Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DA PARAÍBA
CENTRO DE CIÊNCIAS E TECNOLOGIAS
DEPARTAMENTO DE SISTEMA E COMPUTAÇÃO
COORDENAÇÃO DE PÓS-GRADUAÇÃO EM INFORMÁTICA
DISCIPLINA: BANCO DE DADOS AVANÇADOSPROFESSOR: ULRICH SCHIELALUNO: ADRIANO WAGNER ARAÚJO BEZERRA
SISTEMAS DE RECUPERAÇÃO DE INFORMAÇÃO TEXTUAL
Campina Grande -- setembro/98

ÍNDICE
1. INTRODUÇÃO......................................................................................................................3
2. O QUE É UM DOCUMENTO ?.............................................................................................5
3. TÓPICOS DA RECUPERAÇÃO DA INFORMAÇÃO...........................................................63.1. ESTRUTURAS DE ARQUIVOS...................................................................................................................................63.2. CONSULTAS..................................................................................................................................................................73.3. OPERAÇÕES SOBRE CONSULTAS............................................................................................................................83.4. OPERAÇÕES SOBRE TERMOS..............................................................................................................................83.5. OPERAÇÕES SOBRE DOCUMENTOS...................................................................................................................9
4. CONSULTAS BOOLEANAS..............................................................................................104.1. MODELOS BOOLEANOS EXTENDIDOS................................................................................................................11
5. VISÃO FUNCIONAL DE UM SISTEMA DE RECUPERAÇÃO DE INFORMAÇÃO TEXTUAL................................................................................................................................12
6. SISTEMA DE RECUPERAÇÃO DE INFORMAÇÃO X OUTROS TIPOS DE SISTEMAS DE INFORMAÇÃO..................................................................................................................14
7. ESTRUTURAS E ALGORÍTIMOS PARA ARMAZENAMENTO E RECUPERAÇÃO DE INFORMAÇÃO........................................................................................................................15
7.1 . ALGORÍTIMO DE FILTRAGEM.........................................................................................................................157.2 . ALGORÍTIMO DE INDEXAÇÃO........................................................................................................................157.3 . ANÁLISE LÉXICA...............................................................................................................................................167.3.1 ANÁLISE LÉXICA PARA INDEXAÇÃO AUTOMÁTICA.............................................................................167.3.2 ANÁLISE LÉXICA PARA PROCESSAMENTO DE QUERIES......................................................................177.3.3. O CUSTO DA ANÁLISE LÉXICA.....................................................................................................................177.4 . STOPLIST..............................................................................................................................................................187.4.1. IMPLEMENTANDO UMA STOPLIST...................................................................................................................187.5 STEMMING OU TRUNCAGEM............................................................................................................................187.6 . SINÔNIMOS..........................................................................................................................................................197.7 . PESOS DE TERMOS............................................................................................................................................207.8 . CONSTRUÇÃO DE THESAURUS......................................................................................................................227.8.1 CARACTERÍSTICAS DO THESAURUS (NÍVEL COORDENAÇÃO)....................................................................22
8. ARMAZENAMENTO DE INFORMAÇÃO.........................................................................238.1. ARQUIVOS INVERTIDOS.....................................................................................................................................238.1.1. ESTRUTURAS USADAS NOS ARQUIVOS INVERTIDOS.................................................................................258.2. ARQUIVOS DE ASSINATURA.............................................................................................................................26
9. CONCLUSÃO.....................................................................................................................28
10. BIBLIOGRAFIA................................................................................................................29
Sistemas de recuperação de informação textual DSC/CCT/UFPB
2

1. INTRODUÇÃO
Um sistema de recuperação textual é todo o sistema que armazena documentos sob forma de conjuntos de palavras-chaves, e oferece consultas em uma linguagem natural.
Os dados textuais podem estar organizados em inúmeros documentos que não possuem qualquer estruturação explícita( cartas, artigos, publicações, e-mails, páginas WEB, etc.), assim como podem estar estruturados em registros de dados ou tabelas de dados. O que realmente importa não é como ou de que forma os dados estão organizados pelas aplicações, mas sim como eles são tratados internamente pelos sistemas textuais. O tratamento interno dado à estes dados está diretamente relacionado com a recuperação dos mesmos.
As características principais dos sistemas de recuperação textual se encontram nos recursos de pesquisa, através do quais os usuários podem ter acesso a seus dados. Esses sistemas são baseados na recuperação de palavras, permitindo que os usuários recuperem seus dados a partir de qualquer palavra existente em sua base de dados.
A pesquisa por palavra única deve ser o recurso mínimo oferecido pelo sistema. Porém, características e recursos mais elaborados podem fornecer aos usuários uma maior certeza nas informações que estão procurando. Com base nisso, temos outras características importantes, que aumentam o poder das consultas:
Pesquisa por argumento (qualquer palavra existente no banco de dados );
Pesquisa com conectores lógicos ( E, OU, NÃO );
Pesquisa por prefixo, sufixo, ou qualquer outro segmento de uma palavra ( utilizando expressões regulares );
Pesquisa por data, hora ou por intervalos de data e hora;
Pesquisa por ocorrência de valores;
Pesquisas por sentenças compostas ( expressões ou linguagens de consultas );
Pesquisa por fonemas;
Pesquisa por sinônimos;
Pesquisa idéias;
Sistemas de recuperação de informação textual DSC/CCT/UFPB
3

Pesquisa por localização de palavras ( documento, grupo, frase, parágrafo e proximidade)
Existe uma série de algoritmos e estruturas de dados necessárias para construir
sistemas de recuperação de informações. Pesquisadores tem tentado melhorar a performance dos sistemas de recuperação usando informações sobre a distribuição estatística de termos (palavras), isto é, as freqüências com que estes ocorrem nos documentos.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
4

2. O QUE É UM DOCUMENTO ?
Um documento é um objeto de dados, geralmente textual, mas que também pode conter outros tipos de dados, como fotografias, gráficos, imagens, etc. Freqüentemente, os documentos não são armazenados diretamente nos sistemas de recuperação de informação. Estes são representados no sistema por imitações. Por exemplo, um livro é um documento e poderia ser armazenado em sua totalidade no sistema, mas ao invés disso, cria-se uma imitação consistindo de título, autor e abstract. Isto é tipicamente feito, por ser mais eficiente, ou seja, por reduzir o tamanho do banco de dados e o tempo de procura.
Um sistema de recuperação textual deve suportar certas operações básicas, como inserir documentos no banco de dados, alterar e deletar este documentos. Deve ter, também, Maneiras de procurar os documentos e apresentá-los aos usuários.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
5

3. TÓPICOS DA RECUPERAÇÃO DA INFORMAÇÃO
Modelo Estrutura de Operações Operações Operações sobreConceitual Arquivos de Consulta sobre Termos Documentos Booleano Arquivo plano Feedback Radicais Análise
Booleano Arquivo invertido Análise (parse) Pesos Displayextendido
Arquivo de Booleana Thesaurus Cacho (cluster)Probabilístico assinatura
Cacho (cluster) Irrelevância NívelPesquisa de Árvore patríciaCadeias Truncagem Ordenação
Grafos (stemming)Espaço IdentificaçãoVetorial Hashing
Quase todos os sistemas de recuperação hoje, ou são sistemas booleanos ou sistemas de pesquisa por padrões de textos. Queries para pesquisa de padrões de textos são strings ou expressões regulares. Pesquisas por padrões de textos são mais comuns para pesquisas de pequenas coleções , como coleções de arquivos pessoais. A família de ferramentas grep, do Unix, é um exemplo bem conhecido de pesquisa por padrões.
Quase todos os sistemas para pesquisas de grandes documentos são sistemas booleanos. Em um sistema de recuperação booleana, documentos são representados por conjuntos de palavras chaves, geralmente , armazenados em arquivos invertidos. Um arquivo invertido é uma lista de palavras e identificadores dos documentos nos quais eles podem ocorrer.
3.1. ESTRUTURAS DE ARQUIVOS
Uma decisão fundamental num projeto de um sistema de recuperação de informação, é qual o tipo de estrutura de arquivo utilizar para organizar ou indexar os documentos. E entre as estruturas mais utilizadas, temos: Arquivos Flat, arquivos invertidos, arquivos de assinaturas, árvores patrícia e grafos.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
6

No método de arquivos Flat, um ou mais documentos são armazenados em um arquivo, geralmente, como ASCII ou EBCDIC. A pesquisa em arquivos Flat é geralmente feita por comparação de padrões. No Unix, por exemplo, pode-se armazenar uma coleção de documentos em arquivo, dentro de uma estrutura de diretórios, e depois, procurá-los usando ferramentas de pesquisa por padrões, como o Grep.
Um arquivo invertido é um tipo de arquivo indexado. A entrada de um arquivo invertido, geralmente, é uma palavra chave e um identificador de documento e um identificador de campo. A palavra chave é um termo indexador que descreve o documento. O Identificador do documento é único para cada documento e o identificador de campo é, também, um nome único que indica de qual campo no documento a palavra chave vem. Alguns sistemas também incluem informação sobre a localização de parágrafo e sentença, onde o termo ocorre. A pesquisa é feita pela procura dos termos da query no arquivo invertido.
O arquivo de assinatura contém bits de assinatura padrões, que representam os documentos. Um método para isto, por exemplo, é dividir o documento em blocos lógicos, cada um contendo um número fixo de palavras que não fazem parte da stoplist (lista de palavras sem importância ). Cada palavra no bloco tem alguns bits setados para 1. As assinaturas de cada palavra são OR’editadas juntas, para gerar uma assinatura de bloco . As assinaturas de bloco são somadas para gerar a assinatura do documento. A pesquisa é feita pela comparação das assinaturas da query com a assinatura do documento.
Grafos ou rede, são coleções ordenadas de nodos conectados por arcos. São usados para representar documentos de diversas maneiras.
3.2. CONSULTAS
Na recuperação de texto, queries são classificadas de dois tipos:
Consultas booleanas: Por exemplo, “(data or information) and retrieval and (not text)”. Aqui, os usuários especificam termos, conectados com operadores booleanos. Alguns adicionais operadores são, também, suportados como adjacent, ou within n word ou within sentence, com o significado obvio. Por exemplo, a query “data within sentence retrieval” recuperará documentos que contém uma sentença com ambas as palavras “data” e “retrieval”.
Pesquisa por palavra-chave: Nesta, o usuário especifica um conjunto de palavras-chaves , como por exemplo, “data, retrieval, information” ; O sistema de recuperação deverá retornar todos os documentos que contenham as palavras-chaves acima. Esta interface oferece menos controles para o usuário, mas é mais amigável por que não requer que o usuário tenha familiaridade com a lógica booleana.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
7

Vários sistemas permitem, também, a pesquisa por radicais das palavras; por exemplo, “organ*” equivaleria a todas as palavras que iniciam com “organ”, como “organs”, “organization”, “organism”, e assim por diante. O asterisco ( * ) é usado como um caractere de tamanho variável.
3.3. OPERAÇÕES SOBRE CONSULTAS
Queries são declarações formais de informações necessárias, colocadas pelos usuários ao sistema de recuperação textual. Uma operação comum é realizar a operação de parse sobre a query, ou seja, quebra a query em seus elementos constituintes. Queries booleanas , por exemplo, devem ser divididas em seus termos constituintes e operadores.
O conjunto de documentos identificados associados a cada termo da query deve ser recuperado e , depois combinados de acordo com os operadores booloeanos.
3.4. OPERAÇÕES SOBRE TERMOS
Operações sobre termos num sistema de recuperação de informação incluem operações de trucagem (stemming), peso, stoplist e thesaurus. Stemming é a união de palavras relacionadas, ou seja, é a redução das palavras para uma forma raiz comum. Desta maneira, o termo truncado será comparado à varias palavras de mesma raiz.
No thesaurus, uma lista de termos sinônimos ou relacionados é gerada, e dessa forma, a busca a partir de uma palavra retorna um conjunto de termos relacionados.
Stoplist é uma lista de palavras consideradas para não ter índices e são usadas para eliminar potenciais termos indexados. Cada termo indexado é checado contra a stoplist e eliminada se encontrá-la.
No peso, aos termos indexados ou termos da query são atribuídos valores numéricos, usualmente, baseado na informação sobre a distribuição estatística dos termos, ou seja, as freqüências com que os termos ocorrem nos documentos.
3.5. OPERAÇÕES SOBRE DOCUMENTOS
Documentos, como já falado anteriormente, são os objetos primários num sistema de recuperação de informação, e existem muitas operações sobre estes. Na maioria dos sistema de recuperação de informação, os documentos quando inseridos no banco de dados
Sistemas de recuperação de informação textual DSC/CCT/UFPB
8

devem ser unicamente identificados, juntamente com a identificação de seus campos. Uma vez estando no banco de dados, vários tipos de consultas podem ser efetuadas sobre eles, como apresentar o título e o autor do documento recuperado. Pode-se, também, ordenar os documentos recuperados por algum campo, como autor, por exemplo. É possível, por exemplo, ranquear os documentos recuperados, de acordo com a relevância de cada um.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
9

4. CONSULTAS BOOLEANAS
Se aplica, principalmente, a sistema com arquivos invertidos, e envolve vários termos combinados logicamente.
Sejam: P1 e P2 dois termos; U o universo de todos os documentos; D(Pi) o conjunto dos documentos que tratam de Pi.
Temos:
(P1 AND P2) D(P1) D(P2) é o conjunto dos documentos que contém P1 e P2;
(P1 OR P2) D(P1) U D(P2) é o conjunto dos documentos que contém P1 ou P2;
(P1 XOR P2) D(P1) U D(P2) – D(P1) D(P2) é o conjunto dos documentos que contém P1 ou P2, mas não ambos;
NOT(P1) U - D(P1) é o conjunto dos documentos que não contém P1.
Exemplo:
Recupere todos os documentos que tratam de recuperação e de informação, mas não falam em teoria.
( “recuperação” AND “informação”) AND NOT(“teoria”)
(P1 AND P2) produz uma intercalação dos índices de P1 e P2, e só os índices duplicados são mantidos;
(P1 OR P2) produz uma intercalação dos índices de P1 e P2, e todos os índices são mantidos;
(P1 XOR P2) produz uma intercalação dos índices de P1 e P2, e só os índices que aparecem uma vez são mantidos;
Sistemas de recuperação de informação textual DSC/CCT/UFPB
10

(P1 AND NOT(P2) ) primeiro processa (P1 AND P2) para depois intercalar P1 com (P1 AND P2) e remover todos os termos que aparecem mais de uma vez.
Exemplo:
Seja T1 = {D1, D3)T2 = {D1, D2}T3 = (D2, D3,D4}
Calculemos ( (T1 OR T2) AND NOT(T3) )
Intercala(T1,T2) = {D1,D1,D2,D3}T1 OR T2 = {D1,D2,D3}
Intercala( (T1 OR T2), T3) = {D1,D2,D2,D3,D3,D4}( (T1 OR T2) AND T3 ) = {D2,D3}
Intercala ( (T1 OR T2),( (T1 OR T2) AND T3) ) = {D1,D2,D2,D3,D3}
(T1 OR T2) AND NOT(T3) = {D1}
4.1. MODELOS BOOLEANOS EXTENDIDOS
Apesar de sua popularidade, as consultas booleanas podem Ter limitações quanto à recuperação dos documentos corretos:
Para consultas do tipo (A AND B AND C AND D AND E), a resposta será muito restritiva;
Consultas ( A OR B OR C OR D) não distinguem os resultados; Em geral, não é considerado uma hierarquia de importância de resultados; Não há pesos associados aos documentos em relação aos termos, nem aos termos
da consulta.
Para tentar resolver estes problemas, existem outros modelos booleanos para consultas: MMM (Mixed Min Max), Modelo de Paice, Modelo de P-normas
Sistemas de recuperação de informação textual DSC/CCT/UFPB
11

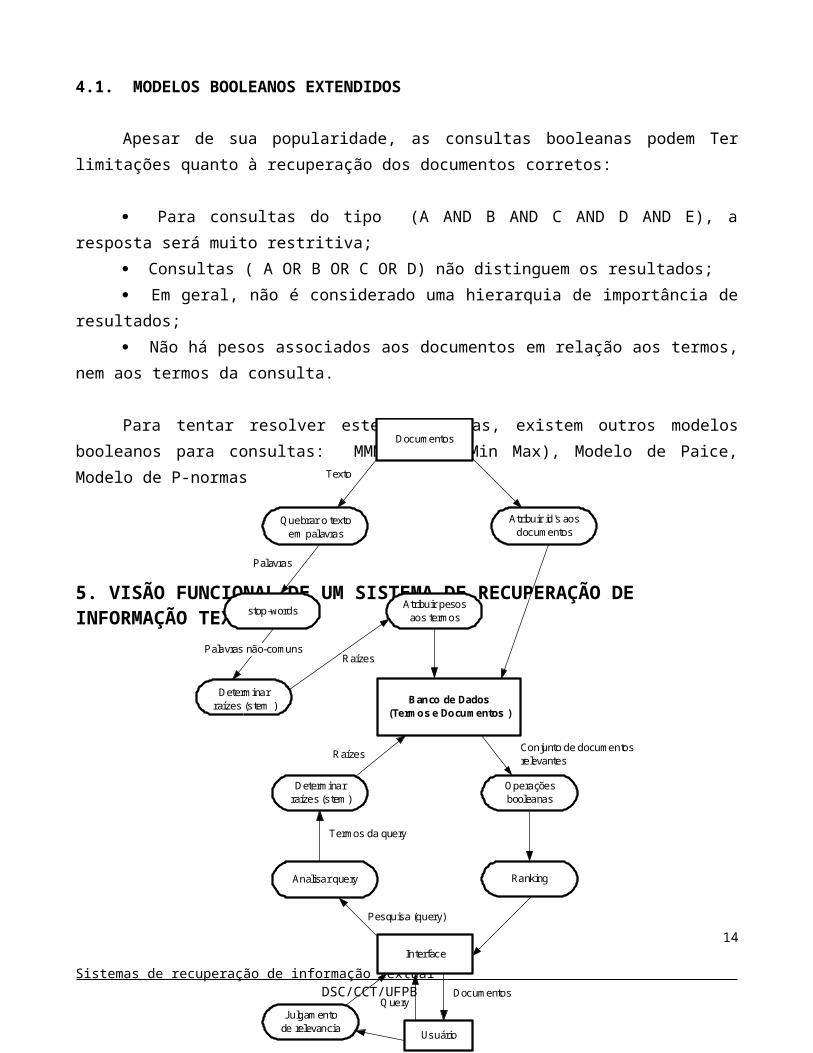
5. VISÃO FUNCIONAL DE UM SISTEMA DE RECUPERAÇÃO DE INFORMAÇÃO TEXTUAL
Sistemas de recuperação de informação textual DSC/CCT/UFPB
12
Documentos
Quebrar o texto em palavras
Atribuir id's aos documentos
stop-words
Determinar raízes (stem )
Atribuir pesos aos termos
Banco de Dados(Termos e Documentos )
Determinar raízes (stem)
Analisar query
Operações booleanas
Ranking
Interface
Julgamento de relevancia
Usuário
Texto
Palavras
Palavras não-comunsRaízes
Raízes
Termos da query
Pesquisa (query)
Conjunto de documentos relevantes
QueryDocumentos

Quando o banco de dados é preenchido, os documentos são analisados um por um, e seus textos são quebrados em palavras. As palavras são comparadas contra uma stoplist. As palavras que não são encontradas na stoplist podem ser truncadas. As palavras podem, também, ser contadas, desde que a frequência das palavras no documento e no banco de dados como um todo, são frequentemente usadas para ranquiar os documentos recuperados. Finalmente, as palavras e informações associadas, tais como os documentos, campos dos documentos e contagem de palavras, são colocadas dentro do banco de dados. O banco de dados deve, então, consistir de pares de identificadores e palavras chaves, como descrito abaixo:
Palavra_chave_1 documento_1 campo_1Palavra_chave_2 documento_2 campo_2,5Palavra_chave_3 documento_3 campo_1,2
. . . . . .
. . .Palavra_chave_n documento_n campo_i,j
Tal estrutura é chamada de arquivo invertido. Em um sistema de recuperação de informação, cada documento deve ter um identificador único, e seus campos de ver Ter nomes únicos.
Para pesquisar o banco de dados, um usuário introduz uma query, consistindo de um conjunto de palavras chaves, conectadas por operadores booleanos (AND, OR, NOT). A query é analisada (parse) em seus termos constituintes e operadores booleanos. Estes termos são procurados nos arquivos invertidos, e a lista de identificadores de documentos correspondentes são combinadas de acordo com os operadores booleanos especificados na query. Se a frequência de informação foi mantida, o conjunto recuperado pode ser indexado de acordo com a relevância. O resultado da pesquisa é, então, apresentado para o usuário. Em alguns sistemas, o usuário faz julgamento sobre a relevância dos documentos recuperados, e esta informação é usada para modificar a query automaticamente, por adicionar termos de documentos relevantes e deletar termos de documentos não relevantes. Sistemas como este tem uma performance longe da ideal, mas muitas técnicas são usadas para melhorá-la.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
13
6. SISTEMA DE RECUPERAÇÃO DE INFORMAÇÃO X OUTROS TIPOS DE SISTEMAS DE INFORMAÇÃO
Objetos Operações Tamanho do BD
SRI Documentos Recuperação Pequeno a (probabilística) muito grande
SGBD Tabela Recuperação Pequeno a (determinística) muito grande
IA Regra Inferência Pequeno
Uma das diferenças entre os tipos de sistemas – SRI com SGBD e IA - é a quantidade de estruturas usáveis em seus objetos de dados. Documentos em geral tem menos estruturas usáveis que tabelas de dados ou estruturas como frames e redes semânticas. Outra característica diferente é que a recuperação é probabilística nos sistemas textuais, Isto significa, que não se tem certeza que os documentos recuperados terão a informação necessitada pelo usuário. Em uma pesquisa típica, em um sistema de recuperação textual, alguns documentos relevantes serão perdidos e alguns não-relevantes serão recuperados. Isso é contrastado à recuperação nos SGBD, onde a recuperação é determinística.
Uma outra característica, que é compartilhada pelos sistemas de recuperação textual e os SGBD’s, é que os bancos de dados são frequentemente muito grandes, geralmente, na faixa de gigabytes.
Em resumo, um sistema de recuperação de informação típicamente deve permitir ao usuário adicionar, deletar e alterar documentos no banco de dados. Deve prover uma maneira para que os usuários procurem por documentos a partir da introdução de queries, e poder examinar os documentos recuperados. Deve acomodar os bancos de dados em espaços na faixa de gigabytes, e recuperar, interativamente, os documentos relevantes em resposta as queries, frequentemente num tempo de 1 à 10 segundos.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
14

7. ESTRUTURAS E ALGORÍTIMOS PARA ARMAZENAMENTO E RECUPERAÇÃO DE INFORMAÇÃO
7.1. ALGORÍTIMO DE FILTRAGEM
Este algoritmo tem como entrada o texto e como saída uma versão processada ou filtrada desse texto. Isto é feito para reduzir o tamanho do texto ou padronizá-lo, tornando a pesquisa mais eficiente. As operações de filtragem mais comuns são:
As palavras comuns são removidas, usando uma lista de stopwords (palavras da stoplist);
Letras maiúsculas são transformadas em minúsculas;
Símbolos especiais são removidos e sequências de múltiplos espaços reduzidos para apenas um espaço;
Números e datas são transformados para o formato padrão;
Palavras são truncadas, removendo sufixos e/ou prefixos;
Extração automática de palavras chaves;
Ranqueamento das palavras.
Estas operações de filtragem possuem, também, algumas desvantagens. Qualquer query, antes de consultar o banco de dados, deve ser filtrada como é o texto; e não é possível pesquisar por palavras comuns, símbolos especiais ou letras maiúsculas, nem distinguir fragmentos de textos que tenham sido mapeados para a mesma forma interna.
7.2. ALGORÍTIMO DE INDEXAÇÃO
O significado de indexação é construir uma estrutura de dados que permitirá uma pesquisa mais rápida e eficiente do documento. Existem muitas classes de índices, baseadas em diferentes métodos de recuperação. Por exemplo, arquivos invertidos, arquivos
Sistemas de recuperação de informação textual DSC/CCT/UFPB
15

de assinaturas, etc. Quase todos os tipos de índices são baseados em algum tipo de árvore ou hashing.
Normalmente, antes da indexação, o texto deve ser filtrado, como falado anteriormente.
Texto Texto filtrado e indexado
O tempo de processamento necessário para construir o índice é amortizado pelo uso destes na pesquisa.
7.3. ANÁLISE LÉXICA
A análise léxica é o primeiro estágio da indexação automática, e do processamento de query. Indexação automática é o processo de algoritmicamente organizar os itens de informação para gerar listas de termos de índices. A fase de análise léxica produz termos de índices candidatos, que podem ser processados e, eventualmente, adicionados para os índices.
Processamento de query é a atividade de analisar a query e compará-la com os índices para encontrar itens relevantes. A análise léxica da query produz tokens, que são analisados (parse) e introduzidos para uma representação adequável para comparação com índices.
Na indexação automática, termos candidatos à ser índices são frequentemente checados para ver se eles estão numa stoplist. Se o termo estiver na stoplist é imediatamente removido de futuras considerações como índices.
7.3.1 ANÁLISE LÉXICA PARA INDEXAÇÃO AUTOMÁTICA
Existe algumas considerações importantes sobre o que poderia ser considerado como token na análise léxica:
Dígitos – A maioria dos números não geram bons termos indexados e, frequentemente, números não devem ser incluídos como token. Entretanto, certos números em alguns tipos de banco de dados podem ser importantes, como em documentos técnicos. Por exemplo, um banco de dados sobre vitaminas conteria
Sistemas de recuperação de informação textual DSC/CCT/UFPB
16
Operações de filtragem
Construção de índices

importantes tokens como “B6”e “B12”. Uma solução para este problema e permitir números , mas não começando com eles.
Hífens -- Uma outra dificuldade é se deve-se quebrar as palavras hifenizadas em suas palavras constituintes, ou mantê-las como tokens únicos. Algumas vezes quebrar as palavras hifenizadas pode causar certas inconsistências, como , por exemplo, tratar as expressões “estado-da-arte” e “estado da arte” igualmente. Hífens, frequentemente, faz parte do nome, e não se pode quebrar as palavras. Por exemplo, “Jean-Claude”, “F-16”, “MS-DOS”.
Outros sinais de pontuação – Outros sinais também são usados como parte de palavras, como o ponto em nomes de arquivos (ex. command.com). Barras, também, são usadas como parte do nome (ex. OS/2). Além desses, o caractere undescore é muito usado em termos de linguagens de programação (ex. max_size).
Maiúsculas e Minúsculas – Geralmente, a diferenciação entre maiúsculas e minúsculas não é importante e, tipicamente, a análise léxica converte as palavras para uma das formas.
7.3.2 ANÁLISE LÉXICA PARA PROCESSAMENTO DE QUERIES
Projetar um analisador léxico para a query é como projetar para indexação automática. Desde que os termos da query devem igualar-se com os índices, os mesmos tokens devem ser distinguidos pelos dois analisadores. Além disso, o analisador léxico de query deve, usualmente, distinguir operadores (como operadores booleanos, stemming ou operadores de truncagem, operadores de peso) e agrupar indicadores (parênteses e colchetes). Um analisador léxico de query deve, também, processar certos caracteres de controles e não permitir pontuação. Tais caracteres são tratados como delimitadores na indexação automática, mas no processamento de query, indicam erro.
7.3.3. O CUSTO DA ANÁLISE LÉXICA
O custo da análise léxica é alto por que requer o exame de todo caractere de entrada, enquanto estágios posteriores de indexação automática e processamento de query não. Geralmente a fase de análise léxica toma 50% do tempo de compilação.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
17

7.4. STOPLIST
A maioria das palavras mais frequentemente usadas na língua inglesa, vistas numa recente pesquisa, são palavras se valor de índice. Entre estas, por exemplo, temos “the”, “of”, “and”, “to”, entre muitas outras. Uma consulta feita com um desses termos retornaria quase todos os itens do banco de dados sem considerar a relevância destes. Estas palavras compõe uma grande fração da maioria dos textos de cada documento. Por conta disso, a eliminação de tais palavras no processo de indexação salva uma enorme quantidade de espaços em índices, e não prejudica a eficácia da recuperação. A lista das palavras filtradas durante a indexação automática, em virtude delas gerarem índices pobres, é chamada de stoplist ou um dicionário negativo.
Uma maneira de melhorar a performance do sistema de recuperação de informação, então, é eliminar as stopword – palavras que fazem parte da stoplist – durante o processo de indexação automática.
Tradicionalmente, nas stoplist devem ser incluídas as palavras mais frequentes, entretanto, algumas palavras muito frequentes são importantes termos indexados. Por exemplo, entre as 200 palavras mais frequente da literatura geral da língua inglesa, temos: “time”, “war”, “home”, “life”, “water” e “world”. Por outro lado, banco de dados especializados conterão muitas palavras sem uso, como termos indexados no ingl6es em geral.
Portanto, a geração da stoplist depende das características do banco de dados, do usuário e do processo de indexação.
7.4.1. IMPLEMENTANDO UMA STOPLIST
Existem duas maneiras duas maneiras de filtrar as stopwords de uma sequência de tokens de entrada. O analisador léxico examinar a saída e remover qualquer stopword, ou remover as stopwords como parte da análise léxica.
O primeiro método, filtrar stopwords da saída do analisador léxico, causa um problema: Todo token deve ser examinado na stoplist e removido da análise se encontrado. A solução mais rápida para isso é a utilização de hashing.
7.5 STEMMING OU TRUNCAGEM
Uma outra técnica para melhorar a performance e eficiência e, também, facilitar as pesquisas para o usuário, é prover aos pesquisadores do sistema meios de encontrar variantes morfológicas dos termos de pesquisa, ou seja, múltiplas representações da
Sistemas de recuperação de informação textual DSC/CCT/UFPB
18

palavras como um único stem (redical). Se, por exemplo, um pesquisador entrar com o termo “comput” como parte da query, é provável que ele ou ela também estará interessado em tais variantes como “computable” , “computation”, “computational” , etc.
Stemming é muito usado nos sistemas de recuperação de informação para reduzir o tamanho dos arquivos de índices. Desde que um único termo truncado (stem) tipicamente corresponde à vários termos completos, armazenar stems ao invés de termos, o fator de compressão chega a 50%.
A vantagem de stemming é a eficiência no tempo de indexação e a compressão do arquivo de índice. A desvantagem de indexar stemming é que a informação sobre os termos completos serão perdidas, ou adicional armazenamento será necessário para armazenar ambas as formas truncadas e não-truncadas.
Uma outra desvantagem é que o uso da truncagem causa um aumento da imprecisão da recuperação, pois o valor da precisão não está baseado em encontrar todos os itens relevantes, mas justamente minimizar a recuperação de termos irrelevantes.
Existem diversos métodos de truncagem. Enter eles, o mais comum é remover sufixos e/ou prefixos dos termos, deixando apenas a raiz do termo. Um outro método, é gerar uma tabela de todos os termos indexados e seus stems. Por exemplo:
Termo StemEngineering EngineerEngineered EngineerEnginer Engineer
Os termos da query e índices poderiam ser, então, truncados via pesquisa na tabela. Usando B-Tree ou hash, tais pesquisas seriam mais rápidas.
Existem problemas com este método. O overhead de armazenamento para tal tabela é bastante grande.
Existem, além desses dois, outros métodos, como variedade de sucessores, n-gram, etc.
7.6. SINÔNIMOS
Em muitas operações de recuperação, especificação de sinônimos podem ser adicionadas para qualquer termo da query, numa formulação de query. Cada sinônimo é então, automaticamente, substituído pelo termo original, ocasionando a recuperação dos documentos com respeito a ambos os termos, o original e o sinônimo. Quando uma query booleana é usada, as especificações de sinônimos podem, simplesmente, ser juntadas aos
Sistemas de recuperação de informação textual DSC/CCT/UFPB
19

termos originais por operadores OR antes da pesquisa ser iniciada. Logo, a query ( (T1 AND T2) OR T3 ) é transformada em ( ( (T1 OR S1) AND T2) OR ( T3 OR S3) ), quando o usuário preenche S1 e S3 como sinônimos de T1 e T3, respectivamente. Quando sinônimos são adicionados à query, o número de itens irrelevantes recuperados na pesquisa pode ser muito maior que antes.
7.7. PESOS DE TERMOS
A importância de pesos para os termos do documento e termos da query , é a de ajudar a distinguir os termos que são mais relevantes para a recuperação da informação. Por exemplo, um particular registro poderia aparecer como Ri = { Ti1, 0.2; Ti2, 0.5; Ti3, 0.6}, mostrando que o termo 3 do registro Ri tem um peso de importância de 0.6, enquanto o termo 1 tem um peso de importância muito menor, que é de 0.2. Quando o peso dos termos são adicionados ao índice do arquivo invertido, os registros podem ser ranqueados em tempo de recuperação, na ordem decrescente do pesos dos termos igualados (matching) entre queries e documentos.
A estratégia de usar critérios de pesos dos termos dos documentos, deve ser simples de gerar e fácil de aplicar. Quando todos os termos estão com pesos atribuídos, é fácil ranquear as saídas dos documentos na ordem decrescente dos peso s dos termos.
Vetor de queries, que expressam a especificação da query, simplesmente como um conjunto de termos, podem ser distinguidos de queries booleanas , que se utilizam de operadores lógicos para relacionar os termos da query. Para vetores de queries, o peso de recuperação de um documento poderia ser, simplesmente, definido como a soma dos pesos de todos os termos do documento, que equivale (match) à uma query dada. Então, se uma query Q consiste de termos (ti, tj, tk), o peso de recuperação de um registro Rn contendo estes termos, simplesmente, seria computado como Wni + Wnj + Wnk, onde Wnp é o peso do termo P no registro N.
Quando uma query booleana é usada, determinando o peso da recuperação, a coisa fica um pouco mais complexa, por que existe muitas formulações de expressões booleanas. Uma possibilidade consiste na transformação de cada query em uma soma de produtos, também, conhecida como forma normal disjuntiva, onde a query aparece como um conjunto de um ou mais termos, isto é, termos inter-conectados por operadores AND, como por exemplo, ( Ti AND Tj AND Tk), e cada conjunto ser cortado pelo operador OR. O exemplo abaixo, mostra o resultado para uma query do tipo ( (T1 AND T2) OR T3).
Vetores de documentos Conjunção de pesos Peso da query(T1 AND T2) (T3) (T1 AND T2) OR T3
Sistemas de recuperação de informação textual DSC/CCT/UFPB
20

D1 = (T1, 0.2; T2, 0.5; T3, 0.6) 0.2 0.6 0.6D2 = (T1, 0.7; T2, 0.2; T3, 0.1) 0.2 0.1 0.2
O peso da recuperação é computado da seguinte maneira:
1. Primeiro, o peso do documento é computado com respeito a cada conjunção na query, como o peso mínimo;
2. Depois, o peso final é estabelecido pela disjunção das conjunções, com o maior dos pesos.
Neste exemplo, temos dois documentos e uma query na forma de soma de produtos. Este exemplo mostra que o score entre a query e o documento D1 é maior que com o documento D2. Logo, D1 seria recuperado antes de D2, para o caso de uma recuperação ranqueada em ordem decrescente de peso.
O método de vetor de peso também permite uma representação matemática e física, onde cada token pode ser considerado uma dimensão na representação do espaço.
T10.2
0.6T3
0.5T2
7.8. CONSTRUÇÃO DE THESAURUS
Thesaurus é usado para coordenar os processos básicos de recuperação e indexação de documentos. Na indexação, uma sucinta representação do documento é derivada enquanto a recuperação refere-se ao processo de pesquisa pelo qual os itens relevantes são identificados. O Thesaurus, tipicamente, contém uma lista de termos, onde um termo é
Sistemas de recuperação de informação textual DSC/CCT/UFPB
21

qualquer palavra ou frase, juntamente, com os relacionamentos entre eles. Ele provê uma vocabulário comum, preciso e controlado, que ajuda na coordenação da indexação e recuperação.
Um bem projetado thesaurus pode ser de grande valor. O indexador é, tipicamente, instruído para selecionar a entrada de thesaurus mais apropriada para representar o documento. Na pesquisa, o usuário pode empregar o thesaurus para projetar a estratégia de pesquisa mais apropriada. Se a pesquisa não recupera documentos suficientes, o thesaurus pode ser usado para expandir a query, por seguir vários links ou relacionamentos entre os termos. Similarmente, se a pesquisa recupera muitos itens, o thesaurus pode sugerir um vocabulário de pesquisa mais específico. Desta maneira, o thesaurus pode ser de grande valor para reformulação das estratégia de pesquisa. É muito comum prover thesauri on-line, que simplifica o processo de reformulação da query. Tais modificações de queries, também podem ser iniciadas pelo sistema em vez do usuário. Entretanto, isto obviamente requer bem mais complexidade de algoritmo, pois o sistema tem que saber não apenas como reformular a query, mas também quando fazer.
7.8.1 CARACTERÍSTICAS DO THESAURUS (nível coordenação)
Coordenação refere-se à construção de frases de termos individuais. Duas opções distintas de coordenação são reconhecidas no thesauri: pré-coordenação e pós-coordenação. A pré-coordenação pode conter frases. Consequentemente, frases estão disponíveis para recuperação e indexação. Um thesauri pós-coodenado não permite frases. Ao invés disso, frases são construídas durante a pesquisa. A escolha entre as duas opções é difícil. A vantagem em pré-coordenação é que o vocabulário é muito preciso, logo reduzindo a ambiguidade na pesquisa e indexação. Entretanto, a desvantagem é que o pesquisador tem que estar ciente das regras de construção de frases empregadas.
A vantagem na pós-coordenação é que o usuário não precisa se preocupar sobre a exata ordens das palavras na frase. Combinação de frases podem ser criadas como e quando seja apropriado durante a pesquisa. A desvantagem é que a precisão da pesquisa pode falhar, como no seguinte exemplo: a distinção entre frases como “venetian blind” e “blind venetian” pode ser perdida. O problema é que a menos que as estratégias de pesquisa sejam definidas cuidadosamente, termos irrelevantes podem ser recuperados.
Pré-coordenação é mais comum na construção de thesauri manuais. Construção de frases automáticas é ainda um pouco difícil e além do mais, a construção automática de thesauri implica pós-coordenação.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
22

8. ARMAZENAMENTO DE INFORMAÇÃO
8.1. ARQUIVOS INVERTIDOS
A estrutura de dados mais comum usada nos sistemas de recuperação de informação é a estrutura de arquivo invertido. Esta estrutura é composta de três arquivos básicos: Um arquivo de documentos, um arquivo de índices ou dicionário, e um arquivo de endereços ou lista de inversão. O nome “arquivo invertido” vem da idéia de armazenar uma inversão dos documentos - inversão dos documentos a partir da perspectiva de que, para cada palavra uma lista de documentos, em que a palavra é encontrada dentro, é armazenada ( a lista de inversão para cada palavra).
FORMA ORIGINAL DO ARQUIVOTermo1 Termo2 Termo3 Termo4
Registro1 1 1 0 1Registro2 0 0 1 1Registro3 1 0 1 1Registro4 0 0 1 1
FORMA INVERTIDA DO ARQUIVORegistro1 Registro2 Registro3 Registro4
Termo1 1 1 0 1Termo2 0 0 1 1Termo3 1 0 1 1Termo4 0 0 1 1
Arquivo de índices Arquivo de endereçamento Arquivo de documentos
Palavra-chave Ocorrências Link Doc# Link... ...1 .2 .7 .8 .... ...
Sistemas de recuperação de informação textual DSC/CCT/UFPB
23
Computação 4 .
Software 2 .
Doc# 1
Doc# 2
. . . . . .

2 .5 ....
.
.
.
O arquivo invertido é um índice ordenado de palavras chaves, com cada palavra contendo encadeamentos que as contém.
A cada documento dentro do sistema é dado um único identificador. É esse identificador que é armazenado na lista de inversão. A maneira de localizar a lista de inversão para cada palavra é via o dicionário. O dicionário é, tipicamente, uma lista ordenada de todas as palavras únicas (tokens processados) no sistema e apontadores para a localização de sua lista de inversão. A lista de inversão contém o identificador para cada documento em que a palavra é encontrada. Todas as ocorrências da palavra são armazenados na lista de inversão, juntamente com a sua posição. Então, por exemplo, se a palavra “computer” foi a décima, décima-segunda e décima-oitava palavra no documento, a lista de inversão apareceria da seguinte forma: Computer: 1(10), 1(12), 1(18).
Pesos, também, podem ser usados nas listas de inversão. Quando uma pesquisa é realizada, as listas de inversão para os termos na query são localizados e a lógica apropriada é aplicada entre as lista, o resultado é uma lista final de itens que satisfazem a query. Por exemplo, a query (“bit” AND “computer”) usaria o dicionário para encontrar a lista de inversão para “bit “e “computer”. Estas duas listas são logicamente AND’editadas: (1,3) AND (1,3,4) resultando uma lista final contendo (1,3).
As principais vantagens da inversão de arquivos é que é bastante fácil de implementar, é rápido de acessar e suporta sinônimos facilmente (sinônimos poderiam ser organizados como uma lista dentro do dicionário). Por estas razões, o método de inversão tem sido adotado na maioria dos sistemas comerciais, como o DIALOG, BRS, MEDLARS, ORBIT e STAIRS.
As desvantagens deste método é o overhead necessário para armazenamento e o custo de atualizar e reorganizar os índices, caso o ambiente seja dinâmico. Métodos de compressão tem sido sugerido para minimizar o tamanho dos índices.
Geralmente, existem algumas restrições impostas nestes índices e, consequentemente, nas pesquisas posteriores. Exemplos dessas restrições são:
Um vocabulário controlado, que é uma coleção de palavras chaves que serão indexadas. Palavras no texto que não estão no vocabulário não serão indexadas e, consequentemente, não serão pesquisáveis;
Sistemas de recuperação de informação textual DSC/CCT/UFPB
24

Uma lista de stopwords (artigos, preposições, etc.), que por questão de volume ou precisão, não serão indexáveis, nem pesquisáveis;
Um conjunto de regras que decida o início de uma palavra ou um pedaço de texto que é indexável;
Nem todos os caracteres são indexáveis. Por exemplo, sequências de caracteres numéricos.
8.1.1. ESTRUTURAS USADAS NOS ARQUIVOS INVERTIDOS
Existem várias estruturas que podem ser usadas na implementação de arquivos invertidos: arrays ordenados, B-trees, tries, hashing.
Array ordenado -- Armazena a lista de palavras chaves dentro de uma array ordenado, incluindo o número de documentos associados com cada palavra-chave e um link para os documentos contendo aquela palavra chave. A principal desvantagem deste método é que a atualização dos índices (por exemplo, adicionando uma nova palavra-chave) é cara. Por outro lado, arrays ordenado serão fácil de implementar e são razoavelmente rápidos.
B-tree – Um caso especial de B-tree, a B-tree de prefixo, usa prefixos de palavras como chaves primárias no índice da B-tree e é, particularmente adequável para armazenamento de índices textuais. Cada chave é a palavra menor (em tamanho) que se distingue das chaves armazenadas no próximo nível. O último nível ou nível folha armazena as próprias palavras chaves, juntamente com seus dados associados.
8.2. ARQUIVOS DE ASSINATURA
O objetivo da estrutura de arquivos de assinatura é prover um teste rápido para eliminar a maioria dos itens que não estão relacionados com a query. Os itens que satisfazem a pesquisa podem ser avaliados por um outro algoritmo de pesquisa para eliminar falsos sucessos (hits), ou ser liberado para que o usuário os reveja. O texto dos itens é representado em uma forma altamente comprimida e desordenada, e requer muito menos espaço que uma estrutura de arquivo invertido.
A pesquisa no arquivo de assinatura é uma procura linear, que tem o tempo de resposta de acordo com o tamanho do arquivo.
O método de arquivo de assinatura funciona da seguinte forma: os documentos são armazenados sequencialmente em um arquivo texto. Para cada documento, é criada uma
Sistemas de recuperação de informação textual DSC/CCT/UFPB
25

assinatura (padrões de bits codificados) e armazenada nos arquivos de assinaturas. Quando uma query é feita, o arquivo de assinatura é varrido e muitos documentos não qualificados são descartados. O resto é checado ou são retornados para o usuário como eles são.
Uma breve qualitativa comparação do método baseado em assinaturas versus seus competidores é a seguinte: Comparado com inversão, ele requer bem menos espaço de armazenamento (em torno de 10 a 20% dos arquivos invertidos). Além do mais, pode controlar melhor as inserções, pois não precisa reorganizar ou rescrever qualquer parte das assinaturas. Mas por outro lado, arquivos de assinaturas podem ser lentos para grandes bancos de dados, por que seu tempo de resposta é linear ao número de itens do banco de dados.
Arquivos de assinaturas, tipicamente, usa codificação sobreposta para criar a assinatura do documento. Por razões de performance, cada documento é dividido em blocos lógicos, isto é, pedaços de textos que contém um constante número D de distintas e não comuns palavras. Cada tal palavra produz uma assinatura de palavra, que é uma sequência de bits de tamanho F, com M bits setados para “1”, enquanto o restante é setado para “0”. F e M são parâmetros determinados. As M posições a serem setadas para “1”, por cada palavra, são definidas por funções hash. As assinaturas de palavras são OR’editadas juntas para formar a assinatura do bloco. As assinaturas dos blocos são concatenadas para formar a assinatura do documento.
No exemplo abaixo, o tamanho do bloco é estabelecido em cinco palavras, o tamanho do código é 16 bits e o número de bits que são permitidos ser “1”, para cada palavra, é cinco.
Palavra Assinatura
Computer 0001 0110 0000 0110Science 1001 0000 1110 0000Graduate 1000 0101 0100 0010Students 0000 0110 0110 0100Study 0000 0110 0110 0100
Assinatura do bloco 1001 0111 1110 0110
As palavras na query são mapeadas para suas assinaturas. A pesquisa é acompanhada por padrões nas posições dos bits especificados pelas palavras na query.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
26

O arquivo de assinaturas pode ser armazenado com cada linha representando um bloco de assinatura. Associado com cada linha, está um apontador para o bloco do texto original.
O processo de recuperação dos registros desejados consiste de quatro etapas:
1. Construir o vetor de sobreposição para a query desejada;2. Fazer o casamento desse vetor com as assinaturas de todos os registros no
conjunto, e identificar aqueles cujas assinaturas contém os bits do vetor da query; ou seja, este vetor tem que um “1” na mesma posição correspondente do vetor do registro.
3. Recuperar os registros correspondentes no arquivo principal;4. Checar os registros recuperados para garantir que eles realmente atendem a
query.
Esta última etapa é necessária para evitar as ocorrências falsas (false hits, false drops). É importante ressaltar, que quando a informação é condensada, alguma coisa é perdida.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
27

9. CONCLUSÃO
Sistemas de gerenciamento e recuperação de textos, que incluem métodos de indexação e pesquisa das informações, fazem parte do paradigma da recuperação de informação. E este paradigma tem como grande virtude facilitar para o usuário a busca e recuperação das informações, geralmente, de maneira on-line. Embora nem sempre as pesquisas retornem com altas taxas de precisão, estes sistemas estão cada vez mais sendo utilizados, principalmente, em pesquisas na rede mundial de computadores, Internet. Mas além da Internet, estes sistemas tem tido diversas outras aplicações, tais como:
Bibliotecas computadorizadas. Por exemplo, a biblioteca do congresso americano;
Armazenamento e recuperação eletrônica de artigos de jornais e revista;
Bancos de dados de consumidores, que contém descrições dos produtos em linguagem natural;
Enciclopédias eletrônicas;
Pesquisas em bancos de dados com descrições de moléculas de DNA;
Pesquisa em bancos de dados de imagens e animações.
Portanto, cada vez mais os sistemas de recuperação de informações textuais se tornam indispensáveis no nosso dia-a-dia, pois a necessidade de ganhar tempo e aumentar a nossa produtividade se faz cada vez mais crescente.
Sistemas de recuperação de informação textual DSC/CCT/UFPB
28

10. BIBLIOGRAFIA
1. Automatic Text ProcessingThe Transformation, Analysis, and Retrievel of Information by ComputerGerald Salton
2. Information RetrievelData Structures & AlgorithmsWilliam B. Frakes / Ricardo Baeza-Yates
3. Information Retrievel SystemsTheory and ImplementationGerald Kowalski
Sistemas de recuperação de informação textual DSC/CCT/UFPB
29





























