Embed Size (px)
Citation preview

Mineração de Dados
Material extraído do minicurso: “Uma introdução à
Mineração de Dados (Data Mining) – com Inteligência
Artificial” ministrado pelos docentes: Prof. Dr. Clodoaldo
Aparecido de Moraes Lima e Profa. Dra. Sarajane
Marques Peres na Segunda Semana de Sistemas de
Informação

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Introdução
2

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
A Evolução
3
Sistemas de Gerenciamento
de Dados em Arquivos (1960)
Sistemas de Gerenciamento de Banco de Dados
(SGBD – SQL – OLTP) (1970-1980)
Nova Geração de Sistemas de Informação e Dados Integrados
(Presente e Futuro)
Sistemas de
Gerenciamento de
Banco de Dados
Avançados (OR – OO –
Espacial – Temporal –
Baseado em
Conhecimento ...)
(1980- atual)
Análise de Dados
Avançada (Data
Warehouse, OLAP,
KDD, Data Mining)
(1980- atual)
Sistemas de Banco de
Dados baseados em
Tecnologia WEB (XML –
Integração e
Recuperação da
Informação )
(1990- atual)
Adaptado de Han & Kamber (2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Tarefas de Mineração de Dados
• Mineração de Dados:
– Tarefas Preditivas
• Classificação incluindo Descoberta de Desvios e
Previsão de Séries
• Regressão
– Tarefas Descritivas
• Regras de Associação incluindo Associações
Temporais
• Agrupamentos
• Sumarização
4 Obs: Predição com Agrupamento !!!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mineração de Dados : interdisciplinaridade
5
(Han & Kamber, 2006)

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
A tarefa de Associação
6
Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
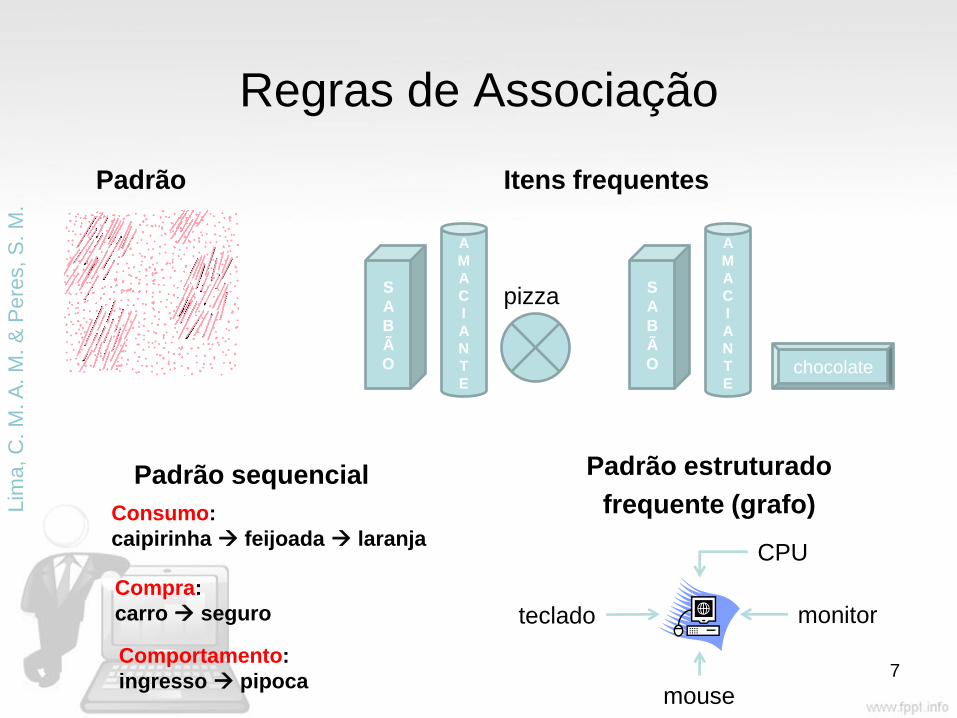
Regras de Associação
Padrão Itens frequentes
7
Padrão sequencial Padrão estruturado
frequente (grafo)
S
A
B
Ã
O
A
M
A
C
I
A
N
T
E
S
A
B
Ã
O
A
M
A
C
I
A
N
T
E
pizza
chocolate
Consumo:
caipirinha feijoada laranja
Compra:
carro seguro teclado
mouse
monitor
CPU
Comportamento:
ingresso pipoca

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Exemplo (Han & Kamber, 2006)
Como gerente da marca AllElectronics, você gostaria de saber mais sobre os hábitos
de compras de seus clientes. Mais especificamente, você gostaria de saber quais
grupos ou conjuntos de items os clientes geralmente compram em uma visita à sua
loja.
Para responder a essa pergunta é necessário fazer uma análise (de mercado) das
compras realizadas, observando os dados provenientes das transações (compras) dos
clientes na loja.
Você poderia usar os resultados dessa análise para planejar estratégias de marketing,
através de anúncios, projeto de novos catálogos, rearranjo do layout da loja.
Por exemplo, itens que são comprados “juntos” (em uma mesma compra) podem ser
colocados em lugares próximos de forma a encorajar a venda de tais items.
8 Continua ...

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Exemplo (Han & Kamber, 2006)
Se clientes que compram computadores também tendem a comprar
antivírus (na mesma compra). Então colocá-los em lugares próximos pode
ajudar a aumentar as vendas dos dois produtos.
Alternativamente, a estratégia pode ser colocá-los em lados opostos da loja
de forma a forçar o cliente andar por toda a loja e, eventualmente, escolher
outros produtos para comprar.
Análise de mercado também pode suportar a decisão sobre quais produtos
colocar em liquidação ou retirar do mercado.
9 Esta seção (teoria sobre Regras de Associação) do
minicurso é baseada no Capítulo 5 de Han & Kamber
(2006).
Fraldas e cervejas:
uma lenda urbana?!?!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Representação: considere seu universo como sendo o
conjunto de produtos (itens) vendidos na loja.
– A existência ou ausência de cada um desses itens pode ser
representada por uma variável booleana.
– Cada compra pode ser representada por um vetor de variáveis
booleanas, sendo que, de fato, nesta compra (transação) foram
comprados apenas os itens valorados com verdadeiro.
– Analisando esses vetores, é possível descobrir itens que
frequentemente aparecem juntos (estão associados), constituindo um
padrão de comportamento.
– Esse “padrão” pode ser representado por meio de uma regra de
associação.
10
computador antivirus
fralda cerveja
(Han & Kamber, 2006)
antecedente consequente

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Formalizando ....
Seja L = {I1, I2, ..., Im} um conjunto de itens.
Seja D, um conjunto de dados relevantes para a tarefa constituído de
transações de banco de dados, onde cada transação T é um conjunto
de itens tal que T L.
Cada transação é associada a um identificador (TID).
Seja A e B subconjuntos de itens.
A transação T contém A se e somente se A T.
Uma regra de associação é uma implicação da
forma A B, onde A L, B L e A B = .
11
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Medidas de “interessabilidade”
Suporte = utilidade da regra
Confiança = certeza sobre a regra
O suporte de 2% para a regra acima significa que 2% de todas as transações
analisadas mostram que computadores e antivirus são comprados juntos.
A confiança de 60% da regra acima significa que 60% dos fregueses que
compram um computador também compram um antivirus.
Regras de associação interessantes são aquelas que possuem um suporte
e uma confiança mínimos (de acordo com um limite inferior pré-
estabelecido) !!
12
computador antivirus [ suporte = 2%, confiança = 60%]
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Uma regra A B existe em um conjunto de transações D com suporte
s, onde s é a porcentagem de transações em D que contém A U B.
– Contém tanto A quanto B
– É calculado como a probabilidade P(AUB), a probabilidade da
transação conter a união do subconjunto A e do subconjunto B.
suporte (A B) = P(AUB)
13
Uma regra A B tem confiança c no conjunto de transações D, onde
c é a porcentagem de transações em D contendo B dado que contém
A. - É calculada como a probabilidade condicional P(B|A).
confiança (A B) = P(B|A)
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Definições
• Itemset: um conjunto de itens.
• k-itemset: um conjunto de k itens.
– 2-itemset: um conjunto de 2 itens
{computador, antivirus}
• Frequencia de ocorrência de um itemset (suporte do itemset): número
de transações que contém o itemset.
• Itemset frequente: um conjunto de itens que satisfaz a um suporte
mínimo.
O conjunto de k-itemsets frequentes é denotado por Lk.
14
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
confiança (AB) =
P(B|A) =
suporte (AUB) / suporte (A) =
suporte do itemset (AUB) / suporte do itemset (A)
Obs.: uma vez que a frequencia dos itemsets foram calculadas, os cálculos do
suporte e da confiança de uma regra podem ser facilmente realizados.
Assim, o problema de minerar regras de associação pode ser reduzido ao
problema de minerar os itemsets frequentes.
15
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Processo de mineração de regras de associação:
16
Encontrar todos
os itemsets
frequentes
Gerar regras de
associação
fortes a partir
destes itemsets
Determine o limite mínimo para o
suporte (min-sup)
(varia para cada aplicação e é
uma decisão de projeto)
Regras de associação fortes são aquelas
que satisfazem ao min-sup e ao min-conf.
Determine o limite mínimo para a
confiança (min-conf)
(varia para cada aplicação e é uma
decisão de projeto)
Passo
mais
custoso!!!
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Principal desafio: encontrar uma maneira eficiente para calcular os
itemsets frequentes de um grande conjunto de dados.
• Observe o seguinte exemplo (Han & Kamber, 2006, p. 231):
17
Um 100-itemset frequente {a1, a2, ..., a100}, contém = 100 1-itemset
frequentes: {a1}, {a2}, ..., {a100}, 2-itemset frequentes: {a1,a2}, {a1,a3},
..., {a99,a100}, e assim por diante.
O número total de itemsets frequentes que ele contém é:
• Esse problema é resolvido com a definição de
fechamento (clausura) de itemsets frequentes.
1
100
2
100
.1027.112100
100
2
100
1
10030100
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Um itemset X é fechado em um conjunto de dados S se não existe nenhum
super-itemset Y tal que Y tenha o mesmo suporte que X em S.
• Um itemset X é um itemset frequente fechado em um conjunto S se X é tanto
fechado quanto frequente em S.
• Um item itemset X é um itemset frequente máximo em um conjunto S se X é
frequente, e não existe nenhum super-itemset tal que X Y e Y é frequente
em S.
• Seja C o conjunto de itemsets frequentes fechados para um conjunto de
dados S, que satisfaz um limite mínimo para suporte, min-sup. Seja M o
conjunto de itemsets frequentes máximos para S satisfazendo min-sup.
– C e a informação sobre suporte de itemsets podem ser usados para
derivar todo o conjunto de itemsets frequentes.
– M registra somente o suporte dos itemsets máximo.
18
Exemplo!
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
Han & Kamber, 2006, p. 232
Supondo um banco de dados com apenas duas transações:
{<a1, a2, ..., a100>};{<a1, a2, ..., a50>}.
Seja sup-min = 1.
Encontramos dois itemsets frequentes fechados e seu suporte:
C = {{a1, a2, ..., a100} : 1; {a1, a2, ..., a50} : 2}
Existe um itemset frequente máximo:
M = {{a1, a2, ..., a100} : 1}.
De C é possível derivar, por exemplo, que:
19
{a2,a45 : 2} desde que {a2,a45} é um sub-itemset de
{a1, a2, ..., a50} : 2
{a2,a55 : 1} desde que {a2,a55 } é um sub-itemset de
{a1, a2, ..., a100} : 1
(Han & Kamber, 2006)

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Regras de Associação
O algoritmo Apriori
20

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori
• Proposto por R. Agrawal e R. Srikant, em 1994.
– Objetiva encontrar itemsets frequentes para descobrir regras de
associação.
– Usa conhecimento apriori referente a propriedades de itemsets
frequentes.
– Implementa uma abordagem iterativa.
21
Resumo...
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori
• Resumo:
– k-itemsets são usados para analisar (k+1)-itemsets
• O conjunto de 1-itemsets e o seu suporte são encontrados
em uma análise do banco de dados de transações.
• Mantém-se aqueles itemsets que satisfazem o sup-min, no
conjunto denominado L1.
• L1 é usado para encontrar L2, e assim por diante, até que
não seja possível encontrar mais k-itemsets.
• A composição de cada Lk exige uma análise completa do
banco de dados de transações.
22
Melhora de eficiência
Propriedade Apriori
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Propriedade Apriori
• Propriedade Apriori
Todos os subconjuntos não vazios de um itemset
frequente deve também ser frequente.
• Analise: – Se um itemset l não satisfaz o limite mínimo para o suporte, min-
sup, então I não é frequente;
– Se um item A é adicionado ao itemset I, então o itemset
resultante (I U A) não pode ocorrer mais frequentemente do que
I.
23
(Han & Kamber, 2006)
É uma propriedade de
antimonotonicidade!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori: ilustrando
24
• Etapa 1:
C1(s=1) C1(k=1) L1
http://www.icmc.usp.br/~biblio/BIBLIOTECA/rel_tec/RT_308.pdf

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Apriori: ilustrando
• Etapa 2:
25
C2(k=2) C2(s=2)
L2
http://www.icmc.usp.br/~biblio/BIBLIOTECA/rel_tec/RT_308.pdf

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Apriori: ilustrando
• Etapa 3:
• Etapa 4:
26
C3(k=3) L3
Conjunto Resposta L –
união dos Lks
http://www.icmc.usp.br/~biblio/BIBLIOTECA/rel_tec/RT_308.pdf

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Apriori: algoritmo
27
Algoritmo Apriori: encontrar itemsets frequentes usando uma abordagem
level-wise iterativa baseada em geração candidata.
(Han & Kamber, 2006, p. 239)
Input:
D, uma base de dados de transações
min-sup, limite mínimo para o suporte de itemsets
Output:
L, itemsets frequentes em D
corpo principal
procedure apriori_gen
procedure has_infrequent_subset
Próximos slides !!
(Han & Kamber, 2006)

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Apriori: corpo principal
28
(1) L1 = find_frequent_1-itemset(D);
(2) for (k = 2; Lk-1 = {}, k++) { (3) Ck = apriori_gen(Lk-1);
(4) for each transaction t ϵ D {// scan D for counts
(5) Ct = subset(Ck,t);// get the subsets of t that are candidates
(6) for each candidate c ϵ Ct
(7) c.count++;
(8) }
(9) Lk = {c ϵ Ck | c.count ≥ min_sup}
(10) }
(11) return L = kLk;
(Han & Kamber, 2006)
Encontra os 1-itemsets frequentes.
Gera Ck candidatos para
encontrar o Lk para k>1.
Conjunto de itemsets frequentes.
Função subset: encontra todos os subconjuntos de
transações que são candidatas. E para cada
subconjunto, o suporte é calculado (count ++).

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori: apriori_gen
procedure apriori_gen (Lk-1:frequent (k-1)-itemsets)
(1) for each itemset l1 ϵ Lk-1 (2) for each itemset l2 ϵ Lk-1 (3) if (l1[1] = l2[1]) ᴧ (l1[2] = l2[2]) ᴧ ... ᴧ
(l1[k-2] = l2[k-2]) ᴧ (l1[k-1] = l2[k-1])
then {
(4) c = l1 |X| l2; // join step: generate candidates
(5) if has_infrequente_subset(c,Lk-1) then
(6) delete c; // prune step: remove unfruitiful candidate
(7) else add c to Ck;
(8) }
(9) return Ck;
29
(Han & Kamber, 2006)
Gera os candidatos e então usa a propriedade Apriori para
eliminar aqueles que tem um subconjunto que não é frequente.
Aplicação da Propriedade Apriori.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori: has_infrequent_subset
procedure has_infrequent_subset (c:candidate k-itemset;
Lk-1: frequent (k-1)-itemsets); // use prior knowledge
(1) for each (k-1)-subset s of c
(2) if s ¬ϵ lk-1 then
(3) return TRUE;
(4) return FALSE;
30
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Assumindo o conjunto de itemsets frequentes encontrados nas transações
de um banco de dados D, é possível gerar regras de associações fortes.
31
Que satisfazem sup_min e conf_min
)(etorte_itemssup
)(etorte_itemssup)|()(confiança
A
BAABPBA
(Han & Kamber, 2006)
• Para cada itemset l, gerar todos os subconjuntos não vazios de l.
• Para todo subconjunto não vazio s de l, retorne a regra “s (l-s)” se
min_conf
emset(s)suporte_it
emset(l)suporte_it
Como os itemsets são frequentes, as regras
geradas, automaticamente, atendem ao
sup_min.
>= 2

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Apriori: ilustrando
32
camiseta tênis
50 / 50 = 1 (todas as vezes que camiseta foi
vendida, tênis também foi vendido)
tênis camiseta
50 / 75 = 0,66 ( em 66% das compras nas quais
tênis foi vendido, camiseta também
foi vendida)
http://www.icmc.usp.br/~biblio/BIBLIOTECA/rel_tec/RT_308.pdf

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Regras de Associação Multinível
Para muitas aplicações, é difícil encontrar associações fortes entre itens de
dados de baixos níveis de abstração, ou primitivos, devido a esparsidade
dos dados nestes níveis. Associações fortes descobertas em altos níveis
de abstração podem representar conhecimento de senso comum (Han &
Kamber, 2006).
• As regras são mineradas usando hierarquias de conceito, sob uma
estrutura de suporte-confiança.
– Estratégia top-down
– Suportes são acumulados
• Calculados a partir dos itemsets frequentes em a cada nível de
conceito.
• Em cada nível, o Apriori ou outro algoritmo de mesmo propósito,
pode ser usado.
33
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Regras de Associação Multinível (exemplos)
34
(Han & Kamber, 2006)
Exemplo de Hierarquia de Conceitos
All
Laptop
Microsoft Dell IBM
Antivirus Office Desktop Printer Mouse Wrist pad Dig.Camera
Computer Computer Accessory Printer & Camera Software
Fellowes Canon HP LogiTech

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Regras de Associação Multinível (exemplos)
35
(Han & Kamber, 2006)
Computer [support = 10%]
Laptop computer [support = 6%] Desktop Computer [support = 4%]
Nível 1
Nível 2
Nível 1
min_sup = 5%
Nível 2
min_sup = 3%
Nível 1
min_sup = 5%
Nível 2
min_sup = 5%
Abordagem de suporte
uniforme
Abordagem de suporte
reduzido

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Regras de Associação Multinível (exemplos)
buys(X,”laptop computer”) buys(X,”HP printer”)
[suporte = 8%, confiança = 70%]
buys(X,”IBM laptop computer”) buys(X,”HP printer”)
[suporte = 2%, confiança = 72%]
• Problema: uma regra pode ser considerada redundante se seu suporte e confiança
estão próximos de seus valores “esperados”, baseado-se no ancestral da regra.
36
(Han & Kamber, 2006)
1
2
Suponha que a regra 1 tenha 70% de confiança e 8% de suporte, e que cerca de um
quarto (¼) de todas as vendas de “laptop computer” são de “IBM laptop computer”.
É esperado que a regra 2 tenha uma confiança de cerca de 70% (já que todos os itens
“IBM laptop computer” são também “laptop computer”) e um suporte de cerca de 2%
(isto é, 8% * ¼).
Se esse é realmente o caso, então a regra 2 não é interessante porque ela não traz
informações adicionais e é menos genérica que a regra 1.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Minerando em um Banco de Dados Relacional ou em um Datawarehouse
– Além de manter a informação sobre quais produtos foram comprados, um
banco de dados relacional ou o datawarehouse também mantém informações
associadas a estes itens: quantidade comprada e/ou preço, idade e/ou
ocupação do comprador, data e/ou hora da compra, compras anteriores, etc.
age (X,”20 ... 29”) AND occupation(X,”student”) buys(X, “laptop”)
37
(Han & Kamber, 2006)
Regra multidimensional - INTERDIMENSIONAL
Regra multidimensional – HÍBRIDA-DIMENSIONAL
age (X,”20 ... 29”) AND buys(X, “laptop”) buys(X, “HP printer”)
Os algoritmos são baseados em Predicados, ao
invés de Itemsets!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Como nós podemos dizer quais regras de associação fortes são realmente
interessantes? (Han & Kamber, 2006, pg 260)
• Exemplo (Han & Kamber, 2006, pg 260) : – De 10.000 transações analisadas, 6.000 incluem venda de jogos de computador, 7.500
incluem venda de videos, e 4.000 incluem ambos.
– Minerando regras de associação com sup_min = 30% e conf_min = 60%, a seguinte regra é
descoberta.
– A regra é, de certa forma, ilusória, porque a probabilidade de comprar vídeos é de 75%, a
qual é bem maior do que 66%.
– Jogos de computadores e videos estão negativamente associados porque a compra de um
“inibe” a compra do outro.
38
(Han & Kamber, 2006)
buys(X, “computer games”) buys(X, “videos”) [suporte = 40% , confiança 66%]

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Análise de Correlação
A B [suporte, confiança, correlação]
• Lift (medida de correlação) – A ocorrência de um itemset A é independente da ocorrência do itemset B se P(A B) =
P(A)P(B); caso contrário, os itemsets A e B são dependentes e correlacionados, enquanto
eventos.
– A medida é dada por
– Se o valor resultante para a medida é menor do que 1, então a ocorrência de A está
negativamente correlacionada com a ocorrência de B.
– Se o valor resultante para a medida é maior do que 1, então A e B estão positivamente
correlacionados, significando que a ocorrência de um implica na ocorrência do outro.
– Se o resultado é igual a 1, então A e B são independentes e não há correlação entre eles.
39
(Han & Kamber, 2006)
.)()(
)(),(
BPAP
BAPBAlift

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras de Associação
• Análise de Correlação – exemplo (Han & Kamber, 2006, pg. 261)
– Seja NOT-GAME referente às transações que não contem “computer games”, e
NOT-VIDEO referente às transações que não contém “videos”.
– Se a probabilidade de comprar:
• Um jogo de computador: P({game}) = 0,60
• Um vídeo: P({video}) = 0,75
• Ambos: P({game, video}) = 0,40
– Pela medida de correlação (Lift)
• O lift da regra do slide anterior é P({game, video}) / P({game}) * P({video}) = 0,40 / (0,60 * 0,75) = 0,89.
– Como o valor é menor do que 1, então existe uma correlação negativa entre a
ocorrência de {game} e {video}
40
(Han & Kamber, 2006)
Outras medidas de correlação poderiam
ser usadas. Veja (Han & Kamber, 2006).

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
WEKA
41

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre o WEKA
• Weka (Waikato Environment for Knowledge Analysis)é uma coleção de algoritmos
de aprendizado de máquina que podem ser usados na implementação de tarefas de
mineração de dados.
• Possui uma interface que permite que os algoritmos seja executados diretamente
sobre o conjunto de dados, ou que eles sejam chamados a partir de algum código
Java.
• Dentre as funcionalidades que podem ser realizadas nestes software, incluem-se: – Pré processamento de dados / Classificação / Regressão / Agrupamento / Regras de Associação /
Visualização
• Weka encontra-se em sua versão 3, e também permite que novos algoritmos sejam
implementados a partir dos recursos que oferece.
• E um software de código aberto, publicado sob a
licença GNU General Public License
(http://www.gnu.org/copyleft/gpl.html).
• Trata-se de uma iniciativa da Universidade de
Waikato, Nova Zelândia.
• Homepage: http://www.cs.waikato.ac.nz/ml/weka/
42
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre o WEKA
• Os algoritmos implementados no WEKA esperam um
formato padrão para os conjuntos de dados que serão
explorados.
• Trata-se do formato ARFF.
• É uma forma de representar dados que contém
instâncias de dados não ordenadas, independentes e
não envolve relacionamento entre elas.
43
Exemplo
(Witten & Frank, 2005)
(Witten & Frank, 2005)

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
% ARFF file for weather data with some numeric features
%
@relation weather
@attribute outlook { sunny, overcast, rainy }
@attribute temperature numeric
@attribute humidity numeric
@attribute windy { true, false }
@attribute play? { yes, no }
@data
%
% 14 instances
%
sunny, 85, 85, false, no
sunny, 80, 90, true, no
overcast, 83, 86, false, yes
rainy, 70, 96, false, yes
rainy, 68, 80, false, yes
rainy, 65, 70, true, no
overcast, 64, 65, true, yes
sunny, 72, 95, false, no
sunny, 69, 70, true, no
rainy, 75, 80, false, yes
sunny, 75, 70, true, yes
overcast, 72, 90, true, yes
overcast, 81, 75, false, yes
rainy, 71, 91, true, no 44
comentário
atributo nominal e os valores
possíveis que os instanciam
nome da relação
bloco de definição
de atributos
atributo de classe
início das instâncias
instâncias são escritas uma por linha, com
valores para cada atributo separados por
vírgula
valores perdidos são representados por “?”
Também admite atributos do tipo: string: @attribute description string
date: @attribute today date
Formato para data/hora: yyyy-MM-ddTHH:mm:ss
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Weka: criando o nosso .arff
• Conjunto de dados: Congressional Voting Records Data Set
• (Frank & Asuncion, 2010)
– Origem: Congressional Quarterly Almanac, 98th Congress, 2nd session 1984, Volume XL:
Congressional Quarterly Inc. Washington, D.C., 1985.
– Doador: Jeff Schlimmer (Jeffrey.Schlimmer '@' a.gp.cs.cmu.edu)
• This data set includes votes for each of the U.S. House of Representatives
Congressmen on the 16 key votes identified by the CQA. The CQA lists nine different
types of votes: voted for, paired for, and announced for (these three simplified to
yea), voted against, paired against, and announced against (these three simplified to
nay), voted present, voted present to avoid conflict of interest, and did not vote or
otherwise make a position known (these three simplified to an unknown disposition).
45

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
46
% 1984 United States Congressional Voting Records Database
%
@relation voting
@attribute handicapped-infants {y,n}
@attribute water-project-cost-sharing {y,n}
@attribute adoption-of-the-budget-resolution {y,n}
@attribute physician-fee-freeze {y,n}
@attribute el-salvador-aid {y,n}
@attribute religious-groups-in-schools {y,n}
@attribute anti-satellite-test-ban {y,n}
@attribute aid-to-nicaraguan-contras {y,n}
@attribute mx-missile {y,n}
@attribute immigration {y,n}
@attribute synfuels-corporation-cutback {y,n}
@attribute education-spending {y,n}
@attribute superfund-right-to-sue {y,n}
@attribute crime {y,n}
@attribute duty-free-exports {y,n}
@attribute export-administration-act-south-africa {y,n}
@attribute class? {democrat, republican}
@data
%
% 435 instances
%
n,y,n,y,y,y,n,n,n,y,?,y,y,y,n,y,republican
n,y,n,y,y,y,n,n,n,n,n,y,y,y,n,?,republican
?,y,y,?,y,y,n,n,n,n,y,n,y,y,n,n,democrat
n,y,y,n,?,y,n,n,n,n,y,n,y,n,n,y,democrat
y,y,y,n,y,y,n,n,n,n,y,?,y,y,y,y,democrat
n,y,y,n,y,y,n,n,n,n,n,n,y,y,y,y,democrat
n,y,n,y,y,y,n,n,n,n,n,n,?,y,y,y,democrat
n,y,n,y,y,y,n,n,n,n,n,n,y,y,?,y,republican
n,y,n,y,y,y,n,n,n,n,n,y,y,y,n,y,republican
... continua ....

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre o WEKA
• Usos do WEKA (Witten & Frank, 2005)
– Aplicação de um método de aprendizado em um conjunto de
dados e analisar as saídas produzidas para aprender mais
sobre os dados;
– Criação de modelos para gerar predições de novas instâncias
(de dados);
– Aplicação de vários e diferentes métodos de aprendizado e
comparação de seus desempenhos a fim de escolher um deles
para a realização da tarefa.
47
• O Weka ainda fornece:
• um módulo de avaliação comum para
medir o desempenho dos algoritmos;
• Ferramentas de pré-processamento,
chamadas filtros.
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Weka
48
Primeiras opções: acesso à interfaces gráficas,
visualizadores e informações sobre a ferramenta.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre o WEKA
• Possui interfaces gráficas
– Explorer: fornece acesso a todas as funcionalidades do WEKA
por meio de menus.
– Knowledge Flow: permite projetar configurações para
processamento de dados streamed, ideal para processar
grandes conjuntos de dados e usar, de maneira combinada,
diversas funcionalidades do WEKA.
– Experimenter: facilita a experimentação de vários métodos
diferentes, usando um corpus de conjuntos de dados, coletando
informações estatísticas e executando diferentes tipos de testes.
49
Uso via linha de comando também
está disponível.
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Weka: explorer
50
Carregando o arquivo
com os dados a serem
analisados ...
Tela inicial do Explorer:
6 abas com as tarefas que
podemos executar (pre-
processamento, classificação,
agrupamento, associação, seleção
de atributos e visualização.
Neste ponto apenas o pré-
processamento está
disponível. É preciso
carregar um arquivo .arff (a
partir de um arquivo, URL,
banco de dados) ou gerar
um arquivo de dados.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Weka: explorer
51
Para editar do arquivo de dados
Para salvar a nova versão do
arquivo de dados
Informações sobre o atributo selecionado: quantos valores
perdidos, quantos valores distintos, tipo dos valores, se
existem valores únicos, quantos valores de cada tipo, e um
histograma (veja próximo slide).
Filtros que podem ser
aplicados sobre os dados.
Depois do pré-
processamento,
as tarefas de
análise de dados
podem ser
executadas.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
52
Frequência de ocorrência cada um dos valores de
classe (republicano - vermelho / democrata - azul) para
cada um dos valores de cada atributo.
Para ver o histograma relacionado todos os
Atributos ao atributo escolhido na lista!
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
53
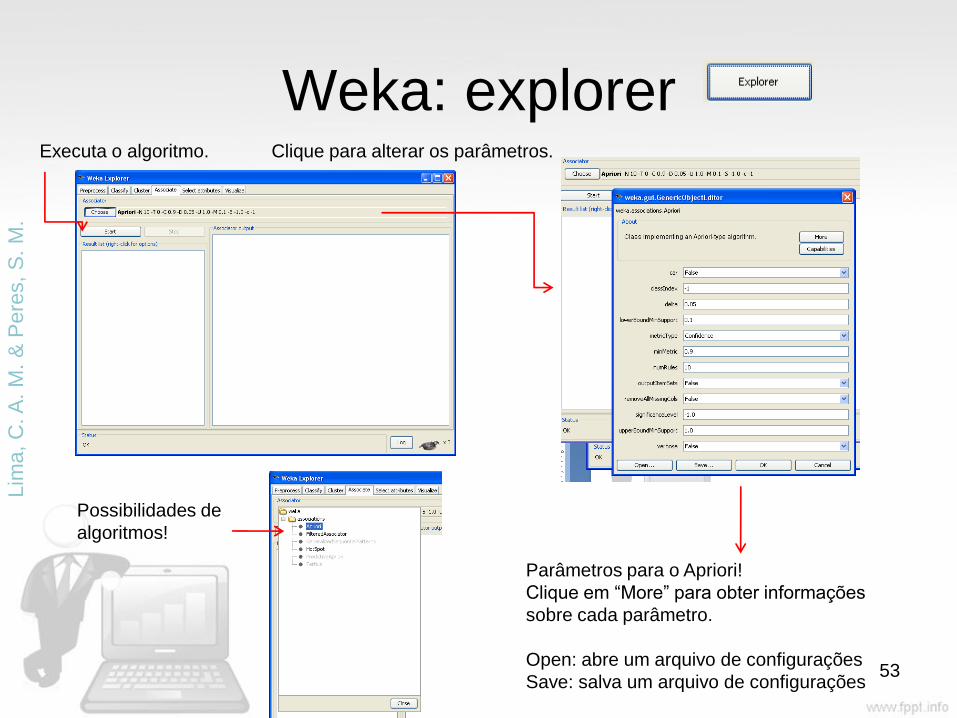
Weka: explorer Clique para alterar os parâmetros.
Possibilidades de
algoritmos!
Parâmetros para o Apriori!
Clique em “More” para obter informações
sobre cada parâmetro.
Open: abre um arquivo de configurações
Save: salva um arquivo de configurações
Executa o algoritmo.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
54
Weka: explorer === Run information ===
Scheme: weka.associations.Apriori -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0 -c -1
Relation: voting
Instances: 435
Attributes: 17
handicapped-infants
water-project-cost-sharing
adoption-of-the-budget-resolution
physician-fee-freeze
el-salvador-aid
religious-groups-in-schools
anti-satellite-test-ban
aid-to-nicaraguan-contras
mx-missile
immigration
synfuels-corporation-cutback
education-spending
superfund-right-to-sue
crime
duty-free-exports
export-administration-act-south-africa
class?
=== Associator model (full training set) ===
Resultado usando os
parâmetros default.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
55
Apriori
=======
Minimum support: 0.45 (196 instances)
Minimum metric <confidence>: 0.9
Number of cycles performed: 11
Generated sets of large itemsets:
Size of set of large itemsets L(1): 20
Size of set of large itemsets L(2): 17
Size of set of large itemsets L(3): 6
Size of set of large itemsets L(4): 1
Resultado usando os
parâmetros default.
Weka: explorer

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Melhores regras encontradas (10 + 1).
1. aprovação de orçamento = sim, congelamento de taxa médica = não 219
==> classe = democrata 219 conf:(1)
2. aprovação de orçamento = sim, congelamento de taxa médica = não, auxílio aos “contras” Nicarágua= sim 198
==> classe = democrata 198 conf:(1)
3. congelamento de taxa médica = não, auxílio aos “contras” Nicarágua= sim 211
==> classe = democrata 210 conf:(1)
4. congelamento de taxa médica = não, gastos com educação = não 202
==> classe = democrata 201 conf:(1)
5. congelamento de taxa médica = não 247 ==> classe = democrata 245 conf:(0.99)
6. auxílio para El Salvador = não, classe = democrata 200 ==> auxílio aos “contras” Nicarágua= sim 197 conf:(0.99)
7. auxílio para El Salvador = não 208 ==> auxílio aos “contras” Nicarágua= sim 204 conf:(0.98)
8. aprovação de orçamento = sim, auxílio aos “contras” Nicarágua= sim, classe = democrata 203
==> congelamento de taxa médica = não 198 conf:(0.98)
9. auxílio para El Salvador = não, auxílio aos “contras” Nicarágua= sim 204 ==> classe = democrata 197 conf:(0.97)
10. auxílio aos “contras” Nicarágua, classe = democrata 218 ==> congelamento de taxa médica = não 210 conf:(0.96)
…
20. auxílio para El Salvador = sim 212 ==> grupos religiosos nas escolas = sim 197 conf:(0.93)
Weka: explorer
Resultado usando os
parâmetros default.
Traduzido!
Alterando um dos parâmetros – número de regras = 20.
56

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
A tarefa de Classificação
57

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
O Problema de Classificação
(Definição Informal) • Dada uma coleção de dados
detalhados, neste caso 5
exemplos de Esperança e 5 de
Gafanhoto, decida a qual tipos de
inseto o exemplo não rotulado
pertence.
• Obs: Esperança: Tipo de
gafanhoto verde
• Esperança ou ganfanhoto?
58

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Para qualquer domínio de interesse podemos medir
características
59

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Coleção de dados
60

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Visualização gráfica
61

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Visualização Gráfica
62

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho
63

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
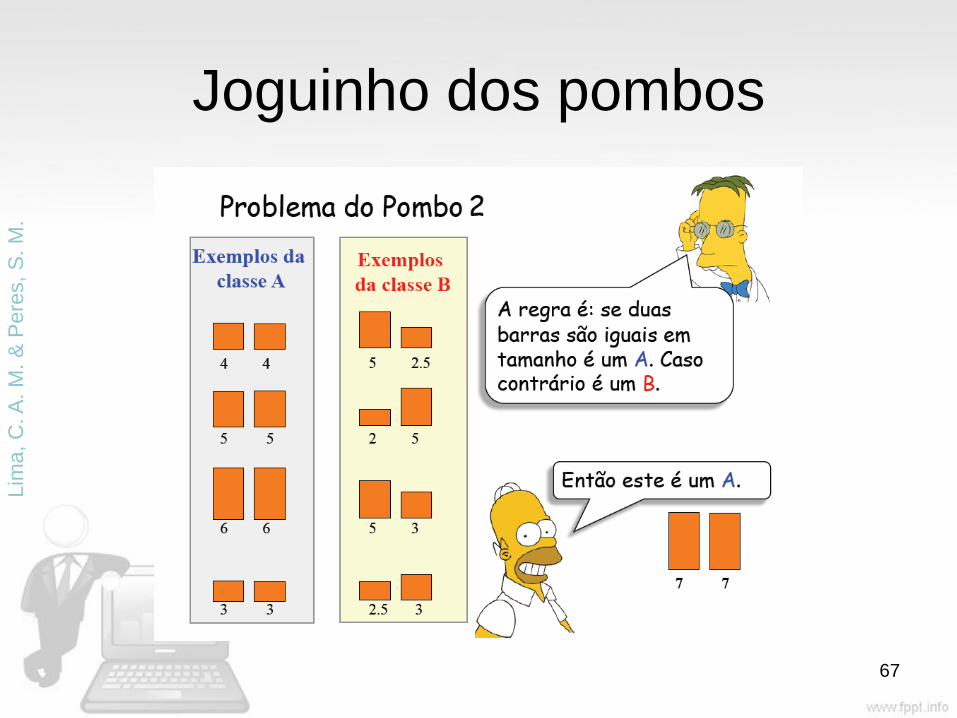
Joguinho dos pombos
64

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos pombos
65

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos pombos
66
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos pombos
67

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos Pombos
68

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos pombos
69

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Joguinho dos pombos
70

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras - Joguinho dos pombos
71

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras – Joguinho dos pombos
72
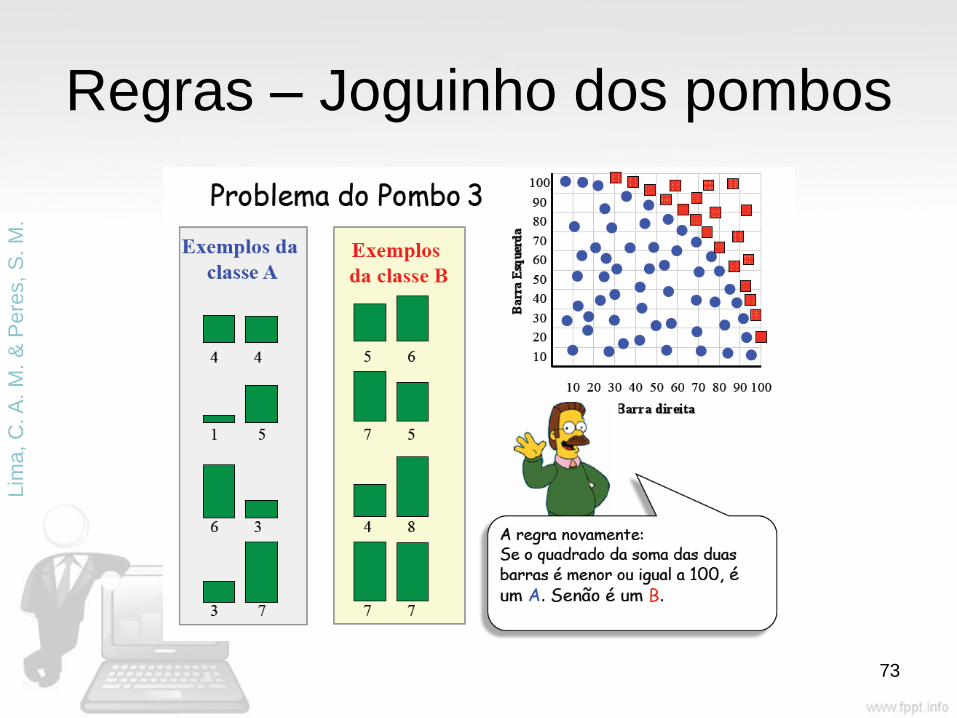
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Regras – Joguinho dos pombos
73

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Problema Inicial
74

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Gafanhoto ou Esperança
75

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Discriminante de Fisher
76

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Espaço de alta dimensão
77

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Espaço de alta dimensão
78

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Espaço de alta dimensão
79

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Redução da dimensionalidade
80
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
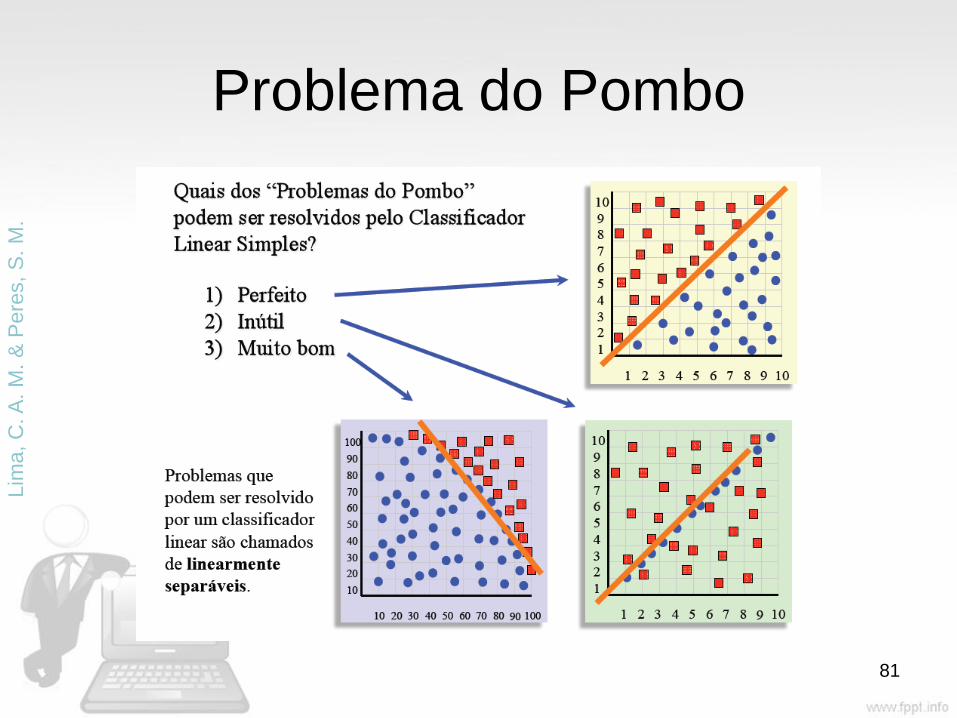
Problema do Pombo
81

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Classificador
• Um exemplo pode ser representado pelo
par: (x, y) = (x, f(x))
• Onde
– x é a entrada;
– f(x) é a saída (f desconhecida!)
– Indução ou inferência indutiva: dada uma
coleção de exemplos de f, retornar uma
função h que aproxima f
– h é denominada uma hipótese sobre f
82
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
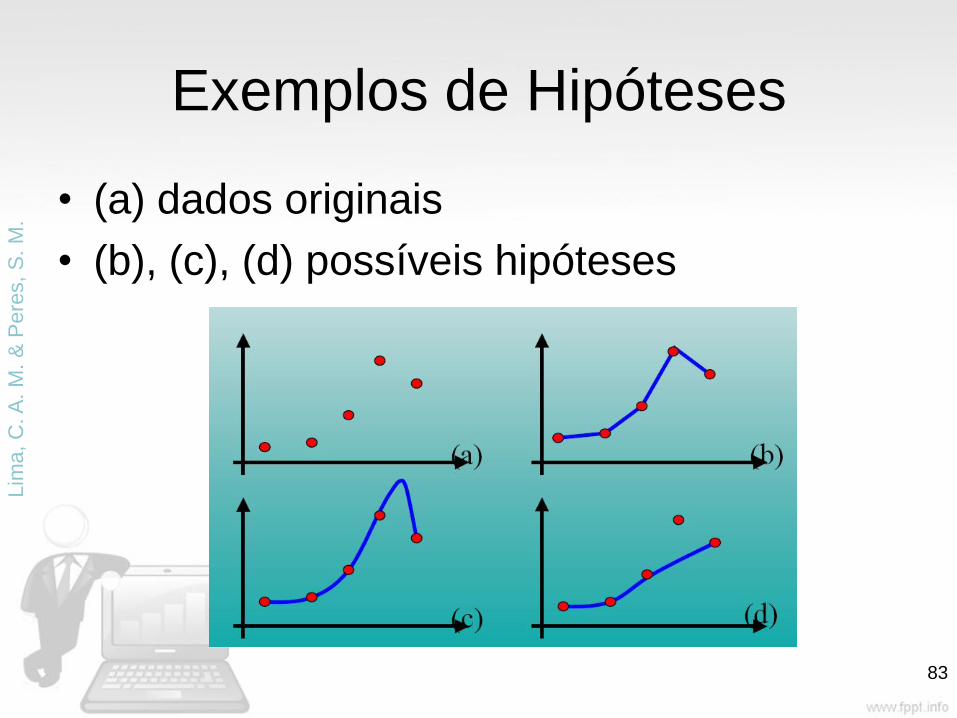
Exemplos de Hipóteses
• (a) dados originais
• (b), (c), (d) possíveis hipóteses
83

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Representação da Classificação
84

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
85
Vetor de atributos ou características
• O que é um vetor de atributos ou características “bom” para uma tarefa de classificação? – A qualidade do vetor de atributos ou características está relacionada com
sua habilidade de discriminar exemplos de diferentes classes • Exemplos da mesma classe deveriam ter valores de atributos ou características
similares
• Exemplos de classes diferentes deveriam ter valores de atributos ou características diferentes
Atributos ou Características
boas
Atributos ou Características
ruins

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
86
Tipos de Problemas de Classificação
Linearmente separável Não-Linearmente separável
Características altamente
correlacionadas Multimodal

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Treinamento e Teste
• O desempenho de um classificador pode ser medido por
meio da taxa de erro:
– A taxa de erro de erro é a proporção de erros obtidos sobre um
conjunto completo de instancias.
– O que interessa é o desempenho do classificador mediante
“novos” dados, e não sobre os dados velhos (usados no
processo de treinamento).
87
O classificador prediz a classe de cada instância; se
ela é correta, é contada como um “sucesso”; se não,
é contada como um “erro”.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Treinamento, validação e teste
• Frequentemente é útil dividir o conjunto de dados disponíveis em
três partes, para três diferentes propósitos:
– Conjunto de treinamento: usado por um ou mais métodos de
aprendizado para construir o classificador.
– Conjunto de validação: usado para otimizar os parâmetros do
classificador, ou para selecionar um em particular.
– Conjunto de teste: usado para clacular a taxa de erro final do modelo já
otimizado.
88
Uma vez que a taxa de erro foi determinada, os dados de testes podem
se juntar aos dados de treinamento para produzir um novo classificador
para o uso real. Não há problema nisso quando usado apenas como uma
forma de maximizar o classificador que será usado na prática. O que é
importante é que a taxa de erro não seja calculada com base nesse último
classificador gerado. Além disso, o mesmo pode ser feito com os dados
de validação. (Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Análise de desempenho
89
Meu classificador apresentou 25% de taxa de erro (75% de taxa de
acerto). Mas o que isso realmente significa? Quanto posso confiar
nesta medida?
É util determinar a taxa de sucesso com relação a um intervalo de
confiança.
Seja S a contagens de respostas corretas obtidas nos testes do
classificador e N o número de testes realizados, então:
• Se S = 750 e N = 1000, a taxa de sucesso é por volta de 75%. Se
considerarmos 80% de confiança na medida, a taxa de sucesso fica entre
73.2% e 76.7%.
•Se S = 75 e N = 100, a taxa de sucesso é por volta de 75%. Se
considerarmos 80% de confiança na medida, a taxa de sucesso fica entre
69.1% e 80.1%.
?

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Processo de Bernoulli
• Sucessão de eventos independentes que ou obtém sucesso ou falham.
• A média e variância de uma única tentativa Bernoulli com taxa de sucesso
p é p e p(1-p), respectivamente. Se N tentativas são executadas, a taxa de
sucesso esperada f = S/N é uma variável randômica com a mesma média
p; a variância é reduzida pelo fator N para p(1-p)/N. Para grandes N, a
distribuição desta variável randômica aproxima uma distribuição normal.
• A probabilidade de uma variável randômica X, com média 0, ficar entre um
certo intervalo de confiança de largura 2z é Pr[ -z <= X <= z] = c.
• Para uma distribuição normal, valores de c e z são dados em tabelas (a
derivação de tais tabelas não está discutida aqui) apresentadas na
literatura da área de Estatística.
90
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• Pr [ X >= z ] = 5% implica que existe 5% de chance que X estar em mais de 1.65 de
desvio padrão acima da média. Como a distribuição normal é simétrica, a chance de
X estar em mais do que 1.65 de desvio padrão da média (acima ou abaixo) é de
10%, ou Pr [ -1.65 <= X <= 1.65 ] = 90%.
• Então é necessário reduzir a variável f para ter média zero e variância 1, e Pr [ -z <
(f-p)/ sqrt(p(1-p)/N)) < z ] = c.
• Para usar a tabela é necessário subtrair c de 1 e então verificar o resultado, tal que
para c = 90% deve-se usar a entrada de 5% da tabela.
91
Processo de Bernoulli (Witten & Frank, 2005)
Limites de confiança para a distribuição normal
Pr [ X >= z ] z
0.1% 3.09
0.5% 2.58
1% 2.33
5% 1.65
10% 1.28
20% 0.84
40% 0.25

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• Para encontrar p:
• O +/- na expressão indica os dois valores para p que
representam os limites superior e inferior de confiança.
92
Processo de Bernoulli (Witten & Frank, 2005)
N
z
N
z
N
f
N
fz
N
zfp
2
2
222
1/42
A asserção da distribuição normal é
válida somente para grandes N (por
exemplo, N > 100).

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Matriz de Confusão
• Oferece uma medida da eficácia do modelo de
classificação,mostrando o número de classificações corretas versus
o número de classificação prevista para cada classe.
93
Classe C1 Prevista C2 Prevista Ck Prevista
C1 Real M(C1,C1) M(C1,C2) M(C1,Ck)
C2 Real M(C2,C1) M(C2,C2) M(C2,Ck)
Ck Real M(Ck,C1) M(Ck,C2) M(Ck,Ck)
}:),({
)(),(iCyTyx
jji CxhCCM

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Matriz de Confusão para duas classes
94
TP = True Positive (verdadeiro positivo)
FN = False Negative(falso negativo)
FP = False Positive (falso positivo)
TN = True Negative (verdadeiro negativo)
n = (TP+FN+FP+TN)
Classe prevista C+ prevista C- Taxa de erro
da classe
Taxa de erro
total
real C+ Tp Fn Fn / (Tp + Fn)
(Fp + Fn) / n
real C- Fp Tn Fp/ (Fp + Tn)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Matriz de Confusão para duas classes
• Outras métricas derivadas da tabela anterior:
95
C+ Predictive Value = Tp / (Tp + Fp)
C- Predictive Value = Tn / (Tn + Fn)
True C+ Rate ou Sesitivity y ou Recall = Tp / (Tp + Fn)
True C- Rate ou Specifity = Tn / (Fp + Tn)
Precision = (Tp + Tn) / n

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Credibilidade: avaliando o que foi aprendido
• É possível avaliar como diferentes métodos de
mineração de dados trabalham e é possível compará-
los.
• É preciso implementar uma forma de predizer os limites
de desempenho de um método, baseado em
experimentos com os dados que estão disponíveis.
– Quando está disponível um grande conjunto de dados a
avaliação pode se basear em um grande conjunto de
treinamento e um grande conjunto de teste.
– Caso contrário, é preciso trabalhar um pouco mais.
96
(Witten & Frank, 2005)
É um trabalho cheio de
controvérsias e discordâncias!!!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Diferentes formas de avaliação
• Para problemas de classificação, pode-se medir o desempenho de
um classificador com base na taxa de erro.
• Regras de associação são avaliadas com base em medidas de
suporte e confiança.
• Tarefas de predição podem ser avaliadas por medidas tais como:
erro quadrático médio, coeficiente de correlação, etc.
• O princípio MDL (minimun description length) pode ser usado para
avaliar tarefas de agrupamento.
97
Veja mais à frente, nestes slides,
como tais medidas são
aplicadas!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Avaliação do classificador
• Para estimar o erro verdadeiro de um classificador, a
amostra para teste deve ser aleatoriamente escolhida
• Amostras não devem ser pré-selecionadas de nenhuma
maneira
• Para problemas reais, tem-se uma amostra de uma
única população, de tamanho n, e a tarefa é estimar o
erro verdadeiro para essa população
98

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos para estimar o erro
verdadeiro de um classificador
– Resubstitution
– Random
– Holdout
– r-fold cross-validation
– r-fold stratified cross-validation
– Leave-one-out
– Bootstrap
99

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Resubstitution
• Gera o classificador e testa a sua performance
com o mesmo conjunto de dados
• Os desempenhos computados com este método
são otimistas e tem grande bias
• Desde que o bias da resubstitution foi
descoberto, os métodos de cross-validation são
usados
100

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Holdout
• Estratégia para teste de classificador que reserva um certo montante de
dados para treino e o restante para teste (podendo ainda usar parte para
validação).
• Comumente esta estratégia uma 1/3 dos dados dados para teste e o
restante para treinamento, escolhido randomicamente.
• É interessante assegurar que a amostragem randômica seja feita de tal
maneira que garanta que cada classe é apropriadamente representada
tanto no conjunto de treinamento quanto no conjunto de teste. Este
procedimento é chamado de estratificação (holdout estratificado).
• Também é útil, para amenizar tendências, repetir todo o processo de treino
e teste várias vezes com diferentes amostragens randômicas (holdout
repetitivo/iterativo).
101
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Random
• I classificadores, I<<n, são induzidos de cada
conjunto de treinamento
• O erro é a média dos erros dos classificadores
medidos por conjuntos de treinamentos gerados
aleatória e independentemente
• Pode produzir estimativas melhores que o
holdout
102

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Cross Validation
• Trata-se de uma estratégia para lidar com um montante de dados
limitado.
• Nesta estratégia decide-se um numero fixos de folds, ou partições
dos dados. Supondo que sejam usados três folds (3-fold cross
validation):
– o conjunto de dado é dividido em três partições de tamanhos aproximadamente
iguais e, de maneira rotativa, cada uma delas é usada para teste enquanto as
duas restantes são usadas para treinamento.
– ou seja: use 2/3 para treinamento e 1/3 para teste e repita o processo três
vezes, tal que, no fim, cada instância tenha sido usadas exatamente uma vez
para teste.
– se a estratificação é adotada, então o procedimento se chama 3-fold cross
validation estratificado (aconselhável).
– o padrão é executar o 10-fold cross validation, 10 vezes.
– o erro final do classificador é a média dos erros obtidos em cada iteração da
estratégia cross-validation
103
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Leave-one-out
• Leave-one-out cross-validation é um n-fold cross-validation, onde n é o
número de instâncias no conjunto de dados.
• A avaliação é sobre a corretude de classificação da instância em teste – um
ou zero para sucesso ou falha, respectivamente.
• Os resultados de todas as n avaliações, uma para cada instância do
conjunto de dados, são analisados via média, e tal média representa o erro
final estimado.
• Motivações:
– o maior número possível de dados é usado para treinamento em cada caso, o
que aumenta as chance do classificador alcançar acuidade.
– o procedimento é determinístico.
• Indicado para conjunto de dados pequenos.
• Não é possível aplicar qualquer procedimento de estratificação.
104
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Boostrap
• Baseado em um procedimento estatístico de amostragem com
reposição.
• Uma instância não é retirada do conjunto de dados original quando
ela é escolhida para compor o conjunto de treinamento.
– Ou seja, a mesma instância pode ser selecionada várias vezes durante
o procedimento de amostragem.
• As instâncias do conjunto original que não foram escolhidas para
compor o conjunto de treinamento, comporão o conjunto de teste.
• O 0,632 bootstrap:
– a probabilidade de uma instância ser escolhida é 1/n. E de não ser escolhida é
de 1-(1/n). Multiplicando essas probabilidades de acordo com o número de
oportunidades de escolha (n), tem-se (1 – (1/n))n ~ e-1 = 0,368 como a
probabilidade de uma instância não ser escolhida.
– assim, para um conjunto de dados grande, o conjunto de testes conterá 36,8%
de instâncias e o conjunto de treinamento, 63,2% delas.
105
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Boostrap
• A medida de erro obtida é uma estimativa pessimista do erro verdadeiro
porque o conjunto de treinamento, embora tenha tamanho n, contém
somente 63% das instâncias, o que não é grande coisa se comparado com
os 90% usados no 10-fold cross-validation.
• Para compesar isso, pode-se combinar o erro do conjunto de teste com o
erro de resubstituição (estimativa otimista).
• O boostrap combina da seguinte forma: – erro = 0,632 * erro de teste + 0.368 * erro de treinamento
• O procedimento deve ser repetido várias vezes, e uma média de erro final
deve ser encontrada.
106
(Witten & Frank, 2005)
O bootstrap é o procedimento mais
indicado para estimar erro para
conjuntos de dados muito pequenos.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Comparando métodos
• Encontrar a taxa de erro para as técnicas comparadas e escolher aquela
com a menor taxa é a forma mais simples de comparação e, pode ser
adequada para problemas isolados.
• Se um novo algoritmo é proposto, seus proponentes devem mostrar que
ele melhora o estado da arte para o problema em estudo e demonstrar que
a melhora observada não é apenas um efeito de sorte do processo de
estimativa do erro.
• O objetivo é determinar se um esquema é melhor ou pior do que o outro,
em média, usando todas as possibilidades de conjuntos de treinamento e
de teste que podem ser criados a partir do domínio. Todos os conjuntos de
dados deveriam ser do mesmo tamanho e o experimento deveria ser
executado várias vezes, com diferentes tamanhos, para obter uma curva de
aprendizado.
107
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• t-test ou Student’s test
– seja um conjunto de amostras x1, x2, ..., xk obtidas por sucessivos 10-
fold cross validation, usando um esquema de aprendizado (um dos
métodos sob comparação), e um segundo conjunto de amostras y1, y2,
..., yk obtidos de sucessivos10-fold cross validation usando o outro.
– cada estimativa cross validation é gerada usando um conjunto de
dados diferente (mas de mesmos tamanhos e do mesmo domínio).
– melhores resultados serão obtidos se ambos os esquemas sob
comparação usarem exatamente as mesmas partições dos dados para
x1 e y1, x2 e y2, e assim por diante.
– a média da primeira amostragem é x e a média da segunda é y.
– a pergunta é: x é significativamente diferente de y ?
108
Comparando métodos (Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
– se existem amostras suficientes, a media (x) de um conjunto de amostras
independente (x1, x2, ..., xk) tem uma distribuição normal, independentemente da
distribuição subjacente à amostra em si; o valor verdadeiro de média seria μ, e a
variância poderia ser estimada e poder-se-ia reduzir a distribuição de x para média
zero e variância 1.
– mas k não é grande, k = 10.
– tem-se uma Student’s distribution com k-1 graus de liberdade.
– a tabela de intervalos de confiança da Student’s distribution deveria ser usada ao
invés da tabela de intervalos de confiança da distribuição normal.
– para o caso do 10-fold cross validation, tem-se o 9 graus de liberdade.
109
Comparando métodos (Witten & Frank, 2005)
Limites de confiança para a Student’s distribution com 9 graus de liberdade
Pr [ X >= z] z
0.1% 4.30
0.5% 3.25
1% 2.82
5% 1.83
10% 1.38
20% 0.88

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
– considera-se pois as diferenças di entre observações
correspondentes, di = xi – yi.
– a média das diferenças é a diferença entre as médias, d = x – y,
e como as médias, as diferenças seguem a Student’s
distribution com k-1 graus de liberdade.
– se a média é a mesma, a diferença é zero (hipótese nula); se
elas são significativamente diferentes, a diferença será
significativamente diferente de zero.
– assim, para um dado nível de confiança, checar-se-á se a
diferença excede um limite de confiança.
110
Comparando métodos (Witten & Frank, 2005)
como??

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• reduza a diferença para média-zero e variância unitária variável
t-statistc, aplicando
t = d / sqrt(σ2d/k)
• onde σ2d é a variância das diferenças.
• decida o nível de confiança – geralmente 5% ou 1%.
• a partir deste limite determine z usando a tabela anterior se k = 10;
• Se o valor de t é maior do que z, ou menor do que –z, a hipótese
nula deve ser rejeitada e conclui-se que há, realmente, uma
diferença significativa entre os dois métodos sob comparação.
111
Comparando métodos (Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Avaliação dos classificadores
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Taxa de Falso Positivo
Taxa d
e V
erd
adeiro P
ositiv
o
E
AC
D
B
• Gráfico ROC com cinco classificadores discretos.
– A é dito um classificador “conservador”, B é o inverso de E, D é
um classificador perfeito e C é dito aleatório.
112

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Avaliação dos classificadores
• Considere as seguintes saídas de um classificador:
• -0,7: TP = 1 FP = 1 ponto (1 ; 1)
• -0,6: TP = 1 FP = 0,5 ponto (0.5 ; 1)
• 0,8: TP = 1 FP = 0 ponto (0 ; 1)
• 0,9: TP = 0,66 FP = 0 ponto (0 ; 0,66)
• 1,0: TP = 0,33 FP = 0 ponto (0 ; 0,33)
z y L (-0.7) L(-0.6) L(0.8) L(0.9) L(1.0) L(>1.0)
-0.7 -1 1 -1 -1 -1 -1 -1
-0.6 -1 1 1 -1 -1 -1 -1
0.8 1 1 1 1 -1 -1 -1
0.9 1 1 1 1 1 -1 -1
1.0 1 1 1 1 1 1 -1
113

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Um método para classificação
Máquinas Vetores Suporte
SVM – Support Vector Machine
114

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
115
Máquinas de Vetores Suporte
(SVM – Support Vector Machines)
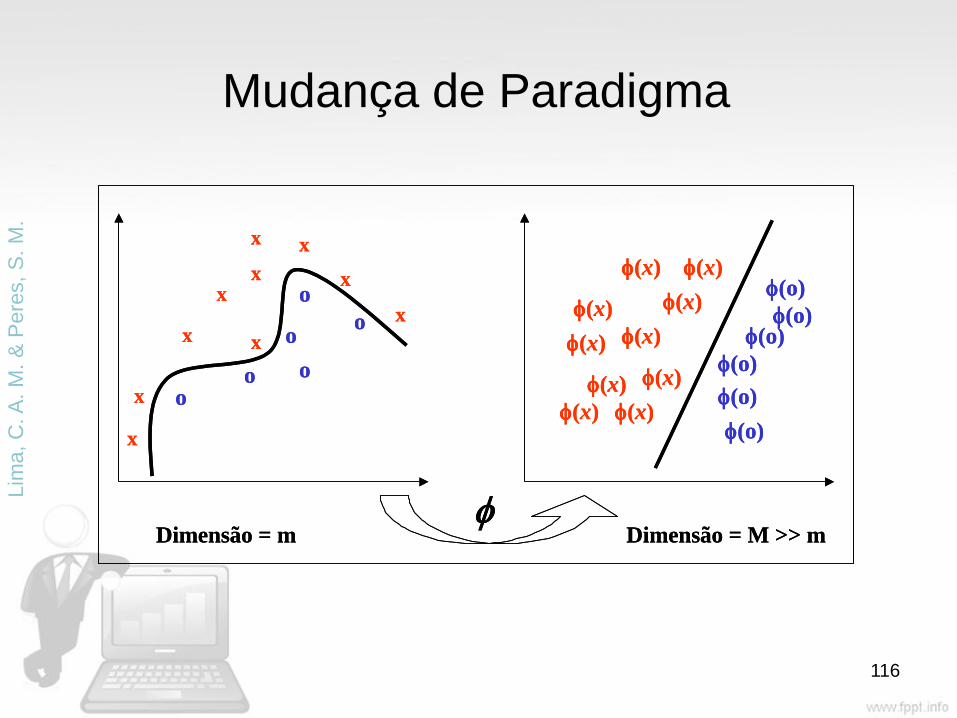
• Máquinas de Vetores Suporte
– Usa espaço de hipótese de funções lineares no espaço de característica de alta dimensionalidade, treinadas com um algoritmo baseado na teoria de otimização que implementa a teoria de aprendizado estatístico.
• Palavras chaves
– Maquinas de aprendizado Linear
– Funções kernel
• Usado para definir o espaço de característica implícito, no qual a máquina de aprendizado linear opera.
• Responsável pelo uso eficiente do espaço de característica de alta dimensionalidade.
– Teoria de Otimização Representação Compacta
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
116
x
x
x
x
xx
x
x
x
xo
o
oo
oo
(x)
(x)
(x)
(x)
(x)
(x)(x)
(x) (x)
(x)
(o)
(o)
(o)
(o)
(o)
(o)
Dimensão = m Dimensão = M >> m
x
x
x
x
xx
x
x
x
xo
o
oo
oo
(x)
(x)
(x)
(x)
(x)
(x)(x)
(x) (x)
(x)
(o)
(o)
(o)
(o)
(o)
(o)
Dimensão = m Dimensão = M >> m
Mudança de Paradigma

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
117
SVM supera dois problemas
• 1) Problema conceitual – Como controlar a complexidade do conjunto de aproximação.
• Funções em alta dimensão a fim de proporcionar boa capacidade de generalização
• Usar estimadores lineares penalizados com um grande número de funções-base
• 2) Problema Computacional – Como realizar otimização numérica em espaço de alta
dimensão
• Usar uma representação kernel dual de funções lineares

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
118
Há infinitas linhas que têm erro de treinamento zero
Qual delas deveremos escolher?
Classificadores lineares sobre problema
linearmente separável

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
119
– vetores Xi
– rótulos yi = ±1
Hiperplano de separação de
margem ótima (Vapnik)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
120
)(sign)( bf XwXw
1
1).( by ii Xw
ww
:min
Hiperplano de separação de
margem ótima (Vapnik)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
121
)(sign by Xw
1)( by ii Xw
ww
:min
Siby ii ,1)( Xw
Si
iii y Xw
– vetores Xi
– rótulos yi = ±1
– Vetores suporte:
Vetores Suporte

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
122
– vetores Xi
– rótulos yi = ±1
– Vetores suporte:
)(sign)( bf XwX
1)( by ii Xw
ww
:min,b
Siby ii ,1)( Xw
Si
iii y Xw )(sign)( byf
Si
iii
XXX
Máquina de Vetores Suporte (SVM)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
123
– vetores Xi
– rótulos yi = ±1
– Vetores suporte:
(vetores da margem
e vetores de erro)
)(sign by Xw
Siby ii ,1)( Xw
Si
iii y Xw )(sign)( byfSi
iii
XXX
Hiperplano de separação com
margem suave
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
124
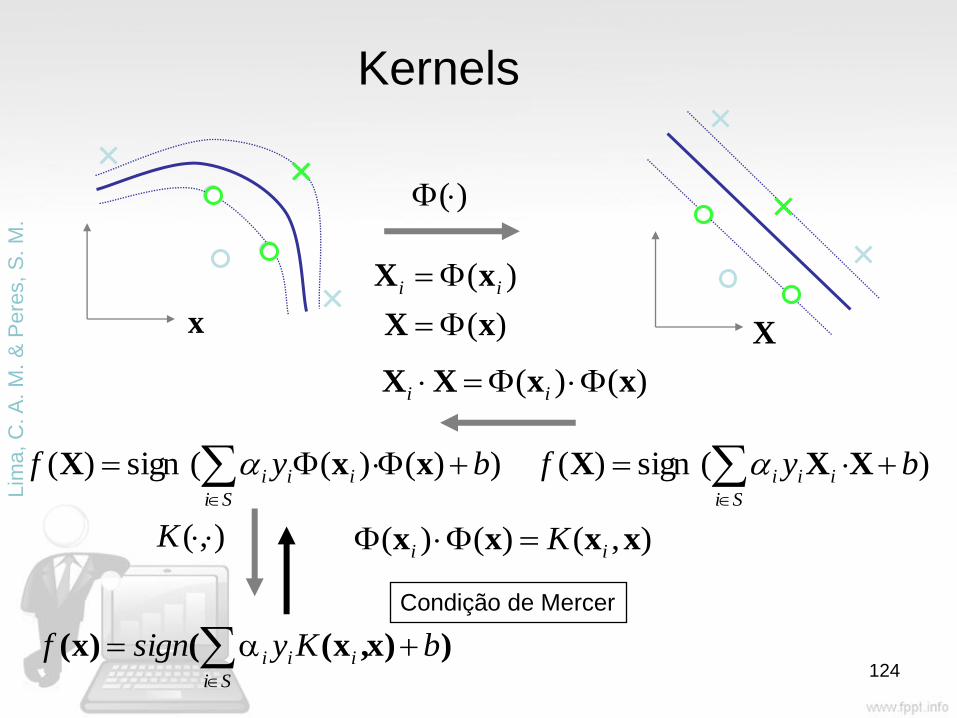
x X
)(
)(
)(
xX
xX
ii
),( K ),()()( xxxx ii K
))x,x(()x( bKysignfSi
iii
))()((sign)( byfSi
iii
xxX
)()( xxXX ii
Condição de Mercer
)(sign)( byfSi
iii
XXX
Kernels

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
125
Tipo de Kernel
i. Linear
ii. Polinomial
iii. Função Gaussiana de Base
Radial
iv. Função Exponencial Base
Radial
yxyxK ),(
dyxyxK )1(),(
2
2
2
)(exp),(
yxyxK
v. Tangente
vi. Séries de Fourier
vii. Linear Splines
viii. Bn-splines
22exp),(
yxyxK
))(tanh(),( cyxbyxK
)(
))((),(
2
1
2
1
yxsin
yxNsinyxK
3
2
),max(3
1
),min(2
)(),min(1),(
yx
yxyx
yxxyxyyxK
)(),( 12 yxByxK n

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
126
• Problema Primal
• Sujeito a
N
i
iFC1
2)(
2
1),( ww
Niby iii ,,1,1 xw
Formulação do SVM para
classificação

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
127
Tipo de Perda

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
128
• Problema dual
• Sujeito a
• Fórmula Usual em Otimização
N
i
i
N
i
N
j
jijiji KyyW11 1
),(2
1)(min
xx
NiCi ,,1,0
N
i
ii y1
0
TT cKW 2
1)(min
NiCi ,,1,0
bA
Formulação do SVM para classificação

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
129
0
0
0
0
0
2
1)(
4
3
2
1
432
4
1
1
4
1,
4321
i
ii
ji
ijjiji
ysujeito
hyyL
9111
1911
1191
1119
K
n
i i
iiii yHyf1
4
1
2* ]1).[()125.0(),()( xxxxx
• Problema dual
• Utilizando o kernel polinomial de ordem 2
• Função
1x
2x
y
Exemplo – Ou Exclusivo

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Spider
130

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Instituto Max Planck
131

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
132
Simulação
• [x,y] = spir(100);
• Ip = find(y==1);
• In = find(y==-1)
• plot(x(Ip,1),x(Ip,2),'r*')
• hold on
• plot(x(In,1),x(In,2),'b*')
• d=data(x,y)
• ker=kernel('rbf',0.4)
• a1=svm({ker,'C=1e4','optimizer="decomp"'})
• [tr2 a2]=train(a1,d)
• plot(a2)
-1 -0.5 0 0.5 1 1.5 2 2.5 3-1
-0.5
0
0.5
1
1.5
2
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
-0.5 0 0.5 1 1.5 2 2.5-0.5
0
0.5
1
1.5
2

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
133
Simulação
• [x,y] = spir(100);
• Ip = find(y==1);
• In = find(y==-1)
• plot(x(Ip,1),x(Ip,2),'r*')
• hold on
• plot(x(In,1),x(In,2),'b*')
• d=data(x,y)
• ker=kernel('rbf',0.4)
• a1=svm({ker,'C=1e4','optimizer="decomp“,’ty
pe=“use2norm”'})
• [tr2 a2]=train(a1,d)
• plot(a2)
-0.5 0 0.5 1 1.5 2 2.5-0.5
0
0.5
1
1.5
2
-1 -0.5 0 0.5 1 1.5 2 2.5 3-1
-0.5
0
0.5
1
1.5
2
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
134
Simulação
• [x,y] = spir(100);
• Ip = find(y==1);
• In = find(y==-1)
• plot(x(Ip,1),x(Ip,2),'r*')
• hold on
• plot(x(In,1),x(In,2),'b*')
• d=data(x,y)
• ker=kernel('rbf',0.4)
• a1=lssvm({ker,'C=1e4})
• [tr2 a2]=train(a1,d)
• plot(a2)
-0.5 0 0.5 1 1.5 2 2.5-0.5
0
0.5
1
1.5
2
-1 -0.5 0 0.5 1 1.5 2 2.5 3-1
-0.5
0
0.5
1
1.5
2
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
135
Simulação
• [x,y] = spir(50);
• d=data(x,y)
• ker=kernel('rbf',0.4)
• a1=lssvm({ker,'C=1e4’})
• a2=selparam(a1)
• [tr3 a3]=train(a2,d)
-10-5
05
1015
2025
-4
-2
0
2
4
0
0.2
0.4
0.6
0.8
x1
Optimization grid after first iteration
x2
cost
-10 -5 0 5 10 15 20 25-3
-2
-1
0
1
2
3
4Optimization grid after first iteration

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
136
Simulação
• [x,y] = spir(50);
• d=data(x,y)
• ker=kernel('rbf',0.4)
• a1=lssvm({ker,'C=1e4’})
• a2=selparam(a1)
• [tr3 a3]=train(a2,d)
-4-2
02
46
-2.5
-2
-1.5
-1
-0.5
0
0.2
0.4
0.6
0.8
log(C)
Grid Otimizacao depois da iteracao 2
cost
-4 -3 -2 -1 0 1 2 3 4 5-3
-2.5
-2
-1.5
-1
-0.5Grid Otimizacao depois da iteracao 2
C= 76.0917 = 0.116834

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
137
Simulação
• [x,y] = spir(50);
• d=data(x,y)
• ker=kernel('rbf',0.116834)
• a1=lssvm({ker,'C=76.0917’})
• [tr2 a2]=train(a1,d)
• plot(a2)
C= 76.0917 = 0.116834
-1 -0.5 0 0.5 1 1.5 2 2.5 3-1
-0.5
0
0.5
1
1.5
2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
A tarefa de Predição
138

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Um método para predição
Máquinas Vetores Suporte
SVM – Support Vector Machine
139

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Classificação e Regressão
• Qual é a diferença entre Classificação e
Regressão ?
• Em problemas de Regressão a variável de
saída y assume valores contínuos,
enquanto que em problemas de
classificação y é estritamente categórica.
140

141
• Desenvolvido por Vapnik (1995)
• Modelo: Dado um conjunto de amostras
estimar a função:
• Minimizando
• )(
2
1),(
1
2
l
i
iFCww
Problema de Regressão
bxwxf ))(()(
RyRxyxyx n
ll ,),,(,),,( 11

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
142
• Problema Primal
• Sujeito a
0
0
,,1,)(
,,1,)(
*
*
i
i
iii
iii
Niybxw
Nibxwy
N
i
i
N
i
Cwww1
*
1
* )(2
1),,(
Formulação do SVM para
Regressão

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
143
Funções de penalidade para
regressão
• -insensível
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
e-Insentive
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
e-Quadratica
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
Huber
• -quadrática

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
144
Formulação do SVM para Regressão
NiCi ,,1,0 *
• Problema dual
• Sujeito a
• Fórmula Usual em Otimização
N
i
iii
N
i
iii
N
i
N
j
jijiji yKW1
*
1
*
1 1
** )()())(,()(2
1)(min
xx
NiCi ,,1,0
TT cHW 2
1)(min
NiCi ,,1,0
bA
NiN
i
N
i
ii ,,1,1 1
*

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Predição - avaliação
• Neste caso erros não são simplesmentes presentes ou
ausentes, e sim de diferentes tamanhos.
• Erro quadrado médio: medida mais usada.
– as vezes a raíz quadrada é usada para trazer a medida para a mesma dimensão
dos valores preditos.
• Erro absoluto médio: alternativa
– ao contrário do erro quadrado médio, não potencializa o efeito dos outliers.
• Erro quadrado relativo:
– toma o erro quadrado total e o normaliza dividindo-o pelo erro quadrado total do
preditor padrão (média dos dados de treinamento).
• Coeficiente de correlação:
– mede a correlação estatísticas entre os valores preditos (p’s) e os valores
esperados (a’s). 1 = correlação perfeita; 0 não há correlação; -1 correlação
perfeita negativa. 145
(Witten & Frank, 2005)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• Exemplo:
146
Predição - avaliação (Witten & Frank, 2005)
Medidas de desempenho para modelos de predição numérica
A B C D
raíz do erro quadrado médio 67.8 91.7 63.3 57.4
erro absoluto médio 41.3 38.5 33.4 29.2
erro quadrado relativo médio 42.2% 57.2% 39.4% 35.8%
erro absoluto médio 43.1% 40.1% 34.8% 30.4%
coeficiente de correlação 0.88 0.88 0.89 0.91
Melhor preditor!
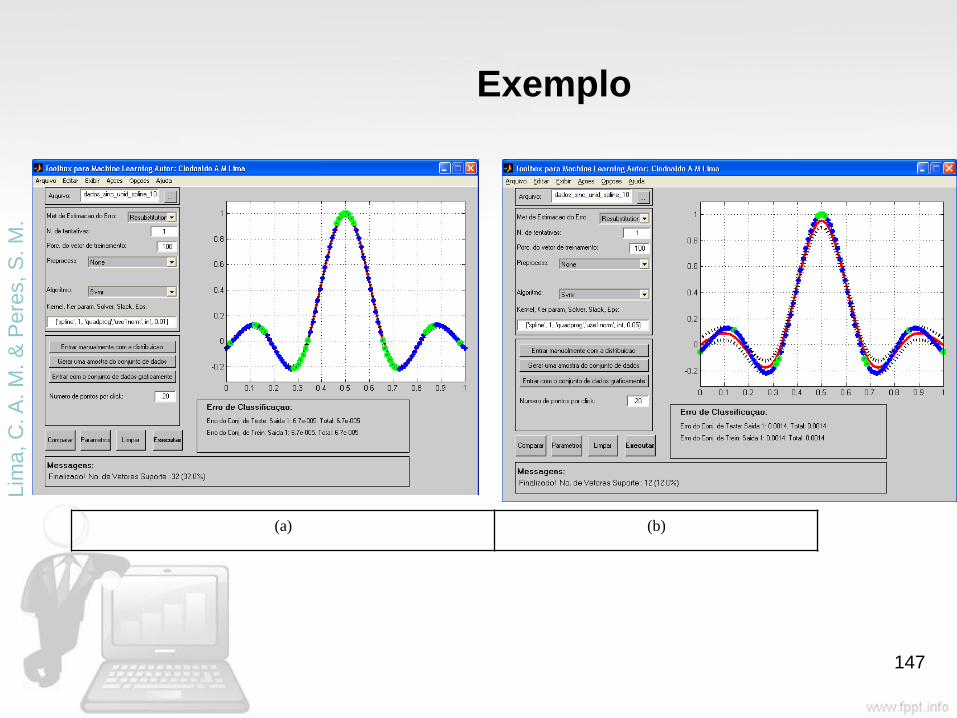
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
147
Exemplo
(a) (b)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
148
(c) (d)
Figura – Aproximação com diferentes níveis de precisão requer um
numero diferente de vetores suporte: 32 SV para =0.01, (b) 12 SV
para = 0.05, (c) 10 SV para = 0.1, (d) 6 SV para = 0.2 para função
de perda norma - insensível.
Exemplo

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
A tarefa de Agrupamento
149

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Agrupamento (clustering)
• A tarefa de agrupamento consiste em agrupar um conjunto de objetos
físicos ou abstratos em grupos de objetos similares.
• Um grupo é uma coleção de objetos que são similares uns aos outros,
dentro de um grupo, e dissimilares aos objetos de outros grupos. – pode ser considerada uma forma de compressão
• O modelo de agrupamento não é construído com base em dados rotulados.
Apenas a informação de similiridade entre os dados é usada. – após o modelo de agrupamento ser construídos, um processo de rotulação dos grupos
formados pode ser útil.
150
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Agrupamento - aplicações
• pesquisa de
mercado
• reconhecimento
de padrões
• análise de dados
• processamento de
imagens ....
151
Os profissionais de marketing são apoiados pelos modelos de
agrupamento na tarefa de descobrir grupos distintos em suas bases
de clientes e na tarefa de caracterizá-los com base nos padrões
descobertos.
Em biologia, essa tarefa pode ser usada na derivação de
taxonomias de plantas e animais, na caracterização de genes com
funcionalidades similares e para descobrir estrutura inerentes a
populações.
Suportar a análise de documentos textuais e criar indexadores para
recuperação de informação na WEB.
Identificação de área de uso similar da terra ou identificação de
grupos de casa em uma cidade, de acordo com a similaridade entre
elas.
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M. • Escalabilidade: trabalham muito bem em pequenos conjuntos de dados e podem
apresentar-se “tendenciosos” em amostras de grandes conjuntos de dados.
• Habilidade de lidar com diferentes tipos de atributos: lidam bem com atributos
numéricos mas apresentam dificuldades com outros tipos de atributos.
• Descoberta de grupos com formas arbitrárias: as medidas de distâncias utilizadas
para medir similaridade podem levar a descoberta de grupos esféricos com
tamanhos e densidades similares.
• Conhecimento do domínio para determinação de parâmetros de entrada: os
resultados geralmente são sensíveis à esses parâmetros.
• Habilidade de lidar com ruído
• Agrupamento incremental e insensitivo à ordem dos dados de entrada
• Alta dimensionalidade
• Agrupamento baseado em restrições
• Interpretabilidade e usabilidade
152
Agrupamento - desafios (Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Categorização dos métodos de
agrupamento
• Métodos de particionamento
• Métodos hierárquicos
• Metodos baseados em densidade
• Métodos baseados em gride
• Métodos baseados em modelos
• Agrupamento de dados de alta-dimensão
• Agrupamento baseado em restrições
153
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos de particionamento
• Métodos de particionamento:
– dado um conjunto de dados com n objetos, um método de
particionamento constrói k partições dos dados, onde cada partição
representa um cluster e k <= n.
– os k grupos satisfazem os seguintes requisitos:
• cada grupo deve conter pelo menos um objeto;
• cada objeto deve pertencer a exatamente um grupo.
– dado k – o número de partições a serem construídas -, um método de
particionamento cria um particionamento inicial e, usa uma técnica de
realocação iterativa que tenta melhorar tal particionamento, trocando
objetos de um grupo para outro.
154
(Han & Kamber, 2006)
O segundo requisito pode ser relaxado
em técnicas de partições fuzzy.
... ,o que pode ser feito sob
diferentes estratégias!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos de particionamento
• Os clusters são encontrados por meio da otimização de critérios tais como
a função de dissimilaridade baseada em distância.
• Para alcançar a otimalidade global, pe necessário enumerar,
exaustivamente, todas as possíveis partições.
• Porém, dado o custo de tal procedimento, métodos heurísticos são usados:
– algoritmo k-means: onde cada cluster é representado pelo valor médio dos
objetos no cluster
– algoritmo k-medóides: onde cada cluster é representado por um dos objetos
localizado próximo ao centro do cluster.
155
(Han & Kamber, 2006)
K-means e K-medóides são os mais comuns
dentro da categoria de particionamento.
Trabalham bem em bases de dados pequenas
e médias e encontram clusters de formas
esféricas.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
K-means
• Técnica baseada em centróide.
• A similaridade do cluster é medida em relação ao valor médio dos
objetos no cluster (centróide ou centro de gravidade).
• Critério do erro quadrado:
156
(Han & Kamber, 2006)
Objetivo: maximizar a similaridade intracluster e minimizar a
similaridade intercluster.
k
i Cp
i
i
mpE1
2
onde E é a soma do erro quadrado (distância) para todos os
objetos no conjunto de dados; p é o ponto em um espaço de
representação do objeto; mi é a média do clusters Ci (tanto p
quanto m são multidimensionais).

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
157
K-means - algoritmo (Han & Kamber, 2006)
Input:
k: o número de clusters;
D: o conjunto de dados com n objetos;
Output:
um conjunto de k clusters (os vetores protótipos de cada
clusters);
Method:
(1)escolha k objetos de D, arbitrariamente, para representar
os centros dos clusters (partições) iniciais;
(2)repeat
(3) (re)associe cada objeto para o cluster que tem seu
centro mais similar ao objeto;
(4) atualize as médias dos clusters, i.e., calcule o valor
médio dos objetos para cada cluster;
(5)until “nenhuma mudança ocorrer” (ou outro critério de
parada);

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
K-means - ilustrando
158
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
K-means - discutindo
• complexidade computacional O(nkt):
– n é o total de objetos no conjunto de dados;
– k é o número de clusters;
– t é o número de iterações.
• geralmente alcança um ótimo local;
• a média do clusters deve ser definível;
– não se aplica a atributos categóricos (a menos que estes sejam
transformados) – ou use o K-modes
• necessita que o usuário especifique k;
• não trabalha bem para cluster em formas não convexas ou com
clusters de diferentes tamanhos;
• é sensível a ruído e a outliers.
159
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Hierárquicos
• Um método hierárquico cria uma decomposição
hierárquica de um conjunto de dados. São classificados
em:
– aglomerativos (bottom-up): inicia com cada objeto formando
um grupo separado e sucessivamente junta os objetos ou
grupos que estão mais próximos um do outro, até que apenas
um grupos seja formado ou alguma condição de parada seja
alcançada.
– divisivos (top-down): inicia com todos os objetos no mesmo
grupo e a cada iteração, os divide em grupos menores, até que
cada objeto esteja em um grupo ou alguma condição de parada
seja alcançada.
160
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Hierárquicos
• Um dendograma é frequentemente usado para
representar um agrupamento hieráquico.
161
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Hierárquicos
• Exemplos de algoritmos: – AGNES: AGlomerative NESting
– DIANA: DIvisive ANALysis
– BIRCH: Balanced Iterative Reducing and Clustering Using Hierarchies
– ROCK: Hierachical Clustering Algorithm for Categorical Attibutes
– Chameleon: Hierarchical Custering Algorithm using Dynamic Modeling 162
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos baseados em densidade
• Idéia básica:
– ou seja, para cada dado dentro de um grupo, a vizinhança
dentro de um raio determinado deve conter pelo menos um
número mínimo de pontos.
– essa classe de algoritmos pode ser usada para filtrar ruído
(outliers) e descobrir grupos de formatos arbitrários.
163
(Han & Kamber, 2006)
“Crescer” um determinado grupo enquanto a densidade
(número de objetos ou dado – data points) na “vizinhança”
excede um limiar específico.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos baseados em densidade
• Exemplos de algoritmos:
– DBSCAN: Density-Based Clustering Method Based
on Connected Regions with Sufficiently High Density.
– OPTICS: Ordering Points to Identify the Clustering
Sructure.
– DENCLUE: Clustering Based on Density Distribution
Functions
164
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Baseados em Gride
• Esses métodos “quantizam” o espaço dos objetos em
um número finito de células que formam uma estrutura
de gride. Todas as operações de agrupamento são
executadas na estrutura de gride (ou seja, no espaço
quantizado).
– tem tempo processamento rápido, o qual depende somente do
número de células em cada dimensão do espaço quantizado.
165
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Baseados em Gride
• Exemplos de algoritmos:
– STING: STatistical INformation Grid
– WaveCluster: Clustering Using Wavelet
Transformation
166
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Método para Altas Dimensões
• É uma tarefa particularmente importante em análise de grupos
(clusters) porque muitas aplicações requerem a análise de objetos
residentes em um espaço com um grande número de dimensões
(dados com muitas características descritivas).
– Textos
– DNA microarrays
• Exemplos de algoritmos
– Clique: CLustering In QUEst – A Dimension-Growth Subspace
Clustering Method
– Proclus: PROjected CLUStering – A Dimension-Reduction Subspace
Clustering Method
– Frequent pattern-based clustering
167
(Han & Kamber, 2006)
Estamos falando de milhares de
características!!!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Clustering Baseado em Restrições
• Resolve a tarefa de agrupamento incorporando
restrições orientadas à aplicação ou restrições
específicas do usuário.
– considera “propriedades” desejáveis no resultado do
agrupamento;
– fornece um meio de interação com o processo de agrupamento.
• Tipos de restrições:
– em objetos individuais;
– na seleção de parâmetros de agrupamento;
– nas funções de distância.
168
(Han & Kamber, 2006)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Métodos Baseados em Modelo
• Criam (encontram) um modelo hipotético para cada
grupo e encontram o melhor “encaixe” do dado para um
modelo.
– Esses algoritmos encontram grupos por meio da construção de
uma função de densidade que reflete a distribuição espacial dos
dados (data points).
– Exemplos de algoritmos:
• Expectation-Maximization (EM)
• Clustering conceitual (clusterização – caracterização)
– COBWEB
• Redes Neurais Artificiais
169
(Han & Kamber, 2006)

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Uma Rede Neural Artificial Não
Supervisionada
Self Organizing Maps (by Teuvo Kohonen)
170

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps
(um método basedo em modelo)
Motivação
171
Pós-
processamento Conjunto de dados
(n-dimensional)
Som bi-dimensional
Visualização dos dados
em um espaço bi-dimensional
Matriz U

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps
(um método basedo em modelo)
Motivação
172
Pós-
processamento Conjunto de dados
(n-dimensional)
Som bi-dimensional
Quantização do espaço
dos dados.
Matriz U (rotulada)
(Costa, 1999)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps - Objetivos
• Aproximação do espaço de entrada:
Um dos objetivos de um SOM é
representar um conjunto grande de
vetores de entrada, por meio de um
conjunto menor de vetores
localizados em um espaço de
dimensão mais baixa. Ou seja,
realizar a quantização do espaço e a
redução de dimensão.
• Visualização do conjunto de dados:
Quando é este o objetivo pode-se
desconsiderar a necessidade de
quantização do espaço.
173

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps - espaços
174
Espaço de entrada:
as distâncias são medidas
vetorialmente.
Espaço de saída:
as distâncias são medidas
matricialmente.
• O espaço de entrada é determinado pelo conjunto de dados
a ser explorado pelo SOM.
• O espaço de saída é determinado pelo projetista da
rede neural.
Organização matricial
com relacões de
vizinhança (matricial).
Organização vetorial
com relacões de
vizinhança (no espaço
vetorial).
(SomToolbox – Matlab) (SomToolbox – Matlab)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps - vizinhanças
175
Vizinhança matricial unidimensional X vizinhança vetorial bidimensional.
Vizinhança matricial bidimensional X vizinhança vetorial bidimensional
Distorção
Topológica
Existem outras
topologias de
vizinhança
matricial!
Raio de vizinhança = 5

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps - arquitetura
• Número de neurônio na camada de entrada.
• Número de neurônios na camada de saída (tamanho mapa)
• Tipo de vizinhança topológica (dimensão e lattice) (forma do mapa)
• Função de vizinhança (...)
176
• 3 neurônios na camada de entrada (espaço vetorial tridimensional)
• 16 neurônios na camada de saída
• mapa bidimensional (espaço matricial bidimensional)
• lattice retangular
(Costa, 1999)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps – algoritmo de aprendizado
(sequencial)
Passo 0:
Determine a arquitetura da rede neural
Inicialize os pesos wij. – posicionar os neurônio no espaço vetorial
Determine os parâmetros da taxa de aprendizado (valor inicial e função de
atualização).
Passo 1: Enquanto condição de parada é falsa, execute os passos 2-8.
Passo 2: Para cada vetor de entrada x, execute os passos 3-5;
Passo 3: Para cada j, compute: D(j) = ∑i (wij – xi).
Passo 4: Encontre o J tal que D(J) seja mínimo.
Passo 5: Para todas as unidades j dentro de uma vizinhança específica de J, e para todo i:
wij(new) = wij(old) + α[xi – wij(old)].
Passo 6: Altere a taxa de aprendizado (se for o caso)
Passo 7: Reduza o raio de vizinhança (se for o caso)
Passo 8: Teste a condição de parada.
177

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Inicialização de pesos
• Aleatório
– posiciona os neurônios do mapa de forma aleatória, dentro do espaço
dos dados.
• Linear
– usa os componentes principais da matriz de autocorrelação do conjunto
de dados X. As posições dos neurônios são determinadas de forma a
distribuir-se na direção dos espaços dos autovetores correspondentes
aos maiores autovalores encontrados.
– os neurônios se distribuem nas direções de maior variância dos dados.
• Usando conhecimento a priori
– usa algum conhecimento sobre os dados para posicionar os neurônio
em locais adequados dentro do espaço dos dados.
178

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Analisando funções de vizinhança
179
wij(new) = wij(old) + g(j)α[xi – wij(old)].
Bubble (b(j))
wij(new) = wij(old) + b(j)α[xi – wij(old)].
Gaussiana (g(j))
(Fausett, 1994)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Estudando a taxa de aprendizado
x
wJ(old)
x – wJ(old)
x
wJ(old)
α[x – wJ(old)] com α = 0.5
x
wJ(old) wJ(old) + α[x – wJ(old)]
wJ(new)
A função de vizinhança é mais um fator
que opera da mesma maneira (vetorial)
que a taxa de aprendizado.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Analisando o ajuste de pesos
181
wij(new) = wij(old) + α[xi – wij(old)]
j varia na vizinhança do neurônio BMU
(Costa, 1999)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Outras decisões e conceitos
• Número de épocas
– fase de ordenação
– fase de sintonização (ajuste fino)
• Função de atualização da taxa de aprendizado
• Função de atualização do raio de vizinhança
• Algoritmo de treinamento em lote (batch)
• BMU – Best Matching Unit
182
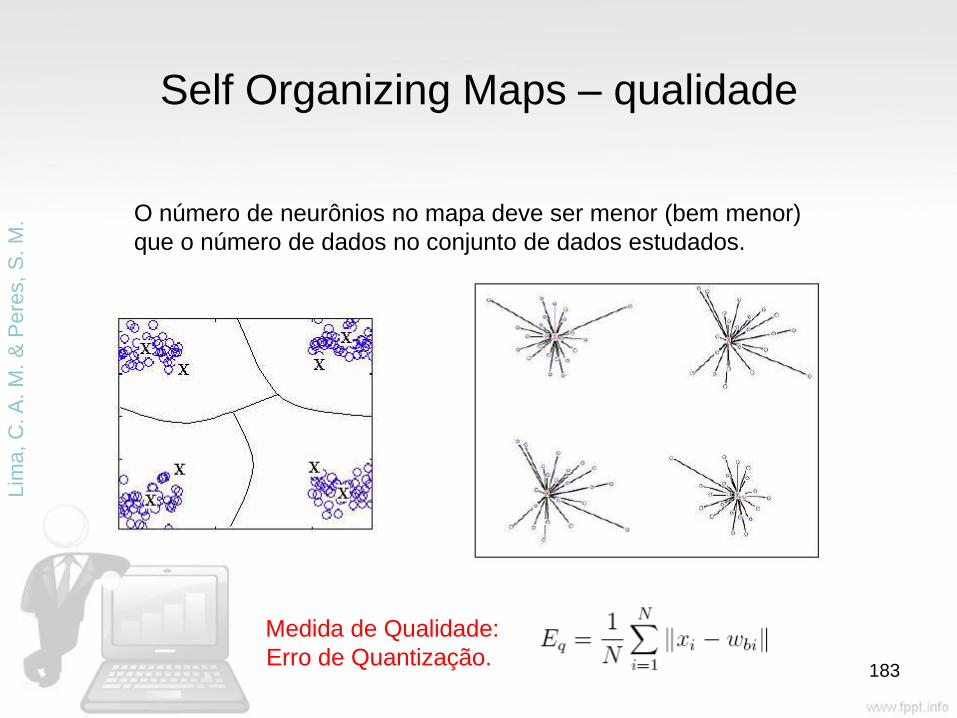
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps – qualidade
183
O número de neurônios no mapa deve ser menor (bem menor)
que o número de dados no conjunto de dados estudados.
Medida de Qualidade:
Erro de Quantização.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Self Organizing Maps – qualidade
• Distorções topológicas
• Erro topológico
184
Existem outras formas de
analisada a qualidade da
preservação topológica!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Pós-processamento – Matriz U
185
(Costa, 1999)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Pós-processamento – Matriz U
186 (Costa, 1999)
Conjunto de dados Chain Link.

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
Ferramentas
187

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
SOM TOOLBOX
(Matlab)
188

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre a SOM TOOLBOX
• Copyrigth …
• SOM Toolbox 2.0, a software library for Matlab 5 implementing theSelf-
Organizing Map algorithm is Copyright (C) 1999 by Esa Alhoniemi,Johan
Himberg, Jukka Parviainen and Juha Vesanto.
• This package is free software; you can redistribute it and/ormodify it under
the terms of the GNU General Public Licenseas published by the Free
Software Foundation; either version 2 of the License, or any later version.
• Note: only part of the files distributed in the package belong to theSOM
Toolbox. The package also contains contributed files, which mayhave their
own copyright notices. If not, the GNU General PublicLicense holds for
them, too, but so that the author(s) of the file have the Copyright.
• …
• If you wish to obtain such permission, you can reach us bypaper mail: SOM
Toolbox team Laboratory of Computer and Information Science P.O.Box
5400 FIN-02015 HUT Finland Europe and by email:

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo1
190
Espaço Matricial
Espaço Vetorial:
inicialização randômica
Espaço Vetorial:
inicialização linear
Espaço Vetorial:
após treinamento
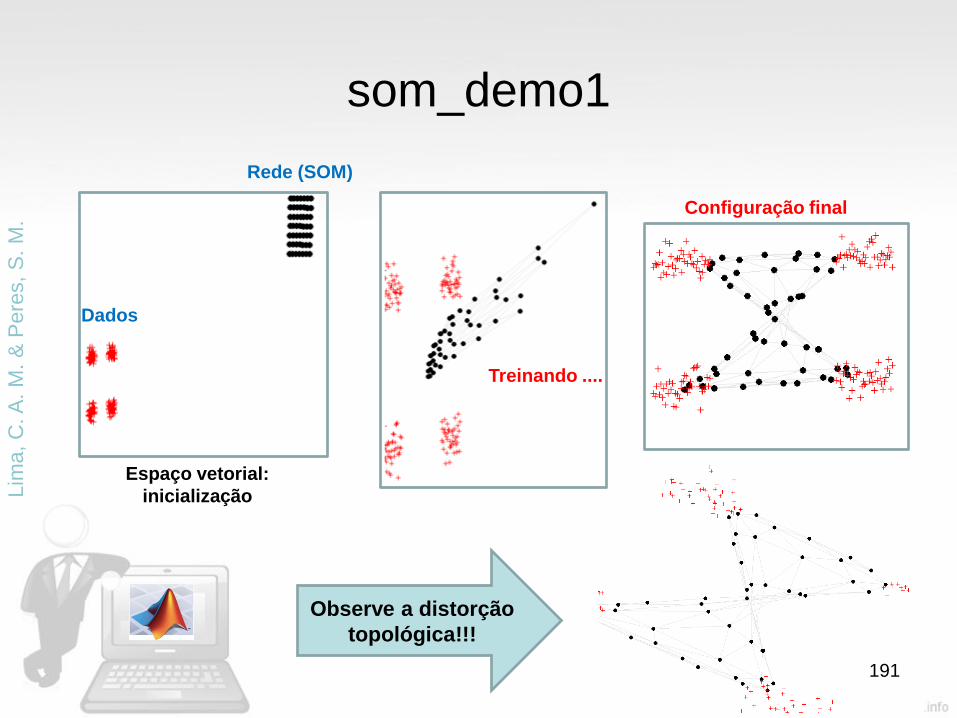
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo1
191
Espaço vetorial:
inicialização
Dados
Rede (SOM)
Treinando ....
Configuração final
Observe a distorção
topológica!!!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo3
192
Dados em três dimensões Classes - coloridas
Neurônios da SOM
Visão tri-dimensional da disposição
dos neurônios no espaço vetorial (dos
dados).
Observe a estrutura matricial presente
no gráfico.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo3
193
Cores similares representam a
similaridade dos dados em relação
a um dos atributos que os
descrevem.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo3
194
Matriz de distâncias
entre os neurônios
Tons de cinza!
Com cores!
Gráfico demonstrando a
representatividade do
neurônio em relação aos
dados.
Matriz U

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo3
195
Matrizes de
distâncias
considerando
cada dimensão
do espaço
vetorial.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo3
196
Exemplos de
organização
matricial para o
mapa de saída
do SOM.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
som_demo4
197
Matriz U com rótulos.
Os neurônios com rótulos
são BMUS para os dados do
conjunto de dados IRIS.
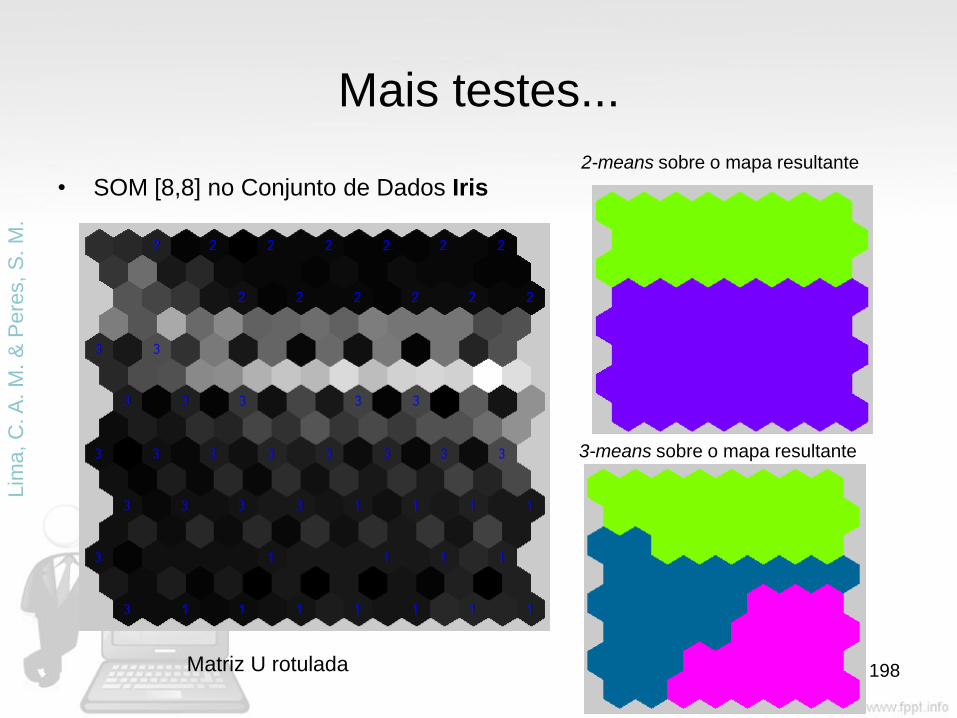
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mais testes...
• SOM [8,8] no Conjunto de Dados Iris
198 Matriz U rotulada
2-means sobre o mapa resultante
3-means sobre o mapa resultante

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mais testes ...
• SOM [40,40] no Conjunto de Dados Iris
199 Matriz U rotulada
2-means sobre o mapa resultante
3-means sobre o mapa resultante

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mais testes ...
• SOM [40,40] no
Conjunto de Dados SpamBase
200 Matriz U rotulada
2-means sobre o mapa resultante
3-means sobre o mapa resultante
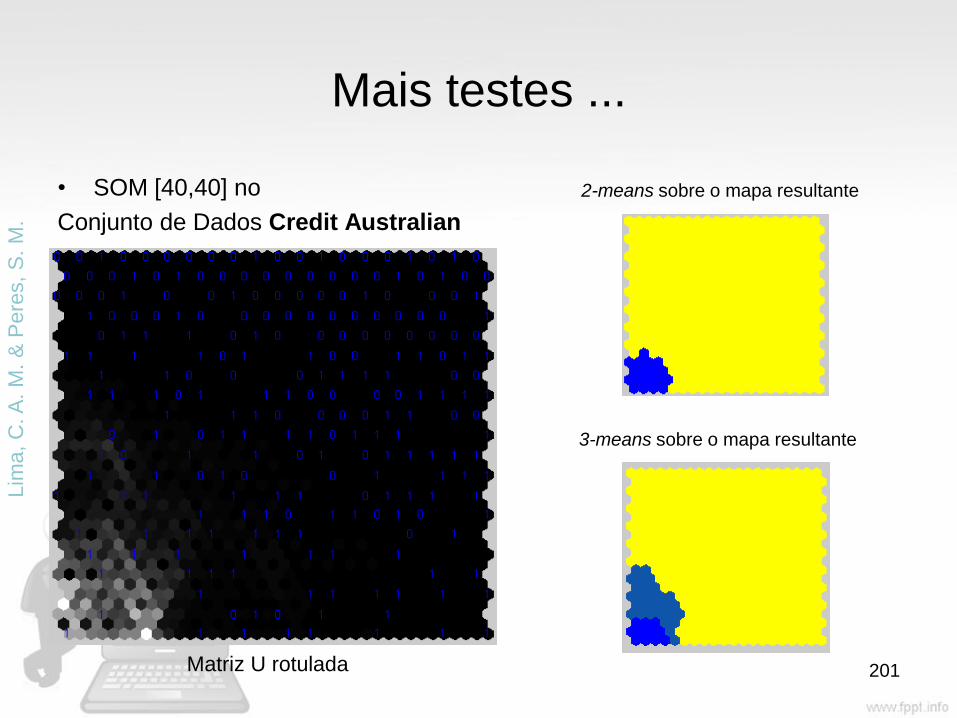
Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mais testes ...
• SOM [40,40] no
Conjunto de Dados Credit Australian
201 Matriz U rotulada
2-means sobre o mapa resultante
3-means sobre o mapa resultante

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Mais testes ...
• SOM [5,5] no
Conjunto de Dados Credit Australian
202 Matriz U rotulada
2-means sobre o mapa resultante
3-means sobre o mapa resultante

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
203
01 - arcos_antihorario
02 - arcos_horario
03 - balancar_curva
04 - balancar_horizontal
05 - balancar_vertical
06 - circulos
07 - curvas_inferior
08 - curvas_superior
09 - ondulatorio_horizontal
10 - ondulatorio_vertical
11 - reta_horizontal
12 - reta_vertical
13 - tremular
14 - ziguezague_horizontal
15 - ziguezague_vertical

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
204 Representação: Coordenadas (X,Y) do centróide do objeto em movimento!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
205 Representação: Coordenadas (X,Y) do centróide do objeto em movimento!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
206 Representação: Coordenadas (X,Y) do centróide do objeto em movimento!

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
207
01 - arcos_antihorario
02 - arcos_horario
03 - balancar_curva
04 - balancar_horizontal
05 - balancar_vertical
06 - circulos
07 - curvas_inferior
08 - curvas_superior
09 - ondulatorio_horizontal
10 - ondulatorio_vertical
11 - reta_horizontal
12 - reta_vertical
13 - tremular
14 - ziguezague_horizontal
15 - ziguezague_vertical

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
208 Representação: Coordenadas (X,Y) do centróide do objeto em movimento, no
espaço de frequências (Fourier)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
209 Representação: Coordenadas (X,Y) do centróide do objeto em movimento, no
espaço de frequências (Fourier)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
15 movimentos - LIBRAS
210 Representação: Coordenadas (X,Y) do centróide do objeto em movimento, no
espaço de frequências (Fourier)

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Support Vector Clustering
211

Lim
a, C
. M
. A
. M
. &
Pere
s, S
. M
.
212
Support Vector Clustering
x
2D
Si Sji
jijiii XXXXXXxR,
2 2)(
X
H.D.
R
a
)(
)(
)(
xX
xX
ii
2D
x)()( xxXX ii
Sji
jiji
Si
ii
xx
xxxxxR
,
2
)()(
)()(2)()()(
),( K ),()()( xxxx ii K
Mercer’s Condition
Sji
jiji
Si
ii xxKxxKxxKxR,
2 ),(),(2),()(

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
213
Support Vector Clustering
Há dois passos principais no Algoritmo SVC Algorithm
Step 1 –Treinamento
SVC
Step 2 – Rotulação
Cluster
Este checa a conectividade para
cada par de pontos baseado no
critério corte obtido do SVC
treinado
Este é responsável para o
treinamento do modelo
Complexidade é O(n2m), onde n é o número de pontos, e m<<n is número
de pontos amostrados sobre vértice que é usualmente constante entre 10
e 20

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
214
• Primal
N
ji
jiji
N
i
iii xxKxxKMin1,1
),(),(
ii Rax 22)(
N
i
iCRMin1
2
• Dual
s.a s.a
NiCi
N
i
i
,,1,0
11
Step 1 – Training SVM

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
• Duas Abordagens
– a)Checar o link entre todos os pairs pontos
– b)Metodo Heuristico
• Ben–Hur et al (2001)
– Checar o link entre todos pairs e support vector
• Jianhua et al (2002)
– Proximity Graph
Delaunay Diagrams
Minimum Spanning Trees
Nearest Neighboors
215
Step 2 – Rotulação dos Cluster
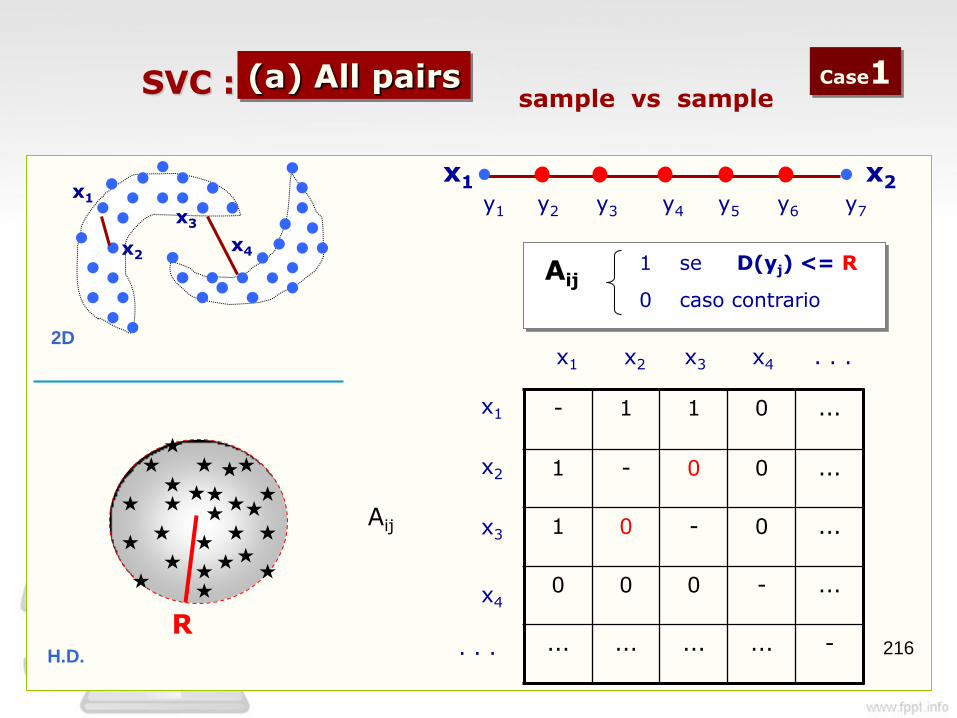
216
SVC : (a) All pairs
- 1 1 0 ...
1 - 0 0 ...
1 0 - 0 ...
0 0 0 - ...
... ... ... ... - R
x1 x2 x3 x4
x1
x2
x3
x4
. . .
x1
x2
x3
x4
. . .
x1 x2
y1 y2 y3 y4 y5
1 se D(yj) <= R
0 caso contrario
y6 y7
Aij
Aij
Case1 sample vs sample
2D
H.D.

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
217
SVC : (b) Ben-Hur (2001)
R
x1
vs1
Case 2 Support vector vs sample
1 0 1 ... ...
0 0 ... ... ...
1 ... - ... ...
0 ... ... - ...
... ... ... ... -
x1 x2 x3 x4 . . .
vs1
vs2
vs3
vs4
. . .
sv1 x1
y1 y2 y3 y4 y5
1 se D(yj) <= R
0 caso contrario
y6 y7
Aij
x2
vs2
2D
H.D.
Aij

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Repositórios
• UCI – Machine Learning Repository
– http://archive.ics.uci.edu/ml/
• StatLib
– http://lib.stat.cmu.edu/datasets/
• Repositórios citados na homepage do software WEKA
– http://www.cs.waikato.ac.nz/~ml/weka/index.html
• Math Forum Internet Mathematics Library
– http://mathforum.org/library/topics/data_sets/
218

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Referências Bibliográficas
(Han & Kamber, 2006) Han, Jiawei & Kamber, Micheline. Data Mining: Concepts and Techniques. 2ed., Morgan
Kaufmann, 2006.
(Witten & Frank, 2005) Witten, Ian H. & Frank, Eibe. Data Mining: Practical machine Learning Tools and Techiniques.
2ed., Morgan Kaufmann, 2005.
(Frank & Asuncion, 2010) Frank, A. & Asuncion, A. (2010). UCI Machine Learning Repository
[http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
(Goldschmidt & Passo, 2005) Goldschmidt & Passos. Data Mining: Um guia prático. Editora Campus, 2005.
(Peres, 2006) Peres, S. M. Dimensão Topológica e Mapas Auto-Organizáveis de Kohonen. Tese de Doutorado
defendida Faculdade de Engenharia Elétrica e de Computação – Unicamp, 2006.
(Costa, 1999) Costas, J. A. F. Classificação Automática e Análise de Dados por Redes Neurais Auto-
Organizáveis.Tese de Doutorado defendida Faculdade de Engenharia Elétrica e de Computação – Unicamp, 1999.
SOM Toolbox http://www.cis.hut.fi/projects/somtoolbox/
(Fausett, 1994) Fausett, L. Fundamentals of Neural Networks, 1994.
(Ville, 2006) Ville, B. Decision Trees for Business Intelligence and Data Mining: Using SAS ® Enterprise MinerTM. 2006,
Sas Institute Inc. Cary, NC, USA
219

Lim
a, C
. A
. M
. &
Pere
s,
S.
M.
Sobre os docentes que
prepararam o minicurso:
• Prof. Dr. Clodoaldo Aparecido de Moares
Lima:
– http://lattes.cnpq.br/3017337174053381
• Profa. Dra. Sarajane Marques Peres
– http://lattes.cnpq.br/6265936760089757
220





























