Embed Size (px)
Citation preview

Projeto e Desenvolvimento de Aplicações Cliente / Servidoras
Para a INTERNET
João Carlos Gluz
Canoas, RS, março de 2001

Projeto e Desenvolvimento de Aplicações para a Internet
2 Copyright 2001 João Carlos Gluz
Sumário
SUMÁRIO ................................................................................................................................................ 2
CAPÍTULO I - O MODELO CLIENTE / SERVIDOR....................................................................... 4 1.1. MOTIVAÇÃO..................................................................................................................................... 4 1.2. TERMINOLOGIA................................................................................................................................ 4 1.3. COMPLEXIDADE RELATIVA .............................................................................................................. 5 1.4. PADRONIZAÇÃO ............................................................................................................................... 6 1.5. PROTOCOLOS DE COMUNICAÇÃO ..................................................................................................... 6 1.6. FORMATOS DE INFORMAÇÕES .......................................................................................................... 6 1.7. PARAMETRIZAÇÃO DE CLIENTES...................................................................................................... 7 1.8. USO DE CONEXÕES........................................................................................................................... 7 1.9. INFORMAÇÕES DE ESTADO ............................................................................................................... 8
CAPÍTULO II - INTERFACE DE PROGRAMAÇÃO PARA APLICAÇÕES DE REDE ............ 9 2.1. CONCORRÊNCIA ............................................................................................................................... 9 2.2. PROCESSOS E PROGRAMAS............................................................................................................. 10 2.3. COMUNICAÇÃO ENTRE PROCESSOS ................................................................................................ 11 2.4. SINCRONISMO................................................................................................................................. 11 2.5. INTERFACES DE PROGRAMAÇÃO..................................................................................................... 12 2.6. INTRODUÇÃO A INTERFACE SOCKET............................................................................................... 13
CAPÍTULO III - INTERFACE SOCKETS ......................................................................................... 16 3.1. CRIANDO E ELIMINANDO SOCKETS .................................................................................................. 16 3.2. ESPECIFICANDO ENDEREÇOS .......................................................................................................... 17 3.3. ESTABELECENDO CONEXÕES.......................................................................................................... 18 3.4. FORÇANDO A AMARRAÇÃO DE ENDEREÇOS .................................................................................... 19 3.5. RECEBENDO CONEXÕES.................................................................................................................. 20 3.6. TRANSFERÊNCIA DE DADOS ........................................................................................................... 21
CAPÍTULO IV - ARQUITETURA GENÉRICA DE CLIENTES................................................... 23 4.1. INTRODUÇÃO.................................................................................................................................. 23 4.2. CARACTERÍSTICAS DE UMA APLICAÇÃO CLIENTE............................................................................ 23 4.3. ALGORITMO BÁSICO DE UM CLIENTE .............................................................................................. 23 4.4. LOCALIZAÇÃO DO SERVIDOR.......................................................................................................... 24 4.4. IDENTIFICAÇÃO DO SERVIÇO........................................................................................................... 26 4.5. PREENCHIMENTO DA ESTRUTURA DE ENDEREÇOS........................................................................... 28 4.6. CRIAÇÃO DO SOCKET ...................................................................................................................... 28 4.7. ESTABELECIMENTO DA CONEXÃO COM O SERVIDOR....................................................................... 29 4.8. TRANSFERÊNCIA DOS DADOS.......................................................................................................... 30 4.9. FINALIZAÇÃO DA CONEXÃO............................................................................................................ 32 4.10. COMUNICAÇÃO POR DATAGRAMAS .............................................................................................. 32

Projeto e Desenvolvimento de Aplicações para a Internet
3 Copyright 2001 João Carlos Gluz
4.11. EXEMPLO DE UM CLIENTE HTTP.................................................................................................. 35
CAPÍTULO V - ARQUITETURA DE APLICAÇÕES SERVIDORAS.......................................... 39 5.1. ALGORITMO BÁSICO....................................................................................................................... 39 5.2. CONCORRÊNCIA VERSUS ITERATIVIDADE NO TRATAMENTO DAS REQUISIÇÕES ............................... 40 5.3. O USO DE CONEXÕES NO TRATAMENTO DAS REQUISIÇÕES.............................................................. 40 5.4. QUANDO USAR CADA TIPO DE SERVIDOR ........................................................................................ 42 5.5. EXEMPLO DE UM SERVIDOR HTTP ................................................................................................. 42
CAPÍTULO VI – O PROTOCOLO HTTP......................................................................................... 57 6.1. OPERAÇÃO GERAL DO PROTOCOLO................................................................................................ 57 6.2. NOTAÇÃO USADA PARA APRESENTAR O FORMATO DAS MENSAGENS .............................................. 58
6.2.1. Definição de um Formato....................................................................................................... 58 6.2.2. Opções de Formatos............................................................................................................... 58 6.2.3. Caracteres / Símbolos Especiais ............................................................................................ 60 6.2.4. Elementos Básicos.................................................................................................................. 60
6.3. FORMATO BÁSICO DAS MENSAGENS ............................................................................................... 60 6.4. MENSAGENS DE REQUISIÇÃO ......................................................................................................... 63
6.4.1. Métodos das Requisições........................................................................................................ 63 6.4.2. Identificador de Recurso da Requisição................................................................................. 64 6.4.3. Cabeçalhos de Requisição...................................................................................................... 65
6.5. MENSAGENS DE RESPOSTA............................................................................................................. 66 6.5.1. Linha de Estado da Resposta ................................................................................................. 66 6.5.2. Códigos de Estados e sua Descrições .................................................................................... 66 6.5.3. Cabeçalhos de Resposta......................................................................................................... 68
6.6. ENTIDADE ...................................................................................................................................... 68 6.7. DESCRIÇÃO DOS MÉTODOS ............................................................................................................ 69
6.7.1. GET........................................................................................................................................ 69 6.7.2. HEAD..................................................................................................................................... 69 6.7.3. POST...................................................................................................................................... 69
6.8. CÓDIGOS DE ESTADO ..................................................................................................................... 70 6.9. CAMPOS DOS CABEÇALHOS............................................................................................................ 72
6.9.1. Cabeçalho Geral .................................................................................................................... 72 6.9.2. Cabeçalho das Requisições .................................................................................................... 73 6.9.3. Cabeçalho das Respostas ....................................................................................................... 74 6.9.4. Cabeçalho das Entidades ....................................................................................................... 75
6.10. AUTENTICAÇÃO DE ACESSO......................................................................................................... 77
CAPÍTULO VII - REQUISIÇÕES HTTP COM FORMUIÁRIOS CODIFICADOS ................... 79 7.1. MÉTODOS APLICÁVEIS ................................................................................................................... 79 7.2. ALGORITMO DE CODIFICAÇÃO ....................................................................................................... 79 7.3. EXEMPLO ....................................................................................................................................... 80 7.4. SUGESTÕES DE TRABALHOS ........................................................................................................... 80
7.4.1. Implementação do Tratamento de Formulários e CGI no WebServ ...................................... 80 7.4.2. Implementação de páginas ativas no WebServ ...................................................................... 82

Projeto e Desenvolvimento de Aplicações para a Internet
4 Copyright 2001 João Carlos Gluz
Capítulo I - O Modelo Cliente / Servidor
A pilha de protocolos TCP/IP provê um serviço genérico fim-a-fim de comunicação entre pares (peer-to-peer)de aplicações ou processos, mas não define como esta comunicação será organizada entre os pares de aplicações.
O modelo ou paradigma dominante (quase que único) para organizar a comunicação entre as aplicações é o modelo denominado:
CLIENTE / SERVIDOR
1.1. Motivação
A principal motivação por trás do uso do modelo cliente/servidor tem a ver com o problema de sincronização da comunicação entre as aplicações tentando interagir, principalmente se se levar em conta a velocidade com que são executadas as aplicações e também são atendidas as solicitações de comunicação pela rede.
O modelo divide as aplicações em duas grandes classes ou categorias:
• Clientes: sempre iniciam o processo de comunicação
• Servidores: sempre esperam que uma (ou mais) aplicação inicie a comunicação
Além disso este modelo resolve uma questão importante relacionada ao funcionamento do TCP/IP:
A pilha TCP/IP não fornece nenhum tipo de mecanismo para ativação (indicação na terminologia OSI/ISO) de aplicações quando da chegada de alguma mensagem particular, portanto deve sempre haver uma aplicação já executando esperando pelas mensagens que chegam da rede. Pela própria maneira como se organizam as aplicações no modelo cliente/servidor este problema fica naturalmente resolvido.
1.2. Terminologia
Clientes e servidores são aplicações, programas ou processos do sistema operacional, isto é, são softwares. Ocasionalmente, entretanto, a terminologia é aplicada, em particular o termo servidor, diretamente para as máquinas que estão executando alguma aplicação servidora. Para não haver confusão estas máquinas serão denominadas no texto de máquinas servidoras e não de servidores. O termo servidor será reservado apenas para as aplicações.
A divisão entre estas duas classes de aplicações será a mesma vista anteriormente:

Projeto e Desenvolvimento de Aplicações para a Internet
5 Copyright 2001 João Carlos Gluz
Os clientes serão sempre as aplicações que começam o processo de comunicação, enviando usualmente uma ou mais requisições para um servidor remoto.
Por sua vez os servidores serão os programas que esperarão por estas requisições, recebidas (tipicamente) através da rede de comunição que os liga com os clientes remotos.
Implicitamente se assumirá que as aplicações cliente/servidoras serão remotas umas das outras, embora isto não seja mandatório (por exemplo em caso de testes pode-se executar tanto o cliente quanto o servidor na mesma máquina).
A troca destas informações entre o par cliente / servidor se dará através de um protocolo de aplicação que é apenas um protocolo de comunicação definido especificamente para tratar dos problemas e questões envolvidas na interação do cliente com o servidor. No caso da Internet a identificação do protocolo de aplicação (e do serviço correspondente) será feita através de portas “lógicas” disponibilizadas pelo protocolo TCP (ou UDP).
Os servidores irão implementar um serviços que serão acessados remotamente pelos clientes através dos protocolos de aplicação. Normalmente os protocolos de aplicação, em aplicações cliente / servidoras, são organizadas em dois tipos de mensagens:
• mensagens de requisição ou solicitação de serviços, que são enviadas dos clientes aos servidores
• mensagens de resposta, que são enviadas dos servidores aos clientes, em resposta as requisições.
As requisições enviadas pelos clientes solicitam aos servidores que executem algum tipo de tarefa. Um servidor ao receber uma requisição de um cliente deverá executar uma ação correspondente e enviar a mensagem de resposta indicando que ação foi tomada. Por exemplo num dado instante o servidor pode realmente executar uma tarefa que atenda a solicitação feita pelo cliente, porém num outro instante de tempo, pelo fato de já estar sobrecarregado de tarefas, o servidor pode não fazer nada e apenas avisar isto ao cliente.
Uma outra questão importante relacionada aos protocolos de aplicação tem a ver com os formatos das mensagens trocadas entre o cliente e o servidor. Em geral, além de ser necessário especificar os formatos de requisições, respostas, etc., pode também ser necessário especificar o formato dos dados ou informações que serao trocados dentro destas mensagens, principalmente quando as questões de formato de informações forem realmente importantes para a aplicação. Neste caso será necessário definir formatos de representação de informações apropriados e que sejam independentes de arquiteturas de máquinas ou sistemas operacionais onde os clientes e servidores estão implementados.
1.3. Complexidade Relativa
Os servidores serão normalmente as aplicações mais complexas de se implementar neste par de aplicações por várias razões:
Servidores usualmente deverão executar com privilégios especiais dentro do sistema operacional não só porque terão que interagir intimamente com o subsistema de rede do S.O. (por ter que esperar

Projeto e Desenvolvimento de Aplicações para a Internet
6 Copyright 2001 João Carlos Gluz
requisições) mas também porque muitas vezes para atender as requisições remotas terão de a necessidade de acessar informações privilegiadas do S.O. e ocasionalmente ter que executar computações laboriosas.
Porém ao executar operações em modo privilegiado os servidores deverão implementar código para executar as seguintes tarefas:
• Autenticação através da verificação da identidade dos usuários (clientes remotos)
• Autorização ou não das requisições de acordo com o perfil do usuário
• Garantir a segurança no acesso aos dados dos usuários
• Garantir a privacidade das informações fornecidas pelos usuários
• Proteçao aos recursos do S.O.
Além disso quando for necessário a execução de computações laboriosas ou extensas o para atender uma dada requisição será necessário utilizar recursos de processamento concorrente do S.O. complicando ainda mais a implementação dos servidores.
1.4. Padronização
As aplicações cliente/servidoras podem ainda ser classificadas em relação ao fato de serem baseadas sobre serviços ou protocolos padronizados (well-known ports definidas através de RFC/STD específica) ou serem baseadas sobre serviços não padrão de uso local a uma organização ou de propriedade de alguma corporação.
1.5. Protocolos de Comunicação
Os protocolos de comunicação entre os pares de clientes e servidores definem formalmente como será a troca de informações entre eles. Estes protocolos podem ser padronizados ou não com visto anteriormente, mas também podem ser genéricos ou específicos, no sentido de que poderão ser usados apenas para um dado serviço (protocolo mais específico) ou poderão ser usados para suportar uma ampla variedade de serviços distintos (mais genérico).
Por exemplo o protocolo TELNET pode ser usado para suportar praticamente qualquer tipo de serviço cuja interação com os usuários esteja baseada no paradigma de terminal de texto remoto.
Por outro lado um protocolo como o FTP tem um uso bem mais restrito, sendo utilizado essencialmente (como o próprio nome indica) apenas para a transferência de arquivos.
1.6. Formatos de Informações
Geralmente são tratadas de forma independente as questões envolvendo a especificação dos protocolos usados na comunicação cliente/servidor e as questões envolvendo o formato das informações trocadas entre estas aplicações. Não que estas questões sejam totalmente independentes, mas apenas que um tratamento diferenciado destes dois tipos de questões facilita a generalização do uso do protocolo, uma

Projeto e Desenvolvimento de Aplicações para a Internet
7 Copyright 2001 João Carlos Gluz
vez que a falta de geralidade de uso de um protocolo está mais intimamente ligada aos formatos de informação que podem ser intercambiados dentro do protocolo do que com a as mensagens de controle usadas pelo mesmo.
Sendo assim atualmente se define um formato padrão único para o “envelope” destas mensagens e se define um formato extensível para o conteúdo destas mensagens.
Exemplos de pares de protocolo / formato:
TELNET / VT-100
HTTP / HTML
SMTP / MIME
SNMP / MIB-II
1.7. Parametrização de Clientes
Quando uma aplicação clientes é definida, normalmente vale a pena permitir que a mesma possa ser parametrizada para uma ampla gama de aplicações. Pelo menos a especificação do endereço e porta a ser usada no servidor remoto devem poder ser parametrizados.
A combinação de um cliente flexível bastante parametrizável com protocolos e formatos de mensagens genéricos permite a criação de verdadeiras aplicações clientes multifuncionais. Por exemplo existem inúmeros tipos de serviços disponibilizados por máquinas servidoras que caem dentro do paradigma de terminal de texto interativo remoto (desde o login remoto do shell até interfaces orientadas a menus ou formulários de aplicações específicas), sendo que se pode usar o cliente TELNET para o acesso a estes diferentes serviços, desde que se possa parametrizar não só o endereço da máquina servidora, mas também a porta TCP e provavelmente o tipo de emulação de terminal requerido.
Um exemplo mais recente de aplicação cliente multifuncional é o dos clientes HTTP/HTML (NetscapeTM, IExplorerTM, etc.) que hoje servem como front-end para um sem número de aplicações e serviços (na verdade quase que substituindo o antigo paradigma de terminal de texto).
1.8. Uso de Conexões
O termo conexão dentro de redes de computadores tem uma semântica bem específica relacionado a criação e uso de um canal de transporte fim-a-fim robusto, confiável e ordenado (uma espécie de “tubo” - pipe) para a troca de informações entre o par de aplicações. Serviços orientados a conexão são então serviços que faze uso deste tipo de canal de comunicação robusto e confiável. Na arquitetura da Internet este é o serviço baseado no protocolo TCP.
Por outro lado as redes de comunicação geralmente também disponibilizam um tipo de serviço de transporte mais segmentado, orientado a mensagens individuais que normalmente não garante nem a confiabilidade na entrega e nem o ordenamento correto de seqüência de mensagens, apesar de ser

Projeto e Desenvolvimento de Aplicações para a Internet
8 Copyright 2001 João Carlos Gluz
baseado no conceito de melhor esforço possível de entrega (best-effort delivery). Na arquitetura da Internet este serviço é fornecido através do protocolo UDP.
Um dos pontos mais importantes que deve ser decidido quando uma aplicação cliente/servidora está sendo especificada é que tipo de serviço de transporte se irá usar: com suporte a conexões ou sem suporte a conexões.
Apesar do fato do uso de conexões implicar no uso de maiores recursos de processamento e memória por parte do sistema operacional, tem-se como regra geral para implementação de aplicações cliente/servidoras que se deve sempre usar o serviço com suporte a conexões (também chamado de serviço orientado a conexão) exceto nos seguintes casos:
1. O protocolo de troca de informações entre o cliente e o servidor já foi especificado (numa RFC por exemplo) e exige o uso de UDP (trata por sua própria conta os problemas de confiabilidade e ordenação).
2. Este tipo de aplicação requer o uso de difusão (broadcast) de mensagens.
3. O custo, em termos de recursos de processamento e memória, necessário para se criar e manter as conexões é realmente inaceitável para a aplicação.
1.9. Informações de Estado
As informações mantidas por um servidor sobre como estão as interações com os seus clientes remotos é denominada de informações de estado. Entretanto a manutenção e armazenamento deste tipo de informação não são obrigatórios, ou seja, existem servidores que não precisam manter informações sobre o estado das suas diversas interações.
A necessidade ou não de um servidor de manter o estado das interações é, na verdade, uma questão de especificação de protocolos: se uma dada mensagem de protocolo somente puder ser corretamente interpretada em função de mensagens recebidas anteriormente então é praticamente impossível construir um servidor que não mantenha informações de estado.
Por outro lado o armazenamento das informações pode reduzir em muito as necessidades de comunicação entre o cliente e o servidor, por permitir que as mensagens façam referência a um contexto de comunicação prévio. Caso contrário seria necessário que cada mensagem encapsula-se todas as informações necessárias para o atendimento de uma dada requisição (operações idempotentes).
Contudo, o uso de informações de estado pode ocasionar sérios problemas se houverem problemas de comunicação entre as duas aplicações. Se mensagens forem perdidas ou duplicadas, as informações de contexto guardadas no servidor poderão se tornar inválidas sem que ele necessariamente o reconheça.
Além disso se o cliente sofrer uma pane, for reinicializado e a comunicação com o servidor for restabelecida sem que o servidor tenha sido informado da pane anterior então as informações de estado armazenadas no servidor serão totalmente errôneas.

Projeto e Desenvolvimento de Aplicações para a Internet
9 Copyright 2001 João Carlos Gluz
Capítulo II - Interface de Programação para Aplicações de Rede
2.1. Concorrência
Genericamente o termo concorrência se refere a execução de um conjunto de computações que parecem estar sendo executadas de forma simultânea. Estas computações podem estar realmente sendo executadas simultaneamente (ou seja sendo executadas em paralelo), ou a sua simultaneidade pode estar sendo simulada através de algum mecanismo de multiplexação de uso da CPU (simulação de paralelismo através da execução em tempo-compartilhado ou time-sharing). Entretanto, para os usuários e programadores , a diferença entre paralelismo simulado e o real é praticamente nula.
Numa rede, as aplicações rodando em diferentes máquinas estão efetivamente executando em paralelo uma em relação as outras. A rede fornece o mecanismo de intercomunicação destas aplicações e deve garantir, entre outras, coisas que a comunicação entre um dado par de aplicações não interfira na comunicação de outro par. Por exemplo supondo a existência de 4 aplicações: A, B, C e D rodando em quatro diferentes máquinas MA, MB , MC e MD , de acordo com a figura abaixo:
A B
C D
M A
M B
M C
M C
Neste caso as aplicações estão realmente executando em paralelo e a troca de informações entre elas está sendo feita de forma realmente simultânea.
Dentro de uma máquina ou computador também pode existir concorrência (tanto simulada quanto real). Por exemplo numa dada estação de trabalho, um usuário pode ter diferentes clientes sendo executados concorrentemente (um ou mais acessos FTP, um acesso TELNET, várias páginas HTML abertas e em processo de transferência, etc.). Atualmente os Sistemas Operacionais (SO) modernos, disponíveis nas nossas estações de trabalhos e computadores pessoais já disponibilizam o processamento concorrente de forma natural para as aplicações clientes.

Projeto e Desenvolvimento de Aplicações para a Internet
10 Copyright 2001 João Carlos Gluz
No caso das aplicações e máquinas servidoras a concorrência é ainda mais crucial para garantir um certo nível de eficiência e desempenho. Por exemplo numa dada máquina servidora de arquivos certamente que a concorrência é importante para garantir que um cliente remoto não fique esperando que os outros (p. ex.) 100 usuários anteriores terminem as transferências dos seus arquivos para, somente então, ser atendido.
Porém em relação às aplicações servidoras, a concorrência geralmente não é naturalmente criada pelo S.O. devendo ser implementada na própria aplicação servidora pelo programador. Isto incorpora um grande grau de complexidade no projeto e implementação de aplicações servidoras. Contudo este tipo de cuidado na implementação é realmente de crucial importância, podendo fazer toda a diferença entre um servidor bem aceito pelo mercado e com excelentes características e um servidor que seja um virtual fracasso em termos de mercado.
2.2. Processos e Programas
Em sistemas concorrentes o termo (ou conceito) de processo define a unidade fundamental de computação. Diferente do conceito de programa o conceito de processo evoca um significado mais dinâmico e ativo: um processo é um programa que está realmente em estado de execução numa dada máquina num dado intervalo de tempo.
Entretanto a relação entre processos e programas é bastante próxima, uma vez que um programa pode ser entendido com a especificação precisa de como um dado processo deve executar. Por exemplo um programa contém código e dados tipicamente armazenados um dado arquivo. Quando um usuário quer que o SO execute um dado programa, na verdade, o que o SO faz em resposta a esta solicitação é criar um processo com as informações fornecidas pelo arquivo de programa. Entre outras tarefas menores o SO criará este novo processo pelos seguintes atividades:
• uma área de código será alocada na memória e o código carregado nela, se porventura uma outra instância ou processo deste programa já não estiver em execução;
• uma área de memória será alocada especificamente para este processo;
• uma estrutura de dados contendo uma descrição do estado do processo (um um descritor de processo) será criada no núcleo do SO para manter o controle de estado da execução do processo.
Finalmente se não houver nenhum outro processo mais prioritário em execução o novo processo será ativado.
Nota: atualmente está se tornando muito comum tanto o termo quanto o uso de threads ou linhas de execução, como unidade de execução concorrente mínima. Na verdade o termo ou conceito de threads está mais relacionado às características que alguns SOs de uso geral, como o Linux e o Windows NT , apresentam quando da criação dos seus processos, do que a alguma diferença fundamental entre este conceito e o conceito de processo. Nestes SOs as threads nada mais são do que apenas “processos leves” (que, aliás, é um termo usado como sinônimo de linha de execução ou thread) que executam no mesmo espaço de dados que o processo “completo” original e que, portanto, são mais “leves” para criar e não exigem tantos recursos do SO para a sua execução.

Projeto e Desenvolvimento de Aplicações para a Internet
11 Copyright 2001 João Carlos Gluz
2.3. Comunicação entre Processos
Existem três grandes formas de processos diferentes se comunicarem entre si. Dependendo tanto do SO subjacente da arquitetura da máquina em que estão em execução, a comunicação entre os processo poderá ser feita através de:
1) Uso de memória compartilhada.
2) Troca de mensagens independentes de informação.
3) Estabelecimento de conexões de comunicação.
A primeira forma, memória compartilhada, geralmente é usada apenas no caso de processos em execução numa arquitetura paralela. No caso de aplicações distribuídas numa rede, são mais usadas as duas últimas formas de comunicação.
O TCP/IP permite o uso de qualquer uma das duas:
• a troca de mensagens pode ser facilmente implementada tanto através do UDP quando as exigências de confiabilidade e sincronismo não são tão grandes. Caso sejam pode-se implementar a troca confiável e síncrona através do TCP,
• a função mais importente desempenhada pelo TCP é justamente a criação e estabelecimento de conexões de comunicação confiáveis e robustas entre pares de aplicações.
2.4. Sincronismo
Tanto no caso da comunicação por mensagens, mas principalmente na comunicação por conexões, existe um requisito básico de “acerto” ou “acordo” temporal entre os pares de aplicações, que é, na verdade, um problema relacionado a como garantir a sincronização entre estes processos, ou seja, como garantir que eles estejam tanto executando quando se comunicando simultaneamente.
Uma forma razoável de resolver este problema seria prevendo nos diversos tipos de serviço de rede a serem providos pelo SO, um mecanismo de sinalização ou de “ativação automática” de um processo / programa quando do recebimento de algum determinado tipo de mensagem ou conexão da rede. Porém, por várias razões (inclusive por problemas de segurança) o TCP/IP não prevê nenhuma forma de sinalização ou ativação automática de processos. Sendo assim somente as mensagens ou conexões que já tenham algum processo ativo esperando por elas é que serão efetivamente tratadas. As demais mensagens serão descartadas e as conexões recusadas.
O modelo cliente/servidor já prevê uma solução apropriada para este problema de sincronismo com a divisão do universo de aplicações em clientes que sempre começam a comunicação e servidoras que estarão sempre esperando pelo estabelecimento de comunicação de algum cliente remoto.
Para que seja possível implementar isto na programação em TCP/IP, o recurso que o SO deverá disponibilizar é algum mecanismo de registro que permita que um processo avise para o SO quais tipos de conexões ou mensagens (portas no caso do TCP) estará disposto a receber.

Projeto e Desenvolvimento de Aplicações para a Internet
12 Copyright 2001 João Carlos Gluz
2.5. Interfaces de Programação
O TCP é como o próprio nome indica apenas um protocolo e não uma interface de programação de aplicações. O TCP normalmente é implementado através de um conjunto de processos ou rotinas do SO, que constituem o módulo ou entidade de controle da camada de transporte de rede.
O protocolo TCP serve justamente para definir precisamente como será forma de comunicação entre as entidades de transporte de um par de máquinas remotas, mas não foi feito para definir como estas entidades de controle de transporte irão se comunicar com os processos de aplicação.
A definição de como este tipo de comunicação entre o módulo de controle do TCP e os diversos processos de aplicação deve ser feita através de uma Interface de Programação de Aplicação (sigla em inglês API - Applications Programming Interface) específica que disponibiliza para os programadores os serviços do módulo TCP.
Reduzida as suas características mínimas uma API é pouco mais do que uma lista que especifica quais são as rotinas e funções de acesso a estes serviços. Quando necessário também é parte constituinte de uma API a especificação dos tipos de dados adicionais necessários para a implementação destes serviços. Do ponto de vista mais moderno uma API é na verdade a porção visível ao programador de um Tipo Abstrato de Dados ou de uma Classe de Objetos (Programação Orientada a Objetos).
Quando o TCP/IP foi incorporado originalmente aos sistemas UNIX, não foi criada imediatamente uma nova API para uso dos serviços destes protocolos. Na época se assumiu que os serviços de rede disponibilizados pelo TCP (notadamente o estabelecimento de conexões) seriam, grosso modo, equivalentes aos serviços fornecidos pelo sistema de arquivos (paradigma open-read-write-close de manipulação arquivos).
Aplic.A
Aplic.B
Arquivo de A para B
Arquivo de B para A
Isto não é tão disparatado quanto possa parecer, porque a comunicação através de uma conexão entre duas aplicações pares pode realmente ser idealizada como sendo feita através de operações de entrada e saída padrão sobre um par de arquivos: um para saída da aplicação A e entrada na B e o outro para o caminho inverso.
Porém este tipo de abstração, embora de bastante valia e ainda presente como um subconjunto da interface atual de desenvolvimento de aplicações TCP/IP, apresenta sérias limitações no que tange a sincronização entre os pares de aplicações.

Projeto e Desenvolvimento de Aplicações para a Internet
13 Copyright 2001 João Carlos Gluz
Foi justamente para resolver este problema que a Universidade da Califórnia em Berkeley criou a interface sockets de programação e uso dos serviços da camada de transporte de rede. A interface sockets se adapta muito bem ao uso do protocolo TCP/IP para comunicação com máquinas remotas, mas nada impede que outros protocolos de transporte sejam usados (ISO TP4 ou Novell IPX/SPX por exemplo), ou que o serviço não possa ser implementado como um mecanismo local de intercomunicação dos processos internos a uma máquina.
2.6. Introdução a Interface Socket
Tanto o TCP quanto o UDP, que são os dois protocolos de transporte usados na Internet, implementam uma série de “portas” de comunicação dentro de um dado computador ou máquina. Estas portas TCP/UDP são, na verdade, pontos internos de atendimentos dos serviços de transporte.
O TCP/UDP suporta até 65.535 portas distintas porque é usado um campo de 16 bits para identificação de porta nestes protocolos. Na estrutura de intercomunicação prevista pelo TCP/IP os serviços e protocolos criados pelas aplicações de rede deverão obrigatoriamente ser mapeados nestas portas.
Os serviços de aplicação padronizados e de uso público são identificados através de números de portas TCP ou UDP reconhecidas publicamente (em inglês well known ports). Tanto as portas quanto os serviços reconhecidos publicamente são definidos através de documentos específicos para isto: as RFCs (Request For Comments) publicados pela IETF (Internet Engineering Task Force) no seu próprio site (www.ietf.org).
Nada impede, entretanto, que se possa definir e usar uma porta qualquer para um serviço proprietário, exceto se esta porta já estiver sendo usada nos computadores em questão para um outro serviço.
Um outro detalhe interessante relacionado ao uso das portas é que, embora não haja nenhuma obrigação para que os serviços fornecidos pelo TCP usem as mesmas portas que os fornecidos através do UDP, tem-se mantido, pelo menos nos serviços públicos que são fornecidos pelos dois protocolos, a compatibilidade entre os números de porta.
O paradigma básico de trabalho no sockets é que a troca de informações entre um par de aplicações deve ser feita por uma conexão de comunicação. Uma vez que esta conexão seja estabelecida todos os dados enviados por uma aplicação são recebidos pela outra, na mesma ordem em que foram enviados. O serviço de sockets não prevê nenhum tipo de estruturação dos dados além do nível de caractere, ou seja, o sockets não faz nenhuma pressuposição sobre como será o formato de mensagens ou registros enviados pela conexão. Se houver algum tipo de estruturação nos dados além do nível de caractere então ela deverá ser tratada pelas aplicações que estarão usando os sockets.

Projeto e Desenvolvimento de Aplicações para a Internet
14 Copyright 2001 João Carlos Gluz
A E
CD
B
Cada um é umsocket distinto
São previstas na interface sockets mecanismos para estabelecer (abrir) conexões e encerrar (fechar) conexões. Também são previstos mecanismos que permitem a um processo de aplicação se registrar junto ao SO indicando qual ou quais portas este processo estará usando tanto para o recebimento de mensagens quanto ao envio. Por último também se pode indicar se o uso destas portas será feito de forma ativa pelo processo, isto é, o processo começará a usá-las abrindo conexões com uma máquina remota (caso típico de um cliente) ou então será empregado passivamente através da espera da chegada de conexões (caso típico de um servidor).
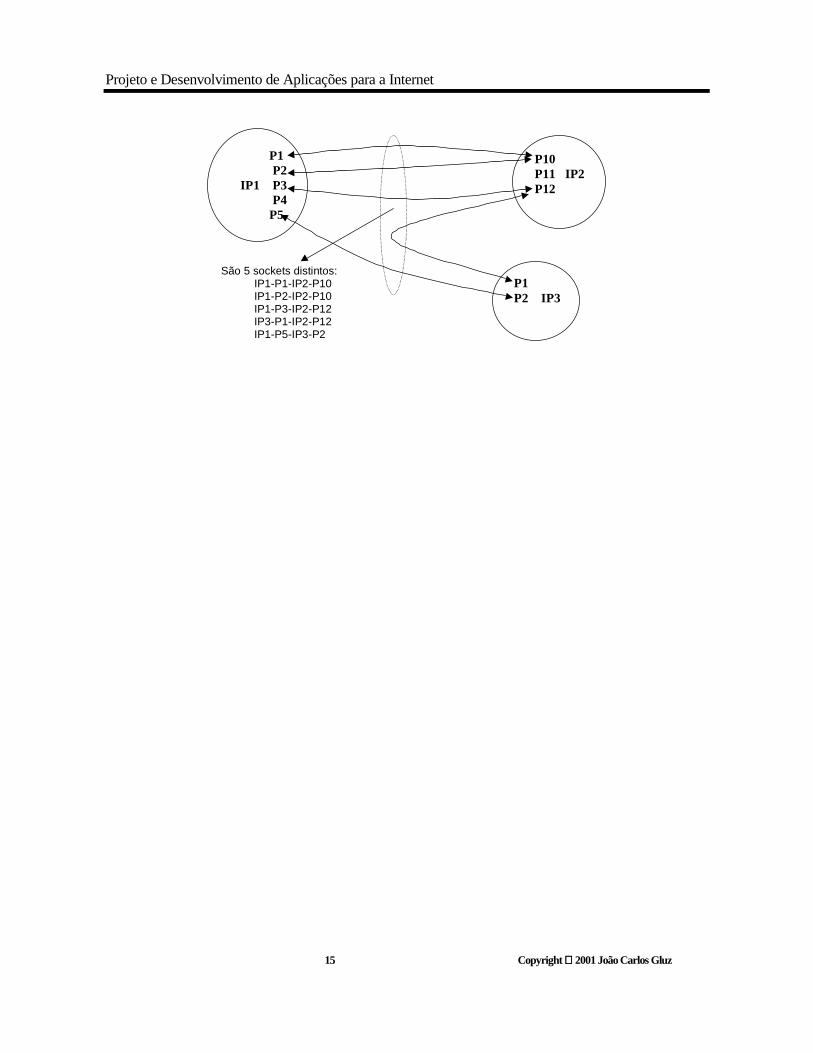
A identificação completa de uma conexão socket de uma máquina A para uma máquina B, dentro do universo de todas as conexões sockets possíveis numa Internet, é formada por quatro números ou endereços distintos:
IP-A: Endereço IP da máquina A Porta-A: Nro. de porta TCP ou UDP da máquina A IP-B: Endereço IP da máquina B Porta-B: Nro. de porta TCP ou UDP da máquina B.
Na figura a seguir pode-se ver a relação entre portas internas e endereço IP. Também fica claro que um socket é idenficado de forma única somente pelos endereços de IP e porta das máquinas de origem e destino:
Projeto e Desenvolvimento de Aplicações para a Internet
15 Copyright 2001 João Carlos Gluz
P1 P2 IP1 P3 P4 P5
P10 P11 IP2 P12
P1 P2 IP3
São 5 sockets distintos:IP1-P1-IP2-P10IP1-P2-IP2-P10IP1-P3-IP2-P12IP3-P1-IP2-P12IP1-P5-IP3-P2

Projeto e Desenvolvimento de Aplicações para a Internet
16 Copyright 2001 João Carlos Gluz
Capítulo III - Interface Sockets
3.1. Criando e eliminando sockets
A primitiva usada para criar um socket é a seguinte:
sock_descr = socket( protocol_family, type, protocol )
onde os parâmetros protocol_family e protocol definem, respectivamente, a família de protocolos e, caso existam vários protocolos nesta família, qual o protocolo específico. Para o caso da arquitetura TCP/IP basta usar PF_INET como valor de protocol_family e 0 como valor de protocol. O parâmetro type define o tipo de serviço que se pretende empregar no socket sendo criado. Para o uso na Internet são possíveis dois tipos de serviço:
SOCK_STREAM serviço orientado a conexão baseado no protocolo de transporte TCP SOCK_DGRAM serviço orientado a datagrama, baseado no protocolo de transporte UDP
O parâmetro retornado sock_descr irá conter o identificador do descritor do novo socket sendo criado, caso não tenha ocorrido nenhum erro na criação do socket. Entretanto se o socket não puder ser criado então a primitiva socket irá retornar um valor negativo.
Quando um socket não necessitar mais ser usado deve-se chamar a primitiva close1:
close( sock_descr )
para informar ao S.O. que o socket não está mais em uso.
// Tenta criar um socket TCP sock_descr = socket( PF_INET, SOCK_STREAM, 0 ). if (sock_descr < 0) { printf(“Erro: socket nao pode ser criado”); exit(0); }
1 A interface WinSockets do Microsoft Windows (TM) usa a primitiva closesocket em vez de close

Projeto e Desenvolvimento de Aplicações para a Internet
17 Copyright 2001 João Carlos Gluz
3.2. Especificando endereços
A primitiva socket cria um socket novo, ou seja, aloca os recursos necessários do S.O. para uso de um socket e também avisa ao S.O. que se vai passar a usar comunicação por sockets neste processo. Esta primitiva, entretanto, não estabelece nenhuma conexão com uma máquina remota.
Para estabelecer conexões (ou enviar mensagens no caso do serviço orientado a datagramas) é necessário especificar o endereço IP da máquina remota, bem como o identificador de porta desta máquina remota.
Isto é feito através das estruturas: sockaddr e sockaddr_in. A primeira destas (sockaddr) descreve o formato genérico dos endereços que podem ser usados na interface sockets e a segunda (sockaddr_in) descreve o formato de endereços específico para a Internet. Como neste texto o enfoque principal é em programação sockets sobre a Internet, somente o formato sockaddr_in será apresentado:
struct in_addr { uint32_t s_addr; }; struct sockaddr_in { unsigned char sin_len; /* tamanho total */ unsigned short sin_family; /* tipo do endereco, deve ser AF_INET */ unsigned short sin_port; /* porta TCP ou UDP */ struct in_addr sin_addr; /* endereco IP */ char sin_zero[8]; /* nao usado (zerado) */ };
O campo sin_len define o tamanho completo do endereço (somente é usado em familias de protocolos com endereços de tamanho variável, pode ser deixado em 0 no caso da Internet).
O campo sin_family define a família de protocolos do endereço (para Internet deve ser AF_INET).
O campo sin_port define qual porta TCP ou UDP será usada e o campo sin_addr define o endereço IP do host a ser contatado.
Importante:
Tanto a porta quanto o endereço devem estar em formato de dados da rede. Portanto caso se esteja alterando o valor destes campos a partir de variáveis internas do tipo short ou long, deve-se obrigatoriamente usar as primitivas de conversão: htons e htonl, que convertem, respectivamente, os tipos short e long do formato de dados de host para o formato de dados da rede.

Projeto e Desenvolvimento de Aplicações para a Internet
18 Copyright 2001 João Carlos Gluz
... sra.sin_port = htons( 80 ); /* vai usar a porta 80 - HTTP */ sra.sin_addr.s_addr = inet_addr(“200.238.29.30”); ...
O contrario também é verdadeiro, para se armazenar estes campos em variáveis internas que depois poderão ser impressas (corretamente) deve-se usar as primitivas de conversão: ntohs e ntohl, que convertem, respectivamente, os tipos short e long do formato de dados de rede para o formato de dados do host.
A rotina inet_addr usada no exemplo converte uma string contendo um endereço IP em notação ponto-decimal para o endereço de binário correspondente, já no formato long da Internet.
3.3. Estabelecendo conexões
De posse do novo socket e do endereço da máquina e porta remota que se pretende contatar (devidamente armazenados numa estrutura sockaddr_in) é possível então estabelecer uma conexão (socket) com a máquina remota se se optou pelo serviço orientado a conexões (baseado no TCP).
É importante notar que o ato de estabelecer ativamente uma conexão com uma máquina remota, caracteriza a aplicação como sendo cliente (somente clientes começam a interação, servidores ficam esperando pela chegada das solicitações). Sendo assim, somente clientes irão tentar estabelecer a conexão inicial.
A primitiva para se estabelecer conexões no sockets é a seguinte:
result = connect( sock_descr, ptr_rem_addr, addrlen )
onde sock_descr contém o descritor de um socket previamente criado, ptr_rem_addr é um apontador para uma estrutura sockaddr_in que contém o endereço IP e a porta da máquina remota e addrlen é fixo devendo ser preenchido com sizeof( sockaddr_in ).
Esta primitiva tentará estabelecer uma conexão TCP com a máquina remota. Se for bem sucedida deverá retornar 0, caso contrário retornará -1. O endereço IP e porta da máquina remota são fornecidos por ptr_rem_addr, porém para o endereço do lado local do socket, se nada mais for especificado, o S.O. usará o endereço IP local do host como endereço IP do lado local. Quanto a porta, também se nada mais for especificado, o S. O. usará a primeira porta TCP que não está sendo utilizada algum outro processo e disponibiliza esta porta para estabelecer a conexão.

Projeto e Desenvolvimento de Aplicações para a Internet
19 Copyright 2001 João Carlos Gluz
... res = connect( sock_descr, &sra, sizeof( sockaddr_in )); if (res<0) { printf(“Erro: nao conseguiu estabelecer conexao!”); exit(0); } ...
3.4. Forçando a amarração de endereços
Do ponto de vista de redes, do lado do cliente pouca coisa é necessário fazer além de criar um socket, estabelecer uma conexão com um servidor remoto, transferir dados de/para o servidor e encerrar o socket. Porém do lado do servidor as coisas são um pouco mais complicadas.
Em primeiro lugar, como o servidor irá ficar esperando passivamente por conexões (ou mensagens datagramas) em determinadas portas é necessário especificar quais serão estas portas, ou seja, não se pode deixar a cargo, como no caso do cliente, do S.O. a definição de que porta usar.
Além disso servidores são, normalmente, máquinas muito poderosas que muitas vezes estão conectadas fisicamente mais de uma rede IP distintas. Neste caso o servidor irá ter um endereço IP diferente para cada uma destas redes, podendo atender a alguns serviços em uma delas mas não necessariamente nas outras (pense num firewall ou num proxy-server que obviamente prestam serviços distintos dependendo de as requisições virem da Intranet ou da Internet).
No caso de servidores ligados a múltiplas redes, também deve-se especificar que serviço (porta) o servidor irá atender para cada endereço IP.
Para resolver estes problemas é usada a primitiva bind:
result = bind( sock_descr, ptr_local_addr, addrlen )
onde sock_descr contém o descritor de um socket previamente criado, ptr_local_addr é um apontador para uma estrutura sockaddr_in que contém o endereço IP e a porta da máquina local e addrlen é fixo devendo ser preenchido com sizeof( sockaddr_in ).
Caso não se queira especificar um endereço IP específico (com o efeito colateral, no caso de servidores com múltiplas portas, de se amarrar a porta a este socket para todos os diferentes endereços IP) pode-se preencher o campo sin_addr da estrutura apontada por ptr_local_addr com o valor INADDR_ANY, indicando então qualquer endereço IP existente na máquina.
Se não houve nenhum problema na amarração do socket então a primitiva retornará 0, caso ocorra algum problema (por exemplo o endereço IP solicitado não existe ou a porta especificada já está em uso) o valor retornado será -1.

Projeto e Desenvolvimento de Aplicações para a Internet
20 Copyright 2001 João Carlos Gluz
... sla.sin_addr = INADDR_ANY; sla.sin_port = htons( 80 ); res = bind( sock_descr, &sla, sizeof( sockaddr_in ) ); ...
3.5. Recebendo conexões
O próximo passo para um servidor é avisar ao S.O. que as conexões remotas poderão ser aceitas. Isto é feito pela primitiva listen:
listen( sock_descr, queue_size )
Esta primitiva não apenas avisa que o socket sock_descr irá ficar num estado passivo de espera de conexões mas também serve para informar o S.O. qual será o tamanho máximo da fila de requisições associada ao socket, através do parâmetro queue_size.
Contudo esta primitiva não espera pelas conexões - ela apenas avisa ao S.O. para que este coloque o socket em modo passivo. Para atender as conexões entrantes será usada a primitiva accept:
new_sock_descr = accept( sock_descr, ptr_rem_addr, ptr_addrlen )
onde sock_descr contém o descritor de um socket previamente criado, que já foi amarrado a um endereço através de bind e que já foi posto em modo passivo através de listen, ptr_rem_addr é um apontador para uma estrutura sockaddr_in que conterá o endereço IP e a porta da máquina remota quanto a conexão for estabelecida e ptr_addrlen é um apontador para um inteiro que (na prática em redes Internet) será preenchido com o valor sizeof( sockaddr_in ).
A primitiva accept é bloqueadora, isto é, a execução da aplicação fica “travada” até que uma nova conexão seja recebida. Somente após a recepção desta conexão é que a aplicação voltará a executar. Além disso os dados desta nova conexão poderão ser acessados através do novo socket sendo criado (new_sock_descr). O socket original sock_descr somente serve para especificar qual o endereço IP e porta a ser usados no lado local (serve também como um ponto de referência para a fila de requisições que o S.O. cria para o socket), mas não deverá ser usado para a troca de dados!
... listen( sock_descr, 15 ); new_sd = accept( sock_descr, ptr_rem_addr, ptr_addrlen ); ...

Projeto e Desenvolvimento de Aplicações para a Internet
21 Copyright 2001 João Carlos Gluz
3.6. Transferência de Dados
Uma vez que a conexão tenha sido estabelecida a troca de dados por meio da interface sockets é uma atividade bastante simples. Existem dois conjuntos de primitivas para esta troca de dados:
• as primitivas de escrita / leitura derivadas da API do sistema de arquivos (read / write) • novas primitivas de envio / recepção específicas da interface sockets (send / recv / sendto /
recvfrom)
A seguir é apresentada a lista destas primitivas, com uma breve descrição da operação das mesmas:
res = read( sock_descr, ptr_buf, len ) res = recv( sock_descr, ptr_buf, len, flags )
Estas duas primitivas recebem dados de um socket definido pelo parâmetro sock_descr. Os dados recebidos na área apontada por ptr_buf, com um tamanho máximo de len bytes. É importante salientar que tanto read quanto recv somente retornam, quando len bytes forem lidos ou em caso contrário a conexão terá sido desfeita e o número de bytes finais que se conseguiu ler sem erro é dado por res. O parâmetro flags serve para solicitar algumas opções especiais da interface sockets (entre estes a opção de se fazer um recv não bloqueante por exemplo).
res = write( sock_descr, ptr_buf, len ) res = send( sock_descr, ptr_buf, len, flags )
Estas duas primitivas escrevem ou enviam dados para o socket definido pelo parâmetro sock_descr. A área apontada por ptr_buf deverá conter os dados (bytes) a serem transferidos e o parâmetro len define o tamanho desta área. Da mesma forma que no caso das primitivas de recepção se o valor retornado pelas primitivas (res) for diferente de len então a conexão foi desfeita e res terá o número dos últimos bytes que se conseguiu efetivamente enviar. O parâmetro flags também serve para solicitar algumas opções especiais da interface socket.
sendto( sock_descr, ptr_buf, len, flags, ptr_dest_addr, addrlen ) recvfrom( sock_descr, ptr_buf, len, flags, ptr_orig_addr, ptr_addrlen )
As primitivas e procedimentos vistos até aqui se adaptam a transferência de dados usando conexões TCP. Mas no caso de se usar o serviço orientado a datagrama do UDP, o processo todo é na verdade muito mais simples:
• do lado do cliente, em vez de estabelecer uma conexão (connect) e depois transferir dados, basta informar qual mensagem e qual a máquina e porta destino. Esta é a função da primitiva sendto, que envia dados para uma máquina e porta remotas.
• do lado do servidor a seqüência de passos ainda implica em se usar bind e listen, porém o uso do accept é desnecessário, pois basta usar a primitiva recvfrom para receber dados de uma máquina e porta remota.

Projeto e Desenvolvimento de Aplicações para a Internet
22 Copyright 2001 João Carlos Gluz
Os parâmetros sock_descr, ptr_buf e len têm os mesmos significados vistos anteriormente. Da mesma forma que no connect o parâmetro ptr_dest_addr aponta para uma estrututura sockaddr_in que contém o endereço da máquina e porta remota que se deseja enviar a mensagem. Também da mesma forma que no accept o parâmetro ptr_orig_addr irá conter o endereço IP e porta da máquina que enviou a mensagem. Os parâmetros addrlen e ptr_addrlen têm significado igual que os parâmetros de mesmo nome em connect e accept.
Nota:
Estas primitivas somente devem ser usadas em sockets que estejam desconectados.

Projeto e Desenvolvimento de Aplicações para a Internet
23 Copyright 2001 João Carlos Gluz
Capítulo IV - Arquitetura Genérica de Clientes
4.1. Introdução
As primitivas sockets de programação vistas até agora permitem a construção de um sem-número de aplicações de rede. Porém, a verdade é que apenas entender quais são as primitivas de comunicação disponibilizadas por uma determinada arquitetura de rede (seja ela TCP/IP, ou Novell IPX/SPX ou Microsoft / IBM NetBIOS ou qualquer outra arquitetura) não é suficiente para se começar a projetar e implementar aplicações de rede úteis, eficientes e muitos menos otimizadas.
Para tanto é necessário também se ater as características e conceitos envolvidos na criação de aplicações para operar em redes. Dito de outra forma: embora um bom conhecimento das capacidades das primitivas de uma dada interface de programação para redes seja necessário ele não é suficiente, tendo que ser complementado pelo conhecimento de como se pode estruturar a comunicação entre as aplicações e programas.
Dando seguimento a este processo agora se passará a analisar as características e conceitos envolvidos em programação de aplicações cliente/servidoras, começando pela arquitetura genérica usada nas aplicações clientes.
4.2. Características de uma aplicação cliente
De maneira geral as aplicações que agem como clientes são conceitualmente mais simples do que as aplicações servidoras:
• Em primeiro lugar, geralmente não é necessário que as aplicações clientes seja capazes ou tenham que tratar concorrentemente as suas conexões com o servidor (ou servidores).
• Usualmente também não é necessário que uma aplicação cliente tenha privilégios especiais de S.O. (como, p.ex., os necessários para se obter acesso ao cadastro de usuários do sistema).
• Por último, em conseqüência disso também não é normalmente necessário que a aplicação cliente tenha que reforçar ou garantir critérios de segurança de acesso (em geral se usa clientes para se ter acesso a sistemas remotos, portanto são os servidores remotos que terão que controlar este acesso).
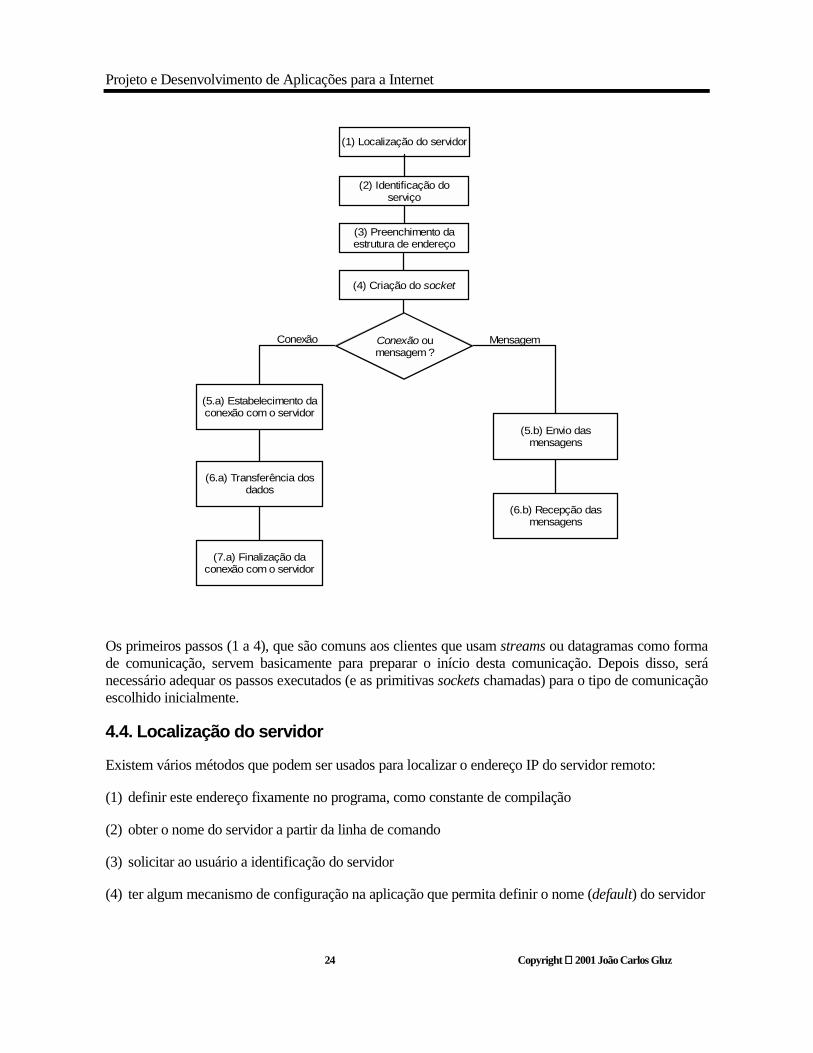
4.3. Algoritmo básico de um cliente
As aplicações clientes tem uma estrutura básica bastante simples seguindo o algoritmo apresentado no diagrama visto a seguir:
Projeto e Desenvolvimento de Aplicações para a Internet
24 Copyright 2001 João Carlos Gluz
(1) Localização do servidor
(3) Preenchimento daestrutura de endereço
(4) Criação do socket
Conexão oumensagem ?
(5.a) Estabelecimento daconexão com o servidor
(6.a) Transferência dosdados
(7.a) Finalização daconexão com o servidor
(5.b) Envio dasmensagens
(6.b) Recepção dasmensagens
(2) Identificação doserviço
Conexão Mensagem
Os primeiros passos (1 a 4), que são comuns aos clientes que usam streams ou datagramas como forma de comunicação, servem basicamente para preparar o início desta comunicação. Depois disso, será necessário adequar os passos executados (e as primitivas sockets chamadas) para o tipo de comunicação escolhido inicialmente.
4.4. Localização do servidor
Existem vários métodos que podem ser usados para localizar o endereço IP do servidor remoto:
(1) definir este endereço fixamente no programa, como constante de compilação
(2) obter o nome do servidor a partir da linha de comando
(3) solicitar ao usuário a identificação do servidor
(4) ter algum mecanismo de configuração na aplicação que permita definir o nome (default) do servidor

Projeto e Desenvolvimento de Aplicações para a Internet
25 Copyright 2001 João Carlos Gluz
(5) obter dados sobre o servidor a partir de arquivos de informação do sistema
(6) usar um outro protocolo / serviço de rede para obter os dados do servidor
O primeiro modo embora possa parecer bastante restritivo, ainda assim pode ser empregado se em vez de se armazenar um endereço IP fixo no código da aplicação, se armazenar um nome de servidor. Desta forma, pelo uso de aliases, um administrador de sistema poderá configurar o cliente para o seu sistema de forma apropriada.
Porém as formas mais usuais para clientes utilizados diretamente por usuários finais são as (2), (3) e (4) que permitem ao cliente ser configurado com o nome do servidor quando é executado pelo usuário.
As formas (5) e (6) também são bastante utilizadas, mas em geral em clientes mais próximos do S.O., que fornecem serviços mais básicos (como acesso a arquivos, impressoras ou portas seriais remotas) ou em outras arquiteturas de rede que não o TCP/IP (a alternativa (6) em particular). A implementação destas alternativas é muito dependente tanto do S.O. sendo usado quanto, também, da arquitetura de rede empregada. Por exemplo, embora o TCP/IP não tenha muitos mecanismos de divulgação de que serviços uma dada irá prestar, existem arquiteturas de redes como o IPX/SPX que são fortemente baseadas em mecanismos de divulgação ou publicação de serviços.
Independente do modo como o identificador do servidor é obtido, é importante que o cliente tenha a capacidade de trabalhar com nomes de servidores e não apenas com endereços IP destas máquinas. Para tanto é necessário não apenas reconhecer e armazenar corretamente estes nomes, mas também chamar as rotinas apropriadas para converter estes nomes em endereços (não esqueça que as primitivas sockets de comunicação usam endereços e não nomes).
A rotina que faz esta conversão é a:
struct hostent *gethostbyname( char *name )
que retorna o endereço referente ao nome na estrutura hostent, vista a seguir:
struct hostent { char *h_name; /* nome oficial do host */ char **h_aliases; /* nomes adicionais */ int h_addrtype; /* tipo do endereco */ int h_length; /* tamanho do endereco */ char **h_addr_list; /* lista de enderecos */ };
Os campos que contem nomes ou endereços são organizados como listas porque as máquinas (hosts) podem ter múltiplas interfaces e, portanto, múltiplos endereços e possivelmente nomes. Porém para o caso mais comum, em que se quer o (primeiro) endereço correspondente a um nome, pode-se usar a notação h_addr ao invés de h_addr_list graças a seguinte definição contida no(s) header(s) da interface sockets:

Projeto e Desenvolvimento de Aplicações para a Internet
26 Copyright 2001 João Carlos Gluz
#define h_addr h_addr_list[0]
Para se obter o endereço correspondente ao nome do servidor, basta usar um trecho de código similar ao seguinte:
... struct hostent *phe; char *serv_name = “www.ulbra.tche.br”; ... if ( (phe = gethostbyname( serv_name )) != NULL ) { /* Endereco IP valido, que esta’ contido em phe->h_addr */ } else { /* Houve algum erro na resolucao do nome */ }
Uma vez de posse do endereço correto do servidor pode-se passar a etapa seguinte.
4.4. Identificação do serviço
O serviço que um dado cliente irá solicitar a um servidor remoto está implícito na própria implementação do cliente (e do servidor também), ou seja, se foi implementado um cliente para se fazer tranferência de arquivos do servidor remoto de/para a máquina local, não se deve esperar que seja possível usar este serviço para fazer, por exemplo, o login remoto ao shell de comandos do servidor remoto.
Apesar disso, a identificação de onde, dentro do servidor remoto, “se encontra” este serviço pode mudar de servidor para servidor. Além disso, diferentes tipos de “serviço”, pelo menos do ponto de vista do usuário final, podem ser acessados por um mesmo tipo de cliente: voltando ao caso do login remoto, um cliente como o TELNET que provê acesso ao login remoto, pode facilmente prover acesso da mesma forma a, por exemplo, uma aplicação de controle de contabilidade que seja baseada em menus e formularios textuais.
Na arquitetura TCP/IP a identificação do serviço é feita por uma porta do TCP ou do UDP, dependendo se ele é prestado por, respectivamente, streams ou datagramas. O TCP/IP não dispôe de um mecanismo genérico de divulgação e publicação automática de serviços (exceto pelo mecanismo relativamente simples implementado pelo DNS), sendo assim a associação de que porta pertence a que serviço (e de que porta remota o cliente deverá usar) é feita através de três formas básicas (não mutuamente exclusivas):
(1) uma definição padrão, publicada em RFC e STD sobre os serviços reconhecidos publicamente, com suas respectivas portas (well known ports)

Projeto e Desenvolvimento de Aplicações para a Internet
27 Copyright 2001 João Carlos Gluz
(2) arquivos locais aos sistemas que dão nomes aos serviços associados as portas, sejam estes serviços públicos ou proprietários
(3) especificação direta do número de porta a ser usada no servidor remota quando da execução do cliente
Desta forma um cliente que busca páginas HTML numa máquina remota, pode se valer do fato de que a porta padrão para este tipo de serviço é a 80 e usar este número se nenhuma informação adicional for fornecida.
Além disso, caso o cliente não tenha internamente armazenado o número propriamente dito da porta padrão dos servidores HTML, ele pode se valer do fato de que esta porta está associada ao protocolo denominado de “http” e buscar no arquivo de identificação de serviços do sistema, qual a porta correspondente a este protocolo.
Por último, o cliente pode solicitar ao usuário que forneça a porta que irá usar para se conectar ao servidor remoto.
Nos casos em que o cliente irá buscar o número da porta pelo nome do protocolo ou serviço (seja ele pré-definido na aplicação ou fornecido pelo usuário) existe uma rotina específica que fará este tipo de tradução:
struct servent *getservbyname( char *nome_servico, char *nome_protocolo )
que retorna a seguinte estrutura de dados:
struct servent { char *s_name; /* nome oficial do servico */ char **s_aliases; /* nomes adicionais */ int s_port; /* porta deste servico */} char *s_proto; /* nome do protocolo (udp ou tcp) */ };
Para se obter a porta padrão para o protocolo “http” basta executar um trecho de código similar ao seguinte:

Projeto e Desenvolvimento de Aplicações para a Internet
28 Copyright 2001 João Carlos Gluz
... struct servent *pse; ... if ( (pse = getservbyname( “http”, “tcp”)) != NULL ) { /* Porta padrao localizada e armazenada em pse->s_port */ } else { /* Nao achou nenhuma pora para o nome de servico e nome de protocolo indicados */ }
4.5. Preenchimento da estrutura de endereços
Depois da localização do servidor remoto e identificação do serviço, basta definir e preencher a estrutura de armazenamento de endereços padrão para a interface sockets (estrutura sockaddr_in). Na seção Especificando endereços do Capítulo III - Interface Sockets, se apresenta esta estrutura e as regras para o seu preenchimento, salientando-se o cuidado que se deve ter em termos de conversão de tipos de dados (principalmente inteiros short e long) do formato padrão da Internet para o formato da arquitetura de máquina em que se está trabalhando (rotinas htons e htonl) e vice-versa (rotinas ntohs e ntohl).
Um ponto importante em relação aos endereços IP, quando se está analisando a operação dos clientes, tem a ver com o fato de que uma identificação completa de um socket na Internet precisa de 4 valores: dois já foram obtidos, o endereço IP e a porta do servidor remoto e dois são relativos à máquina local: o endereço IP desta e a porta TCP ou UDP que se usará como origem para o socket.
A regra básica para os clientes é bastante simples:
No caso dos clientes não se preocupe em especificar o endereço IP ou porta local, deixe esta função para o S.O. que se encarregará de encontrar os valores apropriados.
Forçar a amarração de endereços (através da primitiva bind) poderá ocasionar problemas e conflitos não só com o pool de números de porta sob controle do S.O. mas também poderá ser de difícil gerenciamento principalmente quando a máquina dispuser de diversas interfaces de rede e, por conseguinte, diversos endereços IP.
4.6. Criação do socket
A criação do socket é um processo simples e direto, sem maiores problemas, cujas características já forma apresentadas na primeira seção do documento Parte III - Interface Sockets que é justamente a seção Criando e eliminando sockets. O terceiro parâmetro da primitiva sockets pode ser sempre deixado com zero porque: somente o protocolo TCP fornece o serviço de conexões (SOCK_STREAM) e somente o

Projeto e Desenvolvimento de Aplicações para a Internet
29 Copyright 2001 João Carlos Gluz
UDP fornece o serviço de mensagens / datagramas (SOCK_DGRAM), sendo assim o último parâmetro é irrelevante e pode ser deixado em 0.
Notas:
Existe uma diferença entre a interface WinSocket usada nos sistemas Windows 9x, 2000 e NT e a interface BSD Socket usado nos diversos tipos de UNIX, no Linux e no FreeBSD: o valor retornado pela primitiva socket no caso dos sistemas Windows tem o tipo SOCKET que não pode ser considerado como um int. Sendo assim no caso dos sistemas Windows a regra é testar o valor retornado pela primitiva socket contra a constante INVALID_SOCKET, se eles forem iguais isto implica que o Windows não conseguir criar o novo socket. No caso dos sistemas UNIX-like, uma opção para manter a compatibilidade de código fonte é definir a constante INVALID_SOCKET como (-1).
Outro detalhe importante: nos sistemas Windows, antes de se chamar qualquer primitiva ou rotina da interface sockets é obrigatório chamar a rotina WSAStartup para avisar ao S.O. que esta aplicação irá usar a interface sockets (para saber os detalhes sobre esta rotina consulte a documentação da Microsoft )
4.7. Estabelecimento da conexão com o servidor
Caso tenha sido escolhida a comunicação por conexões, então o próximo passo após a criação do socket é (tentar) estabelecer a conexão com o servidor remoto. Obviamente que este não é um processo determinístico que irá sempre ser atendido. Várias coisas podem acontecer nesta etapa de forma que a conexão não seja estabelecida:
(1) endereço IP fornecido pode ser inválido (não existe máquina com este endereço),
(2) endereço pode ser válido mas o servidor pode estar desligado ou ter sofrido algum tipo de pane,
(3) endereço pode estar OK, o servidor pode estar ligado, mas o segmento de rede que o conecta ao resto da Internet pode estar com algum tipo de falha,
(4) a porta fornecida pode simplesmente estar errada, ou seja, o servidor não atende nenhum serviço nesta porta,
(5) ou ainda a rede pode estar congestionada e o tempo entre o envio de uma requisição e a chegada da resposta (tempo de resposta) pode ser inaceitável (imagine se ele for de 5 minutos!)
(6) endereço pode estar OK, a porta também, a rede OK, o servidor ligado, mas completamente ocupado atendendo outros clientes, neste caso ele apenas recusa a conexão ou logo no início desta avisa ao cliente que ele não pode atendê-lo,
(7) etc., etc. e etc. ( o número e grau de problemas que podem ocorrer numa rede são simplesmente inacreditáveis, na verdade, o fato das redes funcionarem e funcionarem normalmente bem é que é realmente inacreditável).
Esta enorme série de problemas que podem ocorrer no estabelecimento da conexão (alguns deles obviamente também podem ocorrer depois) serve apenas para alertar o projetista e desenvolvedor que se

Projeto e Desenvolvimento de Aplicações para a Internet
30 Copyright 2001 João Carlos Gluz
deve fazer um bom trabalho de reconhecimento de tipo de erro que ocorreu e também permitir ao usuário da aplicação cliente ter a chance de alterar suas opções para tentar buscar ou usar outro servidor, porta, etc.
Afora isto, basta chamar a primitiva socket e testar seu resultado. Esta primitiva irá executar 4 tarefas:
(1) verificar se o identificador de socket é válido,
(2) preencher o endereço remoto do socket com os dados do segundo parâmetro,
(3) escolher, junto com o S.O. um endereço IP e de porta apropriado para o lado local do socket (caso isto não tenha sido pré-definido com a primitiva bind),
(4) iniciar o processo de estabelecimento da conexão TCP com o servidor remoto, retornando uma indicação se este processo teve sucesso ou não.
4.8. Transferência dos dados
A fase de transferência de dados é a parte crítica da aplicação, porque é nela que o serviço será efetivamente prestado. É durante esta fase que deverá entrar em operação o protocolo de aplicação.
Embora as aplicações possam ter distintos tipo de protocolos de aplicação, usando os mais diversos de mecanismos de comunicação, em geral as aplicações de rede que seguem o paradigma cliente / servidor organizam os protocolos de aplicação em interações requisição / resposta.
Este tipo de interação, onde o cliente envia mensagens que fazem requisições ou solicitações ao servidor remoto e, por sua vez, este servidor atende a estas requisições executando alguma tarefa local e enviando uma mensagem de resposta para o cliente, define, na prática, a própria filosofia de se fazer sistemas cliente / servidores.
Além disso, este tipo de interação pode ser facilmente incorporada tanto a operação por conexões (onde a interação requisição / resposta tem um comportamento mais confiável) quanto na operação por datagramas (onde a confiabilidade da interação requisição/resposta não é garantida pela rede, devendo, se necessário, ser garantida pela aplicação).
A seguir é apresentado um trecho de código que justamente demonstra este tipo de interação resposta, para o caso de um cliente HTTP que busca um arquivo remoto (no exemplo se restringiu a operação à versão 0.9 do HTTP, por permitir demonstrar de forma mais simples esta interação):
/* Conseguiu se conectar ao servidor remoto. Agora, usando o protocolo HTTP, solicita o arquivo remoto e o mostra na tela. */ /* Envia um request de arquivo no formato mais simples possivel do HTTP (requisicao GET usada no HTTP 0.9) */ sprintf( sbuf, "GET %s \r\n", argv[3] ); sbuf_len = strlen( sbuf );

Projeto e Desenvolvimento de Aplicações para a Internet
31 Copyright 2001 João Carlos Gluz
if (send( sock_id, sbuf, sbuf_len, 0 ) != sbuf_len) { printf( "Erro na transmissao do request!\n" ); exit(0); } /* Espera pelo arquivo enviado em resposta e apresenta o mesmo na tela */ while ((rbuf_len=recv(sock_id, rbuf, MAXSIZ_RBUF, 0))==MAXSIZ_RBUF) { rbuf[MAXSIZ_RBUF] = '\0'; printf( rbuf ); } if (rbuf_len>0) { rbuf[rbuf_len] = '\0'; printf( rbuf ); }
Um ponto importante deve ser ressaltado na implementação da comunicação entre o par cliente / servidor:
O protocolo TCP não preserva (não fornece) nenhum tipo de limitador para registros ou blocos de dados: um stream TCP ligando um par de aplicações se apresenta como um fluxo contínuo bidirecional de caracteres de 8 bits (bytes) sendo transmitidos de uma aplicação para a outra.
Na sua forma mais simples, dentro deste fluxo não existirá nenhum tipo de caracter especial ou sinalização de qualquer forma implementada pelo TCP. Isto implica que se houverem limitações lógicas, do ponto de vista do protocolo de aplicação, às mensagens trocadas entre o cliente e o servidor isto deverá ser explicitamente implementado nestas aplicações.
Porém um ponto deve ser levado em conta: assim como o TCP não preserva ou controla qualquer tipo de sinalização / limitação de mensagens, assim também não se deve assumir que ao enviar uma mensagem (ou bloco de dados) de tamanho L por uma primitiva send ou write, esta mensagem ou bloco será recebido com o mesmo tamanho por uma primitiva recv ou read equivalente. Muito provavelmente esta mensagem será recebida numa série de blocos menores de tamanho L1, L2, ...,Ln, cuja soma será igual a L, ou seja, L = L1 + L2 + ... + Ln.
Isto obriga que as aplicações devem estar preparadas para receber os blocos de dados vindos da ponta remota em pequenas partes por vez, e, quando necessário, remontar estes pequenos blocos de dados em mensagens lógicas do protocolo de aplicação.
Do lado da transmissão, embora este problema não seja tão crítico deve-se ao menos tentar evitar a transmissão direta (numa única chamada) de blocos muito grandes, que excedam, por exemplo o tamanho máximo de um datagrama IP (algo em torno de 64.000 bytes).

Projeto e Desenvolvimento de Aplicações para a Internet
32 Copyright 2001 João Carlos Gluz
4.9. Finalização da conexão
Normalmente a operação de encerramento da conexão será controlada pelo protocolo de aplicação: quando este protocolo chegar a fase final da transferência de informações entre o servidor e o cliente (e o usuário não fizer nenhuma solicitação adicional) então a conexão poderá ser encerrada.
A forma usual para encerrar uma conexão é através da primitiva close (closesocket no caso dos sistemas Windows). Esta primitiva irá encerrar a comunicação nos dois sentidos, liberar o socket de volta ao S.O e avisar a ponta remota que a conexão TCP foi encerrada.
Entretanto é necessário que tanto a aplicação cliente quanto a servidora estejam preparadas para o encerramento anômalo (abort) da conexão que pode ocorrer pelas mais diversas causas (algumas já vistas na seção que trata do estabelecimento da conexão).
Outra situação que pode ocorrer é se chegar a necessidade de encerrar a conexão apenas num sentido: por exemplo o cliente já enviou todas as requisições que queria ao servidor e não enviará mais nenhuma solicitação, porém não sabe por quanto tempo irá receber mensagens de resposta do servidor. Neste exemplo a conexão poderia ser encerrada apenas num sentido: no sentido de transmissão do cliente ao servidor.
Para tratar destes casos especiais, muitas implementações da interface socket (inclusive a WinSocket) disponibilizam o uso da primitiva shutdown :
errcode = shutdown( sock_id, direction )
que permite encerrar a comunicação em apenas um sentido (ou nos dois se assim for especificado, neste caso ela se reduz a primitiva close ou closesocket ), especificado através do parâmetro direction da seguinte forma:
0 - a recepção de dados não será mais permitida neste socket 1 - este socket não aceitará mais operações de transmissão de dados 2 - nem a transmissão nem a recepção serão permitidas
4.10. Comunicação por datagramas
No caso de um cliente que utiliza datagramas como forma de comunicação e que, portanto, opera sobre o protocolo UDP pode-se duas estratégias usar duas estratégias básicas de projeto e implementação da aplicação:
(a) Usar procedimentos de estabelecimento, transferência e finalização de conexão similares aos empregados na comunicação por conexão (mesmas chamadas connect, send / write e recv / read).
(b) Usar procedimentos específicos para o envio e recepção de mensagens individuais (respectivamente primitivas sendto e recvfrom)
Porém um ponto deve ficar claro, a estratégia (a) não implica que uma conexão real de rede seja estabelecida entre o cliente e o servidor, a estratégia (a) apenas serve para indicar ao S.O. quais os

Projeto e Desenvolvimento de Aplicações para a Internet
33 Copyright 2001 João Carlos Gluz
endereços IP e de porta que devem ser incorporados aos pacotes UDP enviados de uma máquina para outra quando uma chamada send ou write é feita. Nada mais é feito pelo S.O., uma conexão não é estabelecida, mensagens perdidas não são detectadas, se a ordem de chegada das mensagens foi alterada em relação a ordem de saída destas isto também não é percebido pelo S.O. A bem da verdade se uma mensagem foi subdividida em múltiplas mensagens menores, isto também não é detectado.
Se a ocorrência destes eventos pode ocasionar problemas para o cliente ou para o servidor, então código específico para tratar estas ocorrências deve ser incorporado à aplicação.
Descontando estes fatos e as possíveis implicações em termos do projeto e implementação de uma aplicação, a forma de uma aplicação que use a estratégia (a) é bem similar a de uma aplicação que use conexões, tal como já foi apresentado nas diversas seções anteriores.
Já no caso (b) a forma da aplicação muda, sendo composta essencialmente se séries de chamadas as primitivas sendto e recvfrom. No caso do cliente a ordem usual será executar primeiro uma ou mais chamadas a sendto, para enviar a(s) requisição(ões). Depois haverá uma ou mais chamadas a recvfrom para se receber as respostas do servidor remoto.
O trecho de código a seguir exemplifica o caso (b):

Projeto e Desenvolvimento de Aplicações para a Internet
34 Copyright 2001 João Carlos Gluz
... int sock_id; struct sockaddr_in srv_sd; char req_buf[ 512 ]; /* 512 bytes parece ser um tamanho maximo razoavel para o buffer de requisicao */ char resp_buf[ 512 ]; /* idem para o buffer de resposta */ char *file_name; /* apontador para o nome de arquivo */ int req_len; char *serv_address; /* endereco IP do servidor (em ASCII) */ int serv_port; /* numero da porta */ ... /* preenche a solicitacao de tamanho de arquivo */ strcpy( req_buf, “GET-FILE-SIZE ” ); strcat( req_buf, req_buf, file_name ); req_len = strlen( req_buf ); /* preenche o endereco do servidor remoto */ srv_sd.sin_family = AF_INET; srv_sd.sin_port = htons( serv_port ); srv_sd.sin_addr.s_addr = inet_address( serv_address ); /* envia a requisicao de tamanho de arquivo */ if (sendto( sock_id, req_buf, req_len, (struct sockaddr *) &srv_sd, sizeof( srv_sd ) ) == req_len ) { /* agora var esperar pela resposta */ if (recvfrom( sock_id, resp_buf, sizeof( resp_buf ), (struct sockaddr *) &srv_sd, sizeof( srv_sd ) ) > 0) { /* recebeu alguma resposta, pelo protocolo de aplicacao deve ser um string terminado por NUL (caracter 0), sendo assim basta imprimir o tamanho do arquivo */ printf( “O tamanho do arquivo: %s e’ %s\n”, file_name, resp_buf ); } else { /* nao veio resposta do servidor */ printf( “Servidor nao enviou o tamanho do arquivo!\n”); exit(0); } } else { /* nao conseguiu enviar solicitacao */ printf( “Problemas no envio da req. de tam. de arquivo!\n”); exit( 0 ); } ...
Existem alguns cuidados adicionais que se deve ter quando se está implementando um cliente (ou servidor também) orientado a datagramas. O trecho de código acima é omisso nestes cuidados,

Projeto e Desenvolvimento de Aplicações para a Internet
35 Copyright 2001 João Carlos Gluz
essencialmente porque a implementação deles depende de características específicas de S.O. Sendo assim refira-se a documentação de programação do S.O. para implementar os seguintes mecanismos:
• Datagramas UDP podem ser perdidos sem aviso, assim é importante que a espera por uma resposta encapsulada num datagrama UDP tenha um tempo limite máximo (timeout).
• Se este timeout é importante que a requisição possa ser reenviada uma ou mais vezes (novamente até um limite máximo de retransmissões - maxretry) porque, em vez da resposta ter sido perdida o que pode ter ocorrido é a requisição ter sido perdida.
• Somente quando e se maxretry for atingido, é que se desiste de continuar a tentar contatar o servidor.
• Como além da perda de mensagens também pode ocorrer a duplicação ou mudança de ordem de mensagens, tente sempre numerar de forma única cada mensagem, principalmente quando ações críticas podem ser tomadas (como por exemplo apagar um arquivo) em função desta mensagem.
• A bem da verdade evite tomar ações críticas baseadas em serviços implementados sobre UDP.
Em relação a última nota deve-se salientar que, apesar da inexistência de serviços de controle e detecção de erros tornar a implementação dos serviços UDP por parte do S.O. muito mais simples (mais “leve”) que os serviços do TCP, isto ainda assim não deve ser usado como justificativa para a implementação de serviços sobre UDP (principalmente de serviços “críticos”). Ou seja, a regra fundamental para o desenvolvimento de aplicações cliente / servidoras de uso geral é:
Sempre use os serviços orientados a conexão, eles lhe pouparão uma enorme dor de cabeça quando você passar a sua aplicação do ambiente de rede local relativamente seguro e controlado, onde voce a vinha testando, para o ambiente real e cruel das redes de longa distância e mistas.
4.11. Exemplo de um cliente HTTP /******************************************************************** ********************************************************************* ** ** WebSTART - Web STudent's Application Resource Toolkit ** ** Aplicacao CLIENTE HTTP ** ** (C) Copyright 2001 Joao Carlos Gluz ** ********************************************************************* ********************************************************************/ /* Headers incluidos */ #include <stdio.h> #include <stdlib.h> #include <string.h> #ifndef unix #define WIN32

Projeto e Desenvolvimento de Aplicações para a Internet
36 Copyright 2001 João Carlos Gluz
#include <winsock2.h> #include <ctype.h> #else #define closesocket close #define SOCKET int #define INVALID_SOCKET -1 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <netdb.h> #endif /* Constantes */ #define MAXSIZ_SBUF 512 #define MAXSIZ_RBUF 512 /* Variaveis globais ao modulo */ char sbuf[MAXSIZ_SBUF+1]; char rbuf[MAXSIZ_RBUF+1]; /******************************************************************** * * main * * Rotina principal da aplicacao * */ int main( int argc, char *argv[], char *envp[] ) { struct sockaddr_in srv_sd; SOCKET sock_id; struct hostent *phe; struct servent *pse; int sbuf_len; int rbuf_len; #ifdef WIN32 WSADATA wsaData; /* Avisa para o Windows que esta aplicacao ira' usar sockets versao 1.1 (codigo 0x0101 de WSAStartup */ WSAStartup( 0x0101, &wsaData ); #endif /* Verifica se todas as opcoes estao presentes */ if (argc<4)

Projeto e Desenvolvimento de Aplicações para a Internet
37 Copyright 2001 João Carlos Gluz
{ printf( "Cliente WebSTART\n" ); printf( " Recupera um arquivo de um servidor\n" ); printf( " remoto HTTP eo imprime na tela\n" ); printf( "Uso:\n"); printf( " webclient <nome-servidor> {http | <nro-porta>} <nome-arquivo>\n"); exit(0); } /* Preenche as informacoes de endereco do servidor a ser contatado. Preenche o identificador de familia de enderecos. */ srv_sd.sin_family = AF_INET; /* Preenche o endereco IP do servidor */ if (isdigit( argv[1][0] )) { if ((srv_sd.sin_addr.s_addr = inet_addr( argv[1] ))==0) { printf( "Endereco invalido!\n"); exit (0); } } else if ( (phe = gethostbyname( argv[1] )) != NULL ) { /* Endereco IP valido, que esta' contido em phe->h_addr */ memcpy( &srv_sd.sin_addr.s_addr, phe->h_addr, phe->h_length); } else { /* Houve algum erro na resolucao do nome */ printf( "Nome invalido!\n"); exit (0); } /* Preenche o numero da porta */ if (isdigit( argv[2][0] )) srv_sd.sin_port = htons( atoi( argv[2] ) ); else { if (strcmp( argv[2], "http" ) != 0) { printf( "Nome de protocolo invalido!\n"); exit( 0 ); } if ( (pse = getservbyname("http","tcp")) != NULL ) { /* Porta padrao localizada e armazenada em pse->s_port */ srv_sd.sin_port = pse->s_port; } else { /* Nao achou nenhuma porta para o nome de servico e nome de protocolo indicados */ printf( "O sistema nao tem porta registrada para \"http\"!\n"); exit (0); } }

Projeto e Desenvolvimento de Aplicações para a Internet
38 Copyright 2001 João Carlos Gluz
/* Tenta criar o socket */ sock_id = socket( PF_INET, SOCK_STREAM, 0 ); if (sock_id == INVALID_SOCKET) { printf( "Nao conseguiu criar o socket!\n" ); exit (0); } /* Tenta conectar com o servidor remoto */ if (connect( sock_id, (struct sockaddr *) &srv_sd, sizeof( struct sockaddr_in) ) < 0) { printf( "Nao conseguiu se conectar ao servidor!\n" ); exit(0); } /* Conseguiu se conectar ao servidor remoto. Agora, usando o protocolo HTTP, solicita o arquivo remoto e o mostra na tela. */ /* Envia um request de arquivo no formato mais simples possivel do HTTP (requisicao GET usada no HTTP 0.9) */ sprintf( sbuf, "GET %s \r\n", argv[3] ); sbuf_len = strlen( sbuf ); if (send( sock_id, sbuf, sbuf_len, 0 ) != sbuf_len) { printf( "Erro na transmissao do request!\n" ); exit(0); } /* Espera pelo arquivo enviado em resposta e apresenta o mesmo na tela */ while ((rbuf_len=recv( sock_id, rbuf, MAXSIZ_RBUF, 0 )) == MAXSIZ_RBUF ) { rbuf[MAXSIZ_RBUF] = '\0'; printf( rbuf ); } if (rbuf_len>0) { rbuf[rbuf_len] = '\0'; printf( rbuf ); } /* Encerra a conexao */ closesocket( sock_id ); /* E finaliza a aplicacao */ exit(0); }

Projeto e Desenvolvimento de Aplicações para a Internet
39 Copyright 2001 João Carlos Gluz
Capítulo V - Arquitetura de Aplicações Servidoras
5.1. Algoritmo básico
Conceitualmente, todas as aplicações servidoras seguem um algoritmo bastante simples: primeiro cria-se um socket que servirá de base para o serviço, depois se amarra este socket base à porta a ser usada como ponto de acesso público (well known port) ao serviço e se coloca este socket em modo passivo. Por último a aplicação entra num laço infinito, no qual o primeiro se espera por uma requisição de cliente remoto e logo após atende esta requisição, voltando-se então ao laço.
Graficamente o algoritmo básico das aplicações servidoras ficaria algo como:
Apesar de ser um esquema bem simples, ele só se adapta aos servidores mais triviais, essencialmente porque o tratamento das requisições é feito de forma seqüencial, um cliente por vez. Isto implica que, no caso de um servidor de arquivos, se um cliente solicitar um arquivo imenso (50 MBytes por exemplo) e for atendido antes de um outro cliente que somente quer um pequeno arquivo de 1 kbyte, o segundo cliente terá que obrigatoriamente esperar que a transferência do arquivo gigante do primeiro cliente seja concluída para só então ser atendido.
Criação do socket base
Amarração deste àwell-known port (bind)
Colocação do socket baseem modo passivo (listen)
Espera por uma requisiçãoremota (accept)
Tratamento da requisiçãoremota

Projeto e Desenvolvimento de Aplicações para a Internet
40 Copyright 2001 João Carlos Gluz
5.2. Concorrência versus iteratividade no tratamento das requisições
A questão de se usar ou não concorrência no tratamento das requisições, cria a primeira divisão em que irão sendo classificados os diferentes tipo de servidores:
(a) Servidores Iterativos: essencialmente seguem o algoritmo básico e tratam uma requisição por vez, sem nenhum tipo de concorrência.
(b) Servidores Concorrentes: atendem as requisições dos clientes de forma concorrente.
Exceto nos casos mais simples, os servidores deverão implementar algum tipo de concorrência, mesmo que esta não seja suportada pelo S.O. Isto é possível porque o que se quer na verdade é que seja possível manter os canais de comunicação (sockets) com os clientes continuamente abertos e com dados sendo trocados entre os clientes e o servidor. Embora a forma mais simples se implementar a concorrência seja usando recursos do S.O. (processos ou threads concorrentes), pode-se ainda assim, quando tais recursos não estão disponíveis, se implementar a concorrência no tratamento das requisições pela subdivisão destas em “partes” menores. Cada pequena parte de requisição de um cliente é tratada sem concorrência, mas ao terminar de tratar esta parte o servidor vai tratar de outra parte de outra requisição, possivelmente de outro cliente. Para os clientes parece que as requisições estão sendo tratadas concorrentemente e é isto que importa, ou seja:
O termo concorrência, quando aplicado a servidores, indica se o servidor tem a capacidade de tratar múltiplas requisições simultaneamente (concorrentemente) e não se a implementação usa recursos de concorrência do S.O.
É importante salientar, entretanto, que a implementação de tratamento concorrente de requisições através de recursos do S.O. facilita sobremaneira o desenvolvimento da aplicação servidora.
Porém, para fins de classificação se dividirá a concorrência dos servidores em dois tipos:
(b.1) Concorrência real, implementada diretamente pelo S.O. (através de threads por exemplo).
(b.2) Concorrência simulada pela implementação do servidor, que deve ser codificada na própria aplicação servidora.
5.3. O uso de conexões no tratamento das requisições
Um segundo aspecto importante na forma como será feito o tratamento das requisições, tem a ver com o uso ou não de conexões TCP para transportar essas requisições e suas respostas.
A bem da verdade este tema está muito mais ligado a forma como se dará a comunicação com os clientes remotos, ou sendo mais específico, em como será o protocolo de aplicações escolhido para governar esta comunicação, do que com questões relacionadas à algoritmos de implementação de servidores. Porém, o fato é que, dependendo de se optar por usar conexões TCP ou datagramas UDP, existem algumas considerações que se devem respeitar no desenvolvimento do servidor. Considerações estas tratadas a seguir.

Projeto e Desenvolvimento de Aplicações para a Internet
41 Copyright 2001 João Carlos Gluz
Em primeiro lugar só para fins de terminologia os servidores também pode ser classificados em:
(a) Servidores Orientados a Conexão: usam conexões TCP para enviar e receber dados.
(b) Servidores Não-Orientados à Conexões: usam datagramas UDP para enviar e receber dados.
A primeira grande consideração sobre o uso ou não das conexões TCP, está relacionada com a facilidade de implementação: de modo geral a implementação usando conexões é muito mais simples do que usando datagramas.
Aqui valem algumas considerações adicionais: embora uma implementação muito simplificada de um servidor através de datagramas possa parecer até mais simples que a implementação equivalente usando conexões, a verdade é que implementações muito simples usando datagramas são praticamente inúteis. Diferente do algoritmo básico iterativo para os servidores que pode ainda ter alguma utilidade, o problema é que o serviço de datagrama é realmente não confiável, podendo não apenas perder datagramas, mas também duplicá-los ou até mesmo reordená-los, em redes um pouco maiores que uma rede local (mesmo numa rede local os datagramas podem ser perdidos sem nenhum tipo de indicação adicional).
Isto implica que, para ser realmente útil, uma implementação de um servidor (e dos seus clientes) não-orientado a conexões deve incorporar muito do tratamento suportado pelo TCP: controle de perdas por retransmissões, controle de sequenciamento e possíveis duplicações, o que torna a implementação real deste servidor bastante mais complicada do que a implementação orientada a conexão.
Apesar disto, para certos casos específicos e em situações restritas, se tem desenvolvido aplicações cliente / servidoras baseadas no serviço de datagramas. Em particular alguns serviços de rede mais “próximos” ao S.O. como, por exemplo: o serviço de mapeamento de nomes em endereços IP(DNS), os agentes de gerenciamento de redes (SNMP) e alguns protocolos de roteamento (RIP e RIP-2) são construídos sobre datagramas. Isto é possível sem uma considerável complicação adicional se certas restrições bastante fortes forem aplicadas sobre o formato e a significado das mensagens trocadas através destes datagramas. Especificamente, pode-se simplificar bastante a implementação de um servidor não-orientado a conexão se este servidor não preservar informações de estado e, por conseguinte, se o protocolo de aplicação não for dependente de estado. Neste último caso cada mensagem carregando uma requisição será completamente independente da anterior, executando uma mesma operação individual ao ser atendida. A perda das mensagens ainda é um problema sério, mas pode ser tratada pela simples repetição de uma mesma mensagem: se o servidor receber duas mensagens iguais ele executará duas operações em sequência e o resultado final deverá ser igual se ele tivesse recebido apenas uma mensagem.
Como já foi comentado antes isto complica bastante o projeto do protocolo de aplicação, mas simplifica a implementação usando datagramas. Agora resta uma pergunta simples: se é tão complicado usar datagramas tanto do ponto de vista da implementação ou do projeto do protocolo, porque usar então este tipo de transporte de dados.
A resposta para esta pergunta tem a ver essencialmente com o nível de recursos exigidos pelas aplicações que usam conexões em relação às aplicações que usam datagramas: do ponto de vista do S.O. as

Projeto e Desenvolvimento de Aplicações para a Internet
42 Copyright 2001 João Carlos Gluz
aplicações que usam conexões TCP são muito mais “caras”, isto é, exigem muito mais recursos do que as aplicações baseadas sobre datagramas.
Isto ocorre por várias razões: a propria implementação do TCP exigem muitos recursos do S.O., cada conexão separada com um cliente exige um socket inteiramente para ela e além disso, caso ocorra uma falha num cliente remoto, sem que este tenha tido tempo de se desconectar do servidor, a conexão poderá ficar aberta indefinidamente no servidor, ocupando recursos inutilmente se a implementação do servidor não controlar este tipo de situação explicitamente.
De uma forma ou outra cada um destes problemas pode ser devidamente tratado. Mas quando recursos de memória e processamento são um grande prêmio, então pode valer a pena se projetar o protocolo de aplicação de forma a não depender de estado e partir para uma implementação baseada em datagramas. Da mesma forma se o número de requisições de clientes remotos for muito grande e a probabilidade destes falharem no meio do atendimento de uma requisição for grande, possivelmente também valerá a pena partir para o mesmo tipo de implementação com datagramas.
5.4. Quando usar cada tipo de servidor
Iteratividade x Concorrência
Servidores iterativos são obviamente mais fáceis de implementar e manter que servidores concorrentes. Porém somente é possível usar a solução iterativa quando se puder garantir que o tempo de tratamento de toda e qualquer requisição neste tipo de solução será suficientemente curto para não afetar a comunicação com os clientes.
Concorrência real x simulada
De maneira geral use concorrência simulada somente quando o S.O. subjacente não suportar concorrência real. Entretanto, se houver necessidade de haver trocas de informações entre os clientes conectados ao servidor pode ser mais fácil implementar esta troca cruzada de informações se a concorrência for simulada, já que o servidor tem um maior controle sobre o estado da conexão de cada cliente. Porém, mesmo assim, o conselho aqui é quando possível tentar se implementar esta troca cruzada através de mecanismos de compartilhamento de informações do próprio S.O. (semáforos, memória compartilhada, filas, etc.) do que reinventar a roda.
Conexões x Datagramas
Use implementação baseada em datagramas somente em dois casos: se o protocolo de aplicação trata da confiabilidade (por retransmissões e por ser independente de estado, por exemplo), ou quando o ambiente onde a aplicação vai ser usada for restrito a apenas redes locais bem controladas (com pouca perdas de frames). Em todos os outros casos implemente seu servidor com conexões TCP.
5.5. Exemplo de um servidor HTTP /******************************************************************** ********************************************************************* ** ** Projeto START - STudent's Application Resource Toolkit **

Projeto e Desenvolvimento de Aplicações para a Internet
43 Copyright 2001 João Carlos Gluz
** Aplicacao SERVIDOR WEB Versao 1.0 ** ** Implementacao iterativa, sem concorrencia. ** ** webserv1.cpp ** ** Arquivo principal da aplicacao. Pode ser compilado ** e executado tanto em ambiente Linux (GCC 2.95.2) ** quanto MS Windows 9x e NT (TM) (VC++ 5.0) ** ** ** (C) Copyright 2001 Joao Carlos Gluz ** ********************************************************************* ********************************************************************/ /* Headers das bibliotecas */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <ctype.h> #include <sys/stat.h> #include <time.h> #ifndef unix #ifndef WIN32 #define WIN32 #endif #include <winsock2.h> #else /*unix*/ #define closesocket close #define SOCKET int #define INVALID_SOCKET -1 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <netdb.h> #include <unistd.h> #endif /*unix*/ /* Constantes */ #define SERVER_QUEUE_SIZE 15 #define BOOL bool #ifdef unix #define TRUE true #define FALSE false #endif /* unix */ #define HTTP_RESP_BADREQUEST 400 #define HTTP_RESP_UNKNOWN_METHOD 599 #define HTTP_RESP_FILE_NOTFOUND 404 /* Variaveis globais ao modulo

Projeto e Desenvolvimento de Aplicações para a Internet
44 Copyright 2001 João Carlos Gluz
*/ BOOL TraceRequests = TRUE; int DefaultPort; char DefaultHomePageFileName[256]; char DefaultHomePageFilePath[512]; /* Prototipos */ void process_http_request( SOCKET cli_sock_id, struct sockaddr_in *cli_sock_inaddr ); void send_http_requested_file( int rem_cli_sock_id, FILE *request_fp ); BOOL sendline( SOCKET sock_id, char *line ); BOOL sendstring( SOCKET sock_id, char *str ); BOOL recvline( SOCKET sock_id, char *line, int max_linesize ); int recvchar( SOCKET sock_id ); char *get_http_word(char **line); BOOL process_http_request_header( SOCKET cli_sock_id ); BOOL send_http_simple_response( SOCKET rem_cli_sock_id, int resp_id ); BOOL send_http_full_response( SOCKET rem_cli_sock_id, char *request_uri, FILE *request_fp ); /******************************************************************** * * main() * * Rotina principal da aplicacao. * */ int main( int argc, char *argv[], char *envp[] ) { /* Variaveis locais */ struct sockaddr_in loc_srv_inaddr; SOCKET loc_srv_sock_id; struct sockaddr_in rem_cli_inaddr; SOCKET rem_cli_sock_id; int rem_cli_addrsiz; int i; #ifdef WIN32 WSADATA wsaData; /* Avisa para o Windows que esta aplicacao ira' usar sockets versao 1.1 (codigo 0x0101 de WSAStartup */ WSAStartup( 0x0101, &wsaData ); #endif /*WIN32*/ /* Verifica se todas as opcoes estao presentes */ if (argc<2) { printf( "Servidor WebSTART - Versao 1.0\n" ); printf( "Uso:\n"); printf( " webserv1 start <opcao> <opcao> ...\n"); printf( "Onde <opcao> pode ser:\n"); printf( " port <porta-servico>\n"); printf( " dir <diretorio-homepage>\n"); printf( " file <arquivo-indice-homepage>\n");

Projeto e Desenvolvimento de Aplicações para a Internet
45 Copyright 2001 João Carlos Gluz
printf( " trace {on|off}\n"); printf( "Pressione CTRL-C para parar o servidor.\n"); exit(0); } if (strcmp(argv[1],"start")!=0) { printf( "Servidor WebSTART - Versao 1.0\n" ); printf( "Opcao invalida - digite apenas:\n"); printf( " webserv1\n"); printf( "para ajuda.\n"); exit(0); } printf( "Servidor WebSTART - Versao 1.0\n" ); /* Preenche valore default. */ strcpy( DefaultHomePageFileName, "index.html" ); #ifdef unix strcpy( DefaultHomePageFilePath, "/mnt/d-disk/webserv" ); #else /*unix*/ strcpy( DefaultHomePageFilePath, "d:\\webserv" ); #endif /*unix*/ DefaultPort = 80; /* Verifica os parametros: */ for (i=2; i<argc; i++) { if (strcmp(argv[i],"port")==0) { i++; if (i<argc) DefaultPort = atoi(argv[i]); } else if (strcmp(argv[i],"dir")==0) { i++; if (i<argc) strcpy(DefaultHomePageFilePath, argv[i]); } else if (strcmp(argv[i],"file")==0) { i++; if (i<argc) strcpy(DefaultHomePageFileName, argv[i]); } else if (strcmp(argv[i],"trace")==0) { i++; if (i<argc) { if (strcmp(argv[i],"on")==0) TraceRequests = TRUE; else TraceRequests = FALSE; } } else { printf("Opcao invalida: %s\n", argv[i]); printf("Opcoes restantes desconsideradas!\n"); break;

Projeto e Desenvolvimento de Aplicações para a Internet
46 Copyright 2001 João Carlos Gluz
} } /* Tenta criar o socket base para o servico. */ loc_srv_sock_id = socket( PF_INET, SOCK_STREAM, 0 ); if (loc_srv_sock_id == INVALID_SOCKET) { printf( "Nao conseguiu criar o socket do servidor!\n" ); exit (0); } /* Amarra o socket base a porta TCP apropriada. */ loc_srv_inaddr.sin_family = AF_INET; loc_srv_inaddr.sin_addr.s_addr = INADDR_ANY; loc_srv_inaddr.sin_port = htons( DefaultPort ); if (bind(loc_srv_sock_id, (struct sockaddr *)&loc_srv_inaddr, sizeof(sockaddr_in)) < 0) { printf( "Nao conseguiu fazer a amarracao de endereco!\n" ); exit (0); } /* Coloca o socket em modo passivo. */ listen(loc_srv_sock_id, SERVER_QUEUE_SIZE ); /* Vai esperar por conexoes - se algo for teclado, entre as conexoes encerra o servico (CTRL-C, aborta o servico tambem, inclusive no meio da conexao). */ printf( "Operacao iniciada.\n" ); printf( "Parametros de operacao sao:\n"); printf( " Porta: %d\n", DefaultPort ); printf( " HomePage Dir: %s\n", DefaultHomePageFilePath ); printf( " HomePage File: %s\n", DefaultHomePageFileName ); printf( " Trace: "); if (TraceRequests) printf( "ON\n"); else printf( "off\n"); printf( "Pressione CTRL-C para parar o servidor.\n"); while (TRUE) { rem_cli_addrsiz = sizeof( rem_cli_inaddr ); /* Aqui realmente espera pela conexao de um cliente remoto. */ rem_cli_sock_id = accept(loc_srv_sock_id, (struct sockaddr *) &rem_cli_inaddr, #ifdef unix (socklen_t *) &rem_cli_addrsiz ); #else /*unix*/ &rem_cli_addrsiz ); #endif /*unix*/ if (rem_cli_sock_id == INVALID_SOCKET) /* O servico esta sendo desativado, possivelmente pela tecla CTRL-C.

Projeto e Desenvolvimento de Aplicações para a Internet
47 Copyright 2001 João Carlos Gluz
*/ break; /* Processa a requisicao. O novo socket aberto para o cliente sera' fechado na rotina de processamento da requisicao. */ if (TraceRequests) printf( "%s: ", inet_ntoa(rem_cli_inaddr.sin_addr) ); process_http_request( rem_cli_sock_id, &rem_cli_inaddr ); } /* Fecha o socket base do servico. */ closesocket( loc_srv_sock_id ); /* E finaliza a aplicacao */ exit(0); /* Desnecessario, so' para evitar warnings. */ return(0); } /******************************************************************** * * process_http_request() * * Rotina que processa uma requisicao HTTP. * */ void process_http_request( SOCKET cli_sock_id, struct sockaddr_in *cli_sock_inaddr ) { char recvbuf[4096]; char *p_recvbuf; char *request_method; char *request_uri; char *request_version; char *request_form; char request_fname[1024]; FILE *request_fp; BOOL is_version_0_9; /* Comeca a receber e analisar a requisicao HTTP. */ if (!recvline(cli_sock_id, recvbuf, 4096)) /* A conexao foi fechada a conexao. */ goto end_process_http_request; if (strlen(recvbuf) < 3) { /* Tamanho menor que 3, nao pode ser um comando legal HTTP. */ send_http_simple_response( cli_sock_id, HTTP_RESP_BADREQUEST); goto end_process_http_request; }

Projeto e Desenvolvimento de Aplicações para a Internet
48 Copyright 2001 João Carlos Gluz
/* Faz o parse da requisicao, obtendo o metodo (GET|POST), a URI e a versao do protocolo HTTP. */ p_recvbuf=recvbuf; request_method = get_http_word(&p_recvbuf); request_uri = get_http_word(&p_recvbuf); request_version = get_http_word( &p_recvbuf ); /* Verifica se a requisicao tem um formulario codificado na propria URL. */ if ((request_form=strchr(request_uri,'?'))!=NULL) { *request_form='\0'; request_form++; } else request_form=""; /* Verificacoes de seguranca. */ if (strcmp(request_method, "GET") != 0 && strcmp(request_method, "POST") != 0) { send_http_simple_response( cli_sock_id, HTTP_RESP_UNKNOWN_METHOD ); return; } /* Trata, se necessario, as opcoes do cabecalho. */ is_version_0_9 = TRUE; if (request_version!=NULL) if (strlen(request_version)>0) { is_version_0_9 = FALSE; if (!process_http_request_header(cli_sock_id)) /* A propria rotina de processamento do cabecalho HTTP tem que se encarregar de avisar ao cliente porque a conexao nao foi aceita. */ goto end_process_http_request; } /* Salta caracter '/' */ request_uri++; /* Mapeia a URI num nome de recurso (arquivo) local. */ if (*request_uri=='\0') request_uri = DefaultHomePageFileName; strcpy( request_fname, DefaultHomePageFilePath ); #ifdef unix strcat( request_fname, "/" ); #else /*unix*/ strcat( request_fname, "\\" ); #endif /*unix*/ strcat( request_fname, request_uri ); /* Tenta abrir o arquivo local (em modo binario -- ou seja nao fara' conversao alguma ). */

Projeto e Desenvolvimento de Aplicações para a Internet
49 Copyright 2001 João Carlos Gluz
request_fp = fopen( request_fname, "rb" ); if (request_fp==NULL) send_http_simple_response( cli_sock_id, HTTP_RESP_FILE_NOTFOUND ); else { if (TraceRequests) printf( "%s\r\n", request_fname ); /* Achou o arquivo, envia o cabecalho em formato completo e depois o proprio arquivo. */ if (is_version_0_9) send_http_requested_file( cli_sock_id, request_fp ); else if (send_http_full_response( cli_sock_id, request_uri, request_fp)) send_http_requested_file( cli_sock_id, request_fp ); fclose( request_fp ); } end_process_http_request: closesocket( cli_sock_id ); } /******************************************************************** * * process_http_request_header() * * Rotina que processa as opcoes constantes no cabecalho de * uma requisicao HTTP. * */ BOOL process_http_request_header( SOCKET cli_sock_id ) { char linebuf[4096]; while (recvline(cli_sock_id, linebuf, 4096)) { if (strlen(linebuf)<=4) /* Menores opcoes tem pelo menos 4 caracteres -- isto possivelmente e' um erro */ break; if (strncmp(linebuf, "Allow", 5)==0) { /* Insira o codigo para tratar da opcao Allow, de acordo com a RFC 1945, sec. 10.1. */ } else if (strncmp(linebuf, "Authorization", 13)==0) { /* Insira o codigo para tratar da opcao Authorization, de acordo com a RFC 1945, sec. 10.2. */ } else if (strncmp(linebuf, "Content-Encoding", 16)==0) { /* Insira o codigo para tratar da opcao Content-Encoding, de acordo com a RFC 1945, sec. 10.3. */ } else if (strncmp(linebuf, "Content-Length", 14)==0)

Projeto e Desenvolvimento de Aplicações para a Internet
50 Copyright 2001 João Carlos Gluz
{ /* Insira o codigo para tratar da opcao Content-Length, de acordo com a RFC 1945, sec. 10.4. */ } else if (strncmp(linebuf, "Content-Type", 12)==0) { /* Insira o codigo para tratar da opcao Content-Type, de acordo com a RFC 1945, sec. 10.5. */ } else if (strncmp(linebuf, "Date", 4)==0) { /* Insira o codigo para tratar da opcao Date, de acordo com a RFC 1945, sec. 10.6. */ } else if (strncmp(linebuf, "Expires", 7)==0) { /* Insira o codigo para tratar da opcao Expires, de acordo com a RFC 1945, sec. 10.7. */ } else if (strncmp(linebuf, "From", 4)==0) { /* Insira o codigo para tratar da opcao From, de acordo com a RFC 1945, sec. 10.8. */ } else if (strncmp(linebuf, "If-Modified-Since", 17) ==0) { /* Insira o codigo para tratar da opcao If-Modified-Since, de acordo com a RFC 1945, sec. 10.9. */ } else if (strncmp(linebuf, "Last-Modified", 13) ==0) { /* Insira o codigo para tratar da opcao Last-Modified, de acordo com a RFC 1945, sec. 10.10. */ } else if (strncmp(linebuf, "Location", 8) ==0) { /* Insira o codigo para tratar da opcao Location, de acordo com a RFC 1945, sec. 10.11. */ } else if (strncmp(linebuf, "Pragma", 6) ==0) { /* Insira o codigo para tratar da opcao Pragma, de acordo com a RFC 1945, sec. 10.12. */ } else if (strncmp(linebuf, "Referer", 7) ==0) { /* Insira o codigo para tratar da opcao Referer, de acordo com a RFC 1945, sec. 10.13. */ } else if (strncmp(linebuf, "Server", 6) ==0) { /* Insira o codigo para tratar da opcao Server, de acordo com a RFC 1945, sec. 10.14.

Projeto e Desenvolvimento de Aplicações para a Internet
51 Copyright 2001 João Carlos Gluz
*/ } else if (strncmp(linebuf, "User-Agent", 10) ==0) { /* Insira o codigo para tratar da opcao User-Agent, de acordo com a RFC 1945, sec. 10.15. */ } else if (strncmp(linebuf, "WWW-Authenticate", 16) ==0) { /* Insira o codigo para tratar da opcao WWW-Authenticate, de acordo com a RFC 1945, sec. 10.16. */ } } return(TRUE); } /******************************************************************** * * send_http_simple_response() * * Rotina que envia respostas breves, apenas com informacoes de * estado ou com possiveis indicacoes de erros ocorridos na * analise da requisicao HTTP. * */ BOOL send_http_simple_response( SOCKET cli_sock_id, int resp_id ) { char *resp_msg; switch(resp_id) { case HTTP_RESP_BADREQUEST: resp_msg = "400 Bad request"; if (TraceRequests) printf( "BADREQUEST\r\n" ); break; case HTTP_RESP_UNKNOWN_METHOD: resp_msg = "599 Unrecognized method request"; if (TraceRequests) printf( "UNKMETHOD\r\n" ); break; case HTTP_RESP_FILE_NOTFOUND: resp_msg = "404 The file requested was not found"; if (TraceRequests) printf( "NOTFOUND\r\n" ); break; default: resp_msg = "400 Bad request"; if (TraceRequests) printf( "BADREQUEST\r\n" ); break; } sendstring( cli_sock_id, "HTTP/1.0 "); sendline( cli_sock_id, resp_msg ); return TRUE; }

Projeto e Desenvolvimento de Aplicações para a Internet
52 Copyright 2001 João Carlos Gluz
/******************************************************************** * * send_http_full_response() * * Rotina que envia uma resposta HTTP 1.0 completa, como cabecalho * ao arquivo solicitado. Este arquivo, por sua vez, sera' enviado * logo a seguir. * */ BOOL send_http_full_response( SOCKET cli_sock_id, char *request_uri, FILE *request_fp ) { char sendbuf[ 4096 ]; time_t ltime; #ifdef unix struct stat statbuf; #else /*unix*/ struct _stat statbuf; #endif /*unix*/ int i; sprintf( sendbuf,"HTTP/1.0 200 The file requested follows"); if (!sendline( cli_sock_id, sendbuf)) return FALSE; sprintf( sendbuf, "Server: J.C.GLUZ/WebSTART/WebServer-1.0"); if (!sendline( cli_sock_id, sendbuf)) return FALSE; time( <ime ); sprintf(sendbuf, "Date: %s", ctime(<ime) ); /* ctime termina o string de data com um '\n', troca isto por '\r''\n' */ for (i=0; sendbuf[i]!='\n'; i++) ; sendbuf[i++]='\r';sendbuf[i++]='\n';sendbuf[i]='\0'; /* agora envia apenas como string */ if (!sendstring( cli_sock_id, sendbuf)) return FALSE; strcpy(sendbuf, "Content-Type: "); if ((strstr(request_uri,".jpg")!=NULL) || (strstr(request_uri,".JPG")!=NULL) ) strcat(sendbuf, "image/jpeg" ); else if ((strstr(request_uri,".gif")!=NULL) || (strstr(request_uri,".GIF")!=NULL) ) strcat(sendbuf, "image/gif" ); else if ((strstr(request_uri,".txt")!=NULL) || (strstr(request_uri,".TXT")!=NULL) ) strcat(sendbuf, "text/plain" ); else strcat(sendbuf, "text/html" ); if (!sendline( cli_sock_id, sendbuf)) return FALSE;

Projeto e Desenvolvimento de Aplicações para a Internet
53 Copyright 2001 João Carlos Gluz
if (request_fp!=NULL) { #ifdef unix fstat( fileno(request_fp), &statbuf ); #else /*unix*/ _fstat( _fileno(request_fp), &statbuf ); #endif /*unix*/ sprintf(sendbuf, "Content-Length: %lu", statbuf.st_size); if (!sendline( cli_sock_id, sendbuf)) return FALSE; sprintf(sendbuf, "Last-Modified: %s", ctime(&statbuf.st_atime)); /* ctime termina o string de data com um '\n', troca isto por '\r''\n' */ for (i=0; sendbuf[i]!='\n'; i++) ; sendbuf[i++]='\r';sendbuf[i++]='\n';sendbuf[i]='\0'; /* agora envia apenas como string */ if (!sendstring( cli_sock_id, sendbuf)) return FALSE; } if (!sendline( cli_sock_id, "")) return FALSE; return(TRUE); } /******************************************************************** * * send_http_requested_file() * * Rotina que envia para o cliente o arquivo por este solicitado * na requisicao HTTP. * */ void send_http_requested_file( int cli_sock_id, FILE *request_fp ) { char sendbuf[1024]; int nrd; while ((nrd=fread(sendbuf, 1, sizeof(sendbuf), request_fp)) == sizeof(sendbuf)) { if (send( cli_sock_id, sendbuf, nrd , 0) != nrd) return; } send( cli_sock_id, sendbuf, nrd , 0); } /******************************************************************** * * sendline() * sendstring() * * Rotinas utilitarias de envio de dados p/um socket. As rotinas * sendline() e sendstring() enviam strings para a linha. A * diferenca e' que sendline() adiciona a seq. de caracteres de * fim de linha do HTTP (a seq. CR LF -- CR o caracter ASCII 0x0D * e LF o caracter ASCII 0x0A) no fim do string, enquanto sendstring

Projeto e Desenvolvimento de Aplicações para a Internet
54 Copyright 2001 João Carlos Gluz
* apenas envia um string diretamente. * */ BOOL sendline( SOCKET sock_id, char *line ) { if (!sendstring( sock_id, line )) return FALSE; if (!sendstring( sock_id, "\r\n" )) return FALSE; return TRUE; } BOOL sendstring( SOCKET sock_id, char *str ) { int slen; slen = strlen(str); if (send( sock_id, str, slen, 0) != slen) return FALSE; return TRUE; } /******************************************************************** * * recvline() * * Rotina utilitaria de recepcao de linha HTTP de caracteres de um * socket. Com citado em sendline, uma linha HTTP de caracteres e' * uma seq. de caracteres ASCII, finalizada por uma sequencia de * caracteres especiais CR LF * * */ BOOL recvline( SOCKET sock_id, char *line, int max_linesize ) { int c; if (line==NULL) return FALSE; while (max_linesize-- > 1) { if ((c = recvchar(sock_id)) == -1) return FALSE; *line++ = c; if ((unsigned char) c == '\r' ) { c = recvchar(sock_id); if ((unsigned char) c != '\n') /* Deveria ser LF */ return FALSE; if (max_linesize-- > 1) *line++ = c; break; } } *line = '\0';

Projeto e Desenvolvimento de Aplicações para a Internet
55 Copyright 2001 João Carlos Gluz
return TRUE; } /******************************************************************** * * recvchar() * * Rotina utilitaria de recepcao de um caracteres de um * socket. Esta rotina usa um buffer estatico intermediario para * armazenar os blocos de caracteres recebidos do socket. * * */ static char buf[512]; static int bufsiz=0; static int ibuf = 0; int recvchar( SOCKET sock_id ) { int c; if (bufsiz==0) { bufsiz = recv( sock_id, buf, sizeof(buf), 0 ); if (bufsiz==0) return -1; ibuf = 0; } c = (unsigned char) buf[ibuf]; ibuf++; bufsiz--; return c; } /******************************************************************** * * get_http_word * * Obtem uma palavra HTTP. Palavras HTTP sao sequesncias de * caracteres diferentes do espaco em branco ou do TAB, seguidos * por um branco, por um TAB, por um CR ou por um LF. * Esta funcao retorna a posicao inicial da palavra, coloca um * caracter NUL no fim desta e muda o apontador de origem (**line) * para o inicio da nova palavra HTTP. * */ char *get_http_word(char **line) { char *word; char *p; /* Verificacao basica de seguranca */ if (!line || !*line) return NULL; word = *line; while (*word && (*word==' ' || *word=='\t')) word++; for (p=word; *p && *p!=' ' && *p!='\t' && *p!='\n' && *p!='\r'; p++) ;

Projeto e Desenvolvimento de Aplicações para a Internet
56 Copyright 2001 João Carlos Gluz
while (*p && (*p==' ' || *p=='\t' || *p=='\n' || *p=='\r')) *p++ = 0; *line = p; return word; }

Projeto e Desenvolvimento de Aplicações para a Internet
57 Copyright 2001 João Carlos Gluz
Capítulo VI – O Protocolo HTTP
Neste texto será apresentada uma introdução geral ao protocolo HTTP. Esta descrição será centrada sobre a versão 1.0 deste protocolo, tal como descrita na RFC 1945 “Hypertext Transfer Protocol HTTP/1.0”.
O material apresentado neste documento tem caráter introdutório visando apenas propósitos didáticos. Este documento, portanto, não tendo caráter referencial. Para uma referência completa sobre o protocolo HTTP consulte a RFC 1945, ou outra RFC mais atualizada.
6.1. Operação Geral do Protocolo
O HTTP (sigla em inglês para a expressão “Hypertext Transfer Protocol”) é um protocolo relativamente simples, baseado no Modelo Cliente/Servidor de interação e que, a priori, não utiliza nenhum tipo de informação de estado.
Desta forma o universo de aplicações que usam o HTTP é dividido em clientes e servidores. Os clientes enviam mensagens de requisições HTTP para os servidores. Estes servidores devem responder às requisições por meio de mensagens de resposta HTTP.
Um cliente estabelece uma conexão com um servidor e envia uma requisição para este servidor contendo pelo menos: • um método a ser empregado na requisição, • um identificador do arquivo ou recurso que se está buscando, • a indicação de que versão do protocolo HTTP que se está trabalhando
Opcionalmente, uma requisição ainda pode conter: • um conjunto de parâmetros ou opções adicionais que modificam alguns aspectos da requisição • informações adicionais sobre o cliente e • um arquivo ou conjunto de informações que deve ser enviadas do cliente para o servidor
O servidor responde a esta requisição com uma mensagem contendo pelo menos uma linha (de texto) com o estado da resposta, incluindo a versão de HTTP usada e um código de sucesso ou erro no atendimento da requisição.
Além disso esta linha de estado pode ser seguida por uma série de informações adicionais sobre o próprio servidor, sobre as características do arquivo ou sendo retornado e, quando houve sucesso no atendimento, pelo próprio corpo deste arquivo.
Na Internet a comunicação HTTP é feita geralmente (na verdade quase que exclusivamente) sobre o protocolo TCP/IP. O número de porta padrão (default) usado pelo HTTP é 80, porém nada impede que outras portas possam ser usadas para identificar o HTTP. Da mesma forma nada impede que o HTTP seja transportado por outro tipo de protocolo de transporte de rede que não o TCP, desde que este protocolo providencie um serviço de transporte de dados confiável similar ao do TCP.

Projeto e Desenvolvimento de Aplicações para a Internet
58 Copyright 2001 João Carlos Gluz
Exceto para aplicações experimentais, a pratica corrente das interações entre clientes e servidores na Internet define que elas devem ser feitas sempre seguindo os seguintes passos: 1. primeiro uma conexão TCP deve ser estabelecida pelo cliente ao seu servidor , 2. depois uma requisição é enviada do cliente ao servidor por meio desta conexão, 3. logo após o servidor envia uma resposta ao cliente por meio da mesma conexão 4. por último esta conexão é obrigatoriamente encerrada no fim do envio da resposta do servidor ao
cliente.
Se o cliente desejar enviar outra requisição os passos acima deve ser obrigatoriamente repetidos, isto é, outra conexão TCP deverá ser estabelecida.
A seguir serão apresentados os formatos das mensagens usadas neste protocolo. Antes, entretanto, se definirá o tipo de notação empregada para definir estes formatos.
6.2. Notação usada para apresentar o formato das mensagens
O formato ou sintaxe das mensagens será apresentado através de uma notação similar a empregada na descrição de sintaxe de linguagens de programação. Será usada uma notação simplificada, que segue a notação empregada na RFC 1945 (e que também é baseada numa outra RFC, a RFC 822).
6.2.1. Definição de um Formato
A definição de um formato qualquer é feita por regras na seguinte forma:
Nome = Formato
O elemento Nome cria um nome a ser empregado para referenciar o formato sendo definido. O elemento Formato define o formato que realmente será usado na mensagem (ou em parte dela). Isto é, em algum ponto do texto da mensagem deverá aparecer uma seqüência de termos que deverão estar de acordo com o Formato. O elemento Formato é, na verdade, uma combinação das seguintes opções de definições de formatos.
6.2.2. Opções de Formatos
“literal”
Um literal é uma seqüência de caracteres (ASCII, se nada for dito em contrário) que devem aparecer no texto da mensagem de forma literal, isto é, os mesmos caracteres que estão entre as aspas (“”) devem aparecer no texto na mesma ordem. Em princípio o tipo de letra, se maiúscula ou minúscula, não é levado em conta (a não ser que algo seja afirmado em contrário).
“caracter-literal-1” .. “caracter-literal-2”
Qualquer caracter maior ou igual que “caracter-literal-1” e menor ou igual que “caracter-literal-2”, na ordem lexicográfica do código ASCII, será aceito. Por exemplo o formato “a” .. “z” aceita todos as letras minúsculas do ASCII, o formato “0” .. “9” todos os dígitos decimais do ASCII.
<formato definido externamente>

Projeto e Desenvolvimento de Aplicações para a Internet
59 Copyright 2001 João Carlos Gluz
Formatos definidos por uma descrição entre sinais de menor e maior (“<” e “>”) não são definidos neste documento sendo definidos externamente em algum outro documento. Em princípio a referência a este texto é feita dentro do texto descritivo.
Formato1 Formato2 ...
A seqüência de formatos indica uma composição destes formatos. Na mensagem deverá aparecer primeiro texto que está de acordo com o Formato1, depois com o Formato2 e assim sucessivamente.
Observação:
Numa descrição de mensagem dada por uma seqüência de formatos, não é necessário que estes formatos estejam todos na mesma linha da descrição, eles podem estar em linhas distintas. Por outro lado o fato de estarem em linhas distintas não significa que os formatos aparecerão em linhas distintas no texto da mensagem. Isto só ocorrerá se forem explicitamente especificados na seqüência os caracteres de delimitação de linha a serem usados na mensagem (ver caracteres especiais a seguir).
Formato1 | Formato2
A barra vertical é usada para indicar uma opção entre 2 formatos distintos. No caso acima ou texto no Formato1 ou texto no Formato2 será aceito na mensagem (e, obviamente, nada mais será aceito como correto). Ver observação acima sobre o posicionamento dos formatos em distintas linhas.
(Formato1 Formato2 ...)
Os parênteses são usados para indicar um formato composto de 2 ou mais formatos distintos que deve ser tratado como um elemento único. Ver observação acima sobre o posicionamento dos formatos em distintas linhas.
[Formato]
Um formato de mensagem colocado entre colchetes (‘[’ e ‘]’) é considerado como opcional, podendo não aparecer no texto da mensagem.
*Formato
Um asterisco (‘*’) colocado antes de um formato indica que este formato poderá ser repetido zero ou mais vezes. Dito de outra forma, o formato poderá realmente não aparecer no texto da mensagem (i.e. zero vezes), poderá aparecer apenas uma vez, poderá aparecer 2 vezes e assim por diante.
+Formato
Um sinal de adição (‘+’) colocado antes de um formato indica que este formato poderá ser repetido uma ou mais vezes. Dito de outra forma, o formato poderá aparecer apenas uma vez, poderá aparecer 2 vezes e assim por diante. Porém se o formato não aparecer isto será considerado um erro.
; comentário

Projeto e Desenvolvimento de Aplicações para a Internet
60 Copyright 2001 João Carlos Gluz
O ponto-e-vírgula (‘;’) é usado para se inserir comentários nas definições de formato. Tudo que aparece entre o ponto-e-vírgula (inclusive este) e o fim da linha da descrição é desconsiderado, servindo apenas como comentário sobre a definição de formato.
6.2.3. Caracteres / Símbolos Especiais
SP
É o caracter de espaço em branco (‘ ’) no código ASCII. Neste código o valor deste caracter é 32 em decimal ou 20 em hexadecimal.
HT
É o caracter de tabulação horizontal (“Horizontal Tabulation” ou HT em inglês) do código ASCII. Neste código o valor deste caracter é 9 em decimal ou hexadecimal.
CR
É o caracter de “retorno de carro” (“Carriage Return” ou CR em inglês) do código ASCII. Neste código o valor deste caracter é 13 em decimal ou 0D em hexadecimal.
LF
É o caracter de “alimentação de linha” (“Line Feed” ou LF em inglês) do código ASCII. Neste código o valor deste caracter é o 10 em decimal ou 0A em hexadecimal.
CRLF
É a sequencia de fim de linha empregada no protocolo HTTP. É formada por um caracter CR seguido de um caracter LF.
BYTE
Um BYTE é um valor qualquer de 8 bits. Na prática considera-se que um BYTE é equivalente a um caracter, ou seja, considera-se que os caracteres serão valores binários de 8 bits, sendo assim um BYTE é um elemento que pode assumir qualquer valor entre 0 e 255.
6.2.4. Elementos Básicos
PalavraReservada = < elemento token definido na RFC 1945 > StringEntreAspas = < cadeia de caracteres (string) imprimíveis tal como definida na RFC 1945>
6.3. Formato básico das mensagens
As mensagens do protocolo HTTP consistem de requisições emitidas pelos clientes e das respostas retornadas pelos servidores. Sendo assim uma mensagem HTTP pode ter os seguintes formatos:

Projeto e Desenvolvimento de Aplicações para a Internet
61 Copyright 2001 João Carlos Gluz
Mensagem-HTTP = Requisição-Simples | ; mensagens do HTTP/0.9 Resposta-Simples | Requisição-Completa | ; mensagens HTTP/1.0 Resposta-Completa
As mensagens nos formatos Requisição-Simples e Resposta-Simples são consideradas obsoletas e apenas são mantidas para fins de compatibilidade. Um servidor envia deverá enviar uma Resposta-Simples apenas se receber de um antigo cliente uma mensagem no formato Requisição-Simples.
Para transferir informações entre clientes e servidores a opção recomendada é se usar os formatos Requisição-Completa e Resposta-Completa.
As mensagens simples Requisição-Simples e Resposta-Simples tem os seguintes formatos:
Requisição-Simples = "GET" SP URI-da-Requisição CRLF Resposta-Simples = [ Corpo-da-Entidade ]
onde URI-da-Requisição é o identificador unívoco do arquivo (genericamente chamado de entidade) que o cliente está buscando no servidor remoto e o Corpo-da-Entidade é justamente o arquivo, se foi efetivamente encontrado, que é retornado pelo servidor ao cliente.
Um Corpo-da-Entidade é definido simplesmente como uma sequência de 0 ou mais BYTES:
Corpo-da-Entidade = *BYTE
O termo URI-da-Requisição será definido mais a seguir.
As mensagens completas Requisição-Completa e Resposta-Completa tem os seguintes formatos:
Requisição-Completa = Linha-de-Requisição *( Cabeçalho-Geral | Cabeçalho-da-Requisição | Cabeçalho-da-Entidade ) CRLF [ Corpo-da-Entidade ] Resposta-Completa = Linha-de-Estado *( Cabeçalho-Geral | Cabeçalho-da-Resposta | Cabeçalho-da-Entidade )

Projeto e Desenvolvimento de Aplicações para a Internet
62 Copyright 2001 João Carlos Gluz
CRLF [ Corpo-da-Entidade ]
As requisições e respostas completas do HTTP têm um formato muito similar, sendo organizadas em várias linhas de texto. A primeira linha é a mais importante, é ela que define o que está se solicitando numa requisição e no caso da resposta, como esta solicitação foi atendida pelo servidor. Desta forma são os elementos Linha-de-Requisição e Linha-de-Estado que irão definir justamente os formatos destas primeiras linhas para, respectivamente, uma requisição ou para uma resposta.
Os demais elementos definem as linhas subseqüentes da mensagem. Em formato, ou seja em sintaxe, elas são iguais para requisições e respostas, mas em termos de significado ou uso que se dará para estes formatos haverá uma diferenciação clara quando este elemento for utilizado numa requisição ou numa resposta.
Os elementos Cabeçalho-Geral, Cabeçalho-da-Requisição, Cabeçalho-da-Resposta e Cabeçalho-da-Entidade servem para definir cabeçalhos contendo opções adicionais da mensagem. As opções listadas no Cabeçalho-Geral são de cunho geral e, em princípio, podem ser usadas tanto em requisições quanto em respostas, já as opções listadas em Cabeçalho-da-Requisição são particulares para as requisições, as opções listadas em Cabeçalho-da-Resposta são particulares para as respostas e, por último, as opções contidas no Cabeçalho-da-Entidade estão associadas a entidade (arquivo ou recurso) sendo transportada pela mensagem.
Um comentário final: deve ter ficado claro, pelo formato de mensagem, que as entidades (isto é os arquivos ou recursos) podem tanto ser transportados do servidor para o cliente (que é a prática mais comum de uso do HTTP) quanto do cliente para o servidor (que é possível, dependendo do método e do tipo de requisição sendo enviado). Estes temas serão vistos com mais detalhes nas seções a seguir.
Por agora vale a pena somente apresentar a lista de elementos que pode compor os cabeçalhos gerais, que podem aparecer tanto nas requisições quanto nas respostas:
Cabeçalho-Geral = Date | Pragma
Os nomes dos formatos dos campos foram mantidos no original em inglês porque eles são equivalentes aos literais que deverão aparecer numa requisição identificando estes campos.
Para finalizar, um ponto importante deve ser ressaltado em relação às requisições e respostas completas: elas devem ser compostas de no mínimo uma linha de texto contendo a requisição ou contendo o estado da resposta, seguido de uma linha em branco (indicado claramente pela seqüência de fim de linha CRLF nas especificações acima). Os demais elementos são opcionais.

Projeto e Desenvolvimento de Aplicações para a Internet
63 Copyright 2001 João Carlos Gluz
6.4. Mensagens de Requisição
Uma mensagem de requisição inclui, na primeira linha da mensagem, o método que o servidor deverá aplicar para obter o recurso (entidade) sendo solicitado, o identificador deste recurso e a versão de protocolo a ser usada. Apenas por questões de compatibilidade com a versão mais antiga do HTTP, a versão 0.9, é que existem dois formatos de requisição: o formato simples Requisição-Simples e o formato completo Requisição-Completa a ser obrigatoriamente usado a partir da versão 1.0 do HTTP.
Como visto anteriormente uma requisição simples suporta apenas um método de acesso às informações: o GET, seguido do identificador do recurso e sem um campo de versão (o fato deste campo não existir é que indica que se está usando a versão simples do HTTP/0.9).
A primeira linha de uma requisição completa começa o nome do método, seguido pela URI-da-Requisição e pela versão do protocolo, sendo finalizada pela seqüência CRLF de fim de linha. Os elementos são separados por espaços em branco (caracter SP) e (nenhum caracter CR ou LF é permitido no meio da linha). O formato fica então:
Linha-da-Requisição = Método SP URI-da-Requisição SP Versão-HTTP CRLF
Note que a diferença entre uma requisição simples e uma completa é a presença do identificador de versão de HTTP e a possibilidade de se usar outros métodos que não o GET, nas requisições completas.
Para a versão 1.0 do HTTP o elemento Versão-HTTP deverá ser:
Versão-HTTP = “HTTP/1.0”
6.4.1. Métodos das Requisições
O nome identificado por Método indicará o método (no sentido de tarefa ou rotina) a ser executado sobre o recurso sendo solicitado. Diferente dos outros formatos, os nomes de método são sensíveis ao tipo de letra, isto é, sensíveis as diferenças entre letras maiúsculas e minúsculas. Portanto se o nome do método for identificado como “GET” não serão aceitos identificadores tais como “get”, “gEt”, etc. Os métodos aceitos são:
Método = "GET" | "HEAD" | "POST" | Método-Extra Método-Extra = Palavra-Reservada ; Palavra reservada diferente de GET, HEAD e POST

Projeto e Desenvolvimento de Aplicações para a Internet
64 Copyright 2001 João Carlos Gluz
A lista de métodos aceitáveis por um recurso pode mudar dinamicamente: o cliente é avisado através de um código de estado se o uso do método sobre o recurso é permitido ou não. Os servidores que não implementarem um dado tipo de método podem retornar o código “501” indicando que o método não está implementado. Os métodos “GET”. “HEAD” e “POST” são os métodos usuais a serem empregados pelos servidores que suportam o HTTP/1.0. Através do formato Método-Extra outros métodos adicionais, que não os usuais podem ser solicitados ao servidor. Porém, como citado acima, estes métodos são dependentes de implementação e poderão não ser aceitos pelo servidor.
6.4.2. Identificador de Recurso da Requisição
Além do método uma requisição incorpora um identificador de recurso que deve ser universalmente aceito, no sentido de ser independente de servidor. Em inglês a expressão para Identificador Universal de Recurso é “Universal Resource Identifier” ou apenas URI. O formato completo de uma URI-da-Requisição fica:
URI-da-Requisição = URI-Absoluta | Caminho-Absoluto URI-Absoluta = Esquema ":" *CarURI Caminho-Absoluto = "/" Caminho-Relativo Caminho-Relativo = [ Caminho ] [ ";" Parâmetros ] [ "?" Consulta ] Caminho = Primeiro-Segmento *( "/" Segmento ) Primeiro-Segmento = +CarCaminho Segmento = *CarCaminho Parâmetros = Parâmetro *( ";"Parâmetro ) Parâmetro = *(CarCaminho | "/" ) Esquema = +( CarAlfanuméricos | "+" | "-" | "." ) Consulta = *(CarURI | CarReservados ) CarCaminho = CarURI | ":" | "@" | "&" | "=" | "+" CarURI = CarLivres | SeqEscape CarLivres = CarAlfanuméricos | CarSeguros | CarExtras SeqEscape = "%" DigitoHexa DigitoHexa CarReservados = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" CarExtras = "!" | "*" | "'" | "(" | ")" | ","

Projeto e Desenvolvimento de Aplicações para a Internet
65 Copyright 2001 João Carlos Gluz
CarSeguros = "$" | "-" | "_" | "." CarAlfanuméricos = “a” .. “z” | “A” .. “Z” | “0” .. “9” DigitoHexa = “0” ..”9” | “a” .. “f” | “A” .. “F”
As duas opções para a URI-da-Requisição dependem da natureza da requisição. Na verdade o formato URI-Absoluto somente é permitido quando a requisição está sendo encaminhada para um servidor-procurador (servidor “proxy”). Nos casos normais deve-se usar o formato de Caminho-Absoluto. Neste caso o Caminho-Absoluto irá indicar o caminho absoluto dentro do servidor que deverá ser usado para recuperar o recurso. Por exemplo um cliente desejando recuperar o arquivo TheProject.html, localizado no diretório /pub/WWW de um servidor deverá montar o seguinte caminho absoluto:
/pub/WWW/TheProject.html
A Linha-da-Requisição para esta consulta ficará então:
GET /pub/WWW/TheProject.html HTTP/1.0
Observação:
A URI-da-Requisição é uma cadeia de caracteres (string) que pode ter alguns caracteres codificados por uma seqüência de escape no formato SeqEscape. O servidor que receber uma requisição com estas seqüências de escape, deve decodificá-las antes de interpretar a requisição.
6.4.3. Cabeçalhos de Requisição
No cabeçalho da requisição é possível, ao cliente, passar informações adicionais sobre a requisição e sobre o próprio cliente.Um cabeçalho de requisição é formado por uma série de linhas, cada linha contendo um campo de cabeçalho. Cada um destes campos age como um modificador da requisição sendo, na prática, uma opção ou parâmetro extra a ser enviado ao servidor. O formato geral deste cabeçalho, com suas respectivas opções, é apresentado a seguir:
Cabeçalho-da-Requisição = Authorization | From | If-Modified-Since | Referer | User-Agent
O detalhamento dos diversos campos do cabeçalho de requisição será feito em seção a ser vista a seguir. Os nomes dos formatos dos campos foram mantidos no original em inglês porque eles são equivalentes aos literais que deverão aparecer numa requisição identificando estes campos.

Projeto e Desenvolvimento de Aplicações para a Internet
66 Copyright 2001 João Carlos Gluz
6.5. Mensagens de Resposta
Depois de receber e interpretar uma mensagem de requisição, um servidor responde a está requisição com uma mensagem de resposta HTTP. O formato de uma Resposta-Simples, usado no HTTP/0.9, é diretamente o arquivo ou recurso solicitado, já o formato de Resposta-Completa é um pouco mais complexo:
Resposta-Completa = Linha-de-Estado *( Cabeçalho--Geral | Cabeçalho-da-Resposta | Cebeçalho-da-Entidade ) CRLF [ Corpo-da-Entidade ]
Apesar de que uma Resposta-Completa deve ser sempre enviada em resposta a uma Requisição-Completa, um cliente que receba uma resposta que não começe pela Linha-de-Estado deve assumir que está recebendo uma Resposta-Simples, ou seja, que está recebendo o corpo do arquivo (entidade) solicitado.
6.5.1. Linha de Estado da Resposta
A primeira linha de uma Resposta-Completa é a Linha-de-Estado. Esta linha consiste da versão do protocolo, seguida do código numérico de estado, seguido de uma frase descrevendo o estado retornado. Cada um destes elementos é separado por um caracter de espaço (SP). A frase que descreve o estado pode, entretanto, conter espaços em branco separando suas palavras. A linha de estado termina por uma sequência CRLF de fim de linha. O formato desta linha fica então:
Linha-de-Estado = Versão-HTTP SP Código-de-Estado SP Descrição-do-Estado CRLF
Desde que uma linha de estado sempre começa com a versão do protocolo HTTP e o código de estado, basta reconhecer a seguinte sequência de caracteres para identificar a resposta como sendo completa:
"HTTP/" +Dígito "." +Dígito SP Dígito Dígito Dígito SP Dígito = “0” .. “9”
Por exemplo "HTTP/1.0 200 ". Apesar de uma resposta simples ser um arquivo que pode começar com qualquer sequência, inclusive a sequência definida acima, o fato é que como a maior parte dos servidores HTTP/0.9 serem limitados a retornar arquivos de texto no formato HTML (arquivos de tipo “text/html”) então, neste caso graças ao própria especificação do HTML, não haverá conlito.
6.5.2. Códigos de Estados e sua Descrições
O código de estado é um inteiro de 3 digitos indicando o estado do servidor após tentar atender a requisição. A frase de descrição deste estado é um texto que pode ser impresso e apresentado ao usuário,

Projeto e Desenvolvimento de Aplicações para a Internet
67 Copyright 2001 João Carlos Gluz
descrevendo resumidamente este estado. Enquanto que código foi projetado para fins de automatização da análise da resposta, o texto com a descrição pode ser diretamente apresentado para o usuário, ou seja, o software cliente não precisa analisar a frase de descrição de estado.
O primeiro dígito do código define a classe da resposta. Os últimos dois dígitos detalham o evento dentro da classe. Existem 5 classes de respostas:
• 1xx: Informacional - Presentemente não utilizada, mas reservada para uso futuro
• 2xx: Sucesso - A ação (requisição) foi recebida, entendida e aceitada com sucesso.
• 3xx: Redireção - Ações adicionais tem que ser tomadas para completar a requisição.
• 4xx: Erro do Cliente - A requisição está com erro de sintaxe (formato) ou então, apesar de não ter erro de sintaxe, não pode ser atendida por solicitar algo impossível de ser atendido.
• 5xx: Erro no Servidor - O servidor falhou em atender uma requisição aparentemente válida.
Os códigos e as frases descritivas (como comentários) são apresentados a seguir:
Código-de-Estado = "200" | ; OK "201" | ; Created "202" | ; Accepted “204" | ; No Content "301" | ; Moved Permanently “302" | ; Moved Temporarily "304" | ; Not Modified "400" | ; Bad Request "401" | ; Unauthorized "403" | ; Forbidden "404" | ; Not Found "500" | ; Internal Server Error "501" | ; Not Implemented "502" | ; Bad Gateway "503" | ; Service Unavailable Código-de-Extensão
Os códigos de resposta podem ser extendidos através do Código-de-Extensão, ou seja, outros códigos além dos visto acima também podem ser retornados. Os códigos acima são os que podem ser gerado e devem ser reconhecidos pela versão 1.0 do HTTP. Outros códigos são dependentes de implementação ou associados a novas versões do HTTP. Independente disso as aplicações clientes devem reconhecer a classe (o primeiro dígito) mesmo que não reconhecer o tipo particular do evento. O significado dos códigos reconhecidos pelo HTTP/1.0 será apresentado numa seção a ser vista seguir.

Projeto e Desenvolvimento de Aplicações para a Internet
68 Copyright 2001 João Carlos Gluz
6.5.3. Cabeçalhos de Resposta
No cabeçalho da respopsta é possível, ao servidor, passar informações adicionais sobre a resposta (ou sobre o próprio servidord) que não pôde ser colocada na linha de estado. O formato básico de um cabeçalho de resposta é muito similar ao dos outros tipos de cabeçalhos sendo formado por uma série de linhas, cada linha contendo um campo de cabeçalho. O formato geral deste cabeçalho com suas respectivas opções é apresentado a seguir:
Cabeçalho-da-Resposta = Location | Server | WWW-Authenticate
O detalhamento dos diversos campos do cabeçalho de requisição será feita em seção a ser vista seguir. Os nomes dos formatos dos campos foram mantidos no original em inglês porque eles são equivalentes aos literais que deverão aparecer numa requisição identificando estes campos.
6.6. Entidade
A “entidade” é na verdade o arquivo ou o recurso que se está buscando. Tanto uma Requisição-Completa quanto uma Resposta-Completa podem transferir entidades (um arquivo ou recurso), dependendo do método empregado na requisição. Uma entidade, no caso de uma Resposta-Completa será composta de mais do que os dados do arquivo. Estes dados irã compor o Corpo-da-Entidade. Mas além deste corpo uma entidade também poderá conter atributos adicionais definidos no seu Cabeçalho-de-Entidade.
O formato destes dois elementos é dado a seguir:
Cabeçalho-da-Entidade = Allow | Content-Encoding | Content-Length Content-Type | Expires | Last-Modified | Cabeçalho-Extensão Cabeçalho-Extensão = <cabeçalho HTTP adicional(ver RFC 1945)> Corpo-da-Entidade = *BYTE
Cabeçalhos adicionais de entidade (Cabeçalho-Extensão) podem ser definidos sem alterar o protocolo, porém o reconhecimento e tratamento destes campos extras fica dependente de implementação.
Os nomes dos formatos dos campos foram mantidos no original em inglês porque eles são equivalentes aos literais que deverão aparecer numa requisição identificando estes campos.

Projeto e Desenvolvimento de Aplicações para a Internet
69 Copyright 2001 João Carlos Gluz
Os campos de Content-Encoding e Content-Type definem realmente as características de codificação da entidade. São eles que realmente definem o “tipo do arquivo” mais que qualquer terminação de arquivo (isto é eles tem preferência sobre qualquer “.html”, “.htm”, “.pdf”, “.txt”, “.exe”, etc.). O tamanho completo da entidade, do ponto de vista de quantos bytes são necessários para transmiti-lo, é dado em Content-Length. Os demais campos são detalhados numa seção próxima.
6.7. Descrição dos Métodos
Os métodos definidos para o HTTP/1.0 são apresentados a seguir.
6.7.1. GET
O método GET serve para recuperar qualquer informação (na forma de uma entidade) que seja identificada pela URI-da-Requisição. Se a URI-da-Requisição se refere a um arquivo, então são os dados contidos neste arquivo que devem ser retornados como corpo-da-entidade, porém se a URI-da-Requisição se refere a um processo ou um programa que gere as informações dinamicamente, então deverão ser justamente estes dados que devem ser retornados ao cliente e não o arquivo texto ou fonte do programa sendo referenciado.
O método GET é incondicional, porém se houver um campo If-Modified-Since no cabeçalho da requisição então a semântica deste método terá que ser compreendida como condicional: a entidade referenciada por URI-da-Requisição somente necessita ser transferida para o cliente se ela tiver sido modificada desde a data fornecida por If-Modified-Since.
6.7.2. HEAD
O método HEAD é idêntico ao GET, exceto que o servidor não deve enviar o corpo da entidade na resposta. Entretanto, as informações sobre a entidade e sobre o servidor que seriam retornadas nos cabeçalhos da resposta devem ser enviadas da mesma forma como teriam sido enviadas em resposta ao GET. A idéia deste método é que ele seja usado para retornar informações sobre as entidades (data de criação, formato de arquivo, controle de acesso, etc.) sem que o próprio corpo da entidade (o arquivo inteiro) tenha que ser retornado.
Diferente do GET não existe HEAD condicional, ou seja se a cláusula If-Modified-Since existir no cabeçalho da requisição ela deverá ser ignorada.
6.7.3. POST
O método POST é usado para que o servidor aceite a entidade encapsulada na requisição como o novo valor subordinado ao recurso identificado pela URI-da-Requisição na Linha-da-Requisição. Este método foi definido para prover uma maneira uniforme de se executar as seguintes funções: • atualização de recursos (arquivos) existentes; • envio de mensagens para “bulletin boards”, “newsgroup”, listas de discussões, etc.; • envio de blocos de dados de formulários; • adição de novas informações à bases de dados.
A função realmente executada pelo POST é determinada pelo servidor e é usualmente dependente da URI-da-Requisição. Um POST aceito com sucesso não requer que uma entidade nova seja criada ou

Projeto e Desenvolvimento de Aplicações para a Internet
70 Copyright 2001 João Carlos Gluz
disponibilizada para acesso futuro. Neste último caso é perfeitamente válido que o servidor retorne o código 204 (sem conteúdo) indicando que a requisição foi aceita mas nenuma entidade nova foi criada. Se a entidade foi criada então o servidor poderá responder com o código 201 (entidade criada).
Em princípio um campo Content-Length válido no Cabeçalho-da-Entidade é obrigatório em todas as requisições POST do HTTP/1.0. Caso este campo não exista o servidor deve responder com um código 400 (requisição inválida), se não conseguir determinar corretamente o tamanho da entidade.
6.8. Códigos de Estado
Os códigos de estado que podem ser gerados e reconhecidos no HTTP/1.0 são apresentadosa seguir:
200 OK
A requisição teve sucesso. A informação retornada depende do método usado:
GET
O corpo da entidade solicitada é enviado na resposta (incluindo qualquer cabeçalho pertinente).
HEAD
Apenas os cabeçalhos que seria retornados no GET são enviados como resposta.
POST
É retornada uma entidade descrevendo ou contendo o resultado da ação POST.
201 Created
A requisição foi aceita e executada e resultou na criação de um novo recurso. O novo recurso criado pode ser referenciado pela URI retornada no corpo da entidade da resposta.
202 Accepted
A requisição foi aceita para processamento, mas o processament ainda não foi completado.
204 No Content
O servidor aceitou a requisição mas não existe informação a ser enviada em retorno.
301 Moved Permanently
O recurso identificado na requisição foi movido permanentemente para um novo local identificado pela URL contida no campo Location da mensagem de resposta.
302 Moved Temporarily
Similar a 301 apenas que neste caso a alteração é temporária.

Projeto e Desenvolvimento de Aplicações para a Internet
71 Copyright 2001 João Carlos Gluz
304 Not Modified
Se o cliente solicitou um GET condicional (com o campo If-Modified-Since) e o acesso a este recurso é permitido, mas o documento não foi efetivamente modificado desde a dada fornecida então o servidor deve responder com este código de retorno e não deve enviar nenhuma entidade na resposta.
400 Bad Request
Requisição inválida: a requisição não foi aceita pelo servidor por erro de sintaxe.
401 Unauthorized
A requisição requer a autenticação do usuário. A resposta deve incluir um campo WWW-Authenticate contendo os esquemas de autenticação aceitos pelo servidor e desafiando o cliente a enviar uma autenticação correta em algum destes protocolos. Esta resposta pode ser enviada tanto porque a requisição não incluiu um campo de autenticação no cabeçalho (Authorization) ou porque as informações prestadas neste campo não forma aceitas (nome de usuário e senha inválidos).
403 Forbidden
O servidor entendeu corretamente a requisição, mas está se recusando a atendê-la por questões de segurança. Não é uma questão de autorização ou autenticação, o servidor não irá atender esta requisição mesmo com credenciais de usuário corretas.
404 Not Found
O servidor não encontrou nenhum recurso (arquivo) que se encaixe apropriadamente na URI-da-Requisição.
500 Internal Server Error
O servidor encontrou uma condição inesperada ** um “bug” ** que não permite que ele atenda a requisição.
501 Not Implemented
O servidor não suporta a funcionalidade exigida pela requisição. Resposta típica quando o servidor não reconhece o método empregado na requisição.
502 Bad Gateway
O servidor agindo como procurado (“proxy”), recebeu uma resposta inválida do servidor remoto.
503 Service Unavailable
O servidor está temporariamente incapacitado de atender a requisição, tipicamente por falta de recursos ou por excesso de carga ou até mesmo por questões de manutenção.

Projeto e Desenvolvimento de Aplicações para a Internet
72 Copyright 2001 João Carlos Gluz
6.9. Campos dos Cabeçalhos
6.9.1. Cabeçalho Geral
Date
O campo Date representa a data e hora em que a mensagem (seja requisição ou resposta) foi gerada. O formato deste campo é:
Date = "Date" ":" Data-HTTP Data-HTTP = Data-rfc1123 | Data-rfc850 | Data-asctime Data-rfc1123 = wkday "," SP date1 SP time SP "GMT" Data-rfc850 = weekday "," SP date2 SP time SP "GMT" Data-asctime = wkday SP date3 SP time SP Dígito Dígito Dígito Dígito ; day month year (e.g., 02 Jun 1982) date1 = Dígito Dígito SP month SP Dígito Dígito Dígito Dígito ; day-month-year (e.g., 02-Jun-82) date2 = Dígito Dígito "-" month "-" Dígito Dígito ; month day (e.g., Jun 2) date3 = month SP ( Dígito Dígito | ( SP Dígito )) ; 00:00:00 - 23:59:59 time = Dígito Dígito ":"Dígito Dígito ":" Dígito Dígito wkday = "Mon" | "Tue" | "Wed" | "Thu" | "Fri" | "Sat" | "Sun" weekday = "Monday" | "Tuesday" | "Wednesday" | "Thursday" | "Friday" | "Saturday" | "Sunday" month = "Jan" | "Feb" | "Mar" | "Apr" | "May" | "Jun" | "Jul" | "Aug" | "Sep" | "Oct" | "Nov" | "Dec"
Um exemplo:
Date: Tue, 15 Nov 1994 08:12:31 GMT
Pragma
O campo de cabeçalho geral Pragma deve ser usado apenas para incluir diretivas dependentes de implementação. O formato deste campo é:

Projeto e Desenvolvimento de Aplicações para a Internet
73 Copyright 2001 João Carlos Gluz
Pragma = "Pragma" ":" +Diretiva-Pragma Diretiva-Pragma = "no-cache" | Pragma-Extensão Pragma-Extensão = Palavra-Reservada [ "=" (Palavra-Reservada | StringEntreAspas) ]
A opção “no-cache” serve para inibir a utilização de armazenamento temporário (uso de “cache”) no atendimento da requisição.
6.9.2. Cabeçalho das Requisições
Authorization
Um usuário que deseja se autenticar com um servidor -- usualmente, mas não necessariamente, após receber uma resposta com o código 401 -- pode faze isto pela inclusão de um campo Authorization na requisição. Este campo consiste das credenciais (nome de usuário, senha, etc.) do usuário apropriadamente codificadas de acordo com o esquema de autenticação desafiado pelo servidor (campo WWW-Authenticate de uma resposta anterior). O formato fica então:
Authorization = "Authorization" ":" Credenciais
O formato de Credenciais será visto numa seção próxima, específica para controle de acesso.
From
O campo From é opcional e se for fornecido numa requisição indicao endereço de e-mail na Internet do usuário que está controlando o cliente. O endereço deve ser definido de acordo com a RFC 822.
From = "From" ":" <endereço de e-mail tal como definido na RFC 822>
Exemplo:
From: [email protected]
If-Modified-Since
O campo If-Modified-Since transforma uma requisição GET numa requisição condicional: a entidade (o arquivo ou recurso) somente será retornada se tiver sido modificada após a data fornecida neste campo. O formato da data é o mesmo aceito no campo Date. O formato deste campo é:

Projeto e Desenvolvimento de Aplicações para a Internet
74 Copyright 2001 João Carlos Gluz
If-Modified-Since = "If-Modified-Since" ":" Data-HTTP
Um exemplo deste campo:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Referer
O campo opcional Referer permite ao cliente especificar o endereço (URI) do recurso de onde a URI-da-Requisição foi obtida. Isto permite ao servidor geral listas de links reversos de entidades para fins de estatísticas, otimizações, etc. O formato deste campo é:
Referer = "Referer" ":" URI-Absoluta
Exemplo:
Referer: http://www.w3.org/hypertext/DataSources/Overview.html
User-Agent
O campo opcional User-Agent contém informações sobre o software do cliente que está solicitando a requisição. Estas informações somente devem ser usadas para fins estatísticos. O formato deste campo é similar ao campo Server:
User-Agent = "User-Agent" ":" +( Produto | Comentário )
Exemplo:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
6.9.3. Cabeçalho das Respostas
Location
O campo Location define a nova localização do recurso sendo solicitado, no caso em que ele foi movido para outro lugar (outra URL). Em princípio este campo somente faz sentido com os códigos de resposta 3xx. O formato deste campo é:
Location = "Location" ":" URI-Absoluta
Exemplo:

Projeto e Desenvolvimento de Aplicações para a Internet
75 Copyright 2001 João Carlos Gluz
Location: http://www.w3.org/hypertext/WWW/NewLocation.html
Server
O campo opcional Server contém informações sobre o software que está sendo usado no servidor. O formato deste campo é:
Server = "Server" ":" +( Produto | Comentário ) Produto = Palavra-Reservada [ / Versão] Versão = +Digito[“.” Versão] Comentário = <comentário em texto imprimível tal como definido na RFC 1945>
Exemplo:
Server: CERN/3.0 libwww/2.17
WWW-Authenticate
O campo WWW-Authenticate deve ser incluídos em respostas não aceitas por problemas de autorização (código 401). O valor deste campo consiste de pelo menos um esquema de autenticação aceito pelo servidor e desafiando o cliente remoto responder com uma autenticação válida em algum destes esquemas. O formato deste campo é:
WWW-Authenticate = "WWW-Authenticate" ":" +Desafio
O formato de Desafio é apresentado em seção específica sobre controle de acesso, vista a seguir.
6.9.4. Cabeçalho das Entidades
Allow
O campo de entidade Allow lista o conjunto de métodos suportados pela entidade identificada na URI-da-Requisição. O campo Allow não é permitido numa requisição POST, ou seja, serve apenas com fins informativos que o servidor envia para o cliente. O formato do campo é:
Allow = "Allow" ":" +Método
Exemplo:

Projeto e Desenvolvimento de Aplicações para a Internet
76 Copyright 2001 João Carlos Gluz
Allow: GET HEAD
Content-Encoding
O campo Content-Encoding é usado como um modificador do tipo de meio da entidade. Quando presente o seu valor indica que codificação adicional foi aplicada a entidade e portanto qual o mecanismo de decodificação que deve ser aplicado antes de se obter uma entidade do tipo definido no campo Content-Type. Os tipos de codificação definidos em Content-Encoding somente são aplicados às entidades de tipo Content-Type.
Content-Encoding = "Content-Encoding" ":" Codificação-de-conteúdo Codificação-de-conteúdo = "x-gzip" | "x-compress" | Palavra-Reservada
Content-Length
O campo Content-Length o tamanho em bytes do corpo da entidade. Este número é dado em decimal. O formato é:
Content-Length = "Content-Length" ":" +Dígito
Um exemplo:
Content-Length: 3495
O tamanho fornecido neste campo é independente do tipo de meio ou de codificação da entidade. Ele é relativo apenas ao número de bytes que tem que ser transferidos do servidor ao cliente ou vice-versa. Qualquer tamanho maior ou igual a zero é considerado válido.
Content-Type
O campo Content-Type indica o tipo de meio do Corpo-da-Entidade.
Content-Type = "Content-Type" ":" Tipo-de-Meio Tipo-de-Meio = Tipo "/" Subtipo *( ";" Parâmetro ) Tipo = “text” | Palavra-Reservada Subtipo = “html” | Palavra-Reservada Parâmetro = Atributo "=" Valor Atributo = Palavra-Reservada

Projeto e Desenvolvimento de Aplicações para a Internet
77 Copyright 2001 João Carlos Gluz
Valor = Palavra-Reservada| StringEntreAspas
Exemplo:
Content-Type: text/html
Expires
O campo Expires fornece a data e hora em que a entidade deve ser considerada desatualizada. A data e hora é dada no mesmo formato do campo Date. O formato deste campo é:
Expires = "Expires" ":" Data-HTTP
Exemplo:
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Last-Modified
O campo de entidade Last-Modified indica a data e hora em que o agente (cliente ou servidor) que está enviando esta entidade acredita que ela foi modificada pela última vez. A data e hora deve ser fornecida no mesmo formato usado no campo Date. O formato deste campo é:
Last-Modified = "Last-Modified" ":" Data-HTTP
Exemplo:
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
6.10. Autenticação de Acesso
O protocolo HTTP provê um mecanismo simples de desafio-resposta que pode ser usado pelo servidor para desafiar um cliente e para um cliente fornecer informações de autenticação. É usado um mecanismo extensível, baseado em palavras reservadas, insensíveis às diferenças entre maiúsculas e minúsculas, para identificar o esquema de autenticação. O identificador de esquema deve ser seguido por uma lista de pares atributo-valor contendo os parâmetros necessários para satisfazer a autenticação por meio dàquele esquema:
Esquema-Autenticação = Palavra-Reservada Parâmetro-Autenticação = Palavra-Reservada "=" StringEntreAspas

Projeto e Desenvolvimento de Aplicações para a Internet
78 Copyright 2001 João Carlos Gluz
A resposta de código 401 (acesso não autorizado) deve incluir um cabeçalho WWW-Authenticate que contém pelo menos um esquema de autenticação desafiando o cliente a atendê-lo. O formato de um Desafio fica então:
Desafio = Esquema-Autenticação +SP Domínio *( "," Parâmetro-Autenticação ) Domínio = "realm" "=" Valor-do-Domínio Valor-do-Domínio = StringEntreAspas
O atributo Domínio (“realm”) é necessário para todos os esquemas de autenticação que emitem desafios. O valor deste atributo (que é sensível ao tipo de letra maiúscula/minúscula) em combinação com a URL raíz do servidor definirá o espaço ou domínio de proteção do recurso sendo solicitado.
Um usuário que deseje se autenticar com o servidor deve incluir o campo Authorization contendo as credenciais necessárias para satisfazer esta autenticação. O formato das credenciais é:
Credenciais = Credenciais-Básicas | ( Esquema-Autenticação *Parâmetro-Autenticação )
O esquema básico de autenticação (o mais simples dos esquemas aceitos no HTTP) é definido na própria RFC 1945. Este esquema é opcional (e também não é muito seguro, não sendo aconselhado para uso geral). O formato deste esquema básico é:
Credenciais-Básicas = "Basic" SP basic-cookie basic-cookie = <codificação do nome de usuário e senha em base64 (de acordo com a RFC 1521, exceto que não limitada a uma linha de 76 caracteres) >
Neste esquema básico o nome do usuário (username) e a senha (password) são codificadas num formato definido pela RFC1521 para codificar dados em binário em texto ASCII. Um exemplo de requisição usando este formato é apresentado a seguir. neste exemplo o username é “Aladdin” é a password é “open sesame”:
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==

Projeto e Desenvolvimento de Aplicações para a Internet
79 Copyright 2001 João Carlos Gluz
Capítulo VII - Requisições HTTP com FormuIários Codificados
Um formulário HTML é um trecho de fonte HTML que contém uma série de “campos” (variáveis do formulário), com indicações sobre o tipo de dados do campo e de como ele pode ser apresentado (uma janela de edição, uma série de “botões de rádio”, uma série de “chaves liga/desliga”, etc.).
A responsabilidade por apresentar e permitir a edição é da aplicação cliente HTTP (Netscape ou Internet Explorer por exemplo). Quando o usuário termina de alterar os dados do formulário, estes dados são passados para o servidor remoto através de uma técnica que codifica os dados do formulário numa URL.
7.1. Métodos Aplicáveis
A técnica de codificação na URL, está definida na seção 8.2.1 da RFC 1866 que especifica a HTML 2.0. Dois métodos do HTTP podem ser usados para passar as informações de formulários: GET e POST.
O método GET é usado quando o formulário está sendo preenchido para consultar informações numa base de dados, ou seja, quando as informações contidas neste formulário não serão armazenadas no servidor, elas somente servirão para encontrar, localizar ou obter outras informações.
Por outro lado quando as informações contidas no formulário deverão ser armazenadas no servidor remoto, então deve-se usar o método POST. Neste caso as informações continuarão codificadas numa URL, porém esta URL não será usada como parte da URI da requisição, mas será enviada separadamente como corpo da entidade da requisição.
No caso do GET a URI deve ter o seguinte formato:
<script-cgi-a-ser-executado-no-servidor> ‘?’ <informações-do-formulários-codificadas-em-URL>
No caso do POST á URI é mais simples contendo apenas o:
<script-cgi-a-ser-executado-no-servidor>
Porém o corpo da entidade deve conter as:
<informações-do-formulários-codificadas-em-URL>
7.2. Algoritmo de Codificação
A codificação é feita de forma há não haver nenhum caracter de espaço na URL. Isto é feito em dois passos:
1. Primeiro todos os nomes de campos do formulário com seus respectivos valores são alterados de forma a que todos os caracteres problemáticos sejam substituidos por sequências de escape:

Projeto e Desenvolvimento de Aplicações para a Internet
80 Copyright 2001 João Carlos Gluz
(1.a) Todos os caracteres espaço em branco (‘ ’) são substituidos pelo caracter ‘+’; (1.b) Todos os caracteres que não são letras nem dígitos são substituidos pela sequência ‘%HH’, formada por um caracter de percento (‘%’) seguido por dois dígitos hexadecimais representando o código ASCII do caracter. Mesmo linhas em branco que estejam, por exemplo, dentro de valores de campos de formulários são substituidos por sequências de escape, no caso por ‘%0D%0A’.
2. Depois os campos são listadas na ordem em que aparecem no formulário HTML, primeiro o nome do campo e depois o valor do campo. O caracter de igualdade (‘=’) separa o nome do valor do campo. Os campos são separados por um caracter ‘&’. Os campos que tem valores nulos no formulário podem ser omitidos.
7.3. Exemplo
Por exemplo, supondo um formulário que possua os seguintes campos com seus respectivos valores default:
Campo Valor Nome “” sexo “masculino” familiares “” cidade “” apelido “”
Após este formulário ter sido apropriadamente apresentado e editado pelo usuário, os valores deste campo são modificados para:
Campo Valor nome “Jose da Silva” sexo “masculino” familiares “5” cidade “Porto Alegre” apelido “Seu Ze”
A URL codificando estes dados de formulário fica assim:
nome=Jose+da+Silva&sexo=masculino&familiares=5&cidade=Porto+Alegre&apelido=Seu+Ze
7.4. Sugestões de Trabalhos
7.4.1. Implementação do Tratamento de Formulários e CGI no WebServ
O servidor WebServ não suporta o tratamento de formulários. De acordo com a RFC 1866, os formulários são tratados, no lado do servidor, através de um processo composto de três grandes etapas:

Projeto e Desenvolvimento de Aplicações para a Internet
81 Copyright 2001 João Carlos Gluz
(a) Decodificação dos campos do formulário, que estão codificados dentro da URL da requisição numa lista de nomes de variáveis do formulário com seus respectivos valores.
(b) Ativação de uma aplicação externa que irá tratar esta requisição de formulário. O nome da aplicação a ser executada já vem codificada na URL e os parâmetros são passados para esta aplicação por meio de um protocolo especial para isto. Geralmente se usa o protocolo CGI (sigla para Common Gateway Interface), que opera através de variáveis de ambiente de execução, para passar estes parâmetros nos servidores comerciais.
(c) Execução da aplicação externa. Esta aplicação busca as varíaveis, juntamente com seus valores, através de um protocolo padrão para troca de informações com o servidor HTTP (normalmente o CGI como já comentado antes). Todos os dados gerados por esta aplicação e colocados no arquivo de saída padrão (arquivo stdout da linguagem C) são automaticamente enviados para o cliente remoto, isto é, os dados gerados pela aplicação externa são a resposta da requisição. É por isto que, normalmente, deve-se formatar a saída de um programa CGI de acordo com a linguagem HTML.
Na implementação do WebServ não se está solicitando que seja usado o protocolo CGI, nem que a saída padrão (stdout) seja redirecionada para o socket conectado ao cliente remoto. A implementação de formulários e aplicações externas deve atender as seguintes especificações:
Quando um requisição HTTP conter uma submissão de formulário codificada em URL, a lista das variáveis com seus valores deve ser decodificada e colocada num arquivo de texto. Cada linha deste arquivo deve ter o seguinte formato:
<nome-da-variável> ‘=’ <valor-da-variável> CRLF
Cada linha indicará, então, o nome e o valor da variável para aquela consulta (requisição). A primeira linha em branco (que contém apenas um CRLF ou uma combinação de brancos, TABs e o CRLF, indicará o fim da lista de variáveis.
Após esta decodificação ter sido feita com sucesso, o servidor WebServ irá executar a aplicação externa. Todas as aplicações externas usam apenas dois parâmetros na linha de comando:
• o primeiro parâmetro <arq-lista-var> contém o nome do arquivo com a lista de variáveis,
• o segundo parâmetro <arq-resp-html> contém o nome do arquivo que irá conter a página HTML resultante da consulta.
A aplicação externa deverá consultar o arquivo <arq-lista-var> quando precisar saber o valor de alguma variável. Tudo o que deve ser enviado para o cliente remoto deve ser armazenado no arquivo <arq-resp-html>.
Quando o servidor WebServ detectar que a aplicação externa terminou de executar, ele abre o arquivo <arq-resp-html> e o envia para o cliente remoto (durante todo o tempo da execução da aplicação externa o socket com o cliente remoto foi mantido aberto, mas sem nenhum dado sendo enviado).
Após isto, o WebServ apaga os arquivos <arq-lista-var> e <arq-resp-html> e passa para processar outra requisição.

Projeto e Desenvolvimento de Aplicações para a Internet
82 Copyright 2001 João Carlos Gluz
A aplicação externa tanto pode ser um programa executável previamente compilado, quanto pode ser um programa em batch no caso do DOS/Windows ou um programa shell no caso do Unix / Linux.
7.4.2. Implementação de páginas ativas no WebServ
O conceito de páginas ativas no lado do servidor é extremamente importante para se flexibilizar a operação deste servidor de forma a poder atender o maior tipo de aplicações e usos possíveis. Existem diversos tipos de linguagens e técnicas sendo atualmente disponibilizadas para implementar este tipo de página nos servidores HTTP comerciais. Por exemplo o servidor Apache, que detém aproximadamente 60 % do mercado, usa a linguagem PHP implantada diretamente dentro das páginas HTML para implementar este conceito, já a Microsoft dá prioridade a linguagem ASP (uma versão de Basic Microsoft) para este mesmo fim e por último, existe um movimento que está tomando força de se usar um derivado da linguagem Java, a JSP como padrão para páginas ativas.
O WebServ obviamente não implementa nenhum tipo de página ativa. A sugestão de trabalho aqui é incorporar a ele uma linguagem bem simplificada mas que demonstra claramente os conceitos mais importantes de programação de páginas ativas.
Para tanto serão usadas algumas extensões do HTML, que somente terão sentido quando interpretadas diretamente pelo servidor WebServ e que, conversamente, não deverão ter nenhum efeito quando recuperadas por algum outro tipo de servidor HTTP.
Para garantir isto as extensões serão definidas apenas como comentários HTML que somente o WebServ conhecerá e conseguirá interpretar e tratar, quanto aos demais servidore se espera que estes tipos de comentários sejam efetivamente inócuos.
Sendo assim todos os comandos da “linguagem” WSAP (WebServ Active Pages) estarão dentro de comentário HTML (que estão dentro de “<!-- “ e “ -->”) no seguinte formato:
<!-- WSAP: <comando> -->
Os comandos WSAP serão os seguintes:
<!-- WSAP: INCLUDE <nome-de-arquivo> -->
Este comando inclui o arquivo <nome-de-arquivo> a partir da linha seguinte do arquivo HTML/WSAP sendo processado. Somente apos todo o arquivo <nome-de-arquivo> ter sido inserido é que a próxima linha poderá ser continuar sendo processada. O arquivo inserido, mesmo que for HTML não deverá ser tratado como contendo extensões WSAP.
<!-- WSAP: IF <nome-de-arquivo> --> <!-- WSAP: ELSE --> <!-- WSAP: ENDIF -->
Se o arquivo denominado por <nome-de-arquivo> existir então todas as linha que existirem logo após a linha do IF e até a linha do comando ENDIF ou do comando ELSE deverão ser processadas. Caso o arquivo não exista então estas linhas deverão ser ignoradas e somente as linhas após o ELSE ou o ENDIF

Projeto e Desenvolvimento de Aplicações para a Internet
83 Copyright 2001 João Carlos Gluz
(o que vier primeiro) é que deverão ser tratadas. Na WSAP não é permitido o aninhamento de IFs, isto é, não existem IFs dentro de IFs.
<!-- WSAP: EXECUTE <nome-de-programa> <argumento-1> ... <argumento-n> -->
Executa o programa externo indicado por <nome-de-programa> com os parâmetros (que são opcionais) indicados por <argumento-1> ... <argumento-n>. O processamento da próxima linha do arquivo HTML/WSAP somente pode continuar após o fim da execução do programa externo.
<!-- WSAP: DELETE <nome-de-arquivo>
Apaga o arquivo <nome-de-arquivo>.

![evaporadores v2 [Modo de Compatibilidade]professor.unisinos.br/mhmac/Refrigeracao/Evaporadores_2016.pdfproblemas na distribuição do refrigerante em evaporadores de circuitos paralelos](https://img.document.onl/doc/110x75/5b2187c87f8b9acf128b481a/evaporadores-v2-modo-de-compatibilidade-na-distribuicao-do-refrigerante-em-evaporadores.jpg)



























![Capítulo 5 - Sistemas de Múltiplos Estágios e Múltiplos ...professor.unisinos.br/mhmac/Refrigeracao/CAP5_REx1.pdf · e ( ) ( ) 1 − − ( ) − ( ) − & & −) [( ) ( )] ( )](https://img.document.onl/doc/110x75/5a796d207f8b9ac3268d448c/captulo-5-sistemas-de-mltiplos-estgios-e-mltiplos-1-.jpg)