Embed Size (px)
Citation preview

1
Armazenamento de Dados-- Ficheiros & Bases-de-Dados --
Sistemas Informáticos
SLIDES 8
Motivação
Departamento de Engenharia Informática� Numerus clausus = 120, Duração média=4.5anos� Alunos Inscritos… 120x4.5 = 630� Adicionemos alunos de mestrado, doutoramento, docentes e
funcionários… ~ 1000 pessoas
Sistema de Informação…� struct Pessoa {
char nome[80];
long BI;
char morada[200];
pixel_rgb fotografia[640][480];
...
};
� sizeof(Pessoa) ≈≈≈≈ 900 Kbyte
� 900Kbyte * 1000 ≈≈≈≈ 900 Mbyte
Motivação (2)
É necessário armazenar os dados de forma persistente (i.e. não volátil)
Não é possível manter simultaneamente todos os dados em memória, mesmo quando o programa está em execução� Os 900 Mbyte foram uma estimativa por baixo!
Sistemas de Informação
Actualmente, é comum separar-se as aplicações em dados persistentes e “lógica de negócio”� Em sistemas “pequenos”: Ficheiros directos� Em sistemas “grandes”: Bases-de-dados
Lógicade
Controlo
DadosPersistentes
Programa
Sistema de Ficheiros
Sistema de Ficheiros: � Recurso directamente disponível a nível do sistema operativo
O SO apenas oferece primitivas para:� Abrir e fechar ficheiros� Ler e escrever blocos de bytes no ficheiro
O programador é responsável por programar toda a gestão de dados nos ficheiros� Índices para pesquisas rápidas, tolerância a erros, gestão de
concorrência, etc.
AplicaçãoAplicação
Bases-de-Dados
Existe um programa especial (SGBD – Sistema de Gestão de Base-de-Dados) que faz toda a gestão dos dados� Oracle, MS-SQL Server, Postgre, MySQL, etc.
O programa estabelece uma ligação à base-de-dadosutilizando um protocolo chamado ODBC� A BD pode estar na mesma máquina ou noutra máquina
Através da ligação, envia os seus dados e pode fazer pesquisas� SQL = Structured Query Language
AplicaçãoAplicação
Base de
Dados
SGBD (Sistema de
Gestão de BD)
ODBC
2
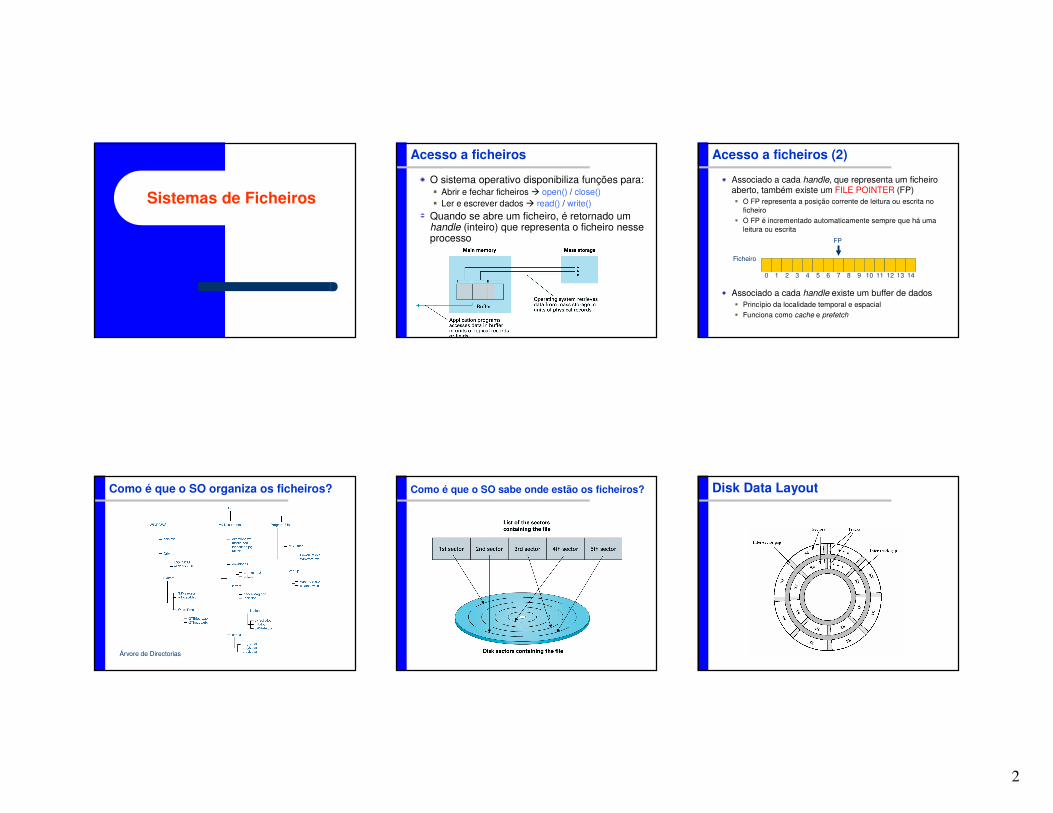
Sistemas de Ficheiros
Acesso a ficheiros
O sistema operativo disponibiliza funções para:� Abrir e fechar ficheiros � open() / close()� Ler e escrever dados � read() / write()
Quando se abre um ficheiro, é retornado um handle (inteiro) que representa o ficheiro nesse processo
Acesso a ficheiros (2)
Associado a cada handle, que representa um ficheiro aberto, também existe um FILE POINTER (FP)� O FP representa a posição corrente de leitura ou escrita no
ficheiro� O FP é incrementado automaticamente sempre que há uma
leitura ou escrita
Associado a cada handle existe um buffer de dados� Princípio da localidade temporal e espacial � Funciona como cache e prefetch
FP
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Ficheiro
Como é que o SO organiza os ficheiros?
Árvore de Directorias
Como é que o SO sabe onde estão os ficheiros? Disk Data Layout

3
Disk Performance Parameters
Access time� Ta = (seek time) + (rotational delay)� The time it takes to get in position to read or write.
Data transfer occurs as the sector moves under the head.
Seek Time & Rotational Delay
Today, the common size of a disk is about 9cm.Average seek time: 5 to 10 ms.
At 10,000 rpm the rotational delay is 3ms.Floppy disks rotate between 300 and 600 rpm. The average delay will be between 100 and 200 ms.
Transfer Time
T = br . N
T = transfer timeb = number of bytes to be transferredN = number of bytes on a trackr = rotation speed, in revolutions per second
Average Total Access Time
Ta = Ts + 1 + b2r rN
Ts = average seek time
Exemplo
Consider a disk with average seek time of 10 ms, rotation speed of 10,000 rpm, 512-byte sectors with 320 sectors per track.Suppose we want to read a file with 2560 sectors for a total of 1.3MBytes.What is the Total Transfer Time?
Exemplo: v1
First, we assume that the file is stored on contiguous on disk, and occupies all the sectors in 8 adjacent tracks (8 tracks x 320 sectors/track = 2560 sectors).
This corresponds to a sequential storage of the file.
T1 = Time to read first track:� T1 = 10 (seek time) + 3 (rotational delay) + 6 (read 320 sectors) = 19ms� Next reads the seek time will be 0.� Each sucessive track is read in (3 + 6) = 9 ms
Total time = 19 + 7 x 9 = 82 ms = 0,082 seconds

4
Exemplo: v2
Now, assume the file is spreaded over the disk, and the acessess to the sectors are distributed randomly.
For each sector we have:� T sector = 10 (seek) + 3 (rotational delay) + 0.01875 (read 1 sector)
Total time = 2560 x 13.01875 = 33328 ms = 33.328 secs
In this case it is 406 times slower!!!
6/320
Conclusions from this example
The order in which the sectors are read from the disk has a tremendous effect on I/O performance.Seek time is the reason for differences in performance.For a single disk request there will be a number of I/O requests.If requests are selected randomly, we will get the worst possible performance.
Disk Scheduling Policies
Disk Scheduling Policies
First-in, first-out (FIFO)� Process request sequentially.� Fair to all processes.� Approaches random scheduling in performance if
there are many processes.
Disk Scheduling Policies
Priority� Goal is not to optimize disk use but to meet other
objectives.� Short batch jobs may have higher priority.� Provide good interactive response time.
Disk Scheduling Policies
Shortest Service Time First (SSTF)� Select the disk I/O request that requires the least
movement of the disk arm from its current position.� Always choose the minimum Seek time.

5
Disk Scheduling Policies
SCAN� The disk arm starts at one end of the disk, and
moves toward the other end, servicing requests until it gets to the other end of the disk, where the head movement is reversed and servicing continues.
LOOK and C-LOOK: variations of SCAN and C-SCAN
Disk Scheduling Policies
C-SCAN� Restricts scanning to one direction only.� The head moves from one end of the disk to the
other, servicing requests as it goes. When it reaches the other end, however, it immediately returns to the beginning of the disk, without servicing any requests on the return trip.
LOOK and C-LOOK: variations of SCAN and C-SCAN
Disk Scheduling Policies
N-step-SCAN� Segments the disk request queue into sub-queues of
length N.� Sub-queues are process one at a time, using SCAN.� New requests added to other queue when queue is
processed.
FSCAN� Two queues.� One queue is empty for new request.
Disk Scheduling: Exemplo
Request queue (0-199).
98, 183, 37, 122, 14, 124, 65, 67
Head pointer 53
FCFS
- total head movement of 640 cylinders.
SSTF
- total head movement of 236 cylinders.

6
SCAN
- total head movement of 208 cylinders.
C-SCAN C-LOOK
Version of C-SCANArm only goes as far as the last request in each direction, then reverses direction immediately, without first going all the way to the end of the disk.
C-LOOK Disk-Scheduling Algorithms
SSTF is common and has a natural appealSCAN and C-SCAN perform better for systems that place a heavy load on the disk.Either SSTF or LOOK is a reasonable choice for the default algorithm.
Performance depends on the number and types of requests.
Requests for disk service can be influenced by the file-allocation method.
Como saber quais os sectores onde está um ficheiro?
Contiguous allocation
Linked allocation
Indexed allocation

7
Contiguous Allocation Linked Allocation FAT: File Allocation Table
Indexed Allocation Um exemplo prático FAT (DOS/Windows)
O disco encontra-se dividido em sectores (clusters), a unidade mínima de informação a que se consegue aceder num disco
No início do disco (disquete) existe:� Boot sector� File Allocation Table (FAT)� Disk Root Directory
FAT
Cada entrada da FAT indica qual o próximo sector que um certo ficheiro ocupaCada entrada da Disk Root Directory indica o nome e atributos de um certo ficheiro, assim como o seu primeiro sector
207 203 EOF 204 205 EOF 202 208 209 215 FREEEOF 214 BAD EOF
200 201 202 203 204 205 206 207 208 209 210 211 212 213 214
Boot FAT Directory Table Data
Frequência.doc RH 2003.12.05-17:30 … 201
Disco
O ficheiro “Frequência.doc”ocupa os sectores 201, 203, 204 e 205
Exame.doc RH 2003.12.06-14:21 … 21010345
14121

8
Questões…
A Disk Root Table apenas contém as entradas do directório raiz do disco. Como é que são guardadas as sub-directorias?
FAT16 quer dizer que os ponteiros na FAT são de 16 bits.� Qual é o número máximo de ficheiros que o disco
pode ter?� Tendo um disco de 40Gbytes, qual seria o tamanho
de cada sector (cluster)? Vê algum problema nisso?(hoje, em Windows, quando não se utiliza NTFS utiliza-se FAT32)
Voltemos ao Sistema de Informação…
Suponhamos que armazenamos todas as pessoas do DEI num ficheiro sequencial…
“Pessoas.dat”
JOANA FRANCISCA 10896534 R. Fernão Lop
Qual é o problema se quisermos encontrar o alunocom o BI Nº 10896534?
Esquecendo as caches…Tempo médio de acesso ao disco = 10msEm média temos de percorrer ½ ficheiro = 500 entradas500 entradas X 10ms = 5000ms = 5s!!!
Utilização de Índices
Se se sabe que vão ser feitas pesquisas por BI, cria-se uma tabela especial que para cada BI indica qual a entrada no ficheiro que a contém.� Esta tabela chama-se um índice sobre o BI
� A tabela é armazenada conjuntamente no ficheiro ou num ficheiro à parte
10896534 12
11843234 43
17345342 234
(…) (…)BI Entrada
“Pessoas.dat” 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 … …
Utilização de Índices
Os índices resultam porque…� Tipicamente o tamanho do índice é muito mais
pequeno do que o tamanho dos dados� Muitas vezes é mesmo possível manter todo o
índice em memória� Os índices podem estar ordenados (pesquisa
binária) ou pode-se fazer hashing
Este tipo de tabelas é conhecida como TABELA INVERTIDA (Inverted Table)
Tamanho do Índice
Atenção: em muitos sistemas, o tamanho dos índices pode tornar-se um problema.
No nosso caso e admitindo que o Sistema de Informação comporta no máximo 10.000 alunos, qual é que teria de ser o tamanho da tabela de índices para BIs?
Bases de Dados

9
Bases-de-Dados
A aplicação estabelece uma ligação ao SGBD que é responsável por manter todos os dados da aplicaçãoO protocolo de comunicação utilizado é ODBCA linguagem utilizada para falar com a BD chama-se SQL (Structured QueryLanguage)
A base-de-dados tem obrigação de:� Mandar os dados de forma
persistente� Facilitar a forma como a
gestão dos dados é realizada� Responder a interrogações e
actualizações de forma rápida
� Tolerar falhas (e.g. faltar a luz a meio de uma escrita)
AplicaçãoAplicação
Base de
Dados
SGBD (Sistema de
Gestão de BD)
ODBC
Modelo de Dados
A maioria das bases-de-dados actuais seguem o chamado MODELO RELACIONAL� No Modelo Relacional, os dados são vistos em
termos de tabelas e relações entre tabelas
Tabela Alunos
Tabelas
Tuplo: Conjunto ordenado de dados relacionados
Chave Primária: Atributo especial que permite identificar univocamente um tuplo
Atributo: Algo que caracteriza a entidade
RelacionamentosTabela Alunos
Tabela Cadeiras
Tabela Inscrições
Relacionamentos
A tabela Inscrições está relacionada com a tabela Alunos e Cadeiras� As chaves primárias dos relacionamentos aparecem
como atributos da chave do relacionamento
NUM_CADEIRA ANO
1 1998
3 1998
1 1998
... ...
NUM_INSC
3243
4321
1232
...
NUM_ALUNO
501003426
...
NOTA
12
13
19
...
501000885
501000885
6 19993487 505404534 NULL
Exemplo Prático – MS Access

10
Queries
Como as tabelas estão relacionadas, é possível fazer “interrogações” (queries) à base-de-dados� Exemplo: “Quais os nomes e anos de nascimento dos alunos
que estiveram inscritos a Tecnologias dos Computadores em 1998”
NUM_CADEIRA ANO
1 1998
3 1998
1 1998
... ...
NUM_INSC
3243
4321
1232
...
NUM_ALUNO
501003426
...
NOTA
12
13
19
...
501000885
501000885
6 19993487 505404534 NULL
12
3 4
5
6
77
Queries - SQL
“Quais os nomes e os anos de nascimento dos alunos que estiveram inscritos a Tecnologias dos Computadores em 1998”
SELECT nome, ano_nascFROM alunos A, cadeiras C, inscrições INSWHERE nome_cadeira=‘Tecnologias dos Computadores’ AND
INS.ano = 1998 ANDC.num_cadeira = INS.num_cadeira ANDINS.num_aluno = A.num_aluno
Queries - SQL
As queries em SQL também retornam tabelas� SELECT nome, ano_nasc
FROM alunos A, cadeiras C, inscrições INSWHERE nome_cadeira=‘Tecnologias dos Computadores’ AND
INS.ano = 1998 ANDC.num_cadeira = INS.num_cadeira ANDINS.num_aluno = A.num_aluno
3 45
67
712
Inserção de Dados - SQL
Também se podem inserir dados na base-de-dados…
INSERT INTO alunos(num_aluno, nome, morada, ano_nasc)
VALUES (5010034322,‘Teresa Matos’,‘R. Alforrecas, 12, 3000-203 Coimbra’,1984)
SELECTINSERTUPDATEDELETE
Outro Exemplo Relacionamento entre tabelas

11
Queries sobre a BD
select Title from Movie where Rating = 'PG'
select Name, Address from Customer
select * from Movie where Genre like '%action%'
select * from Movie where Rating = 'R' order by Title
Operações sobre a BD
insert into Customer values (9876, 'John Smith', '602 Greenbriar Court', '2938 3212 3402 0299')
update Movie set Genre = 'thriller drama' where title = 'Unbreakable'
delete from Movie where Rating = 'R'
Recordemos…
AplicaçãoAplicação
Base de
Dados
SGBD (Sistema de
Gestão de BD)
ODBC
SELECT nome FROM alunos
O que viaja na ligação são estas“ordens”, na linguagem SQL. A aplicação tem de enviar as suasordens nesta linguagem e processar os resultados retornados
Criação de Bases-de-Dados
Na prática, quando se quer fazer uma base-de-dados, não se começa por criar tabelas…� Cria-se (modela-se) o problema:
Modelo CONCEPTURAL da Base-de-dados
� Para criar o modelo conceptual da Base-de-dados, utilizam-se Diagramas ENTIDADE-RELACIONAMENTO (Diagramas ER)
Só após se ter o diagrama Entidade-Relacionamento é que se criam as tabelas:� MODELO FÍSICO da Base-de-dados� Muitas vezes, as ferramentas permitem passar
automaticamente do modelo conceptual para o modelo físico
Modelo Entidade-Relacionamento
Modela o problema em termos de ENTIDADES e RELAÇÕESentre entidadesAs relações podem ser de:� 1 para 1 (1:1)� 1 para N (1:N)� N para N (N:N)
As relações podem ter participação obrigatória ou não
ALUNO CADEIRAInscritoN N
TESTE
Possui
1
N
Leitura do ER
Cada aluno pode estar inscrito em várias cadeiras; cada cadeira pode ter vários alunos inscritosCada aluno tem de estar obrigatoriamente inscrito a uma cadeira; pode haver cadeiras sem alunos (e.g. cadeiras que não funcionam num ano)Em cada cadeira pode haver vários testes; cada teste só pode pertencer a uma cadeiraPode haver cadeiras sem testes; Cada teste tem de ter obrigatoriamente uma cadeira associada

12
Recordemos… Transacções em BDs – Motivação
Base de
Dados
REDE
“Transfere €1.000.000 da conta 43248932 para a conta 43298743”
1: boolean ok = conta1.retira(1000000);2: if (ok)3: {4: conta2.coloca(1000000);5: }
-- E se a aplicação “crasha” na linha 2??-- E se deixa de haver ligação de rede na linha 4??-- E se o servidor “crasha” entre a linha 1 e 2??
Transacções em BDs
Uma das razões muito importantes para se utilizar BDs, para além da performance, é o ter garantias de integridade de dados
Transacção: uma conjunto de operações que devem ser executadas de forma indivisível (i.e. atómica)� Uma operação atómica é aquela em que ou executa
tudo ou não executa nada.� As base-de-dados têm suporte directo para
transacções.
Transacções
Transacção� Tem um início bem definido� Ou existe um COMMIT ou
um ROLLBACK� COMMIT � As alterações
tornam-se permanentes� ROLLBACK � As alterações
são anuladas
Durante uma transacção, as alterações na BD apenas são visíveis para o utilizador que as está a fazer. � Todos os outros utilizadores
vêem os dados como se nada estivesse a acontecer
(...)
trans.beginTransaction();
boolean ok = conta1.retira(1000000);
if (ok){
conta2.coloca(1000000);trans.commitTransaction();
}else
trans.rollbackTransaction();
Transacções – Ideia da Implementação
Sempre que um utilizador inicia uma transacção, todos os dados sobre os quais trabalha são privados (é feita uma cópia)Quando é feito o COMMIT da transacção, a BD é então actualizada� No caso de haver conflito no acesso a dados, pode
ser necessário suspender temporariamente outras transacções Dentro da transacção: é
criada uma cópia de todosos dados que estão a seractualizados
COMMIT: Actualiza-seROLLBACK: Deita-se fora
Para saber mais…
Computer Science – An Overview� Capítulo 8 (8.1, 8.2, 8.3)� Capítulo 9 (9.1, 9.2, 9.3)
Computer Science Illuminated� Capítulo 11 (11.1, 11.2)� Capítulo 12 (12.1, 12.3