Embed Size (px)
Citation preview

Artig
o cie
ntífi
co
Leit
ura c
ríti
ca
Júlio
C. R. P
ereira
11542 AC2-SANDOZ-2cor.indd 1 15/04/11 15:33

Professor-associado do Departamento de Epidemiologia da Faculdade de Saúde Pública da Universidade de
São Paulo. Autor do livro Bioestatística em outras palavras (Edusp, 2010)
CRM-SP 31.033
Júlio C. R. Pereira
11542 AC2-SANDOZ-2cor.indd 2 15/04/11 15:33

Para ler um texto, é necessário conhecer o idioma em que ele é escrito. Num artigo científico, alguma expressão matemática deve aparecer porque a representação numérica faz parte do contexto da ciência moderna. Em Ciências da Saúde, é a Estatística que mais frequentemente cumpre essa função, constituindo-se num idioma usado no texto. Um idioma, quando falado, é uma reunião apropriada de símbolos sonoros que representam coisas; quando escrito, os símbolos são gráficos e servem à mesma fina-lidade. Cada linguagem tem sua ortografia e gramática, por isso, para a Bioestatística, primeiro se examinará brevemente sua estrutura conceitual e depois se oferecerá descrição de algumas de suas expressões idiomáticas, num resumido glossário. Evitar-se-á discutir cálculos em favor do entendi-mento de conceitos, embora o desdobramento dos conceitos em cálculos
Artigo CientífiColeitura crítica
tópicos essenciais em bioestatística
11542 AC2-SANDOZ-2cor.indd 3 15/04/11 15:33

Artigo CientífiColeitura crítica
4
seja o grande responsável pelo formidável progresso que a Estatística experimen-tou ao longo do século XX.
A RePResentAção simbóliCA no PRoCesso de ConheCimento
O conhecimento científico contemporâneo tem como características centrais o reco-nhecimento empírico (sensorial) da natureza e sua representação por medidas. Ga-lileu Galilei (1564-1642) “sustentava que se deve medir o mensurável e transformar em mensurável o que, à primeira vista, não o é”1. As medidas são uma forma de re-presentação simbólica da natureza que se utiliza de números para representar fatos.
A habilidade de representar simbolicamente as coisas foi a característica que distinguiu o Homo sapiens de outras espécies do mesmo gênero (Homo sp). O bipedalismo existe entre hominíneos há 7 milhões de anos2, mas a representação simbólica, há apenas 40 mil anos. O Homo sapiens é a única espécie com capa-cidade de representação simbólica.
Entre os primeiros registros de simbolis-mo na cultura humana estão os desenhos da Gruta Chauvet, na França. A figura 1 mostra desenhos que vieram a ser conhe-cidos como Cavalos de Chagall, provavel-mente por estabelecer analogia com a obra do pintor modernista Marc Chagall (1887-1985), na qual esse animal é tema recor-rente. Representando simbolicamente as coisas, o homem estendeu sua capacidade de distinguir e entender o real por via da abstração do pensamento, da razão. Razão,
2 Neves WA. E no princípio... era o macaco! Estudos Avançados. 2006;20(58):249-85. 1 Da Costa, Newton CA. O conhecimento científico. São Paulo: Discurso Editorial, 1997. p. 55.
Figura 1. Desenhos de cavalos na Gruta de Chauvet, na França.
11542 AC2-SANDOZ-2cor.indd 4 15/04/11 15:33

5
em grego antigo, significava palavra ou verbo (λόγος) e, no grego clássico dos filósofos, veio também a significar quociente ou o resultado de uma operação numérica de divisão. As palavras são sons articulados que representam simboli-camente as coisas a que elas se referem. Os números são grafados com símbolos que se chamam numerais (romanos, arábicos) e apareceram na cultura humana já muito mais tarde: há cerca de cinco mil anos, havia na Suméria um sistema numérico sexagesimal com os numerais cuneiformes: significava a unidade, , a dezena, a combinação significava onze (10 + 1).
O que emerge como importante dessas observações é o fato de que a razão humana encontra na representação simbólica uma forma de conhecer a natu-reza por via do estabelecimento de RELAÇÕES. Por exemplo, se um animal é compatível com a representação da figura 1, então é um cavalo. Se dois animais são compatíveis com a figura, então ambos são cavalos e disso decorre que eles, embora indivíduos distintos, podem ser considerados iguais pela abstração do símbolo que generaliza características comuns a eles. Três tipos de relações interessam à ciência: existência, que responde à pergunta “o que é isto?”; ordem, que responde à pergunta “o que é maior (ou melhor ou mais belo)?”; dependên-cia, que responde à pergunta “o que causou isto?”. “Fora das relações não há nenhuma realidade conhecível”3 e a ciência moderna examina a natureza por meio dessas três relações.
Para qualquer das três relações, podemos admitir uma forma geral do tipo “X R Y” ( X em relação a Y), e dependendo do significado que se dê a cada símbolo, obtêm-se diferentes afirmações que relatam uma das três relações. Por exemplo: “José (x) está (R) doente (y)”; “Câncer de pâncreas (x) é mais letal (R) que câncer de cólon (y)”; “Fumar (x) causa (R) infarto (y)”. Na ciência moderna, tanto X quanto Y são represen-tados por números que expressam uma medida e as relações são operações com esses números, funções matemáticas. Tendo conteúdo variável, X e Y são chamados variáveis que, conforme a natureza da métrica de suas medidas, serão designadas
3 Henry Poincaré (1854-1912), matemático e filósofo da ciência, em Poincaré H. Science and hypothesis. New York: Dover Publications, 1952. p. xxiv.
11542 AC2-SANDOZ-2cor.indd 5 15/04/11 15:33

Artigo CientífiColeitura crítica
6
qualitativas (qltv) ou quantitativas (qttv). As primeiras designam nomes (qltv no-minais) ou atributos com alguma ordem entre si (qltv ordinais). As segundas desig-nam intensidade de um atributo, podendo designar multiplicidade (qttv discretas) ou magnitude (qttv contínuas). De acordo com o tipo da medida, uma ou outra relação poderá ser considerada. Por exemplo, variáveis qltv nominais só permitem o exame da relação igual/diferente (ser ou não ser); as qttv permitem juízos de igualdade/diferença, maior/menor e ainda quanto maior ou menor.
Além dessas medidas fundamentais, há também medidas que se pode deri-var delas. Com uma função lógica ou matemática, pode-se derivar uma medida qltv de uma qttv, por exemplo, pode-se dizer idoso quem tem 60 anos ou mais. O contrário não é verdade, por exemplo de idoso não se chega a uma idade, ou seja, as medidas qttv são mais versáteis. Das medidas derivadas, destacam-se as medidas que são feitas por razão entre duas medidas quantitativas: elas des-crevem intensidade de um atributo por unidade de outro. Quando são ambas de mesma natureza, medem proporções (se as medidas envolvidas são discretas) ou frações (se as medidas são contínuas). Quando são de natureza diferente, medem concentração, densidade e taxa. Aristóteles4 chamou essa últimas olu-gos (ολόγος – homólogos, derivado de λόγος – razão) para indicar a medida que identifica similares pela razão.
As Ciências da Saúde demoraram a incorporar a representação numérica. Em 1826, Jean Civiale (1792-1867)5 usou a contagem de óbitos para demonstrar que a litotripsia era superior à litotomia no tratamento de litíase vesical. A Aca-demia Francesa premiou-o por isso, mas em 1835 condenou seu método de analisar números. Lá se lia que “os casos são tão variáveis e imprevisíveis que nenhuma lei de probabilidade poderia dar conta deles”. Desses comentários fica evidente que para uma representação numérica ser aceita, precisaria incluir algu-ma medida de incerteza por via de alguma teoria de probabilidade.
4 Aristotle. On the parts of animals. Written 350 B.C.E. Book I. Translated by William Ogle. Part 1. Disponível em: http://classics.mit.edu/Aristotle/parts_animals.1.i.html.
5 Poisson, Dulong, Larrey Double. Statistical research on conditions caused by calculi by Doctor Civiale. Reprint in Int J Epidemiol. 2001;30:1246-9.
11542 AC2-SANDOZ-2cor.indd 6 15/04/11 15:33

7
estAtístiCA
A Estatística analisa a ocorrência de fenômenos6 e busca uma generalização
dessa experiência empírica por via de teorias de probabilidade com vistas a in-
ferir a realidade, a conhecer todas as possibilidades de eventos6. A realidade é
tomada como algo incerto: “Tudo é e não é...”, diria Guimarães Rosa7, ou “quem
pode dizer que neste momento não estejamos sonhando”, perguntaria Sócra-
tes8, para lançar dúvida sobre nossa percepção empírica da realidade.
Para atender aos três tipos de relações que interessam à ciência, a Estatística
compreende três conjuntos de orações: de proposição9 de existência, de proposi-
ção de ordem e de proposição de dependência10.
estatística nas relações de existência
A Estatística, como toda a ciência, foge das inquietações metafísicas (será que
isto é?; os sentidos informam a realidade?) e trabalha com um ser proposicio-nal – uma relação X R Y, onde X é algo e Y é um atributo. Por exemplo: isto é belo:
x = isto, R = é e y = belo. Como variáveis, X e Y podem ter qualquer significado
e assumir qualquer valor de um dado espaço de eventos6. Como busca a gene-
ralização, o conhecimento universal, a Estatística não se detém na experiência
individual de um fenômeno e busca examinar o comportamento das ocorrências
de fenômenos do mesmo tipo, por exemplo não se atém à beleza disto, mas como
6 Fenômeno é tudo aquilo experimentado pelos sentidos, que é observado. Para além do que se constata, há o que se infere como universal, o que em Estatística é chamado espaço dos eventos. Evento é qualquer forma racionalmente possível de apresentação de algo. Em coisas representadas por medidas qualitativas, todo e qualquer valor que essa medida possa apresentar; em coisas representadas por medidas quantitativas, todo e qualquer intervalo de valores que essa medida possa apresentar.
7 Rosa JG. Grande sertão: veredas. 19. ed. 9ª reimpressão. Rio de Janeiro: Nova Fronteira, 2001. p. 27.
8 Plato. Theaetetus. Translation by Benjamin Jowett. Disponível em Project Gutenberg: http://www.gutenberg.org/ebooks/1726.
9 Proposição é uma afirmação cuja veracidade pode ser de alguma forma aferida.
10 O leitor curioso poderá buscar explicação mais extensiva em Pereira JCR. Bioestatística em outras palavras. São Paulo: Edusp/Fapesp, 2010.
11542 AC2-SANDOZ-2cor.indd 7 15/04/11 15:33
Artigo CientífiColeitura crítica
8
a beleza ocorre nisto, naquilo e naquele outro. A Estatística examina com que frequência os fenômenos ocorrem.
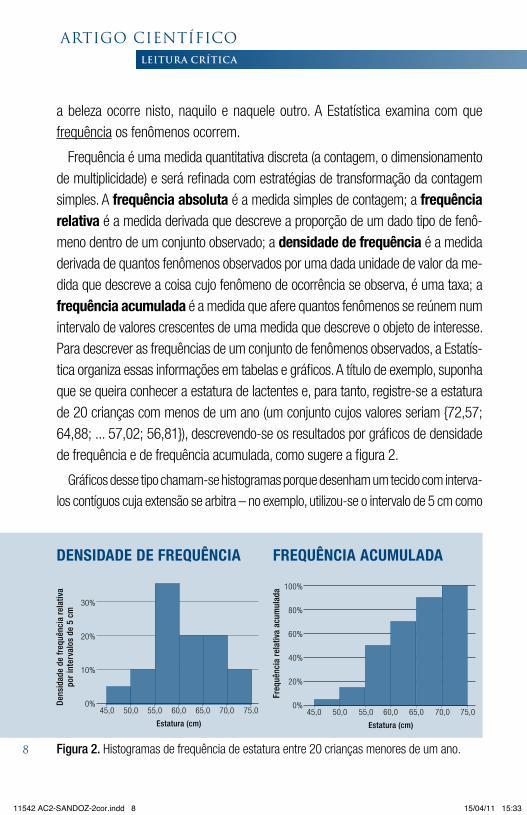
Frequência é uma medida quantitativa discreta (a contagem, o dimensionamento de multiplicidade) e será refinada com estratégias de transformação da contagem simples. A frequência absoluta é a medida simples de contagem; a frequência relativa é a medida derivada que descreve a proporção de um dado tipo de fenô-meno dentro de um conjunto observado; a densidade de frequência é a medida derivada de quantos fenômenos observados por uma dada unidade de valor da me-dida que descreve a coisa cujo fenômeno de ocorrência se observa, é uma taxa; a frequência acumulada é a medida que afere quantos fenômenos se reúnem num intervalo de valores crescentes de uma medida que descreve o objeto de interesse. Para descrever as frequências de um conjunto de fenômenos observados, a Estatís-tica organiza essas informações em tabelas e gráficos. A título de exemplo, suponha que se queira conhecer a estatura de lactentes e, para tanto, registre-se a estatura de 20 crianças com menos de um ano (um conjunto cujos valores seriam {72,57; 64,88; ... 57,02; 56,81}), descrevendo-se os resultados por gráficos de densidade de frequência e de frequência acumulada, como sugere a figura 2.
Gráficos desse tipo chamam-se histogramas porque desenham um tecido com interva-
los contíguos cuja extensão se arbitra – no exemplo, utilizou-se o intervalo de 5 cm como
DEnSiDADE DE FREquênciA
Dens
idad
e de
freq
uênc
ia r
elat
iva
por
inte
rval
os d
e 5
cm
30%
20%
10%
0%45,0 50,0 55,0 60,0
Estatura (cm)
65,0 70,0 75,0
FREquênciA AcumuLADA
Freq
uênc
ia r
elat
iva
acum
ulad
a 100%
80%
60%
40%
20%
0%
Estatura (cm)
45,0 50,0 55,0 60,0 65,0 70,0 75,0
Figura 2. Histogramas de frequência de estatura entre 20 crianças menores de um ano.
11542 AC2-SANDOZ-2cor.indd 8 15/04/11 15:33
9
unidade para as contagens em ambos os histogramas. Usou-se a frequência relativa em
ambos os casos e em cada um se esclareceu tratar-se de densidade ou acumulada. No
entanto, o título da ordenada é geralmente apenas n ou %. Uma leitura crítica exige a ma-
lícia do leitor tanto para bem entender quanto para não se deixar enganar – veja: no gráfi-
co superior, a informação representada é “quantas crianças por ( ) cada (1) intervalo de
5 cm”, pelo que, para saber, por exemplo, o total de crianças com estatura entre 45 cm e
55 cm, calcula-se a soma de 5% (quanto por intervalo) x 1 intervalo (número de interva-
los considerados com essa taxa) + 10% x 1 intervalo, o que resulta em 15%. É isso que
mostra o histograma de frequência acumulada: até 55 cm acumulam-se 15% das 20
crianças observadas, ou seja, três crianças têm menos de 55 cm. Como o histograma tem
intervalos regulares de 5 cm, todas as densidades de frequência são multiplicadas por um
(5 cm = 1 intervalo) e isso deixa a falsa impressão de que a frequência relativa está
registrada no eixo das ordenadas, quando, na verdade, é o produto da densidade pelo
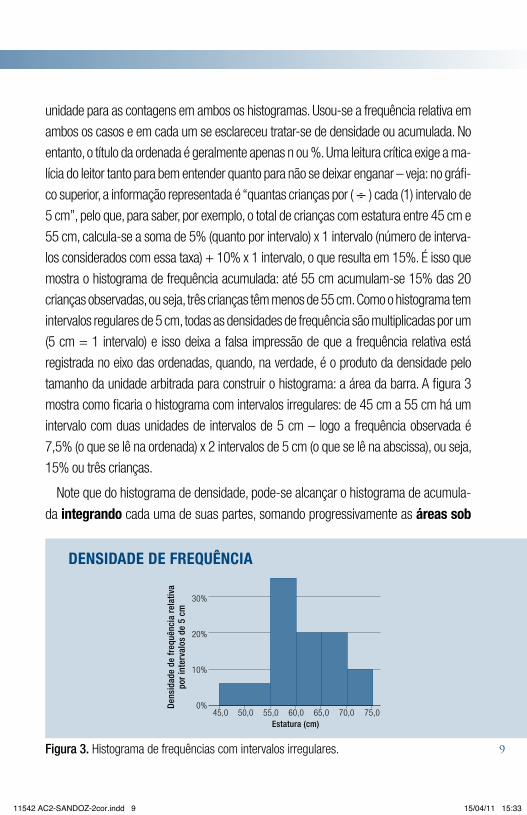
tamanho da unidade arbitrada para construir o histograma: a área da barra. A figura 3
mostra como ficaria o histograma com intervalos irregulares: de 45 cm a 55 cm há um
intervalo com duas unidades de intervalos de 5 cm – logo a frequência observada é
7,5% (o que se lê na ordenada) x 2 intervalos de 5 cm (o que se lê na abscissa), ou seja,
15% ou três crianças.
Note que do histograma de densidade, pode-se alcançar o histograma de acumula-
da integrando cada uma de suas partes, somando progressivamente as áreas sob
Figura 3. Histograma de frequências com intervalos irregulares.
DEnSiDADE DE FREquênciA
Dens
idad
e de
freq
uênc
ia r
elat
iva
por
inte
rval
os d
e 5
cm
30%
20%
10%
0%
Estatura (cm)45,0 50,0 55,0 60,0 65,0 70,0 75,0
11542 AC2-SANDOZ-2cor.indd 9 15/04/11 15:33

Artigo CientífiColeitura crítica
10
o contorno das barras: a área de 45 a 50 + a área de 50 a 55 dá os 15% que são
alcançados no gráfico da acumulada. Da mesma forma, do histograma de acumulada,
pode-se derivar o que seria uma densidade para um intervalo considerado: se entre
45 e 55 se acumulam 15% é porque cada intervalo de 5 cm deve ter uma densidade
de 7,5%, como aparece na figura 3. Derivação e integração são operações de Cálculo,
uma disciplina da Matemática que o leitor de um texto estatístico pode ignorar desde
que compreenda que densidade e acumulada são intercambiáveis por funções de
Cálculo, operações tão intuitivas quanto as que o exemplo anterior sugeriu.
No século XVII, os primeiros trabalhos estatísticos tinham como base as tabelas de
distribuição de frequências. John Graunt (1620-1674), analisando a ocorrência de óbi-
tos segundo a causa, organizou tabelas “para obter uma visão do todo reunido” (so as to have a view of the whole together [sic]). De fato, a figura 2, representação gráfica
de uma tabela, provê conhecimento que de outra forma não é aparente: poucas crian-
ças têm menos de 55 cm ou mais de 70 cm no conjunto de observações; a maioria
concentra-se entre esses dois valores; o que mais ocorre são estaturas entre 55 e 60
cm. No entanto, como corolário dos conceitos já estabelecidos sobre o reconhecimento
das coisas – uma coisa é representada por uma medida, emerge naturalmente uma ex-
pectativa de medida que represente um conjunto de observações: um grupo de coisas
é também em si uma coisa, tanto quanto peixe é uma coisa e cardume também o é.
Para o grupo de 20 crianças do exemplo, qual seria o valor de estatura adequado
para representá-lo? Como se está formando juízo pelo exame de frequência de ocor-
rência, talvez o de maior frequência: neste grupo os mais frequentes são os valores
entre 55 e 60 cm. Um valor, ou um intervalo de valores, que é o mais frequente é cha-
mado – muito intuitivamente! – de moda: o que mais ocorre. É um número, ou um in-
tervalo, que se dedica bem a representar o grupo estudado, mas não parece ser muito
perfeito: afinal, embora seja o que mais ocorre, no exemplo só reúne 35% dos casos...
Tal situação leva a achar que esse não seja um bom número porque sequer separa
metade dos casos do grupo, o que de imediato sugere a pergunta: qual o número que
separa as duas metades, a menor da maior? No exemplo, o valor de estatura de 60,43
cm separa essas duas metades. Esse valor é chamado de mediana, um valor que,
11542 AC2-SANDOZ-2cor.indd 10 15/04/11 15:33

11
no entanto, nenhuma das crianças vistas tem: a metade menor acaba em 59,51 cm
e a metade maior começa em 61,34 cm. Se a mediana corta o conjunto observado
em dois de igual tamanho, poderíamos também pensar em outros cortes: valores que
dividem o conjunto em quatro partes são chamados quartis: um trio de valores em
que o primeiro separa o primeiro quarto dos outros três quartos, o segundo separa
os primeiros dois quartos dos últimos dois quartos (2º quartil = mediana), e assim
por diante. Na verdade, poder-se-ia arbitrar quaisquer cortes fazendo tercis, quintis,
percentis ou o que pareça adequado para melhor representar o conjunto estudado. Ao
utilizar os valores máximo, mínimo, mediana e quartis, constrói-se um gráfico chamado
boxplot que descreve a distribuição de valores observados num grupo segundo essas
medidas-resumo, que são também chamadas de posição, já que marcam a posição
para determinadas proporções de casos dentro de um grupo.
Caso se prossiga nessa linha de raciocínio – identificação de um valor-resumo
com base na distribuição de frequências –, poder-se-á intuitivamente chegar à pro-
posta de conceber um valor que, em vez de arbitrado por o que seja uma frequência
importante (o mais frequente, metade, um quarto etc.), considere importantes todos
os valores e frequências observados no grupo. Essa medida é a média: um valor
formado pela contribuição relativa de cada valor dos elementos do conjunto segundo
sua frequência de ocorrência. No exemplo, os valores de idade são um conjunto sem
qualquer número repetido, ou seja, cada valor tem uma frequência relativa de 1/20,
ou 0,05 ou 5%. Portanto, a média será 72,57 x 0,05 (o primeiro valor observado
trazendo sua contribuição conforme sua frequência relativa) mais 64,88 x 0,05 (o
segundo valor aportando sua contribuição conforme sua frequência relativa) mais... e
assim por diante, até o último elemento do conjunto. Essa operação resulta no valor
61,37 cm, que é a média de estatura desse grupo de crianças: um valor que pode
sequer estar presente no conjunto, mas que representa uma expectativa de valor –
tivessem por inércia todas as crianças a mesma estatura, esse seria o valor.
Se a média for uma boa medida para representação dessa coisa que foi o grupo
de crianças do exercício, então deverá cumprir o papel de ser um símbolo que revela
essa coisa e permite reconhecer seus iguais entre aqueles com o mesmo símbolo
11542 AC2-SANDOZ-2cor.indd 11 15/04/11 15:33

Artigo CientífiColeitura crítica
12
– princípio estabelecido anteriormente. No entanto, diferentes conjuntos de dados
podem ter uma mesma média sem serem iguais. Por exemplo, no exemplo em ques-
tão, um outro grupo de 20 crianças em que todas tenham a estatura de 61,37 terá
também uma média de 61,37, mas será totalmente diferente do grupo do exemplo.
O que os distingue é a variabilidade de valores entre os elementos do conjunto:
no primeiro nenhum valor é repetido, no segundo um valor é repetido 20 vezes.
Portanto, para enunciar a existência de um grupo, para dar-lhe identidade, a média
precisa ser acompanhada de uma informação sobre a variabilidade de valores entre
os elementos. Talvez se pudesse considerar fazê-la acompanhar da informação de
valores mínimo e máximo, mas idealmente a variabilidade deveria ser um número, um
valor (o princípio de que as coisas são reveladas por um símbolo numérico convida a
concepção de um valor para representar a variabilidade).
Para medir a variabilidade, empresta-se o conceito de expectativa presente na
média: tem variabilidade nula o conjunto cujos elementos têm todos o mesmo valor
da média (não há variação, logo variação zero); a variabilidade cresce conforme
cresce a frustração em relação a essa expectativa. Há frustrações de expectativas à
menor e à maior e ambas essas frustrações têm a mesma grandeza, já que a média
constituiu-se em expectativa pela ponderação segundo a frequência dos valores
tanto menores quanto maiores que ela. Assim, caso se deseje medir a frustração de
expectativa no grupo como uma soma de todas as frustrações individuais, de todos
os desvios da expectativa, sempre haverá uma falsa sugestão de variação nula
porque os desvios à menor anulam os desvios à maior. A solução é fazer a soma
dos desvios ao quadrado, o que fará desaparecer o componente negativo. Essa
medida, soma dos desvios de expectativa ao quadrado, no entanto, não serviria
quando se comparassem grupos de tamanhos diferentes – um grupo grande teria
variação grande só pelo fato de ser grande. Para resolver isso, divide-se essa soma
de desvios ao quadrado pelo número de quadrados11 e obtém-se uma medida de-
rivada que indica a taxa de variabilidade por elemento do conjunto (uma média de
11 Computa-se número de quadrados como uma unidade a menos que o número de elementos do conjunto (n-1) porque, presente ou não, um valor igual à média tem um quadrado de desvio nulo.
11542 AC2-SANDOZ-2cor.indd 12 15/04/11 15:33

13
desvios ao quadrado). Essa medida de variabilidade é chamada variância e caso
se efetue a raiz quadrada desse valor para retornar à mesma dimensionalidade
da média, chegar-se-á a um valor que é chamado desvio-padrão (DP) – nome
também muito intuitivo: mede o padrão de desvios, de variabilidade. Assim, chega-
-se a uma métrica para representar conjuntos com um par de medidas: média e
desvio-padrão. Expectativa e variabilidade são dois conceitos centrais para a
Estatística, comparáveis aos conceitos de inércia e força para a Mecânica, em
Física. No grupo do exemplo em questão, DP é 6,7 cm, logo se trata de um grupo
de estatura 61,37 cm no qual variar 6,7 cm a mais ou a menos é o padrão. O outro
suposto grupo de mesma média está claramente distinto dele porque o padrão é
não ter variação, ou seja, DP nulo.
Quando se examina um grupo se está analisando uma pequena parte do
que seria o universo que interessa à ciência. Essa experiência particular só
interessa à ciência se puder ser generalizada. O universal, no entanto, não é
acessível (por exemplo, um censo que aponte uma população de X milhões
de pessoas não garante que esse seja o número de pessoas porque se altera
com nascimentos e óbitos a cada dia, mesmo durante a coleta dos dados) e só
pode ser estimado por abstração. Faça, então, um exercício de abstração com
o exemplo da estatura de lactentes: meça a estatura de mil crianças menores
de um ano para simular um universo, tomando mil como um número grande. O
histograma teria um aspecto semelhante ao sugerido pela figura 4: intervalos
muito pequenos com muitas ocorrências. A média desses mil casos foi 61,53
cm e o desvio-padrão (DP), 6,46 cm – como se vê, não exatamente igual ao
grupo visto, mas algo semelhante. O histograma parece tentar definir uma
curva suave como a sugerida pela linha tracejada: essa curva seria alcançada
caso se chegasse às infinitas observações do universo: a estatura de todas
as crianças que hão, houve e haverão – um número infinito de crianças. Ela
descreve a densidade de ocorrências para cada valor infinitesimal de estatura
e permite que se calcule quantos casos por intervalos de valores: a área sob
o contorno da curva, como se viu, é obtida pela integração das partes. Essa
11542 AC2-SANDOZ-2cor.indd 13 15/04/11 15:33

Artigo CientífiColeitura crítica
14
integração agora já não é tão facilmente calculada como quando se examinou
o histograma de 20 crianças e demanda procedimentos de Cálculo, pelo que
os livros de Estatística trazem para ela uma tabela de cálculos prontos. Mas o
que é essa curva, o que representa? Ela não é a coisa – grupo de 20 ou grupo
de 1.000 – ela é a sobrecoisa, para usar uma expressão rosiana12.
Essa curva já não descreve mais densidade de frequência relativa de um gru-
po, mas de uma classe que reúne elementos de todos os grupos possíveis –
descreve probabilidade. Aqui, a probabilidade está sendo entendida como uma
extensão do conceito de frequência relativa: se frequência relativa é a razão entre
o número de fenômenos observados num intervalo e o total das observações, a
probabilidade é a razão entre todos os eventos experimentados ou escolhidos
como fenômenos num intervalo de valores da medida considerada e todas as
possibilidades de eventos contidas no universo, no espaço de eventos. A exemplo
do histograma de frequências, a área total delimitada acumula probabilidades
até a unidade (ou o 100%). Curvas de distribuição de probabilidades podem
ter diferentes formas e a retratada na figura 4 representa uma delas, chamada
distribuição normal. Para cada distribuição se pode sempre considerar densidade
de ocorrência ou ocorrências acumuladas, designadas agora, respectivamente,
densidade de probabilidade e probabilidade acumulada ou simplesmente proba-
bilidade. Se para os grupos se calculavam as estatísticas (por exemplo, a média
e o desvio-padrão), para as classes de coisas o que se estimam são os parâme-tros13 da função distribuição. Os parâmetros da distribuição normal são a média
e o desvio-padrão da classe de coisas, com os quais se pode obter a curva em
forma de sino que aparece na figura 4.
12 Guimarães Rosa põe na boca de seu personagem Riobaldo esta expressão de “querer não o caso inteirado em si, mas a sobrecoisa, a outra coisa” (Rosa, op. cit., p. 214). À Estatística interessa a sobrecoisa, não o caso particular de um conjunto específico, seja de vinte ou de mil casos.
13 Parâmetros são constantes que aparecem numa função que transforma uma medida em outra. Por exemplo: a função que transforma uma contagem de unidades para dúzias tem a forma y = x/12. Dado um valor x de contagem, se dividido pelo parâmetro 12, o resultado y é o número de dúzias. À qualquer função corresponde uma representação gráfica, obtida pela substituição do x por seus valores possíveis, de forma a obter diferentes valores de y. O resultado é uma linha, reta ou curva, conforme a relação considerada. Uma função densidade de probabilidades leva valores de uma variável a correspondentes valores de densidade de probabilidade.
11542 AC2-SANDOZ-2cor.indd 14 15/04/11 15:33

15
O conceito de probabilidade permite introduzir um novo conceito de normalidade.
Até a emergência da Estatística, o conceito de normal era apenas funcional, por exem-
plo, um coração é normal se suas funções elétricas (por exemplo, controle de ritmo) ou
mecânicas (por exemplo, fração de ejeção) se processam como prevê a Fisiologia. Com
a Estatística, agora se pode dizer que é normal tudo aquilo que corresponde à expec-
tativa de valor (a média que ocupa a posição central na distribuição normal) com algu-
ma tolerância de desvio a mais ou a menos. Na distribuição de probabilidade normal,
caso se considere tolerável um afastamento com grandeza de até dois desvios-padrão
aquém ou além da média, serão classificadas como normal 95% da classe, como anor-
mal a menor 2,5% e como anormal a maior os outros 2,5%. Se a tolerância de desvio
for para um desvio-padrão, 68% dos elementos da classe serão considerados normais.
Por exemplo, se a média de batimentos cardíacos por minuto (bpm) estimada para uma
população de pessoas adultas (uma classe de coisas, uma reunião de vários grupos)
for frequência cardíaca (FC) = 80 e o desvio-padrão for DP = 10, poder-se-á classi-
ficar como pessoas de frequência cardíaca normal todas cujo ritmo seja de 60 a 100
batimentos por minuto, desde que a tolerância para desvios da expectativa seja de até
dois desvios-padrão – duas vezes a variação habitual que é medida pelo desvio-padrão.
A maioria dos fenômenos biológicos tende a ter uma distribuição normal. Dos exem-
plos citados: estatura, ritmo cardíaco e fração de ejeção. Embora cada um tenha uma
%
8%
6%
4%
2%
50,0 60,0Estatura
70,0
Figura 4. Histograma de frequência de estatura entre 1.000 crianças menores de um ano.
11542 AC2-SANDOZ-2cor.indd 15 15/04/11 15:33

Artigo CientífiColeitura crítica
16
métrica distinta (centímetros, batimentos por minuto, proporção do volume de um
ventrículo que é ejetada), todos podem ser padronizados: trazidos à métrica “núme-
ro de desvios-padrão de distância da média”. É com essa unidade que se constroem
as tabelas de probabilidades dos livros de Estatística. Assim, se uma pessoa tem, por
exemplo, pressão arterial sistólica (PAS) de 160 mmHg e se sabe que, por exemplo, a
média da população é 120 mmHg e o desvio-padrão, 10 mmHg, poder-se-á expressar
sua pressão como quatro desvios-padrão positivos, quatro além da média – sua PAS
é 160 mmHg = quatro desvios (também ditos resíduos) padronizados da média.
Se o tolerável for dois desvios, ela será classificada como hipertensa ainda que suas
funções hemodinâmicas, renais etc. estiverem fisiologicamente normais. Ao se con-
sultar a distribuição normal de probabilidades, verificar-se-á que esse valor de quatro
resíduos padronizados positivos marca a posição que separa aproximadamente os
99,997% de valores menores dos 0,003% de valores maiores, ou seja, a probabili-
dade de pessoas com PAS igual ou superior a 160 mmHg é apenas 0,003% – PAS
tão raras que serão consideradas anormalmente altas.
Dentro das relações de existência, distinguiram-se coisa, conjunto de coisas e clas-
se de coisas. Cada conjunto, por exemplo as 20 ou as 1.000 crianças dos exemplos
das figuras 2 e 4, é uma amostra do universo que constitui a classe de coisas. Cada
amostra, cada experiência sobre uma classe obtida pela observação de um grupo,
com suas estatísticas, sugere diferentes valores para os parâmetros da classe. Por
exemplo, o grupo de 20 crianças sugeriu uma média de 61,53 cm e o grupo de mil
sugeriu uma média de 61,37 cm. Tais grupos têm tamanhos diferentes, mas caso se
classifiquem os grupos segundo seu tamanho, ver-se-á que amostras de mesmo ta-
manho vão ainda prover diferentes estimativas de médias, mercê da variação natural
que têm as medidas. Se, por exemplo, se examinasse a estatura de dez grupos (10
amostras) de 20 lactentes, poder-se-ia obter o seguinte conjunto de médias: {61,37;
58,97; 60,81; 61,10; 61,28; 58,14; 61,17; 60,10; 58,84; 62,92} e o seguinte con-
junto de desvios-padrão: {6,7; 6,2; 5,6; 5,8; 7,0; 5,9; 6,1; 5,6; 6,3; 7,2}. Caso se
calculem a média e o desvio-padrão dessas médias amostrais, obter-se-ão média
= 60,47 cm e desvio-padrão de 1,45 cm – esse desvio-padrão de médias amostrais
11542 AC2-SANDOZ-2cor.indd 16 15/04/11 15:33
17
chama-se erro-padrão da média (EPM), se não por outro motivo, pelo menos para
distingui-lo do desvio-padrão de medidas individuais – ele descreve a variabilidade
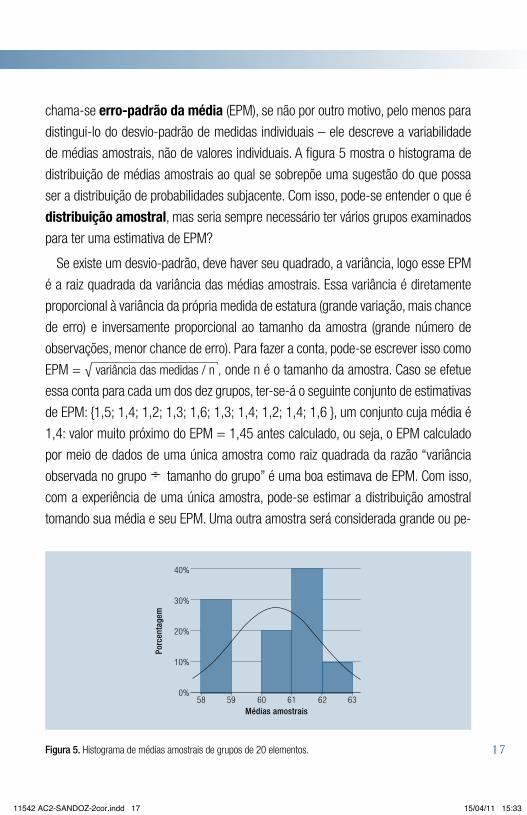
de médias amostrais, não de valores individuais. A figura 5 mostra o histograma de
distribuição de médias amostrais ao qual se sobrepõe uma sugestão do que possa
ser a distribuição de probabilidades subjacente. Com isso, pode-se entender o que é
distribuição amostral, mas seria sempre necessário ter vários grupos examinados
para ter uma estimativa de EPM?
Se existe um desvio-padrão, deve haver seu quadrado, a variância, logo esse EPM
é a raiz quadrada da variância das médias amostrais. Essa variância é diretamente
proporcional à variância da própria medida de estatura (grande variação, mais chance
de erro) e inversamente proporcional ao tamanho da amostra (grande número de
observações, menor chance de erro). Para fazer a conta, pode-se escrever isso como
EPM = √ variância das medidas / n , onde n é o tamanho da amostra. Caso se efetue
essa conta para cada um dos dez grupos, ter-se-á o seguinte conjunto de estimativas
de EPM: {1,5; 1,4; 1,2; 1,3; 1,6; 1,3; 1,4; 1,2; 1,4; 1,6 }, um conjunto cuja média é
1,4: valor muito próximo do EPM = 1,45 antes calculado, ou seja, o EPM calculado
por meio de dados de uma única amostra como raiz quadrada da razão “variância
observada no grupo tamanho do grupo” é uma boa estimava de EPM. Com isso,
com a experiência de uma única amostra, pode-se estimar a distribuição amostral
tomando sua média e seu EPM. Uma outra amostra será considerada grande ou pe-
Porc
enta
gem
40%
30%
20%
10%
0%
Médias amostrais58 59 60 61 62 63
Figura 5. Histograma de médias amostrais de grupos de 20 elementos.
11542 AC2-SANDOZ-2cor.indd 17 15/04/11 15:33

Artigo CientífiColeitura crítica
18
quena conforme o número de EPM que diste dessa tomada como referente: como se
fizeram juízos para elementos de uma classe, agora se fazem juízos para amostras de
uma classe – uma vez padronizado o valor (transformado em unidades de EPM como
antes era transformado em unidades de DP), consulta-se sua posição numa distribui-
ção amostral. Para que uma amostra possa ser tomada como referente, como base
de estimativa de parâmetros populacionais (de classe), sua escolha deve ser cuidado-
sa, considerando-se todos os aspectos conhecidos que condicionam ou modulam a
apresentação do fenômeno de interesse. A isso se chama planejamento amostral e o leitor de um artigo científico deve julgar, com base em seu conhecimento do fe-
nômeno, se o que se apresenta no artigo pode ser considerado uma boa escolha de
amostra para representar população. Disso depende toda e qualquer inferência que
se faça sobre o universo a partir da experiência particular com uma amostra.
Caso se compare um grupo de pessoas submetidas a tratamento contra um ou-tro referente, poder-se-á formar juízos sobre o resultado do tratamento recorrendo à distribuição amostral. Mas isso já é estabelecer relações de ordem.
estatística nas relações de ordem
Tendo ganhado familiaridade com os conceitos apresentados em relações de existência, relações de ordem e de dependência podem ser facilmente compreen-didas, pelo menos na forma. Quando se argui se uma coisa é superior ou inferior a outra, sendo ambas representadas por números, o que se pergunta é se ambas têm a mesma medida ou, em outras palavras, se a diferença entre elas é nula. Quando nula, não há disputa ou dúvida: as coisas são iguais14. Quando, no entan-to, há alguma diferença, pode-se sempre disputar se a diferença não seria insig-nificante – muito pequena para ser considerada diferença verdadeira. Quando a comparação não é de dois elementos singulares, mas de duas amostras de po-pulações, como interessa a ciência em seu esforço de generalização, as medi-das de amostras seguirão uma distribuição amostral, bem como a diferença entre
14 Chama-se de hipótese nula esse ponto de partida para se examinar diferenças.
11542 AC2-SANDOZ-2cor.indd 18 15/04/11 15:33
19
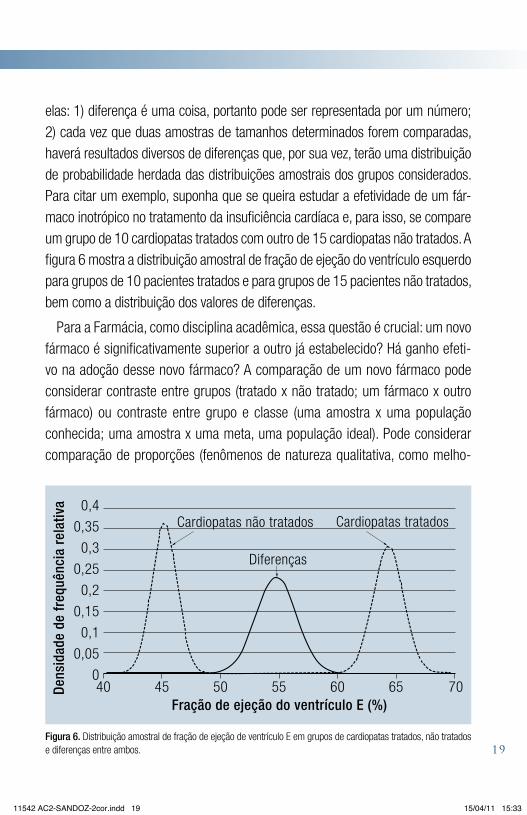
elas: 1) diferença é uma coisa, portanto pode ser representada por um número; 2) cada vez que duas amostras de tamanhos determinados forem comparadas, haverá resultados diversos de diferenças que, por sua vez, terão uma distribuição de probabilidade herdada das distribuições amostrais dos grupos considerados. Para citar um exemplo, suponha que se queira estudar a efetividade de um fár-maco inotrópico no tratamento da insuficiência cardíaca e, para isso, se compare um grupo de 10 cardiopatas tratados com outro de 15 cardiopatas não tratados. A figura 6 mostra a distribuição amostral de fração de ejeção do ventrículo esquerdo para grupos de 10 pacientes tratados e para grupos de 15 pacientes não tratados, bem como a distribuição dos valores de diferenças.
Para a Farmácia, como disciplina acadêmica, essa questão é crucial: um novo fármaco é significativamente superior a outro já estabelecido? Há ganho efeti-vo na adoção desse novo fármaco? A comparação de um novo fármaco pode considerar contraste entre grupos (tratado x não tratado; um fármaco x outro fármaco) ou contraste entre grupo e classe (uma amostra x uma população conhecida; uma amostra x uma meta, uma população ideal). Pode considerar comparação de proporções (fenômenos de natureza qualitativa, como melho-
Dens
idad
e de
freq
uênc
ia r
elat
iva 0,4
0,35
0,3
0,25
0,2
0,15
0,1
0,05
0
Fração de ejeção do ventrículo E (%)40 45 50
Diferenças
Cardiopatas não tratados Cardiopatas tratados
55 60 65 70
Figura 6. Distribuição amostral de fração de ejeção de ventrículo E em grupos de cardiopatas tratados, não tratados e diferenças entre ambos.
11542 AC2-SANDOZ-2cor.indd 19 15/04/11 15:33

Artigo CientífiColeitura crítica
20
rar ou não) ou comparação de médias (fenômenos de natureza quantitativa, como fração de ejeção). Pode considerar diferenças entre grupos distintos ou de um mesmo grupo em momentos diferentes (por exemplo, antes e depois do tratamento). Cada uma dessas formas de comparação envolverá cálculos dis-tintos15, mas subjacente a todas estará sempre o conceito de significância da diferença. Considerando o conceito de normal estatístico (reveja em Estatística nas relações de existência), será considerada significativamente grande uma diferença cuja ocorrência possa ser considerada rara.
Tomando o exemplo sugerido pela figura 6, tem-se um caso particular muito frequente: a comparação de dois grupos de tamanhos distintos cujos parâme-tros populacionais não são conhecidos (não se conhece o universo de pessoas tratadas e não tratadas, não se sabe o que é média ou variância nessas popula-ções). A diferença das médias de cada grupo é, arredondando, 19,19%16. Para fazer juízo se essa diferença é significativamente grande, tem-se que trans-formar essa medida em unidades de erro-padrão da diferença: padronizar a diferença para examinar sua posição numa distribuição de probabilidades. O cálculo do erro-padrão considera as duas sugestões de variância que cada grupo provê fazendo uma média ponderada delas – o resultado é, arredon-dando, 1,72%. Disso resulta que a diferença padronizada é de, arredondando, 11,13. Esse resíduo padronizado tem sua posição examinada numa distribuição de probabilidade adequada: nesse caso é a distribuição “T com 23 graus de liberdade”17. Nela se encontra a informação de que a posição dessa diferença é a que separa, de um lado, 0,9999999999 de ocorrências menores e, de outro,
15 As diferenças de cálculo dirão respeito a diferenças de distribuições de probabilidade a serem utilizadas para o juízo de significância (por exemplo, comparação de proporções utilizará a distribuição normal ou binomial; comparação de médias em grupos pequenos utilizará a distribuição T) e a diferenças de estimativa de erro-padrão para padronizar a diferença (por exemplo, se a variância populacional é conhecida, se a variância de cada amostra comparada pode ser considerada igual a ou diferente da outra).
16 Atenção: a despeito da notação, % não se trata de proporção, mas de fração – medida contínua cujo resumo para um grupo é a média.
17 Não se intimide se não tiver familiaridade com essa distribuição de probabilidades: atenha-se ao conceito – há uma distribuição que pode ser consultada.
11542 AC2-SANDOZ-2cor.indd 20 15/04/11 15:33

21
0,0000000001 de ocorrências maiores, ou seja, a probabilidade de valores de diferença como o encontrando ou, ainda, mais extremos (quer a menor ou a maior) é de 1 em cada 10 bilhões de tentativas. Se fosse verdade que não há diferença – premissa sob a qual se construiu a distribuição de probabilidades de diferenças –, uma diferença como esta seria muito rara, pelo que se conclui tratar-se de uma diferença significantemente grande ou, simplesmente, uma diferença significativa, uma diferença dificilmente atribuível ao acaso, uma dife-rença que deve indicar que o tratamento tem, de fato, efeito.
Quando se comparam mais de dois grupos, em vez de se examinar a probabi-lidade de ocorrência de diferenças, examina-se a probabilidade de as variações entre as médias dos grupos serem maiores que as variações dos elementos de cada grupo. O procedimento se chama análise de variância ou, simplesmente, ANOVA (consulte o glossário).
estatística nas relações de dependência
Se uma coisa depende de outra, sugere-se que essa última seja sua causa. Conhecer a causa, por exemplo, de doenças, é ponto de inequívoco interesse para as Ciências da Saúde, e a Estatística presta auxílio a isso formalizando as relações de dependência. Para tanto, considera um aspecto particular do conceito de causalidade: a variação concomitante. Se alguma coisa varia conforme varia a outra, deve haver dependência entre elas, devem estar as-sociadas uma a outra.
Para falar de variação, há que se partir de uma posição de inércia que, rompi-da, caracterize a presença de variação – foi assim que se estabeleceu a medida de variância: uma média dos desvios quadrados da média (ponto de inércia) de uma medida quantitativa. Os quadrados da variância constituem uma di-mensão plana onde abscissa e ordenada são iguais, algo como a variação de mim comigo. Disso decorre a sugestão de tratar variação concomitante com algo do tipo variação de mim contigo: em vez de um quadrado com lados representando a repetição de uma mesma medida, um retângulo com lados
11542 AC2-SANDOZ-2cor.indd 21 15/04/11 15:33

Artigo CientífiColeitura crítica
22
representando duas medidas distintas. A figura 7 ilustra este raciocínio: o ponto (x
i, y
i) mostra um par qualquer de medidas de x e y; a origem dos eixos x e y é
deslocada para o ponto de inércia do encontro das médias de x e y; o quadrado de x (área hachurada) mostra uma unidade de variância de x; o retângulo x.y (área cinza) mostra uma unidade de covariação. Se as observações de x e y forem repetidas numa amostra de indivíduos onde ambos os atributos sejam examinados, haverá uma grande área cinza, soma de vários retângulos de va-riação concomitante. A exemplo do cálculo de variância, mede-se covariância como uma média desses retângulos (concentração de área cinza por unidade de observação)18. Se essa medida fosse tomada para expressar a dependên-cia entre os fenômenos x e y, poder-se-ia ter valores grandes só por força da métrica de x e y – por isso, para expressar dependência, as medidas de x e y devem ser padronizadas, expressas em unidades de desvio-padrão de cada medida: o resultado dessa operação é uma medida que se chama coeficiente de correlação (r), cujos valores, à mercê da padronização, variarão entre - 1 e + 1. Fenômenos totalmente dependentes um do outro terão o valor absoluto máximo de r=|1|, sendo negativo se a associação entre eles for inversa (quan-do um aumenta, o outro diminui) e positivo se a associação for direta (quando
Figura 7. Representação gráfica de variação e covariação.
18 A exemplo da variância onde o número de quadrados é n-1, o número de retângulos a ser considerado na experiência com uma amostra é também o número de elementos da amostra diminuído de 1.
11542 AC2-SANDOZ-2cor.indd 22 15/04/11 15:33
23
um aumenta, o outro também aumenta). Fenômenos totalmente independentes terão o valor mínimo de r = 0. Valores de r entre 0 e ± 1 descrevem diferentes intensidades de associação. A estimativa de r variará em diferentes experiên-cias com diversas amostras: conhecerá uma distribuição de probabilidades que permitirá aferir se um dado r é estatisticamente significativo, se não é apenas variação aleatória de uma correlação nula.
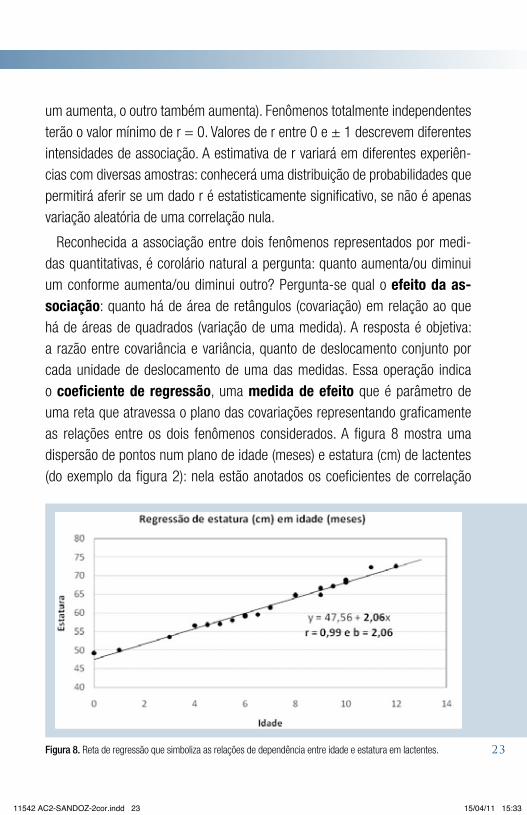
Reconhecida a associação entre dois fenômenos representados por medi-das quantitativas, é corolário natural a pergunta: quanto aumenta/ou diminui um conforme aumenta/ou diminui outro? Pergunta-se qual o efeito da as-sociação: quanto há de área de retângulos (covariação) em relação ao que há de áreas de quadrados (variação de uma medida). A resposta é objetiva: a razão entre covariância e variância, quanto de deslocamento conjunto por cada unidade de deslocamento de uma das medidas. Essa operação indica o coeficiente de regressão, uma medida de efeito que é parâmetro de uma reta que atravessa o plano das covariações representando graficamente as relações entre os dois fenômenos considerados. A figura 8 mostra uma dispersão de pontos num plano de idade (meses) e estatura (cm) de lactentes (do exemplo da figura 2): nela estão anotados os coeficientes de correlação
Figura 8. Reta de regressão que simboliza as relações de dependência entre idade e estatura em lactentes.
11542 AC2-SANDOZ-2cor.indd 23 15/04/11 15:33

Artigo CientífiColeitura crítica
24
(r) e de regressão (b, segundo termo de uma equação de reta). Também o coeficiente de regressão terá uma distribuição de probabilidades que permitirá juízos sobre sua significância estatística.
Quando os fenômenos sobre os quais se argua dependência forem de natureza qualitativa, a medida de associação terá cálculos distintos, mas a estrutura conceitu-al será a mesma: dimensionar a covariação. Um evento qualitativo, por exemplo uma categoria de uma variável qualitativa, tem como ponto de inércia a expectativa de ocorrência sugerida pela probabilidade do evento. Por exemplo: 1) se as categorias de sexo forem masculino e feminino e a probabilidade de cada uma for, por exemplo, p = 0,50, então esse será o ponto de partida para se medir variação; 2) se houver uma doença que se suspeite associada a sexo, por exemplo câncer de bexiga, e sua probabilidade for, por exemplo, p = 0,20, qualquer distanciamento disso será uma variação de expectativa. Quando se tomar uma amostra de pessoas para examinar esses dois atributos, o ponto de partida para cada combinação de categorias será o produto das duas probabilidades19. A tabela 1 examina a distribuição de uma amos-tra de 100 pessoas segundo sexo e doença, onde a proporção dos sexos é igual a (p = 50/100 = 0,5) e a proporção de doentes é (p = 20/100 = 0,2)
Encontram-se 15 homens doentes, quando por inércia só se esperariam 10 (0,5*0,2 = 0,10, que, aplicado ao total de pessoas na amostra, resulta em 10): um resíduo de + 5. Como consequência desse desvio, também as outras combinações terão desvios compensatórios e a soma para estimar as cova-riações resultará nula. Utilizando o mesmo expediente já usado, somam-se os desvios ao quadrado – no entanto, esse número absoluto também demanda padronização para não ser superestimado, pelo que cada desvio quadrado é padronizado para unidades de valores esperados. No exemplo em questão, o resíduo 5, quando se esperava 10, resultará num desvio padronizado de 2,5: (resíduo2/esperado = 52/10).
19 Considerando-se como hipótese nula a não dependência entre as duas variáveis, aplica-se uma regra, dita da multiplicação, para expressar a probabilidade de uma coisa e outra.
11542 AC2-SANDOZ-2cor.indd 24 15/04/11 15:33

25
Somando todos os resíduos padronizados, alcança-se uma medida de associação que é nomeada qui-quadrado (x2). Como essa medida tem uma distribuição conhe-cida, também chamada qui-quadrado, pode-se examinar a posição desse valor para formar juízos se ele é significativamente grande ou não. No exemplo, o qui-quadrado resulta em χ2 = 6,25. A distribuição qui-quadrado informa que, em tabelas 2 x 2 (ditas de um grau de liberdade), a probabilidade de valores como este ou ainda mais extremos é de p = 0,012, ou seja, quando não houver associação entre sexo e do-ença, pode-se esperar que, apenas por força da aleatoriedade própria da distribui-ção de probabilidades, 12 em cada mil vezes ocorram situações como a verificada na tabela 1. Como isso soa raro, sugere-se que esse valor seja significativamente grande, ou seja, que há associação entre sexo e doença: essa doença parece afetar as pessoas de forma diferente, dependendo de seu sexo. Em Epidemiologia se dirá que o sexo masculino é um componente causal da doença.
Para conhecer o efeito da associação entre medidas qualitativas, calcula-se quanto as chances de evento de interesse (doença) estão aumentadas na presença de um componente causal (sexo masculino) em relação à sua ausência (sexo feminino). Ao examinar a tabela 1, há duas possibilidades distintas:
1. O grupo de 100 pessoas examinadas é uma amostra representativa da po-pulação. Isso significa que as proporções que se registram na tabela são as que se encontrariam na população, no universo, ou seja, são probabilida-des. Neste caso, a probabilidade de doença (evento de interesse) entre os homens (categoria causal) é de p = 0,3, enquanto entre as mulheres é de
TAbELA 1. ExAmE DA ASSociAÇão EnTRE SExo E DoEnÇA numA TAbELA DE conTingênciA
sexo
Feminino masculino ToTal
Ca bexiga Não 45 35 80
Sim 5 15 20
Total 50 50 100
11542 AC2-SANDOZ-2cor.indd 25 15/04/11 15:33

Artigo CientífiColeitura crítica
26
p = 0,1. Logo, as chances de doença estão aumentadas em três vezes – a essa medida de efeito se atribui a designação de risco relativo (risco, ou chance, de doença em homens em relação à mesma chance em mulheres).
2. O grupo não é amostra de população: as cem pessoas seriam, por exem-plo, pacientes de um ambulatório de Oncologia. Nesse caso, as propor-ções não são estimativas de probabilidade e há que se aferir chances de outra forma: odds, palavra inglesa que significa chances e é uma medida da forma quantos eventos de interesse contra quantos complementares, os sins contra os nãos. A odds para doença entre os homens é 15/35, entre as mulheres é 5/45 – homens têm 3,86 vezes mais chance de do-ença que as mulheres. Essa razão de chance é geralmente referida pelo original em inglês odds ratio: o odds ratio = (15/35) / (5/45) = 3,86.
É uma alternativa de medida de efeito para situações em que não se dispõe de informações de probabilidade.
Note que risco relativo e odds ratio são duas estimativas distintas, cada uma apropriada a uma situação distinta. Essas estimativas só se aproximam quando o evento de interesse, por exemplo, uma doença, é um evento raro.
GlossáRio de PRoCedimentos mAis fRequentes
Amostragem: um procedimento de planejamento de pesquisa que arbitra as características de casos que devem ser incluídos numa amostra com vistas a bem representar o universo sobre o qual se busca conhecimento. Demanda conhecimento do objeto investigado: com que frequência e variabilidade se apresenta, como sua manifestação é influenciada por outros fenômenos. Da consideração desses as-pectos e do plano de análise dos dados (finalidade do estudo), pode-se extrair sugestão sobre o tamanho da amostra. Este, no entanto, é apenas um aspecto do planejamento amostral e não deve ser supervalo-rizado: mais importante do que quantos é quais.
Análise de sobrevivência: analisa a ocorrência de eventos de interesse, por exemplo óbito, ao longo do tempo de observação e possibilita medir o efeito tanto do tempo quanto de atributos de interesse em contraste com atributos referentes. Afere o efeito do tempo construindo curvas de sobrevivência (proporção de indivíduos ainda não afetados pelo evento de interesse ao longo do tempo) e curvas de dano (em inglês, hazard, proporção de indivíduos afetados ao longo do tempo; são curvas comple-
11542 AC2-SANDOZ-2cor.indd 26 15/04/11 15:33

27
mentares às de sobrevida). O método mais frequentemente usado para construir essas curvas é o de Kaplan-Meier. Com ele, pode-se estimar a probabilidade de se alcançar um determinado tempo livre do evento (sobrevivendo). Pode-se também ajuizar a significância da diferença entre duas curvas distintas, de indivíduos com atributos distintos, por meio de um teste chamado log-rank que provê uma estatística cuja posição numa distribuição qui-quadrado provê juízo de significância. Exemplo: recidiva de obstrução coronária em pacientes submetidos a dois tipos de stents. Para cada um dos stents é possível calcular a probabilidade de sobrevida (não recidiva) até qualquer tempo de seguimento (um ano, cinco anos). Com o teste log-rank, pode-se ajuizar se os dois stents podem ser considerados iguais ou não. Para aferir o efeito de usar-se um stent em comparação a outro, geralmente se contrastam as curvas hazard numa regressão de Cox (veja).
AnoVA: análise de variâncias (analysis of variance, em inglês). Examina quantas vezes uma variância é superior a outra: na chamada de um fator (one-way ANOVA – veja em Relações de ordem), quanto as variações entre grupos é superior às variações dentro dos grupos. Provê uma estatística F, cuja posição pode ser examinada numa distribuição de probabilidades de mesmo nome. Pode-se considerar dois fatores (two-way ANOVA – fator é a variável qualitativa nominal que separa diferentes grupos para comparação) ou generalizar-se para múltiplos fatores (factorial ANOVA). Quando o fenômeno estudado é considerado segundo diferentes medidas, para examinar seu comportamento conforme um ou mais fatores, essas medidas são resumidas a uma única por procedimentos de transformação das medidas originais (MANOVA: multiple ANOVA). Quando a manifestação de um fenômeno é estudada num mesmo grupo em diferentes tempos, usa-se a ANOVA com medidas repetidas, um procedimento que considera a dependência entre as medidas. Todas essas alternativas aferem o efeito de determinadas situações (fatores ou covariáveis) sobre a manifestação de um fenômeno de interesse revelado por uma ou mais medidas quantitativas, ajudando a ajuizar-se se todas as situações podem ser consideradas iguais ou não. Quando não, essas análises precisam ser complementadas por procedimentos de análise de res-postas múltiplas (veja em teste de Bonferroni) para se conhecer quais as situações de diferença.
bayes – teorema: procedimento para calcular probabilidades condicionais – probabilidade de um even-to em uma partição do espaço de eventos com probabilidade anterior conhecida ou arbitrada por um educated guess, um valor arbitrado por conhecimento reconhecido sobre o comportamento do evento de interesse.
bayes – modelos: modelos estatísticos que permitem introduzir subjetividade nos cálculos de probabi-lidade. Opõem-se em termo epistemológicos aos modelos estocásticos clássicos. Em Ciências da Saúde, têm ganho ampla aplicação.
coeficiente de correlação: veja em Relações de dependência.
coeficiente de determinação: é o coeficiente de correlação (r) ao quadrado, geralmente denotado por R2. Afere qual a fração de variação de uma medida pode ser atribuída a outra com a qual tem correlação. Pode também ser interpretado como a proporção dos casos de variação de uma medida que é devida a outra com a qual tem correlação. Quando se examina o efeito da ação de uma variável sobre outra correlacionada por meio de uma reta de regressão, informa a expectativa de acertos de previsão com essa reta.
11542 AC2-SANDOZ-2cor.indd 27 15/04/11 15:33

Artigo CientífiColeitura crítica
28
coeficiente de variação: é uma medida relativa de variabilidade de valores com referência à expec-
tativa de valor: a razão entre o desvio-padrão e a média. Geralmente expressa como porcentagem,
permite ajuizar quão mais variáveis são as medidas de um conjunto em relação a outro.
correlação de Spearman (rS): quando se quer saber a associação entre duas variáveis para as
quais não se aplica o coeficiente de correlação (r de Pearson), os valores das duas variáveis são
ordenados (as medidas devem ser pelo menos qualitativas ordinais) e as diferenças de ordem são
examinadas de forma a oferecer uma estatística cujos valores variam entre - 1 e + 1. A interpretação
do rS é semelhante à do r: intensidade da associação. A distribuição de r
S converge para uma normal,
permitindo juízos de significância estatística.
correlação parcial: é um coeficiente de correlação para o qual foi removido o efeito de uma
variável que interfere na associação. Por exemplo: a correlação entre idade e estatura em escolares
pode ser controlada por sexo, de forma a eliminar as diferenças de ritmo de crescimento entre
meninos e meninas.
Erro tipo i: quando se comparam dois grupos (veja Relações de ordem), é a probabilidade de se
concluir por um juízo de diferença quando ela não existe. É o nível de significância fixado em testes de
hipótese, cuja probabilidade é designada a.
Erro tipo ii: quando se comparam dois grupos, é a probabilidade de se ajuizar ausência de diferença
quando ela existe. Sua probabilidade é designada b e calculada examinando-se a posição do valor
relativo ao nível de significância na distribuição de valores tomados como verdadeiros.
Especificidade: num rastreamento de doentes, é a proporção de verdadeiramente negativos entre os
não doentes. Generalizando, é a probabilidade de teste negativo entre pessoas não doentes.
gEE: sigla para generalized estimating equation. Procedimento para estimar parâmetros de um GLM
quando há dependência entre as medidas.
gLm: sigla para generalized linear models. Procedimento que generaliza os general linear models,
os modelos de regressão, permitindo que a variável resposta tenha diferentes distribuições de pro-
babilidade e que a ligação com as variáveis causais seja arbitrada entre igual, logaritmo ou logito.
Quando a função de ligação é o logito, os coeficientes são interpretados como odds ratios.
Hazard rate: densidade de ocorrência de eventos adversos no tempo calculada em análise de sobrevi-
da. A equivalente acumulada informa a probabilidade do evento de interesse.
Hazard rate ratio: razão de duas funções hazard, informa o risco relativo instantâneo. Quando conside-
rada a acumulada, informa risco relativo.
intervalo de confiança: dada uma estimativa de média amostral, é o intervalo de valores em torno
da média que se considera variação aceitável. Na comparação de duas amostras, intervalos que
se sobrepõem sugerem igualdade porque possíveis valores de uma encontram-se entre possíveis
valores de outra.
Kappa: medida de concordância entre duas medidas categóricas. Exprime a proporção de casos de
concordância controlado com o efeito da concordância aleatória. É a diferença entre casos observados e
esperados (O-E) como fração do espaço complementar ao esperado (1-E).
11542 AC2-SANDOZ-2cor.indd 28 15/04/11 15:33

29
Likehood ratio: em testes diagnósticos, na ausência de dados de prevalência de doença, não se
pode calcular valores preditivos positivo ou negativo e a likelihood ratio é um substituto apto. A like-lihood ratio positiva informa quantas vezes a proporção de verdadeiros-positivos é maior que a de
falsos-positivos. A likelihood ratio negativa informa quantas vezes a proporção de falsos-negativos é
maior que a de verdadeiros negativos. Assim, dado um paciente com teste positivo, sabe-se em quan-
to sua chance de ser doente está aumentada em relação a não ser doente. Com um teste negativo,
sabe-se quantas vezes está aumentada a chance de ser doente em relação a não ser. Um teste é tão
bom quanto maior que 1 for a LR+ e menor que 1 for a LR-.
Likehood ratio function: uma função usada para estimar parâmetros de distribuição de probabilidades
ou parâmetros de modelos de regressão. Tem como referencial conceitual o teorema de Bayes.
nível de significância: valor de probabilidade arbitrado num teste de hipótese como barreira para
juízos de grande ou pequeno. A um valor grande de medida corresponde um valor pequeno de pro-
babilidade e o nível de significância é fixado por um juízo do que seja uma probabilidade pequena.
Do costume, considera-se probabilidade pequena 5%, ou seja, uma ocorrência a cada 20 tentativas.
nível descritivo: veja valor de p.
Poder de teste estatístico: é o complemento do erro tipo II, cuja probabilidade é calculada como 1-b.
Mede as chances de se afirmar diferenças corretamente.
Razão de prevalência: medida de efeito que contrasta duas estimativas de probabilidade. É estimada
pela razão das probabilidades acumuladas em regressões de Poisson, Cox e em modelos GLM.
Regressão de cox: também chamada modelo de riscos proporcionais. Ao assumir regularidade de
ocorrências no tempo (premissa de proporcionalidade), contrasta duas funções de hazard rate acumula-
das (veja análise de sobrevida) para gerar uma estimativa de risco relativo.
Regressão de Poisson: uma regressão em que a variável resposta é quantitativa discreta, uma conta-
gem. O coeficiente de regressão mede o efeito sobre a média de ocorrências. Com transformação logito,
o efeito expressa odds ratio.
Regressão logística: uma regressão em que a variável resposta é um logito, uma razão entre presen-
ças e ausências do fenômeno estudado. Tem ampla aplicação em estudos médicos porque o antilog dos
coeficientes de regressão estima odds ratio.
Regressão multinível: aplicável a dados de inquéritos populacionais com amostragem complexa em
que o fenômeno estudado tem vários níveis de expressão, por exemplo individual, familiar, regional. Este
modelo pondera as variâncias de cada nível para fornecer estimativas mais precisas e acuradas.
Risco: termo usado para expressar probabilidade em nível individual. Por exemplo, se a probabili-
dade de um evento numa população é p = 0,30, diz-se que uma pessoa tem risco de 0,30 para o
evento. Trata-se de uma abstração, visto que em âmbito individual o evento só pode estar presente
ou ausente. Pode ser calculado como risco instantâneo, por exemplo risco numa dada idade, o
que corresponde à densidade de probabilidade, ou como a integral de riscos instantâneos para um
intervalo de valores, por exemplo, para todas as idades, quando é denominado simplesmente risco
ou probabilidade.
11542 AC2-SANDOZ-2cor.indd 29 15/04/11 15:33

Artigo CientífiColeitura crítica
30
Risco atribuível: medida de efeito que expressa a diferença de risco (probabilidade) entre duas
situações, uma com um atributo de interesse caracteriza exposição e outra sem esse atributo
caracteriza não exposição. Quando expresso como fração do risco no grupo exposto, denomina-se
risco atribuível proporcional e com correções para prevalência de exposição origina o risco atribuí-
vel proporcional de população.
Sensibilidade: num rastreamento de doentes, é a proporção de verdadeiramente positivos entre os
doentes. Generalizando, é a probabilidade de teste positivo entre pessoas doentes.
Significância: termo cunhado por Ronald Fisher (1890-1962) para reconhecer como relevante uma
grandeza. Por exemplo, uma diferença é significativa se pode ser dita grande demais para ser resultado
do acaso. Valores grandes ocupam posições extremas em distribuições de probabilidade e a significância
é medida como a probabilidade de valores tão grandes quanto o considerado ou ainda mais extremos
(veja valor de p).
Teste bicaudal: quando se examina a diferença entre duas amostras, pode-se considerar diferenças
a maior ou a menor. Quando ambas são de interesse, o teste da diferença (veja Relações de ordem)
estima a probabilidade de diferenças maiores positivas ou negativas. Um teste de diferença de dois
tempos distintos de um fármaco cujo metabolismo não é conhecido deve ser feito com teste bicaudal,
já que não se sabe se o fármaco será catabolizado no intervalo ou será potencializado no tempo por
alguma interação. Se de uma situação para outra é sensato considerar tanto diferenças positivas
quanto negativas, o teste deve ser bicaudal e o nível descritivo (veja valor de p) será a soma das
probabilidades de cada cauda da distribuição de probabilidades.
Teste de bonferroni: procedimento de ajuste de nível de significância ou nível descritivo em
comparações múltiplas após um teste de ANOVA com resultado significativo. Faz a comparação de
pares dos grupos considerados na ANOVA, mas torna mais exigente a conclusão de significância
para dar conta de se tratar de uma análise (comparação dois a dois) dentro de outra (ANOVA –
comparação de vários grupos).
Teste de hipótese: teste de diferenças em que se estabelece, além da hipótese nula de igualdade, uma
hipótese alternativa e fixa-se de antemão um valor de probabilidade a ser considerado significativo (valor
do erro tipo I, a). Neste teste, em vez de se formar opinião sobre o “valor de p” relativo à posição de
uma diferença numa distribuição de probabilidades, apenas se decide pela igualdade ou pela hipótese
alternativa conforme a barreira fixada por a seja ou não superada.
Teste de mcnemar: teste para comparar proporções com dependência. A exemplo do teste T para
examinar médias pareadas (de um mesmo grupo em duas situações distintas), o teste de McNemar
compara proporções pareadas, repetidas nos indivíduos de um mesmo grupo. A estatística calculada
recorre à distribuição qui-quadrado para formar juízo de significância.
Teste exato de Fisher: usado para averiguar a associação entre variáveis qualitativas quando o teste
do qui-quadrado não se aplica: amostras muito pequenas, inúmeros valores esperados muito pequenos.
Este teste calcula probabilidades exatas numa distribuição hipergeométrica, do que tira o nome exato.
É um teste mais rigoroso que o qui-quadrado para concluir por associações, mas quando a amostra é
grande, os resultados são convergentes.
11542 AC2-SANDOZ-2cor.indd 30 15/04/11 15:33

31
Teste monocaudal: teste que considera apenas as probabilidades de valores mais extremos a maior ou a menor, ou seja, considera apenas as diferenças positivas ou as negativas. Em ensaios clínicos, é muitas vezes uma imposição ética: não se testa um tratamento considerando que ele possa melhorar ou piorar a situação de doença. Testa-se se ele melhora contra não afeta ou piora.
Teste T: teste que examina a significância de diferenças de médias segundo a distribuição T. Essa distri-buição tem como parâmetro apenas o número de graus de liberdade, pelo que permite a comparação de grupos à revelia do conhecimento de parâmetros populacionais (por exemplo, média, desvio-padrão). É necessário para amostras pequenas e para amostras de cujo universo não se tenha conhecimento, do qual não se saiba a variância necessária ao cálculo do erro-padrão que padroniza a diferença.
Valor de p: o nome correto é nível descritivo. É o valor de probabilidade que descreve as chances de ocorrências de uma diferença tão grande quanto a encontrada ou ainda mais extrema. Pode-se referir a diferenças positivas ou negativas, em testes bicaudais, ou apenas a uma delas, em testes monocaudais. O valor de p instrui o juízo de significância. Um valor de p de, por exemplo, p = 0,05, ou 5%, significa que quando não existem diferenças, por pura obra do acaso se poderia encontrar a diferença considerada ou, ainda, outras mais extremas em cinco de cada 100 tentativas.
Valor preditivo negativo: medida da probabilidade de um indivíduo com teste negativo para doença ser, de fato, sadio. É uma probabilidade condicional cujo cálculo demanda conhecimento da probabilida-de de doença, de prevalência da doença na população.
Valor preditivo positivo: medida da probabilidade de um indivíduo com teste positivo para doença ser, de fato, doente. É uma probabilidade condicional cujo cálculo demanda conhecimento da probabilidade de doença, de prevalência da doença na população.
Rua Anseriz, 27, Campo Belo – 04618-050 – São Paulo, SP. Fone: 11 3093-3300 www.segmentofarma.com.br • [email protected]
Diretor-geral: Idelcio D. Patricio Diretor executivo: Jorge Rangel Gerente financeira: Andréa Rangel Gerente comercial: Rodrigo Mourão Editora-chefe: Daniela Barros MTb 39.311 Comunicações médicas: Cristiana Bravo Gerentes de negócios: Claudia Serrano, Marcela Crespi, Phillip Santos e Valeria Freitas Coordenadora comercial: Andrea Figueiro Gerente editorial: Cristiane Mezzari Coordenadora editorial: Fabiana de Paula Souza Diretora de criação: Renata Variso Peres Designer: Rogério Chagas Revisoras: Renata Del Nero e Patrizia Zagni Produtor gráfico: Fabio Rangel • Cód. da publicação: 11542.04.2011
O conteúdo desta obra é de inteira responsabilidade de seu(s) autor(es). Produzido por Segmento Farma Editores Ltda., sob encomenda de Sandoz, em abril de 2011.
MatERial DE DistRibuição ExClusiva à ClassE MéDiCa.
11542 AC2-SANDOZ-2cor.indd 31 15/04/11 15:33

QUIM
IO 1
108
- M
ARÇO
/201
1
11542 AC2-SANDOZ-2cor.indd 32 15/04/11 15:33





























