Embed Size (px)
Citation preview

Mineração de Dados: Conceitos e aplicação de
algoritmos em uma Base de Dados na área da saúde
Felipe Cebulski Soczek¹, Regiane Orlovski²
¹,² Tecnologia em Análise e Desenvolvimento de Sistemas – Faculdade Guairacá
CEP 85010-000 – Guarapuava – PR – Brasil
¹[email protected], ²[email protected]
Abstract: The purpose of this article is to apply Data Mining thus presenting
the basic concepts, followed by the application of algorithms in two databases
in healthcare on Breast Cancer, thus showing how many people have chances
of developing Breast Cancer Benign or Cancer Maligo. The tool used was the
Weka software, which enabled to use the acquired knowledge to the literature
by putting them into practice. The algorithms presented best results among
several that were used were Jrip of Classification Rules, Decision Trees LMT
as well as Artificial Neural Networks.
Keywords: Data Mining; Concepts; Application Algorithm; Software Weka.
Resumo: O objetivo deste artigo é aplicar a Mineração de Dados
apresentando assim seus conceitos básicos, seguido da aplicação de
algoritmos em duas Bases de Dados na área da saúde sobre o Câncer de
Mama, apresentando assim quantas pessoas possuem chances de desenvolver
Câncer de Mama Benigno ou Câncer Maligo. A ferramenta utilizada foi o
software Weka, que possibilitou utilizar os conhecimentos adquiridos com o
levantamento bibliográfico colocando-os em prática. Os algoritmos que
melhor apresentaram resultados dentre os vários que foram utilizados foram o
Jrip de Regras de Classificação, LMT de Árvores de Decisão e também as
Redes Neurais Artificiais.
Palavras chaves: Mineração de Dados; Conceitos; Aplicação de Algoritmos;
Software Weka.
Introdução
Atualmente existe uma grande quantia de áreas de trabalho e pesquisa que estão
informatizados, contando assim com diferentes sistemas que auxiliam diariamente e
armazenam dados e informações. Com a utilização dos meios corretos para esta retirada
de conhecimento destes dados, podem-se visar melhorias de serviços, observar padrões,
auxiliar em estudos, entre outras finalidades.
Devido aos avanços tecnológicos nos dias atuais, as áreas corporativas e de
pesquisa vêm se mostrando cada vez mais preparadas para este armazenamento de
dados, dessa forma é extremamente necessário o estudo sobre a Mineração de Dados e o
investimento neste setor de busca de informação útil. Para se demonstrar algumas
informações que são obtidas com a utilização da Mineração de Dados, foi escolhida
uma Base de Dados na área da saúde, que trata particularmente sobre o Câncer de
Mama. Existem diversas áreas passiveis da utilização da Mineração de dados, porém a

área da saúde é um diferencial, pois os avanços dela são de interesse mútuo das pessoas,
assim fazem-se necessários estudos nesta área com este tipo de aplicação.
O objetivo do trabalho é aplicar a Mineração de Dados com o software Weka,
apresentando as diversas estatísticas obtidas com os diferentes algoritmos utilizados e
mostrar as informações retornadas da Base de Dados, dividindo assim as pessoas com
potencial de desenvolvimento de Câncer Benigno ou Câncer Maligno.
Fundamentação Teórica
Com a necessidade de busca de informação constante, seja em qualquer área do
conhecimento, faz-se necessária uma ferramenta que proporcione tais possibilidades de
auxílio à decisão, busca de informações corretas e seguras. Afirma Côrtes (2002), que a
Mineração de Dados esta progredindo e fazendo-se necessária cada vez mais, sendo
uma ferramenta segura para se buscar informações úteis, possibilitando guiar tomadas
de decisões em condições de certeza limitada.
Com a grande quantia de informação obtida diariamente Amorim (2006), cita
que nos dias atuais as organizações mostram que estão avançadas nesta obtenção diária
de informações, porém a grande maioria não utiliza os meios corretos para extrair
informação dessas imensas bases de dados. Ainda nas palavras de Amorim (2006), essa
forma inadequada de extrair informação desses dados prejudica e muito as suas
atividades, sendo que com grandes investimentos nessa área de armazenamento de
dados faz-se necessária o estudo da forma correta da busca de informação. Cita
Bortoleto (2007), que as empresas estão em um cenário de constante competição por
mercados cada vez menores, sendo assim, as melhoras nos serviços e a busca constante
de melhorias é o que possibilitará a sobrevivência e progresso das empresas, ou de
qualquer área.
Nas palavras de Dantas (2008), a grande importância da utilização da
Mineração se da às grandes quantias de informações guardadas, onde esses arquivos
possuem informações úteis, porém de difícil interpretação, auxiliando em previsões
futuras tornando então dados sem utilidades e desorganizados em grandes fontes de
informação.
Para ressaltar a importância da praticidade e confiabilidade da Mineração de
Dados, Cita Goldshmidt (2011), que com a grande quantia de informação que se
aglomera em grandes bases de dados faz-se necessário o estimulo sobre o estudo da
Mineração de Dados e suas técnicas, buscando conhecimento que auxiliarão na
competitividade de serviços de empresas e micro empresas podendo assim melhorar
seus negócios, traduzindo-se em diferenciais mercadológicos trazendo lucros.
Reforçando esta idéia Gomes (2008), cita que com a crescente informatização no
mundo em todos os tipos de negócio, o volume de dados armazenados é enorme, e
tornam-se cada vez mais difíceis de serem trabalhados com formas e métodos
tradicionais, sendo assim, para contornar tais problemas surgiram os conceitos de
Mineração de Dados, onde a mesma faz parte do processo de Descoberta de
Conhecimento em Bases de Dados / Knowledge Discovery in Database (KDD) que tem
a finalidade de auxiliar na busca e descoberta de conhecimento e informações úteis em
grandes volumes de dados.
Para melhor explicar este processo no qual a Mineração de Dados faz parte
Maimon (2009), cita que KDD é o processo organizado que visam buscar novos

padrões e informações úteis dentro de grandes complexos conjuntos de dados, sendo o
núcleo desse processo a Mineração de Dados que envolvem seus algoritmos de que
exploram os dados, modelando e encontrando padrões até então desconhecidos. Ainda
nas palavras de Maimon (2009), estima-se que as informações que se encontram
armazenadas estão dobrando de tamanho a cada 20 meses, sendo assim, fica
extremamente difícil compreender e fazer uso destas informações sem a Mineração de
Dados, com esse ritmo acelerado de armazenamento.
Para o auxílio e explicação da função do KDD Usama (1996), confirma que o
KDD é o conjunto de métodos desenvolvidos para buscar nos dados informações úteis e
que façam sentido, sendo sua utilidade principal mapear os dados tornando-os mais
compactos e mais fáceis de trabalhar, aplicando assim a Mineração de Dados a fim de
buscarem dados relevantes.
Para Han e Kamber (2006), o KDD se divide em sete passos, sendo eles:
Limpeza de Dados, Integração dos Dados, Seleções de Dados, Transformação dos
Dados/Pré-Processamento, Aplicação do algoritmo de Mineração de Dados e Avaliação
de Padrões.
Ainda nas palavras de Han e Kamber (2006), a Limpeza de Dados consiste em
corrigir erros que são encontrados facilmente em bases de dados, sendo que essas
imperfeições se não forem corrigidas, contornadas ou minimizadas, comprometem
muito a eficácia do resultado da Mineração de Dados.
A definição de Integração dos dados para Macêdo (2009), é a integração e
agrupamento se necessário dos dados que estão separados em diferentes partições,
ajustando assim os dados e visando ter mais informações sobre determinado assunto.
Santos (2005), afirma que a Seleções de Dados é onde o analisador separa a
informação, visando os arquivos necessários para se obter informações valiosas, e
descartando os arquivos sem utilidades, mais para isso o analisador tem que ter
profundo conhecimento e domínio das informações trabalhadas, não podendo assim
eliminar dados que possam influenciar no bom resultado final.
Para explicar a Transformação dos Dados/Pré-Processamento Graças (2009),
cita que é a etapa que prepara a informação e as transforma para receber a Mineração de
Dados em formato apropriado, sendo que essa etapa proporciona diferentes operações
para diferentes fins, sendo limpeza, integração, transformação de dados, entre outras.
Utilizando novamente as palavras de Graças (2009), afirma que a etapa da
aplicação do algoritmo de Mineração de Dados que se efetua a entrada com os dados já
organizados e limpos em busca da informação trazendo os padrões solicitados, sendo
que os diferentes tipos de algoritmos de Mineração de Dados vão diferenciar os tipos de
dados que serão retornados. Esta etapa é o coração do processo de KDD.
Para Moreira (2002), é na Avaliação de Padrões que se estudam os dados
retornados, sendo assim interpretados e avaliados, selecionando os dados úteis e
esquematizando-os de forma que possam ser utilizados.
As etapas explicadas anteriormente podem ser ilustradas na Figura 1:

Figura 1: Etapas do KDD. Fonte: Adaptação feita a partir de Han; Kamber (2006).
Nas palavras de Bonnard (2010), um dos maiores índices de fracasso e
informações incorretas vem da etapa de Pré-Processamento mal aplicada, sendo comuns
as Bases de Dados estarem dispostas fora de formato adequado, contendo também
dados ruidosos, dados faltantes ou incompletos, sendo assim, é fundamental para o
sucesso da Mineração de Dados aplicarem métodos de tratamento, limpeza e redução do
volume de dados, pois dessa forma pode-se ter uma maior confiança e credibilidade
sobre as informações que serão retiradas.
Nessa etapa de Pré-processamento Pereira (2006), descreve estas tarefas, sendo
elas:
- Integração dos dados: visa arrumar falhas e inconsistências dos nomes e
valores de atributos;
- Limpar os dados: corrige os erros, substituindo ou eliminando valores
perdidos;
- Converter dados: dados nominais ou em códigos para números inteiros;
- Redução de domínio: diminui a colocação dos valores em seus espaços
originalmente possíveis;
- Derivar ou construir novos atributos;

- Discretizar os dados: transforma os dados de atributos contínuos para
categóricos;
- Selecionar: seleciona os atributos que são relevantes para especificada tarefa.
Seguindo essas informações sobre Pré-Processamento de Dados, Bertholdo
(2012), cita que a Discretização, que também faz parte do Pré-Processamento, sendo de
grande importância para a preparação dos dados para a aplicação da Mineração de
Dados, pois é com ela que se podem separar os dados com maior relevância,
convertendo um atributo contínuo em discreto, definindo as categorias e mapeamento
dos valores.
Segundo Oliveira (2009), a Mineração de Dados é reconhecida pela execução de
suas diversas tarefas, sendo as mais comuns:
- Descrição: descreve padrões e tendências reveladas pelos dados, geralmente
oferecendo uma interpretação dos dados obtidos;
- Classificação: determina a qual classe um registro pertence, analisando assim
os conjuntos de registros fornecidos;
- Estimação ou Regressão: pode se estimar o valor de uma variável analisando as
demais;
- Agrupamento: aproxima os registros similares, identificando assim seus
grupos;
- Associação: identifica quais atributos estão relacionados;
Na Mineração de Dados existem diversos algoritmos para diferentes finalidades
se adaptando assim para diferentes buscas de dados, porém Halmenschlager (2002), cita
que entre as técnicas mais utilizadas estão as Árvores de Decisão, Regras de
Classificação e Redes Neurais, sendo que as Árvores de Decisão e as Regras de
Classificação são consideradas métodos simbólicos que representam por meio de
expressões o que é aprendido sobre os atributos dados, e já as Redes Neurais são
métodos conexionistas, onde consiste em ajustar pesos em uma rede.
Ainda nas palavras de Halmenschlager (2002), as Árvores de Decisão podem ser
aplicadas tranquilamente em grandes quantidades de dados se adequando também a
qualquer tipo de dado disponibilizando assim a facilidade de serem entendidas,
proporcionando ao usuário usar diretamente as informações obtidas.
Segundo Amo (2009), a Árvore de Decisão é uma estrutura de árvore sendo que
cada nó interno é um atributo do banco de dados de amostras, diferente dos atributos
classe, sendo as folhas valores do atributo classe, onde cada ramo é ligado de um nó-
filho a um nó-pai que é etiquetado com um valor do atributo do nó-pai, sendo assim,
existem tantos ramos quantos valores possíveis para tal atributo e um atributo que
aparece em um nó não podem aparecer nos nós descendentes.
Para ilustrar uma Árvore de Decisão, tem-se a Figura 2:

Figura 2: Árvore de Decisão. Fonte: Adaptação feita a partir da internet (2013).
Segundo Souza (2002), as Regras de Classificação é a predição de um valor que
um determinado atributo do conjunto assumirá dado um conjunto de valores dos demais
atributos do conjunto. Ainda nas palavras de Souza (2002), cita que os dois modelos
mais conhecidos de Regras de Classificação são:
- Stricto sensu: Se apresenta na forma de SE <Condição> ENTÃO
<Classificação>, sendo que se os valores assumidos atendem as condições do
antecedente da regra, então recebe a classe indicada pelo valor do atributo da
classificação.
- Indiretas: Sob forma de Árvores de Decisão, usando sequência hierárquica
construída ao longo de uma estrutura de Árvore com nós e folhas representando as
classes, podendo assim a Árvore exprimir diferentes Regras de Classificação.
Como no estudo será aplicado as Redes Neurais Artificiais, Antonio (2009), as
Redes Neurais Artificiais são uma abstração computacional que visa imitar o sistema
nervoso do ser humano em um computador com as funcionalidades do cérebro, fazendo
uso de um modelo abstrato matemático do neurônio, onde as ligações dos neurônios
(sinapses) são emuladas a partir de pesos, que são ajustadas durante o processo de
evolução do treinamento e aprendizado da rede. Antonio (2009), ainda cita que o corpo
celular é emulado pela composição de duas funções chamadas de funções de ativação e
propagação onde estas funções realizam o mapeamento e a transferência dos sinais de
entrada em um único sinal de saída, então esta saída é propagada para os neurônios
seguintes da rede, como no modelo biológico.
Segundo Haykin (1999), o neurônio é uma unidade de informação e
processamento que o coração de uma Rede Neural formada por um conjunto de sinapses
ou elos de conexão onde cada uma se caracteriza por um peso ou força, um somador
para adicionar sinais da entrada ponderados pelas sinapses do neurônio, e uma função
de ativação para restringir a amplitude da saída de um neurônio, que também é referida
como função restritiva já que limita o intervalo do sinal de saída a um valor finito.
Para melhor ilustrar como um neurônio artificial é disposto, tem-se a Figura 3:

Figura 3: Neurônio Artificial. Fonte: Adaptação feita a partir da internet (2013).
Para a utilização prática foi escolhido o software Weka, onde cita R. Bouckaert
(2010), que esta ferramenta foi criada em 1993 na Universidade de Waikato na Nova
Zelândia, utiliza linguagem Java dentro das especificações da GPL (General Public
License) apropriada para se iniciar os estudos em Mineração de Dados, sendo assim
utilizada no meio acadêmico, dando a oportunidade de serem aprendidos os conceitos
básicos da Mineração de Dados. Ainda nas palavras de R. Bouckaert (2010), com esta
ferramenta podem ser conduzidos processos de Mineração de Dados de forma simples,
avaliando assim seus resultados obtidos, oferecendo também recursos para executar Pré-
Processamentos de dados, Classificação, Clusterização, Associação, e vários outros
suportes tais como a visualização dos dados, edição dos atributos, também tendo como
característica principal sua portabilidade, podendo rodar nas mais diversas plataformas,
sendo assim, se beneficia da linguagem orientada a objetos com vantagens como
polimorfismo, encapsulamento, reutilização de código, dentre outras.
O software Weka disponibiliza na sua interpretação dos dados a estatística
Kappa, onde cita Simões (2011), que é de grande importância sendo que com esta
estatística pode se avaliar o nível de concordância e ligação dos dados dentro de uma
Base de Dados, sendo que se o número estatístico ficar próximo do 0 (zero) significa
uma maior discordância das informações, e ficando o mais próximo do 1 (um) indica
assim uma maior ligação e concordância.
Reforçando este conceito sobre a importância da Estatística Kappa, Castro
(2010), cita que é muito valiosa para se mensurar a qualidade da classificação e para dar
a estatística de quanto às observações se afastam daquelas esperadas, frutos do acaso e
indicando assim quão legítimas as interpretações são de acordo com a Tabela 1.
Tabela 1: Valores da Estatística Kappa. Fonte: Landis e Koch, 1977.
Ainda nas palavras de Castro (2010), o Weka disponibiliza outra forma para
auxiliar na representação da qualidade da classificação que é a Matriz de confusão, que

é uma representação em linhas e colunas correspondentes às áreas de teste e
treinamento, ela mostra a hipótese h oferecendo uma medida efetiva do modelo de
classificação, ao mostrar o número de classificações corretas versus as classificações
preditas para cada classe, sobre um conjunto de exemplos t.
Após então a escolha da ferramenta passou para a etapa de análise e seleção da
Base de Dados, onde foram escolhidas duas bases na área da saúde, que tratam sobre o
câncer de mama. Como cita Fátima (2009), conhecimento e informação, são quesitos
fundamentais para o bom funcionamento e progressão, tanto na área da saúde bem como
no controle social, tomada de decisão, instituições de ensino, mercado financeiro,
empresas de produção, setores esses que estão crescentemente encontrando na
Mineração de Dados maneiras de melhor monitorar seus dados, seja para previsões de
risco, consumo de clientes, monitoramento de arrecadações, riscos do mercado,
colocando assim a Mineração de Dados em seus cotidianos.
Segundo Dreyer (2009), a informática tem se apresentado extremamente
crescente na última década auxiliando a área da Saúde por meio de utilizações de
recursos tecnológicos. Assim com essa utilização da informática na Saúde facilita o
acesso de informações dando suporte à prática nos serviços da saúde, pois as
informações retiradas da mesma são complexas. Citam-se a seguir alguns pontos
positivos na sua utilização, tais como:
- Aumento da adesão aos protocolos clínicos;
- Melhorias na capacidade de monitorar doenças, suas condições e sintomas;
- Redução de erros nas medicações e diagnósticos;
- Melhor aproveitamento do tempo dos profissionais;
Como cita Bernardes (2007), faz-se muito necessário no setor da saúde uma
ferramenta que de suporte e que traga informações exatas para auxiliar nas suas tomadas
de decisões, buscando assim em suas informações obtidas dados relevantes que venham
a ser necessários.
Ainda nas palavras de Bernardes (2007), no segmento hospitalar e da saúde,
guardam-se informações muito relevantes dos pacientes, diagnósticos, tratamentos,
exames, medicamentos, assim sendo difícil de encontrar informação útil dentro de toda
essa concentração de dados, é então que a tecnologia se aplica. Dessa forma, com a
aplicação da Mineração de Dados, contando com dados sólidos e esquematizados, pode
se encontrar grandes auxílios para o progresso na área da saúde, selando assim a
confirmação de que tecnologia anda ao lado de todas as ciências.
Segundo L. Houston (1999), as características de uma população podem ser
estudadas para apresentar fatores associados com um resultado, estudos observacionais
como Estatística, Mineração de Dados, Aprendizagem, são de muita ajuda para associar
essas informações com devidas metas, reforçando assim que o estudo dos dados está se
tornando um grande reforço para as áreas científicas como a medicina, biotecnologia e
pesquisas em geral.
Seguindo o pensamento sobe estudos observacionais que envolvem o ser
humano e a área da saúde, o Instituto Nacional de Câncer (2012), cita que o Câncer é
uma das doenças que mais ocorrem no Brasil, onde este estudo chamado incidência de
Câncer no Brasil traz anualmente relatórios desta enfermidade mostrando os tipos de

Câncer que mais atingem a população. Ainda no relatório do Instituto Nacional de
Câncer (2012), traz a estatística sobre o Câncer de mama atingir aproximadamente 53
mil mulheres em 2012/2013, ficando assim em terceiro lugar entre os Cânceres com
mais ocorrência e vítimas no Brasil.
Segundo Swaroop (2009), o Câncer de mama é uma doença onde as células se
dão formação nos tecidos da mama, sendo a segunda principal causa de morte por
câncer entre as mulheres perdendo somente para o Câncer de pulmão, sendo também o
câncer mais comum entre mulheres com exceção do Câncer de pele.
Citando novamente os dados do Instituto Nacional de Câncer (2012), o Câncer
de mama é a doença que mais atinge as mulheres em todo o mundo, tanto em países
desenvolvidos como em países em desenvolvimento, sendo que o fator principal de
risco é a idade, o Brasil oferece o exame clínico das mamas a partir dos 40 anos e um
exame mamográfico a cada dois anos, para mulheres de 50 a 69 anos.
Etapas do desenvolvimento do trabalho
A visão sobre a elaboração do trabalho baseia-se em minerar dados focando a área da
saúde, sendo esta área muito promissora junto a Mineração de Dados. Com várias
opções na área da saúde passíveis de serem trabalhadas com a Mineração de dados foi
escolhido trabalhar com duas bases de dados sobre o Câncer de Mama, que é um tema
de grande relevância, sendo uma doença que atinge mulheres do mundo todo.
Buscou-se então uma ferramenta que poderia ser utilizada para retirar
informações e estatísticas das bases escolhidas. Foi escolhida então a ferramenta Weka,
que é utilizada no meio acadêmico para se iniciar os estudos em Mineração de Dados,
contando com uma vasta literatura sobre seu funcionamento e utilização.
O Weka também proporciona uma grande biblioteca de algoritmos de Mineração
de Dados que pode suprir e trazer bons resultados para poder ser apresentados e
comprovarem a eficácia da Mineração de Dados.
Entrando na parte prática do trabalho, primeiramente foram estudadas as bases
escolhidas, analisando assim seus dados e o que ela proporcionava para ser trabalhado.
Nesta etapa foram verificados os atributos das duas bases, trazendo informação sobre os
mesmos para melhor se entender suas relações e qual as suas relevâncias perante a
aplicação dos algoritmos e quais resultados poderiam trazer. A descrição dos atributos
das duas Bases de Dados utilizadas estão apresentadas nos apêndices A e B.
Com os atributos citados nas duas bases nota-se a sua divisão em dois tipos de
dados, sendo eles Integer ou Varchar, que estipulam qual o grau da relevância dos seus
dados sobre números ou palavras. A estipulação destes valores sobre os dados são
efetuados dentro da Base de Dados conforme eles são recebidos e agrupados dentro de
suas referentes classes.
Um processo que também está presente na Mineração de dados e também foi
utilizado no trabalho é a Discretização, que visa melhor dispor os dados dentro de uma
classe, criando padrões onde tais dados serão alocados. A utilização deste processo visa
aumentar a chance de acerto do algoritmo de Mineração de Dados, porém não é sempre
que a sua utilização resultara em melhorias e mudanças. Tudo depende de como a Base
de Dados está disposta e como seus dados estão organizados.

Os algoritmos escolhidos para aplicação prática se dividem em:
- Jrip, OneR e ZeroR de Regras de Classificação;
- J48, REPTree, LMT de Árvores de Decisão;
- MultilayerPerceptron de Redes Neurais Artificiais;
Além da aplicação dos algoritmos de Mineração de dados, o Weka oferece os
Algoritmos de Fragmentação, que tratam da forma que o programa vai interagir com a
Base de Dados. Os dois utilizados são: Cross-Validation (Folds) e Percentage Split.
Na Cross-Validation o algoritmo realiza um laço de repetição de iterações, onde
os folds são os números de pares e subconjuntos treinamento-teste fornecidos na
entrada. Os resultados dos testes geram dados estatísticos, sendo finalizado e gerando as
informações. O número de Folds altera o resultado final da aplicação do Algoritmo de
Mineração de dados, dessa forma para se atingir um bom resultado deve-se testar
crescentemente ou decrescentemente o número dos mesmos.
Na Percentage Split cria-se um subconjunto de treinamento com i% do tamanho
da Base de Dados fornecida, sendo i a percentagem dada. Basicamente então, trata-se da
redução do tamanho da Base de Dados em uma percentagem do seu total, visando à
melhoria das estatísticas.
Para melhor entender as aplicações e estatísticas que serão apresentadas a seguir
deve-se relembrar que:
Discretização: Resume-se em Discretizar o atributo chave, ou não Discretizar
nenhum atributo. Na prática este processo foi utilizado para visar melhores resultados,
onde somente não foi aplicado nas Redes Neurais Artificiais;
Algoritmos de Fragmentação: Cross-Validation (Folds) que foram testados
crescente ou decrescentemente visando uma melhoria das estatísticas, e Split que divide
a Base de Dados, parte validando e outra parte treinando;
Algoritmo: Algoritmo Escolhido;
Acerto: A taxa geral de quanto o algoritmo conseguiu classificações corretas e
seguras;
Estatística Kappa: Mede o nível da concordância e ligação dos dados;
Matriz de Confusão: Apresenta em números a quantidade de classificações
corretas e incorretas. A diagonal direita representa os números das instâncias
classificadas corretamente, sendo elas A: Quantas tem riscos de desenvolver um Câncer
de Mama Benigno (superior esquerda) e B: Quantas tem riscos de desenvolver um
Câncer de Mama Maligno (inferior direita). Na diagonal esquerda estão apresentadas as
classificações erradas;
Segue então as informações obtidas com as aplicações de algoritmos de Regras
de Classificação na Base de Dados breast-w:
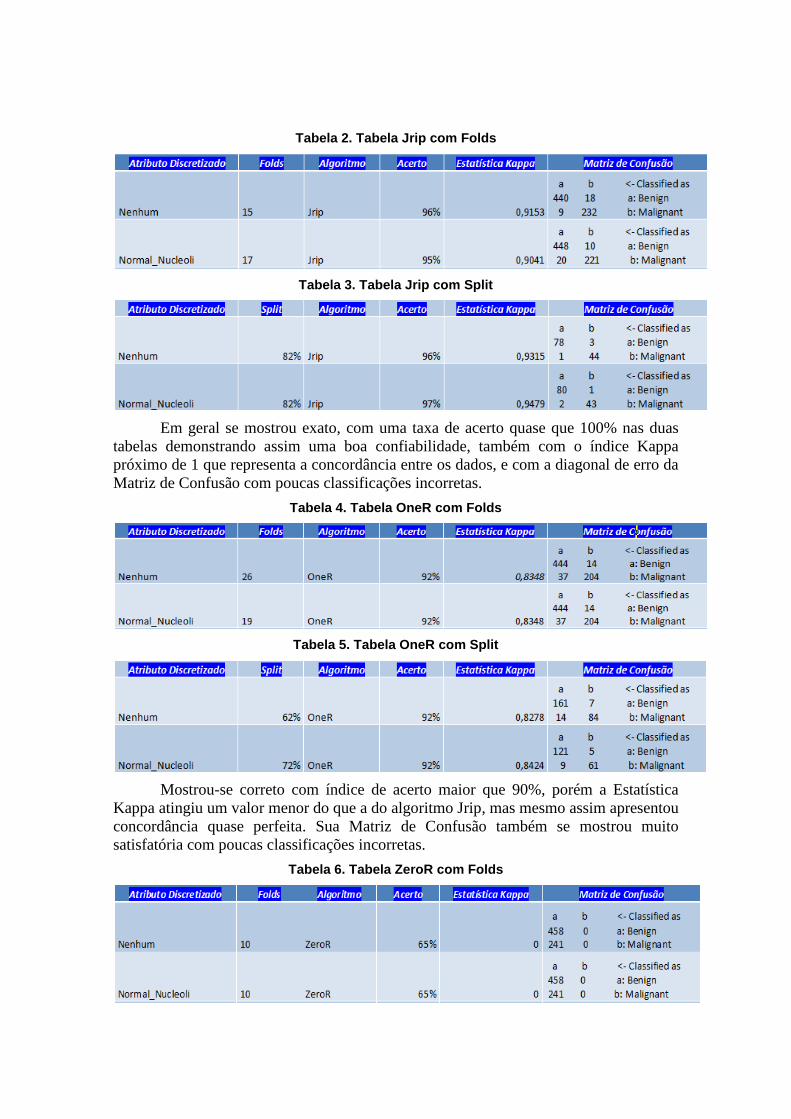
Tabela 2. Tabela Jrip com Folds
Tabela 3. Tabela Jrip com Split
Em geral se mostrou exato, com uma taxa de acerto quase que 100% nas duas
tabelas demonstrando assim uma boa confiabilidade, também com o índice Kappa
próximo de 1 que representa a concordância entre os dados, e com a diagonal de erro da
Matriz de Confusão com poucas classificações incorretas.
Tabela 4. Tabela OneR com Folds
Tabela 5. Tabela OneR com Split
Mostrou-se correto com índice de acerto maior que 90%, porém a Estatística
Kappa atingiu um valor menor do que a do algoritmo Jrip, mas mesmo assim apresentou
concordância quase perfeita. Sua Matriz de Confusão também se mostrou muito
satisfatória com poucas classificações incorretas.
Tabela 6. Tabela ZeroR com Folds
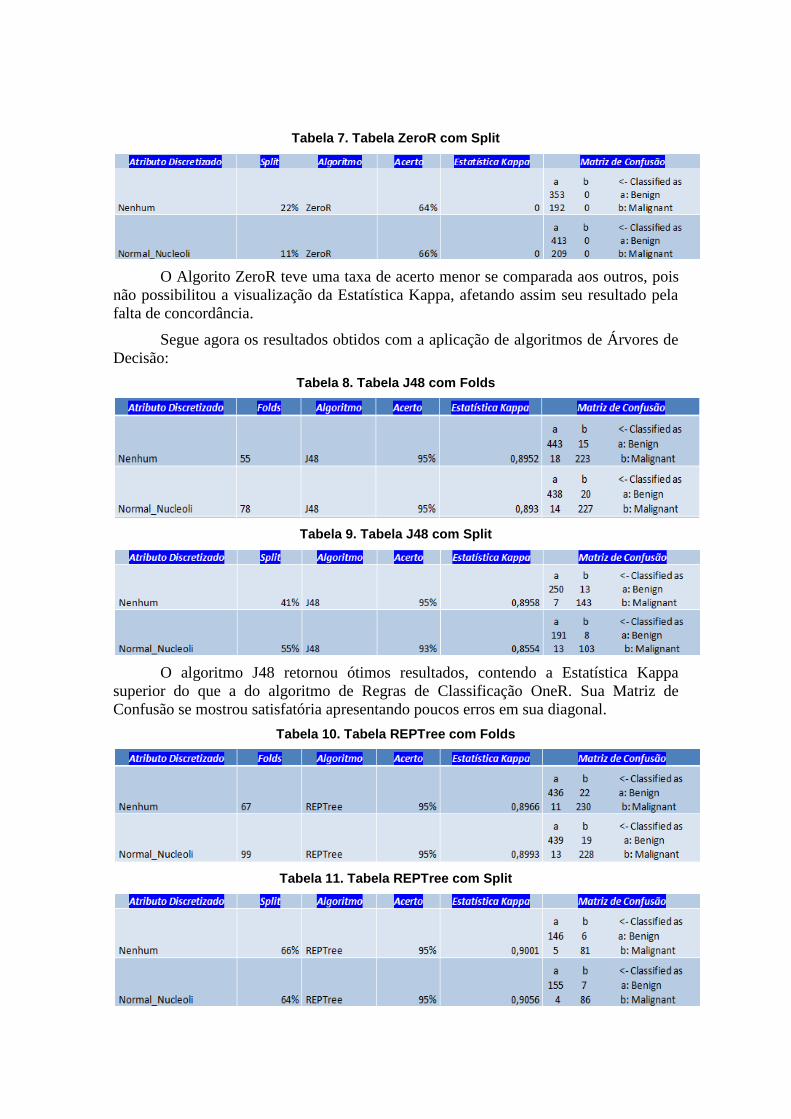
Tabela 7. Tabela ZeroR com Split
O Algorito ZeroR teve uma taxa de acerto menor se comparada aos outros, pois
não possibilitou a visualização da Estatística Kappa, afetando assim seu resultado pela
falta de concordância.
Segue agora os resultados obtidos com a aplicação de algoritmos de Árvores de
Decisão:
Tabela 8. Tabela J48 com Folds
Tabela 9. Tabela J48 com Split
O algoritmo J48 retornou ótimos resultados, contendo a Estatística Kappa
superior do que a do algoritmo de Regras de Classificação OneR. Sua Matriz de
Confusão se mostrou satisfatória apresentando poucos erros em sua diagonal.
Tabela 10. Tabela REPTree com Folds
Tabela 11. Tabela REPTree com Split
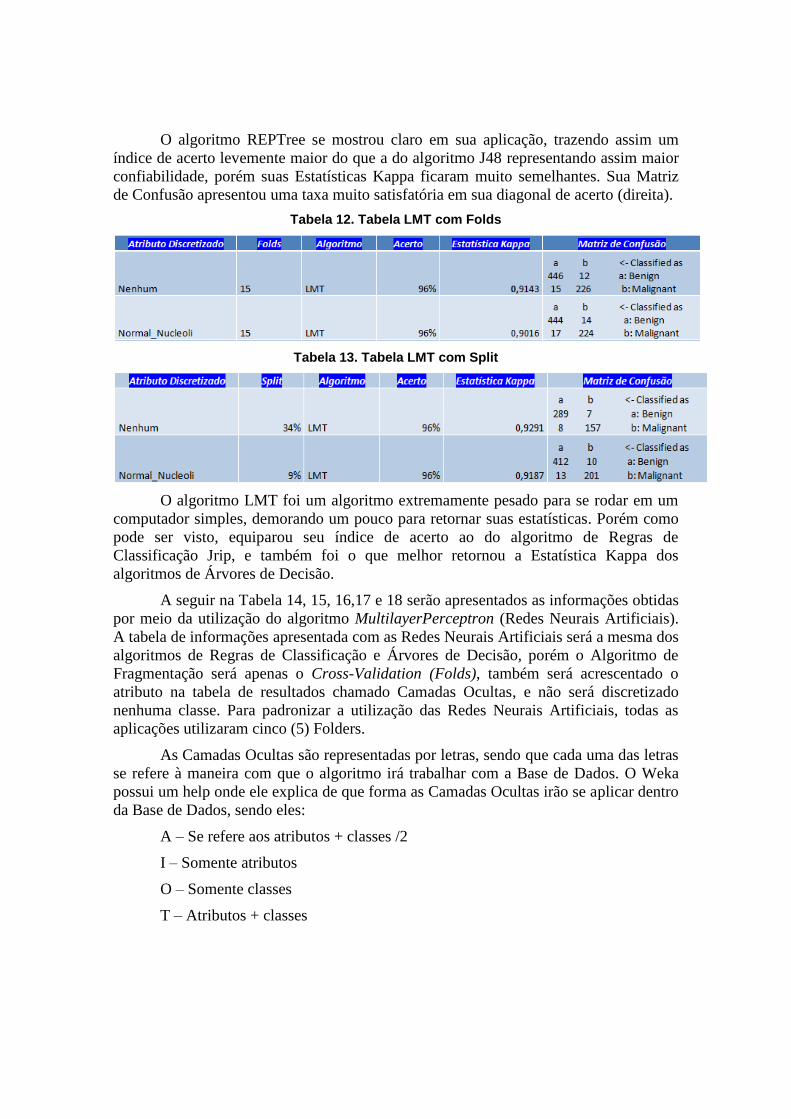
O algoritmo REPTree se mostrou claro em sua aplicação, trazendo assim um
índice de acerto levemente maior do que a do algoritmo J48 representando assim maior
confiabilidade, porém suas Estatísticas Kappa ficaram muito semelhantes. Sua Matriz
de Confusão apresentou uma taxa muito satisfatória em sua diagonal de acerto (direita).
Tabela 12. Tabela LMT com Folds
Tabela 13. Tabela LMT com Split
O algoritmo LMT foi um algoritmo extremamente pesado para se rodar em um
computador simples, demorando um pouco para retornar suas estatísticas. Porém como
pode ser visto, equiparou seu índice de acerto ao do algoritmo de Regras de
Classificação Jrip, e também foi o que melhor retornou a Estatística Kappa dos
algoritmos de Árvores de Decisão.
A seguir na Tabela 14, 15, 16,17 e 18 serão apresentados as informações obtidas
por meio da utilização do algoritmo MultilayerPerceptron (Redes Neurais Artificiais).
A tabela de informações apresentada com as Redes Neurais Artificiais será a mesma dos
algoritmos de Regras de Classificação e Árvores de Decisão, porém o Algoritmo de
Fragmentação será apenas o Cross-Validation (Folds), também será acrescentado o
atributo na tabela de resultados chamado Camadas Ocultas, e não será discretizado
nenhuma classe. Para padronizar a utilização das Redes Neurais Artificiais, todas as
aplicações utilizaram cinco (5) Folders.
As Camadas Ocultas são representadas por letras, sendo que cada uma das letras
se refere à maneira com que o algoritmo irá trabalhar com a Base de Dados. O Weka
possui um help onde ele explica de que forma as Camadas Ocultas irão se aplicar dentro
da Base de Dados, sendo eles:
A – Se refere aos atributos + classes /2
I – Somente atributos
O – Somente classes
T – Atributos + classes

Tabela 14. Tabela MultilayerPerceptron com Camadas ocultas A
Nesta aplicação foi utilizada para se ilustrar uma Rede Neural Artificial a figura
gerada pelo software Weka. Segue então a Figura 4:
Figura 4: Rede Neural Artificial. Fonte: Adaptação feita a partir do software Weka (2013).
Esta aplicação mostrou um acerto de 95%, com a Estatística Kappa com
concordância quase perfeita, gerando poucas classificações incorretas na Matriz de
Confusão. Sua Camada Oculta é A, desta forma utilizando atributos e classes da Base
de Dados, dividindo-os por dois.
Tabela 15. Tabela MultilayerPerceptron com Camadas ocultas I
A aplicação com a Camada Oculta I mostrou estatísticas levemente abaixo das
oferecidas pela Camada Oculta A, continuando assim à apresentar dados confiáveis e
uma Matriz de Confusão muito satisfatória.
Tabela 16. Tabela MultilayerPerceptron com Camadas ocultas O
As estatísticas alcançadas por meio das Camadas Ocultas O, se equipararam
quase que identicamente das do A, porém com algumas diferenças em suas Matrizes de
Confusão.
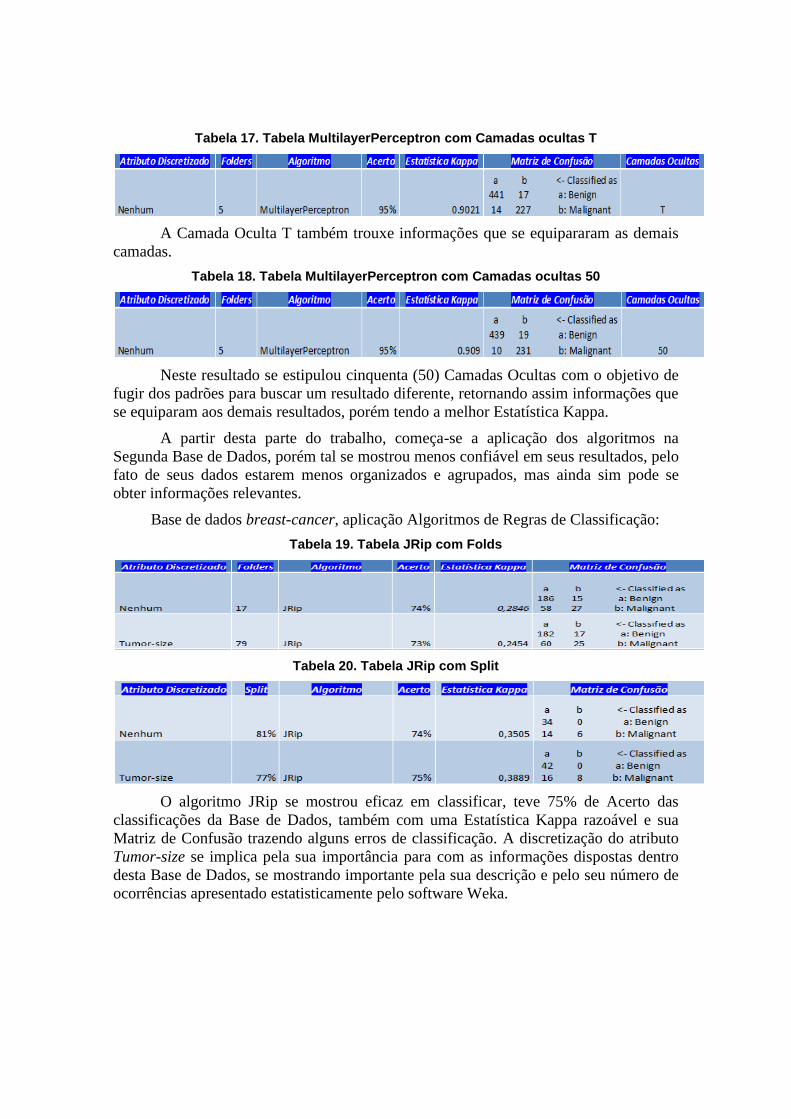
Tabela 17. Tabela MultilayerPerceptron com Camadas ocultas T
A Camada Oculta T também trouxe informações que se equipararam as demais
camadas.
Tabela 18. Tabela MultilayerPerceptron com Camadas ocultas 50
Neste resultado se estipulou cinquenta (50) Camadas Ocultas com o objetivo de
fugir dos padrões para buscar um resultado diferente, retornando assim informações que
se equiparam aos demais resultados, porém tendo a melhor Estatística Kappa.
A partir desta parte do trabalho, começa-se a aplicação dos algoritmos na
Segunda Base de Dados, porém tal se mostrou menos confiável em seus resultados, pelo
fato de seus dados estarem menos organizados e agrupados, mas ainda sim pode se
obter informações relevantes.
Base de dados breast-cancer, aplicação Algoritmos de Regras de Classificação:
Tabela 19. Tabela JRip com Folds
Tabela 20. Tabela JRip com Split
O algoritmo JRip se mostrou eficaz em classificar, teve 75% de Acerto das
classificações da Base de Dados, também com uma Estatística Kappa razoável e sua
Matriz de Confusão trazendo alguns erros de classificação. A discretização do atributo
Tumor-size se implica pela sua importância para com as informações dispostas dentro
desta Base de Dados, se mostrando importante pela sua descrição e pelo seu número de
ocorrências apresentado estatisticamente pelo software Weka.
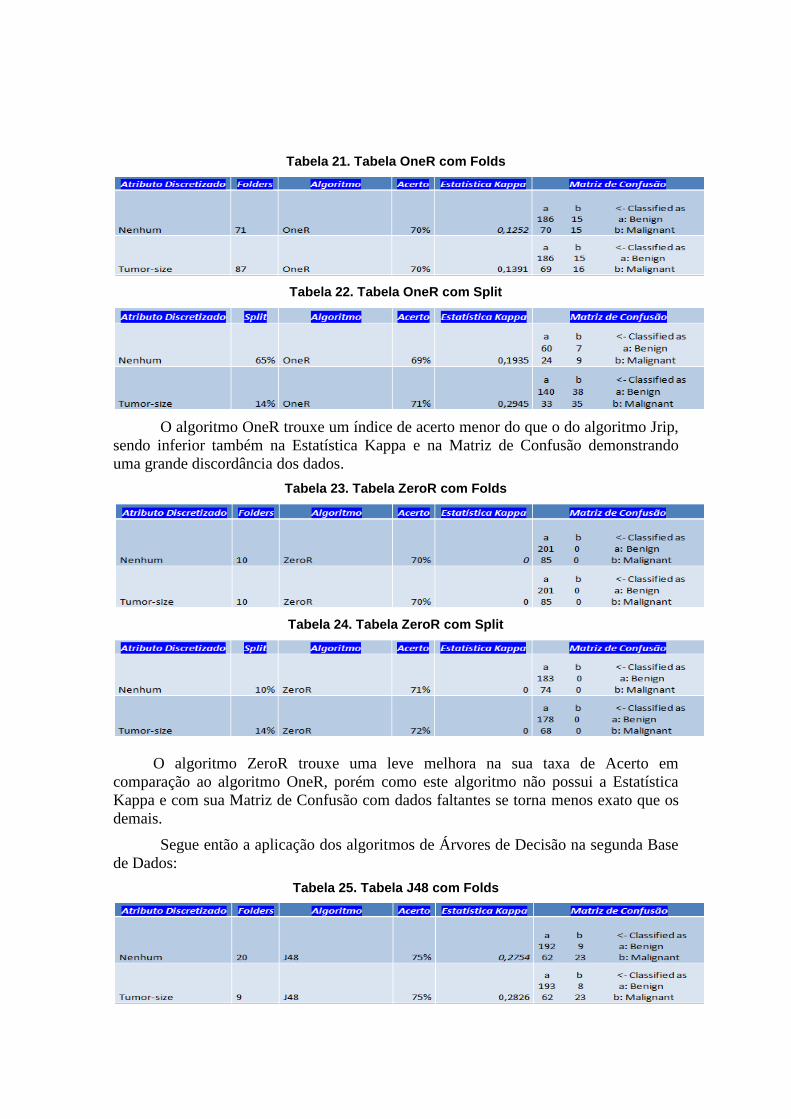
Tabela 21. Tabela OneR com Folds
Tabela 22. Tabela OneR com Split
O algoritmo OneR trouxe um índice de acerto menor do que o do algoritmo Jrip,
sendo inferior também na Estatística Kappa e na Matriz de Confusão demonstrando
uma grande discordância dos dados.
Tabela 23. Tabela ZeroR com Folds
Tabela 24. Tabela ZeroR com Split
O algoritmo ZeroR trouxe uma leve melhora na sua taxa de Acerto em
comparação ao algoritmo OneR, porém como este algoritmo não possui a Estatística
Kappa e com sua Matriz de Confusão com dados faltantes se torna menos exato que os
demais.
Segue então a aplicação dos algoritmos de Árvores de Decisão na segunda Base
de Dados:
Tabela 25. Tabela J48 com Folds
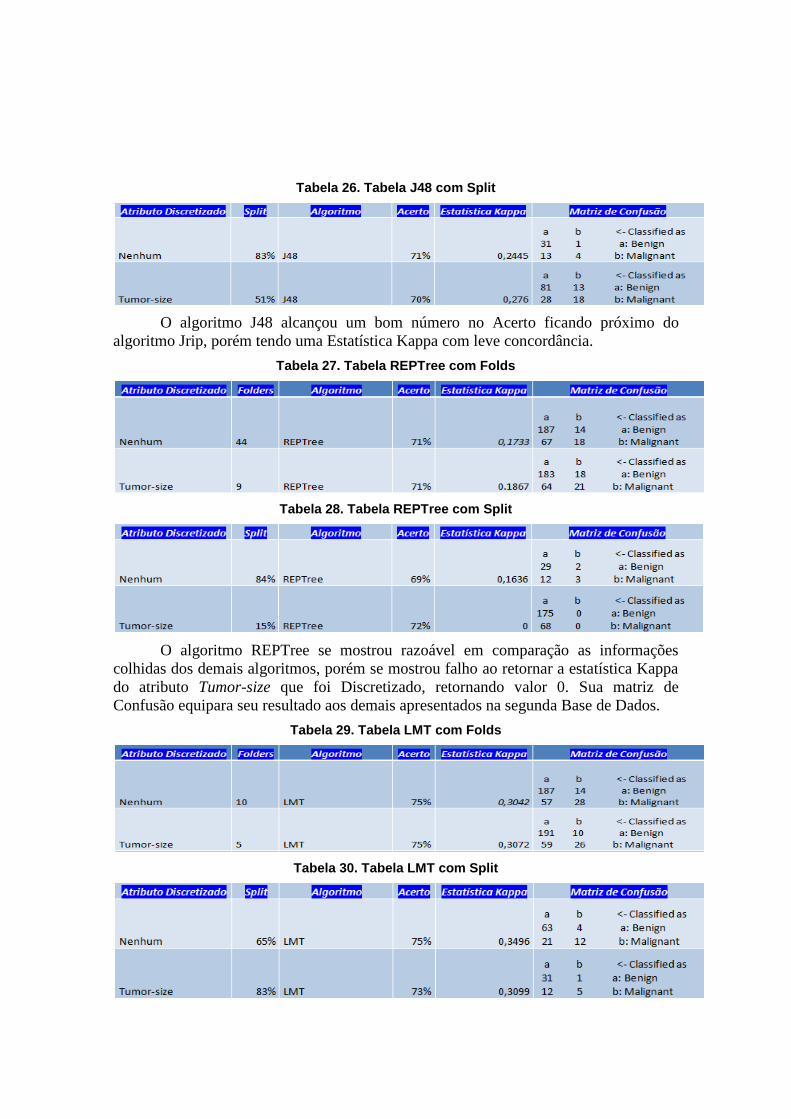
Tabela 26. Tabela J48 com Split
O algoritmo J48 alcançou um bom número no Acerto ficando próximo do
algoritmo Jrip, porém tendo uma Estatística Kappa com leve concordância.
Tabela 27. Tabela REPTree com Folds
Tabela 28. Tabela REPTree com Split
O algoritmo REPTree se mostrou razoável em comparação as informações
colhidas dos demais algoritmos, porém se mostrou falho ao retornar a estatística Kappa
do atributo Tumor-size que foi Discretizado, retornando valor 0. Sua matriz de
Confusão equipara seu resultado aos demais apresentados na segunda Base de Dados.
Tabela 29. Tabela LMT com Folds
Tabela 30. Tabela LMT com Split
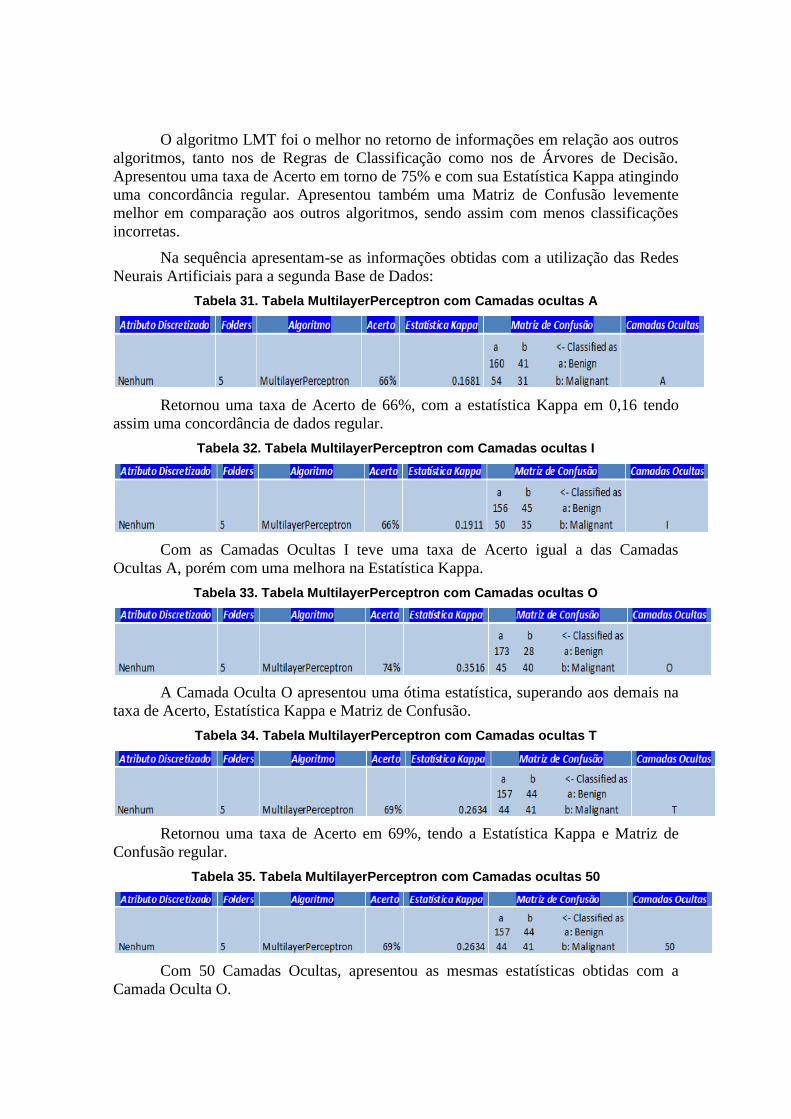
O algoritmo LMT foi o melhor no retorno de informações em relação aos outros
algoritmos, tanto nos de Regras de Classificação como nos de Árvores de Decisão.
Apresentou uma taxa de Acerto em torno de 75% e com sua Estatística Kappa atingindo
uma concordância regular. Apresentou também uma Matriz de Confusão levemente
melhor em comparação aos outros algoritmos, sendo assim com menos classificações
incorretas.
Na sequência apresentam-se as informações obtidas com a utilização das Redes
Neurais Artificiais para a segunda Base de Dados:
Tabela 31. Tabela MultilayerPerceptron com Camadas ocultas A
Retornou uma taxa de Acerto de 66%, com a estatística Kappa em 0,16 tendo
assim uma concordância de dados regular.
Tabela 32. Tabela MultilayerPerceptron com Camadas ocultas I
Com as Camadas Ocultas I teve uma taxa de Acerto igual a das Camadas
Ocultas A, porém com uma melhora na Estatística Kappa.
Tabela 33. Tabela MultilayerPerceptron com Camadas ocultas O
A Camada Oculta O apresentou uma ótima estatística, superando aos demais na
taxa de Acerto, Estatística Kappa e Matriz de Confusão.
Tabela 34. Tabela MultilayerPerceptron com Camadas ocultas T
Retornou uma taxa de Acerto em 69%, tendo a Estatística Kappa e Matriz de
Confusão regular.
Tabela 35. Tabela MultilayerPerceptron com Camadas ocultas 50
Com 50 Camadas Ocultas, apresentou as mesmas estatísticas obtidas com a
Camada Oculta O.

A aplicação dos algoritmos nas duas Bases de Dados retornou o mesmo tipo de
informação de saída, especificando a quantia de pessoas com suas diferentes
características podem desenvolver um Câncer Maligno ou um Câncer Benigno. Desta
forma, medem a recorrência dos fatores cancerígenos nos diferentes casos relatados nas
bases, agrupando e classificando os casos em uma das saídas (Maligno ou Benigno).
Como as duas bases têm o mesmo fim, a aplicação nesta área da saúde teria a
finalidade de mostrar e dividir os casos de pessoas que foram arquivados, e
estatisticamente classificá-los para se dizer quantos casos tem grandes chances de
desenvolver um Câncer Maligno e quantos casos têm a chance de desenvolver um
Câncer Benigno.
Resultados
Com a aplicação dos algoritmos de Mineração de Dados fornecidos pode-se ver as
diferentes estatísticas e informações levantadas, podendo desta forma ver os algoritmos
que melhor se comportaram para esta finalidade, que é classificar os pacientes que
podem desenvolver um Câncer de Mama Benigno ou Câncer Maligno.
O software Weka se comportou de forma esperada junto às Bases de Dados,
trazendo assim informações claras das aplicações de seus diferentes algoritmos e
estatísticas, podendo aplicar assim os conteúdos estudados e levantados nas referências
bibliográficas em prática.
O processo de Discretização que faz parte do Pré-Processamento de Dados pode
ser visto utilizado na prática, mostrando assim casos em que trouxe melhorias das
estatísticas gerais, aplicado nos atributos chaves das Bases de Dados organizando-os.
Dentre o processo de Discretização pode ser visto também em prática a utilização dos
Algoritmos de Fragmentação e a sua relevância para o resultado dos algoritmos
principais, sendo eles modificados em cada aplicação visando à melhoria dos resultados,
também a importância da Taxa de Acerto, Estatística Kappa e Matriz de Confusão,
auxiliando o entendimento sobre as aplicações e exatidão das informações levantadas.
Em relação à primeira Base de Dados, o algoritmo de Regras de Classificação
que apresentou melhores resultados é o JRIP utilizando Split, com Acerto de 97% e
Estatística Kappa 0,9479. A Matriz de Confusão que melhor alcançou resultados
apresentou 80 pessoas com chances de Câncer de Mama Benigno, e 43 Malignos. O
melhor algoritmo de Árvores de Decisão foi o LMT também utilizando Split,
alcançando 96% de Acerto, Estatística Kappa chegando a 0,9291. Em sua melhor
Matriz de Confusão, classificou 289 casos com chances de desenvolver Câncer de
Mama Benigno e 157 Maligno. Com o algoritmo de Redes Neurais Artificiais, seu
melhor resultado foi com a utilização de 50 Camadas Ocultas e 5 Folds, com 95% de
acerto e chegando á 0,909 de Estatística Kappa. Em sua melhor Matriz de Confusão
classificou 439 casos com chance de desenvolver um Câncer de Mama Benigno e 231
Maligno. O algoritmo que menos se mostrou exato em sua aplicação na Base de Dados
foi o ZeroR de Regras de Classificação, retornando uma taxa de acerto de 65% e
impossibilitando a visualização da Estatística Kappa e Matriz de Confusão.
Na segunda Base de Dados não foi possível equiparar os níveis de informações
obtidos na primeira Base de Dados, pois seus dados são completamente diferentes, desta
forma retornando um padrão diferente de obtenção de resultados.

Em relação aos algoritmos de Regras de Classificação na segunda base, o
algoritmo JRip apresentou Acerto de 75% utilizando Split, e 0,3889 de Estatística
Kappa. Sua melhor Matriz de Confusão apresentou 42 casos com potencial de
desenvolvimento de Câncer de Mama Benigno e 8 de Maligno. De Árvores de Decisão
o LMT apresentou 75% de Acerto utilizando o Split, com a Estatística Kappa de 0,3496.
Sua melhor Matriz de Confusão classificou 63 casos com potencial para Câncer de
Mama Benigno e 12 para Maligno. Com o algoritmo de Redes Neurais Artificiais, seu
melhor Acerto foi com a Camada Oculta O, que alcançou 74% com 5 Folds, e 0.3516
de Estatística Kappa. Sua melhor Matriz de Confusão classificou 173 casos com
potencial para Câncer Benigno e 40 para Maligno. O algoritmo ZeroR continuou sendo
o menos confiável, não apresentando a Estatística Kappa nem as classificações da
Matriz de Confusão.
Considerações Finais
A Mineração de Dados vem se mostrando cada vez mais necessária e disseminada nos
mais diversos campos e ambientes, facilitando e agilizando o processo de busca de
informação útil dentro de grandes quantidades de dados.
Com este trabalho foi possível compreender as etapas e conceitos que envolvem
a Mineração de Dados, dando ênfase na aplicação dos algoritmos de Regras de
Classificação, Árvores de Decisão e Redes Neurais Artificiais e suas estatísticas. A
aplicação destes diversos algoritmos é interessante pelo fato de poder assim tentar
alcançar melhores resultados com cada um, independente dos dados sendo trabalhados,
podendo assim comparar suas estatísticas, identificar os mais exatos e chegar aos
resultados mais corretos.
Também foi possível ter uma introdução sobre as informações que envolvem a
Mineração de Dados e seus conceitos, seguida então da aplicação de vários algoritmos
podendo assim ver quais tem o melhor desempenho em se tratando do foco das Bases de
Dados, que é a de classificar os atributos e seus tipos de dados informando quantas
pessoas estão passíveis de desenvolver um Câncer de Mama Maligno ou Benigno.
Como as duas bases têm a mesma finalidade, a aplicação nesta área da saúde
com estes tipos de dados visou à classificação de casos de Câncer de Mama que
poderiam ser Benignos ou Malignos, desta forma, este tipo de informação levantada
apresentado neste trabalho visa estatisticamente mostrar em arquivos de consultórios
médicos especializados no assunto, arquivos hospitalares, entre outras, quantas pessoas
apresentam fatores de risco que irão determinar o desenvolvimento de um Câncer
Benigno ou Maligno, podendo assim estudar estes fatores de risco e assim visar
melhorias em seus tratamentos ou prevenção.
Referências
Amo, Sandra de. Técnicas de Mineração de Dados. Uberlândia, 2009. Disponível em:
<http://www.lsi.ufu.br/documentos/publicacoes/ano/2004/JAI-cap5.pdf>. Acesso
em: 16/04/13.
Amorim, Thiago. Conceitos, técnicas, ferramentas e aplicações de Mineração de
Dados para gerar conhecimento a partir de bases de dados. Pernambuco. 2006.
Disponível em: <http://www.cin.ufpe.br/~tg/2006-2/tmas.pdf> Acesso em:
03/04/2013.

Antonio Carlos Gay, Thomé. Redes Neurais - Uma Ferramenta Para KDD e Data
mining. Rio de Janeiro, 2009. Disponível em:
<http://funk.on.br/esantos/doutorado/INTELIG%CANCIA%20ARTIFICIAL/T%C9
CNICAS/REDES%20NEURAIS/CURSO%20UFRJ%20de%20RN/22.pdf>. Acesso
em: 16/04/13.
Bernardes Ribeiro da Costa, Rodrigo. Aplicação do Processo de Mineração de Dados
para Auxílio à Gestão do Pronto-Socorro de Clínica Médica do Hospital
Universitário de Brasília. Brasília, 2007. Disponível em: <monografias.cic.unb.br/-
dspace/bitstream/123456789/120/1/RODRIGO_BERNARDES_MONOGRAFIA.-
pdf>. Acesso em: 01/03/2013
Bertholdo, Leonardo. Técnicas De Mineração De Dados Na Classificação De
Ecotoxicidade De Água Para Aplicação Na Gestão De Corpos Hídricos.
Campinas, 2012. Disponível em:
<http://www.excelenciaemgestao.org/Portals/2/documents/cneg8/anais/T12_0480_2
516.pdf>. Acesso em: 16/04/13.
Bonnard Schonhorst, Gustavo. Mineração de Regras de Associação Aplicada à
Modelagem dos Dados Transacionais de um Supermercado. Itajubá, 2010.
Disponível em: <http://juno.unifei.edu.br/bim/0036319.pdf> Acesso em: 03/04/2013.
Bortoleto, Silvio. Aplicação de um sistema para mineração de dados de vendas.
Curitiba, 2007. Disponível em:
<http://www.aedb.br/seget/artigos07/1405_SetsMiner_V8B.pdf> Acesso em:
03/04/2013.
Castro, Dayan. Procedimentos de data mining na definição de valores para as
análises de multicritérios como apoio à tomada de decisões e análise espaciais
urbanas. Minas Gerais, 2010. Disponível em:
<http://www.arq.ufmg.br/SiteLabGeo/Laboratorio_Geo/Artigos/CBC2010_02-
CT03-1-VF.pdf> Acesso em: 05/06/2013.
Costa Cortês, Sérgio da. Mineração de Dados – Funcionalidades, Técnicas e
abordagens. Rio de Janeiro, 2002. Disponível em: <ftp://ftp.inf.puc-
rio.br/pub/docs/techreports/02_10_cortes.pdf> Acesso em: 03/04/2013.
Dantas, Eric. O Uso da Descoberta de Conhecimento em Base de Dados para
Apoiar a Tomada de Decisões. João Pessoa, 2008. Disponível em:
<http://www.aedb.br/seget/artigos08/331_331_Artigo_SEGET_EJDR_Versao_Final
_010808.pdf> Acesso em: 03/04/2013.
Das Graças J. M. Tomazela, Maria. Aplicação de Técnicas de Mineração de Dados
para Caracterização de Grupos de Cidades Produtoras de Cana-De-Açúcar do
Estado de São Paulo e Definição de Políticas Especificas. Indaituba, 2009.
Disponível em:
<http://www.fatecindaiatuba.edu.br/reverte_online/8aedicao/Artigo11.pdf>. Acesso
em: 16/04/13.
Dos Santos Cabral, Rafael. Mineração De Dados. Brasília, 2005. Disponível em:
<http://www.paulotarso.com/Files/FSI/Mineracao%20de%20Dados.pdf>. Acesso
em: 16/04/13.

Dreyer Galvão, Noemi. Aplicação da mineração de dados em bancos da segurança e
saúde pública em acidentes de transporte. São Paulo, 2009. Disponível em:
<http://www.saude.mt.gov.br/upload/documento/104/aplicacao-da-mineracao-de-
dados-em-bancos-da-seguranca-e-saude-publica-em-acidentes-de-transporte-[104-
180610-SES-MT].pdf>. Acesso em: 03/04/2013.
Fátima Marin, Heimar. Técnica de mineração de dados: Uma revisão da literatura.
Cuiabá, 2009. Disponível em: <http://www.scielo.br/pdf/ape/v22n5/14.pdf> Acesso
em: 03/04/20013.
Goldschmidt, Ronaldo. Mineração de dados: Aplicação prática em pequenas e
médias empresas. Jacarepaguá, 2011. Disponível em:
<http://www.fij.br/revista/arq/vol01_01/datamining.pdf> Acesso em: 03/04/2013.
Gomes de Sousa, Douglas. Mineração de Dados para Descoberta de Padrões:
Estudo Aplicado à Base de Dados da Delegacia Regional do Trabalho. Pelotas,
2008. Disponível em:
<http://www.ufpel.tche.br/prg/sisbi/bibct/acervo/info/2008/mono_douglas_sousa.pdf
> Acesso em: 03/04/2013.
Halmenschlager, Carine. Um Algoritmo Para Indução De Árvores E Regras De
Decisão. Porto Alegre, 2002. Disponível em:
<http://www.lume.ufrgs.br/bitstream/handle/10183/2755/000325797.pdf?sequence=
1>. Acesso em: 16/04/13.
Han, Jiawei & Kamber, Micheline. Data Mining: Concepts and Techniques, 2nd Ed.
Munich, 2006. Disponível em: <http://www.cs.uiuc.edu/~hanj/bk2/> Acesso em:
03/04/2013.
Haykin, Simon. Redes Neurais – 2ed. England, 1999. Disponível em:
<http://books.google.com.br/books?hl=pt-
BR&lr=&id=lBp0X5qfyjUC&oi=fnd&pg=PA27&dq=Redes+Neurais:+Princ%C3%
ADpios+e+Pr%C3%A1ticas+-
+Simon+Haykin&ots=sxs1dHKA0X&sig=9X1zgdInm_Yg6aXZdUPyb7H69jE>
Acesso em: 23/04/13.
Instituto Nacional de Câncer José Alencar Gomes da Silva. Estimativa 2012 –
Incidência de Câncer no Brasil. Rio de Janeiro, 2012. Disponível em:
<http://www.inca.gov.br/rbc/n_57/v04/pdf/13_resenha_estimativa2012_incidencia_d
e_cancer_no_brasil.pdf>. Acesso em: 16/04/13.
L. Houston, Andrea. Medical Data Mining on the Internet: Research on a Cancer
Information System. Netherlands, 1999. Disponível em:
<http://citeseerx.ist.psu.edu/viewdoc/download?rep=rep1&type=pdf&doi=10.1.1.9.5
219>. Acesso em: 03/04/2013.
Macêdo Marques Gouveia, Roberta. Mineração De Dados Em Data Warehouse Para
Sistema De Abastecimento De Água. João Pessoa, 2009. Disponível em:
<http://www.lenhs.ct.ufpb.br/html/downloads/serea/teses/teses/dissertacao_roberta.p
df> Acesso em: 16/04/13.
Maimon, Oded. Introduction To Knowledge Discovery In Databases. Israel, 2009.
Disponível em: <http://www.ise.bgu.ac.il/faculty/liorr/hbchap1.pdf>. Acesso em:
16/04/13.

Moreira Pitoni, Rafael. Mineração de Regras de Associação nos Canais de
Informação do Direto. Porto Alegre, 2002. Disponível em:
<ftp://ftp.inf.ufrgs.br/pub/geyer/Alunos/RafaelPitoni/Dissertacao_Pitoni.pdf>.
Acesso em: 16/04/13.
Oliveira Camilo, Cássio. Mineração de Dados: Conceitos, Tarefas, Métodos e
Ferramentas. Goiás, 2009. Disponível em:
<http://www.inf.ufg.br/sites/default/files/uploads/relatorios-tecnicos/RT-INF_001-
09.pdf>. Acesso em: 03/04/2013.
Pereira Leite Filho, Hugo. Aplicabilidade de memória lógica como ferramenta
coadjuvante no diagnóstico das doenças genéticas. Goiânia, 2006. Disponível em:
<http://tede.biblioteca.ucg.br/tde_busca/arquivo.php?codArquivo=425>. Acesso em:
03/04/2013.
R. Bouckaert, Remco. WEKA—Experiences with a Java Open-Source Project. New
Zealand, 2010. Disponível em:
<http://www.cs.waikato.ac.nz/~eibe/pubs/bouckaert10a.pdf>. Acesso em: 16/04/13.
Simões Pellucci, Paulo Roberto. Utilização de técnicas de Aprendizado de Máquina
no reconhecimento de entidades nomeadas no Português. Belo Horizonte, 2011.
Disponível em: <http://revistas.unibh.br/index.php/dcet/article/view/305/164>
Acesso em: 30/04/13.
Souza Vasconcelos, Benitz de. Mineração de Regras de Classificação com Sistemas
de Banco de Dados Objeto-Relacional. Campina Grande, 2002. Disponível em:
<http://docs.computacao.ufcg.edu.br/posgraduacao/dissertacoes/2002/Dissertacao_B
enitzDeSouzaVasconcelos.pdf>. Acesso em: 16/04/13.
Swaroop, Prem. Data Mining: Introduction and a Health Care Application.
Maryland, 2009. Disponível em:
<http://www.rhsmith.umd.edu/faculty/bgolden/classes_links/2009_jan_data%20mini
ng_BUDT%20758.pdf>. Acesso em: 03/04/2013.
Usama Fayyad, Gregory. From Data Mining to Knowledge Discovery in Databases.
Boston, 1996. Disponível em: <http://www.kdnuggets.com/gpspubs/aimag-kdd-
overview-1996-Fayyad.pdf>. Acesso em: 16/04/13.
Apêndices
Descrição dos atributos das Bases de Dados
o Apêndice A: Descrição de atributos Base de Dados breast-w
Atributo Descrição Tipo de dado
Clump_Tchikness
Na sua espessura as células
benignas tendem a ser agrupadas
nas
monocamadas, enquanto que as
células cancerosas são muitas vezes
agrupadas em
multicamadas
Integer (1,10)
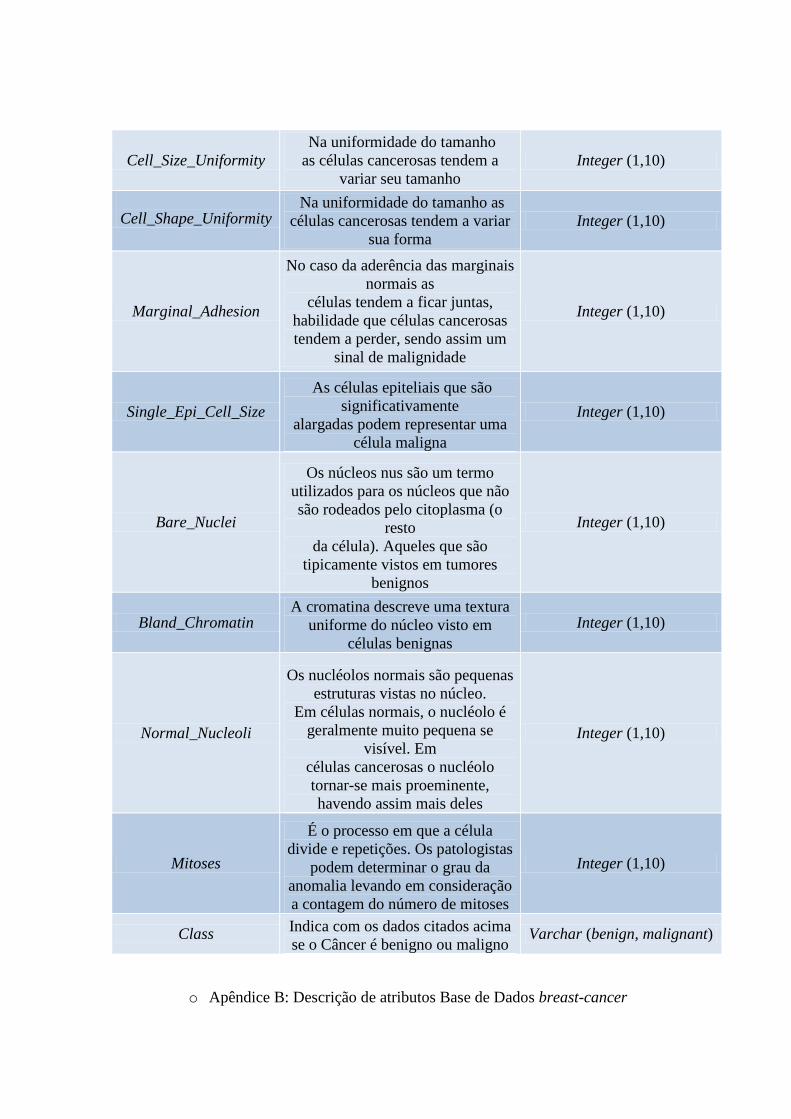
Cell_Size_Uniformity
Na uniformidade do tamanho
as células cancerosas tendem a
variar seu tamanho
Integer (1,10)
Cell_Shape_Uniformity Na uniformidade do tamanho as
células cancerosas tendem a variar
sua forma
Integer (1,10)
Marginal_Adhesion
No caso da aderência das marginais
normais as
células tendem a ficar juntas,
habilidade que células cancerosas
tendem a perder, sendo assim um
sinal de malignidade
Integer (1,10)
Single_Epi_Cell_Size
As células epiteliais que são
significativamente
alargadas podem representar uma
célula maligna
Integer (1,10)
Bare_Nuclei
Os núcleos nus são um termo
utilizados para os núcleos que não
são rodeados pelo citoplasma (o
resto
da célula). Aqueles que são
tipicamente vistos em tumores
benignos
Integer (1,10)
Bland_Chromatin A cromatina descreve uma textura
uniforme do núcleo visto em
células benignas
Integer (1,10)
Normal_Nucleoli
Os nucléolos normais são pequenas
estruturas vistas no núcleo.
Em células normais, o nucléolo é
geralmente muito pequena se
visível. Em
células cancerosas o nucléolo
tornar-se mais proeminente,
havendo assim mais deles
Integer (1,10)
Mitoses
É o processo em que a célula
divide e repetições. Os patologistas
podem determinar o grau da
anomalia levando em consideração
a contagem do número de mitoses
Integer (1,10)
Class Indica com os dados citados acima
se o Câncer é benigno ou maligno Varchar (benign, malignant)
o Apêndice B: Descrição de atributos Base de Dados breast-cancer
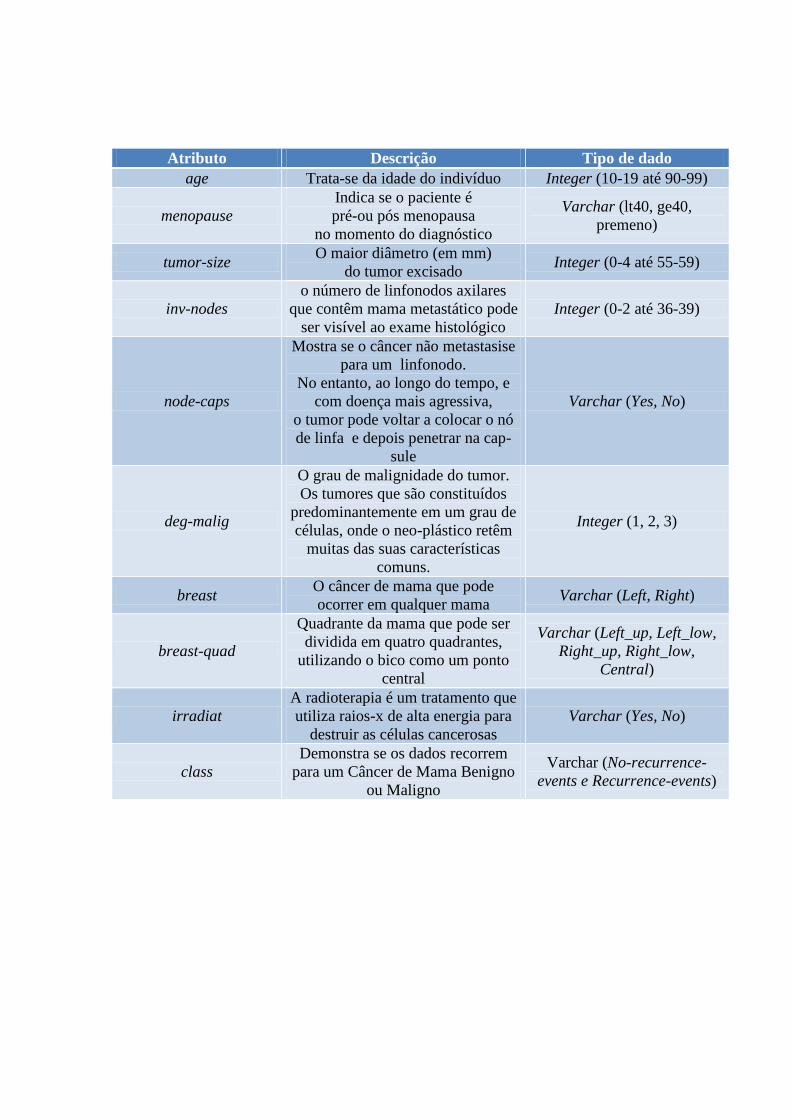
Atributo Descrição Tipo de dado
age Trata-se da idade do indivíduo Integer (10-19 até 90-99)
menopause
Indica se o paciente é
pré-ou pós menopausa
no momento do diagnóstico
Varchar (lt40, ge40,
premeno)
tumor-size O maior diâmetro (em mm)
do tumor excisado Integer (0-4 até 55-59)
inv-nodes
o número de linfonodos axilares
que contêm mama metastático pode
ser visível ao exame histológico
Integer (0-2 até 36-39)
node-caps
Mostra se o câncer não metastasise
para um linfonodo.
No entanto, ao longo do tempo, e
com doença mais agressiva,
o tumor pode voltar a colocar o nó
de linfa e depois penetrar na cap-
sule
Varchar (Yes, No)
deg-malig
O grau de malignidade do tumor.
Os tumores que são constituídos
predominantemente em um grau de
células, onde o neo-plástico retêm
muitas das suas características
comuns.
Integer (1, 2, 3)
breast O câncer de mama que pode
ocorrer em qualquer mama Varchar (Left, Right)
breast-quad
Quadrante da mama que pode ser
dividida em quatro quadrantes,
utilizando o bico como um ponto
central
Varchar (Left_up, Left_low,
Right_up, Right_low,
Central)
irradiat
A radioterapia é um tratamento que
utiliza raios-x de alta energia para
destruir as células cancerosas
Varchar (Yes, No)
class
Demonstra se os dados recorrem
para um Câncer de Mama Benigno
ou Maligno
Varchar (No-recurrence-
events e Recurrence-events)





























