Embed Size (px)
Citation preview

Manual de Tecnologia Caché®

Índice
MODELAGEM DE DADOS – ACESSO RELACIONAL OU POR OBJETOTecnologia Relacional Tecnologia de Objeto e de Base de Dados de ObjetoAcesso Relacional vs. Acesso a Objeto
Panorama do Modelo de Dados de Objetos do Caché e da Programação Orientada a Objetos
Conceitos-Chave de ObjetoPor que escolher Objetos para o seu Modelo de Dados?
SERVIDOR DE DADOS MULTIDIMENSIONAL DO CACHÉAcesso Integrado a Bases de DadosModelo de Dados Multidimensional Acesso SQLObjetos do CachéBusca de Texto com Reconhecimento de PalavrasIndexação de Bit-Map TransacionalEnterprise Caché Protocol para Sistemas DistribuídosTolerância a ErrosModelo de Segurança
SERVIDOR DE APLICAÇÕES CACHÉ A Máquina Virtual Caché e Linguagens de ScriptCaché ObjectScriptBasicMVBasic C++JavaCaché & Jalapeño Caché & .Net Caché & XMLCaché & Web Services Caché & Multivalue
CRIAÇÃO RÁPIDA DE APLICAÇÕES DE ALTA PERFORMANCE WEB COM CACHÉ SERVER PAGES (CSP)
O Modelo Caché Server PagesArquitetura de Classe de Páginas WebEstratégias Múltiplas de DesenvolvimentoArquivos CSPHipereventos (Hyper-Events) Intersystems Zen & Web Pages Baseada em Componentes
Capítulo 2
Capítulo 3
Capítulo 4
Capítulo 1
Armazenamento de Objetos & Acesso Relacional
Introdução
566
689
101114161820222427
3032384040404244454647
525454555658
9
1
30
50
4
10

Introdução
ALÉM DO BANCO DE DADOS RELACIONAL
Há 30 anos, bases de dados relacionais eram aclamadas como uma grande inovação. Ao invés de monolíticas bases de dados legadas, cada qual com seu esquema de dados único, as informações passariam a ser armazenadas em formato tabulado e estariam acessíveis a qualquer um que conhe-cesse SQL. Os bancos de dados relacionais tiveram grande sucesso e o SQL tornou-se o padrão comum de acesso à base de dados. Entretanto, como é comum no caso de tecnologias mais antigas, essas bases possuem limitações que redu-zem seu uso no mundo atual: primordialmenteno que diz respeito ao desempenho/escalabili-dade, facilidade de uso e adaptação às tecnologias de desenvolvimento atuais.
O uso e a complexidade das aplicações tecnológi-cas estão aumentando de forma explosiva. Os sistemas de hoje em dia, cada vez mais, apresentam necessidades de processamento que superam as capacidades da tecnologia relacional. Muitos dos aplicações-chave que demandam alto desempenho e escalabilidade nunca realizaram a transição para bases de dados relacionais e, atualmente, até mesmo aplicações simples começam a se aproximar dos limites da tecnologia relacional tradicional.
“Problemas de impedância (impedance mismatch)” entre bancos de dados relacionais e as tecno-logias de desenvolvimento atuais passaram a ser um sério problema, tornando o desenvolvimento mais complexo e as chances de falha maiores. Se por um lado a simplicidade de estruturas tabula-res suporta uma linguagem de consulta estruturada (SQL) elegante, por outro, é difícil decompor estruturas de dados do mundo real em linhas e colunas tão simplistas. O resultado é um enorme número de tabelas com inter-relações que são difíceis de lembrar e usar – linhas e colunas são sim-ples, mas a necessidade universal de se programar left outerjoins, stored procedures e triggers não.
Aplicações modernas são normalmente escritas usando tecnologia objeto, a qual permite uma maneira mais rápida e intuitiva de se descrever e usar informações. O desenvolvimento torna-se mais veloz e a confiabilidade aumenta. Infelizmente, objetos não são compatíveis de modo nativo com bases de dados relacionais. As vantagens da tecnologia objeto tornam-se moderadas quando os objetos resultantes são introduzidos.
Os atuais aplicações de processamento transacionais possuem requerimentos que extrapolam as capacidades da tecnologia relacional – eles precisam funcionar em grandes redes, servir a milhares de clientes, mas ainda assim, apresentar um desempenho excelente, compatibilidade com a web, bem como operações simples e com baixo custo. E eles devem ser desenvolvidos rapidamente!
1

Introduzindo o Caché
O Caché® da InterSystems é uma nova geração da tecnologia de banco de dados de desempenho ultra elevado. Ele combina uma base de dados objeto, SQL de alta performance e acesso poderoso a dados multidimensionais – todos podendo acessar simultaneamente os mesmos dados. A informa-ção é descrita somente uma vez em um dicionário de dados único integrado e fica instantaneamente disponível através de todos os métodos de acesso. O Caché supre níveis de desempenho, escalabili-dade, programação rápida e facilidade de uso que são inatingíveis através de tecnologia relacional.
O Caché é, no entanto, muito mais do que um banco de dados. Ele possui também um servidor de aplicações com capacidade avançada de programação de objetos, a habilidade de se integrar facilmente com uma ampla variedade de tecnologias, além de um ambiente de execução de alto desempenho com tecnologia única de caching de dados (data caching).
O Caché vem com várias linguagens de script embutidas: Caché ObjectScript (uma poderosa linguagem de programação orientada a objetos e ainda assim, simples de aprender); Caché Basic (um conjunto de Basic – linguagem de programação amplamente difundida –, o qual inclui extensões para acesso de dados e tecnologia de objetos eficientes); e o Caché MVBasic (uma variante do Basic utilizado por aplicações MultiValue, também conhecidos como aplicações Pick). Outras linguagens, tais como Java, C# e C++, são suportadas através de chamadas diretas ou através de outras interfaces, incluindo ODBC, JDBC, .NET, bem como uma interface de objetos fornecida pelo Caché e que permite acessar a base de dados Caché e outras de suas facilidades como propriedades e métodos.
O Caché também vai além das bases de dados tradicionais ao incorporar um rico ambiente para desenvolvimento de aplicações sofisticados baseados em browser (web). A tecnologia Caché Server Pages (CSP) permite o desenvolvimento e a execução rápida de páginas web gerada de forma dinâmica. Milhares de usuários web simultâneos podem acessar aplicações, mesmo através de hardware de baixo custo.
Para aplicações que não sejam baseados em browser, a interface de usuário é geralmente progra-mada em uma das tecnologias de interface populares, como Java, .NET, Delphi, C# ou C++. Os melhores resultados (programação mais rápida, melhor desempenho e menor manutenção)são geralmente obtidos ao se realizar o resto do desenvolvimento dentro do próprio Caché. Entretanto, o Caché também fornece níveis de interoperabilidade extremamente elevados com outras tecnologias e suporta todas as ferramentas de desenvolvimento mais comumente utilizadas, de modo que uma ampla gama de metodologias de desenvolvimento está disponível.
2


Capítulo 1: Modelagem de Dados – Acesso Relacional ou por Objetos
No início do processo de design de uma nova aplicação, os desenvolvedores devem decidir qual será sua abordagem no que diz respeito à modelagem de dados. Na maioria dos casos, esta é uma decisão que se resume entre a modelagem tradicional de dados como tabelas relacionais ou a abordagem mais recente de modelagem de dados como objetos. Frente à necessidade de lidar com dados complexos, muitos desenvolvedores acreditam que a modelagem em objetos é uma abordagem mais eficiente.
Naturalmente, quando se move uma aplicação já existente para o Caché, o primeiro passo necessário é migrar o modelo de dados existente. Há modos simples de se importar modelos de dados de várias representações relacionais ou de objetos, tal que o resultado seja uma definição padrão de dados Caché. Uma vez que tenham sido migrados para o Caché, os dados podem ser simultaneamente acessados como objetos, tabelas relacionais e arrays multidimensionais.
O Caché suporta tanto acesso SQL quanto objetos de dados nos momentos apropriados. Para entendermos os usos de cada um destes acessos e o porquê da modelagem de dados em objetos ser normalmente preferido pelos desenvolvedores atuais é útil que se compreenda como e por que cada método foi desenvolvido.
Capítulo 1
4

TECNOLOGIA RELACIONAL
Nos primórdios da informática, o processamento de informações era realizado em sistemas mainframe gigantescos e o acesso a dados era em grande parte limitado a profissionais de TI. As bases de dados tendiam a ser criadas internamente e a recuperação de dados exigia conheci-mento completo do banco de dados. Se os usuários quisessem um relatório especial, eles ge-ralmente tinham que solicitar a funcionários sobrecarregados que o preparassem, de forma que geralmente não estavam prontos a tempo de influenciar na tomada de decisões.
Embora a tecnologia relacional tenha sido originalmente desenvolvida no mainframe na década de 70, ela prosseguiu em grande medida como um projeto de pesquisa até começar a aparecer em mini-computadores nos anos 80. Com o advento do PC, o mundo entrou em uma era de informática mais centrada no usuário e de geradores de relatórios mais amigáveis, baseados em SQL – a linguagem de busca introduzida pela tecnologia relacional. Os usuários puderam a partir de então gerar seus próprios relatórios e realizar buscas com finalidades específicas (ad hoc) na base de dados, e assim o uso relacional se expandiu exponencialmente.
O SQL permite o uso de uma linguagem consistente na realização de consultas a uma variedade ampla de dados. O SQL funciona pela visualização de todos os dados em um formato muito simples e padronizado – uma tabela bidimensional com linhas e colunas. Se por um lado este modelo simplificado de dados permitiu a construção de uma linguagem elegante de consulta através da qual se deva questionar informações, por outro ele foi criado a um alto custo. A complexidade inerente às relações de dados do mundo real não se encaixa naturalmente em simples linhas e colunas, de tal forma que os dados são freqüentemente fragmentados em tabelas múltiplas que devem ser “unidas” para que até tarefas simples possam ser completadas. Isso resulta em dois problemas: a) consultas podem se tornar extremamente difíceis de serem escritas, dada a necessidade de se “unir” muitas tabelas (freqüentemente com complexos outerjoints – junções externas); e b) quando bases de dados relacionais têm de lidar com dados complexos, a quantidade de processamento necessário para o código adicional pode ser enorme.
O SQL tornou-se um padrão para interoperabilidade dos bancos de dados e de ferramentas de relatório. No entanto, é importante compreender que enquanto o SQL cresceu a partir dos bancos de dados relacionais, ele não precisa estar restrito a eles. O Caché suporta o SQL padrão como uma linguagem de consulta e atualização, utilizando uma tecnologia de base de dados multidimensional muito mais potente e que é ampliada para incluir capacidades de orientação a objetos.
5

Capítulo 1
TECNOLOGIA DE OBJETOS E DE BASE DE DADOS DE OBJETOS
Programação orientada a objetos e bancos de dados orientados a objetos são o resultado prático de trabalhos para simular as complexas atividades do cérebro. Observou-se que o cérebro é capaz de guardar dados muito complexos e de tipos diferentes e, assim mesmo, ainda pode manipular informação aparentemente diversas de modo simples. Para suportar esta simulação, comporta-mentos muito complexos precisavam ser implementados a programas, ao mesmo tempo em que se escondia esta complexidade – suportando uma lógica mais simples, generalizada e abrangente com um conjunto com funcionalidades reutilizáveis e adaptáveis. Obviamente, estas características são também verdadeiras para os mais avançados aplicações da atualidade e, uma tecnologia que permita aos desenvolvedores trabalhar em uma maneira natural e que seja similar ao modo como os seres humanos pensam é de grande vantagem.
ACESSO RELACIONAL VS. ACESSO POR OBJETOS
Na tecnologia a objetos, a complexidade dos dados está contida dentro do objeto e os dados são acessados através de uma interface simples e consistente. Por outro lado, a tecnologia relacional também apresenta uma interface simples e consistente, porém, dado o fato de que ela não faz nada para gerenciar a complexidade de dados do mundo real, as informações ficam dispersas entre múltiplas tabelas – o usuário ou programador é responsável por lidar constantemente com esta complexidade.
Considerando que objetos podem modelar dados complexos de forma simples, a programação em objetos é a melhor escolha para aplicações complexos. De forma similar, acesso a objetos pelo banco de dados é a melhor escolha para se inserir e atualizar informações na base de dados (como exemplo, para processamento transacional).
O Caché complementa o acesso a objetos com uma linguagem de consulta SQL estendida a objetos. O SQL é uma linguagem eficiente para realizar buscas em uma base de dados e é muito utilizada por ferramentas de relatório. Acreditamos, no entanto, que o SQL é mais apropriado para esse propósito – consultas e relatórios –, do que para processamento transacional (para o qual é incômodo e muitas vezes ineficiente). As extensões de objetos do SQL no Caché elimi-nam muito da incômoda sintaxe de joins, tornando o SQL ainda mais fácil de utilizar.
PANORAMA DO MODELO DE DADOS POR OBJETOS DO CACHÉ E DA PROGRAMAÇÃO ORIENTADA A OBJETOS
O modelo de objetos do Caché é baseado no padrão ODMG (Object Database Management Group) e suporta muitos recursos avançados, incluindo herança múltipla.
A tecnologia de objetos tenta espelhar a maneira como os humanos realmente pensam e usam informações. Diferentemente de tabelas relacionais, objetos formam pacotes que contêm tanto dados quanto códigos. Por exemplo, um objeto de Nota Fiscal pode conter dados, como número de NF e valor total, e códigos como Print().
Conceitualmente, um objeto é um pacote, que inclui valores de dados daquele objeto (“pro-priedades”) e uma cópia de todo o seu código (“métodos”). Os métodos de um objeto enviam mensagens para se comunicar com outros métodos. Para reduzir armazenamento, é comum que objetos da mesma classe compartilhem a mesma cópia de código (ex., não seria realista que cada objeto de NF possuísse sua própria cópia de código particular). Além disso, no Caché, chama-das de métodos geralmente resultam em chamadas de função eficientes, ao invés de persistir com processamento extra de mensagens em trânsito. Entretanto, estas implementações técnicas estão es-condidas do programador. É sempre correto pensar em termos de objetos passando as mensagens.
6
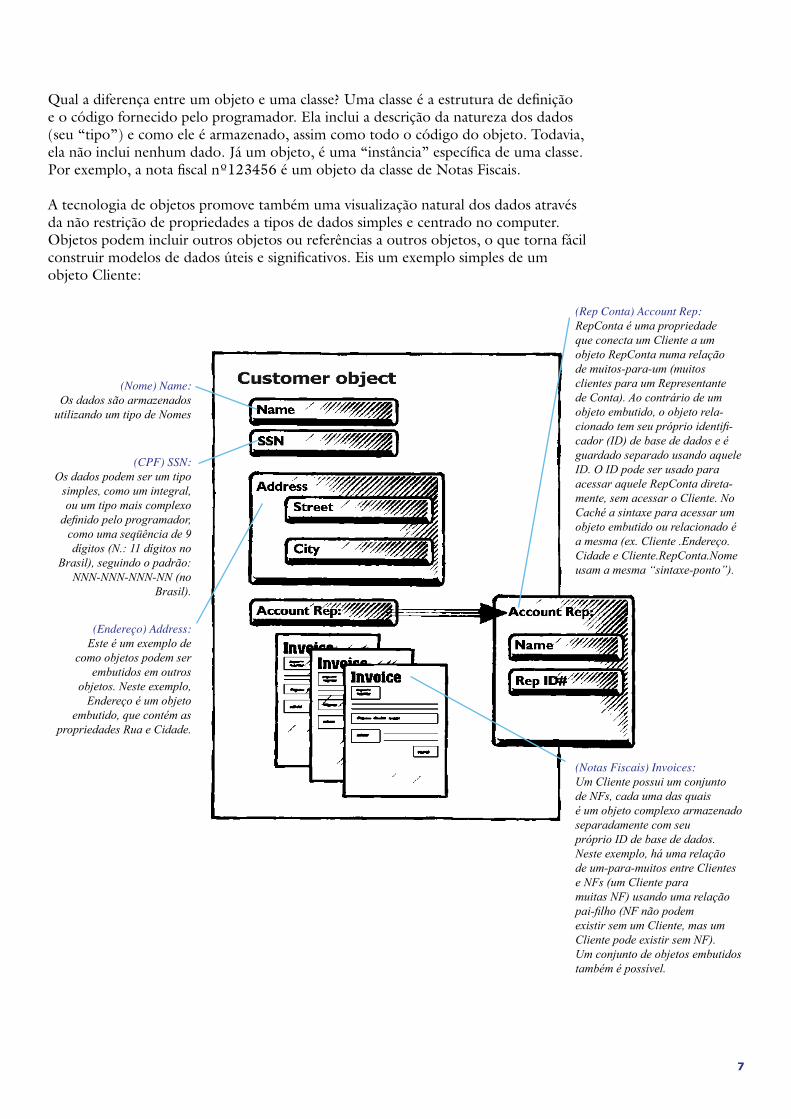
Qual a diferença entre um objeto e uma classe? Uma classe é a estrutura de definição e o código fornecido pelo programador. Ela inclui a descrição da natureza dos dados (seu “tipo”) e como ele é armazenado, assim como todo o código do objeto. Todavia, ela não inclui nenhum dado. Já um objeto, é uma “instância” específica de uma classe. Por exemplo, a nota fiscal nº123456 é um objeto da classe de Notas Fiscais.
A tecnologia de objetos promove também uma visualização natural dos dados através da não restrição de propriedades a tipos de dados simples e centrado no computer. Objetos podem incluir outros objetos ou referências a outros objetos, o que torna fácil construir modelos de dados úteis e significativos. Eis um exemplo simples de um objeto Cliente:
(Nome) Name:Os dados são armazenados
utilizando um tipo de Nomes
(CPF) SSN:Os dados podem ser um tipo
simples, como um integral,ou um tipo mais complexo
definido pelo programador,como uma seqüência de 9 dígitos (N.: 11 dígitos no
Brasil), seguindo o padrão:NNN-NNN-NNN-NN (no
Brasil).
(Endereço) Address:Este é um exemplo de
como objetos podem ser embutidos em outros
objetos. Neste exemplo, Endereço é um objeto
embutido, que contém as propriedades Rua e Cidade.
(Rep Conta) Account Rep:RepConta é uma propriedade que conecta um Cliente a um objeto RepConta numa relação de muitos-para-um (muitos clientes para um Representante de Conta). Ao contrário de um objeto embutido, o objeto rela-cionado tem seu próprio identifi-cador (ID) de base de dados e é guardado separado usando aquele ID. O ID pode ser usado para acessar aquele RepConta direta-mente, sem acessar o Cliente. No Caché a sintaxe para acessar um objeto embutido ou relacionado é a mesma (ex. Cliente .Endereço.Cidade e Cliente.RepConta.Nome usam a mesma “sintaxe-ponto”).
(Notas Fiscais) Invoices:Um Cliente possui um conjunto de NFs, cada uma das quaisé um objeto complexo armazenado separadamente com seupróprio ID de base de dados. Neste exemplo, há uma relaçãode um-para-muitos entre Clientes e NFs (um Cliente paramuitas NF) usando uma relação pai-filho (NF não podemexistir sem um Cliente, mas um Cliente pode existir sem NF).Um conjunto de objetos embutidos também é possível.
7

CONCEITOS-BÁSICOS DE OBJETOS
Herança é a possibilidade de se derivar uma classe de objetos a partir de outra. A nova classe (uma subclasse) contém todas as propriedades e métodos de sua superclasse, bem como proprie-dades adicionais e métodos exclusivos dela. Pode-se pensar em objetos da subclasse como tendo uma relação de “ser um(a)” com sua superclasse. Por exemplo, um cão “é um” mamífero, portan-to faz sentido que a classe Cão herde todas as propriedades e métodos da classe Mamíferos, além de possuir propriedades e métodos adicionais, tais como NumColeiraCao. Uma subclasse pode também desativar uma definição herdada (ex. o método Print() para uma subclasse da classe Nota Fiscal pode ser diferente do método Print() de Nota Fiscal). A herança promove a reutilização do código e torna mais fácil a introdução de grandes melhorias.
Herança múltipla significa que uma subclasse pode ser derivada de mais de uma superclasse. Por exemplo, um cão “é um” mamífero e “é um” animal de estimação, portanto a classe de objetos “Cão” pode herdar as propriedades e métodos de ambas as classes “Mamíferos” e “Animais de Estimação”.
Encapsulamento significa que os objetos podem ser vistos como “caixas-pretas”. Propriedades e métodos públicos podem ser acessados por métodos de qualquer classe, ao passo que proprie-dades e métodos particulares só podem ser acessados por aqueles da mesma classe. Portanto, o aplicação não precisa conhecer o funcionamento interno de um objeto – ele só lida com as propriedades e métodos públicos. A força do encapsulamento está no fato de programadores poderem melhorar o funcionamento interno de uma classe sem afetar o resto do aplicação.
Polimorfismo refere-se ao fato de métodos utilizados em várias classes poderem compartilhar uma interface comum, mesmo quando a implementação subjacente for diferente. Por exemplo, suponha que as classes Carta, Etiqueta Postal e Crachá contenham um método chamado Print(). Para imprimir, um aplicação não precisa saber que tipo de objeto ele está acessando – ele simples-mente chama o método Print() do objeto.
Capítulo 1
8
A VANTAGEM DO CACHÉ
O Caché é completamente habilitado para o uso de objetos, disponibilizando toda a força da tecnologia de objetos para desenvolvedores de aplicações de processamento transacional de alto desempenho.
Modelagem Intuitiva de Dados: A tecnologia de objetos permite aos desenvolvedores pensar e utilizar informação – mesmo informação extremamente complexa – de formas simples e realista, acelerando assim, o processo de desenvolvimento de aplicações.
Desenvolvimento Rápido de Aplicações: Os conceitos de encapsulamento, herança e polimorfismo de objetos permitem a reutilização de classes com novos propósitos e de forma compartilhada entre aplicações, permitindo aos programadores alavancarem seus trabalhos em vários projetos.

POR QUE ESCOLHER OBJETOS PARA SEU MODELO DE DADOS?
Para novas aplicações, a maioria dos desenvolvedores optam por utilizar tecnologia de objetos, pois assim podem desenvolver aplicações complexas mais rapidamente, além de poder modificá-las com maior facilidade posteriormente. A tecnologia de objetos oferece muitos benefícios:
<Objetos suportam uma estrutura de dados mais rica e que descreve informação do mundo real mais naturalmente.
<Programação mais simples – é mais fácil saber o que você está fazendo e o que você está manipulando.
<Versões customizadas de classes podem facilmente substituir versões padronizadas, tornando mais fácil customizar um aplicação.
<A abordagem caixa-preta de encapsulamento proporciona aos programadores a habilidade de melhorar o funcionamento interno de objetos sem afetar o restante do aplicação.
<Objetos proporcionam um modo simples de conectar diferentes tecnologias e aplicações.
<A tecnologia de objetos é um par natural de interfaces gráficas de usuário.
<Diversas novas ferramentas pressupõem tecnologia de objetos.
<Os objetos proporcionam uma boa independência entre a interface de usuário e o restante do aplicação. Assim, quando se tornar necessário adotar uma nova tecnologia de interface de usuário (talvez uma tecnologia futura ainda desconhecida), você poderá reuti- lizar a maior parte do seu código.
ARMAZENAMENTO DE OBJETOS…
Infelizmente, apesar de muitos aplicações serem atualmente escritos em linguagens de programação de objetos, eles freqüentemente tentam formatar forçosamente objetos em tabelas relacionais. Isto diminui significativamente as vantagens da tecnologia de objetos.
O Caché possui uma estrutura de dados multidimensional que armazena naturalmente da-dos de objetos. O resultado disso é o rápido acesso a dados e uma programação mais ágil.
... & ACESSO RELACIONAL
Certamente, muitas ferramentas (tais como geradores de relatórios) utilizam SQL, e não tecnolo-gia de objeto, para o acesso a dados.
O Caché possui um recurso exclusivo através do qual quando uma classe é definida, ele fornece automaticamente acesso SQL completo àqueles dados. Assim, ferramentas baseadas em SQL passam a funcionar imediatamente com os dados Caché sem trabalho adicional nenhum – e até mesmo estas ferramentas passarão a se beneficiar da vantagem proporcionada pelo alto desem-penho do Servidor de Dados Multidimensional do Caché.
O recurso funciona também na direção contrária. Quando uma definição DDL de uma base de dados relacional é importada, o Caché gera automaticamente uma descrição de objetos dos dados, possibilitando a eles o acesso imediato na forma de objetos e também na forma de SQL.
A Arquitetura Unificada de Dados do Caché (Caché Unified Data Architecture) mantém estes caminhos de acesso sincronizados – ficando assim, somente uma descrição de dados para ser editada.
9

Capítulo 2: Servidor de Dados Multidimensional do Caché
ACESSO INTEGRADO À BASE DE DADOS
O Caché dá aos programadores a liberdade de armazenarem e acessarem dados através de objetos, SQL ou acesso direto a estruturas multidimensionais.
Não obstante o método de acesso, todos os dados contidos na base de dados do Caché ficam armazenados nos arrays multidi-mensionais dele.
Uma vez armazenados os dados, todos os três métodos de acesso podem ser utilizados simultaneamente e em completa concomitância em um mesmo dado.
A Arquitetura de Dados Unificado é um recurso exclusivo do Caché. Quando uma classe de objetos de base de dados é definida, o Caché gera de forma automática uma SQL-ready, descrição relacional dos dados. De forma semelhante, se uma descrição DDL de uma base de dados relacional é importada para o Dicionário de Dados, o Caché gera automaticamente
tanto uma descrição de objeto quanto uma descrição relacional dos dados, possibilitando o acesso imediato na forma de objetos. O Caché mantém estas descrições coordenadas, há somente uma definição de dados para ser editada. O programador pode editar e visualizar o dicionário a partir de uma perspectiva de objeto e de uma tabela relacional.
O Caché automaticamente mapeia o modo como objetos e tabelas estão armazenados nas estrutu-ras multidimensionais, ou permite ao programador controlar de forma explícita o mapeamento.
Capítulo 2
Acesso Multimensional
A base de dados de alta performance do Caché utiliza um engine de dados multidimensional que possibilita o armazenamento eficiente e compacto de informações em uma rica estrutura de dados. Objetos e SQL são implementados especificando um dicionário unificado de dados, o qual define as classes e tabelas, bem como realiza um mapeamento das estruturas multidi-mensionais – um mapa que pode ser gerado automaticamente.
10
A VANTAGEM DO CACHÉ
Flexibilidade: Os modos de acesso a dados do Caché – Objeto, SQL e multidimensional – podem ser usados concomitantemente em um mesmo dado. Esta flexibilidade dá aos programadores a liberdade de pensar nos dados do modo que faça mais sentido, utili-zando o método de acesso que melhor se adéqüe às necessidades de cada programa.
Menos Trabalho: A Arquitetura de dados Unificado do Caché descreve automatica-mente os dados tanto como objetos quanto como tabelas, com uma única definição. Não há necessidade de codificar transformações, permitindo assim que aplicações possam ser desenvolvidos e mantidos mais facilmente.
Alavanque Habilidades e Aplicações Já Existentes: Os programadores podem alavancar habilidades relacionais existentes e introduzir gradualmente capacidades de objeto a aplicações já existentes conforme sua evolução.

MODELO DE DADOS MULTIDIMENSIONAL
Em seu núcleo, a base de dados Caché é alimentada por um engine de dados multidimensional extremamente eficiente. As linguagens de script integradas ao Caché suportam acesso direto às estruturas multidimensionais – oferecendo o mais alto desempenho e o maior número de possibilidades de armazenamento. Ademais, muitas aplicações são implementados inteiramente a partir da utilização direta deste engine. “Acesso direto a globais” direto é particularmente comum nos casos de estruturas muito especializadas ou incomuns, além da ausência de necessi-dade em se prover acesso de objeto ou via SQL a elas, ou ainda quando o mais alto desempenho possível é necessário.
Não há dicionário de dados e, portanto, nenhuma definição de dados para o engine de dados multidimensional.
Rica Estrutura de Dados Multidimensionais
Os arrays multidimensionais do Caché são chamados de “globais”. Os dados podem ser arma-zenados em uma global com qualquer quantidade de subscripts. Mais do que isso – os subscripts não possuem um formato/tipo específico e podem conter qualquer espécie de dados. Um subscript poderia ser um número integral – como 34 –, enquanto outro pode ser um nome com significado, como “ItensDeLinha” (“LineItems”) – ainda que no mesmo nível de subscript.
Por exemplo, um aplicação de inventário de estoque que fornece informações sobre itens, tama-nhos, cores e estampas pode ter uma estrutura como esta:
^Estoque(ítem,tamanho,cor,estampa) = quantidade
Eis alguns exemplos de dados:
^Estoque(“vestido verão”,m,”azul”,”floral”)=3
Com esta estrutura, é muito fácil determinar se há algum vestido tipo verão, no tamanho médio (m), com cor azul e estampa floral – e tudo isso simplesmente através do acesso àquele nós de dados. Se uma cliente quer um vestido de verão tamanho médio, mas não tem certeza sobre qual cor ou estampa deseja, é fácil exibir uma lista de todos aqueles, passando por todos os nós de dado abaixo:
^Estoque(“vestido verão”,m).
Neste exemplo, todos os nós de dados possuíam uma forma similar (eles armazenavam quanti-dade), além disso, todos estavam armazenados no mesmo nível de subscript (quatro subscripts) com subscripts semelhantes (o terceiro subscript era sempre texto designando uma cor). Entre-tanto, não é necessário que sempre seja assim. Os nós de dados podem ter números ou tipos diferentes de subscript e eles podem conter tipos diferentes de dados.
Aqui está um exemplo mais complexo de global com dados de uma nota fiscal que possue tipos diversos de dados armazenados em níveis diferentes de subscript:
^NF(nf #,”Cliente”) = Informações do Cliente ^NF(nf #,”Data”) = Data da NF ^NF(nf #,”Ítens”) = Número Ítens da NF ^NF(nf #,”Ítens”,1,”Partes”) = Número de Partes do Ítem 1 ^NF(nf #,”Ítens”,1,”Quantidade”) = Quantidade do Ítem 1 ^NF(nf #,”Ítens”,1,”Preço”) = Preço do Ítem 1 ^NF(nf #,”Ítens”,2,”Partes”) = Número de Partes do Ítem 2 etc.
11

Capítulo 2
Múltiplos Elementos de Dados Por Nó
Muitas vezes somente um único elemento de dados é armazenado em um nó, tal como uma data ou quantidade, mas ocasionalmente, pode ser útil armazenar múltiplos elementos de dados juntos em um único nó. Isto é especialmente útil quando há um conjunto de dados relacionados que são freqüentemente acessados juntos. Isto também pode melhorar o desempenho, uma vez que requer menos acessos à base de dados.
Por exemplo, na nota fiscal acima, cada item incluía um número de partes, quantidade e preços, todos armazenados em nós separados, porém eles poderiam ser armazenados como uma lista de elementos em um único nó:
^NF(nf #,”ÍtensDeLinha”,ítem #).
Para tornar isto simples, o Caché apresenta uma função chamada $list(), que pode agregar múlti-plos elementos de dados em uma seqüência de bytes de tamanho determinado e desagregá-los novamente em outro momento. Os elementos, por sua vez, podem conter sub-elementos, etc.
Bloqueio Lógico Promove Alta Concorrência
Em sistemas com milhares de usuários, reduzir conflitos entre processos concorrentes é crítico para que se obtenha uma alta produtividade. Um dos maiores conflitos é entre transações que tentam acessar os mesmos dados.
Os processos do Caché não bloqueiam páginas de dados inteiras enquanto realizam atualizações. Ao contrário, uma vez que transações precisam de freqüente acesso ou modificações para pequenas quantidades de dados, o bloqueio da base de dados no Caché é feito em um nível de lógica. Conflitos de base de dados são reduzidos ainda mais através da utilização de operações atômicas de adição e subtração, as quais não necessitam de bloqueio. (Estas operações são especialmente úteis no aumento de contadores utilizados para alocar números de identificação e na modificação de contadores de estatísticas).
Com Caché, transações individuais rodam mais rápido, e mais transações podem rodar ao mesmo tempo.
Dados de largura Variável em Arrays Esparsos
Porque os dados no Caché são inerentemente de largura variável e são armazenados em arrays esparsos, o Caché normalmente necessita menos da metade do espaço requerido por um banco relacional. Além de reduzir os requisitos de disco, o armazenamento de dados compactados melho-ra o desempenho, uma vez que mais dados podem ser lidos ou gravados com uma única operação I/O (N.: operação de entrada-saída) e os dados podem serutilizados em memória cache de modo mais eficiente.
Declarações e Definições Não São Necessárias
Os arrays multidimensionais do Caché não possuem um tipo/forma inerentes, ambos em seus dados e em seus subscripts. Não é necessária nenhuma declaração, definição ou alocações de armazenamento. Dados de globais simplesmente são gerados conforme a informação é inserida. Namespaces
No Caché, os dados e códigos são armazenados em arquivos de disco com o nome CACHE.DAT (somente um por diretório). Cada um desses arquivos contém várias “globais” (arrays multidi-mensionais). Dentro de um arquivo, o nome de cada global deve ser único, entretanto, arquivos diferentes podem conter o mesmo nome de global. Pode-se pensar de forma liberal nestes arquivos como sendo bases de dados.12

Ao invés de especificar qual arquivo de base de dados utilizar, cada processo do Caché usa um “namespace” para acessar os dados. Um namespace é um mapa lógico que mapeia os nomes de arrays globais multidimensionais e codifica para bases de dados. Se uma base de dados é transferi-da de um drive ou de um computador para outro, só o mapa de namespace precisa ser atualizado. O aplicação em si continua sem mudanças.
Normalmente, a não ser por alguma informação de sistema, todos os dados para um namespace são armazenados em uma única base de dados. Contudo, os namespaces oferecem uma estrutura flexível que permite o mapeamento arbitrário e, sendo assim, não é incomum que um namespace mapeie o conteúdo de várias bases de dados, inclusive algumas que estejam em outros computadores.
13
A VANTAGEM DO CACHÉ
Desempenho: Ao utilizar modelo de dados multidimensional eficiente com técnicas de armazenamento disperso, ao invés de um labirinto complicado de tabelas bidimen-sionais, o acesso e a atualização de dados são obtidos com menos operações de I/O de disco. Menos I/O significa que os aplicações rodam mais rápido.
Escalabilidade: O modelo transacional de dados multidimensionais permite que apli-cações baseados em Caché tenham sua escala de uso ampliada para vários milhares de clientes sem comprometer o alto desempenho. Isto é porque o acesso a dados em um modelo multidimensional não é significativamente afetado pelo tamanho e complexi-dade da base de dados em comparação a modelos relacionais. As transações podem acessar os dados de que necessitam sem realizar junções complicadas ou ficar pulando de tabela em tabela.
O uso de locks pelo Caché para atualizações, ao invés do bloqueio de páginas físicas é outra contribuição importante para a concomitância. Do mesmo modo, outra contribuição importante para este fim é o sofisticado caching de dados do Caché através de redes. Desenvolvimento Rápido: O desenvolvimento ocorre muito mais rápido com o Caché, pois a estrutura de dados oferece um armazenamento natural e de fácil entendimento a dados complexos, e não requere definições e declarações detalhadas ou complicadas. O acesso direto a globais é muito simples, permitindo a mesma sintaxe de linguagem utilizada no acesso a Arrays locais.
Custo-Efetividade: Comparados a aplicações relacionais de porte semelhante, os aplicações baseados em Caché requerem significativamente menos hardware e não necessitam de administradores de base de dados. A gestão do sistema e suas operações são simples.

Capítulo 2
ACESSO SQL
SQL é a linguagem de consultas do Caché. Ela é suportada por um conjunto completo de capaci-dades de banco de dados relacional – incluindo DDL, transações, integridade referencial, triggers, stored procedures e mais. O Caché suporta acesso através de ODBC e JDBC (usando um driver baseado em Java puro). Os comandos e consultas SQL também podem ser embutidos no Caché ObjectScript e dentro de métodos de objetos.
O SQL acessa dados visualizados na forma de tabelas com linhas e colunas. Como os dados do Caché são, na realidade, armazenados em estruturas multidimensionais eficientes, os aplicações que utilizam SQL obtêm melhor desempenho com o Caché do que com bases tradicionais de dados relacionais.
Além da sintaxe SQL padrão, o Caché suporta várias das extensões mais comumente utilizadas em outros bancos de dados. Sendo assim, muitos dos aplicações baseados em SQL podem rodar no Caché sem modificações – especialmente aqueles escritos com ferramentas independentes de banco de dados. Entretanto, store procedure que sejam específicos de certos fornecedores demandarão algum trabalho e a InterSystems possui tradutores para auxiliar nesta tarefa.
O Caché SQL inclui melhorias de objetos que tornam o código SQL mais simples e intuitivo de se ler e escrever.
SQL TRADICIONAL
SELECT
SC.NomeCompleto, SM.Descr, MS.Valor,
SI.InvData, SI.InvNumero
FROM
VendaPrincipal MS,
VendaItem SI,
VendaProduto SP,
VendaCliente SC,
VendaMercado SM
WHERE
SI.VendaItemID *= MS.VendaItem
AND SP.VendaProdutoID *= MS.Produto
AND SC.VendaClienteID *= MS.Cliente
AND SM.VendasMercadoID *= ‘Martelo’
SQL COM EXTENSÃO DE OBJETO
SELECT
Cliente->NomeCompleto,
Cliente->VendaMercado
->Descr, Valor,
VendaItem->InvData,
VendaItem
->InvNumero
FROM
VendaPrincipal
WHERE
Produto->Descr = ‘Martelo’
14

Acessando Bancos de Dados Relacionais com o Gateway Relacional do Caché
O Gateway Relacional do Caché (Caché Relational Gateway) habilita o envio de uma requisição SQL originada no Caché a ser enviada para outro banco de dados (relacional) para processamento. Usando o Gateway, um aplicação do Caché pode recuperar e atualizar dados armazenados na maio-ria dos bancos de dados.
Além disso, se as classes das bases de dados do Caché estiverem compiladas utilizando a opção CachéSQLStorage, o Gateway permite aos aplicações Caché utilizar bases de dados relacionais de forma transparente. Os aplicações, no entanto, irão rodar mais rápido e serão mais escalonáveis se acessarem a base de dados pós-relacional do Caché.
Gateway Relacional
15
A VANTAGEM DO CACHÉ
SQL Mais Rápido: Aplicações relacionais podem desfrutar de uma melhora de desem-penho significativa ao utilizarem o Caché SQL para acessar na eficiente base de dados pós-relacional do Caché. Desenvolvimento Mais Rápido: No Caché, consultas SQL podem ser escritas de forma mais intuitiva, utilizando menos linhas de código.
Compatibilidade com Aplicações Relacionais e Geradores de Relatório: Os drivers ODBC e JDBC nativos do Caché oferecem acesso de alto desempenho à base de dados do Caché para aplicações relacionais e ferramentas de relatório. O Gateway Relacional do Caché possibilita que aplicações Caché utilizem SQL para acessar outros bancos de dados (relacionais).

Capítulo 2
OBJETOS DO CACHÉ
O modelo de objeto do Caché é baseado no padrão ODMG. O Caché suporta um conjunto completo de conceitos de programação de objetos, incluindo encapsulamento, objetos embutidos, herança múltipla, polimorfismo e coleções.
As linguagens integradas do Caché manipulam estes objetos diretamente. O Caché também exibe as classes Caché como classes Java, EJB, COM, .NET, e C++. As classes do Caché também podem ser automaticamente habilitadas para suportar XML e SOAP através de um simples clique na IDE do Studio. Como resultado, os objetos Caché estão prontamente disponíveis para todas as tecno-logias objeto usadas mais comumente.
Há diversas maneiras para um programa fora do Servidor de Aplicações Caché acessar as classes Caché:
1. Qualquer classe Caché pode ser projetada como uma classe na linguagem nativa. Quando um programa Java, C++, C# ou outro qualquer acessa um objeto Caché, ele ativa um `template´ da classe na linguagem nativa. O `template´ daquela classe (que é gerado automaticamente pelo Caché) se comunica com o Servidor de Aplicações Caché para iniciar métodos no servidor e para acessar ou modificar propriedades. A configuração para objetos do Caché fica armazenada no Servidor de Aplicações Caché. Para acelerar a execução e reduzir o número de mensagens, uma cópia dos dados do objeto é memorizada nas atualizações do cliente e de piggybacks pelo Caché, juntamente, quando possível, a outras mensagens.
2. Uma projeção mais leve pode ser utilizada para classes de base de dados nas quais a classe do `template´ de linguagem nativa acessa diretamente a base – sem passar pelo Servidor de Aplicações. O estado do objeto não é salvo no Servidor de Aplicações; as propriedades na memória só são mantidas no cliente. Esta abordagem oferece uma produtividade signifi- cativamente mais alta, mas com menos funcionalidade, já que métodos de instância lateral de classes do Servidor (isto é, métodos que precisam de acesso às propriedades na memória) não podem ser iniciados.
3. A tecnologia Jalapeño da InterSystems permite que desenvolvedores Java criem primeiramente uma classe de base de dados em Java, como em qualquer outro POJO (Plain Old Java Object), na IDE de sua preferência, e, a partir de então, fazer com que o Caché gere automaticamente um esquema da base de dados e classe do Caché correspondente. Usando esta abordagem, a classe em Java não é alterada e o aplicação continua acessando suas propriedades e métodos. O Caché disponibiliza uma biblioteca de classes (“ObjectManager”) com uma API que é utilizada para armazenar e recuperar objetos de base de dados e gerar consultas.
Com cada uma dessas três abordagens, o objeto aparenta ser algo local para o programa do usuário. O Caché gerencia as comunicações de forma transparente através de call-in ou de TCP.
O `template´ em Java e sua biblioteca de suporte são completamente baseados em Java e podem, portanto, ser utilizados através da web ou em outros dispositivos específicos de Java.
16

Geradores de Métodos
O Caché inclui várias tecnologias avançadas de objeto que são exclusivas – uma das quais é chamada geradores de métodos – generators - Um gerador de métodos é um método executado no momento da compilação, gerando um código que pode ser rodado quando o programa é executado. Um gerador de métodos tem acesso às definições de classe, inclusive à definições e parâme-tros de propriedades e métodos, permitindo a ele gerar um método que seja customizado para a classe. Geradores de Método são particularmente eficientes se combinados com herança múltipla – a funcionalidade pode ser definida em uma classe de herança múltipla que se customiza para a subclasse.
17
A VANTAGEM DO CACHÉ
O Caché é completamente habilitado para objetos, oferecendo todo o poder da tecnologia de objetos a desenvolve-dores de aplicações de processamento transacional de alto desempenho.
Desenvolvimento Rápido de Aplicações: A tecnologia de objetos é uma ferramenta poderosa no aumento da produtividade de programadores. Os desenvolvedores podem pensar e usar objetos – mesmo os extremamente complexos – de modos simples e realista, acelerando assim, o processo de desenvolvimento de aplicações. Além disso, a modulação inata e a interoperabilidade dos objetos simplifi-cam a manutenção dos aplicações, deixando os programadores alavanca-rem seus trabalhos em vários projetos.
Desenvolvimento Natural: Objetos de bases de dados aparecem na forma de objetos nativos à linguagem sendo utilizada pelo desenvolvedor. Não há necessidade de escrever códigos tedio-sos ou decompor objetos em linhas e colunas e reagrupá-los mais tarde.

Capítulo 2
BUSCA DE TEXTO COM RECONHECIMETO DE PALAVRAS
O Caché suporta buscas livres de texto, nas quais as consultas podem procurar por texto contendo palavras de interesse, mesmo que as palavras existentes no texto sejam variações das palavras pesquisadas.
Para utilizar a busca com reconhecimento de palavras, o campo de texto deve ser indexado. Isso ocorre seguindo os seguintes passos:
1. Inicialmente, palavras distintas no campo de texto são identificadas.
2. Palavras que sejam tão comuns a ponto de oferecer pouco valor de pesquisa são removidas (ex. palavras como “o/a” ou “para” são removidas).
3. As palavras restantes são reduzidas às suas raízes (ex.: “buscando” se torna “buscar” e “flores” se torna “flor”).
4. As palavras resultantes são indexadas.
Em buscas com reconhecimento de palavras, o texto pesquisado é geralmente primeiro processado de forma semelhante, e então, o índice resultante é utilizado para produzir combinações.
18
Quebra em palavras
Eliminação de ruído
Redução em raízes
Word-Aware Indexing
I am searching for some text
search for
I am searching for some text
I am searching for some textX X X X

Índices de reconhecimento de palavras são mantidos por atualizações de objeto e de SQL. A busca é mais comumente realizada através de consultas SQL, embora códigos procedurais possam usar os índices diretamente. Tais consultas podem incluir lógicas E/OU para pesquisas mais sofisticadas.
Algoritmos de reconhecimento de palavras são específicos da língua natural que está sendo utilizada. A busca com reconhecimento de palavras está disponível para um amplo leque de línguas naturais, incluindo alemão, espanhol, francês, inglês, italiano, japonês e português. Outras línguas estão sendo adicionadas.
Busca com Reconhecimento de Palavras
Where Descrição%Contém (‘pesquisar’)
O Caché encontra “pesquisar”, “pesquisado”, “pesquisando”,…
Where Descrição%Contém (`close´)
O Caché encontra `close´, `closed´, ... Mas não `closet´ou `disclose
19
A VANTAGEM DO CACHÉ
Poderosas Buscas de Textos Não Estruturadas: Textos não estruturados, como anota-ções médicas ou documentos, podem ser facilmente pesquisados através de palavras-chave ou palavras relacionadas.
Pesquisas Extremamente Rápidas: A união de reconhecimento de palavras e da tecno-logia bit-map do Caché torna possível a realização de buscas de quantidades massivas de texto em uma fração de segundos.

Capítulo 2
INDEXAÇÃO DE BIT-MAP TRANSACIONAL
O Caché oferece de forma exclusiva uma indexação de Bit-Map Transacional, a qual pode melhorar de forma radical o desempenho de consultas complexas, resultando em um desempenho rápido para consultas a datawarehouse.
Índice Tradicional de Propriedade: “Tipo de Animal de Estimação”
Índice Bit-Map de Propriedade: “Cor de Cabelo”
O desempenho do banco de dados depende de forma crítica da existência de índices nas pro-priedades que são freqüentemente usadas nas bus-cas realizadas na base de dados. A maior parte dos bancos de dados usa índices que, para cada valor possível da coluna ou da propriedade, mantêm uma lista das identificações para as linhas/objetos que possuem aquele valor. Um índice bit-map é outro tipo de índice. Índices bit-map contêm um bitmap para cada valor possível de uma coluna/propriedade, com um bit para cada linha/objeto que é armazenado. Um valor de bit igual a 1 significa que a linha/objeto tem aquele valor para a coluna/propriedade.
A vantagem de índices bit-map é que consultas complexas podem ser processadas realizando-se operações de tipo booleano (E, OU) nos índices – determinando de forma eficiente exatamentequais instâncias (linhas) se encaixam nas condições de consulta sem a necessidade de pesquisar toda a base de dados. Índices bit-map podem com
frequência impulsionar o tempo de resposta de consultas que buscam grandes volumes de dados por um fator 100 vezes maior. Os bit-maps padecem tradicionalmente de dois problemas: a) eles podem ser penosamente devagar para se atualizar em bases de dados relacionais, e b) eles podem ocupar espaço demais de armaze-namento. Assim, eles são raramente utilizados em aplicações de processamento transacionais.
O Caché introduziu uma nova tecnologia – a Indexação de Bit-Map Transacional – que alavanca estruturas de dados multidimensionais para eliminar estes dois problemas. Atualizar estes bit-maps é normalmente mais rápido do que os índices tradicionais, e eles utilizam técnicas sofisticadas de compressão para reduzir radicalmente o espaço de armazenagem necessário. O Caché também suporta técnicas sofisticadas de “bit-slicing” (fatiamento de bits). Como resultado, tem-se bit-maps ultra-rápidos, que podem freqüentemente ser utilizados para pesquisar milhões de registros em uma fração de segundo em uma base de dados online de processamento de transa-ções. Business intelligence e aplicações de datawarehousing podem trabalhar com dados “reais”.
O Caché oferece tanto índices bit-map tradicionais, quanto transacionais. Além disso, o Caché suporta índices multi-coluna. Por exemplo, um índice de Estado e ModeloDeCarro pode identificar rapidamente todos que possuem um modelo específico de carro registrado em um estado específico.
20

21
A VANTAGEM DO CACHÉ
Consultas Radicalmente Mais Rápidas: Utilizando as técnicas de bit-map transacional, os usuários podem realizar buscas ultra-velozes de grandes bases de dados – muitas vezes, milhões de dados podem ser pesquisados em uma fração de segundo – em um sistema utilizado primordialmente para processamento de transações.
Análise de Dados em Tempo Real: O Índice Bit-Map Transacional permite a análise de dados em tempo real nos dados disponíveis mais recentes.
Menor Custo: Não há necessidade de um segundo computador dedicado ao suporte de decisões e ao datawarehouse. Tão pouco há a necessidade de operações diárias para se transferir os dados a um segundo sistema deste tipo ou de administradores de base de dados para dar suporte a isto.
Escalabilidade: A velocidade de bit-maps transacionais otimiza a possibilidade de se montar sistemas com quantidades enormes de dados que precisam ser mantidos e pesquisados de forma periódica.

Capítulo 2
ENTERPRISE CACHÉ PROTOCOL PARA SISTEMAS DISTRIBUÍDOS
Desempenho com Escalabilidade em Sistemas Distribuídos
O Enterprise Cache Protocol (ECP) é uma tecnologia de desempenho extremamente performática e com escalabilidade que permite que computadores, em um sistema distribuído, utilizem as bases de dados uns dos outros. O uso do ECP não requer mudanças de aplicações – estes últimos simplesmente tratam as bases de dados como se fossem bases locais.
O ECP funciona assim: cada Servidor de Aplicações Caché inclui seu próprio Servidor de Dados Caché, que pode operar em dados residentes em seus próprios sistemas de disco ou em blocos que foram transferidos a ele a partir de outro Servidor de Dados Caché pelo ECP. Quando um cliente solicita uma informação mantida num Servidor de Dados remoto, o Servidor de Aplicações tenta satisfazer a solicitação a partir do seu Caché local. Caso não tenha sucesso, ele solicitará a infor-mação necessária ao Servidor de Dados remoto. A resposta incluirá o(s) bloco(s) da base de dados
onde aquela informação foi armazenada. Estes blocos são armazenados no cache do Servidor de Aplicações, onde eles ficam disponíveis para todos os aplicações rodando naquele Servidor. O ECP gerencia automatica-mente a consistência do cache através da rede e propaga as mudanças de volta para os Servidores de Dados.
Os benefícios de desempenho e escalabilidade obtidos com o ECP são muitos. Os clientes des-frutam de respostas rápidas, pois se utilizam com freqüência de dados armazenados em cache local-mente. E o caching reduz em muito o tráfico de rede entre a base de dados e os servidores de aplica-ções, permitindo que qualquer rede possa suportar muito mais servidores e clientes. Contudo, se por um lado a maioria dos aplicações se beneficia do ECP, por outro, há alguns cujas arquiteturas não suportam prontamente uma escalabilidade deste porte. A realização de um benchmarking é recomen-dada, e, geralmente, alguns ajustes simples podem aumentar o desempenho.
Enterprise Caché Protocol
22

Fácil de Usar – Sem Modificação de Aplicações
O uso do ECP é invisível para as aplicações. Aquelas que são escritas para rodar em um único servidor rodam em um ambiente de servidores múltiplos sem alteração. Para utilizar o ECP, o gerente do sistema simplesmente identi-fica um ou mais Servidor de Dados para um Servidor de Aplicações. A partir de então, mapeia-se o Namespace para indicar que as referências a algumas ou a todas as globais (ou a partes de globais) se referem àquele Servidor de Dados remoto.
Flexibilidade de Configuração
Cada sistema Caché pode funcionar tanto quanto um Servidor de Aplicações, quanto como um Servidor de Dados para outros sistemas. O ECP suporta qualquer combinação de Servidores de Aplicações e de Dados, bem como qualquer topologia ponto-a-ponto de até 255 sistemas.
23
A VANTAGEM DO CACHÉ
Escalabilidade Massiva: O Enterprise Cache Protocol do Caché permite o acréscimo de servidores de aplicações conforme o crescimento de uso. Cada um destes servidores usa a base de dados como se ela fosse uma base local. Se a produ-tividade de disco tornar-se um gargalo, mais Servidores de Dados podem ser adicionados, sendo que a base de dados será dividida em partições lógicas.
Maior Disponibilidade: Como os usuários estão espalhados entre múltiplos computadores, a falha de um Servidor de Apli-cações afeta um número menor de usuários. Caso um Servidor de Dados trave e tenha que ser reinicializado, ou caso haja uma interrupção temporária na rede, os Servidores de Aplicação podem continuar o processamento sem qualquer efeito perceptível além de uma pequena pausa. Confi-gurar Servidores de Dados como um cluster de hardware para a prevenção de falhas em servi-dores de dados de reserva pode aumentar a disponibilidade de forma significativa.
Menores Custos: Uma grande quantidade de computadores de baixo custo pode ser combi-nada para formar um sistema especialmente forte que suporta processamento pesado – “grid computing”.
Uso Invisível: Os aplicações não precisam ser especificamente escritos para o ECP – aplicações Caché tomam vantagem do ECP de forma automática, sem mudanças.

TOLERÂNCIA A ERROS
Mesmo nos ambientes mais rigorosos, eventos inesperados podem ocorrer – falha de hardware, falta de energia, ou algo mais severo quanto inundações ou outro desastre natural - hospitais, telecomunicações e outras operações críticas não podem, no entanto, se dar ao luxo de estar “fora do ar”. Para satisfazer a padrões tão exigentes, o Caché foi projetado para se recuperar de interrupções de forma elegante, oferecendo uma variedade de prevenções de falha e outras opções para reduzir ou eliminar o impacto aos usuários.
O Caché Write-Image Journaling e outros recursos de integridade garantem a integridade da base de dados na maioria das falhas de hardware – inclusive em caso de falta de energia –, permitindo uma recuperação rápida, ao mesmo tempo em que minimiza o impacto ao usuário.
O Caché também oferece opções de configuração avançada de alta disponibilidade para reduzir ainda mais ou eliminar o impacto ao usuário, incluindo:
<Fail-over Clusters <Shadow Servers <Enterprise Caché Protocol distríbuido
Fail-over Clusters
Ao utilizar um hardware com cluster fail-over, os servidores de dados compartilham acesso aos mesmos discos, embora somente um deles esteja rodando o Caché em um determinado momento. Caso o servidor ativo falhe, o Caché é automaticamente inicializado em outro servidor que passa a ser responsável pelo processamento. Os usuários podem se logar imediata-mente no novo servidor.
Shadow Servers
Os Shadow Servers do Caché são, na verdade, servidores reserva que estão conectados via TCP. O servidor primário envia constantemente um registro lógico de atualizações da base de dados para o Shadow Server, este que sempre possui uma cópia “quase-atual” da base de dados. A mudança para o Shadow Server é menos automatizada do que para os fail-over clusters, mas a sobrevivência é melhorada, pois o hardware não está conectado fisicamente – o Shadow Server pode estar até mesmo em outro local.
Um Shadow Server pode ser mesclado a um fail-over Cluster, com propósito de melhorar ainda mais a tolerância a falhas.
ECP Distribuído
Para sistemas distribuídos utilizando ECP, na ocorrência de uma interrupção temporária de rede ou de um travamento do Servidor de Dados e reinicialização, os servidores de aplicação tentam se reconectar. Caso a reconexão seja bem sucedida dentro de um prazo especifico de tempo, os Servidores de Aplicações reenviam qualquer solicitação não completada e as operações continuam sem efeitos perceptíveis para o usuário, além de uma ligeira pausa.
Se um Servidor de Aplicações ECP falhar, somente os usuários que estejam no Servidor de Aplica-ções com problema serão afetados. Eles poderão então se logar em outro Servidor de Aplicações para continuar trabalhando.
Capítulo 2
24

Um Servidor de Dados ECP é freqüentemente configurado como um Fail-over Cluster. Se o Servidor de Dados primário travar, o servidor reserva assume as funções do Servidor de Dados que falhou, permitindo operações sem inter-rupções, com o usuário passando apenas por uma leve pausa.
Um Cluster ECP Fail-Over
25
A VANTAGEM DO CACHÉ
Bullet-Proof: O Caché Write-Image Journaling e outros recursos de integridade garantem, na maioria dos tipos de falha de hardware, a integridade da base de dados – inclusive em casos de falta de energia.
Configurações de Tolerância a Falhas de Alta Disponibilidade: O uso dos Shadow Servers do Caché, do ECP e/ou de Fail-over Clusters permite a recuperação rápida em casos de falha, ao mesmo tempo em que minimiza, ou em alguns casos elimina, seu impacto no usuário.

Capítulo 2
26

MODELO DE SEGURANÇA
O Caché possui um modelo de segurança moderno, desenhado para dar suporte ao desenvol-vimento de aplicações de três maneiras:
O Caché fornece estas capacidades de segurança ao mesmo tempo em que minimiza o ônus no desempenho de aplicações.
Usuários, Perfis, Recursos e Privilégios
Existe uma gama de recursos (tais como bases de dados, aplicações e serviços) que os usuários devem receber permissão (como LER, GRAVAR ou USAR) do Administrador de Segurança para poder utilizá-los. Além dos recursos definidos no sistema, o Administrador de Segurança pode criar recursos específicos de aplicações e utilizar os mesmos mecanismos para conceder e checar permissões.
Para simplificar, aos usuários normalmente são atribuídos um ou mais “perfis” (ex. “TecDeLab” ou “Salários”). O Administrador de Segurança concede então, privilégios para um recurso especí-fico àqueles perfis e não a usuários individuais. O usuário obtém todos os privilégios concedidos aos perfis que foram atribuídos a ele.
Cada processo possui um nome de usuário (username) associado, mesmo que seja somente `UnkownUser´. O nome de usuário é estabelecido durante a “autenticação”. Um exemplo simples de autenticação é a entrada de um username e senha por um usuário no sistema, e a checagem realizada por este último para confirmar que a senha está correta. Após a autentica-ção, o username é atribuído ao processo e as permissões associadas àquele nome de usuário são concedidas. (Um “usuário” não necessariamente é um ser humano. Ele poderia ser, por exemplo, um dispositivo de medição gerando dados ou um aplicação rodando em outro sistema que se conecta ao Caché). Se o usuário não passa pelo processo de autenticação , ele recebe o nome de `UnkownUser´, o qual só concede àquele processo as permissões atribuídas a qualquer usuário.
A conexão ao Caché é controlada por um conjunto de Serviços. Cada Serviço especifica seé público (o que significa que todos podem utilizá-lo) ou se requere autenticação e, passados os testes de verificação desta, se o usuário possui os privilégios de acesso necessários. Os Serviços podem ainda ser desabilitados individualmente, de modo que o acesso seja negado a todos.
A atribuição e gerenciamento de privilégios normalmente é feita pelo Portal de Administração do Caché.
Protegendo o ambiente Caché propriamente dito.
Tornando fácil aos desenvolvedores integrar recursos de segurança em seus aplicações.
Garantindo que o Caché funcione efetivamente e sem comprometer as tecnologias de segurança do ambiente operacional.
27

Perfis Atribuídos por Aplicações
Muitas vezes é útil que um usuário receba privilégios adicionais de forma temporária, ao invés de tê-los atribuídos de forma permanente. Por exemplo, ao invés do Administrador de Segurança conceder um amplo conjunto de privilégios a um usuário, tal como a capacidade de acessar e modificar a base de dados de pagamento de salários, ele poderia conceder ao usuário apenas o privilégio de acesso àquele aplicação. Este, por sua vez, poderia então elevar os privilégios de usuário enquanto está sendo utilizado.
Para conseguir elevar um usuário, perfis podem ser atribuídos às aplicações. Quando aquela apli-cação é acessada, o usuário adquire perfis adicionais temporariamente. Os perfis adicionais podem ser simplesmente uma lista adquirida por todos aqueles autorizados a utilizar a aplicação, ou podem também ser mais customizados, baseados nos perfis que o usuário já possui.
Este recurso é particularmente útil para aplicações baseados em browser usando o CSP (Caché Server Pages). Com o CSP, uma parte de qualquer URL especifica um nome de aplicação. Após a autenticação e a verificação de que o usuário está autorizado a usar aquele aplicação CSP, o usuário recebe perfis adicionais temporários designados àquele aplicação enquanto persistir a solicitação daquela página.
O Administrador de Segurança pode ainda designar rotinas específicas como sendo capazes de realizar elevação de perfil para receber perfis adicionais de aplicações específicos (após passarem por testes de segurança especificados pelo usuário). Esta facilidade é controlada rigidamente e é por este mecanismo que aplicações não CSP realizam a elevação de perfil.
Autenticação
O Caché suporta vários níveis de autenticação, variando de nenhuma autenticação ao uso de senhas, até o uso de protocolo Kerberos para autenticar a identidade de usuários. O Kerberos fornece uma autenticação muito forte e possui a vantagem de ser rápido, ter escalabilidade e ser fácil de utilizar. Com o Kerberos, as senhas nunca são transmitidas através da rede, o que oferece uma medida extra de segurança. O Caché suporta a implementação de single sign-on.
Capítulo 2
28

Criptografia da Base de Dados
O Caché suporta duas formas de criptografia da base de dados:
<O Administrador de Segurança pode designar um ou mais arquivos CACHE.DAT (bases de dados) para que sejam criptografados no disco. Tudo contido nestes arquivos é então criptografado. <Desenvolvedores podem usar funções de sistema para criptografar/descriptografar dados, os quais podem então ser armazenados na base de dados ou ser transmitidos. Este recurso pode ser utilizado para criptografar dados sensíveis para que sejam protegidos de outros usuários que possuem acesso de leitura à base de dados, mas não possuem a chave (de criptografia).
Por definição, o Caché criptografa dados com uma implantação do Padrão de Criptografia Avançada (Advanced Encryption Standard, ou AES), um algoritmo simétrico que suporta chaves de 128, 192 ou 256 bits. As chaves de criptografia são guardadas em um local protegido da memória. O Caché oferece capacidades completas de gerenciamento de chaves.
O arquivo de journal também pode ser criptografado.
Auditoria
Muitos aplicações, especialmente aqueles que devem satisfazer as regulamentações governa-mentais, tais como TISS (Brasil), HIPAA ou Sarbanes-Oxley (EUA), precisam oferecer auditoria segura. No Caché, todos os eventos de sistema e de aplicações são registrados em um log que só aceita adições ao registro existente (append-only), e o qual é compatível com qualquer consulta ou ferramenta de relatórios que utilize SQL.
29

Capítulo 3: Servidor de Aplicações Caché
Capítulo 3
O servidor de Aplicações Caché oferece capacidades avançadas de programação de objetos, fornece caching sofisticado de dados e integra acesso fácil a uma variedade de tecnologias. O Servidor de Aplicações Caché torna possível desenvolver aplicações sofisticados de forma rápida, bem como operá-los com alto desempenho – além de suportá-los com facilidade.
Mais especificamente, o Servidor de Aplicações Caché oferece:
<Máquina Virtual Caché que roda três linguagens de desenvolvimento tipo script – Caché ObjectScript, Caché Basic, e Caché MVBasic.
<Acesso aos Servidores de Dados Multidimensionais do Caché no mesmo computador ou em outras máquinas com roteamento invisível.
<Software de conectividade com client-side caching para permitir o acesso rápido a Objetos Caché a partir de todas as tecnologias utilizadas mais comumente, incluindo Java, C++, C#, COM, .NET e Delphi. O Caché automaticamente realiza o networking entre o cliente e o Servidor de Aplicações.
<Compatibilidade com SOAP e XML.
<Acesso SQL utilizando ODBC e JDBC, incluindo caching sofisticado no cliente e no servidor de aplicações para alto desempenho.
<Acesso a bancos de dados relacionais.
<Caché Server Pages para aplicações web fáceis de programar e de alta performance.
<Caché Studio – uma IDE para desenvolver e depurar aplicações rapidamente com o Caché.
<O código para as Linguagens de Script é armazenado na base de dados e pode ser modifi- cado online, com as mudanças sendo propagadas automaticamente para todos os servi- dores de aplicações.
MÁQUINA VIRTUAL CACHÉ E LINGUAGENS DE SCRIPT
No núcleo do Servidor de Aplicações Caché está a Máquina Virtual Caché, que é extremamente veloz e suporta as linguagens script do Caché.
<O Caché ObjectScript é uma linguagem poderosa e de fácil aprendizado, com estrutura de dados extremamente flexível.
<O Caché Basic oferece um modo fácil para que programadores de Visual Basic comecem a utilizar o Caché. De forma semelhante ao VBScript, o Caché Basic suporta objetos e é expandido para ter acesso direto aos Arrays Multidimensionais Caché.
<O Caché MVBasic é a variante da linguagem de programação Basic utilizada em aplica- ções MultiValue (Pick). O MVBasic foi expandido para ter suporte a objetos e ter acesso direto aos Arrays Multidimensionais Caché.
30

O acesso à base de dados dentro da Máquina Virtual Caché é altamente otimizado. Cada processo de usuário possui acesso direto às estruturas de dados multidimensionais por meio de chamadas à memória compartilhada, a qual acessa uma base de dados cache compartilhada. Todas as demais tecnologias (Java, C++, ODBC, JDBC, etc.) se conectam através da Máquina Virtual Caché para acessar a base de dados.
Interoperabilidade Completa
Como o Caché ObjectScript, o Basic e o MVBasic estão todos instalados na mesma Máquina Virtual Caché, eles possuem interoperabilidade completa:
<Qualquer método de objeto pode ser escrito em qualquer linguagem – a mesma classe pode usar todas as três linguagens.
<O uso das funções de cada uma das linguagens pode acessar um código escrito nas demais linguagens.
<Eles compartilham variáveis, Arrays e objetos.
Desenvolvimento Rápido/Disponibilização Flexível
Os programadores podem, em quase todos os casos, desenvolverem aplicações mais rapidamente, sendo que estes aplicações rodarão significativamente mais rápidos e com maior escalabilidade se a maior parte possível do código for escrita nestas linguagens de programação (o que permite que eles rodem na Máquina Virtual Caché). Além disso, tal código não requere mudanças na troca de hardware ou de sistemas operacionais. O Caché lida com as diferenças de hardware e de sistema operacional de forma automática.
Linguagens Script
31
A VANTAGEM DO CACHÉ
Desenvolvimento Rápido de Aplica-ções: O desenvolvimento de aplicações complexas com o Caché ObjectScript é radicalmente mais rápido do que com qualquer outra grande linguagem – muitas vezes de 10 a 100 vezes mais rápido. Mais rápido significa dizer que os projetos têm uma chance melhor de sucesso – com menos programadores – e podem ser ajustados mais rapidamente, conforme as aplicações necessitem de modificações.
Curva de Aprendizado Mais Curta: O Basic é talvez a linguagem de computador mais conhecida do mundo. Desenvolvedores que conhecem Visual Basic podem começar a escrever código em Basic de forma instantânea – o modelo de objeto Caché é aprendido facilmente. Mais Rápido e com Mais Escalabi-lidade: A Máquina Virtual Caché, com seu acesso direto à base de dados, oferece aplicações mais rápidas que podem ter seu uso ampliado a dezenas de milhares de usuários utilizando hardware de baixo custo. Flexibilidade: O código que roda na Máquina Virtual Caché pode rodar em outros hardwares e em outros sistemas operacionais sem mudanças. O código é armazenado na base de dados e automaticamente propagado para os Servidores de Aplicações.

Capítulo 3
CACHÉ OBJECTSCRIPT
O Caché ObjectScript é uma poderosa linguagem de programação orientada a objetos e desenhada para permitir o desenvolvimento rápido de aplicações de base de dados. Aqui estão algumas das principais características da linguagem.
Estrutura Geral
O Caché ObjectScript é orientado por comandos, e tem portanto, uma sintaxe do tipo:
set x=a+b
do rotacionar (a,3)
if (x>3)
Há um conjunto de funções integradas do sistema que são especialmente eficientes na manipula-ção de textos. Todos os nomes destas funções sempre se iniciam por um único caractere “$” para distingui-los dos nomes de variáveis e de Arrays Por exemplo:
$extract(string,from,to) // obter um conjunto de caracteres de uma
seqüência $length(string) // determinar o comprimento de uma
seqüência
As expressões utilizam precedência de operação da esquerda para direita assim como na maioria das calculadoras portáteis, exceto nos casos em que os parênteses alteram a ordem de avaliação.
Armazenamento Flexível de Dados
Uma das características mais exclusivas do Caché ObjectScript é sua armazenagem altamente flexível e dinâmica de dados. Os dados podem se armazenados em:
<Propriedades de objetos. <Variáveis. <Arrays esparsos multidimensionais, que permitem todo tipo de dados para os subscripts. <Arquivos de base de dados (“globais”), que são Arrays esparsos multidimensionais.
Com raras exceções, qualquer lugar da linguagem onde uma variável possa ser inserida, também permite a utilização de um array uma propriedade de objeto ou uma referência global.
Na maioria das linguagens de informática, os “tipos” são extensões de conceitos de armaze-namento de hardware (interger,float,char,etc.) Entretanto, o Caché ObjectScript tem a filosofia de que seres-humanos não pensam utilizando estes tipos de armazenamento, e que estes “tipos” infocêntricos simplesmente impedem o desenvolvimento rápido de aplicações. A necessidade de utilizar declarações e afirmações de dimensão introduz bem mais erros do que ajuda a prevenir (ex. erros do tipo extrapolação de 2 bytes integral, ou quando uma seqüência extrapola sua aloca-ção de memória e corrompe outro armazenamento). Contudo, a digitação de objetos, tais como Pessoa, Nota Fiscal ou Animal, é vista como sendo altamente valiosa e consistente com o modo de pensar dos seres-humanos.
32

Assim, no Caché ObjectScript, as propriedades de objeto são fortemente tipi-ficadas, mas os outros três tipos de armazenamento (variáveis, Arrays e nós de globais) são entidades completamente polimórficas e sem um tipo especial, que não precisam ser declaradas ou definidas. Eles simplesmente passam a existir con-forme são utilizados e se moldam às necessidades de dados daquilo que estejam armazenando e da forma como estão sendo utilizados em uma expressão. Mesmo Arrays não requerem nenhuma especificação de tamanho, dimensão ou tipo de subscripts/dados. Por exemplo, um desenvolvedor pode criar um Array chamado Pessoa simplesmente atribuindo:
Set Pessoa (“Silva”, “João”)= “Eu sou uma pessoa boa”
Neste exemplo, os dados foram armazenados num Array bidimensional utilizando dados seqüenciais para os subscripts. Outros módulos de dados neste Array poderiam ter um número diferente de dimensões e poderiam misturar seqüência, integrais ou outro tipo de dados para os subscripts. Por exemplo, podem-se armazenar dados em:
abc(3)
abc(3,-45.6,”Sim”)
abc(“Contar”)
todos no mesmo array.
Acesso Direto à Base de Dados
Uma referência à base de dados (“uma referência à global”) é essencialmente uma referência de Array multidimensional precedida pelo caractere circunflexo “^”. Este caractere indica que se trata de uma referência de dados armazenados na base ao invés de dados privados de processos temporários. Cada um destes Arrays de base de dados é chamado de “global”.
Assim como no caso de Arrays multidimensionais e variáveis, não é necessária nenhuma declaração ou definição ou reserva de espaço de armazenamento para acessar ou guardar os dados na base de dados; dados em globais simplesmente passam a existir conforme os dados são armazenados. Por exemplo, para se armazenar dados na base, pode-se escrever:
set ^Pessoa(“Silva”,”João”)= ”Eu sou uma pessoa muito boa”
E mais tarde, recuperar-se o código conforme:
set x=^Pessoa(“Silva”,”João”)
O programador tem total flexibilidade sobre como estruturar estes Arrays de dados em globais. (vide o Modelo de Dados Multidimensionais).
33

Capítulo 3
34
Referências de Objetos
Os objetos Caché implementam o modelo de dados ODMG com poderosas extensões.
No Caché ObjectScript, uma referência a objetos é utilizada para se acessar um objeto. (uma “oref” é geralmente uma variável cujos valores especificam qual objeto na memória se está fazendo referência). A oref é seguida por um ponto e, a seguir, pelo nome de uma propriedade ou método. Referências de objetos podem ser utilizadas onde quer que se possa usar uma expressão. Por exemplo:
set nome=pessoa.Nome // “pessoa” é a variável cujo valor é uma
oref
// o nome da pessoa é colocado na
variável
“nome” se (pessoa.Idade>x) // veja se a idade da pessoa é maior que
“x” set dinheiro=nf.Total // “Total()” é um método que calcula a
soma de
// todas as notas fiscais (nf) de ítens
de linha Métodos também podem ser executados através de um comando tipo “DO” quando nenhum valor resultante é necessário. Por exemplo:
do parte.Incremento() // “Incremento()” é um método, cujo
valor de
// retorno, se houver, não interessa
A oref não é a mesma coisa que um identificador (ID) de objeto da base de dados; ela é utilizada para recuperar e armazenar um objeto da base de dados. Uma vez estando na memória, o objeto recebe um valor oref reutilizável, que é então usado para acessar os dados do objeto. Na próxima vez que aquele mesmo objeto da base de dados for trazido à memória ele provavelmente receberá um valor oref diferente.

Acesso HTML e SQL HTML para aplicações Web e SQL podem ser embutidos no código Caché ObjectScript.
Código de Chamada
Em algumas linguagens de objeto, todo o código precisa ser parte de algum método. Esta restrição não existe com o Caché Object Script – o código pode ser chamado diretamente ou pode ser chamado através de sintaxe de objeto.
O código normalmente é chamado utilizando um comando do tipo DO.
do rotacionar(a,3)
Código que resulte em um valor também pode ser chamado na forma de uma função. Por exemplo:
set x=a+$$insert(3,y)
Chama o procedimento ou sub-rotina “insert”, escrito por um programador. Um código pode ser também chamado na forma de um método de objeto.
set dinheiro=nf.Total() // Total() dá o valor total das notas
fiscais
nf) parte. Incremento() // “Incremento()” é um método, cujo
valor,
// se houver, não interessa
Tanto a chamada por valor quanto a chamada por referência são suportadas por parâmetros.
35

Capítulo 3
36
Rotinas
O código do Caché ObjectScript é fundamentalmente organizado em um conjunto de “rotinas”. Cada rotina (normalmente até 32KB em tamanho) é atômica, isto é, pode ser editada, armazenada e compilada de forma independente. As rotinas são conectadas de forma dinâmica em tempo de execução não há um passo extra separado da ligação de rotinas para o programador. O código de uma rotina é armazenado na base de dados, assim, rotinas podem ser paginadas de forma dinâmica em toda a rede, ao invés de terem de ser instaladas em cada computador.
Dentro de uma rotina, o código é organizado na forma de um conjunto de procedimentos e ou sub-rotinas. (Um método de objeto é um procedimento, mas é acessado com uma sintaxe diferente).
Quando se solicita um código que está dentro da mesma rotina, somente o nome do procedimento ou da sub-rotina é necessário. Caso contrário, o nome da rotina deve vir junto.
do transferir() // chama “transferir” na mesma rotinado
total^nf() // chama “total” na rotina “nf” (nota
fiscal) Um procedimento (ou sub-rotina) que tenha um valor resultante de interesse deve ser solicitado utilizando a sintaxe de função “$$”
set x=$$total^nf() // chama o mesmo procedimento “total”
mas usa o valor retornado
Rotinas podem ser compiladas e editadas através do Caché Studio.

Métodos de Objeto
Definições de classe e seus códigos de métodos são armazenados em globais, sendo que o Class Compiler compila cada classe em uma ou mais rotinas. Cada método é simplesmente um procedimento em uma rotina, embora só possa ser solicitado através da sintaxe de objeto. Por exemplo, se a classe Paciente define um método Admite e a variável Pac identifica um objeto Paciente específico, então solicitaríamos o método Admite para aquele objeto com a seguinte sintaxe:
do Pac.Admite() // Chama o método admit para Paciente
set x = Pac.Admite() // Chama o mesmo método, mas usa o
valor retornado
Procedimentos e Variáveis Públicas/Privativas
Um procedimento é um bloco de códigos dentro de uma rotina que é similar a uma função em outras linguagens. Um procedimento consiste em um nome, uma lista de parâmetros formal, uma lista de variáveis públicas e um bloco de código delimitado por “{ }”. Por exemplo:
Admite(x,y)[nome,regnum] { ...o código entra aqui }
No Caché ObjectScript, algumas variáveis são públicas (comuns) e outras são privativas de um procedimento em particular. Cada variável utilizada dentro de um procedimento é considerada privativa daquele procedimento a menos que esteja listada na lista pública. No exemplo acima, “nome” e “regnum” acessam as variáveis públicas com aqueles nomes, ao passo que todas as outras demais variáveis existem. somente para esta solicitação, deste procedimento. Variáveis cujos nomes se iniciam pelo caractere “%” são sempre implicitamente públicas.
Procedimentos não podem ser acumulados, embora um procedimento possa conter sub-rotinas.
Sub-rotinas
Rotinas podem conter sub-rotinas, que são mais leves que procedimentos. Uma sub-rotina pode conter uma lista de parâmetros e pode ter um valor de resultado, mas ela não possui uma lista pública ou uma estrutura de blocos formal. Sub-rotinas podem estar embutidas em procedimen-tos ou podem estar no mesmo nível que um procedimento em uma rotina.
Sub-rotinas permitem a solicitação de código utilizando-se do mesmo conjunto de variáveispúblicas/privativas que o solicitante – e elas podem ser solicitadas mais rapidamente. Uma sub-rotina embutida em um procedimento usa o mesmo escopo de variáveis que o procedi-mento em si e só pode ser solicitada a partir de dentro daquele procedimento. Referências de variável a uma sub-rotina que não seja parte de um procedimento são todas as variáveis públicas.
37

Capítulo 3
BASIC
O Basic é talvez a linguagem de programação mais conhecida do mundo. No Caché, o Basic foi expandido para suportar acesso direto às estruturas de dados centrais do Servidor de Aplica-ções – Arrays multidimensionais -, bem como a outros recursos do Servidor de Aplicações Caché. Ele dá suporte direto ao Caché ObjectModel utilizando a sintaxe do Visual Basic, além de ser executado na Máquina Virtual Caché.
O Basic pode ser utilizado tanto como métodos de classes, quanto como rotinas Caché (videa descrição de rotinas do Caché Object Script). O Basic pode solicitar o Caché Object Script (e vice-versa) com ambas as linguagens acessando as mesmas variáveis, Arrays e objetos na memória de processo.
Arrays podem ser expandidos para que sejam bem mais poderosos:
<A presença do caractere “^” antes do nome de um Array indica uma referência a um <Array multidimensional de base de dados; isto é, Arrays persistentes que são compartilha- dos com outros processos.
<Subscripts podem ser de qualquer tipo de dados – seqüências, integers, números decimais, etc.
<Dados podem ser armazenados em níveis múltiplos de subscript em um mesmo Array – por exemplo, dados poderiam ser armazenados em A (“cores”) e em A (“cores”,3).
<Arrays não precisam ser declarados e são sempre esparsos – O Caché só reserva espaço conforme os nós são inseridos.
<Uma função Traverse permite a identificação do subscript seguinte (ou anterior) em um dado nível de subscript.
Outras extensões incluem:
<Comandos de processamento de transações para Iniciar (Start), Confirmar (Commit) e fazer o Rollback de uma transação.
<Uma função de incremento atômica para ser utilizada na base de dados.
<Extensões que promovem uma melhor integração com as capacidades do Servidor de Aplicações Caché.
38

Acesso a Objeto com Basic
No Caché, classes de objetos estão organizadas em pacotes, e nomes de classes incluem o nome do pacote seguido por um ponto. Por exemplo: Folha. Pessoa – é uma classe Pessoa no pacote Folha. O comando do Basic New é usado para criar um objeto:
Person = New Payroll.Person() // cria um novo objeto Pessoa O Basic foi expandido com um comando Open ID para acessar um objeto existente:
Person = OpenID Payroll.Person (54) // abre o objeto pessoa com o ID 54
Aqui estão alguns exemplos de códigos que acessam a propriedade das pessoas:
Person.Name = `Smith´, John // especifica o nome da pessoa Person.Home.City // faz referência à cidade da pessoa Person.Employer.Name // traz o objeto Empregador da pessoa para a // memória e acessa o nome do em pregador
Classes de base de dados podem ser persistidas em disco com o método Salvar. Por exemplo:
Person.Save()salva a pessoa, criando um ID de objeto se esta for a primeira vez que o objeto houver sido arma- zenado. Se objetos relacionados (como o Empregador) também tiverem sido modificados, eles também serão salvos automaticamente.
39

Capítulo 3
MVBASIC
MVBasic é uma outra linguagem de script oferecida pelo Caché e é uma variante do Basic. Ele é, no entanto, feito com a intenção de executar aplicações escritos para sistemas MultiValue (Pick) e, portanto, tem suporte a características extra, incluindo a capacidade de acessar e mani-pular arquivos MultiValue.
O MVBasic pode ser utilizado tanto como métodos de classe como rotinas do Caché (veja a descrição de rotinas do Caché Object Script). O MVBasic pode solicitar tanto o Caché ObjectScript, quanto o Basic – e vice-versa - com todas as três linguagens tendo acesso às mesmas variáveis, Arrays e objetos na memória de processamento.
O Caché MVBasic possui as mesmas extensões do Caché Basic, inclusive acesso a objetos. Contudo, dada a possível ambigüidade, a seqüência de dois caracteres “->” – é utilizada ao invés de um separador tipo ponto, “.” – nas referências de objetos.
C++
Cada classe do Caché pode ser projetada como uma classe C++ com métodos correspondentes a cada propriedade e método da classe Caché. Para programas C++, estas classes possuem exata-mente a mesma aparência de outras classes C++ locais e o Caché automaticamente gerencia todas as consultas entre o cliente e o servidor. As propriedades da classe são armazenadas em memória cache no cliente e solicitações de método C++ criam seus correspondentes métodos server side, incluem-se aí os métodos para armazenar um objeto na base de dados e depois recuperá-los.
JAVA
Java é uma linguagem de programação popular mas, conectar aplicações Java à maior base das bases de dados pode ser desafiador. Conectar-se a uma base de dados relacionais requer ampla codificação SQL, o que demanda muito tempo e inibe muito das vanta-gens da tecnologia Java de objetos. A abordagem do Caché de armazenar os objetos diretamente sem o desenvolvedor ter de se preocupar com a forma na qual os dados substirão e ter de usar sintaxe de objetos é muito mais simples e geralmente preferida.
Alguns desenvolvedores preferem trabalhar exclusiva-mente com POJO’s (Plain Old Java Objects), enquanto outros preferem EJB (Enterprise Java Beans).
Ademais, alguns desenvolvedores preferem primeiro definir o esquema da base de dados e depois gerar automaticamente a classe Java correspondente para cada uma das classes da base de dados, enquanto outros preferem criar primeiro às classes Java e fazer com que o Caché gere um esque-ma da base de dados automaticamente. O Caché suporta todas estas abordagens:
<Qualquer classe Caché pode ser projetada como uma classe Java para que classes e méto dos possam ser acessados como objetos Java. <Classes Caché também podem ser projetadas como Enterprise Java Beans. <JDBC oferece acesso SQL de alta performance usando um driver completamente baseado em Java (tipo 4). <A tecnologia Jalapeño da InterSystems cria classes Caché a partir de descrições de classe em POJO.
Java Supported Several Ways
40

Objetos Acessados Através de Classes Projetadas
Toda classe Caché pode ser projetada como uma classe Java (ou EJB), com métodos correspondentes a cada propriedade e método da classe Caché. Para programas em Java, estas classes aparentam ser como qualquer outra classe Java local. A classe Java gerada se utiliza de uma biblioteca Java fornecida pela InterSystems para lidar com qualquer comunicação entre o Cliente e o Servidor.O estado de cada objeto Caché é mantido no Servidor de Aplicações Caché, embora propriedades de classe estejam também armazenadas em memória cache no cliente para otimizar o desempenho. Chamadas de método solicitam méto-dos correspondentes no Servidor de Aplicações Caché – incluindo métodos para armazenar um objeto na base de dados e depois recuperá-lo. Para o cliente, não é visível qual Servidor de Dados Caché contém as informações ou mesmo se os dados de objeto estão armazenados em uma base de dados relacional acessada pelo Servidor de Aplicações Caché.
Métodos Caché Escritos em Java
Métodos de classe Caché podem ser escritos em Java usando o Caché Studio. Contudo, ao contrário do Caché ObjectScript e do Basic, os métodos Java não são executados pela Máquina Virtual Caché. Ao invés disso, eles são incluídosna classe Java gerada e são executados em qualquer Máquina Virtual Java. Tal tipo de código não é acessível a partir de métodos não Java.
Fornecendo Persistência à Aplicações J2EE
Desenvolvedores de aplicações J2EE, o qual utiliza Enterprise Java Beans (EJB), trabalham primordialmente com objetos até o momento em que necessitam acessar a base de dados – aí eles geralmente são forçados a voltar a utilizar o SQL. Através de sua interface JDBC, o Caché pode oferecer resposta SQL extrema-mente rápida a tais aplicações. No entanto, o acesso SQL geralmente não é a abordagem preferida.
Base de dados de objetos é uma técnica de acesso mais natural para programa-dores de EJB. O Caché projeta classes Caché como EJB’s gerando métodos de persistência de alta performance automaticamente para BMP (Bean-Managed Persistence). Isso evita a sobrecarga do SQL e o mapeamento objeto-relacional – o resultado é uma maior escalabilidade para aplicações J2EE.
A tecnologia Jalapeño da InterSystems também pode ser utilizada em aplicações J2EE com as mesmas vantagens.
41
A VANTAGEM DO CACHÉ
Flexibilidade: Desenvolvedores de Java possuem opções no que diz respeito a acessar objetos Caché – eles podem utilizar SQL e JDBC ou objetos projetados mais natural-mente, como classes Java ou Enter-prise Java Beans. Com o Jalapeño, os desenvolvedores têm a opção de trabalhar inteiramente em seu ambi-ente de desenvolvimento Java predi-leto, deixando o Caché fornecer os métodos para armazenar e recuperar objetos automaticamente sem tocar nas classes de desenvolvedores de base de dados.
Alta Performance: Todos os aplica-ções Java, independentemente de como estão conectados ao Caché, se beneficiam de seu desempenho superior e de sua escalabilidade.
Compatibilidade Nativa com J2EE Significa Desenvolvimento Mais Rápido: Classes Caché podem ser facilmente projetadas como EJB’s, fornecendo a desenvolvedores J2EE um modo simples de se conectar à base de dados pós-relacional do Caché. Quando uma classe Caché é projetada utilizando Bean-Man-aged Persistence, o Caché gera automaticamente o método usado pelo EJB para acessar a base de da-dos. do Caché. Como os desenvol-vedores não precisam mais manusear métodos de persistência de códigos, os aplicações podem ser completa-dos com maior rapidez.

Capítulo 3
Jalapeño Permite Desenvolvimento em Java
Ao invés de iniciar o processo com classes Caché e projetá-las como componentes Java, a tecno-logia da InterSystems faz exatamente o oposto. Ela permite a desenvolvedores Java definir classes de objeto dentro do ambiente de desenvolvimento Java que eles prefiram, fazendo a persistência automática daquelas classes no Caché. A classe Java do desenvolvedor não é alterada – o Caché fornece uma biblioteca de classes com um API que é utilizado para guardar e recuperar objetos e emitir con-sultas às classes do desenvolvedor.
CACHÉ & JALAPEÑO
Desenvolvedores Java que queiram criar novos aplicações hoje em dia se deparam com vários problemas. Geralmente, eles armazenam suas informações em uma base de dados relacional padrão utilizando-se de SQL. Com esta abordagem os desenvolvedores têm de mapear seus objetos Java para estruturas relacionais e escrever consultas SQL tediosas e muitas vezes complexas para acessarem àqueles dados – todos estes pontos podem consumir uma grande porcentagem do tempo de desenvolvimento total. Alternativamente, um desenvolvedor pode fazer uso de uma base de dados objeto, a qual freqüentemente não possui suporte a SQL e as ferramentas de geração de relatório baseadas em SQL, podendo também requerer definições de esquemas.
A tecnologia Jalapeño (JAva LAnguage PErsistence with NO mapping) da InterSystems torna fácil para desenvolvedores Java realizar a persistência de seus objetos dentro da robusta base de dados de objeto Caché, utilizando-se acesso de objeto, ao mesmo tempo em que fornece acesso SQL de alta performance para estes mesmos dados. Os objetos são armazenados nas bases de dados como objetos reais com propriedades, relações, etc. (isto é, não se armazena simples-mente seu estado de série). Mesmo assim, nenhum mapeamento de objeto relacional é necessário.
Utilizando o Jalapeño, o desenvolvedor Java cria classes de bases de dados do mesmo modo que qualquer outra classe POJO, usando a IDE Java de sua escolha. O programador indica então para o Jalapeño quais classes são de bases de dados – geralmente utilizando um plug-in para o IDE do desenvolvedor (fornecido pela Biblioteca Jalapeño Persistence). O Jalapeño analisa as classes, cria automaticamente um esquema de base de dados correspondente (e SQL) e gera todo o suporte de execução para salvar e recuperar tais objetos.
A classe POJO do desenvolvedor não é modificada – e este pode continuar a alterá-la. Durante a execução, de forma normal, a aplicação acessa diretamente as propriedades e os métodos dos objetos POJO. Para salvar e recuperar objetos da base de dados, a aplicação usa as APIs da classe “ObjectManager” fornecida pelo Jalapeño. A classe ObjectManager também oferece métodos que estabelecem uma conexão à base de dados, suporta consultas SQL e fornece semântica de transação (tal como start, commit e rollback).
Uma simples descrição de classe, inclusive uma lista de propriedades e seus tipos, não é em si só elaborada o suficiente para descrever tudo o que se poderia querer em uma base de dados. No mínimo, seria necessário ainda descrever qual propriedade contém o ID do objeto. Um de-senvolvedor geralmente ainda especificaria índices para tornar as consultas mais eficientes. Adicionando-se anotações padrão Java a seus arquivos-fonte desta linguagem, desenvolvedores podem suprir esta e outras especificações da base de dados.
O Jalapeño também suporta “evoluções de esquemas” (“schema evolutions”), através da qual o desenvolvedor pode continuar a modificar a classe, inclusive adicionando propriedades novas ou alterando definições já existentes, sendo que o esquema de definições se adapta sem invalidar qualquer um dos dados já inseridos. Isto resulta em um processo de desenvolvimento natural e interativo.
42
Apesar de o Jalapeño funcionar melhor se utilizado em conjunto com o Caché, ele também pode exportar seus esquemas de base de dados para um esquema relacional correspondente utilizando DDL padrão (Data Definition Language – Linguagem de Definição de Dados). Portanto, apesar do objeto ter sido criado para usar acesso de objeto com o Caché, ele também pode ser disponibilizado em uma base de dados relacional. Neste caso, os API’s do Jalapeño ObjectManager usam automaticamente chamadas JDBC normais para a conectividade da base de dados. Quando conectado à base de dados de objeto Caché, o protocolo de alto desempenho baseado em objeto é utilizado.
A biblioteca Jalapeño é implementada através de Java padrão e roda em qualquer Java 1.5 JVM (ou mais recente) ou em qualquer ambiente de servidor de aplicações J2EE.
Com o Jalapeño, o desenvolvedor Java pode concentrar-se na interface de usuário e na lógica comercial do aplicação, criando classes de base de dados do mesmo modo que com outras classes – e deixando o Caché tomar conta do restante.
No exemplo a seguir, um objeto Cliente é recuperado, seu número de telefone é alterado com um método “set” estabeler, a base de dados é atualizada e, por fim, o objeto na memória é fechado.
Cliente cliente = (Cliente) objectManager.openById(Cliente.
class, clienteId);
cliente.setNumTel(“1144210000”);
objectManager.update(cliente, true);
objectManager.close();
43
A VANTAGEM DO CACHÉ
Desenvolvimento Rápido e Natural Sem Mapeamento Objeto-Relacional: O Jalapeño utiliza introspecção de classes POJO para criar automaticamente um esquema de base de dados de objeto. Os dados são armazenados como objetos e uma representação SQL padrão destes dados também é criada de forma automática. Nenhum mapeamento objeto-relacional é necessário, acelerando assim o desenvolvimento.
Fácil Persistência POJO: Dentro de um aplicação, os desenvolvedores acessam as suas próprias classes de base de dados como se fosse qualquer outra classe. O Jalapeño gera todos os códigos para salvar e recuperar objetos da base de dados utilizando suas API’s de runtime.
Acesso SQL: Todos os objetos dentro da base de dados estão acessíveis de forma automática por SQL utilizando a API de JDBC do Jalapeño – mesmo sem o desenvo-lvedor ter realizado um mapeamento objeto-relacional.
Independência de Plataforma e de Base de Dados: O Caché está disponível em todas as principais plataformas – e se por um lado o Jalapeño funciona melhor se usado com ele, por outro também pode exportar seu esquema de base de dados para um esquema relacional correspondente se utilizar um DDL comum. Portanto, apesar da aplicação haver sido feita para utilizar acesso de objetos com o Caché, ele também pode ser disponibilizado em uma base de dados relacional.

Capítulo 3
CACHÉ & .NET
Graças a seu acesso aberto e flexível a dados, o Caché funciona de forma imper-ceptível com o .NET. Há muitos modos de conectar ambos – incluindo objetos, SQL, XML e SOAP. Desenvolvedores podem criar aplicações com as tecnologias de sua preferência – todas elas se beneficiarão da performance e escalabilidade superior do Caché.
ADO.NET
ADO.NET é uma nova materialização do ADO, otimizado para uso na estrutura .NET. Sua intenção é tornar aplicações .NET “bases de dados independentes”, utilizando normalmente o SQL para se comunicar com estas bases. Através de seu acesso de dados relacionais, o Caché oferece suporte nativo a ADO.NET. Ele também suporta ODBC.NET, da Microsoft, com conectividade read-only (somente leitura) do SOAP, integrada ao ADO.NET.
Web Services
Há duas maneiras de se utilizar web services no .NET. Uma delas é enviando documentos XML por HTTP. A outra é utilizando protocolo SOAP para simpli-ficar o intercâmbio de documentos XML. Como o Caché pode expor dados em ambas as direções, ele funciona de forma imperceptível com web services .NET.
Objetos Caché Gerenciados
O Caché pode gerar automaticamente sessões .NET (ou código-fonte C#) a partir de classes Caché. Um plug-in para Visual Studio permite aos desenvol-vedores que preferem aquele ambiente a acessar objetos Caché facilmente.
44
A VANTAGEM DO CACHÉ
Servidos de Dados Veloz: Aplicações web que utilizam o Caché como um servidor de dados se beneficiam da imensa escalabili-dade e alto desempenho oferecidos pelo engine de dados multidimen-sional do Caché.
Desenvolvimento .NET Mais Rápido: Os desenvolvedores serão mais produtivos se trabalharem com suas ferramentas preferidas em ambientes que lhes seja familiar. O Caché suporta uma ampla varie-dade das mais comuns ferramentas e tecnologias de desenvolvimento, oferecendo ambos os acessos a dados de objeto, como também o acesso SQL.

CACHÉ & XML
Do mesmo modo que HTML é uma linguagem de marcação, compatível com a internet, para a exibição de dados em um navegador, o XML é uma linguagem de marcação para inter-cambiar dados entre aplicações. A estrutura dos dados XML é hierárquica e multidimensional, tornado-a um par natural do motor de dados multidimensionais do Caché.
Exportando XML
Tudo o que é necessário para tornar uma classe Caché compatível com XML é fazer com que ela herde da classe “%XML.Adaptor”, que está incluída no Caché. Isto fornece todos os métodos necessários para:
<Criar ou uma DTD (Document Type Definition), ou um Esquema XML para a classe. O Caché gera Esquemas e DTDs automaticamente, mas desenvolvedores que desejem customizar a formatação XML de uma classe podem fazê-lo.
<Formatar automaticamente os dados de um objeto como XML, de acordo com o DTD ou Esquema definido.
Importando XML
O Caché vem com outras classes que fornecem métodos, possibilitando aos desenvolvedores:
<Importar Esquemas XML e criar classes Caché correspondentes automaticamente.
<Importar dados contidos em documentos XML, trazendo-os como instâncias (objetos) de classes Caché via um API simples.
<Analisar a fundo e validar documentos XML através de um analisador XML (SAX) integrado.
45

Capítulo 3
CACHÉ & WEB SERVICES
Web Services permite o compartilhamento da funcionalidade de um aplicação através da internet e dentro de uma organização ou de um sistema. Web Services possue uma interface descrita em WSDL (Web Service Definition Language) e retornam um documento XML formatado de acordo com o protocolo SOAP.
O Caché possibilita que qualquer método de classe, qualquer procedimento armazenado em SQL e qualquer consulta sejam exibidos automaticamente com um Web Services. O Caché gera o descritor WSDL para o serviço e quando este é solicitado, envia o documento formatado apropriadamente em XML. O Caché também facilita o rápido desenvolvimento, gerando uma pá-gina web automaticamente para testar o serviço, sem ser necessário construir uma aplicação-cliente.
46
A VANTAGEM DO CACHÉ
Conectividade Fácil ao XML: O Caché tira proveito de sua capacidade de herança múltipla para fornecer a qualquer classe Caché uma interface bidirecional com o XML. O resultado: As classes Caché podem ser transformadas em esquemas e documentos XML de forma fácil e rápida. De modo semelhante, esquemas e documentos XML podem ser transformados em definições de classe e objetos Caché.
Desenvolvimento Rápido de Aplicações XML Mais Veloz: Como as estruturas de dados multidimensionais nativas do Caché se ajustam bem aos documentos XML, os desenvol-vedores não precisam codificar manualmente um “mapa” que traduza entre XML e a base de dados Caché.
Web Services Instantâneos: Qualquer método Caché pode ser publicado como um Web Services com apenas alguns cliques do mouse. O Caché gera automaticamente o descri-tor WSDL e a resposta SOAP quando o serviço é solicitado.

CACHÉ & MULTIVALUE
O Caché oferece todas as capacidades necessárias para desenvolver e rodar aplicações MultiValue (também chamados de aplicações baseados em Pick), incluindo os MultiValue abaixo:
<MVBasic <Acesso a arquivos <Linguagem de consultas <Dicionário de dados <“procs” <Command shell (utilitário de entrada de comandos)
Esta funcionalidade MultiValue é fornecida como uma parte integral do Caché – e não como uma implementação MultiValue em separado –, utilizando o valioso motor de base de dados multidi-mensional Caché, a funcionalidade runtime e as tecnologias de desenvolvimento. Isto quer dizer que os usuários de MultiValue podem tomar pleno partido das capacidades oferecidas pelo Caché.
Acesso a Arquivos MultiValue
Aplicações MultiValue geralmente tratam a base de dados como um conjunto de arquivos aces-sados através de operações de registro de Leitura e Escrita (Read and Write) e através de consultas MultiValue. No Caché, cada arquivo MultiValue é armazenado como uma estrutura “global” mul-tidimensional com cada registro sendo igual a um nó global. Este recurso se baseia na capacidade do Caché em armazenar múltiplos elementos de dados por cada nó da global.
Por exemplo, um arquivo MultiValue que armazena informações de nota fiscal poderia ter seguinte estrutura:
NF # ID Ítem
Cliente Atributo 1
DataNF Atributo 2
Partes Atributo 3 (com MultiValue)
Quantidades Atributo 4 (com MultiValue)
Preços Atributo 5 (com MultiValue)
… …
O Caché representará este arquivo MultiValue internamente como a seguinte estrutura global multidimensional equivalente:
^NF(nf #)=
Cliente ^ DataNF ^ Parte1 ] Parte2 ^ Quant1 ] Quant2 ^ Preço1 ]
Preço2k
onde “^” indica o delimitador de atributo normal (ASCII 254), e “]” indica o delimitador de sub-atributo (ASCII 253).
Arquivos MultiValue podem ser acessados por programas MultiValue através dos comandos normais READ/WRITE (Leitura/Escrita) e de consultas MultiValue. Eles também estão acessíveis através tanto do MVBasic, quanto de outras linguagens, por todos os mecanismos normais do Caché, incluindo acesso a objeto, acesso direto a Array multidimensional e SQL.
Arquivos MultiValue podem ser indexados com vários tipos de índices (incluindo índices bit-map) e seqüências de comparações.
47

Capítulo 3
Linguagem de Consulta MultiValue
A Linguagem de Consulta MultiValue fornece as funcionalidades de seleção de dados e de for-matação de relatórios para arquivos MultiValue. A linguagem de consulta pode ser utilizada em MVBasic, no command shell e em “procs”. O Caché traduz consultas MultiValue em consultas Caché SQL com código adicional para permitir suporte a correlativos, formatação de relatórios e vários outros recursos. Como estas consultas utilizam o motor SQL de extrema alta perfor-mance do Caché, a confiabilidade é aumentada, a execução é otimizada e um conjunto sofisticado de capacidades de indexação pode ser utilizado. Obviamente, desenvolvedores MultiValue podem, sempre que desejarem, se utilizar diretamente do Caché SQL.
Dicionário de Dados MultiValue
Um arquivo MultiValue pode ter uma descrição de arquivo correspondente no Dicionário de Dados MultiValue, a qual é editável diretamente através do código MVBasic e pelo editor MultiValue “ED” tradicional. A linguagem de consulta MultiValue se utiliza deste dicionário.
Um arquivo MultiValue pode ter também uma definição de classe Caché correspondente. Uma definição de classe é essencial nos casos em que os dados serão disponibilizados para acesso a objetos ou SQL (embora não seja necessário usar a MultiValue Query Language). Uma definição de classe também é necessária se o arquivo for ser indexado.
Quando se importam aplicações MultiValue mais antigas, as definições de classe do Caché podem ser criadas automaticamente a partir do Dicionário MultiValue. No entanto, na maioria dos casos, a classe resultante terá de ser editada para tornar os dados mais significativos caso o acesso a obje-tos ou ao SQL seja pretendido. O Studio wizard ajuda a automatizar a criação de classes a partir de Dicionários MV e a fornecer mais mapeamentos subseqüentes. Por definição, estas classes são read-only, (sendo que os dados podem ser lidos, mas não atualizados através de SQL e objetos) e são editados separadamente ao Dicionário MV.
Quando se cria um novo arquivo MultiValue, é recomendável criar primeiramente a classe Caché herdeira da superclasse MVAdaptor, o que resultará na utilização de um arquivo de forma-to compatível com o MultiValue para o armazenamento de dados, criando automaticamente uma descrição de arquivo no Dicionário de Dados MultiValue. Os dados do arquivo estarão, a partir de então, acessíveis e atualizáveis através de todos os caminhos de acesso do Caché, inclusive por objetos, SQL e acesso direto via global multidimensional. Deste ponto em diante, um desenvol-vedor normalmente passaria a editar definições de classe e não o Dicionário MultiValue propria-mente dito, dado que as edições de classe são automaticamente refletidas nele.
48

MultiValue e Objetos
O MVBasic foi expandido para utilizar objetos do mesmo modo que o Basic. A exceção está no fato de que o MVBasic se utiliza de uma sintaxe “->” para representar o acesso a um objeto, ao invés do ponto, “.”, do Basic. Qualquer classe no Dicionário de Classe pode ser utilizada, inde-pendentemente da linguagem utilizada nos métodos das classes.
Aqui estão alguns exemplos de código, no qual “pessoa” é uma referência de objeto:
pessoa->Nome = “Silva, João” // fixa o nome da pessoa
pessoa->Resid->Cidade // faz ref. à cidade onde reside
a pessoa
pessoa->Empregador->Nome // traz o objeto empregador da
pessoa para a
// memória e acessa o nome do
empregador pessoa->Save() // salva a pessoa em disco
Command Shell do MultiValue
O command shell do MultiValue pode rodar a partir de um terminal. Além das capacidades nor-mais do command shell do MultiValue, o Caché permite comandos MVBasic serem executados diretamente no utilitário. Por exemplo, digitando:
:; DIM A(34)
:; FOR I = 1 A 34 ; A(I) = I; NEXT
:; FOR I = 1 A 34 ; CRT A(I):” “: ; NEXT
tem-se como resultado:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
26 27 28 29 30 31 32 33 34
49
A VANTAGEM DO CACHÉ
Vida Nova para Aplicações Antigas: o Caché torna fácil atualizar aplicações MultiValue mais antigas através de interfaces do navegador, acesso a objetos, SQL robusto e Web Services. Aplicações MultiValue podem agora existir em uma base de dados avançada, que é bem-aceita em ambientes de alta demanda e que apresenta evolução constante.
Construa Novos Aplicações Rapidamente: Como o MultiValue é implementado como uma linguagem e como um acesso de arquivos no Caché, todas as capacidades nativas do Caché podem ser utilizadas para se construir novas funcionalidades rapidamente. Programadores MultiValue podem começar a tirar proveito da programação de objetos e interagir facilmente com outros aplicações, enquanto seguem utilizando a linguagem MultiValue.
Alta Performance e Escalabilidade com Impressionante Confiabilidade para Usuários MultiValue: O Caché oferece desempenho e escalabilidade dramaticamente superior para usuários MultiValue. Ademais, o Caché é utilizado em ambientes que são críticos 24 horas ao dia, tal como hospitais, que não têm como tolerar sistemas “fora do ar”. O Caché fornece sofisticado journal, processamento de transações, “bases de dados blindadas” e configurações de tolerância a falhas.

Capítulo 4: Criação Rápida de Aplicações de Alta Performnce Web Rápidas com Caché Server Pages (CSP)
“Criação Rápida De Aplicações Web Rápidas...” usa a palavra rápido duas vezes. Isso, primeiramente, porque é possível criar aplicações web sofisticados, orientados a base de dados com CSP mais velozmente do que com outras abordagens tradicio-nais. A outra razão é que a base de dados integrada Caché é a mais rápida do mundo, sendo capaz de rodar sistemas com dezenas de milhares de usuários simultâneos.
Há muitos modos de se escrever aplicações web com Caché – inclusive com todas as formas tradicionais que utilizam SQL para acessar a base de dados. Neste capítulo, discutiremos outra abordagem – mais direta –, chamada CSP - Caché Server Pages.O CSP é uma tecnologia fornecida como parte do Servidor de Aplicações Caché. Ele é a maneira mais rápida para que aplicações Caché interajam com a web, oferecendo:
<Uma abordagem de desenvolvimento avançada, orientada a objetos. <Performance ultra-elevada e escalabilidade em tempo de execução.
O CSP apresenta suporte HTML, XML e a outras linguagens de marcação orientadas à web.
O CSP não é uma ferramenta de web design, embora possa ser utilizada com estas. Enquanto ferramentas de web design normalmente se concentram na produção de HTML estático, o CSP vai além da aparência das páginas e auxilia no desenvolvimento de lógica de aplicação. Ele também fornece o ambiente de execução que possibilita a execução rápida do código contido no Servidor de Aplicações Caché.
O CSP suporta um forte ambiente de programação procedural; tal que os aplicações podem ser escritos com um nível de sofisticação e exatidão que excede as possibilidades de tecnologia pura de geração de aplicações. Ela também suporta desenvolvimento rápido através de sua arquitetura de classe, a qual produz “blocos de construção” de código – estes últimos podem ser combinados entre si – e ainda, através do uso de wizards, que podem produzir rapidamente versões simples de código customizado. O resultado é a possibilidade de se desenvolver velozmente aplicações web muito sofisticadas.
Capítulo 4
50
A VANTAGEM DO CACHÉ
Programação procedural orientada a objeto, juntamente com o Caché Wizards, resultam em aplicações de base de dados sofisticadas, baseados em navegadores web.

Algumas das características do Caché Server Pages são:
<Servidor de Páginas Dinâmicas – Como as páginas são criadas de forma dinâmica no servidor de aplicações, ao invés de fazer com que um servidor web simplesmente retorne ao HTML estático, os aplicações podem responder rapidamente a várias requisições dife- rentes, moldando as páginas resultantes, que são enviadas de volta ao navegador.
<Modelo de Sessão – Todo o processamento relacionado a páginas de um único navega- dor (browser) é considerado parte de uma só sessão – da primeira solicitação do browser até que ou a aplicação seja completada ou um timeout programável ocorra.
<Preservação de Estado do Servidor – Dentro de uma sessão, os dados no servidor – e mesmo o conteúdo da aplicação – podem ser retidos automaticamente através das solici- tações do browser, tornando muito mais fácil desenvolver e rodar aplicações complexas.
<Arquitetura de Objetos – Como cada página corresponde a uma classe, o código e ou- tras características comuns a muitas páginas podem ser facilmente incorporados através da funcionalidade de herança. Os dados são também tipicamente referenciados através de objetos com todos os benefícios da programação de orientação a objetos.
<XML – O XML oferece uma poderosa alternativa ao HTML na construção de páginas web. O CSP funciona com o XML do mesmo modo que trabalha com o HTML. O pro- gramador fornece XML no método Page(), ao invés de HTML.
<Tags de Aplicação Caché para Geração Automática de Código – Estes tags HTML estendidos são tão fáceis de utilizar quanto tags tradicionais de HTML. Quando adicio nados a um documento HTML, eles geram um código de aplicação sofisticado, ofe- recendo uma variedade de funcionalidades, tais como abrir objetos, executar consultas e controlar o fluxo de programas. Estas tags são expansíveis – os desenvolvedores podem criar suas próprias tags, adequadas às necessidades específicas que possuem.
<Integração com Ferramentas Populares de Web Design – O CSP funciona com uma variedade de ferramentas que tornam fácil realizar o layout visual de páginas. Com o Dreamweaver, o CSP vai um passo além de sua capacidade de adicionar tags de Aplica- ções Caché através de simples interações point-and-click (apontar e clicar com o mouse). O CSP inclui ainda um Wizard, que torna fácil criar formas que exibem ou editam dados na base de dados Caché.
<Métodos Servidores Solicitáveis a Partir do Browser – Para facilitar o desenvolvimento de aplicações mais dinâmicas e interativas, o CSP torna fácil solicitar métodos server-side. Quando um evento ocorre no browser – geralmente porque o usuário realizou uma ação – o código de aplicação no servidor pode ser chamado, gerando uma resposta ao evento. Tudo isso, sem a sobrecarga de transmissão e exibição de uma página inteiramente nova.
<Criptografia – O Caché automaticamente criptografa dados na URL para ajudar a auten- ticar solicitações e prevenir adulterações. A chave de criptografia é mantida somente no servidor e é válida somente durante aquela única sessão.
É muita tecnologia – mas não tem que ser difícil de utilizar. Nós nos concentramos em tornar o CSP fácil de usar, com a maioria dessas capacidades funcionando de forma automática para você. Nossa filosofia é “poder através da simplicidade” – a complexidade deve ficar em nossa implementação e não na programação que você realiza.
51

O MODELO CACHÉ SERVER PAGES
Tecnologias Web Tradicionais
Em tecnologias web tradicionais, uma solicitação é enviada ao servidor web. Este recupera um arquivo seqüencial de HTML que é enviado de volta ao browser. Quando os aplicações envolvem dados variáveis, o desenvolvimento se torna mais complicado, com os programadores passando geralmente a utilizar CGI (com linguagens Pearl ou tcl) no servidor web, e enviando consultas SQL e stored procedures para a base de dados. Como se trata de um ambiente de programação, isso deixa muito a desejar; e a execução – particularmente com grande número de usuários – pode ser bem ineficiente quando o servidor web fica demasiadamente sobrecarregado.
Com o CGI, cada solicitação do browser geralmente cria um novo processo. Para evitar esta sobrecarga, os programadores às vezes fazem um link diretamente entre o código de aplicação e o servidor web, com um efeito-colateral inadequado que faz com que um erro em tal código possa levar ao travamento do servidor web inteiro.
Páginas de Servidor Dinâmicas
O CSP utiliza uma abordagem de programação e execução diferenciada: Dynamic Server Page Technology (Tecnologia de Página Dinâmica do Servidor). O conteúdo (HTML, XML, folhas de estilo, imagens e outros tipos) é gerado de forma programada durante a execução no Servidor de Aplicações Caché, ao invés de vir de arquivos seqüenciais, permitindo maior flexibilidade nas respostas às solicitações de página.
A maior parte do código de aplicações é executada no Servidor de Aplicações Caché, o qual pode ou não estar localizado fisicamente no mesmo computador que o servidor web. Alguns códigos – normalmente JavaScript ou Java – podem rodar no navegador, suportando, geralmente, opera-ções como validação de dados, reformatação ou invocando códigos laterais ao servidor.
Com esta abordagem, os processos não precisam mais ser criados para cada requisição do browser (como ocorre na abordagem CGI tradicional), melhorando o desempenho. E já que o código de aplicações não é ligado ao servidor web, um erro nos aplicações não trava este último.
Sessões – O Modelo de Processamento
Todo o processamento relacionado a páginas de um único navegador é considerado parte de uma mesma sessão – desde a primeira solicitação do browser até que os aplicações sejam finalizados ou um timeout programável ocorra. Quando um servidor web recebe uma solicitação de página (URL) com uma extensão “.csp”, esta requisição é enviada (por uma fina camada de código Caché anexada ao servidor web) para o Servidor de Aplicações Caché apropriado, que pode estar fisicamente localizado em outro computador.
Quando o Servidor de Aplicações Caché recebe a solicitação, ele determina se uma sessão já está em andamento para aquele browser. Em caso negativo, uma sessão é iniciada automaticamente. O Caché executa então o código de aplicação associado àquela página em particular – realizando as ações solicitadas pelo usuário e criando de forma programada o HTML, o XML, a imagem ou outro conteúdo que é enviado de volta ao navegador.
Uma sessão termina quando uma propriedade é inserida no objeto de Sessão, terminando-a.
Aplicações que rodam stateless (sem estado definido) podem optar por finalizar a sessão em cada página.
Capítulo 4
52

Preservação de Estado
Um dos desafios enfrentados por desenvolvedores é a natureza inerentemente stateless (sem estado) da web – normalmente não há uma maneira simples de se reter informações no servidor entre uma solicitação e outra. Os aplicações geralmente enviam para o navegador todas as informações de estado que eles precisam reter na forma de URL’s ou de campos escondidos de formulário. Esta não é uma técnica eficiente para aplicações mais complexas, que podem recorrer a salvar temporariamente dados em arquivos ou bases de dados. Infeliz-mente, isto impõe uma sobrecarga significativa ao servidor e torna a programação consideravelmente mais difícil.
O modelo de Sessão do Caché possibilita a este preservar dados automaticamente e eficientemente entre as solicitações de um browser. O CSP fornece um objeto de Sessão que contém informações genéricas sobre a sessão, além de propriedades que permitem ao programador controlar várias características desta. O aplicação pode armazenar seus próprios dados no objeto de Sessão, o qual é retido auto-maticamente de uma solicitação a outra.
O aplicação determina o estado a preservar, estabelecendo a propriedade Preserve no objeto de Sessão para 0 ou 1 (o padrão é 0, o que pode ser modificado de modo dinâmico durante a execução).
<0 – Dados salvos no objeto de Sessão são retidos. (Os dados são simplesmente colocados em uma propriedade multidimensional, que aceita qualquer tipo de dado e permite qualquer número de subscript – inclusive subscripts de valor seqüencial – sem nenhuma declaração).
<1 – O Caché dedica um processo para a sessão, tal que os estados de processo são retidos, inclusive todas as variáveis (e não só aquelas do objeto de Sessão) dispositivos I/O (entrada-saída) e locks.
Uma configuração igual a 0 permite uma partição lógica de todos os dados preservados e permite que múltiplas sessões compartilhem um único processo, porém preserva menos quantidade de estado. Já uma configuração igual a 1 é mais fácil para o programador e oferece um leque de capacidades mais amplo, porém, a um custo maior de recursos de servidor utilizados.
O Objeto de Requisição
O CSP fornece automaticamente vários objetos (além do objeto de Sessão) para auxiliar o programador a processar a página. Um deles é o objeto de Requisição. Quando uma página é recebida, o URL é decodificado e colocado no objeto de Requisição. Este objeto contém todos os pares nome/valor e todos os dados de formulário, juntamente com outras informações úteis. Por exemplo, o valor do nome “FilmeID”, poderia ser obtido com o código:
%request.data(FilmID”, 1) // o 1 indica que queremos o
1º nome para este valor
// caso haja vários valores
para este nome
53
A VANTAGEM DO CACHÉ
Ao preservar a informação de estado no servidor de forma automática, há menos tráfego de rede e menos sobrecarga no servidor, já que os aplicações não precisam ficar arquivando e aces-sando dados para cada página solicitada. E programar o aplicação é mais simples.
O uso de Páginas Dinâmicas de Servidor e do Servidor de Aplicações Caché resulta em uma maior flexibilidade para se respon-der a solicitações, em uma execução mais veloz e sem o risco de erros de aplicações fazerem o servidor web “cair”, bem como em um am-biente de programação mais rico.

Capítulo 4
ARQUITETURA DE CLASSE DE PÁGINAS WEB
Para cada página web há uma classe de página correspondente, a qual contém métodos (código) para gerar o conteúdo da página. Quando uma solicitação é recebida, sua URL é utilizada para identificar a classe Página correspondente, bem como para chamar o método Page() daquela classe. Geralmente, classes de página são derivadas de uma classe de páginas web padrão (“%CSP.Page”), a qual fornece várias capacidades integradas (tais como a geração de cabeçalhos e de criptografia) a todas as páginas. Estas capacidades padrão podem ser desativadas de vários modos – derivando-se de outra superclasse, utilizando herança múltipla ou simplesmente desativando métodos específicos.
Esta arquitetura de classe torna fácil modificar o comportamento de um aplicação inteiro e forçar um estilo comum. Ela também traz todas as demais vantagens programáveis da programação de objetos ao desenvolvimento web.
A classe de página contém código para realizar a ação solicitada, bem como gerar e enviar uma resposta ao navegador. Porém, nem todo o código de aplicações que é executado está naquela classe de página. Na realidade, a maior parte do código executado está em métodos de várias classes de bases de dados e, talvez, em classes extras de lógicas comerciais. Portanto, o processo de desenvolvimento consiste em que tanto classes de páginas, quanto classes de bases de dados (além de, eventualmente, classes adicionais de lógicas comerciais) sejam desenvolvidas.
Nós geralmente recomendamos que as classes de página contivessem somente lógica de interface de usuário. Lógica comercial e lógica de base de dados deveriam ser colocadas em classes diferen-tes para que haja assim uma separação clara do código de interface de usuário destas lógicas – e é mais fácil adicionar interfaces de usuário extras depois.
ESTRATÉGIAS MÚLTIPLAS DE DESENVOLVIMENTO
Uma página de classe é criada para cada página web e contém o código a ser executado por aquela página.
Há vários modos de se construir páginas de classes e a maioria dos aplicações utiliza mais de um deles:
<Arquivo CSP – Um arquivo HTML com Tags de Aplicação Caché embuti- das é escrito utilizando um editor de textos simples ou uma ferramenta de web design. Esse arquivo seqüencial (um “arquivo CSP”) não é enviado diretamente ao navegador – ele é compilado para gerar uma página de classe.
<Programação Direta – Os programadores escrevem as páginas de classe inteiras através da codificação dos métodos apropriados.
<Zen – Programadores criam a página de classe utilizando componentes de objeto inte- rativos pré-construidos.
Páginas simples geralmente são mais rápidas de se desenvolver com arquivos CSP e wizards, mas deve ser mais fácil para programar páginas mais complexas diretamente ou com Zen.
54

ARQUIVOS CSP
Arquivos CSP são arquivos HTML seqüenciais com Tags de aplicações Caché embutidas, que são compiladas em páginas de classe – o mesmo tipo de páginas de classe que um programador talvez escrevesse diretamente. Estas páginas de classe são então compiladas para gerar códigos que rodam no Servidor de Aplicações Caché em resposta às solicitações do browser.
O Caché Studio inclui um Wizard de Formulários que gera automaticamente um arquivo CSP para editar ou visualizar uma classe de base de dados. O usuário simplesmente clica na classe de base de dados de seu interesse e depois seleciona o conjunto de propriedades a ser exibido. O wizard do Caché faz todo o restante, adicionando HTML e tags de aplicações Caché à página. Como o Wizard produz HTML, caso o resultado não esteja em exato acordo com aquilo que você deseja, é muito fácil editá-lo.
A abordagem de arquivos CSP é poderosa, pois:
<Web Designers podem desenhar o layout visual, enquanto os programa- dores se concentram nos códigos.
<Muito da interface de usuário pode ser programada de maneira não pro- cedural em um ambiente visual e ser mantida isolada das lógicas comer- ciais e de base de dados.
<É normalmente mais fácil customizar um aplicação para um usuário indi- vidual específico deixando que não programadores alterem a apresenta- ção visual e adicionem capacidades simples à aplicação.
Como as especificações visuais da aplicação são mantidas separadas da maior parte da lógica de programação, é relativamente fácil modificar a sua aparência sem a necessidade de reprogramá-lo – simplesmente edite o arquivo HTML ou XML e recompile a página.
Embora uma aplicação inteira simples possa ser criado desta maneira, um pro-gramador geralmente imputa códigos adicionais a ele. Este código extra é suprido através de tags de aplicações, que ou incluem o código de procedimento, ou invocam códigos em outras classes. No entanto, páginas complexas com mui-tos códigos procedurais são geralmente mais fáceis de escrever utilizando-se da abordagem de programação direta, ao invés de um arquivo CSP.
O Caché também inclui um add-in para Dreamweaver – a popular ferramenta de design de páginas web. Ela oferece suporte point-and-click para se adicionar Tags de Aplicações Caché, além de contar com um Wizard de Formulários Caché, que gera automaticamente o código necessário para visualizar ou editar um objeto da base de dados.
Tags de Aplicações Caché
Tags de Aplicações Caché podem ser adicionadas ao arquivo CSP. Elas são utilizadas da mesma forma que tags HTML comuns, mas são, em realidade, instruções para que o Caché Web Compiler (Compilador Web do Caché) gere o código de aplicação que vai fornecer várias funcionalidades – como, por exemplo, acessar objetos da base de dados, executar consultas, controlar o fluxo de programas e executar código no Servidor de Aplicações Caché. As tags de Aplicações Caché são expansíveis – os desenvolvedores podem criar suas próprias tags para suprir suas necessidades específicas.
As Tags de Aplicações Caché não estão embutidas no HTML que é enviado a um browser – elas estão somente no arquivo CSP lido pelo Caché Web Compiler. Esse compilador automaticamente as transforma em HTML-padrão, o qual pode ser processado por qualquer navegador. 55

Capítulo 4
HIPEREVENTOS (HYPER-EVENTS)
Os hipereventos CSP permitem que even-tos que ocorram em um navegador (como os cliques do mouse, mudanças em campos de valor ou timeouts) solicitem métodos server-side, bem como atualizem a página atual sem fazer o repaint (recarregamento gráfico completo). Após realizar a ação solicitada, este método tem como produzir um código (geralmente em JavaScript) para que seja executado no browser. Aplicações web que utilizam hipereventos têm melhor resposta e podem se tornar mais interativos.
Dentro de uma página CSP, um método server-side é solicitado simplesmente através da sintaxe:
“#server(...)#”
Por exemplo, suponhamos que quando o usuário clicar em uma imagem de um carrinho de compras, queremos ativar um método servidor chamado AdicAoCarrinho(). A definição HTML para a imagem talvez incluísse então a seguinte sintaxe:
onClick=”Server(AdicAo Carrinho()#”
O web compiler substituirá esta sintaxe com o código JavaScript, que quando rodado no navegador, solicitará o método do servidor Caché.
56


Capítulo 4
INTERSYSTEMS ZEN E WEB PAGES BASEADOS EM COMPONENTES
O Zen oferece uma maneira simples de criar dados ricos e complexos em aplicações Web com visual sofisticado e com uma interface de usuário altamente interativa. O Zen não é uma 4GL; ele é uma rica biblioteca pré-montada de componentes objetos e uma ferramenta de desenvolvimento baseada nas tecnologias CSP (Caché Server Pages) e de orientação a objetos da InterSystems. O Zen é especialmente apropriado para o desenvolvimento de uma versão Web de aplicações cliente/servidor originalmente criados com ferramentas tais como Visual Basic ou PowerBuilder.
Os componentes Zen permitem muito mais interações dinâmicas – você não fica restrito ao mecanismo “submeter” para enviar dados para o servidor. Por exemplo, com o componente de formulário do Zen você pode definir sua própria validação customizada, incluindo chamadas imediatas ao servidor sem a necessidade de realizar uma solicitação de página e uma repaginação subseqüente. Para os usuários, isto representa uma maneira mais natural de inserir dados.
O Zen utiliza o mecanismo de gerenciamento de sessão do CSP, fornecendo autenticação de usuário, criptografia de dados, bem como a retenção de dados persistentes de sessão através das solicitações de páginas. Toda comunicação entre o navegador e o servidor ocorre através do envio e recebimento do objeto utilizando uma versão mais sofisticada da técnica comumente chamada de AJAX (Asynchronous JavaScript and XML).
Páginas baseadas em Zen podem ser facilmente combinadas com páginas desenvolvidas utilizando outros métodos CSP de desenvolvimento de Web.
O que é um Componente Zen?
Um componente Zen é uma definição de classe que especifica a aparência e o comportamento de um componente na página. A definição de classe Zen contém – em um único documento – a definição completa de um componente, incluindo as folhas de estilo, o código servidor e o código cliente.
Ao ser executado, o Zen cria dois objetos para cada componente utilizado em uma página: um objeto client-side (que o Zen cria de forma automática na forma de um objeto JavaScript dentro do navegador) e um objeto server-side. O Zen automaticamente gerencia o estado de ambos os objetos e gerencia o fluxo de informações entre eles.
58

Tipos de Componentes Zen
A biblioteca Zen inclui componentes que implementam todos os tipos padrão de controle HTML: caixas de entrada, caixas de texto, botões, check Box, etc. Estes componentes possuem comportamentos adicionais herdados da classe de controle Zen.
O Zen inclui ainda um conjunto de componentes mais complexos e ricos de dados que automaticamente exibem dados contidos na base de dados e que sabem como atualizar estas informações de modo dinâmico, em resposta a even-tos gerados pelo usuário. Por exemplo, o poderoso componente Zen de tabelas exibe de forma automática os dados contidos em uma tabela HTML utilizando uma busca realizada na base de dados. O componente de tabelas possui suporte a paginação, a rolagem, a organização de colunas, a filtros e a uma variedade de estilos. O conteúdo da tabela pode ser atualizado a partir do servidor sem a necessidade de repaginar novamente toda a página.
Dentre os outros componentes Zen, incluem-se:
<Menu – Uma variedade de menus é suportada. <Grid – Adiciona comportamento a tabela de estilo a uma página Web. <Tree – Exibe dados hierárquicos com um controle em forma de árvore. <Tab – Um componente de tabulação contém uma série de espaços tabu- lares, cada qual contendo uma série de outros componentes. <Chart – Um conjunto rico de componentes de gráficos são implementa- dos utilizando SVG, incluindo gráficos em linha, de área, em barra, gráfi- cos tipo pizza, tipo alto-baixo, bem como gráficos XY. <Graphical Meters – Velocímetros, medidores, etc.; permitem a você exi- bir dados como componentes visuais dinâmicos.
Modificando a Aparência dos Componentes da Biblioteca Zen
Todos os componentes Zen apresentam suporte a um conjunto de propriedades que controlam a aparência visual. Os aplicações podem ajustar estas propriedades ao rodar o sistema para modificarem os valores, o visual e o comportamento de componentes.
A aparência visual também é controlada pelas definições de estilo do Standard CSS (Cascading Style Sheet). Podem-se ignorar estes estilos (para modificar fontes, cores, tamanhos, etc.) no âmbito do aplicação, página ou em nível individual por componente.
Você pode criar subclasses de componentes da biblioteca Zen para ignorar ainda mais definições de aparência e comportamento.
Criando Novos Componentes Zen
Uma dos pontos mais fortes do Zen está na facilidade de criar novos componentes.
Cada componente é implementado como uma classe. Para criar um novo compo-nente: (1) crie uma nova classe de componente, a qual pode ser uma subclasse de um componente já existente; (2) implemente um método que realize o con-teúdo HTML do componente; (3) defina os métodos server-side e client-side que implementem o comportamento de execução do componente; e (4) esteja certo de que a classe inclui as definições de estilo CSS necessárias para se especifi-car a aparência visual do componente.
59

Capítulo 4
Como Localizar Aplicações Zen Para Línguas Diferentes
Caso desejado, o Zen automaticamente mantém um conjunto de todos os valores de texto (títulos, legendas, etc.) exibidos pelos componentes incorporados de um aplicação em uma tabela especial de localização. Você pode exportar a tabela de localização de um aplicação como um documento XML, traduzir os valores para outras línguas e importar as novas tabelas.Durante a execução, o Zen utiliza os valores de texto baseado nas preferências de língua atuais do navegador do usuário.
Suporte a SVG
O SVG (Scalable Vector Graphics) fornece um modo padrão poderoso para a exibição de ricos dados gráficos dentro de uma página Web. O Zen incorpora a possibilidade de criação de com-ponentes gráficos que se auto-restitua através da utilização do SVG e os quais incluem um rico conjunto de componentes pré-desenhados com base no SVG.
Quais Navegadores suportam o Zen?
O Zen funciona com o Firefox (versões 1.5 e superiores) e com o Internet Explorer (versões 6.0 e posteriores). Para o Firefox não há a necessidade de plug-ins – o SVG já vem embutido nele. Para o Internet Explorer, há a necessidade de se utilizar o plug-in Adobe SVG, caso você deseje utilizar os componentes SVG do Zen. A biblioteca gerencia as diferenças entre o SVG do Firefox e o Internet Explorer.
60
A VANTAGEM DO CACHÉ
Ricas Interfaces de Usuário Web: Podem-se gerar páginas visualmente sofisticadas e altamente interativas, as quais são visualmente mais semelhantes a interfaces GUI de aplicações cliente/servidor do que um formulário tradicional e simples de navegador com um botão de SUBMIT. O usuário acha o formato interativo mais natural e fácil de utilizar.
Rápido Desenvolvimento Baseado em Objeto: A utilização de componentes pré-desenhados acelera o desenvolvimento e torna mais simples a realização de modi-ficações posteriores.
Interfaces Consistentes de Usuário: A arquitetura baseada em componentes torna mais fácil de definir e forçar normas de estilo e comportamento no âmbito do aplicação.


InterSystems Caché é marca registrada da InterSystems Corporation. Outros nomes de produtos são marca registrada de seus respectivos fabricantes. Copyright © 2008 InterSystems Corporation. Todos os direitos reservados. 05-08
InterSystems do Brasil
Praça Prof. José Lannes, 40
10º andar - Brooklin Novo
04571-100 - São Paulo - SP
Tel: 55 11 3014 7000
Fax: 55 11 3014 7001
Call Center: 0800 888 22 00
InterSystems.com.br