Embed Size (px)
Citation preview

Monitorização em linha e uso de sensores inferenciais nocontrolo operatório de uma ETAR de pequena dimensão
Catarina Sanches Leitão
Dissertação para obtenção do Grau de Mestre em
Engenharia Biológica
Orientadores: Prof. Helena Maria Rodrigues Vasconcelos PinheiroProf. Carla Isabel Costa Pinheiro
Júri
Presidente: Prof. Arsénio do Carmo Sales Mendes FialhoOrientador: Prof. Helena Maria Rodrigues Vasconcelos Pinheiro
Vogal: Dra. Nídia Dana Mariano Lourenço de Almeida
Novembro de 2015

ii

Agradecimentos
Gostaria de manifestar o meu reconhecido agradecimento a todos aqueles que estiveram presentes ao
longo do meu percurso académico e, em especial, durante esta fase final, contribuindo assim para a
realização desta dissertação de mestrado.
Em primeiro lugar, gostaria de agradecer à empresa Águas de Lisboa e Vale do Tejo (AdLVT) pela
disponibilização do caso de estudo do projeto DEMOCON, constante partilha de informação e apoio
técnico prestado.
À minha orientadora, Professora Helena Pinheiro, gostaria de agradecer a sua disponibilidade, aces-
sibilidade, pela forma exemplar como se dedicou a este projecto e, acima de tudo, a oportunidade que
me proporcionou de trabalhar numa área tão desafiante.
À Eng. Rita Ribeiro, por ter acompanhado de perto a evolução da minha dissertação e pela forma
atenciosa como me acolheu no Núcleo de Engenharia Sanitária (NES) do Laboratório Nacional de
Engenharia Civil (LNEC).
Aos técnicos superiores João Vale e assistente Vítor Napier do NES, pela competência e auxílio
prestados na realização do trabalho experimental.
Ao grupo de trabalho IST, especialmente à minha colega Liliana Fernandes, por todo o apoio ao
longo do desenvolvimento da minha tese (principalmente em questões informáticas!), pelos conselhos
preciosos e pela companhia nas nossas visitas à ETAR.
Aos meus pais, pelos valores que me transmitiram desde sempre, por apoiarem as minhas decisões
e por todos os sacrifícios que fizeram para a minha formação, não só a nível pessoal, como académico.
À minha família, por estar sempre presente em todos os momentos da minha vida e por apoiar
incondicionalmente as minhas decisões.
Aos meus amigos Ana Teresa Benito, Merlin Vieira, Marco Gomes e Vanessa Freitas, um “obrigada”
enorme por todos os momentos que me proporcionaram no meu percurso académico. Foi um prazer
passar estes cinco anos ao vosso lado e tenho a certeza que muitos ainda estão para vir.
Ao melhor padrinho académico, Ricardo Correia, pelos preciosos apontamentos, mas acima de tudo
pela empatia e amizade que desde sempre partilhámos.
À minha grande amiga Maria Ana Batalha, por partilhar comigo os melhores momentos que vivi no
IST ao longo destes 5 anos. Considero um privilégio imenso os nossos caminhos terem-se cruzado e
dou muito valor à amizade que construímos.
À minha melhor amiga, Ana Rita Santos, por todos os momentos que passámos juntas ao longo
destes oito anos, por todos os conselhos, por todas as conversas, pelo apoio incondicional, pela forma
como valoriza e se dedica à nossa amizade.
iii

Ao meu namorado, Francisco de Gusmão, o meu pilar, por acreditar sempre em mim, me encorajar
e mostrar a luz nos momentos mais negros. Percorrer esta jornada juntos tornou os meus dias mais
felizes e não há palavras para descrever o que isso significa para mim.
Um enorme obrigado a todos!
Catarina Leitão
iv

O trabalho desenvolvido contou com o apoio financeiro da empresa Águas de Lisboa e Vale do Tejo S.A
e da Fundação para a Ciência e a Tecnologia no âmbito do projeto PTDC/AAG-TEC/4124/2012.
v

vi

“If you torture the data long enough,
it will confess.”
Ronald Coase
vii

viii

Resumo
Os progressos em medição e automatização possibilitaram a implementação de sistemas de monito-
rização com aquisição de dados a frequência elevada em Estações de Tratamento de Águas Residu-
ais (ETAR). Esta informação permite desenvolver sensores inferenciais para previsão de variáveis não
medidas directamente, por análise multivariada, sendo comumente usadas a Análise de Componen-
tes Principais (PCA) e a regressão por Mínimos Quadrados Parciais (PLS). Neste trabalho visou-se a
construção de sensores inferenciais para previsão de variáveis de qualidade de água, necessárias à
modelação mecanística do tratamento numa ETAR de pequena dimensão. Os dados de entrada foram
adquiridos na ETAR usando um caudalímetro e sondas em linha espectrofotométrica e electroquímica
e em campanhas de amostragem e análises laboratoriais. Efectuou-se uma análise exploratória de
dados incluindo PCA, análise de séries temporais e de correlações para detectar outliers, padrões e
relações. Os modelos PLS para as sondas inferenciais foram desenvolvidos usando validação cruzada
leave-one-out e a sua capacidade preditiva de dados independentes foi avaliada pelo erro quadrático
médio (RMSE). Na previsão do teor em azoto orgânico, obteve-se RMSE normalizados de 19,5% e
18,1%, respectivamente para os sensores usando dados analíticos e espectrais. Para a carência quí-
mica de oxigénio, o modelo interno da sonda espectrofotométrica foi melhor que os desenvolvidos com
os espectros. Foi ainda avaliada a possibilidade de utilização de sondas espectrofotométricas a apenas
um comprimento de onda, com vista à redução dos custos de investimento em monitorização em linha.
Palavras-chave: Tratamento de Águas Residuais, ETAR de pequena dimensão, Monitorização
em linha, Mínimos Quadrados Parciais, Sensores Inferenciais, Previsão
ix

x

Abstract
Advances in measurement and automation technologies enabled the deployment of monitoring systems
with data acquisition at high frequency in Wastewater Treatment Plants (WWTP). The information col-
lected is useful for the development of soft sensors to predict hard-to-measure variables, by multivariate
analysis, like Principal Component Analysis (PCA) and Partial Least Squares (PLS) regression. The
aim of this work was the design of soft sensors to predict quality variables of wastewater required for
mechanistic modeling of biological treatment system in a municipal WWTP. The input data was acquired
in the WWTP using a flowmeter and spectrophotometric and electrochemical online probes, sampling
campaigns and off-line analysis. Exploratory data analysis was performed in order to detect outliers,
patterns and correlations. PLS models for soft sensors were developed using leave-one-out cross va-
lidation and the predictive capacity of independent data was evaluated by mean square error (RMSE).
The normalized RMSE obtained for organic nitrogen prediction were 19.5% and 18.1%, using sensors
with analytical and spectral data, respectively. For chemical oxygen demand (COD), the spectrometric
probe internal model was better than the one developed with spectral information. Finally, the possibility
of using spectrophotometric probes providing measurements of a single wavelength was evaluated in
order to reduce the online monitoring investment costs.
Keywords: Wastewater Treatment, municipal WWTP, Online Monitoring, Partial Least Squares,
Soft sensors, prediction
xi

xii

Conteúdo
Agradecimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Resumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ix
Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xi
Lista de Tabelas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xvii
Lista de Figuras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxi
Lista de Símbolos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxvii
1 Enquadramento e Objectivos 1
2 Revisão Bibliográfica 3
2.1 Sistemas de Lamas Activadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Aplicação de sistemas de controlo em ETAR . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Modelação mecanística de ETAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.4 Análise Exploratória de Dados e Controlo de Qualidade . . . . . . . . . . . . . . . . . . . 9
2.4.1 Filtros de Atenuação de Ruído . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4.2 Histogramas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.3 Boxplots . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.4 Análise de Correlações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.5 Análise de Componentes Principais (PCA) . . . . . . . . . . . . . . . . . . . . . . 13
2.4.5.1 Definição do método PCA . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4.5.2 Contribuição e escolha do número de componentes principais . . . . . . 14
2.4.5.3 Representação gráfica dos componentes principais . . . . . . . . . . . . 14
2.4.5.4 Scores Plot, Loadings Plot e Biplot . . . . . . . . . . . . . . . . . . . . . 14
2.4.6 Mínimos Quadrados Latentes (PLS) . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.6.1 Definição do método PLS . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.6.2 Representação gráfica do método PLS: Scores e pesos (weights) . . . . 17
2.4.6.3 Validação cruzada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4.6.4 Medidas de desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Sensores Inferenciais no Tratamento de Águas Residuais . . . . . . . . . . . . . . . . . . 20
2.5.1 Características dos Dados Industriais . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.5.2 Metodologia de desenvolvimento de sensores inferenciais . . . . . . . . . . . . . . 22
xiii

2.5.2.1 Primeira inspecção dos dados . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.2.2 Selecção de variáveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.2.3 Selecção de amostras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.2.4 Design do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5.2.5 Manutenção do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5.3 Aplicações de sensores inferenciais . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5.3.1 Previsões online . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5.3.2 Monitorização de detecção de falhas no processo . . . . . . . . . . . . . 28
2.5.3.3 Monitorização e detecção de falhas de hardware . . . . . . . . . . . . . . 28
2.5.4 Problemas actuais e Trabalho futuro . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6 Caso de Estudo - ETAR de Bucelas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6.1 Selecção do caso de estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6.2 Sistema de Tratamento da ETAR de Bucelas . . . . . . . . . . . . . . . . . . . . . 32
2.6.2.1 Tratamento da Fase Líquida . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.6.2.2 Tratamento da Fase Sólida . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.6.3 Sistemas de Monitorização e Controlo . . . . . . . . . . . . . . . . . . . . . . . . . 36
3 Metodologias, Resultados e Discussão 37
3.1 Análise de Caudais na Linha de Tratamento da Fase Líquida . . . . . . . . . . . . . . . . 37
3.1.1 Origem dos dados e metodologias aplicadas . . . . . . . . . . . . . . . . . . . . . 37
3.1.2 Pré-tratamento de dados de caudal afluente e efluente . . . . . . . . . . . . . . . 38
3.1.3 Análise das variações anuais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1.4 Análise de variações mensais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.1.5 Análise de variações diárias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.6 Influência da precipitação no caudal afluente . . . . . . . . . . . . . . . . . . . . . 46
3.1.7 Influência da precipitação e evapotranspiração nas valas de oxidação . . . . . . . 47
3.2 Estimativa da quantidade de lamas extraídas . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.2.1 Origem dos dados e metodologias aplicadas . . . . . . . . . . . . . . . . . . . . . 49
3.2.2 Resolução dos Balanços de Massa . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.2.2.1 Eficiência das operações de processamento de lamas . . . . . . . . . . 52
3.2.2.2 Estimativa do período anual de extracção de lamas . . . . . . . . . . . . 53
3.3 Análise de Dados Analíticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.3.1 Origem dos Dados e Metodologias Aplicadas . . . . . . . . . . . . . . . . . . . . . 54
3.3.2 Pré-Tratamento dos dados analíticos . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.3.3 Comparação dos dados s::can com dados da SIMTEJO . . . . . . . . . . . . . . . 57
3.3.4 Comparação dos dados s::can com dados analíticos de campanhas . . . . . . . . 60
3.3.5 Análise de Correlações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.3.6 Análise de Componentes Principais . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.4 Construção de sensores inferenciais baseados em modelos PLS . . . . . . . . . . . . . . 66
xiv

3.4.1 Origem dos Dados e Metodologias Aplicadas . . . . . . . . . . . . . . . . . . . . . 67
3.4.2 Sensores inferenciais baseados em dados analíticos . . . . . . . . . . . . . . . . . 68
3.4.2.1 Pré-tratamento para detecção e exclusão de outliers . . . . . . . . . . . 68
3.4.2.2 Desenvolvimento de Modelos PLS . . . . . . . . . . . . . . . . . . . . . . 68
3.4.3 Sensores inferenciais baseados em informação espectral . . . . . . . . . . . . . . 75
3.4.3.1 Pré-tratamento para detecção e exclusão de outliers . . . . . . . . . . . 75
3.4.3.2 Desenvolvimento de modelos PLS . . . . . . . . . . . . . . . . . . . . . . 76
3.4.4 Comparação entre sensores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4 Conclusões e Perspectivas Futuras 87
Referências 91
A Informações sobre a ETAR de Bucelas 97
B Determinação do caudal do classificador de areias 101
C Resultados das análises laboratoriais na Linha das Lamas 103
D Matrizes de Correlação 107
E Análise PCA mensal dados online 109
F Boxplots dos dados analíticos e de caudal afluente em períodos de campanhas 111
G Sensores Inferenciais baseados em dados analíticos 113
G.1 Análise de Componentes Principais excluindo SST . . . . . . . . . . . . . . . . . . . . . . 113
G.2 Histogramas dos conjuntos de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
G.3 Previsão de Norg com dados de CQO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
H Sensores Inferenciais baseados em dados espectrais 117
H.1 Pré-tratamento dos dados espectrais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
H.2 Análise PCA dos dados espectrais até à Campanha V2 . . . . . . . . . . . . . . . . . . . 121
H.3 Histogramas dos conjuntos de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
H.4 Desenvolvimento de modelos PLS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
xv

xvi

Lista de Tabelas
2.1 Exemplo de uma matriz de correlações de um estudo psicológico, adaptado de [Alcorta
and Ancer, 2008]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Resumo de alguns estudos publicados no contexto da monitorização em tempo real de
parâmetros de qualidade de águas residuais através do desenvolvimento de modelos
PLS com base em informação espectral na região ultravioleta-visível. . . . . . . . . . . . 29
3.1 Valores das variáveis retirados da literatura ou disponibilizados pela SIMTEJO, necessá-
rios para a resolução dos balanços de massa efectuados na linha de tratamento da fase
sólida. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Resultados das análises laboratoriais efectuadas às amostras recolhidas na linha das
lamas durante os períodos de campanhas. . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.3 Concentração de sólidos à saida de operações de processamento de lamas (%) [Tcho-
banoglous et al., 2003] e valores calculados neste trabalho. . . . . . . . . . . . . . . . . . 52
3.4 Caudais, em L/s, determinados através da resolução dos balanços de massa ao filtro de
banda e ao espessador gravítico, usando os valores das tabelas 3.1 e 3.2. . . . . . . . . 52
3.5 % de sólidos capturados em operações de processamento de lamas [Tchobanoglous
et al., 2003] e valores calculados neste trabalho. . . . . . . . . . . . . . . . . . . . . . . . 52
3.6 Caudais medidos no ensaio para determinação dos caudais de lamas recirculadas e
extraídas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.7 Informação sobre as campanhas realizadas na ETAR de Bucelas e a quantidade de da-
dos analíticos recolhidos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.8 Informação do número total de dados analíticos recolhidos em períodos de campanhas
e valores de caudal correspondentes (CQO, SST, NH4-N, Norg e Qaf_SIM) e dos pontos
considerados outliers removidos do dataset. . . . . . . . . . . . . . . . . . . . . . . . . . 69
3.9 Variáveis de entrada, número de componentes, % da variância explicada pela(s) en-
trada(s) e RMSECV para cada modelo. O valor de NRMSECV foi obtido dividindo a
RMSECV pelo range, isto é, a diferença entre o valor máximo e o valor mínimo do con-
junto de dados. O range para os três modelos foi de: 5-23,8 mg/L para Norg, 20-42,75
mg/L para Ntotal e 297-786 mg/s para CargaNtotal. . . . . . . . . . . . . . . . . . . . . . . . 71
xvii

3.10 Previsões do conjunto de validação externa (conjunto de teste) e da campanha V1. O va-
lor de NRMSEP foi obtido dividindo a RMSEP pelo range. O range para os três modelos
foi de: 4,3-15,6 para Norg, 20-46,2 mg/L para Ntotal e 199-630 mg/s para CargaNtotal. . . . 72
3.11 Informação do número total de dados espectrais e dos pontos considerados outliers re-
movidos do dataset. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.12 Modelos PLS de previsão de CQO com pré-processamento mean centering e aplicando
um filtro derivativo (Saviztky-Golay 15 pontos, 2a derivada). Para ambos os modelos
apresentados foram usados 90 pontos. Range do conjunto de calibração: 48-738 mg/L.
Range do conjunto de validação externa: 66-747 mg/L. . . . . . . . . . . . . . . . . . . . 79
3.13 Modelos PLS de previsão de Norg com pré-processamento mean centering e aplicando
um filtro derivativo (Saviztky-Golay 15 pontos, 2a derivada). Para a construção ambos
os modelos apresentados foram usados 44 pontos. Range do conjunto de calibração:
4,3-27,1 mg/L. Range do conjunto de validação externa: 6-18,2 mg/L. . . . . . . . . . . . 79
3.14 Modelos PLS de previsão de CQO antes e após optimização via iPLS. Para todos mo-
delos apresentados foram usados 90 pontos. Range do conjunto de calibração: 48-738
mg/L. Range do conjunto de validação externa: 66-747 mg/L. . . . . . . . . . . . . . . . . 80
3.15 Modelos PLS de previsão de Norg antes e após optimização via iPLS. Para ambos os
modelos apresentados foram usados 44 pontos. Range conjunto de calibração: 4,3-27,1
mg/L. Range conjunto de validação externa: 6-18,2 mg/L. . . . . . . . . . . . . . . . . . . 81
3.16 Modelos PLS de previsão de Norg com adição do caudal afluente e do azoto amoniacal
ao conjunto de dados inicial e ao melhor modelo resultante da optimização iPLS. Para
a construção de todos os modelos apresentados foram usados 44 pontos. Range do
conjunto de calibração: 4,3-27,1 mg/L. Range do conjunto de validação externa: 6-18,2
mg/L. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3.17 Modelos PLS de previsão de CQO com adição do caudal afluente ao conjunto de dados
inicial e ao melhor modelo resultante da optimização iPLS. Para todos modelos apresen-
tados foram usados 90 pontos. Range do conjunto de calibração: 48-738 mg/L. Range
do conjunto de validação externa: 66-747 mg/L. . . . . . . . . . . . . . . . . . . . . . . . 82
3.18 Previsão da campanha V1 para os dois melhores modelos de previsão de CQO e Norg.
O conjunto de dados da V1 é constituído por 24 pontos para o caso do CQO e por 12
pontos para o caso do Norg. Range do conjunto V1 para previsão de CQO: 99-627 mg/L;
Range do conjunto V1 para previsão de Norg: 4,3-15,6 mg/L. . . . . . . . . . . . . . . . . 82
3.19 Comparação entre RMSEP dos dados analíticos disponibilizados pela sonda s::can e o
conjunto de validação externa do modelo CQO_MC_iPLS1. Range do conjunto de dados
analíticos das campanhas P1, P2, C1, C2, C3 e V1: 42-747 mg/L. Range do conjunto de
validação externa do modelo CQO_MC_iPLS1: 66-747 mg/L. . . . . . . . . . . . . . . . . 83
xviii

3.20 NRMSEP (%) dos dados analíticos disponibilizados pela sonda s::can para cada campa-
nha e para todas as campanhas, excepto a V2. Para o cálculo do erro de previsão da
CC2 foram excluídos os pontos com os seguintes timestamps: 14-01-2015 10:30, 14-01-
2015 12:30 e 15-01-2015 12:30, por corresponderem a amostras com valores analíticos
anómalos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.21 Informação sobre os erros de validação cruzada, validação externa e de previsão da
campanha V1 dos sensores inferenciais para previsão do azoto orgânico baseados em
dados analíticos e em dados espectrais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
B.1 Parâmetros utilizados na determinação do caudal do classificador de areias, Qclass. . . . 102
B.2 Valores de altura acima do vértice do descarregador, medidos nas campanhas. O nível
sobre o vértice do descarregador é medido durante o funcionamento do classificador
(durante a paragem não existe descarga). . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
C.1 Valores da quantidade de lamas desidratadas produzidas na ETAR de Bucelas disponi-
bilizados pela SIMTEJO no período de Janeiro de 2013 a Julho de 2015. . . . . . . . . . 104
C.2 Resultados das análises laboratoriais às lamas espessadas, sobrenadante do espessa-
dor gravítico, lamas desidratadas e efluente do filtro de banda recolhidas nas campanhas
V2 e V3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
C.3 Resultados das análises laboratoriais das amostras de lamas extraídas nos períodos das
campanhas P1, P2, C1, C2, C3, V1, V2 e V3. . . . . . . . . . . . . . . . . . . . . . . . . . 105
H.1 Informação relevante para o desenvolvimento de todos os modelos PLS dos sensores
inferenciais baseados em informação espectral para previsão de CQO. Em todos os mo-
delos os conjuntos de dados usados têm as seguintes características: conjunto inicial -
90 pontos; conjunto treino - 63 pontos; conjunto teste: 27 pontos; conjunto V1 - 24 pontos. 124
H.2 Informação relevante para o desenvolvimento de todos os modelos PLS dos sensores
inferenciais baseados em informação espectral para previsão de Norg. Em todos os mo-
delos os conjuntos de dados usados têm as seguintes características: conjunto inicial -
44 pontos; conjunto treino - 31 pontos; conjunto teste: 13 pontos; conjunto V1 - 12 pontos. 125
xix

xx

Lista de Figuras
2.1 Exemplo de histograma que representa a ditribuição do peso (em lb) à nascença dos
bebés de uma população semi-rural para o ano de 2009, retirado de Peck and Devore
[2011]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Exemplo gráfico da definição de IQR, adaptado de Dicker et al. [2006] . . . . . . . . . . . 11
2.3 Representação das partes constituintes de um boxplot, adaptado de Friendly [1991] . . . 11
2.4 Exemplos de diferentes correlações entre duas variáveis X e Y. . . . . . . . . . . . . . . . 12
2.5 Esquema do princípio da técnica PCA, retirado de Böhm et al. [2013] . . . . . . . . . . . 13
2.6 Análise de componentes principais (a) scores plot em que cada observação representa
uma amostra de grão de cacau e (b) loadings plot, onde se representam os 13 parâmetros
que influeciam o perfil de sabor e aroma dos grãos de cacau, retirado de Vazquez-Ovando
et al. [2015]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.7 Exemplo de um biplot que representa a relação das propriedades físicas dos planetas do
Sistema Solar, adaptado de Hamilton [1992] . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.8 Esquema da decomposição das matrizes X e Y da técnica PLS, adaptado de Geladi and
Kowalski [1986]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.9 Representação gráfica do primeiro componente PLS e estimativa do vector de resposta,
adaptado de Eriksson et al. [2013]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.10 Esquema do procedimento de validação cruzada do tipo leave-one-out, retirado de Loh-
ninger [1999]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.11 Visão geral dos passos envolvidos no desenvolvimento de sensores inferenciais e base-
ados em dados, adaptado de Kadlec et al. [2009]. . . . . . . . . . . . . . . . . . . . . . . 23
2.12 Diagrama de Operações do processo de tratamento da fase líquida e a fase sólida da
ETAR de Bucelas. As linhas a cheio significam operação em modo contínuo, enquanto
que as linhas a tracejado correspondem a operação em modo intermitente. Os círcu-
los cinzentos representam os caudalímetros instalados na ETAR e os triângulos verdes
assinalam os locais de recolha de amostras em períodos de campanhas. Quanto às
variáveis, Q representa valores de caudal e X diz respeito à concentração de sólidos
suspensos. O termo EMERG indica correntes de by-pass geral à ETAR, isto é, saídas de
emergência da linha de tratamento da fase líquida. . . . . . . . . . . . . . . . . . . . . . . 32
xxi

2.13 Planta da ETAR de Bucelas, excluindo o tratamento terciário e da fase sólida. A caixa
para onde é encaminhada a lama decantada é fisicamente a mesma que a caixa distri-
buidora do caudal de alimentação às valas de oxidação, Cx_VO. . . . . . . . . . . . . . . 33
2.14 Planta do tratamento da fase sólida efectuado na ETAR de Bucelas. . . . . . . . . . . . . 35
3.1 Aplicação de filtros de atenuação de ruído aos dados de caudal afluente, Qaf_SIM, (à
esquerda) e efluente, Qef, (à direita) do mês de Outubro de 2014. . . . . . . . . . . . . . 39
3.2 Boxplots com dados de caudal afluente, Qaf_SIM, e efluente, Qef, correspondentes ao ano
de 2013 e 2014. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.3 Diagrama de operações da ETAR de Bucelas com o volume de controlo entre os cauda-
límetros de caudal afluente e efluente assinalado a tracejado vermelho. . . . . . . . . . . 41
3.4 Variações mensais de caudais afluente e efluente nos meses de Março e Outubro de
2013 e Abril e Julho de 2014, respectivamente . . . . . . . . . . . . . . . . . . . . . . . . 42
3.5 PCA scores plot onde cada observação representa um dia do mês (à esquerda) e clusters
formados visualmente a partir da análise da distribuição dos scores (à direita). . . . . . . 44
3.6 Perfis diários dos dois melhores clusters formados a partir da análise do gráfico dos
scores para os meses de Julho de 2013, Fevereiro de 2014 e Setembro de 2014. . . . . 45
3.7 Biplots resultantes do modelo PCA construído para a análise da influência da variável
precipitação no caudal afluente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.8 Evolução dos dados de caudal afluente, de precipitação e de evapotranspiração no trata-
mento biológico. Os valores representam médias mensais. . . . . . . . . . . . . . . . . . 47
3.9 Planta da ETAR: indicação dos pontos de monitorização no sistema de desidratação de
lamas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.10 Representação esquemática das operações de processamento de lamas, com volume
de controlo considerado nos balanços de massa assinalado a vermelho. Q representa
valores de caudal e X diz respeito à concentração de sólidos em cada uma das correntes
referidas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.11 Fotografias tiradas durante o ensaio para estimativa dos caudais de recirculação e ex-
tracção de lamas, disponibilizadas pela SIMTEJO. . . . . . . . . . . . . . . . . . . . . . . 53
3.12 Componentes da sonda spectro::lyser v2, retirado de Hofstaedter et al. [2003]. . . . . . . 55
3.13 Aplicação de filtro de atenuação de ruído escolhido - Janela de Hamming 5 pontos - aos
dados da sonda s::can de SST, CQO, e NH4-N no mês de Maio de 2014. . . . . . . . . . 57
3.14 Boxplots contendo informação dos valores medidos online (pela sonda s::can) de SST,
CQO e NH4-N e representação dos valores obtidos na monitorização de rotina efectuada
pela SIMTEJO sob a forma de gráfico de valores médios com barra de erro correspon-
dente ao desvio-padrão. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.15 Representação mensal dos valores medidos online de NH4-N em Outubro de 2014. . . . 59
3.16 Representação mensal dos valores medidos online de SST e CQO desde Novembro até
meados de Dezembro de 2014. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
xxii

3.17 Sobreposição dos dados adquiridos online e dos dados analíticos de SST, CQO NH4-N
para períodos de campanhas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.18 Representação conjunta das quatro variáveis medidas em linha (Qaf_SIM, SST, CQO e
NH4-N) para o mês de Julho de 2014. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.19 Matriz de correlação dos dados medidos em linha para o mês de Julho de 2014. . . . . . 63
3.20 Biplots dos PCA mensais com os dados medidos em linha de SST, CQO, NH4-N, Qaf_SIM
e Qef para Junho, Setembro, Outubro, Novembro e Dezembro de 2014 e Fevereiro de
2015, respectivamente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.21 Biplot representativo da análise PCA, incluindo os dados de SST, CQO, NH4-N, Norg e
Qaf_SIM recolhidos nas campanhas P1, P2, C2, C3 e V1. Os círculos a vermelho assina-
lam os pontos que foram considerados como outliers. . . . . . . . . . . . . . . . . . . . . 69
3.22 Biplot representativo da análise PCA, incluindo os dados recolhidos nas campanhas P1,
P2, C2, C3 e V1 e todas as variáveis consideradas no desenvolvimento dos modelos
PLS, após remoção de outliers. Para a análise PCA foi usado um conjunto de dados com
728 pontos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.23 Previsões das concentrações de azoto orgânico no período das campanhas P1, P2, C1,
C2, C3 e V1 com dados analíticos e dados online de carga de CQO. Dada a diferença
na frequência de amostragem/aquisição de dados de CQO e Qaf_SIM, considerou-se os
valores de caudal em degraus que variam no início de cada hora. Os valores analíticos
de azoto orgânico foram calculados subtraindo os valores de azoto amoniacal aos valores
de azoto total. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.24 Previsões das concentrações de azoto total no período das campanhas com dados ana-
líticos de dados online de CQO e NH4-N. Só foi possível efectuar previsões com base em
dados online para a campanha P1 devido à avaria da sonda de amónia em Outubro de
2014. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
3.25 PCA scores plot, em que os pontos assinalados a vermelho correspondem aos outliers
considerados ao longo da pré-análise efectuada aos dados espectrais. . . . . . . . . . . 75
3.26 Espectros médios correspondentes aos períodos de campanhas, antes e após a exclusão
de outliers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.27 Representação esquemática dos modelos PLS desenvolvidos a partir da informação es-
pectral para pevisão do CQO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
3.28 Representação esquemática dos modelos PLS desenvolvidos a partir da informação es-
pectral para pevisão do Norg . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
3.29 Resultados da optimização via iPLS para os modelos de previsão de CQO e Norg corres-
pondentes à versão lowcost, isto é, considerando apenas 1 intervalo e blocos de tamanho
unitário. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
xxiii

3.30 Valores medidos versus valores previstos de Norg para os sensores inferenciais baseados
em dados analíticos e espectrais. Os dados representados dizem respeito aos conjuntos
de validação externa de ambos os sensores. Para o sensor baseado em dados analíticos,
o conjunto de validação externa contém 32 pontos (range: 3,5-23,8 mg/L). Para o sensor
baseado em dados espectrais, o conjunto de validação externa contém 13 pontos (range:
4,3-27,1 mg/L) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
A.1 Descrição do sistema de tratamento da fase líquida (tratamento preliminar), retirado de
Ribeiro et al. [2014]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
A.2 Descrição do sistema de tratamento da fase líquida (tratamento secundário e terciário),
retirado de Ribeiro et al. [2014]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
A.3 Descrição do sistema de tratamento da fase sólida, retirado de Ribeiro et al. [2014]. . . . 99
A.4 Instrumentação e monitorização instalada na ETAR de Bucelas, retirado de Ribeiro et al.
[2014]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
B.1 Esquema do descarregador de saída do tanque do classificador de areias. . . . . . . . . 101
D.1 Matrizes de correlação dos dados medidos em linha para o mês de Dezembro de 2014 e
para a totalidade do ano de 2014. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
E.1 Biplots dos PCA mensais com os dados medidos em linhas de SST, CQO, NH4-N, Qaf_SIM
e Qef para Abril, Maio, Julho e Agosto de 2014, respectivamente. O mês de Abril não tem
dados de caudal efluente disponíveis, pelo que não foi possível representar esta variável
nos respectivos gráficos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
E.2 Biplots dos PCA mensais com os dados medidos em linhas de SST, CQO, NH4-N, Qaf_SIM
e Qef para Janeiro, Março e Abril de 2015, respectivamente. Os meses de Março e Abril
não têm dados de caudal efluente disponíveis, pelo que não foi possível representar esta
variável nos respectivos gráficos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
F.1 Boxplots dos dados analíticos de SST, CQO e Norg para todas as campanhas até à V2,
onde se identificou a presença de outliers (pontos assinalados com um círculo vermelho).
Julho de 2014 - P1, Outubro de 2014 - P2, Dezembro de 2014 - C1, Janeiro de 2015 - C2,
Março de 2015 - C3, Abril de 2015 - V1, Junho de 2015 - V2. Os outliers correspondem
às seguintes amostras da campanha C2: 14-01-2015 10:30, 14-01-2015 12:30 e 15-01-
2015 12:30. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
F.2 Boxplots dos dados analíticos e caudal afluente medido à entrada da ETAR para todas
as campanhas até à V2, após exclusão de outliers. Julho de 2014 - P1, Outubro de 2014
- P2, Dezembro de 2014 - C1, Janeiro de 2015 - C2, Março de 2015 - C3, Abril de 2015 -
V1, Junho de 2015 - V2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
G.1 Biplot representativo da análise PCA considerando os dados analíticos das campanhas
P1, P2, C1, C2, C3 e V1 e excluindo a variável SST. . . . . . . . . . . . . . . . . . . . . . 113
xxiv

G.2 Histogramas dos conjuntos de dados analíticos de Norg usados no desenvolvimento de
sensores inferenciais baseados em dados analíticos: conjunto original, conjuntos de
treino e validação externa ou teste (após divisão dos dados) e da campanha V1. . . . . . 114
G.3 Histogramas dos conjuntos de dados analíticos de Ntotal usados no desenvolvimento de
sensores inferenciais baseados em dados analíticos: conjunto original, conjuntos de
treino e validação externa ou teste (após divisão dos dados) e da campanha V1. . . . . . 115
G.4 Representação da concentração de azoto orgânico, em mg/L, ao longo da campanha
V1. Os pontos vermelhos dizem respeito aos valores de concentração de Norg previstos
pelo modelo PLS a partir dos dados analíticos de CQO; a verde representa-se os dados
analíticos de Norg obtidos durante o período da campanha - valores observados; a linha
azul representa os dados previstos a partir dos dados de CQO medidos em linha pela
sonda s::can. O tempo zero corresponde às 12:10 do dia 20 de Abril de 2015, quando se
deu o arranque da campanha. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
H.1 Scores plot representativo da análise PCA dos dados espectrais obtidos pela sonda
s::can nos períodos corespondentes às campanhas P1, P2, C1, C2, C3 e V1. . . . . . . . 117
H.2 Scores plot da análise PCA dos dados dos espectros obtidos pela sonda s::can nos perío-
dos corespondentes às campanhas P1, P2, C1, C2, C3 e V1, com os pontos legendados
por ID de campanha. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
H.3 Representação dos espectros dos pontos observados fora do intervalo de confiança de
95%, juntamente com o espectro médio correspondente a cada gráfico. . . . . . . . . . . 119
H.4 Biplot representativo da análise PCA, incluindo os dados analíticos de CQO e SST em
períodos de campanhas, cujos timestamps representam pontos anómalos na análise dos
dados espectrais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
H.5 Biplot representativo da análise PCA, incluindo os dados analíticos de CQO e SST em
períodos de campanhas, cujos timestamps representam pontos anómalos na análise dos
dados espectrais e após remoção dos pontos anómalos identificados na primeira análise
de componentes principais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
H.6 Espectros dos timestamps correspondentes aos outliers identificados no primeiro PCA
dos dados analíticos, após exclusão dos pontos simultaneamente outliers na análise dos
dados analíticos e dos dados espectrais. . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
H.7 Espectros dos timestamps correspondentes aos outliers identificados no segundo PCA
dos dados analíticos, após exlusão dos pontos simultaneamente outliers na análise dos
dados analíticos e dos dados espectrais. . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
H.8 Scores plot da análise PCA considerando todos os espectros correspondentes aos pe-
ríodos das campanhas P1, P2, C1, C2, C3, V1 e V2 . . . . . . . . . . . . . . . . . . . . . 121
H.9 Scores plot da análise PCA considerando todos os espectros correspondentes aos pe-
ríodos das campanhas P1, P2, C1, C2, C3, V1 e V2 com valor analítico com timestamp
coincidente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
xxv

H.10 Histogramas dos conjuntos de dados analíticos de Norg usados no desenvolvimento de
sensores inferenciais baseados em dados espectrais: conjunto original, conjuntos de
treino e validação externa ou teste (após divisão dos dados) e da campanha V1. . . . . . 122
H.11 Histogramas dos conjuntos de dados analíticos de CQO usados no desenvolvimento de
sensores inferenciais baseados em dados espectrais: conjunto original, conjuntos de
treino e validação externa ou teste (após divisão dos dados) e da campanha V1. . . . . . 123
xxvi

Lista de Símbolos
Simbolos gregos
ηdes Eficiência do processo de Desidratação Mecânica de Lamas
ηesp Eficiência do processo de Espessamento Gravítico de Lamas
ρ Coeficiente de Correlação de Spearman
τ Coeficiente de Correlação de Kendall
Simbolos romanos
h largura de intervalos (ou bins) de um histograma
IQR Interquartile Range
k no de intervalos (ou bins) de um histograma
Q1 Primeiro Quartil de uma Distribuição Normal
Q3 Terceiro Quartil de uma Distribuição Normal
r Coeficiente de Correlação de Pearson
te Período anual de extracção de lamas
V anualle Volume anual de Lamas Extraídas
Xs-efb Concentração de Sólidos Totais no Efluente do Filtro de Banda
Xs-ldes Concentração de sólidos Totais nas Lamas Desidratadas
Xs-lesp Concentração de Sólidos Totais nas Lamas Espessadas
Xs-le Concentração de Sólidos Totais nas Lamas Extraídas
Xs-lserv Concentração de Sólidos Totais na Água de Lavagem do Filtro de Banda
Xs-poli Concentração de Sólidos Totais no Polielectrólito
Xs-sesp Concentração de sólidos Totais no Sobrenadante do Espessador
AED Análise Exploratória de Dados
xxvii

ANN Artifical Neural Networks
AS Activated Sludge
ASM Activated Sludge Model
CargaCQO Carga de Carência Química de Oxigénio
CargaNtotal Carga de Azoto Kjeldahl Total
CBOD Carbonaceous Biochemical Oxygen Demand
C1 Campanha de Calibração 1
C2 Campanha de Calibração 2
C3 Campanha de Calibração 3
P1 Campanha Preliminar 1
P2 Campanha Preliminar 2
Qaf_SIM Caudal Afluente medido no canal de Parshall
Q’le Caudal efectivo de extracção de lamas medido no ensaio da SIMTEJO
Qaf Caudal de Afluência ao Tratamento Biológico
Qclass Caudal do Classificador de Areias
Qefb Caudal de Efluente do Filtro de Banda
Qef Caudal Efluente medido após o tratamento secundário
Qevap Caudal de Evapotranspiração nas valas de oxidação
Qin Caudal de Água Residual Afluente à ETAR
Ql-des Caudal de Lamas Desidratadas
Qlesp Caudal de Lamas Espessadas
Qle Caudal de Lamas Extraídas
Qlm Caudal de Licor Misto
Qlr Caudal de Lamas Recirculadas
Qlserv Caudal de Água de Lavagem do Filtro de Banda
Qpoli Caudal de Polielectrólito
Qprec Caudal de Precipitação nas valas de oxidação
Qsesp Caudal de Sobrenadante do Espessador
xxviii

Qsfilt Caudal de Sobrenadante dos Filtros de Areia
Qu Caudal de Lamas no fundo do decantador secundário
V1 Campanha de Validação 1
V2 Campanha de Validação 2
V3 Campanha de Validação 3
DEMOCON DEcentralized wastewater treatment MOnitoring and CONtrol
EMERG Saída de Emergência (purga à ETAR)
NRMSE Normalized Root Mean Square Error
NRMSECV Normalized Root Mean Square Error of Cross Validation
NRMSEP Normalized Root Mean Square Error of Prediction
RMSE Root Mean Square Error
RMSECV Root Mean Square Error of Cross Validation
RMSEP Root Mean Square Error of Prediction
ETAR Estação Tratamento de Águas Residuais
iPLS interval Partial Least Squares
IPMA Instituto Português do Mar e da Atmosfera
IWA International Water Association
LNEC Laboratório Nacional de Engenharia Civil
LOO Leave-One-Out
LV Latent Variable
MSC Multiplicative Scatter Correction
N2 Azoto Gasoso
Norg Concentração de Azoto Orgânico
Ntotal Concentração de Azoto Kjeldahl Total
NH4-N Concentração de Azoto Amoniacal
NH4+ Ião Amónio
NO3- Ião Nitrato
OD Oxigénio Dissolvido
xxix

ORP Oxidation Reduction Potencial
C ′ Matriz dos loadings (ou pesos) de y de um modelo PLS
E Matriz dos resíduos de X de um modelo PLS
F Matriz dos resíduos de Y de um modelo PLS
P Matriz dos loadings (ou pesos) de X de um modelo PLS
T Matriz dos scores de X de um modelo PLS
U Matriz dos scores de Y de um modelo PLS
X Matriz do conjunto de dados originais de um modelo PCA ou dos predictores de um modelo PLS
Y Matriz de resposta de um modelo PLS
PC Principal Component
PCA Principal Component Analysis
PE Person Equivalent
PLS Partial Least Squares
RBCOD Readly Biodegradable Chemical Oxygen Demand
SBCOD Slowly Biodegradable Chemical Oxygen Demand
SG Saviztky-Golay
SNV Standard Normal Variate
SOM Self-Organizing Maps
SST Sólidos Suspensos Totais
SSV Sólidos Suspensos Voláteis
ST Sólidos Totais
SVI Sludge Volume Index
TOC Total Organic Carbon
UV Região Ultravioleta do espectro de radiação
UV-Vis Região Ultravioleta-Visível do espectro de radiação
xxx

Capítulo 1
Enquadramento e Objectivos
A presente dissertação está enquadrada no projecto DEMOCON - Monitorização e controlo de estações
de tratamento de águas residuais descentralizadas (PTDC/AAG-TEC/4124/2012), financiado pela FCT,
executado através duma parceria do IST-ID com a SIMTEJO (actualmente pertencente ao grupo Águas
de Lisboa e Vale do Tejo, AdLVT, após a recente reestruturação do sector de abastecimento de água
e saneamento de águas residuais) e o Laboratório Nacional de Engenharia Civil (LNEC). Este projecto
tem como principal objetivo o desenvolvimento de um sistema simples de monitorização e controlo,
especificamente adaptado a pequenas ETAR descentralizadas.
O trabalho desenvolvido focou-se na construção de sensores inferenciais com base em dados adqui-
ridos em linha. A sua finalidade é a estimativa de variáveis não medidas directamente, que são parte
integrante da estrutura de um modelo dinâmico. Este será usado no desenvolvimento de uma estra-
tégia de controlo preditivo baseado em modelos, para o controlo resistente a falhas no processo de
tratamento implementado numa ETAR de pequena dimensão. Com efeito, a presente dissertação é
composta essencialmente por duas etapas. Na primeira é realizada uma análise dos dados disponíveis
para adquirir um conhecimento integrado do sistema de tratamento, identificar padrões de funciona-
mento operacional e avaliar as relações entre as variáveis medidas pelo sistema de monitorização em
linha. Na segunda fase, os sensores inferenciais são desenvolvidos e, no final, efectua-se uma análise
comparativa da sua performance. Assim, a estrutura deste documento é a seguinte:
Capítulo 2 - Neste capítulo apresenta-se uma revisão do estado da arte na monitorização em linha
de sistemas de tratamento de águas residuais, os conceitos teóricos associados às ferramentas
e técnicas utilizadas no tratamento dos dados e introduz-se o caso de estudo, acompanhado de
uma breve descrição do sistema de tratamento implementado na ETAR em causa;
Capítulo 3 - Neste capítulo são apresentados e discutidos os principais resultados obtidos na aná-
lise dos dados disponíveis e no processo de desenvolvimento dos sensores inferenciais, acompa-
nhados das metodologias aplicadas;
Capítulo 4 - Por fim, neste capítulo resumem-se as principais conclusões deste trabalho, bem
como sugestões para trabalho futuro.
1

2

Capítulo 2
Revisão Bibliográfica
Nos últimos anos tem-se assistido ao crescimento do número de unidades descentralizadas de trata-
mento de águas residuais em relação ao número de unidades centralizadas [Libralato et al., 2012]. Não
existe uma definição standard para os conceitos de ETAR centralizada e descentralizada. A sua classi-
ficação, nos termos da lei, está fortemente dependente do país e normalmente baseia-se no número de
"equivalente de população"(em inglês Person Equivalent, PE) ou da capacidade diária de tratamento,
expressa em m3. No entanto, existem alguns factores largamente aceites para a distinção entre estes
dois tipos de gestão de sistemas de tratamento de águas residuais. O mais comum relaciona-se com
a distância do ponto de emissão do efluente. Assim, considera-se uma ETAR centralizada uma uni-
dade onde as águas residuais são tratadas longe do seu local de emissão, sendo encaminhadas até
à estação de tratamento através de um sistema de condutas. Por sua vez, uma ETAR descentralizada
corresponde a uma unidade de tratamento de águas residuais no local onde são produzidas ou perto
dele. A dimensão da estação de tratamento também constitui um factor de diferenciação importante.
Geralmente, os sistemas centralizados dizem respeito a ETAR de grande dimensão, onde se tratam
elevados volumes de água e, consequentemente, requerem maior investimento, não só na construção
de infra-estruturas, como na operação e manutenção do processo (p.e., as condutas são mais largas e
as bombas têm uma maior custo energético associado). Os sistemas descentralizados podem ser de
grande ou de pequena dimensão. Na presente dissertação considera-se apenas o conceito de sistemas
descentralizados de pequena dimensão, integrados no conjunto de sistemas designados por ETAR mu-
nicipais ou urbanas. Estes correspondem a unidades de tratamento que servem pequenas populações
e constituem a solução adequada para gestão de águas residuais em meios de pequena escala ou
áreas rurais, pois permitem uma redução dos custos de investimento, operação e manutenação face a
sistemas centralizados [Massoud et al., 2009; Barjenbruch, 2012]. A sua gestão, sendo mais flexível,
permite um ajuste do processo de modo a ir ao encontro dos objectivos estipulados para o tratamento.
Contudo, há que ter em conta que a descentralização também tem algumas desvantagens associadas,
das quais se destacam: (i) sobredimensionamento do sistema de tratamento, de modo a permitir o
funcionamento da ETAR sem constante supervisão por parte dos técnicos operacionais, o que resulta,
inevitavelmente, num aumento do custo per capita; (ii) conhecimento operacional reduzido, devido à
3

ausência, em muitos casos, de sistemas de monitorização em linha e/ou medições off-line insuficientes
e (iii) estratégias de controlo limitadas, que dificultam a optimização do processo de tratamento [Ribeiro,
2011]. Por fim, o efluente encaminhado para um sistema centralizado ou descentralizado também apre-
senta características diferentes. As ETAR centralizadas recebem, frequentemente, águas residuais de
origem urbana e industrial, cujo tratamento é mais exigente. Por seu turno, as ETAR descentralizadas
normalmente tratam apenas efluentes urbanos, uma vez que os sistemas de tratamento implementa-
dos são mais simples. No entanto, é possível projectar uma unidade descentralizada para tratamento
exclusivo de águas residuais de origem industrial, solução muito recorrente junto a Parques Industriais
[Massoud et al., 2009].
A monitorização em ETAR urbanas tem usualmente o propósito de efectuar um controlo de qualidade
da descarga de efluente tratado e a medição de alguns parâmetros indicativos do estado do sistema
de tratamento para apoio à operação. Em termos de instrumentação, isto traduz-se na instalação de
medidores de caudal e amostradores automáticos para análises off-line. No entanto, pode-se efectuar
um tipo de monitorização mais avançada, concretamente efectuar o controlo operativo do processo.
Para tal, procede-se à instalação de sensores que fornecem informação em tempo real. Actualmente, a
utilização de sistemas de controlo automático é limitada a ETAR de grande dimensão. Estes sistemas
correspondem a aneis de controlo básicos, destinados à medição e regulação de caudais e arejamento.
Em ETAR descentralizadas, de pequena dimensão, raramente se implementam estes sistemas de con-
trolo devido aos custos desproporcionados dos equipamentos de monitorização e actuação. A insta-
lação de instrumentação nestas unidades têm como finalidade a realização de estudos de simulação
dinâmica do funcionamento do sistema de tratamento [Ribeiro, 2011].
O objetivo de controlo é variável consoante as características da ETAR: enquanto que em unidades
de grande dimensão as estratégias de controlo estão direccionadas para a remoção de azoto e de
fósforo, em sistemas de pequena dimensão pretende-se aumentar a eficiência de remoção de material
orgânico. Neste último caso, as estratégias de controlo vão depender do tipo de sistema tratamento
adoptado. Este pode assentar no uso de tecnologias intensivas, como os sistemas de lamas activadas,
discos rotativos aeróbios e valas de oxidação, ou extensivas, como lagoas de estabilização, filtros lentos
de areia e leitos de macrófitas [Ribeiro, 2011].
2.1 Sistemas de Lamas Activadas
O processo de lamas activadas (em inglês activated sludge, AS) é a estratégia de tratamento de águas
residuais mais comumente usada [Gernaey et al., 2004]. Ainda que existam diversas configurações
possíveis, o conceito de lamas activadas assenta em 3 componentes principais: um tanque de areja-
mento, que funciona como bioreactor, um tanque decantador, onde se dá a separação entre os sólidos
das lamas e a água residual tratada, e um equipamento que se encarrega da transferência das lamas
activadas retidas no decantador para a entrada do sistema de tratamento. No bioreactor, a mistura das
águas residuais com a população de biomassa em suspensão, designada licor misto (em inglês Mixed
Liquor ), é sujeita a um período de arejamento através do fornecimento de ar atmosférico, favorável à
4

ocorrência de processos biológicos responsáveis pela diminuição da concentração de poluentes. O licor
misto é, de seguida, descarregado num tanque decantador e o sobrenadante (água residual tratada) se-
gue para o tratamento terciário antes de ser descarregado. As lamas sedimentadas retornam ao tanque
de arejamento. Em determinadas alturas pode ser necessário extrair lamas em excesso do sistema de
tratamento, essencialmente com o intuito de controlar o tempo de residência de biomassa no sistema
de tratamento biológico 1. Estas são posteriormente sujeitas a processos de digestão, espessamento e
desidratação e, por fim, armazenadas em contentores apropriados para serem reencaminhadas para o
seu destino final.
Existe um conjunto de variantes do sistema de tratamento por lamas activadas, dos quais se destaca,
para a presente dissertação, as valas de oxidação. Na sua vertente de arejamento prolongado, este
sistema possibilita, no mesmo orgão, a ocorrência simultânea de fenómenos de oxidação da matéria or-
gânica e nitrificação/desnitrificação sequencial. Os processos aeróbios são primeiramente usados para
remover carência bioquímica de oxigénio (CBO) e nitirificar amónia (NH4+). Os processos anóxicos pro-
movem a acção de bactérias desnitricantes que reduzem nitrato (NO3-) a azoto gasoso (N2) [Gernaey
et al., 2004]. Embora existam outros métodos para remoção de azoto orgânico das águas residuais, o
processo biológico de nitrificação/desnitrificação tem demonstrado ser o mais exequível, tanto do ponto
de vista técnico como económico, em sistemas centralizados e descentralizados [Oakley, 2005].
2.2 Aplicação de sistemas de controlo em ETAR
Quando comparadas com outros processos industriais, as ETAR, principalmente municipais, sofrem
perturbações significativas [Ribeiro, 2011; Haimi et al., 2013], das quais se destacam:
• Variações, com padrão diário e semanal, do caudal e da concentração das espécies presentes
nas águas residuais;
• Variações sazonais nos valores de temperatura das águas residuais;
• Variações sazonais associadas a fenómenos meteorológicos, como períodos de intensa precipi-
tação e infiltrações em águas subterrâneas;
• Variações abruptas nas características da afluência, como presença de produtos tóxicos para o
processo de tratamento e cargas orgânicas muito elevadas;
Por esta razão, é importante garantir que o sistema de tratamento se mantém na gama operacional óp-
tima e permite o cumprimento dos objectivos operacionais estipulados. Nesse sentido, existem diversas
estratégias para controlo que visam o ajuste do funcionamento do sistema de tratamento. De seguida,
enumeram-se as mais importantes aplicáveis em sistemas de tratamento de lamas activadas [Ribeiro,
2011]:
• Controlo de variáveis hidráulicas, nomeadamente o caudal de recirculação de lamas, que ac-
tua sobre a distribuição de massa de sólidos ao longo do sistema de tratamento, e o caudal de1http://www.iwawaterwiki.org/xwiki/bin/view/Articles/Activatedsludgeprocess, consultado em 4 de Outubro de 2015
5

extracção de lamas, que permite controlar a quantidade e o tempo de residência de biomassa
activa;
• Controlo da concentração de oxigénio dissolvido no tanque de arejamento, que permite, por
exemplo, ajustar o sistema de tratamento em condições de elevada carga de afluência orgânica e
azotada;
• Controlo da altura do manto de lamas no decantador secundário, com o intuito de minimizar o
arrastamento de biomassa activa para fora do sistema de tratamento;
• Controlo da quantidade de produtos químicos introduzidos no sistema para precipitação do
fósforo, floculação e correcção do pH.
Das estratégias apresentadas, as que demonstraram ter melhor performance no tratamento de águas
residuais urbanas em sistemas de lamas activadas foram o controlo do caudal de recirculação e de
extracção de lamas e o controlo do arejamento do licor misto. Para actuar sobre estas variáveis, existem
diferentes tipos de controlo que podem ser utilizados [Vrecko et al., 2003; Ribeiro, 2011]:
• Controlo por realimentação (em inglês feedback control): actua com base na informação contida
na resposta do sistema, de modo a atenuar ou suprimir efeitos indesejáveis de perturbações. O
sistema de controlo funciona em cadeia fechada, exigindo um sensor por variável de saída;
• Controlo por antecipação ou previsional (em inglês feedforward): visa a compensação de
efeitos potenciais das perturbações nas variáveis medidas à saída, isto é, actua no processo
quando as perturbações surgem, mas antes destas causarem alterações nas variáveis de saída.
Neste caso, o sistema funciona em cadeia aberta;
• Controlo por realimentação conjugado com controlo previsional (em inglês feedforward-
feedback control): compensa as aproximações do modelo e corrige a própria resposta do sistema
de controlo. Requer a utilização de um maior número de sensores, uma vez que são monitoriza-
das variáveis de entrada e saída;
• Controlo baseado em modelos (em inglês model-based control): faz uma estimativa dos valores
das variáveis controladas, através de modelação matemática. Estas variáveis podem correspon-
der a sensores inferenciais (em inglês soft sensors). Caso utilize modelos descritivos do processo
de tratamento, o controlo pode ter um carácter preditivo e permitir uma estimativa do resultado de
possíveis acções de controlo.
Os sistemas de lamas activadas são caracterizados por acumularem inércia [Vrecko et al., 2003], isto é,
terem atrasos devido à presença de circuitos internos de recirculação ou desfasamentos, tempos mor-
tos de operação, entre outros. Nestes casos, a utilização de controlo feedback não é viável, uma vez
que a informação chega com atraso ao controlador, comprometendo a sua performance e introduzindo
instabilidade no sistema [Bishop, 1992]. Assim, um controlo por antecipação baseado em modelos
revela-se uma estratégia mais adequada. A presença de modelos estáticos descritivos do processo,
6

como os modelos ASM (em inglês Activated Sludge Models), [Henze, 2000]), permite capturar a dinâ-
mica do sistema e o carácter antecipatório do controlador dá um boa indicação do comportamento do
sistema face a perturbações futuras [O’Brien et al., 2011].
2.3 Modelação mecanística de ETAR
A actividade bioquímica e a performance de processos de lamas activadas é regularmente descrita
através de modelos matemáticos que visam o design, optimização e controlo do processo. Revelam-se
especialmente úteis na avaliação de cenários operacionais para a melhoria da eficiência do sistema
de tratamento de ETAR que estão ainda a ser projectadas ou que já estejam a operar. A formulação
de modelos mecanísticos é, frequentemente, a estratégia adoptada. Este tipo de modelos envolve
o estabelecimento de malanços mássicos descritos por equações matemáticas, o que requere um
conhecimento aprofundado da estequiometria e cinética envolvidas no processo [Seviour and Nielsen,
2010; Henze, 2000].
Os modelos mais populares foram desenvolvidos pela International Water Association (IWA) com o pro-
pósito de facilitar a aplicação de modelos práticos no design e operação de sistemas de tratamento
de águas residuais por lamas activadas [Henze, 2000; Gernaey et al., 2004]. O objectivo foi a criação
de um modelo uniformizado e um procedimento para a sua utilização. É neste contexto que surge o
Activated Sludge Model No. 1, ASM1. Este trata-se, portanto, de um modelo mecanístico descritivo
do processo de remoção de matéria orgânica e de azoto através de nitirificação e desnitrificação num
sistema de lamas activadas e consiste em expressões cinéticas e estequiométricas descritivas dos
processos bioquímicos dos compostos solúveis e particulados envolvidos. As expressões estequiomé-
tricas indicam se os compostos são produzidos ou consumidos num determinado processo bioquímico
de acordo com um conjunto de coeficientes de rendimento. As expressões cinéticas correspondem a
reacções do tipo Monod e indicam a velocidade a que ocorrem os processos bioquímicos.
Para uma descrição mais fidedigna do processo de tratamento por lamas activadas os compostos azo-
tados e a carência química de oxigénio (CQO) afluentes foram divididos em duas fracções diferentes
dependendo do seu grau de biodegradibilidade. No caso da remoção da carga orgânica, a fracção de
CQO não-biodegradável corresponde à parte inerte, isto é, os compostos solúveis e particulados que se
mantêm inalterados depois de passar pelo tratamento. Por sua vez, a fracção biodegrável subdivide-se
em duas partes: fracção de CQO facilmente biodegradável, RBCOD (do termo readly biodegrada-
ble Chemical Oxygen Demand) e dificilmente biodegradável, SBCOD (do termo slowly biodegradable
Chemical Oxygen Demand). A fracção RBCOD é composta por substratos simples e solúveis directa-
mente metabolizados para crescimento heterotrófico. A fracção SBCOD consiste em substratos mais
complexos, geralmente em suspensão, que têm primeiro de ser convertidos em RBCOD antes de ser
metabolizados para o crescimento de biomassa. No que diz respeito à remoção da carga azotada,
a fracção não-biodegradável de compostos azotados existe na forma particulada, associada à frac-
ção particulada não-biodegrável de CQO. Já a fracção biodegradável é caracterizada em termos de
azoto amoniacal e é composta pelas fracções de azoto orgânico solúvel e insolúvel ou particulado. O
7

azoto orgânico particulado é hidrolisado de modo a formar azoto orgânico solúvel que, por sua vez, é
convertido em azoto amoniacal pela acção de organismos heterotróficos. A amónia é utilizada para o
crescimento de organismos autotróficos e heterotróficos, sendo que uma parte é assimilada nas duas
populações microbianas e a restante sofre nitrificação e forma nitrato, servindo de fonte energética do
crescimento autotrófico. Em condições anóxicas, o crescimento heterotrófico envolve desnitrificação,
sendo que o modelo considera que a cinética de crescimento anóxico é mais lenta comparada com a
de crescimento aeróbio. O decaimento da biomassa, devido a lise celular e fenómenos de predação
por protozoários, também é um factor tido em conta na modelação, considerando-se válida a hipó-
tese death-regeneration [Seviour and Nielsen, 2010]. Resumidamente, esta hipótese considera que
uma certa fracção da biomassa morre naturalmente ou por predação de protozoários e, eventualmente,
pode ser utilizada pela restante biomassa. Uma parte da biomassa morta constitui material particulado
não biodegradável, enquanto que a restante é biodegradável e contribui para os níveis totais de subs-
trato particulado lentamente biodegradável [Seviour and Blackall, 2012]. Em suma, as transformações
abordadas pelo modelo ASM1 incluem: (i) crescimento aeróbio de seres autotróficos e heterotróficos;
(ii) crescimento anóxico de seres heterotróficos; (iii) processos de decaimento de seres autotróficos e
heterotróficos e (iv) hidrólise de SBCOD e compostos orgânicos azotados.
Desde o aparecimento do ASM1 houve uma preocupação em melhorar o modelo à medida que pro-
blemas decorrentes da sua aplicação foram surgindo. Foram realizados ajustes e adições de modo
a torná-lo mais abrangente e mais representativo do processo de tratamento descrito. Neste sentido,
surgiram novos modelos, como o caso do ASM2 e ASM3 (Activated Sludge Model No. 2 e Activated
Sludge Model No. 3) [Henze, 2000]. Apesar das várias tentativas, estes modelos continuam a ser li-
mitativos no que diz respeito à descrição de fenómenos de bulking, um dos problemas mais comuns e
com mais impacto negativo em sistemas de lamas activadas. Este termo diz respeito à acumulação de
lamas filamentosas como resultado da proliferação de bactérias filamentosas, causando a diminuição
da sua densidade. Consequentemente, existe numa maior perda de sólidos com o efluente final, devido
à deterioração da velocidade de sedimentação e de compactação das lamas activadas [Martins et al.,
2004]. Apesar das desvantagens e limitações, o ASM1 é considerado como o modelo de referência,
continuando a ser aplicado na modelação de sistemas de lamas activadas em projectos científicos e
industrais e implementado em grande parte dos softwares comerciais existentes para simulação da
remoção de azoto em ETAR [Seviour and Nielsen, 2010; Gernaey et al., 2004].
Para a aplicação do modelo ASM1 a um processo de tratamento por lamas activadas é necessário
verificar se há informação disponível dos inputs necessários para a modelação e simulação. Estes
inputs podem ser variáveis cujos valores são medidos ou inferidos. Tendo em conta que o ASM1 tem
como propósito a modelação da remoção de carga orgânica e azotada, então é necessária informação
sobre estas duas variáveis à entrada do sistema de tratamento. A variável CQO é de fácil medição,
pelo que facilmente existem dados disponíveis resultantes de análises off-line e de medições online.
Estes dados devem ser sujeitos a um controlo de qualidade antes de serem introduzidos na simulação,
nomeadamente para detecção e exclusão de outliers. Por seu turno, o azoto orgânico não pode ser
directamente medido, tendo os seus valores de ser inferidos a partir de outras variáveis. Consequen-
8

tente, além do controlo de qualidade efectuado aos dados de CQO, deve ser também efectuada uma
análise exploratória dos restantes dados com o intuito de compreender a sua estrutura e correlações
entre as variáveis.
2.4 Análise Exploratória de Dados e Controlo de Qualidade
2.4.1 Filtros de Atenuação de Ruído
A recolha de dados em processos industriais está associada à propagação de variações aleatórias,
vulgarmente conhecidas por ruído. Existem métodos destinados a reduzir ou a cancelar estes efeitos
que consistem na aplicação de filtros de atenuação de ruído (em inglês Smoothing filters) 2. O princípio
inerente a estes métodos é ajustar uma curva (geralmente do tipo polinomial) aos dados de modo a
eliminar as variações e salientar possíveis tendências e padrões anteriormente escondidos [Brown and
Berthouex, 2002]. Existem dois tipos de métodos de atenuação de ruído: (i) baseados na média (Ave-
raging Methods) e (ii) exponenciais (Exponential Smoothing Methods). Na presente dissertação foram
testados vários filtros, de ambas as categorias, nomeadamente: Média Móvel (simples e centrada),
Janela de Hamming, Janela de Hanning, Saviztky-Golay, Mediana Móvel e Ajuste Exponencial. De
seguida, efectua-se uma abordagem mais detalhada da Média Móvel e da Janela de Hamming. Mais
informação relativa aos restantes filtros pode ser consultada em Brereton [2003]; Brown and Berthouex
[2002]; Meier and Zünd [2005]; Otto [2007].
A Média Móvel (MA, do inglês Moving Average) é um filtro que aplica uma função linear aos dados
brutos, sendo que um determinado ponto é substituído pela média de um conjunto de pontos na sua
vizinhança. Se para o cálculo da média num determinado ponto forem apenas considerados eventos
passados trata-se da média móvel simples. Por outro lado, se um determinado ponto for substituído pela
média dos pontos imediatamente antes e depois, então foi aplicada a média móvel centrada, sendo o
ponto central o ponto atenuado [Brown and Berthouex, 2002; Brereton, 2003].
A largura da janela é um factor importante na escolha do filtro a implementar para o tratamento de
um conjunto de dados. Uma média móvel com mais pontos traduz-se numa atenuação de ruído mais
intensa mas mais facilmente encobre as tendências e ciclos. Por outro lado, considerando menos
pontos, não se consegue reduzir significativamente o ruído, o que dificulta a análise dos eventos e
processos implícitos no diagrama temporal. Deste modo, é necessário encontrar um balanço entre
diminuir o ruído e preservar as tendências. Como tal, a largura da janela deve ser tal que não provoque
distorção dos picos e outras tendências [Otto, 2007].
A Janela de Hamming (em inglês Hamming Window) é uma transformação da média móvel ponderada
que atribui maior peso às observações no centro da janela, e cada vez menos peso a valores mais
afastados do centro; pode ser aplicado com qualquer largura de janela, sendo 5 pontos o tamanho re-
comendado, de acordo com Brereton [2003]. Neste caso, cada um dos 5 pontos terá, respectivamente,
os pesos de 0,0357, 0,2411, 0,4464, 0,2411 e 0,0357. A função através da qual se determinam os
2http://www.itl.nist.gov/div898/handbook/pmc/section4/pmc42.htm, consultado a 17 de Outubro de 2015
9

pesos para a média móvel ponderada pode ser consultada em [Blackman and Tukey, 1958].
2.4.2 Histogramas
Os histogramas tratam-se da ferramenta mais popular e mais antiga para representar graficamente um
conjunto univariado de dados e são frequentemente usados para representar a distribuição de variáveis
quantitativas [Wand, 1997; Chalmer, 1986]. A Figura 2.1 apresenta um exemplo de um histograma para
o peso à nascença dos bebés de uma população semi-rural em 2009 [Peck and Devore, 2011]. No
eixo das abcissas observam-se os diversos intervalos de pesos, enquanto que no eixo das ordenadas
representa-se a frequência de ocorrência de cada um destes intervalos de peso para a população de
bebés em estudo. Da análise do histograma representado verifica-se, por exemplo, que a maioria dos
bebés nasce com um peso que varia entre 5 e 9 lb e que é muito raro um bebé nascer com um peso
superior a 10 lb.
Figura 2.1: Exemplo de histograma que representa a ditribuição do peso (em lb) à nascença dos bebésde uma população semi-rural para o ano de 2009, retirado de Peck and Devore [2011])
Um parâmetro que é necessário especificar na construção de um histograma é o número de intervalos
(k, em inglês bins) em que os dados são agrupados. O número de intervalos pode ser calculado de
acordo com a seguinte expressão: k = max(x)−min(x)h , onde max(x) e min(x) são, respectivamente, os
valores máximo e mínimo dos dados, e h é o valor da largura dos bins. O valor óptimo de h pode ser
determinado através de várias abordagens, tais como a regra de Freedman-Diaconis [Scott, 2015], que
é descrita da seguinte forma: h = 2 IQR(x)n1/3 . Nesta expressão, n é o número de dados considerados para
o cálculo de h, IQR = Q3 − Q1 corresponde à distância inter-quartis (em inglês interquartile range) e
Q3 e Q1 são, respectivamente, aos valores do terceiro quartil e do primeiro quartil de uma distribuição
normal, como se pode observar na Figura 2.2. As equações matemáticas que descrevem a ditribuição
normal podem ser consultadas em [Dixon et al., 1969].
2.4.3 Boxplots
Os boxplots são uma das diversas técnicas estatísticas de análise exploratória de dados, usadas para
identificar visualmente padrões que, de outra forma, podem ficar dissimulados no conjunto de dados.
10

Figura 2.2: Exemplo gráfico da definição de IQR,adaptado de Dicker et al. [2006]
Figura 2.3: Representação das partes constituin-tes de um boxplot, adaptado de Friendly [1991]
Comparativamente com os histogramas, esta forma de representação tem a vantagem de fornecer infor-
mação de aspectos-chave da distribuição dos dados, tais como a mediana, os extremos, e a variância
dos dados em torno da mediana [Williamson et al., 1989].
Estruturalmente, é usual considerar o boxplot tal como representado na Figura 2.3, ou seja, constituído
por 5 partes distintas [Wickham and Stryjewski, 2012]: a mediana; as duas partes que compõem a
“caixa”, correspondentes ao primeiro e ao terceiro quartis (percentil 25% e 75%, respectivamente); os
dados que se situam entre o mínimo da distribuição normal e o primeiro quartil e os dados que se
encontram entre o terceiro quartil e o máximo da distribuição normal. O limite superior é calculado
por (Q3 + 1,5 × IQR) e o limite inferior que é calculado por (Q1 − 1,5 × IQR). Os pontos acima do
limite superior e/ou abaixo do limite inferior são considerados outliers. Na Figura 2.3 é ainda possível
observar a distinção entre outlier e far outlier, sendo que este último equivale a um ponto que esteja
3× IQR acima do limite superior.
2.4.4 Análise de Correlações
A análise de correlações é um método que mede a covariância entre duas variáveis de um conjunto de
dados. A covariância é normalmente expressa em termos de um coeficiente de correlação de X e Y.
Este trata-se de um valor adimensional que pode variar entre -1 e +1. O valor absoluto do coeficiente
avalia a força da correlação, ao passo que o sinal indica a direccção da correlação, isto é, se é positiva
ou negativa 3.
Existem várias definições de coeficientes de correlação, das quais se destacam: (i) o coeficiente de
correlação de Pearson r [Pearson, 1895], (ii) o coeficiente de correlação de Spearman ρ [Myers and
Well, 2003] e (iii) o coeficiente de correlação de Kendall τ [Kendall and Gibbons, 1990]. No decurso
desta dissertação, optou-se por usar o coeficiente de correlação de Pearson que representa uma me-
3http://www3.epa.gov/caddis/da_exploratory_2.html, consultado em 13 de Outubro de 2015
11

dida do grau de correlação linear entre duas variáveis e cuja definição matemática está de acordo com
a Equação 2.1 ([Egghe and Leydesdorff, 2009].
r =
nn∑
i=1
xiyi −(
n∑i=1
xi
)(n∑
i=1
yi
)√n
n∑i=1
x2i −(
n∑i=1
xi
)2√n
n∑i=1
y2i −(
n∑i=1
yi
)2(2.1)
As correlações entre variáveis podem ser visualizadas através de scatter plots ou matrizes de correla-
ção. Os Scatter plots são gráficos onde se representa uma variável no eixo horizontal e outra variável
no eixo vertical (ex: Figura 2.4). São úteis para analisar as relações entre variáveis no conjunto de
dados e identificar possíveis problemas, como a presença de outliers4. Por sua vez, as matrizes de
correlação tratam-se de matrizes quadradas onde se mostram as correlações entre todos os pares de
variáveis. Nesta representação a diagonal é constituída sempre por 1, pois diz respeito à correlação
entre a variável e ela própria e funciona como um eixo de simetria, com os valores da triangular superior
a serem um espelho dos valores da triangular inferior ([Yeh, 2007]).
Figura 2.4: Exemplos de diferentes correlações entre duas variáveis X e Y.
Independentemente da definição de coeficiente usada, os valores de r, ρ e τ podem ser interpretados
da seguinte forma:
• Um coeficiente com valor 0 indica que variáveis não estão relacionadas (Figura 2.4A).
• Um coeficiente com valor positivo indica que, quando uma variável aumenta, a outra também
aumenta, e vice-versa. Se o seu valor for igual a 1, a correlação diz-se perfeita.
• Um coeficiente com valor negativo retrata uma relação inversa, isto é, quando uma variável au-
menta, a outra diminui. No caso de tomar o valor -1, diz-se que as variáveis têm um correlação
negativa perfeita.
• Coeficientes com valores absolutos mais elevados indicam correlações mais fortes, sendo que se
considera uma correlação moderada quando os valores absolutos dos coeficientes oscilam entre
0,3 e 0,7 (Figura 2.4B), e uma correlação forte quando são superiores a 0,7 (Figura 2.4C). Cor-
relações fracas correspondem a situações cujos valores dos coeficientes são inferiores a 0,3.De
4http://www3.epa.gov/caddis/da_exploratory_1.html, consultado em 13 de Outubro de 2015
12

notar que, no caso do coeficiente de Pearson, isto pode dever-se à existência de relações não
lineares entre as variáveis.
A Tabela 2.1 contempla um exemplo de uma matriz de correlação de um estudo psicológico [Alcorta
and Ancer, 2008]. Por exemplo, as variáveis depressão e solidão estão positivamente correlacionadas,
enquanto que as variáveis ansiedade e auto-estima têm uma correlação negativa. O grau de correlação
entre as variáveis solidão e depressão é maior que entre as variáveis ansiedade e auto-estima.
Tabela 2.1: Exemplo de uma matriz de correlações de um estudo psicológico, adaptado de [Alcorta andAncer, 2008].
Solidão Auto-Estima Ansiedade Depressão
Solidão 1Auto-estima -0,49 1Ansiedade 0,30 -0,34 1Depressão 0,48 0,30 0,38 1
2.4.5 Análise de Componentes Principais (PCA)
2.4.5.1 Definição do método PCA
A análise de componentes principais (PCA, em inglês Principal Component Analysis) trata-se de uma
técnica de análise estatística multivariada. A ideia central subjacente a este método é a redução da
dimensionalidade de um conjunto de dados composto por um número considerável de variáveis re-
lacionadas entre si, mantendo o máximo possível da variância presente neste conjunto. Para tal, o
conjunto de variáveis original é transformado num novo conjunto de variáveis de menor dimensão de-
signadas componentes principais (PC, do inglês Principal Component). Os componentes principais são
linearmente independentes entre si e estão ordenados de tal forma que os primeiros retêm o máximo
de informação em termos de variância total do conjunto de dados. Como tal, a representação dos
valores para cada observação nos primeiros dois componentes é a melhor representação possível no
espaço bidimensional [Jolliffe, 2002]. A transformação do conjunto original (matriz X) de dados para
um novo sistema de coordenadas pode ser descrita matematicamente por X = T × P + E, em que: T
corresponde à matriz dos scores, que ilustra a estrutura dos dados; P é matriz dos loadings e mostra
a influência das diferentes variáveis na estrutura dos dados e E designa-se matriz dos erros, já que
contém o ruído presente nos dados originais [Böhm et al., 2013].
Figura 2.5: Esquema do princípio da técnica PCA, retirado de Böhm et al. [2013]
13

2.4.5.2 Contribuição e escolha do número de componentes principais
A contribuição de cada componente principal para a variância do conjunto original é expressa em per-
centagem. É determinada dividindo a variância do componente em questão pela variância total e,
consequentemente, representa a proporção de vâriancia total explicada por esse PC [Varella, 2008].
Na escolha do número de componentes a incluir em determinado modelo, não existe nenhuma aborda-
gem matemática formal. As regras normalmente usadas são de carácter empírico e o facto de serem
tão intuitivas e de funcionarem em grande parte das situações explica a sua vasta aceitação em análise
estatística. É frequente considerar o número de PC necessário aquele que garante que a variância total
explicada é 80-90% [Jolliffe, 2002]. Tendo em conta a definição de PCA, esse número têm obrigatoria-
mente de ser inferior ao número de variáveis originais [Bro and Smilde, 2014].
2.4.5.3 Representação gráfica dos componentes principais
Se existirem correlações fortes no conjunto de dados original, o número de PC necessário é muito in-
ferior ao número de variáveis originais. Muitas vezes verifica-se que os primeiros dois componentes,
PC1 e PC2, contribuem para a maioria da variância do dataset. Desta forma, é possível representar os
dados em apenas duas dimensões, o que facilita a sua visualização e interpretação. Nesta representa-
ção, o PC1, primeiro componente, representa a direcção onde existe maior variância de dados e o PC2,
segundo componente, é orientado de forma a ser ortogonal ao primeiro e a descrever a segunda maior
fonte de variância nos dados [Miller and Miller, 2005]. As observações projectadas neste plano definido
por PC1 e PC2 são designadas scores e, consequentemente, a sua representação gráfica designa-se
scores plot ou gráfico das observações [Eriksson et al., 2013].
2.4.5.4 Scores Plot, Loadings Plot e Biplot
A interpretação dos resultados de uma análise PCA é efectuada através da visualização gráfica dos
scores e dos loadings. A Figura 2.6 apresenta um exemplo de uma análise PCA realizada no âmbito
de um estudo do perfil de aroma e sabor de amostras de grãos de cacau, no qual foram consideradas
quatro propriedades de sabor (doçura, amargura, acidez e adstringência) e nove de aroma (chocolate,
noz, avelã, doce, ácido, tostado, apimentado, mofo e off-flavour ) [Vazquez-Ovando et al., 2015].
Observa-se que o primeiro PC explica 35,93% da variância dos dados e o PC2 descreve 23,93% e,
consequentemente, o plano formado pelos dois primeiros componentes contêm 59,86% da variância
total do conjunto original de dados. O scores plot, tal como mencionado anteriormente, representa a
projecção dos dados no sub-espaço definido pelos componentes principais (normalmente PC1 e PC2).
A sua análise permite identificar relações entre as observações [Esbensen et al., 2002], sendo que
pontos mais próximos têm propriedades semelhantes e pontos mais afastados são mais distintos entre
si. Na Figura 2.6(a), as amostras G5 e G6 são mais semelhantes entre si, ao passo que a amostra
G7 é a que mais se distingue das restantes. O loadings plot permite interpretar as relações entre as
variáveis [Esbensen et al., 2002]. Os ângulos formados entre as linhas num loadings plot indicam a
relação entre as variáveis que estas representam: um ângulo inferior a 90o indica que que as variáveis
14

Figura 2.6: Análise de componentes principais (a) scores plot em que cada observação representa umaamostra de grão de cacau e (b) loadings plot, onde se representam os 13 parâmetros que influeciam operfil de sabor e aroma dos grãos de cacau, retirado de Vazquez-Ovando et al. [2015].
estão positivamente correlacionadas; um ângulo superior a 90o indica que as variáveis estão negati-
vamente correlacionadas; quando o ângulo é 90o, as variáveis não estão correlacionadas. Variáveis
muito próximas (casos em que as linhas praticamente se sobrepõem) contribuem com informação se-
melhante e, por conseguinte, estão muito correlacionadas [Kohler and Luniak, 2005]. Na Figura 2.6(b)
observa-se que os aromas chocolate e avelã estão positivamente correlacionados, os aromas torrado e
apimentado estão inversamente correlacionados e a aroma ácido e sabor amargo formam entre si um
ângulo de 90o, pelo que se tratam de variáveis não correlacionadas. Um exemplo de duas variáveis
que praticamente se sobrepõem é o sabor doce e o aroma doce.
É possível visualizar e interpretar simultaneamente o scores plot e o loadings plot. Efectuando uma
sobreposição destas duas representações e preservando as distâncias o resultado é um gráfico que se
designa biplot [Bro and Smilde, 2014]. A Figura 2.7 apresenta um exemplo de um conjunto de dados em
que as observações correspondem a planetas do Sistema Solar e as variáveis a características físicas,
como a massa, o número de luas e a distância ao sol [Hamilton, 1992]. À excepção da variável anéis,
todas as variáveis estão representadas à escala logarítmica. No total, os dois primeiros componentes
conseguem explicar 98% da variância dos dados.
Num biplot, quanto maior for o tamanho das linhas, maior a variância. Por exemplo, a massa dos pla-
netas é a variável com mais variância associada, observando-se o contrário com a variável anéis. À
semelhança da análise feita para o loadings plot, o ângulo entre as linhas indica a correlação entre
as variáveis que estas representam. Assim, verifica-se que as variáveis anéis e número de luas es-
tão fortemente correlacionadas, enquanto que entre as variáveis distância ao sol e massa não existe
praticamente correlação. Além disso, a densidade e as restantes variáveis estão negativamente correla-
cionadas. As conclusões retiradas da análise do scores plot também podem ser retiradas da análise de
um biplot. Por exemplo, Júpiter e Plutão são os pontos mais afastados pois correspondem aos dois pla-
netas do Sistema Solar mais diferentes entre si, enquanto Urano e Neptuno são os mais semelhantes
e, consequentemente aparecem mais próximos neste gráfico.
Neste tipo de representação, um corte perpendicular de um ponto até à linha de uma variável permite
concluir acerca da importância dessa variável para a observação em questão. Isto significa que, pon-
tos de corte longe e na direcção da linha da variável correspondem a situações em que essa variável
15

Figura 2.7: Exemplo de um biplot que representa a relação das propriedades físicas dos planetas doSistema Solar, adaptado de Hamilton [1992]
tem uma elevada contribuição para a observação considerada. Por outro lado, se os pontos de corte
estiverem longe e na direcção oposta da linha da variável, então a sua contribuição é pequena. Final-
mente, se o ponto de corte cair na origem, então o valor da observação é aproximadamente a média da
respectiva variável. No exemplo apresentado, Júpiter tem a maior massa, seguido de Saturno, Neptuno
e Urano, que têm massas idênticas. Por outro lado, Plutão é o planeta com menor massa [Kohler and
Luniak, 2005].
2.4.6 Mínimos Quadrados Latentes (PLS)
2.4.6.1 Definição do método PLS
O método dos mínimos quadrados latentes ou parciais (PLS, do inglês Partial Least Squares) é uma
técnica de análise multivariada que combina características da análise de componentes principais e
de regressão linear múltipla. O seu propósito é prever um conjunto de variáveis dependentes através
de um conjunto de variáveis independentes designadas predictores. Esta previsão é possível através
da extracção, a partir dos predictores, de um conjunto de factores, designados variáveis latentes, que
têm o melhor poder de previsão possível [Abdi, 2003]. O esquema da Figura 2.8 ilustra o princípio da
técnica PLS.
O objectivo da técnica PLS é prever a matriz Y , designada matriz resposta, a partir de X, matriz dos
predictores. Para tal efectua-se uma decomposição simultânea de X e Y . Esta decomposição pode
ser interpretada como dois modelos PCA: um para a matriz dos predictores, em que T é a matriz dos
scores de X, P é a matriz dos loadings de X e E é a matriz dos resíduos de X; e outro para a matriz
de resposta, em que U é a matriz dos scores de Y , C é a matriz dos pesos de Y e F é a matriz dos
resíduos de Y . O modelos são construídos de tal forma que os scores de X têm a máxima covariância
possível com os scores de Y. Isto significa que é possível prever o primeiro score de Y através do
16

Figura 2.8: Esquema da decomposição das matrizes X e Y da técnica PLS, adaptado de Geladi andKowalski [1986].
primeiro score de X e assim sucessivamente. Conhecendo todos os scores em Y é possível prever Y .
Em suma, o PLS é uma técnica que procura um conjunto de componentes, designados por vectores
ou variáveis latentes, que executam a decomposição simultânea de X e Y , com a condição de que
este componentes expliquem o máximo possível de covariância entre as duas matrizes. No final, a
decomposição de X é usada para prever Y através de uma regressão linear multivariada [Eriksson
et al., 2013; Abdi, 2003].
2.4.6.2 Representação gráfica do método PLS: Scores e pesos (weights)
A análise dos dados na técnica PLS é executada de forma a descrever as relações entre as posições
das observações no espaço predictor (X) e as observações no espaço de resposta (Y ). Na Figura 2.9
observa-se a representação do primeiro componente do modelo PLS. Este orienta-se de modo a des-
crever a nuvem de pontos no espaço X garantindo, em simultâneo, uma boa correlação com o vector
y. As projecções da observações do longo da linha no espaço X dão os scores de cada observação.
Por exemplo, o score ti1 é a projecção da observação i na linha definida pelo primeiro componente.
O conjunto de todos os scores forma o vector t1 que pode ser interpretado como uma nova variável,
variável latente, que contém a informação do conjunto de variáveis originais X, relevante para a pre-
visão da variável de resposta. Os pesos ou loadings fornecem informação acerca da contribuição das
variáveis originais para as "novas variáveis", verificando-se que as variáveis de X que estão fortemente
correlacionadas com as variáveis Y têm valores de pesos maiores. Similarmente, os pesos de Y , ci,
informam como as variáveis de Y são resumidas pelo vector dos scores, ui [Geladi and Kowalski, 1986].
Finalmente a estimativa de y1 é obtida após multiplicação do vector t1 pelo peso de y, c1. Os resíduos de
y representam a variância que ficou por explicar e correspondem à diferença entre o valor observado
e o valor estimado. Consequentemente, um bom modelo é aquele que tem resíduos pequenos. A
representação dos valores observados em função dos valores previstos, frequentemente designada
por recovery function (na Figura 2.9, à direita), permite avaliar graficamente o desempenho do modelo.
Quanto mais próximos os pontos estiverem da diagonal, melhor o modelo PLS construído. A situação
17

ideal corresponde ao caso em que todos os pontos se situam sobre a diagonal, o que traduz um
modelo com resíduos zero [Eriksson et al., 2013]. No gráfico onde se representa a recovery function
apresenta-se, frequentemente, o valor do coeficiente de determinação R2. Este trata-se de uma medida
de ajustamento do um modelo em relação aos valores observados. O R2 varia entre 0 e 1, indicando,
em percentagem, quanto o modelo consegue explicar os valores observados. Assim, a situação ideal
mencionada corresponde a um coeficiente de determinação igual a 1.
Figura 2.9: Representação gráfica do primeiro componente PLS e estimativa do vector de resposta,adaptado de Eriksson et al. [2013].
2.4.6.3 Validação cruzada
Tal como explicado nas secções 2.4.6.1 e 2.4.6.2, na técnica PLS formam-se "novas variáveis de x",
ti, como combinações lineares das variáveis originais, que são usadas como preditores de Y . Apenas
um número de ti (componentes) tem capacidade de previsão significativa [Eriksson et al., 2013]. Isto
acontece porque a qualidade de previsão de um modelo não melhora obrigatoriamente com o aumento
do número de variáveis latentes usado. Tipicamente, a qualidade de previsão aumenta inicialmente
e, a partir de certo ponto, começa a decrescer. Quando a capacidade preditiva de um modelo piora
com o aumento do número de variáveis latentes usadas, significa que há um overfitting dos dados, isto
é, a a informação útil para explicar os dados do conjunto de treino do modelo não é útil para explicar
novas observações [Abdi, 2010]. Assim, a selecção do número óptimo de variáveis latentes a incluir no
modelo releva-se um passo crítico, pois tem repercussões directas na qualidade de previsão do mesmo.
Um procedimento frequentemente adoptado no processo de escolha do número de LV a incluir em de-
terminado modelo PLS é a técnica de validação cruzada (em inglês, Cross Validation). Embora existam
diferentes abordagens deste procedimento, a ideia principal é transversal a todas elas e baseia-se no
seguinte: os dados são divididos em dois conjuntos mutuamente exclusivos, um de maior dimensão
(conjunto de treino ou de calibração) e outro de menor dimensão (conjunto teste ou de validação ex-
terna). O conjunto de treino é usado para desenvolver o modelo PLS, enquanto que o conjunto de
menor dimensão é deixado de fora para validação. O modelo recém construído é usado para prever
o conjunto de validação e a qualidade dos resultados é avaliada em termos de erro quadrático médio
de validação cruzada (em inglês Root Mean Squared Error of Cross Validation), RMSECV, calculado
atrvés da Equação 2.2 [Otto, 2007; Lohninger, 1999]. Este processo é repetido com diferentes sub-
conjuntos de dados até cada um dele ser usado uma vez como conjunto de validação. O tamanho do
18

conjunto teste para cada repetição do procedimento pode ser ajustado e depende essencialmente da
dimensão do conjunto de dados. Quando o número de amostras disponível para construir o modelo é
limitado, é frequente adoptar-se um procedimento de validação cruzada do tipo "leave-one-out"(LOO),
que corresponde a seleccionar apenas uma amostra para o conjunto de validação, tal como ilustrado
na Figura 2.10 [Lourenço et al., 2010; Lohninger, 1999].
Figura 2.10: Esquema do procedimento de validação cruzada do tipo leave-one-out, retirado de Loh-ninger [1999].
2.4.6.4 Medidas de desempenho
Um modelo de previsão só faz sentido quando existem critérios de desempenho adequados que avaliem
a sua performance. As medidas de desempenho são muitas vezes definidas em termos de erro de
previsão, ou resíduos, isto é, a diferença entre entre o valor real e o valor previsto pelo modelo. Uma
das medidas de desempenho mais usadas é o valor de RMSE (Root Mean Squared Error ), determinada
pela Equação 2.2, onde yi é o valor previsto, yi é o valor real medido e n é o número de amostras usadas
para o cálculo do erro Zhang et al. [1998].
RMSE =
√√√√ n∑i=1
(yi − yi)2
n(2.2)
Quanto menor o valor de RMSE, melhor a capacidade preditiva do modelo em questão. Quando se usa
um procedimento de validação cruzada, esta equação é a aplicada ao conjunto de teste e não se efectua
nenhuma optimização após o resultado. Uma vez que uma medida de desempenho é uma quantidade
estimada, há que considerar o facto do seu valor sofrer variações conforme a divisão aleatória dos
dados em conjunto de calibração e conjunto de teste. Por esta razão, é aconselhável repetir o processo,
analisar a distribuição dos erros (através de boxplots ou histogramas) e, caso sejam significativamente
diferentes, calcular uma média dos erros com base no número de divisões efectuada [Varmuza et al.,
2013].
Quando o modelo é usado para prever novos dados, o erro de previsão do conjunto de teste deve ser
comparado com o erro de previsão de novos dados para avaliar sua a robustez. Pretende-se verificar
se o erro de previsão do conjunto teste é menor que o erro de previsão de novos dados. Contudo, isto
não é condição suficiente para avaliar se é necessária recalibração do model; é preciso quantificar se o
aumento do RMSEP (Root Mean Squared Error of Prediction) aquando novas previsões é significativo.
19

Para tal, recorre-se a testes estatísticos, como o Teste de Mann-Whitney Wilcoxon. Este trata-se de
um teste de hipóteses que não requer distribuição normal dos dados, o que é muitas vezes o caso de
pequenas populações. Portanto, perante uma nova previsão, formula-se a hipótese das populações
serem idênticas, isto é, terem uma distribuição dos erros similar. A hipótese é aceite se o resultado
do teste for maior que o p-value para um intervalo de confiança de 95%, caso contrário é rejeitada 5.
Se a hipótese for aceite, o modelo é considerado robusto. Caso seja rejeitada, antes de se avançar a
recalibração do modelo, deve-se avaliar se os novos dados correspondem a uma situação anómala e,
em caso afirmativo, se se pretende efectivamente incluir essa situação no modelo.
2.5 Sensores Inferenciais no Tratamento de Águas Residuais
A monitorização em ETAR é muitas vezes dificultada pela necessidade de efectuar análises online e
offline de variáveis primárias, tipicamente concentrações de amónia, nitratos, azoto total, fosfatos, CBO
(carência bioquímica de oxigénio) e CQO e outras variáveis de processo como a altura do manto de
lamas. Estas variáveis caracterizam-se por serem difíceis de medir (do termo hard-to-measure) ou,
em alguns casos, a sua medição directa não ser possível. A disponibilidade de equipamentos para
efectuar as estas medições, principalmente em linha, depende de factores económicos, uma vez que
é necessário um elevado investimento e existem custos de manutenção associados. Adicionalmente,
coloca-se a problemática dos equipamentos actualmente disponíveis no mercado não serem adequa-
dos ou não terem capacidade de resposta suficiente para efectuar monitorização em tempo real. No
caso do tratamento biológico por lamas activadas, existe ainda o problema das condições do processo
tornarem muito difícil a aquisição de dados fiáveis em períodos de campanhas [Haimi et al., 2013].
O progresso das tecnologias de medição, automatização e de comunicação nos últimos anos pos-
sibilitou que, actualmente, as ETAR sejam equipadas com instrumentos de monitorização online de
variáveis secundárias, com aquisição de dados numa frequência elevada. Estas tratam-se de variá-
veis de processo de fácil medição (do termo easy-to-measure), como a pressão, temperatura, caudais,
medições de nível, condutividade, pH, turbidez e oxigénio dissolvido que dão indicação sobre as condi-
ções operacionais e o estado do processo. Além do seu carácter informativo, as variáveis secundárias
constituem uma oportunidade bastante económica de extrair informação sobre as variáveis primárias.
Uma abordagem comum é analisar as correlações existentes entre variáveis primárias e secundárias e
desenvolver modelos que permitam estimar as variáveis primárias. É neste contexto que surge o con-
ceito de sensor inferencial (em inglês, soft-sensor ). Este trata-se de um software informático que usa
como input a informação contida nas variáveis secundárias e fornece como output informação sobre as
variáveis primárias, de forma semelhante a um sensor físico (em inglês, hardware sensor ) [Haimi et al.,
2013].
Genericamente é possível distinguir duas classes de sensores inferenciais: baseados em modelos
(em inglês model-driven sensors) e baseados em dados (em inglês data-driven models). Os sensores
baseados em modelos são desenvolvidos num contexto de planeamento processual e operacional e
5http://www.ime.unicamp.br/ dias/Ch10.wilcoxon.pdf, consultado a 17 de Outubro de 2015
20

baseiam-se em equações que descrevem os princípios químicos e físicos inerentes ao mesmo. Por
esta razão também são conhecidos por "white-box models", já que requerem o conhecimento total do
processo. Este factor pode constituir uma desvantagem, no sentido em que não é possível ter esse grau
de conhecimento para para determinados processos. Além disso, ao focarem-se na descrição de esta-
dos estacionários ideais do processo, os sensores baseados em modelos revelam-se inadequados para
a descrição de estados transientes, o que muitas vezes é a realidade dos processos industriais. Por
seu turno, os sensores baseados em dados, também conhecidos por "black-box models"dizem respeito
a modelos que têm em conta o histórico do processo, isto é, incluem dados medidos e, consequente-
mente, descrevem as condições reais operacionais, o que os coloca em vantagem relativamente aos
sensores baseados em modelos [Kadlec et al., 2009]. No entanto, é possível enumerar um conjunto de
problemas no desenvolvimento e utilização destes sensores. Os mais comuns estão relacionados com
a existência de ruído nas medições, valores em falta, presença de outliers, colinearidade no conjunto
de dados e diferentes frequências de amostragem (ver Secção 2.5.1). Outro problema está relacionado
com o facto dos processos serem dinâmicos. Face a mudanças abruptas do processo, é muito difícil
a adaptação do sensor inferencial às novas condições, o que causa deterioração da sua capacidade
preditiva.
2.5.1 Características dos Dados Industriais
Nesta secção apresentam-se as características críticas dos dados provenientes de processos industri-
ais no contexto de design e mantuenção de sensores inferenciais [Kadlec et al., 2009].
Dados em falta: correspondem a amostras ou conjuntos de amostras onde uma ou mais variáveis
(medidas) tomam valores que não reflectem as quantidades medidas fisicamente. No contexto in-
dustrial, estes valores surgem devido a falhas e avarias de hardware, remoção dos equipamentos para
manutenção ou erros associados à transmissão de dados entre os sensores e as bases de dados. Visto
que a maior parte das técnicas usadas no desenvolvimento de sensores inferenciais não conseguem
lidar com dados em falta, existem estratégias para a sua reconstrução, tais como (i) substituição dos va-
lores em falta pelo valor médio da variável afectada, (ii) exclusão as amostras em que existam variáveis
com dados em falta e (iii) uso de técnicas de análise multivariada para reconstrução dos dados.
Presença de Outliers: outliers dizem respeito a valores que se desviam dos intervalos de medição
típicos e/ou com significado físico. Subdividem-se em dois grupos distintos: outliers óbvios (em inglês
obvious outliers) e outliers não-óbvios (em inglês non-obvious outliers). Os outliers óbvios correspodem
a valores que violam limitações físicas ou tecnológicas (p.e, valores de caudal não podem ser negativos
ou fora da escala de medição do sensor). Os outliers não-óbvios são mais difíceis de identificar porque
não violam nenhuma limitação mas não reflectem correctamente o estado das variáveis. A detecção
de outliers é preponderante no processo de desenvolvimento do sensor inferencial, uma vez que a
presença de valores anómalos têm reprecussões na performance dos modelos. Nesse sentido, exis-
tem diversas estratégias que visam validação dos valores medidos, sendo que muitas delas assentam
21

numa inspecção manual do conjunto de dados. Embora esta abordagem seja exaustiva, possibilita a
identificação de situações em que existem valores anómalos que não são detectados, ou valores cor-
rectos que são erradamente considerados outliers. Tipicamente recorre-se a técnicas estatísticas para
detecção de outliers, das quais se salientam: (i) o algoritmo 3σ [Pearson, 2002], método univariado que
identifica como outliers todas as amostras fora do intervalo µ(χ)±3σ(χ), em que µ(χ) é a média e σ(χ)
o desvio-padrão da variável χ e (ii) técnicas multivariadas, como a análise de componentes principais,
PCA [Jolliffe, 2002] - ver Secção 2.4.5.
Drifts no conjunto de dados: as flutuações de dados podem ser causadas por mudanças no pro-
cesso e condições externas ao mesmo, como por exemplo, alterações do grau de pureza das matérias-
primas ou inputs e/ou condições meteorológicas. Estes factores afectam os dados e o estado do pro-
cesso, pelo que devem ser accionados mecanismos para eliminar a sua causa. No caso das flutuações
serem devido a alterações nos equipamentos de medição, pode ser tomada a decisão de recalibração
dos sensores ou optar pela sua adaptação às novas condições processuais sem tomar nenhuma acção
correctiva.
Diferente frequências de amostragem: existem variavéis críticas para o controlo do processo e
necessárias para a construção do sensor cujos valores são analisados em laboratório (amostragem
offline), enquanto outras são automaticamente medidas (amostragem online). Quando as frequência de
amostragem são muito diferentes, há que optar por um dos conjuntos de dados, caso contrário podem-
se aplicar técnicas de reconsrtução dos dados em falta, como, por exemplo, modelos de interpolação.
Colinearidade: a redundância na instalação de sensores em processos industriais leva a que os
dados recolhidos sejam fortemente colineares. Isto constitui um problema para o desenvolvimento
de sensores inferenciais, uma vez que a informação redundante apenas contribui para o aumento da
complexidade do modelo, o que afecta a sua performance. Existem duas formas de lidar com este
problema: (i) transformar as variáveis de entrada num espaço com menos colinearidade (p.e., através
das técnicas PCA e PLS) ou (ii) seleccionar um subconjunto de dados das variáveis de entrada com
menos colinearidade.
2.5.2 Metodologia de desenvolvimento de sensores inferenciais
Nesta secção apresenta-se um conjunto de passos práticos que devem ser seguidos no processo de
desenvolvimento de sensores inferenciais (Figura 2.11). De notar que o procedimento é geral, con-
siste num conjunto de passos independentes e é considerado como um processo iterativo, em que as
escolhas efectuadas na fase de design do modelo devem ser revistas antes do sensor inferencial ser
efectivamente implementado [Haimi et al., 2013].
22

Figura 2.11: Visão geral dos passos envolvidos no desenvolvimento de sensores inferenciais e basea-dos em dados, adaptado de Kadlec et al. [2009].
2.5.2.1 Primeira inspecção dos dados
A recolha de dados e sua inspecção são os primeiros passos no desenvolvimento de um sensor infe-
rencial. No decorrer da primeira inspecção efectua-se uma análise exploratória de dados (ver Secção
2.4) com o intuito de perceber a sua estrutura e identificar problemas como a colineridade, valores em
falta e presença de outliers (ver Secção 2.5.1) que contribuem para a deterioração do dataset. É neste
passo que se exclui do conjunto de dados informação redundante ou insignificante e se decide acerca
da complexidade do modelo, isto é, se o sensor inferencial vai ser baseado em modelos de regressão
simples ou multivariados, que podem ser linerares, como o caso PLS, ou não-lineares, como Redes
Neuronais Artificiais (em inglês Artificial Neural Networks, ANN). Esta fase requer muito trabalho ma-
nual, está dependente da experiência de quem desenvolve o modelo e envolve a exploração exaustiva
dos dados, recorrendo à análise de séries temporais, scatter plots, histogramas ou, em alguns casos,
PCA biplots.
2.5.2.2 Selecção de variáveis
A selecção das variáveis de entrada do modelo constitui um passo crucial no desenvolvimento de um
sensor inferencial. Esta fase envolve a escolha das variáveis secundárias que contêm mais informação
relevante para a estimativa das variáveis primárias, de difícil medição. Como o modelo deve ser de fácil
interpretação, é importante manter um número relativamente reduzido de inputs. Uma possível técnica
usada para a selecção de variáveis é a redução da dimensionalidade do conjunto de dados, isto é,
transformação linear das variáveis originais num conjunto mais pequeno de combinação de variáveis
em que há preservação das propriedades e correlações entre os dados. Este é o caso da análise PCA
(ver Secção 2.4.5) e da técnica PLS (ver Secção 2.4.6).
2.5.2.3 Selecção de amostras
Quando está em causa um conjunto de dados reais, é frequente a existência de observações que
diferem da maioria e que podem representar possíveis outliers (ver Secção 2.5.1). A selecção de
amostras consiste na exclusão destas observações anormais, uma vez que a sua presença no conjunto
23

de dados pode conduzir à deterioração da capacidade preditiva do modelo. Este processo de selecção
envolve, mais uma vez, técnicas multivariadas, como PCA e PLS, associadas à análise dos resíduos
[Robinson et al., 2005]. Alternativamente, é possível recorrer à aplicação de métodos de clustering e
de classificação [Hastie et al., 2005].
2.5.2.4 Design do modelo
A selecção do tipo do modelo a implementar no sensor inferencial revela-se uma etapa preponderante
para a sua performance. Actualmente não existe um protocolo unificado para esta tarefa, pelo que o
design do modelo está fortemente dependente de quem o constrói, da sua experiência passada e das
suas preferências pessoais. Ainda assim, é frequente considerar duas tarefas principais: (i) selecção
da estrutura do modelo e (ii) treino, validação e teste do modelo. Muitas vezes inicia-se o processo
com tipos de modelos simples e vai-se aumentando o grau de complexidade dos mesmos até não se
observar uma melhoria significativa na performance. É importante, ao longo deste processo, garantir
que os modelos, além de efectuarem boas previsões, se mantêm simples, eficientes do ponto de vista
computacional, facilmente interpretáveis e com custos de manutenção reduzidos. Por fim, antes de se
efectuar previsões com o modelo recém-calibrado, deve-se proceder sempre à validação dos resultados
usando um conjunto de dados independente.
Selecção da estrutura do modelo: no caso dos modelos serem desenvolvidos para previsões on-
line, é necessário que estes reproduzam as relações existentes entre as variáveis secundárias e as
variáveis primárias. Em casos em que existe um elevado número de variáveis de entrada, é frequente
optar a métodos estatísticos multivariados, PCA, PLS e regressão de componentes principais, PCR de
forma a reduzir o espaço dimensional e facilitar a modelação e interpretação dos modelos desenvolvi-
dos. Existem extensões adaptativas e recursivas do PLS e PCR que podem ser usadas para capturar a
natureza dinâmica dos dados (a estrutura dos dados é variável ao longo do tempo). Por fim, as exten-
ções de kernel das técnicas PCA e PLS (KPCA e KPLS) são uma alternativa a que se recorre quando
os sistemas que se pretende modelar não são lineares [Rosipal and Trejo, 2002].
Treino, validação e teste do modelo: idealmente, se existirem dados disponíveis em quantidade
suficiente, deve ser deixado de fora do processo de calibração um conjunto de dados de validação para
testar a performance do modelo após calibração. Contudo, muitas vezes é complicado ter acesso à
quantidade necessária de dados, pelo que se opta por técnicas de estimativa de erro, como a validação
cruzada (do termo cross validation) - ver Secção 2.4.6.3. Após treino do modelo, a performance do
sensor é avaliada, quantitativa e qualitativamente, recorrendo a um conjunto de dados independente.
2.5.2.5 Manutenção do modelo
A manutenção do modelo é necessária devido a flutuações e mudanças nos dados, responsáveis pela
deterioração do modelo. Assim, é necessário haver uma compensação destes factores que envolve a
24

adaptação ou recalibração do sensor. Actualmente, grande parte dos sensores inferenciais não têm
nenhum mecanismo automático para a sua manutenção. No entanto, foi desenvolvido um conjunto
de abordagens no sentido das alterações no processo e nas condições operacionais serem tidas em
conta pelos modelos. Estas novas técnicas são versões adaptativas e recursivas de métodos multi-
variados, como PCA e PLS, ou são técnicas do tipo "neuro-fuzzy", isto é, mecanismos baseados no
desdobramento de novas unidades na estrutural neuronal do modelo quando uma mudança nos dados
é encontrada [Kadlec et al., 2011].
2.5.3 Aplicações de sensores inferenciais
No contexto do tratamento de águas residuais os sensores inferenciais podem assumir diversas fun-
ções, das quais se destacam: (i) previsão online de variáveis primárias, (ii) monitorização e detecção
de falhas no processo e (iii) monitorização e detecção de falhas de hardware. Ao longo desta secção
são abordadas mais detalhadamente as três aplicações supramencionadas, com especial foco para a
previsão de variáveis online, uma vez tratar-se do tema principal da presente dissertação.
2.5.3.1 Previsões online
A aplicação mais comum de sensores inferenciais é a previsão de valores que não podem ser medidos
online, o que se pode dever a razões de ordem tecnológica (não existe nenhum equipamento capaz
de efectuar a medição necessária) ou de ordem económica (o equipamento necessário é dispendioso).
Neste cenário, os sensores inferenciais podem fornecer a informação necessária sobre as variáveis de
interesse.
Na fase inicial de utilização de sensores inferenciais, as variáveis a prever eram essencialmente con-
centração de sólidos, CBO e CQO. Nas publicações mais recentes é mais frequente estimar a concen-
tração de nutrientes. Este facto reflecte o progresso da tecnologia de tratamento de águas residuais,
no sentido que, actualmente, as ETAR municipais são tipicamente projectadas para operarem proces-
sos de remoção de azoto. Por esta razão, é importante garantir a existência de informação fidedigna
no que diz respeito a concentrações de nutrientes no sistema de tratamento. As variáveis secundárias
mais usadas como input em casos de estudo de processos contínuos incluem caudais, pH, temperatura
e concentração de oxigénio dissolvido (OD). Em processos batch , além do pH e OD, o potencial de
oxidação-redução (em inglês, Oxidation Reduction Potencial, ORP) também é usado como variável de
entrada e os valores estimados são muitas vezes usados para controlar a duração das fases aeróbia
e anóxica [Haimi et al., 2013]. Em processos contínuos e em batch os métodos de modelação mais
usados para a estimativa das variáveis de saída são as Redes Neuronais Artificiais e a técnica PLS.
As variáveis de processo facilmente medidas online caracterizam-se por terem unidades diferentes, um
elevado número de variações não-sistemáticas e incluem essencialmente informação sobre o estado
físico do processo. Em contrapartida, a espectroscopia online para monitorização de processos inclui
informação sobre o estado químico do processo (concentração de substratos, produtos, composição e
concentração de biomassa), contém variações mais sistemáticas e todas as variáveis (comprimentos
25

de onda) são medidas nas mesmas unidades. Adicionalmente, o espectro é, muitas vezes, caracterís-
tico de determinados bioprocessos e, consequentemente, pode ser usado para supervisão e controlo
operacionais. Existem, ainda assim, potenciais dificuldades para a aplicação de espectroscopia in
situ, das quais se destacam: elevada sensibilidade a mudanças nas condições do processo, como
variações de temperatura e alterações das características fisico-químicas e composição do meio, e
ocorrência de efeitos de dispersão de luz (em inglês, light scattering). A optimização e selecção de
comprimentos de onda pode contribuir para ultrapassar alguns deste problemas, já que são considera-
das apenas zonas com menos interferências. Outra alternativa é a aplicação de técnicas matemáticas
de pré-processamento, que permitem corrigir fenómenos de dispersão e remover variações espectrais
indesejáveis [Lourenço et al., 2012].
Quimiometria e Espectroscopia: Define-se quimiometria como o uso de métodos matemáticos e es-
tatísticos para a análise de dados de um sistema químico e para a extracção de informação do estado
do sistema, com o intuito de caracterizar o seu comportamento e compreender os processos que nele
ocorrem. A relação deste conceito com o conceito de espectroscopia deve-se ao facto dos bioproces-
sos com monitorização online de carácter espectrofotométrico fornecerem uma elevada quantidade de
dados, caracterizados por um elevado grau de colinearidade e dos quais é necessário extrair, de forma
rápida, a informação relevante. Este factor associado à não-selectividade dos métodos espectrofoto-
métricos e à necessidade de compreender as relações entre as variáveis levou à aplicação de técnicas
de análise multivariada e outras ferramentas matemáticas aos dados espectrais. Estas técnicas quimi-
ométricas permitem reduzir o número de variáveis e auxiliam a análise e compreensão do processo,
ultrapassando assim problemas associados à redundância e interpretabilidade dos dados. Os métodos
mais usados são o PCA, PCR e PLS. As razões pelas quais estas técnicas são tão comumente aceitas
e usadas pela comunidade científica são: (i) a sua eficiência e simplicidade, (ii) a sua estabilidade ao
longo do tempo e (iii) a fácil interpretabilidade dos modelos. Além disso, este métodos estão por vezes
disponíveis em pacotes de software para operar o espectrofotómetro [Lourenço et al., 2012].
Pré-tratamento matemático dos dados espectrais: O objectivo do pré-tratamento de dados de ori-
gem espectral é eliminar ou, pelo menos, minimizar a variabilidade não relacionada com a propriedade
de interesse, de modo a realçar a informação relevante presente no conjunto de dados [Huang et al.,
2010]. Os métodos clássicos incluem técnicas de normalização, derivativas e de atenuação. Uma vez
que as variáveis, isto é, comprimentos de onda, são medidas na mesma unidade, os dados espectrais
são frequentemente normalizados recorrendo à técnica de mean centering. Esta operação envolve a
subtração da resposta de cada variável à média da resposta de todas as variáveis do dataset e, conse-
quentemente, remove a informação relacionada com a intensidade absoluta de cada variável, realçando
variações anteriormente inperceptíveis. A aplicação de métodos derivativos tem como finalidade elimi-
nar o ruído espectral e o efeito de dispersão da luz devido à presença de partículas [Lourenço et al.,
2006]. Os filtros mais frequentemente usados são o algoritmo de Saviztky-Golay (SG) [Kus et al., 1996]
e, em situações em que o fenómeno de dispersão de luz é dominante, MSC (em inglês, multiplicative
26

scatter correction) e SNV (em inglês, standard normal variate) [Lourenço et al., 2012].
Espectroscopia UV-Vis no contexto do tratamento de águas residuais: Tendo em conta o elevado
pontencial de sistemas de medição em linha para monitorização e controlo de qualidade de águas re-
siduais, a utilização da técnica de espectroscopia de ultravioleta-visível (UV-Vis) constitui-se como uma
ferramenta de apoio à operação de sistemas de tratamento, principalmente em Portugal, onde muitos
destes sistemas ainda se encontram em fase de implementação. A espectroscopia UV-Vis corresponde
à interacção de amostras com a radiação na região espectral de 200 a 780 nm. Trata-se de uma técnica
simples e rápida que tem sido usada como complemento de avaliação da qualidade de águas residu-
ais e identificação de componentes da matriz orgânica, já que a maioria dos compostos orgânicos e
alguns compostos minerais solúveis, como os nitratos, absorvem radiação na região UV-Vis [Lourenço
et al., 2006; Lourenço et al., 2012]. A disponibilidade no mercado de sensores de fibras-ópticas de alta
qualidade aliada ao desenvolvimento de espectrofotómetros submersíveis robustos com sistemas de
limpeza automáticos possibilitou o uso de dados espectrais na região UV-Vis para monitorização multi-
variada em tempo real de processos de tratamento de águas residuais. Métodos quimiométricos como
PCA e PLS têm-se revelado bastante úteis para extracção de informação relevante dos espectros. A
análise de componentes principais de espectros de amostras de águas residuais revelou que a infor-
mação contida nesses espectros pode ser usada para controlo de qualidade. Por sua vez, os modelos
PLS contruídos a partir de informação espectral mostraram ser eficientes na previsão de CQO, carbono
orgânico total (em inglês Total Organic Carbon, TOC), SST e nitratos [Lourenço et al., 2010; Lourenço
et al., 2012, 2008]. A Tabela 2.2 compila a informação de alguns estudos publicados nesta área de
investigação.
Apesar dos estudos apresentados, a aplicação de espectroscopia UV-Vis na monitorização in situ de
águas residuais continua limitada. Este facto pode, em parte, dever-se às desvantagens que decorrem
do uso desta técnica espetrofotométrica, nomeadamente: (i) as amostras serem fortemente afectadas
pela presença de uma segunda fase (líquidos imiscíveis ou existência de partículas em suspensão
dispersas na fase aquosa), o que resulta em efeitos de dispersão de luz significativos, e (ii) haver
necessidade de recorrer ao uso de métodos quimiométricos, uma vez que uma simples visualização
dos dados normalmente não é suficiente para extrair a informação suficiente dos espectros devido
à presença de bandas largas e inespecíficas [Lourenço et al., 2012]. Concretamente, no caso do
desenvolvimento de modelos PLS para estimativa da carga orgânica em sistemas de tratamento de
águas residuais, é necessário considerar a eventualidade de existirem desvios significativos devidos a
alterações na composição da matriz orgânica. Assim, ao contrário dos métodos analíticos, que são
sensíveis a praticamente todo o carbono orgânico presente nas amostras de águas residuais, o método
espectrofotométrico só detecta a fracção que absorve luz na região UV-Vis. Isto significa que uma
parte importante (p.e., ácidos orgânicos, hidratos de carbono) não é detectada, pelo que uma alteração
significativa da sua proporção relativa na água residual em estudo poderá invalidar o modelo PLS
desenvolvido. Por esta razão, a visualização do padrão espectral via análise PCA constitui um passo
essencial na correcta utilização da espectroscopia UV-Vis na monitorização em tempo real de águas
27

residuais, pois permite a rápida detecção de alterações na matriz orgânica [Lourenço et al., 2006;
Lourenço et al., 2008].
2.5.3.2 Monitorização de detecção de falhas no processo
A monitorização e detecção de falhas no processo por parte de sensores inferenciais tem sido alvo de
estudo, existindo actualmente diversas metodologias focadas na sua aplicação em ETAR. Inicialmente,
os sensores inferenciais eram desenvolvidos para a monitorização de episódios de acumulação de
um elevado volume de lamas no sistema, responsáveis pela redução da qualidade do efluente e pela
alteração das condições operatórias dos processos de lamas activadas. Um exemplo é a monitorização
do índice de volume de lamas (em inglês Sludge Volume Index, SVI), que descreve as propriedades
de sedimentação das lamas. Tendo em conta que acumulação de lamas no sistema é um processo
lento e que os modelos estão fortemente dependentes de medidas off-line, é razoável que os objectivos
da monitorização de falhas sejam direccionados para a detecção destes episódios anómalos. Com o
avanço das tecnologias de monitorização em tempo real em ETAR, foi possível desenvolver sensores
capazes de monitorizar e detectar anomalias mais abruptas no sistema. Estes podem ser treinados
para descrever situações operacionais normais ou para reconhecer possíveis falhas no processo. As
variáveis de entrada mais usadas para monitorização são caudais, pH, temperatura, OD e concentração
de nutrientes medida em diferentes locais do processo de tratamento. Tipicamente são usados métodos
multivariados como o PCA ou Mapas Auto-Organizáveis (em inglês Self-Organizing Maps, SOM), uma
técnica com base em ANN, combinados com algoritmos de clustering [Kadlec et al., 2009; Haimi et al.,
2013].
2.5.3.3 Monitorização e detecção de falhas de hardware
A maioria das técnicas de modelação não consegue lidar com dados provenientes de sensores com
potenciais avarias. Por esta razão, é necessário garantir que as falhas processuais e de hardware
sejam identificadas e o sensor responsável seja substituído antes de desenvolver e aplicar o modelo de
descrição do tratamento. Tipicamente, são usadas técnicas de análise multivariada, como o PCA, mais
concretamente, a análise do espaço residual. Os estudos publicados nesta área são muito recentes
e estão relacionados com a monitorização de amónia e nitratos num processo de lamas activadas. A
maioria retrata resultados de processos simulados, não existindo publicações em que sejam usados
dados reais de ETAR, o que sugere que a monitorização e detecção de falhas de sensores é uma área
de investigação emergente [Haimi et al., 2013].
28

Tabela 2.2: Resumo de alguns estudos publicados no contexto da monitorização em tempo real de parâmetros de qualidade de águas residuais através dodesenvolvimento de modelos PLS com base em informação espectral na região ultravioleta-visível.
Referência Aplicação Descrição e Objectivos do estudo Sistema espectrofotométrico TécnicasQuimiométricas Principais Resultados
[Lourençoet al., 2010]
3 ETAR municipais(Almada, Portugal)
Monitorização in situ da concentração desólidos, para avaliação das diferenças aolongo da linha de tratamento e entre dife-rentes sistemas de tratamento; Previsão deSST.
Espectrofotómetro UV-VIS CA-DAS 100; Fonte de luz: lâm-pada tungsténio-halogénio; In-tervalo de medição: 282-790 nm
PCA; PLS; Selecção λ
Análise PCA permitiu salientar as diferenças na qualidade dos sólidosnas 3 ETAR e ao longo das linhas de tratamento. É uma ferramentaplausível de ser usada no controlo de qualidade das águas residuais; Aestimativa de SST nos diferentes pontos de amostragem de cada ETARfoi possível usando apenas um único modelo PLS, apesar das variaçõesde concentração de sólidos existentes. O modelo desenvolvido constituiuma alternativa viável às medições de turbicidade.
Lourençoet al. [2008]
ETAR de um parquede combustíveis(CLC, Aveiras deCima, Portugal)
Monitorização da qualidade de um efluentede um sistema de tratamento de águas re-siduais de origem industrial; Previsão TOC.
Espectrofotómetro UV-VIS Spe-cord 200; Fonte de luz: lâm-pada tungsténio-halogénio; In-tervalo de medição: 190-500 nm
PLS; Selecção λ
O modelo PLS desenvolvido e validado é muito satisfatório para a pre-visão de TOC, que se trata de um parâmetro relevante para avaliaçãodo nível de poluição devido à presença de carga orgânica em águasresiduais.
Lourençoet al. [2006]
ETAR de um parquede combustíveis(CLC, Aveiras deCima, Portugal)
Caracterização de amostras recolhidas etentativa de identificação preliminar de con-taminantes na água tratada; Previsão CQOpara monitorização em tempo real desteparâmetro.
Espectrofotómetro Hitachi 150-20 UV-Vis; Fonte de luz: lâm-pada tungsténio-halogénio; In-tervalo de medição: 190-300 nm
PCA; PLS; Selecção λ
O PCA permitiu a identificação preliminar de produtos químicos empre-gues no processo (lubrificantes e detergentes) como prováveis conta-minantes residuais no efluente tratado. O modelo PLS desenvolvidorevelou um elevado potencial de aplicação como método rápido e eco-nómico para a estimativa em linha do parâmetro CQO em descargas deáguas tratadas.
Langergraberet al. [2003]
Amostras dereferência de águasresiduais de origem
industrial
Monitorização in situ de CQO, CQO fil-trado, SST e nitratos
Espectrofotómetro UV-VIS sub-mersível (spectro::lyser, s::can)com sistema de limpeza auto-mático; Fonte de luz: lâmpadade xenon; Intervalo de medição:200-750 nm
PLS; Selecção λ
A calibração global disponível no equipamento é válida para ETAR muni-cipais típicas, não havendo necessidade de calibração local na maioriados casos. O estudo mostrou que as amostras de referência usadas noprocesso de calibração do modelo são críticas para a sua performance,pelo que é necessário garantir a sua qualidade e representabilidade.
Hofstaedteret al. [2003] Conduta de esgoto Monitorização online de nitrato para pre-
venção de odores.
Espectrofotómetro UV-VIS sub-mersível (spectro::lyser, s::can)com sistema de limpeza auto-mático; Fonte de luz: lâmpadade xenon; Intervalo de medição:200-750 nm
PLS; Selecção λ
A utilização de um espectrofotómetro submsersível permite a monito-rização online e in situ da concentração de nitratos numa conduta deesgoto. Isto possibilita o controlo do odor através de um sistema auto-mático de dosagem de nitrato de ferro.
Rieger et al.[2004]
ETAR municipal(Suiça)
Monitorização in situ de NO2,NO3, CQO,carbono orgânico dissolvido e SST numefluente de ETAR
Espectrofotómetro UV-VIS sub-mersível (spectro::lyser, s::can)com sistema de limpeza auto-mático; Fonte de luz: lâmpadade xenon; Intervalo de medição:200-750 nm
PLS; Selecção λ
Boa precisão para os modelos de previsão de CQO e carbono orgânicodissolvido. Medições para SST não foram satisfatórias, uma vez que asonda não cobre a região acima de 700 nm, onde há melhor sinal paraa calibração de SST e uma forte correlação com a turbidez da amostra.
Pons et al.[2005]
ETAR grandedimensão (350 000PE), Nordeste de
França
Estimativa CQO e espécies azotadas(amónia e azoto orgânico) para controloonline da ETAR
Espectrofotómetro: HachDR2400 (turbidez); SecomanAnthelie Light (UV-Vis); Jobin-Yvon JY3, fonte de luz: lâmpadade xenon 150 W e Perkin-ElmerL50B (fluorescência)
PCA; PLS; Selecção λ
Os modelos baseados em informação na região espectral UV-Vis e tur-bidez são semelhantes. No entanto, mostraram necessidade de seremadaptativos para cobrir as variações da actividade humana. Os modelosbaseados em espectroscopia de fluorescência tem uma melhor perfor-mance considerando apenas regiões específicas, relacionadas com apresença de urina e ácidos fúlvicos.
29

2.5.4 Problemas actuais e Trabalho futuro
Actualmente existem 2 problemas principais associados à construção de sensores inferenciais [Kadlec
et al., 2009]. O primeiro está relacionado com a fase de desenvovimento, que exige muito esforço
manual, não só no pré-tratamento dos dados, como também nos passos de selecção e validação do
modelo. É necessário lidar com problemas como a falta de dados e a presença de outliers e, para tal,
o designer do modelo tem de testar diferentes abordagens de pré-processamento e escolher a que
garante uma melhor performance do modelo construído. Adicionalmente, há que ter em conta que, em
muitos casos, o densenvolvimento do modelo é um processo iterativo, o que significa que, quando se
optimiza uma parte, é necessário avaliar a sua influência nas restantes e, caso necessário, efectuar
ajustes nas partes afectadas. O segundo obstáculo diz respeito à deterioração gradual da performance
do sensor. Após o estabelecimento do sensor inferencial, o modelo perde progressivamente capacidade
preditiva, essencialmente devido a mudanças no processo. Isto obriga a que, a determinada altura, o
modelo necessite de manutenção, o que implica a sua recalibração e, em alguns casos, construí-lo
novamente.
A estes constrangimentos, associam-se outros factores como: (i) a falta de técnicos especializados nas
ETAR - os operadores sentem-se mais confortáveis em lidar com os sistemas de monitorização con-
vencionais, como sensores físicos, e não têm conhecimentos suficientes para participar no densenvol-
vimento de soluções alternativas, como o design de sensores inferenciais; e (ii) falta de conhecimentos,
por parte dos engenheiros especializados em sistemas de tratamento de águas residuais, de análise
estatística multivariada e de técnicas de inteligência artificial, úteis para lidar com a elevada quantidade
de dados medidos em ETAR modernas.
Com base nestas considerações, a investigação futura nesta área deve focar-se em alertar para a
importância e potencial da implementação de sensores inferenciais em ETAR como alternativa às so-
luções de monitorização convencionais que se praticam actualmente. Os sensores inferenciais devem
ser construídos numa perspectiva de resolução de problemas e não de desenvolvimento de metodolo-
gias complicadas baseadas em conceitos teóricos. Ou seja, as soluções devem ser simples e aplicadas
de acordo com o problema existente [Haimi et al., 2013].
2.6 Caso de Estudo - ETAR de Bucelas
2.6.1 Selecção do caso de estudo
A metodologia DEMOCON consiste num conjunto de procedimentos baseados na aquisição em linha
de dados do processo e sua utilização num modelo mecanístico para controlo do sistema de tratamento.
Esta metodologia encontra-se subdividida em três fases: (i) etapa de monitorização que visa a obten-
ção de informação sobre o sistema de tratamento, (ii) etapa de diagnóstico operacional, que tem
como objectivo a avaliação do funcionamento do sistema de tratamento e identificação de eventuais
problemas e (iii) etapa de controlo, que consiste no desenvolvimento de estratégias para a melhoria
do funcionamento da ETAR e na aplicação das acções seleccionadas. O trabalho desenvolvimento no
30

decurso da presente dissertação foca-se nas duas primeiras fases [Ribeiro, 2011; Encarnação, 2014].
No contexto da etapa de monitorização, a metodologia DEMOCON apresenta uma forte componente
experimental a ser desenvolvida numa ETAR descentralizada, cujo principal objectivo é o desenvolvi-
mento de sensores inferenciais e de um modelo matemático descritivo do processo de tratamento das
águas residuais afluentes. Com efeito, no período do projecto foram realizadas 9 campanhas para re-
colha de informação: duas preliminares (P1 e P2) para aferir o plano de monitorização e efectuar testes
de procedimentos, quer na ETAR, quer em laboratório; três de calibração (C1, C2 e C3), cujo principal
objectivo foi a recolha de amostras, quer para determinação de parâmetros do modelo matemático,
quer para o desenvolvimento dos modelos PLS; e quatro de validação (V1, V2, V3 e V4), onde foram
realizadas medições para a avaliação do efeito de acções de controlo. A empresa Águas de Lisboa
e Vale do Tejo (AdLVT) participa neste projecto como entidade gestora e possível utilizadora da plata-
forma DEMOCON, fornecendo o caso de estudo. Entre as diversas ETAR exploradas pela AdLVT, a
ETAR de Bucelas é a que reúne as condições requeridas para o desenvolvimento do projecto. O seu
potencial neste contexto deve-se aos seguintes factores [Ribeiro et al., 2014]:
• Pequena Dimensão - a ETAR de Bucelas serve a freguesia de Bucelas com uma população de
cerca de 4600 habitantes (dados dos Censos de 2011);
• Funcionamento Descentralizado - a operação é assegurada através de visitas regulares (diá-
rias) efectuadas pelo pessoal técnico de operações;
• Sistema de Tratamento por Lamas Activadas - a modelação matemática deste tipo de trata-
mento já se encontra muito desenvolvida, existindo, por isso, modelos e formulações estabilizados
e largamente aceites nos domínios técnico e científico (ex: família ASM da IWA - ver Secção 2.3);
• Afluência de águas residuais de origem essencialmente doméstica - este tipo de afluência é
favorável ao desenvolvimento dos processos de tratamento biológico;
• Inexistência de contribuição industrial significativa na afluência - permite diminuir o risco de
ocorrência de fenómenos de toxicidade no tratamento biológico que, além de exigirem interven-
ções técnicas na ETAR, dificultam a modelação;
• Existência de contribuição pluvial na afluência - aumenta o grau de variabilidade da afluência
à ETAR, justificando a utilização de equipamentos de monitorização em linha;
• Infraestruturas em boas condições - a ETAR é de construção recente, tendo sido alvo de me-
lhorias do seu funcionamento, nomeadamente a inclusão de tratamento terciário (filtração e de-
sinfecção UV);
• Nível de automação adequado - a ETAR dispõe de um conjunto de anéis de controlo com pos-
sibilidade de aplicação de diversas programações;
• Condições favoráveis à instalação de dispositivos de monitorização em linha - por exemplo,
é possível a instalação de espectrofotómetros submersíveis a montante e jusante da etapa de
tratamento biológico.
31

2.6.2 Sistema de Tratamento da ETAR de Bucelas
A ETAR de Bucelas está em funcionamento desde 2004 e possui 3 níveis de tratamento: tratamento
preliminar, tratamento secundário em valas de oxidação e tratamento terciário, posteriormente imple-
mentado, que inclui filtração em areia e desinfecção por radiação ultravioleta. O tipo de tratamento
secundário a operar na ETAR (sistema de lamas activadas em vala de oxidação) implica a existência de
uma linha de tratamento de sólidos, onde as lamas em excesso retiradas do sistema são encaminhadas
e devidamente tratadas [Ribeiro et al., 2014].
De seguida, apresenta-se uma breve descrição dos principais processos unitários constituintes do tra-
tamento da fase líquida e da fase sólida da ETAR de Bucelas. O diagrama de operações de todo o
processo de tratamento da ETAR de Bucelas encontra-se representado na Figura 2.12. As Figuras
2.13 e 2.14 apresentam as plantas da ETAR de Bucelas para o tratamento da fase líquida e da fase
sólida, respectivamente.
Figura 2.12: Diagrama de Operações do processo de tratamento da fase líquida e a fase sólida daETAR de Bucelas. As linhas a cheio significam operação em modo contínuo, enquanto que as linhasa tracejado correspondem a operação em modo intermitente. Os círculos cinzentos representam oscaudalímetros instalados na ETAR e os triângulos verdes assinalam os locais de recolha de amostrasem períodos de campanhas. Quanto às variáveis, Q representa valores de caudal e X diz respeito àconcentração de sólidos suspensos. O termo EMERG indica correntes de by-pass geral à ETAR, istoé, saídas de emergência da linha de tratamento da fase líquida.
32

Figura 2.13: Planta da ETAR de Bucelas, excluindo o tratamento terciário e da fase sólida. A caixa paraonde é encaminhada a lama decantada é fisicamente a mesma que a caixa distribuidora do caudal dealimentação às valas de oxidação, Cx_VO.
2.6.2.1 Tratamento da Fase Líquida
Tratamento Preliminar: Esta fase inicial do tratamento inclui as operações a montante do tratamento
biológico, cuja finalidade é a remoção de matérias das águas residuais que possam prejudicar a efici-
ência do tratamento ou danificar os equipamentos subsequentes: elevação inicial, gradagem, remoção
de areias e gorduras e medição de caudal.
À entrada da ETAR, o esgoto bruto é descarregado numa câmara de admissão que alimenta os para-
fusos de Arquimedes, responsáveis pela elevação de caudal necessária ao funcionamento hidráulico
da ETAR. Por questões de segurança, o tanque de chegada está equipado com um by-pass geral à
estação que pode ser usado quando o caudal de entrada é superior à carga suportada pela ETAR.
Após a elevação, as águas afluentes são conduzidas através de um canal que conduz à tamisagem
mecânica. Nesta operação, os gradados são compactados e removidos mecanicamente de modo a
reduzir o seu volume e teor de humidade. Após compactação, são armazenados em contentores e, por
fim, transportados juntamente com as lamas desidratadas até ao seu destino final.
Uma vez removidos os gradados, as águas residuais são encaminhadas para um canal de Parshall
onde é efectuada uma medição de caudal [SIMTEJO, 2004].
O passo seguinte é a remoção de areias e gorduras no desarenador/desengordurador, cujo objectivo
é proteger o equipamento electromecânico instalado a jusante e evitar possíveis obstruções nos co-
lectores e aderência de gorduras às peças do sistema hidráulico. A areia extraída do desarenador é
separada da água num classificador de areias. Neste equipamento, a areia lavada é extraída através
33

de um parafuso sem fim e armazenada em contentores adequados. O líquido é descarregado através
de um sistema de overflow e recirculado ao tanque inicial de admissão do esgoto bruto à ETAR. Rela-
tivamente às gorduras e óleos, estes são recolhidos numa caleira superficial, conduzidos a um tanque
de separação e finalmente armazenados em contentores adequados ao transporte final.
Tratamento Secundário: Após o pré-tratamento, a água residual entra num sistema de tratamento
biológico por lamas activadas na sua variante de arejamento prolongado (ver Secção 2.1). O ambi-
ente aeróbio é conseguido através de uma sistema de arejamento constituído por arejadores de eixo
horizontal do tipo rotor. Teoricamente, num sistema de valas de oxidação, nas zonas próximas ocorre
nitrificação enquanto que, nas zonas mais afastadas, predominam fenómenos de desnitrificação. Con-
tudo, no caso da ETAR de Bucelas isto não se verifica; uma vez que as valas não têm extensão sufi-
ciente, quando o arejamento está a funcionar, o oxigénio fornecido ao sistema é difundido para todo o
líquido (ainda que exista um gradiente de concentrações) impedindo que, nos pontos mais afastados
dos arejadores, se verifiquem condições anóxicas. Consequentemente, é necessário fixar períodos
de arejamento para estabelecimento de condições aeróbias e períodos em que este é interrompido,
garantindo condições de anoxia.
As valas de oxidação têm associado um sistema de recirculação parcial das lamas activadas dos de-
cantadores secundários, de modo a assegurar a manutenção de uma concentração permanente no
tanque. Assim, a purga ou extracção de lamas destina-se a retirar do sistema o excesso de células
produzidas.
Uma vez realizado o tratamento biológico, o efluente segue para dois decantadores de planta circular
com raspadores de fundo para ser clarificado. O design destes equipamentos está feito para que o
efluente entre pelo centro do decantador, o que o obriga a entrar por baixo e percorrer radialmente
a distância até aos descarregadores. Durante este percurso as partículas vão-se sedimentando e
acumulando no fundo do tanque. O efluente decantado sai através de descarregadores triangulares,
passando por baixo do defletor periférico, cuja função é reter partículas em suspensão, que serão
posteriormente retiradas pelo raspador de superfície.
As lamas sedimentadas são descarregadas e conduzidas graviticamente até à estação elevatória de
recirculação de lamas, onde podem ter dois destinos diferentes: ou são conduzidas para a caixa dis-
tribuidora de caudais e retornam às valas de oxidação (recirculação), ou são encaminhadas para o
sistema de tratamento de lamas (extracção de lamas em excesso) [SIMTEJO, 2004].
Tratamento Terciário: O efluente proveniente dos decantadores secundários segue em direcção a
um poço de bombagem, "Estação elevatória do efluente secundário", a partir do qual é elevado em di-
recção a um conjunto de três filtros de areia através de um grupo electrobomba submersível. Este grupo
actua de acordo com o nível no poço de admissão ao tratamento terciário. Por questões de segurança,
o poço está equipado com um descarregador de emergência para o emissário final, o Rio Trancão, que
funciona em caso de avaria ou manutenção do grupo electrobomba. A água filtrada é encaminhada
para o sistema de desinfecção UV. As escorrências de lavagem dos filtros são recirculadas à estação
34

elevatória inicial da ETAR.
Tal como previamente mencionado, a desinfecção do efluente filtrado é efectuada por radiação UV pro-
duzida através de um sistema de UV, instalado a jusante da filtração. Este é constituído por lâmpadas
dispostas horizontalmente em módulos, os quais são colocados paralelamente à direcção do escoa-
mento. À saída do canal encontra-se um descarregador estático que garante o nível de água no canal,
independentemente do caudal. De notar que o funcionamento do sistema de desinfecção não possui
qualquer tipo de automatismo. À saída do canal UV, uma parte da água tratada é descarregada no Rio
Trancão, enquanto que a restante é encaminhada para um reservatório de água tratada, ao qual se en-
contra associada uma bomba centrífuga de lavagem dos filtros, bem como uma central hidropneumática
de água de serviço [SIMTEJO, 2009].
2.6.2.2 Tratamento da Fase Sólida
Figura 2.14: Planta do tratamento da fase sólida efectuado na ETAR de Bucelas.
A linha das lamas, cuja planta se encontra esquematizada na Figura 2.14, começa com o encaminha-
mento das lamas, por acção de grupos electrobomba, desde a Estação Elevatória de Recirculação até
um espessador de planta circular com ponte raspadora (ponto a), onde é reduzido o seu teor de humi-
dade. De seguida, as lamas espessadas são bombeadas para a unidade de desidratação, localizada
no edifício de desidratação de lamas (pontos b e c). A operação de desidratação é precedida de condi-
cionamento químico que consiste na adição de uma solução de polielectrólito catiónico, cujo objectivo
é optimizar o rendimento da operação.
A desidratação das lamas em excesso é feita mediante uma prensa de lamas de dupla tela. A lama
é colocada entre duas telas que convergem uma para a outra, na zona em cunha. Isto faz com que a
lama passe por uma zona de pressão constituída por tambores progressivamente menores, sendo que
os primeiros são perfurados de modo a permitir o escoamento dos filtrados. A redução de diâmetro
provoca uma aumento da pressão exercida sobre a lama, potenciando o processo de extracção de
35

água. Durante todo o período de funcionamento, as telas são lavadas com jactos de água sob pressão
para garantir que estão em perfeito estado de limpeza e permeabilidade.
Por fim, as lamas desidratadas são armazenadas em contentores e tranportadas para o seu destino fi-
nal. Os drenados e escorrências das operações de espessamento e desidratação regressam à estação
elevatória inicial [SIMTEJO, 2004].
2.6.3 Sistemas de Monitorização e Controlo
A ETAR de Bucelas tem diversos tipos de instrumentação instalados para monitoriação das águas
residuais e para controlo operacional dos processos de tratamento. Estes equipamentos encontram-
se colocados em diferentes pontos do sistema de tratamento e funcionam em modo automático. O
sistema de monitorização em linha engloba as seguintes medições: caudal (águas residuais afluentes
e efluente do tratamento secundário) e medição de oxigénio dissolvido (licor misto). A ETAR possui
ainda equipamento para a recolha automática de amostras (águas residuais afluentes e efluente final,
isto é, após etapa de desinfecção). Em termos de controlo operacional, existem diversos sistemas
automáticos nas várias etapas do tratamento [Ribeiro et al., 2014]. No anexo A é possível consultar um
quadro com informação relativa à instrumentação e monitorização instalada na ETAR e um quadro com
uma síntese dos sistemas de controlo implementados.
36

Capítulo 3
Metodologias, Resultados e
Discussão
3.1 Análise de Caudais na Linha de Tratamento da Fase Líquida
Ao longo da linha de tratamento da fase líquida existem dois caudalímetros instalados, que asseguram a
monitorização do caudal afluente e do caudal de efluente biológico. Sendo um dos objectivos principais
do projecto DEMOCON a optimização do processo de tratamento biológico, é importante ter o máximo
conhecimento das características das águas afluentes. Por este motivo, efectuou-se uma análise do
sistema a montante das valas de oxidação (tratamento preliminar) onde se procurou caracterizar cada
uma das correntes representadas no diagrama de operações.
3.1.1 Origem dos dados e metodologias aplicadas
Os dados de caudal são obtidos graças a medidores de caudal instalados na ETAR, sendo que existem
dois pontos de medição, conforme assinalado na Figura 2.12. O caudal de águas afluentes é medido
no canal de Parshall situado após o tamisador, através de um sensor de nível electrónico que faz a
conversão automática de nível para caudal recorrendo, para tal, a uma equação característica. No caso
do caudal de efluente biológico, é usado um caudalímetro electromagnético a jusante do tratamento
biológico e antes da entrada das águas no tratamento terciário. Ambos os medidores fornecem medidas
com uma frequência horária. Nesta análise foram considerados os dados de caudal desde Janeiro de
2013 a Dezembro de 2014.
Os dados de precipitação e evapotranspiração, necessários para ter uma estimativa da influência dos
fenómenos atmosféricos no processo de tratamento das águas residuais, foram extraídos dos relatórios
de agrometeorologia do Instituto Português do Mar e Atmosfera, disponíveis online 1. No caso dos
dados de precipitação, consideraram-se os valores médios decendiais (em mm) para zonas a Norte
do Tejo. Quanto aos dados de evapotranspiração, foram tidos em conta os valores acumulados por
1http://www.ipma.pt/pt/publicacoes/boletins.jsp?cmbDep=agr&cmbTema=fog&cmbAno2013&idDep=agr&idTema=&curAno=-1
37

década do mês após análise da distribuição espacial no território português. Uma vez que os dados
apresentados se tratam de valores acumulados da década, considerou-se a média diária.
Ao longo da análise de caudais foi necessário ter conhecimento de algumas características inerentes ao
equipamento na ETAR onde decorre o tratamento das águas residuais afluentes, nomeadamente a área
das valas de oxidação, disponibilizada em SIMTEJO [2004], e a altura média de água acima do vértice
do descarregador do classificador de areias, necessária para o cálculo do caudal do classificador de
areias. Este último dado foi medido no decorrer das campanhas realizadas na ETAR de Bucelas.
A análise efectuada começou com um pré-processamento dos dados de caudal através da aplicação
de filtros de atenuação de ruído. Uma vez escolhido o melhor filtro, os dados foram filtrados e, de
seguida, as variações foram avaliadas segundo diferentes janelas temporais: representou-se a evolução
do caudal ao longo do mês, para os vários meses do ano, o que permitiu observar o panorama geral
mensal; para comparar directamente o comportamento do caudal para diferentes meses, optou-se por
uma representação do tipo boxplot, pois permite uma visão mais compactada da informação; avaliou-
se ainda os perfis diários de caudal, com o objectivo de detectar tendências e padrões de caudal
e estabelecer relações de causa-efeito com factores externos da ETAR, tais como hábitos e rotinas
da população abrangida por esta unidade de tratamento. Para tal, desenvolveu-se um modelo PCA
considerando que cada dia do mês é uma observação, o que permite comprimir a informação de um dia
num só ponto no scores plot. Avaliando a distribuição das observações é possível identificar clusters, ou
seja, vários dias do mês que seguem a mesma tendência de variação de caudal ao longo do dia. Com
esta análise pretendia-se, ainda, tentar isolar o comportamento da operação de lavagem dos filtros de
areia, uma vez tratar-se de uma corrente de recirculação à estação elevatória inicial para a qual não se
tem qualquer tipo de informação. Para tal, considerou-se um mês onde se sabia à priori que a extracção
de lamas não esteve a decorrer, obrigando ao funcionamento contínuo da lavagem em contra-corrente
dos filtros de areia.
Para tornar a análise de caudais mais completa avaliou-se a influência de factores externos nas carac-
terísticas da afluência e no tratamento. Foi estudada a influência da precipitação no caudal afluente,
através da análise de um biplot representativo da análise PCA em que se considerou cada dia do mês
como observação e as horas do dia e precipitação como variáveis. Uma vez que as valas de oxidação
têm uma área considerável, efectuou-se uma estimativa do caudal de precipitação e evapotranspiração
com o intuito de concluir se estes podem ser desprezados ou se devem ser incluídos no modelo do
tratamento biológico.
Por fim, determinou-se o caudal do classificador de areias tendo em conta o tipo de descarregador de
saída do tanque e assumindo como válida as leis de vazão conhecidas.
3.1.2 Pré-tratamento de dados de caudal afluente e efluente
O primeiro passo do tratamento de dados consistiu num pré-processamento dos dados de caudal aflu-
ente, Qaf_SIM, e caudal efluente, Qef, uma vez que estas medições tem muito ruído associado. Esta
etapa envolveu a escolha de um filtro adequado que garantisse, simultaneamente, atenuação de ruído
38

sem perda de informação relevante. Foram testados vários filtros, recorrendo ao software MS Excel,
sendo que o que preencheu melhor este requisito foi a Janela de Hamming de 5 pontos (ver Secção
2.4.1).
Na Figura 3.1 é possível observar o efeito de três filtros diferentes, para o caudal afluente e efluente
correspondentes ao mês de Outubro de 2014. Como é possível observar, a aplicação do filtro Savitzky-
Golay de 5 pontos produz um efeito contrário ao desejado, uma vez que acrescenta ruído ao que
já existe inicialmente e além disso, altera a gama de valores originais. Por seu lado, recorrendo à
média móvel de 7 pontos centrada, obtém-se o resultado contrário, isto é, há uma atenuação de ruído
exagerada que conduz à perda de informação e que pode esconder tendências que sejam visíveis na
representação das variações de caudais com os valores originais. A Janela de Hamming de 5 pontos
consegue um equilíbrio entre atenuação de ruído e preservação de informação relevante.
(a) Valores Originais
(b) Janela de Hamming 5 pontos
(c) Média Móvel Centrada 7 pontos
(d) Savitzky-Golay 5 pontos
Figura 3.1: Aplicação de filtros de atenuação de ruído aos dados de caudal afluente, Qaf_SIM, (à es-querda) e efluente, Qef, (à direita) do mês de Outubro de 2014.
3.1.3 Análise das variações anuais
A representação sobre a forma de boxplots anuais para o caudal afluente e caudal efluente permite
ter um panorama geral das variações ao longo do ano à entrada da ETAR e à saída do tratamento
39

secundário. Esta forma condensada de representar os dados é especialmente vantajosa para detectar
meses particularmente anómalos, identificar efeitos de sazonalidade e estabelecer uma comparação
directa entre os valores médios de Qaf_SIM e Qef. De seguida apresentam-se os boxplots para os caudais
afluente e efluente, desde Janeiro de 2013 até Dezembro de 2014. Estes foram construídos recorrendo
à linguagem de programação R.
Figura 3.2: Boxplots com dados de caudal afluente, Qaf_SIM, e efluente, Qef, correspondentes ao anode 2013 e 2014.
A partir da observação dos gráficos presentes na Figura 3.2 conclui-se que a variabilidade em termos
de caudal afluente é maior em 2013 que em 2014 mas, em relação ao caudal efluente não existem
diferenças tão significativas. Outro facto relevante é a existência de sazonalidade em termos de caudal
afluente, com reflexão no caudal efluente, uma vez que para meses de Verão a mediana é conside-
ravelmente mais baixa. Por fim, era expectável que os efeitos de variação de caudal afluente fossem
atenuados ao longo do processo de tratamento, fazendo-se sentir menos no caudal efluente. Ou seja,
o resultado deveria ser boxplots de caudal efluente com a mesma tendência observada para o Qaf_SIM,
mas com caixas mais estreitas. No entanto, isto não se verifica em maior parte dos meses, principal-
mente a partir de Janeiro de 2014.
De modo a estabelecer uma comparação dos valores medidos de caudal afluente e efluente, é neces-
sário ter em conta o volume de controlo que engloba estes dois pontos de medição no diagrama de
40

operações e analisar as correntes de entradas e de saída do mesmo. Na Figura 3.3 apresenta-se o
diagrama de operações com o volume de controlo considerado. Como se pode observar, considerando
o volume de controlo assinalado, tem-se como entradas no sistema o caudal de precipitação (Qprec) e
um caudal de água de serviço, usado para quebrar mecanicamente as lamas provenientes das valas
de oxidação antes de seguirem para a decantação secundária (Cx_DS), e como saídas, o caudal do
classificador de areias (Qclass), o caudal de evapotranspiração (Qevap), o caudal de lamas extraídas (Qle)
e a saída de emergência (EMERG), situada antes do caudalímetro que mede o caudal efluente.
Figura 3.3: Diagrama de operações da ETAR de Bucelas com o volume de controlo entre os caudalí-metros de caudal afluente e efluente assinalado a tracejado vermelho.
A comparação entre os valores de Qaf_SIM e Qef deve ter em conta, não só um balanço entre estas
entradas e saídas, como a ordem de grandeza dos caudais envolvidos, de modo a compreender e
justificar as possíveis diferenças existentes. Assim, se Qaf_SIM > Qef significa que as entradas são
superiores às saídas, como é o caso do mês de Setembro de 2014. Como o caudal de precipitação
se revelou desprezável na descrição do tratamento biológico (ver Secção 3.1.7), então considera-se
que a diferença de valores médios entre os caudais afluente e efluente pode ser explicada, em parte,
pelo caudal de água de serviço. Por outro lado, se Qaf_SIM < Qef, as saídas são superiores à entrada,
como é o caso dos meses de Abril de 2013 e Novembro de 2013. Nestas situações os caudais que
podem estar a causar diferenças nos valores médios de caudais afluente e efluente são o Qle, Qclass e o
caudal de emergência, uma vez que à semelhança da precipitação, a evapotranspiração também pode
ser desprezada.
41

3.1.4 Análise de variações mensais
A análise dos boxplot apresentados na Figura 3.2 é essencial para estabelecer uma comparação entre
meses e, com isso, detectar meses com um comportamento anómalo. Esses meses podem ser ana-
lisados mais detalhamente através da representação de uma série de dados mensal, onde é possível
observar as oscilações de caudal que ocorreram e que explicam a conformação da caixa no boxplot
correspondente. A título de exemplo, apresentam-se, na Figura 3.4, quatro situações diferentes.
Figura 3.4: Variações mensais de caudais afluente e efluente nos meses de Março e Outubro de 2013e Abril e Julho de 2014, respectivamente
Em termos de caudal afluente, observando a caixa correspondente ao mês de Outubro de 2013 na
Figura 3.2, verifica-se que tem uma conformação larga, isto é, o intervalo da mediana até aos percentis
25% e 75% é muito grande. Isto significa que os valores de caudal medidos neste mês variaram
bastante. De facto, analisando a Figura 3.4 a), conclui-se que Outubro de 2013 se tratou de um mês com
muitas oscilações de grande amplitude, entre valores muito próximos de zero (situações de paragem
do funcionamento do parafuso de Arquimedes) e valores a rondar os 20 L/s. Por seu lado, o mês
de Julho de 2014, ao apresentar uma caixa menos larga, antecipa um mês com um caudal afluente
mais constante, com menos oscilações, o que se comprova quando se representa a variação mensal
(Figura 3.4 b)).
Em termos de caudal efluente, o mês de Março de 2013 claramente representa uma situação anómala,
uma vez que a respectiva caixa no boxplot é muito estreita. Neste caso, isto significa que os valores
de caudal medidos neste mês foram muito semelhantes entre si, o que de facto se verifica analisando
42

a série de dados mensal da Figura 3.4 c). Os outliers que aparecem dizem respeito a alturas do mês
em que o caudal medido oscilou um pouco para baixo da mediana ( ∼ 15 L/s), como os dias 1, 8 a 10 e
16, ou um pouco acima, como os dias 28 a 30. No caso do mês de Abril de 2014, a caixa encontra-se
acima das restantes, para esse ano. No entanto, comparando com a caixa representativa dos dados
de caudal afluente para o mesmo mês, verifica-se que a mediana é semelhante e que, em termos de
conformação, não existem diferenças significativas. Por esta razão, considerou-se que este mês reporta
uma situação normal.
Por fim, analisando o mês de Agosto de 2014 em termos de Qef, mês com caixa muito larga compa-
rativamente às restantes do mesmo ano (Figura 3.4 d)), conclui-se que esta conformação se deve à
existência de dois comportamentos distintos, um em que se medem valores de caudal entre 5 e 10 L/s
e que se estende até dia 21, e outro com valores a oscilar entre 10 e 15 L/s que prevalece até ao fim
do mês. Como não existem praticamente oscilações bruscas e fora da gama de valores que ambos os
comportamentos englobam, então não se identificam outliers.
3.1.5 Análise de variações diárias
No estudo das variações de caudal afluente ao longo do dia optou-se por escolher dois meses, um
representativo do Inverno e outro do Verão, de modo a efectuar uma análise onde pudessem ser tidos
em conta potenciais efeitos de sazonalidade. Além disso, efectuou-se uma tentativa de isolamento do
comportamento dos filtros de areia, escolhendo, para tal, um mês em que não houve extracção de
lamas. Assim, optou-se por construir modelos PCA recorrendo à linguagem de programação R para
os meses de Julho de 2013, Fevereiro de 2014 e Setembro de 2014. De seguida apresentam-se os
scores plot obtidos, a distribuição das observações em clusters identificados visualmente (Figura 3.5)
e os perfis diários dos dois melhores clusters para cada um dos meses (Figura 3.6).
(a) Scores plot - Julho de 2014 (b) Clusters - Julho de 2014
43

(a) Scores plot - Fevereiro de 2014 (b) Clusters - Fevereiro de 2014
(c) Scores plot - Setembro de 2014 (d) Clusters - Setembro de 2014
Figura 3.5: PCA scores plot onde cada observação representa um dia do mês (à esquerda) e clustersformados visualmente a partir da análise da distribuição dos scores (à direita).
Observando os scores plot antes de efectuar o clustering, não é possível chegar a nenhuma conclusão
relevante. No entanto, quando se formam os clusters, verifica-se de imediato que o mês de Julho de
2013 tem muitos mais aglomerados de dias quando comparado com os meses de Fevereiro e Setembro
de 2014. Isto significa que existe uma maior variabilidade dos dados de caudal que se deve traduzir em
perfis diários com mais oscilações, tal como mostram os gráficos da Figura 3.6.
Como se pode visualizar, os perfis diários representativos do mês de Julho de 2013 apresentam muitas
oscilações, ao contrário do que acontece com os perfis do mês de Fevereiro de 2014. Uma possível
justificação é considerar o efeito de sazonalidade: em Julho, mês de Verão, há uma redução do caudal
de águas afluentes que origina em mais paragens do parafuso de Arquimedes ao longo do dia e o
pára-arranca deste equipamento introduz alguma instabilidade no sistema, o que resulta em oscilações
de caudal significativas sentidas no canal de Parshall ; no Inverno (como é o caso do mês de Fevereiro),
44

como o caudal de águas afluentes à ETAR é mais elevado, o parafuso está sempre em funcionamento,
à mesma velocidade, logo há menos oscilações nas medidas desta variável. O mês de Setembro
representa uma situação intermediária: não existem oscilações tão abruptas mas, possivelmente por
se tratar, de um modo geral, um mês chuvoso, já existe alguma instabilidade em termos de variação
de caudal afluente. Desta forma, torna-se evidente que não é possível traçar perfis diários de caudal
ao longo do mês, uma vez que os dias são muito variáveis. O sistema de elevação, mais concreta-
mente o modo de funcionamento do parafuso, está a sobrepor-se ao regime de afluência, impedindo a
concretização de um dos objectivos desta análise, que consistia em desvendar padrões diários.
Tendo em conta esta conclusão, seria interessante considerar a hipótese de desenvolver um modelo
que permitisse a simulação do modo de funcionamento do sistema de elevação inicial. No entanto, isto
exigiria um conhecimento rigoroso desta parte do sistema de tratamento, de modo a contemplar, não
só os diversos níveis de velocidade de funcionamento do parafuso, como também possíveis atrasos na
resposta a alterações operatórias.
(e) Julho de 2013
(f) Fevereiro de 2014
(g) Setembro de 2014
Figura 3.6: Perfis diários dos dois melhores clusters formados a partir da análise do gráfico dos scorespara os meses de Julho de 2013, Fevereiro de 2014 e Setembro de 2014.
Outra motivação para representação e análise de clusters de perfis diários de caudal era isolar o re-
gime de lavagem dos filtros de areia, uma vez que se suspeitava que este representava um caudal
de recirculação considerável. Para tal, pensou-se em estabelecer uma análise comparativa entre duas
situações muito distintas do estado de funcionamento da ETAR.
1. Avaria no filtro de banda, impedindo a operação de extracção de lamas e obrigando a que todas
as lamas sejam recirculadas. Há arrastamento de lamas para o tratamento terciário, o que torna
necessário um funcionamento contínuo dos filtros. Estes estão constantemente a ser lavados e,
por conseguinte, o caudal de sobrenadante que é recirculado à estação elevatória inicial é maior;
45

2. Linha das Lamas em pleno funcionamento, pelo que a recirculação da lavagem dos filtros de
areia não deve ter tanta influência no caudal medido no canal de Parshall.
Dos meses com perfis diários representados, Julho de 2013 e Fevereiro de 2014 incluem-se no segundo
caso e Setembro de 2014 é o mês que possivelmente representa melhor a primeira situação: mês com
muita acumulação de lamas no sistema, uma vez que o filtro de banda avariou em Maio e foi arranjado
em Outubro de 2014. Mais uma vez, analisando os perfis diários para Setembro de 2014 se conclui que
é impossível isolar a operação de lavagem dos filtros, dado que esta é também mascarada pelo modo
de operação do sistema de elevação inicial.
3.1.6 Influência da precipitação no caudal afluente
Para estudar a influência da precipitação na afluência (Qin) escolheram-se os meses de Julho e de De-
zembro, de modo a ter em conta o factor sazonalidade e usaram-se os dados do mês de Julho de 2013
e de 2014, de modo a considerar situações em que a extracção de lamas estava ou não operacional.
Os resultados da análise de componentes principais realizada no software R foram representados sob
a forma de biplots que se apresentam na Figura 3.7.
(a) Julho de 2013 (b) Julho de 2014 (c) Dezembro de 2013
Figura 3.7: Biplots resultantes do modelo PCA construído para a análise da influência da variávelprecipitação no caudal afluente.
Tendo em conta a definição de biplot, os dias de mês em que o caudal afluente sofre influência da pre-
cipitação são representados por observações que dão origem a pontos de corte longe e na direcção da
linha desta variável. Por outro lado, dias em que a precipitação não contribui muito para as variações de
caudal afluente dão origem a pontos de corte longe e na direcção oposta da variável. Por fim, avaliando
o tamanho da linha que representa a precipitação, pode-se tirar conclusões acerca da variabilidade do
conjunto de dados.
Ao representar como variáveis a precipitação e as horas do dia, tem-se em conta dois aspectos na
distribuição dos scores: a precipitação e o perfil diário. O que se pretende avaliar é se há ou não
um alinhamento na linha da variável precipitação. Nos casos em que isto acontece, conclui-se que
esta variável têm alguma influência nas variações de caudal afluente, caso contrário, conclui-se que
a precipitação não é dominante, isto é, existem outros factores (entre os quais o perfil diário) que se
46

sobrepõem e têm maior contribuição na distribuição dos dias no biplot. Os pontos que caem na origem
dos eixos, uma vez que o PCA é centrado na média, representam dias em que a precipitação esteve
de acordo com a média.
Assim, em Julho de 2014 (Figura 3.7(b)) observa-se que o PC1 praticamente não contribui para explicar
a variância de maior parte das observações (muitos dias caem no plano PC1=0) e que existem muitos
pontos de corte que caem próximos da origem, o que nos indica que os valores das observações
estão na média dos valores de precipitação; não há alinhamento no eixo da precipitação e a linha que
representa esta variável é baixa, pelo que se conclui que a precipitação não é dominante e que os
valores são muito semelhantes e próximos entre si ao longo do mês.
Para o mesmo mês, mas no ano anterior (Figura 3.7(a)), os valores de precipitação estiveram também
de acordo com o valor esperado e ainda mais semelhantes entre si, uma vez que o tamanho da linha
que representa esta variável é ainda menor comparado com o biplot do ano de 2014. Na maioria dos
dias não estão correlacionados com a precipitação, o que nos indica que mais uma vez esta variável
não tem praticamente influência na evolução mensal do caudal.
Por seu lado, no caso do mês de Dezembro (Figura 3.7(c)), visualizam-se 2 grupos de observações
distintos: um primeiro grupo claramente alinhado com a direcção da precipitação e um segundo grupo
com observações situadas na direcção oposta da variável. Ao contrário de Julho, mês de Verão, para
Dezembro a linha da variável precipitação tem um comprimento elevado, o que indica que a variância é
elevada, ou seja, esta variável influencia mais as variações de caudal afluente.
3.1.7 Influência da precipitação e evapotranspiração nas valas de oxidação
A Figura 3.8 representa, segundo um sistema de dois eixos, a relação entre os caudais de precipitação
e evapotranspiração e o caudal afluente ao tratamento biológico. No eixo principal tem-se o caudal aflu-
ente ao tratamento biológico, Qaf, e no eixo secundário os caudais de precipitação e evapotranspiração,
Qprec e Qevap. O caudal afluente (valor horário), Qaf_SIM, foi determinado substraindo o caudal médio
horário do classificador de areias, Qclass (ver Anexo B) aos valores horários filtrados de Qaf_SIM. Por
fim, consideraram-se os valores médios diários para obter um valor médio mensal. No caso dos cau-
dais de precipitação e evapotranspiração, considerou-se a média mensal como uma média dos valores
decendiais.
Figura 3.8: Evolução dos dados de caudal afluente, de precipitação e de evapotranspiração no trata-mento biológico. Os valores representam médias mensais.
47

Face à discrepância de valores na escala dos dois eixos, torna-se evidente que as contribuições da
precipitação e evapotranspiração são desprezáveis na descrição do modelo do sistema de tratamento
biológico. Como tal, considera-se que o caudal afluente, Qaf, é o caudal total de águas a ser tratadas
nas valas de oxidação.
Analisando o gráfico mais detalhadamente é possível concluir acerca de algumas tendências entre os
caudais representados:
• Nos meses de Outono/Inverno geralmente há mais precipitação e, consequentemente, Qprec é
mais elevado, tal como se pode verificar nos períodos de Dezembro de 2013 a Fevereiro de 2014
e de Setembro de 2014 a Novembro de 2014;
• Quando Qprec é elevado, Qaf também é elevado, uma vez que, aumentando a pluviosidade, o
caudal de águas afluentes à entrada da ETAR também aumenta. Esta situação é visível nos
períodos de Outubro de 2013, Dezembro de 2013 a Fevereiro de 2014 e Setembro de 2014 a
Novembro de 2014;
• Nos meses de Verão, ou meses mais quentes de Primavera aumenta a evapotranspiração, pelo
que Qevap aumenta, como acontece nos períodos de Junho de 2013 a Agosto de 2013 e Maio de
2014 a Agosto de 2014;
• Em meses em que a evapotranspiração é elevada, geralmente Qaf diminui, o que se explica pelo
facto de se tratarem de períodos mais secos (menos chuvosos), e portanto a carga afluente à
ETAR diminui consideravelmente. Exemplo desta situação são os meses de Junho de 2013 a
Agosto de 2013 e Abril de 2014 a Agosto de 2014.
3.2 Estimativa da quantidade de lamas extraídas
A linha de tratamento de sólidos carece de qualquer tipo de equipamento que permita uma monitoriza-
ção online quer em termos de caudal, quer em termos de parâmetros de qualidade (composição das
correntes). Como tal, não existem medidas da concentração de sólidos nem de caudais de lamas, o que
dificulta a compreensão desta parte do sistema de tratamento. Além disso, como parte das correntes
de saída da fase de tratamento de sólidos retorna à estação elevatória inicial, não se tem conhecimento
da influência destes caudais no caudal afluente medido no canal de Parshall.
Para ter um melhor conhecimento desta fase do processo, a situação ideal seria instalar caudalímetros
para medir os caudais de lamas extraídas e recirculadas. No entanto, uma vez que esta se trata
de uma solução dispendiosa, em alternativa deveria haver um registo do funcionamento das bombas
que controlam o caudal de lamas recirculadas e extraídas, e medidas pontuais de caudais. Estes
dados ou informações, em conjunto com um melhor conhecimento do funcionamento da válvula de
repartição das lamas extraídas (dado que a posição da válvula influencia os caudais de lamas extraídas
e recirculadas), certamente já permitiriam um grau de conhecimento razoável da linha de tratamento de
sólidos e permitiriam uma optimização do controlo e gestão desta parte do processo. Contudo, já que
48

não existem registos do funcionamento das bombas, optou-se por fazer uma estimativa da ordem de
grandeza dos caudais da linha das lamas e comparar os valores obtidos com valores da literatura.
3.2.1 Origem dos dados e metodologias aplicadas
O cálculo do caudal de lamas extraídas assentou no estabelecimento de balanços de massa às ope-
rações de desidratação mecânica e de espessamento gravítico. Uma vez que os únicos dados de
lamas disponíveis são relativos à quantidade de lamas desidratadas (disponibilizados pela SIMTEJO2),
começou-se por estabelecer um balanço à operação final, desidratação mecânica, e retroceder no pro-
cesso até se obter o caudal de lamas extraídas.
Os balanços ao componente foram estabelecidos em termos de sólidos totais (ST) e permitiram iden-
tificar as variáveis para as quais se tinha informação e as variáveis que era ainda necessário estimar.
Face a esta situação, procedeu-se a um alargamento dos procedimentos de rotina das campanhas da
parte do grupo LNEC/IST com o intuito de determinar os valores em falta.
À excepção das amostras de lamas extraídas, recolhidas na caixa EE_lamas (ver Figura 2.13) desde
o ínicio das campanhas, as amostras foram recolhidas durante as campanhas V2 e V3 nos seguin-
tes pontos do circuito de lamas, assinalados na Figura 3.9: tubagem de alimentação – lamas espes-
sadas (código amostra: Lesp_V#); lamas desidratadas (código amostra: Ldes_V#); efluente do filtro
banda (código amostra: Lefb_V#); descarga do sobrenadante do espessador gravítico (código amos-
tra: Lsb_esp_V#).
Figura 3.9: Planta da ETAR: indicação dos pontos de monitorização no sistema de desidratação delamas.
2Empresa actualmente extinta após reestruturação do sector de abastecimento de água e saneamento de águas residuaisque deu origem à AdLVT
49

A sua análise laboratorial permitiu a determinação da concentração de sólidos totais nas lamas desi-
dratadas, lamas espessadas, lamas extraídas, no efluente do filtro de banda e no sobrenadamente do
espessamento. Além disso, procedeu-se à determinação da densidade das lamas com base no peso
de 25 mL de uma amostra de lamas extraídas. O valor obtido foi de 1002,9 kg/m3.
Além da determinação da concentração de sólidos totais nas correntes das linhas de lamas foi neces-
sário considerar a informação disponibilizada pela SIMTEJO, bem como assumir alguns valores típicos
da literatura, de modo a conseguir resolver os balanços de massa efectuados.
3.2.2 Resolução dos Balanços de Massa
De seguida apresentam-se os balanços de massa (global e ao componente) realizados por peça de
equipamento, acompanhados do esquema do mesmo (Figura 3.10). As Equações 3.1 e 3.2 dizem
respeito aos balanços à desidratação mecânica, enquanto que as Equações 3.3 e 3.4 descrevem os
balanços efectuados ao espessador gravítico.
(a) Operação de desidratação mecânica. (b) Operação de espessamento gravítico.
Figura 3.10: Representação esquemática das operações de processamento de lamas, com volume decontrolo considerado nos balanços de massa assinalado a vermelho. Q representa valores de caudal eX diz respeito à concentração de sólidos em cada uma das correntes referidas.
Qlesp +Qpoli +Qlserv = Qldes +Qefb (3.1)
Xs−lesp ×Qlesp +Xs−poli ×Qpoli +Xs−lserv ×Qlserv = Xs−ldes ×Qldes +Xs−efb ×Qefb (3.2)
Qle = Qlesp +Qsesp (3.3)
Xs−le ×Qle = Xs−lesp ×Qlesp +Xs−sesp ×Qsesp (3.4)
O objectivo do balanço ao filtro de banda é a determinação do caudal de lamas espessadas, Qlesp e do
50

caudal de efluente do filtro de banda, Qefb. Uma vez conhecida a quantidade de lamas espessadas, é
possível resolver o balanço ao espessador gravítico, onde as incógnitas são o caudal de lamas extraídas
Qle e o caudal de sobrenadante do espessamento Qsesp.
Tal como referido anteriomente, para resolver os balanços de massa, foi necessário considerar valo-
res da literatura e valores disponibilizados pela SIMTEJO para algumas das variáveis presentes (Ta-
bela 3.1). A esta informação juntam-se os resultados laboratoriais das amostras recolhidas na linha das
lamas (Anexo C).
Tabela 3.1: Valores das variáveis retirados da literatura ou disponibilizados pela SIMTEJO, necessáriospara a resolução dos balanços de massa efectuados na linha de tratamento da fase sólida.
Variável Valor Unidades Fonte
Qldes mensal ton [SIMTEJO, 2004]Xs-poli 5 g/L [SIMTEJO, 2004]Qpoli 0,25-0,4a m3/h [Tchobanoglous et al., 2003]Qlserv 5,4b m3/h [Tchobanoglous et al., 2003]Xs-lserv 0c g/L Assumidoa Assumiu-se o valor médio.b Assumiu-se o valor de 24 gal.min-1.m-1 e considerou-se a largura da tela
igual a 1 metro, conforme descrito em [SIMTEJO, 2004].c Assumiu-se que a água de serviço contém uma concentração vestigial de
ST que pode ser desprezada.
Na Tabela 3.2 apresentam-se os valores considerados para cada uma das variáveis Xs envolvidas
nos balanços de massa, assim como o valor determinado para a densidade das lamas. De notar que
os valores de concentração de sólidos correspondem à média de todos os resultados das análises
laboratoriais efectuadas ao longo dos períodos de campanha V2 e V3. Uma vez que apenas se tinham
disponíveis valores para Xle em termos de SST para os períodos das campanhas P1, P2, C1, C2,
C3, V1 e V2 (ver Tabela 3.7) considerou-se que a fracção de sólidos dissolvidos é desprezável face à
fracção de sólidos suspensos, ou seja, ST≈SST. Para a campanha V3, foram considerados valores em
termos de ST.
Tabela 3.2: Resultados das análises laboratoriais efectuadas às amostras recolhidas na linha das lamasdurante os períodos de campanhas.
Variável Valor Unidades
Xs-ldes 14,2 ± 0,8 % MSXs-lesp 4,0 ± 2,6 % MSXs-le 5044 ± 1185 g/m3
Xs-efb 1142,3 ± 435,6 g/m3
Xs-sesp 503,3 ± 90,1 g/m3
De modo a validar estes resultados obtidos para a concentração de lamas espessadas e desidratadas,
os valores foram comparados com os valores na literatura [Tchobanoglous et al., 2003] típicos para este
tipo de operações (Tabela 3.3). Concluiu-se que, ainda que as condições em que as amostras foram
recolhidas não sejam óptimas, os valores obtidos são representativos, na medida em que os resultados
das análises laboratoriais são razoáveis face às gamas típicas para as operações de desidratação e
espessamento.
51

Tabela 3.3: Concentração de sólidos à saida de operações de processamento de lamas (%) [Tchoba-noglous et al., 2003] e valores calculados neste trabalho.
Equipamento/Descrição Operação Gama Típico Calculado
Espessadores gravíticos, lamas activadas+lamas primárias 2-6 4 4Prensa de banda, com adição de polímero 15-30 22 14,2
Tendo em conta a informação supracitada foi possível resolver os 2 sistemas de equações corres-
pondentes aos balanços ao filtro de banda e ao espessador gravítico. Os resultados encontram-se
resumidos na Tabela 3.4.
Tabela 3.4: Caudais, em L/s, determinados através da resolução dos balanços de massa ao filtro debanda e ao espessador gravítico, usando os valores das tabelas 3.1 e 3.2.
Caudais Valor (L/s)
Qlesp 0,07Qefb 1,65Qsesp 0,55Qle 0,63
3.2.2.1 Eficiência das operações de processamento de lamas
Efectuou-se, de seguida, o cálculo da eficiência das operações de desidratação mecânica, ηdes, e
espessamento gravítico, ηesp, com base nas equações 3.6 e 3.5 e comparou-se os resultados obtidos
com os valores da literatura. A Tabela 3.5 apresenta os valores de eficiência típicos e os valores
calculados com base nos resultados dos balanços de massa à linha das lamas.
ηesp =Xs−sesp ×Qsesp
Xs−le ×Qle(3.5)
ηdes =Xs−efb ×Qefb
Xs−lesp ×Qlesp(3.6)
Tabela 3.5: % de sólidos capturados em operações de processamento de lamas [Tchobanoglous et al.,2003] e valores calculados neste trabalho.
Equipamento/Descrição Operação Gama Típico Calculado
Espessadores gravíticos, lamas activadas + lamas primárias 80-90 85 91,2Prensa de banda, com adição de polímero 85-98 93 34,6
Observando a Tabela 3.5 verifica-se que a eficiência do espessador gravítico é ligeiramente superior
ao valor típico, enquanto que, no caso da desidratação mecânica, o valor obtido é francamente inferior.
Para fazer uma análise crítica das eficiências das operações de processamento de lamas é necessário
ter em conta que a ETAR de Bucelas se trata de um sistema de pequena dimensão, estando por
isso, sobredimensionada. Este facto explica a elevada eficiência do espessador gravítico. Por seu
lado, o valor obtido para a eficiência do filtro de banda sugere que a operação de adição de polímero
52

não está optimizada, uma vez que as lamas desidratadas têm mais humidade e, consequentemente,
menor concentração em sólidos. Isto significa que o efluente do filtro de banda, que retorna à estação
elevatória inicial, tem mais carga de sólidos. Contudo, uma vez que a ETAR está sobredimensionada
e a operação de extracção de lamas é intermitente, não há influência significativa desta corrente no
sistema de tratamento.
3.2.2.2 Estimativa do período anual de extracção de lamas
Com o intuito de obter mais informação sobre a linha das lamas, foi realizado um ensaio pela SIMTEJO
para determinação do caudal efectivo de lamas extraídas e de lamas recirculadas (assinalada como
EE_lamas na Figura 2.13). Este envolveu a introdução de um caudalímetro na caixa onde se dá a bifur-
cação entre as lamas que são recirculadas ao sistema de tratamento biológico e as que são extraídas
e continuam para a linha das lamas. As figuras seguintes mostram as condições em que foi realizado o
ensaio.
Figura 3.11: Fotografias tiradas durante o ensaio para estimativa dos caudais de recirculação e extrac-ção de lamas, disponibilizadas pela SIMTEJO.
Na Tabela 3.6 apresentam-se os resultados obtidos. Tendo em conta o modo de operação, considerou-
se um caudal médio de 46 L/s que se assumiu como caudal efectivo de recirculação e para o caudal
efectivo de lamas extraídas considerou-se como valor máximo correspondente às duas bombas a fun-
cionar em simultâneo e sem alteração da posição da válvula.
Tabela 3.6: Caudais medidos no ensaio para determinação dos caudais de lamas recirculadas e ex-traídas.
Caudal (L/s)
Bomba de recirculação 1 44Bomba de recirculação 2 482 bombas em simultâneo 67,5
A diferença entre o valor para o caudal de lamas extraídas obtido experimentalmente e por resolução
dos balanços de massa deve-se ao factor da operação de extracção ser intermitente. Assim, com
base nestes dois valores, é possível efectuar uma estimativa do tempo de extracção, de acordo com a
Equação 3.7, em que V anualle é o volume anual de lamas extraídas, determinado a partir do valor de Qle
eQ′le corresponde ao caudal efectivo de extracção de lamas, medido no ensaio da SIMTEJO. Obteve-se
53

um valor de, aproximadamente, 3,4 dias.
te =V anualle
Q′le(3.7)
3.3 Análise de Dados Analíticos
Neste capítulo efectua-se uma análise aos dados de cargas afluentes: sólidos suspensos totais (SST),
carência química de oxigénio (CQO) e azoto amoniacal (NH4-N). Esta tem como objectivo avaliar quali-
tativamente os dados disponíveis, o que permite efectuar uma monitorização e controlo das condições
operatórias. Desta forma, é possível a identificação de situações anómalas do funcionamento da ETAR,
falhas no processo e nos sensores instalados e a tomada de decisão sobre a informação a incluir nos
modelos de previsão de variáveis não medidas directamente e nos modelos de simulação do processo
de tratamento.
3.3.1 Origem dos Dados e Metodologias Aplicadas
Os dados analíticos disponíveis têm três proveniências diferentes: dados medidos em linha, dados
anlíticos recolhidos em períodos de campanha e dados analíticos disponibilizados pela SIMTEJO.
Dados medidos em linha: valores com uma frequência de amostragem de 10 minutos, disponíveis
desde Abril de 2014 até ao final do projecto, com interrupção na aquisição entre Junho de 2014 e Se-
tembro de 2014 para arranjo de uma avaria. Na presente dissertação foram apenas tidos em conta dos
dados até ao período da campanha V2. O sistema de aquisição de dados usado na ETAR de Bucelas é
composto por um espectrofotómetro submersível spectro::lyser v2 com terminal de controlo con::cube
e uma sonda de azoto que consiste num sensor electroquímico ammo::lyser, ambos da marca s::can
Messtechnik, Vienna [Ribeiro et al., 2014]. O espectrofotómetro spectro::lyser v2, cuja representação
esquemática se apresenta na Figura 3.12, trata-se de uma sonda com 600 mm de comprimento e 44
mm de diâmetro, com um percurso óptico de 5 mm, que mede a atenuação da luz pelas substân-
cias dissolvidas ou em suspensão numa gama de comprimentos de onda que contempla as regiões
ultravioleta e visível. Concretamente, a informação adquirida consiste num conjunto de medições de
absorvâncias para comprimentos de onda de 220-737,5 nm, com um intervalo de 2,5 nm, e com uma
frequência de amostragem de 10 minutos. A fonte de luz é uma lâmpada de xénon de feixe duplo, de
256 pixel, que permite uma compensação automática das leituras. O controlo do funcionamento é feito
através de um microprocessador, a saída do sinal é digital e o tempo de resposta é de 15 a 30 segun-
dos. O espectrofotómetro está, ainda, equipado com um sistema de limpeza automática com utilização
de ar comprimido, que permite a limpeza periódica das janelas de leitura óptica através da injecção
de ar entre 3 a 5 bar, por acção de uma electroválvula ligada ao terminal de controlo. O equipamento
já fornece uma calibração global para os parâmetros de interesse, baseada numa análise estatística
multivariada (regressão PLS) de bases de dados de grande dimensão que incluem espectros e resulta-
54

dos de amostras colhidas em locais de monitorização com características semelhantes à aplicação em
causa [Hofstaedter et al., 2003; Ribeiro et al., 2008].
Figura 3.12: Componentes da sonda spectro::lyser v2, retirado de Hofstaedter et al. [2003].
Dados analíticos obtidos em períodos de campanhas: amostras pontuais e refrigeradas, sendo a
frequência de amostragem variável de acordo com a duração da campanha. A Tabela 3.7 resume a
informação relevante sobre dados analíticos recolhidos durante as campanhas efectuadas na ETAR de
Bucelas. Todas as amostras foram recolhidas em amostradores da marca Teledyne Isco, Inc. As aná-
lises de parâmetros de qualidade foram efectuadas recorrendo a kits analíticos da marca Hach-Lange,
referências LCK114 (CQO, 150-1000 mg O2/L), LCK314 (CQO, 15-150 mg O2/L), LCK338 (azoto total,
Ntotal, 20-100 mg N/L) e LCK303 (azoto amoniacal, NH4-N, 2-47 mg N/L), seguindo as instruções do
fabricante [Ribeiro et al., 2014]. A determinação de sólidos suspensos totais (SST), sólidos suspensos
voláteis (SSV) e sólidos totais (ST) é realizada segundo a metodologia descrita no Standard Methods
for the Examination of Water and Wastewater [Rand et al., 1976].
Tabela 3.7: Informação sobre as campanhas realizadas na ETAR de Bucelas e a quantidade de dadosanalíticos recolhidos.
ID Datas Duração(h)
FrequênciaAmostragem (h)
no dadosSST
no dadosCQO
no dadosNH4-N
no dadosNtotal
P1 15 a 16 Jul. 2014 24 2 12 12 6 6P2 15 a 17 Out. 2014 48 4 12 12 6 6C1 10 a 12 Dez. 2014 48 2 0a 24 12 12C2 14 a 16 Jan. 2015 48 2 24 24 12 12C3 18 a 20 Mar. 2015 48 2 24 24 12 12V1 20 a 24 Abr. 2015 96 4 24 24 12 12V2 22 a 26 Jun. 2015 96 4 18 18 9 9
a Não foi possível efectuar as análises das amostras de sólidos suspensos totais na campanha C1 devido a uma avaria da câmarafrigorífica.
Dados disponibilizados pela SIMTEJO: amostras compostas de 24 horas, não sujeitas a refrigera-
ção, com uma frequência de amostragem de dois valores mensais (sensivelmente de duas em duas
semanas) para o caso das variáveis SST e CQO, e um valor mensal para o caso do NH4-N. As análises
de parâmetros de qualidade CQO, NH4-N e azoto total foram realizadas pela técnica de volumetria (ISO
6060:189, 5564:1984 e 5663:1984, respectivamente), enquanto que o parâmetro SST foi analisado
recorrendo à técnica de gravimetria (método PTA-2 SMEWW 2450-D).
55

A análise dos dados analíticos começou, à semelhança do que foi feito com as variáveis caudal, com
a aplicação de filtros de atenuação de ruído aos dados analíticos em linha disponibilizados pela sonda
espectrofotométrica. De seguida, efectuou-se uma comparação entre os dados de concentrações aflu-
entes das diversas proveniências.
A comparação estabelecida entre os dados medidos em linha e os dados analíticos da monitorização
de rotina da SIMTEJO teve como finalidade salientar as vantagens de possuir um equipamento com
medições online e, com base nos dados aquiridos, detectar situações particularmente anómalas na
afluência. Para tal, os dados medidos em linha foram representados sob a forma de boxplot, ao passo
que para os dados SIMTEJO se optou por uma representação num gráfico de valores médios (repre-
sentando o desvio-padrão). Os dados s::can foram ainda representados com os dados de campanhas,
num gráfico onde se sobrepuseram as séries de dados de todas as campanhas. Esta análise visou
validar os dados da sonda s::can para esses períodos.
Depois de estabelecer a comparação entre os dados provenientes de origens diferentes, efectuou-
se uma análise de correlações das variáveis medidas em linha que caracterizam a afluência (SST,
CQO, NH4-N e Qaf_SIM), através de gráficos com sobreposição de dados e de mapas de correlação
com informação quantitativa do grau de correlação. Por fim, realizou-se uma análise de componentes
principais com representação sob a forma de biplots mensais para avaliar tendências de variações
mensais e detectar meses com comportamento anormal.
3.3.2 Pré-Tratamento dos dados analíticos
À semelhança do que se verificou para os dados de caudal (ver Secção 3.1.2), foi necessário aplicar
um filtro de atenuação de ruído nos dados de cargas afluentes provenientes da sonda s::can. Mais uma
vez, o filtro que mostrou melhor performance, isto é, garantiu simultaneamente a atenuação do ruído
sem perda de informação relevante, foi a Janela de Hamming de 5 pontos.
De seguida representa-se dados para o mês de Maio de 2014, antes e após aplicação do filtro, para as
variáveis SST, CQO e NH4-N.
56
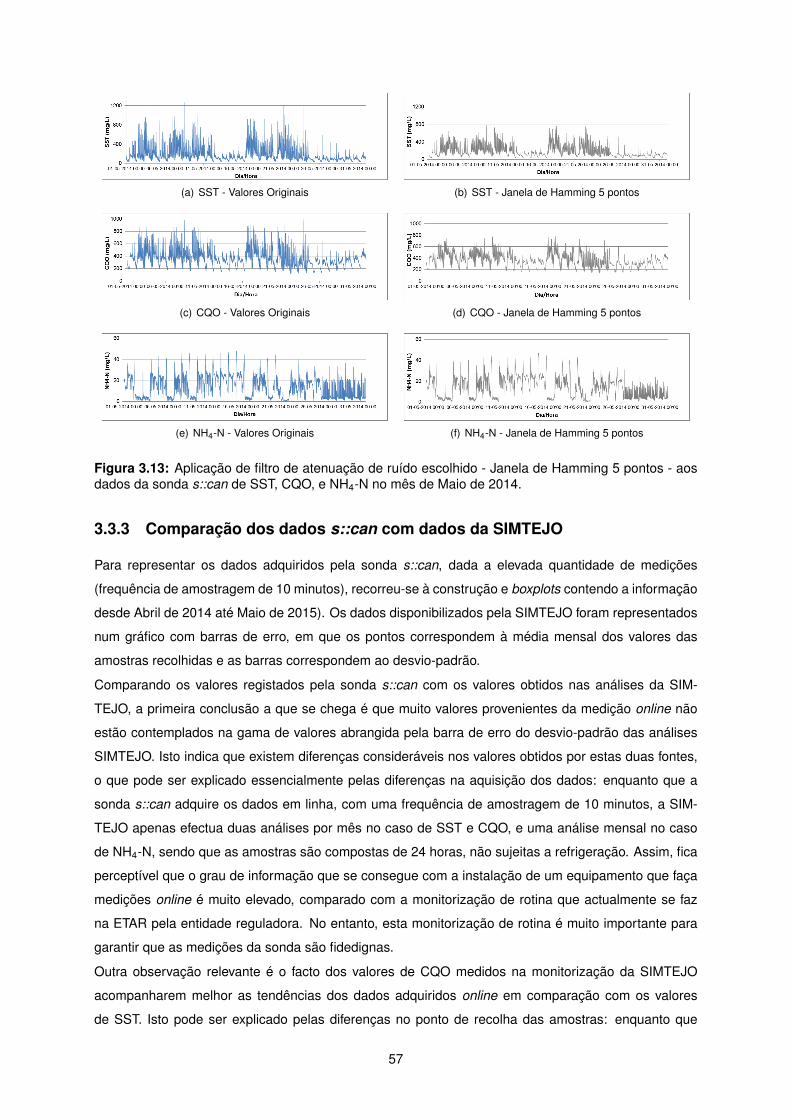
(a) SST - Valores Originais (b) SST - Janela de Hamming 5 pontos
(c) CQO - Valores Originais (d) CQO - Janela de Hamming 5 pontos
(e) NH4-N - Valores Originais (f) NH4-N - Janela de Hamming 5 pontos
Figura 3.13: Aplicação de filtro de atenuação de ruído escolhido - Janela de Hamming 5 pontos - aosdados da sonda s::can de SST, CQO, e NH4-N no mês de Maio de 2014.
3.3.3 Comparação dos dados s::can com dados da SIMTEJO
Para representar os dados adquiridos pela sonda s::can, dada a elevada quantidade de medições
(frequência de amostragem de 10 minutos), recorreu-se à construção e boxplots contendo a informação
desde Abril de 2014 até Maio de 2015). Os dados disponibilizados pela SIMTEJO foram representados
num gráfico com barras de erro, em que os pontos correspondem à média mensal dos valores das
amostras recolhidas e as barras correspondem ao desvio-padrão.
Comparando os valores registados pela sonda s::can com os valores obtidos nas análises da SIM-
TEJO, a primeira conclusão a que se chega é que muito valores provenientes da medição online não
estão contemplados na gama de valores abrangida pela barra de erro do desvio-padrão das análises
SIMTEJO. Isto indica que existem diferenças consideráveis nos valores obtidos por estas duas fontes,
o que pode ser explicado essencialmente pelas diferenças na aquisição dos dados: enquanto que a
sonda s::can adquire os dados em linha, com uma frequência de amostragem de 10 minutos, a SIM-
TEJO apenas efectua duas análises por mês no caso de SST e CQO, e uma análise mensal no caso
de NH4-N, sendo que as amostras são compostas de 24 horas, não sujeitas a refrigeração. Assim, fica
perceptível que o grau de informação que se consegue com a instalação de um equipamento que faça
medições online é muito elevado, comparado com a monitorização de rotina que actualmente se faz
na ETAR pela entidade reguladora. No entanto, esta monitorização de rotina é muito importante para
garantir que as medições da sonda são fidedignas.
Outra observação relevante é o facto dos valores de CQO medidos na monitorização da SIMTEJO
acompanharem melhor as tendências dos dados adquiridos online em comparação com os valores
de SST. Isto pode ser explicado pelas diferenças no ponto de recolha das amostras: enquanto que
57

(a) SST
(b) CQO
(c) NH4-N
Figura 3.14: Boxplots contendo informação dos valores medidos online (pela sonda s::can) de SST,CQO e NH4-N e representação dos valores obtidos na monitorização de rotina efectuada pela SIMTEJOsob a forma de gráfico de valores médios com barra de erro correspondente ao desvio-padrão.
58

a SIMTEJO recolhe amostras no canal do tamisador, os dados online são medidos junto ao local de
instalação da sonda, no tanque de desarenação, onde há mais probabilidade de ocorrer sedimentação
(a área de escoamento é maior, o que diminui a velocidade de escoamento da água). Nos momen-
tos em que funciona o ar comprimido, há mais turbulência no tanque e, consequentemente, não há
sedimentação. Por outro lado, sempre que o sistema de compressão de ar se encontra desligado, há
mais sedimentação no tanque, o que interfere com as medidas de sólidos suspensos totais. Assim, as
medidas de SST registadas pela sonda são menos representativas que as obtidas na monitorização de
rotina da SIMTEJO.
Analisando agora a conformação das caixas, verifica-se que:
• A mediana é praticamente constante ao longo dos meses, para todas as variáveis;
• Os whiskers têm tamanhos diferentes, sendo o superior mais extenso. Isto significa que os valores
medidos são mais variáveis acima do percentil 75% e variam muito pouco abaixo do percentil 25%;
• Existem vários meses em que se identifica um elevado número de outliers acima do whisker
superior. Quando isto acontece, significa que temos dois comportamentos muito distintos ao
longo do mês em questão, sendo que o que mais tempo predomina é o que é descrito pela caixa.
Um exemplo relevante desta última situação é o mês de Outubro de 2014, para o caso do azoto amo-
niacal. A conformação do boxplot é diferente dos restantes meses, uma vez que, apesar da caixa ser
também estreita, existe um elevado número de outliers. Uma forma de completar esta análise, é avaliar
a representação da série mensal na Figura 3.15.
Figura 3.15: Representação mensal dos valores medidos online de NH4-N em Outubro de 2014.
Como se pode verificar, a partir de dia 7 de Outubro a sonda começa a medir valores próximos de zero e
permanece assim até ao final do mês (área sombreada a cinzento na Figura 3.15). Consequentemente,
o boxplot correspondente origina uma caixa muito estreita. Os outliers que se detectam dizem respeito
aos valores que a sonda mede até dia 7 de Outubro. Este comportamento levantou suspeitas de uma
possível avaria da sonda, teoria essa que se confirmou após comparação destes valores com os dados
analíticos em períodos de campanhas, como se pode observar na Figura 3.17.
Outra informação que interessa analisar é a questão da avaria do filtro de banda (linha das lamas) no
período de Maio a Outubro de 2014. Esta avaria impossibilitou a extracção de lamas do sistema de tra-
tamento, o que levou a uma acumulação excessiva de sólidos e carga biológica na ETAR, uma vez que
praticamente toda a lama era recirculada. O espessador gravítico continuou a funcionar, mas apenas
com a função de acumular lamas e, os filtros de areia operaram com lavagem quase em contínuo, o
59

que aumentou a frequência das recirculações à estação elevatória inicial. O sobrenadante recirculado
do tratamento terciário numa situação destas é um sobrenadante com uma carga biológica muito mais
elevada que o suposto. Como tal, seria de esperar que durante estes meses, os boxplots de SST e
CQO apresentassem uma mediana mais elevada. A partir de Outubro, devido ao arranjo do filtro de
banda, o facto de existirem menos recirculações faz com que os valores medidos de SST e CQO dimi-
nuam. No entanto, não se pode dizer que exista uma tendência nesse sentido, o que sugere que as
recirculações não têm um impacto tão grande como se pensava no estado da ETAR.
Destaca-se, ainda, o caso do mês de Novembro de 2014, cujo boxplot para as variáveis SST e CQO
é uma caixa muito larga. Analisando a Figura 3.16, conclui-se que a conformação da caixa se deve ao
facto de existirem dois comportamentos distintos, igualmente distribuídos ao longo do mês. De facto,
sabe-se que a sonda registou valores fidedignos de sólidos supensos totais e carência química de oxi-
génio até dia 18 de Novembro e, nesse dia, teve uma avaria no sistema de ar comprimido, responsável
pela limpeza da janela óptica, pelo que os dados adquiridos nos restantes dias do mês não são realis-
tas. Em Dezembro ainda se detecta no boxplot os efeitos desta avaria, pelo menos até dia 3, período a
partir do qual a sonda volta a adquirir valores normais. Provavelmente estes valores correspondem aos
outliers detectados neste mês.
Figura 3.16: Representação mensal dos valores medidos online de SST e CQO desde Novembro atémeados de Dezembro de 2014.
Por fim, salienta-se que, a partir de Janeiro de 2015 a sonda começa a dar valores de SST próximos de
zero, o que revelou tratar-se de um problema de software e impossibilitou a utilização da variável SST
nos modelos de previsão de azoto orgânico posteriormente contruídos.
3.3.4 Comparação dos dados s::can com dados analíticos de campanhas
A comparação dos dados adquiridos pela sonda s::can com os dados adquiridos em campanhas é
especialmente relevante para validação das medições online. O facto das amostras recolhidas serem
pontuais e conservadas no frio até à análise laboratorial coloca estes dados em vantagem relativamente
aos dados disponibilizados pela SIMTEJO (amostras compostas de 24 horas, não sujeitas a refrigera-
60

ção) e permite retirar conclusões mais acertadas e realistas acerca da veracidade e representatividade
dos dados recolhidos em linha. Na Figura 3.17 sobrepõem-se os dados analíticos recolhidos em todas
as campanhas (pontos pretos) com os dados aquiridos pela sonda s::can nos períodos de campanha
até à V2 (linhas coloridas por ID de campanha), para as variáveis SST, CQO e NH4-N. Da visualização
dos gráficos é possível concluir que:
Figura 3.17: Sobreposição dos dados adquiridos online e dos dados analíticos de SST, CQO NH4-Npara períodos de campanhas.
• Existe uma melhor sobreposição entre dados s::can e de campanhas para a variável CQO;
• No caso dos sólidos, não existe sobreposição para a campanha P1 mas, apesar dos erros na
aquisição de dados pela sonda s::can a partir de Janeiro de 2015, os dados adquiridos em linha
são coerentes com os dados analíticos ;
• A partir da campanha P2, não existe sobreposição dos dados de NH4-N;
• Não existe sobreposição dos dados recolhidos em linha com os dados analíticos para a campanha
V2.
Esta última situação foi analisada mais detalhadamente, uma vez que se suspeitava de uma avaria da
sonda de amónia, após representação das cargas afluentes em boxplots (ver Secção 3.3.3). Obser-
vando a sobreposição dos dados analíticos da campanha preliminar 2 com os dados s::can foi possível
verificar que a partir desta altura a sonda começa a dar valores anormais e os dados analíticos deixam
de coincidir minimamente com os dados online. Assumiu-se, então, uma avaria da sonda de amónia
que impossibilitou a utilização dos dados da sonda adquiridos a partir de Outubro de 2014.
61

3.3.5 Análise de Correlações
Sendo um dos objectivos principais deste trabalho o desenvolvimento de sensores inferenciais baseado
em modelos PLS para previsão de parâmetros de qualidade de águas residuais, é importante analisar
a correlação entre as diversas variáveis medidas. Para tal, pode-se recorrer a representações mensais
das quatro variáveis medidas em linha (Qaf_SIM, SST, CQO e NH4-N) e procurar tendências comuns, ou
construir matrizes de correlação.
Escolhendo pela primeira opção, o resultado é algo semelhante ao gráfico da Figura 3.18. Neste,
as quatro variáveis foram representadas mensalmente, em dois eixos (o principal para SST e CQO e
o secundário para NH4-N e Qaf_SIM) e, sempre que necessário, foram aplicados factores de modo a
facilitar a visualização dos dados (descritos nas legendas dos eixos).
Figura 3.18: Representação conjunta das quatro variáveis medidas em linha (Qaf_SIM, SST, CQO eNH4-N) para o mês de Julho de 2014.
Este tipo de gráfico é suficiente para se concluir que existem algumas variáveis que seguem tendências
comuns, como o caso do CQO e SST ao longo de todo o mês. No entanto, apenas permite uma
análise qualitativa, isto é, não existe nenhum parâmetro a quantificar o grau de correlação existente
entre as variáveis representadas. Outra desvantagem inerente a este tipo de representação manifesta-
se quando se pretende comparar graus de correlação entre variáveis para diversos meses, que é um
dos objectivos desta análise. Para eliminar estes problemas, construíram-se matrizes de correlação
mensais recorrendo à linguagem de programação R, representando-se na triangular inferior scatter
plots e na triangular superior os coeficientes de correlação de Pearson. Nesta matriz, a informação
usada para construir o gráfico presente na Figura 3.18 aparece como se apresenta na Figura 3.19.
Tendo em conta o significado deste coeficiente (ver Secção 2.4.4) conclui-se que, no mês de Julho de
2014, existe uma forte correlação entre SST e CQO, as correlações com a variável NH4-N são sempre
fracas, e a correlação de SST e CQO com Qaf_SIM é moderada/forte.
Para apurar se existia ou não efeito de sazonalidade, representou-se a matriz de correlação para o mês
de Dezembro de 2014, mês de Inverno e verificou-se que as correlações se mantiveram. Por esta razão
conclui-se que, face à elevada quantidade de dados, o efeito de sazonalidade não é suficientemente
relevante ao ponto de alterar as correlações existentes entre as variáveis e, consequentemente, é
possível condensar todos os dados do ano de 2014 numa só matriz e avaliar as correlações a partir
dessa representação. As matrizes podem ser consultadas no Anexo D. As conclusões extraídas da
62

Figura 3.19: Matriz de correlação dos dados medidos em linha para o mês de Julho de 2014.
matriz anual coincidem com as já referidas para o mês de Julho, excepto que, como se já se tinha
verificado para Dezembro (Anexo D), se bem que em menor grau, as correlações de Qaf_SIM com CQO
e SST passam a revelar-se fracas. A invalidação destas correlações quando se consideram dados de
outros meses de 2014 pode ter tido origem na variabilidade do efeito da pluviosidade, que pode conduzir
ora a diluição, ora a arrastamento intenso de depósitos das condutas da rede colectora afluente.
3.3.6 Análise de Componentes Principais
Nesta secção apresentam-se os biplots obtidos a partir a análise componentes principais efectuada aos
dados da sonda s::can. É importante referir que a sua leitura e interpretação deve ser feita em parceria
com a análise das séries de dados mensais, em que se representa conjuntamente as quatro variáveis
medidas em linha, como o gráfico da Figura 3.18. Só assim é possível fazer a ponte entre a linguagem
do PCA e os acontecimentos reais.
Neste estudo, além das quatro variáveis medidas em linha à entrada da ETAR, representou-se a va-
riável caudal efluente, Qef, sempre que existiram dados disponíveis, de modo a completar a análise
em termos de correlação entre caudal afluente e efluente. A Figura 3.20 apresenta alguns dos biplots
mensais obtidos em 2014 e 2015 (os restantes podem ser consultados no Anexo E). Como se pode
observar, para todos os meses tem-se uma percentagem de variância explicada superior a 70% para os
dois primeiros componentes principais. Isto significa que a representação neste plano permite analisar
grande parte da informação, o que é óptimo para fundamentar as tendências observadas.
Analisando os gráficos, verifica-se que a tendência geral é haver uma forte correlação entre CQO e
SST e estas duas variáveis não se correlacionarem com Qaf_SIM. Este facto pode ser explicado pelas
condições de admissão das águas afluentes à ETAR: enquanto que o tanque inicial tem um volume
pequeno, não permitindo equalização das concentrações afluentes, o regime de funcionamento do
parafuso de Arquimedes amortece o caudal.
63

(a) Junho de 2014 (b) Setembro de 2014
(c) Outubro de 2014 (d) Novembro de 2014
(e) Dezembro de 2014 (f) Fevereiro de 2015
Figura 3.20: Biplots dos PCA mensais com os dados medidos em linha de SST, CQO, NH4-N, Qaf_SIMe Qef para Junho, Setembro, Outubro, Novembro e Dezembro de 2014 e Fevereiro de 2015, respectiva-mente.
64

Outra tendência que se observa é que, na maioria dos meses, o Qaf_SIM e o NH4-N têm uma relação
de anti-correlação, isto é, são representados por linhas em direcções opostas, sendo que Qaf_SIM tem
contribuição positiva no PC2 e NH4-N contribuição negativa. No entanto, existem períodos em que esta
disposição inverte, isto é, o caudal afluente passa a ter contribuição negativa para o PC2 e o azoto
amoniacal fica com contribuição positiva (Setembro e Outubro de 2014).
A relação de anti-correlação pode ser explicada com base nos processos que ocorrem no esgoto, ao
longo do percurso até à estação elevatória inicial da ETAR. Sabe-se que a água do esgoto é composta
maioritariamente por CQO e Norg que, ao longo do seu percurso até às estações de tratamento, sofrem
transformações. A matéria orgânica sofre oxidação, mas assumiu-se que não existiam grandes altera-
ções, pelo que a sua concentração se mantém ao longo do percurso na conduta, desde o local de emis-
são até à ETAR. O azoto orgânico sofre amonificação, isto é, a reacção de conversão/transformação
do azoto orgânico em azoto amoniacal. Deste modo, da fracção inicial de azoto orgânico, parte dá
origem a uma fracção de azoto amoniacal e outra permanece sob a forma de azoto orgânico. Quando
o caudal de águas afluentes à ETAR diminui, o tempo de permanência na conduta de esgoto é maior, o
que potencia a reacção de conversão de azoto orgânico em azoto amoniacal [Hvitved-Jacobsen et al.,
2013].
Com a finalidade de tentar interpretar a inversão na disposição das variáveis Qaf_SIM e NH4-N no biplot,
averiguou-se a situação mais pormenorizadamente, isto é, analisou-se a série mensal da evolução dos
dados medidos em linha e verificou-se que os valores de caudal duplicam neste período; contudo, não
se verificam alterações nas concentrações afluentes. Trata-se, portanto, de situação nova que pode
ser atribuída a: (i) aumento da pluviosidade durante este período e (ii) caudais de recirculação mais
frequentes dada a avaria do filtro de banda (paragem do funcionamento da extracção de lamas).
Confrontando a possibilidade da precipitação tomar valores elevados neste período, analisou-se os da-
dos disponibilizados pelo IPMA, mais concretamente o gráfico representado na Figura 3.8 (ver Secção
3.1.7), e verificou-se que efectivamente havia um pico de valores de precipitação para os meses de
Setembro, Outubro e Novembro de 2014. Portanto com um caudal mais elevado, há diluição das con-
centrações de CQO e SST e, consequentemente tem-se uma representação biplot semelhante à da
Figura 3.20(f). No caso da hipótese de aumento dos caudais de recirculação em resposta à paragem
da extracção de lamas do processo de tratamento, seria de esperar que com o aumento de Qaf_SIM,
pelo menos a concentração de SST também aumentasse, uma vez que há arrastamento de sólidos
ao longo do processo, situação esta que não se verifica. No entanto, isto não significa que as recircu-
lações não expliquem, de todo, a alteração da posição das variáveis no biplot. Há que ter em conta
que nem todas as correntes que recirculam à estação elevatória inicial arrastam sólidos. Por exemplo,
o sobrenadante do espessador e o efluente do filtro de banda são correntes com uma % residual de
sólidos em condições normais de funcionamento das operações de espessamento e de desidratação,
respectivamente. Assim, o que se pode concluir é que estes dois comportamentos podem ter influência
na alteração do biplot, mas a hipótese desta ser atribuída ao aumento da precipitação é aparentemente
mais fundamentada pelos dados disponíveis.
Outra situação que tem interesse em ser analisada é o biplot correspondente ao mês de Novembro
65

de 2014, onde se distinguem nitidamente dois comportamentos: (i) elevada variabilidade ao longo da
direcção do caudal, com valores de CQO e SST baixos e (ii) valores de CQO e SST muito elevados, com
uma elevada quantidade de dados dispostos na direcção destas duas variáveis. A mancha de valores
de CQO e SST elevados reporta a avaria do compressor que impossibilitou a limpeza da janela óptica
de leitura da sonda a partir de dia 18 de Novembro. Tendo a janela de leitura suja, os valores medidos
pela sonda desviaram-se para valores elevados, muito diferentes dos medidos na primeira quinzena do
mês. Portanto, é esta mudança abrupta nas medidas de CQO e SST que explica os dois agrupamentos
de valores observados no biplot do mês de Novembro. De notar que a avaria se prolongou até ao início
do mês de Dezembro e, como se pode observar no respectivo gráfico, existe efectivamente um cluster
de valores especialmente elevados na direcção de CQO e SST.
Por fim, a correlação entre Qaf_SIM e Qef, como seria de esperar, é positiva para todos os meses, exis-
tindo casos em que existe praticamente sobreposição entre as linhas que representam estas duas
variáveis, como os meses de Abril e Junho de 2014. Por outro lado, observam-se situações em que as
linhas que dizem respeito a Qaf_SIM e Qef formam entre si um ângulo superior a 45o, nomeadamente o
mês de Fevereiro de 2015, em que quase é possível afirmar que estas variáveis não estão correlacio-
nadas (descrevem um ângulo de 90o entre si). No entanto, a análise dos boxplots dos dados de caudal
(Secção 3.1.3) não sugere nenhum comportamento particularmente anómalo.
O tipo de análise descrito nesta secção permite efectuar um controlo de qualidade dos dados medidos
em linha e detectar alterações nas condições operatórias que representem situações anómalas. Isto é
especialmente importante para o desenvolvimento de sensores inferenciais, principalmente baseados
em informação espectral, uma vez que a qualidade dos espectros usados como input dos modelos
influencia a performance dos mesmos.
3.4 Construção de sensores inferenciais baseados em modelos
PLS
O principal objectivo deste trabalho é a construção de sensores inferenciais com base em modelos
PLS para previsão da concentração de azoto orgânico à entrada do tratamento biológico. É necessá-
rio prever esta variável porque se trata de um input do modelo ASM1 desenvolvido para descrição e
simulação do sistema de tratamento das águas residuais e, ao contrário dos parâmetros CQO, SST e
NH4-N, não pode ser medida directamente. Foram desenvolvidos sensores inferenciais baseados em
dados analíticos e em dados espectrais. No caso dos sensores baseados em informação espectral,
além do azoto orgânico, optou-se por também prever o CQO, de modo a concluir se era vantajoso partir
da informação espectral ou se, pelo contrário, eram preferíveis os dados analíticos disponibilizados pela
sonda s::can. Adicionalmente, numa perspectiva de redução de custos associados à manutenção de
um equipamento de medição online, foi estudada a hipótese de adquirir sondas lowcost, isto é, com
medição a comprimentos de onda mais pontuais.
66

3.4.1 Origem dos Dados e Metodologias Aplicadas
No desenvolvimento dos sensores inferenciais baseados em dados analíticos recorreu-se ao software
R e utilizaram-se os dados analíticos recolhidos ao longo das campanhas. Os dados disponibilizados
pela sonda s::can foram usados na verificação das previsões (ver Secção 3.3.1). Os modelos PLS
foram calibrados usando apenas dados analíticos recolhidos em campanhas, por se tratarem de de
dados mais fidedignos. Por sua vez, os sensores inferenciais a partir de dados espectrais foram cons-
truídos no software MATLAB 7.9.0, a partir da informação espectral adquirida pela sonda s::can. Foram
apenas usados os espectros respeitantes aos períodos de campanha e para os quais existiam valores
analíticos.
Face à possibilidade da existência de outliers, o primeiro passo foi a elaboração de modelos PCA, quer
para os dados analíticos, quer para os dados espectrais, de modo a definir o conjunto de dados a usar
na calibração dos modelos PLS. No caso dos dados analíticos, uma vez que a frequência de amos-
tragem para os parâmetros CQO e SST é diferente da frequência para NH4-N e Norg, na construção
da matriz de dados, optou-se por interpolar valores de azoto amoniacal e azoto orgânico, recorrendo
a um modelo de interpolação linear simples. No caso dos dados espectrais, após a identificação dos
espectros anómalos, foi ainda necessário avaliar se estes eram coerentes com os outliers detectados
no pré-tratamento dos dados analíticos.
Uma vez definido o dataset, avançou-se para a construção dos modelos de previsão com base na
técnica PLS. Seguiu-se uma estratégia de validação cruzada do tipo leave-one-out (ver Secção 2.4.6.3).
Portanto, em primeiro lugar procedeu-se a uma subdivisão dos dados em conjunto de calibração (70%)
e em conjunto para validação externa (30%). Os subconjuntos foram representados em histogramas
para garantir que a sua distribuição era semelhante à do conjunto de dados original. No entanto, dada
a reduzida dimensão dos conjuntos de dados originais, isto nem sempre se verificou (ver Anexos G.2 e
H.3). Os dados do conjunto de calibração são usados para validação cruzada através de uma estratégia
de leave-one-out, obtendo-se como resultado a percentagem de variância explicada e o RMSECV, que
permitem uma tomada de decisão acerca do número de componentes principais a incluir no modelo e
a escolha das variáveis de entrada.
Após calibração do modelo, é efectuada uma validação externa, com o conjunto com 30% dos dados
e calcula-se o erro de previsão (RMSEP). Por fim, este erro é comparado com o erro de previsão
da campanha V1, recorrendo ao teste de Mann-Whitney Wilcoxon (ver Secção 2.4.6.4) para avaliar
a robustez do modelo. O teste de Mann-Whitney-Wilcoxon foi realizado para os desvios (previsto -
observado) das duas validações (validação externa e validação de V1). A hipótese nula é estas duas
populações serem idênticas. Caso o p-value seja < 0.05, a hipótese nula é rejeitada, caso contrário é
aceite. Se a hipótese do teste for rejeitada, antes de se proceder à recalibração do modelo, deve-se
avaliar se os novos dados correspondem a uma situação anómala e, em caso afirmativo, se se pretende
efectivamente incluir esta situação no modelo. Por exemplo, se o objectivo for ter um modelo de previsão
robusto para o funcionamento normal da ETAR e que detecte situações anómalas, então estes novos
dados não devem ser incluídos no conjunto de calibração.
Um requisito fundamental no estabelecimento de um modelo PLS com dados de origem espectral é a
67

escolha dos comprimentos de onda apropriados, já que parte da informação contida no espetro com-
pleto é redundante. Adicionalmente, os sinais medidos a comprimentos de onda específicos podem
apresentar uma relação não-linear com os dados analíticos, representar ruído ou conter informação
inútil para o objectivo proposto. Nesta perspectiva, e tendo em vista a utilização de uma sonda lowcost,
recorreu-se à ferramenta Interval PLS (ou iPLS) disponível na PLS Toolbox 5.0 no MATLAB. Este soft-
ware permite uma optimização dos modelos PLS construídos a partir de dados dos espectros e sugere
gamas de intervalos de comprimentos de onda que deêm origem a modelos com menores valores de
RMSE. É possível escolher o número de variáveis e de intervalos a incluir no modelo optimizado. Neste
trabalho foram testadas três hipóteses diferentes: blocos de 20 comprimendos de onda, blocos de 10
comprimentos de onda e a versão lowcost, onde apenas é utilizada uma variável e um intervalo.
No final, efectuou-se uma análise comparativa entre os sensores desenvolvidos. Para as previsões de
azoto orgânico, comparou-se os erros de previsão da campanha de validação 1 para o sensor baseado
em dados analíticos e para o sensor com base em dados espectrais. No caso da previsão de CQO,
avaliou-se se é vantajoso ter disponível a informação espectral ou se os dados analíticos determinados
pelo modelo interno da sonda s::can têm menor erro de previsão associado. Para tal, calculou-se o
RMSEP dos dados analíticos disponibilizados pela sonda e comparou-se com o valor obtido para o
sensor inferencial construído.
3.4.2 Sensores inferenciais baseados em dados analíticos
3.4.2.1 Pré-tratamento para detecção e exclusão de outliers
Na primeira fase de construção dos sensores inferenciais baseados em dados analíticos foi efectuado
um estudo dos dados analíticos recolhidos nos períodos correspondentes às campanhas P1, P2, C1,
C2, C3 e V1 com o intuito de identificar e excluir outliers. De seguida apresenta-se na Figura 3.21
o biplot que representa a análise PCA com todos dados de SST, CQO, NH4-N, Norg e Qaf_SIM para
todas as campanhas, excluindo a C1. A exclusão desta campanha deveu-se ao facto de uma avaria
no sistema de refrigeração de amostras impossibilitar a determinação analítica de SST. Foi igualmente
testada a hipótese de excluir a variável SST como entrada do modelo e considerar a campanha C1
(PCA biplot no Anexo G.1). Contudo, concluiu-se que existia uma forte correlação entre SST e Norg e,
consequentemente, optou-se por excluir a campanha C1 do dataset.
Após avaliação da distribuição dos scores, considerou-se como outliers os pontos assinalados com um
círculo vermelho. Estes pontos correspondem às seguintes amostras da campanha C2: 14-01-2015
10:30, 14-01-2015 12:30 e 15-01-2015 12:30.
3.4.2.2 Desenvolvimento de Modelos PLS
Na Figura 3.22 apresenta-se o biplot da análise PCA de todas as variáveis de entrada consideradas
para o desenvolvimento dos vários modelos PLS. As tabelas 3.9 e 3.10 resumem os resultados obtidos
para os modelos PLS testados, em termos de processo de escolha do número de LV e em termos
de comparação dos valores RMSEP de validação externa e novas previsões. De seguida explica-se
68

Tabela 3.8: Informação do número total de dados analíticos recolhidos em períodos de campanhase valores de caudal correspondentes (CQO, SST, NH4-N, Norg e Qaf_SIM) e dos pontos consideradosoutliers removidos do dataset.
No pontos
Total (conjunto original) 355Fora do intervalo 95% confiança 5Outliers 3
Figura 3.21: Biplot representativo da análise PCA, incluindo os dados de SST, CQO, NH4-N, Norg eQaf_SIM recolhidos nas campanhas P1, P2, C2, C3 e V1. Os círculos a vermelho assinalam os pontosque foram considerados como outliers.
todo o processo envolvido na construção do sensor inferencial baseado em dados analíticos. Em todos
os modelos desenvolvidos, considerou-se o conjunto de dados das campanhas P1, P2, C2 e C3 para
calibração e validação externa. A campanha V1 foi prevista com base no modelo PLS recém-calibrado.
Inicialmente, pretendia-se prever a concentração de azoto orgânico à entrada do tratamento biológico
a partir do azoto amoniacal. Contudo, quando se representou o biplot da análise PCA com as variáveis
directamente medidas (SST, CQO, NH4-N, Ntotal e Qaf_SIM) constatou-se que estas duas variáveis não
estavam praticamente correlacionadas. Na verdade, as variáveis mais correlacionadas com Norg foram
CQO e SST. Uma vez que, tal como explicado na Secção 3.3.3, as medidas em linha de SST apresen-
tam problemas de representatividade a partir de Janeiro de 2015, optou-se por não incluir esta variável
como input do sensor inferencial. Construiu-se, assim, o primeiro modelo para previsão de azoto orgâ-
nico com dados de CQO. Quando se efectuou a previsão da campanha V1 e se representou os valores
previstos juntamente com os valores observados (ver Anexo G.3), concluiu-se que, apesar do erro de
previsão não ser especialmente elevado e o resultado do teste de hipóteses indicar que a distribuição
dos erros é idêntica à do conjunto de teste, não há sobreposição de valores nem acompanhamento das
tendências ao longo do período da campanha. Em suma, a campanha é mal prevista por este modelo.
Tentou-se explicar as diferenças encontradas com base nos processos que ocorrem no esgoto, ao longo
do percurso, desde do local de emissão do efluente até à estação elevatória inicial da ETAR. Conforme
69

Figura 3.22: Biplot representativo da análise PCA, incluindo os dados recolhidos nas campanhas P1,P2, C2, C3 e V1 e todas as variáveis consideradas no desenvolvimento dos modelos PLS, após remo-ção de outliers. Para a análise PCA foi usado um conjunto de dados com 728 pontos.
referido anteriormente (ver Secção 3.3.6), a água do esgoto é composta maioritariamente por CQO e
Norg e, ao longo do seu percurso até às estações de tratamento, estas espécies sofrem transformações,
nomeadamente a conversão/transformação do azoto orgânico em azoto amoniacal. Uma vez que não
se sabe ao certo a extensão desta reacção, pensou-se que seria mais correcto considerar a fracção
total de azoto como variável a prever. Deste modo, é possível considerar no modelo o tempo que as
águas residuais permanecem na conduta do esgoto, factor este importante visto que, quanto maior for
o tempo de permanência, maior a reacção de amonificação. Uma forma de ter em conta esta depen-
dência é criar uma relação com o caudal, que dá origem a novas variáveis: variáveis de carga. De notar
que, apesar destas serem combinações lineares das variáveis originais, têm significado bioquímico. Por
fim, tendo os valores de Ntotal previstos pelo modelo, basta subtrair os valores de azoto amoniacal para
obter a fracção orgânica.
CargaCQO = CQO×Qaf_SIM (3.8)
CargaNtotal= Ntotal ×Qaf_SIM (3.9)
O objectivo de criar estas variáveis é averiguar se, entrando como inputs nos modelos PLS, conseguem
melhorar a previsão e tornar o sensor inferencial mais robusto. Estas foram representadas no biplot e
as suas direcções e correlações foram avaliadas de modo a construir novos modelos (Figura 3.22).
Depois de avaliar a distribuição dos loadings no biplot construíram-se modelos para previsão da con-
70

Tabela 3.9: Variáveis de entrada, número de componentes, % da variância explicada pela(s) entrada(s)e RMSECV para cada modelo. O valor de NRMSECV foi obtido dividindo a RMSECV pelo range, isto é,a diferença entre o valor máximo e o valor mínimo do conjunto de dados. O range para os três modelosfoi de: 5-23,8 mg/L para Norg, 20-42,75 mg/L para Ntotal e 297-786 mg/s para CargaNtotal.
Variávela prever
Variáveisentrada no LV % var.
explicadaRMSECV
(mg/L)NRMSECV
(%)
Norg
CQO 1 100 3,71 16,3
CargaCQO 1 100 3,72 16,3
CQO, NH4-N, SST,Qaf_SIM, CargaCQO
1 55,23 3,62 15,92 63,94 3,90 17,13 89,18 3,82 16,84 99,83 3,75 16,45 100 3,96 17,4
Ntotal
CQO, NH4-N 1 69,62 3,92 10,62 100 3,80 10,3
CQO 1 100 7,00 18,9
NH4-N 1 100 4.26 11.5
CQO, NH4-N, SST,Qaf_SIM, CargaCQO
1 48,36 5,48 14,82 82,99 4,46 12,13 93,72 3,88 10,54 99,84 3,75 10,15 100 3,94 10,6
CargaNtotal
CQO, CargaCQO1 97,73 131 13,32 100 127 12,9
CQO 1 100 136 13,8
CQO, NH4-N, SST,Qaf_SIM, CargaCQO
1 54,44 118 12,02 67,41 81,5 8,293 94,03 77,3 7,864 99,84 74,7 7,605 100 79,6 8,10
centração de Ntotal e de CargaNtotal (Tabela 3.9). Concluiu-se que as previsões desta nova variável de
carga não melhoram substancialmente comparativamente às previsões efectuadas para os modelos de
azoto total. O melhor modelo é o de previsão de Ntotal que contém os dados de azoto amoniacal, com
um erro de previsão da campanha V1 francamente mais baixo em comparação com os outros modelos.
No entanto, dada a ausência de dados fiáveis na medição em linha do azoto amoniacal desde Outubro
de 2014 (avaria da sonda), é arriscado usar modelos que prevejam o azoto total, porque será sempre
necessário subtrair os valores de NH4-N para ter os valores de azoto orgânico. Face a esta situação,
optou-se por construir ainda outro modelo, de previsão directa de Norg, usando os dados de CargaCQO.
Avaliando a distribuição das variáveis no biplot, é imediatamente perceptível que este novo modelo tem
mais potencial que o modelo de previsão de azoto orgânico construído inicialmente, dada a proximidade
das linhas que representam Norg e CargaCQO.
Após desenvolvimento de todos os modelos (ver Tabela 3.10), conclui-se que os dois melhores mode-
los são para a previsão de azoto total, usando os dados de CQO e NH4-N, e para a previsão de azoto
orgânico com dados de CargaCQO. Cada um destes modelos apresenta vantagens e desvantagens que
71

Tabela 3.10: Previsões do conjunto de validação externa (conjunto de teste) e da campanha V1. Ovalor de NRMSEP foi obtido dividindo a RMSEP pelo range. O range para os três modelos foi de:4,3-15,6 para Norg, 20-46,2 mg/L para Ntotal e 199-630 mg/s para CargaNtotal.
Variávela prever
Variáveisentrada no LV RMSEP NRMSEP (%) Teste
WilcoxonTeste CV1 Teste CV1
NorgCQO 1 3,78 3,31 20,1 29,3 0,0826
CargaCQO 1 3,67 3,01 19,5 26,6 0,0559
NtotalCQO, NH4-N 1 3,68 3,36 16,2 12,8 0,0943
CQO 1 5,39 7,13 23,7 27,2 0,0269
CargaNtotal CQO 1 123 115 24,2 26,7 0,1566
devem ser tidas em conta quando se optar por um em detrimento do outro. Para uma avaliação visual
da performance de cada um dos sensores, efectuaram-se previsões, usando os dados analíticos e os
dados medidos em linha, para todas as campanhas e os dados previstos foram representandos junta-
mente com os dados observados. Os resultados foram analisados, os prós e contras de cada modelo
foram ponderados de modo a tomar a decisão final. As Figuras 3.23 e 3.24 apresentam as previsões
para cada campanha, para o modelo de estimativa do azoto orgânico e de azoto total, respectivamente.
Como se pode observar, o modelo de previsão de azoto total com base nos dados de CQO e NH4-N
tem, no geral, um melhor desempenho, principalmente para previsão de valores extremos (muito altos e
muito baixos), o que sugere que a fracção de azoto amoniacal pesa muito para a concentração de azoto
total. Por outro lado, com o modelo de previsão directa de azoto orgânico a partir da carga de CQO
perde-se os finos mas, ainda assim, é possível captar a tendência geral de evolução da concentração
de Norg. Esperava-se contudo que, ao introduzir a variável caudal, as previsões melhorassem, uma vez
que o modelo passa a ter informação sobre o tempo de residência no colector. Assim, fica comprovado
que as oscilações são essencialmente devidas ao azoto amoniacal, dado que usando dados de NH4-N
se capturam todas as variações.
Face à ausência de dados fiáveis na medição de azoto amoniacal desde Outubro de 2014, não faz sen-
tido escolher o modelo que prevê a concentração de azoto total, pois será sempre necessário subtrair a
fracção de NH4-N para se obter valores de Norg (previsão indirecta). Com o modelo de previsão directa
de Norg, mesmo perdendo as oscilações mais finas, é possível efectuar boas previsões em termos de
tendências gerais e elimina-se o problema da disponibilidade dos dados recolhidos em linha. Fixou-se
então, como sensor inferencial, o modelo PLS de previsão de azoto orgânico com base em dados de
Carga de CQO.
72

(a) Campanha Preliminar 1 (b) Campanha Preliminar 2
(c) Campanha de Calibração 1 (d) Campanha de Calibração 2
(e) Campanha de Calibração 3 (f) Campanha de Validação 1
Figura 3.23: Previsões das concentrações de azoto orgânico no período das campanhas P1, P2, C1,C2, C3 e V1 com dados analíticos e dados online de carga de CQO. Dada a diferença na frequênciade amostragem/aquisição de dados de CQO e Qaf_SIM, considerou-se os valores de caudal em degrausque variam no início de cada hora. Os valores analíticos de azoto orgânico foram calculados subtraindoos valores de azoto amoniacal aos valores de azoto total.
73

(a) Campanha Preliminar 1 (b) Campanha Preliminar 2
(c) Campanha de Calibração 1 (d) Campanha de Calibração 2
(e) Campanha de Calibração 3 (f) Campanha de Validação 1
Figura 3.24: Previsões das concentrações de azoto total no período das campanhas com dados analí-ticos de dados online de CQO e NH4-N. Só foi possível efectuar previsões com base em dados onlinepara a campanha P1 devido à avaria da sonda de amónia em Outubro de 2014.
74

3.4.3 Sensores inferenciais baseados em informação espectral
3.4.3.1 Pré-tratamento para detecção e exclusão de outliers
Na primeira fase de construção dos sensores inferenciais baseados em dados espectrais foi efectuado
um estudo dos espectros obtidos pela sonda s::can para os períodos correspondentes às campanhas
P1, P2, C1, C2, C3 e V1. Este teve como objectivo identificar e excluir outliers do conjunto de dados
espectrais. Consideraram-se outliers todos os pontos simultaneamente anómalos nas análises dos
dados espectrais e analíticos e os que representavam espectros com tendências e formatos diferentes
do espectro médio. O procedimento é descrito mais detalhamente no Anexo H.1.
A Tabela 3.11 resume os pontos que foram considerados ouliers ao longo desta análise. Estes foram
destacados no Scores plot resultante da análise PCA, como se pode observar na Figura 3.25. Por fim,
apresenta-se um gráfico com os espectros médios antes e após a remoção de outliers (Figura 3.26).
Neste verifica-se que ambos os espectros representados têm a mesma tendência, embora o espectro
médio do conjunto de dados sem outliers se tenha deslocado ligeiramente para valores de absorvân-
cia mais baixos. Isto explica-se pelo facto de se terem eliminados mais pontos cujos espectros se
encontravam em gamas de valores de absorvância acima do espectro médio.
Tabela 3.11: Informação do número total de dados espectrais e dos pontos considerados outliers re-movidos do dataset.
No pontos
Total pontos (conjunto original) 1843Fora do intervalo 95% confiança 59Outliers 21Outliers por diferença de formato do espectro 16Outliers simultâneos na análise de dados espectrais e analíticos 5
Figura 3.25: PCA scores plot, em que os pontosassinalados a vermelho correspondem aos outli-ers considerados ao longo da pré-análise efectu-ada aos dados espectrais.
Figura 3.26: Espectros médios correspondentesaos períodos de campanhas, antes e após a ex-clusão de outliers.
75

3.4.3.2 Desenvolvimento de modelos PLS
O processo de desenvolvimento de sensores inferenciais seguiu quatro trajectórias diferentes, que se-
rão analisadas de seguida:
1. Escolha do método de pré-processamento dos dados espectrais mais adequado;
2. Optimização dos comprimentos de onda a usar nas previsões recorrendo à ferramenta iPLS;
3. Avaliação da influência de factores externos na capacidade preditiva dos modelos;
4. Avaliação da capacidade de previsão de novos dados.
Os dados usados na calibração dos modelos englobam todos os dados espectrais com correspondente
amostra dos períodos das campanhas P1, P2, C1, C2 e C3, sendo que a campanha V1 foi deixada de
fora para validação externa.
Nas figuras 3.27 e 3.28 apresenta-se um esquema dos modelos PLS desenvolvidos para previsão do
CQO e Norg partindo da informação espectral disponibilizada pela sonda s::can. Os modelos foram
identificados de modo a facilitar a sua referência no texto. No Anexo H.4 é possível consultar tabe-
las com o resumo de todos os modelos construídos, com informação relevante acerca dos mesmos,
nomeadamente o número de pontos usados, número de variáveis latentes consideradas, detalhes da
optimização via iPLS, etc.
Escolha do método de pré-processamento dos dados espectrais: Genericamente, na gama do
UV-Vis, as substâncias dissolvidas tendem a originar bandas de absorção estreitas e bem definidas.
Apenas em casos em que a quantidade de partículas dissolvidas numa solução é elevada e estas ab-
sorvem radiação a comprimentos de onda diferentes, é que se observa sobreposição dos picos e estes
podem aparecer mais largos. Por seu turno, as partículas em suspensão tendem a originar espectros
de dispersão de radiação (desvio da direcção da radiação, quando atinge uma partícula sólida) com
picos bastante mais largos. Além deste efeito, há que ter em conta que estas substâncias podem ab-
sorver radiação no mesmo comprimento de onda que as partículas dissolvidas e, quando isto acontece,
a informação química contida no espectro pode ficar escondida. Assim, a aplicação de filtros derivati-
vos tem como finalidade a atenuação de bandas de absorvância mais largas, associadas ao efeito de
dispersão de radiação, e o realce de picos mais estreitos que tenham ficado mascarados pelo efeito
absorção de radiação por partículas sólidas (ver Secção 2.5.3.1). Neste trabalho testou-se aplicar, além
de mean centering, um filtro do tipo Saviztky-Golay com 2a derivada de modo a realçar a informação
química de solutos contida nos espectros, uma vez que se admite que esta se correlaciona mais for-
temente com os resultados das análises de CQO e de Norg, ainda que estes incluam as contribuições
das partes dissolvidas e em suspensão (análises totais). No final comparou-se os resultados com os
modelos em que não foram aplicados filtros derivativos. As tabelas 3.12 e 3.13 resumem a informação
principal dos modelos de previsão de CQO e Norg com e sem aplicação de filtros derivativos.
76

Figura 3.27: Representação esquemática dos modelos PLS desenvolvidos a partir da informação espectral para pevisão do CQO
77

Figura 3.28: Representação esquemática dos modelos PLS desenvolvidos a partir da informação espectral para pevisão do Norg
78

Tabela 3.12: Modelos PLS de previsão de CQO com pré-processamento mean centering e aplicandoum filtro derivativo (Saviztky-Golay 15 pontos, 2a derivada). Para ambos os modelos apresentados fo-ram usados 90 pontos. Range do conjunto de calibração: 48-738 mg/L. Range do conjunto de validaçãoexterna: 66-747 mg/L.
ID modelo no LV Gama λ usados(nm)
NRMSECV(%)
NRMSEP(val.ext., %)
CQO_MC_completo 5 220-737,5 9,90 20,65CQO_SG_completo 7 220-737,5 8,35 24,40
Tabela 3.13: Modelos PLS de previsão de Norg com pré-processamento mean centering e aplicandoum filtro derivativo (Saviztky-Golay 15 pontos, 2a derivada). Para a construção ambos os modelosapresentados foram usados 44 pontos. Range do conjunto de calibração: 4,3-27,1 mg/L. Range doconjunto de validação externa: 6-18,2 mg/L.
ID modelo no LV Gama λ usados(nm)
NRMSECV(%)
NRMSEP(val.ext., %)
Norg_MC_completo 5 220-737,5 21,10 38,70Norg_SG_completo 6 220-737,5 21,50 45,60
Comparando os erros de CV para os modelos de previsão de CQO e Norg verifica-se que no primeiro
caso há uma melhoria ligeira resultante da aplicação de filtros, enquanto que no segundo os valores
são praticamente iguais. Já os erros de previsão do conjunto teste aumentam para ambas as variá-
veis a prever. Portanto, os modelos não melhoraram com a adição de filtros derivativos. Isto pode
indicar que, para este efluente bruto em particular, os sólidos suspensos (identificados pelo efeito de
dispersão de radiação) estão aparentemente correlacionados com CQO e Norg de modo significativo,
não podendo ser desprezada a sua contribuição face à da absorção de luz. Assim, a optar por um dos
modelos, é preferível usar como método de pré-processamento simplesmente o mean centering dado
que, recorrendo a filtros derivativos, se corre o risco de introduzir ruído extra nos dados.
Optimização dos comprimentos de onda a usar nas previsões via iPLS: Partindo dos modelos
iniciais, isto é, com todas as variáveis (informação espectral na gama de comprimentos de onda de 220
a 737,5 nm), foram testadas 3 optimizações com tamanho de blocos de variáveis progressivamente
menor: blocos de 20 variáveis, blocos de 10 variáveis e a situação limite, que se designou versão low-
cost, que corresponde a uma sonda com medida em apenas um comprimento de onda. A Figura 3.29
apresenta os gráficos obtidos após optimização dos modelos originais de previsão de CQO e Norg, res-
pectivamente. Nas Tabelas 3.14 e 3.15 encontra-se a informação relativa aos modelos optimizados via
iPLS para CQO e Norg, respectivamente.
A Figura 3.29 mostra o RMSECV obtido para cada intervalo (sendo que a linha a preto representa o
espectro médio). O modo Forward indica a forma como o iPLS é operado. Neste caso, o algoritmo
começa por criar modelos PLS individuais, cada um usando o intervalo pré-definido de variáveis (neste
exemplo, apenas 1 comprimento de onda) e os intervalos são adicionados sequencialmente até ser
encontrado o modelo com o menor RMSECV. No exemplo apresentado, como só se pretende que um
intervalo seja seleccionado, o algoritmo pára no primeiro ciclo, isto é, quando o intervalo com o menor
79

(a) CQO - λ optimizado=352,5 nm (b) Norg - λ optimizado=542,5 nm
Figura 3.29: Resultados da optimização via iPLS para os modelos de previsão de CQO e Norg corres-pondentes à versão lowcost, isto é, considerando apenas 1 intervalo e blocos de tamanho unitário.
valor de RMSECV é encontrado. A barra verde distingue o comprimento de onda seleccionado (352,5
nm para o modelo de previsão CQO e 542,5 nm para o Norg). As linhas horizontais a tracejado indicam
o RMSECV obtido quando são usadas todas as variáveis e 1 ou 16 LV no caso do CQO, e 1 ou 5 LV no
caso do azoto orgânico.
Verifica-se que, em ambos os gráficos, o modelo com o intervalo seleccionado dá melhor resultado
(menor valor de RMSECV) do que o modelo usando todas as variáveis e só 1 LV. No entanto, um modelo
com 16 LV (no caso do CQO) ou 5 LV (no caso do Norg) e com todas as variáveis (208 comprimentos
de onda) continua a ser preferível ao modelo optimizado.
Tabela 3.14: Modelos PLS de previsão de CQO antes e após optimização via iPLS. Para todos modelosapresentados foram usados 90 pontos. Range do conjunto de calibração: 48-738 mg/L. Range doconjunto de validação externa: 66-747 mg/L.
ID modelo no LV Gama λ usados NRMSECV(%)
NRMSEP(val.ext., %)
CQO_MC_completo 5 220-737,5 9,9 20,65
CQO_MC_iPLS20 5 220-417,5670-717,5 10,0 20,1
CQO_MC_iPLS10 5
220-242,5395-417,5
445,0-467,5595-617,5
10,4 23,9
CQO_MC_iPLS1 1 362,5 10,2 14,5
80

Tabela 3.15: Modelos PLS de previsão de Norg antes e após optimização via iPLS. Para ambos osmodelos apresentados foram usados 44 pontos. Range conjunto de calibração: 4,3-27,1 mg/L. Rangeconjunto de validação externa: 6-18,2 mg/L.
ID modelo no LV Gama λ usados(nm)
NRMSECV(%)
NRMSEP(val.ext., %)
Norg_MC_completo 5 220-737,5 21,1 38,7Norg_MC_iPLS20 5 420-517,5 19,3 47,0Norg_MC_iPLS10 5 520-542,5 22,8 23,5Norg_MC_iPLS1 1 542,5 22,5 19,8
O principal objectivo desta tentativa de optimização era analisar se, optando por uma sonda versão
lowcost, a capacidade de previsão do modelo não era fortemente afectada. Para ambas as variáveis
concluiu-se que o iPLS não afectava praticamente o erro de validação cruzada (RMSECV), o que já era
observável nos gráficos da Figura 3.29 (a diferença do erro entre o modelo com o intervalo seleccionado
- barra verde - e o modelo com todas as variáveis e 1 LV - linha rosa a tracejado - era muito pequena).
Quanto às previsões do conjunto de validação externa, no caso do CQO verificou-se que, curiosamente,
a versão lowcost é a que apresenta menor RMSEP. No caso do azoto orgânico, o iPLS com blocos de
20 e de 10 variáveis origina modelos com RMSEP do conjunto de validação externa muito elevados. À
semelhança do que se observou para o CQO, os erros de CV são bastante semelhantes em todas as
versões e a opção lowcost volta a ser o modelo que garante um menor valor de RMSEP do conjunto
de validação externa (quase metade em comparação com o modelo original). Em suma, os melhores
modelos de previsão de CQO e Norg correspondem às versões lowcost, isto é, modelos optimizados
via iPLS a partir do modelo inicial (espectro completo) que usam apenas 1 comprimento de onda e 1
intervalo.
Avaliação da influência de factores externos na capacidade preditiva dos modelos: Aos melho-
res modelos resultantes da optimização via iPLS foram adicionados factores externos, concretamente,
as variáveis caudal e azoto amoniacal, na tentativa de melhorar as previsões. A adição de dados azoto
amoniacal ao dataset foi entendida como uma forma de melhorar os modelos face à conclusão a que
se chegou na secção anterior de que as previsões melhoram para modelos que contenham informação
sobre esta variável. Por seu turno, a adição do caudal afluente pretende fornecer mais informação ao
modelo acerca do sistema, nomeadamente o tempo de permanência na conduta de esgoto, que se
trata de um factor importante, como se concluiu anteriormente (ver Secção 3.4.2.2). Como a frequência
de obtenção de espectros pela sonda é de 10 minutos e a do caudal é horária, optou-se por considerar
valores constantes de caudal entre os intervalos da sua medição (degraus). Visto que a escala das
variáveis é diferente foi aplicado auto-scaling além de mean-centering na fase de pré-tratamento dos
dados. De acordo com a informação presente nas tabelas 3.16 e 3.17, conclui-se que adição das va-
riáveis Qaf_SIM e NH4-N não traz vantagens para a previsão de CQO e Norg. As melhorias em termos
de RMSEP do conjunto de validação externa, quando se verificam, não são significativas. Contudo,
volta mais uma vez a verificar-se que a presença de informação de azoto amoniacal nos modelos de
previsão de azoto orgânico contribui para uma ligeira melhoria da sua capacidade preditiva.
81

Tabela 3.16: Modelos PLS de previsão de Norg com adição do caudal afluente e do azoto amoniacalao conjunto de dados inicial e ao melhor modelo resultante da optimização iPLS. Para a construção detodos os modelos apresentados foram usados 44 pontos. Range do conjunto de calibração: 4,3-27,1mg/L. Range do conjunto de validação externa: 6-18,2 mg/L.
ID modelo no LV Gama λ usados(nm)
NRMSECV(%)
NRMSEP(val.ext., %)
Norg_MC_completo 5 220-737,5 21,10 38,70Norg_MC+Q_completo 6 220-737,5 21,10 46,30Norg_MC+NH4-N_completo 6 220-737,5 21,30 38,00
Norg_MC_iPLS1 1 542,5 22,50 19,80Norg_MC+Q_iPLS1 2 542,5 23,20 26,30Norg_MC+NH4-N_iPLS1 2 542,5 22,40 18,10
Tabela 3.17: Modelos PLS de previsão de CQO com adição do caudal afluente ao conjunto de dadosinicial e ao melhor modelo resultante da optimização iPLS. Para todos modelos apresentados foramusados 90 pontos. Range do conjunto de calibração: 48-738 mg/L. Range do conjunto de validaçãoexterna: 66-747 mg/L.
ID modelo no LV Gama λusados
NRMSECV(%)
NRMSEP(val.ext., %)
CQO_MC_completo 5 220-737,5 9,90 20,65CQO_MC+Q_completo 5 220-737,5 9,40 52,80
CQO_MC_iPLS1 1 362.5 10,2 14,50CQO_MC+Q_iPLS1 1 362.5 10,5 14,4
Avaliação da capacidade de previsão de novos dados: Para avaliar a capacidade preditiva de
novos dados, escolheu-se o melhor modelo para CQO e Norg e efectuou-se a previsão da campanha
V1. À semelhança do que foi feito para os sensores desenvolvidos com base em dados analíticos,
recorreu-se ao Teste de Mann-Whitney-Wilcoxon para avaliar a necessidade de recalibração do modelo.
A campanha V2 não foi considerada para previsão visto que, como já era visível na Figura 3.17, não
existe sobreposição entre os dados analíticos recolhidos na campanha e os dados da sonda s::can.
Além disso, observando os scores plot da análise PCA com os dados espectrais dos períodos de
campanhas (Anexo H.2), verifica-se que os pontos correspondentes à campanha V2 se localizam numa
região diferente dos restantes, pelo que dificilmente iriam ser previstos pelo modelo construído com os
restantes dados.
Tabela 3.18: Previsão da campanha V1 para os dois melhores modelos de previsão de CQO e Norg.O conjunto de dados da V1 é constituído por 24 pontos para o caso do CQO e por 12 pontos para ocaso do Norg. Range do conjunto V1 para previsão de CQO: 99-627 mg/L; Range do conjunto V1 paraprevisão de Norg: 4,3-15,6 mg/L.
Variávela prever ID modelo no LV Gama λ
usados (nm)NRMSEP
(val.ext., %)NRMSEP(CV1, %)
TesteWilcoxon
CQO CQO_MC_iPLS1 1 362.5 14,48 12,43 0,1897Norg Norg_MC+NH4-N_iPLS1 2 542,50 18,10 25,50 2,50E-05
Da leitura da Tabela 3.18 conclui-se que a distribuição dos erros dos conjuntos de dados de validação
externa e da campanha V1 para o modelo de previsão de Norg não é idêntica, uma vez que o resultado
82

do teste Mann-Whitney-Wilcoxon é muito inferior ao p-value para um intervalo de confiança de 95%
(0,05), ou seja, a hipótese formulada é rejeitada. Isto indica que há a necessidade de recalibrar o mo-
delo. O próximo passo seria então proceder a uma verificação dos dados, nomeadamente recorrendo
a PCA e à análise de histogramas, de modo a perceber se estes dão conta de uma situação anómala
na ETAR. Caso isso não se verifique, então estes dados devem ser introduzidos no modelo de modo
a torná-lo mais robusto. Assim, para já, pode-se afirmar que o sensor inferencial desenvolvido per-
mite prever razoavelemente a concentração de Norg. No entanto, o modelo ainda não abarca todas as
situações, pelo que pode haver a necessidade de sofrer actualizações no futuro.
3.4.4 Comparação entre sensores
Uma vez definidos os sensores inferenciais para previsão de CQO e azoto orgânico baseados em
informação espectral, efectuou-se uma análise comparativa com o intuito de dar respostas às seguintes
questões:
1. É vantajoso ter disponíveis os dados espectrais para previsão de CQO ou os dados analíticos
determinados pelo modelo interno da sonda s::can têm um menor erro associado?
2. Qual o melhor sensor inferencial de previsão de azoto orgânico: sensor inferencial baseado em
dados analíticos ou espectrais?
Para responder à primeira questão, determinou-se o erro de previsão dos dados analíticos disponibi-
lizados pela sonda s::can, recorrendo à definição de RMSEP. Para este cálculo foram considerados
os dados analíticos obtidos pela sonda com timestamps coincidentes com as amostras recolhidas nas
campanhas P1, P2, C1, C2, C3 e V1. O valor obtido foi comparado com o RMSEP do conjunto de
validação externa do modelo CQO_MC_iPLS1, conforme apresentado na Tabela 3.19. A Tabela 3.20
apresenta os valores de RMSEP determinados para cada campanha, onde mais uma vez se torna
evidente a razão pela qual se excluiu a campanha V2 para previsão.
Tabela 3.19: Comparação entre RMSEP dos dados analíticos disponibilizados pela sonda s::can e oconjunto de validação externa do modelo CQO_MC_iPLS1. Range do conjunto de dados analíticos dascampanhas P1, P2, C1, C2, C3 e V1: 42-747 mg/L. Range do conjunto de validação externa do modeloCQO_MC_iPLS1: 66-747 mg/L.
Conjunto de Dados RMSEP(mg/L)
NRMSEP(%)
Dados analíticos sonda s::can 231,17 13,45Dados validação externa modelo CQO_MC_iPLS1 98,58 14,48
De acordo com a informação presente na Tabela 3.19, verifica-se que o erro de previsão associado
modelo interno da sonda é inferior, pelo que não existe vantagem em usar directamente os dados
espectrais para prever a variável CQO.
83

Tabela 3.20: NRMSEP (%) dos dados analíticos disponibilizados pela sonda s::can para cada cam-panha e para todas as campanhas, excepto a V2. Para o cálculo do erro de previsão da CC2 foramexcluídos os pontos com os seguintes timestamps: 14-01-2015 10:30, 14-01-2015 12:30 e 15-01-201512:30, por corresponderem a amostras com valores analíticos anómalos.
ID campanha NRMSEP(%)
P1 17,84P2 23,80C1 11,32C2 17,29C3 16,52V1 15,89V2 94,35
Todas (excepto V2) 13,45
Relativamente à escolha do melhor sensor para previsão do azoto orgânico, comparou-se o erro de
previsão do conjunto de validação externa para os sensores baseados em dados analíticos e espectrais.
Os valores previstos foram representados em função dos valores medidos, conforme se apresenta na
Figura 3.30. Na Tabela 3.21 resumem-se os valores dos erros de validação cruzada, previsão do
conjunto de validação externa e dos dados da campanha V1 para ambos os sensores.
(a) (b).
Figura 3.30: Valores medidos versus valores previstos de Norg para os sensores inferenciais baseadosem dados analíticos e espectrais. Os dados representados dizem respeito aos conjuntos de validaçãoexterna de ambos os sensores. Para o sensor baseado em dados analíticos, o conjunto de validaçãoexterna contém 32 pontos (range: 3,5-23,8 mg/L). Para o sensor baseado em dados espectrais, oconjunto de validação externa contém 13 pontos (range: 4,3-27,1 mg/L)
Tabela 3.21: Informação sobre os erros de validação cruzada, validação externa e de previsão dacampanha V1 dos sensores inferenciais para previsão do azoto orgânico baseados em dados analíticose em dados espectrais.
Tipo de Sensor NRMSECV(%)
NRMSEP(val. ext., %)
NRMSEP(CV1, %)
TesteWilcoxon
Dados Analíticos 16,30 19,50 26,60 0,0559Dados Espectrais 22,37 18,10 25,50 2,50E-05
Analisando os resultados obtidos para ambos os sensores, optou-se pelo sensor inferencial baseado
84

em dados analíticos para previsão de Norg uma vez que, apesar dos erros de previsão tomarem valo-
res ligeiramente mais elevados, o modelo é mais robusto, como indica o resultado do teste de Mann-
Whitney-Wilcoxon. No entanto, considera-se importante uma actualização de ambos os modelos, dado
que o sensor baseado em dados analíticos está no limite de validade do teste estatístico aplicado.
85

86

Capítulo 4
Conclusões e Perspectivas Futuras
O objectivo da presente dissertação consistiu no desenvolvimento de sensores inferenciais baseados
em modelos PLS para previsão de variáveis não medidas directamente e inputs do modelo de simu-
lação dinâmica do tratamento biológico numa ETAR de pequena dimensão. O design dos sensores
assenta na utilização de dados medidos em linha (caudal afluente e parâmetros de qualidade), com
aquisição a frequência elevada. Como tal, foi necessário efectuar uma análise exploratória de dados
que incluiu o desenvolvimento de modelos PCA, análise de séries temporais e análise de correlações
para detectar padrões e avaliar as relações e estrutura dos dados. Adicionalmente, efectuou-se uma
tentativa de caracterização da linha de tratamento da fase sólida, para a qual a informação disponível
é muito reduzida, uma vez que esta carece de qualquer tipo de sistema de monitorização online de
parâmetros de qualidade ou caudal. A pré-análise dos dados teve como finalidade a melhoria do grau
de conhecimento do sistema de tratamento e, em último caso, facilitar a identificação de problemas
operatórios ou anomalias de hardware. Este último aspecto é especialmente relevante no processo de
desenvolvimento de sensores inferenciais, durante o qual é necessária uma tomada de decisão sobre
os inputs a incluir na calibração dos modelos PLS.
Para o design de sensores inferenciais foi tida em conta informação analítica e espectral. Os sensores
baseados em dados analíticos foram construídos numa perspectiva de utilização de dados em linha,
pelo que só se consideraram como possíveis inputs variaveis com monitorização em tempo real. No
entanto, optou-se por incluir dados de confiança na calibração dos modelos PLS, utilizando, para tal,
os dados analíticos medidos em amostras recolhidas nos períodos de campanhas. Assim, a forte
componente experimental do projecto DEMOCON desempenha uma função de validação dos valores
analíticos disponibilizados pelo sistema de monitorização em linha. Após a calibração, o objectivo será
então usar directamente os dados online para previsão de variáveis não medidas directamente. Os
modelos desenvolvidos foram precedidos de uma análise de componentes principais, onde se analisou
as correlações com a variável a prever, a concentração de azoto orgânico. Das variáveis medidas em
linha, as que apresentavam um maior grau de correlação com o azoto orgânico foram o CQO e SST. A
falta de representabilidade de alguns valores de SST medidos online levou a que esta variável não fosse
considerada como input do modelo. No caso do azoto amoniacal, a detecção de uma avaria da sonda
87

devido a saturação da membrana impossibilitou a utilização desta variável. Seria importante averiguar,
junto do fabricante, possíveis problemas da sonda, nomeadamente a eventual incompatibilidade das
condições de funcionamento da ETAR com a utilização deste tipo de equipamento, bem como possíveis
interferências na medição da concentração de azoto amoniacal. Uma vez que a sonda foi alvo de
reparação recentemente, deve efectuar-se um novo teste para garantir as condições adequadas de
instalação e funcionamento da mesma.
Tendo em conta o panorama apresentado, a variável CQO foi considerada a mais plausível de ser
usada na previsão da concentração de azoto orgânico através de um sensor inferencial baseado em
dados analíticos. Na verdade, foi a combinação desta variável com o caudal afluente medido no canal
de Parshall que deu origem ao melhor modelo de previsão directa de azoto orgânico com base em
dados analíticos. Para avaliar a capacidade de previsão de CQO do modelo interno implementado na
sonda, desenvolveu-se um sensor para previsão desta variável partindo directamente de dados espec-
trais. Verificou-se que o erro de previsão associado ao software da sonda era inferior relativamente ao
erro de previsão do modelo PLS desenvolvido. Consequentemente, concluiu-se, à partida, não existir
vantagem em utilizar os dados espectrais para previsão de CQO, uma vez que o modelo interno da
sonda possibilita uma boa previsão deste parâmetro de qualidade. Ainda assim, seria aconselhável
num próximo passo realizar o teste de Wilcoxon para avaliar as distribuições dos erros de ambos os
conjuntos, de modo a fundamentar melhor esta decisão.
Foram igualmente construídos modelos para previsão de azoto orgânico baseados em dados espec-
trais com o intuito de estabelecer uma comparação com o sensor inferencial com informação de ca-
rácter analítico. O sensor baseado em dados analíticos mostrou ser mais robusto relativamente ao
sensor baseado em dados espectrais. Este último, embora apresentasse uma capacidade de previsão
ligeiramente melhor, falhou o teste de Wilcoxon. Ainda assim, dado que o valor do teste de Wilcoxon
para o sensor baseado em dados analíticos está muito próximo do limite de validade, aconselha-se,
futuramente, proceder à actualização de ambos os sensores e estabelecer uma nova comparação.
Tal como mencionado anteriormente, verificou-se a existência de uma forte correlação entre a con-
centração de sólidos suspensos totais e a concentração de azoto orgânico. Contudo, o surgimento
de alguns problemas na medição online desta variável, colocando em causa a representabilidade dos
valores medidos, impossibilitou a sua utilização na previsão de azoto orgânico. Futuramente seria inte-
ressante recorrer ao uso da informação espectral para construção um sensor de previsão de SST e, de
seguida, avaliar a sua capacidade de previsão face ao modelo interno do software da sonda.
Relativamente à concentração de azoto amoniacal, concluiu-se que a sua inclusão nos modelos PLS
originava sensores inferenciais baseados em dados analíticos ou espectrais com melhor capacidade
de previsão. Como tal, seria importante ter disponível informação aquirida em linha sobre esta variável
no sentido de possibilitar uma melhor estimativa do teor em azoto orgânico à entrada do tratamento
biológico.
Por fim, é importante analisar os prós e contras associados a sistemas de monitorização e controlo
online em ETAR descentralizadas. Entre os benefícios associados, destacam-se: o aviso precoce de
alterações de caudal e qualidade da água, a possibilidade de caracterização de condições típicas de
88

funcionamento, a maior eficiência na exploração dos sistemas e a melhor fundamentação de decisões
operacionais, obtidas através de um conhecimento acrescido dos padrões de consumo de água e pro-
dução de águas residuais, e a redução de custos operacionais associados ao consumo de energia e
de reagentes químicos, conseguida através da adopção de estratégias de controlo mais eficientes. Em
particular, a espectroscopia UV-Vis, além de possibilitar a incorporação das características de quali-
dade do efluente às ETAR nos modelos dinâmicos, permite implementar a modelação mecanística dos
processos. Deste modo, é possível explorar os modelos para avaliar o impacto das acções de melhoria
de operação, de variações nas afluências e de configuração da própria ETAR.
Contudo, continuam a colocar-se barreiras à implementação de sistemas online, sendo a principal o
facto das ETAR a operar actualmente não terem condições infra-estruturais para instalação de sistemas
de controlo em tempo real. Adicionalmente, os sistemas descentralizados de pequena dimensão foram
projectados no sentido do efluente tratado cumprir os requisitos do tratamento sem serem necessárias
estratégias de controlo avançado, estando, por isso, sobredimensionados. Contudo, o aumento do grau
de exigência nos requisitos de qualidade das descargas de efluentes urbanos no meio hídrico receptor,
em simultâneo com uma maior pressão com vista ao aumento da eficiência na operação de ETAR,
antevê a crescente implemententação de novas tecnologias de monitorização e controlo em tempo real.
Estas representam, no entanto, um elevado custo de investimento, principalmente o caso de sondas
com uma gama ampla de medição de comprimentos de onda, como é o caso da sonda s::can. Na
presente dissertação foi feito um esforço no sentido de reduzir este custo, através do desenvolvimento
de sensores inferenciais baseados em medições em apenas um comprimento de sonda, os quais de
designaram versões lowcost. No caso de estudo, a ETAR de Bucelas, estes sensores revelaram uma
boa capacidade de previsão, em alguns casos superior aos sensores com dados de todo o espectro, o
que sustenta a ideia de que é possível instalar sistemas de monitorização online menos dispendiosos.
Considerando todas as vantagens que um sistema de monitorização e controlo em tempo real repre-
senta, a questão de ser justificável a sua instalação em sistemas descentralizados de pequena dimen-
são continua em aberto, estando não só dependente da crescente evolução das tecnologias associadas
aos equipamentos de medição em linha, como também da sensibilização de todos os agentes envol-
vidos na gestão de águas residuais e desenvolvimento de competências na operação e manutenção
deste tipo de equipamentos.
89

90

Referências
Abdi, H. (2003). Partial least squares regression (PLS-regression). Encyclopedia for research methods
for the social sciences, pages 792–795.
Abdi, H. (2010). Partial least squares regression and projection on latent structure regression (PLS
Regression). Wiley Interdisciplinary Reviews: Computational Statistics, 2(1):97–106.
Alcorta, A. and Ancer, J. (2008). Measurement of psychosocial health in medical students: Validation of
the Jefferson Medical’s College’s Questionnaire in Mexico. Interdisciplinaria, 25(1):101–119.
Barjenbruch, M. (2012). Wastewater disposal in rural areas. Desalination and Water Treatment, 39(1-
3):291–295.
Bishop, P. (1992). Dynamics and control of the activated sludge process, volume 6. CRC Press.
Blackman, R. and Tukey, J. (1958). The measurement of power spectra from the point of view of com-
munication engineering. Dover Publications.
Böhm, K., Smidt, E., and Tintner, J. (2013). Application of Multivariate Data Analyses in Waste Mana-
gement. INTECH Open Access Publisher.
Brereton, R. G. (2003). Chemometrics: Data Analysis for the Laboratory and Chemical Plant. John
Wiley & Sons, Ltd.
Bro, R. and Smilde, A. K. (2014). Principal component analysis. Anal. Methods, 6:2812–2831.
Brown, L. and Berthouex, P. (2002). Statistics for Environmental Engineers, Second Edition. Taylor &
Francis.
Chalmer, B. (1986). Understanding Statistics. Taylor & Francis.
Dicker, R. C., Coronado, F., Koo, D., and Parrish, R. G. (2006). Principles of Epidemiology in Public
Health Practice: An Introduction to Applied Epidemiology and Biostatistics. U.S. Department of Health
and Human Services, Centers for Disease Control and Prevention (CDC), Office of Workforce and
Career Development.
Dixon, W. J., Massey, F. J., et al. (1969). Introduction to statistical analysis, volume 344. McGraw-Hill
New York.
Egghe, L. and Leydesdorff, L. (2009). The relation between Pearson’s correlation coefficient r and
Salton’s cosine measure. Journal of the American Society for Information Science and Technology,
60(5):1027–1036.
Encarnação, N. (2014). Respirometria aplicada à modelação de uma ETAR descentralizada. Master’s
thesis, Instituto Superior Técnico, Lisboa.
91

Eriksson, L., Byrne, T., Johansson, E., Trygg, J., and Vikström, C. (2013). Multi- and Megavariate Data
Analysis Basic Principles and Applications:. Umetrics Academy.
Esbensen, K., Guyot, D., Westad, F., and Houmoller, L. (2002). Multivariate Data Analysis - in Practice:
An Introduction to Multivariate Data Analysis and Experimental Design. Camo Process AS.
Friendly, M. (1991). SAS System for Statistical Graphics. SAS Institute, 1st edition.
Geladi, P. and Kowalski, B. R. (1986). Partial least-squares regression: a tutorial. Analytica chimica
acta, 185:1–17.
Gernaey, K. V., van Loosdrecht, M. C., Henze, M., Lind, M., and Jørgensen, S. B. (2004). Activated
sludge wastewater treatment plant modelling and simulation: state of the art. Environmental Modelling
& Software, 19(9):763–783.
Haimi, H., Mulas, M., Corona, F., and Vahala, R. (2013). Data-derived soft-sensors for biological was-
tewater treatment plants: An overview. Environmental Modelling & Software, 47:88–107.
Hamilton, L. (1992). Regression with Graphics: A Second Course in Applied Statistics. Brooks/Cole
Publishing Company.
Hastie, T., Tibshirani, R., Friedman, J., and Franklin, J. (2005). The elements of statistical learning: data
mining, inference and prediction. The Mathematical Intelligencer, 27(2):83–85.
Henze, M. (2000). Activated Sludge Models ASM1, ASM2, ASM2d and ASM3. Scientific and Technical
Report - International Water Association. IWA Publishing.
Hofstaedter, F., Ertl, T., Langergraber, G., Lettl, W., and Weingartner, A. (2003). On-line nitrate moni-
toring in sewers using UV/VIS spectroscopy. In Proceedings of the 5th International Conference of
ACECR “Odpadni vody–Wastewater, pages 13–15.
Huang, J., Romero.Torres, S., and Moshgbar, M. (2010). Practical considerations in data pre-treatment
for NIR and Raman spectroscopy. American Pharmaceutical Review, 13(9):116.
Hvitved-Jacobsen, T., Vollertsen, J., and Nielsen, A. (2013). Sewer Processes: Microbial and Chemical
Process Engineering of Sewer Networks, Second Edition. Taylor & Francis.
Jolliffe, I. (2002). Principal component analysis. Wiley Online Library.
Jördening, H. and Winter, J. (2006). Environmental Biotechnology: Concepts and Applications. Wiley.
Kadlec, P., Gabrys, B., and Strandt, S. (2009). Data-driven soft sensors in the process industry. Com-
puters & Chemical Engineering, 33(4):795–814.
Kadlec, P., Grbic, R., and Gabrys, B. (2011). Review of adaptation mechanisms for data-driven soft
sensors. Computers & chemical engineering, 35(1):1–24.
Kendall, M. G. and Gibbons, J. D. (1990). Rank Correlation Methods. Edward Arnold, 5th edition.
92

Kohler, U. and Luniak, M. (2005). Data inspection using biplots. Stata Journal, 5(2):208–223(16).
Kus, S., Marczenko, Z., and Obarski, N. (1996). Derivative UV-VIS spectrophotometry in analytical
chemistry. Chemia Analityczna(Warsaw), 41:899–927.
Langergraber, G., Fleischmann, N., Hofstaedter, F., et al. (2003). A multivariate calibration procedure
for UV/VIS spectrometric quantification of organic matter and nitrate in wastewater. Water science &
technology, 47(2):63–71.
Libralato, G., Ghirardini, A. V., and Avezzù, F. (2012). To centralise or to decentralise: An overview of the
most recent trends in wastewater treatment management. Journal of Environmental Management,
94(1):61–68.
Lohninger, H. (1999). Teach/Me Data Analysis. Springer-Verlag.
Lourenço, N., Lopes, J., Almeida, C., Sarraguça, M., and Pinheiro, H. (2012). Bioreactor monitoring with
spectroscopy and chemometrics: a review. Analytical and bioanalytical chemistry, 404(4):1211–1237.
Lourenço, N., Menezes, J., Pinheiro, H., and Diniz, D. (2008). Development of PLS calibration mo-
dels from UV-VIS spectra for TOC estimation at the outlet of a fuel park wastewater treatment plant.
Environmental technology, 29(8):891–898.
Lourenço, N., Chaves, C., Menezes, J. M., H.M., P., and Diniz, D. (2006). A espectroscopia ultravioleta-
visível na prevenção de descargas não-conformes de águas residuais industriais. Revista Engenharia
Química, 4:56–62.
Lourenço, N. D., Paixão, F., Pinheiro, H. M., and Sousa, A. (2010). Use of spectra in the visible and
near-mid-ultraviolet range with principal component analysis and partial least squares processing for
monitoring of suspended solids in municipal wastewater treatment plants. Applied Spectroscopy,
64(9):1061–1067.
Martins, A., Pagilla, K., Heijnen, J., and van Loosdrecht, M. (2004). Filamentous bulking sludge—a
critical review. Water research, 38(4):793–817.
Massoud, M. A., Tarhini, A., and Nasr, J. A. (2009). Decentralized approaches to wastewater treat-
ment and management: applicability in developing countries. Journal of environmental management,
90(1):652–659.
Meier, P. and Zünd, R. (2005). Statistical Methods in Analytical Chemistry. Chemical Analysis: A Series
of Monographs on Analytical Chemistry and Its Applications. Wiley.
Miller, J. N. and Miller, J. C. (2005). Statistics and chemometrics for analytical chemistry. Pearson
Education.
Myers, J. and Well, A. (2003). Research Design and Statistical Analysis. Lawrence Erlbaum, 2nd edition.
Nelson, M. and Sidhu, H. (2009). Analysis of the activated sludge model (number 1). Applied Mathema-
tics Letters, 22(5):629 – 635.
93

Oakley, S. (2005). Onsite nitrogen removal: National decentralized water resources capacity develop-
ment project for university curriculum development for decentralized wastewater management. United
States Environmental Protection Agency/Consortium of Institutes for Decentralized Wastewater Tre-
atment/Washington University.
O’Brien, M., Mack, J., Lennox, B., Lovett, D., and Wall, A. (2011). Model predictive control of an activated
sludge process: A case study. Control Engineering Practice, 19(1):54–61.
Otto, M. (2007). Chemometrics. Wiley.
Pearson, K. (1895). Note on regression and inheritance in the case of two parents. Proceedings of the
Royal Society of London, pages 240–242.
Pearson, R. (2002). Outliers in process modeling and identification. Control Systems Technology, IEEE
Transactions on, 10(1):55–63.
Peck, R. and Devore, J. (2011). Statistics: The Exploration & Analysis of Data. Cengage Learning.
Pons, M., Wu, J., and Potier, O. (2005). Chemometric estimation of wastewater composition for the
on-line control of treatment plants. In 16th IFAC Triennial World Congress, Prague, Czech Republic.
Quintela, A. (1981). Hidráulica. Calouste Gulbenkian.
Rand, M., Greenberg, A. E., Taras, M. J., et al. (1976). Standard Methods for the Examination of Water
and Wastewater. Prepared and published jointly by American Public Health Association, American
Water Works Association, and Water Pollution Control Federation., 14th edition.
Ribeiro, R. (2011). Avaliação e controlo da eficiência do tratamento de águas residuais e aplicação a
sistemas de pequena dimensão. PhD thesis, Instituto Superior Técnico.
Ribeiro, R., ALmeida, M., Ilharco, O., and Pais, A. (2008). Avaliação da eficiência de tratamento em
etar de pequena dimensão: aspectos de instrumentação. Technical report, Laboratório Nacional de
Engenharia Civil, Lisboa.
Ribeiro, R., Pinheiro, H., Pinheiro, C., ALmeida, M., and Arriaga, T. (2014). DEMOCON - opções de
monitorização e controlo em ETAR de pequena dimensão- Estruturação do trabalho experimental.
Technical report, Instituto Superior Técnico & Laboratório Nacional de Engenharia Civil.
Rieger, L., Langergraber, G., Thomann, M., Fleischmann, N., and Siegrist, H. (2004). Spectral in-situ
analysis of NO2, NO3, COD, DOC and TSS in the effluent of a WWTP. Water Science and technology,
50(11):143–152.
Robinson, R., Cox, C., and Odom, K. (2005). Identifying outliers in correlated water quality data. Journal
of environmental engineering, 131(4):651–657.
Rosipal, R. and Trejo, L. (2002). Kernel partial least squares regression in reproducing kernel hilbert
space. The Journal of Machine Learning Research, 2:97–123.
94

Scott, D. W. (2015). Multivariate density estimation: theory, practice, and visualization. John Wiley &
Sons.
Seviour, R. and Blackall, L. (2012). The Microbiology of Activated Sludge. Springer Netherlands.
Seviour, R. and Nielsen, P. (2010). Microbial Ecology of Activated Sludge. IWA Publishing.
SIMTEJO (2004). Manual de Exploração - Descrição de Funcionamento da ETAR de Bucelas (1a parte).
Technical report, SIMTEJO, S.A.
SIMTEJO (2009). Empreitada de Execução dos Sistemas de Filtração e Desinfecção - Instruções de
Funcionamento. Technical report, SIMTEJO, S.A.
Tchobanoglous, G., Burton, F., Stensel, H., and Eddy, M. . (2003). Wastewater Engineering: Treatment
and Reuse. McGraw-Hill Education, 4th edition.
Vanrolleghem, P. A. and Lee, D. S. (2003). On-line monitoring equipment for wastewater treatment
processes: state of the art. Water Science & Technology, 47(2):1–34.
Varella, C. A. A. (2008). Análise de componentes principais. Universidade Federal Rural do Rio de
Janeiro, 18.
Varmuza, K., Filzmoser, P., and Dehmer, M. (2013). Multivariate linear QSPR/QSAR models: Rigorous
evaluation of variable selection for PLS. Computational and structural biotechnology journal, 5(6):1–
10.
Vazquez-Ovando, A., Chacón-Martinéz, L., Betancur-Ancona, D., Escalona-Buendía, H., and Salvador-
Figueroa, M. (2015). Sensory descriptors of cocoa beans from cultivated trees of Soconusco, Chiapas,
Mexico. Food Science and Technology (Campinas), 35:285 – 290.
Vrecko, D., Hvala, N., and Carlsson, B. (2003). Feedforward-feedback control of an activated sludge
process: a simulation study. Water Science & Technology, 47(12):19–26.
Wand, M. (1997). Data-based choice of histogram bin width. The American Statistician, 51(1):59–64.
Wickham, H. and Stryjewski, L. (2012). 40 years of boxplots. Technical report, had.co.nz.
Williamson, D. F., Parker, R. A., and Kendrick, J. S. (1989). The box plot: a simple visual method to
interpret data. Annals of internal medicine, 110(11):916–921.
Yeh, S. (2007). Exploratory visualization of correlation matrices. In NorthEast SAS Users Group (NE-
SUG) conference 2007.
Zhang, G., Eddy Patuwo, B., and Y Hu, M. (1998). Forecasting with artificial neural networks: The state
of the art. International journal of forecasting, 14(1):35–62.
95

96

Anexo A
Informações sobre a ETAR de Bucelas
Figura A.1: Descrição do sistema de tratamento da fase líquida (tratamento preliminar), retirado deRibeiro et al. [2014].
97

Figura A.2: Descrição do sistema de tratamento da fase líquida (tratamento secundário e terciário),retirado de Ribeiro et al. [2014].
98

Figura A.3: Descrição do sistema de tratamento da fase sólida, retirado de Ribeiro et al. [2014].
Figura A.4: Instrumentação e monitorização instalada na ETAR de Bucelas, retirado de Ribeiro et al.[2014].
99

100

Anexo B
Determinação do caudal do
classificador de areias
O caudal do classificador de areias foi determinado considerando o tipo de descarregador de saída do
tanque e assumindo como válidas as leis de vazão conhecidas [Quintela, 1981]. Para o cálculo do valor
médio horário foi tido em conta o regime de funcionamento deste equipamento.
Visto que o descarregador em questão é triangular, de soleira delgada e com um ângulo de abertura
de 90o (Figura B.1), aplica-se a equação (B.1).
Figura B.1: Esquema do descarregador de saída do tanque do classificador de areias.
Qclass =
(8
15× CvCA
×√2g × hCA
52
)× n (B.1)
A Tabela B.1 resume os valores considerados para os parâmetros da Equação B.1. De notar que foi
usado um valor médio de hDS, tendo em conta as medidas de altura do líquido acima do vértice do
descarregador efectuadas nas campanhas C3 e V1, discriminadas na Tabela B.2.
Para determinação caudal de afluência ao tratamento biológico, Qaf, é necessário considerar um caudal
médio horário para o classficador de areias, dado pela Equação B.2, em que Qclassmax é o caudal de-
terminado na Equação B.1, em L/s, nON corresponde ao número de vezes que o classificador funciona
por hora e tON é o tempo de funcionamento do equipamento durante o período activo, em segundos.
Tendo em conta o modo de operação: 10 min em funcionamento, 20 minutos de paragem (2 períodos
101

Tabela B.1: Parâmetros utilizados na determinação do caudal do classificador de areias, Qclass.
Parâmetros Descrição Valor
CvCA Coeficiente de vazão do descarregador do classificador de areias 0.62hCA Altura média de água (m) acima do vértice do descarregador 0,0362g Aceleração da gravidade (m/s2) 9.81n Número de descarregadores triangulares 6
Tabela B.2: Valores de altura acima do vértice do descarregador, medidos nas campanhas. O nível so-bre o vértice do descarregador é medido durante o funcionamento do classificador (durante a paragemnão existe descarga).
ID Campanha hCA (cm)
C3 3,4V1 4,1V2 3,5V3 3,5
de funcionamento por hora), obtém-se um caudal médio horário de 0,74 L/s. De notar que existe um
curto período de transição logo a seguir à paragem do equipamento onde se regista uma diminuição
gradual de caudal. Como não é viável determinar a evolução do caudal nestas condições, optou-se por
não considerar este regime.
Qclass = Qclassmax× nON × tON (B.2)
102

Anexo C
Resultados das análises laboratoriais
na Linha das Lamas
Neste anexo apresentam-se os valores obtidos após análise laboratorial das amostras recolhidas ao
longo dos períodos de campanhas necessárias para a resolução dos balanços de massa na linha
das lamas. A Tabela C.1 apresenta os valores, em toneladas, de lamas desidratadas disponibilizados
pela SIMTEJO. As Tabelas C.2 e C.3 contêm os resultados das análises laboratoriais das amostras
recolhidas durante os períodos de campanha. Para a resolução dos balanços de conta foi necessário
ter em conta as seguintes considerações:
• Os valores de concentração de lamas espessadas, Xs-lesp foram determinados em termos de g/m3
para a campanha V2 e em termos de % para a campanha V3. O valor médio desta variável
apenas tem em conta os valores determinados na campanha V3.
• Os resultados para a concentração de sólidos de lamas extraídas, à excepção da campanha V3,
estão explicitados em termos de SST. Uma vez que os balanços foram estabelecidos em termos
de ST, assumiu-se que a fracção de sólidos dissolvida é desprezável face à fracção de sólidos
suspensa, pelo que ST≈SST.
• A densidade das lamas foi determinada com base no peso, em grama, de 25 mL de lamas extraí-
das/recirculadas no decurso da campanha V3. Os valores medidos foram: 25,05, 25,09, 25,08 e
25,07, tendo-se assumido o valor médio.
103

Tabela C.1: Valores da quantidade de lamas desidratadas produzidas na ETAR de Bucelas disponibili-zados pela SIMTEJO no período de Janeiro de 2013 a Julho de 2015.
Mês/AnoLamas
Desidratadas(ton)
jan-13 5,97fev-13 23,88mar-13 5,97abr-13 0,00mai-13 0,00jun-13 11,94jul-13 17,91
ago-13 17,91set-13 5,97out-13 5,97nov-13 11,94dez-13 0jan-14 0fev-14 0mar-14 0abr-14 0mai-14 0jun-14 17,91jul-14 17,91
ago-14 11,94set-14 17,91out-14 17,91nov-14 0dez-14 17,91jan-15 5,97fev-15 11,94mar-15 29,85abr-15 0mai-15 0jun-15 29jul-15 35,82
TOTAL 322,38Média diária 0,88
104
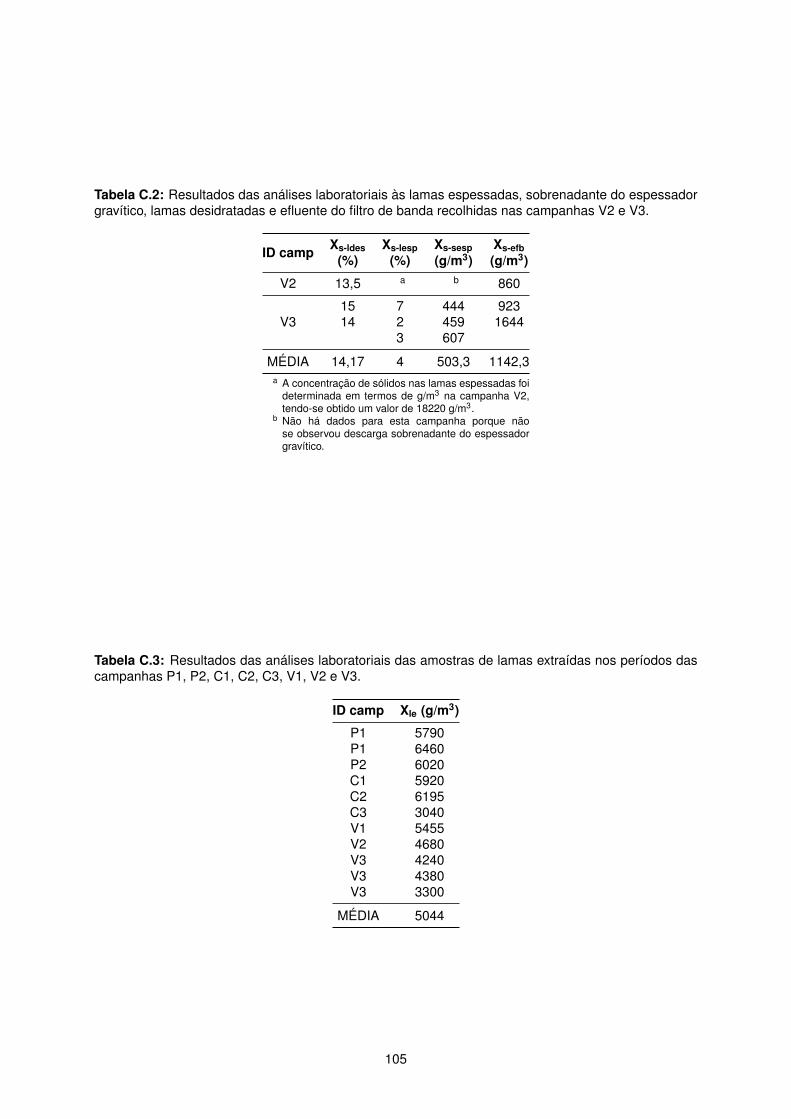
Tabela C.2: Resultados das análises laboratoriais às lamas espessadas, sobrenadante do espessadorgravítico, lamas desidratadas e efluente do filtro de banda recolhidas nas campanhas V2 e V3.
ID camp Xs-ldes(%)
Xs-lesp(%)
Xs-sesp(g/m3)
Xs-efb(g/m3)
V2 13,5 a b 860
V315 7 444 92314 2 459 1644
3 607
MÉDIA 14,17 4 503,3 1142,3a A concentração de sólidos nas lamas espessadas foi
determinada em termos de g/m3 na campanha V2,tendo-se obtido um valor de 18220 g/m3.
b Não há dados para esta campanha porque nãose observou descarga sobrenadante do espessadorgravítico.
Tabela C.3: Resultados das análises laboratoriais das amostras de lamas extraídas nos períodos dascampanhas P1, P2, C1, C2, C3, V1, V2 e V3.
ID camp Xle (g/m3)
P1 5790P1 6460P2 6020C1 5920C2 6195C3 3040V1 5455V2 4680V3 4240V3 4380V3 3300
MÉDIA 5044
105

106

Anexo D
Matrizes de Correlação
(a) Dezembro de 2014 (b) Ano 2014
Figura D.1: Matrizes de correlação dos dados medidos em linha para o mês de Dezembro de 2014 epara a totalidade do ano de 2014.
107

108

Anexo E
Análise PCA mensal dados online
(a) Abril de 2014 (b) Maio de 2014
(c) Julho de 2014 (d) Agosto de 2014
Figura E.1: Biplots dos PCA mensais com os dados medidos em linhas de SST, CQO, NH4-N, Qaf_SIMe Qef para Abril, Maio, Julho e Agosto de 2014, respectivamente. O mês de Abril não tem dados decaudal efluente disponíveis, pelo que não foi possível representar esta variável nos respectivos gráficos.
109
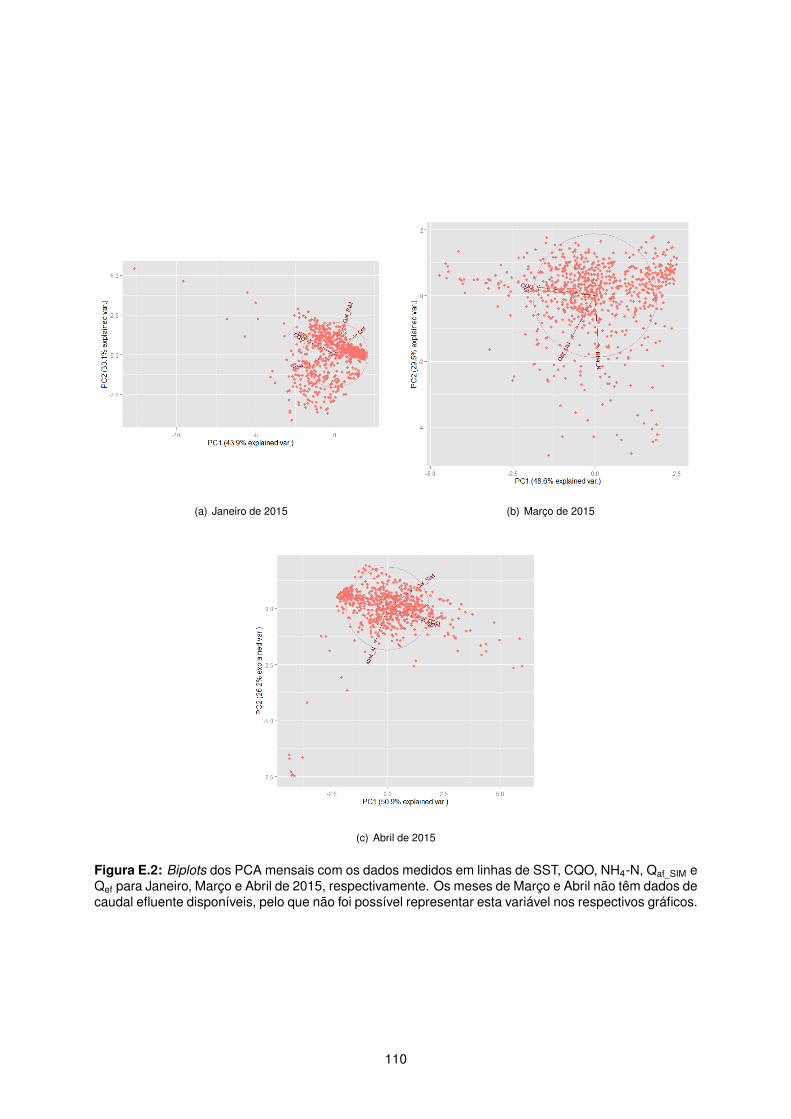
(a) Janeiro de 2015 (b) Março de 2015
(c) Abril de 2015
Figura E.2: Biplots dos PCA mensais com os dados medidos em linhas de SST, CQO, NH4-N, Qaf_SIM eQef para Janeiro, Março e Abril de 2015, respectivamente. Os meses de Março e Abril não têm dados decaudal efluente disponíveis, pelo que não foi possível representar esta variável nos respectivos gráficos.
110

Anexo F
Boxplots dos dados analíticos e de
caudal afluente em períodos de
campanhas
(a) SST (b) CQO (c) Norg
Figura F.1: Boxplots dos dados analíticos de SST, CQO e Norg para todas as campanhas até à V2,onde se identificou a presença de outliers (pontos assinalados com um círculo vermelho). Julho de2014 - P1, Outubro de 2014 - P2, Dezembro de 2014 - C1, Janeiro de 2015 - C2, Março de 2015 - C3,Abril de 2015 - V1, Junho de 2015 - V2. Os outliers correspondem às seguintes amostras da campanhaC2: 14-01-2015 10:30, 14-01-2015 12:30 e 15-01-2015 12:30.
111

(a) SST (b) CQO (c) NH4-N
(d) Norg (e) QafSIM
Figura F.2: Boxplots dos dados analíticos e caudal afluente medido à entrada da ETAR para todas ascampanhas até à V2, após exclusão de outliers. Julho de 2014 - P1, Outubro de 2014 - P2, Dezembrode 2014 - C1, Janeiro de 2015 - C2, Março de 2015 - C3, Abril de 2015 - V1, Junho de 2015 - V2.
112

Anexo G
Sensores Inferenciais baseados em
dados analíticos
G.1 Análise de Componentes Principais excluindo SST
Figura G.1: Biplot representativo da análise PCA considerando os dados analíticos das campanhasP1, P2, C1, C2, C3 e V1 e excluindo a variável SST.
113

G.2 Histogramas dos conjuntos de dados
(a) Conjunto Original (b) Conjunto de calibração ou treino
(c) Conjunto de validação externa ou teste (d) Conjunto da campanha V1
Figura G.2: Histogramas dos conjuntos de dados analíticos de Norg usados no desenvolvimento desensores inferenciais baseados em dados analíticos: conjunto original, conjuntos de treino e validaçãoexterna ou teste (após divisão dos dados) e da campanha V1.
114

(a) Conjunto Original (b) Conjunto de calibração ou treino
(c) Conjunto de validação externa ou teste (d) Conjunto da campanha V1
Figura G.3: Histogramas dos conjuntos de dados analíticos de Ntotal usados no desenvolvimento desensores inferenciais baseados em dados analíticos: conjunto original, conjuntos de treino e validaçãoexterna ou teste (após divisão dos dados) e da campanha V1.
115

G.3 Previsão de Norg com dados de CQO
Figura G.4: Representação da concentração de azoto orgânico, em mg/L, ao longo da campanha V1.Os pontos vermelhos dizem respeito aos valores de concentração de Norg previstos pelo modelo PLS apartir dos dados analíticos de CQO; a verde representa-se os dados analíticos de Norg obtidos duranteo período da campanha - valores observados; a linha azul representa os dados previstos a partir dosdados de CQO medidos em linha pela sonda s::can. O tempo zero corresponde às 12:10 do dia 20 deAbril de 2015, quando se deu o arranque da campanha.
116

Anexo H
Sensores Inferenciais baseados em
dados espectrais
H.1 Pré-tratamento dos dados espectrais
Na primeira fase da construção do sensor inferencial foi efectuado um estudo dos espectros obtidos
pela sonda s::can para períodos das campanhas P1, P2, C1, C2, C3 e V1. Realizou-se uma análise de
componentes principais e representou-se o resultado num scores plot que se apresenta na Figura H.1.
Verifica-se que, com apenas dois componentes principais consegue-se captar praticamente toda a infor-
mação contida nos dados, com uma variância acumulada de 99.28%. De modo a facilitar a observação
e identificação das observações, especialmente as que estão fora do intervalo de confiança de 95%,
representou-se no mesmo gráfico etiquetas de acordo com a identificação da campanha a que os da-
dos dizem respeito (Figura H.2). Como se pode concluir da visualização deste gráfico, a grande parte
dos outliers observados estão relacionados sobretudo com a campanha de calibração 2 (C2).
Figura H.1: Scores plot representativo da aná-lise PCA dos dados espectrais obtidos pela sondas::can nos períodos corespondentes às campa-nhas P1, P2, C1, C2, C3 e V1.
Figura H.2: Scores plot da análise PCA dos da-dos dos espectros obtidos pela sonda s::can nosperíodos corespondentes às campanhas P1, P2,C1, C2, C3 e V1, com os pontos legendados porID de campanha.
117

Uma vez detectados os outliers na análise de componentes principais aos dados espectrais, é im-
portante analisar se estes estão coerentes com os pontos anómalos identificados na mesma análise
efectuada aos dados analíticos. É a comparação entre estas duas análises que vai permitir decidir
quais os dados que devem ser retirados do dataset a incluir no desenvolvimento do sensor inferencial.
Além disso, é necessário confirmar se existem pontos anómalos no scores plot dos dados espectrais
que representem espectros com tendências e formatos diferentes e que, por esta razão, devem também
ser excluídos do conjunto de dados. Desta forma, começou-se por calcular, para cada comprimento de
onda, a média da absorvância observada de modo a obter o espectro médio. Foram seleccionados 59
pontos fora do intervalo de confiança de 95% e os respectivos espectros foram representados em seis
gráficos diferentes para facilitar a sua análise, compilados na Figura H.3. Observando o conjunto de
espectros na Figura H.3 concluiu-se que:
• Nas figuras (a), (b) e (c) destacam-se alguns pontos cujos espectros se encontram acima do
médio. No entanto, uma vez que têm as mesmas tendências, não foram considerados outliers;
• Na figura (d) existem espectros acima e abaixo do espectro médio. Os espectros abaixo do
espectro médio têm um formato diferente, assim como os três espectros mais acima, pelo que
foram considerados outliers. A figura (e) apresenta quatros espectros no topo que também foram
considerados outliers pela mesma razão.
• Na figura (f) apenas o espectro correspondente ao timestamp 15-01-2015 18:40 apresenta a
mesma tendência que o espectro médio, pelo que todos os outros foram identificados como outli-
ers.
Prosseguiu-se a análise dos espectros no sentido de avaliar se os outliers identificados no PCA dos da-
dos espectrais eram simultaneamente outliers no PCA dos dados analíticos. Para tal, realizou-se uma
análise de componentes principais com os dados analíticos cujos timestamps correspondem a pontos
anómalos no PCA dos espectros. O biplot correspondente encontra-se na Figura H.4. Neste gráfico
foram excluídos os outliers, todos pertencentes à campanha de calibração 2 e, de seguida, efectuou-se
um novo PCA de modo a detectar mais pontos anómalos (Figura H.5). Cocnluiu-se que existem, de
facto, outliers concordantes mas nem todos os pontos anómalos no PCA dos dados analíticos corres-
pondem a outliers no PCA dos dados dos espectros.
Os pontos que revelaram ser outliers simultaneamente na análise dos dados espectrais e dos dados
analíticos foram excluídos do conjunto de dados. Para os restantes pontos anómalos dos dados analí-
ticos representou-se os respectivos espectros (Figuras H.6 e H.5), com a ressalva que não se obteve
nenhum espectro para o timestamp 15-07-2014 17:10. Avaliou-se o formato dos espetros em compa-
ração com o espectro médio e concluiu-se que as tendências são semelhantes, pelo que os restantes
pontos não foram considerados anómalos.
118
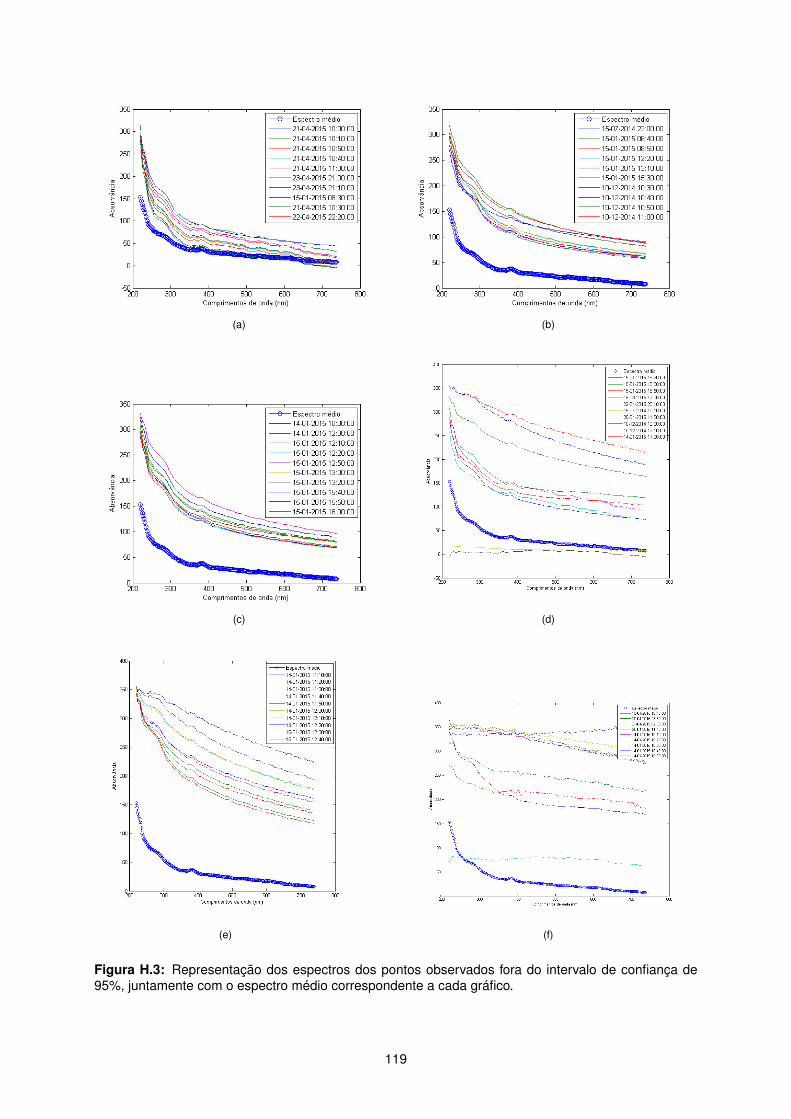
(a) (b)
(c) (d)
(e) (f)
Figura H.3: Representação dos espectros dos pontos observados fora do intervalo de confiança de95%, juntamente com o espectro médio correspondente a cada gráfico.
119

Figura H.4: Biplot representativo da análise PCA, incluindo os dados analíticos de CQO e SST emperíodos de campanhas, cujos timestamps representam pontos anómalos na análise dos dados espec-trais.
Figura H.5: Biplot representativo da análise PCA, incluindo os dados analíticos de CQO e SST em pe-ríodos de campanhas, cujos timestamps representam pontos anómalos na análise dos dados espectraise após remoção dos pontos anómalos identificados na primeira análise de componentes principais.
120

Figura H.6: Espectros dos timestamps correspon-dentes aos outliers identificados no primeiro PCAdos dados analíticos, após exclusão dos pontos si-multaneamente outliers na análise dos dados ana-líticos e dos dados espectrais.
Figura H.7: Espectros dos timestamps correspon-dentes aos outliers identificados no segundo PCAdos dados analíticos, após exlusão dos pontos si-multaneamente outliers na análise dos dados ana-líticos e dos dados espectrais.
H.2 Análise PCA dos dados espectrais até à Campanha V2
Figura H.8: Scores plot da análise PCA conside-rando todos os espectros correspondentes aos pe-ríodos das campanhas P1, P2, C1, C2, C3, V1 eV2
Figura H.9: Scores plot da análise PCA conside-rando todos os espectros correspondentes aos pe-ríodos das campanhas P1, P2, C1, C2, C3, V1 eV2 com valor analítico com timestamp coincidente.
121

H.3 Histogramas dos conjuntos de dados
(a) Conjunto Original (b) Conjunto de calibração ou treino
(c) Conjunto de validação externa ou teste (d) Conjunto da campanha V1
Figura H.10: Histogramas dos conjuntos de dados analíticos de Norg usados no desenvolvimento desensores inferenciais baseados em dados espectrais: conjunto original, conjuntos de treino e validaçãoexterna ou teste (após divisão dos dados) e da campanha V1.
122

(a) Conjunto Original (b) Conjunto de calibração ou treino
(c) Conjunto de validação externa ou teste (d) Conjunto da campanha V1
Figura H.11: Histogramas dos conjuntos de dados analíticos de CQO usados no desenvolvimento desensores inferenciais baseados em dados espectrais: conjunto original, conjuntos de treino e validaçãoexterna ou teste (após divisão dos dados) e da campanha V1.
H.4 Desenvolvimento de modelos PLS
As Tabelas H.1 e H.2 resumem toda a informação respeitante aos modelos PLS desenvolvidos com
base em informação espectral para estimativa de CQO e azoto orgânico, respectivamente.
123

Tabela H.1: Informação relevante para o desenvolvimento de todos os modelos PLS dos sensores inferenciais baseados em informação espectral para previsãode CQO. Em todos os modelos os conjuntos de dados usados têm as seguintes características: conjunto inicial - 90 pontos; conjunto treino - 63 pontos; conjuntoteste: 27 pontos; conjunto V1 - 24 pontos.
Pré-Processamento Info Modelo LV % var.explicada
InfoiPLS
No
variáveisusadas
λ usados(nm)
NRMSECV(%)
NRMSEP(%, val. ext.)
NRMSEP(%, CV1)
Mean Centering
Espectrocompleto 5 99,96 — 208 220-737.5 9,9 20,65 14,89
iPLS5 100 tamanho blocos: 20
no intervalos: Auto 100 220-417.5670-717.5 10,0 20,1 9,2
5 99,98 tamanho blocos: 10no Intervalos: Auto 40
220-242.5395-417.5
445.0-467.5595-617.5
10,4 23,9 10,6
1 100 tamanho blocos: 1no intervalos: 1 1 362.5 10,2 14,5 12,4
Filtro Derivativo(Saviztky-Golay 15
pontos, 2a derivada)+ Mean Centering
Espectrocompleto 7 99,94 — 208 220-737.5 8,35 24,40 10,68
iPLS7 99,95 tamanho blocos: 20
no intervalos: Auto 100 320-367.5670-717.5 7,8 21,2 13,9
7 99,99 tamanho blocos: 10no intervalos: Auto 40
220-317.5395-417.5595-617.5670-692.5
9,3 23,0 26,8
1 100 tamanho blocos: 1no intervalos: 1 1 605 9,5 16,1 16,4
Auto-scaling+
Mean Centering
Espectro completo +caudal afluente 5 99,89 — 209 220-737.5 9,4 52,8 12,1
iPLS +caudal afluente
5 99,93 tamanho blocos: 20 101 220-417.5670-717.5 9,9 21,5 16,1
1 100 tamanho blocos: 1 2 362.5 10,5 14,4 13,2
124

Tabela H.2: Informação relevante para o desenvolvimento de todos os modelos PLS dos sensores inferenciais baseados em informação espectral para previsãode Norg. Em todos os modelos os conjuntos de dados usados têm as seguintes características: conjunto inicial - 44 pontos; conjunto treino - 31 pontos; conjuntoteste: 13 pontos; conjunto V1 - 12 pontos.
Pré-Processamento InfoModelo LV % var.
explicadaInfoiPLS
No
variáveisusadas
λ usados(nm)
NRMSECV(%)
NRMSEP(%, val. ext.)
NRMSEP(%, CV1)
Mean Centering
Espectro completo 5 99,98 — 208 220-737.5 21,1 38,7 42,8
iPLS5 100 tamanho blocos: 20
no intervalos: Auto 40 420-517.5 19,3 47,0 50,7
5 100 tamanho blocos: 10no intervalos: Auto 10 520-542.5 22,8 23,5 101,1
1 100 tamanho blocos: 1no intervalos: 1 1 542.5 22,5 19,8 26,8
Filtro Derivativo(Saviztky-Golay 15
pontos, 2a derivada)+ Mean Centering
Espectro completo 6 99,90 — 208 220-737.5 21,5 45,6 31,9
iPLS6 99,97 tamanho blocos: 20
no intervalos: Auto 60 270-317.5620-717.5 18,0 47,8 59,5
6 99,95 tamanho blocos: 10no intervalos: Auto 30 295-317.5
645-692.5 15,7 37,0 64,9
1 100 tamanho blocos: 1no intervalos: 1 1 692.5 21,4 20,9 68,7
Auto-scaling+
Mean Centering
Espectro completo +caudal afluente 8 99,99 — 209 220-737.5 21,1 46,3 82,5
iPLS +caudal afluente 2 100 tamanho blocos: 1 2 542.5 23,2 26,3 28,4
Espectro completo +NH4-N 6 99,49 — 209 220-737.5 21,3 38,0 43,2
iPLS + NH4-N 2 100 tamanho blocos: 1 2 542.5 22,4 18,1 25,5
125

126

———————————————————————-
127





























