Embed Size (px)
Citation preview

SIMANFIS: Simplificação da Arquitetura Neuro-Fuzzy ANFIS
Fábio Luiz Usberti Faculdade de Engenharia Elétrica e de Computação - UNICAMP
Cidade Universitária Zeferino Vaz - CP 6101 - CEP 13083-970 - Campinas - SP [email protected]
RESUMO O ANFIS consiste em uma rede neuro-fuzzy com uma poderosa capacidade de aproximação e que vem sendo aplicada no mapeamento de funções não-lineares, identificação de sistemas e predição de séries temporais. Recentemente foi proposta uma nova arquitetura, denominada Modified ANFIS (MANFIS), visando eliminar a “maldição da dimensionalidade”, inerente ao ANFIS. Esse trabalho apresenta uma terceira opção de arquitetura neuro-fuzzy, denominada Simplified ANFIS (SIMANFIS). Foram realizados dois testes comparativos entre as redes mencionadas: o primeiro teste consistiu na aproximação de uma função não-linear e o segundo na predição da série temporal Mackey-Glass. Foram avaliados a qualidade da aproximação, a partir do erro quadrático médio, e o tempo computacional. Com base nos resultados obtidos, pode-se afirmar que a arquitetura SIMANFIS promete ser uma boa alternativa com relação às já existentes, considerando que seus resultados são competitivos, sobretudo o tempo computacional, bastante reduzido em virtude das simplificações impostas à rede.
PALAVRAS CHAVE. Redes Neuro-Fuzzy. Predição de Séries Temporais. Aproximação de Funções. Estatística.
ABSTRACT ANFIS is a neuro-fuzzy network with excellent approximation capability which has been used on non-linear functionals mapping, system identification and time series prediction. A newly ANFIS based architecture, called Modified ANFIS (or just MANFIS), has been proposed recently in order to eliminate ANFIS inherited “dimensionality curse”. This work presents another brand new neuro-fuzzy architecture, denominated Simplified ANFIS (SIMANFIS). Comparative tests have taken place concerning a non-linear functional approximation with three input variables as well as Mackey-Glass time series prediction. The avaliation method relies on approximation quality through the mean quadratic error and computational time. Based upon the obtained results, SIMANFIS can be considered for replacing the previous neuro-fuzzy architectures in virtue of competitive approximation quality in addition to low computational requirement due to imposed simplifications of the network.
KEYWORDS. Neuro-Fuzzy Networks. Time Series Forecasting. Functional Approximation. Statistics.
XXXIX SBPO [924]

I. INTRODUÇÃO O ANFIS (“Adaptive Network-Based Fuzzy Inference System”) consiste em uma rede
adaptativa neuro-fuzzy com elevada capacidade de aproximação, cuja arquitetura original foi desenvolvida por Jang (1993). Esse sistema procura aliar aspectos positivos de redes neurais e de sistemas de inferência nebuloso. As redes neurais são muito difundidas como excelentes aproximadores universais, no entanto deixam a desejar no aspecto de interpretação do processo de funcionamento da rede, característica que a define como uma caixa-preta. Nesse aspecto, os sistemas nebulosos se revelam muito bons por trabalharem com regras lógicas que tornam o sistema facilmente interpretável.
Uma característica negativa do ANFIS consiste no fato de que um acréscimo linear de variáveis de entrada resulta em um aumento exponencial do número de parâmetros ajustáveis, característica bastante discutida na literatura e que se denomina “maldição da dimensionalidade”. Recentemente Jovanovic e Reljin (2004) desenvolveram uma nova arquitetura baseada no ANFIS, denominada Modified ANFIS (ou somente MANFIS), que visa conter esse crescimento excessivo do custo computacional. O objetivo desse trabalho consiste em apresentar uma terceira alternativa às duas arquiteturas já existentes, a partir de uma simplificação da rede original, justificando o seu nome: Simplified ANFIS (ou somente SIMANFIS). Essa arquitetura procura alterar a rede de modo a reduzir sua complexidade e conseqüentemente, a sensibilidade do tempo computacional à entrada, sem que isso deteriore demasiadamente a capacidade adaptativa e aproximativa da rede. Foi realizada uma comparação de desempenho das diferentes arquiteturas, no que diz respeito ao tempo de processamento e o erro quadrático médio atingido na aproximação de uma função não-linear com três variáveis de entrada e a predição da série temporal de Mackey-Glass.
II. REGRAS E SISTEMAS DE INFERÊNCIA NEBULOSOS
1. Conjuntos Nebulosos Na lógica clássica, uma determinada variável X pode ser classificada como pertencente
ou não a um determinado conjunto A. Já na lógica nebulosa, atribui-se um determinado grau de pertinência à variável X com relação ao conjunto A. Essa pertinência é um valor real contido no intervalo [0,1] e indica o quanto X pertence a um determinado conjunto. Essa notação é útil para as situações nas quais as fronteiras do conjunto A não são definidas com precisão. Matematicamente, esses conceitos podem ser descritos da seguinte forma:
( )( ){ }( ) { }( ) [ ] nebulosalógicax
clássicalógicaxxxxA
A
A
A
→⊂→⊂
ℜ∈=
1,01,0
/,
μμ
μ
2. Regras Nebulosas SE-ENTÃO
Regras nebulosas SE-ENTÃO são expressões da forma “se A então B”, onde A e B são rótulos lingüísticos ou conjuntos nebulosos, caracterizados por funções de pertinência. A parte condicional da regra “se A” é denominada antecedente, enquanto a parte “então B” é denominada conseqüente da regra. Um exemplo simples de uma regra nebulosa é “se pressão é alta, então volume é pequeno”. Nesse exemplo, “pressão” e “volume” são as variáveis lingüísticas, às quais são atribuídos os rótulos “alta” e “pequeno”.
Outra forma de regra nebulosa SE-ENTÃO, proposta por Tagaki e Sugeno (1985), possui conjuntos nebulosos somente na parte antecedente da regra, enquanto que na parte conseqüente da regra se apresenta uma função que retorna um valor “crisp”. Por exemplo, “se velocidade é alta, então força = k * (velocidade)2”
3. Sistemas de Inferência Nebulosos
Os sistemas de inferência nebulosos, também conhecidos por sistemas baseados em regras nebulosas, são constituídos dos seguintes componentes:
XXXIX SBPO [925]

• Uma base de regras contendo um certo número de regras nebulosas se-então; • Uma base de dados que definem as funções de pertinência dos conjuntos nebulosos. • Uma unidade de tomada de decisão, que realiza a inferência sobre as regras. • Uma interface de “fuzzificação”, que transforma uma entrada “crisp” em um grau de
equivalência com os conjuntos nebulosos (a partir das funções de pertinência). • Uma interface de “defuzzificação”, que transforma os resultados obtidos no processo
de inferência em uma saída “crisp”. As etapas do processo de inferência de um sistema nebuloso são: 1. Comparar as variáveis de entrada com as funções de pertinência das partes
condicionais das regras, obtendo os graus de pertinência de cada rótulo lingüístico. 2. Combinar (através de um operador norma-T) os graus de pertinência da parte
condicional, de modo a obter o grau de ativação de cada regra. 3. Gerar uma saída qualificada de cada regra, dependendo do seu grau de ativação. 4. Agregar as saídas qualificadas produzindo uma saída “crisp”.
Figura 1. Sistema de Inferência Nebuloso
4. Aplicações das Redes Neuro-Fuzzy
As aplicações das redes neuro-fuzzy são diversas, destacando-se mapeamento de funções não-lineares, identificação de sistemas e predição de séries temporais. Um problema inerente às redes neurais artificiais consiste na difícil extração de conhecimento da sua estrutura (pesos e conexões), o que lhe dá a característica de caixa-preta. Por sua vez, uma dificuldade dos sistemas de inferência nebulosos consiste em se estabelecer as regras da sua base de conhecimento. Assim, a associação das redes neurais artificiais com sistemas de inferência nebulosos, que ocorre no SIMANFIS, se beneficia das habilidades de cada componente, atenuando as dificuldades inerentes de cada um.
5. Arquitetura SIMANFIS
A Figura 2 apresenta um caso particular de um sistema neuro-fuzzy com a arquitetura SIMANFIS, constituído de duas variáveis de entrada.
Figura 2. SIMANFIS com duas entradas.
XXXIX SBPO [926]

Serão apresentadas a seguir as operações efetuadas sobre as entradas de cada camada da rede da Figura 2:
CAMADA 1: Entrada: Os valores das variáveis x e y. Saída (O1): Valor da função de pertinência (sino, gaussiana, dentre outras) cuja equação é
mostrada a seguir.
(sino) (gaussiana)
O conjunto {a, b, c} representa os parâmetros não-lineares do SIMANFIS. CAMADA 2: Entrada: O1 Saída (O2): Operação E lógico fuzzy, que consiste na multiplicação dos graus de
pertinência cujos rótulos lingüísticos correspondentes (conjuntos nebulosos) se deseja combinar. A saída dessa camada representa o grau de ativação da regra (“firing-strengh”).
( ) ( ) 2,12 =×== ixxwOii AAii μμ
CAMADA 3: Entrada: O2 Saída (O3): Calcula o grau de ativação normalizado, cuja equação é mostrada a seguir:
2,121
3 =+
===∑
iww
ww
wwO iiii
CAMADA 4: Entrada: O3 Saída (O4): Nessa camada é feito a multiplicação da saída da camada 3 com uma função
fi, que é uma combinação linear dos valores das entradas x e y, como segue: ( ) 2,14 =++== iryqxpwfwO iiiiiii
O conjunto {p, q, r} consiste nos parâmetros lineares conseqüentes do SIMANFIS. CAMADA 5: Entrada: O4 Saída (O5): Nessa camada é realizado o cômputo da saída geral do sistema, que consiste
na somatório das saídas qualificadas dos nós da camada 4.
∑=
=2
1
5
iii fwO
6. Aprendizagem Híbrida do SIMANFIS
A aprendizagem no SIMANFIS, que consiste no ajuste dos seus parâmetros lineares e não-lineares, se dá em duas etapas. Em uma, os parâmetros lineares são determinados por mínimos quadrados, enquanto que na outra, os parâmetros não-lineares são determinados via backpropagation (vide Tabela 1).
Tabela 1. Dois passos no procedimento de aprendizagem híbrido do SIMANFIS.
Passagem para Frente Passagem para TrásParâmetros Antecedentes Fixos Gradiente DescendenteParâmetros Conseqüentes Estimativa por Mínimos Quadrados Fixos
Sinais Saídas Nodais Taxas de Erros
( ) ( ) ( )⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+
==2
21 exp
1
1a
cxx
ba
cxxxO AAA μμμ
XXXIX SBPO [927]

III. BACKPROPAGATION Observa-se na Tabela 1, os parâmetros antecedentes (não-lineares da parte condicional da
regra) são determinados a partir do método do gradiente descendente, onde o vetor gradiente, por sua vez, é determinado a partir do algoritmo de retropropagação do erro (“backpropagation”).
A seguir será mostrada a formulação da retropropagação do erro para as três arquiteturas em estudo. O erro do sistema para a entrada de dados p pode ser representado por:
( )25ppp OTE −=
onde Tp é o resultado esperado e Op o resultado fornecido pelo sistema na entrada de dado p. O erro geral do sistema é uma somatória dos erros quadráticos Ep.
( )∑=
−=P
pppp OTE
1
25
Note que P é o número total de dados disponíveis. O objetivo do algoritmo de retropropagação do erro consiste em obter o vetor gradiente que servirá na atualização do parâmetro não-linear genérico α. A fórmula de atualização é a seguinte:
∑ ⎟⎠⎞
⎜⎝⎛
=−=Δ
α δαδ
ηδαδηα 2E
kE
onde η é a taxa de aprendizagem. A relação do erro global pode ser expressa como uma somatória dos erros com relação a cada entrada p de dado.
∑=
=P
p
pEE1 δαδ
δαδ
Pela regra da cadeia, podemos deduzir que:
∑∈
=SO
p OOEE
*
*
* δαδ
δδ
δαδ
onde O* são as camadas cujos nós possuem funções que dependem do parâmetro α. Como os parâmetros não-lineares se encontram na camada 1, a equação acima, que consiste na variação do erro quadrático em função do parâmetro não-linear α, fica:
δαδ
δδ
δαδ 1
1
OOEE pp =
A segunda derivada parcial da equação anterior consiste na derivada da função de pertinência com relação ao parâmetro α. Serão mostradas a seguir as derivadas da função de pertinência “sino” com relação aos seus três parâmetros.
( )( )
( )( )( )
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛ −+
−=
∂∂
=∂∂
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛ −+
−=
∂∂
=∂∂
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛ −+
−=
∂∂
=∂∂
2
2
22
1
2
2
22
21
2
2
23
21
1
2
11
2
acxba
cxbcc
O
acxba
cxbb
O
acxa
cbxaa
O μμμ
Agora que temos a segunda derivada parcial da equação da variação do erro quadrático em função do parâmetro α, a primeira derivada parcial (variação do erro quadrático em função da saída da camada 1) pode ser obtida a partir da seguinte regra da cadeia:
( )
∑+
=
+
+ ∂
∂
∂
∂=
∂
∂ 1#
1 ,
1,
1,,
k
mk
pi
kpm
kpm
pk
pi
p
OO
OE
OE
onde k é a camada considerada; i é o nó que se encontra na camada k e que depende do parâmetro α; p é a entrada atual de dados; #(k+1) é o número de nós da camada k+1.
Para determinar a taxa de erro em função da camada 1, é necessário saber a variação do erro quadrático em função da camada 2 e assim sucessivamente até a última camada. A derivada do erro quadrático em função da camada 5 (que é a última camada), é de fácil obtenção e a partir dela são determinadas as derivadas das camadas internas, a partir da última equação mostrada. A seguir, serão demonstradas as formulações da variação do erro quadrático em função de um parâmetro não-linear genérico α, para as arquiteturas do ANFIS, SIMANFIS e MANFIS. A formulação das duas primeiras é equivalente, enquanto que a formulação do MANFIS difere na Camada 1.
XXXIX SBPO [928]

1. Formulação do Backpropagation para o ANFIS e para o SIMANFIS
( )( )
( ) ( )( )
( ) ( )5,1,1
2
13,
4,5
,1,1
4#
13,
4,
4,
3,
5,1,1
1
14,
5,5
,1,1
5#
14,
5,
5,
4,
5,1,15
,1
223
224
25
ppim pi
pmpp
m pi
pm
pm
p
pi
p
ppm pi
pmpp
m pi
pm
pm
p
pi
p
ppp
p
OTfO
OOT
O
O
O
E
O
ECamada
OTO
OOT
O
O
O
E
O
ECamada
OTO
ECamada
−−=∂
∂−−=
∂
∂
∂
∂=
∂
∂→
−−=∂
∂−−=
∂
∂
∂
∂=
∂
∂→
−−=∂
∂→
∑∑
∑∑
==
==
( )( )
( )
( )
( )
( )( )( )
( ) ( )( )
( )( )( )
( )( )( ) ( )
( ) ( )[ ]( )
∑∑
∑∑
∑∑
∑∑
∑∑∑
∑
∑∑∑
∑∑
∑∑
===
=
=
==
−−
=−+−−=∂
∂
=−
−−+−−=
∂
∂
⎪⎪⎪⎪
⎩
⎪⎪⎪⎪
⎨
⎧
−=
∂
⎟⎟⎠
⎞⎜⎜⎝
⎛∂
=∂
∂=
−=∂
⎟⎟⎠
⎞⎜⎜⎝
⎛∂
=∂
∂≠
∂
∂−=
∂
∂
∂
∂=
∂
∂→
3#
12
5,1,1
3#
12
5,1,1
3#
12
5,1,12
,
3#
1
25,1,1
3#
12
5,1,12
,
22,
3,
22,
3,
3#
12,
3,5
,1,1
3#
12,
3,
3,
2,
222
:então :que Note
22
: temosAssim,
:m i Para
:mi Para
22
mmmi
ppm
m
mppi
m
mppm
pi
p
mmi
ippi
m
mppm
pi
p
i
i
i
pi
pm
m
i
m
pi
pm
m pi
pmppm
m pi
pm
pm
p
pi
p
wffw
OTf
wwOTf
wwOTf
OE
www
w
wwOTf
wwOTf
OE
w
www
ww
OO
ww
ww
w
OO
OO
OTfOO
OE
OE
Camada
( ) ( )
( )( )[ ]
( )
( )( )
( )[ ]( )
( )
∑
∑ ∑∑
∑ ∑∑
∑
=
= =
= ==
∂
∂
∂
∂=
∂
∂→
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂∴
=∂∂
=∂
∂
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
∂
∂−
−=
∂
∂
∂
∂=
∂
∂→
2#
1
1,
1,
)2(#
1
3#
12
5,1,1
1,
im1,
2,
)2(#
11,
2,
3#
12
5,1,1
2#
11,
2,
2,
1,
2
de dependem que wos para :que Temos
21
m
pm
pm
pp
m i
m
jjji
ppm
pi
p
i
m
i
m
pi
pm
m pi
pm
jjji
ppm
m pi
pm
pm
p
pi
p
OOEE
Parâmetro
wwffw
OTfOE
wwOO
OO
wffw
OTfOO
OE
OE
Camada
ααα
μ
μμμ
( )( )
( )[ ]( )
( )( )
( )[ ]( )
∑ ∑∑
∑ ∑∑
= =
= =
∂∂
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂∴
∂
∂
∂
∂
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂
)2(#
1
3#
12
5,1,1
1,
)2(#
1
1,
3#
12
5,1,1
2
a relação com apertinênci de função da derivada a é Onde
2
m
m
i
m
jjji
ppmp
pm
m
pm
i
m
jjji
ppmp
wwffw
OTfE
O
Owwffw
OTfE
αμ
μα
αα
αμα
2. Formulação do Backpropagation para o MANFIS
Em essência, a formulação do MANFIS é igual ao das outras duas redes, porém devido à arquitetura peculiar dessa rede, é possível fazer uma simplificação na expressão da Camada 1, do seguinte modo:
( ) ( )( ) ( )[ ]
( )
( )( ) ( )[ ]
( )
∑ ∑∑
∑ ∑∑
∑
= =
= ==
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂∴
⎪⎪⎩
⎪⎪⎨
⎧
=∂
∂=
=∂
∂≠
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
∂
∂−
−=
∂
∂
∂
∂=
∂
∂→
)2(#
1
3#
12
5,1,1
1,
1,
2,
1,
2,
)2(#
11,
2,
3#
12
5,1,1
2#
11,
2,
2,
1,
2
1:m i Para
0:mi Para
21
m jjji
ppm
pi
p
pi
pm
pi
pm
m pi
pm
jjji
ppm
m pi
pm
pm
p
pi
p
wffw
OTfOE
OOOO
OO
wffw
OTfOO
OE
OE
Camada
XXXIX SBPO [929]

( )
( )( )
( )[ ]( )
( )( )
( )[ ]( )
∑ ∑∑
∑ ∑∑
∑
= =
= =
=
∂∂
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂∴
∂
∂
∂
∂
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−
=∂
∂
∂
∂
∂
∂=
∂
∂→
)2(#
1
3#
12
5,1,1
1,
)2(#
1
1,
3#
12
5,1,1
2#
1
1,
1,
2
a relação com apertinênci de função da derivada a é Onde
2
m
m
jjji
ppmp
pm
m
pm
jjji
ppmp
m
pm
pm
pp
wffw
OTfE
O
Owff
w
OTfE
OOEE
Parâmetro
αμ
α
αα
αα
ααα
3. Estimativa por Mínimos Quadrados
Na rede da Figura 2, a saída global zp, para a entrada de dado p, pode ser escrita como:
( ) ( )pppppppppppp
ppppppp
ppppp
rwqywpxwrwqywpxwz
ryqxpwryqxpwz
fwfwz
22222111111
22211111
2211
+++++=∴
+++++=⇒
+=
BAX
z
z
z
B
rqprqp
X
Pentrada
pentrada
entrada
wywxwwywxw
wywxwwywxw
wywxwwywxw
A
PP
p
PPPPPPPPPPP
pppppppppp
p
=∴
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
←
←
←
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
××
× 1
1
162
2
2
1
1
1
6222111
222111
12
112
12
1111
111 1
M
M
MMMMMM
MMMMMM
Note que AX=B é um sistema sobredeterminado, logo não possui solução. No entanto, por mínimos quadrados, é possível determinar o vetor X que minimiza a diferença AX-B. Para tanto, determina-se a pseudo-inversa de A (A*), aplicando-a na equação abaixo. O vetor X obtido conterá os valores dos parâmetros lineares conseqüentes atualizados.
( ) BABAAAX TT *1==
−
IV. DIFERENÇA ENTRE ARQUITETURAS A Figura 3 revela as diferentes formações das bases de regras de cada rede neuro-fuzzy.
No ANFIS, por exemplo, ocorre a combinação de todos os conjuntos nebulosos da camada 1. Já na arquitetura MANFIS, não ocorre nenhuma combinação de rótulos. Finalmente, na arquitetura SIMANFIS, a combinação ocorre somente entre os rótulos correspondentes.
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
w3
w4
w5
w6
w7
w8
wn1
wn2
wn3
wn4
wn5
wn6
wn7
wn8
f1wn1
f2wn2
f3wn3
f4wn4
f5wn5
f6wn6
f7wn7
f8wn8
Σ Z
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
w3
w4
w5
w6
w7
w8
wn1
wn2
wn3
wn4
wn5
wn6
wn7
wn8
f1wn1
f2wn2
f3wn3
f4wn4
f5wn5
f6wn6
f7wn7
f8wn8
Σ Z
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
w3
w4
w5
w6
wn1
wn2
wn3
wn4
wn5
wn6
f1wn1
f2wn2
f3wn3
f4wn4
f5wn5
f6wn6
Σ Z
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
w3
w4
w5
w6
wn1
wn2
wn3
wn4
wn5
wn6
f1wn1
f2wn2
f3wn3
f4wn4
f5wn5
f6wn6
Σ Z
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
wn1
wn2
f1wn1
f2wn2
Σ Z
X1
X2
X3
μ11
μ12
μ21
μ22
μ31
μ32
w1
w2
wn1
wn2
f1wn1
f2wn2
Σ Z
Figura 3. Arquiteturas ANFIS (esquerda), MANFIS (centro) e SIMANFIS (direita).
1. Maldição da Dimensionalidade A partir da arquitetura neuro-fuzzy utilizada, é possível determinar o número de
parâmetros lineares e não-lineares que serão estimados no processo de treinamento. As equações a seguir mostram como esse cálculo é feito:
ANFIS: ( )1),,( ++= nnnpmpmnF p MANFIS: ( )1),,( ++= nnpnpmpmnF SIMANFIS: ( )1),,( ++= npnpmpmnF
onde n = Variáveis de Entrada; p = Partições Fuzzy por Entrada; m = Parâmetros na Pertinência.
XXXIX SBPO [930]

Pode-se perceber que no ANFIS existe um termo que cresce exponencialmente com o aumento de variáveis de entrada. Esse crescimento explosivo do número de parâmetros a serem determinados implica em uma maior quantidade de dados a serem utilizados para o treinamento, chegando muitas vezes a quantidades infactíveis. Desse modo, pode-se afirmar que a arquitetura ANFIS sofre do “mal da dimensionalidade”. A Tabela 2 ilustra esse problema, mostrando para alguns casos o número de parâmetros a serem determinados para as três arquiteturas.
Tabela 2. Número de Parâmetros estimados na rede.
2. Posicionando Pertinências A disposição inicial das funções de pertinência influencia consideravelmente a
convergência da solução. Em SIMANFIS foi adotado o mesmo critério de Jang (1993), onde as funções são posicionadas uniformemente ao longo do domínio das variáveis de entrada (Figura 4). Além disso, é feito com que a interseção entre duas funções consecutivas ocorra no grau de pertinência 0,5, garantindo uma boa transição entre os conjuntos nebulosos.
0
0,5
1
-4 -3 -2 -1 0 1 2 3 4
Valor da variável de entrada
Valo
r da
funç
ão d
e pe
rtin
ênci
a
Figura 4. Disposição inicial dos conjuntos fuzzy.
V. PODER DE APROXIMAÇÃO
O exemplo a seguir revela a capacidade de aproximação da arquitetura SIMANFIS. Foi utilizada a função não linear ( ) ( )4450,0cos 2 ≤≤−±= xxxz onde x é a variável de entrada. Foram utilizadas três configurações quanto ao número de regras nebulosas: 2, 4 e 8, resultando em erros quadráticos médios de 0,131, 0,109 e 0,029, respectivamente. Os demais parâmetros da rede mantiveram-se constantes: função de pertinência “sino”, passo inicial 0,01, 200 épocas.
A Figura 5 mostra as diferentes respostas da rede SIMANFIS na aproximação da função não-linear ( ) ( )4450,0cos 2 ≤≤−±= xxxz para diferentes números de regras nebulosas. Os mapeamentos apresentados ilustram a capacidade de adaptação da rede à sua entrada, de acordo com o número de regras nebulosas de que dispõe. Quanto maior é esse número, mais facilmente a rede se conforma à função mapeada. Os erros quadráticos médios do conjunto de dados de treinamento e teste revelam uma tendência de queda ao longo das iterações, sugerindo a convergência da aproximação.
XXXIX SBPO [931]

-6
0
6
-5 0 5
Entrada
Saíd
a
Saída Real Saída do Sistema
0,129
0,1295
0,13
0,1305
0,131
0,1315
0,132
0,1325
0,133
0,1335
0,134
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99 106 113 120 127 134 141 148 155 162 169 176 183 190 197
Épocas
Trei
nam
ento
0,13
0,1305
0,131
0,1315
0,132
0,1325
0,133
0,1335
Valid
ação
Treinamento Validação
-6
0
6
-5 0 5
Entrada
Saíd
a
Saída Real Saída do Sistema
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99 106 113 120 127 134 141 148 155 162 169 176 183 190 197
Épocas
Trei
nam
ento
0,095
0,1
0,105
0,11
0,115
0,12
0,125
0,13
0,135
Valid
ação
Treinamento Validação
-6
0
6
-5 0 5
Entrada
Saíd
a
Saída Real Saída do Sistema
0
0,005
0,01
0,015
0,02
0,025
0,03
0,035
0,04
0,045
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99 106 113 120 127 134 141 148 155 162 169 176 183 190 197
Épocas
Trei
nam
ento
0
0,005
0,01
0,015
0,02
0,025
0,03
0,035
0,04
0,045
Valid
ação
Treinamento Validação
Figura 5. Mapeamento da função z = xcos(x²) (coluna 1). Variação do erro quadrático médio ao longo das épocas (coluna 2). Número de regras nebulosas: 2 (linha 1), 4 (linha 2), 8 (linha 3).
VI. SOBRE-AJUSTE
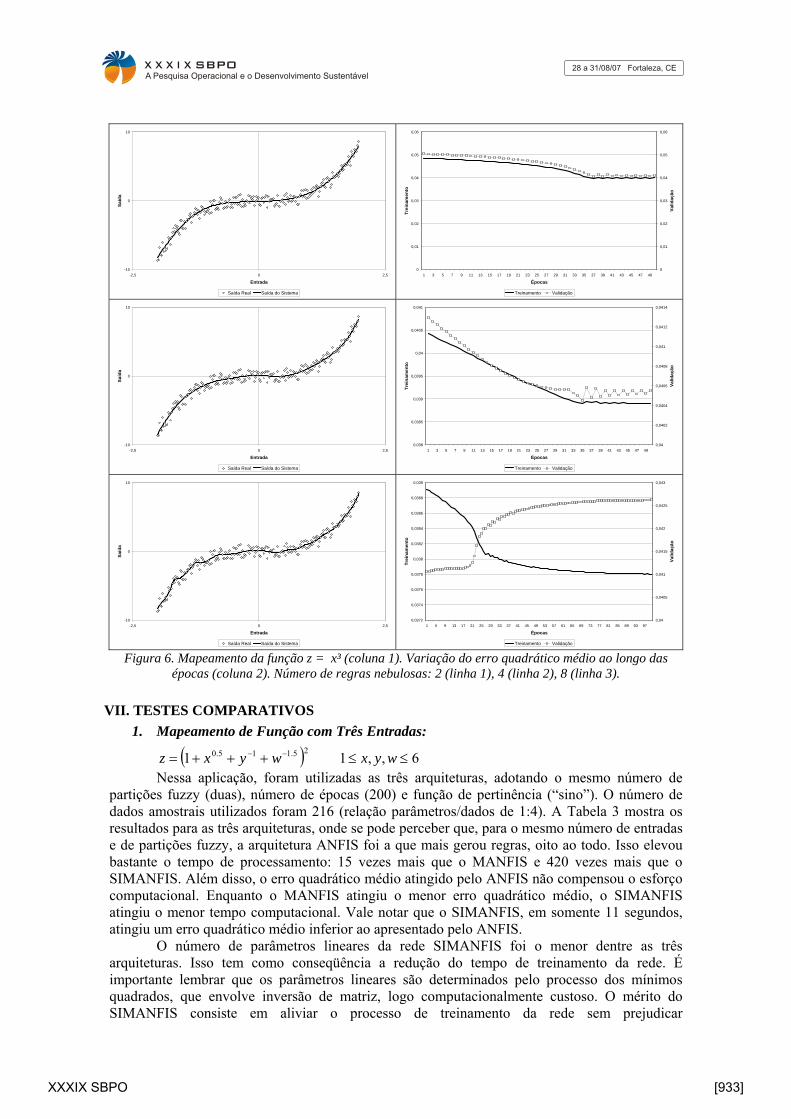
Deve-se ressaltar a importância de manter um número de regras nebulosas não muito maior do que o suficiente para a representação de uma dada função, caso contrário, além de arcar com um tempo computacional excessivo, a representatividade da rede pode se degenerar devido ao que se costuma denominar sobre-ajuste (“over-fitting”). O exemplo a seguir procura ressaltar essa situação a partir de uma função cúbica ( )440,13 ≤≤−±= xxz .
Observando-se a Figura 6, é possível perceber que com somente duas regras nebulosas, foi possível obter uma boa aproximação da função cúbica. Duplicando o número de regras, um início de sobre-ajuste pode ser observado pelo comportamento da curva de erro quadrático dos dados de validação, que a partir da iteração 33, se instabiliza e começa a deteriorar. Por fim, duplicando-se novamente o número de regras, o sobre-ajuste torna-se evidente, tanto na curva de erro quadrático dos dados de validação, quanto no próprio gráfico da saída do sistema.
XXXIX SBPO [932]
-10
0
10
-2,5 0 2,5
Entrada
Saíd
a
Saída Real Saída do Sistema
0
0,01
0,02
0,03
0,04
0,05
0,06
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Épocas
Trei
nam
ento
0
0,01
0,02
0,03
0,04
0,05
0,06
Valid
ação
Treinamento Validação
-10
0
10
-2,5 0 2,5
Entrada
Saíd
a
Saída Real Saída do Sistema
0,038
0,0385
0,039
0,0395
0,04
0,0405
0,041
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Épocas
Trei
nam
ento
0,04
0,0402
0,0404
0,0406
0,0408
0,041
0,0412
0,0414
Valid
ação
Treinamento Validação
-10
0
10
-2,5 0 2,5
Entrada
Saíd
a
Saída Real Saída do Sistema
0,0372
0,0374
0,0376
0,0378
0,038
0,0382
0,0384
0,0386
0,0388
0,039
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97
Épocas
Trei
nam
ento
0,04
0,0405
0,041
0,0415
0,042
0,0425
0,043
Valid
ação
Treinamento Validação
Figura 6. Mapeamento da função z = x³ (coluna 1). Variação do erro quadrático médio ao longo das épocas (coluna 2). Número de regras nebulosas: 2 (linha 1), 4 (linha 2), 8 (linha 3).
VII. TESTES COMPARATIVOS
1. Mapeamento de Função com Três Entradas:
( ) 6,,11 25.115.0 ≤≤+++= −− wyxwyxz Nessa aplicação, foram utilizadas as três arquiteturas, adotando o mesmo número de
partições fuzzy (duas), número de épocas (200) e função de pertinência (“sino”). O número de dados amostrais utilizados foram 216 (relação parâmetros/dados de 1:4). A Tabela 3 mostra os resultados para as três arquiteturas, onde se pode perceber que, para o mesmo número de entradas e de partições fuzzy, a arquitetura ANFIS foi a que mais gerou regras, oito ao todo. Isso elevou bastante o tempo de processamento: 15 vezes mais que o MANFIS e 420 vezes mais que o SIMANFIS. Além disso, o erro quadrático médio atingido pelo ANFIS não compensou o esforço computacional. Enquanto o MANFIS atingiu o menor erro quadrático médio, o SIMANFIS atingiu o menor tempo computacional. Vale notar que o SIMANFIS, em somente 11 segundos, atingiu um erro quadrático médio inferior ao apresentado pelo ANFIS.
O número de parâmetros lineares da rede SIMANFIS foi o menor dentre as três arquiteturas. Isso tem como conseqüência a redução do tempo de treinamento da rede. É importante lembrar que os parâmetros lineares são determinados pelo processo dos mínimos quadrados, que envolve inversão de matriz, logo computacionalmente custoso. O mérito do SIMANFIS consiste em aliviar o processo de treinamento da rede sem prejudicar
XXXIX SBPO [933]

demasiadamente a qualidade da aproximação. A manutenção dessa qualidade pode ser explicada pelo número de parâmetros não-lineares (iguais nas três arquiteturas), que fornecem grande parte da capacidade de ajuste da rede, sobretudo no mapeamento de funções não-lineares.
2. Predição de Série Temporal
A série temporal caótica descrita por Mackey e Glass (1977), amplamente utilizada em testes comparativos de métodos de predição, gerada pela seguinte equação diferencial ordinária:
( )( ) ( ) ( ) ( ) ( ) ( )[ ]6tx;tx,6-tx,12-tx,18-tx)(1.0
12.0)(
10 +−−+−
=∂
∂ txtx
txttx
ττ
A predição foi realizada a partir de quatro entradas (x(t-18) a x(t)), 500 dados de treinamento (118 ≤ t ≤ 617) e 500 de teste (618 ≤ t ≤ 1117) Os resultados dos testes se resumem na Tabela 3. Verifica-se que em termos do menor erro quadrático, o ANFIS superou as demais arquiteturas. Não obstante, o tempo de processamento foi muito mais elevado, chegando a passar de três horas, enquanto que para o MANFIS, foi aproximadamente vinte minutos e o SIMANFIS levou somente onze segundos. Essa diferença nos tempos pode ser novamente explicada pelo número de parâmetros lineares das redes. Nota-se que enquanto o SIMANFIS treinou somente 10 parâmetros lineares, o MANFIS e o ANFIS treinaram quatro e oito vezes mais respectivamente, sobrecarregando a etapa de ajuste por mínimos quadrados e resultando nos tempos observados.
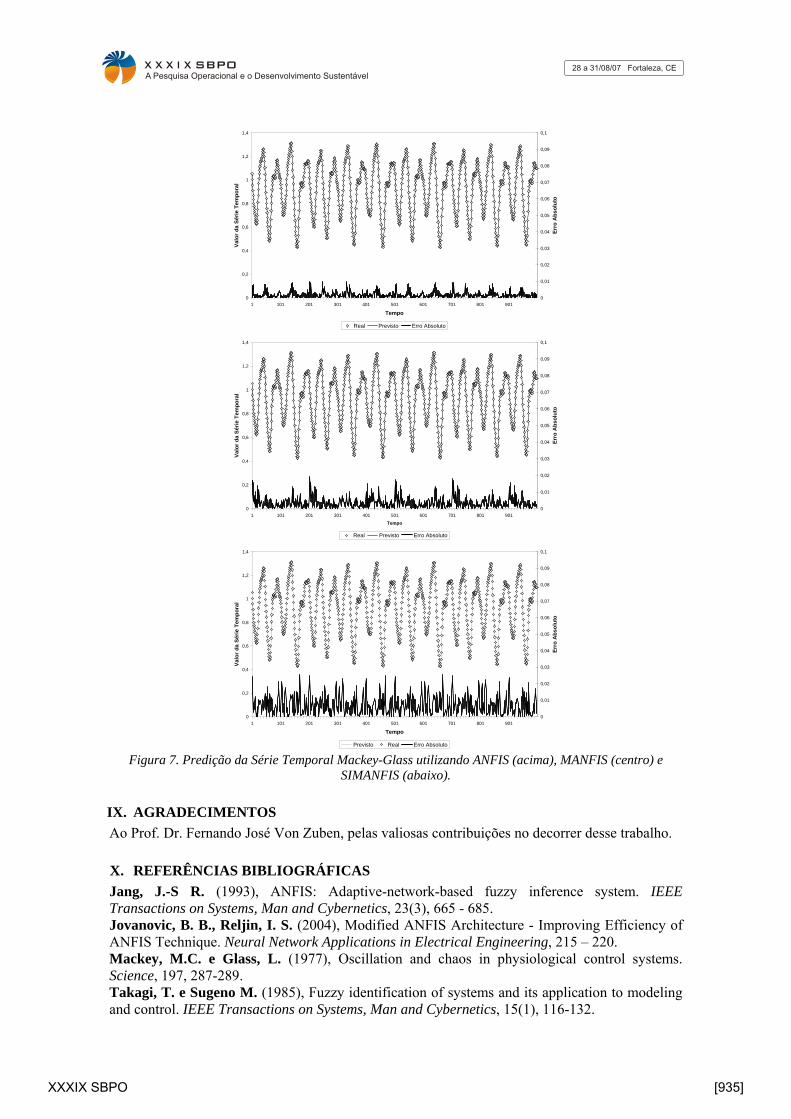
Os gráficos da Figura 7 revelam o resultado da predição para as três arquiteturas, ou seja, a saída real (pontilhada) versus a saída prevista (contínua) e abaixo dessas duas o erro absoluto (diferença em módulo entre a saída real e prevista). Nota-se que houve uma excelente predição não somente nos dados de treinamento, mas também nos de teste. O tempo de treinamento da rede ANFIS foi de tal ordem elevado, que foi conveniente aplicar somente uma época. Em contrapartida, as redes MANFIS e SIMANFIS, devido aos tempos serem bem inferiores à primeira, foram treinadas por 10 e 100 épocas respectivamente.
Tabela 3. Resultado dos testes computacionais.
ANFIS MANFIS SIMANFIS ANFIS MANFIS SIMANFISNúmero de Variáveis 3 3 3 4 4 4
Número de Funções de Pertinência 2 2 2 2 2 2Número de Regras 8 6 2 16 8 2
Tipo de Função de Pertinência Sino Sino Sino Sino Sino SinoValor do Passo Inicial 0.01 0.01 0.01 0.01 0.01 0.01
Número de Épocas 200 200 200 1 10 100Criitério de Parada por Convergência do Erro 0.00000001 0.00000001 0.00000001 0.00000001 0.00000001 0.00000001
Tempo de Processamento 1 h, 17 min, 53 s 0 h, 5 min, 8 s 0 min, 11 s 3 h, 4 min, 25 s 0 h, 20 min, 29 s 0 h, 0 min, 11 sNúmero de Épocas Efetuadas 200 200 200 1 10 100
Erro Quadrático Médio atingido 0.00233343 0.000447576 0.003234188 0.000124034 0.000222299 0.000412803Número de Parâmetros não-Lineares 18 18 18 24 24 24
Número de Parâmetros Lineares 32 24 8 80 40 10Total de Parâmetros Determinados 50 42 26 104 64 34
Número de Dados Amostrais 216 216 216 500 500 500
Problema 1 - Função Não-Linear com Três Entradas Problema 2 - Série Temporal de Mackey-Glass
VIII. CONCLUSÕES
As redes neuro-fuzzy, como pôde ser observado nas aplicações mostradas nesse trabalho, possuem excelente capacidade de aproximação. A maldição da dimensionalidade da arquitetura ANFIS pôde ser claramente observada nas aplicações mostradas, onde o tempo de processamento atingiu valores bastante elevados. As arquiteturas MANFIS e SIMANFIS, por não apresentarem do mesmo mal que o ANFIS, são boas alternativas para problemas com um número grande de variáveis de entrada. Os erros quadráticos médios obtidos pela arquitetura MANFIS mostraram-se abaixo dos valores obtidos por SIMANFIS, no entanto esse último atingiu bons valores de erro quadrático médio a um tempo computacional bastante reduzido. Nesse sentido, recomenda-se a arquitetura SIMANFIS nos casos que não requer elevada exatidão dos resultados ou ainda nos casos que se deseja rapidez na obtenção das aproximações.
XXXIX SBPO [934]
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 101 201 301 401 501 601 701 801 901
Tempo
Valo
r da
Série
Tem
pora
l
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
0,09
0,1
Erro
Abs
olut
o
Real Previsto Erro Absoluto
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 101 201 301 401 501 601 701 801 901
Tempo
Valo
r da
Série
Tem
pora
l
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
0,09
0,1
Erro
Abs
olut
o
Real Previsto Erro Absoluto
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 101 201 301 401 501 601 701 801 901
Tempo
Valo
r da
Série
Tem
pora
l
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
0,09
0,1Er
ro A
bsol
uto
Previsto Real Erro Absoluto Figura 7. Predição da Série Temporal Mackey-Glass utilizando ANFIS (acima), MANFIS (centro) e
SIMANFIS (abaixo).
IX. AGRADECIMENTOS Ao Prof. Dr. Fernando José Von Zuben, pelas valiosas contribuições no decorrer desse trabalho.
X. REFERÊNCIAS BIBLIOGRÁFICAS Jang, J.-S R. (1993), ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man and Cybernetics, 23(3), 665 - 685. Jovanovic, B. B., Reljin, I. S. (2004), Modified ANFIS Architecture - Improving Efficiency of ANFIS Technique. Neural Network Applications in Electrical Engineering, 215 – 220. Mackey, M.C. e Glass, L. (1977), Oscillation and chaos in physiological control systems. Science, 197, 287-289. Takagi, T. e Sugeno M. (1985), Fuzzy identification of systems and its application to modeling and control. IEEE Transactions on Systems, Man and Cybernetics, 15(1), 116-132.
XXXIX SBPO [935]





























