Embed Size (px)
Citation preview

VITOR HUGO BEZERRA
INCLUSÃO DE TÉCNICAS DE INTERPOLAÇÃO DEPONTOS EM ALGORITMOS DE DESCOBERTA ON-LINE
DO PADRÃO FLOCK
LONDRINA–PR
2016


VITOR HUGO BEZERRA
INCLUSÃO DE TÉCNICAS DE INTERPOLAÇÃO DEPONTOS EM ALGORITMOS DE DESCOBERTA ON-LINE
DO PADRÃO FLOCK
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
Orientador: Prof(a). Dr(a). Daniel dos San-tos Kaster
LONDRINA–PR
2016

Vitor Hugo BezerraInclusão de técnicas de interpolação de pontos em algoritmos de descoberta
on-line do padrão flock/ Vitor Hugo Bezerra. – Londrina–PR, 2016-60 p. : il. (algumas color.) ; 30 cm.
Orientador: Prof(a). Dr(a). Daniel dos Santos Kaster
– Universidade Estadual de Londrina, 2016.
1. Banco de Dados Espaço-Temporais. 2. Padrão Flock. I. Prof(a). Dr(a).Daniel dos Santos Kaster. II. Universidade Estadual de Londrina. III. Bacharelado
CDU 02:141:005.7

VITOR HUGO BEZERRA
INCLUSÃO DE TÉCNICAS DE INTERPOLAÇÃO DEPONTOS EM ALGORITMOS DE DESCOBERTA ON-LINE
DO PADRÃO FLOCK
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
BANCA EXAMINADORA
Prof(a). Dr(a). Daniel dos Santos KasterUniversidade Estadual de Londrina
Orientador
Prof. Dr. Alan Salvany FelintoUniversidade Estadual de Londrina
Prof. Ms. Fábio Cezar MartinsUniversidade Estadual de Londrina
Londrina–PR, 16 de dezembro de 2016


A minha família que sempre me deram suporte incondicional .


AGRADECIMENTOS
Agradeço aos meus pais e minha irmã que sempre me incentivaram e apoiarammesmo nos momentos mais difíceis.
A Denis E. Sanches pela atenção e suporte na construção desse trabalho.
Aos meus professores pelos seus ensinamentos, em especial ao meu orientador,Daniel Kaster, pela sua atenção, dedicação e aprendizado como professor e orientador.
Por fim mas não menos importante, a todos meus amigos que fiz no decorrer docurso, pelos ensinamentos, companheirismo, risadas que ajudaram nessa jornada.


"Se vi mais longe foi por estar de pé sobre ombros de gigantes."(Isaac Newton)


BEZERRA, V. H.. Inclusão de técnicas de interpolação de pontos em algoritmosde descoberta on-line do padrão flock. 60 p. Trabalho de Conclusão de Curso (Bacha-relado em Ciência da Computação) – Universidade Estadual de Londrina, Londrina–PR,2016.
RESUMO
O barateamento de dispositivos de localização e sua disponibilidade em veículos, celularese outros aparelhos, gera um aumento de dados espaço-temporais, o que gera a necessidadede métodos para a análise e interpretação destes dados, que podem ser utilizados parareconhecimento de padrões como migração de animais, congestionamentos de carros erastreamento de objetos.Um dos métodos de análise é o padrão flock, que pode ser definido como um númeromínimo de entidades dentro de um espaço delimitado por uma circunferência de raiodelimitado que se deslocam juntos por um certo intervalo de tempo. Na coleta de dadosde trajetórias de objetos móveis, é normal que apresentem irregularidades por problemas,como falha do aparelho, falha de envio da posição, por exemplo na passagem por túneis,etc., gerando incerteza nos dados. Devido a perdas de um ou mais pontos, há diminuiçãono tempo de um padrão flock ou simplesmente o não reconhecimento do padrão apesarde, na realidade, existir ocasionando a não identificação de, por exemplo, um "arrastão",ou um grupo de animais se locomovendo.Para resolver este problema, precisamos tratar os dados coletados e achar os dados espaço-temporais que não foram reportados, utilizando interpolação de pontos. Técnica que a par-tir de pontos já coletados, calcula geometricamente os prováveis pontos entre um pontoconhecido e outro, frequente usada no tratamento de incerteza em dados de trajetória.O objetivo desse trabalho é a implementação e avaliação da inclusão de técnicas de in-terpolação para o tratamento de entradas para algoritmos de descoberta do padrão flock.Foram desenvolvidas duas técnicas de tratamento, uma offline utilizando todo conjuntode dados, e on-line focada para o uso de algoritmos on-line de descoberta do padrão flock.Os resultados mostraram bons resultados de recuperação de respostas dos algoritmostestados.
Palavras-chave: Bancos de dados espaço-temporais; padrão flock; detecção de padrões;interpolação de trajetória;


BEZERRA, V. H.. Inclusion of path interpolation techniques in flock patternon-line discovery algorithms. 60 p. Final Project (Bachelor of Science in ComputerScience) – State University of Londrina, Londrina–PR, 2016.
ABSTRACT
With the decreasing costs of tracking devices and their availability in vehicles, smart-phones and other devices, there is an increase of spatio-temporal data. This increasecreates the need for methods to analyze and interpret this data, which can be used torecognize patterns, such as, migration of animals, car congestion and object tracking.One of the methods to analyze these patterns is the flock pattern, which can be definedas a minimal number of entities within a defined radius circle moving together during acertain time-window.As the trajectories of different objects are collected, they may be irregular. Problems suchas system failures, passing through tunnels or underground and network-related problems.These problems cause the loss of spatio-temporal data, changing the real flock or simplynot recognizing them, despite its existence in the real world.To solve these problems, we need to treat the trajectory data and find the spation-temporalpoints which were not reported, using path interpolation. The path interpolation is thetechnique that geometrically generates new spatio-temporal points based on the datacollected. The objective of this work is the implementation and evaluation of the inclusionof interpolation techniques for the treatment of entries for flock pattern algorithms. Twotreatment techniques were developed, one offline using the entire dataset, and on-linefocused on the use of on-line flock pattern algorithms. The results showed good results ofthe algorithms tested.
Keywords: Spatiotemporal databases; flock pattern; pattern detection; path interpola-tion;


LISTA DE ILUSTRAÇÕES
Figura 1 – Padrões de movimentação espaço-temporais (retirada de [1]). . . . . . . 27
Figura 2 – Exemplo de padrão flock, com 𝜇 = 3 e 𝛿 = 3 (retirada de [2]). . . . . . 28
Figura 3 – Exemplo de interpolação linear. . . . . . . . . . . . . . . . . . . . . . . 32
Figura 4 – Exemplo de interpolação Random Walk. . . . . . . . . . . . . . . . . . 34
Figura 5 – Exemplo de interpolação Bezier. . . . . . . . . . . . . . . . . . . . . . . 35
Figura 6 – Resultados dos experimentos com os conjuntos alterados sem trata-mento Cars (1a linha), Buses (2a linha) e Caribous (3a linha) variando𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿
(duração - 3a coluna). . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Figura 7 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Nega-tivos alterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha)e CARIBOUS 1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖
(diâmetro dos discos - 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . 41
Figura 8 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Posi-tivos alterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha)e CARIBOUS 1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖
(diâmetro dos discos - 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . 42
Figura 9 – Resultados dos experimentos com o conjunto BUSES Falsos Negativosalterado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1%(3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos- 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . 43
Figura 10 – Resultados dos experimentos com o conjunto BUSES Falsos Positivosalterado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1%(3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos- 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . 44
Figura 11 – Resultados dos experimentos com o conjunto CARS Falsos Negativosalterado Cars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a
coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . . . . 45
Figura 12 – Resultados dos experimentos com o conjunto CARS Falsos Positivosalterado Cars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a
coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . . . . 46
Figura 13 – Exemplo do método proposto com a utilização de seis buffers. . . . . . 48

Figura 14 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Nega-tivos alterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha)e CARIBOUS 1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖
(diâmetro dos discos - 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . 50Figura 15 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Posi-
tivos alterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha)e CARIBOUS 1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖
(diâmetro dos discos - 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . 51Figura 16 – Resultados dos experimentos com o conjunto BUSES Falsos Negativos
alterado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1%(3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos- 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . 52
Figura 17 – Resultados dos experimentos com o conjunto BUSES Falsos Positivosalterado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1%(3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos- 2a coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . 53
Figura 18 – Resultados dos experimentos com o conjunto CARS Falsos Negativosalterado Cars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a
coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . . . . 54Figura 19 – Resultados dos experimentos com o conjunto CARS Falsos Positivos
alterado Cars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a
coluna) e 𝛿 (duração - 3a coluna). . . . . . . . . . . . . . . . . . . . . . 55

LISTA DE TABELAS
Tabela 1 – Número de objetos, quantidade de posições e valores de parâmetrostestados para cada conjunto de dados. . . . . . . . . . . . . . . . . . . 38


LISTA DE ABREVIATURAS E SIGLAS
BFE Basic Flock Evaluation
GPS Global Positioning System
PSI Plane Sweeping, Binary Signatures and Inverted Index


SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2 DESCOBERTA DE PADRÕES DE MOVIMENTAÇÃO EMBANCOS DE DADOS DE TRAJETÓRIAS . . . . . . . . . . . 25
2.1 Padrões de Movimentação . . . . . . . . . . . . . . . . . . . . . . 262.2 O Padrão Flock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3 Algoritmos para Detecção do Padrão Flock . . . . . . . . . . . 28
3 TÉCNICAS DE INTERPOLAÇÃO EM TRAJETÓRIAS . . . 313.1 Interpolação Linear . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2 Interpolação por Random Walk Restrito . . . . . . . . . . . . . 323.3 Interpolação pela Curva de Bézier . . . . . . . . . . . . . . . . . 34
4 PROPOSTA DE INCLUSÃO DE INTERPOLAÇÃO EM AL-GORITMOS ON-LINE PARA O PADRÃO FLOCK . . . . . 37
4.1 Análise da Sensibilidade dos Algoritmos de Detecção de Flocksà Falta de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Avaliação do Uso de Técnicas de Interpolação na Detecção deFlocks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.3 Proposta de Inclusão de Interpolação nos Algoritmos de De-tecção On-line de Flocks . . . . . . . . . . . . . . . . . . . . . . . 47
4.4 Resultados dos Algoritmos On-line com Interpolação . . . . . 48
5 CONCLUSÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . 59


23
1 INTRODUÇÃO
A crescente quantidade de dados espaço-temporais adquiridos atualmente tem res-saltado a necessidade de algoritmos para interpretar esses dados armazenados em grandesbancos de dados. A análise desse tipo de dado complexo, embora seja uma operação caracomputacionalmente, pode identificar comportamentos similares entre objetos como, porexemplo, migração de animais, detecção de congestionamentos em vias e de lugares comgrande movimentação. Dentre as várias formas de análise de dados espaço-temporais,estão as de identificação de padrões de grupos de objetos em movimentando, mais especi-ficamente aquele com representação em disco, que explora a distância máxima entre umnúmero mínimo de entidades quaisquer não excedendo um diâmetro de disco definido emuma busca. Um dos padrões mais representativos da categoria de discos é o flock, quecompreende um conjunto mínimo de objetos que estão espacialmente próximos por umintervalo de tempo pré-definido. Dados um número mínimo de entidades 𝜇, um diâmetrode distância 𝜖 e um número de instantes de tempo 𝛿, um flock é um conjunto de 𝜇 ou maisentidades que permanecem por pelo menos 𝛿 instantes de tInterpolacaoempo consecutivosrespeitando o espaço definido por um disco de diâmetro 𝜖 em cada instante de tempo [2].
Entretanto, assim como no recebimento quanto na própria coleta desses dados detrajetórias, podem ocorrer falhas e ruídos, acarretando em atrasos e até mesmo perda decertas localizações coletadas. Essa possível irregularidade é causada por problemas comofalhas em sistemas e dispositivos, por passagens por túneis ou subterrâneos, pela própriadiferenciação das taxas de amostragem dos pontos de localização entre os diversos sistemasde coleta, etc. Como consequência desses possíveis gaps nas trajetórias, a identificação dospadrões flock pode ficar comprometida, devido à restrição temporal sequencial do padrão.Na prática, isto pode resultar na não identificação de um grupo de animais migrando, umgrupo de bandidos praticando assaltos em uma região ou um grupo de turistas se movendo,por exemplo. Para o tratamento das trajetórias problemáticas, uma das técnicas que podeser utilizada é a interpolação de pontos. Esta consiste em, a partir de determinados pontoscoletados, interpolar e inserir pontos nos gaps dessas trajetórias.
Neste contexto, o objetivo deste trabalho é tratar o problema de detecção de flocksem trajetórias sujeitas a dados com variação de taxa de amostragem e gaps por falhas e/ouruídos na coleta. A proposta é inserir técnicas de interpolação de pontos em algoritmospara a detecção on-line do padrão flock, possibilitando o tratamento de streams de dadosde trajetórias de objetos móveis. Nossa proposta armazena dados recebidos em instantessubsequentes de tempo, guardando-os em estruturas de dados (buffers), detecta a falta deuma determinada posição e realiza a interpolação, gerando uma estimada para o objeto.Experimentos realizados em trajetórias com pontos de localização retirados mostram que

24
a proposta obteve uma grande recuperação de resultados perdidos quando comparadoscom os resultados com as trajetórias originais completas. Neste trabalho são reportadosresultados que confirmam que a taxa de respostas perdidas foi reduzida em até 80%,embora o uso de interpolação seja sujeito à inclusão de respostas erradas, ou seja, falso-positivos.
Este trabalho está organizado da seguinte maneira, na Seção 2 apresenta-se osconceitos de dados de trajetória e padrões de movimentação, como também o padrãoflock e os algoritmos de detecção utilizados neste trabalho,a Seção 3 as interpolaçõesutilizadas no trabalho, na Seção 4 o método proposto de tratamento e seus resultados eas métricas utilizadas para avaliação e na Seção 5 as conclusões e trabalhos futuros.

25
2 DESCOBERTA DE PADRÕES DE MOVIMENTAÇÃO EMBANCOS DE DADOS DE TRAJETÓRIAS
O aumento e barateamento de equipamentos de geração de dados espaço-temporais,técnicas de análise e de melhor armazenamento são mais requisitadas. Estes tipos de dadospodem ser aplicados em várias áreas do conhecimento como por exemplo:
∙ Transporte: planejamento de tráfego, rastreamento de veículos e monitoramentode tráfego;
∙ Ecologia: rastreamento de poluição e investigação de causas em mudanças ambi-entais;
∙ Biologia: movimentação de animais, realocação animal e extinção.
Para entendimento de fenômenos espaço-temporais geralmente é feito um proces-samento, análise e mineração de grande volume de dados desse tipo, acompanhados comvariáveis temáticas ou temporais. A modelagem dos acontecimentos espaço-temporais éuma tarefa difícil devido a dois fatores: um deles é pela mudança dos dados, discreto oucontínuo, também chamadas de ruído, que podem ser causado por defeitos no aparelhoou sinal fraco de GPS (sistema de posicionamento global – Global Positioning System). Osegundo é a influência de objetos vizinhos ao objeto em estudo, por exemplo, na análiseda chuva e sua influência em engarrafamentos em centros urbanos. A posição relativa dosveículos define a ocorrência de congestionamentos e suas propriedades, duração, exten-são, etc. Mas a variação da intensidade da chuva no momento analisado, como tambéma distribuição espacial da chuva, são dados que não podem ser ignorados na análise.Assim, é preciso fazer um cruzamento das informações da chuva junto com os padrõesde movimentação dos veículos, junto com dados históricos para se obter resultados maisrelevantes [3].
De uma forma geral, principal objetivo é a descoberta de padrões ou relaciona-mentos existentes no banco de dados. Neste processo, são necessárias técnicas que lidemcom ambos aspectos de dados espaço-temporais, o que torna a mineração dos dados maistrabalhosa do que quando se utiliza somente dados em texto ou numéricos. Este capítuloaborda conceitos relacionados à descoberta padrões de movimentação em bancos de dadosde trajetórias de objetos móveis, em particular, referentes ao padrão flock. A Seção 2.1descreve os padrões de movimentação que mais têm sido explorados na literatura. A Se-ção 2.2 define o padrão flock, que é o padrão tratado deste trabalho. Por fim, e a Seção 2.3apresenta os principais algoritmos para detecção deste padrão.

26
2.1 Padrões de Movimentação
Padrões de movimentação na maioria das vezes apresentam relacionamentos entretrajetórias em bancos espaço-temporais. Uma trajetória pode ser definida como umasequência de pontos marcados com local e tempo que foram coletados, também podendoter outros atributos associados a essas marcações [4]. Possuindo as trajetórias é possíveldescrever padrões de agrupamentos espaço-temporais e comportamentais mais voltadosao estudo de paradas e movimentos, que buscam o entendimento do tipo comportamentaldos movimentos de objetos específicos. Neste contexto, a detecção e classificação dospadrões gerados a partir de dados espaços-temporais são tarefas importantes no processode compreensão do comportamento dos objetos de estudo. Alguns dos tipos de padrõesde movimentações espaço-temporais mais importantes, representados na Figura 1, são:
∙ Flock: são entidades se movimentando próximas de si, respeitando um disco dediâmetro 𝜖, por um certo período de tempo, onde estão dentro de um diâmetro 𝜖 deum disco especificado em uma busca;
∙ Ponto de encontro: marca a reunião espacial de um número de objetos;
∙ Local Frequente: região onde um objeto fica por bastante tempo;
∙ Padrão Periódico: pode ser identificado como é um tipo de movimentação ondehá repetição de comportamento em um determinado local com intervalos regularesde tempo.

27
ponto deencontro
local frequente
padrãoperiódico
flock de três entidades
Figura 1 – Padrões de movimentação espaço-temporais (retirada de [1]).
2.2 O Padrão Flock
Na literatura, podem ser encontrados muitas pesquisas de descoberta de padrõesem dados de objetos móveis. Podem ser pesquisas focadas em animais, que utilizam decoleiras especiais com GPS, ou coleta de dados de veículos se movimentando, coletandoa posição a um certo intervalo de tempo. Estas pesquisas são importântes, pois destespadrões dos objetos podem ser encotrados em animais pelo movimento do seu grupo,sinais de processo migratório ou de extinção [5] [3].
Um dos padrões que podem ser vistos no estudo é o padrão flock (flock pattern).Podem ser encontradas diferentes definições para o padrão flock na literatura. Um exemploé a definição de flock que é usada no trabalho de Gudmundsson, Kreveld e Speckmann[6],em que se considera somente um instante de tempo. A definição mais abrangente, emais utilizada na literatura, é a que um flock é definido como um grupo de 𝑚 entidadesmovendo-se em um disco de diâmetro 𝜖 por um intervalo 𝑘 de tempo [2, 7, 8, 9, 10].Seguindo esta linha, a formalização do padrão flock utilizada neste trabalho é dada peladefinição proposta por Vieira, Bakalov e Tsotras[2], reproduzida na Definição 1.
Definição 1 (Padrão Flock) Dado um conjunto de trajetórias 𝜏 , um número mínimode trajetórias 𝜇 > 1 (𝜇 ∈ N) , uma distância máxima 𝜖 > 0 definida por uma métricade distância d e uma duração mínima de 𝛿 > 1 instantes de tempo (𝛿 ∈ N), um padrão

28
flock(𝜇,𝜖,𝛿) reporta um conjunto F contendo todos os flocks 𝑓𝑘, que são conjuntos detrajetórias de tamanho máximal tais que: para cada 𝑓𝑘 ∈ F, o número de trajetórias émaior ou igual a 𝜇 e existem 𝛿 instâncias de tempo consecutivas 𝑡𝑗, . . . , 𝑡𝑗+𝛿−1 em queexiste um disco com centro 𝑐𝑡𝑖
𝑘 e diâmetro 𝜖 cobrindo todos os pontos das trajetórias de𝑓 𝑡𝑖
𝑘 , que é flock 𝑓𝑘 no instante 𝑡𝑖, 𝑗 ≤ 𝑖 ≤ 𝑗 + 𝛿.
A Figura 2 mostra um exemplo do padrão flock com duas ocorrências envolvendotrês entidades, que são respectivamente: flock formado nas pelas trajetórias 𝑇1, 𝑇2 e 𝑇3
nos discos 𝑐11, 𝑐2
1 e 𝑐31 e floco composto por 𝑇4, 𝑇5 e 𝑇6 nos discos 𝑐2
2, 𝑐32 e 𝑐4
2.
Figura 2 – Exemplo de padrão flock, com 𝜇 = 3 e 𝛿 = 3 (retirada de [2]).
2.3 Algoritmos para Detecção do Padrão Flock
Na literatura encontram-se vários algoritmos para a detecção do padrão flock comdiversos tipos de abordagens. As abordagens existentes podem ser classificadas em trêscategorias: (i) detecção de flocks utilizando-se mapeamento de espaços de alta dimensiona-lidade, (ii) algoritmos baseados em mapeamento por transações e identificação conjuntosde itens frequentes, e (iii) algoritmos que utilizam apenas propriedades espaço-temporaisdos dados.
Dentre os trabalhos da categoria de abordagens que utiliza mapeamento paraespaços altamente dimensionais, destaca-se o trabalho de Benkert et al.[7]. Neste trabalho,os autores buscam uma solução que não precisasse manter os candidatos a flock entre asdiferentes instâncias de tempo. Para isso, fazem a transformação das trajetórias parapontos em um espaço altamente dimensional. Segundo o processo descrito no trabalho, é

29
feita uma Skip Quadtree [11, 12] para cada tempo inicial possível do padrão de tamanho𝛿. Porém, este tipo de abordagem gera uma dependência exponencial na duração do flock𝛿 (prova disponível no Lema 9, em [7]) [13]. Além disso, devido ao mapeamento para oespaço altamente dimensional, os dados sofrem uma distorção que faz com que as respostassejam aproximações no que se diz respeito ao diâmetro do flock.
Já na categoria de abordagens de mapeamento para transações, costuma-se definirtodos os agrupamentos descobertos no conjunto de dados, identificar cada um deles demaneira unívoca e depois fazer o mapeamento para transações. A motivação de se fazertal mapeamento é possibilitar a descoberta de flocks com a utilização de algoritmos demineração de padrões frequentes (MPF). Por exemplo, no artigo de Romero[14] foi uti-lizada a MPF para identificação de flocks de comprimento maximal (i.e., flocks com omaior número de instantes de tempo). Nesse trabalho, o processo de mapeamento envolvea identificação unívoca de cada um dos possíveis discos do banco de dados, que é aliado auma tabela adicional que guarda informações de quais trajetórias visitaram quais discosem um intervalo de tempo específico. Esta representação permite obter uma versão tran-sacional das trajetórias que, por sua vez, alimenta o algoritmo de mineração de padrõesfrequentes LCM (Linear time Closed itemset Miner).
Por fim, na categoria de algoritmos que utilizam apenas propriedades espaço-temporais dos dados, sem efetuar transformações, destacam-se os algoritmos BFE, PSIe suas variações. Uma característica fundamental desses algoritmos é que eles fazem adetecção on-line de flocks, isto é, não precisam conhecer todo o conjunto de dados a pri-ori, sendo, assim, capazes de processar fluxos de dados espaçotemporais (spatiotemporaldata streams). O algoritmo BFE (Basic Flock Evaluation) foi proposto por Vieira, Ba-kalov e Tsotras[2], que utiliza um índice baseado em grade para processar os dados emcada instante de tempo das trajetórias. Primeiro, o algoritmo faz a seleção a candidatosa flock, identificando discos candidatos percorrendo o índice baseado em grade e man-tendo apenas os maximais, em termos do número de entidades (𝜇). Os demais discos sãoeliminados. Depois disso, é feita uma junção desses discos com os candidatos da instân-cia de tempo anterior. Os discos candidatos que não aparecerem na instância anteriorsão descartados do conjunto de candidatos a flock. Este processo se repete até que umdisco no conjunto de candidatos tenha se repetido em 𝛿 instâncias de tempo diferentes,quando é reportado um novo flock. O algoritmo PSI (Plane Sweeping, Binary Signaturesand Inverted Index) se baseia no BFE e foi proposto por Tanaka, Vieira e Kaster[10].Este algoritmo utiliza técnicas e estruturas de dados para detectar flocks de forma maisrápida que o BFE, sendo as principais varredura de plano, assinaturas binárias e índicesinvertidos. Primeiramente, o PSI faz uma varredura de plano para processar os dados deum instante de tempo. Quando discos candidatos são encontrados, o algoritmo utiliza as-sinaturas binárias para eliminar candidatos não maximais sem a necessidade de operaçõesde comparação de conjuntos, pois as assinaturas binárias permitem identificar conjuntos

30
de entidades que não são subconjuntos uns dos outros. Após identificar os candidatos emum instante de tempo, a fase de junção desses candidatos com os candidatos do instanteanterior utiliza um índice invertido para podar rapidamente discos da instância de tempoanterior que não se mantiveram na instância atual. Nos testes apresentados pelos autores,o PSI apresentou desempenho superior ao BFE em vários conjuntos de dados reais para amaior parte das combinações de parâmetros do padrão. O mesmo aconteceu para a maiorparte das variações dos algoritmos, cujos detalhes podem ser encontrados nas referênciasoriginais ou em [3].

31
3 TÉCNICAS DE INTERPOLAÇÃO EM TRAJETÓRIAS
Dados de trajetórias de objetos móveis podem ser incertos, incompletos ou im-precisos, por vários motivos. Exemplos vão desde imprecisões na coleta dos pontos datrajetória, pois os dispositivos utilizados podem ser imprecisos, até a dificuldade de cap-tura de dados de um objeto que está se movendo constantemente, pois pode ser que suaposição só possa ser guardada em um certo período de tempo [15, 16]. Os problemaspodem se estender a problemas de comunicação via rede, causada por falta de sinal deantena, falha em equipamentos ou até mesmo falha humana ao desligar o aparelho decoleta em algum momento, por exemplo, por falta de bateria. A incerteza também podeadvir da natureza do conjunto de dados, pois algumas aplicações não estão interessadasna trajetória inteira, mas sim em pequenas partes, referentes a intervalos de tempo es-pecíficos [16]. Estas amostras, quando analizadas mais detalhadamente, podem ter váriasimprecisões e questões referentes ao sincronismo de tempo de coleta e transmissão dospontos.
Para os algoritmos de flock, incertezas nos dados de entrada são bastante prejudi-ciais, porque no momento da junção dos discos candidatos com os da instância anterior,a falta da posição de um objeto em um determinado intervalo de tempo pode fazer comque um flock tenha um número menor que o mínimo especificado, eliminando vários can-didatos a flock que, na verdade, formaram um flock mas não foram detectados por falhasnos dados. Este problema que afeta praticamente todos os algoritmos citados no capítuloanterior, incluindo o BFE e o PSI, que são de particular interesse para esse trabalho, poissão algoritmos on-line.
Na literatura se encontram várias técnicas para o tratamento dos dados, incluindotratamentos com o uso de técnicas de range queries para conseguir os dados ideias paraserem utilizados[15], aumentar o tempo entre um ponto e outro retirando alguns pontos,utilização de filtros como o Kalman Filter [17]. e outras. As técnicas abordadas nessetrabalho para tratamento de incertezas nos dados realizam interpolação de pontos. Inter-polação é a ação de se estimar um novo ponto em um instante de tempo não contido naamostra de dados com base em dados existentes nessa amostra [18]. Para a sua utilizaçãoé nescessário pontos de um objeto, anteriores e/ou posteriores ao instente de tempo de-sejado, estimando-se o posicionamento do objeto móvel no instante por meio de equaçõesmatemáticas. Este capítulo apresenta três métodos de interpolação, que foram utilizadosno trabalho, sua funcionalidade, e casos de uso: a interpolação linear (Seção 3.1), a in-terpolação baseada em random walk restrito (Seção 3.2) e a curva de Bézier (Seção 3.3).A escolha dos métodos concentrou-se em abordagens aplicáveis a dados “brutos” de tra-jetória, isto é, sem considerar-se informação adicional, como malha viária e informações

32
semânticas.
3.1 Interpolação Linear
A interpolação linear funciona fazendo a estimativa da localização de um objetopor uma linha reta entre dois pontos conhecidos. É o método mais simples de ser imple-mentado e possui resultados muito bons para faltas sensíveis de dados. É muito presentena literatura e utilizado como parâmetro de comparação em estudos. Segundo Long[19],um ponto (𝑧(𝑡𝑢)) é obtido na interpolação linear por meio da seguinte equação:
𝑧(𝑡𝑢) = 𝑧(𝑡𝑖) + 𝑡𝑢 − 𝑡𝑖
𝑡𝑗 − 𝑡𝑖
(𝑧(𝑡𝑗) − 𝑧(𝑡𝑖)) (3.1)
Onde 𝑧(𝑡𝑖) um ponto em um tempo passado, 𝑧(𝑡𝑗) um ponto em um tempo futuroe 𝑧(𝑡𝑢) ponto que queremos encontrar em um tempo 𝑡𝑈 . Um exemplo dessa interpolaçãopode ser visto na Figura 3, onde os quadrados brancos são os pontos interpolados (𝑧(𝑡𝑢))e os pontos pretos são os pontos conhecidos (𝑧(𝑡𝑖)) pontos no passado no caso ((0,0) e(0,-3)) e (𝑧(𝑡𝑗)) pontos no futuro ((10,10) e (13,10)).
0 2 4 6 8 10 12
−2
02
46
810
x
y
Exemplo de interpolação Linear
Pontos existentes
Pontos interpolados
Figura 3 – Exemplo de interpolação linear.
3.2 Interpolação por Random Walk Restrito
A interpolação por random walk restrito (constrained random walk) consiste emrealizar uma interpolação independente da posição anterior do objeto móvel na trajetória.

33
A interpolação é criada a partir de amostras aleatórias de duas distribuições: a distribuiçãodo comprimento de passo (𝑙) e a distribuição do ângulo de rotação (𝜃). Com isso o pontopode ser calculado pela seguinte equação [19]:
𝑧𝑥(𝑡𝑢) = 𝑧𝑥(𝑡𝑖) + 𝑙𝑐𝑜𝑠(𝜃)
𝑧𝑦(𝑡𝑢) = 𝑧𝑦(𝑡𝑖) + 𝑙𝑠𝑖𝑛(𝜃)(3.2)
Por utilizar dessas amostras aleatórias, este método não consegue prever o trajetose for de um determinado ponto 𝑧(𝑡𝑖) a outro 𝑧(𝑡𝑗), mas sim interpola limitado pelo prismageográfico de espaço-tempo, conseguindo uma trajetória não totalmente aleatória. Para ocálculo, uma potencial área para o ponto para o tempo 𝑡𝑢 é computado pela intersecçãocom os futuros e passados cones espaços temporais de 𝑡𝑖 a 𝑡𝑢 e de 𝑡𝑗 a 𝑡𝑢 respectivamente.Depois o algoritmo aleatoriamente escolhe uma dessas potenciais localizações para 𝑡𝑢.Quando mais de um ponto precisa ser interpolado o algoritmo conta a tendência de umarandom walk percorrer o primeiro ponto e depois um caminho mais curto para o segundoponto, por aleatoriamente ordenando os 𝑡𝑢s para serem interpolados.
Recomendado em trajetórias em que o objeto observado tem um caminho difícilde se prever, como por exemplo, animais que não tem um trajeto usual, pois não seguemum caminho direto até uma localização, como, por exemplo, macacos[20]. Um exemplodessa interpolação pode ser visto na Figura 4, onde os quadrados brancos são os pontosinterpolados (𝑧(𝑡𝑢)) e os pontos pretos são os pontos conhecidos (𝑧(𝑡𝑖)) pontos no passadono caso ((0,0) e (0,-3)) e (𝑧(𝑡𝑗)) pontos no futuro ((10,10) e (13,10)).

34
0 2 4 6 8 10 12
−2
02
46
810
x
y
Exemplo de interpolação Random Walk
Pontos existentes
Pontos interpolados
Figura 4 – Exemplo de interpolação Random Walk.
3.3 Interpolação pela Curva de Bézier
A curva cúbica de Bézier requer a definição de quatro pontos âncora. Dois delessão a origem 𝑃1 = 𝑧(𝑡𝑖) e destino 𝑃4 = 𝑧(𝑡𝑗) do segmento de trajetória a ser interpoladoe os outros dois, 𝑃2 e 𝑃3, são os responsáveis pela forma da curva. Sendo 𝑧(𝑡𝑖) um pontoem um tempo passado, 𝑧(𝑡𝑗) um ponto em um tempo futuro e 𝑧(𝑡𝑢) ponto que queremosencontrar em um tempo 𝑡𝑈 . O formato da curva também leva em conta a velocidade inicial𝑣𝑖 e final 𝑣𝑗 do objeto no segmento de trajetória. O cálculo dos pontos âncora 𝑃2 e 𝑃3 e ocálculo do ponto interpolado pode ser descritos abaixo [19]:
𝑃2 = 𝑧(𝑡𝑖) + 𝑣(𝑡𝑖)12(𝑡𝑗 − 𝑡𝑖) (3.3)
𝑃3 = 𝑧(𝑡𝑗) − 𝑣(𝑡𝑗)12(𝑡𝑗 − 𝑡𝑖) (3.4)
𝑧(𝑡𝑢) = (1 − 𝛿)3𝑃1 + 3(1 − 𝛿)2𝛿𝑃2 + 3(1 − 𝛿)𝛿2𝑃3 + 𝛿3𝑃4 (3.5)
onde 𝛿 = 𝑡𝑢−𝑡𝑖
𝑡𝑗−𝑡𝑖, sendo 𝛿 o tempo que se quer interpolar escalado por unidade.
Método bastante recomendado para trajetórias com curvas como por exemploanimais marítimos[21]. Um exemplo dessa interpolação pode ser visto na Figura 5, ondeos quadrados brancos são os pontos interpolados (𝑧(𝑡𝑢)) e os pontos pretos são os pontos

35
conhecidos (𝑧(𝑡𝑖)) pontos no passado no caso ((0,0) e (0,-3)) e (𝑧(𝑡𝑗)) pontos no futuro((10,10) e (13,10)).
0 2 4 6 8 10 12
−2
02
46
810
x
y
Exemplo de interpolação Bezier
Pontos existentes
Pontos interpolados
Figura 5 – Exemplo de interpolação Bezier.


37
4 PROPOSTA DE INCLUSÃO DE INTERPOLAÇÃO EMALGORITMOS ON-LINE PARA O PADRÃO FLOCK
Dado os problemas de incerteza em trajetória, e técnicas de interpolação apresenta-dos anteriormente, foram desenvolvidos algoritmos para o estudo e solução do problema.Nesse capítulo são descritos os métodos desenvolvidos nesse trabalho, o tratamento dedados desenvolvido para os algoritmos de detecção do padrão flock, scripts para a criaçãodos conjuntos de dados para teste e métricas para a avaliação dos resultados.
4.1 Análise da Sensibilidade dos Algoritmos de Detecção deFlocks à Falta de Dados
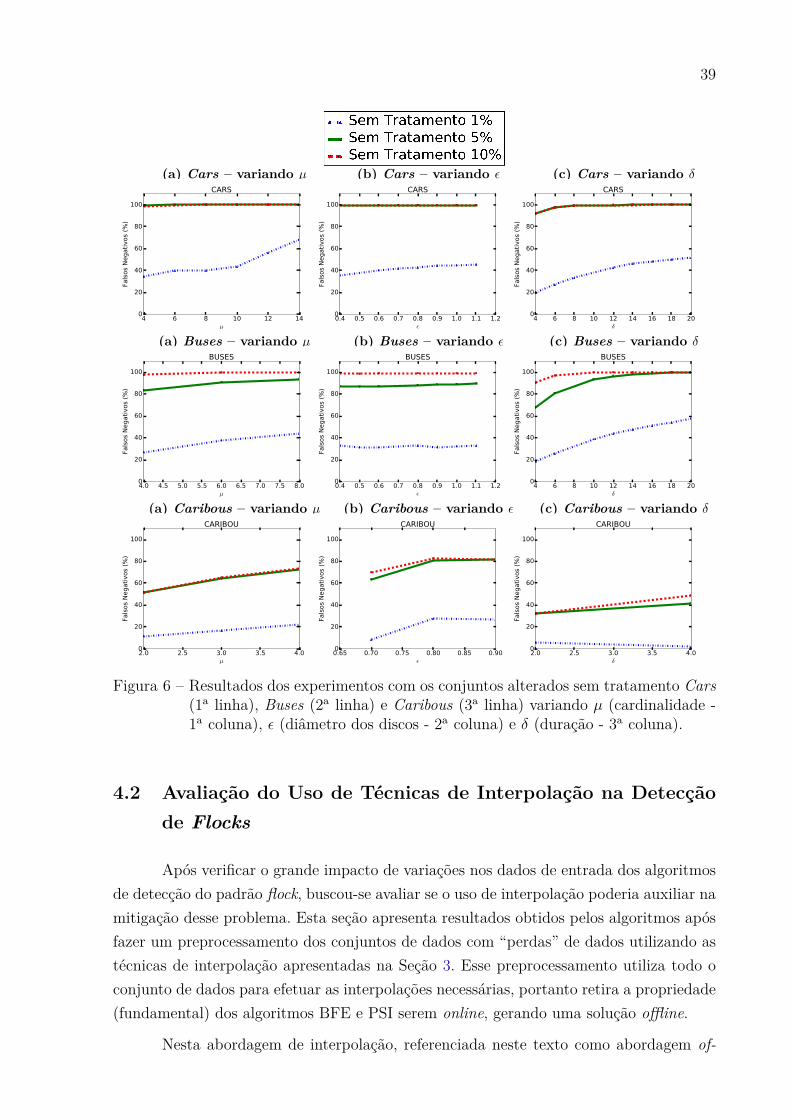
A falta de pontos em certos intervalos de tempo pode ser bastante prejudiciala execução dos algoritmos BFE e PSI. Como mostra na Figura 6, os algoritmos sãomuito sensíveis a falhas, pois uma falha pequena de 1% consegue destruir várias respostasdo algoritmo. Uma falha de 5% e 10% são bastante semelhantes na perda de respostaconseguindo praticamente destruir todas as respostas dos algoritmos. Percebe-se que como crescimento das variáveis 𝜇, 𝜖 e 𝛿, há um aumento no número de respostas que sãodestruídas.
Para simular a falta de pontos em um conjunto de dados e ainda manter um“padrão ouro” que permitisse comparar as respostas obtidas mediante diferentes situaçõesde falta de dados, optou-se por fazer retirada controlada de pontos do conjunto de dadosem teste. Desta forma, as respostas obtidas utilizando-se o conjunto de dados originalformam o “padrão ouro” e os conjuntos com pontos retirados simulam situações de faltade dados, possibilitando avaliar a sensibilidade dos algoritmos quanto a esse quesito.
Para uma testar o desempenho dos tratamentos utilizados neste trabalho foramutilizados três conjuntos de dados. São eles: Buses, Caribous e Cars. Estes conjuntos foramescolhidos por terem sido utilizados nos trabalhos que propuseram os algoritmos BFE ePSI para detecção on-line do padrão flock, bem como suas variações (vide Seção 2.3).O conjunto de dados Buses contém 66.096 posições de ônibus se movendo na cidade deAtenas, na Grécia. O segundo conjunto de dados é denominado Caribous e foi gerado apartir da movimentação de 43 cervídeos na região noroeste do Canadá, com um total de15.796 localizações. Já o conjunto Cars é composto de 134.264 posições coletadas a partirda movimentação de 183 carros privados movimentando-se em Copenhague, capital daDinamarca1.
Para fazer a retirada controlada de pontos, foi desenvolvido um script em Python.1 <www.daisy.aau.dk>

38
Este script trata separadamente os pontos de cada objeto do conjunto de dados. Para cadaobjeto, é feita a contagem dos pontos, seguida da retirada aleatória uma certa porcentagemdos pontos dos objetos, fornecida como parâmetro. Desta forma, garante-se que a retiradade pontos seja homogênea para todos os objetos do conjunto de dados. De cada conjuntode dados foram derivados três outros conjuntos, considerando as porcentagens de retiradade pontos 1%, 5% e 10%.
Esta seção apresenta os resultados obtidos com os testes para a avaliação do com-portamento dos tratamento nos algoritmos flock, por meio da execução dos conjuntos dedados com as alterações de perda de dados e variando os parâmetros do padrão (𝜇, 𝜖 e 𝛿)como demonstrado na Tabela 1, . Na tabela é apresentado os valores testados para cadaconjunto de dados aasim como os valores padrão utilizados (entre colchetes).
Para a comparação das saídas dos algoritmos, foi criado outro script em Python.Inicialmente, é feita uma limpeza dos dados, guardando-se os flocks reportados (conjuntode objetos que formam o flock e intervalo de tempo) em listas ordenadas pelo instantede início do intervalo de tempo em que o flock foi identificado. Em seguida, é feita acomparação dos flocks reportados em cada arquivo, indicando-se as taxas de falsos nega-tivos (i.e., flocks que deveriam ter sido reportados, mas não foram) e de falsos positivos(i.e., flocks que não deveriam ter sido reportados, mas foram), para cada combinação devalores de parâmetros (𝜇, 𝜖 e 𝛿). Para evitar resultados tendenciosos derivados da retiradade pontos, foram executadas em 30 repetições de cada conjunto de dados com cada taxade retirada de pontos (1%, 5% e 10%), sempre retirando-se pontos de forma aleatória emcada repetição.
Em seguida, foram executados os algoritmos BFE e PSI comparando-se as respos-tas obtidas com cada taxa de retirada de pontos com as respostas obtidas no conjuntooriginal. Os valores de parâmetros avaliados são apresentados na Tabela 1, sendo que osvalores em negrito entre colchetes são os valores padrão. Os algoritmos foram desenvolvi-dos em C++11 e compilados com compilador GNU G++ 4.9.3 em um sistema operacionalElementary OS 0.3.2 Freya (Ubuntu 14.04.3) 64-bit. Como era de se esperar, os resulta-dos obtidos pelo BFE e o PSI foram idênticos em todos os casos, portanto não será feitareferência ao algoritmo na análise dos resultados que se segue, apenas qual o conjunto dedados.
Conjunto Posições Objetos 𝜇 𝜖 𝛿Cars 134,264 183 4, 6, . . . , 20 [5] 0,4, 0,5, . . . , 1,1 [0,6] 4, 6, . . . , 20 [10]Buses 66,096 145 4, 6, . . . , 20 [5] 0,3, 0,4, . . . , 1,0 [0,7] 4, 6, . . . , 20 [10]Caribous 15,796 43 2, 3, . . . , 10 [5] 0,1, 0,2, . . . , 0,8 [0,7] 2, 4, . . . , 20 [10]
Tabela 1 – Número de objetos, quantidade de posições e valores de parâmetros testadospara cada conjunto de dados.
39
(a) Cars – variando 𝜇 (b) Cars – variando 𝜖 (c) Cars – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS
(a) Buses – variando 𝜇 (b) Buses – variando 𝜖 (c) Buses – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
BUSES
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
BUSES
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
BUSES
(a) Caribous – variando 𝜇 (b) Caribous – variando 𝜖 (c) Caribous – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARIBOU
0.65 0.70 0.75 0.80 0.85 0.90ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARIBOU
2.0 2.5 3.0 3.5 4.0δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARIBOU
Figura 6 – Resultados dos experimentos com os conjuntos alterados sem tratamento Cars(1a linha), Buses (2a linha) e Caribous (3a linha) variando 𝜇 (cardinalidade -1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração - 3a coluna).
4.2 Avaliação do Uso de Técnicas de Interpolação na Detecçãode Flocks
Após verificar o grande impacto de variações nos dados de entrada dos algoritmosde detecção do padrão flock, buscou-se avaliar se o uso de interpolação poderia auxiliar namitigação desse problema. Esta seção apresenta resultados obtidos pelos algoritmos apósfazer um preprocessamento dos conjuntos de dados com “perdas” de dados utilizando astécnicas de interpolação apresentadas na Seção 3. Esse preprocessamento utiliza todo oconjunto de dados para efetuar as interpolações necessárias, portanto retira a propriedade(fundamental) dos algoritmos BFE e PSI serem online, gerando uma solução offline.
Nesta abordagem de interpolação, referenciada neste texto como abordagem of-

40
fline, inicialmente são identificados os pontos que faltam de cada objeto até o tempomáximo em que esse objeto aparece. Utilizando as implementações das técnicas citadasno capítulo de algoritmos de interpolação implementadas por [19] na linguagem R, Emseguida, cada ponto interpolado é definido com base nos pontos mais próximos do mesmo,utilizando a técnica específica de interpolação (linear, por random walk restrito ou pelacurva de Bézier). A saída é uma base completa tratada e pronta para os algoritmos dedetecção de flock, isto é, as posições que estavam faltando no conjunto de dados (porquehaviam sido retiradas) são preenchidas no processo de interpolação. Vale ressaltar quenessa abordagem não são utilizados pontos interpolados para definir a interpolação denovo ponto, mas somente os pontos “reais”, i.e., pontos existentes no conjunto de dadosde entrada.
Nas Figuras 7, 8, 11, 12, 9 e 10 mostram os resultados dos experimentos utilizandoo algoritmo BFE para as alterações de 10%, 5% e 1% respectivamente e variando os valorespara os parâmetros 𝜇, 𝜖 e 𝛿, de acordo com a Tabela 1. Todos os gráficos mostram a médiada porcentagem de respostas de flock perdidas no eixo y. Para uma melhor análise foramretirados os pontos onde não havia respostas no conjunto de dados não alterado.
Como o conjunto de dados Caribous possui poucos objetos e também apresentapoucas respostas de flock, foi o conjunto de dados menos afetado, e as técnicas de interpo-lação conseguiram um bom desempenho, conseguindo diminuir a perda de respostas aténas alterações de 10%.
O conjunto Buses obteve um bom resultado de recuperação nas alterações de 1%dos pontos retirados, apenas a interpolação Bezier que teve uma perda de 10%. Nas outrasalterações, de 10 % e 5 %, os resultados mostram a perda de respostas entre 10% de perdade resultados, sendo a interpolação Bezier com o pior resultado que ficou entre 20 e 30porcento. Os erros são estáveis nas variáveis 𝜇 e 𝜖, mas percebe-se um aumento da perdade respostas pelas interpolações quando se varia o 𝛿. A taxa de falsos positivos, Figura 10,teve como menor taxa a interpolação linear e a pior a interpolação Bezier.
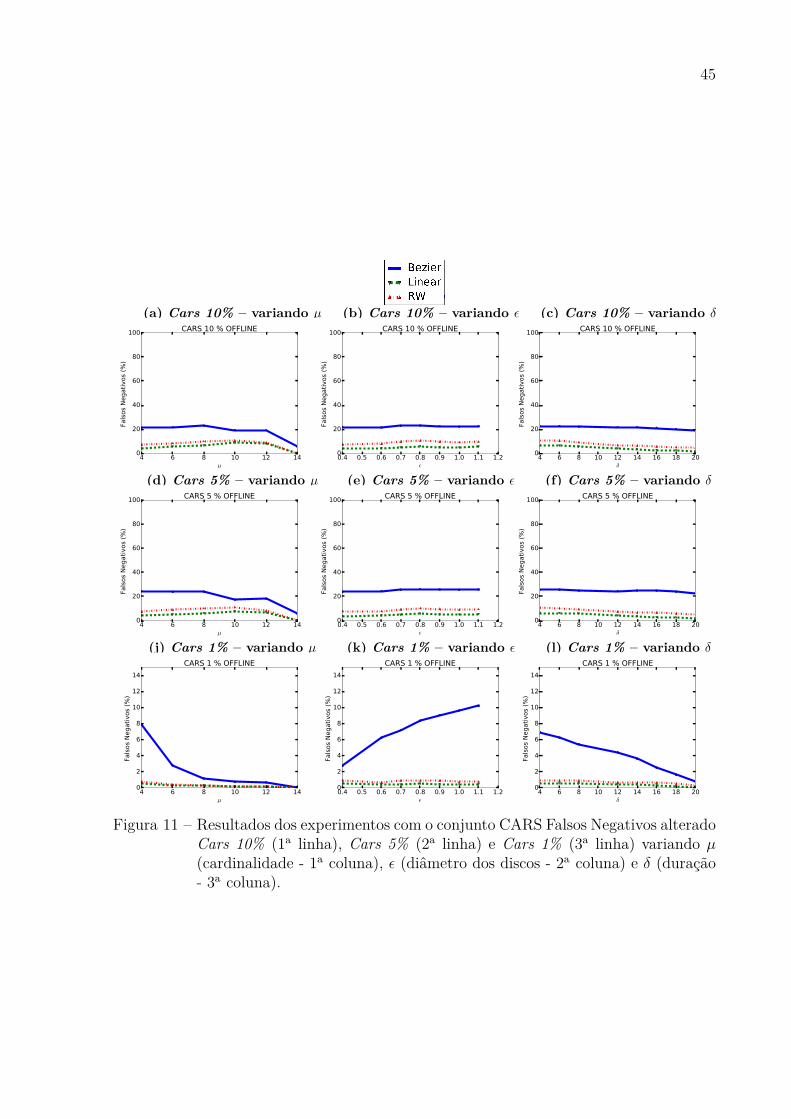
Por último o conjunto Cars, a melhor interpolação foi a Linear que obteve o piorresultado de 10 % de perda de respostas. A pior interpolação foi a Bezier que obteve maisde 20 % de perda de respostas. Quando há um aumento nas variáveis 𝜇 e 𝛿 ocorre umadiminuição do número de respostas perdidas, o contrario acontece quando se aumenta o𝜖 em que há um aumento da perda de respostas.
No geral o melhor algoritmo de interpolação foi a Linear e o pior foi a Beziernos conjuntos de dados. Nas alterações de 1% dos conjuntos de dados, os algoritmosconseguiram fazer um bom tratamento e conseguir amenizar o impacto que chegava a serde até 70% de perda de respostas como pode ser visto na Figura 6.

41
(a) Caribous 10% – variando 𝜇 (b) Caribous 10% – variando 𝜖 (c) Caribous 10% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
5
10
15
20
Fals
os
Negati
vos
(%)
CARIBOUS 10 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
5
10
15
20
Fals
os
Negati
vos
(%)
CARIBOUS 10 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0
5
10
15
20
Fals
os
Negati
vos
(%)
CARIBOUS 10 % OFFLINE
(d) Caribous 5% – variando 𝜇 (e) Caribous 5% – variando 𝜖 (f) Caribous 5% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARIBOUS 5 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARIBOUS 5 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARIBOUS 5 % OFFLINE
(j) Caribous 1% – variando 𝜇 (k) Caribous 1% – variando 𝜖 (l) Caribous 1% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Negati
vos
(%)
CARIBOUS 1 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Negati
vos
(%)
CARIBOUS 1 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Negati
vos
(%)
CARIBOUS 1 % OFFLINE
Figura 7 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Negativosalterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha) e CARIBOUS1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos -2a coluna) e 𝛿 (duração - 3a coluna).

42
(a) Caribous 10% – variando 𝜇 (b) Caribous 10% – variando 𝜖 (c) Caribous 10% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
CARIBOUS 10 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
5
10
15
20Fa
lsos
Posi
tivos
(%)
CARIBOUS 10 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
CARIBOUS 10 % OFFLINE
(d) Caribous 5% – variando 𝜇 (e) Caribous 5% – variando 𝜖 (f) Caribous 5% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % OFFLINE
(j) Caribous 1% – variando 𝜇 (k) Caribous 1% – variando 𝜖 (l) Caribous 1% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % OFFLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % OFFLINE
2.0 2.5 3.0 3.5 4.0δ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % OFFLINE
Figura 8 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Positivosalterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha) e CARIBOUS1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos -2a coluna) e 𝛿 (duração - 3a coluna).

43
(a) BUSES 10% – variando 𝜇 (b) BUSES 10% – variando 𝜖 (c) BUSES 10% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
5
10
15
20
25
30
Fals
os
Negati
vos
(%)
BUSES 10 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
5
10
15
20
25
30
Fals
os
Negati
vos
(%)
BUSES 10 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
5
10
15
20
25
30
Fals
os
Negati
vos
(%)
BUSES 10 % OFFLINE
(d) BUSES 5% – variando 𝜇 (e) BUSES 5% – variando 𝜖 (f) BUSES 5% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % OFFLINE
(j) BUSES 1% – variando 𝜇 (k) BUSES 1% – variando 𝜖 (l) BUSES 1% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
2
4
6
8
10
12
Fals
os
Negati
vos
(%)
BUSES 1 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
12
Fals
os
Negati
vos
(%)
BUSES 1 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
12
Fals
os
Negati
vos
(%)
BUSES 1 % OFFLINE
Figura 9 – Resultados dos experimentos com o conjunto BUSES Falsos Negativos alteradoBUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1% (3a linha) variando𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração- 3a coluna).

44
(a) BUSES 10% – variando 𝜇 (b) BUSES 10% – variando 𝜖 (c) BUSES 10% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
5
10
15
20
25
Fals
os
Posi
tivos
(%)
BUSES 10 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
5
10
15
20
25
Fals
os
Posi
tivos
(%)
BUSES 10 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
5
10
15
20
25
Fals
os
Posi
tivos
(%)
BUSES 10 % OFFLINE
(d) BUSES 5% – variando 𝜇 (e) BUSES 5% – variando 𝜖 (f) BUSES 5% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 5 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 5 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 5 % OFFLINE
(j) BUSES 1% – variando 𝜇 (k) BUSES 1% – variando 𝜖 (l) BUSES 1% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Fals
os
Posi
tivos
(%)
BUSES 1 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Fals
os
Posi
tivos
(%)
BUSES 1 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Fals
os
Posi
tivos
(%)
BUSES 1 % OFFLINE
Figura 10 – Resultados dos experimentos com o conjunto BUSES Falsos Positivos alte-rado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e𝛿 (duração - 3a coluna).
45
(a) Cars 10% – variando 𝜇 (b) Cars 10% – variando 𝜖 (c) Cars 10% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % OFFLINE
(d) Cars 5% – variando 𝜇 (e) Cars 5% – variando 𝜖 (f) Cars 5% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % OFFLINE
(j) Cars 1% – variando 𝜇 (k) Cars 1% – variando 𝜖 (l) Cars 1% – variando 𝛿
4 6 8 10 12 14µ
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARS 1 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARS 1 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARS 1 % OFFLINE
Figura 11 – Resultados dos experimentos com o conjunto CARS Falsos Negativos alteradoCars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha) variando 𝜇(cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração- 3a coluna).

46
(a) Cars 10% – variando 𝜇 (b) Cars 10% – variando 𝜖 (c) Cars 10% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % OFFLINE
(d) Cars 5% – variando 𝜇 (e) Cars 5% – variando 𝜖 (f) Cars 5% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % OFFLINE
(j) Cars 1% – variando 𝜇 (k) Cars 1% – variando 𝜖 (l) Cars 1% – variando 𝛿
4 6 8 10 12 14µ
0
1
2
3
4
5
Fals
os
Posi
tivos
(%)
CARS 1 % OFFLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
1
2
3
4
5
Fals
os
Posi
tivos
(%)
CARS 1 % OFFLINE
4 6 8 10 12 14 16 18 20δ
0
1
2
3
4
5
Fals
os
Posi
tivos
(%)
CARS 1 % OFFLINE
Figura 12 – Resultados dos experimentos com o conjunto CARS Falsos Positivos alteradoCars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha) variando 𝜇(cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração- 3a coluna).

47
4.3 Proposta de Inclusão de Interpolação nos Algoritmos de De-tecção On-line de Flocks
Algoritmos de detecção do padrão flock on-line recebem os dados da posição dosobjetos a cada instante de tempo. Para a utilização das interpolações anteriores era neces-sário o uso de todo o conjunto de dados para o tratamento dos dados. De modo utilizar asinterpolações, que já apresentaram bons resultados no tratamento de dados, é propostoum método on-line de interpolação. O método proposto aqui armazena as posições decada instante de tempo dos objetos em estruturas, chamadas de buffers. Cada estruturaguarda as posições de todos os objetos em um certo tempo 𝑡. Destes buffers um é escolhidoe é comparado os objetos contidos no buffer atual com os do buffer 𝑡 − 1. Se houver afalta de um objeto, então ele é interpolado com base nos dados desse objeto nos buffersde tempos anteriores ou futuros. Após a análise deste buffer, ele é liberado e os dadosseguem para o algoritmo de detecção de flock.
Um exemplo do método pode ser visto na Figura 13, onde é ilustrado o métodoproposto com a utilização de seis buffers, representados na figura pelos cilindros. Naimagem o buffer em vermelho é o que está sendo analisado e contém as posições dosobjetos em um tempo 𝑡, ele é comparado com as posições apresentadas no buffer verde,que contém o tempo 𝑡 − 1. Se houver um objeto que reportou uma posição no tempoanterior e não reportou no tempo 𝑡, o ponto será interpolado com base nas posições doobjeto contidos nos buffers, caso não tenha posições suficientes para a interpolação oobjeto não é interpolado e continua a análise. Depois de interpolado a posição é retornadapara o buffer, no fim da análise a estrutura é enviada para o algoritmo de flock.
Para melhor desempenho as estruturas de dados e algoritmos de interpolação como algoritmo de flock, as interpolações foram convertidas em C++ e foi utilizada a estruturade armazenamento de posições já presente no algoritmo. Nos resultados demonstrados napróxima seção foram utilizados no total 6 buffers para o armazenamento dos tempos, sendoalternados a cada recebimento de pontos de um novo tempo. Esse número é justificadopelo uso da interpolação Bezier, que se utiliza de 4 pontos de controle, assim se temmais um buffer para caso se falte um ponto do futuro se tenha mais um de reserva. Ainterpolação de um objeto é parada quando não se há pontos desse objeto suficientes paraa interpolação em buffers de tempos futuros.

48
Figura 13 – Exemplo do método proposto com a utilização de seis buffers.
4.4 Resultados dos Algoritmos On-line com Interpolação
Neste capítulo são apresentados os resultados obtidos pelo tratamento de dadosproposto.
Nas Figuras 14, 15, 18, 19, 16 e 17 mostram os resultados dos experimentos utili-zando o algoritmo BFE para as alterações de 10%, 5% e 1% respectivamente e variandoos valores para os parâmetros 𝜇, 𝜖 e 𝛿, de acordo com a Tabela 1.
Como não possui todo o conjunto de dados para ser analisado percebe-se um piorresultado comparado as resultados do método offline. Pode ser visto também a interfe-rência nos flocks causados pelos pontos interpolados, diferente do método offline não eramutilizados os pontos interpolados para se fazer a interpolação de outro ponto. Tambémpela utilização de seis buffers há casos onde os algoritmos não conseguiram interpolar,pois faltavam pontos nos buffers para conseguir cumprir o requerimento de pontos paraa interpolação.
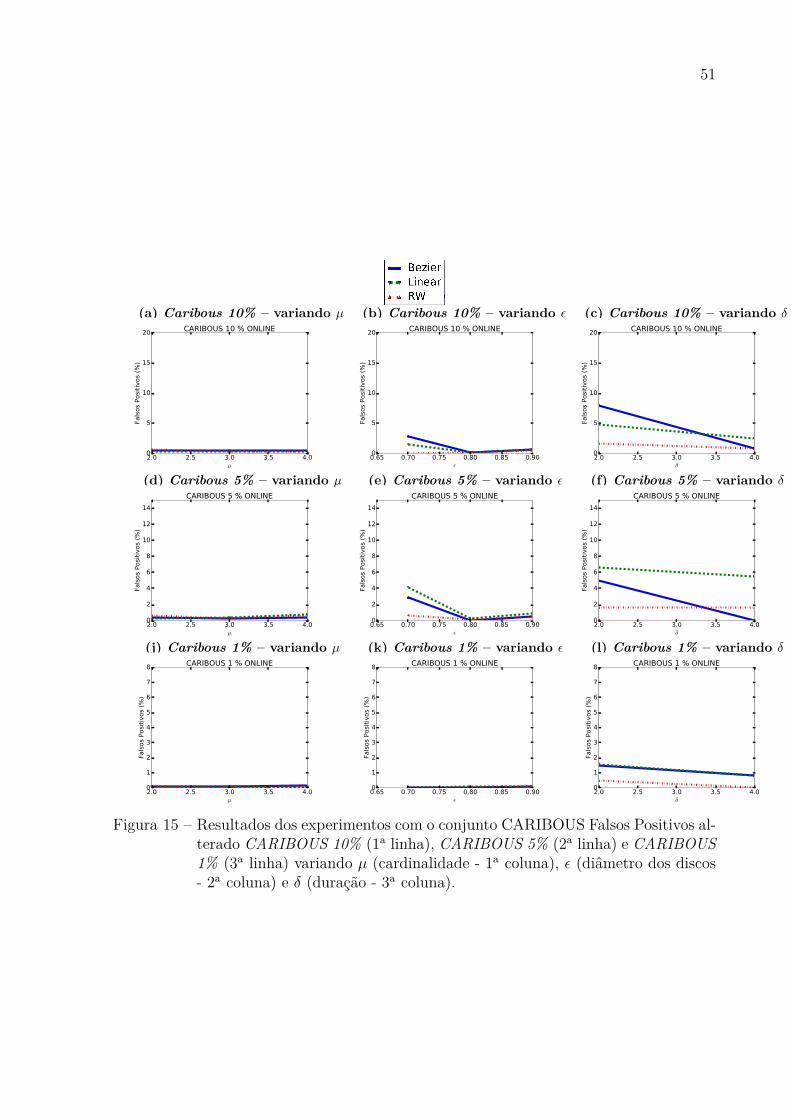
O conjunto de dados Caribous teve os melhores resultados, sendo a interpolaçãoLinear que conseguiu a menor perda de respostas, o pior resultado nesse conjunto dedados foi a interpolação Random Walk mas conseguindo ainda ficar abaixo de 10% .
Já o conjunto Buses teve a interpolação Linear com pior resultado de perda de 30%das respostas, e a pior interpolação foi novamente a Random Walk com o pior resultadode 70% de perda de respostas. Há um aumento no número de perda de respostas quando

49
há um aumento em 𝛿. A taxa de falsos positivos teve ficou bem semelhante entre as trêsinterpolações ficando com máxima de 40%.
Por último o conjunto Cars teve a melhor interpolação a Linear com pior resultadode 20% de perda e a pior interpolação Random Walk com pior resultado de 70% de perda.Quando há um aumento nas variáveis 𝜇, 𝜖 e 𝛿 também ocorre um aumento na porcen-tagem de respostas perdidas pelos algoritmos de interpolação. A taxa de falsos positivosa interpolação Linear teve a menor taxa ficando entre 20% e a pior foi a interpolaçãoRandom Walk com pior caso de 60%.
Novamente temos que o melhor algoritmos de interpolação nos testes foi a interpo-lação Linear, mas há uma mudança no algoritmo de pior resultado que foi a interpolaçãoRandom Walk, que teve grande impacto nas respostas, pois foram utilizados pontos in-terpolados para fazer outras interpolações.

50
(a) Caribous 10% – variando 𝜇 (b) Caribous 10% – variando 𝜖 (c) Caribous 10% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
5
10
15
20
Fals
os
Negati
vos
(%)
CARIBOUS 10 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
5
10
15
20Fa
lsos
Negati
vos
(%)
CARIBOUS 10 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
5
10
15
20
Fals
os
Negati
vos
(%)
CARIBOUS 10 % ONLINE
(d) Caribous 5% – variando 𝜇 (e) Caribous 5% – variando 𝜖 (f) Caribous 5% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARIBOUS 5 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARIBOUS 5 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
2
4
6
8
10
12
14
Fals
os
Negati
vos
(%)
CARIBOUS 5 % ONLINE
(j) Caribous 1% – variando 𝜇 (k) Caribous 1% – variando 𝜖 (l) Caribous 1% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
1
2
3
4
5
6
7
8
Fals
os
Negati
vos
(%)
CARIBOUS 1 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
1
2
3
4
5
6
7
8
Fals
os
Negati
vos
(%)
CARIBOUS 1 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
1
2
3
4
5
6
7
8
Fals
os
Negati
vos
(%)
CARIBOUS 1 % ONLINE
Figura 14 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Negativosalterado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha) e CARI-BOUS 1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dosdiscos - 2a coluna) e 𝛿 (duração - 3a coluna).
51
(a) Caribous 10% – variando 𝜇 (b) Caribous 10% – variando 𝜖 (c) Caribous 10% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
CARIBOUS 10 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
5
10
15
20
Fals
os
Posi
tivos
(%)
CARIBOUS 10 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
CARIBOUS 10 % ONLINE
(d) Caribous 5% – variando 𝜇 (e) Caribous 5% – variando 𝜖 (f) Caribous 5% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
2
4
6
8
10
12
14
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
2
4
6
8
10
12
14
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
2
4
6
8
10
12
14
Fals
os
Posi
tivos
(%)
CARIBOUS 5 % ONLINE
(j) Caribous 1% – variando 𝜇 (k) Caribous 1% – variando 𝜖 (l) Caribous 1% – variando 𝛿
2.0 2.5 3.0 3.5 4.0µ
0
1
2
3
4
5
6
7
8
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % ONLINE
0.65 0.70 0.75 0.80 0.85 0.90ε
0
1
2
3
4
5
6
7
8
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % ONLINE
2.0 2.5 3.0 3.5 4.0δ
0
1
2
3
4
5
6
7
8
Fals
os
Posi
tivos
(%)
CARIBOUS 1 % ONLINE
Figura 15 – Resultados dos experimentos com o conjunto CARIBOUS Falsos Positivos al-terado CARIBOUS 10% (1a linha), CARIBOUS 5% (2a linha) e CARIBOUS1% (3a linha) variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos- 2a coluna) e 𝛿 (duração - 3a coluna).

52
(a) BUSES 10% – variando 𝜇 (b) BUSES 10% – variando 𝜖 (c) BUSES 10% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
10
20
30
40
50
60
70
Fals
os
Negati
vos
(%)
BUSES 10 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
10
20
30
40
50
60
70
Fals
os
Negati
vos
(%)
BUSES 10 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
10
20
30
40
50
60
70
Fals
os
Negati
vos
(%)
BUSES 10 % ONLINE
(d) BUSES 5% – variando 𝜇 (e) BUSES 5% – variando 𝜖 (f) BUSES 5% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
5
10
15
20
Fals
os
Negati
vos
(%)
BUSES 5 % ONLINE
(j) BUSES 1% – variando 𝜇 (k) BUSES 1% – variando 𝜖 (l) BUSES 1% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
BUSES 1 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
BUSES 1 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
BUSES 1 % ONLINE
Figura 16 – Resultados dos experimentos com o conjunto BUSES Falsos Negativos alte-rado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e𝛿 (duração - 3a coluna).

53
(a) BUSES 10% – variando 𝜇 (b) BUSES 10% – variando 𝜖 (c) BUSES 10% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
10
20
30
40
50
60
70
Fals
os
Posi
tivos
(%)
BUSES 10 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
10
20
30
40
50
60
70
Fals
os
Posi
tivos
(%)
BUSES 10 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
10
20
30
40
50
60
70
Fals
os
Posi
tivos
(%)
BUSES 10 % ONLINE
(d) BUSES 5% – variando 𝜇 (e) BUSES 5% – variando 𝜖 (f) BUSES 5% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
BUSES 5 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
5
10
15
20
Fals
os
Posi
tivos
(%)
BUSES 5 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
5
10
15
20
Fals
os
Posi
tivos
(%)
BUSES 5 % ONLINE
(j) BUSES 1% – variando 𝜇 (k) BUSES 1% – variando 𝜖 (l) BUSES 1% – variando 𝛿
4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0µ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 1 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 1 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
BUSES 1 % ONLINE
Figura 17 – Resultados dos experimentos com o conjunto BUSES Falsos Positivos alte-rado BUSES 10% (1a linha), BUSES 5% (2a linha) e BUSES 1% (3a linha)variando 𝜇 (cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e𝛿 (duração - 3a coluna).

54
(a) Cars 10% – variando 𝜇 (b) Cars 10% – variando 𝜖 (c) Cars 10% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 10 % ONLINE
(d) Cars 5% – variando 𝜇 (e) Cars 5% – variando 𝜖 (f) Cars 5% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Negati
vos
(%)
CARS 5 % ONLINE
(j) Cars 1% – variando 𝜇 (k) Cars 1% – variando 𝜖 (l) Cars 1% – variando 𝛿
4 6 8 10 12 14µ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARS 1 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARS 1 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
Fals
os
Negati
vos
(%)
CARS 1 % ONLINE
Figura 18 – Resultados dos experimentos com o conjunto CARS Falsos Negativos alteradoCars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha) variando 𝜇(cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração- 3a coluna).

55
(a) Cars 10% – variando 𝜇 (b) Cars 10% – variando 𝜖 (c) Cars 10% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 10 % ONLINE
(d) Cars 5% – variando 𝜇 (e) Cars 5% – variando 𝜖 (f) Cars 5% – variando 𝛿
4 6 8 10 12 14µ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
20
40
60
80
100
Fals
os
Posi
tivos
(%)
CARS 5 % ONLINE
(j) Cars 1% – variando 𝜇 (k) Cars 1% – variando 𝜖 (l) Cars 1% – variando 𝛿
4 6 8 10 12 14µ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARS 1 % ONLINE
0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2ε
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARS 1 % ONLINE
4 6 8 10 12 14 16 18 20δ
0
2
4
6
8
10
Fals
os
Posi
tivos
(%)
CARS 1 % ONLINE
Figura 19 – Resultados dos experimentos com o conjunto CARS Falsos Positivos alteradoCars 10% (1a linha), Cars 5% (2a linha) e Cars 1% (3a linha) variando 𝜇(cardinalidade - 1a coluna), 𝜖 (diâmetro dos discos - 2a coluna) e 𝛿 (duração- 3a coluna).


57
5 CONCLUSÃO
A maior quantidade de dados espaço-temporais tem criado uma demanda de al-goritmos de descoberta de padrões. A descoberta destes padrões podem descrever umamigração de animais, grupos de turistas, congestionamento de carros, etc. Dos váriospadrões de movimentação que podem ser encontrados na literatura, o estudado neste tra-balho é o padrão flock. O padrão flock pode ser descrito como um conjunto mínimo deobjetos que estão espacialmente próximos por um intervalo de tempo.
No recebimento da entrada para a identificação de um padrão de movimentação,esses dados podem conter falhas de pontos que podem ser causadas por diversos fatoresexternos como região sem rede, passagem por túneis ou subterrâneo, etc, como tambémdo próprio aparelho e sua precisão, pois é um objeto em movimento que seus dados podemser guardados em algum instante de tempo.
Neste contexto, esse trabalho avaliou e desenvolveu formas para o tratamento defalta de pontos em trajetórias, por meio de técnicas de interpolação de pontos. Foramtestadas três tipos de interpolação Linear, Constrained Random Walk e Bezier. Cada umadessas interpolações foram encontrados na literatura onde possuem seus melhores usos.Foram desenvolvidos dois métodos para o tratamento offline e online. O primeiro utilizatodos os pontos da trajetória para fazer as interpolações, assim não se utiliza pontosinterpolados para a criação de novos pontos.
O segundo método desenvolvido, chamado de online, é focado para o uso online derecebimento de dados. Ele utiliza de estruturas de dados que guardam um certo intervalode tempo. Como há um número limitado de dados para se realizar as interpolações, tam-bém são utilizados os pontos interpolados para a criação de novos pontos. Os resultadosmostraram que os algoritmos são muito sensíveis pois uma pequena perda nos pontos temuma grande impacto fazendo perder várias repostas. Também que quando as variáveis dopadrão flock são muito especificas, ou seja, valores pequenos de quantidade de objetos,intervalo de tempo e raio do circulo, a perda de flocks tende a ser menor.
Nos testes das interpolações, método offline, apresentou melhores resultados tendoa interpolação Linear como a melhor em todos os testes, conseguindo diminuir a perda depontos. Por ter menos pontos a disposição o método proposto, online, teve desempenhoum bom desempenho, mas por utilizar pontos interpolados para a criação de novos pontos,se viu uma grande interferência das interpolações no aumento da diferença de respostas.Nos métodos offline e online a melhor interpolação foi a Linear, que causou pouco impactonas interpolações do método online e offline. As piores interpolações foram a Bezier nométodo offline e Constrained Random Walk no método online, pelas suas interferências

58
na interpolação.
Trabalhos futuros são a análise de filtros, que precisariam de um espaço maiorpara o armazenamento. O uso de interpolações que só utilizam pontos do passado, quetem uma acurácia menor mas não necessitariam do uso de pontos do futuro, diminuindo amemória utiliza pelos algoritmos, análise de um aumento ou diminuição do tamanho dosbuffers e seu impacto, como eficiência de tempo e memória. Também uma análise melhordas diferenças dos flocks reportados e quanto este flock ainda é relevante mesmo com umafalta de algumas entidades, para uma diminuição na porcentagem de falsos positivos.

59
REFERÊNCIAS
[1] GUDMUNDSSON, J.; LAUBE, P.; WOLLE, T. Movement patterns in spatio-temporal data. In: Encyclopedia of GIS. [S.l.]: Springer, 2008. p. 726–732.
[2] VIEIRA, M. R.; BAKALOV, P.; TSOTRAS, V. J. On-line discovery of flockpatterns in spatio-temporal data. In: Proceedings of the 17th ACM SIGSPATIALInternational Conference on Advances in Geographic Information Systems - GIS’09. New York, New York, USA: ACM Press, 2009. p. 286. ISBN 9781605586496.Disponível em: <http://dl.acm.org/citation.cfm?id=1653771.1653812>.
[3] TANAKA, P. S. Algoritmos eficientes para detecção do padrão Floco em banco dedados de trajetórias. Tese (Mestrado) — Universidade Estadual de Londrina, 2016.
[4] DODGE, S.; WEIBEL, R.; LAUTENSCHÜTZ, A.-K. Towards a taxonomy ofmovement patterns. In: . [S.l.]: SAGE Publications, 2008. v. 7, n. 3-4, p. 240–252.
[5] BALME, G.; HUNTER, L. Mortality in a protected leopard population, PhindaPrivate Game Reserve, South Africa: a population in decline. Ecological Journal,2004. Disponível em: <https://www.panthera.org/sites/default/files/Balme\_Hunter\_2004\_Mortality\_in\_a\_protected\_leopard\_population\_in\_South\_Africa\_0.pdf>.
[6] GUDMUNDSSON, J.; KREVELD, M. van; SPECKMANN, B. EfficientDetection of Motion Patterns in Spatio-temporal Data Sets. In: Proceedingsof the 12th Annual ACM International Workshop on Geographic InformationSystems. [s.n.], 2004. p. 250–257. ISBN 1-58113-979-9. Disponível em: <http://doi.acm.org/10.1145/1032222.1032259>.
[7] BENKERT, M. et al. Reporting flock patterns. In: . [S.l.]: Elsevier, 2008. v. 41, n. 3,p. 111–125.
[8] ARIMURA, H.; TAKAGI, T. Finding All Maximal Duration Flock Patternsin High-dimensional Trajectories. Manuscript, DCS, IST, Hokkaido University,Apr, 2014. Disponível em: <http://www-ikn.ist.hokudai.ac.jp/~arim/papers/maxlenflock201404r4.pdf>.
[9] GUDMUNDSSON, J.; KREVELD, M. van. Computing longest duration flocksin trajectory data. In: Proceedings of the 14th annual ACM internationalsymposium on Advances in geographic information systems - GIS 2006. New York,New York, USA: ACM Press, 2006. p. 35. ISBN 1595935290. Disponível em:<http://dl.acm.org/citation.cfm?id=1183471.1183479>.
[10] TANAKA, P. S.; VIEIRA, M. R.; KASTER, D. S. Efficient algorithms to discoverflock patterns in trajectories. In: XVI Brazilian Symposium on Geoinformatics(GEOINFO). São Paulo, Brazil: [s.n.], 2015. v. 1, n. XVI, p. 56–67.
[11] MEHTA, D. P.; SAHNI, S. Handbook of data structures and applications. [S.l.]: CRCPress, 2004.

60
[12] EPPSTEIN, D.; GOODRICH, M. T.; SUN, J. Z. Skip quadtrees: Dynamic datastructures for multidimensional point sets. International Journal of ComputationalGeometry & Applications, World Scientific, v. 18, n. 01n02, p. 131–160, 2008.
[13] AL-NAYMAT, G.; CHAWLA, S.; GUDMUNDSSON, J. Dimensionality reductionfor long duration and complex spatio-temporal queries. In: Proceedings ofthe 2007 ACM symposium on Applied computing - SAC ’07. New York, NewYork, USA: ACM Press, 2007. p. 393. ISBN 1595934804. Disponível em:<http://dl.acm.org/citation.cfm?id=1244002.1244095>.
[14] ROMERO, A. O. C. Mining moving flock patterns in large spatio-temporal datasetsusing a frequent pattern mining approach. Tese (Mestrado) — University ofTwente, 2011. Disponível em: <http://admin.banrepcultural.org/sites/default/files/calderon\_andres\_tesis.pdf>.
[15] ZHENG, Y.; ZHOU, X. Computing with spatial trajectories. [S.l.]: Springer Science& Business Media, 2011.
[16] PARENT, C. et al. Semantic trajectories modeling and analysis. ACM Comput.Surv., ACM, New York, NY, USA, v. 45, n. 4, p. 42:1–42:32, ago. 2013. ISSN0360-0300. Disponível em: <http://doi.acm.org/10.1145/2501654.2501656>.
[17] GUSTAFSSON, F. et al. Particle filters for positioning, navigation, and tracking.IEEE Transactions on signal processing, IEEE, v. 50, n. 2, p. 425–437, 2002.
[18] LI, L.; REVESZ, P. A comparison of spatio-temporal interpolation methods. In:Geographic Information Science. [S.l.]: Springer, 2002. p. 145–160.
[19] LONG, J. A. Kinematic interpolation of movement data. International Journal ofGeographical Information Science, Taylor & Francis, v. 30, n. 5, p. 854–868, 2016.
[20] WENTZ, E. A.; CAMPBELL, A. F.; HOUSTON, R. A comparison of two methodsto create tracks of moving objects: linear weighted distance and constrained randomwalk. International Journal of Geographical Information Science, v. 17, n. 7, p.623–645, 2003. Disponível em: <http://dx.doi.org/10.1080/1365881031000135492>.
[21] TREMBLAY, Y. et al. Interpolation of animal tracking data in a fluid environment.Journal of Experimental Biology, The Company of Biologists Ltd, v. 209, n. 1, p.128–140, 2006.





























