Embed Size (px)
DESCRIPTION
Resumo sobre econometria
Citation preview

1
Capítulo I O modelo de regressão define-se pelo seguinte conjunto de hipóteses clássicas: [H0]: Existe numa certa população uma relação linear de dependência – suportada por coeficientes de regressão, variáveis explicativas e uma perturbação aleatória não observável.
𝑌𝑖 = 𝛽1 + 𝛽2𝑋2𝑖 +𝛽3𝑋3𝑖+𝛽4𝑋4𝑖+ … + 𝛽𝑘𝑋𝑘𝑖 + 𝑢𝑖 [H1]: O valor médio de cada perturbação aleatória é nulo.
E(𝑢𝑖) = 0
[H2]: A variância das perturbações aleatórias é constante (hipótese de homoscedasticidade).
Var (𝑢𝑖) = 0 [H3]: A Covariância entre perturbações é nula (hipótese de ausência de autocorrelação).
Cov (𝑢𝑖; 𝑢𝑗) = 0
[H4]: As variáveis explicativas (𝑋2𝑖, 𝑋3𝑖,𝑋4𝑖, …, 𝑋𝑘𝑖) são variáveis não aleatórias. [H5]:Na amostra, de dimensão n > K, são linearmente independentes as variáveis explicativas e o termo independente, se incluído. OBS: Esta hipótese postula, em primeiro lugar, que n > k, ou seja, que a dimensão da amostra é superior ao número de coeficientes de regressão. O número de parâmetros desconhecidos do modelo é k + 1 (os coeficientes de regressão e a variância do termos de perturbação). Se o número de observações fosse igual a k, ou menor, não seria possível estimar k + 1 coeficientes desconhecidos. Em segundo, as variáveis explicativas não podem ser linearmente dependentes entre si. Teorema de Gauss-Markov: verificadas as hipóteses clássicas do modelo de regressão linear, os estimadores de mínimos quadrados ou OLS são estimadores de variância mínima, na classe de estimadores cêntricos e lineares em Y, isto é, BLUE (Best Linear UnbiasedEstimators). [H6]: As perturbações 𝑢𝑖 seguem uma distribuição normal:
𝒖𝒊 ~ N(0, 𝝈𝟐)
Com a consideração da hipótese 6, é possível afirmar que os estimadores de mínimos quadrados ou OLS têm variância mínima na classe dos estimadores de cêntricos (corolário do teorema de Gaus Markov). Isto é, são BUE (BestUnbiasedEstimators).
𝑹𝟐(coeficiente de determinação):significa que x% da variaçãoamostral de Y em torno da sua média é explicada pelo modelo de regressão linear. Isto é, x% da variação amostral de Y é explicada por variações ocorridas em 𝑋2𝑖, 𝑋3𝑖,𝑋4𝑖, …, 𝑋𝑘𝑖 (variáveis explicativas).

2
OBS: O𝑅2 só tem sentido num modelo com termo independente, e mais próximo de 1 melhor. Tratando-se de ajustamentos envolvendo distintas variáveis dependentes, os coeficientes de determinação não são, na sua totalidade, diretamente comparáveis entre si.
𝑹𝟐 (coeficiente de determinação corrigido): não é de possível interpretação. Vai ter como intervalo:
1−𝑘
𝑛−𝑘≤ 𝑹𝟐 ≤ 1
Matrizes 11 de fevereiro de 2010 - Grupo III alínea d e e 14 de Janeiro de 2014 – grupo b e c 27 de janeiro de 2010 – Grupo III As matrizes são:
Modelo com termo independente Modelo sem termo independente
𝑌𝑖 = 𝛽1 + 𝛽2𝑋2𝑖 +𝛽3𝑋3𝑖+𝛽4𝑋4𝑖+ … + 𝛽𝑘𝑋𝑘𝑖 + 𝑢𝑖
Y =
[ 𝑌1
𝑌2
𝑌3
𝑌4
⋮𝑌𝑛]
𝛽 =
[ 𝛽1
𝛽2
𝛽3
𝛽4
⋮𝛽𝑛]
u =
[ 𝑢1
𝑢2
𝑢3
𝑢4
⋮𝑢𝑛]
X =
[ 1 𝑋21 𝑋31 𝑋41 ⋯ 𝑋𝑘1
1 𝑋22 𝑋32 𝑋42 ⋯ 𝑋𝑘2
1 𝑋23 𝑋33 𝑋43 ⋯ 𝑋𝑘3
1 𝑋24 𝑋34 𝑋44 ⋯ 𝑋𝑘4
⋮ ⋮ ⋮ ⋮ ⋱ ⋮1 𝑋2𝑛 𝑋3𝑛 𝑋4𝑛 ⋯ 𝑋𝑘𝑛]
𝑌𝑖 = 𝛽2𝑋2+𝛽3𝑋3+ 𝛽4𝑋4 +…+ 𝛽𝑘𝑋𝑘 + 𝑢𝑖
Y =
[ 𝑌1
𝑌2
𝑌3
𝑌4
⋮𝑌𝑛]
𝛽 =
[ 𝛽2
𝛽3
𝛽4
⋮𝛽𝑛]
u =
[ 𝑢1
𝑢2
𝑢3
𝑢4
⋮𝑢𝑛]
X =
[ 𝑋21 𝑋31 𝑋41 ⋯ 𝑋𝑘1
𝑋22 𝑋32 𝑋42 ⋯ 𝑋𝑘2
𝑋23 𝑋33 𝑋43 ⋯ 𝑋𝑘3
𝑋24 𝑋34 𝑋44 ⋯ 𝑋𝑘4
⋮ ⋮ ⋮ ⋱ ⋮𝑋2𝑛 𝑋3𝑛 𝑋4𝑛 ⋯ 𝑋𝑘𝑛]
3
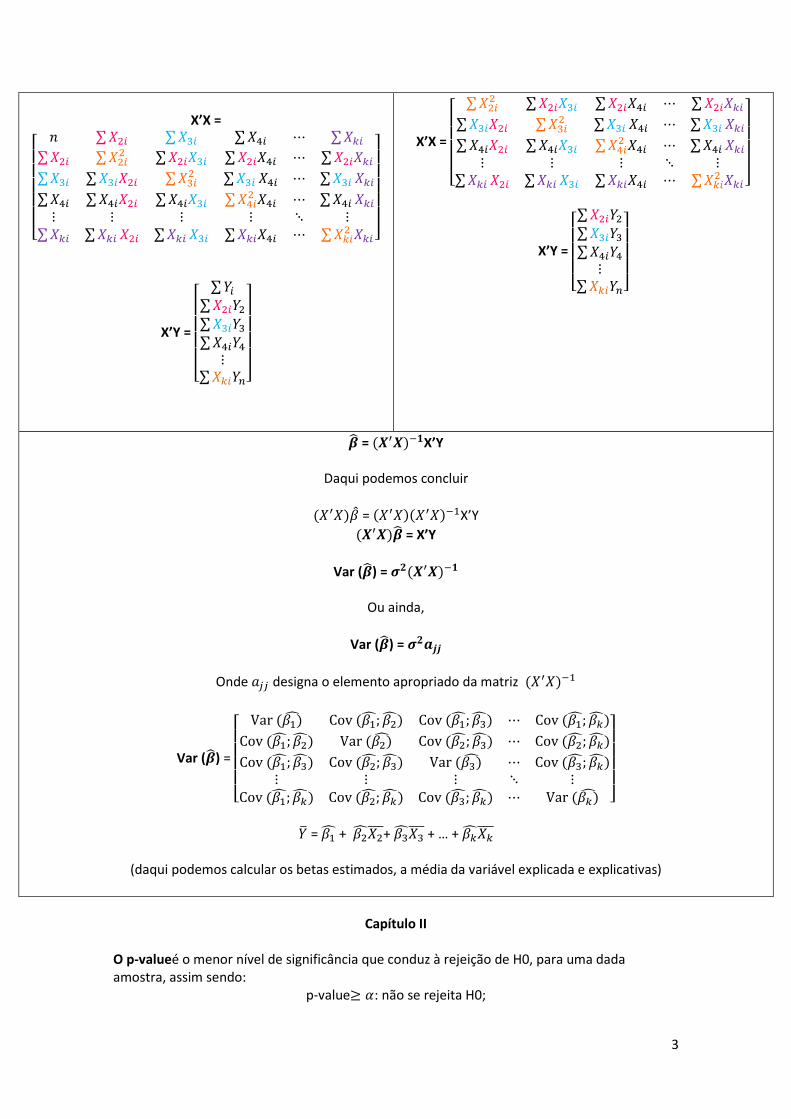
X’X =
[
𝑛 ∑𝑋2𝑖 ∑𝑋3𝑖 ∑𝑋4𝑖 ⋯ ∑𝑋𝑘𝑖
∑𝑋2𝑖 ∑𝑋2𝑖2 ∑𝑋2𝑖𝑋3𝑖 ∑𝑋2𝑖𝑋4𝑖 ⋯ ∑𝑋2𝑖𝑋𝑘𝑖
∑𝑋3𝑖 ∑𝑋3𝑖𝑋2𝑖 ∑𝑋3𝑖2 ∑𝑋3𝑖 𝑋4𝑖 ⋯ ∑𝑋3𝑖 𝑋𝑘𝑖
∑𝑋4𝑖 ∑𝑋4𝑖𝑋2𝑖 ∑𝑋4𝑖𝑋3𝑖 ∑𝑋4𝑖2 𝑋4𝑖 ⋯ ∑𝑋4𝑖 𝑋𝑘𝑖
⋮ ⋮ ⋮ ⋮ ⋱ ⋮∑𝑋𝑘𝑖 ∑𝑋𝑘𝑖 𝑋2𝑖 ∑𝑋𝑘𝑖 𝑋3𝑖 ∑𝑋𝑘𝑖𝑋4𝑖 ⋯ ∑𝑋𝑘𝑖
2 𝑋𝑘𝑖 ]
X’Y =
[
∑𝑌𝑖
∑𝑋2𝑖𝑌2
∑𝑋3𝑖𝑌3
∑𝑋4𝑖𝑌4
⋮∑𝑋𝑘𝑖𝑌𝑛]
X’X =
[
∑𝑋2𝑖2 ∑𝑋2𝑖𝑋3𝑖 ∑𝑋2𝑖𝑋4𝑖 ⋯ ∑𝑋2𝑖𝑋𝑘𝑖
∑𝑋3𝑖𝑋2𝑖 ∑𝑋3𝑖2 ∑𝑋3𝑖 𝑋4𝑖 ⋯ ∑𝑋3𝑖 𝑋𝑘𝑖
∑𝑋4𝑖𝑋2𝑖 ∑𝑋4𝑖𝑋3𝑖 ∑𝑋4𝑖2 𝑋4𝑖 ⋯ ∑𝑋4𝑖 𝑋𝑘𝑖
⋮ ⋮ ⋮ ⋱ ⋮∑𝑋𝑘𝑖 𝑋2𝑖 ∑𝑋𝑘𝑖 𝑋3𝑖 ∑𝑋𝑘𝑖𝑋4𝑖 ⋯ ∑𝑋𝑘𝑖
2 𝑋𝑘𝑖 ]
X’Y =
[ ∑𝑋2𝑖𝑌2
∑𝑋3𝑖𝑌3
∑𝑋4𝑖𝑌4
⋮∑𝑋𝑘𝑖𝑌𝑛]
= (𝑿′𝑿)−𝟏X’Y
Daqui podemos concluir
(𝑋′𝑋) = (𝑋′𝑋)(𝑋′𝑋)−1X’Y
(𝑿′𝑿) = X’Y
Var () = 𝝈𝟐(𝑿′𝑿)−𝟏
Ou ainda,
Var () = 𝝈𝟐𝒂𝒋𝒋
Onde 𝑎𝑗𝑗 designa o elemento apropriado da matriz (𝑋′𝑋)−1
Var () =
[
Var (𝛽1) Cov (𝛽1; 𝛽2) Cov (𝛽1; 𝛽3) ⋯ Cov (𝛽1; 𝛽)
Cov (𝛽1; 𝛽2) Var (𝛽2) Cov (𝛽2; 𝛽3) ⋯ Cov (𝛽2; 𝛽)
Cov (𝛽1; 𝛽3) Cov (𝛽2; 𝛽3) Var (𝛽3) ⋯ Cov (𝛽3; 𝛽)⋮ ⋮ ⋮ ⋱ ⋮
Cov (𝛽1; 𝛽) Cov (𝛽2; 𝛽) Cov (𝛽3; 𝛽) ⋯ Var (𝛽𝑘) ]
= 𝛽1 + 𝛽2𝑋2 + 𝛽3𝑋3
+ … + 𝛽𝑋𝑘
(daqui podemos calcular os betas estimados, a média da variável explicada e explicativas)
Capítulo II
O p-valueé o menor nível de significância que conduz à rejeição de H0, para uma dada amostra, assim sendo:
p-value≥ 𝛼: não se rejeita H0;

4
p-value<𝛼: rejeita-se H0;
Teste de Significância Individual Sendo o modelo
(indicar o modelo em causa) O par de hipóteses em teste é:
𝐻0: 𝛽𝑗= z
𝐻1: 𝛽𝑗 ≠ z
Sob 𝐻0 demonstra-se que:
Est. Teste =>𝑗−𝑧
√𝑉𝑎𝑟 (𝑗)
~ t(n-k)
No caso, o valor amostral da estatística é:
𝑡𝑜𝑏𝑠 =
Consultando a tabela da distribuição T, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝑡𝐶𝑟í𝑡𝑖𝑐𝑜 = ∓ .
1º possibilidade: Sendo que 𝑡𝑜𝑏𝑠 não pertence ao intervalo de rejeição, não rejeitámos 𝐻0.
Assim sendo, para o dado nível de significância definida e de acordo com a informação
estatística disponível, podemos concluir que a variável explicativa é, mantendo tudo resto
constante.
1º possibilidade: Sendo que 𝑡𝑜𝑏𝑠 pertence ao intervalo de rejeição, rejeitámos 𝐻0. Assim
sendo, para o dado nível de significância definida e de acordo com a informação estatística
disponível, podemos concluir que a variável explicativa é, mantendo tudo resto constante.
Nota bem: Para um teste bilateral, temos que fazer 𝛼2⁄ . Quando se trata de um teste
unilateral (esquerda como direita), basta usar 𝛼.
A região critica será:
RC: ]-∝; - 𝑡𝑐[ ∪ ]𝑡𝑐; +∝[, se H1 for 𝛽𝑗 ≠ 𝛽𝑗*;
RC: ]-∝; 𝑡𝑐[, se H1 for 𝛽𝑗<𝛽𝑗*;
RC: ]𝑡𝑐; +∝[, se H1 for 𝛽𝑗>𝛽𝑗*;
Teste de Combinação Linear

5
Sendo o modelo
(indicar o modelo em causa) O par de hipóteses em teste é:
𝐻0: 𝛽𝑗 + 𝛽𝑙= z
𝐻1: 𝛽𝑗 + 𝛽𝑙 ≠ z
Sob 𝐻0 demonstra-se que:
Est. Teste =>𝑗+ 𝛽−𝑧
√𝑉𝑎𝑟 (𝑗+ 𝛽
𝑗)
~ t(n-k)
No caso, o valor amostral da estatística é:
𝑡𝑜𝑏𝑠 =
Consultando a tabela da distribuição T, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝑡𝐶𝑟í𝑡𝑖𝑐𝑜 = ∓ .
1º possibilidade: Sendo que 𝑡𝑜𝑏𝑠 não pertence ao intervalo de rejeição, não rejeitámos 𝐻0.
Assim sendo, para o dado nível de significância definida e de acordo com a informação
estatística disponível, podemos concluir que a variável explicativa é…
1º possibilidade: Sendo que 𝑡𝑜𝑏𝑠 pertence ao intervalo de rejeição, rejeitámos 𝐻0. Assim
sendo, para o dado nível de significância definida e de acordo com a informação estatística
disponível, podemos concluir que a variável explicativa é…
Nota bem: Para um teste bilateral, temos que fazer 𝛼2⁄ . Quando se trata de um teste
unilateral (esquerda como direita), basta usar 𝛼.
Nota bem:
Var(aX + bY) = 𝑎2 * Var(X) + 𝑏2 * Var(y) + 2abCov(X;Y)
Var(aX - bY) = 𝑎2 * Var(X) + 𝑏2 * Var(y) - 2abCov(X;Y)
(temos que ter sempre uma matriz de variâncias e co-variâncias)
OBS:No modelo de regressão linear simples, temos uma relação especial entre o teste de significância individual de 𝛽2 e o teste de significância global. Isto é:
(𝒕𝑶𝒃𝒔)𝟐= 𝑭𝑶𝒃𝒔
(𝒕𝒄𝒓í𝒕𝒊𝒄𝒐)𝟐= 𝑭𝒄𝒓í𝒕𝒊𝒄𝒐
Teste de Significância Global de Regressão

6
Sendo o modelo
𝑌𝑖 = 𝛽1 + 𝛽2𝑋2 +𝛽3𝑋3+ … + 𝛽𝑘𝑋𝑘 + 𝑢𝑖 O par de hipóteses em teste é:
𝐻0: 𝛽2 = 𝛽3 = … = 𝛽𝑘 = 0 (os coeficiente com variáveis explicativas) 𝐻1: ∃𝛽𝑗 ≠ 0, j = 2,3,…
Sob 𝐻0 demonstra-se que:
Est. Teste =>
𝑅2
𝑘−1
1− 𝑅2
𝑛−𝑘
~ F (k-1, n-k)
No caso, o valor amostral da estatística é:
𝐹𝑜𝑏𝑠 =
Consultando a tabela da distribuição F, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝐹𝐶𝑟í𝑡𝑖𝑐𝑜 = .
1º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível de
significância definida e de acordo com a informação estatística disponível, podemos concluir
que há evidências de que a regressão é globalmente significativa para explicar Y.
2º possibilidade: Sendo que 𝐹𝑜𝑏𝑠<𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que há evidências de que a regressão não seja globalmente significativa para explicar
Y.
OBS:No modelo de regressão linear simples, temos uma relação especial entre o teste de significância individual de 𝛽2 e o teste de significância global. Isto é:
(𝒕𝑶𝒃𝒔)𝟐= 𝑭𝑶𝒃𝒔
(𝒕𝒄𝒓í𝒕𝒊𝒄𝒐)𝟐= 𝑭𝒄𝒓í𝒕𝒊𝒄𝒐
Teste de Melhoria de Ajustamento Sendo o modelo I
(indicar o modelo em causa)
Sendo o modelo II
(indicar o modelo com as variáveis adicionais)
O par de hipóteses em teste é:
𝐻0: 𝛿1= 𝛿2 = … = 𝛿𝑟 = 0 (os coeficiente das variáveis adicionais)

7
𝐻1: ∃𝛿𝑗 ≠ 0, j = 1, …, 3
Sob 𝐻0 demonstra-se que:
Est. Teste =>
𝑅𝐼𝐼2 − 𝑅𝐼
2
𝑟
1− 𝑅𝐼𝐼2
𝑛−(𝑘+𝑟)
~ F (r, n-k-r)
No caso, o valor amostral da estatística é:
𝐹𝑜𝑏𝑠 =
Consultando a tabela da distribuição F, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝐹𝐶𝑟í𝑡𝑖𝑐𝑜 = .
1º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0. Assim sendo, para o dado nível de
significância definida e de acordo com a informação estatística disponível, podemos concluir
pela significância da melhoria do ajustamento pela introdução das r variáveis, ou seja, pode-se
concluir que o ajustamento II é significativamente melhor do que o ajustamento I.
2º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir pela não significância da melhoria do ajustamento pela introdução das r variáveis, ou
seja, pode-se concluir que o ajustamento II é não significativamente melhor do que o
ajustamento I.
Intervalo de Previsão para Y
Sem matrizes Com matrizes
Sendo o modelo
(indicar o modelo em causa)
𝒀𝟎 = 𝟎 ± c √𝟐[𝟏 + 𝟏
𝒏+ (
(𝑿𝟎−) 𝟐
∑𝒙𝒊𝟐 )]
Ou
𝒀𝟎 = 𝟎 ± c √𝟐[𝟏 + 𝟏
𝒏+ (
(𝑿𝟎−) 𝟐
∑(𝑿𝒊−𝑿) 𝟐)]
𝟎: usando o modelo em questão, é só calcular substituindo as variáveis explicativas; c: consultar a tabela em questão para determinar o valor crítico (n-k);
𝟐: indicado no output do eviews como S.E. ofRegression; 𝑿𝟎: a variável dependente em questão; : para determinarmos a média da variável explicável usamos o mean dependente var;
Sendo o modelo (indicar o modelo em causa) Sendo:
𝑿𝟎′ = [1 𝑋20𝑋30 … 𝑋𝑘0 ]
(a matriz de dos X’s que temos que substituir para
determinar o 𝟎)
𝟎 = 𝑿𝟎′
𝟎 = [1 𝑋20𝑋30 … 𝑋𝑘0 ] Vamos ter:
𝒀𝟎 = 𝟎 ± c √𝟐[𝟏 + 𝑿𝟎′ (𝑿′𝑿)−𝟏𝑿𝟎
′ )]
𝒀𝟎 = [1 𝑋20𝑋30 … 𝑋𝑘0 ] ± c√𝟐[𝟏 + 𝑿𝟎′ (𝑿′𝑿)−𝟏𝑿𝟎
′ )]

8
∑𝒙𝒊𝟐
ou ∑(𝑿𝒊 − 𝑿) 𝟐: para calcularmos este valor,
vamos usar a fórmula de 2(está no formulário)
Var (2) = 𝟐
∑𝒙𝒊𝟐 ou Var (2) =
𝟐
∑(𝑿𝒊−𝑿) 𝟐
1º possibilidade: Utilizando o intervalo de confiança de [;], para x nível de confiança, o valor
pertence ao nesse intervalo de precisão. Assim sendo, para o dado nível de confiança definido
e de acordo com a informação estatística disponível, podemos concluir que essa informação
não é compatível com o nosso modelo de estudo/tendência.
2º possibilidade:Utilizando o intervalo de confiança de [;], para x nível de confiança, o valor
não pertence ao nesse intervalo de precisão. Assim sendo, para o dado nível de confiança
definido e de acordo com a informação estatística disponível, podemos concluir que essa
informação não é compatível com o nosso modelo de estudo/tendência.
OBS: tudo que esteja dentro da raiz é o raio – lembrar que amplitude é o dobro do raio.
Intervalo de Previsão para 𝜷
Sendo o modelo
(indicar o modelo em causa)
𝛽𝑗 = 𝑗 ± c √𝑉𝑎𝑟 (𝛽𝑗)
1º possibilidade: Utilizando o intervalo de confiança de [;], para x nível de confiança, o valor
indicado no enunciado não está incluído nesse intervalo. Assim sendo, para o dado nível de
confiança definido e de acordo com a informação estatística disponível, podemos concluir que
essa informação não é compatível
2º possibilidade: Utilizando o intervalo de confiança de [;], para x nível de confiança, o valor
indicado no enunciado está incluído nesse intervalo. Assim sendo, para o dado nível de
confiança definido e de acordo com a informação estatística disponível, podemos concluir que
essa informação é compatível.
Capítulo III Interpretação 8 de Setembro de 2009 - Grupo III 17 de fevereiro de 2009 – Grupo I e III 27 de janeiro de 2009 – Grupo I 7 de Setembro de 2010 – Grupo II e III 11 de Fevereiro de 2010 – Grupo II 8 de Fevereiro de 2011 – Grupo III 5 de Setembro de 20122 – Grupo II 17 de janeiro de 2012 – Grupo III
9
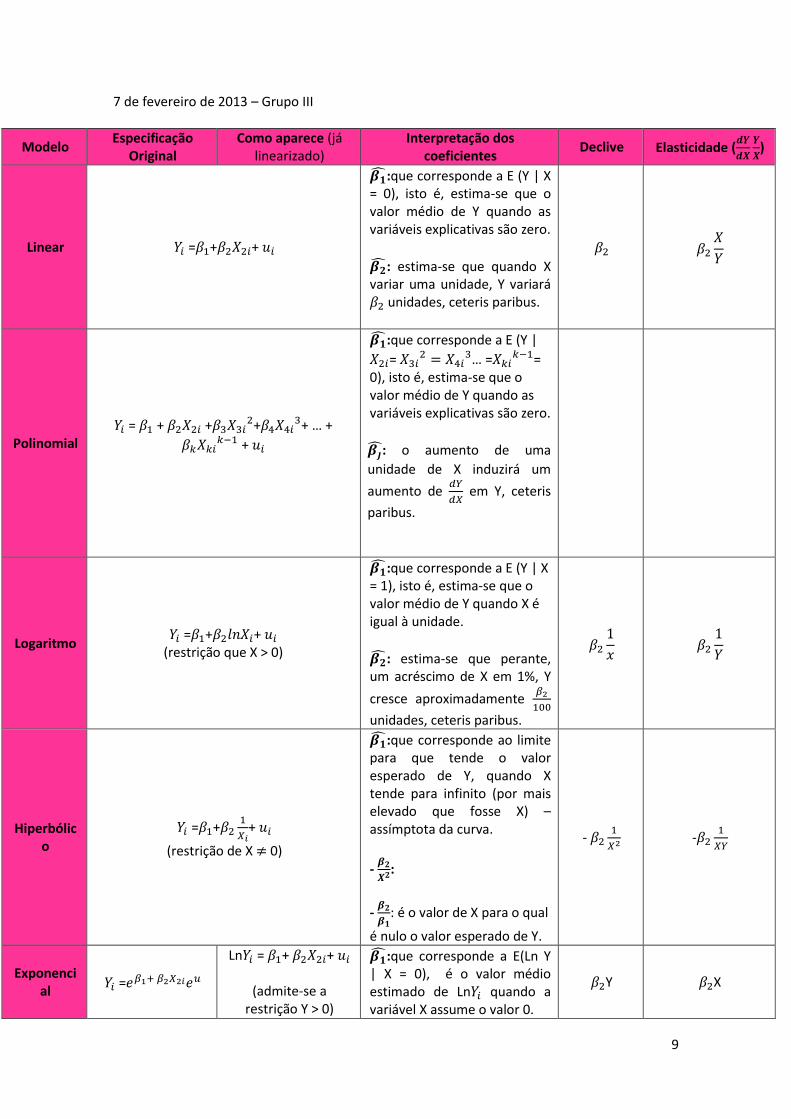
7 de fevereiro de 2013 – Grupo III
Modelo Especificação
Original Como aparece (já
linearizado) Interpretação dos
coeficientes Declive Elasticidade (
𝒅𝒀
𝒅𝑿
𝒀
𝑿)
Linear 𝑌𝑖 =𝛽1+𝛽2𝑋2𝑖+ 𝑢𝑖
𝜷:que corresponde a E (Y | X = 0), isto é, estima-se que o valor médio de Y quando as variáveis explicativas são zero.
𝜷: estima-se que quando X variar uma unidade, Y variará 𝛽2 unidades, ceteris paribus.
𝛽2 𝛽2
𝑋
𝑌
Polinomial 𝑌𝑖 = 𝛽1 + 𝛽2𝑋2𝑖 +𝛽3𝑋3𝑖
2+𝛽4𝑋4𝑖3+ … +
𝛽𝑘𝑋𝑘𝑖𝑘−1 + 𝑢𝑖
𝜷:que corresponde a E (Y |
𝑋2𝑖= 𝑋3𝑖2 = 𝑋4𝑖
3… =𝑋𝑘𝑖𝑘−1=
0), isto é, estima-se que o valor médio de Y quando as variáveis explicativas são zero.
𝜷: o aumento de uma
unidade de X induzirá um
aumento de 𝑑𝑌
𝑑𝑋 em Y, ceteris
paribus.
Logaritmo 𝑌𝑖 =𝛽1+𝛽2𝑙𝑛𝑋𝑖+ 𝑢𝑖
(restrição que X > 0)
𝜷:que corresponde a E (Y | X = 1), isto é, estima-se que o valor médio de Y quando X é igual à unidade.
𝜷: estima-se que perante, um acréscimo de X em 1%, Y
cresce aproximadamente 𝛽2
100
unidades, ceteris paribus.
𝛽2
1
𝑥 𝛽2
1
𝑌
Hiperbólico
𝑌𝑖 =𝛽1+𝛽21
𝑋𝑖+ 𝑢𝑖
(restrição de X ≠ 0)
𝜷:que corresponde ao limite para que tende o valor esperado de Y, quando X tende para infinito (por mais elevado que fosse X) – assímptota da curva.
- 𝜷𝟐
𝑿𝟐:
- 𝜷𝟐
𝜷𝟏: é o valor de X para o qual
é nulo o valor esperado de Y.
- 𝛽21
𝑋2 -𝛽21
𝑋𝑌
Exponencial
𝑌𝑖 =𝑒𝛽1+ 𝛽2𝑋2𝑖𝑒𝑢
Ln𝑌𝑖 = 𝛽1+ 𝛽2𝑋2𝑖+ 𝑢𝑖
(admite-se a restrição Y > 0)
𝜷:que corresponde a E(Ln Y | X = 0), é o valor médio estimado de Ln𝑌𝑖 quando a variável X assume o valor 0.
𝛽2Y 𝛽2X
10
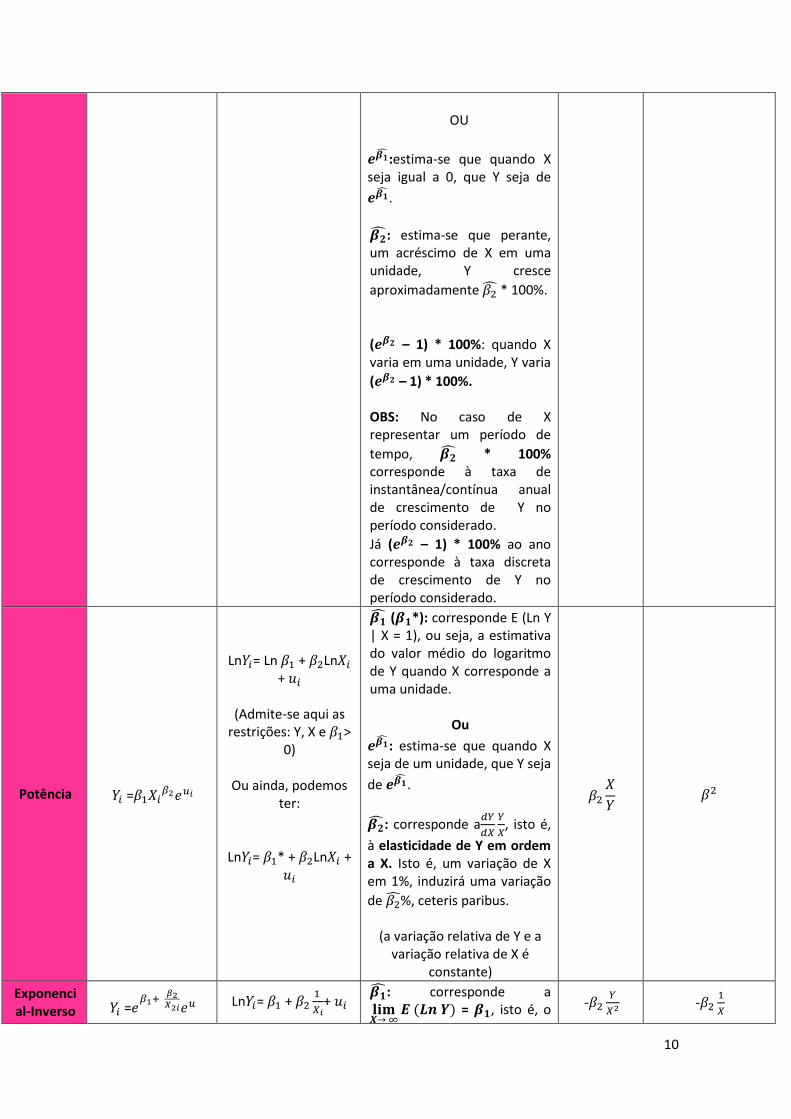
OU
𝒆𝜷:estima-se que quando X seja igual a 0, que Y seja de
𝒆𝜷.
𝜷: estima-se que perante, um acréscimo de X em uma unidade, Y cresce
aproximadamente 𝛽2 * 100%.
(𝒆𝜷𝟐 – 1) * 100%: quando X varia em uma unidade, Y varia
(𝒆𝜷𝟐 – 1) * 100%. OBS: No caso de X representar um período de
tempo, 𝜷 * 100% corresponde à taxa de instantânea/contínua anual de crescimento de Y no período considerado.
Já (𝒆𝜷𝟐 – 1) * 100% ao ano corresponde à taxa discreta de crescimento de Y no período considerado.
Potência 𝑌𝑖 =𝛽1𝑋𝑖𝛽2𝑒𝑢𝑖
Ln𝑌𝑖= Ln 𝛽1 + 𝛽2Ln𝑋𝑖 + 𝑢𝑖
(Admite-se aqui as
restrições: Y, X e 𝛽1> 0)
Ou ainda, podemos ter:
Ln𝑌𝑖= 𝛽1* + 𝛽2Ln𝑋𝑖 + 𝑢𝑖
𝜷 (𝜷𝟏*): corresponde E (Ln Y | X = 1), ou seja, a estimativa do valor médio do logaritmo de Y quando X corresponde a uma unidade.
Ou
𝒆𝜷: estima-se que quando X seja de um unidade, que Y seja
de 𝒆𝜷.
𝜷: corresponde a𝑑𝑌
𝑑𝑋
𝑌
𝑋, isto é,
à elasticidade de Y em ordem a X. Isto é, um variação de X em 1%, induzirá uma variação
de 𝛽2%, ceteris paribus.
(a variação relativa de Y e a variação relativa de X é
constante)
𝛽2
𝑋
𝑌 𝛽2
Exponencial-Inverso 𝑌𝑖 =𝑒
𝛽1+ 𝛽2𝑋2𝑖𝑒𝑢 Ln𝑌𝑖= 𝛽1 + 𝛽2
1
𝑋𝑖+ 𝑢𝑖
𝜷: corresponde a 𝐥𝐢𝐦𝑿→ ∞
𝑬 (𝑳𝒏 𝒀) = 𝜷𝟏, isto é, o -𝛽2𝑌
𝑋2 -𝛽21
𝑋

11
(admite-se que 𝛽2< 0, Y > 0 e X ≠ 0)
valor medio de Ln Y estabiliza no valor assimptótico 𝛽1; Ln Y tende para o valor assimptótico 𝛽1.
𝒆𝜷: é o valor esperado para qual tende assimptoticamente Y quando X aumenta.
- 𝜷𝟐
𝟐 é um ponto de inflexão,
isto é, até ao valor X igual a - 𝜷𝟐
𝟐, Y cresce a taxas crescentes
e, a partir desse valor cresce a taxas decrescentes.
Modelos de tendência Sazonalidade Sendo o modelo Modelo I: modelo original Modelo II: modelo original + as dummys sazonais O par de hipóteses em teste é:
𝐻0: 𝛿1= 𝛿2 = … = 𝛿𝑟 = 0 (os coeficiente das dummys) 𝐻1: ∃𝛿𝑗 ≠ 0, j = 1, …, 3
Sob 𝐻0 demonstra-se que:
Est. Teste =>
𝑅𝐼𝐼2 − 𝑅𝐼
2
𝑟
1− 𝑅𝐼𝐼2
𝑛−(𝑘+𝑟)
~ F (r, n-k-r)
No caso, o valor amostral da estatística é:
𝐹𝑜𝑏𝑠 =
Consultando a tabela da distribuição F, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝐹𝐶𝑟í𝑡𝑖𝑐𝑜 = .
1º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0. Assim sendo, para o dado nível de
significância definida e de acordo com a informação estatística disponível, podemos concluir
que há evidências de sazonalidade.

12
2º possibilidade: Sendo que 𝐹𝑜𝑏𝑠<𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que não há evidências de sazonalidade.
Testes de Estrutura Os testes de estrutura que estudamos são: teste de Chow e o teste de Gujarati. Ambos conduzem à mesma conclusão, à mesma estatística observada e valor crítico. 1-Teste de Chow Sendo os modelos
(identificar os dois modelos) O par de hipóteses em teste é:
𝐻0: 𝛽1𝑄𝑢𝑎𝑑𝑟𝑜 𝐼= 𝛽1
𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼˄𝛽2𝑄𝑢𝑎𝑑𝑟𝑜 𝐼 = 𝛽2
𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼˄ … ˄𝛽𝑘𝑄𝑢𝑎𝑑𝑟𝑜 𝐼= 𝛽𝑘
𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼
𝐻1:𝛽1𝑄𝑢𝑎𝑑𝑟𝑜 𝐼
≠ 𝛽1𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼
˅𝛽2𝑄𝑢𝑎𝑑𝑟𝑜 𝐼
≠ 𝛽2𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼
˅ … ˅𝛽𝑘𝑄𝑢𝑎𝑑𝑟𝑜 𝐼
≠ 𝛽𝑘𝑄𝑢𝑎𝑑𝑟𝑜 𝐼𝐼
Sob 𝐻0 demonstra-se que:
Est. Teste =>𝑒′𝑒−( 𝑒1
′ 𝑒1+ 𝑒2′ 𝑒2)
𝑘
𝑒1′ 𝑒1+ 𝑒2
′ 𝑒2𝑛1+ 𝑛2−2𝑘
~ F (k, 𝑛1 + 𝑛2 − 2𝐾)
No caso, o valor amostral da estatística é:
𝐹𝑜𝑏𝑠 =
Consultando a tabela da distribuição F, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝐹𝐶𝑟í𝑡𝑖𝑐𝑜 = .
1º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível de
significância definida e de acordo com a informação estatística disponível, podemos concluir
que há evidências de que terá havido quebra de estrutura.
2º possibilidade: Sendo que 𝐹𝑜𝑏𝑠<𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que não há evidências de que não terá havido quebra de estrutura.
OBS:
Sum Square Resid = e’e = ∑𝒆𝒊𝟐
2 - Teste de Gujarati Sendo o modelo

13
(indicar o modelo em causa) Temos que estimar o seguinte modelo: 𝑌𝑖 = 𝛽1 + 𝛽2𝑋𝑖 + … + 𝛽𝑘𝑍𝑖 + 𝛿1𝐷𝑖+ 𝛿2𝐷𝑖𝑋𝑖 + … + 𝛿𝑟𝐷𝑖𝑍𝑖+ 𝑣𝑖, em que O par de hipóteses em teste é:
𝐻0: 𝛿1= 𝛿2 = … = 𝛿𝑟 = 0 𝐻1: ∃𝛿𝑗 ≠ 0, j = 1, …, 3
Sob 𝐻0 demonstra-se que:
Est. Teste =>
𝑅𝐼𝐼2 − 𝑅𝐼
2
𝑟
1− 𝑅𝐼𝐼2
𝑛−(𝑘+𝑟)
~ F (r, n-k-r)
No caso, o valor amostral da estatística é:
𝐹𝑜𝑏𝑠 =
Consultando a tabela da distribuição F, para i graus de liberdade, para um nível de significância
de 5%, temos que 𝐹𝐶𝑟í𝑡𝑖𝑐𝑜 = .
1º possibilidade: Sendo que 𝐹𝑜𝑏𝑠>𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível de
significância definida e de acordo com a informação estatística disponível, podemos concluir
que há evidências de que terá havido quebra de estrutura.
2º possibilidade: Sendo que 𝐹𝑜𝑏𝑠<𝐹𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que não há evidências de que não terá havido quebra de estrutura.
Capítulo IV
Estimadores GLS Sob as hipóteses definidas para o modelo de regressão generalizado (página 240), os estimadores GLS têm as seguintes características: - são lineares em Y; - são estimadores cêntricos e consistentes; - (ver fórmula de variância no formulário) - são os estimadores de variância na classe dos estimadores lineares e cêntricos. Esta característica resulta do teorema de Aitken: sob [H0] – [H5], com [H2’] e [H3’], sendo Ω (ou V) uma matriz conhecida, simétrica e definida positiva, os estimadores GLS são os de variância mínima na classe dos estimadores lineares em Y e cêntricos.

14
Como Ω é desconhecida, será preciso estimá-la. Assim sendo, vamos usar os estimadores EGLS.
Capítulo V Heteroscedasticidade
“A variância do termo de perturbação aleatória, dadas as variáveis explicativas, não é
constante.”
Uma vez detetada a presença de autocorrelação e/ou heteroscedasticidade no modelo
original, os estimadores de OLS continuam a ser cêntricos, geralmente consistentes, no
entanto deixam de ser eficientes. Por isso, a inferência estatística deixa de ser válida, isto é, os
testes de significância individual e testes de significância global. Ou seja, subavaliamos as
verdadeiras variâncias, e portanto, a sobrevalorização das estatísticas T (em valor absoluto) e
F.
Deteção informal O incremento da variável X (explicativa ou independente) é acompanhado por uma dispersão dos pontos. Isso implica que a variância do termo aleatório será tanto maior quanto maiores forem os valores da variável explicativa X.
O incremento da variável X (explicativa ou independente) é acompanhado por uma dispersão dos pontos. Isso implica que a variância do termo aleatório será tanto menor quanto maiores forem os valores da variável explicativa X.
OBS: S.E ofregressioncorresponde ao desvio-padrão dos termos de perturbação (𝑢𝑖). Sendo a variável dependente da função desta variável, representa igualmente o desvio-padrão do Modelo Linear. Teste de White

15
Sendo o modelo
(indicar o modelo em causa) A regressão auxiliar é:
𝑒𝑖2 =𝛼0 + 𝛼1 ∑𝑋𝑖 + 𝛼2 ∑𝑋𝑖
2+ 𝛼3 ∑(𝑋𝑖 ∗ 𝑌𝑖) +𝛼4 ∑𝑌𝑖 + 𝛼5 ∑𝑌𝑖2+𝑣𝑖 , em que 𝑣𝑖 é uma
perturbação aleatória que segue as hipóteses clássicas:
E(𝑣𝑖) = 0; Var(𝑣𝑖) = 𝜎2∀ i; Cov(𝑣𝑖;𝑣𝑗) = 0;
O par de hipóteses em teste é:
𝐻0: 𝛼1= 𝛼2 = 𝛼3 = 0 𝐻1: ∃𝛼𝑖 ≠ 0, i = 1, …, r
Sob 𝐻0 demonstra-se que:
Est. Teste => n * 𝑅2 ~ 𝑋2(r)
No caso, o valor amostral da estatística é:
𝑋2𝑜𝑏𝑠 =
Consultando a tabela da distribuição 𝑋2, para i graus de liberdade, para um nível de
significância de 5%, temos que 𝑋2𝐶𝑟í𝑡𝑖𝑐𝑜= .
1º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠>𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que há evidências de heteroscedasticidade.
2º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠<𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado
nível de significância definida e de acordo com a informação estatística disponível, podemos
concluir que não há evidências de heteroscedasticidade.
Notas importantes:
- No e-views temos a estatística teste como Obs*R-squared e o p-value é Prob. Chi-Square.
Teste de Breush-Pagan Sendo o modelo
(indicar o modelo em causa) A regressão auxiliar é:

16
𝑒𝑖2 = o que nos é dado +𝑣𝑖
O par de hipóteses em teste é:
𝐻0: 𝛼1= 𝛼2 = 𝛼3 = 0 𝐻1: ∃𝛼𝑖 ≠ 0, i = 1, …, r
Sob 𝐻0 demonstra-se que:
Est. Teste =>1
2 2 * SQE~ 𝑋2(p)
No caso, o valor amostral da estatística é:
𝑋2𝑜𝑏𝑠 =
Consultando a tabela da distribuição 𝑋2, para i graus de liberdade, para um nível de
significância de 5%, temos que 𝑋2𝐶𝑟í𝑡𝑖𝑐𝑜= .
1º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠>𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, podemos
concluir que há evidências de heteroscedasticidade.
2º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠<𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado
nível de significância definida e de acordo com a informação estatística disponível, podemos
concluir que não há evidências de heteroscedasticidade.
OBS: Assume-se, neste caso, que a variância das perturbações é uma função não especificada
de uma combinação linear de p variáveis, isto é: 𝜎𝑖2 = f(𝛼0+ 𝛼1𝑍𝑙𝑖 + …+ 𝛼𝑝𝑍𝑝𝑖). As variáveis 𝑍1,
𝑍2,…, 𝑍𝑝 podem ou não ser variáveis explicativas incluídas em X.
Notas importantes:
-A estatística teste é indicada como ScaledExplained SS e ainda temos Prob. Chi-Square.
- SQE (Soma de Quadrado Explicada)da equação auxiliar de BP é calculada usando as
seguintes fórmulas:
𝑅2 = 𝑆𝑄𝐸
𝑆𝑄𝐸+𝑆𝑄𝑅
Ou
SQE = 𝑅2 * SQT = 𝑅2 * (SQE + SQR)
- 𝟒 do modelo original do pode ser calculado usando:
𝟒𝑶𝑳𝑺 = (𝑆. 𝐸 𝑜𝑓 𝑅𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛)𝟒 = (𝑚𝑒𝑎𝑛 𝑑𝑒𝑝𝑒𝑛𝑡 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒 𝑑𝑎 𝑟𝑒𝑔𝑟𝑒𝑠𝑠ã𝑜 𝑎𝑢𝑥𝑖𝑙𝑖𝑎𝑟)𝟐 =
(∑𝒆𝒊
𝟐
𝒏−𝒌)𝟐 = (
𝑺𝑸𝑹
𝒏−𝒌)𝟐

17
𝟒𝑴𝑽 = (
(𝑺.𝑬 𝒐𝒇 𝑹𝒆𝒈𝒓𝒆𝒔𝒔𝒊𝒐𝒏)𝟐∗(𝒏−𝒌)
𝒏)𝟐
OBS: Os testes de White e de Breusch-Pagan são testes que têm validade assimptótica, e conduzem, no limite, a uma conclusão idêntica sobre a existência ou não da heteroscedasticidade. No entanto, pode acontecer que em amostras de dimensão finita, que levem a conclusões contraditórias. OBS: O Teorema de Gauss-Markov, que afirma que os estimadores de MQO ou OLS são os melhores estimadores lineares não enviesados (BLUE). No entanto, a presença da heterocedasticidade, esses estimadores não são mais BLUE e nem eficientes. Correcção da Heteroscedasticidade Quando conhecido Ω (padrão de heteroscedasticidade)
Para corrigir o modelo original dividimos o modelo original por √Ω e obtemos o modelo transformado, isto é: 𝑌𝑡= 𝛽1+ 𝛽2𝑋2 + … + 𝛽𝑘𝑋𝑘+ 𝑢𝑖 (modelo original)
𝑌𝑡
√Ω=
𝛽1
√Ω+
𝛽2𝑋2
√Ω + … +
𝛽𝑘𝑋𝑘
√Ω+
𝑢𝑖
√Ω
𝑌𝑡* = 𝛽1𝑋1* + 𝛽2𝑋2* + … + 𝛽𝑘𝑋𝑘* + 𝑣𝑡 (modelo transformado)
Em que,
𝑌𝑡*= 𝑌𝑡
√Ω
𝑋1*= 1
√Ω
𝑋𝑗𝑖*= 𝑋𝑗𝑖
√Ω
A perturbação do modelo transformado satisfaz todas as hipóteses clássicas H1, H2 e H3:
E(𝑣𝑖) = E(𝑢𝑖
√Ω) =
1
√Ω E(𝑢𝑖) = 0∀
Var(𝑣𝑖) = Var(𝑢𝑖
√Ω) =
1
(√Ω2) Var(𝑢𝑖) =
1
ΩΩ 𝜎2 = 𝜎2∀i
Cov (𝑣𝑖; 𝑣𝑗) = E(𝑣𝑖𝑣𝑗) = E(𝑢𝑖
√Ω𝑖
𝑢𝑗
√Ω𝑗) =
1
√Ω𝑖
1
√Ω𝑗= E(𝑢𝑖𝑢𝑗) = 0 ∀ i, j, i ≠ j
OBS:Outro ponto a destacar é que o modelo transformado tem um estrutura ligeiramente diferente porque não tem termo independente e 𝛽1 surge como coeficiente de uma nova
variável explicativa, que é simplesmente o inverso de √Ω. As estimativas dos coeficientes do modelo transformado serão exatamente iguais à estimação do modelo original por GLS. Quando édesconhecido Ω (padrão de heteroscedasticidade)

18
White propôs uma estimação da matriz Var (), em que temos:
Var () = (𝑋′𝑋)−1 S (𝑋′𝑋)−1 em que S seria:
S = X’
[ 𝒆𝟏
𝟐 𝟎 ⋯ 𝟎
𝟎 𝒆𝟐𝟐 ⋯ 𝟎
⋮ ⋮ ⋱ ⋮𝟎 𝟎 ⋯ 𝒆𝑵
𝟐 ]
X
Este estimador é consistente em presença de heteroscedasticidade, para recalcular as estimativas dos desvios-padrão dos estimadores. Assim repõe-se validade das inferências estatísticas. OBS: As estimativas dos coeficientes desta propostas serão exatamente iguais ao modelo inicial.
Capítulo VI Autocorrelação
Havendo autocorrelação, os estimadores OLS são cêntricos e consistentes, mas não são os de
variância mínima entre os estimadores lineares e cêntricos. Isto é, deixam de ser eficientes.
Por isso, a inferência estatística deixa de ser válida, isto é, os testes de significância individual e
testes de significância global. Ou seja, subavaliamos as verdadeiras variâncias, e portanto, a
sobrevalorização das estatísticas T (em valor absoluto) e F.
Autocorrelação positiva (o mais comum em economia): a um valor positivo de 𝑢𝑖 num
período segue uma infinidade de valores também positivos subsequentes; um valor negativo
de 𝑢𝑖, por sua vez, iniciaria uma sequência de valores todos negativos.
Autocorrelação negativa: há uma alternância de sinais entre os resíduos.
OBS: o Teorema de Gauss-Markov, que afirma que os estimadores de MQO ou OLS são os
melhores estimadores lineares não enviesados (BLUE). No entanto, a presença de
autocorrelação, esses estimadores não são mais BLUE e nem eficientes.
Teste de Breusch-Godfrey
Sendo o modelo (indicar o modelo em causa)
Partimos do pressuposto que as perturbações seguem um processo de auto-regressivo de ordem p, isto é:
AR(p): 𝑢𝑡 =𝜌1𝑢𝑡−1+𝜌2𝑢𝑡−2 + … + 휀𝑡 Em que, - −1 < 𝜌 <1; - 휀𝑡 é ruído branco e satisfaz as hipóteses clássicas:

19
E (휀𝑡) = 0; Var (휀𝑡) = 𝜎2∀ t;
Cov (휀𝑡;휀𝑡−𝑠) = 0 ∀ t ≠ s; A regressão auxiliar é:
𝑒𝑡 = modelo original + 𝜌1𝑒𝑡−1+ 𝜌2𝑒𝑡−2 + … + 𝑣𝑡 O par de hipóteses em teste é:
𝐻0: 𝜌1= 𝜌2 = … =𝜌𝑖 = 0 𝐻1: ∃𝜌𝑖 ≠ 0, i = 1, …, r
Sob 𝐻0 demonstra-se que:
Est. Teste => n * 𝑅2 ~ 𝑋2(p)
No caso, o valor amostral da estatística é:
𝑋2𝑜𝑏𝑠 =
Consultando a tabela da distribuição 𝑋2, para i graus de liberdade, para um nível de
significância de 5%, temos que 𝑋2𝐶𝑟í𝑡𝑖𝑐𝑜= .
1º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠>𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, rejeitámos 𝐻0 . Assim sendo, para o dado nível
de significância definida e de acordo com a informação estatística disponível, o testedetecta
Auto correlação do tipo AR(p).
2º possibilidade: Sendo que 𝑋2𝑜𝑏𝑠<𝑋2
𝐶𝑟í𝑡𝑖𝑐𝑜, não rejeitámos 𝐻0. Assim sendo, para o dado
nível de significância definida e de acordo com a informação estatística disponível, o teste não
detecta Auto correlação do tipo AR(p).
No e-views temos a estatística teste como Obs*R-squared e o p-value é Prob. Chi-Square.
Vantagens do teste de Breusch-Godfrey - Permite testar hipóteses em que a eventual autocorrelação seja gerada por um processo autorregressivo mais complexo do que AR(1). Desvantagens do teste de Breusch-Godfrey - Tem validade apenas assimptótica – amostras de grande dimensão. OBS: Definimos um 𝜌 de acordo com a periodicidade dos dados: - anuais: 1 ou 2; - trimestrais: 4; - mensais: 12; Teste de Durbin-Watson
Sendo o modelo
(indicar o modelo em causa)

20
Partimos do pressuposto que as perturbações seguem um processo de auto-regressivo de ordem 1, isto é:
AR(1): 𝑢𝑡 = 𝜌1𝑢𝑡−1+ 휀𝑡 Em que, - −1 < 𝜌 < 1; - 휀𝑡 é ruído branco, e obedece as seguintes características:
E (휀𝑡) = 0; Var (휀𝑡) = 𝜎2∀ i;
Cov (휀𝑡;휀𝑡−𝑠) = 0∀ t≠ s;
Se 0 < Durbin-Wat< 2 Se 2 < Durbin-Wat< 4
Uma vez que o valor para a estatística d é , um valor compreendido entre 0 e 2, o par de hipóteses em teste é:
𝐻0: 𝜌 = 0 𝐻1: 𝜌 > 0
Consultando a tabela de Durbin Watson, para o nível de significância de 𝛼%, para n =, e k’ = k -1 =, obtêm-se os valores: dl = du=
1º possibilidade: Sendo que, rejeita-se a hipótese nula, concluindo para um nível de significância de 𝛼%, pela existência de autocorrelação positiva do tipo AR(1). 2º possibilidade: Sendo que, não se rejeita a hipótese nula, concluindo para um nível de significância de 𝛼%, pela não existência de autocorrelação do tipo AR(1).
Uma vez que o valor para a estatística d é , um valor compreendido entre 0 e 2, o par de hipóteses em teste é:
𝐻0: 𝜌 = 0 𝐻1: 𝜌 < 0
Consultando a tabela de Durbin Watson, para o nível de significância de 𝛼%, para n =, e k’ = k -1 =, obtêm-se os valores: dl = du =
1º possibilidade: Sendo que, rejeita-se a hipótese nula, concluindo para um nível de significância de 𝛼%, pela existênciadeautocorrelação negativa do tipo AR(1). 2º possibilidade: Sendo que, não se rejeita a hipótese nula, concluindo para um nível de significância de 𝛼%, pela não existência de autocorrelação do tipo AR(1).
Nota importante: Para se proceder o teste de Durbin-Watson é necessário que:
- o modelo tenha termo independente;
- não haja quebra dos dados;

21
- as variáveis explicativas podem ser consideradas não aleatórias – pressupondo a habitual
hipótese [H4];
Desvantagens do teste de Durbin-Watson
1- Possível inconclusividade do teste;
2- Supõe-se que o modelo foi ajustado com termo independente;
3- Pode falhar quando estivermos perante uma autocorrelação que não seja de primeira
ordem;
4- Pressupõe-se que as variáveis explicativas são não aleatórias;
5- Pressupõe-se que a amostra deve consistir de observações respeitantes a períodos
consecutivos, se, quebras.
Vantagens do teste de Durbin-Watson
1- Simplicidade do cálculo;
2- Funciona bem como detector de autocorrelação mesmo em situações para os quais
não foi originalmente projectado.
Métodos de estimação sendo conhecido a matriz Ω (𝝆) conhecida
Método das diferenças generalizadas de 1º ordem
Sendo que:
𝑢𝑡 = 𝜌𝑢𝑡−1 + 휀𝑡, ∀ t
E tendo:
𝑌𝑡 = 𝛽1 + 𝛽2𝑡𝑋2 +𝛽3𝑋3𝑡+ … + 𝛽𝑘𝑋𝑘𝑡 + 𝑢𝑡
E ainda:
𝜌𝑌𝑡−1 = 𝜌𝛽1 + 𝛽2𝜌𝑋2,𝑡−1 + 𝛽3𝜌𝑋3,𝑡−1 + … + 𝛽𝑘𝜌𝑋𝑘,𝑡−1 + 𝜌𝑢𝑡−1
Vamos ter: 𝑌𝑡 -𝜌𝑌𝑡−1= 𝛽1- 𝜌𝛽1+ 𝛽2𝑡𝑋2 - 𝛽2𝜌𝑋2,𝑡−1 +𝛽3𝑋3𝑡 -𝛽3𝜌𝑋3,𝑡−1+ … + 𝛽𝑘𝑋𝑘𝑡 - 𝛽𝑘𝜌𝑋𝑘,𝑡−1 + 𝑢𝑡 - 𝜌𝑢𝑡−1
Ou
𝑌𝑡 - 𝜌𝑌𝑡−1 = 𝛽1 (1 - 𝜌) + 𝛽2 (𝑋2 - 𝜌𝑋2,𝑡−1) + 𝛽3 (𝑋3 - 𝜌𝑋3,𝑡−1) + … + 𝛽𝑘 (𝑋𝑘𝑡 -𝜌𝑋𝑘,𝑡−1) + 𝑢𝑡 -𝜌𝑢𝑡−1
Ou
𝑌𝑡=𝜌𝑌𝑡−1+ 𝛽1 (1 - 𝜌) + 𝛽2 (𝑋2 - 𝜌𝑋2,𝑡−1) + 𝛽3 (𝑋3 - 𝜌𝑋3,𝑡−1) + … + 𝛽𝑘 (𝑋𝑘𝑡 -𝜌𝑋𝑘,𝑡−1) + 𝑢𝑡 -𝜌𝑢𝑡−1
(excepto pelo termo constante, tem os mesmos coeficientes de regressão do modelo original)

22
𝑌𝑡* = 𝛽1* + 𝛽2 𝑋2* +𝛽3𝑋3*+ … + 𝛽𝑘𝑋𝑘* + 휀𝑡
A primeira observação será recuperável fazendo:
𝑌𝑡* =𝑌1√1 − 𝜌2
E ainda temos:
𝛽1* = 𝛽1 (1 - 𝜌)
𝑋𝑗1* =𝑋𝐽1√1 − 𝜌2
𝛽1 = 𝛽1∗
(1 − 𝜌)
𝒖𝒕
𝟐 = 𝜺𝒕
𝟐
(𝟏 – 𝝆𝟐)
As matrizes serão:
Y* =
[ 𝑌1√1 − 𝜌2
𝑌2 − 𝜌𝑌1
⋮𝑌𝑛 − 𝜌𝑌𝑛−1]
X* =
[ √1 − 𝜌2 𝑋21√1 − 𝜌2 ⋯ 𝑋𝑘1√1 − 𝜌2
1 − 𝜌 𝑋22 − 𝜌𝑋21 ⋯ 𝑋𝑘2 − 𝜌𝑋𝑘1
⋮ ⋮ ⋱ ⋮1 − 𝜌 𝑋2𝑛 − 𝜌𝑋2,𝑛−1 ⋯ 𝑋𝑘𝑛 − 𝜌𝑋𝑘,𝑛−1]
u* =
[ 𝑢1√1 − 𝜌2
𝑢2 − 𝜌𝑢1
⋮𝑢𝑛 − 𝜌𝑢𝑛−1]
Nota Importante: A estimação por GLS é equivalente à estimação por OLS do modelo original depois de transformado pelo método das diferenças generalizadas de 1º ordem. Assim sendo, esses estimadores tornam-se BLUE, pois o vector u* obedece as hipóteses clássicas. Métodos de estimação sendo desconhecido o coeficiente 𝝆
Método de Cochrane-Orcutt
Método de Mínimos Quadrados não Lineares ou NLS
Método de Durbin em dois passos
O método de Cochrane-Orcutt é apresentado em dois passos: 1º passo: Uma vez estimado o modelo original, obtemos a série
Neste método pretende-se minimizar a soma dos quadrados dos resíduos:
1º passo: Transforma-se o modelo original pelo método das diferenças generalizadas de 1º ordem, escrevendo o modelo transformado da seguinte forma:

23
dos respectivos resíduos de estimação. E determina-se uma estimativas de 𝜌, a partir da estimação por OLS do seguinte modelo sem termo de independente:
𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 em que 𝑣𝑡 é uma perturbação aleatória. 2º passo: Utiliza-se a estimativa de 𝜌, obtida no 1º passo, para construir as variáveis transformadas. 𝑌𝑡 –𝑌𝑡−1= 𝛽1 (1 -)+ 𝛽2(𝑋2,𝑡 - 𝑋2,𝑡−1)+ … + 𝛽𝑘(𝑋𝑘,𝑡 - 𝑋𝑘,𝑡−1)+𝑢𝑡 - 𝑢𝑡−1
Ou 𝑌𝑡*= 𝛽1*+ 𝛽2𝑋2𝑡*+ … + 𝛽𝑘𝑋𝑘𝑡* + 𝑢𝑡
- 𝜌^𝑢𝑡−1
(exatamente igual ao 2° passo do método das diferenças
generalizadas)
em que, t = 2, 3,…, n. E ainda,
𝛽1* = 𝛽1 (1 -)
𝛽1 = 𝛽1∗
(1 − )
Síntese: Este método permite estimar o coeficiente de Auto correlação (𝜌). Aqui admite-se que o termo de perturbação segue um processo AR(1), ou seja:
𝑢𝑡 = 𝜌1𝑢𝑡−1+ 휀𝑡 No entanto, no 1º passo do Método de CochraneOrcutt, estima-se por OLS uma prooxi do AR(1) através da regressão:
∑(𝑌𝑡 − 𝑓𝑡 )2
𝑛
𝑡=1
Em que
𝑓𝑡=𝛽1 (1 -) + 𝛽2(𝑋2,𝑡 - 𝑋2,𝑡−1) + … + 𝛽𝑘(𝑋𝑘,𝑡 -
𝑋𝑘,𝑡−1) + 𝑌𝑡−1 Este problema de minimização dá origem a um sistema não linear de (k + 1) equações em que as estimativas de 𝛽1, 𝛽2, …, 𝛽𝑘 e 𝜌, que não tem solução analítica. Os programas informáticos ultrapassam esse problema utilizando algoritmos de optimização numérica. Admitindo que os termos de perturbação seguem um processo AR(1), e a partir da transformação do modelo original segundo o método das diferenças generalizadas de 1º ordem, pode escrever-se: 𝑌𝑡= 𝛽1 (1 - 𝜌)+ 𝛽2(𝑋2,𝑡- 𝜌𝑋2,𝑡−1) + … + 𝛽𝑘(𝑋𝑘,𝑡-
𝜌𝑋𝑘,𝑡−1) +𝝆𝒀𝒕−𝟏+𝜖𝑡
Ou
𝑌𝑡= 𝛽1 (1 - 𝜌)+ 𝛽2(𝑋2,𝑡- 𝑋2,𝑡−1) + … + 𝛽𝑘(𝑋𝑘,𝑡-
𝑋𝑘,𝑡−1) + AR(1)+ 𝜖𝑡
em que, t = 2, 3,…, n. (ver página 342 para ver os diferentes outputs do eviews) Dica: Aparece sempre no Output em questão “Convergenceachievedafter …”. Notas: Neste método, a contaste do modelo já corresponde à estimativa de 𝛽1. Como nos restantes métodos, as restantes estimativas são dadas directamente. É frequente nestes programas impor-se a restrição de 𝝆 estar contido no intervalo ]-1, 1[, e garante ainda que as estimativas dos coeficientes das variáveis obedecerão à restrição 𝛽𝑗 = - 𝜌𝛽𝑗.
𝑌𝑡= 𝑌𝑡−1+𝛽1 (1 -)+ 𝛽2𝑋2,𝑡 -𝛽2𝑋2,𝑡−1+ … + 𝛽𝑘𝑋𝑘,𝑡 - 𝛽𝑘𝑋𝑘,𝑡−1+ 𝑢𝑡 - 𝑢𝑡−1
Ou 𝑌𝑡=𝑌𝑡−1+𝛽1* + 𝛽2𝑋2𝑡 +𝛽2*𝑋2,𝑡−1+…
+𝛽𝑘𝑋𝑘𝑡 + 𝛽𝑘* 𝑋𝑘,𝑡−1+𝑢𝑡 - 𝜌^𝑢𝑡−1 Estimando este modelo por OLS, a estimativa do termo 𝑌𝑡−1 dá-nos a estimativa de 𝜌. 2º passo: Utiliza-se a estimativa de 𝜌 para construir as variáveis transformadas, obtendo o seguinte modelo transformado: 𝑌𝑡 –𝑌𝑡−1= 𝛽1 (1 -)+ 𝛽2(𝑋2,𝑡 - 𝑋2,𝑡−1)+ … + 𝛽𝑘(𝑋𝑘,𝑡 - 𝑋𝑘,𝑡−1)+ 𝑢𝑡 -
𝑢𝑡−1
Ou 𝑌𝑡*= 𝛽1* + 𝛽2𝑋2𝑡*+ … + 𝛽𝑘𝑋𝑘𝑡* + 𝑢𝑡 -
𝜌^𝑢𝑡−1
(exatamente igual ao 2° passo do método das diferenças generalizadas)
em que, t = 2, 3,…, n.
E ainda,
𝛽1* = 𝛽1 (1 -)
𝛽1 = 𝛽1∗
(1 − )
OBS: Este modelo tem a vantagem da simplicidade, no entanto pode-se estimar um 𝜌 fora do intervalo admissível. Ainda podemos ter situações em que seja impossível estimar a regressão auxiliar. Assim, a regressão só é exequível se for n-1>2k. No caso em que tenhamos t como variável explicativa, nunca conseguiremos usar este método

24
𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 , em que
𝑣𝑡 é uma perturbação aleatória.
No output do Eviews, o S.E ofRegression se refere ao 휀, isto é, 𝜀𝑡
. Para determinarmos o
𝑢𝑡 temos:
𝜺𝒕 = (1 – 𝝆𝟐) 𝒖𝒕
𝒖𝒕 =
𝜺𝒕
(𝟏 – 𝝆𝟐)
porque temos a violação da hipótese 5, existindo uma relação de dependência entre colunas. Ou seja, por haver colinearidade perfeita entre duas variáveis a matriz (X’X) não é invertível e logo não consigo estimar por OLS.
Procedimento de Newey-West
Uma vez detetada a presença de autocorrelação e/ou heteroscedasticidade no modelo
original, os estimadores de OLS continuam a ser cêntricos, geralmente consistentes, no
entanto deixam de ser eficientes. Por isso, a inferência estatística deixa de ser válida, isto é, os
testes de significância individual e testes de significância global. Ou seja, subavaliamos as
verdadeiras variâncias, e portanto, a sobrevalorização das estatísticas T (em valor absoluto) e
F.
Com o procedimento do Newey West, temos um estimador de Var (𝛽𝑂𝐿)que é consistente em
presença de heteroscedasticidade e/ou autocorrelação que viabiliza assimptoticamente a
inferência estatística conduzida através de OLS.
As estimativas dos coeficientes são iguais aos obtidos por OLS mas com variâncias e
covariâncias dadas por





























