Embed Size (px)
Citation preview

outubro de 2014
Universidade do MinhoEscola de Engenharia
Simão Pedro Oliveira Afonso
UM
inho
|201
4Si
mão
Ped
ro O
livei
ra A
fons
o
Reconhecimento de Voz Multilingue paraControlo de Procedimentos Endoscópicos
Re
con
he
cim
en
to d
e V
oz
Mu
ltili
ng
ue
pa
ra C
on
tro
lo d
e P
roce
dim
en
tos
En
do
scó
pic
os

Dissertação de Mestrado Mestrado Integrado em Engenharia Biomédica Ramo de Informática Médica
Trabalho efetuado sob a orientação do Professor Doutor Victor Manuel Rodrigues Alves e daMestre Isabel Maria Cunha Laranjo
outubro de 2014
Universidade do MinhoEscola de Engenharia
Simão Pedro Oliveira Afonso
Reconhecimento de Voz Multilingue paraControlo de Procedimentos Endoscópicos

ii
DECLARAÇÃO
Nome: Simão Pedro Oliveira Afonso
Título dissertação: Reconhecimento de Voz Multilingue para Controlo de Procedimentos Endoscópicos
Orientador: Professor Doutor Victor Manuel Rodrigues Alves e Mestre Isabel Maria Cunha Laranjo
Ano de conclusão: 2014
Designação do Mestrado: Mestrado Integrado em Engenharia Biomédica
Ramo: Informática Médica
Escola: de Engenharia
Departamento: de Informática
DE ACORDO COM A LEGISLAÇÃO EM VIGOR, NÃO É PERMITIDA A REPRODUÇÃO DE QUALQUER PARTE
DESTA DISSERTAÇÃO
Universidade do Minho, ____/____/________
Assinatura: _____________________________________________________________________

iii
AGRADECIMENTOS
Todo o meu percurso nos últimos 5 anos culmina neste trabalho final, pelo que o número de pessoas a
quem este trabalho se deve é muito grande. Toda a gente com quem contactei durante esta etapa da
minha vida contribui de que maneira fosse para o meu crescimento como pessoa nos últimos anos.
Em primeiro lugar gostaria de agradecer ao Professor Doutor Victor Alves não só pelo apoio que me deu
durante este trabalho, mas também por ter acreditado que eu era capaz de trazer mais-valias para o
projeto onde fui inserido. Os seus conselhos foram sempre valiosos.
Dentro do projeto MyEndoscopy gostaria de agradecer aos meus coorientadores, e agora também amigos,
Isabel e Joel. Sempre contribuíram com o seu melhor para ter a certeza que as minhas perguntas eram
respondidas, as minhas preocupações aplacadas, e os meus erros corrigidos. Além destes coorientadores
“formais”, gostaria de agradecer também a todos os residentes do ISLab, que me deram não só um
espaço para trabalhar, como me acolheram e trataram como um entre iguais.
Uma palavra especial para a Margarida, que se tornou durante este último ano um partner in crime. Ela
teve de aturar durante mais tempo a minha presença, constantes referências a coisas obscuras, e outras
idiossincrasias, tendo sempre palavras de amizade e compreensão. Agradeço também a todos aqueles
amigos que conheci durante o curso e fora dele nos últimos anos, principalmente ao Alberto, Palmeiras e
Ricardo. Até ao Valliant.
Para a minha família tenho a última palavra. Aos meus pais, que são os principais responsáveis por eu
poder estar aqui, agradeço profundamente a compreensão e acompanhamento nos bons e nos maus
momentos. Apesar de estar longe fisicamente, a distância que nos separa continua a mesma que existia
em Elvas. À Rita por aturar as minhas provocações. Às minhas tias por levaram comigo todos os fins-de-
semana. Á Daniela por não me ignorar quando a chateio. Dedico especialmente este trabalho aos
membros da minha família que não estão entre nós para ver mas que continuam a ter orgulho em mim.

iv

v
RESUMO
Os exames endoscópicos são prescritos em grandes quantidades, pois são eficazes no diagnóstico,
baratos quando comparados com outros exames e estarem generalizados há muito tempo, pois podem
ser realizados em quase todos os hospitais. O resultado deste exame é normalmente um relatório que
inclui anotações médicas complementadas com algumas imagens retiradas durante o exame.
Alguns dos exames realizados são apenas feitos para confirmar informação já recolhida, o que leva a uma
duplicação de esforços desnecessária e desperdício de recursos. Os profissionais de saúde podem
descartar informação relevante ao não conseguirem anotar em pormenor uma região de interesse para
posterior análise mais cuidada.
O objetivo deste trabalho consiste na criação de um sistema que consiga resolver o problema apresentado
anteriormente, usando tecnologia de reconhecimento de voz. Este sistema deve reconhecer um pequeno
vocabulário, independentemente do falante, usado para anotar regiões de interesse nos exames.
O sistema MyEndoscopy atua como uma cloud privada, que contém vários dispositivos que usam e
providenciam serviços entre si. O dispositivo central deste sistema é a MIVbox, que se liga ao endoscópio
e permite a captura digital do sinal de vídeo que este gera. A principal funcionalidade providenciada por
este sistema é a capacidade de armazenar indefinidamente os vídeos completos que são produzidos
durante exames endoscópicos, bem como disponibilizar estes vídeos e outros dados para outros
profissionais de saúde que os necessitem de consultar.
Nesta dissertação apresenta-se um módulo de reconhecimento de voz para línguas portuguesa e inglesa,
denominado MIVcontrol, totalmente integrado no sistema MyEndoscopy. Este módulo reconhece um
pequeno vocabulário, que consiste em comandos usado para controlar os outros módulos. O MIVcontrol é
apresentado como uma alternativa a sistemas similares baseados na cloud, que resolve certos problemas
relacionados com proteção de dados e segurança.
Foi realizado um estudo sobre o módulo desenvolvido para determinar a sua eficácia em comparação ao
estado da arte. Na sequência desse estudo conclui-se que o sistema tinha uma taxa de erro comparável a
sistemas similares para outras línguas, e que como resultado é passível de ser usado em ambientes reais.

vi

vii
ABSTRACT Endoscopic procedures are prescribed in large quantities, since they are effective in diagnostics, cheap
when compared to other exams and are generalized for a long time, as almost all hospitals can perform
them. The result produced by this exam is usually a report which includes medical annotations,
complemented with some images produced during the exam.
Some exams have as only purpose confirming previously gathered information, which leads to unnecessary
duplication of effort and waste of scarce resources. Health professionals might discard important
information if they can not mark with a reasonable detail level certain interesting regions, for further
analysis.
The objective of this thesis consists in creating a system that is able to solve the problem posed before,
using voice recognition technology. This system should be able to recognize a small vocabulary, speaker-
independent, used to annotate interesting regions during endoscopic exams.
The MyEndoscopy system acts as a private cloud, which contains several devices that both use and
provide services. The central device of this system is the MIVbox, which connects to the endoscope and
allows capturing the digital video signal it generates. The main functionality provided by the system is the
ability of indefinitively store the complete video files produced during endoscopic procedures, as well make
these videos and other data available to other healthcare professionals who need them.
In this thesis it is presented a voice recognition module for Portuguese and English, named MIVcontrol,
completely integrated in the MyEndoscopy system. This module recognizes a small vocabulary which
consists of commands used to control other modules of the system. MIVcontrol is presented as an
alternative to similar cloud-based systems, which solves certain problems related to data protection and
security.
The module was studied to determine its efficiency compared to the state-of-the-art. That study concluded
that the system had an error rate comparable to that of other similar systems developed for other
languages, and thus can be used in the field.

viii

ix
ÍNDICE
RESUMO ....................................................................................................................................................V
ABSTRACT ............................................................................................................................................... VII
LISTA DE FIGURAS ...................................................................................................................................... XI
LISTA DE TABELAS ..................................................................................................................................... XI
NOTAÇÃO E ACRÓNIMOS ........................................................................................................................... XIII
CAPÍTULO 1 INTRODUÇÃO ........................................................................................................................... 1
1.1 Enquadramento .................................................................................................................................................... 3
1.2 Endoscopia .......................................................................................................................................................... 3
1.2.1 Tipos de Endoscopia ..................................................................................................................................... 4
1.2.2 Técnicas Endoscópicas ................................................................................................................................. 5
1.3 Problema ........................................................................................................................................................... 10
1.4 Objetivos ............................................................................................................................................................ 11
1.5 Metodologia de Investigação ................................................................................................................................ 11
1.6 Organização do Documento ................................................................................................................................. 12
CAPÍTULO 2 ESTADO DA ARTE ................................................................................................................... 15
2.1 Sistemas de Arquivo e Gestão de Gastroenterologia ............................................................................................... 17
2.1.1 Sistemas Existentes .................................................................................................................................... 17
2.1.2 Base Tecnológica........................................................................................................................................ 20
2.2 Criação de Imagens Tridimensionais em Computador ............................................................................................ 30
2.2.1 Sistemas Existentes .................................................................................................................................... 30
2.2.2 Base Tecnológica........................................................................................................................................ 34
2.3 Reconhecimento de Voz ...................................................................................................................................... 36
2.3.1 Sistemas Existentes .................................................................................................................................... 36
2.3.2 Base Tecnológica........................................................................................................................................ 39
CAPÍTULO 3 MYENDOSCOPY - MIVCONTROL ............................................................................................... 45
3.1 Contextualização ................................................................................................................................................. 47
3.1.1 MyEndoscopy ............................................................................................................................................. 47
3.1.2 Workflow típico de uma consulta de gastroenterologia .................................................................................... 48
3.2 MIVcontrol .......................................................................................................................................................... 49

x
3.2.1 Criação de um corpus de reconhecimento .................................................................................................... 49
3.2.2 Aplicação Principal ..................................................................................................................................... 52
3.2.3 Resultados ................................................................................................................................................. 55
CAPÍTULO 4 CONCLUSÃO .......................................................................................................................... 59
4.1 Sinopse ............................................................................................................................................................. 61
4.2 Contribuições ..................................................................................................................................................... 61
4.3 Conclusões ........................................................................................................................................................ 63
REFERÊNCIAS.......................................................................................................................................... 67

xi
LISTA DE FIGURAS
Figura 1.1 Áreas passíveis de exame usando técnicas endoscópicas (adaptado de [11]) ...................................................... 5
Figura 1.2 Regiões abrangidas pela Endoscopia Alta (adaptado de [12]) ............................................................................. 6
Figura 1.3 Possíveis achados endoscópicos encontrados através da Endoscopia Alta (retirado de [11]) ................................. 6
Figura 1.4 Regiões abrangidas pela Endoscopia Baixa (retirado de [14]) ............................................................................. 7
Figura 1.5 Possíveis achados endoscópicos encontrados com Endoscopia Baixa (retirado de [15]) ....................................... 7
Figura 1.6 Cápsula Endoscópica com a sua instrumentação visível (retirado de [17]) .......................................................... 8
Figura 1.7 Colonoscopia Virtual, visão geral e ampliação (retirado de [22]) ......................................................................... 9
Figura 2.1 Interface principal do endoPRO iQ (retirado de [27]) ....................................................................................... 18
Figura 2.2 Interface principal do DiVAS Image and Video Analysis (retirado de [28]) .......................................................... 18
Figura 2.3 Interface principal do SiiMA Gastro (retirado de [29]) ...................................................................................... 19
Figura 2.4 Interface principal do VictOR HD (retirado de [30]) .......................................................................................... 20
Figura 2.5 Esquema do paradigma MVC (adaptado de [31]) ............................................................................................ 21
Figura 2.6 Esquema do paradigma MVVM ..................................................................................................................... 22
Figura 2.7 Interface VisualAID (retirado de [65]) ........................................................................................................... 32
Figura 2.8 Interface bioWeb3D (retirado de [66]).......................................................................................................... 33
Figura 2.9 Monitorização de redes elétricas inteligentes (retirado de [67])......................................................................... 34
Figura 2.10 Frame capturada (a) e malha correspondente (b, c) [19]............................................................................... 35
Figura 2.11 Arquitetura do sistema Embedded ViaVoice (retirado de [74]) ................................................................... 38
Figura 3.1 Arquitetura geral do sistema MyEndoscopy (retirado de [96]) ........................................................................... 48
Figura 3.2 Workflow típico de um procedimento endoscópico (adaptado de[97]) ............................................................... 49
Figura 3.3 Procedimento para criação de um modelo de voz (adaptado de [97]) ............................................................... 50
Figura 3.4 Integração do MIVcontrol na MIVbox (adaptado de [97]) .................................................................................. 53
LISTA DE TABELAS
Tabela 2.1 Escala AIS (adaptado de [65]) ...................................................................................................................... 31
Tabela 3.1 Matriz de confusão para língua inglesa; 100 gaussian mixtures e 8 tied states .................................................. 56
Tabela 3.2 Matriz de confusão para língua portuguesa; 150 gaussian mixtures e 8 tied states ............................................ 57

xii

xiii
NOTAÇÃO E ACRÓNIMOS
NOTAÇÃO GERAL
A notação ao longo do documento segue a seguinte convenção:
Texto em itálico – para palavras em língua estrangeira (e.g., Inglês, Latim, Francês), equações e
fórmulas matemáticas. Também utilizado para dar ênfase a um determinado termo ou expressão
e para destacar nomes próprios.
Texto em negrito – para enfatizar alguns termos técnicos, de marcas ou de produtos. Também
usado para enfatizar referências internas no documento.
A presente dissertação foi elaborada ao abrigo do novo acordo ortográfico.
ACRÓNIMOS
A
ACID Atomicidade, Consistência, Integridade, Durabilidade
AIS Abbreviated Injury Scale
AJAX Asynchronous Javascript And XML
API Application Programming Interface
ASR Automatic Speech Recognition
B
BSD Berkley Software Distribution
C
CPRE ColangioPancreatografia Retrógrada Endoscópica

xiv
D
DBMS DataBase Management System
H
HMM Hidden Markov Models
HTML HypertText Markup Language
HTTP Hypertext Transfer Protocol
I
IPA International Phonetic Alphabet
J
JSON JavaScript Object Notation
JSGF Java Speech Grammar Format
L
LED Light Emitting Diode
LVCSR Large Vocabulary Continuous Speech Recognition
M
MCDT Meios Complementares de Diagnóstico e Terapêutica
MVC Model View Controller
MVVM Model View ViewModel
R
RDBMS Relational Database Management System
RIS Radiology Information System
RM Ressonância Magnética
S
SQL Structured Query Language
T
TAC Tomografia Axial Computadorizada
U
URL Uniform Resource Locator

xv
W
WCE Wireless Capsule Endoscopy
X
XML eXtensible Markup Language

xvi

Capítulo 1
INTRODUÇÃO

CAPÍTULO 1. INTRODUÇÃO
2

CAPÍTULO 1. INTRODUÇÃO
3
1.1 ENQUADRAMENTO
A Informática Médica surgiu com a invenção e rápida disseminação dos computadores digitais e o
desenvolvimento de ferramentas de comunicação e informação baseados nesses computadores [1]. Esta
mudança teve grande impacto na medicina, ao ponto de ser inimaginável hoje em dia não ter acesso a
ferramentas como tomografia computadorizada, software que verifica interações medicamentosas
prejudiciais, bases de dados de publicações de alta qualidade, ou até o processo clínico eletrónico. A
conferência de Reisensburg em 1972 [2] catalisou todo o desenvolvimento até aos nossos dias [1].
Portugal tem dado passos importantes neste aspeto, embora ainda falte preencher várias lacunas tanto
em organismos privados como públicos [3].
A prestação de cuidados de saúde teve grandes avanços tecnológicos nos últimos anos. Os Meios
Complementares de Diagnóstico e Terapêutica (MCDT) continuam a ter o maior peso no financiamento
dos hospitais, logo a seguir aos medicamentos. Segundo dados de 2007, cada utente dos Centros de
Saúde do Serviço Nacional de Saúde originava, em média, um custo em MCDT de 64,7€, o que equivale a
20% do total. Este valor é ligeiramente superior ao gasto em vencimentos dos médicos [4]. Atualmente os
MCDT são essenciais na prestação de cuidados de saúde, pois possibilitam ao profissional de saúde uma
confirmação adicional no momento da validação do diagnóstico e na prescrição do tratamento mais
adequado em cada situação [5]. A combinação destes dois fatores leva a que a pressão para diminuir os
custos dos MCDT seja elevada, pois sendo estes essenciais à prática médica moderna, incentivos à sua
diminuição levam a uma degradação da qualidade dos serviços prestados às populações [4], [5].
Os exames de endoscopia digestiva (alta e baixa) assumem cada vez mais um papel preponderante,
devido ao facto de serem eficazes no diagnóstico e apresentarem um custo reduzido, apesar de serem
invasivos [6]. Além disso, são exames que se encontram generalizados há muito tempo e tem a aceitação
plena dos profissionais de saúde [7]. Mais recentemente foi desenvolvida também a cápsula endoscópica,
explicada em maior pormenor nas secções seguintes.
1.2 ENDOSCOPIA
Endoscopia é um termo genérico que indica um procedimento médico que permite observar cavidades
internas do corpo humano. Apesar de esta técnica já estar descrita na Antiga Grécia, só no último século é

CAPÍTULO 1. INTRODUÇÃO
4
que a evolução tecnológica permitiu o aparecimento de endoscópios flexíveis, essenciais para uma elevada
qualidade do exame, dada a irregularidade do interior do corpo humano [8].
1.2.1 TIPOS DE ENDOSCOPIA
Como foi referido anteriormente, endoscopia é um termo genérico que abrange uma grande quantidade
de técnicas desenvolvidas em paralelo por várias áreas da medicina. Várias áreas recorrem a uma versão
da endoscopia para estudar os órgãos internos do seu foro, cada uma delas com especificidades e
particularidades que as distinguem umas das outras.
Dentro da endoscopia digestiva convencional, as técnicas existentes correspondem a um conjunto de
órgãos que se pretendem observar: EsofagoGastroDuodenoscopia, para observar o tubo digestivo alto;
Colonoscopia, para observar o cólon e o resto do intestino grosso; ColangioPancreatografia Retrógrada
Endoscópica (CPRE), para observar o pâncreas e as vias biliares; Enteroscopia, para observar o intestino
delgado.
Ainda nesta área, existem técnicas mais recentes que são ainda experimentais. A Endoscopia Virtual, que
consiste em criar um modelo tridimensional a partir de imagens médicas como as que resultam de
Ressonância Magnética (RM) ou Tomografia Axial Computadorizada (TAC) [9], e a Cápsula Endoscópica
que permite visualizar as zonas mais inacessíveis do intestino delgado de forma não invasiva, se bem que
com certas limitações [10]. Estas novas técnicas vão ser exploradas em mais detalhe nas próximas
secções.
Na Figura 1.1 é possível observar um conjunto de áreas do corpo humano que podem ser observadas e
analisadas com recurso à endoscopia.

CAPÍTULO 1. INTRODUÇÃO
5
Figura 1.1 Áreas passíveis de exame usando técnicas endoscópicas (adaptado de [11])
1.2.2 TÉCNICAS ENDOSCÓPICAS
1.2.2.1 ENDOSCOPIA DIGESTIVA ALTA
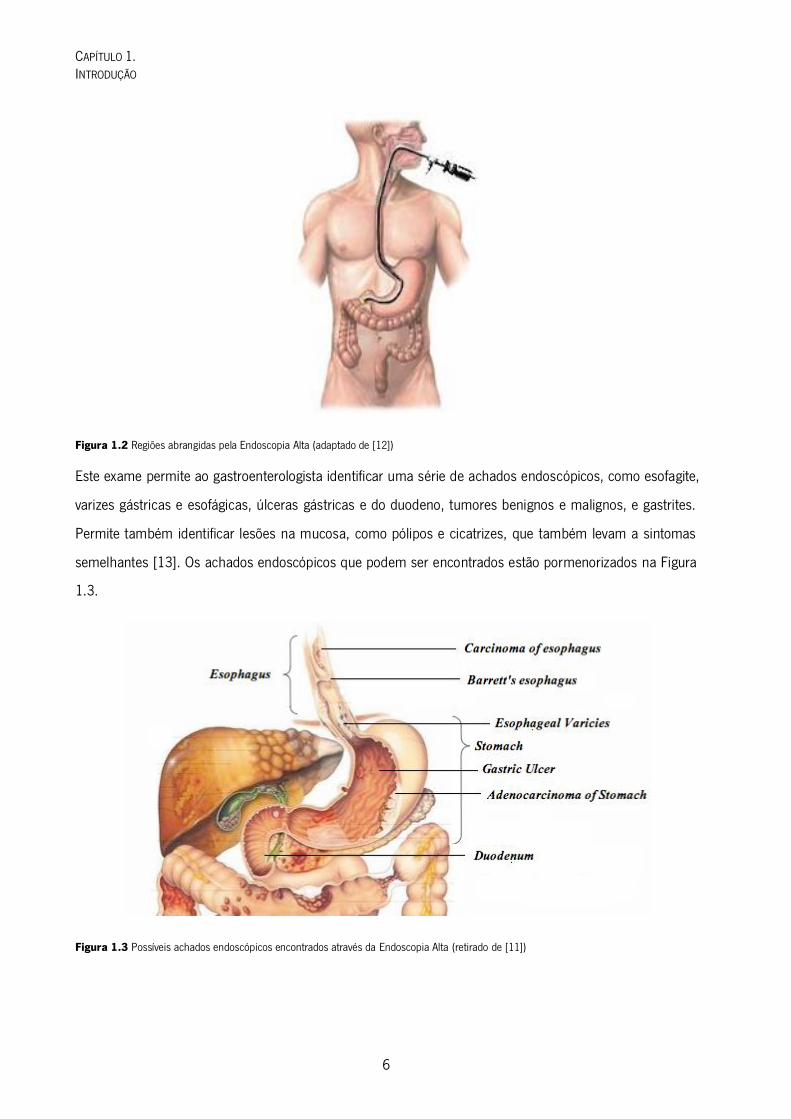
A endoscopia alta, também conhecida como EsofagoGastroDuodenoscopia, é utilizada para examinar a
parte superior do trato gastrointestinal. Permite examinar o esófago, o estômago e a parte superior do
duodeno, e é realizada por um gastroenterologista. As regiões abrangidas por esta técnica estão
representadas na Figura 1.2.
CAPÍTULO 1. INTRODUÇÃO
6
Figura 1.2 Regiões abrangidas pela Endoscopia Alta (adaptado de [12])
Este exame permite ao gastroenterologista identificar uma série de achados endoscópicos, como esofagite,
varizes gástricas e esofágicas, úlceras gástricas e do duodeno, tumores benignos e malignos, e gastrites.
Permite também identificar lesões na mucosa, como pólipos e cicatrizes, que também levam a sintomas
semelhantes [13]. Os achados endoscópicos que podem ser encontrados estão pormenorizados na Figura
1.3.
Figura 1.3 Possíveis achados endoscópicos encontrados através da Endoscopia Alta (retirado de [11])
CAPÍTULO 1. INTRODUÇÃO
7
1.2.2.2 ENDOSCOPIA DIGESTIVA BAIXA
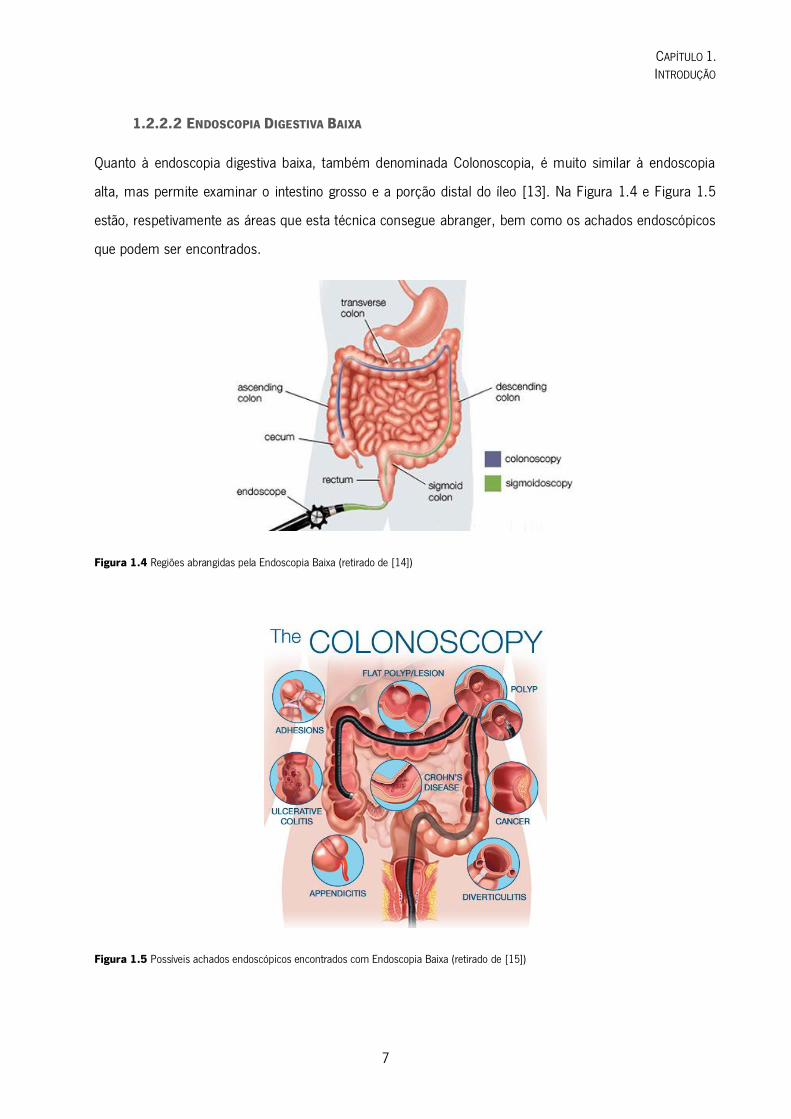
Quanto à endoscopia digestiva baixa, também denominada Colonoscopia, é muito similar à endoscopia
alta, mas permite examinar o intestino grosso e a porção distal do íleo [13]. Na Figura 1.4 e Figura 1.5
estão, respetivamente as áreas que esta técnica consegue abranger, bem como os achados endoscópicos
que podem ser encontrados.
Figura 1.4 Regiões abrangidas pela Endoscopia Baixa (retirado de [14])
Figura 1.5 Possíveis achados endoscópicos encontrados com Endoscopia Baixa (retirado de [15])

CAPÍTULO 1. INTRODUÇÃO
8
1.2.2.3 CÁPSULA ENDOSCÓPICA
A cápsula endoscópica, conhecida na sua sigla em inglês Wireless Capsule Endoscopy (WCE), permite
visualizar áreas do intestino (e.g. delgado) inacessíveis pela técnica convencional e diminuir o desconforto
provocado nos utentes [10]. A cápsula é engolida pelo paciente e por peristáltese viaja através do sistema
digestivo, enquanto captura imagens, até ser eliminada naturalmente [16]. Na Figura 1.6 pode ser
observada uma cápsula transparente que permite visualizar a sua instrumentação interior.
Figura 1.6 Cápsula Endoscópica com a sua instrumentação visível (retirado de [17])
A cápsula é um dispositivo em forma de comprimido, com uma ou várias câmaras, um ou mais LED (do
inglês Light Emitting Diode) para iluminar o interior do intestino, um sistema de transmissão de dados sem
fios, e uma bateria para alimentar tudo isto. No exterior do corpo é necessário colocar um dispositivo que
recebe e armazena as imagens enviadas pela cápsula, para visualização futura. Dependendo do tipo de
cápsula, a taxa de atualização oscila entre 2 e 10 imagens capturadas por segundo. A análise deste
exame é realizada por um gastroenterologista, que analisa todas as imagens para anotar zonas com
sangramento, pólipos ou outras anomalias. Estas anotações são usadas para produzir um relatório final.
Este é um processo moroso, porque a maioria das imagens produzidas não têm problemas e a
quantidade de dados produzida é substancial [18], [19].

CAPÍTULO 1. INTRODUÇÃO
9
Apesar de esta tecnologia ser interessante, encontra-se ainda numa fase inicial do seu desenvolvimento,
pelo que não está tão difundida como a endoscopia convencional, é mais dispendiosa e não consegue
obter resultados tão bons. Além disso, está ligada inextricavelmente a dois problemas técnicos mais
abrangentes, que limitam a sua função: o desenvolvimento de sistemas práticos de transmissão de
energia sem fios, para que a limitação de tempo e de taxa de atualização que advém do facto de a bateria
ter de se localizar dentro da cápsula seja eliminada, e a criação de um mecanismo de locomoção da
cápsula no corpo humano, para que as imagens capturadas não estejam à mercê dos movimentos
imprevisíveis do sistema digestivo, e seja possível dar mais atenção há certas localizações mais
interessantes [20].
1.2.2.4 ENDOSCOPIA VIRTUAL
Endoscopia Virtual é a designação de um conjunto de técnicas que pretende ser uma alternativa aos
métodos convencionais de criação de imagens da superfície mucosa do colon. Usa métodos não-invasivos
de imagem médica, como RM e TAC para criar uma representação tridimensional do trato digestivo
passível de ser analisado pela colonoscopia convencional. Um exemplo dos dados produzidos por esta
técnica encontra-se na Figura 1.7. Um estudo que comparou a endoscopia virtual com a colonoscopia
convencional não encontrou diferenças significativas na eficácia de deteção de pólipos e carcinomas [21].
Figura 1.7 Colonoscopia Virtual, visão geral e ampliação (retirado de [22])
Apesar de esta técnica pretender substituir os métodos invasivos, como colonoscopia, alguns passos
necessários continuam a apresentar potencial desconforto para os pacientes. Estes passos são comuns às

CAPÍTULO 1. INTRODUÇÃO
10
técnicas convencionais, logo a redução do desconforto é uma possibilidade. A técnica consiste em 4
passos. Antes de mais, o cólon do paciente é limpo de impurezas e cheio com ar, para que o contraste
entre o lúmen e a parede seja mais evidente. Estes passos são comuns com a colonoscopia convencional.
Para recolher os dados, é realizada uma RM helical do abdómen com uma alta precisão, para capturar
detalhes importantes. Depois de recolhidos os dados, estes são processados para gerar imagens,
interactive flythroughs e animações, usados para diagnosticar anomalias [9].
1.3 PROBLEMA
Atualmente, os profissionais de saúde que realizam exames endoscópicos, os gastrenterologistas, não têm
possibilidade de anotar (em pormenor) as regiões de interesse que encontram durante o exame (i.e.
achados endoscópicos), para que possam ser visualizados e interpretados mais tarde de uma modo mais
rigoroso e completo, sem a pressão do exame. Durante a realização do exame, o gastroenterologista retira
um conjunto limitado de frames do vídeo que ilustrem os achados endoscópicos que encontre, para
realização do relatório final. O exame completo, ou seja o vídeo produzido pelo endoscópio, é descartado,
só as frames retiradas e o relatório ficam disponíveis para uma posterior análise. Este fenómeno de
compartimentalização e incompatibilidade entre sistemas é conhecido como “ilhas de dados” [23]. Ao
descartar informação relevante, muitas vezes é necessário repetir os exames para obter resultados
similares, para confirmar informação que foi recolhida e depois descartada.
Este problema pode ser resolvido em várias etapas:
Guardar os exames completos (i.e. o vídeo), além dos relatórios, para que seja possível aceder
aos exames anteriores durante o diagnóstico, evitando a repetição redundante de exames;
Recolher estes dados automaticamente, sem qualquer intervenção por parte dos profissionais de
saúde, de uma forma integrada com os sistemas já existentes;
Criar um sistema que permita anotar achados endoscópicos durante o exame, de maneira a não
afetar o workflow atualmente usado pelos profissionais de saúde;
Criar uma interface de visualização dos exames anteriores que tenha acesso a todos os
metadados identificados, principalmente os achados endoscópicos, para poder poupar tempo nas
visualizações posteriores.

CAPÍTULO 1. INTRODUÇÃO
11
Outro problema que os gastroenterologistas enfrentam é que os sistemas endoscópicos usam interfaces
arcaicas para aceder a funções básicas do aparelho. Para um gastroenterologista selecionar uma frame
para capturar necessita de um processo com vários passos: pressionar um botão no endoscópio para
congelar a imagem e posteriormente carregar num pedal que captura e grava a imagem. Este
procedimento não é ótimo e causa vários problemas como limitar os movimentos de todos os envolvidos e
distrair os profissionais de saúde do objetivo do exame, que é o de diagnosticar anomalias.
1.4 OBJETIVOS
No contexto apresentado e como objetivo principal deste trabalho, propõem-se a conceção e
desenvolvimento de um sistema que permita reconhecer a voz do profissional de saúde que está a realizar
o exame, com vista a que o gastroenterologista consiga controlar o endoscópio e o sistema de captura a
ele conectado.
Mais especificamente, podem considerar-se os seguintes objetivos:
O reconhecimento de voz deve ser independente do falante, ou seja não é necessário que cada
utilizador realize um treino prévio para conseguir obter resultados;
Integração total do sistema desenvolvido com o sistema MyEndoscopy; deve permitir controlar o
exame usando os comandos de voz reconhecidos, ao realizar interface com o MIVprocessing.
Sendo o MyEndoscopy um sistema umbrella, que contém vários módulos sob a sua alçada, o sistema
desenvolvido deve ser um dos seus módulos.
1.5 METODOLOGIA DE INVESTIGAÇÃO
A presente dissertação foi realizada durante o quinto ano do Mestrado Integrado em Engenharia
Biomédica, no ramo de Informática Médica. A realização dos objetivos apresentados seguiu a metodologia
Ação-Pesquisa. Esta metodologia comporta uma série de passos [24].
1. Formulação de uma teoria;
2. Teste da teoria em situações reais;
3. Feedback em relação ao teste em situações reais;
4. Modificação da teoria em função do feedback recebido;

CAPÍTULO 1. INTRODUÇÃO
12
5. Retorno ao ponto 2.
As metas a atingir com esta metodologia são as seguintes [25], [26]:
Identificação do problema e especificação das suas características;
Atualização contínua do estado da arte em todas as vertentes do trabalho;
Modelação e desenvolvimento de um protótipo que satisfaça as especificações indicadas;
Análise dos resultados obtidos, e correção do protótipo baseado nesse feedback;
Validação do protótipo em situações reais;
Publicação dos resultados obtidos e do conhecimento produzido junto da comunidade científica.
No capítulo introdutório está identificado o problema e especificadas as características do sistema a
desenvolver. De seguida, no Estado da Arte está contida toda a investigação realizada continuamente com
vista a obter uma visão geral sobre outros trabalhos nesta área. Nos capítulos seguintes concretizam-se
todos os outros pontos desta metodologia. O sistema desenvolvido foi inicialmente prototipado, para pode
ser validado. Os resultados obtidos levaram a novas versões, que tiveram em conta o feedback recebido
anteriormente. As versões mais completas foram testadas mais intensivamente. Por fim, os resultados
obtidos foram publicados em revistas científicas.
1.6 ORGANIZAÇÃO DO DOCUMENTO
A presente dissertação compreende, para além deste capítulo introdutório, três capítulos estruturados da
seguinte forma:
No Capítulo 2 é realizada uma revisão dos fundamentos teóricos e um levantamento do estado da arte
sobre os assuntos abordados nesta dissertação. Mais propriamente, são abordadas três áreas com
especial atenção. Primeiro, são estudados os sistemas de apoio à decisão para diagnósticos médicos,
focando principalmente aqueles que envolvam endoscopia, que é o foco do sistema MyEndoscopy. De
seguida é apresentada a representação de imagens tridimensionais em computador, e como se pode criar
estes dados a partir de exames endoscópicos. Por fim, é investigado o reconhecimento de voz, tanto nos
seus princípios teóricos como na sua aplicação prática.
No Capítulo 3 é apresentado o módulo MIVcontrol, justificando as decisões que foram tomadas na sua
criação. Inclui-se também os métodos de teste que foram realizados para validar o módulo, bem como os

CAPÍTULO 1. INTRODUÇÃO
13
resultados dessa validação. É apresentado um estudo mais aprofundado da MIVbox, com vários aspetos
técnicos inerentes na sua conceção e implementação.
Finalmente, no Capítulo 4 são apresentadas uma sinopse de todo o trabalho realizado, a lista de
contribuições realizadas no decorrer desta dissertação e as conclusões retiradas do trabalho. São também
indicadas as propostas de trabalho futuro em todos os temas abordados.

CAPÍTULO 1. INTRODUÇÃO
14

Capítulo 2
ESTADO DA ARTE

CAPÍTULO 2.
ESTADO da Arte
16

CAPÍTULO 2.
ESTADO da Arte
17
O desenvolvimento de qualquer sistema deve ter em conta o estado da arte existente, para que seja
possível identificar os problemas existentes nas soluções atuais e tentar encontrar uma solução eficiente
para os resolver. Faz-se de seguida uma revisão dos fundamentos teóricos e um levantamento do estado
da arte sobre os assuntos abordados neste trabalho.
Neste capítulo é apresentada uma revisão dos fundamentos teóricos e um levantamento do estado da arte
sobre os assuntos abordados nesta dissertação. De modo sucinto, pode-se dividir este capítulo em três
secções principais. Na primeira secção são estudados os sistemas de apoio à decisão para diagnósticos
médicos, focando principalmente aqueles que envolvam endoscopia, que é o foco do sistema
MyEndoscopy. De seguida é apresentada a representação de imagens tridimensionais em computador, e
como se pode criar estes dados a partir de exames endoscópicos. Por fim, é investigado o reconhecimento
de voz, tanto nos seus princípios teóricos como na sua aplicação prática.
2.1 SISTEMAS DE ARQUIVO E GESTÃO DE GASTROENTEROLOGIA
Dentro da informática médica, os sistemas mais importantes tratam da gestão de utentes. Este é uma
tarefa complexa, com várias especificidades para cada especialidade médica. O caso da gastroenterologia
não é diferente, exigindo o uso de sistemas especializados para fazer a sua gestão. Os sistemas mais
avançados integram-se com os dispositivos médicos, permitindo armazenar não só metadados sobre os
exames, bem como os exames completos (que incluem o vídeo completo produzido pelo endoscópio, para
além de relatórios médicos e imagens retiradas durante o exame), devidamente organizados e acessíveis.
2.1.1 SISTEMAS EXISTENTES
2.1.1.1 ENDOPRO IQ
A PENTAX desenvolveu um conjunto de aplicações para uso em endoscopia, agregadas sob a marca
comum endoPRO iQ, que contêm várias ferramentas que permitem inclusive fazer uma gestão completa
dos utentes, incluindo agendamento de procedimentos e geração de relatórios. De entre essas aplicações,
destaca-se a HD Motion Picture Studio que é capaz de capturar vídeo e imagens a partir de um
endoscópio, que podem ser utilizadas posteriormente em relatórios médicos. Está limitada a endoscópios
do mesmo fabricante, e só está disponível para Windows, além de só poder ser usada no computador que
está ligado diretamente ao endoscópio [27]. A sua interface principal pode ser observada na Figura 2.1.

CAPÍTULO 2.
ESTADO da Arte
18
Figura 2.1 Interface principal do endoPRO iQ (retirado de [27])
2.1.1.2 DIVAS IMAGE AND VIDEO ANALYSIS
A DiVAS Image and Video Analysis é uma aplicação desenvolvida pela XION que permite a gravação,
arquivo, representação e processamento de dados de vídeos em formatos específicos. O nível de
processamento de dados permitido resume-se a selecionar imagens individuais ou trechos de vídeos, e
gerar relatórios simplificados [28]. A sua interface principal pode ser observada na Figura 2.2.
Figura 2.2 Interface principal do DiVAS Image and Video Analysis (retirado de [28])

CAPÍTULO 2.
ESTADO da Arte
19
2.1.1.3 SIIMA GASTRO
O SiiMA é um conjunto de aplicações desenvolvido pela First Solutions, S.A., que permite a gestão de
MCDT em diversas áreas clínicas, com módulos diferentes para cada especialidade. De particular
importância é o módulo SiiMA Gastro, que tem como objetivo a gestão integrada de um sistema de
Gastroenterologia. Incorpora suporte para todas as modalidades, e permite a aquisição de imagens e
vídeo, anotações e medições nas imagens, geração de relatórios e estatísticas, e também gravação de
dados em formato físico [29]. A sua interface principal pode ser observada na Figura 2.3.
Figura 2.3 Interface principal do SiiMA Gastro (retirado de [29])
2.1.1.4 VICTOR HD
Richard Wolf desenvolveu a aplicação VictOR HD, que inclui uma interface através de um ecrã sensível ao
toque. Pode ser usada para gerir dados do doente, capturar e editar imagens estáticas, vídeo, e áudio, e
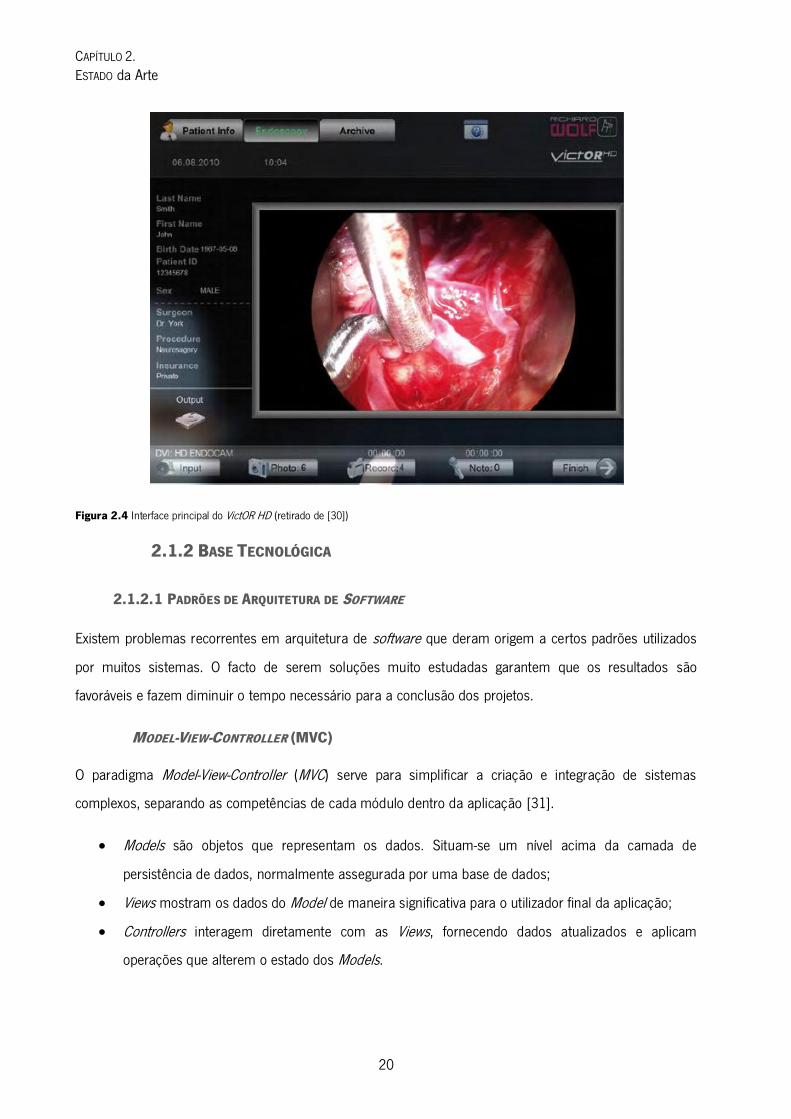
exportação de dados para formatos físicos [30]. A sua interface principal pode ser observada na Figura 2.4.
CAPÍTULO 2.
ESTADO da Arte
20
Figura 2.4 Interface principal do VictOR HD (retirado de [30])
2.1.2 BASE TECNOLÓGICA
2.1.2.1 PADRÕES DE ARQUITETURA DE SOFTWARE
Existem problemas recorrentes em arquitetura de software que deram origem a certos padrões utilizados
por muitos sistemas. O facto de serem soluções muito estudadas garantem que os resultados são
favoráveis e fazem diminuir o tempo necessário para a conclusão dos projetos.
MODEL-VIEW-CONTROLLER (MVC)
O paradigma Model-View-Controller (MVC) serve para simplificar a criação e integração de sistemas
complexos, separando as competências de cada módulo dentro da aplicação [31].
Models são objetos que representam os dados. Situam-se um nível acima da camada de
persistência de dados, normalmente assegurada por uma base de dados;
Views mostram os dados do Model de maneira significativa para o utilizador final da aplicação;
Controllers interagem diretamente com as Views, fornecendo dados atualizados e aplicam
operações que alterem o estado dos Models.
CAPÍTULO 2.
ESTADO da Arte
21
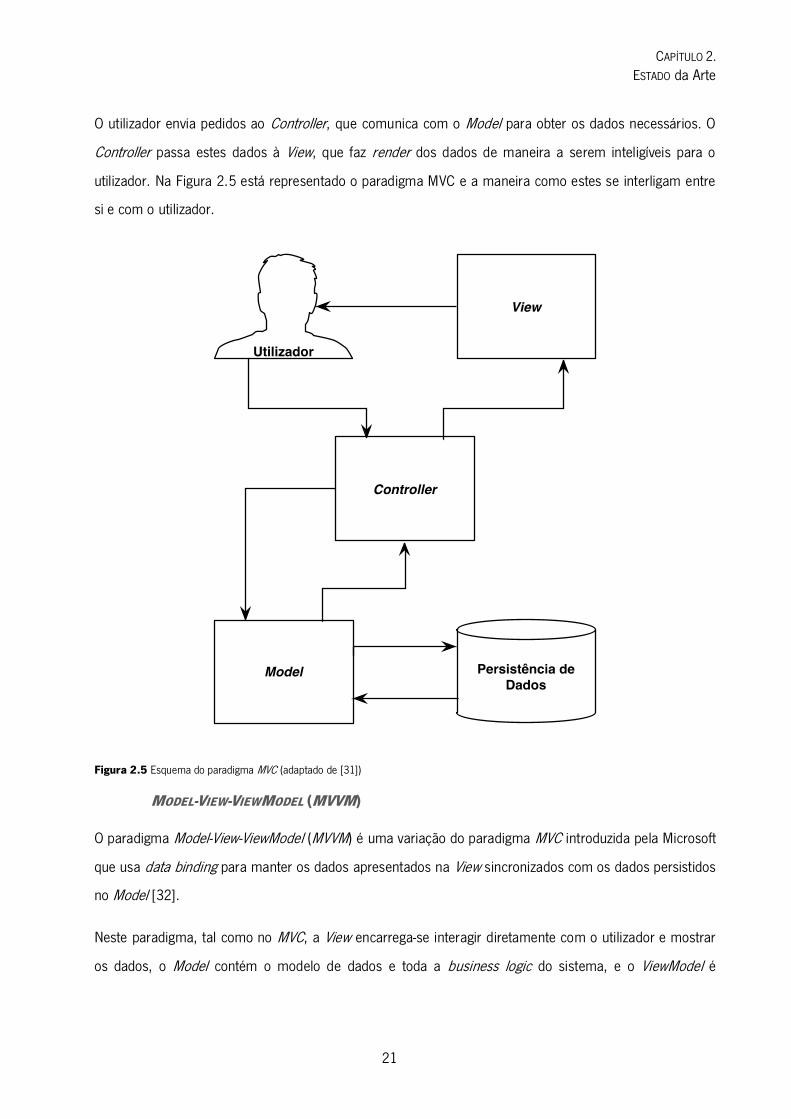
O utilizador envia pedidos ao Controller, que comunica com o Model para obter os dados necessários. O
Controller passa estes dados à View, que faz render dos dados de maneira a serem inteligíveis para o
utilizador. Na Figura 2.5 está representado o paradigma MVC e a maneira como estes se interligam entre
si e com o utilizador.
Figura 2.5 Esquema do paradigma MVC (adaptado de [31])
MODEL-VIEW-VIEWMODEL (MVVM)
O paradigma Model-View-ViewModel (MVVM) é uma variação do paradigma MVC introduzida pela Microsoft
que usa data binding para manter os dados apresentados na View sincronizados com os dados persistidos
no Model [32].
Neste paradigma, tal como no MVC, a View encarrega-se interagir diretamente com o utilizador e mostrar
os dados, o Model contém o modelo de dados e toda a business logic do sistema, e o ViewModel é

CAPÍTULO 2.
ESTADO da Arte
22
responsável por levar os dados do Model para a View e contém o estado da aplicação, como o registo que
está a ser editado e outra informação relevante [32]. Este paradigma está representado na Figura 2.6.
Figura 2.6 Esquema do paradigma MVVM
2.1.2.2 APLICAÇÕES WEB
Até há pouco tempo, as aplicações nativas (que necessitam de ser instaladas no computador do utilizador)
eram a única opção viável para distribuição alargada de aplicações. Estas conseguem aceder totalmente
aos recursos disponíveis, e têm uma performance superior, pois encontram-se numa camada de
abstração inferior. Apesar disto, não são facilmente convertidas para outros sistemas operativos e
arquiteturas, dependem do hardware existente localmente, sendo que operações computacionalmente
intensivas podem não ter uma performance adequada, além de que necessitam de preocupações

CAPÍTULO 2.
ESTADO da Arte
23
adicionais (incluindo por parte do utilizador, em alguns casos) para manter a aplicação atualizada.
Algumas destas desvantagens podem ser minimizadas. No caso do desenvolvimento de uma aplicação de
raiz, é possível utilizar frameworks cross-platform que facilitem o processo de conversão para outros
sistemas operativos. Mesmo que a aplicação não possa ser modificada, existem layers de compatibilidade
que permitem correr programas compilados para um sistema operativo noutro sistema diferente [33].
A Web nasceu como uma maneira de publicar documentos multimédia numa rede de computadores. Uma
das grandes inovações foi o conceito de hypermedia, que permite ligar vários documentos entre si [34].
Baseia-se numa arquitetura cliente-servidor [35], em que o cliente efetua pedidos ao servidor usando o
protocolo HTTP (do inglês HyperText Transfer Protocol). A identificação dos documentos faz-se por URL
(do inglês Uniform Resource Locator), e estes estão escritos na linguagem HTML (do inglês HyperText
Markup Language).
Recentemente, avanços na área dos web browsers, o aparecimento de tecnologias como AJAX (do inglês
Asynchronous Javascript and XML), e o surgimento de standards modernos, como HTML5, permitiram a
criação de aplicações dinâmicas e assíncronas, denominadas como Rich Internet Applications, que
rivalizam em funções com as aplicações nativas [36]. A explosão na adoção de dispositivos móveis trouxe
também uma redobrada ênfase dada à interface com o utilizador, que pode agora aceder a uma aplicação
web num ecrã de dimensões muito diferentes, o que leva a um aumento no tempo de desenvolvimento e
de testes [36].
2.1.2.3 DISTRIBUIÇÃO DE TAREFAS ENTRE SERVIDOR E CLIENTE
Considerando o paradigma MVC e as suas variações, existem duas arquiteturas principais que diferem na
distribuição de tarefas entre cliente e servidor [37].
THIN CLIENT
Para aplicações que correm maioritariamente no servidor correspondem no paradigma MVC a ter o cliente
como View, e o servidor como Controller e Model. Assim, o cliente faz pedidos e recebe respostas, sendo
apenas responsável por mostrar os dados recebidos. Esta arquitetura é similar às mainframes do passado,
e pode ser também denominada por thin client. É ideal para clientes com pouca capacidade de
processamento, como smartphones e outros dispositivos móveis e integrados, mas o aumento do número
de clientes leva a uma exigência maior na capacidade do servidor.

CAPÍTULO 2.
ESTADO da Arte
24
Este é o paradigma mais usado atualmente para aplicações web, devido ao facto dos web browsers terem
historicamente fracas capacidades de processamento de dados. O servidor está normalmente no que
denomina por cloud [38].
THICK CLIENT
Para aplicações que correm maioritariamente no cliente corresponde no paradigma MVC a ter o cliente
como View e Controller, e o servidor como Model, além de enviar a aplicação para o cliente. Assim, o
servidor aloja os dados e envia a aplicação para o cliente, que a executa localmente. Esta arquitetura pode
ser denominada por thick client. Como vantagens tem uma capacidade muito maior de comportar uma
grande quantidade de clientes a aceder ao serviço, mas os clientes deve ser capazes de processar os
dados que recebem, o que deixa dispositivos menos potentes em desvantagem.
2.1.2.4 VÍDEO
De forma armazenar as grandes quantidades de vídeo produzidas durante procedimentos endoscópicos, é
necessário proceder à sua compressão. Como o vídeo produzido é usado para realizar diagnósticos, é
importante que não haja perda de informação clínica nem introdução de artefactos durante o processo de
compressão, que possam levar a diagnósticos errados.
CODIFICAÇÃO
O método como o vídeo é comprimido para ser armazenado ou transmitido, e depois descomprimido para
ser visualizado designa-se por codec, que é uma abreviatura de compressor-decompressor [39]. Os
codecs podem ser lossless, se for possível recuperam os dados iniciais, ou lossy, se a compressão levar a
perdas de informação irreversíveis. Um codec lossless cria ficheiros muito grandes que podem ser
impraticáveis de armazenar ou transmitir, enquanto um codec lossy pode levar a que os vídeos percam a
sua utilidade para diagnóstico. Este equilíbrio atinge-se realizando testes com os tipos de vídeos a
comprimir [39]. Para que os ficheiros de vídeo sejam passíveis de serem transmitidos, é necessário
“empacotar” os dados produzidos pelo codec com um container que indique metadados sobre os codecs
do vídeo e permita juntar várias streams num único ficheiro. Estes metadados permitem que o ficheiro
possa ser reproduzido sem que o utilizador necessite de indicar o codec com que o vídeo foi comprimido
[40].
Muitos codecs produzem cada stream de vídeo de uma maneira monolítica, gerando uma stream de bits
para cada stream de vídeo. Isto denomina-se codificação de vídeo não escalável, e tem como vantagens

CAPÍTULO 2.
ESTADO da Arte
25
uma maior eficiência de codificação. Por outro lado, pode ser vantajoso dividir cada stream de vídeo em
várias streams de bits independentes. Normalmente, uma das streams é considerada a principal e pode
ser descodificada imediatamente, produzindo uma imagem de baixa qualidade. Subsequentes streams
são refinamentos da stream principal, sendo que não podem ser descodificadas senão em conjunto com a
stream principal [41].
Para comprimir o vídeo podem ser usados uma variedade de codecs e containers com características
diferentes, adequados para aplicações diversas. Segue-se uma overview pelos codecs e containers mais
utilizados.
CODECS
MPEG2 é um codec já antigo inicialmente pensado para televisão digital. É uma extensão do MPEG1
que permite resoluções mais elevadas [42]. É o standard usado para codificar o vídeo presente nos DVD,
e inclui codificação de vídeo escalável [39].
H.264, ou na sua designação ISO MPEG4 AVC, foi publicado em 2005 [43], e é o codec mais usado
atualmente. É muito escalável, devido à grande quantidade de perfis que define, o que permite ser usado
numa variedade de situações, desde dispositivos integrados, com pouca capacidade de processamento,
até computadores muito poderosos que podem processar vídeo com alta qualidade e definição. Este
codec está patenteado, pelo que requer pagamento de licenças para codificação e descodificação [40]. É
um dos codecs usados nos BluRay, e também permite codificação de vídeo escalável [40], [43].
Theora foi desenvolvido pela fundação Xiph.Org a partir do codec VP3, e é dos poucos codecs livres de
patentes [44]. A implementação de referência é open-source e está disponível para todos os sistemas
operativos, estando disponível por omissão em quase todas as distribuições de Linux [40].
VP8 é outro codec desenvolvido a partir do VP3 [45]. Em 2010, a Google comprou a empresa que o
criou e libertou as patentes que esta detinha, pelo que este codec não requer pagamento de qualquer
licença para ser usado [40]. Produz resultados ao nível do perfil avançado do H.264 com baixa
complexidade de descodificação, equivalente ao perfil básico do H.264.

CAPÍTULO 2.
ESTADO da Arte
26
CONTAINERS
AVI é um container muito antigo e simples, desenvolvido pela Microsoft, que não suporta quase nenhum
codec nem sequer metadados. Foi estendido não-oficialmente ao longo dos anos, mas nesta altura é
considerado legacy [40].
MPEG2 Transport Streams são usadas nos formatos físicos como DVD e BluRay. Permitem features
como múltiplas streams de áudio e vídeo, legendas e outros tipos de dados. Normalmente o codec usado
é MPEG2 ou H.264, mas permite outros codecs [39].
MP4, ou a sua designação ISO MPEG4 Part 14, é o container mais usado atualmente [46]. Permite
múltiplas streams, metadados e outras features avançadas. É baseado no QuickTime desenvolvido pela
Apple [40].
OGG é um standard aberto, livre de qualquer patente e disponível sob uma licença open-source [47].
Permite uma grande quantidade de codecs, contém metadados e está disponível para todos os sistemas
operativos, estando instalado por omissão em quase todas as distribuições de Linux [40].
WebM é um standard aberto criado propositadamente para transmissão de vídeo na web, para ser usado
com HTML5. Permite vários codecs, mas está vocacionado para VP8 como codec de vídeo e Vorbis de
áudio [40]. É suportado pelos browsers principais em todas as plataformas. Tecnicamente é um
subconjunto do Matroska, e como este permite uma grande variedade de streams e metadados.
MODOS DE TRANSMISSÃO
A transmissão de vídeo através da Internet pode ser dividida em dois modos distintos, dependendo do
comportamento do cliente e do servidor: em diferido ou em tempo real, também denominado como
streaming [41].
Transmissão em diferido consiste em providenciar o vídeo como um ficheiro que pode ser descarregado
para o cliente, e aí reproduzido. Se o protocolo de descarga obtiver os dados ordenadamente e o formato
do vídeo o permitir, é possível reproduzir partes do vídeo antes de ele estar completamente descarregado
[41].
Streaming permite aceder ao vídeo em tempo real, permitindo ao cliente parar e retomar a reprodução,
mudar a velocidade (incluindo inverter o sentido) e até aceder a trechos aleatórios do vídeo. Este processo

CAPÍTULO 2.
ESTADO da Arte
27
está necessariamente dependente da qualidade da ligação, necessitando de um mínimo de largura de
banda, latência, e perda de dados para ser possível obter uma experiência adequada [41].
Apesar disto, a Internet é uma rede best-effort, que não garante qualquer destas características para
nenhuma aplicação, pelo que é necessário usar outros mecanismos para manter a qualidade do serviço.
Os mais importantes são a escolha de codecs e containers adequados, aplicação de algoritmos de
controlo de congestão, configuração adequada dos serviços de rede e do servidor que providencia o vídeo,
e a escolha e configuração dos protocolos de transmissão de vídeo [41]. Mais propriamente, a escolha de
codecs que providenciam codificação de vídeo escalável (ver secção Codificação acima) permite que
mesmo em situações de pouca largura de banda alguma informação seja transmitida, mesmo com baixa
qualidade.
2.1.2.5 PERSISTÊNCIA DE DADOS
O arquivo de dados em formato digital é uma forma eficiente de armazenar uma grande quantidade de
informação de uma maneira acessível. A maneira de organizar esta informação designa-se por Data Base
Management System (DBMS), sendo que existem vários modelos de organização.
Já em 1970 foi implementado o modelo de base de dados relacional (do inglês Relational DataBase
Management System, abreviado para RDBMS), que continua a ser o mais comum hoje em dia [48]. A
necessidade de tratar uma crescente quantidade de dados sem que as capacidades dos computadores
individuais aumentasse tão rapidamente levou a uma necessidade de dividir as tarefas. Aparecem assim
novos modelos de organização como bases de dados paralelas e distribuídas [49], divididas em clusters
[50], bem como um novo conceito de data warehouse [51]. Cada um destes modelos tem vantagens e
desvantagens, mas pretendem resolver alguns problemas de escalabilidade das RDBMS.
Na procura de maiores performances com grandes quantidades de dados, foram também desenvolvidas
bases de dados não-relacionais, que muitas vezes trocam características ACID (Atomicidade, Consistência,
Isolamento, Durabilidade) por maior performance [50]. Este novo paradigma é denominado NoSQL, pois
a maneira como os dados estão organizados não é relacional, logo não permitir realizar queries
estruturadas. As arquiteturas utilizadas são normalmente pares chave-valor, em que cada componente do
sistema armazena uma parte de todo o dataset, e existem componentes que indexar a localização dos
dados [50]. Para analisar os dados podem ser utilizados algoritmos como o MapReduce [52], que podem

CAPÍTULO 2.
ESTADO da Arte
28
tanto ser usados para operações simples, equivalentes a queries SQL (do inglês Structured Query
Language), como realizar operações muito complexas que não podem ser expressas em SQL.
BASES DE DADOS RELACIONAIS
As bases de dados relacionais baseiam-se no conceito matemático de relação, apresentado por Codd em
1970 [48].
Dados os conjuntos , não necessariamente distintos, é uma relação nesses conjuntos
se for um tuplo de valores, sendo o primeiro um elemento do conjunto , o segundo elemento do
conjunto , e assim sucessivamente. Ou de maneira concisa,
[48].
A maneira mais comum de representar esta relação é como uma tabela, cujo título indica a relação, e
cada uma das colunas representa um domínio dessa relação. Esta representação tem as seguintes
propriedades [48]:
Cada linha representa um -tuplo da relação ;
Cada coluna representa um domínio da relação ;
A ordem das linhas é irrelevante;
A ordem das colunas é importante, porque define a relação;
Todas as linhas são diferentes.
Cada domínio deve ser anotado com o seu tipo, para que a consistência dos dados seja mantida. Como
uma relação pode ter múltiplos domínios do mesmo tipo, é recomendável que nestes casos seja também
indicado o seu papel na relação [48].
Domínios que identificam univocamente cada tuplo da sua relação são denominados chaves primárias.
Referências a outras relações são expressas como chaves estrangeiras, definidas como domínios que não
são chaves primárias da sua relação mas cujos seus elementos são valores da chave primária de outra
relação ( e podem indicar a mesma relação) [48].
A primeira e mais bem-sucedida linguagem para manipular bases de dados que usam o modelo relacional
foi SQL, desenvolvida em pela IBM e pela Oracle, que foi estandardizada em 1992 [53]. A linguagem
continuou a evoluir, mas o standard de 1992 é o último certificado por uma entidade independente [54].

CAPÍTULO 2.
ESTADO da Arte
29
Codd [55] apresentou em 1990 uma nova versão do modelo relacional que vinha colmatar algumas falhas
identificadas entretanto, bem como apresentar os erros nas implementações do seu modelo, tais como
[55]:
SQL permite linhas duplicadas;
Chaves primárias omitidas ou tornadas opcionais;
Omissões relevantes no que toca a indicações sobre o significado dos dados (incluindo domínios);
Erros no uso de índices;
Omissão de quase todas as features relacionadas com integridade dos dados.
BASES DE DADOS NÃO-RELACIONAIS
As bases de dados não-relacionais são uma inovação recente, idealizadas para dados não estruturados,
que garantem altas performances, são mais facilmente escaláveis para quantidade de dados massivas
necessárias em algumas aplicações, e apresentam custos inferiores devido à sua simplicidade [56], [57].
Os modelos de dados usados nestes sistemas podem ser classificados em:
Os modelos chave-valor (do inglês key-value) associam valores a certas chaves, o que permite
facilmente dividir a base de dados em vários nodos, com outros nodos diretores que direcionam a
query para o nodo que contém os dados. A base de dados mais usada com este modelo é Redis
[58].
Os modelos baseados em documentos (do inglês document-based) são similares aos modelos
chave-valor, mas o valor neste caso corresponde a um ficheiro estruturado (como JSON (do inglês
JavaScript Object Notation) ou XML (do inglês eXtensible Markup Language)), que contém os
dados relacionados com cada chave. MongoDB usa este modelo de dados [59], tal como
CouchDB [60].
Os modelos orientados às colunas invertem o modelo relacional, ao agregar os dados de cada
coluna em vez de cada linha das tabelas. Isto permite trabalhar nos dados proximamente
relacionados entre si, para evitar carregar tantos dados de uma só vez. Exemplos deste modelo
são Cassandra [61] e Vertica [49].

CAPÍTULO 2.
ESTADO da Arte
30
2.2 CRIAÇÃO DE IMAGENS TRIDIMENSIONAIS EM COMPUTADOR
A criação de imagens tridimensionais em computador é um tema vasto, que tem sido objeto de muita
atenção tanto por parte de investigadores como nas várias indústrias que fazem uso desta tecnologia.
Os dois algoritmos principais usados nesta área denominam-se ray casting e ray tracing.
Ray casting é o algoritmo mais usado, devido ao facto de apresentar uma melhor performance.
Simplificando, para cada pixel da imagem gerado é emitido um raio, que é usado para calcular a cor
desse pixel. Pode ser inclusive usado em dados volumétricos diretamente, o que garante uma
performance em tempo real até para hardware já antigo [62].
Ray tracing apresenta resultados muito melhores, devido ao facto de ser baseado em propriedades físicas
da interação da luz com objetos. Sendo baseado em processos físicos, as imagens produzidas são foto
realistas. Necessita de uma capacidade de processamento muito superior, não sendo adequado a
aplicações em tempo real. Para aplicações que realizem offline render, ou seja criem imagens
antecipadamente, este método é o mais adequado.
Com as tecnologias atuais, é possível representar modelos tridimensionais com um grau de realismo
elevado, mesmo em hardware modesto em termos de capacidade de processamento [63]. Já é possível
realizar ray tracing em tempo real, mas com performances ainda modestas [64].
No caso da área médica, a maior parte dos datasets encontram-se sob a forma de dados volumétricos, e
os computadores usados são muito específicos, tendo normalmente altas capacidades de processamento.
Estes dados resultam normalmente de exames como RM e TAC [9].
2.2.1 SISTEMAS EXISTENTES
2.2.1.1 VISUALAID
Kulaga et al [65] criaram um sistema denominado Visual AID que cria representações gráficas de lesões
no corpo humano. Os dados podem ser obtidos a partir de registos médicos ou a partir de simulações. As
imagens criadas permitem uma identificação mais fácil do estado do utente, mesmo por pessoas sem
treino médico. Este sistema usa imagens 2D, renders de modelos tridimensionais [65].

CAPÍTULO 2.
ESTADO da Arte
31
O sistema usa a escala AIS (do inglês Abbreviated Injury Scale, ou Escala Abreviada de Lesões) para
classificar a gravidade das lesões, atribuindo a cada nível uma certa cor. As cores usadas estão
apresentadas na Tabela 2.1.
Tabela 2.1 Escala AIS (adaptado de [65])
AIS Nível de Lesão Tipo de Lesão
1 Mínimo Superficial
2 Moderado Lesões reversíveis; Requer cuidados médicos
3 Sério Lesões Reversíveis; Requer hospitalização
4 Severo Lesões Irreversíveis
Recuperação possível com tratamento médico
5 Crítico Lesões Irreversíveis
Recuperação impossível mesmo com tratamento médico
6 Máximo Quase impossível de sobreviver
9 Desconhecido
O modelo do corpo humano usado foi o Zygote Human Anatomy 3D Model, que permite manter o
anonimato do utente sem comprometer a utilidade médica. O modelo 3D foi subdividido num programa de
modelação 3D, sendo posteriormente criadas uma série de imagens para cada nível da escala AIS e
rotação no espaço. O sistema recebe como input uma série de códigos correspondentes a partes de corpo
e gravidade das lesões, e cria uma imagem sobrepondo as imagens correspondentes a uma imagem de
corpo inteiro. A sua interface pode ser observada na Figura 2.7.
Este sistema tem várias desvantagens importantes. A sobreposição das imagens pode criar ambiguidades
na representação, criando representações anatomicamente incorretas que podem confundir tanto
especialistas como leigos. Outra desvantagem prende-se com o facto do sistema de navegação ser
extremamente limitado. O sistema permite visualizar o corpo de 24 ângulos diferentes, todos na mesma
posição vertical [65].

CAPÍTULO 2.
ESTADO da Arte
32
Figura 2.7 Interface VisualAID (retirado de [65])
Kulaga identifica estas limitações e sugere o uso da tecnologia WebGL para resolver estes problemas. Se
os objetos anatómicos forem representados em 3D, a sobreposição existente passa a ser anatomicamente
correta, e permite a visualização do corpo a partir de qualquer ângulo. Para além disso, aumenta o
potencial das anotações, neste caso para desenhar caminhos tomados por balas, selecionando feridas de
entrada e saída [65].
2.2.1.2 BIOWEB3D
Pettit e Marioni [66] criaram uma ferramenta open-source baseada no browser que permite representar
dados tridimensionais de uma forma acessível a utilizadores sem treino prévio, denominada bioWeb3D.
Esta ferramenta usa WebGL e a biblioteca Three.js para ler dados nos formatos XML ou JSON e
representar esses dados em três dimensões num browser. Os dados podem ser lidos de ficheiros remotos
ou locais. A segurança dos dados está assegurada, pois não há comunicação com o exterior depois do
carregamento inicial [66]. A interface apresentada por esta ferramenta pode ser observada na Figura 2.8.

CAPÍTULO 2.
ESTADO da Arte
33
Figura 2.8 Interface bioWeb3D (retirado de [66])
Depois de analisar o software existente, os autores concluíram que não havia uma solução genérica que
permitisse visualizar dados num browser, sem instalação de programas ou plugins adicionais. Além disso,
a maior parte dos programas existentes são muito complexos para serem usados sem treino anterior e
são muitas vezes proprietários, o que exige investimentos iniciais consideráveis.
2.2.1.3 MONITORIZAÇÃO DE REDES ELÉTRICAS INTELIGENTES
Zhang et al criaram uma aplicação Web para monitorizar uma rede elétrica inteligente. Com recurso à
biblioteca X3DOM, é possível mostrar o estado de cada nodo da rede, os fluxos entre nodos e as cargas
para cada componente. Além de usar WebGL, este projeto serve-se de AJAX para fazer pedidos
assíncronos ao servidor e assim ter informação atualizada automaticamente [67]. A sua interface pode ser
observada na Figura 2.9.

CAPÍTULO 2.
ESTADO da Arte
34
Figura 2.9 Monitorização de redes elétricas inteligentes (retirado de [67])
2.2.2 BASE TECNOLÓGICA
2.2.2.1 WEBGL
WebGL é uma tecnologia recentemente desenvolvida pelo Khronos Group que permite usar a placa
gráfica presente em muitos computadores atualmente para fazer renders tridimensionais num browser,
sem utilizar quaisquer plugins. Esta tecnologia está integrada com o standard HTML5, que contém
elementos nativos para áudio e vídeo, permitindo a criação de páginas web com conteúdos interativos [68].
WebGL permite explorar o potencial das placas gráficas modernas presentes na maioria dos
computadores pessoais a partir das páginas web, usando programas escritos em JavaScript. WebGL é
baseada na API (do inglês Application Programming Interface) OpenGL ES2.0 Esta é uma API de baixo
nível, sendo que foram desenvolvidas várias bibliotecas de alto nível para ser mais fácil usar esta
tecnologia, como Three.js, PhiloGS, X3D, X3DOM, entre outras.
WebGL, assim como o seu predecessor OpenGL, foi criado com o intuito de mostrar volumes
tridimensionais usando polígonos texturados para criar superfícies. Na área médica há necessidade de
mostrar dados tridimensionais, normalmente denominados por voxels. São normalmente implementados
criando shaders específicos para esta função, usando as capacidades já existentes. Tanto X3D como
X3DOM têm extensões standard usadas na área médica para este efeito, denominadas MedX3D e
MedX3DOM [69].

CAPÍTULO 2.
ESTADO da Arte
35
2.2.2.2 MODELO DE ANÉIS DEFORMÁVEIS
As cápsulas endoscópicas conseguem capturar no máximo 10 imagens por segundo, pelo que é
impossível conseguir extrair informação tridimensional da sua vizinhança apenas com esta informação.
Szczypinski et al [19] apresentam uma técnica segundo a qual é possível criar uma representação
tridimensional simplificada do intestino, usando as imagens produzidas pelo exame da cápsula
endoscópica, que serve como referência ao gastroenterologista, que indica a localização da cápsula no
intestino e uma estimativa da sua velocidade [19].
O tubo digestivo pode ser simplificado como um cilindro colapsado, e assumindo que na maioria do tempo
a cápsula se alinha numa direção paralela ao tubo digestivo, as imagens seguem o mesmo padrão,
nomeadamente imagens das paredes do tubo, que convergem num ponto central. Assumindo que a
cápsula nunca volta para trás, à medida que o tempo do exame avança, a parte visível desloca-se para o
centro da imagem. Este modelo do movimento da cápsula corresponde razoavelmente ao movimento real,
e torna possível o processamento automático das imagens [19].
Figura 2.10 Frame capturada (a) e malha correspondente (b, c) [19]
O Modelo de Anéis Deformáveis consiste num conjunto de nodos, cada um com informação sobre as
propriedades da imagem correspondente a uma localização específica do tubo digestivo. Para cada
imagem capturada durante o exame é criada uma malha cujos nodos estão dispostos em circunferências
concêntricas, representadas na Figura 2.10. Cada circunferência corresponde a um corte perpendicular
do tubo digestivo. Para criar a malha da frame seguinte, usa-se a anterior para procurar nodos
semelhantes, o que indica o movimento que a cápsula realizou nesse intervalo de tempo. Assim, é
possível criar um modelo contínuo da textura de todo o lúmen interno [19].

CAPÍTULO 2.
ESTADO da Arte
36
2.3 RECONHECIMENTO DE VOZ
Reconhecimento Automático de Voz (ASR, na sigla em inglês, correspondente a Automatic Speech
Recognition) é um processo através do qual um computador processa voz gravada e cria uma
representação textual das palavras faladas. Este processo tem duas áreas de estudo principais: discurso
discreto e discurso contínuo [70].
O discurso discreto indica que os sistemas são capazes de reconhecer apenas uma pequena parte
previamente selecionada de entre todas as palavras e frases válidas que podem ser ditas. Normalmente, a
própria gramática usada é artificial e não corresponde em nada à linguagem natural. Este tipo de sistemas
é ideal para a criação de texto interpretável por um computador, pois a gramática pode ser desenhada de
maneira a eliminar qualquer ambiguidade de interpretação. As aplicações principais são sistemas
controláveis por voz, em que um computador reconhece apenas certos comandos de voz [70].
O discurso contínuo, que pode ser também denominado ditação, pretende imitar a maneira como as
pessoas comunicam entre si. Normalmente, estes sistemas pretendem reconhecer o maior vocabulário
possível, permitindo a utilização de linguagem natural. As principais aplicações são sistemas que auxiliem
a transcrição de grandes quantidades de áudio, transcrição automática de voz em tempo real e sistemas
que apoiem pessoas com dificuldades auditivas [70]. Uma área de estudo relacionada é o processamento
de linguagem natural, que tem como objetivo usar métodos automáticos para perceber o significado de
comandos que não sigam gramáticas artificiais e restritivas, mas sim linguagem natural. Os sistemas
existentes ainda são embrionários, se bem que já há sistemas que atingem resultados razoáveis em
condições especiais [71].
Há também que reconhecer a diferença entre reconhecimento de voz e reconhecimento de discurso
(speech em inglês). O reconhecimento de voz é a expressão usada para designar sistemas criados à
medida de utilizadores específicos, enquanto o reconhecimento de discurso designa sistemas gerais, que
têm como objetivo reconhecer a voz de qualquer pessoa, sem necessidade de treino prévio [72].
2.3.1 SISTEMAS EXISTENTES
Na área médica, já estão a ser usados vários sistemas de reconhecimento de voz em certas
especialidades que têm de realizar muitos relatórios, como radiologia. Além destes sistemas, que muitas

CAPÍTULO 2.
ESTADO da Arte
37
vezes são centralizados, muitos médicos têm acesso a software individual de reconhecimento de voz para
acelerar a sua produção de relatórios [73].
Noutra área de estudo, há sistemas experimentais de telemedicina que produzem resultados ainda
preliminares no sentido de automatizar os diagnósticos mais simples, sem qualquer intervenção humana
[73].
De seguida são apresentados alguns sistemas existentes em mais detalhe.
2.3.1.1 IBM VIAVOICE
O sistema ViaVoice foi desenvolvido pela IBM e pretende ser um motor de reconhecimento de voz
generalista, independente do falante, disponível para várias línguas. Uma das suas versões está otimizada
para sistemas integrados, como smartphones, computadores de bordo, etc., denominando-se Embedded
ViaVoice [74].
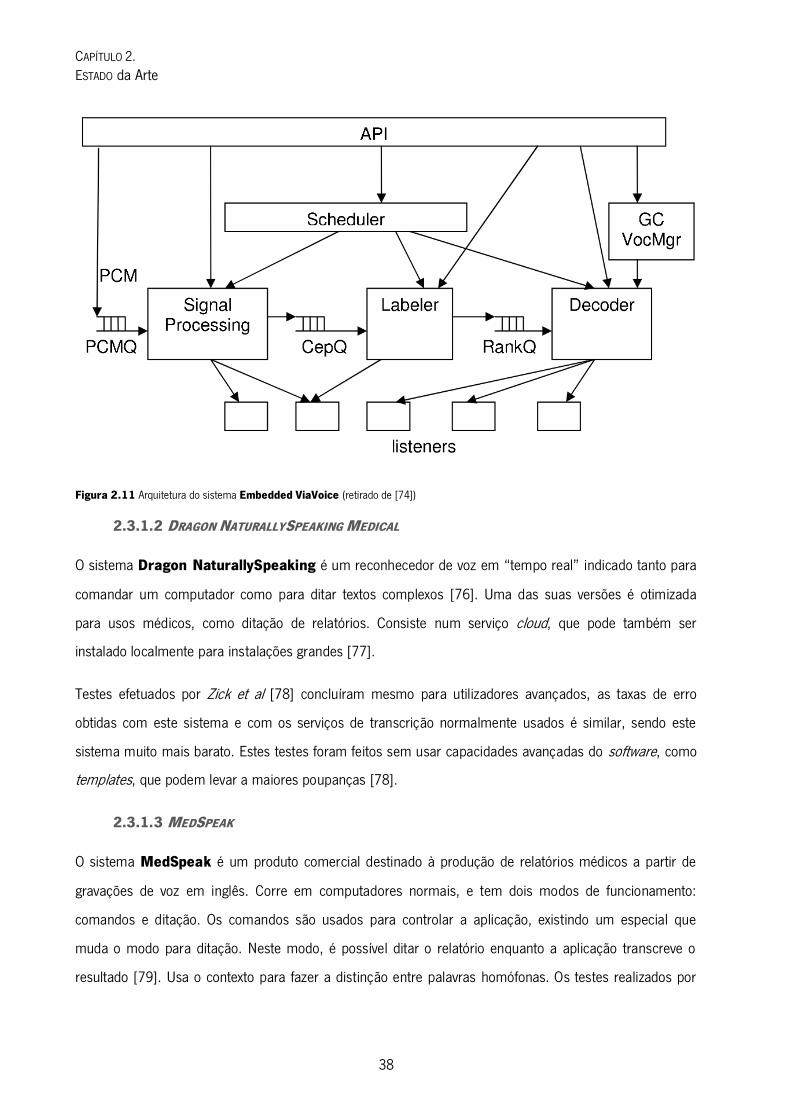
A sua arquitetura interna está dividida em vários módulos especializados que expõem uma API comum,
que permite a sua integração fácil nos sistemas existentes. Esta integração é ainda mais facilitada pelo
facto do sistema ser independente tanto da plataforma onde corre como do sistema operativo usado. A
Figura 2.11 esquematiza esta arquitetura de maneira simplificada.
Existe também uma versão que funciona em desktops denominado ViaVoice Millennium. Testes
efetuados por Borowitz [75] indicam que esta ferramenta leva a uma diminuição dramática na velocidade
de produção de relatórios em relação ao processo anterior de recorrer a um serviço especializado, mesmo
considerando que a ditação não é perfeita. O valor destas ferramentas é reduzir a escrita de um relatório
completo a um processo simples de correções a um documento já existente [75].
CAPÍTULO 2.
ESTADO da Arte
38
Figura 2.11 Arquitetura do sistema Embedded ViaVoice (retirado de [74])
2.3.1.2 DRAGON NATURALLYSPEAKING MEDICAL
O sistema Dragon NaturallySpeaking é um reconhecedor de voz em “tempo real” indicado tanto para
comandar um computador como para ditar textos complexos [76]. Uma das suas versões é otimizada
para usos médicos, como ditação de relatórios. Consiste num serviço cloud, que pode também ser
instalado localmente para instalações grandes [77].
Testes efetuados por Zick et al [78] concluíram mesmo para utilizadores avançados, as taxas de erro
obtidas com este sistema e com os serviços de transcrição normalmente usados é similar, sendo este
sistema muito mais barato. Estes testes foram feitos sem usar capacidades avançadas do software, como
templates, que podem levar a maiores poupanças [78].
2.3.1.3 MEDSPEAK
O sistema MedSpeak é um produto comercial destinado à produção de relatórios médicos a partir de
gravações de voz em inglês. Corre em computadores normais, e tem dois modos de funcionamento:
comandos e ditação. Os comandos são usados para controlar a aplicação, existindo um especial que
muda o modo para ditação. Neste modo, é possível ditar o relatório enquanto a aplicação transcreve o
resultado [79]. Usa o contexto para fazer a distinção entre palavras homófonas. Os testes realizados por

CAPÍTULO 2.
ESTADO da Arte
39
Rosenthal et al [79] obtiveram taxas de erro da ordem dos 3%, sendo muito mais económico que os
serviços de transcrição normalmente usados.
2.3.1.4 SPEECH RECOGNITION SYSTEM IN RIS
Wang et al [80] usaram dados já existentes com o sistema CMU Sphinx para criar um sistema de
reconhecimento de voz em Mandarim para uso específico na geração de relatórios para o Serviço de
Informação de Radiologia (RIS, do inglês Radiology Information System). Reconhece as 395 palavras mais
usadas na elaboração destes relatórios, e é dependente do falante, sendo que exige um treino inicial de
aproximadamente 40 minutos. Comparado com o ViaVoice, este sistema obteve uma menor taxa de erro,
devido ao facto de conter um dicionário sem palavras irrelevantes e ser dependente do falante [80].
2.3.2 BASE TECNOLÓGICA
Apesar de experiências com reconhecimento de voz existirem há muito tempo, a abordagem atual tem
como base teórica os modelos HMM (do inglês Hidden Markov Models). A vantagem desta abordagem é
que esta arquitetura é simples de implementar num computador atual e permite que a fase de treino seja
automatizada [72]. O reconhecimento de voz faz parte de um campo mais vasto denominado
processamento de linguagem natural.
2.3.2.1 PROCESSAMENTO DE LINGUAGEM NATURAL
O processamento de linguagem natural é uma área de investigação que tem como objetivo “ensinar”
computadores a compreender linguagens naturais (texto livre ou voz), para que possam ser comandados
usando essas interfaces. Envolve compreender a maneira como os humanos percebem e interiorizam as
linguagens naturais, para que seja possível produzir ferramentas que usem estas técnicas [71].
O reconhecimento de voz é uma parte importante do processamento de linguagem natural, que envolve
vários níveis de reconhecimento, hierarquicamente distribuídos, em que se pode classificar um discurso.
Cada nível usa informação proveniente de níveis inferiores para retirar inferências que podem ser usadas a
níveis superiores. Apesar de serem apresentados como classificações independentes e estanques, há
estudos psicolinguísticos que mostram que o processamento de linguagem realizado por humanos é mais
fluido que isto, usando informação de níveis superiores para desambiguar análises a níveis inferiores [81].
Sendo assim, os níveis de linguagem podem ser classificados, do mais baixo para o mais alto nível, como:

CAPÍTULO 2.
ESTADO da Arte
40
FONOLÓGICO
Este nível lida com interpretação dos sons contidos na voz humana, usando regras simples, para produzir
uma representação intermédia livre de ambiguidades. Esta análise abrange três tipos de regras: fonéticas,
para sons dentro das palavras; fonémicos, para variações na pronúncia quando algumas palavras se
encontram adjacentes; prosódicas, para flutuações de tom através de frases [81]. Naturalmente, sistemas
de information retrieval que trabalham apenas sobre texto não necessitam deste nível de reconhecimento
[82].
MORFOLÓGICO
Este nível lida com palavras, que são compostas por morfemas, as unidades mais pequenas que indicam
o significado, incluindo prefixos e sufixos [71]. O significado de cada morfema mantêm-se igual entre
palavras diferentes, logo é possível compreender uma palavra complexa dividindo-a em morfemas e
considerando o sentido de cada um [81]. Os sistemas que chegam a este nível conseguem perceber se
uma palavra está no plural ou no singular, ou reconhecer o tempo de formas verbais regulares. O seu uso
automático sem reconhecimento de nível superior pode levar a confusões entre palavra com morfemas
semelhantes com significados diferentes [82].
LEXICAL
Este nível representa o significado de palavras individuais. Mais propriamente, é identificado para cada
palavra a sua função sintática (nome, adjetivo, verbo). Isto é muito útil para palavras que têm apenas um
significado possível, pois evita processamento adicional nos níveis superiores [81].
O contexto é muito importante para realizar esta identificação por isso muitas vezes não se distingue nível
lexical de nível sintático.
SINTÁTICO
O nível sintático é similar ao nível lexical, que identifica as funções sintáticas de cada palavra, mas usa o
contexto para desambiguar certas palavras com vários sentidos. O objetivo é criar uma estrutura
gramatical de cada frase, que possa ser posteriormente analisada a um nível superior [81].
A gramática usada pode ser mais ou menos complexa dependendo da aplicação a que se destina. Por
exemplo, para cada palavra pode ser identificada a sua função sintática ou podem ser inferidas relações
mais complexas que ajudem a perceber o sentido da frase [82].

CAPÍTULO 2.
ESTADO da Arte
41
SEMÂNTICO
Este nível é aquele que é normalmente considerado como aquele onde o verdadeiro significado das
palavras é identificado. Usa o contexto em conjunto com um dicionário para identificar o sentido de cada
palavra, para eliminar qualquer ambiguidade que existe entre palavras. Na maior parte das línguas
existem nomes compostos por várias palavras, que indicam conceitos diferentes dos seus constituintes.
Este nível deve ser capaz de reconhecer estes nomes, usando informação sintática e semântica,
dependendo do contexto [81], [82].
DISCURSO
Este nível trata de compreender o texto como mais que a soma das suas frases individuais, tentando
inferir sentidos comuns ao texto como um todo. É comum realizar Resolução de Anáforas, que consiste
em substituir certas palavras como pronomes pessoais, que não indicam significado isoladamente, pelas
entidades que estes referenciam [81]. Outra tarefa consiste em dividir um texto numa estrutura comum a
certas classes de textos que possa até ajudar na compreensão do significado das frases lá incluídas. Um
dos exemplos é dividir uma notícia de jornal nas suas partes constituintes, identificando conclusões,
previsões, factos ou opiniões [82].
PRAGMÁTICO
Um sistema de reconhecimento pragmático é aquele que faz inferências sobre o texto considerando
informação que não está contida no texto mas que se relaciona com informação sobre o mundo exterior
[71]. Isto exige que essa informação exterior esteja armazenada numa forma que o sistema possa
entender. Uma das maneiras de criar estas bases de dados é recolher toda a informação que temos sobre
o mundo e coloca-la numa só base de dados, que indique intenções, planos e objetivos de uma variedade
de entidades. Esta é uma tarefa titânica, que leva muito tempo e não é capaz de adicionar rapidamente
informação nova, pelo que está condenada a estar permanentemente incompleta [81], [82].
2.3.2.2 MODELOS DE MARKOV (HMM)
Os HMM são construídos com base numa biblioteca de dados que contém áudio, anotado com a
correspondente representação textual. Dependendo do objetivo do sistema, pode conter ou não uma
grande variedade de frases, provenientes de várias pessoas ou apenas de uma. Os níveis de
reconhecimento são os seguintes [72]:
Modelo Acústico:

CAPÍTULO 2.
ESTADO da Arte
42
Contém as diferentes características para cada gravação áudio na biblioteca de dados;
Contém informação que mapeia áudio para uma representação intermédia, como IPA (do
inglês International Phonetic Alphabet);
Modelo Lexical:
Contém a probabilidade de diferentes sons serem contíguos;
Contém informação sobre o contexto onde os sons aparecem, para corrigir o modelo
acústico;
Modelo Gramatical:
Identifica características de alto nível, como palavras e frases;
Contém informação sobre o contexto gramatical, para corrigir o modelo lexical;
O modelo gramatical pode não ser usado, principalmente em aplicações de discurso contínuo, pois a
gramática pode ser demasiado complexa para ser representada de maneira eficiente [83].
IMPLEMENTAÇÕES
Alguns sistemas proprietários de reconhecimento de voz referidos acima, como ViaVoice, Dragon
NaturallySpeaking e MedSpeak, usam implementações desconhecidas para realizar o
reconhecimento. Quanto a software open-source, passível de ser analisado, as principais implementações
de HMM são o HTK Toolkit e o CMU Sphinx.
HTK TOOLKIT
O HTK Toolkit é um conjunto de bibliotecas usadas para investigação em reconhecimento automático de
voz, implementando HMM para reconhecer vocábulos. Inclui também ferramentas externas para criação
de modelos passíveis de serem utilizados com estas bibliotecas.
O primeiro sistema de Reconhecimento Contínuo de Discurso de Grande Vocabulário (do inglês Large
Vocabulary Continuous Speech Recognition, LVCSR) baseado no HTK Toolkit foi criado na Universidade
de Cambridge em 1993, usando uma versão que já continha clustering de árvores de decisão e usava
modelos desenvolvidos separadamente [84]. No ano seguinte este trabalho foi continuado, adicionando
uma fase de pré-processamento consistindo em adaptação por regressão linear, que nunca chegou a ser
adaptado à versão disponível atualmente ao público [85]. Nessa altura foi instituída a DARPA Challenge,
que avaliava vários sistemas de reconhecimento de voz com várias bibliotecas de dados diferentes. A
Universidade de Cambridge participou, com apoio da Entropic, e o sistema foi testado em todos eles,

CAPÍTULO 2.
ESTADO da Arte
43
desde notícias televisivas a conversas telefónicas, sendo necessário introduzir várias novas características
que aumentassem a sua fiabilidade [86], [87]. Houve também experiências com dados sem pré-
processamento, que criaram um sistema verdadeiro automático, que foi usado para realizar transcrição
automática de programas televisivos [88]. Em 2003 foi pela primeira vez adaptado a uma língua que não
a inglesa, neste caso Mandarim, incorporando todas as evoluções desenvolvidas até este momento [89].
O código é detido pela Microsoft, mas é atualmente mantido pelo Departamento de Engenharia da
Universidade de Cambridge. O código está disponível mediante registo, e a licença está vocacionada para
uso académico, e impede a criação de produtos comerciais que incluam alguma parte deste código. É
apenas permitido usar o HTK Toolkit para treinar modelos que sejam posteriormente usados em
aplicações comerciais. A sua última versão é v3.4.1 e foi lançada em 2009 [90].
CMU SPHINX
O CMU Sphinx é um conjunto de ferramentas que auxiliam na criação de aplicações que necessitem de
reconhecer vozes.
O projeto SPHINX inclui neste momento quatro versões principais. A primeira versão foi o primeiro
sistema de LVCSR que, usando HMM, conseguiu ser independente do falante [91]. Para a próxima versão,
denominada SPHINX II, o projeto foi aberto à comunidade, mantendo a equipa que criou a primeira
versão, com objetivo de melhorar a rapidez de reconhecimento e a sua qualidade [92]. Depois disto,
focando-se na qualidade do reconhecimento em detrimento da rapidez, SPHINX-III foi criado como uma
versão offline (i.e. incapaz de correr em tempo real) dos sistemas anteriores, com uma representação
interna incompatível, que permitisse uma taxa de erro menor. Além disso é também aplicada uma bateria
de algoritmos de pré-processamento aos sinais antes de serem processados. Apesar de avanços no
hardware disponível permitirem correr o sistema SPHINX-III em quase tempo real, este não foi
desenhado para esse efeito, o que piora os resultados obtidos [93]. A última versão, SPHINX-4,
reescreve a maior parte do sistema para criar um sistema mais flexível e modular, que possa aceitar
várias fontes de dados de uma maneira elegante, mantendo o seu propósito como reconhecimento offline.
Usa Java na sua implementação e é uma joint-venture entre Mitsubishi Electric Research
Laboratories e a Sun Microsystems [83]. A licença deste projeto é BSD (do inglês Berkley Software
Distribution), pelo que permite ser incorporado até em projetos comerciais.

CAPÍTULO 2.
ESTADO da Arte
44
Sendo baseados no mesmo princípio teórico, as diferenças entre estes dois sistemas são desprezáveis,
como foi confirmado por vários estudos independentes [94], [95]. A maior diferença prende-se na licença
sob o qual o código é publicado. Enquanto a licença do HTK Toolkit é restritiva, apenas permitindo o seu
uso para fins académicos e de investigação, não disponibilizando o código sem registo prévio na sua
plataforma, o sistema CMU Sphinx está disponível sob uma licença BSD, que permite inclusive o seu
uso em programas comerciais. Talvez por essa razão o projeto SPHINX está ainda ativo, sendo que a
última versão do HTK Toolkit foi lançada em 2009.

Capítulo 3
MYENDOSCOPY -
MIVCONTROL

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
46

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
47
Durante o desenvolvimento de uma aplicação deve ter sido em conta o contexto onde ela vai ser usada e o
meio onde ela vai estar integrada, para se seja facilitada a integração com outras aplicações ou usar
recursos partilhados com outras aplicações. Neste caso concreto, o sistema MyEndoscopy, com o seu
dispositivo central MIVbox, é tido como o ambiente que serve de referência a todas as implementações
realizadas. Sendo assim, é importante estudar a sua organização, incluindo todas as tecnologias que o
sistema utiliza.
O módulo MIVcontrol consiste num programa que usa um corpus de dados como modelo para realizar
reconhecimento de voz. Neste capítulo são ainda explorados a criação deste corpus bem como do
programa que o interpreta.
3.1 CONTEXTUALIZAÇÃO
3.1.1 MYENDOSCOPY
O sistema MyEndoscopy foi desenvolvido para ligar várias entidades e estandardizar o processamento do
processo clínico eletrónico, de maneira a promover a partilha de informação entre várias instituições, e é
baseado numa interface web [6]. Na Figura 3.1 está representada a sua arquitetura geral, com todos os
módulos que este contém.
Atua como uma cloud privada, com vários dispositivos que se ligam a ela, usando ou providenciando
serviços usando protocolos comuns. À medida que mais instituições usam estes serviços, os custos destes
serviços podem ser mantidos sob controlo se estas clouds forem partilhadas entre si, permitindo um
aumento de escala de maneira económica [6].
O dispositivo central deste sistema é a MIVbox, desenvolvida para resolver certas dificuldades que os
profissionais de saúde encontram quando realizam procedimentos endoscópicos. Digitaliza o vídeo
adquirido pelo endoscópio e integra-se no sistema MyEndoscopy, permitindo a todos os outros dispositivos
acederem ao vídeo através da interface web [6].

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
48
Figura 3.1 Arquitetura geral do sistema MyEndoscopy (retirado de [96])
3.1.2 WORKFLOW TÍPICO DE UMA CONSULTA DE GASTROENTEROLOGIA
Na Figura 3.2 está representado um workflow típico que descreve os momentos que ocorrem durante um
consulta médica de gastroenterologia numa unidade de saúde que resulta num procedimento endoscópico.
Segundo a Figura 3.2 uma consulta de gastroenterologia pode ser dividida em vários momentos. Quando
o utente tem sintomas, marca uma consulta com o seu médico. No primeiro momento, o médico recolhe
a informação necessária e, caso seja necessário, prescreve um MCDT para confirmar o diagnóstico. De
seguida, durante a realização da Endoscopia, o gastroenterologista toma as ações necessárias para a sua
realização e recolhe a informação necessária para o diagnóstico. A criação do relatório compreende o
momento seguinte, onde o gastroenterologista consulta casos semelhantes. Finalmente, o último
momento consiste no médico receber os resultados e informar o utente.
O módulo MIVcontrol pode ser integrado diretamente no workflow existente ao permitir ao
gastroenterologista controlar o módulo MIVacquisition usando comandos de voz.

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
49
Figura 3.2 Workflow típico de um procedimento endoscópico (adaptado de[97])
3.2 MIVCONTROL
O objetivo principal do módulo MIVcontrol é substituir o pedal, usado atualmente pelos gastrenterologistas
para capturar frames, por comandos de voz que interagem diretamente com o MIVacquisition e o
MIVengine. Estes módulos recebem e controlam o vídeo diretamente da torre do endoscópio e permitem
aos outros módulos acederem a estes dados [96].
3.2.1 CRIAÇÃO DE UM CORPUS DE RECONHECIMENTO
Para realizar reconhecimento de voz é necessário ter um corpus de reconhecimento adequado à aplicação
que se destina. Neste caso, o sistema necessita apenas de reconhecer um pequeno número de comandos,
em várias línguas. Os corpora existentes adaptados para a biblioteca PocketSphinx não incluem a língua
portuguesa, além de que são indicados para aplicações gerais, que tentam reconhecer o maior número
possível de vocábulos. Sendo assim, optou-se por criar um corpus para cada língua a reconhecer,
adaptado unicamente a esta aplicação.
À combinação de um modelo acústico com um modelo textual foi dado o nome de modelo de voz. Este
indica uma base comum para realizar testes e obter resultados reproduzíveis. O procedimento adotado na
sua criação está esquematizado na Figura 3.3.
A criação do modelo divide-se em dois subprocessos: criação do modelo acústico e criação do modelo
textual. O modelo acústico requer partes do modelo textual, pelo que este é gerado primeiro. Na Figura
3.3 está representada a criação do modelo acústico pelo subprocesso AmCreate. Já o subprocesso
LmCreate representa a criação do modelo textual.

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
50
Figura 3.3 Procedimento para criação de um modelo de voz (adaptado de [97])
Nas próximas secções são explicados estes dois modelos em maior pormenor.
3.2.1.1 MODELO ACÚSTICO
O modelo acústico é usado para obter fonemas a partir dos sons a processar e é criado com recurso a
uma biblioteca com uma grande quantidade de áudio previamente reconhecida manualmente. Estes
dados são etiquetados de acordo com os resultados da mesma extração de características usados durante
o reconhecimento. Estas características são usadas para criar o modelo automaticamente, usando
aprendizagem máquina, mais propriamente HMM (ver secção 2.3.2.2 ).

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
51
3.2.1.2 MODELO TEXTUAL
O modelo textual é usado posteriormente, usando os resultados do modelo acústico para criar a
representação textual correspondente. Cada fonema é analisado dependendo do contexto, e esta análise
está subdividida em níveis:
DICIONÁRIO
O dicionário é um mapa entre cada palavra reconhecida e os fonemas que esta contém. Se a quantidade
de comandos a reconhecer for pequena o suficiente, pode ser criada manualmente, de preferência
recorrendo a estudos fonéticos. Para certas aplicações, como reconhecedores de discurso contínuo (ver
secção 2.3 ), a quantidade de palavras que devem ser reconhecidas torna imprático esta abordagem e é
necessário recorrer a métodos automáticos [81].
MODELO DE LINGUAGEM
O modelo de linguagem é uma descrição de alto nível de todas as frases (i.e. sequências de palavras)
numa certa língua, pelo que a escolha deste modelo depende da aplicação a que se destina. Dividem-se
em dois tipos: modelos de linguagem estatísticos e gramáticas livres de contexto.
MODELOS DE LINGUAGEM ESTATÍSTICOS
Os modelos de linguagem estatísticos tentam prever todas as frases possíveis para uma certa língua,
combinando as palavras conhecidas em todas combinações possíveis [98]. Posteriormente, para reduzir o
espaço de procura, é necessário escolher as combinações mais comuns no discurso que vai ser
reconhecido, o que é normalmente realizado usando dados que são produzidos como texto e lidos por
pessoas, como audiolivros, notícias jornalísticas e outras fontes [99].
Estes modelos são representados como listas de -gramas (sequência de palavras) com a sua
probabilidade correspondente. A lista de -gramas é criada combinando uma lista de palavras possíveis.
Se a lista de palavras corresponder a uma linguagem natural (Inglês, Português, etc.), é impraticável criar
-gramas com , devido ao facto das combinações possíveis crescerem exponencialmente [92].
Huang et al criaram bigramas que consideravam não as palavras adjacentes mas aquelas que se
encontram a longas distâncias no texto, e concluíram que, apesar da informação obtida por estes
bigramas de longa distância ser possível de ser medida, não é praticável que seja usada na prática pois
requer um grande esforço para uma melhoria dos resultados desprezável [92].

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
52
Necessitam de grandes quantidades de dados para se obter uma fiabilidade aceitável, mas é
relativamente fácil agregar estes dados automaticamente, durante longos períodos de tempo. Além da
coleção de dados poder ser automatizada, também o treino destes modelos é realizado automaticamente.
É também possível mudar o procedimento de treino para aumentar a fiabilidade dos modelos, mantendo
os mesmos dados, aumentando o número de -gramas criados, à custa de ser necessário mais tempo e
recursos para os criar.
GRAMÁTICA LIVRE DE CONTEXTO
As gramáticas livres de contexto restringem as frases reconhecidas a um restrito subconjunto de todas as
frases possíveis, determinado durante o treino. Todas as frases que não caibam no modelo são
descartadas. Assim, os resultados produzidos por reconhecedores que usem estes modelos são
determinísticas e podem ser processadas automaticamente mais facilmente.
Estas gramáticas são normalmente produzidas manualmente, pois normalmente modelam gramáticas
artificiais muito mais simples que as que existem em linguagens faladas. Além disso, a performance dos
reconhecedores que usam estes modelos está diretamente ligada à sua complexidade.
Estas gramáticas podem ser representadas de várias formas, sendo o standard adotado pela indústria
definido como JSGF (do inglês Java Speech Grammar Format) [100]. Estas representações passam por
um processamento inicial que as converte num formato passível de ser interpretado por um computador,
criando essencialmente um programa executado pelo reconhecedor. Ao contrário dos modelos estatísticos,
que consistem em apenas dados, cada modelo é um programa diferente, o que leva a que a sua
performance dependa da quantidade de dados a processar e da complexidade das regras gramaticais
estabelecidas.
Para aplicações de discurso contínuo (ver secção 2.3 ), o modelo mais adequado consiste em modelos de
linguagem estatísticos. Já para aplicações de discurso discreto (ver secção 2.3 ), devem ser usadas
gramáticas livres de contexto.
3.2.2 APLICAÇÃO PRINCIPAL
Além de ter sido criado um corpus de reconhecimento, foi também criado o programa que usa esses
dados para efetuar reconhecimento de voz. O sistema processa áudio em tempo-real, divide a stream em

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
53
comandos discretos e produz uma linha de texto para cada comando reconhecido. Este sistema corre na
MIVbox como um dos seus módulos. A integração deste módulo na MIVbox está esquematizada na Figura
3.4.
Figura 3.4 Integração do MIVcontrol na MIVbox (adaptado de [97])
O áudio é lido do sistema e guardado num buffer em memória. A primeira etapa de pré-processamento
envolve dividir o áudio em frases, correspondentes a comandos, tendo em conta os períodos de silêncio
entre elas. São também aplicados filtros com vista a reduzir o ruído de entrada, para conseguir reconhecer
períodos de silêncio de maneira mais robusta e fiável. Depois desta divisão em frases independentes, cada
segmento é processado para criar um conjunto de features, que são aplicados como input ao HMM, que
usa o modelo para encontrar o comando que mais se assemelha à frase recebida. Este é o resultado final,
que é comunicado ao sistema seguinte.
A primeira implementação foi criada como proof-of-concept, para verificar se a arquitetura e as bibliotecas
utilizadas, combinadas com uma versão preliminar do corpus de reconhecimento seriam adequadas a
esta aplicação. Foi desenvolvido em Linux, o corpus consistia em poucos minutos de voz gravada apenas
por uma pessoa, e o programa foi criado em C, usando como base o programa de teste providenciado

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
54
pelo projeto PocketSphinx. Esta implementação foi validada, com a produção de resultados favoráveis,
pelo que se avançou para a integração deste conhecimento no software que serve de base à MIVbox.
A implementação da versão integrada na MIVbox foi simplificada pelas escolhas feitas anteriormente. As
bibliotecas de reconhecimento PocketSphinx são cross-platform, pelo que estão disponíveis tanto em
Linux, usado durante o desenvolvimento, como no MacOS X, sistema operativo usado em produção. Além
disso, o Qt permite a integração de bibliotecas escritas em C diretamente, sem ser necessário qualquer
tipo de layer de compatibilidade.
A primeira implementação usava os métodos providenciados pelas bibliotecas PocketSphinx para
recolher e segmentar áudio do sistema. Esta abordagem permitiu a criação de um protótipo muito
rapidamente, mas tornava o programa difícil de converter para o sistema MacOS X, pois a capacidade de
recolher o áudio neste sistema operativo pelas bibliotecas PocketSphinx estava planeada mas não
implementada. Além disso, a performance não era aceitável, com atrasos de vários segundos. Assim, foi
necessário implementar esta parte significativa do sistema de maneira cross-platform. As bibliotecas Qt
incluem a funcionalidade de gravar áudio do sistema de modo cross-platform, pelo que foi imediatamente
escolhida como solução.
A segunda implementação usava as bibliotecas Qt para recolher áudio do sistema, uma implementação
de uma máquina de estados finitos para segmentar o áudio recolhido e as bibliotecas PocketSphinx
para efetuar reconhecimento das frases recolhidas. Com esta versão foi possível pela primeira vez
compilar e testar todo o sistema no MacOS X. O problema da performance ainda se mantinha, por isso foi
decidido isolar todo o módulo MIVcontrol numa thread separada, já que a comunicação entre módulos é
mínima e é assegurada pela implementação de sinais das bibliotecas do Qt, que permite comunicação
segura entre diferentes threads.
A implementação final contém todo o módulo MIVcontrol numa thread separada da thread principal da
MIVbox, e usa as bibliotecas PocketSphinx apenas para reconhecimento. Com estas funcionalidades, o
reconhecimento é quase instantâneo, sendo que a taxa de erros não piorou desde a primeira
implementação, pois os dados fornecidos às bibliotecas PocketSphinx são similares.

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
55
3.2.3 RESULTADOS
O corpus de reconhecimento usado contém duas línguas: Português e Inglês, com um total de 1405
gravações, totalizando 25 minutos de voz, sendo 5 vozes femininas e 7 vozes masculinas. Para testar este
modelo fui usada 10-fold cross validation em todos os dados incluídos no corpus. O vocabulário foi
escolhido de maneira a ser possível ser aplicado diretamente no contexto de exames endoscópicos.
Os parâmetros de teste que produzem maior variação são a distribuição de misturas Gaussianas (em
inglês, Gaussian mixture distribution) e o número de estados empatados (em inglês, number of tied states).
Foram variados estes parâmetros em todas as combinações possíveis, sendo os melhores resultados
analisados mais pormenorizadamente. Esta primeira seleção dos resultados foi realizada recorrendo a
uma métrica referida na literatura [101] como Taxa de Erro por Palavra (em inglês, Word Error Rate), que
indica a percentagem de palavras corretamente identificadas pelo sistema.
Os resultados são apresentados como matrizes de confusão, ou precision-recall, onde as linhas indicam o
comando fornecido ao sistema e as colunas indicam o comando previsto pelo sistema. Os comandos
estão dentro de aspas, sendo que a etiqueta “OUTRO” indica comandos irreconhecíveis ou palavras fora
do vocabulário.
Para o modelo em língua inglesa verificou-se que os melhores resultados eram obtidos com 100
distribuições Gaussianas de misturas e 8 estados empatados. Com estes parâmetros, a Taxa de Erro por
Palavra é de 23.17%, o que corresponde a 128 erros em 550 comandos. A matriz de confusão está
representada na Tabela 3.1.
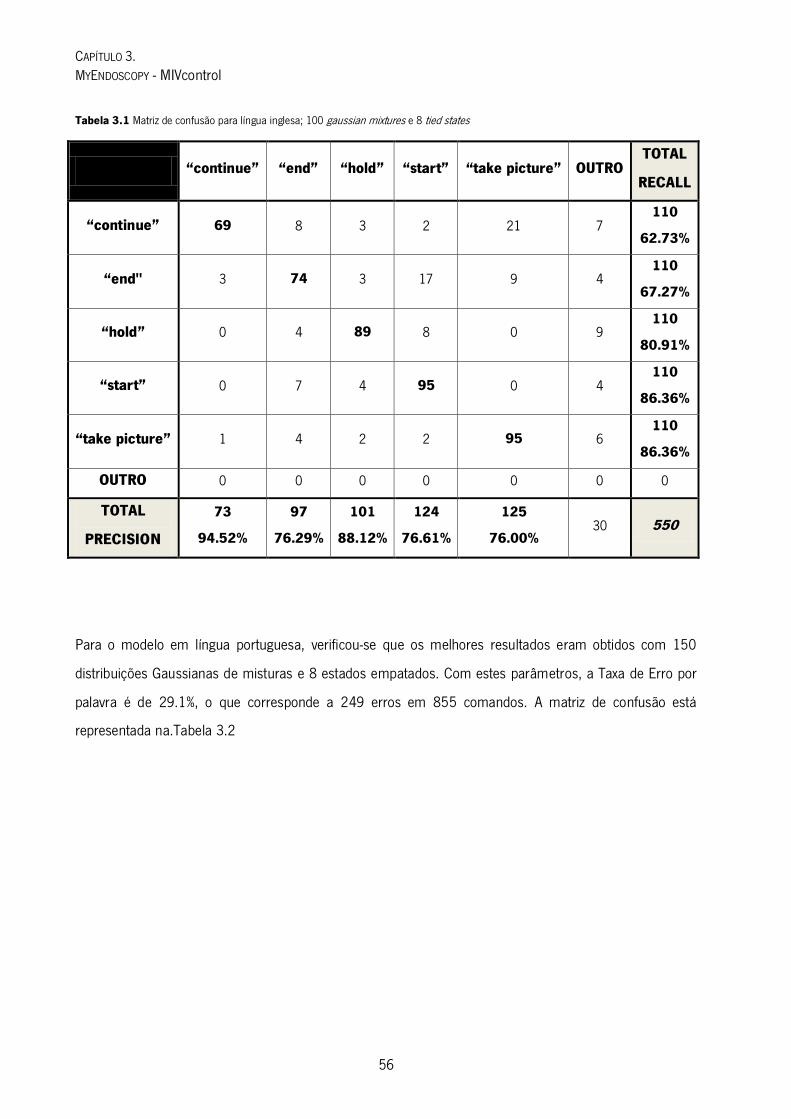
CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
56
Tabela 3.1 Matriz de confusão para língua inglesa; 100 gaussian mixtures e 8 tied states
“continue” “end” “hold” “start” “take picture” OUTRO TOTAL
RECALL
“continue” 69 8 3 2 21 7 110
62.73%
“end" 3 74 3 17 9 4 110
67.27%
“hold” 0 4 89 8 0 9 110
80.91%
“start” 0 7 4 95 0 4 110
86.36%
“take picture” 1 4 2 2 95 6 110
86.36%
OUTRO 0 0 0 0 0 0 0
TOTAL
PRECISION
73
94.52%
97
76.29%
101
88.12%
124
76.61%
125
76.00% 30 550
Para o modelo em língua portuguesa, verificou-se que os melhores resultados eram obtidos com 150
distribuições Gaussianas de misturas e 8 estados empatados. Com estes parâmetros, a Taxa de Erro por
palavra é de 29.1%, o que corresponde a 249 erros em 855 comandos. A matriz de confusão está
representada na.Tabela 3.2
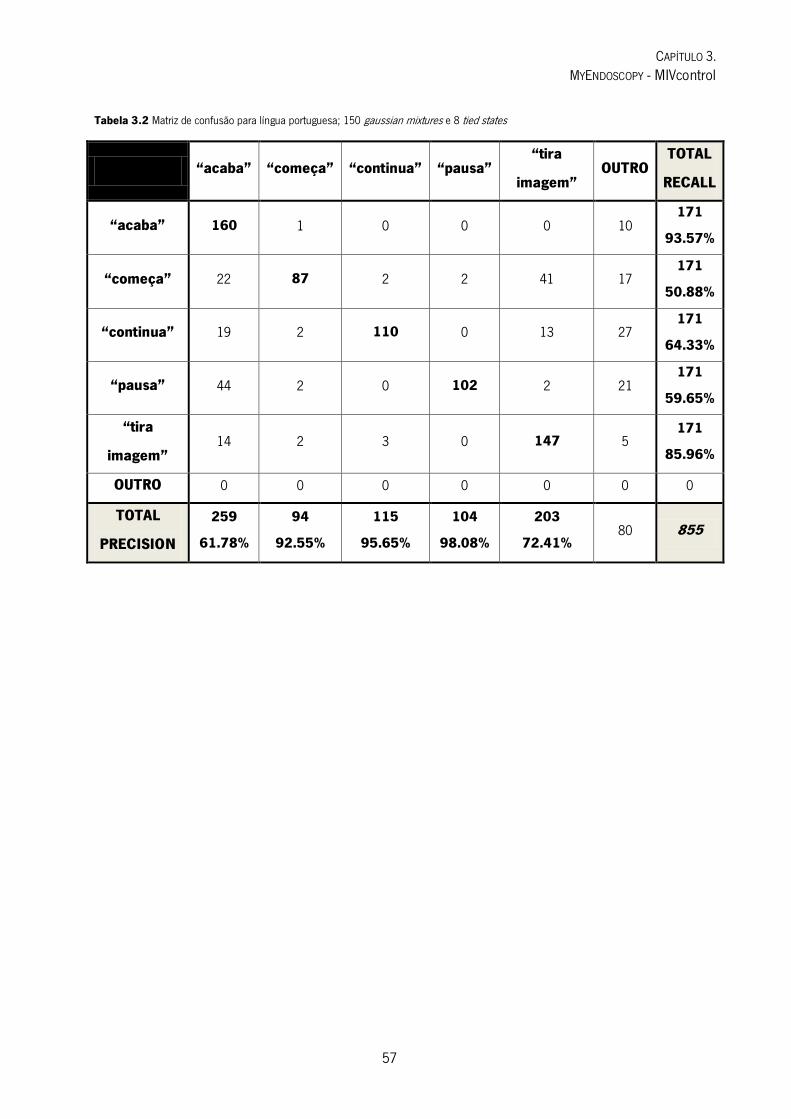
CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
57
Tabela 3.2 Matriz de confusão para língua portuguesa; 150 gaussian mixtures e 8 tied states
“acaba” “começa” “continua” “pausa” “tira
imagem” OUTRO
TOTAL
RECALL
“acaba” 160 1 0 0 0 10 171
93.57%
“começa” 22 87 2 2 41 17 171
50.88%
“continua” 19 2 110 0 13 27 171
64.33%
“pausa” 44 2 0 102 2 21 171
59.65%
“tira
imagem” 14 2 3 0 147 5
171
85.96%
OUTRO 0 0 0 0 0 0 0
TOTAL
PRECISION
259
61.78%
94
92.55%
115
95.65%
104
98.08%
203
72.41% 80 855

CAPÍTULO 3.
MYENDOSCOPY - MIVcontrol
58

Capítulo 4
CONCLUSÃO

CAPÍTULO 4. CONCLUSÃO
60

CAPÍTULO 4. CONCLUSÃO
61
Este capítulo reúne e sintetiza o trabalho efetuado, apresentado uma sinopse deste documento, as
contribuições realizadas com este trabalho e as conclusões finais que advieram da realização deste
trabalho. Indica também as propostas de trabalho futuro que usam este trabalho como base.
4.1 SINOPSE
De seguida resumem-se os resultados obtidos com a presente dissertação, capítulo a capítulo.
Como introdução enquadra-se este trabalho no domínio da informática médica, introduzindo os objetivos
desta área de estudo. Descrevem-se os meios complementares de diagnóstico, com foco especial na
endoscopia, como métodos de apoio à decisão, e são apresentados dados que comprovam a importância
destes exames no ato médico. As técnicas endoscópicas são aqui apresentadas de um modo resumido.
São também introduzidos os problemas que este trabalho visa solucionar, os objetivos a que se propõe e a
metodologia de investigação seguida. Posteriormente é realizado um levantamento do estado da arte para
os três assuntos principais deste trabalho: Sistemas de Arquivo e Gestão de Gastroenterologia, Criação de
Imagens Tridimensionais em Computador e Reconhecimento de Voz. Para cada um destes temas é
explorada a tecnologia que incorporam, bem como uma listagem não-exaustiva de sistemas já existentes
cujas capacidades e objetivos se aproximem dos objetivos deste trabalho. Antes de apresentar o trabalho
realizado no âmbito da criação do módulo de reconhecimento de voz para a MIVbox, é feita uma exposição
aprofundada sobre todas as tecnologias usadas na MIVbox, que servem de base a muito do trabalho
realizado. Quanto ao trabalho realizado, é descrito o processo de criação do programa e as suas
capacidades, explicitando o caminho que foi percorrido até chegar à versão final. É também realizado uma
descrição pormenorizada dos passos necessários à criação do modelo de dados que permite efetuar o
reconhecimento de voz.
Por fim, são apresentados os resultados obtidos nos testes efetuados, e feita a sua interpretação à luz do
resto do trabalho.
4.2 CONTRIBUIÇÕES
As contribuições deste trabalho para a melhoria das condições atuais podem ser classificadas de acordo
com o alvo dessa melhoria: utentes, profissionais de saúde, entidades prestadoras de cuidados de saúde,
e investigadores.

CAPÍTULO 4. CONCLUSÃO
62
Para os profissionais de saúde, uma nova interface que resolva alguns dos problemas levantados durante
a endoscopia só pode contribuir para a realização de um trabalho mais produtivo, levando a um enfoque
maior nos resultados a obter, e menos tempo e concentração perdidas em questões técnicas.
O facto dos profissionais de saúde terem melhores ferramentas para a realização de exames leva a uma
melhoria na qualidade do serviço de saúde prestado. Ainda que indiretamente, os utentes sofrem menos
desconforto durante os exames que tiverem de realizar, para além dos efeitos positivos nos diagnósticos
relacionados.
As entidades prestadoras de cuidados de saúde têm à sua disposição uma nova ferramenta que lhes
permite rentabilizar o tempo dos profissionais de saúde de maneira a atingir o seu objetivo de aumentar
os standards de atendimento aos utentes.
Finalmente, os investigadores que trabalhem nesta área têm acesso a um sistema MIVbox melhorado,
com a adição de novas interfaces de controlo, que podem servir como modelo para outros trabalhos. Está
também disponível a possibilidade de usar as bibliotecas do PocketSphinx a partir do Qt, adaptando o
código desenvolvido.
A partir do trabalho desenvolvido resultaram duas publicações científicas, intituladas “Endoscopic
Procedures Control Using Speech Recognition” [97] e “Multilingual Voice Control for Endoscopic
Procedures” [102]. Este facto é consistente com a metodologia de investigação delineada na Introdução.
Foi também realizado um levantamento do estado da arte sobre Criação de Imagens Tridimensionais em
Computador com vista à sua implementação como um módulo separado da MIVbox. A implementação
deste módulo foi devidamente planeada, com um conjunto de metas com datas definidas, que coincidiam
com a conclusão deste trabalho. Pouco tempo depois foi decidido que implementar um sistema de
reconhecimento de voz era mais importante, devido ao facto do projecto MyEndoscopy estar a aproximar-
se do final. Já que foi dada prioridade à implementação do módulo MIVcontrol, não houve oportunidade de
concluir este desenvolvimento, pelo que é proposto como trabalho futuro, partindo desta base.

CAPÍTULO 4. CONCLUSÃO
63
4.3 CONCLUSÕES
O trabalho efetuado no âmbito da presente dissertação teve como resultado a criação de um módulo de
reconhecimento de voz para a MIVbox. Este módulo permite a um profissional de saúde controlar o
endoscópio usando comandos de voz.
O MIVcontrol é um reconhecedor de voz para um pequeno vocabulário, que é usado como sistema de
comando e controlo, integrado no projeto MyEndoscopy, mais propriamente na MIVbox. As capacidades
existentes do projeto CMU Sphinx são utilizadas em pleno, particularmente das bibliotecas
PocketSphinx. O sistema foi criado para responder às necessidades dos gastroenterologistas e deve ser
tido como alternativa a sistemas baseados na cloud, devido a requerimentos mais exigentes quanto toca à
segurança e privacidade dos pacientes. O facto de ser completamente self-contained, sem dependências
externas torna-o atrativo e aumenta as probabilidades de ser adotado na prática.
Os resultados obtidos resultam de tuning extensivo aos parâmetros do PocketSphinx, necessário para
adaptar estas bibliotecas a línguas como português, que iam para além dos testes realizados pelos seus
criadores. Conseguiu-se uma taxa de erro comparável com outras adaptações já realizadas para línguas
diversas, desde línguas de Índios Americanos e Romani [103], Espanhol do México [101], Mandarim
[104], Árabe [105], e Sueco [106].
No capítulo do estado da arte está apresentado a Criação de Imagens Tridimensionais em Computador.
Como trabalho futuro, este capítulo pode ser desenvolvido até tornar-se um módulo separado da MIVbox,
tentativamente denominado MIV3D. Este módulo deverá ser capaz de localizar as ocorrências
endoscópicas num modelo tridimensional realístico do corpo humano. Esta localização deve ser
automática, aproveitando os dados já existentes para reduzir ao mínimo a intervenção dos profissionais de
saúde.

CAPÍTULO 4. CONCLUSÃO
64

REFERÊNCIAS
[1] R. Haux, “Medical Informatics: Past, Present, Future,” Int. J. Med. Inform., vol. 79, no. 9, pp. 599–610, Sep. 2010.
[2] J. R. Moehr, “The quest for identity of health informatics and for guidance to education in it: the German Reisensburg Conference of 1973 revisited,” IMIA Yearb. Med. Informatics, pp. 201–210, 2004.
[3] Á. Rocha and J. Vasconcelos, “Os Modelos de Maturidade na Gestão de Sistemas de Informação,” Revista da Faculdade de Ciência e Tecnologia, Porto, pp. 93–107, 2000.
[4] L. Pisco, “A Reforma dos Cuidados de Saúde Primários,” Cadernos de Economia, pp. 60–66, 2007.
[5] T. L. de S. Pereira, “Unidades de Saúde Familiar – A Evolução na Gestão dos Cuidados de Saúde Primários em Portugal,” 2011.
[6] I. Laranjo, J. Braga, D. Assunção, A. Silva, C. Rolanda, L. Lopes, J. Correia-Pinto, and V. Alves, “Web-Based Solution for Acquisition, Processing, Archiving and Diffusion of Endoscopy Studies,” in Distributed Computing and Artificial Intelligence, vol. 217, Springer International Publishing, 2013, pp. 317–24.
[7] W. K. Hirota, M. J. Zuckerman, D. G. Adler, R. E. Davila, J. Egan, J. A. Leighton, W. A. Qureshi, E. Rajan, R. Fanelli, J. Wheeler-Harbaugh, T. H. Baron, and D. O. Faigel, “ASGE guideline: the role of endoscopy in the surveillance of premalignant conditions of the upper GI tract.,” Apr. 2006.
[8] M. Classen, G. N. J. Tytgat, and C. J. Lightdale, Gastroenterological endoscopy, vol. 34, no. 10. Thieme, 2002, p. 777.
[9] L. Hong, A. E. Kaufman, Y.-C. Wei, A. Viswambharan, M. Wax, and Z. Liang, “3D virtual colonoscopy,” in Proceedings 1995 Biomedical Visualization, 1995, pp. 26–32,83.
[10] G. D. Meron, “The development of the swallowable video capsule (M2A),” Gastrointest. Endosc., vol. 52, no. 6, pp. 817–819, 2000.
[11] Portascope.com, “Complimentary Endoscope Information and Inspection Procedures,” Olympus Pentax Fujinon Endoscopes Endoscopy Equipment Inventory, 2012. [Online]. Available: http://www.1800endoscope.com/faq.htm. [Accessed: 01-Sep-2014].
[12] BeverlyOaksSugery, “Endoscopy,” Beverly Oaks Surgery, 2014. [Online]. Available: http://www.beverlyoakssurgery.com/colonoscopy/endoscopy/. [Accessed: 25-Sep-2014].
[13] J. M. Canard, J.-C. Létard, L. Palazzo, I. Penman, and A. M. Lennon, Gastrointestinal Endoscopy in Practice, 1st ed. Churchill Livingstone, 2011, p. 492.

REFERÊNCIAS
66
[14] J. Vanamburg, “Colonoscopy / Endoscopy,” Van Amburg Surgery Care, 2014. [Online]. Available: http://www.vanamburgsurgery.com/colonoscopy/. [Accessed: 25-Sep-2014].
[15] EugeneGI, “Colonoscopy,” Eugene Gastroenterology Consultants, 2014. [Online]. Available: http://www.eugenegi.com/procedures/procedures. [Accessed: 20-Sep-2014].
[16] B. Penna, T. Tillo, M. Grangetto, E. Magli, and G. Olmo, “A technique for blood detection in wireless capsule endoscopy images,” 17th Eur. Signal Process. Conf., pp. 1864–1868, 2009.
[17] B. S. Lewis and P. Swain, “Capsule endoscopy in the evaluation of patients with suspected small intestinal bleeding: Results of a pilot study,” Gastrointest. Endosc., vol. 56, no. 3, pp. 349–353, Sep. 2002.
[18] T. Tillo, E. Lim, Z. Wang, J. Hang, and R. Qian, “Inverse Projection of the Wireless Capsule Endoscopy Images,” in 2010 International Conference on Biomedical Engineering and Computer Science, 2010, pp. 1–4.
[19] P. M. Szczypinski, P. V. J. Sriram, R. D. Sriram, and D. N. Reddy, “Model of deformable rings for aiding the wireless capsule endoscopy video interpretation and reporting,” in Computer Vision and Graphics, K. Wojciechowski, B. Smolka, H. Palus, R. S. Kozera, W. Skarbek, and L. Noakes, Eds. Warsaw: Kluwer Academic Publishers, 2004, pp. 167–172.
[20] G. Pan and L. Wang, “Swallowable Wireless Capsule Endoscopy: Progress and Technical Challenges,” Gastroenterology Research and Practice, vol. 2012. pp. 1–9, 2012.
[21] H. M. Fenlon, D. P. Nunes, P. C. Schroy III, M. A. Barish, P. D. Clarke, and J. T. Ferrucci, “A comparison of virtual and conventional colonoscopy for the detection of colorectal polyps.,” N. Engl. J. Med., vol. 341, no. 20, p. 14961503, Nov. 1999.
[22] D. Ibrahim, “Apple Core Sign - Cancer Colon,” Radiopedia, 2014. [Online]. Available: http://radiopaedia.org/cases/apple-core-sign-cancer-colon-1. [Accessed: 26-Sep-2014].
[23] R. Prus, “Generic Social Processes: Maximizing Conceptual Development in Ethnographic Research,” J. Contemp. Ethnogr., vol. 16, no. 3, pp. 250–293, Oct. 1987.
[24] D. E. Avison, F. Lau, M. D. Myers, and P. A. Nielsen, “Action research,” Commun. ACM, vol. 42, no. 1, pp. 94–97, Jan. 1999.
[25] B. Somekh, Action research : a methodology for change and development. 2006, p. 225.
[26] J. McNiff, Action research for professional development. 2002, p. 32.
[27] PENTAX, “PENTAX endoPro iQ Technology Solutions,” 2010.
[28] XION, “DiVAS Image and Video Analysis,” XION Medical, 2010. [Online]. Available: http://www.xion-medical.com/en/components/divas-software/image-and-video-analysis. [Accessed: 30-Oct-2014].

REFERÊNCIAS
67
[29] SiiMA, “SiiMA - management of SMDTs in clinical services,” 2011.
[30] RichardWolf, “VictOR HD HDTV Recording Technology - a touching experience,” 2011.
[31] M. Veit and S. Herrmann, “Model-view-controller and object teams,” in Proceedings of the 2nd international conference on Aspect-oriented software development - AOSD ’03, 2003, pp. 140–149.
[32] A. Raja, “Introduction to the Model-View-ViewModel Pattern,” INFRAGISTICS, 2012. [Online]. Available: http://www.infragistics.com/community/blogs/anand_raja/archive/2012/02/20/the-model-view-viewmodel-101-part-1.aspx.
[33] A. Skendzic, B. Kovacic, and I. Jugo, “Decreasing information technology expenses by using emulators on Windows and Linux platforms,” 2011 Proc. 34th Int. Conv. MIPRO, pp. 1387–1390, 2011.
[34] M. Jazayeri, “Some Trends in Web Application Development,” in Future of Software Engineering (FOSE ’07), 2007, pp. 199–213.
[35] P. Fraternali, “Tools and approaches for developing data-intensive Web applications: a survey,” ACM Comput. Surv., vol. 31, no. 3, pp. 227–263, Sep. 1999.
[36] G. Rossi, Web Engineering: Modelling and Implementing Web Applications, vol. 12. London: Springer London, 2008, p. 464.
[37] M. Jern, “‘Thin’ vs. ‘fat’ visualization clients,” in Proceedings of the working conference on Advanced visual interfaces - AVI ’98, 1998, p. 270.
[38] S. P. Mirashe and N. V. Kalyankar, “Cloud Computing,” Commun. ACM, vol. 51, p. 9, Mar. 2010.
[39] L. Case, “All About Video Codecs and Containers,” PCWorld, 2010. [Online]. Available: http://www.techhive.com/article/213612/all_about_video_codecs_and_containers.html?page=0. [Accessed: 20-Aug-2014].
[40] M. Pilgrim, “Video on the Web,” in HTML5: Up & Running, O’Reilly, 2010, p. 53.
[41] Dapeng Wu, Y. T. Hou, W. Zhu, Y.-Q. Zhang, and J. M. Peha, “Streaming video over the Internet: approaches and directions,” IEEE Trans. Circuits Syst. Video Technol., vol. 11, no. 3, pp. 282–300, Mar. 2001.
[42] N. Rump, “MPEG-2 Video 1,” 2006.
[43] J.-R. Ohm and G. Sullivan, “MPEG-4 Advanced Video Coding,” 2005.
[44] Xiph.Org, “Theora Specification,” 2011.
[45] J. Bankoski, J. Koleszar, L. Quillio, J. Salonen, P. Wilkins, and Y. Xu, “VP8 Data Format and Decoding Guide,” 2011.

REFERÊNCIAS
68
[46] V. K. M. Vadakital and D. Singer, “ISO/IEC JTC1/SC29/WG11 - Coding of Moving Pictures and Audio,” Geneva, Switzerland, 2013.
[47] S. Pfeiffer and A. Mankin, “The Ogg Encapsulation Format Version 0,” Feb. 2003.
[48] E. F. Codd, “A relational model of data for large shared data banks,” Commun. ACM, vol. 13, no. 6, pp. 377–387, Jun. 1970.
[49] A. Pavlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, S. Madden, and M. Stonebraker, “A comparison of approaches to large-scale data analysis,” in Proceedings of the 35th SIGMOD international conference on Management of data - SIGMOD ’09, 2009, p. 165.
[50] J. Han, M. Song, and J. Song, “A Novel Solution of Distributed Memory NoSQL Database for Cloud Computing,” in 2011 10th IEEE/ACIS International Conference on Computer and Information Science, 2011, pp. 351–355.
[51] N. Tryfona, F. Busborg, and J. G. Borch Christiansen, “starER,” in Proceedings of the 2nd ACM international workshop on Data warehousing and OLAP - DOLAP ’99, 1999, pp. 3–8.
[52] J. Dean and S. Ghemawat, “MapReduce: a flexible data processing tool,” Commun. ACM, vol. 53, no. 1, p. 72, Jan. 2010.
[53] C. J. Date and H. Darwen, A Guide to the SQL Standard. New York, New York, USA: Addison-Wesley, 1987, p. 544.
[54] S. Doll, “Is SQL a standard anymore?,” TechRepublic’s Builder.com, p. 3, 2002.
[55] E. F. Codd, The relational model for database management, version 2. Reading, MA: Addison-Wesley, 1990, p. 538.
[56] J. S. van der Veen, B. van der Waaij, and R. J. Meijer, “Sensor Data Storage Performance: SQL or NoSQL, Physical or Virtual,” in 2012 IEEE Fifth International Conference on Cloud Computing, 2012, pp. 431–438.
[57] J. Han, H. E, G. Le, and J. Du, “Survey on NoSQL database,” in 2011 6th International Conference on Pervasive Computing and Applications, 2011, pp. 363–366.
[58] T. Macedo and F. Oliveira, Redis Cookbook. O’Reilly, 2011, p. 72.
[59] K. Chodorow and M. Dirolf, MongoDB: the definitive guide. O’Reilly, 2010, p. 432.
[60] J. C. Anderson, J. Lehnardt, and N. Slater, CouchDB: the definitive guide. O’Reilly, 2010, p. 272.
[61] A. Lakshman and P. Malik, “Cassandra: a decentralized structured storage system,” ACM SIGOPS Oper. Syst. Rev., vol. 44, no. 2, p. 35, Apr. 2010.

REFERÊNCIAS
69
[62] M. Hadwiger, C. Sigg, H. Scharsach, K. Bühler, and M. Gross, “Real-Time Ray-Casting and Advanced Shading of Discrete Isosurfaces,” Comput. Graph. Forum, vol. 24, no. 3, pp. 303–312, Sep. 2005.
[63] J. Spoerk, C. Gendrin, C. Weber, M. Figl, S. A. Pawiro, H. Furtado, D. Fabri, C. Bloch, H. Bergmann, E. Gröller, and W. Birkfellner, “High-performance GPU-based rendering for real-time, rigid 2D/3D-image registration and motion prediction in radiation oncology.,” Z. Med. Phys., vol. 22, no. 1, pp. 13–20, Feb. 2012.
[64] S. Parker, P. Shirley, Y. Livnat, C. Hansen, and P.-P. Sloan, “Interactive Ray Tracing for Isosurface Rendering,” in Proceedings of the Conference on Visualization ’98, 1998, pp. 233–238.
[65] A. Kulaga and P. Gillich, “Investigation of Integrating Three-Dimensional (3-D) Geometry into the Visual Anatomical Injury Descriptor (Visual AID) Using WebGL,” 2011.
[66] J.-B. Pettit and J. C. Marioni, “bioWeb3D: an online webGL 3D data visualisation tool,” BMC Bioinformatics, vol. 14, no. 1, p. 185, Jan. 2013.
[67] W. Zhang, H. Yuan, J. Wang, and Z. Yan, “A WebGL-based method for visualization of intelligent grid,” no. 2010, pp. 1546–1548, 2011.
[68] C. Marin, “WebGL Specification,” 2011.
[69] J. Congote, “MEDX3DOM: MEDX3D for X3DOM,” in Proceedings of the 17th International Conference on 3D Web Technology, 2012, pp. 91–147.
[70] A. P. Harvey, R. J. McCrindle, K. Lundqvist, and P. Parslow, “Automatic speech recognition for assistive technology devices,” in Proc. 8th Intl Conf. Disability, Virtual Reality & Associated Technologies, Valparaíso, 2010, pp. 273–282.
[71] G. G. Chowdhury, “Natural language processing,” Annu. Rev. Inf. Sci. Technol., vol. 37, no. 1, pp. 51–89, 2003.
[72] M. Aymen, A. Abdelaziz, S. Halim, and H. Maaref, “Hidden Markov Models for automatic speech recognition,” in 2011 International Conference on Communications, Computing and Control Applications (CCCA), 2011, pp. 1–6.
[73] Y. Zhao, “Speech-Recognition Technology in Health Care and Special-Needs Assistance,” IEEE Signal Process. Mag., vol. 26, no. 3, pp. 87–90, May 2009.
[74] T. Beran, V. Bergl, R. Hampl, P. Krbec, J. Šedivý, B. Tydlitát, and J. Vopička, “Embedded ViaVoice,” in Text, Speech and Dialogue, vol. 3206, P. Sojka, I. Kopeček, and K. Pala, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2004, pp. 269–274.
[75] S. M. Borowitz, “Computer-based Speech Recognition as an Alternative to Medical Transcription,” J. Am. Med. Informatics Assoc., vol. 8, no. 1, pp. 101–102, Jan. 2001.
[76] Nuance, “Dragon NaturallySpeaking Version 13 User Guide.” p. 260, 2014.

REFERÊNCIAS
70
[77] Nuance, “Dragon Medical 360 | Network Edition,” Nuance Products, 2014. [Online]. Available: http://www.nuance.com/products/dragon-medical-360-network-edition/index.htm. [Accessed: 01-Sep-2014].
[78] R. G. Zick and J. Olsen, “Voice Recognition Software versus a Traditional Transcription Service for Physician Charting in the ED,” Am. J. Emerg. Med., vol. 19, no. 4, pp. 295–8, Jul. 2001.
[79] D. I. Rosenthal, F. S. Chew, D. E. Dupuy, S. V. Kattapuram, W. E. Palmer, R. M. Yap, and L. A. Levine, “Computer-Based Speech Recognition as a Replacement for Medical Transcription,” Am. J. Roentgenol., vol. 170, no. 1, pp. 23–25, Jan. 1998.
[80] X. Wang, F. Wu, and Z. Ye, “The Application of Speech Recognition in Radiology Information System,” in 2010 International Conference on Biomedical Engineering and Computer Science, 2010, no. 09, pp. 1–3.
[81] E. D. Liddy, “Natural language processing,” in Encyclopedia of Library and Information Science, Marcel Decker, Inc, 2003, pp. 2126–2136.
[82] S. Feldman, “NLP Meets the Jabberwocky: Natural Language Processing in Information Retrieval,” ONLINE, vol. 23, no. 3, pp. 62–71, 1999.
[83] P. Lamere, P. Kwok, E. Gouvea, B. Raj, R. Singh, W. Walker, M. Warmuth, and P. Wolf, “The CMU SPHINX-4 speech recognition system,” in IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2003), Hong Kong, 2003, vol. 1, pp. 2–5.
[84] P. Woodland, J. Odell, V. Valtchev, and S. Young, “Large Vocabulary Continuous Speech Recognition using HTK,” in 1994 IEEE International Conference on Acoustics, Speech, and Signal Processing, 1994. ICASSP-94., 1994, pp. 7–10.
[85] P. Woodland, C. J. Leggetter, J. Odell, V. Valtchev, and S. Young, “The 1994 HTK large vocabulary speech recognition system,” in 1995 International Conference on Acoustics, Speech, and Signal Processing, vol. 1, Detroit: IEEE, 1995, pp. 73–76.
[86] P. Woodland, D. Pye, M. Gales, and S. Young, “The Development of the 1996 HTK Broadcast News Transcription System,” in Proc. DARPA Speech Recognition Workshop ’97, 1996, pp. 73–78.
[87] J. Odell, P. Woodland, and T. Hain, “The CUHTK-Entropic 10xRT Broadcast News Transcription System,” in Proc DARPA Broadcast News Workshop, 1999, pp. 271–275.
[88] P. Woodland, T. Hain, S. E. Johnson, T. R. Niesler, A. Tuerk, and S. Young, “Experiments in broadcast news transcription,” in Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP ’98 (Cat. No.98CH36181), 1998, vol. 2, pp. 909–912.
[89] B. Jia, K. C. Sim, M. Gales, T. Hain, A. Liu, P. Woodland, and K. Yu, “CU-HTK RT03 Mandarin CTS System,” in Rich Transcription Workshop 2003, 2003, pp. 60–73.

REFERÊNCIAS
71
[90] S. Young, G. Evermann, D. Kershaw, G. Moore, J. Odell, D. Ollason, V. Valtchev, and P. Woodland, “HTK Speech Recognition Toolkit.” [Online]. Available: http://htk.eng.cam.ac.uk/. [Accessed: 03-Feb-2014].
[91] K.-F. Lee, H.-W. Hon, and R. Reddy, “An overview of the SPHINX speech recognition system,” IEEE Trans. Acoust., vol. 38, no. 1, pp. 35–45, 1990.
[92] X. Huang, F. Alleva, H.-W. Hon, M.-Y. Hwang, K.-F. Lee, and R. Rosenfeld, “The SPHINX-II speech recognition system: an overview,” Comput. Speech Lang., vol. 7, no. 2, pp. 137–148, Apr. 1993.
[93] M. Seltzer, “SPHINX III Signal Processing Front End Specification 31,” 1999.
[94] K. Vertanen, “Baseline WSJ Acoustic Models for HTK and Sphinx: Training recipes and recognition experiments,” Cavendish Lab. Univ. Cambridge, 2006.
[95] V. de F. Oliveira and F. G. V. R. Junior, “Reconhecimento de fala contínua para o português brasileiro baseado em HTK e SPHINX,” Universidade Federal do Rio de Janeiro, 2010.
[96] I. Laranjo, J. Braga, L. Lopes, C. Rolanda, J. Correia-Pinto, and V. Alves, “MyEndoscopy - Technical report,” Braga, 2013.
[97] S. Afonso, I. Laranjo, J. Braga, and V. Alves, “Endoscopic Procedures Control Using Speech Recognition,” in Advances in Information Science and Applications, 2014, vol. II, pp. 404–409.
[98] P. Clarkson and R. Rosenfeld, “Statistical language modeling using the CMU-cambridge toolkit,” in 5th European Conference on Speech Communication and Technology, 1997, pp. 2707–2710.
[99] A. Bundy and L. Wallen, “Context-Free Grammar,” in Catalogue of Artificial Intelligence Tools, A. Bundy and L. Wallen, Eds. Springer Berlin - Heidelberg, 1984, pp. 22–23.
[100] A. Hunt, “JSpeech Grammar Format,” 2000.
[101] A. Varela, H. Cuayáhuitl, and J. A. Nolazco-Flores, “Creating a Mexican Spanish version of the CMU Sphinx-III speech recognition system,” in Progress in Pattern Recognition, Speech and Image Analysis, vol. 2905, A. Sanfeliu and J. Ruiz-Shulcloper, Eds. Springer Berlin - Heidelberg, 2003, pp. 251–258.
[102] S. Afonso, I. Laranjo, J. Braga, V. Alves, and J. Neves, “Multilingual Voice Control for Endoscopic Procedures,” in HealthyIOT, 2014, p. 6.
[103] V. John, “Phonetic decomposition for Speech Recognition of Lesser-Studied Languages,” in Proceeding of the 2009 International Workshop on Intercultural Collaboration, 2009, p. 253.
[104] Y. Wang and X. Zhang, “Realization of Mandarin continuous digits speech recognition system using Sphinx,” 2010 Int. Symp. Comput. Commun. Control Autom., pp. 378–380, May 2010.
[105] H. Hyassat and R. Abu Zitar, “Arabic speech recognition using SPHINX engine,” Int. J. Speech Technol., vol. 9, no. 3–4, pp. 133–150, Oct. 2008.

REFERÊNCIAS
72
[106] G. Salvi, “Developing acoustic models for automatic speech recognition,” 1998.