Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DE GOIÁSINSTITUTO DE INFORMÁTICA
EDJALMA QUEIROZ DA SILVA
Invenire:Um método evolucionário para combinar resultados das
técnicas de sistemas de recomendação baseado emfiltragem colaborativa
Goiânia2014

UNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
AUTORIZAÇÃO PARA PUBLICAÇÃO DE DISSERTAÇÃO
EM FORMATO ELETRÔNICO
Na qualidade de titular dos direitos de autor, AUTORIZO o Instituto deInformática da Universidade Federal de Goiás – UFG a reproduzir, inclusive em outroformato ou mídia e através de armazenamento permanente ou temporário, bem comoa publicar na rede mundial de computadores (Internet) e na biblioteca virtual da UFG,entendendo-se os termos “reproduzir” e “publicar” conforme definições dos incisos VIe I, respectivamente, do artigo 5o da Lei no 9610/98 de 10/02/1998, a obra abaixoespecificada, sem que me seja devido pagamento a título de direitos autorais, desde quea reprodução e/ou publicação tenham a finalidade exclusiva de uso por quem a consulta,e a título de divulgação da produção acadêmica gerada pela Universidade, a partir destadata.
Título: Invenire: Um método evolucionário para combinar resultados das técnicas desistemas de recomendação baseado em filtragem colaborativa
Autor(a): Edjalma Queiroz da Silva
Goiânia, 20 de Agosto de 2014.
Edjalma Queiroz da Silva – Autor
Celso Gonçalves Camilo Junior – Orientador

EDJALMA QUEIROZ DA SILVA
Invenire:Um método evolucionário para combinar resultados das
técnicas de sistemas de recomendação baseado emfiltragem colaborativa
Dissertação apresentada ao Programa de Pós–Graduação doInstituto de Informática da Universidade Federal de Goiás,como requisito parcial para obtenção do título de Mestre emCOMPUTAÇÃO.
Área de concentração: CIÊNCIA DA COMPUTAÇÃO.
Orientador: Prof. Celso Gonçalves Camilo Junior
Goiânia2014

EDJALMA QUEIROZ DA SILVA
Invenire:Um método evolucionário para combinar resultados das
técnicas de sistemas de recomendação baseado emfiltragem colaborativa
Dissertação defendida no Programa de Pós–Graduação do Instituto deInformática da Universidade Federal de Goiás como requisito parcialpara obtenção do título de Mestre em COMPUTAÇÃO, aprovada em20 de Agosto de 2014, pela Banca Examinadora constituída pelosprofessores:
Prof. Celso Gonçalves Camilo JuniorInstituto de Informática – UFG
Presidente da Banca
Prof. Keiji YamanakaUniversidade Federal de Uberlândia – UFU
Prof. Thierson Couto RosaUniversidade Federal de Goiás – UFG

Todos os direitos reservados. É proibida a reprodução total ou parcial dotrabalho sem autorização da universidade, do autor e do orientador(a).
Edjalma Queiroz da Silva
Graduou-se em Análise de Sistemas pela Universidade Salgado de Oliveira,campus Goiânia. Especializou-se em Tecnologia da Informação e NegóciosEletrônicos pela Universidade Salgado de Oliveira, campus Goiânia. Duranteo Mestrado na UFG, participou de grupo de pesquisa em Sistemasde Recomendação. Atua como Analista de Sistemas junto à SEMARH(Secretaria Estadual do Meio Ambiente e de Recursos Hídricos), participandode atividades de análise, desenvolvimento e implantação de sistemas deinformação. Atua também como docente universitário nas instituiçõesSENAI/FATESG e Faculdade Sul Americana.

Dedico este trabalho primeiramente a Deus.Aos meus pais, Jovelci e Áurea, por terem sempre me apoiado em meus projetos.À minha noiva, Janete, pelo companheirismo, compreensão e carinho.Ao meu irmão, Telmo, que sempre me ensinou a ver os problemas de maneira
simples.À família de meu amigo Claudisson, que esteve presente em todos os momentos.

Agradecimentos
Algumas pessoas foram essenciais para a realização desse trabalho. Colaborandodireta ou indiretamente, muita gente teve um papel fundamental para que os objetivosfossem concretizados. Com o trabalho pronto, chegou a hora de agradecer.
Ao meu orientador, Celso G. Camilo Junior, pela oportunidade, pelosensinamentos fornecidos para que a pesquisa pudesse ser realizada e por acreditar eme mostrar que a pesquisa científica é um desafio extremamente necessário para se obterbons resultados.
Ao professor Thierson C. Rosa, pelo empenho, paciência e pela dedicação comque ajudou no desenvolvimento do artigo publicado.
Ao Instituto de Informática da UFG, pela excelente estrutura, suporte e ambienteoferecidos aos alunos, e a todos os professores, principalmente aos que eu tive aoportunidade de conhecer e aprender tantas coisas.
Aos amigos que contribuíram diretamente para a realização dessa pesquisa eforam muito importantes durante o andamento do trabalho.
A minha mãe, meu pai, meu irmão, minha cunhada e minha sobrinha que nosfelicita com sua presença. E aos demais familiares, em especial aos meus avós, que mesmodistantes, eu sei que torceram e acreditaram na realização desse trabalho.
A minha noiva, que com o carinho e apoio soube me incentivar a continuar.A todos, o meu “muito obrigado”!

Dedicação Produz Dedicação; Preguiça produz Preguiça.
João Crisóstomo,Foi um teólogo e escritor cristão, arcebispo de Constantinopla no fim do
século IV e início do V.

Resumo
Silva, Edjalma Queiroz. Invenire: Um método evolucionário para combinarresultados das técnicas de sistemas de recomendação baseado em filtragemcolaborativa. Goiânia, 2014. 150p. Dissertação de Mestrado. Instituto deInformática, Universidade Federal de Goiás.
Sistemas de Recomendação funcionam como um conselheiro, comportando-se de talforma a orientar as pessoas na descoberta de produtos de interesse. Existem várias técnicase abordagens na literatura que permitem gerar recomendações. Isso é interessante porqueenfatiza a diversidade de opções; por outro lado, pode causar dúvida para o projetistado sistema sobre qual é a melhor técnica para usar. Cada uma destas abordagens temparticularidades e dependem do contexto para serem aplicadas. Assim, a decisão deescolher entre técnicas se torna complexa para ser feita manualmente. Este trabalhopropõe uma abordagem evolutiva para automatizar a busca pela melhor combinaçãode resultados de técnicas de Sistemas de Recomendação e produzir menos erros nasrecomendações. Para avaliar a proposta, foram realizados experimentos com um conjuntode dados da MovieLens e algumas das técnicas de Filtragem Colaborativa. Os resultadosmostram que a metodologia de combinação, proposta neste trabalho, tem um desempenhomelhor do que qualquer uma das técnicas isoladas de filtragem colaborativa no contextoabordado. A melhora varia de 3,6% a 118,99% dependendo da técnica e do experimentoexecutado.
Palavras–chave
Sistemas de Recomendação, Filtragem Colaborativa, combinar resultados,similaridade e Invenire

Abstract
Silva, Edjalma Queiroz. Invenire: Um método evolucionário para combinarresultados das técnicas de sistemas de recomendação baseado em filtragemcolaborativa. Goiânia, 2014. 150p. MSc. Dissertation. Instituto de Informática,Universidade Federal de Goiás.
Recommendation systems function as a guide, helping users to discover products ofinterest. There are various techniques and approaches in the literature that enable thegeneration of recommendations. This is interesting because it emphasizes the diversity ofoptions; on the other hand, it can cause doubt the system designer about which is the besttechnique to use. Each of these approaches has particularities and depends on the contextto be applied. Therefore, the decision to choose between the techniques is complex tobe done manually. This work proposes an evolutionary approach for combining resultsof recommendation techniques (Invenire) in order to automate the choice of techniquesand get fewer errors in recommendations. To evaluate the proposal, experiments wereperformed with a dataset from MovieLens and some Collaborative Filtering techniques.The results show that the combining methodology proposed in this paper performsbetter than any one collaborative filtering technique separately in the context addressed.The improvement varies from 3,6% to 118,99% depending on the technique and theexperiment executed.
Keywords
Recommender Systems, Collaborative Filtering, combining results, similarityand Invenire

Lista de Abreviaturas e Siglas
SR - Sistemas de RecomendaçãoFC - Filtragem ColaborativaFBC - Filtragem Baseada em ConteúdoFBU - Filtragem Baseada em UtilidadeRMSE - Root Mean Square Error
HTTP - Hypertext Transfer Protocol
SPADE - Sequential PAttern Discovery using Equivalence classes
TF-IDF - Term Frequency-Inverse Document Frequency
k-NN - k-Nearest Neighbors algorithm
MAE - Mean Absolute Error
AG - Algoritmo GenéticoES - Evolutionary Strategies
AE - Algoritmos EvolucionáriosEI - Evolução InterativaMOP - Problema Multi-Objetivo de OtimizaçãoAGG - Algoritmo Genético GeracionalAGEE - Algoritmo Genético de Estado EstacionáriomAG - Algoritmo Genético “sujo”EI - Evolução InterativaIEEE - Institute of Electrical and Electronics Engineers
CEC - Congress on Evolutionary Computation
LGPL - Lesser General Public License
CPL - Common Public License
JSci - Science API for Java
API - Application Programming Interface
JDK - Java Development Kit
PHP - Hypertext Preprocessor
SQL - Structured Query Language
JNDI - Java Naming and Directory Interface
CSV - Comma-separated values

ID - Identity
SGD - Stochastic gradient descent
SVM - Support Vector Machines
HMM - Hidden Markov Models
EM - Expectation Maximization
PCA - Principal Components Analysis
GDA - Gaussian Discriminative Analysis
FAQ - Frequently Asked Questions
IMDb - Internet Movie Database
TAD - Tipo Abstrato de DadosCE - Computação EvolucionáriaPE - Programação EvolucionáriaEE - Estratégia EvolutivaPG - Programação GenéticaSC - Sistemas ClassificadoresAE - Algoritmo EvolucionárioVM - Máquina Virtual

Sumário
Lista de Abreviaturas e Siglas 9
Lista de Figuras 14
Lista de Tabelas 16
1 Introdução 181.1 Justificativa 191.2 Objetivos 211.3 Trabalhos Correlatos 21
1.3.1 Utilizando algoritmo genético para modelos híbridos de filtragem colaborativa
em recomendações on-line 231.4 Organização da Dissertação 24
2 Fundamentos Teóricos 252.1 Sistemas de Recomendação 25
2.1.1 Taxonomia de Sistemas de Recomendação 25Qualidade das predições 28
2.1.2 Personalização através de Sistemas de Recomendação 312.1.3 Usuário e o seu perfil 32
Identidade do Usuário 32Coleta de Informações 34Privacidade em Sistemas de Recomendação 35
2.1.4 Estratégias de Recomendação 38Reputação do Produto 38Recomendação por Associação 39Associação por Conteúdo 40Análise de Sequências de Ações 41
2.1.5 Técnicas de Recomendação 41Filtragem Baseada em Conteúdo 41Filtragem Colaborativa 44Filtragem Híbrida 47Filtragem Baseada em Aspectos Demográficos 49Filtragem Baseada em Conhecimento 49Filtragem Baseada em Utilidade 50Filtragem Baseada em Aspectos Psicológicos 51
2.2 Algoritmos Genéticos 522.2.1 Definição 522.2.2 AG Canônico 54

3 Invenire: Algoritmo evolucionário para combinar resultados das técnicas desistemas de recomendação 583.1 Modelagem matemática do problema 593.2 Arquitetura do Invenire 593.3 Análise de complexidade 613.4 Avaliação do Sistema de Recomendação 613.5 O AG proposto 62
3.5.1 Representação Cromossômica 623.5.2 Fluxo do AG 63
4 Experimentos e Resultados 664.1 Experimento I - Calibração do AG 664.2 Experimento II - AG vs Técnicas de FC isoladas 674.3 Experimento III - Análise do comportamento das 5 técnicas de FC quando
varia-se a quantidade de avaliações do usuário-alvo 704.4 Experimento IV - AG versus técnicas isoladas de FC em um cenário com poucas
avaliações do usuário-alvo 714.5 Experimento V - O modelo aprendido em uma matriz M aplicado em outras matrizes 724.6 Experimento VI - O efeito da variação de kt nas técnicas de FC e no GAM 744.7 Experimento VII - Os modelos especialista e generalista em cenários de
mudança de quantidade de avaliações 76
5 Considerações Finais 825.1 Conclusão 825.2 Contribuições 835.3 Trabalhos Futuros 83
Referências Bibliográficas 85
A Frameworks para Sistemas de Recomendação 100A.1 C/Matlab Toolkit para filtragem colaborativa 100A.2 Suggest 101A.3 COFI 102A.4 Trove 102A.5 PHPSQL 103A.6 Apache Mahout 104
B Apache Mahout 105B.1 A arquitetura do Mahout 105
B.1.1 Exemplo prático - recomendação baseada em usuário 107B.1.2 Exemplo prático - Recomendação Baseada em Item 108B.1.3 Algoritmos para determinação de vizinhos 109
B.2 Representação dos dados no recomendador 111B.2.1 Como um conjunto de avaliações são armazenadas internamente no Mahout? 113
B.3 Algoritmos disponíveis no Mahout 114B.3.1 Classificação 114B.3.2 Agrupamento 115B.3.3 Mineração 115

B.3.4 Regressão 115B.3.5 Redução (Dimensão) 115B.3.6 Algoritmos Evolucionários 116B.3.7 Recomendador baseado em filtragem colaborativa 116B.3.8 Vetor de similaridade 116B.3.9 Outros 116
C Avaliação do Framework Apache Mahout 117C.1 Metodologia 118
C.1.1 Conjunto de dados 118C.1.2 Determinando o Problema 119C.1.3 Estudo de caso 119C.1.4 Algoritmo de recomendação 120
C.2 Resultados 120
D Computação Evolucionária 122D.1 Introdução 122D.2 Algoritmos Evolucionários - AEs 124D.3 Algoritmo Genético - AG 125
D.3.1 História 125D.3.2 AG Canônico 127D.3.3 Representação cromossômica 128
Representação Binária 130Representação Gray 130Representação Real 131
D.3.4 População inicial 132D.3.5 Tamanho da população 133D.3.6 Função de avaliação - fitness 134D.3.7 Seleção 136
Seleção por Roleta 137Seleção por Torneio 137Seleção por Elitismo 138
D.3.8 Operadoradores genético 138Crossover 139Mutação 140
D.3.9 Variantes de AG 140Método de reposição de cromossomo 140Algoritmos genéticos “Sujo” - mAG 141Evolução Interativa - EI 142Algoritmos genéticos “Ilha” 142
D.4 Estratégia Evolutiva - EE 143D.5 Programação Evolucionária - PE 144D.6 Programação Genética - PG 146D.7 Diferenças entre AG, EE e PE 148D.8 Conclusão 150

Lista de Figuras
2.1 Taxonomia dos sistemas de recomendação proposto porRoberto Torres [TORRES 2004], baseado no modelo de Schafer[Schafer, Konstan e Riedl 2001]. 26
2.2 Modelos tradicionais de recomendação e seus relacionamentos[Bobadilla et al. 2013]. 28
2.3 Determinantes para a Reputação do Usuário 342.4 Exemplo de recomendação do website da Amazon.com 362.5 Exemplo de Coleta de Dados para melhoria das recomendações do
website da Submarino (www.submarino.com.br ) 362.6 Política de privacidade do website da Amazon.com. 372.7 Selos de Privacidade. 372.8 Avaliação de um ar-condicionado no site do Carrefour
(www.carrefour.com.br ). 392.9 Recomendação por Associação no site da Amazon (www.amazon.com). 392.10 Recomendação por Associação no site da Submarino. 402.11 Cálculo de similaridade item-a-item 432.12 Filtragem Híbrida 482.13 Função hipotética com um máximo local e outro global. 532.14 Diagrama de fluxo de um Algoritmo Genético 56
3.1 Fluxo geral do Invenire. 603.2 A estrutura de um cromossomo usado pelo AG. 623.3 Cálculo do RMSE para cada técnica e para o cromossomo que
corresponde a uma solução candidata. 63
4.1 RMSE das técnicas de FC em relação ao tamanho da lista final L 694.2 RMSE de técnicas de FC individualizadas e do AG 694.3 Resultados das técnicas de cálculo de similaridade em FC variando o
número de retiradas 704.4 Cálculo do RMSE para cada técnica e para o cromossomo que
corresponde a uma solução candidata. 774.5 Desempenho em RMSE dos AGs e das técnicas de FC. 80
B.1 Apache Mahout e os projetos que o deram origem. (Apache SoftwareFoundation) 105
B.2 Ciclo de execução que resume o processo de Recomendação no Mahout 106B.3 Relação entre os vários componentes do Mahout em um Recomendador
baseado no usuário. 107

B.4 Uma ilustração da definição de um bairro de usuários mais semelhantesao escolher um número fixo de vizinhos mais próximos. 111
B.5 Definição de um bairro de maioria dos usuários semelhantes com umlimiar de similaridade 111
B.6 Uma representação menos eficiente de preferências utilizando uma matrizde objetos preferenciais. As áreas em cinza representam, a grossomodo, a sobrecarga de Objeto. As áreas brancas são dados, incluindoreferências a objetos. 114
B.7 Uma representação mais eficiente usando GenericUserPreferenceArray. 114
D.1 Representação de um indivíduo - Codificação binária. 130D.2 Distância Hamming para representação Binária e Gray. 131D.3 Exemplo do método de Seleção da Roleta 137D.4 comportamento típico de algoritmos evolutivos envolvendo seleção e
cruzamento (crossover ) 147D.5 Programação funcional LISP 148

Lista de Tabelas
2.1 Matriz de avaliações de usuários à itens 452.2 Técnicas de cálculo de similaridade 46
3.1 Exemplo de cromossomos (cada linha corresponde a um cromossomodistinto) 63
4.1 Configuração de valores de variáveis para execução do AG 674.2 Itens recomendados pelas técnicas de FC 684.3 Representação cromossômica dos três melhores indivíduos encontrados
pelo AG 714.4 Resultado do AG (GAM) aprendido na matriz M aplicado nas matrizes M1
e M2 734.5 Resultado do GAM e das técnicas de FC nas matrizes M1 e M2 variando kt 754.6 Resultado do AG aprendido em uma matriz aplicado em matrizes futuras
versus técnicas de FC 78
C.1 Cálculo da previsão 121
D.1 Principais tipos de representação 129D.2 Representação Binária e Gray. 131

Lista de Códigos
B.1 Na linha 16 através da classe UserNeighborhood é demonstrado aimplementação da definição de um conjunto de vizinhos agrupados doisà dois. 109
B.2 Classe exemplo de como inserir e recuperar objetos na matriz deRecomendação utilizando a classe GenericPreference 112
D.1 Método para inicializar Elementos - AG 132

CAPÍTULO 1Introdução
Para diminuir as dúvidas e necessidades que temos frente à escolha entrealternativas, geralmente confiamos nas recomendações que são passadas por outraspessoas, as quais podem chegar de forma direta (“word of mouth”) ou através de textos derecomendação, opiniões de revisores de filmes e livros, impressos de jornais, dentre outros[Shardanand e Maes 1995]. Os Sistemas de Recomendação (SR) auxiliam no aumentoda capacidade e eficácia deste processo de indicação, já bastante conhecido na relaçãosocial entre seres humanos [Resnick e Varian 1997]. Um dos grandes desafios deste tipode sistema é realizar a combinação adequada entre as expectativas dos usuários e osprodutos e serviços a serem recomendados aos mesmos, ou seja, definir e descobrir esterelacionamento de interesses é um grande problema [Cazella, Nunes e Reategui 2010,Cacheda et al. 2011].
Assim, esses sistemas têm por objetivo reduzir a sobrecarga de informação,através da seleção de conteúdo a ser apresentado ao usuário que esteja interagindocom o sistema. Além disso, SR se apoiam em experiência de compra (bem ou malsucedida) dos usuários para sugerir (recomendar) produtos a outros usuários que estãode alguma forma relacionados. Goldberg et al. [Goldberg et al. 1992] criaram o primeirosistema de recomendação (denominado Tapestry) e introduziram o conceito de “filtragemcolaborativa”, visando criar um tipo específico de recomendação no qual a informação erafiltrada levando-se em consideração a relação entre o usuário-alvo (usuário que receberáas recomendações) e outros usuários mais parecidos com este.
Assume-se que sistemas de Filtragem Colaborativa (FC) e sistemas deFiltragem Baseada em Conteúdo (FBC) são tipos de sistemas de recomendaçãoque aplicam abordagens distintas, mas possuem como finalidade única arecomendação [Cazella, Nunes e Reategui 2010]. Diante destas definições Adomavicius[Adomavicius e Tuzhilin 2005] classifica os sistemas de recomendação em três grandescategorias no que tange à abordagem utilizada para se gerar as recomendações:
1. Abordagem baseada em conteúdo, nos quais são recomendados itens similares comaqueles que o usuário mostrou preferência no passado;

1.1 Justificativa 19
2. Abordagem colaborativa, na qual são recomendados itens escolhidos por pessoascom preferências similares às do usuário e;
3. Abordagens híbridas, que de alguma forma combinam técnicas na tentativa desolucionar alguns problemas potenciais das abordagens anteriores.
1.1 Justificativa
Sistemas de recomendação tornou-se uma importante área de pesquisa desdemeados da década de 1990, quando surgiram os primeiros artigos sobre FC. Houve muitotrabalho desenvolvido na indústria e na academia no que diz respeito ao desenvolvimentode novas abordagens para sistemas de recomendação ao longo da última década. Noentanto, apesar de todos esses avanços, a atual geração de sistemas de recomendaçãoainda requer melhorias. Tais melhorias poderiam tornar os métodos de recomendaçãomais eficazes e aplicáveis a uma gama ainda maior de aplicações na vida real. Podemoscitar como aplicação da vida real, a recomendação de férias, a recomendação de certostipos de serviços financeiros para os investidores, e os produtos para comprar em uma lojaque fosse feito por um “inteligente” carrinho de compras.
Dentre as abordagens dos sistemas de recomendação, a FC é uma das maisutilizadas. A ideia básica por trás deste método é que ele reúne as opiniões de outrosusuários que compartilham interesses semelhantes com um usuário de destino (referidoneste trabalho como o “usuário-alvo”) e auxilia este a identificar itens de interessecom base em pareceres de seus semelhantes [Hu e Pu 2010]. Ou seja, esta abordagemconsiste em identificar similaridade entre um usuário alvo e outros usuários com basena semelhança das avaliações passadas sobre itens em comum. Com isso, usa-se estasimilaridade para gerar recomendações sobre itens ou conteúdos ainda não consumidospelo usuário alvo [Herlocker et al. 1999, Linden 2008].
Os primeiros sistemas de FC requeriam de maneira explícita, que os usuáriosindicassem os itens de seu interesse. O próximo passo da evolução destes sistemasfoi o armazenamento das avaliações dos itens feitas pelos usuários em forma decoleções1. De posse destas coleções é possível criar uma base de conhecimento o quepossibilita a criação de grupos de pessoas (comunidade) com “gostos” e/ou “experiências”semelhantes, o que permite o beneficiamento de outros usuários na comunidade.
Sistemas de FC simples apresentam para o usuário uma média de pontuaçõespara cada item com potencial de interesse. Esta pontuação permite ao usuário descobriritens que são considerados de interesse pelo grupo e evitar os itens que são considerados
1As coleções aqui são tratadas como um conjunto de produtos e/ou serviços que o usuário em questãoavaliou, geralmente informando uma nota que pode variar por exemplo entre 0 a 5.

1.1 Justificativa 20
de pouco interesse. Sistemas mais avançados descobrem de maneira automática relaçõesentre usuários (vizinhos mais próximos), baseado na descoberta de padrões comuns decomportamento [Reategui e Cazella 2005].
Desta forma, a abordagem de FC foi se tornando popular nos campos daacademia e da indústria com grande velocidade. Empresas como Google, Amazon e Netflix
fazem uso intenso dessas técnicas computacionais com as quais obtêm grande vantagemcompetitiva. Até os dias atuais, o desenvolvimento de algoritmos de FC se concentraramprincipalmente sobre como fornecer recomendações precisas [Goldberg et al. 1992]. Estaabordagem segue basicamente quatro passos [TORRES 2004, Reategui e Cazella 2005]:
1. Calcular a similaridade de cada usuário em relação ao usuário alvo (métrica desimilaridade).
2. Selecionar um subconjunto de usuários com maiores similaridades (vizinhos) paraconsiderar na predição.
3. Normalizar as avaliações e computar as predições ponderando as avaliações dosvizinhos com seus pesos. O peso nesse caso é o valor da similaridade entre o vizinhoe o usuário alvo.
4. Ordenar de forma decrescente os valores das notas preditas e apresentar os n
melhores itens.
Contudo, a FC pode ser dividida em dois tipos de algoritmos, os que sãobaseado em memória (memory-based) e os que são baseado em modelo (model-based)[Bobadilla et al. 2013]. Eles se diferem na forma em como processam a matriz deavaliações (Usuario X Item). A FC baseado em memória usa toda a tabela paracalcular a sua previsão. Geralmente, fazem o uso de medidas de similaridade paraselecionar usuários (ou itens) que são semelhantes para o usuário alvo. Em seguida,a previsão é calculada a partir das classificações desses vizinhos. Esses algoritmospodem ser subdivididos em algoritmos baseados em usuário (user-based), onde ofoco da obtenção de vizinhos está no usuário [Shardanand e Maes 1995] ou algoritmosbaseados em itens (item-based), onde o foco de obtenção de vizinhos está no item[Sarwar et al. 2000]. Já os algoritmos de FC baseado em modelo, primeiro constremum modelo que representa a matriz de avaliações (off-line), ou seja, que represente ocomportamento dos usuários, e por conseguinte, preveem (on-line) as suas avaliações[Cacheda et al. 2011, Resnick et al. 1994, Shardanand e Maes 1995].
Na literatura são apresentadas várias técnicas (Euclidiana, Tanimoto, Correlaçãode Pearson, etc) para o cálculo da similaridade entre usuários como alternativas demedidas de similaridades a serem utilizadas na abordagem de memory-based. Isso ébom pois privilegia a diversidade de opções, por outro lado, isto pode causar dúvida emqual técnica escolher para recomendar n itens. Cada uma dessas abordagens possuem

1.2 Objetivos 21
particularidades e dependem do contexto a ser aplicado, por isso, cada caso deve ser bemanalisado antes da escolha de qual técnica adotar.
Não foram encontrados trabalhos que combinam os resultados das técnicasde recomendação, a fim de produzir uma classificação final de n itens compostos dosmelhores itens sugeridos por cada técnica isoladamente. Além disso, sabemos quenenhuma técnica seria a melhor para todos os contextos. Por isso, levanta-se a hipótesede que a combinação dos rankings de recomendações, resultantes das técnicas dememory-based, teriam um melhor resultado do que uma delas isoladamente.
1.2 Objetivos
Como o ato de se descobrir uma boa combinação manualmente é uma tarefadifícil, deseja-se que a combinação seja automatizada. Para tanto, é proposto umAlgoritmo Genético (AG)[Holland 1975, Goldberg e Holland 1988] que seja capaz deautomatizar a combinação de resultados das diversas técnicas de memory-based. OAG foi escolhido por se tratar de uma técnica amplamente utilizada, modular, de fácilimplementação e eficaz em realizar busca global em problemas complexos.
Nesta abordagem, o AG (INVENIRE) deve ser capaz de gerar uma lista (L) de n
itens a serem recomendados. Estes itens são escolhidos a partir dos ranking das técnicasde Sistema de Recomendação utilizadas na combinação. Por isso, a lista formada pelo AGdepende do desempenho de cada técnica. As técnicas que obtiverem menor erro (RMSE)terão mais itens entre os n finais. Um exemplo de composição desta lista, para o caso de‖L‖ = 10, seria: 3 itens vindos do ranking da técnica A, 3 itens vindos do ranking datécnica B e 4 itens oriundos do ranking da técnica C, totalizando 10 itens na lista finalproposta pelo AG.
Além disso, criou-se um cenário para testar o desempenho da proposta em umcontexto multi-objetivo, ou seja, o AG além de buscar uma solução com baixo erro(RMSE), tenta maximizar a retirada de avaliações do usuário antes da recomendação. Estecenário tem o objetivo de identificar um balanço entre o erro na previsão e a quantidademínima de avaliações do usuário-alvo. Para que isso seja possível, criamos duas variáveisw1 e w2, onde w1 se dá ao objetivo de minimizar o erro da recomendação e w2 é o pesoque se dá ao objetivo de reduzir avaliações do usuário-alvo. O objetivo destas variáveis éentão criar a possibilidade de simular diversos cenários de banco de dados.
Dessa forma, o objetivo deste trabalho é desenvolver um sistema computacionalcapaz de:
1. Aprender a melhor combinação (L) de resultados de técnicas de Sistemas deRecomendação a partir de uma matriz de avaliações;

1.3 Trabalhos Correlatos 22
2. Identificar um balanço entre o erro na previsão e a quantidade mínima de avaliaçõesdo usuário-alvo.
1.3 Trabalhos Correlatos
O ato de se recomendar pode ser feito de diversas maneiras, como descritona seção 2.1. Uma das abordagem mais utilizada é a Filtragem Colaborativa (FC), queconsiste em efetuar o casamento entre o perfil do usuário identificado e as característicasdos itens disponíveis.
O primeiro sistema criado utilizando a abordagem FC foi o Tapestry
[Goldberg et al. 1992, Resnick e Varian 1997], que era um sistema com recursoscompletos de filtragem de documentos eletrônicos. Neste sistema um usuário poderiacriar regras de filtragem de e-mail como “Mostre-me todos os documentos que sãorespondidos por outros membros do meu grupo de pesquisa”. Este sistema exigia que ousuário, para determinar as relações relevantes preditivas, ficasse com uma grande cargacognitiva, como resultado, esses sistemas só foram valiosos em pequenas comunidadesfechadas onde todo mundo estava ciente de interesses e deveres de outros usuários.
Dellarocas em [Dellarocas 2000] prevê a utilização de técnicas de FCcombinadas com mecanismos básicos (domínio de valor) e avançados (domínio defrequência), para geração de estimativas de reputação personalizadas, e para melhorproteger o sistema contra manipulação de entidades mal intencionadas. Herlocker et al.em [Herlocker 2000] propõe ajustes na técnica de FC com a aplicação de um peso sobreo coeficiente de similaridade conferido a cada avaliação, com base na quantidade de itensem comum avaliados anteriormente com o usuário alvo.
Existem trabalhos que propõem métodos para calcular de forma mais precisaa similaridade entre usuários, como em [Lopes 2006], outros trabalhos comparammétodos tradicionais de FC e propostas de esquemas híbridos [Fong, Ho e Hang 2008,Cacheda et al. 2011].
No trabalho de Rong e Pu [Hu e Pu 2010], é proposto um método que combinacaracterísticas da personalidade humana com a técnica de FC baseado em usuário(user-based). Os resultados do autor mostram que a aplicação de informações depersonalidade em sistemas de filtragem colaborativa tradicionais baseado em usuário poderesponder de forma eficaz para o problema de “novo usuário”.
Em seu trabalho Liu [Liu, Dolan e Pedersen 2010] apresenta sua pesquisa sobreo desenvolvimento de sistema de recomendação de notícias personalizadas no site doGoogle News. Para os usuários que estão conectados e Em que o histórico estejaexplicitamente habilitado, o sistema de recomendação constrói perfis de interesse de

1.3 Trabalhos Correlatos 23
notícias com base no comportamento do usuário. O comportamento do usuário éconstruído pelo sistema on-line, capturando-se os seus cliques em notícias do site.
No trabalho de [Qingshui e Meiyu 2010], é apresentado um modelo híbrido paramelhorar os algoritmos de FC. O autor combina técnicas de Filtragem Baseada emConteúdo com as Colaborativas. De maneira geral, é utilizada a técnica de filtragembaseada em conteúdo nos itens consumidos por usuários de um e-commerce, e a partirdisso montado um vetor com características comuns desses produtos relacionados àusuários que os consumiram, chamado no artigo de Vetor de Interesse. Após issoé aplicado à técnica de Filtragem Colaborativa para determinar os usuários maissemelhantes (vizinhos), calcular a predição e gerar as recomendações.
Com o argumento de que o uso de sistemas de recomendação tornou-seconsolidado na web, Bobadilla et al. [Bobadilla et al. 2011] criou um tipo de estrutura(framework) que possibilita a avaliação das medidas de FC. De acordo com o autor, oframework é capaz de testar os resultados de previsão das recomendações e ainda provêmecanismos para medir o grau de novidade e de confiança. Os autores ressaltam quemedir a qualidade dos resultados de confiança nas recomendações é complicado, poisadentra em campo subjetivo, onde cada usuário pode dar mais ou menos importância avários aspectos e por conta disso não foram avaliadas em profundidade.
Em seu outro trabalho Bobadilla et al. [Bobadilla et al. 2012] apresentam aponderação das classificações dos itens de acordo com a sua importância, como umnovo método para melhorar as informações usadas em processos de FC. Os autoresformalizam o processo de Filtragem Colaborativa baseada no conceito de significância.Desta forma, os k-vizinhos (k-neighbors) são calculados levando em conta as avaliaçõesdos itens, a importância dos itens e a significância dada por cada usuário, para assim, gerarrecomendações a outros usuários. Os autores estendem os conceitos relacionados com amedida de similaridade, assim como as medidas de qualidade da previsão. Os resultadosapresentados confirmam a vantagem de introduzir o conceito de significância em sistemasde recomendação em geral e especialmente em sistemas de recomendação em que é fácildeterminar a importância relativa dos itens, como por exemplo, em e-commerce, sistemasde TV e entretenimento.
Outros trabalhos, como o de Lampropoulos, Sotiropoulos e Tsihrintzis[Lampropoulos, Sotiropoulos e Tsihrintzis 2012], propõe uma recomendação em cascatahíbrida como uma combinação de classificação One-Class e FC. O artigo decompõe oproblema da recomendação em um esquema de recomendação em cascata de dois níveisonde o objetivo é obter benefícios das metodologias de FC e da abordagem baseada emconteúdo. O primeiro nível faz o uso da abordagem baseada em conteúdo aplicando-seo paradigma de classificação One-Class a fim de incorporar as preferências do usuáriode maneira individualizada (subjetiva) dentro do processo de recomendação. O segundo

1.3 Trabalhos Correlatos 24
nível tem a finalidade de atribuir graus específicos aos itens para classifica-los. Já Ahere Lobo [Aher e Lobo 2013] combinam técnicas de mineração de dados (clustering ealgoritmo de regras de associação) para gerar recomendações de cursos a alunos emplataforma de aprendizado (Moodle).
A próxima subseção 1.3.1 apresenta um experimento que julgamos interessantepara a proposta que apresentaremos no capitulo 3
1.3.1 Utilizando algoritmo genético para modelos híbridos defiltragem colaborativa em recomendações on-line
Os autores Fong, Ho e Hang apresentam em seu trabalho [Fong, Ho e Hang 2008],um algoritmo genético que tem o objetivo de combinar variáveis de entrada, para codificaro cromossomo. As variáveis de entrada utilizada no AG são uma combinação entreatributos demográficos, preferências pessoais sobre filmes e características e gênerosdo filme, como por exemplo: idade, sexo, ocupação como atributos demográficos;preferência sobre tipo de filme e idioma como preferências pessoais acerca de filmes;e estilo do filme (ação, comédia, drama, etc), diretor e língua como características egêneros do filme.
No primeiro experimento foram calculados os pesos para cada variável deentrada. E após isso, foram solicitados a 10 usuários que informassem qual a importânciadestas característica para eles. Com isso foi observado que características comoclassificação, idade, sexo, ocupação, preferência por tipo de filme, preferência pordiretor, preferência por atriz, preferência por ator, preferência por produtor, preferênciapor escritor, preferência por editor são mais relevantes que as demais características.Após isso foram feitos experimentos usando diferentes conjuntos de variáveis de entrada,para mostrar como e o que afeta a função de aptidão e o desempenho do AG.
Os autores comparam o seu AG com método tradicional de filtragem colaborativautilizando “Coeficiente de Pearson”. Foi observado que a precisão do AG é muito maiordo que a de Pearson (cerca de 18,21% melhor) em relação a previsão de avaliaçãodo usuário. Outro fator a ser observado é que existe uma melhora nos resultados depredição, quando é feita a incorporação de características de perfil do usuário que sãomais significativas para ele.
O trabalho de Fong, Ho e Hang difere da proposta apresentada na Seção3, por combinar características do usuário e do filme para melhorar a acurácia dasrecomendações. Dessa forma os autores fizeram o uso da técnica de Euclidean em seuAG baseado em FC, porém poderiam utilizar outras técnicas como as descritas na Seção2.1.5. Assim, o AG proposto na Seção 3 pode contribuir com o trabalho de Fong, Ho

1.4 Organização da Dissertação 25
e Hang sugerindo qual técnica (ou quais) de FC a ser (em) utilizada (s) para gerar asrecomendações.
1.4 Organização da Dissertação
O restante deste trabalho está dividido em capítulos, sendo o capítulo 2 sobreFundamentos Teóricos, onde são apresentados os Sistemas de Recomendação e osAlgoritmos Genéticos; o capítulo 3 sobre o projeto Invenire − algoritmo evolucionáriopara combinar resultados das técnicas de sistemas de recomendação; o capítulo 4 sobreos experimentos realizados e os resultados alcançados; e, por fim, o capítulo 5 apresentaa conclusão e trabalhos futuros.

CAPÍTULO 2Fundamentos Teóricos
O objetivo desta seção é dar fundamentação teórica a dissertação, desta formaforam estudados sobre Sistemas de Recomendação e Algoritmos Genéticos. O resultadodeste estudo são apresentadas nas Seções 2.1 e 2.2, respectivamente.
2.1 Sistemas de Recomendação
Sistemas de Recomendação se tornou uma importante área de pesquisa desde osurgimento dos primeiros artigos sobre Filtragem Colaborativa em meados da década de1990. Houve muito trabalho desenvolvido na indústria e na academia no que diz respeitoao desenvolvimento de novas abordagens para sistemas de recomendação ao longo daúltima década. O interesse por esta área ainda permanece elevado porque constitui umrico problema na área de pesquisa e por causa da abundância de aplicações práticas queajudam os usuários a lidar com a sobrecarga de informações e fornecer recomendaçõespersonalizadas, conteúdo e serviços para eles. Exemplos dessas aplicações incluem arecomendação de livros, CDs e outros produtos na Amazon.com1 e de filmes pelaMovieLens2. Além disso, alguns fornecedores de tecnologia incorporaram capacidadesde recomendações em seus servidores de comércio eletrônicos.
2.1.1 Taxonomia de Sistemas de Recomendação
Ao longo dos anos os Sistemas de Recomendação foram classificadosde diversas maneiras por diversos autores, entretanto não há uma classificaçãocompletamente aceita pela comunidade de usuários, profissionais e pesquisadores.Schafer [Schafer, Konstan e Riedl 2001] modelou a arquitetura de um sistema de
1Empresa pioneira no comércio eletrônico e grande desenvolvedor e utilizadora de Sistemas deRecomendação. Seu site pode ser acessado em http://www.amazon.com
2MovieLens é um sistema de recomendação e site da comunidade virtual que recomenda filmes para seususuários assistirem, com base em suas preferências de filmes e usando filtragem colaborativa. O site é umprojeto da GroupLens Research, um laboratório de pesquisa no Departamento de Ciência da Computação eEngenharia da Universidade de Minnesota, que criou MovieLens em 1997

2.1 Sistemas de Recomendação 27
recomendação e produziu uma taxonomia bastante abrangente que considera diversascaracterísticas de um sistema de recomendação.
A arquitetura da taxonomia proposta por Schafer[Schafer, Konstan e Riedl 2001]pode ser observada na Figura 2.1 e envolve 3 módulos distintos, cada um deles pode sermodelado e implementado de maneiras diferentes. Essa divisão em blocos facilita oentendimento desses sistemas. Os blocos são separados da seguinte maneira:
• Usuário-Alvo: Módulo responsável por coletar informações acerca do usuário alvo.• Comunidade: Informações de interações do usuário-alvo e de outros usuários com
o sistema. Essas interações ocorrerem no momento em que o usuário avalia umproduto por exemplo.• Saída: Representa a resposta do sistema como uma sugestão de produto ou serviço.
Figura 2.1: Taxonomia dos sistemas de recomendação propostopor Roberto Torres [TORRES 2004], baseado nomodelo de Schafer [Schafer, Konstan e Riedl 2001].
Ainda de acordo com Schafer [Schafer, Konstan e Riedl 2001], as aplicaçõesque visam gerar “recomendações” a usuários em sistemas de e-commerce combinaminformações sobre o usuário-alvo com as comunidades em que os produtos e o usuárioestão inseridas. Dessa forma sites usam as decisões sobre o nível de personalizaçãoe o método de entrega para transformá-las em pacotes de recomendação específica,

2.1 Sistemas de Recomendação 28
garantindo assim a personalização nas recomendações. Comentários e avaliações dousuário acerca da recomendação recebida ou até mesmo de um produto específico podegerar entradas adicionais para futuras recomendações.
De acordo com Bobadilla et al. [Bobadilla et al. 2013], a taxonomiaamplamente aceita divide os métodos de recomendação em duas categorias:método baseado em modelo e baseado em memória. Os métodos baseadosem Memória [Adomavicius e Tuzhilin 2005, Candillier, Meyer e Boullé 2007,Symeonidis, Nanopoulos e Manolopoulos 2009] podem ser definidos como os métodosque (a) atuam apenas na matriz de avaliações dos utilizadores e (b) faz o uso de qualqueravaliação gerada antes do processo de referência (ou seja, os seus resultados são sempreatualizados). Métodos baseados em memória geralmente usam as métricas de similaridadedescritas na Tabela 2.2 da Seção 2.1.5 para obter a distância entre dois usuários, oudois itens, com base em sua matriz de avaliações. Os métodos baseados em modelo[Adomavicius e Tuzhilin 2005, Su e Khoshgoftaar 2009] usam a matriz de avaliaçãopara aprender um modelo, que é então usado para fazer previsões de avaliações. Entre osmodelos mais utilizados temos classificadores bayesianos [Park, Hong e Cho 2007], redesneurais[Roh, Oh e Han 2003], sistemas nebulosos [Yager 2003], algoritmos genéticos[Ho, Fong e Yan 2007], características latentes [Hofmann 2004, Zhong e Li 2010] e damatriz de fatoração [Luo, Xia e Zhu 2012], dentre outros.
O gráfico da Figura 2.2 de Bobadilla et al. mostra os métodos tradicionais derecomendação, as técnicas e algoritmos para o processo de recomendação, bem como assuas relações e agrupamentos. Podemos observar pela Figura 2.2 que:
• É utilizado banco de dados como modelo para alguns dos métodos tradicionais defiltragem (baseada em conteúdo, demográfica e de filtragem colaborativa);• As abordagens baseadas em modelo (model-based), tais como algoritmos
genéticos, redes neurais, dentre outras, fazem o uso destes modelos;• Assim como as baseadas em modelo, as abordagens baseadas em memória
(memory-based), tais como Item-a-item, Usuário-a-usuário e as híbridas, utilizamas mesmas informações como entrada.
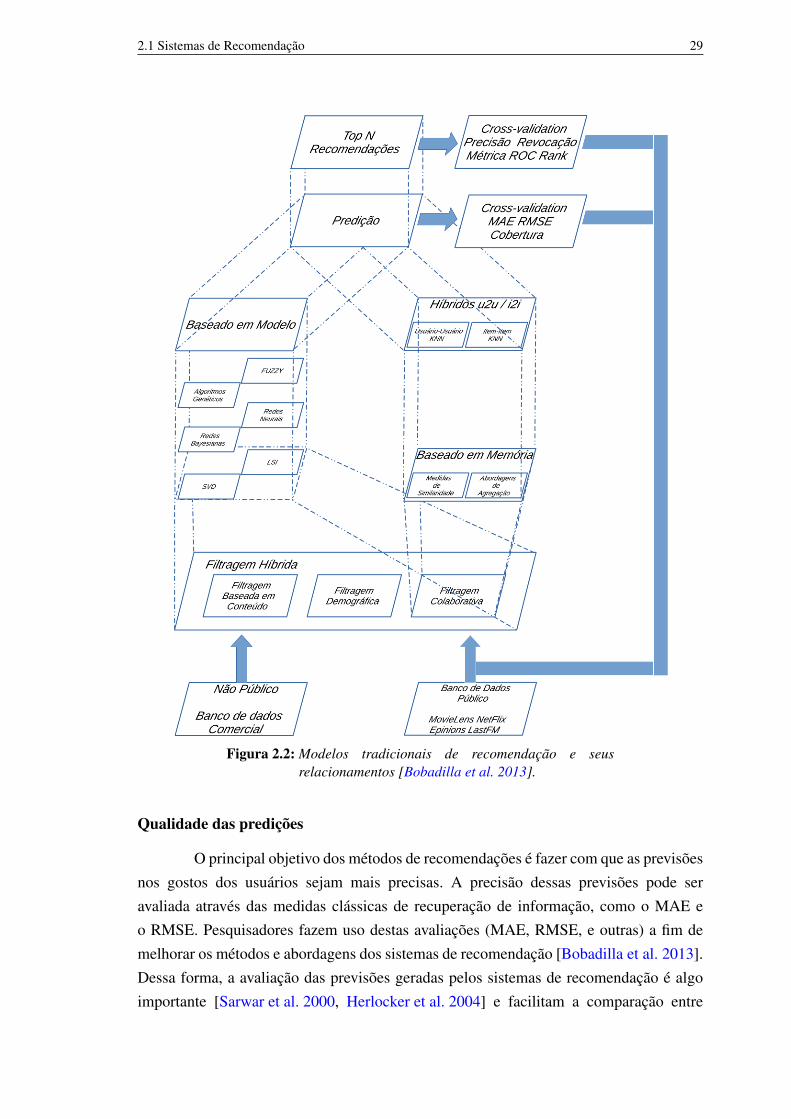
2.1 Sistemas de Recomendação 29
Figura 2.2: Modelos tradicionais de recomendação e seusrelacionamentos [Bobadilla et al. 2013].
Qualidade das predições
O principal objetivo dos métodos de recomendações é fazer com que as previsõesnos gostos dos usuários sejam mais precisas. A precisão dessas previsões pode seravaliada através das medidas clássicas de recuperação de informação, como o MAE eo RMSE. Pesquisadores fazem uso destas avaliações (MAE, RMSE, e outras) a fim demelhorar os métodos e abordagens dos sistemas de recomendação [Bobadilla et al. 2013].Dessa forma, a avaliação das previsões geradas pelos sistemas de recomendação é algoimportante [Sarwar et al. 2000, Herlocker et al. 2004] e facilitam a comparação entre

2.1 Sistemas de Recomendação 30
várias soluções para o mesmo problema.Os autores [Cacheda et al. 2011] destacam que existe uma preocupação
constante em se medir a qualidade das recomendações, e dessa forma os SRsforam gradualmente testados e melhorados. Os autores [Olmo e Gaudioso 2008,Gunawardana e Shani 2009] indicam que as medidas de qualidade mais utilizadasem SRs são: (i) avaliação de previsão, (ii) avaliação de conjuntos de recomendações,(iii) avaliação de recomendações como lista de classificação (ranking), e (iv)diversidade e novidade. Já as métricas de avaliação podem ser classificadas como[Antunes et al. 2008, Herlocker et al. 2004, Gunawardana e Shani 2009]:
• métricas de previsão: MAE (Mean Absolute Error), RMSE (Root of Mean Square
Error) e o NMAE (Normalized Mean Average Error)• métricas de conjunto: Precisão (Precision), Revocação (Recall) e o ROC (Receiver
Operating Characteristic)[Schein et al. 2002].• métricas de lista de classificação (ranking): meia-vida (half-life)
[Breese, Heckerman e Kadie 1998] e o “desconto de ganho acumulado”[Baltrunas, Makcinskas e Ricci 2010].• métricas de diversidade: diversidade e a novidade de itens recomendados
[Hurley e Zhang 2011].
Os autores [Herlocker et al. 2004, Olmo e Gaudioso 2008, Antunes et al. 2008,Gunawardana e Shani 2009, Cacheda et al. 2011] e Bobadilla et al.[Bobadilla et al. 2013],formalização alguns dos indicadores mais utilizados. Dessa forma, definimos U como umconjunto de usuários de um SR, I como um conjunto de itens, ru,i como sendo a avaliaçãodada pelo usuário u ao item i, ru,i = • como sendo o item i não avaliado pelo usuário u,pu,i como sendo a avaliação predita do usuário u para o item i feita pelo recomendador, epor fim, Ou = {i ∈ I|pu,i 6= •∧ ru,i 6= •} como sendo o conjunto de itens avaliados pelousuário u e que contenham predições de avaliação.
Dessa forma, a diferença absoluta entre a avaliação real dada pelo usuário e aavaliação prevista (|ru,i− pu,i|), informa o erro na previsão. As equações Eq.2.1 e Eq.2.2definem, respectivamente, o cálculo para o RMSE e para o MAE.
RMSE =1
#U ∑u∈U
√1
#Ou∑
i∈Ou
(pu,i− ru,i)2 (2.1)
MAE =1
#U ∑u∈U
(1
#Ou∑
i∈Ou
|pu,i− ru,i|) (2.2)
Assim, a cobertura é definida como a capacidade de se prever uma avaliação aser dada pelo usuário-alvo a um item, à partir de uma métrica específica aplicada a um SR[Bobadilla et al. 2013]. A cobertura calcula o percentual de situações em que pelo menos

2.1 Sistemas de Recomendação 31
um k−vizinho de cada usuário-alvo, avalie um item que ainda não foi avaliado por esseusuário-alvo. Definimos então, ku,i como um conjunto de vizinhos de u que avaliaram oitem i. Seja: Cu = {i ∈ I|ru,i = •∧ku,i 6= /0} e Du = {i ∈ I|ru,i = •}. Assim, de acordo com[Bobadilla et al. 2013], a cobertura do sistema, como a média de cobertura do usuário, édada na Eq.2.3.
cobertura =1
#U ∑u∈U
(100× #Cu
#Du) (2.3)
Ainda de acordo com Bobadila et al., a confiança dos usuários em umdeterminado SR não depende diretamente da precisão que este SR alcançou para todo oconjunto de itens recomendados, mas sim para um conjunto reduzido de recomendaçõesfeitas pelo SR. Dessa forma, a precisão (Eq.2.4) indica a proporção de itens recomendadosrelevantes do número total de itens recomendados, a revocação (Eq.2.5) indica aproporção de itens recomendados relevantes em relação ao número de itens relevante.Podemos ainda, combinar a precisão e a revocação como forma de avaliar a qualidade daspredições (Eq.2.6).
precisao =1
#U ∑u∈U
#{i ∈ Zu|ru,i ≥ 0}n
(2.4)
revocacao =1
#U ∑u∈U
#{i ∈ Zu|ru,i ≥ 0}#{i ∈ Zu|ru,i ≥ 0}+#{i ∈ Zc
u|ru,i ≥ 0}(2.5)
F1 =2× precisao× revocacao
precisao+ revocacao(2.6)
Onde, Xu é o conjunto de todas as recomendações para o u. E Zu é o conjunto de n itensrecomendados para u, assumindo que todos os usuários aceitaram as n recomendações.
Quando o número L de itens recomendados não é pequeno, os usuáriostendem a dar maior importância aos primeiros itens da lista de recomendações. Dessaforma os erros cometidos nos primeiros itens da lista são mais graves do que nosdemais. Para considerar essa situação, temos as medidas de ranking. Entre as medidasde ranking mais utilizados, podemos citar [Bobadilla et al. 2013]: (i) meia-vida (Eq.2.7)[Breese, Heckerman e Kadie 1998], o que pressupõe uma diminuição exponencial dointeresse dos usuários em relação ao primeiro item da lista e o segundo, entre o segundoe o terceiro e assim sucessivamente até atingir o ultimo item da lista; e (ii) desconto deganho acumulado (2.8)[Baltrunas, Makcinskas e Ricci 2010], onde a decadência citadaanteriormente deixa de ser exponencial e passa a ser logarítmica.
MV =1
#U ∑u∈U
N
∑i=1
max(ru,pi−d,0)2(i−1)/(α−1)
(2.7)

2.1 Sistemas de Recomendação 32
DGAk =1
#U ∑u∈U
(r−u, p1 +k
∑i=2
ru,pi
log2(i)) (2.8)
Nas equações 2.7 e 2.8, {p1, . . . , pn} representa a lista de recomendação, ru,pi
representa a avaliação verdadeira que o usuário u deu para o item i (pi), k é a avaliação doitem avaliado, d é a avaliação padrão, e α é o número do item na lista de tal forma que háuma chance de 50% que o usuário irá rever esse item.
Bobadilla et al. indica que, outra métrica importante diz respeito ao quanto denovidade o item recomendado representa ao usuário (Eq.2.10). Já a medida de qualidade(Eq.2.9) da diversidade indica o quanto um item é diferente dentre os demais itensrecomendados. Atualmente, as medidas de novidade e diversidade não possuem umpadrão; portanto, diferentes autores propõem diferentes métricas [Nehring e Puppe 2002,Vargas e Castells 2011]. Certos autores, como [Hurley e Zhang 2011] usaram o seguinte:
novidadei =1
#Zu−1 ∑j∈Zu
[1− sim(i, j)], i ∈ Zu (2.9)
diversidadeZu =1
#Zu(#Zu−1) ∑i∈Zu
∑j∈Zu, j 6=i
[1− sim(i, j)] (2.10)
Onde, sim(i, j) indica medida de similaridade item-a-item baseada em memória.
2.1.2 Personalização através de Sistemas de Recomendação
A adequação de um produto ou serviço para atender as necessidades de umindivíduo podem trazer várias vantagens. Por exemplo, através da constante seleção deconteúdos relacionados aos interesses do usuário, um sistema personalizado pode reduziro tempo em que este usuário leva para encontrar informações relevantes. O tratamentoindividualizado do usuário em sistema computacional necessita de um conjunto específicode funções. Enquanto o usuário navega no sistema, toda sua interação deve ser monitoradade alguma forma como citado em 2.1.3. A apresentação do documento pode sermodificada de modo a sugerir ao usuário os próximos passos. Em um contexto geralos sistemas de recomendação conseguem solucionar este problema com a criação de umapágina personalizada por usuário, ou seja, cada usuário possui sua “própria” home page.Nestas páginas o sistema adiciona, remove, modifica e reorganiza links com o intuitode apresentar, esconder ou enfatizar fragmentos de uma página, assegurando que seuconteúdo inclua informação apropriada para o usuário em questão.
Desta forma a probabilidade de que um usuário acesse ou adquira um item ébem maior do que em sistemas não personalizados. Do ponto de vista empresarial eadotando esta abordagem sistemática de “recomendar” itens mais interessantes para o

2.1 Sistemas de Recomendação 33
usuário, o sistema consegue “fidelizar” um cliente pois representa um “conselheiro” paraos usuários, passando a conquistar sua confiança e possibilitando o aumento de valores devendas para as empresas, através da qualidade das recomendações apresentadas.
Os Sistemas de Recomendação são grandes aliados da personalização desistemas computacionais, principalmente na plataforma web. Da literatura, a definiçãodo termo “sistema de recomendação” varia de acordo com o autor. Alguns pesquisadoresusam “filtragem colaborativa” e “Filtragem social”[Breese, Heckerman e Kadie 1998].Inversamente, outros “sistema de recomendação”, e “filtragem social” tratam“sistema de recomendação”, como um descritor genérico que representa diversasrecomendação/previsões técnicas, incluindo colaboração, social e filtragem baseada emconteúdo, redes Bayesianas e regras de associação [Terveen e Hill 2001, Delgado 2000].
2.1.3 Usuário e o seu perfil
Para que seja possível recomendar produtos, serviços ou pessoas a um usuárioé necessário ter-se conhecimento sobre quem é este usuário. Antes mesmo de pensarem capturar e armazenar suas informações pessoais e comportamentais é necessárioidentificar qual o tipo de informação será relevante para a geração da recomendaçãovisando uma eficiente personalização dos produtos, serviços e pessoas. Para a corretageração da recomendação a definição do perfil do usuário e coleta de informações éimprescindível [Cazella, Nunes e Reategui 2010].
De acordo com Cazella et al. [Cazella, Nunes e Reategui 2010] para a formaçãode perfis de usuários é necessário estar atento a 3 aspectos que serão tratados nas próximasseções.
Identidade do Usuário
Note que no mundo virtual onde não há presença física e consequentementenão há percepção de características sutis da Identidade, várias pistas que possivelmenteidentificariam dicas de preferências, comportamentos, habilidades sociais, entre outras,são ausentes, ao contrário do que ocorre no mundo real [Donath 1999]. Donath[Donath 2000] afirma que conhecer a Identidade da pessoa é vital para uma adequadapersonalização de uma ambiente no mundo virtual. Giddens [Giddens 1991] concordaque sem experiências sociais o “eu” não pode internalizar evolução. Giddens ainda afirmaque a identidade de um individuo não é estática, ela pode ser representada em constanteevolução, principalmente porque o componente social é dinâmico e esta sempre sendomodificado.
Considerando a identidade como um canal importante onde as característicasobjetivas e subjetivas das pessoas emergem, denomina-se de fundamental importância

2.1 Sistemas de Recomendação 34
seu uso em Sistemas de Recomendação no intuito de fornecer pistas sobre os futuroscomportamentos e necessidades dos usuários em um dado ambiente onde a personalizaçãose faz eficaz, por exemplo.
Donath [Donath 1999] afirma que para a formação eficiente de uma IdentidadeVirtual é crucial que o usuário tenha definida sua Identidade Interna e sua IdentidadeSocial. No mundo virtual a Identidade Interna do usuário é definida por ele próprio similarao mundo real (algumas vezes também é descoberta através de técnicas de Aprendizadode Máquina3). Enquanto a Identidade Social é definida pelos outros membros do mundovirtual. Tanto a Identidade Interna, como a Identidade Social são armazenadas no Perfildo Usuário.
Já os perfis de usuários[Nunes, Cerri e Blanc 2008] são conceitos aproximados,eles refletem o interesse do usuário com relação a vários assuntos em um momentoparticular. Cada termo que um Perfil de Usuário expressa é, num certo grau, característicasde um usuário particular [Poo, Chng e Goh 2003] incluindo todas as informaçõesdiretamente solicitadas a ele e aprendidas implicitamente durante sua interação na web[Carreira et al. 2004]. Fisicamente, o Perfil do Usuário pode ser visto como uma basede dados onde a informação sobre o usuário, incluindo seus interesses e preferências, éarmazenada e pode ser dinamicamente mantido [Poo, Chng e Goh 2003].
A Reputação do usuário é uma extensão de um Perfil de Usuário. De acordocom Resnick [Resnick et al. 2000] a Reputação pode ser definida como uma coleção dosfeedbacks (comentários) recebidos sobre o comportamento efetuado pelos participantesde uma comunidade. A Reputação é caracterizada como o retorno social recebido sobrea personalidade de alguém. Josang et al. [Josang, Ismail e Boyd 2007] descreve que aReputação pode ser ou não compatível com a descrição feita no Perfil do Usuário.Segundo Resnick, a Reputação ajuda as pessoas escolherem parceiros confiáveis nomundo virtual que são confiáveis no mundo real. Geralmente nas redes de Reputação,os usuários encorajam os comportamentos confiáveis discriminando a participação depessoas desabilitadas moralmente ou desonestas
A Reputação pode ser também definida como um completo sistema deinformações sobre o Usuário, que inclui todos os aspectos de um modelo de referência.A Figura 2.3 exibe um ícone para este modelo de referência. Esse modelo de referênciaé baseado em dez aspectos determinantes: conhecimento (1), experiência (2), credenciais(3), endossos (4), contribuidores (5), conexões (6), sinais (7), comentário (8), contexto (9)e valores sociais (10) [Rein 2005].
3Aprendizado de Máquina é uma área da Inteligência Artificial cujo objetivo é o desenvolvimento detécnicas computacionais sobre o aprendizado bem como a construção de sistemas capazes de adquirirconhecimento de forma automática

2.1 Sistemas de Recomendação 35
Figura 2.3: Determinantes para a Reputação do Usuário
Em processos comerciais, como por exemplo, no eBay [Resnick et al. 2000,Resnick et al. 2006] um consumidor compra um certo produto de alguém. Depois disso,ele deixa um feedback sobre o produto comprado e, ou o comportamento do vendedordurante o processo de venda.
Em contraste, em situações sociais como, por exemplo, Orkut, IKarma,Opinity, LinkedIn, Mendeley [Jensen, Davis e Farnham 2002], usuários são membros decomunidades virtuais ou redes sociais. Eles são capazes de coletar gerenciar e promoverReputação de usuário entre seus clientes e contatos da comunidade ou rede. Isto é,usuários (prestadores de serviço) que tem profile na Rede de Reputação, que é tambémuma rede social podem ser “tagged” e rankeados pelos seus clientes e, ou contatos.Usuários podem ser encontrados através de tags em e-mail ou, também, alguém podeencontrar um contato de um prestador de serviço simplesmente procurando em tags naprópria rede de reputação.
Coleta de Informações
Hoje é bastante comum no mundo dos negócios a coleta de informações dousuário. Ao abrir uma conta bancária, adquirir um bem imobilizado ou até para fazeruma compra pela internet por exemplo, é exigido que o cliente forneça dados pessoaiscomo nome, endereço, telefone e até números de documentos. E isso se torna importantepara se ter conhecimento sobre quem é este usuário.

2.1 Sistemas de Recomendação 36
Diante deste fato é necessário identificar o usuário no momento em que eleacessa o sistema onde foram implantadas as rotinas de recomendação. De acordo com[Reategui e Cazella 2005] há duas formas mais habituais de identificação de usuário.
A primeira é a Identificação no servidor, que normalmente disponibiliza aousuário uma área de cadastro com informações pessoais, tais como: nome, data denascimento e outros. Além disso, solicita obrigatoriamente um login4 e senha. Estemecanismo permite que o web site identifique com mais precisão o usuário que nele seconecta.
A segunda forma é a Identificação no cliente, que normalmente utiliza cookies5,um mecanismo pelo qual um web site consegue identificar que determinado computadorestá se conectando mais uma vez a ele. Este método assume que a máquina conectadaé utilizada sempre pela mesma pessoa. Trata de um mecanismo mais simples queo primeiro, porém menos confiável, principalmente se o computador identificado forutilizado por mais de uma pessoa.
Ainda de acordo com [Reategui e Cazella 2005] depois de identificar o usuário,é possível coletar dados sobre este de forma implícita ou explícita. Na modalidade decoleta explícita o usuário indica espontaneamente o que lhe é importante. Por exemplo,o usuário pode indicar suas seções favoritas em uma livraria virtual são Design eMúsica. Na modalidade implícita, através de ações do usuário infere-se informações sobresuas necessidades e preferências. Por exemplo, armazenando-se dados de navegação dousuário (páginas consultadas, produtos visualizados, etc) é possível detectar que ele seinteressa por A ou B.
Utilizando-se desta estratégia é possível conhecer melhor a preferência dosusuários sem que eles tenham que fornecer informações explicitamente, e em seguidautilizar estes dados para fazer recomendações. A Figura 2.4 mostra uma página daAmazon.com personalizada para um usuário que se mostra interessado por diversosassuntos listados na parte inferior da página.
4 De acordo com a Wikipédia : Em termos informáticos, Login (derivado do inglês log in, sendo porvezes também utilizada a alternativa sign in) define o processo através do qual o acesso a um sistemainformático é controlado através da identificação e autenticação do utilizador através de credenciaisfornecidas por esse mesmo utilizador. Essas credenciais são normalmente constituídas por um Nome deUtilizador (do inglês username) e uma Palavra-passe ou Senha (do inglês Password) - ocasionalmente,dependendo do sistema, apenas é pedida a Senha.
5De acordo com a Wikipédia: Cookie, é um testemunho de conexão, onde um conjunto de dados sãotrocados entre o navegador e o servidor de páginas. Esse conjunto de dados são armazenados em um arquivo(ficheiro) de texto criado no computador do utilizador. A sua função principal é a de manter a persistênciade sessões HTTP.
2.1 Sistemas de Recomendação 37
Figura 2.4: Exemplo de recomendação do website da Amazon.com
Privacidade em Sistemas de Recomendação
Pesquisas mostram que a maior parte dos usuários está disposta a fornecerinformações suas para que possam receber ofertas personalizadas. No entanto, o censoamericano mostra que 75% dos usuários daquele país se preocupam com a possíveldivulgação de dados que fornecem às empresas [TORRES 2004]. Os usuários buscamsempre conhecer os objetivos da coleta de dados e se estes dados serão fornecidos aterceiros. A Figura 2.5 mostra uma coleta de dados incentivando a participação do usuáriopara que as recomendações feitas a ele sejam mais eficientes.
Figura 2.5: Exemplo de Coleta de Dados para melhoriadas recomendações do website da Submarino(www.submarino.com.br)
Ao analisar a informação anterior notamos que não teria problema algum seas empresas que empregam Sistemas de Recomendação tivessem uma coleta de dados

2.1 Sistemas de Recomendação 38
associada a uma política de privacidade adequada. Porém, não é incomum encontrarempresas que, além de coletar dados para personalizar o relacionamento com seusclientes, vendam estes dados para outras empresas, uma prática que alimenta o aumento despam. Estas atitudes prejudicam o relacionamento com o cliente e aumentam a distânciaentre estes e a empresa.
Figura 2.6: Política de privacidade do website da Amazon.com.
A Figura 2.6 mostra um trecho da página contendo a política de privacidade doserviço de coleta de dados para melhoria das recomendações do website da Amazon.com.Sites como este cumprem uma exigência legal, que visa garantir que uma empresa agirácom honestidade e protegerá as informações dos seus clientes.
Algumas instituições com a preocupação de transmitir ao usuário uma melhorreputação (Seção 2.1.4) trabalham com selos que garantem que a política de privacidadeé adequada e cumprida com rigor. A Figura 2.7 apresenta dois destes selos, fornecidospor grandes instituições na área (TRUSTe, BBBOnline).
Figura 2.7: Selos de Privacidade.

2.1 Sistemas de Recomendação 39
Apesar das garantias oferecidas por estas instituições, questiona-se o fato de quemuitas vezes os padrões exigidos não são rígidos o suficiente, e as estratégias de controledas normas não são rigorosas [Cline 2003].
2.1.4 Estratégias de Recomendação
Dizemos que o principal objetivo dos Sistemas de Recomendação é a fidelizaçãodo cliente para uma dada empresa, trazendo lucratividade como principal benefício. Paratal, empresas investem em sistemas que trata cada usuário como sendo único. Para queisso ocorra existem diversas técnicas, tais como:
• Lista de Produtos Recomendados: é uma técnica bem simples que gera uma lista deprodutos por algum critério de avaliação, como: mais vistos, mais vendidos, listade interesse, dentre outros. Dessa forma o sistema mostra para todos os usuários amesma lista sem nenhuma personalização da mesma.• Itens Semelhantes: é uma técnica que recomenda produtos semelhantes ao que
está sendo comprado pelo usuário. O sistema varre o banco de dados em busca deprodutos que já foram vistos, avaliados ou comprados por este ou outros usuáriosque se assemelha de alguma forma ao item corrente.• Mala Direta Personalizada: é uma técnica baseada em contato direto com o
usuário através do e-mail. Este contato pode se dar por algum motivo, mas semprebaseado no interesse do usuário, tal como: produto indisponível e que passou estardisponível, promoção de algum produto, recomendação de algum item baseado natécnica “Itens Semelhantes”, dentre outras.
Os Sistemas de Recomendação realizam “filtragens” para definir quais produtosserão recomendados a cada perfil de usuário, esse ato é conhecido como Técnicas deRecomendação e será tratado na seção 2.1.5.
Reputação do Produto
Um grande exemplo de empresas que se apoiam neste mecanismo são asempresas que exploram o mercado de comércio eletrônico. Elas utilizam Sistemas deRecomendação baseada no uso das avaliações dos usuários sobre um produto paraestabelecer qual é o grau de satisfação que este produto representa para pessoas que ocompraram. A eficiência deste tipo de abordagem está relacionada com a ideia de queas pessoas que compraram o produto voltarão ao site para avaliar o produto adquirido epublicar sua opinião, acreditando assim na veracidade das informações fornecidas. Algunssistemas utilizam da técnica de incentivo dando ao usuário brindes, descontos entre outros,para estimular usuários a contribuir com as suas opiniões.

2.1 Sistemas de Recomendação 40
Figura 2.8: Avaliação de um ar-condicionado no site do Carrefour(www.carrefour.com.br).
Avaliações de clientes são importantes, porém é preciso que haja veracidade nasopiniões fornecidas. Do ponto de vista de implementação, este também é um mecanismofácil de implementar, na medida em que não exige nenhum tipo de dispositivo commaiores capacidades de análise de dados [Cazella, Nunes e Reategui 2010].
Recomendação por Associação
É um outro tipo de recomendação bastante utilizado por web sites de comércioeletrônico. Em uma base de dados que contem as avaliações dos produtos descrita em2.1.4, o sistema consegue encontrar associação entre os produtos e recomendar estesprodutos ao usuário. Os produtos recomendados são aqueles com as melhores avaliações(melhor reputação) ao qual o usuário demonstrou interesse.
Figura 2.9: Recomendação por Associação no site da Amazon(www.amazon.com).
Esta apresentação é a implementação do termo, “Clientes que compraram esteitem também comprou. . . ”. No exemplo mostrado na Figura 2.9, a partir da seleção de

2.1 Sistemas de Recomendação 41
um Livro sobre “Mineração de Dados em Redes Sociais”, o sistema apresentou itenssimilares de interesse do usuário.
Este tipo de recomendação é mais complexa que a Reputação do Produto2.1.4, pois exige uma análise mais profunda dos hábitos do usuário para aidentificação de padrões e recomendação de itens com base nestes padrões[Cazella, Nunes e Reategui 2010].
Associação por Conteúdo
A associação por conteúdo faz a recomendação de duas formas, a primeira é arecomendação de objetos classificados no perfil do usuário e a segunda é a recomendaçãode objetos similares aos objetos que o usuário já comprou.
Para a primeira forma de recomendação é feito o uso da avaliação do conteúdo deum determinado item, por exemplo, um autor, um compositor ou uma outra propriedadeespecífica. Os itens que possuírem maior “ranking” e que se encaixem no critério debusca serão recomendados para o usuário.
Independente da forma escolhida, a recomendação neste tipo de técnica trabalhaem um escopo mais restrito e sempre vai retornar produtos bastante similares aos que ousuário está visualizando. Ela se baseia na ideia de busca de produto por algum critérioimportante mostrando para o usuário os itens de maior relevância.
Figura 2.10: Recomendação por Associação no site da Submarino.
Na exemplo ilustrado na Figura 2.10 a partir da seleção de um câmerafotográfica outras câmeras são apresentadas. Note que não são apresentados produtoscomo filmadoras, celulares e notebooks que também tem a função de câmera fotográfica,porém não sendo este o foco principal destes tipos de produtos não entram eles assim nocritério de seleção.

2.1 Sistemas de Recomendação 42
Análise de Sequências de Ações
Assim como ocorre na medicina, administração, no direito e em outros domíniosa análise de Sequências de Ações é um tipo importante de coleta de informações. Deacordo com [Cazella, Nunes e Reategui 2010] na web, sequências podem ser utilizadaspara capturar o comportamento de usuários através de históricos de atividade temporal,como em weblogs e histórico de compras de clientes. As informações encontradas nestassequências temporais podem ser empregadas nas identificações de padrões de navegaçãoe consumo, que em seguida podem servir aos Sistemas de Recomendação.
De acordo com Demir [Demir, Uyar e Oguducu 2007] alguns algoritmos buscamagrupar as sequências de ações em clusters como forma de identificar e representaros padrões de comportamentos encontrados nos dados. Por exemplo, representampadrões de sequências em grafos não direcionados e utilizam algoritmos evolucionárioscom múltiplos objetivos como no processo de clusterização. No entanto, um dosalgoritmos mais conhecidos na análise de sequência de ações é o SPADE (Sequential
PAttern Discovery using Equivalence classes - Descoberta de Padrões Sequenciaisutilizando classes equivalentes) [Zaki 2001]. O algoritmo busca associar a cada sequênciaencontrada, com uma lista de objetos nos quais ela ocorre. Através deste mecanismo abusca por objetos e sequências é otimizada. O algoritmo também reduz o número devarreduras na busca por padrões, o que implica em um tempo de execução menor.
2.1.5 Técnicas de Recomendação
Sistemas de Recomendação como dito na seção 2.1.4 funcionam como umconselheiro, se comportando de tal maneira a guiar as pessoas em suas descobertas deprodutos que podem vir a gostar, agindo assim como um amigo que lhe recomenda umlivro ou um restaurante.
Os autores Schafer, Konstan e Riedl[Schafer, Konstan e Riedl 2001,Adomavicius e Tuzhilin 2005] classificam as técnicas que implementam as estratégias derecomendação (vista na Seção 2.1.4) em três tipos: A primeira são às Técnicas Baseadasem Conteúdo, a segunda são as baseadas na Filtragem Colaborativa e a terceira sãouma Abordagem Híbrida. No entanto, outros autores [Burke 2002, Gonzalez et al. 2007,Nunes e Aranha 2009, Cazella, Nunes e Reategui 2010, Calvo e D’Mello 2010] trazemoutros tipos de técnicas que também visam à identificação de padrões de comportamento(consumo, pesquisa e outros) e utilização destes padrões na personalização dorelacionamento com os usuários. Essas técnicas são a base dos Sistemas deRecomendação e são apresentadas nas próximas seções.

2.1 Sistemas de Recomendação 43
Filtragem Baseada em Conteúdo
É notório que a web é formada por um grande volume de informação,esse acumulo de dados também é a realidade de inúmeros sistemas que armazenaminformações dos mais variados tipos e assuntos. Um problema bastante comum é aocorrência da sobrecarga de informações. Abstrair informações de grande importâncianeste mar de informação, gerando de forma automática descrições dos conteúdos dos itense comparar estas descrições com os interesses dos usuários é conhecida como FiltragemBaseada em Conteúdo (FBC). Ela é conhecida por este nome por realizar uma seleçãobaseada na análise de conteúdo dos itens e no perfil do usuário.
A obtenção de informação relevante é o objetivo de alguns softwares quefazem uso da técnica de FBC. Esses softwares não são os primeiros com este objetivoque, na verdade, tem suas origens na área de recuperação de informação. De acordocom [Cazella, Nunes e Reategui 2010] devido aos significativos avanços feitos pelascomunidades de filtragem de informação e filtragem de conteúdo, muitos sistemasbaseados em filtragem de conteúdo focam na recomendação de itens com informaçõestextuais, como documentos e websites. As melhorias sobre os sistemas tradicionais derecuperação de informação vieram com a utilização do perfil do usuário, que contém suaspreferências e necessidades.
Aplicando-se técnicas como indexação de frequência de termos é possívelobter informações de interesses do usuário através da análise das informações cedidaspelo próprio usuário ou através de mapeamento de suas interações com o sistema,como aquisição de itens (produtos), pesquisa de produtos, dentre outras. Segundo[Reategui e Cazella 2005] neste tipo de indexação, informações dos documentos enecessidades dos usuários são descritas por vetores com uma dimensão para cada palavraque ocorre na base de dados. Cada componente do vetor é a frequência que uma respectivapalavra ocorre em um documento ou na consulta do usuário. Claramente, os vetores dosdocumentos que estão próximos aos vetores da consulta do usuário são considerados osmais relevantes para ele.
Ainda de acordo com [Reategui e Cazella 2005] outros exemplos de tecnologiasaplicadas para FBC são índices de busca booleana, onde a consulta constitui-se emum conjunto de palavras- chave unidas por operadores booleanos; sistemas de filtragemprobabilística, onde raciocínio probabilístico é aplicado para determinar a probabilidadeque um documento possui de atender as necessidades de informação de um usuário; einterfaces de consultas com linguagem natural, onde segundo o autor as consultas sãocolocadas em sentenças naturais.
A FBC foca no principio de que usuários tendem a interessar-se por itenssimilares aos objetos que o usuário já comprou ou que demonstrou algum tipo deinteresse. Assim vários itens são comparados com itens que o usuário gostou no passado e

2.1 Sistemas de Recomendação 44
que foram avaliado positivamente, e os itens com maior similaridade serão recomendados.Vale lembrar que estabelecer essa similaridade pode ser mais difícil de ocorrer emalguns casos. Adomavícius [Adomavicius e Tuzhilin 2005] formaliza os Sistemas deRecomendação baseado em conteúdo (ContentBasedPRofile(c)) como sendo o perfil dousuário c. Este perfil é obtido através de uma análise do conteúdo dos itens previamenteavaliados pelo usuário utilizando técnicas de recuperação de informação. Por exemplo,ContentBasedProfile(c) pode ser definido como um vetor de pesos (wc1, ...,wck) ondecada peso wci denota a importância do termo ki para o usuário c utilizando-se a medidaTF-IDF (Term Frequency-Inverse Document Frequency).
Em Sistemas de Recomendação Baseados em Conteúdo, a função de utilidadeu(c,s) é geralmente definida conforme a equação 2.11[Adomavicius e Tuzhilin 2005]:
u(c,s) = score(ContentBasedPro f ile(c),Content(s))
(2.11)Tanto o ContentBasedProfile(c) do usuário c como o Content(s)) podem ser
representados como vetores (TF-IDF) de pesos e termos −→wc e −→ws. Além disso, a funçãoutilidade u(c,s) normalmente é representada, na literatura de recuperação de informação,por algum tipo de pontuação heurística sobre vetores, como por exemplo, a medidade similaridade do cosseno da Tabela 2.2. Desta forma, o cálculo de similaridade érealizado computando o cosseno do ângulo formado pelos dois vetores que representam osdocumentos (termos e frequências). A descrição de interesses do usuário é obtida atravésde informações fornecidas por ele próprio ou através de ações, como seleção e aquisiçãode itens.
Assim, o ato de computar a similaridade entre itens e selecionar os maissemelhantes é um ponto crítico da Filtragem Baseada em conteúdo [Karypis 2000,Bobadilla et al. 2011, Pinto, Tanscheit e Vellasco 2011]. A ideia básica no cálculo desimilaridade entre dois itens i e j é, primeiramente, isolar usuários que tenham avaliadosesses itens e então aplicar a técnica de cálculo de similaridade para determinar asimilaridade si j entre eles. A Figura 2.11 apresenta o processo, onde as linhas da matrizrepresentam usuários e as colunas, itens.

2.1 Sistemas de Recomendação 45
Figura 2.11: Cálculo de similaridade item-a-item
Segundo Adomavícius [Adomavicius e Tuzhilin 2005], a abordagem baseada emconteúdo tem as seguintes limitações:
1. Análise de conteúdo é limitado: o conteúdo de dados pouco estruturados é difícilde ser analisado. A aplicação da filtragem baseada em conteúdo para extração eanálise de conteúdo multimídia por exemplo (vídeo, som), é muita mais complexado que a extração e análise de documentos textuais. Outro problema, relativo aanálise de conteúdo textual, é que sistemas baseados em filtragem em conteúdonão conseguem distinguir um artigo bem escrito de um artigo mal escrito se elesutilizam termos muito semelhantes.
2. Super-especialização: quando o Sistema de Recomendação pode recomendarsomente itens similares a itens avaliados positivamente, pode ocorrer asuper-especialização. Desta forma, os itens que não fechem com o perfil dousuário não serão apresentados.
Filtragem Colaborativa
Na Filtragem Colaborativa (FC), ações de um usuário bem como a análise arespeito das informações gravadas (por exemplo utilizando-se a reputação do produto2.1.4) de um determinado item são utilizadas para o benefício de uma comunidade maior.Sendo assim membros dessa comunidade podem se beneficiar da experiência de outrosusuários antes de decidir sobre a compra de um determinado produto. A não exigênciade reconhecer ou compreender conteúdo dos itens torna-se a grande diferença entreFiltragem baseada em conteúdo e a Filtragem Colaborativa.
A essência da abordagem da Filtragem Colaborativa está na forma como é geradaa recomendação. A recomendação ocorre em função das experiências entre as pessoasque possuem interesses comuns, os itens então são filtrados baseado nas avaliaçõesfeitas pelos usuários. O primeiro sistema criado com esta abordagem foi o Tapestry

2.1 Sistemas de Recomendação 46
[Goldberg et al. 1992], que era um sistema com recursos completos de filtragem dedocumentos eletrônicos. Neste sistema um usuário poderia criar regras de filtragem dee-mail como “Mostre-me todos os documentos que são respondidos por outros membrosdo meu grupo de pesquisa”. Este sistema exigia que o usuário para determinar as relaçõesrelevantes preditivas ficasse com uma grande carga cognitiva, como resultado, essessistemas só foram valiosos em pequenas comunidades fechadas onde todo mundo estavaciente de interesses e deveres de outros usuários.
Um sistema baseado em FC parte da premissa de que, se dois usuário tivereminteresses similares, então os usuários demonstrarão interesses pelos mesmos produtos.De maneira geral, considere-se uma lista de U usuários U = {u1,u2, . . . ,u‖U‖} e umalista de I itens I = {i1, i2, . . . , i‖I‖}. Cada usuário ui possui uma lista de itens m para osquais expressou seu interesse. Logo, se m ⊂ I (é possível que m seja um conjunto nulo),existe um usuário distinguível Ua ∈U , denominado usuário alvo a, para o qual é tarefa dofiltro colaborativo encontrar um item de interesse, em particular buscando recomendações.Assim, haverá uma lista de n itens, n ⊂ I, pelos quais o usuário alvo mais se interessará.A lista recomendada deve ser de itens ainda não avaliados pelo usuário alvo, ordenada deforma decrescente os valores das notas preditas pelo filtro colaborativo. Esta interface dosalgoritmos de Filtragem Colaborativa é também conhecida como recomendação “Top-N”[Karypis 2000, Pinto, Tanscheit e Vellasco 2011].
Tomando a tabela 2.1 como modelo, podemos apresentar na prática como aplicara filtragem colaborativa. O primeiro passo do sistema baseado em FC é procurar usuárioscom hábitos de consumo semelhantes, ou seja, calcular a similaridade entre usuários.Ao analisarmos os usuários 1 e 5 observa-se que para o item (i1) a diferença entre suasavaliações é de 1.0, no item (i2) não há diferença e para o (i3) a diferença é de 0,5. Dessaforma poderiamos dizer que os usuários 1 e 5 são semelhantes. Pelo mesmo raciocínio,os usuários 1 e 2 não seriam tão semelhantes. O cálculo de similaridade só pode ocorrerem itens que ambos os usuários têm expressado preferência.
Tabela 2.1: Matriz de avaliações de usuários à itens
Item(i1) Item(i2) Item(i3)
User(u1) 5,0 3,0 2,5
User(u2) 2,0 2,5 5,0
User(u3) 2,5 − −
User(u4) 5,0 − 3,0
User(u5) 4,0 3,0 2,0
Para calcular a similaridade entre usuários existem diversas técnicas e de acordo

2.1 Sistemas de Recomendação 47
com os autores [Owen et al. 2011, TORRES 2004, Reategui e Cazella 2005] as maiscomuns podem ser observadas na tabela 2.2, onde:
• wa,u é a correlação do usuário alvo a com um determinado usuario u;• ra,i é a avaliação que o usuário alvo deu para o item i;• ra é a média de todas as avaliações do usuário alvo (a);• wa é a utilidade esperada do item i para o usuário a;• d é a classificação padrão (geralmente uma avaliação; não-comprometedora, ou
ligeiramente negativa);• α é a meia-vida. A meia-vida é o posto do item na lista, de tal forma que há uma
chance de 50% que o usuário irá visualizar esse item.
Tabela 2.2: Técnicas de cálculo de similaridade
TÉCNICA EQUAÇÃO REFERÊNCIA
Pearson correlation 2.12 [Schafer et al. 2007, TORRES 2004, Adomavicius e Tuzhilin 2005]
Euclidean 2.13 [D.Manning, Raghavan e Schutze 2009]
Cosine 2.14 [Schafer et al. 2007, TORRES 2004, Adomavicius e Tuzhilin 2005]
Spearman Rank6 2.12 [Herlocker 2000]
Tanimoto 2.15 [Marmanis e Babenko 2009]
log-Likelihood test 2.16 [Breese, Heckerman e Kadie 1998, MacKay 2002, Herlocker 2000]
EQUAÇÕES
wa,u =∑
mi=1(ra,i−ra)(ru,i−ru)√
∑mi=1(ra,i−ra)2 ∑
mi=1(ru,i−ru)2 (2.12)
wa,u =√
∑mi=1(ra,i− ru,i)2 (2.13)
wa,u =∑
mi=1(ra,i∗ru,i)√
∑mi=1(ra,i)2
√∑
mi=1(ru,i)2 (2.14)
wa,u =|ma∩mu|
(|ma|+|mu|)−(|ma∩mu|) (2.15)
wa = ∑imax(ra,i−d,0)
2(i−1)/(α−1) (2.16)
O segundo passo do sistema baseado em FC é selecionar um subconjunto deusuários com maiores similaridade. Após isso, o próximo passo é calcular as predições.

2.1 Sistemas de Recomendação 48
A predição é o ato de inferir qual valor de avaliação o usuário daria a um produtoque ele ainda não avaliou. Um exemplo deste cálculo, observando a tabela 2.1, seria opreenchimento das lacunas deixadas pelo usuário u3 nos itens i2 e i3 e do usuário u4
no item i2. Logo, a predição é feita independente da técnica de cálculo de similaridadeadotada, pois ela será gerada através de uma média ponderada das avaliações dos vizinhos.De acordo com os autores [MacKay 2002, TORRES 2004, Reategui e Cazella 2005,Cazella, Nunes e Reategui 2010, Bobadilla et al. 2011, Adomavicius e Tuzhilin 2005] apredição pode ser calculada pela equacão 2.17, onde h é a quantidade de melhoresvizinhos.
pa,i = ra +∑
hu=1(ru,i− ru)∗wa,u
∑hu=1 |wa,u|
(2.17)
A quantidade h de melhores vizinhos fica a critério de cada sistema que utiliza a filtragemcolaborativa.
Por fim é feito a ordenação de forma decrescente dos valores das predições eretornados os n melhores itens como recomendações.
Apesar de a filtragem colaborativa apresentar-se como uma boa opção na maioriadas aplicações e apresentar a vantagem de sugerir aos usuários produtos inesperados,ainda existem grandes desafios, por este tipo de sistema apresentar alguns problemascomo: “Problema do primeiro avaliador” − que é a situação onde um novo item apareceno banco de dados e não existe assim uma maneira deste ser recomendado para o usuário;“Problema de pontuações esparsas”− caso o número de usuários seja pequeno em relaçãoao volume de informações no sistema; “Similaridade” − que é a situação em que umusuário tenha gostos que variam do normal este terá dificuldades para encontrar outrosusuários com gostos similares. Esses problemas tornam-se mais evidentes em aplicaçõesreais de filtragem colaborativa para sistemas de recomendação, pois tais aplicações tratamcom grande volume de produto, o que torna a avaliação dos usuários em cima de umaquantidade substancial de itens uma tarefa difícil.
Filtragem Híbrida
A abordagem da Filtragem Híbrida procura, basicamente, combinar os pontosfortes da Filtragem Colaborativa e Filtragem Baseada em conteúdo visando criar umsistema que possa melhor atender as necessidades do usuário.
A Figura 2.12 expressa bem a definição da abordagem híbrida que propõe unirduas das melhores técnicas de filtragem de informação, eliminando as fraquezas existenteem cada uma. Entre as vantagens da abordagem híbrida é que é possível recomendarbons itens a um usuário mesmo que não haja usuários semelhantes a ele, pois com essaabordagem é possível lidar com itens não vistos por outros usuários e caso ocorra o

2.1 Sistemas de Recomendação 49
contrário as experiências de outros usuários são levadas em consideração e o sistemaassim sugere alguns itens. [Herlocker 2000].
Figura 2.12: Filtragem Híbrida
Entretanto, há pesquisadores que classificam a Filtragem híbrida como qualquersistema de recomendação que combina várias técnicas de recomendação em conjunto.Burker [Burke 2007] diz não haver nenhuma razão pela qual várias técnicas diferentesdo mesmo tipo não possam ser combinadas, como por exemplo, dois diferentesrecomendadores baseados em conteúdo. Como outro exemplo, Burker cita o trabalhode Billsus e Pazzani [Billsus e Pazzani 2000] que propuseram o NewsDude, que usatanto naive Bayes quanto classificadores k-NN (k-Nearest Neighbors algorithm) paragerar recomendações de notícias. Dessa forma, identificou-se sete principais tipos deabordagem híbrida [Burke 2002]:
• Pesada: A pontuação de diferentes abordagens de recomendação são combinadasnumericamente.• Comutação: O sistema escolhe entre as abordagens de recomendação e aplica a
selecionada.• Mista: Recomendações de diferentes recomendadores são apresentados juntos.• Combinação de Características: Recursos derivados de diferentes fontes de
conhecimento são combinados e será dado a um único algoritmo de recomendação.• Aumento de Característica: Uma técnica de recomendação é usada para calcular
uma característica ou um conjunto de características, o que é, então, parte da entradapara a próxima técnica.• Cascata: Recomendadores têm prioridade estrita, as de menor prioridade são
utilizadas como critério de desempate na pontuação das mais altas.• Meta-nível: Uma técnica de recomendação é aplicada e produz um tipo de modelo,
que é então a entrada utilizada pela técnica seguinte.
Contudo, se combinarmos as cinco principais abordagens de recomendaçãocom as sete técnicas de hibridização, teríamos então 53 possíveis formas de se gerarrecomendação. A complexidade da taxonomia aumenta pelo fato de alguns modeloshíbridos não são logicamente distinguíveis de outros e outras combinações são inviáveis.

2.1 Sistemas de Recomendação 50
Filtragem Baseada em Aspectos Demográficos
Alguns autores como [Nunes 2010, Montaner, Lopez e Rosa 2003,Schafer, Konstan e Riedl 1999], definem a abordagem Demográfica, como a técnicaonde os itens recomendados são baseados em características demográficas, taiscomo, idade, gênero (masculino, feminino), dentre outras. O perfil de usuárioconsiste em dados demográficos pessoais do usuário. De acordo com Schafer[Schafer, Konstan e Riedl 1999], isto é uma correlação pessoa-para-pessoa baseadaem dados demográficos.
Segundo os autores [Cazella, Nunes e Reategui 2010], a filtragem demográficautiliza a descrição de um indivíduo para aprender o relacionamento entre um item emparticular e o tipo de indivíduo que poderia vir a se interessar. Este tipo de abordagemutiliza as descrições das pessoas para conseguir aprender o relacionamento entre um iteme o tipo de pessoa que gostaria deste. Ainda segundo os autores, o perfil do usuário écriado pela classificação dos usuários em estereótipos que representam as característicasde uma classe de usuário. Dados pessoais são requisitados ao usuário, geralmente emformulário de registro, e usados como caracterização dos usuários e seus interesses.
De acordo com Nunes [Nunes 2010], diferentemente das abordagensColaborativa e de Conteúdo, a abordagem de Filtragem Demográfica não requer umhistórico de avaliações do usuário. Algumas obras clássicas com base nesta abordagemsão de Rich [Rich 1979], onde é recomendado livros levando em consideração oestereótipo do usuário e de Krulwich [Krulwich 1997], onde foi desenvolvido umagente inteligente que interage com os usuários na internet e com base em seus perfisdemográficos, recomenda páginas.
Filtragem Baseada em Conhecimento
Nesta abordagem são feitas recomendações dos itens baseando-se nas inferênciasdas preferências do usuário e suas necessidades através de conhecimento estruturado deforma funcional. O perfil do usuário é composto de conhecimento funcional estruturadoe interpretados por uma máquina de inferência [Nunes 2010].
Existem poucos exemplos que incorporam recomendação baseada noconhecimento, pois se trata de uma área que ainda não foi totalmente explorada. Arecomendação baseada no conhecimento é o cerne de um programa de pesquisa conhecidocomo Find-Me Systems ([Burke, Hammond e Young 1997, Burke 1999, Burke 2000]),dentre as pesquisas desenvolvidas o Entree7, é o mais conhecido. Mais tarde Burke[Burke 2002] introduz o EntreeC, um modelo em cascata baseado em conhecimento e
7Sistema de recomendação de pratos para restaurantes

2.1 Sistemas de Recomendação 51
que acrescenta a filtragem colaborativa para gerar recomendações de prato principal.Algumas obras clássicas baseada em conhecimento são: (i) Google [Brin e Page 1998],onde recomenda-se os links mais populares de páginas da web que contenham a consultafornecida pelo usuário. A abordagem de implementação utiliza modelos probabilísticos;(ii) Entreé [Burke 2002], onde recomenda-se restaurantes com base em característicasdesejadas pelo usuário. A abordagem de implementação é a recuperação por semelhançado conhecimento com base no raciocínio baseado em casos.
Segundo Burker [Burke 2002], num certo sentido , todas as técnicas derecomendação poderia ser descrito como fazer algum tipo de inferência. Abordagensbaseadas no conhecimento são diferenciadas por possuírem conhecimento funcional: elastêm conhecimento sobre como um determinado item atende a uma necessidade do usuárioem particular, e portanto, pode raciocinar sobre a relação entre uma necessidade e umapossível recomendação.
Ainda de acordo com Burker, o perfil do usuário pode ser qualquer estruturade conhecimento que suporta esta inferência. No caso mais simples , como no Google,ela pode simplesmente ser a a própria consulta que o usuário tenha formulado.Em outras, pode ser uma representação mais detalhada das necessidades do usuário[Towle e Quinn 2000]. O conhecimento utilizado por um recomendador baseado noconhecimento, também pode assumir muitas formas. Google usa as informações sobreas ligações entre as páginas (links) da web para inferir a popularidade e o valor autorizado[Brin e Page 1998]. Entreé usa o conhecimento de cozinhas para inferir semelhança entrerestaurantes.
Filtragem Baseada em Utilidade
Segundo Burker ([Burke 2002]), a abordagem de Filtragem Baseada emUtilidade (FBU) calcula um valor de utilidade para objetos a serem recomendados e entãorecomenda itens considerando qual a utilidade deles para o usuário. Em princípio, taiscálculos podem ser baseados em conhecimento funcional.
Algumas obras clássicas com base nesta técnica de recomendação são: (i)Tête-à-Tête[Guttman 1998], recomenda produtos de vendas no varejo. A recomendaçãoé fornecida com base em uma negociação considerando múltiplos atributos de umatransação. O sistema é baseado em negociação, a abordagem de implementação aplicadaé o problema de satisfazer as restrições; (ii) PersonaLogic [Guttman 1998], evitarecomendar produtos que sejam indesejáveis para os usuários. O perfil do usuário éespecificado considerando restrições sobre as características de um produto. O métodode implementação é a filtragem de informações.
No entanto, os sistemas existentes não usam tal inferência, exigindo que ospróprios usuários façam o mapeamento entre suas necessidades e as características

2.1 Sistemas de Recomendação 52
dos produtos, seja na forma de funções de preferência para cada recurso no caso deTête-à-Tête ou respondendo um detalhado questionário, no caso do PersonaLogic.
Ainda de acordo com Burker, os recomendadores baseado em Utilidade nãoobjetivam construir generalizações de longo prazo sobre os seus usuários, mas sim emse basear nos seus pareceres (feedbacks) sobre a avaliação da necessidade de um usuárioe do conjunto de opções disponíveis. Dessa forma estes recomendadores, fazem sugestõescom base em um cálculo da utilidade de cada objeto para o usuário.
O desafio então está em como criar uma função de serviço para cada usuário.Tanto Tête-à-Tête, como o site de e-commerce PersonaLogic possuem diferentes técnicaspara chegar a uma função de utilidade específica do usuário e aplicá-lo para os objetivosem questão([Guttman 1998]). Por conseguinte, o perfil de utilizador é a função deutilidade que o sistema tenha calculado para o usuário. A partir deste momento, o sistemaemprega técnicas de satisfação de restrição para localizar a melhor combinação.
O benefício da recomendação baseada na utilidade é que ela não fica restritaapenas a informações acerca do produto. Este tipo de recomendação pode levarem consideração outras variáveis, tais como a confiabilidade do fornecedor e adisponibilidade do produto, tornando possível, por exemplo, alteração de preço doproduto para um usuário específico que tem uma necessidade imediata.
Filtragem Baseada em Aspectos Psicológicos
Os seres humanos naturalmente procuram fazer parte de grupos sociais, a partirdos quais objetivam alcançar suas metas, sejam elas de estudos, trabalho, diversão, dentreoutras. O ingresso de um indivíduo em grupo, assim como sua permanência neste, sãodecisões a serem tomadas e sobre as quais as características psicológicas dos envolvidos,tais como personalidade, emoções e identidade, possuem grande peso. Pesquisadorestêm demonstrado que as pessoas preferem e tendem a interagir com outras que tenhampersonalidades similares às suas [Nass et al. 1995, Nass e Lee 2000].
Sistemas atuais levam em consideração outros fatores para melhorar a qualidadedas recomendações. Podemos citar como exemplos de novos fatores a utilização doambiente (contexto) em que o usuário se encontra, o perfil psicológico, o estadoemocional, dentre outras. Baseado nestes novos fatores Burke [Burke 2002] propõetécnicas de recomendação complementares. Mais tarde, em uma versão estendida defiltragem baseada em outros contextos, Nunes [Nunes e Aranha 2009] propõe a filtragembaseada em aspectos psicológicos.
De acordo com Calvo e D’Mello [Calvo e D’Mello 2010], essas variáveis podemser exploradas no processo de recomendação. Neste sentido, a computação afetiva buscaestreitar as relações entre emoções humanas e aplicações computacionais, através desistemas capazes de reconhecer e responder aos estados afetivos do usuário, como

2.2 Algoritmos Genéticos 53
humor e emoção. Compactuando do mesmo pensamento de Calvo e D’Mello, Cazella[Cazella, Nunes e Reategui 2010] diz acreditar que perfis de usuário devem representardiferentes e ricos aspectos da experiência diária de um usuário, considerando a vida realcomo modelo.
Picard [Picard 1995] já definia que a computação afetiva é aquela que estárelacionada com as emoções. Gonzalez em seu trabalho [Gonzalez et al. 2007], cita queem sistemas de recomendação, várias técnicas de modelagem do usuário vem sendocriadas e estudadas, havendo porém pouca atenção em analisar informações de emoçãoneste processo.
De acordo com Nunes [Nunes 2010], aspectos psicológicos humanos(personalidade e emoções) são importantes no processo de tomada de decisãohumana. Ainda de acordo com Nunes, algumas pesquisas vêm sendo realizadas naárea da “Computação Afetiva”, onde o foco é na identificação e na modelagemda emoção do usuário em sistemas computacionais [Damasio 1994, Simon 1983,Goleman 1997, Paiva 2000, Picard 1997, Trappl, Payr e Petta 2003, Thagard 2006,Lisetti 2002, Picard 1997, Paiva 2000].
A técnica de recomendação baseada em personalidade geralmente é aplicadajuntamente a outra técnica como a filtragem colaborativa e/ou baseada em conteúdo,representando uma técnica de recomendação híbrida. Note que para que seja viávela recomendação baseada na personalidade do usuário necessita-se a representação dapersonalidade, cada projetista de sistema pode usar uma abordagem diferenciada.
2.2 Algoritmos Genéticos
Algoritmos genéticos (AG) são um dos primeiros modelos dealgoritmos desenvolvidos para simular sistemas genéticos. Primeiramente propostopor Fraser [Fraser 1957], e mais tarde por Bremermann, Rogson e Salaff[Bremermann, Rogson e Salaff 1966], porém, foi o extenso trabalho realizado porHolland [Holland 1975] que popularizou os AGs. Por isso Holland é considerado opai de AGs.
Em um AG, os genótipos8 são utilizados para expressar características dosindivíduos. Os principais operadores de condução de um AG são a seleção (modelo desobrevivência do mais apto) e a recombinação através da aplicação de um operador decrossover9 (para o modelo reprodução) [Rothlauf 2006, Engelbrecht 2007, Ahn 2006].
8 Ao conjunto dos genes de um indivíduo damos o nome de genótipo.9Algo que se mistura
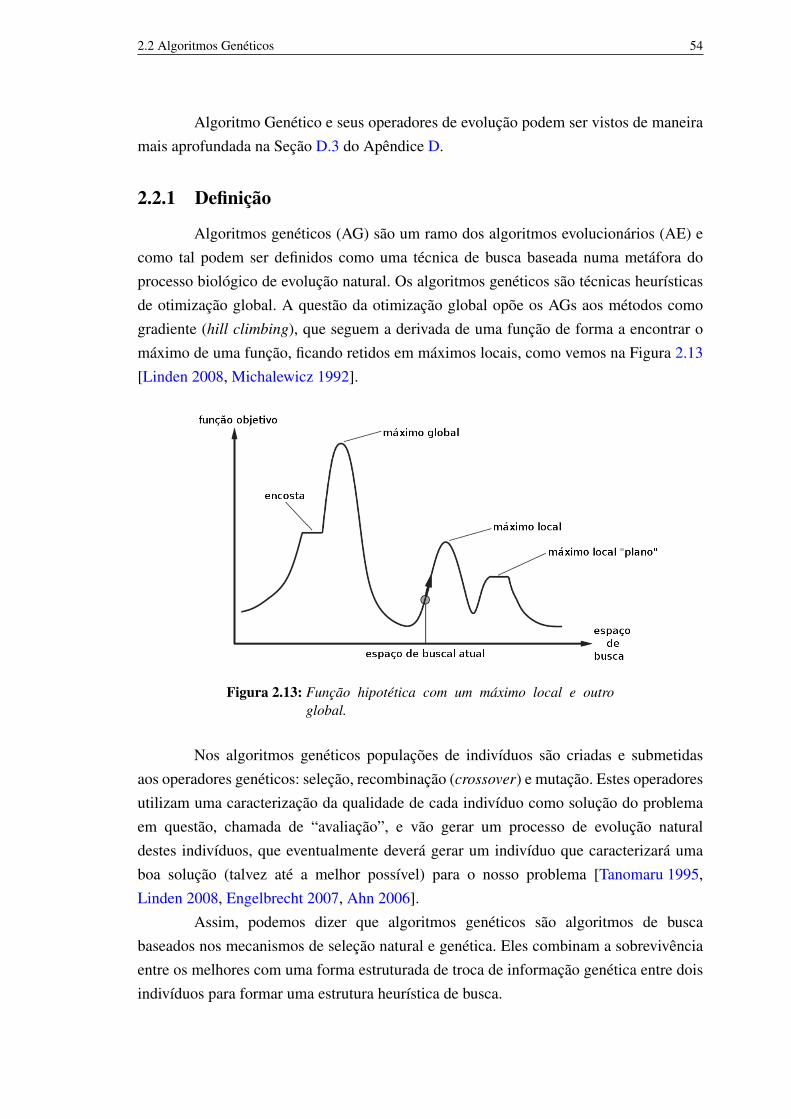
2.2 Algoritmos Genéticos 54
Algoritmo Genético e seus operadores de evolução podem ser vistos de maneiramais aprofundada na Seção D.3 do Apêndice D.
2.2.1 Definição
Algoritmos genéticos (AG) são um ramo dos algoritmos evolucionários (AE) ecomo tal podem ser definidos como uma técnica de busca baseada numa metáfora doprocesso biológico de evolução natural. Os algoritmos genéticos são técnicas heurísticasde otimização global. A questão da otimização global opõe os AGs aos métodos comogradiente (hill climbing), que seguem a derivada de uma função de forma a encontrar omáximo de uma função, ficando retidos em máximos locais, como vemos na Figura 2.13[Linden 2008, Michalewicz 1992].
Figura 2.13: Função hipotética com um máximo local e outroglobal.
Nos algoritmos genéticos populações de indivíduos são criadas e submetidasaos operadores genéticos: seleção, recombinação (crossover) e mutação. Estes operadoresutilizam uma caracterização da qualidade de cada indivíduo como solução do problemaem questão, chamada de “avaliação”, e vão gerar um processo de evolução naturaldestes indivíduos, que eventualmente deverá gerar um indivíduo que caracterizará umaboa solução (talvez até a melhor possível) para o nosso problema [Tanomaru 1995,Linden 2008, Engelbrecht 2007, Ahn 2006].
Assim, podemos dizer que algoritmos genéticos são algoritmos de buscabaseados nos mecanismos de seleção natural e genética. Eles combinam a sobrevivênciaentre os melhores com uma forma estruturada de troca de informação genética entre doisindivíduos para formar uma estrutura heurística de busca.

2.2 Algoritmos Genéticos 55
Na evolução natural isto também decorre de circunstancias que mudam deum momento para outro. Uma bactéria pode ser a melhor em um ambiente livre deantibióticos, mas quando estes são usados, outras que antes eram menos fortes tornam-seas únicas sobreviventes por serem as únicas adaptadas. No caso dos algoritmos genéticos,o ambiente normalmente é um só. Entretanto, conforme as gerações vão se passando eos operadores genéticos vão atuando, faz-se uma grande busca pelo espaço de soluções,busca esta que seria realizada pela evolução natural (das bactérias ou de qualqueroutro organismo) se elas ficassem permanentemente em um ambiente imutável. Mas,ao contrário do que as pessoas costumam pensar, é importante ser ressaltado que aevolução natural não é um processo dirigido à obtenção da solução ótima. Na verdade,o processo simplesmente consiste em fazer competir uma série de indivíduos e peloprocesso de sobrevivência do mais apto, os melhores indivíduos tendem a sobreviver[Tanomaru 1995, Engelbrecht 2007, Ahn 2006, Mitchell 1998].
Um AG tem o mesmo comportamento que a evolução natural: a competição entreos indivíduos é que determina as soluções obtidas. Eventualmente, devido à sobrevivênciado mais apto, os melhores indivíduos prevalecerão. É claro que pode acontecer de umageração ser muito pior que a geração que antecedeu, apesar de isto não ser muito comum(nem provável). Sendo assim, devemos salientar que um AGs, apesar do seu nomeimplicar no contrário, não constituem um algoritmo de busca da solução ótima de umproblema, mas sim uma heurística que encontra boas soluções a cada execução, mas nãonecessariamente a mesma todas as vezes (podemos encontrar máximos - ou mínimos -locais, próximos ou não do máximo global) [Linden 2008, Mitchell 1998].
A “codificação” da informação em cromossomos é um ponto crucial dentro doAG, e é, junto com a função de avaliação, o que liga o AG ao problema a ser resolvido. Sea codificação for feita de forma inteligente, esta já incluirá as idiossincrasias do problema(como por exemplo restrições sobre quando podemos ligar ou desligar uma máquina etc.)e permitirá que se evitem testes de viabilidade de cada uma das soluções geradas. Aofim da execução do nosso algoritmo a solução deve ser decodificada para ser utilizada naprática. Assim como na natureza, a informação deve ser codificada nos cromossomos (ougenomas) e a reprodução (que no caso dos AGs é equivalente à reprodução sexuada) seencarregará de fazer com que a população evolua. A mutação cria diversidade, mudandoaleatoriamente genes dentro de indivíduos e, assim como na natureza, é aplicada de formamenos frequente que a recombinação, que é o fruto da reprodução (e que, dentro desteartigo será chamada de crossover) [Rothlauf 2006, Linden 2008, Tanomaru 1995].
A reprodução e a mutação são aplicadas em indivíduos selecionados dentro danossa população. A seleção deve ser feita de tal forma que os indivíduos mais aptossejam selecionados mais frequente do que aqueles menos aptos, de forma que as boascaracterísticas daqueles passem a predominar dentro da nova população de soluções. De

2.2 Algoritmos Genéticos 56
forma alguma os indivíduos menos aptos têm que ser todos descartados da populaçãoreprodutora. Isto causaria uma rápida “convergência genética” de todas as soluções paraum mesmo conjunto de características e evitaria uma busca mais ampla pelo espaço desoluções. A convergência genética se traduz em uma população com baixa diversidadegenética que, por possuir genes similares, não consegue evoluir, a não ser pela ocorrênciade mutações aleatórias que sejam positivas. Isto pode ser traduzido em outro conceitointeressante, a “perda da diversidade”, que pode ser definida como sendo o número deindivíduos que nunca são escolhidos pelo método de seleção de pais. Quanto maiorfor a perda de diversidade, mais rápida será a convergência genética de nosso AG[Tanomaru 1995, TORRES 2004, Engelbrecht 2007, Ahn 2006].
2.2.2 AG Canônico
Como pode ser visto no Apêndice D.3, os algoritmos genéticos são um ramoda computação evolucionária que busca resolver problemas através da utilização demecanismos encontrados na genética.
Os algoritmos evolutivos, foram baseados na “Teoria da Evolução” de CharlesDarwin [Darwin 1995] onde é afirmado que a vida na Terra é o resultado de um processode seleção em que os indivíduos mais aptos e adaptados possuirão mais chances desobreviver e reproduzir.
Os sistemas baseados em AG lidam com indivíduos10 de uma população desoluções onde são realizadas operações genéticas tais como seleção, reprodução, mutação,dentre outros.
Para aplicação de AG o primeiro passo é representar cada possível solução χ
no espaço de busca como uma sequência de símbolos sim gerados a partir de um dadoalfabeto finito A. No caso mais simples da representação cromossômica, é utilizadoo alfabeto binário A = {0,1}, mas no caso geral tanto o método de representaçãoquanto o alfabeto genético dependem de cada problema. Dessa forma cada sequênciasim corresponde metaforicamente a um cromossomo, e cada elemento de sim a um gene,podendo o gene assumir qualquer valor do alfabeto A. Assim cada elemento de A éequivalente a um alelo, ou seja, um valor possível para um dado gene. A grande maioriados AGs propostos na literatura usam uma população de número fixo de indivíduos, comcromossomos também de tamanho constante [Tanomaru 1995, Linden 2008].
Após a definição da representação cromossômica para o problema, gera-se umconjunto de possíveis soluções, chamadas de soluções-candidatas. Soluções-candidatassão um conjunto de soluções codificadas de acordo com a representação cromossômica
10Os indivíduos são soluções candidatas para um problema. O conjunto destes indivíduos é chamado dePopulação.

2.2 Algoritmos Genéticos 57
selecionada e corresponde, então, a uma população de indivíduos. A população de
indivíduos também é conhecida como geração e geralmente a primeira geração (POP0) éinicializada de maneira aleatória. Cada indivíduo de POP0 é então avaliado através de umafunção de fitness. A função de fitness tem por objetivo retornar um valor que representaa medida de adaptação do indivíduo. A seleção é realizada em função desta medida deadaptação e pode ocorrer utilizando diversos mecanismos tais como: roleta, ranking, pordiversidade, dentre outros.
Dessa forma, o diagrama da Figura 2.14 ilustra os passos executados por um AG[Tanomaru 1995, Linden 2008].
Figura 2.14: Diagrama de fluxo de um Algoritmo Genético
Após a seleção, diversas operações genéticas podem ser executadas, a fim deobter melhores soluções. As operações mais clássicas são:
• reprodução - é uma operação que combina dois ou mais indivíduos de umapopulação para criar um novo indivíduo. O objetivo principal desta operação é atroca de informações entre diferentes indivíduos.• mutação - é uma operação que modifica aleatoriamente genes de um indivíduo.
Esta operação tem como objetivo diminuir a probabilidade do Algoritmo Genéticoconvergir para uma solução considerada um ótimo local;

2.2 Algoritmos Genéticos 58
• elitismo - é uma operação que copia os melhores indivíduos de uma geração depopulação para a próxima geração. Esta operação visa principalmente manter asmelhores soluções entre gerações de uma população;
Além destas operações clássicas, recentemente, diversos pesquisadores têmapresentado abordagens, também relacionadas com conceitos da genética tais comoreprodução in vitro [Camilo-Junior e Yamanaka 2011].
Finalmente, um Algoritmo Genético pode utilizar algumas formas distintas paraavaliar a condição de parada. Entre elas, a primeira forma utilizada para a parada é oprévio estabelecimento de uma quantidade fixa de iterações para a execução. Quando estaquantidade é alcançada, o algoritmo para e retorna a população atual como resultado.A segunda forma utilizada para a parada é a avaliação dos melhores indivíduos de cadaiteração. Se a medida de adaptação destes indivíduos não variar muito, com base em umparâmetro previamente estabelecido, diz-se que a população convergiu para uma solução.Assim, o algoritmo para, retornando esta população.

CAPÍTULO 3Invenire: Algoritmo evolucionário paracombinar resultados das técnicas de sistemas derecomendação
Neste capítulo1 nós descrevemos o método Invenire que produz uma lista (L)
de itens a serem recomendados. L é composto pela escolha de alguns dos melhoresitens do ranking produzido por cada técnica de filtragem colaborativa utilizada (Pearson,distância Euclidiana, Spearman, Tanimoto e Loglikelihood). Para tal, o AG foi utilizadopara combinar os resultados das técnicas de recomendação.
Assim, o objetivo do AG é o de obter uma boa solução (cromossomo) para oproblema da escolha do número apropriado de itens de cada técnica utilizada. Os itensescolhidos são utilizados para compor o ranking final. Um exemplo de composição destalista, para o caso de L igual a 10, seria: 3 itens vindos do ranking da técnica A, 3 itensvindos do ranking da técnica B e 4 itens oriundos do ranking da técnica C, totalizando 10itens na lista final proposta pelo método proposto.
O AG foi escolhido como método de testar e validar a hipótese proposta.A escolha do AG será justificada pela análise feita na seção 3.1. Embora existamoutras formas para combinar automaticamente as técnicas de cálculo de similaridade,os experimentos mostraram que o uso do AG permite resultados consistentes, sendoque a combinação por ele obtida tem acurácia superior à de qualquer uma das técnicasconsideradas individualmente.
Além disso, nós também estamos interessados na obtenção de uma boa soluçãoem cenários difíceis que há poucas avaliações do usuário alvo na matriz de avaliação.Para este fim, introduzimos outra informação em cada cromossomo, que é o número deavaliações que serão removidas da matriz de avaliação.
1Partes deste capítulo foram publicados anteriormente como um artigo da conferência IEEE Congresson Evolutionary Computation − CEC 2014 [Silva et al. 2014]

3.1 Modelagem matemática do problema 60
3.1 Modelagem matemática do problema
Define-se este problema como uma combinação dos resultados de várias técnicasde recomendação com o objetivo de produzir uma lista com menor erro no cálculo deprevisão de avaliação.
Dessa forma, define-se T = {t | t é uma técnica de recomendação} como oconjunto de técnicas de recomendação. Esse conjunto apresenta uma cardinalidade c
pertencente ao conjunto dos números naturais N∗.Cada técnica produz uma lista de recomendações Lt = {i ∈ I | i é uma
recomendação da técnica t}. Esta lista apresenta um cardinalidade l pertencente aoconjunto dos números naturais N∗.
Desta forma o problema apresenta l listas de recomendações, cada uma detamanho s, sendo s a quantidade de itens não avaliados pelo usuário-alvo. Assim, podemaparecer s× l itens recomendados. Entretanto o sistema deve, por fim, recomendar apenass itens ao usuário-alvo. Neste momento o Invenire entra em ação, para combinar osresultados de cada lista a fim de gerar uma lista L f inal de cardinalidade s. Esta lista L f inal
deve ser uma lista que atinja menor erro no cálculo de previsão de avaliação e que sejaválido para todos os usuários.
Este problema se torna complexo devido ao tamanho da lista final L f inal
e sua cardinalidade e, principalmente, devido a quantidade de técnicas existentes esuas possíveis combinações. Entende-se como técnica, neste trabalho, uma medida desimilaridade qualquer em sistemas de recomendação, como por exemplo, a correlação dePearson, a distância Euclidiana, a medida dos Cossenos, dentre outras. Porém, sem perdade generalidade, uma técnica pode ser vista como um método de recomendação completo,por exemplo, uma abordagem baseada em modelo.
3.2 Arquitetura do Invenire
O objetivo da Arquitetura de Software é definir os componentes de um sistema,suas propriedades externas e seu relacionamento com seres humanos, demais sistemas esensores [Silveira 2011]. A figura 3.1 demonstra a arquitetura utilizada no Invenire, onde:
• SR é um Sistema de Recomendação;• LPEA,LEUC,LSPE ,LTAN e LLOG são listas de itens recomendados por cada técnica
de Filtragem Colaborativa configurada no Invenire;• AG é o Algoritmo Genético;• S1,S2 e St são soluções candidatas, onde cada uma representa um cromossomo na
população de indivíduos do AG;
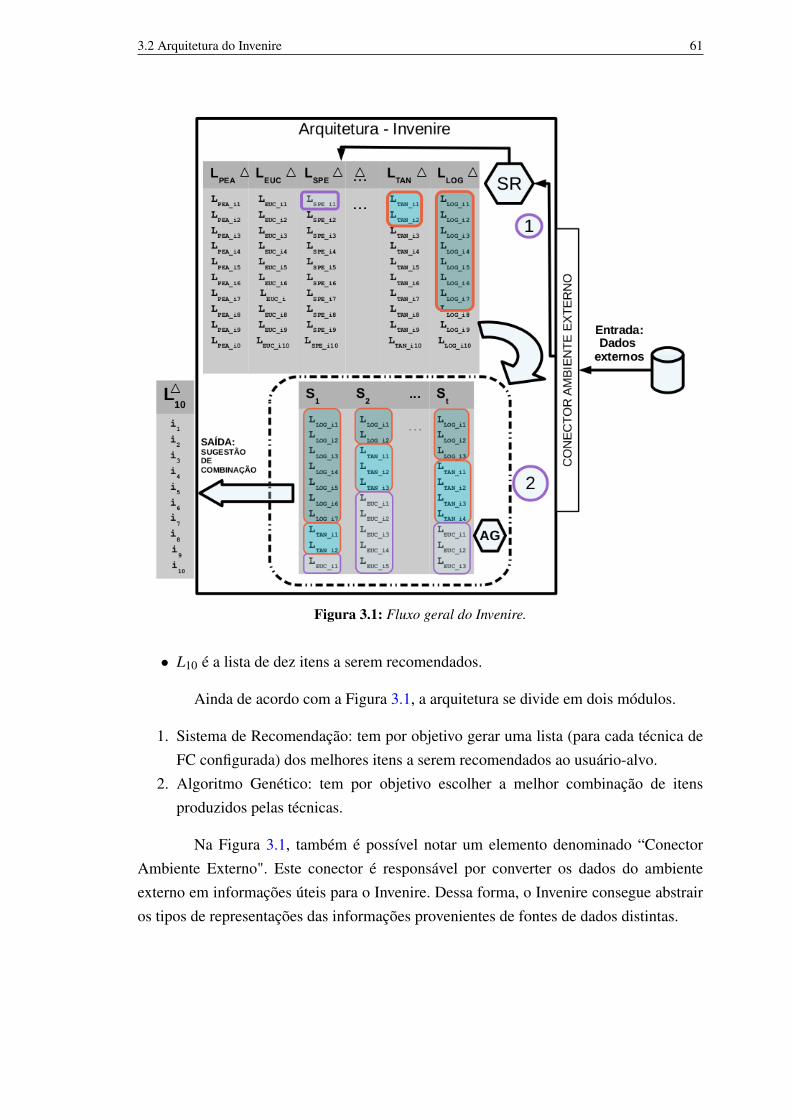
3.2 Arquitetura do Invenire 61
Figura 3.1: Fluxo geral do Invenire.
• L10 é a lista de dez itens a serem recomendados.
Ainda de acordo com a Figura 3.1, a arquitetura se divide em dois módulos.
1. Sistema de Recomendação: tem por objetivo gerar uma lista (para cada técnica deFC configurada) dos melhores itens a serem recomendados ao usuário-alvo.
2. Algoritmo Genético: tem por objetivo escolher a melhor combinação de itensproduzidos pelas técnicas.
Na Figura 3.1, também é possível notar um elemento denominado “ConectorAmbiente Externo". Este conector é responsável por converter os dados do ambienteexterno em informações úteis para o Invenire. Dessa forma, o Invenire consegue abstrairos tipos de representações das informações provenientes de fontes de dados distintas.

3.3 Análise de complexidade 62
3.3 Análise de complexidade
Para conseguir definir a lista final L f inal , é necessário as listas de todas as técnicasem avaliação. Fazendo uma análise assintótica, suponha que em média a recomendaçãogerada por uma técnica seja O(u×n) [Cacheda et al. 2011], onde u é o número de usuáriose n é o número de itens não avaliados.
Para simplificar, suponha ainda que a cardinalidade de usuário é igual acardinalidade de itens não avaliados. Assim, temos que cada técnica é quadrática (O(n2)).Como o Invenire precisa calcular a lista das t técnicas, sua complexidade no módulo 1 dofluxo geral é dada por:
O(t×n2) (3.1)
No modulo 2, caso a técnica de busca usada seja a exaustiva, a complexidade éde O(2s×t), dado o espaço de busca definido na equação 3.2.
(s× t)!s!× ((s× t)− s)!
(3.2)
Dessa forma, o problema a ser resolvido tem complexidade de O(2s×t).Percebe-se, que mesmo com poucas técnicas, o custo computacional é muito alto. Porisso, optou-se pelo uso de um Algoritmo Genético (meta-heurística) no módulo 2.
3.4 Avaliação do Sistema de Recomendação
A entrada para o Sistema de Recomendação (Recomendador) é uma matriz deavaliação M, similar a apresentada na Tabela 2.1. Para avaliar uma recomendação doalgoritmo A, outra matriz Mt é obtida a partir de M, removendo k avaliações. Mt (matriz de
teste) é usada como entrada para o algoritmo de recomendação a ser avaliado. O objetivodo algoritmo A é prever corretamente os valores das avaliações ausentes da matriz teste.
Seja R= {r1,r2, . . . ,rk} um conjunto de avaliações ausentes em Mt . O AlgoritmoA tenta adivinhar os valores correspondentes em R, produzindo um conjunto de previsõesP = {p1, p2, . . . , pk}. A avaliação de A é feito computando o erro acumulado produzidopor A em suas previsões.
Existem diferentes métricas utilizadas para calcular o erro de um algoritmode recomendação. Neste trabalho utilizamos o Root Mean Squared error (RMSE)[Marmanis e Babenko 2009, Bobadilla et al. 2013], que se tornou muito popular nosúltimos anos, após ter sido usado na competição Netflix Prize [Cacheda et al. 2011]. ORMSE é uma técnica simples mas robusta, para avaliar a precisão das recomendações.Para obter o erro do algoritmo A o RMSE é calculado conforme descrito na Equação

3.5 O AG proposto 63
(3.3):
RMSEA =
√∑
ki=1(pi− ri)2
k(3.3)
Onde pi e ri são, respectivamente, a previsão dada pelo algoritmo e a avaliaçãoverdadeira. O algoritmo mais preciso é o que obter o valor de RMSE mais baixo para umadeterminada matriz de teste Mt .
3.5 O AG proposto
A população inicial POP0 usado pelo AG é criada aleatoriamente, com xi e ki,recebendo quaisquer valores aleatórios, uma vez que estes valores satisfaçam a restriçãoespecificado na Eq. 3.4.
‖T‖
∑t=1
xt = ‖L‖ (3.4)
Onde ‖L‖ é o tamanho final da lista ranqueada produzida pelo AG, que é um valorconhecido com antecedência.
3.5.1 Representação Cromossômica
Considere um conjunto de técnicas T = {t1, t2, t3, . . . , t‖T‖}, onde cada técnica t
em T utiliza diferentes cálculo de similaridade.O cromossomo que corresponde a cada indivíduo é composto de ‖T‖ genes,
onde cada gene corresponde a um par, como mostrado na Figura 3.2, onde xi representa
Figura 3.2: A estrutura de um cromossomo usado pelo AG.
a quantidade de itens obtidos do topo da lista (ranking) produzida pela técnica ti ∈ T queé utilizada para compor a classificação final. O segundo elemento do par (ki) correspondeao número de avaliações que serão removidas da matriz M para gerar a matriz Mt .
A Tabela 3.1 mostra exemplos de cromossomos que satisfazem a restrição dadana Eq. 3.4 para ‖L‖= 10.

3.5 O AG proposto 64
Tabela 3.1: Exemplo de cromossomos (cada linha corresponde aum cromossomo distinto)
PEA EUC SPE TAN LOG
X k X k X k X k X k
3 0 2 0 2 0 1 0 2 0
1 0 6 0 1 0 1 0 1 0
0 0 0 0 0 0 0 0 10 0
3.5.2 Fluxo do AG
Para cada cromossomo em uma dada população POP o AG calcula o RMSEacumulado (RMSEt) para cada técnica de t. Os valores acumulados de RMSE para astécnicas são usadas para compor a função aptidão, que é utilizada para avaliar cadacromossomo, como será explicado mais adiante nesta seção.
A Figura 3.3 mostra como o AG calcula o RMSE para cada técnica e como estescálculos parciais de RMSE são totalizados para gerar o RMSE para um cromossomo.
Figura 3.3: Cálculo do RMSE para cada técnica e parao cromossomo que corresponde a uma soluçãocandidata.
Onde:
• t é uma das técnicas de T ;• u é um dos usuários de M;• M f ull é a matriz completa contendo todas as avaliações dos usuários para os itens,
como exemplificado na Tabela 2.1. Além de dar valor à matriz M, a matriz M f ull

3.5 O AG proposto 65
objetiva fornecer o valor da classificação real (ri) que o usuário inseriu para o itemque será usado para o cálculo do RMSEu;• M é a matriz composta pelas avaliações de 5% dos usuários contido em M f ull −283
primeiros usuários encontrados. Foi utilizado 5% de M f ull devido ao grande númerode usuários no banco de dados, o que implicaria em grande custo computacionalpara processamento;• k é o número de avaliações feitas pelo usuário-alvo u e removidas de M para obter
a matriz Mt ;• Mt é a matriz reduzida resultante a partir da matriz de classificação M, eliminando
k avaliações do usuário u;• x é o número de recomendações a serem geradas para o cálculo de RMSE do usuário
u na técnica de t;• RMSEu é o valor do RMSE para as previsões de uma técnica t de um determinado
usuário u;• RMSEt são os valores acumulados de RMSEu devido às previsões feita pela técnica
de t para cada usuário u.
Para calcular o valor de RMSEt para cada técnica de t o AG produz uma matrizMt para cada usuário u. A matriz Mt é obtida copiando as avaliações de M e após isso,removendo kt avaliações do usuário u, onde kt corresponde ao segundo componente dogene t do cromossomo. Em seguida, as previsões (pi) são geradas para o usuário u usandoa técnica t aplicada sobre a matriz Mt . Os valores reais (ri) de cada item são obtidos atravésda realização de consultas a matriz M f ull . Em seguida, o valor do RMSEu é calculadopara o usuário u usando a Equação 3.3, mas substituindo x na equação pelo valor de xt docromossomo. O valor do RMSEu é então acumulado em RMSEt . O processamento acimaé repetido para cada usuário.
Os valores acumulados RMSEt são calculados para cada técnica de t, comoexplicado e estes valores também são acumulados para obter o total geral (RMSEtotal)que é usado para avaliar a aptidão do cromossomo (individuo).
Depois que os valores são acumulados em RMSEt o cromossomo é avaliadousando a função de aptidão expressa pela Equação 3.5.
MIN( f (x)) =w1 ∑
‖T‖t=1 RMSEt +w2 ∑
‖T‖t=1(1−q)
‖T‖(3.5)
Onde:
• RMSEt é o valor acumulado do RMSE de cada técnica t;• w1 e w2 são parâmetros de entrada para a técnica t utilizados pelo AG, com valores
válidos no intervalo entre [0,1]. w1 é usado como um peso para a importância

3.5 O AG proposto 66
da acurácia da técnica na composição da classificação final produzido pelo AG.w2 corresponde ao peso dado à quantidade de avaliações que são removidas dousuário-alvo ao gerar a matriz Mt , conforme mostrado na Figura 3.3;• q é o valor calculado pela Equação 3.6, onde rm é a quantidade de avaliações de
cada usuário contida na matriz M.
q =k
rm−1(3.6)
A função de aptidão (Eq. 3.5) é composta por dois componentes. O primeiro
componente (w1 ∑‖T‖t=1 RMSEt‖T‖ ) é responsável pela totalização do erro no processo de previsão,
para tal, como métrica avaliativa das predições foi escolhida o RMSE. O segundo
componente (w2 ∑‖T‖t=1 (1−q)‖T‖ ) totaliza a quantidade de informação utilizada por cada técnica
e, com isso, indica a complexidade do cenário no qual a técnica foi submetida. Acomplexidade de gerar previsões está relacionada com a quantidade de avaliações dousuário-alvo utilizada pela técnica. Dessa forma, a soma destes dois componentes guiao AG na busca de soluções.
Os parâmetros de entrada w1 e w2 são variáveis utilizadas pelo projetista paradeterminar qual componente quer dar prioridade.
Todo o processo descrito acima é repetido para cada cromossomo da populaçãoPOP. Assim, o AG aplicará operadores genéticos nos cromossomos com o objetivo deencontrar o menor RMSE possível. Este processo gera novos cromossomos que farãoparte da nova população POP′. Dessa forma, o AG repete todo o processo com a novapopulação POP′. A geração de novas populações é repetida até que a condição de paradaseja satisfeita. No AG proposto foram utilizados a convergência genética ou um númeropré-definido de iterações (100 gerações) como condições de parada. O AG termina sempreque pelo menos um desses critérios ocorre.

CAPÍTULO 4Experimentos e Resultados
Para testar a proposta, este capítulo apresenta experimentos comparativos entreo Invenire e cinco métodos tradicionais e muito utilizados de FC (Correlação de Pearson,Distância Euclidiana, Correlação de Spearman, Coeficiente de Tanimoto e Loglikelihood)para ‖L‖= 10. No entanto, é importante ressaltar que o método proposto avalia qualquertipo de abordagem de recomendação e qualquer tamanho de L.
Usou-se da base de dados da MovieLens (MovieLens 1M Data Set (.zip)1)para execução dos experimentos. Esse arquivo contém 1.000.209 avaliações anônimasde aproximadamente 3.900 filmes, feitas por 6.040 usuários da MovieLens em 2000.Para esta base de dados demos o nome de M f ull . Para a execução dos experimentosutilizamos 5% da M f ull como BD, o que corresponde à 283 usuários onde cada usuáriopossuem 10 avaliações. Para a implementação do modelo proposto fizemos o uso de doisframeworks consagrados em suas respectivas áreas, Apache Mahout2[Owen et al. 2011]como recomendador e Jenes 2.03 como motor do AG.
4.1 Experimento I - Calibração do AG
A calibração AG foi realizada para que se pudesse obter a melhor configuraçãode variáveis que será usado pelo AG no cenário de comparação com as técnicasindividuais.
Os AG’s são processos estocásticos, sendo assim foram realizados diversosexperimentos embrionários afim de identificar a melhor configuração dos seusparâmetros. Foram feitas 30 execuções para cada configuração do algoritmo conformevariações expressas na Tabela 4.1. Por esses experimentos não identificou-se impactossignificativos nos resultados pelas alterações das variáveis de controle.
1A base de dados pode ser obtida através do link da página: http://www.grouplens.org/node/73 ouacessando diretamente em: http://www.grouplens.org/system/files/ml-1m.zip
2http://mahout.apache.org3http://jenes.intelligentia.it/

4.2 Experimento II - AG vs Técnicas de FC isoladas 68
Tabela 4.1: Configuração de valores de variáveis para execuçãodo AG
PROPRIEDADE VALOR
w1 1
w2 0∗
Probabilidade de Cruzamento 60%, 70%, 80%, 90%
Método de Cruzamento Um ponto , Dois pontos(**)
Elitismo 1 Indivíduo, Pior (**)
Seleção Torneio (**)
Mutação 2%, 5%, 10%, 30%
População 100
Critério de Parada Convergência Genética ou o limitede 100 gerações.
Número de Execuções 30∗ Ao realizar o cálculo de aptidão do indivíduo, o AG não levaráem consideração as retiradas de avaliações do usuário-alvo∗∗ [Luke 2009, Engelbrecht 2007]
Assim, foram escolhidos os seguintes parâmetros de controle para o AG:Probabilidade de Cruzamento em 80%, Método de Cruzamento de Um Ponto, estratégiade Elitismo de 1 Indivíduo (aleatoriamente substituído), Torneio como critérios de Seleçãoe taxa de Mutação em 2%. Para todos os experimentos foram considerados o valor dekt = 0, a fim de dar as mesmas condições aos experimentos.
4.2 Experimento II - AG vs Técnicas de FC isoladas
Após a calibração do AG foram feitas novas baterias de testes. O objetivo daexecução deste experimento é verificar se o desempenho (menor erro) da combinação dastécnicas é melhor do que alguma técnica isolada.
Neste experimento, fixou-se os valores de todos os kt dos cromossomos daspopulações em zero. Isso foi feito porque a intenção do presente experimento foi a decomparar a acurácia da combinação de resultados produzido pelo AG com a acurácia decada técnica isolada.
Na Tabela 4.2 é demonstrado um exemplo de execução (de parte algoritmo) paraos usuários-alvo 22, 23 e 26, onde R é a avaliação real dada pelo usuário ao item e P
é a avaliação prevista pelo Recomendador. Não houve nenhum critério para a escolhadestes usuários. Dessa forma, é possível observar quais foram as recomendações geradas
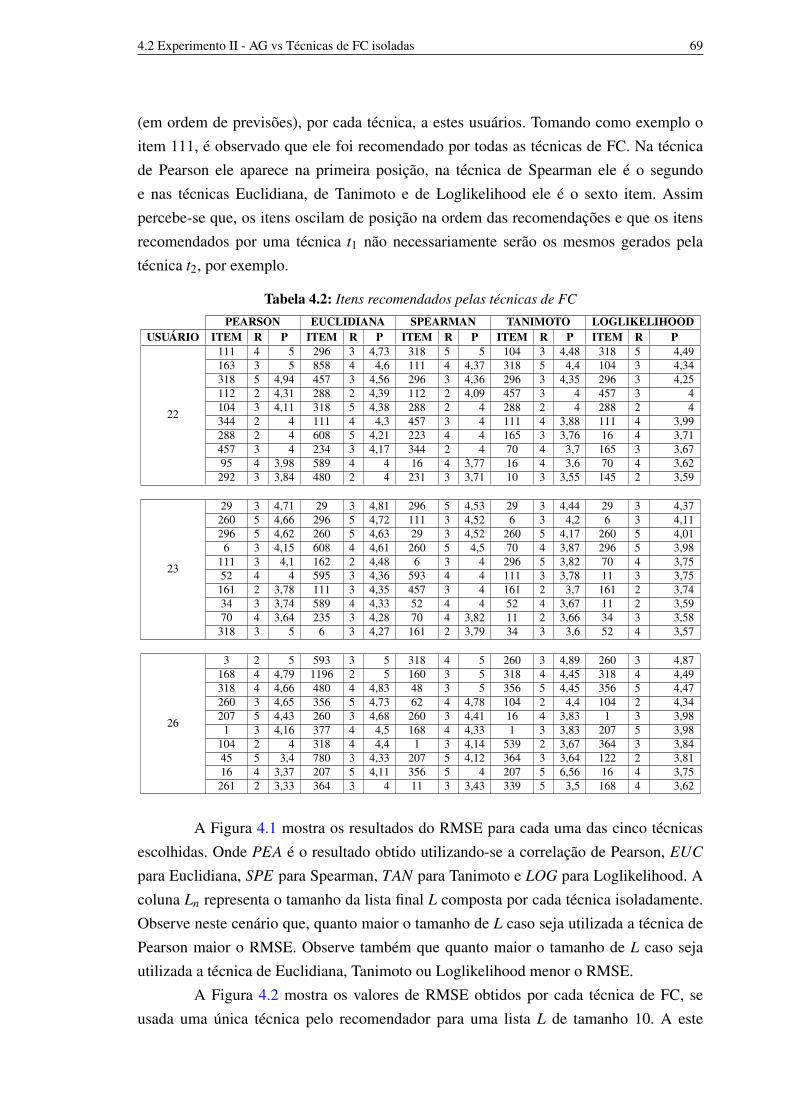
4.2 Experimento II - AG vs Técnicas de FC isoladas 69
(em ordem de previsões), por cada técnica, a estes usuários. Tomando como exemplo oitem 111, é observado que ele foi recomendado por todas as técnicas de FC. Na técnicade Pearson ele aparece na primeira posição, na técnica de Spearman ele é o segundoe nas técnicas Euclidiana, de Tanimoto e de Loglikelihood ele é o sexto item. Assimpercebe-se que, os itens oscilam de posição na ordem das recomendações e que os itensrecomendados por uma técnica t1 não necessariamente serão os mesmos gerados pelatécnica t2, por exemplo.
Tabela 4.2: Itens recomendados pelas técnicas de FC
PEARSON EUCLIDIANA SPEARMAN TANIMOTO LOGLIKELIHOODUSUÁRIO ITEM R P ITEM R P ITEM R P ITEM R P ITEM R P
22
111 4 5 296 3 4,73 318 5 5 104 3 4,48 318 5 4,49163 3 5 858 4 4,6 111 4 4,37 318 5 4,4 104 3 4,34318 5 4,94 457 3 4,56 296 3 4,36 296 3 4,35 296 3 4,25112 2 4,31 288 2 4,39 112 2 4,09 457 3 4 457 3 4104 3 4,11 318 5 4,38 288 2 4 288 2 4 288 2 4344 2 4 111 4 4,3 457 3 4 111 4 3,88 111 4 3,99288 2 4 608 5 4,21 223 4 4 165 3 3,76 16 4 3,71457 3 4 234 3 4,17 344 2 4 70 4 3,7 165 3 3,6795 4 3,98 589 4 4 16 4 3,77 16 4 3,6 70 4 3,62
292 3 3,84 480 2 4 231 3 3,71 10 3 3,55 145 2 3,59
23
29 3 4,71 29 3 4,81 296 5 4,53 29 3 4,44 29 3 4,37260 5 4,66 296 5 4,72 111 3 4,52 6 3 4,2 6 3 4,11296 5 4,62 260 5 4,63 29 3 4,52 260 5 4,17 260 5 4,016 3 4,15 608 4 4,61 260 5 4,5 70 4 3,87 296 5 3,98
111 3 4,1 162 2 4,48 6 3 4 296 5 3,82 70 4 3,7552 4 4 595 3 4,36 593 4 4 111 3 3,78 11 3 3,75
161 2 3,78 111 3 4,35 457 3 4 161 2 3,7 161 2 3,7434 3 3,74 589 4 4,33 52 4 4 52 4 3,67 11 2 3,5970 4 3,64 235 3 4,28 70 4 3,82 11 2 3,66 34 3 3,58
318 3 5 6 3 4,27 161 2 3,79 34 3 3,6 52 4 3,57
26
3 2 5 593 3 5 318 4 5 260 3 4,89 260 3 4,87168 4 4,79 1196 2 5 160 3 5 318 4 4,45 318 4 4,49318 4 4,66 480 4 4,83 48 3 5 356 5 4,45 356 5 4,47260 3 4,65 356 5 4,73 62 4 4,78 104 2 4,4 104 2 4,34207 5 4,43 260 3 4,68 260 3 4,41 16 4 3,83 1 3 3,981 3 4,16 377 4 4,5 168 4 4,33 1 3 3,83 207 5 3,98
104 2 4 318 4 4,4 1 3 4,14 539 2 3,67 364 3 3,8445 5 3,4 780 3 4,33 207 5 4,12 364 3 3,64 122 2 3,8116 4 3,37 207 5 4,11 356 5 4 207 5 6,56 16 4 3,75
261 2 3,33 364 3 4 11 3 3,43 339 5 3,5 168 4 3,62
A Figura 4.1 mostra os resultados do RMSE para cada uma das cinco técnicasescolhidas. Onde PEA é o resultado obtido utilizando-se a correlação de Pearson, EUC
para Euclidiana, SPE para Spearman, TAN para Tanimoto e LOG para Loglikelihood. Acoluna Ln representa o tamanho da lista final L composta por cada técnica isoladamente.Observe neste cenário que, quanto maior o tamanho de L caso seja utilizada a técnica dePearson maior o RMSE. Observe também que quanto maior o tamanho de L caso sejautilizada a técnica de Euclidiana, Tanimoto ou Loglikelihood menor o RMSE.
A Figura 4.2 mostra os valores de RMSE obtidos por cada técnica de FC, seusada uma única técnica pelo recomendador para uma lista L de tamanho 10. A este
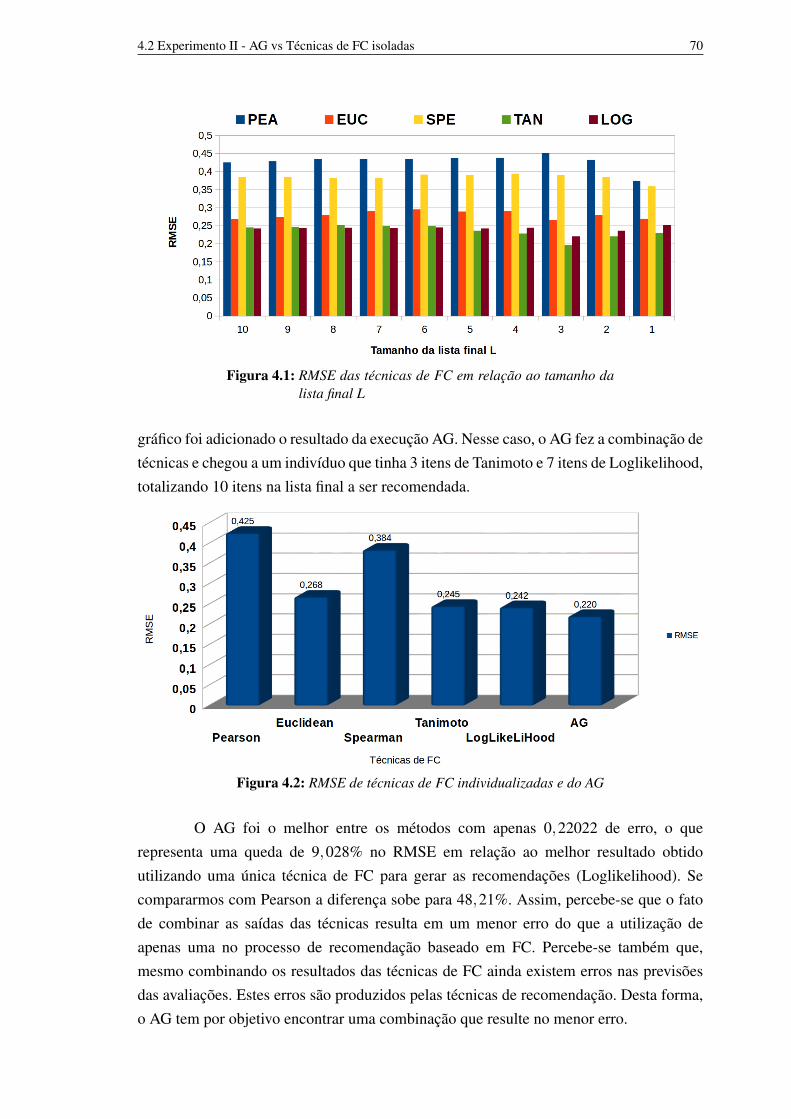
4.2 Experimento II - AG vs Técnicas de FC isoladas 70
Figura 4.1: RMSE das técnicas de FC em relação ao tamanho dalista final L
gráfico foi adicionado o resultado da execução AG. Nesse caso, o AG fez a combinação detécnicas e chegou a um indivíduo que tinha 3 itens de Tanimoto e 7 itens de Loglikelihood,totalizando 10 itens na lista final a ser recomendada.
Figura 4.2: RMSE de técnicas de FC individualizadas e do AG
O AG foi o melhor entre os métodos com apenas 0,22022 de erro, o querepresenta uma queda de 9,028% no RMSE em relação ao melhor resultado obtidoutilizando uma única técnica de FC para gerar as recomendações (Loglikelihood). Secompararmos com Pearson a diferença sobe para 48,21%. Assim, percebe-se que o fatode combinar as saídas das técnicas resulta em um menor erro do que a utilização deapenas uma no processo de recomendação baseado em FC. Percebe-se também que,mesmo combinando os resultados das técnicas de FC ainda existem erros nas previsõesdas avaliações. Estes erros são produzidos pelas técnicas de recomendação. Desta forma,o AG tem por objetivo encontrar uma combinação que resulte no menor erro.
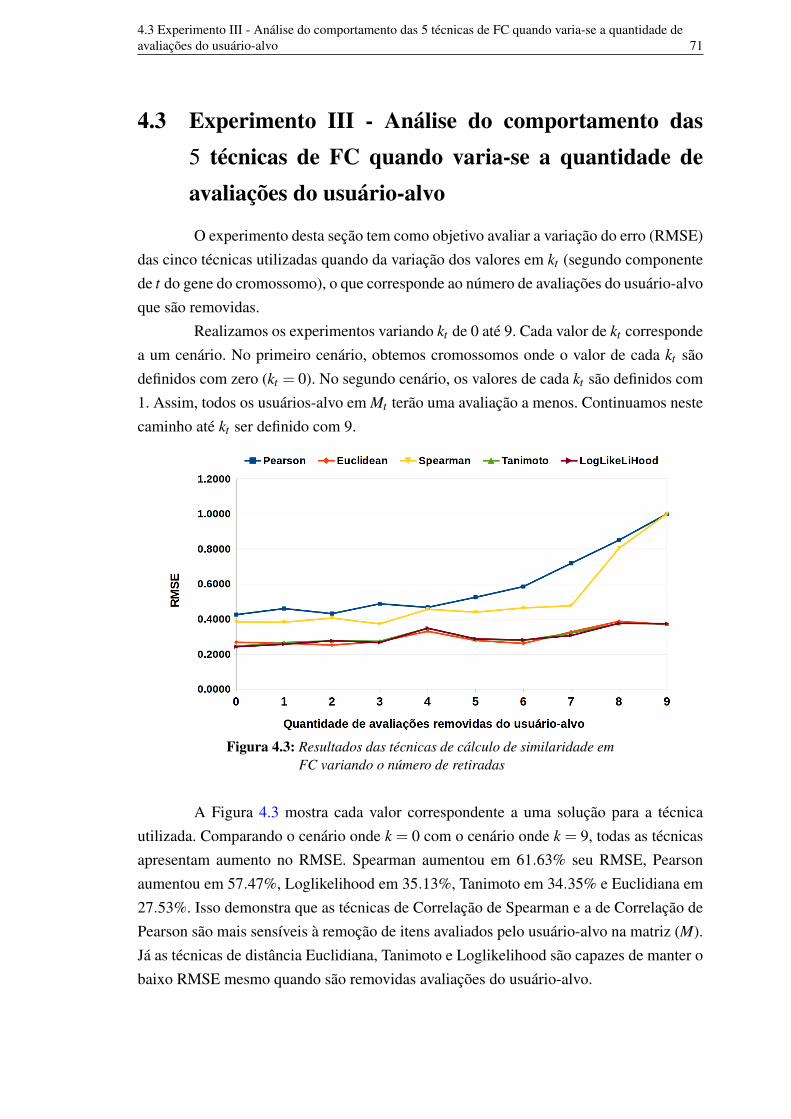
4.3 Experimento III - Análise do comportamento das 5 técnicas de FC quando varia-se a quantidade deavaliações do usuário-alvo 71
4.3 Experimento III - Análise do comportamento das5 técnicas de FC quando varia-se a quantidade deavaliações do usuário-alvo
O experimento desta seção tem como objetivo avaliar a variação do erro (RMSE)das cinco técnicas utilizadas quando da variação dos valores em kt (segundo componentede t do gene do cromossomo), o que corresponde ao número de avaliações do usuário-alvoque são removidas.
Realizamos os experimentos variando kt de 0 até 9. Cada valor de kt correspondea um cenário. No primeiro cenário, obtemos cromossomos onde o valor de cada kt sãodefinidos com zero (kt = 0). No segundo cenário, os valores de cada kt são definidos com1. Assim, todos os usuários-alvo em Mt terão uma avaliação a menos. Continuamos nestecaminho até kt ser definido com 9.
Figura 4.3: Resultados das técnicas de cálculo de similaridade emFC variando o número de retiradas
A Figura 4.3 mostra cada valor correspondente a uma solução para a técnicautilizada. Comparando o cenário onde k = 0 com o cenário onde k = 9, todas as técnicasapresentam aumento no RMSE. Spearman aumentou em 61.63% seu RMSE, Pearsonaumentou em 57.47%, Loglikelihood em 35.13%, Tanimoto em 34.35% e Euclidiana em27.53%. Isso demonstra que as técnicas de Correlação de Spearman e a de Correlação dePearson são mais sensíveis à remoção de itens avaliados pelo usuário-alvo na matriz (M).Já as técnicas de distância Euclidiana, Tanimoto e Loglikelihood são capazes de manter obaixo RMSE mesmo quando são removidas avaliações do usuário-alvo.

4.4 Experimento IV - AG versus técnicas isoladas de FC em um cenário com poucas avaliações dousuário-alvo 72
4.4 Experimento IV - AG versus técnicas isoladasde FC em um cenário com poucas avaliações dousuário-alvo
Foram realizados experimentos para o problema multi-objetivo: obter umasolução com baixo RMSE e reduzir o número de avaliações do usuário-alvo. Comisso tenta-se descobrir a melhor combinação em cenários com poucas avaliações dousuário-alvo. Para tal fez-se necessário utilizar-se das variáveis w1 e w2 definidas nasubseção 4.1 com os valores 0,2 e 0,8 respectivamente.
Ao atribuir estes valores as variáveis w1 e w2 o AG é forçado a privilegiarindivíduos que tiveram mais avaliações removidas, sem deixar de ponderar o RMSE dasrecomendações. Os três melhores indivíduos podem ser observados na tabela 4.3. Observeque no cenário o AG tende a utilizar mais itens de Euclidiana, Tanimoto ou Loglikelihood.Isso é justificado com a análise feita na subseção 4.3.
Tabela 4.3: Representação cromossômica dos três melhoresindivíduos encontrados pelo AG
PEA EUC SPE TAN LOG
X1 k1 X2 k2 X3 k3 X4 k4 X5 k5 RMSE
0 0 8 9 0 0 1 9 1 9 0,3297
0 0 1 9 0 0 8 9 1 9 0,3316
0 0 1 9 0 0 1 9 8 9 0,3316
Pode-se concluir também que mesmo em ambiente onde se tem poucasavaliações do usuário-alvo, é possível obter boas recomendações. Comparando-se osresultados do melhor indivíduo (RMSE de 0,3297, k = 9) da tabela 4.3 e as técnicas daFigura 4.3 é possível perceber que o AG mesmo com 1 avaliação do usuário-alvo, superaa técnica de PEA (menor RMSE de 0,4252, k = 0) e de SPE (menor RMSE de 0,3836,k = 0) em qualquer quantidade. Mesmo retirando 9 itens das avaliações do usuário-alvoo AG (0,3297) teve desempenho melhor do que todas as técnicas, o que representa umaredução de 11,65% no RMSE quando comparado com o resultado da melhor técnica deFC (Loglikelihood). Quando removemos 8 avaliações de todas as técnicas, o AG (RMSEde 0,3297, mesmo com k = 9) tem melhor desempenho, alcançando uma redução de12,10% no RMSE quando comparado com o resultado da melhor técnica neste cenário(Tanimoto).

4.5 Experimento V - O modelo aprendido em uma matriz M aplicado em outras matrizes 73
Conclui-se que o AG é capaz de gerar boas combinações de técnicas emcenários de poucas avaliações do usuário-alvo, ou seja, o AG criado consegue captar asparticularidades da matriz de avalição, gerando assim boas soluções.
4.5 Experimento V - O modelo aprendido em uma matrizM aplicado em outras matrizes
No experimento 4.2 é demonstrado que combinar as técnicas de FC é melhor doque a escolha de uma isoladamente. Ao final da execução do AG utilizando a matriz M
como entrada, verificou-se que a melhor combinação (melhor indivíduo) é a que faz usode 3 itens de Tanimoto e 7 itens de Loglikelihood para compor uma lista final (Ln) de 10itens, a este indivíduo daremos o nome de GAM (especialista em M).
De acordo com a Tabela 4.4 o AG gasta em média 13 horas e 13 minutos paraencontrar a melhor combinação. Este tempo é muito alto se comparado ao tempo de gerarrecomendação utilizando uma técnica de FC isoladamente (1 segundo).
Por isso, o objetivo deste experimento é verificar se o melhor indivíduo (GAM) égeneralizável a outras M (matriz de entrada), o que reduziria consideravelmente o custocomputacional.
Para atingir o objetivo, executamos o GAM utilizando M1 como matriz de entradae após isso fizemos o mesmo procedimento com as técnicas de FC escolhidas. Este mesmoprocedimento também foi realizado utilizando a matriz M2. Neste experimento fixamoskt = 0.
A criação de M1 e M2 seguem o mesmo critério em que foi submetida a matrizM. M1 e M2 são matrizes formadas pelas avaliações de 5% dos usuários contidos emM f ull (283 usuários de M f ull diferentes de M). É importante ressaltar que M1∩M2 = /0.
Assim, para computar o RMSE de cada técnica e de GAM, substituímos amatriz M da Figura 3.3 pela matriz M1 e o resultado pode ser verificado na Tabela 4.4.Executamos novamente, porém, substituímos a matriz M da Figura 3.3 pela matriz M2 eo resultado pode ser observado na Tabela 4.4.
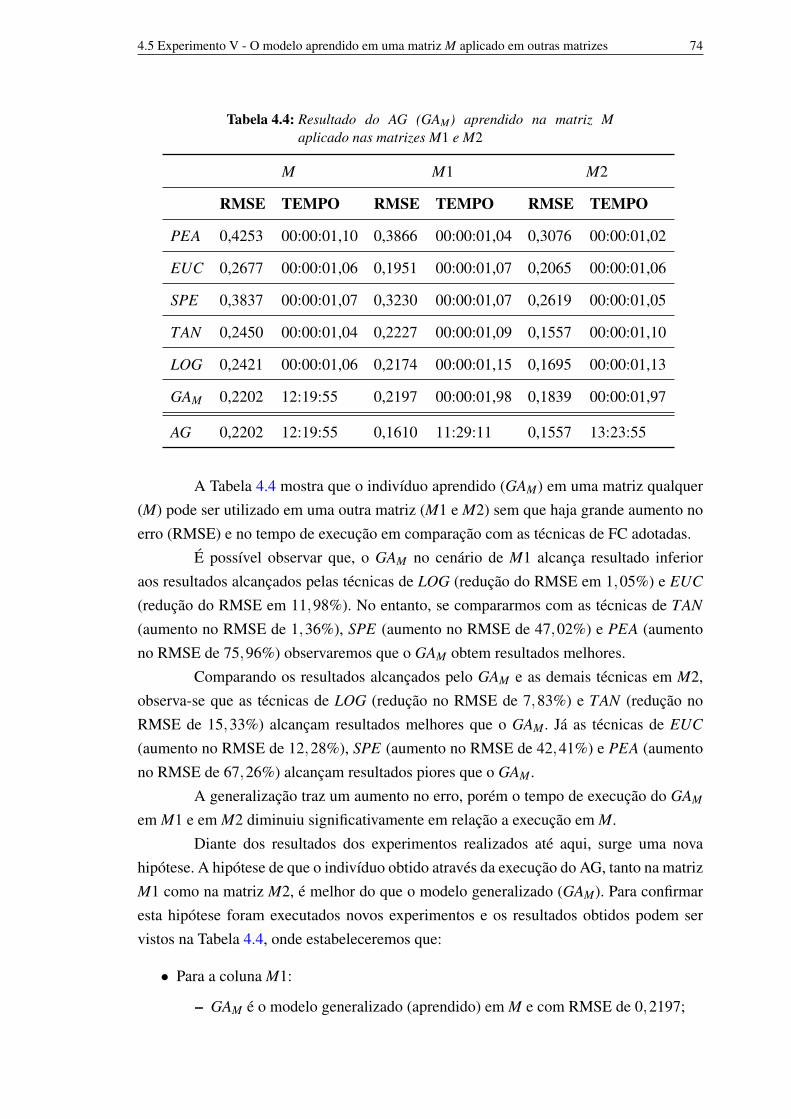
4.5 Experimento V - O modelo aprendido em uma matriz M aplicado em outras matrizes 74
Tabela 4.4: Resultado do AG (GAM) aprendido na matriz Maplicado nas matrizes M1 e M2
M M1 M2
RMSE TEMPO RMSE TEMPO RMSE TEMPO
PEA 0,4253 00:00:01,10 0,3866 00:00:01,04 0,3076 00:00:01,02
EUC 0,2677 00:00:01,06 0,1951 00:00:01,07 0,2065 00:00:01,06
SPE 0,3837 00:00:01,07 0,3230 00:00:01,07 0,2619 00:00:01,05
TAN 0,2450 00:00:01,04 0,2227 00:00:01,09 0,1557 00:00:01,10
LOG 0,2421 00:00:01,06 0,2174 00:00:01,15 0,1695 00:00:01,13
GAM 0,2202 12:19:55 0,2197 00:00:01,98 0,1839 00:00:01,97
AG 0,2202 12:19:55 0,1610 11:29:11 0,1557 13:23:55
A Tabela 4.4 mostra que o indivíduo aprendido (GAM) em uma matriz qualquer(M) pode ser utilizado em uma outra matriz (M1 e M2) sem que haja grande aumento noerro (RMSE) e no tempo de execução em comparação com as técnicas de FC adotadas.
É possível observar que, o GAM no cenário de M1 alcança resultado inferioraos resultados alcançados pelas técnicas de LOG (redução do RMSE em 1,05%) e EUC
(redução do RMSE em 11,98%). No entanto, se compararmos com as técnicas de TAN
(aumento no RMSE de 1,36%), SPE (aumento no RMSE de 47,02%) e PEA (aumentono RMSE de 75,96%) observaremos que o GAM obtem resultados melhores.
Comparando os resultados alcançados pelo GAM e as demais técnicas em M2,observa-se que as técnicas de LOG (redução no RMSE de 7,83%) e TAN (redução noRMSE de 15,33%) alcançam resultados melhores que o GAM. Já as técnicas de EUC
(aumento no RMSE de 12,28%), SPE (aumento no RMSE de 42,41%) e PEA (aumentono RMSE de 67,26%) alcançam resultados piores que o GAM.
A generalização traz um aumento no erro, porém o tempo de execução do GAM
em M1 e em M2 diminuiu significativamente em relação a execução em M.Diante dos resultados dos experimentos realizados até aqui, surge uma nova
hipótese. A hipótese de que o indivíduo obtido através da execução do AG, tanto na matrizM1 como na matriz M2, é melhor do que o modelo generalizado (GAM). Para confirmaresta hipótese foram executados novos experimentos e os resultados obtidos podem servistos na Tabela 4.4, onde estabeleceremos que:
• Para a coluna M1:
– GAM é o modelo generalizado (aprendido) em M e com RMSE de 0,2197;

4.6 Experimento VI - O efeito da variação de kt nas técnicas de FC e no GAM 75
– GAM1 é o modelo especialista, onde o melhor indivíduo (9 itens da técnica deEuclidiana e 1 item da técnica de Tanimoto) obteve RMSE de 0,1610.
• Para M2:
– GAM é o modelo generalizado (aprendido) em M e com RMSE de 0,1839;– GAM2 é o modelo especialista, onde o melhor indivíduo (10 itens da técnica
de Tanimoto) obteve RMSE de 0,1557.
Dessa forma em M1 a redução do RMSE do GAM1 para o GAM foi de 26.74%.Já em M2 a redução RMSE do GAM2 para o GAM foi de 15.34%. Portanto, conclui-se queexecutar o AG na nova matriz (M1 e M2) é a melhor escolha para se alcançar o menorerro.
4.6 Experimento VI - O efeito da variação de kt nastécnicas de FC e no GAM
No experimento 4.3 é demonstrado que as técnicas de Spearman e de Pearsonsão sensíveis à remoção de itens do usuário-alvo na matriz M. Já as técnicas de distânciaEuclidiana, Tanimoto e Loglikelihood conseguem manter o baixo valor do RMSE quandosão removidas avaliações do usuário-alvo.
O objetivo deste experimento é verificar se o melhor indivíduo (GAM) égeneralizável para matrizes de entrada (M1 e M2) em cenários onde existe variação daquantidade de avaliações do usuário-alvo (kt). A criação de M1 e M2 seguem o mesmocritério realizado no experimento 4.5.
Para todas as técnicas escolhidas e para o GAM variou-se os valores de kt
(segundo gene do cromossomo do individuo) que corresponde ao número de avaliaçõesque serão removidas do usuário alvo.
Realizamos experimentos variando kt de 0 até 9. No primeiro cenário obtemoscromossomos onde o valor de cada kt é definido como sendo 0. No segundo cenário, osvalores de cada kt é definido como sendo 1, ou seja, todos os usuários-alvo em M1 eM2 terão 1 avaliação a menos. Continuamos desta maneira até que todos os kt de cadacromossomo sejam definidos como 9.
Assim, para computar o RMSE de cada técnica e de GAM, substituímos amatriz M da Figura 3.3 pela matriz M1 e o resultado pode ser verificado na Tabela 4.5.Executamos novamente, porém, substituímos a matriz M da Figura 3.3 pela matriz M2 eo resultado também pode ser observado na Tabela 4.5.
Através da tabela 4.5 e comparando o cenário de k = 0 contra k = 9, todas astécnicas e o GAM apresentaram aumento no RMSE, tanto em M1 como em M2. Em M1
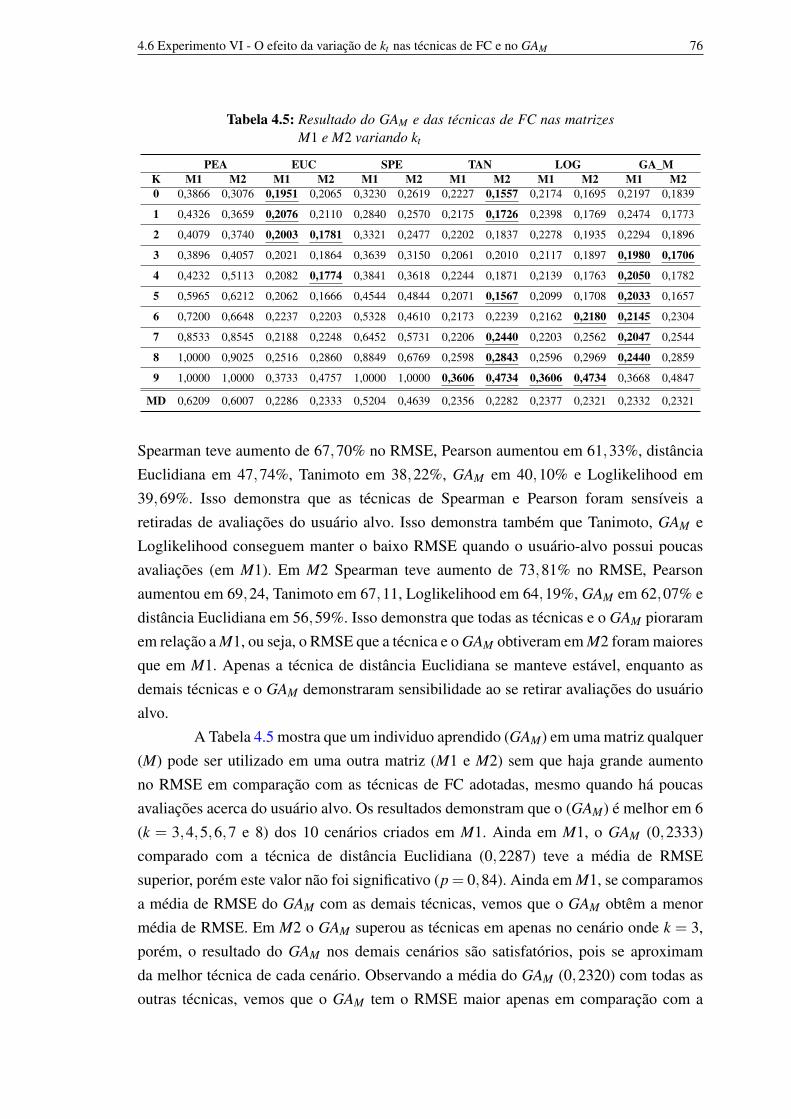
4.6 Experimento VI - O efeito da variação de kt nas técnicas de FC e no GAM 76
Tabela 4.5: Resultado do GAM e das técnicas de FC nas matrizesM1 e M2 variando kt
PEA EUC SPE TAN LOG GA_MK M1 M2 M1 M2 M1 M2 M1 M2 M1 M2 M1 M20 0,3866 0,3076 0,1951 0,2065 0,3230 0,2619 0,2227 0,1557 0,2174 0,1695 0,2197 0,1839
1 0,4326 0,3659 0,2076 0,2110 0,2840 0,2570 0,2175 0,1726 0,2398 0,1769 0,2474 0,1773
2 0,4079 0,3740 0,2003 0,1781 0,3321 0,2477 0,2202 0,1837 0,2278 0,1935 0,2294 0,1896
3 0,3896 0,4057 0,2021 0,1864 0,3639 0,3150 0,2061 0,2010 0,2117 0,1897 0,1980 0,1706
4 0,4232 0,5113 0,2082 0,1774 0,3841 0,3618 0,2244 0,1871 0,2139 0,1763 0,2050 0,1782
5 0,5965 0,6212 0,2062 0,1666 0,4544 0,4844 0,2071 0,1567 0,2099 0,1708 0,2033 0,1657
6 0,7200 0,6648 0,2237 0,2203 0,5328 0,4610 0,2173 0,2239 0,2162 0,2180 0,2145 0,2304
7 0,8533 0,8545 0,2188 0,2248 0,6452 0,5731 0,2206 0,2440 0,2203 0,2562 0,2047 0,2544
8 1,0000 0,9025 0,2516 0,2860 0,8849 0,6769 0,2598 0,2843 0,2596 0,2969 0,2440 0,2859
9 1,0000 1,0000 0,3733 0,4757 1,0000 1,0000 0,3606 0,4734 0,3606 0,4734 0,3668 0,4847
MD 0,6209 0,6007 0,2286 0,2333 0,5204 0,4639 0,2356 0,2282 0,2377 0,2321 0,2332 0,2321
Spearman teve aumento de 67,70% no RMSE, Pearson aumentou em 61,33%, distânciaEuclidiana em 47,74%, Tanimoto em 38,22%, GAM em 40,10% e Loglikelihood em39,69%. Isso demonstra que as técnicas de Spearman e Pearson foram sensíveis aretiradas de avaliações do usuário alvo. Isso demonstra também que Tanimoto, GAM eLoglikelihood conseguem manter o baixo RMSE quando o usuário-alvo possui poucasavaliações (em M1). Em M2 Spearman teve aumento de 73,81% no RMSE, Pearsonaumentou em 69,24, Tanimoto em 67,11, Loglikelihood em 64,19%, GAM em 62,07% edistância Euclidiana em 56,59%. Isso demonstra que todas as técnicas e o GAM pioraramem relação a M1, ou seja, o RMSE que a técnica e o GAM obtiveram em M2 foram maioresque em M1. Apenas a técnica de distância Euclidiana se manteve estável, enquanto asdemais técnicas e o GAM demonstraram sensibilidade ao se retirar avaliações do usuárioalvo.
A Tabela 4.5 mostra que um individuo aprendido (GAM) em uma matriz qualquer(M) pode ser utilizado em uma outra matriz (M1 e M2) sem que haja grande aumentono RMSE em comparação com as técnicas de FC adotadas, mesmo quando há poucasavaliações acerca do usuário alvo. Os resultados demonstram que o (GAM) é melhor em 6(k = 3,4,5,6,7 e 8) dos 10 cenários criados em M1. Ainda em M1, o GAM (0,2333)comparado com a técnica de distância Euclidiana (0,2287) teve a média de RMSEsuperior, porém este valor não foi significativo (p = 0,84). Ainda em M1, se comparamosa média de RMSE do GAM com as demais técnicas, vemos que o GAM obtêm a menormédia de RMSE. Em M2 o GAM superou as técnicas em apenas no cenário onde k = 3,porém, o resultado do GAM nos demais cenários são satisfatórios, pois se aproximamda melhor técnica de cada cenário. Observando a média do GAM (0,2320) com todas asoutras técnicas, vemos que o GAM tem o RMSE maior apenas em comparação com a

4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 77
técnica de Tanimoto (0,2282), porém este valor não foi significativo (p = 0,93). Quandocomparamos o GAM com as demais técnicas, o GAM possui a média de RMSE menor. Épossível notar também que o GAM é melhor que as técnicas de Pearson e Spearman emqualquer cenário, tanto para M1 quanto para M2.
Conclui-se que o fato da generalização não atingir sempre o menor RMSE, indicaa necessidade de escolher a técnica adequada a cada M.
4.7 Experimento VII - Os modelos especialista egeneralista em cenários de mudança de quantidadede avaliações
Nos experimentos anteriores as retiradas de kt avalições são feitas somente nousuário-alvo, simulando um usuário com menos avalições em relação aos demais. Jáneste experimento objetiva-se retirar kt avaliações de todos os usuários ao mesmo tempo,simulando assim um aumento gradual da base de dados ao longo do tempo.
Para a realização dos experimentos a matriz utilizada como entrada continuasendo M − M contém 283 usuários e cada um desses usuários possuem 10 avaliações,totalizando 2830 avaliações. As matrizes Mk são geradas à partir de M tendo comoparâmetro o valor de kt (segundo gene do cromossomo do indivíduo), onde k representaráa quantidade de retirada de avaliações de todos os usuários da base de dados. Por exemplo,supondo que k seja igual a 8, isso significa que a nova matriz Mk8 conterá as 2 primeirasavaliações de cada usuário encontrado em M, contendo assim um total de 566 avaliações,caso k seja igual a 7, a nova matriz Mk7 conterá 849 avaliações, e assim por diante.
O fluxo para o cálculo do RMSE de cada estratégia, para uma lista (Ln) derecomendação de tamanho 10 é demonstrado na figura 4.4.
A Tabela 4.6 demostra o resultado obtido do RMSE de cada uma das 5 técnicastestadas, juntamente com o comportamento dos AGs, onde:
• matriz (Mk8 até Mk0) são matrizes criadas ao variar kt = 8 até kt = 0, sendo utilizadacomo entrada pelo AG.• GAMk8 é o especialista em Mk8 e generalista quando aplicado nos demais cenários.
O GAMk8 especialista é composto pela combinação de 1 item da técnica Euclidiana,1 item de Tanimoto e 8 itens de Loglikelihood.• GAMk5 é o especialista em Mk5 e generalista quando aplicado nos demais cenários.
O GAMk5 especialista é composto pela combinação de 8 itens da técnica Euclidiana,1 item de Tanimoto e 1 item de Loglikelihood.
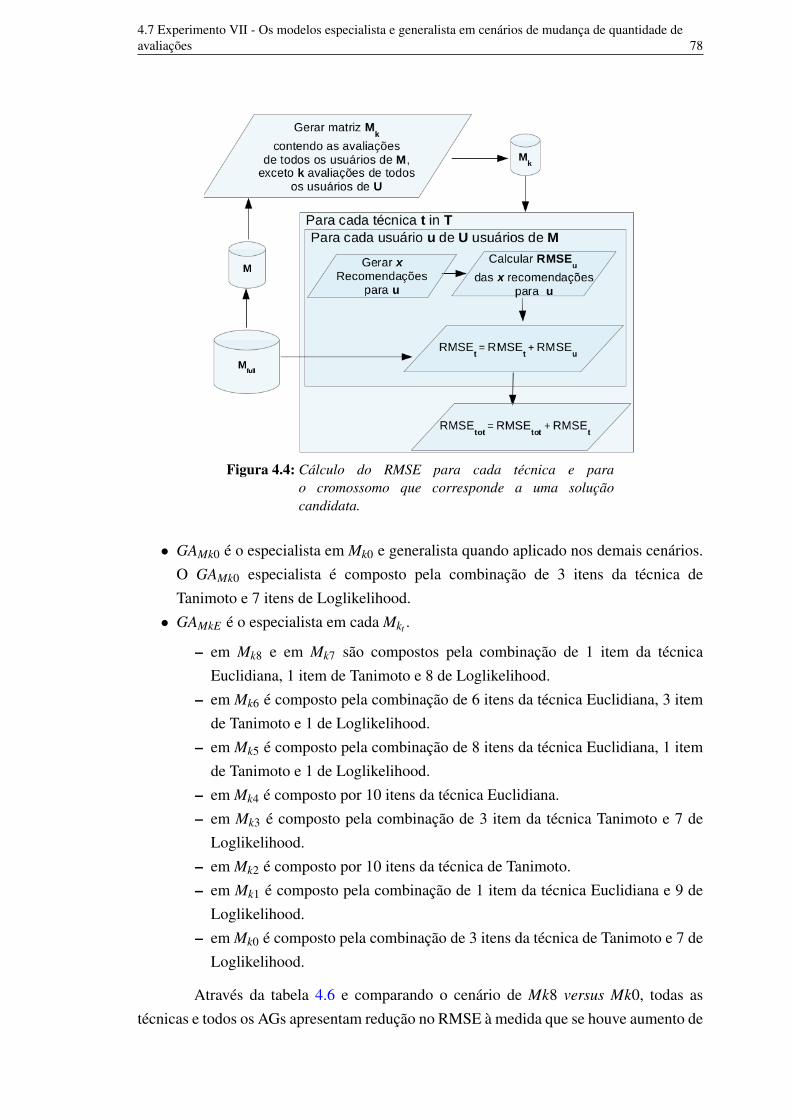
4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 78
Figura 4.4: Cálculo do RMSE para cada técnica e parao cromossomo que corresponde a uma soluçãocandidata.
• GAMk0 é o especialista em Mk0 e generalista quando aplicado nos demais cenários.O GAMk0 especialista é composto pela combinação de 3 itens da técnica deTanimoto e 7 itens de Loglikelihood.• GAMkE é o especialista em cada Mkt .
– em Mk8 e em Mk7 são compostos pela combinação de 1 item da técnicaEuclidiana, 1 item de Tanimoto e 8 de Loglikelihood.
– em Mk6 é composto pela combinação de 6 itens da técnica Euclidiana, 3 itemde Tanimoto e 1 de Loglikelihood.
– em Mk5 é composto pela combinação de 8 itens da técnica Euclidiana, 1 itemde Tanimoto e 1 de Loglikelihood.
– em Mk4 é composto por 10 itens da técnica Euclidiana.– em Mk3 é composto pela combinação de 3 item da técnica Tanimoto e 7 de
Loglikelihood.– em Mk2 é composto por 10 itens da técnica de Tanimoto.– em Mk1 é composto pela combinação de 1 item da técnica Euclidiana e 9 de
Loglikelihood.– em Mk0 é composto pela combinação de 3 itens da técnica de Tanimoto e 7 de
Loglikelihood.
Através da tabela 4.6 e comparando o cenário de Mk8 versus Mk0, todas astécnicas e todos os AGs apresentam redução no RMSE à medida que se houve aumento de
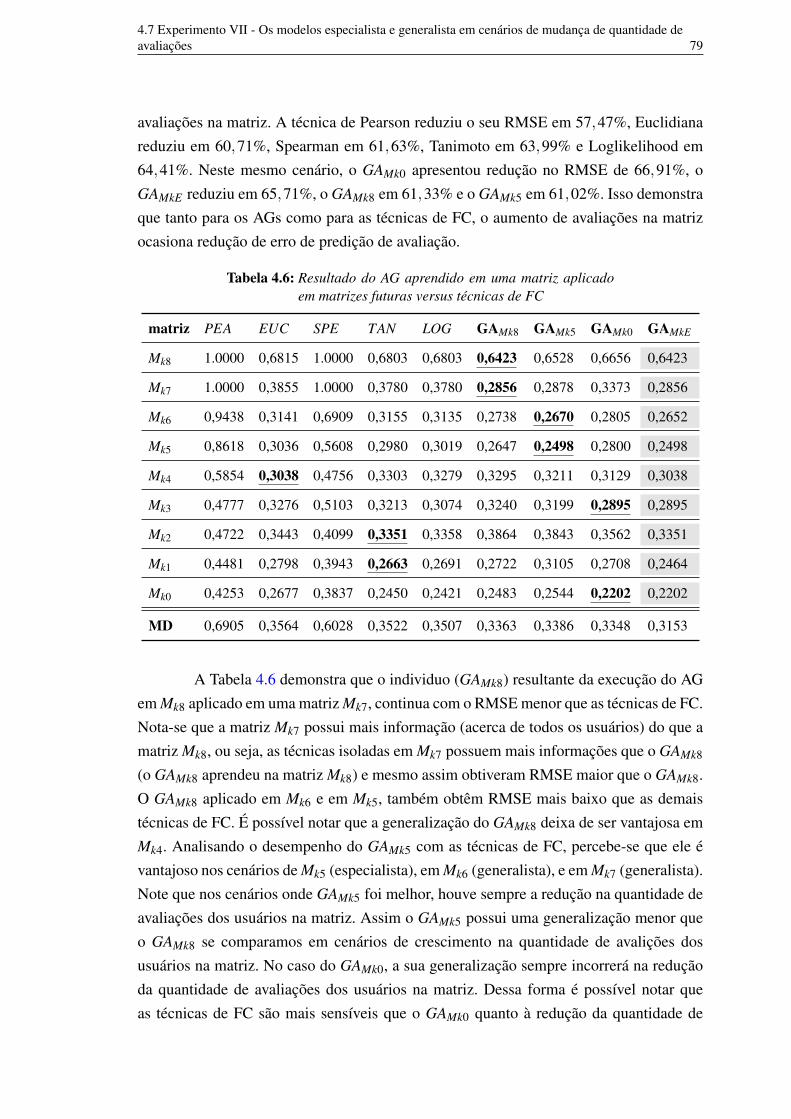
4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 79
avaliações na matriz. A técnica de Pearson reduziu o seu RMSE em 57,47%, Euclidianareduziu em 60,71%, Spearman em 61,63%, Tanimoto em 63,99% e Loglikelihood em64,41%. Neste mesmo cenário, o GAMk0 apresentou redução no RMSE de 66,91%, oGAMkE reduziu em 65,71%, o GAMk8 em 61,33% e o GAMk5 em 61,02%. Isso demonstraque tanto para os AGs como para as técnicas de FC, o aumento de avaliações na matrizocasiona redução de erro de predição de avaliação.
Tabela 4.6: Resultado do AG aprendido em uma matriz aplicadoem matrizes futuras versus técnicas de FC
matriz PEA EUC SPE TAN LOG GAMk8 GAMk5 GAMk0 GAMkE
Mk8 1.0000 0,6815 1.0000 0,6803 0,6803 0,6423 0,6528 0,6656 0,6423
Mk7 1.0000 0,3855 1.0000 0,3780 0,3780 0,2856 0,2878 0,3373 0,2856
Mk6 0,9438 0,3141 0,6909 0,3155 0,3135 0,2738 0,2670 0,2805 0,2652
Mk5 0,8618 0,3036 0,5608 0,2980 0,3019 0,2647 0,2498 0,2800 0,2498
Mk4 0,5854 0,3038 0,4756 0,3303 0,3279 0,3295 0,3211 0,3129 0,3038
Mk3 0,4777 0,3276 0,5103 0,3213 0,3074 0,3240 0,3199 0,2895 0,2895
Mk2 0,4722 0,3443 0,4099 0,3351 0,3358 0,3864 0,3843 0,3562 0,3351
Mk1 0,4481 0,2798 0,3943 0,2663 0,2691 0,2722 0,3105 0,2708 0,2464
Mk0 0,4253 0,2677 0,3837 0,2450 0,2421 0,2483 0,2544 0,2202 0,2202
MD 0,6905 0,3564 0,6028 0,3522 0,3507 0,3363 0,3386 0,3348 0,3153
A Tabela 4.6 demonstra que o individuo (GAMk8) resultante da execução do AGem Mk8 aplicado em uma matriz Mk7, continua com o RMSE menor que as técnicas de FC.Nota-se que a matriz Mk7 possui mais informação (acerca de todos os usuários) do que amatriz Mk8, ou seja, as técnicas isoladas em Mk7 possuem mais informações que o GAMk8
(o GAMk8 aprendeu na matriz Mk8) e mesmo assim obtiveram RMSE maior que o GAMk8.O GAMk8 aplicado em Mk6 e em Mk5, também obtêm RMSE mais baixo que as demaistécnicas de FC. É possível notar que a generalização do GAMk8 deixa de ser vantajosa emMk4. Analisando o desempenho do GAMk5 com as técnicas de FC, percebe-se que ele évantajoso nos cenários de Mk5 (especialista), em Mk6 (generalista), e em Mk7 (generalista).Note que nos cenários onde GAMk5 foi melhor, houve sempre a redução na quantidade deavaliações dos usuários na matriz. Assim o GAMk5 possui uma generalização menor queo GAMk8 se comparamos em cenários de crescimento na quantidade de avalições dosusuários na matriz. No caso do GAMk0, a sua generalização sempre incorrerá na reduçãoda quantidade de avaliações dos usuários na matriz. Dessa forma é possível notar queas técnicas de FC são mais sensíveis que o GAMk0 quanto à redução da quantidade de

4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 80
avaliações em Mk. Assim a generalização do GAMk0 é vantajosa em Mk0, Mk3, Mk5, Mk6,Mk7 e em Mk8.
Ainda de acordo com a Tabela 4.6, percebe-se que a média do RMSE do GAMk8
é menor que todas as médias das técnicas de FC, mesmo o GAMk8 tendo aprendido commenos informações acerca do usuário-alvo do que as técnicas de FC. Comparando-se amédia do GAMk8 com a menor média dentre as técnicas de FC (Loglikelihood), a reduçãodo RMSE corresponde a 4,3% e caso seja comparada com a maior média dentre astécnicas de FC (Pearson), a redução é de 105,32%. A média do GAMk5 também é menorque todas as médias das técnicas de FC. Comparando-se a média do GAMk5 com a menormédia dentre as técnicas de FC (Loglikelihood), a redução do RMSE corresponde a 3,6%e caso seja comparada com a maior média dentre as técnicas de FC (Pearson), a reduçãoé de 103,93%. A média do GAMk0 também é menor que todas as médias das técnicasde FC. Comparando-se a média do GAMk0 com a menor média dentre as técnicas de FC(Loglikelihood), a redução do RMSE corresponde a 4,8% e caso seja comparada com amaior média dentre as técnicas de FC (Pearson), a redução é de 106,25%. Assim, aindaobservando a média dos RMSEs das técnicas de FC e dos AGs, observa-se que o GAMkE
consegue reduzir ainda mais o RMSE. A redução do RMSE do GAMkE em relação amenor média dos RMSEs dentre as técnicas de FC (Loglikelihood) foi de 11,23% e emrelação a maior média dos RMSEs dentre as técnicas de FC (Pearson) foi de 118,99%. Aredução do RMSE alcançado pelo GAMkE pode ser explicado pelo fato de ele ser sempreexecutado a cada matriz Mk, em contrapartida isso eleva o custo computacional desseprocedimento. Por fim, comparando-se a média do RMSE entre GAMk0 (0,3348), GAMk5
(0,3386) e GAMk8 (0,3363), é observado que a diferença entre elas é pequena, o que validaà hipótese de que método da combinação é robusto, mesmo aplicado em cenários onde hácerto grau de generalização, como por exemplo, nos cenários do GAMk8. Contudo, existesempre a possibilidade de melhoria do RMSE, caso o projetista opte pela especialização(GAMkE).
Observando a coluna GAMkE da Tabela 4.6, é possível constatar que o AGespecialista (executado a cada cenário), tendo como entrada a matriz corrente (Mkt ),possui o RMSE mais baixo dentre todas as técnicas e demais AGs. Com isso é validado ahipótese de que combinar é melhor do que escolher uma técnica isoladamente, mesmo emcenários onde há um crescimento na quantidade de avaliações acerca de todos os usuáriosna matriz.
Ainda de acordo com a coluna GAMkE da Tabela 4.6 é possível verificar queao executar o GA em Mk0 o RMSE foi de 0,2202, fazendo o uso de 5% da M f ull . E aoexecutar o GA em Mk5 o RMSE foi de 0,2498, fazendo o uso de 2,5% da M f ull . Com isso,a diferença de RMSE do GAMk0 para o GAMk5 aumenta em 0,029, que não consideramosser tão grande e que nos da um indicativo de que há um limiar de tolerância entre fazer
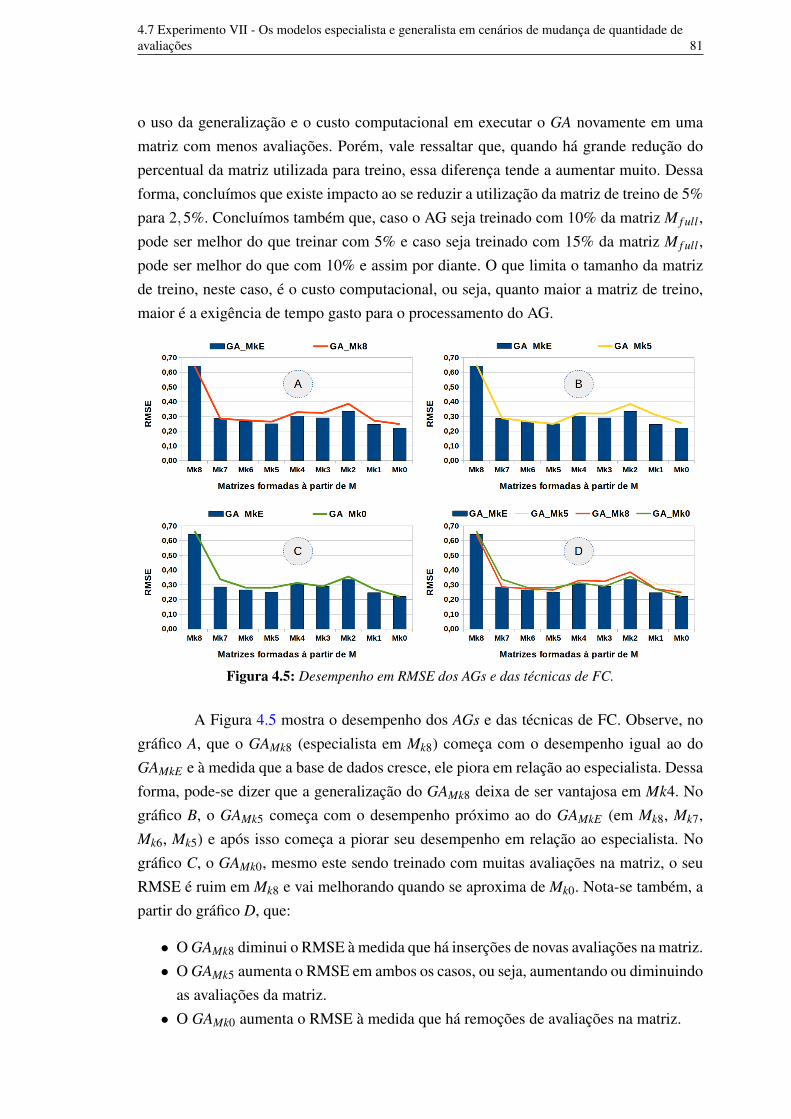
4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 81
o uso da generalização e o custo computacional em executar o GA novamente em umamatriz com menos avaliações. Porém, vale ressaltar que, quando há grande redução dopercentual da matriz utilizada para treino, essa diferença tende a aumentar muito. Dessaforma, concluímos que existe impacto ao se reduzir a utilização da matriz de treino de 5%para 2,5%. Concluímos também que, caso o AG seja treinado com 10% da matriz M f ull ,pode ser melhor do que treinar com 5% e caso seja treinado com 15% da matriz M f ull ,pode ser melhor do que com 10% e assim por diante. O que limita o tamanho da matrizde treino, neste caso, é o custo computacional, ou seja, quanto maior a matriz de treino,maior é a exigência de tempo gasto para o processamento do AG.
Figura 4.5: Desempenho em RMSE dos AGs e das técnicas de FC.
A Figura 4.5 mostra o desempenho dos AGs e das técnicas de FC. Observe, nográfico A, que o GAMk8 (especialista em Mk8) começa com o desempenho igual ao doGAMkE e à medida que a base de dados cresce, ele piora em relação ao especialista. Dessaforma, pode-se dizer que a generalização do GAMk8 deixa de ser vantajosa em Mk4. Nográfico B, o GAMk5 começa com o desempenho próximo ao do GAMkE (em Mk8, Mk7,Mk6, Mk5) e após isso começa a piorar seu desempenho em relação ao especialista. Nográfico C, o GAMk0, mesmo este sendo treinado com muitas avaliações na matriz, o seuRMSE é ruim em Mk8 e vai melhorando quando se aproxima de Mk0. Nota-se também, apartir do gráfico D, que:
• O GAMk8 diminui o RMSE à medida que há inserções de novas avaliações na matriz.• O GAMk5 aumenta o RMSE em ambos os casos, ou seja, aumentando ou diminuindo
as avaliações da matriz.• O GAMk0 aumenta o RMSE à medida que há remoções de avaliações na matriz.

4.7 Experimento VII - Os modelos especialista e generalista em cenários de mudança de quantidade deavaliações 82
Conclui-se, portanto, que os resultados alcançados nos outros experimentosmantem-se válidos em cenários onde a retirada de avaliações se aplica a todos osusuários da matriz. Podemos concluir que o AG aprendido em uma matriz Mk8 porexemplo, pode ser aplicado em matrizes futuras (Mk7), porém quando o volume de dadosaumenta de maneira significativa é prudente reexecutar o AG e obter um individuo melhoradaptado, pois o AG especialista sempre alcançará menor RMSE (se comparado com AGsgeneralistas e técnicas de FC).

CAPÍTULO 5Considerações Finais
Após a apresentação deste trabalho e dos resultados alcançados nos estudos decaso, a Seção 5.1 apresenta algumas conclusões e a Seção 5.3 direciona os trabalhosfuturos com sugestões de aprimoramento e aplicações em novas áreas.
5.1 Conclusão
Este trabalho teve como objetivo testar uma abordagem evolutiva para combinarresultados de técnicas de SR baseadas em FC. Os experimentos realizados mostraram queao fazer esta combinação, o erro (RMSE) para a previsão de avaliação do Recomendadordiminui em comparação com a abordagem usando apenas uma técnica.
Os resultados mostram que há uma redução do RMSE de, pelo menos, 9,028%,quando comparados com a melhor técnica isolada, e esta diferença aumenta para 48,21%,quando comparados com a pior técnica, como pode ser observado nos experimentosapresentados na subseção 4.2. Nos experimentos realizados na subseção 4.3, demonstra-seque no caso de poucas informações sobre o usuário-alvo e se tem que escolher umatécnica única para o cálculo de similaridade, uma boa opção seria usar a Euclidiana, ade Tanimoto ou a Loglikelihood porque elas foram capazes de manter um baixo valor deRMSE, mesmo quando algumas avaliações são removidas do usuário-alvo.
O AG apresentou também um bom desempenho, mesmo no cenário em que ousuário-alvo tem poucas avaliações, para este caso observamos uma redução de 11,65%do RMSE em comparação com o melhor resultado (Loglikelihood), como também podeser observado, com mais detalhes, no experimento apresentado na subseção 4.4.
Outro ponto a ser observado, é que a generalização pode ser aplicada de formasatisfatória, por não aumentar significantemente o erro do Recomendador e por serexecutado em tempo equivalente ao das técnicas de FC, como pode ser observado noexperimento 4.5. Este mesmo comportamento pode ser observado também em cenáriosonde existe variação da quantidade de avaliações do usuário-alvo, como pode serobservado no experimento 4.6.

5.2 Contribuições 84
Porém, para casos onde existem variações da quantidade de avaliações de todosos usuários ao mesmo tempo, existe um aumento no RMSE à medida que são inseridasnovas avaliações na matriz, levando a necessidade de reexecutar o AG, quando o volumede dados aumenta de maneira significativa, como pode ser observado no experimento 4.7.
5.2 Contribuições
A contribuição do Invenire se dá em problemas onde o projetista, tenha queescolher qual técnica de recomendação será utilizada. O problema da escolha de umaopção de técnica de recomendação, dentre as várias disponíveis, é muito difícil de serresolvida, pois demanda um grande esforço humano na descoberta da técnica que tem omenor erro em suas predições.
O algoritmo proposto por este trabalho busca resolver esta questão com autilização de Algoritmos Genéticos no aprendizado do grau de importância de cada umadas técnicas utilizadas na tomada de decisão. Este aprendizado pode ser realizado a partirde qualquer base de dados histórica.
Desta forma, a partir de uma base de dados histórica que contenha as avaliaçõesdos usuários, é possível empregar o Invenire para a escolha da melhor combinação deresultados de técnicas de recomendação. O Invenire pode ser empregado também emoutras abordagens, tais como baseada em Conteúdo e Híbridas.
Na etapa final deste trabalho, foi escrito o artigo “An evolutionary approach for
combining results of Recommender Systems techniques based on Collaborative Filtering”
que apresenta o algoritmo que faz uso da abordagem colaborativa. Este artigo foi aceitona IEEE Congress on Evolutionary Computation.
5.3 Trabalhos Futuros
Considerando-se a independência da proposta para as técnicas de recomendaçãoutilizada, sugere-se como trabalhos futuros, realizar experimentos com outras abordagensde SR, tais como algoritmos baseados em conteúdo e abordagens híbridas.
O Invenire para realizar o experimento 4.4, fez o uso das variáveis w1 e w2definidas na subseção 4.1 de maneira manual, sendo esses valores uma decisão doprojetista. Sugere-se que os valores dessas variáveis sejam encontrados dinamicamentepelo algoritmo.
Sugere-se também que seja empregado técnicas de programação paralela paraotimizar o processamento do AG e com isso diminuir o custo computacional de execução.

5.3 Trabalhos Futuros 85
Finalmente, é sugerido o emprego de outros modelos de algoritmos/técnicaspara a proposta da Seção 3, tais como a programação dinâmica e outros algoritmosevolucionários.

Referências Bibliográficas
[Adomavicius e Tuzhilin 2005]ADOMAVICIUS, G.; TUZHILIN, A. Toward the next
generation of recommender systems: a survey of the state-of-the-art and possible
extensions. Knowledge and Data Engineering, IEEE Transactions on, v. 17, n. 6, p.
734–749, 2005. ISSN 1041-4347.
[Aher e Lobo 2013]AHER, S. B.; LOBO, L. Combination of machine learning algorithms
for recommendation of courses in e-learning system based on historical data.
Knowledge-Based Systems, v. 51, n. 0, p. 1 – 14, 2013. ISSN 0950-7051. Disponível
em: <http://www.sciencedirect.com/science/article/pii/S0950705113001275>.
[Ahn 2006]AHN, C. W. Advances in Evolutionary Algorithms: Theory, Design and Practice
(Studies in Computational Intelligence). Secaucus, NJ, USA: Springer-Verlag New York,
Inc., 2006. ISBN 3540317589.
[Antunes et al. 2008]ANTUNES, P. et al. Structuring dimensions for collaborative
systems evaluation. ACM Comput. Surv., ACM, New York, NY, USA,
v. 44, n. 2, p. 8:1–8:28, mar. 2008. ISSN 0360-0300. Disponível em:
<http://doi.acm.org/10.1145/2089125.2089128>.
[Ashlock 2005]ASHLOCK, D. Evolutionary Computation for Modeling and Optimization.
[S.l.]: Springer, 2005.
[Back, Fogel e Michalewicz 1997]BACK, T.; FOGEL, D. B.; MICHALEWICZ, Z. (Ed.).
Handbook of Evolutionary Computation. 1st. ed. Bristol, UK, UK: IOP Publishing Ltd.,
1997. ISBN 0750303921.
[Back, Hammel e Schwefel 1996]BACK, T.; HAMMEL, U.; SCHWEFEL, H. P. Evolutionary
Computation: An Overview. [S.l.]: Proc. 3rd IEEE Conf. on Evolutionary Computation,
1996. 20-29 p.
[Back, Rudolph e Schwefel 1995]BACK, T.; RUDOLPH, G.; SCHWEFEL, H. P.
Programming and Evolution “Evolutionary Strategies: Similarities and Differnces”.
Granda, Spain: Proc. Od European Conf. on Alife, 1995.

Referências Bibliográficas 87
[Back e Schwefel 1993]BACK, T.; SCHWEFEL, H. P. An Overview of Evolutionary
Algorithms for Parameters Optimization. [S.l.]: Evolutionary Computation, 1993. 1-27 p.
[Baltrunas, Makcinskas e Ricci 2010]BALTRUNAS, L.; MAKCINSKAS, T.; RICCI, F. Group
recommendations with rank aggregation and collaborative filtering. In: Proceedings
of the Fourth ACM Conference on Recommender Systems. New York, NY, USA:
ACM, 2010. (RecSys 10), p. 119–126. ISBN 978-1-60558-906-0. Disponível em:
<http://doi.acm.org/10.1145/1864708.1864733>.
[BARRETO 1997]BARRETO, J. Inteligência artificial - no limiar do século xxi. ppp Edições,
1997.
[Belew e Forrest 1998]BELEW, R.; FORREST, S. Learning and Programming in Classsifier
System. [S.l.]: Machine Learning, 1998.
[Billsus e Pazzani 2000]BILLSUS, D.; PAZZANI, M. J. User modeling for adaptive news
access. User Modeling and User-Adapted Interaction, Kluwer Academic Publishers,
Hingham, MA, USA, v. 10, n. 2-3, p. 147–180, fev. 2000. ISSN 0924-1868. Disponível
em: <http://dx.doi.org/10.1023/A:1026501525781>.
[Bledsoe 1961]BLEDSOE, W. W. The use of biological concepts in the analytical study
of systems. Panoramic Research Report, ORSA-TIMS National Meeting, San Francisco,
1961.
[Bobadilla et al. 2011]BOBADILLA, J. et al. A framework for collaborative
filtering recommender systems. Expert Systems with Applications, Elsevier Ltd,
v. 38, n. 12, p. 14609–14623, nov. 2011. ISSN 09574174. Disponível em:
<http://linkinghub.elsevier.com/retrieve/pii/S0957417411008049>.
[Bobadilla et al. 2012]BOBADILLA, J. et al. Collaborative filtering based on significances.
Inf. Sci., Elsevier Science Inc., New York, NY, USA, v. 185, n. 1, p. 1–17, fev. 2012. ISSN
0020-0255. Disponível em: <http://dx.doi.org/10.1016/j.ins.2011.09.014>.
[Bobadilla et al. 2013]BOBADILLA, J. et al. Recommender systems survey. Know-Based
Systems, Elsevier Science Publishers B. V., Amsterdam, The Netherlands, The
Netherlands, v. 46, p. 109–132, jul. 2013. ISSN 0950-7051. Disponível em:
<http://dx.doi.org/10.1016/j.knosys.2013.03.012>.
[Booker, Goldberg e Holland 1989]BOOKER, L. B.; GOLDBERG, D. E.; HOLLAND, J. H.
Classifier Systems and Genetic Algorithms. [S.l.]: Artificial Intelligence, 1989.
[Box 1957]BOX, G. E. P. Evolutionary Operation: A Method for Increasing Industrial
Productivity. Applied Statistics, v. 6, n. 2, p. 81–101, jun. 1957.

Referências Bibliográficas 88
[Breese, Heckerman e Kadie 1998]BREESE, J.; HECKERMAN, D.; KADIE, C. Empirical
analysis of predictive algorithms for collaborative filtering. Proceedings of the Fourteenth
. . . , 1998. Disponível em: <http://dl.acm.org/citation.cfm?id=2074100>.
[Breese, Heckerman e Kadie 1998]BREESE, J. S.; HECKERMAN, D.; KADIE, C.
Empirical analysis of predictive algorithms for collaborative filtering. In: Proceedings of
the Fourteenth Conference on Uncertainty in Artificial Intelligence. San Francisco, CA,
USA: Morgan Kaufmann Publishers Inc., 1998. (UAI’98), p. 43–52. ISBN 1-55860-555-X.
Disponível em: <http://dl.acm.org/citation.cfm?id=2074094.2074100>.
[Bremermann 1962]BREMERMANN, H. J. Optimization through evolution and
recombination. In: YOVITS, M. C.; JACOBI, G. T.; GOLSTINE, G. D. (Ed.). Proceedings
of the Conference on Self-Organizing Systems – 1962. Washington, DC: Spartan Books,
1962. p. 93–106.
[Bremermann, Rogson e Salaff 1966]BREMERMANN, H. J.; ROGSON, M.; SALAFF, S.
Global properties of evolution processes. Spartan Books,, Publisher, Washington D.C,
1966.
[Brin e Page 1998]BRIN, S.; PAGE, L. The anatomy of a large-scale
hypertextual Web search engine. Computer networks and ISDN systems,
v. 30, n. 1-7, p. 107–117, abr. 1998. ISSN 01697552. Disponível em:
<http://linkinghub.elsevier.com/retrieve/pii/S016975529800110X>.
[Burke 1999]BURKE, R. The wasabi personal shopper: A case-based recommender
system. In: Proceedings of the Sixteenth National Conference on Artificial Intelligence
and the Eleventh Innovative Applications of Artificial Intelligence Conference Innovative
Applications of Artificial Intelligence. Menlo Park, CA, USA: American Association for
Artificial Intelligence, 1999. (AAAI ’99/IAAI ’99), p. 844–849. ISBN 0-262-51106-1.
Disponível em: <http://dl.acm.org/citation.cfm?id=315149.315486>.
[Burke 2000]BURKE, R. Knowledge-based recommender systems. In: ENCYCLOPEDIA
OF LIBRARY AND INFORMATION SYSTEMS. [S.l.]: Marcel Dekker, 2000. p. 2000.
[Burke 2002]BURKE, R. Hybrid recommender systems: Survey and experiments.
User modeling and user-adapted interaction, p. 1–29, 2002. Disponível em:
<http://link.springer.com/article/10.1023/A:1021240730564>.
[Burke 2007]BURKE, R. The adaptive web. In: BRUSILOVSKY, P.; KOBSA, A.; NEJDL,
W. (Ed.). The adaptive web. Berlin, Heidelberg: Springer-Verlag, 2007. cap. Hybrid
Web Recommender Systems, p. 377–408. ISBN 978-3-540-72078-2. Disponível em:
<http://dl.acm.org/citation.cfm?id=1768197.1768211>.

Referências Bibliográficas 89
[Burke, Hammond e Young 1997]BURKE, R. D.; HAMMOND, K. J.; YOUNG, B. C.
The findme approach to assisted browsing. IEEE Expert: Intelligent Systems
and Their Applications, IEEE Educational Activities Department, Piscataway, NJ,
USA, v. 12, n. 4, p. 32–40, jul. 1997. ISSN 0885-9000. Disponível em:
<http://dx.doi.org/10.1109/64.608186>.
[Cacheda et al. 2011]CACHEDA, F. et al. Comparison of collaborative filtering algorithms.
ACM Transactions on the Web, v. 5, n. 1, p. 1–33, fev. 2011. ISSN 15591131. Disponível
em: <http://portal.acm.org/citation.cfm?doid=1921591.1921593>.
[Cacheda et al. 2011]CACHEDA, F. et al. Comparison of collaborative filtering
algorithms: Limitations of current techniques and proposals for scalable,
high-performance recommender systems. ACM Trans. Web, ACM, New York,
NY, USA, v. 5, n. 1, p. 2:1–2:33, fev. 2011. ISSN 1559-1131. Disponível em:
<http://doi.acm.org/10.1145/1921591.1921593>.
[Calvo e D’Mello 2010]CALVO, R.; D’MELLO, S. Affect detection: An interdisciplinary
review of models, methods, and their applications. Affective Computing, IEEE
Transactions on, v. 1, n. 1, p. 18–37, 2010. ISSN 1949-3045.
[Camilo-Junior e Yamanaka 2011]CAMILO-JUNIOR, C. G.; YAMANAKA,
K. In Vitro Fertilization Genetic Algorithm, Evolutionary Algorithms.
Eisuke Kita (Ed.), 2011. ISBN 978-953-307-171-8. Disponível em:
<http://www.intechopen.com/articles/show/title/in-vitro-fertilization-genetic-algorithm>.
[Campos, Oliveira e Jungbeck 2004]CAMPOS, T. J. de; OLIVEIRA, J. R. de; JUNGBECK,
M. Programação genética aplicada ao desenvolvimento de hardware evolutivo.
Congresso Brasileiro de Automática, 2004.
[Candillier, Meyer e Boullé 2007]CANDILLIER, L.; MEYER, F.; BOULLé, M. Comparing
state-of-the-art collaborative filtering systems. In: PERNER, P. (Ed.). Machine Learning
and Data Mining in Pattern Recognition. Springer Berlin Heidelberg, 2007, (Lecture Notes
in Computer Science, v. 4571). p. 548–562. ISBN 978-3-540-73498-7. Disponível em:
<http://dx.doi.org/10.1007/978-3-540-73499-441>.
[Carreira et al. 2004]CARREIRA, R. et al. Evaluating adaptive user profiles for news
classification. Proceedings of the 9th international conference on Intelligent user
interfaces, New York, NY, USA. ACM Press, p. 206–212, 2004.
[Cazella, Nunes e Reategui 2010]CAZELLA, S.; NUNES, M.; REATEGUI, E. A Ciência da
Opinião: Estado da arte em Sistemas de Recomendação. CSBC - XXX Congresso da

Referências Bibliográficas 90
SBC - Jornada de Atualização de Informática-JAI, p. 161–216, 2010. Disponível em:
<http://www.dcomp.ufs.br/ gutanunes/hp/publications/JAI4.pdf>.
[Cline 2003]CLINE, J. Web Site Privacy Seals: Are they worth it? [S.l.]: Computer World,
2003.
[CORREA e CAZELLA 2007]CORREA, I.; CAZELLA, S. C. Um modelo para
recomendação de itens baseado em filtragem colaborativa para dispositivos móveis.
[S.l.: s.n.], 2007. Workshop on undergraduate research, Gramado. Webmedia.
[Damasio 1994]DAMASIO, A. R. Descartes’ Error. Emotion, reason and the human brain.
New York: Avon Books, 1994.
[Darwin 1995]DARWIN, C. The Origin of Species. [S.l.]: Gramercy, 1995. Hardcover. ISBN
0517123207.
[Davis 1991]DAVIS, L. Handbook of Genetic Algorithms. [S.l.]: Van Nostrand Reinhold,
1991.
[DeJong 1975]DEJONG, K. An analysis of the Behavior of a Class of Genetic Adptive
Systems. Tese (Doutorado) — Univ. Of Michigan, 1975.
[DeJong 1994]DEJONG, K. A. Genetic Algorithms: A 25 Year perspective. [S.l.]: R. J.
Marks II, and C. J. Robinson, 1994. 125-134 p.
[Delgado 2000]DELGADO, J. A. Agent-Based Information Filtering and Recommender
System on the Internet. Tese (Doutorado) — Nagoya Institute of Technology. Dept. of
Intelligence Computer Science, March 2000.
[Dellarocas 2000]DELLAROCAS, C. Immunizing online reputation reporting systems
against unfair ratings and discriminatory behavior. In: Proceedings of the 2nd ACM
conference on Electronic commerce. ACM, 2000. p. 150–157. ISBN 1581132727.
Disponível em: <http://dl.acm.org/citation.cfm?id=352889>.
[Demir, Uyar e Oguducu 2007]DEMIR, G. N.; UYAR, A. S.; OGUDUCU, S. G.
Graph-based sequence clustering through multiobjective evolutionary algorithms
for web recommender systems. In: Proceedings of the 9th Annual Conference
on Genetic and Evolutionary Computation. New York, NY, USA: ACM, 2007.
(GECCO ’07), p. 1943–1950. ISBN 978-1-59593-697-4. Disponível em:
<http://doi.acm.org/10.1145/1276958.1277346>.
[D.Manning, Raghavan e Schutze 2009]D.MANNING, C.; RAGHAVAN, P.; SCHUTZE, H.
An Introduction to Information Retrieval. Cambridge University Press, p. 581, 2009.

Referências Bibliográficas 91
[Donath 1999]DONATH, J. S. Identity and deception in the virtual community. M. A. Smith
and P. Kollock, editors, Communities in Cyberspace, Routledge, London, v. 1, n. 2, p.
29–59, 1999.
[Donath 2000]DONATH, J. S. Being real: Questions of tele-identity. Ken Goldberg, editor,
The Robot in the Garden: Telerobotics and Telepistemology in the Age of the Internet,
The MIT Press, v. 1, n. 16, p. 296–311, 2000.
[Eiben e Smith 2003]EIBEN, A.; SMITH, J. Introduction To Evolutionary Computing. [S.l.]:
Springer, 2003.
[Engelbrecht 2007]ENGELBRECHT, A. P. Computational Intelligence - An Introduction. 2.
ed. [S.l.]: Andries P. Engelbrecht, 2007.
[Fogel 1994]FOGEL, D. An introduction to simulated evolutionary optimization. Neural
Networks, IEEE Transactions on, v. 5, n. 1, p. 3–14, Jan 1994. ISSN 1045-9227.
[Fogel, Owens e Walsh 1996]FOGEL, L.; OWENS, A. J.; WALSH, M. J. Artificial Intelligent
Through Simulated Evolution. [S.l.]: John Wiley, 1996.
[Fong, Ho e Hang 2008]FONG, S.; HO, Y.; HANG, Y. Using genetic algorithm for hybrid
modes of collaborative filtering in online recommenders. 2008 Eighth International
Conference on Hybrid Intelligent Systems, IEEE, p. 174–179, set. 2008. Disponível em:
<http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=4626625>.
[Fraser 1957]FRASER, A. S. Simulation of genetic systems by automatic digital computers.
Australian Journal of Biological Sciences, v. 10, p. 484–491, 1957.
[Giddens 1991]GIDDENS, A. Modernity and self-identity. self and society in the late
modern age. Stanford university Press, Stanford, California, 1991.
[Goldberg et al. 1992]GOLDBERG, D. et al. Using collaborative filtering to
weave an information tapestry. Commun. ACM, ACM, New York, NY,
USA, v. 35, p. 61–70, December 1992. ISSN 0001-0782. Disponível em:
<http://doi.acm.org/10.1145/138859.138867>.
[Goldberg 1989]GOLDBERG, D. E. Genetic Algorithms in Search. [S.l.]: Optimization and
Machine Learning, 1989.
[Goldberg e Holland 1988]GOLDBERG, D. E.; HOLLAND, J. H. Genetic algorithms and
machine learning. Machine learning, Springer, v. 3, n. 2, p. 95–99, 1988.
[Goleman 1997]GOLEMAN, D. Emotional Intelligence: Why It Can Matter More Than IQ.
[S.l.]: Bantam, 1997. Paperback. ISBN 0553375067.

Referências Bibliográficas 92
[Gomes e Saavedra 1999]GOMES, J. R.; SAAVEDRA, O. R. Optimal Reactive Power
Dispatch using Evolutionary Computation: Extend Algorithms. [S.l.]: IEE Proc.-Gene.,
1999.
[Gonzalez et al. 2007]GONZALEZ, G. et al. Embedding emotional context in
recommender systems. In: Data Engineering Workshop, 2007 IEEE 23rd International
Conference on. [S.l.: s.n.], 2007. p. 845–852.
[GROSSMAN 2009]GROSSMAN, L. How computers know what we
want - before we do. [S.l.: s.n.], 2009. Available online on
http://www.time.com/time/magazine/article/0,9171,1992403-1,00.htm.
[Gunawardana e Shani 2009]GUNAWARDANA, A.; SHANI, G. A survey of
accuracy evaluation metrics of recommendation tasks. J. Mach. Learn. Res.,
JMLR.org, v. 10, p. 2935–2962, dez. 2009. ISSN 1532-4435. Disponível em:
<http://dl.acm.org/citation.cfm?id=1577069.1755883>.
[Guttman 1998]GUTTMAN, R. Agent-mediated electronic commerce:
a survey. Knowledge Engineering . . . , 1998. Disponível em:
<http://journals.cambridge.org/production/action/cjoGetFulltext?fulltextid=71016>.
[Herlocker 2000]HERLOCKER, J. L. Understanding and improving automated
collaborative filtering systems. Tese (Doutorado) — University of Minnesota, 2000.
AAI9983577.
[Herlocker et al. 1999]HERLOCKER, J. L. et al. An algorithmic framework for performing
collaborative filtering. Workshop on Social Recommender Systems (SRS’10), p. 13, 1999.
[Herlocker et al. 2004]HERLOCKER, J. L. et al. Evaluating collaborative
filtering recommender systems. ACM Trans. Inf. Syst., ACM, New York, NY,
USA, v. 22, n. 1, p. 5–53, jan. 2004. ISSN 1046-8188. Disponível em:
<http://doi.acm.org/10.1145/963770.963772>.
[Ho, Fong e Yan 2007]HO, Y.; FONG, S.; YAN, Z. A hybrid ga-based collaborative
filtering model for online recommenders. In: FILIPE, J. et al. (Ed.). ICE-B.
INSTICC Press, 2007. p. 200–203. ISBN 978-989-8111-11-1. Disponível em:
<http://dblp.uni-trier.de/db/conf/icete/ice-b2007.htmlHoFY07>.
[Hofmann 2004]HOFMANN, T. Latent semantic models for collaborative filtering. ACM
Trans. Inf. Syst., ACM, New York, NY, USA, v. 22, n. 1, p. 89–115, jan. 2004. ISSN
1046-8188. Disponível em: <http://doi.acm.org/10.1145/963770.963774>.

Referências Bibliográficas 93
[Holland 1975]HOLLAND, J. Adaptation in Natural and Artificial Systems. [S.l.]: HOLLAND,
J.H, 1975.
[Holland 1992]HOLLAND, J. Genetic Algorithms. [S.l.]: Scientific American, 1992. 66-72 p.
[Holland 1986]HOLLAND, J. H. Induction: Processes of Inference, Learning, and
Discovery. Tese (Doutorado) — MIT Press, 1986.
[Hu e Pu 2010]HU, R.; PU, P. Using Personality Information in Collaborative Filtering for
New Users. Recommender Systems and the Social Web, p. 17–24, 2010. Disponível em:
<http://www.dcs.warwick.ac.uk/ ssanand/RSWeb_files/Proceedings_RSWEB-10.pdf>.
[Hurley e Zhang 2011]HURLEY, N.; ZHANG, M. Novelty and diversity in top-n
recommendation – analysis and evaluation. ACM Trans. Internet Technol., ACM, New
York, NY, USA, v. 10, n. 4, p. 14:1–14:30, mar. 2011. ISSN 1533-5399. Disponível em:
<http://doi.acm.org/10.1145/1944339.1944341>.
[Jensen, Davis e Farnham 2002]JENSEN, C.; DAVIS, J.; FARNHAM, S. Finding others
online: reputation systems for social online spaces. Proceedings of the SIGCHI
conference on Human factors in computing systems, New York,NY, USA.ACM., p.
447–454, 2002.
[Josang, Ismail e Boyd 2007]JOSANG, A.; ISMAIL, R.; BOYD, C. A survey of
trust and reputation systems for online service provision. Decis. Support
Syst., Elsevier Science Publishers B. V., Amsterdam, The Netherlands, The
Netherlands, v. 43, n. 2, p. 618–644, mar. 2007. ISSN 0167-9236. Disponível em:
<http://dx.doi.org/10.1016/j.dss.2005.05.019>.
[Karypis 2000]KARYPIS, G. Evaluation of item-based top-n recommendation algorithms.
In: . [S.l.: s.n.], 2000. p. 247–254.
[Koza 1992]KOZA, J. Genetic Programming: On the Programming of Computers by means
of Natural Selection. Granda, Spain: MIT Press, 1992.
[Koza 1994]KOZA, J. Genetic Programming II: Automatic Discovery of Reusable
Programs. [S.l.]: MIT Press, 1994.
[Krulwich 1997]KRULWICH, B. Lifestyle finder: Intelligent user profiling using large-scale
demographic data. AI Magazine, v. 18, n. 2, p. 37–45, 1997.
[Lampropoulos, Sotiropoulos e Tsihrintzis 2012]LAMPROPOULOS, A. S.;
SOTIROPOULOS, D. N.; TSIHRINTZIS, G. A. Evaluation of a cascade hybrid
recommendation as a combination of one-class classification and collaborative filtering.

Referências Bibliográficas 94
IEEE 24th International Conference on Tools with Artificial Intelligence, Athens, Greece,
November 7-9, 2012, IEEE, p. 674–681, 2012.
[Langdon e Poli 1998]LANGDON, W. B.; POLI, R. Foundations of genetic programming.
[S.l.]: Springer, 1998.
[Linden 2008]LINDEN, R. Algoritmos genéticos. 2. ed. [S.l.]: Brasport, 2008.
[Lisetti 2002]LISETTI, C. L. Personality, affect and emotion taxonomy for socially intelligent
agents. In: Proceedings of the Fifteenth International Florida Artificial Intelligence
Research Society Conference. AAAI Press, 2002. p. 397–401. ISBN 1-57735-141-X.
Disponível em: <http://dl.acm.org/citation.cfm?id=646815.708305>.
[Liu, Dolan e Pedersen 2010]LIU, J.; DOLAN, P.; PEDERSEN, E. R. Personalized
news recommendation based on click behavior. In: Proceedings of the 15th
International Conference on Intelligent User Interfaces. New York, NY, USA:
ACM, 2010. (IUI ’10), p. 31–40. ISBN 978-1-60558-515-4. Disponível em:
<http://doi.acm.org/10.1145/1719970.1719976>.
[Lopes 2006]LOPES, A. C. F. Geração de estimativas de eeputação mais precisas perante
a oscilação de comportamento das entidades avaliadas. Dissertação (Dissertação de
Mestrado) — Universidade Federal Fluminense, 2006.
[Luke 2009]LUKE, S. Essentials of Metaheuristics. [S.l.]: Lulu, 2009. Available for free at
http://cs.gmu.edu/∼sean/book/metaheuristics/.
[Luo, Xia e Zhu 2012]LUO, X.; XIA, Y.; ZHU, Q. Incremental collaborative
filtering recommender based on regularized matrix factorization. Know.-Based
Syst., Elsevier Science Publishers B. V., Amsterdam, The Netherlands, The
Netherlands, v. 27, p. 271–280, mar. 2012. ISSN 0950-7051. Disponível em:
<http://dx.doi.org/10.1016/j.knosys.2011.09.006>.
[MacKay 2002]MACKAY, D. J. C. Information Theory, Inference & Learning Algorithms.
New York, NY, USA: Cambridge University Press, 2002. ISBN 0521642981.
[Marmanis e Babenko 2009]MARMANIS, H.; BABENKO, D. Algorithms of the intelligent
web. Manning Publications Co., 2009. ISBN 9781933988665. Disponível em:
<http://dl.acm.org/citation.cfm?id=1717301>.
[Michalewicz 1992]MICHALEWICZ, Z. Genetic algorithms + data structures = evolution
programs. 3. ed. [S.l.]: Michalewicz, Zbigniew, 1992.
[MITCHELL 1997]MITCHELL, M. An introduction to genetic algorithms. Cambridge: Mit
Press, 1997.

Referências Bibliográficas 95
[Mitchell 1998]MITCHELL, M. An introduction to genetic algorithms. [S.l.]: MIT press, 1998.
ISBN 0-262-13316-4.
[Montaner, Lopez e Rosa 2003]MONTANER, M.; LOPEZ, B.; ROSA, J. D. L. A taxonomy
of recommender agents on the internet. Artificial intelligence review, p. 285–330, 2003.
Disponível em: <http://link.springer.com/article/10.1023/A:1022850703159>.
[Nass e Lee 2000]NASS, C.; LEE, K. Does computer-generated speech manifest
personality? An experimental test of similarity-attraction. Proceedings of the SIGCHI
conference on Human . . . , ACM Press, New York, New York, USA, v. 2, n. 1, p.
329–336, 2000. Disponível em: <http://portal.acm.org/citation.cfm?doid=332040.332452
http://dl.acm.org/citation.cfm?id=332452>.
[Nass et al. 1995]NASS, C. et al. Can computer personalities be human
personalities? International Journal of Human-Computer Studies,
v. 43, n. 2, p. 223 – 239, 1995. ISSN 1071-5819. Disponível em:
<http://www.sciencedirect.com/science/article/pii/S1071581985710427>.
[Nehring e Puppe 2002]NEHRING, K.; PUPPE, C. A theory of diversity. Econometrica,
v. 70, n. 3, p. 1155–1198, May 2002. Doi: 10.1111/1468-0262.00321. Disponível em:
<http://www.blackwell-synergy.com/doi/abs/10.1111/1468-0262.00321>.
[Nikolaev, Iba e Slavov 1999]NIKOLAEV, N.; IBA, H.; SLAVOV, V. In ductive genetic
programming with immune network dynamics. [S.l.]: Advances in Genetic Programming,
1999. 355-376 p.
[Nogueira e Saavedra 1999]NOGUEIRA, M.; SAAVEDRA, O. R. Estratégias evolutivas
aplicadas à resolução de otimização multimodal. Simpósio Brasileiro de Automação
Inteligente, 1999.
[Nunes e Aranha 2009]NUNES, M.; ARANHA, C. Tendências à Tomada de
Decisão computacional. Proceedings of W3C. W3C Brasil, 2009. Disponível em:
<http://200.17.141.213/ gutanunes/hp/publications/W3C2009.pdf>.
[Nunes 2010]NUNES, M. A. S. Towards to psychological-based recommenders systems:
A survey on recommender systems. Scientia Plena, Associação Sergipana de Ciências,
São Cristóvão, SE, Brasil, v. 6, n. 8, p. 1–28, ago. 2010. ISSN 1808-2793. Disponível em:
<http://www.scientiaplena.org.br/ojs/index.php/sp/article/view/119>.
[Nunes, Cerri e Blanc 2008]NUNES, M. A. S. N.; CERRI, S. A.; BLANC,
N. Towards user psychological profile. IHC ’08, Sociedade Brasileira de
Computação, Porto Alegre, Brazil, Brazil, p. 196–203, 2008. Disponível em:
<http://dl.acm.org/citation.cfm?id=1497470.1497492>.

Referências Bibliográficas 96
[Olmo e Gaudioso 2008]OLMO, F. Hernandez del; GAUDIOSO, E. Evaluation of
recommender systems: A new approach. Expert Syst. Appl., Pergamon Press, Inc.,
Tarrytown, NY, USA, v. 35, n. 3, p. 790–804, out. 2008. ISSN 0957-4174. Disponível
em: <http://dx.doi.org/10.1016/j.eswa.2007.07.047>.
[Owen et al. 2011]OWEN, S. et al. Mahout in Action. [S.l.]: Manning Publications, 2011.
415 p. ISBN 9781935182689.
[Paiva 2000]PAIVA, A. (Ed.). Affective Interactions, Towards a New Generation of
Computer Interfaces., v. 1814 de Lecture Notes in Computer Science, (Lecture Notes
in Computer Science, v. 1814). Springer, 2000. ISBN 3-540-41520-3. Disponível em:
<http://dblp.uni-trier.de/db/conf/iwai/iwai1999.html>.
[Park, Hong e Cho 2007]PARK, M.-H.; HONG, J.-H.; CHO, S.-B. Location-based
recommendation system using bayesian user’s preference model in mobile
devices. In: Proceedings of the 4th International Conference on Ubiquitous
Intelligence and Computing. Berlin, Heidelberg: Springer-Verlag, 2007. (UIC’07),
p. 1130–1139. ISBN 3-540-73548-8, 978-3-540-73548-9. Disponível em:
<http://dl.acm.org/citation.cfm?id=2391319.2391438>.
[Picard 1995]PICARD, R. Affective computing. [S.l.]: MIT Media Laboratory, 1995.
[Picard 1997]PICARD, R. W. Affective Computing. Cambridge, MA, USA: MIT Press, 1997.
ISBN 0-262-16170-2.
[Pinto, Tanscheit e Vellasco 2011]PINTO, M. A. G.; TANSCHEIT, R.; VELLASCO, M.
Sistema de recomendação de produtos em marketing com uso de métodos de apoio
à decisão. Computational Intelligence, d, p. 1–7, 2011.
[Poo, Chng e Goh 2003]POO, D.; CHNG, B.; GOH, J. A hybrid approach for user profiling.
Proceedings of the 36th Annual Hawaii International Conference on System Sciences
(HICSS’03) - IEEE Computer Society, 2003.
[Qingshui e Meiyu 2010]QINGSHUI, L.; MEIYU, Z. The study of personalized
recommendation technology based content and project collaborative filtering combines.
In: Advanced Computer Theory and Engineering (ICACTE), 2010 3rd International
Conference on. [S.l.: s.n.], 2010. v. 5, p. V5–506–V5–510. ISSN 2154-7491.
[Reategui e Cazella 2005]REATEGUI, E. B.; CAZELLA, S. C. Sistemas de
Recomendação. XXV Congresso da Sociedade Brasileira de Computação. A
Universalidade da Computação: Um Agente de Inovação e Conhecimento, p. 306–348,
2005.

Referências Bibliográficas 97
[Rechenberg 1973]RECHENBERG, I. Evolutions strategie: Optimierung Technischer
Systems nach Prinzipien der Biolgischen Evolution. [S.l.]: Frommann-Holzboog Verlag,
1973.
[Rechenberg 1994]RECHENBERG, I. Evolution Strategy. [S.l.]: IEEE Press, 1994.
147-159 p.
[Rein 2005]REIN, G. L. Reputation information systems: A reference model. In: System
Sciences, 2005. HICSS ’05. Proceedings of the 38th Annual Hawaii International
Conference on. [S.l.: s.n.], 2005. p. 26a–26a. ISSN 1530-1605.
[Resnick et al. 1994]RESNICK, P. et al. Grouplens: an open architecture for collaborative
filtering of netnews. In: Proceedings of the 1994 ACM conference on Computer supported
cooperative work. New York, NY, USA: ACM, 1994. (CSCW ’94), p. 175–186. ISBN
0-89791-689-1. Disponível em: <http://doi.acm.org/10.1145/192844.192905>.
[Resnick et al. 2000]RESNICK, P. et al. Reputation systems. Commun. ACM, p. 45–48,
2000.
[Resnick e Varian 1997]RESNICK, P.; VARIAN, H. R. Recommender systems. Commun.
ACM, ACM, New York, NY, USA, v. 40, p. 56–58, March 1997. ISSN 0001-0782.
Disponível em: <http://doi.acm.org/10.1145/245108.245121>.
[Resnick et al. 2006]RESNICK, P. et al. The value of reputation on ebay: A controlled
experiment. Experimental Economics, p. 79–101, 2006.
[Rich 1979]RICH, E. User modeling via stereotypes. Cognitive Science, Morgan Kaufmann
Publishers Inc., v. 3, p. 329–354, 1979.
[Roh, Oh e Han 2003]ROH, T. H.; OH, K. J.; HAN, I. The collaborative filtering
recommendation based on SOM cluster-indexing CBR. Expert Systems with
Applications, v. 25, n. 3, p. 413–423, out. 2003.
[Rothlauf 2006]ROTHLAUF, F. Representations for genetic and evolutionary
algorithms. Second. pub-SV:adr: Springer-Verlag, 2006. First published 2002,
2nd edition available electronically. ISBN 3-540-25059-X. Disponível em:
<http://download-ebook.org/index.php?target=descebookid=5771>.
[Sarwar et al. 2000]SARWAR, B. et al. Analysis of recommendation algorithms for
e-commerce. In: Proceedings of the 2nd ACM conference on Electronic commerce. New
York, NY, USA: ACM, 2000. (EC ’00), p. 158–167. ISBN 1-58113-272-7. Disponível em:
<http://doi.acm.org/10.1145/352871.352887>.

Referências Bibliográficas 98
[Schafer, Konstan e Riedl 2001]SCHAFER, J.; KONSTAN, J.; RIEDL, J. E-commerce
recommendation applications. Data Mining and Knowledge Discovery, v. 5, n. Kluwer
Academic Publishers. Manufactured in The Netherlands., p. 115–153, 2001. Disponível
em: <http://link.springer.com/chapter/10.1007/978-1-4615-1627-9_6>.
[Schafer et al. 2007]SCHAFER, J. B. et al. The adaptive web. In:
BRUSILOVSKY, P.; KOBSA, A.; NEJDL, W. (Ed.). The Adaptive Web.
Berlin, Heidelberg: Springer-Verlag, 2007. cap. Collaborative Filtering
Recommender Systems, p. 291–324. ISBN 978-3-540-72078-2. Disponível em:
<http://dl.acm.org/citation.cfm?id=1768197.1768208>.
[Schafer, Konstan e Riedl 1999]SCHAFER, J. B.; KONSTAN, J.; RIEDL, J. Recommender
systems in e-commerce. In: Proceedings of the 1st ACM Conference on Electronic
Commerce. New York, NY, USA: ACM, 1999. (EC ’99), p. 158–166. ISBN 1-58113-176-3.
Disponível em: <http://doi.acm.org/10.1145/336992.337035>.
[Schein et al. 2002]SCHEIN, A. I. et al. Methods and metrics for cold-start
recommendations. In: Proceedings of the 25th Annual International ACM SIGIR
Conference on Research and Development in Information Retrieval. New York, NY,
USA: ACM, 2002. (SIGIR ’02), p. 253–260. ISBN 1-58113-561-0. Disponível em:
<http://doi.acm.org/10.1145/564376.564421>.
[Shardanand e Maes 1995]SHARDANAND, U.; MAES, P. Social information filtering:
algorithms for automating “word of mouth”. Proceedings of the SIGCHI conference, p.
210–217, 1995. Disponível em: <http://dl.acm.org/citation.cfm?id=223931>.
[Silva et al. 2014]SILVA, E. Q. da et al. An evolutionary approach for combining results
of recommender systems techniques based on collaborative filtering. In: Evolutionary
Computation (CEC), 2014 IEEE Congress on. [S.l.: s.n.], 2014. p. 959–966.
[Silveira 2011]SILVEIRA, S. L. . P. S. . G. Introdução à Arquitetura e Design de Software -
Uma Visão Sobre a Plataforma Java. São Paulo: ELSEVIER - CAMPUS, 2011.
[Simon 1983]SIMON, H. Reason in human affairs. Oxford: Blackwell, 1983. ISBN
0631134093.
[Su e Khoshgoftaar 2009]SU, X.; KHOSHGOFTAAR, T. M. A survey of collaborative
filtering techniques. Adv. in Artif. Intell., Hindawi Publishing Corp., New York, NY,
United States, v. 2009, p. 4:2–4:2, jan. 2009. ISSN 1687-7470. Disponível em:
<http://dx.doi.org/10.1155/2009/421425>.
[Symeonidis, Nanopoulos e Manolopoulos 2009]SYMEONIDIS, P.; NANOPOULOS, A.;
MANOLOPOULOS, Y. Moviexplain: A recommender system with explanations. In:

Referências Bibliográficas 99
Proceedings of the Third ACM Conference on Recommender Systems. New York, NY,
USA: ACM, 2009. (RecSys ’09), p. 317–320. ISBN 978-1-60558-435-5. Disponível em:
<http://doi.acm.org/10.1145/1639714.1639777>.
[Tanomaru 1995]TANOMARU, J. Motivação, fundamentos e aplicações de algoritmos
genéticos. Anais do II Congresso Brasileiro de Redes Neurais, 1995.
[Terveen e Hill 2001]TERVEEN, L.; HILL, W. Beyond recommender systems: Helping
people help each other. In: HCI in the New Millennium. [S.l.]: Addison-Wesley, 2001.
p. 487–509.
[Thagard 2006]THAGARD, P. (Ed.). Hot Thought: Mechanisms and Applications of
Emotional Cognition. Cambridge, MA, USA: A Bradford Book, 2006. ISBN 026220164X.
[TORRES 2004]TORRES, R. Personalização na Internet: Como Descobrir os Hábitos de
Consumo de Seus Clientes, Fidelizá-los e Aumentar o Lucro de Seu Negócio. [S.l.]:
Novatec Editora, 2004.
[Towle e Quinn 2000]TOWLE, B.; QUINN, C. Knowledge based recommender systems
using explicit user models. In: Papers from the AAAI Workshop, AAAI Technical Report
WS-00-04. [S.l.]: Menlo Park, CA: AAAI Press, 2000. p. 74–77.
[Trappl, Payr e Petta 2003]TRAPPL, R.; PAYR, S.; PETTA, P. (Ed.). Emotions in Humans
and Artifacts. Cambridge, MA, USA: MIT Press, 2003. ISBN 0262201429.
[Vargas e Castells 2011]VARGAS, S.; CASTELLS, P. Rank and relevance in
novelty and diversity metrics for recommender systems. In: Proceedings of
the Fifth ACM Conference on Recommender Systems. New York, NY, USA:
ACM, 2011. (RecSys ’11), p. 109–116. ISBN 978-1-4503-0683-6. Disponível em:
<http://doi.acm.org/10.1145/2043932.2043955>.
[Whitley et al. 2000]WHITLEY, L. D. et al. (Ed.). Proceedings of the Genetic and
Evolutionary Computation Conference (GECCO ’00), Las Vegas, Nevada, USA, July
8-12, 2000. [S.l.]: Morgan Kaufmann, 2000. ISBN 1-55860-708-0.
[Wilson e Goldberg 1989]WILSON, S. W.; GOLDBERG, D. E. A critical Review of Classifier
Systems. [S.l.]: Proc. Third Int. Conf. Genetic Algorithms, 1989. 244-255 p.
[Yager 2003]YAGER, R. R. Fuzzy logic methods in recommender systems. Fuzzy
Sets Syst., Elsevier North-Holland, Inc., Amsterdam, The Netherlands, The
Netherlands, v. 136, n. 2, p. 133–149, jun. 2003. ISSN 0165-0114. Disponível em:
<http://dx.doi.org/10.1016/S0165-0114(02)00223-3>.

Referências Bibliográficas 100
[Yao e Liu 1993]YAO, X.; LIU, Y. Fast Evolution Strategies. [S.l.]: Proc. 5th Annual Conf.
Evolutionary Programming, 1993. 451-460 p.
[Yao, Liu e Lin 1999]YAO, X.; LIU, Y.; LIN, G. Evolutionary programming made faster.
IEEE Trans. Evolutionary Computation, v. 3, n. 2, p. 82–102, 1999. Disponível em:
<http://dblp.uni-trier.de/db/journals/tec/tec3.htmlYaoLL99>.
[Zaki 2001]ZAKI, M. J. Spade: An efficient algorithm for mining frequent sequences. In:
Machine Learning. [S.l.: s.n.], 2001. p. 31–60.
[Zhong e Li 2010]ZHONG, J.; LI, X. Unified collaborative filtering model based on
combination of latent features. Expert Syst. Appl., v. 37, n. 8, p. 5666–5672, 2010.
Disponível em: <http://dblp.uni-trier.de/db/journals/eswa/eswa37.htmlZhongL10>.

APÊNDICE AFrameworks para Sistemas de Recomendação
Este Apêndice apresenta de maneira simples, alguns framework disponíveis parao desenvolvimento e teste de aplicações de sistemas de recomendação. Os textos daspróximas seções foram retirados e traduzidos livremente do site da ferramenta (acessadosem Dezembro de 2012). A estes textos foram acrescidas informações que julgamos sernecessárias para o entendimento completo da ferramenta.
A.1 C/Matlab Toolkit para filtragem colaborativa
C/Matlab Toolkit1 é um conjunto de funções que implementa vários modelosde filtragem colaborativa desenvolvidas em C e Matlab. Além da implementaçãode vários algoritmos propostos na literatura recente, também fornece funções paracarregar, manusear e avaliar métodos de filtragem colaborativa. Os principais móduloscomputacionais são implementados em C como arquivos mex que são chamados a partirde um ambiente Matlab alcançando assim a computação eficiente das rotinas bottlenck.
O kit de ferramentas é destinado a executar a partir de um ambiente Matlab. O kité independente de plataforma e deve funcionar em qualquer uma das versões recentes doMatlab(6-6,5). As rotinas de computação intensiva foram escritas em C como arquivosmex e chamadas de Matlab usando a interface de programa de aplicação Mathworks.Os arquivos mex estão disponíveis em uma forma pré-compilada para PC (.dll). Se okit de ferramentas é usado em uma plataforma diferente, os arquivos mex tem que sercompilados usando o comando mex do Matlab.
Preparando o software :
•Download de todos os arquivos disponíveis (disponível como um arquivo zip 2) emum único diretório.
1http://www.cs.cmu.edu/ lebanon/IR-lab.htm2http://www.cs.cmu.edu/ lebanon/IR-lab/CF-toolkit.zip

Apêndice A 102
•Recompilar os arquivos mex, se necessário usando o comando mex -O
computePosteriorPD.c e mex -O memoryBasedModels.c. A sinalizador -O indica onível de otimização.
Para mais informações do kit de ferramentas acesse o tutorial no site da ferramenta3.
A.2 Suggest
Suggest4 é um framework de recomendação Top-N que implementa umavariedade de algoritmos de recomendação. Sistemas de recomendação Top-N, baseada emfiltragem de informação personalizada, são usados para identificar um conjunto de “N”itens que serão de interesse para um determinado usuário. Nos últimos anos, sistemas derecomendação Top-N têm sido utilizados num número de diferentes aplicações, tais como,recomendar produtos para um cliente; recomendar filmes, programas de TV ou música,identificar páginas web que serão de interesse, ou mesmo sugerir formas alternativas debusca de informações.
Os algoritmos implementados por Suggest são baseados em filtragemcolaborativa que é a abordagem de maior sucesso e amplamente utilizada para aconstrução de sistemas de recomendação. Suggest implementa duas classes de algoritmosde colaboração Top-N, a baseada em usuário e a baseada em item. As suas principaiscaracterísticas são:
•Fornece recomendações de alta qualidade: em uma grande variedade de conjuntosde dados, os algoritmos de recomendação baseado em item, produziram resultadoscuja qualidade é até 30% melhor do que a obtida através de algoritmos tradicionaisbaseados em filtragem colaborativa•Atinge baixa latência recomendação: os algoritmos item-based podem calcular“top-10” recomendações em menos que 5s em estações de trabalho e servidoresmodernos.•Escalável para grandes conjuntos de dados: ambos os algoritmos podemser escalados para grandes bases de dados, sem degradação significativa nodesempenho.
O download da ferramenta pode ser obtido através do link 5.
3http://www.cs.cmu.edu/ lebanon/IR-lab/tutorial.htm4http://glaros.dtc.umn.edu/gkhome/suggest/overview5http://glaros.dtc.umn.edu/gkhome/suggest/download

Apêndice A 103
A.3 COFI
O CofiRank, também é denominado de COFI, é um framework de filtragemcolaborativa. Atualmente, os programadores que querem usar filtragem colaborativa temque ler a literatura e aplicar seus próprios algoritmos. Provavelmente os programadorescriaram os seus próprios algoritmos e eles geralmente produzem algoritmos sub-ótimos.Queremos construir uma base de algoritmos já testados e documentados que podem serusados em uma ampla gama de contextos de investigação para aplicações.
O princípio orientador é que o projeto deve ser pequeno. Cofi não quer ser tudopara todas as pessoas. Assim, o foco está em fornecer poucas linhas de código, e contarcom o programador para fornecer a integração necessária para a sua aplicação. O projetopossui os seguintes aspectos:
•Faz o uso das tecnologias de otimização, tornando-o aplicável a grandes bases dedados;•Está apto a gerar previsões estruturadas, por exemplo, prever a ordem de preferênciade filmes em vez de prever apenas a nota que o usuário avaliaria.•O modelo possui a propriedade de prever se o usuário-alvo gosta ou não do item;•É facilmente paralelizável, o que aumenta a velocidade e o desempenho doalgoritmo de recomendação.
Para criar um exemplo de aplicação, faça:
•Baixe o pacote de código fonte Java (http://www.nongnu.org/cofi/cofi-code.zip). Énecessário adicionar as bibliotecas do gnu.trove (LGPL) e JUnit (CPL) no Java
Build Path. Alguns códigos esperam JSci (LGPL) embora não seja necessário parausar a biblioteca.•Crie um projeto Java
•Copie a pasta cofi (descompactada do arquivo zipado baixado no item 1) para dentrode src
•Adicione as bibliotecas baixadas no item 1.1 no Path do projeto•Adicione também a biblioteca JSci
A.4 Trove
A biblioteca Trove fornece coleções de alta velocidade para trabalhar comcoleções em Java, ela tem dois objetivos:
•Utilização “livre”, rápidos, leves implementações da API Collections do pacotejava.util. Essas implementações são projetados para serem substitutos conectáveispara seus equivalentes do JDK.

Apêndice A 104
•Fornecer coleções primitivos com APIs semelhante ao anterior. Estas lacunasno JDK são frequentemente abordadas usando o wrapper (java.lang.Integer,java.lang.Float, etc) como o objeto-base de coleções. Para a maioria das aplicações,no entanto, as coleções que armazenam objetos primitivos diretamente exigirámenos espaço e produzir ganhos significativos de performance.
Trove permite aplicações tanto do lado do Servidor6 como no Cliente7, com o objetivo deser executado mais rápido e usar menos memória.
A.5 PHPSQL
Em 2004, o PHP foi uma das 5 mais populares linguagens de programação domundo. A maioria das aplicações baseadas em PHP usam um banco de dados relacionalcom uma interface SQL. Assim, projetar um sistema de recomendação em PHP/SQL é umproblema importante. Enquanto usamos a sintaxe MySQL8, nossa abordagem minimalistapara o SQL irá assegurar a portabilidade. O leitor deve observar que é possível removergrande parte do código PHP que está sendo usando e ter uma abordagem SQL pura, mastal abordagem teria que fornecer um banco de dados específico.
Para executarmos um exemplo prático, vamos assumimos classificaçõesnuméricas e inteiras entre 0 e 10. É armazenado para cada utilizador (Usuário - coluna“UserID”) a avaliação dada para aquele produto (“itemID”) em especifico. Assim, omodelo da tabela (ratingValue) para armazenar essas informações seria:
•CREATE TABLE rating ( userID INT PRIMARYKEY, itemID INT NOT NULL,
ratingValue INT NOT NULL, datetimestamp TIMESTAMPNOTNULL);
Para armazenar o resultado da pré-computação feita pelo engine, será criada atabela dev.
•CREATE TABLE dev ( itemID1 int(11) NOTNULL default ’0’, itemID2 int(11)
NOTNULL default ’0’, count int (11) NOTNULL default ’0’, sum int(11) NOTNULL
default ’0’, PRIMARYKEY);
Após isso executaremos o passo a passo abaixo para rodar um exemplo:
•CREATE TABLE dev ( itemID1 int(11) NOTNULL default ’0’, itemID2 int(11)
NOTNULL;
•Instale PHP5, apache2 e mysqlDb
6O processamento interno utiliza os recursos físicos da maquina em que a aplicação está implantada7O processamento é feito fazendo uso de recursos físicos na máquina de quem está utilizando a aplicação8Banco de dados relacional

Apêndice A 105
•Vá no arquivo /etc/php5/apache2/php.ini e altere a propriedadeupload-max-filesize = 4M, mude as variáveis de exibição de erros e logs para“On”, reinicie o apache
•abra o phpmyadmin e crie o banco de dados: rating-php-sql
•Faça o importe da base de dados: dump.sql
•Rode o arquivo populate-db-movielens.php no navegador (Irá popular a base dedados com o arquivo da movieLens: u.data.•Rode o engine.php para gerar as associações dos itens.
Execute o SQL abaixo para retornar os itens relacionados com o item 1
•SELECT itemID2, ( sum / count ) AS average FROM dev WHERE count > 2 AND
itemID1 = 1 ORDER BY ( sum / count ) DESC LIMIT 10;
A.6 Apache Mahout
O Apache Mahout9 incorporou o projeto Taste10, com o objetivo de construiruma biblioteca de aprendizado de máquina escalável. Com escalável queremos dizer:
•Escalável para grandes base de dados: Nossos algoritmos básicos paraclusterização, classificação e filtragem colaborativa são implementados em cima desistemas escaláveis e distribuídos. No entanto, as contribuições que são executadosem uma única máquina são bem vindas também.•Escalável para apoiar o seu processo de negócio: Mahout é distribuído sob umalicença Apache Software, que o torna comercialmente amigável.•Escalável para a comunidade: O objetivo do Mahout é construir uma sensívelcomunidade vibrante e diversificada para facilitar as discussões, não só sobre oprojeto em si, mas também sobre os casos de uso em potencial.
Atualmente Mahout apoia principalmente três casos de uso: Mineração,Clusterização e Classificação. Acessando o site11 é possível obter mais informações sobrea ferramenta e criar projeto de exemplo.
9http://mahout.apache.org10http://sourceforge.net/projects/taste/11http://mahout.apache.org/users/basics/quickstart.html

APÊNDICE BApache Mahout
Este Apêndice apresenta a arquitetura e alguns exemplos da utilização doframework Apache Mahout. Mahout foi escolhido para ser o nosso recomendador, porapresentar bom desempenho e fácil implementação.
B.1 A arquitetura do Mahout
Mahout é uma biblioteca que tem como objetivo oferecer ferramentas paraaprendizado de máquina escaláveis sob a licença Apache. O objetivo é a construção dealgoritmos de aprendizado de máquina práticos e escaláveis prontos para utilização emprodução para, mas não limitados a, clusterização, classificação e filtragem colaborativa.O Mahout utiliza outra ferramenta conhecida como Hadoop para garantir a escalabilidadepara várias implementações, mas não depende só dele. Muitos algoritmos de aprendizadode máquina simplesmente não se adequam ao modelo de Map Reduce, desta maneira sãoutilizado outros meios quando apropriado [Owen et al. 2011]. A Figura B.1 demonstracomo foi desenvolvido o Mahout. Inicialmente se chamava Taste, após isso foi melhoradoe passou a se chamar Mahout, e em seguida foi fomentado pela Apache Software
Foundation (ASF), e incorporada ao projeto Lucene e Hadoop, ambos da ASF dandoorigem então ao Apache Mahout.
Figura B.1: Apache Mahout e os projetos que o deram origem.(Apache Software Foundation)
As principais características que estão incluídas no Mahout são:
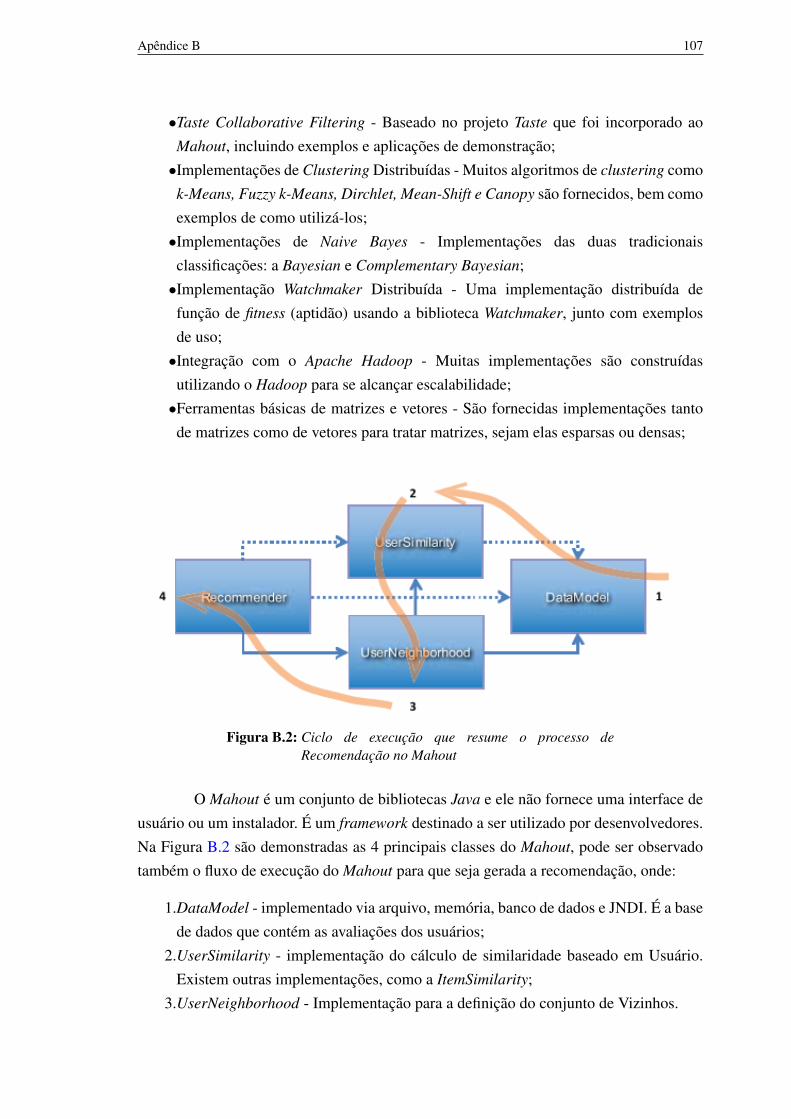
Apêndice B 107
•Taste Collaborative Filtering - Baseado no projeto Taste que foi incorporado aoMahout, incluindo exemplos e aplicações de demonstração;•Implementações de Clustering Distribuídas - Muitos algoritmos de clustering comok-Means, Fuzzy k-Means, Dirchlet, Mean-Shift e Canopy são fornecidos, bem comoexemplos de como utilizá-los;•Implementações de Naive Bayes - Implementações das duas tradicionaisclassificações: a Bayesian e Complementary Bayesian;•Implementação Watchmaker Distribuída - Uma implementação distribuída defunção de fitness (aptidão) usando a biblioteca Watchmaker, junto com exemplosde uso;•Integração com o Apache Hadoop - Muitas implementações são construídasutilizando o Hadoop para se alcançar escalabilidade;•Ferramentas básicas de matrizes e vetores - São fornecidas implementações tanto
de matrizes como de vetores para tratar matrizes, sejam elas esparsas ou densas;
Figura B.2: Ciclo de execução que resume o processo deRecomendação no Mahout
O Mahout é um conjunto de bibliotecas Java e ele não fornece uma interface deusuário ou um instalador. É um framework destinado a ser utilizado por desenvolvedores.Na Figura B.2 são demonstradas as 4 principais classes do Mahout, pode ser observadotambém o fluxo de execução do Mahout para que seja gerada a recomendação, onde:
1.DataModel - implementado via arquivo, memória, banco de dados e JNDI. É a basede dados que contém as avaliações dos usuários;
2.UserSimilarity - implementação do cálculo de similaridade baseado em Usuário.Existem outras implementações, como a ItemSimilarity;
3.UserNeighborhood - Implementação para a definição do conjunto de Vizinhos.
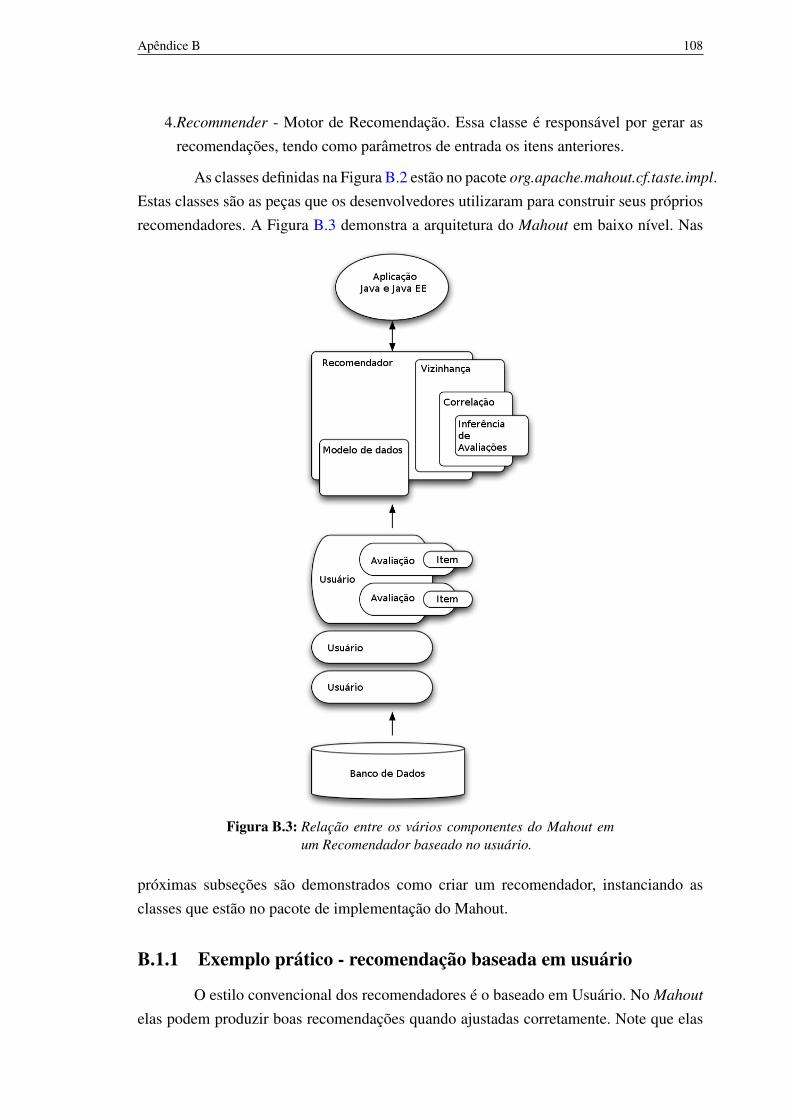
Apêndice B 108
4.Recommender - Motor de Recomendação. Essa classe é responsável por gerar asrecomendações, tendo como parâmetros de entrada os itens anteriores.
As classes definidas na Figura B.2 estão no pacote org.apache.mahout.cf.taste.impl.Estas classes são as peças que os desenvolvedores utilizaram para construir seus própriosrecomendadores. A Figura B.3 demonstra a arquitetura do Mahout em baixo nível. Nas
Figura B.3: Relação entre os vários componentes do Mahout emum Recomendador baseado no usuário.
próximas subseções são demonstrados como criar um recomendador, instanciando asclasses que estão no pacote de implementação do Mahout.
B.1.1 Exemplo prático - recomendação baseada em usuário
O estilo convencional dos recomendadores é o baseado em Usuário. No Mahout
elas podem produzir boas recomendações quando ajustadas corretamente. Note que elas

Apêndice B 109
não são necessariamente os sistemas mais rápidos de recomendação e são, portanto,adequadas para pequenos conjuntos de dados. Vamos demonstrar na prática como gerarrecomendações de filmes a um usuário específico.
Para realizar a recomendação o Mahout necessita saber informações sobre osusuários. Dessa forma, a titulo de exemplo, vamos criar um DataModel baseado emarquivo (poderia ser um banco de dados). O arquivo deve estar no formato CSV, como layout: userID, itemID, prefValue(por exemplo, 3854,564,3.5), a este arquivo daremoso nome de data.txt:
No primeiro passo, alimentamos o sistema com a base de dados a ser utilizadapara gerar as recomendações:
DataModel model = new FileDataModel (new File(‘‘data.txt’’));
No segundo passo é definido qual será o algoritmo de cálculo de similaridade.Neste exemplo, fizemos o uso do algoritmo da Correlação de Pearson:
UserSimilarity userSimilarity =
new PearsonCorrelationSimilarity(model);
No terceiro passo definimos o tamanho da vizinhança. A critério de exemploutilizamos apenas os três mais próximos:
UserNeighborhood neighborhood =
new NearestNUserNeighborhood(3, userSimilarity,model);
Por fim, solicitamos ao recomendador que nos retorne 10 recomendações para ousuário 1234:
Recommender recommender = new GenericUserBasedRecommender(
model, neighborhood,userSimilarity);
List<RecommendedItem> recomendacoes =
recommender.recommend(1234, 10);
B.1.2 Exemplo prático - Recomendação Baseada em Item
Vamos começar novamente com um FileDataModel:
DataModel modelo = new FileDataModel(new File ("data.txt"));
Para definir o quanto um item é similar a outro utilizaremos a classeItemSimilarity. Poderíamos usar a classe PearsonCorrelationSimilarity, que calculasemelhança item em tempo real, mas este é demasiadamente lento. Em vez disso, em umaplicativo real, você poderia alimentar uma lista de correlações pré-calculadas e atribuir aum GenericItemSimilarity:

Apêndice B 110
// Constrói uma lista com correlações pré-calculadas
Collection<GenericItemSimilarity.ItemItemSimilarity>
correlations = ...;
ItemSimilarity itemSimilarity =
new GenericItemSimilarity(correlations);
Então, podemos produzir novamente 10 recomendações para o usuário 1234:
Recommender recommender = new GenericItemBasedRecommender(model,
itemSimilarity); ...
List<RecommendedItem> recomendacoes =
recommender.recommend(1234, 10);
B.1.3 Algoritmos para determinação de vizinhos
Em um recomendador baseado em usuário, as recomendações são produzidos àpartir da definição primeiramente da “vizinhança” - o quanto um usuário é similar a outroagrupando-os em um conjunto de tamanho pré-definido. A classe UserNeighborhood
define um meio de determinar esta “vizinhança” - por exemplo os 10 mais próximosusuários. Para implementar uma solução geralmente é necessário utilizar uma outraclasse que define os critérios de avalição de similaridade, no exemplo dado na ListagemB.1 é utilizado a classe “UserSimilarity” e a implementação dada através da classe“PearsonCorrelationSimilarity”.
1 public class RecommenderIntro {
2
3 public static void main(String[] args) throws Exception {
4 DataModel model = new FileDataModel(
5 new File("ra.test"));
6 /*
7 * fornece alguma noção de quão semelhantes
8 * são dois usuários
9 */
10 UserSimilarity similarity = new
11 PearsonCorrelationSimilarity(model);
12 /*
13 * define a noção de um grupo de usuários
14 * que são mais semelhantes a um determinado usuário
15 */
16 UserNeighborhood neighborhood =
17 new NearestNUserNeighborhood(2, similarity , model);

Apêndice B 111
18 /*
19 * puxa todos estes componentes juntos para
20 * recomendar itens para os usuários.
21 */
22 Recommender recommender =
23 new GenericUserBasedRecommender(model ,
24 neighborhood , similarity);
25
26 for (int i = 1; i <= 69878; i++) {
27 /*
28 * parametro (x,y) onde x é o usuario
29 * e y é a quantidade de produtos a ser recomendado à ele
30 */
31 List <RecommendedItem > recommendations =
32 recommender.recommend(i, 2);
33 /*
34 * Imprime a lista de itens recomendados
35 */
36 for (RecommendedItem recommendacao : recommendations) {
37 System.out.println("Usuario "+ i +" "+ recommendacao);
38 }
39 }
40 }
41 }
Código B.1: Na linha 16 através da classe UserNeighborhood é
demonstrado a implementação da definição de um
conjunto de vizinhos agrupados dois à dois.
No momento, as recomendações do código na Listagem B.1 são derivadas de umbairro de 2 usuários mais similares. A decisão de usar apenas 2 usuários cuja semelhançaé maior, a fim de fazer recomendações é arbitrária. E se o melhor para este caso fosse10 ou 100? Poderiam ocorrer recomendações que seriam baseadas em usuários maissemelhantes, não excluindo alguns usuários menos similares de consideração? A FiguraB.4 mostra a separação de usuários em um bairro.

Apêndice B 112
Figura B.4: Uma ilustração da definição de um bairro de usuáriosmais semelhantes ao escolher um número fixo devizinhos mais próximos.
No momento, nosso exemplo usa o padrão de correlação de Pearson como atécnica de similaridade. Podemos melhorar essa relação alterando a linha 16 do código daListagem B.1 para o seguinte código:
UserSimilarity similarity =
new ThresholdUserNeighborhood(0.7, similarity, model)
Sabemos que em uma correlação o valor de 0,7 ou acima é uma correlação alta econstitui uma sensível definição de muito semelhante (Este valor é dado entre o intervalor0 e 1). A Figura B.5 destaca a maneira como o nosso algoritmo forma a vizinhançautilizando uma taxa de limite entre usuários deixando nosso algoritmo sensível a estadefinição de similaridade.
Figura B.5: Definição de um bairro de maioria dos usuáriossemelhantes com um limiar de similaridade
B.2 Representação dos dados no recomendador
Podemos dizer que a entrada para o algoritmo de recomendação, é o quantoum usuário gosta de um item. E isso pode ser demonstrado através da avaliação doproduto feita pelo usuário. Isto é feito de maneira simples tendo a seguinte estrutura:ID do usuário, ID do item e a avaliação. Desta forma é criado um objeto na memóriapelo qual tem a responsabilidade de representar a preferência do usuário para um

Apêndice B 113
item específico. As avaliações dos produtos podem ser criadas dentro do Mahout
instanciando a classe GenericPreference e passando os parâmetros na seguinte ordem:id do usuário, id do produto e a avaliação. Um exemplo seria escrito da seguinte forma:new GenericPreference(123,456,3.0f), aqui é criada uma preferência de 3 para o item 456feito pelo usuário 123. A implementação pode ser observado na Listagem B.2, onde écriado uma avaliação e logo em seguida demonstrado como acessar as informações doobjeto.
1 package br.ufg.mestrado.exemplos;
2
3 import org.apache.mahout.cf.taste.*;
4
5 public class SettingPreference {
6 public static void main(String[] args) {
7 /*
8 * Para inserir um objeto na matriz;
9 * cria um array com um (1) Cliente
10 */
11 PreferenceArray usuario1 =
12 new GenericUserPreferenceArray (1);
13 //seta o id do primeiro Cliente
14 usuario1.setUserID(0, 1L);
15 //seta o id do Item
16 usuario1.setItemID(0, 101L);
17 //Seta a avaliação do cliente para este o Item.
18 usuario1.setValue(0, 2.0f);
19 /*
20 * Para recuperar objeto na matriz;
21 * 1 é o objeto na matriz
22 */
23 Preference pref = usuario1.get(1);
24 }
25 }
Código B.2: Classe exemplo de como inserir e recuperar objetos
na matriz de Recomendação utilizando a classe
GenericPreference

Apêndice B 114
B.2.1 Como um conjunto de avaliações são armazenadasinternamente no Mahout?
Geralmente pensamos em representar um conjunto de dados utilizando ascoleções do Java (Interface Collection) ou através de uma matriz (array []). Pensandodessa forma estaremos errados na maioria dos casos no Mahout. Matrizes e coleçõesacabam sendo muito ineficientes para representar um grande número de objetos.
Caso nunca tenha estudado sobre sobrecarga de um objeto em Java prepare-seentão para se surpreender. Uma única GenericPreference contém 20 bytes de dados úteis,divididos da seguinte forma: um ID para o usuário de 8 bytes (long), um identificadorpara o item de 8 bytes (long), e um campo de 4 bytes (float) para armazenar o valor dapreferência, totalizando assim os 20 bytes. Caso este objeto fosse criado através de umacoleção do Java, haveria a quantidade surpreendente de sobrecarga de: 28 bytes! Nestevalor estão inclusos 8 bytes de referência para o objeto em questão e os mesmos 20 bytes
para a representação do objeto em si. Assim qualquer objeto consome 140 por cento amais do que precisamos, apenas, devido à sobrecarga. Esse valor real de sobrecarga variadependendo da implementação da JVM.
A classe PreferenceArray, representa uma interface cuja implementaçãorepresenta uma coleção de preferências utilizando matriz. Por exemplo,GenericUser-PreferenceArray representa todas preferências associadas a um usuário.Internamente, ela mantém um ID de usuário único, uma matriz de IDs de itens, e umamatriz de valores preferenciais. A memória marginal necessária por preferência nestarepresentação é de apenas 12 bytes (um identificador para o item de 8 bytes e um campopara armazenar o valor de preferência 4 byte em um array). Compare isso com os cercade 48 bytes necessários para um objeto de preferência integral.

Apêndice B 115
Figura B.6: Uma representação menos eficiente de preferênciasutilizando uma matriz de objetos preferenciais. Asáreas em cinza representam, a grosso modo, asobrecarga de Objeto. As áreas brancas são dados,incluindo referências a objetos.
Figura B.7: Uma representação mais eficiente usandoGenericUserPreferenceArray.
A economia de memória é em torno de quatro vezes e por si só justifica estaimplementação especial, porém o ganho de desempenho ainda é pequeno, porque osobjetos muito pequenos devem ser alocados e examinadas pelo coletor de lixo do Java,tornando o processo ainda ineficiente. As Figuras B.6 e B.7 demonstram como entenderas economias realizadas.
B.3 Algoritmos disponíveis no Mahout
Esta seção contém os principais algoritmos implementados peloMahout. É possível obter mais informações sobre estes algoritmos no sitehttps://cwiki.apache.org/confluence/display/MAHOUT/Algorithms. Os algoritmos serãoagrupados abaixo pela aplicabilidade:
B.3.1 Classificação
Uma introdução geral aos algoritmos de classificação mais comuns podem serencontrados no link:
http://answers.google.com/answers/main?cmd=threadview&id=225316.
O Mahout possui (ou em desenvolvimento) as implementações:

Apêndice B 116
•Logistic Regression (SGD)
•Bayesian
•Support Vector Machines (SVM)
•Perceptron and Winnow
•Neural Network
•Random Forests
•Restricted Boltzmann Machines
•Online Passive Aggressive
•Boosting
•Hidden Markov Models (HMM)
B.3.2 Agrupamento
•Reference Reading
•Canopy Clustering
•K-Means Clustering
•Fuzzy K-Means
•Expectation Maximization (EM)
•Mean Shift Clustering
•Hierarchical Clustering
•Dirichlet Process Clustering
•Latent Dirichlet Allocation
•Spectral Clustering
•Minhash Clustering
•Top Down Clustering
B.3.3 Mineração
•Parallel FP Growth Algorithm (Também conhecida como mineração de conjunto deItem (Itemset))
B.3.4 Regressão
•Locally Weighted Linear Regression (código aberto)
B.3.5 Redução (Dimensão)
•Singular Value Decomposition and other Dimension Reduction Techniques
(available since 0.3)
•Stochastic Singular Value Decomposition

Apêndice B 117
•Principal Components Analysis (PCA) (código aberto)
•Independent Component Analysis (código aberto)
•Gaussian Discriminative Analysis (GDA) (código aberto)
B.3.6 Algoritmos Evolucionários
Veja também: MAHOUT-56Introdução e tutoriais:
•Introdução a Algoritmos Evolucionários•Como distribuir a avaliação da aptidão usando Mahout. (Algoritmo Genético)
Exemplos:
•Traveling Salesman
•Class Discovery
B.3.7 Recomendador baseado em filtragem colaborativa
Mahout contém tanto simples implementações que rodam localmente, quanto asque rodam de forma distribuída, utilizando para isso o Hadoop.
•Recomendação não-distribuida (Taste)•Filtragem colaborativa baseada no Item•Filtragem colaboratica usando Matriz de Fatoração Paralela (First-timer FAQ)•First-timer FAQ
B.3.8 Vetor de similaridade
Mahout contém implementações que permitem comparar um ou mais vetorescom outro conjunto de vetores. Isto pode ser útil se por exemplo fosse necessário calculara semelhança entre todos os documentos (ou um subconjunto de documentos) em umconjunto.
•RowSimilarityJob - Constrói um índice invertido e, em seguida, calcula distânciasentre os itens que têm co-ocorrências. Este é um cálculo completamente distribuído.•VectorDistanceJob
B.3.9 Outros
•Collocations - é definida como uma sequência de palavras ou termos queco-ocorrem com mais frequência do que seria esperado pelo acaso.

APÊNDICE CAvaliação do Framework Apache Mahout
O objetivo deste Apêndice é o de avaliar o recomendador do Mahout1, do pontode vista de produção de boas recomendações. Entendemos que aplicativos modernos,principalmente os que funcionam na internet, possuem mecanismos para aprender aspreferências de seus usuários.
Alguns usuários já acreditam na capacidade dos computadores de anteciparemsuas vontades, antes mesmo delas existirem [GROSSMAN 2009]. Combinando váriastécnicas computacionais é possível selecionar itens personalizados com base nosinteresses dos usuários e o espaço no qual estes estão inseridos. Tais itens, podem assumirformas bem variadas como por exemplo: livros, filmes, notícias, música, vídeos, anúncios,etc.
Filtros colaborativos se baseiam em um banco de dados de experiências dosusuários com itens para tentar adivinhar itens adicionais de interesse para seus usuários.Em um cenário típico há u usuários {u1,u2, . . . ,u‖U‖} e i itens {i1, i2, . . . , i‖I‖}, ecada usuário ui tem uma lista de itens m, com uma classificação do usuário paracada item. O conjunto de m avaliações de cada usuário forma a matriz de avaliaçõesM. As classificações podem ser indicadores explícitos de gosto e não gosto ou emescala de Likert (1 a 5) [Schafer et al. 2007], ou até mesmo indicações implícitas deinteração como compras de itens, visualizações e clicks [CORREA e CAZELLA 2007,Schafer et al. 2007, TORRES 2004]
Dessa forma a filtragem colaborativa é uma técnica onde é possível recomendaritens (produtos, serviços, dentre outros) a usuários baseando-se na troca de experiênciasentre as pessoas que possuem interesse comum. Nestes sistemas, os itens são filtradosbaseando-se nas avaliações feitas pelos usuários acerca de produtos de seu interesse.
O problema a ser resolvido com algoritmos de filtragem colaborativa é o depre-dizer a avaliação de um usuário para um item não conhecido.
1Utilizado a versão 0.0.7, obtido diretamente do site: http://mahout.apache.org

Apêndice C 119
C.1 Metodologia
Sistemas de recomendação definem uma classe de sistemas que podem serdesenvolvidos utilizando diversas técnicas e com diferentes propósitos, mas com acaracterística em comum de prover recomendações de itens a seus usuários.
Neste trabalho, são considerados os sistemas de recomendação que aproveitaminformações de diversos usuários para realizar recomendações específicas, sendo queeste tipo de técnica é conhecida como filtro colaborativo [Su e Khoshgoftaar 2009].Há diferentes formas para programar um filtro colaborativo, dentre as quais podemoscitar: Correlação de Pearson, Redes Bayesianas, Modelos de Agrupamento (clustering):K-means, C-means (lógica fuzzy), Similaridades de Vetores (Cosseno).
Neste trabalho adotamos a correlação de Pearson como técnica de cálculo desimilaridade na implementação do filtro colaborativo. Na Seção C.1.1 é apresentado oconjunto de dados utilizado para exercitar os modelos e técnicas de aprendizado, bemcomo também é definido formalmente o problema a ser resolvido com a métrica deavaliação.
C.1.1 Conjunto de dados
A escolha do conjunto de dados (matriz M) foi pautada por uma busca aum conjunto clássico da literatura. O conjunto de dados escolhido foi da MovieLens[Herlocker et al. 1999] disponibilizado pelo projeto de Pesquisa GroupLens Research
Project da Universidade de Minesota. Os dados deste conjunto foram coletados a partirdo site MovieLens2.
Esses dados foram tratados e disponibilizados em três versões:
•100 mil avaliações, variando de 1 a 5, de 1.000 usuários para 1.700 filmes•1 milhão de avaliações de 6.000 usuários para 4.000 filmes•10 milhões de avaliações e 100.000 tags aplicados a 10.000 filmes por 72.000usuários
Foi escolhida a versão com 100 mil avaliações. Os dados disponíveis neste conjunto sãolistados a seguir:
•100 mil avaliações, variando de 1 a 5, de 1.000 usuários para 1.700 filmes.•Cada usuário avaliou pelo menos 10 filmes.•Informações demográficas e dados do usuários foram ignoradas.•Informações sobre o filme, como título, data de lançamento, data de lançamento emvídeo, IMDb URL, e o gênero (pode ter mais de um) forma ignorados.
2Disponível em http://www.grouplens.org/node/73

Apêndice C 120
•Os dados considerados para o estudo foram o id do usuário, id do item avaliado eavaliação;
C.1.2 Determinando o Problema
O problema a ser resolvido é o de se prever a avaliação de um usuário para umitem ainda não avaliado. Considera-se nesta previsão todas as avaliações já realizadaspelos usuários para os itens. Resumidamente, o sistema colaborativo funciona da seguinteforma:
•as opiniões dos usuários sobre os itens são armazenadas;•baseado nestas opiniões, usuários com perfis semelhantes são agrupados;•produtos bem avaliados pelos vizinhos são recomendados ao usuário-alvo;
Essas avaliações são representadas por um número inteiro, geralmente aplica-se a escalade Likert (avaliações entre 1 e 5), e quanto maior o número, mais o usuário gostou do item[TORRES 2004].
C.1.3 Estudo de caso
O objetivo é avaliar o recomendador, do ponto de vista de produção de boasrecomendações. Para medir o desempenho do recomendador foram utilizadas as métricasde revocação (recall) e de precisão (precision). Dessa forma, foi observado a quantidadede itens recomendados, que são do interesse do usuário, em relação ao conjunto detodos os itens que lhe são recomendados. E por seguinte calculamos a precisão daavaliação. A precisão indica o quanto uma previsão é próxima da avaliação real feita pelousuário. Fizemos o uso destas duas métricas de avaliação, por serem métricas comumenteutilizadas na literatura.
Assim, para atingir o objetivo, os passos abaixo foram executados:
•São geradas e armazenadas recomendações para o usuário-alvo;•Por seguinte, da matriz de avaliações (M), são removidas 3 avaliações dousuário-alvo;•Novamente, são geradas recomendações para o usuário-alvo;•Após isso, é verificado se os 3 itens removidos no passo 2, estão presentes nasrecomendações do passo 3;•Dessa forma, as medidas de revocação e precisão podem ser calculadas:
–Revocação: Os produtos removidos estão nas novas recomendações? Se sim,o sistema é assertivo na precisão da quantidade de itens recomendados aousuário em relação ao conjunto de dados.

Apêndice C 121
–Precisão: Qual a diferença entre a nota predita e a nota verdadeira? Quantomais próximo de zero, maior a acurácia.
C.1.4 Algoritmo de recomendação
Como foi citado anteriormente, o Mahout utiliza-se de aprendizado de máquinae outras técnicas estocásticas (Naive Bayes por exemplo). Na literatura é destacado quealgoritmos que fazem o uso deste recurso, apresentam melhores resultados em relação àoutros algoritmos que não usam aprendizado de máquina [Owen et al. 2011].
Para verificarmos a real diferença de desempenho nas recomendaçõesproduzidas, desenvolvemos um algoritmo de recomendação. Este algoritmo não fazo uso de aprendizado de máquina. Na implementação deste algoritmo fizemos o uso datécnica de correlação de Pearson para o cálculo de similaridade e assim determinar oconjunto de vizinhos.
Os passos abaixo foram seguidos, para criar um algoritmo recomendador:
•Para cada u usuários é preciso calcular a correlação de Pearson com os outros u−1usuários (cálculo para definição de vizinhos).•Determinar uma quantidade fixa de melhores vizinhos.•Dos vizinhos selecionados, verificar para o usuário-alvo u os itens que ele nãoavaliou em relação a sua vizinhança.•Criar uma estrutura de dados que armazene a relação item não avaliado Item_na χ
usuarios. Onde para um Item_na, tenhamos a relação dos u usuários.•Percorrer a estrutura de dados dos itens Item_na, e para cada usuário associado àum item, calcular a previsão de avaliação;•Normalizar os resultados para a escala de Likert.
Para a criação do algoritmo, utilizamos o tipo abstrato de dados (TAD) doMahout chamado FastByIDMap<E>. TAD é uma estrutura de dados que implementaum hashmap do Java. Criamos uma estrutura de dados, onde existe uma entidade (User),que possui uma lista de avaliações.
Adotamos a FastByIDMap<E> como estrutura de dados, porque de acordo com[Owen et al. 2011], a estrutura FastByIDMap apresenta melhor desempenho em relaçãoas estruturas de dados genéricas disponibilizadas pela linguagem de programação Java,como pode ser visto no Apêndice B.
C.2 Resultados
A Tabela C.1, apresenta o resultado obtido pelo Algoritmo desenvolvido, que nãofaz o uso do aprendizado de máquina, e o algoritmo do Mahout. Os resultados obtidos pelo
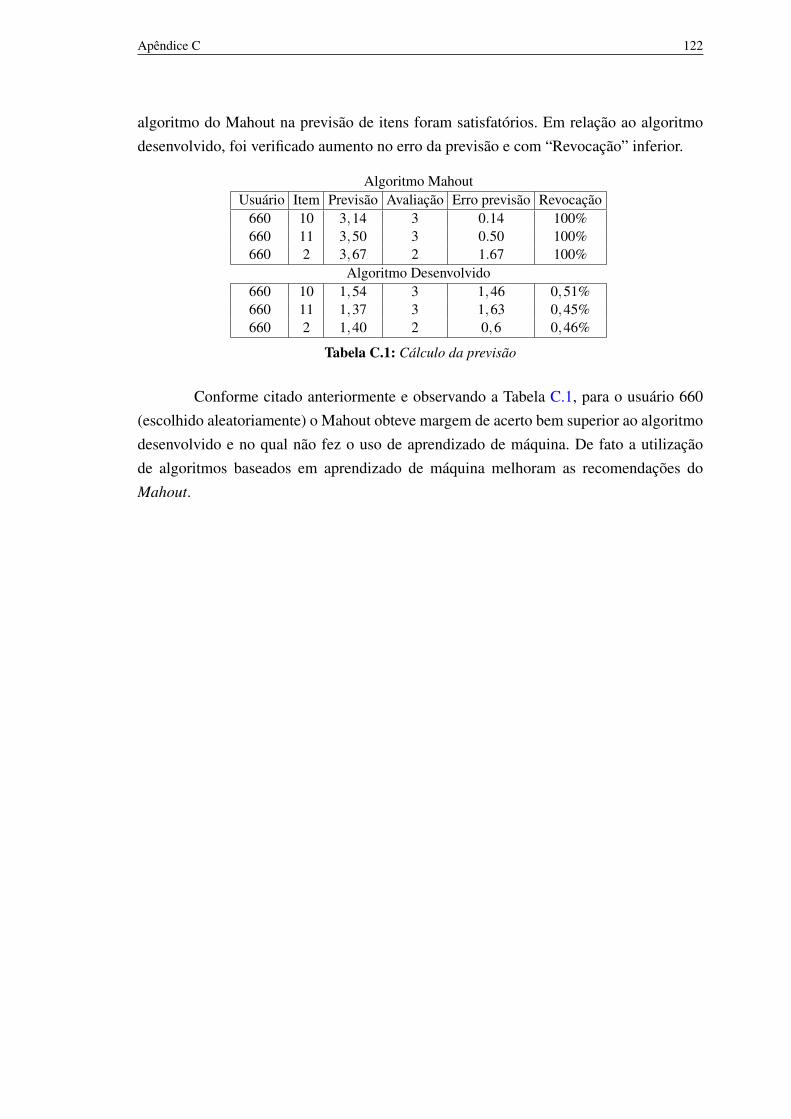
Apêndice C 122
algoritmo do Mahout na previsão de itens foram satisfatórios. Em relação ao algoritmodesenvolvido, foi verificado aumento no erro da previsão e com “Revocação” inferior.
Algoritmo MahoutUsuário Item Previsão Avaliação Erro previsão Revocação
660 10 3,14 3 0.14 100%660 11 3,50 3 0.50 100%660 2 3,67 2 1.67 100%
Algoritmo Desenvolvido660 10 1,54 3 1,46 0,51%660 11 1,37 3 1,63 0,45%660 2 1,40 2 0,6 0,46%
Tabela C.1: Cálculo da previsão
Conforme citado anteriormente e observando a Tabela C.1, para o usuário 660(escolhido aleatoriamente) o Mahout obteve margem de acerto bem superior ao algoritmodesenvolvido e no qual não fez o uso de aprendizado de máquina. De fato a utilizaçãode algoritmos baseados em aprendizado de máquina melhoram as recomendações doMahout.

APÊNDICE DComputação Evolucionária
Este Apêndice tem por objetivo o levantamento bibliográfico da ComputaçãoEvolucionária, em especial os Algoritmos Evolucionários: Algoritmos Genéticos,Estratégias Evolutivas e Programação Evolucionária.
D.1 Introdução
Existem diversas maneiras de implementar um sistema para atacar um dadoproblema [Ashlock 2005]. A Computação evolucionária é um nome ambicioso para umaideia simples: usar a teoria da evolução como um algoritmo.
A área da computação evolucionária (CE) tem muitos fundadores e muitosnomes. A estratégia evolutiva desenvolvida por Rechenberg (1973) foi inicialmenteproposta com o objetivo de solucionar problemas de otimização discreta e continua.Durante a década de 80, os avanços realizados permitiram a aplicação dos algoritmosevolutivos para a solução de problemas de otimização de empresas comerciais e naindústria. A partir deste ponto iniciou-se uma convergência sobre as pesquisas relativasaos algoritmos evolutivos [Ashlock 2005].
Os algoritmos genéticos foram propostos por Holland em 1962. A programaçãoevolucionária, introduzida por Fogel em 1962, foi originalmente proposta para como umatentativa de criar métodos inteligentes. Esta abordagem visava utilizar máquinas de estadofinito para prever eventos baseados em observações prévias. Mas novamente a técnica semostrou útil para a resolução de problemas de otimização.
Em termos históricos, três algoritmos para computação evolutiva foramdesenvolvidos independentemente:
•algoritmos genéticos: HOLLAND em 1962, BREMMERMANN em 1962 eFRASER em 1957;•programação evolutiva: FOGEL em 1962;•estratégias evolutivas: RECHENBERG em 1965 e SCHWEFEL em 1965.

Apêndice D 124
Atualmente, CE engloba um número crescente de paradigmas e métodos, dosquais os mais importantes são os Algoritmos Genéticos (AGs)[Davis 1991, DeJong 1975,DeJong 1994, Holland 1986, Goldberg 1989, Holland 1992], Programação Evolucionária(PE) [Fogel, Owens e Walsh 1996], Estratégias Evolutiva (EEs) [Rechenberg 1973,Rechenberg 1994], Programação Genética (PG) [Koza 1992, Koza 1994], e SistemasClassificadores (SCs) [Belew e Forrest 1998, Booker, Goldberg e Holland 1989,Goldberg 1989, Wilson e Goldberg 1989], dentre outros.
A computação evolucionária engloba, portanto, uma família de algoritmosinspirados na teoria evolutiva de Darwin. Na literatura, os primeiros livros e teses sobrecomputação evolutiva, escritos por alguns dos próprios pioneiros da área, já apresentavamdemonstrações impressionantes acerca da capacidade dos algoritmos evolutivos, apesardas limitações de hardware existentes na época.
No entanto, de modo similar a outras iniciativas de propor métodos de solução deproblemas inspirados na natureza, tal como redes neurais artificiais e sistemas nebulosos,os algoritmos evolutivos também tiveram que atravessar um longo período de rejeiçãoe incompreensão antes de receber o reconhecimento da comunidade científica. Osprogressos verificados nos anos 90 confirmaram o poder impressionante dos algoritmosevolutivos na solução de problemas de elevada complexidade, assim como evidenciaramsuas limitações.
Uma referência elaborada com o intuito de ser completa, didática e muitoadequada para descrever o estado da arte da pesquisa em computação evolutiva é o livro:Handbook of Evolutionary Computation de [Back, Fogel e Michalewicz 1997], tendo suaversão atualizada no ano de 2000. Outros trabalhos importantes para um aprofundamentono estudo desta técnica, sob vários pontos de vista, são: [Back e Schwefel 1993,Koza 1992, Koza 1994, Michalewicz 1992, MITCHELL 1997, Mitchell 1998], e[Back, Rudolph e Schwefel 1995]. É importante ressaltar que os algoritmos evolutivosnão devem ser considerados “prontos para uso”, mas sim um elenco de procedimentosgerais que podem ser prontamente adaptados a cada contexto de aplicação. Basicamente,eles são modelos computacionais que recebem como entrada:
•uma população de indivíduos em representação genotípica (geração inicial), quecorrespondem a soluções-candidatas junto a problemas específicos; e•uma função que mede a aptidão relativa de cada indivíduo frente aos demais (funçãode adequação, adaptabilidade ou fitness).
A representação genotípica corresponde a uma descrição de cada indivíduo dapopulação através de uma lista ordenada (cromossomo) ou árvore de atributos, descritosa partir de um alfabeto finito. Cada atributo da lista ou árvore é equivalente a um gene, eo valor do atributo corresponde a um alelo. O tamanho da lista ou árvore está diretamente

Apêndice D 125
associado ao número mínimo de atributos necessários para descrever cada indivíduo(solução-candidata) da população. No caso de representação em lista, os indivíduos dapopulação geralmente têm tamanho único, embora já existam abordagem que permitemo tratamento de cromossomos de tamanho variável, ou seja, indivíduos mais e menoscomplexos coexistindo em uma dada geração. A representação em árvore é necessáriasempre que uma lista de atributos não for capaz de descrever um indivíduo da população,e aí o tamanho da árvore é sempre variável.
D.2 Algoritmos Evolucionários - AEs
A história sugere que há muitas variantes de diferentes algoritmosevolucionários. A ideia comum subjacente a todas estas técnicas é a mesma: dadauma população de indivíduos, a pressão ambiental faz com que haja a seleção natural(sobrevivência do mais apto). O que provoca um aumento da aptidão da população.Dada uma função de qualidade a ser maximizada, pode-se aleatoriamente criar umconjunto de soluções candidatas, ou seja, elementos do domínio da função, e aplicara função de qualidade como uma medida de fitness abstratas - quanto maior, melhor[Eiben e Smith 2003].
Com base nesta fitness, alguns dos melhores candidatos são escolhidos para apróxima geração de sementes através da aplicação de recombinação e, ou mutação paraeles. Recombinação e mutação leva a um conjunto de novos candidatos (os filhos) queconcorrem - com base na sua aptidão (e possivelmente idade) - com os antigos por umlugar na próxima geração [Eiben e Smith 2003].
Este processo pode ser repetido até que um candidato com qualidade suficiente(uma solução) é encontrada ou um limite computacional definido anteriormente é atingido[Eiben e Smith 2003]. Neste processo há duas forças fundamentais que formam a base desistemas evolutivos:
•Operadores de variação (recombinação e mutação) para se criar a diversidadenecessária.•Seleção, que atua como uma força empurrando a qualidade.
Algoritmos evolucionários possuem uma série de características que podemajudar a posicioná-los dentro da família de métodos gerar e testar [Eiben e Smith 2003]:
•AEs são populações com base que processam toda uma coleção de soluçõescandidatas simultaneamente.•AES utilizam principalmente a recombinação como um processo de misturarinformações, para se alcançar candidatos (soluções) aptos.•AEs são estocásticos.

Apêndice D 126
Algoritmos evolucionários usam modelos computacionais dos processos naturaisde evolução como uma ferramenta para resolver problemas. Apesar de haver uma grandevariedade de modelos computacionais propostos, todos eles têm em comum o conceito desimulação da evolução das espécies através de seleção, mutação e reprodução, processosestes que dependem do “desempenho” dos indivíduos desta espécie dentro do “ambiente”.
Os algoritmos evolucionários funcionam mantendo uma população de estruturas,denominadas indivíduos ou cromossomos, que se comportam de forma semelhante àevolução das espécies. A estas estruturas são aplicados os chamados operadores genéticos,como recombinação e mutação, entre outros. Cada indivíduo recebe uma avaliação queé quantificada da sua qualidade como solução do problema em questão. Com base nestaavaliação serão aplicados os operadores genéticos de forma a simular a sobrevivênciado mais apto. Os operadores genéticos consistem em aproximações computacionaisde fenômenos vistos na natureza, como a reprodução sexuada, a mutação genética equaisquer outros que a imaginação dos programadores consiga reproduzir.
De maneira geral, os algoritmos evolucionários são utilizados para resolveraqueles problemas cujos algoritmos são extraordinariamente lentos (problemasNP-completos) ou incapazes de obter solução (como, por exemplo, problemas demaximização de funções multimodais).
D.3 Algoritmo Genético - AG
A história dos algoritmos genéticos se inicia na década de 40, quando oscientistas se inspiraram na natureza para criar a inteligência artificial. A pesquisa sedesenvolveu mais nos ramos da pesquisa cognitiva e na compreensão dos processosde raciocínio e aprendizado até o final da década de 50, quando começou-se a buscarmodelos de sistemas genéricos que pudessem gerar soluções candidatas para problemasque eram difíceis demais para resolver computacionalmente [Mitchell 1998, Linden 2008,Engelbrecht 2007, Ahn 2006].
Esta seção discute em detalhes os AGs e seus operadores de sua evolução.
D.3.1 História
A história dos algoritmos genéticos se inicia na década de 40, quando oscientistas começam a tentar se inspirar na natureza para criar o ramo da inteligênciaartificial. A pesquisa se desenvolveu mais nos ramos da pesquisa cognitiva e nacompreensão dos processos de raciocínio e aprendizado até o final da década de 50,quando começou-se a buscar modelos de sistemas genéricos que pudessem gerar soluções

Apêndice D 127
candidatas para problemas que eram difíceis demais para resolver computacionalmente[Mitchell 1998, Linden 2008, Engelbrecht 2007, Ahn 2006].
Uma das primeiras tentativas de se associar a evolução natural a problemasde otimização foi feita em 1957, quando Box [Box 1957] apresentou seu esquema deoperações evolucionárias. Estas eram um método de perturbar de forma sistemática duasou três variáveis de controle de uma instalação, de forma análoga ao que entendemoshoje como operadores de mutação e seleção [Goldberg e Holland 1988]. Logo depois, nocomeço da década de 1960, Bledsoe [Bledsoe 1961] e Bremmerman [Bremermann 1962]começaram a trabalhar com genes, usando tanto a representação binária quanto a inteirae a real, e desenvolvendo os precursores dos operadores de recombinação (crossover)[Linden 2008].
Uma tentativa de usar processos evolutivos para resolver problemas foi feitapor Rechenberg [Rechenberg 1973], na primeira metade da década de 60, quando eledesenvolveu as estratégias evolucionária (ES - evolutionary strategies). Esta mantinhauma população de dois indivíduos com cromossomos compostos de números reais emcada instante, sendo que um dos dois era filho do outro, e era gerado através da aplicaçãoexclusiva do operador de mutação.
O processo descrito por Rechenberg tinha ampla fundamentação teórica, sendoque a mutação era aplicada a partir de uma distribuição gaussiana dos parâmetros e foiusado com sucesso em vários problemas práticos. Mesmo que o trabalho de Rechenbergnão incluía conceitos amplamente aceitos atualmente, tais como operador de crossover
e uma maior população de indivíduos, seu trabalho é considerado pioneiro, por terintroduzido a computação evolucionária às aplicações práticas [Linden 2008].
Em trabalhos posteriores as estratégias evolucionárias supririam estas falhas,sendo modificadas para incluir conceitos de população e operador de crossover. Amaneira como elas aplicam este operador é interessante pois inclui a ideia de utilizar amédia como operador além de poder envolver muitos pais.
Entretanto, apesar de não ser o primeiro investigador da área, aquele que seriadesignado o pai dos algoritmos genéticos mostrou-se no final da década de 60, quandoJohn Holland [Holland 1975] “inventa” os Algoritmos Genéticos, embora concentradoeminentemente na codificação discreta. Holland estudou formalmente a evolução dasespécies e propôs um modelo heurístico computacional que quando implementadopoderia oferecer boas soluções para problemas extremamente difíceis que eram insolúveiscomputacionalmente até aquela época [Linden 2008].
Em 1975 Holland publicou seu livro, “Adptation in Natural and Artificial
Systems”[Holland 1975], no qual faz um estudo dos processos evolutivos, em vez deprojetar novos algoritmos, como a maioria pensa. O trabalho de Holland apresenta osalgoritmos genéticos como uma metáfora para os processos evolutivos, de forma que

Apêndice D 128
ele pudesse estudar a adaptação e a evolução no mundo real, simulando-a dentro decomputadores. Entretanto, os algoritmos genéticos transcenderam o papel originalmenteimaginado por Holland e transformaram-se em uma ferramenta de uso disseminado peloscientistas da computação [Holland 1975].
Um fato interessante quanto ao trabalho de Holland e sua influência na áreade AG é que ele usou originalmente cromossomos binários, cujos genes eram apenaszeros e uns. Esta limitação foi abolida por pesquisadores posteriores, mas ainda hojemuitos cientistas insistem em usar apenas a representação binária, mesmo quandohá outras que podem se mostrar mais adequadas para a resolução do problema emquestão. Desde então os algoritmos genéticos começaram a se expandir por toda acomunidade científica, gerando uma série de aplicações que puderam ajudar a resolverproblemas extremamente importantes que talvez não fossem abordados de outra maneira[Mitchell 1998, Linden 2008].
Além deste progresso científico, também houve o desenvolvimento comercial:nos anos 80 surgiram pacotes comerciais usando algoritmos genéticos. Muitos artigosafirmam que o primeiro pacote comercial desenvolvido foi o Evolver R©, que já estavadisponível desde 1988 e que inclui um programa adicional para o Excel R© e uma API
(Interface de Programação de Aplicativos) para desenvolver programas que acessemdados provenientes de diferentes aplicativos.
Hoje existem dezenas de outros aplicativos que têm as mesmas características.Na década de 80, o progresso dos algoritmos evolucionários e sua popularização no meiocientífico fizeram com que surgissem as primeiras conferências dedicadas exclusivamentea estes tópicos. Hoje em dia, os algoritmos genéticos tem se beneficiado muito dainterdisciplinaridade. Cada vez mais cientistas da computação buscam inspiração emoutra área de pesquisa de forma a absorver suas ideias e fazer com que os AGs sejammais eficientes e inteligentes na resolução de problemas [Linden 2008].
D.3.2 AG Canônico
Os sistemas baseados em AG lidam com indivíduos1 de uma população desoluções onde são realizadas operações genéticas tais como seleção, reprodução, mutação,dentre outros.
Assim, o fluxo geral de um AG simples é dado pelos passos abaixo [Linden 2008,Tanomaru 1995]:
1.Inicialize a população de cromossomos.
1Os indivíduos são soluções candidatas para um problema. O conjunto destes indivíduos é chamado dePopulação.

Apêndice D 129
2.Avalie cada cromossomo na população.3.Selecione os pais para gerar novos cromossomos.4.Aplique os operadores de recombinação e mutação.5.Apague os velhos membros da população.6.Avalie todos os novos cromossomos e insira-os na população.7.Se o tempo acabou, ou o melhor cromossomo satisfaz os requerimentos e
desempenho, retorne-o, caso contrário, volte para o passo 3.
Após a seleção, diversas operações genéticas podem ser executadas, a fim deobter melhores respostas. As operações mais clássicas são:
•reprodução - é uma operação que combina dois ou mais indivíduos de umapopulação para criar um novo indivíduo. O objetivo principal desta operação é atroca de informações entre diferentes indivíduos.•mutação - é uma operação que modifica aleatoriamente genes de um indivíduo.Esta operação tem como objetivo diminuir a probabilidade do Algoritmo Genéticoconvergir para uma solução considerada um ótimo local;•elitismo - é uma operação que copia os melhores indivíduos de uma geração depopulação para a próxima geração. Esta operação visa principalmente manter asmelhores soluções entre gerações de uma população;
Além destas operações clássicas, recentemente, diversos pesquisadores têmapresentado abordagens, também relacionadas com conceitos da genética tais comoreprodução in vitro [Camilo-Junior e Yamanaka 2011].
Finalmente, um Algoritmo Genético pode utilizar algumas formas distintas paraavaliar a condição de parada. Entre elas, a primeira forma utilizada para a parada é oprévio estabelecimento de uma quantidade fixa de iterações para a execução. Quando estaquantidade é alcançada, o algoritmo para e retorna a população atual como resultado.A segunda forma utilizada para a parada é a avaliação dos melhores indivíduos de cadaiteração. Se a medida de adaptação destes indivíduos não variar muito, com base emum parâmetro previamente estabelecido, diz-se que que a população convergiu para umasolução. Desta forma, o algoritmo para, retornando esta população.
D.3.3 Representação cromossômica
A representação cromossômica tem importante papel para o algoritmo genéticoapresentado no tópico 2.2.2. A representação cromossômica consiste em uma maneirade traduzir a informação do nosso problema em uma maneira viável de ser tratada pelocomputador. Quanto mais ela for adequada ao problema, maior a qualidade dos resultadosobtidos [Linden 2008].

Apêndice D 130
Cada pedaço indivisível desta representação é chamado de um gene2, poranalogia com as partes fundamentais que compõem um cromossomo biológico[Linden 2008, Michalewicz 1992]. Cada indivíduo tem uma sequência única de genes.Uma forma alternativa de um gene é referida como um alelo [Engelbrecht 2007].
Dessa forma, cada indivíduo representa uma solução candidata para umproblema de otimização. As características de um indivíduo são representadas porum cromossomo, também conhecido como genoma. Estas características referem-se àsvariáveis do problema de otimização, para o qual uma alocação ótima é pedida. Cadavariável que precisa ser otimizada é referida como gene, a menor unidade de informação.
As características de um indivíduo podem ser divididas em duas classes deinformação evolutiva: genótipos e fenótipos. Um genótipo descreve a composiçãogenética de um indivíduo, como herança de seus pais, representa que o indivíduopossui alelo. Um fenótipo é expresso os traços comportamentais de um indivíduo emum ambiente específico, que define o que uma pessoa se parece. Complexas relaçõesexistentes entre o genótipo e fenótipo [Engelbrecht 2007]:
•Pleiotropia, quando a modificação aleatória de genes provoca variações inesperadasnas características fenotípicas e;•Poligenia, onde vários genes interagem para produzir uma característica fenotípicaespecífica.
Um passo importante no projeto de um AG é encontrar uma representaçãoadequada das soluções candidatas (ou seja, cromossomos). A eficiência e a complexidadedo algoritmo de busca depende muito do esquema de representação [Engelbrecht 2007].Os principais tipos de representação são apresentados pela Tabela D.1.
Tabela D.1: Principais tipos de representação
Representação Problemas
Binária Numéricos, Inteiros
Números Reais Numéricos
Permutação deSímbolos
Baseados emOrdem
Símbolos Repetidos Grupamento
É importante notar que a representação cromossômica é completamentearbitrária, ficando sua definição de acordo com o gosto do programador e com a
2 Na definição da genética clássica, é a unidade fundamental da hereditariedade. Cada gene é formadopor uma sequência específica de ácidos nucléicos - biomoléculas mais importantes do controle celular, poiscontêm a informação genética.

Apêndice D 131
adequação ao problema. É interessante apenas que algumas regras gerais sejam seguidas[Linden 2008]:
1.A representação deve ser a mais simples possível;2.Se houver soluções proibidas ao problema, então elas não devem ter uma
representação;3.Se o problema impuser condições de algum tipo, estas devem estar implícitas dentro
da representação.
São apresentadas, nas próximas seções, três das principais formas derepresentação de soluções nos AGs. Na Seção D.3.3 a representação binária, na SeçãoD.3.3 a representação Gray e na Seção D.3.3 a representação Real.
Representação Binária
O esquema de representação clássica para os AGs são vetores binários decomprimento fixo. Nas representações binárias os cromossomos são formados por umacadeia de bits {0,1}. No caso de um espaço de busca nx−dimensional, cada indivíduo écomposto por variáveis nx com cada variável codificada como uma cadeia de bits. Se asvariáveis têm valores binários, o comprimento de cada cromossomo é nx bits. No caso devariáveis de valores nominais, cada valor nominal pode ser codificado como um vetor debits nd−dimensional, onde 2nd é o número total de valores nominais distintos para essavariável.
A Figura D.1 ilustra um cromossomo representado através da codificaçãobinária. Nesse exemplo, os três primeiros genes representam a variável X e os dois últimosa variável Y [Camilo-Junior e Yamanaka 2011].
Figura D.1: Representação de um indivíduo - Codificação binária.
Para resolver problemas de otimização com variáveis de valores contínuos,o problema de espaço de busca contínua pode ser mapeada como um problema daprogramação discreta. Para este efeito, funções de mapeamento são necessárias paraconverter o espaço {0,1}nb ao espaço de Rnx . Para tal mapeamento, cada variável de valorcontínua é mapeado para um vetor de bits nd−dimensional, dado por [Engelbrecht 2007,Koza 1994]:
Φ : R→ (0,1)nd (4.1)
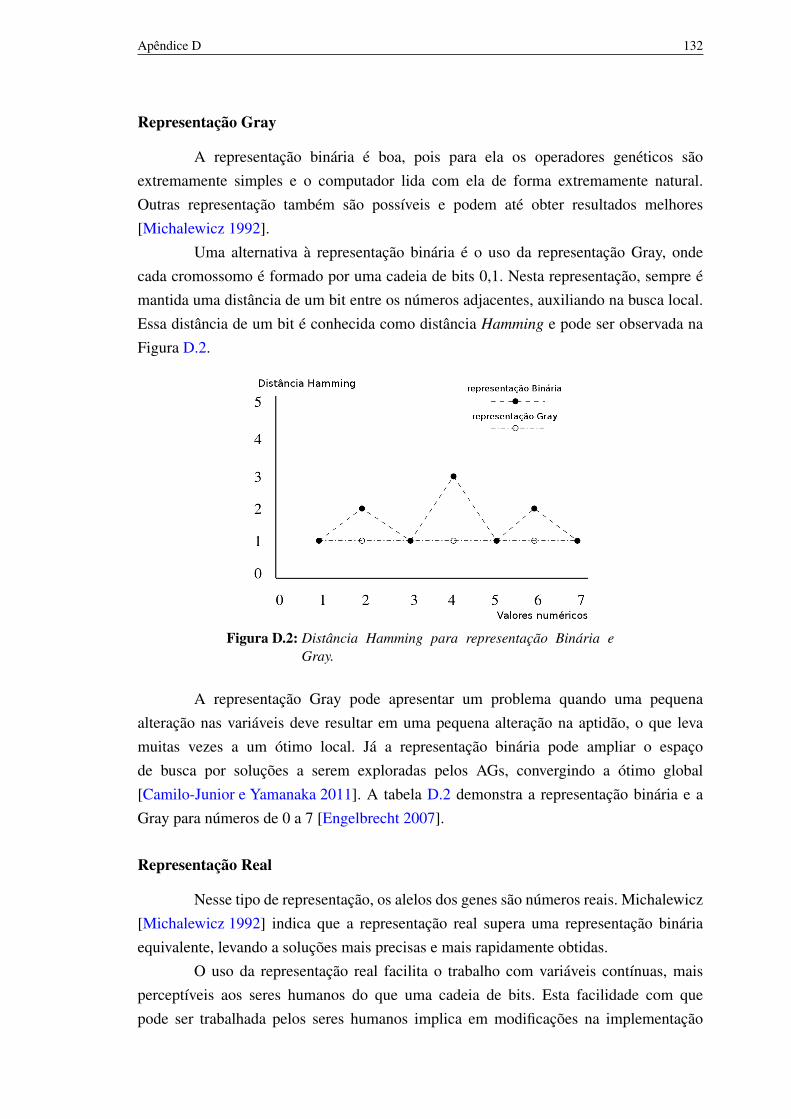
Apêndice D 132
Representação Gray
A representação binária é boa, pois para ela os operadores genéticos sãoextremamente simples e o computador lida com ela de forma extremamente natural.Outras representação também são possíveis e podem até obter resultados melhores[Michalewicz 1992].
Uma alternativa à representação binária é o uso da representação Gray, ondecada cromossomo é formado por uma cadeia de bits 0,1. Nesta representação, sempre émantida uma distância de um bit entre os números adjacentes, auxiliando na busca local.Essa distância de um bit é conhecida como distância Hamming e pode ser observada naFigura D.2.
Figura D.2: Distância Hamming para representação Binária eGray.
A representação Gray pode apresentar um problema quando uma pequenaalteração nas variáveis deve resultar em uma pequena alteração na aptidão, o que levamuitas vezes a um ótimo local. Já a representação binária pode ampliar o espaçode busca por soluções a serem exploradas pelos AGs, convergindo a ótimo global[Camilo-Junior e Yamanaka 2011]. A tabela D.2 demonstra a representação binária e aGray para números de 0 a 7 [Engelbrecht 2007].
Representação Real
Nesse tipo de representação, os alelos dos genes são números reais. Michalewicz[Michalewicz 1992] indica que a representação real supera uma representação bináriaequivalente, levando a soluções mais precisas e mais rapidamente obtidas.
O uso da representação real facilita o trabalho com variáveis contínuas, maisperceptíveis aos seres humanos do que uma cadeia de bits. Esta facilidade com quepode ser trabalhada pelos seres humanos implica em modificações na implementação

Apêndice D 133
Tabela D.2: Representação Binária e Gray.
Binário Gray
0 0 0 0 0 0 0
1 0 0 1 0 0 1
2 0 1 0 0 1 1
3 0 1 1 0 1 0
4 1 0 0 1 1 0
5 1 0 1 1 1 1
6 1 1 0 1 0 1
7 1 1 1 1 0 0
dos operadores genéticos de cruzamento (crossover) e mutação (mutation). Com isso,é necessária a implementação de operadores específicos para esse tipo de representação[Camilo-Junior e Yamanaka 2011].
Outras representações que têm sido usadas incluem representações deinteiros, permutações, representações de estados finitos, representações de árvores, erepresentações misto-inteiras [Engelbrecht 2007, Michalewicz 1992].
D.3.4 População inicial
A inicialização da população, na maioria dos trabalhos feitos na área, é feitada forma mais simples possível, fazendo-se uma escolha aleatória independente paracada indivíduo da população inicial. A lei das probabilidades sugere que teremos umadistribuição que cobre praticamente todo o espaço de soluções, mas isto não pode sergarantido, pois a população tem tamanho finito [Michalewicz 1992, MITCHELL 1997].
O objetivo da geração aleatória é garantir que a população inicial é umarepresentação uniforme do espaço de busca inteira. Se as regiões do espaço debusca não são cobertas pela população inicial, as chances são de que as partesserão negligenciadas pelo processo de pesquisa [Engelbrecht 2007, Rechenberg 1994,Davis 1991, Belew e Forrest 1998].
O tamanho da população inicial tem consequências em termos de complexidadecomputacional e habilidades de exploração. O grande número de indivíduosaumenta a diversidade melhorando assim a capacidade de exploração da população.Entretanto, quanto mais indivíduos, maior a complexidade computacional porgeração. A pequena população, por outro lado, irá representar uma pequena partedo espaço de busca. Enquanto a complexidade de tempo por geração é baixa[Engelbrecht 2007, Rechenberg 1994, Davis 1991].

Apêndice D 134
A prática da área, como dito antes, é usar a estratégia mais simples deinicialização, que consiste em simplesmente escolher n indivíduos de forma aleatória.Isto se deve ao fato, de forma geral, o processo gera uma boa distribuição das soluçõesno espaço de busca e o uso do operador de mutação de forma eficaz garante umaboa exploração (componente exploration) de todo o espaço de busca [Linden 2008,MITCHELL 1997, Engelbrecht 2007].
Na Listagem D.1 é demonstrada uma função de exemplo para inicializarindivíduos de uma população:
1 private void inicializaElemento(int tamanho){
2 this.valor = "";
3 for (int i = 0; i < tamanho; ++i) {
4 if(Math.random() < 0.5){
5 this.valor = this.valor+"0";
6 }else{
7 this.valor = this.valor+"1";
8 }
9 }
10 }
Código D.1: Método para inicializar Elementos - AG
D.3.5 Tamanho da população
O desempenho do algoritmo genético é extremamente sensível ao tamanhoda população, logo este parâmetro deve ser definido com muito cuidado. Caso estenúmero seja pequeno demais, não haverá espaço para termos uma variedade genéticasuficientemente grande dentro da nossa população, o que fará com que nosso algoritmoseja incapaz de achar boas soluções. Caso este número seja grande demais, oalgoritmo demorará demais e poderemos estar nos aproximando perigosamente de umabusca exaustiva [Goldberg 1989, Wilson e Goldberg 1989, Koza 1994, Rechenberg 1994,Davis 1991, Linden 2008].
É difícil dizer com precisão qual é o limite mínimo para o qual o AG aindaterá um bom desempenho, pois este limite varia com o número de genes presentes emcada indivíduo. Outro ponto que afeta o tamanho mínimo da população de um AG é adistância esperada entre a população ótima, distância esta que só pode ser estimada. Deb(1998) realiza testes precisos com o número de indivíduos que devem estar presentes emcada população, mas infelizmente os cálculos só são válidos se estamos usando apenasoperador de mutação. Se estivermos utilizando também o operador de recombinação,

Apêndice D 135
voltamos à estaca zero quanto à definição deste parâmetro [Linden 2008, Koza 1994,Rechenberg 1994, Davis 1991].
Ashlock [Ashlock 2005] faz a seguinte definição sobre este tópico: “O tamanhoda população de um algoritmo evolutivo é o número de estruturas de dados na populaçãoem evolução.” Ashlock ainda aponta possíveis problemas, tais como:
•Populações maiores, com maior diversidade inicial, deve apresentar menornecessidade de preservar a diversidade. Você esperaria que populações maioressejam de maior valor na preservação da diversidade em um problema unimodalou multimodal em comparação com a diversidade de técnicas de preservação comoa seleção de torneio?•Dê um modelo de evolução que pode processar uma grande população de formamais eficiente (para o problema “evolver string”). Sugestão: concentrar-se empequenos subgrupos da população sem ignorar completamente qualquer um.•Não há nenhuma exigência na teoria de algoritmos evolutivos quanto àobrigatoriedade de se ter população. Na verdade, quando fazemos 100 execuçõesexperimentais, estamos usando 100 diferentes populações.
A capacidade de armazenamento de estados de um AG é exponencialmenteproporcional ao número de indivíduos presentes. Consequentemente, há um limitesuperior para o tamanho da população onde ainda verifica-se melhora na performance
conforme aumenta-se o tamanho da população [Linden 2008, Engelbrecht 2007,Koza 1994, Rechenberg 1994, Davis 1991].
O número de indivíduos avaliados em uma execução do AG é igual ao número deindivíduos na população vezes o número de rodadas que o algoritmo irá executar. Logo, éinteressante considerar este número total e ver qual o percentual do espaço de busca estásendo coberto pela execução total do AG [Linden 2008].
Este número não é preciso, pois existirão repetições nos indivíduos em diferentesgerações, mas este número serve como um guia para o que estamos fazendo. Se apercentagem de soluções avaliadas for muito alta, pode-se considerar alguma heurísticainformada como técnica alternativa de resolução do problema. Por outro lado, adificuldade da função de avaliação deve ser um fator que afete a escolha deste doisparâmetros [Goldberg 1989, Wilson e Goldberg 1989, Eiben e Smith 2003, Ahn 2006].
Entretanto, definir o que é uma percentagem muito alta da população é umatarefa complicada. Se os operadores genéticos forem muito destrutivos, isto é, se elesgerarem filhos extremamente diferentes dos pais, é necessário fazer com que o tamanhoda população seja bastante grande, assim como o número de gerações adotadas. Um casotípico dessa situação é quando usamos programação genética em que as árvores usadascomo cromossomos são rompidas com extrema facilidade pelos operadores, o que diminui

Apêndice D 136
a força do componente de aproveitamento (explotation). Assim, precisamos buscarmais soluções, ampliando a componente de exploração (exploration) [Goldberg 1989,Wilson e Goldberg 1989, Eiben e Smith 2003, Ahn 2006, Linden 2008].
Sempre é necessário um lugar para começar. Dentro deste raciocínio, podemosestipular que uma tentativa inicial razoável para o número de indivíduos dentro da suapopulação é dado por 40×número de características em seu cromossomo. Isto é, se o seucromossomo representa, por exemplo, dois números, você pode usar uma população decerca de 80 indivíduos. Entenda isso como um “chute” e saiba que outras configuraçõespoderiam eventualmente gerar bons resultados. Entretanto, este “chute” é um bom lugarpara se começar − mas não para terminar [Linden 2008, Ahn 2006].
D.3.6 Função de avaliação - fitness
A função de avaliação (ou função de fitness) é a maneira utilizada pelos AGspara determinar a qualidade de um indivíduo como solução do problema em questão[Rothlauf 2006, Linden 2008, Koza 1992].
Dada a generalidade dos AGs, a função de avaliação, em muitos casos, é aúnica ligação verdadeira do programa com o problema real. Isto decorre do fato quea função de avaliação só julga a qualidade da solução que está sendo apresentada poraquele indivíduo, sem armazenar qualquer tipo de informação sobre as técnicas deresolução do problema. Isto leva à conclusão de que o mesmo AG pode ser usado paradescobrir o máximo de toda e qualquer função de n variáveis sem nenhuma alteração dasestruturas de dados e procedimentos adotados, alterando-se, apenas, a função de avaliação[Rechenberg 1994, Linden 2008].
O mais importante conceito a ter em mente é que a função de avaliaçãodeve refletir os objetivos a serem alcançados na resolução de um problemae é derivada diretamente das condições impostas por este problema e semprereflete os objetivos do problema de forma numérica [Koza 1992, Ahn 2006,Campos, Oliveira e Jungbeck 2004].
Assim, de acordo com Rothlauf [Rothlauf 2006], podemos definir Φg como oespaço de busca genotípica3 onde os operadores genéticos, tais como a recombinaçãoou mutação são aplicados. Um problema de otimização em Φg poderia ser formulado daseguinte forma: A busca no espaço Φg é discreto ou contínuo, e a função da Equação 4.2atribui um elemento em R para cada elemento no espaço genótipo Φg.
f (x) : Φg→ R (4.2)
3Refere-se aos genes que os descendentes podem apresentar

Apêndice D 137
O problema de otimização é definido por encontrar a solução ideal dada naEquação 4.3 onde x é um vetor de variáveis de decisão e f (x) é o objetivo ou funçãode fitness. O vetor x̂ é o máximo global.
x̂ = maxx∈Φg
f (x) (4.3)
Ilustramos um problema de maximização, mas sem perda de generalidade,poderíamos também modelar um problema de minimização. Para aplicarmos AG a umproblema, a função inversa f−1 não precisa existir. Em geral, a cardinalidade de Φg podeser maior do que dois.
Ainda de acordo com Rothlauf, a inclusão de uma representação explícita énecessária se o fenótipo4 de um problema pode ser descrito como uma sequência decaracteres ou de uma outra forma que o AG entenda. Além disso, a inclusão de umarepresentação pode ser útil se houver limitações ou restrições de espaço de busca, ondepode ser vantajoso modelar uma codificação específica [Rothlauf 2006, Ahn 2006].
Finalmente, podemos usar os mesmos genótipos para diferentes tipos deproblemas, e apenas interpretá-los de forma diferente, usando um mapeamentogenótipo-fenótipo diferente, o que nos permite usar operadores genéticos padrão compropriedades conhecidas. Uma vez que nós ganhamos algum conhecimento sobre tiposespecíficos de genótipos, podemos facilmente reutilizar esse conhecimento, e não énecessário o desenvolvimento de todos os novos operadores [Rothlauf 2006].
É importante perceber neste ponto que existe diferentes tipos de problemas deotimização e isso influenciará diretamente a formulação da função de avaliação, porexemplo:
•problemas de otimização irrestrita, onde a função de avaliação é simplesmente afunção objetivo.•problemas de otimização restrita. Para resolver problemas limitados, alguns AGs
alteram a função de fitness para conter dois objetivos: um é a função objetivooriginal, e a outra é uma função de penalização.•problemas multi-objetivo de otimização (MOP). MOPs pode ser resolvido usandouma abordagem de “agregação ponderada”, onde a função de fitness é uma somaponderada de todos os sub-objetivos.•problemas dinâmico e “ruidoso”, onde os valores da função de soluções mudamao longo do tempo. Funções de aptidão dinâmicas são dependentes do tempoenquanto que funções “ruidosas” geralmente têm um componente Gaussian deruído adicionado.
4Refere-se às suas características

Apêndice D 138
Como um comentário final sobre a função de fitness, é importante ressaltar o seupapel em um AG. Os operadores evolutivos, por exemplo, seleção, crossover, mutaçãoe elitismo, geralmente fazem uso da avaliação da aptidão do cromossomo. Por exemplo,operadores de seleção são inclinados para os indivíduos mais aptos ao selecionar os paispara o cruzamento, enquanto que a mutação se inclina para os indivíduos menos apto[Engelbrecht 2007].
D.3.7 Seleção
O método de seleção de pais deve simular o mecanismo de seleção naturalque atua sobre as espécies biológicas, em que os pais mais capazes geram mais filhos,ao mesmo tempo em que os pais menos aptos também podem gerar descendentes.Consequentemente, temos que privilegiar os indivíduos com função de avaliação alta,sem desprezar completamente aqueles indivíduos com função de avaliação extremamentebaixa.
Esta decisão é razoável pois até indivíduos com péssima avaliação podem tercaracterísticas genéticas que sejam favoráveis à criação de um indivíduo que seja a melhorsolução para o problema que está sendo atacado, características estas que podem não estarpresentes em nenhum outro cromossomo de nossa população [Linden 2008].
É importante entender que se deixarmos apenas os melhores indivíduos sereproduzirem, a população tenderá a ser composta de indivíduos cada vez maissemelhantes e faltará diversidade a esta população para que a evolução possa prosseguir deforma satisfatória. A este efeito denominamos “convergência genética”, e se selecionadode forma justa os indivíduos menos aptos da população podemos evitá-lo, ou pelo menosminimizá-lo [Rothlauf 2006, Linden 2008].
São apresentadas, nas seções seguintes, três dos principais métodos utilizadospelos AGs para a realização da seleção de pais. Na Seção D.3.7 a Seleção por Roleta, naSeção D.3.7 a Seleção por Torneio e na Seção D.3.7 a Seleção por Elitismo. Existemdiversos outros métodos que também podem ser utilizados como, a Pressão Seletiva,Seleção Aleatória, Seleção Proporcional, Seleção baseada em Ranking, Seleção deBoltzmann, Seleção-(µ,λ) e a Seleção Hall da Fama [Engelbrecht 2007, Rothlauf 2006].
Seleção por Roleta
O método de seleção por roleta atribui a cada indivíduo de uma populaçãouma probabilidade de passar para a próxima geração proporcional a sua aptidão,dada pela função de fitness, em relação à somatória da aptidão da geração atual[Fogel 1994, Michalewicz 1992]. A Figura D.3 ilustra o funcionamento do método deSeleção por Roleta. A Equação 4.4 define a probabilidade de seleção de pi, de um

Apêndice D 139
indivíduo i, com aptidão f (xi), onde N representa o total de indivíduos da populaçãoatual [Camilo-Junior e Yamanaka 2011].
pi =f (xi)
∑Nk=1 f (xk)
(4.4)
Figura D.3: Exemplo do método de Seleção da Roleta
Contudo, a seleção de indivíduos por Roleta pode fazer com que o melhorindivíduo da população seja perdido, ou seja, não passe para a próxima geração. De acordocom Michalewicz [Michalewicz 1992], uma alternativa seria optar por manter o melhorindivíduo da geração atual na geração seguinte, estratégia essa conhecida como seleçãoelitista.
Seleção por Torneio
O método do Torneio seleciona um grupo de indivíduos (nis) aleatoriamente dapopulação total de indivíduos (nt) e dentre estes indivíduos o que tiver a maior aptidão éselecionado como progenitor. Mesmo que a seleção torneio utilize informações da aptidãodos indivíduos para selecionar o melhor de um torneio, a seleção aleatória dos indivíduosque compõem o torneio reduz a pressão seletiva em relação à seleção proporcional. Essemétodo tem pressão de seleção constante, pois seleciona a partir do ranking de indivíduos.Dessa forma, evita o problema de oscilação de pressão de seleção encontrado no métododa roleta [Camilo-Junior e Yamanaka 2011].
No entanto, note que a pressão seletiva está diretamente relacionada ao númerode indivíduos selecionados da população total de indivíduos. Se esta relação for igual, ouseja nis = ns, o melhor indivíduo será sempre selecionado, o que resulta em uma pressãoseletiva muito elevada. Por outro lado é obtida uma seleção aleatória se nis = 1.
Seleção por Elitismo
Elitismo é uma pequena modificação no módulo de população que quase nãoaltera o tempo de processamento, mas que garante que o desempenho do AG semprecresce com o decorrer das gerações. A ideia básica por trás do elitismo é a seguinte: osn melhores indivíduos de cada geração não devem “morrer” junto com a sua geração,

Apêndice D 140
mas sim passar para a próxima visando garantir que seus genomas sejam preservados[Koza 1994, Rechenberg 1994].
Sabendo-se que a maioria dos esquemas de avaliação (por exemplo a funçãofitness que será vista na Seção D.3.6) de desempenho de um AG medem apenas aadequação da melhor solução dentre todos os indivíduos, a manutenção do melhorindivíduo da geração t na população da geração t +1 garante que o melhor indivíduo dageração t +1 é, no mínimo, igual ao melhor indivíduo da geração t. Isto permite garantirque o gráfico da avaliação do melhor indivíduo como função do número de geraçõesdecorridas é uma função monotonamente crescente [Koza 1994, Rechenberg 1994,Linden 2008].
O overhead de processamento é realmente muito pequeno, visto que já temosque determinar a avaliação de cada indivíduo para aplicação de seleção dos pais (roleta,torneio, dentre outras). Este pequeno ato, apesar de sua simplicidade, normalmentecolabora de forma dramática para a melhoria do desempenho de uma execução deum AG. Isto ocorre pois mantemos dentro da população os esquemas responsáveispelas boas avaliações das melhores soluções, o que aumenta o componente de memóriade nosso algoritmo genético. Consequentemente, é aumentada o seu componente deaproveitamento (explotation), sem prejudicar o desempenho de seu componente deexploração (exploration), que continua a atuar livremente em n−k indivíduos, onde n > k
[Davis 1991, Belew e Forrest 1998, Goldberg 1989, Linden 2008].
D.3.8 Operadoradores genético
Durante a fase de seleção de pais do algoritmo genético é comum usar doisoperadores genéticos clássicos: mutação e cruzamento. Como mencionado anteriormente,as mutações alteram um ou mais genes (posições de um cromossomo) com umaprobabilidade igual à taxa de mutação.
Crossover
Operadores de crossover pode ser dividido em três categorias principais combase na raridade (ou seja, o número de pais usados) do operador. Isso resulta em trêsclasses principais de operadores de crossover [Engelbrecht 2007, Ahn 2006, Ahn 2006]:
•assexuada, onde um filho é gerado de um pai.•sexuada, onde os dois pais são usados para produzir um ou dois filhos.•multi-recombinação, onde mais de dois pais são usados para produzir um ou maisfilhos.
Operadores de crossover são ainda classificados com base no esquemade representação utilizado. Por exemplo, operadores binários específicos têm sido

Apêndice D 141
desenvolvidos para representações de sequência binária, e operadores específicos pararepresentações de ponto flutuante [Engelbrecht 2007, Ahn 2006].
Os pais são selecionados usando qualquer um dos esquemas de seleção: Pressãoseletiva, Seleção aleatória, Seleção proporcional, Seleção de Torneio, Seleção Baseada emRank, Seleção de Boltzmann, dentre outras. No entanto, os pais não são necessariamentecompanheiros, pois a recombinação é aplicada de maneira probabilística. Cada par (ougrupo) de pais têm uma probabilidade, de produzir descendentes. Normalmente, umaalta probabilidade de cruzamento (também referida como a taxa de crossover) é usada[Engelbrecht 2007, Ahn 2006].
Na seleção dos pais, os seguintes aspectos precisam ser considerados:
•Devido à seleção probabilística dos pais, pode acontecer que o mesmo indivíduo éselecionado como ambos os pais, caso em que a prole gerada será uma cópia dopai. O processo de seleção pai deve, portanto, incorporar um teste para evitar quetais operações desnecessárias.•Também é possível que um mesmo indivíduo participe em mais de uma aplicaçãodo operador de crossover. Quando são usadas técnicas de adequação proporcional,isso se torna um problema.
Além da seleção dos pais e o processo de recombinação, o operador de crossover
considera uma política de substituição. Se um filho é gerado, o filho pode substituir o piorpai. Essa substituição pode ser baseada na restrição de que a prole deve ser mais aptado que o pior pai, ou pode ser forçada. Alternativamente, a Seleção de Boltzmann podeser usada para decidir se os filhos devem substituir o pior pai. Operadores de crossover
também têm sido implementadas quando a prole substitui o pior indivíduo da população.Uma estratégia similar pode ser usada para o caso de dois filhos [Engelbrecht 2007,Rothlauf 2006, Ahn 2006].
Mutação
O objetivo da mutação é introduzir novo material genético em um indivíduojá existentes; isto é, incluir a diversidade das características genéticas da população.Mutação é utilizada em apoio ao crossover para assegurar que toda a gama de alelo éacessível para cada gene. Mutação é aplicada a uma certa probabilidade pM para cadagene dos descendentes, Xi(t), para produzir a prole mutante, X’i(t). A probabilidade demutação, também referida como a taxa de mutação, geralmente é um valor pequeno,entre 0 e 1, para garantir que boas soluções não são distorcidas demais [Rothlauf 2006,Engelbrecht 2007, Ahn 2006].
Depois de compostos os filhos, entra em ação o operador de mutação. Esteopera da seguinte forma: ele tem associada uma probabilidade extremamente baixa (da

Apêndice D 142
ordem de 0,5 por cento) e nós sorteamos um número entre 0 e 1. Se ele for menor que aprobabilidade predeterminada então o operador atua sobre o gene em questão, alterandoo valor aleatoriamente. Repete-se então o processo para todos os genes componentes dosdois filhos [Rothlauf 2006, Linden 2008, Koza 1994].
O valor da probabilidade que decide se o operador de mutação será ou nãoaplicado é um dos parâmetros do AG que apenas a experiência pode determinar[Linden 2008, Koza 1994, Engelbrecht 2007, Rothlauf 2006].
D.3.9 Variantes de AG
Com base no AG geral, implementações diferentes de um AG podem ser obtidasutilizando diferentes combinações de seleção, crossover, e operadores de mutação. Naspróximas sub-seções são descritas algumas dessas variantes.
Método de reposição de cromossomo
Os AGs como discutido até agora diferem de modelos biológicos de evolução emque os tamanhos populacionais são fixos. Isso permite que o processo de seleção possaser descrito em duas etapas:
•Seleção de pais•Uma estratégia de seleção que decide quem irá substituir a prole dos pais.
Duas classes principais de AGs são identificados com base na estratégia de reposiçãoutilizada, ou seja, Algoritmo Genético Geracional (AGG) e Algoritmo Genético de EstadoEstacionário (AGEE), também referidos como AGs incremental. Para AGG’s a estratégiade substituição substitui todos os pais com seus filhos depois que todos os filhos foramcriados e modificados. Isso faz com que não haja sobreposição entre a população atuale a nova população (assumindo que o elitismo não é usado). Para AGEE’s, uma decisãoé tomada imediatamente após um filho ser gerado, são gerados mutantes, dessa geraçãocom o objetivo de saber se o pai ou o filho sobrevive para a próxima geração. Assim, existeuma sobreposição entre as populações atuais e as novas. A quantidade de sobreposiçãoentre as populações atuais e as novas é referido como a diferença entre gerações. AGG’spossuem um conflito de gerações zero, enquanto AGEE’s possuem lacunas na geração[Engelbrecht 2007, Ahn 2006].
Algoritmos genéticos “Sujo” - mAG
Para um espaço de busca nx−dimensional, usar populações AGs padrão, ondetodos os indivíduos são de tamanho fixo, um AG padrão pode encontrar uma soluçãoatravés da aplicação dos operadores evolutivos. Pode acontecer que as pessoas boas são

Apêndice D 143
encontradas, mas pode acontecer também que alguns dos genes desses indivíduos não sejao ideal. Pode ser difícil encontrar o ideal para tais genes através da aplicação de crossover
e mutação no indivíduo inteiro. Pode até acontecer que haja perda de genes ou grupos degenes, no cruzamento otimizado [Engelbrecht 2007, Ahn 2006].
Goldberg [Goldberg 1989] desenvolveu o AG messy (“sujo”) (mAG) queencontra soluções ideais pela evolução de blocos de construção e combinando blocosde construção. Aqui, um bloco de construção refere-se a um grupo de genes. Indivíduosem um bagunçado AG são de comprimento variável, e especificadas por uma lista deposição-valor pares. A posição especifica o índice do gene, e o valor especifica o alelopara esse gene. Estes pares são referidos como genes bagunçados. Como exemplo,se nx = 4, então o indivíduo, ((1,0)(3,1), (4,0)(1,1)), representa o indivíduo 0 ∗ 10[Engelbrecht 2007, Ahn 2006].
A representação messy pode resultar em indivíduos que estão sobre-especificadoou sub-especificado. O exemplo acima ilustra ambos os casos. O indivíduo ésobre-especificado porque um gene ocorre duas vezes. É sub-especificado porquegene 2 não ocorre, e não tem valor atribuído. A avaliação da aptidão dos indivíduosdesorganizados exige estratégias para lidar com tais indivíduos. Para sobre-especificadoindivíduos, uma abordagem: primeiro a chegar é o primeiro a ser servido, em seguidao primeiro valor especificado é atribuído ao gene da repetição. Para indivíduossub-especificado, um gene alelo em falta é obtido a partir de um modelo competitivo. Omodelo competitivo é uma solução ótima local. Como exemplo, se 1101 é o modelo, aaptidão de 0∗10 é avaliada como a aptidão de 0101. O objetivo do SMG é evoluir blocosde construção ideal, e de forma incremental combinar blocos de construção otimizadospara formar uma solução ótima. Um MAG é implementado usando dois laços. O loop
interno consiste em três etapas [Engelbrecht 2007, Ahn 2006]:
•Inicialização para criar uma população de blocos de construção de umcomprimento especificado, nm.•Primordial, que tem como objetivo gerar pequenas, porém, promissores blocos deconstrução.•Justapostas, para combinar blocos de construção.
O loop externo especifica o tamanho dos blocos de construção a seremconsiderados, começando com o menor tamanho de um, e gradativamente aumentandoo tamanho até que um tamanho máximo seja atingido, ou uma solução aceitávelé encontrada. O loop externo também define a melhor solução obtida a partirda “justaposição” passo que o modelo competitivo para a próxima iteração[Engelbrecht 2007, Ahn 2006].

Apêndice D 144
Evolução Interativa - EI
No AG padrão, o usuário humano desempenha um papel passivo. A seleçãoé baseada em uma função definida explicitamente analítica, utilizada para quantificar aqualidade de uma solução candidata. É, no entanto, o caso de que tal função não pode serdefinido para certas áreas de aplicação, por exemplo, evolução da arte, música, animações,etc. Para áreas de aplicação, tais julgamento subjetivo é necessária, baseada na “intuiçãohumana”, valores estéticos ou gosto. Isto requer a interação de um avaliador humanocomo a “função de fitness” [Engelbrecht 2007, Ahn 2006].
Evolução Interativa (EI) necessita de intervenção humana nos processos deseleção e variação. O processo de busca é agora dirigido por meio da seleção desoluções interativas feitas pelo usuário humano, em vez de uma função aptidão absoluta[Engelbrecht 2007, Ahn 2006].
Além de atuar como mecanismo de seleção, o usuário também pode especificarinterativamente os operadores de reprodução e parâmetros populacionais. Em vez deo usuário realizar a seleção humana, a interação pode ser da forma em que o usuárioatribui uma pontuação de fitness para os indivíduos. A Seleção automática é entãoaplicada, usando essas medidas de qualidade atribuídas pelo usuário [Engelbrecht 2007,Ahn 2006].
Algoritmos genéticos “Ilha”
AGs utilizam-se da implementação paralela. Três categorias principais de AGparalelas foram identificadas [Engelbrecht 2007, Ahn 2006]:
•AGs de única população mestre-escravo, onde a avaliação de aptidão é distribuídapor vários processadores.•AGs de única população de granulação fina, onde cada indivíduo é atribuído a umprocessador, e cada processador é atribuído um único indivíduo. Um bairro pequenoé definido para cada indivíduo, e seleção e reprodução são restritas aos bairros.Whitley [Whitley et al. 2000] refere-se a estes AGs como celular.•Multi-população, ou AGs de ilha, onde as várias populações são utilizadas, cadauma em um processador separado. As informações são trocadas entre as populaçõesatravés de uma política de migração. Embora desenvolvido para aplicação emparalelo, AGs ilha pode ser implementado em um sistema único processador.
Em um AG modelo Ilha, uma série de sub-populações são evoluídas emparalelo, em um quadro de cooperação. Neste modelo de AG, um número de ilhasocorre, onde cada ilha representa uma população. Cruzamento, seleção e mutaçãoocorre em cada subpopulação independentemente do subpopulações outros. Além

Apêndice D 145
disso, os indivíduos estão autorizados a migrar entre as ilhas (ou subpopulações)[Engelbrecht 2007, Ahn 2006].
D.4 Estratégia Evolutiva - EE
As EE’s foram desenvolvidas inicialmente na Alemanha, na década de 60[Gomes e Saavedra 1999], focalizando a resolução de problemas contínuos de otimizaçãoparamétrica, sendo estendidas recentemente para tratamento de problemas discretos.
A computação evolutiva é dividida em três grandes áreas: algoritmos genéticos(AG’s), programação evolutiva (PE’s) e estratégias evolutivas (EE’s) [Yao e Liu 1993].Em todos estes três paradigmas, é simulada uma evolução neo-Darwiniana, onde umapopulação de soluções candidatas de um problema é submetida a um processo derecombinação (cruzamento), mutação e competição pela sobrevivência.
Assumindo algumas hipóteses, é possível provar que as EE’s convergem aoótimo global com probabilidade 1, considerando um tempo de busca suficientementelongo. Uma primeira versão de EE’s focaliza um processo de busca no esquema 1 genitor- 1 descendente. Isto foi denominado (1+1)-EE , onde um único filho é criado a partir deum único genitor e ambos são confrontados numa competição por sobrevivência, onde aseleção elimina a solução mais pobre. Um aspecto negativo observado é a convergêncialenta, além da busca ponto a ponto ser susceptível a estagnar em mínimos locais.
Outras versões foram desenvolvidas com o objetivo de resolver tais problemas.Estas estratégias são denominadas multi-indivíduos, onde o tamanho da populaçãoé maior que 1. As EE’s multi-membros foram aperfeiçoadas tendo-se atualmentedois principais tipos (µ+λ)-EE e (µ,λ)-EE. Na primeira, µ indivíduos produzem λ
descendentes, gerando-se uma população temporária de (µ+λ) indivíduos, de onde sãoescolhidos µ indivíduos para a próxima geração. Na versão (µ,λ)-EE, µ indivíduosproduzem λ descendentes, com µ< λ, sendo que a nova população de µ indivíduos éformada por apenas indivíduos selecionados do conjunto de λ descendentes. Assim, operíodo de vida de cada indivíduo é limitado a apenas uma geração. Este tipo de estratégiatem bom desempenho em problemas onde o ponto ótimo é em função do tempo, ou ondea função é afetada por ruído.
EE’s: Algoritmo Padrão Considerando cada elemento composto por um par devetores na forma v = (x,σ), o algoritmo para o modelo (µ + λ) - EE é mostrado a seguir:
1.Inicializa-se uma população de µ indivíduos com variância 1 para cada posição dex.
2.Faz-se uma recombinação dos µ pais até gerar λ descendentes.3.Faz-se a mutação dos descendentes. E das variâncias seguindo as seguintes
expressões: xi j = xi j + N (0, σ) σi j = σi j. exp(τ’ N (0,1) + τ N j (0,1)) onde

Apêndice D 146
i = 1,...,λ; j = 1,...,n. N(0,1) representa um número Gaussiano com média zeroe variância 1, nota-se que esse número é o mesmo para todos os indivíduosquando multiplicado pelo fator τ’. O numero Gaussiano que multiplica a τ
deve ser obtido independentemente para valor de j. Os parâmetros τ’ e τ foramsugeridos pelos autores [Back e Schwefel 1993, Back, Hammel e Schwefel 1996,Back, Rudolph e Schwefel 1995] como: τ′ = (2n)− 1 e τ = (4x2n)− 1. Note quena mutação dos descendentes a variância será diferente a cada geração (autoadaptação)
4.Avalia-se o fitness5 de genitores e descendentes, onde serão escolhidos os µ
indivíduos com os melhores valores de fitness (competição), os quais serão os paisna próxima geração.
5.Repete-se o processo a partir do passo II até ser atingido o critério de paradaespecificado.
No passo 1 a população inicial é gerada aleatoriamente, porém atendendo ásrestrições impostas pelo problema. O passo 2 é iniciado o processo da geração dapopulação de descendentes, que só estará finalizada após o término do passo 3, ouseja, após a mutação. No passo 4 ocorre a competição entre todos os indivíduos, tantogenitores como descendentes. O critério de competição é a fitness, que neste problemacorresponde à função objetivo a ser otimizada. Este processo é determinístico, levandoem consideração que apenas µ indivíduos sobrevivam e passem para a próxima geraçãona qualidade de genitores. O critério de parada especificado no passo 5 é geralmente umacerta quantidade de gerações definidas pelo usuário.
D.5 Programação Evolucionária - PE
A programação evolucionária foi inicialmente proposta por Laurence Fogel em1962, como uma ferramenta estocástica de otimização similar aos algoritmos genéticos,entretanto enfatiza a relação entre a geração de pais e a geração de descendentes, aoinvés de utilizar operadores genéticos. A programação evolucionária é um método deotimização, capaz de resolver problemas onde a resolução analítica encontra dificuldadepara solucionar o problema. Como os algoritmos genéticos, existe a premissa da análise dofitness para a obtenção da melhor solução. O problema de otimização pode ser formuladode forma a minimizar uma função objetivo.
Desta forma, o problema de minimização global pode ser formulado como umpar (S, d) onde S ⊆ Rn é o conjunto limitado em Rn e d : S à R é uma função de valores
5 Entende-se por fitness a medida do desempenho do indivíduo na geração atual. Neste caso, a fitnesscorresponde ao valor da função objetivo do problema.

Apêndice D 147
reais n-dimensional. O problema é a determinação do ponto xmin ∈ S tal que d(xmin) éo mínimo global de S. Mais especificamente, é necessário encontrar xmin ∈ S tal que:∀x ∈ S : d(xmn) ≤ d(x) onde d não precisa ser contínua, mas precisa ler limitada. Bäck eSchwefel (1993) demonstram que o algoritmo de programação evolucionária com taxa demutação adaptativa possui um melhor desempenho em relação ao algoritmo com taxa demutação constante.
Deve-se enfatizar que a programação evolucionária não utiliza nenhum operadorde crossover como operador evolutivo. Existem dois pontos relevantes que diferenciamos algoritmos genéticos da programação evolucionária: primeiro a representação dassoluções não são codificadas, no caso dos algoritmos genéticos canônicos (representaçãobinária ou genotípica) a análise é realizada em cromossomos codificados, geralmentede forma binária. Na programação evolutiva, a representação segue de acordo com oproblema (representação fenotípica), por exemplo, uma rede neural pode ser representadada mesma forma que é implementada. E em segundo, o operador de mutação modificaa solução de acordo com uma distribuição estatística, de forma a existir uma pequenavariação entre gerações.
Abaixo é apresentado o algoritmo que representa uma programaçãoevolucionária com taxa de mutação adaptativa, proposto pelos autores Yao, Liu e Lin[Yao, Liu e Lin 1999]:
1.Gerar a população inicial com µ indivíduos e k = 1. Cada indivíduo é escolhidocomo um par de vetores reais, (xi,ηi), ∀i ∈ {1, . . . ,µ}, onde xi são as variáveisobjetivos e η i são os desvios padrão para a mutação.
2.Avaliar o resultado do fitness para cada indivíduo (xi,η i), ∀i ∈ {1, . . . ,µ}, dapopulação baseado no função objetivo d(xi).
3.Cada elemento pai (xi,ηi), i = 1, . . . ,µ, cria um descendente (xi′,ηi′). Para j =
1, . . . ,n. Tem-se que :
xi′( j) = xi( j)+ηi( j)N j(0,1) (4.5)
ηi′( j) = ηi( j)exp(τ′N(0,1)+ τN j(0,1)) (4.6)
onde xi(j), xi’(j),η i(j) e η i’(j) representam o j-ésimo componente do vetor xi ,xi’ ,η i e η i’ , respectivamente. N(0,1) indica a geração de um número aleatório dedistribuição normal e média zero e desvio padrão igual a 1; Nj(0,1) indica a geraçãode um número aleatório com distribuição normal para cada j. Os fatores τ e τ’ sãogeralmente designados como (2n)-1 e (2n)-1.
4.Calcular o fitness de cada membro da nova geração (xi′,′ ), ∀i ∈ {1, ...,µ}.

Apêndice D 148
5.Conduzir uma comparação de cada par entre a geração pai (xi, η i) e a geraçãodescendente (xi′,′ ), ∀i ∈ {1, ...,µ}. Para cada elemento, q oponentes são escolhidosde forma aleatória entre todos os elementos da geração pai e geração descendente.Para cada comparação, se o fitness individual é maior que o do oponente, ele recebeuma “vitória”.
6.Selecionar os µ indivíduos de (xi,ηi) e (xi′,ηi′) , ∀i∈ {1, ...,µ}, que possuem maiornúmero de “vitórias” para formarem a próxima geração pai.
7.Suspender o algoritmo se um critério de parada for alcançado, caso contráriok = k+1 e retorna-se ao passo 3.
Pode-se resumir o algoritmo de programação evolucionária a uma sequênciasimples de passos, conforme mostrado abaixo:
1.Gerar a população inicial;2.Enquanto não atingir o critério de parada faça;3.Avaliar o fitness de cada elemento da população;4.Cada elemento pai gera um descendente utilizando as equações (1) e (2);5.Avaliar o fitness de cada elemento da nova geração;6.Cada elemento da geração pai é comparado algumas vezes com alguns elementos
da nova população, o elemento com o melhor fitness, a cada comparação, acumulauma vitória;
7.Selecionar os elementos com o maior número de vitórias para compor a novageração;
8.Fim Enquanto;9.Retorna resultado.
D.6 Programação Genética - PG
Seres vivos são divididos em espécies. Ao longo do tempo (que pode serrelativamente curto ou muito longo) as espécies mudaram, ou seja, elas evoluem. Existemvários componentes essenciais para a evolução natural. Indivíduos (por exemplo, animaisou plantas) dentro de uma população de espécies são diferentes. Como resultado, algunssobrevivem até a idade adulta (seleção natural), vivem mais e são mais propensosa procriarem . Estes animais (ou plantas, etc) são ditos mais apto. Às vezes, avariação tem um componente genético, ou seja, os filhos podem herdar de seus pais.Consequentemente, após um número de gerações, a proporção de indivíduos dentro dasespécies com esta característica favorável tende a aumentar. Ou seja, ao longo do tempoa espécie como um todo muda ou evolui [Langdon e Poli 1998].

Apêndice D 149
Figura D.4: comportamento típico de algoritmos evolutivosenvolvendo seleção e cruzamento (crossover)
Programação genética (PG) tem sido aplicada com sucesso a um grande númerode problemas difíceis como reconhecimento de padrões, mineração de dados, controle derobótica, síntese de arquiteturas neurais artificiais (redes neurais), bioinformática, gerandomodelos para ajustar os dados, música e geração de imagem [Langdon e Poli 1998].
Qualquer técnica de geração automática do programa pode ser visto como aprocura de qualquer programa entre todos os programas possíveis. Além de ser enormeo campo de busca. Essa busca é assumidamente contínua, e assim técnicas clássicas deotimização numérica são incapazes de resolver os nossos problemas. Técnicas de pesquisaestocástica, como PG, têm sido utilizado [Langdon e Poli 1998].
Programação Genética, é uma forma de computação baseada na simulação daevolução de indivíduos. Tem como base, o fato de que a evolução na natureza é criativa,pois produz muitas vezes resultados inesperados, impensados e não-lineares, diferentedo modo da programação usual. Algumas características importantes da ProgramaçãoGenética são descritas a seguir [Koza 1992].
Tanto os algoritmos genéticos quanto a programação genética são abordagensbaseadas nas ideias da teoria da evolução. As duas abordagens utilizam populações deindivíduos, selecionam indivíduos de acordo com sua aptidão e introduzem variaçãogenética utilizando um ou mais operadores genéticos. A diferença fundamental entre osdois reside na natureza dos indivíduos: nos algoritmos genéticos os indivíduos são cadeiaslineares (cromossomos) e sua sintaxe é livre, na programação genética os indivíduos sãoentidades não lineares (árvores) e devem ter sua sintaxe preservada.
Na programação genética as soluções são codificadas para permitir que oscromossomos (programas) sejam executados diretamente usando um interpretadorapropriado.
No algoritmo genético o cruzamento de pais iguais levam a filhos iguais. Naprogramação genética isto não acontece: dois pais iguais geram filhos diferentes abrindo apossibilidade para partir de uma população pré-definida próxima a uma solução de projetodesejada, aumentando a velocidade de convergência.
Na programação Genética as árvores (indivíduos) possuem funções e terminais,

Apêndice D 150
que determinam suas características e definem seu comportamento no ambiente. Cadafunção é um ramo da árvore, e cada terminal é uma folha. As funções podem ser,por exemplo, operações lógicas ou matemáticas, e os terminais podem ser variáveis,constantes, ou funções que não recebem argumentos[Nikolaev, Iba e Slavov 1999].Programação genética usa uma estrutura cromossômica em árvore inspirada pelaprogramação funcional LISP, proposto por John McCarthy em 1958. Um exemplo émostrado na Figura D.5, onde a expressão T 3 é filha de T 1 e T 2 e as linhas pontilhadasindicam o conteúdo trocado durante a operação de crossover.
Figura D.5: Programação funcional LISP
Um indivíduo de uma população em programação genética é uma composiçãohierárquica de funções primitivas e terminais apropriados a um domínio de problema emparticular. Neste
D.7 Diferenças entre AG, EE e PE
A Computação Evolucionária compreende um conjunto de técnicas debusca e otimização inspiradas na evolução natural das espécies. Desta forma, cria-seuma população de indivíduos que vão reproduzir e competir pela sobrevivência.Os melhores sobrevivem e transferem suas características às novas gerações. Astécnicas atualmente incluem [BARRETO 1997]: Programação Evolucionária, EstratégiasEvolutiva, Algoritmos Genéticos e Programação Genética. Estes métodos estão sendoutilizados, cada vez mais, pela comunidade de inteligência artificial para obter modelosde inteligência computacional.

Apêndice D 151
Algoritmos Genéticos (AG) e Programação Genética (PG) são as duas principaisfrentes de pesquisa em CE. Os Algoritmos Genéticos (AG) foram concebidos em 1960por John Holland [Holland 1975], com o objetivo inicial de estudar os fenômenosrelacionados à adaptação das espécies e da seleção natural que ocorre na natureza(Darwin em 1859), bem como desenvolver uma maneira de incorporar estes conceitosaos computadores [MITCHELL 1997].
Os AGs possuem uma larga aplicação em muitas áreas científicas, entre asquais podem ser citados problemas de otimização de soluções, aprendizado de máquina,desenvolvimento de estratégias e fórmulas matemáticas, análise de modelos econômicos,problemas de engenharia, diversas aplicações na Biologia como simulação de bactérias,sistemas imunológicos, ecossistemas, descoberta de formato e propriedades de moléculasorgânicas [MITCHELL 1997].
Programação Genética (PG) é uma técnica de geração automática de programasde computador criada por John Koza [Koza 1992], inspirada na teoria de AGs de Holland.Em PG é possível criar e manipular software geneticamente, aplicando conceitos herdadosda biologia para gerar programas de computador automaticamente. A diferença essencialentre AG e PG é que em PG as estruturas manipuladas são bem mais complexas, assimcomo várias das operações realizadas pelo algoritmo. Ambas as técnicas compartilham amesma base teórica, inspirada na competição entre indivíduos pela sobrevivência, porémnão mantêm vínculos de dependência ou subordinação.
PG e AGs representam um campo novo de pesquisa dentro da Ciência daComputação. Neste campo muitos problemas continuam em aberto e a espera denovas soluções e ferramentas. Apesar disso, este paradigma vem se mostrando bastantepoderoso e muitos trabalhos vêm explorando o uso de AGs e PG para solucionar diversosproblemas em diferentes áreas do conhecimento [Whitley et al. 2000].
As EE’s e PE’s são semelhantes sendo que nestas últimas os indivíduos nãosão submetidos a cruzamentos. Os AG’s enfatizam o aspecto cromossômico de cadaindivíduo. Nas EE’s, um indivíduo é representado por um par de vetores reais da formav=(x,σ), onde x representa o ponto de busca no espaço e σ o vetor de desvio padrãoassociado. Nas versões atuais, a descendência é obtida submetendo-se os indivíduosda geração a dois operadores: cruzamento e mutação. O cruzamento é feito de formaaleatória e a mutação é feita tipicamente através de uma perturbação Gaussiana demédia nula e desvio padrão unitário, porém outros tipos de mutação são possíveis[Yao e Liu 1993, Gomes e Saavedra 1999, Nogueira e Saavedra 1999]. Observa-se que oparâmetro σ (que determina a mutação de x) também está sujeito ao processo de evoluçãotambém através de mutação. Esta é uma característica fundamental das EE’s, que permiteo auto ajuste de seus parâmetros.
Como dito anteriormente, existem dois pontos relevantes que diferenciam

Apêndice D 152
os algoritmos genéticos da programação evolucionária: primeiro a representação dassoluções não são codificadas, no caso dos algoritmos genéticos canônicos (representaçãobinária ou genotípica) a análise é realizada em cromossomos codificados, geralmentede forma binária. Na programação evolutiva, a representação segue de acordo com oproblema (representação fenotípica), por exemplo, uma rede neural pode ser representadada mesma forma que é implementada. E em segundo, o operador de mutação modificaa solução de acordo com uma distribuição estatística, de forma a existir uma pequenavariação entre gerações.
D.8 Conclusão
A computação evolutiva representa uma iniciativa de implementaçãocomputacional de regras de evolução muito simples: os indivíduos sofrem variaçõesaleatórias de geração em geração (via operadores genéticos responsáveis pelaimplementação dos processos de busca), estando sujeitos à seleção natural sob recursoslimitados.
Os indivíduos mais adaptados (exemplares localizados em regiões promissorasdo espaço de busca) sobrevivem e se reproduzem, propagando seu material genético àspróximas gerações. Assumindo que o tamanho da população é fixo ao longo das gerações(simulação da existência de recursos limitados), então os indivíduos mais adaptadosda geração atual terão maior chance de transmitir seu código genético para a próximageração.
Existe portanto um compromisso entre mecanismos de exploração global doespaço de busca (manutenção de diversidade na população) e de exploração local dasregiões promissoras detectadas (aplicação de operadores genéticos em conjunto comprocessos de seleção baseadas no nível de adaptação de cada indivíduo).
Este levantamento bibliográfico procurou formalizar os principais conceitos,dando uma visão ampla e introdutória da Computação Evolucionária, especialmente osalgoritmos evolucionários: algoritmos genéticos, estratégias evolutivas e programaçãoevolucionária.





























