Embed Size (px)
Citation preview

SBD I
SISTEMAS
DE BANCO DE DADOS I
Versão 2000/2

Sistemas de Bancos de Dados I Índice 1. Introdução............................................................................................................................. 4
1.1. Dado ................................................................................................................................ 4 1.2. Informação....................................................................................................................... 4 1.3. A Informação como Recurso da Empresa ....................................................................... 4
2. Organizações Básicas de Arquivos ...................................................................................... 5 2.1. Conceitos......................................................................................................................... 5 2.2. Estruturas de Arquivos..................................................................................................... 5
2.2.1. Arquivo seqüencial..................................................................................................... 5 2.2.2. Arquivo seqüencial-indexado..................................................................................... 6 2.2.3. Arquivo indexado ....................................................................................................... 7 2.2.4. Arquivo direto............................................................................................................. 8
3. Bancos de Dados ................................................................................................................. 9 3.1. Banco de Dados (BD) ...................................................................................................... 9 3.2. Sistema de Gerência de Banco de Dados (SGBD).......................................................... 9
3.2.1. Processamento de Dados sem Banco de Dados....................................................... 9 3.2.2. Processamento de dados com uso de SGBD.......................................................... 10 3.2.3. Principais Componentes de um Sgbd...................................................................... 10 3.2.4. Características de um Sgbd..................................................................................... 10
3.3. Abstração de Dados ...................................................................................................... 11 3.4. Modelos de Bancos de Dados ....................................................................................... 11 3.5. Independência de Dados ............................................................................................... 12 3.6. Funções relacionadas ao Sgbd ..................................................................................... 12
3.6.1. Administrador de Dados .......................................................................................... 12 3.6.2. Administrador de Banco de Dados .......................................................................... 12 3.6.3. Projetista da Base de Dados.................................................................................... 12 3.6.4. Analista de Sistemas ............................................................................................... 12
3.7. Arquiteturas para uso do Sgbd ...................................................................................... 13 3.7.1. Mono-usuário ........................................................................................................... 13 3.7.2. Multi-Usuário com Processamento Central.............................................................. 13 3.7.3. Arquitetura em Rede com Servidor de Arquivos ...................................................... 13 3.7.4. Arquitetura Cliente/Servidor ..................................................................................... 13
3.8. Fases do Projeto de Bd ................................................................................................. 13 3.8.1. Construir o Modelo Conceitual................................................................................ 13 3.8.2. Construir o Modelo Lógico ....................................................................................... 13 3.8.3. Construir o Modelo Físico ........................................................................................ 13 3.8.4. Avaliar o Modelo Físico............................................................................................ 13 3.8.5. Implementar o BD.................................................................................................... 14
4. MODELAGEM DE DADOS................................................................................................. 14 4.1. Conceitos....................................................................................................................... 14 4.2. Tipos de Abstração ........................................................................................................ 14
4.2.1. Classificação............................................................................................................ 14 4.2.2. Agregação................................................................................................................ 14 4.2.3. Generalização.......................................................................................................... 14
4.3. Requisitos para Modelagem de Dados .......................................................................... 14 4.4. Modelos Conceituais...................................................................................................... 14 4.5. Modelos Lógicos ............................................................................................................ 15
4.5.1. Modelo Hierárquico.................................................................................................. 15 4.5.2. Modelo de Rede....................................................................................................... 15 4.5.3. Modelo Relacional ................................................................................................... 16

4.6. Modelo de Dados Físico ................................................................................................ 17 5. MODELO ENTIDADE-RELACIONAMENTO (M.E.R.) ........................................................ 18
5.1. Introdução...................................................................................................................... 18 5.2. Entidade......................................................................................................................... 18 5.3. Relacionamento............................................................................................................. 18
5.3.1. Auto-relacionamento................................................................................................ 19 5.3.2. Cardinalidade de Relacionamentos ......................................................................... 20 5.3.3. Cardinalidade Máxima ............................................................................................. 20 5.3.4. Classificação de Relacionamentos Binários ............................................................ 20 5.3.5. Relacionamento ternário.......................................................................................... 22 5.3.6. Cardinalidade mínima .............................................................................................. 22
5.4. Notações Alternativas .................................................................................................... 23 5.5. Atributo .......................................................................................................................... 23
5.5.1. Domínio ................................................................................................................... 24 5.5.2. Tipos de Atributos .................................................................................................... 24 5.5.3. Atributo de Relacionamento..................................................................................... 24 5.5.4. Identificador de Entidades ....................................................................................... 24 5.5.5. Relacionamento Identificador (Entidade Fraca) ....................................................... 25 5.5.6. Identificador de Relacionamentos............................................................................ 25
5.6. Generalização/Especialização....................................................................................... 25 5.7. Entidade Associativa (Agregação) ................................................................................. 27 5.8. Relacionamento Mutuamente Exclusivo ........................................................................ 28 5.9. Restrição de Persistência no Relacionamento .............................................................. 28 5.10. Esquema Textual do MER .......................................................................................... 29

Sistemas de Bancos de Dados I - 4
Sistemas de Bancos de Dados I
1. INTRODUÇÃO
1.1. DADO Representação de um evento do mundo físico, de um fato ou de uma idéia Representação de uma propriedade ou característica de um objeto real Não tem significado por si só Ex.: quantidade de Kwh consumidos em uma residência.
1.2. INFORMAÇÃO Organização e agregação dos dados, permitindo uma interpretação Informação interpretação dos dados Ex.: Consumo de energia comparado com a capacidade geradora da usina.
Dados Identificados Organizados Agrupados
Armazenados Recuperados
geram Informação
1.3. A INFORMAÇÃO COMO RECURSO DA EMPRESA

Sistemas de Bancos de Dados I - 5
2. ORGANIZAÇÕES BÁSICAS DE ARQUIVOS
2.1. CONCEITOS Estruturas de Dados: define a forma como os dados estão organizados, como se relacionam e como
serão manipulados pelos programas. Ex: vetores e matrizes, registros, filas, pilhas, árvores, grafos, etc.
Arquivo: coleção de registros lógicos, cada um deles representando um objeto ou entidade. Na prática os arquivos geralmente estão armazenados na memória secundária (fitas e discos) e são usados para armazenar os resultados intermediários de processamento ou armazenar os dados de forma permanente.
Registro lógico (registro) : seqüência de itens, cada item sendo chamado de campo ou atributo, correspondendo a uma característica do objeto representado. Os registros podem ser de tamanho fixo ou de tamanho variável.
Campo: item de dados do registro, com um nome e um tipo associados Bloco: unidade de armazenamento do arquivo em disco, também denominado registro físico. Um
registro físico normalmente é composto por vários registros lógicos. Cada bloco armazena um número inteiro de registros.
Chave: é uma seqüência de um ou mais campos em um arquivo Chave primária: é uma chave que apresenta um valor diferente para cada registro do arquivo. É
usada para identificar, de forma única, cada registro. Chave secundaria: é uma chave que pode possuir o mesmo valor em registro distintos. É
normalmente usada para identificar um conjunto de registros. Chave de acesso: é uma chave usada para identificar o(s) registro(s) desejado(s) em uma operação de
acesso ao arquivo.
2.2. ESTRUTURAS DE ARQUIVOS
2.2.1. ARQUIVO SEQÜENCIAL Nos arquivos seqüenciais a ordem lógica e física dos registros armazenados é a mesma. Os
registros podem estar dispostos seguindo a seqüência determinada por uma chave primária (chamada chave de ordenação), ou podem estar dispostos aleatoriamente.
# Numero Nome Idade Salario 0 1000 ADEMAR 25 600 1 1050 AFONSO 27 700 2 1075 CARLOS 28 500 3 1100 CESAR 30 1000 4 1150 DARCI 23 1500 5 1180 EBER 22 2000 6 1250 ENIO 27 750 7 1270 FLAVIO 28 600 8 1300 IVAN 30 700 9 1325 MIGUEL 34 1000 10 1340 MARIA 35 1500 11 1360 RAMON 32 2000 12 1400 SANDRA 29 700 13 1450 TATIANA 30 500
a) Acesso a um registro
Podemos considerar dois tipos de acesso: seqüencial ou aleatório. O acesso seqüencial consiste em acessar os registros na ordem em que estão armazenados, ou
seja, o registro obtido é sempre o posterior ao último acessado. Como os registros são armazenados em sucessão contínua, acessar o registro “n” de um arquivo requer a leitura dos “n-1” registros anteriores.

Sistemas de Bancos de Dados I - 6
O acesso aleatório se caracteriza pela utilização de um “argumento de pesquisa” (chave de acesso), que indica qual o registro desejado. Neste caso, a ordem em que os registros são acessados pode ser diferente da ordem em que eles estão armazenados fisicamente. Se o arquivo está ordenado e a chave de acesso coincide com a chave de ordenação, podemos utilizar a pesquisa binária. Caso contrário, deve ser realizada uma pesquisa seqüencial no arquivo. b) Inserção de um registro
Se o arquivo não está ordenado, o registro pode ser simplesmente inserido após o último registro armazenado.
Se o arquivo está ordenado, normalmente é adotado o seguinte procedimento: Dado um arquivo base B, é construído um arquivo de transações T, que contem os registros a
serem inseridos, ordenado pela mesma chave que o arquivo B. Os arquivos B e T são então intercalados, gerando o arquivo A, que é a versão atualizada de B.
Arquivo B Arquivo T Arquivo A # Num Nome Idade # Num Nome Idade # Num Nome Idade 0 1000 ADEMAR 25 0 1070 ANGELA 25 0 1000 ADEMAR 25 1 1050 AFONSO 27 1 1120 CLAUDIA 27 1 1050 AFONSO 27 2 1075 CARLOS 28 2 1280 IARA 28 2 1070 ANGELA 25 3 1100 CESAR 30 3 1310 LUIS 30 3 1075 CARLOS 28 4 1150 DARCI 23 4 1420 SONIA 23 4 1100 CESAR 30 5 1180 EBER 22 5 1120 CLAUDIA 27 6 1250 ENIO 27 6 1150 DARCI 23 7 1270 FLAVIO 28 7 1180 EBER 22 8 1300 IVAN 30 8 1250 ENIO 27 9 1325 MIGUEL 34 9 1270 FLAVIO 28 10 1340 MARIA 35 10 1280 IARA 28 11 1360 RAMON 32 11 1300 IVAN 30 12 1400 SANDRA 29 12 1310 LUIS 30 13 1450 TATIANA 30 13 1325 MIGUEL 34
14 1340 MARIA 35 15 1360 RAMON 32 16 1400 SANDRA 29 17 1420 SONIA 23
18 1450 TATIANA 30
c) Exclusão de um registro
Normalmente é implementada como a inserção, com a criação de um arquivo de transações que contém os registros a serem excluídos, que é processado posteriormente.
Pode ainda ser implementada através de um campo adicional no arquivo que indique o estado (status) de cada registro. Na exclusão, o valor deste campo seria alterado para “excluído”. Posteriormente, é feita a leitura seqüencial de todos os registros, sendo que os registros que não estiverem marcados como “excluídos” são copiados para um novo arquivo. d) Alteração de um registro
Consiste na modificação do valor de um ou mais atributos de um registro. O registro deve ser localizado, lido e os campos alterados, sendo gravado novamente, na mesma posição.
A alteração é feita sem problemas, desde que ela não altere o tamanho do registro nem modifique o valor de um campo usado como chave de ordenação.
2.2.2. ARQUIVO SEQÜENCIAL-INDEXADO Quando o volume de acessos aleatórios em um arquivo seqüencial torna-se muito grande, é
necessário utilizar uma estrutura de acesso que ofereça maior eficiência na localização de um registro com base em uma chave de acesso.
O arquivo seqüencial-indexado é um arquivo seqüencial acrescido de uma estrutura de acesso (índice). Um índice é formado por uma coleção de pares, associando um valor da chave de acesso a um endereço de registro. Deve existir um índice específico para cada chave de acesso.

Sistemas de Bancos de Dados I - 7
Índice Primário Índice Secundário Arquivo # Num End. # Num End. # Num Nome Idade 0 1300 0 0 1070 0 0 1000 ADEMAR 25 1 1605 3 1 1200 3 1 1050 AFONSO 27 2 ** 6 2 1300 6 2 1070 ANGELA 25
3 1430 9 3 1075 CARLOS 28 4 1520 12 4 1100 CESAR 30 5 1605 15 5 1200 CLAUDIA 25 6 1710 18 6 1250 CRISTIE 26 7 1745 21 7 1275 DARCI 29 8 ** 24 8 1300 DIOGO 25 9 1310 ELBER 27 10 1400 EDISON 25 11 1430 EDMUNDO 28 12 1470 ENIO 30 13 1510 FLAVIO 25 14 1520 GENARO 26 15 1530 GERSON 29 16 1590 HELENA 25 17 1605 IARA 27 18 1650 IVAN 25 19 1700 LUIS 28 20 1710 MARIA 30 21 1730 MIGUEL 25 22 1740 RAMON 26 23 1745 SANDRA 29 24 1800 SONIA 32 25 1905 TATIANA 34
** Maior valor que a chave pode assumir
** Maior valor que a chave pode assumir
26 2010 WILSON 20
2.2.3. ARQUIVO INDEXADO O arquivo indexado é aquele em que os registros são acessados através de um ou mais índices,
não havendo qualquer compromisso com a ordem em que os registros estão armazenados. Podem existir tantos índices quantas forem as chaves de acesso aos registros. As entradas no
índice são ordenadas pelo valor das chaves de acesso, sendo cada uma delas constituída por um par (chave do registro, endereço do registro).
Índice Arquivo Num End. # Num Nome Idade Salário 1000 1 0 2010 WILSON 26 1000 1050 13 1 1000 ADEMAR 32 250 1070 2 2 1070 ANGELA 28 300 1075 16 3 1200 CLAUDIA 25 750 1100 22 4 1300 DIOGO 24 400 1200 3 5 1400 EDISON 22 1500 1250 10 6 1510 FLAVIO 30 250 1275 19 7 1590 HELENA 26 300 1300 4 8 1650 IVAN 32 750 1310 14 9 1730 MIGUEL 28 400 1400 5 10 1250 CRISTIE 25 1500 1430 17 11 1520 GENARO 24 750 1470 23 12 1740 RAMON 22 400 1510 6 13 1050 AFONSO 30 1500 1520 11 14 1310 ELBER 26 250 1530 20 15 1605 IARA 32 300 1590 7 16 1075 CARLOS 28 750 1605 15 17 1430 EDMUNDO 26 400 1650 8 18 1700 LUIS 32 1500 1700 18 19 1275 DARCI 26 750 1710 24 20 1530 GERSON 26 400 1730 9 21 1745 SANDRA 32 400 1740 12 22 1100 CESAR 28 1500 1745 21 23 1470 ENIO 25 750 1800 25 24 1710 MARIA 24 400 1905 26 25 1800 SONIA 22 750 2010 0 26 1905 TATIANA 30 400
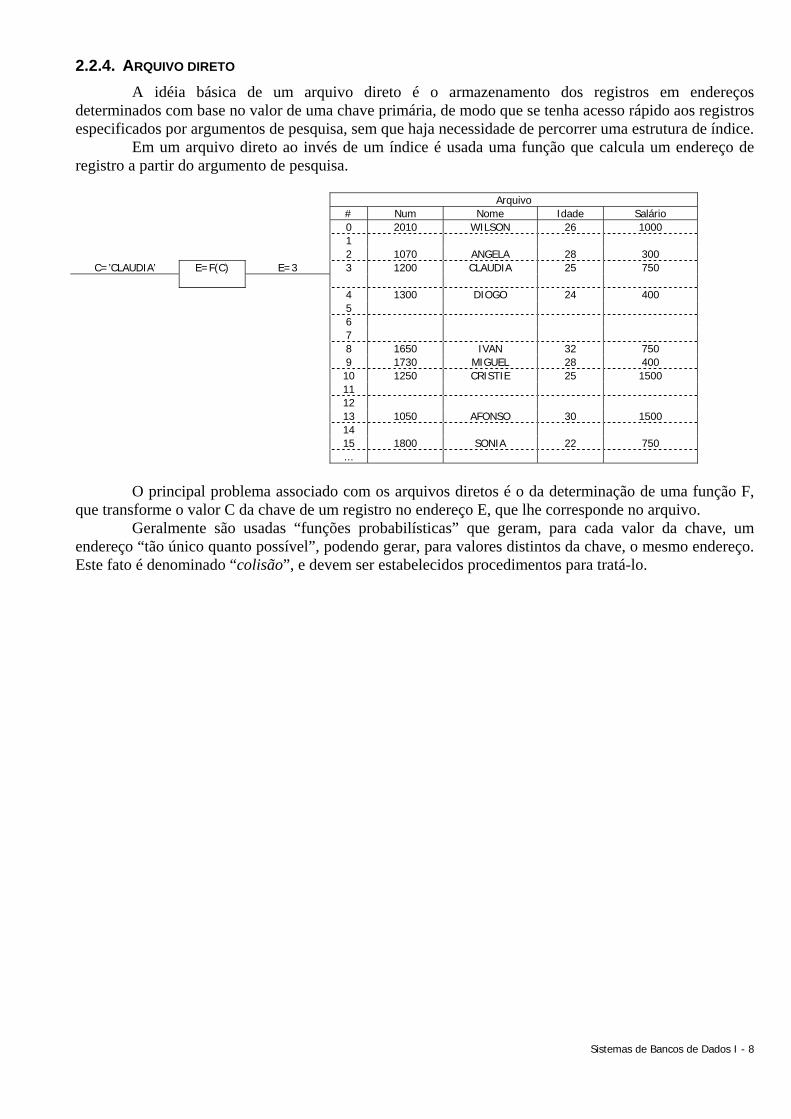
Sistemas de Bancos de Dados I - 8
2.2.4. ARQUIVO DIRETO A idéia básica de um arquivo direto é o armazenamento dos registros em endereços
determinados com base no valor de uma chave primária, de modo que se tenha acesso rápido aos registros especificados por argumentos de pesquisa, sem que haja necessidade de percorrer uma estrutura de índice.
Em um arquivo direto ao invés de um índice é usada uma função que calcula um endereço de registro a partir do argumento de pesquisa.
Arquivo # Num Nome Idade Salário 0 2010 WILSON 26 1000 1 2 1070 ANGELA 28 300
C=’CLAUDIA’ E=3
E=F(C)
3 1200 CLAUDIA 25 750
4 1300 DIOGO 24 400 5 6 7 8 1650 IVAN 32 750 9 1730 MIGUEL 28 400 10 1250 CRISTIE 25 1500 11 12 13 1050 AFONSO 30 1500 14 15 1800 SONIA 22 750 ...
O principal problema associado com os arquivos diretos é o da determinação de uma função F,
que transforme o valor C da chave de um registro no endereço E, que lhe corresponde no arquivo. Geralmente são usadas “funções probabilísticas” que geram, para cada valor da chave, um
endereço “tão único quanto possível”, podendo gerar, para valores distintos da chave, o mesmo endereço. Este fato é denominado “colisão”, e devem ser estabelecidos procedimentos para tratá-lo.

Sistemas de Bancos de Dados I - 9
3. BANCOS DE DADOS
3.1. BANCO DE DADOS (BD) Um Banco de Dados (BD) pode ser definido como uma coleção de dados interrelacionados,
armazenados de forma centralizada ou distribuída, com redundância controlada, para servir a uma ou mais aplicações.
3.2. SISTEMA DE GERÊNCIA DE BANCO DE DADOS (SGBD) Conjunto de software para gerenciar (definir, criar, modificar, usar) um BD e garantir a
integridade e segurança dos dados. O SGBD é a interface entre os programas de aplicação e o BD. Em inglês é denominado DataBase Management System (DBMS).
3.2.1. PROCESSAMENTO DE DADOS SEM BANCO DE DADOS Dados de diferentes aplicações não estão integrados, pois são projetados para atender a uma
aplicação específica.

Sistemas de Bancos de Dados I - 10
Problemas da falta de integração de dados: O mesmo objeto da realidade é múltiplas vezes representado na base de dados. Exemplo:
dados de um produto em uma indústria Redundância não controlada de dados: Não há gerência automática da redundância, o que
leva a inconsistência dos dados devido a redigitação de informações Dificuldade de extração de informações: os dados são projetados para atender aplicações
especificas gerando dificuldades para o cruzamento de informações Dados pouco confiáveis e de baixa disponibilidade
3.2.2. PROCESSAMENTO DE DADOS COM USO DE SGBD Os dados usados por uma comunidade de usuários são integrados no Banco de Dados. Cada
informação é armazenada uma única vez, sendo que as eventuais redundâncias são controladas pelo sistema em computador, ficando transparentes para os usuários.
3.2.3. PRINCIPAIS COMPONENTES DE UM SGBD Dicionário de dados (Data Dictionary): Descreve os dados e suas relações em forma conceitual e
independente de seu envolvimento nas diversas aplicações. Fornece referências cruzadas entre os dados e as aplicações.
Linguagem de definição de dados (DDL - Data Definition Language): Descreve os dados que estão armazenados no BD. As descrições dos dados são guardadas em um “meta banco de dados”.
Linguagem de acesso (DML - Data Manipulation Language): Usada para escrever as instruções que trabalham sobre a base de dados, permitindo o acesso e atualização dos dados pelos programas de aplicação. Geralmente integrada com a DDL.
Linguagem de consulta (QUERY): Permite que o usuário final, com poucos conhecimentos técnicos, possa obter de forma simples, informações do BD.
Utilitários administrativos: Programas auxiliares para carregar, reorganizar, adicionar, modificar a descrição do BD, obter cópias de reserva e recuperar a integridade física em caso de acidentes.
3.2.4. CARACTERÍSTICAS DE UM SGBD Um princípio básico em BD determina que cada item de dado deveria ser capturado apenas uma
vez e então armazenado, de modo que possa tornar disponível para atender a qualquer necessidade de acesso qualquer momento.
Alguns pontos importantes são: Independência dos dados: O SGBD deve oferecer isolamento das aplicações em relação aos
dados. Esta característica permite modificar o modelo de dados do BD sem necessidade de reescrever ou recompilar todos os programas que estão prontos. As definições dos dados e os relacionamentos entre os dados são separados dos códigos os programas. Mais de 80 % do

Sistemas de Bancos de Dados I - 11
tempo dos analistas e programadores é gasto na manutenção de programas. A principal causa deste elevado tempo reside na falta de independência entre dados e programas.
Facilidade uso/desempenho: Embora o SGBD trabalhe com estruturas de dados complexas, os arquivos devem ser projetados para atender a diferentes necessidades, permitindo desenvolver aplicações melhores, mais seguras e mais rapidamente. Deve possui comandos poderosos em sua linguagem de acesso.
Integridade dos dados: O SGBD deve garantir a integridade dos dados, através da implementação de restrições adequadas. Isto significa que os dados devem ser precisos e válidos.
Redundância dos dados: O SGBD deve manter a redundância de dados sob controle, ou seja, ainda que existam diversas representações do mesmo dado, do ponto de vista do usuário é como se existisse uma única representação.
Segurança e privacidade dos dados: O SGBD deve assegurar que estes só poderão ser acessados ou modificados por usuários autorizados.
Rápida recuperação após falha: Os dados são de importância vital e não podem ser perdidos. Assim, o SGBD deve implementar sistemas de tolerância a falhas, tais como estrutura automática de recover e uso do conceito de transação.
Uso compartilhado: O BD pode ser acessado concorrentemente por múltiplos usuários. Controle do espaço de armazenamento: O SGBD deve manter controle das áreas de disco
ocupadas, evitando a ocorrência de falhas por falta de espaço de armazenamento.
3.3. ABSTRAÇÃO DE DADOS Um propósito central de um SGBD é proporcionar aos usuários uma visão abstrata dos dados,
isto é, o sistema esconde certos detalhes de como os dados são armazenados ou mantidos. No entanto, os dados precisam ser recuperados eficientemente.
A preocupação com a eficiência leva a concepção de estruturas de dados complexas para representação dos dados no BD. Porém, uma vez que SGBD são freqüentemente usados por pessoas sem treinamento na área de computação, esta complexidade precisa ser escondida dos usuários. Isto é conseguido definindo-se diversos níveis de abstração pelos quais o BD pode ser visto:
NÍVEL FÍSICO: É o nível mais baixo de abstração, no qual se descreve como os dados são armazenados. Estruturas complexas, de baixo nível, são descritas em detalhe.
NÍVEL CONCEITUAL: É o nível que descreve quais os dados são realmente armazenados no BD e quais os relacionamentos existentes entre eles. Este nível descreve o BD como um pequeno número de estruturas relativamente simples. Muito embora a implementação de estruturas simples no nível conceitual possa envolver estruturas complexas no nível físico, o usuário do nível conceitual não precisa saber disto.
NÍVEL VISÃO: Este é o nível mais alto de abstração, no qual se expõe apenas parte do BD. Na maioria das vezes os usuários não estão preocupados com todas as informações do BD e sim com apenas parte delas (Visões dos Usuários)
3.4. MODELOS DE BANCOS DE DADOS Um modelo de (banco de) dados é uma descrição dos tipos de informações que estão
armazenadas em um banco de dados, ou seja, é a descrição formal da estrutura de BD. Estes modelos podem ser escritos em linguagens textuais ou linguagens gráficas. Cada
apresentação do modelo é denominado “esquema de banco de dados”. Se tomarmos como exemplo uma indústria, o modelo de dados deve mostrar que são
armazenadas informações sobre produtos, tais como código, descrição e preço. Porém o modelo de dados não vai informar quais produtos estão armazenados no Banco de Dados.
No projeto de um banco de dados, geralmente são considerados 3 modelos: conceitual, lógico e físico.

Sistemas de Bancos de Dados I - 12
Modelo conceitual: É uma descrição mais abstrata da base de dados. Não contém detalhes de implementação e é independente do tipo de SGBD usado. É o ponto de partida para o projeto da base de dados.
Modelo Lógico: É a descrição da base de dados conforme é vista pelos usuário do SGBD (programadores e aplicações). É dependente do tipo de SGBD escolhido, mas não contém detalhes da implementação (uma vez que o SGBD oferece abstração e independência de dados).
Modelo físico (interno): Descrição de como a base de dados é armazenada internamente. Geralmente só é alterada para ajuste de desempenho. A tendência dos produtos modernos é ocultar cada vez mais os detalhes físicos de implementação.
3.5. INDEPENDÊNCIA DE DADOS Independência de dados a nível físico: a capacidade de se modificar o modelo físico, sem precisar
reescrever os programas de aplicação. Independência dados a nível lógico: a capacidade de se modificar o esquema lógico, sem a
necessidade de reescrever os programas de aplicação. Modificações no nível lógico são necessárias sempre que a estrutura lógica do BD for alterada. Em alguns casos a recompilação pode ser requerida.
3.6. FUNÇÕES RELACIONADAS AO SGBD
3.6.1. ADMINISTRADOR DE DADOS Gerenciar o dado como um recurso da empresa. Planejar, desenvolver e divulgar as bases de dados da empresa. Permitir a descentralização dos processos, mas manter centralizado os dados. Permitir fácil e rápido acesso as informações a partir dos dados armazenados. O grande objetivo de administrador de dados é permitir que vários usuários compartilhem os mesmos
dados. Deste modo, os dados não pertencem a nenhum sistema ou usuário de forma específica, e sim, à organização como um todo. Assim, o administrador de dados se preocupa basicamente com a organização dos dados e não com o seu armazenamento.
3.6.2. ADMINISTRADOR DE BANCO DE DADOS O DBA (DataBase Administrator) é pessoa ou grupo de pessoas responsável pelo controle do
SGBD. São tarefas do DBA: Responsabilidade pelos modelos lógico e físico (definindo a estrutura de armazenamento) Coordenar o acesso ao SGBD (usuários e senhas) Definir a estratégia de backup Melhorar o desempenho do SGBD Manter o dicionário de dados
3.6.3. PROJETISTA DA BASE DE DADOS Constrói o modelo conceitual de uma parte da base de dados, com a participaçào do usuário.
Junto com o DBA integra as novas partes ao banco de dados global.
3.6.4. ANALISTA DE SISTEMAS Define e projeta aplicação que irão usar a base de dados existente. Utiliza o modelo conceitual e
o modelo lógico existentes, mas não define os dados da base de dados.

Sistemas de Bancos de Dados I - 13
3.7. ARQUITETURAS PARA USO DO SGBD
3.7.1. MONO-USUÁRIO BD está no mesmo computador que as aplicações Não há múltiplos usuários Recuperação geralmente através de backup Típico de computadores pessoais
3.7.2. MULTI-USUÁRIO COM PROCESSAMENTO CENTRAL BD está no mesmo computador que as aplicações Múltiplos usuários acessando através de terminais Típico de ambientes com mainframe
3.7.3. ARQUITETURA EM REDE COM SERVIDOR DE ARQUIVOS Multi-usuário Servidor de arquivos contém todos os arquivos do banco de dados As estações clientes executam as aplicações e o software de BD Gera alto tráfego na rede Típico de redes pequenas (peer-to-peer)
3.7.4. ARQUITETURA CLIENTE/SERVIDOR Multi-usuário Servidor dedicado ao Banco de Dados, executando o SGBD As estações clientes executam apenas as aplicações Tráfego na rede é menor Arquitetura atualmente em uso
3.8. FASES DO PROJETO DE BD
3.8.1. CONSTRUIR O MODELO CONCEITUAL Modelo de alto nível, independente da implementação Etapa de levantamento de dados Uso de uma técnica de modelagem de dados Abstração do ambiente de hardware/software
3.8.2. CONSTRUIR O MODELO LÓGICO Modelo implementável, dependente do tipo de SGBD a ser usado Considera as necessidades de processamento Considera as características e restrições do SGBD Etapa de normalização dos dados
3.8.3. CONSTRUIR O MODELO FÍSICO Modelo implementável, com métodos de acesso e estrutura física Considera necessidades de desempenho Considera as características e restrições do SGBD Dependente das características de hardware/software
3.8.4. AVALIAR O MODELO FÍSICO Avaliar o desempenho das aplicações Avaliar os caminhos de acesso aos dados e estruturas utilizadas

Sistemas de Bancos de Dados I - 14
3.8.5. IMPLEMENTAR O BD Etapa de carga (load) dos dados Gerar as interfaces com outras aplicações
4. MODELAGEM DE DADOS
4.1. CONCEITOS Abstração: processo mental através do qual selecionamos determinadas propriedades ou
características dos objetos e excluímos outras, consideradas menos relevantes para o problema sendo analisado.
Modelo: é uma abstração, uma representação simplificada, de uma parcela do mundo real, composta por objetos reais.
Modelagem: atividade através da qual se cria um modelo. Modelo de dados: Um modelo de dados é uma descrição das informações que devem ser
armazenadas em um banco de dados, ou seja, é a descrição formal da estrutura de BD (descrição dos dados, dos relacionamentos entre os dados, da semântica e das restrições impostas aos dados).
4.2. TIPOS DE ABSTRAÇÃO
4.2.1. CLASSIFICAÇÃO Os objetos do mundo real são organizados segundo suas propriedades ou características comuns,
formando classes de objetos. Um objeto pode pertencer simultaneamente a várias classes.
4.2.2. AGREGAÇÃO Uma classe é definida a partir de um conjunto de outras classes, que representam suas partes
componentes.
4.2.3. GENERALIZAÇÃO Define uma nova classe a partir de características comuns de outras classes. A classe genérica
que reúne as características comuns é denominada superclasse e as classes que herdam estas características são denominadas subclasses.
4.3. REQUISITOS PARA MODELAGEM DE DADOS Entender a realidade em questão, identificando os objetos que compõe a parte da realidade que vai ser
modelada.. Representar formalmente a realidade analisada, construindo um modelo de dados. Estruturar o modelo obtido e adequá-lo ao SGBD a ser usado, transformando o modelo conceitual em
modelo lógico.
4.4. MODELOS CONCEITUAIS São usados para descrição de dados no nível conceitual. Proporcionam grande capacidade de
estruturação e permitem a especificação de restrições de dados de forma explícita. Exemplos: Modelo Entidade-Relacionamento (M.E.R.) Modelo de Semântica de dados Modelo Infológico Modelos Orientados para Objetos (OO)

Sistemas de Bancos de Dados I - 15
4.5. MODELOS LÓGICOS São usados na descrição dos dados no nível lógico. Em contraste com modelos conceituais,
esses modelos são usados para especificar tanto a estrutura lógica global do BD como uma descrição em alto nível da implementação.
4.5.1. MODELO HIERÁRQUICO Um BD hierárquico é uma coleção de árvores de registros. Os registros são usados para
representar os dados e ponteiros são usados para representar o relacionamento entre os dados, numa ligação do tipo pai-filho. A restrição é que um determinado registro somente pode possuir um registro pai.
4.5.2. MODELO DE REDE O BD em rede é um grafo, onde os nós representam os registros e os arcos representam os
relacionamentos entre os registros, através de ligações pai-filho. Diferente do modelo hierárquico, um registro pode possuir diversos registros pai.

Sistemas de Bancos de Dados I - 16
4.5.3. MODELO RELACIONAL Um BD relacional possui apenas um tipo de construção, a tabela. Uma tabela é composta por
linhas (tuplas) e colunas (atributos). Os relacionamentos entre os dados também são representados ou por tabelas, ou através da reprodução dos valores de atributos.

Sistemas de Bancos de Dados I - 17
4.6. MODELO DE DADOS FÍSICO Usados para descrever os dados em seu nível mais baixo. Capturam os aspectos de
implementação do SGBD.

Sistemas de Bancos de Dados I - 18
5. MODELO ENTIDADE-RELACIONAMENTO (M.E.R.)
5.1. INTRODUÇÃO Apresentado por Peter Chen, em 1976 É a técnica mais difundida para construir modelos conceituais de bases de dados É o padrão para modelagem conceitual, tendo sofrido diversas extensões Está baseado na percepção de uma realidade constituída por um grupo básico de objetos chamados
ENTIDADES e por RELACIONAMENTOS entre estas entidades Seu objetivo é definir um modelo de alto nível independente de implementação O modelo é representado graficamente por um Diagrama de Entidade-Relacionamento (DER), que é
simples e fácil de ser entendido por usuários não técnicos Conceitos centrais do MER: entidade, relacionamento, atributo, generalização/especialização,
agregação (entidade associativa)
5.2. ENTIDADE Conjunto de objetos da realidade modelada sobre os quais deseja-se manter informações no Banco de
Dados Uma entidade pode representar objetos concretos da realidade (pessoas, automóveis, material, nota
fiscal) quanto objetos abstratos (departamentos, disciplinas, cidades) A entidade se refere a um conjunto de objetos; para se referir a um objeto em particular é usado o
termo instância (ou ocorrência) No DER, uma entidade é representada através de um retângulo que contém o nome da entidade
5.3. RELACIONAMENTO É toda associação entre entidades, sobre a qual deseja-se manter informações no Banco de Dados. Os relacionamentos representam fatos ou situações da realidade, onde as entidades interagem de
alguma forma Um dado por si só não faz uma informação, pois não tem sentido próprio; é necessário que haja uma
associação de dados para que a informação seja obtida. Exemplos:
Fornecimento: entre as entidades FORNECEDOR e MATERIAL Matrícula: entre as entidades ALUNO e DISCIPLINA Financiamento: entre as entidades PROJETO e AGENTE FINANCEIRO
No DER, os relacionamentos são representados por losangos, ligados às entidades que participam do relacionamento
PESSOA DEPARTAMENTO
DEPARTAMENTO PESSOALOTAÇÃ

Sistemas de Bancos de Dados I - 19
Diagrama de ocorrências de relacionamentos:
5.3.1. AUTO-RELACIONAMENTO Relacionamento entre ocorrências da mesma entidade. Diagrama de ocorrências no auto-relacionamento:
O papel da entidade no relacionamento indica a função que uma ocorrência de uma entidade
cumpre em uma ocorrência de um relacionamento.
marido esposa
PESSOA
CASAMENTO
Sistemas de Bancos de Dados I - 20
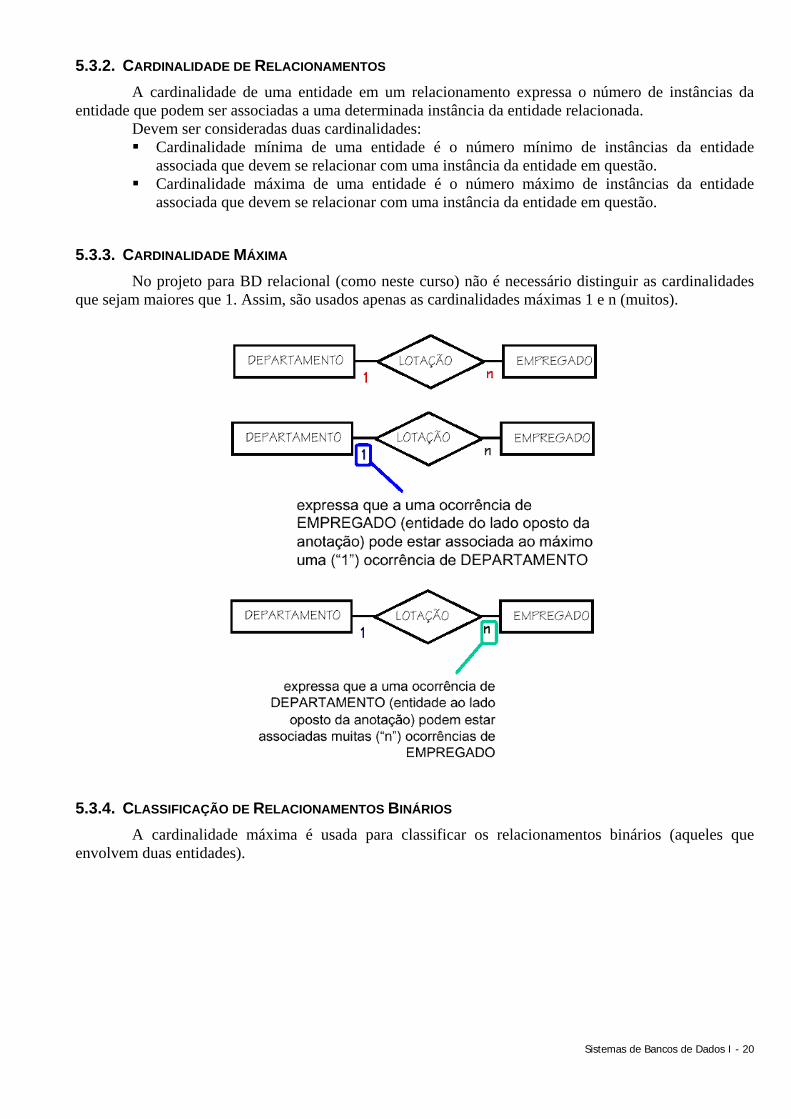
5.3.2. CARDINALIDADE DE RELACIONAMENTOS A cardinalidade de uma entidade em um relacionamento expressa o número de instâncias da
entidade que podem ser associadas a uma determinada instância da entidade relacionada. Devem ser consideradas duas cardinalidades: Cardinalidade mínima de uma entidade é o número mínimo de instâncias da entidade
associada que devem se relacionar com uma instância da entidade em questão. Cardinalidade máxima de uma entidade é o número máximo de instâncias da entidade
associada que devem se relacionar com uma instância da entidade em questão.
5.3.3. CARDINALIDADE MÁXIMA No projeto para BD relacional (como neste curso) não é necessário distinguir as cardinalidades
que sejam maiores que 1. Assim, são usados apenas as cardinalidades máximas 1 e n (muitos).
5.3.4. CLASSIFICAÇÃO DE RELACIONAMENTOS BINÁRIOS A cardinalidade máxima é usada para classificar os relacionamentos binários (aqueles que
envolvem duas entidades).

Sistemas de Bancos de Dados I - 21
a) Relacionamentos 1:1 (um-para-um)
b) Relacionamentos 1:N (um-para-muitos)
c) Relacionamentos N:N (muitos-para-muitos)

Sistemas de Bancos de Dados I - 22
5.3.5. RELACIONAMENTO TERNÁRIO É o relacionamento formado pela associação de três entidades
Cardinalidade em relacionamentos ternários:
5.3.6. CARDINALIDADE MÍNIMA A cardinalidade mínima é usada para indicar o tipo de participação da entidade em um
relacionamento. Esta participação pode ser: Parcial ou Opcional: quando uma ocorrência da entidade pode ou não participar de
determinado relacionamento; é indicado pela cardinalidade mínima = 0 (zero). Total ou Obrigatória: quando todas as ocorrências de uma entidade devem participar de
determinado relacionamento; é indicado pela cardinalidade mínima > 0 (zero). Exemplos: Um cliente pode fazer pedidos ou não, mas todos os pedidos devem estar associados a um
cliente.
1 N CLIENTE REALIZA PEDIDO
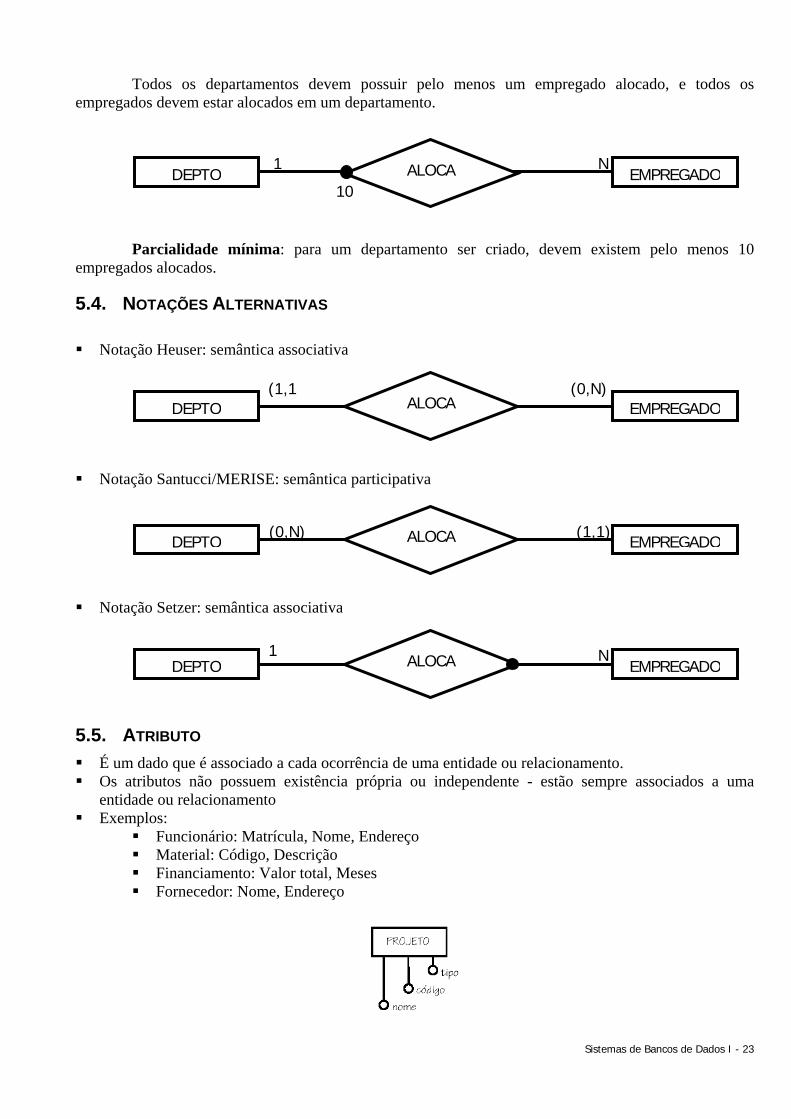
1 N DEPTO ALOCA EMPREGADO
Sistemas de Bancos de Dados I - 23
Todos os departamentos devem possuir pelo menos um empregado alocado, e todos os
empregados devem estar alocados em um departamento. Parcialidade mínima: para um departamento ser criado, devem existem pelo menos 10
empregados alocados.
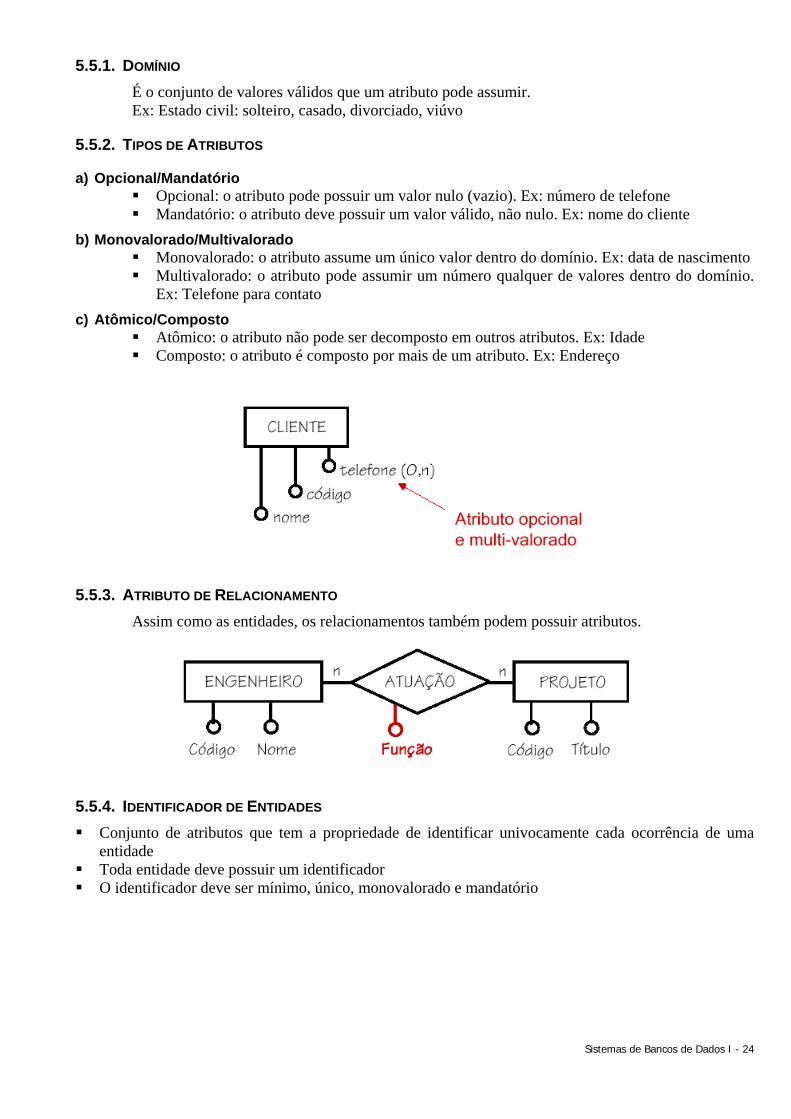
5.4. NOTAÇÕES ALTERNATIVAS Notação Heuser: semântica associativa
Notação Santucci/MERISE: semântica participativa
Notação Setzer: semântica associativa
5.5. ATRIBUTO É um dado que é associado a cada ocorrência de uma entidade ou relacionamento. Os atributos não possuem existência própria ou independente - estão sempre associados a uma
entidade ou relacionamento Exemplos:
Funcionário: Matrícula, Nome, Endereço Material: Código, Descrição Financiamento: Valor total, Meses Fornecedor: Nome, Endereço
10
1 N DEPTO ALOCA EMPREGADO
(1,1 (0,N) DEPTO ALOCA EMPREGADO
(0,N) (1,1) DEPTO ALOCA EMPREGADO
1 N DEPTO ALOCA EMPREGADO
Sistemas de Bancos de Dados I - 24
5.5.1. DOMÍNIO É o conjunto de valores válidos que um atributo pode assumir. Ex: Estado civil: solteiro, casado, divorciado, viúvo
5.5.2. TIPOS DE ATRIBUTOS
a) Opcional/Mandatório Opcional: o atributo pode possuir um valor nulo (vazio). Ex: número de telefone Mandatório: o atributo deve possuir um valor válido, não nulo. Ex: nome do cliente
b) Monovalorado/Multivalorado Monovalorado: o atributo assume um único valor dentro do domínio. Ex: data de nascimento Multivalorado: o atributo pode assumir um número qualquer de valores dentro do domínio.
Ex: Telefone para contato c) Atômico/Composto
Atômico: o atributo não pode ser decomposto em outros atributos. Ex: Idade Composto: o atributo é composto por mais de um atributo. Ex: Endereço
5.5.3. ATRIBUTO DE RELACIONAMENTO Assim como as entidades, os relacionamentos também podem possuir atributos.
5.5.4. IDENTIFICADOR DE ENTIDADES Conjunto de atributos que tem a propriedade de identificar univocamente cada ocorrência de uma
entidade Toda entidade deve possuir um identificador O identificador deve ser mínimo, único, monovalorado e mandatório

Sistemas de Bancos de Dados I - 25
5.5.5. RELACIONAMENTO IDENTIFICADOR (ENTIDADE FRACA) Existem casos em que uma entidade não pode ser identificada apenas com seus próprios
atributos, mas necessita de atributos de outras entidades com as quais se relaciona. Este relacionamento é denominado Relacionamento Identificador. Alguns autores denominam uma entidade nesta situação de Entidade Fraca.
5.5.6. IDENTIFICADOR DE RELACIONAMENTOS Uma ocorrência de relacionamento diferencia-se das demais pelas ocorrências das entidades que
participam do relacionamento. No exemplo
No exemplo, uma ocorrência de ALOCAÇÃO é identificada pela ocorrência de Engenheiro e
pela ocorrência de Projeto. Ou seja, para cada par (engenheiro, projeto) há no máximo um relacionamento de alocação.
Em certos casos, será necessário o uso de atributos identificadores de relacionamentos. Por exemplo:
Como o mesmo médico pode consultar o mesmo paciente em diversas ocasiões, é necessário o
uso de um atributo que diferencie uma consulta da outra.
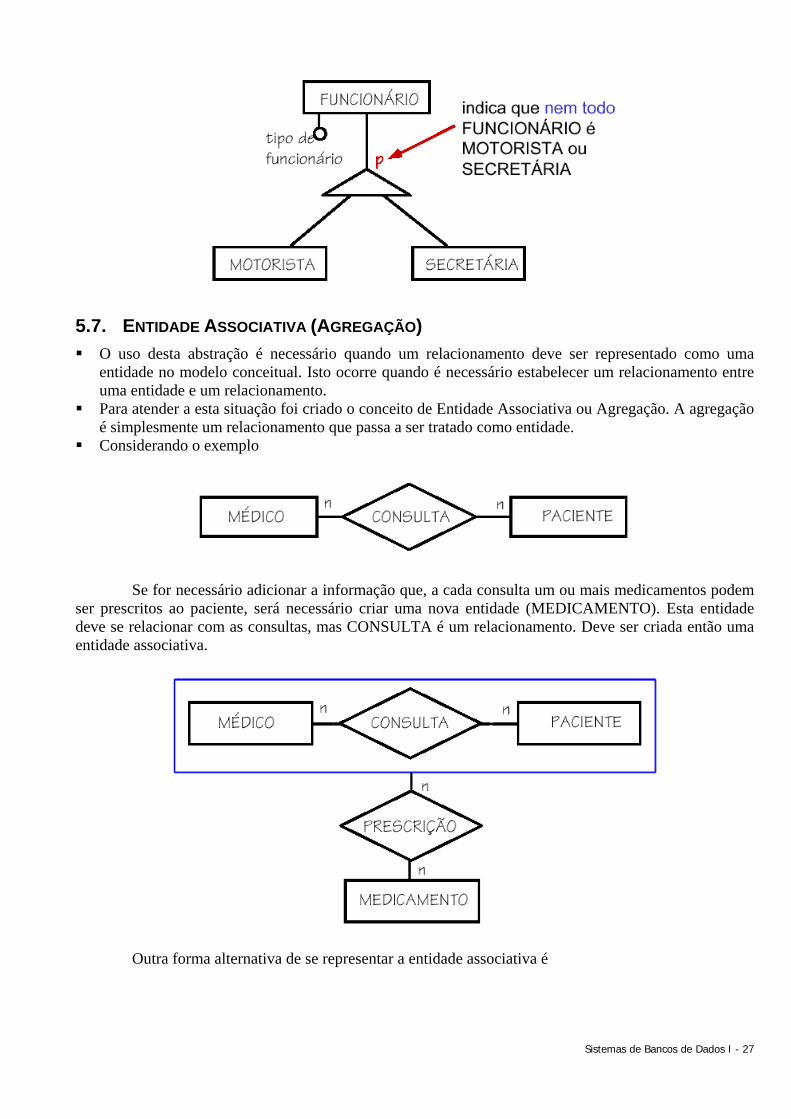
5.6. GENERALIZAÇÃO/ESPECIALIZAÇÃO A generalização é um processo de abstração em que vários tipos de entidade são agrupados em uma
única entidade genérica, que mantém as propriedades comuns A especialização é o processo inverso, ou seja, novas entidades especializadas são criadas, com
atributos que acrescentam detalhes à entidade genérica existente

Sistemas de Bancos de Dados I - 26
A entidade genérica é denominada superclasse e as entidades especializadas são as subclasses. A superclasse armazena os dados gerais de uma entidade, as subclasses armazenam os dados particulares
Este conceito está associado à idéia de herança de propriedades. Isto significa que as subclasses possuem, além de seus próprios atributos, os atributos da superclasse correspondente.
Usada quando é necessário caracterizar entidades com atributos próprios ou participação em relacionamentos específicos
Uma generalização/especialização pode ser total ou parcial: É total quando, para cada ocorrência da entidade genérica, existe sempre uma ocorrência em
uma das entidades especializadas. É parcial quando nem toda ocorrência da entidade genérica possui uma ocorrência
correspondente em uma entidade especializada.
Sistemas de Bancos de Dados I - 27
5.7. ENTIDADE ASSOCIATIVA (AGREGAÇÃO) O uso desta abstração é necessário quando um relacionamento deve ser representado como uma
entidade no modelo conceitual. Isto ocorre quando é necessário estabelecer um relacionamento entre uma entidade e um relacionamento.
Para atender a esta situação foi criado o conceito de Entidade Associativa ou Agregação. A agregação é simplesmente um relacionamento que passa a ser tratado como entidade.
Considerando o exemplo
Se for necessário adicionar a informação que, a cada consulta um ou mais medicamentos podem ser prescritos ao paciente, será necessário criar uma nova entidade (MEDICAMENTO). Esta entidade deve se relacionar com as consultas, mas CONSULTA é um relacionamento. Deve ser criada então uma entidade associativa.
Outra forma alternativa de se representar a entidade associativa é

Sistemas de Bancos de Dados I - 28
5.8. RELACIONAMENTO MUTUAMENTE EXCLUSIVO Neste tipo de relacionamento uma ocorrência de um entidade pode estar associada com
ocorrências de outras entidades, mas não simultaneamente.
5.9. RESTRIÇÃO DE PERSISTÊNCIA NO RELACIONAMENTO Um relacionamento é persistente quando, depois de criado, ele não puder ser removido
indiretamente pela remoção de uma ocorrência de uma das entidades associadas.
AVIÃO
PASSAGEIRO
CARGATRANSPORTE
TRANSPORTE
1 N ALUNO
EMPRÉS-TIMO LIVRO

Sistemas de Bancos de Dados I - 29
5.10. ESQUEMA TEXTUAL DO MER Um esquema ER pode ser um texto. Abaixo é definida uma sintaxe para uma linguagem textual
para definição de esquemas ER. Nesta sintaxe, são usadas as seguintes convenções: colchetes indicam opcionalidade, o sufixo LISTA denota uma seqüência de elementos separados por vírgulas e o sufixo NOME denota os identificadores.
ESQUEMA → Esquema: ESQUEMA_NOME SEÇÃO_ENTIDADE SEÇÃO_GENERALIZAÇÃO SEÇÃO_AGREGAÇÃO SEÇÃO_RELACIONAMENTO SEÇÃO_ENTIDADE → (DECL_ENT) DECL_ENT → Entidade: ENTIDADE_NOME {SEÇÃO_ATRIBUTO} {SEÇÃO_IDENTIFICADOR} SEÇÃO_ATRIBUTO → Atributos: {DECL_ATRIB} DECL_ATRIB → [(MIN_CARD, MAX_CARD)] ATRIBUTO_NOME [: DECL_TIPO] MIN_CARD → 0 | 1 MAX_CARD → 1 | N DECL_TIPO → inteiro|real|boolean|texto(inteiro)|enum(LISTA_VALORES)|data SEÇÃO_IDENTIFICADOR → Identificadores: {DECL_IDENT} DECL_IDENT → (IDENTIFICADOR) IDENTIFICADOR → ATRIBUTO_NOME SEÇÃO_GENERALIZAÇÃO → {DECL_HIERARQUIA_GEN} DECL_HIERARQUIA_GEN → Generalização[(CORBERTURA)]; NOME_GEN PAI: NOME_ENTIDADE FILHO: LISTA_NOME_ENTIDADE COBERTURA → t | p SEÇÃO_AGREGAÇÃO →{DECL_ENT_ASSOC} DECL_ENT_ASSOC → EntidadeAssociativa: NOME_RELACIONAMENTO SEÇÃO_RELACIONAMENTO → {DECL_RELACIONAMENTO} DECL_RELACIONAMENTO → Relacionamento: NOME_RELACIONAMENTO Entidades: {DECL_ENT-RELACIONADA} [ Atributos: {DECL_ATRIB} ] [ Identificadores: {DECL_IDENT}] DECL_ENT-RELACIONADA → [(MIN_CARD,MAX_CARD)] NOME_ENTIDADE Exemplo: Esquema: EMPRESA Entidade: DEPARTAMENTO Atributos: código: inteiro; Nome: texto(20); Ativo: boolean; Identificador: código Entidade: EMPREGADO Atributos: matrícula: inteiro; Nome: texto(50); DataNasc : data; Identificador: matrícula Relacionamento: ALOCA Entidades: (0,N) DEPARTAMENTO (1,1) EMPREGADO





























