Embed Size (px)
Citation preview

Projecto de Colaboração entre o
Observatório das Ciências e Tecnologias e o
Departamento de Informática da Universidade do Minho
Para obtenção de Estatísticas do WWW em Portugal
Relatório Preliminar de
Setembro de 2001

Resumo
Utilizando um método automático baseado na utilização dum Robot WWW, foi feito um percurso exaustivo pelo espaço Web estático ou com dinamismo só dependente do tempo, publicamente acessível sob o domínio de topo pt, em Julho e Agosto de 2001 (durante 45 dias).
Durante esse percurso foi feita uma contagem em que se apuraram 6 797 616 recursos Web únicos, 3 906 228 páginas HTML diferentes num total de 21 742 sites hospedados em 5 757 máquinas distintas Esta informação corresponde a um total de 505,17 Gigabytes de informação não contando com recursos replicados.
Os recursos colectados, em número (e volume), encontram-se repartidos da seguinte forma pelos principais tipo MIME: texto 62,19% (27,5%), aplicação 6,22% (55,7%) , imagem 30,59% (7,1%), audio 0,93% (8,1%), vídeo 0,04% (1,5%) e outros 0,01% (0,1%).
Para se obter uma ideia retrospectiva do crescimento do Web, utilizou-se a data da última modificação dos documentos obtendo-se que 30% não têm data (1,3 % em volume), 28% (46%) foram pela última vez alterados em 2001, 20% (29,3 %) em 2000, 11% (13%) em 1999, 7% (5,4 %) em 1998, 2% (3%) em 1997 e 2% (2%) até 1996. Como conclusão temos que quase metade dos recursos Web (75,3 % em volume) actualmente disponíveis foram modificados ou disponibilizados nos últimos dois anos.Tratam-se de dados de uma única recolha que precisam de ser validados com novas recolhas e outras metodologias de varrimento do espaço Web
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
I

Índice
Enquadramento...............................................................................1
Equipa do NetCensus..................................................................1
Objectivos...........................................................................................1
Que parte do Web foi medida?...............................................2
Como foi feita a recolha?.........................................................3
Estatísticas para Recursos Web..........................................5
Páginas HMTL.................................................................................9
Servidores Visitados...................................................................10
Ambiente para Medição...........................................................12
O sistema NetCensus...............................................................14
Objectos e Métricas Web.........................................................16
Discussão.........................................................................................21
Próximos Passos..........................................................................22
Referências.....................................................................................24
Glossário e acrónimos...............................................................25
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
II

Enquadramento
O presente documento constitui um Relatório Preliminar dos resultados obtidos pelo projecto NetCensus, no âmbito de um protocolo de colaboração entre o Observatório das Ciências e Tecnologias ( OCT) e a Universidade do Minho (UM).
Este projecto enquadra-se numa das áreas de trabalho do OCT, iniciada em 1999 que tem como objectivo a produção de indicadores estatísticos para a Sociedade de Informação.
O objectivo do NetCensus é a obtenção de indicadores estatísticos para a informação do Web Português, isto é a informação WWW de acesso público e gratuita em sub-domínios do domínio de topo pt. Para esse efeito é necessária a concepção e concretização duma plataforma hardware, software e comunicações que permita a recolha periódica destes indicadores.
Equipa do NetCensus
A equipa do NetCensus é constituída por um grupo multidisciplinar integrado por pessoas com experiência em redes de computadores, serviços de informação Internet e bases de dados.. Tratam-se de investigadores do Departamento de Informática, integrada por 2 PhD e 2 MsC dos Grupos de Comunicações por Computador (GCOM) e Inteligência Artificial (IA): Alexandre Santos (GCOM), António Costa (GOM), Joaquim Macedo (GCOM) e Orlando Belo (IA).
Objectivos
Como objectivo desta primeira fase do projecto definiu-se:
A concepção e instalação dum sistema (software, hardware, comunicações) que permita percorrer exaustivamente o espaço Web em Portugal em tempo útil.
A definicão dum conjunto de medidas quantitativas a realizar nesse espaço Web nomeadamente
o Número de recursos Web (identificados por um URL)
o Tamanho em bytes dos recursos Web
o Número de páginas HTML (subconjunto dos recursos web)
Distribuição de recursos Web (número e tamanho em bytes) por tipos MIME (e subtipos mais importantes) isto é: Texto, Aplicação, Imagem, Audio, Vídeo , Outros
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
1

Distribuição de recursos Web (número e tamanhos) nos diferentes tipos MIME por datas de última modificação
Para já definiu-se como espaço de contagem o domínio de topo .pt e neste instante obteve-se apenas uma única amostra que ainda não foi validada
Que parte do Web foi medida?
O robot que foi usado na obtenção das medidas que vão ser a seguir apresentadas tem ainda algumas limitações e por esse facto o percurso realizado inclui apenas uma percentagem do espaço Web. Esta afirmação é suportada pelo tipo de dinamismo existente na Web pela forma como os robots o conseguem manipular.
Na figura 1 é identificada a porção do Web que pode ser percorrida actualmente pelo Robot. Trata-se apenas da porção estática do Web, que corresponde à descarga pura e simples dos ficheiros armazenados, e à parte dinâmica que depende apenas do tempo.
Do Web dinâmico não é descarregada a parte cujo dinamismo é provocado pelo código embebido no cliente, como aliás acontece com todos os robots (a vermelho). Para além disso, e nesta fase não é colectada uma parte do Web Personalizado [8] e o Web escondido [4], que exige alguma supervisão dum operador. Como exemplo de partes correspondentes ao Web Personalizado
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 1: Classificação do Web de acordo com o dinamismo e dificuldade dos robots (retirada de [4])
Dinâmico
Temporal Baseado no cliente
Formulário Estático
Tipo de Conteúdo
Mecanismo de geração
Ficheiros Armazenados
Programas no Servidor
Código embebido (executado no servidor)
Código embebido (executado no cliente)
Web Escondido
Web Personalizado
Não Aplicável
Não Aplicável
2

apresenta-se sub-espaços web a que normalmente temos acesso apresentando credenciais e do Web escondido aquela que só temos acesso preenchendo formulários como é o caso de páginas mantidas em BDs.
De acordo com artigos da literatura a maior parte do Web é dinâmico ( 80% segundo Laurence and Giles, 1997) e a tendência é aumentar, com a existência de ferramentas cada vez mais sofisticadas. Por este facto, os dados a seguir apresentados e que correspondem apenas à parte estática do Web português têm que ser considerados com cautela. O Google [6], por exemplo, já percorre uma parte do Web escondido e personalizado em modo supervisionado. Trata-se de tecnologia que é necessário analisar se se pretender uma contagem mais precisa do Web Português. Uma outra parte do Web que não é para já percorrida é a acessível usando o HTTPS, protocolo que por enquanto não faz parte da máquina protocolar utilizada. Há que acrescentar para a parte em falta os servidores web em Portugal registados em domínios como .com .org e .net , etc isto é servidores fora da sub-árvore .pt. Para resolver este último caso basta arranjar heurísticas que permitam navegar nesses sub-domínios enquanto o primeiro exige que se inclua na máquina protocolar utilizada pelo robot o protocolo https.Resta apenas o conjunto de servidores que mantém um ficheiro de exclusão de robots que por este facto também não foi visitado.
Como foi feita a recolha?
A recolha durou aproximadamente 45 dias (24h/dia). Ocorreu durante quase todo o mês de Julho e parte de Agosto de 2001. A média de documentos transferida foi ligeiramente mais baixa que 10 documentos/segundo.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 2: Recursos Web e dias de recolha 3

Foram descobertos aproximadamente 18 milhões de recursos Web dos quais foram apenas descarregados pouco mais de 11 milhões. Desses apenas 6 milhões e tal são recursos Web únicos. A diferença entre os recursos descobertos e descarregados está naqueles que correspondem a recursos replicados (usando a mesma referência) ou que são hospedados por servidores aos quais não se conseguiu aceder. A diferença entre os recursos descarregados e únicos corresponde a recursos que estão replicados mas com URLs distintos. Houve ainda uma quantidade residual de recursos (2,7% do total de descargas) que não foram transferidos devido a diversos erros que são apresentados na Figura 3.
Quer os dados a respeito dos recursos como a informação detalhada dos erros de descarga é apresentada em gráficos nas Figuras 2 e 3.
Resta incluir informação a respeito da forma como foi feita a descarga dos recursos do espaço Web analisado . A taxa de transferência teve uma média durante os 45 dias à volta de 1,8 Mbit/s. O número de filas de espera não vazias (ou o número de fios de execução) começou em 500 e foi diminuindo até atingir um valor inferior a 5. Analisados os URLs nessas 5 filas de espera chegou-se à conclusão tratarem-se de sites com ratoeiras para robots e também de mirrors ftp principalmente de software. Na altura, considerou-se na um estado razoável para terminação da recolha. As ratoeiras para robots geram dinamicamente uma grande quantidade de URLs fictícios para colocar o robot em ciclo.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
41
48540
122482
86330
5600
33395
296388
0 50000 100000 150000 200000 250000 300000 350000
Erro de leitura de dados
Transferência de dadosinterrompida
Conexão recusada
Sem rota para o host
Erro no Socket
Exclusões do Robot (robots.txt)
Total de Erros
2,7 % do total de
descargas
Figura 3: Erros durante a recolha
4

Estatísticas para Recursos Web
Na Tabela 1, apresentam-se as estatísticas correspondentes aos recursos web visitados. São indicados os valores totais e os parciais (em valor absoluto e percentagem) para os principais tipos MIME.
Embora a quantidade de recursos em texto seja maior, o seu pequeno tamanho faz com constituam apenas aproximadamente 27,5 % do volume de informação global contra 55,7% do volume ocupado pelo tipo aplicação. Os subtipos do tipo aplicação mais volumosos fazem pensar que grande parte do volume Web recolhido é ocupado por mirrors ftp para distribuição de software.
Estes dados de volume são aproximados porque, por um erro no software, uma percentagem bastante grande de ficheiros de texto ficaram sem o seu tamanho registado. O erro resultou do facto de se esperar que o servidor Web preenchesse o campo de tamanho, o que em certos casos
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Tabela 1: Recursos Web Colectados por tipo MIME ( em número e volume)
Figura 4: Volumes de dados em Gigabytes por tipos MIME e data da última modificação
5

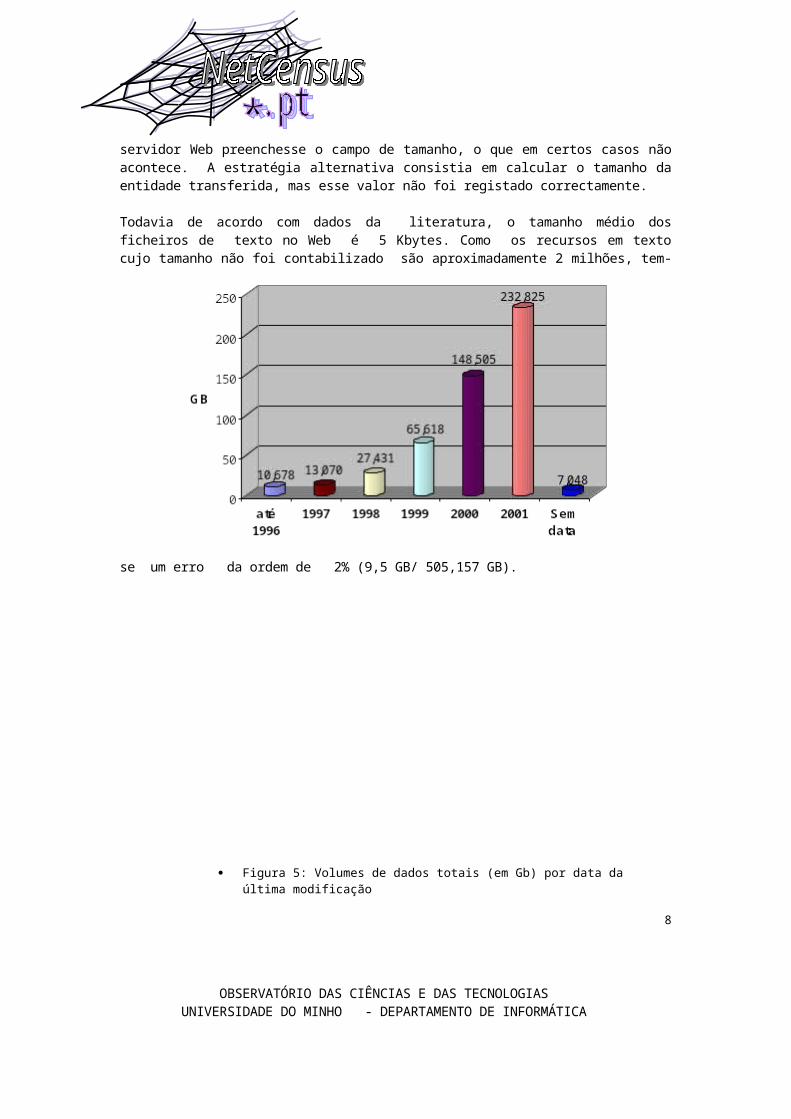
não acontece. A estratégia alternativa consistia em calcular o tamanho da entidade transferida, mas esse valor não foi registado correctamente. Todavia de acordo com dados da literatura, o tamanho médio dos ficheiros de texto no Web é 5 Kbytes. Como os recursos em texto cujo tamanho não foi contabilizado são aproximadamente 2 milhões, tem-se um erro da ordem de 2% (9,5 GB/ 505,157 GB).
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 5: Volumes de dados totais (em Gb) por data da última modificação
6

Embora disponhamos apenas de uma única recolha, um dado interessante e que nos pode dar
uma estimativa da idade dos documentos na web, é obter estatísticas usando como parâmetro a data da última modificação fornecida pelo servidor HTTP. A data da úiltima modificação não permite determinar com exactidão a idade dos documentos, uma vez que um documento mais antigo pode sofrer alterações posteriores à data da criação de um documento mais novo, tendo portanto uma data de última modificação mais recente. Podemos sempre afirmar com exactidão, que um documento existe, pelo menos, desde a data da sua última alteração. Esta informação pode, no entanto, se for usada com cautela, dar uma ideia retrospectiva do crescimento do Web Português. Esta informação é ainda menos esclarecedora pelo facto de haver um grande número de documentos, do tipo texto mais uma vez, que não exibem qualquer data. Pela inspecção feita a alguns URLs, trata-se em grande parte, de páginas geradas dinamicamente, para as quais só o tipo MIME é disponibilizado. Os valores obtidos para os vários tipos MIME e por data da última modificação estão apresentados nas Tabelas 3 (volume) e 2 (número de recursos) .
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 6: Número de recursos Web por tipo MIME e última data de modificação
7

Para facilitar, esta mesma informação é também apresentada graficamente. Os dois primeiros gráficos (Fig. 4 e 5) correspondem a volumes (em Gigabytes) e os dois seguintes a número de recursos Web (Fig. 6 e 7) . Em cada um dos casos tem-se em primeiro lugar um gráfico por tipo MIME e a seguir um gráfico com os valores totais. Embora haja muitos documentos sem data o respectivo volume é uma pequena percentagem do total. O volume de documentos modificados cresce exponencialmente para os principais tipos. Para termos mais certezas nesta abordagem retrospectiva, seria importante obter mais informação a respeito do intervalo entre actualizações dos documentos.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Tabela 2: Volume de dados em Gigabytes por tipo MIME e data da última modificação
Tabela 3: Número de Recursos Web por tipo MIME e data da última modificação
8
Uma outra informação que se obteve relativamente aos recursos Web foi a evolução ao longo dos vários anos dos subtipos para os principais tipos MIME. Isto permite-nos ter uma ideia da variedade de recursos que foram estando disponíveis. No gráfico seguinte, ver Figura 8, apresentam-se o número de subtipos encontrados para os principais tipos MIME. A maior evolução em termos da variedade ocorreu nos tipos aplicação e texto. Esta informação é apresentada na Fig 8.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 8: Evolução do número de subtipos disponíveis para os principais tipos MIME
Figura 7: Total de Recursos Web por data da última modificação
9

Páginas HMTL
Um subconjunto das páginas Web existentes são páginas escritas em HTML. As medidas apresentadas na Figura 9 foram obtidas analisando o conteúdo desse subconjunto de páginas. Interessa caracterizar as páginas HTML existentes em termos dos elementos que as compõem. Nesse sentido seleccionaram-se algumas estatísticas consideradas importantes que estão incluídas no gráfico apresentado. Parte dessas estatísticas dão conta do cuidado com que se criam as páginas nomeadamente se incluem o título, autor, descrição, software gerador e a versão HTML. As outras componentes dão conta das páginas que contêm tabelas, imagens e frames permitindo ter uma ideia do formato das páginas.
Por fim, indicam-se páginas com scripts e applets dando uma medida do seu dinamismo. Os formulários são uma medida indicativa de pontos de entrada para partes de web que possam dar acesso a motores de busca, bases de dados e web personalizado.
Como se pode observar, as imagens e tabelas são usadas muito frequentemente (em aproximadamente 80% das páginas). As frames são raramente usadas. Pouco menos de terço das páginas têm indicação da versão HTML e do software gerador, enquanto apenas 14,2 % aparecem com descrição e 8,5% preenchem o campo autor.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
3.906.228
3.616.682
916.959
712.182
894.770
1.170.695
1.210.506
32.525
2.337.216
3.189.413
539.706
3.258.630
0 500000 1000000 1500000 2000000 2500000 3000000 3500000 4000000 4500000
Total de Páginas
Com Título
Com Autor
Com Descrição
Com Software gerador
Com versão HTML
Com formulários
Com Applets
Com Scripts
Com Tabelas
Com Frames
Com Imagens
Nº de ocorrências
(83,4%)
(13,8 %)
(81,6%)
(59,8%)
(0,8%)
(31,0%)
(30,0%)
(22,9%)
(18,2%)
(23,5%))
(92,6%)
Figura 9: Estatísticas de componentes para as páginas HTML
10

Os pontos de entrada para partes mais dinâmicas do Web representam 41% do total de páginas enquanto quase 30% apresentam formulários permitindo de alguma forma uma personalização dos conteúdos a visualizar ou mesmo acesso a BDs. Relativamente às páginas colectadas aproximadamente 73% não têm a versão HTML especificada, enquanto quase 21% indicam a versão 4.0 e quase 6% a versão 3.2. Só 23,5% das páginas preenchem o campo autor.
Servidores Visitados
Na Figura 10, são apresentados os servidores visitados e os host contados pelo RIPE. Se considerarmos as máquinas contadas pelo RIPE (www.ripe.net, Julho de 2001) como o total de máquinas, temos que apenas 2,4% correspondem a servidores Web. As restantes correspondem a PCs individuais e servidores usados para outras aplicações.
Dos nomes usados para servidores web apenas 40% têm nomes apelativos começados por www. Toma-se como uma aproximação do total de servidores os visitados pelo NetCensus.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Figura 10: Servidores visitados versus servidores contados pelo RIPE
11

Com dados obtidos relativamente aos hosts visitados é interessante observar a relação entre os nomes dos servidores web e respectivos endereços IP, que nos indica quantos sites residem na mesma máquina. Esta relação é dada pela Figura 11. Pode- verificar-se que 43 máquinas (ou os respectivos endereços IP) hospedam mais que 50 nomes de servidores. Em particular, existem três hosts com mais de mil domínios distintos, 30 máquinas que hospedam entre 100 e 1000 sites e 10 que hospedam entre 100 e 50 sites. Existem para além disso 161 máquinas que suportam entre 10 e 50 sites, 191 com entre 10 e 5, ficando as restantes com entre 2 e 5 nomes e 4305 com um único nome. Os dados relativos a endereços IP por cada nome (máquinas duplicadas para tolerância a faltas ou distribuição de carga) apontam para poucos sites com duas máquinas.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
43 161 191
1057
4305
> 5010-505-102-51
Figura 11: Número de nomes versus endereços IP para servidores Web
Figura 12: Distribuição de servidores visitados por sistema operativo
22%
60%
11%7% 0%
WindowsUnixLinuxDesconhecidoOutros
12

As máquinas com mais que 50 sites pertencem na sua maior parte a máquinas de fornecedores de serviço, as com uma dezena de sites pertencem a grandes organizações e as com 2 nomes correspondem na sua maior parte a duas designações para uma mesma máquina (um deles começa quase sempre por www)Ainda se obteve mais informação, nomeadamente o sistema operativo utilizado e o software de servidor Web correspondente. A maior parte dos servidores Web usados correm Unix ou Linux (71%) e o servidor Web mais utilizado é o Apache (75%). Para além disso, 97% dos servidores visitados dispõem da versão 1.1 do Protocolo HTTP.
Ambiente para Medição
Para melhor compreensão do problema a resolver, é apresentada nesta secção um modelo do ambiente em que são realizadas as medições, ilustrado na figura 14.
Existem k fornecedores de serviço Internet (ISP) que dão conectividade Internet a um grande número n(k) de organizações (Org) , cada uma das quais está ligada usando uma linha (L) de débito variável e dispõe de um certo número de servidores de documentos (SD) onde são mantidas centenas e mesmo milhares de páginas (P) WWW.
Os fornecedores de serviço (ISPs) estão interligados entre si pelo Portuguese Internet Exchanger (PIX), através de ligações dum débito (Lxk) variável.
Cada organização está ligada ao seu fornecedor de serviço Internet com uma linha (Lj) com determinado débito e mantém um conjunto de servidores com um certo número de páginas. Nesse servidor mantém algumas páginas originais com informação própria. Algumas dessas páginas podem estar em várias línguas (tipicamente português e inglês) por necessidades de
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
75%
21%
1% 3%ApacheMicrosoftNetscapeOutros
Figura 13: Distribuição das máquinas visitadas por software do servidor Web
13

internacionalização. Há páginas que podem ser de acesso restrito aos membros da organização, isto é serem acessíveis apenas na Intranet da organização.
Podem ser mantidas algumas páginas replicadas estaticamente (por exemplo mirrors http) para facilitar o acesso a essas páginas aos utilizadores locais à organização ou mesmo de organizações da mesma região ou mesmo país. Esse tipo de replicação estática é usada também para prevenir situações de congestão no servidor, quando se prevê que pode ser acesso simultâneo por
Para diminuir a latência da rede, os ISPs mantêm réplicas dinâmicas das páginas remotas mais populares para os seus utilizadores em servidores de cache local.
A plataforma NetCensus é por enquanto mantida com única ligação de 2 Mbits à RCTS2 . Por este facto, é de esperar que o acesso a páginas de organizações possa ter como ponto de estrangulamento o PIX, pelo menos para organizações ligadas a ISPs que não mantenham uma boa conectividade com o PIX. Esta má conectividade é por vezes justificada não apenas por razões técnicas ou financeiras, mas também por razões comerciais.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
PIXISP1 ISP2Lx2
Org 2
NetCensusNetCensus
Linha de acesso
Org 1
Lx1
L1
Cache
Página Replicada
ServidorWWWPágina
Original
PIXISP1 ISP2Lx2
Org 2
NetCensusNetCensus
Linha de acesso
Org 1
Lx1
L1
Cache
Página Replicada
ServidorWWWPágina
Original
Figura 14: Modelo do ambiente sob medição do NetCensus
14

O sistema NetCensus
Na figura seguinte é apresentado o fluxo de trabalho a realizar pela plataforma NetCensus. Os componentes com um fundo acinzentado ainda não foram concretizados. Na secção em que se apresentou uma classificação do Web quanto ao seu dinamismo, já se explicou o que é o Web escondido e personalizado. A BD relacional com as estatísticas está em fase avançada de concretização.
O NetCensus na sua versão final vai consistir num sistema que precisa de ser assistido por um
operador para, pelo menos para já , ajudar o Robot a percorrer uma parte do Web dinâmico [10].
Estão neste instante concretizados os componentes ou que permitem contar as páginas estáticas ou com dinamismo dependente do tempo em subdomínios de PT. Um gerador de sementes que usa informação disponível no Serviço de Resolução de Nomes( DNS) e que também pode usar, após a primeira recolha, informação da BD de estatísticas [9] com URLs ou endereços IP visitados em recolhas anteriores. O gerador de sementes pode ainda obter informação usando ligações com sistemas intermediários (routers) onde estejam disponíveis endereços de rede da maior parte dos ISPs em Portugal. Essa informação pode ser usada para, percorrendo exaustiva ou aleatoriamente a parte do endereço correspondente ao host, realizar correspondências
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Site Web com estatísticas
Robot WWW
ImagemDisco Local
URL sementes
Gerador de sementes
Aprendizagem supervisionada
para Web escondidoe personalizado
Carregador da BD Relacional
BD Relacional com
Estatísticas
Gerador de Relatórios
Navegação
Interrogação
UtilizadorOperador
Site Web
Domínio
Robot DNS
Site Web com estatísticas
Robot WWW
ImagemDisco Local
URL sementes
Gerador de sementesGerador de sementes
Aprendizagem supervisionada
para Web escondidoe personalizado
Carregador da BD Relacional
BD Relacional com
Estatísticas
Gerador de Relatórios
Navegação
Interrogação
UtilizadorOperador
Site Web
Domínio
Robot DNS
Figura 15: Fluxo de trabalho no NetCensus
15

reversas no Serviço de Resolução de Nomes (DNS) para obtenção de nomes de máquinas que são posteriormente verificadas para a presença de servidores Web. Essa estratégia permite obter sites em sub-domínios fora da sub-árvore de pt. Usando as várias estratégias apresentadas anteriormente consegue-se obter um bom conjunto de sementes.
Com base nas sementes, são realizados percursos que usam essas sementes como ponto de partida. Todas as páginas desse percurso que cumprirem um determinado conjunto de restrições (em que a principal é a estarem no sub-domínio pt) são descarregadas para disco local. Cada página é processada para extracção de referências e da informação considerada relevante para efeito das estatísticas. Essas referências são colocadas em filas de espera para posterior processamento. Mantém-se uma estrutura de dados com a assinatura dos URLs já descarregados para evitar que o objecto por ele referenciado seja descarregado mais que uma vez. Como mesmo objecto pode ser referenciado por mais que um URL, mantém-se também uma estrutura de dados com assinatura dos conteúdos já processados, para não processar várias vezes o mesmo conteúdo [1,6]. Esta última informação pode dar indicações a respeito do nível de replicação dos conteúdos entre os sites Web em Portugal. Para se saber se determinado conteúdo é uma réplica nacional dum original estrangeiro, podem ser usadas algumas heurísticas.
O processo de descarga carrega suavemente cada servidor, estabelecendo a sequência de pedidos de forma delicada (um pedido de cada vez e com intervalo de tempo entre pedidos parametrizável). O método utilizado é colocar todos os URLs correspondentes ao mesmo host na mesma fila de espera, que é tratada sequencialmente por um mesmo fio de execução.
O objectivo da descarga é armazenar em disco local uma imagem do espaço Web a analisar. Se forem feitas descargas periódicas é possível dispor de várias imagens do espaço em análise em instantes de tempo diferente, podendo obter informação sobre a sua variação ao longo do tempo (ver figura 16).
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
Imagem 1
Disco Local
Web Site
Imagem 2
Imagem 3
Imagem 1
Disco Local
Web Site
Imagem 2
Imagem 3
Figura 16: Descarga de Recursos Web para disco local
16

A informação a respeito das várias transações realizadas pelo Robot é igualmente armazenada porque permite obter dados de acessibilidade para cada recurso (tempo médio de acesso), organização e ISP, entre outras informações. Guardam-se todas as transações ,quer sejam bem sucedidas ou não.
Objectos e Métricas Web
A obtenção de estatísticas tem como pressuposto a definição clara das entidades ou objectos que estão sob medição. Posteriormente é necessário determinar que características ou actividades desses objectos vão ser medidas isto é as métricas utilizadas.
Os conceitos e definições apresentadas nesta secção são baseadas em trabalho desenvolvido no âmbito do W3C e OCLC [11,12].
Terminologia
Comecemos pela definição dos elementos primitivos que são aqueles conceitos e termos que permitem descrever um espaço de informação como o Web.
Recurso : qualquer coisa com identificação. Como exemplo pode-se apresentar um documento electrónico, uma imagem, um serviço. Nem todos os recursos estão acessíveis pela rede. Exemplos: Página Web, colecção de páginas Web, serviço que disponibiliza informação de uma BD, mensagem de correio electrónico, Classes Java
Identificador Universal de Recurso (URI1) : uma cadeia compacta de caracteres para identificação dum recurso físico ou abstracto.
Manifestação de Recurso : é a forma assumida por recurso num ponto específico do tempo e do espaço. Existe uma correspondência conceptual entre um recurso e uma sua manifestação ou conjunto de manifestações. A razão é que há uma série de propriedades do recurso herdadas pelas suas manifestações embora haja outras propriedade tal como estrutura, forma e conteúdo que variam com o ambiente em que é visualizada, instante de acesso, etc… Exemplo: página web multimédia acedida por um cliente particular.
Referência : expressa uma ou mais relações explícita ou implícita entre dois recursos. Exemplo: um elemento HTML <a href="http://www.uminho.pt/index.html#Events">…</a> ou <img src="http://www.uminho.pt/icons/log.gif ">
Âncora : Um área dentro de recursos que pode ser a fonte ou destino de um ou mais referências. Uma âncora pode referenciar todo o recurso, partes deles ou manifestações particulares do recurso. Exemplo: um elemento HTML <a href="http://www.uminho.pt/index.html#Events">…</a>.
1 Universal Resource Identifier, em inglês
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
17

Cliente: o papel adoptado por uma aplicação ao ir buscar e/ou mostrar recursos ou manifestações de recursos. Exemplos: browser WWW, leitor de correio, etc…
Servidor: o papel adoptado por uma aplicação que disponibiliza recursos ou manifestações de recursos. Exemplos: servidor HTTP, servidor de ficheiros, etc…
Proxy: um proxy actua como intermediário e funciona como cliente e servidor com objectivo de aceder a recursos ou suas manifestações no lugar de outros clientes. Os clientes que usam um proxy sabem disso. Exemplo: servidor proxy para firewall.
Gateway: um gateway é um intermediário que actua como servidor em lugar de outro servidor qualquer disponibilizando os recursos ou as suas manifestações de outro servidor. Os clientes sabem que o gateway está presente mas não sabem que ele funciona como um intermediário. Exemplo: gateway para acesso HTTP a uma base de dados.
Mensagem: uma unidade de dados trocada entre serviços ou camadas de rede equivalentes localizadas em diferentes computadores. Exemplos: datagramas trocados entre as camadas internet de dois computadores ou uma mensagem enviada por um leitor de correio electrónico e recebida por outro.
Pedido: Uma mensagem que descreve uma operação atómica a ser realizada no contexto dum recurso específico. Exemplo: Um GET, POST ou HEAD HTTP.
Resposta: A mensagem que contém o resultado de um pedido executado. Exemplo: Um documento HTML, uma mensagem de erro do servidor….
Utilizador: o principal a usar um cliente para aceder e visualizar interactivamente recursos ou as suas manifestações. Exemplo: uma pessoa a usar um browser Web ou um leitor de correio electrónico.
Responsável pela publicação: o principal responsável pela publicação dum dado recurso e pela correspondência entre o recurso e as suas manifestações. Exemplo: pessoa a escrever uma mensagem de correio electrónico ou a compor uma página Web.
Terminologia para caracterização do Web
Os conceitos acima apresentados são bastante úteis quando se fala do Web em termos genéricos mas são demasiado genéricos quando se pretende caracterizar o Web com um determinado nível de rigor.
Para efeitos da sua caracterização o Web consiste em três componentes: o núcleo, a vizinhança e a periferia.
Núcleo Web : uma colecção de recursos residentes na Internet que podem ser acedidos usando uma das versões implementadas do HTTP como parte da pilha de protocolos, quer directamente como através de um intermediário
Recurso Web: um recurso identificado por um URI que é membro do Núcleo Web.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
18

Manifestação de Recurso Web: uma manifestação gerada por um recurso Web.
Vizinhança Web: um conjunto de recursos directamente referenciados por um recursos Web.
Recurso da Vizinhança Web: um recurso, identificado por um URI, que seja membro da vizinhança Web. Exemplo: uma referência ftp dentro dum documento HTML que possa ser acedido via HTTP ou uma referência mailto num documento HTML acessível por HTTP.
Periferia Web: colecção de recursos no Web que não façam parte do núcleo Web nem da Vizinhança Web.
Clientes Web: passam-se a apresentar conceitos relacionados com o acesso a recursos Web e a visualização de manifestações de recursos Web.
Cliente Web : um cliente capaz de aceder a recursos Web fazendo pedidos e mostrando as manifestações dos recursos Web
Pedido Web : trata-se dum pedido feito por um cliente Web. O pedido pode ser explícito ou implícito, embebido ou introduzido pelo utilizador.
Exemplos: o utilizar segue uma referência numa página html (explícito, embebido); o cliente Web vai buscar o documentoe pedido e também faz um pedido adicional para essa imagem (implícito, embebido); o utilizador vê um endereço numa revista e coloca-lo no cliente (explícito, introduzido pelo utilizador).
Cabeçalho de Pedido Web: contém informação a respeito do pedido, do cliente e potencialmente informação a respeito da manifestação.
Corpo de Pedido Web: casos há em que se usa o Post e a informação vem no corpo do pedido.
Sessão de Utilizador: um conjunto delimitado de clicks do utilizador em um ou mais servidores Web. Exemplo: numa biblioteca, um utilizador senta-se num terminal acede a uma ou mais páginas Web e cede o lugar a outro utilizador.
Episódio: um subconjunto de clicks relacionados que ocorrem numa sessão do utilizador. Exemplo: O utilizador do exemplo anterior acede a informação sobre o tempo (episódio 1) e vai ler o Jornal (episódio 2).
Servidores Web: conceitos relacionados com o processo de fornecer manifestações de recursos Web.
Servidor Web: servidor que disponibiliza recursos Web e que fornece manifestações de recursos para o requisitante.
Resposta Web: resposta dada por um servidor Web
Cabeçalho de Resposta Web: contém informação a respeito da resposta, o servidor em si e potencialmente duma manifestação do recurso que pode conter ou não.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
19

Corpo de Resposta Web: se existir contem a totalidade da informação útil mensagem HTTP
Visita ou Sessão de servidor : conjunto de clicks do utilizador num mesmo servidor durante a sessão.
Cookie: dados enviados pelo servidor ao cliente, a serem mantidos localmente pelo cliente e enviados ao servidor nos pedidos subsequentes.
Exemplo: Quando o site Web dum jornal é acedido pela primeira vez por um cliente particular, pode-lhe ser atribuído um cookie que depois poder usado para determinar pela administração do site o seu padrões de leitura.
Estruturas de Recursos: conceitos relacionados com a estrutura do conteúdo do Web.
Página Web: colecção de informação, consistindo dum ou mais recursos Web, concebidos para serem manipulados simultaneamente, e identificados por um único URI. Mais especificamente uma página Web consiste dum recurso Web com zero, um ou mais recursos Web embebidos concebidos para serem manipulados com uma única unidade, e referidos pelo recurso não embebido.
Exemplo: um ficheiro HTML, um ficheiro de imagem e um applet identificados e acedidos por um único URI e visualizados simultaneamente por um cliente Web como apresentado na figura anterior. Esta distinção é importante porque vão ser apresentadas estatísticas de recursos Web e de páginas Web, pelo que estes dois conceitos não devem ser confundidos.
Vista de Página Web: visualização duma página Web particular por um cliente particular num determinado instante de tempo.
Exemplo: uma página tem vistas diferentes quando visualizada usando o Internet Explorer ou o Netscape Navigator.
Página de Host: a página identificada pelo URI que contém a componente <autorithy> e cujo path é vazio ou contém apenas /
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
http://www.uminho.pt/info.htm
http://www.uminho.pt/images/logo.gif
http://www.uminho.pt/applet.class
http://www.uminho.pt/info.htm
http://www.uminho.pt/images/logo.gif
http://www.uminho.pt/applet.class
Figura 17: Relação entre recursos e páginas web
20

Exemplos. www.mct.pt e www.uminho.pt .
Site Web: um conjunto de páginas Web interligadas, incluindo um página de host, residindo na mesma localização de rede. Interligadas aqui significa que qualquer página Web que pertença ao Web site pode ser acedida a partir de uma sequência de referências começando na pagina de host do site, passando por zero, uma ou mais páginas localizadas no mesmo site e terminado na página Web em questão.
Página Web Independente: uma página web que não é parte do Site Web associado com a sua localização de rede. Especificamente não é possível chegar à página em questão percorrendo uma sequência de links internos ao site, a partir da página de host.
Responsável por publicação de Site Web: uma pessoa ou organismo que reclama os benefícios resultantes do uso do site web, suportando pelo menos uma parte dos custos de produção e acessibilidade do site, e exercendo o controlo editorial sobre o seu conteúdo.
Exemplo: o Departamento de Informática da Universidade do Minho é responsável pela publicação do site www.di.uminho.pt.
Subsite: um aglomerado de páginas Web num site que é mantido por um responsável de publicação diferente que o do site Web pai. O responsável pela publicação do subsite exerce controlo editorial sobre as suas páginas, talvez de acordo com regras mais gerais definidas pelo responsável pela publicação do site pai.
Exemplo: um fornecedor de serviços Internet, disponibilizando serviços de hospedagem para os seus clientes. Os sites web dos clientes podem residir na mesma máquina ou endereço IP, mas representam sites independentes logicamente (podem inclusive ter nomes de domínio diferentes, no caso da hospedagem virtual).
Colecção Web: uma porção ou secção do site Web, consistindo de uma ou mais páginas Web, que represente um recurso não trivial, auto-contido, mas mantido pelo mesmo responsável pela publicação do site.
Exemplo: Jornal Web, monografia electrónica, etc…
Supersite: Um único site Web que pode estender-se por várias localizações de rede, mas é suposto ser visto como um único site Web. É transparente ao utilizador que o site esteja distribuído por várias localizações. Uma única hostpage pode ser aplica a todo o supersite.
Exemplo: o caso de grandes organizações como a Universidade do Minho.
Métricas a usar no Web
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
21

Associada a cada métrica [13] podem ser associadas algumas propriedades nomeadamente o elemento a que diz respeito, a população alvo da medição a realizar e o tempo em que vai ser feita a observação. De acordo com o elemento as métricas podem ser classificadas em: espaço web, utilizador web, cliente web, servidor web, site web e da colecção web. Como nos restringimos a medidas que possam ser obtidas usando apenas informação publicamente acessível, limitamos para já a nossa atenção para as seguintes métricas:
As métricas do Web: tamanho em bytes, tamanho em bytes por tipo Mime, tamanho em bytes por método de acesso, número de servidores Web, número de sites Web, número de sites web únicos, número de páginas Web, relação entre o tamanho do núcleo e a periferia, percentagem de protocolos através da periferia, fiabilidade e localidade.
As métricas dos Sites Web: tamanho em bytes, tamanho em bytes por site Mime, tamanho em bytes por método de acesso, descrição textual do conteúdo do site, nº de páginas web, profundidade, fiabilidade, localidade e popularidade.
As métricas das Páginas Web : tamanho agregado dos recursos Web componentes (em bytes), número e tipo de objectos não textuais embebidos, referências por página, número de páginas em que é referenciada, percentagem de tipos MIME nas referências, percentagem de protocolos nas , razão entre referências internas e externas , percentagem de referências inválidas, percentagem de referências , elementos HTML , gerador de páginas, fiabilidade e localidade.
Discussão
Foi apresentado um sistema que permite a medição automática , de acordo com métricas estabelecidas em normas internacionais ou propostas de normas, do espaço Web em Portugal. Por se tratar dum sistema em desenvolvimento e por se ter feito apenas uma recolha as estatísticas apresentadas neste relatório devem ser interpretadas com prudência.
Em termos técnicos o sistema precisa ainda de dispor de técnicas alternativas de colecta de dados para verificação dos dados obtidos e novos módulos que permitam percorrer o Web escondido, personalizado e seguro. Algumas destas partes do Web exigem tecnologia mais sofisticada (embora já disponível) e alguns casos mesmo de supervisão humana.
Há aspectos legais e éticos não menos importantes que devem ser contemplados para um melhor relacionamento entre as entidades que disponibilizam a informação na Web e a entidade ou organização que realiza a colecta. Esses aspectos assumem muita importância na qualidade das medições obtidas no sentido de se minimizar ratoeiras ou mesmo o ficheiro de exclusão de robots.
Existem outras fontes de informação como registos históricos de servidores e clientes, inquéritos aos utilizadores que se disponíveis permitiriam enriquecer bastante a qualidade e a quantidade de métricas e das medições.
Embora seja um sistema que precisa ainda de muito trabalho adicional (como se verá na próxima secção) não restam dúvidas que só por esta via se conseguem estatísticas fiáveis dos conteúdos disponíveis no Web em Portugal.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
22

Próximos Passos
Pelos dados recolhidos vemos que o número de URLs semente (usados como ponto de partida) é muito importante para o desempenho do Robot. A primeira colheita arrancou com 13.836 sementes “descobertas” com heurísticas de varrimento do Serviço de Resolução de Nomes: todos os WWW.qualquer.coisa.pt e todos os nomes de domínio de topo com endereço IP associado...
A segunda colheita poderá arrancar com todos os sites descobertos na primeira colheita. Deverão ser acrescentadas algumas heurísticas que permitem colectar informação em organizações em Portugal que estejam registadas noutros domínios como .com, .org, etc..
Em termos das sementes, o varrimento do espaço de nomes feito via DNS, deverá ser complementado com o varrimento do espaço de endereços e detecção de servidores HTTP. O varrimento do espaço de endereços deve ser complementada com a correspondência reversa de endereços em nomes usando o Serviço de Resolução de Nomes2.
No Robot, deverá ser feito um controlo do fluxo de pedidos por fio de execução por forma a não exceder a largura de banda disponível. Para o tornar mais robusto será ainda necessário introduzir algumas heurísticas para detectar situações de falha da rede e adaptar o seu funcionamento a essas situações.
Para além de acrescentar o módulo HTTPS na máquina protocolar do Robot, deverá ser acrescentada a maquinaria necessária para com o mínimo de supervisão colectar o máximo possível do Web escondido e personalizado.
Para validação de resultados deverão ser combinadas as estratégias de percurso aleatório com percurso exaustivo e deveram ser feitas correlações e comparações com outras fontes de dados (RIPE, etc...)
O funcionamento do NetCensus e em particular o do UMBOT poderá ser optimizado usando técnicas de simulação. O simlulador poderá ser submetido a traces reais obtidos com o Robot.A utilização da simulação permitirá determinar os recursos mínimos para uma qualidade pré-definida de recolha e a determinação dos recursos necessários no NetCensus para obter determinado desempenho com o aumento da escala (sites, páginas, recursos, actualizações).
Embora nesta primeira fase se pretendam obter apenas estatísticas quantitativas do espaço Web em Portugal poder-se-á evoluir para obtenção de estatísticas mais qualitativas.
Poderá ser obtida a quantidade de erros de HTML, número de hiperligações quebradas, informação inconsistente e incompleta. Relativamente às páginas poderá ainda ser detectada a língua em que estão escritas (português e inglês, por exemplo) e erros ortográficos.
A colocação da informação colectada pelo Robot numa BD relacional permite a médio prazo a concepção e concretização duma Interface Web, possibilitando a obtenção de estatísticas mais específicas e sensíveis a respeito de cada site. Apresenta-se como exemplo alguma informação
2 Vulgo DNS (Domain Name System)
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
23

que pode ser obtida utilizando essa interface: pontuação de Sites em tamanho, qualidade das páginas, númetro de ligações de entrada e número de ligações de saída; pontuação de páginas por número de ligações de entrada e número de ligações de saída; etc... Em particular a exploração das relações entre páginas potenciam a obtenção de informação muito interessante. Relativamente ao conteúdo das páginas poderá quando possível ser associada uma localização geográfica que permita localizar o objecto ou entidade descrita numa localidade em Portugal. Relativamente aos objectos referenciados ( URLs) poderão ser associados países ou região dentro do pais se houver muitas referências.
Outro tipo de informação qualitativa que pode ser extraída semi-automaticamente é a classificação das páginas por tipo (pessoais, de host, lojas) e por tema usando heurísticas e algoritmos de aprendizagem supervisionada.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
24

Referências
1. Mercator: A Scalable, Extensible Web Crawler, Technical Report, Compaq Systems Research Center, Palo Alto, CA,USA , 1995
2. On Near-Uniform URL Sampling, Monika Henziger, Allan Heyton, Michel Mitzenmacher and Marc Najork. WWW00 Conference, Amesterdam, Holland, 2000.
3. Measuring Index Quality using Random Walks on the Web, Monika Henziger, Allan Heyton, Michel Mitzenmacher and Marc Najork. WWW99 Conference, Canada, 1999.
4. Crawling the Hidden Web, Sriram Raghavan, Hector Garcia Molina, Technical Report,
Stanford University, USA
5. Breadth-first search crawling yields high-quality pages, Marq Najork, Janet L.Wiener, Technical Report, Compaq Systems Research Center, Palo Alto, CA,USA
.6. The anatomy of large scale hipertextual search engine, L.Page and S.Brin, WWW98
Conference, Brisbane, Australia, 1998. 7. Archiving the Internet, B.Kahle, Technical Report, Internet Archive, 1997.
8. Sphinx: a framework for creating personal, site-specific web crawlers, WWW98 Conference, Brisbane, Australia, 1998.
9. ParaSite: Mining the Structural Information on the World-Wide Web, Ellen Spertus, PhD Thesis, MIT, USA, 1998.
10. Machine Learning, Tom Mitchel, Mc-Graw Hill, 1997.11. Web Characterization Terminology & Definitios Sheet, Brian Lavoie, Henrik Nielsen, W3C
Working Draft, Maio de 1999.
12. Web Characterization Metrics, Brian Lavoie, Technical Report, OCLC, Maio 1999.
13. The OCLC Web Characterization Project, Ed O’Neil, Brain Lavoie e Pat MacLain, W3C Web Characterization Group Conference, Maio de 1998.
14. Caracterização da Informação WWW na RCCN, Maria João Nicolau, Joaquim Macedo e António Costa, WorkShop de Redes da RCCN, Março de 1997.
15. Measuring the Web, Tim Bray, 5th WWW Conference, Paris, 1996.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
25

Glossário e acrónimos
IP (Internet Protocol) – Protocolo de rede usado por todas as máquinas ligadas à Internet.
ISP (internet Service Provider) – Fornecedor de Serviço Internet.
MIME (Multipurpose Internet Mail Extensions) - trata-se duma norma Internet que especifica como as mensagens devem ser formatadas para serem trocadas entre diferentes sistemas de correio electrónico. Trata-se dum formato bastante flexível que permite que se troca qualquer tipo de ficheiro ou documento através duma mensagem de correio lectrónico. Especificamente as mensagens MIME podem conter texto, imagens, audio, video ou formatos específicos para aplicações. É um formato muito parecido com o usado para trocas de informação entre um servidor e um cliente Web, usando o protocolo HTTP. Para os principais tipos de dados MIME (texto, imagens, audio, video, aplicação, etc, ) podem ainda ser definidos subtipos. Por exemplo o html é um subtipo do tipo texto e o msword é um subtipo de aplicação.
PIX (Portuguese Internet eXchanger) – Serviço de Interligação entre os ISPs em Portugal, gerido pela FCCN.
RCTS (Rede Ciência, Tecnologia e Sociedade) – gerida pela FCCN para ligação à Internet de instituições de ensino. A RCTS2 é uma rede mais rápida para ligação de isntituições de ensino universitário e laboratórios de investigação.
RIPE (Réseaux IP Européens) – é uma organização à escala europeia participada pelos ISPs na Europa para assegurar alguma coordenação administrativa. Para além de manter bases de dados com informação de administração de redes produz algumas estatísticas sobre as redes dos vários países.
Rota – Percurso a realizar para chegar a determinado destino.
Robot – Programa que percorre o WWW usando um algoritmo recursivo que vai processando cada página e extraindo os URLs referenciados para continuar o seu processamento. O processamento a realizar depende da aplicação.
Script – Programas escritos em várias linguagens embedidos ou referenciados em páginas HTML que podem ser executados no cliente ou no servidor.
Servidor – Máquina de maior porte onde residem as aplicações que prestam serviços a clientes
que normalmente residem em PCs dos utilizadores.
Sistema Intermediário (Router) – Equipamentos que são responsáveis pelo encaminhamento dos pacotes originados pelos hosts (Sistemas finais ou hosts) desde a origem até ao destinatário.Socket – dispositivo do sistema operativo usado pelas aplicações para comunicação entre processos na mesma máquina e entre máquinas diferentes.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
26

URI (Uniform Resource Locator) – nome que identifica univocamente os recursos Web. URL (Uniform Resource Locator) – nome que indica a localização ou endereço dos recursos Web na rede.
OBSERVATÓRIO DAS CIÊNCIAS E DAS TECNOLOGIASUNIVERSIDADE DO MINHO - DEPARTAMENTO DE INFORMÁTICA
27





























