Embed Size (px)
Citation preview

Geração de Metadata Associada a Conteúdos Multimédia
Sérgio Alexandre Bento Esteves Gomes
Dissertação para obtenção do Grau de Mestre em
Engenharia Informática e de Computadores
Júri
Presidente: Prof. Doutor António Manuel Ferreira Rito da Silva
Orientador: Prof. Doutor João Paulo da Silva Neto
Co-Orientador: Prof. Doutor Nuno João das Neves Mamede
Vogal: Prof. Doutor João Dias Pereira
Outubro de 2010


Resumo
Está em curso uma revolução na televisão digital. Tanto o número de canais como os serviços estão
a aumentar, criando uma necessidade iminente de sistemas para extracção, indexação, recuperação e
personalização da informação presente nesses canais. No entanto, os mecanismos de interacção com a
televisão são ainda muito básicos, o que se deve, em grande parte, à falta de metadados associados aos
conteúdos. Neste cenário encontrámos a motivação para o trabalho a desenvolver, que é a possibilidade
de enriquecer a experiência do utilizador perante este meio de comunicação.
O objectivo do trabalho é o desenvolvimento de um sistema que habilita a construção de uma des-
crição, o mais detalhada possível, de uma emissão televisiva de um canal de televisão. Essa descrição
incide sobre a estrutura e conteúdo da emissão. Apresentam-se vários sistemas e tecnologias relevantes
para o trabalho, onde a abordagem mais frequente é a geração de metadados sem dispensar a interven-
ção humana.
Duas aplicações compõem o sistema proposto. A primeira encapsula o processamento do áudio,
fazendo uso do sistema Audimus, o qual foi também sujeito a modificações. A segunda gere os metada-
dos e permite a parametrização do sistema. A geração de metadados tem como técnica base a detecção
de referências usando uma modificação optimizada do algoritmo DTW.
Demonstrou-se que a detecção de referências é uma abordagem válida tanto para segmentar a emis-
são, através da identificação de jingles, como para identificar os anúncios nela presentes, tendo sido
obtidas uma precisão de 100% e uma abrangência nunca inferior a 90%.
Palavras-chave: metadados, multimédia, geração automática, DTW.
i


Abstract
There is an ongoing revolution in digital television. Both the number of channels and services are in-
creasing, creating an imminent need of systems for extracting, indexing, retrieval and personalization
of the information in these channels. However, the interaction mechanisms with television are still very
basic, which is due in large part to the lack of metadata associated with content. In this scenario we have
found the motivation to our work, which is the possibility of enriching the user experience before this
medium.
The aim of this work is to develop a system that enables the construction of a description, as detailed
as possible, of a television channel broadcast. This description focuses on the broadcast’s structure and
content. We present various systems and technologies relevant to the work, where the most common
approach is the generation of metadata without dispensing human intervention.
Two applications form the proposed system. The first encapsulates audio processing, making use of
the Audimus system, which was also subject to changes. The second one manages the metadata and
allows the system’s parameterization. The technical basis for metadata generation is reference detection
using a modified and optimized DTW algorithm.
It was demonstrated that reference detection is a valid approach to target both the broadcast seg-
mentation, using jingle identification, and advertisement detection, achieving a precision of 100 % and
a recall of no less than 90 %.
Keywords: metadata, multimedia, automatic generation, DTW.
iii


Agradecimentos
Durante o tempo em que me dediquei a elaborar este trabalho, desde os primeiros passos até ao mo-
mento da sua conclusão, precisei da ajuda e disponibilidade de diversas pessoas. Ajuda essa que não se
limitou às questões técnicas, sendo muitas vezes uma palavra de ânimo e motivação.
Agradeço ao Professor João Paulo Neto, pela proposta, orientação e supervisão do trabalho, bem
como pela oportunidade de trabalhar no L2F, um grupo experiente e acolhedor. A sua perspectiva
pragmática dos problemas e soluções foi principalmente motivadora e desafiante.
Um agradecimento especial é devido ao Bruno Almeida, amigo e companheiro de trabalho de longa
data, pela troca saudável de ideias sobre ambos os nossos trabalhos e, acima de tudo, a palavra amiga
nos momentos de frustração.
Não menos importante foi o apoio e simpatia de todo o pessoal da VoiceInteraction, a quem desejo
o maior sucesso pessoal e profissional. Por diversas vezes interromperam os seus trabalhos para me
fornecer pacientes explicações e conselhos.
Exprimo aqui os meus sinceros agradecimentos a todos aqueles que, de uma forma ou de outra,
foram contribuindo nas diversas discussões informais ao longo deste trabalho, através de ideias ou
críticas construtivas, mantendo sempre a boa disposição e espírito de companheirismo.
Por último, mas não menos importante, quero exprimir eterna gratidão e admiração pelos meus Pais.
Foram incansáveis durante todos estes anos de estudos, proporcionando excelentes condições, em todos
os aspectos, que foram decisivas para que pudesse chegar a esta meta e agora rumar a novos desafios.
Muito obrigado!
v


Conteúdo
Resumo i
Abstract iii
Agradecimentos v
Lista de Tabelas xii
Lista de Figuras xiv
Lista de Abreviações xv
1 Introdução 1
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Contextualização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Objectivos do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Estrutura da Dissertação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Trabalho Relacionado 5
2.1 Media Monitoring System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Sail Labs Media Mining System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 O Sistema SceneCabinet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Geração de Metadados Usando Redes Associativas . . . . . . . . . . . . . . . . . . . . . . 9
2.5 O Projecto SmartPush . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.6 A Patente US7548565 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.7 O Sistema MUVIS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.8 Geração de Sumários MPEG-7 Genéricos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.9 O Sistema BNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.10 Sistemas para Geração de Metadados no Domínio do Futebol . . . . . . . . . . . . . . . . 15
2.11 Ferramentas para Anotação de Conteúdo Audiovisual . . . . . . . . . . . . . . . . . . . . 16
2.12 Geração de Metadados a Partir de Folksonomias . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.13 Detecção de Referências . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.14 Conclusões do Trabalho Relacionado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
vii

3 Desenvolvimento 21
3.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Caracterização do Sinal de Entrada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3 O Sistema Audimus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4 PipelineServer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.5 Detecção de Referências . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.5.1 Detecção de Referências com MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.5.2 Detecção de Referências com DTW . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.6 Novos Componentes Audimus para Detectar Referências . . . . . . . . . . . . . . . . . . . 31
3.6.1 DTWComponent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.6.2 DTWStateMachineComponent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.7 MetadataProducer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.7.1 Estratégias de Detecção de Referências . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.8 Protocolo de Comunicação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.8.1 Descrição XML dos Eventos Audimus . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4 Avaliação 41
4.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3 Abordagem com MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.4 Desenvolvimento e Optimização do Protótipo DTW . . . . . . . . . . . . . . . . . . . . . . 44
4.5 Integração no Audimus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.6 Avaliação do Sistema Final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.6.1 Detecção e Refinamento Incremental . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.6.2 Análise Detalhada de Desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5 Conclusões 57
5.1 Sumário . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.2 Aplicações do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.3 Trabalho Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Bibliografia 61
A Exemplo de Ficheiro de Configuração de Arquitectura 67
B FunctionGeneratorInputBuffer - Documentação Sumária 69
B.1 Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
B.2 Argumentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
C Informação Sobre Scripts Desenvolvidos 71
D Interface da Aplicação de Treino de Referências 73
viii

E Descrição do Formato dos Ficheiros PFile 75
E.1 Cabeçalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
E.2 Conteúdo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
F Guia de Instalação de Software Necessário para o Desenvolvimento 79
F.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
F.2 Software a Instalar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
F.3 Estrutura das Directorias do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
F.4 Variáveis de Ambiente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
F.5 Compilação e Instalação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
F.6 Activação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
G Criar um Novo Componente ou Buffer no Audimus 85
G.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
G.2 Criar um Novo Componente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
G.3 Criar um Novo Buffer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
H DTWComponent - Documentação Sumária 89
H.1 Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
H.2 Entradas e Saídas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
H.3 Entradas e Saídas Externas ao Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
H.4 Parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
H.5 Eventos e Propriedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
I DTWStateMachineComponent - Documentação Sumária 91
I.1 Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
I.2 Entradas e Saídas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
I.3 Entradas e Saídas Externas ao Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
I.4 Parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
I.5 Eventos e Propriedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
J Exemplo de Relatório de Detecção 95
K Interfaces da Aplicação MetadataProducer 97
L Configuração do MetadataProducer 101
M Preparação do Corpus RTP.2009-09-17 103
N Preparação do Corpus jingle0.testpack 109
ix

O FramePrinterComponent - Documentação Sumária 111
O.1 Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
O.2 Entradas e Saídas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
O.3 Entradas e Saídas Externas ao Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
O.4 Parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
O.5 Eventos e Propriedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
x

Lista de Tabelas
2.1 Características desejadas para os metadados, segundo Jokela (2001). . . . . . . . . . . . . 12
2.2 Modos de entrega de metadados ao cliente. . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1 Tipos de mensagens no protocolo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.1 Especificações mais relevantes da máquina de testes. . . . . . . . . . . . . . . . . . . . . . 41
4.2 Descrição das etapas de optimização do protótipo. . . . . . . . . . . . . . . . . . . . . . . . 46
4.3 Detalhes dos resultados da sexta e última optimização do protótipo, no contexto do cor-
pus jingle0.testpack. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.4 Detalhe dos resultados da detecção do jingle0 no corpus RTP.2009-09-17. Apenas existem
linhas na tabela para as horas onde o jingle0 está presente. As detecções foram feitas em
paralelo, em grupos de 4 horas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.5 Testes dos Componentes DTW e DTWSM integrados no pipeline. . . . . . . . . . . . . . . . 50
4.6 Sumarização do erro de detecção ao longo das iterações. . . . . . . . . . . . . . . . . . . . 53
4.7 Sumarização do erro de duração ao longo das iterações. . . . . . . . . . . . . . . . . . . . . 54
C.1 Lista de scripts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
F.1 Software a instalar. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
F.2 Aplicações de linha de comandos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
F.3 Descrição das directorias principais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
F.4 Variáveis de ambiente user-wide. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
K.1 Índice de interfaces da aplicação MetadataProducer. . . . . . . . . . . . . . . . . . . . . 97
L.1 Chaves dos parâmetros do MetadataProducer. . . . . . . . . . . . . . . . . . . . . . . . 101
M.1 Listagem de programas no corpus RTP.2009-09-17 segundo o site da RTP. . . . . . . . . . . 104
M.2 Listagem de programas no corpus RTP.2009-09-17, obtida manualmente. . . . . . . . . . . 105
M.3 Lista dos ficheiros RAW presentes no corpus RTP.2009-09-17, correspondentes às 23 horas
de gravação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
M.4 Duração de cada jingle presente no corpus. . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
M.5 Lista dos jingles presentes no corpus. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
xi

N.1 Características dos ficheiros base do corpus jingle0.testpack. . . . . . . . . . . . . . . . . . 109
N.2 Instantes do jingle0 em cada ficheiro base do corpus jingle0.testpack. . . . . . . . . . . . . 110
xii

Lista de Figuras
1.1 Fluxo unidireccional de informação entre o produtor de conteúdo e o consumidor. . . . . 2
1.2 Fluxo de informação entre o produtor de conteúdo e o consumidor, com canal de retorno. 2
2.1 Diagrama de blocos funcionais do Media Monitoring System (Meinedo, 2008). . . . . . . 6
3.1 Vista geral do sistema. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Topologia de um exemplo simplificado de um pipeline do Audimus. . . . . . . . . . . . . . 23
3.3 Ilustração da relação entre MacroComponent e Component. . . . . . . . . . . . . . . . . . 24
3.4 Diagrama de classes das entidades já apresentadas. . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Ilustração do fragmento do pipeline correspondente a um splitter. . . . . . . . . . . . . 25
3.6 Principais componentes do PipelineServer. . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.7 Máquina de estados do PipelineController. . . . . . . . . . . . . . . . . . . . . . . . . 26
3.8 Arquitectura do pipeline Audimus usado para detecção de referências. . . . . . . . . . . . 27
3.9 Processo de treino e detecção de referências. . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.10 Processo de cálculo de scores do DTW entre uma base e uma referência. . . . . . . . . . . . 30
3.11 Elementos calculados numa matriz DTW 10×10 usando restrição diagonal com tolerância
30%. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.12 Gráfico dos scores do DTW numa região em que se encontra um hit. . . . . . . . . . . . . . 32
3.13 Principais componentes do MetadataProducer. . . . . . . . . . . . . . . . . . . . . . . . 34
3.14 Cadeia de processamento de eventos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.15 Estratégia boundary de detecção de referência. . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.16 Estrutura de um pacote do protocolo de comunicação. . . . . . . . . . . . . . . . . . . . . . 38
4.1 Fases da evolução do trabalho. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2 Desempenho médio do protótipo DTW por etapa de optimização, no contexto do corpus
jingle0.testpack. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3 Procedimento em cada iteração da experiência. . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.4 Abrangência da detecção em cada iteração. . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.5 Número de referências a detectar vs ×RT médio. . . . . . . . . . . . . . . . . . . . . . . . . 53
4.6 Cobertura do bloco de anúncios em função do número de referências a detectar. . . . . . 54
4.7 Valor de ×RT em função do número de referências e do comprimento da base. . . . . . . 55
xiii

4.8 Valor de ×RT em função da duração de uma referência. . . . . . . . . . . . . . . . . . . . . 56
E.1 Ilustração da estrutura e conteúdo de um PFile com 13 segmentos. . . . . . . . . . . . . . 77
F.1 Estrutura das directorias usada nesta dissertação. . . . . . . . . . . . . . . . . . . . . . . . 81
J.1 Exemplo de relatório de detecção gerado pelo MetadataProducer. . . . . . . . . . . . . 96
K.1 Interface MDI base do MetadataProducer. . . . . . . . . . . . . . . . . . . . . . . . . . . 98
K.2 Interface de gestão da ligação com o PipelineServer. . . . . . . . . . . . . . . . . . . . 98
K.3 Interface de gestão de pipeline jobs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
K.4 Interface de edição de um pipeline job. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
K.5 Interface de gestão de referências. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
K.6 Interface de edição de uma referência. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
K.7 Interface de execução de um pipeline job. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
K.8 Interface de apresentação de referências identificadas. . . . . . . . . . . . . . . . . . . . . . 100
K.9 Interface de apresentação dos segmentos não identificados. . . . . . . . . . . . . . . . . . . 100
xiv

Lista de Abreviações
Abreviações Designação em Inglês Designação em Português
AFS Andrew File SystemASCII American Standard Code for Information In-
terchangeCPU Central Processing Unit Unidade Central de ProcessamentoCSS Cascading Style SheetsCVS Concurrent Versions SystemDLL Dynamically Linked Library Biblioteca de Ligação DinâmicaDTD Document Type Definition Definição de Tipo de DocumentoDTW Dynamic Time WarpingDVR Digital Video Recording Gravação de Vídeo DigitalEPG Electronic Program Guide Guia Electrónico de ProgramasFIFO First In First Outfps Frames per second Frames por segundoIDE Integrated Development Environment Ambiente Integrado de DesenvolvimentoIP Internet Protocolkbps Kilobits per second Kilobits por segundoL2F Spoken Language Systems Lab Laboratório de Língua FaladaMDI Multiple document interfaceMFCC Mel-Frequency Cepstral CoefficientsMLP MultiLayer Perceptron Perceptrão MulticamadaMPEG Motion Picture Experts GroupOO Object Oriented Orientado a ObjectosPLP Perceptual Linear PredictiveTCP Transmission Control ProtocolQoS Quality of Service Qualidade de ServiçoRAW Raw audio formatRDF Resource Description FrameworkRTP Rádio Televisão PortuguesaURL Uniform Resource LocatorWAV WAVeform audio formatXML eXtensible Markup Language×RT times Real Time
xv


Capítulo 1
Introdução
1.1 Motivação
NA década de 90 observou-se um crescimento exponencial do tráfego na Internet (K.Coffman
& Odlyzko, 1999). Como consequência, uma maior quantidade de informação passou a es-
tar disponível para um conjunto mais diversificado de pessoas. O público reconheceu, desde
cedo, um grande potencial na Internet. Contudo, não foi de imediato que se apercebeu como se podia
tirar partido de toda a informação contida nos recursos disponibilizados. Estes recursos, na sua mai-
oria de natureza textual, encontravam-se e encontram-se interligados através de hiperligações. Havia
muita informação e dificuldade em aceder-lhe. Imediatamente se colocou a questão: como explorar o
conhecimento embebido nessa rede de informação à escala mundial? Para solucionar este problema
surgiram os motores de busca, que recolhem, organizam e facilitam o acesso à informação na Internet.
Foi necessário guiar os utilizadores na sua procura pela informação.
Tal como referido em Blanco-Fernández et al. (2008), a mesma revolução está a acontecer com a
televisão digital. Tanto o número de canais como de serviços está a aumentar. Há uma necessidade
iminente de sistemas para extracção, indexação, recuperação e personalização da informação presente
nesses canais. Esses sistemas devem procurar ser automáticos e interoperáveis, tanto quanto possível.
No entanto, a intervenção humana nestes sistemas não pode por enquanto, ser totalmente dispensada.
Tem ainda um peso muito grande o que dificulta o acesso à informação.
Tradicionalmente a televisão é um meio de comunicação em que o espectador é passivo. No entanto,
essa visão tem sofrido grandes mudanças nos últimos anos, como observado por Sandbank (2001). A
experiência proporcionada ao espectador pode ir muito além da selecção de canais. O presente trabalho
vai, através do desenvolvimento de métodos para complementar a informação associada a conteúdos
multimédia, permitir enriquecer essa experiência. Ao complementar o sinal audiovisual com uma des-
crição semântica espera-se facilitar a criação de serviços que envolvam o utilizador na sua experiência
frente ao ecrã, tornando-o num espectador activo e não apenas um receptor passivo.
Não só os conteúdos televisivos podem beneficiar de uma descrição semântica rica. Qualquer do-
cumento multimédia pode ser aumentado com uma descrição semântica, seja ela gerada automática ou
manualmente. No entanto, o trabalho vai focar-se em sinais provenientes de emissões televisivas.
1

Na última década temos vindo a observar o fenómeno da convergência digital. Segundo Jokela
(2001) entende-se por convergência digital todos os esforços para que a comunicação, computação e as
indústrias de conteúdos se fundam numa só indústria interligada.
O trabalho tem como principal objectivo o desenvolvimento de um sistema que possibilite a geração
de uma descrição de uma emissão televisiva. Para tal, e tendo em conta a estrutura e conteúdo de um
canal generalista, é aplicado um método de detecção de zonas de interesse presentes na emissão, bem
como a aplicação que permite gerir todo o processo. Um sistema já existente no L2F, o Audimus, foi
parte integrante do trabalho, tendo sido necessárias modificações e acrescentos significativos ao seu
código, pelo que será apresentado com algum detalhe.
A motivação para este trabalho passa pela possibilidade de contribuir para uma experiência mais rica
do ponto de vista do utilizador e a abertura de novos horizontes na descrição automática de conteúdos
digitais.
1.2 Contextualização
Na figura 1.1, encontramos uma representação simplificada da cadeia de distribuição de conteúdos
multimédia. No produtor desenrolam-se todas as actividades de captura, processamento e gestão dos
elementos multimédia. O consumidor corresponde, tipicamente, a um terminal audiovisual com de-
terminadas capacidades de processamento, colocado junto dos espectadores. Tradicionalmente, uma
televisão analógica ocupava esse lugar. Hoje em dia, como já foi referido, encontramos cada vez mais
dispositivos com capacidades de processamento e armazenamento significativas, as Set-Top Boxes com
facilidades de gravação de vídeo digital (DVR). Ainda na mesma figura, a seta representa o fluxo uni-
direccional de informação, partindo do produtor para o consumidor. Neste cenário não se contempla a
existência de feedback a partir do consumidor, isto é, não existe canal de retorno.
Figura 1.1: Fluxo unidireccional de informação entre o produtor de conteúdo e o consumidor.
Num cenário alternativo, representado na figura 1.2, já se contempla a existência de um canal de
retorno. A bidireccionalidade da comunicação abre as portas a aplicações mais dinâmicas e potencial-
mente mais interessantes.
Figura 1.2: Fluxo de informação entre o produtor de conteúdo e o consumidor, com canal de retorno.
Estes dois cenários identificam-se com duas formas de entrega de metadados, push e pull (Jokela,
2001). Na entrega push o consumidor recebe todos os metadados e executa localmente as acções apro-
priadas, como por exemplo filtragem ou recomendação. Na forma pull, apenas são enviados metadados
2

para responder a pedidos do consumidor, pelo que tem que existir canal de retorno. Nesta situação é
também necessário definir uma linguagem comum para esses pedidos, uma Query Language. Adiante,
no capítulo do Trabalho Relacionado, pode encontrar-se uma classificação mais completa das formas de
entrega de metadados em Sull et al. (2009).
O sistema a desenvolver vai inserir-se num contexto push, ou seja, não se contempla a existência de
um canal de retorno.
A informação gerada pelo produtor vai facilitar o desenvolvimento de aplicações no consumidor,
na medida em que enriquece o sinal da emissão televisiva com informação de segmentação e conteú-
dos. No entanto, o trabalho debruçou-se sobre a parte do produtor e não sobre as restantes (canal de
comunicação e consumidor).
1.3 Objectivos do Trabalho
O objectivo do trabalho foi desenvolver um sistema que habilite a construção de uma descrição, o mais
detalhada possível, de uma emissão televisiva de um canal de televisão. Essa descrição (os metadados)
incide sobre a estrutura e conteúdo da emissão.
Segundo Kiranyaz & Gabbouj (2006), o áudio é uma medida estável e única do conteúdo. Surge
como um candidato natural para a análise do conteúdo de uma emissão audiovisual. Para realizar
essa análise necessitamos de obter características do áudio. Uma característica de um sinal áudio é
qualquer medida quantitativa ou qualitativa de um aspecto desse som (Bullock, 2007). As características
do áudio podem situar-se numa gama vasta de abstracção, conforme estão mais próximas do som como
objecto matemático ou mais próximas do significado que um ouvinte lhe atribui1. As características de
baixo nível, como por exemplo a altura2, a energia, o volume, a largura de banda, são tema de estudo
recorrente na literatura (Meinedo, 2008; Liu et al., 1998b; Mierswa & Morik, 2005; Liang et al., 2005;
Bullock, 2007). A partir dessas características de baixo nível podemos construir outras, usando modelos
cada vez mais complexos do áudio. Como características de mais alto nível temos, por exemplo, a
transcrição, informação de segmentação, presença ou ausência de música, e outras referências.
Para habilitar a descrição da estrutura e conteúdo da emissão, o trabalho baseia-se em características
de alto nível, nomeadamente a presença de determinadas referências no áudio da emissão. Por referên-
cia entende-se um qualquer segmento de áudio com significado semântico para o ouvinte, como é o caso
dos jingles3. É necessário integrar no sistema a desenvolver um mecanismo parametrizável de detecção
dessas referências.
É também essencial que no sistema exista uma funcionalidade de gestão de um conjunto de referên-
cias a detectar, para que o utilizador possa realizar as parametrizações desejadas de modo a obter os
metadados pretendidos.
1Esse significado pode não ser único.2Do Inglês, pitch.3Jingles são padrões musicais usados para atrair a atenção do espectador.
3

1.4 Estrutura da Dissertação
Após esta introdução, os restantes conteúdos da dissertação estão organizados da seguinte forma. No
capítulo 2 descrevem-se os trabalhos que, na nossa opinião, são os mais relevantes no contexto do pro-
jecto desenvolvido. Seguidamente, no capítulo 3, fala-se da arquitectura e implementação da solução.
A metodologia e avaliação da solução são descritas no capítulo 4. No capítulo 5 apresentam-se as con-
clusões do trabalho, bem como sugestões para trabalho futuro. Por fim enumeram-se as referências
mencionadas no texto desta dissertação, seguidas dos anexos.
4

Capítulo 2
Trabalho Relacionado
NO sistema desenvolvido, o áudio tem um papel fundamental na extracção dos metadados.
Contudo, a extracção de informação é uma actividade que pode ser aplicada em diversos do-
mínios como o do áudio, vídeo, texto, imagem, entre outros. É possível, inclusive, combinar
várias fontes de informação já existentes para obter uma descrição mais rica e diversificada, ao estilo
das mashups 1.
Através do estudo do trabalho relacionado, acreditamos ter sido possível contactar com ideias em
diferentes campos, todos relacionados de alguma forma com a extracção, tratamento, armazenamento e
disseminação de informação, nas suas mais diversas formas.
Nas sub-secções seguintes apresentam-se os sistemas e tecnologias que, na nossa opinião, são os
mais relevantes para fundamentar o trabalho a desenvolver.
2.1 Media Monitoring System
Um trabalho muito importante é a dissertação de Meinedo (2008). Nessa dissertação apresenta-se uma
parte do trabalho feito no contexto do desenvolvimento de um sistema para a disseminação de informa-
ção multimédia, o Media Monitoring System.
O Media Monitoring System foi desenvolvido para conteúdos noticiosos, especificamente noticiá-
rios televisivos. O trabalho dividiu-se em 4 tarefas diferentes: recolha de recursos de fala em noti-
ciários, desenvolvimento de modelos acústicos apropriados, desenvolvimento de algoritmos de pré-
processamento de áudio e criação de um protótipo.
Este sistema é composto por vários blocos funcionais: detecção de jingles, pré-processamento de
áudio, reconhecedor automático de fala, sumarização, detecção de tópicos, base de dados, emparelha-
mento de tópicos, interface web e bloco de envio de alertas. A arquitectura é inspirada no estilo pipes and
filters.
O sistema monitoriza um conjunto de canais de televisão, indexando os tópicos que são de interesse
para os utilizadores registados. Se há emparelhamento entre algum tópico e um perfil, é enviado um
1Segundo http://www.openmashup.org/, uma mashup é a combinação e reutilização de várias fontes de dados, estrutura-
dos ou não, num só serviço.
5

e-mail ao utilizador respectivo com o título da notícia, um breve sumário e uma ligação para o vídeo da
notícia. Observe-se o diagrama funcional do sistema na figura 2.1.
Figura 2.1: Diagrama de blocos funcionais do Media Monitoring System (Meinedo, 2008).
O bloco de detecção de jingles é responsável por determinar em que instantes começa e termina um
noticiário.
Dentro do pré-processamento de áudio, temos os seguintes blocos, sub-blocos e respectivas respon-
sabilidades:
• segmentação do áudio
– detecção de mudanças acústicas - detecção de zonas do áudio em que houve alterações nos
oradores ou nas condições de fundo.
• classificação do áudio
– fala / não fala - determinar se uma região de áudio tem fala ou ausência de fala;
– condições de fundo - determinar se o áudio de fundo está limpo, tem ruído ou música.
• classificação do orador
– detecção de género - distinguir entre oradores masculinos e femininos;
– clustering de oradores - identificar todos os segmentos de fala produzidos por um dado ora-
dor;
– identificação de oradores - determinar a identidade de alguns oradores recorrentes como
pivôs de noticiários ou personalidades importantes.
O Media Monitoring system está desenhado para funcionar em modo online, ou seja, procura-se que
o sinal seja processado à medida que é recebido. No desenvolvimento da versão mais recente do bloco
do pré-processamento houve um esforço para minimizar o atraso que é necessário introduzir para que
a legendagem seja possível.
No sistema é feita também a detecção de tópicos, tarefa para dividir a stream de notícias em diferentes
histórias. Classificam-se as histórias segundo um conjunto de tópicos hierárquicos, usando informação
dos blocos de pré-processamento e reconhecimento da fala. A detecção de tópicos é um passo impor-
tante para permitir a indexação e recuperação com facilidade.
Note-se que no projecto ALERT, predecessor do Media Monitoring System, estavam interessados
em indexar todas as histórias, não só aquelas que estavam de acordo com algum perfil. Os resultados
6

do processamento do áudio são armazenados numa base de dados. É guardado tanto o vídeo original
como uma descrição XML do mesmo.
2.2 Sail Labs Media Mining System
Um outro sistema semelhante é o Sail Labs Media Mining System, descrito em Pfeiffer et al. (2008). O
sistema foi desenhado para recolher grandes volumes de dados provenientes de fontes abertas mas não
estruturadas, como por exemplo a televisão, rádio, páginas web, RSS2 feeds, entre outras. O sistema
consiste num conjunto de tecnologias embebidas em componentes e modelos, que se combinam para
formar uma cadeia de processamento. São disponibilizados toolkits que permitem ao utilizador actua-
lizar e refinar modelos. Os modelos são baseados em estatísticas extraídas de amostras de dados. Os
componentes podem ser agrupados segundo configurações diferentes, dando flexibilidade ao sistema.
Os resultados do processamento e agregação das várias fontes são disponibilizados para procura, aná-
lise e visualização através de um servidor, o Media Mining Indexer. Os resultados são documentos no
formato MPEG-7.
O Media Mining System tem uma arquitectura Cliente/Servidor (Clements et al., 2003), permitindo
uma instalação dos vários componentes em diferentes máquinas e plataformas. Também podemos iden-
tificar traços do estilo arquitectural Pipes and Filters, uma vez que os componentes se organizam em
fontes, processadores e visualizadores de dados.
As fontes de dados, apelidadas de feeders, podem ter variados formatos. Existem feeders para áudio/-
vídeo (um deles especializado em noticiários), recolha de informação na web (páginas web e RSS feeds),
e-mails, documentos impressos, rádio, telefone, entre outras possibilidades. A recolha de informação é
parametrizada através de interfaces gráficas. Depois de recolhidos os dados nos feeders, estes são pro-
cessados no Media Mining Indexer, o cérebro do sistema. É feita uma análise do áudio, vídeo e texto
recolhidos. Os resultados são combinados e estruturados num documento MPEG-7.
Os componentes do Media Mining Indexer estão implementados por um mecanismo de plug-ins.
Deste modo, numa instalação do sistema podemos ter componentes oriundos de várias fontes, podendo
ser substituídos por outros se as necessidades do consumidor mudarem. Também permite a quem
desenvolve componentes especializar-se no processamento de um tipo específico de dados, como por
exemplo, dados audiovisuais. Em seguida, descrevem-se as tecnologias de maior interesse no contexto
do presente trabalho, presentes no Media Mining Indexer.
O processamento da fala inicia-se com o pré-processamento de áudio. Este, por sua vez, encontra-se
dividido em processamento de sinal e segmentação. No processamento de sinal são extraídas caracterís-
ticas do áudio e aplicadas técnicas de normalização e conversão. Na segmentação o sinal é dividido em
segmentos homogéneos. Os pontos de segmentação são determinados de acordo com um modelo, que
inclui, entre outros, sons da linguagem falada. Analisa-se a proporção de fala / não-fala para determinar
como um dado segmento deve ser processado nos componentes seguintes.
Em seguida, realiza-se a identificação de oradores, onde os segmentos são agrupados de acordo com
2Really Simple Syndication
7

o seu orador. O sistema identifica oradores conhecidos como pivôs, pessoas de interesse público, entre
outros. Oradores cuja identidade não pode ser determinada são, mesmo assim, agrupados e etiquetados
univocamente. Em qualquer um dos casos tenta-se determinar o género do orador.
O passo seguinte consiste na aplicação de um reconhecedor automático de fala aos segmentos clas-
sificados como fala. O reconhecedor usado no sistema realiza uma descodificação de fala contínua em
tempo real, multi-língua, independente do orador e de vocabulário muito alargado.
O sistema permite processar recursos textuais, sejam eles provenientes de feeders textuais ou resul-
tado do reconhecedor de fala. O processamento de texto começa pela normalização do texto, onde se
trata de forma especial números, símbolos, abreviações, acrónimos, entre outros elementos. Em seguida
detectam-se as entidades nomeadas como pessoas, organizações e números. Esta detecção é baseada
tanto em padrões como em modelos estatísticos de n-gramas3 de palavras. É feita também uma detec-
ção de tópicos no texto, segundo uma hierarquia. Os parágrafos de texto são tomados como unidade de
classificação inicial, depois refinada através da fusão de parágrafos adjacentes com a mesma classifica-
ção.
É importante referir que, visto que o sistema está preparado para lidar com recursos em várias lín-
guas, é necessário um componente de identificação da língua. Conforme a língua detectada assim se
decide quais os modelos de linguagem a usar, pelo que este é um componente essencial tanto para o
processamento de recursos áudio como textuais.
Os resultados do processamento, em formato XML, são armazenados e indexados numa base de da-
dos. A gestão do sistema é feita via web, bem como consultas e actualizações dos dados. Tudo isto se
desenrola no Media Mining Server. As consultas podem ser restritas a uma porção dos dados como, por
exemplo, tópicos, canais, oradores ou períodos de tempo. Também foi incluído um componente de no-
tificação que emite um alerta assim que seja encontrado um recurso que coincide com um determinado
perfil.
Como já foi referido, a natureza distribuída do sistema permite manter em máquinas separadas os
feeders, os Media Mining Indexers e os Media Mining Servers. Todo o processamento é feito em pipeline,
o que permite maximizar a velocidade de processamento. O Sail Labs Media Mining System tem como
principal vantagem a diversidade de fontes de informação com que se pode relacionar. Consegue-se
assim um repositório de metadados semanticamente enriquecido.
Contudo, apesar de uma arquitectura promissora, não é apresentada no artigo uma análise quantita-
tiva do sistema em contexto real de utilização. Também não se descreve explicitamente que descritores
MPEG-7 foram usados para armazenar a informação produzida pelo sistema.
2.3 O Sistema SceneCabinet
No artigo Kuwano et al. (2004) encontramos um sistema muito semelhante ao que se pretende desen-
volver no presente trabalho. Partilha a visão de que os metadados são um elemento fundamental para
que sejam possíveis novos modos de interagir com a televisão. Os metadados para um noticiário devem
3Um n-grama é uma subsequência de n itens de uma dada sequência.
8

descrever o conteúdo de cada notícia individual. Para um programa desportivo devem descrever os
tempos em que ocorrem eventos interessantes como golos ou home runs. Por outro lado, a tarefa de ge-
ração manual destes metadados semânticos baseados em cenas requer um esforço considerável. Deste
modo, reduzir o custo da geração de metadados é a chave para distribuir mais conteúdos que permitam
uma visualização mais avançada. É descrito o sistema SceneCabinet, que extrai automaticamente meta-
dados semânticos. São extraídos segmentos de vídeo com significado, bem como o seu título, resumo e
palavras-chave. Para que tal seja possível, usam-se os resultados de ferramentas de processamento da
fala, reconhecimento de texto no ecrã e listagens de guiões de programas.
Para descrição de cada segmento de vídeo usa-se o formato de metadados proposto pelo TV-Anytime
Forum. Os metadados de cada segmento incluem tempos de início e fim dentro do programa (apelida-
dos de metadados temporais) e informação textual como o título do segmento, resumo e palavras-chave
(apelidados de metadados semânticos). O sistema funciona em dois passos:
1. geração automática dos metadados: composta pela indexação de áudio, vídeo e processamento de
língua natural;
2. enriquecimento manual: verificação e revisão da informação obtida no 1o passo.
A geração de metadados temporais é feita detectando os intervalos temporais de cada cena, texto
no ecrã, fala e música. Nos noticiários, os tópicos podem ser detectados a partir destas características,
visto que estes começam, em geral, por uma imagem do pivô e um texto com título. Um interface
gráfico permite ao operador humano visualisar as imagens-chave extraídas, bem como os seus tempos,
permitindo ajustes aos tempos extraídos automaticamente. Os metadados semânticos são o resultado
do reconhecimento automático de texto no ecrã e fala, bem como da extracção de palavras e frases que
correspondem a títulos, resumos e palavras-chave a partir deste reconhecimento. Este procedimento
tem a vantagem de poder ser realizado dispensando a análise do vídeo.
A avaliação consiste na comparação dos tempos de geração de metadados temporais e semânticos
para um noticiário, manualmente e com assistência da geração automática. Mostra-se que, usando o
SceneCabinet, é possível reduzir os tempos da tarefa para cerca de 46% do tempo requerido pelo pro-
cesso manual. Características como as regras das tarefas para os operadores humanos e a variabilidade
da sua experiência no tema do vídeo que estão a processar, podem influenciar o custo da geração dos
metadados.
2.4 Geração de Metadados Usando Redes Associativas
O artigo Rodriguez et al. (2009) começa por observar que os metadados são um recurso dispendioso de
criar, manter e/ou recuperar manualmente. Como consequência, tem havido grande interesse na gera-
ção automática de metadados. Veja-se, a título de exemplo, a aplicação de técnicas de processamento
de língua natural e de análise de imagens de documentos para extrair palavras-chave, categorias temá-
ticas, autores e citações, a partir de manuscritos. O autor remete-nos para os trabalhos de Yang & Lee
(2005); Giuffrida et al. (2000); Sebastiani (2002); Han et al. (2003); Mao et al. (2004) e Greenberg (2003).
9

No entanto, abordagens baseadas no conteúdo dos recursos podem ser computacionalmente dispendi-
osas e ineficientes, como indicado em Kuwano et al. (2004). Consequentemente, tem vindo a observar-se
um interesse crescente em métodos para a geração de metadados que não dependem do conteúdo dos
recursos, como por exemplo as folksonomias 4.
A geração de metadados não tem que implicar, necessariamente, a análise do conteúdo do docu-
mento original. Assim defende Rodriguez et al. (2009), ao propor um sistema de geração automática de
metadados que se baseia nas relações entre recursos e não nos seus conteúdos. Essas relações, extrapo-
ladas a partir de metadados existentes, servem como veículo para a propagação dos mesmos.
O sistema descrito tem como ponto de partida um repositório heterogéneo que contém recursos
para os quais estão disponíveis metadados com diversos graus de detalhe. Parte-se do princípio que os
recursos que são semelhantes (segundo algum critério, como por exemplo a data de publicação) então
é mais provável que partilhem metadados. O sistema tenta extrapolar metadados a partir dos recursos
“ricos” em metadados para recursos mais “pobres” em metadados, mas semelhantes. O procedimento
é composto pela seguintes fases:
1. algoritmos geram uma rede dos recursos presentes no repositório;
2. propagam-se os metadados tendo em conta a topologia da rede;
3. actualiza-se o repositório, havendo possibilidade de validação humana dos resultados da propa-
gação.
O artigo explica como se construiu uma framework genérica para construir as redes de recursos, bem
como os algoritmos de propagação. Realizaram-se experiências para validação e avaliação dos métodos
propostos num conjunto de dados bibliográficos. Os recursos são relacionados de acordo com regras
semânticas como por exemplo “o autor a escreveu o manuscrito m”, “o manuscrito m foi publicado na
data d”, “o autor a trabalha para a organização o”, “o manuscrito m foi publicado na revista r”, entre
outras. Trabalhou-se com um total de 29014 manuscritos, tendo sido obtidos bons resultados, mas há
lugar para muitas variações na framework. Ficou também demonstrado que a intervenção humana é
importante na afinação do algoritmo de propagação. Propõe-se, como trabalho futuro, a realização
de um estudo que indique quanto o processo de criação de metadados precisos e fidedignos pode ser
acelerado, com este sistema.
2.5 O Projecto SmartPush
Na dissertação de Jokela (2001) exploram-se vertentes mais teóricas relacionadas com os metadados. As
empresas relacionadas com os media são capazes de criar um volume considerável de conteúdos mas
necessitam de métodos flexíveis para gerir o que produzem. Como resultado, tem aumentado a depen-
dência de sistemas computacionais. Visto apresentarem uma inteligência reduzida, os seus resultados
são muitas vezes considerados incompletos do ponto de vista das expectativas e exigências humanas.
4Segundo Peters (2009) uma folksonomia é um sistema de classificação derivado de colaborativamente criar e gerir etiquetas
(tags) para anotar e caracterizar conteúdo. Também conhecida como social tagging.
10

Por essa razão é necessário aumentar a essência do conteúdo difundido com descrições explícitas dos
seus atributos, os metadados.
Segundo o autor, os metadados semânticos são um tipo de metadados que descrevem a semântica
da essência do conteúdo. Estes metadados, para serem úteis, têm de respeitar algumas características. A
sua natureza deve ser clara, isto é, o seu significado não pode ser ambíguo. Além disso, a sua estrutura
e modo de utilização têm que estar correctamente especificados. Entre as várias contribuições do autor,
destacam-se as seguintes:
• identificação de características desejadas para os metadados;
• desenvolvimento de uma ferramenta de criação de metadados.
A natureza dos metadados é muito diversificada. Nesse sentido, o autor avança com algumas defini-
ções relacionadas com metadados, que achamos importante mencionar. Os metadados podem ser man-
tidos junto do conteúdo que descrevem, sendo apelidados de metadados implícitos ou tightly-coupled,
ou mantidos noutro lado, sendo metadados explícitos ou loosely-coupled. Estes últimos têm a vantagem
de poder ser transmitidos em separado. Quando o conteúdo não pode ser usado sem os metadados,
dizemos que estes são metadados essenciais. Um exemplo é a informação sobre o algoritmo a utilizar
para descodificar um sinal áudio. Podemos classificar ainda os metadados como estáticos ou dinâmi-
cos, conforme estes sejam sujeitos, ou não, a alterações ao longo do tempo. O esquema de classificação
apresentado baseia-se numa categorização por papéis. Os metadados podem ser classificados como:
• estruturais - descrevem o formato do conteúdo, mas não contêm informação sobre o seu signifi-
cado (ex: informação de codificação de vídeo, áudio, formatos gráficos);
• de controlo - controlam o fluxo do conteúdo na cadeia de valor (ex: informação de QoS 5, gestão
de erros);
• descritivos
– contextuais - descrevem o ambiente e condições relacionadas com o conteúdo e sua criação
(ex: informação geoespacial, temporizações, equipamento usado para produzir o conteúdo);
– semânticos, baseados no conteúdo - descrevem o que significa o conteúdo (ex: sujeitos, lo-
calizações, nomes, palavras-chave num noticiário). A utilização de metadados semânticos
pressupõe um acordo entre o produtor de conteúdo e o consumidor. É crucial estabelecer
uma interpretação comum dos conceitos descritos.
O autor estabelece como características desejadas para os metadados semânticos os atributos indica-
dos na tabela 2.1.
O autor afirma que não é recomendável ter extracção automática de metadados sem controlo hu-
mano pois tal abordagem pode resultar em metadados de qualidade inferior.
5Capacidade de disponibilizar diferentes prioridades a determinadas aplicações, de modo a garantir um determinado nível de
desempenho de um sistema.
11

Característica Descrição
Expressividade Cobrir as necessidades para que foram desenhados.Extensibilidade Adaptação à mudança.Neutralidade Media platform neutrality.Imutabilidade Ao longo da cadeia de valor.Compacidade Representar as características chave, sendo sintéticos.Alto valor Contendo benefícios para todos os intervenientes.Uniformidade Existência de métodos padronizados para a sua descrição.Abertura Os padrões para os metadados devem estar disponíveis para todos.Versionamento Acompanhamento das mudanças nos metadados.Identificação única Localização do conteúdo e metadados sem ambiguidade.
Tabela 2.1: Características desejadas para os metadados, segundo Jokela (2001).
Seguidamente, o autor apresenta o projecto SmartPush, que pretende ser uma prova de conceito para
a distribuição de informação personalizada, com base em metadados semânticos e perfis de utilização.
O foco do projecto está na criação e aquisição do conteúdo, criação dos metadados, filtragem e entrega
personalizada ao consumidor. A maioria das experiências levadas a cabo no projecto foram com con-
teúdos noticiosos. Um desafio presente neste tipo de conteúdos é a sua natureza dinâmica, onde novas
palavras são introduzidas diariamente e o significado de palavras existentes sofre alterações regulares.
Construiu-se uma ontologia para noticiários contendo categorias como natureza, tráfego, desporto e
economia. Também dentro do projecto foi criada uma ferramenta de extracção de informação, a Content
Provider Tool, que foi refinada iterativamente com o apoio de peritos.
A criação dos metadados é semi-automática, ou seja, a ferramenta dá sugestões que são, ou não,
aprovadas por um operador humano. É referido que a automação do processo de geração dos metada-
dos pode reduzir os custos da sua criação, mas a qualidade poderá ser afectada, especialmente se este
processo exigir inteligência humana. Por essa razão, optou-se por desenvolver a Content Provider Tool
semi-automática.
2.6 A Patente US7548565
A recente patente US7548565 de Sull et al. (2009) realça que a proliferação de gravadores de vídeo digi-
tal permitiu aos utilizadores assistirem aos programas de uma forma mais independente. Se estiverem
disponíveis metadados de segmentação, tanto inter como intra-programas, os espectadores podem fa-
cilmente escolher os segmentos que mais lhes agradam. Podem ainda visualizar destaques e sumários.
Como sugerido em Sull et al. (2009) considere-se um cenário em que os metadados descritivos de um
programa são entregues ao consumidor enquanto o programa está a ser emitido. No caso da emissão
ao vivo de eventos como jogos desportivos, o espectador pode querer ver os segmentos do seu jogador
favorito ou um resumo de todos os golos. Sem a existência de metadados que descrevam o programa em
detalhe, tal não é uma tarefa fácil. Afirma-se também que com as tecnologias actuais em processamento
de imagem e reconhecimento da fala é difícil detectar destaques e sumários de eventos ou objectos em
tempo real. O problema dos falsos positivos é real e o autor afirma que a geração de destaques usáveis e
12

semanticamente significativos ainda requer a intervenção humana. O sistema descrito apresenta então
uma combinação de indexação de destaques em jogos de futebol mas com a intervenção manual para
efectuar refinamentos. Os metadados resultantes podem ser representados em formatos proprietários
ou em standards internacionais abertos de especificações multimédia, como o MPEG-7 ou TV-Anytime,
ambos baseados no XML Schema.
Uma contribuição importante de Sull et al. (2009) é a identificação de vários modos de entrega dos
metadados, apresentada na tabela 2.2.
Modo Descrição
Entrega incremental Os metadados para o conteúdo mais recente são refinados e en-
tregues.
Entrega incremental periódica Entrega incremental mas em intervalos de tempo bem definidos.
Entrega periódica Todos os metadados mais recentes são entregues em intervalos
de tempo bem definidos.
Entrega pontual Imediatamente após o conteúdo ser transmitido, todos os meta-
dados são entregues.
Entrega pontual atrasada Entrega de todos os metadados em algum ponto do tempo após
o fim do conteúdo.
Entrega a pedido Todos os metadados são entregues a pedido do terminal DVR.
Tabela 2.2: Modos de entrega de metadados ao cliente.
2.7 O Sistema MUVIS
O sistema MUVIS, descrito em Kiranyaz et al. (2003), é uma framework de indexação e recuperação de vá-
rios tipos de objectos multimédia, mais concretamente, objectos áudio, vídeo e imagens. A contribuição
mais importante do sistema foi a definição de uma interface para se integrarem facilmente algoritmos
de extracção de características dos objectos. Destacam-se as principais características do sistema:
• captura, codificação e gravação de vídeo e áudio em tempo real;
• sumarização de vídeo através da detecção de cenas;
• integração de algoritmos de extracção de características auditivas e visuais;
• suporte para vários formatos multimédia e esquemas de codificação áudio e vídeo.
A introdução de um novo algoritmo de classificação de áudio ou vídeo requer apenas a implemen-
tação, numa DLL, de uma interface. Dessa interface constam funções para inicialização e finalização do
algoritmo, cálculo de distâncias e extracção das características em si.
Para ilustrar o funcionamento do MUVIS, descreve-se o processamento de um sinal áudio. Em pri-
meiro lugar, classifica-se e segmenta-se o sinal. As categorias são “silêncio”, “fala” e “música”. Em
13

seguida é realizada a extracção de características no módulo AFeX (Audio Feature eXtraction) da qual
resultam características para fala e música. Após este passo é feita a extracção de key frames represen-
tativos do conteúdo, através de uma técnica de clustering . No final realiza-se a operação de indexação,
adicionando os key frames à base de dados áudio.
No que respeita à avaliação do MUVIS afirma-se apenas que se obtiveram resultados que demonstra-
ram a eficácia da framework bem como de um desempenho significativo no processamento de consultas.
2.8 Geração de Sumários MPEG-7 Genéricos
Em Matos & Pereira (2008) é descrita uma aplicação de sumarização completamente automática para
conteúdos audiovisuais genéricos. A sumarização é descrita em MPEG-7. A aplicação pretende ser
genérica, pelo que tem que fazer uma modelação do que podem ser conteúdos interessantes para o uti-
lizador, dignos de figurarem na sumarização. O trabalho foi motivado pela crescente quantidade de
material audiovisual e o tempo limitado dos espectadores. São extraídas três características do sinal
audiovisual e depois combinadas segundo um modelo de entusiasmo. Modela-se o entusiasmo sen-
tido pelo espectador perante o conteúdo. Os sumários vão conter os segmentos que provocam maior
entusiasmo, permitindo assim sumarizar qualquer conteúdo, independentemente do seu tipo e origem.
O sistema tem dois requisitos fundamentais. O primeiro é a flexibilidade, permitindo ao espectador
a criação de diferentes sumários para preencher diferentes necessidades. O segundo é a interopera-
bilidade, onde o sumário criado seja capaz de interoperar com outros sistemas. O uso de sumários
hierárquicos e a escolha de MPEG-7 para a sua descrição permitiram satisfazer ambos os requisitos. O
MPEG-7 tem a facilidade de representar sumários hierárquicos, através da description tool Hierarchical-
Summary.
A avaliação consistiu num questionário sobre os resultados da sumarização de seis vídeos: três des-
portivos e três séries de TV. O questionário interrogou um grupo de 15 voluntários, que responderam
subjectivamente a duas questões: “O sumário contém os segmentos mais relevantes?” e “O sumário não
incluiu algum segmento que considera relevante?”. A primeira resposta foi quantificada de 1 (“de modo
nenhum”) a 5 (“totalmente”). Mais de 80% dos inquiridos atribuiu uma pontuação de 4 ou superior. A
segunda pergunta foi quantificada de 1 (“todos”) a 5 (“nenhum”). Mais de 70% dos inquiridos atribuiu
uma pontuação de 4 ou superior. Para ambas as perguntas não houve insatisfação total (pontuação igual
a 1).
Os autores acreditam que se obtiveram melhores resultados para os vídeos desportivos do que nas
séries televisivas devido à interpretação menos subjectiva dos momentos-chave.
2.9 O Sistema BNN
O sistema Broadcast News Navigator (BNN), apresentado em Merlino et al. (1997), faz a captura, análise,
anotação, segmentação, sumarização e armazenamento de noticiários. A inovação está no uso de pistas
textuais e visuais para guiar uma máquina de estados finitos que determina os segmentos do noticiário.
14

A segmentação gerada inclui apresentações, histórias, destaques, anúncios, boletins meteorológicos,
reportagens exteriores, entre outros tipos de segmentos.
As pistas textuais, extraídas da legendagem, permitem identificar pontos temporais como a introdu-
ção de uma história, uma reportagem no exterior, um boletim meteorológico ou um orador convidado.
Como pistas textuais temos, por exemplo, “Hello”, “Hello and welcome”, “I’m <person X>”, “That’s all”
e “Thanks for watching”. Para a detecção de boletins meteorológicos temos palavras como “weather”,
“forecast”, “frontal system” e “pressure”. As pistas visuais são, entre outras, a detecção de logótipos,
presença ou ausência de legendas e cor dos frames. Para cada segmento identificado guarda-se o tema,
um sumário e um keyframe. Esta informação é guardada numa base de dados para posterior procura e
recuperação.
A avaliação do sistema consistiu na segmentação de 5 noticiários, tendo sido obtidos bons resul-
tados. Atingiu-se uma precisão de 0,74 (percentagem de segmentos detectados que efectivamente são
segmentos) e abrangência de 0,97 (percentagem de todos os segmentos verdadeiros que foram detecta-
dos)
2.10 Sistemas para Geração de Metadados no Domínio do Futebol
Os metadados no contexto dos jogos de futebol é interessante pois este é um desporto muito popular.
Naturalmente, um dos momentos de maior interesse é o golo. Tradicionalmente, as abordagens para
detecção de golos de futebol são unimodais. Em Chen et al. (2004) é proposta uma framework para iden-
tificação de golos usando análise multimodal combinada e árvores de decisão. A informação extraída
pode ser usada para indexação de vídeos de futebol. A análise feita é baseada em planos de vídeo6 pois estes são a unidade básica de indexação de conteúdo. Como as amostras positivas (golos) são
muito poucas, aproximadamente 1%, é necessário filtrar os dados de entrada para que estes sejam o
mais específicos possível.
Inicialmente é feito um passo de pré-filtragem para eliminar ruído e reduzir os dados irrelevantes. A
pré-filtragem assenta em regras empíricas para decidir se um plano é candidato a processamento poste-
rior. Mostrou-se que 81% dos planos de vídeo podem ser eliminados aplicando estas regras. Em seguida
treina-se o sistema, construindo a árvore de decisão. A árvore de decisão é construída pelo particiona-
mento recursivo do conjunto de treino em ordem a um certo critério, até que todas as instâncias numa
partição tenham a mesma etiqueta, ou não existam mais atributos para continuar o particionamento.
Finalmente classificam-se os planos de teste através de um processo guiado pela árvore de decisão.
São extraídas características tanto áudio como vídeo para a classificação. Destaca-se a utilização de um
detector não supervisionado de área relvada, importante para o domínio do problema.
A avaliação do sistema consistiu na análise de 27 jogos de futebol, cerca de 10h de material audiovi-
sual. Dos 4885 planos de vídeo originais, apenas 886 restaram após pré-filtragem. Desses, 41 são planos
em que se encontram golos. Separaram-se os planos em dois conjuntos: treino (25%) e teste (75%).
Da classificação automática obtiveram-se resultados bastante satisfatórios, com precisão e abrangência
6Do Inglês, video shots.
15

superiores a 90%.
Outro sistema relevante é descrito por Alan et al. (2008), que extrai os metadados a partir de texto.
Para guiar a extracção criaram uma ontologia para o domínio do futebol. A extracção pode ser manual
ou automática. Os metadados, no formato MPEG7, são armazenados numa base de dados orientada
a objectos (db4o 7). A extracção automática baseia-se na informação presente em sítios especializados
da web. A diversidade de fontes existente permite não só a obtenção de metadados detalhados como a
validação da informação, através do cruzamento das fontes. Estas fontes também fornecem os tempos
dos eventos, permitindo a sincronização dos metadados com o vídeo. A construção de ontologias para
unificar vários domínios é extensivamente explorada em Hunter (2001).
2.11 Ferramentas para Anotação de Conteúdo Audiovisual
As ferramentas de anotação de conteúdo consistem essencialmente num interface gráfico com uma re-
gião para visualizar e controlar a reprodução do conteúdo audiovisual e controlos para a introdução de
informação textual como títulos, descrições e legendas. Todas as ferramentas aqui descritas trabalham
com MPEG-7.
A ferramenta IBM 8 VideoAnnEx 9 permite inserir anotações de eventos, cenários e objectos. As
cenas são detectadas automaticamente através de algoritmos de detecção de transições mas a anota-
ção é manual. Outro sistema originário na IBM, o MARVEL 10, ajuda a organizar os dados multimédia
através da etiquetagem automática do conteúdo. É capaz de extrair até 200 conceitos semânticos dife-
rentes, usando técnicas de aprendizagem automática. Menos de 5% do conteúdo tem que ser anotado
manualmente, sendo que o restante trabalho é concretizado através de uma abordagem estatística mul-
timodal. O desempenho na recuperação da informação é aumentado através da utilização de ontologias
para explorar as relações semânticas. O MPEG-7 é usado para codificar as descrições extraídas, para
descrever procuras por palavras-chave ou exemplo e, finalmente, para personalização dos resultados às
preferências do utilizador.
Usando a RICOH 11 MovieTool podemos criar descrições hierárquicas do vídeo. A geração de uma
descrição da estrutura do vídeo é automática, permitindo editar manualmente os pormenores de cada
cena. Podemos ver imediatamente a correspondência entre a estrutura do vídeo e as cenas descritas,
procurar e saltar directamente para uma cena específica. De acordo com Afonso & Ferreira (2003) esta
ferramenta tem o problema de não lidar correctamente com ficheiros MPEG-7 criados por outros siste-
mas.
A SpokenContent Tool da Canon 12 permite gerar uma descrição automática de um ficheiro áudio
no formato WAV. A ferramenta baseia-se numa tecnologia de reconhecimento da fala, também desen-
volvida pela Canon. Contudo, está limitada em termos do tamanho dos ficheiros que pode processar.
7http://www.db4o.com/ (Último acesso em 14 de Novembro de 2010).8http://www.ibm.com/ (Último acesso em 14 de Novembro de 2010).9http://www.research.ibm.com/VideoAnnEx/ (Último acesso em 14 de Novembro de 2010).
10http://www.alphaworks.ibm.com/tech/marvels (Último acesso em 14 de Novembro de 2010).11http://www.ricoh.com/ (Último acesso em 14 de Novembro de 2010).12http://www.canon.com/ (Último acesso em 14 de Novembro de 2010).
16

Existem outras ferramentas de anotação com descrições em MPEG-7, como o POLYSEMA MPEG-7
Video Annotator 13, MPEG-7 Metadata Authoring Tool (Ryu et al., 2002) ou a Cataloguing Tool (Ro-
vira et al., 2004). Em Tummarello et al. (2004) encontramos uma ferramenta um pouco diferente, onde
são geradas descrições RDF automaticamente, a partir de metadados MPEG-7 proveniente de fontes
heterogéneas.
2.12 Geração de Metadados a Partir de Folksonomias
O uso de folksonomias para a geração de metadados tem sido muito explorado recentemente. Em Al-
Khalifa & Rubart (2008) encontra-se um protótipo para gerar metadados semânticos para recursos web.
As fontes do processo de extração são o título, URL, número de pessoas que marcaram a página como
favorita 14 e lista de etiquetas. Esta informação passa por um filtro de normalização, que pretende
remover o ruído nas etiquetas. Cada etiqueta é associada com um número, a sua frequência num dado
recurso. Em seguida emparelham-se as etiquetas com uma ontologia restrita, que funciona como um
filtro conservativo dos termos. Um sistema semelhante (Al-Khalifa & Davis, 2007) contempla também
um gerador de metadados a partir de folksonomias para descrever recursos CSS. As etiquetas extraídas
são primeiro processadas por filtros. Como exemplos de filtros temos a de conversão para minúsculas,
agrupamento de etiquetas semelhantes, remoção de palavras não inglesas, entre outros. Por fim, faz-se
também o mapeamento numa ontologia.
2.13 Detecção de Referências
As experiências de detecção de referências áudio remontam a 1990, como por exemplo em Lourens
(1990), onde são detectados anúncios apenas a partir do seu áudio. Nessa abordagem, da correlação
entre as assinaturas de energia dos anúncios e da emissão extraem-se os instantes candidatos a uma
correspondência. Estes são identificados nos pontos mínimos da correlação. A correlação só é aplicada
a segmentos cujas propriedades os tornem potenciais candidatos a correspondências, o que permite
optimizar o processo.
Outra abordagem para detecção de referências numa stream áudio é o algoritmo DTW. Este, ao con-
trário da correlação, é flexível em relação à velocidade dos sinais. Calcula o score do melhor alinhamento
entre dois sinais, isto é, o quão semelhantes eles são, segundo critérios definidos (por exemplo, a distân-
cia entre as amostras do sinal). O algoritmo vai ser descrito em detalhe no capítulo 3.
Em Conejero & Anguera (2008) encontramos um sistema cujo objectivo é a detecção e agrupamento
de anúncios, baseado apenas no sinal áudio. O processo de detecção é composto por várias fases. Em
primeiro lugar, é feita a extracção de características MFCC do áudio de entrada, seguido pela detecção
dos instantes de energia mínimos. Em seguida é aplicado um detector de mudança acústica focado
na identidade do orador. Finalmente, segmentam-se os intervalos nos pontos de mudança acústica e
comparam-se os comprimentos dos intervalos obtidos com comprimentos padrão de anúncios conhe-
13http://sourceforge.net/projects/polysemaannot/ (Último acesso em 14 de Novembro de 2010).14Do Inglês, bookmark.
17

cidos. O agrupamento de anúncios é feito comparando cada segmento com uma base de dados de
anúncios. Foram usadas três abordagens para detecção de anúncios: DTW, DTW modificada (com res-
trição à diagonal) e a correlação cruzada generalizada. Mostrou-se que a abordagem baseada num DTW
modificado era a mais acertada. Num conjunto de teste com 3h50m de duração e 135 anúncios, corres-
pondentes a 38 minutos do conjunto, conseguiu-se uma precisão de 81,16% e abrangência de 82,96%.
Outra actividade relacionada com a detecção de referências é a detecção de objectos repetidos, como
apresentado no sistema ARGOS Herley (2006). O objectivo é a detecção de segmentos áudio que se
repetem em janelas temporais diversas, desde algumas horas até mesmo semanas.
2.14 Conclusões do Trabalho Relacionado
Nesta sub-secção pretendemos apresentar uma visão geral tanto dos sistemas e tecnologias descritos
anteriormente, como de outros trabalhos relacionados, tecendo alguns comentários e relacionando os
aspectos de maior interesse, no contexto do sistema a desenvolver.
No estudo realizado pudémos constatar que as folksonomias são uma área de grande interesse prin-
cipalmente por serem uma fonte de dados provenientes de uma inteligência colectiva. Combinando a
informação extraída com uma filtragem guiada por ontologias conseguem obter-se resultados interes-
santes, como indicado por Al-Khalifa & Rubart (2008); Al-Khalifa & Davis (2007) e Wu et al. (2006).
A possibilidade de combinar diversas fontes de informação, não focando apenas no que se pode
extrair directamente do conteúdo audiovisual mas procurando integrar conhecimento da web, é muito
atractiva. Os metadados produzidos são mais completos e diversificados (Pfeiffer et al., 2008).
Nas arquitecturas estudadas encontramos um traço predominante, o padrão arquitectural pipes and
filters, como por exemplo em Meinedo (2008); Kiranyaz et al. (2003) e Pfeiffer et al. (2008). Tal não é
surpreendente pois a extracção de metadados pode ser vista como um processo de refinamento, com-
posição e inferência de informação. Partindo dos dados, obter os metadados. As arquitecturas como a
do MUVIS (Kiranyaz et al., 2003) procuram ser altamente parametrizáveis, através de mecanismos de
plug-ins. Esse aspecto torna-as boas plataformas de prototipagem e avaliação de novos algoritmos de
extração de características.
A ideia de extrapolação de metadados entre recursos proposta por Rodriguez et al. (2009) tem alguns
problemas. Uma escolha pouco rigorosa do critério de semelhança pode levar a extrapolações de meta-
dados que não façam sentido, propagando erroneamente uma ou mais propriedades. Não é analisado
o que acontece se o repositório não for uniforme em termos de propriedades partilhadas. O peso da va-
lidação humana no processo pode tornar-se um ponto de estrangulamento do desempenho do sistema,
se realmente queremos garantir a qualidade dos metadados do repositório. Apesar de tudo, o método
proposto pode ser independente do conteúdo, desde que se estabeleçam correctamente os critérios de
semelhanç.
A utilização de máquinas de estado para modelar a estrutura de programas é muito usada, estando
presente, por exemplo, em Merlino et al. (1997); Meinedo (2008); Zhai et al. (2005). É uma técnica que
permite obter bons resultados seja para identificar segmentos de programas ou para detectar eventos de
18

interesse. Características do áudio e do vídeo condicionam as transições entre estados.
As máquinas de estados têm uma vantagem sobre outros métodos de classificação pois não neces-
sitam de treino prévio, como os modelos de Markov não observáveis15 ou as máquinas de suporte
vectorial. No entanto a máquina de estados tem que ser específica do conteúdo a processar. Mudanças
na estrutura do conteúdo obrigam ao redesenho parcial ou total da máquina de estados. A máquina de
estados de Merlino et al. (1997) contém 22 estados e mais de uma centena de transições, o que a pode
tornar difícil de manter. Nesse sentido, uma crítica que pode ser feita a esse sistema é que a avaliação do
sistema podia ter sido mais extensiva em termos da quantidade de material audiovisual testado. Uma
vez que é usada uma máquina de estados dependente da legendagem, esta determina a qualidade e pre-
cisão do resultados obtidos. É também importante referir que o sistema BNN, ao contrário do sistema
descrito por Meinedo (2008), não realiza o processamento em tempo real. No sistema BNN, um noti-
ciário pode levar mais de 1h para ser completamente segmentado, sendo este um dos pontos propostos
para optimização futura. Dada a diversidade de programas e anúncios numa emissão é de grande in-
teresse a utilização de máquinas de estado para modelar a sua estrutura, desde que sejam isoladas em
módulos fáceis de manter.
Três técnicas muito usadas para classificação são os modelos de markov não observáveis, as máqui-
nas de suporte vectorial e os modelos de misturas gaussianas16. Os primeiros são conhecidos pela sua
capacidade de modelação temporal (Amaral et al., 2006). Usam-se em diversos sistemas para classificar
conteúdo, com bons resultados (Liu et al., 1998a; Meinedo, 2008; Köhler et al., 2001; Gibert et al., 2003). Já
as máquinas de suporte vectorial são apropriadas para situações em que os exemplos a classificar per-
tencem a uma de duas categorias 17. Nos trabalhos de Han et al. (2003); Lin & Hauptmann (2002); Guo
& Li (2003) encontramos aplicações desta técnica ao contexto da classificação de conteúdo multimédia.
As misturas gaussianas (Moore, 2004) são usadas, por exemplo, para classificação do género do orador
e condições de fundo (Meinedo, 2008) e para detectar aplausos, fala e música (Otsuka et al., 2006).
Outra estrutura de classificação é o perceptrão multicamada (MLP), um tipo de rede neuronal ar-
tificial. A sua utilização foi adoptada, por exemplo, em Liu et al. (1998b), Meinedo (2008) e Lamya &
Houacine (2007). São bem conhecidas as suas capacidades discriminatórias de padrões (Amaral et al.,
2006). Uma alternativa às redes neuronais é o algoritmo DTW, que permite alinhar dois sinais de modo
a determinar a sua similaridade. Deve ser combinada com extracção de características, isto é, uma re-
dução dimensional, de modo a beneficiar em termos de desempenho.
A transcrição é uma forma de metadados contemplada em diversos sistemas (Meinedo, 2008; Köhler
et al., 2001; Pfeiffer et al., 2008; Kuwano et al., 2004). A utilização da transcrição como base para ou-
tras classificações deve ser feita com cuidado. Os sistemas de reconhecimento da fala são normalmente
desenhados com um certo domínio em mente, como por exemplo os noticiários. A qualidade do reco-
nhecimento não é garantida para toda e qualquer situação. As palavras-chave e os sumários são também
populares, podendo ser extraídos da transcrição ou directamente do conteúdo. Contudo, a qualidade
15Do Inglês, Hidden Markov Model (HMM).16Do Inglês, Gaussian Mixture Model (GMM).17As SVM’s multiclasse são uma extensão das SVM’s. Como o nome indica, permitem classificação em problemas com múltiplas
classes.
19

da transcrição influencia de forma decisiva os processos que dela dependem, pelo que uma transcrição
incorrecta pode ser um inibidor da qualidade global do sistema.
Para extracção de metadados existem também abordagens baseadas no vídeo, como por exemplo
Chang et al. (1997); Zhang et al. (1995); Boavida et al. (2005); Toklu et al. (2000), e multimodais, como
Köhler et al. (2001); Chen et al. (2004); Pfeiffer et al. (2008). A combinação de anotações visuais e faladas
permite melhorar o taxa de sucesso de um sistema (Köhler et al., 2001).
Uma extracção de informação multimodal é bem exemplificada em Pfeiffer et al. (2008). Nele en-
contramos blocos para extracção de características visuais como detecção de cenas, identificação facial
(também presente em Köhler et al. (2001)) e identificação de objectos; características da fala como identi-
ficação de orador, género e linguagem, tal como em Köhler et al. (2001); Meinedo (2008); interfaces com
a web, e-mail e fax.
A abordagem de modelar o entusiasmo associado a um segmento de áudio (Matos & Pereira, 2008),
aparentemente, não é uma técnica comum. Apesar dos bons resultados descritos, a aplicação foi sujeita
a uma avaliação algo limitada. Escolheram-se apenas duas áreas temáticas, o que nos parece pouco
tendo em conta que o sistema foi proposto para sumarização genérica.
Em muitos sistemas a geração dos metadados não é verdadeiramente automática, pois usam-se fon-
tes de informação que exigem intervenção humana significativa, directa ou indirectamente. O sistema
torna-se menos autónomo e mesmo assim sujeito a erros (Merlino et al., 1997; Alan et al., 2008).
Terminamos esta análise notando que a abordagem mais comum para a geração de metadados é a
semi-automática. Mesmo existindo processos complexos de extracção e combinação de informação há
lugar para um operador humano. A contribuição humana pode ir desde correcções pontuais até ser
completamente indispensável. Tal não é desejável num processo de geração em modo online.
20

Capítulo 3
Desenvolvimento
3.1 Introdução
AO longo deste capítulo vai ser apresentado o desenvolvimento dos elementos do sistema,
abordando diversos aspectos de arquitectura e implementação. Recorde-se que, tal como re-
ferido na Introdução, o objectivo do trabalho é o desenvolvimento de um sistema que habilite
a construção de uma descrição, o mais detalhada possível, de uma emissão televisiva de um canal de
televisão. Essa descrição (os metadados) incide sobre a estrutura e conteúdo da emissão. Este sistema é
um produtor de metadados, gerados a partir do sinal áudio de uma emissão televisiva. O contexto de
comunicação é o produtor-consumidor sem canal de retorno.
O sistema desenvolvido é composto por duas aplicações e um canal de comunicação. Na figura
3.1 encontra-se uma vista de componente e conector que ilustra as relações de alto nível entre as duas
aplicações. O MetadataProducer é a aplicação que fornece um interface para gerir a geração dos me-
tadados, permitindo uma perspectiva de controlo e avaliação sobre os processos executados no sistema.
O PipelineServer encapsula a execução de um subsistema, o Audimus, que realiza a identificação de
referências no sinal de entrada, e transporta os resultados desse subsistema para o MetadataProducer
através de uma ligação TCP/IP. O PipelineServer foi desenvolvido em C/C++ e o MetadataProducer
em C#/.NET 4.0. A escolha de C/C++ foi motivada pela compatibilidade com a base de código exis-
tente. Já o C# foi escolhido pela facilidade de desenho de interfaces no Microsoft Visual Studio 2010,
diversidade de classes de suporte na .NET framework 4.0 e conhecimentos prévios do autor.
Figura 3.1: Vista geral do sistema.
21

Em primeiro lugar vai ser caracterizado o sinal de entrada do sistema, isto é, o que se assume
acerca do sinal aúdio a partir do qual vão ser gerados os metadados. Seguidamente, apresenta-se o
Audimus, um subsistema componente que é essencial na identificação de segmentos conhecidos no
sinal de entrada. Depois são apresentadas as estratégias abordadas para detecção de referências e os
novos componentes Audimus criados para suportar essa actividade. Em seguida, é apresentado o
PipelineServer, que tem um papel de encapsular o Audimus, coordenando a sua execução e comu-
nicando com o MetadataProducer, que será descrito depois. O MetadataProducer é a aplicação
que interage de uma forma mais directa com o utilizador, permitindo a este gerir todo o sistema. Apesar
do desenvolvimento do MetadataProducer e PipelineServer ter sido uma evolução em paralelo,
não independente nem sequencial, será esta a ordem de exposição das mesmas. Por fim, descrevem-se
os detalhes da comunicação entre as duas aplicações.
3.2 Caracterização do Sinal de Entrada
Para o trabalho assumimos que uma emissão tipíca de uma estação de televisão tem como constituintes
dois elementos de alto nível: programas e anúncios. Podemos encontrar blocos de publicidade, isto
é, uma sequência de anúncios delimitada por jingles, entre muitos pares de programas televisivos. No
entanto, não é necessário que entre cada dois programas consecutivos exista um bloco de anúncios ou
até mesmo um jingle. Cada emissão de televisão tem as suas características particulares em termos de
estrutura. Mesmo assim, assumimos que, em geral, existem programas, anúncios e um conjunto de
jingles que tende a separar conteúdos.
Procurou orientar-se o desenvolvimento do sistema à geração de metadados para 24h de uma emis-
são televisiva, devido às aplicações interessantes que traz em termos de emissões televisivas. No en-
tanto, diversos testes foram feitos tendo por base segmentos de áudio menores, também representativos
de resultados atingidos com este trabalho, que podem facilmente ser expandidos.
Assume-se também que o sinal de entrada apresenta baixo ruído e a gravação é digital. Pode haver
variações no sinal de entrada relativamente ao original da emissão mas as fontes de erros não são di-
versificadas como em sinais analógicos. Visto que o trabalho se enquadra num contexto de produção
de metadados, assume-se que este está próximo das fontes do sinal de emissão, tanto fisicamente como
funcionalmente. Isto significa que não há problemas de latência nem interrupção da emissão, e o sinal
recebido é idealmente igual ao original, sem modificações de processos analógicos ou digitais.
3.3 O Sistema Audimus
Uma parte do sistema desenvolvido no presente trabalho integrou-se noutro já existente, denominado
Audimus. A visão aqui apresentada do Audimus é a resultante da experiência adquirida pelo autor
desta dissertação ao longo dos cinco meses em que contactou com o código e sobre ele construiu parte
do sistema apresentado nesta tese, passando por diversas experiências e protótipos mais ou menos
focados no objectivo final. Houve um grande esforço de compreensão e reutilização de elementos já
existentes.
22

Do ponto de vista da execução, o Audimus apresenta uma arquitectura canais-e-filtros1. No Audimus
cada um dos filtros designa-se por Componente2 (Component). Cada Componente tem uma funci-
onalidade que o destaca dos restantes, bem como múltiplas entradas e saídas. Tipicamente, o Com-
ponente vai ler informação das suas entradas, realizar uma operação, e escrever os resultados nas suas
saídas. Efectua estas acções em ciclo, até que não haja mais dados para ler nas entradas ou seja ordenado
para terminar a execução. Nas entradas e saídas do Componente existem espaços de armazenamento
FIFO denominados buffers, que o Componente pode criar ou referenciar aqueles já instanciados por ou-
tros Componentes. Através destas referências para buffers noutros Componentes, formam-se ligações,
criando-se uma rede de nós de processamento a que chamamos pipeline.
Podemos encontrar no Audimus uma grande diversidade de Componentes e buffers, alguns dos
quais serão detalhados adiante. Existem trinta e sete Componentes ou, mais precisamente, tipos de
Componente, e dezasseis tipos de buffer. Os buffers podem ser de entrada, saída ou entrada/saída,
conforme podem sobre eles ser efectuadas, respectivamente, leituras, escritas ou ambas as operações.
Na figura 3.2 ilustra-se um exemplo simplificado de um pipeline. Nela podemos observar quatro
Componentes, com as suas entradas e saídas. Algumas dessas entradas e saídas têm um buffer associado
enquanto outras têm referências para buffers de outros Componentes, definindo assim as interligações
do pipeline. Esta distinção entre buffers e referências para buffers é relevante para compreender os assuntos
que se seguem.
Figura 3.2: Topologia de um exemplo simplificado de um pipeline do Audimus.
O pipeline é especificado através de um ficheiro de configuração XML, denominado ficheiro de confi-
guração de arquitectura do pipeline (Architecture Configuration File). Um exemplo deste artefacto encontra-
se no anexo A.
Outro conceito importante é o de macro Componente (MacroComponent). Um MacroComponent
é uma especialização de Component cuja particularidade é conter outros Componentes. Contudo, a
sua utilização não é arbitrária. Em cada pipeline tem de existir um e só um MacroComponent que o
envolve, também especificado no ficheiro de configuração de arquitectura. Na figura 3.3 está ilustrada
esta composição.
1Do Inglês, pipes-and-filters.2A escrita da palavra “Componente” e não “componente” serve para diferenciar entre o conceito presente no Audimus e o
conceito de arquitectura de software apresentado em (Clements et al., 2003).
23

Figura 3.3: Ilustração da relação entre MacroComponent e Component.
Um MacroComponent, sendo um Componente, tem entradas e saídas. No entanto, tem uma e só
uma entrada e uma e só uma saída, ao contrário de um Componente que tem uma ou mais entradas e
uma ou mais saídas. Um dos Componentes do pipeline pode referenciar, numa das suas entradas, o buffer
instanciado na entrada do MacroComponent. Um dos Componentes do pipeline pode referenciar, numa
das suas saídas, o buffer instanciado na saída do MacroComponent. Por outro lado, a entrada e saída
do MacroComponent podem não ser utilizadas por Componentes. A decisão de usar uma entrada do
MacroComponent como entrada do pipeline fica a cargo de quem escreve o ficheiro de configuração de
arquitectura. O mesmo se passa com a saída do MacroComponent.
Dos inúmeros Componentes existentes apenas vão ser detalhados adiante aqueles que foram de-
senvolvidos no contexto desta dissertação e que têm relevância para este capítulo: DTWComponent e
DTWStateMachineComponent. Na hierarquia de classes dos buffers encontramos os buffers de entrada
(herança simples de InputBuffer), os buffers de saída (herança simples de OutputBuffer) e os buf-
fers de entrada/saída (herança múltipla de InputBuffer e OutputBuffer). No anexo B encontra-se
a documentação técnica sumária de um buffer desenvolvido no contexto do trabalho.
No sistema Audimus existe também a entidade Item. Até agora foram apresentados os nós de
processamento do pipeline e as interconexões entre esses nós. O Item é uma generalização de uma
unidade de informação do pipeline, isto é, representa um elemento básico de informação no pipeline.Das
várias especializações de Item existentes, a que mais interessa apresentar aqui é o FrameItem. O
FrameItem representa um frame genérico, ou seja, um contentor de bytes que podem representar, por
exemplo, uma amostra de áudio ou resultado de um algoritmo.
Na figura 3.4 encontra-se um diagrama de classes das entidades já apresentadas. O MacroComponent
contém um ou mais Components, um Component tem (ou referencia) pelo menos dois buffers: um ou
mais de entrada (InputBuffer) e um ou mais de saída (OutputBuffer). Um buffer tem uma lista de
Items. Note-se que um Item pode estar associado a um buffer ou a nenhum buffer, caso em que está as-
sociado a um Component. Quando um Item é lido de um buffer por um Component, esse Item passa
a estar sob controlo do Component, sendo eliminada a associação com o buffer. Como consequência,
observe-se que um buffer só pode ser lido por um e só um Component. A nível do ficheiro de configura-
ção de arquitectura isso significa que um buffer só pode ser referenciado por um e só um Componente.
Suponha-se que dois Componentes têm uma referência para um dado buffer e que, num dado mo-
mento da execução do pipeline, existe nesse buffer um Item disponível para ser lido. O primeiro com-
ponente lê o Item com sucesso, sendo este retirado do buffer. Quando o segundo Componente tentar
24

ler desse buffer vai concluir que não existem Items para ler. Como consequência, o comportamento
do pipeline não seria o desejado. Uma forma mais simples de exprimir esta ideia é dizer que um buffer
não pode estar ligado a mais do que um Componente. Caso haja necessidade de o fazer, pode recorrer-
se a uma especialização de Componente criada para esse fim, o Splitter. Um Splitter serve de
intermediário entre um buffer e múltiplos Componentes interessados em realizar leituras desse buffer.
Cada Item disponível no buffer é copiado tantas vezes quantas as necessárias para garantir que todos
os Componentes têm uma cópia desse Item. Na figura 3.5 está ilustrado esse fragmento de arquitectura
de pipeline.
Figura 3.4: Diagrama de classes das entidades já apresentadas.
Figura 3.5: Ilustração do fragmento do pipeline correspondente a um splitter.
Em termos de execução, cada Componente do pipeline é executado numa thread própria em que o
método run é o seu ponto de entrada. O código dos buffers pode ser executado em múltiplas threads,
conforme quem invoca a operação de leitura ou escrita.
Uma forma de comunicação do pipeline com o seu exterior são os eventos. Um evento (Event) é
uma mensagem emitida a partir de um Componente e cujo destino é uma qualquer entidade do tipo
EventListener, que se tenha declarado como receptora de eventos do pipeline. A comunicação segue
o modelo de event/callback e, sendo unidireccional, não permite que um Componente receba mensagens
oriundas do exterior do pipeline. Cada evento tem um identificador, um marcador temporal com o
instante da sua criação e uma colecção de propriedades, cada uma também com o seu identificador.
25

3.4 PipelineServer
Para interligar o pipeline com uma aplicação externa criou-se o PipelineServer, que o encapsula
e disponibiliza um ponto de controlo e report de eventos, que segue um protocolo de comunicação
também desenvolvido de raíz. Uma vista de componentes do PipelineServer encontra-se na figura
3.6.
Figura 3.6: Principais componentes do PipelineServer.
O pipeline Audimus subjacente é controlado pelo componente PipelineController. A sua finali-
dade é controlar a execução do pipeline de modo a que este execute a tarefa especificada, de acordo com
o especificado no ficheiro de configuração de arquitectura. Mantém também uma máquina de estados,
representada na figura 3.7, que acompanha o estado interno do pipeline, impedindo que se executem
operações inválidas sobre o pipeline.
Figura 3.7: Máquina de estados do PipelineController.
O pipeline inicia a sua actividade no estado UNLOADED, significando que ainda não foi carregado
nenhum ficheiro de configuração de arquitectura. Quando se cria o pipeline (operação create) a confi-
guração é carregada e o estado transita para STOPPED, significando que o pipeline ainda não está em
26

execução. A operação start coloca o pipeline em execução, transitando este para o estado EXECUTING.
Em seguida, o componente aguarda que a execução termine (operação wait), finaliza o pipeline (operação
destroy) e regressa ao estado inicial. A remoção de listeners de eventos pode ser feito em qualquer estado
do pipeline.
A sequência de execução do pipeline é, no caso sem erros: create . register . start . wait . unregister . des-
troy. No final destas operações o pipeline está pronto para iniciar nova execução. Esta sequência de opera-
ções está encapsulada no único método que o componente fornece para o exterior, visto ser a única ope-
ração que é relevante do ponto de vista de serviços para o componente PipelineServerEndpoint.
Em caso de erro o pipeline é finalizado (operação destroy), regressando ao estado UNLOADED.
A arquitectura do pipeline usado no sistema para detecção de referências encontra-se detalhado na
figura 3.8. São extraídas as características PLP do áudio de entrada, através do Componente Rasta.
Em seguida, no Componente Splitter, essas características são distribuídas por vários Componentes
DTW. Cada Componente DTW está especializado em calcular o score do melhor alinhamento entre uma
janela das características do áudio de entrada e as características de uma dada referência, aplicando o
algoritmo DTW com tolerância diagonal tal como descrito na sub-secção 3.5.2. O score de cada janela é
transportado para uma máquina de estados DTW, que determina quais os mínimos locais desses valores.
Note-se que temos tantos pares <DTW, máquina de estados DTW> quantas as referências que queremos
detectar. Cada máquina de estados emite um evento assim que é identificado um mínimo local do
score. O Componente de cálculo dos scores é o DTWComponent e a máquina de estados é o Componente
DTWStateMachineComponent.
Figura 3.8: Arquitectura do pipeline Audimus usado para detecção de referências.
O PipelineServerEndpoint é a porta do PipelineServer para o exterior. Este gere a ligação
27

com o MetadataProducer, processando comandos recebidos e enviando eventos descritos em XML.
Na secção 3.8 encontra-se informação detalhada sobre o protocolo de comunicação. Recebe eventos do
pipeline Audimus, pois em cada execução regista-se nele como event listener. Sempre que um evento é
emitido a partir da máquina de estados DTW no pipeline, o PipelineServerEndpoint é notificado
através de uma callback. Nesse instante, o evento é serializado para a sua representação em XML e envi-
ado para o MetadataProducer numa mensagem apropriada. Quando o PipelineServerEndpoint
recebe uma mensagem de pedido de execução do pipeline, este trata de invocar no PipelineController
a operação de execução do pipeline.Na implementação actual apenas é permitido que, num dado ins-
tante, um MetadataProducer esteja ligado a um PipelineServer. Apesar disso, o sistema foi de-
senhado para que facilmente se possa avançar para um cenário com múltiplos MetadataProducers.
3.5 Detecção de Referências
O sistema desenvolvido tem como processo fundamental de suporte a detecção de referências num sinal
de entrada, tipicamente um ficheiro áudio de uma emissão televisiva. No entanto, o sistema é sufici-
entemente genérico para que se possa considerar uma plataforma de gestão e detecção de referências,
isto é, um conjunto de ferramentas para gestão e identificação de referências, bem como elaboração de
relatórios com resultados. O problema da detecção de referências consiste em identificar, num sinal
áudio, denominado base, todos os instantes em que se encontra uma instância de um dado segmento,
denominado referência. As instâncias não têm que ter o mesmo padrão de bits da referência, havendo
espaço para variações.
3.5.1 Detecção de Referências com MLP
A primeira abordagem ao problema de detectar uma referência áudio foi a utilização de MLP. Um MLP
é um tipo de rede neuronal artificial que, após treinada, identifica um conjunto de padrões pré estabe-
lecidos. Foi desenvolvido um conjunto de scripts de suporte ao treino de redes neuronais. Estes scripts,
descritos no anexo C, foram desenvolvidos, de raíz, em python. Isto deveu-se ao facto de todos os
scripts e materiais de apoio existentes se destinarem à utilização em Linux. Os scripts necessários foram
reescritos e foi feita uma cópia local de conteúdos existentes no AFS.
Em seguida, e para uniformizar e agilizar o processo de treino de referências, foi desenvolvida uma
aplicação cujo interface se encontra no anexo D. Esta aplicação permite coordenar a execução de todos
os scripts necessários para o treino da referência, isto é, a geração dos pesos da rede neuronal usada na
detecção de uma dada referência.
Começámos por tentar detectar um jingle num segmento áudio. Devido aos bons resultados de
Meinedo (2008) com esta técnica. O processo de treino e detecção encontra-se esquematizado na figura
3.9.
No treino são apresentados à rede um conjunto de segmentos representativos do padrão a reconhe-
cer (exemplos positivos) e um conjunto de segmentos representativos de tudo o que não é o padrão
(exemplos negativos ou “mundo”). Neste trabalho, esses segmentos são uma variação do jingle que se
28

Figura 3.9: Processo de treino e detecção de referências.
pretende identificar e são gerados através da variação da amplitude da referência original, que na fi-
gura 3.9 é X.raw. Em seguida, gera-se um PFile que é usado na geração dos pesos da rede neuronal.
Mais informação sobre PFiles encontra-se no anexo E. A detecção consiste em usar a rede neuronal para
classificar cada janela do sinal de entrada (input.raw).
Na secção 4.3 podemos ver que esta abordagem não teve os resultados esperados para se qualificar
como parte da solução final. Através de inspecção de configurações e parâmetros de treinos já existentes,
a par de muito esforço e tempo investido, não foi possível identificar os problemas que estiveram na ori-
gem dos fracos resultados da detecção de jingles usando os MLPs. Após alguma reflexão e investigação
de trabalho relacionado, sintetizada na sub-secção 2.13, esta abordagem foi abandonada.
3.5.2 Detecção de Referências com DTW
Depois dos resultados insatisfatórios dos MLPs, realizou-se uma pesquisa para determinar outras abor-
dagens para discriminação de padrões no contexto da detecção de referências áudio em emissões televi-
sivas. O algoritmo DTW destacou-se como alternativa pela sua simplicidade de implementação e bons
resultados demonstrados.
Este algoritmo, na sua versão mais simples, calcula o score do melhor alinhamento entre duas sequên-
cias que podem variar no tempo. No nosso caso uma das sequências é a base e outra a referência. A
referência é o padrão a identificar e a base é a informação onde procurar. As seqências não contêm amos-
29

tras áudio mas sim vectores de características PLP extraídas do áudio, tanto da base como da referência.
A finalidade de aplicar a DTW a características e não directamente a amostras áudio é a garantia de uma
redução dimensional dos sinais a comparar, tornando o processo mais eficiente.
Na listagem 3.1 encontra-se o pseudo-código do algoritmo DTW, na sua versão básica. O algoritmo
calcula o score do melhor alinhamento entre os dois vectores de entrada. Uma matriz é construída
usando técnicas de programação dinâmica, em que o custo de cada entrada na matriz é a soma da
distância entre dois elementos dos vectores e o valor mínimo de três dos vizinhos dessa entrada, que
representam um insert, delete ou match no alinhamento.
1 funct ion dtw ( vec tor x [ n ] , vec tor y [m] ) :
matrix DTW[ 0 . . n , 0 . .m]
3 for k = 1 . . n :
DTW[ 0 , k ] = i n f i n i t y
5 for k = 1 . .m:
DTW[ k , 0 ] = i n f i n i t y
7 DTW[ 0 , 0 ] = 0
for i = 1 . . n :
9 for j = 1 . .m:
c o s t = d i s t ( x [ i ] , y [ j ] )
11 DTW[ i , j ] = c o s t + min (DTW[ i −1, j ] , DTW[ i , j −1] , DTW[ i −1, j −1])
return DTW[ n , m]
Listagem 3.1: Pseudo-código da versão simples do DTW.
Foi feita uma primeira implementação do algoritmo DTW num protótipo totalmente isolado do sis-
tema Audimus. Essa implementação passou por várias fases de avaliação e optimização iterativa, da
qual resultou um protótipo para aplicar o DTW. O protótipo recebe os PFiles do áudio base e da referên-
cia e calcula o score do melhor alinhamento entre cada janela da base e a referência. Na figura 3.10 está
ilustrado este processo.
Figura 3.10: Processo de cálculo de scores do DTW entre uma base e uma referência.
A avaliação e optimização deste protótipo encontra-se descrita na secção 4.4.
A optimização mais significativa feita ao algoritmo é a denominada restrição diagonal. O algoritmo
DTW, tal como foi implementado, constrói uma matriz para cada comparação entre base e referência.
Essa matriz é quadrada, contendo N × N elementos. Sem esta optimização, todos os elementos são
30

calculados. Com a optimização através da restrição diagonal, apenas são calculados os elementos numa
faixa da diagonal principal da matriz. A restrição diagonal tem uma tolerância, parametrizável, que
indica, para cada linha da matriz, quantos elementos vizinhos da diagonal principal são calculados. Na
figura 3.11 encontra-se um exemplo, onde são indicados os elementos calculados numa matriz 10× 10 e
usando restrição à diagonal de 30%. Em cada linha, são calculados, no máximo 30%N elementos.
Figura 3.11: Elementos calculados numa matriz DTW 10× 10 usando restrição diagonal com tolerância 30%.
3.6 Novos Componentes Audimus para Detectar Referências
3.6.1 DTWComponent
No Audimus já existia um Componente para cálculo de DTW. No entanto, segundo apurado, a docu-
mentação era inexistente, a pessoa que o criou já não se encontrava disponível para esclarecimentos e
havia problemas de funcionamento não totalmente compreendidos. Perante este cenário, e após uma
breve inspecção ao código fonte, decidiu-se eliminar o Componente existente e criar um novo. Depois
da implementação do DTW em protótipo isolado estar terminada e testada, colocou-se o código num
Componente novo do Audimus, o DTWComponent.
Para esta integração foi necessário descobrir e explorar vários conceitos e interacções existentes no
Audimus. As descobertas principais já foram apresentadas na secção 3.3. Foram implementados incre-
mentalmente Componentes de funcionalidade reduzida (HelloWorld, HelloProducer,
HelloConsumer, HelloEvents) com vista a perceber o funcionamento do sistema Audimus. As
aprendizagens resultantes destas implementações contribuiram para o desenvolvimento dos anexos F e
G.
Este Componente tem duas entradas, ambas buffers de FrameItems, de onde lê as características PLP
da referência e da base. As características da referência são lidas no início da execução do componente,
e ficam armazenadas em memória. Em seguida, lêem-se janelas sucessivas de características da base,
em número igual às características lidas da referência, e aplica-se o algoritmo DTW optimizado com
restrição diagonal. Por cada janela analisada é colocado, na saída do Componente, o score respectivo. A
saída também é um buffer de FrameItems.
A dificuldade desta parte do trabalho residiu essencialmente na construção de um Componente no
Audimus. A migração do código do protótipo já desenvolvido em separado para o novo Componente
31

decorreu sem problemas significativos. Note-se que este componente opera num modo online, isto é, o
score de uma janela é escrito na saída assim que é calculado.
No anexo H encontra-se a documentação técnica sumária deste Componente.
3.6.2 DTWStateMachineComponent
Para detectar uma referência não basta calcular os scores do DTW para cada janela, é também necessário
analisar a sequência de scores ao longo do tempo e perceber onde se encontram os valores mínimos.
As janelas da base para as quais o score da DTW é mínimo, são potenciais hits, isto é, correspondem
a instantes de tempo em que se identifica positivamente a referência em questão. Esta abordagem de
identificar os mínimos tem dois problemas. O primeiro é o problema do limiar, isto é, como determinar
um valor limiar do score, abaixo do qual se considera que uma determinada janela corresponde a um hit.
Há que dar alguma margem de erro para o score e não seguir a abordagem radical de apenas aceitar hits
com score igual a zero (correspondência absoluta entre a referência e a janela analisada). A escolha deste
limiar tem um impacto crucial nos resultados da detecção, pelo que foi afinado de acordo com experiên-
cias sumarizadas no capítulo 4. O segundo problema é o da identificação de mínimos locais, isto é, como
delimitar um intervalo de tempo sobre o qual determinar o mínimo. Como se pretendeu desenvolver
este Componente numa perspectiva online, isto é, com o objectivo de identificar as referências assim que
possível (e não só após ter consumido todo o sinal de entrada). Na figura 3.12 vemos representada uma
região em que se encontra um hit. Está definido um limiar que separa duas regiões, ABOVE e BELOW.
Elas representam regiões em que o score está acima e abaixo do limiar, respectivamente.
Figura 3.12: Gráfico dos scores do DTW numa região em que se encontra um hit.
O racional para a detecção da referência é o seguinte. As janelas do início da referência correspondem
aos scores mais baixos de cada sequência de janelas que estão completamente abaixo do limiar. Deste
modo, para detectar o instante de início de uma referência basta determinar a janela que apresenta o
score mínimo numa dada sequência. O valor mínimo só pode ser assinalado definitivamente no ponto
da transição para a região acima do limiar, pelo que o instante correspondente, t̂hit, é uma aproximação
32

do verdadeiro instante do hit, thit. No entanto, como será mostrado na Avaliação, estamos a falar de
desvios na ordem dos milisegundos, que, na nossa opinião, não são significativos no contexto em que o
trabalho se enquadra.
Para realizar esta análise automaticamente foi desenvolvida uma máquina de estados, que consiste
em dois estados, ABOVE e BELOW, conforme a região onde se encontra o gráfico do scores. Nas transições
BELOW → ABOVE é emitido um evento que assinala a detecção da referência em questão. Opcional-
mente, os resultados da detecção, incluindo transições, podem ser escritos num ficheiro.
A entrada do Componente consiste num buffer de FrameItems, em que cada FrameItem contém
um float com o último score calculado pelo componente DTWComponent. A saída do Componente não
é relevante e deve ser ignorada. Os resultados da detecção de referências são divulgados, como já foi
explicado, através da emissão de um evento e escrita em ficheiro de log. Note-se que este componente
também opera num modo online.
Em termos de evolução, este processo começou por ser um script MATLAB para análise manual
dos scores do DTWComponent. Com a convergência para o desenvolvimento em Audimus, o código foi
transformado numa classe C++ que ultimamente foi a base para o DTWStateMachineComponent.
Mais informações podem ser encontradas no anexo I, que contém a documentação técnica sumária
deste Componente.
3.7 MetadataProducer
O processo de geração dos metadados é partilhado também com o MetadataProducer, uma aplicação
que se liga a um PipelineServer, podendo controlá-lo e receber notificações de eventos que corres-
pondem a detecções de referências no pipeline. Faz também a ponte com o utilizador, através de um
conjunto de interfaces. As principais funcionalidades percepcionadas pelo utilizador são:
• Adicionar, remover e modificar um conjunto de referências a detectar pelo pipeline;
• Adicionar, remover e modificar um conjunto de pipeline jobs, que são tarefas de detecção aplicadas
a um ou mais ficheiros áudio;
• Controlar a execução de um pipeline remoto, através da comunicação com um PipelineServer;
• Detectar referências usando uma de duas estratégias, full e boundary, detalhadas na sub-secção
3.7.1;
• Gerar relatórios com os resultados de uma execução do pipeline. Um exemplo do relatório gerado
pelo MetadataProducer, contendo resultados de uma detecção, pode ser encontrado no anexo
J;
• Assinalar segmentos desconhecidos no áudio a processar, permitindo que sejam analisados pelo
utilizador, e possivelmente realimentados no sistema como novas referências.
33

Screenshots dos diversos interfaces existentes para suportar estas e outras funcionalidades são apre-
sentadas no anexo K. Para suportar estar funcionalidades, um conjunto de processos tem de ser efectu-
ado nos bastidores. O interface gráfico é apenas um de vários componentes do MetadataProducer.
Uma vista de componentes do MetadataProducer encontra-se na figura 3.13.
Figura 3.13: Principais componentes do MetadataProducer.
Dentro do MetadataProducer, o componente que gere toda a comunicação com o PipelineServer
é o PipelineClient. Nesse componente encontram-se métodos de: 1) gestão da comunicação; 2)
abstracção dos serviços do pipeline; 3) recepção e processamento de eventos. Para gestão da comuni-
cação TCP/IP existem métodos para iniciar e terminar ordeiramente a ligação, bem como uma propri-
edade que indica o estado da mesma. Os serviços do pipeline abstraídos são dois, um para definir o
ficheiro de configuração de arquitectura a usar no pipeline e outro para iniciar uma execução do pipe-
line. Relativamente ao processamento de eventos, existe um ciclo de recepção de mensagens oriundas
do PipelineServer. Estas mensagens são detalhadas na secção 3.8. Este ciclo é iniciado com uma
execução do pipeline e só é terminado quando é recebida a mensagem que indica a finalização dessa
execução.
Quando uma mensagem é recebida, o PipelineClient verifica se é um evento serializado ou uma
resposta a um comando previamente enviado. Caso seja um evento serializado, este é deserializado
e transformado num objecto em memória do tipo PipelineEvent. Este evento é armazenado local-
mente, pois apenas será processado após todos os eventos relativos a uma execução do pipeline serem
recebidos. Os eventos recebidos são ordenados de acordo com o seu hit time, ou seja, o instante em
que foi detectada a referência respectiva. Caso seja a reposta a um comando, então terá que ser um co-
mando de execução de pipeline, pois enquando o pipeline está numa execução, outra não pode ter início.
34

O ciclo de recepção de comandos é terminado ordeiramente e notifica-se o GUI que a execução termi-
nou. Essa notificação é feita pela invocação do delegate 3 OnExecutePipelineCompletedNotify,
passando como argumento o resultado da execução, seja sucesso ou falha.
Quando a execução do pipeline termina, é invocado o método de processamento de eventos. Os
eventos que foram sendo recebidos ao longo da execução do pipeline, ordenados temporalmente, são
passados, um a um, como argumento, ao delegate OnPipelineEventReceivedNotify. O compo-
nente PipelineEventProcessorChain está subscrito ao delegate event hook, de forma a passar cada
evento recebido através de uma cadeia de processadores de eventos, ilustrada na figura 3.14.
Figura 3.14: Cadeia de processamento de eventos.
O componente PipelineEventProcessorChain implementa um gestor de processadores de even-
tos, inspirado no padrão InterceptingFilter 4. Há dois processadores de eventos, um para cada modo
de detecção de referências (ver sub-secção 3.7.1). O processador BoundaryReferenceProcessor
especializa-se na detecção de referências cuja estratégia de detecção é boundary, explicada adiante na
sub-secção 3.7.1. Caso uma referência não seja detectada neste processador, o evento é passado ao se-
guinte, o processador FullReferenceProcessor, que se dedica à detecção de referências em cujo
modo de detecção é o full. Ambos os processadores necessitam de aceder ao repositório de referências
do MetadataProducer, para obterem informação sobre as mesmas.
Quando um dos processadores detecta uma referência, invoca o delegate
OnReferenceMatchDelegate, passando como argumento um objecto ReferenceMatch. O inter-
face ReferenceMatchesForm vai ser então notificado dessa identificação e apresenta a referência de-
tectada para o utilizador. O processo repete-se para todas as referências detectadas de modo a que no
final da execução do pipeline estas sejam apresentadas no interface. Se um evento recebido não conduz à
detecção de uma referência, ele é ignorado mas tal facto fica registado nos logs do MetadataProducer,
para eventuais averiguações.
No MetadataProducer o utilizador gere um conjunto de referências que pretende que o sistema
detecte. Cada referência tem, entre outras propriedades, um identificador único, um título, etiquetas
textuais, um modo de detecção e um limiar DTW associado. O identificador e o limiar DTW são es-3http://msdn.microsoft.com/en-us/library/900fyy8e%28VS.71%29.aspx (Último acesso em 14 de Novembro
de 2010).4http://java.sun.com/blueprints/corej2eepatterns/Patterns/InterceptingFilter.html (Último acesso
em 14 de Novembro de 2010).
35

pecialmente importantes para saber como parametrizar os Componentes do pipeline que se dedicam à
detecção dessa referência.
Note-se que a arquitectura do pipeline tem de ser configurada de modo a suportar a identificação
das referências existentes, no modo de detecção e limiar DTW respectivos. Antes de cada execução do
pipeline, é enviado o comando de definição de ficheiro de configuração de arquitectura, em que esse fi-
cheiro descreve a arquitectura do pipeline necessária para a detecção das referências seleccionadas. Este
ficheiro é gerado antes de cada execução, e define uma estrutura como se explica em seguida. Cada
referência cujo modo de detecção é full vai dar origem a um par de Componentes: DTWComponent
e DTWStateMachineComponent. O primeiro Componente é parametrizado com o PFile da referên-
cia a detectar. O segundo Componente é parametrizado com o limiar para o score a usar para essa
referência. Ambos recebem também o identificador da referência. O modo de detecção da referência
boundary é implementado no pipeline através da instanciação de duas detecções em modo full, uma para
cada extremo da referência a detectar, denominados begin e end. Os identificadores associados aos pares
DTW+StateMachine para cada extremo são a concatenação do identificador da referência original com
_begin e _end, respectivamente. Isto permite ao MetadataProducer diferenciar os eventos do pi-
peline relativos às fronteiras de uma detecção em modo boundary dos eventos relativos a detecções em
modo full.
É importante notar que os eventos são tratados internamente à medida que são recebidos mas ape-
nas são apresentados ao utilizador no final da execução do pipeline sobre o segmento áudio de entrada.
Inicialmente todo o sistema estava pensado para um funcionamento online. No entanto, durante a im-
plementação apercebemo-nos que o facto de cada Componente ser executado numa thread separada,
leva a que diferentes Componentes processem o mesmo ficheiro de entrada a diferentes velocidades,
pelo que os eventos que geram não são recebidos necessáriamente pela ordem temporal relativa ao fi-
cheiro de entrada. Isto significa que para duas referências distintas, presentes no áudio de entrada nos
instantes t1 e t2, respectivamente, com t1 < t2, os instantes dos eventos que as assinalam, e1 e e2, respec-
tivamente, podem não verificar e1 < e2. A primeira abordagem para este problema foi a implementação,
no PipelineClient, de um buffer de reordenação de eventos. A custo de um atraso de menos de um
segundo foi possível, em alguns casos de teste, ordenar os eventos sem adiar toda a ordenação para o
final. No entanto, experiências posteriores exigiram que se aumentasse o tempo de atraso para orde-
nação, aproximando a solução desenvolvida de uma ordenação global, que foi a solução adoptada na
versão final. Houve claramente um compromisso entre a funcionalidade completamente online do sis-
tema face à correcção e simplicidade da solução. Optou-se pela correcção e simplicidade, que, na nossa
opinião, são aspectos de maior valor para o trabalho.
Finalmente, o MetadataProducer pode ser parametrizado manualmente em alguns aspectos do
seu funcionamento. Os detalhes da sua parametrização estão no anexo L.
3.7.1 Estratégias de Detecção de Referências
Foram desenvolvidas duas estratégias de detecção de uma referência. A primeira estratégia, denomi-
nada full, consiste em identificar numa stream audio um segmento definido à partida, aplicando o algo-
36

ritmo DTW em conjunto com a máquina de estados DTW, parametrizada com um limiar. A segunda
estratégia, denominada boundary, resultou da constatação de que, à medida que a duração da referência
aumenta, o desempenho diminui quadraticamente. Nesta estratégia usam-se as fronteiras da referência
como duas sub-referências a detectar, denominadas begin e end, respectivamente as fronteiras de início
e fim da referência. Se essas duas sub-referências são detectadas em instantes tais que o intervalo por
elas formado tem a duração esperada para a referência, então assinala-se um hit para essa referência.
Ambas as fronteiras são detectadas em modo full. Os dois eventos provenientes do PipelineServer
que assinalam as fronteiras contêm um identificador que permite ao MetadataProducer saber que
referência elas delimitam.
Como ilustrado na figura 3.15, as fronteiras de início e fim, com duração B, são detectadas, res-
pectivamente, nos instantes tbegin e tend. A duração real da referência R é D e duração estimada é
D′ = tend − tbegin + B. O erro de duração é, portanto, a diferença e = D − D′. Para que seja assina-
lado um hit na referência R são necessárias três condições: 1) o identificador das fronteiras é o mesmo
de R; 2) o valor absoluto do erro de duração, e, é menor que uma tolerância, boundaryTol, ou seja,
|e| < boundaryTol; 3) não ocorrem outros eventos entre os que assinalam as fronteiras.
Figura 3.15: Estratégia boundary de detecção de referência.
A estratégia de detecção boundary é apropriada para anúncios e outros segmentos de duração supe-
rior à dos jingles (≈ 5s) A avaliação inicial do primeiro protótipo desta estratégia encontra-se na secção
4.4. Uma avaliação mais detalhada pode ser encontrada na sub-secção 4.6.1, onde esta estratégia se uti-
lizou para detectar um conjunto de anúncios e apresentar uma prova de conceito da funcionalidade do
sistema.
37

3.8 Protocolo de Comunicação
As aplicações MetadataProducer e PipelineServer comunicam numa óptica de mestre-escravo. O
papel de escravo é do PipelineServer, que reporta os eventos do pipeline para o MetadataProducer.
Este, por sua vez, processa os eventos recebidos e controla o PipelineServer em termos de configu-
ração e execução do pipeline subjacente. A comunicação assenta sobre sockets em modo stream sobre
Internet (TCP/IP socket). A ligação é persistente ao longo das diversas mensagens enviadas. Após o
MetadataProducer estabelecer a ligação com o PipelineServer, esta mantém-se persistente ao
longo de diversas interacções, até que seja terminada pelo utilizador ou devido a erros.
As mensagens entre as aplicações têm um tipo e argumento, separados pelo carácter ’:’. A essa
informação junta-se o seu comprimento, indicado nos primeiros 4 bytes enviados como prefixo de toda
a comunicação. Esta estrutura denomina-se pacote do protocolo de comunicação e está ilustrada na
figura 3.16.
Figura 3.16: Estrutura de um pacote do protocolo de comunicação.
O tipo, separador e argumentos da mensagem são codificados em ASCII. O comprimento é um in-
teiro sem sinal, transmitido em network order. Foi codificada uma camada de funções, em C# e C++, que
permitem isolar ambas as aplicações dos detalhes do protocolo, e lidar apenas com mensagens, os seus
tipos e argumentos. Na tabela 3.1 encontram-se os vários tipos de mensagens do protocolo, os seus ar-
gumentos e descrição, agrupados pelo seu sentido. Os comandos são enviados do MetadataProducer
para o PipelineServer e as respostas vice-versa. Todos os comandos têm uma resposta assim que
são executados. No caso da execução do pipeline isso só acontece, naturalmente, quando esta termina.
3.8.1 Descrição XML dos Eventos Audimus
Para descrever os eventos foi necessário perceber exactamente que informação neles está contida. Para
isso começou por se analisar a classe que modela eventos no código fonte do Audimus, Event.
Foi escolhida uma representação XML compacta para um evento, exemplificada na listagem 3.2. Os
atributos do evento são atributos do nó raíz do XML. O nó raíz tem uma sequência de nós filhos, as
propriedades, identificadas pelo atributo ID. O texto interno de cada nó é o valor da propriedade. Esta
representação permite um mapeamento exacto da classe que modela eventos no Audimus para a sua
serialização em XML.
A escolha de sockets TCP/IP e XML como tecnologias de suporte à comunicação tem vantagens e
38

Tipo Argumento Descrição
MetadataProducer→ PipelineServer
SetConfigurationFileName fileName Definir fileName como ficheiro actual de configu-
ração de arquitectura a usar pelo pipelineExecutePipeline Executar o pipeline.
PipelineServer→ MetadataProducer
OK command Comando command executado com sucesso.ERROR errorMessage Erro na execução do último comando. A mensagem
de erro é errorMessage.EVENT eventXML Chegada de um evento do pipeline, serializado no
XML eventXML.
Tabela 3.1: Tipos de mensagens no protocolo.
desvantagens. Como principais desvantagens temos: 1) latência adicional na comunicação comparati-
vamente a uma invocação de função; 2) complexidade adicional na comunicação; 3) consequente esforço
de programação. No entanto há claras vantagens, sendo as mais significativas: 1) maior independência
entre aplicações; 2) utilização de tecnologias padronizadas; 3) reutilização de bibliotecas de software.
Fora implementados módulos de serialização/deserialização de eventos tanto no PipelineServer
(EventToXMLTransformer) como no MetadataProducer (XMLToEventTransformer).
<event ID= ’ 2311 ’ timestamp= ’ 1284204919 ’>
<property ID= ’ 6 ’ > <![CDATA[ hel lo , <xml/> event .]] > </ property >
</event >
Listagem 3.2: Exemplo de representação XML de evento.
39


Capítulo 4
Avaliação
4.1 Introdução
AO longo do desenvolvimento do trabalho foi sendo feita uma avaliação a diversos aspectos do
trabalho. A avaliação constante permitiu identificar problemas de software e oportunidades
de melhoria. Os dois ângulos principais da avaliação foram o conteúdo e o desempenho. O
conteúdo diz respeito ao que é identificado numa detecção de referências e como se relaciona com o
que se pretendeu identificar, ou seja, diz respeito aos metadados gerados. No desempenho procurámos
medir aspectos relacionados com a duração e instantes de tempo. Este capítulo reúne as experiências
mais significativas realizadas ao longo da dissertação e respectivos resultados, os quais contribuiram
para demonstrarmos a qualidade do sistema desenvolvido.
Na secção seguinte explica-se a metodologia de avaliação. Nas secções restantes apresentam-se os
principais momentos de avaliação. A ordem dessas secções está de acordo com a ordem temporal da
evolução do trabalho, ilustrada na figura 4.1. Houve, naturalmente, um maior foco na avaliação da
versão final do sistema.
Figura 4.1: Fases da evolução do trabalho.
Na tabela 4.1 encontram-se as especificações da máquina usada na avaliação do trabalho.
Característica Valor
Processador Intel Core i5 M 520 2.40 GhzMemória 8GB DDR3 SDRAMSistema Operativo Windows 7 Home Premium x64
Tabela 4.1: Especificações mais relevantes da máquina de testes.
41

4.2 Metodologia
Na literatura analisada encontramos com frequência uma técnica para a avaliação de sistemas de ge-
ração de metadados. Essa técnica passa pelo estabelecimento de um conjunto de teste, para os quais
se sabe à partida que resultados são esperados, ou seja, que informação deve ser gerada. Em seguida,
comparam-se os resultados do sistema com os resultados esperados, estabelecendo métricas de acordo
com o problema em questão. Veja-se, a título de exemplo, os trabalhos de Meinedo (2008); Chen et al.
(2004) e Merlino et al. (1997). A criação deste conjunto de teste pode ser feita automática ou manual-
mente, embora se prefira a anotação manual nos casos em que a informação tem uma grande compo-
nente semântica. No presente trabalho o material de teste foi obtido manualmente e encontra-se descrito
nos anexos M e N. As experiências descritas nas secções seguintes fazem referência ao material descrito
nestes anexos.
Na avaliação do conteúdo, duas métricas amplamente usadas na literatura são a precisão 1 e a abran-
gência 2. A precisão é uma medida da capacidade de um sistema em apresentar apenas itens relevantes
e corresponde à razão entre o número de itens relevantes identificados sobre o número total de itens
identificados. A abrangência é uma medida da capacidade de um sistema em apresentar todos os itens
relevantes e corresponde à razão entre o número de itens relevantes identificados sobre o número total
de itens relevantes. Estas duas métricas foram consideradas na avaliação do trabalho. Os erros na clas-
sificação são habitualmente contabilizados através do número de falsos positivos e falsos negativos. Os
falsos positivos são os itens não relevantes identificados (false alarms). Os falsos negativos são os itens
relevantes não identificados (ou misses).
Na avaliação de desempenho foram medidos tempos de execução de processos 3, erros (temporais)
de detecção e o desempenho da detecção. O tempo de execução contabiliza o tempo que leva a executar
um determinado processo. O erro temporal na detecção mede o erro absoluto entre dois instantes, o
verdadeiro valor e o valor sugerido pelo sistema. O desempenho da detecção mediu-se em termos
de fracção do tempo real (×RT), ou seja, a razão entre o tempo que se leva a processar um segmento de
áudio e a duração desse segmento. Esta medida é de grande importância pois diz-nos qual a capacidade
do sistema em potencial funcionamento online. Pontualmente, foram consideradas outras métricas, que
serão introduzidas na experiência específica em que estão inseridas, como é o caso da cobertura e do
erro de duração.
Outras metodologias passam por envolver os espectadores no processo de avaliação. Como cons-
tatado por Matos & Pereira (2008), caso a metadada seja subjectiva, a opinião dos espectadores sobre a
informação gerada é especialmente importante. Em Kuwano et al. (2004) encontramos outro exemplo
de interacção humana na avaliação, onde são medidos os tempos de uma tarefa, com e sem suporte do
sistema de geração de metadados. O presente trabalho não incluiu formas de avaliação com utilizadores.
1Do Inglês, precision.2Do Inglês, recall.3Mais precisamente, os tempos médios de execução. Nos resultados em que se apresentam valores médios, note-se que foram
feitas 5 medições.
42

4.3 Abordagem com MLP
A primeira abordagem ao problema da detecção de referências consistiu na utilização de perceptrões
multi-camada (MLPs), um tipo de rede neuronal artificial. Durante esta fase, as referências consideradas
foram apenas jingles, mais precisamente o jingle0 e algumas variações. Esta abordagem foi considerada
devido aos bons resultados num contexto semelhante, apresentados em Meinedo (2008).
Inicialmente realizou-se um treino de um MLP especializado em detectar o jingle0. O primeiro teste
consistiu na validação do treino com alguns casos triviais, como o próprio jingle0, doublejingle0 e tri-
plejingle0 (concatenação de três jingles jingle0). O jingle foi detectado nos instantes correctos, sem falsos
positivos nem falsos negativos, implicando uma precisão e abrangência de 100%. Foi também realizado
um teste com o segmento nojingle0. Nesse teste houve um falso positivo, ou seja, o MLP assinalou um
padrão jingle0 quando se sabe que no segmento de teste não existe o jingle0.
Outro teste realizado foi a detecção do jingle0 no corpus RTP.2009-09-17. Foram assinaladas 325
ocorrências do padrão jingle0. Sabemos que, na realidade, apenas há 23 ocorrências no corpus. Das
325 ocorrências assinaladas apenas 5 coincidiram com ocorrências do jingle0, com um erro de detecção
menor que 1s. Sendo assim, obtiveram-se 320 falsos positivos e 18 falsos negativos. A precisão obtida foi
de 1,54% e a abrangência 21,74%. O erro médio de detecção foi de 0,665s. Foram extraídos alguns falsos
positivos para análise manual. Não apresentavam qualquer semelhança com o padrão, quer em termos
aurais quer em tipo de conteúdo. Para tentar perceber por que razão aqueles segmentos tinham sido
considerados como match, realizou-se a experiência seguinte. Concatenou-se o triplejingle0, que tinha
sido um teste bem sucedido, com um dos falsos positivos assinalados. Realizou-se nova detecção sobre
este segmento. Tal como se esperava, foram assinaladas três ocorrências do jingle0, com um erro de
detecção médio de 0,48s. Contudo, surgiram 4 falsos positivos, não só na região originalmente oriunda
do falso positivo do corpus, mas também na região do triplejingle0. Finalmente, realizou-se uma nova
detecção após repetir o treino do MLP para o jingle0, adicionando o falso positivo extraído do corpus ao
conjunto de exemplos negativos. Não se obtiveram alterações aos resultados.
Apesar da abordagem globalmente não ter tido sucesso, um aspecto muito positivo desta técnica,
comparativamente à do DTW, é o seu desempenho. No teste com o corpus RTP.2009-09-17 o tempo de
execução foi de 1h13m25s, o que significa um valor de ×RT de 0,053.
Tentaram-se diversas estratégias para explorar e procurar solucionar os problemas de baixa precisão,
abrangência e elevado número de falsos positivos. As principais estratégias foram:
• Adicionar aos exemplos negativos no treino do MLP os falsos positivos, realizando nova detecção
em seguida. Era esperado que esta realimentação negativa fizesse o MLP convergir para os pesos
mais apropriados, mas tal não aconteceu;
• No treino do MLP, procurar equilibrar os conjuntos de exemplos positivos e negativos. Isto não se
revelou exequível, pois os exemplos positivos, no caso de um jingle, não são abundantes como se
pode perceber, ao contrário de segmentos de fala;
• No treino do MLP, adicionar aos exemplos negativos breves (<5s) segmentos de fala, de modo a
43

tentar impedir que o MLP se especializasse em segmentos de fala, que era o tipo de conteúdo que
surgia com frequência nos falsos positivos (os jingles são compostos unicamente por música).
• Utilização da parte mais “relevante"do jingle0. No treino do MLP estava a ser usado, inicialmente,
todo o sinal áudio do jingle. No entanto, foi sugerido usar apenas a região cuja música é facilmente
distiguível em termos aurais de outros segmentos, o “core” do jingle. No início do jingle0 encon-
tramos uma região que pode ser confundida com ruído, que não contribuía para a classificação
correcta no MLP. Apesar desta estratégia ter um racional sólido, os resultados não a validaram,
continuando a surgir um conjunto aparentemente aleatório de falsos positivos;
Todos os esforços de análise e investigação feitos no sentido de melhorar os maus resultados ob-
tidos com esta abordagem revelaram-se infrutíferos, nunca tendo sido descoberta qualquer pista que
permitisse melhorar significativamente a precisão, abrangência e diminuir os falsos positivos, que foi o
principal ponto fraco da abordagem. Como já foi explicado no capítulo 3, decidiu-se que uma mudança
de abordagem era a atitude mais prudente.
4.4 Desenvolvimento e Optimização do Protótipo DTW
Depois dos resultados insatisfatórios resultantes da abordagem com MLP, enveredou-se por uma linha
de exploração distinta. Optou-se por implementar o algoritmo DTW para detectar uma referência con-
tida num segmento áudio denominado base. Foi desenvolvido um primeiro protótipo para detecção
de referências usando o algoritmo DTW, na sua versão mais elementar. Esta primeira versão consistia
numa implementação matricial e recursiva da DTW em C++, não optimizada em qualquer aspecto. A
alocação de memória para a matriz era feita no stack e a comparação feita pela implementação do DTW
era entre amostras áudio. Para validar esta abordagem, foi realizado um pequeno teste. A referência
jingle0 foi inserida manualmente em diversos segmentos áudio maiores, oriundos do corpus RTP.2009-
09-17. Fora feitas detecções do jingle0 em cada um desses segmentos, tendo o jingle0 sido detectado
correctamente em cada um dos casos. Não se registaram falsos positivos nem falsos negativos.
No entanto, apesar destes bons resultados a nível do conteúdo, o desempenho estava muito acima
de tempo real (×RT >> 1), o que impedia uma evolução do protótipo para cenários práticos e realis-
tas. Numa primeira inspecção ao código identificaram-se pontos de melhoria cuja optimização trouxe
ganhos imediatos de desempenho. Foram eles 1) a transformação do algoritmo de cálculo dos scores
de uma versão recursiva para iterativa; 2) alocação de memória para a matriz DTW feita na heap e 3)
redução dimensional do sinal de entrada, usando características PLP. O ganho mais significativo foi na
utilização de características ao invés de amostras áudio, pois permitiu uma redução imediata do número
de elementos a processar pelo algoritmo.
Os aspectos a optimizar em seguida não foram fruto do acaso. Antes de iniciar o trabalho de optimi-
zação, foi usada uma ferramenta de profiling, o gprof 4, através da qual foi possível identificar os pontos
cuja melhoria poderia trazer os maiores benefícios para o desempenho global. Determinou-se que mais
4http://www.gnu.org/software/binutils/ (Último acesso em 14 de Novembro de 2010).
44

de 90% do tempo de execução da aplicação era dedicado ao cálculo da distância entre vectores, daí o
investimento na análise de mais do que uma métrica. Considerou-se a possibilidade de usar diversas
métricas de similaridade no cálculo das distâncias. No entanto, as distâncias Euclideana2 e de Manhat-
tan foram as preferidas para análise, pois, além da sua simplicidade, podem ser calculadas apenas com
operações simples (+,−,×, | · |). Em segundo lugar estava o ciclo principal de cálculo dos scores DTW,
que tem que iterar pelas entradas da matriz DTW. Nesse sentido, procurou-se optimizar esse ciclo e o
número de entradas da matriz visitadas. Outro ponto óbvio de melhoria foi o número de elementos do
vector de características usado no cálculo da distância. A comparação entre a base e a referência não
assenta directamente em amostras aúdio mas sim em vectores de características PLP com 26 coeficien-
tes. Como os coeficientes c14 . . . c26 são as derivadas de c1 . . . c13, considerou-se a utilização apenas dos
primeiros 13 coeficientes. Os coeficientes das derivadas têm interesse em aplicações de processamento
da fala e, neste contexto, em que se pretende detectar um segmento áudio tipicamente composto por
música, não se mostraram relevantes. A utilização de apenas metade do vector de características teve
como benefício imediato a diminuição do tempo de execução e consequente melhoria do ×RT.
Em síntese, os aspectos de variação nos cenários de teste foram:
• Compilação:
– Flags de optimização: sem optimização vs -O3;
– Flag -floop-optimize2 5.
• Reestruturação de código (não afectam output):
– Inlining de funções;
– Evitar invocações de funções;
– Mover código invariante do ciclo principal de cálculo dos scores para uma função de iniciali-
zação.
• Parametrizações (afectam output):
– Métricas de distância usadas (Euclideana2 vs Manhattan);
– Restrições ao caminho do alinhamento na matriz (como explicado no capítulo 3, usar tolerân-
cia diagonal);
– Tamanho do vector de características usadas (13 vs 26).
Na tabela 4.2 encontra-se descrita cada uma das etapas de optimização do protótipo.
Na tabela 4.3 apresentam-se os resultados detalhados da avaliação após a optimização da sexta etapa.
Os resultados das restantes etapas não se encontram detalhados devido a limitações de espaço. No
entanto, o gráfico do desempenho médio do protótipo em cada etapa encontra-se na figura 4.2.
Tanto na última etapa como nas anteriores os resultados foram surpreendentes. Em termos do erro
da detecção todos os valores foram inferiores a 10ms. Note-se que houve uma clara melhoria do desem-
penho do protótipo. Inicialmente observou-se um×RT de 3,26 e, após a etapa final de optimização, esse
valor baixou para os 0,13, o que significa praticamente 10% do tempo real.
5http://linux.die.net/man/1/gcc (Último acesso em 14 de Novembro de 2010).
45

Casos de teste Compilação Estrutura do código Parametrização
Etapa
1
jingle0, doublejin-
gle0, quadjingle0,
nojingle0
Sem flags de opti-
mização.
Estrutura inicial. Distância Euclideana2,
26 coeficientes, sem
restrições à diagonal.
Etapa
2
+ octojingle0, one-
jingle0, twojingles0
-O3,
-floop-optimize2
Inlining de funções,
mover código invari-
ante e evitar chamadas
a funções.
Tolerância diagonal
50%.
Etapa
3
Tolerância diagonal
25%.
Etapa
4
Tolerância diagonal
10%.
Etapa
5
Distância de Manhattan.
Etapa
6
+ Todos os ca-
sos do corpus
RTP.2009-09-17.
Distância Euclideana2,
13 coeficientes.
Tabela 4.2: Descrição das etapas de optimização do protótipo.
O limiar usado ao longo das seis etapas não foi o mesmo. O processo de optimização também teve
como objectivo afinar o limiar usado no DTW, para o fixar em fases posteriores do trabalho. Nas pri-
meiras 5 etapas, o limiar usado foi 2000. Este valor foi obtido por observação do gráfico dos scores da
DTW, correlacionando os pontos mínimos com instantes onde se iniciava a referência a detectar. Não
se verificaram nestas etapas quaisquer falsos positivos ou falsos negativos, implicando uma precisão e
abrangência de 100%. Contudo, na etapa 6, apesar das melhorias significativas no desempenho do pro-
tótipo, os valores dos scores do DTW passaram para uma escala de valores mais baixos, o que implicou
a alteração do limiar para 75.
Após feitos os testes no contexto do corpus jingle0.testpack, passou-se ao contexto do corpus RTP.2009-
09-17. Foram detectados todos os jingles nele existentes (jingle0 . . . jingle4) em cada hora do corpus. Para
estas experiências usou-se, como foi explicado, um limiar de 75. A partir deste ponto o limiar foi fixado
em 75 para as experiências que se seguiram. Na detecção global dos cinco jingles não se registaram fal-
sos positivos nem falsos negativos, o que implica uma precisão e abrangência de 100%. Em termos de
erro de detecção, atingiu-se um valor absoluto médio de 41ms, nunca sendo superior a 150ms. O tempo
de execução médio foi de 828,483s e o ×RT médio 0,23. No entanto, é importante referir que os testes
no contexto do corpus jingle0.testpack foram feitos em série, uma detecção de cada vez. Já os testes no
contexto do corpus RTP.2009-09-17 foram feitos usando os quatro cores disponíveis no processador, com
quatro detecções em paralelo. Desse modo percebe-se porque o valor médio de ×RT foi de 0,13 no jin-
gle0.testpack e 0,23 no RTP.2009-09-17. Ao paralelizar a detecção de referências, apesar de se aumentar o
46

Base Texec (s) ×RT hitTime (s) Erro (s)
jingle0 0,340 0,07 0,00 0,000
doublejingle0 1,119 0,11 0,00 0,000
4,90 0,000
quadjingle0 2,642 0,13 0,00 0,000
4,90 0,000
9,79 0,006
14,69 0,002
octojingle0 6,136 0,16 0,00 0,000
4,90 0,000
9,79 0,006
14,69 0,002
19,58 0,008
24,48 0,004
29,38 0,000
34,27 0,006
nojingle0 23,956 0,15 95,89 (não aplic.)
onejingle0 22,191 0,15 16,67 0,005
twojingles0 26,505 0,16 16,67 0,005
93,46 0,007
Tabela 4.3: Detalhes dos resultados da sexta e última optimização do protótipo, no contexto do corpus
jingle0.testpack.
tempo de execução de cada uma, também se completam mais detecções em menos tempo, conseguindo
um tempo de execução global menor. Numa breve experiência realizada para quantificar esta afirma-
ção, executou-se a detecção do jingle0 no corpus RTP.2009-09-17 de duas formas. Na primeira, as 23
detecções foram feitas sequencialmente, tendo sido obtido um tempo total de detecção de 10796,71s.
Na segunda, paralelizaram-se as detecções em grupos de quatro, uma por core, tendo sido obtido um
tempo total de detecção de 4844,53s. O speedup observado foi de S = 10796, 71/4844, 53 = 2, 23. Fica
assim exemplificado o compromisso introduzido pela paralelização.
Na tabela 4.4 apresentam-se os resultados detalhados da detecção do jingle0 no contexto do corpus
RTP.2009-09-17. A tabela inclui apenas as linhas para as horas do corpus em que o jingle0 está realmente
presente. Os resultados dos restantes jingles são muito semelhantes e já foram abordados na síntese
global do parágrafo anterior.
Duas notas finais sobre a optimização. Apesar das flags -O3 e -floop-optimize2 já representarem
uma promessa de desdobramento de ciclos, foi também compilada uma versão do código em que essa
47

Figura 4.2: Desempenho médio do protótipo DTW por etapa de optimização, no contexto do corpus
jingle0.testpack.
optimização foi feita manualmente. Foram experimentados diversos desdobramentos de ciclos mas o
aumento do desempenho não foi notório, pelo que se conclui que o compilador fez um bom trabalho na
optimização de ciclos. Por outro lado, a métrica de distância que ficou implementada foi a Euclideana2,
visto que os ganhos de desempenho devidos à utilização da distância de Manhattan não foram significa-
tivos (diminuição em 0,01 do valor médio de×RT). Além disso, a distância Euclideana2 tem a vantagem
de amplificar as diferenças entre vectores, permitindo uma diferenciação mais clara das regiões abaixo
e acima do limiar.
Findas estas experiências de optimização e avaliação, deu-se por terminada a fase do protótipo DTW.
4.5 Integração no Audimus
Como já foi relatado no capítulo 3, a integração do protótipo DTW inicial no Audimus implicou a criação
dos componentes DTWComponent e DTWStateMachineComponent, daqui em diante apelidados por
Componentes DTW e DTWSM.
Depois da migração do código para Componentes Audimus, repetiram-se as experiências de detec-
ção de todos os jingles no corpus jingle0.testpack. Os resultados encontram-se na tabela 4.5
Podemos observar que em todo o corpus o erro de detecção é sempre inferior a 10 ms. O ficheiro
jingle0 usado como base de controlo foi correctamente detectado com um score de 0, o que era esperado,
visto que tanto a base como a referência são o mesmo padrão de bits. Também não foram assinalados
hits na base nojingle0, o que era esperado, visto nesse segmento não estar presente a referência. Por
outro lado, foram identificadas todas as instâncias da referência no corpus. Neste teste não houve falsos
positivos ou falsos negativos, o que implica uma precisão e abrangência de 100%. No entanto, note-se
a variabilidade do valor de ×RT com a duração da base, muito superior à verificada no protótipo DTW
não integrado no Audimus. Alguns valores de ×RT voltaram a situar-se acima de tempo real (×RT > 1)
48
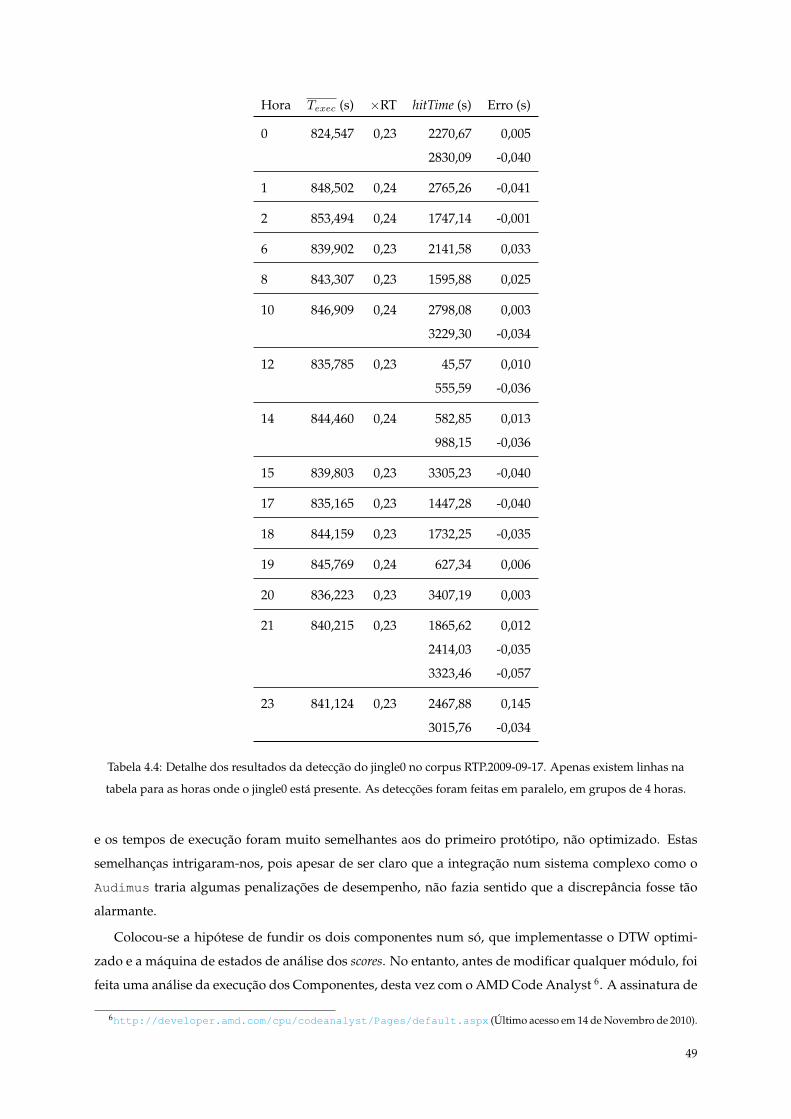
Hora Texec (s) ×RT hitTime (s) Erro (s)
0 824,547 0,23 2270,67 0,005
2830,09 -0,040
1 848,502 0,24 2765,26 -0,041
2 853,494 0,24 1747,14 -0,001
6 839,902 0,23 2141,58 0,033
8 843,307 0,23 1595,88 0,025
10 846,909 0,24 2798,08 0,003
3229,30 -0,034
12 835,785 0,23 45,57 0,010
555,59 -0,036
14 844,460 0,24 582,85 0,013
988,15 -0,036
15 839,803 0,23 3305,23 -0,040
17 835,165 0,23 1447,28 -0,040
18 844,159 0,23 1732,25 -0,035
19 845,769 0,24 627,34 0,006
20 836,223 0,23 3407,19 0,003
21 840,215 0,23 1865,62 0,012
2414,03 -0,035
3323,46 -0,057
23 841,124 0,23 2467,88 0,145
3015,76 -0,034
Tabela 4.4: Detalhe dos resultados da detecção do jingle0 no corpus RTP.2009-09-17. Apenas existem linhas na
tabela para as horas onde o jingle0 está presente. As detecções foram feitas em paralelo, em grupos de 4 horas.
e os tempos de execução foram muito semelhantes aos do primeiro protótipo, não optimizado. Estas
semelhanças intrigaram-nos, pois apesar de ser claro que a integração num sistema complexo como o
Audimus traria algumas penalizações de desempenho, não fazia sentido que a discrepância fosse tão
alarmante.
Colocou-se a hipótese de fundir os dois componentes num só, que implementasse o DTW optimi-
zado e a máquina de estados de análise dos scores. No entanto, antes de modificar qualquer módulo, foi
feita uma análise da execução dos Componentes, desta vez com o AMD Code Analyst 6. A assinatura de
6http://developer.amd.com/cpu/codeanalyst/Pages/default.aspx (Último acesso em 14 de Novembro de 2010).
49

Base Texec (s) ×RT hitTime (s) Erro (s)
jingle0 0,604 0,12 0,00 0,000
doublejingle0 5,631 0,58 0,00 0,000
4,90 0,000
quadjingle0 16,222 0,83 0,00 0,000
4,90 0,000
9,79 0,006
14,69 0,002
octojingle0 36,138 0,92 0,00 0,000
4,90 0,000
9,79 0,006
14,69 0,002
19,58 0,008
24,48 0,004
29,38 0,000
34,27 0,006
nojingle0 160,790 1,02 (sem hits)
onejingle0 149,435 1,02 16,67 0,005
twojingles0 181,726 1,08 16,67 0,005
93,46 0,007
Tabela 4.5: Testes dos Componentes DTW e DTWSM integrados no pipeline.
execução do processo era muito semelhante à encontrada no protótipo não optimizado. Concluiu-se que
o problema se encontrava no sistema de construção de software do Audimus. Na compilação do Compo-
nente DTW não estavam a ser adicionadas as flags de optimização necessárias, pois por omissão tal não
acontece em modo debug. Corrigida esta situação procedeu-se a uma reavaliação de conteúdo do sis-
tema já integrado, da qual se concluiu que tanto no corpus jingle0.testpack como no RTP.2009-09-17, em
termos de desempenho e erros de detecção, obtiveram-se valores iguais aos do protótipo optimizado.
Isso demonstrou que a integração no sistema Audimus não representou uma penalização significativa
em termos de desempenho.
Estando o Audimus já munido de Componentes que, em conjunto, implementam um detector de re-
ferências baseado no algoritmo DTW, pôde avançar-se para a fase seguinte, mais complexa e demorada,
a evolução para o sistema final. Em termos de conteúdo, neste ponto, tanto a precisão como a abrangên-
cia do sistema foi de 100% nos corpora jingle0.testpack e RTP.2009-09-17, não existindo quaisquer falsos
positivos ou falsos negativos. Em termos de desempenho o valor médio de ×RT foi de 0,13. Conseguiu-
se que a integração no Audimus não tivesse impacto considerável nesta medida de desempenho, o que
50

foi extremamente motivador.
4.6 Avaliação do Sistema Final
4.6.1 Detecção e Refinamento Incremental
De modo a validar que o sistema efectivamente cumpre o seu objectivo último, de habilitar a construção
de uma descrição de conteúdo e estrutura, realizou-se uma experiência focada na demonstração dessa
actividade no contexto de um bloco de anúncios. Esta experiência teve como objectivo a identificação
dos anúncios presentes num bloco de anúncios sequenciais, delimitado por dois jingles (jingle0), e cuja
duração é de 564.705s. Existem no total 27 referências únicas: 26 anúncios e 1 jingle delimitador. O modo
de detecção usado para o jingle foi o full e para todos os anúncios foi o boundary.
No início da experiência o sistema não tinha conhecimento de qualquer referência (neste caso, anún-
cios ou jingles). Realizaram-se em seguida 29 iterações. Em cada iteração realizou-se uma detecção de
referências em que a base foi o bloco de anúncios. Na primeira iteração adicionou-se ao sistema o jin-
gle0 e, após a primeira detecção, foram identificados com sucesso as duas ocorrências desse jingle, que
delimitam o bloco de publicidade. Em cada iteração adicionou-se uma referência nova, caso a iteração
anterior tivesse tido sucesso, ou seja, não se verificassem falsos positivos nem falsos negativos. Caso
contrário não se adicionava referência nova e era feita uma parametrização da referência seguida de
uma detecção. Este procedimento aplicado em cada iteração, ilustrado na figura 4.3, é o proposto para
o refinamento do sistema em termos de qualidade da detecção de referências.
Em todas as iterações identificaram-se referências e em nenhuma houve falsos positivos, o que signi-
fica que a precisão, tanto por iteração como global foi de 100%. No entanto, nas iterações 20 e 27 houve
falsos negativos (misses), o que implicou parametrizações de referências para efectuar correcções. Como
consequência, a abrangência média por iteração ficou-se nos 99,54%, nunca tendo sido inferior a 90,48%.
Na figura 4.4 encontra-se o gráfico da abrangência por iteração.
É importante realçar a causa dos falsos negativos obtidos nestas duas iterações. Na iteração 20, o
áudio dos anúncio respectivo tinha um grau de auto-similaridade tal, no início do segmento, que o de-
tector desse início estava a assinalar o começo da referência tarde demais, o que fez com que a duração
esperada e a real divergissem ao ponto de o match ser rejeitado. A parametrização feita na detecção da
referência foi a diminuição do valor limiar do DTW (de 75 para 25). Deste modo, conseguiu-se ultrapas-
sar a dificuldade introduzida pela região de auto-similaridade, a par de uma maior especialização do
detector dessa referência. Na iteração 27 bastou diminuir o limiar de 75 para 70.
Não se devem encarar estas correcções como falhas, bem pelo contrário. Ficou demonstrada a ca-
pacidade do sistema em permitir as parametrizações necessárias de forma a suportar as necessidades
específicas de cada referência a detectar. O processo de enriquecimento do conjunto de referências
pretende-se iterativo e incremental. Após a iteração final, todas as ocorrências de referências no bloco
base foram detectadas, sem se verificarem falsos negativos ou falsos positivos. Atingiu-se o objectivo
proposto com uma precisão e abrangência de 100%.
Também o desempenho foi alvo de avaliação. Na figura 4.5 encontra-se o gráfico do valor médio do
51

Figura 4.3: Procedimento em cada iteração da experiência.
Figura 4.4: Abrangência da detecção em cada iteração.
52
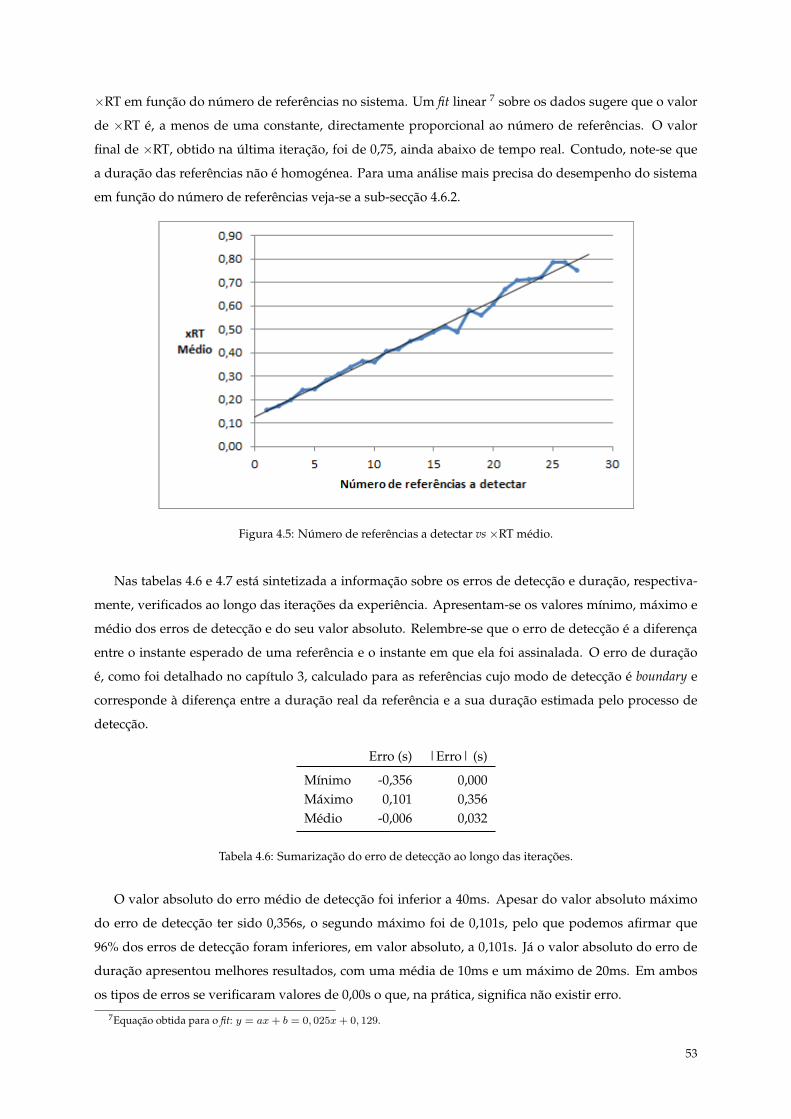
×RT em função do número de referências no sistema. Um fit linear 7 sobre os dados sugere que o valor
de ×RT é, a menos de uma constante, directamente proporcional ao número de referências. O valor
final de ×RT, obtido na última iteração, foi de 0,75, ainda abaixo de tempo real. Contudo, note-se que
a duração das referências não é homogénea. Para uma análise mais precisa do desempenho do sistema
em função do número de referências veja-se a sub-secção 4.6.2.
Figura 4.5: Número de referências a detectar vs ×RT médio.
Nas tabelas 4.6 e 4.7 está sintetizada a informação sobre os erros de detecção e duração, respectiva-
mente, verificados ao longo das iterações da experiência. Apresentam-se os valores mínimo, máximo e
médio dos erros de detecção e do seu valor absoluto. Relembre-se que o erro de detecção é a diferença
entre o instante esperado de uma referência e o instante em que ela foi assinalada. O erro de duração
é, como foi detalhado no capítulo 3, calculado para as referências cujo modo de detecção é boundary e
corresponde à diferença entre a duração real da referência e a sua duração estimada pelo processo de
detecção.
Erro (s) |Erro| (s)
Mínimo -0,356 0,000Máximo 0,101 0,356Médio -0,006 0,032
Tabela 4.6: Sumarização do erro de detecção ao longo das iterações.
O valor absoluto do erro médio de detecção foi inferior a 40ms. Apesar do valor absoluto máximo
do erro de detecção ter sido 0,356s, o segundo máximo foi de 0,101s, pelo que podemos afirmar que
96% dos erros de detecção foram inferiores, em valor absoluto, a 0,101s. Já o valor absoluto do erro de
duração apresentou melhores resultados, com uma média de 10ms e um máximo de 20ms. Em ambos
os tipos de erros se verificaram valores de 0,00s o que, na prática, significa não existir erro.
7Equação obtida para o fit: y = ax+ b = 0, 025x+ 0, 129.
53

Erro (s) |Erro| (s)
Mínimo -0,02 0,00Máximo 0,00 0,02Médio -0,01 0,01
Tabela 4.7: Sumarização do erro de duração ao longo das iterações.
Finalmente apresenta-se, na figura 4.6, a cobertura da detecção em função da iteração. Por cobertura
entende-se a fracção de tempo do segmento base que foi identificado, isto é, a soma de todos os tempos
das ocorrências de referências detectadas divididas pelo tempo total do áudio de entrada.
Figura 4.6: Cobertura do bloco de anúncios em função do número de referências a detectar.
Tal como as métricas de precisão e abrangência por iteração, também a cobertura foi convergindo
para um valor próximo de 1 (100%). A cobertura final, após a última iteração, foi de 99,98%. Não se
atingiu 100% pois não foram adicionados como referêcias os breves interstícios dos anúncios e progra-
mas. Habitualmente são compostos por períodos de silêncio que não faria sentido usar como referência.
Podem ser interessantes para outros estudos mas nesta experiência foram ignorados.
4.6.2 Análise Detalhada de Desempenho
Através de duas experiências, foi realizada uma análise detalhada do desempenho do sistema, em que
foi determinado o valor de ×RT para um conjunto de detecções. As três variáveis consideradas foram
o número de referências a detectar, o comprimento de cada referência e o comprimento do segmento
base (áudio sobre o qual se realiza a detecção). O modo de detecção de cada referência foi o full. Não foi
considerado o modo boundary dado que este se constrói com base no full.
Na primeira experiência, usaram-se 5 bases de durações diferentes e referências distintas mas de
tamanho fixo. As durações das bases são 60s, 120s, 240s, 480s e 960s. Para cada base, realizaram-se 11
detecções, em que se variou o número de referências envolvidas de acordo com a sequência 1, 2, 4, 6,
54

. . . , 18, 20. O valor de ×RT em cada detecção, em função do número de referências e do comprimento
da base, encontra-se ilustrado no gráfico da figura 4.7. Note-se que a região em que ×RT > 1, o tempo
de processamento é superior ao tempo real, isto é, à duração da base, situação que não é desejável num
modo de operação online.
Figura 4.7: Valor de ×RT em função do número de referências e do comprimento da base.
Verifica-se que o número de referências é o factor determinante para o desempenho, ao contrário da
duração da base, que praticamente não tem impacto. Isso significa que o sistema tem uma escalabilidade
de processamento a segmentos de maiores dimensões. Contudo, é sensível à variação do número de
referências a detectar. Um fit linear 8 sobre o valor médio de ×RT por número de referências sugere que
o valor de ×RT é, a menos de uma constante, directamente proporcional ao número de referências.
Na segunda experiência fixou-se a duração da base em 60s e analisou-se o valor de ×RT em função
da duração de uma referência, cujo gráfico se encontra na figura 4.8. Já mostrámos que o número de
referências a detectar tem influência no desempenho do sistema. A duração das referências têm ainda
mais impacto que essa variável.
Um fit polinomial de segundo grau 9 sobre os dados sugere que o valor de ×RT é função quadrática
da duração da referência. Isto implica que o comportamento do desempenho de uma detecção é domi-
nado pela duração das referências, ainda mais do que pelo número de referências. Note-se que a partir
de 15s de comprimento o valor de ×RT fica acima de tempo real. Há um compromisso entre o número
de referências utilizadas numa detecção e a sua duração, se pretendermos manter o sistema a funcionar
abaixo de tempo real.
Para finalizar, é importante relembrar que esta análise pode ser estendida ao modo de detecção
boundary, pois uma referência detectada com este modo corresponde a duas detecções de referências
full, de comprimento igual ao comprimento definido para a fronteira.
8Equação obtida para o fit: y = ax+ b = 0, 063x+ 0, 067.9Equação obtida para o fit: y = ax2 + b+ c = 0, 003x2 + 0, 029x− 0, 034.
55

Figura 4.8: Valor de ×RT em função da duração de uma referência.
56

Capítulo 5
Conclusões
5.1 Sumário
ACTUALMENTE observa-se um ritmo de crescimento muito acelerado na quantidade de infor-
mação disponível. Diariamente é produzido um volume muito grande de informação, do
qual uma extensa porção corresponde a material audiovisual (Pfeiffer et al., 2008), difundido
por meios como a Internet e a televisão. No entanto, os mecanismos de interacção com a televisão são
ainda muito básicos e isso deve-se, em grande parte, à falta de meta-informação associada aos conteú-
dos. A motivação para o trabalho a desenvolver passou pela possibilidade de enriquecer a experiência
do utilizador perante este meio de comunicação.
O trabalho teve como principal objectivo o desenvolvimento de um sistema que possibilite a geração
de uma descrição de uma emissão televisiva. Para tal, e tendo em conta a estrutura e conteúdo de um
canal generalista, foi aplicado um método de detecção de zonas de interesse presentes na emissão, bem
como uma aplicação que permite gerir todo o processo. O sistema Audimus, já existente no L2F, foi
parte integrante do trabalho, tendo sido feitas modificações e acrescentos significativos ao seu código.
Foram apresentados vários sistemas e tecnologias relacionadas com o processo de extracção, repre-
sentação e disseminação de informação. Pudemos perceber que a abordagem mais difundida é a da
geração semi-automática, ou seja, aquela em que intervenção humana não pode ser dispensada. No
entanto, no sistema desenvolvido, esta é apenas necessária para o refinamento dos resultados. Todo o
processo de detecção de referências e geração dos metadados é automático.
A contribuição mais importante deste trabalho foi o desenvolvimento de um sistema que facilita a ca-
racterização, de forma detalhada, de um sinal áudio num contexto muito concreto, uma emissão televi-
siva. Esse sinal áudio não é um sinal qualquer, genérico e sem estrutura mas sim uma sequência de inter-
valos, ou segmentos, que estão, em princípio, bem definidos e delimitados no tempo. Aproveitaram-se
algumas características dessa estrutura para assentar os principais mecanismos do sistema desenvol-
vido, nomeadamente a presença de jingles como delimitadores de blocos de publicidade.
A arquitectura do sistema apresentado consiste em duas aplicações, PipelineServer e
MetadataProducer. No PipelineServer coordena-se a execução de um pipeline Audimus onde são
feitas as detecções de referências, isto é, segmentos de interesse, através da aplicação de um algoritmo
57

DTW modificado e uma máquina de estados. A aplicação MetadataProducer controla essa execução
e é notificada dos resultados da detecção, existindo para isso um canal de comunicação entre as duas
aplicações. Foram desenvolvidas duas estratégias para detecção, full e boundary, que permitem adaptar
os recursos computacionais ao comprimento da referência. Deste modo, mostrou-se que o algoritmo
DTW modificado é uma opção a considerar perante problemas de detecção de conteúdos. Tanto o al-
goritmo DTW modificado como a máquina de estados foram implementados, na sua versão final, como
parte integrante do sistema Audimus.
Foi desenvolvida a comunicação entre entre o Audimus e uma aplicação em C#. Deste modo expandiu-
se o âmbito de interoperação do Audimus com outros componentes, em termos de linguagens de pro-
gramação. Note-se que tanto a linguagem C# como a framework .NET, nas suas versões 4.0, foram lança-
dos recentemente, em Abril de 20101. A comunicação assenta num protocolo aplicacional flexível sobre
TCP/IP, o que permite, além da separação física das máquinas onde se executam ambos os processos,
uma extensão do protocolo em trabalhos futuros.
Ficou demonstrado que a detecção de referências é uma abordagem válida tanto para segmentar a
emissão, através da identificação de jingles diversos, como para identificar os anúncios presentes numa
emissão, tendo sido obtidas uma precisão de 100% e uma abrangência nunca inferior a 90%. Contudo,
os falsos negativos podem efectivamente ser eliminados através da reparametrização do sistema e seu
consequente refinamento. Apesar dos bons resultados obtidos, temos consciência de que a detecção de
referências não é uma abordagem apropriada para identificar todo e qualquer conteúdo de uma emis-
são televisiva. Apenas os segmentos áudio conhecidos à partida podem ser identificados. No entanto,
outras abordagens podem ser fundamentadas na informação de referências, como é o caso da activação
condicional de blocos de processamento da fala. Além disso, o sistema desenvolvido inclui uma fun-
cionalidade de listagem de segmentos desconhecidos, o que permite guiar o utilizador em direcção ao
conteúdo que ainda não é conhecido e, caso este seja passível de detecção através da nossa abordagem,
adicioná-lo imediatamente ao sistema para ser reconhecido em futuras detecções.
5.2 Aplicações do Trabalho
Na secção anterior apresentaram-se as principais contribuições desta dissertação. No entanto ainda po-
dem, e devem, ser desenvolvidos trabalhos de melhoria e aprofundamento. Diversas aplicações reais
beneficiam dos estudos desenvolvidos neste trabalho, sendo potenciais candidatas para trabalhos futu-
ros as seguintes:
• Eliminação de blocos ou partes de blocos de publicidade;
• Suporte à construção de bibliotecas de objectos aúdio digitais, incluindo indexação e pesquisa;
• Sistemas de personalização de conteúdos;
1http://www.microsoft.com/downloads/details.aspx?displaylang=en&FamilyID=
0a391abd-25c1-4fc0-919f-b21f31ab88b7 (último acesso em 14 de Novembro de 2010).
58

• Estatísticas de emissão por referência, incluindo contagens de reprodução e listas de referências
mais e menos frequentes;
• Monitorização de emissão;
• Geração automática de guias electrónicos.
5.3 Trabalho Futuro
Apesar dos resultados motivadores já descritos, uma lição importante a retirar deste trabalho é a difi-
culdade de realizar investigação na área da caracterização de sinais áudio, num contexto de Mestrado.
As linhas de investigação já existentes são diversas o que obriga, num contexto em que o trabalho é de
carácter individual e o tempo muito limitado, a enveredar por caminhos exploratórios que podem não
se revelar os melhores para o objectivo desejado. Além disso, a pesquisa bibliográfica efectuada revelou
que, para sistemas cujo âmbito é ambicioso e, consequentemente, a complexidade elevada, o tempo de
pesquisa e desenvolvimento pode atingir vários anos e os recursos humanos envolvidos raramente são
uma só pessoa. Apesar de tudo, achamos ser possível elevar o sistema desenvolvido para um nível de
maior qualidade nos seguintes aspectos:
• Cobertura mais ampla dos conteúdos, em termos de caracterização da emissão televisiva;
• Melhor desempenho global do sistema, optimizando os principais algoritmos e explorando mais
o paralelismo de dados e tarefas;
• Assegurar a usabilidade das interfaces desenvolvidas.
Nesta secção apresentamos, com maior detalhe, as principais sugestões para futuros trabalhos que se
suportem no presente sistema, ou que nele se inspirem, bem como diversas oportunidades de melhoria.
Esperamos assim lançar as linhas guia para que o sistema possa convergir para os pontos atrás mencio-
nados, tornando-se mais competitivo e, eventualmente, dar origem a uma aplicação final orientada para
os mercados da televisão digital e interactiva.
As principais oportunidades de melhoria do sistema, priorizadas, de acordo com a nossa visão, são
as seguintes:
1. Alinhamento das referências detectadas com uma grelha de programação electrónica, por exemplo
a da ZON 2. É possível usar a informação de segmentação já gerada para determinar os programas
entre os blocos de anúncios, bem como beneficiar de outros elementos de metadados como os
resumos e a tipologia dos programas (filmes, notícias, desporto, séries, . . . );
2. Migração de todo o sistema para modo de operação online. Apesar dos Componentes Audimus
desenvolvidos operarem em modo online, no MetadataProducer tal ainda não acontece, devido
ao problema de ordenação de eventos descrito no capítulo 3. Uma ideia no sentido de resolver
2http://www.zon.pt/televisao/Programacao.aspx (Último acesso em 14 de Novembro de 2010).
59

este problema seria a sincronização periódica dos detectores de referências, através de uma estra-
tégia de checkpoints. Esta solução pode revelar uma complexidade técnica elevada, mas permitiria
manter os vários detectores em paralelo sincronizados até ao grau de granularidade temporal de-
sejada;
3. Activação condicional de detectores de referências, isto é, não ter activos todos os detectores ao
mesmo tempo. Um detector ficaria activo, por exemplo, a uma determinada hora do dia ou
quando outro evento fosse disparado;
4. Permitir a ligação de um MetadataProducer com mais do que um PipelineServer, permi-
tindo a distribuição da carga na detecção de referências, explorando o paralelismo de operação
desta actividade. Deste modo seria possível, através da escalabilidade horizontal, responder às
necessidades computacionais de um crescente número de referências para detectar. Um cenário
possível é o seguinte. Suponhamos que existem 200 anúncios numa emissão ao longo de um dia.
Concluiu-se que o limiar de tempo real é atingido com 20 anúncios por máquina. Deste modo, são
necessárias dez máquinas dedicadas à detecção, executando PipelineServers, e uma execu-
tando um MetadataProducer, para agregar e apresentar os resultados. O sistema foi desenvol-
vido já com esta melhoria em vista. Os módulos de comunicação entre aplicações estão estáveis,
o protocolo de comunicação bem definido assenta sobre TCP/IP e as classes que implementam o
controlo de execução de pipelines remotos encontram-se isoladas e com as dependências minimi-
zadas;
5. Funcionalidade de visualização gráfica do pipeline Audimus usado para detectar as referências,
permitindo uma gestão mais eficiente dos ficheiros de configuração de arquitectura e uma adapta-
ção mais rápida de novos utilizadores. Como exemplos, vejam-se os interfaces e funcionalidades
do Yahoo! Pipes 3 e do ARIS MashZone 4;
6. Adicionar ao MetadataProducer um módulo de estatísticas, permitindo saber, por exemplo,
que referências surgem mais na emissão e qual a sua frequência;
7. Permitir a modificação da arquitectura do pipeline em tempo de execução. Esta funcionalidade já
se encontra implementada no Audimus mas ainda não foi exaustivamente testada, pelo que não
foi considerada para o presente trabalho;
8. Tipificação forte das entradas e saídas dos componentes.
Em termos de possibilidades futuras de investigação, as principais linhas-guia, são, na nossa opinião,
as seguintes:
1. Experimentar outras características para a redução dimensional do sinal áudio, como por exem-
plo as MFCC. As características usadas, PLP, são optimizadas para o contexto da fala, pelo que
poderá haver outras características mais apropriadas para os diferentes contextos presentes numa
emissão;3http://pipes.yahoo.com/pipes (Último acesso em 14 de Novembro de 2010).4http://www.mashzone.com/en/mashzone (Último acesso em 14 de Novembro de 2010).
60

2. Ligação do sistema desenvolvido a um sistema consumidor de metadados, contemplando a possi-
bilidade de um canal de retorno e as novas possibilidades que daí resultam. Isto significa investir
na integração com um sistema consumidor de metadados;
3. Incluir na descrição gerada outras formas de metadados, como por exemplo a transcrição. No
entanto, a integração desta no sistema desenvolvido pode não ser trivial. Por outro lado, a sua
utilização como base de geração de metadados deve ser cuidadosamente ponderada, pois a sua
qualidade pode ser um inibidor da qualidade do resultado final;
4. Na aplicação do algoritmo DTW podia ser analisada apenas uma janela em cada N , ou seja, não
seria analisada cada janela do sinal de entrada. Deste modo seria reduzido o tempo de execução
do algoritmo, permitindo mais detecções em paralelo no mesmo intervalo de tempo. No entanto,
também traria potenciais alterações à precisão global do sistema, bem como ao número de falsos
positivos;
5. Publicação dos metadados gerados num formato standard, como o MPEG7. O trabalho relacio-
nado mostra que há uma forte aposta na uniformização dos metadados, pelo que este tema será
relevante caso se pretenda avançar para um produto final e competitivo no mercado.
Com este trabalho, esperamos ter potenciado o desenvolvimento de novas aplicações que facultem
ao utilizador toda a informação que ele quer, quando quer e como quer. O presente trabalho contri-
bui para diminuir a distância entre o volume de dados existente e a capacidade dos espectadores para
seleccionarem os conteúdos que realmente lhe interessam.
61


Bibliografia
Afonso, Pedro, & Ferreira, Ricardo. 2003. Indexação automática e identificação de áudio e vídeo. Tech. rept.
FEUP.
Al-Khalifa, Hend, & Davis, Hugh. 2007. FAsTA: A Folksonomy-Based Automatic Metadata Generator.
Al-Khalifa, Hend, & Rubart, Jessica. 2008. Automatic document-level semantic metadata annotation
using folksonomies and domain ontologies. SIGWEB Newsletter, 2008(Autumn), 1–3.
Alan, O., Akpinar, S., Sabuncu, O., Cicekli, N., & Alpaslan, F. 2008 (Oct). Ontological video annota-
tion and querying system for soccer games. Pages 1–6 of: ISCIS’08. 23rd International Symposium on
Computer and Information Sciences.
Amaral, R., Meinedo, H., Caseiro, D., Trancoso, I., & Neto, J. 2006. Automatic vs. Manual Topic Segmen-
tation and Indexation In Broadcast News. In: IV Jornadas en Tecnologia del Habla.
Blanco-Fernández, Yolanda, Pazos-Arias, José J., Gil-Solla, Alberto, Ramos-Cabrer, Manuel, López-
Nores, Martín, García-Duque, Jorge, Fernández-Vilas, Ana, Díaz-Redondo, Rebeca P., & Bermejo-
Muñoz, Jesús. 2008. An MHP framework to provide intelligent personalized recommendations about
digital TV contents. Software: Practice and Experience, 38(9), 925–960.
Boavida, Miguel, Cabaço, Susana, & Correia, Nuno. 2005. VideoZapper: a system for delivering perso-
nalized video content. Multimedia Tools and Applications, 25, 345–360.
Bullock, Jamie. 2007. LibXtract: A Lightweight Library for Audio Feature Extraction. In: Proceedings of
the international computer music conference. Copenhagen, Denmark: ICMA.
Chang, Shih-Fu, Chen, William, Meng, Horace, Sundaram, Hari, & Zhong, Di. 1997. VideoQ: an au-
tomated content based video search system using visual cues. Pages 313–324 of: MULTIMEDIA ’97:
Proceedings of the fifth ACM international conference on Multimedia. New York, NY, USA: ACM.
Chen, Shu-Ching, Shyu, Mei-Ling, Chen, Min, & Zhang, Chengcui. 2004 (June). A decision tree-based
multimodal data mining framework for soccer goal detection. Pages 265–268 of: ICME ’04. IEEE Inter-
national Conference on Multimedia and Expo, vol. 1.
Clements, Paul, Bachmann, Felix, Bass, Len, Garlan, David, Ivers, James, Little, Reed, Nord, Robert, &
Stafford, Judith. 2003. Documenting Software Architectures: Views and Beyond. Addison-Wesley Profes-
sional.
Conejero, David, & Anguera, Xavier. 2008. Tv advertisements detection and clustering based on acoustic
information. Computational intelligence for modelling, control and automation, international conference on,
0, 452–457.
63

Gibert, X., Huiping, Li, & Doermann, D. 2003 (July). Sports video classification using HMMs. Pages
II–345–8 vol.2 of: ICME ’03 Proceedings. International Conference on Multimedia and Expo, 2003, vol. 2.
Giuffrida, Giovanni, Shek, Eddie, & Yang, Jihoon. 2000. Knowledge-based metadata extraction from
PostScript files. Pages 77–84 of: DL ’00: Proceedings of the fifth ACM conference on Digital libraries. New
York, NY, USA: ACM.
Greenberg, Jane. 2003. Metadata extraction and harvesting: A comparison of two automatic metadata
generation applications. Journal of internet cataloging, 6(4), 59–82.
Guo, Guodong, & Li, Stan Z. 2003. Content-Based Audio Classification and Retrieval by Support Vector
Machines. Ieee transactions on neural networks.
Han, Hui, Giles, Lee, Manavoglu, Eren, Zha, Hongyuan, Zhang, Zhenyue, & Fox, Edward. 2003. Au-
tomatic document metadata extraction using support vector machines. Pages 37–48 of: JCDL ’03:
Proceedings of the 3rd ACM/IEEE-CS joint conference on Digital libraries. Washington, DC, USA: IEEE
Computer Society.
Herley, C. 2006. Argos: automatically extracting repeating objects from multimedia streams. Multimedia,
ieee transactions on, 8(1), 115 – 129.
Hunter, Jane. 2001. Adding Multimedia to the Semantic Web - Building an MPEG-7 Ontology. Pages
261–281 of: International Semantic Web Working Symposium (SWWS).
Jokela, Sami. 2001. Metadata Enhanced Content Management in Media Companies. Ph.D. thesis, Helsinki
University of Technology.
K.Coffman, & Odlyzko, A. 1999. The Size and Growth Rate of the Internet. Tech. rept. AT&T Labs Research.
Köhler, Joachim, Biatov, Konstantin, Larson, Martha, Eckes, Christian, & Eickeler, Stefan. 2001 (Septem-
ber). Automatic generation of meta data for audio-visual content in the context of MPEG-7. Pages
219–222 of: Cast 2001 - the information society landscape.
Kiranyaz, S., & Gabbouj, M. 2006. Generic content-based audio indexing and retrieval framework. IEEE
Proceedings on Vision, Image and Signal Processing, 153(3), 285–297.
Kiranyaz, S., Caglar, K., Guldogan, E., Guldogan, O., & Gabbouj, M. 2003 (July). MUVIS: a content-based
multimedia indexing and retrieval framework. Pages 1–8 vol.1 of: Seventh International Symposium on
Signal Processing and Its Applications, 2003., vol. 1.
Kuwano, Hidetaka, Matsuo, Yoshihiro, & Kawazoe, Katsuhiko. 2004. Reducing the Cost of Metadata
Generation by Using Video/Audio Indexing and Natural Language Processing Techniques. .
Lamya, Fergani, & Houacine, Amrane. 2007. Artificial Neural Network genre classification of musical
signals. In: SETIT 2007: 4th International Conference on Sciences of Electronic, Technologies .
Liang, Bai, Yaali, Hu, Songyang, Lao, Jianyun, Chen, & Lingda, Wu. 2005 (Oct). Feature analysis and
extraction for audio automatic classification. Pages 767–772 Vol. 1 of: 2005 IEEE International Conference
on Systems, Man and Cybernetics, vol. 1.
Lin, Wei-Hao, & Hauptmann, Alexander. 2002. News video classification using SVM-based multimodal
classifiers and combination strategies. Pages 323–326 of: MULTIMEDIA ’02: Proceedings of the tenth
ACM international conference on Multimedia. New York, NY, USA: ACM.
64

Liu, Z., Huang, J., & Wang, Y. 1998a (Dec). Classification TV programs based on audio information using
hidden Markov model. Pages 27–32 of: 1998 IEEE Second Workshop on Multimedia Signal Processing.
Liu, Zhu, Wang, Yao, & Chen, Tsuhan. 1998b. Audio Feature Extraction and Analysis for Scene Segmen-
tation and Classification. Journal of VLSI Signal Processing Systems, 20(1/2), 61–79.
Lourens, J.G. 1990. Detection and logging advertisements using its sound. Broadcasting, ieee transactions
on, 36(3), 231 –233.
Mao, Song, Kim, Jong Woo, & Thoma, George R. 2004. A Dynamic Feature Generation System for Au-
tomated Metadata Extraction in Preservation of Digital Materials. International workshop on document
image analysis for libraries, 0, 225.
Matos, Nuno, & Pereira, Fernando. 2008. Using MPEG-7 for Generic Audiovisual Content Automatic
Summarization. Pages 41–45 of: WIAMIS ’08: Proceedings of the 2008 Ninth International Workshop on
Image Analysis for Multimedia Interactive Services. Washington, DC, USA: IEEE Computer Society.
Meinedo, Hugo. 2008. Audio Pre-processing and Speech Recognition for Broadcast News. Ph.D. thesis, Insti-
tuto Superior Técnico da Universidade Técnica de Lisboa.
Merlino, Andrew, Morey, Daryl, & Maybury, Mark. 1997. Broadcast news navigation using story seg-
mentation. Pages 381–391 of: MULTIMEDIA ’97: Proceedings of the fifth ACM international conference on
Multimedia. New York, NY, USA: ACM.
Mierswa, Ingo, & Morik, Katharina. 2005. Automatic Feature Extraction for Classifying Audio Data.
Journal of Machine Learning, 58(2-3), 127–149.
Moore, Andrew. 2004. Clustering With Gaussian Mixtures.
Otsuka, I., Radhakrishnan, R., Siracusa, M., Divakaran, A., & Mishima, H. 2006. An enhanced video
summarization system using audio features for a personal video recorder. IEEE Transactions on Con-
sumer Electronics, 52(1), 168–172.
Peters, Isabella. 2009. Folksonomies. Indexing and Retrieval in Web 2.0. K.G. Saur Verlag.
Pfeiffer, M., Avila, M., Backfried, G., Pfannerer, N., & Riedler, J. 2008 (May). Next Generation Data
Fusion Open Source Intelligence (OSINT) System Based on MPEG7. Pages 41–46 of: IEEE Conference
on Technologies for Homeland Security, 2008.
Rodriguez, Marko A., Bollen, Johan, & de Sompel, Herbert Van. 2009. Automatic metadata generation
using associative networks. ACM Transactions on Information Systems, 27(2).
Rovira, M., Gonzalez, J., Lopez, A., Mas, J., Puig, A., Fabregat, J., & Fernandez, G. 2004. IndexTV:
a MPEG-7 based personalized recommendation system for digital TV. ICME ’04. IEEE International
Conference on Multimedia and Expo.
Ryu, Jeewoong, Sohn, Yumi, & Kim, Munchuri. 2002. MPEG-7 metadata authoring tool. Pages 267–270
of: MULTIMEDIA ’02: Proceedings of the tenth ACM international conference on Multimedia. New York,
NY, USA: ACM.
Sandbank, Charles. 2001. Digital TV in the Convergent Environment. Ieee computer graphics and applica-
tions, 21(1), 32–36.
Sebastiani, Fabrizio. 2002. Machine learning in automated text categorization. ACM Computer Survey,
34(1), 1–47.
65

Sull, Sanghoon, Kim, Hyeokman, cheon Yoon, Ja, & Chung, Min Gyo. 2009 (June). Method and apparatus
for fast metadata generation, delivery and access for live broadcast program.
Toklu, C., Liou, S., & Das, M. 2000. Videoabstract: a hybrid approach to generate semantically meaning-
ful video summaries. Pages 1333–1336 vol.3 of: ICME 2000: IEEE International Conference on Multimedia
and Expo, vol. 3.
Tummarello, Giovanni, Morbidoni, Christian, Piazza, Francesco, & Puliti, Paolo. 2004. MPEG7ADB:
Automatic RDF annotation of audio files from low level MPEG-7 metadata.
Wu, Harris, Zubair, Mohammad, & Maly, Kurt. 2006. Harvesting social knowledge from folksonomies.
Pages 111–114 of: HYPERTEXT ’06: Proceedings of the seventeenth conference on Hypertext and hypermedia.
New York, NY, USA: ACM.
Yang, Hsin-Chang, & Lee, Chung-Hong. 2005. Automatic Metadata Generation for Web Pages Using a
Text Mining Approach. Pages 186–194 of: WIRI ’05: Proceedings of the International Workshop on Challen-
ges in Web Information Retrieval and Integration. Washington, DC, USA: IEEE Computer Society.
Zhai, Y., Rasheed, Z., & Shah, M. 2005. Semantic classification of movie scenes using finite state machi-
nes. IEE Proceedings - Vision, Image and Signal Processing, 152(6), 896–901.
Zhang, HongJiang, Tan, Shuang Yeo, Smoliar, Stephen W., & Yihong, Gong. 1995. Automatic parsing
and indexing of news video. Multimedia syst., 2(6), 256–266.
66

Apêndice A
Exemplo de Ficheiro de Configuração
de Arquitectura
Na listagem A.1 encontra-se um exemplo de ficheiro de configuração de arquitectura.
1 <?xml vers ion=" 1 . 0 " encoding=" iso −8859−1" ?>
<!DOCTYPE macrocomponent SYSTEM "D:\ t e s e \deploy\audimus\AudimusConfig . dtd ">
3 <macrocomponent name="Audimus">
<f e a t u r e s >
5 < f e a t u r e name=" UserManager " value=" t rue "/>
< f e a t u r e name=" TaskManager " value=" f a l s e "/>
7 < f e a t u r e name=" SentenceManager " value=" f a l s e "/>
</f e a t u r e s >
9 <input type= ’ Null InputBuffer ’ name= ’ nul l Input ’ a c t i o n = ’ c r e a t e ’/>
<output type = " Fi leOutputBuffer " name=" f i l eOutput " a c t i o n =" c r e a t e ">
11 <args >
<arg name=" frameSize " value=" 64 "/>
13 <arg name=" f i l e P a t h " value=" f i l e . output "/>
</args >
15 </output >
<component name=" hel lo_producer " type=" HelloProducer ">
17 <params>
<param name="MyParam" value=" MyValue "/>
19 </params>
<input name=" nul l Input " a c t i o n =" use "/>
21 <output type = " Fi leOutputBuffer " name=" f i l eOutput " a c t i o n =" use "/>
</component>
23 </macrocomponent>
Listagem A.1: Conteúdo do ficheiro de configuração de arquitectura
67


Apêndice B
FunctionGeneratorInputBuffer -
Documentação Sumária
B.1 Geral
Nome: FunctionGeneratorInputBuffer
Título: Buffer gerador de funçõesCódigo fonte: src\buffers
Descrição: Este buffer, quando colocado na entrada de um Componente, providencia uma fonte de
FrameItems. O conteúdo (body) de cada frame é determinado pela função seleccionada. O
identificador de frame (frameID) é sempre zero. O identificador de frase (sentenceID) é o
número de frames já geradas. Quando o número máximo de frames a gerar é atingido, cada
frame gerada a partir de aí é assinalada como sendo EOF. Este buffer pode ser útil para gerar
amostras de entrada para um Componente em teste, tendo sido essa necessidade o motor da
sua criação.
B.2 Argumentos
O tipo de dados das amostras geradas depende função seleccionada. Na função constante cada amostra
é um float. Caso contrário, um int. No entanto, ambos os tipos de dados ocupam 4 bytes.
69

Nome Descrição
samplesPerFrame Número de amostras por frame emitido.function Função do gerador (constant - valor constante -
ou random - inteiro pseudo-aleatório).maxFrames Número de amostras a gerar até começar a emitir
EOF.Argumentos se function = constant
constant Valor da constante (float).Argumentos se function = random
randomMin Inteiro mínimo inclusivo a gerar na sequência
pseudo-aleatória.randomMax Inteiro máximo inclusivo a gerar na sequência
pseudo-aleatória.
70

Apêndice C
Informação Sobre Scripts
Desenvolvidos
Na tabela C.1 listam-se os principais scripts desenvolvidos ao longo da dissertação, a sua localização e
uma breve descrição. A localização indicada é relativa à directoria raíz dos scripts, tese\scripts.
Ficheiro Directoria Descrição
AudimusDeploy.bat audimus Instalação do Audimus.
EngineUtilsDeploy.bat audimus Instalação do EngineUtils.
cleanThesisEnv.bat environment Limpeza das variáveis de ambiente da tese.
setThesisEnv.bat environment Definição das variáveis de ambiente da tese.
viewThesisEnv.bat environment Visualização das variáveis de ambiente da tese.
extract-begin-end.py misc Extrair os segmentos de início e fim de um RAW.
extract-segment.bat misc Extrair um segmento de um RAW.
raw2wav.bat misc Converter um RAW para WAV.
TailLog.bat misc Abrir um ficheiro de log com tail -f.
wav2raw.bat misc Converter um WAV para RAW.
generate-desired.py neuralnetworks Gerar um ficheiro de saídas desejadas.
generate-mlp-weights.py neuralnetworks Gerar um ficheiro de pesos para MLP.
generate-pfile-13sentences.py neuralnetworks Gerar um pfile a partir de 13 variações de um
segmento.
generate-pfile.py neuralnetworks Gerar um pfile a partir de um segmento.
generate-scaling.py neuralnetworks Gerar 13 variações de um segmento.
generate-segments.py neuralnetworks Extrair segmentos de um segmento de áudio.
Tabela C.1: Lista de scripts.
71


Apêndice D
Interface da Aplicação de Treino de
Referências
73


Apêndice E
Descrição do Formato dos Ficheiros
PFile
Os ficheiros PFile, ou ficheiros de features, são muito usados, tanto nas tarefas já executadas pelo Audimus
até agora, como no sistema desenvolvido neste trabalho. No contexto da extracção de metadados é ha-
bitual realizar uma operação de redução dimensional, isto é, representar o sinal original usando outro
que, embora não retenha toda a informação presente no original, retenha a sua “essência", ou seja, ca-
racterísticas (features) relevantes que o possam representar. Estas características são escolhidas tendo em
conta os requisitos de uma dada aplicação. Um exemplo são as características PLP.
Os ficheiros PFile são os contentores de características para um conjunto de segmentos áudio. São
compostos por duas partes, o cabeçalho e o conteúdo, que se descrevem em seguida.
E.1 Cabeçalho
O cabeçalho de um PFile é um bloco de tamanho fixo. No início desse bloco encontramos informações
em formato de texto, de forma a serem facilmente legíveis por humanos, pois contêm informações úteis
para quem com eles trabalha e frequentemente consulta este cabeçalho. Na listagem E.1 encontra-se a
região textual do cabeçalho de um PFile real.
1 −p f i l e _ h e a d e r vers ion 0 s i z e 32768
−num_sentences 13
3 −num_frames 24689
−num_labels 40
5 −num_features 26
−format d d f f f f f f f f f f f f f f f f f f f f f f f f f f d
7 −f i r s t _ f e a t u r e _ c o l u m n 2
−f i r s t _ l a b e l _ c o l u m n 28
9 −data s i z e 715981 o f f s e t 0 ndim 2 nrow 24689 ncol 29
−end
Listagem E.1: Informação textual no cabeçalho de um PFile.
75

Este cabeçalho descreve as propriedades do PFile necessárias à sua manipulação:
pfile_header version 0 size 32768 Versão do formato PFile (0) e tamanho do cabeçalho (32768
bytes).
num_sentences 13 Número de segmentos (13).
num_frames 24689 Número total de frames nos segmentos (24689).
num_labels 40 Número de etiquetas para frames (40).
num_features 26 Número de características por frame (26).
format ddffffffffffffffffffffffffffd Tipos de dados dos elementos dos vectores que des-
crevem os frames. Neste caso, são, por esta ordem, dois inteiros (int) seguidos de 26 floats (float)
e terminando com um inteiro. Os dois primeiros inteiros dão-nos o número do segmento e o nú-
mero de frame dentro desse segmento, respectivamente. Os 26 floats são as características extraídas
para este par (segmento, frame) e o último inteiro indica qual o número da etiqueta que lhe deve
ser aplicada (neste caso, de 0 a 39). Note-se que informação adicional sobre as etiquetas não se
encontra no PFile. É armazenada externamente.
first_feature_column 2 Índice baseado em zero da primeira característica em cada vector (2).
first_label_column 28 Índice baseado em zero da etiqueta do vector (28).
data size 715981 offset 0 ndim 2 nrow 24689 ncol 29 Estrutura do conteúdo do PFile.
Mais informações na secção E.2.
end Terminador do cabeçalho.
Após a parte textual do cabeçalho encontra-se uma sequência de bytes com valor 0. A sua finalidade
é garantir que o tamanho do cabeçalho é aquele especificado na propriedade size (null padding bytes).
E.2 Conteúdo
Imediatamente a seguir ao cabeçalho vem o conteúdo do PFile, que se encontra num formato exclusi-
vamente binário. A figura E.1 ilustra a estrutura desta região, no contexto do exemplo introduzido na
secção anterior.
O conteúdo é uma sequência de vectores. A cada vector estão associados um segmento e um frame.
O vector tem 29 elementos e têm o formato especificado na linha format do cabeçalho. Logo, por cada
frame vamos ter um vector que encapsula, além das características extraídas, informação adicional.
Sabendo que cada elemento do vector é de tipo inteiro ou float1 tem-se que um vector ocupa 29 = 116
bytes. Consequentemente, o espaço ocupado por todo o conteúdo é o produto do número de vectores
pelo tamanho de cada um, ou seja, 24689× 116 = 2863924 bytes.
1Na implementação actual do Audimus tanto um inteiro (sizeof(int)) como um float (sizeof(float)) ocupam 4 bytes.
76

Figura E.1: Ilustração da estrutura e conteúdo de um PFile com 13 segmentos.
Na linha data do cabeçalho encontramos informação sobre o número total de elementos no con-
teúdo (715981), que pode ser calculado multiplicando o número de frames pelo número de elementos
por frame: 24689 × 29 = 715981. Partindo deste valor também se pode determinar o espaço ocupado
pelo conteúdo, multiplicando-o pelo espaço ocupado por cada elemento: 715981× 4 = 2863924 bytes.
77


Apêndice F
Guia de Instalação de Software
Necessário para o Desenvolvimento
F.1 Introdução
Este guia é o ponto de partida para quem pretenda fazer desenvolvimento de software dentro dos sis-
temas Audimus, PipelineServer e MetadataProducer. As instruções fornecidas contemplam os
pré-requisitos, a compilação e execução do código, bem como recomendações de carácter geral.
O sistema operativo recomendado é o Windows 7 Professional 64-bits e, além disso, todas as activida-
des aqui descritas devem ser executadas numa conta com acesso privilegiado.Em termos de linguagens
de programação, são importantes conhecimentos de C/C++ (Audimus e PipelineServer) bem como
de C# (MetadataProducer). Também são úteis conhecimentos de Windows Batch Script.
Para começar, é necessário o código fonte dos seguintes artefactos:
• Audimus versão 2.3-8 (Agosto de 2010) com as modificações resultantes do trabalho da disser-
tação (ver capítulo 3);
• EngineUtils versão 0.6.6 (Agosto de 2010);
• MetadataProducer versão 1.0.0 (Agosto de 2010).
Caso se pretenda desenvolver apenas no sistema Audimus então não necessita das modificações refe-
ridas no primeiro item, nem do MetadataProducer. O PipelineServer está incluído nestas modi-
ficações, pelo que a compilação do Audimus como um todo vai também compilar o PipelineServer.
Os códigos fonte do Audimus e do EngineUtils encontram-se no repositório CVS do L2F, nos
módulos audimus e engine_utils, respectivamente. Note-se que, aquando da leitura deste guia, as
versões podem já não ser as indicadas. No entanto, foram estas as versões utilizadas no contexto desta
dissertação, pelo que serão as assumidas nas secções seguintes.
79

F.2 Software a Instalar
O software necessário para o desenvolvimento é o indicado na tabela F.1. A ordem de instalação é rele-
vante, pelo que se deve começar pelo título indicado na primeira linha da tabela.
Título Executável
Microsoft Visual Studio 2008
Microsoft SDK v6.1
Microsoft DirectX SDK August 2007 dxsdk_aug2007.exe
Microsoft Visual Studio 2008 SP1 Update vs08sp1-KB945140-ENU.exe
Microsoft Visual studio 2008 Redistributables x64 vcredist_x64.exe
Java Development Kit (JDK) 1.6 jdk-6u21-windows-x64.exe
Intel MKL 10.1.0.018 w_mkl_p_10.1.0.018.exe
MinGW 5.1.4 MinGW-5.1.4.exe
Microsoft Visual Studio 2010
Python 3.1.2 python-3.1.2.amd64.msi
WinFF 1.1 winff-1.1-setup.exe
Tabela F.1: Software a instalar.
Durante a instalação do Microsoft Visual Studio (2008 e 2010) devem ser incluídos todos os compo-
nentes relacionados com C# e C++. Em caso de dúvida, realizar uma instalação completa.
O IDE recomendado para codificação no Audimus é o Eclipse 1 CDT (C Development Tools). No en-
tanto, a compilação deve ser feita fora do Eclipse, a partir de uma consola. A consola usada para a
compilação do Audimus é a Visual Studio 2008 x64 Win64 Command Prompt, que pode ser
encontrada em Start . All Programs . Microsoft Visual Studio 2008 . Visual Studio
Tools.Para codificação e compilação no MetadataProducer recomenda-se o IDE incluido no Micro-
soft Visual Studio 2010 e a utilização das configurações por omissão do projecto.
Além do software acima mencionado são ainda necessárias à execução do sistema as seguintes apli-
cações de linha de comandos indicadas na tabela F.2. Os respectivos executáveis e dependências devem
ser colocados numa directoria comum, por exemplo D:\apps. Atenção que são os executáveis que têm
de estar localizados nessa directoria, não basta, por exemplo, descompactar os arquivos para esse local,
no caso de arquivos comprimidos.
Em seguida, apontar a variável JAVA_HOME para a directoria onde está instalado o JDK e adicionar
%JAVA_HOME%\bin ao PATH de sistema. Adicionar também ao PATH as directorias onde se encontram
os binários do MinGW e do WinFF, bem como a directoria onde foram colocadas as aplicações de linha
de comandos (D:\apps).
1http://www.eclipse.org/downloads/ (último acesso em 14 de Novembro de 2010)
80

Título Executável
GNU CoreUtils 5.3 for Windows coreutils-5.3.0.exe, coreutils-5.3.0-dep.zip
Sox 14.3 sox-14.3.0-win32.zip
Gawk for Windows gawk-3.1.6-1-setup.exe
WaveSurfer wavesurfer-185-win.zip
grep for Windows grep-2.5.4-bin.zip, grep-2.5.4-dep.zip
Tabela F.2: Aplicações de linha de comandos.
F.3 Estrutura das Directorias do Trabalho
Com vista a beneficiar de diversos automatismos criados para agilizar o desenvolvimento, bem como
para garantir que este guia é eficaz, deve garantir que a estrutura de directorias do trabalho é a indicada
na figura F.1.
Figura F.1: Estrutura das directorias usada nesta dissertação.
Esta é a estrutura de directorias mínima para o ambiente de desenvolvimento. A raíz, neste caso
D:\tese, foi escolhida a título exemplificativo, mas é a recomendada. Na tabela F.3 encontra-se a
descrição das principais directorias.
Tanto o Audimus como o EngineUtils dependem de um terceiro pacote, chamado 3rdparty. O
3rdparty encontra-se em devel\engine_utils\3rdparty e não necessita de ser compilado. Existe
81

Directoria Descrição
deploy\audimus Destino de diversos executáveis produzidos a partir do có-
digo fonte do Audimus, bem como de todas as dependên-
cias necessárias para a sua execução.devel\AbordagemDTW Artefactos relacionados com a abordagem ao problema de
detecção de referências usando DTWs.devel\AbordagemMLPs Artefactos relacionados com a abordagem ao problema de
detecção de referências usando MLPs.devel\audimus Código fonte do Audimus já com os novos Componentes,
buffers e PipelineServer.devel\AudimusNewModulesTests Testes aos novos Componentes, buffers e
PipelineServer.devel\engine_utils Código fonte do EngineUtils, uma dependência do
Audimus.devel\MetadataProducer Código fonte do MetadataProducer.scripts\audimus Scripts de apoio à instalação do Audimus e EngineUtils.scripts\environment Scripts de apoio à configuração de variáveis de ambiente
específicas do trabalho desenvolvido.scripts\misc Scripts diversos.scripts\neuralnetworks Scripts de apoio a tarefas relacionadas com geração de PFi-
les e treino de redes neuronais.static\afs-mirrors Cópia de diversas directorias do AFS do L2F necessárias à
execução de certas partes do sistema.static\corpus.24h Directoria que contem emissões televisivas.static\jingle0.testpack Especialização de testes num dos jingles identificados no
corpus RTP.2009-09-17.templates Diversos ficheiros modelo.
Tabela F.3: Descrição das directorias principais.
uma ligação simbólica 2 para esta directoria em devel\audimus\3rdparty. Quando o EngineUtils
é compilado, passa a fazer parte do 3rparty que o Audimus usa como dependência de compilação.
F.4 Variáveis de Ambiente
Antes de avançar para a compilação e instalação do sistema, há que configurar variáveis de ambiente
especiais para suporte de diversas aplicações desenvolvidas no contexto da dissertação, incluindo o
MetadataProducer. Na directoria scripts\environment encontram-se três scripts:
setThesisEnv.bat, cleanThesisEnv.bat e showThesisEnv.bat.
O script setThesisEnv.bat define, ao nível das variáveis de ambiente do utilizador, as variá-
veis descritas na tabela F.4. Todas as variáveis relacionadas com directorias dependem da variável
THESIS_ROOT, que define a raíz de todo o trabalho. Note-se que estas variáveis mapeiam para de-
2Do Inglês, symlink.
82

terminadas directorias da estrutura descrita na secção anterior.
Variável Valor Descrição
THESIS_ROOT D:\tese Directoria raíz do trabalho.
THESIS_LIBRARIES_ROOT %THESIS_ROOT%\libraries Bibliotecas de suporte à progra-
mação.THESIS_SCRIPTS_ROOT %THESIS_ROOT%\scripts Directoria raíz de scripts.THESIS_TEMPLATES_ROOT %THESIS_ROOT%\templates Conjunto de templates para di-
versos fins.THESIS_DEVEL_ROOT %THESIS_ROOT%\devel Directoria raíz de todo o código
do trabalho.THESIS_DEPLOY_ROOT %THESIS_ROOT%\deploy Directoria raíz das instalações
de aplicações.
AUDIMUS_DEVEL_ROOT %THESIS_DEVEL_ROOT%\audimus Raíz do código fonte do
Audimus (que contém o
PipelineServer).AUDIMUS_DEPLOY_ROOT %THESIS_DEPLOY_ROOT%\audimus Raíz da instalação do Audimus.AUDIMUS_SCRIPTS_ROOT %THESIS_SCRIPTS_ROOT%\audimus Scripts de apoio à compila-
ção e instalação do Audimus e
EngineUtils.
MODE debug Modo de compilação do
Audimus e EngineUtils
(debug ou release).PLATFORM win64 Plataforma alvo da compilação
do Audimus e EngineUtils
(win32 ou win64).
Tabela F.4: Variáveis de ambiente user-wide.
Após a definição destas variáveis, o script adiciona ao PATH do utilizador (não do sistema) as seguin-
tes directorias: %THESIS_DEPLOY_ROOT%, %AUDIMUS_DEPLOY_ROOT%, %THESIS_SCRIPTS_ROOT%,
%AUDIMUS_SCRIPTS_ROOT%, %THESIS_SCRIPTS_ROOT%\neuralnetworks e
%THESIS_SCRIPTS_ROOT%\misc.
Antes de avançar para a próxima secção, assegure-se que a raíz da estrutura de directorias para o
trabalho está de acordo com a que é definida no setThesisEnv.bat. Recomenda-se a utilização dos
valores por omissão (raíz em D:\tese).
Os restantes dois scripts cleanThesisEnv.bat e showThesisEnv.bat têm como finalidade a
remoção e visualização, respectivamente, das variáveis definidas pelo setThesisEnv.bat.
83

F.5 Compilação e Instalação
Antes de compilar o Audimus é necessário compilar o EngineUtils. Abrir uma consola de compila-
ção, como explicado na Introdução deste guia, e navegar até devel\engine_utils. Executar o co-
mando nmake -f Makefile.Win. Assumindo que a estrutura de directorias é a apresentada na secção
anterior, resta agora fazer a instalação do EngineUtils, executando o script EngineUtilsDeploy,
também na linha de comandos. Os produtos resultantes da compilação do EngineUtils são colo-
cados numa subdirectoria do 3rdparty. Logo, a partir do momento em que se compila e instala o
EngineUtils, o Audimus está pronto a ser compilado.
Para compilar o Audimus, navegar até devel\audimus e executar o comando nmake -f
Makefile.Win. Após a compilação, o Audimus deve ser instalado executando o script AudimusDeploy.
Neste momento a pasta deploy\audimus contém diversas aplicações construídas a partir do código
fonte do Audimus, bem como as suas dependências. O PipelineServer também está compilado,
pois este encontra-se sob a árvore do código fonte do Audimus e integrado naturalmente no seu sistema
de construção de software.
No caso do MetadataProducer, não são necessárias instruções complexas. O projecto pode ser
compilado e executado directamente a partir da solution respectiva, que se encontra em
devel\MetadataProducer\MetadataProducer.sln, e que já contém todas as dependências e
configurações necessárias. Para tal basta abrir a solution no Microsoft Visual Studio 2010 e pres-
sionar F5 (Start Debugging).
Por omissão, tanto no Audimus como no MetadataProducer, todo o código é compilado em modo
debug.
F.6 Activação
Antes de se poder utilizar determinadas aplicações resultantes da compilação do Audimus, este neces-
sita de ser activado. Para isso, abra uma consola e execute a aplicação de activação, passando como
argumento a string da licença: audimus_activate.exe -l “...”. Se na consola surgir a mensa-
gem Activation Status: 1 então o Audimus está correctamente activado.
84

Apêndice G
Criar um Novo Componente ou Buffer
no Audimus
G.1 Introdução
Neste tutorial apresentam-se os passos necessários para criar um novo Componente ou buffer no Audimus.
Recomenda-se a leitura do guia no anexo F antes de iniciar esta actividade. É também importante ter
uma visão geral sobre a estrutura e comportamento do sistema Audimus, que pode ser encontrada na
secção 3.3.
Cada uma das duas secções que se seguem têm, obviamente, uma actividade prévia em comum.
Antes de se iniciar o desenvolvimento de um novo Componente ou buffer é necessário perceber quais as
suas especificações. No caso de Componentes primeiro há que estabelecer a sua função, isto é, qual o
seu papel no pipeline. Em seguida, enumerar as entradas e saídas necessárias, em número e tipo. Final-
mente, introduzir parâmetros que permitam configurar ou modificar o comportamento do Componente.
No caso de buffers, em primeiro lugar há que determinar qual a direcção do fluxo da informação: en-
trada, saída ou entrada/saída. Todas estas especificações devem ser documentadas antes de iniciar a
actividade do desenvolvimento, embora possam ser modificadas durante o mesmo.
Durante o desenvolvimento desta dissertação foram criados diversos Componentes: DTWComponent,
DTWStateMachineComponent, FramePrinter, HelloWorld, HelloConsumer, HelloProducer
e HelloEvents. Os dois primeiros suportam o sistema de detecção de referências, o terceiro pode
ser visto como um utilitário de apoio à depuração e monitorização do pipeline, cuja documentação téc-
nica sumária se encontra no anexo O. Os os restantes são os resultados dos estudos práticos efectuados
com vista a compreender vários aspectos do sistema Audimus e do desenvolvimento de Componentes.
Mais concretamente, o Componente HelloWorld procura ser um ponto de partida para o desenvol-
vimento de Componentes, em termos de estrutura de código e integração no sistema de construção
de software. O par HelloProducer e HelloConsumer exemplificam um cenário simples em que um
Componente é um produtor de Items e outro o consumidor, comunicando através de um buffer inter-
médio. Exemplifica-se assim um cenário simples de fluxo de dados no pipeline, isto é, como transmitir
85

informação entre Componentes. Finalmente, no HelloEvents encontra-se exemplificado o uso do sis-
tema de eventos do Audimus.
G.2 Criar um Novo Componente
Em primeiro lugar há que escrever o código fonte mínimo do novo Componente, integrando-o no código
fonte do Audimus. É também necessário entender a estrutura do código de um Componente, bem como
algumas ideias iniciais sobre o seu funcionamento. Os passos para esta tarefa são os seguintes:
1. Dentro do código fonte do Audimus, navegar até à directoria src\components;
2. Criar uma directoria com o nome do Componente, por exemplo, MyComponent;
3. Para a escrita do código, não é necessário partir de um ficheiro em branco. De acordo com a funci-
onalidade pretendida, pode ser usar o código de um dos restantes Componentes como esqueleto.
Os componentes Hello* apresentados na Introdução têm uma estrutura simples. Em caso de
dúvida, usar como modelo o HelloWorld; Admitindo que se usa como modelo o HelloWorld,
copiem-se os ficheiros HelloWorld.cpp, HelloWorld.h e Makefile.Win para a directoria do
novo Componente;
4. Renomear os ficheiros de código fonte para MyComponent.cpp e MyComponent.h;
5. Editar Makefile.Win e substituir todas as ocorrências de HelloWorld por MyComponent;
6. Editar MyComponent.h e renomear correctamente os header guards para __MY_COMPONENT_H__;
7. Renomear a classe, construtor e destrutor para MyComponent, MyComponent(...) e
MyComponent(), respectivamente. Realizar as operações necessárias tanto no .h como no .cpp;
8. Neste momento, o MyComponent.cpp já conta com os métodos básicos para a criação, parame-
trização, execução e destruição do Componente. No construtor devem ser invocados os métodos
setName e setType passando “MyComponent” como argumento, permitindo ao Audimus iden-
tificar o novo Componente. O logging tem que ser inicializado no construtor e finalizado no des-
trutor. No método run encontra-se a essência do Componente em tempo de execução, ou seja, o
código que vai implementar a funcionalidade atrubuída ao componente, que habitualmente passa
pelo processamento de frames lidos de buffers de entrada e os resultados escritos em buffers de
saída. Neste caso, o código no método run tipicamente será um ciclo que aguarda que as entradas
tenham dados disponíveis e, assim que tal seja verdade, realiza operações sobre esses dados, e
escreve-os nas saídas. Diferentes saídas podem ter diferentes resultados do processamento;
9. Nos métodos setParameters e getParameters existe o esqueleto para os accessors de parâ-
metros do Componente. Os parâmetros (<params/>) no ficheiro de configuração de arquitectura
para o Componente, especificados como pares name/value, são passados um a um ao método
setParameters, fazendo assim a ligação entre o XML e o Componente.
86

Em seguida, integra-se o novo Componente no sistema de construção de software do Audimus, de
acordo com o seguintes passos:
1. Na makefile geral dos Componentes, localizada em src\components\Makefile.Win, encon-
tramos a variável MODULES que indica os módulos a compilar recursivamente. Acrescentar a esta
variável o nome da directoria em que se encontra o novo Componente, MyComponent;
2. Na makefile do macro Componente genérico, em src\macroComponents\Makefile.Win, acres-
centar às directorias de procura por include files a directoria do novo componente, adicionado a
entrada /I..\..\components\MyComponent à variavel INCLUDE_DIRS;
3. Adicionar também uma entrada nas bibliotecas de dependências, a variável AUDIMUS_LIBS, com
o texto $(MAKEDIR)\$(OBJ_DIR)\..\..\components\
MyComponent\AudimusMyComponent.lib.
Para que possamos instanciar o novo componente em ficheiros de configuração de arquitectura, há
que implementar também o código de criação do objecto do Componente a partir do XML. Este código
não está localizado no próprio Componente mas sim numa zona onde se implementa esta tarefa para
todos os Componentes. Seguir os passos como indicado:
1. No ficheiro ComponentSAX2Handler.h, localizado em src\macroComponents\generic, adi-
cionar #include "MyComponent.h";
2. No ficheiro ComponentSAX2Handler.cpp, localizar o método createComponent(...). Aí
encontramos uma sequência de if/else if que determinam qual o Componente a instanciar
dado o tipo especificado no ficheiro de configuração de arquitectura. No XML, este tipo é a string
correspondente ao valor do atributo codetype de um nó component;
3. Para reconhecer o novo tipo de Componente basta adicionar a essa sequência de if/else if o
código apresentado na listagem G.1.
e lse i f ( type == "MyComponent" ) {
component = new MyComponent ( macroComponent ) ;
}
Listagem G.1: Código de criação de Componente a adicionar ao método createComponent.
Recompile-se agora o Audimus, tal como explicado no anexo F. Se tudo correr bem, o novo Com-
ponente está integrado e pronto a testar. A tarefa final é a criação de um ficheiro de configuração de
arquitectura para teste do novo Componente. Comece por integrá-lo num pipeline pouco complexo,
passando depois para cenários mais avançados. Como ponto de partida pode ser usado o XML de teste
do HelloWorld, o ficheiro hello.xml.
87

G.3 Criar um Novo Buffer
Os procedimentos para criação e integração de um novo Buffer são semelhantes aos apresentados na sec-
ção anterior para um novo Componente, mas mais simples. Recomenda-se a leitura da secção anterior
antes de avançar com as tarefas que se seguem.
1. Na directoria src\apis\buffers, criar os ficheiro do código fonte para o buffer, por exemplo,
MyBuffer.cpp e MyBuffer.h. Qualquer outro buffer pode servir de modelo para estruturar
o código. Os buffers são relativamente simples e basta implementar o método read, write ou
ambos, conforme o buffer seja de entrada, saída ou entrada/saída, respectivamente;
2. Depois de codificado, editar a DTD do Audimus, audimus\config\DTDs\AudimusConfig.dtd,
adicionando o nome do novo buffer (MyBuffer.h) aos aceites para tipos de buffer, na lista de atri-
butos para input type e/ou output type. Isto vai permitir a utilização do novo buffer em
ficheiros XML;
3. Na makefile src\buffers\Makefile.Win adicionar MyBuffer.cpp ao alvo CPP_SRC;
4. No ficheiro ComponentSAX2Handler.h, adicionar a directiva #include MyBuffer.h;
5. No ficheiro ComponentSAX2Handler.cpp, localizar a função createInput. Há uma cadeia de
if/else if que implementa a criação do buffer respectivo, dado o tipo e argumentos. Adicionar
um ramo if/else if, para o novo tipo de buffer. É também aqui que se faz o processamento de
eventuais argumentos que o buffer poderá ter, bem como a verificação dos mesmos;
Recompile-se agora o Audimus, tal como explicado no anexo F. Se tudo correr bem, o novo buf-
fer está integrado e pronto a testar. A tarefa final é a criação de um ficheiro de configuração de ar-
quitectura para teste do novo buffer. Comece por integrá-lo num pipeline pouco complexo, passando
depois para cenários mais avançados. Como ponto de partida pode ser usado o XML de teste do
FunctionGeneratorInputBuffer, o ficheiro FunctionGeneratorInputBuffer.xml.
88

Apêndice H
DTWComponent - Documentação
Sumária
H.1 Geral
Nome: DTWComponent
Título: Implementação do algoritmo DTWCódigo fonte: src\components\DTW
Descrição: Este Componente compara uma dada referência com janelas móveis de uma base.
Para cada uma dessas janelas é determinado o score do melhor alinhamento entre
a referência e a janela da base. Para isso, é aplicada uma modificação do algoritmo
DTW, onde se fazem restrições à diagonal da matriz de alinhamento. Para informa-
ções mais detalhadas consultar o capítulo 3.
H.2 Entradas e Saídas
EntradasPosição Tipo Descrição0 Buffer Buffer contendo FrameItems, cada um com um vector de 26 floats, as
características (features) extraídas do áudio da base.1 Buffer Buffer contendo FrameItems, cada um com um vector de 26 floats, as
características (features) extraídas do áudio da referência.SaídasPosição Tipo Descrição0 Buffer Buffer contendo FrameItems, cada um com um float que representa
o score do alinhamento actual. O sentenceID de cada FrameItem con-
tém o número da janela actual (1. . .numWindows).
89

H.3 Entradas e Saídas Externas ao Pipeline
• Este Componente escreve num ficheiro os scores de cada janela analisada. Ver secção H.4 para mais
informação.
H.4 Parâmetros
Nome Valor por Omissão Descrição
diagonalTolerance 0.1 Tolerância do afastamento do alinhamento à diago-
nal principal da matriz DTW (mín: 0, max: 1).numFeaturesUsed 13 Número de características a usar na comparação de
frames (mín: 1, max: 26).outputFileName “DTWValues.txt” Nome do ficheiro onde escrever os scores de cada
janela analisada.saveScores false Se true, regista os scores no ficheiro com o nome
dado pelo parâmetro outputFileName.
H.5 Eventos e Propriedades
Este Componente não emite eventos.
90

Apêndice I
DTWStateMachineComponent -
Documentação Sumária
I.1 Geral
Nome: DTWStateMachineComponent
Título: Máquina de estados da DTWCódigo fonte: src\components\DTWStateMachine
Descrição: Máquina de estados para interpretação do score da DTW perante um limiar. Cada
score emitido pelo Componente DTWComponent guia esta máquina de estados,
que mantém um valor limiar (threshold) para definir regiões onde se procura um
valor mínimo do score. O valor mínimo de uma região de scores abaixo do limiar é
um hit, ou seja, uma correspondência entre o áudio de entrada e a referência.
I.2 Entradas e Saídas
EntradasPosição Tipo Descrição0 Buffer Buffer contendo FrameItems, cada um com um
float que representa o score para esse frame.SaídasPosição Tipo Descrição0 NullOutputBuffer Saída não utilizada, deve ser colocado um
NullOutputBuffer nesta saída.
91

I.3 Entradas e Saídas Externas ao Pipeline
• Este Componente escreve num ficheiro diversas informações sobre a máquina de estados interna,
à medida que a entrada é analisada. Ver secção I.4 para mais informação.
I.4 Parâmetros
Nome Valor por Omissão Descrição
threshold 75 Limiar para delimitar regiões onde procurar míni-
mos do score (mín: 0).frameLength 0.01 Duração de um frame, em segundos (mín: 0).outputFileName DTWStateMachine.txt ficheiro onde escrevem informações de estado in-
terno. A informação registada é controlada pelas
propriedades com o prefixo show.showTransitions false Registar as transições entre estados. Indica também
se a janela final da entrada teve um score abaixo do
limiar (caso em que a análise termina com o score
abaixo do limiar).showHits true Se true, regista informação sobre os hits, pontos
mínimos do score em regiões abaixo do limiar.showHitTime true Se true, regista o instante de tempo em que ocor-
reu um hit, em segundos desde o início do áudio de
entrada. Se esta opção estiver a true e showHits
a false, apenas são registados os instantes tempo-
rais, sem a etiqueta “time: “ antes do instante.showHitCount false Se true, regista no final da análise o número de hits
encontrados.showGlobalMinimum true Se true, regista no final da análise o mínimo global
do score.referenceID “unnamed” Identificador da referência a ser comparada.jobName “unknown job” Nome do pipeline job associado.inputFileName “unknown.raw” Nome do ficheiro áudio de entrada.
I.5 Eventos e Propriedades
Este Componente emite o evento EVENT_DTWSM_HIT (2000) sempre que é assinalado um hit. As pro-
priedades desse evento estão indicadas na tabela que se segue.
92

Identificador Valor Descrição
EVENT_PROPERTY_DTWSM_WINDOW 0 Janela do áudio em que foi assinalado o hit.EVENT_PROPERTY_DTWSM_HIT_WINDOW 1 Janela do áudio em que o hit ocorreu.EVENT_PROPERTY_DTWSM_HIT_SCORE 2 Score da DTW para a janela do hit.EVENT_PROPERTY_DTWSM_HIT_TIME 3 Carimbo temporal do hit.EVENT_PROPERTY_DTWSM_REFERENCE_IDENTIFIER 4 Identificador da referência a ser comparada.EVENT_PROPERTY_DTWSM_JOB_NAME 5 Nome do pipeline job associado.EVENT_PROPERTY_DTWSM_INPUT_FILE_NAME 6 Nome do ficheiro áudio de entrada.
93


Apêndice J
Exemplo de Relatório de Detecção
Depois de efectuada uma execução do pipeline, as referências identificadas podem ser sumarizadas num
relatório. O MetadataProducer dá a possibilidade ao utilizador de gerar um relatório em formato de
texto. Neste relatório consta não só uma listagem detalhada das referências detectadas, mas também
estatísticas sobre a detecção. Um exemplo deste relatório está na figura J.1.
No cabeçalho indica-se o nome do pipeline job seguido pelos ficheiros áudio de entrada que serviram
de base para a detecção. Para cada ficheiro de entrada, listam-se os matches, ou referências identificadas.
Por cada referência identificada indica-se, nesta ordem e da esquerda para a direita:
• Instante em que a referência foi assinalada, relativo a todo o conjunto de ficheiros de entrada, no
formato hh:mm:ss.xxx;
• Instante acima descrito, em segundos;
• Instante em que a referência foi assinalada, relativo ao ficheiros de entrada referido, no formato
hh:mm:ss.xxx;
• Instante acima descrito, em segundos;
• Identificador da referência;
• Título da referência;
• Duração da referência, em segundos;
• Erro de duração, caso o modo de detecção seja boudary.
Em seguida indica-se o número de ocorrências de referências detectadas, seguido dos detalhes da
cobertura da detecção. Termina-se o relatório com detalhes de desempenho, apresentando o tempo de
execução da detecção e o valor calculado de ×RT.
95

Figura J.1: Exemplo de relatório de detecção gerado pelo MetadataProducer.
96

Apêndice K
Interfaces da Aplicação
MetadataProducer
O índice de interfaces da aplicação MetadataProducer encontra-se na tabela K.1. As classes das in-
terfaces encontram-se no namespace MetadataProducer.Forms.
Classe Figura Funcionalidade
MainForm K.1 Interface base da aplicação. Segue o paradigma
MDI.ConnectionForm K.2 Gerir a ligação com o PipelineServer.PipelineJobsForm K.3 Gerir pipeline jobs.EditPipelineJobForm K.4 Editar um pipeline job.ReferencesForm K.5 Gerir referências.EditReferenceForm K.6 Editar referência.JobRunnerForm K.7 Monitor de execução de pipeline jobs.ReferenceMatchesForm K.8 Visualizar referências detectadas na execução de um
pipeline job.ViewUnidentifiedSegments K.9 Visualizar segmentos não identificados na execução
de um pipeline job.
Tabela K.1: Índice de interfaces da aplicação MetadataProducer.
97

Figura K.1: Interface MDI base do MetadataProducer.
Figura K.2: Interface de gestão da ligação com o PipelineServer.
Figura K.3: Interface de gestão de pipeline jobs.
Figura K.4: Interface de edição de um pipeline job.
98

Figura K.5: Interface de gestão de referências.
Figura K.6: Interface de edição de uma referência.
Figura K.7: Interface de execução de um pipeline job.
99

Figura K.8: Interface de apresentação de referências identificadas.
Figura K.9: Interface de apresentação dos segmentos não identificados.
100

Apêndice L
Configuração do MetadataProducer
A configuração do MetadataProducer é feita através do ficheiro App.config. As parametriza-
ções são pares (chave,valor) localizados na secção <appSettings>, em que as chaves admissíveis
encontram-se na tabela L.1, junto com as respectivas descrições.
Chave Descrição
remoteHostName Host name do pipeline por omissão.remotePort Porto TCP do pipeline por omissão.referenceBoundaryTolerance Valor, em segundos, da tolerância boundaryTol, tal como expli-
cado na sub-secção 3.7.1.extractedSegmentsDirectory Directoria por omissão onde gravar os segmentos extraídos.reportsDirectory Directoria por omissão onde gravar os relatórios da detecção.
Tabela L.1: Chaves dos parâmetros do MetadataProducer.
101


Apêndice M
Preparação do Corpus RTP.2009-09-17
Logo que o trabalho teve início, foi recolhido um corpus, ou seja, um conjunto de documentos que
servem de suporte ao estudo1. Os documentos em questão são de carácter multimédia e têm origem
num dia completo de emissão da RTP. Mais concretamente, foram gravados 23 vídeos2, correspondentes
a horas distintas da emissão da RTP1 na data 2009-09-17. As especificações dos vídeos gravados são:
formato MPEG2, resolução 720× 576, 25.00 fps, 3072 kbps.
Depois da recolha dos vídeos, foi obtida, a partir do site da RTP, a lista de programas para o dia em
questão 3, que se encontra reproduzida na tabela M.1.
Observando o conteúdo das gravações verificou-se que o guia electrónico de programação nem sem-
pre é fiel à realidade, em termos da estrutura e conteúdo da emissão. De forma a ter um corpus correcta-
mente documentado, foi produzida manualmente uma lista de todos os programas e respectivos tempos
de início e fim. Esta lista encontra-se na tabela M.2 Entre os programas, existem blocos de publicidade
que, apesar de não estarem representados, correspondem implicitamente aos intervalos de tempo em
que não existe um programa.
Depois de feitas as gravações dos vídeos, foi extraído o áudio de cada vídeo para WAV e RAW. O for-
mato WAV foi considerado pela sua popularidade e aceitação, inclusive pelas aplicações de software. No
entanto, o primeiro contacto com diversas ferramentas computacionais no L2F revelou que o formato
RAW era ali muito mais usado, pelo que também se extraiu o áudio para esse formato. O formato RAW
consiste numa stream de amostras, sem qualquer cabeçalho 4 que a caracterize (ao contrário do WAV).
Consequentemente, para manipular um ficheiro RAW é necessário saber quais os seus parâmetros de
gravação: a taxa de amostragem 5, o tamanho das amostras, a sua codificação e endianess. No nosso
caso concreto, e durante todo o resto do trabalho, os RAWs com que trabalhámos têm as seguintes ca-
1Dicionário Priberam da Língua Portuguesa, http://www.priberam.pt/DLPO/default.aspx?pal=corpus (último
acesso em 14 de Novembro de 2010).2O corpus ficou com vinte e três e não vinte e quatro horas, pois não foi possível trabalhar com o conteúdo da 16a hora, por
motivos técnicos dos quais só nos apercebemos já numa fase adiantada do trabalho.3A programação da RTP1 pode ser encontrada no site http://tv1.rtp.pt/EPG/tv/epg-dia.php (último acesso em 14
de Novembro de 2010).4Diz-se que é um headerless format.5Do Inglês, sampling rate.
103

Hora de início (hh:mm:ss) Título
23:55:00 OS ÚLTIMOS DIAS DO PLANETA TERRA
01:29:00 LONGE DE CASA
02:20:00 AMOR E INTRIGAS
03:19:00 TELEVENDAS
06:04:00 NÓS
06:30:00 BOM DIA PORTUGAL
10:00:00 PRAÇA DA ALEGRIA
13:00:00 JORNAL DA TARDE
14:15:00 CHAMAS DA VIDA
15:00:00 SANGUE DO MEU SANGUE
16:00:00 PORTUGAL NO CORAÇÃO
18:00:00 PORTUGAL EM DIRECTO
19:00:00 CAMPANHA ELEITORAL - LEGISLATIVAS 2009
19:15:00 O PREÇO CERTO
20:00:00 TELEJORNAL
21:00:00 ANTES PELO CONTRÁRIO
21:15:00 OS REIS DA SELVA
22:15:00 JOGO DUPLO
23:15:00 PRESUMÍVEL INOCENTE
Tabela M.1: Listagem de programas no corpus RTP.2009-09-17 segundo o site da RTP.
104

Hora de início
(hh:mm:ss)
Hora de fim
(hh:mm:ss)
Título
00:05:00 00:12:40 Futebol (continuação do dia anterior)00:13:16 00:42:51 OS ÚLTIMOS DIAS DO PLANETA TERRA (1/2)00:52:13 01:42:52 OS ÚLTIMOS DIAS DO PLANETA TERRA (2/2)01:51:10 02:34:07 LONGE DE CASA02:39:26 03:28:40 AMOR E INTRIGAS03:31:56 05:47:29 TELEVENDAS05:47:29 06:03:44 Euronews06:03:44 06:29:26 NÓS06:29:55 06:40:43 BOM DIA PORTUGAL (1/8)06:46:46 06:59:27 BOM DIA PORTUGAL (2/8)06:59:55 07:29:45 BOM DIA PORTUGAL (3/8)07:36:51 07:59:45 BOM DIA PORTUGAL (4/8)08:00:11 08:31:39 BOM DIA PORTUGAL (5/8)08:41:34 08:59:31 BOM DIA PORTUGAL (6/8)08:59:59 09:28:47 BOM DIA PORTUGAL (7/8)09:37:52 09:59:40 BOM DIA PORTUGAL (8/8)09:59:56 10:51:38 PRAÇA DA ALEGRIA (1/4)10:58:54 11:43:41 PRAÇA DA ALEGRIA (2/4)11:51:54 12:05:45 PRAÇA DA ALEGRIA (3/4)12:14:20 12:58:32 PRAÇA DA ALEGRIA (4/4)12:59:56 13:47:27 JORNAL DA TARDE (1/2)13:55:56 14:14:36 JORNAL DA TARDE (2/2)14:21:38 15:22:05 CHAMAS DA VIDA15:22:05 15:52:21 SANGUE DO MEU SANGUE16:00:15 16:37:26 PORTUGAL NO CORAÇÃO (1/3)16:48:01 17:20:59 PORTUGAL NO CORAÇÃO (2/3)17:29:12 17:59:05 PORTUGAL NO CORAÇÃO (3/3)17:59:56 18:23:23 PORTUGAL EM DIRECTO (1/2)18:33:56 18:59:46 PORTUGAL EM DIRECTO (2/2)18:59:57 19:15:27 CAMPANHA ELEITORAL - LEGISLATIVAS 200919:25:41 19:58:38 O PREÇO CERTO19:59:57 20:40:25 TELEJORNAL (1/2)20:48:02 21:01:47 TELEJORNAL (2/2)21:02:06 21:36:05 Jogo Duplo (1/2)21:45:18 22:00:29 Jogo Duplo (2/2)22:22:25 22:00:29 Telerural22:22:25 22:46:30 Contra-Informação22:55:31 23:46:07 Corredor do Poder23:46:07 23:55:20 OS ÚLTIMOS DIAS DO PLANETA TERRA
Tabela M.2: Listagem de programas no corpus RTP.2009-09-17, obtida manualmente.
105

racterísticas: 16000 amostras/segundo, amostras do tipo inteiro com sinal (signed), 2 bytes por amostra,
codificação linear, little endian. Uma lista dos ficheiros extraídos encontra-se na tabela M.3. O nome do
ficheiro é composto pela hora de início da gravação e pela sua duração, em segundos.
00h05m00s-3597s.raw 08h05m00s-3596s.raw 17h05m00s-3595s.raw
01h05m00s-3597s.raw 09h05m00s-3596s.raw 18h05m00s-3596s.raw
02h05m00s-3596s.raw 10h05m00s-3595s.raw 19h05m00s-3597s.raw
03h05m00s-3598s.raw 11h05m00s-3595s.raw 20h05m00s-3594s.raw
04h05m00s-3594s.raw 12h05m00s-3596s.raw 21h05m00s-3597s.raw
05h05m00s-3595s.raw 13h05m00s-3595s.raw 22h05m00s-3594s.raw
06h05m00s-3595s.raw 14h05m00s-3559s.raw 23h05m00s-3590s.raw
07h05m00s-3595s.raw 15h05m00s-3596s.raw
Tabela M.3: Lista dos ficheiros RAW presentes no corpus RTP.2009-09-17, correspondentes às 23 horas de gravação.
Como última tarefa, extrairam-se manualmente todos os cinco jingles distintos presentes no corpus,
anotando os instantes de tempo em que ocorrem ao longo da emissão. Na tabela M.4 encontra-se a
duração de cada jingle. Na tabela M.5 apresentam-se, para cada hora de gravação presente no corpus, os
jingles nelas existentes e o instante temporal em que ocorrem, relativos ao início do ficheiro dessa hora.
Os cinco jingles foram nomeados jingle0, . . . , jingle4.
Jingle Duração (s) Jingle Duração (s)
jingle0 4,896 jingle3 4,678jingle1 5,000 jingle4 4,629jingle2 4,615
Tabela M.4: Duração de cada jingle presente no corpus.
106

#Hora Jingle Instante de início (s) #Hora Jingle Instante de início (s)
0 jingle1 492,426 12 jingle0 45,589jingle0 2270,675 jingle0 555,554jingle0 2830,050 jingle4 3245,043
jingle2 3266,666jingle2 3291,752
1 jingle1 2272,125 13 jingle1 2548,936jingle0 2765,219 jingle2 3051,341
2 jingle0 1747,139 14 jingle0 582,863jingle1 2061,709 jingle0 988,114
jingle3 993,113
3 jingle1 1470,639 15 jingle3 1025,606jingle1 1611,445 jingle1 2841,658
jingle0 3305,190jingle3 3310,190
4 (sem jingles) 16 (não disponível)
5 (sem jingles) 17 jingle1 959,544jingle0 1447,240jingle2 3266,328jingle2 3291,414
6 jingle2 1466,812 18 jingle1 1103,401jingle2 1491,940 jingle0 1732,215jingle0 2141,613jingle2 2502,004jingle2 3267,064jingle2 3292,149
7 jingle1 1483,229 19 jingle0 627,346jingle2 1905,241 jingle3 1237,081jingle2 3281,036 jingle2 3266,175jingle2 3306,163 jingle2 3292,221
8 jingle0 1595,905 20 jingle1 2125,131jingle2 2187,832 jingle2 2577,450jingle2 3266,662 jingle0 3407,193jingle2 3294,706
9 jingle1 1426,814 21 jingle0 1865,632jingle2 1967,474 jingle0 2413,995jingle3 3292,149 jingle0 3323,403
10 jingle0 2798,083 22 jingle1 2498,608jingle0 3229,266 jingle1 3026,263
11 jingle1 2321,142 23 jingle0 2468,025jingle1 2810,515 jingle0 3015,726
Tabela M.5: Lista dos jingles presentes no corpus.
107


Apêndice N
Preparação do Corpus jingle0.testpack
Tal como foi preparado um corpus relacionado com um dia de emissão, também foi criado um pacote de
teste a utilizar em diversos momentos de avaliação em que a referência foi especificamente o jingle0 (ver
anexo M). Ou seja, o corpus jingle0.testpack consiste em 7 segmentos áudio em que se procura testar um
conjunto de situações relacionadas com a presença e ausência da referência jingle0 nesses segmentos.
Também para este corpus foram extraídos os PFiles. As especificações do formato áudio são as mesmas
do RAWs no corpus RTP.2009-09-17.
Na tabela N.1 encontra-se a duração e descrição de cada ficheiro base presente no jingle0.testpack.
Na tabela N.2 listam-se os instantes em que o jingle0 está presente em cada ficheiro base do corpus.
Nome Duração (s) Descrição
jingle0 4,896 O próprio jingle0, para validação do caso trivial.doublejingle0 9,792 Concatenação de duas referências jingle0.quadjingle0 19,584 Concatenação de quatro referências jingle0.octojingle0 39,168 Concatenação de oito referências jingle0.nojingle0 158,090 Segmento sem a presença do jingle0.onejingle0 146,000 Segmento com a presença de um jingle0.twojingles0 168,717 Segmento com a duas referências jingle0 não consecutivas.
Tabela N.1: Características dos ficheiros base do corpus jingle0.testpack.
109

#Hit Instante (s) #Hit Instante (s)
jingle0 nojingle0
1 0,000 Não contém jingle0.doublejingle0 onejingle0
1 0,000 1 16,6752 4,900quadjingle0 twojingles0
1 0,000 1 16,6752 4,900 2 93,4673 9,7964 14,692octojingle0
1 0,0002 4,9003 9,7964 14,6925 19,5886 24,4847 29,3808 34,276
Tabela N.2: Instantes do jingle0 em cada ficheiro base do corpus jingle0.testpack.
110

Apêndice O
FramePrinterComponent -
Documentação Sumária
O.1 Geral
Nome: FramePrinterComponent
Título: Utilitário de visualização de framesCódigo fonte: src\components\FramePrinter
Descrição: Este Componente teve inicialmente o nome de FeaturePrinter, pois foi origi-
nalmente pensado para a visualização das características (features) produzidas pelo
Componente Rasta. Entretando, surgiu a necessidade de visualização do conteúdo
de FrameItems com outros tipos de dados, evoluindo assim este Componente para
a versão aqui apresentada.
O.2 Entradas e Saídas
EntradasPosição Tipo Descrição0 Buffer Buffer contendo FrameItems.SaídasPosição Tipo Descrição0 NullOutputBuffer Saída não utilizada, deve ser colocado um NullOutputBuffer nesta
saída.
O.3 Entradas e Saídas Externas ao Pipeline
• Este Componente escreve num ficheiro informação relativa aos frames que lê da sua entrada. Ver
secção O.4 para mais informação.
111

O.4 Parâmetros
Nome Valor por Omissão Descrição
outputFileName “FramePrinterOutput.txt” Nome do ficheiro onde registar a infor-
mação produzida.sampleType float Tipo de dados dos elementos do vec-
tor contido nos FrameItems lidos da
entrada (opções: byte, char, int e
float). Se o tipo for char então no
ficheiro o conteúdo do frame é escrito
formatado como texto. Caso contrário,
o conteúdo é escrito com formatação
numérica. Exemplo: se este parâmetro
estiver definido como float, o con-
teúdo de cada frame lido da entrada é
interpretado como um vector de amos-
tras do tipo float e impresso numeri-
camente.displayFrameInformation true Registar também informações sobre
o frame: sentenceID, frameID,
bodySize, isEOF, isEOS e
isAutoPause.
O.5 Eventos e Propriedades
Este Componente não emite eventos.
112







![ARQUIVO com extensão metadata [EMP] - [orientações para … · 2015-10-16 · [poderá ser aberto diretamente pelo bloco de notas] 4) No Menu Editar do Bloco de notas clicar em](https://img.document.onl/doc/110x75/5c5bb91809d3f23b368c360e/arquivo-com-extensao-metadata-emp-orientacoes-para-2015-10-16-podera.jpg)





















