Embed Size (px)
Citation preview

FACULDADE DE ECONOMIA E FINANÇAS IBMEC PROGRAMA DE PÓS-GRADUAÇÃO E PESQUISA EM
ADMINISTRAÇÃO E ECONOMIA
DDIISSSSEERRTTAAÇÇÃÃOO DDEE MMEESSTTRRAADDOO PPRROOFFIISSSSIIOONNAALLIIZZAANNTTEE EEMM EECCOONNOOMMIIAA
“PREVISÃO DO FATOR DE REAJUSTAMENTO DE PREÇOS DE
CONTRATOS DE AQUISIÇÃO DE EQUIPAMENTOS SUBMARINOS PELA
PETROBRAS”.
JJUULLIIAANNAA BBAARRRROOSS SSPPIINNOOLLAA DDEE VVAASSCCOONNCCEELLLLOOSS ORIENTADORA: PROF. DR.ª MARIA AUGUSTA SOARES MACHADO
Rio de Janeiro, 08 de novembro de 2011.

“PREVISÃO DO FATOR DE REAJUSTAMENTO DE PREÇOS DE CONTRATOS DE AQUISIÇÃO DE EQUIPAMENTOS SUBMARINOS PELA PETROBRAS”
JULIANA BARROS SPINOLA DE VASCONCELLOS
Dissertação apresentada ao curso de Mestrado Profissionalizante em Economia como requisito parcial para obtenção do Grau de Mestre em Economia. Área de Concentração: Finanças e Controladoria
ORIENTADORA: PROF. DR.ª MARIA AUGUSTA SOARES MACHADO
Rio de Janeiro, 08 de Novembro de 2011.

“PREVISÃO DO FATOR DE REAJUSTAMENTO DE PREÇOS DE CONTRATOS DE AQUISIÇÃO DE EQUIPAMENTOS SUBMARINOS PELA PETROBRAS”
JULIANA BARROS SPINOLA DE VASCONCELLOS
Dissertação apresentada ao curso de Mestrado Profissionalizante em Economia como requisito parcial para obtenção do Grau de Mestre em Economia. Área de Concentração: Finanças e Controladoria
Avaliação:
BANCA EXAMINADORA:
_____________________________________________________
Professora DRA. MARIA AUGUSTA SOARES MACHADO (Orientadora) Instituição: Ibmec-RJ _____________________________________________________
Professor DR. EDSON JOSÉ DALTO Instituição: Ibmec-RJ _____________________________________________________
Professor DR. JESÚS DOMECH MORE Instituição: Universidade Estácio de Sá - RJ Rio de Janeiro, 08 de novembro de 2011.

Ficha Catalográfica
330 A242
Vasconcellos ,Juliana Barros Spinola.
Previsão do fator de Reajustamento de preços de Contratos de Aquisição de Equipamentos Submarinos pela Petrobras / Juliana Barros Spinola Vasconcellos – Rio de Janeiro: Faculdades Ibmec, 2011.
P. 129 Dissertação Apresentada ao curso de Mestrado Profissionalizante em
Economia como requisito parcial para obtenção do Grau de Mestre em Economia.
Área de Concentração: Finança e Controladoria Orientador: Prof. Dr. Maria Augusta Soares Machado 1. Box-Jenkins - Metodologia I . Vasconcellos, Juliana Barros Spinola .II. Prof.Dr. Maria Augusta Soares Machado III.Previsão do fator de Reajustamento de preços de Contratos de Aquisição de Equipamentos Submarinos pela Petrobras da Metodologia Box-Jenkins


vi
DEDICATÓRIA
À minha família.

vii
AGRADECIMENTOS
Aos meus amigos por entender minha ausência e apoiar minha vontade de concluir este
mestrado.
Ao meu chefe, coach e amigo José Antônio Machado pela paciência e vontade de dividir seu
vasto conhecimento.
À Professora Maria Augusta, ao Professor Marcelo Mello, ao Professor Edson José Dalto e ao
Professor Jesús More, pela oportunidade e apoio dados.

viii
RESUMO
O presente trabalho tem por objetivo propor um método de previsão do fator de reajustamento
para os contratos de aquisição de equipamentos submarinos do tipo ponto a ponto pela
Petrobras; permitindo assim uma melhor visibilidade do valor final destes contratos,
aumentando conseqüentemente a previsibilidade da margem de lucro dos equipamentos.
Neste intuito, propomos uma análise da variável dependente, aqui denominada Fator de
Reajustamento e em seguida uma breve análise dos índices setoriais que a compõem.
Posteriormente é aplicada a metodologia Box-Jenkins em modelos univariados permitindo a
análise, previsão e escolha do modelo que melhor se adere à curva da variável. São utilizadas
três diferentes abordagens: variável em nível com tendência estocástica, variável em log com
tendência determinística e variável em log com tendência estocástica. Nove modelos foram
sugeridos e pela comparação da previsão dos três modelos que apresentaram o melhor
desempenho, pudemos comprovar a superioridade da performance do modelo com a variável
dependente em log e primeiras diferenças considerando componentes de ciclo AR(1), MA(4)
e MA(11).
Palavras Chave: Previsão, Fator de Reajustamento, Petrobras, Box-Jenkins

ix
ABSTRACT
This paper aims to propose a forecasting model for escalations of contracts for subsea
equipments purchased by Petrobras. This forecast increases the predictability of equipment
profit margins by providing better visibility of the final contract value. To this end, we
propose an analysis of the dependent variable, hence forward called escalation, then a brief
analysis of sector indexes that compose it. We apply the Box-Jenkins methodology to
univariate models which allows us to analyze, forecast and select the model that best adheres
to the dependent variable’s curve. We use three different approaches: dependent variable in
level with stochastic trend, dependent variable in log with deterministic trend and dependent
variable in log with a stochastic trend. We propose nine models and chose the three with best
performance. By comparing the forecast of those three models, we prove the superiority of
the model with the dependent variable in log with a stochastic trend and cycle components
AR (1), MA (4) and MA (11).
Key Words: Forecast, Escalation, Petrobras, Box-Jenkins

x
LISTA DE FIGURAS
Figura 1 - Fluxograma para Seleção do Modelo Final ............................................................. 16 Figura 2 - Gráfico da Série CRU .............................................................................................. 24 Figura 3 - Gráfico da Série col30 ............................................................................................. 29 Figura 4 - Gráfico da Série maq ............................................................................................... 31 Figura 5 - Gráfico da Série usd ................................................................................................. 34 Figura 6 - Gráfico da Série reaj ................................................................................................ 36 Figura 7 - Histograma da Série reaj .......................................................................................... 40 Figura 8 - Correlograma da Série reaj ...................................................................................... 41 Figura 9 - Gráfico dos resíduos da Série reaj ........................................................................... 42 Figura 10 - Gráfico da série dreaj ............................................................................................. 45 Figura 11 - Histograma da série dreaj ...................................................................................... 48 Figura 12 - Correlograma da série dreaj ................................................................................... 49 Figura 13 - Gráfico dos resíduos da série dreaj ........................................................................ 50 Figura 14 - Correlograma da série sugerida pelo GARMA para Modelo 1A .......................... 52 Figura 15 - Comparação dos Correlogramas dos Modelos 1A e 1B ........................................ 58 Figura 16 - Comparação dos Gráficos dos Resíduos dos Modelos 1A e 1B ............................ 59 Figura 17 - Índices do Forecast do EViews para Modelo 1 ..................................................... 63 Figura 18 - Gráfico do Forecast do Modelo 1 ......................................................................... 64 Figura 19 - Gráfico da série lreaj .............................................................................................. 65 Figura 20 - Histograma da série lreaj ....................................................................................... 66 Figura 21 - Correlograma da série lreaj .................................................................................... 67 Figura 22 - Gráfico dos resíduos da série lreaj ......................................................................... 68 Figura 23 - Correlograma da série sugerida pelo GARMA para Modelo 2 ............................. 74 Figura 24 - Comparação dos Correlogramas dos Modelos 2A e 2C ........................................ 80 Figura 25 - Comparação dos Gráficos dos Resíduos dos Modelos 2A e 2C ............................ 81 Figura 26 - Índices do Forecast do EViews para Modelo 2 ..................................................... 88 Figura 27 - Gráfico do Forecast do Modelo 2 ......................................................................... 89 Figura 28 - Gráfico da série dlreaj ............................................................................................ 91 Figura 29 - Histograma da série dlreaj ..................................................................................... 92 Figura 30 - Correlograma da série dlreaj .................................................................................. 93 Figura 31 - Gráfico dos resíduos da série dlreaj ....................................................................... 94 Figura 32 - Correlograma da série sugerida pelo GARMA para Modelo 3A .......................... 99 Figura 33 - Comparação dos Correlogramas dos Modelos 3A, 3B e 3C ............................... 103 Figura 34 - Comparação dos Gráficos dos Resíduos dos Modelos 3A, 3B e 3C ................... 103 Figura 35 - Índices do Forecast do EViews para Modelo 3 ................................................... 113 Figura 36 - Gráfico do Forecast do Modelo 3 ....................................................................... 114

xi
Figura 37 - Comparação dos Gráficos de Forecast dos Modelos 1, 2 e 3 em relação aos dados reais ................................................................................................................................. 115

xii
LISTA DE TABELAS
Tabela 1 - Regressão da Série reaj incluindo dummies sazonais .............................................. 37 Tabela 2 - Teste de Raiz Unitária da série reaj (Augmented Dickey Fuller e Schwarz Info
Criterion, incluindo Tendência e Intercepto) ................................................................... 43 Tabela 3 - Teste de Raiz Unitária da série reaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Tendência e Intercepto) ................................................................... 44 Tabela 4 - Teste de Raiz Unitária da série dreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, excluindo Tendência e Intercepto)................................................................... 46 Tabela 5 - Teste de Raiz Unitária da série dreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Intercepto) ........................................................................................ 47 Tabela 6 - Tabela PQ (GARMA) da série dreaj ....................................................................... 50 Tabela 7 - Modelo 1A ............................................................................................................... 51 Tabela 8 - Modelo 1B ............................................................................................................... 53 Tabela 9 - Modelo 1C ............................................................................................................... 54 Tabela 10 - Modelo 1C retirando os termos AR(3), AR(4), MA(3) e MA(4).......................... 55 Tabela 11 - Teste de Wald do Modelo 1C dos termos AR(1) e AR(2) .................................... 56 Tabela 12 - Modelo 1C com a retirada dos termos AR(1) e AR(2) ......................................... 56 Tabela 13 - Teste de Wald do Modelo 1C do termo MA(2) .................................................... 57 Tabela 14 - Comparação dos Modelos 1A e 1B pelos critérios SIC e AIC .............................. 57 Tabela 15 - Teste de Wald para Modelo 1B ............................................................................. 59 Tabela 16 - Teste RESET para Modelo 1B ............................................................................... 60 Tabela 17 - Teste de White para Modelo 1B ............................................................................ 61 Tabela 18 - Teste Breush-Godfrey (LM Test) para Modelo 1B ............................................... 62 Tabela 19 - Teste de Raiz Unitária da série lreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, incluindo Tendência e Intercepto) ................................................................... 69 Tabela 20 - Teste de Raiz Unitária da série lreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Tendência e Intercepto) ................................................................... 70 Tabela 21 - Regressão da série lreaj incluindo tendências linear e quadrática......................... 71 Tabela 22 - Regressão da série lreaj incluindo tendências linear, tendência quadrática e
dummies sazonais ............................................................................................................. 72 Tabela 23 - Tabela PQ (GARMA) da série lreaj ...................................................................... 72 Tabela 24 - Sugestão do GARMA para Modelo 2A pelo critério SIC ..................................... 73 Tabela 25 - Modelo 2B ............................................................................................................. 75 Tabela 26 - Teste de Wald do Modelo 2B dos termos AR(4) e AR(11) .................................. 76 Tabela 27 - Modelo 2C ............................................................................................................. 77 Tabela 28 - Teste de Wald do Modelo 2C do termo MA(3) .................................................... 78 Tabela 29 - Forma final Modelo 2C ......................................................................................... 78 Tabela 30 - Comparação dos Modelos 2A e 2C pelos critérios SIC e AIC .............................. 79

xiii
Tabela 31 - Teste RESET para Modelo 2A .............................................................................. 82 Tabela 32 - Teste RESET para Modelo 2C ............................................................................... 83 Tabela 33 - Teste de White para Modelo 2ª ............................................................................. 84 Tabela 34 - Teste de White para Modelo 2C ............................................................................ 85 Tabela 35 - Teste Breush-Godfrey (LM Test) para Modelo 2A ............................................... 86 Tabela 36 - Teste Breush-Godfrey (LM Test) para Modelo 2C ............................................... 87 Tabela 37 - Teste de Raiz Unitária da série dlreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, sem tendência ou intercepto) ........................................................................... 95 Tabela 38 - Teste de Raiz Unitária da série dlreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, com Intercepto) ................................................................................................ 96 Tabela 39 - Regressão da série dlreaj incluindo tendências linear, tendência quadrática e
dummies sazonais ............................................................................................................. 97 Tabela 40 - Tabela PQ (GARMA) da série dlreaj .................................................................... 97 Tabela 41 - Sugestão do GARMA para Modelo 3A pelo critério SIC ..................................... 98 Tabela 42 - Modelo 3B ........................................................................................................... 100 Tabela 43 - Teste de Wald do Modelo 3B dos termos MA(4) e MA(11) .............................. 101 Tabela 44 - Modelo 3C ........................................................................................................... 101 Tabela 45 - Comparação dos Modelos 3A, 3B e 3C pelos critérios SIC e AIC ..................... 102 Tabela 46 - Teste RESET para Modelo 3ª .............................................................................. 104 Tabela 47 - Teste RESET para Modelo 3B ............................................................................. 105 Tabela 48 - Teste RESET para Modelo 3C ............................................................................. 106 Tabela 49 - Teste de White para Modelo 3A ......................................................................... 107 Tabela 50 - Teste de White para Modelo 3B .......................................................................... 108 Tabela 51 - Teste de White para Modelo 3C .......................................................................... 109 Tabela 52 - Teste Breush-Godfrey (LM Test) para Modelo 3A ............................................. 110 Tabela 53 - Teste Breush-Godfrey (LM Test) para Modelo 3B ............................................. 111 Tabela 54 - Teste Breush-Godfrey (LM Test) para Modelo 3C ............................................. 112 Tabela 55 - Comparação do desvio entre Valor Previsto e Valor Observado para os Modelos
1, 2 e 3, separado por período ......................................................................................... 117 Tabela 56 - Comparação de índices calculados para avaliação de Modelos (TIC, Bias Prop.,
Variance Prop. e Covariance Prop.) ............................................................................... 118 Tabela 57 - Cálculo do MSE dos Modelos 1, 2 e 3 em MS Excel .......................................... 119 Tabela 58 - Índices calculados para comparação de Modelos (MSE, RMSE, MAE e MAPE) 120 Tabela 59 - Avaliação Final do Modelo 3 .............................................................................. 124

xiv
LISTA DE ABREVIATURAS
ABDIB Associação Brasileira de da Infra-Estrutura e Indústrias de Base
AC Autocorrelação
ADF Augmented Dickey-Fuller - Dickey-Fuller Aumentado
AIC Akaike Info Criterion - Critério de Informação de Akaike
ANP Agencia Nacional do Petróleo
AR Auto Regressive - Auto-regressivo
ARMA Auto Regressive Moving Averages - Auto-regressivo de Média Móvel
BLUE Best Linear Unbiased Estimador - Melhor Estimador Linear Não-Viesado
CACEX Carteira de Comercio Exterior do Banco do Brasil

xv
CFM Condições de Fornecimento de Material
CNAE Classificação Nacional de Atividades Econômicas
CRP Condições de Reajustamento e Pagamento
CRU Commodities Research Unit Ltd.
CRUSpi Commodities Research Unit Steel Price Index - Índice de Preço do Aço da
Commodities Research Unit Ltd.
DF-GLS Dickey-Fuller Generalized Least Squares - Dickey-Fuller Mínimos
Quadrados Generalizados
DNPM Departamento Nacional da Produção Mineral
FAC Função de Autocorrelação
FACP Função Autocorrelação Parcial
FGV Fundação Getúlio Vargas
IGP Índice Geral de Preços
IPA Índice de Preços por Atacado

xvi
IPA-DI Índice de Preços por Atacado - Disponibilidade Interna
IPA-OG Índice de Preços por Atacado - Oferta Global
IPA-OG-DI Índice de Preços por Atacado - Oferta Global - Disponibilidade Interna
IPC Índice de Preços ao Consumidor
MA Moving Average - Média Móvel
MAE Mean Absolute Error - Erro Absoluto Médio
MAPE Mean Absolute Percentage Error - Erro Percentual Absoluto Médio
MQO Mínimos Quadrados Ordinários
MSE Mean Squared Error - Erro Quadrático Médio ou
PC Autocorrelação Parcial
PETROBRAS Petróleo Brasileiro S.A.
PIA Pesquisa Industrial Anual
PIB Produto Interno Bruto

xvii
RESET Regression Specification Error Test - Teste de Erro de Especificação da
Regressão
RMSE Root Mean Squared Error - Raiz do Erro Quadrático Médio
SIC Schwarz Info Criterion - Critério de Informação de Schwarz
TCL Teorema Central do Limite
TIC Theil Inequality Coefficient - Coeficiente de Desigualdade de Theil
WSA World Steel Association - Associação Mundial do Aço

xviii
SUMÁRIO
DEDICATÓRIA ........................................................................................................... VI
AGRADECIMENTOS ................................................................................................. VII
RESUMO ................................................................................................................... VIII
ABSTRACT ................................................................................................................. IX
LISTA DE FIGURAS .................................................................................................... X
LISTA DE TABELAS ................................................................................................. XII
LISTA DE ABREVIATURAS .................................................................................... XIV
SUMÁRIO ................................................................................................................ XVIII
1 INTRODUÇÃO ....................................................................................................... 1
2 METODOLOGIA .................................................................................................... 4
2.1 Análise das variáveis ....................................................................................................................................... 4 2.1.1 Análise Gráfica ........................................................................................................................................ 4 2.1.2 Análise das estatísticas descritivas .......................................................................................................... 5 2.1.3 Modelos auto-regressivos de médias móveis (arma) .............................................................................. 6 2.1.4 Análise do gráfico dos resíduos .............................................................................................................. 8 2.1.5 Testes de Raiz Unitária ........................................................................................................................... 8
2.2 Testes para seleção de modelos .................................................................................................................... 10 2.2.1 Teste de White ....................................................................................................................................... 10 2.2.2 Teste de Wald ........................................................................................................................................ 10 2.2.3 Teste de Breush-Godfrey (TESTE LM) ............................................................................................... 11 2.2.4 Teste de Erro de Especificação da Regressão, ou Regression Specification Error Test (RESET) ...... 11
2.3 Geração do forecast ....................................................................................................................................... 11 2.3.1 Geração dos Parâmetros de Avaliação do Forecast ............................................................................. 12

xix
2.3.2 Geração do Gráfico do Forecast ........................................................................................................... 12
2.4 Comparação de modelos para a selecão do modelo final após o forecast ............................................... 13 2.4.1 Análise Gráfica do Forecast ................................................................................................................. 13 2.4.2 Coeficiente de Desigualdade de Theil ou Theil Inequality Coefficient (TIC) ..................................... 14 2.4.3 Proporção de Viés ou Bias Proportion ................................................................................................. 14 2.4.4 Proporção de Variância ou Variance Proportion .................................................................................. 14 2.4.5 Proporção de Co-Variância ou Covariance Proportion ....................................................................... 14 2.4.6 Erro Quadrático Médio ou Mean Squared Error (MSE) ...................................................................... 15 2.4.7 Raiz do Erro Quadrático Médio ou Root Mean Squared Error (RMSE) ............................................. 15 2.4.8 Erro Absoluto Médio ou Mean Absolute Error (MAE) ........................................................................ 15 2.4.9 Erro Percentual Absoluto Médio ou Mean Absolute Percentage Error (MAPE)................................ 15
2.5 Fluxograma para seleção do modelo final .................................................................................................. 16
3 DADOS ................................................................................................................ 17
3.1 Nomenclaturas das séries e equações .......................................................................................................... 18
3.2 O Fator de Reajustamento ........................................................................................................................... 19
3.3 Fórmula Paramétrica ................................................................................................................................... 21 3.3.1 CRU Steel Price Index Global (CRUSpi Global) ................................................................................. 23 3.3.2 Coluna 30 – Índice de preço por atacado / Produtos Industriais / Indústria de Transformação / Produtos de Minerais Não-Metálicos (IPA-OG-DI) ........................................................................................... 26 3.3.3 Coluna Máquinas Mecânicas da Associação Brasileira de Infra-estrutura e Indústria de Base (ABDIB) ............................................................................................................................................................... 30 3.3.4 Câmbio ................................................................................................................................................... 33
3.4 Análise da série Fator de Reajustamento ................................................................................................... 35
4 MODELOS E PREVISÕES .................................................................................. 38
4.1 Modelo 1: série fator de reajustamento em nível considerando a presença de tendência estocástica 39 4.1.1 Análise da Série "reaj" .......................................................................................................................... 39 4.1.2 Análise da Série "dreaj" ........................................................................................................................ 45 4.1.3 Avaliação e Seleção do Modelo 1 ......................................................................................................... 50 4.1.4 Forecast do Modelo 1 ........................................................................................................................... 62
4.2 Modelo 2: série fator de reajustamento em log considerando a presença de tendência determinística 65
4.2.1 Análise da Série "lreaj" ......................................................................................................................... 65 4.2.2 Avaliação e Seleção do Modelo 2 ......................................................................................................... 70 4.2.3 Forecast do Modelo 2 ........................................................................................................................... 88
4.3 Modelo 3: série fator de reajustamento em log considerando a presença de tendência estocástica ... 90 4.3.1 Análise da Série "dlreaj" ....................................................................................................................... 90 4.3.2 Avaliação e Seleção do Modelo 3 ......................................................................................................... 96 4.3.3 Forecast do Modelo 3 ......................................................................................................................... 112
4.4 Comparação dos forecasts .......................................................................................................................... 115
5 CONCLUSÃO .................................................................................................... 122
SUGESTÕES PARA TRABALHOS FUTUROS ...................................................... 125

xx
REFERÊNCIAS BIBLIOGRÁFICAS ........................................................................ 127
APÊNDICE A - ANÁLISES COMPLEMENTARES DOS ÍNDICES SETORIAIS E CÂMBIO .................................................................................................................... 130
Análise da série Índice CRUSpi Global ......................................................................................................... 130 Análise da série Índice Coluna 30 (IPA-OG-DI) .......................................................................................... 134 Análise da série Índice Coluna Máquinas Mecânicas ................................................................................. 137 Análise da série Câmbio .................................................................................................................................. 141
APÊNDICE B – OUTROS MODELOS ANALISADOS ............................................ 145
APÊNDICE C – OUTROS FORECASTS REALIZADOS ......................................... 179

1
1 INTRODUÇÃO
O mercado de exploração e produção de petróleo e gás no Brasil vem apresentando
considerável crescimento ao longo dos últimos quinze anos segundo a Agência Nacional do
Petróleo (ANP). Esta ascendência iniciou-se principalmente após a aprovação da Emenda
Constitucional 9 (nove) de 1995 com a quebra do monopólio e foi intensificada pelas
descobertas das reservas na camada do pré-sal que se estendem desde o litoral do Espírito
Santo até Santa Catarina. Ambos os eventos são considerados marcos na história do petróleo
no Brasil e que aliados ao aumento da demanda interna por este produto, contribuem para a
atratividade do mercado brasileiro.
Neste contexto, houve uma expansão dos investimentos das empresas de fornecimento de
equipamentos submarinos para prospecção, completação e produção, em sua maioria
multinacionais estrangeiras, cujas metas são extrair o máximo de óleo a custo viável e
conseqüentemente manter negócios satisfatoriamente rentáveis.
Apesar da abertura do mercado em 1995, a Petrobras ainda detém mais de 50% da produção
de petróleo no Brasil, representando então uma importante e interessante fatia da receita das
empresas que atuam neste ramo.

2
A Petrobras enquanto empresa Estatal, cujo acionista majoritário é o Governo do Brasil
(União), opera suas compras de bens e serviços principalmente através de processo licitatório
de tipo Melhor Preço e Técnica (Decreto 2.745/98). Neste âmbito, aumenta-se a concorrência
entre as empresas fornecedoras e os fatores imprescindíveis para manter-se vivo no mercado,
passam a ser não somente a tecnologia e a qualidade do equipamento, mas também a
previsibilidade de seu custo e receita.
Sendo assim, o objetivo deste trabalho é propor um método de previsão das receitas de
contratos de aquisição de equipamentos submarinos, através da previsão do fator de
reajustamento de preços destes contratos, com o intuito de aumentar a previsibilidade do
negócio.
Primeiramente, abordamos os principais aspectos do mercado e dos contratos de aquisição de
equipamentos submarinos; bem como de suas condições de fornecimento, reajustamento e
pagamento.
Citamos então o histórico, o método de cálculo e propomos uma análise da variável
dependente, aqui denominada como fator de reajustamento e em seguida uma breve análise
dos índices setoriais que compõem a fórmula desta variável: Coluna 30 (FGV – Fundação
Getúlio Vargas), Coluna Máquinas Mecânicas (ABDIB – Associação Brasileira de da Infra-
Estrutura e Indústrias de Base), CRUSpi Global (CRU – Commodities Research Unit Ltd.) e
câmbio.
Em seguida, analisamos a melhor modelagem para a série do fator de reajustamento através
do histórico da própria série, utilizando um modelo univariado através da aplicação da

3
metodologia Box & Jenkins (Box, George e Jenkins, Gwilym, 1970), seguindo 3 (três)
abordagens:
Modelo 1: série fator de reajustamento em nível considerando a presença de tendência
estocástica
Modelo 2: série fator de reajustamento em log considerando a presença de tendência
determinística
Modelo 3: série fator de reajustamento em log considerando a presença de tendência
estocástica
Finalmente, propomos, dentre os modelos acima citados, o modelo que melhor representa a
previsão para o fator de reajustamento.
Cabe destacar que este estudo limita-se a analisar os índices de contratos de fornecimento de
bens e serviços associados à Petrobras, do tipo Ponto a Ponto onde o reajuste é devido desde a
data base do contrato até a data efetiva do cumprimento de cada evento contratual e cuja
fórmula paramétrica é composta por:
40% relativo à variação dos custos dos insumos nacionais medidos através do índice
da Coluna 30 da FGV
40% relativo à variação dos custos de mão-de-obra medidos através da Coluna
máquinas mecânicas com encargos da ABDIB;
20% relativo à variação dos custos dos insumos importados medidos através CRUSpi
Global (CRU Steel Price Index), conjugada à taxa do câmbio comercial para venda do
dólar americano.

4
2 METODOLOGIA
Este capítulo apresenta a metodologia utilizada neste trabalho que proporciona nos capítulos a
seguir, a análise estatística da série fator de reajustamento, bem como a modelagem e previsão
do comportamento da mesma.
2.1 ANÁLISE DAS VARIÁVEIS
2.1.1 Análise Gráfica
Primeiramente fazemos uma análise gráfica da série fator de reajustamento, com o intuito de
entender suas características básicas bem como observamos a possível presença de
componentes de tendência, ciclo ou sazonalidade. Identificamos também nesta fase, quando
aplicável, mudanças anormais que podem comprometer ou modificar os parâmetros de
estimação ou o resultado da previsão.
No sentido de entender melhor o comportamento da série, fazemos também uma breve análise
dos índices setoriais e do câmbio, os quais compõem a fórmula paramétrica cujo produto é a
série fator de reajustamento.

5
2.1.2 Análise das estatísticas descritivas
Fazemos a análise das estatísticas descritivas da série fator de reajustamento, através da
observação do histograma da série e identificando suas medidas de posição. Observa-se
principalmente o resultado do teste de Jarque-Bera (Jarque, Carlos e Bera, Anil K. , 1987), o
qual trata-se de um teste de normalidade, assintótico, onde as hipóteses a serem testadas são:
H0: o erro do modelo de regressão linear possui distribuição normal, contra H1: o erro do
modelo de regressão linear possui distribuição não-normal.
O procedimento do teste utiliza os valores da assimetria, curtose e do tamanho da amostra.
Assim, rejeitamos a hipótese H0 quando o valor da probabilidade (Probability) é inferior ao
nível de significância de 10%. Como tratam-se de uma amostra de 152 observações,
consideramos que pelo Teorema Central do Limite (TCL), o tamanho da amostra é
suficientemente grande e podemos então confiar nos valores dos testes t e F para estimar
satisfatoriamente os regressores pelo método de Mínimos Quadrados, mesmo na presença de
não normalidade, inclusive para os resíduos.
Observam-se também as medidas de curtose ou achatamento (kurtosis) e assimetria
(skewness), de acordo com os parâmetros a seguir:
Se o valor da curtose for = 3 então tem o mesmo achatamento que a distribuição
normal. Chamamos estas funções de mesocúrticas;
Se o valor da curtose é > 3 então a distribuição em questão é mais alta (afunilada) e
concentrada que a distribuição normal. Diz-se desta função probabilidade que é
leptocúrtica, ou que a distribuição tem caudas pesadas;

6
Se o valor da curtose é < 3 então a função de distribuição é mais "achatada" que a
distribuição normal, chamamos a distribuição de platicúrtica;
Se o valor da assimetria for = 0, chamamos a distribuição em questão de simétrica;
Se o valor da assimetria for > 0, chamamos a distribuição em questão assimétrica
positiva;
Se o valor da assimetria for < 0, chamamos a distribuição em questão assimétrica
negativa;
2.1.3 Modelos auto-regressivos de médias móveis (arma)
Para a previsão da série utilizamos o modelo ARMA (Auto Regressive Moving Averages) ou
na literatura em português, Auto-regressivos de Médias Móveis, conhecido também como
metodologia de Box & Jenkins (Box, George e Jenkins, Gwilym, 1970).
Esta metodologia é uma das técnicas quantitativas mais difundidas, descrita por esses autores
na década de 70. Os modelos de Box & Jenkins partem da idéia de que cada valor da série
(temporal) pode ser explicado por valores prévios, a partir do uso da estrutura de correlação
temporal que geralmente há entre os valores da série. Segundo Abdel-Aal & Al-Garni (Abdel-
Aal, R. E. e Al-Garni, Ahmed Z., 1997), os modelos Box e Jenkins (1970) têm sido
largamente utilizados para modelagem e previsão em aplicações médicas, ambientais,
financeiras e de engenharia e segundo Granger e Newbold (Granger, Clive W.J. e Newbold,
P., 1977), são excelentes modelos de previsão de curto prazo.

7
Conforme Gujarati (Gujarati, Damodar N., 2000), pode-se dividir a metodologia de Box &
Jenkins (1970) em quatro etapas:
Identificação: Nesse momento observamos a função autocorrelação (FAC), a função
autocorrelação parcial (FACP) e os correlogramas resultantes, que são as
representações gráficas da FAC e da FACP contra o tamanho da defasagem Gujarati
(2000). Observamos ainda a estatística Q do teste de Ljung-Box (Ljung, Greta e Box,
George E. P., 1978), onde podemos verificar se a hipótese nula H0 será rejeitada caso
o p-valor seja inferior ao nível de significância de 10% quando houver autocorrelação
entre os dados do período K e os períodos anteriores, ou seja, não são
independentemente distribuídos.
Estimativa: Identificado os valores apropriados para os modelos utilizados. Nesta
etapa incluímos, quando necessários, os termos para o tratamento da tendência;
dummies sazonais bem como os termos dos modelos ARMA os quais nos orientamos
pela utilização do programa GARMA.
Checagem: Após escolhermos o modelo ARMA e estimar seus parâmetros, realizamos
a verificação se o modelo em questão se ajusta-se aos dados da série temporal, pois é
possível que outros modelos ARMA. Observamos o gráfico dos resíduos a fim de
identificar a presença de termos de tendência, ciclo ou sazonalidade não captados pelo
modelo, bem como observamos os valores dos testes da estimação: P valor (Prob.),
significativo quando inferior a 10%; t-Statistic, significativo quando valor em módulo
for superior a 2; além dos critérios de Akaike (AIC) (Akaike, Hirotsugo, 1974) e
Schwarz (SC) (Schwarz, G., 1978), que utilizamos para a comparação de modelos.

8
Previsão: Nesta etapa realizamos a checagem da confiabilidade da previsão pelo
método ARMA. Para isto, verificamos a aderência do método para previsão em 12
(doze) períodos à frente.
Alem dos testes já citados, durante a realização das 4 etapas acima listadas, realizamos outros
testes de confiabilidade e aderência dos parâmetros, abaixo listados:
2.1.4 Análise do gráfico dos resíduos
Análise do Gráfico dos Resíduos e do Correlograma dos Resíduos ao Quadrado a fim de
identificar visualmente e estatisticamente através do P valor a presença de componentes de
tendência, ciclo ou sazonalidade não incluídas no modelo. O ideal é que o ruído seja ou se
assemelhe ao comportamento de um ruído branco.
2.1.5 Testes de Raiz Unitária
Para se trabalhar com séries temporais é importante que as variáveis sejam estacionárias ou
passíveis de sua estacionaridade. Essa característica é fundamental para previsão do futuro
com base na regressão de séries temporais, solidificando a premissa de que o futuro se
comportará de acordo com o passado. Segundo Stock e Watson (Stock, James H. E Watson,
Mark W., 2005) para uma série de dados ser estacionária suas variáveis não podem apresentar
tendências e devem ser estáveis ao longo do tempo. Assim, a primeira tarefa que realizamos
no trabalho é a verificação quanto à estacionaridade das variáveis utilizadas, para isto,
utilizamos o teste da raiz unitária.

9
Para testar a presença de raízes unitárias utilizamos os testes Augmented Dickey-Fuller (ADF)
selecionando o número de defasagens pelo critério Schwarz Info Criterion bem como o teste
Dickey-Fuller Generalizad Least Squares (DF-GLS)
O primeiro metodo consite em estimar especificas equacoes de regressao pelo metodo dos
Mínimos Quadrados Ordinarios (MQO) e comparar as estatisticas t resultantes aos valores
criticos gerados por Dickey e Fuller (1981). Para hipoteses conjuntas, a estatistica do teste é
constrida a partir da soma dos quadrados dos resíduos das equacoes de regressao.
O segundo metodo, sugerido por Elliott, Rothenberg, e Stock (1996), pois o mesmo sofre
menos que os demais testes com o problema de baixo poder, por ser estimado em dois
estágios apresenta um grande aumento em potência, sendo considerado um teste eficiente de
raiz unitária. O primeiro estágio é estimar os termos de tendência determinística e intercepto;
e o segundo é fazer o teste Augmented Dickey-Fuller (ADF) tradicional nas variáveis sem essa
tendência. Testes com baixo poder tendem a não rejeitar a hipótese nula mesmo quando ela é
falsa. Para selecionar o número de defasagens, o critério utilizado é o Akaike modificado pois
foi demonstrado que essa combinação possui maior poder na análise de raiz unitária, Schwet
(Schwet, William G.,1989).
Em ambos os testes, a hipótese nula é de não-estacionaridade; assim sendo, H0 será rejeitado
quando o valor t-Statistic for inferior ao valor crítico (Test Critical Values), ao nível de
significancia de 10%.
Caso, após a análise gráfica da série e aplicação do teste da raiz unitária, seja verificado que a
série de dados seja não-estacionária, procedemos para transformação dos dados através da
logaritmização, e ou o cálculo da primeira ou mais diferenças, assim obtendo uma série

10
estacionária e possibilitando a aplicação da metodologia de Box & Jenkis, Mynbaev
(Mynbaev, Kairat T., 2004).
2.2 TESTES PARA SELEÇÃO DE MODELOS
2.2.1 Teste de White
O Teste de White (White, H., 1980) é utilizado para identificar a presença de
heteroscedasticidade e consiste em efetuar uma regressão dos resíduos elevados ao quadrado
contra o as variáveis explicativas usadas na regressão, seus quadrados e os produtos cruzados.
A presença homoscedasticidade indica que a variância dos erros condicionada as variáveis
explicativas é a mesma para todas as combinações de resultado. Se esta hipótese é violada, o
modelo exibe heteroscedasticidade, o que significa que alguma das variáveis independentes
tem algum poder de explicação sobre a variância do erro. Na presença de
heteroscedasticidade, os estimadores MQO continuam sendo não-Viésados, e consistentes,
porem, perde-se eficiência pois o estimador deixa de ser BLUE (Best Linear Unbiased
Estimador - Melhor Estimador Linear Não-Viésado) . O resultado desejado para este teste é
um P-valor maior que 0.05.
2.2.2 Teste de Wald
O teste de Wald (Wald, A., 1950) é utilizado para testar a significância individual ou conjunta
de uma ou mais parâmetros. Testa em sua hipótese nula H0 se os coeficientes dos parâmetros
são iguais a 0. No caso da identificação de insignificância de um ou mais parâmetros, os
mesmos podem ser retirados do modelo de forma a não comprometer a estimação. Sendo
assim, o resultado desejado para este teste é um P-valor menor que 0.05 para mantermos a
variável.

11
2.2.3 Teste de Breush-Godfrey (TESTE LM)
O teste Breush-Godfrey (Breush, T. S., Godfrey, L., 1978), ou também conhecido como LM
Test de certa forma semelhante ao teste de White, porém pretende detectar a correlação serial
dos resíduos, consiste em efetuar uma regressão do resíduo como variável explicada tendo
como explicativas o próprio resíduo defasado no tempo e as variáveis explicativas do modelo
original. Usa-se a estatística “F” de significância conjunta dos parâmetros da equação de teste.
Este teste talvez seja o mais indicado para verificar autocorrelação, pois considera a
possibilidade de resíduos correlacionados com valores defasados acima de um período e pode
ser usada com variáveis explicativas defasadas. Sua hipótese nula H0 é de que não ha
correlação serial dos resíduos, sendo assim, o resultado desejado para este teste é um P-valor
maior que 0.05.
2.2.4 Teste de Erro de Especificação da Regressão, ou Regression Specification Error Test (RESET)
O teste RESET (Ramsey, J. B. 1969) é útil para detectar a má especificação da forma
funcional. Caso o modelo esteja mal especificado, haverá viés de especificação, logo, o
estimador MQO passa a ser visado; porem o teste apenas indica que ha um problema, mas não
indica qual é o erro. Sua hipótese nula H0 é de que a estimação não contém erros de
especificação; sendo assim, o resultado desejado para este teste é um P-valor maior que 0.05.
2.3 GERAÇÃO DO FORECAST
A geração do forecast se dará em duas etapas:

12
2.3.1 Geração dos Parâmetros de Avaliação do Forecast
A geração dos parâmetros de avaliação dos forecasts, os quais serão melhores explicados nos
itens 2.4.2 a 2.4.5, será feita através da ferramenta do EViews a qual gera automaticamente o
forecast de uma série utilizando os seguintes parâmetros:
Série a ser prevista
Nome do forecast a ser gerado; que neste trabalho pode ser "yhat1", "yhat2" ou
"yhat3"
Nome da série de erro padrão a ser gerada; que neste trabalho pode ser "se1", "se2" ou
"se3"
O período da amostra a ser prevista, ou hold-out sample; que sente trabalho considera
o período 2010m9 a 2011m8
Utilizaremos a opção de forecast dinâmico o qual calcula o forecast para períodos após o
primeiro período da amostra, utilizando os valores da variável com seus lags que foram
previstos nos períodos anteriores. Esta opção também é chamada de n-step ahead forecast,
ou em português, previsão n-passos à frente.
2.3.2 Geração do Gráfico do Forecast
O gráfico do forecast será gerado a partir dos seguintes comando no EViews:
smpl 1999m1 2010m8 (define a amostra de estimação)

13
equation eqmodelX.ls SérieX c AR(p) MA(q) (gera a equação do modelo escolhido)
eqmodelX.forecast yhatX seX (gera o forecast e o erro padrão do modelo escolhido)
genr yhat_upX=yhatX+1.96*seX (gera o limite superior do intervalo de confiança do
forecast)
genr yhat_loX=yhatX-1.96*seX (gera o limite inferior do intervalo de confiança do
forecast)
smpl 1999m1 2011m8 (muda o período amostral de forma que se possa visualizar no
gráfico tanto a amostra de estimação quanto o forecast)
group figureX reaj yhatX yhat_upX yhat_loX (gera o grupo de dados para a geração
do gráfico de forecast)
freeze(figure_modelX) figureX.line (gera o gráfico do forecast)
2.4 COMPARAÇÃO DE MODELOS PARA A SELECÃO DO MODELO FINAL APÓS O FORECAST
2.4.1 Análise Gráfica do Forecast
Avaliaremos o gráfico do forecast de cada modelo gerado pelo EViews com o intuito de
compararmos seu comportamento em relação ao período fora da amostra de estimação, hold-
out sample, a fim de verificar se o modelo captou adequadamente os movimentos das
componentes de ciclo, tendência e sazonalidade, quando aplicáveis.

14
2.4.2 Coeficiente de Desigualdade de Theil ou Theil Inequality Coefficient (TIC)
O TIC é um índice de desigualdade que avalia o ajuste da série prevista em relação à série
real. A escala do TIC varia entre 0 e 1, onde 0 indica um ajuste perfeito do forecast e 1 indica
o pior ajuste possível para o forecast em relação a variável que está sendo prevista. Sendo
assim, o valor desejado para esta estatística é que a mesma esteja o mais próxima de 0.
O TIC pode ser decomposto entre 3 proporções de desigualdade cuja soma de seus valores é
sempre igual a 1, os quais são: Proporção de Viés, Proporção de Variância e Proporção de Co-
Variância; as quais são detalhadas a seguir.
2.4.3 Proporção de Viés ou Bias Proportion
A Proporção de Viés indica quanto a média da previsão se afasta da média dos valores reais.
Para esta estatística, desejamos que seu valor também seja o mais próximo de 0; pois um valor
alto de Bias Proportion indicaria um erro sistemático na previsão.
2.4.4 Proporção de Variância ou Variance Proportion
A Proporção de Variância nos diz quanto à variação da previsão se afasta da variação da série
real no horizonte de previsão; sendo assim, também desejamos que este parâmetro seja o
menor possível, pois se a Proporção de Variância é alta, então a série real flutuou
consideravelmente, enquanto o forecast não apresentou o mesmo comportamento.
2.4.5 Proporção de Co-Variância ou Covariance Proportion
A Proporção de Co-Variância mede o erro não sistemático da previsão; sendo assim, o ideal é
que este parâmetro fosse o maior entre as 3 componentes do TIC.

15
2.4.6 Erro Quadrático Médio ou Mean Squared Error (MSE)
O Erro Quadrático Médio ou Mean Squared Error (MSE) quantifica a diferença entre os
valores implícitos por um estimador de densidade e os verdadeiros valores da quantidade a ser
estimada. É uma função de risco, correspondente ao valor esperado da perda de erro quadrado
ou perda quadrática; mede a média dos quadrados dos "erros". O erro é o montante pelo qual
o valor implícito na estimativa difere da quantidade a ser estimada. A diferença ocorre devido
à aleatoriedade ou porque o estimador não leva em conta informações que poderiam produzir
uma estimativa mais precisa. Ele incorpora tanto a variância do estimador quanto seu viés.
Sua unidade de medida é a unidade do valor real ao quadrado. Sendo assim, o valor desejado
para este parâmetro é que ele seja o menor possível.
2.4.7 Raiz do Erro Quadrático Médio ou Root Mean Squared Error (RMSE)
Adotamos também a Raiz do Erro Quadrático Médio, ou Root Mean Squared Error (RMSE)
como forma de avaliação.
2.4.8 Erro Absoluto Médio ou Mean Absolute Error (MAE)
Analisaremos ainda o Erro Absoluto Médio, ou Mean Absolute Error (MAE) observando o
erro na mesma unidade de medida da série original. Utiliza-se o valor absoluto do erro
evitando que erros positivos anulem erros negativos.
2.4.9 Erro Percentual Absoluto Médio ou Mean Absolute Percentage Error (MAPE)
O Erro Percentual Absoluto Médio, ou Mean Absolute Percentage Error (MAPE) é o erro
médio em porcentagem, ao invés de quantidade.

16
2.5 FLUXOGRAMA PARA SELEÇÃO DO MODELO FINAL
Análise das
Variáveis
•Análise Gráfica
•Análise das estatísticas descritivas•Análise do gráfico dos resíduos
•Testes de Raiz Unitária
Geração dos Modelos
• Modelos A: gerados peloprogramaGARMA pelo critério de Schwarz
•Modelos B: gerados peloautoratravés da análisedo Correlograma•Modelos C: gerados peloprogramaGARMA pelo critério de Akaike
Comparação para a Seleção de Modelos
•Teste de White
•Teste de Wald•Teste de Breush‐Godfrey (TESTE LM)
•Teste de Erro de Especificação da Regressão, ou Regression Specification Error Test (RESET)
•Análise do gráfico dos resíduos•Análise do Correlograma
Geração do Forecast
•Modelo 1: série fator de reajustamento em nível considerando a presença de tendência estocástica
•Modelo 2: série fator de reajustamento em log considerando a presença de tendência determinística
•Modelo 3: série fator de reajustamento em log considerando a presença de tendência estocástica
Comparação de Modelos após o
Forecast
•Análise Gráfica do Forecast
•Coeficiente de Desigualdade de Theil ou Theil Inequality Coefficient (TIC) ‐Proporção de Viés ou Bias Proportion, Proporção de Variância ou Variance Proportion, Proporção de Co‐Variância ou Covariance Proportion
•Erro Quadrático Médio ou Mean Squared Error (MSE)•Raiz do Erro Quadrático Médio ou Root Mean Squared Error (RMSE)
•Erro Absoluto Médio ou Mean Absolute Error (MAE)
•Erro Percentual Absoluto Médio ou Mean Absolute Percentage Error (MAPE)
Modelo Final
Figura 1 - Fluxograma para Seleção do Modelo Final

17
3 DADOS
No presente capitulo apresentamos a variável fator de reajustamento, bem como uma breve
análise dos índices setoriais e câmbio que compõem a fórmula de tal fator.
As séries apresentadas a seguir são divulgadas mensalmente por instituições conceituadas e a
amostra das mesmas compõe o período de janeiro de 1999 a agosto de 2011.
Os dados são processados e analisados através da utilização do software EViews na versão
5.0.
Para a especificação e estimação dos modelos bem como para a realização de suas previsões,
são considerados os seguintes parâmetros:
Especificação de data do Banco de Dados: 1999m1 2012 m12
Amostra: 1999m1 2011m8
Amostra de Estimação: 1999m1 2010m8
Hold Out Sample: 2010m9 2011m8

18
3.1 NOMENCLATURAS DAS SÉRIES E EQUAÇÕES
As nomenclaturas para as séries de dados são:
Série Fator de Reajustamento em nível é denominada "reaj"
A primeira diferença da série Fator de Reajustamento em nível é denominada "dreaj"
Série Fator de Reajustamento em log é denominada "lreaj"
A primeira diferença da série Fator de Reajustamento em log é denominada "dlreaj"
A Série Tempo Calendário para tratamento de tendência determinística é denominada
"time"
As séries de dummies Sazonais para tratamento de sazonalidade são denominadas
"d1", "d2", "d3", "d4", "d5", "d6", "d7", "d8", "d9", "d10" e "d11"
As nomenclaturas dos Modelos são:
"model1" é o modelo utilizando a série "reaj" em nível e primeiras diferenças
incluindo as componentes de tratamento de ciclo
"model2" é o modelo utilizando a série "reaj" em log incluindo as componentes de
tratamento de tendência e ciclo

19
"model3" é o modelo utilizando a série "reaj" em log e primeiras diferenças incluindo
as componentes de tratamento de ciclo
As nomenclaturas das séries e equações de forecast são:
"eqmodelX" é a equação do modelo X; que neste trabalho pode ser 1, 2 ou 3
"yhatX" é o valor estimado das equações eqmodel1, eqmodel2 ou eqmodel3 para a
amostra de forecast
"seX" é o valor estimado do desvio padrão para as equações eqmodel1, eqmodel2 ou
eqmodel3 para a amostra de forecast
"yhat_upX" é o resultado da fórmula yhatX+1.96*seX; onde 1.96 é o intervalo de
confiança (superior) para a amostra de forecast
"yhat_loX" é o resultado da fórmula yhatX-1.96*seX; onde 1.96 é o intervalo de
confiança (inferior) para a amostra de forecast
3.2 O FATOR DE REAJUSTAMENTO
Em razão do longo ciclo de fabricação dos bens de capital sob encomenda, os contratos de
fornecimento da indústria do petróleo, em geral utilizam-se de instrumentos para proteger a
receita destes contratos ao longo do tempo. Uma das formas de proteção é a inclusão de um
fator de reajustamento baseado em índices que pretendem capturar a evolução nos preços de
itens relativos de diversas cestas de bens e serviços. Esses índices permitem, à empresa

20
visualizar a evolução dos preços dentro do contexto econômico-financeiro no qual está
situada.
Em setembro de 2005, foi publicado pela Petrobras o documento Condições de Fornecimento
de Material (CFM 2005). O objetivo das CFM 2005 é aprimorar o relacionamento entre a
Petrobras e o mercado fornecedor, com a atualização e adaptação das cláusulas à legislação e
as práticas de mercado atuais a fim de estabelecer as condições que regulam o fornecimento
de Bens e Serviços Associados à Petrobras.
Em seu item 14.8, a CFM 2005 cita o documento Condições de Reajustamento e Pagamento
(CRP 2003), o qual estabelece as condições atuais que regulam o reajustamento de preços e
seus respectivos pagamentos para os contratos de fornecimento de bens e serviços à Petrobras.
Segundo a CRP 2003, os sistemas de reajustamento de preços adotados nos contratos de
fornecimento de bens e serviços são:
Por período: no qual o reajuste é devido desde o mês da data base do contrato até o mês da
data em que se completou o ultimo período entre reajustes e o valor reajustado permanece
fixo até completar novo período, e assim sucessivamente.
Ponto a ponto: no qual o reajuste é devido da data base do contrato até a data efetiva do
cumprimento de cada evento contratual.
O cálculo de reajustamento de preços é definido por fórmulas paramétricas, constantes destas
Condições de Reajustamento e Pagamento, compostas de um ou mais índices setoriais
representativos da variação dos custos de fabricação ou de realização dos serviços

21
contratados, estando estabelecidas no contrato as parcelas e os respectivos índices a serem
adotados em cada fórmula.
Conforme citado anteriormente, este trabalho analisa uma fórmula paramétrica específica para
os contratos de aquisição de bens, e cujo critério de reajuste será do tipo ponto a ponto.
3.3 FÓRMULA PARAMÉTRICA
É a fórmula composta por um ou mais índices setoriais, bem como parcelas de câmbio cujo
produto final será o fator de reajustamento, objeto deste trabalho, cujas parcelas são:
Tp = (ABDIB/ABDIBº) x 0,40 + (col 30 / col 30º) x 0,40 + {(CRUSPI/
CRUSPIº) x (TXC / TXCº) x 0,2}
Sendo:
ABDIB - número índice de mão de obra da coluna de MÁQ. MEC. da ABDIB, na data de
entrega do bem;
ABDIB – número índice de mão de obra da coluna de MÁQ. MEC. da ABDIB relativo à data
do evento serão referentes ao primeiro mês imédiatamente anterior ao da data de emissão do
documento de comprovação do cumprimento do evento (se fax, data da transmissão), da nota
fiscal de entrega do material ou da nota fiscal do serviço realizado;
ABDIBº - número índice de mão de obra da coluna de MÁQ. MEC. da ABDIB relativo à
data-base serão referentes ao primeiro mês imédiatamente anterior ao da data-base;

22
Col 30 - número índice da coluna 30 da FGV;
Col 30 - número índice da coluna 30 da FGV relativo à data do evento será referente ao
primeiro mês imédiatamente anterior ao da data de emissão do documento de comprovação do
cumprimento do evento (se fax, data da transmissão), da nota fiscal de entrega do material ou
da nota fiscal do serviço realizado;
Col 30º - número índice da coluna 30 da FGV relativo à data-base será referente ao primeiro
mês imédiatamente anterior ao da data base;
CRUSPI - índice mensal de aço global (GLOBAL STEEL PRICES) publicado pela CRU;
CRUSPI - índice mensal de aço global (GLOBAL STEEL PRICES) publicado pela CRU
relativo à data do evento serão referente ao primeiro mês imédiatamente anterior ao da data de
emissão do documento de comprovação do cumprimento do evento (se fax, data da
transmissão), da nota fiscal de entrega do material ou da nota fiscal do serviço realizado;
CRUSPIº - índice mensal de aço global (GLOBAL STEEL PRICES) publicado pela CRU
relativo à data-base serão referente ao primeiro mês imédiatamente anterior ao da data-base;
TXC - taxa do câmbio comercial para venda do dólar americano adotada na proposta,
publicada pelo Banco Central do Brasil;
TXC - taxa do câmbio comercial para venda do dólar americano relativo à data do evento ao
dia anterior da emissão do cálculo do realinhamento de preço;

23
TXCº - taxa do câmbio comercial para venda do dólar americano relativo à data-base.
A seguir, do item 3.3.1 ao item 3.3.4, fazemos uma breve análise da parcelas que compõem a
Fórmula Parametrica : Coluna 30 (FGV – Fundação Getúlio Vargas), Coluna Máquinas
Mecânicas (ABDIB – Associação Brasileira de da Infra-Estrutura e Indústrias de Base),
CRUSpi Global (CRU – Commodities Research Unit Ltd.) e câmbio.
3.3.1 CRU Steel Price Index Global (CRUSpi Global)
A Commodities Research Unit Ltd. (CRU), é uma consultoria independente líder mundial para
os setores de mineração, metais, energia, cabos, fertilizantes e produtos químicos. Fundada no
final dos anos 1960, de propriedade privada para garantir a sua independência, a qual possui
escritórios nos principais centros econômicos, empregando mais de 200 empregados alocados
em equipes multidisciplinares.
A unidade de negócios CRU Steel Prices, é voltada a fazer avaliações independentes dos
preços da indústria de aço há mais de 25 anos. Inicialmente, essas avaliações foram utilizadas
principalmente para benchmark de compra / venda baseado no desempenho individual das
empresas contra a média da indústria, mas a utilização destas avaliações pelo mercado
aumenta a cada ano, sendo que hoje são analisados mais de 120 produtos de aço carbono.
O índice CRUSpi Global é divulgado mensalmente e é calculado utilizando a média
ponderada derivada da verificação de preços e dados de volume fornecidos por empresas
renomadas espalhadas por diversos países. A tomada dos preços permeia toda a cadeia de
suprimentos do aço; desde a usina, passando pelos atravessadores, centros de beneficiamento
e consumidores finais.

24
Segue abaixo o gráfico com os dados mensais de janeiro de 1999 a agosto de 2011.
50
100
150
200
250
300
99 00 01 02 03 04 05 06 07 08 09 10 11
CRU
Figura 2 - Gráfico da Série CRU
Analisando o gráfico da série CRU pode-se notar tendência de crescimento o que é bastante
intuitivo visto que o consumo de aço cresce a cada ano devido tanto ao desenvolvimento das
economias emergentes quando ao constante consumo das potencias econômicas, tais como
China e Japão, conforme revelado pela World Steel Association (WSA). Nota-se a presença de
intercepto, porém a sazonalidade e o ciclo não são tão óbvios.
Entendendo melhor a dinâmica do gráfico, notamos uma mudança no patamar do índice do
início de 2004 bem como um pico em Julho de 2008. Segundo o site Current Economics
(2009), a indústria siderúrgica mundial apresentou um superciclo econômico de 4 anos,
impulsionado pelo boom econômico chinês e tendências econômicas positivas em países
desenvolvidos.

25
As três principais causas para a instalação deste superciclo entre o período de 2004-2008
podem ser resumidas como:
Crescimento econômico mundial robusto em países desenvolvidos e emergentes,
notadamente, China, Rússia, Índia e Brasil;
A percepção de que o crescimento nos países emergentes iria se traduzir em demanda
nos países desenvolvidos (decoupling theory) com o crescimento proporcional do
consumo per capita do aço. Mais ainda, a alta do consumo chinês de aço devido à
progressão deste mercado de um mercado de infra-estrutura para um mercado de
consumo;
Déficit de insumos siderúrgicos como minério de ferro e coque de aciaria, forçando as
mineradoras a adaptações drásticas aos novos patamares de consumo e reajustes de
preços.
Após manter-se elevado entre 2004 e metade de 2008, a crise econômica de 2008 trouxe aos
preços do aço acelerada queda, quebrando este superciclo.
A crise americana do sub-prime promoveu redução de investimentos no mercado de
construção civil, mas isto acabou por não afetar a indústria siderúrgica, pois acreditava-se que
a demanda chinesa conseguiria sustentar a baixa demanda norte-americana. Pelo contrário,
este foi o período de maior aumento nos preço de aço (primeiro semestre de 2008), o que, em
princípio apresenta-se como contradição às condições econômicas daquele momento.

26
A progressiva redução do preço do aço após este superciclo deriva da combinação de fatores
já conhecidos:
Contração da demanda final, vinculada à crise econômica instalada em países
desenvolvidos e a retração do crescimento econômico em países emergentes;
Movimento de redução de estoques globais resultando em uma queda ainda mais
acentuada na demanda aparente. Após anos de conflito em se atrelar oferta a preços
voláteis, neste período muitos operadores puderam postergar compras de forma a
descarregar seus estoques e se beneficiar da queda de preços;
Progressiva redução na oferta para se adaptar a mudança repentina nas condições de
demanda, movimento o qual, na indústria siderúrgica foi promovido por cortes
voluntários de produção;
Redução de Investimentos resultantes em queda de valores acionários das empresas
siderúrgicas.
3.3.2 Coluna 30 – Índice de preço por atacado / Produtos Industriais / Indústria de Transformação / Produtos de Minerais Não-Metálicos (IPA-OG-DI)
O Índice de Preço por Atacado (IPA) é calculado, pela Fundação Getulio Vargas (FGV),
desde 1944. Mede a evolução dos preços nas transações inter empresariais e abrange várias
etapas do processo produtivo, anteriores às vendas no varejo. São pesquisados preços de
matérias-primas agrícolas e industriais, produtos intermediários e de uso final.

27
Como conseqüência da grande sensibilidade que apresenta esta série, inúmeras aplicações se
tem dado, destacando-se, além de sua participação como componente fundamental do Índice
Geral de Preços (IGP), a função de indexador nas atualizações contratuais.
O IPA é apresentado em duas diferentes estruturas de classificação de seus itens
componentes:
Origem – Produtos Agropecuários e Industriais;
Estágios de Processamento – Bens Finais, Bens Intermediários e Matérias Primas Brutas.
A série de Disponibilidade Interna (IPA-DI) é composta pelas categorias de uso, tais como
bens de consumo ou bens de produção e a série de Oferta Global (IPA-OG) é composta pelos
setores produtivos.
Sendo assim, a Coluna 30 da FGV é representada pelo Índice de Preços por Atacado, nas
categorias Origem e Disponibilidade Interna (IPA-OG-DI – Produtos Industriais – Indústria
de Transformação – Produtos de Minerais Não-Metálicos).
A série IPA-OG-DI é formada por dezoito índices especiais. Estão organizados para medir a
evolução de preços segundo o destino que se atribui aos bens componentes quer para
consumo, quer para produção. A amostra de produtos do IPA-DI é composta por 481
mercadorias. Foi selecionada de um universo de produtos regularmente comercializados a
nível de atacado, levando-se em conta algumas características predefinidas. Suas estimativas
derivam de variações de preços pesquisados sistematicamente durante o mês calendário (1 a
30 do mês de referência).

28
No processo de cálculo mensal do IPA conjugam-se três elementos: a amostra de produtos, o
sistema de pesos e o sistema de preços. A amostra de produtos refere-se ao conjunto de
mercadorias cujos preços serão objeto de pesquisa sistemática; o sistema de pesos
compreende o conjunto de normas e procedimentos usados na determinação de valores
representativos dos produtos componentes da amostra; e o sistema de preços diz respeito ao
conjunto de procedimentos de pesquisa que possibilitam a construção da série histórica de
preços, da qual se extraem relativos de diferentes variedades de produtos componentes da
amostra.
O critério usado na seleção dos produtos integrantes do IPA foi o Valor da Produção. A
seleção se fez em duas etapas. Primeiramente, foram escolhidas as classes de produtos a
serem representadas e, em seguida, os produtos considerados em cada uma destas classes.
O primeiro passo na montagem da estrutura de pesos do IPA é ponderar as séries Produtos
Agropecuários, Indústria Extrativa Mineral e Indústria de Transformação. Esses grupos são
ponderados de acordo com as participações médias destas atividades no Valor Adicionado
Bruto. A ponderação da série IPA - Produtos Industriais é obtida pela soma das séries
Indústria Extrativa e Indústria de Transformação.
Em seguida, distribuem-se as ponderações destas atividades segundo classes e produtos, de
acordo com os respectivos valores de produção médios. Na parcela industrial do IPA pelo
critério da origem (IPA-OG), o primeiro nível hierárquico abaixo das atividades extrativa
mineral e transformação, correspondente às divisões da Classificação Nacional de Atividades
Econômicas (CNAE), é ponderado proporcionalmente aos valores médios de produção
informados pela Pesquisa Industrial Anual (PIA – Produto) e pelas estatísticas do
Departamento Nacional da Produção Mineral (DNPM), referentes a estas mesmas categorias.
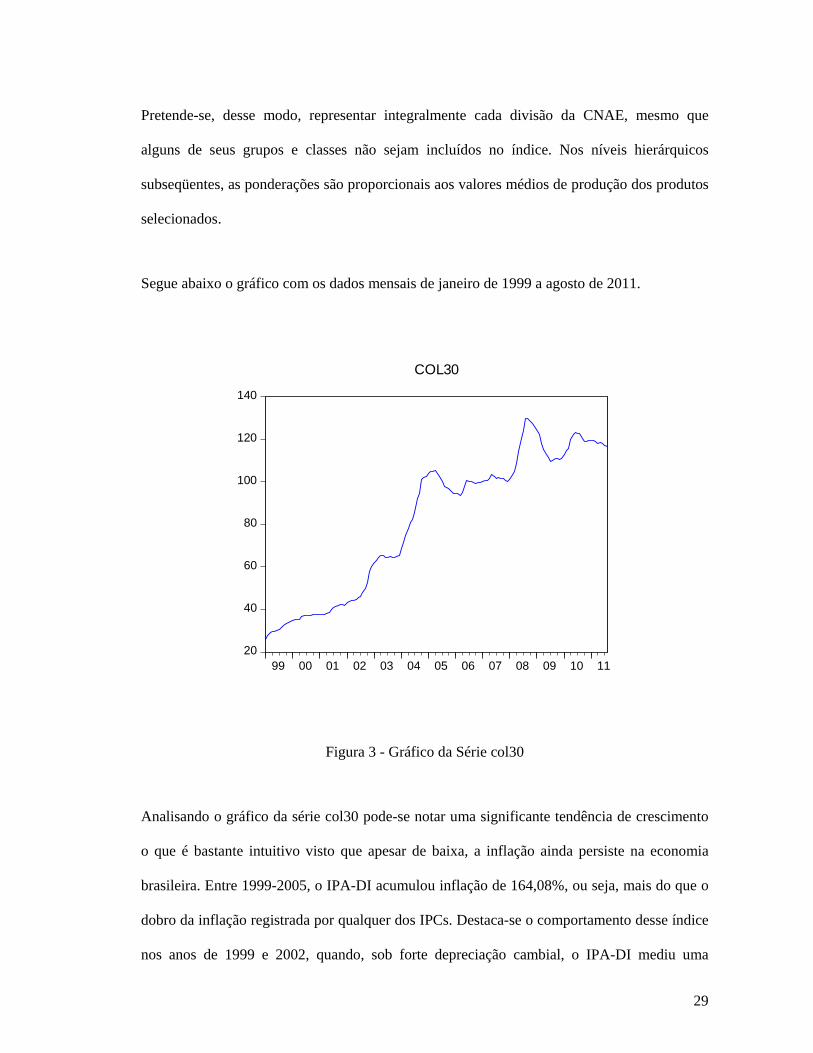
29
Pretende-se, desse modo, representar integralmente cada divisão da CNAE, mesmo que
alguns de seus grupos e classes não sejam incluídos no índice. Nos níveis hierárquicos
subseqüentes, as ponderações são proporcionais aos valores médios de produção dos produtos
selecionados.
Segue abaixo o gráfico com os dados mensais de janeiro de 1999 a agosto de 2011.
20
40
60
80
100
120
140
99 00 01 02 03 04 05 06 07 08 09 10 11
COL30
Figura 3 - Gráfico da Série col30
Analisando o gráfico da série col30 pode-se notar uma significante tendência de crescimento
o que é bastante intuitivo visto que apesar de baixa, a inflação ainda persiste na economia
brasileira. Entre 1999-2005, o IPA-DI acumulou inflação de 164,08%, ou seja, mais do que o
dobro da inflação registrada por qualquer dos IPCs. Destaca-se o comportamento desse índice
nos anos de 1999 e 2002, quando, sob forte depreciação cambial, o IPA-DI mediu uma

30
inflação de 28,88% e 35,41% e entre 1999-2005, o IPA-DI acumulou inflação de 164,08%, o
que pode ser notado no primeiro grande pico no gráfico abaixo. O segundo pico em meados
de 2008 foi caracterizado pelo continuo aumento dos preços das commodities, não somente no
Brasil.
Pode-se também notar um pico ao final de 2008 causado pelo impacto defasado da crise do
sub-prime já descrita acima.
Além da tendência apresentada acima pode-se notar a presença de intercepto, porém a
sazonalidade e o ciclo não são tão óbvios.
3.3.3 Coluna Máquinas Mecânicas da Associação Brasileira de Infra-estrutura e Indústria de Base (ABDIB)
Fundada em 1955, a ABDIB - Associação Brasileira de Infra-estrutura e Indústrias de Base é
uma entidade privada sem fins lucrativos, cuja missão principal é o desenvolvimento
continuado do mercado brasileiro da infra-estrutura e indústrias de base e seu fortalecimento
em padrões de competitividade internacional.
Dentre os diversos serviços oferecidos pela ABDIB, destaca-se a pesquisa e divulgação de
índices setoriais mensais e neste trabalho destacaremos o índice denominado Maquinas
Mecânicas, que é o indicador da evolução do custo da mão-de-obra, cujo objetivo é medir a
variação do salário médio da mão-de-obra direta com a produção de bens de capital sob
encomenda.
O índice ABDIB Maquinas Mecânicas é calculado com base em uma amostra fixa de 23
empresas no setor de Máquinas Mecânicas as quais informam seu salário médio e o número

31
de empregados diretos na produção. Este índice é o resultado do somatório do relativo de
salário médio de cada empresa multiplicado por sua participação no total de empregados da
amostra.
É importante enfatizar que a utilização do índice de custos setorial em contratos de
fornecimento é a melhor opção para ambas as partes, demandante e fornecedor, pois o
comportamento do índice está diretamente associado ao comportamento dos verdadeiros
custos do setor. Essa é uma característica extremamente importante, que torna o emprego do
índice setorial de custos preferível ao emprego de outros índices gerais de preços ou
financeiros, que não tem nenhuma relação direta ou indireta com o setor.
Segue abaixo o gráfico com os dados mensais de janeiro de 1999 a agosto de 2011.
160
200
240
280
320
360
400
440
480
99 00 01 02 03 04 05 06 07 08 09 10 11
MAQ
Figura 4 - Gráfico da Série maq

32
Analisando o gráfico da série maq pode-se notar uma significante tendência de crescimento e
uma possível componente de sazonalidade o que é bastante intuitivo visto que no Brasil são
ainda poucos os setores industriais com alto grau de automatização, como os de química fina,
petroquímica, eletro-eletrônico etc. Nesses setores, embora se observe uma diminuição na
participação percentual dos custos de mão-de-obra direta, sabe-se que são cada vez mais
elevados os gastos com pesquisa e desenvolvimento de novos produtos e processos, nos quais
a remuneração de pesquisadores é muito relevante em alguns casos os salários totais de
técnicos e cientistas podem superar o valor da mão-de-obra direta aplicada à própria
produção.
Além disso, a redução da proporção de mão de MCD em cada unidade de produto não
significa que o total de salários pagos esteja decrescendo. Setores como o das indústrias de
artefatos de couro, de confecções, de móveis, construções civis etc. ainda se caracterizam pelo
uso intensivo de mão-de-obra. No setor terciário da economia, os gastos com remuneração
dos recursos humanos chegam a 70% dos custos totais; e este setor vem aumentando sua
participação no PIB.
Em todos os índices existem fatores que influenciam a sua variação. No caso do índice de
salários, dentre os fatores que determinam a sua variação podemos mencionar:
• Aumentos Salariais: os aumentos salariais provocam uma variação positiva no índice. Esses
aumentos podem advir de reposições salariais que ocorrem mensalmente em decorrência da
aplicação da lei salarial vigente em cada momento ou por efeito de acordos ou dissídios
coletivos.

33
Em geral, nos meses das datas base da categoria, o índice tende a apresentar variações acima
dos outros índices que medem a variação de preços em geral.
• Variações no número de empregados: por se tratar de um índice que capta a variação da
média de salários, quando a composição da mão de obra muda de forma não linear (ou seja,
quando existem acréscimos ou reduções de mão de obra diferenciados nas diversas faixas
salariais) ocorre alteração na média salarial, sendo captada pelo índice. Dessa forma, a
demissão de funcionários que ganham salários na faixa mais alta ou aumento do número de
funcionários que ganham nas faixas salariais mais baixas implicaria em uma diminuição da
média de salários, “puxando”, assim, o índice para baixo. Nesse sentido, a demissão de
engenheiros, que compõem a parcela da mão de obra mais bem remunerada na produção
implicaria em uma tendência à queda do índice. A admissão de operários com pouca ou
nenhuma qualificação teria o mesmo efeito.
Alem da tendência e sazonalidade, nota-se também a presença de intercepto, porém a
componente de ciclo não é tão obvia.
3.3.4 Câmbio
Na fórmula paramétrica é utilizada a taxa do câmbio comercial para venda do dólar
americano, aqui denominado Dólar Comercial, que é a cotação do dólar americano (US$) com
paridade na moeda brasileira (R$), usado como parâmetro de pagamento nas transações
comerciais com importações/exportações de produtos via Carteira de Comercio Exterior do
Banco do Brasil (CACEX).
Da implantação do Plano Real (julho de 1994) até janeiro de 1999, vigorou no Brasil a taxa de
câmbio fixa (ou administrada). Neste regime cambial, a taxa de câmbio não é estabelecida no

34
mercado de divisas. O governo impõe à sociedade a taxa de câmbio que, segundo os objetivos
de sua política econômica, é a mais adequada para o país. Por este motivo, a modelagem das
séries, que virá no capítulo a seguir, utilizará o período entre Janeiro de 1999 e agosto de
2010, excluindo o período de câmbio fixo.
Pode-se também notar uma queda em meados de 2008 causada pelo impacto da crise do sub-
prime já descrita acima.
Segue abaixo o gráfico com os dados mensais de janeiro de 1999 a agosto de 2011.
1.0
1.5
2.0
2.5
3.0
3.5
4.0
99 00 01 02 03 04 05 06 07 08 09 10 11
USD
Figura 5 - Gráfico da Série usd
Analisando o gráfico da série câmbio pode-se notar que os componentes de ciclo, tendência e
sazonalidade não são claramente observados o que é bastante intuitivo visto que desde a
introdução do câmbio flutuante em 1999, o regime enfrentou vários desenvolvimentos

35
adversos, a começar pelo colapso do preço das ações de empresas de alta tecnologia em 2000,
a crise argentina em 2001, os ataques terroristas em 11 de setembro, a crise de confiança de
2002 e, mais recentemente, a crise financeira global. Por outro lado, o ambiente mundial foi
em geral favorável entre 2003 e 2007.
3.4 ANÁLISE DA SÉRIE FATOR DE REAJUSTAMENTO
Analisando o gráfico da série do fator de reajustamento em nível pode-se notar uma
significante tendência de crescimento o que é bastante intuitivo visto que as variáveis que o
compõem apresentam tendência de crescimento, com exceção do dólar, porém, o mesmo
representa apenas uma pequena parcela do fator de reajustamento. Nota-se a presença de
intercepto, porém a sazonalidade e o ciclo parecem ser consideráveis apenas em alguns
períodos, o que avaliamos melhor no capitulo a seguir
As variações abruptas capturadas nos gráficos analisados anteriormente podem também ser
sentidas ao analisarmos o gráfico do fator de reajuste, guardadas as proporções permitidas
pela fórmula paramétrica. Pode-se notar uma mudança no patamar do índice no inicio de 2002
causado pela mudança no patamar do preço do aço. Podemos também observar um pico no
inicio de 2003 causada pela alta do câmbio, bem como picos em meados de 2004 e 2008
também ocasionados por picos no preço do aço.
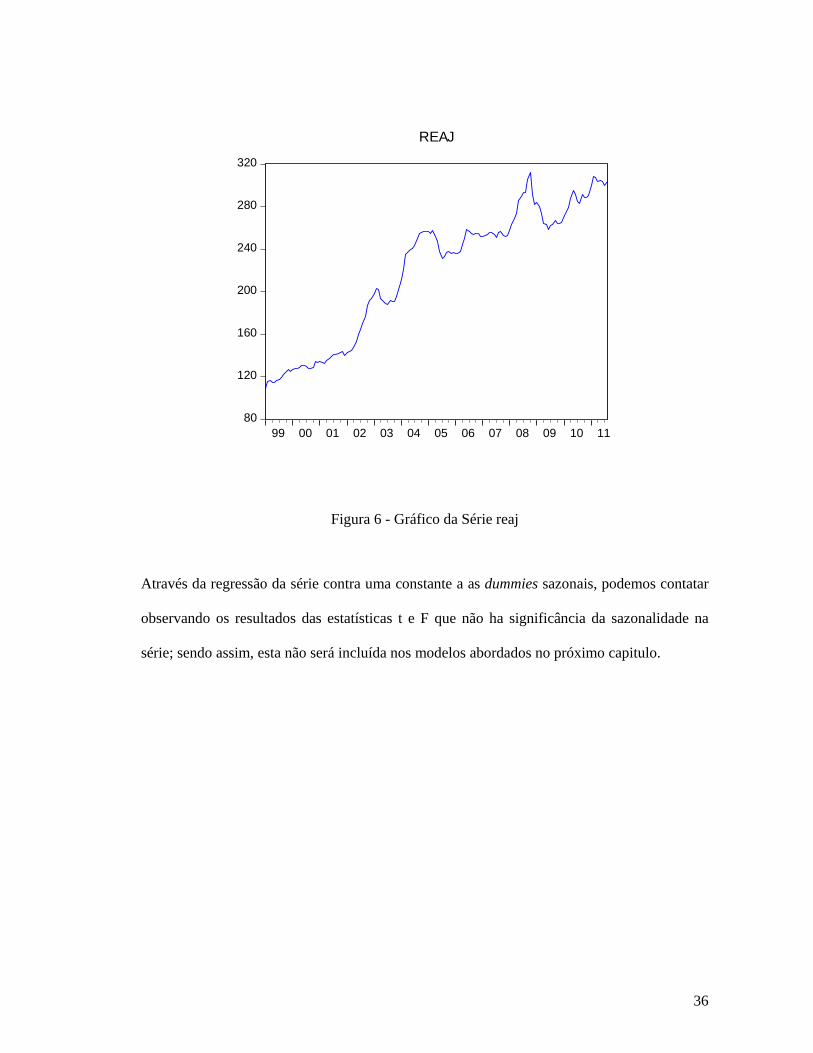
36
80
120
160
200
240
280
320
99 00 01 02 03 04 05 06 07 08 09 10 11
REAJ
Figura 6 - Gráfico da Série reaj
Através da regressão da série contra uma constante a as dummies sazonais, podemos contatar
observando os resultados das estatísticas t e F que não ha significância da sazonalidade na
série; sendo assim, esta não será incluída nos modelos abordados no próximo capitulo.
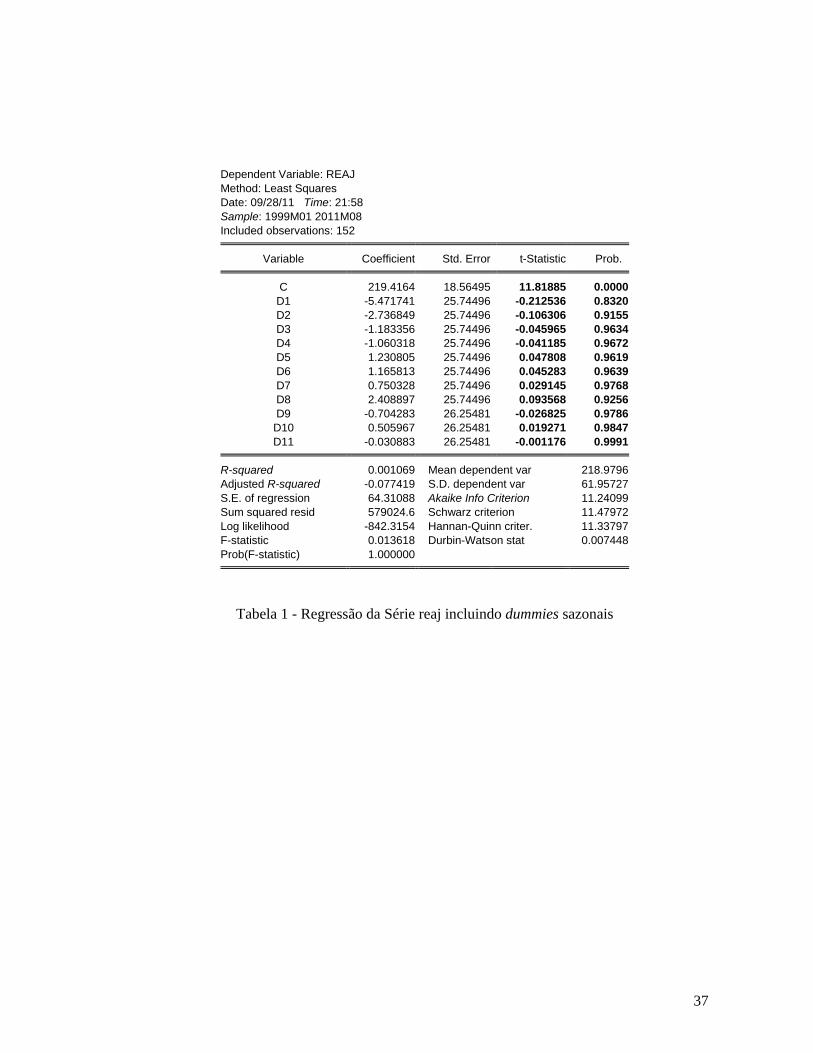
37
Dependent Variable: REAJ Method: Least Squares Date: 09/28/11 Time: 21:58 Sample: 1999M01 2011M08 Included observations: 152
Variable Coefficient Std. Error t-Statistic Prob.
C 219.4164 18.56495 11.81885 0.0000 D1 -5.471741 25.74496 -0.212536 0.8320 D2 -2.736849 25.74496 -0.106306 0.9155 D3 -1.183356 25.74496 -0.045965 0.9634 D4 -1.060318 25.74496 -0.041185 0.9672 D5 1.230805 25.74496 0.047808 0.9619 D6 1.165813 25.74496 0.045283 0.9639 D7 0.750328 25.74496 0.029145 0.9768 D8 2.408897 25.74496 0.093568 0.9256 D9 -0.704283 26.25481 -0.026825 0.9786 D10 0.505967 26.25481 0.019271 0.9847 D11 -0.030883 26.25481 -0.001176 0.9991
R-squared 0.001069 Mean dependent var 218.9796 Adjusted R-squared -0.077419 S.D. dependent var 61.95727 S.E. of regression 64.31088 Akaike Info Criterion 11.24099 Sum squared resid 579024.6 Schwarz criterion 11.47972 Log likelihood -842.3154 Hannan-Quinn criter. 11.33797 F-statistic 0.013618 Durbin-Watson stat 0.007448 Prob(F-statistic) 1.000000
Tabela 1 - Regressão da Série reaj incluindo dummies sazonais

38
4 MODELOS E PREVISÕES
No presente capitulo apresentamos os 9 modelos analisados, sendo 3 modelos sugeridos pelo
programa GARMA pelo critério SIC, 3 modelos por nós sugeridos através da análise dos
correlogramas e 3 modelos sugeridos pelo programa GARMA pelo critério AIC.
Para isto serão realizados os testes propostos no Capitulo 2 e posteriormente os modelos são
comparados a fim de definir o modelo que melhor representa cada uma das análises propostas
neste trabalho, a seguir:
Modelo 1: série fator de reajustamento em nível considerando a presença de tendência
estocástica
Modelo 2: série fator de reajustamento em log considerando a presença de tendência
determinística
Modelo 3: série fator de reajustamento em log considerando a presença de tendência
estocástica

39
Posteriormente realizamos o forecast dos modelos escolhidos e os comparamos conforme
parâmetros citados no Capitulo 2 com o intuito de definir o modelo de forecast que melhor
adere a curva do fator de reajustamento.
4.1 MODELO 1: SÉRIE FATOR DE REAJUSTAMENTO EM NÍVEL CONSIDERANDO A PRESENÇA DE TENDÊNCIA ESTOCÁSTICA
4.1.1 Análise da Série "reaj"
Como realizamos a análise do gráfico da série em nível no capitulo anterior, partiremos para a
análise do histograma apenas modificando para a amostra de estimação.
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica negativa, pois temos um achatamento da curva e notamos mais massa na cauda da
direita.

40
0
4
8
12
16
20
24
28
32
100 120 140 160 180 200 220 240 260 280 300 320
Series: REAJSample 1999M01 2010M08Observations 140
Mean 212.1153Median 237.3306Maximum 312.3544Minimum 108.9476Std. Dev. 59.70396Skewness -0.358226Kurtosis 1.623041
Jarque-Bera 14.05436Probability 0.000887
Figura 7 - Histograma da Série reaj
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma
queda para zero depois de poucos lags, o que caracterizaria um processo de média móvel
(MA).
Podemos também observar na autocorrelação parcial (PC) a presença de lag significativo no
período 1, ao nível de significância de 10%, o que indicaria um modelo AR(1).
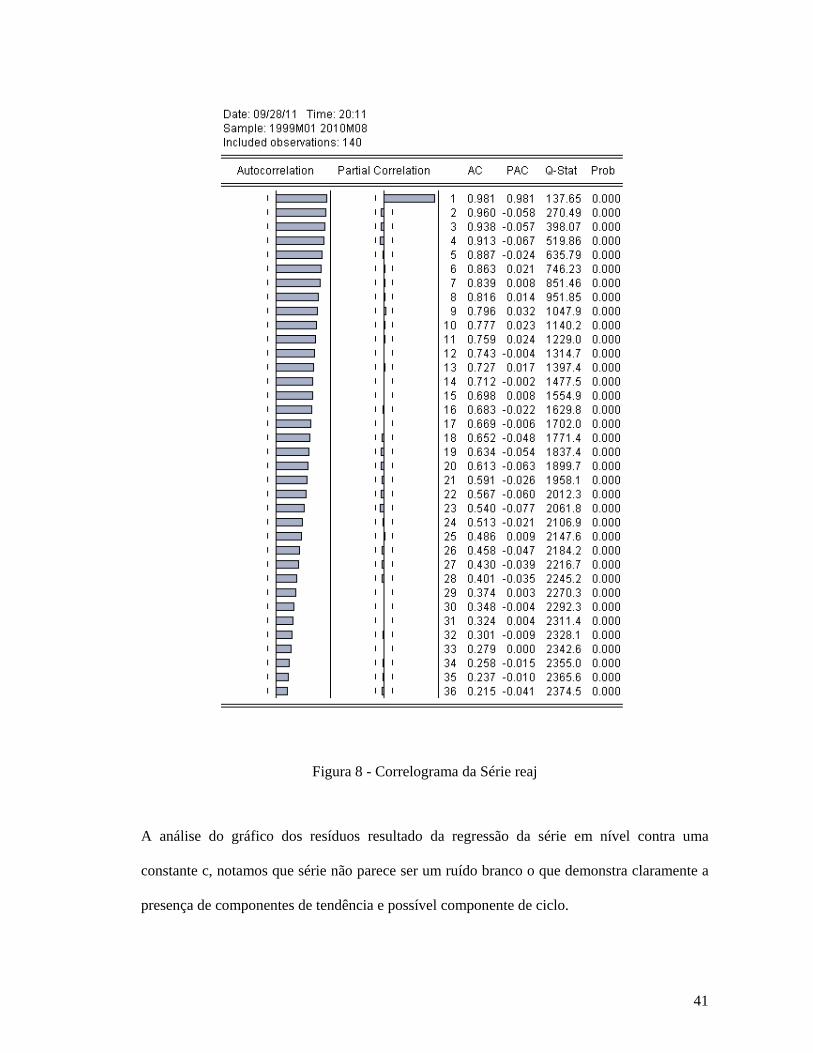
41
Figura 8 - Correlograma da Série reaj
A análise do gráfico dos resíduos resultado da regressão da série em nível contra uma
constante c, notamos que série não parece ser um ruído branco o que demonstra claramente a
presença de componentes de tendência e possível componente de ciclo.

42
-120
-80
-40
0
40
80
120
100
150
200
250
300
350
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 9 - Gráfico dos resíduos da Série reaj
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste Augmented Dickey-Fuller com o critério Schwarz Info
Criterion, incluindo tendência e intercepto, não rejeitamos a hipótese nula de que a série
possui raiz unitária, ou seja, a mesma é não estacionaria; no entanto, ao observarmos as
estatísticas t e F da tendência, notamos que a mesma é não significativa; sendo assim,
refizemos o teste apenas com o intercepto o que confirmou a estacionaridade da seria.
Repetimos este mesmo teste excluindo a tendência, visto que a estatística t da mesma
apresentou-se como não significativa e posteriormente também excluindo o intercepto pelo
mesmo motivo e obtive também o resultado de que a seria possui raiz unitária.

43
Null Hypothesis: REAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=13)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -2.086095 0.5486 Test critical values: 1% level -4.025924
5% level -3.442712 10% level -3.146022
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(REAJ) Method: Least Squares Date: 09/28/11 Time: 20:28 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
REAJ(-1) -0.038807 0.018603 -2.086095 0.0389 D(REAJ(-1)) 0.471977 0.076421 6.176006 0.0000
C 5.294435 2.207103 2.398816 0.0178 @TREND(1999M01) 0.050422 0.027614 1.825996 0.0701
R-squared 0.232303 Mean dependent var 1.209898 Adjusted R-squared 0.215116 S.D. dependent var 4.567765 S.E. of regression 4.046751 Akaike Info Criterion 5.662263 Sum squared resid 2194.410 Schwarz criterion 5.747111 Log likelihood -386.6961 Hannan-Quinn criter. 5.696743 F-statistic 13.51602 Durbin-Watson stat 1.877561 Prob(F-statistic) 0.000000
Tabela 2 - Teste de Raiz Unitária da série reaj (Augmented Dickey Fuller e Schwarz Info
Criterion, incluindo Tendência e Intercepto)
Fazemos então o teste utilizando o tipo de teste Dickey-Fuller GLS (ERS) com o critério
Akaike Info Criterion, incluindo tendência e intercepto e obtemos o mesmo resultado, ou seja,
a série possui raiz unitária, como pode ser observado na tabela abaixo. Podemos observar
também que o valor do teste t fica muito próximo ao valor critico do teste, o que nos coloca
em uma zona de penumbra.

44
Null Hypothesis: REAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 4 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -2.695979 Test critical values: 1% level -3.538000
5% level -2.995000 10% level -2.705000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/28/11 Time: 20:37 Sample (adjusted): 1999M06 2010M08 Included observations: 135 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.050503 0.018733 -2.695979 0.0079 D(GLSRESID(-1)) 0.525971 0.084802 6.202316 0.0000 D(GLSRESID(-2)) -0.165326 0.096426 -1.714538 0.0888 D(GLSRESID(-3)) 0.134285 0.096076 1.397691 0.1646 D(GLSRESID(-4)) 0.169205 0.088083 1.920981 0.0569
R-squared 0.298298 Mean dependent var -0.148802 Adjusted R-squared 0.276708 S.D. dependent var 4.605530 S.E. of regression 3.916847 Akaike Info Criterion 5.604785 Sum squared resid 1994.419 Schwarz criterion 5.712387 Log likelihood -373.3230 Hannan-Quinn criter. 5.648511 Durbin-Watson stat 1.974604
Tabela 3 - Teste de Raiz Unitária da série reaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Tendência e Intercepto)
Por ter sido constatada a presença de raiz unitária, seguiremos para a geração da série dreaj
que é a primeira diferença da série reaj.

45
4.1.2 Análise da Série "dreaj"
-25
-20
-15
-10
-5
0
5
10
15
99 00 01 02 03 04 05 06 07 08 09 10
DREAJ
Figura 10 - Gráfico da série dreaj
Refazemos então o teste de raiz unitária utilizando as duas técnicas citadas acima, DF e GLS,
sem a presença de tendência e intercepto, para identificar se a defasagem em um período foi
suficiente para corrigir a não estacionaridade e podemos constatar em ambos os testes, através
do teste t comparado ao valor critico do teste, que este problema foi solucionado; ou seja, a
série dreaj pode ser considerada estacionaria e integrada de ordem 1.
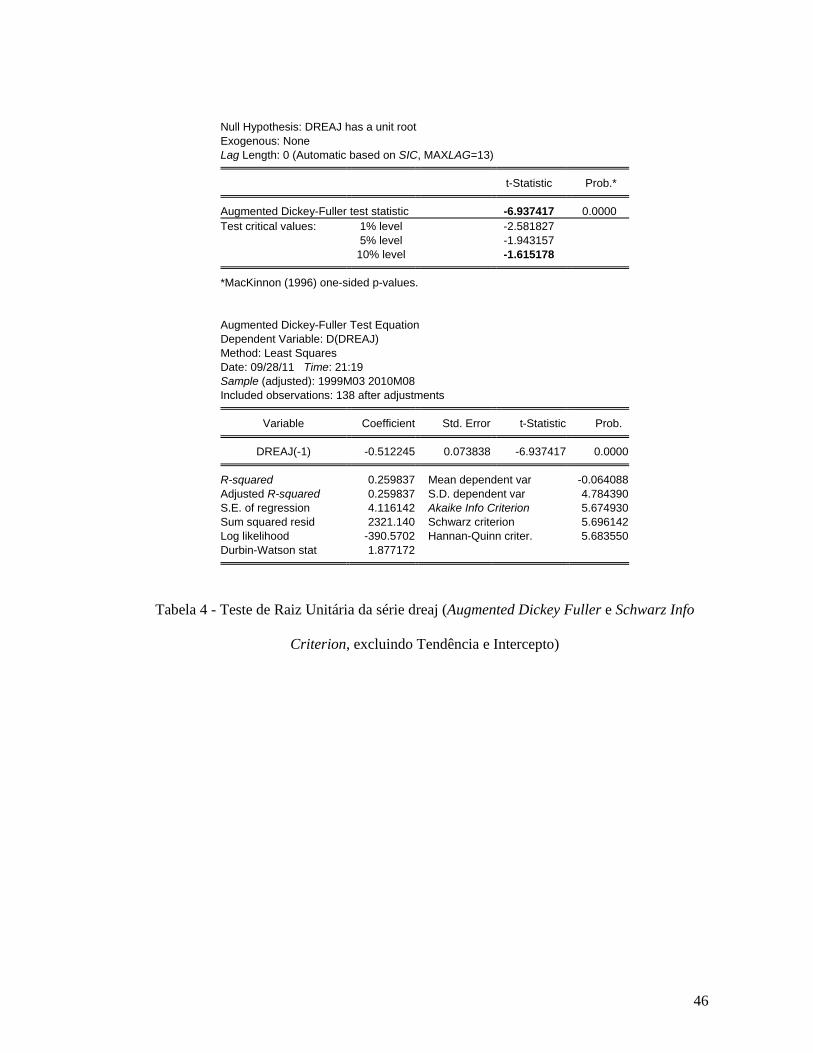
46
Null Hypothesis: DREAJ has a unit root Exogenous: None Lag Length: 0 (Automatic based on SIC, MAXLAG=13)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -6.937417 0.0000 Test critical values: 1% level -2.581827
5% level -1.943157 10% level -1.615178
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(DREAJ) Method: Least Squares Date: 09/28/11 Time: 21:19 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
DREAJ(-1) -0.512245 0.073838 -6.937417 0.0000
R-squared 0.259837 Mean dependent var -0.064088 Adjusted R-squared 0.259837 S.D. dependent var 4.784390 S.E. of regression 4.116142 Akaike Info Criterion 5.674930 Sum squared resid 2321.140 Schwarz criterion 5.696142 Log likelihood -390.5702 Hannan-Quinn criter. 5.683550 Durbin-Watson stat 1.877172
Tabela 4 - Teste de Raiz Unitária da série dreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, excluindo Tendência e Intercepto)

47
Null Hypothesis: DREAJ has a unit root Exogenous: Constant Lag Length: 3 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -2.238610 Test critical values: 1% level -2.582204
5% level -1.943210 10% level -1.615145
*MacKinnon (1996)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/28/11 Time: 21:21 Sample (adjusted): 1999M06 2010M08 Included observations: 135 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.160299 0.071606 -2.238610 0.0269 D(GLSRESID(-1)) -0.232583 0.097382 -2.388352 0.0184 D(GLSRESID(-2)) -0.379618 0.087350 -4.345918 0.0000 D(GLSRESID(-3)) -0.201732 0.086951 -2.320059 0.0219
R-squared 0.263581 Mean dependent var -0.013508 Adjusted R-squared 0.246716 S.D. dependent var 4.792560 S.E. of regression 4.159554 Akaike Info Criterion 5.717875 Sum squared resid 2266.548 Schwarz criterion 5.803957 Log likelihood -381.9565 Hannan-Quinn criter. 5.752856 Durbin-Watson stat 1.981099
Tabela 5 - Teste de Raiz Unitária da série dreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Intercepto)

48
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição leptocúrtica
assimétrica negativa, pois temos um afunilamento da curva e notamos mais massa na cauda da
direita.
0
4
8
12
16
20
24
-20 -15 -10 -5 0 5 10 15
Series: DREAJSample 1999M01 2010M08Observations 139
Mean 1.252173Median 0.993000Maximum 14.10730Minimum -21.22670Std. Dev. 4.578395Skewness -0.693742Kurtosis 6.887338
Jarque-Bera 98.66980Probability 0.000000
Figura 11 - Histograma da série dreaj
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Com a transformação da série para a primeira diferença notamos que a persistência na coluna
de autocorrelação diminui porem, a autocorrelação parcial continua indicando a presença de
um processo média móvel de ordem 1; possivelmente um MA(1), o que verificamos
posteriormente.

49
Figura 12 - Correlograma da série dreaj
A análise do gráfico dos resíduos resultado da regressão da série em primeiras diferenças
contra uma constante c, notamos que série não parece ser um ruído branco pois parece indicar
a presença de um componente de ciclo não especificado no modelo, o que pudemos observar
também no correlograma; porem, pode-se perceber que o tratamento da tendência foi eficaz.
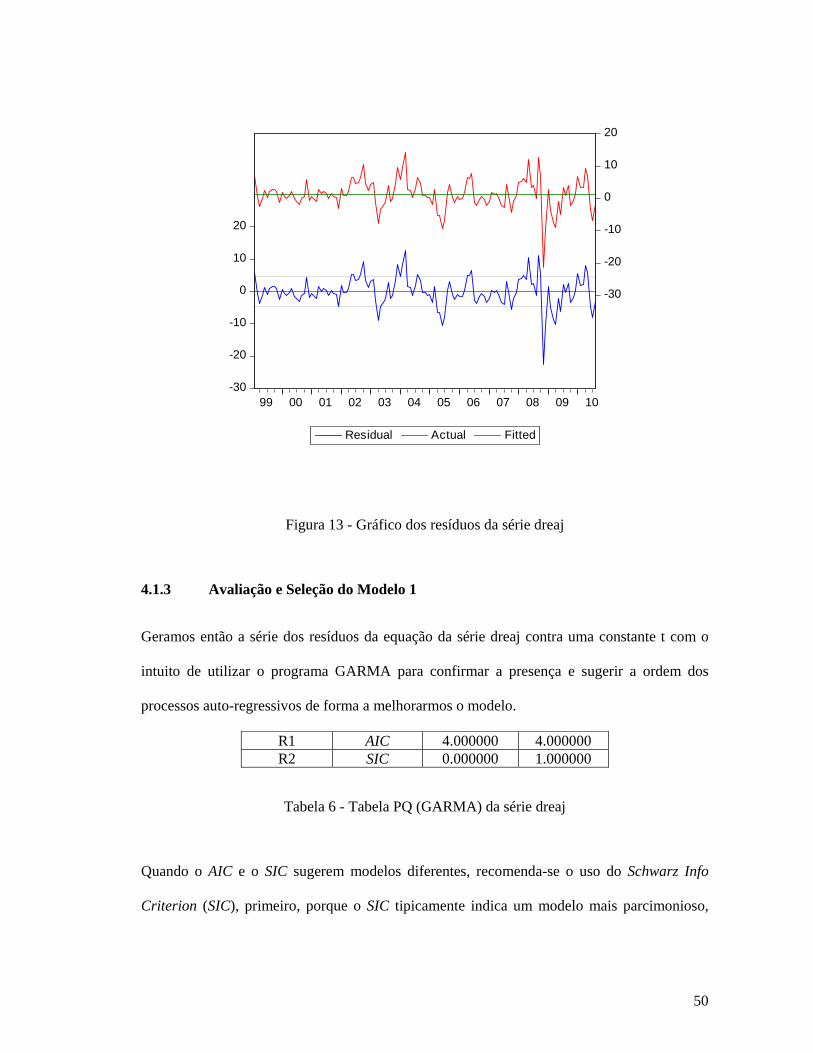
50
-30
-20
-10
0
10
20
-30
-20
-10
0
10
20
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 13 - Gráfico dos resíduos da série dreaj
4.1.3 Avaliação e Seleção do Modelo 1
Geramos então a série dos resíduos da equação da série dreaj contra uma constante t com o
intuito de utilizar o programa GARMA para confirmar a presença e sugerir a ordem dos
processos auto-regressivos de forma a melhorarmos o modelo.
R1 AIC 4.000000 4.000000 R2 SIC 0.000000 1.000000
Tabela 6 - Tabela PQ (GARMA) da série dreaj
Quando o AIC e o SIC sugerem modelos diferentes, recomenda-se o uso do Schwarz Info
Criterion (SIC), primeiro, porque o SIC tipicamente indica um modelo mais parcimonioso,

51
sendo assim preservaríamos melhor os graus de liberdade do modelo e segundo, o SIC tem
boas propriedades de consistência em amostras grandes.
Geramos então a estimação incluindo o termo MA(1), a qual denominaremos Modelo 1A,
com a equação sugerida pelo GARMA com critério SIC.
Dependent Variable: D(REAJ) Method: Least Squares Date: 10/03/11 Time: 19:20 Sample (adjusted): 1999M02 2010M08 Included observations: 139 after adjustments Convergence achieved after 8 iterations MA Backcast: 1999M01
Variable Coefficient Std. Error t-Statistic Prob.
C 1.255608 0.512431 2.450294 0.0155 MA(1) 0.496618 0.073746 6.734127 0.0000
R-squared 0.225936 Mean dependent var 1.252173 Adjusted R-squared 0.220286 S.D. dependent var 4.578395 S.E. of regression 4.042788 Akaike Info Criterion 5.646030 Sum squared resid 2239.146 Schwarz criterion 5.688253 Log likelihood -390.3991 Hannan-Quinn criter. 5.663188 F-statistic 39.98797 Durbin-Watson stat 1.912179 Prob(F-statistic) 0.000000
Inverted MA Roots -.50
Tabela 7 - Modelo 1A
Observamos que as estatísticas t e F são significativas, então analisaremos o correlograma.

52
Figura 14 - Correlograma da série sugerida pelo GARMA para Modelo 1A
Podemos observar uma melhora na dinâmica do correlograma, visto que comparado com a
Figura 11 (Correlograma da Série dreaj), passamos a não rejeitar a hipótese nula de que o
resíduo é um ruído branco; no entanto, ainda podemos ver nos períodos 4 e 11 estamos fora

53
do intervalo de confiança o que poderia indicar componentes de ciclo não incluídas no
modelo.
Criamos então o Modelo 1B incluindo os termos MA(1), sugerido pelo GARMA e também os
termos AR(4) e AR(11), sugeridos pelo correlograma.
Dependent Variable: D(REAJ) Method: Least Squares Date: 10/03/11 Time: 19:38 Sample (adjusted): 2000M01 2010M08 Included observations: 128 after adjustments Convergence achieved after 7 iterations MA Backcast: 1999M12
Variable Coefficient Std. Error t-Statistic Prob.
C 1.212784 0.506364 2.395083 0.0181 AR(4) 0.204722 0.087017 2.352655 0.0202 AR(11) -0.238529 0.088483 -2.695757 0.0080 MA(1) 0.486948 0.079402 6.132710 0.0000
R-squared 0.302353 Mean dependent var 1.231150 Adjusted R-squared 0.285474 S.D. dependent var 4.718394 S.E. of regression 3.988441 Akaike Info Criterion 5.635429 Sum squared resid 1972.550 Schwarz criterion 5.724555 Log likelihood -356.6675 Hannan-Quinn criter. 5.671642 F-statistic 17.91340 Durbin-Watson stat 1.964695 Prob(F-statistic) 0.000000
Inverted AR Roots .86-.22i .86+.22i .55+.65i .55-.65i .11+.89i .11-.89i -.34+.80i -.34-.80i -.73-.45i -.73+.45i -.91
Inverted MA Roots -.49
Tabela 8 - Modelo 1B
Observamos que as estatísticas t e F são significativas também na Tabela 8. Observamos
também o valor do R-squared, visto que um valor muito alto poderia indicar uma regressão
espúria, mas esta não foi o caso.
Criamos ainda o Modelo 1C que representa o modelo sugerido pelo GARMA com o critério
AIC.
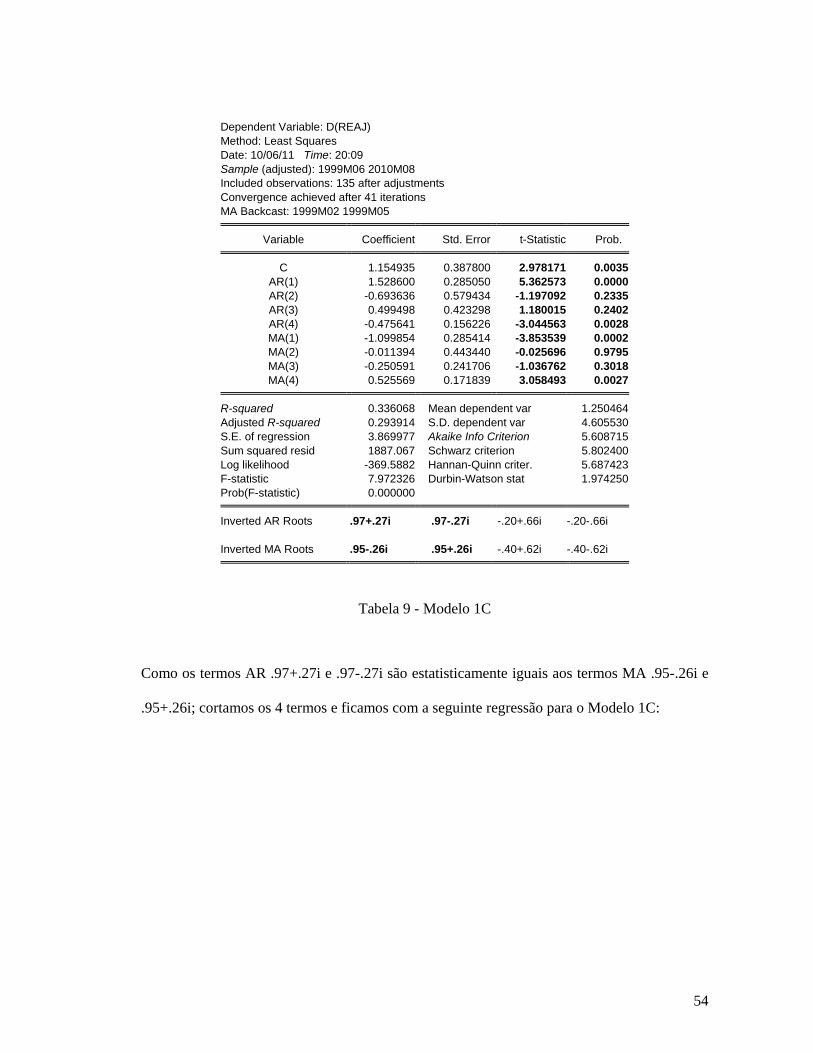
54
Dependent Variable: D(REAJ) Method: Least Squares Date: 10/06/11 Time: 20:09 Sample (adjusted): 1999M06 2010M08 Included observations: 135 after adjustments Convergence achieved after 41 iterations MA Backcast: 1999M02 1999M05
Variable Coefficient Std. Error t-Statistic Prob.
C 1.154935 0.387800 2.978171 0.0035 AR(1) 1.528600 0.285050 5.362573 0.0000 AR(2) -0.693636 0.579434 -1.197092 0.2335 AR(3) 0.499498 0.423298 1.180015 0.2402 AR(4) -0.475641 0.156226 -3.044563 0.0028 MA(1) -1.099854 0.285414 -3.853539 0.0002 MA(2) -0.011394 0.443440 -0.025696 0.9795 MA(3) -0.250591 0.241706 -1.036762 0.3018 MA(4) 0.525569 0.171839 3.058493 0.0027
R-squared 0.336068 Mean dependent var 1.250464 Adjusted R-squared 0.293914 S.D. dependent var 4.605530 S.E. of regression 3.869977 Akaike Info Criterion 5.608715 Sum squared resid 1887.067 Schwarz criterion 5.802400 Log likelihood -369.5882 Hannan-Quinn criter. 5.687423 F-statistic 7.972326 Durbin-Watson stat 1.974250 Prob(F-statistic) 0.000000
Inverted AR Roots .97+.27i .97-.27i -.20+.66i -.20-.66i
Inverted MA Roots .95-.26i .95+.26i -.40+.62i -.40-.62i
Tabela 9 - Modelo 1C
Como os termos AR .97+.27i e .97-.27i são estatisticamente iguais aos termos MA .95-.26i e
.95+.26i; cortamos os 4 termos e ficamos com a seguinte regressão para o Modelo 1C:

55
Dependent Variable: D(REAJ) Method: Least Squares Date: 10/06/11 Time: 20:14 Sample (adjusted): 1999M04 2010M08 Included observations: 137 after adjustments Convergence achieved after 27 iterations MA Backcast: 1999M02 1999M03
Variable Coefficient Std. Error t-Statistic Prob.
C 1.229149 0.521596 2.356514 0.0199 AR(1) -0.335414 0.386596 -0.867607 0.3872 AR(2) -0.200860 0.187233 -1.072781 0.2853 MA(1) 0.875376 0.380517 2.300492 0.0230 MA(2) 0.441295 0.173323 2.546094 0.0120
R-squared 0.240689 Mean dependent var 1.213875 Adjusted R-squared 0.217680 S.D. dependent var 4.584288 S.E. of regression 4.054751 Akaike Info Criterion 5.673469 Sum squared resid 2170.213 Schwarz criterion 5.780038 Log likelihood -383.6326 Hannan-Quinn criter. 5.716776 F-statistic 10.46045 Durbin-Watson stat 1.966156 Prob(F-statistic) 0.000000
Inverted AR Roots -.17-.42i -.17+.42i Inverted MA Roots -.44+.50i -.44-.50i
Tabela 10 - Modelo 1C retirando os termos AR(3), AR(4), MA(3) e MA(4)
Testamos a significância dos termos AR(1) e AR(2) através do teste de Wald com o intuito de
verificar se os mesmos poderiam ser igual a zero; o que foi comprovado através da análise do
P-valor; sendo assim, os mesmos também poderiam ser retirados do modelo.

56
Wald Test: Equation: EQDREAJ
Test Statistic Value df Probability
F-statistic 1.696490 (2, 132) 0.1873 Chi-square 3.392981 2 0.1833
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(2) -0.335414 0.386596 C(3) -0.200860 0.187233
Tabela 11 - Teste de Wald do Modelo 1C dos termos AR(1) e AR(2)
Obtivemos a seguinte regressão após a retirada dos termos do Modelo 1C:
Dependent Variable: D(REAJ) Method: Least Squares Date: 10/06/11 Time: 20:28 Sample (adjusted): 1999M02 2010M08 Included observations: 139 after adjustments Convergence achieved after 8 iterations MA Backcast: 1998M12 1999M01
Variable Coefficient Std. Error t-Statistic Prob.
C 1.255622 0.567527 2.212446 0.0286 MA(1) 0.556753 0.084901 6.557660 0.0000 MA(2) 0.103926 0.085087 1.221416 0.2240
R-squared 0.233803 Mean dependent var 1.252173 Adjusted R-squared 0.222535 S.D. dependent var 4.578395 S.E. of regression 4.036953 Akaike Info Criterion 5.650204 Sum squared resid 2216.390 Schwarz criterion 5.713538 Log likelihood -389.6892 Hannan-Quinn criter. 5.675941 F-statistic 20.74998 Durbin-Watson stat 2.025431 Prob(F-statistic) 0.000000
Inverted MA Roots -.28+.16i -.28-.16i
Tabela 12 - Modelo 1C com a retirada dos termos AR(1) e AR(2)

57
Vemos que os resultados do teste t e F da tabela acima não são satisfatórios, sendo assim,
testamos também a significância do termo MA(2) e identificamos que o mesmo também
poderia ser retirado do modelo.
Wald Test: Equation: EQDREAJ
Test Statistic Value df Probability
F-statistic 1.491856 (1, 136) 0.2240 Chi-square 1.491856 1 0.2219
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(3) 0.103926 0.085087
Restrictions are linear in coefficients.
Tabela 13 - Teste de Wald do Modelo 1C do termo MA(2)
Com a retirada do termo MA(2), o Modelo 1C ficou idêntico ao Modelo 1A, podendo então
ser descartado.
Seguimos então para a comparação dos Modelos 1A e 1B.
Iniciamos pela análise dos critérios SIC e AIC gerados nas regressões dos modelos, e pudemos
observar que pelo critério AIC optaríamos pelo Modelo 1B e pelo critério SIC, optaríamos
pelo Modelo 1A; pois quanto menor o valor do parâmetro, melhor é o modelo.
Modelo 1A Modelo 1B Modelos d(reaj) c MA(1) d(reaj) c AR(4) AR(11) MA(1) AIC 5.646030 5.635429SIC 5.688253 5.724555
Tabela 14 - Comparação dos Modelos 1A e 1B pelos critérios SIC e AIC

58
Como a comparação da Tabela 9 não foi conclusiva, comparamos também os correlogramas
dos modelos 1A e 1B, a qual segue abaixo. Podemos observar que no Modelo 1B, todos os
períodos encontram-se dentro dos intervalos de confiança. O mesmo não pode ser observado
no Modelo 1A pois os períodos 4 e 11 encontram-se fora dos intervalos de confiança,
conforme havíamos observado anteriormente.
Figura 15 - Comparação dos Correlogramas dos Modelos 1A e 1B
Como critério para a seleção entre os Modelos 1A e 1B, também observamos os gráficos dos
resíduos e pudemos ver que ha menos dinâmica nos resíduos do Modelo 1B, visto que os

59
resíduos do Modelo 1A parecem indicar componentes de ciclo entre os períodos de 2002 e
2005.
Figura 16 - Comparação dos Gráficos dos Resíduos dos Modelos 1A e 1B
Fizemos então o teste de Wald para verificar a significância dos termos AR(4) e AR(11)
rejeitamos a hipótese nula de que os mesmos podem ser iguais a zero, conforme tabela abaixo.
Wald Test: Equation: EQDREAJ
Test Statistic Value df Probability
F-statistic 24.51671 (2, 124) 0.0000 Chi-square 49.03342 2 0.0000
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(3) -0.238529 0.088483 C(4) 0.486948 0.079402
Restrictions are linear in coefficients.
Tabela 15 - Teste de Wald para Modelo 1B
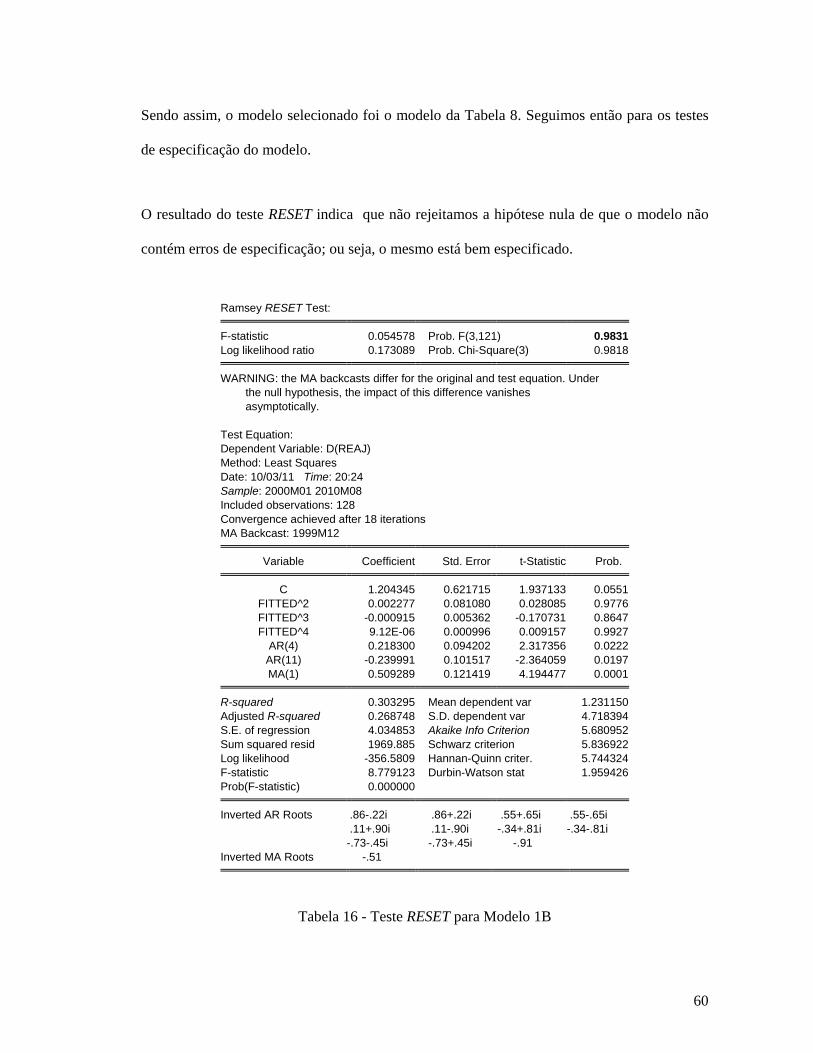
60
Sendo assim, o modelo selecionado foi o modelo da Tabela 8. Seguimos então para os testes
de especificação do modelo.
O resultado do teste RESET indica que não rejeitamos a hipótese nula de que o modelo não
contém erros de especificação; ou seja, o mesmo está bem especificado.
Ramsey RESET Test:
F-statistic 0.054578 Prob. F(3,121) 0.9831 Log likelihood ratio 0.173089 Prob. Chi-Square(3) 0.9818
WARNING: the MA backcasts differ for the original and test equation. Under the null hypothesis, the impact of this difference vanishes asymptotically.
Test Equation: Dependent Variable: D(REAJ) Method: Least Squares Date: 10/03/11 Time: 20:24 Sample: 2000M01 2010M08 Included observations: 128 Convergence achieved after 18 iterations MA Backcast: 1999M12
Variable Coefficient Std. Error t-Statistic Prob.
C 1.204345 0.621715 1.937133 0.0551 FITTED^2 0.002277 0.081080 0.028085 0.9776 FITTED^3 -0.000915 0.005362 -0.170731 0.8647 FITTED^4 9.12E-06 0.000996 0.009157 0.9927
AR(4) 0.218300 0.094202 2.317356 0.0222 AR(11) -0.239991 0.101517 -2.364059 0.0197 MA(1) 0.509289 0.121419 4.194477 0.0001
R-squared 0.303295 Mean dependent var 1.231150 Adjusted R-squared 0.268748 S.D. dependent var 4.718394 S.E. of regression 4.034853 Akaike Info Criterion 5.680952 Sum squared resid 1969.885 Schwarz criterion 5.836922 Log likelihood -356.5809 Hannan-Quinn criter. 5.744324 F-statistic 8.779123 Durbin-Watson stat 1.959426 Prob(F-statistic) 0.000000
Inverted AR Roots .86-.22i .86+.22i .55+.65i .55-.65i .11+.90i .11-.90i -.34+.81i -.34-.81i -.73-.45i -.73+.45i -.91
Inverted MA Roots -.51
Tabela 16 - Teste RESET para Modelo 1B
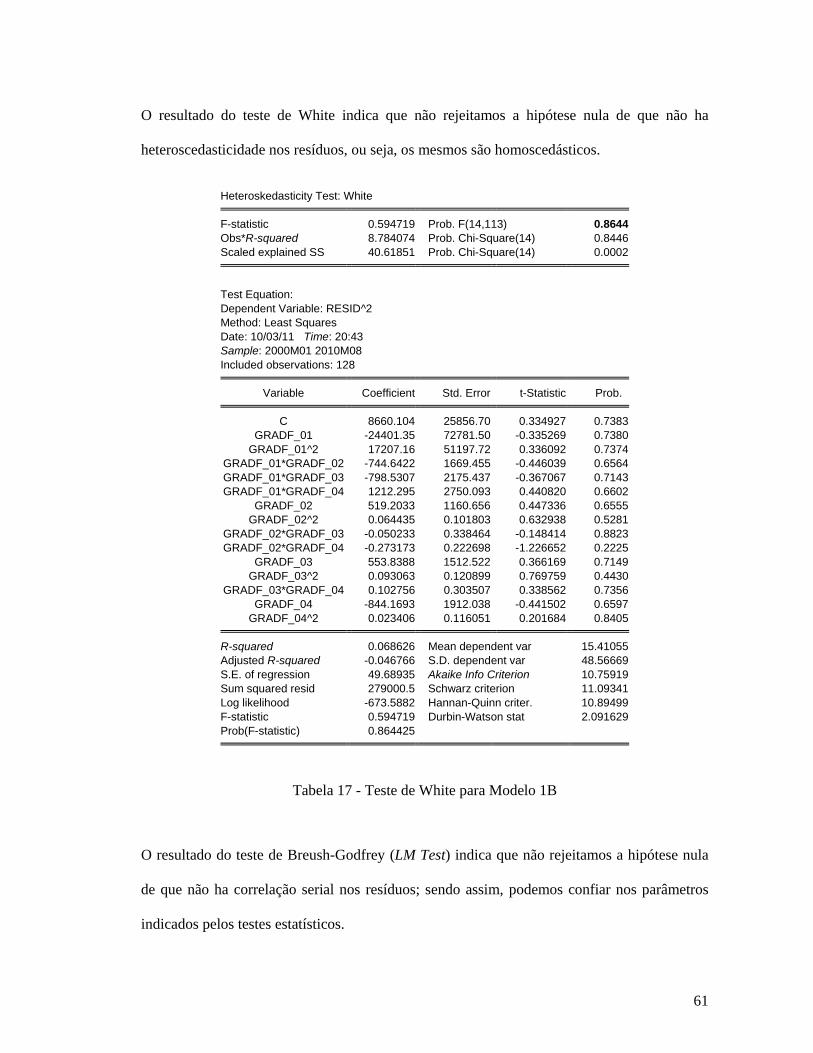
61
O resultado do teste de White indica que não rejeitamos a hipótese nula de que não ha
heteroscedasticidade nos resíduos, ou seja, os mesmos são homoscedásticos.
Heteroskedasticity Test: White
F-statistic 0.594719 Prob. F(14,113) 0.8644 Obs*R-squared 8.784074 Prob. Chi-Square(14) 0.8446 Scaled explained SS 40.61851 Prob. Chi-Square(14) 0.0002
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/03/11 Time: 20:43 Sample: 2000M01 2010M08 Included observations: 128
Variable Coefficient Std. Error t-Statistic Prob.
C 8660.104 25856.70 0.334927 0.7383 GRADF_01 -24401.35 72781.50 -0.335269 0.7380
GRADF_01^2 17207.16 51197.72 0.336092 0.7374 GRADF_01*GRADF_02 -744.6422 1669.455 -0.446039 0.6564 GRADF_01*GRADF_03 -798.5307 2175.437 -0.367067 0.7143 GRADF_01*GRADF_04 1212.295 2750.093 0.440820 0.6602
GRADF_02 519.2033 1160.656 0.447336 0.6555 GRADF_02^2 0.064435 0.101803 0.632938 0.5281
GRADF_02*GRADF_03 -0.050233 0.338464 -0.148414 0.8823 GRADF_02*GRADF_04 -0.273173 0.222698 -1.226652 0.2225
GRADF_03 553.8388 1512.522 0.366169 0.7149 GRADF_03^2 0.093063 0.120899 0.769759 0.4430
GRADF_03*GRADF_04 0.102756 0.303507 0.338562 0.7356 GRADF_04 -844.1693 1912.038 -0.441502 0.6597
GRADF_04^2 0.023406 0.116051 0.201684 0.8405
R-squared 0.068626 Mean dependent var 15.41055 Adjusted R-squared -0.046766 S.D. dependent var 48.56669 S.E. of regression 49.68935 Akaike Info Criterion 10.75919 Sum squared resid 279000.5 Schwarz criterion 11.09341 Log likelihood -673.5882 Hannan-Quinn criter. 10.89499 F-statistic 0.594719 Durbin-Watson stat 2.091629 Prob(F-statistic) 0.864425
Tabela 17 - Teste de White para Modelo 1B
O resultado do teste de Breush-Godfrey (LM Test) indica que não rejeitamos a hipótese nula
de que não ha correlação serial nos resíduos; sendo assim, podemos confiar nos parâmetros
indicados pelos testes estatísticos.

62
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 0.148145 Prob. F(2,122) 0.8625 Obs*R-squared 0.310011 Prob. Chi-Square(2) 0.8564
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/07/11 Time: 21:41 Sample: 2000M01 2010M08 Included observations: 128 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C -0.006773 0.510263 -0.013274 0.9894 AR(4) 0.005291 0.095339 0.055501 0.9558 AR(11) 0.010843 0.091422 0.118603 0.9058 MA(1) 0.061312 0.365716 0.167649 0.8671
RESID(-1) -0.043647 0.377849 -0.115515 0.9082 RESID(-2) 0.074564 0.201897 0.369317 0.7125
R-squared 0.002422 Mean dependent var -0.003422 Adjusted R-squared -0.038462 S.D. dependent var 3.941050 S.E. of regression 4.016126 Akaike Info Criterion 5.664254 Sum squared resid 1967.771 Schwarz criterion 5.797943 Log likelihood -356.5122 Hannan-Quinn criter. 5.718572 F-statistic 0.059239 Durbin-Watson stat 1.997550 Prob(F-statistic) 0.997653
Tabela 18 - Teste Breush-Godfrey (LM Test) para Modelo 1B
Conforme resultados acima listados consideramos que o Modelo 1B satisfaz aos critérios
indicados no capitulo 2; sendo assim, o denominaremos Modelo 1 pois representa o melhor
modelo em nível e primeiras diferenças, especificado como: d(reaj) c AR(4) AR(11) MA(1).
4.1.4 Forecast do Modelo 1
Para gerarmos o forecast do Modelo 1 iniciaremos criando o Forecast automático oferecido
pelo EViews para o período 2010m9 a 2011m8 utilizando a ferramenta de forecast dinâmico.

63
240
260
280
300
320
340
2010Q4 2011Q1 2011Q2 2011Q3
YHAT1 ± 2 S.E.
Forecast: YHAT1Actual: REAJForecast sample: 2010M09 2011M08Included observations: 12Root Mean Squared Error 13.33686Mean Absolute Error 11.49031Mean Abs. Percent Error 3.793229Theil Inequality Coefficient 0.022731 Bias Proportion 0.742260 Variance Proportion 0.121295 Covariance Proportion 0.136446
Figura 17 - Índices do Forecast do EViews para Modelo 1
Consideramos que o valor do Erro Absoluto Médio, Mean Absolute Error (MAE), é
satisfatório quando o comparamos com a escala dos valores reais, cujo mínimo é 108,94 e o
máximo é 312,35. Consideramos que o Erro Percentual Absoluto Médio, Mean Absolute
Percentage Error (MAPE), é também satisfatório visto que a mesma encontra-se abaixo de
10%.
Consideramos que o Coeficiente de Desigualdade de Theil (TIC) é satisfatório visto que o seu
valor de 0,022731 não se aproxima muito de 1; porem quando observamos a Proporção de
Viés, Bias Proportion, consideramos que seu valor de 0,742260 está muito elevado, o que
poderia indicar um erro sistemático na previsão. A Proporção de Variância, Variance
Proportion, apresentou um valor de 0,121295 o qual consideramos satisfatório o que indica
que variação da previsão se afasta pouco da variação da série real; porem a Proporção de Co-
Variância, Covariance Proportion, apresentou um valor de 0,136446, o que consideramos

64
muito baixo visto que desejamos que os erros não sistemáticos da previsão sejam mais
significantes que os parâmetros de Viés e Variância no somatório das 3 componentes do TIC.
Posteriormente geramos o gráfico do forecast com o intuito de observar seu comportamento
comparado com os dados do hold-out sample.
100
150
200
250
300
350
99 00 01 02 03 04 05 06 07 08 09 10 11
REAJ YHAT1YHAT_UP1 YHAT_LO1
Figura 18 - Gráfico do Forecast do Modelo 1
Analisando o gráfico do forecast do Modelo 1 podemos verificar que os valores reais, REAJ,
ficaram dentro do intervalo de confiança, YHAT_UP1 e YHAT_LO1. Podemos ainda
observar que os valores de forecast, YHAT1, ficaram abaixo dos valores reais, o que indica
que o forecast esta subestimado.

65
4.2 MODELO 2: SÉRIE FATOR DE REAJUSTAMENTO EM LOG CONSIDERANDO A PRESENÇA DE TENDÊNCIA DETERMINÍSTICA
4.2.1 Análise da Série "lreaj"
Analisando o gráfico da série do fator de reajustamento em log pode-se notar uma significante
tendência de crescimento o que é bastante intuitivo visto que também o observamos na série
em nível. Nota-se a presença de intercepto, porém a sazonalidade e o ciclo parecem ser
consideráveis apenas em alguns períodos.
As variações abruptas capturadas nos gráficos analisados anteriormente podem também ser
sentidas ao analisarmos o gráfico do fator da série em log.
4.6
4.8
5.0
5.2
5.4
5.6
5.8
99 00 01 02 03 04 05 06 07 08 09 10
LREAJ
Figura 19 - Gráfico da série lreaj

66
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica negativa, pois temos um achatamento da curva e notamos mais massa na cauda da
direita.
0
5
10
15
20
25
30
4.8 5.0 5.2 5.4 5.6
Series: LREAJSample 1999M01 2010M08Observations 140
Mean 5.311955Median 5.469454Maximum 5.744138Minimum 4.690867Std. Dev. 0.312303Skewness -0.568046Kurtosis 1.757839
Jarque-Bera 16.52975Probability 0.000257
Figura 20 - Histograma da série lreaj
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma

67
queda para zero depois de poucos lags, o que caracterizaria um processo de média móvel
(MA).
Podemos também observar na autocorrelação parcial (PC) a presença de lag significativo no
período 1, ao nível de significância de 10%, o que indicaria um modelo AR(1).
Figura 21 - Correlograma da série lreaj

68
A análise do gráfico dos resíduos resultado da regressão da série em log contra uma constante
c, notamos que série não parece ser um ruído branco o que demonstra claramente a presença
de componentes de tendência e possível componente de ciclo.
-.8
-.6
-.4
-.2
.0
.2
.4
.6
4.6
4.8
5.0
5.2
5.4
5.6
5.8
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 22 - Gráfico dos resíduos da série lreaj
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste Augmented Dickey-Fuller com o critério Schwarz Info
Criterion, incluindo tendência e intercepto, não rejeitamos a hipótese nula de que a série
possui raiz unitária, ou seja, a mesma é não estacionaria. No entanto, ao observarmos as
estatísticas t e F da tendência, notamos que a mesma é não significativa; sendo assim,
refizemos o teste apenas com o intercepto e posteriormente retirando também o intercepto, e
obtemos o mesmo resultado; ou seja, a não estacionaridade da série em log.

69
Null Hypothesis: LREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=13)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -1.319644 0.8789 Test critical values: 1% level -4.025924
5% level -3.442712 10% level -3.146022
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LREAJ) Method: Least Squares Date: 10/05/11 Time: 21:06 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LREAJ(-1) -0.018376 0.013925 -1.319644 0.1892 D(LREAJ(-1)) 0.455176 0.075149 6.056986 0.0000
C 0.093972 0.066854 1.405626 0.1621 @TREND(1999M01) 9.89E-05 0.000108 0.912368 0.3632
R-squared 0.234518 Mean dependent var 0.006461 Adjusted R-squared 0.217381 S.D. dependent var 0.019696 S.E. of regression 0.017424 Akaike Info Criterion -5.233384 Sum squared resid 0.040682 Schwarz criterion -5.148536 Log likelihood 365.1035 Hannan-Quinn criter. -5.198904 F-statistic 13.68439 Durbin-Watson stat 1.835876 Prob(F-statistic) 0.000000
Tabela 19 - Teste de Raiz Unitária da série lreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, incluindo Tendência e Intercepto)
Como o teste realizado acima sofre de baixo poder; ou seja, a hipótese nula pode ser rejeitada
mesmo na presença de estacionaridade, fazemos então o teste utilizando o tipo de teste
Dickey-Fuller GLS (ERS) com o critério Akaike Info Criterion, incluindo tendência e
intercepto e obtemos o mesmo resultado, ou seja, a série possui raiz unitária, como pode ser
observado na tabela abaixo; porem como o resultado do teste de raiz unitária da série em nível
para todo o período da amostra nos colocou em uma zona de penumbra; seguimos analisando
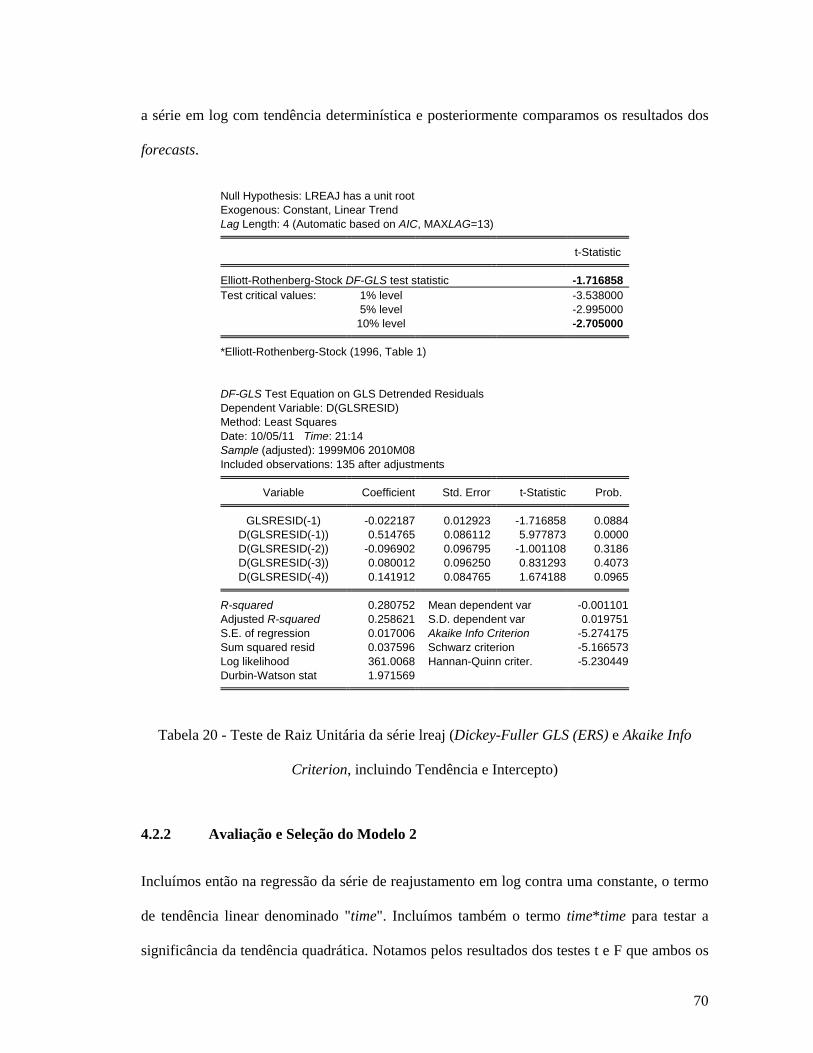
70
a série em log com tendência determinística e posteriormente comparamos os resultados dos
forecasts.
Null Hypothesis: LREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 4 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.716858 Test critical values: 1% level -3.538000
5% level -2.995000 10% level -2.705000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 10/05/11 Time: 21:14 Sample (adjusted): 1999M06 2010M08 Included observations: 135 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.022187 0.012923 -1.716858 0.0884 D(GLSRESID(-1)) 0.514765 0.086112 5.977873 0.0000 D(GLSRESID(-2)) -0.096902 0.096795 -1.001108 0.3186 D(GLSRESID(-3)) 0.080012 0.096250 0.831293 0.4073 D(GLSRESID(-4)) 0.141912 0.084765 1.674188 0.0965
R-squared 0.280752 Mean dependent var -0.001101 Adjusted R-squared 0.258621 S.D. dependent var 0.019751 S.E. of regression 0.017006 Akaike Info Criterion -5.274175 Sum squared resid 0.037596 Schwarz criterion -5.166573 Log likelihood 361.0068 Hannan-Quinn criter. -5.230449 Durbin-Watson stat 1.971569
Tabela 20 - Teste de Raiz Unitária da série lreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, incluindo Tendência e Intercepto)
4.2.2 Avaliação e Seleção do Modelo 2
Incluímos então na regressão da série de reajustamento em log contra uma constante, o termo
de tendência linear denominado "time". Incluímos também o termo time*time para testar a
significância da tendência quadrática. Notamos pelos resultados dos testes t e F que ambos os

71
termos são significativos, conforme tabela abaixo. Testamos também a tendência cúbica e a
mesma mostrou-se pouquíssimo significativa; sendo assim optamos por não incluí-la no
modelo visto que a mesma também pode roubar parte da significância da componente de
ciclo.
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/05/11 Time: 21:21 Sample: 1999M01 2010M08 Included observations: 140
Variable Coefficient Std. Error t-Statistic Prob.
C 4.626891 0.017213 268.8090 0.0000 TIME 0.015183 0.000572 26.53448 0.0000
TIME*TIME -5.73E-05 3.98E-06 -14.37504 0.0000
R-squared 0.952084 Mean dependent var 5.311955 Adjusted R-squared 0.951385 S.D. dependent var 0.312303 S.E. of regression 0.068859 Akaike Info Criterion -2.492305 Sum squared resid 0.649601 Schwarz criterion -2.429270 Log likelihood 177.4614 Hannan-Quinn criter. -2.466689 F-statistic 1361.091 Durbin-Watson stat 0.084147 Prob(F-statistic) 0.000000
Tabela 21 - Regressão da série lreaj incluindo tendências linear e quadrática
Através da regressão da série acima citada e com a inclusão das dummies sazonais, podemos
constatar observando os resultados das estatísticas t e F que não há significância da
sazonalidade na série; sendo assim, estas não foram incluídas no modelo.

72
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/05/11 Time: 21:28 Sample: 1999M01 2010M08 Included observations: 140
Variable Coefficient Std. Error t-Statistic Prob.
C 4.615703 0.027892 165.4860 0.0000 TIME 0.015204 0.000597 25.45536 0.0000
TIME*TIME -5.74E-05 4.16E-06 -13.79750 0.0000 D1 0.011730 0.029921 0.392022 0.6957 D2 0.017374 0.029917 0.580735 0.5625 D3 0.017422 0.029914 0.582414 0.5613 D4 0.011887 0.029911 0.397414 0.6917 D5 0.015679 0.029910 0.524209 0.6011 D6 0.011216 0.029910 0.374999 0.7083 D7 0.004309 0.029911 0.144047 0.8857 D8 0.005237 0.029913 0.175062 0.8613 D9 0.010820 0.030534 0.354371 0.7237 D10 0.012050 0.030532 0.394655 0.6938 D11 0.007631 0.030531 0.249953 0.8030
R-squared 0.952352 Mean dependent var 5.311955 Adjusted R-squared 0.947436 S.D. dependent var 0.312303 S.E. of regression 0.071602 Akaike Info Criterion -2.340760 Sum squared resid 0.645975 Schwarz criterion -2.046596 Log likelihood 177.8532 Hannan-Quinn criter. -2.221221 F-statistic 193.7211 Durbin-Watson stat 0.079658 Prob(F-statistic) 0.000000
Tabela 22 - Regressão da série lreaj incluindo tendências linear, tendência quadrática e
dummies sazonais
Geramos então a série dos resíduos da equação da série lreaj contra uma constante incluindo
os termos de tendência linear e quadrática com o intuito de utilizar o programa GARMA para
confirmar a presença e sugerir a ordem dos processos auto-regressivos de forma a
melhorarmos o modelo.
R1 AIC 2.000000 4.000000 R2 SIC 2.000000 0.000000
Tabela 23 - Tabela PQ (GARMA) da série lreaj

73
Quando o AIC e o SIC sugerem modelos diferentes, recomenda-se o uso do Schwarz Info
Criterion (SIC), primeiro, porque o SIC tipicamente indica um modelo mais parcimonioso,
sendo assim preservaríamos melhor os graus de liberdade do modelo e segundo, o SIC tem
boas propriedades de consistência em amostras grandes.
Geramos então a estimação com a equação sugerida pelo GARMA e obtivemos os seguintes
resultados:
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/05/11 Time: 21:49 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments Convergence achieved after 4 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 4.523593 0.087114 51.92740 0.0000 TIME 0.017801 0.002459 7.239281 0.0000
TIME*TIME -7.16E-05 1.52E-05 -4.715117 0.0000 AR(1) 1.404260 0.073281 19.16267 0.0000 AR(2) -0.473683 0.073058 -6.483620 0.0000
R-squared 0.997050 Mean dependent var 5.320500 Adjusted R-squared 0.996961 S.D. dependent var 0.306259 S.E. of regression 0.016883 Akaike Info Criterion -5.289432 Sum squared resid 0.037911 Schwarz criterion -5.183372 Log likelihood 369.9708 Hannan-Quinn criter. -5.246332 F-statistic 11236.84 Durbin-Watson stat 1.901993 Prob(F-statistic) 0.000000
Inverted AR Roots .84 .56
Tabela 24 - Sugestão do GARMA para Modelo 2A pelo critério SIC
Observamos que as estatísticas t e F são significativas, então analisaremos o correlograma.

74
Figura 23 - Correlograma da série sugerida pelo GARMA para Modelo 2
Podemos observar uma melhora na dinâmica do correlograma, visto que comparado com a
Figura 20 (Correlograma da Série lreaj), passamos a não rejeitar a hipótese nula de que o
resíduo é um ruído branco; no entanto, ainda podemos ver nos períodos 4 e 11 estamos fora

75
do intervalo de confiança o que poderia indicar componentes de ciclo não incluídas no
modelo, da mesma forma que vimos no modelo 1A.
Criamos então o Modelo 2B incluindo os termos MA(1), sugerido pelo GARMA e também os
termos AR(4) e AR(11), sugeridos pelo correlograma.
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/06/11 Time: 21:18 Sample (adjusted): 1999M12 2010M08 Included observations: 129 after adjustments Convergence achieved after 5 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 4.487108 0.096085 46.69912 0.0000 TIME 0.018829 0.002562 7.348607 0.0000
TIME*TIME -7.78E-05 1.53E-05 -5.091969 0.0000 AR(1) 1.379287 0.086299 15.98262 0.0000 AR(2) -0.400428 0.111702 -3.584799 0.0005 AR(4) -0.064580 0.056248 -1.148143 0.2532 AR(11) 0.000765 0.024667 0.031011 0.9753
R-squared 0.996498 Mean dependent var 5.358296 Adjusted R-squared 0.996326 S.D. dependent var 0.279690 S.E. of regression 0.016953 Akaike Info Criterion -5.263981 Sum squared resid 0.035064 Schwarz criterion -5.108797 Log likelihood 346.5268 Hannan-Quinn criter. -5.200927 F-statistic 5786.061 Durbin-Watson stat 1.943226 Prob(F-statistic) 0.000000
Inverted AR Roots .79+.16i .79-.16i .56 .30+.37i .30-.37i -.01+.47i -.01-.47i -.26-.39i -.26+.39i -.41+.15i -.41-.15i
Tabela 25 - Modelo 2B
Observamos que as estatísticas t e F não são significativas, então testamos a significância dos
termos AR(4) e AR(11) através do teste de Wald com o intuito de verificar se os mesmos
poderiam ser igual a zero; o que foi comprovado através da análise do P-valor; sendo assim,
os mesmos também poderiam ser retirados do modelo.

76
Wald Test: Equation: EQLREAJ
Test Statistic Value df Probability
F-statistic 0.788183 (2, 122) 0.4570 Chi-square 1.576366 2 0.4547
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(6) -0.064580 0.056248 C(7) 0.000765 0.024667
Restrictions are linear in coefficients.
Tabela 26 - Teste de Wald do Modelo 2B dos termos AR(4) e AR(11)
Com a retirada dos termos AR(4) e AR(11), o Modelo 2B ficou idêntico ao Modelo 2A,
podendo então ser descartado.
Criamos ainda o Modelo 2C que representa o modelo sugerido pelo GARMA com o critério
AIC.
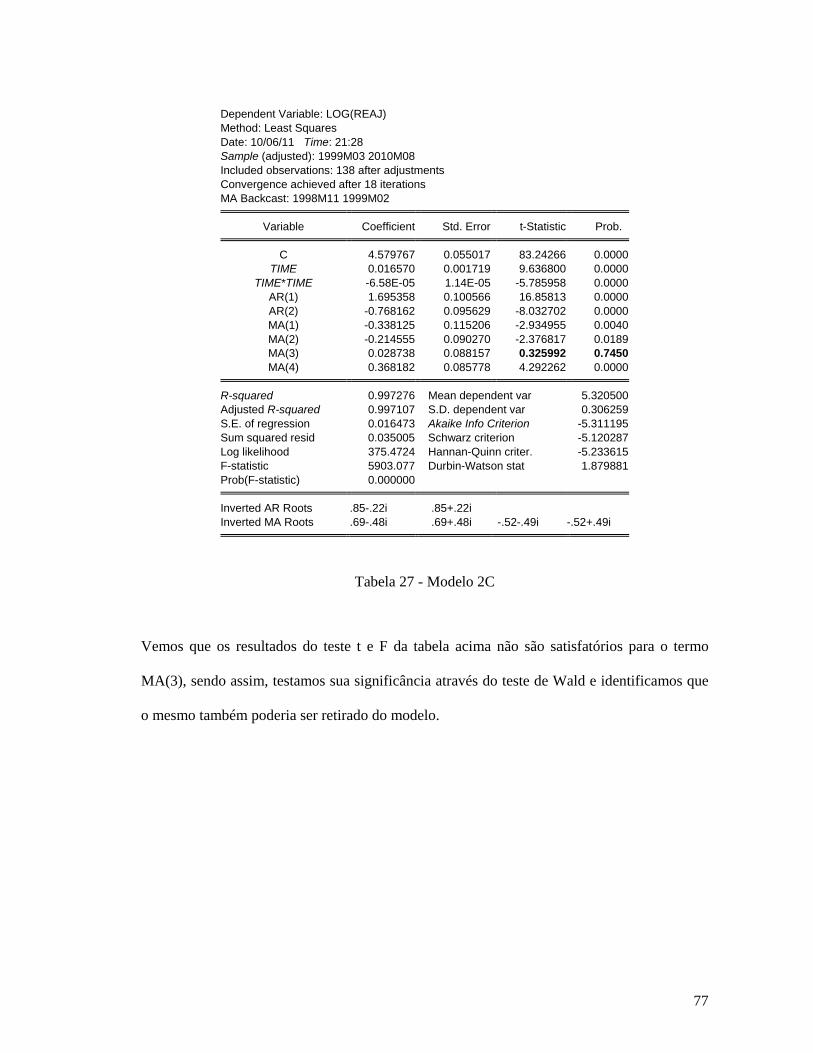
77
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/06/11 Time: 21:28 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments Convergence achieved after 18 iterations MA Backcast: 1998M11 1999M02
Variable Coefficient Std. Error t-Statistic Prob.
C 4.579767 0.055017 83.24266 0.0000 TIME 0.016570 0.001719 9.636800 0.0000
TIME*TIME -6.58E-05 1.14E-05 -5.785958 0.0000 AR(1) 1.695358 0.100566 16.85813 0.0000 AR(2) -0.768162 0.095629 -8.032702 0.0000 MA(1) -0.338125 0.115206 -2.934955 0.0040 MA(2) -0.214555 0.090270 -2.376817 0.0189 MA(3) 0.028738 0.088157 0.325992 0.7450 MA(4) 0.368182 0.085778 4.292262 0.0000
R-squared 0.997276 Mean dependent var 5.320500 Adjusted R-squared 0.997107 S.D. dependent var 0.306259 S.E. of regression 0.016473 Akaike Info Criterion -5.311195 Sum squared resid 0.035005 Schwarz criterion -5.120287 Log likelihood 375.4724 Hannan-Quinn criter. -5.233615 F-statistic 5903.077 Durbin-Watson stat 1.879881 Prob(F-statistic) 0.000000
Inverted AR Roots .85-.22i .85+.22i Inverted MA Roots .69-.48i .69+.48i -.52-.49i -.52+.49i
Tabela 27 - Modelo 2C
Vemos que os resultados do teste t e F da tabela acima não são satisfatórios para o termo
MA(3), sendo assim, testamos sua significância através do teste de Wald e identificamos que
o mesmo também poderia ser retirado do modelo.

78
Wald Test: Equation: EQLREAJ
Test Statistic Value df Probability
F-statistic 0.106271 (1, 129) 0.7450 Chi-square 0.106271 1 0.7444
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(8) 0.028738 0.088157
Restrictions are linear in coefficients.
Tabela 28 - Teste de Wald do Modelo 2C do termo MA(3)
A forma final para o Modelo 2C ficou conforme a seguir:
Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/06/11 Time: 21:33 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments Convergence achieved after 12 iterations MA Backcast: 1998M11 1999M02
Variable Coefficient Std. Error t-Statistic Prob.
C 4.579393 0.055116 83.08586 0.0000 TIME 0.016575 0.001722 9.625999 0.0000
TIME*TIME -6.58E-05 1.14E-05 -5.779871 0.0000 AR(1) 1.695220 0.100392 16.88599 0.0000 AR(2) -0.767356 0.095709 -8.017618 0.0000 MA(1) -0.333620 0.114220 -2.920864 0.0041 MA(2) -0.206479 0.087995 -2.346486 0.0205 MA(4) 0.380381 0.080615 4.718501 0.0000
R-squared 0.997274 Mean dependent var 5.320500 Adjusted R-squared 0.997127 S.D. dependent var 0.306259 S.E. of regression 0.016414 Akaike Info Criterion -5.325106 Sum squared resid 0.035026 Schwarz criterion -5.155410 Log likelihood 375.4323 Hannan-Quinn criter. -5.256146 F-statistic 6794.710 Durbin-Watson stat 1.890931 Prob(F-statistic) 0.000000
Inverted AR Roots .85-.22i .85+.22i Inverted MA Roots .69-.48i .69+.48i -.52-.51i -.52+.51i
Tabela 29 - Forma final Modelo 2C

79
Seguimos então para a comparação dos Modelos 2A e 2C.
Iniciamos pela análise dos critérios SIC e AIC gerados nas regressões dos modelos, e pudemos
observar que pelo critério AIC optaríamos pelo Modelo 2C e pelo critério SIC, optaríamos
pelo Modelo 2A; pois quanto menor o valor do parâmetro, melhor é o modelo.
Modelo 2A Modelo 2C
Modelos log(reaj) c Time Time*Time
AR(1) AR(2)
log(reaj) c Time Time*Time AR(1) AR(2) MA(1) MA(2)
MA(4) AIC -5.289432 -5.325106SIC -5.183372 -5.155410
Tabela 30 - Comparação dos Modelos 2A e 2C pelos critérios SIC e AIC
Como a comparação da Tabela 30 não foi conclusiva, comparamos também os correlogramas
dos modelos 2A e 2C, a qual segue abaixo. Podemos observar que no Modelo 2C, todos os
períodos encontram-se dentro dos intervalos de confiança. O mesmo não pode ser observado
no Modelo 2A pois os períodos 4 e 11 encontram-se fora dos intervalos de confiança,
conforme havíamos observado anteriormente também no modelo em nível e primeiras
diferenças.

80
Figura 24 - Comparação dos Correlogramas dos Modelos 2A e 2C
Como critério para a seleção entre os Modelos 2A e 2C, também observamos os gráficos dos
resíduos e pudemos ver que em ambos não notamos dinâmicas que indicariam a presença de
componentes não incluídas nos modelos.

81
Figura 25 - Comparação dos Gráficos dos Resíduos dos Modelos 2A e 2C
Decidimos então fazer os testes de especificação de modelo para ambos os modelos.
O resultado do teste RESET indica que não rejeitamos a hipótese nula de que ambos os
modelo não contém erros de especificação; ou seja, ambos estão bem especificados.

82
Ramsey RESET Test:
F-statistic 1.765149 Prob. F(2,131) 0.1752 Log likelihood ratio 3.669712 Prob. Chi-Square(2) 0.1596
Test Equation: Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/07/11 Time: 20:37 Sample: 1999M03 2010M08 Included observations: 138 Convergence achieved after 7 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 1.233394 0.393191 3.136882 0.0021 TIME -0.000549 0.000514 -1.068673 0.2872
TIME*TIME 2.94E-06 2.58E-06 1.139315 0.2567 FITTED^2 0.245116 0.042113 5.820392 0.0000 FITTED^3 -0.018773 0.005205 -3.606523 0.0004
AR(1) 0.028380 0.091409 0.310476 0.7567 AR(2) -0.106005 0.092685 -1.143716 0.2548
R-squared 0.997127 Mean dependent var 5.320500 Adjusted R-squared 0.996996 S.D. dependent var 0.306259 S.E. of regression 0.016787 Akaike Info Criterion -5.287039 Sum squared resid 0.036916 Schwarz criterion -5.138555 Log likelihood 371.8057 Hannan-Quinn criter. -5.226699 F-statistic 7578.008 Durbin-Watson stat 1.984596 Prob(F-statistic) 0.000000
Inverted AR Roots .01-.33i .01+.33i
Tabela 31 - Teste RESET para Modelo 2A

83
Ramsey RESET Test:
F-statistic 0.642311 Prob. F(2,128) 0.5278 Log likelihood ratio 1.378080 Prob. Chi-Square(2) 0.5021
WARNING: the MA backcasts differ for the original and test equation. Under the null hypothesis, the impact of this difference vanishes asymptotically.
Test Equation: Dependent Variable: LOG(REAJ) Method: Least Squares Date: 10/07/11 Time: 20:38 Sample: 1999M03 2010M08 Included observations: 138 Convergence achieved after 1 iteration MA Backcast: 1998M11 1999M02
Variable Coefficient Std. Error t-Statistic Prob.
C 1.502540 0.422507 3.556245 0.0005 TIME -0.000133 0.000654 -0.203921 0.8387
TIME*TIME 8.63E-07 3.14E-06 0.274835 0.7839 FITTED^2 0.217168 0.044814 4.845948 0.0000 FITTED^3 -0.015427 0.005502 -2.803955 0.0058
AR(1) 0.002516 20.18508 0.000125 0.9999 AR(2) 0.002510 11.63238 0.000216 0.9998 MA(1) 0.002516 20.17705 0.000125 0.9999 MA(2) 0.002511 11.54556 0.000217 0.9998 MA(4) 0.002461 0.112162 0.021938 0.9825
R-squared 0.997301 Mean dependent var 5.320500 Adjusted R-squared 0.997112 S.D. dependent var 0.306259 S.E. of regression 0.016460 Akaike Info Criterion -5.306107 Sum squared resid 0.034678 Schwarz criterion -5.093987 Log likelihood 376.1214 Hannan-Quinn criter. -5.219907 F-statistic 5255.835 Durbin-Watson stat 1.904709 Prob(F-statistic) 0.000000
Inverted AR Roots .05 -.05 Inverted MA Roots .15-.16i .15+.16i -.16-.16i -.16+.16i
Tabela 32 - Teste RESET para Modelo 2C
Para o Modelo 2C, o resultado do teste de White indica que não rejeitamos a hipótese nula de
que não ha heteroscedasticidade nos resíduos, ou seja, os mesmos são homoscedásticos; no
entanto, para o Modelo 2A, o teste não rejeita a presença de heteroscedasticidade.

84
Heteroskedasticity Test: White
F-statistic 2.276502 Prob. F(13,124) 0.0100 Obs*R-squared 26.58978 Prob. Chi-Square(13) 0.0142 Scaled explained SS 49.07116 Prob. Chi-Square(13) 0.0000
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/07/11 Time: 20:27 Sample: 1999M03 2010M08 Included observations: 138 Collinear test regressors dropped from specification
Variable Coefficient Std. Error t-Statistic Prob.
C -0.002558 0.001721 -1.485990 0.1398 GRADF_01*GRADF_02 0.037619 0.020780 1.810323 0.0727 GRADF_01*GRADF_03 -0.000841 0.000419 -2.005341 0.0471 GRADF_01*GRADF_04 0.014151 0.158732 0.089153 0.9291 GRADF_01*GRADF_05 0.084245 0.158100 0.532862 0.5951 GRADF_02*GRADF_03 7.53E-06 3.46E-06 2.174445 0.0316 GRADF_02*GRADF_04 4.74E-05 0.004277 0.011082 0.9912 GRADF_02*GRADF_05 -0.003025 0.004143 -0.730224 0.4666
GRADF_03^2 -2.31E-08 1.01E-08 -2.297995 0.0232 GRADF_03*GRADF_04 5.17E-06 2.59E-05 0.199717 0.8420 GRADF_03*GRADF_05 1.91E-05 2.49E-05 0.764597 0.4460
GRADF_04^2 -0.056789 0.077152 -0.736064 0.4631 GRADF_04*GRADF_05 0.156741 0.145133 1.079983 0.2822
GRADF_05^2 -0.090610 0.073409 -1.234315 0.2194
R-squared 0.192680 Mean dependent var 0.000275 Adjusted R-squared 0.108041 S.D. dependent var 0.000550 S.E. of regression 0.000519 Akaike Info Criterion -12.19310 Sum squared resid 3.34E-05 Schwarz criterion -11.89614 Log likelihood 855.3242 Hannan-Quinn criter. -12.07242 F-statistic 2.276502 Durbin-Watson stat 2.242117 Prob(F-statistic) 0.010010
Tabela 33 - Teste de White para Modelo 2ª

85
Heteroskedasticity Test: White
F-statistic 0.930544 Prob. F(44,93) 0.5968 Obs*R-squared 42.18379 Prob. Chi-Square(44) 0.5497 Scaled explained SS 66.99172 Prob. Chi-Square(44) 0.0143
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/07/11 Time: 20:27 Sample: 1999M03 2010M08 Included observations: 138
Variable Coefficient Std. Error t-Statistic Prob.
C -0.006214 0.035000 -0.177542 0.8595 GRADF_01 -0.185442 0.591689 -0.313412 0.7547
GRADF_01^2 3.048307 3.996711 0.762704 0.4476 GRADF_02 0.023898 0.032011 0.746562 0.4572
GRADF_02^2 0.000752 0.013127 0.057320 0.9544 GRADF_03 -0.000422 0.001641 -0.257285 0.7975
GRADF_03^2 -6.32E-09 7.63E-09 -0.827998 0.4098 GRADF_04 0.289936 0.330962 0.876039 0.3833
GRADF_04^2 -0.040157 0.298235 -0.134648 0.8932 GRADF_05 -0.147933 0.416253 -0.355391 0.7231
GRADF_05^2 -0.048791 0.287017 -0.169993 0.8654 GRADF_06 -0.138275 0.363204 -0.380708 0.7043
GRADF_06^2 -0.335909 0.294144 -1.141986 0.2564 GRADF_07 0.025393 0.206008 0.123262 0.9022
GRADF_07^2 -0.405361 0.163349 -2.481563 0.0149 GRADF_08 -0.144262 0.172475 -0.836419 0.4051
GRADF_08^2 -0.168252 0.146927 -1.145135 0.2551
R-squared 0.305680 Mean dependent var 0.000254 Adjusted R-squared -0.022816 S.D. dependent var 0.000482 S.E. of regression 0.000487 Akaike Info Criterion -12.15750 Sum squared resid 2.21E-05 Schwarz criterion -11.20296 Log likelihood 883.8677 Hannan-Quinn criter. -11.76960 F-statistic 0.930544 Durbin-Watson stat 2.135478 Prob(F-statistic) 0.596764
Tabela 34 - Teste de White para Modelo 2C
O resultado do teste de Breush-Godfrey (LM Test) indicou para ambos os modelos que não
rejeitamos a hipótese nula de que não ha correlação serial nos resíduos; sendo assim, podemos
confiar nos parâmetros indicados pelos testes estatísticos.

86
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 0.700205 Prob. F(2,131) 0.4983 Obs*R-squared 1.459637 Prob. Chi-Square(2) 0.4820
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/07/11 Time: 21:57 Sample: 1999M03 2010M08 Included observations: 138 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C -0.009799 0.087974 -0.111387 0.9115 TIME 0.000208 0.002484 0.083578 0.9335
TIME*TIME -9.62E-07 1.53E-05 -0.062741 0.9501 AR(1) -0.003686 0.202878 -0.018166 0.9855 AR(2) 0.009092 0.189379 0.048010 0.9618
RESID(-1) 0.051730 0.217179 0.238192 0.8121 RESID(-2) -0.094727 0.132238 -0.716337 0.4751
R-squared 0.010577 Mean dependent var 4.89E-12 Adjusted R-squared -0.034740 S.D. dependent var 0.016635 S.E. of regression 0.016921 Akaike Info Criterion -5.271080 Sum squared resid 0.037510 Schwarz criterion -5.122596 Log likelihood 370.7045 Hannan-Quinn criter. -5.210740 F-statistic 0.233402 Durbin-Watson stat 1.980467 Prob(F-statistic) 0.964994
Tabela 35 - Teste Breush-Godfrey (LM Test) para Modelo 2A

87
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 1.003676 Prob. F(2,128) 0.3694 Obs*R-squared 2.121632 Prob. Chi-Square(2) 0.3462
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/07/11 Time: 21:55 Sample: 1999M03 2010M08 Included observations: 138 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C 0.005769 0.055325 0.104269 0.9171 TIME -0.000193 0.001729 -0.111891 0.9111
TIME*TIME 1.31E-06 1.14E-05 0.114198 0.9093 AR(1) -0.055603 0.107822 -0.515694 0.6070 AR(2) 0.047941 0.101508 0.472286 0.6375 MA(1) -0.200816 0.214430 -0.936510 0.3508 MA(2) 0.119683 0.216924 0.551727 0.5821 MA(4) -0.011741 0.092331 -0.127164 0.8990
RESID(-1) 0.303117 0.245178 1.236315 0.2186 RESID(-2) 0.018336 0.190113 0.096449 0.9233
R-squared 0.015374 Mean dependent var -0.000131 Adjusted R-squared -0.053857 S.D. dependent var 0.015989 S.E. of regression 0.016414 Akaike Info Criterion -5.311681 Sum squared resid 0.034485 Schwarz criterion -5.099562 Log likelihood 376.5060 Hannan-Quinn criter. -5.225481 F-statistic 0.222069 Durbin-Watson stat 2.008572 Prob(F-statistic) 0.990870
Tabela 36 - Teste Breush-Godfrey (LM Test) para Modelo 2C
Considerando os resultados acima listados e motivamos principalmente pelos resultados da
comparação dos correlogramas e também pelos resultados do teste de White, consideramos
que o Modelo 2C satisfaz melhor aos critérios indicados no capitulo 2; sendo assim, o
denominaremos Modelo 2 pois representa o melhor modelo em log, especificado como:
log(reaj) c Time Time*Time AR(1) AR(2) MA(1) MA(2) MA(4).

88
4.2.3 Forecast do Modelo 2
Para gerarmos o forecast do Modelo 2 iniciaremos criando o Forecast automático oferecido
pelo EViews para o período 2010m9 a 2011m8 utilizando a ferramenta de forecast dinâmico.
220
230
240
250
260
270
280
290
300
310
2010Q4 2011Q1 2011Q2 2011Q3
YHAT2 ± 2 S.E.
Forecast: YHAT2Actual: REAJForecast sample: 2010M09 2011M08Included observations: 12Root Mean Squared Error 33.21736Mean Absolute Error 30.10755Mean Abs. Percent Error 9.964028Theil Inequality Coefficient 0.058460 Bias Proportion 0.821525 Variance Proportion 0.000079 Covariance Proportion 0.178396
Figura 26 - Índices do Forecast do EViews para Modelo 2
Consideramos que o valor do Erro Absoluto Médio, Mean Absolute Error (MAE), não é
satisfatório quando o comparamos com a escala dos valores reais, cujo mínimo é 108,94 e o
máximo é 312,35; porem, consideramos que o Erro Percentual Absoluto Médio, Mean
Absolute Percentage Error (MAPE), é satisfatório visto que a mesma encontra-se abaixo de
10%.
Consideramos que o Coeficiente de Desigualdade de Theil (TIC) é satisfatório visto que o seu
valor de 0,058460 não se aproxima muito de 1; porem quando observamos a Proporção de
Viés, Bias Proportion, consideramos que seu valor de 0,821525 está muito elevado, o que
poderia indicar um erro sistemático na previsão. A Proporção de Variância, Variance

89
Proportion, apresentou um valor de 0,000079 o qual consideramos satisfatório o que indica
que variação da previsão se afasta pouco da variação da série real; porem a Proporção de Co-
Variância, Covariance Proportion, apresentou um valor de 0,178396, o que consideramos
muito baixo visto que desejamos que os erros não sistemáticos da previsão sejam mais
significantes que os parâmetros de Viés e Variância no somatório das 3 componentes do TIC.
Posteriormente geramos o gráfico do forecast com o intuito de observar seu comportamento
comparado com os dados do hold-out sample.
80
120
160
200
240
280
320
99 00 01 02 03 04 05 06 07 08 09 10 11
REAJ YHAT2YHAT_UP2 YHAT_LO2
Figura 27 - Gráfico do Forecast do Modelo 2
Analisando o gráfico do forecast do Modelo 2 podemos verificar que os valores reais, REAJ,
não se encontram dentro do intervalo de confiança, YHAT_UP1 e YHAT_LO1, o que

90
compromete a confiabilidade da previsão. Podemos ainda observar que os valores de forecast,
YHAT1, ficaram muito abaixo dos valores reais, o que indica que o forecast está
extremamente subestimado.
Pela análise dos parâmetros de avaliação do forecast bem como pela análise gráfica, não
consideramos que o Modelo 2 ficou bem especificado.
4.3 MODELO 3: SÉRIE FATOR DE REAJUSTAMENTO EM LOG CONSIDERANDO A PRESENÇA DE TENDÊNCIA ESTOCÁSTICA
4.3.1 Análise da Série "dlreaj"
Analisando o gráfico da série do fator de reajustamento em log e primeiras diferenças não
nota-se tendência pois a mesma foi tratada com a aplicação da primeira diferença no entanto,
podemos notar a presença de componentes de ciclo.

91
-.08
-.06
-.04
-.02
.00
.02
.04
.06
.08
99 00 01 02 03 04 05 06 07 08 09 10
DLREAJ
Figura 28 - Gráfico da série dlreaj
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição leptocúrtica
assimétrica negativa, pois temos um achatamento da curva e notamos mais massa na cauda da
direita.

92
0
4
8
12
16
20
24
-0.075 -0.050 -0.025 0.000 0.025 0.050
Series: DLREAJSample 1999M01 2010M08Observations 139
Mean 0.006867Median 0.005058Maximum 0.063014Minimum -0.070376Std. Dev. 0.020202Skewness -0.085450Kurtosis 4.453676
Jarque-Bera 12.40796Probability 0.002021
Figura 29 - Histograma da série dlreaj
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo de média
móvel (MA) pois AC diminui rapidamente havendo uma queda para zero depois de poucos
lags.
Podemos também observar na autocorrelação parcial (PC) a presença de lag significativo no
período 1, ao nível de significância de 10%, o que indicaria um modelo MA(1).

93
Figura 30 - Correlograma da série dlreaj
A análise do gráfico dos resíduos resultado da regressão da série em primeiras diferenças
contra uma constante c, notamos que série não parece ser um ruído branco pois parece indicar
a presença de um componente de ciclo não especificado no modelo, o que pudemos observar
também no correlograma; porem, pode-se perceber que o tratamento da tendência foi eficaz.

94
-.08
-.04
.00
.04
.08
-.08
-.04
.00
.04
.08
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 31 - Gráfico dos resíduos da série dlreaj
Através na análise da estatística t (t-Statistic) das tabelas abaixo, geradas pelos Testes de Raiz
Unitária, utilizando o tipo de teste Augmented Dickey-Fuller com o critério Schwarz Info
Criterion, sem tendência ou intercepto e posteriormente também o teste Dickey-Fuller (GLS)
com critério Akaike Info Criterion, com a presença de intercepto; rejeitamos em ambos os
testes a hipótese nula de que a série possui raiz unitária, ou seja, a mesma é estacionaria.
Como a primeira diferença foi suficiente para tornar a série estacionaria podemos indicar que
a mesma é integrada de ordem 1.

95
Null Hypothesis: DLREAJ has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on SIC, MAXLAG=13)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -7.382454 0.0000 Test critical values: 1% level -3.478189
5% level -2.882433 10% level -2.577990
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(DLREAJ) Method: Least Squares Date: 10/08/11 Time: 15:29 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
DLREAJ(-1) -0.544055 0.073696 -7.382454 0.0000 C 0.003286 0.001573 2.089737 0.0385
R-squared 0.286092 Mean dependent var -0.000501 Adjusted R-squared 0.280842 S.D. dependent var 0.020592 S.E. of regression 0.017463 Akaike Info Criterion -5.243112 Sum squared resid 0.041473 Schwarz criterion -5.200688 Log likelihood 363.7747 Hannan-Quinn criter. -5.225872 F-statistic 54.50062 Durbin-Watson stat 1.837186 Prob(F-statistic) 0.000000
Tabela 37 - Teste de Raiz Unitária da série dlreaj (Augmented Dickey Fuller e Schwarz Info
Criterion, sem tendência ou intercepto)

96
Null Hypothesis: DLREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 3 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -2.795482 Test critical values: 1% level -3.538000
5% level -2.995000 10% level -2.705000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 10/08/11 Time: 15:49 Sample (adjusted): 1999M06 2010M08 Included observations: 135 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.179277 0.066510 -2.695482 0.0080 D(GLSRESID(-1)) -0.244962 0.092924 -2.636156 0.0094 D(GLSRESID(-2)) -0.308212 0.085974 -3.584960 0.0005 D(GLSRESID(-3)) -0.183068 0.082758 -2.212080 0.1287
R-squared 0.241570 Mean dependent var 0.000419 Adjusted R-squared 0.224202 S.D. dependent var 0.019987 S.E. of regression 0.017605 Akaike Info Criterion -5.212117 Sum squared resid 0.040600 Schwarz criterion -5.126035 Log likelihood 355.8179 Hannan-Quinn criter. -5.177136 Durbin-Watson stat 1.979773
Tabela 38 - Teste de Raiz Unitária da série dlreaj (Dickey-Fuller GLS (ERS) e Akaike Info
Criterion, com Intercepto)
4.3.2 Avaliação e Seleção do Modelo 3
Através da regressão da série acima citada e com a inclusão das dummies sazonais, podemos
constatar observando os resultados das estatísticas t e F que não ha significância da
sazonalidade na série; sendo assim, estas não serão incluídas no modelo.

97
Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 15:56 Sample (adjusted): 1999M02 2010M08 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C -0.000519 0.006137 -0.084647 0.9327 D1 0.013480 0.008679 1.553079 0.1229 D2 0.013734 0.008497 1.616475 0.1085 D3 0.008024 0.008497 0.944391 0.3468 D4 0.002326 0.008497 0.273766 0.7847 D5 0.011538 0.008497 1.357987 0.1769 D6 0.003168 0.008497 0.372911 0.7098 D7 0.000609 0.008497 0.071673 0.9430 D8 0.008330 0.008497 0.980385 0.3288 D9 0.015377 0.008679 1.771717 0.0788 D10 0.009090 0.008679 1.047352 0.2969 D11 0.003328 0.008679 0.383418 0.7021
R-squared 0.065732 Mean dependent var 0.006867 Adjusted R-squared -0.015189 S.D. dependent var 0.020202 S.E. of regression 0.020355 Akaike Info Criterion -4.868626 Sum squared resid 0.052618 Schwarz criterion -4.615290 Log likelihood 350.3695 Hannan-Quinn criter. -4.765677 F-statistic 0.812300 Durbin-Watson stat 0.977765 Prob(F-statistic) 0.627737
Tabela 39 - Regressão da série dlreaj incluindo tendências linear, tendência quadrática e
dummies sazonais
Geramos então a série dos resíduos da equação da série lreaj contra uma constante incluindo
os termos de tendência linear e quadrática com o intuito de utilizar o programa GARMA para
confirmar a presença e sugerir a ordem dos processos auto-regressivos de forma a
melhorarmos o modelo.
R1 AIC 3.000000 2.000000 R2 SIC 1.000000 0.000000
Tabela 40 - Tabela PQ (GARMA) da série dlreaj
Quando o AIC e o SIC sugerem modelos diferentes, recomenda-se o uso do Schwarz Info
Criterion (SIC), primeiro, porque o SIC tipicamente indica um modelo mais parcimonioso,

98
sendo assim preservaríamos melhor os graus de liberdade do modelo e segundo, o SIC tem
boas propriedades de consistência em amostras grandes.
Geramos então a estimação com a equação sugerida pelo GARMA e obtivemos os seguintes
resultados:
Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 15:58 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments Convergence achieved after 3 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 0.006040 0.002735 2.208406 0.0289 AR(1) 0.455945 0.073696 6.186861 0.0000
R-squared 0.219634 Mean dependent var 0.006461 Adjusted R-squared 0.213896 S.D. dependent var 0.019696 S.E. of regression 0.017463 Akaike Info Criterion -5.243112 Sum squared resid 0.041473 Schwarz criterion -5.200688 Log likelihood 363.7747 Hannan-Quinn criter. -5.225872 F-statistic 38.27725 Durbin-Watson stat 1.837186 Prob(F-statistic) 0.000000
Inverted AR Roots .46
Tabela 41 - Sugestão do GARMA para Modelo 3A pelo critério SIC
Observamos que as estatísticas t e F são significativas, então analisaremos o correlograma.

99
Figura 32 - Correlograma da série sugerida pelo GARMA para Modelo 3A
Podemos observar uma melhora na dinâmica do correlograma, visto que comparado com a
Figura 29 (Correlograma da Série dlreaj), passamos a não rejeitar a hipótese nula de que o
resíduo é um ruído branco; no entanto, ainda podemos ver nos períodos 4 e 11 estamos fora

100
do intervalo de confiança o que poderia indicar componentes de ciclo não incluídas no
modelo.
Criamos então o Modelo 3B incluindo os termos AR(1), sugerido pelo GARMA e também os
termos MA(4) e MA(11), sugeridos pelo correlograma.
Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 16:03 Sample (adjusted): 1999M03 2010M08 Included observations: 138 after adjustments Convergence achieved after 7 iterations MA Backcast: 1998M04 1999M02
Variable Coefficient Std. Error t-Statistic Prob.
C 0.006096 0.002394 2.546574 0.0120 AR(1) 0.418779 0.077230 5.422491 0.0000 MA(4) 0.233586 0.080610 2.897730 0.0044
MA(11) -0.273480 0.086240 -3.171140 0.0019
R-squared 0.297376 Mean dependent var 0.006461 Adjusted R-squared 0.281645 S.D. dependent var 0.019696 S.E. of regression 0.016693 Akaike Info Criterion -5.319067 Sum squared resid 0.037341 Schwarz criterion -5.234219 Log likelihood 371.0156 Hannan-Quinn criter. -5.284587 F-statistic 18.90454 Durbin-Watson stat 1.834381 Prob(F-statistic) 0.000000
Inverted AR Roots .42 Inverted MA Roots .86 .75+.51i .75-.51i .40+.80i
.40-.80i -.14+.85i -.14-.85i -.61-.69i -.61+.69i -.83-.27i -.83+.27i
Tabela 42 - Modelo 3B
Observamos que as estatísticas t e F não são significativas, então testamos a significância dos
termos MA(4) e MA(11) através do teste de Wald com o intuito de verificar se os mesmos
poderiam ser igual a zero; o que foi rejeitado através da análise do P-valor; sendo assim, os
mesmos devem ser mantidos no modelo.

101
Wald Test: Equation: EQDLREAJ
Test Statistic Value df Probability
F-statistic 9.560355 (2, 134) 0.0001 Chi-square 19.12071 2 0.0001
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(3) 0.233586 0.080610 C(4) -0.273480 0.086240
Restrictions are linear in coefficients.
Tabela 43 - Teste de Wald do Modelo 3B dos termos MA(4) e MA(11)
Criamos ainda o Modelo 3C que representa o modelo sugerido pelo GARMA com o critério
AIC e observamos na tabela abaixo que as estatísticas t e F são significativas.
Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 16:16 Sample (adjusted): 1999M05 2010M08 Included observations: 136 after adjustments Convergence achieved after 155 iterations MA Backcast: 1999M03 1999M04
Variable Coefficient Std. Error t-Statistic Prob.
C 0.006720 0.002892 2.323372 0.0217 AR(1) 0.486893 0.075785 6.424705 0.0000 AR(2) -1.005835 0.024138 -41.67021 0.0000 AR(3) 0.501264 0.079347 6.317361 0.0000 MA(1) 0.042917 0.018742 2.289945 0.0236 MA(2) 0.980773 0.011363 86.31299 0.0000
R-squared 0.282828 Mean dependent var 0.006678 Adjusted R-squared 0.255245 S.D. dependent var 0.019684 S.E. of regression 0.016987 Akaike Info Criterion -5.269568 Sum squared resid 0.037515 Schwarz criterion -5.141068 Log likelihood 364.3306 Hannan-Quinn criter. -5.217349 F-statistic 10.25351 Durbin-Watson stat 2.014771 Prob(F-statistic) 0.000000
Inverted AR Roots .50 -.00+1.01i -.00-1.01i Inverted MA Roots -.02+.99i -.02-.99i
Tabela 44 - Modelo 3C

102
Seguimos então para a comparação dos Modelos 3A, 3B e 3C.
Iniciamos pela análise dos critérios SIC e AIC gerados nas regressões dos modelos, e pudemos
observar que ambos os critérios indicam o Modelo 3B; pois quanto menor o valor do
parâmetro, melhor é o modelo.
Modelo 3A Modelo 3B Modelo 3C
Modelos d(log(reaj)) c AR(1)
d(log(reaj)) c AR(1) MA(4) MA(11)
d(log(reaj)) c AR(1) AR(2) AR(3) MA(1) MA(2)
AIC -5.243112 -5.319067 -5.269568SIC -5.200688 -5.234219 -5.141068
Tabela 45 - Comparação dos Modelos 3A, 3B e 3C pelos critérios SIC e AIC
Comparamos também os correlogramas dos três modelos e pudemos observar que nos três
modelos havia períodos fora dos intervalos de confiança; porem o Modelo 2B foi o único
modelo que não rejeitou a hipótese de que seus resíduos são ruído branco em todos os
períodos.

103
Figura 33 - Comparação dos Correlogramas dos Modelos 3A, 3B e 3C
Observamos então os gráficos dos resíduos e pudemos ver que em todos os modelos não
notamos dinâmicas que indicariam a presença de componentes não incluídas nos modelos.
Figura 34 - Comparação dos Gráficos dos Resíduos dos Modelos 3A, 3B e 3C
Decidimos então fazer os testes de especificação de modelo para os três modelos.

104
O resultado do teste RESET indica que não rejeitamos a hipótese nula de que todos os
modelos não contêm erros de especificação; ou seja, estão bem especificados.
Ramsey RESET Test:
F-statistic 1.527078 Prob. F(2,134) 0.2209 Log likelihood ratio 3.110016 Prob. Chi-Square(2) 0.2112
Test Equation: Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 19:22 Sample: 1999M03 2010M08 Included observations: 138 Convergence achieved after 11 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 0.005967 0.002869 2.079586 0.0395 FITTED^2 -0.259440 10.73438 -0.024169 0.9808 FITTED^3 314.4172 236.2643 1.330786 0.1855
AR(1) 0.443488 0.090180 4.917781 0.0000
R-squared 0.237024 Mean dependent var 0.006461 Adjusted R-squared 0.219943 S.D. dependent var 0.019696 S.E. of regression 0.017395 Akaike Info Criterion -5.236663 Sum squared resid 0.040548 Schwarz criterion -5.151815 Log likelihood 365.3297 Hannan-Quinn criter. -5.202183 F-statistic 13.87603 Durbin-Watson stat 1.971050 Prob(F-statistic) 0.000000
Inverted AR Roots .44
Tabela 46 - Teste RESET para Modelo 3ª

105
Ramsey RESET Test:
F-statistic 0.422961 Prob. F(2,132) 0.6560 Log likelihood ratio 0.881551 Prob. Chi-Square(2) 0.6435
WARNING: the MA backcasts differ for the original and test equation. Under the null hypothesis, the impact of this difference vanishes asymptotically.
Test Equation: Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 19:20 Sample: 1999M03 2010M08 Included observations: 138 Convergence achieved after 15 iterations MA Backcast: 1998M04 1999M02
Variable Coefficient Std. Error t-Statistic Prob.
C 0.005994 0.002531 2.368625 0.0193 FITTED^2 -0.590482 7.285392 -0.081050 0.9355 FITTED^3 153.3157 177.4243 0.864119 0.3891
AR(1) 0.412586 0.086129 4.790305 0.0000 MA(4) 0.190528 0.085998 2.215496 0.0284
MA(11) -0.244247 0.096625 -2.527767 0.0127
R-squared 0.301850 Mean dependent var 0.006461 Adjusted R-squared 0.275405 S.D. dependent var 0.019696 S.E. of regression 0.016766 Akaike Info Criterion -5.296470 Sum squared resid 0.037103 Schwarz criterion -5.169198 Log likelihood 371.4564 Hannan-Quinn criter. -5.244750 F-statistic 11.41422 Durbin-Watson stat 1.921801 Prob(F-statistic) 0.000000
Inverted AR Roots .41 Inverted MA Roots .86 .74-.50i .74+.50i .39-.79i
.39+.79i -.13-.85i -.13+.85i -.60-.68i -.60+.68i -.83-.27i -.83+.27i
Tabela 47 - Teste RESET para Modelo 3B
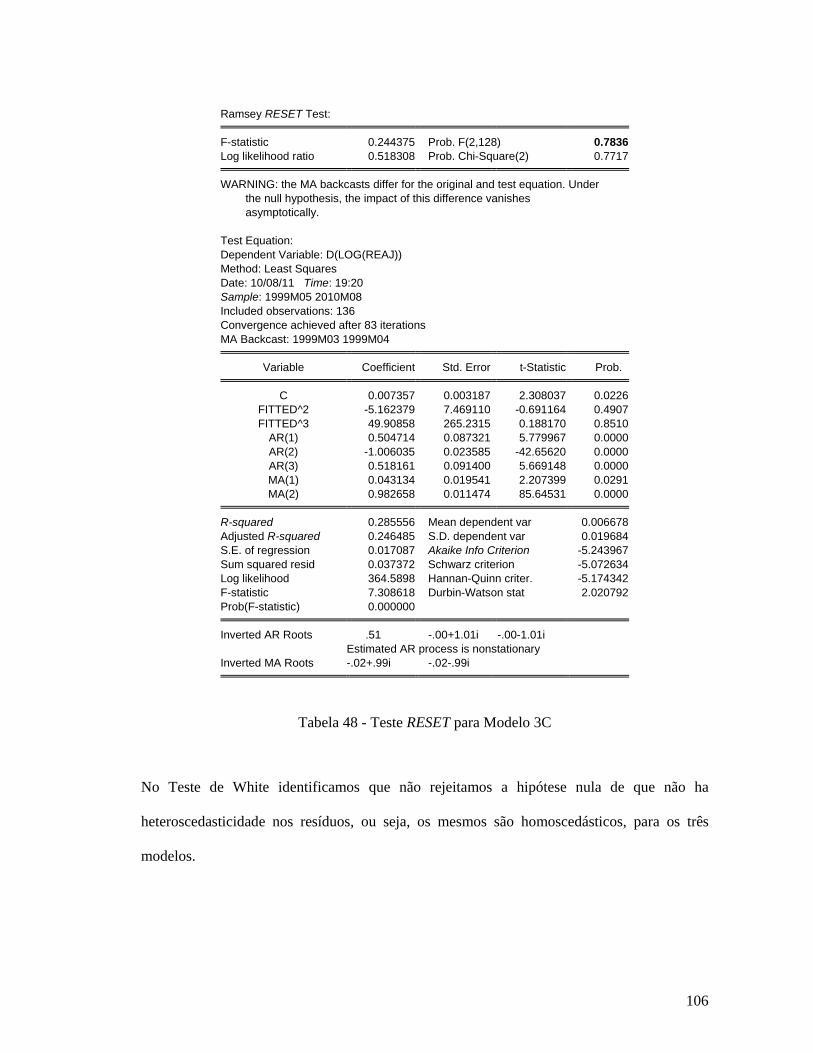
106
Ramsey RESET Test:
F-statistic 0.244375 Prob. F(2,128) 0.7836 Log likelihood ratio 0.518308 Prob. Chi-Square(2) 0.7717
WARNING: the MA backcasts differ for the original and test equation. Under the null hypothesis, the impact of this difference vanishes asymptotically.
Test Equation: Dependent Variable: D(LOG(REAJ)) Method: Least Squares Date: 10/08/11 Time: 19:20 Sample: 1999M05 2010M08 Included observations: 136 Convergence achieved after 83 iterations MA Backcast: 1999M03 1999M04
Variable Coefficient Std. Error t-Statistic Prob.
C 0.007357 0.003187 2.308037 0.0226 FITTED^2 -5.162379 7.469110 -0.691164 0.4907 FITTED^3 49.90858 265.2315 0.188170 0.8510
AR(1) 0.504714 0.087321 5.779967 0.0000 AR(2) -1.006035 0.023585 -42.65620 0.0000 AR(3) 0.518161 0.091400 5.669148 0.0000 MA(1) 0.043134 0.019541 2.207399 0.0291 MA(2) 0.982658 0.011474 85.64531 0.0000
R-squared 0.285556 Mean dependent var 0.006678 Adjusted R-squared 0.246485 S.D. dependent var 0.019684 S.E. of regression 0.017087 Akaike Info Criterion -5.243967 Sum squared resid 0.037372 Schwarz criterion -5.072634 Log likelihood 364.5898 Hannan-Quinn criter. -5.174342 F-statistic 7.308618 Durbin-Watson stat 2.020792 Prob(F-statistic) 0.000000
Inverted AR Roots .51 -.00+1.01i -.00-1.01i Estimated AR process is nonstationary
Inverted MA Roots -.02+.99i -.02-.99i
Tabela 48 - Teste RESET para Modelo 3C
No Teste de White identificamos que não rejeitamos a hipótese nula de que não ha
heteroscedasticidade nos resíduos, ou seja, os mesmos são homoscedásticos, para os três
modelos.

107
Heteroskedasticity Test: White
F-statistic 0.915995 Prob. F(2,135) 0.4026 Obs*R-squared 1.847628 Prob. Chi-Square(2) 0.3970 Scaled explained SS 4.469675 Prob. Chi-Square(2) 0.1070
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/08/11 Time: 19:25 Sample: 1999M03 2010M08 Included observations: 138 Collinear test regressors dropped from specification
Variable Coefficient Std. Error t-Statistic Prob.
C 0.000287 6.52E-05 4.397129 0.0000 GRADF_01*GRADF_02 0.006864 0.005225 1.313637 0.1912
GRADF_02^2 0.025117 0.075991 0.330534 0.7415
R-squared 0.013389 Mean dependent var 0.000301 Adjusted R-squared -0.001228 S.D. dependent var 0.000673 S.E. of regression 0.000674 Akaike Info Criterion -11.74632 Sum squared resid 6.13E-05 Schwarz criterion -11.68268 Log likelihood 813.4957 Hannan-Quinn criter. -11.72045 F-statistic 0.915995 Durbin-Watson stat 2.103783 Prob(F-statistic) 0.402591
Tabela 49 - Teste de White para Modelo 3A

108
Heteroskedasticity Test: White
F-statistic 0.426712 Prob. F(14,123) 0.9635 Obs*R-squared 6.392049 Prob. Chi-Square(14) 0.9556 Scaled explained SS 17.81466 Prob. Chi-Square(14) 0.2154
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/08/11 Time: 19:26 Sample: 1999M03 2010M08 Included observations: 138
Variable Coefficient Std. Error t-Statistic Prob.
C -0.001866 0.011410 -0.163576 0.8703 GRADF_01 0.007243 0.043004 0.168434 0.8665
GRADF_01^2 -0.006133 0.039982 -0.153383 0.8783 GRADF_01*GRADF_02 -0.005402 0.127717 -0.042294 0.9663 GRADF_01*GRADF_03 0.044016 0.129704 0.339359 0.7349 GRADF_01*GRADF_04 -0.056627 0.186046 -0.304371 0.7614
GRADF_02 0.006956 0.076290 0.091176 0.9275 GRADF_02^2 -0.052264 0.110109 -0.474659 0.6359
GRADF_02*GRADF_03 0.203942 0.218098 0.935091 0.3516 GRADF_02*GRADF_04 -0.102097 0.237609 -0.429684 0.6682
GRADF_03 -0.024539 0.077684 -0.315886 0.7526 GRADF_03^2 -0.050846 0.098763 -0.514823 0.6076
GRADF_03*GRADF_04 -0.158745 0.290811 -0.545870 0.5861 GRADF_04 0.032405 0.111925 0.289524 0.7727
GRADF_04^2 0.096640 0.105938 0.912231 0.3634
R-squared 0.046319 Mean dependent var 0.000271 Adjusted R-squared -0.062230 S.D. dependent var 0.000660 S.E. of regression 0.000681 Akaike Info Criterion -11.64505 Sum squared resid 5.70E-05 Schwarz criterion -11.32687 Log likelihood 818.5082 Hannan-Quinn criter. -11.51575 F-statistic 0.426712 Durbin-Watson stat 2.040466 Prob(F-statistic) 0.963538
Tabela 50 - Teste de White para Modelo 3B

109
Heteroskedasticity Test: White
F-statistic 1.068718 Prob. F(27,108) 0.3898 Obs*R-squared 28.67504 Prob. Chi-Square(27) 0.3768 Scaled explained SS 62.67233 Prob. Chi-Square(27) 0.0001
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 10/08/11 Time: 19:26 Sample: 1999M05 2010M08 Included observations: 136
Variable Coefficient Std. Error t-Statistic Prob.
C -0.038783 0.026181 -1.481354 0.1414 GRADF_01 0.156703 0.105552 1.484600 0.1406
GRADF_01^2 -0.156204 0.104990 -1.487797 0.1397 GRADF_01*GRADF_02 0.032695 0.129210 0.253036 0.8007 GRADF_01*GRADF_03 -0.087587 0.092479 -0.947104 0.3457 GRADF_01*GRADF_04 0.015841 0.118711 0.133445 0.8941 GRADF_01*GRADF_05 0.001973 0.081296 0.024268 0.9807 GRADF_01*GRADF_06 0.128268 0.062871 2.040172 0.0438
GRADF_02 -0.014295 0.064190 -0.222699 0.8242 GRADF_02^2 0.039268 0.108912 0.360549 0.7191
GRADF_02*GRADF_03 -0.011279 0.057188 -0.197230 0.8440 GRADF_02*GRADF_04 -0.049334 0.217415 -0.226911 0.8209 GRADF_02*GRADF_05 -0.093603 0.093462 -1.001515 0.3188 GRADF_02*GRADF_06 -0.006989 0.051455 -0.135818 0.8922
GRADF_03 0.046089 0.046478 0.991625 0.3236 GRADF_03^2 -0.046145 0.023532 -1.960984 0.0525
GRADF_03*GRADF_04 0.073578 0.057648 1.276335 0.2046 GRADF_03*GRADF_05 0.088515 0.044521 1.988150 0.0493 GRADF_03*GRADF_06 0.038319 0.046809 0.818637 0.4148
GRADF_04 -0.005348 0.058992 -0.090661 0.9279 GRADF_04^2 -0.030539 0.122353 -0.249594 0.8034
GRADF_04*GRADF_05 0.026705 0.072060 0.370592 0.7117 GRADF_04*GRADF_06 -0.032885 0.056618 -0.580832 0.5626
GRADF_05 0.000350 0.040863 0.008558 0.9932 GRADF_05^2 0.057694 0.039268 1.469237 0.1447
GRADF_05*GRADF_06 -0.033604 0.036509 -0.920425 0.3594 GRADF_06 -0.064816 0.031610 -2.050504 0.0427
GRADF_06^2 -0.045301 0.021134 -2.143483 0.0343
R-squared 0.210846 Mean dependent var 0.000276 Adjusted R-squared 0.013557 S.D. dependent var 0.000606 S.E. of regression 0.000601 Akaike Info Criterion -11.81323 Sum squared resid 3.91E-05 Schwarz criterion -11.21357 Log likelihood 831.2997 Hannan-Quinn criter. -11.56954 F-statistic 1.068718 Durbin-Watson stat 1.988905 Prob(F-statistic) 0.389785
Tabela 51 - Teste de White para Modelo 3C

110
O resultado do teste de Breush-Godfrey (LM Test) também indicou para todos os modelos que
não rejeitamos a hipótese nula de que não ha correlação serial nos resíduos; sendo assim,
podemos confiar nos parâmetros indicados pelos testes estatísticos.
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 1.408926 Prob. F(2,134) 0.2480 Obs*R-squared 2.842200 Prob. Chi-Square(2) 0.2414
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/08/11 Time: 19:32 Sample: 1999M03 2010M08 Included observations: 138 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C 0.000322 0.002747 0.117223 0.9069 AR(1) -0.184496 0.221967 -0.831187 0.4073
RESID(-1) 0.258938 0.231092 1.120501 0.2645 RESID(-2) -0.017737 0.133011 -0.133349 0.8941
R-squared 0.020596 Mean dependent var 2.41E-10 Adjusted R-squared -0.001331 S.D. dependent var 0.017399 S.E. of regression 0.017410 Akaike Info Criterion -5.234937 Sum squared resid 0.040618 Schwarz criterion -5.150089 Log likelihood 365.2107 Hannan-Quinn criter. -5.200457 F-statistic 0.939284 Durbin-Watson stat 1.973177 Prob(F-statistic) 0.423666
Tabela 52 - Teste Breush-Godfrey (LM Test) para Modelo 3A

111
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 1.839996 Prob. F(2,132) 0.1629 Obs*R-squared 3.742774 Prob. Chi-Square(2) 0.1539
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/08/11 Time: 19:32 Sample: 1999M03 2010M08 Included observations: 138 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C 0.000441 0.002396 0.184216 0.8541 AR(1) -0.338462 0.241558 -1.401162 0.1635 MA(4) 0.014384 0.081920 0.175581 0.8609
MA(11) 0.010428 0.085910 0.121382 0.9036 RESID(-1) 0.410964 0.248634 1.652886 0.1007 RESID(-2) 0.059776 0.133601 0.447425 0.6553
R-squared 0.027122 Mean dependent var 1.69E-05 Adjusted R-squared -0.009730 S.D. dependent var 0.016509 S.E. of regression 0.016590 Akaike Info Criterion -5.317579 Sum squared resid 0.036328 Schwarz criterion -5.190307 Log likelihood 372.9129 Hannan-Quinn criter. -5.265859 F-statistic 0.735969 Durbin-Watson stat 2.005865 Prob(F-statistic) 0.597766
Tabela 53 - Teste Breush-Godfrey (LM Test) para Modelo 3B
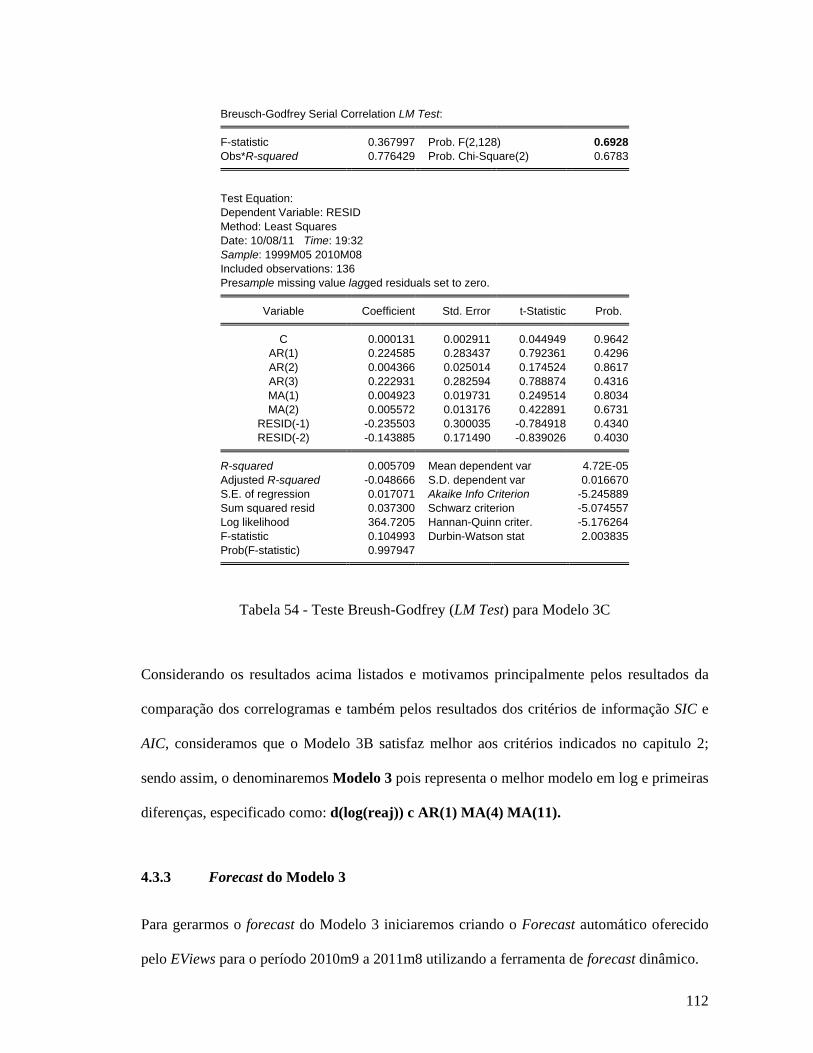
112
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 0.367997 Prob. F(2,128) 0.6928 Obs*R-squared 0.776429 Prob. Chi-Square(2) 0.6783
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 10/08/11 Time: 19:32 Sample: 1999M05 2010M08 Included observations: 136 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
C 0.000131 0.002911 0.044949 0.9642 AR(1) 0.224585 0.283437 0.792361 0.4296 AR(2) 0.004366 0.025014 0.174524 0.8617 AR(3) 0.222931 0.282594 0.788874 0.4316 MA(1) 0.004923 0.019731 0.249514 0.8034 MA(2) 0.005572 0.013176 0.422891 0.6731
RESID(-1) -0.235503 0.300035 -0.784918 0.4340 RESID(-2) -0.143885 0.171490 -0.839026 0.4030
R-squared 0.005709 Mean dependent var 4.72E-05 Adjusted R-squared -0.048666 S.D. dependent var 0.016670 S.E. of regression 0.017071 Akaike Info Criterion -5.245889 Sum squared resid 0.037300 Schwarz criterion -5.074557 Log likelihood 364.7205 Hannan-Quinn criter. -5.176264 F-statistic 0.104993 Durbin-Watson stat 2.003835 Prob(F-statistic) 0.997947
Tabela 54 - Teste Breush-Godfrey (LM Test) para Modelo 3C
Considerando os resultados acima listados e motivamos principalmente pelos resultados da
comparação dos correlogramas e também pelos resultados dos critérios de informação SIC e
AIC, consideramos que o Modelo 3B satisfaz melhor aos critérios indicados no capitulo 2;
sendo assim, o denominaremos Modelo 3 pois representa o melhor modelo em log e primeiras
diferenças, especificado como: d(log(reaj)) c AR(1) MA(4) MA(11).
4.3.3 Forecast do Modelo 3
Para gerarmos o forecast do Modelo 3 iniciaremos criando o Forecast automático oferecido
pelo EViews para o período 2010m9 a 2011m8 utilizando a ferramenta de forecast dinâmico.

113
240
260
280
300
320
340
360
380
2010Q4 2011Q1 2011Q2 2011Q3
YHAT3 ± 2 S.E.
Forecast: YHAT3Actual: REAJForecast sample: 2010M09 2011M08Included observations: 12Root Mean Squared Error 10.38971Mean Absolute Error 7.844102Mean Abs. Percent Error 2.585019Theil Inequality Coefficient 0.017597 Bias Proportion 0.570006 Variance Proportion 0.034499 Covariance Proportion 0.395495
Figura 35 - Índices do Forecast do EViews para Modelo 3
Consideramos que o valor do Erro Absoluto Médio, Mean Absolute Error (MAE), é
satisfatório quando o comparamos com a escala dos valores reais, cujo mínimo é 108,94 e o
máximo é 312,35. Consideramos que o Erro Percentual Absoluto Médio, Mean Absolute
Percentage Error (MAPE), é também satisfatório visto que a mesma encontra-se abaixo de
10%.
Consideramos que o Coeficiente de Desigualdade de Theil (TIC) é satisfatório visto que o seu
valor de 0,017597 não se aproxima muito de 1; porem quando observamos a Proporção de
Viés, Bias Proportion, consideramos que seu valor de 0,570006 está um pouco elevado, o que
poderia indicar um erro sistemático na previsão. A Proporção de Variância, Variance
Proportion, apresentou um valor de 0,034499 o qual consideramos satisfatório o que indica
que variação da previsão se afasta pouco da variação da série real; porem a Proporção de Co-
Variância, Covariance Proportion, apresentou um valor de 0,395495, o que consideramos

114
também satisfatório indicando que os erros não sistemáticos são parte significante das 3
componentes do TIC.
Posteriormente geramos o gráfico do forecast com o intuito de observar seu comportamento
comparado com os dados do hold-out sample.
100
150
200
250
300
350
400
99 00 01 02 03 04 05 06 07 08 09 10 11
REAJ YHAT3YHAT_UP3 YHAT_LO3
Figura 36 - Gráfico do Forecast do Modelo 3
Analisando o gráfico do forecast do Modelo 3 podemos verificar que os valores reais, REAJ,
ficaram dentro do intervalo de confiança, YHAT_UP1 e YHAT_LO1. Podemos ainda
observar que os valores de forecast, YHAT1, ficaram próximos aos valores da série REAJ.

115
4.4 COMPARAÇÃO DOS FORECASTS
A seguir comparamos os Modelos 1, 2 e 3 de acordo com os parâmetros estabelecidos no item
2.4 do Capitulo 2.
250
260
270
280
290
300
310
09M07 10M01 10M07 11M01 11M07 12M01 12M07
REAJ YHAT1YHAT2 YHAT3
Figura 37 - Comparação dos Gráficos de Forecast dos Modelos 1, 2 e 3 em relação aos dados
reais
Pela comparação do gráfico dos forecasts podemos observar que o Modelo 3 (YHAT3) é o
que mais se aproxima dos valores da série real (REAJ). Observamos que o Modelo 1
(YHAT1) tem um comportamento semelhante ao Modelo 3 porém está subestimado em
relação aos valores da série real (REAJ). Podemos ver ainda que o Modelo 2 (YHAT2)
encontra-se totalmente afastado dos valores da série real (REAJ), o que indica que o mesmo
está extremamente subestimado.

116
Observa-se também que dentre os 3 modelos, o Modelo 3 é o que apresenta mais persistência,
ou seja, demora mais para convergir para a média condicional.
Sendo assim, consideramos pela análise do gráfico dos forecasts que o Modelo 3 é o que
melhor representa o forecast para o fator de reajustamento.

117
Tabela 55 - Comparação do desvio entre Valor Previsto e Valor Observado para os Modelos
1, 2 e 3, separado por período

118
Observando a tabela acima, a qual indica o desvio entre os valores previstos e os valores reais
separados em cada período, podemos perceber que o Modelo 3 foi o que indicou o melhor
desempenho pois indicou o menor desvio percentual em todos os períodos. Podemos também
identificar que o Modelo 2 apresentou o pior desempenho.
Tabela 56 - Comparação de índices calculados para avaliação de Modelos (TIC, Bias Prop.,
Variance Prop. e Covariance Prop.)
Comparando os índices de avaliação dos modelos podemos novamente observar a
superioridade do Modelo 3 pois apresentou o menor valor de TIC bem como apresentou a
melhor Proporção para a distribuição das componentes de TIC, ou seja, uma Proporção de Co-
Variância elevada, uma Proporção de Variância baixa e uma Proporção de Viés que
consideramos satisfatória quando a comparamos com os demais modelos.

119
Tabela 57 - Cálculo do MSE dos Modelos 1, 2 e 3 em MS Excel

120
Tabela 58 - Índices calculados para comparação de Modelos (MSE, RMSE, MAE e MAPE)
Finalmente, analisando as medidas de aderência MSE, RMSE, MAE e MAPE, podemos
confirmar a superioridade do Modelo 3 em relação aos demais modelos pois apresentou o
menor valor para todos os parâmetros.
Dadas as comparações acima citadas, identificamos que o Modelo 3 é o modelo que melhor
representa a previsão para o fator de reajustamento. O modelo que a apresentou o segundo
melhor desempenho foi o Modelo 1 e o modelo que apresentou o pior desempenho foi o
Modelo 2.
Modelo 3
Comando de Estimação: LS(DERIV=AA) D(LOG(REAJ)) C AR(1) MA(4) MA(11)
Equação de Estimação: D(LOG(REAJ)) = C(1) + [AR(1)=C(2), MA(4)=C(3),
MA(11)=C(4)

121
Coeficientes: D(LOG(REAJ)) = 0.00609555641514 + [AR(1)=0.41877890989,
MA(4)=0.233586424318, MA(11)=-0.273480180017

122
5 CONCLUSÃO
O presente trabalho teve como objetivo propor um modelo para a previsão do Fator de
Reajustamento para os contratos de aquisição de equipamentos submarinos do tipo ponto a
ponto pela Petrobras, com o intuito de auxiliar na previsibilidade do valor final destes
contratos aumentando conseqüentemente a previsibilidade da rentabilidade deste negócio.
Neste sentido propusemos uma análise do Fator de Reajustamento e dos índices que o
compõem. Esta análise foi restrita a fórmula paramétrica composta por: 40% relativo à
variação dos custos dos insumos nacionais medidos através do índice da Coluna 30 divulgada
pela Fundação Getulio Vargas; 40% relativo à variação dos custos de mão-de-obra medidos
através da Coluna máquinas mecânicas divulgada pela Associação Brasileira de da Infra-
estrutura e Indústrias de Base e 20% relativo à variação dos custos dos insumos importados
medidos através CRUSpi Global (Commodities Research Unit Ltd. Steel Price Index),
conjugada à taxa do câmbio comercial para venda do dólar americano
Para este estudo foi aplicada a metodologia Box-Jenkins em modelos univariados permitindo
a análise, previsão e escolha do modelo proposto, com base em três diferentes abordagens:
variável em nível com tendência estocástica, variável em log com tendência determinística e
variável em log com tendência estocástica.

123
Em cada uma das abordagens foram analisados 3 modelos: dois modelos indicados pelos
critérios SIC e AIC de programa GARMA e um modelo indicado pelo autor através da análise
dos correlogramas.
Dentre os 9 modelos, foram escolhidos 3 modelos os quais foram utilizados para realizar as
possíveis previsões do Fator de Reajustamento, os quais foram posteriormente comparados de
forma a indicar dentre eles, o que melhor se aderia à curva de reajustamento.
A definição dos modelos foi feita com os dados do periodo1999m1 a 2010m8, contendo 140
observações e a avaliação e comparação de modelos foi feita com os dados do período
2010m9 a 2010m11, contendo 12 observações.
Cabe também destacar a não significância da sazonalidade para a série Fator de
Reajustamento bem como a persistência de indicação de componentes de ciclo nos períodos 4
e 11 em praticamente todos os modelos estudados.
Ressaltamos ainda a forte indicação de que a série fator de reajustamento é não estacionaria;
ou seja, é fortemente influenciada por tendência uma estocástica, o que indicaria que a melhor
previsão para o Fator de reajustamento amanha, é o valor do mesmo no dia de hoje. Isto pode
ser identificado pelo poder de previsão dos Modelos 1 e 3, ambos utilizando como base a
presença de tendência estocástica; pelo baixo desempenho apresentado pelo Modelo 2 o qual
sugeria a presença de uma tendência determinística e também pela análise dos índices que
compõem o fator de reajustamentos os quais também se apresentaram como não estacionários.
Finalmente, O estudo demonstrou a superioridade do Modelo 3 que pode ser constatada em
todos os parâmetros de comparação propostos no Capitulo 2, cujos resultados seguem abaixo:
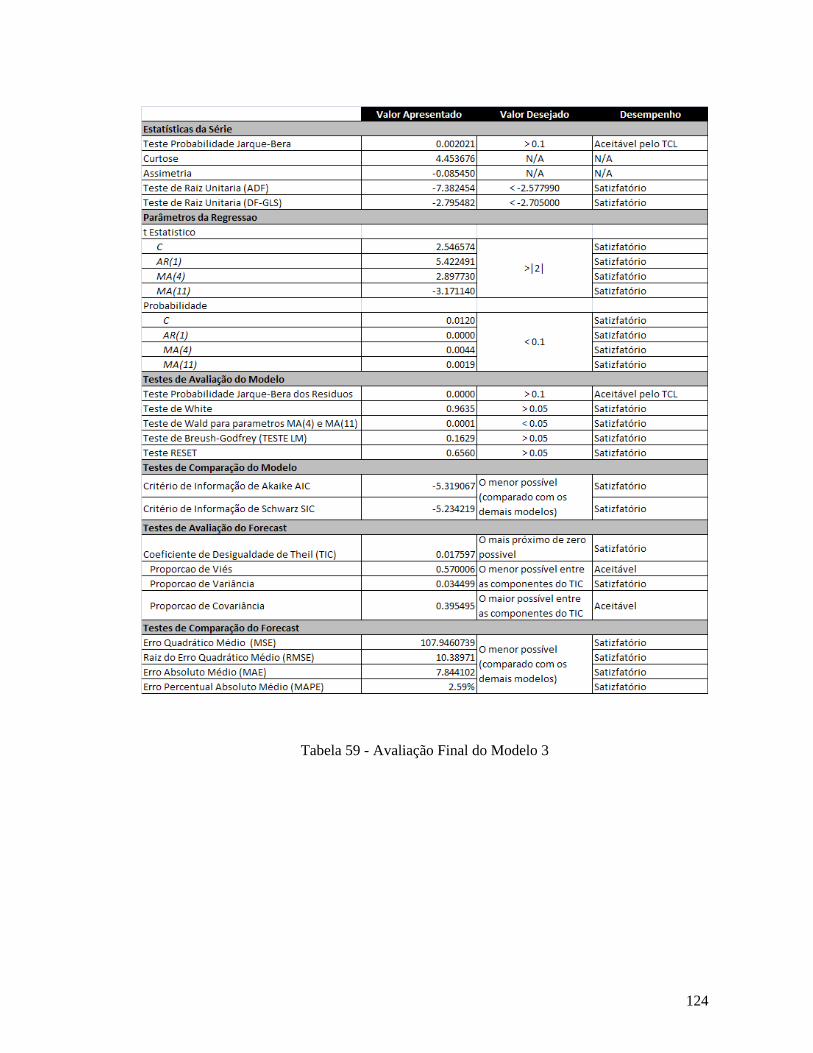
124
Tabela 59 - Avaliação Final do Modelo 3

125
SUGESTÕES PARA TRABALHOS FUTUROS
Avaliação do impacto do câmbio sobre os índices setoriais de forma a expurgar a incerteza do
câmbio, o que acreditamos que aumentaria significativamente o nível de previsibilidade do
modelo pois através da análise do gráfico e dos dados dos índices setoriais, pudemos observar
que o câmbio está fortemente correlacionado com o erro de previsão destes índices setoriais.
Avaliação do forecast pelo método VAR-VEC, utilizando variáveis explicativas como forma
de melhorar o modelo de previsão. As variáveis poderiam ser, por exemplo, o preço do
petróleo que poderia estar correlacionado ao preço do aço (CRUSpi); a inflação que poderia
estar correlacionada ao custo dos insumos nacionais (Col 30); a renda que poderia estar
correlacionada com o índice de mão-de-obra (ABDIB); dentre outras possíveis variáveis
independentes.
Combinação de forecasts com metodologia Box-Jenkins. Previsão dos índices setoriais
individualmente e posterior aplicação na fórmula paramétrica para a geração da previsão do
fator de reajustamento.

126
Avaliação da composição de custo dos equipamentos submarinos e avaliação da aderência
desta curva ao cálculo da fórmula paramétrica; ou seja, avaliar se a fórmula paramétrica
realmente corrige as oscilações de preço, protegendo assim o custo dos projetos e aumentando
a previsibilidade da rentabilidade deste negócio.

127
REFERÊNCIAS BIBLIOGRÁFICAS
ANDRADE, João S.. Apontamentos de Econometria Aplicada. Disponível em: <http://www4.fe.uc.pt/jasa/estudos/econometria.pdf>. Data de acesso: 23 de Outubro de 2011.
ASSOCIACAO BRASILEIRA DA INFRA- ESTRUTURA E INDÚSTRIAS DE BASE. Coluna Máquinas Mecânicas. Disponível em: <http://www.abdib.org.br/index/index.cfm?CFID=1838197&CFTOKEN=69703839>. Data de acesso: 23 de Outubro de 2011.
BANCO CENTRAL DO BRASIL. Câmbio e Capitais Internacionais – Taxas de Câmbio. Disponível em: <http://www.sisbacen.gov.br/>. Data de acesso: 23 de Outubro de 2011.
BOSTON COLLEGE. Time Series Econometrics. Disponível em: < http://fmwww.bc.edu/ec-c/s2003/821/ec821.sect05.nn1.pdf>. Data de acesso: 23 de Outubro de 2011.
CALDEIRA, Tereza M. Estatística Descritiva. Disponível em: <http://mail.esa.ipcb.pt/tmlc/EST_DESC.pdf>. Data de acesso: 23 de Outubro de 2011.
COMMODITIES RESEARCH UNIT. Steel Price Index. Disponível em: <http://cruonline.crugroup.com/Steel/CRUSpi.aspx>. Data de acesso: 23 de Outubro de 2011.
CUNHA, Ricardo Igor T. Sustentabilidade Fiscal. Dissertação de Mestrado Profissionalizante em Economia, IBMEC-RJ, 2010.
DECRETO nº. 2.745, de 24 de agosto de 1998. Aprova o Regulamento do Procedimento Licitatório Simplificado da Petróleo Brasileiro S.A. - PETROBRÁS previsto no art. 67 da Lei nº 9.478, de 6 de agosto de 1997. Disponível em: <http://www.planalto.gov.br/ccivil_03/decreto/D2745.htm> Data de acesso: 25 de agosto de 2010.
DIEBOLD, X. Francis. Elements of Forecasting. Editora Thomson South-Western, 4a edição, 2007.
EGLER, Cláudio A.G.; PIRES DO RIO, Gisela A.. Territórios do petróleo no Brasil: redes globais e governança local. Disponível em: <http://www.laget.igeo.ufrj.br/egler/pdf/Egler_Rio.pdf>. Data de acesso: 25 de agosto de 2010.

128
FARIA, Eduardo S., Previsão do Consumo de Cerveja no Estado do Rio de Janeiro. Dissertação de Mestrado Profissionalizante em Economia, IBMEC-RJ, 2009
FUNDAÇÃO GETULIO VARGAS. Índice Geral de Preços. Disponível em: <http://www.fgv.br/principal/idx_principal.asp>. Data de acesso: 23 de Outubro de 2011.
GAYAWAN, Erza; IPINYOMI, Rueben A. A Comparison of Akaike, Schwarz and R Square Criteria for Model Selection Using Some Fertility Models. Disponível em: <http://www.insipub.com/ajbas/2009/3524-3530.pdf>. Data de acesso: 23 de Outubro de 2011.
HEIJI, Christiaan; BOER, Paul de; FRANSES, Philip H.; KLOEK, Teun; DJIK, Herman, K. van. Econometric Methods with Application in Business and Economics, Editora Oxford, 1ª Edição, 2004.
LIMA, Samanta. Multinacionais investem em tecnologia para exploração do pré-sal. Disponível em: <http://www1.folha.uol.com.br/mercado/773194-multinacionais-investem-em-tecnologia-para-exploracao-do-pre-sal.shtml>. Data de acesso: 25 de agosto de 2010.
MCQUARRIE, Allan D. R.; TSAI, Chih-Ling. Regression and Time Series Model Selection. Disponível em: <http://books.google.com.br/books?id=INw5s0jA14wC&pg=PA228&lpg=PA228&dq=compare+model++negative+SIC+AIC&source=bl&ots=Zkx9QtzlQ5&sig=Yfw2wmFL_6qUmgcbi-kxOauqvAk&hl=pt-BR#v=onepage&q&f=false>. Data de acesso: 23 de Outubro de 2011.
LEMOS, Alan; MYNBAEV, Kairat T. Manual de Econometria, Editora FGV, 1ª Edição, 2004.
LEROY, Felipe L. D. Projeção do preço futuro de uma ação da Usiminas: Uma abordagem econométrica. Disponível em: <http://www.fac.br/multiplosarquivos/Vol5Parte03.pdf>. Data de acesso: 23 de Outubro de 2011.
NAU, Robert F. How to Compare Models. Disponível em: <http://www.duke.edu/~rnau/compare.htm>. Data de acesso: 23 de Outubro de 2011.
PETROBRAS. CRP 2003 - Condições de Reajustamento e Pagamento da Petrobras. Disponível em: <http://www2.petrobras.com.br/CanalFornecedor/portugues/requisitocontratacao/requisito_condicoesdereajustamento-2003.asp> Data de acesso: 25 de agosto de 2010.
PINDYCK, Robert S.; RUBINFELD, Daniel L. Econometric Models and Economic Forecasts. Editora McGraw-Hill/Irwin, 4a Edição, 1997.
PROCESSO licitatório na administração pública: um estudo de caso na Petróleo Brasileiro S.A. – Petrobras. Disponível em: <http://www.cfc.org.br/uparq/TerceiroLugar.pdf>. Data de acesso: 25 de agosto de 2010.
RICHARDS, Robert. Forecasting Using EViews 2.0: An Overview. Disponível em: <http://faculty.washington.edu/ezivot/introforecast.PDF>. Data de acesso: 23 de Outubro de 2011.

129
SOUZA, Vanderlei S.; TIMOFEICZYK, Romano; ALMEIDA, Alexandre N. EISFELD, Cristiane L. Análise de séries temporais de preços de compensado no estado do Paraná, com a utilização da metodologia de Box & Jenkins. Disponível em: <http://www.ecopar.ufpr.br/artigos/a7_083.pdf>. Data de acesso: 23 de Outubro de 2011.
STOCK, James H.; WATSON, Mark W. Econometria. Editora Pierson, 1ª Edição, 2004
WOOLDRIDGE, Jeffrey M. Introdução à Econometria – Uma Abordagem Moderna. Editora Cengage Learning, 1ª Edição, 2006.

130
APÊNDICE A - ANÁLISES COMPLEMENTARES DOS ÍNDICES SETORIAIS E CÂMBIO
Análise da série Índice CRUSpi Global
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica positiva, pois temos um achatamento da curva e notamos mais massa na cauda da
esquerda.
0
4
8
12
16
20
4.2 4.4 4.6 4.8 5.0 5.2 5.4 5.6
Series: LCRUSPIGLOBALSample 1999M01 2011M04Observations 148
Mean 4.845424Median 4.931625Maximum 5.681673Minimum 4.232946Std. Dev. 0.367156Skewness 0.047135Kurtosis 2.024871
Jarque-Bera 5.918543Probability 0.051857
Figura 2 – Histograma da série lcruspiglobal (log da série cruspiglobal)

131
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box (1978) apresenta a autocorrelação como significativas pois
rejeitamos a hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através da função de autocorrelação (FAC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma
queda para zero depois de poucos lags, o que caracterizaria um processo de média móvel
(MA).
Podemos também observar na função de autocorrelação parcial (FACP) a presença de lags
significativos nos períodos 1, 2, ao nível de significância de 10%.
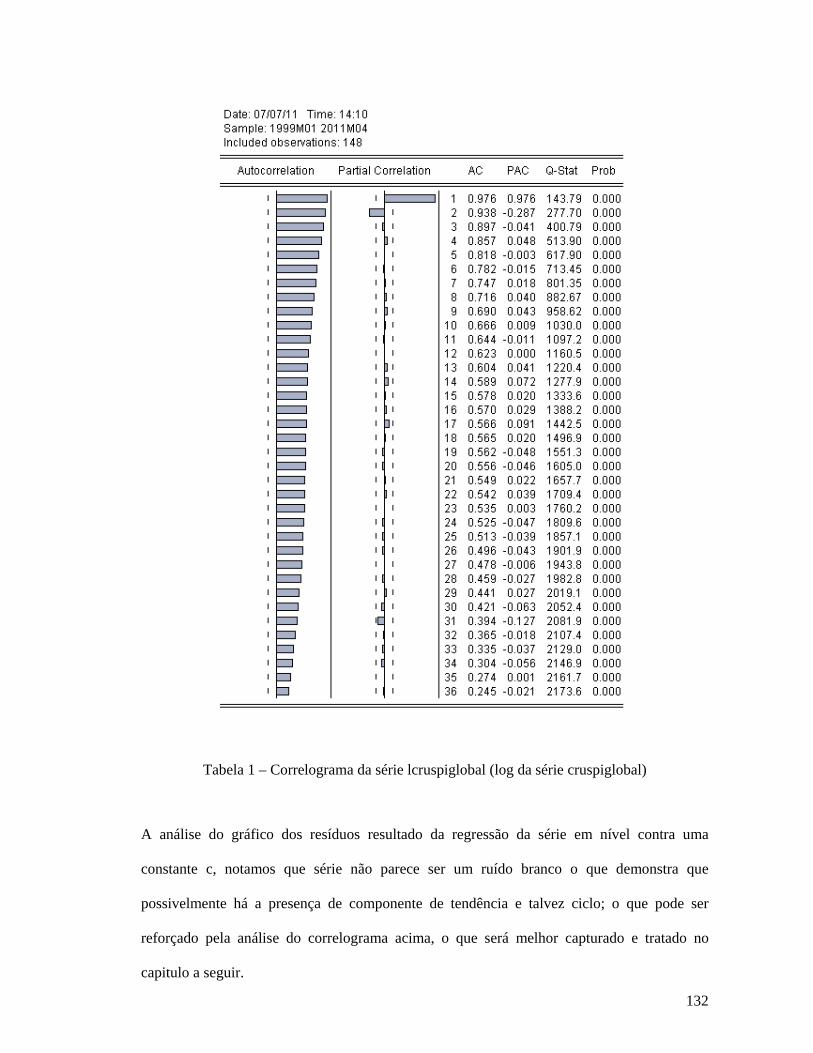
132
Tabela 1 – Correlograma da série lcruspiglobal (log da série cruspiglobal)
A análise do gráfico dos resíduos resultado da regressão da série em nível contra uma
constante c, notamos que série não parece ser um ruído branco o que demonstra que
possivelmente há a presença de componente de tendência e talvez ciclo; o que pode ser
reforçado pela análise do correlograma acima, o que será melhor capturado e tratado no
capitulo a seguir.
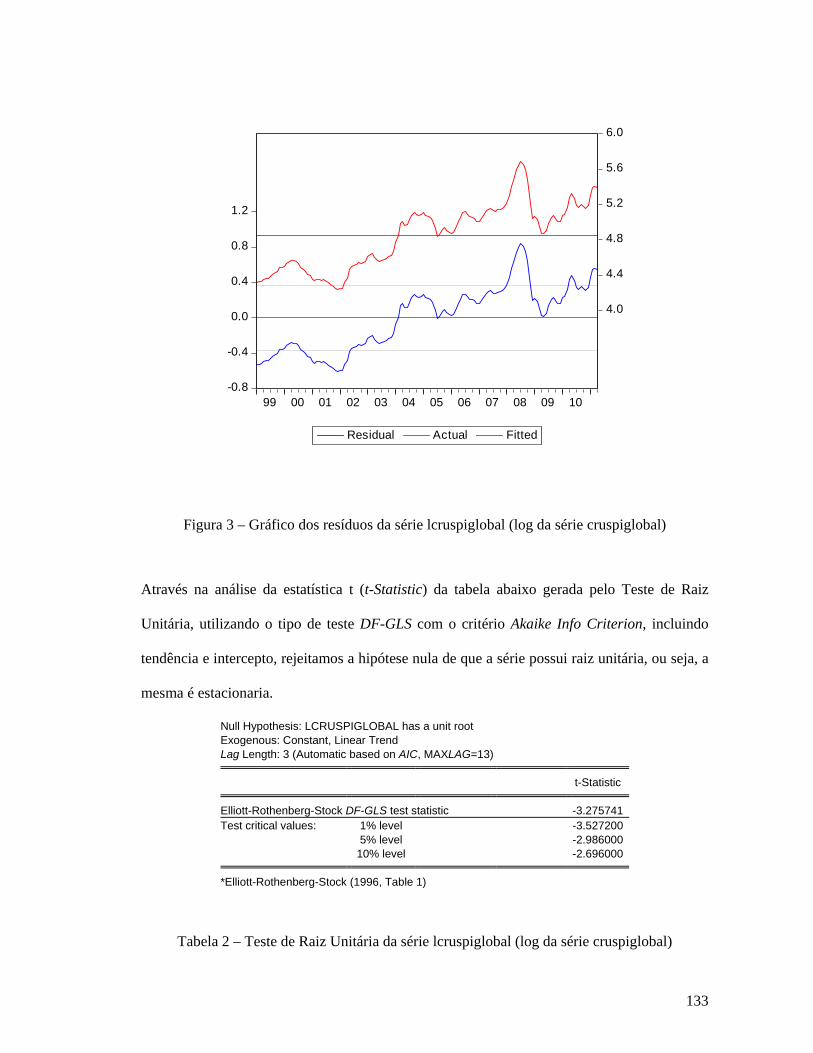
133
-0.8
-0.4
0.0
0.4
0.8
1.2
4.0
4.4
4.8
5.2
5.6
6.0
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 3 – Gráfico dos resíduos da série lcruspiglobal (log da série cruspiglobal)
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste DF-GLS com o critério Akaike Info Criterion, incluindo
tendência e intercepto, rejeitamos a hipótese nula de que a série possui raiz unitária, ou seja, a
mesma é estacionaria.
Null Hypothesis: LCRUSPIGLOBAL has a unit root Exogenous: Constant, Linear Trend Lag Length: 3 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -3.275741 Test critical values: 1% level -3.527200
5% level -2.986000 10% level -2.696000
*Elliott-Rothenberg-Stock (1996, Table 1)
Tabela 2 – Teste de Raiz Unitária da série lcruspiglobal (log da série cruspiglobal)

134
Análise da série Índice Coluna 30 (IPA-OG-DI)
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica negativa, pois temos um achatamento da curva e notamos mais massa na cauda da
direita.
0
4
8
12
16
20
24
28
3.4 3.6 3.8 4.0 4.2 4.4 4.6 4.8
Series: LCOL30Sample 1999M01 2011M04Observations 148
Mean 4.287711Median 4.555043Maximum 4.866934Minimum 3.261437Std. Dev. 0.486838Skewness -0.579183Kurtosis 1.777468
Jarque-Bera 17.49111Probability 0.000159
Figura 5 – Histograma da série lcol30 (log da série col30)
Analisando o correlograma da série podemos observar que o P valor (Prob.) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-

135
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma queda
para zero depois de poucos lags, o que caracterizaria um processo de média móvel (MA).
Podemos também observar na autocorrelação parcial (PC) a presença lag significativo no
período 1, ao nível de significância de 10%.
Tabela 3 – Correlograma da série lcol30 (log da série col30)
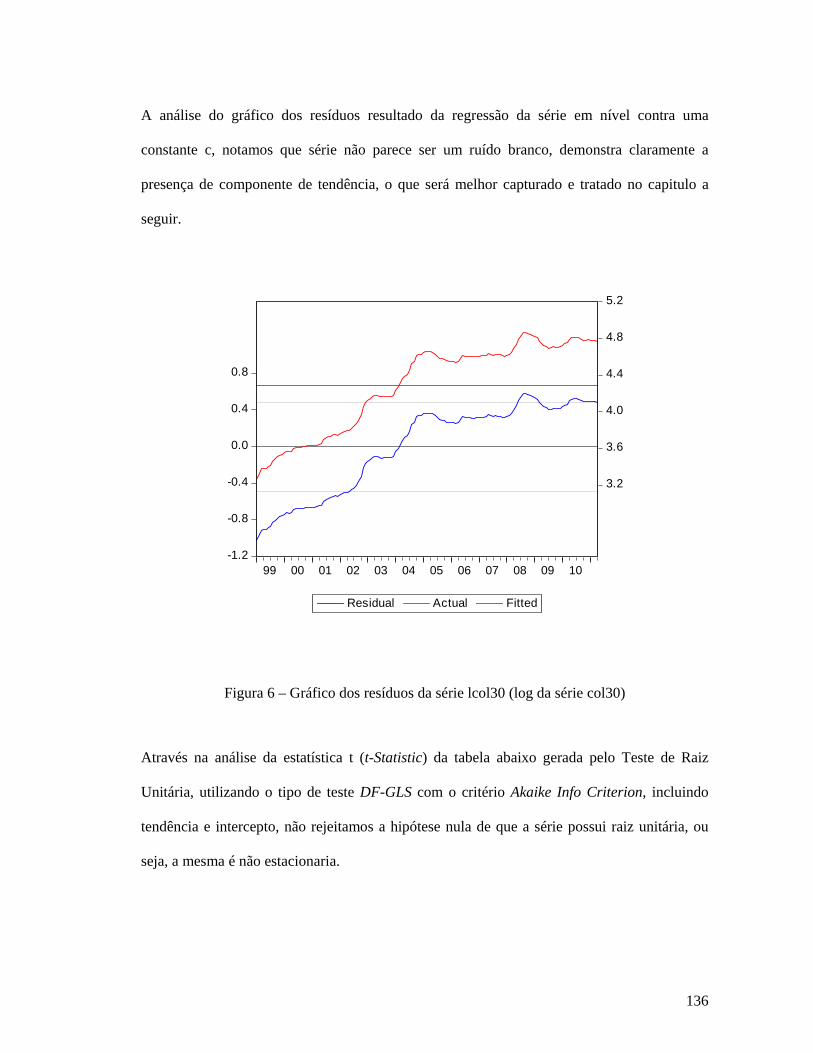
136
A análise do gráfico dos resíduos resultado da regressão da série em nível contra uma
constante c, notamos que série não parece ser um ruído branco, demonstra claramente a
presença de componente de tendência, o que será melhor capturado e tratado no capitulo a
seguir.
-1.2
-0.8
-0.4
0.0
0.4
0.8
3.2
3.6
4.0
4.4
4.8
5.2
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 6 – Gráfico dos resíduos da série lcol30 (log da série col30)
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste DF-GLS com o critério Akaike Info Criterion, incluindo
tendência e intercepto, não rejeitamos a hipótese nula de que a série possui raiz unitária, ou
seja, a mesma é não estacionaria.

137
Null Hypothesis: LCOL30 has a unit root Exogenous: Constant, Linear Trend Lag Length: 2 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.068969 Test critical values: 1% level -3.526000
5% level -2.985000 10% level -2.695000
*Elliott-Rothenberg-Stock (1996, Table 1)
Tabela 4 – Teste de Raiz Unitária da série lcol30 (log da série col30)
Análise da série Índice Coluna Máquinas Mecânicas
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica negativa, pois temos um achatamento da curva e notamos mais massa na cauda da
direita.

138
0
2
4
6
8
10
12
14
5.250 5.375 5.500 5.625 5.750 5.875 6.000 6.125
Series: LMAQMEQSample 1999M01 2011M04Observations 148
Mean 5.709047Median 5.781221Maximum 6.147977Minimum 5.244020Std. Dev. 0.280739Skewness -0.249346Kurtosis 1.663941
Jarque-Bera 12.54144Probability 0.001891
Figura 8 – Histograma da série lmaqmec (log da série maqmec)
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma queda
para zero depois de poucos lags, o que caracterizaria um processo de média móvel (MA).
Podemos também observar na autocorrelação parcial (PC) a presença de lag significativo no
período 1, ao nível de significância de 10%.
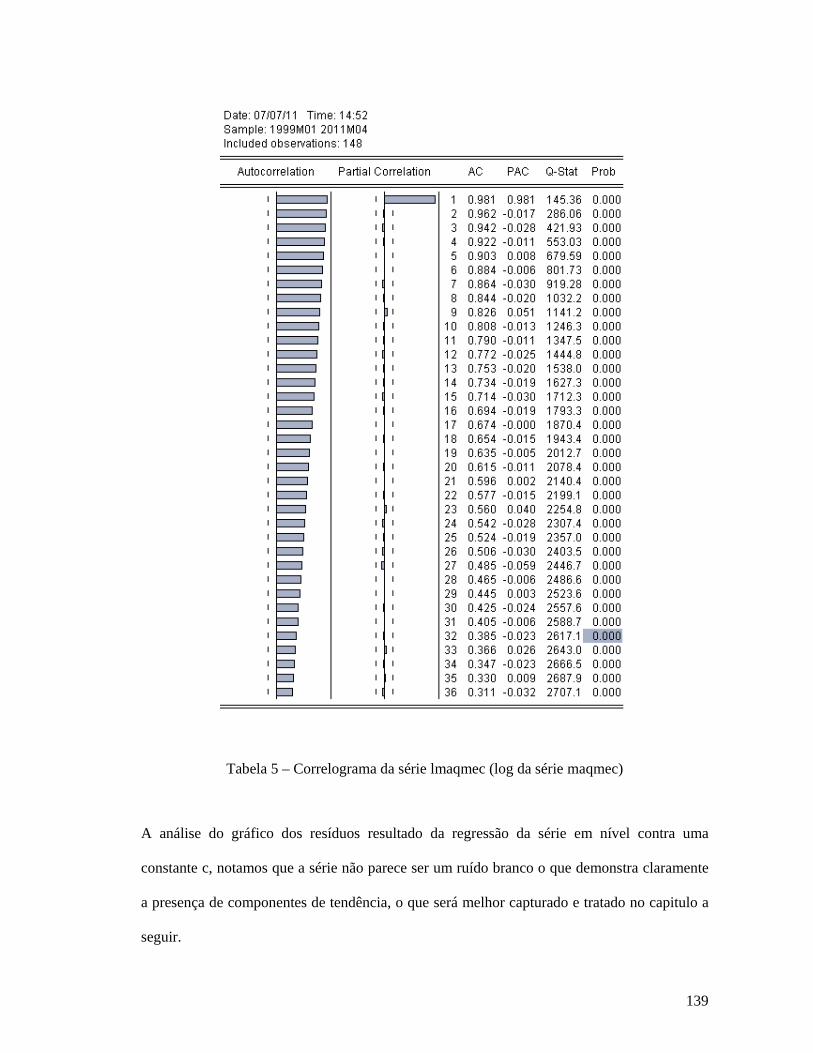
139
Tabela 5 – Correlograma da série lmaqmec (log da série maqmec)
A análise do gráfico dos resíduos resultado da regressão da série em nível contra uma
constante c, notamos que a série não parece ser um ruído branco o que demonstra claramente
a presença de componentes de tendência, o que será melhor capturado e tratado no capitulo a
seguir.

140
-.6
-.4
-.2
.0
.2
.4
.6
5.2
5.4
5.6
5.8
6.0
6.2
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 9 – Gráfico dos resíduos da série lmaqmec (log da série maqmec)
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste DF-GLS com o critério Akaike Info Criterion, incluindo
tendência e intercepto, não rejeitamos a hipótese nula de que a série possui raiz unitária, ou
seja, a mesma é não estacionaria.
Null Hypothesis: LMAQMEQ has a unit root Exogenous: Constant, Linear Trend Lag Length: 13 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.838253 Test critical values: 1% level -3.539200
5% level -2.996000 10% level -2.706000
*Elliott-Rothenberg-Stock (1996, Table 1)
Tabela 6 – Teste de Raiz Unitária da série lmaqmec (log da série maqmec)

141
Análise da série Câmbio
Analisando o histograma da série pode-se notar através do resultado da Probabilidade (P
Valor), que rejeitamos a hipótese de normalidade, ou seja, trata-se de uma série com
distribuição não normal. Podemos também notar que trata-se de uma distribuição platicúrtica
assimétrica positiva, pois temos um achatamento da curva e notamos mais massa na cauda da
esquerda.
0
2
4
6
8
10
12
14
0.500 0.625 0.750 0.875 1.000 1.125 1.250
Series: LCAMBIOSample 1999M01 2011M04Observations 148
Mean 0.782095Median 0.765933Maximum 1.336552Minimum 0.406731Std. Dev. 0.218802Skewness 0.536541Kurtosis 2.307770
Jarque-Bera 10.05590Probability 0.006552
Figura 11 – Histograma da série lcâmbio (log da série câmbio)
Analisando o correlograma da série podemos observar que o P valor (Prob) confirma que a
estatística Q de Lijung-Box apresenta a autocorrelação como significativas pois rejeitamos a
hipótese nula de não existência da correlação em todas as ordens apresentadas.
Através do índice da autocorrelação (AC), que é o coeficiente de correlação para valores da
série separados por K períodos, podemos supor que tal série segue um processo auto-
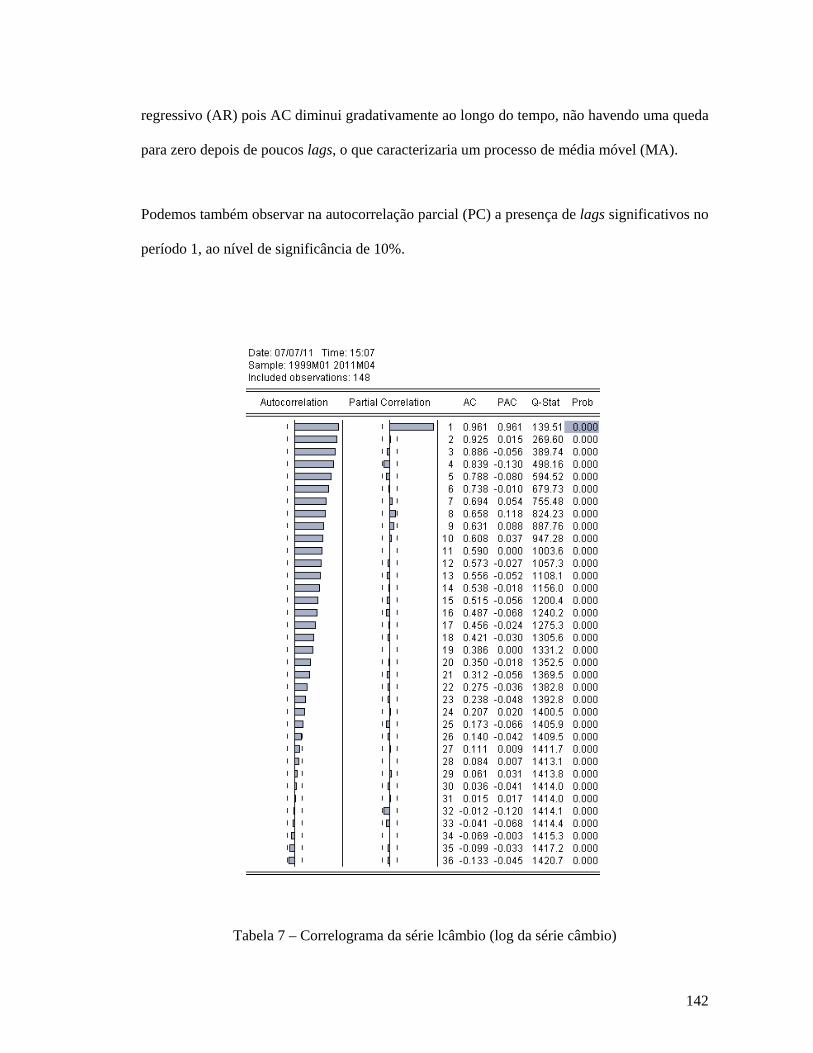
142
regressivo (AR) pois AC diminui gradativamente ao longo do tempo, não havendo uma queda
para zero depois de poucos lags, o que caracterizaria um processo de média móvel (MA).
Podemos também observar na autocorrelação parcial (PC) a presença de lags significativos no
período 1, ao nível de significância de 10%.
Tabela 7 – Correlograma da série lcâmbio (log da série câmbio)

143
A análise do gráfico dos resíduos resultado da regressão da série em nível contra uma
constante c, notamos que série não parece ser um ruído branco o que demonstra claramente a
presença de componentes de tendência; bem como a presença de mudanças na tendência, o
que será melhor capturado e tratado no capitulo a seguir.
-.4
-.2
.0
.2
.4
.6
0.2
0.4
0.6
0.8
1.0
1.2
1.4
99 00 01 02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Figura 12 – Gráfico dos resíduos da série lcâmbio (log da série câmbio)
Através na análise da estatística t (t-Statistic) da tabela abaixo gerada pelo Teste de Raiz
Unitária, utilizando o tipo de teste DF-GLS com o critério Akaike Info Criterion, incluindo
intercepto, não rejeitamos a hipótese nula de que a série possui raiz unitária, ou seja, a mesma
é não estacionaria.

144
Null Hypothesis: LCÂMBIO has a unit root Exogenous: Constant Lag Length: 1 (Automatic based on AIC, MAXLAG=13)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.039050 Test critical values: 1% level -2.580897
5% level -1.943027 10% level -1.615260
*MacKinnon (1996)
Tabela 8 – Teste de Raiz Unitária da série lcâmbio (log da série câmbio)

145
APÊNDICE B – OUTROS MODELOS ANALISADOS Refazendo o banco de dados com dados de 2002m1 a 2011m10 Especificação de data do Banco de Dados: 2001m1 2011 m10 Amostra: 2002m1 2011m4 Amostra de Estimação: 2002m1 2010m4 Hold Out Sample: 2010m5 2011m4 Gero lreaj Mudo smpl para amostra de estimação Gráfico do reajuste em nível
120
160
200
240
280
320
02 03 04 05 06 07 08 09
REAJ
Teste de raiz unitária com tendência e intercepto Augmented Dickey Fuller com Schwarz Info Criterion Null Hypothesis: REAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -2.923058 0.1600 Test critical values: 1% level -4.054393

146
5% level -3.456319 10% level -3.153989
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(REAJ) Method: Least Squares Date: 09/23/11 Time: 17:49 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
REAJ(-1) -0.070816 0.024227 -2.923058 0.0043D(REAJ(-1)) 0.479768 0.089625 5.353049 0.0000
C 14.38235 4.494126 3.200255 0.0019@TREND(2002M01) 0.067003 0.032134 2.085092 0.0398
R-squared 0.292836 Mean dependent var 1.467720Adjusted R-squared 0.270267 S.D. dependent var 5.188379S.E. of regression 4.432143 Akaike Info Criterion 5.855603Sum squared resid 1846.526 Schwarz criterion 5.961112Log likelihood -282.9246 Hannan-Quinn criter. 5.898280F-statistic 12.97509 Durbin-Watson stat 1.915566Prob(F-statistic) 0.000000
Possui raiz unitária Teste de raiz unitária com DF-GLS Akaike Info Criterion com tendência e intercepto Null Hypothesis: REAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 4 (Automatic based on AIC, MAXLAG=12)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -2.600264Test critical values: 1% level -3.599000
5% level -3.046000 10% level -2.755000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/23/11 Time: 17:50 Sample (adjusted): 2002M06 2010M04 Included observations: 95 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.055707 0.021424 -2.600264 0.0109D(GLSRESID(-1)) 0.529893 0.101359 5.227905 0.0000D(GLSRESID(-2)) -0.157707 0.115296 -1.367836 0.1748D(GLSRESID(-3)) 0.170482 0.114137 1.493665 0.1388D(GLSRESID(-4)) 0.184723 0.105373 1.753043 0.0830

147
R-squared 0.329701 Mean dependent var -0.077403Adjusted R-squared 0.299910 S.D. dependent var 5.244602S.E. of regression 4.388232 Akaike Info Criterion 5.846926Sum squared resid 1733.092 Schwarz criterion 5.981340Log likelihood -272.7290 Hannan-Quinn criter. 5.901239Durbin-Watson stat 1.979894
Possui raiz unitária Histograma
0
4
8
12
16
20
140 160 180 200 220 240 260 280 300
Series: REAJSample 2002M01 2010M04Observations 100
Mean 239.0385Median 252.4175Maximum 312.3544Minimum 143.2486Std. Dev. 38.51728Skewness -0.825226Kurtosis 3.048091
Jarque-Bera 11.35960Probability 0.003414
Analisando o Correlograma
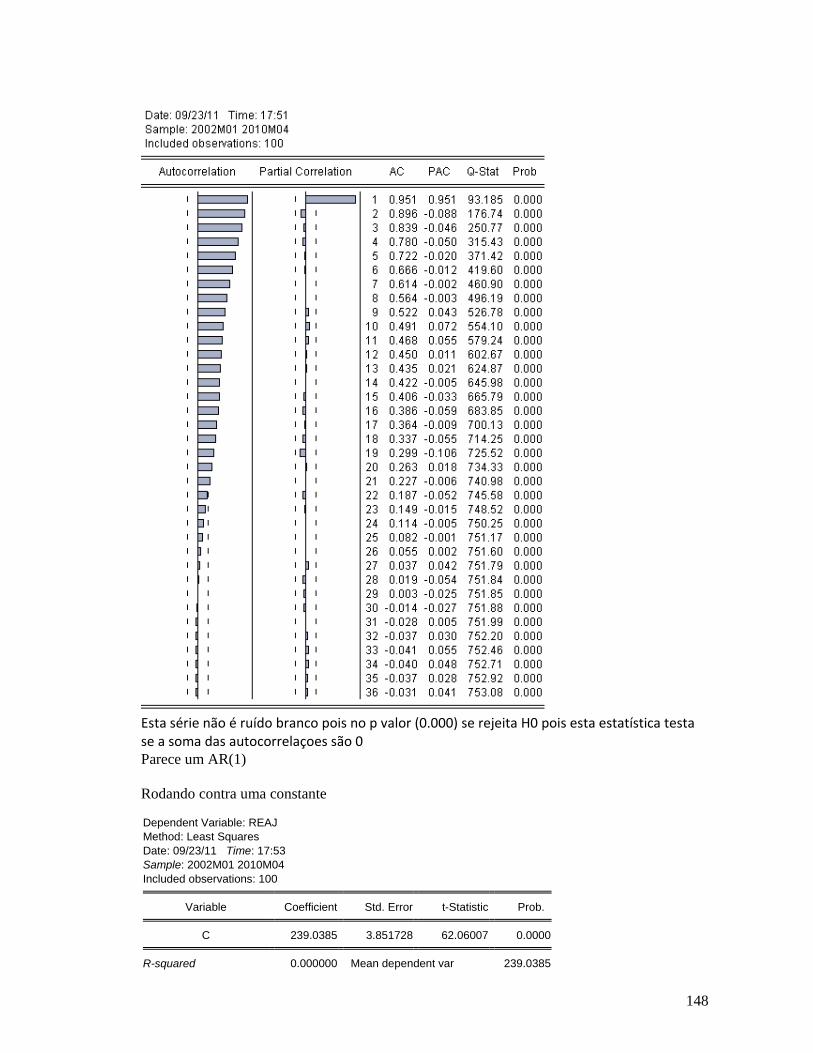
148
Esta série não é ruído branco pois no p valor (0.000) se rejeita H0 pois esta estatística testa se a soma das autocorrelaçoes são 0 Parece um AR(1) Rodando contra uma constante Dependent Variable: REAJ Method: Least Squares Date: 09/23/11 Time: 17:53 Sample: 2002M01 2010M04 Included observations: 100
Variable Coefficient Std. Error t-Statistic Prob.
C 239.0385 3.851728 62.06007 0.0000
R-squared 0.000000 Mean dependent var 239.0385

149
Adjusted R-squared 0.000000 S.D. dependent var 38.51728S.E. of regression 38.51728 Akaike Info Criterion 10.15004Sum squared resid 146874.5 Schwarz criterion 10.17609Log likelihood -506.5020 Hannan-Quinn criter. 10.16058Durbin-Watson stat 0.019220
Gráfico dos resíduos
-120
-80
-40
0
40
80
120
160
200
240
280
320
02 03 04 05 06 07 08 09
Residual Actual Fitted
Testando sazonalidade genr d1=@seas(1) genr d2=@seas(2) genr d3=@seas(3) genr d3=@seas(3) genr d4=@seas(4) genr d5=@seas(5) genr d6=@seas(6) genr d7=@seas(7) genr d8=@seas(8) genr d9=@seas(9) genr d10=@seas(10) genr d11=@seas(11) Dependent Variable: REAJ Method: Least Squares Date: 09/24/11 Time: 11:03 Sample (adjusted): 2002M01 2011M04 Included observations: 112 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
D1 -7.126576 19.47135 -0.366003 0.7151D10 1.018189 19.97718 0.050968 0.9595D11 -0.601100 19.97718 -0.030089 0.9761D2 -4.316356 19.47135 -0.221677 0.8250D3 -2.255176 19.47135 -0.115820 0.9080D4 -2.206976 19.47135 -0.113345 0.9100D5 -5.790633 19.97718 -0.289862 0.7725

150
D6 -6.232711 19.97718 -0.311991 0.7557D7 -6.601611 19.97718 -0.330458 0.7417D8 -4.582578 19.97718 -0.229391 0.8190D9 -0.153767 19.97718 -0.007697 0.9939C 248.2257 14.12600 17.57225 0.0000
R-squared 0.004689 Mean dependent var 244.9618Adjusted R-squared -0.104795 S.D. dependent var 40.31807S.E. of regression 42.37801 Akaike Info Criterion 10.43209Sum squared resid 179589.6 Schwarz criterion 10.72336Log likelihood -572.1972 Hannan-Quinn criter. 10.55027F-statistic 0.042830 Durbin-Watson stat 0.022528Prob(F-statistic) 0.999999
Nenhuma dummy apresentou-se significativa Analisando em log
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09
LREAJ
Teste de raiz unitária com augmented , schwaz info, tendência e intercepto Null Hypothesis: LREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.192668 0.0920 Test critical values: 1% level -4.054393
5% level -3.456319 10% level -3.153989
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LREAJ)

151
Method: Least Squares Date: 09/23/11 Time: 18:08 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LREAJ(-1) -0.061787 0.019353 -3.192668 0.0019D(LREAJ(-1)) 0.516488 0.085047 6.072963 0.0000
C 0.329480 0.100867 3.266478 0.0015@TREND(2002M01) 0.000233 0.000118 1.976823 0.0510
R-squared 0.380095 Mean dependent var 0.007065Adjusted R-squared 0.360311 S.D. dependent var 0.021551S.E. of regression 0.017237 Akaike Info Criterion -5.243582Sum squared resid 0.027928 Schwarz criterion -5.138073Log likelihood 260.9355 Hannan-Quinn criter. -5.200905F-statistic 19.21208 Durbin-Watson stat 1.922823Prob(F-statistic) 0.000000
Não possui raiz unitária Fazendo teste com DF-GLS, Akaike info, tendência e intercepto Null Hypothesis: LREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 3 (Automatic based on AIC, MAXLAG=12)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.919729Test critical values: 1% level -3.595200
5% level -3.042800 10% level -2.752000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/23/11 Time: 18:10 Sample (adjusted): 2002M05 2010M04 Included observations: 96 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.029663 0.015452 -1.919729 0.0580D(GLSRESID(-1)) 0.624428 0.100810 6.194120 0.0000D(GLSRESID(-2)) -0.199830 0.117585 -1.699441 0.0926D(GLSRESID(-3)) 0.240483 0.102351 2.349587 0.0209
R-squared 0.362592 Mean dependent var -0.000296Adjusted R-squared 0.341807 S.D. dependent var 0.021763S.E. of regression 0.017656 Akaike Info Criterion -5.194671Sum squared resid 0.028681 Schwarz criterion -5.087823Log likelihood 253.3442 Hannan-Quinn criter. -5.151481Durbin-Watson stat 2.042330
Possui raiz unitária

152
Histograma
0
5
10
15
20
25
30
5.0 5.1 5.2 5.3 5.4 5.5 5.6 5.7
Series: LREAJSample 2002M01 2010M04Observations 100
Mean 5.461982Median 5.531084Maximum 5.744138Minimum 4.964582Std. Dev. 0.178113Skewness -1.181131Kurtosis 3.744398
Jarque-Bera 25.56003Probability 0.000003
Correlograma
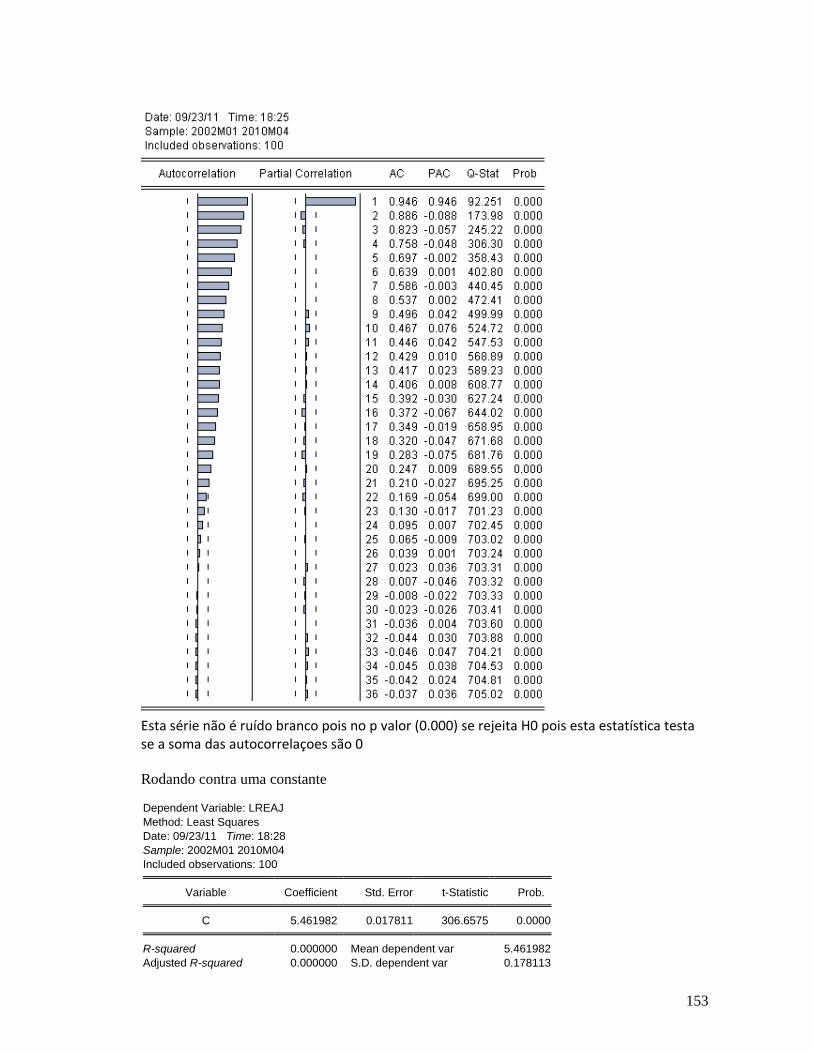
153
Esta série não é ruído branco pois no p valor (0.000) se rejeita H0 pois esta estatística testa se a soma das autocorrelaçoes são 0 Rodando contra uma constante Dependent Variable: LREAJ Method: Least Squares Date: 09/23/11 Time: 18:28 Sample: 2002M01 2010M04 Included observations: 100
Variable Coefficient Std. Error t-Statistic Prob.
C 5.461982 0.017811 306.6575 0.0000
R-squared 0.000000 Mean dependent var 5.461982Adjusted R-squared 0.000000 S.D. dependent var 0.178113

154
S.E. of regression 0.178113 Akaike Info Criterion -0.602843Sum squared resid 3.140714 Schwarz criterion -0.576791Log likelihood 31.14214 Hannan-Quinn criter. -0.592299Durbin-Watson stat 0.015912
Gráfico dos resíduos
-.6
-.4
-.2
.0
.2
.4
4.8
5.0
5.2
5.4
5.6
5.8
02 03 04 05 06 07 08 09
Residual Actual Fitted
Geraremos então 3 modelos: Modelo 1: em nível com tendência estocástica Modelo 2: em log com tendência determinística Modelo 3: em log com tendência estocástica Voltei com smpl para @all Gerei genr dlreaj=d(log(reaj)) Gerei time=@trend+1 Voltei com smpl 2002m1 2010m4 Analisando dlreaj Gráfico
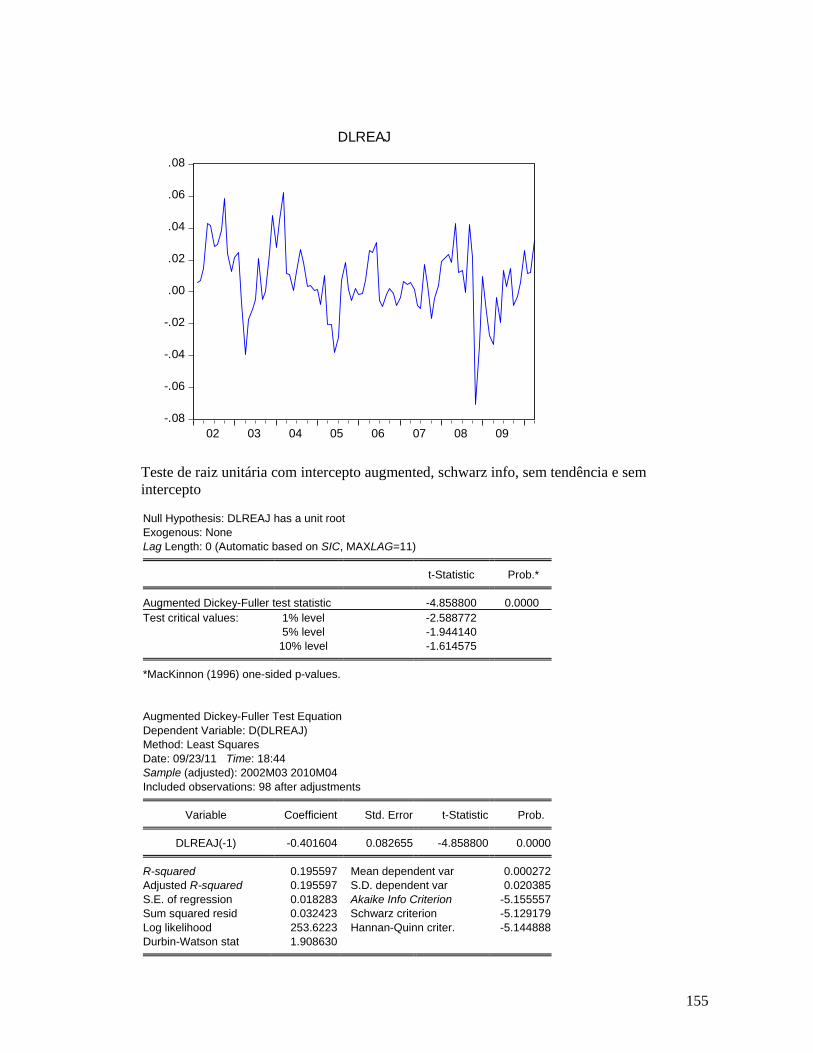
155
-.08
-.06
-.04
-.02
.00
.02
.04
.06
.08
02 03 04 05 06 07 08 09
DLREAJ
Teste de raiz unitária com intercepto augmented, schwarz info, sem tendência e sem intercepto Null Hypothesis: DLREAJ has a unit root Exogenous: None Lag Length: 0 (Automatic based on SIC, MAXLAG=11)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -4.858800 0.0000 Test critical values: 1% level -2.588772
5% level -1.944140 10% level -1.614575
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(DLREAJ) Method: Least Squares Date: 09/23/11 Time: 18:44 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
DLREAJ(-1) -0.401604 0.082655 -4.858800 0.0000
R-squared 0.195597 Mean dependent var 0.000272Adjusted R-squared 0.195597 S.D. dependent var 0.020385S.E. of regression 0.018283 Akaike Info Criterion -5.155557Sum squared resid 0.032423 Schwarz criterion -5.129179Log likelihood 253.6223 Hannan-Quinn criter. -5.144888Durbin-Watson stat 1.908630
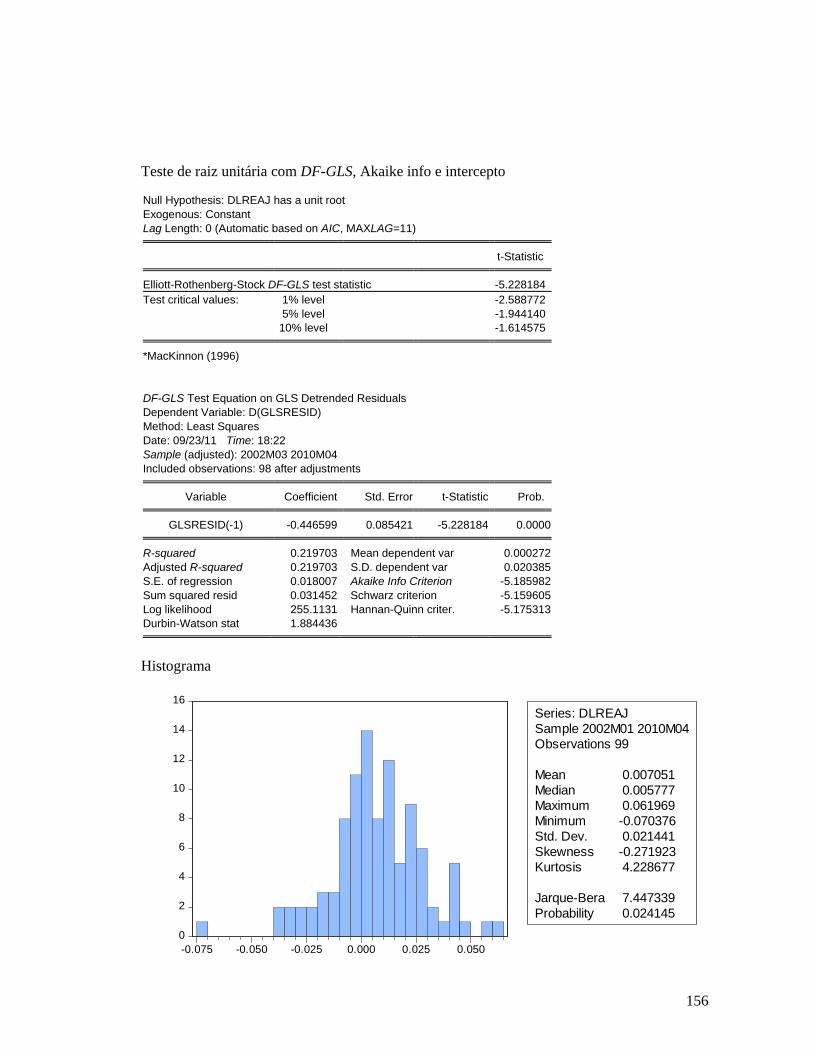
156
Teste de raiz unitária com DF-GLS, Akaike info e intercepto Null Hypothesis: DLREAJ has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on AIC, MAXLAG=11)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -5.228184Test critical values: 1% level -2.588772
5% level -1.944140 10% level -1.614575
*MacKinnon (1996)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/23/11 Time: 18:22 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.446599 0.085421 -5.228184 0.0000
R-squared 0.219703 Mean dependent var 0.000272Adjusted R-squared 0.219703 S.D. dependent var 0.020385S.E. of regression 0.018007 Akaike Info Criterion -5.185982Sum squared resid 0.031452 Schwarz criterion -5.159605Log likelihood 255.1131 Hannan-Quinn criter. -5.175313Durbin-Watson stat 1.884436
Histograma
0
2
4
6
8
10
12
14
16
-0.075 -0.050 -0.025 0.000 0.025 0.050
Series: DLREAJSample 2002M01 2010M04Observations 99
Mean 0.007051Median 0.005777Maximum 0.061969Minimum -0.070376Std. Dev. 0.021441Skewness -0.271923Kurtosis 4.228677
Jarque-Bera 7.447339Probability 0.024145

157
Correlograma
Esta série não é ruído branco pois no p valor (0.000) se rejeita H0 pois esta estatística testa se a soma das autocorrelaçoes são 0 Rodando contra uma constante Dependent Variable: DLREAJ Method: Least Squares Date: 09/23/11 Time: 18:29 Sample (adjusted): 2002M02 2010M04 Included observations: 99 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 0.007051 0.002155 3.272114 0.0015
R-squared 0.000000 Mean dependent var 0.007051

158
Adjusted R-squared 0.000000 S.D. dependent var 0.021441S.E. of regression 0.021441 Akaike Info Criterion -4.836937Sum squared resid 0.045054 Schwarz criterion -4.810723Log likelihood 240.4284 Hannan-Quinn criter. -4.826331Durbin-Watson stat 0.894810
Gráfico dos resíduos
-.08
-.04
.00
.04
.08
-.08
-.04
.00
.04
.08
2002 2003 2004 2005 2006 2007 2008 2009
Residual Actual Fitted
Modelo 1: em nível com tendência estocástica Gerando a série da primeira diferença do reajuste em nível smpl @all genr dreaj=d(reaj) Gráfico

159
-25
-20
-15
-10
-5
0
5
10
15
02 03 04 05 06 07 08 09
DREAJ
Teste de raiz unitária com augmented, schwarz info, sem tendência e sem intercepto Null Hypothesis: DREAJ has a unit root Exogenous: None Lag Length: 0 (Automatic based on SIC, MAXLAG=11)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -5.442496 0.0000 Test critical values: 1% level -2.588772
5% level -1.944140 10% level -1.614575
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(DREAJ) Method: Least Squares Date: 09/23/11 Time: 18:41 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
DREAJ(-1) -0.482646 0.088681 -5.442496 0.0000
R-squared 0.233733 Mean dependent var 0.085206Adjusted R-squared 0.233733 S.D. dependent var 5.301736S.E. of regression 4.640963 Akaike Info Criterion 5.917873Sum squared resid 2089.238 Schwarz criterion 5.944250Log likelihood -288.9758 Hannan-Quinn criter. 5.928542Durbin-Watson stat 1.886337
Teste de raiz unitária com DF-GLS, akaike, com intercepto

160
Null Hypothesis: DREAJ has a unit root Exogenous: Constant Lag Length: 2 (Automatic based on AIC, MAXLAG=11)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -3.754456Test critical values: 1% level -2.589273
5% level -1.944211 10% level -1.614532
*MacKinnon (1996)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/23/11 Time: 18:42 Sample (adjusted): 2002M05 2010M04 Included observations: 96 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.454108 0.120952 -3.754456 0.0003D(GLSRESID(-1)) 0.011619 0.112817 0.102992 0.9182D(GLSRESID(-2)) -0.218462 0.102576 -2.129754 0.0358
R-squared 0.299190 Mean dependent var 0.073450Adjusted R-squared 0.284119 S.D. dependent var 5.356201S.E. of regression 4.531868 Akaike Info Criterion 5.890897Sum squared resid 1910.018 Schwarz criterion 5.971033Log likelihood -279.7631 Hannan-Quinn criter. 5.923289Durbin-Watson stat 2.023228
Histograma
0
2
4
6
8
10
12
14
-20 -15 -10 -5 0 5 10 15
Series: DREAJSample 2002M01 2010M04Observations 99
Mean 1.461237Median 1.257200Maximum 14.10730Minimum -21.22670Std. Dev. 5.162243Skewness -0.775499Kurtosis 6.013458
Jarque-Bera 47.38193Probability 0.000000
Correlograma

161
Esta série não é ruído branco pois no p valor (0.000) se rejeita H0 pois esta estatística testa se a soma das autocorrelaçoes são 0 Rodando contra uma constante Dependent Variable: DREAJ Method: Least Squares Date: 09/23/11 Time: 18:47 Sample (adjusted): 2002M02 2010M04 Included observations: 99 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 1.461237 0.518825 2.816437 0.0059
R-squared 0.000000 Mean dependent var 1.461237Adjusted R-squared 0.000000 S.D. dependent var 5.162243S.E. of regression 5.162243 Akaike Info Criterion 6.130669

162
Sum squared resid 2611.577 Schwarz criterion 6.156882Log likelihood -302.4681 Hannan-Quinn criter. 6.141275Durbin-Watson stat 1.044283
Gráfico dos resíduos
-30
-20
-10
0
10
20
-30
-20
-10
0
10
20
2002 2003 2004 2005 2006 2007 2008 2009
Residual Actual Fitted
Vendo significância das dummies sazonais Dependent Variable: DREAJ Method: Least Squares Date: 09/24/11 Time: 11:05 Sample (adjusted): 2002M02 2011M04 Included observations: 111 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
D1 3.144600 2.424144 1.297200 0.1976D10 0.570856 2.424144 0.235487 0.8143D11 -2.220389 2.424144 -0.915948 0.3619D2 2.209120 2.362763 0.934973 0.3521D3 1.460080 2.362763 0.617954 0.5380D4 -0.552900 2.362763 -0.234006 0.8155D5 2.173900 2.424144 0.896770 0.3720D6 -1.043178 2.424144 -0.430328 0.6679D7 -0.970000 2.424144 -0.400141 0.6899D8 1.417933 2.424144 0.584921 0.5599D9 3.827711 2.424144 1.578995 0.1175C 0.601100 1.714129 0.350674 0.7266
R-squared 0.115496 Mean dependent var 1.441423Adjusted R-squared 0.017218 S.D. dependent var 5.187237S.E. of regression 5.142386 Akaike Info Criterion 6.214717Sum squared resid 2617.970 Schwarz criterion 6.507640Log likelihood -332.9168 Hannan-Quinn criter. 6.333547F-statistic 1.175198 Durbin-Watson stat 1.013781Prob(F-statistic) 0.314002

163
Não significativas Mudando o sample 2002m1 2010m4 Rodando contra uma constante para gerar o resíduo e depois gerar a série u=resid Rodando Garma
R1 AIC 4.000000 3.000000 R2 SIC 0.000000 1.000000
Opto por modelar com um MA(1) Dependent Variable: DREAJ Method: Least Squares Date: 09/26/11 Time: 20:59 Sample (adjusted): 2002M02 2010M04 Included observations: 99 after adjustments Convergence achieved after 8 iterations MA Backcast: 2002M01
Variable Coefficient Std. Error t-Statistic Prob.
MA(1) 0.524828 0.086372 6.076358 0.0000
R-squared 0.197406 Mean dependent var 1.461237Adjusted R-squared 0.197406 S.D. dependent var 5.162243S.E. of regression 4.624730 Akaike Info Criterion 5.910763Sum squared resid 2096.036 Schwarz criterion 5.936976Log likelihood -291.5828 Hannan-Quinn criter. 5.921369Durbin-Watson stat 1.824315
Inverted MA Roots -.52
Vendo o correlograma

164
O correlograma indica lags fora do intervalo de confiança nos períodos 4 e 11 Incluo primeiramente o termo AR(4), devido a indicação do critério AIC gerado pelo programa GARMA Dependent Variable: DREAJ Method: Least Squares Date: 09/26/11 Time: 21:03 Sample (adjusted): 2002M06 2010M04 Included observations: 95 after adjustments Convergence achieved after 7 iterations MA Backcast: 2002M05
Variable Coefficient Std. Error t-Statistic Prob.
AR(4) 0.257875 0.103107 2.501041 0.0141MA(1) 0.525088 0.088701 5.919768 0.0000

165
R-squared 0.249006 Mean dependent var 1.413231Adjusted R-squared 0.240931 S.D. dependent var 5.244602S.E. of regression 4.569338 Akaike Info Criterion 5.897442Sum squared resid 1941.733 Schwarz criterion 5.951207Log likelihood -278.1285 Hannan-Quinn criter. 5.919167Durbin-Watson stat 1.904470
Inverted AR Roots .71 .00-.71i .00+.71i -.71 Inverted MA Roots -.53
As estatísticas t e f são significativas Analisando o correlograma
Nota-se que melhorou, não tem estrutura Vendo o gráfico dos resíduos
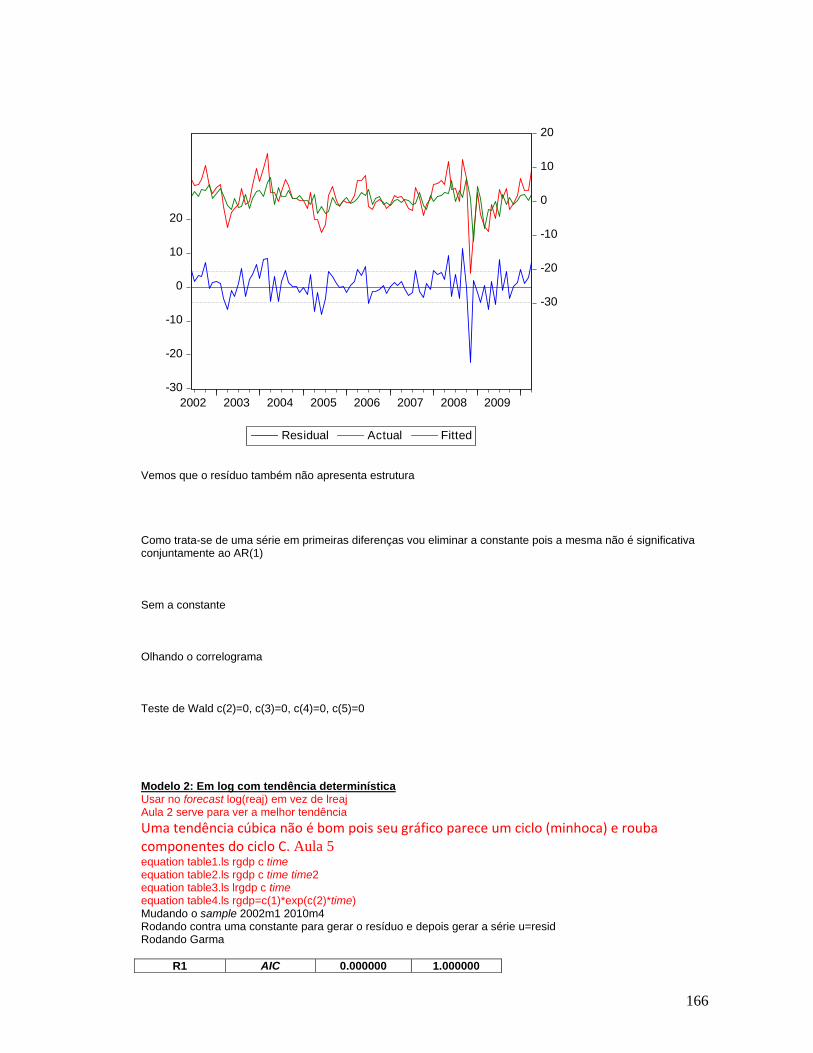
166
-30
-20
-10
0
10
20
-30
-20
-10
0
10
20
2002 2003 2004 2005 2006 2007 2008 2009
Residual Actual Fitted
Vemos que o resíduo também não apresenta estrutura Como trata-se de uma série em primeiras diferenças vou eliminar a constante pois a mesma não é significativa conjuntamente ao AR(1) Sem a constante Olhando o correlograma Teste de Wald c(2)=0, c(3)=0, c(4)=0, c(5)=0 Modelo 2: Em log com tendência determinística Usar no forecast log(reaj) em vez de lreaj Aula 2 serve para ver a melhor tendência
Uma tendência cúbica não é bom pois seu gráfico parece um ciclo (minhoca) e rouba componentes do ciclo C. Aula 5 equation table1.ls rgdp c time equation table2.ls rgdp c time time2 equation table3.ls lrgdp c time equation table4.ls rgdp=c(1)*exp(c(2)*time) Mudando o sample 2002m1 2010m4 Rodando contra uma constante para gerar o resíduo e depois gerar a série u=resid Rodando Garma
R1 AIC 0.000000 1.000000

167
R2 SIC 0.000000 1.000000
Modelo 3: em log com tendência estocástica Usar no forecast d(log(reaj)) em vez de dlreaj Mudando o sample 2002m1 2010m4 Rodando contra uma constante para gerar o resíduo e depois gerar a série u=resid Rodando Garma
R1 AIC 2.000000 2.000000 R2 SIC 2.000000 2.000000
Eq final log(reaj) log(reaj(‐1)) ar(1) ar(2) ar(3) ar(4) ma(1) ma(2) ma(3)
Box Jenkins Maquinas Mecânicas
5.4
5.5
5.6
5.7
5.8
5.9
6.0
6.1
6.2
02 03 04 05 06 07 08 09 10
LMAQ
Teste de Raiz unitária Null Hypothesis: LMAQ has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -1.882599 0.6569 Test critical values: 1% level -4.042819
5% level -3.450807 10% level -3.150766
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LMAQ) Method: Least Squares Date: 09/21/11 Time: 16:06

168
Sample (adjusted): 2002M02 2011M04 Included observations: 111 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LMAQ(-1) -0.054418 0.028906 -1.882599 0.0624C 0.307569 0.158926 1.935290 0.0556
@TREND(2002M01) 0.000286 0.000176 1.623451 0.1074
R-squared 0.039831 Mean dependent var 0.006308Adjusted R-squared 0.022050 S.D. dependent var 0.013252S.E. of regression 0.013105 Akaike Info Criterion -5.804979Sum squared resid 0.018548 Schwarz criterion -5.731748Log likelihood 325.1763 Hannan-Quinn criter. -5.775272F-statistic 2.240071 Durbin-Watson stat 2.048799Prob(F-statistic) 0.111375
A tendência deu não significativa, voltei e tirei a tendência Null Hypothesis: LMAQ has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -1.348065 0.6051 Test critical values: 1% level -3.490210
5% level -2.887665 10% level -2.580778
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LMAQ) Method: Least Squares Date: 09/21/11 Time: 16:07 Sample (adjusted): 2002M02 2011M04 Included observations: 111 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LMAQ(-1) -0.008642 0.006411 -1.348065 0.1804C 0.056697 0.037400 1.515972 0.1324
R-squared 0.016399 Mean dependent var 0.006308Adjusted R-squared 0.007375 S.D. dependent var 0.013252S.E. of regression 0.013203 Akaike Info Criterion -5.798886Sum squared resid 0.019001 Schwarz criterion -5.750066Log likelihood 323.8382 Hannan-Quinn criter. -5.779081F-statistic 1.817280 Durbin-Watson stat 2.093811Prob(F-statistic) 0.180432
A constante deu não significativa, voltei e tirei o intercepto Null Hypothesis: LMAQ has a unit root Exogenous: None Lag Length: 0 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*

169
Augmented Dickey-Fuller test statistic 4.956398 1.0000 Test critical values: 1% level -2.585962
5% level -1.943741 10% level -1.614818
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LMAQ) Method: Least Squares Date: 09/21/11 Time: 16:07 Sample (adjusted): 2002M02 2011M04 Included observations: 111 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LMAQ(-1) 0.001071 0.000216 4.956398 0.0000
R-squared -0.004339 Mean dependent var 0.006308Adjusted R-squared -0.004339 S.D. dependent var 0.013252S.E. of regression 0.013281 Akaike Info Criterion -5.796039Sum squared resid 0.019402 Schwarz criterion -5.771629Log likelihood 322.6802 Hannan-Quinn criter. -5.786137Durbin-Watson stat 2.070575
Continuou dando raiz unitária então por este teste pode-se dizer que a mesma não é estacionaria Para confirmar vou fazer com DF-GLS e Akaike Info Criterion que tem maior poder Null Hypothesis: LMAQ has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic based on AIC, MAXLAG=12)
t-Statistic
Elliott-Rothenberg-Stock DF-GLS test statistic -1.434399Test critical values: 1% level -3.566800
5% level -3.019000 10% level -2.729000
*Elliott-Rothenberg-Stock (1996, Table 1)
DF-GLS Test Equation on GLS Detrended Residuals Dependent Variable: D(GLSRESID) Method: Least Squares Date: 09/21/11 Time: 16:09 Sample (adjusted): 2002M02 2011M04 Included observations: 111 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GLSRESID(-1) -0.037791 0.026346 -1.434399 0.1543
R-squared 0.018308 Mean dependent var -9.69E-05Adjusted R-squared 0.018308 S.D. dependent var 0.013252S.E. of regression 0.013130 Akaike Info Criterion -5.818847Sum squared resid 0.018964 Schwarz criterion -5.794437
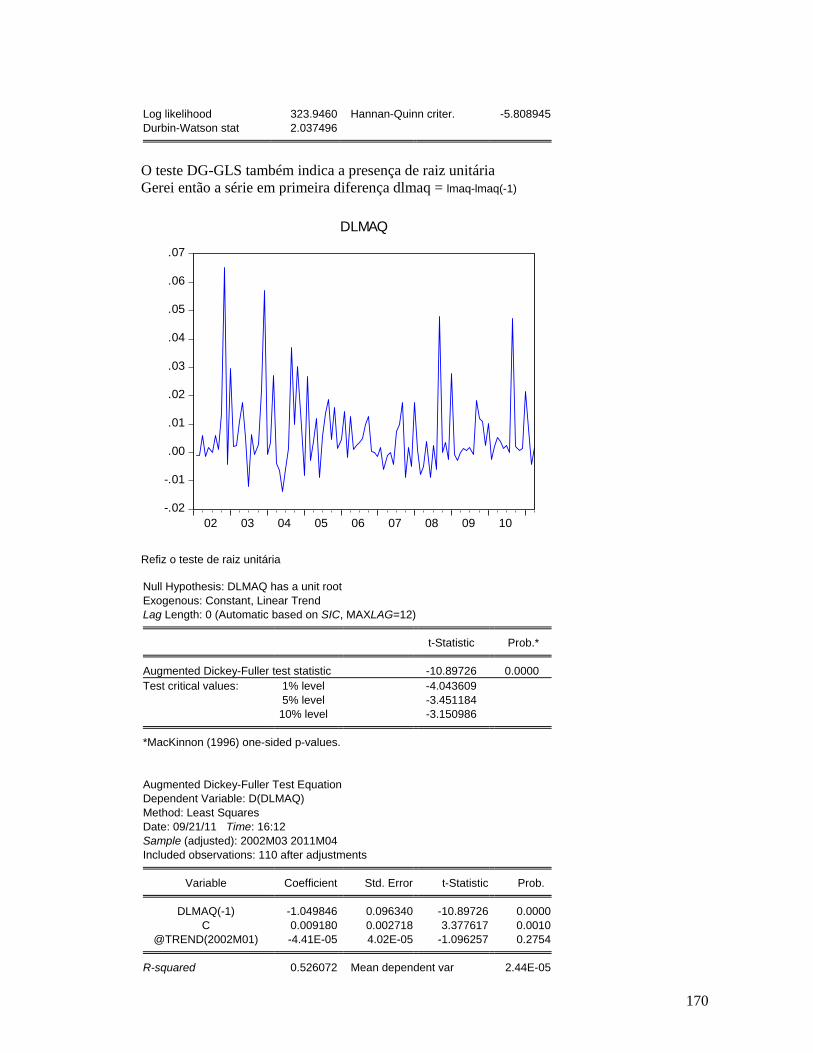
170
Log likelihood 323.9460 Hannan-Quinn criter. -5.808945Durbin-Watson stat 2.037496
O teste DG-GLS também indica a presença de raiz unitária Gerei então a série em primeira diferença dlmaq = lmaq-lmaq(-1)
-.02
-.01
.00
.01
.02
.03
.04
.05
.06
.07
02 03 04 05 06 07 08 09 10
DLMAQ
Refiz o teste de raiz unitária Null Hypothesis: DLMAQ has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -10.89726 0.0000 Test critical values: 1% level -4.043609
5% level -3.451184 10% level -3.150986
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(DLMAQ) Method: Least Squares Date: 09/21/11 Time: 16:12 Sample (adjusted): 2002M03 2011M04 Included observations: 110 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
DLMAQ(-1) -1.049846 0.096340 -10.89726 0.0000C 0.009180 0.002718 3.377617 0.0010
@TREND(2002M01) -4.41E-05 4.02E-05 -1.096257 0.2754
R-squared 0.526072 Mean dependent var 2.44E-05

171
Adjusted R-squared 0.517213 S.D. dependent var 0.019187S.E. of regression 0.013332 Akaike Info Criterion -5.770407Sum squared resid 0.019018 Schwarz criterion -5.696758Log likelihood 320.3724 Hannan-Quinn criter. -5.740535F-statistic 59.38623 Durbin-Watson stat 2.002693Prob(F-statistic) 0.000000
Agora vemos que a série se tornou estacionaria, podemos também dizer que é integrada de ordem 1 Analisando o correlograma vemos que o mesmo não possui nenhuma estrutura Date: 09/21/11 Time: 16:14 Sample: 2002M01 2011M04 Included observations: 111
Autocorrelation Partial Correlation AC PAC Q-Stat Prob
.|. | .|. | 1 -0.041 -0.041 0.1879 0.665 .|. | .|. | 2 0.029 0.028 0.2864 0.867 .|. | .|. | 3 -0.039 -0.036 0.4589 0.928 .|. | .|. | 4 -0.012 -0.015 0.4749 0.976 *|. | *|. | 5 -0.129 -0.128 2.4333 0.787 *|. | *|. | 6 -0.101 -0.114 3.6499 0.724 *|. | *|. | 7 -0.088 -0.096 4.5791 0.711 .|. | *|. | 8 -0.054 -0.073 4.9407 0.764 .|. | .|. | 9 0.036 0.018 5.0969 0.826 .|. | .|. | 10 0.039 0.016 5.2826 0.872 .|* | .|* | 11 0.143 0.114 7.8322 0.728 .|** | .|** | 12 0.242 0.238 15.227 0.229 .|* | .|* | 13 0.087 0.106 16.197 0.239 .|* | .|* | 14 0.078 0.108 16.989 0.257 *|. | *|. | 15 -0.133 -0.099 19.301 0.200 .|. | .|* | 16 0.058 0.093 19.745 0.232 .|. | .|* | 17 -0.038 0.077 19.942 0.277 *|. | *|. | 18 -0.147 -0.075 22.846 0.197 *|. | *|. | 19 -0.146 -0.096 25.748 0.137 .|. | .|. | 20 0.044 0.038 26.015 0.165 .|. | .|. | 21 -0.043 -0.063 26.276 0.196 .|* | .|. | 22 0.077 0.024 27.104 0.207 .|* | .|. | 23 0.080 -0.015 28.010 0.215 .|** | .|* | 24 0.220 0.138 34.970 0.069 .|. | .|. | 25 0.010 -0.038 34.986 0.088 *|. | *|. | 26 -0.097 -0.171 36.377 0.085 .|. | .|. | 27 -0.002 0.011 36.378 0.107 .|. | .|. | 28 0.016 0.027 36.416 0.132 .|. | .|. | 29 -0.054 0.010 36.869 0.150 *|. | .|. | 30 -0.091 -0.018 38.141 0.146 *|. | .|. | 31 -0.091 -0.036 39.443 0.142 .|. | .|. | 32 0.008 0.036 39.454 0.171 .|. | .|. | 33 0.004 -0.040 39.457 0.204 .|* | .|. | 34 0.092 0.032 40.833 0.195 .|. | .|. | 35 -0.011 -0.021 40.853 0.229 .|* | .|. | 36 0.103 -0.029 42.637 0.207
Analisando o histograma

172
0
5
10
15
20
25
30
0.000 0.025 0.050
Series: DLMAQSample 2002M01 2011M04Observations 111
Mean 0.006308Median 0.002119Maximum 0.065117Minimum -0.013592Std. Dev. 0.013252Skewness 2.045817Kurtosis 8.167108
Jarque-Bera 200.9122Probability 0.000000
Tendência, ciclo e sazonalidade foram testadas e não se apresentaram com significativas Os resíduos não apresentam estrutura
-.04
-.02
.00
.02
.04
.06-.02
.00
.02
.04
.06
.08
02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Histograma dos resíduos deu Normal Como a melhor previsão para o índice de amanha é o índice de hoje, simplesmente manterei os valores da Hold Out Sample (período fora da amostra) CRUSpi x Dolar genr cruusd=CRU*usd genr lcruusd=log(cruusd)

173
5.0
5.2
5.4
5.6
5.8
6.0
6.2
6.4
02 03 04 05 06 07 08 09 10
LCRUUSD
Analisando o teste de raiz unitária Augmented Dickey Fuller e Schwarz Info Criterion com tendência e intercepto Null Hypothesis: LCRUUSD has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.879344 0.0161 Test critical values: 1% level -4.043609
5% level -3.451184 10% level -3.150986
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LCRUUSD) Method: Least Squares Date: 09/21/11 Time: 16:34 Sample (adjusted): 2002M03 2011M04 Included observations: 110 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LCRUUSD(-1) -0.098059 0.025277 -3.879344 0.0002D(LCRUUSD(-1)) 0.478482 0.080312 5.957788 0.0000
C 0.578211 0.146049 3.959023 0.0001@TREND(2002M01) -0.000100 0.000162 -0.616736 0.5387
R-squared 0.337155 Mean dependent var 0.006492Adjusted R-squared 0.318395 S.D. dependent var 0.064277S.E. of regression 0.053066 Akaike Info Criterion -2.998865Sum squared resid 0.298499 Schwarz criterion -2.900665Log likelihood 168.9375 Hannan-Quinn criter. -2.959034

174
F-statistic 17.97225 Durbin-Watson stat 2.001673Prob(F-statistic) 0.000000
A série é estacionaria Tendência quadrática significativa Dependent Variable: LCRUUSD Method: Least Squares Date: 09/21/11 Time: 16:46 Sample: 2002M01 2011M04 Included observations: 112
Variable Coefficient Std. Error t-Statistic Prob.
C 5.533169 0.051911 106.5905 0.0000TIME 0.012466 0.002161 5.767802 0.0000
TIME*TIME -0.000102 1.88E-05 -5.438626 0.0000
R-squared 0.235565 Mean dependent var 5.802257Adjusted R-squared 0.221539 S.D. dependent var 0.211268S.E. of regression 0.186403 Akaike Info Criterion -0.495392Sum squared resid 3.787318 Schwarz criterion -0.422575Log likelihood 30.74197 Hannan-Quinn criter. -0.465848F-statistic 16.79452 Durbin-Watson stat 0.117259Prob(F-statistic) 0.000000
Dummies sazonais não significativas Dependent Variable: LCRUUSD Method: Least Squares Date: 09/21/11 Time: 16:43 Sample: 2002M01 2011M04 Included observations: 112
Variable Coefficient Std. Error t-Statistic Prob.
C 5.511317 0.084537 65.19379 0.0000TIME 0.012401 0.002281 5.436186 0.0000
TIME*TIME -0.000102 1.99E-05 -5.119757 0.0000M1 -0.015043 0.089980 -0.167186 0.8676M2 0.012268 0.089962 0.136370 0.8918M3 0.039663 0.089949 0.440943 0.6602M4 0.028920 0.089942 0.321535 0.7485M5 0.035584 0.092251 0.385729 0.7005M6 0.028205 0.092228 0.305817 0.7604M7 0.019437 0.092209 0.210798 0.8335M8 0.034032 0.092193 0.369141 0.7128M9 0.048027 0.092180 0.521014 0.6035M10 0.045903 0.092171 0.498023 0.6196M11 0.000207 0.092166 0.002242 0.9982
R-squared 0.243918 Mean dependent var 5.802257Adjusted R-squared 0.143622 S.D. dependent var 0.211268S.E. of regression 0.195509 Akaike Info Criterion -0.309951Sum squared resid 3.745935 Schwarz criterion 0.029862Log likelihood 31.35723 Hannan-Quinn criter. -0.172078F-statistic 2.431969 Durbin-Watson stat 0.109672Prob(F-statistic) 0.006797

175
Analisando o histograma Date: 09/21/11 Time: 17:02 Sample: 2002M01 2011M04 Included observations: 112
Autocorrelation Partial Correlation AC PAC Q-Stat Prob
.|******* .|******* 1 0.913 0.913 95.920 0.000 .|******| ***|. | 2 0.769 -0.392 164.52 0.000 .|**** | *|. | 3 0.606 -0.097 207.47 0.000 .|*** | *|. | 4 0.441 -0.079 230.42 0.000 .|** | *|. | 5 0.283 -0.071 239.96 0.000 .|* | *|. | 6 0.130 -0.121 241.98 0.000 .|. | .|. | 7 -0.001 0.014 241.98 0.000 *|. | *|. | 8 -0.114 -0.096 243.58 0.000 *|. | .|. | 9 -0.198 0.032 248.42 0.000 **|. | .|. | 10 -0.254 -0.035 256.51 0.000 **|. | *|. | 11 -0.301 -0.115 267.93 0.000 **|. | .|* | 12 -0.315 0.100 280.63 0.000 **|. | .|. | 13 -0.304 0.001 292.56 0.000 **|. | .|. | 14 -0.265 0.055 301.70 0.000 **|. | .|. | 15 -0.214 -0.034 307.72 0.000 *|. | .|. | 16 -0.161 -0.011 311.15 0.000 *|. | .|. | 17 -0.104 0.010 312.60 0.000 .|. | .|. | 18 -0.052 -0.006 312.97 0.000 .|. | *|. | 19 -0.012 -0.075 312.99 0.000 .|. | .|. | 20 0.010 -0.030 313.01 0.000 .|. | .|. | 21 0.017 -0.024 313.05 0.000 .|. | .|. | 22 0.019 0.013 313.10 0.000 .|. | .|. | 23 0.018 0.010 313.15 0.000 .|. | *|. | 24 -0.001 -0.142 313.15 0.000 .|. | .|. | 25 -0.031 0.008 313.29 0.000 *|. | .|. | 26 -0.068 -0.043 313.97 0.000 *|. | .|. | 27 -0.099 0.013 315.46 0.000 *|. | *|. | 28 -0.140 -0.152 318.45 0.000 *|. | .|. | 29 -0.185 -0.031 323.72 0.000 **|. | *|. | 30 -0.233 -0.107 332.15 0.000 **|. | .|. | 31 -0.276 -0.025 344.15 0.000 **|. | .|. | 32 -0.298 -0.003 358.29 0.000 **|. | *|. | 33 -0.307 -0.080 373.52 0.000 **|. | *|. | 34 -0.310 -0.069 389.27 0.000 **|. | .|. | 35 -0.302 -0.017 404.42 0.000 **|. | .|. | 36 -0.274 0.034 417.02 0.000
O gráfico dos resíduos mostra que ha uma componente de ciclo não capturada

176
-.6
-.4
-.2
.0
.2
.4
5.0
5.2
5.4
5.6
5.8
6.0
6.2
6.4
02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Gerando a série dos resíduos para utilizar o GARMA genr hs_sem=resid+5.802257 genr u=resid Rodando o garma
R1 4.000000 4.000000R2 2.000000 0.000000 Pelo principio da parcimônia utilizarei R2 (Schwarz) quem indica um AR(2) Voltei na equação e inclui os termos AR(1) e AR(2) Dependent Variable: LCRUUSD Method: Least Squares Date: 09/21/11 Time: 17:15 Sample (adjusted): 2002M03 2011M04 Included observations: 110 after adjustments Convergence achieved after 4 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 5.805436 0.201837 28.76295 0.0000TIME 0.002943 0.007407 0.397275 0.6920
TIME*TIME -3.16E-05 5.85E-05 -0.540306 0.5901AR(1) 1.384719 0.084628 16.36244 0.0000AR(2) -0.489355 0.083358 -5.870521 0.0000
R-squared 0.925979 Mean dependent var 5.814554Adjusted R-squared 0.923159 S.D. dependent var 0.192106S.E. of regression 0.053252 Akaike Info Criterion -2.983164Sum squared resid 0.297759 Schwarz criterion -2.860415Log likelihood 169.0740 Hannan-Quinn criter. -2.933376F-statistic 328.3773 Durbin-Watson stat 2.015008Prob(F-statistic) 0.000000
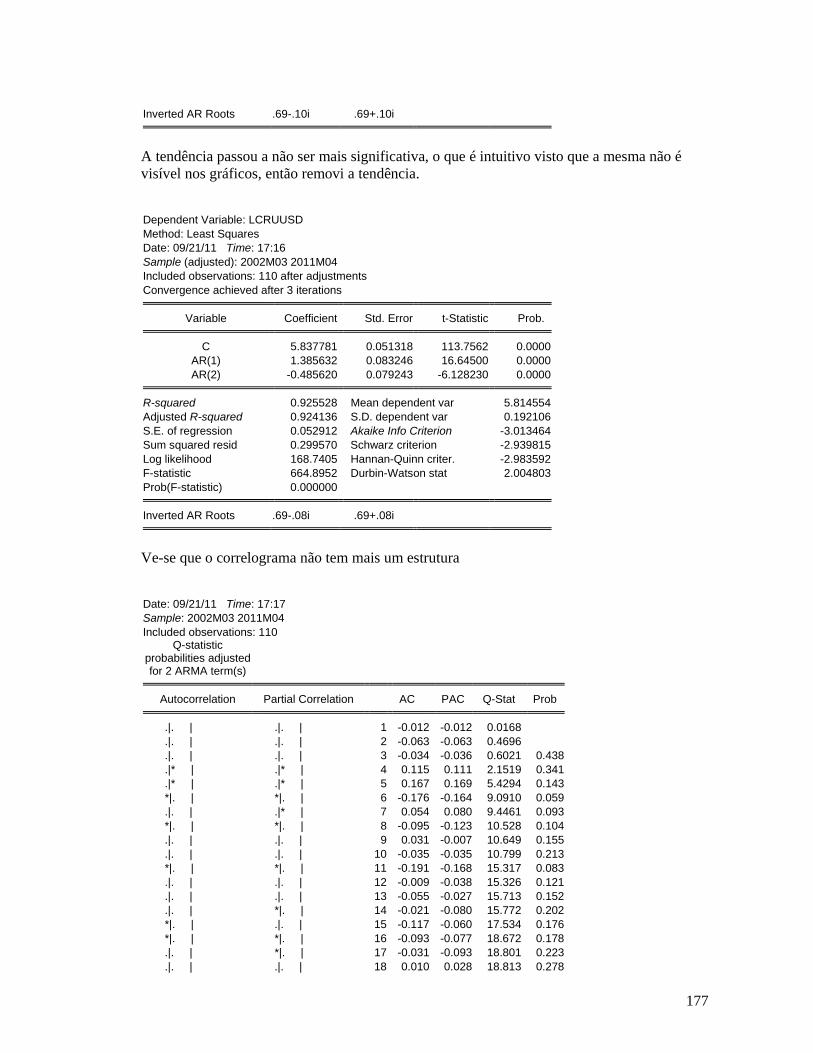
177
Inverted AR Roots .69-.10i .69+.10i
A tendência passou a não ser mais significativa, o que é intuitivo visto que a mesma não é visível nos gráficos, então removi a tendência. Dependent Variable: LCRUUSD Method: Least Squares Date: 09/21/11 Time: 17:16 Sample (adjusted): 2002M03 2011M04 Included observations: 110 after adjustments Convergence achieved after 3 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 5.837781 0.051318 113.7562 0.0000AR(1) 1.385632 0.083246 16.64500 0.0000AR(2) -0.485620 0.079243 -6.128230 0.0000
R-squared 0.925528 Mean dependent var 5.814554Adjusted R-squared 0.924136 S.D. dependent var 0.192106S.E. of regression 0.052912 Akaike Info Criterion -3.013464Sum squared resid 0.299570 Schwarz criterion -2.939815Log likelihood 168.7405 Hannan-Quinn criter. -2.983592F-statistic 664.8952 Durbin-Watson stat 2.004803Prob(F-statistic) 0.000000
Inverted AR Roots .69-.08i .69+.08i
Ve-se que o correlograma não tem mais um estrutura Date: 09/21/11 Time: 17:17 Sample: 2002M03 2011M04 Included observations: 110
Q-statistic probabilities adjusted for 2 ARMA term(s)
Autocorrelation Partial Correlation AC PAC Q-Stat Prob
.|. | .|. | 1 -0.012 -0.012 0.0168 .|. | .|. | 2 -0.063 -0.063 0.4696 .|. | .|. | 3 -0.034 -0.036 0.6021 0.438 .|* | .|* | 4 0.115 0.111 2.1519 0.341 .|* | .|* | 5 0.167 0.169 5.4294 0.143 *|. | *|. | 6 -0.176 -0.164 9.0910 0.059 .|. | .|* | 7 0.054 0.080 9.4461 0.093 *|. | *|. | 8 -0.095 -0.123 10.528 0.104 .|. | .|. | 9 0.031 -0.007 10.649 0.155 .|. | .|. | 10 -0.035 -0.035 10.799 0.213 *|. | *|. | 11 -0.191 -0.168 15.317 0.083 .|. | .|. | 12 -0.009 -0.038 15.326 0.121 .|. | .|. | 13 -0.055 -0.027 15.713 0.152 .|. | *|. | 14 -0.021 -0.080 15.772 0.202 *|. | .|. | 15 -0.117 -0.060 17.534 0.176 *|. | *|. | 16 -0.093 -0.077 18.672 0.178 .|. | *|. | 17 -0.031 -0.093 18.801 0.223 .|. | .|. | 18 0.010 0.028 18.813 0.278

178
.|* | .|. | 19 0.083 0.060 19.756 0.287 .|. | .|. | 20 0.020 0.057 19.812 0.343 *|. | *|. | 21 -0.100 -0.105 21.188 0.327 .|. | *|. | 22 -0.031 -0.074 21.319 0.379 .|* | .|. | 23 0.083 0.017 22.299 0.382 .|. | .|. | 24 0.046 -0.021 22.608 0.424 .|. | .|. | 25 0.060 0.069 23.126 0.453 *|. | *|. | 26 -0.078 -0.080 24.013 0.461 .|* | .|. | 27 0.075 0.024 24.851 0.471 .|. | .|. | 28 0.024 -0.027 24.935 0.523 .|. | .|. | 29 0.027 0.004 25.048 0.572 *|. | *|. | 30 -0.081 -0.103 26.064 0.570 .|. | .|. | 31 -0.046 -0.019 26.389 0.605 .|. | *|. | 32 -0.013 -0.143 26.417 0.654 .|. | .|. | 33 -0.005 0.014 26.421 0.701 .|. | .|. | 34 -0.011 -0.015 26.439 0.744 *|. | .|. | 35 -0.105 -0.063 28.239 0.703 .|. | .|. | 36 -0.013 -0.023 28.265 0.744
Os resíduos não apresentam estrutura mesmo após a retirada dos termos de tendência
-.3
-.2
-.1
.0
.1
5.0
5.2
5.4
5.6
5.8
6.0
6.2
6.4
02 03 04 05 06 07 08 09 10
Residual Actual Fitted
Sendo assim, minha equação final ficou Estimation Command: ========================= LS LCRUUSD C AR(1) AR(2) Estimation Equation: ========================= LCRUUSD = C(1) + [AR(1)=C(2),AR(2)=C(3)] Substituted Coefficients: ========================= LCRUUSD = 5.83778080075 + [AR(1)=1.38563249656,AR(2)=-0.48561983121] Gerando o forecast
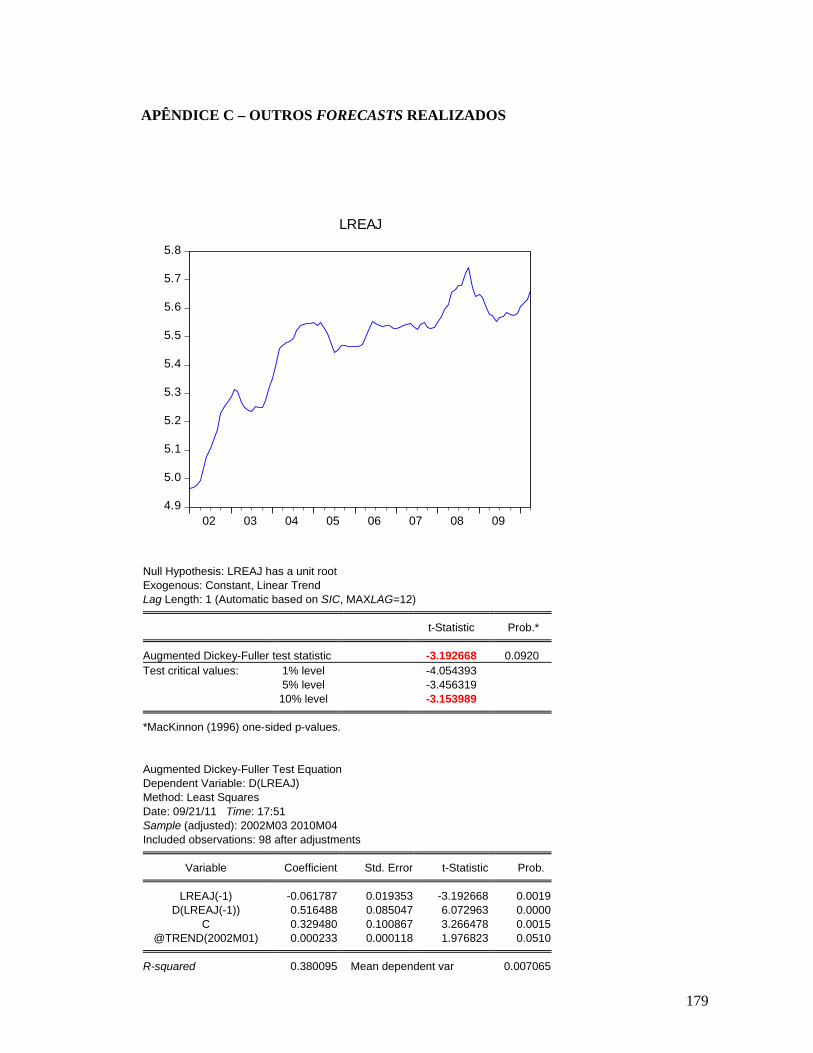
179
APÊNDICE C – OUTROS FORECASTS REALIZADOS
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09
LREAJ
Null Hypothesis: LREAJ has a unit root Exogenous: Constant, Linear Trend Lag Length: 1 (Automatic based on SIC, MAXLAG=12)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.192668 0.0920 Test critical values: 1% level -4.054393
5% level -3.456319 10% level -3.153989
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LREAJ) Method: Least Squares Date: 09/21/11 Time: 17:51 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LREAJ(-1) -0.061787 0.019353 -3.192668 0.0019D(LREAJ(-1)) 0.516488 0.085047 6.072963 0.0000
C 0.329480 0.100867 3.266478 0.0015@TREND(2002M01) 0.000233 0.000118 1.976823 0.0510
R-squared 0.380095 Mean dependent var 0.007065

180
Adjusted R-squared 0.360311 S.D. dependent var 0.021551S.E. of regression 0.017237 Akaike Info Criterion -5.243582Sum squared resid 0.027928 Schwarz criterion -5.138073Log likelihood 260.9355 Hannan-Quinn criter. -5.200905F-statistic 19.21208 Durbin-Watson stat 1.922823Prob(F-statistic) 0.000000
Dependent Variable: LREAJ Method: Least Squares Date: 09/21/11 Time: 17:50 Sample: 2002M01 2010M04 Included observations: 100
Variable Coefficient Std. Error t-Statistic Prob.
C 5.202776 0.018551 280.4528 0.0000TIME 0.005236 0.000324 16.17456 0.0000
R-squared 0.727487 Mean dependent var 5.461982Adjusted R-squared 0.724707 S.D. dependent var 0.178113S.E. of regression 0.093453 Akaike Info Criterion -1.882913Sum squared resid 0.855884 Schwarz criterion -1.830810Log likelihood 96.14566 Hannan-Quinn criter. -1.861826F-statistic 261.6164 Durbin-Watson stat 0.053021Prob(F-statistic) 0.000000
Dependent Variable: LREAJ Method: Least Squares Date: 09/21/11 Time: 17:52 Sample: 2002M01 2010M04 Included observations: 100
Variable Coefficient Std. Error t-Statistic Prob.
C 5.054906 0.018685 270.5346 0.0000TIME 0.014290 0.000872 16.38181 0.0000
TIME*TIME -9.14E-05 8.53E-06 -10.72572 0.0000
R-squared 0.875337 Mean dependent var 5.461982Adjusted R-squared 0.872766 S.D. dependent var 0.178113S.E. of regression 0.063533 Akaike Info Criterion -2.644982Sum squared resid 0.391532 Schwarz criterion -2.566827Log likelihood 135.2491 Hannan-Quinn criter. -2.613351F-statistic 340.5481 Durbin-Watson stat 0.108950Prob(F-statistic) 0.000000
Pelo principio da parcimônia fico com a tendência linear pela pouca diferença entre os critérios de AIC e SC Dependent Variable: LREAJ Method: Least Squares Date: 09/21/11 Time: 18:11 Sample: 2002M01 2010M04 Included observations: 100

181
Variable Coefficient Std. Error t-Statistic Prob.
C 5.202776 0.018551 280.4528 0.0000TIME 0.005236 0.000324 16.17456 0.0000
R-squared 0.727487 Mean dependent var 5.461982Adjusted R-squared 0.724707 S.D. dependent var 0.178113S.E. of regression 0.093453 Akaike Info Criterion -1.882913Sum squared resid 0.855884 Schwarz criterion -1.830810Log likelihood 96.14566 Hannan-Quinn criter. -1.861826F-statistic 261.6164 Durbin-Watson stat 0.053021Prob(F-statistic) 0.000000
Dummies não significativas Dependent Variable: LREAJ Method: Least Squares Date: 09/21/11 Time: 18:15 Sample: 2002M01 2010M04 Included observations: 100
Variable Coefficient Std. Error t-Statistic Prob.
C 5.208853 0.039345 132.3905 0.0000TIME 0.005229 0.000343 15.25520 0.0000M1 -0.020563 0.047996 -0.428429 0.6694M2 -0.015500 0.047985 -0.323025 0.7475M3 -0.010454 0.047976 -0.217898 0.8280M4 -0.013887 0.047970 -0.289485 0.7729M5 -0.002787 0.049414 -0.056400 0.9552M6 -0.007027 0.049399 -0.142253 0.8872M7 -0.009879 0.049386 -0.200044 0.8419M8 -0.003203 0.049375 -0.064879 0.9484M9 0.007861 0.049367 0.159236 0.8739M10 0.010506 0.049361 0.212844 0.8319M11 0.001330 0.049357 0.026949 0.9786
R-squared 0.730083 Mean dependent var 5.461982Adjusted R-squared 0.692854 S.D. dependent var 0.178113S.E. of regression 0.098712 Akaike Info Criterion -1.672485Sum squared resid 0.847731 Schwarz criterion -1.333813Log likelihood 96.62425 Hannan-Quinn criter. -1.535418F-statistic 19.61015 Durbin-Watson stat 0.057175Prob(F-statistic) 0.000000
Removo as dummies e analiso o correlograma e o gráfico dos resíduos
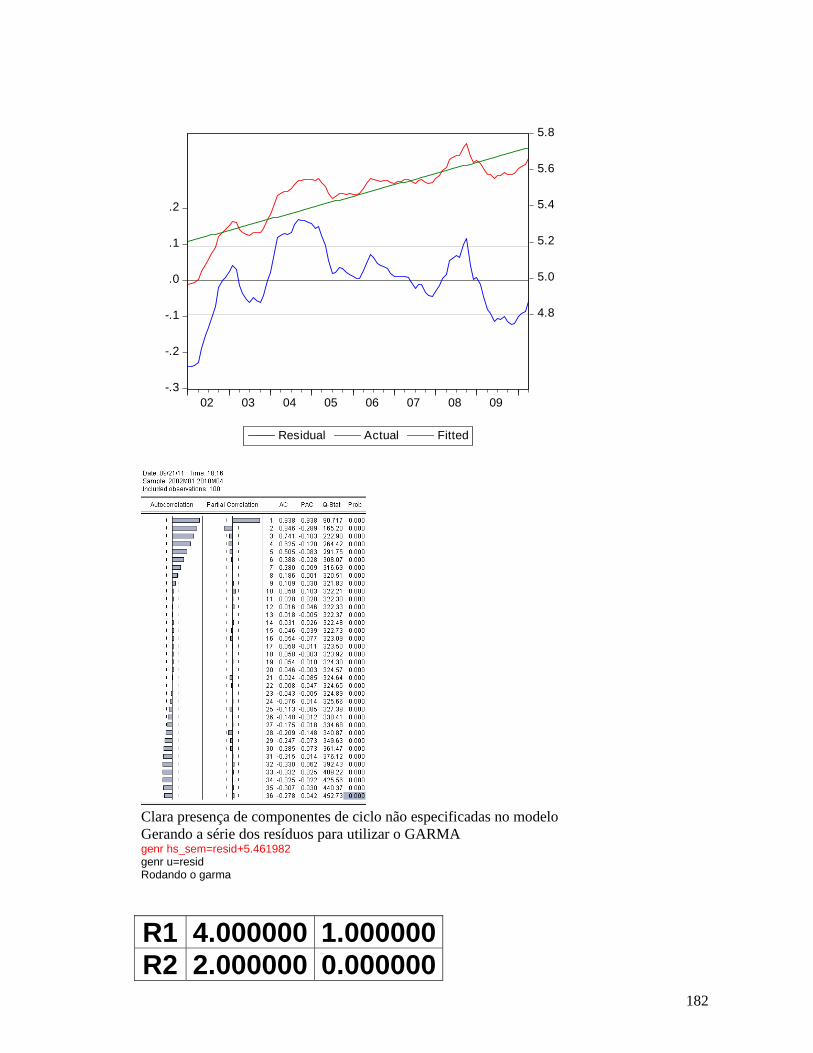
182
-.3
-.2
-.1
.0
.1
.2
4.8
5.0
5.2
5.4
5.6
5.8
02 03 04 05 06 07 08 09
Residual Actual Fitted
Clara presença de componentes de ciclo não especificadas no modelo Gerando a série dos resíduos para utilizar o GARMA genr hs_sem=resid+5.461982 genr u=resid Rodando o garma
R1 4.000000 1.000000R2 2.000000 0.000000
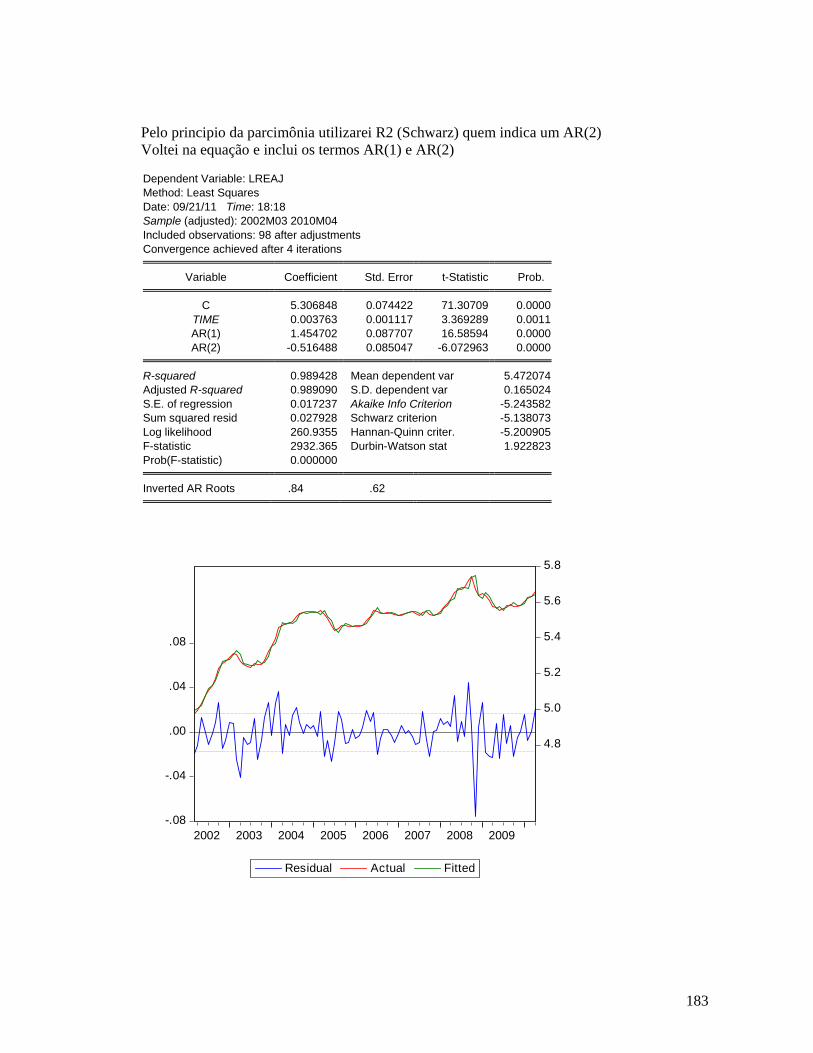
183
Pelo principio da parcimônia utilizarei R2 (Schwarz) quem indica um AR(2) Voltei na equação e inclui os termos AR(1) e AR(2) Dependent Variable: LREAJ Method: Least Squares Date: 09/21/11 Time: 18:18 Sample (adjusted): 2002M03 2010M04 Included observations: 98 after adjustments Convergence achieved after 4 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 5.306848 0.074422 71.30709 0.0000TIME 0.003763 0.001117 3.369289 0.0011AR(1) 1.454702 0.087707 16.58594 0.0000AR(2) -0.516488 0.085047 -6.072963 0.0000
R-squared 0.989428 Mean dependent var 5.472074Adjusted R-squared 0.989090 S.D. dependent var 0.165024S.E. of regression 0.017237 Akaike Info Criterion -5.243582Sum squared resid 0.027928 Schwarz criterion -5.138073Log likelihood 260.9355 Hannan-Quinn criter. -5.200905F-statistic 2932.365 Durbin-Watson stat 1.922823Prob(F-statistic) 0.000000
Inverted AR Roots .84 .62
-.08
-.04
.00
.04
.08
4.8
5.0
5.2
5.4
5.6
5.8
2002 2003 2004 2005 2006 2007 2008 2009
Residual Actual Fitted
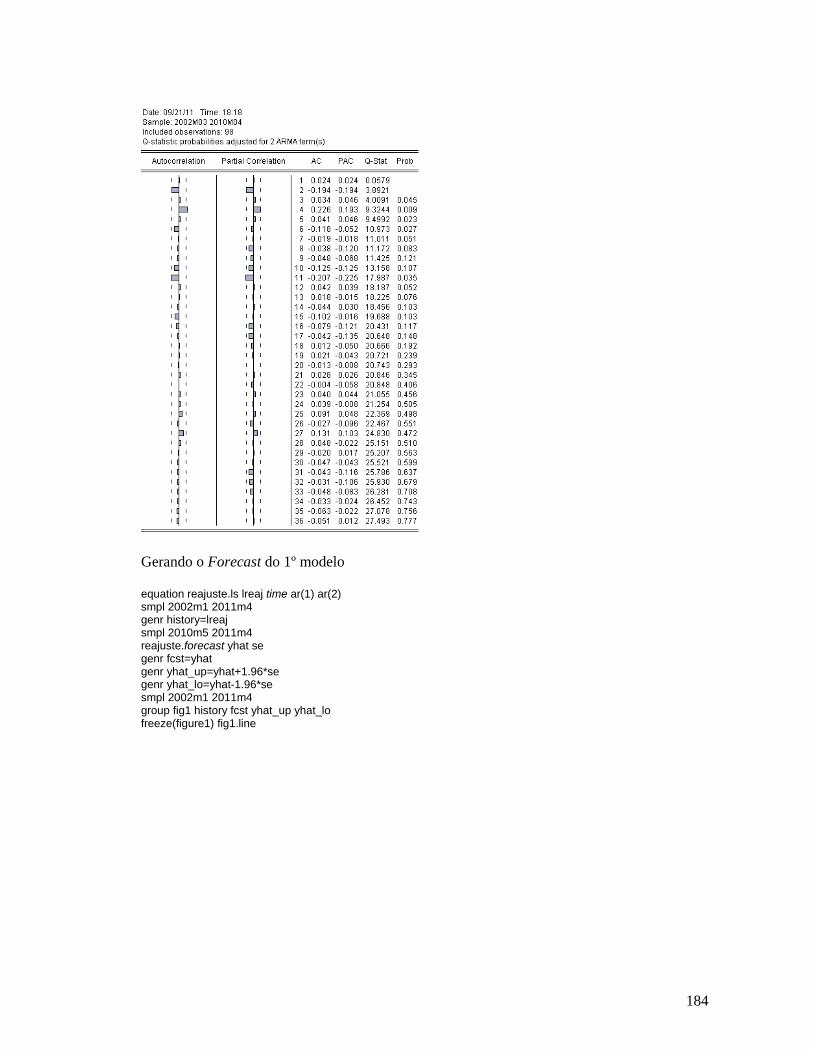
184
Gerando o Forecast do 1º modelo equation reajuste.ls lreaj time ar(1) ar(2) smpl 2002m1 2011m4 genr history=lreaj smpl 2010m5 2011m4 reajuste.forecast yhat se genr fcst=yhat genr yhat_up=yhat+1.96*se genr yhat_lo=yhat-1.96*se smpl 2002m1 2011m4 group fig1 history fcst yhat_up yhat_lo freeze(figure1) fig1.line

185
4.8
5.0
5.2
5.4
5.6
5.8
6.0
6.2
02 03 04 05 06 07 08 09 10
HISTORY FCSTYHAT_UP YHAT_LO
Gerando o segundo modelo incluindo novamente a tendência quadrática equation reajuste2.ls lreaj time time*time ar(1) ar(2) smpl 2002m1 2011m4 genr history2=lreaj smpl 2010m5 2011m4 reajuste2.forecast yhat2 se2 genr fcst2=yhat2 genr yhat_up2=yhat2+1.96*se genr yhat_lo2=yhat2-1.96*se smpl 2002m1 2011m4 group fig2 history2 fcst2 yhat_up2 yhat_lo2 freeze(figure2) fig2.line
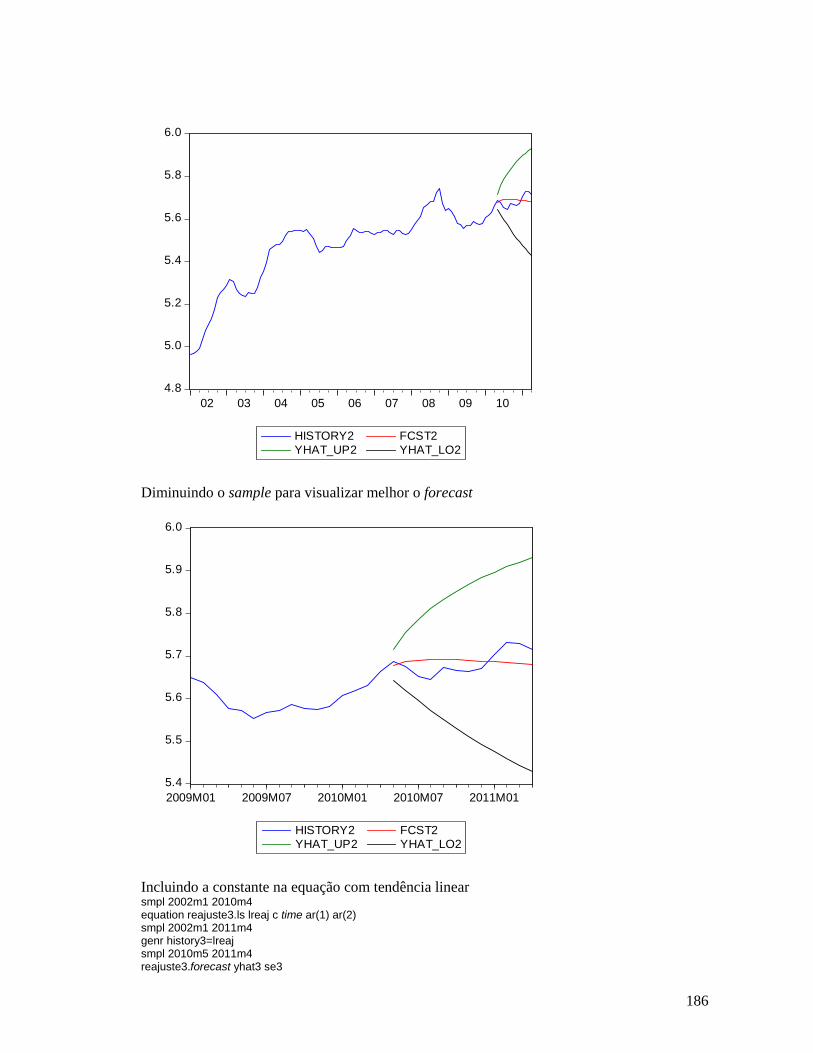
186
4.8
5.0
5.2
5.4
5.6
5.8
6.0
02 03 04 05 06 07 08 09 10
HISTORY2 FCST2YHAT_UP2 YHAT_LO2
Diminuindo o sample para visualizar melhor o forecast
5.4
5.5
5.6
5.7
5.8
5.9
6.0
2009M01 2009M07 2010M01 2010M07 2011M01
HISTORY2 FCST2YHAT_UP2 YHAT_LO2
Incluindo a constante na equação com tendência linear smpl 2002m1 2010m4 equation reajuste3.ls lreaj c time ar(1) ar(2) smpl 2002m1 2011m4 genr history3=lreaj smpl 2010m5 2011m4 reajuste3.forecast yhat3 se3

187
genr fcst3=yhat3 genr yhat_up3=yhat3+1.96*se3 genr yhat_lo3=yhat3-1.96*se3 smpl 2002m1 2011m4 group fig3 history3 fcst3 yhat_up3 yhat_lo3 freeze(figure3) fig3.line
4.8
5.0
5.2
5.4
5.6
5.8
6.0
02 03 04 05 06 07 08 09 10
HISTORY3 FCST3YHAT_UP3 YHAT_LO3
Gerando o modelo com tendência quadrática e constante smpl 2002m1 2010m4 equation reajuste4.ls lreaj c time time*time ar(1) ar(2) smpl 2002m1 2011m4 genr history4=lreaj smpl 2010m5 2011m4 reajuste4.forecast yhat4 se4 genr fcst4=yhat4 genr yhat_up4=yhat4+1.96*se4 genr yhat_lo4=yhat4-1.96*se4 smpl 2002m1 2011m4 group fig4 history4 fcst4 yhat_up4 yhat_lo4 freeze(figure4) fig4.line

188
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09 10
HISTORY4 FCST4YHAT_UP4 YHAT_LO4
Gerando novamente o modelo sem constante e tendência quadrática (modelo 2) com SE correto smpl 2002m1 2010m4 equation reajuste5.ls lreaj time time*time ar(1) ar(2) smpl 2002m1 2011m4 genr history5=lreaj smpl 2010m5 2011m4 reajuste5.forecast yhat5 se5 genr fcst5=yhat5 genr yhat_up5=yhat5+1.96*se5 genr yhat_lo5=yhat5-1.96*se5 smpl 2002m1 2011m4 group fig5 history5 fcst5 yhat_up5 yhat_lo5 freeze(figure5) fig5.line

189
4.8
5.0
5.2
5.4
5.6
5.8
6.0
02 03 04 05 06 07 08 09 10
HISTORY5 FCST5YHAT_UP5 YHAT_LO5
Fazendo forecast com tendência quadrática, linear e AR(4) smpl 2002m1 2010m4 equation reajuste6.ls lreaj c time time*time ar(1) ar(2) ar(3) ar(4) smpl 2002m1 2011m4 genr history6= lreaj smpl 2010m5 2011m4 reajuste6.forecast yhat6 se6 genr fcst6=yhat6 genr yhat_up6=yhat6+1.96*se6 genr yhat_lo6=yhat6-1.96*se6 smpl 2002m1 2011m4 group fig6 history6 fcst6 yhat_up6 yhat_lo6 freeze(figure6) fig6.line

190
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09 10
HISTORY6 FCST6YHAT_UP6 YHAT_LO6
Aumentando o Hold Out sample de 2008m2 a 2011m4 smpl 2002m1 2008m1 equation reajuste7.ls lreaj c time time*time ar(1) ar(2) ar(3) ar(4) smpl 2002m1 2011m4 genr history7= lreaj smpl 2008m2 2011m4 reajuste7.forecast yhat7 se7 genr fcst7=yhat7 genr yhat_up7=yhat7+1.96*se7 genr yhat_lo7=yhat7-1.96*se7 smpl 2002m1 2011m4 group fig7 history7 fcst7 yhat_up7 yhat_lo7 freeze(figure7) fig7.line

191
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09 10
HISTORY7 FCST7YHAT_UP7 YHAT_LO7
Mudando o hold out sample para 2009m1 a 2011m4 para AR(4) smpl 2002m1 2008m12 equation reajuste8.ls lreaj c time time*time ar(1) ar(2) ar(3) ar(4) smpl 2002m1 2011m4 genr history8= lreaj smpl 2009m1 2011m4 reajuste8.forecast yhat8 se8 genr fcst8=yhat8 genr yhat_up8=yhat8+1.96*se8 genr yhat_lo8=yhat8-1.96*se8 smpl 2002m1 2011m4 group fig8 history8 fcst8 yhat_up8 yhat_lo8 freeze(figure8) fig8.line

192
4.9
5.0
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
02 03 04 05 06 07 08 09 10
HISTORY8 FCST8YHAT_UP8 YHAT_LO8
Aumentando o Hold out sample para equação com tendência linear ar(2) smpl 2002m1 2008m12 equation reajuste9.ls lreaj c time ar(1) ar(2) smpl 2002m1 2011m4 genr history9=lreaj smpl 2009m1 2011m4 reajuste9.forecast yhat9 se9 genr fcst9=yhat9 genr yhat_up9=yhat9+1.96*se9 genr yhat_lo9=yhat9-1.96*se9 smpl 2002m1 2011m4 group fig9 history9 fcst9 yhat_up9 yhat_lo9 freeze(figure9) fig9.line

193
4.8
5.0
5.2
5.4
5.6
5.8
6.0
02 03 04 05 06 07 08 09 10
HISTORY9 FCST9YHAT_UP9 YHAT_LO9
Fiquei entre os modelos 3 e 9
O modelo escolhido foi o modelo 3 Não dá para fazer análise recursiva quando tem AR(p), então onde estava AR(1) AR(2) vamos substituir por lreaj(-1) lreaj(-2) lreaj c time lreaj(-1) lreaj(-2) View / estability test / recursive estimates / recursive residuals / c(1) c(2) c(3) c(4) /

194
-.10
-.08
-.06
-.04
-.02
.00
.02
.04
.06
2003 2004 2005 2006 2007 2008 2009
Recursive Residuals ± 2 S.E.
CUSUM
-30
-20
-10
0
10
20
30
2003 2004 2005 2006 2007 2008 2009
CUSUM 5% Significance
CUSUM of Square test

195
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
2003 2004 2005 2006 2007 2008 2009
CUSUM of Squares 5% Significance
One step probability
.000
.025
.050
.075
.100
.125
.150
-.100
-.075
-.050
-.025
.000
.025
.050
2003 2004 2005 2006 2007 2008 2009
One-Step ProbabilityRecursive Residuals
N-step

196
.000
.025
.050
.075
.100
.125
.150
-.100
-.075
-.050
-.025
.000
.025
.050
2003 2004 2005 2006 2007 2008 2009
N-Step ProbabilityRecursive Residuals
Recursive estimates
Teste de White