Embed Size (px)
Citation preview

Revisão (Alguns Conceitos Básicos de
Estatística)
Prof.a Dr.a Simone Daniela Sartorio de Medeiros
DTAiSeR-Ar
1

Estatística é a ciência que se ocupa de coletar,
organizar, analisar e interpretar dados
a fim de tomar decisões.
O que é estatística?
Após a determinação dos elementos ou unidades experimentais...
Elemento significa cada uma das unidades observadas no estudo que
vai gerar cada dado.
Dependendo da área, também conhecida como:
parcela;
unidade experimental; ou
unidade amostral.
2
medi-los,
observá-los,
contá-los .
O que fazer com os elementos?
Surgindo um conjunto
de respostas (dados)
que receberá a
denominação de
variável.
Pode-se:
3
Variável Características de interesse observadas que assumem valores
diferentes em diferentes indivíduos, locais, situações ou objetos, ou seja,
apresentam variabilidade ou variação. Notação: Variável de interesse:
Y (letra maiúscula); Valores por ela assumidos: y (letra minúscula).
Quando os valores assumidos por uma variável são o produto de
fatores causais e estes não podem ser preditos com exatidão, esta é
chamada de variável aleatória.
• n.º de leitos,
• quantidade de funcionários de uma empresa.
• n.º de brotos de pés de laranja.
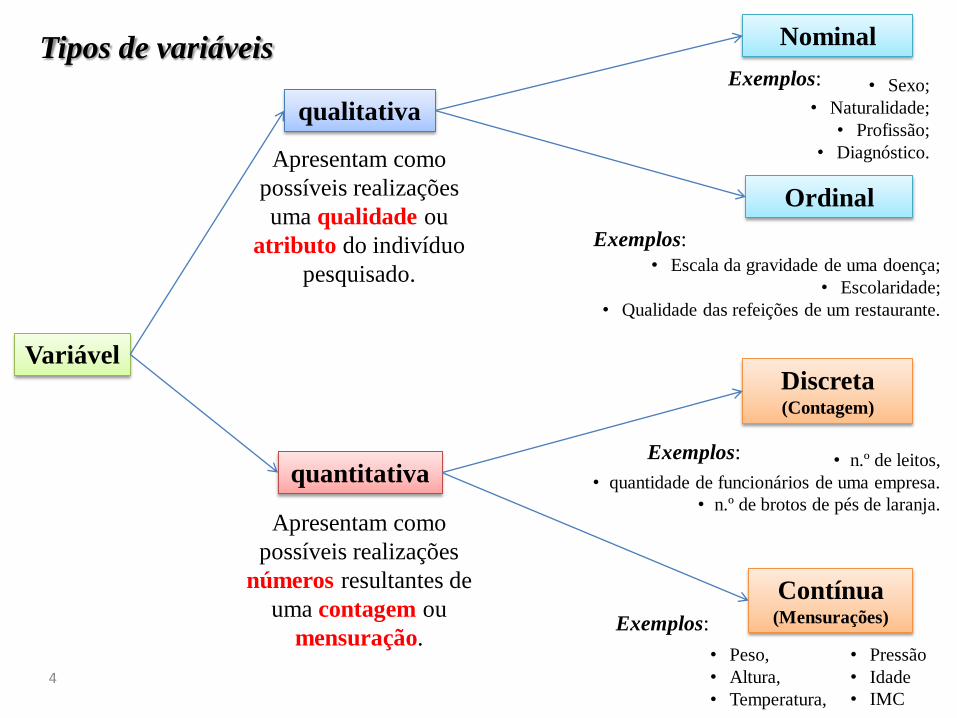
Tipos de variáveis
qualitativa
Nominal
Ordinal
Discreta (Contagem)
Contínua (Mensurações)
Variável
quantitativa
Apresentam como
possíveis realizações
números resultantes de
uma contagem ou
mensuração.
Apresentam como
possíveis realizações
uma qualidade ou
atributo do indivíduo
pesquisado. • Escala da gravidade de uma doença;
• Escolaridade;
• Qualidade das refeições de um restaurante.
• Sexo;
• Naturalidade;
• Profissão;
• Diagnóstico.
Exemplos:
Exemplos:
Exemplos:
• Peso,
• Altura,
• Temperatura,
• Pressão
• Idade
• IMC
Exemplos:
4

Os conjuntos de trabalho da estatística
5
População Conjunto de elementos que tem pelo menos
uma característica (variável) em comum.
Amostra Subconjunto de elementos de uma
população.
OBS: Seus elementos devem ser
representativos da população.
OBS: Esta característica deve delimitar
corretamente quais são os elementos da população
(que podem ser animados ou inanimados).
ou
A Estatística trabalha com dados, os quais podem ser obtidos por meio:
Na grande maioria das situações, não é possível realizar o censo de uma
população, porque ou a população é muito grande ou é de tamanho infinito.
Para contornar este problema, o pesquisador pode retirar uma amostra da
população e a partir desta amostra caracterizar a população de onde a amostra
foi retirada sem nenhum viés.
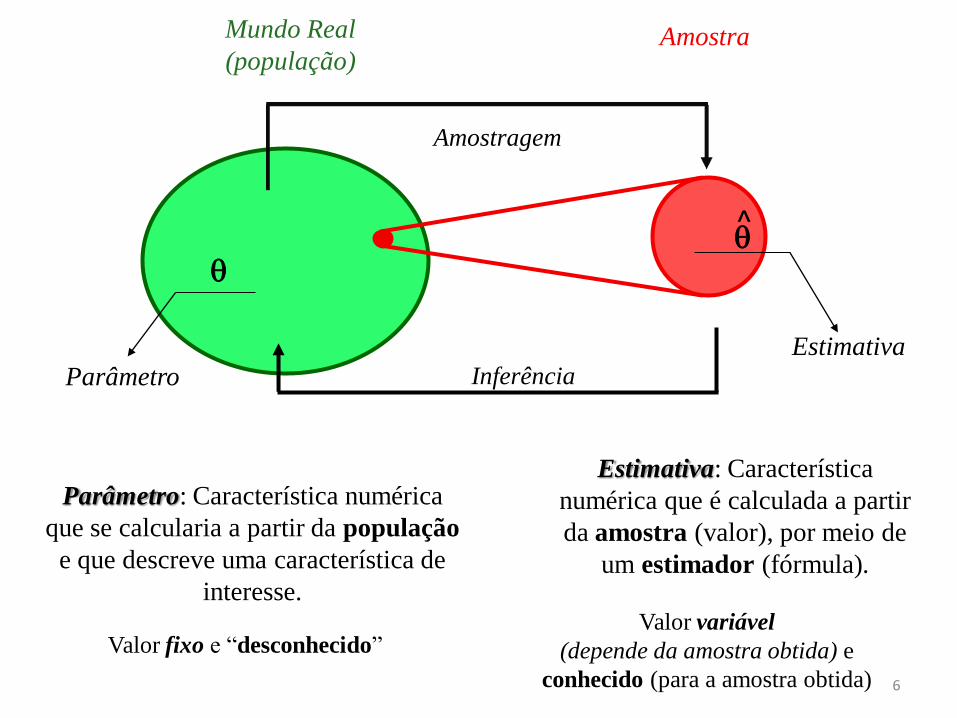
Mundo Real
(população) Amostra
Parâmetro: Característica numérica
que se calcularia a partir da população
e que descreve uma característica de
interesse.
Estimativa: Característica
numérica que é calculada a partir
da amostra (valor), por meio de
um estimador (fórmula).
Valor fixo e “desconhecido” Valor variável
(depende da amostra obtida) e
conhecido (para a amostra obtida)
Parâmetro
Estimativa
^
Inferência
Amostragem
6

Exemplos de estimadores:
• média aritmética amostral, m (ou x, ou µ), que é usada para estimar a média
populacional m (ou µ); e
• variância amostral, s2 (ou σ , ou ), que é usada para estimar a variância
populacional 2.
• correlação amostral , r, que é usada para estimar a correlação populacional .
^ ^
^2
Para alcançar este objetivo deve-se usar fórmulas estatísticas, conhecidas
como estimadores, que apresentem características estatísticas desejáveis, tais
como não-tendenciosidade, variância mínima, fornecer estimativas que se
aproximem do valor paramétrico à medida que o tamanho da amostra aumenta, e
etc..
)(ˆ XV
7

O parâmetro é sempre um valor constante, pois para a obtenção do mesmo são usados
todos os elementos da população.
Por outro lado, o estimador representa uma variável aleatória, pois os seus valores
mudam de amostra para amostra. Isto acontece porque os elementos que pertencem a
uma amostra geralmente não são os mesmos em outras amostras.
Estes diferentes valores que um estimador assume são também
conhecidos como estimativas.
Observe que algumas vezes a simbologia usada para representar os parâmetros e
seus respectivos estimadores é muito parecida. A diferença entre o parâmetro e o seu
estimador é o chapéu que existe no símbolo usado para representar o estimador.
Isto parece ser uma diferença mínima, mas do ponto de vista estatístico, a
diferença conceitual entre parâmetro e estimador é enorme.
Consequentemente, é possível estabelecer uma distribuição de
probabilidades para os valores de um estimador. Para o parâmetro, isto
não é possível, pois se assume que ele tem um valor constante.
8

Teste de hipóteses
Os testes de hipóteses fazem parte de um conjunto de procedimentos
inferenciais usados em estatística.
O uso de tais procedimentos permite ao pesquisador fazer inferências
a respeito de uma população a partir de uma ou mais amostras
representativas da população da qual as amostras foram retiradas.
9

No dia a dia usamos de inferência para tomarmos certas decisões.
Porém, em ciência é necessário que todos os procedimentos sejam
padronizados e bem especificados. Assim, é fornecer os conceitos
teóricos fundamentais para um correto uso dos testes de hipóteses.
Exemplo (o princípio básico do teste de hipóteses)
Quando vamos a feira para comprar abacaxi e um feirante nos oferece um pedaço
de abacaxi. Qual o nosso procedimento?
• Se aquele pedaço de abacaxi for doce...concluímos que...
• Por outro lado, se o pedaço for azedo, inferimos que ...
É lógico que podemos tomar decisões erradas devido à amostragem.
Por exemplo, corremos o risco de levar abacaxi azedo para casa, mesmo que a
nossa prova tenha sido doce. Isto pode acontecer por um dos dois motivos...
10

Conceitos fundamentais em testes de hipóteses
1. Parâmetro
É possível caracterizar uma população por meio de duas medidas principais:
As medidas de posição
As medidas de dispersão
11

Medidas de posição
São também conhecidas como medidas de tendência central,
pois elas indicam em que posição, a distribuição dos valores de
uma população tendem a se concentrar.
Exemplos:
a média aritmética (m = µ = E(X)),
a mediana (Md); e
a moda (Mo).
12
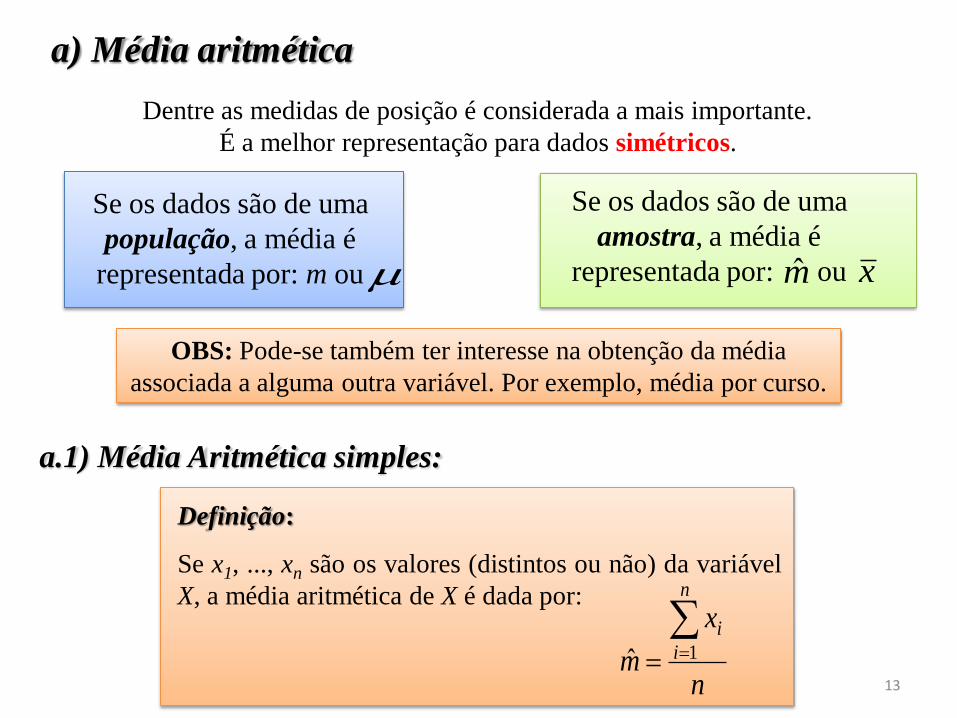
Dentre as medidas de posição é considerada a mais importante.
É a melhor representação para dados simétricos.
Se os dados são de uma
amostra, a média é
representada por: ou x
Se os dados são de uma
população, a média é
representada por: m ou
a) Média aritmética
OBS: Pode-se também ter interesse na obtenção da média
associada a alguma outra variável. Por exemplo, média por curso.
m̂
13
a.1) Média Aritmética simples:
Definição:
Se x1, ..., xn são os valores (distintos ou não) da variável
X, a média aritmética de X é dada por:
n
x
m
n
i
i 1ˆ
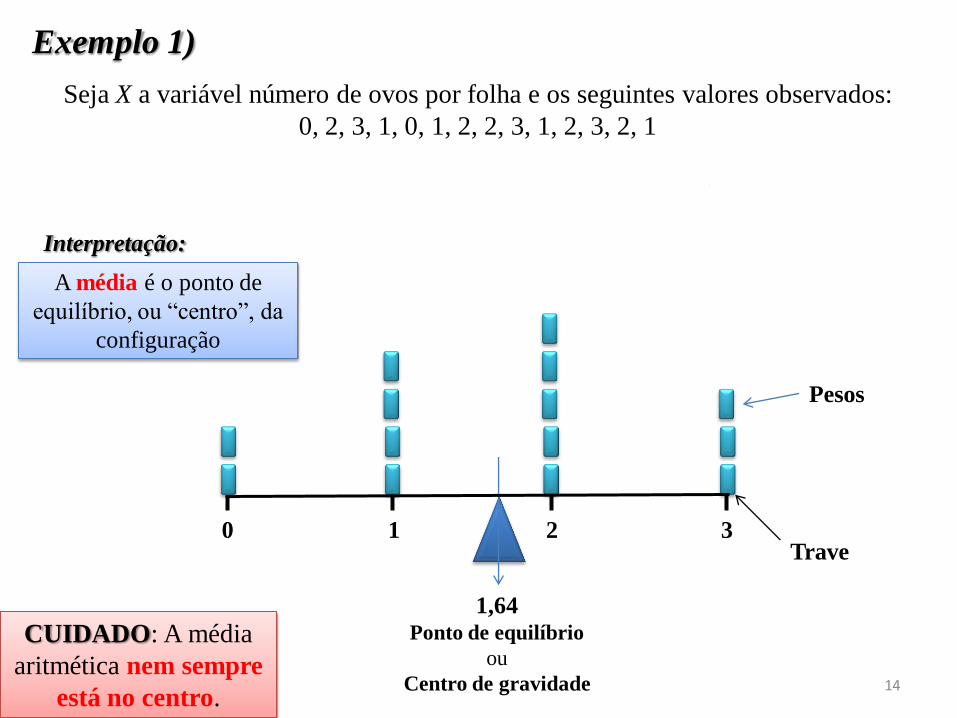
1,64 Ponto de equilíbrio
ou
Centro de gravidade
Pesos
Trave 3 2 1 0
A média é o ponto de
equilíbrio, ou “centro”, da
configuração
Seja X a variável número de ovos por folha e os seguintes valores observados:
0, 2, 3, 1, 0, 1, 2, 2, 3, 1, 2, 3, 2, 1
m = 0 + 2 + 3 +... + 3 + 2 + 1 = 23 = 1,64 ovos por folha
14 14
^
Exemplo 1)
CUIDADO: A média
aritmética nem sempre
está no centro. 14
Interpretação:

Conclusão:
A média não nem sempre é uma medida
adequada para a representação de um
conjunto de dados.
Principalmente quando temos a presença
de algum outlier.
Exemplo 2)
Suponha que uma empresa possui cinco funcionários e que cada um
receba em R$:
400,00 545,00 610,00 475,00 5500,00.
Média salarial: m = R$ 1506,00 ^
15

Medidas de dispersão
Indicam quanto os valores de uma população estão
dispersos em torno de sua média.
Exemplos:
a variância amostral (s2); e
o desvio-padrão amostral (s).
16

11
)ˆ(
2
1
1
2
1
2
2
n
n
x
x
n
mx
s
n
i
in
i
i
n
i
i
OBS: esse é o
melhor
estimador para a
variância
populacional
(dividir por n-1)
N tamanho populacional
n tamanho amostral
Fórmula
alternativa
(mais usada)
a) Variância amostral (s2) ou estimativa da variância populacional (σ2)
É a média dos quadrados dos desvios em relação a média aritmética
amostral
Vantagem :
A interpretação é mais fácil, pois possui a
mesma unidade dos dados originais. Já na
variância, a unidade é elevada ao quadrado.
2ss
b) Desvio padrão amostral (s ou n-1)
É a raiz quadrada da variância amostral (s2)
17

Tarefa 1
Sejam Y a variável peso (em tonelada) e 4 tipos de colheitadeira. Retirou-se uma
amostra de tamanho 4 de cada colheitadeira, os dados se encontram na tabela
abaixo.
Calcule as medidas de posição (média, mediana e moda) e variação (variância e
desvio padrão) das observações relativas a cada colheitadeira: A, B, C e D.
Interprete as medidas e baseada nelas, comente sobre o desempenho de cada
colheitadeira.
Colheitadeira
Amostra A B C D
1 5 4 10 0
2 4 6 5 3
3 5 6 0 7
4 6 4 5 10
18

Algumas distribuições
probabilísticas contínuas
importantes
a) Distribuição Normal (ou Gaussiana);
b) Distribuição Qui-Quadrado;
c) Distribuição t-Student;
d) Distribuição F de Snedecor.
19

a) Distribuição Gaussiana (ou normal)
Modelo fundamental em probabilidade e inferência estatística.
Representa grande parte das variáveis aleatórias contínuas.
Alguns motivos para seu uso:
Muitos testes e modelos estatísticos têm como pressuposição a “normalidade
dos dados”, isto é, que os dados seguem uma distribuição Normal;
Muitas variáveis biométricas tendem a ter distribuição Normal;
A distribuição das médias amostrais de uma variável aleatória qualquer
tendem a ter distribuição Normal, mesmo que a variável em si não tenha
distribuição Normal.
20
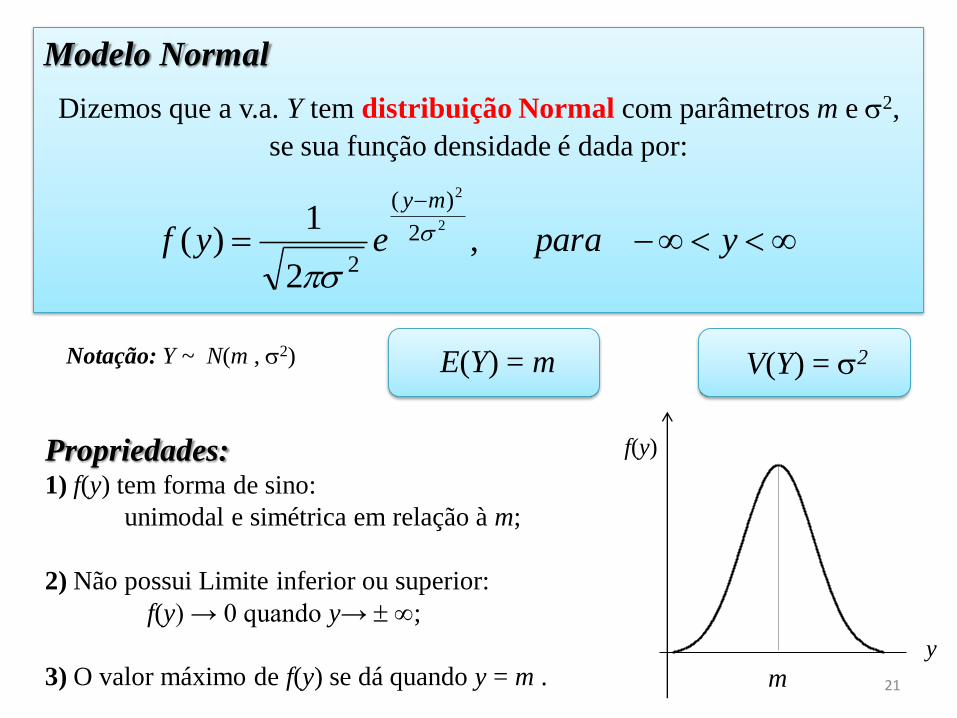
Modelo Normal
Dizemos que a v.a. Y tem distribuição Normal com parâmetros m e 2,
se sua função densidade é dada por:
Notação: Y ~ N(m , 2) E(Y) = m V(Y) = 2
yparaeyf
my
,2
1)(
2
2
2
)(
2
Propriedades: 1) f(y) tem forma de sino:
unimodal e simétrica em relação à m;
2) Não possui Limite inferior ou superior:
f(y) → 0 quando y→ ;
3) O valor máximo de f(y) se dá quando y = m . m
y
f(y)
21
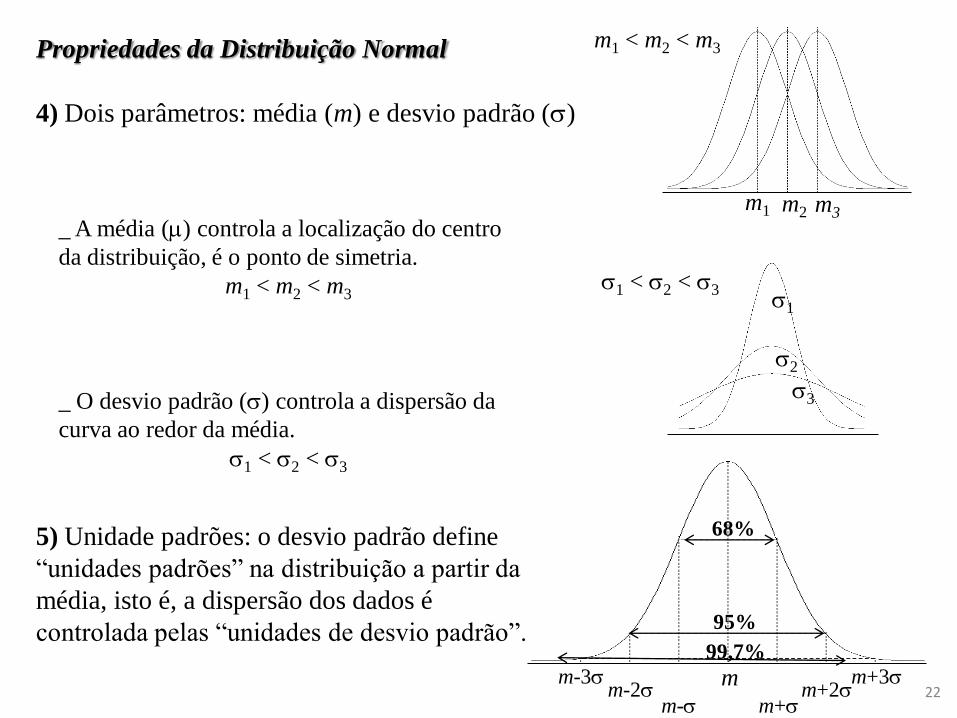
m-3 m-2 m-
m+3 m+2 m+
m
Propriedades da Distribuição Normal
4) Dois parâmetros: média (m) e desvio padrão ()
m1 < m2 < m3
m1 m2 m3
1
2
3
1 < 2 < 3
_ A média () controla a localização do centro
da distribuição, é o ponto de simetria.
m1 < m2 < m3
_ O desvio padrão () controla a dispersão da
curva ao redor da média.
1 < 2 < 3
5) Unidade padrões: o desvio padrão define
“unidades padrões” na distribuição a partir da
média, isto é, a dispersão dos dados é
controlada pelas “unidades de desvio padrão”.
68%
95%
99,7%
22

Como calcular a probabilidade, por exemplo, de um
intervalo (a, b) qualquer de uma v.a.c. Y que segue uma
distribuição normal?
b
a
my
dyebYaP2
2
2
)(
22
1)(
Muita
CALMA
nessa
hora!!!
Para calcular probabilidades precisamos resolver a integral:
Esta integral só pode ser resolvida de modo aproximado.
Então essas probabilidades podem ser calculadas através
do uso de tabelas ou pelo computador.
SÓ QUE para cada valor de m e 2 diferentes, obtemos uma
distribuição (função) diferente, ou seja, teremos
INFINITAS TABELAS!!!! 23

Calcular probabilidades no modelo Normal
Para calcular probabilidades precisamos resolver a integral:
Para se utilizar apenas uma tabela, utiliza-se uma transformação da variável
Y que conduz sempre ao cálculo de probabilidades com uma variável normal
com parâmetros (0,1), isto é, média igual a 0 e variância igual a 1.
Essa variável Z transformada terá
distribuição N(0,1) e será denominada
de distribuição Normal Padrão.
Notação: Z ~ N(0 , 1)
b
a
my
dyebYaP2
2
2
)(
22
1)(
mXZ
24
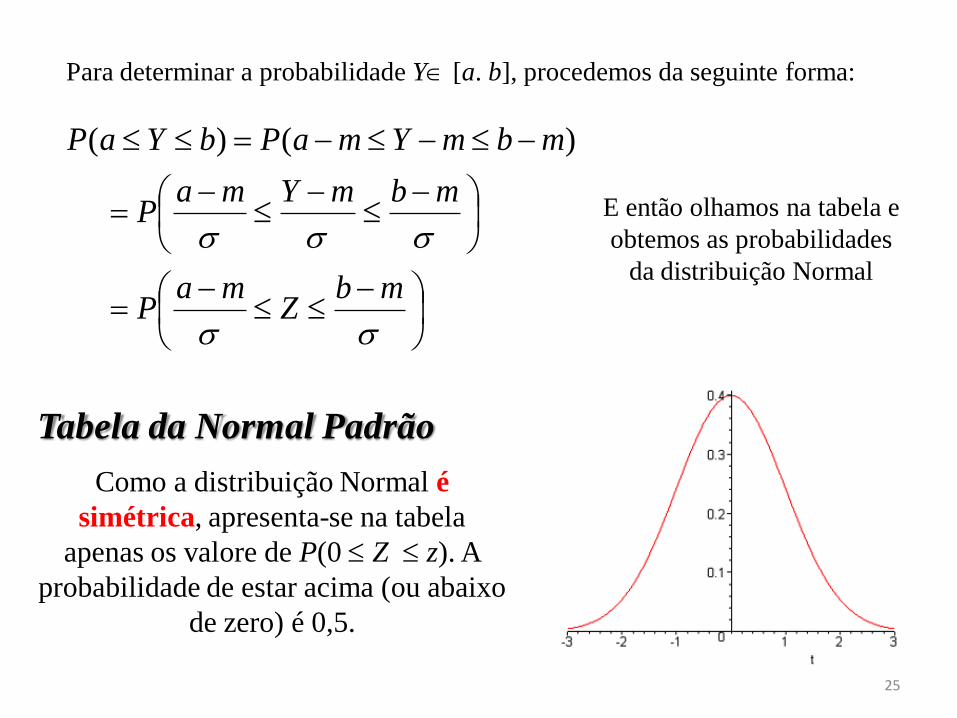
Para determinar a probabilidade Y [a. b], procedemos da seguinte forma:
E então olhamos na tabela e
obtemos as probabilidades
da distribuição Normal
mbZ
maP
mbmYmaP
mbmYmaPbYaP )()(
Tabela da Normal Padrão
Como a distribuição Normal é
simétrica, apresenta-se na tabela
apenas os valore de P(0 Z z). A
probabilidade de estar acima (ou abaixo
de zero) é 0,5.
25
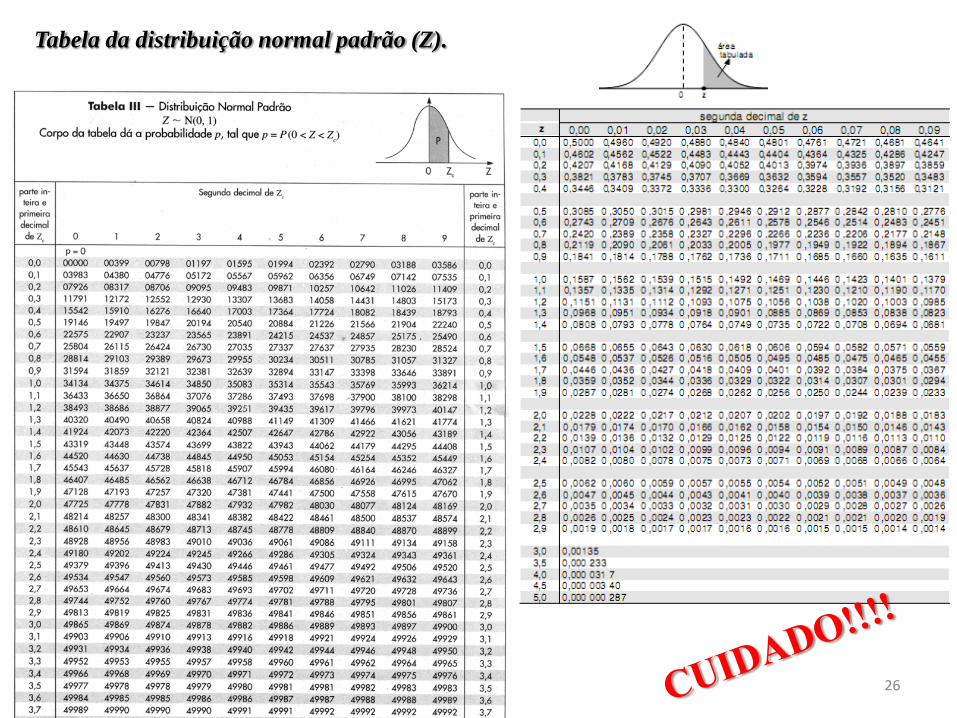
Tabela da distribuição normal padrão (Z).
26

27
Sabendo-se que Z ~ N(0,1), calcule:
Exercício 1
a) P(0 < Z < 2,14) =
b) P(0 < Z < 1,5) =
c) P(–3,01 < Z < 0) =
d) P(–2,17 < Z < 1,5) =
e) P(Z > 0) =
f) P(Z > –1) =
g) P(Z < 1) =
h) P(Z > 1) =
i) P(Z < –1) =
Seja X v.a.c. peso com média 59,6 kg e variância 16 kg2. Calcule a probabilidade:
Exercício 2
a) P(X 70) =
b) P(50 X < 65) =
c) P(X > 68) =
Tarefa 2

2
)(1
222
2
2
1 ~... v
v
iiv ZZZZX
Sejam {Z1, Z2, ..., Zv} uma amostra aleatória de v elementos retirados
de uma distribuição normal padronizada, isto é, N(0, 1).
Então, a v.a.
Ou então, podemos obter a qui-quadrado pela seguinte relação:
b) Distribuição Qui-quadrado
Definição:
Seja a v.a. X tal que, fazendo-se no modelo gama = /2 e = 2, com > 0
inteiro, tem-se a distribuição qui-quadrado, com graus de liberdade e
densidade dada por:
Notação: X ~ 2()
28
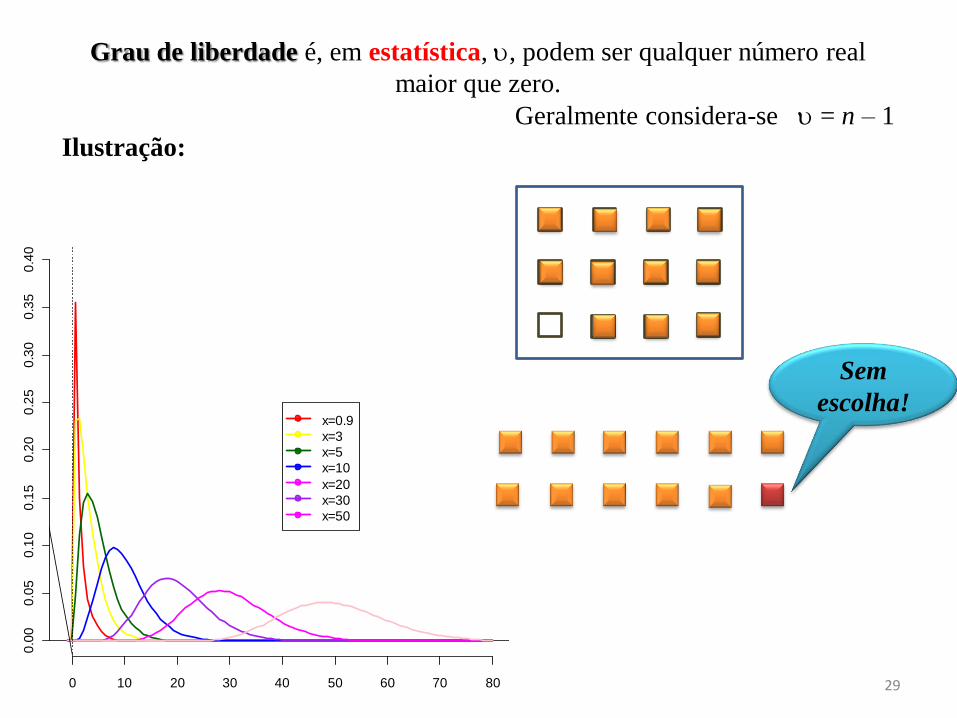
Grau de liberdade é, em estatística, , podem ser qualquer número real
maior que zero.
Geralmente considera-se = n – 1
Ilustração:
Sem
escolha! x=0.9
x=3
x=5
x=10
x=20
x=30
x=50
0.0
00
.05
0.1
00
.15
0.2
00
.25
0.3
00
.35
0.4
0
0 10 20 30 40 50 60 70 80 29
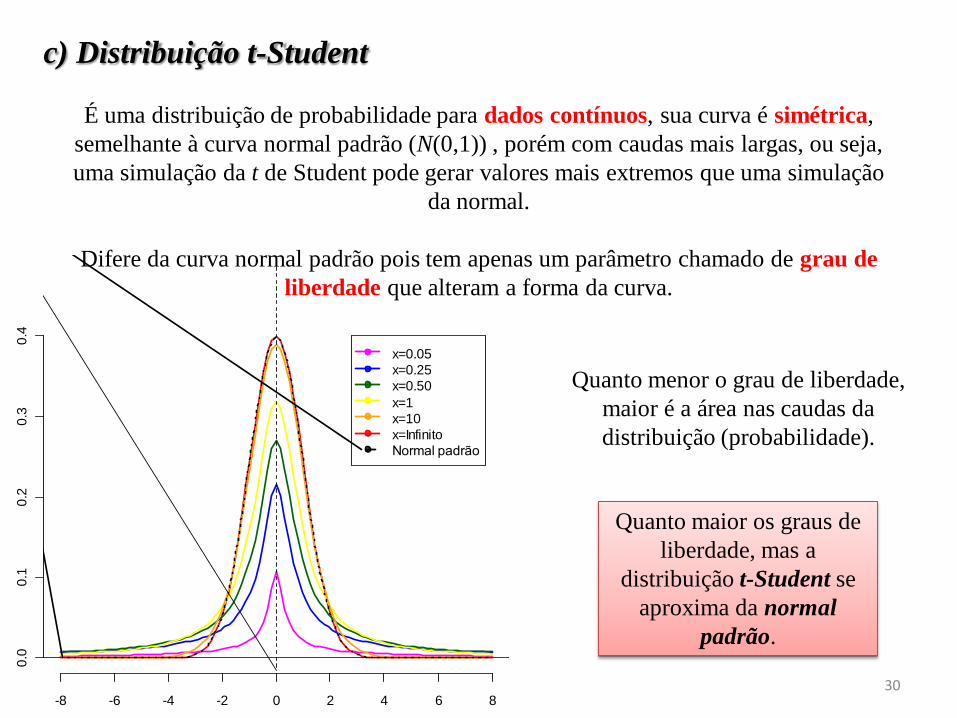
c) Distribuição t-Student
É uma distribuição de probabilidade para dados contínuos, sua curva é simétrica,
semelhante à curva normal padrão (N(0,1)) , porém com caudas mais largas, ou seja,
uma simulação da t de Student pode gerar valores mais extremos que uma simulação
da normal.
Difere da curva normal padrão pois tem apenas um parâmetro chamado de grau de
liberdade que alteram a forma da curva.
x=0.05
x=0.25
x=0.50
x=1
x=10
x=Infinito
Normal padrão
0.0
0.1
0.2
0.3
0.4
-8 -6 -4 -2 0 2 4 6 8
Quanto menor o grau de liberdade,
maior é a área nas caudas da
distribuição (probabilidade).
Quanto maior os graus de
liberdade, mas a
distribuição t-Student se
aproxima da normal
padrão.
30

Definição:
Uma v.a. X tem distribuição t-Student se a função densidade de
probabilidade é dada por:
• Sendo – < x < +
• são os graus de liberdade da distribuição
e = n – 1
• (.) represente a função gama
Essa distribuição é
utilizada para dados
contínuos, simétricos, que
a amostra é pequena, ou
seja, n < 30.
Sejam Z ~ N(0, 1) e Q ~ 2()
v.a.’s independentes. Então, a
variável:
Notação: X ~ t()
)(~
tQ
ZX
Ou então, podemos obter a distribuição t-Student pela seguinte relação:
31

d) Distribuição F
A distribuição F de Fisher-Snedecor, mais conhecida como distribuição F de
Fisher (em honra a Ronald Fisher) ou distribuição F de Snedecor (em honra
a Georde W. Snedecor) mede a razão entre duas qui-quadrados independentes
Ronald Fisher
Georde W. Snedecor
Sejam U e V duas v. a.
independentes, cada uma com
distribuição qui-quadrado, com
1 e 2 graus de liberdade,
respectivamente.
Então, a v.a.
),(
2
1
21~
/
/
F
V
UW
Notação: W ~ F(1, 2)
32

CALMA!!!
Para obter as probabilidades também
utiliza-se uma Tabela.
Definição:
Uma v.a. W tem distribuição F de Snedecor, com 1 e 2 graus de
liberdade, se possui a densidade dada por:
Ou então, pela definição teórica:
33
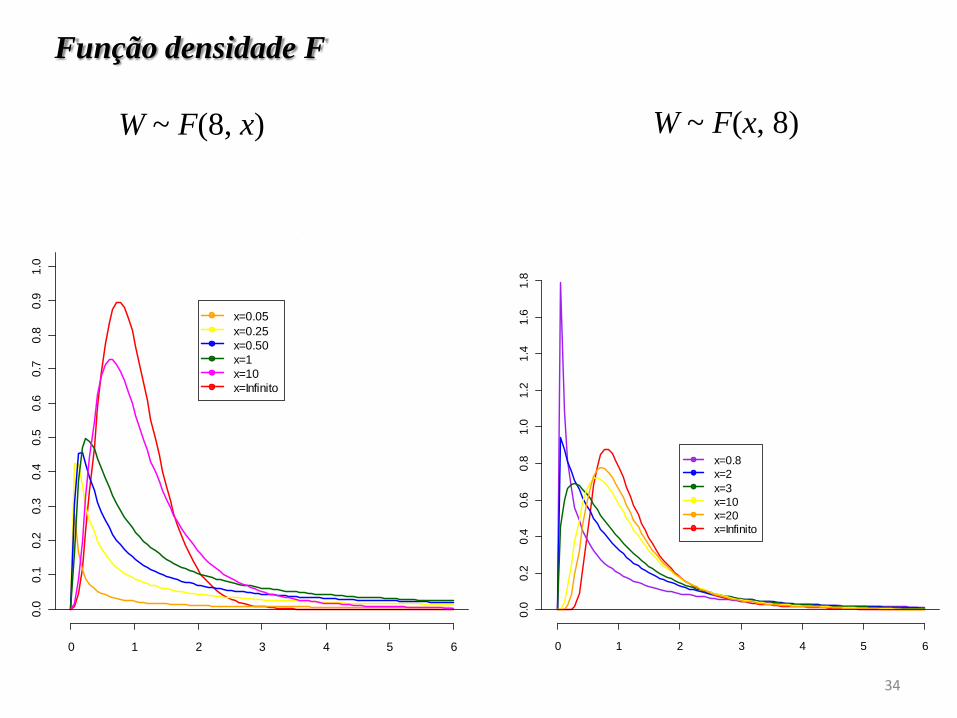
Função densidade F
W ~ F(8, x)
Distribuições F(8,x)
x=0.05
x=0.25
x=0.50
x=1
x=10
x=Infinito
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
0 1 2 3 4 5 6
Distribuições F(x,8)
x=0.8
x=2
x=3
x=10
x=20
x=Infinito0
.00
.20
.40
.60
.81
.01
.21
.41
.61
.8
0 1 2 3 4 5 6
W ~ F(x, 8)
34

Intervalo de Confiança
35
Nível de confiança: = 1 – ;
Nível de significância: (o quanto se permite errar);
Ambos assumem valores entre 0 e 1.
Para uma amostra de tamanho n, quanto maior o exigido
para o IC, maior será a amplitude deste.

População Normal
a) Se a variância populacional 2 é conhecida.
Para qualquer n :
b) Se a variância populacional 2 é desconhecida.
Amostra pequena (n 30):
c) Se a variância populacional 2 é desconhecida
Amostra grande (n > 30) :
1) Intervalo de confiança para a média
nzmmIC
2/ˆ%)100;(
n
stmmIC n )1(ˆ%)100;(
n
szmmIC 2/ˆ%)100;(
36
E ainda temos outros IC, por exemplo:
2) IC para proporção (p);
3) IC para a variância (2), entre outros...
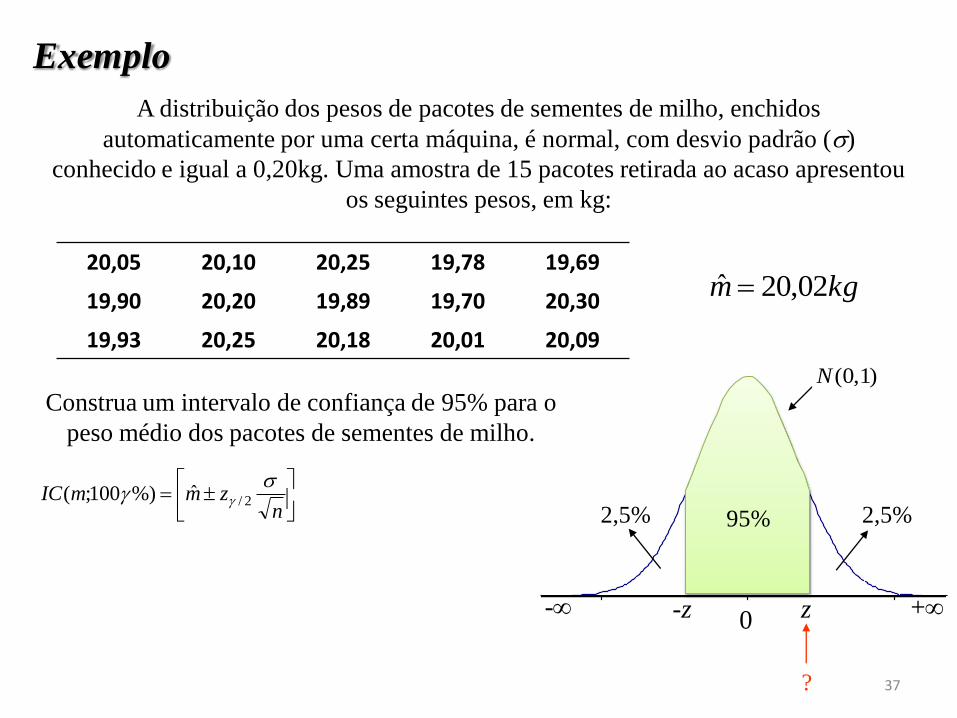
A distribuição dos pesos de pacotes de sementes de milho, enchidos
automaticamente por uma certa máquina, é normal, com desvio padrão ()
conhecido e igual a 0,20kg. Uma amostra de 15 pacotes retirada ao acaso apresentou
os seguintes pesos, em kg:
Exemplo
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0 5 10 15 20- + 0
(0,1)N
95%
z -z
2,5% 2,5%
?
20,05 20,10 20,25 19,78 19,69
19,90 20,20 19,89 19,70 20,30
19,93 20,25 20,18 20,01 20,09
Construa um intervalo de confiança de 95% para o
peso médio dos pacotes de sementes de milho.
kgm 02,20ˆ
nzmmIC
2/ˆ%)100;(
37
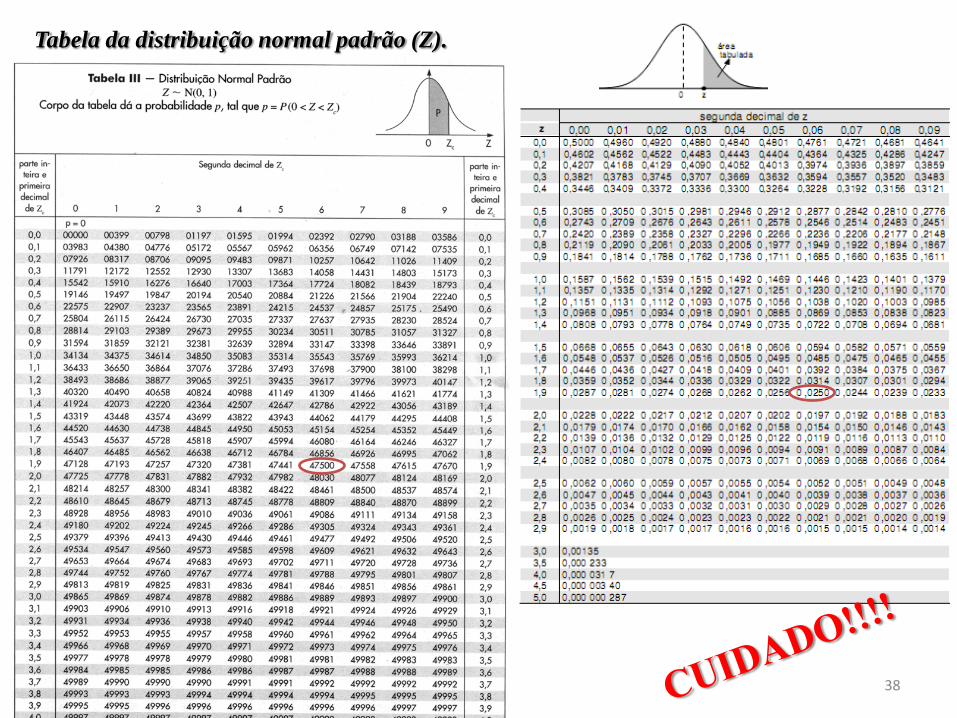
Tabela da distribuição normal padrão (Z).
38

A distribuição dos pesos de pacotes de sementes de milho, enchidos
automaticamente por uma certa máquina, é normal, com desvio padrão ()
conhecido e igual a 0,20kg. Uma amostra de 15 pacotes retirada ao acaso apresentou
os seguintes pesos, em kg:
Exemplo 1
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0 5 10 15 20- + 0
(0,1)N
95%
z -z
2,5% 2,5%
? 1,96
12,20;92,19%)95;( mIC
20,05 20,10 20,25 19,78 19,69
19,90 20,20 19,89 19,70 20,30
19,93 20,25 20,18 20,01 20,09
Construa um intervalo de confiança de 95% para o
peso médio dos pacotes de sementes de milho.
Portanto, com 95% de confiança, podemos
dizer que o peso médio dos pacotes de semente
de milho é um valor entre 19,92 kg e 20,12 kg.
kgm 02,20ˆ
nzmmIC
2/ˆ%)100;(
39
40
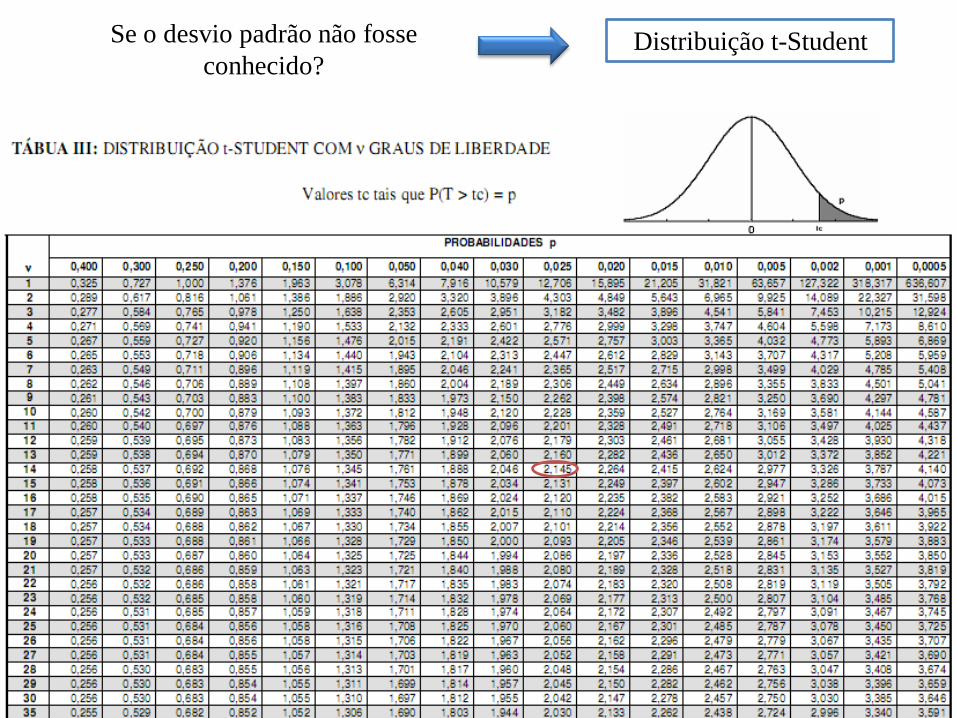
Se o desvio padrão não fosse
conhecido? Distribuição t-Student

Para re-lembrar:
_ Conceitos básicos.
_ Como entrar com os dados na calculadora científica?
_ Notação usada e descrever as contas.
_ Como era as principais representações gráficas de estatística descritiva, como
fazer elas e sua interpretação.
41

Tarefa 3
Os dados abaixo são referentes à altura de 100 plantas de milho, amostradas ao acaso.
Proceda ao sorteio de duas amostras de 20 plantas cada e obtenha:
a) As medidas de posição (média, mediana);
b) As medidas de dispersão (variância, desvio padrão, variância e erro padrão da média);
c) A tabela de distribuição de frequências (considere 6 classes);
d) O histograma de frequências absolutas;
e) O gráfico de ogiva;
f) O gráfico boxplot (interpretando-os em relação a variável observada).
g) Intervalo de confiança para a média e variância populacional de cada amostra ao nível de 5%
de significância e interprete-os.
158 194 215 163 212 219 218 174 178 213
213 210 218 169 214 175 190 232 201 200
201 211 199 187 167 201 182 217 195 154
197 209 219 188 192 158 206 183 213 158
178 202 174 196 198 167 216 214 167 203
159 205 168 202 191 178 157 156 169 233
176 198 192 217 206 187 159 198 218 222
189 186 195 223 216 221 185 189 229 199
259 177 217 195 225 219 231 169 207 183
289 185 203 215 193 201 177 166 204 195
42

Teste de hipótese
43
Existem 3 “pensamento” diferentes para se realizar um TH:
a) Método comum;
b) Valor-p;
c) Procedimento “mecânico” (por estatística).

A construção de um teste de hipóteses requer a especificação de duas hipóteses,
denominadas:
Hipótese Nula (H0):
É a hipótese que sugere um valor para o parâmetro populacional ou a
igualdade dos parâmetros em teste.
Geralmente expressa o conceito de ‘nenhuma diferença’.
Hipótese alternativa (H1 ou Ha):
É a hipótese que sugere que a afirmação que estamos fazendo na hipótese nula é falsa.
Geralmente, H1 representa a suposição que o pesquisador quer provar, sendo que H0 é
formulado com o propósito de ser rejeitada.
A construção da hipótese alternativa depende das
informações que se têm do problema em estudo. 44
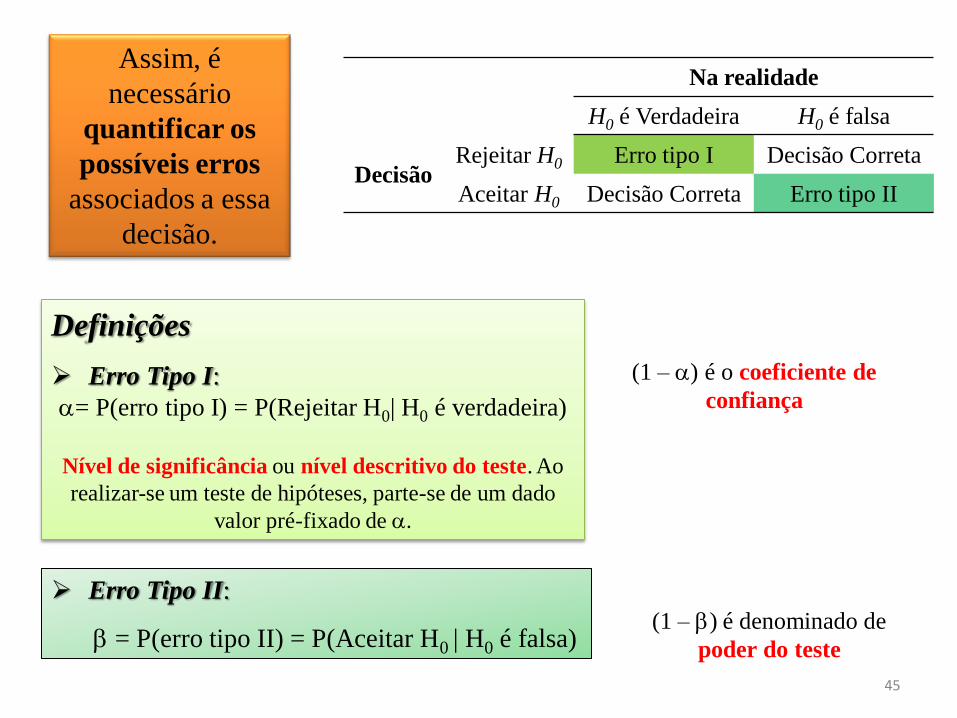
Definições
Erro Tipo I:
= P(erro tipo I) = P(Rejeitar H0| H0 é verdadeira)
Nível de significância ou nível descritivo do teste. Ao
realizar-se um teste de hipóteses, parte-se de um dado
valor pré-fixado de .
Na realidade
H0 é Verdadeira H0 é falsa
Decisão Rejeitar H0 Erro tipo I Decisão Correta
Aceitar H0 Decisão Correta Erro tipo II
Erro Tipo II:
= P(erro tipo II) = P(Aceitar H0 | H0 é falsa)
Assim, é
necessário
quantificar os
possíveis erros
associados a essa
decisão.
(1 – ) é o coeficiente de
confiança
(1 – ) é denominado de
poder do teste
45

Teste de hipóteses para média de populações normais
a) A afirmação diz respeito a uma média populacional.
b) A afirmação diz que as médias de duas populações são todas iguais.
c) A afirmação diz que as médias de três ou mais populações são todas iguais.
Objetivo: avaliar afirmações sobre média(s) populacional(is).
Existem, basicamente, 3 tipos de afirmações que se podem fazer
quando se estudam médias populacionais:
46

1) Teste para média de uma
população normal
47
1 população normal

1.o Passo: Defina a hipótese de nulidade (H0) e a hipótese alternativa (Ha),
em que m0 é um valor constante que se deseja testar.
Teste sobre a média de uma populacional
H0: m = m0
Ha: m < m0
H0: m = m0
Ha: m > m0
H0: m = m0
Ha: m m0
Teste unilateral
à esquerda
Teste unilateral
à direita Teste bilateral
48 RA: Região de Aceitação de H0
RR: Região de Rejeição de H0

Procedimento
“mecânico”
49

2.o Passo: Escolher a estatística adequada para julgar a hipótese H0
População Normal
a) Se a variância populacional 2 é conhecida
e n é qualquer:
b) Se a variância populacional 2 é desconhecida e a
amostra é pequena (n 30)
c) Se a variância populacional 2 é desconhecida e a
amostra é grande (n > 30) :
)1,0(~ˆ
2
0 N
n
mmZ
)1(2
0 ~ˆ
nt
n
s
mmT
)1,0(~ˆ
2
0 N
n
s
mmZ
Teste sobre a média de uma populacional
Estatística
OBS: Serve também para uma população com
distribuição qualquer e tamanho da amostra grande 50

H0: m = m0
Ha: m < m0
H0: m = m0
Ha: m > m0
H0: m = m0
Ha: m m0
Unilateral esquerdo Unilateral direito bilateral
z
t
zc
tc
-zc
-tc
-zc
-tc
zc
tc
1 – 1 –
1 – 1 –
1 –
1 –
Estatística
Z
T
3.o Passo: Fixar a probabilidade e usar esse valor para construir a região
crítica (RC) com os valores tabelados (zc ou tc).
0
0
0
0
0
0
Testes
Teste sobre a média de uma populacional
51

n
mmzcalc
2
0ˆ
n
s
mmtcalc
2
0ˆ
n
s
mmzcalc
2
0ˆ
Teste sobre a média de uma populacional
a) b) c)
4.o Passo: Usar as informações da amostra para encontrar o valor da
estatística (valor calculado ou observado) que definirá a decisão do teste:
52
5.o Passo: Concluir:
Se o valor amostral observado (zcal ou tcal) pertencer à região de rejeição
(RR) determinada pelo(s) ztab ou ttab, então rejeita-se H0, concluindo que
m m0 (ou m m0 , ou m m0).
Se o valor amostral observado (zcal ou tcal) pertencer à região de aceitação
(RA) determinada pelo(s) ztab ou ttab, então aceita-se H0, concluindo que m = m0.

Exemplo
Foi retirada uma amostra de tamanho 10, da população de pesos aos 210
dias de bezerros da raça Nelore. Os valores, em kg, foram os seguintes:
Desconfia-se que o peso é menor que 186, teste as hipóteses ao nível de
significância de 5%.
Teste sobre a média de uma população com variância desconhecida
178 199 182 186 188 191 189 185 174 158
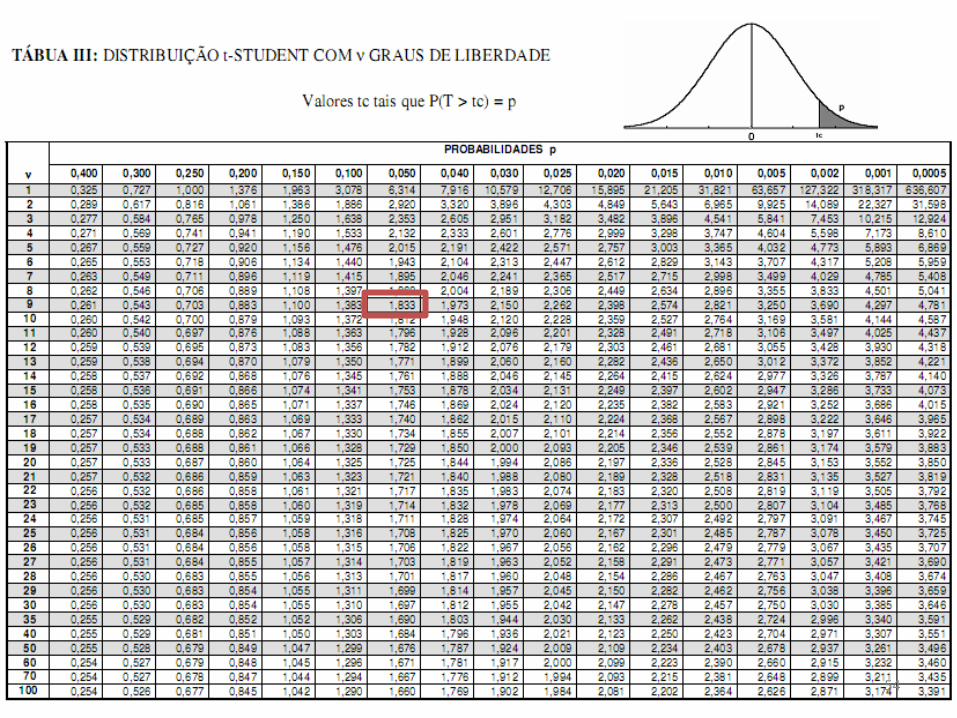
?%)5,9( tttab
847,0
10
18,11
186183ˆ
2
0
n
s
mmtcalc
10
18,11
183ˆ
n
kgs
kgm
As hipóteses: H0: m = 186 versus
H1: m < 186
53
54

Exemplo 1 (Andrade e Ogliari, 2010)
Foi retirada uma amostra de tamanho 10, da população de pesos aos 210
dias de bezerros da raça Nelore. Os valores, em kg, foram os seguintes:
Desconfia-se que o peso é menor que 186, teste as hipóteses ao nível de
significância de 5%.
Teste sobre a média de uma população com variância desconhecida
178 199 182 186 188 191 189 185 174 158
847,0
10
18,11
186183ˆ
2
0
n
s
mmtcalc
833,1%)5,9( tttab
Logo, aceita-se H0 ao nível
de 5% de significância,
concluindo que o peso dos
bezerros é igual a 186 kg. 10
18,11
183ˆ
n
kgs
kgm
As hipóteses: H0: m = 186 versus
H1: m < 186
55

valor-p
ou
p-value
56

O valor-p (ou p-value)
É o nome que se dá à probabilidade de se observar um resultado tão ou mais
extremo do que o obtido pelo pesquisador (por meio da amostra), supondo que a
hipótese nula seja verdadeira:
valor-p = P(rejeitar H0 usando o valor da amostra como corte| H0 é verdadeira)
OBS: O valor p é calculado com base na amostra, enquanto que é o
maior valor p que leva à rejeição da hipótese nula.
Regra prática:
Se o valor-p < Rejeita-se H0
Se o valor-p > Aceita-se H0
Um valor p pequeno significa uma das
duas situações:
1) Ou o pesquisador observou um
resultado pouco provável de ocorrer,
supondo a H0 verdadeira; ou
2) A H0 é falsa.
57

peso<- c(178, 199, 182, 186, 188, 191, 189, 185, 174, 158)
length(peso)
t.test(peso, mu=186, alternative="less", conf.level = 0.95)
# One Sample t-test
#
# data: peso
# t = -0.8482, df = 9, p-value = 0.2092
# alternative hypothesis: true mean is less than 186
# 95 percent confidence interval:
# -Inf 189.4839
# sample estimates:
# mean of x
# 183
58
1 população
Exemplo 1: Pesos aos 210 dias de bezerros da raça Nelore
Tarefa 4
a) Instale o software R em seu computador.
59
Site: http://www.r-project.org
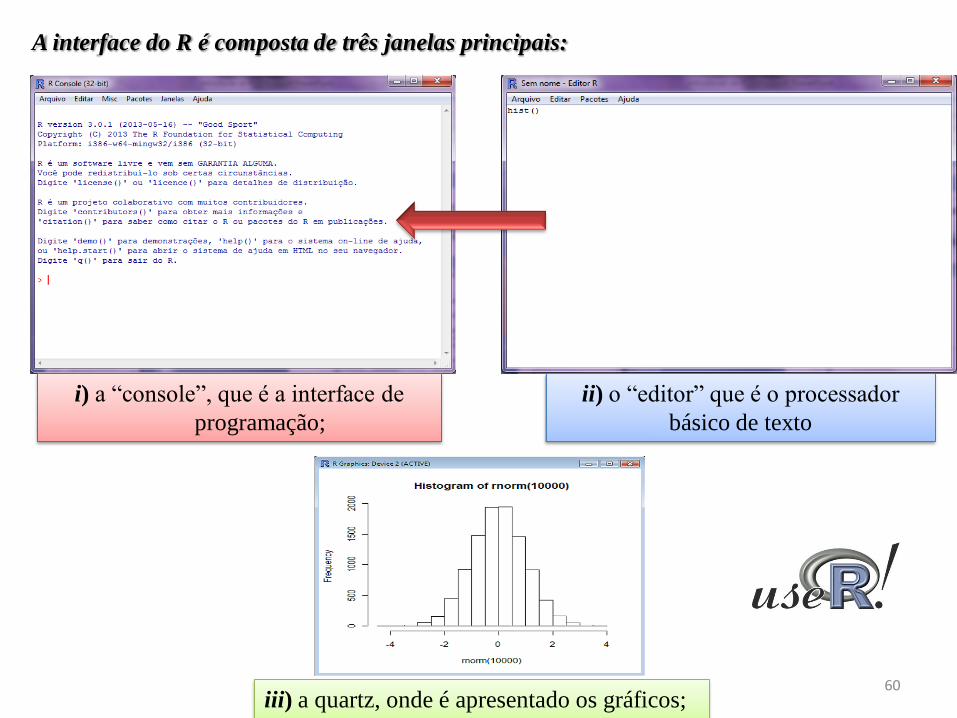
ii) o “editor” que é o processador
básico de texto
i) a “console”, que é a interface de
programação;
iii) a quartz, onde é apresentado os gráficos;
A interface do R é composta de três janelas principais:
60
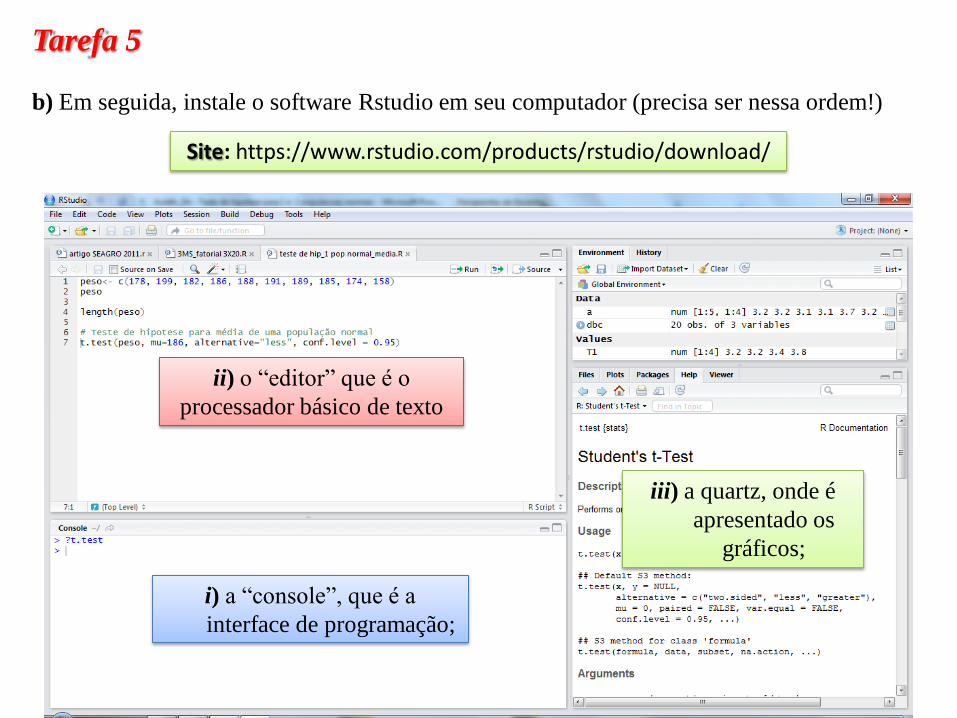
Tarefa 5
b) Em seguida, instale o software Rstudio em seu computador (precisa ser nessa ordem!)
61
Site: https://www.rstudio.com/products/rstudio/download/
ii) o “editor” que é o
processador básico de texto
i) a “console”, que é a
interface de programação;
iii) a quartz, onde é
apresentado os
gráficos;

Álgebra de matrizes
62

Álgebra matricial
Para a estatística ser usada (teórica ou aplicada), alguma álgebra matricial é
necessária. Todo software estatístico “entende” as informações do experimento
(dados) por meio de matrizes, por essa razão é útil, se não essencial, ter pelo
menos algum conhecimento nesta área da matemática.
A primeira vista, a notação de álgebra matricial é um pouco amedrontadora.
No entanto, não é difícil entender os princípios básicos, desde que alguns
detalhes sejam aceitos na fé.
a) Matrizes e vetores
a11 a12 ... a1n
a21 a22 ... a2n
.
.
.
.
.
.
...
...
...
.
.
.
am1 am2 ... amn
A(m n) =
Uma matriz m n é um
arranjo de números com m
linhas e n colunas,
considerado como uma
única entidade, da forma:
Se m = n então
ela é uma matriz
quadrada.

64
Se existe somente uma linha, tal como:
ou
c1
c2
.
.
.
cm
c(m 1) =
Se existe somente uma coluna, tal como:
então ela é chamada um vetor coluna.
r(1 n) =
então ela é chamada um vetor linha.
r1 r2 ... rn
r = (r1, r2, ..., rn)
O negrito é usado para
indicar matrizes e
vetores.

a11 a21 ... am1
a12 a22 ... am2
.
.
.
.
.
.
...
...
...
.
.
.
a1n a2n ... amn
A’(n m) =
A transposta de uma matriz é obtida trocando-se as linhas pelas colunas. Então a
transposta da matriz A já vista é:
Também a transposta de um vetor c é:
c’ = (c1, c2, ..., cn),
e a transposta do vetor linha r é o vetor coluna r’.





























