Embed Size (px)
Citation preview

Prefácio
As distribuições Linux estão de um modo geral se tornando muito fáceis de usar, até mesmo mais fáceis de usar que o Windows em algumas áreas. Mas isso acaba deixando um gosto amargo na boca. Afinal, onde está o desafio?
Em outros casos as coisas não funcionam tão bem assim e o gosto amargo fica por conta do modem, webcam, placa 3D ou placa wireless que não está funcionando ou outro problema qualquer, que não pode ser solucionado usando as ferramentas gráficas.
Este livro é uma coleção de dicas que ensinam a configurar e corrigir problemas "na unha", manipulando diretamente os arquivos de configuração e módulos do sistema, sem depender de nenhum configurador, escrever shell scripts, instalar drivers manualmente e dominar ferramentas de diagnóstico e recuperação do sistema.
É ideal para quem gosta de fuçar e quer entender melhor como o sistema funciona internamente, editando arquivos de configuração, compilando módulos e escrevendo scripts.
Nesta segunda edição, o livro recebeu uma grande quantidade de atualizações em todos os capítulos e muitas das dicas antigas foram substituídas por novas.
O capítulo sobre shell script foi expandido, trazendo mais informações sobre o desenvolvimento de scripts gráficos, ferramentas de configuração e também scripts e regras para o hotplug e udev, que permitem abrir programas e executar tarefas diversas quando novos dispositivos são plugados na máquina.
Foi incluído também um novo capítulo, que ensina a desenvolver novas distribuições ou soluções baseadas no Kurumin e outros live-CDs derivados do Knoppix, que permitem colocar em prática as dicas aprendidas no restante do livro.
Por ser escrito em uma linguagem simples e didática e com um nível crescente de dificuldade, este livro é indicado tanto para usuários avançados, quanto iniciantes que desejam compreender mais profundamente o sistema.

Capítulo 1: Entendendo a estrutura do sistema
Como funciona o suporte a hardware no Linux Os componentes do sistema Kernel Módulos Os processos de boot e os arquivos de inicialização Ativando e desativando serviços X Gerenciador de login Xfree e Xorg A árvore genealógica das distribuições
Capítulo 2: Configuração, ferramentas e dicas
Editando o /etc/fstab Configurando o lilo
o Dual-Boot com dois HDs o Usando uma imagem de fundo
Configurando o grub Configurando o vídeo: /etc/X11/xorg.conf KVM via software com o Synergy Usando o hdparm Recompilando o Kernel
o Baixando os fontes o Configurando o Compilando o Instalando o Recompilando o Kernel à moda Debian o Aplicando patches
Criando patches Acelerando a compilação com o distcc Criando pacotes a partir dos fontes com o checkinstall Escrevendo scripts de backup Usando o autofs/automount Acessando dispositivos USB
o Configurando manualmente o Devs e hotplug o Entendendo o udev o Renomeando interfaces de rede com o udev
Fazendo backup e recuperando a MBR e tabela de partições o Usando o Gpart o Usando o Testdisk
Recuperando partições danificadas Gerenciamento de setores defeituosos como o ReiserFS Monitorando a saúde do HD com o SMART Copiando dados de HDs ou CDs defeituosos Aproveitando módulos de memória defeituosos

Eliminando dados com segurança Administrando a memória swap Ativando o suporte a mair de 1GB de memória RAM Clonando partições com o Partimage
o Instalando o Funções básicas o Fazendo uma imagem de todo o HD o Gravando imagens num compartilhamento da rede
Segurança: detectando rootkits Instalando o Kurumin 7 (e outras distros) num pendrive ou cartão Salvando as configurações Monitores de temperatura e coolers Gerenciamento de energia
Capítulo 3: Instalando drivers adicionais
Verificando links, arquivos e compiladores Configurando softmodems no Linux
o A idéia básica o Driver da Smartlink o Intel AC97 e ATI IXP o Intel 537 e 536 o Lucent e Agere o PC-Tel PCI o Modems com chipset Conexant
Instalando placas wireless o Ndiswrapper o ACX100 e ACX111 o MadWiFi o ADMteck ADM8211 o Realtek 8180 o Orinoco USB o Broadcom o IPW2100 e IPW2200 o Ralink 2400 e 2500 o Linux-wlan-ng
Suporte a webcams o Driver apca5xx o Logitech QuickCam o Sqcam
Modems ADSL USB Driver da nVidia
o Instalando manualmente o Ativando os recursos especiais o FSAA o Configurador gráfico o Twin View o Instalando à moda Debian

Driver para placas com chipset nForce o Ativando o driver de rede o Ativando o driver de som
Driver 3D da ATI o Instalando o Configurando e solucionando problemas
Tablets Configurando placas de TV
o Gravando Configurando mouses touchpad com funções especiais Bootsplash
Capítulo 4: Programando em shell script
O básico Fazendo perguntas Mais dicas sobre o kdialog Controlando aplicativos via DCOP Usando os servicemenus do KDE Detectando hardware Alterando arquivos de configuração Corrigindo erros Pacotes auto-instaláveis Mais exemplos úteis Criando interfaces no Kommander Criando scripts para o hotplug Criando regras para o udev
Capítulo 5: Remasterizando o Kurumin e outros live-CDs
O básico Extraindo Fechando a nova imagem Personalizando o KDE e programas Scripts de inicialização Mudando a lingua padrão e traduzindo as mensagens de boot Mudando o usuário padrão Criando um DVD de recuperação Criando seus próprios pacotes .deb
Como funciona o suporte a hardware no Linux?
As distribuições Linux sempre vêm de fábrica com suporte a muitos dispositivos, em geral

quase tudo é detectado automaticamente. Os maiores problemas são, em geral, os softmodems que precisam ser instalados manualmente. O mesmo se aplica se você tiver uma placa de vídeo da nVidia ou da ATI ou outros dispositivos (como várias placas de rede wireless), cujos fabricantes disponibilizam drivers proprietários.
Mas, afinal, como é a instalação destes drivers no Linux? Cadê o assistente para a instalação de novo hardware? Onde que eu aponto a pasta onde estão os arquivos? Calma, vamos chegar lá :-).
O suporte a dispositivos no Linux é feito através de "módulos" incluídos no Kernel, arquivos que ficam dentro da pasta "/lib/modules/versão_do_kernel_usada/". Estes módulos são a coisa mais parecida com um "driver" dentro da concepção que temos no Windows. Para ativar suporte a um certo dispositivo, você precisa apenas carregar o módulo referente a ele.
Veja que os módulos ficam organizados em pastas: a pasta "kernel/drivers/net/" contém drivers para placas de rede, a pasta "kernel/drivers/usb/" agrupa os que dão suporte dispositivos USB e assim por diante.
Até o Kernel 2.4, os módulos de Kernel utilizavam a extensão ".o", que é uma extensão genérica para objetos em C. A partir do Kernel 2.6, passou a ser usada a extensão ".ko" (kernel object), que é mais específica.
Quase sempre, os módulos possuem nomes que dão uma idéia do dispositivo a que oferecem suporte. O "8139too.ko" dá suporte às placas de rede com o chipset Realtek 8139, o "sis900.ko" dá suporte às placas SiS 900, enquanto o "e100.ko" ativa as placas Intel E100.
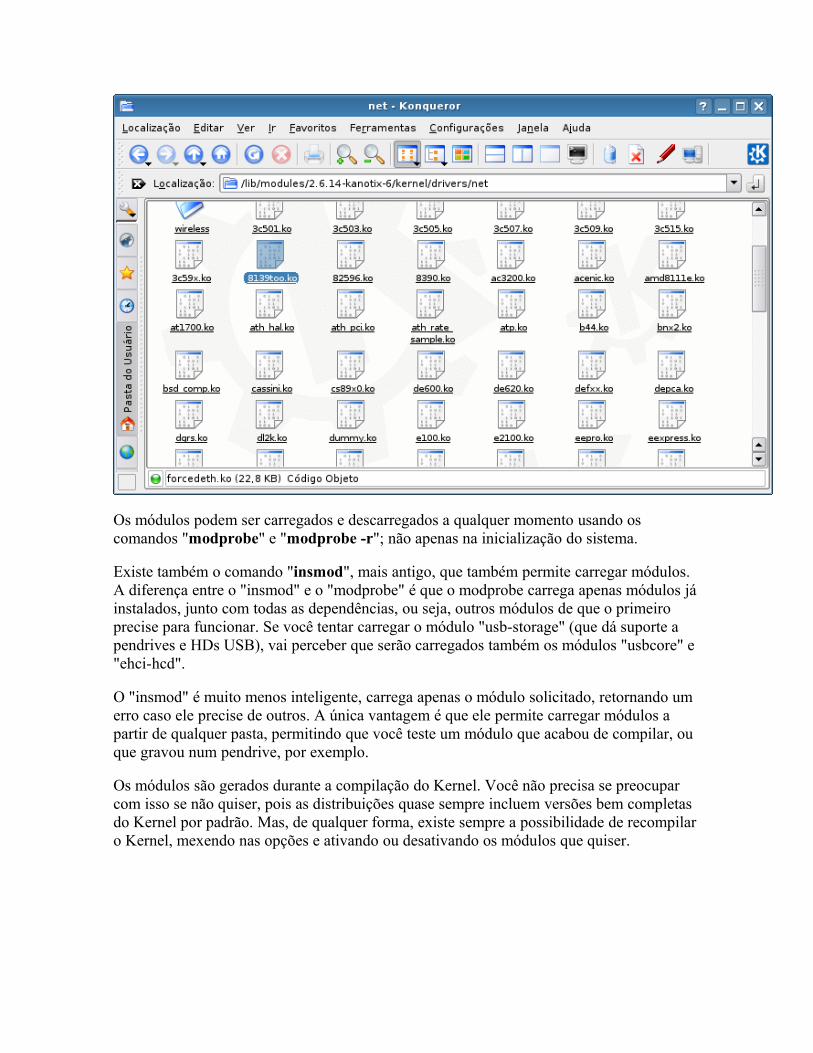
Os módulos podem ser carregados e descarregados a qualquer momento usando os comandos "modprobe" e "modprobe -r"; não apenas na inicialização do sistema.
Existe também o comando "insmod", mais antigo, que também permite carregar módulos. A diferença entre o "insmod" e o "modprobe" é que o modprobe carrega apenas módulos já instalados, junto com todas as dependências, ou seja, outros módulos de que o primeiro precise para funcionar. Se você tentar carregar o módulo "usb-storage" (que dá suporte a pendrives e HDs USB), vai perceber que serão carregados também os módulos "usbcore" e "ehci-hcd".
O "insmod" é muito menos inteligente, carrega apenas o módulo solicitado, retornando um erro caso ele precise de outros. A única vantagem é que ele permite carregar módulos a partir de qualquer pasta, permitindo que você teste um módulo que acabou de compilar, ou que gravou num pendrive, por exemplo.
Os módulos são gerados durante a compilação do Kernel. Você não precisa se preocupar com isso se não quiser, pois as distribuições quase sempre incluem versões bem completas do Kernel por padrão. Mas, de qualquer forma, existe sempre a possibilidade de recompilar o Kernel, mexendo nas opções e ativando ou desativando os módulos que quiser.
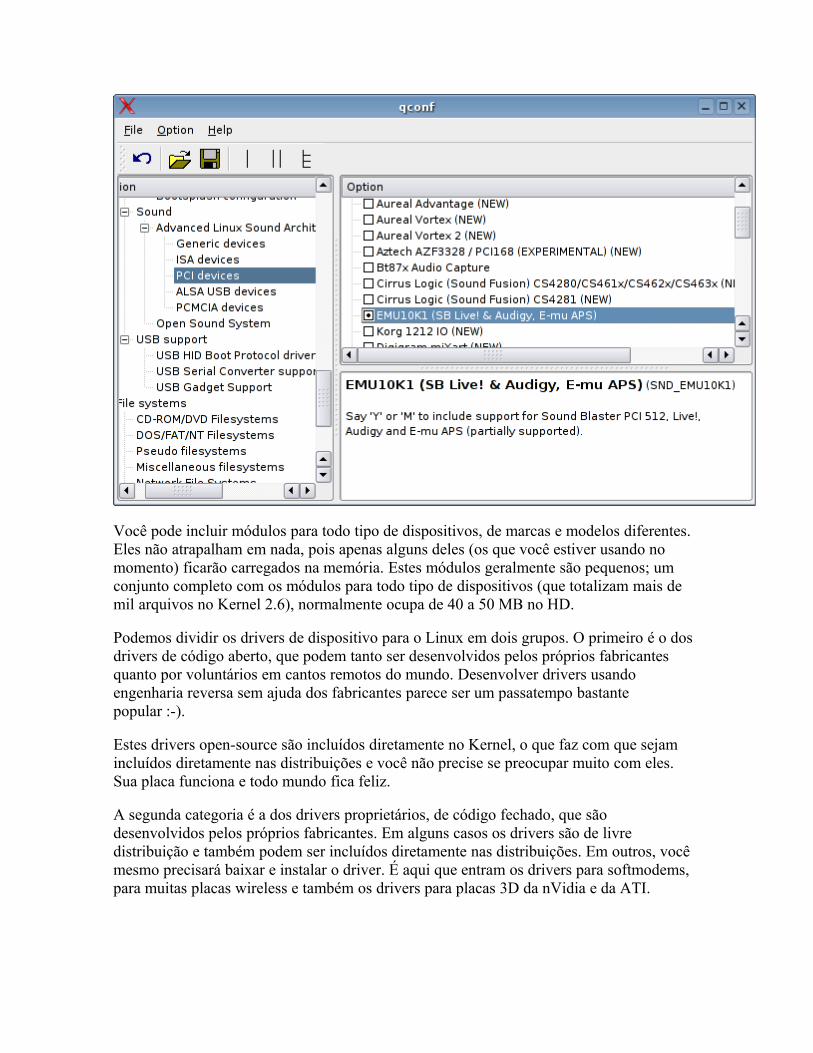
Você pode incluir módulos para todo tipo de dispositivos, de marcas e modelos diferentes. Eles não atrapalham em nada, pois apenas alguns deles (os que você estiver usando no momento) ficarão carregados na memória. Estes módulos geralmente são pequenos; um conjunto completo com os módulos para todo tipo de dispositivos (que totalizam mais de mil arquivos no Kernel 2.6), normalmente ocupa de 40 a 50 MB no HD.
Podemos dividir os drivers de dispositivo para o Linux em dois grupos. O primeiro é o dos drivers de código aberto, que podem tanto ser desenvolvidos pelos próprios fabricantes quanto por voluntários em cantos remotos do mundo. Desenvolver drivers usando engenharia reversa sem ajuda dos fabricantes parece ser um passatempo bastante popular :-).
Estes drivers open-source são incluídos diretamente no Kernel, o que faz com que sejam incluídos diretamente nas distribuições e você não precise se preocupar muito com eles. Sua placa funciona e todo mundo fica feliz.
A segunda categoria é a dos drivers proprietários, de código fechado, que são desenvolvidos pelos próprios fabricantes. Em alguns casos os drivers são de livre distribuição e também podem ser incluídos diretamente nas distribuições. Em outros, você mesmo precisará baixar e instalar o driver. É aqui que entram os drivers para softmodems, para muitas placas wireless e também os drivers para placas 3D da nVidia e da ATI.

A psicologia para lidar com eles é a seguinte: instalar um destes drivers envolve duas tarefas: baixar e instalar o módulo propriamente dito e criar um "dispositivo" (device), um atalho que aponta para o endereço de hardware usado por ele.
Ao instalar um modem Lucent, por exemplo, é criado um dispositivo "/dev/ttyLT0" por onde o modem é acessado. Para facilitar esta tarefa, geralmente os drivers vêm com algum tipo de instalador, geralmente um script simples de modo texto que cuida disso para você.
Os módulos são parte integrante do Kernel, por isso os módulos para uma determinada distribuição não funcionam em outra, a menos que por uma grande coincidência as duas utilizem exatamente a mesma versão do Kernel. Isso é bastante improvável já que o Kernel do Linux é atualizado quase que diariamente.
Se você usar uma distribuição popular, Mandriva, Fedora, SuSE, etc., é possível que você encontre um driver pré-compilado para download (que pode ser encontrado com a ajuda do Google ;). Neste caso, você só vai precisar instalar um pacote RPM ou executar um arquivo de instalação. Em outras situações, você encontrará apenas um arquivo genérico ainda não compilado, contendo um instalador que se encarrega de compilar um módulo sob medida para o Kernel em uso.
Como ele não tem como adivinhar qual distribuição ou Kernel você está utilizando, é necessário ter instalados dois pacotes que acompanham qualquer distribuição: kernel-source e kernel-headers. No Mandriva, por exemplo, você pode instalá-los usando os comandos:
# urpmi kernel-source # urpmi kernel-headers
Naturalmente, para que ele possa compilar qualquer coisa, você precisará também de um compilador, o gcc, que também acompanha as distribuições. Se você tiver estas três coisas, vai conseguir instalar qualquer driver sem maiores problemas, basta seguir as instruções na página de download ou no arquivo INSTALL ou README dentro do pacote.
Uma grande parte deste livro é justamente dedicada a falar sobre a instalação destes drivers difíceis, abordando também os problemas de instalação mais comuns.
Um lembrete importante sobre a nomenclatura adotada neste livro e em outros tipos de documentação é que a cerquilha (#) no início do comando indica que ele deve ser executado como root, o que é necessário ao instalar programas e editar arquivos de configuração. Os comandos com um dólar ($) por sua vez devem ser executados usando uma conta de usuário.
Lembre-se de que, em qualquer distribuição, você pode usar o comando "su" (seguido da senha) para virar root. No caso do Ubuntu, além do Kurumin e outras distribuições derivadas do Knoppix, você pode usar também o "sudo".

Os componentes do sistema
Todas as coisas grandes começam pequenas e com o Linux não foi diferente. Para entender melhor os componentes que formam o sistema, nada melhor do que falar um pouco sobre a história do Linux, sobre como e por que eles foram introduzidos, e entender o processo de inicialização do sistema.
Kernel
Tudo começou em 1991, com a primeira versão do Kernel disponibilizada por Linus Torvalds. O "Freax" (renomeado para "Linux" pelo responsável pelo FTP onde o arquivo foi disponibilizado, uma alma sábia e caridosa :) ainda estava na versão 0.02 e era um sistema monolítico, um grande bloco de código que, além do núcleo do sistema, continha drivers de dispositivos e tudo mais.
Para compilar o código fonte do Kernel, era necessário usar o Minix, outro sistema baseado em Unix que na época era bastante popular entre os estudantes. Você começava compilando o Kernel e em seguida algumas ferramentas básicas como o gerenciador de boot, o bash (o interpretador de comandos) e o gcc (o compilador). A partir de um certo ponto, você podia dar boot no próprio Linux e compilar os demais programas a partir dele mesmo.
Os primeiros aplicativos a rodarem sobre o Linux foram justamente ferramentas de desenvolvimento, como o Emacs, e emuladores de terminal, usados para acessar outras máquinas Unix remotamente.
Nesta época começaram a surgir as primeiras "distribuições" Linux, na forma de projetos amadores, onde alguém gravava o sistema compilado em um conjunto de disquetes e tirava cópias para os amigos.
Este procedimento de usar outro sistema operacional instalado para compilar uma instalação do Linux é de certa forma usada até hoje para gerar versões do sistema destinadas a serem usadas em dispositivos embarcados, como palms e celulares. Neles você usa uma cópia do Linux instalada num PC para "montar" o sistema que vai rodar no dispositivo, compilando primeiro o Kernel e depois os demais aplicativos necessários, deixando para finalmente transferir para o dispositivo no final do processo. Isto é chamado de "cross-compiling".
Atualmente o Kernel, junto com vários aplicativos, pode ser compilado para rodar em várias plataformas diferentes. O código fonte do Kernel, disponível no http://kernel.org (e diversos mirrors), inclui o código necessário para gerar um Kernel para qualquer arquitetura suportada.

Na verdade, quase 95% do código Kernel é independente da arquitetura, por isso portar o Kernel para uma nova plataforma é um trabalho relativamente simples (pelo menos se levarmos em conta a complexidade do código envolvido). As partes que mudam de uma arquitetura a outra são organizadas na pasta "/usr/src/linux/arch/".
Ainda assim, e um trabalho complexo e tedioso, muitas coisas precisam ser ajustadas e é necessário encontrar programas específicos, que se ajustem à configuração de hardware da plataforma alvo. Você pode rodar Linux num celular com 2 MB de memória, mas com certeza não vai conseguir rodar o Firefox nele. Vai precisar encontrar um navegador mais leve, que rode confortavelmente com pouca memória e a tela minúscula do aparelho.
Aqui temos um screenshot do Familiar, uma distribuição Linux para o Ipaq, que pode ser instalado em substituição ao Pocket PC Windows, que vem originalmente instalado. Veja que ele é bem diferente das distribuições para micros PC:
Você pode entender melhor sobre como isto funciona instalando o "Linux from Scratch", uma distribuição Linux que pode ser toda compilada manualmente a partir dos pacotes com código fonte, disponível no: http://www.linuxfromscratch.org/.
Voltando à história, no início o projeto ainda não tinha muita utilidade prática. O conjunto de aplicativos que rodava no sistema era pequeno. Era muito mais fácil usar o Minix, ou, se você tivesse condições financeiras, uma versão comercial do Unix, como o SunOS, que mais tarde deu origem ao Solaris e ao OpenSolaris.
O que fez com que o Linux crescesse até o ponto em que está hoje foi principalmente o fato de não apenas o código fonte do sistema ser aberto e estar disponível, mas também a forma aberta como o sistema foi desenvolvido desde o início.

É normal encontrar muitos problemas e deficiências ao tentar usar um software em estágio primário de desenvolvimento. Se você for um programador, vai acabar dando uma olhada no código e fazendo algumas modificações. Se você estiver desenvolvendo algum projeto parecido, é provável que você resolva aproveitar algumas idéias e pedaços de código para implementar alguma nova função e assim por diante.
No caso do Linux, estas modificações eram bem-vindas e acabavam sendo incluídas no sistema muito rapidamente. Isto criou uma comunidade bastante ativa, gente usando o sistema nos mais diversos ambientes e ajudando a torná-lo adequado para todo tipo de tarefa.
Inicialmente era tudo um grande hobby. Mas logo o sistema começou a ficar maduro o suficiente para concorrer com as várias versões do Unix e, mais tarde, também com o Windows, inicialmente nos servidores, depois nos dispositivos embarcados e finalmente no desktop. Com isso, mesmo grandes empresas como a IBM e a Novell começaram a contribuir com o desenvolvimento do Kernel, a fim de tornar o sistema mais robusto e adicionar recursos necessários para uso em diversas tarefas.
Este modelo é diferente do adotado pela Microsoft, por exemplo, que vende caixinhas do Windows e Office. Estas empresas ganham mais vendendo soluções, onde é fornecido um pacote, com o sistema operacional, aplicativos, suporte e garantias.
Neste caso, faz sentido contribuir para a construção de uma base comum (o Kernel) pois, no final, sai muito mais barato do que investir em um sistema próprio. A partir desta base comum, as empresas podem diferenciar-se das demais investindo nos outros componentes do pacote. Usar Linux acaba virando então uma questão de competitividade: outra empresa que resolvesse desenvolver um sistema próprio sairia em desvantagem, pois precisaria investir muito tempo e dinheiro para chegar no mesmo nível dos outros.
Originalmente, o termo "Linux" era usado especificamente com relação ao Kernel desenvolvido por Linus Torvalds. Mas, hoje em dia, é mais comum nos referirmos à plataforma como um todo, incluindo o Kernel, ferramentas e aplicativos. Muitos dos aplicativos que usamos hoje no Linux vieram de outras versões do Unix e este fluxo continua até hoje, nos dois sentidos.
O Kernel é a base do sistema. Ele controla o acesso à memória, ao HD e demais componentes do micro, dividindo os recursos disponíveis entre os programas. Todos os demais programas, desde os aplicativos de linha de comando, até os aplicativos gráficos rodam sobre o Kernel.
Imagine, por exemplo, que você está desenvolvendo um aplicativo de edição de áudio. Você precisa incluir no seu programa várias funções de edição, filtros e assim por diante. Mas, você não precisa se preocupar diretamente em oferecer suporte aos diferentes modelos de placas de som que temos no mercado, pois o Kernel cuida disso.
Ao tocar um arquivo de áudio qualquer, o seu programa precisa apenas mandar o fluxo de áudio para o device "/dev/dsp". O Kernel recebe o fluxo de áudio e se encarrega de enviá-lo

à placa de som. Quando é preciso ajustar o volume, seu programa acessa o dispositivo "/dev/mixer", e assim por diante.
Naturalmente, uma Sound Blaster Live e uma placa AC'97 onboard, por exemplo, oferecem conjuntos diferentes de recursos e se comunicam com o sistema de uma forma particular, ou seja, falam línguas diferentes. Por isso o Kernel inclui vários intérpretes, os drivers de dispositivo.
Driver em inglês significa "motorista" ou, "controlador". Cada chipset de placa de som, vídeo, rede ou modem possui um driver próprio.
Podemos dizer que os módulos são as partes do Kernel mais intimamente ligadas ao hardware. Os módulos são as partes do Kernel que mudam de máquina para máquina. Depois vem o bloco principal, "genérico" do Kernel.
Sobre ele roda o shell, o interpretador de comandos responsável por executar os aplicativos de modo texto e servidores, como o Samba e o Apache. Estes aplicativos são independentes do modo gráfico, você não precisa manter o X aberto para instalar e configurar um servidor Samba, por exemplo, embora as ferramentas gráficas possam ajudar bastante na etapa de configuração.
Quando você executa o comando "cat arquivo.txt", por exemplo, o bash entende que deve usar o programa "cat" para ler o "arquivo.txt". O Kernel oferece uma série de serviços e comandos que podem ser usados pelos aplicativos. Neste caso, o bash dá a ordem para que o executável "cat", junto com o arquivo sejam carregados na memória.
Para que isso aconteça, o Kernel precisa ler os dois arquivos no HD e carregá-los na memória RAM. No processo são usadas chamadas de vários módulos diferentes, como o responsável pelo acesso à porta IDE onde o HD está conectado, o responsável pelo sistema de arquivos em que o HD está formatado e o módulo responsável pelo suporte ao controlador de memória da placa-mãe.
No caso de programas muito grandes, a memória RAM pode ficar lotada, obrigando o Kernel a usar o subsistema de memória virtual para gravar as informações excedentes na partição swap.
Só depois de tudo isso que o "cat" pode ser executado e mostrar o conteúdo do arquivo na tela (usando mais um comando do Kernel, que aciona a placa de vídeo). Graças ao trabalho do Kernel, você não precisa se preocupar com nada disso, apenas com os programas que precisa executar.
Depois vem o X, o servidor gráfico, responsável por acessar a placa de vídeo e mostrar imagens no monitor. Ele serve como base para os aplicativos gráficos, que podem ser divididos em duas categorias. Primeiro temos os gerenciadores, como o KDE e o Gnome, que são responsáveis por gerenciar as janelas, mostrar a barra de tarefas e assim por diante. Eles servem como uma base para que você possa abrir e controlar os demais aplicativos gráficos.

Mesmo dentro do modo gráfico, você continua tendo acesso aos recursos do modo texto. Programas como o Xterm e o Konsole são usados para rodar uma instância do bash dentro do modo gráfico, permitindo executar todos os aplicativos de linha de comando e scripts. Ou seja, o X roda com uma perna no Kernel e outra no interpretador de comandos.
Módulos
Como vimos, uma das tarefas mais importantes do Kernel é oferecer suporte ao hardware da máquina.
No começo, a questão era mais simples, pois não existiam periféricos USB, softmodems e muito menos placas wireless. O Kernel oferecia suporte apenas aos dispositivos mais essenciais, como HD, placa de vídeo e drive de disquetes.
Com o tempo, foi sendo adicionado suporte a muitos outros dispositivos: placas de som, placas de rede, controladoras SCSI, e assim por diante. O fato do Kernel ser monolítico começou a atrapalhar bastante.
Você podia escolher os componentes a ativar na hora de compilar o Kernel. Se você habilitasse tudo, não teria problemas com nenhum dispositivo suportado, tudo iria funcionar facilmente. Mas, por outro lado, você teria um Kernel gigantesco, que rodaria muito devagar no seu 486 com 8 MB de RAM.
Se, por outro lado, você compilasse um Kernel enxuto e esquecesse de habilitar o suporte a algum recurso necessário, teria que recompilar tudo de novo para ativá-lo.
Este problema foi resolvido durante o desenvolvimento do Kernel 2.0, através do suporte a módulos. Os módulos são peças independentes que podem ser ativadas ou desativadas com o sistema em uso. Do Kernel 2.2 em diante, quase tudo pode ser compilado como módulo.
Isso tornou as coisas muito mais práticas, pois passou ser possível compilar um Kernel com suporte a quase tudo, com todas as partes não essenciais compiladas como módulos. O Kernel em si é um executável pequeno, que consome pouca RAM e roda rápido, enquanto os módulos ficam guardados numa pasta do HD até que você precise deles.

Você podia carregar o módulo para a SoundBlaster 16 (do 486 que você usava na época ;-) por exemplo, com um:
# modprobe sb
E descarregá-lo com um:
# modprobe -r sb
Esta idéia dos módulos deu tão certo que é usada até hoje e num nível cada vez mais extremo. Para você ter uma idéia, no Kernel 2.6 até mesmo o suporte a teclado pode ser desativado ou compilado como módulo, uma modificação que parece besteira num PC, mas que é útil para quem desenvolve versões para roteadores e outros dispositivos que realmente não possuem teclado.
As distribuições passaram então a vir com versões do Kernel cada vez mais completas, incluindo em muitos casos um grande número de patches para adicionar suporte a ainda mais dispositivos, naturalmente quase tudo compilado como módulos.
Nas distribuições atuais, o hardware da máquina é detectado durante a instalação e o sistema é configurado para carregar os módulos necessários durante o boot. Isto pode ser feito de duas formas:
1- Os módulos para ativar a placa de som, rede, modem e qualquer outro dispositivo "não essencial" são especificados no arquivo "/etc/modules". Programas de detecção, como o hotplug e o udev ficam de olho nas mensagens do Kernel e carregam módulos adicionais conforme novos dispositivos (uma câmera digital USB, em modo de transferência, por exemplo) são detectados.
Sua placa de som seria ativada durante o boot através de um módulo especificado no "/etc/modules", assim como o suporte genérico a dispositivos USB. Mas, o seu pendrive, que você pluga e despluga toda hora é ativado e desativado dinamicamente através da detecção feita pelo hotplug ou udev.
A detecção de novos periféricos (principalmente ao usar o Kernel 2.6) é muito simplificada graças ao próprio Kernel, que gera mensagens sempre que um novo dispositivo é encontrado. Você pode acompanhar este log rodando o comando "dmesg". Por exemplo, ao plugar um pendrive USB, você verá algo como:
usb 2-2: new high speed USB device using address scsi1 : SCSI emulation for USB Mass Storage devicesVendor: LG CNS Model: Rev: 1.00Type: Direct-Access ANSI SCSI revision: 02SCSI device sda: 249856 512-byte hdwr sectors (128 MB)sda: Write Protect is offsda: Mode Sense: 03 00 00 00sda: assuming drive cache: write throughsda: sda1Attached scsi removable disk sda at scsi1, channel 0, id 0, lun 0Attached scsi generic sg0 at scsi1, channel 0, id 0, lun 0, type 0USB Mass Storage device found at 5

Veja que aqui estão quase todas as informações referentes a ele. O fabricante (LG), o dispositivo pelo qual ele será acessado pelo sistema (sda), a capacidade (128 MB) e até as partições existentes (neste caso uma única partição, nomeada "sda1").
Um segundo arquivo, o "/etc/modules.conf" (ou "/etc/modprobe.conf", dependendo da distribuição usada), especifica opções e parâmetros para os módulos, quando necessário. Este arquivo normalmente é gerado automaticamente pelas ferramentas de detecção de hardware ou ao rodar o comando "update-modules", mas pode também ser editado manualmente, caso necessário.
Outra peça importante é o arquivo "/lib/modules/2.6.x/modules.dep", que guarda uma tabela com as dependências dos módulos, ou seja, de quais outros módulos cada um precisa para ser carregado corretamente. Este último arquivo é gerado automaticamente ao rodar o comando "depmod -a". Em geral, este comando é executado de forma automática durante o boot, sempre que necessário. O "2.6.x" neste caso corresponde à versão do Kernel usado na sua máquina.
2- Se o suporte a algo essencial nas etapas iniciais do boot não está incluído no Kernel, é criado um initrd, uma imagem com os módulos necessários, que, diferentemente dos módulos especificados no "/etc/modules", são carregados logo no início do boot. O initrd é guardado na pasta /boot, junto com o executável principal do Kernel: o arquivo "vmlinuz".
Imagine, por exemplo, que você está usando uma distribuição onde o suporte ao sistema de arquivos ReiserFS foi compilado como módulo, mas quer instalar o sistema justamente numa partição ReiserFS.
Isso gera um problema do tipo o ovo e a galinha, já que o sistema precisa do módulo para acessar a partição, mas precisa de acesso à partição para poder ler o módulo.
Para evitar este tipo de problema, o próprio instalador da distribuição, ao perceber que você formatou a partição raiz em ReiserFS, vai se encarregar de gerar o arquivo initrd que, embora não seja obrigatório (é possível compilar tudo diretamente no Kernel), é bastante usado.

O processo de boot e os arquivos de inicialização
Quando você liga o micro, o primeiro software que é carregado é o BIOS da placa-mãe, que faz a contagem da memória RAM, uma detecção rápida dos dispositivos instalados e por fim carrega o sistema operacional principal a partir do HD, CD-ROM, disquete, rede, ou o que quer que seja. Este procedimento inicial é chamado de POST (Power-on self test)
Seria bom se a função do BIOS se limitasse a isso, mas na verdade ele continua residente, mesmo depois que o sistema operacional é carregado.
Na época do MS-DOS era bem conhecida a divisão entre a memória real (os primeiros 640 KB da memória RAM) e a memória extendida (do primeiro MB em diante, englobando quase toda a memória instalada). O MS-DOS rodava em modo real, onde o processador trabalha simulando um 8088 (o processador usado no XT) que era capaz de acessar apenas 640 KB de memória. Mesmo os processadores modernos conservam este modo de operação, mas os sistemas operacionais atuais rodam inteiramente em modo protegido, onde são usados todos os recursos da máquina.
O espaço entre os primeiros 640 KB, onde termina a memória real, e os 1024 KB, onde começa a memória extendida, é justamente reservado para o BIOS da placa-mãe.
Ele é originalmente gravado de forma compactada num chip de memória flash instalado na placa-mãe. Durante o processo de boot ele é descompactado e copiado para este espaço reservado (chamado de shadow RAM), onde fica disponível.
O BIOS oferece funções prontas para acessar o HD, acionar recursos de gerenciamento de energia e muitas outras coisas. Mas, os sistemas operacionais quase não utilizam estas funções, pois existem muitas diferenças na forma como BIOS de diferentes placas-mãe trabalham e, em muitos casos, as funções simplesmente não funcionam ou produzem erros inesperados.
Os fabricantes de placas-mãe disponibilizam upgrades de BIOS freqüentemente para corrigir estes problemas, mas a maior parte dos usuários nem chega a procurá-los, fazendo com que exista um enorme contingente de placas bugadas por aí, com problemas no ACPI, DMA e outros recursos básicos.
Existe até mesmo um projeto para substituir o BIOS da placa-mãe por uma versão compacta do Kernel do Linux, que executa as mesmas funções, mas de uma forma mais confiável e flexível. Você pode obter mais informações sobre ele no: http://www.linuxbios.org/.
Outra tecnologia (já em uso) que substitui o BIOS é o EFI (Extensible Firmware Interface), usada em placas-mãe para o Intel Itanium e também nos Macs com processadores Intel. O EFI utiliza uma arquitetura modular, bem mais limpa e eficiente, que permite o uso de módulos personalizados para os dispositivos de cada-placa mãe, mantendo (opcionalmente) compatibilidade com o sistema antigo.

No caso dos Macs, esta camada de compatibilidade é desativada (de forma a dificultar a vida de quem pretende instalar Linux ou windows em dual boot com o MacOS) mas, no caso de placas avulsas, o EFI viria com o modo de compatibilidade ativado, permitindo rodar qualquer sistema.
De qualquer forma, depois de fazer seu trabalho, o BIOS carrega o sistema operacional, lendo o primeiro setor do disco rígido o "Master Boot Record" (MBR), também conhecido como trilha zero ou trilha MBR.
No MBR vai o gerenciador de boot. Os dois mais usados no Linux são o lilo e o grub.
Na verdade, no MBR mesmo vai apenas um bootstrap, um pequeno software que instrui o BIOS a carregar o executável do lilo ou grub em um ponto específico do HD. O MBR propriamente dito ocupa um único setor do HD (apenas 512 bytes), de modo que não é possível armazenar muita coisa diretamente nele.
O gerenciador de boot utiliza os primeiros 446 bytes do MBR. Os 66 bytes restantes são usados para armazenar a tabela de partições, que guarda informações sobre onde cada partição começa e termina. Alguns vírus, além de acidentes em geral, podem danificar os dados armazenados na tabela de partição, fazendo com que pareça que o HD foi formatado. Mas, na maioria dos casos, os dados continuam lá.
Mais adiante, veremos como fazer um backup da tabela de partições e restaurá-la quando necessário.
Voltando ao tema inicial, o gerenciador de boot tem a função de carregar o Kernel e, a partir dele, todo o restante do sistema. O lilo e o grub podem ser configurados ainda para carregar o Windows ou outros sistemas instalados em dual boot. Muitas distribuições configuram isso automaticamente durante a instalação.
Inicialmente, o Kernel é um arquivo compactado e somente-leitura, o arquivo "/boot/vmlinuz". Ele é descompactado em uma área reservada da memória RAM e roda a partir daí, aproveitando o fato de que a memória RAM é muito mais rápida que o HD.
Este executável principal do Kernel nunca é alterado durante o uso normal do sistema, ele muda apenas quando você recompila o Kernel manualmente ou instala uma nova versão.
Se você prestou atenção quando citei a necessidade de usar um initrd quando a partição raiz do sistema está formatada num sistema de arquivos que não está compilado diretamente no Kernel, deve ter notado uma contradição aqui. Afinal é o que está sendo feito até agora.
Nem o BIOS, nem o lilo possuem suporte a ReiserFS e o Kernel precisa ser carregado antes que ele tenha a chance de carregar o initrd. E, além do mais, para carregar o initrd, o próprio Kernel precisaria ler o arquivo dentro da partição.

Isto tudo funciona porque tanto o BIOS quanto o lilo não procuram entender o sistema de arquivos em que o HD está formatado. Pode ser EXT2, ReiserFS, XFS, ou o que seja: para eles não faz diferença. Eles simplesmente lêem os uns e zeros gravados numa área específica do HD e assim carregam o Kernel e o initrd. Eles não fazem alterações nos dados gravados, por isso este "acesso direto" não traz possibilidade de danos às estruturas do sistema de arquivos.
Depois de carregado, a primeira coisa que o Kernel faz é montar a partição raiz, onde o sistema está instalado, inicialmente como somente-leitura. Neste estágio ele carrega o init, o software que inicia o boot normal do sistema, lendo os scripts de inicialização e carregando os módulos e softwares especificados neles.
O arquivo de configuração do init é o "/etc/inittab". Ele é geralmente o primeiro arquivo de configuração lido durante o boot. A principal tarefa dele é carregar os demais scripts de inicialização, usados para carregar os demais componentes do sistema e fazer todas as operações de checagem, necessárias durante o boot.
No /etc/inittab do Debian por exemplo, você verá a linha:
# Boot-time system configuration/initialization script.si::sysinit:/etc/init.d/rcS
Esta linha executa o script "/etc/init.d/rcS". Se você examiná-lo também, vai encontrar o seguinte:
for i in /etc/rcS.d/S??*do...$i start....done
Os "..." indicam partes dos script que removi para deixar apenas as partes que interessam aqui. Estas linhas são um shell script, que vai executar os scripts dentro da pasta "/etc/rcS.d/". Esta pasta contém scripts que devem ser executados sempre, a cada boot, e são responsáveis por etapas fundamentais do boot.
Alguns exemplos de scripts e programas executados nesta etapa são:
keymap.sh: Carrega o layout do teclado que será usado no modo texto. Você não gostaria de encontrar seu teclado com as teclas trocadas para o Russo quando precisar arrumar qualquer coisa no modo texto, não é? ;-), O KDE possui um configurador próprio, o kxkb, que é configurado dentro do Painel de Controle. O layout usado pelo kxkb subscreve o configurado pelo keymap.sh dentro do KDE.
checkroot.sh: Este script roda o fsck, reiserfsck ou outro programa adequado para verificar a estrutura da partição raiz (a partição onde o sistema está instalado), corrigindo erros causados por desligamentos incorretos do sistema. Este processo é análogo ao scandisk do Windows. Só depois da verificação é que a partição raiz passa a ser acessada em modo leitura e escrita.

modutils: Este é o script que lê os arquivos "/etc/modules" e "/etc/modules.conf", ativando a placa de som, rede e todos os outros dispositivos de hardware "não essenciais", para os quais o suporte não foi habilitado diretamente no Kernel. Atualmente, a maioria das distribuições inclui alguma ferramenta de detecção de hardware, que é executada a cada boot, fazendo com que o arquivo "/etc/modules" sirva apenas para especificar manualmente módulos que ativem periféricos que não estejam sendo detectados automaticamente.
checkfs.sh: Este script é parecido com o checkroot.sh. Ele se destina a checar as demais partições do HD.
mountall.sh: É aqui que é lido o arquivo "/etc/fstab" e as demais partições, unidades de rede, e tudo mais que estiver especificado nele é ativado. Se você estiver usando uma partição home separada ou um compartilhamento de rede via NFS para guardar arquivos, por exemplo, é a partir deste ponto que eles ficarão disponíveis.
networking: Ativa a rede, carregando a configuração de IP, DNS, gateway, etc., ou obtendo a configuração via DHCP. A configuração da rede é geralmente armazenada dentro da pasta "/etc/sysconfig/network-scripts/" ou no arquivo "/etc/network/interfaces", variando de acordo com a distribuição usada.
De acordo com a distribuição usada, são carregados neste ponto outros serviços, para ativar suporte a placas PCMCIA, placas ISA, ou outros tipos de hardware, ativar o suporte a compartilhamentos de rede e, assim por diante. É possível executar praticamente qualquer tipo de comando ou programa nesta etapa, justamente por isso os passos executados durante o boot mudam de distribuição para distribuição, de acordo com o que os desenvolvedores consideram mais adequado. A idéia aqui é apenas dar uma base, mostrando alguns passos essenciais que são sempre executados.
Depois desta rodada inicial, são executados os scripts correspondentes ao runlevel padrão do sistema, que é configurado no "/etc/inittab", na linha:
# The default runlevel.id:5:initdefault:
O número (5 no exemplo) indica o runlevel que será usado, que pode ser um número de 1 a 5. Cada runlevel corresponde a uma pasta, com um conjunto diferente de scripts de inicialização. É uma forma de ter vários "profiles", para uso do sistema em diferentes situações.
A configuração mais comum é a seguinte:
Runlevel 1: Single user. É um modo de recuperação onde nem o modo gráfico, nem o suporte à rede, nem qualquer outro serviço "não essencial" é carregado, de forma a minimizar a possibilidade de problemas. A idéia é que o sistema "dê boot" para que você possa corrigir o que está errado. Atualmente, uma forma mais prática para corrigir problemas é dar boot com uma distribuição em live-CD (como o Kurumin),

onde você tem acesso à internet e vários programas e, a partir dele, montar a partição onde o sistema está instalado e corrigir o problema.
Runlevel 3: Boot em modo texto. Neste modo todos os serviços são carregados, com exceção do gerenciador de boot (KDM ou GDM), que é responsável por carregar o modo gráfico. Este modo é muito usado em servidores.
Runlevel 5: É o modo padrão na maioria das distribuições, onde você tem o sistema "completo", com modo gráfico e todos os demais serviços. Uma exceção importante é o Slackware, onde o modo gráfico é carregado no runlevel 4.
Usando o runlevel 5, são carregados os scripts dentro da pasta "/etc/rc5.d/", enquanto que, usando o runlevel 3, são carregados os scripts dentro da pasta "/etc/rc3.d/". Nada impede que você modifique a organização dos arquivos manualmente, de forma a fazer o X carregar também no runlevel 3, ou qualquer outra coisa que quiser. São apenas pastas com scripts e links simbólicos dentro, nenhuma caixa preta.

Ativando e desativando serviços
Nas distribuições que seguem o padrão do Debian, os executáveis que iniciam os serviços de sistema ficam todos dentro da pasta "/etc/init.d/". Para parar, iniciar ou reiniciar o serviço ssh, por exemplo, use os comandos:
# /etc/init.d/ssh start# /etc/init.d/ssh stop# /etc/init.d/ssh restart
No Kurumin, Mandriva e algumas outras distribuições, existe o comando service, que facilita um pouco as coisas, permitindo que, ao invés de ter de digitar o caminho completo, você possa controlar os serviços através dos comandos:
# service ssh start# service ssh stop# service ssh restart
Os scripts que estão na pasta "/etc/init.d/" servem para "chamar" os executáveis dos servidores. Eles apenas fazem as verificações necessárias e em seguida inicializam ou encerram os executáveis propriamente ditos, que em geral estão na pasta "/usr/bin/" ou "/usr/sbin/".
A pasta "/etc/init.d/" contém scripts para quase todos os serviços que estão instalados no sistema. Quando você instala o Samba pelo apt-get, por exemplo, é criado o script "/etc/init.d/samba", mesmo que ele não exista anteriormente.
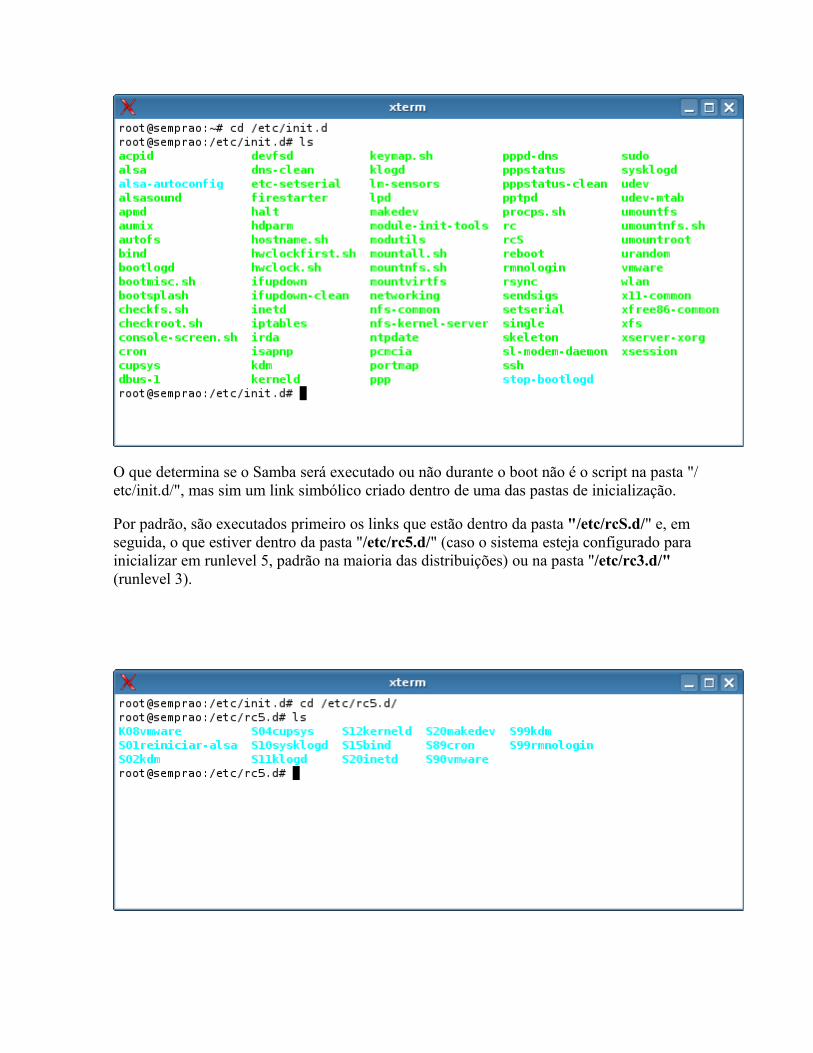
O que determina se o Samba será executado ou não durante o boot não é o script na pasta "/etc/init.d/", mas sim um link simbólico criado dentro de uma das pastas de inicialização.
Por padrão, são executados primeiro os links que estão dentro da pasta "/etc/rcS.d/" e, em seguida, o que estiver dentro da pasta "/etc/rc5.d/" (caso o sistema esteja configurado para inicializar em runlevel 5, padrão na maioria das distribuições) ou na pasta "/etc/rc3.d/" (runlevel 3).

Os números antes dos nomes dos serviços dentro da pasta "/etc/rc5.d/" determinam a ordem em que eles serão executados. Você vai querer que o firewall seja sempre ativado antes do Samba por exemplo.
O "S" (start) indica que o serviço será inicializado no boot. A partir daí, o sistema vai inicializando um por vez, começando com os serviços com número mais baixo. Caso dois estejam com o mesmo número, eles são executados em ordem alfabética.
Para que um determinado serviço pare de ser inicializado automaticamente no boot, basta deletar a entrada dentro da pasta, como em:
# rm -f /etc/rc5.d/S20samba
Para que o serviço volte a ser inicializado você deve criar novamente o link, apontando para o script na pasta /etc/init.d, como em:
# cd /etc/rc5.d/# ln -s ../init.d/samba S20samba
ou: # ln -s ../init.d/ssh S21ssh
Esta é a forma "correta" de criar os links: acessando primeiro a pasta onde eles são criados e criando os links com as localizações relativas. Se estamos na pasta "/etc/rc5.d" e criamos o link apontando para "../init.d/samba", significa que o sistema vai subir um nível de diretório (vai para o /etc) e em seguida acessa a pasta "init.d/".
Nada impede que você crie o link diretamente, como em:
# ln -s /etc/init.d/ssh /etc/rc5.d/S21ssh
Ele vai funcionar da mesma forma, mas ferramentas de configuração automática, como o "update-rc.d" (do Debian), vão reclamar do "erro" ao atualizar ou remover o link. Este é, na verdade, um daqueles casos em que precisamos contornar manualmente a falta de recursos da ferramenta.
Existe um utilitário de modo texto, do Debian, que facilita esta tarefa, o rcconf, que pode ser instalado via apt-get. Chamando-o com a opção "--now", os serviços marcados são inicializados imediatamente, caso contrário ele apenas cria os links, de forma que eles fiquem ativos a partir do próximo boot.
No Fedora, Mandriva e outras distribuições derivadas do Red Hat, você pode ativar ou desativar a inicialização dos serviços no boot usando o comando "chkconfig", como em:
# chkconfig ssh on (ativa)# chkconfig ssh off (desativa)

Você pode também usar o utilitário "ntsysv" ou outro configurador disponível. O Mandriva, por exemplo, inclui um painel de administração de serviços dentro do Mandriva Control Center. Muitas distribuições incluem o "services-admin", outro utilitário gráfico que faz parte do pacote "gnome-system-tools".

X
Diferentemente do que temos no Windows, onde a interface gráfica é um componente essencial do sistema, no Linux o modo gráfico é uma camada independente. Temos um "servidor gráfico", o famoso X que provê a infra-estrutura necessária. É ele que controla o acesso à placa de vídeo, lê as teclas digitadas no teclado e os clicks do mouse e oferece todos os recursos necessários para os programas criarem janelas e mostrarem conteúdo na tela.
Se você chamar o X sozinho, a partir do modo texto (o que pode ser feito com o comando "X" ou "X :2" caso você queira abrir uma segunda seção do X), você verá apenas uma tela cinza, com um X que representa o cursor do mouse. Ou seja, o X é apenas uma base, ele sozinho não faz muita coisa.
Se você chamá-lo com o comando "xinit" ou "xinit -- :2", você já abrirá junto uma janela de terminal, que poderá ser usada para abrir programas. Porém, ao abrir qualquer programa gráfico, você perceberá que algo está estranho. A janela do programa é aberta, mas fica fixa na tela, você não tem como minimizá-la, alternar para outra janela, nem nenhuma outra opção:
Isto acontece porque estas tarefas são controladas pelo gerenciador de janelas, que (em quase todas as distribuições) não é carregado com o comando xinit. Existem vários gerenciadores de janelas, como o KDE, Gnome, Window Maker, Fluxbox, IceWM e assim por diante. A idéia é que você possa escolher qual lhe agrada mais.

Chamando o X através do comando "startx", ou configurando o sistema para carregar o X automaticamente durante a inicialização, finalmente carregamos o conjunto completo, com o X e algum gerenciador de janelas rodando sobre ele.
O Xfree utiliza uma arquitetura cliente-servidor, onde o X em si atua como o servidor e os programas como clientes, que recebem dele os clicks do mouse e as teclas digitadas no teclado e enviam de volta as janelas a serem mostradas na tela.
A grande vantagem deste sistema é que além de rodar programas localmente é possível rodar programas instalados em outras máquinas da rede. Existem várias formas de fazer isto. Você pode, por exemplo, abrir uma janela de terminal dentro do X, conectar-se à outra máquina, via SSH e começar a chamar os programas desejados. Para isso, use o comando "ssh -X IP_da_maquina", como em:
# ssh -X 192.168.0.1
O parâmetro -X ativa a execução de aplicativos gráficos via SSH, que vem desativado por padrão em algumas distribuições. Para usar o ssh, o serviço "ssh" deve estar ativo na máquina que está sendo acessada.
Outra opção é usar o XDMCP, o protocolo nativo do X para obter a tela de login da máquina remota e a partir daí carregar um gerenciador de janelas e rodar todos os programas via rede. Neste caso você precisaria configurar a outra máquina para aceitar as conexões via XDMCP nos arquivos kdmrc e Xaccess, que vão dentro da pasta "/etc/kde3/kdm/" ou "/usr/share/config/kdm/kdmrc" (ao usar o KDM) ou no gdmsetup (ao usar o GDM) e inicializar o X com o comando "X :2 -query IP_da_maquina" no PC cliente, como em:
# X :2 -query 192.168.0.1
Muita gente diz que este sistema cliente/servidor do X é uma arquitetura ultrapassada, que é responsável por um desempenho ruim se comparado com outros sistemas operacionais, pois tudo teria que passar pela rede antes de ir para o monitor.
Esta idéia é errada, pois, ao rodar localmente, o X se comunica diretamente com a placa de vídeo, usando todos os recursos de aceleração suportados. Entra aí a questão do driver. Se você tentar rodar um game 3D qualquer, antes de instalar os drivers 3D (da nVidia) para sua placa nVidia, por exemplo, ele vai rodar com um desempenho muito baixo, simplesmente porque os recursos 3D da placa não estão ativados. O driver open-source do X para placas nVidia (o driver "nv") oferece apenas suporte 2D.
Algumas placas realmente não possuem ainda drivers 3D no X, como, por exemplo, a maior parte das placas onboard da SiS. Isto tem mais a ver com a boa vontade (ou falta desta) do fabricante em desenvolver drivers ou pelo menos disponibilizar as especificações das placas. A SiS é um dos fabricantes mais hostis, o que faz com que suas placas tenham um suporte ruim. Como sempre é questão de pesquisar antes de comprar.

Os comandos de atualização das janelas e outros recursos usados são transmitidos pelo X através de uma interface de rede local (a famosa interface de loopback), o que num PC moderno tem um overhead muito pequeno. Os problemas de desempenho em algumas placas estão mais relacionados à qualidade dos drivers.

Gerenciador de login
Antigamente, era muito comum dar boot em modo texto e deixar para abrir o X manualmente rodando o comando "startx" apenas quando necessário, pois os PCs eram lentos e o X demorava para abrir.
Atualmente, o mais comum é usar um gerenciador de login, como o KDM (do KDE) ou o GDM (do Gnome). A função do gerenciador de login é carregar o X, mostrar uma tela de login gráfica e, a partir dela, carregar o KDE, Gnome ou outro gerenciador de janelas escolhido.
Em geral, as distribuições que usam o KDE como interface padrão usam o KDM, enquanto as que usam o Gnome preferem o GDM. Isto tem a ver com o problema das bibliotecas: ao carregar apenas um programa baseado nas bibliotecas do KDE dentro do Gnome ou vice-versa, são carregadas todas as bibliotecas correspondentes, não há o que fazer. O programa demora mais para abrir, e no final, o sistema acaba consumindo muito mais memória.
O gerenciador de login é aberto como um serviço de sistema, da mesma forma que o Apache e outros servidores. Você pode parar o KDM e assim fechar o modo gráfico usando o comando "/etc/init.d/kdm stop" e reabri-lo a partir do modo texto com o comando "/etc/init.d/kdm start".
Como sempre, tudo é aberto através de um conjunto de scripts. O KDM guarda a base das configurações no arquivo "/etc/kde3/kdm/kdmrc" (ou "/usr/share/config/kdm/kdmrc", dependendo da distribuição) e coloca um conjunto de scripts de inicialização, um para cada interface instalada, dentro da pasta "/usr/share/apps/kdm/sessions/".
A configuração do kdmrc serve para configurar as opções da tela de login, que vão desde opções cosméticas, até a opção de aceitar que outras máquinas da rede rodem aplicativos remotamente via XDMCP. Ao fazer login, é executado o script correspondente à interface escolhida. Ao usar o Fluxbox, por exemplo, é executado o script "/usr/share/apps/kdm/sessions/fluxbox".
Até mesmo o comando startx é um script, que geralmente vai na pasta "/usr/X11R6/bin/". Você pode alterá-lo para carregar o que quiser, mas normalmente ele carrega o gerenciador especificado no arquivo .xinitrc, dentro da pasta home do usuário.

Xfree x X.org
Atualmente estão em uso no mundo Linux duas versões diferentes do X, o Xfree e o X.org. O Xfree é o projeto mais antigo e tradicional, o grupo que originalmente portou o X para o Linux, e foi o principal mantenedor do projeto desde então.
Com o passar do tempo, começaram a surgir críticas, principalmente direcionadas à demora para incluir correções e atualizações nos drivers existentes. Isto foi se agravando com o tempo, até que uma decisão dos desenvolvedores em fazer uma pequena mudança na licença em vigor a partir do Xfree 4.4 foi a gota d'água para que um consórcio formado por membros de várias distribuições, desenvolvedores descontentes com o modo de desenvolvimento antigo, se juntassem para criar um fork do Xfree, o X.org.
O X.org utilizou como base inicial a última versão de desenvolvimento da série 4.3 do Xfree, disponibilizada antes da mudança da licença. Desde então, foram incluídas muitas atualizações e correções, como novos drivers e vários recursos cosméticos, como, por exemplo, suporte a janelas transparentes. A página oficial é a http://x.org.
Inicialmente, as diferenças eram pequenas, mas depois de um certo tempo o X.org passou a concentrar a maior parte das atualizações e novos drivers, sendo desenvolvido num ritmo muito mais rápido. A tendência é que ele substitua completamente o Xfree num futuro próximo.
A partir da versão 7.0, o X.org passou a utilizar uma arquitetura modular, que visa facilitar o desenvolvimento de novos recursos, que podem ser integrados ao sistema na forma de módulos, sem depender do aval prévio dos desenvolvedores do X.org. Esta mudança, que à primeira vista parece simples, tem potencial para intensificar o desenvolvimento de forma radical.
Para quem configura, a principal diferença está nos nomes do arquivo de configuração e utilitários. As opções dentro do arquivo continuam as mesmas, incluindo os nomes dos drivers (radeon, nv, intel, sis, etc.) e é possível inclusive usar um arquivo de configuração de uma distribuição com o Xfree em outra (instalada na mesma máquina) com o X.org. Aqui vai uma pequena tabela com algumas diferenças:
- Arquivo de configuração principal: /etc/X11/XF86Config-4 = /etc/X11/xorg.conf
- Utilitários de configuração:xf86cfg = xorgfgxf86config = xorgconfig
É possível também eliminar estas diferenças criando um conjunto de links apontando para os nomes trocados. Assim o XF86Config-4 vira um link para o xorg.conf, por exemplo, fazendo com que usuários desavisados e até utilitários de configuração consigam encontrar os arquivos sem muitos problemas.

A árvore genealógica das distribuições
Por causa da filosofia de código aberto e compartilhamento de informações que existe no mundo Linux, é muito raro que uma nova distribuição seja desenvolvida do zero. Quase sempre as distribuições surgem como forks ou personalizações de uma outra distribuição mais antiga e preservam a maior parte das características da distribuição original. Isso faz com que distribuições dentro da mesma linhagem conservem mais semelhanças do que diferenças entre si.
Das primeiras distribuições Linux, que surgiram entre 1991 e 1993, a única que sobrevive até hoje é o Slackware, que deu origem a algumas outras distribuições conhecidas, como o Vector, Slax e o College.
O Slax é um live-CD, desenvolvido para caber em um mini-CD; o Vector é uma distribuição enxuta, otimizada para micros antigos, enquanto o College é uma distribuição desenvolvida com foco no público estudantil, com o objetivo de ser fácil de usar.
Os três utilizam pacotes .tgz do Slackware e são quase sempre compatíveis com os pacotes do Slackware da versão correspondente. Os utilitários de configuração do Slackware, como o netconfig continuam disponíveis, junto com vários novos scripts que facilitam a configuração do sistema. O Vector, por exemplo, inclui o Vasm, uma ferramenta central de configuração.
O Debian apareceu pouco depois e, ao longo dos anos, acabou dando origem a quase metade das distribuições atualmente em uso. Algumas, como o Knoppix e o Kurumin, continuam utilizando os pacotes dos repositórios Debian, apenas acrescentando novos pacotes e ferramentas, enquanto outras, como o Lycoris e o Ubuntu, utilizam repositórios separados, apenas parcialmente compatíveis com os pacotes originais, mas sempre mantendo o uso do apt-get e a estrutura básica do sistema.
Embora o Debian não seja exatamente uma distribuição fácil de usar, o apt-get e o gigantesco número de pacotes disponíveis nos repositórios formam uma base muito sólida para o desenvolvimento de personalizações e novas distribuições.
Um dos principais destaques é que, nas versões Testing e Unstable, o desenvolvimento do sistema é contínuo e, mesmo no Stable, é possível atualizar de um release para outro sem reinstalar nem fazer muitas modificações no sistema. Você pode manter o sistema atualizado usando indefinidamente o comando "apt-get upgrade". Isso permite que os desenvolvedores de distribuições derivadas deixem o trabalho de atualização dos pacotes para a equipe do Debian e se concentrem em adicionar novos recursos e corrigir problemas.
Um dos exemplos de maior sucesso é o Knoppix, que chega a ser um marco. Ele se tornou rapidamente uma das distribuições live-CD mais usadas e deu origem a um universo gigantesco de novas distribuições, incluindo o Kurumin. Uma coisa interessante é que o

Knoppix mantém a estrutura Debian quase intacta, o que fez com que instalar o Knoppix no HD acabasse tornando-se uma forma alternativa de instalar o Debian. Outro exemplo de sucesso é o Ubuntu, uma versão do Debian destinada a iniciantes e a empresas, que rapidamente se transformou em umas das distribuições mais usadas no mundo.
As distribuições derivadas do Knoppix muitas vezes vão além, incluindo novos componentes que tornam o sistema mais adequado para usos específicos. O Kurumin inclui muitas personalizações e scripts destinados a tornar o sistema mais fácil de usar e mais adequado para uso em desktop. O Kanotix inclui muitos patches no Kernel, com o objetivo de oferecer suporte a mais hardware e novos recursos, enquanto o Morphix usa uma estrutura modular, que acabou servindo de base para o desenvolvimento de mais uma safra de distribuições, já bisnetas do Debian.
Mais adiante, teremos um capítulo dedicado a explicar o processo de personalização do Kurumin e outros live-CDs derivados do Knoppix, permitindo que você desenvolva suas próprias soluções.
Tanto o Debian quanto o Slackware são distribuições basicamente não comerciais. Mas isso não impede que distribuições como o Lycoris, Xandros e Linspire sejam desenvolvidas por empresas tradicionais, com fins lucrativos. Elas procuram se diferenciar das distribuições gratuitas, investindo em marketing e no desenvolvimento de ferramentas de configuração e facilidades em geral.
Durante o livro, vou sempre citar muitos comandos que se aplicam ao Debian, lembre-se de que eles também se aplicam à outras distribuições derivadas dele, como o Ubuntu, Kurumin e o Knoppix.
A terceira distribuição "mãe" é o Red Hat, que deu origem ao Mandrake e Conectiva (que mais tarde se juntaram, formando o atual Mandriva), Fedora e, mais recentemente, a um enorme conjunto de distribuições menores. As distribuições derivadas do Red Hat não utilizam um repositório comum, como no caso do Debian, e nem mesmo um gerenciador de pacotes comum. Temos o yun do Fedora, o urpmi do Mandriva e também o próprio apt-get, portado pela equipe do Conectiva. Temos ainda vários repositórios independentes, que complementam os repositórios oficiais das distribuições.
As distribuições derivadas do Red Hat são, junto com o Debian e derivados, as mais usadas em servidores. O Fedora, Red Hat e SuSE possuem também uma penetração relativamente grande nos desktops nas empresas, enquanto o Mandriva tem o maior público entre os usuários domésticos.
Embora todas estas distribuições utilizem pacotes rpm, não existe garantia de compatibilidade entre os pacotes de diferentes distribuições. Os pacotes de uma versão recente do SuSE na maioria das vezes funcionam também numa versão equivalente do Mandriva, por exemplo, mas isto não é uma regra.
O Gentoo inaugurou uma nova linhagem trazendo uma abordagem diferente das demais distribuições para a questão da instalação de programas e instalação do sistema.

Tradicionalmente, novos programas são instalados através de pacotes pré-compilados, que são basicamente arquivos compactados, contendo os executáveis, bibliotecas e arquivos de configuração usados pelo programa. Estes pacotes são gerenciados pelo apt-get, urpmi, yun ou outro gerenciador usado pela distribuição. Compilar programas a partir dos fontes é quase sempre um último recurso para instalar programas recentes, que ainda não possuem pacotes disponíveis.
O Gentoo utiliza o Portage, um gerenciador de pacotes que segue a idéia dos ports do FreeBSD. Os pacotes não contém binários, mas sim o código fonte do programa, junto com um arquivo com parâmetros que são usados na compilação. Você pode ativar as otimizações que quiser, mas o processo de compilação e instalação é automático. Você pode instalar todo o KDE, por exemplo, com um "emerge kde". O Portage baixa os pacotes com os fontes (de forma similar ao apt-get), compila e instala.
O ponto positivo desta abordagem é que você pode compilar todo o sistema com otimizações para o processador usado na sua máquina. Isso resulta em ganhos de 2 a 5% na maior parte dos programas, mas pode chegar a 30% em alguns aplicativos específicos.
A parte ruim é que compilar programas grandes demora um bocado, mesmo em máquinas atuais. Instalar um sistema completo, com o X, KDE e OpenOffice demora um dia inteiro num Athlon 2800+ e pode tomar um final de semana numa máquina um pouco mais antiga. Você pode usar o Portage também para atualizar todo sistema, usando os comandos "emerge sync && emerge -u world" de uma forma similar ao "apt-get upgrade" do Debian.
Nas versões atuais do Gentoo, você pode escolher entre diferentes modos de instalação. No stage 1 tudo é compilado a partir dos fontes, incluindo o Kernel e as bibliotecas básicas. No stage 2 é instalado um sistema base pré-compilado e apenas os aplicativos são compilados. No stage 3 o sistema inteiro é instalado a partir de pacotes pré-compilados, de forma similar a outras distribuições. A única exceção fica por conta do Kernel, que sempre precisa ser compilado localmente, mesmo ao usar o stage 2 ou 3.
O stage 1 é naturalmente a instalação mais demorada, mas é onde você pode ativar otimizações para todos os componentes do sistema.
Já existe um conjunto crescente de distribuições baseadas no Gentoo, como vários live-CDs, com games e versões modificadas do sistema, alguns desenvolvidos pela equipe oficial, outros por colaboradores. Uma das primeiras distribuições a utilizar o Gentoo como base foi o Vidalinux.
Embora seja uma das distribuições mais difíceis, cuja instalação envolve mais trabalho manual, o Gentoo consegue ser popular entre os usuários avançados, o que acabou por criar uma grande comunidade de colaboradores em torno do projeto. Isto faz com que o Portage ofereça um conjunto muito grande de pacotes, quase tantos quanto no apt-get do Debian, incluindo drivers para placas nVidia e ATI, entre outros drivers proprietários, e exista uma grande quantidade de documentação disponível, com textos quase sempre atualizados.

Capítulo 2: Configuração, ferramentas e dicas
A melhor forma de aprender é sempre praticando, certo? Este capítulo é uma coleção de dicas sobre os arquivos de configuração, ferramentas e utilitários úteis, que tem o objetivo de aprofundar seus conhecimentos sobre o sistema. Os tópicos estão organizados por nível de dificuldade.
Editando o /etc/fstab
O arquivo "/etc/fstab" permite configurar o sistema para montar partições, CD-ROMs, disquetes e compartilhamentos de rede durante o boot. Cada linha é responsável por um ponto de montagem. É através do "/etc/fstab" que o sistema é capaz de acessar o seu CD-ROM, por exemplo. O fstab é um dos arquivos essenciais para o funcionamento do sistema, por isso, antes de editá-lo, faça sempre uma cópia de segurança:
# cp /etc/fstab /etc/fstab-original
O fstab é um arquivo de texto simples, assim como a maior parte dos arquivos de configuração do sistema. Você pode abri-lo usando qualquer editor de textos, mas sempre como root:
# kedit /etc/fstab
À primeira vista o fstab parece ser mais um daqueles arquivos indecifráveis. Ele possui uma lógica própria que parece um pouco complicada no início, mas é relativamente fácil de entender. Uma vez que você entenda a sintaxe das opções, você poderá editar o fstab para adicionar um segundo drive de CD ou fazer com que um compartilhamento de rede seja montado automaticamente durante o boot, sem depender de configuradores automáticos.
Vamos começar dando uma olhada no "/etc/fstab" de uma máquina que está com o Kurumin instalado na partição hda2:
# /etc/fstab: filesystem table.# filesystem mountpoint type options dump pass
/dev/hda2 / reiserfs defaults 0 1/dev/hda5 none swap sw 0 0proc /proc proc defaults 0 0/dev/fd0 /floppy vfat defaults,user,noauto,showexec,umask=022 0 0/dev/cdrom /mnt/cdrom iso9660 defaults,ro,user,noexec,noauto 0 0
# partições encontradas pelo instalador:/dev/hda1 /mnt/hda1 reiserfs noauto,users,exec 0 0/dev/hda2 /mnt/hda2 reiserfs noauto,users,exec 0 0

/dev/hda3 /mnt/hda3 reiserfs noauto,users,exec 0 0/dev/hda6 /mnt/hda6 reiserfs noauto,users,exec 0 0
# Monta a partição /home, adicionado pelo instalador do Kurumin/dev/hda3 /home reiserfs notail 0 2
# Ativa o USBusbdevfs /proc/bus/usb usbdevfs defaults 0 0
Este é o arquivo gerado automaticamente durante a instalação, por isso ele está um pouco sujo. Vamos começar entendo o que cada linha significa. Lembre-se de que as linhas começadas com # não fazem nada, são apenas comentários.
/dev/hda2 / reiserfs defaults 0 1
Esta linha monta o diretório raiz do sistema. No exemplo, o Kurumin está instalado na partição /dev/hda2 que está formatada em ReiserFS. O "/" é o ponto de montagem, ou seja, onde esta partição fica acessível. A barra indica que esta é a partição raiz, onde o sistema está instalado. Se, por acaso, a partição estivesse formatada em outro sistema de arquivos, em EXT3, por exemplo, a linha ficaria: "/dev/hda2 / ext3 defaults 0 1".
Os dois números depois do "defaults" são instruções para programas externos.
O primeiro número é usado pelo programa dump, que examina a partição em busca de arquivos modificados. Esta informação é usada por alguns programas de backup, para decidir quais arquivos devem ser incluídos num backup incremental. O número 0 desativa e o número 1 ativa a checagem.
O dump só trabalha em partições EXT2 ou EXT3, de forma que ao usar uma partição em ReiserFS ou XFS você sempre deve usar o número 0.
O segundo número (1 no exemplo) é uma instrução para o fsck, encarregado de examinar os arquivos dentro da partição quando o sistema é desligado incorretamente. Temos três opções aqui: o número 0 desativa a checagem a cada boot (torna o boot um pouco mais rápido, mas não é recomendável), enquanto o número 1 faz com que a partição seja checada antes das demais.
Usamos o número 1 apenas para a partição raiz, onde o sistema está instalado. Para as demais partições usamos o número 2 que indica que a partição deve ser checada, porém só depois da partição raiz.
/dev/hda5 none swap sw 0 0
Esta segunda linha é responsável por ativar a memória swap, que no meu caso é a partição /dev/hda5. Veja que o ponto de montagem para ela é "none", pois a partição swap não é montada em nenhuma pasta, ela serve apenas para uso interno do sistema.
/dev/cdrom /mnt/cdrom iso9660 defaults,user,noauto 0 0
Esta linha habilita o drive de CD-ROM. O /dev/cdrom é o dispositivo do CD-ROM, na verdade um link que é criado durante a configuração inicial do sistema e aponta para a

localização correta do CD-ROM. De acordo com a porta em que o CD-ROM estiver instalado, o dispositivo real do CD-ROM pode ser:
/dev/hdc: Um CD-ROM instalado como master na segunda porta IDE da placa-mãe.
/dev/hdd: CD-ROM instalado como slave na segunda porta IDE
/dev/sda ou /dev/sr0: Em distribuições que usam o Kernel 2.4, os gravadores de CD IDE são detectados pelo sistema como se fossem discos SCSI. Dependendo da distribuição eles podem ser detectados como "/dev/sda" ou "/dev/sr0". Caso você tenha dois gravadores, o segundo é reconhecido como "/dev/sdb" ou "/dev/sr1". No Kernel 2.6, não é mais usada a emulação SCSI, de forma que os gravadores são acessados diretamente através dos dispositivos "/dev/hdc" ou "/dev/hdd".
/dev/sr0 ou /dev/sr1: Leitores e gravadores de CD USB também são detectados como CDs SCSI. Ao plugar um drive externo ligado à porta USB, ele será detectado como "/dev/sr0" (ou "/dev/sr1", caso a primeira posição já esteja ocupada). No caso dos leitores e gravadores USB, não importa se está sendo usado o Kernel 2.4 ou 2.6.
Para que os arquivos do CD-ROM fiquem acessíveis, ele precisa ser montado em algum lugar. A próxima entrada da linha é o "/mnt/cdrom", que indica a pasta onde ele fica acessível. O iso9660 é o sistema de arquivos universalmente usado em CD-ROMs de dados, é graças a ele que não existem problemas para ler o mesmo CD no Linux ou Windows.
Em seguida temos três opções: defaults,user,noauto. Elas fazem o seguinte:
user: Permite que você monte e desmonte o CD-ROM mesmo sem estar logado como root.
noauto: faz com que o CD-ROM seja montado apenas quando você for acessá-lo e não automaticamente durante o boot, como no caso da partição raiz, por exemplo.
Caso você queira ativar um segundo drive de CD, adicionaria uma linha assim:
/dev/hdd /mnt/cdrom1 iso9660 defaults,user,noauto 0 0
Veja que mudaram duas coisas: o dispositivo do CD-ROM (/dev/hdd) e a pasta onde ele fica acessível (/mnt/cdrom1). Para acessar o segundo CD-ROM, você digitaria "mount /mnt/cdrom1"
O KDE oferece um recurso muito interessante que é a possibilidade de montar e desmontar as entradas incluídas no /etc/fstab através de ícones no desktop, como os usados para acessar as partições do HD ao rodar o Kurumin do CD.
Para criar um destes ícones, clique com o botão direito sobre a área de trabalho e vá em: "Criar novo", escolha "Disco rígido ou CD-ROM" e aponte a entrada do fstab referente a ele nas propriedades:

Para montar e acessar os arquivos, basta clicar sobre o ícone e para desmontar, clique com o botão direito e escolha "desmontar".
A linha seguinte do arquivo serve para montar a partição home, que no exemplo foi colocada em uma partição separada:
/dev/hda3 /home reiserfs notail 0 2
Traduzindo para o português, a linha diz: "Monte a partição /dev/hda3 no diretório /home. Esta partição está formatada em reiserfs e você deve usar a opção notail".
O notail é uma opção do sistema de arquivos ReiserFS, que melhora um pouco a velocidade de acesso ao trabalhar com arquivos grandes. Cada sistema de arquivos possui algumas opções extras, que podem ser usadas para melhorar o desempenho ou tolerância a falhas em determinadas situações. O parâmetro "noatime", por exemplo, faz com que o sistema não atualize as propriedades dos arquivos conforme eles ao acessados (altera apenas quando eles são modificados). Ela melhora absurdamente o desempenho do sistema

em algumas áreas específicas, onde os mesmos arquivos são acessados continuamente, como nos servidores de banco de dados. É muito comum combinar as duas opções, como em:
/dev/hda3 /home reiserfs notail,noatime 0 2
Usar uma partição home separada permite que você possa reinstalar o sistema sem perder seus arquivos e configurações, o que é especialmente interessante no caso do Kurumin e outras distribuições atualizadas freqüentemente.
Usando um diretório home separado, as reinstalações tornam-se mais transparentes. Você ainda precisa reinstalar os programas, mas todas as configurações dos aplicativos são preservadas.
Cada programa armazena suas configurações dentro de uma pasta oculta dentro do seu diretório de usuário, como ".mozilla", ".kde", etc. Mesmo ao reinstalar o sistema, estas pastas são reconhecidas e as configurações antigas preservadas. Basta tomar o cuidado de guardar também todos os seus arquivos dentro do diretório home e você não perderá quase nada ao reinstalar.
Continuando, temos as entradas para outras partições que foram encontradas pelo instalador:
# partições encontradas pelo instalador:/dev/hda1 /mnt/hda1 reiserfs noauto,users,exec 0 0/dev/hda2 /mnt/hda2 reiserfs noauto,users,exec 0 0/dev/hda3 /mnt/hda3 reiserfs noauto,users,exec 0 0/dev/hda6 /mnt/hda6 reiserfs noauto,users,exec 0 0
Veja que as partições "/dev/hda2" e "/dev/hda3" já estão sendo usadas, por isso as duas linhas referentes a elas são redundantes e podem ser removidas. As linhas para as outras duas partições, "/dev/hda1" (uma instalação do Mandriva) e "/dev/hda6" (uma partição de arquivos) estão com a opção "noauto", como no caso do CD-ROM, que faz com que elas sejam montadas apenas quando você clica nos ícones do desktop. Se você preferir que elas sejam montadas automaticamente durante o boot, basta eliminar esta opção. Neste caso as linhas ficariam assim:
/dev/hda1 /mnt/hda1 reiserfs users,exec 0 0/dev/hda6 /mnt/hda6 reiserfs users,exec 0 0
Além de montar as partições e CD-ROMs locais, o fstab pode ser configurado para montar também compartilhamentos de rede. Você pode tanto configurar para que os compartilhamentos fiquem acessíveis automaticamente durante o boot (no caso de um servidor que fique sempre ligado) ou montá-los através de ícones no desktop, como no caso do CD-ROM.
Para montar um compartilhamento de rede NFS, a linha seria:
192.168.0.1:/home/arquivos /mnt/arquivos nfs noauto,users,exec 0 0

Neste exemplo o "192.168.0.1:/home/arquivos" é o IP do servidor, seguido pela pasta compartilhada e o "/mnt/arquivos" é a pasta local onde este compartilhamento ficará acessível.
Você pode incluir várias linhas, caso deseje montar vários compartilhamentos. Caso o servidor fique sempre ligado e você queira que o compartilhamento seja montado automaticamente durante o boot, retire o "noauto", caso contrário você pode acessar o compartilhamento usando o comando:
# mount /mnt/arquivos
Para montar um compartilhamento de rede Windows ou de um servidor Linux rodando o Samba, a linha seria:
//192.168.0.1/teste /home/teste smb noauto,user,username=maria,password=abcde 0 0
Veja que neste caso a sintaxe já é um pouco mais complicada. Em primeiro lugar, a entrada que fala sobre o compartilhamento usa a sintaxe: "//ip_do_servidor/compartilhamento", por isso você usa "//192.168.0.1/teste" e não "192.168.0.1:/teste" como seria num compartilhamento NFS.
Em seguida vem a pasta onde o compartilhamento ficará acessível, "/home/teste" no exemplo. Não se esqueça de criar a pasta, caso não exista.
O smb é o nome do protocolo usado para acessar os compartilhamentos Windows da rede. Outra etapa importante é colocar o usuário e senha que será usado para acessar o compartilhamento, como em: "user,username=maria,password=abcde". Caso o compartilhamento não use senha (como os compartilhamentos do Windows 95/98), a linha fica mais simples:
//192.168.0.1/arquivos /home/arquivos smb noauto,user 0 0
Assim como no caso do NFS, para montar o compartilhamento use o comando:
# mount /home/arquivos
Se preferir que ele seja montado durante o boot, basta retirar o "noauto". Neste caso a linha no fstab ficaria:
//192.168.0.1/teste /home/teste smb user,username=maria,password=abcde 0 0
Ao colocar as senhas dos compartilhamentos de rede no "/etc/fstab" é necessário tomar uma precaução de segurança. Rode o comando:
# chmod 600 /etc/fstab
Isto fará com que apenas o root possa ler o arquivo e conseqüentemente ver as senhas. O default na maioria das distribuições é 644, o que permite que os outros usuários da máquina possam ler o arquivo, uma grande brecha de segurança neste caso.

Uma coisa que você deve ter percebido é que o KDE só oferece a opção de criar ícones para montar partições, disquetes e CD-ROMs, mas não para criar ícones para montar compartilhamentos de rede. Mas é possível criar os ícones manualmente.
Os ícones do KDE, incluindo os do desktop e do iniciar, são arquivos de texto comuns, cujo nome termina com .desktop. Isto faz com que o KDE os veja como ícones, e não simples arquivos de texto. Naturalmente estes arquivos possuem uma sintaxe especial, mas nada tão exótico.
Em primeiro lugar, o desktop no KDE corresponde à pasta Desktop, dentro do seu diretório de usuário, como em "/home/kurumin/Desktop". Para criar um novo ícone no desktop basta criar um arquivo de texto, cujo nome termine com ".desktop":
$ kedit /home/carlos/Desktop/compartilhamento.desktop
Dentro do novo arquivo, vai o seguinte:
[Desktop Entry]Type=FSDeviceDev=192.168.1.34:/arquivosMountPoint=/mnt/nfsFSType=nfsReadOnly=0Icon=hdd_mountUnmountIcon=hdd_unmountName=192.168.1.34:/arquivos
O "192.168.1.34:/mnt/hda6" é o endereço do compartilhamento e o "nfs" é o protocolo. O "/mnt/nfs" é a pasta onde ele ficará acessível. O texto que vai na opção "Name" é o nome que aparecerá no desktop, você pode usar qualquer texto. No meu caso simplesmente repeti o endereço do compartilhamento para facilitar a identificação.
Para um compartilhamento Windows o texto seria:
[Desktop Entry]Type=FSDeviceDev=//192.168.1.34/arquivosMountPoint=/mnt/sambaFSType=smbReadOnly=0Icon=hdd_mountUnmountIcon=hdd_unmountName=arquivos
Salvando o arquivo, o ícone já aparecerá no desktop e se comportará da mesma forma que o do CD-ROM. Basta clicar para ver os arquivos ou acionar o "desmontar" para desativar:

Configurando o lilo
O lilo e o grub disputam o posto de gerenciador de boot default entre as distribuições Linux. O lilo é o mais antigo e mais simples de configurar, enquanto o grub é o que oferece mais opções. Mas, ao invés de ficar discutindo qual é melhor, vamos aprender logo a configurar e resolver problemas nos dois :-).
O lilo utiliza um único arquivo de configuração, o "/etc/lilo.conf". Ao fazer qualquer alteração neste arquivo é preciso chamar (como root) o executável do lilo, o "/sbin/lilo" ou simplesmente "lilo" para que ele leia o arquivo e salve as alterações.
Vamos começar entendendo a função das linhas de uma configuração típica. Abra o arquivo "/etc/lilo.conf" da sua máquina e acompanhe opção a opção.
boot=/dev/hda
Esta é quase sempre a primeira linha do arquivo. Ela indica onde o lilo será instalado. Indicando um dispositivo, como em "/dev/hda", ele é instalado na trilha MBR do HD. Indicando uma partição, como em "/dev/hda1" ele é instalado no primeiro setor da partição, sem reescrever a MBR.
Ao instalar vários sistemas no HD, seja Linux e Windows ou várias distribuições diferentes, apenas um deles deve ter o lilo gravado na MBR. Este terá a função de inicializar todos os outros, cujos gerenciadores foram instalados nas respectivas partições.
Ao verificar esta linha, lembre-se de verificar qual é o dispositivo do HD na sua instalação. Um HD serial ATA, por exemplo, será detectado como "/dev/sda" e não como "/dev/hda".
Se você tiver dois HDs, e estiver instalando o sistema numa partição do segundo ("/dev/hdb1", por exemplo), e usar a linha "boot=/dev/hdb", o lilo será instalado no MBR do segundo HD, não do primeiro. Durante o boot, o BIOS vai continuar lendo o MBR do primeiro HD, fazendo com que continue sendo carregado o sistema antigo. Se você quiser que o sistema instalado no segundo HD passe a ser o principal, use a linha "boot=/dev/hda", que gravará no MBR do primeiro HD.
bitmap = /boot/kurumin.bmpbmp-colors = 255,9,;9,255,bmp-table = 61,15,1,12bmp-timer = 73,29,255,9

Estas linhas ativam o uso de uma imagem como pano de fundo da tela de boot, ao invés do feio menu em texto, ainda usado em algumas distribuições. Veremos mais detalhes sobre este recurso logo a seguir.
vga=788
Esta é uma das linhas mais importantes do arquivo, que ajusta a resolução de vídeo em modo texto (usando frame-buffer). Use "vga=785" para 640x480, "vga=788" para 800x600, "vga=791" para 1024x768 ou "vga=normal" para desabilitar o frame-buffer e usar o modo texto padrão.
Quase todas as placas de vídeo suportam frame-buffer, pois ele utiliza resoluções e recursos previstos pelo padrão VESA. Apesar disso, algumas placas, mesmo modelos recentes, suportam apenas 800x600. Ao tentar usar 1024x768 num destes modelos, o sistema exibe uma mensagem no início do boot, avisando que o modo não é suportado e o boot continua em texto puro. O "vga=788" é um valor "seguro", que funciona em praticamente todas as placas e monitores.
O lilo pode ser configurado para inicializar vários sistemas operacionais diferentes. A linha "prompt" faz com que ele mostre um menu com as opções disponíveis na hora do boot. Ela é quase sempre usada por padrão. A linha "default=" diz qual é o sistema padrão, o que fica pré-selecionado na tela de boot.
promptcompactdefault=Linuxtimeout=100
A linha "timeout=" indica o tempo de espera antes de entrar no sistema padrão, em décimos de segundo. O valor máximo é 30000 (3.000 segundos). Não use um número maior que isto, ou o lilo acusará o erro e não será gravado corretamente. Ao usar o número "0" ou omitir a opção, o lilo espera indefinidamente. Se, ao contrário, você quiser que ele inicie direto o sistema padrão, sem perguntar, você tem duas opções: usar a timeout=1 (que faz com ele espere só 0.1 segundo, imperceptível), ou remover a linha "prompt".
A linha "compact" otimiza a fase inicial do boot (incluindo o carregamento inicial do Kernel), fazendo com que a controladora do HD leia vários setores seqüenciais em cada leitura. Normalmente ela reduz o tempo de boot em cerca de 2 segundos. Não é nada drástico, mas não deixa de ser um pequeno ganho.
append = "nomce quiet noapic"
A linha "append" contém parâmetros que são repassados ao Kernel, de forma a alterar o comportamento padrão do sistema e corrigir problemas de inicialização. Você pode incluir um número indefinido de opções, separando-as com um espaço.
A opção mais relevante e mais usada aqui é o "acpi=off", que desabilita o uso do ACPI, resolvendo problemas de travamento ou bugs diversos em muitas placas. Note que o ACPI é um recurso cada vez mais importante, sobretudo em notebooks, onde é usado não apenas para monitorar o estado das baterias, mas também para controlar diversas funções e até

mesmo fazer o desligamento da máquina. Use o apci=off" apenas quando realmente necessário.
Uma variação é o "acpi=ht", que ao invés de desabilitar o ACPI completamente, mantém ativas as funções necessárias para habilitar o suporte a Hyper Treading nos processadores Pentium 4. É útil em máquinas baseadas neles.
Outra opção comumente usada para solucionar problemas é a "noapci", que desabilita a realocação dinâmica de endereços por parte do BIOS, deixando que o sistema operacional assuma a função. Inúmeros modelos de placas-mãe possuem problemas relacionados a isso, que podem causar desde problemas menores, como a placa de som ou rede não ser detectada pelo sistema, até travamentos durante o boot. Este problemas são solucionados ao incluir o "noapic".
A opção "quiet" faz com que sejam exibidas menos mensagens na fase inicial do boot, quando o Kernel é inicializado; tem uma função puramente estética. A opção "apm=power-off" faz com que sejam usadas as funções do APM para desligar o micro, ao invés do ACPI. Adicionar esta opção resolve problemas de desligamento em muitas máquinas. Outra opção útil é a "reboot=b", que resolve problemas de travamento ao reiniciar em algumas máquinas. As duas podem ser usadas simultaneamente caso necessário.
Todas estas opções, quando usadas, são incluídas dentro da linha append (separadas por espaço), como em:
append = "nomce quiet noapic acpi=off apm=power-off reboot=b"
Em seguida, vem a seção principal, responsável por inicializar o sistema. Ela contém a localização do executável principal do Kernel e do arquivo initrd, caso seja usado um:
image=/boot/vmlinuz-2.6.14label=Linuxroot=/dev/hda1read-onlyinitrd=/boot/initrd.gz
A linha "root=" indica a partição onde o sistema está instalado, ou seja, onde o lilo vai procurar os arquivos especificados. O "Label" é o nome do sistema, da forma como você escreve na opção "default=". Uma observação importante é que o nome pode ter no máximo 14 caracteres e não deve conter caracteres especiais. O lilo é bastante chato com relação a erros dentro do arquivo, se recusando a fazer a gravação até que o erro seja corrigido.
Esta é a seção que é duplicada ao instalar um segundo Kernel. Caso você instalasse o pacote "kernel-image-2.6.15_i368.deb", por exemplo, que criasse o arquivo "/boot/vmlinuz-2.6.15", você adicionaria as linhas:
image=/boot/vmlinuz-2.6.15label=kernel-2.6.15root=/dev/hda1

read-onlyinitrd=/boot/initrd.gz
Ao reiniciar o micro, você passaria a escolher entre os dois kernels na hora do boot. Se quisesse tornar o 2.6.15 a opção padrão, bastaria fazer a alteração na linha "default=".
Ao instalar vários sistemas na mesma máquina, você pode adicionar linhas extras referentes a cada um. Neste caso, fazemos uma coisa chamada "chain load", onde o lilo carrega o gerenciador de boot do outro sistema (instalado na partição) e deixa que ele faça seu trabalho, carregando o respectivo sistema. A configuração para outros sistemas é bem simples, pois você só precisa indicar a partição de instalação e o nome de cada um, como em:
other=/dev/hda2label=Slackware
other=/dev/hda3label=Mandriva
other=/dev/hda5label=Fedora
other=/dev/hda6label=OpenSuSE
Para referenciar as outras instalações deste modo, é necessário que o lilo de cada um esteja instalado no primeiro setor da partição. No lilo.conf do Slackware, por exemplo, haveria a linha "boot=/dev/hda2". No caso do Windows, você não precisa se preocupar, pois ele instala o gerenciador de boot simultaneamente no MBR e na partição.
Existe uma receita simples para alterar e reinstalar o lilo de outras distribuições instaladas no HD em caso de problemas. Imagine, por exemplo, que você instalou o Kurumin e acabou instalando o lilo no MBR, subscrevendo o lilo do Mandriva, que agora não dá mais boot.
Isso pode ser solucionado facilmente, editando o "/etc/lilo.conf" do Mandriva, para que ele seja reinstalado na partição e adicionando as duas linhas que chamam outros sistemas no lilo do Kurumin.
Você pode editar o lilo do Mandriva e regravá-lo rapidamente através do próprio Kurumin (ou outra distribuição instalada), ou dando boot com um CD do Kurumin ou Knoppix.
Dê boot pelo CD e abra um terminal. Defina a senha de root usando o comando "sudo passwd" e logue-se como root usando o "su". Monte a partição onde o Mandriva está instalado:
# mount -t reiserfs /dev/hda1 /mnt/hda1

Agora usamos o comando chroot para "entrar" na partição montada, a fim de editar o lilo.conf e gravar o lilo. Todos os comandos dados dentro do chroot são na verdade executados no sistema que está instalado na partição.
É preciso Indicar o sistema de arquivos em que a partição está formatada ao montar (como no exemplo acima), caso contrário o chroot vai dar um erro de permissão.
# chroot /dev/hda1
Agora use um editor de texto em modo texto, como o mcedit ou o joe para alterar o arquivo "/etc/lilo.conf" e chame o executável do lilo para salvar as alterações. Depois de terminar, pressione Ctrl+D para sair do chroot.
# mcedit /etc/lilo.conf# lilo
É possível também remover o lilo, usando o comando "lilo -u" ("u" de uninstall). Ao ser instalado pela primeira vez, o lilo faz um backup do conteúdo da MBR e ao ser removido este backup é recuperado. Esta opção pode ser útil em casos onde você instala o lilo na MBR (sem querer) e precisa recuperar o sistema anterior.
Dual-Boot com dois HDs
Em casos onde você realmente não queira saber do menor risco para seus arquivos de trabalho ao configurar o dual boot, existe ainda a opção de usar dois HDs.
Instale o HD que abrigará as distribuições Linux como master da primeira IDE e o HD com o Windows como slave. Deixe a segunda IDE reservada para o CD-ROM ou gravador, o que garantirá um melhor desempenho a partir dos dois sistemas.
Detecte ambos os HDs no Setup e instale as distribuições desejadas no primeiro, configurando o lilo para inicializar todos os sistemas.
Depois de terminar, adicione as linhas que iniciarão o Windows. Como ele está instalado no segundo HD, usaremos um pequeno truque que troca a posição dos drivers, fazendo o Windows pensar que o HD onde está instalado continua instalado como primary master:
other=/dev/hdb1label=Windowstable=/dev/hdbmap-drive = 0x80to = 0x81map-drive = 0x81to = 0x80
Isso funciona com o Windows NT, 2000 e XP. Basicamente as linhas carregam a tabela de partição do segundo HD e a partir daí dão boot a partir do drive C: do Windows. As últimas quatro linhas são responsáveis por trocar a posição dos drives.

Usando uma imagem de fundo
Como você pôde ver no exemplo, a configuração necessária para que o lilo exiba um menu de boot gráfico ocupa apenas 4 linhas no início do arquivo. Nem todas as distribuições usam este recurso por padrão (como o Slackware), mas é simples ativar manualmente.
Em primeiro lugar, você precisa de uma imagem de 640x480 com 256 cores (indexada), salva em .bmp. No Gimp existe a opção de codificar a imagem usando RLE, o que diminui muito o tamanho, sem quebrar a compatibilidade com o lilo. Você pode baixar algumas imagens prontas no http://www.kde-look.org, basta salvar a imagem escolhida dentro da pasta /boot.
A localização do arquivo com a imagem, dentro da partição do sistema, vai na linha "bitmap =", como em:
bitmap = /boot/imagem.bmp
O próximo passo é definir as cores e coordenadas do menu com a lista dos sistemas disponíveis e da contagem de tempo.
A configuração das cores é a parte mais complicada, pois os códigos variam de acordo com a paleta usada na imagem escolhida. Abra a imagem no Gimp e clique em "Diálogos > Mapa de Cores". Isso mostra as cores usadas e o número (índice da cor) de cada uma. As cores usadas no lilo são definidas na opção "bmp-colors", onde você define uma cor para a opção selecionada e outra para as outras opções do menu. Cada uma das duas escolhas tem três cores, uma para as letras, outra para o fundo e uma terceira (opcional) para um efeito de sombra no texto, como em: "bmp-colors = 255,9,35;9,255,35" . Se não quiser usar a sombra, simplesmente omita o terceiro valor, como em:
bmp-colors = 255,9,;9,255,
Em seguida vem a parte mais importante, que é definir as coordenadas e o tamanho da caixa de seleção dos sistemas disponíveis, que será exibida sobre a imagem. Os dois primeiros valores indicam as coordenadas (x e y) e os dois valores seguintes indicam o número de colunas (geralmente apenas uma) e o número de linhas, que indica o número máximo de entradas que poderão ser usadas:
bmp-table = 61,15,1,12
Finalmente, temos a posição do timer, que mostra o tempo disponível para escolher antes que seja inicializada a entrada padrão. A configuração do timer tem 5 valores, indicando as coordenadas x e y e as cores (texto, fundo e sombra). Novamente, o valor da sombra é opcional:
bmp-timer = 73,29,255,9

Ao terminar, não se esqueça de salvar as alterações, regravando o Lilo. Aqui está um exemplo de tela de boot, usando estas configurações:
Configurando o grub
Muitas distribuições permitem que você escolha entre usar o lilo ou o grub durante a instalação. Outras simplesmente usam um dos dois por padrão. De uma forma geral, o grub oferece mais opções que o lilo e inclui um utilitário, o update-grub que gera um arquivo de configuração básico automaticamente. Por outro lado, a sintaxe do arquivo de configuração do grub é mais complexa o que o torna bem mais difícil de editar manualmente que o do lilo. O grub inclui ainda um prompt de comando, novamente nenhum exemplo de amigabilidade.
De resto, os dois possuem a mesma e essencial função. Sem o gerenciador de boot o sistema simplesmente não dá boot :-).
O grub usa o arquivo de configuração "/boot/grub/menu.lst". Este arquivo é lido a cada boot, por isso não é necessário reinstalar o grub ao fazer alterações, como no caso do lilo.

Para entender melhor como o grub funciona, vamos a um exemplo de como instalá-lo no Kurumin, substituindo o lilo que é usado por padrão. Estes mesmos passos podem ser usados em outras distribuições derivadas do Debian, que utilizem o lilo.
Em primeiro lugar, você precisa instalar o pacote do grub via apt-get. Ele não possui dependências externas, inclui apenas os executáveis principais. Você pode até mesmo arriscar compilar a versão mais recente, baixada no site do projeto.
# apt-get install grub
Depois de instalar, crie a pasta "/boot/grub/" e use o "update-grub" para gerar o arquivo "menu.lst". Basta responder "y" na pergunta e o arquivo é gerado automaticamente:
# mkdir /boot/grub # update-grub
Testing for an existing GRUB menu.list file...Could not find /boot/grub/menu.lst file. Would you like /boot/grub/menu.lst generated for you? (y/N) y
Searching for splash image... none found, skipping...Found kernel: /boot/vmlinuz-2.6.15Found kernel: /boot/memtest86.binUpdating /boot/grub/menu.lst ... done
Agora só falta instalar o grub na MBR usando o comando:
# grub-install /dev/hda
Ao gravar o grub, ele naturalmente substitui o lilo ou qualquer outro gerenciador de boot que esteja sendo usado.
Se você mudar de idéia mais tarde e quiser regravar o lilo, subscrevendo o grub, basta chamá-lo novamente:
# lilo
Assim como no caso do lilo, o arquivo de configuração do grub inclui uma seção separada para cada sistema que aparece no menu de boot. O update-grub não é muito eficiente em detectar outros sistemas instalados, por isso, depois de gerar o arquivo você ainda precisará adicionar as linhas referentes a eles no final do arquivo "/boot/grub/menu.lst".
Para que o grub inicialize uma cópia do Windows, instalada na primeira partição, /dev/hda1, adicione as linhas:
title Windowsrootnoverify (hd0,0)chainloader +1
Elas equivalem à opção "other=/dev/hda1" que seria usada no arquivo do lilo. A linha "title" contém apenas a legenda que é mostrada no menu de boot. O que interessa mesmo é a linha rootnoverify (hd0,0), que indica o HD e a partição onde o outro sistema está

instalado. O primeiro número indica o HD e o segundo a partição dentro deste. Na nomenclatura adotada pelo grub temos:
/dev/hda = 0/dev/hdb = 1/dev/hdc = 2/dev/hdd = 3
As partições dentro de cada HD são também nomeadas a partir do zero:
/dev/hda1 = 0,0/dev/hda2 = 0,1/dev/hda3 = 0,2/dev/hda4 = 0,3/dev/hda5 = 0,4/dev/hda6 = 0,5etc...
Se você quisesse que o grub iniciasse também uma instalação do Mandriva no /dev/hda3, cujo lilo (ou grub) foi instalado na partição, adicionaria as linhas:
title Mandrivarootnoverify (hd0,2)chainloader +1
A linha "chainloader +1" especifica que o grub vai apenas chamar o gerenciador de boot instalado na partição e deixar que ele carregue o outro sistema, assim como fizemos ao editar o arquivo do lilo.
No caso de outras distribuições Linux, instaladas no mesmo HD, você pode usar o grub para carregar diretamente o outro sistema, sem precisar passar pelo outro gerenciador de boot. Neste caso você usaria as linhas:
title Mandrivaroot (hd0,2)kernel /boot/vmlinuz-2.6.8 root=/dev/hda3 ro savedefaultboot
Veja que neste caso você precisa especificar a localização do executável do Kernel dentro da partição. Você pode especificar também opções para o Kernel e usar um arquivo initrd, se necessário, como neste segundo exemplo:
title Mandrivaroot (hd0,2)kernel /boot/vmlinuz-2.6.8 root=/dev/hda3 ro vga=791 acpi=off splash=verbose initrd /boot/initrd.gzsavedefaultboot
Assim como no caso do lilo, você pode usar um CD do Kurumin ou Knoppix para reinstalar o grub, caso ele seja subscrito por uma instalação do Windows ou outra distribuição Linux.
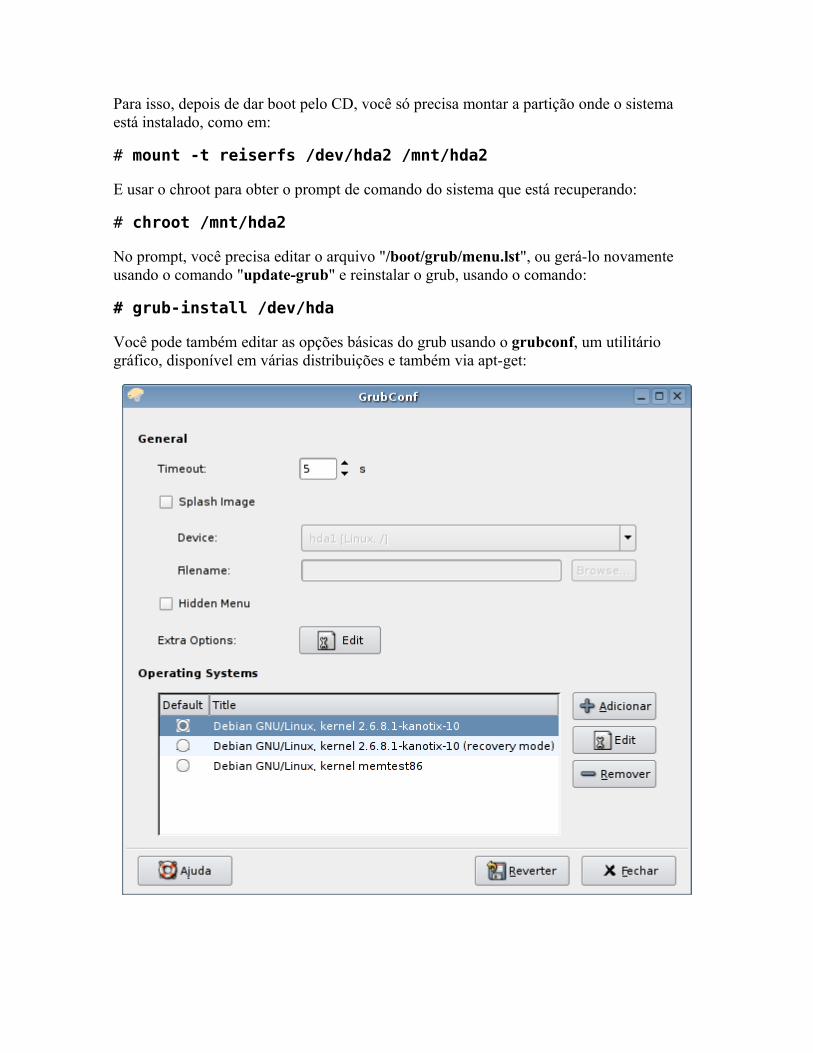
Para isso, depois de dar boot pelo CD, você só precisa montar a partição onde o sistema está instalado, como em:
# mount -t reiserfs /dev/hda2 /mnt/hda2
E usar o chroot para obter o prompt de comando do sistema que está recuperando:
# chroot /mnt/hda2
No prompt, você precisa editar o arquivo "/boot/grub/menu.lst", ou gerá-lo novamente usando o comando "update-grub" e reinstalar o grub, usando o comando:
# grub-install /dev/hda
Você pode também editar as opções básicas do grub usando o grubconf, um utilitário gráfico, disponível em várias distribuições e também via apt-get:

Configurando o vídeo: /etc/X11/xorg.conf
O suporte a vídeo no Linux é provido pelo X, que já vem com drivers para as placas suportadas. Além dos drivers open-source incluídos no X você pode instalar os drivers binários distribuídos pela nVidia e ATI.
Como vimos no primeiro capítulo, existem duas versões do X em uso: o Xfree, o mais antigo e tradicional e o X.org, a versão mais usada atualmente.
Antigamente, até a versão 3.x, o Xfree possuía várias versões separadas, com drivers para diferentes chipsets de vídeo. Isso complicava a configuração e obrigava as distribuições a manterem instaladas todas as diferentes versões simultaneamente, o que também desperdiçava muito espaço em disco.
A partir do Xfree 4.0 e em todas as versões do X.org existe apenas uma única versão unificada, com drivers para todas as placas e recursos suportados. Melhor ainda, cada driver dá suporte a todas as placas de um determinado fabricante, o "sis" dá suporte a todas as placas da SiS, o "trident" dá suporte a todas as placas da Trident e assim por diante. Temos ainda dois drivers genéricos, o "vesa" e o "fbdev", que servem como um mínimo múltiplo comum, uma opção para fazer funcionar placas novas (ou muito antigas), que não sejam suportadas pelos drivers titulares.
Outro detalhe interessante é que toda a configuração do vídeo, incluindo o mouse e o suporte a 3D, é feita através de um único arquivo de configuração, o "/etc/X11/XF86Config-4" (nas distribuições que usam o Xfree) ou "/etc/X11/xorg.conf" (nas que usam o X.org), que é relativamente simples de editar e funciona em todas as distribuições que utilizam o Xfree 4.0 em diante ou X.org (ou seja, praticamente todas as usadas atualmente). Isto significa que você pode pegar o arquivo de configuração gerado pelo Kurumin e usar no Slackware, por exemplo.
Existem várias ferramentas de configuração que perguntam ou autodetectam a configuração e geram o arquivo, como o "mkxf86config" (do Knoppix) "kxconfig", "xf86cfg" entre outros. Mas, neste tópico vamos ver como configurar manualmente o arquivo, adaptando ou corrigindo as configurações geradas pelos configuradores.
O arquivo é dividido em seções. Basicamente, temos (não necessariamente nesta ordem) uma seção "Server", com parâmetros gerais, a seção "Files" com a localização das fontes de tela e bibliotecas, duas seções "InputDevice", uma com a configuração do teclado e outra com a do mouse, uma seção "Monitor" e outra "Device", com a configuração do monitor e placa de vídeo e por último a seção "Screen" onde é dito qual resolução e profundidade de cor usar.
A ordem com que estas configurações aparecem no arquivo pode mudar de distribuição para distribuição, mas a ordem não importa muito, desde que estejam todas lá.

Como em outros arquivos de configuração, você pode incluir comentários, usando um "#" no início das linhas. Linhas em branco, espaços e tabs também são ignorados e podem ser usadas para melhorar a formatação do arquivo e melhorar a organização das informações.
Vamos a uma descrição geral das opções disponíveis, usando como exemplo o modelo de configuração que uso no Kurumin. Abra o arquivo /etc/X11/xorg.conf ou /etc/X11/XF86config-4 da sua máquina e acompanhe o exemplo; prestando atenção nas diferenças entre o exemplo e o arquivo da sua máquina e tentando entender a função de cada seção:
Section "ServerLayout"Identifier "X.Org do Kurumin"Screen 0 "Screen0" 0 0InputDevice "Keyboard0" "CoreKeyboard"InputDevice "USB Mouse" "CorePointer"EndSection
Nesta seção vai a configuração geral. Ela é uma espécie de "índice" das seções abaixo. O campo "Identifier" pode conter qualquer texto, é apenas uma descrição. O "USB Mouse" indica o nome da seção que será usada. Abaixo deve existir uma seção com este mesmo nome, contendo a configuração do mouse propriamente dita. Esta organização permite que você (ou o utilitário de configuração usado) adicione várias configurações diferentes, onde você pode trocar rapidamente entre elas modificando esta linha.
Nas distribuições que usam o Kernel 2.6, é possível usar a mesma configuração para mouses PS/2, mouses USB e também mouses touchpad (notebooks), pois todos utilizam um driver comum. É possível até mesmo usar dois mouses simultaneamente (o touchpad do notebook e um mouse USB externo, por exemplo), sem precisar alterar a configuração. Apenas os antigos mouses seriais ainda precisam de uma configuração própria.
O Kurumin usa um arquivo de configuração que vem com várias configurações de mouse prontas (as opções disponíveis são: "USB Mouse", "PS/2 Mouse" e "Serial Mouse"), mas apenas a informada nesta primeira seção é usada. Como disse, ao usar um mouse PS/2 ou USB, qualquer uma das duas entradas funcionará. Mas, caso você tenha ou pretenda usar um mouse serial, altere a configuração para:
InputDevice "Serial Mouse" "CorePointer"
Se seu micro tiver mais de um mouse conectado simultaneamente, você pode duplicar a configuração do mouse, como abaixo. Isso faz com que o X tente ativar ambos os mouses na inicialização, ativando apenas os que estiverem realmente presentes:
Section "ServerLayout"Identifier "X.Org do Kurumin"Screen 0 "Screen0" 0 0InputDevice "Keyboard0" "CoreKeyboard"InputDevice "USB Mouse" "CorePointer"InputDevice "Serial Mouse" "CorePointer"EndSection
Na seção "ServerFlags" vão opções gerais. É aqui que colocamos, por exemplo, a opção que inicializa o Xinerama, que dá suporte a uma segunda placa de vídeo e monitor. Neste

exemplo, está sendo usada apenas a opção "AllowMouseOpenFail" "true" que permite que o modo gráfico abra mesmo que o mouse esteja desconectado.
Section "ServerFlags"Option "AllowMouseOpenFail" "true"EndSection
Seria estúpido parar toda a abertura do modo gráfico e voltar para o modo texto porque o mouse não foi detectado, pois você ainda pode usar o mouse virtual do KDE como uma solução temporária até que consiga solucionar o problema. Para ativar o mouse virtual, pressione a tecla Shift junto com a tecla NumLock do teclado numérico. A partir daí as teclas 1, 2, 3, 4, 6, 7, 8 e 9 ficam responsáveis pela movimentação do mouse, enquanto a tecla 5 simula o clique do botão esquerdo (pressionando 5 duas vezes você simula um duplo clique). Para arrastar e soltar pressione a tecla 0 para prender e depois a tecla 5 para soltar.
Para simular os outros botões você usa as teclas "/" (botão direito), "*" (botão central) e "-" (para voltar ao botão esquerdo), que funcionam como teclas modificadoras. Para desativar o mouse virtual, pressione "Shift + NumLock" novamente.
Voltando ao arquivo de configuração, temos a seguir as seções "Files" e "Modules", que indicam respectivamente as pastas com as fontes TrueType, Type 1 e outras que serão usadas pelo sistema e os módulos de extensões do Xfree que serão usados.
Section "Files"RgbPath "/usr/X11R6/lib/X11/rgb"ModulePath "/usr/X11R6/lib/modules"FontPath "/usr/X11R6/lib/X11/fonts/misc:unscaled"FontPath "/usr/X11R6/lib/X11/fonts/misc"FontPath "/usr/X11R6/lib/X11/fonts/75dpi:unscaled"FontPath "/usr/X11R6/lib/X11/fonts/75dpi"FontPath "/usr/X11R6/lib/X11/fonts/100dpi:unscaled"FontPath "/usr/X11R6/lib/X11/fonts/100dpi"FontPath "/usr/X11R6/lib/X11/fonts/PEX"FontPath "/usr/X11R6/lib/X11/fonts/cyrillic"FontPath "/usr/share/fonts/truetype/openoffice"FontPath "/usr/X11R6/lib/X11/fonts/defoma/CID"FontPath "/usr/X11R6/lib/X11/fonts/defoma/TrueType"EndSection
Section "Module"Load "ddc"Load "GLcore"Load "dbe"Load "dri"Load "extmod"Load "glx"Load "bitmap"Load "speedo"Load "type1"Load "freetype"Load "record"EndSection

Estas duas seções geralmente não precisam ser alteradas, a menos que você instale algum novo conjunto de fontes TrueType e queira habilitá-lo manualmente ou caso instale um novo driver de vídeo (como o driver da nVidia) e o read-me diga para desativar algum dos módulos.
Outra possibilidade é que você queira intencionalmente desativar algum recurso, ou tentar solucionar problemas. O módulo "dri", por exemplo, habilita o suporte a 3D para a placa de vídeo. As placas onboard com chipset Intel (i810, MGA 900, etc.), placas ATI Rage e ATI Radeon e as antigas Voodoo 2 e Voodoo 3 possuem suporte 3D nativo no X.org.
Mas, ao instalar o driver 3D da nVidia você precisa remover esta opção, pois o driver do Xfree conflita com o que é instalado junto com o driver. Pode ser também que por algum motivo você queira desabilitar o 3D da sua i810 onboard (para evitar que fiquem jogando TuxRacer durante o expediente, por exemplo ;). Em qualquer um dos casos, você poderia comentar a linha "Load "dri".
Em seguida vem a configuração do teclado. O "abnt2" indica o layout de teclado que será usado por padrão. No KDE e Gnome, o layout indicado aqui perde o efeito, pois eles possuem ferramentas próprias para configurar o teclado. No caso do KDE é usado o kxkb, que você configura na seção Regional & Acessibilidade do Kcontrol. Mas, esta configuração de teclado do X é útil para quem usa outras interfaces.
Estes são dois exemplos de configuração para (respectivamente) um teclado ABNT2 e um teclado US Internacional. Você só pode incluir uma das duas no arquivo:
# Teclado ABNT2Section "InputDevice"Identifier "Keyboard0"Driver "kbd"Option "CoreKeyboard"Option "XkbRules" "xorg"Option "XkbModel" "abnt2"Option "XkbLayout" "br"Option "XkbVariant" "abnt2"EndSection
# Teclado US InternacionalSection "InputDevice"Identifier "Keyboard0"Driver "kbd"Option "CoreKeyboard"Option "XkbRules" "xorg"Option "XkbModel" "pc105"Option "XkbLayout" "abnt2"EndSection
Você deve lembrar que acima, na seção "ServerLayout" informamos que o X iria usar o "USB Mouse". Este é apenas um nome que indica a seção (com a configuração do mouse propriamente dita) que será usada. Isso permite que você tenha várias seções com configurações de mouses diferentes. Basta indicar a correta na seção de cima e as demais serão ignoradas.

Estas são as seções com as configurações usadas no Kurumin. Dentro de cada seção vai a porta e driver usados pelo mouse e outras opções necessárias em cada caso. Você pode usá-las como modelos para configurar o mouse em outras distribuições:
Section "InputDevice"Identifier "USB Mouse"Driver "mouse"Option "Protocol" "auto"Option "Device" "/dev/input/mice"Option "SendCoreEvents" "true"Option "ZAxisMapping" "4 5"Option "Buttons" "5"EndSection
Section "InputDevice"Identifier "Serial Mouse"Driver "mouse"Option "Protocol" "Microsoft"Option "Device" "/dev/ttyS0"Option "Emulate3Buttons" "true"Option "Emulate3Timeout" "70"Option "SendCoreEvents" "true"EndSection
A linha "Option "ZAxisMapping" "4 5" ativa a rodinha do mouse, quando disponível. Do ponto de vista do sistema operacional, a rodinha é um conjunto de dois botões extras (botões 4 e 5) e os giros da roda correspondem a cliques nos botões extra.
É seguro usar esta linha sempre, pois ela é ignorada ao usar um mouse sem a rodinha. O mais importante no caso é o protocolo usado. Com relação a mouses PS/2 e USB no Kernel 2.6, recomendo que use sempre a opção "Option "Protocol" "auto", que detecta corretamente o protocolo do mouse na grande maioria dos casos.
Em casos específicos, onde o mouse não funcione corretamente, você pode substituir o "Option "Protocol" "auto" por "Option "Protocol" "IMPS/2", que é o protocolo padrão para mouses de três botões, com roda, ou "Option "Protocol" "PS/2", que é o protocolo para mouses PS/2 antigos, sem roda.
No caso de mouses com 5 botões, com uma ou duas rodas, o protocolo usado muda para "ExplorerPS/2 e você precisa especificar a configuração dos botões extras. Para um mouse com 5 botões e uma roda, a seção fica:
Section "InputDevice"Identifier "Mouse"Driver "mouse"Option "Protocol" "ExplorerPS/2"Option "ZAxisMapping" "4 5"Option "Buttons" "7"Option "Device" "/dev/input/mice"EndSection
Se a função dos dois botões extra e da roda ficarem trocadas, substitua a linha "Option "ZAxisMapping" "4 5" por "Option "ZAxisMapping" "6 7".

No caso dos mouses com duas rodas, a configuração fica:
Section "InputDevice"Identifier "Mouse"Driver "mouse"Option "Protocol" "ExplorerPS/2"Option "ZAxisMapping" "6 7 8 9"Option "Buttons" "9"Option "Device" "/dev/input/mice"EndSection
Note que, ao usar o Kernel 2.6, não existe necessidade de especificar se o mouse é PS/2 ou USB, pois a porta "/dev/input/mice" é compartilhada por ambos. As versões atuais do Firefox e outros aplicativos atribuem funções para os botões extras automaticamente. Os dois botões laterais assumem as funções dos botões para avançar e voltar no Firefox, por exemplo.
Continuando, temos a configuração do monitor e placa de vídeo, que afinal são os componentes mais importantes neste caso. Ela é dividida em três seções, com a configuração do monitor, da placa de vídeo e uma seção "screen" que, com base nas duas anteriores indica qual resolução e profundidade de cores será usada.
A configuração do monitor precisa incluir apenas as taxas de varredura horizontal e vertical usadas por ele. Você pode encontrar estes dados no manual do monitor ou no site do fabricante. As opções Identifier, VendorName e ModelName são apenas descritivas, podem conter qualquer texto:
Section "Monitor"Identifier "Monitor0"VendorName "GSM"ModelName "GSM3b60"HorizSync 30 - 63 VertRefresh 50 - 75 EndSection
Se você não souber as taxas de varredura usadas pelo seu monitor e quiser alguma configuração genérica que funcione em qualquer monitor contemporâneo, experimente usar esta, que permite trabalhar a até 1024x768 com 60 Hz de atualização:
Section "Monitor"Identifier "Meu Monitor"HorizSync 31.5 - 50.0VertRefresh 40-90EndSection
Em geral, os configuradores incluem várias seções "Modeline" dentro da seção "Monitor", com as resoluções e taxas de atualização suportadas pelo monitor.
Estes dados são fornecidos pelo próprio monitor, via DDC (uma espécie de plug-and-play para monitores) e não é necessário alterá-los a menos que você esteja escrevendo o arquivo manualmente do zero, o que não é muito aconselhável já que é sempre muito mais fácil usar um arquivo copiado de outro micro como base. Esta configuração dos modelines não é

obrigatória no XFree 4.x ou X.org, pois o X é capaz de deduzir a configuração a partir das taxas de varredura do monitor, informadas dentro da seção. Eles são usados atualmente mais como uma forma de corrigir problemas.
Este é um exemplo de configuração para um monitor de 17", incluindo modelines para usar 1280x1024, 1024x768 e 800x600. Note que cada seção "Modeline" ocupa uma única linha:
Section "Monitor"Identifier "Monitor0"VendorNam "GSM"ModelName "GSM3b60"HorizSync 30 - 63 VertRefresh 50 - 75 ModeLine "1280x1024" 135.00 1280 1296 1440 1688 1024 1025 1028 1066 +hsync +vsyncModeLine "1024x768" 78.75 1024 1040 1136 1312 768 769 772 800 +hsync +vsyncModeLine "800x600" 49.50 800 816 896 1056 600 601 604 625 +hsync +vsyncEndSection
Em seguida vem a seção "Device" que indica a configuração da placa de vídeo. As opções Identifier, VendorName e BoardName são apenas descrições, o que interessa mesmo é o Driver usado:
Section "Device"Option "sw_cursor"Identifier "Card0"Driver "nv"VendorName "nVidia"BoardName "GeForce4 MX"EndSection
Os drivers disponíveis são:
- fbdev: Este driver usa o recurso de framebuffer suportado pelo Kernel como driver de vídeo. Neste modo o Kernel manipula diretamente a memória da placa de vídeo, gravando as imagens que serão mostradas no monitor. O desempenho não é dos melhores e a utilização do processador é maior que nos outros drivers pois não existe aceleração de vídeo
Mas, por outro lado, este é um driver que funciona com a maioria das placas de vídeo e é o único onde você não precisa se preocupar com a configuração das taxas de atualização do monitor. As placas usam sempre uma taxa de atualização baixa, de 56 ou 60 Hz, que é fixa.
Ao usar o fbdev como driver de vídeo, a configuração da resolução não é feita no arquivo xorg.conf, mas no "/etc/lilo.conf" (pois o parâmetro é passado diretamente ao Kernel durante o boot), como vimos anteriormente.
- i740: Usado pelas placas de vídeo (offboard) com chipset Intel i740. Estas placas foram uma tentativa frustrada da Intel de entrar no ramo de placas 3D. O desempenho era fraco comparado com as placas da nVidia e ATI, mas o projeto acabou sendo usado como base para os chipsets de vídeo onboard que passaram a ser usados nos chipsets Intel.

- i810: Este é o driver usado por todas as placas de vídeo onboard com chipset Intel. A lista de compatibilidade inclui quase todos os chipsets para Pentium III, Pentium 4 e Pentium M, incluindo as placas com o chipset Intel 900 e Intel Extreme.
- nv: É o driver genérico para placas nVidia, que oferece apenas suporte 2D. Para ativar os recursos 3D você precisa instalar os drivers da nVidia (veja mais detalhes no capítulo 3).
- r128: Driver para as placas ATI Rage (a família anterior às ATI Radeon). Este driver oferece um bom suporte 3D, permitindo que estas placas funcionem usando quase todo seu potencial 3D (que não é grande coisa hoje em dia, mas ainda permite rodar vários jogos).
- radeon / ati: Este é o driver open-source para as placas ATI Radeon. Nas versões antigas do Xfree e do X.org, o driver se chamava "radeon", mas ele passou a se chamar "ati" nas versões recentes do X.org (a partir do 6.8.2). Você pode verificar qual é a versão do X instalada, usando o comando "X -version".
Para que a aceleração 3D funcione, é necessário que os módulos do Kernel que cuidam da comunicação de baixo nível com a placa de vídeo estejam carregados. Nem todas as distribuições carregam estes módulos automaticamente, mesmo ao detectar a placa corretamente. Se a aceleração 3D não estiver funcionando, apesar da configuração do X estar correta, adicione as linhas abaixo num dos arquivos de inicialização do sistema:
modprobe agpgartmodprobe ati-agpmodprobe drmmodprobe radeon
Existe uma certa polêmica sobre utilizar o driver do X, ou utilizar o driver proprietário fornecido pela ATI que, embora não trabalhe em conjunto com algumas placas, oferece um desempenho 3D superior quando funciona. Veja mais detalhes sobre como instalá-lo no capítulo 3.
- s3virge: Placas com chipset S3 Virge. Estas placas foram muito usadas por volta da época do lançamento do Pentium MMX.
- sis: Este é o driver que funciona em todas as placas da SiS suportadas. Caso você encontre algum chipset novo, que não funcione com ele, experimente usar o driver vesa ou fbdev.
Uma observação importante é que a SiS não desenvolve drivers 3D para o Linux e não divulga as especificações técnicas que permitiriam o desenvolvimento de drivers 3D por parte da comunidade. Atualmente as placas de vídeo e chipsets da SiS são os com pior suporte no Linux por causa da falta de cooperação do fabricante e devem ser evitadas na hora da compra.
O driver oferece apenas suporte 2D, as placas funcionam mas não servem para rodar jogos 3D ou trabalhar com aplicativos 3D profissionais, por exemplo. Até o Xfree 4.0 existia um esforço para desenvolver suporte 3D, mas o fabricante divulgava tão pouca informação e os chipsets possuíam tantos problemas (o que pode ser percebido pela relativa instabilidade dos próprios drivers for Windows) que o projeto acabou sendo levado adiante por um único

desenvolvedor. Você pode obter mais informações sobre o status do driver (2D) no:http://www.winischhofer.at/linuxsisvga.shtml
O X.org inclui um driver 3D precário, que oferece suporte limitado às placas com chipset SiS 300, 305, 630 e 730, porém não inclui suporte aos demais modelos. Entre as placas onboard, as com melhor suporte no Linux são as placas Intel, suportadas pelo driver i810.
- tdfx: Driver para as placas da 3Dfx, as famosas Voodoo, que fizeram muito sucesso a até meia década atrás. Este driver oferece suporte 3D para as placas Voodoo 2 e Voodoo 3.
- trident: Placas de vídeo da Trident. Ele funciona bem com placas Trident Blade e os novos chipsets usados em notebooks, mas o suporte às antigas 9440 e 9680 é ruim e em muitos casos elas funcionam a apenas 640x480. Pensando nestas placas, algumas distribuições, como o Mandriva oferecem a opção de usar o driver do antigo Xfree 3.3, que oferecia um suporte mais completo a elas.
Apesar de brutalmente ultrapassadas, as Trident 9440 e 9680 foram as mais vendidas durante a maior parte da década de 1990 e por isso ainda são usadas em muitos micros antigos.
- vesa: Este é o "curinga", um driver genérico que utiliza apenas as extensões do padrão vesa que em teoria é suportado por todas as placas de vídeo PCI e também pelas antigas placas VLB. Algumas placas antigas, como as Trident 9680 não funcionam com ele, mas são exceções.
Como este driver não suporta aceleração, você notará que o desempenho em algumas tarefas ficará abaixo do normal. É normal também que os vídeos assistidos no Kaffeine ou Xine fiquem granulados ao serem exibidos em tela cheia. Outra limitação é que a resolução, na maioria das placas, fica limitada a 1024x768.
- via: Este é o driver que dá suporte ao chipset Via Unicrome, usado como vídeo onboard na maior parte das placas-mãe atuais com chipset Via. Originalmente, este driver era apenas 2D, como o nv e o sis, mas a partir de abril de 2005 a Via passou a publicar um driver 3D open-source, que pode ser encontrado nas versões recentes do X.org. Para que a aceleração 3D oferecida por ele funcione, é necessário que os módulos "via-agp" e "via" estejam carregados. Adicione as linhas abaixo num dos arquivos de inicialização do sistema:
modprobe via-agp modprobe via
- savage: Este driver dá suporte às placas S3 Savage e Pro Savage, relativamente populares a alguns anos atrás. Ele inclui aceleração 3D caso você esteja utilizando uma versão recente do X.org (a partir do 6.8.2), em conjunto com o pacote "libgl1-mesa-dri" (que inclui os drivers 3D desenvolvidos pelo projeto Mesa GL).
Outros drivers, pouco usados são:

- cirrus: A Cirrus Logic fabricou alguns modelos de placas de vídeo PCI, concorrentes das Trident 9440 e 9680. Elas são encontradas apenas em micros antigos.
- cyrix: Placas com o chipset Cyrix MediaGX, também raros atualmente.
- chips: Placas da "Chips and Technologies", um fabricante pouco conhecido.
- glint: Esta é uma família de placas antigas lançada pela 3D Labs.
- neomagic: Placas com chipset Neomagic, usadas em alguns notebooks antigos.
- rendition: Placas Rendition Verite, da Micron.
- tseng: Placas da Tseng Labs, outro fabricante pouco conhecido.
- vga: Este é um driver VGA genérico que trabalha 640x480 com 16 cores. Serve como um "fail safe" que funciona em todas as placas.
Cada um destes drivers oferece algumas opções de configuração que podem ser usadas em casos de problemas ou por quem quiser fuçar na configuração. Você pode encontrar mais informações sobre cada um no: http://www.xfree86.org/4.4.0/.
Finalmente, vai a configuração da seção "Screen", que indica a resolução que será usada. As várias seções determinam as resoluções disponíveis para cada configuração de profundidade de cor, enquanto a opção "DefaultColorDepth" determina qual será usada:
Section "Screen"Identifier "Screen0"Device "Card0"Monitor "Monitor0"DefaultColorDepth 24
SubSection "Display"Depth 8Modes "1024x768" "800x600" "640x480"EndSubSection
SubSection "Display"Depth 16Modes "1024x768" "800x600" "640x480"EndSubSection
SubSection "Display"Depth 24Modes "1024x768" "800x600" "640x480"EndSubSectionEndSection
Neste exemplo o vídeo está configurado para usar 24 bits de cor. Se você quisesse usar 16 bits, bastaria mudar o número na opção "DefaultColorDepth". Dentro de cada uma das três seções (Depth 8, Depth 16 e Depth 24), vai a resolução que será usada para cada uma.

Na linha que começa com "Modes" vão as resoluções de tela. A primeira da lista (1024x768 no exemplo) é a default. As outras duas, 800x600 e 640x480 são usadas apenas se a primeira falhar (se a placa de vídeo ou monitor não a suportarem) ou se você alternar manualmente entre as resoluções, pressionando "Ctrl Alt +" ou "Ctrl Alt -" .
Sempre que você fizer alterações no arquivo e quiser testar a configuração, reinicie o X pressionando "Ctrl+Alt+Backspace". Não é preciso reiniciar o micro.
KVM via software com o Synergy
Um KVM é um adaptador que permite ligar dois ou mais micros no mesmo teclado, mouse e monitor. Você pode chavear entre eles pressionando uma combinação de teclas, como "Scroll Lock, Scroll Lock, seta pra cima", o que passa não apenas o controle do mouse e teclado, mas troca também a imagem mostrada no monitor.
O Synergy permite fazer algo semelhante via software, "anexando" telas de outros micros, de forma a usar todos simultaneamente, com um único teclado e mouse. Imagine que você tem um desktop e um notebook, onde o notebook fica na mesa bem ao lado do monitor do desktop e você precisa se contorcer todo quando precisa fazer alguma coisa no notebook.
Usando o Synergy você pode anexar a tela do notebook ao seu desktop, fazendo com que ao mover o mouse para a direita (ou esquerda, de acordo com a configuração) ele mude automaticamente para a tela do notebook. Junto com o mouse, muda o foco do teclado e até mesmo a área de transferência é unificada, permitindo que você copie texto de um micro para o outro. Tudo é feito via rede, com uma baixa utilização do processador e um excelente desempenho.
No Linux, o Synergy pode tanto ser configurado manualmente, através do arquivo ".synergy.conf" (dentro do seu diretório de usuário), ou do arquivo "/etc/synergy.conf" (que vale para todos os usuários do sistema), quanto através do Quicksynergy, um configurador gráfico. Vamos começar aprendendo como fazer a configuração manualmente.
O primeiro passo é, naturalmente, instalar o Synergy nas duas máquinas. Ele é um programa comum, incluído em muitas distribuições. Nos derivados do Debian, instale-o via apt-get:
# apt-get install synergy
Caso você não encontre um pacote para a sua distribuição, você pode baixar um pacote .rpm genérico, ou mesmo o pacote com o código fonte no: http://synergy2.sourceforge.net/.
Imagine que você quer controlar o notebook a partir do desktop e que o desktop está à esquerda e o notebook à direita. O nome do desktop na rede é "semprao" e o nome do notebook é "kurumin", onde o endereço IP do desktop é "192.168.0.10" e o do notebook é "192.168.0.48".

Desktop Notebooknome: semprao kuruminip: 192.168.0.10 192.168.0.48posição: à esquerda à direita
Estas informações precisam ser especificadas no arquivo de configuração, ".synergy.conf" ou "/etc/synergy.conf". Ele é um arquivo simples com três seções, onde são especificados os nomes das máquinas (conforme definido na configuração da rede, ou no arquivo "/etc/hostname" e "/etc/hosts"), a posição de cada uma e os respectivos endereços IP. Em caso de dúvida sobre o nome de cada máquina, cheque com o comando "hostname".
Este arquivo é criado no PC que controlará os outros, o desktop no nosso caso. No nosso exemplo o arquivo ficaria:
section: screenssemprao:kurumin:endsection: linkssemprao:right = kuruminkurumin:left = sempraoendsection: aliaseskurumin:192.168.0.48end
Note que usei tabs para formatar o arquivo de forma que ele ficasse mais organizado, mas elas não influenciam a configuração. Como em outros arquivos, você pode usar tabs, espaços e quebras de linha extras para formatar o arquivo da maneira que quiser. Use este arquivo como exemplo, alterando apenas os nomes e endereços IP dos micros.
Na seção "screens", vão os nomes das duas máquinas e na seção "links" é especificado quem fica à direita e quem fica à esquerda. No caso estou dizendo que o kurumin está à direita do semprao e vice-versa.
Finalmente, na seção "aliases" você relaciona o nome da máquina que será acessada a seu endereço IP.
Com o arquivo criado nas duas máquinas, falta apenas efetuar a conexão. Uma particularidade do Synergy é que o micro principal (o desktop no nosso exemplo) é o servidor, enquanto o micro que vai ser controlado por ele (o notebook) é o cliente. É por isso que a configuração é feita no desktop e não no notebook.
Para ativar o "servidor" Synergy no desktop, permitindo que o notebook se conecte a ele, usamos o comando:
$ synergys -f
Para que o notebook se conecte e seja controlado por ele, usamos o comando:

$ synergyc -f 192.168.0.10
...onde o 192.168.0.10 é o endereço IP do desktop. Ambos os comandos devem ser sempre executados usando seu login de usuário, não como root.
Se o notebook estiver em outra posição, à esquerda, acima ou abaixo da tela principal, use os parâmetros "left =", "up =" e "down =" na configuração. É possível ainda conectar dois ou mais micros simultaneamente, especificando a posição de cada um na configuração. Se, por exemplo, além do notebook à direita, tivermos um segundo desktop chamado "fedora" com o IP "192.168.0.21" à esquerda, o arquivo de configuração ficaria:
section: screenssemprao:kurumin:fedora:endsection: linkssemprao:right = kuruminleft = fedorakurumin:left = sempraofedora:right = sempraoendsection: aliaseskurumin:192.168.0.48fedora:192.168.0.21end
Originalmente, o rastro do mouse muda de uma tela para a outra simplesmente por chegar ao canto da tela. Isso pode ser um pouco desagradável em muitas situações, pois é justamente nos cantos da tela que ficam as barras de rolagem, bordas e botões da janela.
A resposta para o problema é a opção "switchDelay", que permite especificar um tempo de espera em milessegundos antes do mouse mudar para outra tela. Ele evita transições involuntárias, pois você precisa realmente manter o mouse no canto da tela por uma fração de segundo para mudá-lo para a outra tela.
Para usar a opção inclua-a no final do arquivo, como em:
section: optionsswitchDelay = 250end
Como pode ver, ela vai dentro de uma nova seção a "options", que não incluímos antes no arquivo por que não tínhamos nada a declarar. O "250" é o tempo em milessegundos que o synergy espera antes de fazer a transição de telas, em milessegundos. Este é o valor que eu considero mais confortável, mas você pode testar intervalos maiores ou menores até achar o ideal para você.

Outra configuração útil é a heartbeat que faz com que seu micro detecte a desconexão dos outros micros configurados (quando eles forem desligados, por exemplo), desativando o uso das telas virtuais até que eles se reconectem. Ela pode ser incluída dentro da seção "options", junto com a switchDelay (o 5000 indica o tempo entre as verificações, no caso 5 segundos):
section: optionsswitchDelay = 250heartbeat = 5000end
Mais uma opção útil é a "switchCorners", que faz com que o Synergy trave os cantos da tela, permitindo que você clique no botão iniciar, nos botões de fechar e redimensionar janelas e outras funções sem mudar para as telas adjacentes. Ao usar esta opção, o chaveamento é feito apenas pelo espaço central da tela, o que torna o sistema bem mais confortável. Para usar a opção, adicione as linhas abaixo dentro da seção "options", logo abaixo da linha "heartbeat = 5000":
switchCorners = allswitchCornerSize = 50
O "50"indica o tamanho (em pixels) da área que será considerada como canto pelo Synergy. No caso estou reservando os 50 pixels superiores e inferiores.
Outra opção útil, sobretudo ao usar três telas dispostas horizontalmente, é utilizar teclas de atalho para chavear entre elas. Para isso, você pode utilizar a opção "keystroke", especificando uma sequência de atalho e o nome da tela para a qual irá o cursor, como em:
keystroke(Alt+Z) = switchToScreen(hp)keystroke(Alt+X) = switchToScreen(semprao)keystroke(Alt+C) = switchToScreen(m5)
Concluindo, ao usar um firewall no "servidor", mantenha aberta a porta "24800", usada pelo Synergy.
Se você começar a usar o Synergy regularmente, a melhor forma de simplificar o processo é criar dois ícones no desktop do KDE (um no desktop, outro no notebook), que executam os comandos para estabelescer o link. Outra opção, é colocar o ícone com o comando na pasta ".kde/Autostart" (dentro do seu diretório home) de cada um, assim o Synergy passa a ser ativado automaticamente durante o boot.

Depois de feita a conexão, experimente passear com o mouse entre os dois desktops e abrir programas. Você pode também colar texto e até mesmo imagens de um desktop para o outro, usando o Ctrl+C, Ctrl+V, ou usando o botão do meio do mouse. Para transferir arquivos, você pode usar o SSH, ou criar um compartilhamento de rede, usando o NFS ou o Samba.
Uma das vantagens do Synergy é que ele é multiplataforma. Na página de download você encontra também uma versão Windows, que pode ser usada em conjunto com a versão Linux. Você pode controlar uma máquina Windows a partir de um desktop Linux e vice-versa.
A versão Windows apresenta inclusive uma vantagem, que é o fato de ser configurada através de uma interface gráfica, ao invés do arquivo de configuração. Uma opção de interface gráfica para a versão Linux é o Quicksynergy, que você pode baixar no: http://quicksynergy.sourceforge.net/.
O principal problema com o Quicksynergy é que, apesar de ser um programa bastante simples, ele está disponível apenas em código fonte e tem uma longa lista de dependências. Isso faz com que você acabe tendo que baixar 30 MB de compiladores e bibliotecas para instalar um programa de 500 KB.
Se estiver disposto a encarar a encrenca, use o comando abaixo para baixar tudo via apt-get (Debian Etch). Note que os nomes dos pacotes podem mudar sutilmente em outras distribuições:
# apt-get install automake gcc g++ ibglade2-dev libgtk2.0-dev libgnomeui-dev
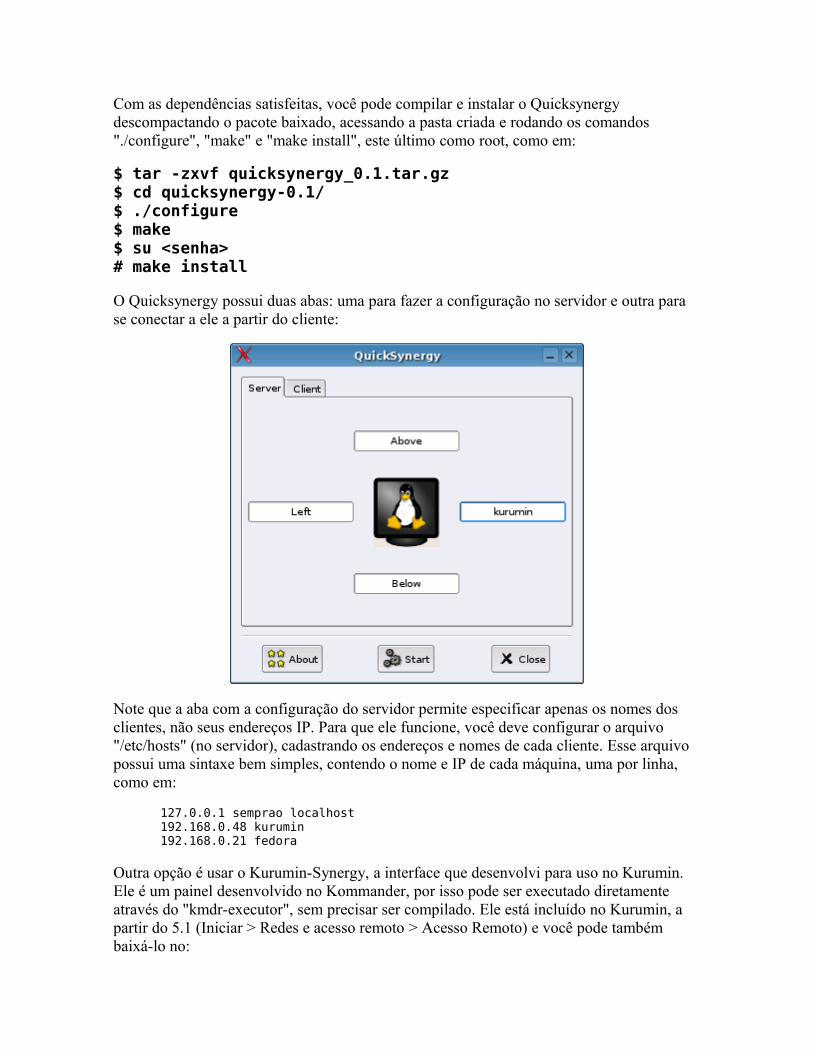
Com as dependências satisfeitas, você pode compilar e instalar o Quicksynergy descompactando o pacote baixado, acessando a pasta criada e rodando os comandos "./configure", "make" e "make install", este último como root, como em:
$ tar -zxvf quicksynergy_0.1.tar.gz$ cd quicksynergy-0.1/ $ ./configure$ make$ su <senha># make install
O Quicksynergy possui duas abas: uma para fazer a configuração no servidor e outra para se conectar a ele a partir do cliente:
Note que a aba com a configuração do servidor permite especificar apenas os nomes dos clientes, não seus endereços IP. Para que ele funcione, você deve configurar o arquivo "/etc/hosts" (no servidor), cadastrando os endereços e nomes de cada cliente. Esse arquivo possui uma sintaxe bem simples, contendo o nome e IP de cada máquina, uma por linha, como em:
127.0.0.1 semprao localhost192.168.0.48 kurumin192.168.0.21 fedora
Outra opção é usar o Kurumin-Synergy, a interface que desenvolvi para uso no Kurumin. Ele é um painel desenvolvido no Kommander, por isso pode ser executado diretamente através do "kmdr-executor", sem precisar ser compilado. Ele está incluído no Kurumin, a partir do 5.1 (Iniciar > Redes e acesso remoto > Acesso Remoto) e você pode também baixá-lo no:

http://www.guiadohardware.net/kurumin/painel/kurumin-synergy.kmdr
Para executar, você precisa ter o pacote "kommander" instalado. Execute-o usando o comando:
$ kmdr-executor kurumin-synergy.kmdr
A interface é bem similar à do Quicksynergy, com uma aba para ativar o servidor e outra para conectar os clientes. As diferenças são que ele permite especificar diretamente os endereços IP dos clientes (sem precisar editar o "/etc/hosts") e que ele oferece a opção de criar um ícone no desktop para reativar a conexão de forma rápida depois.
Lembre-se de que ele é apenas a interface. De qualquer forma, você precisa ter o pacote "synergy" instalado. Ao estabelecer a conexão, é aberta uma janela de terminal, onde você pode acompanhar as mensagens. Para fechar a conexão, pressione "Ctrl+C" no terminal.
No capítulo sobre shell script, veremos passo a passo como este script do Kurumin Synergy foi desenvolvido, permitindo que você inclua melhorias ou desenvolva seus próprios scripts.
Usando o hdparm
O hdparm é um utilitário muito usado, que permite ativar otimizações para o HD. Não se trata necessariamente de um utilitário para "turbinar" o seu sistema, mas para descobrir e corrigir problemas na configuração do HD, que podem comprometer o desempenho.

Logue-se como root e rode o comando:
# hdparm -c -d /dev/hda (substituindo o /dev/hda pela localização correta caso o HD esteja em outra posição)
Você receberá um relatório como o abaixo:
/dev/hda:IO_support = 0 (default 16-bit)using_dma = 0 (off)
Este é o pior caso possível. Veja que tanto o acesso de 32 bits quanto o DMA do HD estão desativados. Você pode atestar isso através do comando:
# hdparm -t /dev/hda
O relatório mostra a velocidade de leitura do HD. Neste caso temos um HD Fujitsu de 4.3 GB, um HD extremamente antigo. Mesmo assim, a velocidade de leitura está bem abaixo do normal, apenas 2.72 MB/s, o que beira o ridículo:
/dev/hda:
Timing buffered disk reads: 64 MB in 23.57 seconds = 2.72 MB/sec
Podemos melhorar isto ativando os dois recursos, o que pode ser feito através do comando:
# hdparm -c 1 -d 1 /dev/hda
Algumas placas-mãe antigas, de Pentium 1 ou 486 podem não suportar o modo DMA, mas quase todas suportarão pelo menos o acesso de 32 bits. Naturalmente em qualquer equipamento mais atual ambos os recursos devem estar obrigatoriamente habilitados. Rodando novamente o comando "hdparm -t /dev/hda" vemos que a velocidade de acesso melhorou bastante:
/dev/hda:Timing buffered disk reads: 64 MB in 10.76 seconds = 5.96 MB/sec
Para que a alteração torne-se definitiva, edite o arquivo "/etc/rc.d/rc.local", adicionando a linha:
hdparm -c 1 -d 1 /dev/hda
Isto fará com que a configuração seja ativada a cada reboot. Nas distribuições derivadas Debian, você pode adicionar o comando no arquivo "/etc/init.d/bootmisc.sh", já que ele não utiliza o arquivo "rc.local".

Muitos tutoriais adicionam também a opção "-k 1" no comando. Ela faz com que a configuração seja mantida em casos de erros, onde a controladora do HD realiza um soft reset. Isto ocorre em casos de erros de leitura em setores do HD e outros problemas relativamente graves. Sem o "-k 1", estes erros fazem com que o DMA seja desativado.
Eu particularmente prefiro esta configuração (sem o -k 1), pois serve como uma espécie de "alarme". Um erro ocorre, o DMA é desativado e, pela lentidão do sistema, você percebe que algo está errado. Usando o comando "dmesg" você pode verificar o que ocorreu e decidir se é o caso de atualizar os backups ou trocar de HD.
Naturalmente, os resultados não serão tão animadores nos casos em que a distribuição se encarrega de detectar e ativar os recursos durante a instalação, mas não deixa de valer a pena sempre verificar se está tudo ok.
Versões antigas do Red Hat usavam uma configuração bem conservadora, o que fazia com que o ultra DMA ficasse desativado em muitas placas, onde ele funciona perfeitamente ao ser ativado manualmente.
Caso o hdparm não esteja instalado, use o comando "urpmi hdparm" (no Mandriva), "apt-get install hdparm" (Debian e derivados) ou procure pelo pacote nos CDs da distribuição em uso. Ele é um utilitário padrão do sistema.
Na grande maioria dos casos, simplesmente ativar o DMA e modo de transferência de 32 bits já fazem com que o HD trabalhe de forma otimizada, pois o hdparm detecta as configurações suportadas pela controladora.
Mas, em alguns casos, você pode conseguir pequenos ganhos ajustando o modo Ultra DMA usado pelo HD. Neste caso, use os parâmetros "-X66" (UDMA 33), "-X68" (UDMA 66) ou "-X69" (UDMA 100), como em:
# hdparm -X69 /dev/hda
Esta opção deve ser usada apenas em conjunto com HDs IDE, nunca com os HDs serial ATA, que já operam nativamente a 150, 300 ou 600 MB/s.
Ao tentar forçar um modo de transferência não suportado pelo seu drive, você recebe uma mensagem de erro, como em:
# hdparm -X70 /dev/hda
/dev/hda:setting xfermode to 70 (UltraDMA mode6)HDIO_DRIVE_CMD(setxfermode) failed: Input/output error
Nestes casos, o padrão do hdparm é voltar à configuração anterior para evitar perda de dados. Mas, em alguns poucos casos, forçar um modo não suportado pode realmente corromper os dados do HD, por isso uso este recurso com cautela.

Você pode verificar os modos suportados pelo seu drive usando o comando "hdparm -i drive", na linha "UDMA Modes:", como em:
# hdparm -i /dev/hda
/dev/hda:Model=IC25N080ATMR04-0, FwRev=MO4OAD4A, SerialNo=MRG40FK4JP27HHConfig={ HardSect NotMFM HdSw>15uSec Fixed DTR>10Mbs }RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=4BuffType=DualPortCache, BuffSize=7884kB, MaxMultSect=16, MultSect=16CurCHS=17475/15/63, CurSects=16513875, LBA=yes, LBAsects=156301488IORDY=on/off, tPIO={min:240,w/IORDY:120}, tDMA={min:120,rec:120}PIO modes: pio0 pio1 pio2 pio3 pio4DMA modes: mdma0 mdma1 mdma2UDMA modes: udma0 udma1 udma2 udma3 udma4 *udma5AdvancedPM=yes: mode=0x80 (128) WriteCache=enabledDrive conforms to: ATA/ATAPI-6 T13 1410D revision 3a:* signifies the current active mode
Com relação ao gerenciamento de energia, você pode ajustar o tempo de espera, ou seja, o tempo de inatividade que o sistema espera antes de colocar o HD em modo de economia de energia usando a opção "-S" seguida por um número que vai de 1 a 255.
Esta opção uma notação peculiar, onde os números de 1 a 240 indicam múltiplos de 5 segundos (1 para 5 segundos, 10 para 50 segundos e 240 para 20 minutos) e os números de 241 em diante indicam múltiplos de 30 minutos (242 indica uma hora, 244 duas horas, e assim por diante). Para um tempo de espera de 10 minutos, por exemplo, use:
# hdparm -S 120 /dev/hda
Está disponível também a opção "-y", que faz o drive entrar em modo de economia de energia imediatamente.
Uma opção menos conhecida, mas que é bastante útil em alguns HDs é o gerenciamento acústico que, quando suportado pelo HD, permite escolher entre um modo de funcionamento "silencioso", onde o HD gira a uma velocidade mais baixa, produz menos barulho e consome menos energia, ou um modo "barulhento", onde ele simplesmente funciona com o melhor desempenho possível.
Esta opção é definida usando o parâmetro "-M", seguido de um número entre 128 e 254, onde 128 é o modo silencioso e o 254 é o modo barulhento. Alguns HDs suportam números intermediários, que permitem escolher a melhor relação performance/barulho.
Para descobrir quais os valores suportados pelo seu dive, use o comando "hdparm -I" (i maiúsculo), como em:
# hdparm -I /dev/hda | grep acoustic
Recommended acoustic management value: 128, current value: 254
Para alterar a configuração, indique o valor desejado, como em:

# hdparm -M128 /dev/hda
Lembre-se de que apenas alguns HDs suportam efetivamente este recurso. Nos demais modelos, a configuração não altera nada.
O hdparm pode ser usado também para limitar a velocidade do CD-ROM, o que pode ser útil em drives muito barulhentos, ou em notebooks, onde você queira economizar energia. Para isso, use o parâmetro "-B", seguido da velocidade e o drive, como em:
# hdparm -E 8 /dev/hdc
Todas as configurações do hdparm não são persistentes. Por isso, lembre-se de incluir os comandos em algum dos arquivos de inicialização, para que sejam executados durante o boot.
Recompilando o Kernel
O Kernel é o coração do sistema, o Linux em si. Todos os demais programas, incluindo até mesmo o bash, o programa que controla o prompt de comando são softwares que rodam sobre o Kernel. É ele quem cria a ponte entre os programas e o hardware.
O Kernel inclui todos os drivers de dispositivos suportados pelo sistema e até mesmo alguns programas, como o Iptables, o firewall nativo do Linux a partir do Kernel 2.4. Mesmo alguns programas "externos" como o VMware e o Qemu (com o módulo Kqemu) utilizam um módulo no Kernel para ter acesso direto ao hardware e assim rodar com um melhor desempenho.
Para manter a compatibilidade com o maior número possível de dispositivos, as distribuições devem incluir também quase todos os drivers de dispositivos disponíveis para o Linux. Para evitar que isto torne o Kernel muito grande, criam um Kernel básico, com os drivers mais importantes e incluem os demais drivers como módulos. Durante a instalação, ou a rodar algum utilitário de detecção e configuração de hardware, apenas os módulos necessários são carregados.
Os módulos oferecem mais uma vantagem: podem ser carregados e descarregados conforme necessário, sem ficarem o tempo todo consumindo memória RAM e recursos do sistema. Uma distribuição típica, com o Kernel 2.6, inclui uma pasta de módulos com cerca de 50 MB, com pouco mais de mil módulos diferentes. Mas, em geral, apenas 15 ou 20 deles ficam carregados durante o uso.
Recompilar o Kernel lhe dá a chance de criar um Kernel adaptado às suas necessidades, ao contrário do tamanho único incluído nas distribuições. Você vai precisar recompilar o Kernel caso precise adicionar o suporte a algum dispositivo, cujo driver só está disponível na versão mais recente. USB 2.0? Wireless? Bluetooth? Estas tecnologias já eram suportadas pelo Linux bem antes dos primeiros produtos chegarem ao mercado, mas quem possui uma versão antiga do Kernel precisa atualizá-lo para adicionar o suporte.

É possível adicionar também patches com recursos experimentais, ainda não incluídos no Kernel oficial, incluindo novos drivers, suporte a novos sistemas de arquivos (como o suporte ao módulo Cloop ou UnionFS) ou melhorias de desempenho.
Felizmente, atualizar ou personalizar o Kernel é uma tarefa relativamente simples, que pode se tornar até corriqueira, já que numa máquina atual, um Athlon de 2.0 GHz por exemplo, a compilação do executável principal de um Kernel da série 2.6 demora por volta de 5 minutos. Em seguida vem a compilação dos módulos, que é bem mais demorada mas não é necessária ao fazer apenas pequenas modificações no Kernel atualmente em uso.
O processo todo pode ser dividido nos seguintes passos:
1- Baixar o código fonte da versão escolhida.
2- Aplicar patches (opcional).
3- Configurar as opções desejadas, ativando ou desativando componentes e opções, o que é feito através dos comandos "make xconfig" ou "make menuconfig".
4- Compilar o executável principal do Kernel (o arquivo vmlinuz, que vai na pasta boot).
5- Compilar os módulos.
6- Instalar o novo Kernel, os módulos e configurar o lilo ou grub para utilizá-lo.
É possível manter vários Kernels instalados na mesma distribuição e escolher entre eles na hora do boot. Assim você pode manter o Kernel antigo instalado e voltar para ele em caso de problemas com o novo.
Você pode encontrar detalhes sobre as atualizações e mudanças incluídas em cada versão do Kernel no: http://wiki.kernelnewbies.org/LinuxChanges.
Baixando os fontes
O primeiro passo é naturalmente obter o código fonte do Kernel, que iremos compilar. Se você quer apenas criar um Kernel personalizado, pode usar como base o código fonte do próprio Kernel incluído na sua distribuição. Durante a instalação, quase sempre existe a opção de instalar o código fonte do Kernel (o pacote kernel-source) e os compiladores.
Você pode também instalá-los posteriormente. No Mandriva, por exemplo, use o comando:
# urpmi kernel-source
No Debian, existem várias versões diferentes do Kernel disponíveis no apt-get. Você deve primeiro checar a versão em uso, usando o comando "uname -a", e em seguida instalar o pacote correto, como em:
# apt-get install kernel-source-2.6.15

No Kurumin, Kanotix e em algumas outras distribuições, está disponível o script "install-kernel-source-vanilla.sh", desenvolvido pelo Kano, que se encarrega de baixar os fontes do Kernel atual, junto com um conjunto de patches úteis.
É sempre muito mais fácil usar como base o fonte e configuração do Kernel que está instalado na sua máquina, com todos os patches e modificações. Assim você começa com uma configuração que está funcionando e faz apenas as alterações desejadas, com uma possibilidade muito menor de surgirem problemas.
Depois de pegar um pouco de prática, você pode se aventurar a baixar uma versão "crua" da última versão do Kernel no http://www.kernel.org e fazer uma experiência começando do zero.
Salve o arquivo no diretório "/usr/src/" onde por padrão ficam armazenados os fontes do Kernel. Não se assuste, o arquivo com o fonte do Kernel é mesmo grande, quase 50 MB (compactado em .tar.gz) nas versões recentes.
Depois de baixar o pacote, você ainda precisará descompactá-lo, usando o comando:
# tar -zxvf linux-2.6.x.tar.gz
Se o arquivo tiver a extensão tar.bz2, então o comando fica:
# tar -jxvf linux-2.6.x.tar.bz2
Aproveite que está aqui para criar o link "linux", que deve apontar para a localização da pasta com o código fonte do novo Kernel:
# ln -sf linux-2.6.x linux
Em geral, ao instalar o pacote "kernel-source" incluído na distribuição, será apenas copiado o arquivo compactado para dentro da pasta "/usr/src/". Você ainda precisará descompactar e criar o link "/usr/src/linux", como ao baixar manualmente.
Na verdade o link "/usr/src/linux" é apenas uma localização padrão, usada por muitas ferramentas, assim como um discador de internet vai sempre, por padrão, tentar acessar o modem usando o device "/dev/modem". De qualquer forma, todo o trabalho de compilação será feito dentro da pasta com o fonte do Kernel, como em: /usr/src/linux-2.6.15/.
Configurando
Acesse o diretório "/usr/src/" e, dentro dele, a pasta onde está a versão do Kernel que será recompilada, como em:
# cd /usr/src/2.6.x/
Usado o ls, você vai ver as várias pastas e arquivos que formam o código do Kernel. Se você quer realmente aprender a programar em C, vai aprender bastante examinando o

código. Comece pela pasta "Documentation/", que contém muitas informações úteis sobre os componentes e módulos. Um bom livro (em Inglês) para quem quer entender melhor o funcionamento interno do Kernel é o Understanding the Linux Kernel, 3rd Edition, da ed. O'Reilly. Outra boa referência é o Linux Device Drivers, 3rd Edition, também da ed. O'Reilly, voltado para o desenvolvimento de drivers.
Com o código em mãos, o próximo passo é definir os componentes que serão incluídos no novo Kernel, usando o xconfig (gráfico) ou menuconfig (texto), duas opções de ferramentas de configuração.
O objetivo destas duas ferramentas é apenas ajudar a selecionar as opções disponíveis e gerar um arquivo de texto, o ".config", que será usado durante a compilação. Como todo arquivo de texto, ele pode ser até mesmo editado manualmente, mas isto não é muito prático num arquivo com quase 3.000 linhas :-).
Mãos à obra então:
# make xconfig

No Kernel 2.6 o "make xconfig" chama o Qconf, um utilitário bem mais amigável, criado usando a biblioteca QT. Para usá-lo, é necessário ter instalada a biblioteca de desenvolvimento do QT. No Debian Etch, instale o pacote "libqt3-mt-dev":
# apt-get install libqt3-mt-dev
Caso necessário, instale o pacote a partir do Unstable. É comum que ele fique quebrado durante as atualizações do KDE. Se estiver usando alguma distribuição baseada no antigo Debian Sarge, use o pacote "libqt3-dev".
No Kernel 2.4 o mesmo comando chama um utilitário bem mais simples, baseado na biblioteca tk:
Em qualquer um dos casos, ao recompilar o Kernel incluído na distribuição, o primeiro passo é carregar o arquivo .config com a configuração atual do Kernel. Isso evita muitos problemas, pois você começa com o Kernel configurado com exatamente as mesmas opções atualmente em uso.
Fica mais fácil localizar e corrigir problemas assim, pois você precisa se preocupar apenas com as opções que alterou.
Por padrão, o arquivo com a configuração do Kernel vai sempre na pasta /boot, como em: "/boot/config-2.6.8.14-kanotix-6" ou "/boot/config-2.6.8.1-12mdk".
No Qconf, vá em "File > Load" e aponte o arquivo:
As opções estão divididas em categorias, com uma descrição resumida de cada opção no nível mais baixo. A esmagadora maioria das opções está relacionada justamente com suporte a dispositivos.
Para cada módulo existem três opções: compilar no executável principal do Kernel (built-in, representado por um símbolo de "Ok" no no Qconf ou um "Y" no xconfig antigo), compilar como módulo (um ponto no Qconf ou um "M" no antigo) ou desativar.
Compilar o componente na forma de um módulo faz com que ele seja carregado apenas quando necessário, sem inchar o Kernel. Esta é a opção ideal para todos os componentes que quiser manter, mas não tem certeza se serão usados freqüentemente.
Coisas como o suporte à sua placa de rede, som, suporte a gerenciamento de energia para o seu notebook podem ser compilados diretamente no Kernel. Mas, não exagere, pois um Kernel muito grande vai demorar para ser compilado, aumentará o tempo de boot da máquina e terá um desempenho um pouco inferior. O ideal é compilar tudo o que não for essencial como módulo, como fazem as principais distribuições.
Uma ressalva importante é que você SEMPRE deve adicionar o suporte ao sistema de arquivos no qual a partição raiz do sistema está formatada (ReiserFS, EXT3, XFS, etc.) diretamente no Kernel e não como módulo, caso contrário você cria um problema do tipo o ovo e a galinha: o Kernel precisa carregar o módulo reiserfs para acessar a partição, mas precisa acessar a partição para carregar o módulo. No final das contas, você acaba com um Kernel panic.
Os módulos com o suporte aos sistemas de arquivos principais (EXT, ReiserFS, XFS, JFS, etc.) estão logo no diretório principal da seção "File systems" do Qconf.
O suporte a sistemas de arquivos menos comuns estão nos subdiretórios. Você deve compilar o suporte a ReiserFS diretamente no Kernel se a partição raiz do sistema está formatada neste sistema de arquivos, mas pode compilar como módulo se a partição raiz
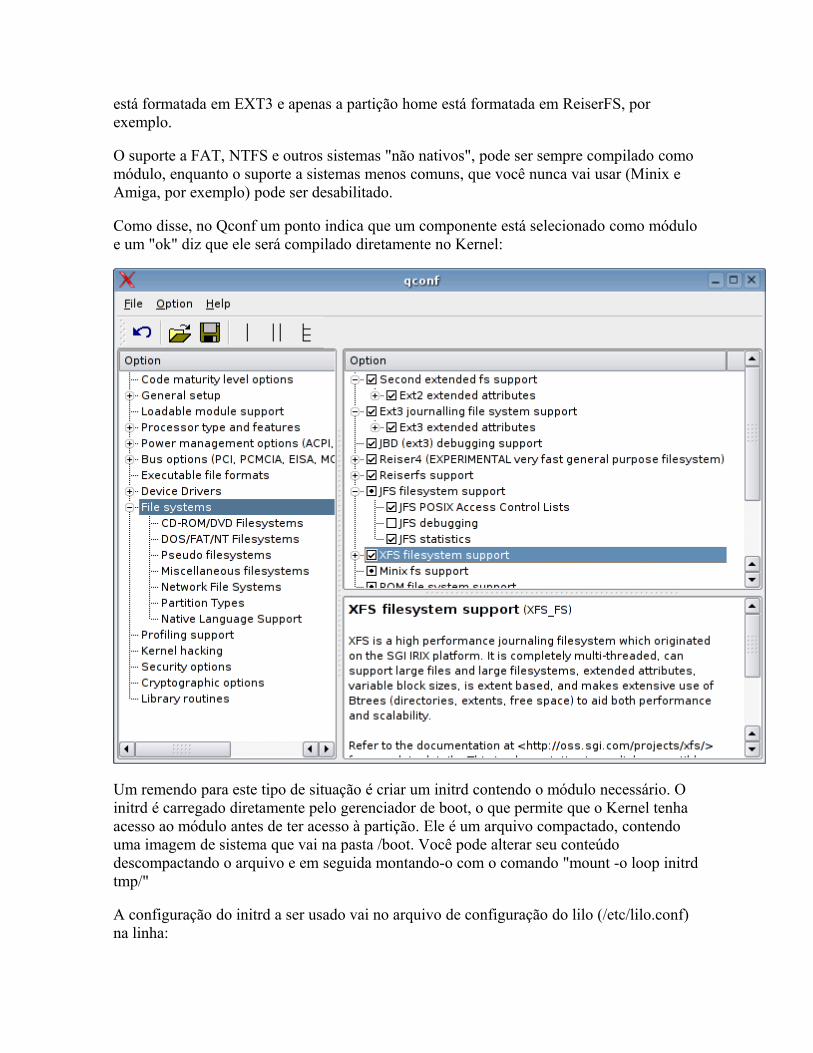
está formatada em EXT3 e apenas a partição home está formatada em ReiserFS, por exemplo.
O suporte a FAT, NTFS e outros sistemas "não nativos", pode ser sempre compilado como módulo, enquanto o suporte a sistemas menos comuns, que você nunca vai usar (Minix e Amiga, por exemplo) pode ser desabilitado.
Como disse, no Qconf um ponto indica que um componente está selecionado como módulo e um "ok" diz que ele será compilado diretamente no Kernel:
Um remendo para este tipo de situação é criar um initrd contendo o módulo necessário. O initrd é carregado diretamente pelo gerenciador de boot, o que permite que o Kernel tenha acesso ao módulo antes de ter acesso à partição. Ele é um arquivo compactado, contendo uma imagem de sistema que vai na pasta /boot. Você pode alterar seu conteúdo descompactando o arquivo e em seguida montando-o com o comando "mount -o loop initrd tmp/"
A configuração do initrd a ser usado vai no arquivo de configuração do lilo (/etc/lilo.conf) na linha:

initrd=/boot/initrd.gz
Para ativar o suporte a ACPI, por exemplo, acesse a categoria "Power management options" e ative o "ACPI Support", junto com os módulos "AC Adapter" (usado em micros desktop ou notebooks ligados na tomada) e "Battery" (que monitora o estado da bateria do notebook e ativa os recursos de economia de energia suportados).
Os outros módulos adicionam mais funções úteis: a opção "Fan" permite diminuir a rotação dos coolers, o módulo "Processor" permite diminuir a freqüência do processador para economizar energia, e assim por diante.
Quase todas as opções possuem descrições, mas é preciso ter bons conhecimentos de hardware para entender a função da maioria delas. A pasta "Documentation/", dentro da pasta com o fonte, contém descrições bem mais completas sobre a função de cada módulo. Os textos falam mais sobre os componentes e recursos suportados por cada módulo do que sobre programação, por isso os textos também são muito úteis para quem está estudando sobre hardware e suporte a dispositivos no Linux.
A opção mais importante com relação ao desempenho é indicar qual processador está sendo utilizado. Isto fará com que o Kernel seja compilado com otimizações para a arquitetura, o
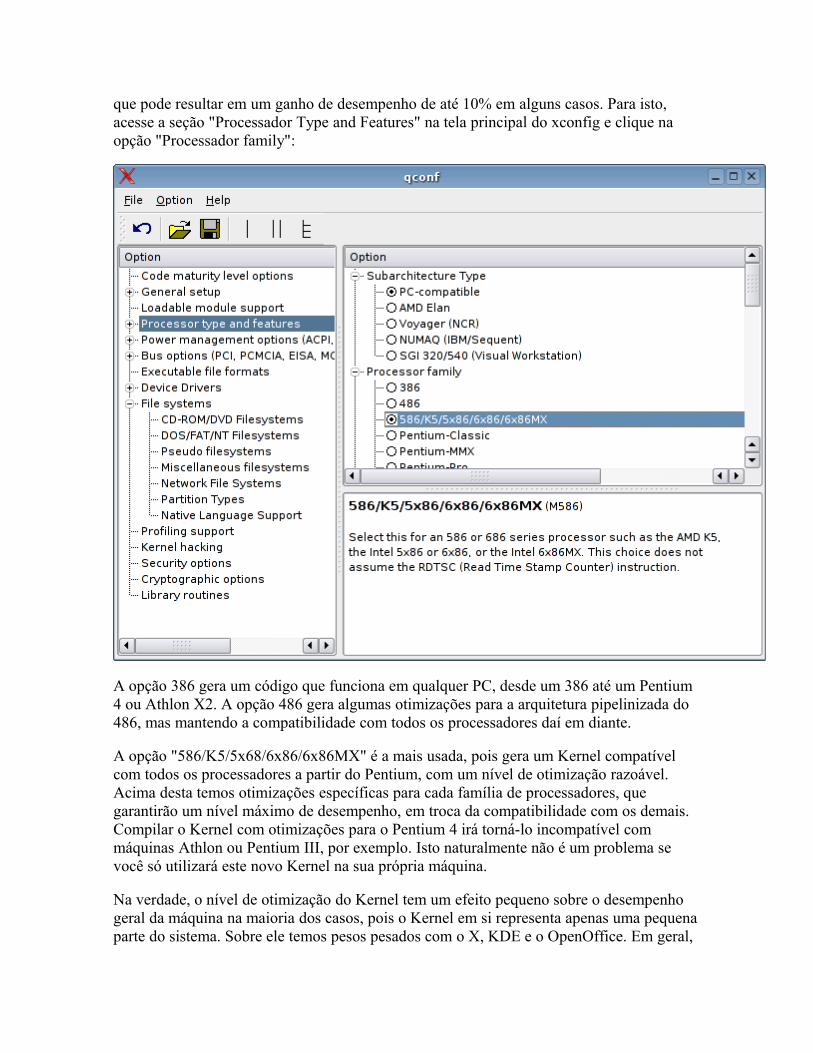
que pode resultar em um ganho de desempenho de até 10% em alguns casos. Para isto, acesse a seção "Processador Type and Features" na tela principal do xconfig e clique na opção "Processador family":
A opção 386 gera um código que funciona em qualquer PC, desde um 386 até um Pentium 4 ou Athlon X2. A opção 486 gera algumas otimizações para a arquitetura pipelinizada do 486, mas mantendo a compatibilidade com todos os processadores daí em diante.
A opção "586/K5/5x68/6x86/6x86MX" é a mais usada, pois gera um Kernel compatível com todos os processadores a partir do Pentium, com um nível de otimização razoável. Acima desta temos otimizações específicas para cada família de processadores, que garantirão um nível máximo de desempenho, em troca da compatibilidade com os demais. Compilar o Kernel com otimizações para o Pentium 4 irá torná-lo incompatível com máquinas Athlon ou Pentium III, por exemplo. Isto naturalmente não é um problema se você só utilizará este novo Kernel na sua própria máquina.
Na verdade, o nível de otimização do Kernel tem um efeito pequeno sobre o desempenho geral da máquina na maioria dos casos, pois o Kernel em si representa apenas uma pequena parte do sistema. Sobre ele temos pesos pesados com o X, KDE e o OpenOffice. Em geral,

otimizar o Kernel para o seu processador, sem mexer nos demais programas, resulta num ganho médio de apenas 2 ou 3%.
Outra opção comum é ativar o suporte a dois processadores. Esta opção é necessária caso você esteja usando um micro com dois processadores, ou um Processador Pentium 4 com HT, e queira que o sistema reconheça o segundo processador lógico.
Em troca, ativar o suporte a multiprocessamento diminui sutilmente o desempenho do sistema em máquinas com apenas um processador, pois o sistema continua com o código necessário carregado na memória. Para ativar, habilite (ainda dentro da seção "Processador Type and Features") a opção: "Symmetric multi-processing support".
Depois de terminar, clique na opção "Save and Exit" no menu principal para salvar todas as alterações.
Além do xconfig, você pode utilizar também o menuconfig, que oferece basicamente as mesmas opções, mas numa interface de modo texto. Ele serve como segunda opção caso o xconfig (que no Kernel 2.6 depende da biblioteca Qt) esteja indisponível. Para chamá-lo, use o comando:
# make menuconfig
Tanto faz utilizar o xconfig ou o menuconfig, pois os dois gravam as alterações no mesmo arquivo, o .config, dentro do diretório "/usr/src/linux". Existe ainda uma quarta opção, ainda mais espartana: o "make config", que chama um programa de modo texto que

simplesmente vai perguntando um a um quais componentes devem ser incluídos (e exige uma boa dose de paciência..:).
Compilando
Depois de configurar o novo Kernel, você pode compilar e instalar usando os quatro comandos abaixo. Lembre-se de que, para compilar qualquer programa no Linux, é necessário ter o compilador gcc instalado.
# make clean
O "make clean" serve para limpar a casa, removendo restos de compilações anteriores e módulos desnecessários. Ao recompilar um Kernel da série 2.4, é necessário rodar também o comando "make dep", que verifica a cadeia de interdependências do Kernel.
Ao executar o "make clean", todos os módulos e componentes anteriormente compilados são removidos, fazendo com que a compilação seja realmente feita a partir do zero. Se você já compilou o Kernel anteriormente e fez agora apenas uma pequena modificação (como ativar um módulo adicional), pode omitir o "make clean", de forma que os objetos gerados na compilação anterior sejam aproveitados e a compilação seja muito mais rápida.
# make bzImage
Este é o comando que compila o executável principal do Kernel, o arquivo que vai na pasta /boot. O tempo varia de acordo com a velocidade do processador, mas é sempre relativamente rápido, já que estamos falando de um executável de geralmente 1.5 ou 2 MB. Num PC atual não demora mais do que 4 ou 6 minutos.
Em máquinas com dois processadores, você pode reduzir o tempo de compilação usando a opção "-j4", que faz com que o make processe 4 módulos de cada vez, ao invés de apenas um como faria por padrão. Isto faz com que o segundo processador realmente fique ocupado, reduzindo em até 40% o tempo de compilação. Neste caso o comando fica:
# make -j4 bzImage
Este comando também pode ser utilizado em máquinas com apenas um processador (ou com um Pentium 4 com HT), mas neste caso o ganho de performance é bem menor. Geralmente você terá melhores resultados usando a opção "-j2" (apenas dois módulos por vez, ao invés de quatro).
Em versões antigas do Kernel, era usado o comando "make zImage" mas ele tem uma limitação quanto ao tamanho máximo do Kernel a ser gerado, por isso só funciona em Kernels muito antigos, da série 2.0. O "bzImage" permite gerar Kernels sem limite de tamanho.
Uma observação importante, é que, embora tradicional, o comando "make bzImage" só é usado até o Kernel 2.6.15. A partir do 2.6.16, o comando de compilação foi simplificado, já

que, por causa do limite de tamanho, não existe mais nenhum motivo para alguém gerar uma "zImage". O comando para compilar o executável do Kernel passou a ser apenas "make", como em outros programas:
# make
Ao tirar proveito da compilação paralela do make, use:
# make -j4
Em qualquer um dos dois casos, depois de compilar o executável principal, temos o:
# make modules
... que conclui o trabalho, compilando todos os componentes marcados como módulos. Numa distribuição típica, esta é a etapa mais demorada, pois quase tudo é compilado como módulo, gerando um total de 40 ou 50 MB de arquivos, o que demora proporcionalmente mais. O tempo de compilação cai bastante se você começar a desativar os módulos que não for usar. Assim como no comando anterior, você pode acrescentar o "-j4" ou "-j2" para reduzir o tempo de compilação.
Instalando
O novo Kernel será gravado no arquivo "/usr/src/linux-2.6.x/arch/i386/boot/bzImage". O próximo passo é copiá-lo para o diretório /boot e em seguida configurar o lilo para inicializar o novo Kernel ao invés do antigo. Para copiar, use o comando:
# cp /usr/src/linux-2.6.x/arch/i386/boot/bzImage /boot/novo_kernel
Substituindo sempre o "linux-2.6.x" pelo nome correto da pasta onde está o Kernel. Isso também renomeará o arquivo para "novo_kernel", que pode ser alterado para outro nome qualquer.
Além do arquivo principal, é necessário instalar também os componentes compilados como módulos, que ficam armazenados num diretório separado, na pasta /lib/modules/. Para isto, basta usar o comando:
# make modules_install
Concluindo, você deve copiar também o arquivo "System.map", que contém a imagem de sistema inicial, carregada durante o boot:
# cp /usr/src/linux-2.xx/System.map /boot/System.map
O próximo passo é configurar o lilo. Para isso, abra o arquivo "/etc/lilo.conf":
# kedit /etc/lilo.conf

Aqui estão as opções de inicialização que são dadas durante o boot. O que precisamos é adicionar uma nova opção, que inicializará o novo Kernel. Basta incluir as linhas no final do arquivo e salvá-lo:
image = /boot/novo_kernellabel = novo_kernelread-only
Ao reiniciar o sistema você verá uma nova opção no menu do lilo, justamente o "novo_kernel" que acabamos de adicionar, junto com a entrada para inicializar o Kernel antigo.
Teste o novo Kernel e quando tiver certeza de que ele está funcionando adequadamente, edite novamente o /etc/lilo.conf colocando o nome da entrada referente ao novo Kernel na opção "default". Isto fará com que ele passe a ser inicializado por default. Seu lilo.conf ficará parecido com este:
boot=/dev/hda timeout=100message=/boot/messagevga=788default= novo-kernel
image = /boot/novo-kernellabel = novo-kernelroot=/dev/hda1append="quiet noapic"read-only
image=/boot/vmlinuzlabel=linuxroot=/dev/hda1initrd=/boot/initrd.imgappend="quiet noapic"read-only
Você pode ter quantos Kernels diferentes quiser, basta salvar cada arquivo com um nome diferente e adicionar uma entrada no arquivo.
Recompilando o Kernel à moda Debian
O Debian oferece uma ferramenta chamada kernel-package que facilita bastante a recompilação do Kernel. Ele cuida de todo o processo de compilação e no final gera um arquivo .deb com o novo Kernel, que pode ser rapidamente instalado usando o comando "dpkg -i" e, inclusive, instalado em outros micros.
Como de praxe, o primeiro passo é acessar a pasta com os fontes do Kernel. O que muda são os comandos executados dentro dela. Ao invés do "make bzImage", "make modules" e "make modules_install", todo o restante do processo é automatizado por dois comandos:
# make-kpkg clean# make-kpkg kernel_image

No final do processo será gerado um arquivo "kernel-image" dentro da pasta "/usr/src" com o novo Kernel, como em "/usr/src/kernel-image-2.6.15_10.00.Custom_i386.deb".
Este pacote contém a imagem completa, incluindo o arquivo vmlinuz que vai na pasta /boot, módulos e um script de instalação (executado ao instalar o pacote) que automatiza a instalação.
O processo de compilação de um Kernel da série 2.6 com uma configuração típica demora em média 45 minutos num Sempron 2200. Por isso, tenha paciência. Você pode ir fazendo outras coisas enquanto isso.
Caso a compilação termine em uma mensagem de erro, experimente começar novamente, desativando o módulo que deu problemas. Erros de compilação também podem ser causados por erros de hardware. No Kurumin rode o stress-test (encontrado no Kurumin em Iniciar > Sistema) ou outro teste de hardware para verificar se a sua máquina está estável.
Você pode instalar o pacote gerado rodando o dpkg -i, como em:
# dpkg -i /usr/src/kernel-image-2.6.15_10.00.Custom_i386.deb
Durante a instalação existe uma pegadinha. O instalador pergunta "Do You Whant to stop Now? (Y/n)". O "Y" é o default, então se você simplesmente pressionar Enter sem ler, a instalação será abortada. Para continuar você precisa digitar "n" e dar Enter. Leia as outras perguntas com atenção.
Se você quer que sejam gerados também pacotes com o fonte e os headers do Kernel, use o comando:
# make-kpkg kernel_image kernel_source kernel_headers
Neste caso, serão gerados três pacotes no total, contendo o "kit completo" do Kernel gerado. Isto vai ser muito útil se você pretende distribuir o Kernel o instalá-lo em várias máquinas.
O pacote com o fonte permite que outras pessoas recompilem o seu Kernel, fazendo alterações, enquanto os headers são necessários para instalar drivers de softmodems, os drivers 3D da nVidia e outros drivers proprietários.
Aplicando patches
Os patches são muitas vezes o principal motivo para recompilar o Kernel. Muitos novos recursos demoram a ser incluídos no Kernel oficial e, enquanto isso (muitas vezes durante vários anos), ficam disponíveis apenas através de patches.
Como exemplo podemos citar o Xen, o Freeswan (VPN), o Bootsplash (boot gráfico) e o OpenMosix (Cluster) entre muitos outros. Lendo muitos howtos você verá a necessidade de instalar patches diversos no Kernel para utilizar várias soluções.

Em muitos casos, recursos incluídos em novas versões do Kernel (o lowlatency e o preempt, adicionados no Kernel 2.6, para melhorar as respostas do sistema) são disponibilizados como backports para versões anteriores do Kernel, novamente primeiro na forma de patches.
Para aplicar um patch, comece descompactando o arquivo baixado. Geralmente os patches possuem a extensão ".patch", mas isso não é uma regra. Muitos patches podem ser baixados diretamente pelo apt-get. Digite "apt-get install kernel-patch" e pressione a tecla TAB duas vezes para ver todas as opções disponíveis.
Como exemplo, vou mostrar como instalar os patches do xen, bluez e debianlogo numa versão recente do Kernel 2.6. Este último altera o tux que aparece durante o boot pelo logo do Debian, apenas para você ter certeza que o novo Kernel foi realmente compilado com os patches. Para instalar os três pelo apt-get, use os comandos:
# apt-get install kernel-patch-xen# apt-get install kernel-patch-2.6-bluez # apt-get install kernel-patch-debianlogo
Todos os patches instalados pelo apt-get vão para a pasta "/usr/src/kernel-paches". Em geral, são instalados vários arquivos compactados, com versões específicas do patch para várias versões do Kernel. Descompacte apenas o arquivo que mais se aproxima da versão do Kernel que você está compilando, como em:
$ cd /usr/src/kernel-patches/diffs/debianlogo# gunzip debian-logo-2.6.2.gz
Para aplicar o patch descompactado, acesse a pasta onde estão os sources do Kernel, como em:
$ cd /usr/src/kernel-source-2.6.16/
O próximo passo é aplicar o patch usando o comando patch -p1 < localização_do_patch, como em:
# patch -p1 < /usr/src/kernel-patches/diffs/debianlogo/debian-logo-2.6.2
Note que este comando deve ser usado apenas dentro da pasta com os sources do Kernel. Depois de aplicar todos os patches, siga o procedimento normal para gerar o novo Kernel:
# make xconfig# make-kpkg clean# make-kpkg kernel_image
Um bom lugar para se manter informado sobre as novidades relacionadas ao desenvolvimento do Kernel, novos patches, etc. é o http://kerneltrap.org.

Criando patches
Os patches são largamente usados não apenas no desenvolvimento do Kernel, mas em praticamente todos os projetos open-source. Um patch nada mais é do que um arquivo de texto contendo as diferenças entre dois arquivos, uma forma prática de enviar correções e modificações para os mantenedores dos projetos.
Por serem pequenos, os patches podem ser facilmente enviados via e-mail e são fáceis de auditar, pois permitem verificar as poucas linhas alteradas, ao invés de checar o código fonte completo. Enviar um patch pode ser a única forma de ter sua correção ou melhoria aceita.
Vamos a um exemplo rápido de como criar um patch para um shell script simples, que instala o Acrobat Reader no Debian:
apt-get install acroread apt-get install mozilla-acroreadln -sf /usr/lib/Adobe/Acrobat7.0/browser/intellinux/nppdf.so \/usr/lib/firefox/plugins/nppdf.so
Imagine que o script faz parte de um programam maior, que está localizado na pasta "programa/", dentro do seu diretório home, junto com outros arquivos. O arquivo do script por coincidência se chama "script".
O script original não está funcionando corretamente e você descobriu que o programa são dois erros simples nas localizações das pastas. Depois das modificações, o script ficou:
apt-get install acroread apt-get install mozilla-acroreadln -sf /usr/lib/Adobe/Acrobat7.0/Browser/intellinux/nppdf.so \/usr/lib/mozilla-firefox/plugins/nppdf.so
Você precisa agora gerar um patch e enviá-lo para o mantenedor do programa, para que ele possa aplicar sua correção. Para isso, você vai precisar de duas pastas, uma contendo o código fonte do programa original e outra contendo o código fonte depois de suas alterações. Não importa se você alterou apenas um arquivo ou se fez alterações em vários. O patch conterá todas as diferenças entre as duas pastas.
Imagine que a pasta original se chama "programa" e a pasta com as modificações se chama "programa-mod". O comando para gerar o patch seria:
$ diff -uNr programa programa-mod/
diff -uNr programa/script programa-mod/script--- programa/script 2005-08-09 11:38:55.000000000 -0300+++ programa-mod/script 2005-08-09 11:38:47.000000000 -0300@@ -1,4 +1,4 @@apt-get install acroreadapt-get install mozilla-acroread-ln -sf /usr/lib/Adobe/Acrobat7.0/browser/intellinux/nppdf.so \-/usr/lib/firefox/plugins/nppdf.so

+ln -sf /usr/lib/Adobe/Acrobat7.0/Browser/intellinux/nppdf.so \+/usr/lib/mozilla-firefox/plugins/nppdf.so
Veja que ele devolve as diferenças diretamente na tela. Para que ele gere o patch, direcione a saída do comando para um arquivo:
$ diff -uNr programa programa-mod/ > patch
É isso aí :). Seu primeiro patch está pronto, espero que seja o primeiro de muitos outros. Basta enviá-lo por e-mail para o mantenedor do programa, explicando o que foi feito.
Para aplicar seu patch, o mantenedor acessaria a pasta com o fonte do programa (a pasta programa/ no exemplo) e, dentro dela, usaria o comando:
$ patch -p1 < /algum_lugar/patch
Neste caso usei como exemplo um shell script, mas os patches podem ser criados a partir de código fonte em qualquer linguagem, ou até mesmo a partir de arquivos binários.
Acelerando a compilação com o distcc
Mais uma dica é que você pode utilizar outros micros da rede para reduzir o tempo de compilação utilizando o distcc. Ele permite que os jobs da compilação (criados usando a opção -j) sejam processados por diferentes PCs da rede, reduzindo o tempo de compilação quase que proporcionalmente. Com 5 micros de configuração similar, a compilação é realizada em aproximadamente 1/4 do tempo. Ele é usado pelos desenvolvedores de muitos projetos para diminuir o tempo perdido com cada compilação e assim acelerar o desenvolvimento, sobretudo nas fases de teste.
Para usar o distcc não é necessário que todos os micros possuam configuração similar, nem que estejam rodando a mesma distribuição. É recomendável apenas que sejam sempre utilizadas versões similares do distcc em todos, para evitar problemas inesperados.
Ele está disponível na maioria das distribuições. Procure pelo pacote "distcc". Nas distribuições derivadas do Debian ele pode ser instalado através do apt-get:
# apt-get install distcc
Naturalmente, você deve instalá-lo em todas as máquinas que serão usadas. Como medida de segurança, mesmo depois de instalado ele fica explicitamente desabilitado no arquivo "/etc/default/distcc". Para ativar, edite o arquivo e mude a opção "STARTDISTCC="false" para:
STARTDISTCC="true"
A seguir, na opção "ALLOWEDNETS" você deve especificar quais micros poderão usar o servidor, especificando diretamente o IP ou nome de cada um, ou autorizando diretamente toda a faixa de endereços da rede local, como em:

ALLOWEDNETS="192.168.1.0/24"
Concluída a configuração, reinicie o serviço, em todas as máquinas:
# /etc/init.d/distcc restart
A grosso modo, o distcc trabalha enviando trechos de código para as demais máquinas da rede, juntamente com os parâmetros de compilação necessários e recebe de volta os binários já compilados. Apenas o seu micro precisa ter o código fonte do que está sendo compilado, mas todas as máquinas que forem usadas precisam ter os compiladores necessários para compilá-lo. Ao instalar o sistema em cada máquina, aproveite para sempre habilitar a categoria de desenvolvimento na seleção dos pacotes. É desejável também que, mesmo que sejam usadas distribuições diferentes, todas as máquinas tenham instaladas versões idênticas ou pelo menos similares do gcc e g++.
Na hora de compilar, comece criando a variável "DISTCC_HOSTS" no shell, que especifica quais máquinas da rede serão utilizadas pelo distcc durante a compilação, como em:
$ export DISTCC_HOSTS='127.0.0.1 192.168.1.33 192.168.1.100 192.168.1.156'
Se preferir, você pode tornar esta configuração permanente, salvando a lista dentro do arquivo ".distcc/hosts", no diretório home do usuário usado nas compilações. Depois de criar a pasta .distcc, você pode usar o comando:
$ echo '127.0.0.1 192.168.1.33 192.168.1.100 192.168.1.156' > ~/.distcc/hosts
Depois de criada a lista com os hosts, você pode compilar da forma usual, adicionando os parâmetros "-jX CC=distcc" depois do "make", onde o X é o número de jobs simultâneos que serão criados. Ao usar o distcc, uma regra geral é usar 3 jobs por processador, por máquina. Com 4 máquinas monoprocessadas, -j12 é um bom número. Em algumas situações, usar um número maior de jobs pode reduzir um pouco o tempo de compilação e em outras vai simplesmente retardar o processo.
No caso da compilação do Kernel, os comandos seriam:
$ make -j12 CC=distcc bzImage (make -j12 CC=distcc no Kernel 2.6.16, em diante)
$ make -j12 CC=distcc modules # make modules install
Note que não usei o distcc no "make modules install", pois ele não envolve compilação, apenas a instalação dos módulos gerados no comando anterior. O mais correto é sempre fazer compilações usando um login de usuário e usar o root apenas para rodar os comandos de instalação. Para fazer isso, é necessário que a conta de usuário tenha sempre permissão de acesso completa à pasta com o código fonte. Se você está compilando o Kernel, e o

fonte está na pasta "/usr/src/linux/2.6.15/" (que originalmente pertence ao root), você pode pode usar o comando:
# chown -R joao.joao /usr/src/linux/2.6.15/
... para transferir a posse da pasta para o usuário joao, grupo joao, de forma que ele possa fazer a compilação sem enfrentar problemas de permissão.
Criando pacotes a partir dos fontes com o checkinstall
Todas as distribuições incluem um conjunto generoso de pacotes, seja diretamente nos CDs de instalação, seja em repositórios disponíveis via web. Os repositórios oficiais do Debian, por exemplo, combinados com o repositório non-free e mais alguns repositórios não oficiais, podem facilmente oferecer mais de 22.000 pacotes diferentes.
Mesmo assim, muitos drivers e softwares não estão disponíveis nos repositórios e precisam ser instalados manualmente a partir do código fonte. O checkinstall facilita esta tarefa, principalmente se você precisa instalar o mesmo software em várias máquinas ou quer distribuí-lo para amigos, gerando um pacote .deb, .tgz ou .rpm com o software pré-compilado, que pode ser rapidamente instalado usando o gerenciador de pacotes.
Para usá-lo, comece instalando o pacote através do gerenciador de pacotes disponível. Ele é um pacote bastante comum, que vem incluído em todas as principais distribuições. No Debian você pode instalá-lo pelo apt-get:
# apt-get install checkinstall
O funcionamento do checkinstall é simples. Ao instalar qualquer pacote a partir do código fonte, substitua o comando "make install" pelo comando apropriado do checkinstall. Onde:
# checkinstall -D(gera um pacote .deb, para distribuições derivadas do Debian)
# checkinstall -R(gera um pacote .rpm, que pode ser usado em distribuições derivadas do Red Hat)
# checkinstall -S(gera um pacote .tgz, para o Slackware)
Por exemplo, para gerar um pacote .deb, contendo os módulos e utilitários do driver para modems 537EP, disponível no http://linmodems.technion.ac.il/packages/, os comandos seriam:
$ tar -zxvf intel-537EP-2.60.80.0.tgz $ cd intel-537EP-2.60.80.0/$ make clean

$ make 537# checkinstall -D
O checkinstall deve ser sempre executado como root. Ele vai gerar o pacote, salvando-o no diretório a partir de onde foi chamado (/home/kurumin/intel-537EP-2.60.80.0/intel-537ep-2.60.80.0_2.60.80.0-1_i386.deb no meu caso) e em seguida instalá-lo na sua máquina.
Durante a geração do pacote, ele fará algumas perguntas, a fim de gerar o arquivo de controle que contém informações como o mantenedor do pacote (você no caso), uma descrição do pacote (um texto de poucas linhas explicando o que ele faz) e a versão.
Ao gerar seus próprios pacotes, você pode ter problemas de instalação, caso seu pacote inclua algum arquivo que também exista em outro pacote já instalado no sistema, gerando erros como:
(Lendo banco de dados ... 68608 arquivos e diretórios atualmente instalados.)Descompactando intel-537ep-2.60.80.0 (de .../intel-537ep-2.60.80.0_2.60.80.0-1_i386.deb) ...dpkg: erro processando /home/kurumin/intel-537EP-2.60.80.0/intel-537ep-2.60.80.0_2.60.80.0-1_i386.deb (--install):tentando sobrescrever `/lib/modules/2.6.8.1-kanotix-10/modules.usbmap', que também está no pacote qemudpkg-deb: subprocesso paste morto por sinal (Broken pipe)
Erros foram encontrados durante processamento de:/home/kurumin/intel-537EP-2.60.80.0/intel-537ep-2.60.80.0_2.60.80.0-1_i386.deb
Nestes casos você pode modificar o pacote, para não incluir o arquivo, desinstalar o outro pacote com quem ele conflita (o qemu no caso) ou, caso perceba que é um problema benigno, que não trará maiores conseqüências, forçar a instalação do seu pacote, para que ele subscreva o arquivo usado por outro.
No caso de um pacote .deb, o comando para forçar a instalação seria:
# dpkg -i --force-all pacote.deb
No caso de um pacote do .rpm, o comando seria:
# rpm -iv --replacefiles pacote.rpmou: # rpm -iv --force pacote.rpm
No Slackware não existe a necessidade de forçar a instalação de pacotes, pois o gerenciador não checa dependências ou arquivos duplicados, deixando que você faça o que bem entender. Isto é ao mesmo tempo uma vantagem (você pode fazer o que quiser) e uma grande desvantagem (você pode destruir o sistema se não souber o que está fazendo).
Existem ainda algumas limitações gerais com pacotes pré-compilados, que você deve levar em consideração:

Em primeiro lugar, o pacote gerado foi compilado para a sua máquina e para a distribuição atualmente em uso. Não existe garantia que o mesmo pacote vai funcionar para distribuições diferentes, mesmo que elas utilizem o mesmo padrão de pacotes.
No caso de pacotes contendo drivers, como o driver para modems 537EP que usei no exemplo, é gerado um módulo pré-compilado, que vai funcionar apenas em distribuições que utilizem a mesma versão do Kernel. Ou seja, basicamente apenas na mesma versão da mesma distribuição que você está usando. Não adianta compilar um pacote no Mandriva 2006 e esperar que ele funcione no Slackware 10.2, por exemplo. Você pode ver mais detalhes sobre a instalação de drivers no Linux no capítulo 3 deste livro.

Escrevendo scripts de backup
Durante a década de 70, vários utilitários foram desenvolvidos para fazer backup de arquivos armazenados em servidores Linux. Os computadores da época eram muito limitados, por isso os utilitários precisavam ser simples e eficientes, e deveriam existir meios de agendar os backups para horários de pouco uso das máquinas.
Sugiram então utilitários como o tar e o gzip e mais tarde ferramentas como o rsync. Estes utilitários eram tão eficientes que continuaram sendo usados ao longo do tempo. Por incrível que possa parecer, são usados sem grandes modificações até os dias hoje.
Naturalmente, existem muitos utilitários amigáveis de backup, como o Amanda (para servidores) e o Konserve (um utilitário mais simples, voltado para usuários domésticos). Mas, internamente, eles continuam utilizando como base o o dump, tar, gzip e outros trigenários.
Mais incrível ainda, é que estes utilitários possuem uma penetração relativamente pequena. A maior parte dos backups ainda é feita através de scripts personalizados, escritos pelo próprio administrador. E, novamente, estes scripts utilizam o tar, gzip, rsync e outros.
É justamente sobre estes scripts personalizados que vou falar aqui. Vamos começar com alguns exemplos simples:
Para compactar o conteúdo de uma pasta, usamos o tar combinado com o gzip ou bzip2. O tar agrupa os arquivos e o gzip os compacta. Os arquivos compactados com o gzip usam por padrão a extensão "tar.gz", enquanto os compactados com o bzip2 usam a extensão "tar.bz2". O bzip2 é mais eficiente, chega a obter 10% ou mais de compressão adicional, mas em compensação é bem mais pesado: demora cerca de 3 vezes mais para compactar os mesmos arquivos. Você escolhe entre um e outro de acordo com a tarefa.
O comando para compactar uma parta é similar ao "tar -zxvf" que usamos para descompactar arquivos. Para compactar a pasta "arquivos/", criando o arquivo "arquivos.tar.gz", o comando seria:
$ tar -zcvf arquivos.tar.gz arquivos/
O "c" indica que o tar deve criar um novo arquivo e o "v" faz com que exiba informações na tela enquanto trabalha. Se preferir comprimir em bz2, muda apenas a primeira letra; ao invés de "z" usamos "j":
$ tar -jcvf arquivos.tar.bz2 arquivos/
Estes comandos seriam ideais para fazer um backup completo, de uma ou várias pastas do sistema, gerando um arquivo compactado que poderia ser armazenado num HD externo, gravado num DVD ou mesmo transferido via rede para outro servidor.

Imagine agora um outro cenário, onde você precisa fazer backup dos arquivos de uma pasta de trabalho diariamente. Os arquivos gerados não são muito grandes e você tem muito espaço disponível, mas é necessário que os backups diários feitos em arquivos separados e sejam guardados por um certo período, de forma que seja possível recuperar um arquivo qualquer a partir da data.
Ao invés de ficar renomeando os arquivos, você poderia usar um pequeno script para que os arquivos fossem gerados já com a data e hora incluída no nome do arquivo:
DATA=`date +%Y-%m-%d-%H.%M.%S`cd /mnt/backup tar -zcvf trabalho-"$DATA".tar.gz /mnt/hda6/trabalho/
A primeira linha do script cria uma variável "DATA", contendo o resultado do comando "date +%Y-%m-%d-%H.%M.%S". O comando date retorna a data e hora atual, como em "Sex Set 16 12:36:06 BRST 2005". A saída padrão dele não é muito adequada para usar em nomes de arquivos, por isso usamos as opções para alterar o formato de saída, de modo que o resultado seja "2005-09-16-12.37" (ano, mês, dia, hora, minuto, segundo). Usamos este valor no nome do arquivo com o backup, de forma que, cada vez que você chame o script, seja gerado um arquivo com a data e hora em que foi gerado, sem a possibilidade de dois arquivos saírem com o mesmo nome.
O próximo passo é fazer com que este script de backup seja executado diariamente de forma automática, o que pode ser feito usando o cron.
Em primeiro lugar, salve os comandos num arquivo de texto, que vamos chamar de "backup.sh" e transforme-o num executável usando o comando "chmod +x backup.sh".
Para que ele seja executado automaticamente todos os dias, copie-o para dentro da pasta "/etc/cron.daily" e certifique-se de que o serviço "cron" esteja ativo:
# cp -a backup-sh /etc/cron.daily# /etc/init.d/cron start
Se preferir que o script seja executado apenas uma vez por semana, ou mesmo uma vez por hora, use as pastas "/etc/cron.weekly" ou a "/etc/cron.hourly". Por padrão, os scripts dentro da pasta "/etc/cron.daily" são executados pouco depois das 6 da manhã (o horário exato varia de acordo com a distribuição). Para alterar o horário, edite o arquivo "/etc/crontab", alterando a linha:
25 6 * * * root test -x /usr/sbin/anacron || run-parts --report /etc/cron.daily
O "25 6" indica o minuto e a hora. Se quiser que o script seja executado às 11 da noite, por exemplo, mude para "00 23".
Neste exemplo usei a pasta "/mnt/backup" para salvar os arquivos. Esta pasta pode ser o ponto de montagem de um HD externo ou de um compartilhamento de rede por exemplo. O seu script pode conter os comandos necessários para montar e desmontar a pasta automaticamente.

Imagine, por exemplo, que o backup é sempre feito na primeira partição de um HD externo, ligado na porta USB, que é sempre detectada pelo sistema como "/dev/sda1". O script deve ser capaz de montar a partição, gravar o arquivo de backup e depois desmontá-la. Se por acaso o HD não estiver plugado, o script deve abortar o procedimento. Para isso precisamos verificar se o HD realmente foi montado depois de executar o comando "mount /dev/sda1 /mnt/sda1". Existem muitas formas de fazer isso, uma simples é simplesmente filtrar a saída do comando "mount" (que mostra todos os dispositivos montados) usando o grep para ver se o "/mnt/sda1" aparece na lista. Se não estiver, o script termina, caso esteja, ele continua, executando os comandos de backup:
mount /dev/sda1 /mnt/sda1montado=`mount | grep /mnt/sda1`
if [ -z "$montado" ]; thenexit 1else DATA=`date +%Y-%m-%d-%H.%M`cd /mnt/backup tar -zcvf trabalho-"$DATA".tar.gz /mnt/hda6/trabalho/umount /mnt/sda1fi
A partir daí, sempre que você deixar o HD externo plugado no final do expediente, o backup é feito e estará pronto no outro dia. Se esquecer de plugar o HD num dia, o script percebe e não faz nada.
Se preferir que o script grave o backup num DVD, ao invés de simplesmente salvar numa pasta, você pode usar o "growisofs" para gravá-lo no DVD. Neste caso, vamos gerar o arquivo numa pasta temporária e deletá-lo depois da gravação:
DATA=`date +%Y-%m-%d-%H.%M`rm -rf /tmp/backup; mkdir /tmp/backup; cd /tmp/backuptar -zcvf trabalho-"$DATA".tar.gz /mnt/hda6/trabalho/growisofs -speed=2 -Z /dev/dvd -R -J /tmp/backup/trabalho-"$DATA".tar.gzrm -rf /tmp/backup
O "-speed=2" permite que você especifique a velocidade de gravação do DVD, enquanto o "-Z" cria uma nova seção. É possível usar o mesmo disco para gravar vários backups (se o espaço permitir) usando a opção "-M" a partir da segunda gravação, que adiciona novas seções no DVD, até que o espaço se acabe.
O "/dev/dvd" indica o dispositivo do drive de DVD. A maioria das distribuições cria o link /dev/dvd apontando para o dispositivo correto, mas, em caso de problemas, você pode indicar diretamente o dispositivo correto, como, por exemplo, "/dev/hdc". As opções "-R -J" adicionam suporte às extensões RockRidge e Joilet.
Se o cron for configurado para executar o script todos os dias, você só precisará se preocupar em deixar o DVD no drive antes de sair.
Se preferir fazer os backups em CDR ("em que século você vive?" ;), crie uma imagem ISO usando o mkisofs e em seguida grave-a no CD usando o cdrecord, como em:

mkisofs -r -J -o trabalho.iso /tmp/backup/trabalho-"$DATA".tar.gzcdrecord dev=/dev/hdc trabalho.iso
Este comando do cdrecord funciona em distribuições recentes, que utilizam o Kernel 2.6 em diante (com o módulo ide-cd). No Kernel 2.4, era usada emulação SCSI para acessar o gravador de CD, fazendo com que ele fosse visto e acessado pelo sistema como se fosse um gravador SCSI. Neste caso, o comando de gravação seria "cdrecord dev=0,0,0 -data trabalho.iso", onde o "0,0,0" é o dispositivo do gravador, que você descobre através do comando "cdrecord -scanbus".
Outro grande aliado na hora de programar backups é o rsync. Ele permite sincronizar o conteúdo de duas pastas, transferindo apenas as modificações. Ele não trabalha apenas comparando arquivo por arquivo, mas também comparando o conteúdo de cada um. Se apenas uma pequena parte do arquivo foi alterada, o rsync transferirá apenas ela, sem copiar novamente todo o arquivo.
Ele é uma forma simples de fazer backups incrementais, de grandes quantidades de arquivos, ou mesmo partições inteiras, mantendo uma única cópia atualizada de tudo num HD externo ou num servidor remoto. Este backup incremental pode ser atualizado todo dia e complementado por um backup completo (para o caso de um desastre acontecer), feito uma vez por semana ou uma vez por mês.
Para instalar o rsync, procure pelo pacote "rsync" no gerenciador de pacotes. No Debian instale com um "apt-get install rsync" e no Mandriva com um "urpmi rsync".
Para fazer um backup local, basta informar a pasta de origem e a pasta de destino, para onde os arquivos serão copiados:
$ rsync -av /mnt/hda6/trabalho /mnt/backup/
A opção "-a" (archive) faz com que todas as permissões e atributos dos arquivos sejam mantidos, da mesma forma que ao criar os arquivos com o tar e o "v" (verbose) mostra o progresso na tela.
A cópia inicial vai demorar um pouco, mais do que demoraria uma cópia simples dos arquivos. Mas, a partir da segunda vez, a operação será muito mais rápida.
Note que neste comando estamos copiando a pasta "trabalho" recursivamente para dentro da "/mnt/backup", de forma que seja criada a pasta "/mnt/backup/trabalho". Adicionando uma barra, como em "/mnt/hda6/trabalho/", o rsync copiaria o conteúdo interno da pasta diretamente para dentro da "/mnt/backup".
Se algum desastre acontecer e você precisar recuperar os dados, basta inverter a ordem das pastas no comando, como em:
$ rsync -av /mnt/backup/trabalho /mnt/hda6/trabalho/

O rsync pode ser também usado remotamente. Originalmente ele não utiliza nenhum tipo de criptografia, o que faz com que ele não seja muito adequado para backups via internet. Mas este problema pode ser resolvido com a ajuda do SSH, que pode ser utilizado como meio de transporte. Não é à toa que o SSH é chamado de canivete suíço, ele realmente faz de tudo.
Neste caso o comando ficaria um pouco mais complexo:
$ rsync -av --rsh="ssh -C -l tux" /mnt/hda6/trabalho \[email protected]:/mnt/backup/
Veja que foi adicionado um parâmetro adicional, o --rsh="ssh -C -l tux", que orienta o rsync a utilizar o SSH como meio de transporte. O "-C" orienta o SSH a comprimir todos os dados (economizando banda da rede) e a se conectar ao servidor remoto usando o login tux (-l tux). Naturalmente, para que o comando funcione, é preciso que o servidor esteja com o SSH habilitado, e você tenha um login de acesso.
Em seguida vem a pasta local com os arquivos, o endereço IP (ou domínio) do servidor e a pasta (do servidor) para onde vão os arquivos.
Uma observação é que usando apenas os parâmetros "-av", o rsync apenas atualiza e grava novos arquivos na pasta do servidor, sem remover arquivos que tenham sido deletados na pasta local. Por um lado isto é bom, pois permite recuperar arquivos deletados acidentalmente, mas por outro pode causar confusão. Se você preferir que os arquivos que não existem mais sejam deletados, adicione o parâmetro "--delete", como em:
$ rsync -av --delete --rsh="ssh -C -l tux" /mnt/hda6/trabalho \[email protected]:/mnt/backup/
Para recuperar o backup, basta novamente inverter a ordem do comando, como em:
$ rsync -av --rsh="ssh -C -l tux" [email protected]:/mnt/backup/ \/mnt/hda6/trabalho
Originalmente, você vai precisar fornecer a senha de acesso ao servidor cada vez que executar o comando. Ao usar o comando dentro do script de backup, você pode gerar uma chave de autenticação, tornando o login automático. Esta opção é menos segura, pois caso alguém consiga copiar a chave (o arquivo .ssh/id_rsa dentro no home do usuário), poderá ganhar acesso ao servidor.
De qualquer forma, para usar este recurso, rode o comando "ssh-keygen -t rsa" (que gera a chave de autenticação) usando o login do usuário que executará o script de backup, deixando a passprase em branco. Em seguida, copie-o para o servidor, usando o comando:
$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]

A partir daí, o script de backup pode ser executado diretamente, através do cron, pois não será mais solicitada a senha.

Usando o autofs/automount
O suporte à montagem automática do drive de CD-ROM e disquete é usado a tempos em várias distribuições Linux. Apesar disso, muitas distribuições não trazem este recurso habilitado por default, pois automount não é o sistema mais estável do mundo. Ele trava ou se confunde com uma certa freqüência, fazendo com que seja necessário ficar forçando a montagem ou ejeção do CD manualmente.
O Kurumin é um exemplo de distribuição que não usa o automount por padrão. Nele você encontra dois ícones no Desktop para acessar o CD e ejetá-lo.
Este ícone para ejetar o CD, encontrado no Kurumin é uma solução para um problema comum. No Linux você não consegue desmontar, muito menos ejetar o CD-ROM enquanto existe algum programa acessando os arquivos. Se você esquecer uma janela do Konqueror ou uma instância do OpenOffice acessando algum arquivo do CD, você vai ficar com ele preso até se fechá-la ou reiniciar a máquina. Isto é irritante às vezes. Em muitos casos você quer simplesmente uma forma rápida de ejetar o CD, custe o que custar.
O ícone para ejetar o CD roda os comandos: "fuser -k /mnt/cdrom; umount /mnt/cdrom; eject /mnt/cdrom".
O "fuser" fecha qualquer programa que esteja acessando a pasta /mnt/cdrom, para que o CD-ROM possa ser desmontado e ejetado. É um sistema manual, mas que pelo menos funciona sempre, de uma forma previsível.
Mesmo assim, você pode ativar o suporte à montagem automática de uma forma simples na maioria dos casos.
O autofs/automount é a combinação de um módulo de Kernel e um conjunto de utilitários e arquivos de configuração, que são instalados com o pacote autofs.
Em primeiro lugar, certifique-se que o módulo "autofs" ou "autofs4" está carregado. Rode o comando "lsmod" e verifique se ele aparece na lista. Caso não esteja carregado, habilite-o com o comando "modprobe autofs4" (ou "modprobe autofs", dependendo da distribuição) e adicione a linha "autofs4" no final do arquivo "/etc/modules", para que ele seja carregado automaticamente durante o boot.
Se este módulo não estiver presente, as coisas se complicam, pois você precisaria recompilar o Kernel, instalando o patch e ativando o suporte a ele.
O próximo passo é instalar o pacote "autofs" usando o gerenciador de pacotes incluído na sua distribuição. Nas derivadas do Debian instale usando o comando:
# apt-get install autofs
No Slackware o pacote está disponível dentro da pasta "extras", disponível no segundo CD.

O autofs é configurado através do arquivo /etc/auto.master. Um exemplo de configuração para este arquivo é:
# /etc/auto.master# Linha que ativa o automount para o CD-ROM:/mnt/auto /etc/auto.misc --timeout=5
A pasta "/mnt/auto" é a pasta que será usada como ponto de montagem quando um CD-ROM for inserido. Você pode usar qualquer pasta, como "/autofs" ou "/auto", por exemplo. Porém, lembre-se de sempre usar uma pasta exclusiva, pois ao configurar o autofs para usar uma pasta com outros arquivos ou pastas dentro, eles ficarão inacessíveis até que ele seja desativado.
A opção seguinte, "/etc/auto.misc" indica um segundo arquivo, onde vão mais opções, incluindo os drives que serão monitorados. Você pode alterar o nome do arquivo, o importante é seu conteúdo. A última opção, "--timeout=5" especifica que depois de 5 segundos de inatividade o CD-ROM ou disquete é automaticamente desmontado, permitindo que você use o botão de ejetar do drive. Como disse, ele não conseguirá ejetar o CD-ROM se houver algum aplicativo acessando o CD (uma janela do gerenciador de arquivos acessando a pasta /mnt/auto/cdrom, por exemplo). Você primeiro terá que fechar tudo para depois conseguir ejetar o CD.
O arquivo "/etc/auto.misc" que estou usando no exemplo contem:
# /etc/auto.misc# Estas linhas contém as instruções necessárias para ativar o # autofs para o CD-ROM e floppy. cdrom -fstype=iso9660,ro,nosuid,nodev :/dev/cdromfloppy -fstype=auto,noatime,sync,umask=0 :/dev/fd0
Agora falta apenas iniciar o serviço do autofs:
# /etc/init.d/autofs start
O CD-ROM ficará acessível através da pasta "/mnt/auto/cdrom" e o disquete na pasta "/mnt/auto/floppy", indicadas no segundo arquivo. Lembre-se de criar a pasta "/mnt/auto" caso ela não exista.
Ao simplesmente acessar a pasta "/mnt/auto/" você não verá o "cdrom". Para acessar o CD é preciso ir direto ao ponto, acessando a pasta "/mnt/auto/cdrom" diretamente. Para facilitar isso, você pode criar um link "cdrom" dentro do diretório home, ou no desktop. Assim você clica sobre o "cdrom" e já vai direto à pasta. Para isso, use o comando:
$ ln -s /mnt/auto/cdrom ~/cdrom
Acessando dispositivos USB
Graças a todas as melhorias nas funções de detecção no próprio Kernel, além do udev, hotplug e outras ferramentas de configuração, acessar um pendrive ou instalar uma

impressora ou qualquer outro periférico USB suportado é uma tarefa simples, muitas vezes automatizada por scripts incluídos nas distribuições.
Mesmo assim, é importante entender como funciona o processo de detecção e aprender como configurar dispositivos manualmente, a fim de corrigir problemas e personalizar o sistema. Vamos em seguida ver como estes passos são automatizados através do hotplug e do udev.
onfigurando manualmente
O primeiro passo para ativar qualquer dispositivo USB no Linux, é carregar o suporte à própria controladora USB da placa-mãe. No Kernel 2.6 existem três módulos diferentes destinados a esta função. O módulo "ehci-hcd" é o mais recente, que dá suporte a controladores e dispositivos USB 2.0 em geral. Ele é o módulo usado na grande maioria dos casos.
No caso de micros antigos, que ainda utilizam controladoras USB 1.1, entram em ação os módulos "ohci-hcd" e "uhci-hcd". A diferença entre os dois é que o ohci-hcd dá suporte aos controladores usados pela Via e outros fabricantes, enquanto o uhci-hcd dá suporte aos controladores USB usados pela Intel. Em distribuições antigas, baseadas no Kernel 2.4, os módulos mudam de nome, passam a ser "usb-ohci" e "usb-uhci".
A diferença entre o USB 1.1 e o 2.0 é o brutal aumento na capacidade de transmissão. O padrão USB original foi desenvolvido como um substituto para as portas seriais, com o objetivo de conectar impressoras, teclados, mouses e similares. Com o tempo, o USB começou a ser usado para pendrives, HDs externos, placas de rede, câmeras e outros periféricos "rápidos", capazes de transmitir dados a muito mais que 12 megabits por segundo.
O USB 2.0 surgiu como um padrão "definitivo", que opera a 480 megabits (cerca de 50 MB/s reais, descontando o overhead do gerado protocolo de comunicação e pacotes de controle). Os periféricos USB 2.0 são compatíveis com placas antigas e vice-versa, mas sempre nivelando por baixo. Seu pendrive USB 1.1 vai continuar trabalhando a 12 megabits se conectado numa controladora USB 2.0.
Os três módulos são capazes de detectar os controladores a que dão suporte e por isso convivem muito bem entre si. Você pode tentar simplesmente carregar os três em seqüência, começando pelo "ehci-hcd". Ao encontrar uma controladora antiga, ou que não seja compatível, ele vai automaticamente passar o controle a um dos outros dois.
# modprobe ehci-hcd# modprobe ohci-hcd# modprobe uhci-hcd
Em seguida entra em ação o módulo "usbcore" que oferece funções genéricas, usadas por todos os dispositivos USB, incluindo chamadas de sistema para conectar ou desconectar um dispositivo, reservar banda de transmissão e outras funções.

O módulo usbcore se encarrega de detectar novos dispositivos USB conforme ele são conectados, criando uma lista dentro da pasta "/proc/bus/usb", que é utilizada por programas de detecção, como o hotplug e o udev. Caso necessário, monte-a manualmente, usando o comando:
# mount -t usbfs /proc/bus/usb /proc/bus/usb
A partir daí, você pode carregar os drivers para os dispositivos conectados:
Os módulos "usbmouse" e "usbkbd" ativam o suporte genérico a mouses e teclados USB. Existe também um módulo mais antigo, o "usbhid", que além de prover comunicação com nobreaks e alguns outros periféricos, oferece as funções básicas usadas por mouses e teclados. Completando, temos o módulo "joydev", que dá suporte a joysticks.
Caso você tenha um conversor serial/USB, use o módulo "serial". Os adaptadores USB para teclados e mouses PS/2 não precisam de drivers adicionais, mas alguns mouses PS/2 não funcionam em conjunto com eles, pois é necessário a inclusão de um circuito adicional.
Em caso de problemas com o teclado ou mouse, verifique também se a opção "USB LEGACY SUPPORT" está desativada no setup. Esta opção ativa uma camada de compatibilidade, destinada a fazer o teclado e mouse funcionarem no MS-DOS e Windows 9x, que em algumas placas faz com que o sistema deixe de detectar os dispositivos e ativar os drivers necessários durante o boot.
O módulo usbserial habilita suporte à comunicação com Palms, Pocket PCs (com o Windows CE) e outros dispositivos que transfiram dados através da porta USB, usando-a como se fosse uma porta serial. A comunicação com estes dispositivos (do ponto de vista do sistema) é feita de uma forma diferente que seria com um dispositivo de armazenamento, como um pendrive, por exemplo. O cartão de memória é visto como se fosse um HD externo, enquanto no caso do Palm a porta USB é usada como substituta para uma porta serial.
Complementando o usbserial, é geralmente necessário um segundo módulo, que habilita o dispositivo. Para fazer sincronismo com um Palm, ative o módulo "visor" e, para um Pocket PC, o módulo "ipaq". Com o módulo carregado, você pode usar um programa de sincronismo, como o Kpilot, ou o SynCE. Os outros drivers disponíveis vão na pasta "/lib/modules/2.6.x/kernel/drivers/usb/serial".
O primeiro dispositivo serial conectado aparece como o dispositivo "/dev/ttyUSB0", o segundo como "/dev/ttyUSB1" e assim por diante. Configure o programa de sincronismo para utilizar uma destas portas e tente abrir a conexão.
Uma dica é que, no caso dos Palms você precisa primeiro pressionar o botão de hotsync no Palm (o que faz com que ele seja detectado), para só depois conseguir estabelecer a conexão dentro do programa de sincronismo.
Um módulo similar é o "usblp", que ativa o suporte genérico a impressoras USB, que ficam acessíveis através dos devices "/dev/usb/lp0", "/dev/usb/lp1", etc. Para o suporte a

scanners, existe o módulo "scanner", que ativa o device "/dev/usbscanner". Um problema comum é que os dispositivos ficam por padrão disponíveis apenas para o root. Para imprimir ou usar o scanner usando um login de usuário, é preciso abrir as permissões do dispositivo, como em "chmod 666 /dev/usbscanner".
No caso das webcams, são usados os módulos "spca5xx", "stv680", "ultracam", "quickcam", "ibmcam", "konicawc", "sqcam" ou "vicam", de acordo com o modelo. O módulo "spca5xx" é o que dá suporte a maior parte dos modelos, mas ele não vem instalado por padrão em muitas distribuições. Veja como instalá-lo manualmente no capítulo sobre drivers.
Existem no mercado algumas caixas de som e headsets USB que, ao contrário das caixas e microfones ligados na placa de som, são detectados como dispositivos de áudio independentes, como se fossem uma segunda placa de som. Estes dispositivos são, de uma forma geral, bem suportados no Linux, através do módulo "snd-usb-audio", que faz parte do Alsa.
Alguns drivers mais incomuns são o "aiptek", que dá suporte a vários tablets USB, o "rt2570", que dá suporte às placas wireless USB com chipset RT2500 (Ralink) e o rtl8150, que dá suporte aos adaptadores de rede USB com o chipset de mesmo nome. Você pode encontrar uma lista com vários outros drivers incomuns no: http://www.qbik.ch/usb/devices/drivers.php.
Para acessar pendrives, HDs USB e também câmeras e outros dispositivos compatíveis com o protocolo storage, usamos o módulo "usb-storage". Ele trabalha em conjunto com o módulo "sg" (SCSI Generic), que permite que os dispositivos sejam acessados usando o driver de acesso a dispositivos SCSI. Você pode pensar no módulo usb-storage como uma espécie de adaptador, que faz com que dispositivos de armazenamento USB sejam vistos pelo sistema como HDs SCSI.
O primeiro dispositivo fica acessível como "/dev/sda", o segundo como "/dev/sdb" e assim por diante. No caso de adaptadores para cartões de diversos formatos, cada conector é visto pelo sistema como um dispositivo independente. O cartão sd pode ficar acessível através do "/dev/sdc" e o memory stick através do "/dev/sdd", por exemplo, mesmo que nenhum dos outros encaixes esteja sendo usado. Para acessar, basta montar o dispositivo correto, como em:
# mount /dev/sda1 /mnt/sda1
Uma dica é que, no Kernel 2.6, sempre que um pendrive ou cartão é detectado, é criada automaticamente uma pasta dentro do diretório "/sys/block", como em "/sys/block/sda". Dentro da pasta você encontra o arquivo "size", que contém a capacidade do dispositivo (em blocos de 512 bytes) e uma sub-pasta para cada partição, como "/sys/block/sda/sda1". No capítulo sobre shell script, veremos um exemplo de script que cria um ícone no desktop automaticamente, sempre que um pendrive é conectado, baseado justamente nestas informações.

Voltando à explicação inicial, o pendrive ou cartão pode ser particionado normalmente, através do cfdisk, gparted ou qualquer outro particionador, como se fosse realmente um HD externo.
O mais comum é que seja usada uma única partição, formatada em FAT32, o que permite que ele seja acessado tanto no Linux quanto no Windows. Mas nada impede que você formate seu pendrive em ReiserFS ou qualquer outro sistema de arquivos. Lembre-se de que você pode formatar partição usando os comandos "mkfs.ext3", "mkfs.reiserfs" ou "mkfs.vfat" (para FAT32).
Uma desvantagem é que o ReiserFS, EXT3, XFS e JFS consomem uma quantidade de espaço relativamente grande para armazenar a estrutura do sistema de arquivos, deixando menos espaço útil disponível. Eles são mais apropriados para formatar HDs e unidades de maior capacidade.
Alguns mp3players baratos utilizam um padrão de formatação chamado "superfloppy", onde o dispositivo é formatado diretamente em FAT32 (como se fosse um disquete gigante), ao invés de ser criada uma partição. Nestes casos, você acessa os arquivos diretamente pelo "/dev/sda", ao invés do "/dev/sda1".
Se você tiver a curiosidade de particionar o mp3player, criando uma partição e formatando, vai perceber que embora consiga montar e acessar os dados normalmente, o mp3player não vai mais conseguir achar os arquivos das músicas. Para voltar à formatação padrão, use o comando "mkfs.vfat -I /dev/sda" onde o "-I" (i maiúsculo) especifica o tipo de formatação.
Outra dica é que, a partir do Kernel 2.6.12 houve uma mudança importante no modo padrão de acesso a pendrives, mp3players e outros dispositivos de armazenamento USB. Para aumentar a segurança da gravação de dados, muitas distribuições montam os drives usando a opção "sync", que sincroniza a gravação dos dados, diminuindo a probabilidade de perder arquivos ao remover o pendrive sem desmontar.
O problema é que na nova versão do driver usb-storage, a opção passou à ser seguida a risca, fazendo com que a cada setor gravado, seja feita uma atualização na tabela de alocação de arquivos da partição. Isto faz com que a velocidade de gravação fique assustadoramente baixa, algo em torno de 40 kb/s nos pendrives USB 1.1 e de 200 a 300 kb/s nos 2.0.
A solução é passar a montar os pendrives usando a opção "async", se necessário via terminal, usando o comando:
# mount -o async /dev/sda1 /mnt/sda1
Além do problema da lentidão, montar os drives com a opção "sync" pode causar danos depois de algum tempo de uso, pois as freqüentes gravações aos primeiros setores (onde está a tabela de alocação) podem rapidamente exceder o limite de gravações das memórias flash mais baratas, inutilizando o pendrive, como reportado aqui: http://readlist.com/lists/vger.kernel.org/linux-kernel/22/111748.html

Note que este "problema" só afeta os Kernels recentes, a partir do 2.6.12. Você só precisa se preocupar com isso se está usando uma versão recente e está tendo o problema de lentidão ao gravar dados no pendrive que citei.
Devfs e hotplug
Podemos dividir o processo de ativação de um dispositivo no Linux em três passos: em primeiro lugar é carregado o módulo que dá suporte a ele, em seguida é criado um device (como "/dev/sda"), um arquivo especial através do qual ele é acessado e, opcionalmente, é executado algum script ou ação adicional.
Ao plugar uma webcam, seria carregado (por exemplo) o módulo "spca5xx" e criado o device "/dev/video0", através do qual os programas podem acessar a câmera. Ao plugar um pendrive seria carregado o módulo "usb-storage" e, assim por diante. Em muitos casos, é preciso carregar mais de um módulo. Para sincronizar o Kpilot com um Palm USB, por exemplo, é preciso carregar os módulos usbserial e visor.
Um device é a combinação de dois endereços de Kernel: um major number e um minor number. O major number é usado para indicar uma categoria de dispositivos, enquanto o minor number identifica o dispositivo em si. Por exemplo, o major number "180" é usado em relação a impressoras USB. A primeira impressora conectada recebe o device "/dev/usb/lp0", que é formado pela combinação do major number "180" e o minor number "1". A segunda impressora conectada recebe o device "/dev/usb/lp1", que é formado pelo major number "180" e pelo minor number "2" e assim por diante.
Tradicionalmente, o responsável por criar e manter os devices correspondentes a cada dispositivo era o devfs. Ele cumpre a função usando uma abordagem bem simples: o diretório "/dev" contém devices prontos para todos os dispositivos suportados, mesmo que poucos deles estejam realmente em uso. Os devices vão sendo atribuídos conforme novos dispositivos são ativados.
O hotplug entra em cena com a função de detectar novos dispositivos. É ele o responsável por carregar os módulos apropriados, ajustar permissões e executar tarefas diversas sempre que um novo dispositivo é conectado. Sem o hotplug, seu pendrive ainda funciona normalmente, mas você passa a ter o trabalho de ter que carregar os módulos e montar o dispositivo sempre que quiser acessá-lo; sua impressora passa a aparecer no gerenciador de impressão apenas depois que você carrega os módulos apropriados e a configura manualmente através do kaddprinterwizard (ou outro gerenciador), e assim por diante.
O hotplug surgiu originalmente como um script responsável por detectar e ativar dispositivos USB conforme eram plugados no micro. Embora tenha um funcionamento interno relativamente simples, o hotplug se mostrou bastante eficiente e passou a ser expandido para assumir a configuração de outros dispositivos. Atualmente, o hotplug não se limita a apenas pendrives, impressoras e câmeras, mas dá suporte a todo tipo de dispositivo firewire, PCMCIA, PCI e SCSI.

A partir do Kernel 2.6, o hotplug se tornou um componente padrão do sistema. Ele vem pré-instalado em qualquer distribuição que se preze. Mesmo o Slackware que é espartano em termos de ferramentas automáticas de detecção passou a incluí-lo a partir da versão 9.2. Verifique apenas se o serviço "hotplug" está ativo e, se necessário, ative-o com o comando:
# /etc/init.d/hotplug startou# /etc/rc.d/rc.hotplug start(no Slackware)
Os arquivos de configuração do hotplug estão concentrados dentro da pasta "/etc/hotplug". O hotplug trabalha com os códigos de identificação dos dispositivos, carregando módulos ou executando scripts com funções diversas sempre que dispositivos conhecidos são conectados.
Na maioria das distribuições, é incluído o arquivo "/etc/hotplug/usb.distmap", que contém uma grande quantidade de regras pré-configuradas. Você pode incluir regras adicionais usando o arquivo "/etc/hotplug/usb.usermap". A possibilidade mais interessante é executar scripts personalizados quando determinados dispositivos são plugados. Isto permite fazer desde coisas simples, como tocar um som, ou abrir um determinado programa, até incluir scripts mais complexos, que fazem backups automáticos ou outras operações complicadas. Veremos isso com mais detalhes no capítulo sobre shell script.
Outro arquivo útil dentro da configuração do hotplug é o "/etc/hotplug/blacklist", onde são especificados módulos que não devem ser carregados automaticamente pelo hotplug. Este arquivo permite solucionar problemas causados por módulos "mal comportados", que causam travamentos ou problemas diversos ao serem carregados. Isto é relativamente comum com relação a módulos proprietários, como os drivers para softmodems e para algumas placas wireless, que em muitas situações chegam a congelar o sistema caso o dispositivo a que dão suporte não esteja presente, ou ao tentarem (incorretamente) ativar um dispositivo similar, mas que não é inteiramente compatível com ele.
Um exemplo é o módulo "Intel537", que dá suporte a modems Intel Ambient. Os modems Intel Ambient "legítimos" possuem um chip DSP grande, com a marca "Ambient" decalcada. Existem muitos modems com chips Intel537AA ou 537EA (fáceis de reconhecer, pois possuem chips bem menores) que não são compatíveis com o driver. Ao tentar carregar o módulo Intel537 com um destes modems instalado, o sistema em muitos casos simplesmente trava, mesmo que o modem nem esteja em uso.
Em geral, as distribuições já vêm com o arquivo populado com vários drivers que reconhecidamente possuem problemas. No Kurumin, por exemplo, incluo os módulos dos softmodems, que podem ser carregados manualmente através dos ícones no menu:
ltmodemIntel537pctelslamr

Além dos periféricos USB, o hotplug é capaz de detectar outros tipos de dispositivos, que são configurados através de arquivos como o pci.agent, scsi.agent, tape.agent, ieee1394.agent, net.agent e wlan.agent. Todos estes arquivos são na verdade scripts, que são executados durante o boot e conforme o hotplug encontra novos dispositivos. Individualmente, os scripts são rápidos, mas executá-los em massa faz com que a inicialização das versões recentes do hotplug seja relativamente demorada, aumentando o tempo de boot da máquina. Conforme o hotplug cresce em complexidade e incorpora mais scripts, a tendência é que o tempo se torne cada vez maior.
Isso é apontado como um dos pontos negativos do hotplug em relação ao udev, que vem ganhando espaço e substituindo-o em muitas distribuições.
Entendendo o udev
Recentemente, surgiu um terceiro componente, o udev, que substitui o devfs e assume parte das funções do hotplug, com a opção de se integrar a ele, oferecendo suporte aos scripts e outras personalizações, ou substituí-lo completamente, opção adotada por muitas distribuições.
A principal vantagem do udev é que nele é possível definir devices "fixos" para cada periférico. Sua impressora pode passar a receber sempre o device "/dev/printer/epson" e seu pendrive o "/dev/pendrive", mesmo que você tenha outros dispositivos instalados. É possível também executar scripts quando eles são conectados ou removidos, criando um leque muito grande de opções.
Os devices são criados conforme os periféricos são conectados, fazendo com que o /dev contenha entrada apenas para os periféricos detectados.
No devfs, o diretório "/dev" contém devices para todo tipo de componente que é suportado pelo Kernel, resultando num número absurdo de pastas e devices dentro do diretório. Outra limitação é que os periféricos podem ser associados a devices diferentes, de acordo com a ordem em que são plugados. Digamos que você tenha um pendrive e um HD externo, ambos USB. Se você plugar o pendrive primeiro, ele será o "/dev/sda", enquanto o HD será o "/dev/sdb". Mas, se você inverter a ordem, o HD é que será o "/dev/sda". Se você tiver um HD serial ATA, então o HD será o "/dev/sda", o pendrive será o "/dev/sdb" e o HD externo será o "/dev/sdc" e, assim por diante. Essa confusão toda torna complicado fazer um script de backup ou qualquer outra coisa que dependa do pendrive estar disponível sempre no mesmo lugar.
Outra vantagem do udev é que, por ser escrito em C e ter um funcionamento interno muito mais simples, ele é também mais rápido que o hotplug, o que faz diferença em muitas situações.
A parte em que o udev e o hotplug se sobrepõem é com relação a automatização de tarefas. O hotplug suporta o uso de scripts, que são executados sempre que um dispositivo em particular, ou algum dispositivo dentro de uma categoria definida, é plugado. Estes scripts

permitem fazer com que seja criado um ícone no desktop ao plugar um pendrive, fazer com que o configurador de impressoras seja aberto quando uma nova impressora USB é conectada, entre inúmeras outras possibilidades.
O udev suporta o uso de "regras", que, entre outras coisas, também permitem o uso de scripts. Ele oferece compatibilidade com os scripts do hotplug, mas esta funcionalidade não vem ativada em todas as distribuições. De uma forma geral, o udev está sendo adotado rapidamente em todas as principais distribuições e, em distribuições que o utilizam, é mais recomendado trabalhar com regras do udev do que com scripts do hotplug. Mais adiante, no capítulo sobre shell script, veremos com mais detalhes como escrever tanto scripts para o hotplug quanto regras para o udev.
Em algumas distribuições, o udev é configurado de forma a substituir o hotplug completamente, enquanto outras optam por integrar os dois. Nestes casos, o hotplug deixa de ser um serviço separado e passa a ser iniciado juntamente com o serviço "udev":
# /etc/init.d/udev start
Uma observação é, que ao contrário do devfs e mesmo do hotplug, o udev é independente do Kernel, ele pode ser instalado, removido e atualizado rapidamente, como qualquer outro programa. Se algum periférico não estiver sendo detectado ou você estiver tendo problemas gerais, experimente atualizar o pacote "udev" a partir do repositório com atualizações para a distribuição em uso. Nas distribuições derivadas do Debian, você pode atualizá-lo via apt-get:
# apt-get install udev
Na maior parte das distribuições, você encontrará vários arquivos com regras pré-configuradas dentro do diretório "/etc/udev", destinados a executar funções previamente executadas pelo devfs, hotplug e scripts diversos. O arquivo "/etc/udev/devfs.rules", por exemplo, tem a função de criar os devices de acesso a diversos dispositivos, incluindo as portas seriais e paralelas, mouses PS/2, joysticks e muitos outros periféricos não plug-and-play.
O arquivo "/etc/udev/links.conf" permite definir devices adicionais manualmente, de forma que eles sejam recriados a cada boot. Isto é necessário pois no udev o diretório /dev é dinâmico, fazendo que dispositivos não utilizados sejam perdidos a cada reboot.
Uma configuração comum, é adicionar regras que criam os devices utilizados pelo VMware, de forma que eles não se percam ao reiniciar, como em:
M vmmon --mode 666 c 10 165M vmnet0 --mode 666 c 119 0M vmnet1 --mode 666 c 119 1M vmnet8 --mode 666 c 119 8
As regras permitem também criar links. Se você quer que seja criado o link "/dev/modem", apontando para o modem que está na porta "/dev/ttyS3", adicione:
L modem /dev/ttyS3

A as letras "L" e "M" no início das linhas indicam o tipo de dispositivo que será criado. O "L" indica que estamos falando de um dispositivo de caracteres (que incluem modems, palms e tudo que é visto pelo sistema como um dispositivo serial) e o "M" indica um dispositivo de bloco, como uma partição num HD ou pendrive, ou ainda uma interface de rede virtual, como no caso do VMware. O "--mode" indica as permissões de acesso, enquanto os dois números depois do "c" indicam o major e minor number, os mesmos endereços que são fornecidos ao criar o dispositivo manualmente usando o comando "mknod".
Renomeando interfaces de rede com o udev
Os nomes atribuídos às placas de rede no Linux sempre causarem uma certa dose de transtornos para quem utiliza duas ou mais placas, sobretudo se forem duas placas com o mesmo chipset.
Tradicionalmente, as placas de rede recebem nomes como "eth0" e "eth1", que são atribuídos conforme o sistema detecta as placas durante o boot. Isso significa que, de acordo com a distribuição usada, as placas podem trocar de posição, sem falar que é comum que os nomes troquem ao reiniciar a máquina, fazendo com que a placa eth1 passe a ser vista como eth0 e vice-versa, quebrando toda a configuração da rede.
Com a introdução do udev, as trocar de nomes ao reiniciar se tornaram ainda mais comuns. Cheguei a ver a placa wireless de um notebook Centrino trocar de nome três vezes em três reboots: primeiro eth2, depois eth1, em seguida eth0 e novamente eth1.
Antigamente, a solução para o problema era criar aliases para as placas de rede no arquivo "/etc/modules.conf", relacionando cada interface ao driver usado, como em:
alias eth0 via-rhinealias eth1 8139too
Entretanto, os aliases não ajudavam muito em casos em que eram utilizadas duas placas iguais, sem falar que esta configuração não funciona mais em distribuições recentes, que utilizam o udev. Nelas, podemos atribuir os nomes de forma muito mais confiável adicionando regras do udev.
As regras podem ser criadas com base no endereço MAC de cada placa de rede (a forma mais confiável, já que o MAC só muda ao trocar de placa), ou através do módulo usado por ela.
Você pode descobrir o endereço MAC das placas rapidamente através do comando "ifconfig". Para descobrir o módulo, você pode fazer uma pesquisa no Google, ou usar o comando "ethtool -i", como em:
# ethtool -i eth1

driver: ipw2200version: git-1.1.1firmware-version: ABG:9.0.2.6 (Mar 22 2005)bus-info: 0000:01:05.0
O ethtool não vem instalado por padrão em todas as distribuições, mas normalmente está disponível como pacote extra nos repositórios. Nas distribuições derivadas do Debian você pode instala-lo via apt-get: apt-get install ethtool.
Agora que já sabe o MAC e o driver de cada uma das placas, crie o arquivo "/etc/udev/rules.d/z99-network.rules", onde vão as regras.
Para relacionar com base no endereço MAC, adicione linhas como:
SUBSYSTEM=="net", SYSFS{address}=="00:15:00:4b:68:db", NAME="ipw0"
Para relacionar com base no módulo usado (o que só funciona ao usar duas placas diferentes), use regras como:
SUBSYSTEM=="net", DRIVER=="ipw2200", NAME="ipw0"
O udev lê todos os arquivos dentro da pasta "/etc/udev/rules.d" e processa todas as regras contidas neles. A opção SUBSYSTEM=="net" especifica que a regra só se aplica a placas de rede. Usamos em seguida a opção "SYSFS{address}==" ou "DRIVER==" para especificar a informação que permite ao sistema diferenciar a placa desejada das demais instaladas no sistema. Finalmente, a opção "NAME=" especifica o nome que passará a ser usado pela placa.
Imagine que você tem uma placa Realtek e uma SiS900. Para atribuir os nomes baseado no endereço MAC, você usaria as regras:
SUBSYSTEM=="net", SYSFS{address}=="00:E0:7D:9B:F9:04", NAME="rtl0"SUBSYSTEM=="net", SYSFS{address}=="00:11:D8:41:52:78", NAME="sis0"
Ao atribuir com base no módulo, você usaria as regras:
SUBSYSTEM=="net", DRIVER=="8139too", NAME="rtl0"SUBSYSTEM=="net", DRIVER=="sis900", NAME="sis0"
Nos exemplos, usei "ipw0", "rtl0" e "sis0" como nomes para as placas, mas você pode atribuir qualquer nome. O único porém é que algumas ferramentas de configuração de rede não encontram as placas caso elas usem nomes fora do padrão. Neste caso, você pode usar nomes mais comuns, como "eth2" e "eth3", desde que diferentes dos que as placas usavam anteriormente, para evitar situações onde o udev possa tentar atribuir o mesmo nome às duas placas.

Para que a alteração entre em vigor, é necessário recarregar os módulos das placas, ou simplesmente reiniciar o micro. Naturalmente, você precisará reconfigurar a rede, mas em compensação, só precisará fazer isso uma vez ;).

Fazendo backup e recuperando a MBR e tabela de partições
Ao comprar um novo HD, você precisa primeiro formatá-lo antes de poder instalar qualquer sistema operacional. Existem vários programas de particionamento, como o qtparted, gparted, cfdisk e outros.
Os programas de particionamento salvam o particionamento na tabela de partição, gravada no início do HD. Esta tabela contém informações sobre o tipo, endereço de início e final de cada partição. Depois do particionamento, vem a formatação de cada partição, onde você pode escolher o sistema de arquivos que será usado em cada uma (ReiserFS, EXT3, FAT, etc.).
Ao instalar o sistema operacional, é gravado mais um componente: o gerenciador de boot, responsável por carregar o sistema durante o boot.
Tanto o gerenciador de boot quanto a tabela de particionamento do HD são salvos no primeiro setor do HD, a famosa trilha MBR, que contém apenas 512 bytes. Destes, 446 bytes são reservados para o setor de boot, enquanto os outros 66 bytes guardam a tabela de partição.
Ao trocar de sistema operacional, você geralmente subscreve a MBR com um novo gerenciador de boot, mas a tabela de particionamento só é modificada ao criar ou deletar partições. Caso por qualquer motivo, os 66 bytes da tabela de particionamento sejam subscritos ou danificados, você perde acesso a todas as partições do HD. O HD fica parecendo vazio, como se tivesse sido completamente apagado.
Para evitar isso, você pode fazer um backup da trilha MBR do HD. Assim, você pode recuperar tudo caso ocorra qualquer eventualidade. Para fazer o backup, use o comando:
# dd if=/dev/hda of=backup.mbr bs=512 count=1
O comando vai fazer uma cópia dos primeiros 512 bytes do "/dev/hda" no arquivo "backup.mbr". Se o seu HD estivesse instalado na IDE secundária (como master), ele seria visto pelo sistema como "/dev/hdc". Basta indicar a localização correta no comando.
Você pode salvar o arquivo num disquete ou pendrive, mandar para a sua conta do gmail, etc. Caso no futuro, depois da enésima reinstalação do Windows XP, vírus, falha de hardware ou de um comando errado a tabela de particionamento for pro espaço, você pode dar boot com o CD do Kurumin e regravar o backup com o comando:
# dd if=backup.mbr of=/dev/hda
Lembre-se de que o backup vai armazenar a tabela de particionamento atual. Sempre que você reparticionar o HD, não se esqueça de atualizar o backup.

Usando o Gpart
Caso o pior aconteça, a tabela de particionamento seja perdida e você não tenha backup, ainda existe uma esperança. O Gpart é capaz de recuperar a tabela de partição e salvá-la de volta no HD na maioria dos casos. Você pode executá-lo dando boot pelo CD do Kurumin, ou baixá-lo no: http://www.stud.uni-hannover.de/user/76201/gpart/#download.
Baixe o "gpart.linux" que é o programa já compilado. Basta marcar a permissão de execução para ele:
# chmod +x gpart.linux
Nas distribuições derivadas do Debian, você pode instalá-lo pelo apt-get:
# apt-get install gpart
Execute o programa indicando o HD que deve ser analisado:
# ./gpart.linux /dev/hda (ou simplesmente "gpart /dev/hda" se você tiver instalado pelo apt-get)
O teste demora um pouco, pois ele precisará ler o HD inteiro para determinar onde começa e termina cada partição. No final, ele exibe um relatório com o que encontrou:
Primary partition(1)type: 007(0x07)(OS/2 HPFS, NTFS, QNX or Advanced UNIX)size: 3145mb #s(6442000) s(63-6442062)chs: (0/1/1)-(1023/15/63)d (0/1/1)-(6390/14/61)r
Primary partition(2)type: 131(0x83)(Linux ext2 filesystem)size: 478mb #s(979964) s(16739730-17719693)chs: (1023/15/63)-(1023/15/63)d (16606/14/1)-(17579/0/62)r
Primary partition(3)type: 130(0x82)(Linux swap or Solaris/x86)size: 478mb #s(979896) s(17719758-18699653)chs: (1023/15/63)-(1023/15/63)d (17579/2/1)-(18551/3/57)r
Se as informações estiverem corretas, você pode salvar a tabela no HD usando o parâmetro "-W":
# gpart -W /dev/hda /dev/hda
Veja que é preciso indicar o HD duas vezes. Na primeira você indica o HD que será vasculhado e em seguida em qual HD o resultado será salvo. Em casos especiais, onde você tenha dois HDs iguais, por exemplo, você pode gravar num segundo HD, com em: "gpart -W /dev/hda /dev/hdc".

O gpart não é muito eficiente em localizar partições extendidas (hda5, hda6, etc.). Em boa parte dos casos ele só vai conseguir identificar as partições primárias (hda1, hda2, hda3 e hda4). Nestas situações, você pode usar o cfdisk ou outro programa de particionamento para criar manualmente as demais partições (apenas crie as partições e salve, não formate!). Se você souber indicar os tamanhos aproximados, principalmente onde cada uma começa, você conseguirá acessar os dados depois.
Usando o Testdisk
Outra ferramenta "sem preço" para recuperação de partições é o Testdisk. Embora a função seja a mesma, ele utiliza um algoritmo bastante diferente para detectar partições, o que faz com que ele funcione em algumas situações em que o Gpart não detecta as partições corretamente e vice-versa. Por isso vale a pena ter ambos na caixa de ferramentas.
Lembre-se que ambos são capazes de recuperar partições apenas enquanto as informações não são subscritas. Se você acabou de apagar a sua partição de trabalho, é bem provável que consiga recuperá-la, mas se o HD já tiver sido reparticionado e formatado depois do acidente, as coisas ficam muito mais complicadas. Sempre que um acidente acontecer, pare tudo e volte a usar o HD só depois de recuperar os dados.
O Testdisk permite recuperar desde partições isoladas (incluindo as extendidas), até toda a tabela de partição, caso o HD tenha sido zerado. Ele suporta todos os principais sistemas de arquivos, incluindo FAT16, FAT32, NTFS, EXT2, EXT3, ReiserFS, XFS, LVM e Linux Raid.
A página oficial é a http://www.cgsecurity.org/testdisk.html onde, além da versão Linux, você encontra versões para Windows, DOS e até para o Solaris.
Embora não seja exatamente um utilitário famoso, o Testdisk é incluído em muitas distribuições. Nos derivados do Debian, você pode instalá-lo via apt-get:
# apt-get install testdisk
Para instalar a versão em código fonte, além dos compiladores básicos (veja mais detalhes no capítulo 3), é necessário ter instalado o pacote "ncurses-dev" ou "libncurses-dev". A instalação propriamente dita é feita usando a receita tradicional: descompactar o arquivo, acessar a pasta criada e rodar os comandos "./configure", "make" e "make install".
Vamos a um exemplo prático de como recuperar duas partições deletadas "acidentalmente". Onde o cfdisk está mostrando "Free Space" existem na verdade as partições "/dev/hda2" e "/dev/hda3", que removi previamente:
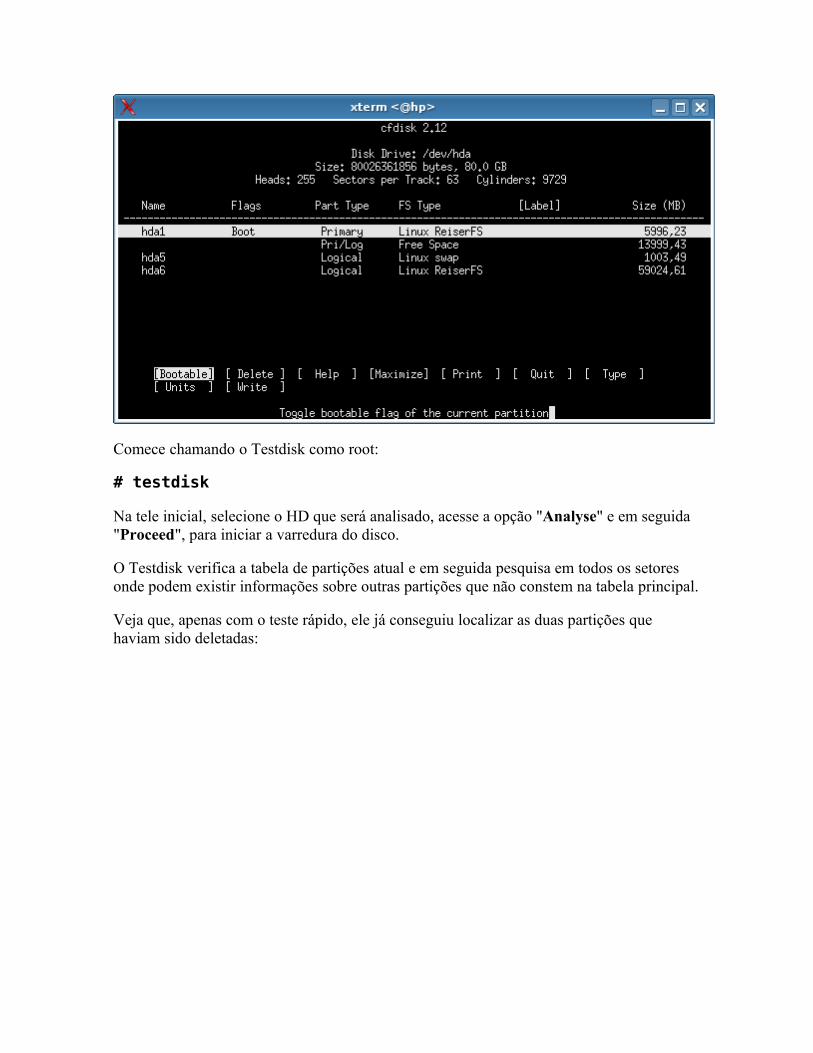
Comece chamando o Testdisk como root:
# testdisk
Na tele inicial, selecione o HD que será analisado, acesse a opção "Analyse" e em seguida "Proceed", para iniciar a varredura do disco.
O Testdisk verifica a tabela de partições atual e em seguida pesquisa em todos os setores onde podem existir informações sobre outras partições que não constem na tabela principal.
Veja que, apenas com o teste rápido, ele já conseguiu localizar as duas partições que haviam sido deletadas:

Pressionando a tecla "P" você pode ver os dados dentro da partição, para ter certeza que os arquivos estão lá (a versão disponível no apt-get não consegue mostrar arquivos dentro de partições ReiserFS, mas a recuperação funciona normalmente).
Nos raros casos onde ele localize a partição, mas identifique incorretamente o sistema de arquivos, use a opção "T" para indicar o correto.
Depois de checar se o particionamento detectado está correto, pressione "Enter" mais uma vez e você chega à tela final, onde você pode salvar as alterações, usando a opção "Write". Reinicie o micro e monte a partição para checar os dados.
Caso a lista não exiba a partição que você está procurando, use a opção "Search" no lugar do Write. Isto ativa o teste mais longo, onde ele vasculha todos os setores do HD em busca de partições deletadas. Este segundo teste demora alguns minutos e, num HD com bastante uso, pode retornar uma longa lista de partições que foram criadas e deletadas durante a vida útil do HD. Neste caso, preste atenção para recuperar a partição correta.

Todas as partições listadas aqui parecem com o atributo "D", que significa que a partição foi deletada. Para recuperar uma partição, selecione-a usando as setas para cima/baixo e use a seta para a direita para mudar o atributo para "*" (se ele for uma partição primária e bootável, como o drive C: no Windows), "P" se ela for uma partição primária ou "L" se ela for uma partição lógica. Lembre-se de que. no Linux, as partições de 1 a 4 são primárias e de 5 em diante são extendidas.
É possível também adicionar uma partição manualmente, caso você saiba os setores de início e final, mas isso raramente é necessário.
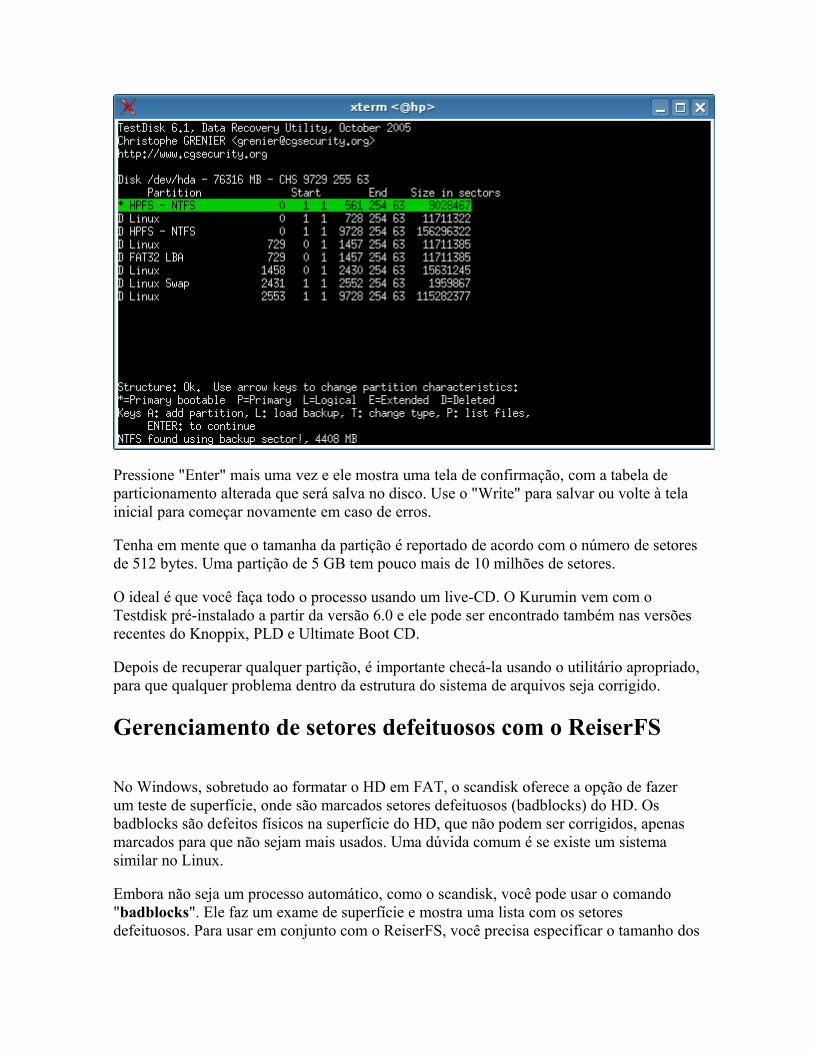
Pressione "Enter" mais uma vez e ele mostra uma tela de confirmação, com a tabela de particionamento alterada que será salva no disco. Use o "Write" para salvar ou volte à tela inicial para começar novamente em caso de erros.
Tenha em mente que o tamanha da partição é reportado de acordo com o número de setores de 512 bytes. Uma partição de 5 GB tem pouco mais de 10 milhões de setores.
O ideal é que você faça todo o processo usando um live-CD. O Kurumin vem com o Testdisk pré-instalado a partir da versão 6.0 e ele pode ser encontrado também nas versões recentes do Knoppix, PLD e Ultimate Boot CD.
Depois de recuperar qualquer partição, é importante checá-la usando o utilitário apropriado, para que qualquer problema dentro da estrutura do sistema de arquivos seja corrigido.
Gerenciamento de setores defeituosos com o ReiserFS
No Windows, sobretudo ao formatar o HD em FAT, o scandisk oferece a opção de fazer um teste de superfície, onde são marcados setores defeituosos (badblocks) do HD. Os badblocks são defeitos físicos na superfície do HD, que não podem ser corrigidos, apenas marcados para que não sejam mais usados. Uma dúvida comum é se existe um sistema similar no Linux.
Embora não seja um processo automático, como o scandisk, você pode usar o comando "badblocks". Ele faz um exame de superfície e mostra uma lista com os setores defeituosos. Para usar em conjunto com o ReiserFS, você precisa especificar o tamanho dos

blocos (em bytes). Se você não usou nenhuma opção especial ao formatar a partição, os blocos terão 1024 bytes. O comando para verificar a partição /dev/hda1 por exemplo, fica:
# badblocks -b 1024 /dev/hda1(como root)
Isso demora alguns minutos. Se estiver tudo certo, ele não vai retornar nada no final do teste.
Hoje em dia, os HDs são capazes de marcar automaticamente os setores defeituosos, a própria controladora faz isso, independentemente do sistema operacional.
Existe uma área reservada no início do disco chamada "defect map" (mapa de defeitos) com alguns milhares de setores que ficam reservados para alocação posterior. Sempre que a controladora do HD encontra um erro ao ler ou gravar num determinado setor, ela remapeia o setor defeituoso, substituindo-o pelo endereço de um setor "bom", dentro do defect map. Como a alocação é feita pela própria controladora, o HD continua parecendo intacto para o sistema operacional.
Os setores só realmente começam a aparecer quando o HD já possui muitos setores defeituosos e o defect map já está cheio. Isso é um indício de um problema grave. O HD já deu o que tinha que dar e o melhor é trocá-lo o mais rápido possível para não arriscar perder os dados.
Alguns sintomas de que o HD está desfrutando de seus últimos dias de vida são:
- Muitos badblocks (causados por envelhecimento da mídia).
- Desempenho muito abaixo do normal (isso indica problemas de leitura, o que faz com que a cabeça de leitura tenha que ler várias vezes o mesmo setor para finalmente conseguir acessar os dados).
- Um barulho de click-click (o famoso click da morte, que indica problemas no sistema de movimentação da cabeça de leitura, um indício de que o HD está realmente nas últimas).
De qualquer forma, o ReiserFS é capaz de marcar via software setores defeituosos que for encontrando. Isso é feito automaticamente, assim como no NTFS do Windows XP. Só é preciso marcar setores defeituosos manualmente em sistemas de arquivos antigos, como o FAT32 e o EXT2.
Você pode ver a lista de setores marcados como defeituosos em uma determinada partição usando o comando abaixo, que salva a lista no arquivo "bads" dentro do diretório atual:
# debugreiserfs -B bads /dev/hda1
Ou seja, para marcar setores defeituosos que por ventura existam, você só precisa copiar um monte de arquivos, até encher a partição. Para ver se existem setores defeituosos na partição, marcados via software, rode o comando:

# debugreiserfs /dev/hda1
Caso exista algum erro no sistema de arquivos, causados por desligamentos incorretos, por exemplo, você pode corrigir com o comando:
# reiserfsck /dev/hda1
Este comando deve ser executado com a partição desmontada. O ideal é dar boot pelo CD do Kurumin e rodar a partir dele.
Em casos mais extremos, onde você tenha um HD cheio de badblocks em mãos e queira usá-lo mesmo assim (num micro que não é usado para nada importante, por exemplo), você pode fazer o seguinte:
Comece enchendo o HD de bits zero, isso vai forçar a controladora a escrever em todos os setores e marcar via hardware os setores defeituosos que conseguir. Isso pode ser feito usando o dd. Naturalmente isso vai apagar todos os dados. A forma ideal de fazer isso é dando boot através do CD do Kurumin:
# dd if=/dev/zero of=/dev/hda(onde o /dev/hda é o dispositivo do HD. Na dúvida, dê uma olhada no qtparted)
Reparticione o HD usando o cfdisk e formate as partições em ReiserFS, como em:
# mkreiserfs /dev/hda1
Monte a partição e copie arquivos (qualquer coisa) para dentro dela até encher. Isso deve marcar via software os setores defeituosos que sobrarem. A partir daí você pode ir usando o HD até que ele pife definitivamente.
É possível também gerar uma lista dos setores defeituosos usando o comando badblocks e especificar a lista ao formatar a partição, fazendo com que os setores defeituosos preexistentes encontrados pelo badblocks sejam marcados para não serem usados pelo mkreiserfs. Esta receita pode ser útil no caso de HDs com alguns setores defeituosos, que estejam "estabilizados", usados por tempo considerável sem que novos setores apareçam.
Para isso, comece gerando o arquivo com a lista dos setores defeituosos da partição desejada:
# badblocks -b 1024 -o bads.list /dev/hda1
Neste caso estamos dizendo ao badblocks que ele deve verificar a partição "/dev/hda1" e salvar a lista no arquivo "bads.list", salvo no diretório atual.
De posse do arquivo, formate a partição usando o comando:
# mkreiserfs -B bads.list /dev/hda1
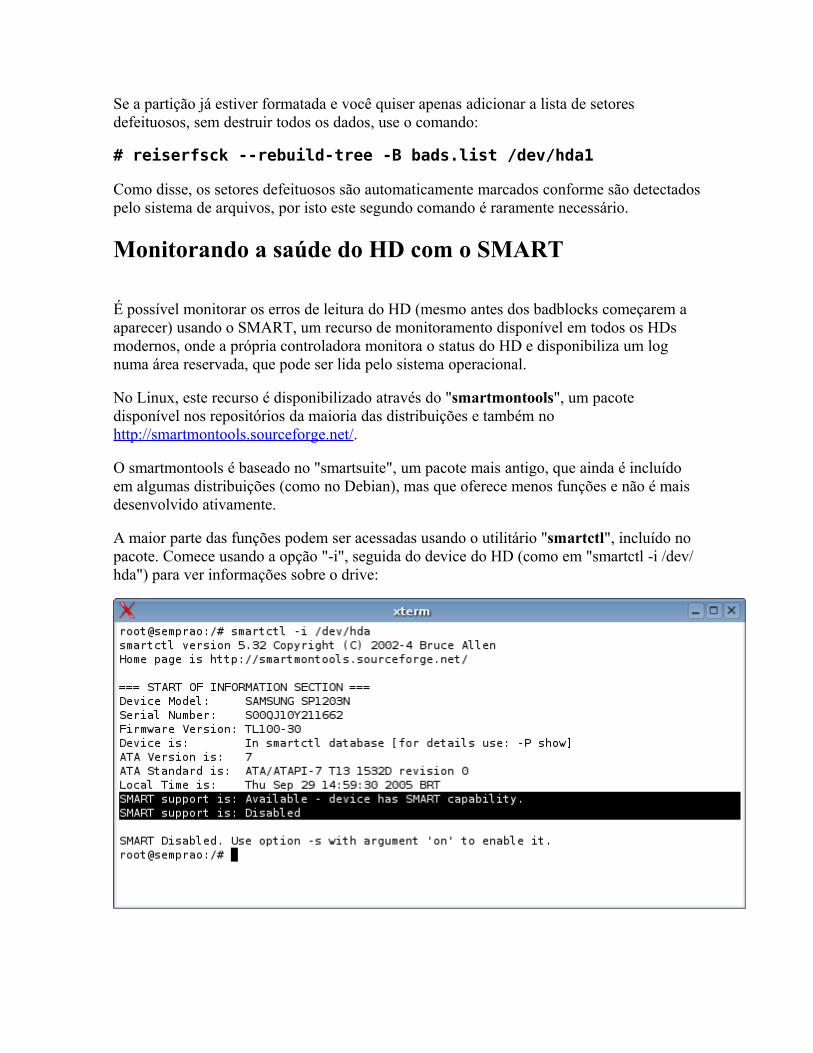
Se a partição já estiver formatada e você quiser apenas adicionar a lista de setores defeituosos, sem destruir todos os dados, use o comando:
# reiserfsck --rebuild-tree -B bads.list /dev/hda1
Como disse, os setores defeituosos são automaticamente marcados conforme são detectados pelo sistema de arquivos, por isto este segundo comando é raramente necessário.
Monitorando a saúde do HD com o SMART
É possível monitorar os erros de leitura do HD (mesmo antes dos badblocks começarem a aparecer) usando o SMART, um recurso de monitoramento disponível em todos os HDs modernos, onde a própria controladora monitora o status do HD e disponibiliza um log numa área reservada, que pode ser lida pelo sistema operacional.
No Linux, este recurso é disponibilizado através do "smartmontools", um pacote disponível nos repositórios da maioria das distribuições e também no http://smartmontools.sourceforge.net/.
O smartmontools é baseado no "smartsuite", um pacote mais antigo, que ainda é incluído em algumas distribuições (como no Debian), mas que oferece menos funções e não é mais desenvolvido ativamente.
A maior parte das funções podem ser acessadas usando o utilitário "smartctl", incluído no pacote. Comece usando a opção "-i", seguida do device do HD (como em "smartctl -i /dev/hda") para ver informações sobre o drive:

Note que neste caso, embora o SMART seja suportado pelo drive, ele está desativado. Antes de mais nada, precisamos ativá-lo, usando o comando:
# smartctl -s on /dev/hda
Para um diagnóstico rápido da saúde do drive (fornecido pela própria controladora), use o parâmetro "-t short", que executa um teste rápido, de cerca de dois minutos, e (depois de alguns minutos) o parâmetro "-l selftest" que exibe o relatório do teste:
# smartctl -t short /dev/hda
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun.Please wait 2 minutes for test to complete.
# smartctl -l selftest /dev/hda
Este comando exibe um relatório de todos os autotestes realizados e o status de cada um. Num HD saudável, todos reportarão "Completed without error".
Você pode executar também um teste longo (que dura cerca de uma hora) usando o parâmetro "-t long". Ambos os testes não interferem com a operação normal do HD, por isso podem ser executados com o sistema rodando. Em casos de erros, o campo "LBA_of_first_error" indica o número do primeiro setor do HD que apresentou erros de leitura, como em:
Status Remaining LBA_of_first_errorCompleted: unknown failure 90% 0xfff00000
Nestes casos, execute novamente o teste e verifique se o erro continua aparecendo. Se ele desaparecer no teste seguinte, significa que o setor defeituoso foi remapeado pela controladora, um sintoma benigno. Caso o erro persista, significa que não se trata de um badblock isolado, mas sim o indício de um problema mais grave.
O parâmetro "-H" (health) exibe um diagnóstico rápido da saúde do drive, fornecido pela própria controladora:
# smartctl -H /dev/hda
SMART overall-health self-assessment test result: PASSED
Neste caso, o SMART informa que não foi detectado nenhum problema com o drive. Em casos de problemas iminentes, ele exibirá a mensagem "FAILING". Este diagnóstico da controladora é baseado em várias informações, como erros de leitura, velocidade de rotação do disco e movimentação da cabeça de leitura.
Um disco "FAILING" não é um local seguro para guardar seus dados, mas em muitos casos ainda pode funcionar por alguns meses. Se ainda não houver muitos sintomas aparentes, você pode aproveitá-los em micros sem muita importância, como estações que são usados apenas para acessar a Web, que não armazenam dados importantes. Note que, embora

relativamente raro, em muitos casos o drive pode realmente se perder menos de 24 horas depois de indicado o erro, por isso transfira todos os dados importantes imediatamente.
Você pode ver mais detalhes sobre o status de erro do HD usando o parâmetro "-A", que mostra todos os atributos suportados pelo HD e o status de cada um. Na sexta coluna (Type) você pode verificar a importância de cada um; os marcados como "Old_age" indicam sintomas de que o HD está no final de sua vida útil, mas não significam por si só problemas iminentes. Os mais graves são os "Pre-Fail", que indicam que o HD está com os dias contados.
Na coluna "WHEN_FAILED" (a mais importante), você vê o status de cada opção. Num HD saudável, esta coluna fica limpa para todas as opções, indicando que o HD nunca apresentou os erros:
O número de setores defeituosos no drive (não remapeados) pode ser visto nos atributos "197 Current_Pending_Sector" e "198 Offline_Uncorrectable", onde o número de badblocks é informado na última coluna. Em situações normais, os badblocks não remapeados contém pedaços de arquivos, que a controladora muitas vezes tenta ler por muito tempo antes de desistir.
Em casos extremos, onde existam vários badblocks não marcados, você pode usar o truque de encher o HD com zeros, usando o comando "dd if=/dev/zero of=/dev/hda" para forçar a controladora a escrever em todos os blocos e assim remapear os setores (perdendo todos os dados, naturalmente).

O número de setores defeituosos já remapeados, por sua vez, pode ser acompanhado através dos atributos "5 Reallocated_Sector_Ct" e "196 Reallocated_Event_Count".
Naturalmente, não basta executar estes testes apenas uma vez, pois erros graves podem aparecer a qualquer momento. Você só terá segurança se eles forem executados periodicamente.
Para automatizar isso, existe o serviço "smartd" ("smartmontools" no Debian), que fica responsável por executar o teste a cada 30 minutos e salvar os resultados no log do sistema, que você pode acompanhar usando o comando "dmesg".
No caso do Debian, além de configurar o sistema para inicializar o serviço no boot, você precisa configurar também o arquivo "/etc/default/smartmontools", descomentando a linha "start_smartd=yes".
O padrão do serviço é monitorar todos os HDs disponíveis. Você pode também especificar manualmente os HDs que serão monitorados e os parâmetros para cada um através do arquivo "/etc/smartd.conf".
Comece comentando a linha "DEVICESCAN". O arquivo contém vários exemplos de configuração manual. Uma configuração comum é a seguinte:
/dev/hda -H -l error -l selftest -t -I 194 -m [email protected]
Esta linha monitora os logs do "/dev/hda" (erros e testes realizados) e monitora mudanças em todos os atributos (incluindo a contagem de badblocks e setores remapeados), com exceção da temperatura (que muda freqüentemente), e envia e-mails para a conta especificada sempre que detectar mudanças. Para que ele use apenas o log do sistema, sem enviar o e-mail, remova a opção "-m".
Para que os relatórios via e-mail funcionem, é preciso que exista algum MTA instalado na máquina, como o Sendmail ou o Postfix. O smartd simplesmente usa o comando "mail" (que permite o envio de e-mails via linha de comando) para enviar as mensagens. No Debian (além do MTA) é necessário que o pacote "mailutils" esteja instalado.
Depois de alterar a configuração, lembre-se de reiniciar o serviço, usando o comando:
# /etc/init.d/smartd restartou:# /etc/init.d/smartmontools restart
Caso o SMART indique algum erro grave e o HD ainda esteja na garantia, você pode imprimir o relatório e pedir a troca.
A vida útil média de um HD IDE é de cerca de dois anos de uso contínuo. HDs em micros que não ficam ligados continuamente podem durar muito mais, por isso é saudável trocar os HDs dos micros que guardam dados importantes anualmente e ir movendo os HDs mais antigos para outros micros.

Normalmente, os fabricantes dão um ano de garantia para os HDs destinados à venda direta ao consumidor e seis meses para os HDs OEM (que são vendidos aos integradores, para uso em micros montados, mas que freqüentemente acabam sendo revendidos). Uma dica geral na hora de comprar HDs é nunca comprar HDs com apenas três meses de garantia, que normalmente é dada só para HDs remanufaturados.
Copiando dados de HDs ou CDs defeituosos
É difícil copiar arquivos, por meios normais, a partir de um HD com badblocks, ou um CD-ROM riscado. Os programas fazem a cópia apenas até o ponto em que encontram o primeiro erro de leitura. Mesmo que exista apenas um setor defeituoso no meio do arquivo, você nunca conseguirá copiar o arquivo inteiro, apenas a metade inicial.
Existe um utilitário eficiente para fazer cópias a partir de mídias ruins, o dd_rescue. Ele faz a cópia das partes boas, ignorando os setores defeituosos. Funciona bem para recuperar arquivos de texto, imagens, vídeos, músicas, qualquer tipo de arquivo que possa ser aberto mesmo que estejam faltando alguns pedaços.
Você pode instalar o dd_rescue pelo apt-get:
# apt-get install ddrescue
Para usá-lo, indique a localização da partição ou CD-ROM que será copiado e um arquivo de destino. Ao copiar uma partição, você sempre precisa copiar o arquivo para dentro de uma partição diferente. A partição ou CD-ROM de origem deve sempre estar desmontada.
Para copiar um CD-ROM:
# dd_rescue /dev/cdrom /mnt/hda6/cdrom.img
Para copiar uma partição:
# dd_rescue /dev/hda1 /mnt/hda6/hda1.img
Para acessar os arquivos dentro da imagem, você deve montá-la usando a opção "-o loop" do mount, que monta um arquivo como se fosse um dispositivo:
# mount -o loop /mnt/hda6/cdrom.img /home/kurumin/cdromou:# mount -o loop /mnt/hda6/hda1.img /home/kurumin/hda1
Você verá todos os arquivos dentro da pasta, e poderá acessar o que foi possível ler.
Um problema do dd_rescue é que ele lê cada setor defeituoso várias vezes, de forma a tentar obter os dados a qualquer custo. Por um lado, isto é positivo, pois ele realmente acaba conseguindo recuperar vários setores que falham na primeira leitura, mas por outro

lado, faz com que o processo de recuperação fique extremamente lento em mídias com muitos setores defeituosos.
Isto é especialmente problemático ao recuperar dados em HDs, pois se o teste demora muito, a possibilidade do drive dar seu último suspiro durante a recuperação, levando consigo os dados restantes é muito maior.
Uma solução é usar o "dd_rhelp", um programa que trabalha em conjunto com o dd_rescue, otimizando seu comportamento.
Ao usar o dd_rhelp, o processo de recuperação é dividido em duas etapas. Na primeira ele recupera os dados, pulando os setores defeituosos. Quando a recuperação está completa, ele carrega lista dos setores que falharam na primeira leitura e aí sim, passa ao comportamento padrão, lendo cada setor várias vezes. A diferença é que no caso você já está com os dados seguros.
Você pode baixar o dd_rhelp no http://www.kalysto.org/utilities/dd_rhelp/download/index.en.html ou http://freshmeat.net/projects/dd_rhelp/.
No site está disponível apenas o pacote com o código fonte, mas ele é relativamente simples de compilar. Descompacte o arquivo, acesse a pasta que será criada e use os comandos:
# ./configure# make
Isto vai criar o executável dentro da pasta atual. Ao usá-lo, a sintaxe é a mesma do dd_rescue:
# ./dd_rhelp /dev/cdrom /mnt/hda6/cdrom.img
Eliminando dados com segurança
Ao "formatar" uma partição, ou ao remover todas as partições do HD, são alterados apenas os índices utilizados pelo sistema operacional para encontrar os arquivos. Os dados propriamente ditos continuam intactos na superfície magnética do HD, até serem efetivamente apagados reescritos.
Isso cria um problema para quem precisa vender ou descartar HDs usados. Afinal, você não vai querer que seus arquivos pessoais, ou informações confidenciais da sua empresa sejam dadas "de brinde" junto com o HD descartado.
Alguns órgãos governamentais chegam a manter políticas estritas quanto ao descarte de HDs. Em muitos casos um HD só pode ser descartado depois de passar por um software de eliminação de dados e, em outras, os HDs são simplesmente destruídos.

Destruir um HD é fácil. "Amacie" usando uma marreta de 20 kg, depois incinere. Se preferir, você pode usar o HD como alvo num clube de tiro, ou destruir a superfície magnética dos discos com ácido. ;)
Claro, nada disso é realmente necessário se você sabe o que está fazendo. Da mesma maneira que é possível recuperar dados usando as ferramentas corretas, também é possível apagá-los de forma que seja impossível recuperá-los.
A maneira mais rudimentar seria simplesmente reescrever todos os dados. Você poderia, por exemplo, encher o HD com zeros, usando o dd, como em:
# dd if=/dev/zero of=/dev/hda
Aqui os dados já não poderiam mais ser recuperados por via normais, mas algumas empresas de recuperação possuem máquinas (com cabeças de leitura mais sensíveis que as originalmente usadas no HD) que conseguem recuperar a maior parte dos dados. Elas funcionam lendo a carga residual que sobra nas trilhas. Como este comando simplesmente enche o HD com zeros, ainda sobra um sinal fraco onde existiam bits 1.
Uma forma mais segura, seria encher o HD com bits aleatórios, modificando o comando para ler as informações de entrada a partir do "/dev/urandom", outro dispositivo virtual, que fornece bits aleatórios:
# dd if=/dev/urandom of=/dev/hda
Aqui a recuperação fica muito mais complicada. Mas, em teoria, ainda seria possível recuperar alguns trechos dos arquivos usando os processos adequados. A Seagate e alguns outros fabricantes oferecem este tipo de serviço a preços exorbitantes.
Para realmente eliminar qualquer possibilidade de recuperação, você poderia executar o comando várias vezes. A cada passada a chance de recuperar qualquer coisa fica exponencialmente menor.
Ao invés de fazer isso manualmente, você pode usar o "shred", um pequeno utilitário encontrado na maioria das distribuições. Você pode usá-lo também a partir de um CD de boot do Kurumin.
Um exemplo bem efetivo de uso seria:
# shred -n 5 -vz /dev/hda
Usado com estas opções, o shred vai encher o HD com bits aleatórios, repetindo a operação 5 vezes (-n 5) . Como o processo é demorado, usamos a opção "-v" (verbose) para que ele exiba um indicador de progresso, concluindo com o "z", que faz com que, depois de concluído o processo, ele encha o HD com zeros, para despistar e esconder o fato de que você fez o apagamento.

Administrando a memória swap
Você pode acompanhar o uso de memória do sistema através do comando "free" que exibe um relatório de quanta memória (física e swap) está sendo usada e quanto ainda está disponível.
Um recurso que vem bem a calhar é que você pode criar, a qualquer momento, um arquivo de memória swap temporário, usando o espaço livre do HD. Isso vai ajudar bastante no dia em que você estiver trabalhando com uma partição swap pequena e precisar editar um vídeo ou uma animação em 3D pesada :).
Para isso, basta usar os comandos abaixo:
# dd if=/dev/zero of=/swap bs=1024 count=131070# mkswap /swap# swapon /swap
Substitua o número 131070 pela quantidade de memória swap desejada, em kbytes. 131070 são 128 MB, mas não é preciso usar um número exato, você pode usar "250000", por exemplo. O arquivo temporário é desativado automaticamente ao reiniciar o micro, mas você pode fazê-lo a qualquer momento usando os comandos:
# swapoff /swap# rmdir /swap
O Linux tem um comportamento particular ao lidar com falta de memória. Numa situação de fartura, ao ter, por exemplo, 512 MB de RAM onde apenas 100 MB estão ocupados, ele passa a utilizar a maior parte da memória disponível como cache de disco e arquivos. Isso melhora muito o desempenho do sistema, pois tanto arquivos recentemente acessados, quanto arquivos com uma grande chance de serem requisitados em seguida já estarão carregados na memória e não precisarão ser lidos no HD, que é centenas de vezes mais lento.
Conforme mais e mais memória física vai sendo ocupada, o sistema vai abrindo mão do cache de disco para liberar memória para os aplicativos. Com o passar o tempo, alguns dados relacionados a programas que estão ociosos a muito tempo começam a lentamente serem movidos para a memória swap, fazendo com que o sistema recupere parte do espaço e volte a fazer cache de disco. O desempenho volta a melhorar. Esta é uma tarefa que o Linux desempenha com muita competência, pelo menos enquanto houver memória swap disponível...
Se você continua abrindo programas e até mesmo a memória swap comece a acabar, o sistema vai abrir mão primeiro do cache de disco e depois começará a limitar a memória utilizada pelos aplicativos. Com isto o sistema começará a ficar cada vez mais lento, pois o objetivo passa ser "sobreviver", ou seja, continuar abrindo os programas solicitados. Isto

vai continuar até o limite extremo, quando finalmente você receberá uma mensagem de falta de memória e terá que começar a fechar programas.
Tudo isso pode ser acompanhado usando o "free", que mostra com exatidão a memória física e swap ocupadas e quanto de memória está sendo destinada ao cache de disco.
No screenshot abaixo temos uma situação em que o sistema começa a ficar lento.
Temos aqui 256 MB de RAM e mais 256 MB de swap e um batalhão de programas abertos. Veja que a política de "selecionar os programas mais importantes" já ocupou toda a memória swap, deixando apenas 72 KB livres. Ainda temos quase 80 MB de memória física que estão sendo usados pelo cache de disco, e apenas mais 5 MB realmente livres. Ou seja, estamos próximos do ponto de saturação em que o sistema desiste de fazer cache de disco e começa a restringir o uso de memória dos programas; o Athlon XP está prestes a começar a virar uma carroça. Hora de criar uma memória swap temporária com os comandos acima.
Moral da história: para ter um bom desempenho você precisa ter de preferência muita memória RAM ou, pelo menos, uma quantidade suficiente de memória RAM combinada com uma partição swap de tamanho generoso. Se você tem um HD de boa capacidade, não faz mal reservar 1 ou 2 GB para a partição swap.
Prefira sempre ter uma partição swap maior do que usar o arquivo temporário, pois a partição swap é sempre mais rápida, por utilizar um sistema de arquivos próprio, otimizado para a tarefa.
Outra polêmica é com relação à real necessidade de usar uma partição ou arquivo de swap em micros com 512 MB de RAM, que são suficientes para a maioria das tarefas. Lembre-se de que, embora todos os manuais digam para criar uma partição swap durante a instalação do sistema, ela não é obrigatória.
Um dos defensores da idéia de que é sempre importante usar uma partição swap, independentemente da quantidade de memória RAM física que esteja disponível, é Andrew Morton, o próprio mantenedor do Kernel 2.6. Numa discussão em 2004 na lista de desenvolvimento do Kernel, ele concluiu uma mensagem com vários argumentos técnicos com a frase:
"Vou colocar os dedos nos ouvidos e cantar 'la la la' enquanto existir gente me dizendo 'Desabilitei a memória swap e isso não deu o resultado que esperava'."

A moral da história é que, por contraditório que possa parecer, o sistema passa a utilizar a memória virtual apenas em situações onde isso vai resultar em ganhos de desempenho. Mantendo mais memória RAM livre, novos programas carregam mais rápido e o sistema tem como fazer cache de disco.
No Kernel 2.6 estes algoritmos foram bastante refinados. Num micro com 512 MB de RAM, você notará que o sistema geralmente só começa a fazer swap depois que mais da metade da memória RAM está ocupada e, mesmo assim, movendo para ela apenas bibliotecas e componentes do sistema de uso muito esporádico. O uso do swap vai crescendo apenas conforme realmente existe necessidade.
Ainda assim (ao usar uma distribuição com o Kernel 2.6), você pode configurar o comportamento do sistema em relação à memória swap através de um parâmetro do Kernel, definido através do arquivo "/proc/sys/vm/swappiness". Este arquivo contém um número de 0 a 100, que determina a predisposição do sistema para usar swap. Um número baixo faz com que ele deixe para usar swap apenas em situações extremas (configuração adequada a micros com muita RAM), enquanto um número alto faz com que ele use mais swap, o que mantém mais memória RAM livre para uso do cache de disco, melhorando o desempenho em micros com pouca memória.
Se você tem um micro com 1 GB de RAM e quer que o sistema quase nunca use swap, use:
# echo "20" > /proc/sys/vm/swappiness
Em micros com 256 MB ou menos, aumentar o uso de swap mantém mais memória disponível para abrir novos aplicativos e fazer cache de disco. O programa que está sendo usado no momento e novos programas abertos ficam mais rápidos mas, em troca, programas minimizados a muito tempo são movidos para a swap e demoram mais para responder quando reativados. Para aumentar o uso de swap, use:
# echo "80" > /proc/sys/vm/swappiness
Para tornar a alteração definitiva, adicione o comando em algum arquivo de inicialização do sistema, como o "/etc/rc.d/rc.local" ou "/etc/init.d/bootmisc.sh".
Suporte a mais de 1 GB de memória RAM
Tradicionalmente, os processadores x86 utilizam uma tabela de 32 bits para o endereçamento da memória RAM e são por isso capazes de endereçar até 4 GB de memória (dois elevado à 32º potência são 4.294.967.296 endereços, um por byte de memória).
Esta limitação existe desde o 386. Na época, ninguém se importava muito com isso, pois a memória RAM era muito cara e era incomum alguém usar mais do que 8 ou 16 MB.
A partir da década de 90, os 4 GB começaram a ser um limitante para servidores de bancos de dados e outras aplicações de grande porte, que consomem grandes quantidades de memória. Surgiu então o PAE (Physical Address Extension), um hack implementado pela

Intel em alguns processadores a partir do Pentium Pro. O PAE consiste numa segunda tabela de endereços, com 4 bits adicionais, que permitem endereçar 16 páginas de memória, cada uma com 4 GB.
Com o PAE, passa a ser possível endereçar até 64 GB de memória. A desvantagem é que o processador continua sendo capaz de acessar apenas 4 GB por vez e o chaveamento entre diferentes páginas de memória toma um certo tempo, que acaba prejudicando bastante o desempenho.
Mesmo usando o PAE, a maioria dos aplicativos continua tendo acesso a apenas 4 GB. A vantagem é que passa a ser possível executar vários aplicativos diferentes, cada um consumindo até 4 GB de memória, sem o uso de memória virtual. Apenas alguns aplicativos cuidadosamente desenvolvidos são capazes de distribuir dados entre diferentes páginas de memória, realmente aproveitando a memória adicional.
O PAE pode ser encontrado apenas em alguns processadores Intel de 32 bits destinados a servidores, basicamente apenas o Pentium Pro e o Xeon. Para que funcione, é necessário que exista suporte também no chipset da placa-mãe e no sistema operacional usado.
A solução definitiva para quem precisa de mais de 4 GB de memória é usar um processador de 64 bits, já que eles trabalham com tabelas de endereçamento de 64 bits e são por isso capazes de acessar quantidades praticamente ilimitadas de memória.
Ao utilizar um processador de 32 bits, o Linux oferece suporte nativo a até 4 GB de memória usando o modo normal de operação do processador e a até 64 GB usando o PAE. Ou seja, ele simplesmente acompanha o suporte disponível no hardware, sem nenhuma limitação adicional.
Para melhorar o desempenho do sistema em máquinas antigas, que utilizam 1 GB de memória ou menos, existe uma terceira opção, onde o Kernel endereça apenas 1 GB de memória, sendo que 960 MB ficam disponíveis para os aplicativos e o restante é reservado para uso do Kernel. Neste modo de operação, o comando "free" vai reportar que existem apenas 960 MB de memória disponível, mesmo que você possua 1 GB ou mais.
É possível escolher entre as três opções ao compilar o Kernel, na opção "Processor Type and Features > High Memory Support". Até pouco tempo, a maioria das distribuições vinha com o suporte a apenas 1 GB ativado por padrão. Nestes casos você precisa recompilar o Kernel, usando a opção "4 GB".
Note que ao recompilar o Kernel padrão da distribuição (sem alterar a versão), você pode apenas gerar o executável principal e fazer as modificações necessárias na configuração do lilo ou grub para que ele seja inicializável, sem precisar gerar os módulos.

A desvantagem de ativar o suporte a 4 GB é que o sistema ficará um pouco mais lento em micros com menos de 1 GB de memória (justamente por isso existe a primeira opção). O suporte a 64 GB só pode ser ativado caso você esteja usando um Intel Xeon ou outro processador com suporte ao PAE. Um Kernel gerado com esta opção não vai dar boot em processadores que não são compatíveis com o recurso.
A partir daí, o sistema será capaz de ativar toda a memória instalada. Em caso de problemas, você pode forçar o uso de toda a memória disponível adicionando a opção "mem=2048M" (onde o 2048 indica a quantidade de memória instalada) na linha append do "/etc/lilo.conf", juntamente com as outras opções, como em:
append="mem=2048M, noapic"
Ao usar o grub, use a opção na linha referente ao novo Kernel no arquivo "/boot/grub/menu.lst", como em:
kernel /boot/vmlinuz-2.6.15hm root=/dev/hda1 ro mem=2048M
Clonando partições com o Partimage
O Partimage substitui o Norton Ghost, com a vantagem de ser livre e gratuito. Ele pode fazer imagens de partições do HD e até mesmo de HDs inteiros. É interessante tanto para fazer backup, quanto para clonar HDs quando é necessário instalar o sistema em vários micros iguais.
Ele possui uma interface de texto e graças a isso ele é bem pequeno. A versão estaticamente compilada, que inclui todas as bibliotecas necessárias no próprio pacote e por isso raramente dá problemas na instalação, tem menos de 1 MB e a versão shared, que depende que um certo conjunto de bibliotecas esteja instalado no sistema, possui apenas 300 KB.

O fato de rodar em modo texto também flexibiliza o uso do Partimage, pois permite usá-lo praticamente em qualquer situação, sem precisar se preocupar em achar alguma distribuição que consiga configurar o vídeo daquele notebook jurássico ou convencer o administrador a instalar o Xfree naquele servidor que sempre funcionou muito bem sem ele :). O Partimage pode também ser controlado via script, o que permite criar e restaurar as imagens de forma automatizada, criando, por exemplo, DVDs de recuperação, como nos micros de grife, que restauram uma imagem do sistema automaticamente durante a inicialização.
Em 2002 publiquei no Guia do Hardware um artigo sobre o G4U, outra ferramenta similar, que você pode ler em: http://www.guiadohardware.net/artigos/215/.
O G4U é um disquete bootável que faz uma cópia completa do HD para um servidor de FTP habilitado em outro micro da rede ou na internet. Os dois compactam os dados, mas a diferença fundamental entre o Partimage e o G4U é que o Partimage copia apenas os dados dentro da partição, gerando um arquivo proporcional ao espaço ocupado. Se você tiver uma partição de 40 GB, mas com apenas 600 MB ocupados, o arquivo de imagem (compactado) terá apenas uns 200 e poucos MB. O G4U já funciona de uma mais parecida com o dd, simplesmente copiando os uns e zeros do HD, criando imagens muito maiores.
O Partimage também é capaz de quebrar a imagem em vários arquivos (você especifica o tamanho desejado), permitindo que os backups possam ser facilmente gravados em DVD, múltiplos CDs, ou até mesmo mini-DVDs de 1.4 GB cada.
Instalando
Existem duas opções para usar o Partimage. Você pode instalá-lo (Linux) como qualquer outro programa, ou usar um CD bootável que já venha com ele pré-instalado. A idéia do CD é geralmente a mais prática, pois permite que você faça e restaure os backups mesmo que só tenha o Windows instalado no HD.
Os pacotes de instalação do Partimage podem ser baixados no:http://www.partimage.org/download.en.html
Baixe o "Static i386 binary tarball" que funciona em qualquer distribuição. Esta versão dispensa instalação, você só precisa descompactar o arquivo e executar o "partimage" que está dentro. Se preferir fazer isso via terminal, os comandos são:
# tar -jxvf partimage-static-i386-0.6.2.tar.bz2 # cd partimage-static-i386-0.6.2 # ./partimage
Se optar por usar um live-CD, pode utilizar o Kurumin, Knoppix, Kanotix ou mesmo o Gentoo Live-CD.
Modéstia à parte, o Kurumin é a melhor opção neste caso, pois além do Partimage você terá mais ferramentas à disposição, como o gparted, que, além de gráfico, permite o redimensionamento de partições, inclusive NTFS.
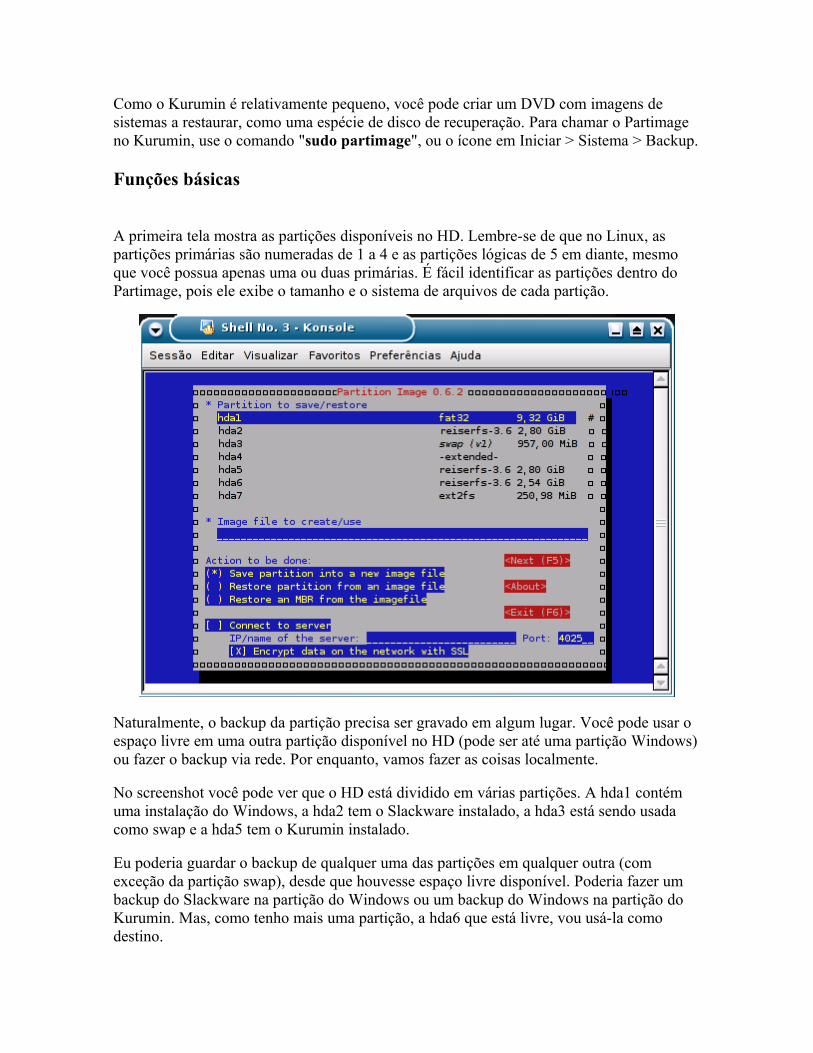
Como o Kurumin é relativamente pequeno, você pode criar um DVD com imagens de sistemas a restaurar, como uma espécie de disco de recuperação. Para chamar o Partimage no Kurumin, use o comando "sudo partimage", ou o ícone em Iniciar > Sistema > Backup.
Funções básicas
A primeira tela mostra as partições disponíveis no HD. Lembre-se de que no Linux, as partições primárias são numeradas de 1 a 4 e as partições lógicas de 5 em diante, mesmo que você possua apenas uma ou duas primárias. É fácil identificar as partições dentro do Partimage, pois ele exibe o tamanho e o sistema de arquivos de cada partição.
Naturalmente, o backup da partição precisa ser gravado em algum lugar. Você pode usar o espaço livre em uma outra partição disponível no HD (pode ser até uma partição Windows) ou fazer o backup via rede. Por enquanto, vamos fazer as coisas localmente.
No screenshot você pode ver que o HD está dividido em várias partições. A hda1 contém uma instalação do Windows, a hda2 tem o Slackware instalado, a hda3 está sendo usada como swap e a hda5 tem o Kurumin instalado.
Eu poderia guardar o backup de qualquer uma das partições em qualquer outra (com exceção da partição swap), desde que houvesse espaço livre disponível. Poderia fazer um backup do Slackware na partição do Windows ou um backup do Windows na partição do Kurumin. Mas, como tenho mais uma partição, a hda6 que está livre, vou usá-la como destino.

Para gravar qualquer coisa numa partição, você precisa primeiro montá-la dentro de alguma pasta. Relembrando, o comando "genérico" para montar partições no Linux, é o mount seguido do sistema de arquivos em que a partição está formatada, o dispositivo (começando com /dev) e finalmente a pasta onde esta partição ficará disponível. No meu caso, quero montar a partição hda6, formatada em reiserfs (informado na tela do Partimage) na pasta /mnt/hda6. O comando então seria:
# mount -t reiserfs /dev/hda6 /mnt/hda6
Se fosse montar a partição hda1 do Windows na pasta /mnt/hda1, usaria o comando:
# mount -t vfat /dev/hda1 /mnt/hda1
Lembre-se de que o suporte à escrita em Partições NTFS no Linux ainda é muito limitado. Muitas distribuições vêm com o suporte à escrita desabilitado e mesmo nas demais não é recomendável usá-lo. Você pode perfeitamente usar o Partimage para fazer backup de partições NTFS do Windows, mas é sempre recomendável salvar os backups em partições formatadas em outros sistemas de arquivo. Não tente salvar o backup em outra partição NTFS.
De volta à tela principal do Partimage, precisamos selecionar a partição fonte, de que será feita a imagem e o arquivo destino, onde esta imagem será copiada. No meu caso estou salvando uma imagem da partição hda5 do Kurumin no arquivo "/mnt/hda6/kurumin.img".
Esta interface de texto pode parecer estranha para quem não está acostumado. Mas as funções são simples: a tecla Tab permite navegar entre os campos, as setas alternam entre

as opções e a barra de espaço permite marcar e desmarcar opções. Depois de terminar, pressione F5 para ir para a próxima tela, ou F6 para sair.
Na tela seguinte você terá várias opções para a criação da imagem:
- Compression level:
None: Simplesmente não comprime nada. Se houver 600 MB ocupados na partição, a imagem terá 600 MB.Gzip: O padrão, consegue comprimir de 50 a 65%, em média.Bzip2: Consegue comprimir de 5 a 10% mais que o Gzip, mas em compensação a compressão é bem mais lenta.
- Options:
Check before saving: Executa uma verificação na partição, mostrando o tamanho, espaço ocupado e se existe algum tipo de erro no sistema de arquivos. Enter description: Descrição que aparece na hora de recuperar a imagem, opcional.
Overwrite without prompt: Se houver um arquivo com o mesmo nome, ele é subscrito automaticamente.
- If finished successfully (Depois de terminar de gerar ou recuperar a imagem):
Wait : Não faz nada, exibe uma janela de relatório e fica esperando você dar ok. Halt: Desliga a máquina (bom para fazer os backups de madrugada).

Reboot: Reinicia (bom para discos de recuperação automáticos).Quit: Só fecha o programa.
- Image split mode (este é um dos recursos mais interessantes do partimage, ele pode quebrar a imagem em vários arquivos pequenos, facilitando o transporte):
Automatic split: Este é o modo default, ele grava a imagem até que o espaço livre na partição destino se esgote. Quando isso acontece, ele para e pede um novo local para gravar o restante da imagem. Into files whose size is: Quebra em vários arquivos do tamanho especificado, em kbytes. Se você quer gravar a imagem em vários CDs de 700 MB, por exemplo, os arquivos devem ter 715776 kb (699 MB). Wait after each volume change: Ao marcar essa opção num backup dividido em várias imagens, ele exibe um aviso e espera a confirmação cada vez que for gerar um novo arquivo. É útil em casos onde é preciso trocar a mídia.
Ao dividir em vários volumes, o partimage adicionará uma extensão ".000", "001", "002", etc. aos arquivos, como num arquivo .rar dividido em vários volumes. Na hora de restaurar a imagem, você precisa apenas colocá-los todos no mesmo diretório e apontar para o arquivo .000.
Pressionando F5 novamente, você vai para a tela de criação da imagem. Agora é só ir tomar um café e voltar depois de alguns minutos.
O principal determinante na velocidade de geração da imagem é o processador. O backup de uma partição com 1.3 GB ocupados num Athlon de 1.0 GHz com compactação em gzip, demora cerca de 15 minutos:
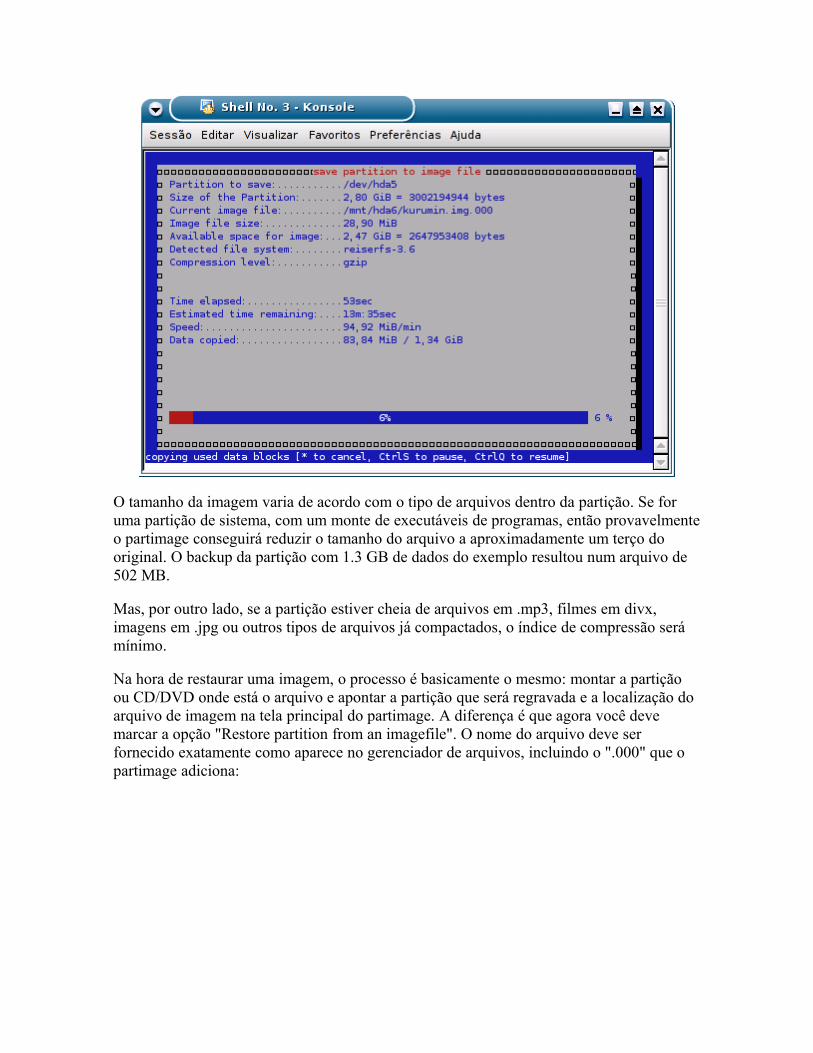
O tamanho da imagem varia de acordo com o tipo de arquivos dentro da partição. Se for uma partição de sistema, com um monte de executáveis de programas, então provavelmente o partimage conseguirá reduzir o tamanho do arquivo a aproximadamente um terço do original. O backup da partição com 1.3 GB de dados do exemplo resultou num arquivo de 502 MB.
Mas, por outro lado, se a partição estiver cheia de arquivos em .mp3, filmes em divx, imagens em .jpg ou outros tipos de arquivos já compactados, o índice de compressão será mínimo.
Na hora de restaurar uma imagem, o processo é basicamente o mesmo: montar a partição ou CD/DVD onde está o arquivo e apontar a partição que será regravada e a localização do arquivo de imagem na tela principal do partimage. A diferença é que agora você deve marcar a opção "Restore partition from an imagefile". O nome do arquivo deve ser fornecido exatamente como aparece no gerenciador de arquivos, incluindo o ".000" que o partimage adiciona:
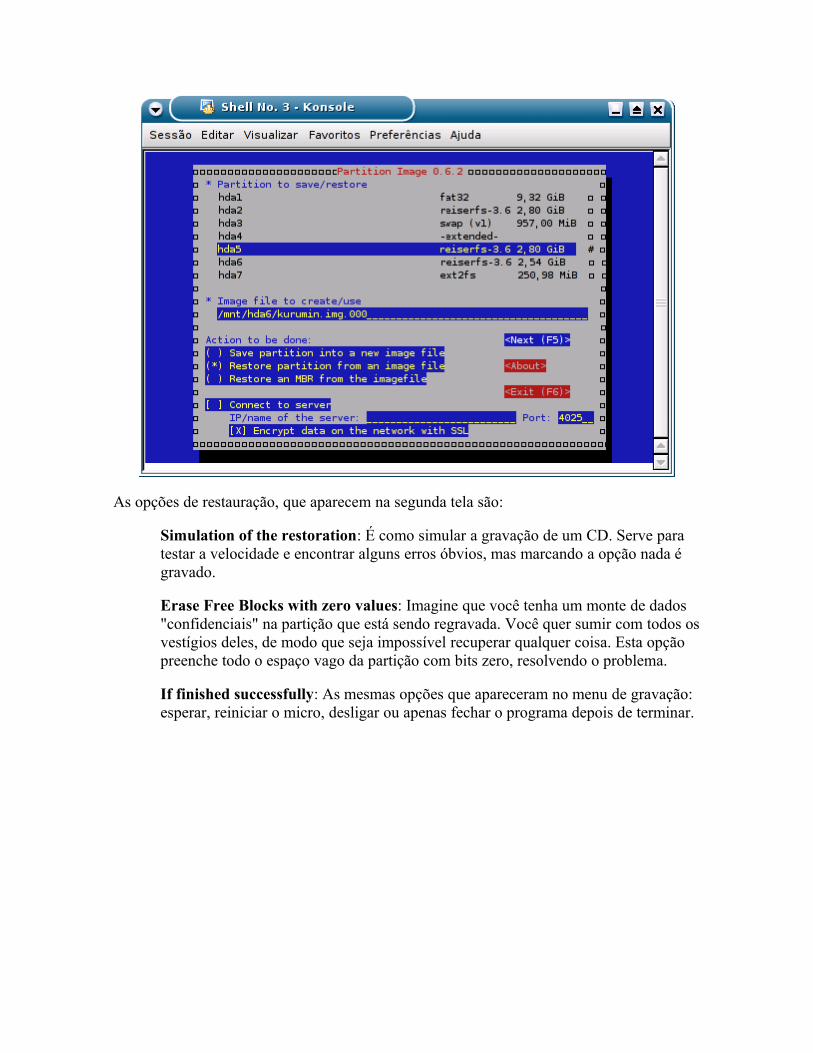
As opções de restauração, que aparecem na segunda tela são:
Simulation of the restoration: É como simular a gravação de um CD. Serve para testar a velocidade e encontrar alguns erros óbvios, mas marcando a opção nada é gravado.
Erase Free Blocks with zero values: Imagine que você tenha um monte de dados "confidenciais" na partição que está sendo regravada. Você quer sumir com todos os vestígios deles, de modo que seja impossível recuperar qualquer coisa. Esta opção preenche todo o espaço vago da partição com bits zero, resolvendo o problema.
If finished successfully: As mesmas opções que apareceram no menu de gravação: esperar, reiniciar o micro, desligar ou apenas fechar o programa depois de terminar.
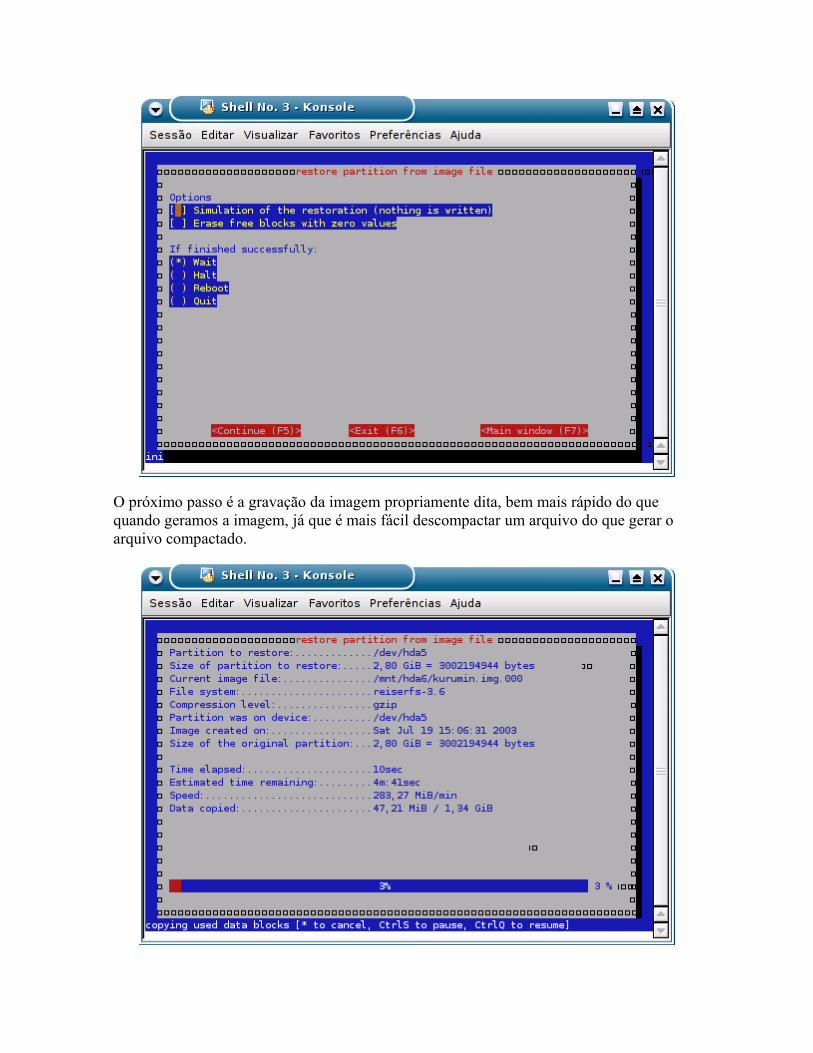
O próximo passo é a gravação da imagem propriamente dita, bem mais rápido do que quando geramos a imagem, já que é mais fácil descompactar um arquivo do que gerar o arquivo compactado.

Fazendo uma imagem de todo o HD
O partimage não oferece a opção de fazer uma cópia completa do HD, apenas de partições isoladas. Mas, é possível fazer isso se você utilizar um comando adicional, para copiar também a trilha MBR e a tabela de partição do HD. Com as três coisas em mãos é possível realmente clonar um HD inteiro.
Para isso, são necessários mais dois comandos. Acesse o diretório onde você está armazenando as imagens e execute:
# dd if=/dev/hda of=hda.mbr count=1 bs=512
Este comando faz uma cópia do setor de boot do HD, aqueles primeiros 512 bytes de extrema importância onde fica instalado o gerenciador de boot.
# sfdisk -d /dev/hda > hda.sf
Este segundo faz uma cópia da tabela de partição do HD. Se você restaurar estes dois arquivos num HD limpo, ele ficará particionado exatamente da mesma forma que o primeiro. Se depois disto você restaurar também as imagens das partições, ficará com uma cópia idêntica de todo o conteúdo do HD.
O HD destino não precisa necessariamente ser do mesmo tamanho que o primeiro; você pode usar um HD maior sem problemas. Neste caso, o excedente ficará vago e você poderá criar novas partições depois. Naturalmente, o HD destino não pode ser menor que o original, caso contrário você vai ficar com um particionamento inválido e dados faltando; ou seja, uma receita para o desastre.
Na hora de restaurar os backups, acesse a pasta onde estão os arquivos e inverta os comandos, para que eles sejam restaurados:
# dd if=hda.mbr of=/dev/hda # sfdisk --force /dev/hda < hda.sf
Se você tem um HD dividido em duas partições ("hda1" e "hda2", por exemplo), é necessário fazer imagens das duas partições usando o Partimage e fazer o backup da MBR e da tabela de particionamento usando os comandos acima. Na hora de restaurar, comece gravando os dois arquivos (MBR e tabela de partição), deixando para regravar as imagens das partições por último.
Um jeito fácil de fazer e recuperar os backups é instalar temporariamente um segundo HD na máquina. Se você instalá-lo como master da segunda IDE, ele será reconhecido como "hdc" pelo sistema e a primeira partição aparecerá como "hdc1".
Gravando imagens num compartilhamento da rede

O partimage inclui também um servidor chamado partimaged, que permite fazer backups via rede. Este programa já vem incluído no "Static i386 binary tarball", que baixamos no início do artigo. Basta acessar a pasta onde descompactou o arquivo e chama-lo com o comando:
# ./partimaged(sempre como root)
Se você usa o Kurumin ou outra distribuição baseada no Debian, você pode instalá-lo com o comando:
# apt-get install partimage-server
No final da instalação ele perguntará sobre o diretório padrão do servidor, aceite o default que é "/var/lib/partimaged". Depois de concluída a instalação, inicialize o servidor com o comando:
# partimaged
Para que o servidor funcione corretamente você deve criar o usuário "partimag" que você usará ao se conectar a partir dos clientes:
# adduser partimag # passwd partimag
Aproveite para dar permissão para que este novo usuário possa gravar arquivos no diretório padrão do Partimage:
# chown -R partimag.partimag /var/lib/partimaged
A possibilidade de salvar as imagens no servidor vai ser útil principalmente se você estiver usando o Kurumin rodando direto do CD. Isto resolve aquele velho problema de fazer backups em micros de clientes antes de mexer no sistema. Você pode levar um micro já configurado para isso, ou um notebook com um HD razoavelmente grande, dar boot com o CD do Kurumin, configurar a rede, salvar a imagem e depois trabalhar tranqüilo, sabendo que, mesmo que alguma tragédia aconteça, será só restaurar a imagem.
Para se conectar ao servidor, você deve marcar a opção "Connect to server" e fornecer o endereço IP do servidor na primeira tela de geração da imagem. Lembra-se do diretório padrão que você escolheu ao instalar o partimage-server? Você deve informá-lo na linha do "Image file to create use" seguido do nome do arquivo, como em "/var/lib/partimaged/kurumin.img":
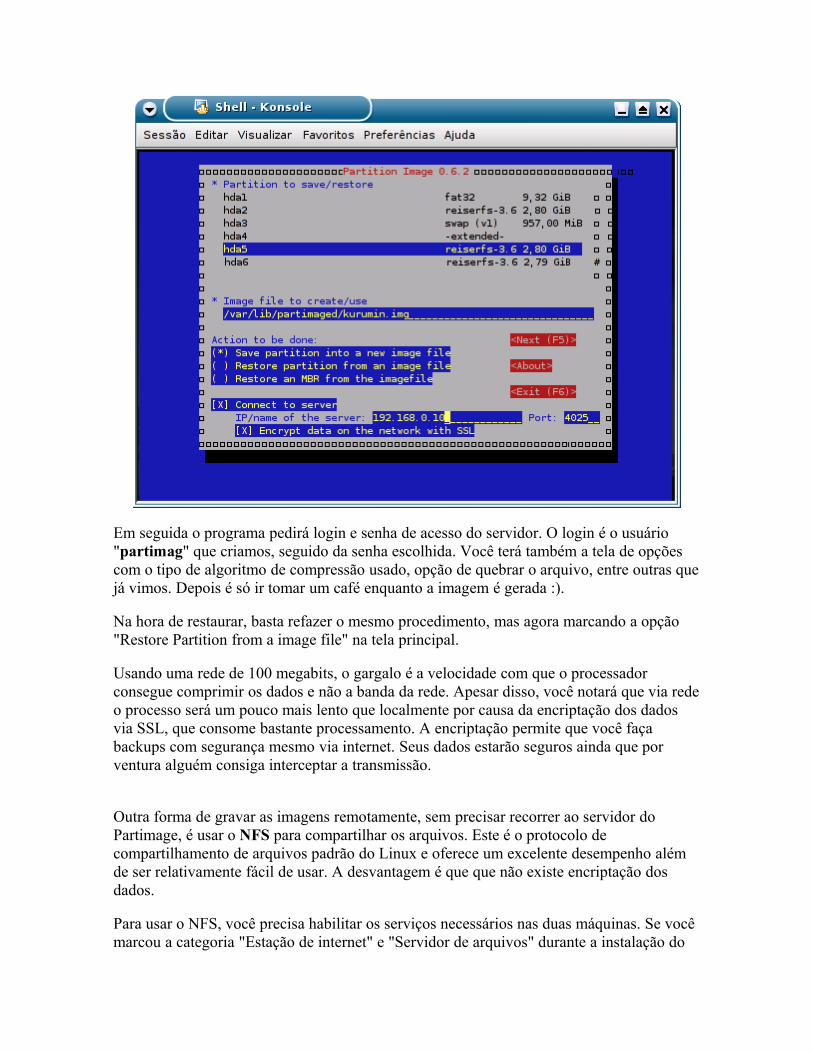
Em seguida o programa pedirá login e senha de acesso do servidor. O login é o usuário "partimag" que criamos, seguido da senha escolhida. Você terá também a tela de opções com o tipo de algoritmo de compressão usado, opção de quebrar o arquivo, entre outras que já vimos. Depois é só ir tomar um café enquanto a imagem é gerada :).
Na hora de restaurar, basta refazer o mesmo procedimento, mas agora marcando a opção "Restore Partition from a image file" na tela principal.
Usando uma rede de 100 megabits, o gargalo é a velocidade com que o processador consegue comprimir os dados e não a banda da rede. Apesar disso, você notará que via rede o processo será um pouco mais lento que localmente por causa da encriptação dos dados via SSL, que consome bastante processamento. A encriptação permite que você faça backups com segurança mesmo via internet. Seus dados estarão seguros ainda que por ventura alguém consiga interceptar a transmissão.
Outra forma de gravar as imagens remotamente, sem precisar recorrer ao servidor do Partimage, é usar o NFS para compartilhar os arquivos. Este é o protocolo de compartilhamento de arquivos padrão do Linux e oferece um excelente desempenho além de ser relativamente fácil de usar. A desvantagem é que que não existe encriptação dos dados.
Para usar o NFS, você precisa habilitar os serviços necessários nas duas máquinas. Se você marcou a categoria "Estação de internet" e "Servidor de arquivos" durante a instalação do

Mandriva ou Fedora, os serviços já devem estar ativos na máquina, mas não custa nada verificar.
Para usar o Mandriva como servidor NFS, você deve ativar os serviços "Netfs", "Portmap" e "Nfslock" no Mandriva Control Center.
Nos clientes Kurumin você deve ativar os serviços "nfs-common" e "portmap". Se você quiser usar uma máquina Kurumin também como servidor, então ative também o serviço "nfs-kernel-server".
Para ativar estes três serviços no Kurumin, use os comandos abaixo (como root):
# /etc/init.d/portmap start # /etc/init.d/nfs-common start # /etc/init.d/nfs-kernel-server start
... ou use o ícone mágico disponível no Iniciar > Redes e acesso remoto > NFS.
Para que os comandos sejam executados automaticamente durante o boot, você pode adicionar adicionar as linhas no final do arquivo "/etc/init.d/bootmisc.sh".
As pastas são compartilhadas editando o arquivo "/etc/exports" no servidor. Basta adicionar as pastas que serão compartilhadas, uma por linha, seguindo os exemplos abaixo:
Para compartilhar a pasta /home/kurumin/arquivos como somente leitura, para todos os micros da sua rede local, adicione a linha:
/home/kurumin/arquivos 192.168.0.*(ro) # (onde o 192.168.0. é a faixa de endereços usada na rede)
Para compartilhar a pasta "/home/kurumin/imagens" com permissão de leitura e escrita (que você precisaria para gravar as imagens do Partimage), adicione a linha:
/home/kurumin/imagens 192.168.0.*(rw)
Para compartilhar a pasta /imagens, com apenas o micro 192.168.0.3:
/imagens 192.168.0.3(rw)
Depois de editar o arquivo, você deve reiniciar o servidor NFS pra que as alterações entrem em vigor. Isso pode ser feito com os comandos:
# service netfs restart (no Mandriva)
# /etc/init.d/nfs-kernel-server restart (no Kurumin e outras distribuições derivadas do Debian)
Os clientes podem montar as pastas compartilhadas através do comando:
# mount -t nfs 192.168.0.1:/home/arquivos /home/arquivos

Onde o "192.168.0.1:/home/arquivos" é o endereço do servidor, seguido pela pasta que está sendo compartilhada e o "/home/arquivos" é a pasta local onde o compartilhamento está sendo montado.
Para que a alteração seja definitiva, você deve adicionar esta instrução no arquivo "/etc/fstab". A sintaxe fica um pouco diferente, mas os parâmetros são basicamente os mesmos. O comando acima ficaria assim se adicionado no fstab:
192.168.0.1:/home/arquivos /home/arquivos nfs defaults 0 0
Você pode salvar e restaurar imagens em uma pasta montada via NFS da mesma forma que faria com um arquivo local, basta indicar a localização do arquivo dentro da pasta.
Segurança: detectando rootkits
Um tipo de ataque grave e relativamente comum contra máquinas Linux são os famosos rootkits, softwares que exploram um conjunto de vulnerabilidades conhecidas para tentar obter privilégios de root na máquina afetada. Existem vários rootkits que podem ser baixados da Net, variando em nível de eficiência e atualização.
Os rootkits podem ser instalados tanto localmente (quando alguém tem acesso físico à sua máquina) quanto remotamente, caso o intruso tenha acesso via SSH, VNC, XDMCP ou qualquer outra forma de acesso remoto. Neste caso, ele precisará primeiro descobrir a senha de algum dos usuários do sistema para poder fazer login e instalar o programa.
O alvo mais comum neste caso são contas com senhas fáceis. Qualquer instalação com o SSH ou telnet ativo e alguma conta de usuário com uma senha fácil (ou sem senha) é muito vulnerável a este tipo de ataque.
A instalação do rootkit é em geral o último passo de uma série de ataques que visam obter acesso a uma conta de usuário do sistema. A partir do momento que é possível logar na máquina, o atacante executa o rootkit para tentar obter privilégios de root.
Uma vez instalado, o rootkit vai alterar binários do sistema, instalar novos módulos no Kernel e alterar o comportamento do sistema de várias formas para que não seja facilmente detectável. O processo do rootkit não aparecerá ao rodar o "ps -aux", o módulo que ele inseriu no Kernel para alterar o comportamento do sistema não vai aparecer ao rodar o "lsmod", e assim por diante.
Aparentemente vai estar tudo normal, você vai poder continuar usando a máquina normalmente, mas existirão outras pessoas com acesso irrestrito a ela, que poderão usá-la remotamente da forma que quiserem. Se num desktop isso já parece assustador, imagine num servidor importante.
Naturalmente também existem programas capazes de detectar rootkits. Um dos mais populares é o chkrootkit, que pode ser encontrado no: http://www.chkrootkit.org/.
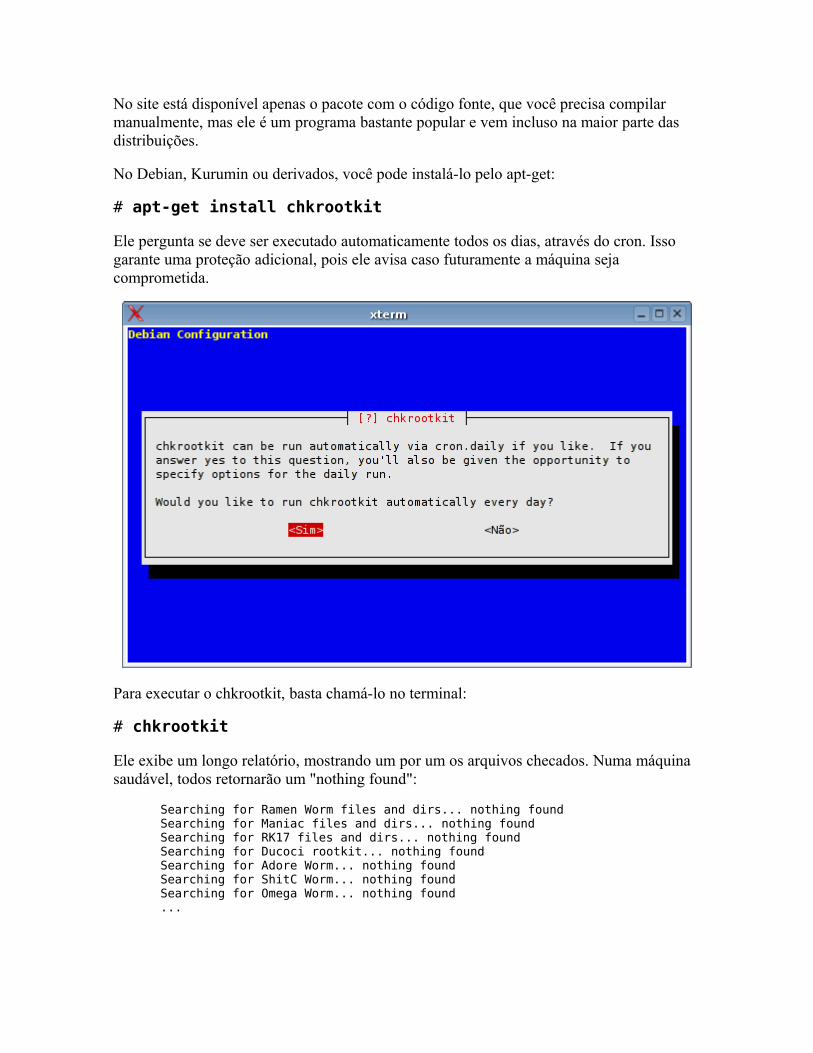
No site está disponível apenas o pacote com o código fonte, que você precisa compilar manualmente, mas ele é um programa bastante popular e vem incluso na maior parte das distribuições.
No Debian, Kurumin ou derivados, você pode instalá-lo pelo apt-get:
# apt-get install chkrootkit
Ele pergunta se deve ser executado automaticamente todos os dias, através do cron. Isso garante uma proteção adicional, pois ele avisa caso futuramente a máquina seja comprometida.
Para executar o chkrootkit, basta chamá-lo no terminal:
# chkrootkit
Ele exibe um longo relatório, mostrando um por um os arquivos checados. Numa máquina saudável, todos retornarão um "nothing found":
Searching for Ramen Worm files and dirs... nothing foundSearching for Maniac files and dirs... nothing foundSearching for RK17 files and dirs... nothing foundSearching for Ducoci rootkit... nothing foundSearching for Adore Worm... nothing foundSearching for ShitC Worm... nothing foundSearching for Omega Worm... nothing found...

Uma parte importante é a checagem das interfaces de rede, que aparece no final do relatório:
Checking `sniffer'... lo: not promisc and no packet sniffer socketseth0: not promisc and no packet sniffer sockets
Os sniffers são usados para monitorar o tráfego da rede e assim obter senhas e outras informações não apenas do servidor infectado, mas também de outras máquinas da rede local. Um dos sintomas de que existe algum sniffer ativo é a placa da rede estar em modo promíscuo, onde são recebidos também pacotes destinados a outros micros da rede local.
Alguns programas, como o VMware, o Ethereal e o Nessus colocam a rede em modo promíscuo ao serem abertos, mas caso isso aconteça sem que você tenha instalado nenhum destes programas, é possível que outra pessoa o tenha feito.
Caso o teste do chkrootkit detecte algo, o melhor é desligar o micro da rede, reiniciar usando um live-CD, salvar arquivos importantes e depois reinstalar completamente o sistema. Da próxima vez mantenha o firewall ativo, mantenha o sistema atualizado e fique de olho no que outras pessoas com acesso ao sistema estão fazendo.
Se a intrusão for um servidor importante e ele for ser enviado para análise, simplesmente desconecte-o da rede. Alguns indícios se perdem ao desligar ou reiniciar a máquina.
Infelizmente o teste do chkrootkit não é confiável caso seja executado em uma máquina já infectada, pois muitos rootkits modificam os binários do sistema, de forma que ele não descubra as alterações feitas.
A única forma realmente confiável de fazer o teste é dar boot em algum live-CD e executar o teste a partir dele, um sistema limpo.
Neste caso, monte a partição onde o sistema principal está instalado e execute o chkrootkit usando o parâmetro "-r", que permite especificar o diretório onde será feito o teste:
# mount /dev/hda1 /mnt/hda1# chkrootkit /mnt/hda1
O Knoppix inclui o chkrootkit instalado por padrão. Você pode também remasterizar o Kurumin para incluí-lo.
Instalando o Kurumin 7 (e outras distros) num pendrive ou cartão
Os cartões de memória flash sempre foram dispositivos caros, restritos a palmtops e dispositivos embarcados e, mesmo neles, quase sempre em pequenas quantidades, sempre combinados com memória RAM ou ROM (mais baratas). Na maioria dos palmtops, você encontra uma pequena quantidade de memória flash, que armazena o sistema operacional e uma quantidade maior de memória SRAM, que além de ser usada pelo sistema, armazena

todos os aplicativos e arquivos. Apenas recentemente um número expressivo de palmtops passou a usar memória flash como meio primário de armazenamento.
A memória flash é um tipo de memória de estado sólido constituída por células que "aprisionam" um impulso elétrico, preservando-o por anos, sem necessidade de alimentação elétrica. Só é necessário energia na hora de ler ou escrever dados.
Por não ter partes móveis, a resistência mecânica é muito boa. Se você começasse a espancar seu computador impiedosamente, o cartão de memória seria provavelmente um dos últimos componentes a ser danificado ;).
As limitações da memória flash são o custo por megabyte e uma vida útil relativamente curta, estimada em 1 milhão ciclos de leitura ou gravação, o que restringe seu uso em algumas áreas. Você nunca deve usar um cartão de memória flash para armazenar uma partição swap, por exemplo.
O custo por megabyte sempre será muito mais alto que o de um HD. A diferença é que o custo unitário do HD é mais ou menos fixo, enquanto num pendrive ou cartão o custo é proporcional à capacidade. Nenhum HD (novo) custa menos que uns 80 dólares, o que evolui é a capacidade. Por outro lado, em fevereiro de 2007, um cartão SD de 2 GB já podia ser comprado por R$ 80, bem menos que um HD.
Desde o início do milênio, o custo memória flash tem caído pela metade a cada ano, esmagado pelas melhorias no processo de fabricação e novas tecnologias, que permitiram que cada célula passasse a armazenar mais de um bit. Atualmente a memória flash já custa bem menos que a memória RAM e já começa a substituir os HDs em alguns nichos, onde a portabilidade e o baixo consumo são importantes. Além disso, os cartões de memória substituíram rapidamente os disquetes como meio de armazenamento, hoje em dia quase todo mundo tem um :).
A grande maioria das placas-mãe recentes são capazes de dar boot através de um pendrive ou leitor de cartões plugado na porta USB, como se fosse um HD removível. No Linux, estes dispositivos são detectados como se fossem HDs SCSI: um pendrive é detectado como "/dev/sda" e, num leitor com várias portas, cada tipo de cartão é visto como um dispositivo diferente. No meu, por exemplo, o cartão SD é visto como "/dev/sdc", o cartão compact-flash é visto como "/dev/sda" e o memory-stick como "/dev/sdd".
Existem ainda adaptadores, que permitem ligar um cartão compact-flash diretamente a uma das portas IDE da placa-mãe, fazendo com que ele seja detectado como um HD. Neste caso, ele será detectado pelo sistema como "/dev/hda" ou "/dev/hdc", por exemplo.

A novidade é que você pode instalar Linux no pendrive ou cartão e dar boot diretamente através dele. Você pode usar esta idéia para ter um sistema portátil, que pode transportar para qualquer lugar, ou para montar micros sem HD, que usam memória flash como mídia de armazenamento.
Existem duas opções. Você pode instalar diretamente o sistema no pendrive, como se fosse um HD, ou instalar a imagem de um live-CD, como o Kurumin ou o Damn Small, e usar o espaço excedente para armazenar arquivos.
Fazer uma instalação "real" é a opção mais simples. Você precisa apenas escolher uma distribuição razoavelmente atual, cujo instalador seja capaz de detectar o pendrive, e fazer uma instalação normal, particionando e instalando. Por outro lado, esta é a opção mais dispendiosa, pois o sistema instalado consume bem mais espaço que a imagem compactada usada no CD.
Um segundo problema é que a instalação serviria apenas para o PC usado durante a instalação. Sempre que fosse usar o pendrive em outro micro, você teria que reconfigurar o sistema para trabalhar na nova configuração, um trabalho pouco agradável :-).
A segunda opção, instalar a imagem de um live-CD, é mais econômica do ponto de vista do espaço e permite usar o pendrive em vários micros diferentes, pois o sistema detecta o hardware durante o boot, como ao rodar a partir do CD. Se você tem um pendrive ou cartão de 2 GB, pode rodar praticamente qualquer distribuição live-CD, ficando ainda com mais de 1 GB de espaço livre para guardar arquivos. Você pode também remasterizar o CD, de forma a deixar o sistema mais enxuto, ou usar uma distribuição mais compacta, como o Slax ou o Damn Small.
Vou usar como exemplo o Kurumin 7, mas esta mesma receita pode ser usada no Knoppix e (com pequenas adaptações) em praticamente qualquer outra distribuição em live-CD.
Para melhorar a compatibilidade, vamos utilizar o grub como gerenciador de boot. Ele oferece uma boa flexibilidade e apresenta menos problemas de compatibilidade com placas diversas. Note que apenas placas-mãe relativamente recentes realmente suportam boot através da porta USB. Muitas chegam a oferecer a opção no setup, mas falham na hora H.

Esta receita realmente funciona. Se você seguir todos os passos corretamente e ainda assim receber um "Grub: Disk error" ou "Error 21", provavelmente o problema é com o BIOS da placa mãe. Em alguns casos, atualizar o BIOS pode resolver, mas em outros você vai ter que esperar até conseguir trocar de placa.
Os problemas de compatibilidade são justamente o principal problema dos pendrives bootáveis; se você quer algo que funcione em qualquer micro, é melhor continuar usando o CD-ROM :p.
Comece particionando o pendrive. Você pode também usar um cartão com a ajuda de um leitor USB. Ambos são reconhecidos pelo sistema da mesma forma. Se você tem um pendrive de 2 GB, o ideal é deixar uma partição FAT no início, para guardar arquivos e criar uma partição de 600 ou 700 MB (de acordo com o tamanho da distribuição que for utilizar) para a imagem do sistema. A partição FAT no início permite que você continue acessando o pendrive normalmente através do Windows.
A imagem do Kurumin 7 tem 604 MB. Como precisaremos de algum espaço adicional para os arquivos do grub e sempre algum espaço é perdido ao formatar, é recomendável criar uma partição de 650 MB para o sistema. Ao usar outras distribuições, calcule o espaço necessário de acordo com o tamanho do sistema.
Os pendrives já vem formatados de fábrica, com uma grande partição FAT. Você pode usar o gparted para redimensioná-la e criar uma partição EXT2 para o sistema. Naturalmente, você poderia usar outro sistema de arquivos, mas o EXT2 é suficiente para o que precisamos.
Num pendrive de 2 GB, ficaria assim:
sda1: 1.3 GB (FAT)sda2: 650 MB (EXT2)
Para formatar as partições pelo terminal, use os comandos:
# mkfs.vfat /dev/sda1# mkfs.ext2 /dev/sda2(onde o /dev/sda o dispositivo referente ao pendrive)
O primeiro passo é montar o CD-ROM ou o arquivo ISO do sistema e copie todos os arquivos para dentro da segunda partição do pendrive, deixando-a com a mesma estrutura de pastas que o CD-ROM:
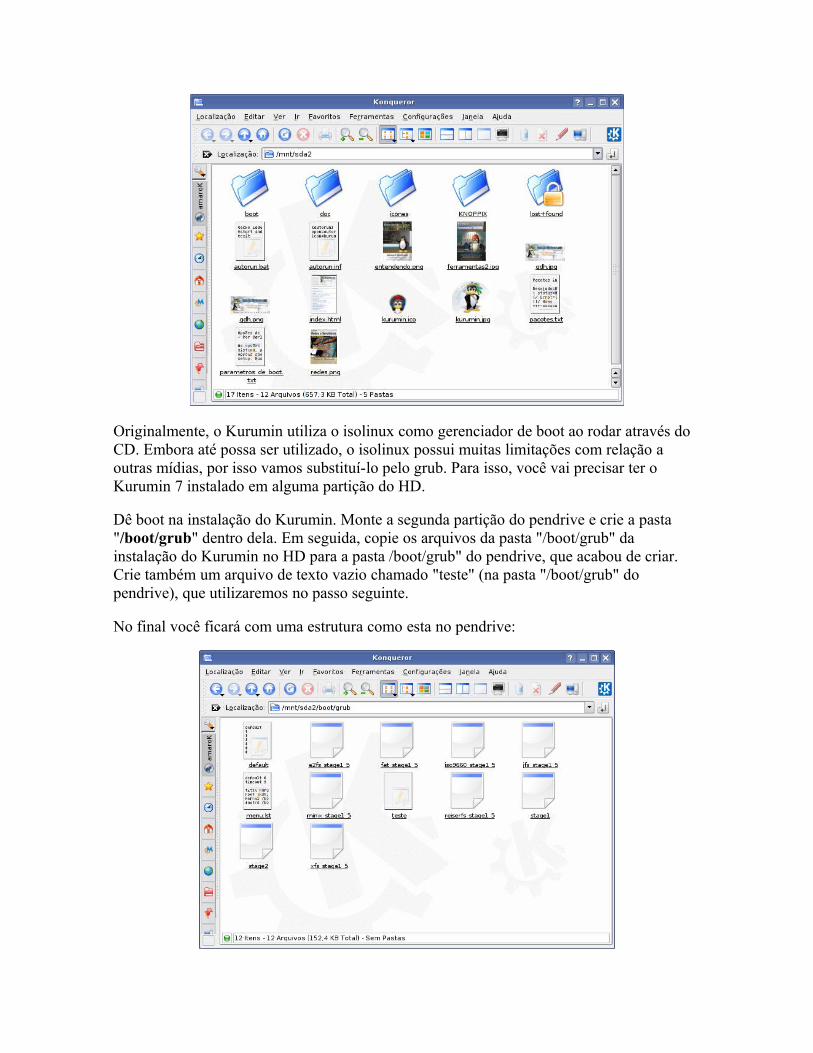
Originalmente, o Kurumin utiliza o isolinux como gerenciador de boot ao rodar através do CD. Embora até possa ser utilizado, o isolinux possui muitas limitações com relação a outras mídias, por isso vamos substituí-lo pelo grub. Para isso, você vai precisar ter o Kurumin 7 instalado em alguma partição do HD.
Dê boot na instalação do Kurumin. Monte a segunda partição do pendrive e crie a pasta "/boot/grub" dentro dela. Em seguida, copie os arquivos da pasta "/boot/grub" da instalação do Kurumin no HD para a pasta /boot/grub" do pendrive, que acabou de criar. Crie também um arquivo de texto vazio chamado "teste" (na pasta "/boot/grub" do pendrive), que utilizaremos no passo seguinte.
No final você ficará com uma estrutura como esta no pendrive:

Simplesmente copiar os arquivos do grub para dentro do pendrive não basta. Precisamos agora instalar o grub no setor de boot do pendrive, de forma que ele se torne bootável. Para isso, usaremos o prompt do grub. Para acessá-lo use (a partir da instalação do Kurumin 7 no HD) o comando "grub" (como root). Você verá um prompt como este:
GNU GRUB version 0.97 (640K lower / 3072K upper memory)
[ Minimal BASH-like line editing is supported. For the first word, TABlists possible command completions. Anywhere else TAB lists the possiblecompletions of a device/filename. ]
grub>
O grub utiliza uma nomenclatura peculiar para nomear os drives. É aqui que o arquivo "teste" vazio nos vai ser útil. Podemos utilizá-lo para descobrir como o grub identificou o pendrive. Para isso, use o comando "find /boot/grub/teste" no prompt do grub:
grub> find /boot/grub/teste
(hd1,1)
A resposta indica que (na nomenclatura usada pelo grub) o arquivo foi encontrado na partição 1 do hd1. O grub nomeia os dispositivos e partições a partir do zero, de forma que isso equivale à segunda partição, do segundo HD, ou seja, a segunda partição do pendrive :).
Falta agora só instalar o grub na partição indicada. Preste atenção nesta etapa, pois instalar no dispositivo errado pode ser desastroso :). Use os comandos "root (hd1,1)", "setup (hd1)", "setup (hd1,1)" e "quit", substituindo os endereços, caso diferentes no seu caso. Note que instalei o grub duas vezes, uma no raiz do pendrive e outra na partição. Isto não é realmente necessário (instalar no raiz é suficiente), faço apenas por desencargo:
grub> root (hd1,1)
Filesystem type is ext2fs, partition type 0x83
grub> setup (hd1)
Checking if "/boot/grub/stage1" exists... yesChecking if "/boot/grub/stage2" exists... yesChecking if "/boot/grub/e2fs_stage1_5" exists... yesRunning "embed /boot/grub/e2fs_stage1_5 (hd1)"... 15 sectors are embedded.SucceededRunning "install /boot/grub/stage1 (hd1) (hd1)1+15 p (hd1,1)/boot/grub/stage2 /boot/grub/menu.lst"... succeededDone.
grub> setup (hd1,1)
Checking if "/boot/grub/stage1" exists... yesChecking if "/boot/grub/stage2" exists... yesChecking if "/boot/grub/e2fs_stage1_5" exists... yesRunning "embed /boot/grub/e2fs_stage1_5 (hd1,1)"... failed (this is not fatal)Running "embed /boot/grub/e2fs_stage1_5 (hd1,1)"... failed (this is not

fatal)Running "install /boot/grub/stage1 (hd1,1) /boot/grub/stage2 p /boot/grub/menu.lst "... succeededDone.
grub> quit
A esta altura, você terá uma estrutura similar a esta no pendrive:
/boot/grub/boot/isolinux/KNOPPIX
A pasta "/boot/isolinux" contém os arquivos de boot originais do sistema (como o Kernel e o arquivo initrd.gz), enquanto a pasta "/KNOPPIX" contém a imagem compactada do sistema. O próximo passo é justamente adaptar a cópia do grub que criamos para utilizar estes arquivos.
Acesse a parta "/boot/grub" (no pendrive) e delete o arquivo "device.map", ele contém um cache dos dispositivos disponíveis na máquina, que deletamos para que o grub detecte tudo a cada boot, já que o pendrive será utilizado em várias máquinas diferentes.
Abra agora o arquivo "menu.lst". Apague todo o seu conteúdo e substitua pelas linhas abaixo:
default 0timeout 9
title Kurumin Linuxroot (hd0,1)kernel /boot/isolinux/linux26 ramdisk_size=100000 init=/etc/init vga=791 quiet lang=usinitrd /boot/isolinux/minirt.gz
title BOOT pelo HDroot (hd1)chainloader +1
Independentemente de como o grub tenha detectado o pendrive na etapa anterior, quando você dá boot através dele, o grub sempre o vê como "(hd0)". O sistema está instalado na segunda partição, o que nos leva ao endereço "(hd0,1)", que usamos na opção principal, responsável por carregar o sistema instalado no pendrive. Se por acaso você estiver usando uma única partição no pendrive, substitua o "(hd0,1)" por "(hd0,0)"
Note que as opções "/boot/isolinux/linux26" e "/boot/isolinux/minirt.gz" indicam a localização da imagem de Kernel e o arquivo initrd que serão utilizados. O nome dos arquivos pode mudar de distribuição para distribuição, por isso é sempre importante confirmar.
A segunda opção (title BOOT pelo HD) oferece a opção de dar um boot normal, carregando o sistema instalado no HD, sem que você precise remover o pendrive.

Com isto, você já tem um pendrive ou cartão bootável, basta configurar o setup para inicializar através dele e testar. Procure pela opção "First Boot Device" e configure-a com a opção "Generic USB Flash", "USB-HDD" ou "Removable Devices", de acordo com o que estiver disponível. Algumas placas (mesmo alguns modelos relativamente recentes), são problemáticas com relação ao boot através de pendrives. Numa Asus A7N8X-X que testei, por exemplo, o pendrive só era detectado pelo BIOS caso a opção "APIC Function" (que não tem nada a ver com a história) estivesse habilitada.
Uma pegadinha é que o BIOS só aceita inicializar através do pendrive se você ativar a flag "bootable" para a partição (do pendrive) onde salvou a imagem do sistema. Sem isso, o boot para uma uma mensagem reclamando de que o dispositivo não é bootável.
Para fazer isso através do gparted, clique com o botão direito sobre a partição "/dev/sda2" e acesse a opção "Manage Flags". No menu, marque a opção "boot":

No cfdisk, selecione a partição e ative a opção "[Bootable]". Inicialmente a tela de boot é bastante simples, contendo apenas um menu de texto com as duas opções definidas no arquivo "menu.lst", mas você pode melhorá-la adicionando uma imagem de fundo ou cores. A configuração visual não muda em relação a uma instalação normal do grub.
O interessante é que isto pode ser feito com outros dispositivos compatíveis com o padrão usb-storage (onde o cartão é visto pelo sistema como se fosse um pendrive), como câmeras e até mesmo palms. Ou seja, com um cartão de capacidade suficiente, sua câmera pode, além de tirar fotos e guardar arquivos, servir como sistema de boot.
Mais um detalhe importante é com relação à velocidade da porta USB e também à velocidade do pendrive, cartão ou câmera usada. As portas USB 1.1 têm a velocidade de transferência limitada a cerca de 800 KB/s, o que torna o carregamento do sistema lento, quase como se desse boot a partir de um CD-ROM 6x.
As portas USB 2.0 são muito mais rápidas, fazendo com que o limitante seja a velocidade do cartão ou pendrive usado. Os de fabricação recente têm geralmente tem uma velocidade de leitura entre 20 e 40 MB/s, o que já oferece um desempenho satisfatório.
O grande problema fica por conta de algumas câmeras e pendrives antigos, onde a taxa de transferência é muito mais baixa, muitas vezes menos de 300 kb/s. Nada o impede de utilizá-los, mas o desempenho do sistema será muito ruim.
Salvando as configurações
Até aqui, o sistema dá boot como se estivesse rodando a partir do CD, nenhuma grande vantagem. Podemos incrementar isso usando o espaço livre para criar imagens de loopback, para armazenar configurações e programas instalados. Fazendo isso, o sistema lembra as suas configurações e permite a instalação de programas adicionais, praticamente como se estivesse instalado.
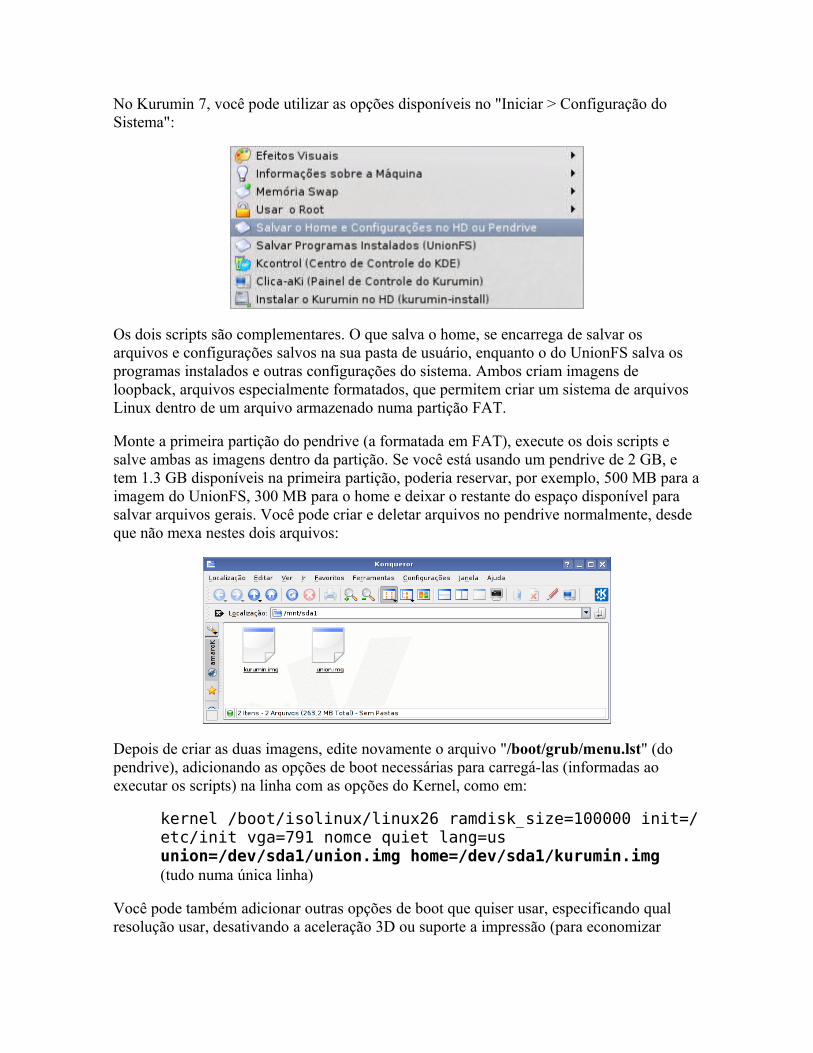
No Kurumin 7, você pode utilizar as opções disponíveis no "Iniciar > Configuração do Sistema":
Os dois scripts são complementares. O que salva o home, se encarrega de salvar os arquivos e configurações salvos na sua pasta de usuário, enquanto o do UnionFS salva os programas instalados e outras configurações do sistema. Ambos criam imagens de loopback, arquivos especialmente formatados, que permitem criar um sistema de arquivos Linux dentro de um arquivo armazenado numa partição FAT.
Monte a primeira partição do pendrive (a formatada em FAT), execute os dois scripts e salve ambas as imagens dentro da partição. Se você está usando um pendrive de 2 GB, e tem 1.3 GB disponíveis na primeira partição, poderia reservar, por exemplo, 500 MB para a imagem do UnionFS, 300 MB para o home e deixar o restante do espaço disponível para salvar arquivos gerais. Você pode criar e deletar arquivos no pendrive normalmente, desde que não mexa nestes dois arquivos:
Depois de criar as duas imagens, edite novamente o arquivo "/boot/grub/menu.lst" (do pendrive), adicionando as opções de boot necessárias para carregá-las (informadas ao executar os scripts) na linha com as opções do Kernel, como em:
kernel /boot/isolinux/linux26 ramdisk_size=100000 init=/etc/init vga=791 nomce quiet lang=us union=/dev/sda1/union.img home=/dev/sda1/kurumin.img (tudo numa única linha)
Você pode também adicionar outras opções de boot que quiser usar, especificando qual resolução usar, desativando a aceleração 3D ou suporte a impressão (para economizar

memória), e assim or diante. Se você usa a opção de boot "kurumin screen=1024x768 xmodule=i810 nocups", por exemplo, a linha completa ficaria:
kernel /boot/isolinux/linux26 ramdisk_size=100000 init=/etc/init vga=791 nomce quiet lang=us union=/dev/sda1/union.img home=/dev/sda1/kurumin.img screen=1024x768 xmodule=i810 nocups
A partir daí, o sistema passa a inicializar usando as imagens do home e UnionFS por padrão, preservando suas configurações e programas instalados, rodando quase que da mesma forma que um sistema instalado.
O Knoppix, Kanotix e várias outras distribuições oferecem opções similares para salvar as configurações no pendrive, que podem ser usadas da mesma maneira, sempre gerando a imagem com as configurações e adicionando a opção de boot apropriada no arquivo "/boot/grub/menu.lst" do pendrive, para que ela seja executada a cada boot.
Monitores de temperatura e coolers
A partir da época do Pentium II, as placas-mãe passaram a vir com sensores de temperatura para o processador e, mais tarde, com sensores para o chipset e também monitores de rotação dos coolers.
Como os processadores dissipam cada vez mais calor, os sensores acabam sendo um recurso importante. Se o processador trabalha a uma temperatura alta mesmo nos dias frios, significa que provavelmente vai começar a travar nos dias mais quentes. Com o tempo os coolers acumulam sujeira, que com o tempo faz com que girem mais devagar, perdendo eficiência. Com os sensores você pode tomar conhecimento deste tipo de problema antes que seu micro comece a travar.
No Linux, o suporte aos sensores da placa-mãe é provido por dois projetos, o I2C e o LM-sensors. Até o Kernel 2.4 era necessário baixar os pacotes e compilá-los manualmente, mas, a partir do 2.6, eles foram incluídos oficialmente no Kernel, o que facilitou as coisas. Usando uma distribuição atual você já encontrará os módulos pré-instalados.
Os pacotes para distribuições antigas, baseadas no Kernel 2.4 ou anterior, podem ser baixados no:http://secure.netroedge.com/~lm78/download.html.
Com os módulos disponíveis, falta apenas instalar o pacote "lm-sensors" que contém os utilitários de configuração e arquivos necessários. Ele inclui o script "sensors-detect", que ajuda na configuração inicial, detectando os sensores presentes na placa-mãe e dizendo quais módulos devem ser carregados para habilitar o suporte:
# sensors-detect

Ele faz várias perguntas, e exibe vários textos explicativos. Você pode simplesmente ir aceitando os valores defaults, que fazem ele executar todos os testes.
Caso os sensores da sua placa-mãe sejam suportados, ele exibirá no final um relatório com os passos necessários para ativá-los, oferecendo a opção de fazer as alterações necessárias automaticamente:
To make the sensors modules behave correctly, add these lines to /etc/modules:
#----cut here----# I2C adapter driversi2c-nforce2# I2C chip driversasb100w83l785tseeprom#----cut here----
Do you want to add these lines to /etc/modules automatically? (yes/NO)
No meu caso, é preciso apenas carregar os módulos i2c-nforce2, asb100, w83l785ts e eeprom, o que pode ser feito manualmente, usando o comando "modprobe", ou de forma definitiva, adicionado as linhas no final do arquivo "/etc/modules", o que orienta o sistema a carregá-los durante o boot.
Outra opção é incluir os comandos que carregam os módulos no final do arquivo "/etc/rc.d/rc.local" ou "/etc/init.d/boomisc.sh" (no Debian e derivados), o que também fará com que os módulos sejam carregados no boot. Neste caso, as linhas a serem inseridas são:
modprobe i2c-nforce2modprobe asb100modprobe w83l785tsmodprobe eeprom
Você pode ver uma lista dos chips suportados por cada módulo no:http://secure.netroedge.com/~lm78/supported.html.
Com os sensores habilitados, você pode ver um relatório com as informações disponíveis usando os comandos:
# sensors -s$ sensors
O primeiro precisa ser executado como root e calibra os valores dos sensores usando uma série de parâmetros específicos para cada chipset. A partir daí, você pode usar o segundo comando como usuário, para verificar os valores já calibrados.

Não é muito prático ficar abrindo o terminal cada vez que quiser checar a temperatura. Você pode resolver isso instalando um monitor gráfico, como o Ksensors e o Gkrellm, instalados através dos pacotes de mesmo nome. O Ksensors é interessante para quem usa o KDE, pois permite usar um ícone com a temperatura ao lado do relógio, enquanto o Gkrellm tem seu público fiel graças ao bom design.
Em ambos os casos, você precisa ativar os sensores que serão exibidos na janela de configuração. No Ksensors existe a opção de exibir cada mostrador ao lado do relógio (Dock) ou na barra do programa (Panel).
Na configuração, existe uma opção para que o Ksensors seja aberto durante a inicialização do KDE. Mas, em versões antigas do programa, esta opção não funciona, fazendo com que você precise sempre inicializá-lo manualmente. Se for o caso, adicione manualmente uma entrada para ele dentro da pasta "/home/$USER/.kde/Autostart/", onde ficam ícones de atalho para todos os programas que serão inicializados durante o boot.
Existem ainda vários tipos de scripts, painéis do Superkaramba e diversos pequenos programas que monitoram a temperatura e oferecem funções diversas. Estes scripts são fáceis de escrever, pois simplesmente utilizam as informações exibidas pelo comando "sensors". Um exemplo é o pequeno script abaixo, que gera um arquivo chamado "/tmp/cpu" e o atualiza a cada dois segundos com a temperatura do processador. O texto deste arquivo poderia ser exibido numa barra do Superkaramba ou postado numa página web, por exemplo.
while [ 1 = 1 ]; do sensors | grep 'temp:' | sed -r 's/ +/ /g' | cut -d " " -f2 > /tmp/cpu sleep 2 done
Em alguns casos, os sensores vêm de fábrica desativados, de forma que funcionam apenas em conjunto com o driver for Windows. Este é o caso de, por exemplo, algumas placas-mãe da Asus e alguns notebooks da Toshiba, como o A70 e A75. Nestes casos não existe uma forma simples de ativar os sensores no Linux.
Outra forma de acompanhar a temperatura (que funciona em muitos notebooks que não são compatíveis com o lm-sensors) é usar o comando "acpi -V", que mostra informações sobre o status da bateria e também a temperatura do processador e placa-mãe, como em:

$ acpi -V
Battery 1: charged, 100%Thermal 1: active[2], 62.0 degrees CThermal 2: ok, 49.0 degrees CThermal 3: ok, 31.0 degrees CAC Adapter 1: on-line
Veja que neste caso o notebook tem três sensores de temperatura: para o processador, chipset da placa-mãe e HD.
Com relação à bateria, você pode encontrar algumas informações interessantes também dentro da pasta "/proc/acpi/battery/". Dentro da pasta, você encontra subpastas para cada bateria disponível e, dentro de cada uma, o arquivo de texto "info". Você pode listar todos de uma vez usando o comando:
$ cat /proc/acpi/battery/*/info
present: yesdesign capacity: 3788 mAhlast full capacity: 3788 mAhbattery technology: rechargeabledesign voltage: 10800 mVdesign capacity warning: 190 mAhdesign capacity low: 38 mAhcapacity granularity 1: 100 mAhcapacity granularity 2: 100 mAhmodel number: Primaryserial number: 57353 2005/03/19battery type: LIonOEM info: Hewlett-Packard
Por aqui você sabe que o notebook usa uma bateria Li-Ion (do tipo que não tem problemas com o efeito memória) e que a bateria está em bom estado, já que na última carga ela atingiu a carga máxima. Quando a bateria começa a ficar viciada, a carga máxima atingida vai ficando cada vez mais abaixo da máxima, acompanhado por uma redução ainda maior na autonomia. Por estas informações você tem como verificar a saúde da bateria sem precisar ficar carregando e descarregando para cronometrar o tempo de autonomia.
Além de usar os sensores do ACPI, é possível acompanhar a temperatura do HD através do "hddtemp". Ele é um pacote extremamente pequeno, que está disponível na maioria das distribuições. No Debian você pode instalar via apt-get:# apt-get install hddtemp
Com ele instalado, use o comando "hddtemp" para checar a temperatura do HD desejado, como em:
$ hddtemp /dev/hda
/dev/hda: SAMSUNG SP1203N: 29°C
Muitos programas de monitoramento, como o Gkrellm e vários temas do Superkaramba, são capazes de acompanhar o relatório do hddtemp, exibindo a temperatura em tempo real.

Gerenciamento de energia
Você saberia dizer qual é o aplicativo mais usado atualmente, considerando todas as categorias de aplicativos existentes, incluindo os jogos e aplicativos profissionais? Se você respondeu que é o Word, ou o OpenOffice, errou, o aplicativo mais usado ainda é o jogo de paciência (em suas várias versões), competindo com os navegadores.
Apesar dos processadores estarem cada vez mais poderosos, a maioria dos usuários passa o dia rodando aplicativos leves, ou jogando paciência, utilizando apenas uma pequena parcela do poder de processamento do micro.
Prevendo isso, quase todos os processadores atuais oferecem recursos de economia de energia, que reduzem a freqüência, tensão usada, ou desligam componentes do processador que não estão em uso, reduzindo o consumo enquanto o processador é sub-utilizado.
Naturalmente, estes recursos de gerenciamento também podem ser ativados no Linux. Vamos a um resumo das opções disponíveis.
O primeiro passo é instalar o pacote "powernowd", o daemon responsável por monitorar o processador, ajustando a freqüência e recursos de acordo com a situação. Nas distribuições derivadas do Debian, instale-o via apt-get, como em:
# apt-get install powernowd
No Ubuntu e Kubuntu o comando é o mesmo, você deve apenas ter o cuidado de descomentar a linha referente ao repositório "Universe" dentro do arquivo "/etc/apt/sources.list".
No Mandriva, instale-o usando o comando "urpmi powernowd". No Fedora e outras distribuições que não o incluam nos repositórios padrão, você pode instalar a partir do pacote com os fontes, disponível no: http://www.deater.net/john/powernowd.html.
O powernowd trabalha em conjunto com um módulo de kernel, responsável pelo trabalho pesado. O módulo varia de acordo com o processador usado:
speedstep-centrino: Este é o módulo usado por todos os processadores Intel atuais, incluindo todos o Core Solo, Core Duo, Pentium M e Pentium 4 Mobile. A exceção fica por conta do Celeron M (veja mais detalhes abaixo), que tem o circuito de gerenciamento desativado.
powernow-k8: Este é o módulo usado pelos processadores AMD de 64 bits (tanto os Athlon 64, quanto os Turion), que oferecem suporte ao PowerNow!. O driver também oferece suporte aos Semprons, que oferecem uma opção mais limitada de gerenciamento.

powernow-k7: Antes do Athlon 64, a AMD produziu diversas versões do Athlon XP Mobile, uma versão de baixo consumo destinada a notebooks. Este módulo dá suporte a eles. No caso dos Athlons e Durons antigos, você pode usar o "athcool", que apresento mais adiante.
longhaul: Este módulo dá suporte aos processadores Via C3, baseados no core Nehemiah. Ele é encontrado em placas mãe mini-ITX e em alguns notebooks.
Para ativar o powernowd, você começa carregando o módulo "acpi" (caso já não esteja carregado), seguido do módulo "freq_table" (que obtém a lista das frequências suportadas pelo processador) e um dos 4 módulos que descrevi acima. A partir daí a base está pronta e o powernowd pode ser finalmente ativado.
Se você usasse um Athlon 64, por exemplo, os comandos seriam:
# modprobe acpi# modprobe freq_table# modprobe powernow-k8# /etc/init.d/powernowd restart
Para um Core 2 Duo, os comandos seriam os mesmos, mudando apenas o módulo referente ao processador. Ao invés do "powernow-k8", seria usado o "speedstep-centrino":
# modprobe acpi# modprobe freq_table# modprobe speedstep-centrino# /etc/init.d/powernowd restart
Ao instalar o pacote do powernowd, ele ficará configurado para ser carregado durante o boot. Mas, ainda falta fazer com que o sistema carregue os módulos necessários. Para isso, adicione a lista dos módulos no final do arquivo "/etc/modules" (sem o "modprobre"), como em:
acpifreq_tablepowernow-k8
Você pode acompanhar a freqüência de operação do processador através do comando "cpufreq-info". Caso ele não esteja disponível, procure pelo pacote "cpufrequtils" no gerenciador de pacotes.
$ cpufreq-info
cpufrequtils 002: cpufreq-info (C) Dominik Brodowski 2004-2006Report errors and bugs to [email protected], please.analyzing CPU 0:
driver: powernow-k8CPUs which need to switch frequency at the same time: 0hardware limits: 1000 MHz - 2.00 GHzavailable frequency steps: 2.00 GHz, 1.80 GHz, 1000 MHz

available cpufreq governors: powersave, performance, userspacecurrent policy: frequency should be within 1000 MHz and 2.00 GHz.The governor "userspace" may decide which speed to usewithin this range.current CPU frequency is 1000 MHz (asserted by call to hardware).
Neste exemplo, estou usando um Athlon 64 3000+, que opera nativamente a 2.0 GHz. Apesar disso, o processador suporta também 1.8 e 1.0 GHz (com variações na tensão usada). O chaveamento entre as três frequências é feito de forma muito rápida, de acordo com a carga de processamento exigida. Na maior parte do tempo, o processador trabalha a apenas 1.0 GHz, onde consome menos de 10 watts (algo similar a um Pentium 133).
O fato da freqüência de operação do processador nunca cair abaixo de 1.0 GHz e o chaveamento entre as freqüências ser muito rápido, faz com que seja realmente difícil de perceber qualquer diferença de desempenho com o gerenciamento ativado ou desativado.
Ao usar um notebook, você pode ativar também os perfis de performance do cpufreq. Eles permitem que você escolha o perfil de gerenciamento a utilizar, alternando entre eles conforme desejado.
Para isso, carregue também os três módulos abaixo, usando o modprobe:
cpufreq_ondemandcpufreq_performancecpufreq_powersave
Adicione-os também no final do arquivo "/etc/modules", de forma que sejam carregados durante o boot.
Originalmente, você alternaria entre eles usando o comando "cpufreq-set -g", o que, convenhamos, não é uma opção muito prática.
Mas, se você usa o KDE, pode configurar o Klaptop, de forma a alternar entre eles clicando no ícone da bateria. Para isso, clique com o botão direito sobre o ícone da bateria ao lado do relógio e acesse a opção "Configurar Klaptop":
Dentro da janela, acesse a aba "Configurar ACPI" (a última) e clique no botão "Definir Aplicação Auxiliar". Forneça a senha de root, e, de volta à janela principal, marque todas as opções e clique no "Aplicar":
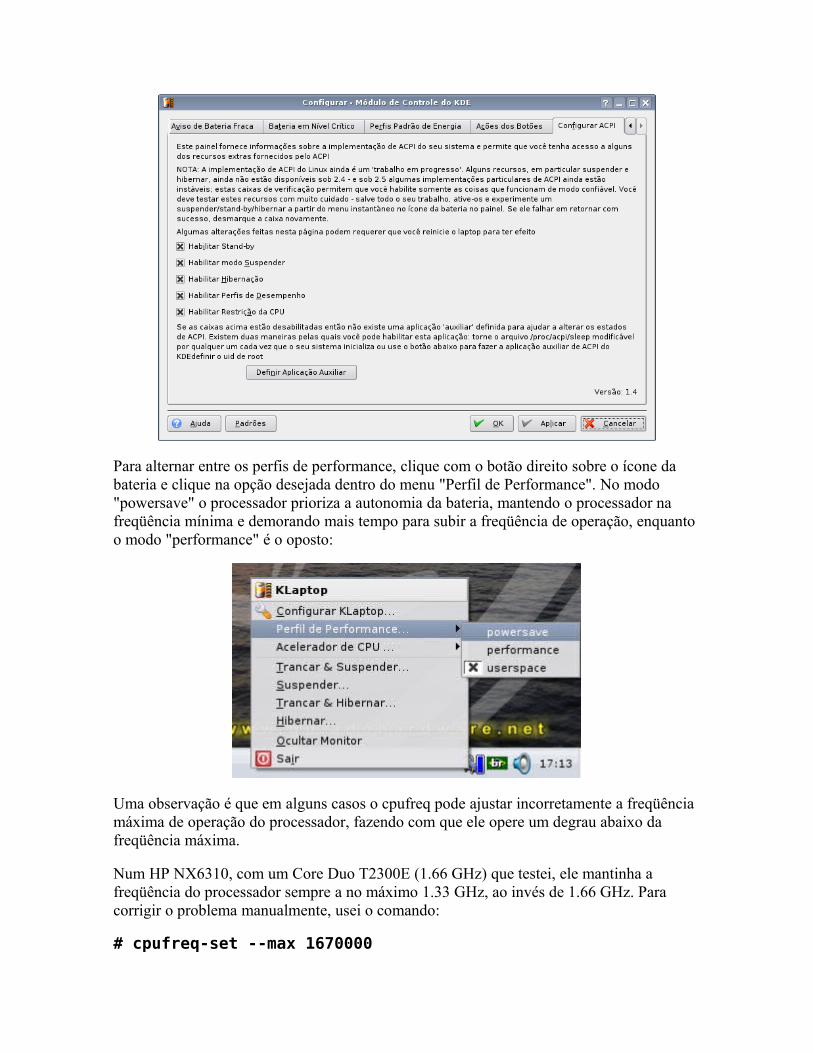
Para alternar entre os perfis de performance, clique com o botão direito sobre o ícone da bateria e clique na opção desejada dentro do menu "Perfil de Performance". No modo "powersave" o processador prioriza a autonomia da bateria, mantendo o processador na freqüência mínima e demorando mais tempo para subir a freqüência de operação, enquanto o modo "performance" é o oposto:
Uma observação é que em alguns casos o cpufreq pode ajustar incorretamente a freqüência máxima de operação do processador, fazendo com que ele opere um degrau abaixo da freqüência máxima.
Num HP NX6310, com um Core Duo T2300E (1.66 GHz) que testei, ele mantinha a freqüência do processador sempre a no máximo 1.33 GHz, ao invés de 1.66 GHz. Para corrigir o problema manualmente, usei o comando:
# cpufreq-set --max 1670000

O número indica a freqüência máxima do processador (em khz, por isso o monte de zeros), corrigindo o problema.
Finalmente, chegamos ao caso do Celeron M, que é a exceção à regra. Embora seja baseado no mesmo núcleo do Pentium M, ele tem o circuito de gerenciamento desativado, de forma a não concorrer diretamente com os processadores mais caros. Trata-se de uma castração intencional, que não pode ser revertida via software.
Você até pode reduzir a freqüência de operação do processador usando o cpufreq-set (como em "cpufreq-set -f 175000", que força o processador a trabalhar a 175 MHz). O comando é executado sem erros e usando o comando "cpufreq-info" ele realmente informa que o processador está trabalhando a 175 MHz. Porém, esta informação é irreal. Na verdade o que acontece é que o processador continua funcionando na freqüência máxima, porém inclui ciclos de espera entre os ciclos usados para processar instruções. Ou seja, no Celeron M, o que o comando faz é simplesmente limitar artificialmente o desempenho do processador, sem com isto reduzir de forma substancial o consumo. Ao forçar uma freqüência baixa, o notebook vai ficar extremamente lento, mas vai continuar esquentando quase da mesma maneira e a carga da bateria durando praticamente o mesmo tempo.
No caso dos notebooks baseados no Celeron M, as únicas formas de realmente economizar energia de forma considerável são reduzir o brilho da tela e desativar o transmissor da placa wireless. A idéia da Intel é justamente que você leve para casa um Pentium-M ou Core Duo, que são seus processadores mais caros.
Uma última dica é com relação aos Athlons e Durons antigos, que não são compatíveis com o powernowd. No caso deles, você pode usar o athcool, que utiliza instruções HLT e outros recursos disponíveis para reduzir o consumo e aquecimento do processador.
Usá-lo é bastante simples, basta instalar o pacote e rodar o comando:
# athcool on
Para desativar, use:
# athcool off
Na hora de instalar, procure pelo pacote "athcool", que é encontrado em todas as principais distribuições. Se ele não estiver disponível, você pode também recorrer à opção de baixar o pacote com o código fonte, disponível no: http://members.jcom.home.ne.jp/jacobi/linux/softwares.html
O athcool funciona perfeitamente em mais de 90% dos casos, mesmo em algumas das piores placas da PC-Chips. Entretanto, em algumas placas, o athcool pode causar irregularidades no som (deixando o áudio cortado), ou ao assistir vídeos. Algumas poucas placas travam quando ele é ativado e, embora muito raro, ele pode causar perda de arquivos se usado em algumas placas com o chipset SiS 640, como a Asus L3340M.

Capítulo 3: Instalando drivers adicionais
Além dos drivers open-source incluídos no Kernel, existe um conjunto de drivers proprietários ou semi-proprietários, na maioria dos casos desenvolvidos pelos próprios fabricantes. Muitos fabricantes receiam que abrindo as especificações das suas placas de vídeo, modems e placas de rede, os concorrentes terão mais facilidade em fazer engenharia reversa para descobrir seus segredos e usá-los em seus próprios produtos.
Muitos destes drivers precisam também do firmware do dispositivo para funcionar. O firmware é o responsável pela comunicação entre o driver e o hardware e é um dos componentes do driver for Windows, que vem incluído no CD de drivers que acompanha a placa.
Por não terem código aberto, estes drivers não são incluídos diretamente no Kernel e pelo mesmo motivo geralmente também não são incluídos nas distribuições, deixando para o dono o trabalho de baixar e instalá-los manualmente. Em alguns casos a instalação pode ser um pouco trabalhosa, por isso este capítulo inteiro é dedicado ao tema.
Verificando links, arquivos e compiladores
Uma das coisas mais chatas com relação a estes drivers é que os módulos gerados durante a instalação funcionam apenas numa versão específica do Kernel. Ao atualizar o Kernel, ou reinstalar uma distribuição diferente, você precisará sempre reinstalar os drivers.
Existem muitas coisas que podem dar errado na hora de compilar estes drivers. Vamos a um checklist dos problemas mais comuns:
- Kernel Headers: Os headers do Kernel são um pré-requisito para instalar qualquer driver. Os arquivos vão na pasta "/usr/src/kernel-headers-2.6.x/" ou "/usr/src/linux-headers-2.6.x/".
Os headers, ou cabeçalhos, incluem um conjunto de endereços e comandos, necessários para que o instalador do driver conheça o Kernel em que está trabalhando e consiga gerar um módulo sob medida para ele, mesmo sem ter o código fonte completo. É como um marceneiro que constrói móveis sob medida apenas com as medidas dos cômodos da casa.
Dentro da pasta devem existir pelo menos as pastas "arch/", "include/" e "scripts/":
Geralmente, o pacote "kernel-headers" incluído nas distribuições inclui apenas a pasta "include", que não é suficiente para instalar muitos drivers, incluindo o VMware, por exemplo. Nestes casos você precisará instalar também o pacote "kernel-source" que contém o código fonte completo do Kernel, copiando as outras duas pastas de que precisamos a partir da pasta "/usr/src/linux/2.6.x".
Outra coisa importante a verificar o conteúdo da pasta "arch/". Ela deve conter a pasta "i386" e dentro desta, um conjunto com várias pastas e arquivos. Em muitas distribuições, a pasta arch vem vazia dentro do pacote kernel-headers e o conteúdo é movido para dentro do pacote kernel-source. Nestes casos você precisa mesmo ter instalados os dois pacotes.
- Kernel Source: O código fonte completo do Kernel vai na pasta "/usr/src/linux-2.6.x/" ou em alguns casos na pasta "/usr/src/kernel-source-2.6.x", onde o "2.6.x" é a versão do Kernel.
Em muitos casos, como no Debian por exemplo, ao instalar o pacote kernel-source será apenas copiado um arquivo compactado em .tar.bz2 para a pasta "/usr/src/". Para concluir a instalação, você ainda precisará descompactá-lo com o comando "tar -jxvf kernel-source-2.6.x".
Dentro da pasta "/usr/src/linux-2.x.x" devem existir as pastas "arch/", "include/" e "scripts/", juntamente com vários outras que contém o restante do código fonte. Em alguns casos, o source não contém a pasta include/. Neste caso, copie-a a partir da pasta com os headers.
Desde que as três pastas estejam em ordem, o source completo substitui a pasta com os headers e pode ser usado no lugar deles na hora de compilar drivers.
- O link "/usr/src/linux": Em geral, os scripts de instalação dos drivers não se preocupam em tentar descobrir em qual pasta estão os headers do Kernel. No lugar disso eles

simplesmente acessam a pasta "/usr/src/linux", que é na verdade um link simbólico que deve apontar a pasta correta, com os headers ou o source do Kernel.
Em alguns casos, ele é criado automaticamente a instalar os pacotes com os headers ou o fonte do Kernel, em outros você deverá criá-lo manualmente, apontando ou para a pasta com os headers, ou para a pasta com o fonte completo.
Lembre-se de que os links simbólicos são criados com o comando "ln -s pasta_destino link", como em "ln -s /usr/src/linux-headers-2.6.14-kanotix-6 /usr/src/linux".
- O link /lib/modules/2.x.x/build: Muitos scripts checam outro link, o build, dentro da pasta com os módulos do Kernel, que também deve apontar para os headers ou os fontes do Kernel. Caso seja necessário criá-lo manualmente, rode o comando:
# ln -s /usr/src/kernel-headers-2.6.x /lib/modules/2.6.x/build
Não se esqueça de substituir o "2.6.x" em todos os exemplos pela versão do Kernel instalada na sua máquina.
- A versão do gcc: O compilador mais usado no Linux é o gcc. Ele compila não apenas código fonte em C mas também em várias outras linguagens.
Infelizmente, o gcc possui um histórico de incompatibilidades entre suas diferentes versões, o que faz com que o mesmo código fonte compilado em versões diferentes gere binários diferentes e em muitos casos até mesmo incompatíveis entre si.
Os desenvolvedores conhecem bem estes problemas, por isso sempre recomendam que você sempre use a mesma versão do gcc que foi usada para compilar o Kernel para compilar qualquer módulo ou driver que seja instalado posteriormente. Módulos compilados com versões diferentes do gcc muitas vezes não funcionam ou apresentam problemas diversos.
Normalmente as distribuições incluem sempre a mesma versão do gcc que foi usada para compilar o Kernel. Mas, caso você tenha atualizado o gcc ou atualizado o Kernel, vai acabar com versões diferentes.
A partir daí, muitos drivers não vão mais compilar, reclamando que a versão do gcc instalada é diferente da usada para compilar o Kernel.
Nestes casos, a solução ideal é procurar a versão correta do gcc e instalá-la. Mas, se por qualquer motivo não for possível fazer isso, você pode forçar os instaladores a usarem a versão instalada configurando a variável CC do sistema para apontar para a versão atual do CC. Este comando deve ser dado no terminal, antes de chamar o instalador. Ele não é persistente, você deve usá-lo antes de cada instalação:

# export CC=/usr/bin/gcc-4.0(onde o "/usr/bin/gcc-4.0" é a localização do executável do gcc atualmente instalado)
Caso isso não seja suficiente, configure a variável IGNORE_CC_MISMATCH com o valor 1, o que faz com que a checagem da versão do GCC seja desativado completamente:
# export IGNORE_CC_MISMATCH=1
- Outros compiladores: Além do gcc, alguns drivers podem precisar de outros compiladores ou bibliotecas, como o g++ e o libc6-dev. Por isso é sempre interessante marcar a categoria "compiladores" durante a instalação da distribuição. Isso assegura que você possui o conjunto completo. No Kurumin você pode usar o ícone mágico "instalar-compiladores".
Configurando softmodems no Linux
Apesar de serem tecnicamente inferiores, por diminuírem o desempenho do processador principal, proporcionarem conexões menos estáveis, etc., os softmodems são muito mais baratos e justamente por isso são a esmagadora maioria hoje em dia.
Como, apesar do avanço do ADSL e outras variedades de banda larga, quase 60% dos brasileiros ainda acessam via modem e destes provavelmente mais de três quartos utilizam softmodems, é inegável que o suporte a eles no Linux é essencial. Mesmo quem acessa via banda larga, normalmente possui algum tipo de softmodem instalado no desktop ou notebook, que usa de vez em quando, seja ao viajar, seja em casos de problemas com o ADSL.
Infelizmente, poucas distribuições Linux contam com suporte nativo a softmodems. No Mandriva, Fedora, SuSE, e na maioria das outras distribuições, o modem precisa ser instalado manualmente. Mas, isso não significa que eles não sejam compatíveis com o sistema. Pelo contrário, além de atualmente a maior parte dos modelos ser compatível, muitos apresentam um melhor desempenho e uma menor utilização do processador no Linux.
Antes de mais nada, você precisa descobrir qual é o chipset do seu modem. Não importa se ele é Clone, Genius, Aoca, ou qualquer outra marca, apenas o chipset utilizado. Para isso, basta dar uma boa olhada no modem. O chipset é chip principal e o nome do fabricante estará decalcado sobre ele. Se você estiver com o Windows instalado, uma olhada no gerenciador de dispositivos também pode ajudar.
No Linux a forma mais rápida de descobrir o modelo do modem é utilizando o comando:
# lspci
Ele retorna uma lista com todas as placas PCI e PCMCIA encontradas no micro:

00:00.0 Host bridge: Silicon Integrated Systems [SiS] 740 Host (rev 01)00:01.0 PCI bridge: Silicon Integrated Systems [SiS] SiS 530 Virtual PCI-to-PCI bridge (AGP)00:02.0 ISA bridge: Silicon Integrated Systems [SiS] 85C503/5513 (rev 10)00:02.5 IDE interface: Silicon Integrated Systems [SiS] 5513 [IDE] (rev d0)00:02.7 Multimedia audio controller: Silicon Integrated Systems [SiS] SiS7012 PCI Audio Accelerator (rev a0)00:03.0 Ethernet controller: Silicon Integrated Systems [SiS] SiS900 10/100 Ethernet (rev 90)00:05.0 Communication controller: Conexant HSF 56k HSFi Modem (rev 01)00:07.0 FireWire (IEEE 1394): VIA Technologies, Inc. IEEE 1394 Host Controller (rev 46)00:08.0 USB Controller: VIA Technologies, Inc. USB (rev 50)00:08.1 USB Controller: VIA Technologies, Inc. USB (rev 50)00:08.2 USB Controller: VIA Technologies, Inc. USB 2.0 (rev 51)01:00.0 VGA compatible controller: Silicon Integrated Systems [SiS] SiS650/651/M650/740 PCI/AGP VGA Display Adapter
No nosso caso a linha mais interessante é a:
00:05.0 Communication controller: Conexant HSF 56k HSFi Modem (rev 01)
Que indica que o modem é um Conexant HSF. Este modem é encontrado nos desknotes da PC-Chips e alguns modelos de notebooks.
O Kurumin já vem com a maior parte dos drivers disponíveis pré-instalados, disponíveis direto do CD. Você pode usá-lo para testar o seu modem e verificar com qual driver ele funciona. Você pode testar vários e se por acaso um driver incorreto fizer o micro congelar na hora de discar, basta reiniciar e tentar de novo
O objetivo deste capítulo é tanto ajudar os usuários de outras distribuições, cujos desenvolvedores não têm o cuidado e atenção de adicionar suporte aos softmodems, ou servir de fonte de consulta para quando você quiser atualizar os drivers incluídos no Kurumin. Os drivers disponíveis no Kurumin 5.x e 6.0 (que utilizam o Kernel 2.6) são os seguintes:
A idéia básica
O suporte a dispositivos no Linux é obtido através de módulos do Kernel. Estes módulos têm uma função semelhante aos drivers de dispositivos do Windows. As distribuições já incluem muitos módulos prontos para a maioria dos dispositivos de hardware. É por isso que geralmente a sua placa de som, rede, etc., são detectadas sem problemas.
No caso dos modens, tudo o que precisamos fazer para que eles possam ser usados é baixar o driver, gerar o módulo para a versão do Kernel incluída na sua distribuição e finalmente instalá-lo. Os módulos são arquivos instalados na pasta "/lib/modules/2.6.x/", onde o "2.6.x" é a versão do Kernel instalado.

Durante o processo de instalação é criado um arquivo (device) dentro do diretório "/dev", por onde o modem é acessado. No caso dos modem com chipset Lucent e Agere, por exemplo, o dispositivo é "/dev/ttyLT0", O passo final é criar um link "/dev/modem" apontando para o dispositivo do modem.
A partir daí você pode usar o modem normalmente, discando através do kppp, pppconfig, wvdial, ou outro discador de sua preferência. O programa acessa o link "/dev/modem", que é a localização padrão do modem no Linux, o link aponta para o dispositivo e daí em diante o próprio Kernel cuida de tudo, com a ajuda do módulo.
Veja que a idéia não é complicada. O maior obstáculo é que os módulos precisam ser gerados para cada versão de cada distribuição. Um pacote compilado para o Mandriva 2006 só funcionará nele mesmo, outro compilado para o Fedora 4 só funcionará no Fedora 4, e assim por diante.
Se você não encontrar um pacote específico para a distribuição que está usando (o que é muito comum), a segunda opção é baixar o pacote .tar.gz com o código fonte e compilá-lo você mesmo. Esta é a forma mais segura de instalar, pois gerará um módulo produzido sob medida para o seu Kernel. Esta também será a única opção caso você esteja usando um Kernel personalizado, diferente do que veio originalmente na distribuição, ou alguma distribuição Linux menos famosa.
Para compilar qualquer driver de modem você precisa ter instalados os pacotes de desenvolvimento, necessários para compilar qualquer programa distribuído em código fonte, além dos pacotes kernel-source e kernel-headers, que contém o código fonte do Kernel usado.
Estes pacotes devem estar no CD da distribuição, basta instalá-los da forma usual. Lembre-se, você deve usar os pacotes do CD da distribuição, eles precisam ser iguais ao Kernel que está instalado.
Esta é a idéia básica, daqui em diante o processo de instalação varia de acordo com o modem usado.
Driver da Smartlink
A Smartlink é um fabricante de modems com chipset PC-Tel. Os drivers desenvolvidos por eles possuem uma boa qualidade e são os drivers "oficiais" para todo tipo de modem com chipset PC-Tel, tanto onboard, quanto em versão PCI.
A lista de modems suportados por este driver inclui:
a) Quase todos os modems PC-Tel onboard e AMR, incluindo os das placas M810, M812, e outros modelos da PC-Chips/ECS, além de vários notebooks. O driver permite usar a placa de som onboard ao mesmo tempo que o modem.

b) Modems PCI com chipset PC-Tel recentes, como os LG-Netodragon. Estes modems possuem um chipset relativamente grande, com a marca "Smartlink" decalcada.
c) Alguns modems com chipset Intel. O driver da Smartlink era usado nestes casos como uma solução precária, até que a própria Intel lançou seus drivers.
A página de download dos drivers é a http://www.smlink.com/ (Support > Drivers Download > Linux Drivers). Um link alternativo é o http://linmodems.technion.ac.il/packages/smartlink/, que contém um arquivo com várias versões do driver.
Antigamente, existiam duas versões do driver, o "slmdm" era o driver antigo, que funcionava nas distribuições com Kernel 2.4, enquanto o "slmodem" era a versão recente, que funcionava no Kernel 2.6. Mas, as versões recentes do slmodem passaram a funcionar tanto no Kernel 2.6, quanto no antigo 2.4, tornando o outro driver obsoleto.
Para instalar, comece descompactando o arquivo baixado, como em:
$ tar -zxvf slmodem-2.9.10.tar.gz
Acesse a pasta que será criada:
$ cd slmodem-2.9.10/
Leia o arquivo README que contém várias informações sobre o driver e os modems suportados por ele, além das instruções de instalação.
O procedimento básico de instalação é rodar o comando "make" (dentro da pasta) que vai compilar o driver e em seguida o comando "make install" (que faz a instalação propriamente dita, como root).
O próprio instalador se encarrega de adicionar a linha necessária no arquivo "/etc/modules.conf", criar o device, criar o link "/dev/modem" apontando para ele e adicionar uma entrada para o módulo "slamr" no arquivo "/etc/modules.conf", para que ele seja carregado durante o boot.

A maior parte dos problemas de instalação deste driver ocorrem por falta da instalação dos compiladores ou por falta do pacote kernel-source. Na maioria das distribuições, especialmente no caso do Mandriva, apenas o pacote kernel-headers não é suficiente, você precisa instalar mesmo o pacote kernel-source. Ele é grande, mas é necessário neste caso.
Entre os compiladores, verifique especialmente se o pacote de desenvolvimento do glibc está instalado. No Debian, o pacote se chama "libc6-dev" e está disponível via apt-get. Em outras distribuições, procure pelo pacote "glibc-devel" ou "glibc-dev".
A versão atual do driver da Smartlink (slmodem) trabalha de uma forma um pouco diferente das antigas. É importante entender como o driver funciona, já que é muito comum aparecerem problemas diversos ao tentar conectar.
Ao instalar, além dos módulos do Kernel, copiados para a pasta "/lib/modules/2.x.x/extra", é instalado um aplicativo de gerenciamento, o "/usr/sbin/slmodemd", que cria uma pasta de logs, a "/var/lib/slmodem".
Estes são os passos para ativar o driver manualmente caso necessário:
a) Criar os dispositivos:
# mknod -m 600 /dev/slamr0 c 212 0 ; mknod -m 600 /dev/slamr1 c 212 1 ; mknod -m 600 /dev/slamr2 c 212 2 ; mknod -m 600/dev/slamr3 c 212 3
b) Carregar o módulo do modem:
# modprobe slamr
c) Ativar o slmodemd. Ele precisa ficar ativo, pois ao fechá-lo o modem deixa de funcionar. Por isso o executamos incluindo o "&":
# slmodemd --country=BRAZIL /dev/slamr0 &
d) Ao abrir o slmodemd é criado o dispositivo /dev/ttySL0. Crie o link /dev/modem apontando para ele:
# ln -sf /dev/ttySL0 /dev/modem
O driver oferece suporte também a modems PC-Tel USB (raros aqui no Brasil). Caso você tenha um destes, use o módulo "slusb" no lugar do "slamr".
Em casos de problemas na hora de discar, experimente abrir o kppp como root. Isso evita muitos problemas relacionados a permissões de acesso a dispositivos e arquivos de configuração.
Caso a conexão seja efetuada normalmente, mas você não consiga navegar, verifique se o endereço do servidor DNS do provedor (ou qualquer outro DNS válido) foi adicionado

corretamente ao arquivo "/etc/resolv.conf". Isto é muito comum quando o kppp é aberto com um login normal de usuário.
Se o problema persistir, pode ser que o sistema não esteja usando o modem como rota padrão (isso é comum se você tiver também uma placa de rede). Para ajustar isso manualmente, use o comando:
# route add default ppp0
Em versões antigas, era necessário usar o comando "route del default" (que remove a rota padrão anterior) antes do "route add default ppp0" (que indica o uso do modem). Atualmente apenas o segundo comando basta.
Este procedimento básico se aplica a todas as versões do Kernel 2.6, até o 2.6.12. A partir do 2.6.13, as coisas se complicaram um pouco, pois restrições no acesso às funções internas do Kernel impostas a módulos que não são GPL fizeram com que o driver deixasse de funcionar.
O driver não compila acusando um erro no arquivo "modem.c" e, mesmo depois que o erro dentro do código é manualmente corrigido, ele continua não funcionando, exibindo um erro ao carregar o módulo:
insmod: error inserting '/lib/modules/2.6.14-kanotix-6/misc/slamr.ko': -1 Unknown symbol in module
Este erro é conhecido e afeta todas as distribuições recentes, baseadas no Kernel 2.6.13 em diante. A Smartlink ainda não disponibilizou uma versão corrigida do driver e nem existe previsão para isto, já que a última versão do driver foi lançada em abril de 2005, quando o problema já existia.
Mesmo na lista do Kernel, a única referência sobre o problema é esta mensagem, que simplesmente recomenda o uso dos drivers open-source incluídos recentemente no Alsa (veja a seguir), sem indicar uma solução para o driver original: http://www.kernel-traffic.org/kernel-traffic/kt20041019_278.txt
Pesquisando mais a fundo, encontrei dois patches distintos, um postado na lista do Fedora e outro no Linux-on-Laptops. Isoladamente, nenhum dos dois corrige o problema, mas combinando ambos é possível chegar a uma versão corrigida do driver, que funciona perfeitamente no Kernel 2.6.14 e, possivelmente, qualquer outra versão recente onde o driver regular apresenta o problema.
http://forums.fedoraforum.org/showthread.php?t=60278http://linux-on-laptops.com/forum/archive/index.php/t-3.html
Aplicar os patches envolve modificar o código fonte da camada do driver que faz a junção com o Kernel, o que é trabalhoso. O primeiro patch pode ser aplicado diretamente usando o comando "patch" (que aprendemos a usar no capítulo 2), enquanto o outro precisa ser

aplicado manualmente. Outro problema é que, para que o driver funcione, é necessário alterar a linha com a licença para "GPL".
Isso é mais problemático (do ponto de vista legal) do que pode parecer à primeira vista. Nas versões atuais do Kernel, muitas funções estão disponíveis apenas para uso de módulos marcados como GPL. A alteração da licença dentro do código do driver burla isso, fazendo com que o driver da Smartlink seja tratado como se fosse um módulo GPL pelo Kernel, embora seja um módulo proprietário.
Tecnicamente, isto é uma violação tanto da licença da Smartlink quanto da própria licença GPL, sob a qual é distribuído o Kernel.
Embora você possa aplicar a modificação e gerar o módulo para uso pessoal, não é permitido redistribuir o módulo modificado. Você pode ver mais detalhes sobre esta parte legal aqui: http://www.ussg.iu.edu/hypermail/linux/kernel/0511.0/0285.html.
Este parece ser o principal motivo de não existir até hoje uma versão atualizada do driver. Para não violar a GPL, a Smartlink precisaria ou disponibilizar o código, transformando-o num módulo GPL, ou modificar o driver de forma que ele não utilize nenhuma das funções restritas do Kernel (o que seria trabalhoso e provavelmente demorado).
A única solução imediata é que cada um aplique as modificações e compile o módulo localmente, sem redistribuir o módulo gerado. Você pode ensinar seu amigo a compilar o driver, pode escrever um script para fazer isso automaticamente para ele, mas ele é quem deve apertar o botão. Bem, você já deve ter entendido o espírito da coisa ;).
Voltando à parte técnica, baixe o arquivo "slmodem-2.9.10.tar.gz" aqui:http://www.guiadohardware.net/kurumin/download/slmodem-2.9.10.tar.gz
Baixe o patch com as modificações aqui, salvando-o na mesma pasta que o driver:http://www.guiadohardware.net/kurumin/download/slmodem-2.9.10.patch
Descompacte o arquivo do driver:
$ tar -zxvf slmodem-2.9.10.tar.gz
Aplique o patch (você deve ter o pacote "patch" instalado):
$ patch -p0 < slmodem-2.9.10.patch
Acesse agora a pasta com o driver e compile da forma usual:
$ cd slmodem-2.9.10$ make# make install
Isto conclui a instalação normal do driver. Fica faltando apenas iniciar o slmodemd com o comando que vimos a pouco e discar usando o Kppp ou outro discador. O default dos
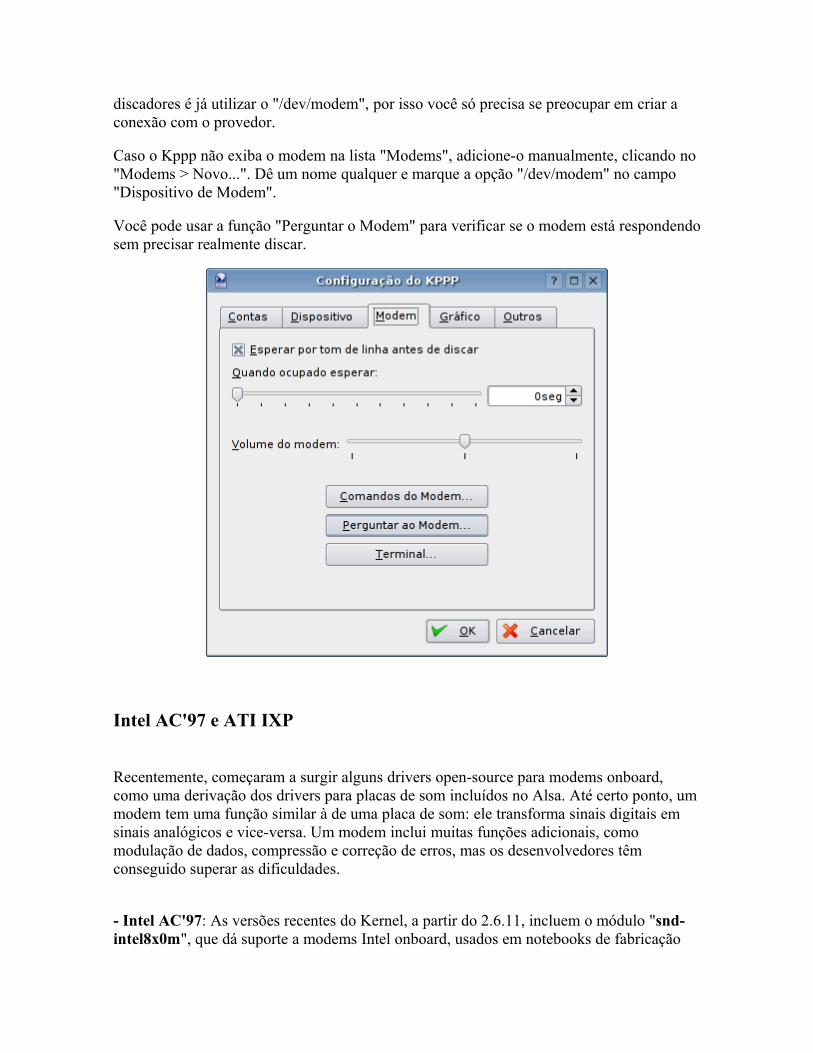
discadores é já utilizar o "/dev/modem", por isso você só precisa se preocupar em criar a conexão com o provedor.
Caso o Kppp não exiba o modem na lista "Modems", adicione-o manualmente, clicando no "Modems > Novo...". Dê um nome qualquer e marque a opção "/dev/modem" no campo "Dispositivo de Modem".
Você pode usar a função "Perguntar o Modem" para verificar se o modem está respondendo sem precisar realmente discar.
Intel AC'97 e ATI IXP
Recentemente, começaram a surgir alguns drivers open-source para modems onboard, como uma derivação dos drivers para placas de som incluídos no Alsa. Até certo ponto, um modem tem uma função similar à de uma placa de som: ele transforma sinais digitais em sinais analógicos e vice-versa. Um modem inclui muitas funções adicionais, como modulação de dados, compressão e correção de erros, mas os desenvolvedores têm conseguido superar as dificuldades.
- Intel AC'97: As versões recentes do Kernel, a partir do 2.6.11, incluem o módulo "snd-intel8x0m", que dá suporte a modems Intel onboard, usados em notebooks de fabricação

recente (como o HP NX6110), que não são compatíveis com o driver do Intel 537, e também aos modems onboard encontrados em placas-mãe com chipset nForce, que apesar de não parecer, são bem similares. O mesmo driver dá suporte também a vários modems com chipset PC-Tel, substituindo parcialmente o driver da Smartlink.
- ATI IXP: Este é outro driver open-source, que faz parte do Alsa. Ele dá suporte aos modems onboard encontrados em notebooks com o chipset ATI IXP, como o Toshiba A70. Ele é carregado através do driver "snd-atiixp-modem".
Estão disponíveis também os drivers "snd-via82xxx-modem" (que dão suporte aos modems onboard encontrados em placas-mãe recentes, com chipset Via) e também o "snd-ali5451-modem" (ainda em estágio primário de desenvolvimento) que visa oferecer suporte aos modems encontrados em placas com chipset ALI 5451.
Todos estes drivers funcionam em conjunto com o driver da Smartlink. Ao usá-los, procure uma versão com um Kernel recente, de preferência o 2.6.14 ou mais atual. Em versões anteriores estes drivers não eram estáveis, conflitavam com a placa de som ou simplesmente não funcionaram.
A primeira parte é carregar o módulo que dá suporte ao modem (carregado no lugar do slamr), como em:
# modprobe snd-intel8x0m(ou snd-atiixp-modem, snd-via82xxx-modem ou snd-ali5451-modem, de acordo com o modem usado).
Para que ele passe a ser carregado automaticamente durante o boot, adicione o módulo no final do arquivo "/etc/modules".
O passo seguinte é compilar o executável "/usr/sbin/slmodemd" com suporte aos módulos Alsa. Para isso, baixe o pacote "slmodem-2.9.9d-alsa.tar.gz" (ou a versão mais recente no momento em que estiver lendo) no http://linmodems.technion.ac.il/packages/smartlink/. Note que você precisa baixar um dos arquivos com "alsa" no nome.
Descompacte o arquivo, acesse a pasta que será criada e rode os comandos:
$ cd modem/$ make SUPPORT_ALSA=1# make install
Para compilar o driver com suporte a Alsa, além dos compiladores de praxe, você precisará do pacote "libasound2-dev". Lembre-se também de que ao instalar uma versão do driver anterior à 2.9.11 num Kernel recente, você precisará primeiro instalar o patch para o driver Smartlink, que citei anteriormente.
Como neste caso você precisa apenas do executável do slmodem e não dos módulos slamr e slusb, você pode em muitos casos utilizar os pacotes incluídos nas distribuições, ao invés de

precisar compilar dos fontes. Nas distribuições derivadas do Debian, instale o pacote "sl-modem-daemon":
# apt-get install sl-modem-daemon
Em outras distribuições, procure pelo pacote "slmodem" ou "sl-modem".
Com o "/usr/sbin/slmodemd" instalado, execute-o, especificando o parâmetro "--alsa", que especifica que ele deve usar o driver do alsa, ao invés do slamr:
# /usr/sbin/slmodemd --country=BRAZIL --alsa modem:1
O "modem:1" especifica o dispositivo do modem (da forma como é referenciado pelo driver). Dependendo da versão do driver usada, o modem pode ser visto como "modem:1", "hw:1", "modem:0" (atribuído geralmente ao ATI IXP) ou "hw:0". Você pode testar as 4 possibilidades até encontrar o correto no seu caso.
Ao executar o comando, você verá uma mensagem como:
SmartLink Soft Modem: version 2.9.9d Sep 27 2005 00:00:18symbolic link `/dev/ttySL0' -> `/dev/pts/4' created.modem `modem:1' created. TTY is `/dev/pts/4'
Use `/dev/ttySL0' as modem device, Ctrl+C for termination.
Como pode ver, o slmodemd é um programa que fica residente. Ao fechá-lo, o acesso ao modem é desativado. Se não quiser que ele obstrua o terminal, use o "&" no final do comando.
O "/dev/ttySL0" é o dispositivo por onde o modem é acessado. Crie o link "/dev/modem" apontando para ele, assim fica muito mais fácil localizar o modem dentro do programa de discagem:
# ln -sf /dev/ttySL0 /dev/modem
Ao usar o pacote do Debian, você pode ativar o driver de uma forma mais simples, usando o comando "/etc/init.d/sl-modem-daemon start". Ele se encarrega de ativar o slmodemd e criar o link "/dev/modem" apontando para o dispositivo correto.
A partir daí, você pode discar usando o KPPP. Este é o resultado do relatório gerado pelo "perguntar ao modem" do KPPP de um Intel AC'97 usado no HP NX6110. Como pode ver, ele é detectado como se fosse um modem Smartlink, por causa do uso do slmodemd. A pista para o driver que está realmente sendo usado é a linha "modem:1 alsa modem driver".

Intel 537 e 536
A Intel tem feito um trabalho razoável com relação ao suporte para seus modems no Linux. Existe suporte oficial também para as placas IPW2100 e IPW2200, usadas nos notebooks Intel Centrino e, de forma geral, para quase todos os chipsets e outros periféricos produzidos por eles.
Com relação aos modems, existem três drivers diferentes que podem ser usados sob o Kernel 2.6. Os dois drivers mais usados são o "intel-537EP" e o "intel-537", usados pelos modems Intel Ambient vendidos atualmente. Você pode diferenciar os dois usando o comando "lspci". O 537 aparece como "Intel Tigerjet" enquanto o 537ep aparece como "Intel Ambient".
Os modems Ambient com chip TigerJet são os mais comuns, na dúvida experimente primeiro o driver "intel-537". Caso o kppp trave no "Procurando Modem" ou ao tentar estabelecer a conexão, tente o "537EP".

Os dois drivers estão disponíveis no: http://linmodems.technion.ac.il/packages/Intel/537/.
A página é um arquivo com várias versões do driver, incluindo versões antigas, que só funcionam no Kernel 2.4. Enquanto escrevo, as versão mais recentes dos drivers para o Kernel são ainda os arquivos "intel-537-2.60.80.0.tgz" e "intel-537EP-2.60.80.0.tgz", lançados em outubro de 2004.
O terceiro driver é o "intel-536ep", que dá suporte aos modems Intel 536EP, um modelo de modem relativamente comum por volta do início de 2003. No chipset vem escrito "Intel Han".
O driver para ele está disponível no http://linmodems.technion.ac.il/packages/Intel/536/.
Ao instalar em qualquer distribuição com o Kernel 2.6, baixe o arquivo "intel-536EP-2.56.76.0.tgz" (ou mais recente).
A instalação dos três drivers é similar. Depois de baixar o arquivo correspondente, descompacte-o e acesse a pasta criada, como em:
$ tar -zxvf intel-537-2.60.80.0.tgz $ cd cd intel-537-2.60.80.0/
Compile e instale o driver usando os comandos:
$ make 537# make install
No caso do driver para o Intel 536EP, o segundo comando é "make 536". Isso vai gerar o módulo "Intel537.ko" (ou Intel536.ko), que será instalado na pasta /lib/modules/2.6.x.x/misc/", de forma automática.
Assim como o driver da Smartlink, os três drivers da Intel possuem um pequeno problema com o Kernel 2.6.11 (em diante), onde o driver simplesmente não compila. Este parece ser um problema generalizado com relação a drivers proprietários, que quase nunca são atualizados na mesma velocidade do Kernel.
Para corrigir o problema, baixe e descompacte o arquivo, acesse a pasta que será criada e, antes de rodar os comandos "make 537" e "make install", rode o comando:
$ sed -i -e 's/PM_SAVE_STATE/PM_SUSPEND_MEM/g' coredrv/coredrv.c
Como você pode ver, ele faz uma pequena alteração no arquivo coredrv/coredrv.c, que resolve o problema. Depois disso, execute o comando "make 537" e o driver compilará normalmente.
Esta mesma dica serve para os três drivers, sem nenhuma alteração no comando.

O instalador tenta carregar os drivers no final do processo. Caso você esteja instalando o driver correto, o modem já estará pronto para usar.
Os passos para carregar os módulos manualmente em casos de problemas com a instalação estão abaixo. Para usá-los, você deve ter, pelo menos, conseguido compilar o módulo.
# insmod -f Intel537.ko# rm -f rm /dev/ham; rm -f /dev/modem# mknod /dev/ham c 240 1# ln -s /dev/ham /dev/modem# chmod 666 /dev/modem
Você pode encontrar as versões mais recentes dos drivers para modems Intel também no: http://developer.intel.com/design/modems/support/drivers.htm. A página é desorganizada, mas é o melhor lugar para encontrar as últimas versões dos pacotes, antes que eles sejam publicados no Linmodems e outros sites.
Lucent e Agere
Os modems Lucent estão entre os primeiros softmodems a serem suportados no Linux. O driver "ltmodem" está entre os melhores desenvolvidos, com atualizações freqüentes, incluindo adaptações necessárias para que o driver continue funcionando corretamente em novas versões do Kernel. O hardware em si também é de boa qualidade, recebendo em geral recomendações por parte dos usuários.
Se os modems Lucent originais ainda fossem fabricados, a pergunta "qual o melhor softmodem para usar no Linux?" teria uma resposta fácil. O problema é que eles deixaram de ser fabricados por volta do final de 2002, quando foram substituídos pelos modems SV92, SV92B e SV92P fabricados pela Agere, que são incompatíveis com o driver original. Neles, o driver é carregado normalmente e detecta o modem, mas não consegue abrir a linha, fazendo com que você fique num eterno "sem tom de discagem".
O código do modelo vem decalcado no chip do modem. Esta é uma foto do chipset de um SV92P, um dos modems que não funcionam:

O driver para os modems Lucent antigos pode ser baixado no:http://linmodems.technion.ac.il/packages/ltmodem/kernel-2.6/
Para instalar, comece descompactando o arquivo e acessando a pasta que será criada:
$ tar -zxvf ltmodem-8.31b1.tar.gz $ cd ltmodem-8.31b1/
Leia o arquivo 1ST-READ que contém as instruções de instalação. O programa de instalação é bem explicativo, funciona como uma espécie de wizard, orientando durante a instalação e avisando sobre problemas comuns que podem ocorrer. Os três comandos que fazem a instalação propriamente dita são:
$ ./build_module# ./ltinst2# ./autoload
O primeiro comando gera os módulos "ltmodem.ko" e "ltserial.ko", o segundo copia-os para a pasta de módulos do Kernel e gera o link "/dev/modem" apontando para o dispositivo correto, enquanto o terceiro gera um script que se encarrega de carregar os módulos durante o boot.
Existe um driver antigo que dá suporte a uma variação do Agere SV92, usado como modem onboard em alguns notebooks IBM Thinkpad. Este é um driver específico, que não dá suporte aos SV92 encontrados em versão PCI: http://linmodems.technion.ac.il/packages/ageresoftmodem/.
PC-Tel PCI

O driver para modems Pctel PCI (HSP, Micromodem) foi portado para o Kernel 2.6 apenas em agosto de 2005.
Ele pode ser baixado no: http://linmodems.technion.ac.il/pctel-linux/welcome.html.
Enquanto escrevo, a versão mais atual é o arquivo: pctel-0.9.7-9-rht-4c.tar.gz.
Para instalá-lo, descompacte o arquivo, acesse a pasta "pctel-0.9.7-9-rht-4c/src/" e rode o comando "./configure -manual", como root:
$ tar -zxvf pctel-0.9.7-9-rht-4c.tar.gz$ cd pctel-0.9.7-9-rht-4c/src/# ./configure -manual
O instalador pergunta o chipset para o qual será gerado o módulo. Responda "pct789", que é o usado no PC-Tel Micromodem. Os outros módulos ainda não funcionam no Kernel 2.6, pelo menos nesta versão do driver.
please enter your hal typechoose one of: pct789, cm8738, i8xx, sis, via686ahal type: pct789
Se você tem um PC-Tel onboard numa PC-Chips M748, por exemplo, que usa a opção cm8738, vai precisar esperar mais um pouco. Os outros tipos são atendidos pelo driver da Smartlink, por isso talvez nunca sejam portados.
Falta agora apenas compilar o módulo e concluir a instalação, usando os comandos make e make install. Como de praxe, você precisa ter os headers do Kernel e um conjunto básico de compiladores para que a instalação seja bem-sucedida:
# make # make install
No meu caso, a primeira tentativa voltou um erro numa função não declarada dentro de um dos arquivos, um erro simples, que pode ser corrigido sem muita dificuldade:
make[1]: Entering directory `/usr/src/kernel-headers-2.6.14-kanotix-6'LD /home/kurumin/tmp/pctel-0.9.7-9-rht-4/src/built-in.oCC [M] /home/kurumin/tmp/pctel-0.9.7-9-rht-4/src/linmodem-2.6.o
pctel-0.9.7-9-rht-4/src/linmodem-2.6.c: In function`linmodem_config_port':?pctel-0.9.7-9-rht-4/src/linmodem-2.6.c:1004: error: `MCA_bus'undeclared (first use in this function)
make[2]: ** [pctel-0.9.7-9-rht-4/src/linmodem-2.6.o] Erro 1make[1]: ** [pctel-0.9.7-9-rht-4/src] Erro 2make[1]: Leaving directory `/usr/src/kernel-headers-2.6.14-6'make: ** [all] Erro 2

Como pode ver pela mensagem de erro, o instalador está reclamando de uma função chamada "MCA_bus", dentro do arquivo "linmodem-2.6.c". Abrindo o arquivo, e usando a função de procura do editor de texto, encontrei este trecho:
#ifdef CONFIG_MCA/** Don't probe for MCA ports on non-MCA machines.*/if (p->port.flags & UPF_BOOT_ONLYMCA && !MCA_bus)return;#endif
Como esta é apenas uma função de verificação (nada essencial), você pode simplesmente apagar toda a função e salvar o arquivo. Isto fez o módulo passar a compilar sem erros, instalando os arquivos "linmodem.ko", "pctel.ko" e "pctel_hw.ko" dentro da pasta "/lib/modules/2.6.x/misc/".
Para ativar o modem é necessário carregar os três módulos e criar o link "/dev/modem" apontando para o dispositivo que será criado:
# modprobe linmodem# modprobe pctel country_code=33# modprobe pctel_hw
# rm -f /dev/modem# ln -sf /dev/ttyS_PCTEL0 /dev/modem# chmod 666 /dev/modem
Depois é só abrir o KPPP, testar o modem e tentar discar. Para que o carregamento dos módulos seja feito automaticamente durante o boot, inclua os comandos no final do arquivo "/etc/init.d/bootmisc.sh" ou "/etc/rc.d/rc.local".
Modems com chipset Conexant
Os modems Conexant também são bem suportados. Eles podem ser encontrados tanto em versão PCI, quanto onboard em alguns modelos de placas da PC-Chips, ECS e alguns outros fabricantes e também em alguns dos Desknotes da PC-Chips.
Estes drivers são "semi-abertos", a Conexant disponibilizou um módulo binário, que controla as funções básicas do modem e o restante do driver passou a ser desenvolvido pela Linuxant, de modo que a parte open-source é independente da parte proprietária.
A Linuxant, desenvolve os drivers e dá suporte a eles, sem apoio do fabricante. O problema é que o driver é vendido por US$ 19, com a opção de uma versão de demonstração limitada a 14.4k. O driver pode ser baixado no: http://www.linuxant.com/drivers/hsf/full/downloads.php.
Para instalar, descompacte o arquivo e, dentro da pasta, execute os comandos:

# make install# hsfconfig
O primeiro faz a instalação do driver e o segundo detecta o modem instalado, compila o módulo e faz a configuração necessária. É nesta parte que você precisa fornecer a chave de instalação, obtida ao comprar o driver. Sem a chave, o driver funciona em modo "demo", com a velocidade limitada a 14.4k.
Embora o driver seja de boa qualidade, o valor só é justificável para quem tem um notebook com o modem onboard e realmente o usa. Para quem tem um desktop, sai mais barato trocar o modem por um dos modelos suportados.
Por causa da limitação, estes drivers não são incluídos nas versões recentes do Kurumin. Acesso discado já é lento; a 14.4 então, é melhor nem perder tempo ;).
Instalando placas wireless
Depois dos modems, as placas wireless são provavelmente a categoria de periféricos que mais causam dores de cabeça no Linux. Quase todas as placas funcionam no Linux de uma forma ou de outra, mas muitas usam drivers ou firmwares binários, que, assim como no caso dos softmodems, precisam ser instalados manualmente.
O número de chipsets, assim como o número de drivers disponíveis cresceram assombrosamente do início de 2004 para cá. Ao usar qualquer placa relativamente atual, é importante, antes de mais nada, usar uma distribuição recente, de preferência com o Kernel 2.6.11 em diante.

Tenho colocado bastante ênfase na versão do Kernel, pois ela é o quesito mais importante com relação a suporte a dispositivos. Novas versões do Kernel trazem sempre novos drivers e atualizações dos drivers antigos, que dão suporte a novos modelos. É sempre uma briga de gato e rato.
Com relação aos drivers, as placas wireless podem ser divididas em dois grupos. O primeiro é o das placas com drivers nativos, como as com chipset Prism, Lucent Wavelan (usado, por exemplo, nas placas Oricono), Atmel, Atheros, Intel IPW2100 e IPW2200, ACX100 e 111 e, recentemente, também as Ralink e Realtek 8180. O segundo grupo é o das placas que não possuem drivers nativos, mas podem ser usadas através do Ndiswrapper, que permite ativar a placa usando o driver do Windows.
Note que o fato da placa ter um driver disponível não significa que ele venha pré-instalado em qualquer distribuição. Muitos dos drivers são parcialmente proprietários, outros são completamente abertos, mas precisam do arquivo de firmware da placa, que por sua vez é proprietário. Muitas distribuições incluem um conjunto bastante reduzido de drivers por padrão, outras incluem os drivers, mas não incluem os firmwares, que são igualmente necessários.
Isso faz com que muita gente que possui placas com drivers nativos acabe utilizando-as em conjunto com o Ndiswrapper, muitas vezes com um desempenho ou estabilidade inferiores aos que teriam usando o driver nativo. Este é mais um campo em que conhecer e saber como instalar cada um dos drivers disponíveis pode poupá-lo de muita dor de cabeça.
Uma observação importante é que, para usar qualquer placa wireless no Linux, você deve ter instalado o pacote "wireless-tools", que contém os comandos necessários para configurar a placa, como o iwconfig. Hoje em dia, quase todas as distribuições o instalam por padrão, mas não custa verificar.
Os comandos "de baixo nível" para configurar os parâmetros da rede wireless são:
# iwconfig wlan0 essid minharede(configura o ESSID da rede)
# iwconfig wlan0 channel 10(configura o canal usado)
# iwconfig wlan0 key restricted 123456789Aou# iwconfig wlan0 key restricted s:qwert(configura a chave de encriptação da rede, ao usar WEP. O primeiro comando usa uma chave em hexa e o segundo uma chave ASCII).
Depois de definir os parâmetros da rede, rode o comando "iwconfig". Ele mostra os detalhes da rede e o endereço MAC do ponto de acesso ao qual a placa está associada:
ath0 IEEE 802.11g ESSID:"minharede"Mode:Managed Frequency:2.462 GHz Access Point: 00:50:50:84:31:45Bit Rate:11 Mb/s Tx-Power:18 dBm Sensitivity=0/3

Retry:off RTS thr:off Fragment thr:offPower Management:offLink Quality=52/94 Signal level=-43 dBm Noise level=-95 dBmRx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0Tx excessive retries:0 Invalid misc:0 Missed beacon:5
A partir daí, a conexão wireless é configurada da mesma forma que uma cabeada, com a definição do endereço IP, máscara de sub-rede, gateway e DNS. Praticamente todas as distribuições trazem ferramentas para configurar a rede de forma mais prática; as duas mais genéricas são o "wireless-config" (do Gnome) e o "Kwifimanager" (do KDE).
Naturalmente, só é possível configurar a rede wireless depois que a placa é detectada pelo sistema e, para isso, é necessário que o driver adequado esteja instalado e o módulo correspondente carregado.
Ndiswrapper
O Ndiswrapper é uma espécie de Wine para drivers de placas de rede wireless. Ele funciona como uma camada de abstração entre driver e o sistema operacional, permitindo que placas originalmente não suportadas no Linux funcionem usando os drivers do Windows.
Em alguns casos o próprio driver para Windows XP que acompanha a placa funcionará. Em outros é preciso usar alguma versão específica do driver. Você pode encontrar várias dicas

sobre placas testadas por outros usuários do Ndiswrapper no:http://ndiswrapper.sourceforge.net/wiki/index.php/List
Os drivers para Windows são arquivos executáveis, que servem de intérpretes entre a placa e o sistema operacional. Eles contém o firmware da placa e outras funções necessárias para fazê-la funcionar.
Cada placa é diferente; por isso, os drivers de uma não funcionam na outra. Mas, todos os drivers conversam com o sistema operacional usando uma linguagem específica de comandos. Ou seja, do ponto de vista do sistema operacional todos os drivers são parecidos.
O Ndiswrapper consegue executar o driver e "conversar" com ele usando esta linguagem. Ele trabalha como um intérprete, convertendo os comandos enviados pelo Kernel do Linux em comandos que o driver entende e vice-versa. O Kernel acha que está conversando com uma placa suportada, o driver acha que está rodando dentro de um sistema Windows e a placa finalmente funciona, mesmo que o fabricante não tenha se dignado a escrever um driver nativo.
O Ndiswrapper não funciona com todas as placas e, em outras, alguns recursos como o WPA não funcionam. Apesar disso, na maior parte dos casos ele faz um bom trabalho.
A página do projeto é a: http://ndiswrapper.sourceforge.net.
Muitas distribuições já trazem o Ndiswrapper instalado por padrão. Nestes casos, você pode pular este tópico sobre a instalação e ir direto para a configuração. Procure pelo pacote "ndiswrapper" no gerenciador de pacotes ou veja se o módulo e o comando "ndiswrapper" estão disponíveis.
- Instalando: Na página você encontrará apenas um pacote com o código fonte. Como o Ndiswrapper precisa de um módulo instalado no Kernel, seria complicado para os desenvolvedores manter versões para muitas distribuições diferentes. Assim como no caso dos softmodems, para compilar o pacote você precisa ter instalados os pacotes kernel-headers e/ou kernel-source e os compiladores. A versão mais recente pode ser baixada no: http://sourceforge.net/projects/ndiswrapper/
Descompacte o arquivo e acesse a pasta que será criada. Para compilar e instalar, basta rodar o comando:
# make install(como root)
O Ndiswrapper é composto de basicamente dois componentes. Um módulo, o ndiswrapper.ko (ou ndiswrapper.o se você estiver usando uma distribuição com o Kernel 2.4), que vai na pasta "/lib/modules/2.x.x/misc/" e um executável, também chamado "ndiswrapper", que é usado para configurar o driver, apontar a localização do driver Windows que será usado, etc.

Se você estiver usando uma distribuição que já venha com uma versão antiga do Ndiswrapper instalada, você deve primeiro remover o pacote antes de instalar uma versão mais atual. Caso a localização do módulo ou do executável no pacote da distribuição seja diferente, pode acontecer de continuar sendo usado o driver antigo, mesmo depois que o novo for instalado.
- Configurando: Depois de instalar o Ndiswrapper, o próximo passo é rodar o comando "depmod -a" (como root) para que a lista de módulos do Kernel seja atualizada e o novo módulo seja realmente instalado. Isto é normalmente feito automaticamente pelo script de instalação, é apenas uma precaução.
Antes de ativar o Ndiswrapper, você deve apontar a localização do arquivo ".inf" dentro da pasta com os drivers para Windows para a sua placa. Em geral os drivers para Windows XP são os que funcionam melhor, seguidos pelos drivers para Windows 2000. Você pode usar os próprios drivers incluídos no CD de instalação da placa. Se eles não funcionarem, experimente baixar o driver mais atual no site do fabricante, ou pesquisar uma versão de driver testada no ndiswapper no:http://ndiswrapper.sourceforge.net/wiki/index.php/List
Para carregar o arquivo do driver, rode o comando "ndiswrapper -i", seguido do caminho completo para o arquivo, como em:
# ndiswrapper -i /mnt/hda6/Driver/WinXP/GPLUS.inf
Rode agora o comando "ndiswrapper -l" para verificar se o driver foi mesmo ativado. Você verá uma lista como:
Installed ndis drivers:gplus driver present, hardware present
Com o driver carregado, você já pode carregar o módulo usando o modprobe:
# modprobe ndiswrapper
Se tudo estiver ok, o led da placa irá acender, indicando que ela está ativa. Agora falta apenas configurar os parâmetros da rede wireless.
Se a placa não for ativada, você ainda pode tentar uma versão diferente do driver. Neste você precisa primeiro descarregar o primeiro driver. Rode o ndiswrapper -l para ver o nome do driver e em seguida descarregue-o com o comando "ndiswrapper -e".
No meu caso o driver se chama "gplus" então o comando fica:
# ndiswrapper -e gplus
Para que a configuração seja salva e o Ndiswrapper seja carregado durante o boot, você deve rodar o comando:
# ndiswrapper -m

E em seguida adicionar a linha "ndiswrapper" no final do arquivo "/etc/modules", para que o módulo seja carregado durante o boot.
Você pode também fazer a configuração utilizando o "ndisgtk", um utilitário gráfico, disponível nos repositórios do Debian, no Ubuntu e em outras distribuições.
ACX100 e ACX111
Os chipsets ACX100 e ACX111, fabricados pela Texas Instruments, são usados em placas de vários fabricantes, incluindo modelos da DLink, LG, Siemens, Sitecom e 3Com. Eles estão entre os chipsets wireless mais baratos atualmente, por isso são encontrados sobretudo nas placas de baixo custo.
Uma coisa importante a notar é que não existe uma nomenclatura rígida entre os modelos das placas e os chipsets usados. Por exemplo, as placas Dlink DWL-650 inicialmente vinham com chipsets PRISM (que possuem um excelente driver nativo a partir do Kernel 2.6), depois passaram a vir com o chipset Atheros (que funciona usando o Driver MadWiFi ou o Ndiswrapper) e, finalmente, passaram a vir com o chipset ACX100. Depois sugiram as placas DWL650+, que usam o chipset ACX111. Ou seja, dentro de um mesmo modelo foram fabricadas placas com 4 chipsets diferentes!
A única forma confiável de verificar qual é o chipset usado na placa é checando a identificação do chipset, o que pode ser feito usando o comando lspci.
Exemplos de IDs de placas com o chipset ACX são:
02:00.0 Network controller: Texas Instruments ACX 111 54Mbps Wireless Interface 00:08.0 Network controller: Texas Instruments ACX 100 22Mbps Wireless Interface
Estas placas funcionam também usando o Ndiswrapper, mas usando o driver nativo a utilização do processador é mais baixa e existem menos relatos de problemas de

estabilidade. Recomendo que você experimente primeiro o driver nativo e deixe o Ndiswrapper como segunda alternativa.
A página oficial do driver é: http://acx100.sourceforge.net/.
A página de download dos pacotes com código fonte é a: http://rhlx01.fht-esslingen.de/~andi/acx100/.
Para instalar, descompacte o arquivo tar.gz, acesse a pasta que será criada e rode os tradicionais:
# make# make install
Isto copiará o módulo "acx_pci.ko" para a pasta "/lib/modules/2.6.x/net/". Para garantir que o módulo foi instalado corretamente, rode também o comando "depmod -a".
Para que a placa funcione, além do módulo é necessário ter o arquivo com o firmware da placa. O firmware é o software com as funções que controlam o hardware. Sem o firmware, a placa é um pedaço inútil de metal e silício.
O driver acx_pci é open-source, mas o firmware não. Embora o arquivo (o firmware) possa ser redistribuído, assim como um freeware qualquer, muitas distribuições não o incluem por não concordarem com os termos da licença.
Para baixar o firmware da placa, rode o script "fetch_firmware" que está dentro da pasta scripts/, na pasta onde foi descompactado o arquivo com o driver:
# ./fetch_firmware
Ele perguntará:
Locating a suitable download tool...
Searching for ACX1xx cards on this system...Which firmware files package would you like to download?
a) for ACX100 (TNETW1100) chipset based cardsb) for ACX111 (TNETW1130/1230) chipset based cardsc) for both chipsetsd) none
Use a opção "C", assim ele já baixa de uma vez os arquivos para os dois chipsets. Isto é feito baixando o driver do Windows e extraindo os arquivos que compõem o firmware para a pasta firmware/, novamente dentro da pasta do driver. Você deve copiá-los para pasta "/usr/share/acx/", que é a localização padrão, onde o módulo procurará por eles ao ser carregado. Crie a pasta caso necessário:
# mkdir /usr/share/acx/# cp -a /tmp/acx100-0.2.0pre8_plus_fixes_37/firmware/* /usr/share/acx/

Feito isso, você já pode experimentar carregar o módulo para ativar a placa. Antes de carregar qualquer módulo de placa wireless, você deve carregar o módulo "wlan", que contém os componentes genéricos:
# modprobe wlan# modprobe acx_pci
A partir daí o led da placa acenderá indicando que a placa está funcionando e está faltando apenas configurar a rede.
Para que o módulo seja carregado automaticamente durante o boot, adicione as linhas "wlan" e "acx_pci" no final do arquivo "/etc/modules".
Em algumas placas em que testei, o led simplesmente não acende ao ativar o driver, embora a placa funcione normalmente.
As placas D-Link DWL-650+, que utilizam o chipset ACX111 usam um firmware específico. No caso delas, você deve usar o firmware incluído no CD de drivers da placa. Copie o arquivo "Driver/Drivers/WinXP/GPLUS.bin" do CD para a pasta "/usr/share/acx/" e o renomeie para FW1130.BIN, substituindo o antigo.
Eventualmente, você pode encontrar outras placas ACX111 que não funcionam com o firmware padrão. Neste caso, experimente a receita de pegar o arquivo .BIN dentro da pasta de drivers para Windows XP, copiar para a pasta "/usr/share/acx/" e renomear.
Caso você tenha copiado os arquivos do firmware para outra pasta, pode especificar isso na hora de carregar o driver, com o parâmetro "firmware_dir=", como em:
# modprobe acx_pci firmware_dir=/home/carlos/firmware/
MadWiFi
O MadWiFi dá suporte a placas com chipset Atheros, usado em placas da D-link (como a DWL-G520), AirLink, 3Com, Linksys, Netgear, AT&T e outros. Este chipset também é muito usado em placas mini-PCI, para notebooks. Ele pode ser encontrado, por exemplo, nos Toshiba A70 e A75.
Assim como no caso das placas com chipset ACX, muitos dos modelos com o chip Atheros possuem variantes com outros chipsets. Por exemplo, a D-Link DWL-G520 usa o chip Atheros, enquanto a DWL-G520+ usa o chip ACX100.
A melhor forma de checar se você tem em mãos uma placa com o chip Atheros, é rodar o lspci. Você verá uma linha como:
02:00.0 Ethernet controller: Atheros Communications, Inc. AR5212 802.11abg NIC (rev 01)

A página do projeto é a: http://madwifi.sourceforge.net/.
O driver pode ser baixado no: http://snapshots.madwifi.org/.
Assim como o driver para placas ACX100, o Madwifi é dividido em dois componentes: o driver propriamente dito e o firmware. A diferença é que o firmware já vem incluído no pacote; não é necessário baixá-lo separadamente.
Recentemente, o driver recebeu uma grande quantidade de novos recursos, incluindo suporte a virtual APs (onde um PC é configurado para atuar como um ponto de acesso), HAL, WDS e outros recursos. Como as modificações são profundas e radicais, os desenvolvedores decidiram dividir o projeto em dois drivers, atualizados separadamente.
O novo driver é chamado de "madwifi-ng" (ng de "new generation"), enquanto o driver antigo passou a ser chamado "madwifi-old". Geralmente, ninguém gosta de usar coisas "velhas", mas atualmente (março de 2006) o driver antigo é ainda muito mais estável, por isso é a opção recomendada. Caso no futuro você tenha problemas com ele, ou caso realmente precise de algum dos novos recursos, experimente o madwifi-ng.
Para instalar, descompacte o arquivo "madwifi-old-r1417-20060128.tar.gz" (ou mais recente) e acesse a pasta que será criada. Rode os comandos de sempre:
# make# make install
Depois de instalado, você pode carregar os módulos com os comandos:
# modprobe wlan# modprobe ath_hal# modprobe ath_pci
O módulo wlan contém os componentes genéricos que dão suporte a placas wireless no Linux. O ath_hal contém o firmware da placa e o ath_pci contém o driver propriamente dito, que deve ser sempre carregado depois dos dois.
Ao carregar os módulos, o led da placa já irá acender, indicando que ela está ativa. Para que eles sejam carregados automaticamente durante o boot, adicione as linhas "wlan", "ath_hal" e "ath_pci" no final do arquivo "/etc/modules".
Este outro link ensina a compilar pacotes .deb com os drivers, procedimento ideal para quem usa distribuições derivadas do Debian, como o Kurumin. Lembre-se de que os pacotes gerados conterão os módulos compilados para o Kernel usado na sua instalação, e não funcionarão em instalações com versões diferentes do Kernel. http://www.marlow.dk/site.php/tech/madwifi.
ADMteck ADM8211

Este é mais um chipset wireless de baixo custo, encontrado tanto em placas PC-Card quanto PCI, incluindo alguns modelos da 3Com e D-link e algumas placas PCI baratas, sem pedigree.
É fácil reconhecer estas placas pelo chipset, que trás decalcado o modelo. Rodando o comando lspci você verá algo como:
00:08.0 Network controller: Linksys ADMtek ADM8211 802.11b Wireless Interface (rev 11)
O driver para elas pode ser baixado no: http://aluminum.sourmilk.net/adm8211/.
Enquanto escrevo, a versão mais recente é a "adm8211-20051031.tar.bz2". Durante um certo tempo, este driver foi desenvolvido de forma bastante ativa, com novas versões sendo lançadas praticamente a cada semana, depois entrou num período de manutenção, com atualizações mais esparsas, destinadas basicamente a acompanhar mudanças no Kernel.
Para instalar, basta descompactar o arquivo, acessar a pasta e rodar o comando:
# make install
A instalação consiste em gerar o módulo "adm8211.ko" e copiá-lo para a pasta "/lib/modules/2.6.x/kernel/drivers/net/wireless/". O script de instalação cuida de tudo automaticamente.
Para ativar a placa, carregue o módulo com os comandos:
# modprobe wlan# modprobe adm8211
Para que o módulo seja carregado automaticamente durante o boot, adicione as linhas "wlan" e "adm8211" no final do arquivo "/etc/modules". Depois falta só configurar os parâmetros da rede.

Embora o driver seja de boa qualidade, as placas em si possuem problemas freqüentes relacionados ao rádio. Algumas captam muita interferência, outras simplesmente usam transmissores baratos, ou antenas de baixa potência, o que faz com que a qualidade do sinal fique muitas vezes comprometida. De uma forma geral, não são muito recomendáveis.
Realtek 8180
Este chipset é encontrado em alguns modelos de placas PCI, principalmente em modelos vendidos pela LG. Embora seja mais raro, você também encontrará algumas placas PCMCIA e até algumas placas-mãe com ela onboard.
A Realtek chegou a disponibilizar um driver for Linux, mas ele funciona apenas em distribuições com Kernel 2.4.18 ou 2.4.20: http://www.realtek.com.tw/downloads/.
Existe um driver open-source, o "rtl8180-sa2400" (desenvolvido de forma independente), este sim atualizado. O nome surgiu porque originalmente este driver dava suporte apenas a um pequeno conjunto de placas, que utilizavam o transmissor de rádio Philips sa2400. Com o tempo, o conjunto de placas suportadas cresceu bastante e atualmente ele já suporta quase todas as placas baseadas no chipset Realtek 8180, produzidas por vários fabricantes.
Ele funciona tanto em distribuições com o Kernel 2.4 quanto com o 2.6, e está disponível no:http://rtl8180-sa2400.sourceforge.net/
Para instalar, descompacte o arquivo e rode o comando "make" dentro da pasta. Ele vai gerar 4 módulos: ieee80211_crypt-r8180.ko, ieee80211_crypt_wep-r8180.ko, ieee80211-r8180.ko e r8180.ko, que precisam ser carregados usando o comando insmod, nesta ordem:
# insmod ieee80211_crypt-r8180.ko # insmod ieee80211_crypt_wep-r8180.ko # insmod ieee80211-r8180.ko # insmod r8180.ko
Para facilitar, você pode simplesmente rodar o script "module_load" dentro da pasta do driver, que automatiza estes quatro comandos.
Para realmente instalar os drivers, de forma a poder carregá-los usando o comando modprobe, copie-os para dentro da pasta "/lib/modules/2.6.x/misc/" e rode o comando "depmod -a" para que o sistema atualize a base de módulos instalados.
A partir daí, você pode incluir as linhas abaixo no final do arquivo "/etc/modules" para que eles sejam carregados automaticamente durante o boot:
ieee80211-r8180_crypt-r8180 ieee80211_crypt_wep-r8180 ieee80211-r8180 r8180

Estas placas funcionam também usando o Ndiswrapper, que pode ser usado como segunda opção em caso de problemas com o driver nativo.
Orinoco-USB
Este driver é destinado às placas USB com o chipset Prism, como as Compaq WL215 e W200, encontradas principalmente em notebooks Compaq Evo. Este driver foi durante um bom tempo desenvolvido como um driver separado, até ser incorporado ao driver Orinoco principal.
Se você está usando uma distribuição recente, baseada no Kernel 2.6.8 em diante, é provável que sua placa funcione simplesmente carregando o módulo "orinoco":
# modprobe orinoco
Caso você esteja usando uma distribuição antiga, que ainda utilize o driver orinoco sem suporte aos modelos USB, você pode instalar manualmente o driver antigo, disponível no:http://orinoco-usb.alioth.debian.org
Na página estão disponíveis pacotes para o Debian e o Red Hat, mas lembre-se de que os pacotes só funcionam nas versões do Kernel para que foram compilados. Eles só serão úteis se você estiver usando um Kernel padrão das distribuições.
A forma mais rápida de obter o código fonte do driver para instala-lá manualmente é via CVS. É mais fácil do que parece. Em primeiro lugar, você precisará instalar o pacote "cvs" encontrado na distribuição em uso, com um "apt-get install cvs" ou "urpmi cvs" por exemplo. Com o CVS instalado, rode os comandos:
# export CVS_RSH="ssh"# cvs -z3 -d:pserver:[email protected]:/sources/orinoco co orinoco
Isso criará uma pasta "orinoco" no diretório atual. Acesse-a e rode os comandos:
# make# make install
Para que o driver funcione, você precisará tanto dos módulos instalados pelo "make; make install" quanto do firmware da placa. Ainda dentro da pasta com o código fonte, acesse a sub-pasta "firmware" e execute o script "get_ezusb_fw", que baixa o firmware destinado às Prism USB:
# cd firmware/# ./get_ezusb_fw

Isto gerará o arquivo "orinoco_ezusb_fw", que deve ser copiado para a pasta "/usr/lib/hotplug/firmware/", ou "/lib/firmware" (nas distribuições que utilizam o udev).
Isto será suficiente para que o hotplug passe a detectar e ativar a placa no boot. Caso seja necessário ativa-la manualmente, rode o comando:
# modprobe orinoco_usb
Broadcom
O chipset Broadcom pode ser encontrado em vários notebooks (como o HP nx6110 e outros modelos similares) e também em diversas placas PCMCIA. Este é um chipset de boa qualidade, que até recentemente não possuía um driver nativo, embora funcione bem através do Ndiswrapper, na maioria dos casos.
Em novembro de 2005, um grupo de desenvolvedores conseguiu obter as especificações do chipset via engenharia reversa, permitindo que fosse iniciado o projeto de desenvolvimento de um driver nativo, disponível no: http://bcm43xx.berlios.de/.
O driver ainda está em estágio inicial de desenvolvimento, mas como existe uma demanda grande para um driver para estas placas, é possível que ele evolua muito rápido.
IPW2100 e IPW2200
Os chipsets IPW2100 e IPW2200 são fabricados pela Intel e vendidos na forma de placas mini-PCI destinadas a notebooks. Elas são encontradas em notebooks com a tecnologia Centrino.
Trata-se na verdade de um golpe de marketing da Intel para vender mais placas, chipsets e processadores. Para usar a marca "Centrino", um notebook precisa usar um processador Pentium M, um chipset Intel e uma placa wireless IPW2100 ou IPW2200. Os fabricantes acabam comprando então os três componentes da Intel, ao invés de usar uma placa wireless ou chipset de outro fabricante. Note que existem muitos notebooks com processadores Pentium M ou Celeron M e placas wireless de outros fabricantes, mas eles não são "Centrino".
Embora raro, é possível comprar as placas separadamente para uso em outros modelos que possuam um slot mini-PCI livre (neste caso, as placas são vendidas sem a marca "Centrino"). Embora a foto não dê uma boa noção de perspectiva, as placas mini-PCI são realmente pequenas, quase do tamanho de uma caixa de fósforos.

Você pode verificar o modelo correto usando o lspci e em seguida baixar o driver no:
http://ipw2100.sourceforge.net/ouhttp://ipw2200.sourceforge.net/
Em ambos os casos, você precisará de dois arquivos. O driver propriamente dito e o firmware, novamente um arquivo separado. Como de praxe, os drivers são de código aberto mas o firmware não.
O driver em si já vem pré-instalado na maioria das distribuições e foi incluído oficialmente no Kernel a partir do 2.6.14, de forma que você já o encontrará pré-instalado em praticamente qualquer versão atual.
De qualquer forma, se você precisar instalá-lo ou atualizá-lo manualmente, basta baixar e descompactar o arquivo e rodar os comandos:
# make# make install
Isto gerará e copiará os módulos ipw2200.ko, ieee80211.ko, ieee80211_crypt.ko e ieee80211_crypt_wep.ko para a pasta "/lib/modules/2.6.x/kernel/drivers/net/wireless/".
Em seguida vem o passo que é quase sempre necessário: baixar o arquivo com o firmware ("ipw2200-fw-2.4.tgz", no meu caso), descompactar e copiar os arquivos para dentro da pasta "/lib/firmware" (em distribuições que usam o udev) ou "/usr/lib/hotplug/firmware/" (nas distribuições que ainda usam o hotplug), como em:
# cp -a ipw2200-fw-2.4.tgz /lib/firmware/# cd /lib/firmware/# tar -zxvf ipw2200-fw-2.4.tgz

A partir daí, a placa deve ser ativada automaticamente durante o boot. Caso você queira ativar e desativar o suporte manualmente, use os comandos:
# modprobe ipw2200 (para carregar)
# modprobe -r ipw2200 (para desativar)
Caso não tenha certeza sobre o uso do hotplug ou udev, não existe problema em copiar os arquivos para ambas as pastas, ou criar um link apontando para a outra. Ao ser carregado, o módulo procura os arquivos na pasta correta. Outra observação é que nas versões recentes você deve manter o arquivo "ipw2200-fw-2.4.tgz" compactado dentro da pasta "/lib/firmware", pois o módulo procura diretamente por ele, ao invés dos arquivos descompactados.
Uma pegadinha, é que existem várias versões do firmware disponíveis no http://ipw2200.sourceforge.net/firmware.php, acompanhando as diferentes versões do driver. A versão 2.4 funciona em conjunto com o driver de versão 1.07 até 1.10 (usado no Kurumin 6.0, por exemplo), enquanto o firmware versão 3.0 funciona em conjunto com o 1.11 em diante. Ao instalar uma nova versão do driver, lembre-se também de checar e, se necessário, atualizar também o firmware.
Você pode checar qual é a versão instalada usando o comando:
# modinfo ipw2200(ou modinfo ipw2100)
Ao instalar uma nova versão do firmware, tome sempre o cuidado de primeiro remover os arquivos da anterior, pois em muitos casos os nomes dos arquivos mudam de uma versão para a outra, fazendo com que os arquivos fiquem duplicados ao instalar por cima.
Se você estiver usando uma distribuição recente, que utilize o udev, pode existir um complicador a mais. O hotplug carrega automaticamente o firmware a partir da pasta "/usr/lib/hotplug/hotplug/firmware" quando o módulo é carregado. O udev também pode fazer isso automaticamente, desde que exista uma regra apropriada dentro do diretório "/etc/udev/rules.d" e que o executável "/sbin/firmware_helper" esteja disponível.
O grande problema é que muitas distribuições, com destaque para o Debian, propositalmente não incluem os dois componentes, talvez com o objetivo de dificultar a vida de quem quer carregar os "firmwares proprietários do mal". Neste caso, você vai precisar instalar manualmente.
Comece baixando o código fonte do udev no http://www.us.kernel.org/pub/linux/utils/kernel/hotplug/. No meu caso, baixei o arquivo "udev-081.tar.gz".
Descompacte o arquivo e, dentro da pasta que será criada, rode o comando:

# make EXTRAS=extras/firmware
Isso vai compilar apenas o firmware_helper, dentro da pasta "extras/firmware/", sem compilar o udev inteiro. O próximo passo é copiá-lo para dentro da pasta "/sbin/".Verifique também se ele está com a permissão de execução ativa:
# cp -a extras/firmware/firmware_helper /sbin/# chmod +x /sbin/firmware_helper
Falta agora criar a regra que instrui o udev a usá-lo. Acesse a pasta "/etc/udev/rules.d" e crie o arquivo "z99_firmware", contendo a linha:
ACTION=="add", SUBSYSTEM=="firmware", RUN+="/sbin/firmware_helper"
Esta regra diz que sempre que for encontrado um dispositivo cujo módulo precise carregar um determinado firmware, o udev deve executar o "/sbin/firmware_helper", que se encarrega de fazer o carregamento. Para que a regra entre em vigor, reinicie o udev com o comando "/etc/init.d/udev/restart".
Um último complicador, desta vez não relacionado com o driver é que em muitos notebooks o atalho de teclado para ativar e desativar o transmissor wireless é controlado via software e só funciona em conjunto com um driver específico. Você encontra uma lista detalhada dos notebooks problemáticos e dicas para ativar o transmissor em cada um no: http://rfswitch.sourceforge.net/?page=laptop_matrix.
Em alguns casos, é necessário carregar um módulo adicional, em outros é necessário alterar manualmente algum parâmetro do ACPI, enquanto em alguns (como no Asus M5) a única opção é dar um boot no Windows e ativar o transmissor usando o utilitário do fabricante. Estranhamente, neste caso a configuração é salva em algum lugar no CMOS, tornando-se definitiva.
Com os arquivos do firmware no local correto e o hotplug/udev funcionando corretamente, o driver vai funcionar corretamente. Você pode verificar as mensagens de inicialização usando o comando "dmesg | grep ipw", como em:
# dmesg | grep ipw
ipw2200: Intel(R) PRO/Wireless 2200/2915 Network Driver, 1.0.8ipw2200: Copyright(c) 2003-2005 Intel Corporationipw2200: Detected Intel PRO/Wireless 2200BG Network Connection
Se, por outro lado, o comando exibir algo como:
ipw2200: Intel(R) PRO/Wireless 2200/2915 Network Driver, 1.0.8ipw2200: Copyright(c) 2003-2005 Intel Corporationipw2200: Detected Intel PRO/Wireless 2200BG Network Connectionipw2200: Unable to load ucode: -62ipw2200: Unable to load firmware: -62ipw2200: failed to register network deviceipw2200: probe of 0000:01:05.0 failed with error -5
... rode os comandos abaixo para recarregar o driver:

# echo 100 > /sys/class/firmware/timeout# modprobe -r ipw2200# modprobe ipw2200
A partir daí a placa passará a funcionar normalmente. Você pode incluir os comandos no final do arquivo "/etc/init.d/bootmisc.sh", ou "/etc/rc.d/rc.local" para que eles sejam executados automaticamente durante o boot.
O primeiro comando aumenta o tempo de espera do Kernel na hora de carregar o firmware. O default são 10 milessegundos, o que não é suficiente em algumas versões do driver. Aumentando o tempo de espera, o driver passa a carregar corretamente.
Ralink 2400, 2500 e RT61
A Ralink é um fabricante relativamente novo, que fabrica os chipsets rt2400 e rt2500, dois chips de baixo custo, que estão sendo usados em muitas placas, muitas vezes substituindo os chips acx111 e rtl8180, que são mais caros do que eles.
Muita gente utiliza (com sucesso) o ndiswrapper para ativar estas placas, mas também existe um driver nativo, que pode ser baixado no: http://prdownloads.sourceforge.net/rt2400/.
Nele você encontrará os arquivos "rt2400-1.x.x.tar.gz" (o driver antigo, que dá suporte às rt2400) e o "rt2500-1.x.x.tar.gz", que dá suporte às rt2500. Você pode verificar qual dois dois chipsets é usado na sua placa usando o comando "lspci", ou verificar uma lista de placas baseadas nos dois chipsets no: http://ralink.rapla.net/.
Para instalar o "rt2400-1.x.x.tar.gz", descompacte o arquivo e acesse a pasta que será criada. Dentro dela, acesse a pasta "Module" e rode os comandos "make" e "make install". Será instalado o módulo "rt2400". Ao carregá-lo usando o modprobe, a placa será vista pelo sistema como "/dev/ra0", ao invés de "/dev/wlan0" como seria mais comum.
Para o "rt2500-1.x.x.tar.gz", o procedimento de instalação é o mesmo, rodar os comandos "make" e "make install" dentro da pasta "Module". A única diferença é que neste caso é instalado o módulo "rt2500".
Para as placas Ralink RT61, use o driver "rt61-1.1.0-b1.tar.gz" (ou mais recente). Ele é instalado da mesma forma que os outros, usando os comandos "make" e "make install". Isto gerará o módulo "rt61", que deve ser carregado para ativar a placa.
Você encontrará na página também o arquivo "rt2x00-2.0.0-xx.tar.gz", que é um driver novo e experimental, escrito do zero, com o objetivo de dar suporte às duas placas simultaneamente. Ele está disponível apenas para testes. Mas, por estar concentrando a maior parte do desenvolvimento, este novo driver tende a se tornar a melhor opção assim que estiver concluído.
Duas últimas observações:

Sempre que atualizar um destes drivers, use o comando "locate" para verificar se já não existe uma versão antiga do driver instalada em outra pasta dentro da árvore do Kernel. Caso exista, primeiro remova o módulo antigo.
Em casos onde a placa de rede wireless fique trocando de posição a cada boot, crie um arquivo de texto chamado "/etc/udev/rules.d/001-network.rules" e adicione as três linhas abaixo. Elas orientam o sistema a usar o device "ra0" para a rede wireless, sempre que for encontrada uma placa Ralink:
SUBSYSTEM=="net", DRIVERS=="rt2500", NAME="ra0"SUBSYSTEM=="net", DRIVERS=="rt2570", NAME="ra0"SUBSYSTEM=="net", DRIVERS=="rt61", NAME="ra0"
Linux-wlan-ng
O pacote linux-wlan-ng inclui suporte a várias variações do chipset Prism, incluindo o Prism2. Este pacote vem incluído na maior parte das distribuições, por ser completamente open-source.
Ele é (nas distribuições) geralmente dividido em dois pacotes. O pacote "linux-wlan-ng" inclui os scripts e utilitários, enquanto o pacote "linux-wlan-ng-modules" contém os módulos de Kernel das placas suportadas. Algumas distribuições incluem apenas os scripts e utilitários, mas não os módulos do Kernel. Caso você precise instalá-los manualmente, baixe o pacote no:ftp://ftp.linux-wlan.org/pub/linux-wlan-ng/.
A instalação é similar aos outros drivers que vimos até aqui. Descompacte o arquivo e rode o comando:
# make config
O script confirma a localização do código fonte do Kernel e pergunta quais dos módulos devem ser gerados. Existem três drivers disponíveis, o "prism2_plx" (para placas Prism2 PLX9052), "prism2_pci" (para placas com chipset Prism2 em versão PCI ou PC-Card) e "prism2_usb" (a versão para placas USB).
Em seguida rode os comandos:
# make all# make install
... que concluirão a instalação. Os módulos são carregados automaticamente durante o boot pelo hotplug, mas se for necessário carregar manualmente, use os comandos: "modprobe prism2_pci", "modprobe prim2_usb" ou "modprobe prim2_plx".
Suporte a webcams

Assim como no caso dos softmodems e placas wireless, existe suporte no Linux para a maior parte das webcams que podem ser encontradas no mercado. A maioria dos drivers são incluídos diretamente no Kernel, com duas importante exceções: o spca5xx e o qc-usb, que dão suporte à vários modelos de câmeras comuns. Algumas distribuições já trazem estes dois drivers pré-instalados, em outras é preciso instalá-los manualmente.
Uma vez que os módulos estiverem instalados, o hotplug (ou udev) passa a detectar a câmera automaticamente, assim que ela é plugada à porta USB.
O programa de videoconferência mais famoso (embora longe de ser o mais usado) é o GnomeMeeting (apt-get install gnomemeeting). Ele é compatível com o Microsoft Netmeeting, porém não com o sistema usado no MSN, que é esmagadoramente mais popular.
A partir do Amsn 0.95, do Mercury 1710, do Kopete 0.11 (lançado juntamente com o KDE 3.5) e do Gaim 2.0 (final), todos os principais mensageiros passaram a oferecer suporte a webcam no MSN de forma quase que simultânea, embora com níveis variados de sucesso.
Entre eles, o Mercury é (pelo menos por enquanto) o mais limitado, pois ele utiliza o JMI, um plug-in Java para acesso à webcam, que não é compatível com um número muito grande de modelos, mesmo que a câmera esteja funcionando perfeitamente em outros aplicativos. Nos demais, a compatibilidade é similar: basta que a câmera seja detectada pelo sistema.
Você pode também colocar as imagens da webcam dentro de uma página web, de forma que elas sejam atualizadas automaticamente com uma certa freqüência. Uma boa forma de saber o que anda acontecendo em casa quando você não está :-p.
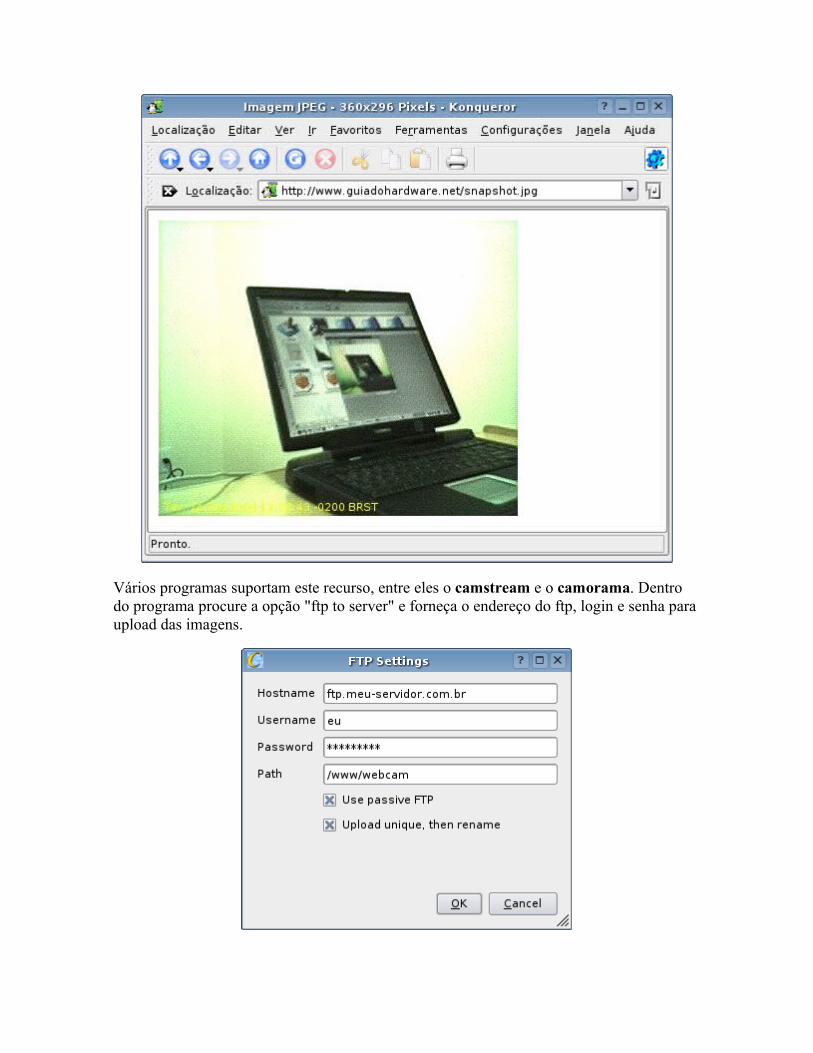
Vários programas suportam este recurso, entre eles o camstream e o camorama. Dentro do programa procure a opção "ftp to server" e forneça o endereço do ftp, login e senha para upload das imagens.

Driver spca5xx
Este driver é uma espécie de curinga, suporta quase 100 modelos diferentes de webcams, com combinações de vários chipsets e sensores diferentes. A lista dos modelos suportados está disponível no: http://mxhaard.free.fr/spca5xx.html.
A página de download é a: http://mxhaard.free.fr/download.html.
O driver é atualizado com muita freqüência. Enquanto escrevo, a versão mais atual é o arquivo "spca5xx-20050328.tar.gz".
Como de praxe, para instalá-lo é necessário ter instalados os compiladores e o código fonte do Kernel. Descompacte o arquivo com o comando "tar -zxvf spca5xx-20050328.tar.gz", acesse a pasta spca5xx-20050328 que será criada e rode os comandos:
$ make # make install
O script vai compilar o módulo spca50x.ko e copiá-lo para a pasta "/lib/modules/2.x.x/kernel/drivers/usb/media"
Para carregá-lo manualmente, use o comando "modprobe spca50x". Para fazer com que ele seja carregado automaticamente durante o boot, adicione a linha "spca50x" no final do arquivo "/etc/modules".
Teste a câmera no Kopete, Gnomemeeting, Camstream, Camorama, Gqcam ou outro programa de conferência ou captura.
Logitech QuickCam
Segundo o desenvolvedor, este driver suporta as câmeras Logitech Quickcam Express (o modelo antigo), Logitech Quickcam Web, LegoCam, Dexxa Webcam, Labtec Webcam e alguns modelos da Logitech QuickCam Notebook.
Para instalá-lo, o primeiro passo é baixar o driver disponível no: http://qce-ga.sourceforge.net/.

O driver mais atual é o "qc-usb", que oferece os mesmos recursos do driver antigo, o qce-ga, mas com várias atualizações.
Para instalar, descompacte o pacote, acesse a pasta que será criada e gere o arquivo do módulo com o comando:
# make all
Ative o módulo com o comando:
# insmod mod_quickcam.ko
Por último, rode o script que instala o módulo e os utilitários:
# ./quickcam.sh
Para que o módulo seja carregado automaticamente durante o boot, adicione a linha "quickcam" no final do arquivo /etc/modules.conf.
Sqcam
Mais um driver pouco conhecido é o Sqcam, que dá suporte às BreezeCam e outras câmeras baratas, que funcionam também como webcam, baseadas no chipset SQ905 e variantes. Baixe a versão mais recente do driver no: http://prdownloads.sourceforge.net/sqcam/.
No meu caso, baixei o arquivo "sqcam_driver_for_kernel_2_6-0.1b.tar.gz". Depois de descompactar e acessar a pasta criada, compile o módulo usando o comando:

# make
Caso a compilação falhe com um erro como "*** Warning: "remap_page_range" [sqcam_driver_for_kernel_2_6/sqcam.ko] undefined!", abra o arquivo "sq905.c" (o arquivo que gera o erro) e substitua a linha:
if (remap_page_range(vma, start, page, PAGE_SIZE, PAGE_SHARED)) {
por:
if (remap_pfn_range(vma, start, page>>PAGE_SHIFT, PAGE_SIZE, PAGE_SHARED)) {
Este erro (descrito no http://dev.openwengo.com/trac/openwengo/trac.cgi/wiki/SqCam) acontece devido a mudanças nas funções internas do Kernel, a partir da versão 2.6.11. Ele deve ser corrigido em futuras versões do driver.
Depois de rodar o "make" novamente, será gerado o arquivo "sqcam.ko", que você deve copiar para a pasta "misc/", dentro da pasta de módulos do kernel, como em:
# cp sqcam.ko /lib/modules/2.6.14-kanotix-6/misc/
Rode o comando "depmod -a" para atualizar a lista dos módulos disponíveis e carregue o novo módulo:
# modprobe sqcam
Modems ADSL USB
Os modems ADSL podem ser divididos em três categorias. Os modems bridge, os que podem ser configurados como router e os modems USB, que são os modelos mais baratos, simples e de um modo geral de mais baixa qualidade.
Os modems que são conectados na placa de rede são muito simples de configurar, pois conversam com o sistema operacional usando um protocolo padrão, o próprio protocolo Ethernet.

Os modelos atuais podem ser configurados como bridge ou router. Em modo bridge (ponte) o modem serve apenas como um ponto de comunicação entre sua placa de rede e o roteador instalado na central telefônica. Para se conectar você precisa utilizar um utilitário de autenticação, como o pppoeconf ou o rp-pppoe e informar seu login e senha de acesso, fornecidos pelo provedor.
Ao configurar o modem como roteador, sua vida fica muito mais simples, pois o próprio modem faz a autenticação e compartilha a conexão com o seu micro. Você precisa apenas configurar a rede via DHCP para navegar. O modem pode ainda configurar a conexão com vários micros e serve como firewall para a rede.
A configuração do modem pode ser alterada através de uma interface de configuração acessível via navegador. O modem vem configurado de fábrica com um IP como 10.0.0.138 ou 192.168.1.254 e um login e senha padrão, informações que você encontra no manual. Você precisa apenas acessar este endereço padrão usando o navegador, a partir do micro conectado no modem.
Os modems USB por sua vez são uma espécie que trabalha de forma muito mais precária. Em primeiro lugar, eles precisam de um driver para funcionar, o que nos faz cair no mesmo problema dos softmodems: os drivers são muitas vezes proprietários, muitas vezes contém bugs e não vêm pré-instalados na maioria das distribuições.
Além do driver, é necessário o arquivo do firmware correspondente ao seu modem. O firmware é um software que é carregado no próprio modem quando ele é ativado e é responsável por controlar o hardware, permitindo que ele se comunique com o driver instalado na sua máquina. Sem o firmware correto, o modem simplesmente não funciona.
Se você tem a opção de escolher, troque imediatamente seu modem ADSL USB por um modelo completo, ligado na placa de rede. Sua vida será muito mais longa e feliz. Caso contrário, aceite minhas condolências e continue lendo... :-P.
O driver para o Speedtouch USB (que inclui suporte para o Speedtouch 330 da Alcatel), o modelo USB mais popular aqui no Brasil, pode ser encontrado no:http://sourceforge.net/projects/speedtouch/.
Este é aquele modelo pequeno, que parece uma pulga em cima do monitor. Ele foi bastante popular numa certa época, quando a diferença de preço entre ele e os modems roteadores ainda era grande. Hoje em dia os modems ADSL de uma forma geral caíram muito de preço e deixou de existir uma diferença significativa.
Você precisa baixar dois arquivos. O driver propriamente dito está enquanto escrevo na versão 1.3 e pode ser baixado no: http://prdownloads.sourceforge.net/speedtouch/speedtouch-1.3.tar.gz.
Na página estão disponíveis também alguns pacotes pré-compilados para o Fedora e Mandriva.
O segundo arquivo é o firmware do modem, o arquivo SpeedTouch330_firmware_3012.zip que pode ser baixado no: http://www.speedtouch.com/driver_upgrade_lx_3.0.1.2.htm.

Para instalar o driver, descompacte o arquivo, acesse a pasta que será criada e rode os comandos de sempre:
$ ./configure$ make$ su <senha># make install
Depois de instalado o driver, copie o arquivo do firmware para a pasta /etc/speedtouch/, criada durante a instalação.
A configuração do modem é feita pelo comando:
# speedtouch-setup
Nesta etapa você precisa informar os valores VPI e VCI usados pela operadora. Estes valores são necessários para configurar todo tipo de modem, por isso você pode obtê-los com o suporte técnico ou no Google. Para a Telefonica, por exemplo, o VCI é 35 e o VPI 8.
Para conectar, chame o comando
# speedtouch-pppoe start
Num certo ponto ele pedirá a localização do firmware do modem. No passo anterior foram criados dois arquivos dentro da pasta /etc/speedtouch, o KQD6_3.012 (usado pelo Speedtouch 330 Rev 0200) e o ZZZL_3.012 (Speedtoch 330 Rev 0400). O Rev 0400 é o mais comum nas instalações da Telefonica; na dúvida tente ele primeiro.
Se o driver estiver corretamente instalado, o script vai fazer o upload do firmware para o modem e ativá-lo. As luzes ficam piscando por pouco mais de um minuto e a conexão é finalmente efetuada.
Para desconectar, use o comando:
# speedtouch-pppoe stop
Se você quer um utilitário de configuração mais amigável para conectar e desconectar, pode experimentar o gnome-ppx, disponível no: http://gnome-ppx.berlios.de/.
Na seção de download dentro da página clique no "Download Installer version". Isso baixa um script baseado no autopackage, que baixa e instala o pacote automaticamente, como os ícones mágicos do Kurumin.
Basta dar permissão de execução a ele e executá-lo com o comando:
# ./gnome-ppx-0.6.1.package
Depois de instalado, chame o programa com o comando:
# pppoe_dialer
Outro modelo que precisa de drivers adicionais é o Zyxel630, que é muito popular em Portugal, vendido geralmente como "Octal a360". Este modelo não é tão comum no Brasil, mas é possível encontrá-lo à venda em algumas lojas online.
O driver pode ser baixado no: http://sourceforge.net/projects/zyxel630-11.
Uma outra página dedicada a prestar suporte a este modem, que inclusive disponibiliza um driver alternativo é a: http://gulest.est.ips.pt/octal/.
Enquanto escrevo, a versão mais recente é o arquivo "amedyn-2004-08-04-src.tgz". Este driver foi declarado estável, por isso não é mais atualizado com tanta freqüência.
Descompacte o pacote e, dentro da pasta amedyn/ que será criada, rode o comando:
# make
Este driver pode ser problemático de instalar em algumas distribuições. Em várias, o script de instalação simplesmente não funciona, terminando com vários erros. Nestes casos você pode compilar apenas o módulo e copiar o script de inicialização manualmente:
1- Acesse a pasta "amedyn/module/" e rode os comandos:
# ./configure# make
Copie os módulos "amedyndbg.ko" e "amedyn.ko" que serão gerados para a pasta "/lib/modules/2.x.x/extra/" e rode o comando "depmod -a".
2- Acesse agora a pasta "amedyn/scripts/" e instale-os com o comando:
# make
Edite agora o arquivo /etc/amedyn, onde vai a configuração do protocolo e do provedor. Ele ficará:

PROTOCOL_MODE=4VPI=8VCI=35
Substitua os valores VPI e VCI pelos do seu provedor. Para conectar, você precisa carregar os dois módulos que dão suporte ao modem, usando o modprobe e executar o script que ativa o modem:
# modprobe amedyn# modprobe amedyndbg # amstart.sh
O próximo passo é configurar a conexão, com as informações do provedor, login e senha e conectar. Você pode usar "gnome-ppx", que citei no tópico anterior, que é o programa gráfico mais usado atualmente.
Outros programas, mais antigos, mas que ainda podem ser usados são o "gpppoe-conf" e o comando "adsl-setup". Ao usar um dos dois, deixe para executar o comando amstart.sh depois de configurar a conexão.
Driver da nVidia
As placas 3D da nVidia são atualmente as melhores placas 3D para uso no Linux. Elas são as melhores suportadas dentro do Cedega/WineX e nos games e aplicativos 3D for Linux em geral.
Apesar de ter o código fonte fechado, o driver 3D da nVidia é distribuído com uma licença liberal, que permite sua livre distribuição, desde que não sejam feitas alterações nem engenharia reversa.
Graças a isto, um grande número de distribuições vem com o driver pré-instalado, ou disponibilizam scripts ou pacotes prontos, o que é bom tanto para os usuários, quanto para a própria nVidia, que tem a chance de vender mais placas graças ao bom suporte por parte das distribuições.
Instalando manualmente
A nVidia disponibiliza um instalador genérico, que usa uma interface de modo texto simples e consegue ser compatível com quase todas as distribuições sem precisar de qualquer modificação. O driver pode ser baixado na seção "Download Drivers > Linux and FreeBSD drivers" no http://www.nvidia.com.
Na página de download estão disponíveis versões para processadores x86 (Pentium, Athlon, Duron, etc.), o Linux IA32, uma versão para processadores AMD64 (Linux AMD64/EM64T) e até uma versão para PCs com processadores Intel Itanium (Linux IA64):
Nas primeiras versões, os drivers eram bem mais complicados de instalar e eram disponibilizados pacotes separados para cada principal distribuição. A partir da versão 1.0-4349 (março de 2003), o driver foi unificado, e o mesmo executável passou a atender todas as distribuições.
Este arquivo executável substitui os dois arquivos com o o GLX e o Kernel driver, que precisavam ser instalados separadamente nas versões antigas do driver. Um instalador simples, em modo texto, cuida da maior parte do trabalho.
A segunda grande mudança ocorreu a partir do 1.0-7664 (junho de 2005). Até o 1.0-7174, o driver dava suporte a toda a família nVidia, das antigas TNT e TNT2, às placas mais recentes.
A partir do 1.0-7664 foi removido o suporte às placas TNT e TNT2 (incluindo as Vanta, Pro e Ultra), além das GeForce 256, GeForce DDR, GeForce2 GTS, Ti e Ultra, que passaram a ser consideradas placas "de legado". Se você tem uma, a única opção é continuar usando o antigo driver 1.0-7174, que continua disponível no arquivo: http://www.nvidia.com/object/linux_display_archive.html.
Enquanto escrevo, a versão mais atual é a 1.0 release 8178, o que faz com que o arquivo se chame NVIDIA-Linux-x86-1.0-8178-pkg1.run.

Este é um arquivo binário, diferente dos pacotes .RPM ou .DEB a que estamos acostumados. Você não precisa usar nenhum gerenciador de pacotes, basta rodá-lo diretamente em qualquer distribuição.
Como de praxe, para executá-lo você precisa antes de mais nada dar permissão de execução para ele, o que pode ser feito com o comando:
$ chmod +x NVIDIA-Linux-x86-1.0-8178-pkg1.run
Por precaução, o instalador exige que você o execute em modo texto puro. O problema todo é que se você já estiver usando uma versão anterior dos drivers da nVidia, ele não terá como substituir os módulos antigos enquanto eles estiverem em uso (ou seja, enquanto o modo gráfico estiver aberto). Para fechar o X e poder iniciar a instalação do driver, é necessário parar o KDM ou GDM, voltando para o modo texto. Dependendo da distribuição usada, você pode usar um dos comandos abaixo para fechar o gerenciador de login:
# /etc/init.d/kdm stop# /etc/init.d/gdm stop# service dm stop
... ou usar o comando telinit (ou init) para mudar para o runlevel 3, que não inclui a abertura do modo gráfico:
# telinit 3# init 3
No terminal, logue-se como root, acesse a pasta onde o arquivo foi baixado e finalmente execute-o com o comando:
# ./NVIDIA-Linux-x86-1.0-8178-pkg1.run
Antes de mais nada, você precisa aceitar o bom e velho contrato de licença. Muita gente se pergunta por que a nVidia não abre de uma vez o código fonte do driver para que ele já seja incluído diretamente nas distribuições.
Bem, o problema todo tem três letras: ATI. Atualmente a ATI está à frente da nVidia do ponto de vista do hardware. As placas são na maioria dos casos mais rápidas. O problema é que a ATI não consegue fazer drivers tão bons quanto a nVidia, o que mantém as duas mais ou menos em pé de igualdade. Abrir os drivers neste caso poderia beneficiar a ATI, já que o código fonte do driver diz muito sobre como a placa funciona e que tipo de otimizações e truques foram implementados.

A maior parte da instalação consiste em simplesmente copiar alguns arquivos e bibliotecas. Mas, existe um componente que precisa ser gerado sob medida para o seu sistema, que é o módulo de Kernel, que permite que o driver tenha acesso de baixo nível ao hardware.
O instalador já traz vários módulos pré-compilados para várias distribuições, incluindo Mandriva, SuSe, Fedora e outras. Ao usar uma delas, ele simplesmente vai instalar o que já tem sem fazer mais perguntas. Caso contrário, ele verificará se existe algum módulo disponível no FTP da nVidia onde é mantido um banco constantemente atualizado.
Se você estiver usando uma distribuição mais incomum, ou tenha compilado seu próprio Kernel, ele recorrerá ao último recurso, que é compilar localmente um módulo adequado para a sua máquina. Neste caso, você precisará ter os pacotes kernel-sources, kernel-headers e gcc instalados, da mesma forma que ao compilar um dos drivers para softmodems ou placas wireless.
Estes pacotes precisam ser obrigatoriamente os que vêm nos CDs da sua distribuição. É preciso que as versões batam com o Kernel que está instalado no seu sistema. De resto é só deixar o próprio programa se encarregar do resto:
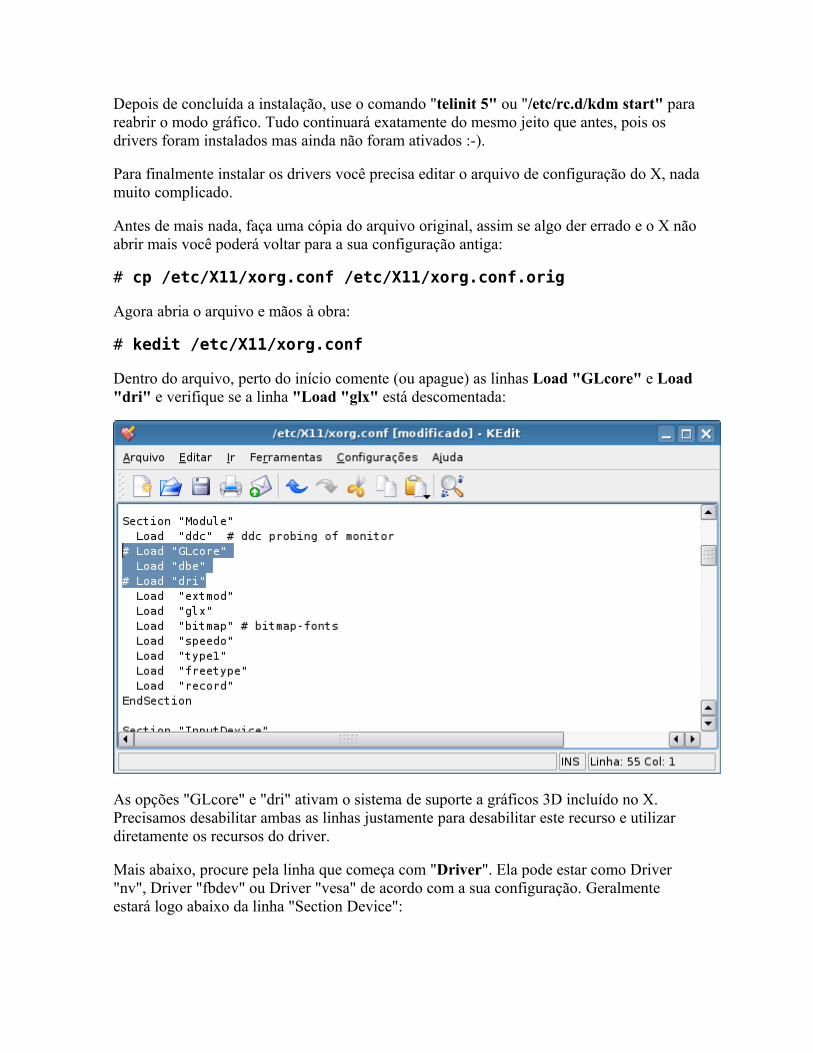
Depois de concluída a instalação, use o comando "telinit 5" ou "/etc/rc.d/kdm start" para reabrir o modo gráfico. Tudo continuará exatamente do mesmo jeito que antes, pois os drivers foram instalados mas ainda não foram ativados :-).
Para finalmente instalar os drivers você precisa editar o arquivo de configuração do X, nada muito complicado.
Antes de mais nada, faça uma cópia do arquivo original, assim se algo der errado e o X não abrir mais você poderá voltar para a sua configuração antiga:
# cp /etc/X11/xorg.conf /etc/X11/xorg.conf.orig
Agora abria o arquivo e mãos à obra:
# kedit /etc/X11/xorg.conf
Dentro do arquivo, perto do início comente (ou apague) as linhas Load "GLcore" e Load "dri" e verifique se a linha "Load "glx" está descomentada:
As opções "GLcore" e "dri" ativam o sistema de suporte a gráficos 3D incluído no X. Precisamos desabilitar ambas as linhas justamente para desabilitar este recurso e utilizar diretamente os recursos do driver.
Mais abaixo, procure pela linha que começa com "Driver". Ela pode estar como Driver "nv", Driver "fbdev" ou Driver "vesa" de acordo com a sua configuração. Geralmente estará logo abaixo da linha "Section Device":

Section "Device" Identifier "Card0" Driver "nv"
Para ativar o driver da nVidia, você deve alterar o valor para Driver "nvidia", indicando que o X deve usar o novo driver:
Depois destas três alterações, a configuração está completa. Pressione Ctrl+Alt+Backspace ou reinicie o micro e você verá o splash da nVidia indicando que tudo está certo. Experimente rodar o "glxgears", ou testar algum game ou aplicativos 3D. Em caso de problemas, basta desfazer as alterações para desativar o driver e voltar a usar o driver "nv".
Se você estiver usando o Debian, ou outra distribuição derivada dele, como o Knoppix, Kurumin, Lycoris, Linspire, etc., você precisará dar mais dois comandos (como root) para concluir a instalação:
# echo "alias char-major-195 nvidia" >> /etc/modules.conf # echo "alias char-major-195 nvidia " >> /etc/modutils/aliases
Uma terceira alteração que pode ser necessária dependendo do modelo da sua placa-mãe é desabilitar o double buffer extension. Procure pela linha:
Load "dbe" # Double buffer extension
e comente-a, deixando:
#Load "dbe" # Double buffer extension

Desabilitar esta opção vai causar uma pequena queda no desempenho. Deixe para desativá-la apenas caso ocorram travamentos ou instabilidade ao rodar games 3D.
Outra configuração que causa problemas freqüentemente é a "NvAGP", que indica qual driver AGP o driver irá utilizar. Existem três opções:
NvAGP "0": desativa o uso do AGP. Isto faz com que a placa de vídeo seja acessada como se fosse uma placa PCI, sem armazenar texturas na memória e outros recursos permitidos pelo AGP. O desempenho naturalmente cai, principalmente nos games mais pesados ou ao usar resoluções mais altas, mas os problemas são minimizados.
NvAGP "2": usa o driver "agpgart", que é o driver AGP padrão, incluído no próprio Kernel. Este é um driver genérico, que ativa todas as funções do barramento AGP, sem nenhuma otimização em especial.
NvAGP "1": usa o driver AGP interno da nVidia, uma versão fortemente otimizada, incluída no próprio driver. Esta é a opção mais rápida (de 10 a 20% mais que ao usar o agpgart), porém a mais problemática, pois apresenta incompatibilidades diversas com um grande número de placas-mãe.
Para usar esta opção, o módulo "agpgart" não deve ser carregado durante o boot. Muitas ferramentas de detecção o carregam automaticamente, o que faz com que o driver AGP da nVidia não funcione corretamente e o driver trave durante a abertura do X. Para evitar esse problema, adicione a linhas:
modprobe -r agpgartmodprobe nvidia
... no final do arquivo "/etc/init.d/bootmisc.sh" ou "/etc/rc.d/rc.local".
É preciso também que a placa-mãe usada seja compatível com o driver. Isso você descobre apenas testando. Se o driver travar na abertura do X, mude para o NvAGP "2" ou NvAGP "0".
NvAGP "3": este é o valor default do driver, um valor "seguro", onde a placa testa ambos os drivers, tentando primeiro usar o agpgart e passando para o nVidia AGP caso possível. Colocar esta opção no arquivo é redundante, já que ela é usada por padrão quando a linha é omitida. Você precisa se preocupar apenas ao usar um dos outros valores.
A opção NvAGP é adicionada dentro da seção "Device", acima da linha Driver "nvidia", como em:
Section "Device"Option "NvAGP" "0" Identifier "Card0"Driver "nvidia"VendorName "All"

BoardName "All"EndSection
Em teoria, todas as placas-mãe deveriam suportar pelo menos o uso da opção NvAGP "2", onde é usado o agpgart. Mas, na prática, um número relativamente grande de placas (sobretudo as com alguns chipsets da SiS) só funciona em conjunto com a NvAGP "0". Se o driver travar durante a abertura do X, adicione a linha e teste novamente.
Em muitos casos, você pode resolver problemas de estabilidade causados por problemas da placa-mãe reduzindo a freqüência do barramento AGP no setup. Usar "AGP 2x" ou mesmo "AGP 1x" ao invés de "AGP 4x" reduz os problemas em muitos casos e não tem um impacto tão grande no desempenho quanto usar a opção NvAGP "0".
Em alguns casos, os travamentos nos jogos podem também ser causados por problemas com os drivers da placa de som ou do modem, já que não é incomum que ao travar o driver leve junto todo o sistema.
Outras possíveis causas de instabilidade são superaquecimento da placa de vídeo (neste caso experimente comprar um slot cooler, ou instalar um exaustor próximo à placa de vídeo, melhorando a ventilação) ou problemas com a fonte de alimentação do micro (muitas fontes de baixa qualidade não são capazes de fornecer energia suficiente para a placa de vídeo).
Algumas placas-mãe da PC-Chips utilizam capacitores baratos, que fazem com que o slot AGP não consiga fornecer energia suficiente para a placa 3D. Como estas placas são freqüentemente usadas em conjunto com fontes de baixa qualidade (uma economia leva à outra), acabam sendo uma fonte freqüente de problemas.
Mais uma coisa que deve ser levada em consideração é que existem placas de vários fabricantes com chipsets nVidia. Mesmo placas com o mesmo chipset muitas vezes possuem diferenças na temporização da memória, ou mesmo na freqüência do chipset (alguns fabricantes vendem placas overclocadas para diferenciar seus produtos dos concorrentes) e assim por diante. Cada fabricante tenta fazer suas placas serem mais rápidas ou mais baratas que as dos concorrentes, com resultados variados. Estas diferenças podem levar a incompatibilidades diversas com alguns modelos de placas-mãe.
Ativando os recursos especiais
Os drivers permitem ativar também o TwinView, o suporte a dois monitores na mesma placa, disponível em alguns modelos, suporte a FSAA, etc. A configuração pode ser feita "no muque" direto nos arquivos de configuração, ou usando o nvidia-settings, o configurador gráfico incluído nas versões recentes do driver. Vamos dar uma olhada geral nas opções disponíveis:
FSAA

Para ativar o suporte a FSAA nas placas GeForce, basta dar um único comando no terminal, como root:
# export __GL_FSAA_MODE=4
O número 4 pode ser substituído por outro número de 0 a 7, que indica a configuração desejada, que varia de acordo com o modelo da placa.
Aqui vai uma compilação das tabelas divulgadas pela nVidia:
GeForce4 MX, GeForce4 4xx Go (notebooks), Quadro4 380,550,580 XGL e Quadro4 NVS--------------------------------------------------
0: FSAA desativado1: 2x Bilinear Multisampling2: 2x Quincunx Multisampling3: FSAA desativado4: 2 x 2 Supersampling5: FSAA desativado6: FSAA desativado7: FSAA desativado
GeForce3, Quadro DCC, GeForce4 Ti, GeForce4 4200 Go Quadro4 700,750,780,900,980 XGL--------------------------------------------------------------
0: FSAA desativado1: 2x Bilinear Multisampling2: 2x Quincunx Multisampling3: FSAA desativado4: 4x Bilinear Multisampling5: 4x Gaussian Multisampling6: 2x Bilinear Multisampling por 4x Supersampling7: FSAA desativado
GeForce FX, GeForce 6xxx, GeForce 7xxx, Quadro FX---------------------------------------------------------------
0: FSAA desativado1: 2x Bilinear Multisampling2: 2x Quincunx Multisampling3: FSAA desativado4: 4x Bilinear Multisampling5: 4x Gaussian Multisampling6: 2x Bilinear Multisampling por 4x Supersampling7: 4x Bilinear Multisampling por 4x Supersampling
Você deve chamar o comando antes de abrir o jogo ou aplicativo. Se você tem uma GeForce FX e quer rodar o Doom 3 com FSAA 4x Bilinear, por exemplo, os comandos seriam:
$ export __GL_FSAA_MODE=6$ doom3

Este comando é temporário, vale apenas para a seção atual. Se você quiser tornar a configuração definitiva, adicione-o no final do arquivo "/etc/profile". Você pode usar também o configurador gráfico da nVidia (veja a seguir).
O FSAA suaviza os contornos em imagens, adicionando pontos de cores intermediários. Isto diminui muito aquele efeito serrilhado em volta dos personagens e objetos nos jogos. Este é um recurso cada vez mais utilizado nos jogos 3D, com o objetivo de melhorar a qualidade de imagem, sobretudo ao se utilizar baixas resoluções.
Isto é obtido através de uma "super-renderização". A placa de vídeo simplesmente passa a renderizar uma imagem 2 ou 4 vezes maior do que a que será exibida no monitor e em seguida diminui seu tamanho, aplicando um algoritmo de anti-aliasing, antes de exibi-la. Com isto as imagens ganham muito em qualidade mas em compensação o desempenho cai drasticamente.
O FSAA é ideal para jogos mais leves, como o Quake III, Counter Strike ou outros títulos antigos, onde a placa consiga exibir um FPS mais que suficiente mesmo a 1024x768. Com o FSAA você pode transformar este excesso de desempenho em mais qualidade de imagem. Em geral, os games ficam mais bonitos visualmente usando 800x600 com o FSAA ativo, do que a 1024x768.
Configurador gráfico
A partir da versão 1.0 do driver da nVidia, você pode usar o configurador oficial, o nvidia-settings, que facilita o acesso a diversas opções, que antes precisavam ser ativadas manualmente no arquivo de configuração do X, ou via linha de comando.
Você pode usá-lo para ajustar o gama e equilíbrio de cores, ativar o FSAA e o Anisotropic Filtering, entre outras opções, que variam de acordo com a placa instalada.
Com o driver da nVidia instalado, basta chamá-lo num terminal. Não é preciso abri-lo como root, poi ele salva as configurações no arquivo ".nvidia-settings-rc", dentro do home.
$ nvidia-settings

Entre as opções oferecidas, está o ajuste do FSAA (Antialiasing Settings) e do Anisotropic Filtering. O FSAA faz com que a placa renderize os gráficos 3D numa resolução maior que a mostrada na tela e em seguida reduza a imagem, usando um algoritmo de antialiasing para suavizar os contornos, melhorando perceptivelmente a qualidade dos gráficos, em troca de uma grande redução do frame-rate.
Em games onde o FPS estiver abaixo de 60 ou 70 quadros, você terá melhores resultados ativando a opção "Sync to VBlank" (VSync), que sincroniza a atualização dos quadros com a taxa de atualização do monitor. Ativando-a, a placa passa a gerar um novo quadro precisamente a cada duas atualizações do monitor. Se você estiver usando 70 Hz, por exemplo, terá 35 FPS.
À primeira vista, parece um mau negócio, pois você está reduzindo ainda mais o FPS, mas na prática o resultado visual acaba sendo melhor. Se o monitor está trabalhando a 70 Hz e a placa roda o game com a 55 FPS, por exemplo, significa que em algumas atualizações do monitor é mostrado um novo quadro e em outras não, gerando uma movimentação irregular. Com o VSync, você tem 35 FPS, mas exibidos de forma uniforme. Lembre-se de que os filmes são gravados com apenas 24 quadros, e isso é considerado satisfatório pela maioria das pessoas.
Outro recurso interessante é o anisotropic filtering, que melhora a qualidade das texturas aplicadas sobre superfícies inclinadas. O exemplo mais clássico é o texto de abertura dos filmes do StarWars.

Em geral, o efeito é melhor percebido em jogos de primeira pessoa, nas paredes e objetos mais próximos. Pense no Anisotropic Filtering como uma espécie de evolução dos velhos bilinear e trilinear filtering que encontramos nas configurações de quase todos os games.
Essa imagem mostra bem o conceito: do lado esquerdo temos o texto aplicado usando o velho trilinear filtering e do lado direito temos o mesmo feito com nível máximo de qualidade do anisotropic filtering, o que tornou o texto mais legível:
A perda de desempenho é mais difícil de estimar, pois os algoritmos usados tanto das placas da nVidia quanto nas placas da ATI são adaptativos, ou seja, eles utilizam um número de amostras proporcional ao ganho que pode ser obtido em cada cena. Isso faz com que a perda de desempenho seja maior nos jogos em que existe maior ganho de qualidade.
É difícil traçar um padrão, pois a perda de desempenho varia muito de game para game. Pode ser de 10% ou de 30% dependendo do título. A melhor técnica é simplesmente experimentar ativar o recurso e ver se você percebe uma melhora na qualidade ou perda perceptível no desempenho e depois pesar as duas coisas na balança.
Assim como no caso do FSAA, é possível ajustar a configuração do anisotropic filtering também via terminal, executando o comando antes de executar o comando que abre o game:
$ export __GL_DEFAULT_LOG_ANISO=1
Nas GeForce3 em diante, existem três níveis de detalhe. O 1 é o nível mais baixo, 2 é o nível médio e 3 é o nível máximo. Você pode tornar a alteração definitiva adicionando o comando no final do arquivo "/etc/profile".
Muitas placas, principalmente as GeForce MX, suportam overclocks generosos, dada a

freqüência relativamente baixa com que muitos modelos operam. Você pode aproveitar este "potencial oculto" usando o NVClock, que permite ajustar a freqüência de operação da placa, fazendo overclock. Ele está disponível no http://www.linuxhardware.org/nvclock.
No site está disponível apenas a versão com código fonte. Para instalar, descompacte o arquivo e instale usando os comandos "./configure", "make", "make install".
Nas versões atuais, o NVClock possui duas opções de interface, o "nvclock_gtk" e o "nvclock_qt". Além do visual, os dois possuem opções ligeiramente diferentes, por isso convém testar ambos. Ao compilar, você precisa ter instaladas tanto as bibliotecas de desenvolvimento do QT, quanto do GTK, caso contrário o instalador vai gerar apenas a versão em modo texto.
Se você estiver usando o Debian (e derivados), Knoppix ou Kurumin pode instalá-lo mais facilmente através do apt-get. Ao usar outra distribuição, cheque se o repositório (da distribuição) inclui os três pacotes.
# apt-get install nvclock# apt-get install nvclock-gtk# apt-get install nvclock-qt
Ao ser aberto, ele detecta o modelo da sua placa de vídeo e oferece um intervalo de freqüências compatíveis com ela. Caso tenha dúvidas, você pode ver algumas informações sobre a placa nas abas "Card Info" e "AGP Info". Comece sempre fazendo pequenos overclocks e vá subindo a freqüência aos poucos, em intervalos de 1 ou 2 MHz. Se o vídeo travar, significa que você atingiu o limite da placa. Reinicie e ajuste novamente, desta vez com uma freqüência um pouco mais baixa.
Note que apesar de danos serem muito raros, os overclocks aumentam a dissipação de calor e o consumo elétrico da placa, o que pode reduzir a estabilidade geral do micro e, a longo prazo, reduzir a vida útil da placa. O ideal é que você ative o overclock apenas ao rodar algum game pesado.
A partir da versão 0.8, o NVClock permite ajustar manualmente a velocidade de rotação dos coolers (em placas compatíveis) e ativar os sensores de temperatura e rotação dos coolers, disponíveis nas placas mais recentes. De posse destas informações, você pode acompanhar melhor como a placa está reagindo ao overclock e definir o melhor valor.

Outro uso comum, principalmente entre os usuários de notebooks, é usar o NVClock para reduzir a freqüência de operação da placa, a fim de diminuir o aquecimento e o consumo. Se você fica navegando e usando aplicativos 2D na maior parte do tempo e resolve jogar só de vez em quando, isso faz bastante sentido, pois, mesmo em underclock, a placa vai oferecer um desempenho mais do que satisfatório para estas tarefas básicas. Na hora de jogar, é só abrir o NVClock novamente e aumentar a freqüência.
A configuração feita através das duas interfaces não é persistente; você precisa abrir e aplicar novamente os ajustes a cada boot. Para criar uma configuração persistente, a melhor opção é usar a interface de linha de comando do NVClock, adicionando o comando num dos arquivos de inicialização. Use o comando "nvclock", seguido pelas opções "-n clock" (para ajustar o clock da GPU) e "-m clock" (para ajustar a freqüência da memória), como em:
# nvclock -n 275 -m 350
Tome sempre o cuidado de testar a freqüência desejada antes de adicionar o comando num dos arquivos de inicialização; caso contrário, você pode chegar a uma situação em que o micro trava durante o boot e a única opção é dar boot com um live-CD para montar a partição e remover o comando.
TwinView
O TwinView é um recurso disponível em muitas placas GeForce2 MX em diante. A placa de vídeo possui dois conectores, permitindo que você tenha um sistema dual monitor usando uma única placa. É algo muito semelhante ao dual head encontrado nas placas da Matrox.

O TwinView é interessante, pois pode ser encontrado mesmo em placas relativamente baratas. Você acaba gastando bem menos do que se fosse comprar duas placas 3D separadas.
Para ativar este recurso no Linux, teremos que novamente recorrer à edição do "/etc/X11/xorg.conf". No read-me dos drivers está dito para incluir as seguintes linhas na seção "Device":
Option "TwinView"Option "SecondMonitorHorizSync" "<hsync range(s)>"Option "SecondMonitorVertRefresh" "<vrefresh range(s)>"Option "MetaModes" "<list of metamodes>"
Vamos entender o que isso significa.
O Option "TwinView" é a opção que ativa o recurso, enquanto o Option "SecondMonitorHorizSync" e o Option "SecondMonitorVertRefresh" indicam as taxas de atualização vertical e horizontal suportadas pelo segundo monitor, informações que você pode conferir no manual. Finalmente, a opção "Metamodes" indica as resoluções de vídeo que serão usadas em ambos os monitores.
Esta configuração do TwinView não interfere com a configuração do monitor principal. Isso permite que você use dois monitores diferentes, até mesmo com resoluções e taxas de atualização diferentes.
Então vamos a um exemplo prático. Estas linhas poderiam ser usadas por alguém que está usando dois monitores de 17":
Option "TwinView" "True"Option "TwinViewOrientation" "RightOf"Option "UseEdidFreqs" "True"Option "MetaModes" "1280x1024, 1280x1024"Option "SecondMonitorHorizSync" "31.5-95"Option "SecondMonitorVertRefresh" "50-150
Se você estiver usando dois monitores iguais, pode simplesmente copiar as freqüências do primeiro monitor, que já está configurado. Procure pelas linhas "HorizSync" e "VertRefresh" que estão mais acima no arquivo de configuração. Caso contrário, você pode descobrir os valores usados pelo segundo monitor através do manual, ou ligando-o em outra máquina e dando boot com um CD do Kurumin para que ele detecte as configurações do vídeo e você possa copiar os valores a partir do arquivo "/etc/X11/xorg.conf".
Os meta modes indicam as resoluções que serão usadas. O "1280x1024,1280x1024; 1024x768,1024x768" que coloquei no exemplo especifica dois modos. O X primeiro tentará usar 1280x1024 nos dois monitores e, se por algum motivo os monitores não suportarem esta resolução, ele usará 1024x768 em ambos.
Se você estiver usando dois monitores de tamanhos diferentes, provavelmente vai precisar usar resoluções diferentes em ambos. Neste caso a linha ficaria assim:
Option "MetaModes" "1280x1024,1024x768; 1024x768,800x600"
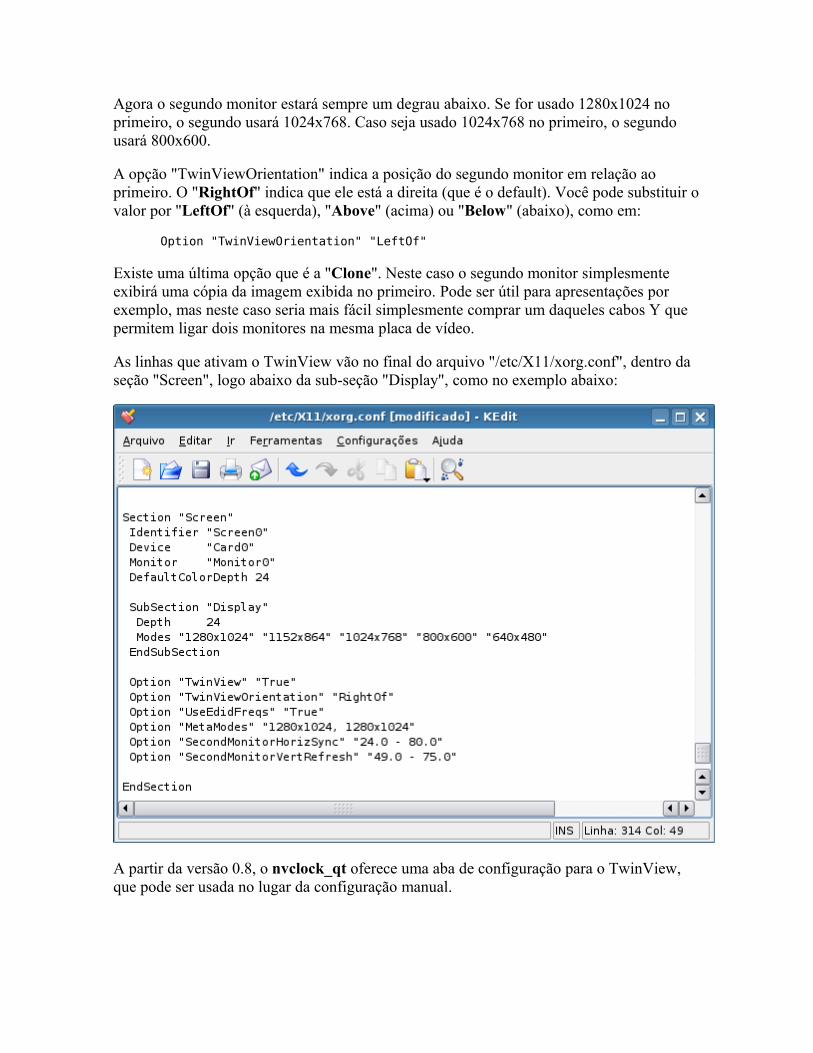
Agora o segundo monitor estará sempre um degrau abaixo. Se for usado 1280x1024 no primeiro, o segundo usará 1024x768. Caso seja usado 1024x768 no primeiro, o segundo usará 800x600.
A opção "TwinViewOrientation" indica a posição do segundo monitor em relação ao primeiro. O "RightOf" indica que ele está a direita (que é o default). Você pode substituir o valor por "LeftOf" (à esquerda), "Above" (acima) ou "Below" (abaixo), como em:
Option "TwinViewOrientation" "LeftOf"
Existe uma última opção que é a "Clone". Neste caso o segundo monitor simplesmente exibirá uma cópia da imagem exibida no primeiro. Pode ser útil para apresentações por exemplo, mas neste caso seria mais fácil simplesmente comprar um daqueles cabos Y que permitem ligar dois monitores na mesma placa de vídeo.
As linhas que ativam o TwinView vão no final do arquivo "/etc/X11/xorg.conf", dentro da seção "Screen", logo abaixo da sub-seção "Display", como no exemplo abaixo:
A partir da versão 0.8, o nvclock_qt oferece uma aba de configuração para o TwinView, que pode ser usada no lugar da configuração manual.

Instalando à moda Debian
Em distribuições derivadas do Debian, o driver da nVidia pode ser instalado tanto do jeito "normal", baixando o driver binário do site da nVidia e executando o instalador no modo texto, ou instalando o driver através do apt-get.
O driver é dividido em duas partes: um módulo no Kernel, que precisa ser compilado durante a instalação do driver (já que o módulo é diferente para cada versão do Kernel) e uma coleção de bibliotecas e utilitários que são independentes da versão do Kernel.
A instalação do driver pode ser problemática em alguns casos, pois é necessário ter instalados os compiladores e os headers do Kernel, além de que a versão do gcc instalada precisa ser a mesma que foi usada para compilar o Kernel.
A minha idéia aqui é ensinar como criar pacote pré-compilados que podem ser distribuídos ou incluídos em personalizações do sistema. Distribuir um pacote pré-compilado elimina a necessidade de ter os headers e compiladores (para quem vai instalar) e minimiza os possíveis problemas de instalação.
Por outro lado, o pacote pré-compilado só vai funcionar no Kernel específico para que foi compilado, o que limita o público alvo.
Para gerar um pacote .deb com o módulo pré-compilado:
# apt-get install module-assistant nvidia-kernel-common# module-assistant auto-install nvidia
No final da instalação você verá que é gerado um pacote .deb com o módulo compilado para o Kernel atual:
Done with /usr/src/nvidia-kernel-2.6.15_1.0.8178-1+1_i386.deb .Selecionando pacote previamente não selecionado nvidia-kernel-2.6.15.(Lendo banco de dados ... 82561 arquivos e diretórios atualmente instalados.)Descompactando nvidia-kernel-2.6.15 (de .../nvidia-kernel-2.6.15_1.0.8178-1+1_i386.deb) ...Instalando nvidia-kernel-2.6.15 (1.0.8178-1+1) ...
Você pode instalar este pacote em outras máquinas, que estejam rodando a mesma versão do sistema, ou pelo menos estejam utilizando a mesma versão do Kernel. O pacote .deb gerado fica disponível na pasta "/usr/src/".
Falta agora instalar o restante do driver, incluindo as bibliotecas 3D. Estes componentes fazem parte do pacote nvidia-glx, que também pode ser instalado pelo apt-get:
# apt-get install nvidia-glx

A partir daí, basta distribuir o pacote "nvidia-kernel-2.6.15" gerado, junto com o pacote "nvidia-glx".
A segunda maneira é reempacotar o driver binário da nVidia, incluindo o módulo para a versão atual do Kernel. Para isso, baixe a versão mais atual do driver no http://www.nvidia.com e execute-o com a opção "--add-this-kernel", como em:
# ./NVIDIA-Linux-x86-1.0-8178-pkg1.run --add-this-kernel
Isto vai gerar um novo pacote com o módulo para o Kernel atual incluído. Ao instalar você verificará que ele simplesmente usará o módulo pré-compilado, sem tentar compilar novamente.
Em qualquer um dos dois casos, depois de instalar o pacote ainda é necessário fazer as mudanças no arquivo de configuração do vídeo. Isso pode ser automatizado através de um script, usando o sed ou o awk para alterar os campos necessários no arquivo /etc/X11/xorg.conf. Veja mais detalhes de como fazer isso no capítulo sobre shell script.
Driver para placas com chipset nForce
Além do driver para placas 3D, a nVidia disponibiliza também um driver para o som e rede onboard das placas-mãe com chipset nForce e nForce2.
O nForce é um chipset desenvolvido para competir com a Via e SiS também no ramo das placas-mãe, complementando o negócio das placas 3D. O som e a rede onboard utilizam uma arquitetura própria, otimizada para games, com uma baixa utilização do processador e tempos de latência mais baixos, que ajudam a melhorar os tempos de resposta nos jogos em rede.
Opcionalmente, as placas podem incluir também vídeo GeForce onboard, usando memória compartilhada. Para diminuir a perda de desempenho do vídeo é usado o Twin Bank, um recurso onde dois pentes de memória DDR espetados na placa são acessados simultaneamente, dobrando a velocidade de acesso.

Para o vídeo, usamos os drivers 3D normais, que vimos a pouco. No Kernel 2.6 já existe suporte também para o som (inclusive suporte a 6 canais ao usar o Alsa) e para a rede onboard.
Mesmo assim, os drivers da nVidia ativam algumas otimizações que não existem nos drivers padrão. Você também vai precisar instalá-los se estiver usando uma distribuição antiga, baseada no Kernel 2.4. Uma observação é que até o 2.4.26 não existe suporte à rede onboard e o suporte ao som é deficiente.
Os drivers para o nForce estão disponíveis no site da nVidia, na mesma página dos drivers 3D. Baixe o "nForce Drivers > Linux IA32 Drivers".
A partir da versão 1.0, temos um arquivo executável, assim como no caso do driver 3D. Basta dar permissão de execução (chmod +x) e em seguida executar o arquivo com um:
# ./NFORCE-Linux-x86-1.0-0301-pkg1.run
A instalação é muito parecida com a do driver 3D. O pacote inclui módulos pré-compilados para o Mandriva, SuSE e Fedora. Em outras distribuições ele compila os módulos automaticamente, você precisa apenas ter os headers do Kernel e o GCC instalados.
A maior dificuldade é que as distribuições muitas vezes detectam a rede e som usando os drivers nativos. Para usar os novos drivers é preciso alterar manualmente os arquivos de configuração, trocando os módulos usados. É aqui que a coisa fica um pouco complicada, pois você precisa entender um pouco sobre os arquivos de inicialização da distribuição que está usando.
Ativando o driver de rede

Para ativar o driver de rede é preciso fazer o sistema usar o módulo "nvnet" (o driver da nVidia) ao invés do módulo "forcedeth", que é o driver open-source, incluído no Kernel.
Comece editando o arquivo "/etc/modules". Caso exista a linha "forcedeth", comente-a e adicione a linha "nvnet" logo abaixo.
A próxima parada é o arquivo "/etc/modules.conf". Comente a linha "alias eth0 forcedeth" (caso exista) e adicione a linha "alias eth0 nvnet" logo abaixo dela.
Caso a distribuição em uso execute algum utilitário de detecção de hardware na hora do boot, esta configuração vai ser sempre perdida. Neste caso você tem duas opções:
1: A primeira opção é desativar a detecção de hardware no boot. Para desativar a detecção no Mandriva desative o serviço "harddrake" no Painel de Controle. No Fedora desative o Kudzu e no Kurumin desative o script "/etc/rcS.d/S36hwsetup". Naturalmente, isso pode fazer com que alguns periféricos deixem de funcionar, por isso nem sempre é uma boa idéia.
2: A segunda opção é criar o script para carregar o módulo nvnet a cada boot. Para isso, adicione as linhas abaixo no final do arquivo "/etc/rc.d/rc.local" ou "/etc/init.d/bootmisc.sh":
modprobe -r forcedethmodprobe nvnet/etc/init.d/networking restart
Tenha em mente que, de dependendo da distribuição, o serviço responsável pela configuração da rede pode se chamar também "network" ou "internet". Nestes casos altere a última linha do script para que seja chamado o script correto.
Naturalmente, tudo isso se aplica apenas às distribuições baseadas no Kernel 2.6 ou no Kernel 2.4.26 em diante, que incluem o módulo forcedeth. Em distribuições mais antigas a instalação fica muito mais simples: você precisará apenas adicionar a linha "nvnet" no arquivo "/etc/modules" e a linha "alias eth0 nvnet" no final do arquivo /etc/modules.conf.
Ativando o driver de som
Para ativar o driver de som, edite o arquivo "/etc/modprobe.d/sound" ou "/etc/modprobe.conf" e comente as linhas referentes ao módulo "snd-intel8x0", substituindo-as pelas linhas abaixo, que carregam o nvsound, que é o driver da nVidia:
#alias snd-card-0 snd-intel8x0#alias sound-slot-0 snd-intel8x0# install snd-intel8x0 /sbin/modprobe --ignore-install snd-intel8x0 # usr/lib/alsa/modprobe-post-install snd-intel8x0
alias snd-card-0 nvsoundalias sound-slot-0 nvsound

install nvsound /sbin/modprobe --ignore-install nvsound; sleep 1 /usr/bin/nvmix-reg -f /etc/nvmixrc -L >/dev/null 2>&1 || :remove nvsound { /usr/bin/nvmix-reg -f /etc/nvmixrc -S >/dev/null 2>&1 || : ; }/sbin/modprobe -r --ignore-remove nvsound
Caso exista a linha "snd-intel8x0" no arquivo /etc/modules, comente-a a adicione a linha "nvsound".
Você pode configurar várias opções relacionadas ao som no utilitário "nvmixer", instalado junto com o driver.
Driver 3D da ATI
As placas da ATI sempre foram relativamente bem suportadas pelo Xfree. Tanto as antigas Riva 128 quanto as Radeon possuem drivers nativos a partir do Xfree 4.3 e em todas as versões do X.org, através dos drivers "r128" e "ati" (ou "radeon", nas versões anteriores do X).
Estes drivers oferecem um desempenho 3D razoável, em parte graças à própria ATI, que contribuiu no desenvolvimento e abriu parte das especificações das placas, de forma a facilitar o trabalho da equipe de desenvolvimento.
Porém, em 2003, a ATI resolveu seguir o mesmo caminho da nVidia, passando a desenvolver um driver 3D proprietário e parou de contribuir com o desenvolvimento do driver open-source. Apesar disso, o driver aberto continuou evoluindo, incluindo suporte a novas placas e melhorias no desempenho, embora o driver proprietário seja mais rápido, já que é desenvolvido pela equipe da ATI que tem acesso a todas as especificações das placas.
Se você usa apenas aplicativos em 2D, filmes, música, e games 3D leves, não vai perceber muita diferença, pois os drivers abertos oferecem um desempenho mais que satisfatório para tarefas gerais.
Mas, se você roda games 3D pesados, ou usa aplicativos de modelagem em 3D, como o Blender ou o PovRay, vai ver que a diferença é significativa. O desempenho dos drivers proprietários da ATI chega a ser de 2 a 3 vezes maior que o do driver open-source, mas eles possuem sua dose de problemas.
O driver da nVidia apresenta problemas em conjunto com algumas combinações de placas de vídeo e placas-mãe baratas, principalmente em placas com chipset SiS. Em algumas você só consegue usar o 3D configurando o vídeo com a opção Option "NvAgp" "0", que desativa o uso do barramento AGP, diminuindo brutalmente o desempenho da placa, e em outras o 3D simplesmente não funciona (muitas vezes nem no Windows) por limitações elétricas da placa-mãe.
No caso dos drivers da ATI, além dos mesmos problemas de compatibilidade de hardware com algumas placas-mãe, temos sempre um conjunto de deficiências relacionadas com o

próprio driver, incluindo problemas de estabilidade em conjunto com algumas versões do X e alguns games.
O driver for Linux também não oferece suporte completo a todas as instruções do padrão OpenGL, o que causa pequenos problemas visuais em diversos games, principalmente alguns títulos do Windows executados através do Cedega (WineX). O próprio desempenho do driver fica abaixo do obtido no Windows.
Honestamente falando, se o driver do X está funcionando corretamente, não existe muita vantagem em mudar para o driver binário da ATI, dada a baixa qualidade do driver e os diversos problemas. Ele oferece um desempenho 3D superior em conjunto com muitas placas, mas ainda muito inferior ao desempenho do driver Windows. Em resumo, se você quer estabilidade, fique com o driver padrão do X e, se está preocupado com o desempenho ou qualidade gráfica, compre uma placa da nVidia, que oferece drivers melhores.
Você pode encontrar um comparativo entre a diferença de desempenho entre os drivers Linux e Windows da ATI e da nVidia (no mesmo hardware) nestes dois links:
http://www.phoronix.com/scan.php?page=article&item=357http://www.phoronix.com/scan.php?page=article&item=359
Outros dois links (bem mais antigos), com benchmarks comparativos:
http://www.anandtech.com/printarticle.aspx?i=2229http://www.anandtech.com/printarticle.aspx?i=2302
Depois dessa "seção choradeira", vamos ao que interessa, que é a instalação do driver propriamente dito.
É importante lembrar que ele só tem o funcionamento garantido nas placas off-board Radeon 8500 em diante. Ele não funciona em muitos notebooks com placas ATI onboard (muitos fabricantes alteram a programação ou o barramento dos chipsets, tornando-os incompatíveis com o driver), nem em conjunto com as placas antigas. Se você possui uma, utilize o driver "ati" do X.org, que oferece suporte 3D às placas onboard e a quase todos os modelos antigos.
Se você chegar a instalar o driver num equipamento incompatível e o sistema passar a travar durante a abertura do X, dê boot com um CD do Kurumin e desfaça as alterações feitas no "/etc/X11/xorg.conf", voltando a usar o driver "ati".
Instalando
Inicialmente, o driver da ATI estava disponível apenas em versão RPM e o pacote precisava ser convertido usando o alien ou rpm2tgz para ser instalado em outras distribuições. Nas versões recentes, a ATI passou a disponibilizar um instalador gráfico "universal", que tornou a instalação muito mais simples.

Antes de começar, tenha em mente que o driver da ATI não é simples de instalar. Ele possui um instalador gráfico "bonitinho mas ordinário", que faz apenas parte do trabalho. Para que o driver funcione, é necessário que o módulo do Kernel esteja carregado, o "/dev/shm" esteja montado e toda a configuração dentro do "/etc/X11/xorg.conf" ou "XF86Config-4" esteja correta. Se você esquecer de uma única opção, vai acabar com uma tela preta ou com caracteres coloridos embaralhados. Por isso, siga com atenção todos os passos.
Se tiver duas máquinas, deixe o servidor SSH ativado, assim você poderá usar a outra para se conectar na primeira e revisar a configuração caso o X deixe de abrir. Se tiver apenas uma, use um CD do Kurumin para dar boot, montar a partição e assim alterar a configuração.
Para finalmente instalar, baixe o "ATI driver installer" no http://www.ati.com, na seção "Drivers & Software > Linux Display Drivers". A partir da versão 8.21.7, o tamanho do pacote foi reduzido brutalmente, de quase 70 MB para 35 MB. Como de praxe, o primeiro passo é marcar a permissão e executa-lo como root:
$ chmod +x ati-driver-installer-8.21.7-i386.run# ./ati-driver-installer-8.21.7-i386.run
Ao contrário do driver da nVidia, você não precisa fechar o X, pois o instalador da ATI roda tanto em modo gráfico quanto texto. Não se anime, pois como ele precisa compilar o módulo para o Kernel, está sujeito aos mesmos problemas relacionados aos compiladores e headers do Kernel que os outros drivers que vimos até aqui. Para que ele funcione corretamente, é necessário que esteja tudo em ordem.
É preciso prestar atenção também nas versões do X suportadas pelo driver e eventuais problemas com versões recentes do Kernel. A ATI não é particularmente rápida em lançar atualizações. Enquanto escrevo este tópico (fevereiro de 2006), por exemplo, ainda não existe suporte ao X.org 6.9, que foi lançado no início de Dezembro e (dependendo dos patches adicionados pela distribuição) nem mesmo ao 6.8.2, lançado bem antes. O pior é que o driver não detecta se a versão do X é suportada ou não, fazendo com que você só perceba depois de fazer todas as alterações. Você pode checar qual versão do X está instalada usando o comando "X -version".

Assim como no caso do driver da nVidia, é possível gerar um pacote pré-compilado para a distribuição em uso, o que facilita as coisas em casos onde você precisa instalar o driver em várias máquinas. Para isso, use a opção "Generate Distribution Specific Driver Package". Os pacotes gerados por essa opção podem ser instalados em qualquer máquina que esteja rodando a mesma distribuição e versão.
Configurando e solucionando problemas
Com o driver instalado, falta fazer as alterações no xorg.conf, alterando o driver de "ati" ou "radeon" para "fglrx", e incluindo as opções apropriadas. O driver inclui o "aticonfig", um assistente de modo texto que automatiza a configuração. Faça sempre um backup do arquivo "/etc/X11/xorg.conf" antes de usá-lo, pois ele edita diretamente o arquivo existente, gerando muitas vezes uma configuração inválida.
Para usar a configuração automática, execute-o usando a opção "--initial":
# aticonfig --initial
Você pode também forçar o uso de uma determinada resolução, como em:

# aticonfig --initial --resolution=1024x768
O comando suporta diversas outras opções. Você pode ver uma lista resumida chamando o comando "aticonfig" sem parâmetros. Para que ele gere uma configuração para dois monitores (numa placa com duas saídas), onde o segundo está à direita do primeiro, por exemplo, use:
# aticonfig --initial=dual-head --screen-layout=right
Caso ele reclame que o arquivo de configuração atual tem opções inválidas, você pode usar a opção "-f", que força a alteração do arquivo. Note que neste caso pode ser que você precise fazer algumas alterações manualmente depois, por isso é importante salvar um backup do arquivo original.
# aticonfig --initial --resolution=1024x768 -f
Você pode alterar as configurações da saída de TV e do segundo monitor usando o "fireglcontrolpanel", um utilitário gráfico instalado juntamente com o driver:
Tenha em mente que, ao fazer qualquer alteração, é necessário reiniciar o X para que as modificações entrem em vigor.
Para que a aceleração 3D funcione, é necessário que o módulo "fglrx" esteja carregado. Ele conflita com os módulos "radeon" e "drm", que fazem parte do módulo open-source. Se ao tentar carregá-lo você receber uma mensagem como:
# modprobe fglrx
FATAL: Error inserting fglrx (/lib/modules/2.6.12/kernel/drivers/char/drm/fglrx.ko): Operation not permitted
Significa que os dois módulos estão carregados. Neste caso, desative-os e tente novamente:

# modprobe -r radeon# modprobe -r drm# modprobe fglrx
Caso necessário, adicione os três comandos no final do arquivo "/etc/rc.d/rc.local" ou "/etc/init.d/bootmisc.sh" para que eles sejam executados a cada boot. Isso é necessário em muitas distribuições, pois muitas ferramentas de detecção carregam os dois módulos sempre que uma placa ATI está instalada. Caso o módulo "fglrx" não esteja disponível, significa que algo deu errado durante a instalação do driver, provavelmente relacionado aos headers do Kernel ou aos compiladores. Verifique tudo e tente novamente.
Outro recurso utilizado pelo driver é o device "/dev/shm" (que ativa o suporte ao padrão POSIX de memória compartilhada), que deve estar disponível e montado. Para isso, adicione a linha abaixo no final do arquivo "/etc/fstab":
tmpfs /dev/shm tmpfs defaults 0 0
Para que ele seja montado sem precisar reiniciar, use o comando:
# mount /dev/shm
Vamos entender melhor as alterações que precisam ser feitas no arquivo de configuração do X, para que você saiba como fazê-las manualmente e corrigir os freqüentes problemas criados pelo aticonfig. Lembre-se de que você pode localizar as linhas que precisam ser alteradas mais rapidamente usando a função "localizar" do editor de textos.
O primeiro passo é alterar a seção "Device", que indica qual driver de vídeo será usado e permite incluir configurações para ele. Substitua a linha Driver "ati", Driver "radeon" ou Driver "vesa" por:
Driver "fglrx"Option "UseInternalAGPGART" "no"Option "VideoOverlay" "on"Option "OpenGLOverlay" "off"Option "MonitorLayout" "AUTO, AUTO"
A opção "MonitorLayout" "AUTO, AUTO" é especialmente importante. Sem ela, o driver se embanana com as saídas de vídeo em placas com duas saídas ou saída de TV e o vídeo não abre. Existem mais opções relacionadas a esta opção, que veremos a seguir. Comente também a linha Option "sw_cursor", caso esteja inclusa no arquivo.
Um exemplo da seção "Device" completa é:
Section "Device"Identifier "Card0"Driver "fglrx"VendorName "All"BoardName "All"Option "UseInternalAGPGART" "no"Option "VideoOverlay" "on"Option "OpenGLOverlay" "off"

Option "MonitorLayout" "AUTO, AUTO"EndSection
A seção "Module" do arquivo de configuração deve ficar similar a esta:
Section "Module"Load "ddc"Load "dbe"Load "dri"SubSection "extmod"Option "omit xfree86-dga"EndSubSectionLoad "glx"Load "bitmap" # bitmap-fontsLoad "speedo"Load "type1"Load "freetype"Load "record"EndSection
As linhas referentes às fontes podem mudar de uma distribuição para outra, mas as sete linhas em negrito devem estar sempre presentes. Note que ao contrário da configuração para o driver da nVidia, você não deve comentar a linha "Load dri". Note também que o driver precisa da opção "omit xfree86-dga" (dentro da subseção), que precisa ser incluída manualmente.
Dentro da seção "Monitor" verifique se as taxas de varredura estão corretas (compare com o arquivo de configuração antigo, ou outro arquivo que esteja funcionando) e remova todas as linhas com modelines. Elas não são usadas pelo driver da ATI e podem causar problemas em muitos casos. Um exemplo de seção "Monitor" funcional é:
Section "Monitor" Identifier "Monitor0"HorizSync 28.0 - 96.0VertRefresh 50.0 - 75.0Option "DPMS" "true"EndSection
Por último, verifique a seção "Screen". O driver da ATI não suporta o uso de 16 bits de cor (usado por padrão em muitas distribuições), por isso é necessário usar sempre 24 bits de cor. Se encontrar a linha "DefaultColorDepth 16" e mude-a para "DefaultColorDepth 24".
A seção "screen" é especialmente importante dentro do arquivo, pois ela "junta tudo", fazendo com que o X use a configuração da placa de vídeo, monitor, teclado e mouse para abrir o servidor gráfico.
Cada uma das outras seções dentro do arquivo recebe um nome. No nosso exemplo, a placa de vídeo recebeu como nome "Card0" e o monitor recebeu "Monitor0". No nome não importa muito, mas é preciso que você indique-os corretamente dentro da seção "Screen", junto com a configuração de cor e resolução que será usada, como em:
Section "Screen"Identifier "Screen0"Device "Card0"

Monitor "Monitor0"DefaultDepth 24SubSection "Display"Depth 24Modes "1024x768"EndSubSectionEndSection
Ao usar pedaços retirados de outros arquivos de configuração, lembre-se sempre de verificar e alterar os nomes de cada seção ou as referências dentro da seção "Screen".
Depois de testar pela primeira vez, experimente mudar a opção "UseInternalAGPGART" "no" para "yes". Isso ativa o uso do driver AGP incluído no driver, desenvolvido pela equipe da ATI, ao invés de utilizar o driver agpgart genérico, aproveitando melhor os recursos da placa.
Note que ativar esta opção pode causar travamentos em algumas placas. Neste caso basta desfazer a alteração e reiniciar o X. Se necessário, você pode fazer isso dando boot com um CD do Kurumin e editando o arquivo dentro da partição.
Um problema bastante comum é que, depois de iniciar, a imagem fique simplesmente preta. Isso pode acontecer em casos em que o driver é incompatível com a versão do X.org instalada, ou em casos de placas com saída de TV, onde o driver usa a saída errada para enviar o sinal. No segundo caso, o problema é fácil de resolver, adicione a opção abaixo dentro da seção "Device", logo depois do Option "OpenGLOverlay" "off":
Option "ForceMonitors" "notv"
Caso você tenha uma placa com duas saídas (VGA e DVI) e a primeira opção não resolva, experimente substituir a linha Option "MonitorLayout" "AUTO, AUTO" por uma das duas linhas abaixo. Use a primeira caso você tenha um monitor LCD ligado na saída DVI e a segunda caso tenha um CRT ou LCD ligado na saída VGA:
Option "MonitorLayout" "TMDS, NONE"Option "MonitorLayout" "CRT, NONE"
Estas duas opções são incluídas automaticamente ao chamar o aticonfig usando a opção "--force-monitor=crt1,notv", como em:
# aticonfig --force-monitor=crt1,notv
Caso mesmo depois de testar todas as opções o X continuar não abrindo, experimente alterar também as configurações relacionadas ao AGP no setup da placa-mãe, reduzindo a velocidade do barramento AGP e aumentando a quantidade de memória reservada para pelo menos 64 MB (algumas placas só funcionam corretamente com 128 MB) na opção "AGP Aperture".

Caso você queira ativar o FSAA, adicione as linhas abaixo na seção "driver" (onde vai a linha Driver "fglrx") do arquivo de configuração, logo depois da linha "Option "OpenGLOverlay" "off":
Option "FSAAEnable" "yes"Option "FSAAScale" "4" # (escolha entre 0, 2, 4 e 6)
A linha Option "FSAAScale" "4" indica o nível de FSAA usado. Neste exemplo estou usando o FSAA 4x. Na versão atual, o driver ainda não oferece suporte a FSAA 8x e também a nenhum nível de Anisotropic Filter. A linha "Screen 0" indica para qual tela o FSAA será ativado, no caso de uma configuração com dois ou mais monitores.
Uma observação é que algumas distribuições, como o Ubuntu e o Mandriva oferecem pacotes pré-compilados com driver da ATI, que reduzem as possibilidades de problemas.
Nas distribuições derivadas do Debian, você pode utilizar também o script "install-radeon-debian.sh" desenvolvido pelo Kano, do Kanotix, que está disponível no: http://kanotix.com/files/. Este script deve ser executado com o sistema em texto puro (assim como o instalador da nVidia) e é necessário que o pacote "alien" esteja instalado.
Tablets
Outra classe de dispositivos que está se popularizando são os tablets, usados principalmente pelo pessoal da área gráfica. O tablet permite que você "desenhe" sobre uma superfície retangular, com o traço da caneta sobre a superfície do tablet controlando o movimento do mouse.
O driver wizard-pen dá suporte à maioria dos modelos, incluindo toda a linha Wizard Pen e Mouse Pen da Genius (modelos USB) e diversos modelos de outros fabricantes, que são na verdade fabricados pela Genius e revendidos em regime OEM.
O driver pode ser obtido no http://www.stud.fit.vutbr.cz/~xhorak28/ (clique no link WizardPen Driver). Como ele é um módulo para o X, e não um módulo para o Kernel, como no caso dos drivers de modems e placas wireless, os requisitos de instalação são um pouco diferentes da maioria dos drivers.
Além dos compiladores básicos, você precisará também dos pacotes de desenvolvimento do X. Nas distribuições derivadas do Debian, instale os pacotes "x-dev", "libx11-dev",

"libxext-dev" e "xutils-dev". Nas distribuições derivadas do Red Hat, procure pelo pacote "xserver-xorg-dev".
Com os pacotes instalados, descompacte o arquivo do driver, acesse a pasta e execute o comando "xmkmf":
$ tar -zxvf wizardpen-driver-0.5.0.tar.gz$ cd wizardpen-driver-0.5.0$ xmkmf
No meu caso ele retornava um erro, reclamando da falta de um arquivo temporário:
./Imakefile:5: error: /usr/X11R6/lib/X11/config/Server.tmpl: Arquivo ou diretório não encontrado
Na verdade, o problema é que a pasta "/usr/X11R6/lib/X11/config" não existia, e por isso ele não conseguia criar o arquivo. Resolvi criando a pasta manualmente e em seguida criando um arquivo vazio dentro dela:
# mkdir -p /usr/X11R6/lib/X11/config/# touch /usr/X11R6/lib/X11/config/Server.tmpl
Depois de conseguir rodar o "xmkmf" sem erros, rode o comando "make" para finalmente compilar o driver:
$ make
Será gerado o arquivo "wizardpen_drv.o" (o driver em si), que precisa ser copiado para a pasta com módulos de entrada do X, que normalmente é a "/usr/lib/xorg/modules/input/" ou "/usr/X11R6/lib/modules/input/".
Com o driver instalado, falta fazer a configuração do X, para que o tablet seja usado como mouse. Note que muitas distribuições já vem com o módulo "wizardpen_drv.o" instalado; nestes casos você pode pular toda esta parte de instalação e ir direto para a configuração.
Comece carregando os módulos "acecad" e "evdev", que adicionam suporte ao tablet no Kernel. Adicione os dois no final do arquivo "/etc/modules", de forma que sejam carregados na hora do boot:
# modprobe acecad # modprobe evdev# echo 'acecad' >> /etc/modules# echo 'evdev' >> /etc/modules
Precisamos agora descobrir como o sistema detectou o tablet. Normalmente ele aparecerá como "/dev/input/event2", mas não custa verificar. Rode o comando "cat /proc/bus/input/devices" e procure a seção referente ao tablet, como em:
I: Bus=0003 Vendor=5543 Product=0004 Version=0000N: Name=" TABLET DEVICE"

P: Phys=usb-0000:00:10.2-1/input0H: Handlers=mouse1 event2 B: EV=1f B: KEY=400 0 3f0000 0 0 0 0 0 0 0 0 B: REL=303 B: ABS=7f00 1000003 B: MSC=10
Note o "event2" que aparece na quarta linha. É justamente ele que indica o dispositivo usado. Em muitos casos pode ser "/dev/input/event3" ou mesmo "/dev/input/event1".
Abra o arquivo "/etc/X11/xorg.conf". Comece adicionando as linhas abaixo no final do arquivo (ou em qualquer outro ponto, desde que você saiba o que está fazendo ;). Lembre-se de substituir o "event2" pelo dispositivo correto no seu caso:
Section "InputDevice" Identifier "tablet"Driver "wizardpen"Option "Device" "/dev/input/event2"EndSection
Dentro da seção "ServerLayout" (geralmente logo no começo do arquivo) procure a linha referente ao mouse (como em: InputDevice "USB Mouse" "CorePointer") e adicione a linha referente ao tablet logo abaixo, como em:
Section "ServerLayout"Identifier "X.org"Screen 0 "Screen0" 0 0InputDevice "Keyboard0" "CoreKeyboard"InputDevice "USB Mouse" "CorePointer"InputDevice "tablet" "AlwaysCore"EndSection
Um último problema é que em alguns casos o tablet pode conflitar com o mouse, deixando-o impreciso. Para corrigir isso, procure pela linha abaixo dentro do arquivo, que indica o dispositivo usado pelo mouse:
Option "Device" "/dev/input/mice"
Substitua o "/dev/input/mice" por "/dev/input/mouse0", como em:
Option "Device" "/dev/input/mouse0"
O problema aqui é que o "/dev/input/mice" agrupa sinais recebidos de todos os mouses conectados ao micro. Isso é muito bom, pois permite que seu mouse USB seja detectado automaticamente e funcione em conjunto com o touchpad do notebook sem precisar de nenhuma configuração especial. O problema é que, ao ativar o tablet, ele também é visto pelo sistema como mouse, entrando na dança.
Como de praxe, depois de fazer as alterações no arquivo xorg.conf, você precisa reiniciar o X, pressionando "Ctrl+Alt+Backspace" para que elas entrem em vigor.

Alguns programas gráficos podem oferecer opções específicas relacionados com o tablet. No Gimp, por exemplo, clique no Arquivo > Preferências > Dispositivos de Entrada > Configurar Dispositivos de Entrada Estendidos.

Configurando placas de TV
As placas de captura melhor suportadas no Linux são as suportadas pelo módulo bttv, que incluem a maior parte das placas PCI de baixo custo, como as Pixelview PlayTV e Pixelview PlayTV Pro, Pinnacle PCTV Studio/Rave e vários outros modelos. Você pode ver uma lista completa das placas suportadas por este driver no link abaixo:http://linuxtv.org/v4lwiki/index.php/Cardlist.BTTV
Veja um resumo de outros chipsets suportados no Linux aqui:http://tvtime.sourceforge.net/cards.html
Atualmente, existe uma oferta relativamente grande de placas de captura USB, como as Pinnacle Studio PCTV USB. Elas são suportadas através do driver "usbvision", mas ele ainda é um trabalho preliminar, que oferece um conjunto muito pobre de recursos e não funciona em conjunto com muitos programas. Um conselho geral é que evite estes modelos.
Algumas placas PCI recentes utilizam o chip Conexant 2388x, que também é bem suportado, através do módulo cx88xx. Porém, estas placas são geralmente mais caras.
A dica básica para comprar uma placa de TV bem suportada no Linux e pagar pouco é: compre apenas placas PCI, baseadas nos chipset Brooktree Bt848, Bt848A, Bt849, Bt878 ou Bt879. Estes chipsets são fabricados pela Conexant, algumas vezes sob nomes diferentes. O "Conexant Fusion 878A" (usado nas PixelView PlayTV por exemplo), é na verdade o Bt878.
Ao dar boot com o Kurumin num micro com uma destas placas e rodar o comando "lspci", que identifica os componentes, você verá uma linha como:
0000:00:08.1 Multimedia video controller: Brooktree Corporation Bt878 Video Capture
Em geral, a placa inclui as entradas de vídeo para antena, Composite e S-Video e uma saída de áudio que é independente da placa de som.

Você pode ligar as caixas de som direto na placa de captura, ou ligá-las na entrada de áudio da placa de som, usando o cabo que acompanha a placa. Não se esqueça de ativar e ajustar o volume das opções "line" e "capture" no kmix ou aumix. Se o volume ficar muito baixo, experimente a entrada do microfone, que é amplificada (porém mono).
Algumas placas incluem duas entradas coaxiais, uma para antena e outra para sintonizar estações de rádio. O controle remoto incluído em alguns modelos é suportado no Linux através do Lirc. Você pode baixar o pacote com o código fonte no: http://www.lirc.org/.
Para instalá-lo, você vai precisar ter instalados os compiladores e os headers do Kernel. Descompacte o arquivo e rode os comandos "./configure", "make" e "make install", este último como root.
Durante a instalação, escolha "TV Card" e em seguida o modelo da placa. O Lirc é um programa genérico que oferece suporte a todo tipo de controle remoto no Linux, por isso ele é um pouco trabalhoso de configurar.
Para ativar sua placa você precisa apenas carregar o módulo bttv, incluindo a opção correta de tuner, o componente da placa responsável pela sintonia de canais. Existem vários modelos de tuners no mercado, com muitas variações mesmo entre as placas que usam o mesmo chipset.
Para uma PixelView PlayTV Pro, por exemplo, você usaria a opção "card=37 tuner=2" na hora de carregar o módulo.
A maioria das distribuições conseguem detectar a placa durante o boot, mas nem sempre com as opções corretas. Por isso acaba sendo necessário descarregar o módulo bttv para depois carrega-lo novamente com as opções corretas:

# modprobe -r bttv# modprobe -r tuner# modprobe bttv card=37 tuner=2
Para que estes comandos sejam executados automaticamente durante o boot, basta colocá-los no final do arquivo "/etc/rc.d/rc.local" ou "/etc/init.d/bootmisc.sh".
Estes são os números referentes às placas mais comuns aqui no Brasil. Você pode ver a lista completa, incluindo os modelos de tuner no link que coloquei acima, o:http://linuxtv.org/v4lwiki/index.php/Cardlist.BTTV
card=5 - Diamond DTV2000card=11 - MIRO PCTV procard=16 - Pixelview PlayTV (bt878)card=17 - Leadtek WinView 601card=28 - Terratec TerraTV+card=30 - FlyVideo 98card=31 - iProTVcard=32 - Intel Create and Share PCIcard=33 - Terratec TerraTValuecard=34 - Leadtek WinFast 2000card=37 - PixelView PlayTV procard=38 - TView99 CPH06Xcard=39 - Pinnacle PCTV Studio/Ravecard=50 - Prolink PV-BT878P+4E / PixelView PlayTV PAK / Lenco MXTV-9578 CPcard=52 - Pinnacle PCTV Studio Procard=63 - ATI TV-Wondercard=64 - ATI TV-Wonder VEcard=65 - FlyVideo 2000Scard=72 - Prolink PV-BT878P+9B (PlayTV Pro rev.9B FM+NICAM)
Entre os tuners, o mais comum é o Philips NTSC (modelo 2). O nome do fabricante do Tuner vem quase sempre marcado sobre a chapa de metal ou pelo menos escrito na etiqueta, facilitando bastante a identificação.
Você pode também encontrar a opção correta pesquisando pelo modelo da sua placa no Google, que acaba sendo a opção mais rápida na maioria dos casos.
Para as placas com o chipset Conexant 2388x, podem ser usados os módulos cx88xx ou cx8800. Você pode testar os dois para ver qual suporta sua placa.
O mais complicado fica por conta do modelo do tuner. Na verdade, o tuner é um módulo separado, que é usado independentemente do módulo para o chipset principal da placa. Por isso, as mesmas opções de tuner para as placas com o bttv servem também para as com o chipset 2388x e outros modelos.
Por exemplo, numa Hauppauge WinTV 401 os comandos seriam:
# modprobe -r cx8800# modprobe -r tuner# modprobe cx8800 tuner=43
Depois de ativada a placa, falta escolher o programa de visualização. A melhor opção hoje em dia é o Tvtime, que está se tornando extremamente popular e por isso já faz parte das
principais distribuições. Você pode instalá-lo no Debian via apt-get (apt-get install tvtime), no Fedora via Yun, no Mandriva via urpmi, e assim por diante.
Em último caso você pode baixá-lo no: http://tvtime.sourceforge.net/.
Dentro do Tvtime, comece configurando a opção de sintonia no menu "Input Configuration > Television Standard". Lembre-se de que o padrão usado no Brasil é o Pal-M. Na opção "Change Video Source", escolha "US Broadcast".
Acesse a opção "Channel Configuration > Scan channels for signal" para que ele localize os canais disponíveis na TV aberta. Se você tem TV a cabo, basta sintonizar o canal 3.
Em último caso você pode chamar o comando "tvtime-scanner", que faz uma busca longa, testando todas as freqüências possíveis em busca de canais.
O TVtime ignora por padrão canais com sinal muito ruim, o que pode ser um problema se você não usa uma antena externa. Para ver todos os canais, marque a opção "Channel Management > Disable Signal Detection".
Se você tem um DVD Player ou videogame que usa um cabo Composite ou S-Video, ajuste em: "Input Configuration > Change Video Source".
O TVtime inclui várias opções de filtros, usados para melhorar a qualidade da imagem. Lembre-se de que o monitor utiliza uma resolução e taxa de atualização maiores que uma TV, onde temos uma imagem relativamente ruim, com 486 linhas horizontais e uma taxa de atualização de 60 Hz entrelaçados (onde apenas metade das linhas são atualizadas de cada vez). O software precisa compensar tudo isso para exibir uma imagem de boa qualidade no monitor.

Você pode configurar o filtro usado no "Video configuration > Deinterlacer Configuration". O filtro "Television Full Resolution" combina uma boa qualidade de imagem com relativamente pouca utilização do processador. A opção "Blur Vertical" desfoca um pouco a imagem, o que dá a impressão de uma melhor qualidade, sobretudo em cenas com pouco movimento.
Outro filtro interessante é o "Video Processing > Input filters > 2-3 pulldown inversion". Os filmes gravados em película utilizam 24 por segundo, um padrão usado também em muitos formatos de vídeo digital. Como a TV utiliza 30 quadros por segundo (29,97 para ser exato) são incluídos mais 6 frames por segundo (telecinagem), para compatibilizar o sinal. O filtro remove estes frames artificiais, melhorando a fluidez das cenas quando exibidas no monitor.
Você pode também configurar as opções via linha de comando, o que é interessante para uso em scripts. Para abrir em tela cheia, use o comando "tvtime -m", para abrir no canal 12 use: tvtime --channel=12. Veja mais detalhes na página oficial:http://tvtime.sourceforge.net/usage.html.
Uma observação importante, é que o TVtime precisa que a placa de vídeo ofereça suporte ao YUY2, um recurso de aceleração de vídeo, que faz com que a placa de vídeo renderize a imagem da TV, diminuindo bruscamente a utilização do processador principal. Este é um recurso básico, suportado por quase todas as placas de vídeo, com uma exceção importante: as Via VT8378 (S3 UniChrome), usadas como vídeo onboard em muitas das placas-mãe recentes, com chipset Via KM333 ou KM400. Nestas placas o TVtime simplesmente não abre, exibindo um erro no terminal.
Se você utiliza uma destas placas, a única solução para rodar o TVtime é espetar uma placa de vídeo externa. O mesmo acontece ao usar o Vesa ou FBdev como driver de vídeo, ambos também não oferecem aceleração, independentemente da placa de vídeo usada.
Em abril de 2005 a Via liberou um driver de código aberto, que resolve o problema de suporte para suas placas de vídeo. Este driver vem incluído por padrão a partir do X.org 6.9, resolvendo o problema nas distribuições recentes.
Outros dois programas de sintonia de TV, disponíveis no apt-get são o Zapping e o Xawtv. O zapping é um programa baseado na biblioteca GTK, também bastante amigável, porém sem o mesmo desempenho e qualidade de imagem do TVtime. Originalmente ele é capaz de gravar usando a biblioteca rte (os arquivos gerados não possuem uma qualidade tão boa), mas o pacote disponível no apt-get vem com este recurso desativado.
O xawtv é um programa mais antigo, com uma interface bem mais rudimentar. Ele oferece a opção de gravar trechos de vídeo, porém com baixa qualidade. Não existem muitos motivos para usá-lo hoje em dia.
Gravando
O TVtime não oferece a opção de gravar programas, você pode no máximo tirar

screenshots. Embora seja uma sugestão freqüente, os desenvolvedores estão mais concentrados em melhorar a qualidade dos filtros de recepção do que implementar um sistema de gravação.
Outros programas gráficos, como o Xawtv e o Zapping oferecem opções de gravação, mas a qualidade não é boa.
Uma opção mais elaborada é o Mythtv (http://www.mythtv.org/), que cria um VPR doméstico similar a um TiVO. A idéia é usar o micro como um centro de entretenimento, onde você pode agendar a gravação de programas, ouvir CDs de música e muito mais. O problema é que o MyTV é também muito complicado de instalar, com muitas dependências. Não é um programa para instalar e usar casualmente.
Entre os programas de modo texto, o mencoder é o que oferece melhor qualidade. Ele é uma espécie de curinga dos programas de conversão de vídeo, usado como base por uma série de programas gráficos. A lenda diz que ele permite obter vídeo ou áudio de qualquer lugar e converter para qualquer formato ;-).
O problema é que o mencoder possui tantas opções que um simples comando para gravar a Sessão da Tarde se transforma rapidamente em uma novela mexicana. O comando para gravar a programação do canal 12 da TV aberta durante uma hora seria:
$ mencoder tv:// -tv driver=v4l2:input=0:normid=4:channel=12:chanlist=us-bcast:width=640:height=480:device=/dev/video0:adevice=/dev/dsp0:audiorate=32000:forceaudio:forcechan=2:buffersize=64 -quiet -oac mp3lame -lameopts preset=medium -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=3000:keyint=132 -vop pp=lb -endpos 01:00:00 -o /home/kurumin/video.avi
Este comando grava os vídeos com resolução de 640x480, já compactados em divx4. Mesmo assim, os arquivos gerados são relativamente grandes, consumindo cerca de 700 MB por hora de gravação na resolução máxima. Certifique-se de ter espaço suficiente no HD.
A possibilidade de gravar os programas, já compactados, permite transformar seu PC num gravador digital (VPR), aposentando de vez o videocassete. A qualidade é muito superior e um DVD-R permite gravar mais de 3 horas de programação na qualidade máxima, com a vantagem de não mofar com o tempo :-).
A principal desvantagem do mencoder é que não é possível gravar e assistir no TVtime ao mesmo tempo, mas nada impede que você use o micro para gravar e a boa e velha TV para assistir.
O grande problema é que o comando necessário é simplesmente gigante. Se você é um usuário normal, vai querer gravar seu programa sem ter que digitar antes um comando com 348 caracteres e, se é um hacker, vai ter mais o que fazer.
No próximo capítulo veremos como desenvolver um programa de gravação, misturando uma interface em QT, desenhada no Kommander com comandos em shell script para automatizar isto. Continue lendo :-).

Configurando mouses touchpad com funções especiais
Os mouses touchpad usados em notebooks são sempre reconhecidos pelo sistema como mouses PS/2 de dois botões. Mas, muitos dos notebooks atuais usam touchpads com funções especiais e botões de scroll.
Um toque sobre o touchpad equivale a um clique no botão esquerdo, um toque usando três dedos (ou dois, dependendo da configuração) equivale a pressionar o botão direito e assim por diante.
O mouse é sempre detectado durante a instalação, mas as funções especiais muitas vezes precisam ser ativadas manualmente.
Nos touchpads mais simples, com apenas dois botões, geralmente basta adicionar uma opção no arquivo de configuração do lilo para que o driver do mouse seja carregado corretamente durante o boot e os toques passem a funcionar.
Abra o arquivo /etc/lilo.conf e procure pela linha "append", que contém instruções para o Kernel, lidas no início do boot. Adicione a opção "psmouse.proto=imps", sem modificar as outras, como neste exemplo:
append = "psmouse.proto=imps apm=power-off nomce noapic devfs=mount"
Antes de reiniciar, é preciso salvar a nova configuração, chamando o executável do lilo como root:
# lilo
Outros touchpads, especialmente os que incluem botões de scroll funcionam com um driver especial, o Synaptics TouchPad Driver. Originalmente este driver dava suporte a um mouse especial, desenvolvido pela Synaptics (http://www.synaptics.com/products/touchpad.cfm), mas atualmente ele suporta vários tipos de mouses derivados dele.
Dois exemplos são os touchpads com botão de scroll usados em vários dos desknotes da PC-Chips/ECS e o touchpad usado no HP nx6110 (e outros modelos similares), onde o scroll é feito passando o dedo na borda direita do touchpad. Em ambos os casos, o scroll só funciona usando o driver synaptics:

Para saber se o mouse do seu note é compatível com o driver, rode o comando:
# cat /proc/bus/input/devices
Este comando lista os periféricos instalados. A identificação do mouse aparecerá no meio das informações, como em:
I: Bus=0011 Vendor=0002 Product=0007 Version=0000N: Name="SynPS/2 Synaptics TouchPad"P: Phys=isa0060/serio4/input0H: Handlers=mouse0 event0 ts0B: EV=bB: KEY=6420 0 670000 0 0 0 0 0 0 0 0B: ABS=11000003
Este é um driver para o Xfree (ou X.org), não um módulo para o Kernel, como os drivers para softmodems, por isso a instalação é mais simples.
Se você estiver usando uma distribuição derivada do Debian, pode instalá-lo pelo apt-get:
# apt-get install xfree86-driver-synaptics
Caso você não encontre o módulo já compilado para a sua distribuição, pode baixar um pacote genérico no: http://tuxmobil.org/software/synaptics/.
Dentro do pacote você encontrará o arquivo "snyaptics_drv.o", que é o módulo já compilado. Ele deve ser copiado para a pasta de módulo do X,

geralmente a "/usr/X11R6/lib/modules/input/". Este driver funciona no Xfree 4.2, 4.3, 4.4 e também no X.org.
Na pior das hipóteses, você pode compilar o módulo manualmente. Descompacte o arquivo e rode o comando "make" para gerar um novo módulo. Você vai precisar ter os compiladores e as bibliotecas de desenvolvimento do X. Procure pelos pacotes que terminam com "-dev", como "xlibs-dev" ou "xfree86-dev".
O próximo passo é abrir o arquivo de configuração do X, o "/etc/X11/XF86Config-4" ou "/etc/X11/xorg.conf".
Dentro do arquivo, procure pela seção "Module" e adicione a linha "Load "synaptics" (antes do EndSection), sem apagar as demais:
Section "Module"Load "ddc" Load "dbe"Load "extmod"Load "glx"Load "bitmap" # bitmap-fontsLoad "speedo"Load "type1"Load "freetype"Load "record"Load "synaptics"EndSection
Falta agora a configuração do mouse. Adicione as linhas abaixo no final do arquivo:
Section "InputDevice"Identifier "Mouse Synaptics"Driver "synaptics"Option "Device" "/dev/psaux"Option "Protocol" "auto-dev"Option "LeftEdge" "1700"Option "RightEdge" "5300"Option "TopEdge" "1700"Option "BottomEdge" "4200"Option "FingerLow" "25"Option "FingerHigh" "30"Option "MaxTapTime" "180"Option "MaxTapMove" "220"Option "VertScrollDelta" "100"Option "MinSpeed" "0.09"Option "MaxSpeed" "0.18"Option "AccelFactor" "0.0015"Option "SHMConfig" "on"EndSection
Agora falta apenas o último passo, que é dizer para o X usar a configuração que adicionamos. Procure a linha com a configuração do mouse, dentro da seção Section "ServerLayout", que geralmente vai perto do início do arquivo. Geralmente será:

InputDevice "PS/2 Mouse" "CorePointer"
Substitua o "PS/2 Mouse" por "Mouse Synaptics", que fará com que o X passe a usar a configuração que adicionamos. A linha ficará:
InputDevice "Mouse Synaptics" "CorePointer"
O driver precisa que o módulo "evdev" do Kernel esteja carregado para funcionar. Se ele não estiver carregado, o X simplesmente deixará de carregar ao ativar o driver:
# modprobe evdev
Para que ele seja sempre carregado durante o boot e você não tenha mais dor de cabeça, adicione a linha "evdev" no final do arquivo "/etc/modules".
Agora basta salvar o arquivo e reiniciar o X, pressionando Ctrl+Alt+Backspace. Se tudo deu certo, as funções especiais do mouse já estarão funcionando.
Muitas das funções podem ser personalizadas. O programa mais amigável para isso é o ksynaptics, que você pode instalar pelo apt-get:
# apt-get install ksynaptics
Você pode encontrar pacotes para outras distribuições na página do projeto:http://qsynaptics.sourceforge.net/dl.html.
Depois de instalado, ele aparecerá como um módulo no do painel de controle do KDE, dentro da seção "Periféricos":
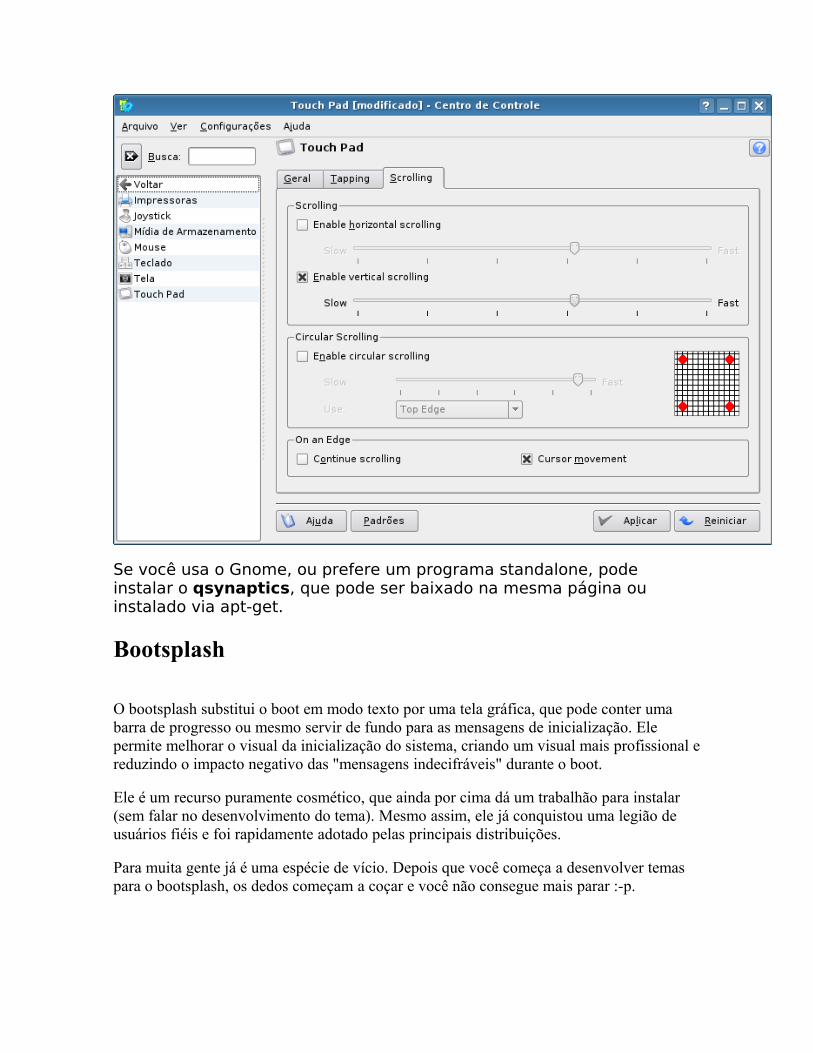
Se você usa o Gnome, ou prefere um programa standalone, pode instalar o qsynaptics, que pode ser baixado na mesma página ou instalado via apt-get.
Bootsplash
O bootsplash substitui o boot em modo texto por uma tela gráfica, que pode conter uma barra de progresso ou mesmo servir de fundo para as mensagens de inicialização. Ele permite melhorar o visual da inicialização do sistema, criando um visual mais profissional e reduzindo o impacto negativo das "mensagens indecifráveis" durante o boot.
Ele é um recurso puramente cosmético, que ainda por cima dá um trabalhão para instalar (sem falar no desenvolvimento do tema). Mesmo assim, ele já conquistou uma legião de usuários fiéis e foi rapidamente adotado pelas principais distribuições.
Para muita gente já é uma espécie de vício. Depois que você começa a desenvolver temas para o bootsplash, os dedos começam a coçar e você não consegue mais parar :-p.
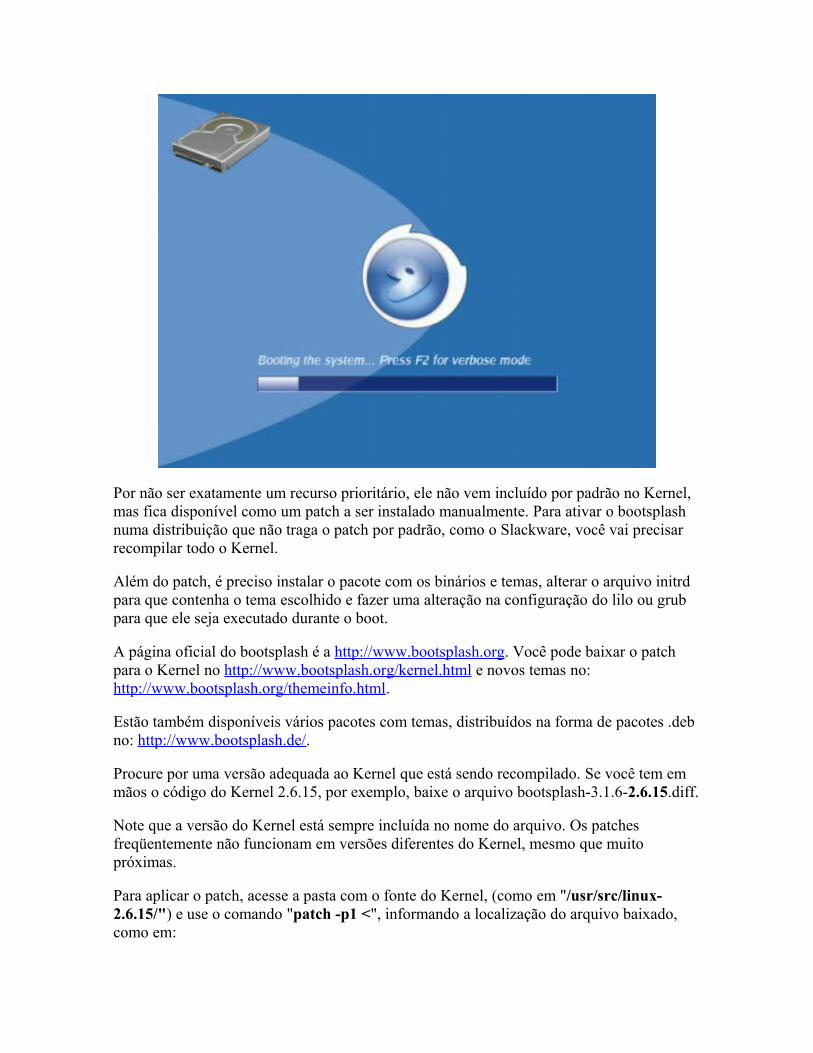
Por não ser exatamente um recurso prioritário, ele não vem incluído por padrão no Kernel, mas fica disponível como um patch a ser instalado manualmente. Para ativar o bootsplash numa distribuição que não traga o patch por padrão, como o Slackware, você vai precisar recompilar todo o Kernel.
Além do patch, é preciso instalar o pacote com os binários e temas, alterar o arquivo initrd para que contenha o tema escolhido e fazer uma alteração na configuração do lilo ou grub para que ele seja executado durante o boot.
A página oficial do bootsplash é a http://www.bootsplash.org. Você pode baixar o patch para o Kernel no http://www.bootsplash.org/kernel.html e novos temas no: http://www.bootsplash.org/themeinfo.html.
Estão também disponíveis vários pacotes com temas, distribuídos na forma de pacotes .deb no: http://www.bootsplash.de/.
Procure por uma versão adequada ao Kernel que está sendo recompilado. Se você tem em mãos o código do Kernel 2.6.15, por exemplo, baixe o arquivo bootsplash-3.1.6-2.6.15.diff.
Note que a versão do Kernel está sempre incluída no nome do arquivo. Os patches freqüentemente não funcionam em versões diferentes do Kernel, mesmo que muito próximas.
Para aplicar o patch, acesse a pasta com o fonte do Kernel, (como em "/usr/src/linux-2.6.15/") e use o comando "patch -p1 <", informando a localização do arquivo baixado, como em:

# patch -p1 < /usr/src/bootsplash-3.1.6-2.6.15.diff
Depois disso entramos no processo normal de recompilação do Kernel. Começando com o comando "make xconfig".
Na tela de configuração, habilite o bootsplash marcando a opção: "Device Drivers > Graphics Support > Bootsplash configuration > Bootup splash screen".
Em seguida, marque também a opção: "Device Drivers > Graphics Support > VESA VGA Graphics Support".
Ela habilita o suporte a frame-buffer, usado pelo bootsplash para mostrar imagens no terminal logo a partir do início do boot, muito antes de qualquer componente do X ser carregado. Esta opção vem habilitada por padrão em quase todas as distribuições, mas não custa checar.
Na mesma seção estão disponíveis drivers de frame-buffer otimizados para várias placas de vídeo. Eles fazem diferença apenas para quem realmente utiliza muito o terminal, ou configura o X para usar o módulo "fbdev". Eles não interessam no nosso caso, pois usar um deles no lugar do módulo VESA padrão fará com que o frame-buffer funcione apenas em máquinas com a placa de vídeo em questão.

O próximo passo é compilar e instalar o novo Kernel, usando os comandos "make clean", "make bzImage" (ou apenas "make", a partir do 2.6.16), "make modules" e "make modules install", como vimos no capítulo 2 deste livro.
A alteração no Kernel é apenas o primeiro passo. Para o bootsplash funcionar é necessário instalar o pacote "bootsplash" e configurar o sistema para usar o tema desejado.
Nas distribuições derivadas do Debian, adicione a linha abaixo no arquivo "/etc/apt/sources.list":
deb http://www.bootsplash.de/files/debian/ unstable main
Rode agora os comandos:
# apt-get update# apt-get install bootsplash
O script de instalação incluído no pacote vai perguntar a localização do arquivo initrd da sua instalação (por padrão é o /boot/initrd ou /boot/initrd.gz), a resolução de vídeo que será usada pelo boot splash durante o boot e no final indicar as linhas que devem ser alteradas no lilo ou grub para que o bootsplash seja ativado. Ou seja, ele automatiza todo o processo de instalação.
Caso não encontre uma versão do pacote para a sua distribuição, use o arquivo genérico: ftp://ftp.openbios.org/pub/bootsplash/rpm-sources/bootsplash/bootsplash-3.0.7.tar.bz2
Em qualquer um dos dois casos, são instalados um conjunto de arquivos de configuração e temas dentro da pasta /etc/bootsplash. Você pode baixar temas adicionais no próprio bootsplash.org, ou em diversos outros sites.
Para usar um novo tema, descompacte os arquivos dentro da pasta "/etc/bootsplash/themes/", como em "/etc/bootsplash/themes/kurumin/".
Cada tema contém pelo menos um arquivo de configuração. Muitos possuem um para cada resolução suportada: um para 800x600 e outro para 1024x768, por exemplo. Neste caso, ao usar a linha "vga=791" no lilo ou grub, é usado o tema para 1024x768 e ao usar "vga=788" é usado o tema para 800x600. Ao usar uma resolução não suportada pelo tema, ou usar a opção "vga=normal", que desabilita o frame-buffer, o bootsplash é desativado e o sistema exibe as mensagens normais de boot.
Para incluir o tema escolhido dentro do arquivo initrd, use o comando a abaixo, indicando o arquivo de configuração do tema e o arquivo initrd que será alterado ou criado, como em:
# splash -s -f /etc/bootsplash/themes/current/config/800x600.cfg > /boot/initrd.splash
Lembre-se de que o arquivo initrd contém módulos necessários durante o boot. Ao trocar o tema do bootsplash, você nunca deve substituir o arquivo initrd que vem por padrão na distribuição; apenas instale o tema no arquivo initrd existente.

Crie um novo arquivo initrd apenas se você compilou seu próprio Kernel e tem certeza que adicionou o suporte ao sistema de arquivos no qual a partição raiz está formatada, junto com outros módulos que podem ser necessários no boot diretamente no executável principal do Kernel.
Em seguida vem a configuração do gerenciador de boot. A maioria dos temas inclui duas opções, o modo "verbose", onde as mensagens normais de boot são mostradas sob o fundo gráfico e o modo "silent", onde é mostrada apenas uma barra de progresso. Você deve especificar o modo desejado, juntamente com o arquivo initrd que será usado.
No lilo adicione as linhas abaixo no final da sessão referente ao Kernel principal:
initrd=/boot/initrd-splashappend="splash=verbose"
A seção toda ficará assim:
image=/boot/vmlinuz-2.6.15label=Kuruminroot=/dev/hda1read-onlyinitrd=/boot/initrd-splashappend="splash=verbose"
No grub, a seção ficaria:
title Kuruminroot (hd0,0)kernel /boot/vmlinuz-2.6.15 root=/dev/hda1 ro vga=788 splash=verbose initrd /boot/initrd-splashsavedefaultboot
Para usar o modo silent, basta trocar o "splash=verbose" por "splash=silent". Para que a barra de progresso funcione, é necessário que o serviço "bootsplash" esteja ativo. É ele que monitora a inicialização do sistema, atualizando a barra de progresso. Ele não é necessário se você está usando o modo verbose, ou se optou por um tema estático, sem a barra.
Capítulo 4: Programando em shell script
Quase tudo no Linux pode ser feito via linha de comando. É possível baixar e instalar programas automaticamente, alterar qualquer tipo de configuração do sistema, carregar programas ou executar operações diversas durante o boot, entre muitas outras possibilidades. Dentro do KDE é possível até mesmo controlar programas gráficos, minimizando uma janela, abrindo um novo e-mail, já com o corpo da mensagem preenchido no kmail, exibir uma mensagem de aviso, criar ou eliminar ícones no desktop, e assim por diante.
Um script é um arquivo de texto, com uma seqüência de comandos que são executados linha a linha. Dentro de um script, você pode utilizar qualquer comando de terminal

(incluindo programas gráficos e parâmetros para eles) e também funções lógicas suportadas pelo shell, que incluem operações de tomada de decisão, comparação, etc. Você pode até mesmo acessar bancos de dados ou configurar outras máquinas remotamente.
Assim como o perl, python e o lua, o shell script é uma linguagem interpretada, onde o próprio script, escrito num editor comum é o executável. Você pode alterá-lo rapidamente e executá-lo logo em seguida para testar a mudança. Nas linguagens tradicionais, o código fonte precisa ser recompilado a cada modificação, o que toma tempo.
A princípio, o shell script lembra um pouco os arquivos .bat do DOS, que também eram arquivos de texto com comandos dentro; da mesma forma que um ser humano e uma ameba conservam muitas coisas em comum, como o fato de possuírem DNA, se reproduzirem e sintetizarem proteínas. Mas, assim como um humano é muito mais inteligente e evoluído que uma ameba, um shell script pode ser incomparavelmente mais poderoso e elaborado que um simples .bat do DOS.
É possível escrever programas complexos em shell script, substituindo aplicativos que demorariam muito mais tempo para ser escritos em uma linguagem mais sofisticada. Seus scripts podem tanto seguir a velha guarda, com interfaces simples de modo texto (ou mesmo não ter interface alguma e serem controlados através de parâmetros), de forma a desempenhar tarefas simples, quanto possuir uma interface gráfica elaborada, escrita usando o kommander e funções do kdialog.
Isso vai de encontro à idéia que muitas pessoas, incluindo até mesmo usuários Linux tarimbados, possuem. O uso de scripts pode ir muito além de simples scripts de configuração. Você pode desenvolver programas bastante complexos se usar as ferramentas certas.
Um exemplo de trabalho desenvolvido em shell script é o painel de controle do Kurumin, que utiliza um conjunto de painéis gráficos, criados usando o Kommander, que ativam um emaranhado de scripts para desempenhar as mais diversas tarefas.
O programa de instalação do Kurumin também é escrito em shell script, assim como a maior parte dos programas encarregados de configurar o sistema durante o boot, os painéis para instalar novos programas, configurar servidores e tudo mais.
O principal motivo para uso de scripts em shell ao invés de programas escritos em C ou C++, por exemplo, é a rapidez de desenvolvimento, combinada com a facilidade de editar os scripts existentes para corrigir problemas ou adicionar novos recursos. Você vai encontrar uma grande quantidade de scripts em qualquer distribuição Linux, incluindo os próprios scripts de inicialização.
O básico
Um shell script é um conjunto de comandos de terminal, organizados de forma a desempenhar alguma tarefa. O bash é extremamente poderoso, o que dá uma grande flexibilidade na hora de escrever scripts. Você pode inclusive incluir trechos com comandos de outras linguagens interpretadas, como perl ou python, por exemplo.
O primeiro passo para escrever um script é descobrir uma forma de fazer o que precisa via linha de comando. Vamos começar um um exemplo simples:
O comando "wget" permite baixar arquivos; podemos usá-lo para baixar o ISO do Kurumin, por exemplo:

$ wget -c http://fisica.ufpr.br/kurumin/kurumin-6.0.iso(o "-c" permite continuar um download interrompido)
Depois de baixar o arquivo, é importante verificar o md5sum para ter certeza que o arquivo está correto:
$ md5sum kurumin-6.0.iso
Estes dois comandos podem ser usados para criar um script rudimentar, que baixa o Kurumin e verifica o md5sum. Abra o kedit ou outro editor de textos que preferir e inclua as três linhas abaixo:
#!/bin/shwget -c http://fisica.ufpr.br/kurumin/kurumin-6.0.isomd5sum kurumin-6.0.iso
O "#!/bin/sh" indica o programa que será usado para interpretar o script, o próprio bash. Por norma, todo script deve começar com esta linha. Na verdade, os scripts funcionam sem ela, pois o bash é o interpretador default de qualquer maneira, mas não custa fazer as coisas certo desde o início. Existe a possibilidade de escrever scripts usando outros interpretadores, ou mesmo comandos, como o sed. Neste caso o script começaria com "#!/bin/sed", por exemplo.
Note que a tralha, "#", é usada para indicar um comentário. Toda linha começada com ela é ignorada pelo bash na hora que o script é executado, por isso a usamos para desativar linhas ou incluir comentários no script. A linha "#!/bin/sh" é a única exceção para esta regra.
Ao terminar, salve o arquivo com um nome qualquer. Você pode usar uma extensão como ".sh" para que outras pessoas saibam que se trata de um shell script, mas isto não é necessário. Lembre-se de que, no Linux, as extensões são apenas parte do nome do arquivo.
Marque a permissão de execução para ele nas propriedades do arquivo, ou use o comando:
$ chmod +x baixar-kurumin.sh
Execute-o colocando um "./" na frente do nome do arquivo, o que faz o interpretador entender que ele deve executar o "baixar-kurumin.sh" que está na pasta atual. Caso contrário ele tenta procurar nas pastas "/bin/", "/usr/bin" e "/usr/local/bin" que são as pastas onde ficam os executáveis do sistema e não acha o script.
$ ./baixar-kurumin.sh
O md5sum soma os bits do arquivo e devolve um número de 32 caracteres. No mesmo diretório do servidor onde foi baixado o arquivo, está disponível um arquivo de texto com o md5sum correto do arquivo. O resultado do md5sum do arquivo baixado deve ser igual ao do arquivo, caso contrário significa que o arquivo veio corrompido e você precisa baixar de novo.

Você já deve estar cansado de baixar as novas versões do Kurumin, e já sabe de tudo isso. Podemos aproveitar para ensinar isso ao nosso script, fazendo com que, depois de baixar o arquivo, ele verifique o md5sum e baixe o arquivo de novo caso ele esteja corrompido.
Isto vai deixar o script um pouco mais complexo:
#!/bin/sh
versao="6.0"mirror="http://fisica.ufpr.br/kurumin/"
wget -c "$mirror"/kurumin-"$versao".isomd5sum=`md5sum kurumin-"$versao".iso`
wget -c "$mirror"/kurumin-"$versao".md5sum.txtmd5sumOK=`cat kurumin-"$versao".md5sum.txt`
if [ "$md5sum" != "$md5sumOK" ]; thenecho "Arquivo corrompido, vou deletar e começar novamente."rm -f kurumin-"$versao".isosleep 120./baixar-kurumin.shelseecho "O arquivo foi baixado corretamente."fi
Você vai perceber que ao executar este segundo script, ele vai tentar baixar o arquivo novamente sempre que o md5sum não bater, se necessário várias vezes. Para isso, começamos a utilizar algumas operações lógicas simples, que lembram um pouco as aulas de pseudo-código que os alunos de Ciências da Computação têm no primeiro ano.
Em primeiro lugar, este segundo script usa variáveis. As variáveis podem armazenar qualquer tipo de informação, como um número, um texto ou o resultado de um comando. Veja que no início do script estou definindo duas variáveis "versao" e "mirror", que utilizo em diversas partes do script.
Ao armazenar qualquer texto ou número dentro de uma variável, você passa a poder utilizá-la em qualquer situação no lugar no valor original. A vantagem de fazer isso é que, quando precisar alterar o valor original, você só vai precisar alterar uma vez. O mesmo script poderia ser adaptado para baixar uma nova versão do Kurumin, ou para baixá-lo a partir de outro mirror simplesmente alterando as duas linhas iniciais. Usar variáveis desta forma permite que seus scripts sejam reutilizáveis, o que a longo prazo pode representar uma grande economia de tempo.
No script anterior, usamos o comando "md5sum kurumin-6.0.iso". Ele simplesmente mostra o md5sum do arquivo na tela, sem fazer mais nada. No segundo script, esta linha ficou um pouco diferente: md5sum=`md5sum kurumin-$versao.iso`. A diferença é que, ao invés de mostrar o mds5um na tela, armazenamos o resultado numa variável, chamada "md5sum".

O sinal usado aqui não é o apóstrofo, como é mais comum em outras linguagens, mas sim a crase (o mesmo do "à"). O shell primeiro executa os comandos dentro das crases e armazena o resultado dentro da variável, que podemos utilizar posteriormente.
Por padrão, os mirrors com o Kurumin sempre contém um arquivo ".md5sum.txt" que contém o md5sum da versão correspondente. Para automatizar, o script baixa também este segundo arquivo e armazena o conteúdo numa segunda variável, a "md5sumOK".
Neste ponto, temos uma variável contendo o md5sum do arquivo baixado, e outra contendo o md5sum correto. As duas podem ser comparadas, de forma que o script possa decidir se deve baixar o arquivo de novo ou não.
Para comparar duas variáveis (contendo texto) num shell script, usamos o símbolo "!=" (não igual, ou seja: diferente). Para saber se o arquivo foi baixado corretamente, comparamos as duas variáveis: [ "$md5sum" != "$md5sumOK" ].
Além do "!=", outros operadores lógicos que podem ser usados são:
= : Igual.-z : A variável está vazia (pode ser usada para verificar se determinado comando gerou algum erro, por exemplo).-n : A variável não está vazia, o oposto do "-z".
Estas funções permitem comparar strings, ou seja, funcionam em casos onde as variáveis contém pedaços de texto ou o resultado de comandos. O bash também é capaz de trabalhar com números e inclusive realizar operações aritméticas. Quando precisar comparar duas variáveis numéricas, use os operadores abaixo:
-lt : (less than), menor que, equivalente ao <.-gt : (greather than), maior que, equivalente ao >.-le : (less or equal), menor ou igual, equivalente ao <=.-ge : (greater or equal), maior ou igual, equivalente ao >=.-eq : (equal), igual, equivale ao =.-ne : (not equal) diferente. Equivale ao != que usamos a pouco.
Mas, apenas comparar não adianta. Precisamos dizer ao script o que fazer depois. Lembre-se de que os computadores são burros, você precisa dizer o que fazer em cada situação. Neste caso temos duas possibilidades: o md5sum pode estar errado ou certo. Se estiver errado, ele deve baixar o arquivo de novo, caso contrário não deve fazer nada.
Usamos então um "if" (se) para criar uma operação de tomada de decisão. Verificamos o mds5um, se ele for diferente do correto, então (then) ele vai deletar o arquivo danificado e começar o download de novo. Caso contrário (else) ele vai simplesmente escrever uma mensagem na tela.
if [ "$md5sum" != "$md5sumOK" ]; thenecho "Arquivo corrompido, vou deletar e começar novamente."rm -f kurumin-"$versao".isosleep 120./baixar-kurumin.sh

elseecho "O arquivo foi baixado corretamente."fi
Veja que dentro da função "then" usei o comando para deletar o arquivo e depois executei de novo o "./baixar-kurumin.sh" que vai executar nosso script de novo, dentro dele mesmo.
Isso vai fazer com que o script fique em loop, obsessivamente, até conseguir baixar o arquivo corretamente. Uma coisa interessante nos scripts é que eles podem ser executados dentro deles mesmos e alterados durante a execução. O script pode até mesmo deletar a si próprio depois de rodar uma vez, uma espécie de script suicida :-P.
É preciso tomar cuidado em situações como esta, pois cada vez que o script executa novamente a si mesmo para tentar baixar o arquivo, é aberta uma nova seção do shell, o que consome um pouco de memória. Um script que entrasse em loop poderia consumir uma quantidade muito grande de memória, deixando o sistema lento. Para evitar isso, incluí um "sleep 120", que faz o script dar uma pausa de 120 segundos entre cada tentativa.
Os scripts são muito úteis para automatizar tarefas, que demorariam muito para serem realizas automaticamente. Imagine que você tem uma coleção de arquivos MP3, todos encodados com 256k de bitrate. O problema é que você comprou um MP3Player xing-ling, que só é capaz de reproduzir (com qualidade) arquivos com bitrate de no máximo 160k. Você decide então reencodar todas as músicas para 128k, para ouvi-las no MP3player.
Existem vários programas gráficos que permitem fazer a conversão, entre eles o Grip. Mas, esse é o tipo de coisa que é mais rápido de fazer via linha de comando, usando o lame, como em:
$ lame -b 128 musica.mp3 128k-musica.mp3
Aqui é gerado o arquivo "128k-musica.mp3" (na mesma pasta), encodado com 128k de bitrate, sem modificar o arquivo original.
Para fazer o mesmo com todos os arquivos no diretório, você poderia usar o comando "for", que permite realizar a mesma operação em vários arquivos de uma vez. Ele é muito usado para renomear ou converter arquivos em massa, baseado em determinados critérios. No nosso caso ele poderia ser usado da seguinte forma:
for arquivo in *.{mp3,MP3} do lame -b 128 "$arquivo" "128k-$arquivo" done
Aqui, a regra se aplica a todos os arquivos dentro do diretório atual que tiverem extensão ".mp3" ou ".MP3". Para cada um dos arquivos é executado o comando 'lame -b 128 "$arquivo" "128k-$arquivo"', onde o "$arquivo" é substituído por cada um dos arquivos dentro do diretório.
Estes dois exemplos são scripts simples, que simplesmente executam alguns comandos,

sem oferecer nenhum tipo de interatividade. Se você quisesse que o primeiro script baixasse outro arquivo, teria que editá-lo manualmente.
Fazendo perguntas
Você pode incluir perguntas no script, para coletar as informações necessárias para montar e executar algum comando complicado.
Por exemplo, o mais legal de ter uma placa de recepção de TV é poder gravar programas usando o micro como um DVR. Porém, programas gráficos como o Xawtv e o Zapping não oferecem uma boa qualidade de gravação.
Entre os programas de modo texto, o mencoder é o que oferece melhor qualidade, mas ele oferece muitas opções e por isso não é exatamente um exemplo de amigabilidade. Como vimos no capítulo 3, o comando para gravar a programação do canal 12 da TV aberta durante uma hora, compactando em Divx4, seria:
$ mencoder tv:// -tv \driver=v4l2:input=0:normid=4:channel=12:chanlist=us-bcast:width=640:height=480:\device=/dev/video0:adevice=/dev/dsp0:audiorate=32000:forceaudio:forcechan=2:buffersize=64 \-quiet -oac mp3lame -lameopts preset=medium -ovc lavc -lavcopts \vcodec=mpeg4:vbitrate=3000:keyint=132 -vop pp=lb -endpos 01:00:00 \-o /home/$USER/video.avi
As partes do comando que mudariam de uma chamada a outra seriam o canal (channel=12) o tempo de gravação ("-endpos 01:00:00", para uma hora) e o arquivo que será gerado (/home/$USER/video.avi). O "$USER" é uma variável interna, que contém sempre o nome do usuário atual, muito útil em scripts.
Podemos fazer com que nosso script pergunte estas informações, armazenando tudo em variáveis e no final monte o comando. Isto transformaria um comando indigesto, de quase 400 caracteres num script amigável que sua avó poderia usar.
Existem várias formas de exibir uma pergunta na tela e armazenar a resposta numa variável. A forma mais simples seria usar o comando "echo" para mostrar a pergunta e o comando "read" para ler a resposta, como em:
echo "Qual canal gostaria de gravar? (ex: 12)"read canalecho "Qual o tempo de gravação? (ex: 01:00:00)"read tempoecho "Em qual arquivo o vídeo será salvo? (ex: /home/$USER/video.avi)"read arquivo
O "read" faz com que o script pare e fique esperando uma resposta. Ao digitar qualquer coisa e pressionar enter, ele vai para a próxima pergunta e assim por diante até executar o último comando. Teríamos então três variáveis, "canal", "tempo" e "arquivo" que poderíamos utilizar para montar o comando principal, que, dentro do script, ficaria:
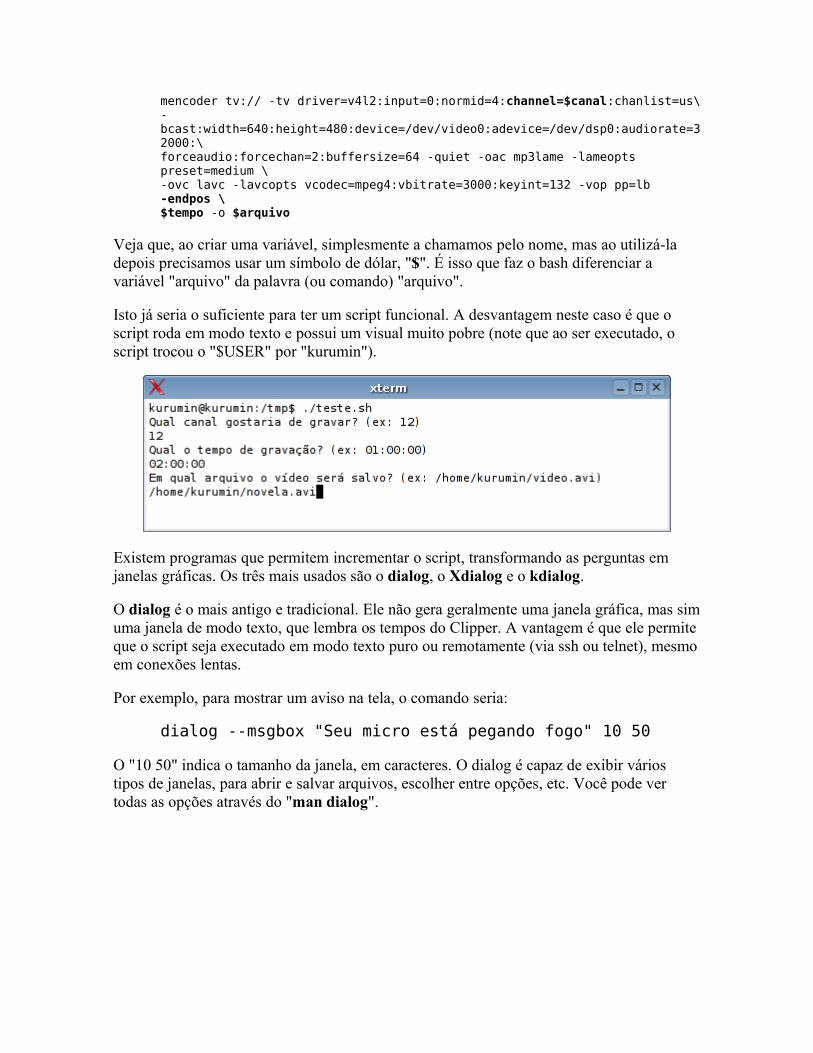
mencoder tv:// -tv driver=v4l2:input=0:normid=4:channel=$canal:chanlist=us\-bcast:width=640:height=480:device=/dev/video0:adevice=/dev/dsp0:audiorate=32000:\forceaudio:forcechan=2:buffersize=64 -quiet -oac mp3lame -lameopts preset=medium \-ovc lavc -lavcopts vcodec=mpeg4:vbitrate=3000:keyint=132 -vop pp=lb -endpos \$tempo -o $arquivo
Veja que, ao criar uma variável, simplesmente a chamamos pelo nome, mas ao utilizá-la depois precisamos usar um símbolo de dólar, "$". É isso que faz o bash diferenciar a variável "arquivo" da palavra (ou comando) "arquivo".
Isto já seria o suficiente para ter um script funcional. A desvantagem neste caso é que o script roda em modo texto e possui um visual muito pobre (note que ao ser executado, o script trocou o "$USER" por "kurumin").
Existem programas que permitem incrementar o script, transformando as perguntas em janelas gráficas. Os três mais usados são o dialog, o Xdialog e o kdialog.
O dialog é o mais antigo e tradicional. Ele não gera geralmente uma janela gráfica, mas sim uma janela de modo texto, que lembra os tempos do Clipper. A vantagem é que ele permite que o script seja executado em modo texto puro ou remotamente (via ssh ou telnet), mesmo em conexões lentas.
Por exemplo, para mostrar um aviso na tela, o comando seria:
dialog --msgbox "Seu micro está pegando fogo" 10 50
O "10 50" indica o tamanho da janela, em caracteres. O dialog é capaz de exibir vários tipos de janelas, para abrir e salvar arquivos, escolher entre opções, etc. Você pode ver todas as opções através do "man dialog".
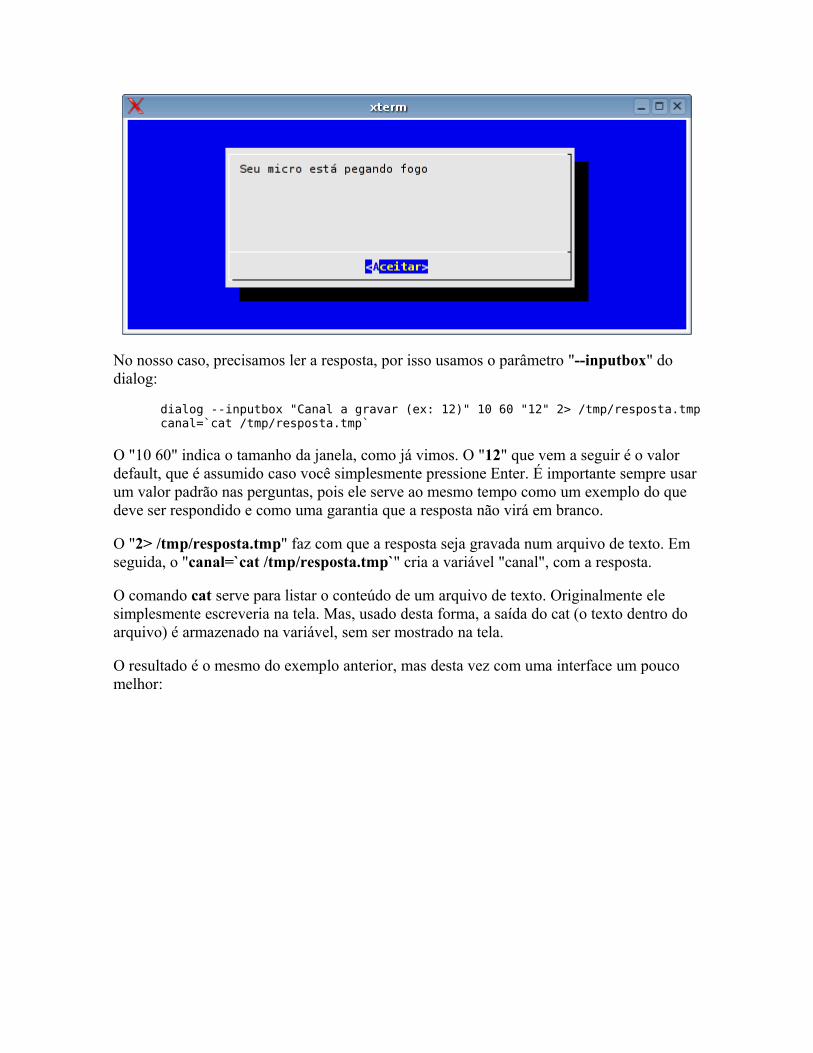
No nosso caso, precisamos ler a resposta, por isso usamos o parâmetro "--inputbox" do dialog:
dialog --inputbox "Canal a gravar (ex: 12)" 10 60 "12" 2> /tmp/resposta.tmpcanal=`cat /tmp/resposta.tmp`
O "10 60" indica o tamanho da janela, como já vimos. O "12" que vem a seguir é o valor default, que é assumido caso você simplesmente pressione Enter. É importante sempre usar um valor padrão nas perguntas, pois ele serve ao mesmo tempo como um exemplo do que deve ser respondido e como uma garantia que a resposta não virá em branco.
O "2> /tmp/resposta.tmp" faz com que a resposta seja gravada num arquivo de texto. Em seguida, o "canal=`cat /tmp/resposta.tmp`" cria a variável "canal", com a resposta.
O comando cat serve para listar o conteúdo de um arquivo de texto. Originalmente ele simplesmente escreveria na tela. Mas, usado desta forma, a saída do cat (o texto dentro do arquivo) é armazenado na variável, sem ser mostrado na tela.
O resultado é o mesmo do exemplo anterior, mas desta vez com uma interface um pouco melhor:
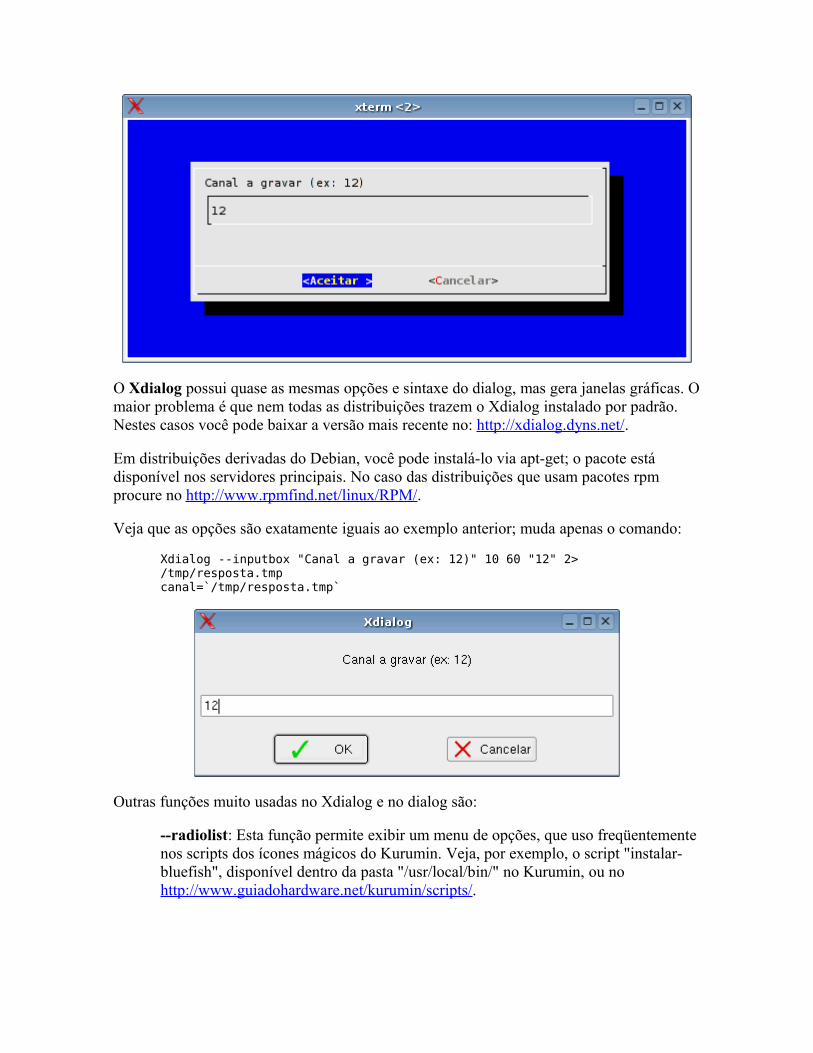
O Xdialog possui quase as mesmas opções e sintaxe do dialog, mas gera janelas gráficas. O maior problema é que nem todas as distribuições trazem o Xdialog instalado por padrão. Nestes casos você pode baixar a versão mais recente no: http://xdialog.dyns.net/.
Em distribuições derivadas do Debian, você pode instalá-lo via apt-get; o pacote está disponível nos servidores principais. No caso das distribuições que usam pacotes rpm procure no http://www.rpmfind.net/linux/RPM/.
Veja que as opções são exatamente iguais ao exemplo anterior; muda apenas o comando:
Xdialog --inputbox "Canal a gravar (ex: 12)" 10 60 "12" 2> /tmp/resposta.tmpcanal=`/tmp/resposta.tmp`
Outras funções muito usadas no Xdialog e no dialog são:
--radiolist: Esta função permite exibir um menu de opções, que uso freqüentemente nos scripts dos ícones mágicos do Kurumin. Veja, por exemplo, o script "instalar-bluefish", disponível dentro da pasta "/usr/local/bin/" no Kurumin, ou no http://www.guiadohardware.net/kurumin/scripts/.

--yesno: Permite fazer perguntas. A resposta é armazenada automaticamente na variável "$?", que você pode checar em seguida. Se a resposta foi "sim", a variável fica com o valor "1" e se for "não", fica com o valor "0". Um exemplo de uso seria:
Xdialog --yesno "Tem certeza que deseja instalar o programa?" 15 60if [ "$?" = "0" ] ; thencomandos...fi
--fselect: Abre um menu de seleção de arquivos. Pode ser usado ao abrir um arquivo, por exemplo. Este é um exemplo rápido que permite escolher um arquivo e tenta abri-lo usado o mplayer:
Xdialog --fselect ./ 30 75 2> /tmp/resposta.tmpvideo=`cat /tmp/resposta.tmp`; rm -f /tmp/resposta.tmpmplayer "$video"
--dselect: É similar ao --fselect, mas abre um menu para escolher um diretório.
O kdialog, por sua vez, é um componente do KDE e por isso é o ideal para ser usado em distribuições que trazem o KDE como desktop principal. As janelas seguem o padrão visual do KDE, respeitando as configurações de cor, fontes e ícones definidas no Centro de Controle do KDE, o que deixa os scripts com uma aparência muito mais profissional.
A principal desvantagem é que, justamente por ser baseado nas bibliotecas do KDE, ele fica mais lento e pesado ao ser usado no Gnome ou outras interfaces, pois para abrir uma simples janela de aviso será preciso carregar as bibliotecas do KDE.
Para abrir a mesma janela em kdialog, o comando seria:
canal=`kdialog --title "Gravar-TV" --inputbox "Canal a gravar (ex: 12)" "12"`
Veja que aqui estou atribuindo o resultado do comando (a resposta) diretamente à variável (como no exemplo do md5sum), ao invés de ter que salvar num arquivo e depois lê-lo. Leríamos: canal é igual ao resultado de kdialog --title "Gravar-TV" --inputbox "Canal a gravar (ex: 12)" "12".
Isso funciona no kdialog e não no dialog ou Xdialog, pois o kdialog envia a resposta para a saída padrão (que seria exibida no terminal), enquanto o Xdialog envia para a saída de erro. Se você quisesse fazer como nos exemplos anteriores, salvando num arquivo e lendo-o em seguida, haveria uma pequena mudança no comando:
kdialog --inputbox "Canal a gravar (ex: 12)" "12" > /tmp/resposta.tmpcanal=`/tmp/resposta.tmp`
Note que, ao invés de usar "2> /tmp/resposta.tmp", usei "> /tmp/resposta.tmp. O "2>" serve para direcionar a saída de erro, enquanto o ">" direciona a saída padrão, fazendo com que ao invés de mostrar na tela, o comando salve o texto dentro do arquivo.
É possível usar ainda o "&>", que direciona simultaneamente ambas as saídas. Por exemplo, é comum que os programas do KDE exibam várias mensagens ao serem abertos
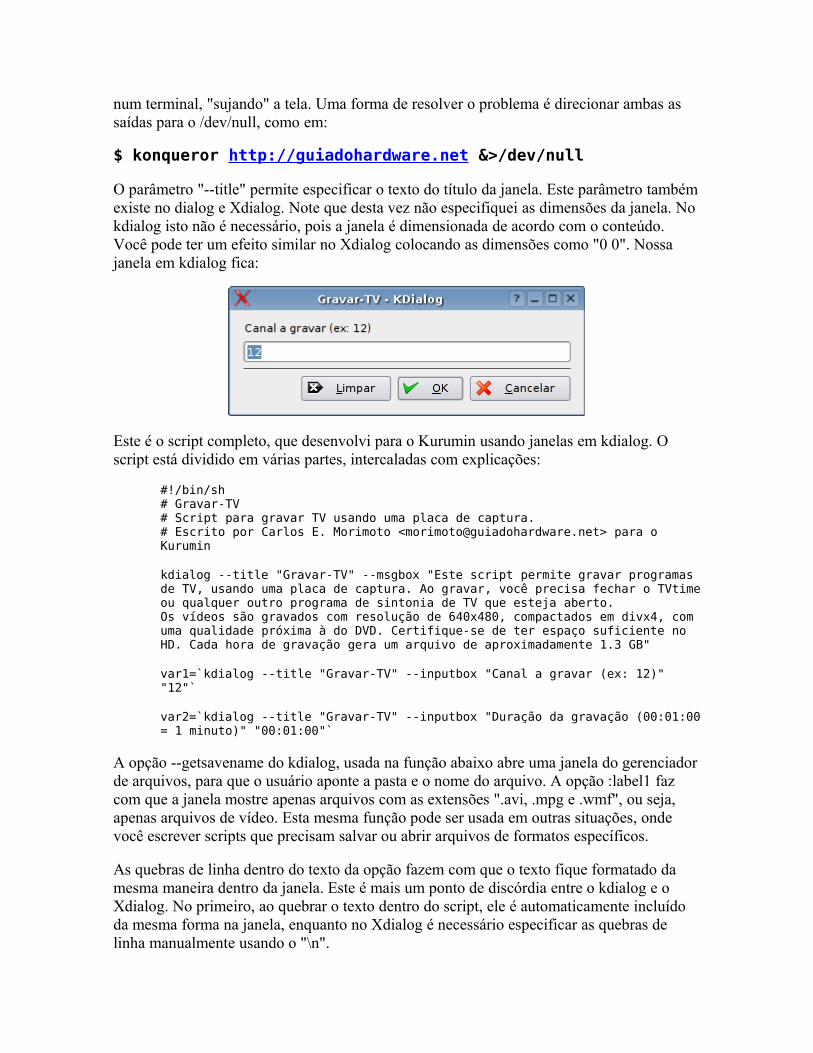
num terminal, "sujando" a tela. Uma forma de resolver o problema é direcionar ambas as saídas para o /dev/null, como em:
$ konqueror http://guiadohardware.net &>/dev/null
O parâmetro "--title" permite especificar o texto do título da janela. Este parâmetro também existe no dialog e Xdialog. Note que desta vez não especifiquei as dimensões da janela. No kdialog isto não é necessário, pois a janela é dimensionada de acordo com o conteúdo. Você pode ter um efeito similar no Xdialog colocando as dimensões como "0 0". Nossa janela em kdialog fica:
Este é o script completo, que desenvolvi para o Kurumin usando janelas em kdialog. O script está dividido em várias partes, intercaladas com explicações:
#!/bin/sh# Gravar-TV# Script para gravar TV usando uma placa de captura. # Escrito por Carlos E. Morimoto <[email protected]> para o Kurumin
kdialog --title "Gravar-TV" --msgbox "Este script permite gravar programas de TV, usando uma placa de captura. Ao gravar, você precisa fechar o TVtime ou qualquer outro programa de sintonia de TV que esteja aberto.Os vídeos são gravados com resolução de 640x480, compactados em divx4, com uma qualidade próxima à do DVD. Certifique-se de ter espaço suficiente no HD. Cada hora de gravação gera um arquivo de aproximadamente 1.3 GB"
var1=`kdialog --title "Gravar-TV" --inputbox "Canal a gravar (ex: 12)" "12"`
var2=`kdialog --title "Gravar-TV" --inputbox "Duração da gravação (00:01:00 = 1 minuto)" "00:01:00"`
A opção --getsavename do kdialog, usada na função abaixo abre uma janela do gerenciador de arquivos, para que o usuário aponte a pasta e o nome do arquivo. A opção :label1 faz com que a janela mostre apenas arquivos com as extensões ".avi, .mpg e .wmf", ou seja, apenas arquivos de vídeo. Esta mesma função pode ser usada em outras situações, onde você escrever scripts que precisam salvar ou abrir arquivos de formatos específicos.
As quebras de linha dentro do texto da opção fazem com que o texto fique formatado da mesma maneira dentro da janela. Este é mais um ponto de discórdia entre o kdialog e o Xdialog. No primeiro, ao quebrar o texto dentro do script, ele é automaticamente incluído da mesma forma na janela, enquanto no Xdialog é necessário especificar as quebras de linha manualmente usando o "\n".

var3=`kdialog --getsavefilename :label1 "*.avi *.mpg *.wmf |Arquivos de vídeo"`
var4=`kdialog --combobox "Padrão de sintonia: us-bcast = TV aberta us-cable = TV a cabo" "us-bcast" "us-cable"`
A opção "--passivepopup" (disponível apenas no Kdialog) mostra um aviso que some depois do tempo especificado (neste caso depois de 6 segundos), ou ao clicar sobre a janela:
kdialog --title "Gravando" --passivepopup "Gravando o canal $var1 por: $var2 horas no arquivo: $var3Feche a janela de terminal para abortar" 6 &>/dev/null &
Aqui vai o comando de gravação, montado usando todas as informações coletadas acima. Depois do comando de gravação, ou seja, depois que a gravação termina, é mostrada mais uma janela de texto, usando o "--passivepopup", desta vez sem o número que especifica o tempo de exibição. Isto faz com que a janela fique no canto da tela até receber um clique se confirmação.
mencoder tv:// -tv driver=v4l2:input=0:normid=4:channel=$var1:chanlist=$var4:\width=640:height=480:device=/dev/video0:adevice=/dev/dsp0:audiorate=32000:\forceaudio:forcechan=2:buffersize=64 -quiet -oac mp3lame -lameopts preset=\medium -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=3000:keyint=132 -vop pp=lb \-endpos $var2 -o $var3
kdialog --title "Gravar-TV" --passivepopup "Ok!A gravação terminou."
exit 0
O "exit" é um comando que denota o fim do script. O "0" é o status de saída, que pode ser lido por programas executados em seguida, no mesmo terminal. O 0 indica que o script terminou normalmente, mas você pode incluir vários "exit" dentro de condicionais e partes específicas do scripts, permitindo que ele "termine de forma elegante" em caso de erros, com um código de saída que permita verificar o que aconteceu.
Este outro script, também escrito para o Kurumin, serve para montar compartilhamentos de rede em NFS. Diferentemente do script de gravar TV, ele foi escrito para funcionar tanto dentro do modo gráfico (usando janelas em Xdialog) ou em modo texto puro, usando o dialog. Uma função no início do script se encarrega de detectar se o modo gráfico está aberto ou não.
Você pode encontrar todos os scripts desenvolvidos para o Kurumin dentro da pasta /usr/local/bin/ do sistema, ou online no: http://www.guiadohardware.net/kurumin/bin/.
Eles são intencionalmente escritos de forma simples, até elementar para facilitar o entendimento. Tudo começa com o "#!/bin/sh", que denota que se trata de um shell script. É de praxe incluir também uma descrição do programa e o nome do autor:

#!/bin/sh # Monta um compartilhamento NFS # por Carlos E. Morimoto
Esta variável ativa o modo de compatibilidade do Xdialog, que melhora a aparência das janelas. Ela é opcional, mas é complicado acertar o texto dentro das janelas sem ela, pois o Xdialog não ajustará automaticamente o texto dentro da janela (faça um teste e veja a diferença). É interessante usá-la em qualquer script que use o Xdialog.
export XDIALOG_HIGH_DIALOG_COMPAT=1
Este script corresponde ao ícone "NFS - Montar Compartilhamento" no iniciar. Ele facilita o acesso a compartilhamentos NFS que normalmente são uma tarefa um tanto quanto indigesta para os iniciantes.
Ele começa perguntando ao usuário qual compartilhamento será montado. Aqui estamos usando as opções "--ok-label" e "--cancel-label" do Xdialog, que alteram o texto dos botões, ajustando-os melhor ao seu script. A opção "--inputbox" faz com que a janela seja exibida como uma pergunta, onde você deve informar o endereço IP do servidor e a pasta compartilhada. Os números "21 70" definem as dimensões da janela (em caracteres) e o '192.168.0.1:/arquivos' é o texto padrão, que aparece no campo de resposta da pergunta. Como disse anteriormente, é importante incluir sempre uma resposta default na pergunta, o que previne erros e enganos. O "\n" adiciona uma quebra de linha, permitindo formatar o texto.
Xdialog --title "Acessar compartilhamento NFS" \--ok-label "Continuar" --cancel-label "Sair" \--inputbox "O NFS é um protocolo que permite compartilhar arquivos facilmente entre máquinas Linux.Este script é um cliente que permite acessar compartilhamentos em outras máquinas. \nPara isso você precisa apenas informar o endereço IP do servidor, seguido da pasta que ele está compartilhando, como em: 192.168.0.1:/arquivos" \ 20 70 '192.168.0.1:/arquivos' 2> /tmp/nfs1
O "2> /tmp/nfs1" faz com que a resposta seja escrita num arquivo (ao invés de ser mostrada na tela). Fazemos com que este arquivo seja lido usando o cat e atribuímos a resposta à variável "SHARE", que inclui o texto digitado na janela.
SHARE=`cat /tmp/nfs1`
Além de saber qual compartilhamento será montado, é preciso saber onde ele será montado. Esta pergunta inclui a pasta "/mnt/nfs" como resposta padrão, que seria um local adequado. Caso o usuário não precise montar num local específico, ele vai simplesmente pressionar Enter, fazendo com que a pergunta não incomode.
Xdialog --title "Acessar compartilhamento NFS" \--ok-label "Continuar" --cancel-label "Sair" \--inputbox "Preciso saber agora em qual pasta local você deseja que o compartilhamento fique acessível. Um recurso interessante do NFS é que os arquivos ficam acessíveis como se fossem arquivos locais, você pode até mesmo gravar um CD diretamente a partir da pasta com o compartilhamento.\n\

nVocê pode usar qualquer pasta dentro do seu diretório de usuário. Se a pasta não existir, vou tentar criá-la para você." \18 70 '/mnt/nfs' 2> /tmp/nfs2
LOCAL=`cat /tmp/nfs2`
Temos agora mais uma variável, agora armazenando o texto com o diretório local onde o compartilhamento será montado.
Esta função verifica se o local informado existe e é realmente um diretório (-d) e faz uma dupla checagem: se ele existe, é usado o comando umount, para ter certeza de que não existe outro compartilhamento ou partição já montada na pasta. Caso ela não exista, o script usa o mkdir para criá-la. É sempre saudável incluir este tipo de checagem em seus scripts, tentando antecipar erros e dificuldades comuns por parte de quem vai usar e incluindo ações apropriadas para cada um.
if [ -d $LOCAL ]; thenumount $LOCALelsemkdir $LOCALfi
Vamos agora iniciar alguns serviços necessários para o NFS funcionar. Não sabemos se eles vão estar ou não abertos na máquina alvo, por isso é melhor ter certeza.
Ao mesmo tempo em que os comandos são executados, eles são escritos na tela, o que tem uma função didática. O sleep 1 faz com que o script pare por um segundo ao executar cada um dos comandos, dando tempo para que qualquer mensagem de erro seja notada.
echo "Executando comando:"echo "/etc/init.d/portmap/start"/etc/init.d/portmap start; sleep 1
echo "Executando comando:"echo "/etc/init.d/nfs-common start"/etc/init.d/nfs-common start; sleep 1
As duas variáveis que foram lidas acima são usadas para montar o comando que acessa o compartilhamento:
echo "Executando comando:"echo "mount -o soft -t nfs $SHARE $LOCAL"mount -o soft -t nfs $SHARE $LOCALsleep 2
Esta linha remove os arquivos temporários que foram usados. É importante deixar a casa limpa, até para evitar problemas caso o script seja executado várias vezes em seguida. Veja mais adiante a dica de como criar arquivos temporários dinâmicos.
rm -f /tmp/nfs1; rm -f /tmp/nfs2
Concluindo, abrimos uma janela do Konqueror já mostrando os arquivos do compartilhamento, provendo gratificação imediata. O "&" no final do comando permite que

o script continue, mesmo que a janela permaneça aberta, enquanto o "&>/dev/null" esconde os avisos e erros que o Konqueror costuma exibir, evitando que ele suje o terminal:
konqueror $LOCAL &>/dev/null &sleep 3
O "&>/dev/null é um redirecionador, que envia qualquer mensagem ou erro que seria mostrado no console para o /dev/null, o "buraco negro" do sistema. Isso é importante no caso de programas como o Konqueror, que sujam a tela com um sem número de mensagens.
Uma outra forma de fazer a mesma coisa, é colocar o comando que deve ser "silenciado" dentro de ":``", como em ":`konqueror $LOCAL`". O ":" é, por estranho que pareça, um comando do shell, que simplesmente não faz nada. Usado desta forma, ele recebe as mensagens exibidas pelo comando e não faz nada. Este é um dos casos em que você pode fazer a mesma coisa usando um comando mais longo, porém mais legível, ou escrever da forma com menos caracteres.
# Esta faz o mesmo que a linha acima:# :`konqueror $LOCAL`
Depois de montar o compartilhamento, entra em ação a segunda parte do script, que oferece a opção de adicionar uma entrada no fstab e criar um ícone no desktop para montar o compartilhamento. A variável "$?" armazena a resposta da pergunta. Se a resposta for sim, ela armazena o valor "0"; e se for não, armazena "1". O script checa o valor e continua apenas se for 0.
Xdialog --title "Acessar compartilhamento NFS" \--ok-label "Sim" --cancel-label "Não" \--yesno "Você gostaria de adicionar uma entrada no '/etc/fstab' e um ícone no desktop, para que este compartilhamento possa ser acessado mais tarde com mais facilidade? Ao responder yes você poderá acessar os arquivos posteriormente apenas clicando no ícone que será criado no desktop." 14 60
if [ "$?" = "0" ] ; then
Da mesma forma que é usado para escrever na tela, o "echo" pode ser usado para adicionar linhas em arquivos de configuração. Neste caso usamos os redirecionadores (>>), especificando o arquivo. O echo "" adiciona uma linha em branco no final do arquivo, o que é uma regra no caso do fstab.
Existe a possibilidade da mesma linha ser adicionada mais de uma vez ao fstab, caso o script seja executado novamente com as mesmas opções. Para evitar isso, o script primeiro checa se a linha já não existe (usando o grep) e adiciona a linha apenas se o resultado for negativo. Veremos mais exemplos do uso do grep, sed e outras ferramentas para filtrar e modificar arquivos mais adiante. Faça uma nota mental de voltar a este exemplo depois de terminar de ler todo o capítulo.
CHECK=`cat /etc/fstab | grep "$SHARE $LOCAL nfs noauto,users,exec,soft 0 0"`

if [ -z "$CHECK" ], thenecho '# Acessa compartilhamento nfs, adicionado pelo nfs-montar:' >> /etc/fstabecho "$SHARE $LOCAL nfs noauto,users,exec,soft 0 0" >> /etc/fstabecho "" >> /etc/fstabfi
Por fim, é criado um ícone no desktop permitindo montar o mesmo compartilhamento facilmente depois. Os ícones do KDE são apenas arquivos de texto comuns, por isso podem ser facilmente criados através de scripts.
Aqui temos mais um problema: Se forem criados vários ícones para compartilhamentos, cada um precisará ter um nome de arquivo diferente. Seria possível pedir para que fosse digitado um número, por exemplo, e usá-lo como nome para o arquivo, mas nada impediria que o usuário simplesmente digitasse o mesmo número repetidamente, o que não resolveria nosso problema.
Uma solução é usar o comando "date", que informa a hora atual, para gerar um número que pode ser usado como nome do arquivo. O que aparece escrito no desktop não é o nome do arquivo, mas sim o campo "Name" dentro do texto. Usado com os parâmetros abaixo, o date retorna algo como "20060228952". O "fi" usado aqui fecha o "if" aberto anteriormente e o "exit 0" indica o final do script:
NOME=`date +%Y%m%d%H%M`
echo "[Desktop Entry]" > ~/Desktop/$nomeecho "Type=FSDevice" >> ~/Desktop/$nomeecho "Dev=$SHARE" >> ~/Desktop/$nomeecho "MountPoint=$LOCAL" >> ~/Desktop/$nomeecho "FSType=nfs" >> ~/Desktop/$nomeecho "ReadOnly=0" >> ~/Desktop/$nomeecho "Icon=hdd_mount" >> ~/Desktop/$nomeecho "UnmountIcon=hdd_unmount" >> ~/Desktop/$nomeecho "Name=$SHARE" >> ~/Desktop/$nome
fiexit 0
Uma dúvida freqüente é sobre o uso das aspas. Num script você pode tanto utilizar aspas duplas ("), quanto aspas simples ('), mas as duas possuem funções ligeiramente diferentes.
As aspas duplas fazem com que o conteúdo seja interpretado literalmente, isso permite incluir nomes de arquivos com espaços entre outras coisas. As aspas simples fazem o mesmo, mas de uma forma mais estrita, sem interpretar variáveis.
Por exemplo, o comando: echo "mount -o soft -t nfs $SHARE $LOCAL" do script anterior usa duas variáveis. Ao executar o script elas são substituídas pelos valores correspondentes, fazendo com que seja mostrado na tela algo como: "mount -t nfs 192.168.0.1/arquivos /mnt/nfs".

Porém, se usássemos aspas simples, como em: echo 'mount -t nfs $SHARE $LOCAL', o resultado do comando seria diferente. O bash escreveria a frase literalmente, sem interpretar as variáveis e veríamos na tela: "mount -t nfs $SHARE $LOCAL".
Ou seja, só usamos aspas simples quando realmente queremos usar um bloco de texto que não deve ser interpretado de forma alguma nem conter variáveis. No restante do tempo, usamos sempre aspas duplas.
No final do script, escrevo o ícone do desktop linha a linha, usando aspas duplas. Note que na primeira linha usei um ">" ao invés de ">>" como nas seguintes. Assim como no caso das aspas, o redirecionador simples tem um efeito diferente do duplo.
O simples (>) apaga todo o conteúdo anterior do arquivo, deixando apenas a linha adicionada. Ele é usada em situações onde você quer ter certeza de que o arquivo está vazio ao invés de deletar e criar o arquivo novamente. O redirecionador duplo, por sua vez, simplesmente adiciona texto no final do arquivo, sem modificar o que já existe.
Continuando, uma opção interessante do comando "read" que vimos a pouco é o "-t" (timeout), que permite especificar um tempo máximo para a resposta. Se nada for digitado, o script continua.
Esta opção pode ser usada para incluir opções do tipo "Pressione uma tecla dentro de 5 segundos para acessar a janela de configurações", onde o script deve continuar se não receber nenhuma resposta. Um exemplo seria:
echo "Pressione uma tecla em 3 segundos para abrir a configuração."read -t 3 resposta if [ -n "$resposta" ]; thenconfigura-programafiabrir-programa
Este é o tipo de função que pode ser usada na abertura do programa, por exemplo. A função "if [ -n "$resposta" ]" verifica se a variável resposta contém alguma coisa. Caso contenha, significa que foi digitado alguma coisa, o que dispara o comando que abre o menu de configuração. No final, é sempre executado o comando que abre o programa, tenha sido aberta a janela de configuração ou não.
Ao invés de usar o if, você pode incluir operações de verificação de forma mais compacta usando o "&&" (que testa se uma condição é verdadeira) e o "||" (que testa se ela é falsa). Por exemplo, ao invés de usar:
if [ -n "$resposta" ]; thenconfigura-programafi
Você poderia usar:
[ -n "$resposta" ] && configura-programa

Aqui ele verifica se a variável resposta está vazia (-n) e, caso esteja, executa o comando "configura-programa". Como pode ver, ele tem a mesma função que o "then" do if.
O "||" por sua vez, verifica se a condição é falsa, tendo uma função similar à do "else". A principal vantagem é que ele pode ser usado diretamente, sem necessidade de incluir um if inteiro, como em:
md5sum=`md5sum kurumin-"$versao".iso`[ "$md5sum" = "$md5sumOK" ] || echo "O arquivo veio corrompido"
Aqui ele verifica se o md5sum do arquivo está correto e mostra a mensagem apenas quando ele não bater.
Tanto o && quanto o || podem ser usados também para testar comandos, avisando caso o comando seja executado corretamente, ou caso surja algum erro, como em:
modprobe snd-emu10k1 && echo "O módulo foi carregado" || echo "Erro no carregamento"
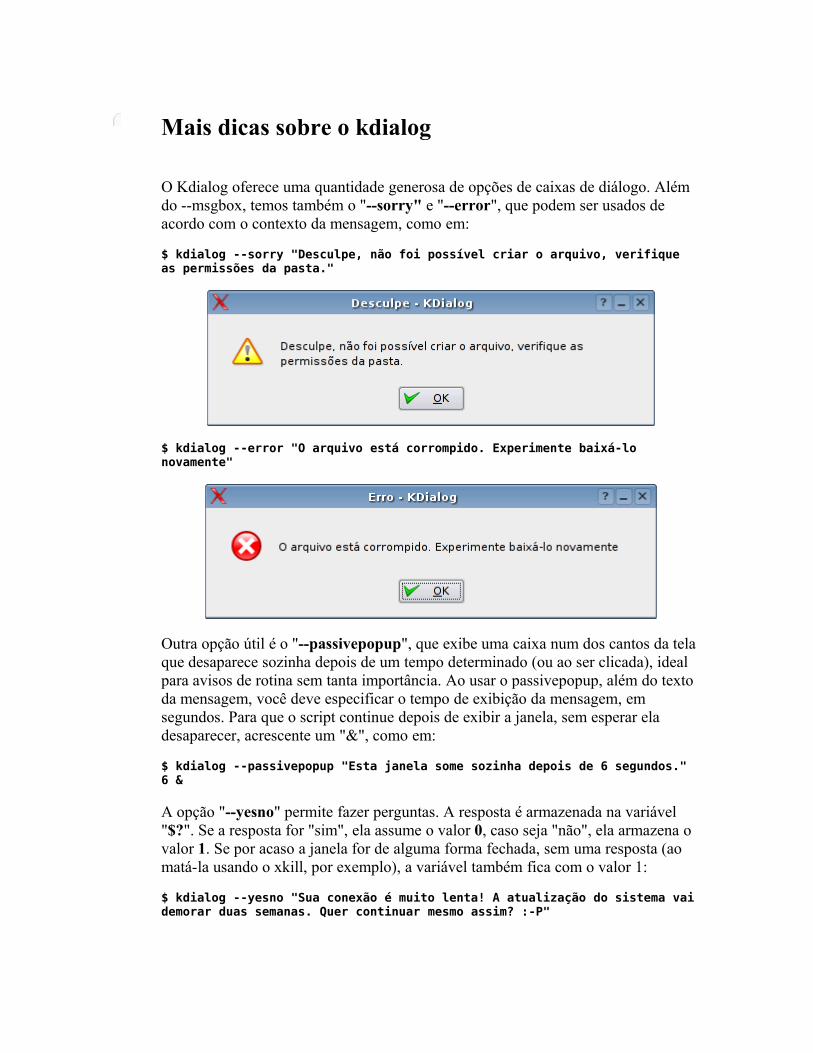
Mais dicas sobre o kdialog
O Kdialog oferece uma quantidade generosa de opções de caixas de diálogo. Além do --msgbox, temos também o "--sorry" e "--error", que podem ser usados de acordo com o contexto da mensagem, como em:
$ kdialog --sorry "Desculpe, não foi possível criar o arquivo, verifique as permissões da pasta."
$ kdialog --error "O arquivo está corrompido. Experimente baixá-lo novamente"
Outra opção útil é o "--passivepopup", que exibe uma caixa num dos cantos da tela que desaparece sozinha depois de um tempo determinado (ou ao ser clicada), ideal para avisos de rotina sem tanta importância. Ao usar o passivepopup, além do texto da mensagem, você deve especificar o tempo de exibição da mensagem, em segundos. Para que o script continue depois de exibir a janela, sem esperar ela desaparecer, acrescente um "&", como em:
$ kdialog --passivepopup "Esta janela some sozinha depois de 6 segundos." 6 &
A opção "--yesno" permite fazer perguntas. A resposta é armazenada na variável "$?". Se a resposta for "sim", ela assume o valor 0, caso seja "não", ela armazena o valor 1. Se por acaso a janela for de alguma forma fechada, sem uma resposta (ao matá-la usando o xkill, por exemplo), a variável também fica com o valor 1:
$ kdialog --yesno "Sua conexão é muito lenta! A atualização do sistema vai demorar duas semanas. Quer continuar mesmo assim? :-P"

Como temos apenas duas possibilidades, você pode usar um if para especificar o que o script deve fazer em cada caso:
resposta=$?
if [ "$resposta" = "0" ]; thenapt-get upgradefi
if [ "$resposta" = "1" ]; thenkdialog --msgbox "Ok, abortando..."fi
Aqui usei dois "if", um para o sim e outro para o não. Você pode economizar algumas linhas usando um "else" (senão):
resposta=$?
if [ "$resposta" = "0" ]; thenapt-get upgradeelsekdialog --msgbox "Ok, abortando..."fi
O else deve ser usado com um pouco mais de cuidado, pois ele se aplica a qualquer caso onde a resposta for diferente de 0 e não apenas no caso de ela ser 1, como ao usar um segundo if. Em algumas situações isso pode abrir margem para acidentes, caso seu script seja usado num contexto diferente do que ele foi projetado.
Existe uma pequena variação do --yesno que é a opção "--warningcontinuecancel", onde a legenda dos botões muda para continuar/cancelar, mas sem alterar o comportamento da janela.
Outra variação é a opção "--yesnocancel" que mostra uma caixa com três opções. Respondendo "Sim" ou "Não", a variável "$?" assume o valor "0" ou "1", mas respondendo "Cancelar" ela assume o valor "2".

A opção "Cancelar" pode ser usada para fechar o script, através do comando "exit", que encerra a execução, sem processar o resto dos comandos. Isto pode ser útil num script longo, com muitos passos.
É importante que nestes casos você encontre uma forma de desfazer as alterações feitas nas opções anteriores, deixando tudo como estava antes de executar o script. Uma boa medida nestes casos é armazenar todas as respostas em variáveis e deixar para fazer todas as operações de uma vez, no final do script.
Como agora temos três possibilidades de resposta, podemos utilizar a função "case", que permite especificar ações para um número indefinido de opções.
kdialog --yesnocancel "Sua conexão é muito lenta! A atualização do sistema vai demorar duas semanas. Quer continuar mesmo assim? :-P"
resposta=$?
case $resposta in0) apt-get upgrade ;;1) kdialog --msgbox "Ok, abortando..." ;;2) exit 0 ;;*) kdialog -- msgbox "Ops, isto não deveria acontecer... :-)" ;;esac
Depois do "case $resposta in", você adiciona cada uma das possibilidades de valor para a variável, seguida de um parênteses. No final de cada linha vai obrigatoriamente um ponto-e-vírgula duplo, que faz o bash entender que deve passar para a próxima opção. Se precisar colocar vários comandos dentro de uma mesma opção, você pode separá-los por um único ponto-e-vírgula como em:
1) apt-get -f install; apt-get update; apt-get upgrade ;;
O "*)" funciona da mesma forma que o else, uma opção "default" que é executada se nenhuma das outras for válida. No meu exemplo, a resposta vem de uma janela com apenas três opções, numeradas de 0) a 2). Ou seja, a menos que algo de muito estranho aconteça, a opção default (*) nunca será usada.
Lembre-se de que os comandos "if" e "case" devem ser sempre fechados, respectivamente pelo "fi" e pelo "esac", indicando onde a condicional termina.
O kdialog oferece três opções de diálogos para abrir, salvar arquivos e selecionar
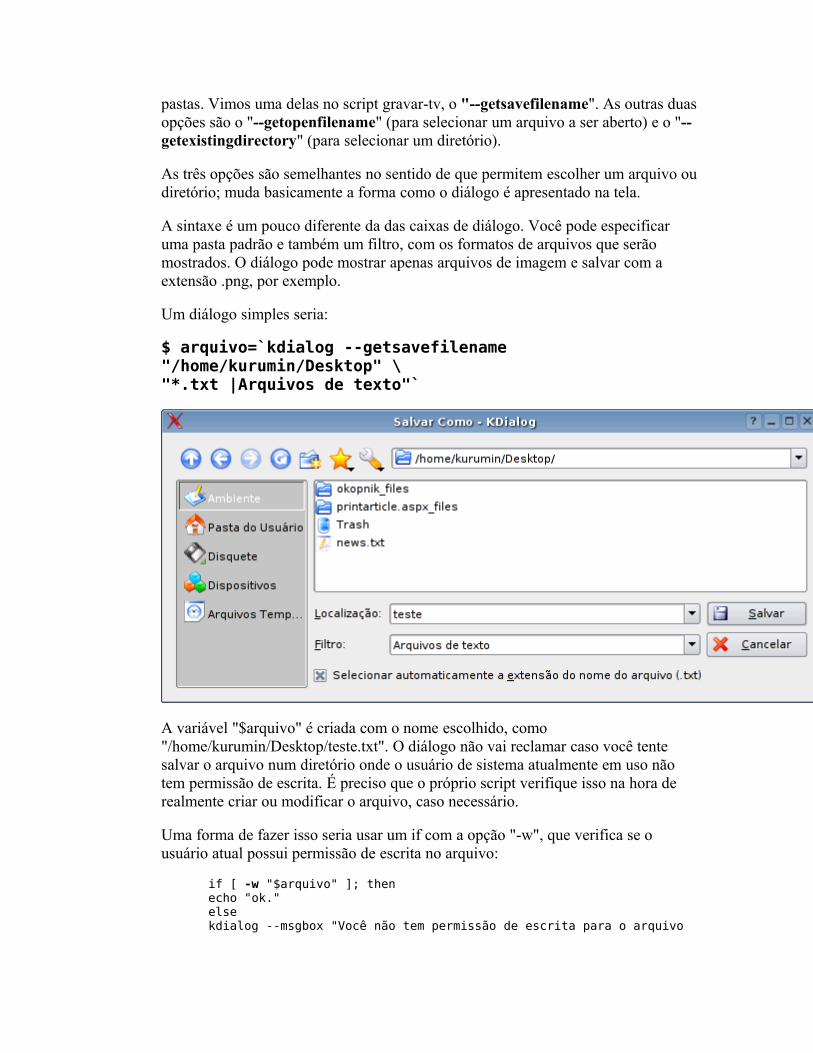
pastas. Vimos uma delas no script gravar-tv, o "--getsavefilename". As outras duas opções são o "--getopenfilename" (para selecionar um arquivo a ser aberto) e o "--getexistingdirectory" (para selecionar um diretório).
As três opções são semelhantes no sentido de que permitem escolher um arquivo ou diretório; muda basicamente a forma como o diálogo é apresentado na tela.
A sintaxe é um pouco diferente da das caixas de diálogo. Você pode especificar uma pasta padrão e também um filtro, com os formatos de arquivos que serão mostrados. O diálogo pode mostrar apenas arquivos de imagem e salvar com a extensão .png, por exemplo.
Um diálogo simples seria:
$ arquivo=`kdialog --getsavefilename "/home/kurumin/Desktop" \"*.txt |Arquivos de texto"`
A variável "$arquivo" é criada com o nome escolhido, como "/home/kurumin/Desktop/teste.txt". O diálogo não vai reclamar caso você tente salvar o arquivo num diretório onde o usuário de sistema atualmente em uso não tem permissão de escrita. É preciso que o próprio script verifique isso na hora de realmente criar ou modificar o arquivo, caso necessário.
Uma forma de fazer isso seria usar um if com a opção "-w", que verifica se o usuário atual possui permissão de escrita no arquivo:
if [ -w "$arquivo" ]; thenecho "ok."elsekdialog --msgbox "Você não tem permissão de escrita para o arquivo

escolhido."fi
O "*.txt |Arquivos de texto" permite especificar os formatos de arquivo que serão mostrados na janela, e a legenda do filtro. Para mostrar apenas arquivos de imagem, deixando a extensão .png como padrão, você poderia utilizar algo como "*.png *.jpg *.gif *bmp |Arquivos de Imagem". Como vê, você só precisa citar as extensões de arquivo permitidas, separadas por espaço e incluir a legenda depois do "|".
A opção --getexistingdirectory é mais simples, você só precisa especificar um diretório padrão, como em:
$ pasta=`kdialog --getexistingdirectory "/home/$USER"`
Como no exemplo anterior, a variável "$pasta" será criada armazenando o diretório escolhido.
Existem ainda três opções diferentes de menus de seleção, criados usando as opções: "--menu", "--checklist" e "--combobox".
Na opção "--menu" é mostrado um menu com as opções, onde você só pode escolher uma, como em:
$ operacao=`kdialog --menu "O que você gostaria de fazer?" \a "Redimensionar a imagem" \b "Girar a imagem" \c "Deletar a imagem" \d "Converter para outro formato"`
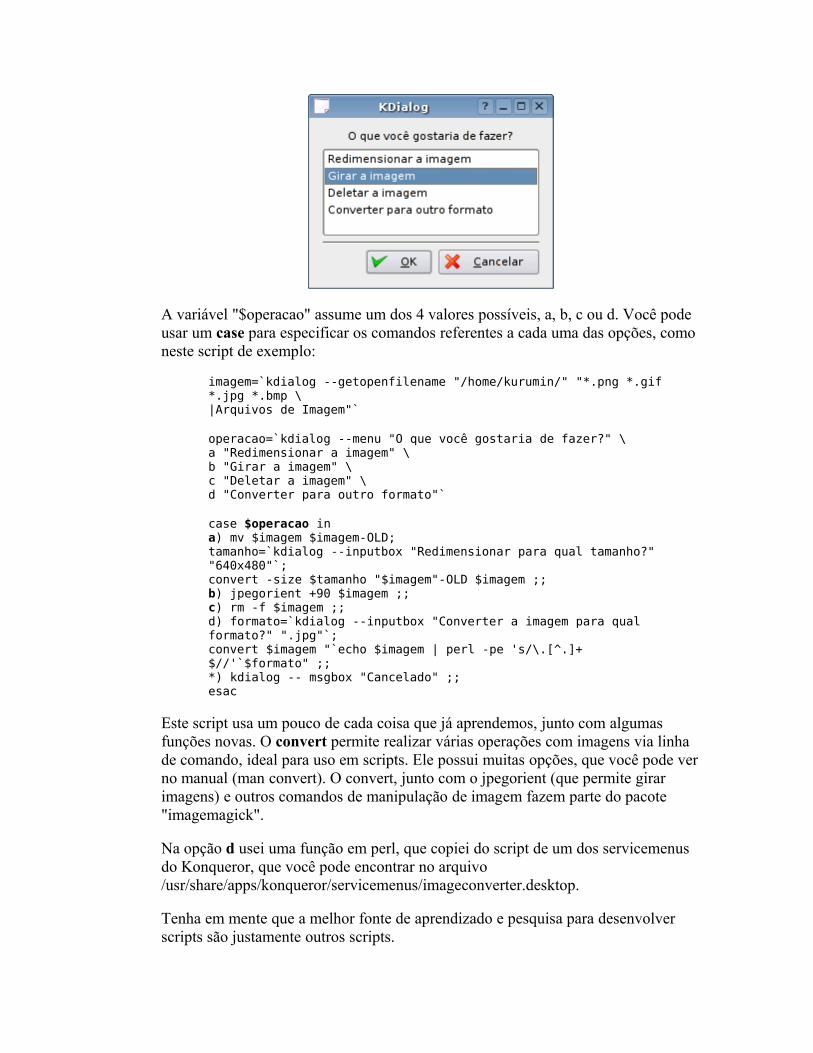
A variável "$operacao" assume um dos 4 valores possíveis, a, b, c ou d. Você pode usar um case para especificar os comandos referentes a cada uma das opções, como neste script de exemplo:
imagem=`kdialog --getopenfilename "/home/kurumin/" "*.png *.gif *.jpg *.bmp \|Arquivos de Imagem"`
operacao=`kdialog --menu "O que você gostaria de fazer?" \a "Redimensionar a imagem" \b "Girar a imagem" \c "Deletar a imagem" \d "Converter para outro formato"`
case $operacao ina) mv $imagem $imagem-OLD; tamanho=`kdialog --inputbox "Redimensionar para qual tamanho?" "640x480"`; convert -size $tamanho "$imagem"-OLD $imagem ;;b) jpegorient +90 $imagem ;;c) rm -f $imagem ;;d) formato=`kdialog --inputbox "Converter a imagem para qual formato?" ".jpg"`;convert $imagem "`echo $imagem | perl -pe 's/\.[^.]+$//'`$formato" ;;*) kdialog -- msgbox "Cancelado" ;;esac
Este script usa um pouco de cada coisa que já aprendemos, junto com algumas funções novas. O convert permite realizar várias operações com imagens via linha de comando, ideal para uso em scripts. Ele possui muitas opções, que você pode ver no manual (man convert). O convert, junto com o jpegorient (que permite girar imagens) e outros comandos de manipulação de imagem fazem parte do pacote "imagemagick".
Na opção d usei uma função em perl, que copiei do script de um dos servicemenus do Konqueror, que você pode encontrar no arquivo /usr/share/apps/konqueror/servicemenus/imageconverter.desktop.
Tenha em mente que a melhor fonte de aprendizado e pesquisa para desenvolver scripts são justamente outros scripts.
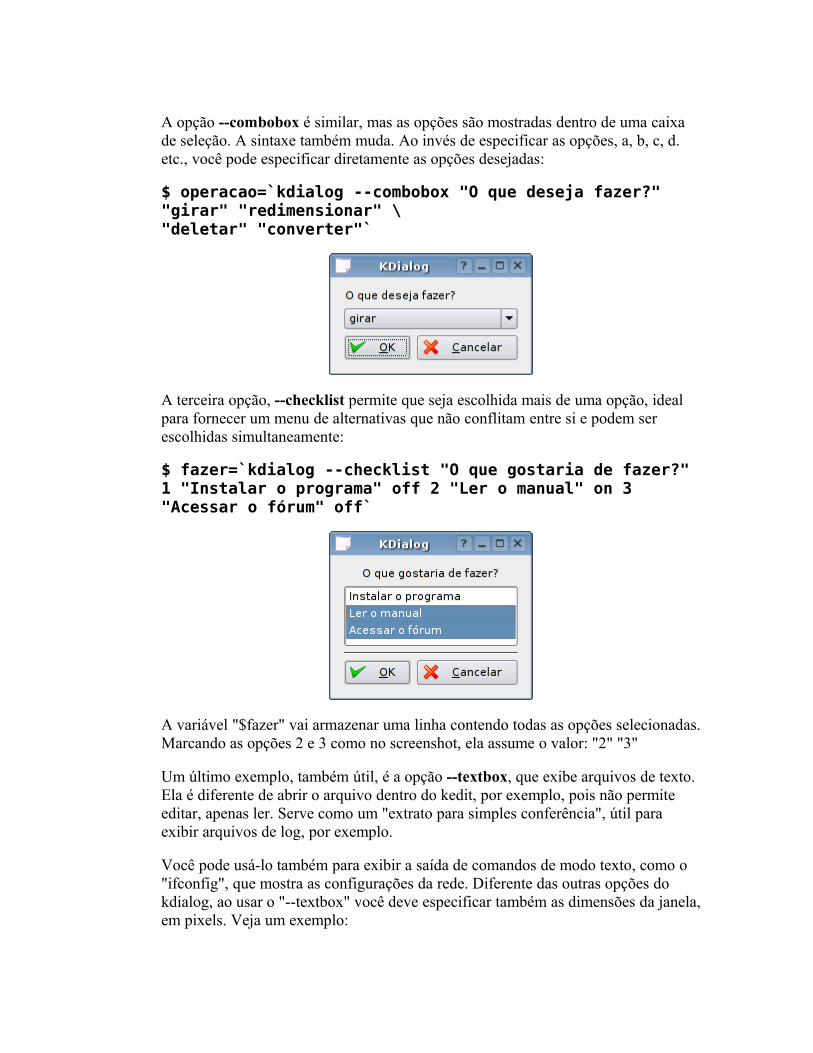
A opção --combobox é similar, mas as opções são mostradas dentro de uma caixa de seleção. A sintaxe também muda. Ao invés de especificar as opções, a, b, c, d. etc., você pode especificar diretamente as opções desejadas:
$ operacao=`kdialog --combobox "O que deseja fazer?" "girar" "redimensionar" \"deletar" "converter"`
A terceira opção, --checklist permite que seja escolhida mais de uma opção, ideal para fornecer um menu de alternativas que não conflitam entre si e podem ser escolhidas simultaneamente:
$ fazer=`kdialog --checklist "O que gostaria de fazer?" 1 "Instalar o programa" off 2 "Ler o manual" on 3 "Acessar o fórum" off`
A variável "$fazer" vai armazenar uma linha contendo todas as opções selecionadas. Marcando as opções 2 e 3 como no screenshot, ela assume o valor: "2" "3"
Um último exemplo, também útil, é a opção --textbox, que exibe arquivos de texto. Ela é diferente de abrir o arquivo dentro do kedit, por exemplo, pois não permite editar, apenas ler. Serve como um "extrato para simples conferência", útil para exibir arquivos de log, por exemplo.
Você pode usá-lo também para exibir a saída de comandos de modo texto, como o "ifconfig", que mostra as configurações da rede. Diferente das outras opções do kdialog, ao usar o "--textbox" você deve especificar também as dimensões da janela, em pixels. Veja um exemplo:

ifconfig > /tmp/ifconfig.txtkdialog --textbox /tmp/ifconfig.txt 500 320
Controlando aplicativos via DCOP
Dentro do KDE você pode utilizar mais um recurso interessante, o DCOP. Ele permite que o script envie sinais para os programas gráficos abertos.
Por exemplo, para abrir o kmix e logo em seguida minimizá-lo ao lado do relógio, você pode usar o comando:
$ kmix & $ dcop kmix kmix-mainwindow#1 hide
O dcop oferece muitas funções, com o tempo você acaba decorando as mais usadas, mas no início a melhor forma de aprender é ir vendo e testando as opções disponíveis para cada programa.
Abra o aplicativo que deseja controlar e rode o comando "dcop" num terminal, sem argumentos. Ele mostrará uma lista dos programas do KDE, que suportam chamadas via DCOP atualmente abertos:
$ dcop
kwin kicker kded

knotify kio_uiserver kcookiejar konsole-16265 klauncher konqueror-21806 khotkeyskdesktop ksmserver
Veja que alguns aplicativos, como o konqueror e o konsole aparecem com números ao lado. Estes são aplicativos que podem ser abertos várias vezes, por isso a necessidade dos números, que permitem identificar cada instância.
Usar funções do dcop para eles é um pouco mais complicado, pois cada vez que são abertos usam um número diferente. Nestes casos uso um "filtro" para obter o nome da primeira instância, seja qual for o número de identificação, e colocá-lo (o nome da instância) numa variável, que posso usar depois:
konqueror=`dcop | grep konqueror | head -n 1`
Outra opção seria aplicar a mesma ação a todas as janelas abertas, caso exista mais de uma. Neste caso, você poderia usar um "for", como em:
for i in `dcop | grep konsole`; do dcop $i konsole-mainwindow#1 minimize done
Executando o comando dentro do script, acabo com o valor "konqueror-21806", a identificação do konqueror atual carregada dentro da variável. Note que isto resolve o problema caso exista apenas uma instância do programa aberta. A variável vai sempre assumir a primeira instância do konqueror que aparecer na lista do DCOP.
Para ver uma lista das opções disponíveis para um determinado aplicativo, rode o comando dcop seguido do aplicativo, como em:
$ dcop $konqueror
qtKBookmarkManager-/home/kurumin/.kde/share/apps/konqueror/bookmarks.xmlKBookmarkNotifierKDebugKIO::SchedulerKonqFavIconMgrKonqHistoryManagerKonqUndoManagerKonquerorIface (default)MainApplication-Interfacehtml-widget1html-widget2html-widget3konqueror-mainwindow#1ksycoca

Cada uma destas opções possui uma lista de funções. Por exemplo, a opção konqueror-mainwindow#1 controla a janela principal do konqueror. Para ver as funções relacionadas a ela, rode o comando:
$ dcop $konqueror konqueror-mainwindow#1
Este comando retorna uma longa lista de opções. Você pode fazer de tudo, desde esconder a janela até mudar a fonte, título, página exibida ou ícone na barra de tarefas. Algumas opções básicas são:
$ dcop $konqueror konqueror-mainwindow#1 maximize$ dcop $konqueror konqueror-mainwindow#1 minimize$ dcop $konqueror konqueror-mainwindow#1 hide$ dcop $konqueror konqueror-mainwindow#1 reload$ dcop $konqueror konqueror-mainwindow#1 show
Este exemplo parece complicado, mas a maioria dos aplicativos suporta a opção "default" que permite que você vá direto à função desejada. Por exemplo, para fazer uma janela aberta do kmail baixar novas mensagens, use o comando:
$ dcop kmail default checkMail
Você pode ver os comandos DCOP disponíveis em cada um dos aplicativos abertos de uma forma mais conveniente usando o "kdcop". Abra-o a partir do terminal, seguido dos aplicativos que deseja controlar. Na janela principal, são exibidos todos os aplicativos abertos que suportam chamadas DCOP, com as chamadas organizadas numa estrutura de árvore. Clicando numa das chamadas, ela é executada, maximizando ou minimizando a janela do aplicativo, por exemplo. Isso permite que você veja rapidamente o que cada uma faz.
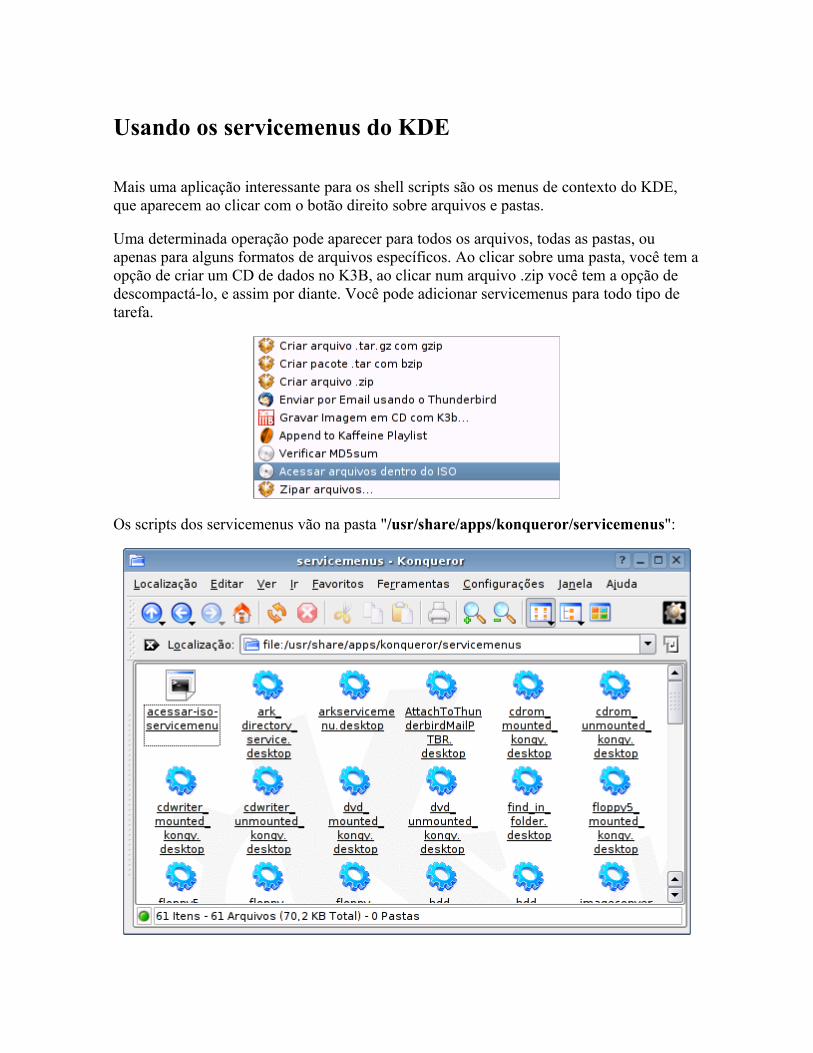
Usando os servicemenus do KDE
Mais uma aplicação interessante para os shell scripts são os menus de contexto do KDE, que aparecem ao clicar com o botão direito sobre arquivos e pastas.
Uma determinada operação pode aparecer para todos os arquivos, todas as pastas, ou apenas para alguns formatos de arquivos específicos. Ao clicar sobre uma pasta, você tem a opção de criar um CD de dados no K3B, ao clicar num arquivo .zip você tem a opção de descompactá-lo, e assim por diante. Você pode adicionar servicemenus para todo tipo de tarefa.
Os scripts dos servicemenus vão na pasta "/usr/share/apps/konqueror/servicemenus":

Todos os arquivos dentro da pasta são scripts, que seguem um padrão próprio, começando pelo nome, que deve sempre terminar com ".desktop".
Por exemplo, o servicemenu responsável pela opção "Acessar arquivos dentro do ISO", que aparece apenas ao clicar sobre um arquivo com a extensão .iso, é o arquivo "montar-iso.desktop", que tem o seguinte conteúdo:
[Desktop Entry]Actions=montarEncoding=UTF-8ServiceTypes=application/x-iso
[Desktop Action montar]Exec=acessar-iso-servicemenu %uIcon=cdrom_unmountName=Acessar arquivos dentro do ISO
A linha "ServiceTypes=application/x-iso" é importante neste caso, pois é nela que você especifica a que tipos de arquivos o servicemenu se destina. É por isso que eles também são chamados em português de "Menus de contexto", pois são mostradas opções diferentes para cada tipo de arquivo. Você pode ver todos os formatos de arquivos reconhecidos pela sua instalação do KDE, e adicionar novas extensões caso necessário no Centro de Controle do KDE, em "Componentes do KDE > Associações de arquivos".

Veja que no início do script você especifica as ações disponíveis no parâmetro "Actions". Mais adiante, você cria uma seção para cada ação especificada contendo o nome (da forma como aparecerá no menu) ícone e o comando que será executado ao acionar a ação no menu.
Neste exemplo é executado o comando "acessar-iso-servicemenu %u". O "%u" é uma variável, que contém o nome do arquivo clicado. Este parâmetro pode ser usado apenas nos scripts dos servicemenus, não em scripts regulares. O KDE oferece um conjunto de variáveis que podem ser utilizadas nos servicemenus:
%u: Esta é a variável que estamos utilizando no script acessar-iso. Ela contém o caminho completo para o arquivo selecionado (como em "file:/home/joao/kurumin.iso").
%U: Também armazena os caminhos completos para os arquivos, a diferença é que o "%u" permite selecionar apenas um arquivo (se você selecionar vários na janela do Konqueror ao executar o script, ele vai ficar apena com o último), enquanto o "%U" permite selecionar vários arquivos. O "%U" pode ser usado em servicemenus que permitem manipular vários arquivos de uma vez, renomeando arquivos ou convertendo de .mp3 para .ogg, por exemplo.
%n: Contém apenas o nome do arquivo selecionado, sem o caminho completo. Faz par com a variável "%N", que permite selecionar vários arquivos.
%d: Esta variável armazena um diretório. Pode ser usada em scripts que manipulem de uma vez todos os arquivos dentro de um diretório, como no caso de um script que gerasse thumbmails de todas as imagens dentro dele. Mesmo que você selecione um arquivo, o KDE remove o nome do arquivo e fica apenas com a pasta. Existe também a variável "%D", que permite selecionar vários diretórios de uma vez. A "%D" poderia ser usada para criar um script que permite criar um CD de dados incluindo o conteúdo de várias pastas, por exemplo.
O "acessar-iso-servicemenu" é um script separado, que pode ir em qualquer uma das pastas de executáveis do sistema: "/usr/local/bin/", "/usr/bin/", "/bin", ou em outra pasta adicionada manualmente no patch.
Este script contém os comandos para montar o arquivo .iso numa pasta e abrir uma janela do Konqueror mostrando o conteúdo. Ao fechar a janela do Konqueror, o arquivo é desmontado, para evitar problemas caso o usuário tente montar vários arquivos em seqüência:
#!/bin/sh
kdesu "mkdir /mnt/iso; umount /mnt/iso; mount -t iso9660 -o loop $1 /mnt/iso"clearkonqueror /mnt/isokdesu umount /mnt/iso

O kdesu é um componente do KDE que permite executar comandos como root. Ao executar um "kdesu konqueror", por exemplo, ele pede a senha de root numa janela e depois executa o comando, abrindo uma janela do Konqueror com permissões de root. Você pode executar uma seqüência de comandos dentro de uma única instância do kdesu (para que ele peça a senha apenas uma vez), colocando os comandos entre aspas, separados por ponto-e-vírgula, como no exemplo. É possível também utilizar o sudo, caso ativado.
Note que neste segundo script não uso a variável "%u" (que pode ser usada apenas dentro do script do servicemenu), mas sim a variável "$1".
Quando você executa um comando qualquer, via linha de comando, a variável "$1" é o primeiro parâmetro, colocado depois do comando em si. Para entender melhor, vamos criar um script "teste", com o seguinte conteúdo:
#!/bin/shecho $1echo $2echo $3
Execute o script, incluindo alguns parâmetros e você verá que ele vai justamente repetir todos os parâmetros que incluir.
Quando clicamos sobre um arquivo chamado "kurumin.iso" e acionamos o servicemenu, a variável "%u" contém o nome do arquivo, ou seja, "kurumin.iso". O servicemenu por sua vez chama o segundo script, adicionando o nome do arquivo depois do comando, o que automaticamente faz com que a variável "$1" também contenha o nome do arquivo. Ou seja, as variáveis "%u" e "$1" neste caso vão sempre possuir o mesmo conteúdo, muda apenas o contexto em que são usadas.
Você pode usar este tipo de troca de parâmetro para desmembrar seus scripts, criando "módulos" que possam ser usados em outros scripts.
Por exemplo, os ícones mágicos do Kurumin utilizam o sudo para executar comandos como root (como ao usar o apt-get para instalar um programa), sem ficar pedindo a senha de root a todo instante. O sudo pode ser ativado e desativado a qualquer momento, fornecendo a senha de root, de forma que você pode mantê-lo desativado, e ativar apenas ao executar algum script que precisa deles.

Para que isso funcione, os scripts sempre executam uma função, que verifica se o sudo está ativado. Caso esteja, eles são executados diretamente, sem pedir senha, caso contrário eles pedem a senha de root.
Isto foi implementado incluindo esta função no início de cada script:
sudo-verificarif [ "$?" = "2" ]; then exit 0; fi
O script "sudo-verificar", chamado por ela, tem o seguinte conteúdo:
#!/bin/sh
sudoativo=`sudo whoami`
if [ "$sudoativo" != "root" ]; then
kdialog --warningyesno "O script que você executou precisa utilizar o sudo para executar alterações no sistema. Atualmente o Kurumin está operando em modo seguro, com o sudo desativado para o usuário atual. Você gostaria de mudar para o modo root, ativando o sudo? Para isso será necessário fornecer a senha de root. Caso prefira abortar a instalação, responda Não. Você pode também executar o script desejado diretamente como root."
retval=$?if [ "$retval" = "0" ]; thensudo-ativar fi
if [ "$retval" = "1" ]; thenexit 2fifi
Este script verifica se o sudo está ativo usando o comando "whoami", que retorna o nome do usuário que o chamou. Caso o sudo esteja ativo, então o "sudo whoami" é executado pelo root e retorna "root". É uma estratégia simples, mas que funciona.
Caso o retorno não seja "root", significa que o sudo está desativado, o que dispara a pergunta. Respondendo "sim", ele executa o script "sudo-ativar", que pede a senha de root. Caso seja respondido "não" ou caso a janela com a pergunta seja fechada, ele roda o comando "exit 2".
O comando "exit" é usado para terminar o script. Você pode incluir um parâmetro depois do exit, (no nosso caso o "2") que é um status de saída, repassado ao primeiro script. Isto permite que os scripts "conversem".
Como vimos, depois de chamar o "sudo-verificar", o primeiro script verifica o status de saída do comando "sudo-verificar", usando a função: "if [ "$?" = "2" ]; then exit 0; fi".
Ou seja, se o status de saída do sudo-verificar for "2", o que significa que o sudo está desativado e o usuário não quis fornecer a senha de root, então o primeiro script roda o comando "exit" e também é finalizado.

Ok, demos uma grande volta agora. Mas, voltando aos servicemenus, é possível incluir várias ações dentro de um mesmo script, que se aplicam a um mesmo tipo de arquivo. Você pode, por exemplo, adicionar uma opção de redimensionar imagens, colocando várias opções de tamanho, ou uma opção para converter arquivos de áudio para vários outros formatos.
Este é um exemplo de script com várias ações, que permite redimensionar imagens:
[Desktop Entry]ServiceTypes=image/*Actions=resize75;resize66;resize50;resize33;resize25;X-KDE-Submenu=Redimensionar a imagem
[Desktop Action resize75]Name=Redimensionar para 75% do tamanho originalIcon=thumbnailExec=img-resize 75 %u
[Desktop Action resize66]Name=Redimensionar para 66% do tamanho originalIcon=thumbnailExec=img-resize 66 %u
[Desktop Action resize50]Name=Redimensionar para 50% do tamanho originalIcon=thumbnailExec=img-resize 50 %u
[Desktop Action resize33]Name=Redimensionar para 33% do tamanho originalIcon=thumbnailExec=img-resize 33 %u
[Desktop Action resize25]Name=Redimensionar para 25% do tamanho originalIcon=thumbnailExec=img-resize 25 %u
Veja que nas primeiras linhas é necessário especificar que ele só se aplica a imagens (ServiceTypes=image/*), e depois especificar todas as ações disponíveis, adicionando uma seção para cada uma mais adiante. Não existe limite para o número de ações que podem ser adicionadas neste caso, só depende da sua paciência :).
Como no exemplo anterior, este script chama um script externo, o "img-resize", para executar as operações. Ele é um script simples, que usa o "convert" (que vimos ao estudar sobre o Kommander) para fazer as conversões:
#!/bin/sh

echo "Convertendo $2 para $1% do tamanho original."echo "Backup da imagem original salvo em: $2.original"
cp $2 $2.originalconvert -quality 90 -sample $1%x$1% $2 $2-outrm -f $2; mv $2-out $2; sleep 1
echo "Ok!"
Os parâmetros "$1" e "$2" são recebidos do script do servicemenu. O $1 é a percentagem de redimensionamento da imagem, enquanto o $2 é o nome do arquivo.
Você pode ainda chamar funções de aplicativos do KDE dentro dos servicemuenus, usando funções do dcop, que estudamos anteriormente. Este é o script do servicemenu que permite adicionar arquivos na playlist do Kaffeine:
ServiceTypes=all/allActions=kaffeine_append_fileEncoding=UTF8
[Desktop Action kaffeine_append_file]Name=Append to Kaffeine PlaylistName[hu]=Felvétel a Kaffeine LejátszólistábaName[de]=Zur Kaffeine Stückliste hinzufügenName[sv]=Lägg till i Kaffeine spellistaExec=dcop kaffeine KaffeineIface appendURL %uIcon=kaffeine
Veja que ele usa a função " dcop kaffeine KaffeineIface appendURL %u" para contatar o Kaffeine e instruí-lo a adicionar o arquivo na playlist.
Os servicemenus podem ser internacionalizados, com traduções das legendas para várias línguas. Para adicionar a tradução para o português neste servicemenu do Kaffeine, basta adicionar a linha "Name[pt_BR]=Adicionar na Playlist do Kaffeine".
Para que a opção seja exibida apenas ao clicar sobre arquivos de vídeo, e não mais sobre qualquer arquivo, substitua a linha "ServiceTypes=all/all" por "ServiceTypes=video/*".
Detectando Hardware
A forma como o suporte a dispositivos no Linux é implementado através de módulos, combinada com ferramentas como o pciutils (incluído por padrão em todas as distribuições), facilita bastante as coisas para quem escreve ferramentas de detecção.
Hoje em dia, quase todas as distribuições detectam o hardware da máquina durante a instalação ou durante o boot através de ferramentas como o kudzu (do Red Hat), drakconf (do Mandriva) Yast (SuSE) e hwsetup (do Knoppix).
Estas ferramentas trabalham usando uma biblioteca com as identificações dos dispositivos suportados e os módulos e parâmetros necessários para cada um.

A biblioteca com as identificações é de uso comum e faz parte do pacote pciutils. Você pode checar os dispositivos instalados através dos comandos lspci (para placas PCI e AGP), lsusb e lspnp (para placas ISA com suporte a plug-and-play):
$ lspci
0000:00:00.0 Host bridge: nVidia Corporation nForce2 AGP (different version?) (rev c1)0000:00:00.1 RAM memory: nVidia Corporation nForce2 Memory Controller 0 (rev c1)0000:00:00.2 RAM memory: nVidia Corporation nForce2 Memory Controller 4 (rev c1)0000:00:00.3 RAM memory: nVidia Corporation nForce2 Memory Controller 3 (rev c1)0000:00:00.4 RAM memory: nVidia Corporation nForce2 Memory Controller 2 (rev c1)0000:00:00.5 RAM memory: nVidia Corporation nForce2 Memory Controller 5 (rev c1)0000:00:01.0 ISA bridge: nVidia Corporation nForce2 ISA Bridge (rev a4)0000:00:01.1 SMBus: nVidia Corporation nForce2 SMBus (MCP) (rev a2)0000:00:02.0 USB Controller: nVidia Corporation nForce2 USB Controller (rev a4)0000:00:02.1 USB Controller: nVidia Corporation nForce2 USB Controller (rev a4)0000:00:02.2 USB Controller: nVidia Corporation nForce2 USB Controller (rev a4)0000:00:04.0 Ethernet controller: nVidia Corporation nForce2 Ethernet Controller (rev a1)0000:00:08.0 PCI bridge: nVidia Corporation nForce2 External PCI Bridge (rev a3)0000:00:09.0 IDE interface: nVidia Corporation nForce2 IDE (rev a2)0000:00:1e.0 PCI bridge: nVidia Corporation nForce2 AGP (rev c1)0000:01:07.0 Multimedia video controller: Brooktree Corporation Bt878 Video Capture (rev 11)0000:01:07.1 Multimedia controller: Brooktree Corporation Bt878 Audio Capture (rev 11)0000:01:0a.0 Multimedia audio controller: Creative Labs SB Live! EMU10k1 (rev 08)0000:01:0a.1 Input device controller: Creative Labs SB Live! MIDI/Game Port (rev 08)0000:02:00.0 VGA compatible controller: nVidia Corporation NV17 [GeForce4 MX 440] (rev a3)
$ lsusb
Bus 002 Device 009: ID 043d:009a Lexmark International, Inc.Bus 002 Device 003: ID 058f:9254 Alcor Micro Corp. HubBus 002 Device 001: ID 0000:0000Bus 001 Device 005: ID 05e3:0760 Genesys Logic, Inc. Card ReaderBus 001 Device 004: ID 0458:003a KYE Systems Corp. (Mouse Systems)Bus 001 Device 001: ID 0000:0000
$ lspnp
lspnp: /proc/bus/pnp not available
Os PCs novos não possuem mais suporte ao barramento ISA (que nas placas antigas é implantado como uma extensão do barramento PCI, através de um circuito adicional, incluído na ponte sul do chipset), por isso a mensagem de erro ao rodar o "lspnp" no meu caso.
Você pode escrever scripts para detectar automaticamente componentes que não são originalmente detectados, ou para softmodems, placas wireless e outros módulos avulsos que tenha instalado manualmente. Isto é muito fácil quando você sabe de antemão qual é a saída do comando lspci, lsusb ou lspnp referente ao dispositivo e quais são os módulos e parâmetros necessários para ativá-los.
Por exemplo, as placas de vídeo onboard, com chipset Intel precisam que o módulo "intel-agp" esteja ativo, para que o suporte a 3D no Xfree funcione corretamente.

Num micro com uma placa destas, o lspci retorna algo similar a:
0000:00:02.0 VGA compatible controller: Intel Corp. 82852/855GM Integrated Graphics Device (rev 02)
A identificação do modelo muda de acordo com a placa usada, mas o "VGA compatible controller: Intel Corp." não. Um exemplo simples de script para detectar e ativar o módulo intel-agp caso necessário poderia ser:
intelonboard=`lspci | grep "VGA compatible controller: Intel Corp."`if [ -n "$intelonboard" ];thenmodprobe intel-agp fi
O grep permite filtrar a saída do comando lspci, mostrando apenas linhas que contenham a string definida entre aspas. Ou seja, o comando só vai retornar alguma coisa em micros com placas de vídeo Intel.
Carregamos a resposta numa variável. O "if [ -n" permite testar se existe algum valor dentro da variável (-n = não nulo), sintoma de que uma placa Intel está presente e então carregar o módulo apropriado.
Outras condicionais que você pode usar para testar valores são:
-e: Usado para verificar se um arquivo existe, como em: if [ -e "/etc/fstab" ]; then <comandos>; fi
-f: É similar ao -e. Também serve para verificar se um arquivo existe, mas ele aceita apenas arquivos normais, deixando de fora links, diretórios e dispositivos.
-d: Também similar ao -e, serve para verificar se um diretório existe.
-L: Usado para verificar se o arquivo é um link simbólico, que aponta para outro arquivo.
-s: Para testar se o arquivo é maior que zero bytes, ou seja, se o arquivo está em branco ou se possui algum conteúdo. É possível criar arquivos vazios usando o comando "touch".
-r: Verifica se o usuário atual (que executou o script) tem permissão de leitura para o arquivo.
-w: Testa se o usuário tem permissão de escrita para o arquivo. Esta opção é boa para funções de verificação, onde o script pode pedir a senha de root para mudar as permissões de acesso do arquivo caso o usuário atual não tenha permissão para executá-lo, como em:if [ -w "$arquivo" ] then echo "ok."; else kdesu "chmod 666 $arquivo"; fi
-x: Verifica se o arquivo é executável.

-ef: EqualFile, permite verificar se dois arquivos são iguais, como em:if [ "/etc/fstab" -ef "/etc/fstab.bk" ] then <comandos>; fi
Você pode ainda usar o parâmetro "-a" (E) para incluir mais de uma condição dentro da mesma função, como em:
if [ "$cdrom1" != "$cdrom2" -a "$cdrom2" != "/etc/sr0" ] ; then <comandos>; fi
Aqui os comandos são executados apenas caso a variável "$cdrom1" seja diferente da "$cdrom2" E a $cdrom2 não seja "/dev/sr0".
Outra possibilidade é usar o "-o" (OU) para fazer com que os comandos sejam executados caso qualquer uma das condições seja verdadeira.
Em muitas situações, a única forma de detectar um determinado componente é via "força bruta", testando várias possibilidades ou endereços para ver se ele está presente. Um exemplo são os leitores de cartões de memória USB. Se você plugar o cartão de memória no leitor e depois plugar o leitor na porta USB, ele será detectado como se fosse um pendrive, permitindo que os scripts incluídos nas distribuições criem um ícone no desktop ou executem outra função do gênero.
Mas, caso você deixe o leitor plugado o tempo todo (como muita gente faz, principalmente no caso dos maiores, com entradas para vários cartões) e plugar/desplugar apenas o cartão em si, não é gerado nenhum tipo de evento. O hotplug não detecta o cartão, não é incluída nenhuma nova entrada no dmesg, nada. Este é um exemplo onde um método "força bruta" pode ser usado.
Embora os cartões não sejam detectados pelo hotplug, é possível "detectá-los" usando o comando "fdisk -l", que verifica e lista as partições disponíveis num determinado dispositivo, como em:
# fdisk -l /dev/sda
Disk /dev/sda: 524 MB, 524025856 bytes17 heads, 59 sectors/track, 1020 cylindersUnits = cylinders of 1003 * 512 = 513536 bytes
Device Boot Start End Blocks Id System/dev/sda1 * 1 1020 511500+ b W95 FAT32
Seria possível detectar o cartão usando um script que testasse um a um os dispositivos "/dev/sda", "/dev/sdb", "/dev/sdc", etc., que são atribuídos a pendrives e cartões de memória, como em:
#!/bin/shmkdir /tmp/leitorcd; cd /tmp/leitorcd
for part in /dev/sd[abcdef]; do PARTICAO=`sudo fdisk -l $part | grep "$part"1 | grep FAT`

if [ -n "$PARTICAO" ]; then DEV=`echo $part | cut -d "/" -f 3`tamanh=`sudo fdisk -s "$part"1`; tamanho=`echo "$tamanh" / 1000 | bc` kdialog --yesno "Detectado o dispositivo "$part"1, com $tamanho MB. Gostaria de criar um ícone para acessar os arquivos no desktop?"
if [ "$?" = "0" ]; then sudo mkdir /mnt/"$DEV"1echo "[Desktop Entry]" > /home/$USER/Desktop/"$DEV"1.desktop echo "Exec=sudo mount -t vfat -o umask=000 /dev/"$DEV"1 /mnt/"$DEV"1; konqueror /mnt/"$DEV"1; sudo umount /mnt/"$DEV"1; sync" >> /home/$USER/Desktop/"$DEV"1.desktop echo "Icon=usbpendrive_unmount" >> /home/$USER/Desktop/"$DEV"1.desktop echo "Name="$DEV"1" >> /home/$USER/Desktop/"$DEV"1.desktop echo "Type=Application" >> /home/$USER/Desktop/"$DEV"1.desktop fi fi done
Neste script usamos um "for" para testar os dispositivos de "/dev/sda" até "/dev/sdf". Para cada um, ele executa o comando "sudo fdisk -l $part | grep "$part"1 | grep FAT" e atribui o resultado à variável "$PARTICAO". Usado desta forma, a saída do fdisk é filtrada, de forma que a variável contenha alguma coisa apenas se existir a partição "/dev/sd?/1" e ela estiver formatada em FAT. A idéia aqui é evitar falsos positivos, já que esta é de longe a formatação mais comum usada em cartões de memória.
Sempre que uma partição válida é encontrada, ele faz uma pergunta usando o kdialog, e, caso a resposta seja afirmativa, cria um ícone no desktop contendo um "mini-script", que monta a partição, abre uma janela do konqueror mostrando os arquivos e sincroniza os dados e desmonta a partição quando a janela é fechada, permitindo que o cartão seja removido com segurança.
As linhas:
DEV=`echo $part | cut -d "/" -f 3`tamanh=`sudo fdisk -s "$part"1`; tamanho=`echo "$tamanh" / 1000 | bc`
... são usadas para remover as partes indesejadas do texto, deixando apenas o nome da partição, como "sda", e calcular seu tamanho, em MB. Aqui estou usando o cut, o grep e o bc, comandos que vou explicar com mais detalhes a seguir.

Alterando arquivos de configuração
Caso sejam executados pelo root, os scripts podem também alterar arquivos de configuração do sistema, modificando entradas existentes ou incluindo novas configurações. O comando mais usado para fazer substituições é o sed. Para simplesmente adicionar linhas no final do arquivo, você pode usar o echo, o mesmo comando que usamos para escrever mensagens na tela.
Por exemplo, um erro comum ao acessar partições do Windows formatadas em NTFS é a partição ser montada com permissão de leitura apenas para o root. Você só consegue ver os arquivos abrindo o gerenciador de arquivos como root, o que é desconfortável.
Isto acontece porque o default do mount é montar partições NTFS e FAT com permissão de acesso apenas para o root. Para que outros usuários possam visualizar os arquivos, é necessário montar incluindo a opção "umask=000".
A tarefa é relativamente simples, basta abrir o arquivo "/etc/fstab" e adicionar a opção na linha referente à partição.
Ao invés de:
/dev/hda1 /mnt/hda1 auto noauto,users,exec 0 0
Ficaríamos com:
/dev/hda1 /mnt/hda1 auto noauto,users,exec,umask=000 0 0
Até aí tudo bem. O problema é que este parâmetro pode ser usado apenas em partições FAT ou NTFS. Se você usar em partições formatadas em ReiserFS ou EXT, elas não montam.
Ou seja, ao fazer isso via script, precisamos primeiro ter certeza de que a partição está formatada em NTFS, antes de alterar o "/etc/fstab".
Uma forma de fazer isto é verificando a saída do comando "fdisk -l", que mostra detalhes sobre as partições, como em:
# fdisk -l /dev/hda
Disk /dev/hda: 20.0 GB, 20003880960 bytes255 heads, 63 sectors/track, 2432 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 401 3221001 7 HPFS/NTFS/dev/hda2 402 1042 5148832+ 83 Linux/dev/hda3 1116 2432 10578802+ 5 Extended/dev/hda4 1043 1115 586372+ 83 Linux

/dev/hda5 1116 1164 393561 82 Linux swap / Solaris/dev/hda6 1165 2432 10185178+ 83 Linux
Podemos então usar o grep para filtrar a saída e carregar o resultado dentro de uma variável, de modo que ela contenha alguma coisa apenas se a partição testada estiver formatada em NTFS, como em:
winntfs=`fdisk -l /dev/hda | grep hda1 | grep NTFS`
Note que aqui estamos usando três comandos diferentes, ligados por pipes. Esta é uma prática comum na hora de filtrar a saída de comandos, já que é difícil chegar a um único comando que faça de uma vez tudo o que você precisa. Neste exemplo, o "grep hda1" vai remover todas as linhas, deixando apenas a linha referente à partição "/dev/hda1". O "grep NTFS" verifica a linha e deixa-a passar apenas se a partição estiver formatada em NTFS, visto que, caso ela esteja formatada em outro sistema, a string com a identificação do sistema de arquivos será outra.
Usamos em seguida uma função que verifica se a variável é não nula (-n). Por causa dos dois comandos do grep, ela só conterá algum texto se o /dev/hda1 estiver formatado em NTFS. Usamos então um if com o comando do sed para alterar a linha no "/etc/fstab" caso positivo:
if [ -n "$winntfs" ]; then
# O gigantesco comando abaixo forma uma única linha:sed -e 's/\/dev\/hda1 \/mnt\/hda1 auto noauto,users,exec 0 0/\/dev\/hda1 \/mnt\/hda1 auto noauto,users,exec,umask=000 0 0/g' /etc/fstab > /tmp/fstab2
rm -f /etc/fstab; mv /etc/fstab2 /etc/fstabfi
Veja que a linha do sed é um pouco longa. A sintaxe básica para fazer substituições é:
$ sed -e 's/texto/novo-texto/g' arquivo > novo-arquivo
Ele sempre gera um novo arquivo com as alterações, por isso depois do comando você ainda precisa remover o arquivo original e renomear o novo arquivo. Caso dentro da string de texto a substituir existam barras ou caracteres especiais, use barras invertidas (\) como no exemplo, para demarcá-los. As barras invertidas indicam que o caractere seguinte não deve ser interpretado.
O comando "sed -e 's/texto/novo-texto/g' arquivo > novo-arquivo" que vimos, simplesmente substitui todas as instâncias da palavra "texto" por "novo-texto". Você precisa certificar-se que a palavra só existe dentro do contexto que imagina, caso contrário, o comando pode facilmente causar acidentes. O ideal é que você seja sempre o mais específico possível.
Para deletar uma linha, use o comando "sed -e '/texto/D' arquivo > novo-arquivo, como em:
$ sed -e '/Load "dri"/D' /etc/X11/xorg.conf > /tmp/xorg.conf.new

O sed suporta também alguns caracteres especiais. O "^", por exemplo, indica o início da linha. Para remover todas as linhas que começam com "#" (ou seja, linhas com comentários), use:
$ sed -e '/^\#/D' /etc/lilo.conf > /tmp/lilo.conf.new
Note que precisei incluir uma barra invertida antes do "#". Para remover todas as linhas em branco de um arquivo, use:
$ sed -e '/^$/D' /etc/X11/xorg.conf > /tmp/xorg.conf.new
É possível também combinar vários comandos do sed usando o pipe, fazendo com que a saída de um passe também pelo outro antes de ser escrita no arquivo final. Para remover todas as linhas com comentários e todas as em branco, o comando seria:
$ sed -e '/^\#/D' /etc/lilo.conf | sed -e '/^$/D' /etc/lilo.conf > /tmp/lilo.conf.new
Para eliminar espaços repetidos num arquivo (útil caso você queira filtrar alguma informação usando o cut):
$ sed -r 's/ +/ /g' /etc/X11/xorg.conf > /tmp/xorg.conf.new
Para substituir todos os espaços por quebras de linha (representadas pelo "\n" dentro do sed):
$ sed -e 's/ /\n/g' /tmp/myfreq >> /tmp/myfreq2
Para remover todas as quebras de linhas de um arquivo, fazendo com que tudo fique numa única linha (o que pode ser útil para facilitar a localização de determinadas informações, que originalmente estavam em várias linhas separadas), use esta função inventada pelo Thobias Salazar:
$ sed ':a;$!N;s/\n//;ta;' ~/.synergy.conf > /tmp/synergy.conf
Você pode usá-la junto com a função sed 's/^/ /', que adiciona um caracter no início de cada linha. Ao usar esta função ('s/^/ /'), você pode substituir o espaço entre a segunda e terceira barra por outro caracter, ou conjunto de caracteres, como em sed 's/^/\&\&/'. Veja um exemplo de uso dos dois combinados, que formata o arquivo ".synergy.conf" (usado pelo Synergy, que vimos no capítulo 2):
$ cat .synergy.conf | sed 's/^/ /' | sed ':a;$!N;s/\n//;ta;'
section: screens kurumin: semprao: end section: links semprao: right = kurumin kurumin: left = semprao end section: aliases kurumin: 192.168.1.102 end
O sed, aliado ao grep, pode ser usado também para criar scripts inteligentes, que verificam a configuração do sistema e, se necessário alteram as linhas necessárias.

Por exemplo, para instalar o FreeNX server no Debian, seguindo o tutorial que publiquei no Guia do Hardware (http://www.guiadohardware.net/tutoriais/109/), é necessário adicionar uma linha no "/etc/apt/sources.list", com o repositório do Kanotix que possui os pacotes. Estes pacotes possuem algumas dependências do Unstable, de forma que o sources.list precisa conter também a linha correspondente.
Este é o trecho do script do ícone mágico que escrevi para o Kurumin, que verifica e altera o arquivo caso necessário:
# Verifica se o sources.list contém entradas para o unstable, # se não tiver adiciona:
unstable=`sed '/^$/d' /etc/apt/sources.list | sed '/#/d' \| grep "unstable main contrib"`
if [ -z "$unstable" ]; thenecho "deb http://ftp.us.debian.org/debian unstable \main contrib non-free" >> /etc/apt/sources.listremover="1" fi
# Adiciona o repositório do freenxkano=`sed '/^$/d' /etc/apt/sources.list \| sed '/#/d' | grep "project/kanotix/unstable/"`
if [ -z "$kano" ]; thenecho 'deb http://debian.tu-bs.de/project/kanotix/unstable\/ ./' >> /etc/apt/sources.listremoverkano="1" fi
# Instala o freenx a partir do unstable do Kanoapt-get updateapt-get install -t unstable freenxnxsetup --install --setup-nomachine-key
# Remove o unstable e/ou o repositorio do kano, se adicionado:if [ "$remover" = "1" ]; thenrm -f /tmp/sources.listsed -e '/deb http:\/\/ftp.us.debian.org\/debian unstable main contrib non-free/D' \/etc/apt/sources.list > /tmp/sources.list rm -f /etc/apt/sources.listcp /tmp/sources.list /etc/apt/sources.listapt-get update fi
if [ "$removerkano" = "1" ]; thenrm -f /tmp/sources.listsed -e '/deb http:\/\/debian.tu-bs.de\/project\/kanotix\/unstable\/ \.\//D' \/etc/apt/sources.list > /tmp/sources.list rm -f /etc/apt/sources.listcp /tmp/sources.list /etc/apt/sources.listapt-get update fi

Logo no início do script são definidas duas variáveis, "unstable" e "kano" que são usadas para verificar se as linhas dos repositórios de que o script precisa estão ou não disponíveis no script. Esta informação é usada para decidir se se elas devem ser adicionadas ou não.
Localizar linhas no arquivo pode ser um pouco complexo. Como explicar para o script que ele deve ignorar a linha caso esteja comentada e como fazer ele ignorar pequenas variações nas linhas (como os códigos de país nas linhas dos repositórios do Debian)?
Prevendo isso, estou usando um "super pipe", que usa dois comandos do sed para remover as linhas em branco (sed '/^$/d'), as linhas comentadas (sed '/#/d') e em seguida o grep para filtrar apenas a linha que estou procurando. Para tornar o script mais flexível, faço a busca por apenas parte da linha, isso evita que a função deixe passar uma entrada similar, mas com outro mirror:
unstable=`sed '/^$/d' /etc/apt/sources.list | sed '/#/d' \| grep "unstable main contrib"`
Caso as variáveis estejam vazias (-z), significa que as linhas não existem no arquivo. Neste caso, entram em ação as funções que coloco em seguida, que adicionam as linhas necessárias e criam mais duas variáveis ("remover" e "removerkano") que são usadas para que o script "lembre" que fez as alterações e remova as linhas no final, deixando o arquivo da forma como estava originalmente.
A função para remover as linhas usa novamente o sed, desta vez numa sintaxe mais simples, que simplesmente deleta as linhas (sed -e '/texto/D') anteriormente adicionadas. O sed não é capaz de salvar as alterações diretamente no arquivo, por isso é sempre necessário salvar num arquivo temporário e depois substituir o arquivo original por ele.
Você pode ver mais dicas e exemplos do uso do sed na página do Aurélio: http://aurelio.net/sed/.
Corrigindo erros
Quase todos os programas geram uma saída erro caso algo anormal ocorra. Esta saída erro pode ser monitorada pelo script, de forma a corrigir problemas comuns de forma automática, ou pelo menos, avisar o usuário de que algo de errado ocorreu.
Por exemplo, ao gravar o lilo com sucesso, ele exibirá uma mensagem como esta:
# liloAdded Kurumin *Added memtest86
Caso exista algum erro no arquivo de configuração, ele avisa do problema e por segurança não salva as alterações:
# liloAdded Kurumin *

Added memtest86Fatal: First sector of /dev/hda4 doesn't have a valid boot signature
Em alguns casos, um comando que não faz sua parte dentro do script pode causar uma pequena tragédia. Por exemplo, durante a instalação do Kurumin, é exibida a opção de revisar a configuração do arquivo, visualizando diretamente o arquivo de configuração. Caso alguma coisa dê errado, o lilo simplesmente não é gravado e o sistema não dá boot depois de instalado.
Uma forma simples de monitorar a saída de erro é usar um "2>>" para direcioná-la para um arquivo de texto, que pode ser vasculhado pelo grep em busca de mensagens de erro.
O programa de instalação do Kurumin usa a função abaixo para detectar erros de gravação do lilo. Toda função roda dentro de um while, de forma que é repetida até que o problema seja solucionado.
while [ "$lilogravado" != "1" ]; do
clear# Remove o arquivo temporário usado rm -f /tmp/lilo.txt
lilo -t -r $TR 2>> /tmp/lilo.txt
testelilo=`cat /tmp/lilo.txt | grep Fatal`
if [ -n "$testelilo" ]; thenBT="Instalador do Kurumin"M1="Existe um erro no arquivo de configuração do lilo que está impedindo a instalação. Vou abrir novamente o arquivo para que você possa revisá-lo. Procure por erros de digitação e em ultimo caso experimente desfazer as alterações feitas.\n\n Ao fechar a janela do Kedit, vou tentar gravar o lilo novamente e avisar caso o erro persista. O erro informado é:\n\n$testelilo"
$DIA --backtitle "$BT" --title "Lilo" --msgbox "$M1" 18 76 kedit $TR/etc/lilo.conf &>/dev/null
else; lilogravado="1"; fidone
O script começa gravando o lilo, direcionando a saída de erros para um arquivo temporário. A variável "$TR" (usada dentro do script de instalação do Kurumin) contém o diretório de instalação do sistema, onde está montada a partição escolhida no início da instalação.
Com a saída salva no arquivo, o grep é usado para verificar se o arquivo contém a palavra "Fatal", sintoma de que o lilo não foi gravado.
Caso a palavra seja encontrada, é executado o restante do script, que exibe a mensagem de erro e pede que o usuário edite novamente o arquivo de configuração do lilo. Depois disso o script é executado novamente. Quando finalmente o lilo é gravado sem erros, a variável "lilogravado" assume o valor 1, encerrando o loop do while.

Em alguns casos, você pode querer que o script salve a saída de texto de uma operação para verificar erros, mas ao mesmo tempo mostre a saída normalmente na tela. Você pode fazer isso usando o comando "tee".
Por exemplo, um erro comum ao tentar instalar programas via apt-get a partir do testing ou unstable (onde os pacotes são atualizados com muita freqüência) é o apt tentar baixar versões antigas dos pacotes, que não estão mais disponíveis. Isso é corrigido facilmente rodando o "apt-get update" que baixa a lista com as versões atuais.
Mas, nosso script pode detectar este erro e se oferecer para rodar o apt-get automaticamente quando necessário. Vamos chamar nosso script de "apt-get". Ele vai ser apenas um "wrapper", que vai repassar os comandos para o apt-get "real" que está na pasta "/usr/bin". Ou seja, quando você chamar o "./apt-get install abiword" vai estar usando nosso script, que vai direcionar os parâmetros para o apt-get e em seguida verificar se houve o erro:
#!/bin/sh
rm -f /tmp/apt# Executa o apt-get "real", passando os parâmetros recebidos:apt-get $1 $2 | tee /tmp/apt
# Verifica se algum pacote não pôde ser baixado:erro1=`cat /tmp/apt | grep "404 Not Found"`
if [ -n "$erro1" ]; thenkdialog --yesno "Alguns pacotes não puderam ser baixados. Isto significa que provavelmente a lista de pacotes do apt-get está desatualizada. Gostaria de rodar o apt-get update para atualizar a lista e repetir a instalação?"
resposta=$?if [ "$resposta" = "0" ]; thenapt-get updateapt-get $1 $2 | tee /tmp/apt
# Verifica novamente, caso o erro persista exibe uma segunda mensagem:erro1=`cat /tmp;/apt | grep "404 Not Found"`if [ -n "$erro1" ]; thenkdialog --msgbox "O erro se repetiu. Isto significa que ou o pacote não está mais disponível, o servidor está fora do ar, ou sua conexão com a web está com problemas."fifi fi
Ao executar um "./apt-get install abiword", usando nosso script num micro com a lista de pacotes desatualizada, você verá a mensagem:

A partir daí você poderia ir incluindo mais funções para corrigir outros problemas comuns. Este tipo de script pode ser muito útil em migrações, para aparar as arestas nos programas em que os usuários estejam tendo dificuldades, tornando o sistema mais inteligente.
Pacotes auto-instaláveis
Muitos programas, como o Java distribuído pela Sun, o VMware e vários games, como o Quake 3, são distribuídos na forma de arquivos auto-executáveis. Você marca a permissão de execução para o arquivo, executa, e um instalador (gráfico, ou em modo texto) cuida do resto. Estes pacotes são uma forma genérica de distribuir programas, pois podem ser instalados em qualquer distribuição, independentemente do sistema de pacotes usado. Eles são o que temos de mais próximo aos .exe do Windows, dentro do mundo Linux.
Na verdade, estes pacotes são muito simples de criar. Tudo começa com um arquivo compactado, que contém os arquivos que serão instalados. No começo deste arquivo vai um shell script, que se encarrega de descompactar o arquivo, fazer perguntas e executar os comandos necessários para concluir a instalação.
Lembre-se de que um shell script é sempre executado seqüencialmente. No final usamos o comando "exit", que faz com que o bash termine a execução do script, mesmo que exista mais texto adiante. Escrevemos então um script que ao ser executado remove o começo do arquivo (o próprio script), deixando apenas o arquivo compactado e, em seguida, o descompacta e executa os demais passos necessários.
Comece reunindo os arquivos do programa, como se fosse criar um pacote .rpm ou .deb. Imagine, por exemplo, que o programa será instalado dentro da pasta "/usr/local/programa/" e colocará alguns arquivos de configuração dentro da pasta "/etc/programa". Naturalmente, o programa deve ser escrito ou compilado de forma a incluir as bibliotecas e executáveis necessários, para que possa ser executado em várias distribuições. Não adianta nada criar um pacote genérico se o programa só funciona no Debian Sarge, por exemplo.
Você criaria então uma pasta, contendo a pasta "usr/local/programa" e a pasta "etc/programa", e colocaria dentro delas os arquivos, mantendo a estrutura que será copiada para o sistema.
Compacte o conteúdo desta pasta usando o tar, como em:
# tar -zcvf programa.tar.gz usr/ etc/

Agora temos um arquivo .tar.gz que, se descompactado no diretório raiz, vai copiar os arquivos do programa para os locais corretos. O próximo passo é incluir o script que fará a instalação.
linhas=6tail -n +$linhas $0 | tar -zxvf - -C / ln -s /usr/local/programa/programa.sh /usr/bin/programa.sh kdialog --msgbox "Instalação concluída. Use o comando 'programa.sh'"exit 0
Ao ser executado, o script precisa remover as 5 primeiras linhas do arquivo antes de descompactá-lo. Para isso, usamos o comando tail. Nosso script tem 5 linhas, por isso dizemos que o tail deve escrever a partir da sexta linha do arquivo (por isso o "linhas=6" e não 5). Normalmente, o tail escreveria tudo na tela, por isso usamos o pipe, que direciona a saída (as linhas válidas do arquivo compactado) para o tar.
O parâmetro "-" faz com que ele descompacte o fluxo de dados que está recebendo através do pipe e o "-C /" faz com que o arquivo seja descompactado no diretório raiz.
Em seguida temos o resto do script de instalação, com uma linha para criar um link para o executável do programa na pasta "/usr/bin/" e um comando para abrir uma mensagem de texto, avisando que a instalação foi concluída. Esta parte cabe a você melhorar ;).
O passo final é juntar o script e o arquivo compactado, criando o arquivo de instalação, o que pode ser feito usando o cat:
# cat script.sh programa.tar.gz > programa.sh
Mais exemplos úteis
A função "for" pode ser usada para executar tarefas repetitivas, como por exemplo:
for arquivo in *.mp3 do lame -b 64 "$arquivo" "64k-$arquivo" done
Isto vai gerar uma cópias de todos os arquivos mp3 da pasta atual encodados com bitrate de 64k, gerando arquivos menores, úteis para escutar num MP3 Player com pouca memória, por exemplo.
Se você precisar formatar de uma vez várias partições do HD, criadas através do cfdisk, poderia usar:
for part in {1,2,3,5,6,7} do

mkreiserfs /dev/hda$part done
Especificamos aqui um conjunto, que inclui os números 1, 2, 3, 4, 6 e 7, correspondentes às partições que queremos formatar em ReiserFS. Para cada um dos números no conjunto, o for executa o comando mkreiserfs, formatando cada uma das partições.
Você pode fazer com que o mesmo comando seja executado várias vezes, usando uma variável incremental com o comando "seq", como em:
for numero in $(seq 1 10)do touch arquivo$numero.txt done
Isto vai fazer com que sejam criados 10 arquivos de texto em branco, numerados de 1 a 10.
O comando cut é outro recurso muito usado e útil. Ele permite "filtrar" a saída de outros comandos, de forma a obter apenas a informação que interessa.
Imagine, por exemplo, que você precisa descobrir o sistema de arquivos que uma determinada partição do sistema está formatada, de forma a usar a informação mais adiante no script.
O comando "mount" mostra todas as partições montadas:
$ mount
/dev/hda1 on / type reiserfs (rw,noatime)none on /proc type proc (rw,nodiratime)/sys on /sys type sysfs (rw)/dev/hda2 on /home type reiserfs (rw,noatime,notail)/dev/hda3 on /home type ext3 (rw)/dev/hda6 on /mnt/hda6 type reiserfs (rw)
Digamos que você esteja interessado apenas na partição hda2. O grep permite eliminar as outras linhas, deixando apenas a referente a ela. Use um pipe ( | ) depois do mount para direcionar a saída para o grep:
$ mount | grep /dev/hda2
/dev/hda2 on /home type reiserfs (rw,noatime,notail)
Mas, como queremos apenas o sistema de arquivos em que a partição está formatada, podemos usar mais um pipe para direcionar a saída para o cut, de forma que ele elimine o resto da linha. Veja que incluí também a função do sed que elimina espaços repetidos. É importante sempre usá-la em funções que usem o cut para procurar por campos específicos, pois muitos comandos usam espaços de forma não padronizada.
$ mount | grep /dev/hda2 | sed -e '/^$/D' | cut -d " " -f 5
reiserfs

A opção "-f' do cut permite especificar os campos que serão mostrados, enquanto a opção "-d" permite especificar o separador entre os campos. No exemplo usei um -d " " para especificar que um espaço separa cada campo e que quero apenas o quinto campo, que é onde está a informação sobre o sistema de arquivos. Da enorme saída do mount, sobra apenas "reiserfs" que é a informação que queremos.
Você pode utilizar qualquer caracter ou string de caracteres como delimitador ao invés do espaço, permitindo localizar campos e expressões dentro de arquivos de configuração.
Usando a opção "-c", o cut exibe apenas os caracteres indicados. Ela é bem menos usada que o "-f", pois na prática é complicado se basear em caracteres ao procurar informações em arquivos, mas ela pode ser útil em algumas funções, como quando o script fizer uma pergunta e a resposta fornecida pelo usuário tiver um tamanho limite, como em:
kdialog --inputbox "Digite seu código com 5 caracteres" | cut -c 1-5 > /tmp/resposta
Aqui, o arquivo de resposta receberá apenas os 5 primeiros caracteres da resposta, não importa o que for digitado.
Mais alguns exemplos úteis:
cut -c 5-: Exibe do quinto caracter em diante, independentemente de quantos existam. cut -d " " -f 5-: Exibe do quinto campo em diante, usando o espaço como delimitador.cut -d "/" -f 1-3: Exibe os três primeiros campos, usando a barra como delimitador (na verdade os dois, pois o cut conta a partir de antes da primeira barra). É bom para filtrar localização de arquivos, por exemplo, ficando apenas com os primeiros campos. Se o texto original é "/mnt/hda6/arquivos/backup", depois de passar pelo cut fica apenas "/mnt/hda6". cut -c -7: Exibe do começo até o sétimo caracter, o mesmo que "cut -c 1-7".
Uma limitação do cut é que ele não possui uma opção para exibir do final da string até um determinado caracter ou delimitador (apenas do começo até certo ponto), mas é possível burlar isso usando outro comando, o "rev", que inverte a ordem dos caracteres. Você pode usá-lo para inverter a string, procurar a partir do início usando o cut e depois inverter de novo. Este é um exemplo de uso, um script que escrevi para baixar arquivos .torrent:
ARQ1=`kdialog --getopenfilename "/home/$USER" "*.torrent |Arquivos .torrent"`ARQ2=`echo $arq | sed -r 's/ /\\\ /g'`
A primeira linha abre uma janela do kdialog, pedindo o arquivo .torrent a ser baixado. Por causa do "|Arquivos .torrent" a janela só mostra os arquivos com a extensão, o que dá um efeito mais profissional e ajuda e evitar enganos. A segunda linha substitui todos os espaços no nome do arquivo por "\ "; ou seja, adiciona as barras invertidas, permitindo que usemos os arquivos diretamente no comando do bittorrent, sem precisar usar aspas.

echo $ARQ2 > /tmp/bt1rev /tmp/bt1 | cut -f 2- -d "/" > /tmp/bt2PASTA=`rev /tmp/bt2` rm -f /tmp/bt1 /tmp/bt2
Esta é a parte do script que usa o cut e o rev. A variável "$PASTA", precisa conter apenas a pasta, sem o nome do arquivo. Como não sei quantos caracteres tem o nome do arquivo, nem posso filtrar a partir do final usando o cut, salvo o conteúdo da variável com o arquivo num temporário, inverto a ordem dos caracteres usando o rev, removo o nome do arquivo usando o sed, desta vez procurando a partir do começo e usando a barra como delimitador e, no final, inverto novamente o conteúdo do arquivo usando o rev.
Se o arquivo original era "/home/morimoto/ANIMES/[Lunar] Bleach - 62 .avi.torrent", no final sobra apenas "/home/morimoto/ANIMES/", que é a pasta onde o arquivo será baixado.
No final, é usada mais uma janela do kdialog, desta vez para perguntar a taxa de upload, e as três variáveis são usadas para montar o comando que baixa o arquivo. Note que o comando é executado dentro de uma janela do Xterm, de forma que basta fechar a janela quando o download for concluído.
UPLOAD=`kdialog --inputbox "Taxa maxima de upload" 8`xterm -e "cd $PASTA; btdownloadcurses --max_upload_rate $UPLOAD $ARQ2" &
Vamos a mais um exemplo. Imagine que você precisa de um script para listar os usuários cadastrados no sistema. Você poderia usar o sed para filtrar o conteúdo do arquivo "/etc/shadow", o arquivo que contém a lista de usuários e senhas do sistema.
Um exemplo (reduzido) do conteúdo deste arquivo seria:
# cat /etc/shadow
root:RRPHE1yRTfEKo:12840:0:99999:7:::daemon:*:11453:0:99999:7:::bin:*:11453:0:99999:7:::proxy:*:11453:0:99999:7:::kurumin:gMBaRFGpJx86c:12840:0:99999:7:::saned:!:12766:0:99999:7:::
Veja que a lista inclui também os usuários ocultos do sistema, usados por programas e serviços, que não interessam neste caso. As linhas referentes a estes usuários ocultos possuem sempre um "!" ou um "*" depois do primeiro ":". Podemos usar o sed para filtrar o arquivo, de forma que sobrem apenas as linhas dos usuários válidos (no caso root e kurumin), usando a opção "D" para deletar as linhas que contenham "!" ou "*".
Um exemplo de script para fazer isso seria:
# Remove as linhas com "*"sed -e '\/*/D' /etc/shadow > /tmp/usuarios1# Remove as linhas com "!"sed -e '\/!/D' /tmp/usuarios1 > /tmp/usuarios2# Remove o restante da linha, deixando apenas o nome do usuário.

# (o cut mostra apenas o primeiro campo da linha, antes do ":"cat /tmp/usuarios2 | cut -d: -f1 >> /tmp/usuarios
# Aqui temos duas variáveis com os nomes dos usuários, que podem ser # usadas de acordo com a situação.# A primeira, "usuarios" mantém as quebras de linha, com um usuário por # linha enquanto a "userlist" contém todos os usuários na mesma linha. usuarios=`cat /tmp/usuarios`userlist=`echo $usuarios`
# Remove os arquivos temporáriosrm -f /tmp/usuarios /tmp/usuarios1 /tmp/usuarios2
# Uma mensagem de aviso:kdialog --msgbox "Os usuários atualmente cadastrados no sistema são: $userlist"
Ao filtrar a saída de comandos que incluam espaços repetidos, use o comando do sed que remove espaços duplicados, como nesta função que diz o número de blocos da partição "/dev/hda1", filtrando a saída do comando "fdisk -l":
# fdisk -l /dev/hda | grep hda1 | sed -r 's/ +/ /g' | cut -d " " -f 5
Sempre que precisar fazer operações aritméticas dentro de um script, use o comando "bc". Ele é uma calculadora de modo texto, que permite realizar todo tipo de operações.
Para multiplicar o número dentro da variável $numero por três, o comando seria:
$ echo "$numero * 3" | bc
Para dividir $numero por 4:
$ echo "$numero / 4" | bc
Por default, o bc trabalha apenas com números inteiros, sempre arredondando os valores das respostas. Para adicionar suporte a casas decimais, ative o matlib, adicionando a opção "-l", como em:
$ echo "$numero / 4.56" | bc -l
O bc oferece um número assustador de opções, se você quiser ir além das quatro operações básicas, dê uma olhada no "man bc".
Outra forma de realizar operações aritméticas é usar o comando "let". Ele não é tão poderoso quanto o bc (trabalha apenas com números inteiros e as operações básicas), mas é mais simples de usar e por isso útil para realizar operações simples.
Para aumentar em 1 o valor de uma variável numérica (no caso de um contador, por exemplo):
$ let "numero=numero+1"

Para multiplicar o valor por dois:
$ let "numero=numero*2"
O comando "import" pode ser usado para tirar screenshots da tela via linha de comando ou via script. Ele pode ser usado, por exemplo, em situações onde você precisar ver o que está acontecendo na tela para fins de suporte. Para tirar um screenshot, o comando é simplesmente:
# import -window root screen.png
Para que o comando funcione, é necessário que ele seja executado dentro da seção gráfica desejada. Um script que ficasse tirando screenshots periódicos da tela, por exemplo, precisaria ser iniciado a partir da pasta ".kde/Autostart" dentro do home do usuário, e não a partir do "/etc/rc.d/rc.local", por exemplo.
Mais um problema no caso do script para tirar screenshots é que ele precisaria usar nomes de arquivos com nome diferente para cada screenshot, incluindo informações sobre a data em que foram tirados. Isto pode ser feito usando o comando "date".
Em seu formato mais simples, o comando date retorna a data no formato: "Ter Fev 21 13:01:06 BRT 2006". Mas, é possível configurá-lo para devolver a data num formato mais propício para ser usada em nomes de arquivos, como "2006-02-21-13.01" (neste caso o comando seria "date +%Y-%m-%d-%H.%M"), atribuir o valor contendo a data corrente a uma variável e usá-la no nome do arquivo. Um script destinado a tirar um screenshot da tela de 1 em 1 minuto, poderia conter:
DATA=`date +%Y-%m-%d-%H.%M`import -window root screen-$DATA.pngsleep 60
Os screenshots poderiam ser salvos num compartilhamento do servidor, montado em NFS, por exemplo, e removidos no final do dia para não ocuparem muito espaço.
Um problema clássico nos scripts é com relação aos arquivos temporários. Ao usar nomes fixos, é necessário que você sempre remova ou verifique se os arquivos já não existem no começo do script. Existe ainda uma pequena possibilidade de algum programa malicioso tentar modificar os arquivos temporários, de forma a alterar o comportamento do seu script.
Uma forma de solucionar ambos os programas é usar arquivos temporários com nomes aleatórios, criados usando o comando "mktemp". No início do script, crie uma variável contendo um arquivo criado através dele:
TMP=`mktemp /tmp/arq.XXXXXX`
Os "XXXXXX" serão substituídos por caracteres aleatórios, fazendo com que o nome do arquivo seja algo como "/tmp/rarq.iutCkB". Para salvar informações dentro do arquivo, use sempre a variável "TMP", como em:

cat /etc/fstab | grep /dev/hda1 >> $TMP
Não se esqueça de remover o temporário no final do script, usando um "rm -f $TMP" para evitar deixar lixo para trás.

Criando interfaces no Kommander
O Kommander permite criar interfaces gráficas para shell scripts, usando a biblioteca Qt do KDE. Ele é dividido em duas partes: o "kmdr-editor" é o editor que permite criar as interfaces, enquanto o "kmdr-executor" executa os arquivos gerados por ele.
Ao instalar o pacote do Kommander, você obtém os dois componentes. Nas distribuições derivadas do Debian você pode instalá-lo com um "apt-get install kommander". Pacotes rpm para várias distribuições podem ser encontrados no http://www.rpmfind.net/.
Em último caso, você pode baixar uma versão genérica no: http://kde-apps.org/content/show.php?content=12865
A interface do kmdr-editor lembra um pouco a do VB ou Delphi, mas é mais simples por conter muito menos funções. Lembre-se de que o objetivo do Kommander é desenvolver interfaces para scripts, ele provê relativamente poucas funções por si só.
Ao criar um novo projeto, no "Arquivo > Novo", você tem a opção de criar um diálogo ou um assistente. Um diálogo cria uma interface simples, com botões e abas, do tipo onde você escolhe entre um conjunto de opções e clica no "Ok" para acionar o script. Já o assistente permite criar uma seqüência de telas interligadas, útil para criar programas de instalação, por exemplo.
Os arquivos gerados no kmdr-editor não são binários, mas sim arquivos em XML, que são interpretados e executados pelo kmdr-executor. Estes arquivos contém os "fontes" da interface. Não é possível criar diretamente um binário através do Kommander, é sempre necessário ter o kmdr-executor para executar os arquivos.
Você pode ver os fontes do Painel de Controle do Kurumin, junto com outros painéis que desenvolvi usando o Kommander, dentro da pasta "/etc/Painel" no Kurumin.
Vamos a um exemplo rápido. Que tal criar uma interface mais amigável para aquele script para gravar programas de TV que havíamos criado usando o kdialog? Usando o kommander poderíamos criar uma interface muito mais elaborada e profissional para ele.
Abra o kmdr-editor e crie um diálogo:
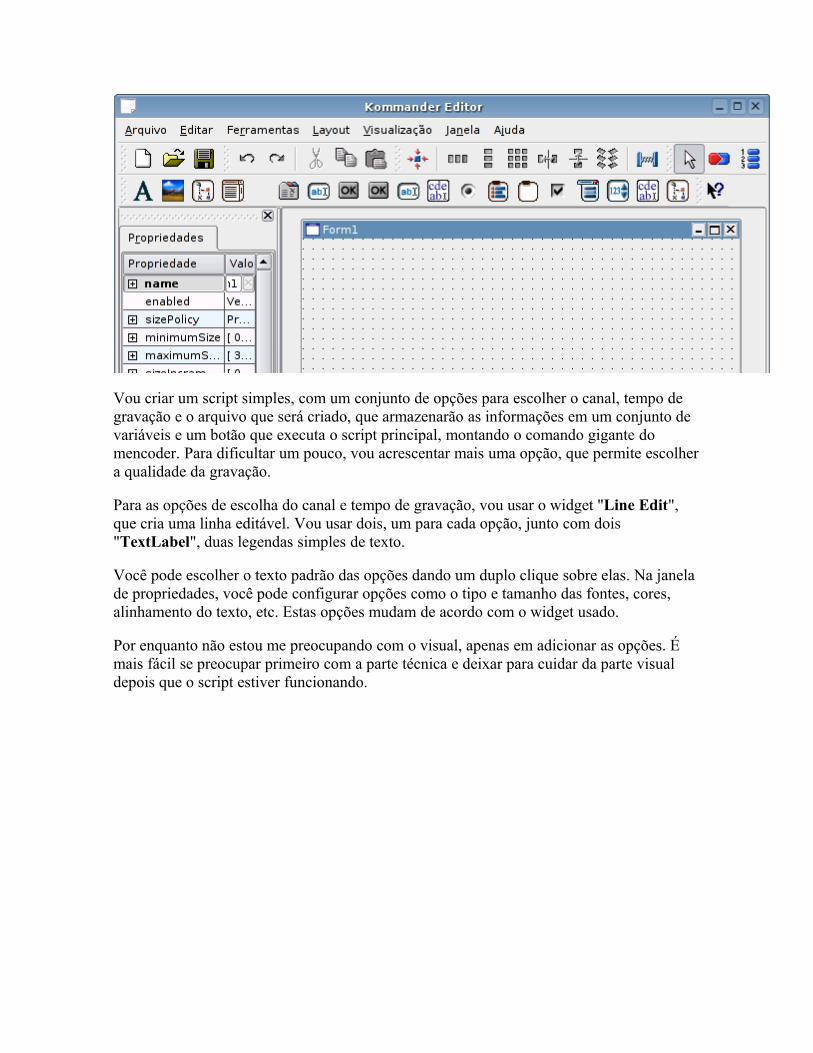
Vou criar um script simples, com um conjunto de opções para escolher o canal, tempo de gravação e o arquivo que será criado, que armazenarão as informações em um conjunto de variáveis e um botão que executa o script principal, montando o comando gigante do mencoder. Para dificultar um pouco, vou acrescentar mais uma opção, que permite escolher a qualidade da gravação.
Para as opções de escolha do canal e tempo de gravação, vou usar o widget "Line Edit", que cria uma linha editável. Vou usar dois, um para cada opção, junto com dois "TextLabel", duas legendas simples de texto.
Você pode escolher o texto padrão das opções dando um duplo clique sobre elas. Na janela de propriedades, você pode configurar opções como o tipo e tamanho das fontes, cores, alinhamento do texto, etc. Estas opções mudam de acordo com o widget usado.
Por enquanto não estou me preocupando com o visual, apenas em adicionar as opções. É mais fácil se preocupar primeiro com a parte técnica e deixar para cuidar da parte visual depois que o script estiver funcionando.
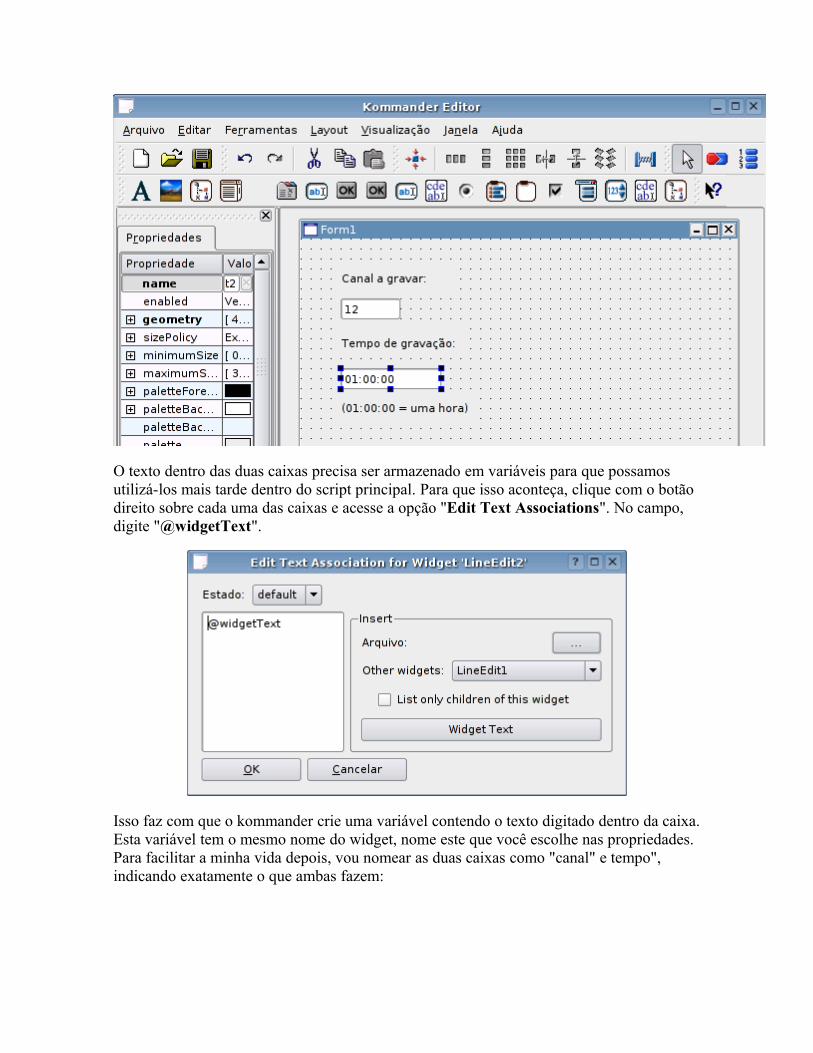
O texto dentro das duas caixas precisa ser armazenado em variáveis para que possamos utilizá-los mais tarde dentro do script principal. Para que isso aconteça, clique com o botão direito sobre cada uma das caixas e acesse a opção "Edit Text Associations". No campo, digite "@widgetText".
Isso faz com que o kommander crie uma variável contendo o texto digitado dentro da caixa. Esta variável tem o mesmo nome do widget, nome este que você escolhe nas propriedades. Para facilitar a minha vida depois, vou nomear as duas caixas como "canal" e tempo", indicando exatamente o que ambas fazem:

É preciso incluir também um widget para salvar o arquivo. O Kommander oferece uma função bem similar ao "--getsavefilename" do kdialog, o widget "File Selector". Adicione um ao programa, como fizemos com as duas caixas de texto.
O File Selector pode ser usado para abrir um arquivo, escolher uma pasta ou salvar um arquivo. Precisamos indicar a função do nosso nas propriedades. Para isso, configure a opção "selectionType" como "Save" (indicando que a janela servirá para salvar um arquivo).
Veja que aproveitei também para configurar a opção "selectionFilter" como "*.avi *.mpg *.wmf", que faz com que a janela do gerenciador de arquivos mostre apenas arquivos de vídeo, com as três extensões especificadas e salve os arquivos com a extensão .avi, mesmo que o usuário não especifique a extensão. A opção "selectionCaption" permite escolher o título da janela para salvar.
Não se esqueça de configurar a opção "Edit Text Associations" do widget como "@widgetTex" como fizemos com as duas caixas de texto e escolher um nome nas propriedades. No meu caso deixei o nome como "arquivo".
Você pode ver um preview da interface que está editando, clicando no "Visualização > Preview Form". Isto é perfeito para ir testando cada opção conforme for adicionando, sem deixar que os erros se acumulem.

Falta incluir a opção para escolher a qualidade de gravação, neste caso dois parâmetros que podem ser especificados na linha de comando do mencoder. Vou criar dois botões separados, um para escolher a resolução do vídeo (640x480 ou 320x240) e outro para escolher o bitrate, que determina a qualidade e tamanho final do arquivo.
No caso da resolução, vou oferecer apenas duas opções, por isso uso o widget "RadioButton", criando dois botões. Estes botões precisam ser exclusivos, ou seja, apenas um deles pode ser selecionado de cada vez. Para isso, vou precisar colocá-los dentro de um "ButtonGroup", outro widget que é uma espécie de moldura, que permite agrupar vários botões de forma que eles se comportem da forma desejada.
Isto vai envolver um número maior de passos. Primeiro crie o ButtonGroup do tamanho desejado e coloque dois botões dentro dele. Nas propriedades, escolha nomes para os três. No meu caso, coloquei "resolucao" (para o ButtonGroup), "resolucao1" e "resolucao2" para os botões.
Nas propriedades do ButtonGroup, configure a opção "RadioButtonExclusive" como "Verdadeiro". Isso faz com que apenas um dos botões dentro dele possa ser marcado de cada vez.
Dentro das propriedades do primeiro botão, deixe a opção "Checked" como "Verdadeiro". Isso faz com que ele fique marcado por padrão.
Ao desenvolver uma interface, é importante fazer com que todas as opções sempre tenham algum valor padrão. Isso diminui a possibilidade de erros por parte do usuário, já que o script vai funcionar mesmo que ele não configure todas as opções.
Falta agora configurar o "Edit Text Associations" dos dois botões, para armazenar o conteúdo da variável que será criada caso cada um deles seja pressionado. Desta vez não vou usar o "@widgetText" pois os botões não contém texto algum. Vou indicar manualmente um valor padrão para cada um dos dois botões.
Um deles conterá o valor "width=640:height=480" e o outro o valor "width=320:height=240", que são as opções que poderão ser incluídas na linha de comando do mencoder que será criada ao executar o programa. Lembre-se de que apenas um dos dois botões pode ser marcado de cada vez, por isso apenas uma das duas opções será usada.
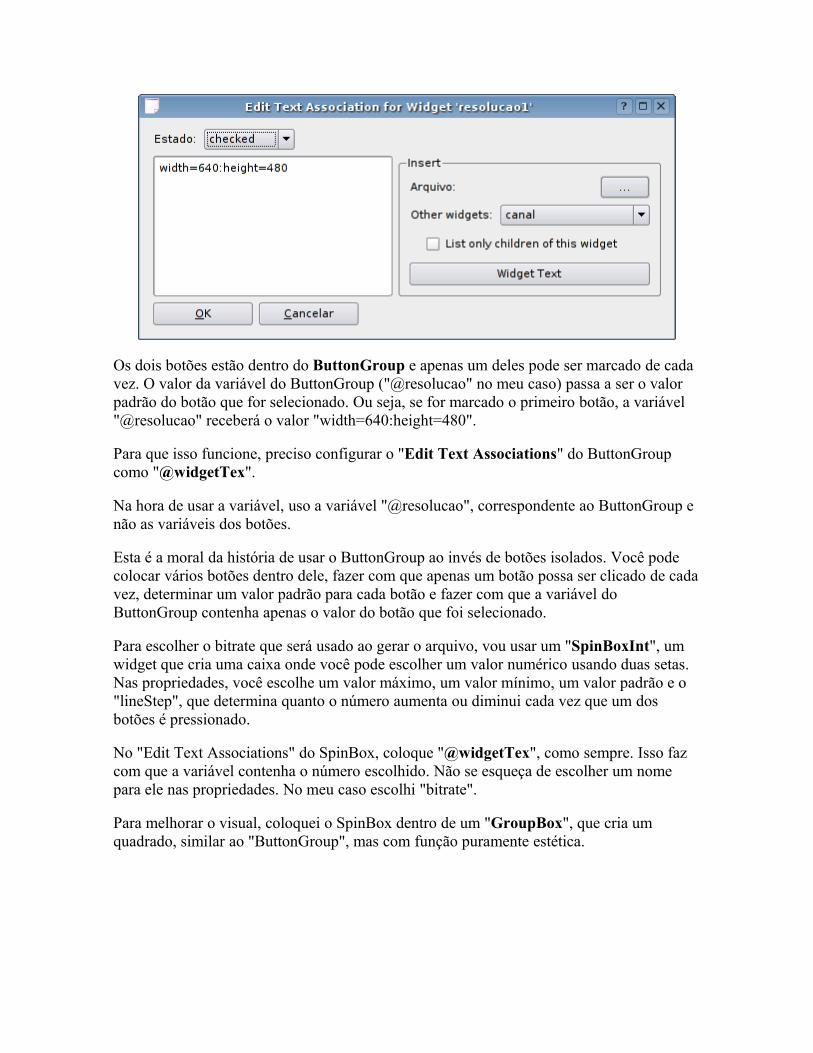
Os dois botões estão dentro do ButtonGroup e apenas um deles pode ser marcado de cada vez. O valor da variável do ButtonGroup ("@resolucao" no meu caso) passa a ser o valor padrão do botão que for selecionado. Ou seja, se for marcado o primeiro botão, a variável "@resolucao" receberá o valor "width=640:height=480".
Para que isso funcione, preciso configurar o "Edit Text Associations" do ButtonGroup como "@widgetTex".
Na hora de usar a variável, uso a variável "@resolucao", correspondente ao ButtonGroup e não as variáveis dos botões.
Esta é a moral da história de usar o ButtonGroup ao invés de botões isolados. Você pode colocar vários botões dentro dele, fazer com que apenas um botão possa ser clicado de cada vez, determinar um valor padrão para cada botão e fazer com que a variável do ButtonGroup contenha apenas o valor do botão que foi selecionado.
Para escolher o bitrate que será usado ao gerar o arquivo, vou usar um "SpinBoxInt", um widget que cria uma caixa onde você pode escolher um valor numérico usando duas setas. Nas propriedades, você escolhe um valor máximo, um valor mínimo, um valor padrão e o "lineStep", que determina quanto o número aumenta ou diminui cada vez que um dos botões é pressionado.
No "Edit Text Associations" do SpinBox, coloque "@widgetTex", como sempre. Isso faz com que a variável contenha o número escolhido. Não se esqueça de escolher um nome para ele nas propriedades. No meu caso escolhi "bitrate".
Para melhorar o visual, coloquei o SpinBox dentro de um "GroupBox", que cria um quadrado, similar ao "ButtonGroup", mas com função puramente estética.

Como disse acima, o bitrate determina a qualidade do vídeo gerado, especificando o número de kbits que serão reservados para cada segundo de vídeo. Um bitrate de 1500 kbits gera arquivos com cerca de 11 MB por minuto de vídeo, quase 700 MB por hora. O tamanho do arquivo aumenta ou diminui proporcionalmente de acordo com o bitrate. Um bitrate muito alto resultaria num arquivo gigantesco e um muito baixo resultaria num arquivo tosco, com uma qualidade muito ruim. Por isso usamos o SpinboxInt para determinar uma margem de valores razoáveis.
Você poderia adicionar mais um SpinBoxInt para oferecer também a opção de alterar o bitrate do som, mas no meu caso não vou incluir isto, pois o áudio comprimido em MP3 representa uma percentagem pequena do tamanho do arquivo.
Depois dessa trabalheira toda, temos as variáveis: @canal, @tempo, @arquivo, @resolucao e @bitrate, que usaremos para gerar a linha de comando do mencoder.
Precisamos agora de um gatilho, um botão que executa o comando final. Vamos usar um simples "ExecButton".
Dentro do "Edit Text Associations" (do botão), vão as linhas:
verificador="@arquivo"if [ -z "$verificador" ]; thenkdialog --msgbox "Você esqueceu de indicar o arquivo onde o vídeo será salvo ;-)"exit 0fi
kdialog --title "Gravando" --passivepopup "Gravando o canal $var1 por: @tempo horas no arquivo: @arquivoFeche a janela de terminal para abortar" 6 &
xterm -e "mencoder tv:// -tv driver=v4l2:input=0:normid=4:channel=@canal:chanlist=us-bcast:@resolucao:device=/dev/video0:adevice=/dev/dsp0:audiorate=48000:forceaudio:forcechan=2:buffersize=64 -quiet -oac mp3lame -lameopts preset=medium -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=@bitrate:keyint=132 -vop pp=lb -endpos @tempo -o @arquivo "
kdialog --title "Gravar-TV" --passivepopup "Ok!A gravação terminou." 5 &
Veja que são os mesmos comandos que usamos no primeiro script, foi preciso apenas adaptar o uso das variáveis. Num script em shell normal as variáveis são identificadas por
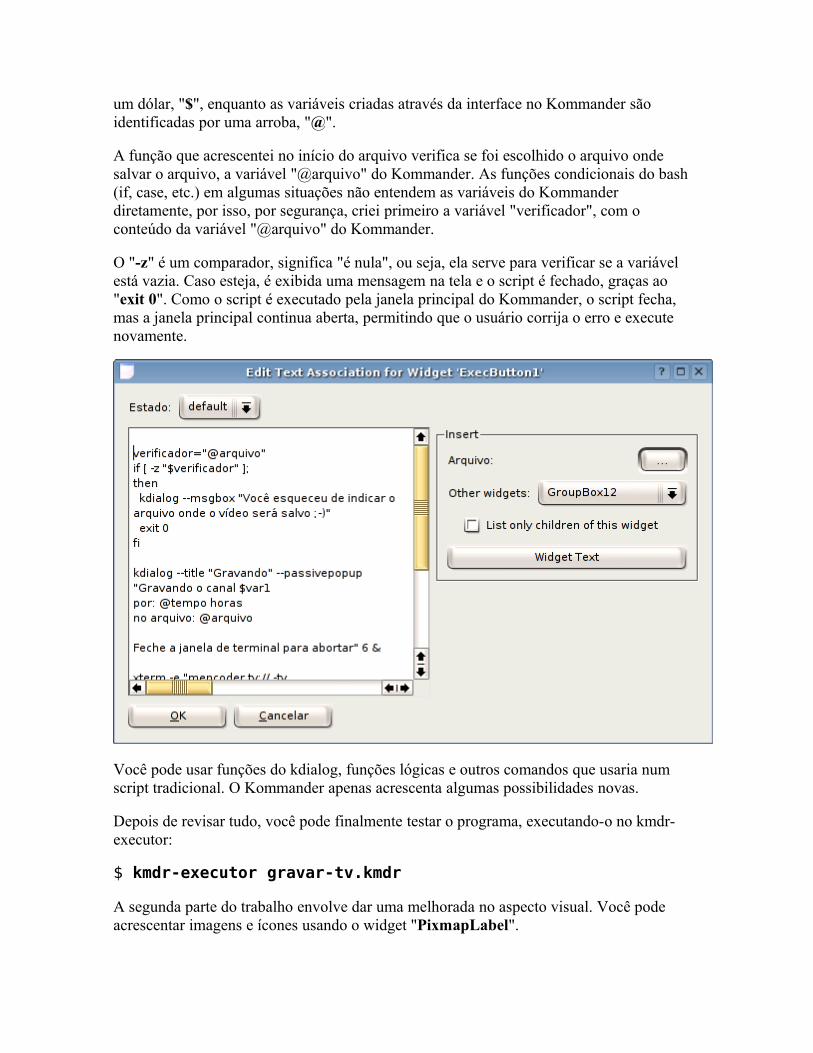
um dólar, "$", enquanto as variáveis criadas através da interface no Kommander são identificadas por uma arroba, "@".
A função que acrescentei no início do arquivo verifica se foi escolhido o arquivo onde salvar o arquivo, a variável "@arquivo" do Kommander. As funções condicionais do bash (if, case, etc.) em algumas situações não entendem as variáveis do Kommander diretamente, por isso, por segurança, criei primeiro a variável "verificador", com o conteúdo da variável "@arquivo" do Kommander.
O "-z" é um comparador, significa "é nula", ou seja, ela serve para verificar se a variável está vazia. Caso esteja, é exibida uma mensagem na tela e o script é fechado, graças ao "exit 0". Como o script é executado pela janela principal do Kommander, o script fecha, mas a janela principal continua aberta, permitindo que o usuário corrija o erro e execute novamente.
Você pode usar funções do kdialog, funções lógicas e outros comandos que usaria num script tradicional. O Kommander apenas acrescenta algumas possibilidades novas.
Depois de revisar tudo, você pode finalmente testar o programa, executando-o no kmdr-executor:
$ kmdr-executor gravar-tv.kmdr
A segunda parte do trabalho envolve dar uma melhorada no aspecto visual. Você pode acrescentar imagens e ícones usando o widget "PixmapLabel".
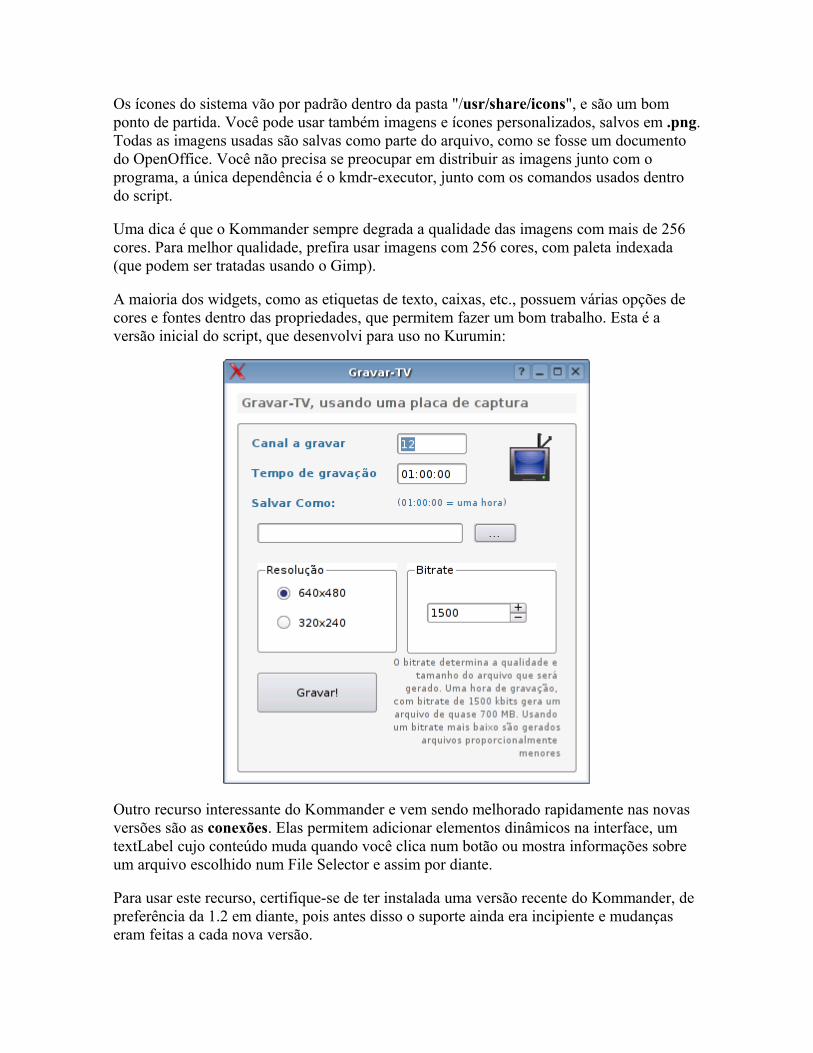
Os ícones do sistema vão por padrão dentro da pasta "/usr/share/icons", e são um bom ponto de partida. Você pode usar também imagens e ícones personalizados, salvos em .png. Todas as imagens usadas são salvas como parte do arquivo, como se fosse um documento do OpenOffice. Você não precisa se preocupar em distribuir as imagens junto com o programa, a única dependência é o kmdr-executor, junto com os comandos usados dentro do script.
Uma dica é que o Kommander sempre degrada a qualidade das imagens com mais de 256 cores. Para melhor qualidade, prefira usar imagens com 256 cores, com paleta indexada (que podem ser tratadas usando o Gimp).
A maioria dos widgets, como as etiquetas de texto, caixas, etc., possuem várias opções de cores e fontes dentro das propriedades, que permitem fazer um bom trabalho. Esta é a versão inicial do script, que desenvolvi para uso no Kurumin:
Outro recurso interessante do Kommander e vem sendo melhorado rapidamente nas novas versões são as conexões. Elas permitem adicionar elementos dinâmicos na interface, um textLabel cujo conteúdo muda quando você clica num botão ou mostra informações sobre um arquivo escolhido num File Selector e assim por diante.
Para usar este recurso, certifique-se de ter instalada uma versão recente do Kommander, de preferência da 1.2 em diante, pois antes disso o suporte ainda era incipiente e mudanças eram feitas a cada nova versão.
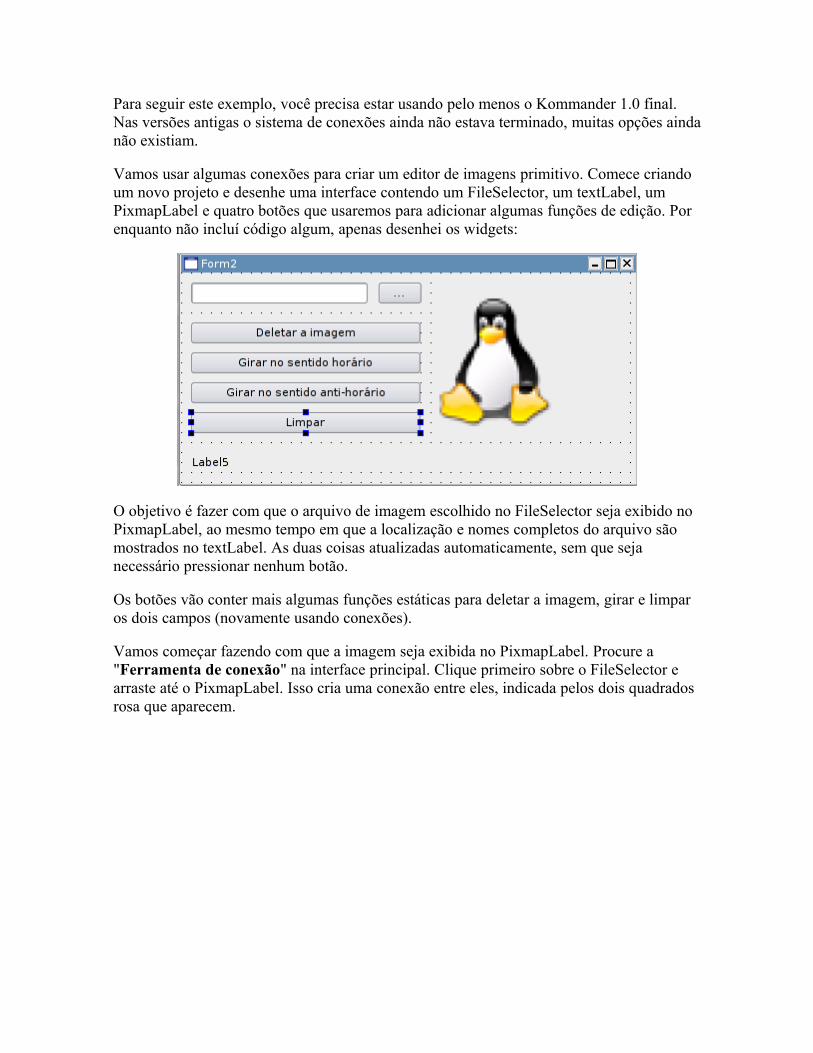
Para seguir este exemplo, você precisa estar usando pelo menos o Kommander 1.0 final. Nas versões antigas o sistema de conexões ainda não estava terminado, muitas opções ainda não existiam.
Vamos usar algumas conexões para criar um editor de imagens primitivo. Comece criando um novo projeto e desenhe uma interface contendo um FileSelector, um textLabel, um PixmapLabel e quatro botões que usaremos para adicionar algumas funções de edição. Por enquanto não incluí código algum, apenas desenhei os widgets:
O objetivo é fazer com que o arquivo de imagem escolhido no FileSelector seja exibido no PixmapLabel, ao mesmo tempo em que a localização e nomes completos do arquivo são mostrados no textLabel. As duas coisas atualizadas automaticamente, sem que seja necessário pressionar nenhum botão.
Os botões vão conter mais algumas funções estáticas para deletar a imagem, girar e limpar os dois campos (novamente usando conexões).
Vamos começar fazendo com que a imagem seja exibida no PixmapLabel. Procure a "Ferramenta de conexão" na interface principal. Clique primeiro sobre o FileSelector e arraste até o PixmapLabel. Isso cria uma conexão entre eles, indicada pelos dois quadrados rosa que aparecem.
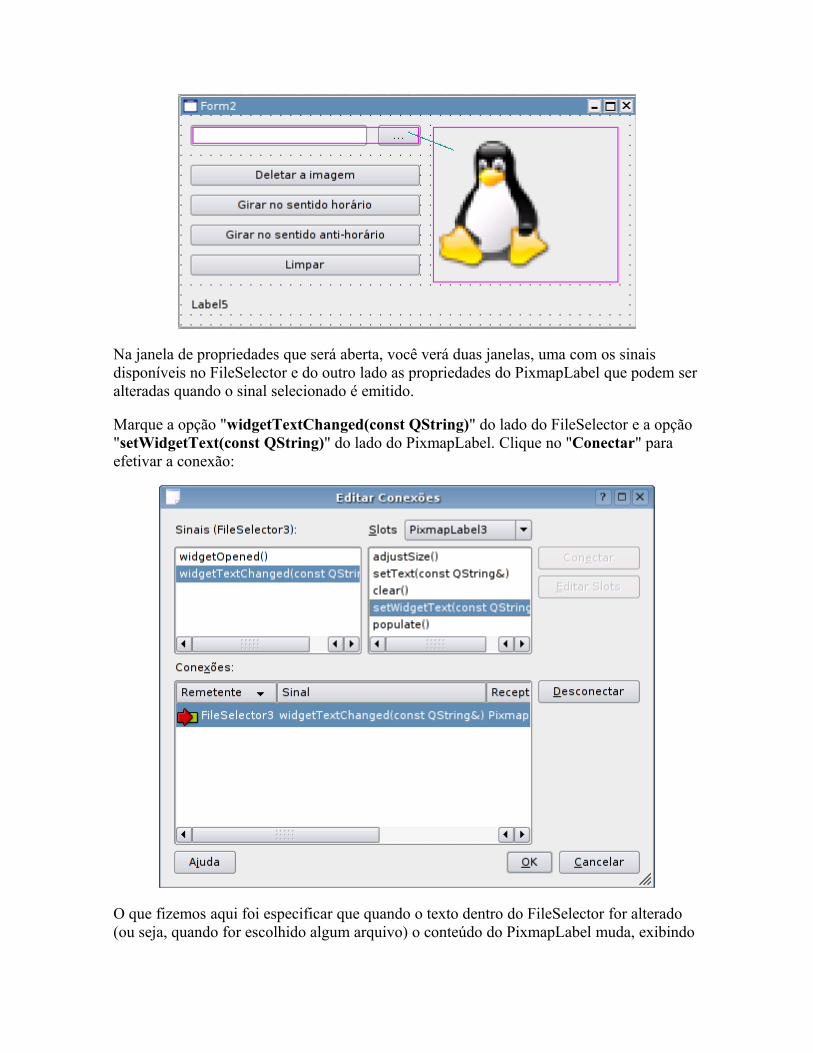
Na janela de propriedades que será aberta, você verá duas janelas, uma com os sinais disponíveis no FileSelector e do outro lado as propriedades do PixmapLabel que podem ser alteradas quando o sinal selecionado é emitido.
Marque a opção "widgetTextChanged(const QString)" do lado do FileSelector e a opção "setWidgetText(const QString)" do lado do PixmapLabel. Clique no "Conectar" para efetivar a conexão:
O que fizemos aqui foi especificar que quando o texto dentro do FileSelector for alterado (ou seja, quando for escolhido algum arquivo) o conteúdo do PixmapLabel muda, exibindo
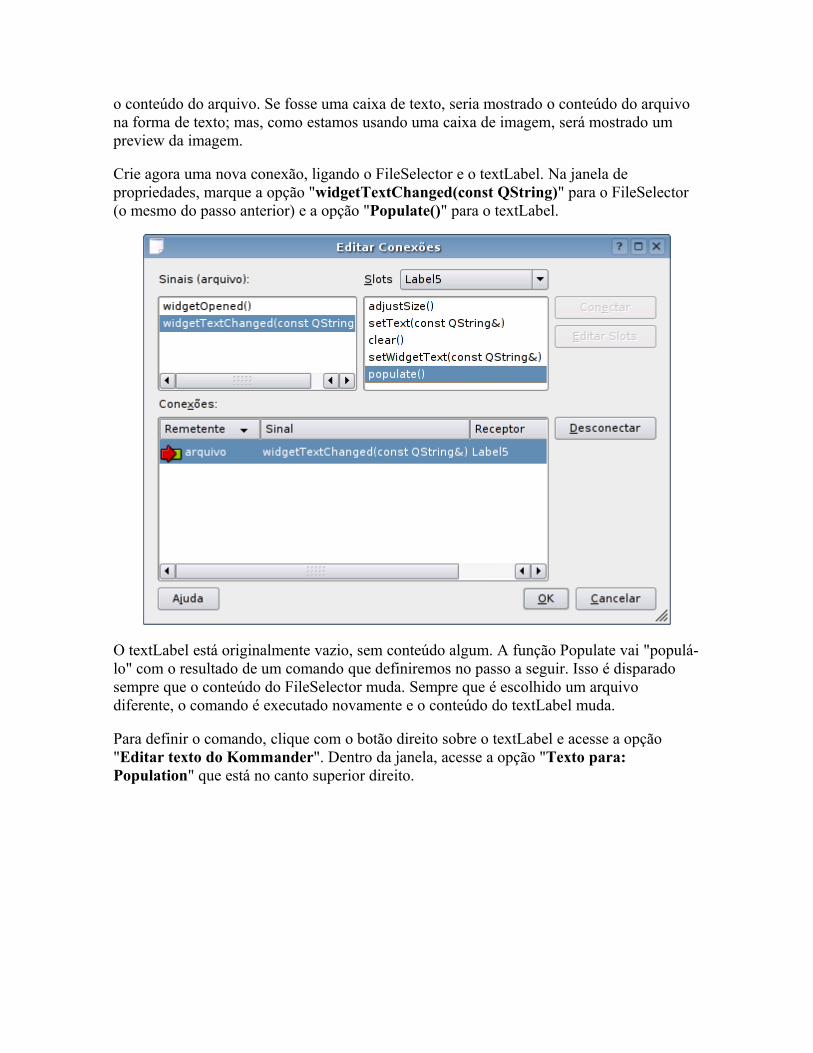
o conteúdo do arquivo. Se fosse uma caixa de texto, seria mostrado o conteúdo do arquivo na forma de texto; mas, como estamos usando uma caixa de imagem, será mostrado um preview da imagem.
Crie agora uma nova conexão, ligando o FileSelector e o textLabel. Na janela de propriedades, marque a opção "widgetTextChanged(const QString)" para o FileSelector (o mesmo do passo anterior) e a opção "Populate()" para o textLabel.
O textLabel está originalmente vazio, sem conteúdo algum. A função Populate vai "populá-lo" com o resultado de um comando que definiremos no passo a seguir. Isso é disparado sempre que o conteúdo do FileSelector muda. Sempre que é escolhido um arquivo diferente, o comando é executado novamente e o conteúdo do textLabel muda.
Para definir o comando, clique com o botão direito sobre o textLabel e acesse a opção "Editar texto do Kommander". Dentro da janela, acesse a opção "Texto para: Population" que está no canto superior direito.

O comando começa com o "@exec", com o comando propriamente dito entre parênteses. Dentro dos parênteses você pode separar uma seqüência de comandos por ponto-e-vírgula, usar o pipe e outros componentes de um shell script normal.
Neste exemplo, estou usando o comando:
@exec(identify "@arquivo.text" | cut -d " " -f 2-10)
O identify é um comando de texto que exibe as propriedades da imagem, como formato e resolução. Nas propriedades do meu FileSelector mudei o nome para "arquivo", logo o "@arquivo.text" se refere ao conteúdo do FileSelector, ou seja, o nome do arquivo que foi escolhido. O "| cut -d " " -f 2-10" é opcional, ele serve apenas para "limpar" a saída do identify, retirando o nome do arquivo e deixando apenas as propriedades da imagem.
Uma observação importante é que o Kommander não é muito bom em executar scripts complexos desta forma. Em muitos casos o Kommander entra em loop ao clicar no botão, ou retorna um valor inesperado, mesmo que que a função usada funcione perfeitamente se executada no terminal.
Embora este seja mais um fator que vem melhorando nas novas versões, é aconselhável que sempre que precisar incluir qualquer coisa mais elaborada, principalmente ao usar muitos pipes e redirecionamentos, prefira criar um script e chamá-lo dentro da função do Kommander, ao invés de tentar colocar todos os comandos diretamente dentro dos parênteses.
Por exemplo, num dos meus scripts uso uma função para popular um campo de texto com uma lista dos compartilhamentos NFS ativos. Isto é feito lendo e filtrando o conteúdo do arquivo "/etc/exports", de forma que apenas as linhas referentes aos compartilhamentos sejam exibidas no campo. A atualização é feita ao clicar sobre um botão na interface.
Se coloco algo como: @exec(sed '/^$/d' /etc/exports | sed '/#/d') ou mesmo: @exec(cat /etc/exports | sed '/^$/d' | sed '/#/d') como função para o botão, o Kommander entra em
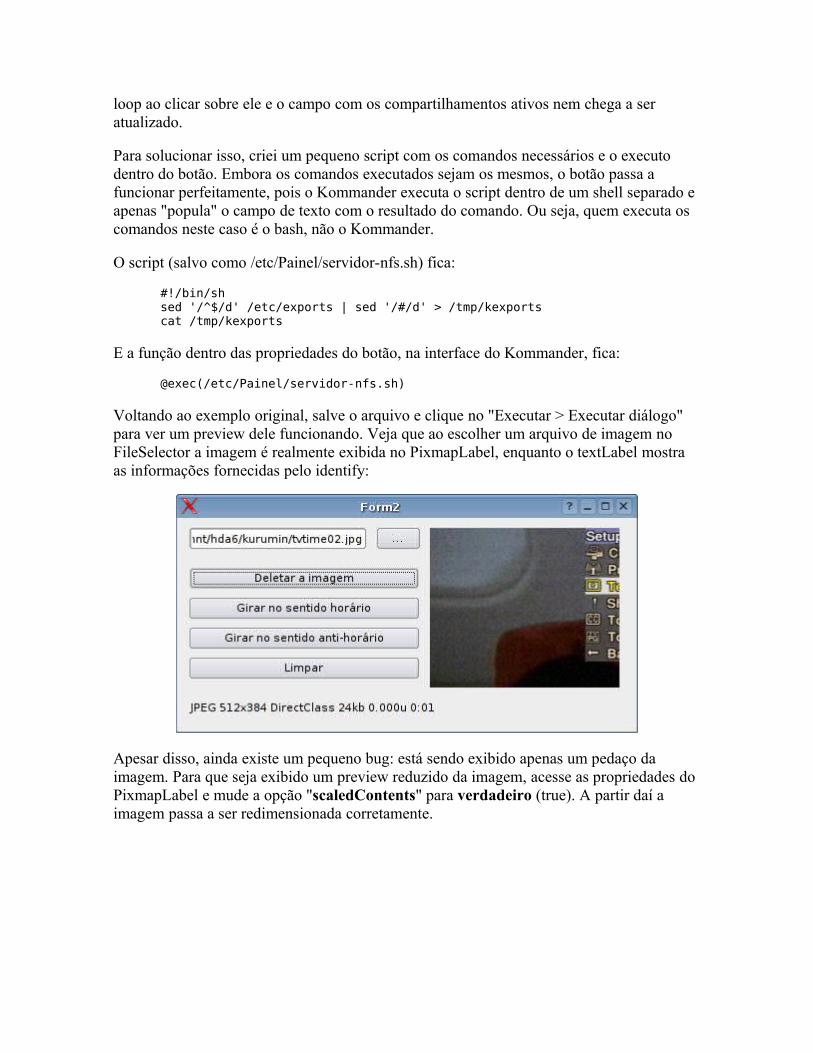
loop ao clicar sobre ele e o campo com os compartilhamentos ativos nem chega a ser atualizado.
Para solucionar isso, criei um pequeno script com os comandos necessários e o executo dentro do botão. Embora os comandos executados sejam os mesmos, o botão passa a funcionar perfeitamente, pois o Kommander executa o script dentro de um shell separado e apenas "popula" o campo de texto com o resultado do comando. Ou seja, quem executa os comandos neste caso é o bash, não o Kommander.
O script (salvo como /etc/Painel/servidor-nfs.sh) fica:
#!/bin/shsed '/^$/d' /etc/exports | sed '/#/d' > /tmp/kexportscat /tmp/kexports
E a função dentro das propriedades do botão, na interface do Kommander, fica:
@exec(/etc/Painel/servidor-nfs.sh)
Voltando ao exemplo original, salve o arquivo e clique no "Executar > Executar diálogo" para ver um preview dele funcionando. Veja que ao escolher um arquivo de imagem no FileSelector a imagem é realmente exibida no PixmapLabel, enquanto o textLabel mostra as informações fornecidas pelo identify:
Apesar disso, ainda existe um pequeno bug: está sendo exibido apenas um pedaço da imagem. Para que seja exibido um preview reduzido da imagem, acesse as propriedades do PixmapLabel e mude a opção "scaledContents" para verdadeiro (true). A partir daí a imagem passa a ser redimensionada corretamente.

Falta agora só dar funções aos botões de edição, que é a parte mais fácil.
Dentro do botão "Deletar a imagem" (botão direito > Editor texto do Kommander) inclua a função:
kdialog --yesno "Tem certeza?"retval=$?if [ "$retval" = "0" ]; thenrm -f @arquivo.textfi
Lembre-se de que a variável "@arquivo.text" contém o caminho completo para o arquivo. Usando "rm -f @arquivo.text" no script, deletamos o arquivo, e não o conteúdo da variável.
Nos botões Girar no sentido horário e girar no sentido anti-horário, inclua (respectivamente) as funções:
jpegorient +90 @arquivo.text
jpegorient +270 @arquivo.text
O jpegorient é mais um comando de edição de imagem em modo texto, que faz parte do pacote ImageMagik. Ele permite justamente girar a imagem no sentido desejado. Não é muito prático para usar no dia-a-dia, mas é muito usado em scripts.
O último botão, "Limpar", vai servir apenas para limpar o conteúdo do PixmapLabel e do textLabel. Para isso, crie uma conexão entre o botão e o PixmapLabel. Marque de um lado a opção "Pressed" e do outro a opção "clear()". Faça o mesmo entre ele e o textLabel.
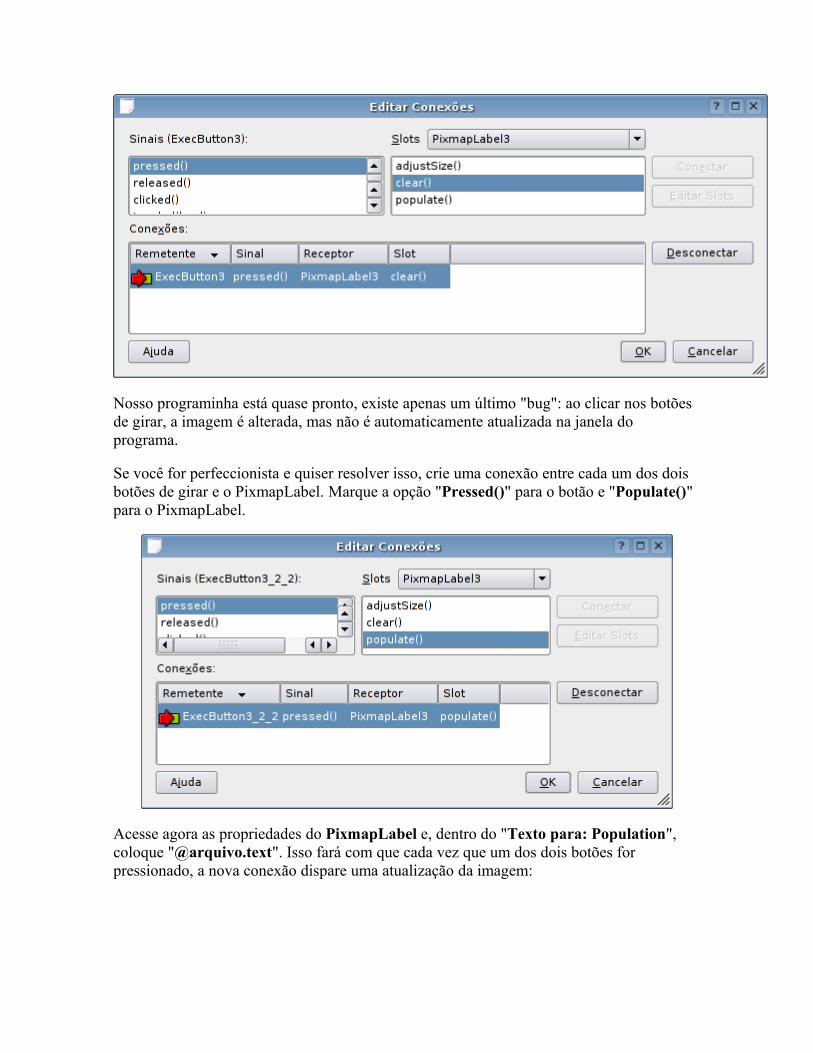
Nosso programinha está quase pronto, existe apenas um último "bug": ao clicar nos botões de girar, a imagem é alterada, mas não é automaticamente atualizada na janela do programa.
Se você for perfeccionista e quiser resolver isso, crie uma conexão entre cada um dos dois botões de girar e o PixmapLabel. Marque a opção "Pressed()" para o botão e "Populate()" para o PixmapLabel.
Acesse agora as propriedades do PixmapLabel e, dentro do "Texto para: Population", coloque "@arquivo.text". Isso fará com que cada vez que um dos dois botões for pressionado, a nova conexão dispare uma atualização da imagem:

Assim como no exemplo para gravar programas de TV, o Kommander pode ser usado para criar interfaces para diversos programas que originalmente são acessíveis apenas via linha de comando. Mais um exemplo é o "Kurumin-synergy", a interface para o Synergy que comentei no segundo capítulo.
Antes de continuar lendo, eu recomendo que releia o tópico do Synergy e teste o programa, já que para escrever uma interface é necessário, antes de mais nada, conhecer bem o programa alvo.
Em primeiro lugar, o Synergy pode ser usado como servidor (o micro principal, que controla os demais) ou como cliente (o micro que é controlado). A idéia é que o script possa ser usado nas duas situações, por isso ele foi criado com duas abas independentes.
A aba do servidor é de longe a mais complexa. Ela possui 4 checkboxes, que podem ser acionadas de forma independente, nomeadas como "cima", "baixo", "esquerda" e "direita". Para cada checkbox, existem dois Line Edits (oito no total), nomeados como "cima_ip", "cima_nome", "baixo_nome", "nome_ip", "esquerda_nome", "esquerda_ip", "direita_nome" e "direita_ip". Existe ainda um ckeckbox extra, chamado "desk_icon", que responde pela função "Criar atalho no desktop".

Nas propriedades de cada um dos 4 checkboxes, certifique-se que a opção "Texto para: checked" está com o valor "1", já que é nisso que o script vai se basear para decidir quais conexões devem ser ativadas. Por segurança, atribuí também o valor "0" para a opção "unchecked" de cada um.
Esta parte de criação da interface é relativamente simples, embora trabalhosa. O principal nesta fase é checar se todos os nomes e propriedades dos campos estão corretos, já que num painel com vários campos é fácil se esquecer de algum.

O principal vai dentro do botão "Ativar o Synergy", que contém o script que verifica o status de cada um dos campos, gera a configuração (salva no arquivo "/home/$USER/.synergy.conf") e ativa o servidor Synergy com as opções selecionadas. Baixe o script completo no http://www.guiadohardware.net/kurumin/painel/kurumin-synergy.kmdr.
Este script é um pouco longo, então vamos por partes.
Na configuração do Synergy é preciso incluir o nome do servidor. Não coloquei isso como mais um campo na janela principal, pois esta é uma informação fácil de descobrir através do comando "hostname". Na primeira linha do script, crio uma variável "server" contendo o resultado do comando, ou seja, o nome da máquina, como em "semprao". As linhas seguintes fecham o Synergy caso aberto (ele não pode ser aberto duas vezes), deleta o arquivo de configuração, caso exista (já que o script cria um novo) e, só para garantir, cria um novo arquivo vazio usando o comando touch.
server=`hostname`killall synergysrm -f /home/$USER/.synergy.conftouch /home/$USER/.synergy.conf
Em seguida, começamos a escrever o arquivo, iniciando pela seção "screens", que contém os nomes do servidor e de cada um dos clientes que poderão se conectar a ele. O nome do servidor está dentro da variável "$server" e os nomes de cada cliente foram escritos nos campos "cima_nome", "baixo_nome", "esquerda_nome" e "direita_nome".

O arquivo deve conter apenas os campos que foram selecionados. Se foram marcados apenas os checkboxes "esquerda" e "direita", ele deve incluir somente os campos "esquerda_nome" e "direita_nome", ignorando os demais.
Uma forma simples de fazer isso é criar um if para cada um dos 4 checkboxes, incluindo cada um dos campos apenas caso ele esteja com o valor "1" (sintoma de que está selecionado). O script fica então:
echo 'section: screens' >> /home/$USER/.synergy.conf
right="@direita"if [ "$right" = "1" ]; thenright_nome="@direita_nome.text"; right_ip="@direita_ip.text"echo "$right_nome:" >> /home/$USER/.synergy.conf; fi
left="@esquerda"if [ "$left" = "1" ]; thenleft_nome="@esquerda_nome.text"; left_ip="@esquerda_ip.text"echo "$left_nome:" >> /home/$USER/.synergy.conf; fi
up="@cima"if [ "$up" = "1" ]; thenup_nome="@cima_nome.text"; up_ip="@cima_ip.text"echo "$up_nome:" >> /home/$USER/.synergy.conf; fi
down="@baixo"if [ "$down" = "1" ]; thendown_nome="@baixo_nome.text"; down_ip="@baixo_ip.text"echo "$down_nome:" >> /home/$USER/.synergy.conf; fi
echo "$server:" >> /home/$USER/.synergy.confecho "end" >> /home/$USER/.synergy.confecho "" >> /home/$USER/.synergy.conf
Veja que aproveitei para criar uma série de variáveis, armazenando os textos dos campos. Este passo não é realmente necessário, pois você pode continuar usando diretamente as variáveis do Kommander.
O resultado deste trecho do script será algo como:
section: screenstoshiba:fedora:semprao:end
O próximo passo é acrescentar a seção "links" dentro do script, que contém a posição de cada um dos clientes em relação ao servidor e a posição do próprio servidor em relação a cada um.
Vamos começar com a seção referente ao servidor. Note que o script inclui apenas os clientes que estão realmente ativados, novamente checando se o valor de cada um dos 4 checkboxes é "1":
echo "section: links" >> /home/$USER/.synergy.conf

echo "$server:" >> /home/$USER/.synergy.confif [ "$right" = "1" ]; thenecho "right = $right_nome" >> /home/$USER/.synergy.conf; fi
if [ "$left" = "1" ]; thenecho "left = $left_nome" >> /home/$USER/.synergy.conf; fi
if [ "$up" = "1" ]; thenecho "up = $up_nome" >> /home/$USER/.synergy.conf; fi
if [ "$down" = "1" ]; thenecho "down = $down_nome" >> /home/$USER/.synergy.conf; fi
Em seguida, é necessário especificar a posição de cada cliente em relação ao servidor. Novamente, estou adotando a filosofia do "mais longo, porém mais fácil", criando um if para cada um:
if [ "$right" = "1" ]; thenecho "$right_nome:" >> /home/$USER/.synergy.confecho "left = $server" >> /home/$USER/.synergy.conf; fi
if [ "$left" = "1" ]; thenecho "$left_nome:" >> /home/$USER/.synergy.confecho "right = $server" >> /home/$USER/.synergy.conf; fi
if [ "$up" = "1" ]; thenecho "$up_nome:" >> /home/$USER/.synergy.confecho "down = $server" >> /home/$USER/.synergy.conf; fi
if [ "$down" = "1" ]; thenecho "$down_nome:" >> /home/$USER/.synergy.confecho "up = $server" >> /home/$USER/.synergy.conf; fi
echo "end" >> /home/$USER/.synergy.confecho "" >> /home/$USER/.synergy.conf
Esta seção do script produz algo como:
section: linkssemprao:right = toshibaleft = fedoratoshiba:left = sempraofedora:right = sempraoend
Finalmente, falta criar a seção "aliases" do arquivo, que relaciona o endereço IP de cada cliente a seu nome. Ela é mais simples que as anteriores, já que temos todas as variáveis em mãos:
echo "section: aliases" >> /home/$USER/.synergy.conf
if [ "$right" = "1" ]; thenecho "$right_nome:" >> /home/$USER/.synergy.confecho "$right_ip" >> /home/$USER/.synergy.conf; fi

if [ "$left" = "1" ]; thenecho "$left_nome:" >> /home/$USER/.synergy.confecho "$left_ip" >> /home/$USER/.synergy.conf; fi
if [ "$up" = "1" ]; thenecho "$up_nome:" >> /home/$USER/.synergy.confecho "$up_ip" >> /home/$USER/.synergy.conf; fi
if [ "$down" = "1" ]; thenecho "$down_nome:" >> /home/$USER/.synergy.confecho "$down_ip" >> /home/$USER/.synergy.conf; fi
echo "end" >> /home/$USER/.synergy.confecho "" >> /home/$USER/.synergy.conf
Com o arquivo criado, chegou a hora de criar o ícone no desktop, caso o checkbox "desk_icon" esteja marcado. O ícone contém o mesmo comando executado no final do script. Ao ser aberto, o synergys lê o arquivo de configuração e carrega com as opções adequadas. A partir daí, o Synergy pode ser ativado simplesmente clicando sobre o ícone no desktop. Só é necessário abrir o painel novamente quando for necessário alterar a configuração.
O trecho do script que cria o ícone fica:
icon="@desk_icon"
if [ "$icon" = "1" ]; thenecho '[Desktop Entry]Exec=xterm -e synergys -fGenericName=Ativar o SynergyIcon=krdcName=Ativar o SynergyType=ApplicationX-KDE-SubstituteUID=false' > /home/$USER/Desktop/Ativar\ o\ Synergy.desktopfi
Como estou usando aspas simples, o echo escreve tudo literalmente, incluindo as quebras de linha. Em situações onde é preciso incluir variáveis dentro do comando ou nome do ícone, é necessário escrever linha a linha, usando aspas duplas, como em:
echo "GenericName=Conectar ao servidor $server" >> /home/$USER/Desktop/server.desktop
Finalmente, temos a última linha do script, o mesmo comando incluído no ícone, que abre o servidor. Note que estou usando o comando "xterm -e", que roda o comando dentro de uma janela do terminal. A idéia aqui é que ele fique visível e possa ser encerrado ao fechar a janela.
xterm -e synergys -f
A segunda aba do script, referente ao cliente, é bem mais simples, contendo apenas um line edit onde vai o IP do servidor e um checkbox para o atalho no desktop.

Além das linhas que criam o ícone no desktop, o botão contém apenas a linha que ativa o cliente Synergy:
server=@ip_server.text
if [ -n "$server" ]; thenxterm -e synergyc -f $serverfi
Em muitas situações, é preciso criar scripts mais dinâmicos, que obtenham e exibam informações automaticamente ao serem abertos e não apenas depois de clicar num botão. É possível fazer com que o script execute comandos e exiba os resultados na forma de opções dentro de um ComboBox, ou um label de texto. Isso permite criar scripts mais inteligentes, que exibem apenas as opções que se aplicam à situação.
Vamos usar como exemplo um script que cria uma interface para o cpufreq-set, (um comando que faz parte do pacote "cpufrequtils"), que permite ajustar a freqüência do processador em notebooks ou desktops com processadores Intel que suportam speed-step.
Ele é ativado carregando os módulos "p4_clockmod", "freq_table", "speedstep_lib", "cpufreq_powersave", "cpufreq_ondemand" e "cpufreq_userspace". A partir daí, você pode ver as freqüências suportadas pelo processador, junto com a freqüência atual usando o comando "cpufreq-info", como em:
# cpufreq-info
cpufrequtils 0.2: cpufreq-info (C) Dominik Brodowski 2004Report errors and bugs to [email protected], please.analyzing CPU 0:driver: p4-clockmodCPUs which need to switch frequency at the same time: 0hardware limits: 175 MHz - 1.40 Ghzavailable frequency steps: 175 MHz, 350 MHz, 525 MHz, 700 MHz, 875 MHz, 1.05 GHz, 1.23 GHz, 1.40 Ghzavailable cpufreq governors: ondemand, powersave, userspacecurrent policy: frequency should be within 175 MHz and 1.40 Ghz.The governor "userspace" may decide which speed to use within this range.
current CPU frequency is 1.40 GHz (asserted by call to hardware).

Pela saída do comando sei que o processador (um Celeron M, por isso o baixo clock) suporta várias freqüências entre 175 MHz e 1.4 GHz e que ele está atualmente operando na freqüência máxima.
Para ajustar a freqüência do processador, você usa o comando "cpufreq-set -f", seguido pela freqüência desejada (em kHz), como em:
# cpufreq-set -f 1050
Existe ainda a opção "-g ondemand", onde a freqüência é ajustada dinamicamente, de acordo com a utilização do processador.
Vamos a um exemplo de script que poderia apresentar estas opções de uma forma mais agradável. Aqui estou usando dois ComboBox (um deles está escondido atrás do texto, vamos ver o porquê em seguida), um TextLabel e dois botões. O restante são caixas de texto explicativas e outros elementos cosméticos que você poderia usar ou não, de acordo com o público ao qual o script se destina:

O TextLabel exibe a freqüência atual, detectada no momento em que o script é aberto, enquanto o primeiro ComboBox mostra uma lista das freqüências suportadas. Ambas as coisas são extraídas da saída do comando "cpufreq-info" usando o grep e o cut.
Tudo começa com um "script auxiliar", que é executado primeiro. Ele carrega os módulos que ativam o cpufreq, filtra a saída do cpufreq-info e salva as informações que vamos precisar exibir dentro do script em dois arquivos de texto e no final carrega o script principal. Note que por causa da necessidade de carregar módulos, é preciso que o script seja executado com permissão de root, através do kdesu ou sudo:
modprobe p4_clockmodmodprobe freq_tablemodprobe speed step_libmodprobe cpufreq_powersavemodprobe cpufreq_ondemandmodprobe cpufreq_userspace
rm -f /tmp/myfreq; rm -f /tmp/freq
availablefreq=`cpufreq-info | grep "frequency steps" | sed -r 's/ +/ /g' | cut -f 5-100 -d " "`myfreq=`echo $availablefreq | sed -e 's/\\.//g' | sed -e 's/ GHz/0000/g' | sed -e 's/ MHz/000/g' | sed -e 's/,//g'`
echo $myfreq | sed -e 's/ /\n/g' | sed -e 's/ //g' >> /tmp/myfreq
cpufreq-info | grep "current CPU frequency is" | sed -r 's/ +/ /g' | cut -f 6-7 -d " " >> /tmp/freq
kmdr-executor k-cpufreqd.kmdr
No final, temos dois arquivos temporários, "/tmp/myfreq" e "/tmp/freq". O primeiro contém as freqüências suportadas pelo processador, que serão exibidas dentro do ComboBox, já convertidas para kHz, como em "175000 350000 525000 700000 875000 1050000 1230000 1400000" (um número por linha), enquanto o segundo contém a freqüência atual, como em "1.40 GHz".
Para fazer com que estas informações sejam incluídas no script principal durante sua abertura, clique com o botão direito sobre uma área vazia do painel principal e em "Editar Texto do Kommander". Dentro da janela, acesse a opção "Texto para: initialization:".
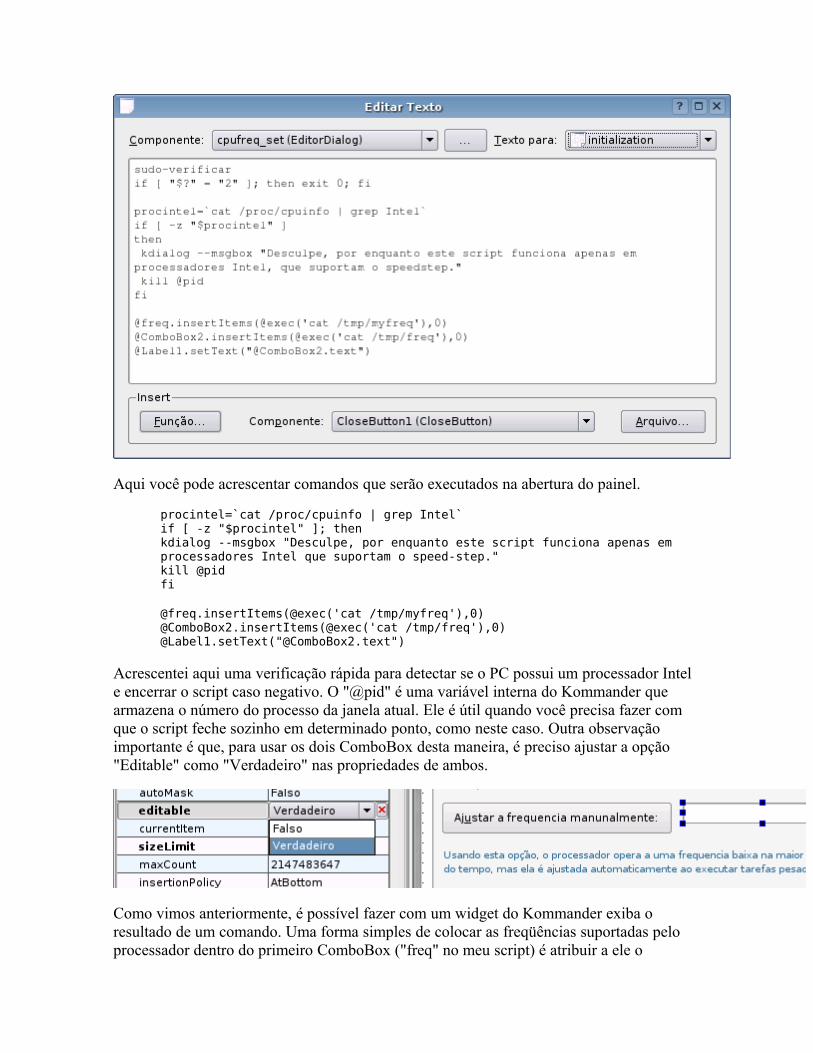
Aqui você pode acrescentar comandos que serão executados na abertura do painel.
procintel=`cat /proc/cpuinfo | grep Intel`if [ -z "$procintel" ]; thenkdialog --msgbox "Desculpe, por enquanto este script funciona apenas em processadores Intel que suportam o speed-step."kill @pidfi
@freq.insertItems(@exec('cat /tmp/myfreq'),0)@ComboBox2.insertItems(@exec('cat /tmp/freq'),0)@Label1.setText("@ComboBox2.text")
Acrescentei aqui uma verificação rápida para detectar se o PC possui um processador Intel e encerrar o script caso negativo. O "@pid" é uma variável interna do Kommander que armazena o número do processo da janela atual. Ele é útil quando você precisa fazer com que o script feche sozinho em determinado ponto, como neste caso. Outra observação importante é que, para usar os dois ComboBox desta maneira, é preciso ajustar a opção "Editable" como "Verdadeiro" nas propriedades de ambos.
Como vimos anteriormente, é possível fazer com um widget do Kommander exiba o resultado de um comando. Uma forma simples de colocar as freqüências suportadas pelo processador dentro do primeiro ComboBox ("freq" no meu script) é atribuir a ele o
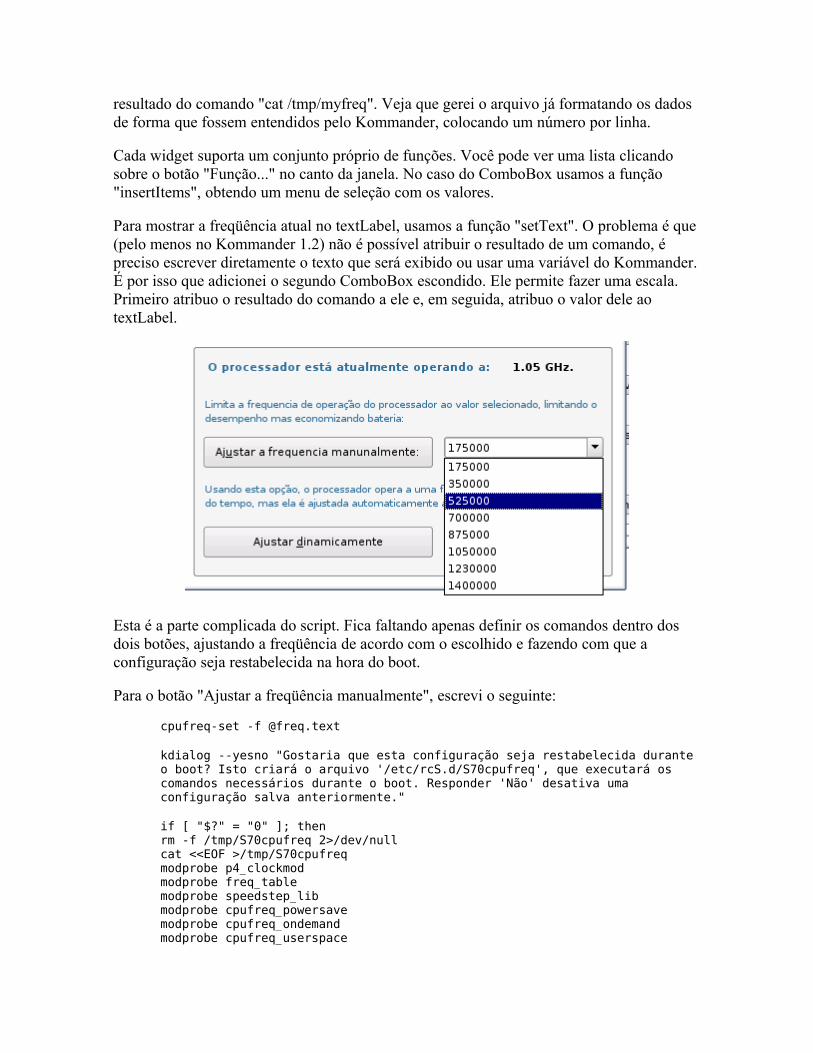
resultado do comando "cat /tmp/myfreq". Veja que gerei o arquivo já formatando os dados de forma que fossem entendidos pelo Kommander, colocando um número por linha.
Cada widget suporta um conjunto próprio de funções. Você pode ver uma lista clicando sobre o botão "Função..." no canto da janela. No caso do ComboBox usamos a função "insertItems", obtendo um menu de seleção com os valores.
Para mostrar a freqüência atual no textLabel, usamos a função "setText". O problema é que (pelo menos no Kommander 1.2) não é possível atribuir o resultado de um comando, é preciso escrever diretamente o texto que será exibido ou usar uma variável do Kommander. É por isso que adicionei o segundo ComboBox escondido. Ele permite fazer uma escala. Primeiro atribuo o resultado do comando a ele e, em seguida, atribuo o valor dele ao textLabel.
Esta é a parte complicada do script. Fica faltando apenas definir os comandos dentro dos dois botões, ajustando a freqüência de acordo com o escolhido e fazendo com que a configuração seja restabelecida na hora do boot.
Para o botão "Ajustar a freqüência manualmente", escrevi o seguinte:
cpufreq-set -f @freq.text
kdialog --yesno "Gostaria que esta configuração seja restabelecida durante o boot? Isto criará o arquivo '/etc/rcS.d/S70cpufreq', que executará os comandos necessários durante o boot. Responder 'Não' desativa uma configuração salva anteriormente."
if [ "$?" = "0" ]; thenrm -f /tmp/S70cpufreq 2>/dev/nullcat <<EOF >/tmp/S70cpufreqmodprobe p4_clockmodmodprobe freq_tablemodprobe speedstep_libmodprobe cpufreq_powersavemodprobe cpufreq_ondemandmodprobe cpufreq_userspace

cpufreq-set -f @freq.textEOF
rm -f /etc/rcS.d/S70cpufreqmv /tmp/S70cpufreq /etc/rcS.d/S70cpufreqchmod +x /etc/rcS.d/S70cpufreq
elserm -f /etc/rcS.d/S70cpufreqfi
Para o botão "Ajustar Dinamicamente" a única coisa que muda é o comando "cpufreq-set -f @freq.text", que passa a ser "cpufreq-set -g ondemand".
Os exemplos que dei até aqui são de scripts relativamente complexos. Mas o Kommander também serve bem como interface para scripts simples. É incrível como um simples painel, com algumas instruções básicas sobre o uso do script e um botão "executar" podem valorizar seu trabalho.
Para finalizar, este é um exemplo de painel simples, que serve como interface para o script para baixar arquivos bittorrent que citei anteriormente. Ele tem apenas dois botões de funções e um botão para fechar. O restante é o trabalho visual e a organização dos botões, que dão um visual mais profissional a um script que originalmente passaria despercebido.
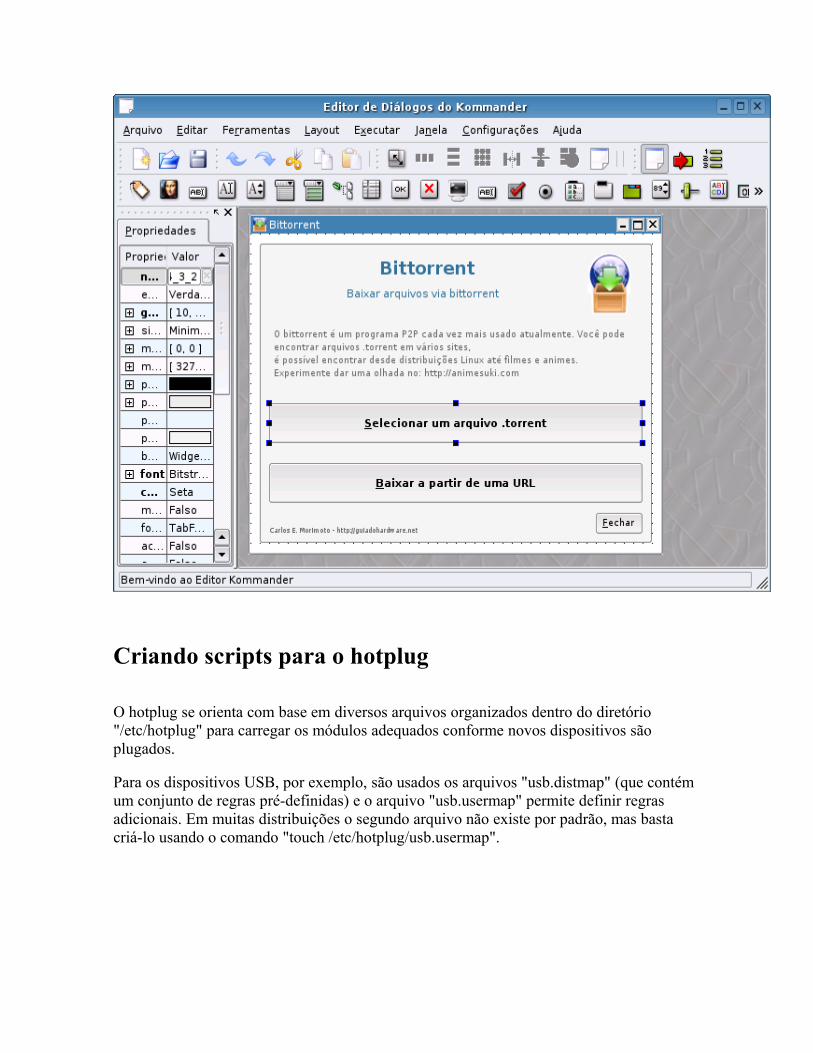
Criando scripts para o hotplug
O hotplug se orienta com base em diversos arquivos organizados dentro do diretório "/etc/hotplug" para carregar os módulos adequados conforme novos dispositivos são plugados.
Para os dispositivos USB, por exemplo, são usados os arquivos "usb.distmap" (que contém um conjunto de regras pré-definidas) e o arquivo "usb.usermap" permite definir regras adicionais. Em muitas distribuições o segundo arquivo não existe por padrão, mas basta criá-lo usando o comando "touch /etc/hotplug/usb.usermap".

Note que estes arquivos só existem em distribuições que realmente utilizam o hotplug. Atualmente, está havendo uma espécie de movimento migratório em relação ao udev (que abordo a seguir). Embora o udev possa conviver com os scripts do hotplug, muitas distribuições preferem realmente eliminá-lo, mantendo apenas o udev. Quase todas as regras do hotplug podem ser reescritas usando funções do udev, mas é interessante entender os dois sistemas, para que você possa utilizar um sistema ou outro de acordo com o sistema usado.
Ambos os arquivos são formados por um conjunto de regras, como a abaixo:
usb-storage 0x000f 0x03ee 0x0000 0x0000 0x0245 0x00 0x00 0x00 0x00 0x00 0x00 0x00000000
O primeiro campo, "usb-storage", indica um script que será executado (ou um módulo que será carregado) quando um dispositivo que se encaixa nas regras descritas nos campos seguintes for encontrado.
A maioria das distribuições traz um conjunto de scripts dentro da pasta "/etc/hotplug/usb/", que são executados quando determinados dispositivos são plugados. Isso faz com que seja criado um ícone no desktop ao ser plugado um pendrive e outras ações do gênero.
Um dos recursos mais interessantes do hotplug é que você pode criar ações adicionais, fazendo com que sejam executadas ações diversas quando você plugar dispositivos USB especificados. Você pode fazer com que seja executado um script de backup automaticamente quando plugar seu HD USB, fazer com que o Amarok ou outro aplicativo seja aberto quando plugar seu MP3Player, fazer com que um determinado game seja aberto ao plugar o joystick, ou qualquer outra coisa que tenha em mente.
O primeiro passo é plugar o dispositivo e rodar o comando "lsusb". Procure a linha com a identificação do dispositivo a que deseja atribuir a ação, como em:
Bus 003 Device 023: ID 05e3:0702 Genesys Logic, Inc. USB 2.0 IDE Adapter
Aqui estou usando uma gaveta de HD, um adaptador que permite ligar um HD de notebook direto na porta USB, fazendo com que ele seja reconhecido como um pendrive. O mais importante é o "ID 05e3:0702", que contém o código do dispositivo, que usaremos na regra. O primeiro número (05e3) é o código do fabricante, enquanto o "0702" é o modelo.
Abra os arquivos "/etc/hotplug/usb.distmap" e "/etc/hotplug/usb.usermap". Dê uma olhada nos exemplos incluídos no "usb.distmap" e copie algum deles para o "usb.usermap", como exemplo.
Como estou fazendo um script para uma gaveta de HD, vou dar um exemplo de como fazer com que seja executado um script que faz automaticamente backup de algumas pastas sempre que ela é plugada.

As linhas adicionadas no "usb.usermap" seguem uma sintaxe especial, com vários campos. Não é prático escrever tudo manualmente, justamente por isso copiamos uma linha do outro arquivo e vamos apenas modificá-la.
Como disse, o primeiro campo indica o script (dentro da pasta "/etc/hotplug/usb/") que será executado. No exemplo, estou indicando o script "gaveta". O terceiro e o quarto campo contém os números de identificação do dispositivo, os dois números que apareceram no lsusb. É através deles que o hotplug saberá diferenciar a gaveta de outros dispositivos USB. Note que é necessário adicionar um "0x" antes de cada um dos dois números, como em:
gaveta 0x0003 0x05e3 0x0702 0x0000 0x0000 0x00 0x00 0x00 0x00 0x00 0x00 0x00000000
O segundo campo (chamado "match_flags") indica como a regra será aplicada. O "0x0003" é o código "padrão" para regras personalizadas, que diz que a regra se aplica apenas a dispositivos com os dois códigos de identificação. A regra vai ser disparada se você plugar uma outra gaveta, exatamente igual à primeira, mas não se plugar um pendrive, por exemplo.
Existem outros códigos, menos usados, que permitem definir regras mais gerais. Usando "0x0000" você cria uma regra que se aplica a qualquer dispositivo USB plugado, independentemente do que seja e o "0x000f", que permite definir exceções, ou seja, dispositivos específicos que não disparam uma regra mais genérica. Mexer com estes códigos permite criar regras mais abrangentes (como as usadas no usb.distmap), que permitem coisas como, por exemplo, disparar uma ação quando qualquer pendrive ou scanner é conectado (independente do fabricante). Mas, trabalhar com eles é um pouco mais complicado, pois você precisa conhecer bem os códigos de identificação dos dispositivos e as regras que podem ser usadas, e ambas as coisas não são bem documentadas.
Para manter as coisas simples, vou me concentrar na criação de regras específicas, usando sempre o " 0x0003" no segundo campo.
Na linha do exemplo, especifiquei que o script "/etc/hotplug/usb/gaveta" deve ser executado sempre que o dispositivo com o código "0x05e3 0x0702" for plugado. O arquivo é um shell script normal, com os comandos que você quer que sejam executados.
Este seria um exemplo de script simples, que faria backup da pasta "/mnt/hda6/ARQUIVOS/":
#!/bin/sh
umount /mnt/sda1; sleep 1mount /dev/sda1 /mnt/sda1montado=`mount | grep /mnt/sda1`
if [ -z "$montado" ]; thenexit 2else rsync -av /mnt/hda6/ARQUIVOS/ /mnt/sda1/ARQUIVOSsync

umount /mnt/sda1fi
touch /tmp/deu_certo
Por segurança, o script primeiro tenta montar a partição de dados da gaveta e roda o comando de backup apenas se ela realmente foi montada. No exemplo estou usando o "rsync", pois a idéia é fazer um backup incremental, rápido. O comando "sync" sincroniza os buffers de dados, gravando qualquer informação não salva. É importante executá-lo sempre antes de desplugar qualquer dispositivo de dados, caso contrário você quase sempre vai perder as últimas alterações.
Da forma como está, o único feedback de que o script foi realmente executado é a criação do arquivo "/tmp/deu_certo". Mesmo que o script seja apenas para uso pessoal, seria interessante melhorar o sistema de feedback, para que você saiba quando o backup terminou.
É fácil fazer perguntas e mostrar mensagens de aviso usando o kdialog. O maior problema é que os scripts executados pelo hotplug são executados num shell separado, fora do modo gráfico. É como se você pressionasse Ctrl+Alt+F1 para mudar para o modo texto e executasse os comandos a partir de lá. Isso faz com que, originalmente, nenhum programa gráfico possa ser usado.
Para resolver isso, adicione o comando "export DISPLAY=:0" no início do script. Isto explica que ele deve usar a tela principal do X para exibir qualquer programa gráfico chamado adiante.
Dependendo da distribuição usada, é necessário também copiar o arquivo ".Xauthority" de dentro do home do usuário que está usando o X para dentro do "/root", de forma que o root possa usar a seção aberta.
Se você usa sempre o mesmo usuário, isso não é problema, basta incluir o comando "cp -f /home/usuario/.Xauthority /root". Mas, se o script vai ser usado por outras pessoas, é necessário torná-lo mais "inteligente", fazê-lo descobrir sozinho qual é o usuário logado e copiar o arquivo.
Ao usar o KDE, é sempre criado um arquivo "/tpm/kde-usuario". Se usarmos o comando "ls /tmp/", deixando só as linhas que contiverem "kde-" (removendo um eventual "kde-root") e, em seguida remover o "kde-" da linha que vai sobrar, ficaremos só com o nome do usuário.
usuario=`ls /tmp/ | grep "kde" | sed -s '/root/D' | cut -f "2" -d "-"`
A limitação aqui é que o script só vai funcionar adequadamente quando houver apenas um usuário do KDE. Para o caso de máquinas que aceitam logins remotos, como um servidor LTSP, por exemplo, sugiro que você use use a saída do comando "w" (que lista os usuários remotos), para deixar na lista apenas o usuário local.
Adicionando a função, nosso script ficaria:

#!/bin/sh
usuario=`ls /tmp/ | grep "kde" | sed -s '/root/D' | cut -f "2" -d "-"`cp -f /home/$usuario/.Xauthority /root/export DISPLAY=:0
kdialog --yesno "Fazer o backup?"resposta=$?
if [ "$resposta" = "0" ]; thenumount /mnt/sda1; sleep 1mount /dev/sda1 /mnt/sda1montado=`mount | grep /mnt/sda1`
if [ -z "$montado" ]; thenexit 2else rsync -av /mnt/hda6/ARQUIVOS/ /mnt/sda1/ARQUIVOSsyncumount /mnt/sda1kdialog --msgbox "Backup completo"fi fi
Veja que adicionei também duas caixas de diálogo. A primeira confirma se você quer fazer o backup e a segunda avisa quando ele é concluído.
Seguindo esta idéia de abrir aplicativos gráficos ao plugar dispositivos USB, podemos criar uma regra que abre o Epsxe (que você pode trocar por outro game ou emulador qualquer), sempre que um joystick USB é plugado.
Seguindo o exemplo anterior, o primeiro passo é adicionar a linha contendo o código de identificação do Joystick no arquivo "/etc/hotplug/usb.usermap":
joypad 0x0003 0x046d 0xc20c 0x0000 0x0000 0x00 0x00 0x00 0x00 0x00 0x00 0x00000000
Aqui especifiquei que será executado o script "/etc/hotplug/usb/joypad". Dentro do script vai a função para rodar aplicativos gráficos, seguida do comando que abre o emulador:
#!/bin/sh
usuario=`ls /tmp/ | grep "kde" | sed -s '/root/D' | cut -f "2" -d "-"`cp -f /home/$usuario/.Xauthority /root/export DISPLAY=:0
sudo -u $usuario epsxe
O comando "sudo -u $usuario epsxe" faz com que o comando seja executado pelo usuário logado, ao invés do root, o que daria margem para problemas de segurança diversos. Este comando pode ser usado sempre que você quiser abrir um programa dentro do ambiente gráfico (como, por exemplo, uma janela do konqueror mostrando os arquivos de um pendrive ou câmera), mas de forma que o programa seja executado dentro das permissões de acesso do usuário.

Criando regras para o udev
A partir do Kernel 2.6, houve uma pequena revolução com relação à detecção de dispositivos no Linux. Graças ao sysfs, sempre que um novo dispositivo é plugado, como um pendrive, ou uma impressora, é adicionada uma entrada dentro da pasta "/sys".
No caso de um pendrive, por exemplo, é criada a pasta "/sys/block/sda" e, dentro dela, uma subpasta para cada partição dentro do pendrive, como "/sys/block/sda/sda1". A pasta é criada quanto o pendrive é detectado, e removida quando ele é desconectado do sistema. Graças a isso, um script de detecção precisa apenas monitorar o conteúdo da pasta /sys, não é mais preciso se preocupar em detectar quando o pendrive é conectado ou desconectado, pois o próprio Kernel (com a ajuda do hotplug ou udev) se encarrega disso.
Este é um exemplo de script que "detecta" pendrives e HDs externos ligados na porta USB, criando e removendo os ícones no desktop conforme eles são plugados e removidos. Ele funciona de forma "independente", baseado apenas nas entradas do diretório /sys, sem utilizar o hotplug nem o udev:
#!/bin/sh# Script para detectar pendrives e cartões, criando e removendo ícones no desktop# Deve ser executado pelo root ou por um usuário com o sudo ativo# Por Carlos E. Morimoto
detecta(){cd /sys/block/ for i in `ls | grep sd`; do cd $i; ls | grep $i; cd /sys/block/done}
while [ 1 = 1 ]; do
# Adiciona íconesfor i in `detecta`; dojaexiste=`ls /home/$USER/Desktop/ | grep $i`if [ -z "$jaexiste" ]; then sudo mkdir /mnt/$i &>/dev/nullarg=''FAT=`sudo fdisk -l | grep $i | grep FAT`[ -n "$FAT" ] && arg='-t vfat -o umask=000'NTFS=`sudo fdisk -l | grep $i | grep NTFS`[ -n "$NTFS" ] && arg='-t ntfs -o umask=000,ro'echo "[Desktop Entry]" >> /home/$USER/Desktop/$i.desktopecho "Exec=sudo mount $arg /dev/$i /mnt/$i; konqueror /mnt/$i; sudo umount /mnt/$i; sync" >> /home/$USER/Desktop/$i.desktopecho "Icon=usbpendrive_unmount" >> /home/$USER/Desktop/$i.desktopecho "Name=$i" >> /home/$USER/Desktop/$i.desktopecho "StartupNotify=true" >> /home/$USER/Desktop/$i.desktopecho "Type=Application" >> /home/$USER/Desktop/$i.desktopecho "X-KDE-SubstituteUID=false" >> /home/$USER/Desktop/$i.desktopecho "X-KDE-Username=" >> /home/$USER/Desktop/$i.desktop fidone
# Remove íconesfor i in `ls /home/$USER/Desktop/ | grep sd | cut -d "." -f 1`; dopresente=`ls /sys/block/sd* | grep $i`[ -z "$presente" ] && rm -f /home/$USER/Desktop/$i.desktopdone

sleep 6done
Note que este script é dividido em duas seções: a primeira adiciona ícones para dispositivos "detectados" e a segunda remove ícones de dispositivos que foram desplugados, assim que percebe que a entrada correspondente no "/sys" foi removida. Este script é executado diretamente com o seu login de usuário e fica em loop, atualizando os ícones freqüentemente. O "sleep 6" no final do script determina a periodicidade com que ele é executado.
Na verdade, incluí este script apenas como um exemplo de como, graças ao trabalho feito pelo próprio Kernel, é simples detectar novos periféricos e executar ações apropriadas. é justamente isso que faz o hotplug e, mais recentemente, o udev.
Embora o udev não substitua diretamente o hotplug, as regras para ele permitem fazer quase tudo que era antes possível através dos scripts do hotplug (entre muitas possibilidades novas), o que explica a migração de muitas distribuições. Vamos entender então como criá-las e o que é possível fazer com elas.
As regras do udev vão por padrão na pasta "/etc/udev/rules.d/". Os arquivos dentro da pasta são executados em ordem numérico-alfabética, de uma forma similar aos arquivos de inicialização dentro da pasta "/etc/rcS.d", em distribuições baseadas no Debian.
O arquivo "025_libgphoto2.rules" é executando antes do "050_linux-wlan-ng.rules", por exemplo. Normalmente, os arquivos são links para arquivos dentro da pasta "/etc/udev/", mas na prática tanto faz seguir o padrão, ou colocar os arquivos diretamente dentro da pasta "/etc/udev/rules.d/".
Quando um novo dispositivo é plugado, o udev vasculha todos os arquivos, na ordem especificada, até encontrar alguma regra que se aplique a ele. Ele pára assim que encontra a primeira, de forma que, se o mesmo dispositivo for referenciado em duas ou mais regras diferentes, vale a primeira. É por isso que a ordem dos arquivos é importante.
Para adicionar suas regras, crie um novo arquivo dentro da pasta, como "/etc/udev/rules.d/01-regras.rules". O importante é que o arquivo use a extensão ".rules" (caso contrário ele não será processado) e comece com um número mais baixo que os demais, para que seja processado primeiro. Isso garante que suas regras não sejam ignoradas em favor das regras padrão incluídas na distribuição.
Dentro do arquivo, cada regra forma uma única linha. Este é um exemplo de regra, que executa um script sempre que um pendrive ou HD USB é conectado:
BUS="usb", ACTION=="add", KERNEL=="sd??", NAME="%k", RUN+="/usr/local/bin/detectar-usb"
Os parâmetros usados são os seguintes:
BUS="usb": Define que a regra se aplica apenas a dispositivos USB. Você pode usar também BUS="scsi", BUS="ide" e BUS="pci" para criar regras para outros

tipos de dispositivos. Usando o BUS="pci", por exemplo, você pode criar devices personalizados para sua placa de som, rede ou modem PCI.
ACTION=="add": A regra se aplica quando um dispositivo for conectado. Existe também o parâmetro "remove", que se aplica quando o dispositivo é desconectado. Sem especificar o ACTION, a regra é executada apenas quando o dispositivo é conectado, ou assim que o udev o detecta durante o boot, mas nada é feito quando ele é desconectado.
KERNEL="sd??": Aqui estamos sendo mais específicos. A regra se aplica apenas a dispositivos cujo device comece com "sd", seguido por duas letras/números, como "/dev/sda1" ou "/dev/sdb2". Como especificamos que a regra só se aplica a dispositivos USB, ela não vai ser disparada caso seja conectado um HD serial ATA ou SCSI, por exemplo.
NAME="%k": O parâmetro "NAME" é responsável por criar o device dentro da pasta "/dev", através do qual o dispositivo será acessado. O parâmetro "%k" corresponde ao nome dado pelo Kernel, e pode ser usado quando você não quiser mudar o nome do dispositivo. Se a partição no pendrive é vista como "sda1", o dispositivo será simplesmente "/dev/sda1", como de costume. Se, por outro lado, você quiser que seu pendrive seja visto como "/dev/pendrive", ou qualquer outro nome especial, indique isso na regra, como em: NAME="pendrive". Se quiser que o device seja "/dev/block/pendrive", use: NAME="block/pendrive".
RUN+=: Aqui especificamos uma ação para a regra. Neste caso estou usando o parâmetro "RUN+=", que executa um script externo, que pode se encarregar de montar o dispositivo, adicionar um ícone no desktop ou outra ação qualquer.
Você pode também usar o parâmetro "SYMLINK=" para criar "apelidos" para os dispositivos, fazendo com que além do device padrão, ele responda também por outro definido por você. Você pode usar, por exemplo os parâmetros NAME="%k" SYMLINK="pendrive" para fazer com que, além de ficar acessível pelo dispositivo "/dev/sda1", seu pendrive possa ser acessado pelo "/dev/pendrive".
Esta é a regra irmã da primeira, que executa outro script quando o dispositivo é desconectado. Ela pode ser usada para reverter os passos executados pelo primeiro script, como, por exemplo, remover o ícone no desktop criado pelo primeiro. A regra para remover deve vir sempre antes da regra para adicionar:
ACTION=="remove", KERNEL=="sd*", RUN+="/usr/local/bin/remover-usb"
Note que a regra para remover tem menos parâmetros que a para adicionar. Aqui estou especificando que o script "/usr/local/bin/remover-usb" deve ser executado sempre que algum dispositivo cujo nome comece com "sd" (sda, sdb, etc., incluindo todas as partições) for removido.
Vamos então a um exemplo prático, com as regras e scripts que usei no Kurumin 6.0, para

que detectasse pendrives e HDs USB, criando ícones no desktop quando eles são plugados e removendo os ícones automaticamente.
O primeiro passo é criar um arquivo com as regras. No meu caso, criei o arquivo "/etc/udev/usb-storage.rules" e o link "/etc/udev/rules.d/010-storage.rules" apontando para ele.
Estas são as duas regras adicionadas no arquivo:
ACTION=="remove", KERNEL=="sd*", RUN+="/usr/local/bin/detectar-cartao3"
BUS="usb", ACTION=="add", KERNEL=="sd??", NAME{all_partitions}="%k", RUN+="/usr/local/bin/detectar-cartao3"
Como pode ver, o script "/usr/local/bin/detectar-cartao3" é executado tanto quando um pendrive é inserido quanto removido, pois optei por colocar as duas funções dentro do mesmo script.
A opção NAME{all_partitions}="%k" faz com que o udev crie os dispositivos "/dev/sdx1" até "/dev/sdx15", incluindo o "/dev/sdx", ao invés de criar apenas devices para as partições encontradas. Sem isso, o udev criará o device "dev/sdx1", mas não o "/dev/sdx" (ou vice-versa, de acordo com a regra usada), fazendo com que você consiga acessar os dados na partição, mas não consiga usar o cfdisk ou outro particionador para reparticionar o dispositivo.
O script executado pela regra é bem similar ao que incluí no início do tópico, mas ele agora inclui uma função para detectar os usuários logados e criar um ícone para o pendrive no desktop de cada um. Ao ser clicado, o ícone executa um script separado, o "montar-pendrive" (que incluo a seguir) que detecta se o usuário está com o sudo ativado e monta o pendrive usando o sudo ou o kdesu.
#!/bin/sh# Por Carlos E. Morimoto
# Esta é a função que lista os dispositivos e partições presentes, gerando uma lista como:# sda1 sda2 sdb1 sdc1 (um por linha)
detecta(){cd /sys/block/ for p in `ls | grep sd`; do cd $p; ls | grep $p; cd /sys/block/done}
# Função que lista os usuários logados no KDE:userfu(){ls /tmp/ | grep "kde" | sed -s '/root/D' | cut -f "2" -d "-"}
# Cria o ícone no desktop de cada usuário logado no kde:for u in `userfu`; dousuario="$u"
for i in `detecta`; dojaexiste=`ls /home/$usuario/Desktop/ | grep $i`

mkdir /mnt/$i &>/dev/nullchmod 777 /mnt/$i &>/dev/nullmyfs=''
# Detecta se a partição é FAT ou NTFSde=`echo $i | cut -c 1-3`FAT=`fdisk -l /dev/$de | grep $i | grep FAT`[ -n "$FAT" ] && myfs='fat'NTFS=`fdisk -l /dev/$de | grep $i | grep NTFS`[ -n "$NTFS" ] && myfs='ntfs'
# Cria o ícone apenas se ele já não existirif [ -z "$jaexiste" ]; then echo "[Desktop Entry]" >> /home/$usuario/Desktop/$i.desktopecho "Encoding=UTF-8" >> /home/$usuario/Desktop/$i.desktopecho "Exec=montar-pendrive $i $myfs; sync; sync" >> /home/$usuario/Desktop/$i.desktopecho "Icon=usbpendrive_unmount" >> /home/$usuario/Desktop/$i.desktopecho "Name=$i" >> /home/$usuario/Desktop/$i.desktopecho "StartupNotify=true" >> /home/$usuario/Desktop/$i.desktopecho "Type=Application" >> /home/$usuario/Desktop/$i.desktopecho "X-KDE-SubstituteUID=false" >> /home/$usuario/Desktop/$i.desktopecho "X-KDE-Username=" >> /home/$usuario/Desktop/$i.desktop fidone
# Remove ícones de dispositivos removidos, do desktop de cada usuário:for i in `ls /home/$usuario/Desktop/ | grep sd | cut -c 1-3`; dopresente=`ls /sys/block/ 2>/dev/null | grep $i`[ -z "$presente" ] && rm -f /home/$usuario/Desktop/$i*.desktopdone
done
# O k-sync sincroniza os dados periodicamente, evitando perda de dados # se o pendrive é removido sem desmontar.
killall k-synck-sync &exit 0
Este é o código do script "montar-pendrive"
#!/bin/sh# Usado pelo script detectar-cartao3# Permite montar uma partição em um pendrive. Detecta se o sudo está ativo ou não. # Usa o kdesu quando o sudo está desativado. # Exemplo de uso: "montar pendrive sda1 fat"# Por Carlos E. Morimoto
sudoativo=`sudo whoami`
if [ "$sudoativo" != "root" ]; thenarg=''[ "$2" = "fat" ] && arg='-t vfat -o umask=000'[ "$2" = "ntfs" ] && arg='-t ntfs -o umask=000,ro'kdesu "mount $arg /dev/$1 /mnt/$1"; konqueror /mnt/$1; sync; kdesu "umount /mnt/$1"
elsearg=''[ "$2" = "fat" ] && arg='-t vfat -o umask=000'[ "$2" = "ntfs" ] && arg='-t ntfs -o umask=000,ro'sudo mount $arg /dev/$1 /mnt/$1; konqueror /mnt/$1; sync; sudo umount /mnt/$1fi
E este o do k-sync, que simplesmente executa o comando "sync" a cada 30 segundos:

#!/bin/shwhile [ "1" != "2" ]; dosync; sleep 30done
Você pode fazer também com que as regras ativem serviços de sistema, quando determinados dispositivos são conectados. Por exemplo, instalando os pacotes "bluez-utils", "bluez-firmware" e "kdebluetooth" você passa a ter um suporte bastante completo a dispositivos bluetooth de uma maneira geral. Mas, para que tudo funcione, é necessário que o serviço "bluez-utils" esteja ativado. A regra abaixo faz com que o serviço seja automaticamente ativado quando algum dispositivo bluetooth é conectado:
ACTION=="add", KERNEL=="bluetooth", RUN+="/etc/init.d/bluez-utils start"
Assim como no hotplug, você pode também criar regras que se aplicam a dispositivos específicos. Neste caso, ao invés de criar uma regra genérica, que se aplica a qualquer dispositivo USB, qualquer device que comece com "sd", ou qualquer coisa do gênero, usamos alguma informação que seja específica do dispositivo em questão.
Por exemplo, sempre que conecto a gaveta de HD USB que usei no exemplo do hotplug, é criada a entrada "/sys/block/sda", contendo várias informações sobre o dispositivo, incluindo as partições e capacidade de cada uma. No arquivo "/sys/block/sda/device/model" aparece o modelo "ATMR04-0".
Você pode ver de uma vez todas as informações disponível sobre o dispositivo usando o comando "udevinfo -a -p", seguido da pasta no diretório "/sys/block" ou "/sys/class" criada quando ele é conectado, como em:
$ udevinfo -a -p /sys/block/sda/
Se souber qual é o device usado por ele, você pode fazer a busca por ele, como em "udevinfo -q path -n /dev/sda". Este comando devolve o caminho para ele dentro do diretório "/sys".
O udevinfo retorna sempre uma grande quantidade de informações. Todas elas estão disponíveis dentro do diretório /sys, o udevinfo apenas as reúne num único lugar. No meu caso, algumas linhas interessantes são:
DRIVER=="usb-storage"SYSFS{product}=="USB TO IDE"SYSFS{size}=="117210240"SYSFS{serial}=="0000:00:13.2"
Ao plugar um joystick USB, é criada a pasta "/sys/class/input/js0". Ao rodar o comando "udevinfo -a -p /sys/class/input/js0" para ver as propriedades, aparecem (entre várias outras coisas), as linhas:
SYSFS{manufacturer}=="Logitech"SYSFS{product}=="WingMan Precision USB"

Como pode ver, é sempre fácil encontrar alguma informação que se aplica apenas ao dispositivo em particular, como o model, product ou serial. Qualquer uma delas pode ser usada para compor a regra.
Esta é uma regra simples para o joystick, que cria o link "/dev/joypad", apontando para o dispositivo real do joystick.
BUS="usb", SYSFS{product}=="WingMan Precision USB", NAME="%k", SYMLINK="joypad"
No caso da gaveta, poderíamos criar uma regra um pouco mais complexa, que além de criar um link, executaria um script de backup sempre que ela é conectada:
BUS="usb", SYSFS{product}=="USB TO IDE", KERNEL="sd?1", NAME="%k", SYMLINK="gavetausb" RUN+="/usr/local/bin/backup"
Note que aqui, além do "SYSFS{product}", que identifica a gaveta USB, estou usando também o parâmetro KERNEL="sd?1". Isso faz com que o link aponte para a primeira partição do HD (como "/dev/sda1"), ao invés de simplesmente apontar para o dispositivo ("/dev/sda"). No caso de HDs e pendrives, isso é importante, pois você sempre monta a partição, não o dispositivo em si.
Sempre que a gaveta é plugada, a regra executa o script "/usr/local/bin/backup". Poderíamos usar o mesmo script de backup que vimos no tópico sobre o hotplug, modificando apenas o device. Ao invés de acessar o HD na gaveta através do "/dev/sda1", passaríamos a usar o link "/dev/gavetausb", que é o endereço personalizado.
A principal diferença aqui é que, mesmo que existam outros pendrives e outros HD USB plugados no micro, o device da gaveta será sempre "/dev/gavetausb", de forma que o script de backup poderá ser executado com bem mais segurança. Esta possibilidade de ter links personalizados e fixos é justamente a maior vantagem do udev.
No caso de dispositivos com várias partições, você pode usar o parâmetro "NAME{all_partitions}="%k" que comentei anteriormente. Ele faz com que o udev crie devices para todas as partições possíveis dentro do dispositivo, permitindo que você monte-as manualmente, à moda antiga.
Mais uma dica é que, normalmente, novos dispositivos são criados com permissão de escrita somente para o root, até que você as modifique manualmente, usando o comando "chmod". O udev permite ajustar as permissões, modificando o dono, grupo e permissões de acesso do dispositivo. Isso pode ser usado para que scanners e outros dispositivos fiquem automaticamente acessíveis para todos os usuários do sistema, evitando dores de cabeça em geral, ou fazer com que um pendrive ou outro dispositivo em particular fique disponível apenas para um determinado usuário, mas não para os demais.
Para fazer com que um palm fique disponível apenas para o "joao", você poderia usar a regra:
SYSFS{idProduct}=="00da", SYSFS{manufacturer}=="Palm_Inc.", NAME="%k", SYMLINK="pendrive", OWNER="joao", MODE="0600"

Você pode encontrar mais alguns documentos sobre o tema, incluindo mais exemplos no:http://www.kernel.org/pub/linux/utils/kernel/hotplug/udev.html.

Capítulo 5: Remasterizando o Kurumin e outros live-CDs
O Knoppix é uma das distribuições mais bem sucedidas. Além de ser uma das distribuições mais populares, ele deu origem a um sem número de distribuições especializadas, que juntas possuem um número de usuários provavelmente maior do que qualquer outra distribuição.
Isso foi possível pois, além de ser fácil de usar como um live-CD, o Knoppix pode ser personalizado, o que permite desenvolver novas distribuições e soluções. Você pode escolher entre começar a partir do Knoppix original ou usar o Kurumin (ou outra das muitas distribuições derivadas dele), corrigindo problemas, adicionando novos recursos ou personalizando o que quiser.
O Kurumin mantém a detecção de hardware, possibilidade de personalização e outras características positivas do Knoppix original, adicionando diversos scripts, personalizações, drivers e ferramentas de configuração que tornam o sistema mais fácil e agradável de usar. Enquanto o Knoppix é um sucesso entre o público técnico, o Kurumin conseguiu crescer rapidamente entre os usuários finais, um terreno que até então parecia difícil de conquistar.
Os exemplos deste capítulo se concentram na remasterização do Kurumin (que é, afinal, uma das soluções mais usadas aqui no Brasil), mas os mesmos passos podem ser usados em outras distribuições recentes, derivadas do Knoppix. É uma uma boa oportunidade de colocar em prática o que aprendemos até aqui.
O básico
O Knoppix é uma distribuição baseada no Debian, que utiliza o módulo cloop para rodar a partir de uma imagem compactada. Além de dar boot diretamente através do CD, DVD ou pendrive, sem alterar os arquivos no HD, ele inclui uma série de utilitários, com destaque para o hwsetup, que se encarrega de detectar todo o hardware da máquina durante o boot.

Não importa qual seja a configuração do PC: se os componentes forem compatíveis com a versão do Kernel usada, ele funciona sem nenhuma intervenção do usuário. Os scripts de inicialização podem ser editados, de forma a incluir suporte a componentes adicionais, que não sejam detectados pelo script padrão, ou executar funções adicionais diversas, como salvar as configurações em um pendrive ou num compartilhamento de rede.
Além do Kurumin, existem hoje em dia algumas centenas de distribuições baseadas no Knoppix ou distribuições "netas", desenvolvidas a partir do Kurumin ou outra das distribuições "filhas". As vantagens em relação a outras distribuições são:
1- Ele detecta e configura o hardware automaticamente, dispensando a configuração manual em cada máquina
2- Além de ser usado como live-CD, ele pode ser instalado no HD, mantendo a configuração e a detecção de hardware feita durante o boot. O próprio instalador pode oferecer opções adicionais e fazer modificações onde necessário.
3- Você pode instalar novos programas a partir dos repositórios do Debian, usando o apt-get, sem precisar manter pacotes ou um repositório externo.
4- O conteúdo do CD é compactado, o que permite instalar quase 2 GB de programas num CD de 700 MB, mais do que suficiente para uma distribuição completa. Os mesmos passos descritos aqui podem ser usados caso seja necessário desenvolver um sistema maior, destinado a ser gravado em DVD, ou uma distribuição compacta, destinada a ser gravada em um mini-CD.
5- É possível instalar drivers para softmodems e outros tipos de hardware não suportados por default, programas binários ou comerciais, e assim por diante. Você
pode até mesmo usar o Wine para rodar alguns aplicativos Windows. Existem inúmeras aplicações para a idéia. Você pode criar uma distribuição padrão para ser instalada em todos os PCs da empresa e, ao mesmo tempo, usá-la como uma forma de introduzir o Linux aos funcionários, mantendo o Windows instalado no HD. É possível criar CDs bootáveis com softwares diversos para apresentar a seus clientes; criar CDs para aplicações específicas, como discos de recuperação, CDs com documentação, e assim por diante. Só depende da sua criatividade.
Dentro da imagem do CD, você encontra apenas alguns arquivos pequenos, incluindo a página html exibida no final do boot, que variam de acordo com a distribuição. Dentro da pasta /KNOPPIX, vai o arquivo compactado com o sistema, que ocupa quase todo o espaço do CD.
Este arquivo nada mais é do que uma imagem compactada da partição raiz do sistema. O módulo cloop "engana" o Kernel, fazendo-o pensar que está acessando uma partição EXT2 no HD, quando, na verdade, os dados dentro da imagem vão sendo descompactados de forma transparente, conforme são requisitados.
Algumas pastas do sistema que precisam de suporte a escrita, como, por exemplo, os diretórios "/home" e "/var", são armazenadas num ramdisk de 2 MB criado no início do boot. Este ramdisk pode crescer conforme necessário, desde que exista memória suficiente. Como nem todo mundo tem 256 MB de RAM ou mais, o sistema usa partições Linux swap, ou arquivos de troca encontrados em partições Windows, caso exista um HD instalado. Na falta dele, o sistema roda inteiramente na memória RAM, lendo os arquivos a partir do CD.
O módulo cloop foi originalmente desenvolvido por Andrew Morton, que é atualmente o mantenedor do Kernel 2.6. Na época ele achou que o módulo não serviria para nada interessante e o descartou. Algum tempo depois ele foi redescoberto pelo Klaus Knopper, que acabou o utilizando como um dos componentes base do Knoppix. É um bom exemplo sobre como as coisas funcionam dentro do open-source.
Nas versões recentes, o ramdisk é usado também para armazenar as alterações feitas com a ajuda do UnionFS. O diretório raiz contém um conjunto de links que apontam para diretórios dentro da pasta "/UNIONFS", que é composta pela combinação do ramdisk

(leitura e escrita) e da pasta "/KNOPPIX", onde é montada a imagem compactada do CD (somente leitura).
Para gerar uma versão customizada, precisamos descompactar esta imagem numa pasta do HD, fazer as modificações desejadas, gerar uma nova imagem compactada e finalmente, gerar o novo arquivo .iso, que pode ser gravado no CD ou DVD.
Para isso, você precisará de uma partição Linux com 2.5 GB de espaço livre (no caso do Kurumin) ou 3.5 GB caso esteja remasterizando o Knoppix ou outra distribuição com 700 MB. No caso das versões em DVD, é necessário um espaço proporcionalmente maior. Calcule um espaço 5 vezes maior que o tamanho do sistema original, pois a imagem descompactada ocupa 3 vezes mais espaço e vai ser necessário guardar também a nova imagem compactada e o arquivo .iso final.
É necessário ter também uma partição Linux swap (ou um arquivo swap) de 1 GB, menos a quantidade de RAM do PC. Se você tem 512 MB de RAM, por exemplo, vai precisar de pelo menos mais 512 MB de swap. O problema neste caso é que o sistema usa a memória para armazenar a imagem compactada enquanto ela está sendo processada, copiando o arquivo para o HD apenas no final do processo.
Note que a quantidade de memória varia de acordo com o tamanho da imagem gerada. Ao gerar uma imagem maior, destinada a ser gravada em DVD, você vai precisar de uma quantidade proporcional de memória ou swap.
Todo o processo de remasterização pode ser feito a partir do próprio CD do Kurumin, ou da distribuição que está sendo modificada. Todas as ferramentas necessárias estão inclusas no próprio CD.
Uma observação importante é que é preciso usar a mesma versão do módulo cloop instalada no sistema de desenvolvimento para fechar o arquivo compactado. Em outras palavras, se você está fazendo um remaster do Kurumin, com uma versão personalizada do Kernel 2.6.16, por exemplo, você vai precisar instalar a mesma imagem do Kernel numa instalação do Kurumin no HD e fechar o novo ISO usando esta instalação.
Se você estiver rodando versões diferentes do Kernel, ou estiver usando outra distribuição, as versões do cloop serão diferentes e o novo CD simplesmente não vai dar boot.

Extraindo
O primeiro passo é dar boot com o CD do Kurumin ou da distribuição em que vai trabalhar. Monte a partição que será usada para extrair o sistema. Você pode aproveitar também a partição de uma distribuição Linux já existente no HD, desde que ele possua espaço livre suficiente.
Um detalhe importante é que (no Kurumin) você deve montar a partição via terminal e não usando os atalhos no desktop. Eles montam as partições adicionando o parâmetro "nodev", que impede que os scripts direcionem suas saídas para o "/dev/null", causando uma série de erros. Vou usar como exemplo a partição "/dev/hda6".
# mount -t reiserfs /dev/hda6 /mnt/hda6
O próximo passo é criar duas pastas, uma para abrigar a imagem descompactada e outra para guardar os arquivos que irão no CD (fora da imagem compactada), como os arquivos de boot e os manuais. Lembre-se de que os arquivos dentro da imagem compactada ficam acessíveis apenas dando boot pelo CD, enquanto os arquivos fora da imagem podem ser acessados a partir de qualquer sistema operacional, como se fosse um CD-ROM comum.
Na época em que comecei a desenvolver o Kurumin, a única referência (embora bem resumido) era o "Knoppix how-to" do Eadz. Em homenagem, continuo até hoje usando os nomes de pastas indicados nele:
# mkdir /mnt/hda6/knxmaster# mkdir /mnt/hda6/knxsource# mkdir /mnt/hda6/knxsource/KNOPPIX
A pasta "knxmaster" é usada para armazenar uma cópia simples dos arquivos do CD, usada para gerar o ISO final. A pasta "knxsource/KNOPPIX" por sua vez armazena a cópia descompactada do sistema, onde fazemos as modificações.
Comece fazendo a cópia completa dos arquivos do CD para dentro da pasta "knxmaster/". Ao dar boot pelo CD, os arquivos ficam disponíveis dentro da pasta "/cdrom":
# cp -a /cdrom/* /mnt/hda6/knxmaster/
Em seguida, vamos criar a imagem descompactada do sistema na pasta knxsource/KNOPPIX/. Para o comando abaixo você deve ter dado boot a partir do CD; ele nada mais é do que uma forma de copiar o sistema de arquivos montado durante o boot para a pasta indicada:
# cp -Rp /KNOPPIX/* /mnt/hda6/knxsource/KNOPPIX/
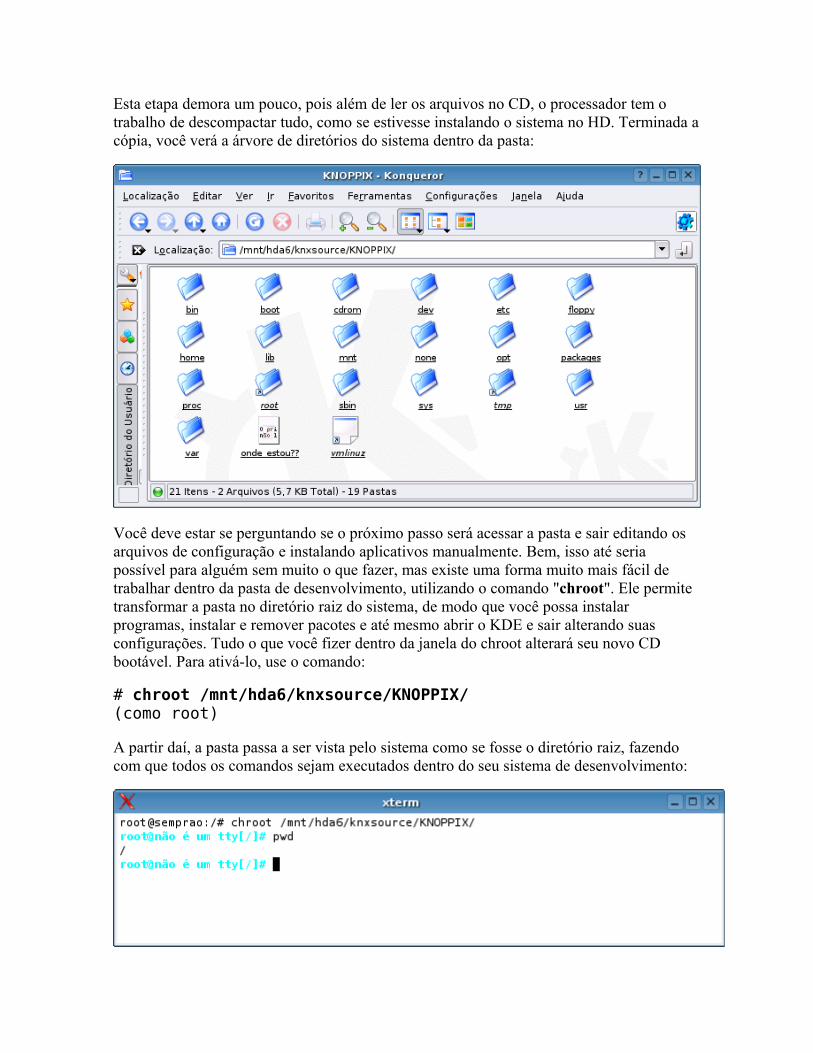
Esta etapa demora um pouco, pois além de ler os arquivos no CD, o processador tem o trabalho de descompactar tudo, como se estivesse instalando o sistema no HD. Terminada a cópia, você verá a árvore de diretórios do sistema dentro da pasta:
Você deve estar se perguntando se o próximo passo será acessar a pasta e sair editando os arquivos de configuração e instalando aplicativos manualmente. Bem, isso até seria possível para alguém sem muito o que fazer, mas existe uma forma muito mais fácil de trabalhar dentro da pasta de desenvolvimento, utilizando o comando "chroot". Ele permite transformar a pasta no diretório raiz do sistema, de modo que você possa instalar programas, instalar e remover pacotes e até mesmo abrir o KDE e sair alterando suas configurações. Tudo o que você fizer dentro da janela do chroot alterará seu novo CD bootável. Para ativá-lo, use o comando:
# chroot /mnt/hda6/knxsource/KNOPPIX/(como root)
A partir daí, a pasta passa a ser vista pelo sistema como se fosse o diretório raiz, fazendo com que todos os comandos sejam executados dentro do seu sistema de desenvolvimento:

Antes de começar a trabalhar, monte o diretório /proc dentro do chroot. Sem isso a funcionalidade será limitada e você receberá erros diversos ao instalar programas:
# mount -t proc /proc proc
Nas versões recentes, que utilizam o udev (usado a partir do Kurumin 6.0), é necessário montar também a pasta "/sys" e o "/dev/pts". Sem os dois, você não conseguirá carregar o modo gráfico, como explico adiante:
# mount -t sysfs sys /sys# mount -t devpts /dev/pts /dev/pts
Para acessar a internet de dentro do chroot e assim poder usar o apt-get para instalar programas, edite o arquivo "/etc/resolv.conf", colocando os endereços dos servidores DNS usados na sua rede, como em:
nameserver 200.199.201.23nameserver 200.177.250.138
A partir daí, você pode instalar novos pacotes via apt-get, como se fosse um sistema instalado. Se precisar instalar pacotes manualmente, copie os arquivos para dentro de uma pasta no diretório e instale usando o comando "dpkg -i". No Kurumin, por exemplo, uso a pasta "/knxsource/KNOPPIX/packages/", que é vista como "/packages" dentro do chroot.
Inicialmente, o chroot permite usar apenas comandos de modo texto. Você pode editar arquivos manualmente usando editores de modo texto, como o mcedit e o vi e usar o apt-get, mas não tem como usar ferramentas gráficas ou mudar configurações no centro de controle do KDE, por exemplo.
É possível carregar o modo gráfico de dentro do chroot, configurando a variável DISPLAY do sistema para que seja usado um servidor X externo. Isso permite carregar o KDE ou outros ambientes gráficos, útil principalmente quando você precisar alterar as opções visuais do sistema, editar o menu do KDE ou alterar a configuração dos aplicativos.
É até possível fazer isso via linha de comando (eu faço ;) editando os arquivos de configuração do KDE (que vão dentro da pasta ".kde/", no home) mas é muito mais simples através do Kcontrol.
Existem duas opções aqui. Você pode abrir um segunda seção do X, ou usar o Xnest (a opção mais simples, porém mais precária), que abre uma instância do X dentro de uma janela.
Para abrir o servidor X "real", use o comando:
# X -dpi 75 :1
Isso abrirá um X "pelado", com a tela cinza e o cursor do mouse. Volte para o X principal pressionando "Ctrl+Alt+F7" e retorne para ele pressionando "Ctrl+Alt+F8".
Para abrir o Xnest, use (neste caso com seu login de usuário, não o root), os comandos:

$ xhost +$ Xnest :1
Em ambos os casos, você terá aberta uma segunda seção do X (:1), que podemos usar de dentro do chroot.
Existem algumas considerações antes de continuar. Inicialmente, você está logado como root dentro do chroot. Ao alterar as configurações do sistema (configurações visuais, menu, programas que serão carregados na abertura do KDE, etc.) precisamos fazer isso como o usuário usado por padrão no sistema, "knoppix" no Knoppix ou "kurumin" no Kurumin.
As configurações padrão vão inicialmente na pasta "/etc/skel". O conteúdo é copiado para a pasta home durante o boot, criando a pasta "/home/kurumin" ou "/home/knoppix". Precisamos refazer esse processo artificialmente, de forma a carregar o ambiente gráfico (e com o usuário certo ;) a partir do chroot.
Comece (ainda como root) copiando os arquivos para a pasta home do usuário desejado. Vou usar como exemplo o usuário kurumin. Lembre-se de que tudo isso é feito dentro da janela do chroot:
# cd /home# cp -R /etc/skel kurumin# chown -R kurumin.kurumin kurumin/# rm -rf /var/tmp/*
Agora logue-se como o usuário kurumin (ainda dentro do chroot) e abra o KDE na instância extra do X que abrimos anteriormente:
# su kurumin$ cd /home/kurumin/$ export DISPLAY=localhost:1$ startkde
Isso abrirá o KDE dentro da segunda seção do X. Se precisar carregar outra interface, substitua o "startkde" pelo comando adequado.
Ao usar o Xnest, é normal que sejam exibidas mensagens de erro diversas (no terminal) durante a abertura do KDE. Alguns aplicativos podem ser comportar de forma estranha, o que também é normal já que ele não oferece todos os recursos do servidor X "real". Pense nele como uma forma rápida de alterar as configurações do sistema que está sendo remasterizado e não como algo livre de falhas.
Depois de alterar todas as configurações desejadas, feche o KDE pelo "Iniciar > Fechar Sessão > Finalizar sessão atual" e, de volta ao terminal do chroot, copie os arquivos modificados do "/home/kurumin" de volta para o "/etc/skel", sem se esquecer de restabelecer as permissões originais:
$ exit# cd /home# cp -Rf kurumin/* /etc/skel/# chown -R root.root /etc/skel# rm -rf /home/kurumin
Fechando a nova imagem
Depois de fazer a primeira rodada de alterações, é hora de fechar a nova imagem e testar. Evite fazer muitas modificações de uma vez, pois assim fica mais difícil de detectar a origem dos problemas. O ideal é fazer algumas alterações, fechar uma nova imagem, testar, fazer mais algumas alterações, fechar outro, e assim por diante. Salve as imagens anteriores, elas podem ser usadas como pontos de recuperação. Com elas, você pode

recuperar o sistema a partir de qualquer ponto, caso aconteça qualquer problema estranho que não consiga resolver sozinho.
Caso, mais adiante, você faça alguma alteração que quebre o sistema, basta dar boot com o último CD gerado, deletar o conteúdo da pasta "/knxsource/KNOPPIX" e extrair a imagem novamente. Você terá seu sistema de volta da forma como estava quando gravou o CD.
Para fazer os testes, você tem duas opções: gravar os CDs e dar boot num segundo micro ou usar uma máquina virtual, configurada para usar o arquivo .iso gerado como CD-ROM (a melhor opção se você tem apenas um PC). Evite gravar as imagens em CD-RW para testar, pois eles apresentam muitos erros de leitura, que podem levar a problemas estranhos no sistema, causados por falta de arquivos. Eles podem fazer você perder muito tempo procurando por problemas que na verdade são causados pela mídia. Use CD-R normais, ou use diretamente os arquivos .iso dentro da VM.
Ao fechar as imagens, comece limpando o cache de pacotes do apt-get dentro do chroot. O apt conserva uma cópia de todos os pacotes baixados, o que desperdiça bastante espaço.
# apt-get clean
Você pode também deletar a base de dados dos pacotes disponíveis (que é gerada ao rodar o "apt-get update"), reduzindo o tamanho da imagem final em quase 10 MB:
# rm -f /var/lib/apt/lists/*(não delete a pasta "/var/lib/apt/lists/partial", apenas os arquivos)
Outro comando útil, que ajuda a liberar espaço é o "deborphan", que lista bibliotecas órfãs, que não são necessárias para nenhum programa instalado. Elas vão surgindo conforme você instala e remove programas.
# deborphan
Os pacotes listados por ele podem ser removidos com segurança usando o "apt-get remove".
Delete também o histórico de comandos do root, que contém os comandos que você executou durante o processo de personalização; não existe necessidade de divulgá-los ao mundo. Aproveite para eliminar também o diretório .rr_moved:
# rm -f /home/root/.bash_history# rm -rf /.rr_moved
Finalmente chegou hora de dar adeus ao chroot e gerar a nova imagem. Comece desmontando o "/dev/pts", o "/sys" e o diretório "/proc" que montamos no início do processo, caso contrário todo o conteúdo da memória e do diretório /dev será incluído na imagem, gerando um arquivo gigante:

# umount /dev/pts# umount /sys# umount /proc
Agora pressione CTRL+D para sair do chroot.
O próximo passo é gerar o novo arquivo compactado. Esta etapa demora um pouco já que o sistema precisa compactar todo o diretório knxsource.
Antes de tentar gerar a imagem, use o comando free para verificar se a memória swap está ativada. Se necessário, formate novamente a partição swap e reative-a com os comandos "mkswap /dev/hda2" e "swapon /dev/hda2", substituindo o "hda2" pela partição correta.
Depois de tudo verificado, o comando para gerar a imagem é:
# mkisofs -R -V "Meu_CD" -hide-rr-moved -pad /mnt/hda6/knxsource/KNOPPIX \| /usr/bin/create_compressed_fs - 65536 > /mnt/hda6/knxmaster/KNOPPIX/KNOPPIX(As duas linhas formam um único comando)
Ele é um pouco longo mesmo, dado o número de parâmetros necessários. Aqui vai uma explicação mais detalhada da função de cada um:
mkisofs: Este é o programa usado para gerar imagens ISO no Linux. Ele é utilizado originalmente por programas de gravação de CD. Graças aos parâmetros extras, ele é "adaptado" para gerar a imagem compactada do sistema.
-R: Ativa as extensões Rock-Ridge, que adicionam suporte a nomes longos no Linux.
-V "Kurumin": O nome do volume. Você pode substituir o "Kurumin" por qualquer outro nome.
-hide-rr-moved: Esconde o diretório RR_MOVED caso encontrado. Apenas uma precaução.
-pad: Para prevenir problemas de leitura, o tamanho total da imagem deve ser sempre um múltiplo de 32 KB. Este parâmetro verifica isso e adiciona alguns bits zero no final da imagem para completar os últimos 32 KB, caso necessário.
/mnt/hda6/knxsource/KNOPPIX: Este é o diretório fonte, onde está a imagem descompactada do sistema. Não se esqueça de substituir o "hda6" pela partição correta.
| /usr/bin/create_compressed_fs - 65536: Este é o grande truque. O pipe direciona toda a saída do comando para o programa "create_compressed_fs" (incluído no sistema), que se encarrega de compactar os dados. Note que por causa do uso deste comando, você só poderá gerar a imagem compactada a partir do Kurumin ou outra distribuição baseada no Knoppix, de preferência uma instalação do próprio sistema que está remasterizando. Você

não conseguirá fazer a partir do Mandriva (por exemplo), pois ele não inclui o executável citado aqui.
> /mnt/hda6/knxmaster/KNOPPIX/KNOPPIX: O redirecionamento (>) faz com que o fluxo de dados gerado pelos comandos anteriores seja salvo no arquivo que especificamos aqui, gerando a imagem compactada do sistema, que será usada no novo arquivo .iso.
Depois de gerar a imagem você notará que o seu micro ficará um pouco lento, pois o processo consome toda a memória RAM disponível. Isso é normal, mova um pouco o mouse e clique nas janelas que ele logo volta ao normal.
Com a nova imagem compactada gerada, falta agora apenas fechar o .iso do CD, usando os arquivos da pasta knxmaster. Este comando é usado nas versões recentes, que utilizam o Kernel 2.6:
# cd /mnt/hda6/knxmaster
# mkisofs -pad -l -r -J -v -V "Kurumin" -no-emul-boot -boot-load-size 4 \-boot-info-table -b boot/isolinux/isolinux.bin -c boot/isolinux/boot.cat \-hide-rr-moved -o /mnt/hda6/kurumin.iso /mnt/hda6/knxmaster
No final será gerado o arquivo "kurumin.iso" dentro da pasta "/mnt/hda6". Você pode alterar o nome do arquivo destino de acordo com a necessidade.
O comando gera um CD bootável usando o isolinux, um sistema de boot que tem uma função similar à do lilo e grub, mas é otimizado para uso em CD-ROMs. Os arquivos vão dentro da pasta "boot/isolinux" no raiz do CD. O comando indica o caminho para o executável do isolinux, que será incluído no CD (boot/isolinux/isolinux.bin).
As versões antigas, com o Kernel 2.4, usavam uma imagem de um disquete de 1.44 como sistema de boot. Este é o sistema mais compatível com placas antigas, mas tem uma séria limitação: o sistema de boot precisa ter menos que 1.44 MB, a capacidade do disquete. Com todas as novidades e melhorias, o Kernel 2.6 ficou muito maior, tornando quase impossível criar um sistema de boot funcional em apenas 1.44 MB.
Caso você precise remasterizar uma versão antiga, ainda com o Kernel 2.4, os passos e comandos para remasterizar são os mesmos, mas o comando para fechar o ISO fica:
# mkisofs -pad -l -r -J -v -V "Meu_CD" -b KNOPPIX/boot.img -c \KNOPPIX/boot.cat -hide-rr-moved -o /mnt/hda6/kurumin.iso /mnt/hda6/knxmaster
Ao remasterizar o Kanotix, ou outra distribuição live-CD que utilize o grub como gerenciador de boot, o comando fica:

# mkisofs -pad -l -r -J -v -V "Kanotix" -b boot/grub/iso9660_stage1_5 -c \boot.cat -no-emul-boot -boot-load-size 4 -boot-info-table -hide -rr -moved \-o /mnt/hda6/kanotix.iso /mnt/hda6/knxmaster
Existem duas variáveis dentro do script de instalação (o arquivo "/usr/local/bin/kurumin-install"), que devem ser alteradas de acordo com o tamanho do sistema. Você pode verificar isso a partir do próprio Konqueror, ou usando o comando "du -sh", como em:
$ du -sh /mnt/hda6/knxsource/
Logo no começo do script, você encontra a função responsável pela barra de progresso exibida durante a cópia dos arquivos. Altere o valor de acordo com o tamanho do sistema informado pelo du:
progressbar(){{TOTAL=1300
Um pouco mais abaixo, pela variável que determina o espaço mínimo necessário para fazer a instalação do sistema. O script aborta a instalação caso a partição destino seja menor que o valor especificado aqui:
FSMIN=1300
Personalizando o KDE e programas
Personalizar a configuração padrão do sistema, ajustando o comportamento dos programas, organizando o menu iniciar e arrumando a parte visual acaba sendo uma das partes mais importantes ao desenvolver um sistema destinado a usuários não técnicos, já que é necessário criar um ambiente familiar, bonito e fácil de usar.
O Kurumin armazena as preferências padrão do usuário kurumin (o usado por default) na pasta "/etc/skel". O conteúdo desta pasta é copiado para a pasta "/ramdisk/home/kurumin" durante o boot e (ao rodar o sistema a partir do CD) todas as alterações são perdidas quando o micro é desligado.
Para alterar as configurações default é preciso ir direto ao ponto, editando diretamente os arquivos da pasta "/etc/skel" dentro do chroot. Navegando dentro dela você encontrará pastas com as preferências do KDE e vários outros programas. Não se esqueça de marcar a opção "marcar arquivos ocultos" no Konqueror.
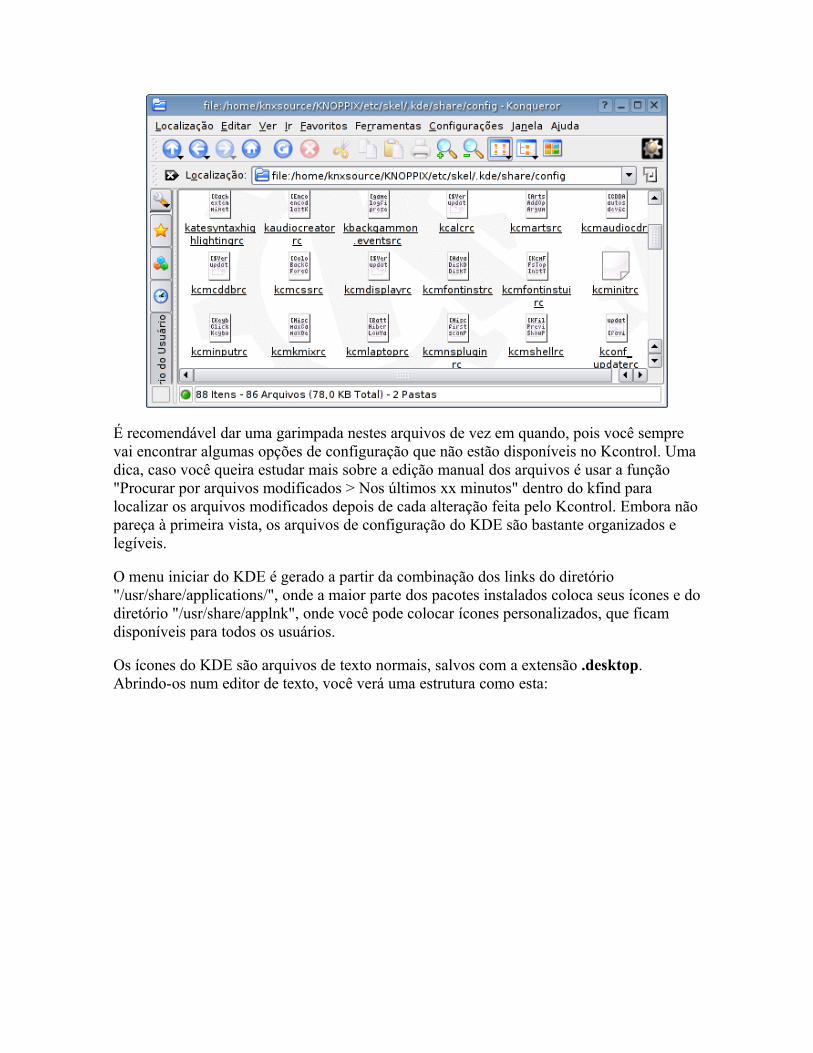
É recomendável dar uma garimpada nestes arquivos de vez em quando, pois você sempre vai encontrar algumas opções de configuração que não estão disponíveis no Kcontrol. Uma dica, caso você queira estudar mais sobre a edição manual dos arquivos é usar a função "Procurar por arquivos modificados > Nos últimos xx minutos" dentro do kfind para localizar os arquivos modificados depois de cada alteração feita pelo Kcontrol. Embora não pareça à primeira vista, os arquivos de configuração do KDE são bastante organizados e legíveis.
O menu iniciar do KDE é gerado a partir da combinação dos links do diretório "/usr/share/applications/", onde a maior parte dos pacotes instalados coloca seus ícones e do diretório "/usr/share/applnk", onde você pode colocar ícones personalizados, que ficam disponíveis para todos os usuários.
Os ícones do KDE são arquivos de texto normais, salvos com a extensão .desktop. Abrindo-os num editor de texto, você verá uma estrutura como esta:
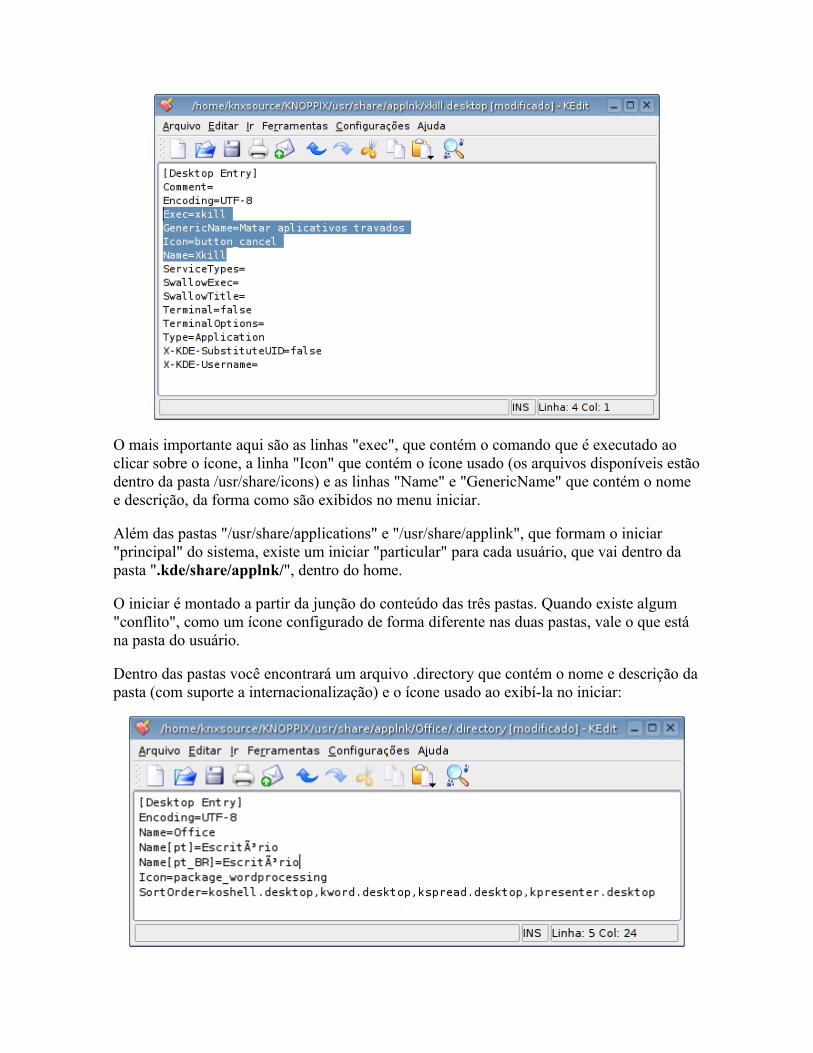
O mais importante aqui são as linhas "exec", que contém o comando que é executado ao clicar sobre o ícone, a linha "Icon" que contém o ícone usado (os arquivos disponíveis estão dentro da pasta /usr/share/icons) e as linhas "Name" e "GenericName" que contém o nome e descrição, da forma como são exibidos no menu iniciar.
Além das pastas "/usr/share/applications" e "/usr/share/applink", que formam o iniciar "principal" do sistema, existe um iniciar "particular" para cada usuário, que vai dentro da pasta ".kde/share/applnk/", dentro do home.
O iniciar é montado a partir da junção do conteúdo das três pastas. Quando existe algum "conflito", como um ícone configurado de forma diferente nas duas pastas, vale o que está na pasta do usuário.
Dentro das pastas você encontrará um arquivo .directory que contém o nome e descrição da pasta (com suporte a internacionalização) e o ícone usado ao exibí-la no iniciar:
Ao editar o iniciar utilizando o kmenuedit, as alterações são salvas nas pastas ".config" e ".local", novamente dentro do home de cada usuário.
Os ícones que aparecem no Desktop do KDE ao dar boot vão na pasta "/etc/skel/Desktop". Estes ícones seguem o mesmo padrão dos ícones do iniciar. Você pode incluir também sub-pastas:
Finalmente, os aplicativos que são executados durante o boot (como a janela do Konqueror exibindo o index.html do CD), são configurados através de ícones colocados na pasta "/etc/skel/.kde/Autostart". A sintaxe dos arquivos .desktop é a mesma em todas estas pastas, você pode arrastar um ícone da pasta "/usr/share/applnk" diretamente para ela, por exemplo:
Assim como o KDE, os demais programas sempre criam pastas de configuração dentro do home. As configurações do XMMS por exemplo, vão dentro da pasta ".xmms", as do gMplayer vão dentro da ".mplayer", e assim por diante. As configurações dos aplicativos do KDE ficam centralizadas dentro da pasta ".kde/share/apps", também dentro do home.

Todas estas pastas que começam com um ponto são vistas pelo sistema como pastas ocultas: para vê-las, você precisa marcar a opção "mostrar arquivos ocultos" no Konqueror.
Esta edição manual dos arquivos é interessante para conhecer melhor o sistema e ter mais controle sobre o que está acontecendo. Mas, por outro lado, ela é trabalhosa e demora até que você consiga dominar um número grande de opções.
A forma mais rápida de personalizar estas configurações é abrir o chroot, logar-se como o usuário desejado copiar as pastas do /etc/skel, rodar o KDE e alterar as configurações desejadas dentro da janela do Xnest e depois salvar as alterações, como vimos anteriormente. A edição manual pode ser usada para corrigir pequenos detalhes e eventuais problemas.
Scripts de inicialização
Depois de instalado, o Kurumin passa a se comportar de forma semelhante a uma instalação do Debian, com os serviços iniciados através de links ou scripts nas pastas "/etc/rcS.d" e "/etc/rc5.d".
Mas, ao rodar a partir do CD, um único script cuida de toda a configuração do sistema, o "/etc/init.d/knoppix-autoconfig". Ele roda o "/usr/bin/hwsetup" (a ferramenta de detecção de hardware), executa o "/usr/sbin/mkxf86config" (que faz a configuração do vídeo) e verifica os parâmetros passados durante o boot (como o "noacpi", "bootfrom=", "noscsi", "xserver=vesa" etc.).
No final do script "/etc/init.d/knoppix-autoconfig", vai o comando "/etc/init.d/kdm start" que inicia o carregamento do modo gráfico. Neste ponto é executado o script "/etc/X11/Xsession.d/45xsession", que verifica os parâmetros de boot relacionados com o ambiente gráfico (desktop=fluxbox ou desktop=gnome, por exemplo), copia o diretório "/etc/skel" para o "/home/kurumin", criando o diretório home do usuário padrão do sistema e, por último, carrega o KDE ou outro ambiente gráfico escolhido.
No Knoppix original e em outras distribuições derivadas dele, o carregamento do modo gráfico não é disparado pela abertura do KDM, mas sim diretamente através de uma entrada no arquivo "/etc/inittab". Na prática isso não faz muita diferença, pois o script "/etc/X11/Xsession.d/45xsession" é executado da mesma forma.
A instalação do Kurumin é feita pelo script "/usr/local/bin/kurumin-install", que copia os arquivos do sistema para a partição, define senhas e faz outras alterações necessárias.
Ao personalizar o sistema, é importante conhecer a função de cada um destes scripts, pois eles permitem modificar o comportamento do sistema durante o boot e fazê-lo executar funções adicionais. Vamos a alguns exemplos:
Quando você precisar fazer alguma alteração no processo inicial de boot, alterar o comportamento de uma das opções de boot ou criar uma nova (como o "kurumin union=" que adicionei no Kurumin 5.1), alterar a configuração padrão do teclado ou linguagem, ou

executar algum comando em especial durante o boot, altere o "/etc/init.d/knoppix-autoconfig".
Por exemplo, esta é a seção do script que verifica se o parâmetro "kurumin noalsa" foi passado no boot e decide se executará ou não os comandos que detectam e ativam a placa de som:
if checkbootparam "noalsa"; thenecho "Abortando a detecção da placa de som, como solicitado no boot."elseif [ -n "$USE_ALSA" -a -x /etc/init.d/alsa-autoconfig ]; thentouch /tmp/modules.dep.temp[ -n "$SOUND_DRIVER" ] && rmmod -r "$SOUND_DRIVER" >/dev/null 2>&1case "$ALSA_CARD" in auto*) ALSA_CARD="";; esacALSA_CARD="$ALSA_CARD" /etc/init.d/alsa-autoconfig [ ! -r /etc/modules.conf ] && \ln -sf /KNOPPIX/etc/modules.conf /etc/modules.conffi/etc/init.d/alsa start# Unmuta o somaumix -w 80 &; aumix -v 80 &; aumix -m 20 &; aumix -c 80 &; aumix -l 50 &# Abre as permissões do som para outros usuários:chmod 666 /dev/dspchmod 666 /dev/mixerfi
Quando você precisa verificar ou alterar algo relacionado com a configuração do vídeo, com a cópia dos arquivos do "/etc/skel" para o "/home/kurumin" ou com as opções de boot que permitem especificar o gerenciador de janelas padrão (kurumin desktop=fluxbox, kurumin desktop=gnome, etc.) procure no "/etc/X11/Xsession.d/45xsession".
Este é um exemplo de configuração, a parte do script que verifica se foi dada alguma opção no boot para usar o fluxbox, gnome ou outro desktop e, caso contrário, carrega o KDE:
[ -f /etc/sysconfig/desktop ] && . /etc/sysconfig/desktopexport QDESKTOP=$(cat $HOME/.wmrc)if [[ -n $QDESKTOP && $QDESKTOP != "default" ]]; thenDESKTOP=$QDESKTOPelse# kde is the default[ -z "$DESKTOP" ] && DESKTOP="kde"fi
Quando precisar alterar algo relacionado com o processo de instalação do sistema, como fazer com que ele se comporte de forma diferente depois de instalado, ou adicionar algum passo adicional na instalação, você pode modificar o instalador, que no caso do Kurumin é o script "/usr/local/bin/kurumin-install".
Ele é uma evolução do "knx-hdinstall", o antigo instalador do Knoppix. Atualmente o Knoppix utiliza um novo instalador, que faz um "live-install", fazendo com que a instalação no HD se comporte da mesma forma que do CD, com o procedimento de detecção de hardware feito a cada boot. É uma idéia diferente de instalação, com alguns pontos positivos e outros negativos.

As versões recentes do Kanotix introduziram um instalador gráfico, com uma interface mais bonita e várias mudanças, que acabou sendo incorporado ao Knoppix como instalador alternativo. Como pode ver, existem outras opções de instaladores, que você pode utilizar na sua personalização.
Como comentei no início deste capítulo, você pode incluir funções adicionais para detectar componentes que não sejam automaticamente ativados pelos scripts padrão. Isto é importante em muitas situações, pois é comum que empresas possuam lotes de impressoras, placas de vídeo ou outros componentes que precisem de alguma configuração adicional para funcionarem. Ao invés de fazer as modificações máquina por máquina, é mais eficiente escrever um script que as faça automaticamente durante o boot do CD.
Você pode encontrar alguns exemplos de funções diversas que uso no Kurumin no arquivo "/usr/local/bin/hwsetup-kurumin", executado no final do boot, através do comando incluído no final do arquivo "/etc/init.d/knoppix-autoconfig".
Este arquivo não é muito longo, pois normalmente as entradas antigas vão sendo removidas com o tempo, conforme vão sendo usadas novas versões do hwsetup, com suporte aos novos componentes.
Como vimos no capítulo sobre shell script, uma forma simples de detectar componentes durante o boot é através da saída do comando "lspci". Veja um trecho da identificação que não mude de um modelo de placa para outra e filtre usando um pipe e o grep, de forma a carregar o módulo apropriado caso a entrada seja encontrada. Estes são dois exemplos que usei no Kurumin 5.1 para detectar placas CMI 8738 e a placa de som virtual usada pelo VMware:
cmi=`lspci | grep "CM8738"`if [ -n "$cmi" ]; then/sbin/modprobe snd-cmipcifi
ensonic=`lspci | grep "Ensoniq ES1371"`if [ -n "$ensonic" ]; then/sbin/modprobe snd-ens1371fi
No caso de placas de vídeo, é necessário fazer alterações no arquivo "/etc/X11/xorg.conf", modificando a linha com o driver usado. No caso de placas com suporte 3D, é muitas vezes necessário também carregar um módulo de Kernel.
A detecção do vídeo é feita pelo script "/usr/sbin/mkxf86config". Ele detecta a placa de vídeo, monitor e outras informações necessárias e gera o arquivo de configuração do vídeo. Quando ele não conhece a identificação de uma determinada placa de vídeo, é normal que ele use o driver "vesa" que, como vimos, é um driver genérico, que possui um baixo desempenho.
Você pode incluir funções no final do script para detectar a placa usando a saída do lspci e substituir a linha com o driver usando o sed. Este é um exemplo que usei para detectar as placas Intel Extreme, usadas no HP NX6110 e outros notebooks. Colocado no final do

arquivo, ele troca o driver de "vesa" para "i810" quando a placa é detectada. Se o driver já estiver correto, ele não faz nada:
# Detecta as Intel Extreme# (mais adiante, o próprio script renomeia o arquivo para xorg.conf)vidintel=`lspci | grep "Intel Corp. Mobile Graphics"`vidintel2=`lspci | grep "Intel Corporation Mobile"`vidintel3=`lspci | grep "915GM/GMS"`if [ -n "$vidintel" -o -n "$vidintel2" -o -n "$vidintel3" ]; thensed -e 's/vesa/i810/g' /etc/X11/XF86Config-4 > /etc/X11/XF86Config-4.1rm -f /etc/X11/XF86Config-4; mv /etc/X11/XF86Config-4.1 /etc/X11/XF86Config-4fi
Em alguns casos, detalhes aparentemente simples podem fazer você perder um bom tempo. Um problema que tive nas versões recentes do Kurumin foi com relação com medidor de bateria do KDE. Você configura se ele deve ser ativado ou não durante o boot através da opção "Controle de energia > Bateria do Laptop" dentro do Painel de Controle do KDE e a configuração é salva no arquivo ".kde/share/config/kcmlaptoprc" (dentro do home).
O problema é que ele só é útil em notebooks. Se você simplesmente o deixar ativo na configuração, ele vai ser aberto sempre, mesmo em desktops, onde ele não tenha serventia alguma.
Uma forma que encontrei para tornar a detecção mais inteligente, fazendo com que ele seja habilitado apenas em notebooks, foi incluir uma função dentro do arquivo "/etc/X11/Xsession.d/45xsession" (que, como vimos, é o responsável pela abertura do X e carregamento do KDE), que verifica se o módulo "battery" está ativo (indício que o sistema está rodando num notebook, com bateria) e altera o arquivo de configuração, desativando o medidor de bateria quando necessário:
bateria=`lsmod | grep battery` if [ -z $bateria ]; then cd /ramdisk/home/kurumin/.kde/share/config/sed -e 's/Enable=true/Enable=false/g' kcmlaptoprc > kcmlaptoprc2rm -f kcmlaptoprc; mv kcmlaptoprc2 /kcmlaptoprcfi
Em alguns casos mais específicos, você pode precisar incluir novas opções de boot. Vimos um exemplo no tópico sobre como instalar o Kurumin e outras distribuições em pendrives, incluindo uma opção de boot para que o sistema usasse uma imagem para salvar as alterações do UnionFS.
Mudando a lingua padrão e traduzindo as mensagens de boot
Hoje em dia, quase todos os programas que usamos no dia-a-dia incluem suporte a internacionalização.
No caso do KDE, as traduções para todos os aplicativos base são agrupadas nos pacotes "kde-i18n", como em "kde-i18n-ptbr" ou "kde-i18n-es" (espanhol), que podem ser instalados via apt-get. Os pacotes não conflitam entre si, de forma que você pode manter

vários deles instalados e definir qual será a língua padrão dentro do Kcontrol, junto com a configuração do teclado e outros detalhes.
O suporte a inglês norte-americano vem instalado por padrão e é usado quando configurado, ou quando nenhum outro pacote de internacionalização estiver instalado.
Os demais programas, são configurados através do pacote "locales". Neste caso, cada programa inclui diretamente as traduções disponíveis e você determina qual será utilizada por padrão e quais outras ficarão instaladas. As demais podem ser removidas automaticamente usando o comando "localepurge", o que economiza um bocado de espaço.
Para alterar a configuração do locales, use o comando:
# dpkg-reconfigure locales
Para remover os arquivos de internacionalização que não estão sendo usados, execute o:
# localepurge
Além dos aplicativos, existem também as mensagens do sistema, exibidas durante o boot quando o sistema roda a partir do CD-ROM.
Para traduzi-las, você precisa ir diretamente nos dois scripts executados durante o boot, o "linuxrc", que fica dentro da imagem compactada de boot (o arquivo "boot/isolinux/minirt26.gz") e o arquivo "/etc/init.d/knoppix-autoconfig", dentro da imagem principal.
Para chegar ao "linuxrc", acesse a pasta "/mnt/hda6/knxmaster/boot/isolinux". Descompacte o arquivo minirt26.gz, crie uma pasta temporária e monte-a dentro da pasta. O "linuxrc" fica logo no diretório raiz. Ao terminar, faça o processo inverso, desmontando e compactando a imagem novamente:
# cd /mnt/hda6/knxmaster/boot/isolinux/# gunzip minirt26.gz# mkdir tmp/# mount -o loop minirt26.gz tmp/# kedit tmp/linuxrc# umount tmp/# gzip minirt26
Para traduzir as mensagens nos dois arquivos, pesquise dentro do arquivo por "echo", usado para escrever a grande maioria das mensagens exibidas na tela.
Mudando o usuário padrão

O usuário padrão do Knoppix é o "knoppix", que foi trocado pelo usuário "kurumin" nas versões recentes do Kurumin.
Os passos básicos para trocar o usuário padrão do sistema ao remasterizar o CD são:
1- Edite o arquivo "/etc/passwd", troque o "kurumin" e o "home/kurumin" pelo nome e o diretório home do novo usuário
2- Edite o arquivo "/etc/shadow" e novamente troque o "kurumin" pelo novo usuário. Este é o arquivo de senhas, que pode ser visto e editado apenas pelo root.
3- Troque o login também no "/etc/sudoers", que é o arquivo com a configuração do sudo.
4- É preciso trocar o nome do usuário também no arquivo "/etc/kde3/kdm/kdmrc" (para manter o autologin do KDE) e no arquivo /etc/X11/Xsession.d/45xsession.
5- Não se esqueça de mudar todas as ocorrências do login no arquivo "/etc/group" e no arquivo "linuxrc", dentro da imagem compactada carregada durante a etapa inicial do boot (o arquivo "boot/isolinux/minirt.gz", que vimos a pouco). Existem também referencias a serem trocadas no script "/etc/init.d/knoppix-autoconfig"
Estas alterações trocam o usuário no sistema, mas falta também fazer as modificações no "/usr/local/bin/kurumin-install", que é o instalador, assim como em mais alguns scripts dos ícones mágicos. Use o kfind para localizar os arquivos que precisam ser modificados com mais facilidade, procurando por linhas que contenham a string "kurumin".
Criando um DVD de recuperação
Ao alterar os scripts de inicialização, você pode mudar radicalmente o comportamento do sistema, fazendo com que ele execute ações específicas durante o boot. Isso permite criar todo tipo de solução, como CDs de demonstração que rodam programas específicos, CDs de diagnóstico, mini-distribuições com conjuntos personalizados de programas, e assim por diante.
Vamos a um exemplo de como criar um DVD de recuperação, que restaura automaticamente uma imagem previamente criada usando o Partimage, de forma a restaurar o sistema originalmente instalado na máquina, como nos micros de grife. Este DVD de recuperação não se limita a restaurar instalações do Linux: você pode restaurar também instalações do Windows, ou instalações com dois ou mais sistemas em dual boot. A única limitação é a capacidade da mídia usada. Dependendo do tamanho da imagem, o sistema de recuperação pode ser gravado num mini-DVD, ou até mesmo num CD-R.
Comece instalando e configurando o sistema normalmente no micro alvo. Depois de terminar, use o Partimage para gerar uma imagem de cada partição do HD, junto com o backup da MBR e da tabela de particionamento, como vimos no capítulo 2.

Coloque todos os arquivos que serão usados dentro da pasta "knxmaster/" na sua partição de trabalho. Você pode colocar tudo dentro de uma sub-pasta para manter as coisas organizadas, como "knxmaster/image/". Lembre-se de que os arquivos colocados na "knxmaster/" não são compactados ao fechar a imagem. Por isso, não se esqueça de ativar a compactação do Partimage ao gerá-los.
O próximo passo é fazer com que o DVD passe a restaurar a imagem automaticamente durante o boot, sem intervenção do usuário. A idéia é que o sistema de recuperação seja o mais simples possível, de forma que seja possível restaurar a imagem rapidamente em caso de problemas.
Uma dica é que, ao invés de fazer um DVD de recuperação que chega "chutando o balde", formatando o HD e deletando todos os arquivos, você pode fornecer os micros com o HD dividido em duas partições: uma com o sistema e outra para dados. O DVD de recuperação pode então restaurar apenas a partição do sistema, sem mexer na partição de dados, dando também a opção de fazer uma restauração completa.
Para que o DVD restaure a imagem durante o boot, precisamos alterar o conteúdo do script "knxsource/KNOPPIX/etc/init.d/knoppix-autoconfig", dentro da partição de trabalho.
Como vimos, este é o script responsável por toda a etapa inicial do boot, onde o hardware é detectado e o KDE carregado.
O que vamos fazer é colocar os comandos para gravar a imagem e reiniciar o micro no final deste arquivo. Isso fará com que o sistema entre em loop. Ele começa o boot, faz a gravação da imagem de recuperação e em seguida reinicia a máquina, sem nem chegar a abrir o KDE. Você pode incrementar este script adicionando mais opções.
O comando que chama o partimage e regrava a imagem sem perguntar nada ao usuário é:
partimage -f action=2 -b restore /dev/hda1 /cdrom/image/sistema.img.000 shutdown -h now
O Partimage possui várias opções de linha de comando, que você pode estudar através do "man partimage". O "-b" faz com que o processo todo seja feito automaticamente, sem pedir confirmação e o "-f action=2" reinicia o micro depois da gravação. O "/dev/hda1" é a partição onde a imagem será escrita, enquanto o "sistema.img.000" é o arquivo de imagem colocado dentro da pasta knxmaster. Note que ao dar boot via CD, todo o conteúdo da pasta "knxmaster/" fica acessível através da pasta "/cdrom", mantendo a mesma estrutura de diretórios.
O "shutdown -h now" abaixo da primeira linha é só pra garantir que o micro vai mesmo reiniciar depois de terminar a gravação. Na verdade ele nem chega a ser usado, pois o próprio comando do Partimage se encarrega de reiniciar no final do processo.
Você pode adicionar as linhas próximo do final do arquivo, logo abaixo das linhas abaixo, que marcam o final da parte de detecção e configuração inicial do sistema:

echo "6" > /proc/sys/kernel/printk# Re-enable signalstrap 2 3 11
O final do arquivo ficará assim:
echo "6" > /proc/sys/kernel/printk# Re-enable signalstrap 2 3 11
partimage -f action=2 -b restore /dev/hda1 /cdrom/image/sistema.img.000 shutdown -h now
# ... seguido pelo restante do script.
Para uma restauração completa do HD, incluindo a MBR e a tabela de particionamento, os comandos seriam:
dd if=/cdrom/image/hda.mbr of=/dev/hda sfdisk --force /dev/hda < /cdrom/image/hda.sf partimage -f action=2 -b restore /dev/hda1 /cdrom/image/sistema.img.000 shutdown -h now
... onde o "hda.mbr" é o arquivo com a cópia dos primeiros 512 bytes do HD, gerado usando o dd e o "hda.sf" é a tabela de particionamento, gerada pelo sfdisk; ambas as coisas incluídas na pasta "image/", junto com a imagem principal.
Note que esta restauração completa vai restaurar o particionamento original do HD, apagando todos os dados. É importante exibir um aviso e pedir duas ou mais confirmações antes de realmente começar o processo. Você pode exibir as mensagens e confirmações usando o dialog, já que elas serão exibidas com o sistema em modo texto.
Caso o HD tenha mais de uma partição (mesmo que vazias), você deve gerar e restaurar a imagem de cada uma usando o partimage.
Depois da modificação, feche o novo ISO, grave o DVD e faça o teste dando boot no micro alvo. Você pode também testar dentro de uma máquina virtual do VMware.
No caso da idéia de oferecer a opção de restaurar apenas a partição do sistema ou fazer a restauração completa, você pode usar um script como o abaixo, que pergunta e executa os comandos apropriados:
dialog --msgbox "Bem vindo o DVD de recuperação do sistema." 8 50
dialog --yes-label "Sistema" --no-label "Completa" --yesno "Você deseja apenas restaurar a instalação do sistema, ou fazer uma restauração completa, apagando todos os dados do HD? \nResponda 'Sistema' para restaurar o sistema ou 'Completa' para fazer a restauração completa." 10 50
if [ "$?" = "0" ]; then partimage -f action=2 -b restore /dev/hda1 /cdrom/image/sistema.img.000 shutdown -h nowelif [ "$?" = "1" ]; then dialog --yesno "Isto vai restaurar o particionamento original, apagando

todos os dados do HD! Tem certeza que quer continuar?" if [ "$?" = "0" ]; then dd if=/cdrom/image/hda.mbr of=/dev/hda sfdisk --force /dev/hda < /cdrom/image/hda.sf partimage -f action=2 -b restore /dev/hda1 /cdrom/image/sistema.img.000 shutdown -h nowelse shutdown -h nowfifi
O Partimage copia apenas os dados dentro da partição para a imagem e ainda compacta tudo. Isso faz com que seja possível colocar uma partição com cerca de 3 GB ocupados (suficiente para uma instalação completa do Ubuntu, Fedora ou Mandriva, ou uma instalação do Windows XP, incluindo alguns programas extras e atualizações) dentro de uma imagem de pouco mais de 1 GB. Mesmo incluindo a imagem do Kurumin, você ainda fica com bastante espaço livre no DVD.
Outra possibilidade é deixar uma partição no final do HD reservada só para armazenar a imagem. As partições Linux não são enxergadas pelo Windows, de modo que o usuário em muitos casos nem vai perceber. Neste caso você precisaria apenas fazer algumas modificações naquelas duas linhas que vão no arquivo /etc/init.d/knoppix-autoconfig. Se você estiver usando a partição "hda5" para armazenar o backup e ela estiver formatada em ReiserFS, as linhas ficariam:
mount -t reiserfs /dev/hda5 /mnt/hda5 partimage -f action=2 -b restore /dev/hda1 /mnt/hda5/winXP.img.000 reboot
Ao gerar versões especializadas, você pode reduzir o tamanho da imagem principal do sistema, deixando mais espaço livre ou tornando-o mais leve, removendo os pacotes e componentes que não serão utilizados, o que pode ser feito através do próprio apt-get.
A forma mais rápida de remover grandes grupos de pacotes (todo o KDE, todas as bibliotecas do Gnome, todos os programas gráficos, etc.) é procurar por "pacotes âncora", ou seja, pacotes que são dependências de grandes grupos de pacotes. Removendo o pacote inicial, você remove de uma vez todos os pacotes que se apóiam sobre ele.
Para remover de uma vez quase todo o KDE e aplicativos, por exemplo, remova o pacote "kdelibs-data":
# apt-get remove kdelibs-data
Para remover todos os aplicativos do Gnome e outros aplicativos baseados na biblioteca GTK2 (útil caso você queira fazer uma personalização com apenas programas do KDE), remova o pacote "libgtk2.0-0" (note que o número da versão varia), como em:
# apt-get remove libgtk2*

Muitos aplicativos aparentemente "independentes", como o Firefox, Thunderbird, Acrobat Reader e Mplayer utilizam o GTK2 e são removidos juntamente com ele, por isso analise bem a lista de pacotes que serão removidos antes de continuar.
Para remover de uma vez todos os programas gráficos, remova o pacote "xlibs-data". Esta medida extrema pode ser útil em casos específicos, onde é usado apenas algum utilitário de modo texto específico, como no nosso exemplo do DVD de recuperação com o partimage.
# apt-get remove xlibs-data
Criando seus próprios pacotes .deb
Em muitas situações, é preciso instalar softwares compilados manualmente, adicionar firmwares ou arquivos diversos necessários para ativar determinados componentes, expandir a funcionalidade de alguns programas específicos, modificar o conteúdo de pacotes já instalados no sistema, ou mesmo instalar novos scripts e utilitários em geral.
Embora a solução mais simples seja sair copiando diretamente os arquivos e modificando o que for necessário, esta não é exatamente uma boa idéia do ponto de vista da manteneabilidade. Com o tempo, você vai esquecer parte das alterações feitas, fazendo com que o sistema fique cheio de arquivos e configurações que não são mais usados, ou que conflitem com outros componentes instalados.
A melhor forma de adicionar novos componentes é sempre através de pacotes, instalados através do apt-get ou dpkg. Quando o componente não é mais necessário, você simplesmente remove o pacote e todos os arquivos relacionados a ele são apagados, de forma rápida e limpa. Em algumas situações, pode ser necessário também modificar o conteúdo de um pacote existente, seja para corrigir dependências marcadas incorretamente, ou mesmo para corrigir eventuais problemas com os arquivos contidos nele, modificando o conteúdo de pacotes gerados através do checkinstall, por exemplo.
Os pacotes do Debian, nada mais são do que arquivos compactados, que contém a árvore de arquivos e diretórios que serão instalados e um conjunto de arquivos de controle, que contém informações sobre o pacote e (opcionalmente) scripts que são executados antes e depois da instalação ou remoção. Quando o pacote é instalado, o apt-get ou dpkg simplesmente descompacta o arquivo e copia os arquivos para o diretório raiz, mantendo a mesma estrutura de pastas usada no pacote.
A moral da história é que é muito mais pratico instalar programas através de um pacote .deb do que seguir uma receita no estilo "descompacte, copie o arquivo, x para a pasta y, depois edite o arquivo k". É um formato muito mais prático para disponibilizar programas e atualizações.
Ao criar seus pacotes, o primeiro passo é criar uma pasta contendo a estrutura de diretórios e arquivos que fazem parte do pacote. Ferramentas como o checkinstall e o dpkg-deb fazem isso automaticamente.

Tome cuidado para não incluir arquivos que façam parte de outros pacotes, pois (além da mensagem de erro exibida ao instalar), ao remover seu pacote, todos os arquivos referentes a ele são deletados, deixando o sistema desfalcado. Caso seu programa precise de arquivos externos, prefira sempre colocar os pacotes que os provém como dependências.
Dentro da pasta com os arquivos do pacote, existe também uma pasta DEBIAN (em maiúsculas mesmo), que armazena os arquivos de controle. O principal (cuja presença é obrigatória em qualquer pacote .deb) é o arquivo "control" onde vão as informações de controle do pacote.
Este é o arquivo "control" do pacote mozilla-firefox:
Package: mozilla-firefoxVersion: 1.5.dfsg+1.5.0.1-1Section: webPriority: optionalArchitecture: allDepends: firefoxInstalled-Size: 96Maintainer: Eric Dorland <[email protected]>Source: firefoxDescription: Transition package for firefox renamePackage to ease upgrading from older mozilla-firefox packages to thenew firefox package..This package can be purged at anytime once the firefox package hasbeen installed.
Destes campos, os únicos realmente obrigatórios são "Package" (que contém o nome do pacote, que não pode conter pontos ou outros caracteres especiais), "Version" (a versão), "Archteture" (a plataforma a que se destina, geralmente i386), Maintainer (o nome e e-mail do mantenedor do pacote, no caso você), "Depends" (a lista de dependências do pacote, com os nomes dos pacotes separados por vírgula e espaço) e "Description", onde você coloca um texto dizendo resumidamente o que ele faz.
O campo "version" é um dos campos importantes, pois é por ele que o apt-get vai se orientar na hora de instalar o pacote. Se você lançar uma atualização do pacote mais tarde, o campo deve ser alterado. Um pacote com versão "1.1" é visto como uma atualização para o pacote de versão "1.0", por exemplo.
Tome cuidado ao usar o campo "Depends", pois marcar as dependências incorretamente pode trazer problemas para quem vai utilizar seu pacote. Deixar de marcar pacotes que são necessários, vai fazer com que muita gente instale seu pacote sem ter alguns dos outros componentes necessários, fazendo com que ele não funcione. Por outro lado, incluir um número grande de dependências vai fazer com que seu pacote seja problemático de instalar, ou mesmo seja removido em futuras atualizações do sistema, quando algum dos outros pacotes de que depende ficar indisponível, ou mudar de nome.
Ao indicar uma dependência, você pode exigir uma versão mínima, como em:
Depends: konqueror (>= 4:3.5.0-1), python
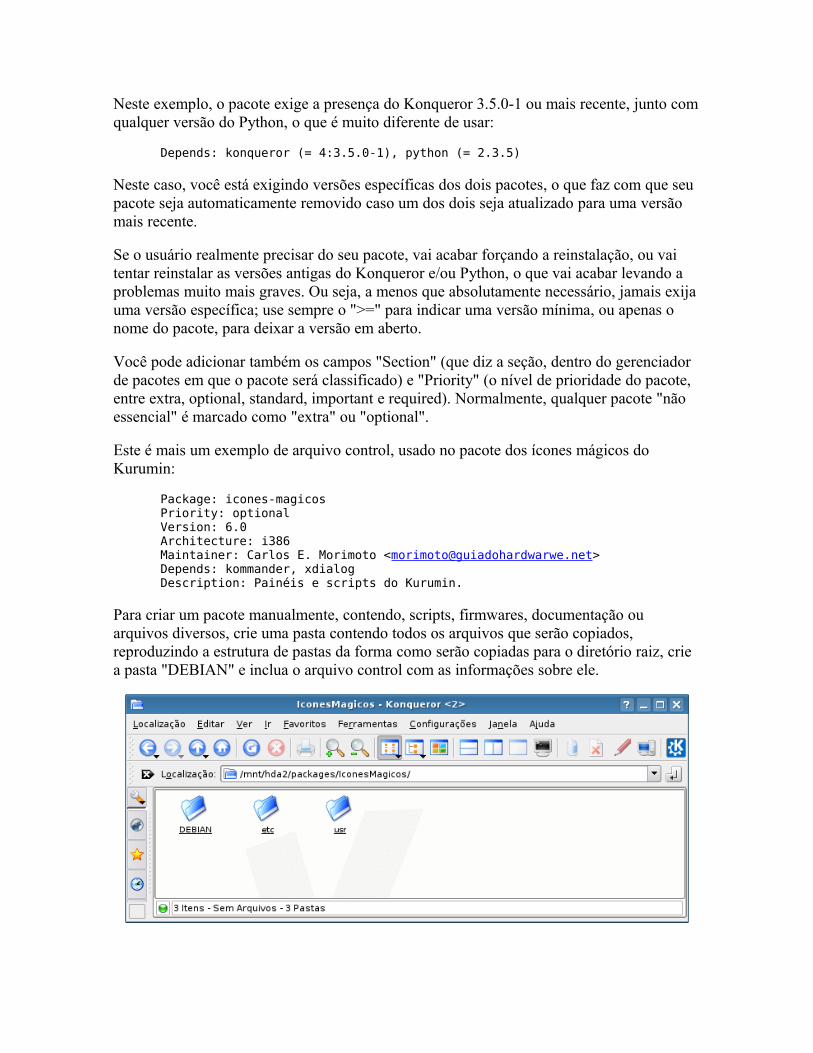
Neste exemplo, o pacote exige a presença do Konqueror 3.5.0-1 ou mais recente, junto com qualquer versão do Python, o que é muito diferente de usar:
Depends: konqueror (= 4:3.5.0-1), python (= 2.3.5)
Neste caso, você está exigindo versões específicas dos dois pacotes, o que faz com que seu pacote seja automaticamente removido caso um dos dois seja atualizado para uma versão mais recente.
Se o usuário realmente precisar do seu pacote, vai acabar forçando a reinstalação, ou vai tentar reinstalar as versões antigas do Konqueror e/ou Python, o que vai acabar levando a problemas muito mais graves. Ou seja, a menos que absolutamente necessário, jamais exija uma versão específica; use sempre o ">=" para indicar uma versão mínima, ou apenas o nome do pacote, para deixar a versão em aberto.
Você pode adicionar também os campos "Section" (que diz a seção, dentro do gerenciador de pacotes em que o pacote será classificado) e "Priority" (o nível de prioridade do pacote, entre extra, optional, standard, important e required). Normalmente, qualquer pacote "não essencial" é marcado como "extra" ou "optional".
Este é mais um exemplo de arquivo control, usado no pacote dos ícones mágicos do Kurumin:
Package: icones-magicosPriority: optionalVersion: 6.0Architecture: i386Maintainer: Carlos E. Morimoto <[email protected]>Depends: kommander, xdialogDescription: Painéis e scripts do Kurumin.
Para criar um pacote manualmente, contendo, scripts, firmwares, documentação ou arquivos diversos, crie uma pasta contendo todos os arquivos que serão copiados, reproduzindo a estrutura de pastas da forma como serão copiadas para o diretório raiz, crie a pasta "DEBIAN" e inclua o arquivo control com as informações sobre ele.

Depois de preencher o arquivo "DEBIAN/control" e verificar se todos os arquivos estão nos lugares corretos, use o comando "dpkg-deb -b" para gerar o pacote. Basta fornecer o diretório onde estão os arquivos do pacote e o nome do arquivo que será criado, como em:
# dpkg-deb -b IconesMagicos/ icones-magicos_6.0.deb
Ao examinar o arquivo gerado usando o Kpackage ou outro gerenciador, você verá que a descrição os arquivos correspondem justamente ao que você colocou dentro da pasta.
Você pode também alterar um pacote já existente, o que é especialmente útil para "arrumar" pacotes gerados automaticamente através do checkinstall, corrigindo a localização de arquivos ou alterando a descrição ou lista de dependências do pacote.
Para extrair um pacote, use o comando "dpkg -x", informando o pacote e a pasta destino, como em:
# dpkg -x mozilla-firefox_1.5.dfsg+1.5.0.1-1_all.deb firefox/
Este comando extrai apenas os arquivos do programa, sem incluir os arquivos de controle. Para extraí-los também, crie a pasta "DEBIAN" dentro da pasta destino e use o comando "dpkg -e", como em:
# dpkg -e mozilla-firefox_1.5.dfsg+1.5.0.1-1_all.deb firefox/DEBIAN/
A partir daí, você tem a árvore original do pacote dentro da pasta. Depois de fazer as alterações desejadas, gere o pacote novamente, usando o "dpkg -b":
# dpkg -b firefox/ mozilla-firefox.deb





























