta mais adequada para medir a dependência espacial. Essa ferramenta é o semivariograma (Vieira et al., 1983). 1. A equação de cálculo O semivariograma é, por definição:
(20) }h)+xZ(-)xZ({E 1/2 = (h) 2iiγ
e pode ser estimado por:
γ ∗ ∑(h) = 1
2 N(h )[Z( x ) - Z( x + h) ]
i=1
N(h)
i i2 (21)
onde N(h) é o número de pares de valores medidos Z(xi), Z(xi+h), separados por um vetor h (Journel & Huijbregts, 1978, pag. 12). O gráfico de γ*(h) versus os valores correspondentes de h,

chamado semivariograma, é uma função do vetor h, e portanto depende de ambos, magnitude e direção de h. Quando o gráfico do semivariograma é idêntico para qualquer direção de h ele é chamado isotrópico e representa uma situação bem mais simples do que quando é anisotrópico. Neste último caso, o semivariograma deve sofrer transformações antes de ser usado. É importante notar que a maioria das variáveis de ciência do solo poderá ter um comportamento anisotrópico, isto é, mudar de maneira diferente para direções diferentes. É óbvio que isso depende muito da propriedade em estudo, das dimensões do campo de estudo e do tipo de solo envolvido. Existem algumas maneiras de se transformar um semivariograma anisotrópico em isotrópico (Journel & Huijbregts, 1978, pag. 175; Burgess & Webster, 1980a). Em geral, a precisão da interpolação ou o tipo de hipótese satisfeita não são afetados se, em vez de se preocupar com a escolha do método de transformação da anisotropia, apenas se limitar a faixa de distância na qual se utiliza o semivariograma. De qualquer maneira, é sempre aconselhável examinar semivariogramas para várias direções, antes de tomar decisões. As principais direções que devem ser examinadas são: 0° - na direção do eixo X, 90° - na direção do eixo Y, 45° e - 45° - nas duas diagonais. O método "jack-knifing", descrito no capítulo IX, é também de grande utilidade para se determinar a faixa de distância na qual o semivariograma pode ser, na prática, considerado isotrópico. De qualquer maneira, sob isotropia ou não, a equação (21) é a que é usada para o cálculo do semivariograma. Os programas de computador, como aqueles listados no apêndice 2, utilizados para calcular o semivariograma, simplesmente calculam aquela equação. Quando os dados forem coletados em transeto, o semivariograma é unidirecional e nada pode ser dito a respeito de anisotropia, mas por outro lado é uma preocupação a menos. 2. As características ideais A figura 1 mostra um semivariograma típico com características bem próximas do ideal, as quais serão discutidas a seguir. Seu comportamento representa o que, intuitivamente, se deve esperar de dados de campo. É de se esperar que as diferenças {Z(xi) - Z(xi+h)} decresçam assim que h, a distância que os separa, decresça. É esperado que medições localizadas próximas sejam mais parecidas entre si do que aquelas separadas por grandes distâncias. Dessa maneira, é de se esperar que γ(h) aumente com a distância h. Por definição, γ(0)=0, como pode ser visto pela equação (21), quando h=0. Entretanto, na prática, à medida que h tende para 0 (zero), γ(h) se aproxima de um valor positivo chamado efeito pepita (“nugget effect”) e que recebe o símbolo C0. Resultados com valores de efeito pepita maiores que zero foram encontrados para precipitação pluvial (Delhomme, 1976), pH (Campbell, 1978), condutância elétrica (Hajrasuliha et al., 1980) e distribuição de tamanho de partículas de solo (Vieira et al., 1983). O valor de C0 revela a descontinuidade do semivariograma para distâncias menores do que a menor distância entre as amostras. Parte dessa descontinuidade pode ser também devida a erros de medição (Delhomme, 1976), mas é impossível quantificar qual contribui mais, se os erros de medição ou a variabilidade em uma escala menor do que aquela amostrada. À medida que h aumenta, γ(h) também aumenta até um valor máximo no qual se estabiliza. Esse valor no qual γ(h) se estabiliza chama-se patamar ("sill"), e é aproximadamente igual à variância dos dados, VAR(z). A distância na qual γ(h) atinge o patamar é chamada de alcance ("range"), recebe o denominação de a, e é a distância limite de dependência espacial. Medições localizadas a distâncias maiores que a tem distribuição espacial aleatória e por isto são independentes entre si. Para essas amostras, a Estatística Clássica pode ser aplicada sem restrições. Por outro lado, amostras separadas por distâncias menores que a, são correlacionadas umas às outras, o que permite que se faça interpolações para espaçamentos menores do que os amostrados. Dessa maneira, o alcance a é a linha divisória para a aplicação de geoestatística ou Estatística Clássica, e por isso o cálculo do semivariograma deveria ser feito rotineiramente para

dados de campo, para garantir as hipóteses estatísticas sob as quais serão analisados. Dados que apresentarem semivariogramas semelhantes ao da figura 1 muito provavelmente poderão ser estacionários de ordem 2, porque têm um patamar claro e definido e, com toda certeza, estarão sob a hipótese intrínseca. Se o semivariograma, ao invés de ser crescente e dependente de h como o mostrado na figura 1, for constante e igual ao patamar para qualquer valor de h, então tem-se um efeito pepita puro ou ausência total de dependência espacial. Isto significa que o alcance a, para os dados em questão, é menor do que o menor espaçamento entre amostras. Para esses dados, tem-se uma distribuição espacial completamente aleatória, e a única estatística aplicável é a Estatística Clássica (Silva et al., 1989). É bastante comum um semivariograma que, partindo do valor do efeito pepita, C0, cresce além do valor do patamar ("sill"), até uma determinada distância e depois cai e apresenta flutuações abaixo do valor do patamar. Pode até apresentar flutuações abaixo do valor do patamar para pequenas distâncias. Isso é indicação de periodicidade nos dados. A periodicidade nos dados requer um tratamento específico chamado densidade espectral. Esse assunto está descrito em McBratney & Webster (1981), Nielsen et al. (1983) e Vieira et al. (1983), onde o leitor encontrará os detalhes necessários. Um outro tipo de semivariograma que pode ocorrer é aquele que cresce, sem limites, para todos os valores de h calculados. Esse semivariograma indica a presença de fenômeno com capacidade infinita de dispersão, o qual não tem variância finita e para o qual a covariância (equação (6)) não pode ser definida. Ele indica, também, que o tamanho do campo amostrado não foi suficiente para exibir toda a variância e é provável que exista uma grande tendência nos dados em determinada direção. Se isto puder ser constatado, tem-se duas alternativas distintas: a) remove-se a tendência e trabalha-se nos resíduos para examinar se se enquadram nas hipóteses de estacionaridade de ordem 2 ou intrínseca; b) trabalha-se com hipótese de tendência nos dados originais. Por simplicidade, deve-se preferir a primeira alternativa. Um método bastante eficiente para retirada da tendência é pela superfície de tendência (Davis, 1973). Se, após retirar a tendência, não houver nenhuma dependência espacial expressa no semivariograma dos resíduos, isto significa que a superfície de tendência encontrada é a melhor representação espacial do fenômeno. Um exemplo de retirada de tendência em dados unidimensionais e análise dos resíduos pode ser encontrado em Vieira et al. (1983) e Vieira & Hatfield (1984). 3.Os modelos O gráfico do semivariograma experimental, γ(h) versus h, calculado usando a equação (21), mostrará uma série de pontos discretos de γ(h) correspondendo a cada valor de h e para o qual uma função contínua deve ser ajustada. Delhomme (1976) discutiu vários modelos de ajuste aplicáveis a diferentes fenômenos. Neste trabalho serão discutidos apenas os principais. O ajuste de um modelo teórico ao semivariograma experimental é um dos aspectos mais importantes das aplicações da Teoria das Variáveis Regionalizadas e pode ser uma das maiores fontes de ambigüidade e polêmica nessas aplicações. Todos os cálculos de geoestatística dependem do valor do modelo do semivariograma para cada distância especificada (Vieira et al., 1981). Por isso, se o modelo ajustado estiver errado, todos os cálculos seguintes também o estarão. Um outro ponto importante é que o ajuste de curvas com calculadoras ou computador, usando métodos automáticos, embora possa ser usado, não é necessário. Existem programas comerciais que fazem ajuste pelo método dos quadrados mínimos, considerando o número de pares como pesos nas ponderações. Da mesma maneira, esses também podem ser usados, embora não seja necessário. O método de tentativa e erro, aliado ao exame dos resultados do "jack-

knifing", como será visto no último capítulo deste trabalho, são suficientes. Como regra, quanto mais simples puder ser o modelo ajustado, melhor, e não se deve dar importância excessiva a pequenas flutuações que podem ser artifícios referentes a um pequeno número de dados. É importante que o modelo ajustado represente a tendência de γ(h) em relação a h. Matemática e estatisticamente, é obrigatório que o modelo ajustado tenha positividade definida condicional (Journel & Huijbregts, 1978), embora o significado desta exigência esteja além dos objetivos deste trabalho. Além disso, essa condição não é fácil de entender nem de testar. A grosso modo, o modelo que satisfaça a condição acima garantirá que γ(h) > 0 e γ(-h) = γ(h), qualquer que seja h. De qualquer modo, os modelos apresentados neste trabalho satisfazem a exigência de positividade definida condicional e são suficientes para praticamente qualquer situação. Dependendo do comportamento de γ(h) para altos valores de h, os modelos podem ser classificados em: modelos com patamar ("sill") e modelos sem patamar. 3.1 Modelos com patamar Nos modelos seguintes, C0 é o efeito pepita, C0 + C1 é o patamar e a é o alcance do semivariograma. a) Modelo linear:
γ
γ
(h) = C + Ca
h 0 < h < a
(h) = C + C h > a
01
0 1
(22)
onde C1/a é o coeficiente angular para 0<h<a. Nesse modelo, o patamar é determinado por inspeção; o coeficiente angular, C1/a, é determinado pela inclinação da reta que passa pelos primeiros pontos de γ(h), dando-se maior peso àqueles que correspondem ao maior número de pares; o efeito pepita, C0, é determinado pela interseção da reta no eixo γ(h); o alcance, a, é o valor de h correspondente ao cruzamento da reta inicial com o patamar; e C1 = patamar - C0. b) Modelo esférico:
γ
γ
(h) = C + C [32
(ha
)-12
(ha
) ] 0 < h < a
(h) = C + C h > a
0 13
0 1
(23)
O modelo esférico é obtido selecionando-se os valores do efeito pepita, C0, e do patamar, C0 + C1, depois passando-se uma reta que intercepte o eixo y em C0 e seja tangente aos primeiros pontos próximos de h=0. Essa reta cruzará o patamar à distância, a'=2/3 a. Assim, o alcance, a, será a=3a'/2. O modelo esférico é linear até aproximadamente 1/3 a. c) Modelo exponencial:

γ (h) = C + C [1- (-3 ha
)] 0 < h < d0 1 exp (24)
onde d é a máxima distância na qual o semivariograma é definido. Uma diferença fundamental entre o modelo exponencial e o esférico é que o exponencial atinge o patamar apenas assintóticamente, enquanto que o modelo esférico o atinge no valor do alcance. O parâmetro a é determinado visualmente como a distância após a qual o semivariograma se estabiliza. Os parâmetros C0 e C1 para os modelos exponencial e gaussiano (explicado a seguir) são determinados da mesma maneira que para o esférico. d) Modelo gaussiano:
γ (h) = C + C [1- (-3 (ha
) )] 0 < h < d0 12exp (25)
3.2. Modelos sem patamar Esses modelos correspondem a fenômenos que têm uma capacidade infinita de dispersão e, por isso, não têm variância finita e a covariância não pode ser definida. Podem ser escritos da seguinte maneira :
(26) γ (h) = C+ Ah 0 < B < 2B
O parâmetro B tem que ser estritamente maior que zero e menor que 2, a fim de garantir que o semivariograma tenha positividade definida condicional. Alguns fenômenos podem ter semivariogramas que mostram estrutura entrelaçada, ou seja, mais de um patamar e mais de um alcance. Isso acontece quando se tem diferentes escalas de variabilidade nos dados. McBratney et al. (1982), analisando a variabilidade de teores de cobre e cobalto extraídos de amostras retiradas da superfície do solo do sudoeste da Escócia, encontraram três estruturas: uma correspondente à variação de uma fazenda a outra, com alcance de 3 km, uma correspondente à escala geológica, com alcance de 15 km, e a última espacialmente independente, ou efeito pepita puro. Em situações como essa é necessário ajustar mais de um modelo, ou um modelo para cada estrutura, pois um modelo único não é suficiente para representar o semivariograma. 4. Os exemplos Dois conjuntos de dados obtidos por Waynick e Sharp (1919) serão utilizados neste trabalho como exemplo. A figura 2 mostra o diagrama das áreas amostradas, com os locais de onde as amostras foram tomadas. Os autores esclarecem que os campos foram amostrados na forma apresentada na figura 2, com a finalidade de verificar o efeito da distância entre amostras na variabilidade. Dois campos foram amostrados no Estado da Califórnia, EUA. Um, na então chamada Fazenda Universitária em Davis, em solo franco argiloso, e o outro, perto da cidade de Oakley, em solo arenoso. Os campos foram selecionados por parecerem uniformes e porque se encontravam sem vegetação na época da amostragem. Ambos eram quase perfeitamente planos. As amostras foram coletadas com um trado de 7,62cm de diâmetro e levadas ao laboratório para análise de nitrogênio e carbono totais. Os resultados são dados em porcentagem. Os dados originais estão listados no apêndice 1 e os principais momentos estatísticos estão no quadro 1. Os coeficientes de simetria e curtose são apresentados no quadro 1, para comparação com a

distribuição normal, para a qual esses coeficientes têm valores 0 e 3 respectivamente. Não é intenção, neste trabalho, procurar a distribuição exata das variáveis estudadas. Entretanto, é importante notar que, exceto para nitrogênio-Davis, as demais variáveis têm distribuição diferente da normal. Isso pode ser visto principalmente pelos altos coeficientes de curtose, indicando um excesso de valores próximos à média. Outro fato notável é a baixíssima variância. Com a finalidade de comparar os semivariogramas e, conseqüentemente, as variabilidades espaciais de cada uma das variáveis, pode-se realizar do seu escalonamento, como o utilizado por Vieira et al. (1991). Os semivariogramas escalonados médios para as quatro variáveis (C e N nos dois locais) estão mostrados na figura 3. É chamado de semivariograma médio porque a direção dos vetores h não é considerada e, implicitamente, assume-se isotropia, ou seja, variabilidade idêntica em todas as direções. Esse deve ser o procedimento adotado como rotina, pois é inútil explorar a anisotropia quando não existe dependência espacial na média. Após o exame dos semivariogramas médios, se a dependência espacial for encontrada, então deve-se examinar os semivariogramas direcionais. O exame dos semivariogramas da figura 3 revela alguns fatos importantes. Deduz-se que a variabilidade espacial das duas variáveis (carbono e nitrogênio), nos dois locais (Davis e Oakley), têm alguma semelhança. Em geral, pode-se notar também que as duas variáveis têm semivariâncias maiores no solo arenoso de Oakley do que no solo franco argiloso de Davis. Um outro fato bastante importante é que nenhum desses semivariogramas tem patamar bem definido, denotando a falta de estacionaridade nestes dados. Os semivariogramas para as relações C/N para os dois locais estão na figura 4, onde se observa que, para Oakley, não existe dependência espacial para esta variável e, para Davis, a dependência espacial é pequena, como se pode notar pelo alto valor do efeito pepita em relação ao patamar. Assim, para Oakley, os valores da relação C/N não tem nenhuma relação com seus vizinhos, isto é, valores próximos não são necessariamente mais parecidos entre si do que valores distantes. Nesse caso, o valor médio pode representar o fenômeno. Devido à aparente falta de estacionaridade para carbono e nitrogênio para os dois locais, como indicado na figura 3, devem ser calculadas as superfícies parabólicas de tendências de acordo com Davis (1973), usando a equação,
(27) est 0 1 2 32
42
5Z (x, y) = A + A .x+ A .y+ A .x + A .y + A .xy
pelo método dos quadrados mínimos. Dessa maneira, pode-se calcular o resíduo
(28) res estZ (x, y) = Z(x, y) - Z (x, y)
Os semivariogramas da variável Zres devem ter patamar indicando que o procedimento para remoção da tendência foi eficiente. Os semivariogramas resultantes dos resíduos da tendência para carbono e nitrogênio para os dois locais, estão mostrados na figura 5. De seu exame pode-se deduzir que a maior tendência existia, na realidade, para os dados relativos ao solo de Davis, pois nas figuras 5a e 5c pode-se ver que os semivariogramas para Zres têm um patamar bem definido, quando antes não o tinham. Por outro lado, para o solo de Oakley, os semivariogramas para Z e Zres são quase idênticos, indicando que não havia tendência retirável pela superfície parabólica. Nesse caso, pode-se usar os dados originais sem problema; porém, para dar condições iguais aos de Davis, quando escalonados, os resíduos serão usados A figura 6 mostra os semivariogramas para os resíduos de tendência para carbono e nitrogênio de ambos os solos. É notável tanto o efeito da remoção da tendência, estabelecendo nitidamente o patamar, como também a semelhança nas variabilidades de carbono para os dois locais e de nitrogênio para os dois locais . O carbono apresenta uma variabilidade inicial maior do que o nitrogênio, como indica o valor do efeito pepita (0,4). Já o nitrogênio tem efeito pepita nulo

em ambos os solos. Pela semelhança entre esses semivariogramas escalonados, pode-se dizer que, apesar das diferenças básicas de textura dos dois solos, os fenômenos que regeram a concentração desses elementos no solo foram parecidos, fazendo com que suas variabilidades fossem parecidas. É provável que o efeito climático ao longo dos anos tenha sido o maior responsável por estas concentrações, uma vez que os locais amostrados estavam livres de vegetação na época da amostragem. O semivariograma para a relação C/N para Davis está na figura 7, com um modelo esférico (Esf), com 0,3 de efeito pepita, 1,0 de patamar e 25,0 m de alcance. A relação C/N não apresenta uma dependência espacial muito boa, implicando alta incerteza na estimativa pela krigagem, devido à alta variação ao acaso em distâncias pequenas, mas não se pode negar que ela existe.

IV. A KRIGAGEM Conhecido o semivariograma da variável, e havendo dependência espacial entre as amostras, como mostram os semivariogramas para C e N, para Davis e Oakley (Figura 6), pode-se interpolar valores em qualquer posição no campo de estudo, sem tendência e com variância mínima. O método de interpolação chama-se krigagem, nome dado por Matheron (1963) em homenagem ao matemático sul-africano Krige. Suponha-se, então, que se queira expressar o resultado do trabalho em forma de mapa de isolinhas ou de superfície tridimensional. A precisão da localização das isolinhas entre dois pontos é extremamente dependente da densidade de pontos por área e, conseqüentemente, da distância entre os pontos. A maneira mais comum de localizar uma isolinha entre dois pontos é pela interpolação linear. Existem programas de computador para se ajustar polinômios bidimensionais, chamados superfície de tendência (“trend surface”; Davis, 1973). Entretanto, a forma na qual os dados variam de um local para outro no campo não tem, necessariamente, que seguir equações lineares ou polinômios. Na verdade, é comumente impossível determinar com exatidão que tipo de equação matemática descreve a variação dos dados no campo. E, mesmo que se consiga, na prática, ajustar algum polinômio aos dados, sua forma e grau podem não ter nenhuma interpretação física para o fenômeno, fato que é revelado no semivariograma, embora não se conheça a equação que descreveria os dados. Os dados de Waynick e Sharp (1919) usados nesse trabalho foram amostrados na distância básica de 9,12m, com uma minoria de amostras a 4,56m e 3,04m umas das outras. A distância de 9,12m é muito grande para se ter uma boa precisão na localização de isolinhas, e ficaria bem mais fácil se houvesse mais dois pontos entre os amostrados a 9,12m. Isso significa ter um espaçamento básico de 3,04m para todo o campo. O pesquisador que fosse começar esse experimento poderia ter a opção de amostrar já no espaçamento de 3,04m. Porém, essa seria uma opção muito cara, e a krigagem pode estimar valores nesse ou qualquer outro espaçamento menor, sem gastos de amostragem, análise e processamento, e sem tendência e com variância mínima, como será visto a seguir. 1. O estimador Suponha-se que se queira estimar valores, z*, para qualquer local, x0, onde não se tem valores medidos, e que a estimativa deve ser uma combinação linear dos valores medidos, ou seja
(29) )( x = )x(* ii
N
1i=0 zλ∑z
onde N é o número de valores medidos, z(xi), envolvidos na estimativa, e λi são os pesos associados a cada valor medido, z(xi). A determinação do número de vizinhos envolvidos na estimativa de um valor constitui-se em assunto complexo e merece ser tratado separadamente, o que se fará no capítulo VIII deste trabalho. Tomando-se z(xi) como uma realização da função aleatória Z(xi) e, por hora, assumindo estacionaridade de ordem 2, o estimador fica,
)xi Z(iN
1=i = )x0(*Z λ∑ (30)
Note-se que o estimador anterior não apresenta nada de novidade pois praticamente todos os métodos de interpolação seguem essa forma. Por exemplo, na interpolação linear os pesos são

todos iguais a 1/N, e na interpolação baseada no inverso do quadrado das distâncias os pesos recebem valores variáveis de acordo com o inverso do quadrado da distância que separa o valor interpolado dos valores medidos usados. No método da krigagem, os pesos são variáveis de acordo com a variabilidade espacial expressa no semivariograma. Esse estimador nada mais é que uma média móvel ponderada. O que torna a krigagem um interpolador ótimo, então, é a maneira como os pesos são distribuídos, como será visto a seguir. 2. As condições requeridas Para que o estimador seja ótimo, ele não pode ser tendencioso e deve ter variância mínima. Matematicamente,
(31) E {Z * ( x ) - Z( x )} = 00 0
e
(32) mínima = })]x Z(- )x(*{[Z E = )}xZ(-)x(*{Z VAR 20000
As equações (31) e (32) representam as condições de não-tendência e de variância mínima, respectivamente. Essas duas condições devem ser rigorosamente satisfeitas e, para tanto, são usadas como ponto de partida para a dedução das equações. A condição de não-tendência significa que, em média, a diferença entre valores estimados e medidos para o mesmo ponto deve ser nula. A condição de variância mínima significa que, embora possam existir diferenças ponto por ponto entre o valor estimado e o medido, essas diferenças devem ser mínimas. À primeira vista, pode parecer estranho quando se fala em diferenças entre valor estimado e medido, quando o propósito da krigagem é justamente estimar valores para locais onde estes não foram medidos. Porém, as condições impostas nas equações (31) e (32) são feitas tendo-se em mente o que poderia acontecer se o valor naquele ponto fosse conhecido. Em outras palavras, o objetivo é que a estimativa represente, o melhor possível, o que seria o valor medido para aquele local. Na verdade, essas duas condições e o raciocínio anterior constituem o princípio básico do "jack-knifing", que será discutido no capítulo IX deste trabalho. 3. A dedução do sistema de equações O raciocínio geral na dedução do sistema de equações da krigagem envolve aplicação da fórmula do estimador (equação (30)) na condição de não tendência, encontrando-se a primeira restrição imposta nos pesos. Em seguida, aplicando-se esta restrição na condição de variância mínima e empregando técnicas de Lagrange para minimização de equações, chega-se ao sistema de equações da krigagem. Esta dedução será mantida com todos os detalhes para facilidade de acompanhamento e compreensão. Substituindo-se a equação (30) na equação (31) tem-se:
0=)}x0Z(-)xi Z(iN
1=i{ E = )}x0Z(-)x0(Z*{ E λ∑ (33)
Aplicando a linearidade do operador valor esperado, E, tem-se:
0=)}x0{Z( E-)}xi{Z( E iN
1=i{ = )}x0Z(-)x0(Z*{ E λ∑ (34)

Substituindo-se a primeira condição de estacionaridade, expressa na equação (5), tem-se
0=1) - iN
1=i( m =} m - m i
N
1=i{ = )}x0Z(-)x0(Z*{ E λλ ∑∑ (35)
Para que a equação (35) seja verdade para qualquer valor de m, é necessário que
0=1- iN
1=iλ∑
ou seja,
1 iN
1=i
=∑λ
(36)
Portanto, para que a estimativa não tenha tendência, é necessário que a soma dos pesos seja igual a 1, qualquer que seja a distribuição de seus valores. Desenvolvendo a equação (32) e chamando-a de σ2
kZ(x0), variância da estimativa, tem-se:
(37) K
2 *0
*0 0
2
*0
20
*0 0
Z ( x ) = E {Z ( x ) - Z( x ) } =
= E {Z ( x )+ Z ( x )- 2 Z ( x ) Z( x )}2
σ
Cada termo do lado direito da equação (37) será individualmente desenvolvido a seguir. Substituindo-se a equação (30), no primeiro termo,
})2)xi Z(iN
1=i{( E = )}x0(Z*2{ E λ∑ (38)
Aplicando-se propriedades de operações com álgebra linear tem-se:
(39)
)}x j Z()x i{Z( E j iN
1=j
N
1=i=
)}x j Z()x i Z(jN
1=j i
N
1=i{ E=
)}x j Z(jN
i=j)x i Z(i
N
1=i{ E = )}x 0(Z * 2{ E
λλ
λλ
λλ
∑∑
∑∑
∑∑
A equação (6)
pode ser reordenada para C(h)= E{Z( x )Z( x + h)} - mi i2
(40) E {Z( x ) Z( x + h)} = C(h) + mi i2
Substituindo-se a equação (40) na equação (39), tem-se:
(41) E {Z ( x )} = C( x ,x ) + m2*
0i=1
N
j=1
N
i j i j2∑ ∑ λ λ

onde C(xi, xj) refere-se à função covariância correspondente a um vetor h, com origem em xi e extremidade em xj. O segundo termo no lado direito da equação (37) é:
(42) E {Z ( x )} = E {Z( x )Z( x +0)}20 0 0
Substituindo a equação (40) na equação (42) para o valor apropriado de h tem-se:
(43) E {Z ( x )} = C(0) + m20
2
O terceiro termo no lado direito da equação (37) é:
)}x0 Z()xi{Z( E iN
1=i=
)}x0 Z()xi Z(iN
1=i{ E = )}x0)Z(x0(Z*{ E
λ
λ
∑
∑
(44)
Substituindo-se a equação (40) na equação (44), tem-se:
]m2 + )x0 ,xi[C( iN
1=i = )}x0 Z()x0(Z*{ E λ∑ (45)
Substituindo-se as equações (41), (43) e (45) na equação (37), tem-se:
)m2 + )x0 ,xiC( iN
1=i( 2-
m2 + C(0) + m2 + )x j ,xiC( jiN
1=j
N
1=i = )x0Z(2k
λ
λλσ
∑
∑∑
ou simplificando:
)]x0 ,xiC( iN
1=i[ 2-
C(0) + )x j ,xiC( jiN
1=j
N
1=i = )x0Z(2k
λ
λλσ
∑
∑∑
(46)
A equação (46) deve ser minimizada sob a restrição de que
1 = iN
1=iλ∑
Esse processo de minimização pode ser feito pelas técnicas de Lagrange, as quais podem ser encontradas em livros de cálculo avançado. Para satisfazer a condição expressa na equação (32), é preciso que as N derivadas parciais

λλµσ i / )1N
1=i 2-)x0(2( k ∂∑∂ (47)
sejam igualadas a 0 (zero); µ é um multiplicador de Lagrange. Assim, se a derivada parcial expressa na equação (47) for efetuada obtém-se,
0= 2 - )x0 ,xi2C( - )x j ,xiC( iN
1=i2 µλ∑ (48)
Cancelando o fator 2, rearranjando e combinando com a equação (36), tem-se o sistema de krigagem expresso em termos de função covariância:
1 = jN
1=j
N a 1=i ),x0 ,xiC( = - )x j ,xiC( j N
1=j
λ
µλ
∑
∑
(49)
As primeiras N equações no sistema (49) podem ser rearranjadas em:
)x0 ,xiC( + = )x j ,xiC( jN
1=jµλ∑ (50)
Substituindo a equação (50) na equação (46), tem-se:
)x0 ,xiC(iN
1=i-+C(0) = )x0Z(2k
)x0 ,xiC(iN
1=i2-)x0 ,xiC(i
N
1=i++C(0) = )x0Z(2k
)x0 ,xiC( iN
1=i2-C(0)+))x0 ,xiC(+(i
N
1=i = )x0Z(2k
λµσ
λλµσ
λµλσ
∑
∑∑
∑∑
(51)
A equação (51) é expressão da variância mínima da estimativa. Quando a estacionaridade de ordem 2 puder ser aceita, o sistema krigagem (49) e a variância da estimativa expressa na equação (51) podem ser escritos ambos na forma de função covariância, C(h), ou de semivariograma, γ(h). Existem algumas vantagens computacionais em se usar covariância, que serão discutidas no final deste capítulo. Entretanto, se a hipótese intrínseca for o máximo que se puder assumir, então, obrigatoriamente, tem-se que usar o semivariograma, γ(h), nas equações (50) e (51). A transformação do sistema de krigagem (49) e da variância da estimativa (51), em termos de semivariograma, pode ser feita através da equação (13), substituindo-se C(h) por C(0) - γ(h). Assim, o sistema de krigagem fica:

(52)
1 = jN
1=j
N a 1=i ),x0 ,xi( = +)x j ,xi(jN
1=j
λ
γµγλ
∑
∑
e a variância da estimativa, σ2k Z(x0), fica
)x0 ,xi(iN
1=i + = )x0Z(2k γλµσ ∑ (53)
Os sistemas (49) e (52) contêm N+1 equações e N+1 incógnitas, e uma única solução produz N pesos, λ, e um multiplicador de Lagrange, µ. 4. Sistema matricial O sistema de krigagem da equação (49) pode ser escrito em notação matricial como
[C] [ ] = [b]λ (54)
ou, quando se usa semivariograma,
[ ] [ ] = [b]γ λ (55)
cujas soluções são
(56) [ ] = [C ] [b]-1λ
ou
(57) [ ] = [ ] [b]-1λ γ
onde, [C] é a matriz covariância, [γ] é a matriz semivariância, [C]-1 e [γ]-1 são seus inversos, respectivamente, [λ] é a matriz dos pesos procurados λi, e [b] é o lado direito das equações (49) ou (52), quando se usa C(h) ou γ(h), respectivamente. As equações (51) e (53), da variância da estimativa, podem ser expressas em notação matricial, como
(58) [b] ][ - C(0) = )xZ(ot
02
k λ
ou
(59) [b] ][ = )xZ(ot
02
k λ
respectivamente, quando se usa C(h) ou γ(h). A matriz [λ]t é o transposto da matriz [λ]. Suponha que N=4. Então as matrizes [C] e [γ] são matrizes 5x5 e podem ser, explicitamente, escritas como

(60)
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
01111
1)x,xC()x,xC()x,xC()x,xC(
1)x,xC()x,xC()x,xC()x,xC(
1)x,xC()x,xC()x,xC()x,xC(
1)x,xC()x,xC()x,xC()x,xC(
=[C]
44342414
43332313
42322212
41312111
ou
(61)
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
01111
1)x,x()x,x()x,x()x,x(
1)x,x()x,x()x,x()x,x(
1)x,x()x,x()x,x()x,x(
1)x,x()x,x()x,x()x,x(
=][
44342414
43332313
42322212
41312111
γγγγ
γγγγ
γγγγ
γγγγ
γ
A matriz de lâmbdas [λ] pode ser escrita como
(62)
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
µλλλλ
λ
-
=] [
4
3
2
1
ou
(63)
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
µλλλλ
λ
4
3
2
1
=] [
E a matriz do lado direito dos sistemas de krigeagem pode ser escrita como,
(64)
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
0)x,xC()x,xC()x,xC()x,xC(
=[b]
04
03
02
01
ou

(65)
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
0)x,x()x,x()x,x()x,x(
=[b]
04
03
02
01
γγγγ
respectivamente, quando se usa C(h) ou γ(h). 5. Particularidades do sistema e métodos de solução Os sistemas de krigagem das equações (49) e (52) têm algumas particularidades que facilitam grandemente os cálculos e a solução do sistema e mesmo a análise de esquemas de amostragem. É preciso lembrar que, para cada estimativa ou interpolação efetuada, ter-se-á um sistema de equações de krigagem para o qual ter-se-á que achar a solução. Essa operação é a que envolve o maior tempo de processamento de computador, e quando esse tempo é pago, é a operação que envolve os maiores custos. Por isto, é imprescindível que se faça uso das particularidades do sistema de krigagem para aumentar eficiência, precisão e velocidade e diminuir custo de estimativa. Primeiramente serão examinadas as particularidades da matriz de coeficientes, ou seja, as matrizes covariância ou semivariograma, expressas em (60) e (61) para o caso particular de N=4. Tanto as funções covariância, C(h), ou semivariograma, γ(h), são simétricas ao redor de zero (0). Isso significa que C(h)=C(-h) e γ(h)=γ(-h). Isso faz com que as matrizes (60) e (61) sejam simétricas, isto é, a parte que fica acima da diagonal principal é exatamente igual à parte que fica abaixo dela, porque C(x1, x3) = C(x3, x1) ou γ(x1, x3) = γ(x3, x1). Uma outra particularidade importante é a diagonal principal, a qual deve ser preenchida com valores de C(h) ou γ(h), correspondentes a vetores nulos, isto é, para h=0. Isso faz com que a diagonal principal para a matriz (60) tenha valores máximos e iguais a C(0) e para a matriz (61) tenha zeros (0). Isso acontece porque C(0) é o máximo valor da função covariância e é igual ao patamar do semivariograma, e γ(0)=0 qualquer que seja o efeito pepita, C(0). Esta afirmação pode parecer estranha, mas o que deve ser mantido é que γ(0)=0, e γ(e) = C(0) (efeito pepita), onde e é a menor distância entre amostras. Existem vários métodos de solução de sistemas lineares de equação como o do sistema de krigagem (Burden et al., 1978, pag. 299 a 361), como também existem métodos mais eficientes que levam em conta as particularidades das matrizes (Journel e Huijbregts, 1978, pag. 357 a 360). O método mais comum seria o de inverter a matriz de coeficientes, (60) ou (61), e multiplicar do lado direito. Porém esse é também o método mais demorado em termos de tempo de processamento e o que envolve o maior número de operações de multiplicação/divisão e soma/subtração e, por isso, é também o que apresenta a maior propagação de erros. O método de eliminação Gaussiana envolve um número bastante menor de operações e, por isso mesmo, é mais rápido e mais preciso. Esse método procura, primeiramente, o elemento chamado pivô, o qual é o valor máximo encontrado em cada coluna da matriz. Desse modo, se for usada a covariância, C(h), no sistema de krigagem, poder-se-á eliminar essa operação de procura do pivô, pois na matriz de covariância (60) a diagonal sempre vai conter o elemento máximo. Quanto à ressalva de estacionaridade de ordem 2 e conseqüente existência de covariância finita, Journel & Huijbregts, (1978, pag. 357) recomendam que se pode definir uma função pseudocovariância C(h)=A - γ(h), onde A é uma constante maior que qualquer γ(h) usado no sistema. Devido à condição de não tendência, (Σλi=1), o valor A será eliminado do sistema da krigagem, e esta

operação não altera os valores dos pesos calculados na solução. 6. Os exemplos Uma vez que existe uma distância bastante grande entre os pontos medidos, com alguns pontos mais próximos (Figura 2), é desejável fazer estimativas para os locais não medidos, para construção de mapas. Além disso, graças à existência de dependência espacial, expressa pelos semivariogramas da Figura 6, pode-se utilizar krigagem para efetuar as estimativas. Dessa maneira, foram estimados valores para cada ponto localizado na grade quadrada de 1,52m, regularizando assim a distância de separação entre amostras em todo o campo. Usando-se esses dados para cada uma das variáveis, construíram-se os mapas de isolinhas para cada uma das variáveis, mostrados nas Figuras 8, 9, 10 e 11. Com esses mapas pode-se ver agora, por exemplo, porque o carbono e nitrogênio para o solo de Davis têm semivariogramas parecidos, pois variam de maneiras muito semelhantes. Isso pode ser observado nas figuras 8 e 9, respectivamente para carbono e nitrogênio para o solo de Davis, onde, para quase todas situações de máximo ou de mínimo para carbono, corresponde uma situação igual para nitrogênio. Outro fato notório nas Figuras 8 e 9 é a tendência de crescimento na direção y, o que confirma a tendência encontrada.

V. O SEMIVARIOGRAMA CRUZADO Em Ciência do Solo, freqüentemente algumas variáveis são relacionadas com outras, sendo possível utilizar essa vantagem. Exemplos comuns incluem condutividade hidráulica e retenção de água, cuja medição é difícil e cara, e além disso são normalmente correlacionadas a variáveis cuja medição é mais fácil, como teores de partículas na camada superficial do solo. A facilidade de se utilizar de teores granulométricos em estimativas, tem atraído o interesse de pesquisadores que utilizam modelos para predição de rendimento de culturas, erosão e potencial de produção. Em situações em que existe a correlação espacial entre duas propriedades, a estimativa de uma delas pode ser feita usando-se informações de ambas expressas no semivariograma cruzado e o método chamado co-krigagem, o qual pode ser mais preciso do que o da krigagem em si. Devido, talvez, às maiores dificuldades envolvidas nesse método, do que com a krigagem em si, o número de trabalhos nesta área é bastante limitado (Vauclin et al., 1983; Vieira et al., 1983). 1. As definições pertinentes De maneira semelhante ao estabelecido para uma única variável, considera-se um campo para o qual dois conjuntos de variáveis, {Z1(x1i), i=1, N1} e {Z2(x2j), j=1, N2}, foram medidos, correspondendo a realizações particulares das funções aleatórias Z1(x1i) e Z2(x2i), respectivamente. Considere-se também que a variável Z2 tenha sido, por alguma razão, subamostrada, em relação a Z1, ou seja, N1 > N2; por isto, Z2 deverá ser estimado para os locais não medidos. Assumindo estacionaridade de segunda ordem, os momentos de primeira ordem de Z1(x1i) e Z2(x2j) são, respectivamente:
(66) Sde dentro x1i qualquer para ,m1 = )}x1i(Z1{ E (67) Sde dentro x2j qualquer para ,m2 = )}x2j(Z2{ E
As covariâncias de Z1(x1i) e Z2(x2j) são, respectivamente:
(68) 11 1 1i 1 1j 12C (h) = E {Z ( x + h) Z ( x )} - m
e
(69) 22 2 2i 2 2j 22C (h) = E {Z ( x + h) Z ( x )} - m
A covariância cruzada entre Z1(x1i) e Z2(x2j) é:
(70) 12 1 1 2 2 1 2C (h) = E {Z ( x i + h) Z ( x j)} - m m
e a covariância cruzada entre Z2(x2j) e Z1(x1i) é:
(71) 21 2 2j 1 1i 2 1C (h) = E {Z ( x + h) Z ( x )} - m m
Os semivariogramas de Z1(x1i) e Z2(x2j) são, respectivamente:
(72) 11 1 1i 1 1i2(h) = 1 / 2 E {Z ( x + h) - Z ( x ) }γ

(73) 22 2 2j 2 2j2(h) = 1 / 2 E {Z ( x + h) - Z ( x ) }γ
O semivariograma cruzado entre Z1(x1i) e Z2(x2i), igual ao semivariograma cruzado entre Z2(x2j) e Z1(x1i), é:
(74) )]}x(Z- h)+x(Z)][x(Z- h)+x(Z{[ E 1/2 = )h( = (h)2j22j21i1i112112
γγ
2. A equação de cálculo A equação (74) pode ser estimada por:
])x2j(Z 2-h)+x2j(Z 2)][x1i(Z 1-h)+x1i(Z 1[N(h)
1i=2N(h)1=(h)12 ∑γ (75)
onde N(h) é o número de valores de Z1 e Z2 separados por um vetor h. Comparando-se a equação (75) do semivariograma cruzado com a equação (21) do semivariograma, pode-se notar que o semivariograma é um caso particular do semivariograma cruzado, quando as duas variáveis são idênticas. Este fato, aliado ao produto da diferença de duas variáveis, faz com que fique bastante difícil de visualizar o que deve, intuitivamente, acontecer com γ12(h) quando h aumenta de zero (0) até a distância máxima. Considerando que h é um vetor e portanto possui magnitude e direção, é de se esperar que o semivariograma cruzado seja dependente de direção, podendo ser anisotrópico. Porém, se já é difícil interpretar anisotropia de semivariograma, por causa do produto das diferenças é pior ainda para o semivariograma cruzado. Uma característica interessante da equação (75) é que não importa que uma das variáveis tenha milhões de valores medidos, pois o semivariograma cruzado só será calculado usando as informações existentes para posições geográficas coincidentes. Isto significa que Z1 e Z2 tem que ser, necessariamente, definidos para os mesmos locais, e as informações excedentes deverão ser excluídas do cálculo. Assim, o programa de computador que for escrito para executar a equação (75) deverá, primeiramente, verificar se os dois conjuntos de dados são definidos para posições idênticas, para então calcular as diferenças. 3. As características ideais Um semivariograma cruzado, com características que podem ser identificadas como ideais teria aparência do semivariograma mostrado na figura 1, porém com significados diferentes, pelo simples fato de envolver o produto das diferenças de duas variáveis diferentes. Por exemplo, ao contrário do semivariograma, não é óbvio que o valor do semivariograma cruzado para h=0 deva ser nulo. Assim, além de espaços menores do que a distância de amostragem, acumulado no mesmo parâmetro, está a falta de correlação entre as duas variáveis. O alcance aqui representa apenas o final ou a distância máxima de dependência espacial entre as variáveis. Já o patamar do semivariograma cruzado, se existir, deve aproximar-se do valor da covariância entre as duas variáveis. Assim, quando as duas variáveis forem de correlação inversa, isto é, quando uma aumenta e a outra diminui, a covariância será negativa e, conseqüentemente, o semivariograma cruzado será negativo. Os modelos utilizados para o semivariograma cruzado são os mesmos já requeridos para o semivariograma. 4. Os exemplos

Os semivariogramas cruzados para carbono vs. nitrogênio estão na figura 12, para Davis e Oakley. Ambos são razoavelmente descritos por um modelo Gaussiano único, portanto ambos com patamares positivos e escalonados, com alcance de 13,0m. O exame dos porquês da correlação entre carbono e nitrogênio nesses dois solos está além dos objetivos deste trabalho e não será considerado aqui. Entretanto, o formato do semivariograma cruzado revela que a correlação espacial entre as duas variáveis é semelhante nos dois solos. Suponha-se, então, que seja mais fácil e mais barato medir carbono do que nitrogênio. Nesse caso, o nitrogênio não precisa ser amostrado na mesma intensidade que o carbono, pois pode-se usar a dependência espacial entre eles para estimar o teor de nitrogênio. Essa possibilidade, juntamente com suas vantagens, será examinada no capítulo VI.

VI - A CO-KRIGAGEM O método geoestatístico de interpolação mostrado no capítulo IV, a krigagem, é um caso particular do método co-krigagem que será discutido em seguida. Uma vez que exista a dependência espacial para cada uma das variáveis Z1 e Z2, e que também exista dependência espacial entre Z1 e Z2, então é possível utilizar a co-krigagem para estimar valores. Essa estimativa pode ser mais precisa do que a krigagem de uma variável simples (Vauclin et al., 1983), quando o semivariograma cruzado mostrar dependência entre as duas variáveis. 1. O estimador Suponha que se queira estimar valores, Z2*, para qualquer local, x0, e que a estimativa deva ser uma combinação linear de ambos Z1 e Z2, ou seja
(76) )x( + )x( = )x(*2j22j
N 2
1=i1i11i
N1
1=i02 zzz λλ ∑∑
onde N1 e N2 são os números de vizinhos de Z1 e Z2, respectivamente, e λ1 e λ2 são os pesos associados a cada valor de Z1 e Z2. Tomando z1(x1i) e z2(x2j) como sendo uma realização das funções aleatórias Z1(x1i) e Z2(x2j), respectivamente, e assumindo estacionaridade de ordem 2, o estimador pode ser reescrito em
(77) )( xZ + )x(Z = )x(Z 2j22j
N
=1i1i11i
N
=1i0
*2
21
λλ ∑∑
A equação (77) então expressa que a estimativa da variável Z2 deverá ser uma combinação linear de ambos Z1 e Z2, com os pesos λ1 e λ2 distribuídos de acordo com a dependência espacial de cada uma das variáveis entre si e com a correlação cruzada entre elas. 2. As condições requeridas Para que o estimador seja ótimo, ele não pode ter tendência e tem que ter variância mínima. Em outras palavras, para que o estimador seja o melhor possível é necessário que ele não superestime nem subestime valores, e que a confiança nas estimativas seja máxima. Matematicamente, isso pode ser escrito:
(78) 0 = )}x(Z-)x(Z{ E 020*2
e
(79) mínima = }])x(Z-)x(Z{[ E = )}x(Z-)x(Z{ VAR 2020
*2020
*2
Essas duas condições devem ser rigorosamente satisfeitas e para isso são usadas como ponto de partida para a dedução das equações, a exemplo do que já foi dito para a estimativa com a krigagem. É importante notar que, apesar de a estimativa ser feita usando-se uma combinação das duas variáveis (equação (77)), as condições (78) e (79) são impostas na variável estimada. 3. A dedução do sistema de equações

O raciocínio básico para dedução do sistema de equações da co-krigagem é idêntico ao da krigagem, com uma diferença que, neste caso, envolve duas variáveis e, por isto, envolve equações mais longas, com subscritos, complicando um pouco mais a situação. Porém, o raciocínio e, por conseguinte, a álgebra envolvida, são os mesmos. A exemplo do que foi feito para a krigagem no capítulo IV, a dedução será feita passo a passo. Substituindo-se a equação (77) na equação (78) tem-se:
0 = )}x0(Z 2-)x2j(2Z2j+)x1i(Z 11i{ E = )}x0(Z 2-)x0(Z*2{ EN 2
1=j
N 1
1=i
λλ ∑∑
Aplicando-se a linearidade do operador valor esperado, E, tem-se
0 = )}x 0(2Z{ E-
-)}x 2j(Z 2{ E )x 2j(2jN 2
1=i+)}x 1i(Z 1{ E 1i
N 1
1=i = )}x 0(Z 2-)x 0(Z *2{ E λλ ∑∑
Substituindo-se a equação (5), tem-se
0 = m - m + m 2
2N
1j2j2
1N
1i1i1 ∑∑
==λλ
ou
(80) 0 = 1) - ( m + m2N
1j2j2
1N
1i1i1 ∑∑
==λλ
Uma vez que não se pode, necessariamente, exigir que m1 e m2 sejam nulos, para satisfazer a equação (80) e, por conseguinte, para que a estimativa não tenha tendência, é necessário que
(81) 1 = 2j
N
1=j
2
λ∑
(82) 0 = i1
N
1=i
1
λ∑
Desse modo, para que a estimativa não tenha tendência, qualquer que seja a distribuição dos pesos, a soma daqueles associados com a variável estimada deve ser igual a 1 e a soma daqueles associadas à outra variável tem que ser nula. Essas duas condições serão usadas como restrição na etapa seguinte. Desenvolvendo-se o quadrado na equação (79), chamando-o de σ2k2(x0), tem-se
(83) )}x(Z)x(Z-)x(Z)x(Z-
-)x(Z+)x(Z{ E=}])x(Z-)x(Z{[ E=)x(
0*202020
*2
0220
*2
2020
*20K
22σ
Aplicando a linearidade do operador E, tem-se:

(84)
)}x(Z)x(Z{ E-
-)}x(Z)x(Z{ E - )}x(ZE{+)}x(Z{ E=)x(
0*202
020*20
220
*20K
2 2
2σ
Chamando os termos do lado direito da equação (84) de A, B, C e D, tem-se:
(85) D - C - B + A = )x( 0K2
2σ
Desenvolvendo individualmente cada termo da equação (85), tem-se:
(86) A = E {Z ( x )} = E {Z ( x ) Z ( x )}2*
0 2*
0 2*
02
Substituindo-se a equação (77) na equação (86):
(87) A = E Z ( x )+ Z ( x ) Z ( x )+ Z ( x ) i
1i 1 1ij
2j 2 2jk
1k 1 1kl
2l 2 2l∑ ∑ ∑ ∑⎛
⎝⎜
⎞
⎠⎟⎛⎝⎜
⎞⎠⎟
⎧⎨⎪
⎩⎪
⎫⎬⎪
⎭⎪λ λ λ λ
Efetuando-se as multiplicações nos colchetes, tem-se:
(88)
)}x(Z)x(Z+)x(Z)x(Z+
+)x(Z)x(ZxZ)x(Z{ E = A
2l22l
l2j22j
j1k11k
k2j22j
j
2l22l
l1i11i
i1k11k
k1i11i
i+)(
λλλλ
λλλλ
∑∑∑∑
∑∑∑∑
Rearranjando os somatórios e usando a linearidade do operador E:
(89)
)}x(Z)x(Z{ E +)}x(Z)x(Z{ E +
}x(Z)x(Z{ E +)}x(Z)x(Z{ E = A
2l22j22l2j
l
jik12j21k2j
k
j
2l21i12l1i
l
i1k11i1ik1i
ki
λλλλ
λλλλ
∑∑∑∑
∑∑∑∑
Substituindo-se as equações (68), (69), (70) e (71) na equação (89):
(90)
]m + )x,x(C[ +]m m+
+)x,x(C[ +]m m+)x,x(C[
+)m+)x,x(C( =A
222l2j222l2j
l
j12
1k2j211k2j
k
j212l1i12
l21i
l
i
211k1i111k1i
k
i
λλ
λλ
λλλλ
∑∑
∑∑
∑∑∑∑
Multiplicando dentro dos colchetes:

(91)
A = C ( x ,x )+ C ( x ,x )+
+ C ( x ,x )+ C ( x ,x ) + m
i
k
1i 1k 11 1i 1ki
l
1i 2l 12 1i 2l
j
k
2j 1k 21 2j 1kj
l
2j 2l 22 2j 2l 22
∑∑ ∑ ∑
∑∑ ∑∑
λ λ λ λ
λ λ λ λ
Desenvolvendo o termo B da equação (85) tem-se:
(92) B = E {Z ( x )} = E {Z ( x )Z ( x +0)}22
0 2 0 2 0
Usando a equação (69) para h=0 e substituindo em (92) fica:
(93) B = C (0) + m22 22
Desenvolvendo o termo C da equação (85) tem-se:
(94) C = E {Z ( x ) Z ( x )}2*
0 2 0
Aplicando a equação (77) na equação (94) fica:
)}x(Z)]x(Z+)x(Z{[ E = C 022i22i
i1k11k
kλλ ∑∑
Multiplicando-se dentro dos colchetes e usando a linearidade do operador E fica:
(95) )}x(Z)x(ZE{+)}x(Z)x(Z{ E = C 022i22i
i021k11k
kλλ ∑∑
Substituindo as equações (69) e (70) na equação (95) fica:
(96) C = C x x m m ) + C x x mk
1k 12 1k 0 1 2i
2i 22 2i 0 22( ( , ) + ( ( , ) + )∑ ∑λ λ
Multiplicando dentro dos colchetes tem-se:
(97)
λ
λλλ
2i
i
22
02i222i
ik1
k2101k121k
k
m+
+)x,x(C mm + )x,x(C = C +
∑
∑∑∑
Aplicando as condições (81) e (82) nos termos constantes na equação (97) fica:
(98) C = C ( x ,x ) + C ( x ,x )+ mk
1k 12 1k 0i
2i 22 2i 0 22∑ ∑λ λ
Desenvolvendo o termo D da equação (85) tem-se:
(99) D = E {Z ( x ) Z ( x )}2 0 2*
0
Aplicando a equação (77) na equação (99) tem-se:

)]}x(Z+)x(Z)[x(Z{ E = D 2i22i
i1k11k
k02 λλ ∑∑
Multiplicando dentro dos colchetes e usando a linearidade do operador E tem-se:
(100) )}x(Z)x(Z{ E+)}x(Z)x(Z{ E = D 2i2022i
i1k1021k
k λλ ∑∑
Substituindo as equações (69) e (71) na equação (100) tem-se:
), , m+)xx(C(+)mm+)xx(C( = D 222i0222i
i121k0211k
kλλ ∑∑
Multiplicando dentro dos colchetes tem-se:
(101)
λ
λλλ
2i
i
22
222i0222i
i1k
k121k0211k
k
m+
+)m+x,x(Cmm+)xx(C = D + ,
∑
∑∑∑
Aplicando as condições (81) e (82) tem-se:
(102) m+)xx(C+)xx(C = D 222i0222i
i1k0211k
k, , λλ ∑∑
Substituindo as equações (91), (93), (98) e (102) na equação (85):
k22
0i k
1i 1k 11 1i 1ki l
1i 2l 12 1i 2l
j k2j 1k 21 2j 1k
j l2j 2l 22 2j 2l 2
2
22 22
k1k 12 1k 0
i2i 22 2i 0
22
k1k 21 0 1k
i2i
( x )= C ( x ,x )+ C ( x ,x )+
+ C ( x ,x )+ C ( x ,x )+ m +
+ C (0)+ m - C ( x ,x )- C ( x ,x )-
- m - C ( x ,x )-
σ λ λ λ λ
λ λ λ λ
λ λ
λ λ
∑∑ ∑∑
∑∑ ∑∑
∑ ∑
∑ ∑ 22 0 2i 22C ( x ,x )- m
(103)
Cancelando os m22 e lembrando que C(h) = C(-h) e Ck'k(h) = Ckk'(h), a equação (103)
pode ser reescrita como:

(0)C+)x,x(C2-)x,x(C2-
)x,x(C+)x,x(C +
+)x,x(C+)x,x(C=)x(
2202i222ii
01k121kk
l2j2222l2jlj
1k2j211k2jkj
2l1i122l1ili
1k1i111k1iki
02
k2
λλ
λλλλ
λλλλσ
∑∑
∑∑∑∑
∑∑∑∑
− (104)
A minimização da variância da estimativa σk2(x0), expressa na equação (104), pode ser feita aplicando técnicas de Lagrange expressas por:
0=)/2-)x(( 2i2ii
202
k2 ∂λµσ∂ ∑ (105)
e por
0=)/2-)x(( k1k1k
102
k2 ∂λµσ∂ ∑ (106)
onde µ1 e µ2 são multiplicadores de Lagrange. A equação (105) torna-se:
2 C ( x ,x )+ C ( x ,x )+
C ( x ,x )- 2C ( x ,x )- 2 = 0
i1i 11 1i 1k
l2l 12 1i 2l
j2j 21 2j 1k 12 1k 0 1
∑ ∑
∑
λ λ
λ µ
(107)
Lembrando-se que Ck'k(h) = Ckk'(h) e substituindo o subíndice "l" por "j", a equação (107) torna-se:
∑ ∑ =−−+i j
10k112j2i112j2k1i111i1 02)x,x(C2)x,x(C2)x,x(C2 µλλ (108)
Cancelando o fator 2 e rearranjando tem-se:
i1i 11 1i 1k
j2j 12 1k 2j 1 12 1k 0C ( x ,x )+ C ( x ,x ) - = C ( x ,x )∑ ∑λ λ µ (109)
i1i 12 1i 2i
j2j 22 2j 2i 2 22 2i 0C ( x ,x )+ C ( x ,x ) - = C ( x ,x )∑ ∑λ λ µ
Seguindo raciocínio idêntico, a equação (106) torna-se:
)x,x(C=-)x,x(C+)x,x(C 02l2222k2k222kk
2l1l121ll
µλλ ∑∑ (110)
Combinando as equações (81), (82), (109) e (110) resulta no sistema de equações da co-krigagem(111):
i=1
N
1i 11 1i 1kj=1
N
2j 12 1k 2j 1
12 1k 0 1
1 2
C ( x ,x )+ C ( x ,x )- =
= C ( x ,x ), k = 1,...N
∑ ∑λ λ µ

(111)
1 =
0 =
N1,... = l ),x,x(C=
-)x,x(C+)x,x(C
2j
N
1=j
1i
N
1=i
202l22
122l2j222j
N
1=j2l1i121i
N
1=i
2
1
21
λ
λ
µµλλ
∑
∑
∑∑ +
Rearranjando o primeiro e segundo conjunto de equações do sistema (111), e substituindo-os na equação (104), resulta na variância da estimativa da co-krigagem,
(112) )x,x(C-)x,x(C-+(0)C=)x( 02j222j
N
j=101i121i
N
=1i1220
2k
21
2λλµσ ∑∑
O sistema co-krigagem (111) e a variância da estimativa (112) podem ser escritos em termos de semivariograma, usando a equação (14) sob hipótese de estacionaridade de ordem 2, ou a relação sugerida em Journel e Huijbregts, 1978 (pag. 357). Assim, o sistema da co-krigagem, em termos de semivariograma, fica:
N1,... = k ),x,x(=
=-)x,x(+)x,x(
101k12
12j1k122j
N
1=j1k1i111i
N
1=i
21
γ
µγλγλ ∑∑
(113)
1 =
0 =
N1,... = l ),x,x(=
=-)x,x(+)x,x(
2j
N
1=j
1i
N
1=i
202l22
22l2j222j
N
1=j2l1i121i
N
1=i
2
1
21
λ
λ
γ
µγλγλ
∑
∑
∑∑
e a variância da estimativa fica:
(114) )x,x(+)x,x(++=)x( 02j222j
N
1=j01i121i
N
1=i210
2k
21
2γλγλµµσ ∑∑

A solução do sistema da co-krigagem produzirá N1 pesos λ1i e N2 pesos λ2j e os multiplicadores de Lagrange, µ1 e µ2.
4. Sistema Matricial O sistema de co-krigagem da equação (113) pode ser escrito em notação matricial como:
[ ] [ ] = [b]λ γ (115)
cuja solução é:
(116) [ ] = [ ] [b]-1λ γ
onde [γ]-1 é o inverso da matriz de coeficientes [γ], [λ] é a matriz dos pesos procurados, λ1i e λ2j, e [b] é o lado direito da equação (113). A variância da estimativa, por sua vez, pode ser escrita como:
(117) [b] ][ = )x( t0
2k2
λσ
onde [λ]t é o transposto da matriz [λ]. Suponha-se então que o número de vizinhos de Z2 usados seja N2=2, e de Z1, N1=4. A matriz [γ] será então de 8x8 e pode ser escrita como:
(118
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
00110000
00001111
10)x,x()x,x()x,x()x,x(x,x()x,x(
10)x,x()x,x()x,x()x,x()x,x()x,x(
01)x,x()x,x()x,x()x,x()x,x()x,x(
01)x,x()x,x()x,x()x,x()x,x()x,x(
01)x,x()x,x()x,x()x,x()x,x()x,x(
01)x,x()x,x()x,x()x,x()x,x()x,x(
222222212222221412221312221212221112
222122212122211412211312211212211112
221412211412141411141311141211141112
221312211312131411131311131211131111
221212211212121411121311121211121111
221112211112111411111311111211111111
γγγγγγ
γγγγγγ
γγγγγγ
γγγγγγ
γγγγγγ
γγγγγγ
)
A matriz [λ] poderá ser escrita como:
(119)
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
µµλλλλλλ
λ
2
1
22
21
14
13
12
11
=] [
A matriz [b], do lado direito, fica:

(120)
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
)x,x()x,x()x,x()x,x()x,x()x,x(
=[b]
02222
02122
01412
01312
01212
01112
γγγγγγ
A matriz de coeficientes em (118) mostra algumas propriedades inerentes à co-krigagem. Primeiramente, as grandezas que preenchem a matriz são calculadas com base no modelo ajustado ao semivariograma ou semivariograma cruzado, para o vetor tendo início no primeiro argumento e fim no segundo argumento. Note-se, também, que a matriz (118) foi derivada usando-se a relação γ12(x1i,x2j) = γ21(x2j,x1i), e que então, ela é simétrica com respeito à diagonal principal. Neste exemplo, quando N1=2 e N1=4, a matriz (118) pode ser dividida em quatro partes, constantes de: uma matriz γ11 de 4x4; uma γ12 de 4x2; uma γ12 de 2x4 e uma γ22 de 2x2, além de zeros (0) e uns (1) provenientes das condições de não tendência. Um fato de alta importância também é que, para se efetuar uma estimativa usando a co-krigagem, é preciso que exista dependência espacial da segunda variável (γ22) e correlação cruzada entre elas (γ12 ou γ21). Deste modo, a estimativa com co-krigagem é bastante mais exigente do que aquela com krigagem de uma variável simplesmente. 5. Os exemplos Como foi visto acima, para que se possam efetuar estimativas de valores para os locais não medidos através da co-krigagem, é necessário que exista dependência espacial para cada uma das variáveis envolvidas e também a dependência espacial cruzada entre elas. Neste exemplo, a variável nitrogênio Oakley será usada para ser estimada, usando os valores de carbono como variável associada. Para tanto, é necessário que existam: dependência espacial para nitrogênio-Oakley; para carbono- Oakley; e também a dependência espacial cruzada para carbono-Oakley e nitrogênio-Oakley. A dependência espacial para carbono-Oakley está mostrada no semivariograma da figura 6a com o modelo esférico, Esf(0,4; 0,6; 15). Para nitrogênio-Oakley o modelo é o esférico Esf(0; 1,0; 25), como mostra a figura 6b. A dependência espacial cruzada entre carbono-Oakley e nitrogênio-Oakley está mostrada no semivariograma cruzado da figura 12, com um modelo gaussiano, Gau(0; 1,0; 13). A co-krigagem foi efetuada usando o mesmo reticulado já utilizado para a krigagem, para fins de comparação. O resultado é o mapa de isolinhas mostrado na figura 13. Comparando-se o mapa para nitrogênio Oakley obtido com o uso dos valores estimados pela co-krigagem, mostrado na figura 13, com aquele obtido através da krigagem simples, mostrado na figura 11, nota-se que não existe uma grande diferença entre eles. Isso significa que, não houve ganho no uso de co-krigagem em relação à krigagem simples, ou a dependência espacial do nitrogênio Oakley expressa pelo semivariograma da figura 6b é tão forte que mascara o efeito do carbono Oakley tanto no semivariograma cruzado carbono versus nitrogênio Oakley (figura 12) como também no mapa mostrado na figura 13. Nesse sentido, é supérfluo e desnecessário usar a co-krigagem. A vantagem do uso da co-krigagem existiria se, por exemplo, a variável a ser estimada tivesse uma menor densidade de amostragem do que a variável associada, o que não é o caso do exemplo aqui utilizado.

VII - A VARIÂNCIA DA ESTIMATIVA 1. Significado O simples fato de que, pela krigagem ou co-krigagem, pode-se conhecer também a variância da estimativa, diferencia-os de qualquer outro método. Essa é uma propriedade interessantíssima pois, além de permitir a estimativa de valores sem tendência para os locais onde estes não foram medidos, ainda se pode conhecer a confiança associada a essas estimativas, as quais podem ser chamadas ótimas. 2. Utilidade Uma vez que esta é uma variância, pode-se naturalmente comparar com a variância dos dados medidos. Assim, quanto menor for o efeito pepita do semivariograma, menor será a variância da estimativa. Mais precisamente, quanto menor for a proporção do efeito pepita em relação ao patamar do semivariograma, maior a continuidade do fenômeno, menor a variância da estimativa ou maior a confiança que se pode ter na estimativa. A própria intuição poderia levar a esperar tal comportamento pois, se a variável estudada varia grandemente entre locais medidos, então não é de se esperar grande confiança na estimativa, como também poderia acontecer se esse valor fosse medido, pois a variabilidade é grande. Além disso, a pior variância da estimativa ainda será menor do que a variância dos dados medidos. Examinando-se as equações (53) e (114), relativas aos cálculos das variâncias da estimativa de krigagem e co-krigagem, respectivamente, nota-se que são apenas indiretamente dependentes dos valores medidos. Isso porque o semivariograma e o semivariograma cruzado representam a maneira como a variável regionalizada varia de um local para o outro no campo, e os pesos são conseqüências deste fato. Porém, uma vez que se conhece o semivariograma de uma propriedade, qualquer tipo de esquema de amostragem pode ser desenhado para variâncias da estimativa pré-especificadas. Obviamente, sendo a variância da estimativa uma função da distância ou distribuição espacial das amostras, será máxima nos locais mais distantes de valores medidos. Assim, com base em semivariogramas de variáveis medidas em caráter de reconhecimento, amostragens definitivas podem ser desenhadas para satisfazer condições pré-especificadas. A localização ideal de uma rede de pluviômetros em bacias hidrográficas constitui um exemplo prático desse procedimento. O mesmo pode também ser utilizado pela co-krigagem, ambos com algumas complicações e vantagens . A principal complicação é que neste caso, depende-se de três correlações espaciais (de cada variável, individualmente, e entre elas), o que não é sempre fácil. Entretanto, quando as variáveis são amostradas em espaçamentos diferentes, haverá pontos onde apenas a variável auxiliar foi medida. Para esses pontos quase sempre a variância da estimativa da co-krigagem é melhor do que a da krigagem. Com essa vantagem em mente, pode-se desenhar esquemas de amostragem que envolvam ambas as variáveis, em densidades de amostragem bem diferentes, de acordo com o grau de dependência espacial encontrado e a dificuldade de medição. Qualquer que seja o método, krigagem ou co-krigagem, a variância da estimativa é extremamente sensível à forma do semivariograma ou semivariograma cruzado, como será mostrado no capítulo IX deste trabalho. Com base na discussão acima, o mapa de isolinhas ou tridimensional de uma variável usando valores estimados por um dos métodos geoestatísticos deve ser sempre acompanhado pelo mapa correspondente da variância da estimativa, para que se possa visualizar os locais onde a confiança na estimativa é limitada ou é suficiente. Entretanto, uma vez que a variância da estimativa é uma função indireta da distância dos vizinhos ao redor

do local da estimativa, então em amostragens tomadas em distâncias regulares no reticulado quadrado o mapa da variância da estimativa será, simplesmente, uma coleção de círculos, com maiores valores onde o ponto estimado é mais distante. Nesses casos, o mapa da variância tem pouca utilidade e o exame de células compostas de vizinhos, fechando o primeiro polígono em volta do valor estimado e mostrando a variância da estimativa, ilustra esse ponto suficientemente bem. Uma excelente discussão sobre o efeito do número de amostras disponíveis na variância da estimativa em co-krigagem pode ser visto em Vauclin et al. (1983).

VIII - A VIZINHANÇA USADA NA ESTIMATIVA Visto que todos os cálculos advindos da geoestatística usando semivariogramas são função principalmente de distâncias especificadas, a vizinhança usada na estimativa torna-se um ponto de extrema importância. Vários são os métodos que podem ser utilizados, cada um com vantagens e desvantagens, como será discutido em seguida. Qualquer que seja o critério usado para a escolha do método, deve-se levar em conta o ganho de precisão em relação ao aumento de tempo de computação. 1. Vizinhança única Quando o tamanho do conjunto de dados, em termos de número de amostras disponíveis, for razoável, relativo à quantidade de memória e tempo de processamento disponíveis no computador, pode-se usar o procedimento chamado vizinhança única. Nesse procedimento todos os valores medidos são considerados vizinhos e serão utilizados na estimativa. Nesse caso, a solução mais prática do sistema matricial deverá ser obtida invertendo a matriz de coeficientes e depois multiplicando no lado direito. Essa inversão deverá ser feita apenas uma vez, e o fator que fará mudar os pesos de um local para outro será o lado direito, o qual depende da localização do ponto estimado. Deve-se sempre lembrar que a decisão de se usar vizinhança única normalmente deve se basear em sua praticidade relativa ao tamanho do conjunto de dados, e não na precisão obtida na estimativa. A razão para tanto reside no alcance do semivariograma pois, os pesos associados a vizinhos separados por distâncias maiores do que o alcance não devem ter contribuição significativa no valor estimado. Outro ponto importante é que, para se usar vizinhança única, é necessário que o semivariograma seja definido até a maior distância existente no campo. A grande vantagem desse método reside no fato de que, uma vez invertida a matriz de coeficientes, as estimativas podem ser feitas para qualquer espaçamento com um pequeno consumo de tempo de processamento de computador. Desse modo, a matriz invertida pode ser arquivada no computador e usada quantas vezes for necessário, desde que não se mude o modelo do semivariograma e a distribuição dos pontos amostrados no campo. Existem algumas variáveis que, embora mudem as magnitudes de variação, preservam entre si a maneira como variam no espaço, apresentando semivariogramas que podem ser agrupados em um único, quando divididos individualmente pelas respectivas variâncias. Como exemplo, pode-se incluir umidade do solo amostrada em pequenos espaços de tempo. Nesse caso, as vantagens da vizinhança única aumentam porque modelos de semivariograma escalonados podem ser usados para obter pesos comuns a todas as variáveis (Vieira et al., 1997). 2. Distância constante Neste método, para cada ponto estimado é selecionada uma vizinhança, constando de todos os vizinhos localizados dentro de um círculo de raio especificado. Consequentemente, nos cantos de um campo retangular ocorre 1/4 de círculo, com 1/4 do número de vizinhos. A grande vantagem deste método está no fato que se conhece exatamente a distância na qual os vizinhos para estimativa são procurados. Isso é particularmente importante, porque se pode limitar o uso do semivariograma quanto à distância sobre a qual ele será calculado. Por outro lado, o número de vizinhos pode mudar bastante ao longo do campo, fazendo com que o tamanho do sistema matricial seja variável. Em termos de programação de computador, isso pode se tornar um

problema se exceder o valor usado na dimensão das matrizes. 3. Número constante de vizinhos Um outro método bastante usado é o que mantém constante o número de vizinhos em qualquer posição no campo. Para tanto, vizinhos são procurados primeiramente dentro de um raio inicial. Se o número de vizinhos encontrados for menor do que o limite especificado, a distância é incrementada, e o processo é reiniciado. Se, por outro lado, o número encontrado for maior do que o limite, apenas o número especificado mais próximo será usado. Conseqüentemente, a distância sobre a qual se procura vizinhos varia sobre o campo. Obviamente, as vantagens deste método são as desvantagens do anterior (distância constante) e vice-versa. Porém, em situações em que a amostragem foi efetuada em espaçamentos regulares, a distância de procura por vizinhos não muda muito e as desvantagens deste método são minimizadas. Este método é o mais comumente utilizado, por suas facilidades inerentes e porque as amostragens regulares são mais usadas. 4. Quadrantes Uma alternativa interessante e bastante fundamentada, em termos geoestatísticos é usar um número especificado de vizinhos em cada quadrante ao redor do valor a ser estimado. O fundamento reside na distribuição do número de vizinhos ao redor do valor estimado, o que fará com que a estimativa receba contribuição semelhante em número de todas as direções. Muitas vezes, quando não se impõe esta restrição, pode-se, desapercebidamente, utilizar tendenciosamente sempre um número maior de vizinhos de um lado do que de outro. Porém, isso ainda apresentaria problemas nos cantos e extremidades do campo e também o fato de que nunca se sabe qual a distância na qual os vizinhos se localizam. Por essas razões, este método apresenta mais problemas do que vantagens.

i
IX - A AUTO VALIDAÇÃO - UMA PODEROSA FERRAMENTA Desde o começo deste trabalho têm-se discutido métodos ideais de estimativa de valores em locais não medidos, usando-se informações contidas na maneira como os dados disponíveis variam no espaço. Isso implica, necessariamente, na formulação de hipóteses de estacionaridade, seguida do cálculo do semivariograma e semivariograma cruzado, aos quais se deve ajustar um modelo. Em toda essa seqüência, existe sempre um certo grau de incerteza sobre as hipóteses assumidas ou sobre os parâmetros ajustados aos modelos. Essa incerteza é o erro da estimativa, o qual pode ser avaliado usando o procedimento de autovalidação comumente chamado de “jack-knifing”. Resumidamente, esse procedimento envolve a estimativa de cada ponto medido "fazendo de conta" que ele não existe, durante a sua estimativa. Há necessidade absoluta de se "fazer de conta" que o valor que está sendo estimado não existe porque, senão, a solução do sistema de krigagem fornecerá o peso associado a ele com valor unitário (λ=1) e todos os outros pesos iguais a zero. A razão para isso é que a krigagem é um interpolador exato, passando exatamente pelo ponto medido, quando este é usado no cálculo. Porém, quando se "faz de conta" que o valor não existe, ele será estimado normalmente como se fosse ponto perdido, levando em conta a variabilidade espacial local expressa nas primeiras distâncias no semivariograma. Então, quando se executa o “jack-knifing”, está se perguntando "se a krigagem for mesmo representativa da variabilidade, e se as hipóteses assumidas forem verdadeiras", então como é seu desempenho para estimar valores conhecidos? As possíveis respostas a essa pergunta podem ser esclarecidas pela execução de um ou mais dos procedimentos descritos a seguir. Detalhes e embasamento teórico desse procedimento podem ser encontrados em Journel & Huijbregts (1978). 1. O gráfico 1:1 - Medido vs Estimado Se, para cada um dos N locais onde se tem um valor medido Z(xi), se estimar um valor pela krigagem (ou co-krigagem), Z*(xi), então poder-se-á fazer um gráfico dos valores pareados de Z(xi) e, Z*(xi) e calcular a regressão linear entre eles. A regressão será então:
(120) *
iZ ( x ) = a+b Z( x )
onde A é a interseção, B é o coeficiente angular da reta e r2 é o coeficiente de correlação entre Z*(xi) e Z(xi). Assim, se a estimativa (Z*(xi)) fosse idêntica ao valor medido (Z(xi)), então A seria nulo, B e r2 seriam iguais à unidade (1,0), e o gráfico de Z(xi) vs Z*(xi) seria uma série de pontos na linha 1:1. À medida que os valores de A aumentam de 0 (zero) para valores positivos, isso indica que estimador Z*(xi) está superestimando valores pequenos de Z(xi) e subestimando valores grandes. À medida que A decresce de 0 (zero) para valores negativos, o contrário acontece. Este último caso, porém, não é comum. Desse modo, a qualidade da estimativa pode ser medida pelo julgamento desses parâmetros. 2. O erro absoluto Uma vez que se tem o conjunto de N valores medidos e estimados, Z(xi) e Z*(xi), pode-se definir o erro absoluto como:

i (121) EA( x ) = Z ( x ) - Z( x )i*
i
Aplicando-se as condições de não tendência (31) e de variância mínima (32), nos erros absolutos, pode-se dizer que:
EA = E {EA( x )} = E {Z ( x )- Z( x )} = 0i*
i i (122)
e
mínima = }))xZ(-)x(Z{( E = )EAVAR( 2ii
* (123)
Se estas condições não forem satisfeitas, alguma das condições previamente assumidas estará sendo violada. Porém, a equação (123) é bastante difícil de ser verificada, porque o conceito de ser mínimo torna-se subjetivo quando não se tem uma referência. O procedimento seguinte pode contribuir nesse sentido. 3. O erro reduzido
Lembrando que no cálculo dos valores estimados, Z*(xi), sempre se tem a variância da estimativa, σ2
k(xi), então pode-se definir o erro reduzido como: ER( x ) = ( Z ( x )- Z( x )) / ( x )i
*i i k iσ (124)
A divisão pela raiz quadrada da variância da estimativa faz com que os ER(xi) sejam sem dimensão e que, por isso, as condições de não tendência e de variância mínima requeiram que:
ER = E {ER( x )} = E {( Z ( x )- Z( x )) / ( x )} = 0i*
i i k iσ (125)
e
VAR( ER ) = E {( Z ( x ) - Z( x )) / ( x ) } = 1*i i k 0
2σ (126)
Essas propriedades fazem desse tipo de erro uma ferramenta valiosa e de fácil uso nas aplicações de geoestatística. O fato de terem valores ideais fixos em 0 (zero) e 1 (um), e de serem sem dimensão, facilita seu julgamento e estudo, e também permite sua comparação com outras situações expressas em unidades diferentes. 4. Os exemplos O quadro 2 apresenta os resultados do "jack-knifing" para nitrogênio-Oakley. Esses valores foram calculados assumindo-se que o semivariograma para nitrogênio-Oakley, mostrado na figura 6b, não mudaria cada vez que se eliminasse um valor medido para se efetuar sua estimativa. Esses cálculos são feitos usando-se número de vizinhos crescentes, no caso, de 4 até 24, para se verificar também qual o número ideal de vizinhos a serem usados na krigagem. O julgamento desses resultados deve ser feito de uma maneira global, examinando-se todos os parâmetros. Os valores ideais procurados são: a=0, b=1, r2=1, média do erro absoluto=0, variância do erro absoluto=mínimo, média do erro reduzido=0, variância do erro reduzido=1. Assim, pode-se notar que a vizinhança que proporcionou os melhores parâmetros é a de 8 vizinhos, embora os erros reduzidos estejam longe dos valores ideais. Situação bastante semelhante pode ser observada nos resultados referentes a carbono-Oakley, mostrados no quadro 3. Um fato notório no quadro 2

é que os erros absolutos médios são negativos, embora todos pequenos, da ordem de 10-3. Isso significa dizer que a krigagem, usando os parâmetros dos semivariogramas adotados, em média, subestima os valores. Outro fato é que os coeficientes de correlação, R2, são ligeiramente baixos, da ordem de 0,6, o que significa que o gráfico 1:1 dos valores medidos versus estimados tem um grande espalhamento em torno da regressão. É provável que existam valores extremamente pequenos ou extremamente grandes, o que pode estar perturbando a regressão. Isso pode ser notado pela distribuição de freqüências, a qual parece aproximar-se da lognormal, como indicam os coeficientes de simetria e curtose para nitrogênio-Oakley no quadro 1. Isso pode também ser a causa dos valores bastante baixos das variâncias dos erros reduzidos, os quais deveriam ser 1.
X - CONCLUSÕES As técnicas mostradas neste trabalho permitem concluir que é possível melhorar significativamente a profundidade e a precisão da análise dos dados quando se aplica a geoestatística. Muitos aspectos particulares dos dados ficariam escondidos se não fosse o uso de semivariogramas mostrando, por exemplo, a tendência parabólica nos dados do solo de Davis. Informações como essas não são mostradas quando se usam apenas parâmetros clássicos como médias e variâncias. Nesse sentido, a geoestatística deve ser adotada como rotina em análises de dados, para possibilitar maior precisão científica nas recomendações.

XI – REFERÊNCIAS BIBLIOGRÁFICAS BALL, D.F. & WILLIAMS, W.M. Variability of soil chemical properties in two uncultivated
brown earths. The Journal of Soil Science, Oxford, 19: 379-391, 1968. BARTLETT, M.S. Stochastic processes. 2. ed., London, Cambridge University Press, 1966. BECKETT, P.H.T. & WEBSTER, R. Soil variability: a review. Soils Fert., Farnham Royal, 34:
1-15, 1971. BLAIS, R.A. & CARLIER, P.A. Applications of geostatistics in ore evaluation. In: CANADIAN
INSTITUTE OF MINING AND METALLURGY, Ore reserve estimation and grade control, Montreal, 1968. p. 41-48. (Special Volume, 9)
BURDEN, R.L.; FAIRES, J.D. & REYNOLDS, A.C. Numerical analysis. Boston, Prindle, Weber & Schmidt, 1978. 578p.
BURGESS, T.M. & WEBSTER, R. Optimal interpolation and isarithmic mapping of soil properties. I. The semivariogram and punctual kriging. The Journal of Soil Science, Oxford, 31: 315-331, 1980a.
BURGESS, T.M. & WEBSTER, R. Optimal interpolation and isarithmic mapping of soil properties. II. Block kriging. The Journal of Soil Science, Oxford, 31: 333-341, 1980b.
CAMPBELL, J.B. Spatial variation of sand content and pH within single contiguous delineation of two soil mapping units. Soil Science Society of America Journal, Madison, 42: 460-464, 1978.
DAVID, M. Geostatistical ore reserve estimation. Amsterdam, Elsevier, 1977. 364p. DAVID, M. The geostatistical estimation of porphyry-type deposits and scale factor problems.
In: PRIBAM MINING CONGRESS, Praga, 1970, Proceedings ..., Praga, 1970,91-109. DAVIS, J.C. Statistics and data analysis in geology. New York, John Wiley, 1973. 550p. DELHOMME, J.P. Kriging in hydrosciences. Fontainebleau, Centre D'Informatique
Geologique, 1976. 94p. FISHER, R.A. Statistical methods and scientific inference. Edinburg, Oliver & Boyd, 1956.
175p. HAJRASULIHA, S.; BANIABBASSI, J.; METTHEY, J. & NIELSEN, D.R. Spatial variability of
soil sampling for salinity studies in southwest Iran. Irrigation Science, Berlin, 1: 197-208, 1980.
HARRADINE, F.F. The variability of soil properties in relation to stage of profile development. Soil Science Society of America Proceedings, Madison, 14: 302-311, 1949.
HARRIS, J.A. Practical universality of field heterogeneity as a factor influencing plot yields. Journal Agr.JOURNEL, A.G. Geostatistical for conditional simulation of orebodies. Economic Geology,
Lancaster, 79(5):673-687, 1974. JOURNEL, A.G. & HUIJBREGTS, Ch.J. Mining geostatistics. London, Academic Press, 1978,
600p. KRIGE, D.G. A statistical approach to some basic mine evaluation problems on the
witwatersrand. Journal of South African Institution of Minning and Mettalurgy, Johanesburg, 52: 119-139, 1951.
MATHERON, G. Principles of geostatistics. Economic Geology, Lancaster, 58: 1246-1266, 1963.
MATHERON, G. The theory of regionalized variables and its application. Les Cahiers du centre de Morphologie Mathematique, Fas. 5, C. G. Fontainebleau. 1971.
McBRATNEY, A.B. & WEBSTER, R. Detection of ridge and furrow pattern by spectral analysis of crop yield. International Statistical Review, Voorburb, 49: 49-52, 1981.
McBRATNEY, A.B.; WEBSTER, R.; McLAREN, R.G. & SPIERS, R.B. Regional variation of extractable copper and cobalt in the topsoil of southwest Scotland. Agronomie, Paris, 2:

969-982, 1982. MONTGOMERY, E.G. Experiments in wheat breeding: experimental error in the nursery
and variation in nitrogen and yield. Washington, U.S. Dept. Agric.., 1913. 61p. (Bur. Plant Indust. Bul., 269).
NIELSEN, D.R.; TILLOTSON, P.M. & VIEIRA, S.R. Analysing field-measured soil-water properties. Agricultural Water Management, Amsterdam, 6: 93-109, 1983.
OLEA, R.A. Measuring spatial dependence with semivariograms. Lawrence, Kansas, University of Kansas, Kansas Geol. Survey, 1977. 153p. (Series on Spatial Analysis, 3)
OLEA, R.A. Optimum mapping techniques using regionalized variable theory. Lawrence, Kansas, Kansas Geol. Survey, University of Kansas, 1975. 137p. (Series on Spatial Analysis, 2)
PENDLETON, R.L. Are soils mapped under a given type name by the Bureau of Soils method closely similar to one another? Agricultural Sciences, Davis, 3:369-498, 1919.
ROBINSON, G.W. & LLOYD, W.E. On the probable error of sampling in soil surveys. The Journal
SILVA, A.P. da.; LIBARDI, P.L. & VIEIRA, S.R. Variabilidade espacial da resistência à penetração de um latossolo vermelho-escuro ao longo de uma transeção. Revista Brasileira de Ciência do Solo, Campinas, 13: 1-5, 1989.
SMITH, L.H. Plot arrangement for variety experiment with corn. Proc. Amer. Soc. Agron., Madison, V. I. 1907/09, p. 84-89, 1910.
SNEDECOR, G.W. & COCHRAN, W.G. Statistical methods. 6. ed., Ames, Iowa State University Press, 1967. 593 p.
UGARTE, A. Ejemplos de modelos de estimacion a corto e largo plans. Boletin de Geostadistica, s.l.p., 4:3-22, 1972.
VAUCLIN, M.; VIEIRA, S.R.; BERNARD, R. & HATFIELD, J.L. Spatial variability of two transects of a bare soil. Water Resources Research, Washington, 18: 1677-1686, 1982.
VAUCLIN, M.; VIEIRA, S.R.; VAUCHAUD, G. & NIELSEN, D.R. The use of cokriging with limited fVIEIRA, S.R. & HATFIELD, J.L. Temporal variability of air temperature and remotely sensed
surface temperature for bare soil. International Journal of Remote Sensing, Basingstole, 5: 587-596, 1984.
VIEIRA, S.R.; DE MARIA, I.C.; CASTRO, O.M. de; DECHEN, S.C.F. & LOMBARDI NETO, F. Utilização de análise de Fourier no estudo do efeito residual da adubação em uva, na crotalária. Revista Brasileira de Ciência do Solo, Campinas, 11:7-10, 1987.
VIEIRA, S.R.; DE MARIA; I.C.; LOMBARDI NETO, F.; DECHEN, S.C.F. & CASTRO, O.M. de. Caracterização da variabilidade espacial de propriedades físicas. In: Lombardi Neto, F. & Camargo, O.A. de. Microbacia do Córrego São Joaquim (Município de Pirassununga, SP)., Campinas, Instituto Agronômico, 1992. p. 41-51. (Documentos IAC, 29)
VIEIRA, S.R.; HATFIELD, T.L.; NIELSEN, D.R. & BIGGAR, J.W. Geostatistical theory and application to variability of some agronomical properties. Hilgardia, Berkeley, 51: 1-75, 1983.
VIEIRA, S.R.; LOMBARDI NETO, F. & BURROWS, I.T. Mapeamento da chuva máxima provável para o Estado de São Paulo. Revista Brasileira de Ciência do Solo, Campinas, 15: 93-98, 1991.
VIEIRA, S.R.; NIELSEN, D.R. & BIGGAR, J.W. Spatial variability of field-measured infiltration rate. Soil Science Society of America Journal, Madison, 45: 1040-1048, 1981.
VIEIRA, S.R.; NIELSEN, D.R.; BIGGAR, J.W. & TILLOTSON, P.M. The Scaling of semivariograms and the kriging estimation. Revista Brasileira de Ciência do Solo, Viçosa, 21:525-533, 1997.

WAYNICK, D.D. Variability in soils and its significance to past and future soil investigations. I. Statistical study of nitrification in soils. Agricultural Sciences, Davis, 3: 243-270, 1918.
WAYNICK, D.D. & SHARP, L.T. Variability in soils and its significance to past and future soil investigations. II. Variation in nitrogen and carbon in field soils and their relation to the accuracy of field trials. Agricultural Sciences, Davis, 4: 121-139, 1919.
WEBSTER, R. Automatic soil boundary location for transect data. Mathematical Geology, New York, 5: 27-37, 1973.
WEBSTER, R. & BURGESS, T.M. Optimal interpolation and isarithmic mapping of soil properties. III. Changing drift and universal kriging. The Journal of Soil Science, Oxford, 31: 505-524, 1980.
WEBSTER, R. & CUANALO, H.E. de la C. Soil transects correlograms of north Oxfordshire and their interpretation. The Journal of Soil Science, Oxford, 26: 176-194, 1975.
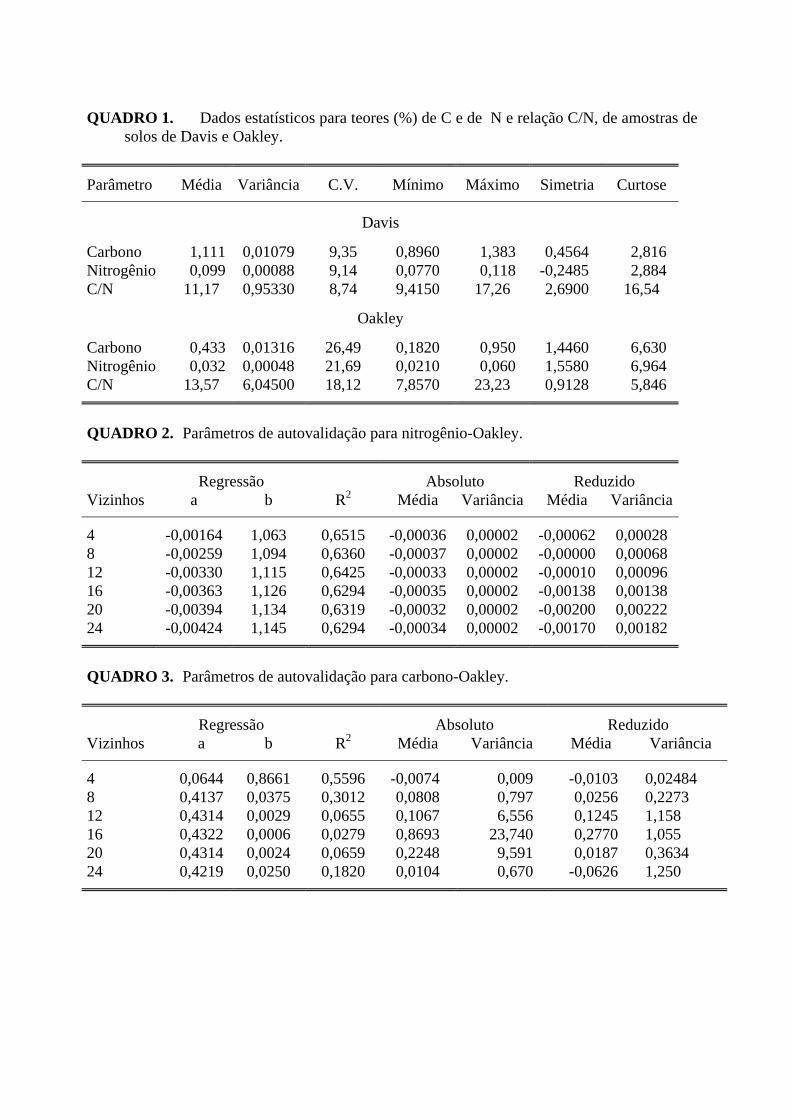
QUADRO 1. Dados estatísticos para teores (%) de C e de N e relação C/N, de amostras de solos de Davis e Oakley.
Parâmetro Média Variância C.V. Mínimo Máximo Simetria Curtose
Davis
Carbono 1,111 0,01079 9,35 0,8960 1,383 0,4564 2,816 Nitrogênio 0,099 0,00088 9,14 0,0770 0,118 -0,2485 2,884 C/N 11,17 0,95330 8,74 9,4150 17,26 2,6900 16,54
Oakley
Carbono 0,433 0,01316 26,49 0,1820 0,950 1,4460 6,630 Nitrogênio 0,032 0,00048 21,69 0,0210 0,060 1,5580 6,964 C/N 13,57 6,04500 18,12 7,8570 23,23 0,9128 5,846
QUADRO 2. Parâmetros de autovalidação para nitrogênio-Oakley.
Regressão Absoluto Reduzido Vizinhos a b R2 Média Variância Média Variância
4 -0,00164 1,063 0,6515 -0,00036 0,00002 -0,00062 0,00028 8 -0,00259 1,094 0,6360 -0,00037 0,00002 -0,00000 0,00068 12 -0,00330 1,115 0,6425 -0,00033 0,00002 -0,00010 0,00096 16 -0,00363 1,126 0,6294 -0,00035 0,00002 -0,00138 0,00138 20 -0,00394 1,134 0,6319 -0,00032 0,00002 -0,00200 0,00222 24 -0,00424 1,145 0,6294 -0,00034 0,00002 -0,00170 0,00182
QUADRO 3. Parâmetros de autovalidação para carbono-Oakley.
Regressão Absoluto Reduzido Vizinhos a b R2 Média Variância Média Variância
4 0,0644 0,8661 0,5596 -0,0074 0,009 -0,0103 0,02484 8 0,4137 0,0375 0,3012 0,0808 0,797 0,0256 0,2273 12 0,4314 0,0029 0,0655 0,1067 6,556 0,1245 1,158 16 0,4322 0,0006 0,0279 0,8693 23,740 0,2770 1,055 20 0,4314 0,0024 0,0659 0,2248 9,591 0,0187 0,3634 24 0,4219 0,0250 0,1820 0,0104 0,670 -0,0626 1,250
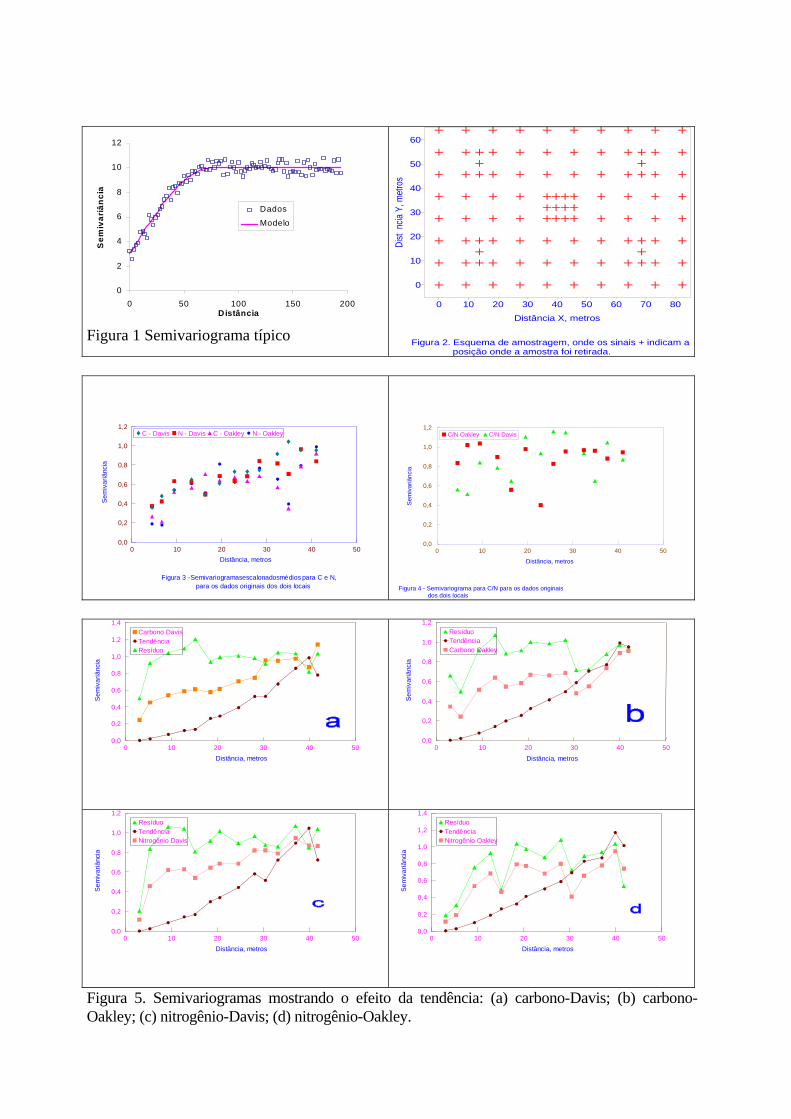
0
2
4
6
8
10
12
0 50 100 150 200Distância
Sem
ivar
iân
cia
Dados
Modelo
Figura 1 Semivariograma típico
0 10 20 30 40 50 60 70 80
Distância X, metros
0
10
20
30
40
50
60
Dist
ncia
Y, m
etro
s
Figura 2. Esquema de amostragem, onde os sinais + indicam a posição onde a amostra foi retirada.
Figura 3 -Semivariogramasescalonadosmédios para C e N,para os dados originais dos dois locais
0 10 20 30 40 500,0
0,2
0,4
0,6
0,8
1,0
1,2
Figura 4 - Semivariograma para C/N para os dados originais dos dois locais.
0 10 20 30 40 500,0
0,2
0,4
0,6
0,8
1,0
1,2
Distância, metros
Sem
ivar
iânc
ia
C - Davis N - Davis C - Oakley N - Oakley
Distância, metros
Sem
ivar
iânc
ia
C/N Oakley C/N Davis
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
Sem
ivar
iânc
ia
Carbono DavisTendênciaResíduo
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
Sem
ivar
iânc
ia
Carbono OakleyTendênciaResíduo
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
Sem
ivar
iânc
ia
Nitrogênio DavisTendênciaResíduo
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
Sem
ivar
iânc
ia
Nitrogênio OakleyTendênciaResíduo
Figura 5. Semivariogramas mostrando o efeito da tendência: (a) carbono-Davis; (b) carbono-Oakley; (c) nitrogênio-Davis; (d) nitrogênio-Oakley.
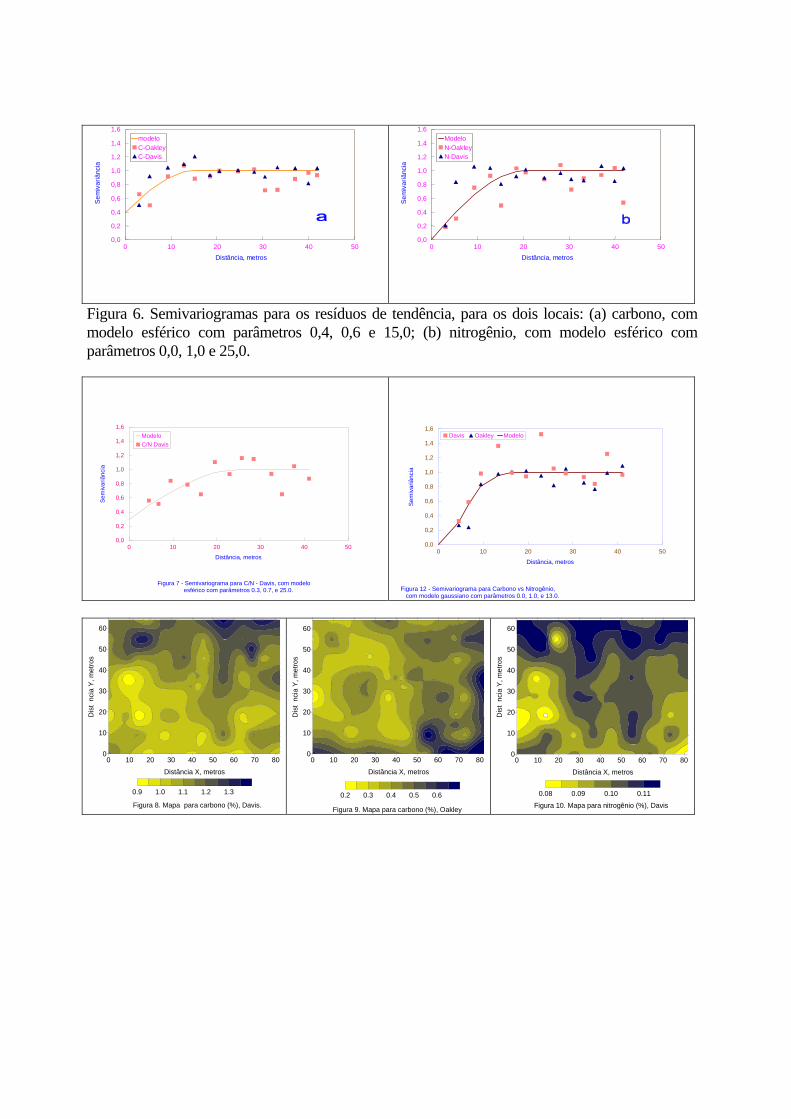
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
1,6
Sem
ivar
iânc
ia
C-DavisC-Oakleymodelo
0 10 20 30 40 50Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
1,6
Sem
ivar
iânc
ia
N-DavisN-OakleyModelo
Figura 6. Semivariogramas para os resíduos de tendência, para os dois locais: (a) carbono, com modelo esférico com parâmetros 0,4, 0,6 e 15,0; (b) nitrogênio, com modelo esférico com parâmetros 0,0, 1,0 e 25,0.
Figura 7 - Semivariograma para C/N - Davis, com modelo esférico com parâmetros 0.3, 0.7, e 25.0.
0 10 20 30 40 50
Distância, metros
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
1,6
Sem
ivar
iânc
ia
C/N DavisModelo
Figura 12 - Semivariograma para Carbono vs Nitrogênio, com modelo gaussiano com parâmetros 0.0, 1.0, e 13.0.
0 10 20 30 40 500,0
0,2
0,4
0,6
0,8
1,0
1,2
1,4
1,6
Distância, metros
Sem
ivar
iânc
ia
Davis Oakley Modelo
Figura 8. Mapa para carbono (%), Davis.
0 10 20 30 40 50 60 70 80
Distância X, metros
0
10
20
30
40
50
60
Dis
tnc
ia Y
, met
ros
0.9 1.0 1.1 1.2 1.3
0 10 20 30 40 50 60 70 80
Distância X, metros
0
10
20
30
40
50
60
Dis
tnc
ia Y
, met
ros
0.2 0.3 0.4 0.5 0.6
Figura 9. Mapa para carbono (%), Oakley
0 10 20 30 40 50 60 70 8
Distância X, metros
00
10
20
30
40
50
60
Dis
tnc
ia Y
, met
ros
0.08 0.09 0.10 0.11Figura 10. Mapa para nitrogênio (%), Davis
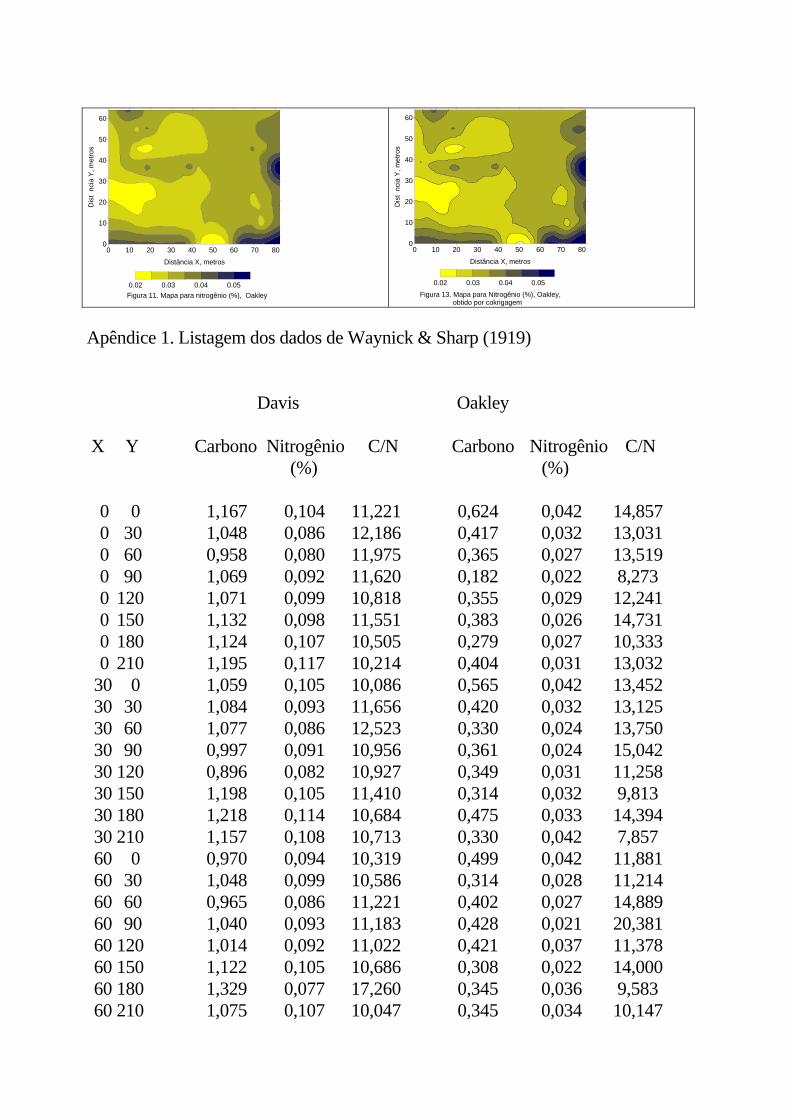
0 10 20 30 40 50 60 70 80
Distância X, metros
0
10
20
30
40
50
60
Dis
tnc
ia Y
, met
ros
0.02 0.03 0.04 0.05Figura 11. Mapa para nitrogênio (%), Oakley
0 10 20 30 40 50 60 70 80
Distância X, metros
0
10
20
30
40
50
60
Dis
tnc
ia Y
, met
ros
Figura 13. Mapa para Nitrogênio (%), Oakley, obtido por cokrigagem
0.02 0.03 0.04 0.05
Apêndice 1. Listagem dos dados de Waynick & Sharp (1919) Davis Oakley X Y Carbono Nitrogênio C/N Carbono Nitrogênio C/N (%) (%) 0 0 1,167 0,104 11,221 0,624 0,042 14,857 0 30 1,048 0,086 12,186 0,417 0,032 13,031 0 60 0,958 0,080 11,975 0,365 0,027 13,519 0 90 1,069 0,092 11,620 0,182 0,022 8,273 0 120 1,071 0,099 10,818 0,355 0,029 12,241 0 150 1,132 0,098 11,551 0,383 0,026 14,731 0 180 1,124 0,107 10,505 0,279 0,027 10,333 0 210 1,195 0,117 10,214 0,404 0,031 13,032 30 0 1,059 0,105 10,086 0,565 0,042 13,452 30 30 1,084 0,093 11,656 0,420 0,032 13,125 30 60 1,077 0,086 12,523 0,330 0,024 13,750 30 90 0,997 0,091 10,956 0,361 0,024 15,042 30 120 0,896 0,082 10,927 0,349 0,031 11,258 30 150 1,198 0,105 11,410 0,314 0,032 9,813 30 180 1,218 0,114 10,684 0,475 0,033 14,394 30 210 1,157 0,108 10,713 0,330 0,042 7,857 60 0 0,970 0,094 10,319 0,499 0,042 11,881 60 30 1,048 0,099 10,586 0,314 0,028 11,214 60 60 0,965 0,086 11,221 0,402 0,027 14,889 60 90 1,040 0,093 11,183 0,428 0,021 20,381 60 120 1,014 0,092 11,022 0,421 0,037 11,378 60 150 1,122 0,105 10,686 0,308 0,022 14,000 60 180 1,329 0,077 17,260 0,345 0,036 9,583 60 210 1,075 0,107 10,047 0,345 0,034 10,147
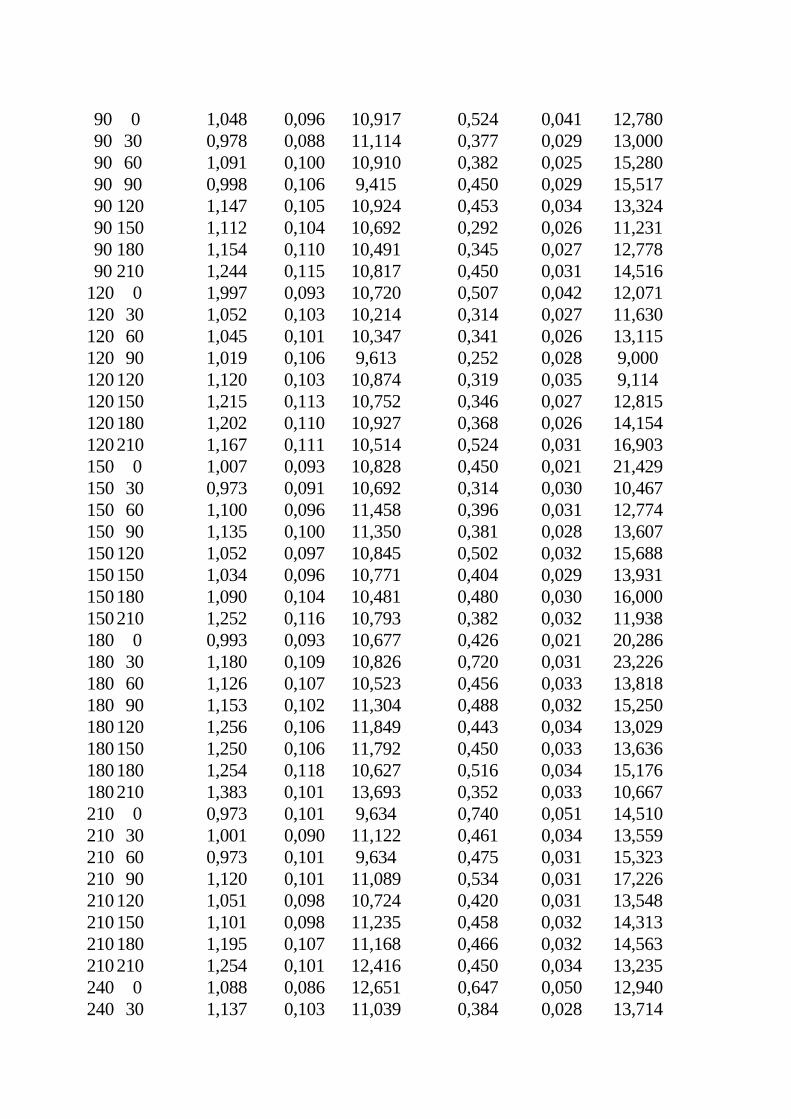
90 0 1,048 0,096 10,917 0,524 0,041 12,780 90 30 0,978 0,088 11,114 0,377 0,029 13,000 90 60 1,091 0,100 10,910 0,382 0,025 15,280 90 90 0,998 0,106 9,415 0,450 0,029 15,517 90 120 1,147 0,105 10,924 0,453 0,034 13,324 90 150 1,112 0,104 10,692 0,292 0,026 11,231 90 180 1,154 0,110 10,491 0,345 0,027 12,778 90 210 1,244 0,115 10,817 0,450 0,031 14,516 120 0 1,997 0,093 10,720 0,507 0,042 12,071 120 30 1,052 0,103 10,214 0,314 0,027 11,630 120 60 1,045 0,101 10,347 0,341 0,026 13,115 120 90 1,019 0,106 9,613 0,252 0,028 9,000 120 120 1,120 0,103 10,874 0,319 0,035 9,114 120 150 1,215 0,113 10,752 0,346 0,027 12,815 120 180 1,202 0,110 10,927 0,368 0,026 14,154 120 210 1,167 0,111 10,514 0,524 0,031 16,903 150 0 1,007 0,093 10,828 0,450 0,021 21,429 150 30 0,973 0,091 10,692 0,314 0,030 10,467 150 60 1,100 0,096 11,458 0,396 0,031 12,774 150 90 1,135 0,100 11,350 0,381 0,028 13,607 150 120 1,052 0,097 10,845 0,502 0,032 15,688 150 150 1,034 0,096 10,771 0,404 0,029 13,931 150 180 1,090 0,104 10,481 0,480 0,030 16,000 150 210 1,252 0,116 10,793 0,382 0,032 11,938 180 0 0,993 0,093 10,677 0,426 0,021 20,286 180 30 1,180 0,109 10,826 0,720 0,031 23,226 180 60 1,126 0,107 10,523 0,456 0,033 13,818 180 90 1,153 0,102 11,304 0,488 0,032 15,250 180 120 1,256 0,106 11,849 0,443 0,034 13,029 180 150 1,250 0,106 11,792 0,450 0,033 13,636 180 180 1,254 0,118 10,627 0,516 0,034 15,176 180 210 1,383 0,101 13,693 0,352 0,033 10,667 210 0 0,973 0,101 9,634 0,740 0,051 14,510 210 30 1,001 0,090 11,122 0,461 0,034 13,559 210 60 0,973 0,101 9,634 0,475 0,031 15,323 210 90 1,120 0,101 11,089 0,534 0,031 17,226 210 120 1,051 0,098 10,724 0,420 0,031 13,548 210 150 1,101 0,098 11,235 0,458 0,032 14,313 210 180 1,195 0,107 11,168 0,466 0,032 14,563 210 210 1,254 0,101 12,416 0,450 0,034 13,235 240 0 1,088 0,086 12,651 0,647 0,050 12,940 240 30 1,137 0,103 11,039 0,384 0,028 13,714
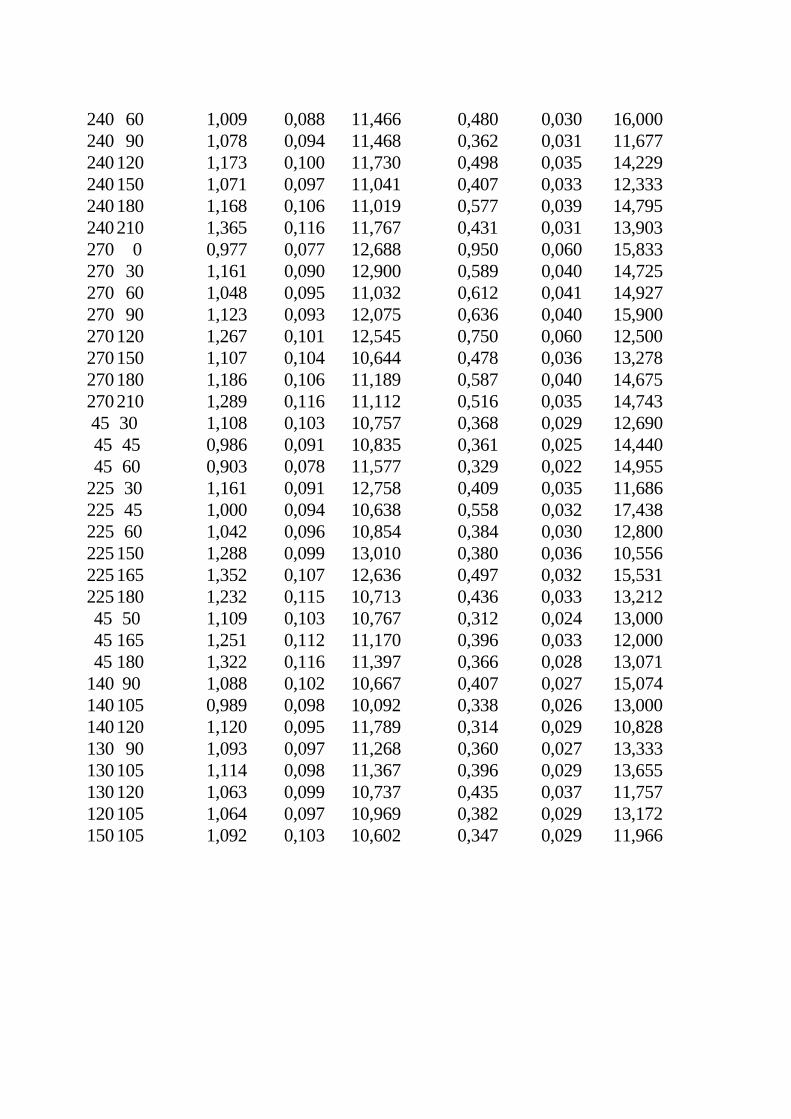
240 60 1,009 0,088 11,466 0,480 0,030 16,000 240 90 1,078 0,094 11,468 0,362 0,031 11,677 240 120 1,173 0,100 11,730 0,498 0,035 14,229 240 150 1,071 0,097 11,041 0,407 0,033 12,333 240 180 1,168 0,106 11,019 0,577 0,039 14,795 240 210 1,365 0,116 11,767 0,431 0,031 13,903 270 0 0,977 0,077 12,688 0,950 0,060 15,833 270 30 1,161 0,090 12,900 0,589 0,040 14,725 270 60 1,048 0,095 11,032 0,612 0,041 14,927 270 90 1,123 0,093 12,075 0,636 0,040 15,900 270 120 1,267 0,101 12,545 0,750 0,060 12,500 270 150 1,107 0,104 10,644 0,478 0,036 13,278 270 180 1,186 0,106 11,189 0,587 0,040 14,675 270 210 1,289 0,116 11,112 0,516 0,035 14,743 45 30 1,108 0,103 10,757 0,368 0,029 12,690 45 45 0,986 0,091 10,835 0,361 0,025 14,440 45 60 0,903 0,078 11,577 0,329 0,022 14,955 225 30 1,161 0,091 12,758 0,409 0,035 11,686 225 45 1,000 0,094 10,638 0,558 0,032 17,438 225 60 1,042 0,096 10,854 0,384 0,030 12,800 225 150 1,288 0,099 13,010 0,380 0,036 10,556 225 165 1,352 0,107 12,636 0,497 0,032 15,531 225 180 1,232 0,115 10,713 0,436 0,033 13,212 45 50 1,109 0,103 10,767 0,312 0,024 13,000 45 165 1,251 0,112 11,170 0,396 0,033 12,000 45 180 1,322 0,116 11,397 0,366 0,028 13,071 140 90 1,088 0,102 10,667 0,407 0,027 15,074 140 105 0,989 0,098 10,092 0,338 0,026 13,000 140 120 1,120 0,095 11,789 0,314 0,029 10,828 130 90 1,093 0,097 11,268 0,360 0,027 13,333 130 105 1,114 0,098 11,367 0,396 0,029 13,655 130 120 1,063 0,099 10,737 0,435 0,037 11,757 120 105 1,064 0,097 10,969 0,382 0,029 13,172 150 105 1,092 0,103 10,602 0,347 0,029 11,966
![LSHTM Research Online...yet, bearing distinct mutational profiles on rpsL, rrs and gyrA genes [5]. A characteristic deletion of spacers 38–43 in the Direct Repeat locus has also](https://img.document.onl/doc/110x75/5f4f8ae0ecafa451263dc75c/lshtm-research-online-yet-bearing-distinct-mutational-profiles-on-rpsl-rrs.jpg)




























