Embed Size (px)
Citation preview

INF70 – Gerenciamento de Banco de Dados 2Introdução à Organização de Arquivos
(Métodos de Acesso/Índices)
Ilmério Reis da [email protected]/~ilmerio/gbd2UFU/FACOM/BCC

UFU/FACOM/BCC GBD2 Página:.2
Organização de Arquivos
OBJETIVO
entender como os dados podem ser organizados no espaço em disco para alcançar bom desempenho e segurança nas operações com S GBDs

UFU/FACOM/BCC GBD2 Página:.3
Fundamentos de Organização de Arquivos
Def.: Organização de arquivos é o método de
dispor os registros em um arquivo armazenado em disco
Exemplo: tuplas do esquema empregado(nome, idade, salario) serão armazenadas em registros de um arquivo em disco podendo ser organizados por:
– Opção 1: ordem cronológica de inserção – Opção 2: ordem de nome– Opção 3: ordem de idade– Opção 4: aleatoriamente– etc.

UFU/FACOM/BCC GBD2 Página:.4
Fundamentos de Organização de Arquivos Características de dados em memória externa• Unidade de acesso é página (ex: 4KB, 8KB)• Custo dominante é I/O, cujo tempo gasto é fixo para
qualquer página acessada aleatoriamente• Acesso sequencial diminui tempo pois diminui o número
médio de seeks por registro

UFU/FACOM/BCC GBD2 Página:.5
Fundamentos de Organização de ArquivosInteração entre subcamadas do SGBD O Método de acesso a arquivo:
recebe do processador de consultas requisição de registro, índice, ou arquivo
gerencia páginas alocadas para cada arquivo manipula registros gerencia espaço disponível nas páginas solicita páginas ao Gerenciador de buffer pool que:
verifica se página está no bufferse necessário, solicita página ao Gerenciador de
espaço em disco que– faz acesso ao disco e transmite/recebe páginas
para/do buffer pool.

UFU/FACOM/BCC GBD2 Página:.6
Tipos de Organização de Arquivos• Arquivo não ordenado (heap file)
registros distribuídos aleatoriamente nas páginas• Arquivo ordenado (sorted file)
registros armazenados em ordem da chave de busca• Arquivo hash
registros armazenados em buckets indexados por uma função hash H : KeySet → BucketSet
• Arquivo indexado registros armazenados de acordo com uma estrutura de
índice • Índice
estrutura auxiliar que otimiza busca em arquivos

UFU/FACOM/BCC GBD2 Página:.7
ÍndicesPrincipais Características de Índices• chave de busca, simples ou compostaestrutura facilita busca baseada na chave • facilita atualização e remoção aleatória• entretanto, múltiplos índices causam sobrecarga na
inserção, atualização e remoção
REGISTRO
CHAVE

UFU/FACOM/BCC GBD2 Página:.8
ÍndicesPrincipais Características de Índices • ALTERNATIVAS PARA DADOS ASSOCIADOS À
CHAVE – DATA ENTRY (1) <registro>: este é o arquivo indexado ou arquivo
hash (2) <k + rid> : chave mais um identificador de registro (3) <k + lista_rids>: chave mais uma lista de
identificadores• temos no máximo um índice usa alternativa (1)• agrupados/não agrupados (Figuras)• Denso / não denso = esparso (Figura)• primário / secundário(Figura)

UFU/FACOM/BCC GBD2 Página:.9
ÍndicesPrincipais Características de Índices • Índice agrupado e não agrupado, Alternativa 2

UFU/FACOM/BCC GBD2 Página:.10
ÍndicesPrincipais Características de Índices • Exemplo de índice agrupado - Alternativa 2
Paulo, 44, 2000Pedro, 35, 2000Carlos, 44, 2000José, 40, 2500João, 35, 3000Ilmério, 40, 3500Rodrigo, 40, 3500Maria, 30, 4000Sara, 35, 4000Sabrina, 31, 5000
200020002000250030003500
40003500
40005000
Registros de dadosEntradas

UFU/FACOM/BCC GBD2 Página:.11
ÍndicesPrincipais Características de Índices • Exemplo de índice não agrupado - Alternativa 2
Paulo, 44, 2000Pedro, 35, 2000Carlos, 44, 2000José, 40, 2500João, 35, 3000Ilmério, 40, 3500Rodrigo, 40, 3500Maria, 30, 4000Sara, 35, 4000Sabrina, 31, 5000
200020002000250050003000
35003500
4000
Registros de dadosEntradas
H
4000
H(sal) = 01
H(sal) = 11
H(sal) = 00

UFU/FACOM/BCC GBD2 Página:.12
ÍndicesPrincipais Características de Índices • Índice denso: se para cada valor k da chave de busca
existe uma entrada (k,rid)

UFU/FACOM/BCC GBD2 Página:.13
ÍndicesPrincipais Características de Índices • Índice esparso = não denso (tem que ser agrupado)

UFU/FACOM/BCC GBD2 Página:.14
ÍndicesPrincipais Características de Índices • Índice Primário : chave do índice é chave primária do
arquivo• Índice Secundário: chave pode ocorrer mais de uma vez

UFU/FACOM/BCC GBD2 Página:.15
ÍndicesPrincipais Estruturas de Índices Índice Baseado em Hash• Chave• Entradas (Alternativa1=<registro>,
Alternativa2=<k+rid>, ou Alternativa3=<k+lista_rids>) distribuídas em buckets, cada um formado por uma página primária e zero ou mais páginas de overflow
• Função Hash H : KeySet → BucketSet acesso em um ou dois I/O se hash sem overflow

UFU/FACOM/BCC GBD2 Página:.16
ÍndicesPrincipais Estruturas de Índices Índice Baseado em Hash

UFU/FACOM/BCC GBD2 Página:.17
ÍndicesPrincipais Estruturas de Índices Índice Baseado em Árvore
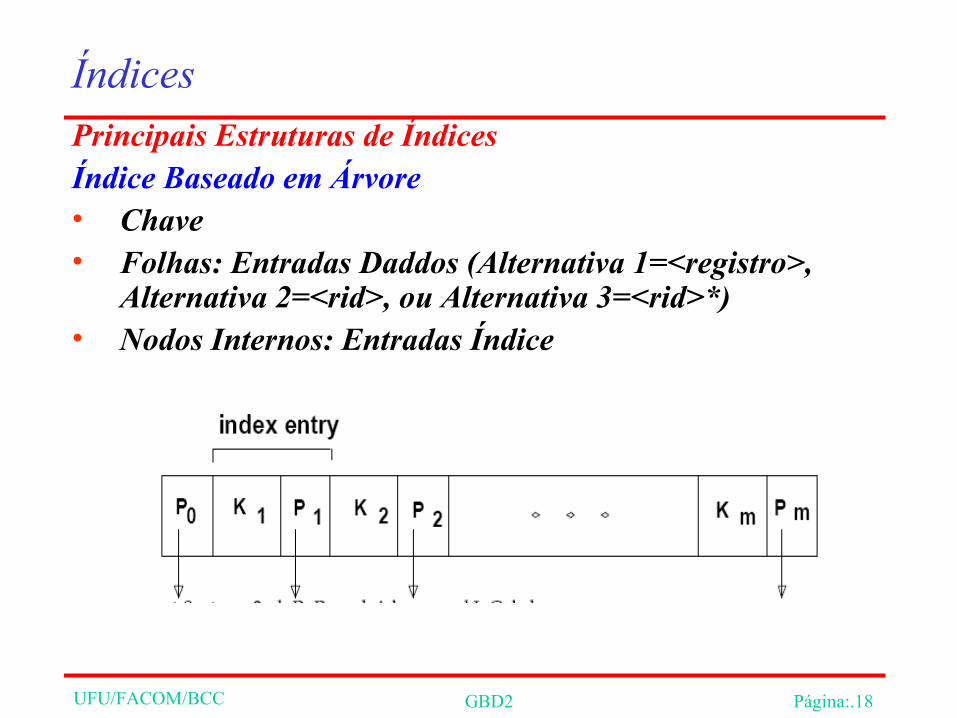
UFU/FACOM/BCC GBD2 Página:.18
ÍndicesPrincipais Estruturas de Índices Índice Baseado em Árvore• Chave• Folhas: Entradas Daddos (Alternativa 1=<registro>,
Alternativa 2=<rid>, ou Alternativa 3=<rid>*) • Nodos Internos: Entradas Índice

UFU/FACOM/BCC GBD2 Página:.19
ÍndicesPrincipais Estruturas de Índices Índice Baseado em Árvore Características das Árvores B+ • Caminho de tamanho uniforme da raiz até a folha• Fan-out(F) é o número de filhos do nó interno• Profundidade (h) é o tamanho do caminho raiz/folha• Se Número de folhas = N, entãoN = Fh
Logo, h = logF N• Facilita busca por intervalo

UFU/FACOM/BCC GBD2 Página:.20
Comparação de Desempenho de Arquivos
• Operações• Modelo de Custo• Alternativas de arquivos/indices• Tabela Comparativa

UFU/FACOM/BCC GBD2 Página:.21
Comparação de Desempenho de Arquivos Operações em Arquivos e Índices• Scan (varredura) : ler todos os registros de um arquivo
Carregar páginas do arquivo no Buffer Pool Buscar registros em cada página
• Busca Igual (com predicado de igualdade k = valor) Carregar páginas com os registros selecionados Buscar registros em cada página Se o predicado não for pela chave, então realizar varredura
• Busca por faixa de valores (intervalo i.e. (x < k < y)) Carregar páginas com os registros selecionados Buscar registros em cada página Se o predicado não for pela chave, então realizar varredura.

UFU/FACOM/BCC GBD2 Página:.22
Comparação de Desempenho de ArquivosOperações em Arquivos
• Inserção : Identificar página na qual o registro deve ser inserido Carregar a página no Buffer Pool Incluir registro na página Escrever página modificada no disco
• Remoção : Identificar a página contendo o registro Carregar a página no Buffer Pool Modificar a página Escrever a página modificada no disco

UFU/FACOM/BCC GBD2 Página:.23
Comparação de Desempenho de ArquivosModelo de Custo
• B = número de Páginas• R = número de registros por página • D = tempo médio para ler ou escrever uma página no disco• C = tempo médio para processar um registro • H = tempo para aplicação da função Hash• C e H da ordem de nanosegundos e D microsegundos, logo
o tempo gasto com IO é o custo dominante• Essas considerações são simplistas mas suficientes para
mostrar a intuição das estruturas que serão estudadas em detalhe.

UFU/FACOM/BCC GBD2 Página:.24
Comparação de Desempenho de ArquivosAlternativas a serem comparadas
• Arquivo não Ordenado (Heap)• Arquivo Ordenado• Arquivo Indexado Hash (sem overflow)• Arquivo Indexado Arvore B+ • Arquivo Heap + Indice Hash usando Alternativa 2• Arquivo Heap + Indice Arvore B+, não agrupada, usando
Alternativa 2

UFU/FACOM/BCC GBD2 Página:.25
Comparação de Desempenho de ArquivosConsiderações Gerais
• Um registro resultante da busca com igualdade• Arquivo Ordenado com compactação após remoção • Arquivo Hash com 80% de ocupação buckets, logo,
tamanho total do arquivo = 1,25B páginas• Árvore Agrupada (Alternativa 1) com 67% ocupação, logo,
folhas na árvore ocupam 1,5B páginas • Índices Árvore B+ não agrupada e Hash, usando
Alternativa 2 com entradas de tamanho igual a 10% do registro e 67% de ocupação, logo:
– média de 6,7R entradas por página/bucket – Hash com 0,15B páginas – Idem para folhas da árvore.

UFU/FACOM/BCC GBD2 Página:.26
Comparação de Desempenho de Arquivos
Considerações sobre oArquivo não Ordenado (Heap)
• Inserção por ordem de chegada, sempre no final do arquivo
• Sem compactação em remoção

UFU/FACOM/BCC GBD2 Página:.27
Comparação de Desempenho de ArquivosArquivo Heap
• Varredura(Scan) Ler todas as páginas (BD) Processar R registros por página (BRC) Tempo = B (D + RC) Custo IOs = B

UFU/FACOM/BCC GBD2 Página:.28
Comparação de Desempenho de ArquivosArquivo Heap
• BuscaIgual (predicado k = valor) Ler metade do arquivo(em média) para encontrar a
página do registro (0,5BD) Processar todos registros de cada página lida à procura do
registro especificado (0,5BRC) Tempo = 0,5B(D + RC) Custo IO = 0,5B

UFU/FACOM/BCC GBD2 Página:.29
Comparação de Desempenho de ArquivosArquivo Heap
• BuscaFaixa(intervalo ) Ler todas as páginas do arquivo em busca de registros do
intervalo (BD) Processar todos os registros de cada página (BRC) Tempo = B(D + RC) Custo IO = B

UFU/FACOM/BCC GBD2 Página:.30
Comparação de Desempenho de ArquivosArquivo Heap
• Inserção Ler a última página do arquivo (D) Inserir o registro na página(C) Rescrever a página modificada no disco(D) Tempo = D + C + D = 2D + C Custo IO = 2

UFU/FACOM/BCC GBD2 Página:.31
Comparação de Desempenho de ArquivosArquivo Heap
• Remoção Localizar o registro a ser removido(BuscaIgual) Remover o registro da página (C) Rescrever a página modificada no disco (D) Tempo = BuscaIgual + C + D Custo IO = 0,5B + 1 Obs: lembrando que o arquivo não será comprimido após
remoção.

UFU/FACOM/BCC GBD2 Página:.32
Comparação de Desempenho de Arquivos
Considerações sobre oArquivo Ordenado
Inserção em ordem de uma chave de busca Busca binária no arquivo para localizar um registro Reorganização das páginas após inserção Compactação do arquivo após remoção

UFU/FACOM/BCC GBD2 Página:.33
Comparação de Desempenho de ArquivosArquivo Ordenado
• Varredura(Scan) Ler todas as páginas (BD) Processar R registros por página (BRC) Tempo = B (D + RC) Custo IOs = B

UFU/FACOM/BCC GBD2 Página:.34
Comparação de Desempenho de ArquivosArquivo Ordenado
• BuscaIgual (predicado k = valor) Localizar página por meio de busca binária no
arquivo (Dlog2B) Processar 2 registros(extremidades) por página em
cada passo da busca (2Clog2B) Realizar busca binária na página onde se localiza o
registro (Clog2R) Tempo = (D+2C)log2B + C log2R Custo IO = log2B

UFU/FACOM/BCC GBD2 Página:.35
Comparação de Desempenho de ArquivosArquivo Ordenado
• BuscaFaixa(intervalo ) Localizar a página e registro de início do intervalo
(BuscaIgual) Ler todos os registros subsequentes na página (0,5RC) Ler as demais páginas e processar seus registros até encontrar
o final do intervalo. Seja #pgm o número adicional de páginas com registros no intervalo (#pgm (D+RC))
Tempo = BuscaIgual + #pgm D + RC (#pgm + 0,5) Custo IO = log2B + #pgm

UFU/FACOM/BCC GBD2 Página:.36
Comparação de Desempenho de ArquivosArquivo Ordenado
• Inserção Localizar página para inserção (BuscaIgual) Seja 2C o custo de inserir e realizar o shift dos registros
na página. Ler todas as páginas a partir da posição corrente(metade
do arquivo) (0,5BD) Realizar o shift em todas as páginas a partir da posição
corrente (0,5B 2C) Reescrever todas as páginas a partir da posição corrente
(0,5BD) Tempo = BuscaIgual + B (D + C) Custo IO = B + log2B

UFU/FACOM/BCC GBD2 Página:.37
Comparação de Desempenho de ArquivosArquivo Ordenado
• Remoção Localizar página para remoção (BuscaIgual) Seja 2C o custo de remover e realizar o unshift dos
registros em uma página Ler as páginas à partir da posição corrente(metade do
arquivo) (0,5 BD) Realizar a remoção e unshift dos registros (0,5B 2C) Reescrever todas as páginas a partir da posição corrente
(0,5BD) Tempo = BuscaIgual + B (D + C) Custo IO = B + log2B

UFU/FACOM/BCC GBD2 Página:.38
Comparação de Desempenho de Arquivos
Arquivo Ordenado
• Observações: A reorganização do arquivo na inserção e remoção torna
essas operações muito custosas Uma alternativa é adiar a reorganização para ser feita
periodicamente, prejudicando as buscas Mas a principal solução deste problema é o arquivo
indexado que mantem o custo de busca na mesma ordem e diminui consideravelmente o custo de inserção e remoção

UFU/FACOM/BCC GBD2 Página:.39
Comparação de Desempenho de Arquivos
Considerações sobre o Arquivo Indexado baseado em Hash
Hash com entradas do tipo Alternativa 1 Hash sem overflow Páginas são ocupadas em 80%, pois espaço livre é
deixado nas páginas para evitar overflow no bucket em caso de novas inserções
Número de páginas no hash será:
B/0,80 = 1,25B

UFU/FACOM/BCC GBD2 Página:.40
Comparação de Desempenho de ArquivosArquivo Hash
• Varredura(Scan)
Ler todas as páginas (1,25 BD) Processar 0,8R registros em cada página (1,25B 0,8RC) Tempo = 1,25B(D + 0,8RC) Custo IO = 1,25B

UFU/FACOM/BCC GBD2 Página:.41
Comparação de Desempenho de ArquivosArquivo Hash
• BuscaIgual (predicado k = valor) Calcular a função hash (H) Ler o bucket (D) Assumindo varredura média de metade do bucket para
localizar o registro (0,4RC) Tempo = H + D + 0,4RC Custo IO = 1

UFU/FACOM/BCC GBD2 Página:.42
Comparação de Desempenho de ArquivosArquivo Hash
• BuscaFaixa(intervalo) Ler todas as páginas do hash em busca de registros do
intervalo (1,25BD) Processar os registros de cada página (1,25B 0,8RC) Tempo = 1,25B(D+0,8RC) Custo IO = 1,25B

UFU/FACOM/BCC GBD2 Página:.43
Comparação de Desempenho de ArquivosArquivo Hash
• Inserção Calcular a função hash (H) Ler o bucket (sem overflow) (D) Inserir registro no final do bucket (C) Reescrever o bucket (D) Tempo = H + C + 2D Custo IO = 2

UFU/FACOM/BCC GBD2 Página:.44
Comparação de Desempenho de ArquivosArquivo Hash
• Remoção Localizar o registro (BuscaIgual) Remover o registro, reorganizando o bucket (0,4RC) Escrever o bucket modificado (D) Tempo = BuscaIgual + 0,4RC + D Custo IO = 2

UFU/FACOM/BCC GBD2 Página:.45
Comparação de Desempenho de Arquivos
Considerações sobre o Arquivo Indexado baseado em Arvore B+ Agrupada
Entrada nas folhas do tipo Alternativa 1 Folhas são ocupadas em 67%, pois espaço livre é deixado
para novas inserções Número de folhas = B / 0,67 = 1,5B Número de registros por folha = 0,67R
Seja F o número médio de filhos de cada nó interno, então, a altura da ávore h = logF1,5B

UFU/FACOM/BCC GBD2 Página:.46
Comparação de Desempenho de ArquivosArvore B+ Agrupada
• Varredura(Scan) Ler todas as folhas da árovore (1,5BD) Processar os registros de cada folha (1,5B 0,67RC) Tempo = B(1,5D + RC) Custo IO = 1,5B

UFU/FACOM/BCC GBD2 Página:.47
Comparação de Desempenho de ArquivosArvore B+ Agrupada
• BuscaIgual (predicado k = valor) Localizar folha por meio de busca em profundidade
na árvore (DlogF1,5B) Em cada nível, processar uma média de log2(F-1)
entradas para localizar ponteiro: ((logF1,5B)(Clog2(F-1)))
Localizar registro na folha por meio de busca binária (Clog20,67R)
Tempo = logF1,5B (D + Clog2(F-1)) + C log2 0,67 R Custo IO = logF1,5B

UFU/FACOM/BCC GBD2 Página:.48
Comparação de Desempenho de ArquivosArvore B+ Agrupada
• BuscaFaixa(intervalo) Localizar início do intervalo (BuscaIgual) Ler folhas subsequentes até encontrar o final do intervalo
(1,5 #pgm D) Processa entradas de cada folha (1,5 #pgm 0,67RC) Tempo = BuscaIgual + 1.5 #pgm D + R #pgm C
= BuscaIgual + 1,5 #pgm (D + 0,67RC) Custo IO = BuscaIgual + 1,5 #pgm

UFU/FACOM/BCC GBD2 Página:.49
Comparação de Desempenho de ArquivosArvore B+ Agrupada
• Inserção Localizar a folha onde será inserido o novo registro
(BuscaIgual) Inserir nova entrada na folha, fazendo um shift de suas
entradas. Seja 2C o custo do shift (2C) Reescrever a folha (D) Tempo = BuscaIgual + 2C + D Custo IO = 1 + BuscaIgual

UFU/FACOM/BCC GBD2 Página:.50
Comparação de Desempenho de ArquivosArvore B+ Agrupada
• Remoção Localizar a folha onde será removido o registro
(BuscaIgual) Remover a entrada na página, fazendo um unshift de suas
entradas. Seja 2C o custo do unshift (2C) Reescreve folha (D) Tempo = BuscaIgual + 2C + D Custo IO = 1 + BuscaIgual

UFU/FACOM/BCC GBD2 Página:.51
Comparação de Desempenho de Arquivos
Considerações sobre o Arquivo Heap com Índice baseado Arvore B+ não agrupada
• A entrada nas folhas da árvore ocupa 10% do registro• 67% de ocupação das folhas• Portanto serão 6,7R entradas em cada folha• O número de folhas da ávore será N= 0,1B/0,67 = 0,15B

UFU/FACOM/BCC GBD2 Página:.52
Comparação de Desempenho de ArquivosArquivo Heap + Arvore B+ não agrupada
• Varredura(Scan) Varrer o índice não é viável, pois seria necessário
varrer as folhas e mais um IO no arquivo de dados para cada registro i.e., Custo IO > BR
Então, varrer o heapTempo = B (D + RC)Custo IOs = B

UFU/FACOM/BCC GBD2 Página:.53
Comparação de Desempenho de ArquivosArquivo Heap + Arvore B+ não agrupada
• BuscaIgual (predicado k = valor) Localizar a folha por meio de busca em profundidade
na árvore (DlogF0.15B) Processar uma média de log2(F-1) entradas por nível
(logF0.15B)(Clog2(F-1)) Localizar a entrada na folha por meio de busca binária
(Clog26,7R) Ler a página de dados (D) e processar o registro (C) Tempo = logF0,15B(D + Clog2(F-1)) +
Clog26,7R+D+C Custo IO = 1 + logF0,15B

UFU/FACOM/BCC GBD2 Página:.54
Comparação de Desempenho de ArquivosArquivo Heap + Arvore B+ não agrupada
• BuscaFaixa(intervalo) Localizar início do intervalo (BuscaIgual) Ler folhas subsequentes até encontrar o final do
intervalo (0,15D #pgm) Processar cada entrada (C R #pgm) Para cada entrada na folha:
Ler página no arquivo de dados (D R #pgm) Processar cada registro (C R #pgm)
Tempo = BuscaIgual + 0,15D#pgm + R#pgm (D + 2C) Custo IO = BuscaIgual + #pgm (0,15 + R)

UFU/FACOM/BCC GBD2 Página:.55
Comparação de Desempenho de ArquivosArquivo Heap + Arvore B+ não agrupada
• Inserção Localizar a folha onde será inserida a nova entrada e
página de dados onde será inserido o novo registro (BuscaIgual)
Inserir nova entrada na folha, fazendo um shift de suas entradas (2C)
Inserir novo registro na página do heap (C) Reescrever folha e página de dados (2D) Tempo = BuscaIgual + 2D + 3C Custo IO = 2 + BuscaIgual

UFU/FACOM/BCC GBD2 Página:.56
Comparação de Desempenho de ArquivosArquivo Heap + Arvore B+ não agrupada
• Remoção Localizar a folha de onde será removida a nova entrada e
página de dados de onde será removido o novo registro (BuscaIgual)
Remover nova entrada na folha, fazendo um unshift de suas entradas (2C)
Remover novo registro na página de dados (C) Reescrever folha e página de dados (2D) Tempo = BuscaIgual + 3C + 2D Custo IO = 2 + BuscaIgual

UFU/FACOM/BCC GBD2 Página:.57
Comparação de Desempenho de Arquivos
Considerações sobre Arquivo Heap com Índice baseado Hash
• Hash com entradas do tipo Alternativa 2• Hash sem overflow• Páginas são ocupadas em 67%• Entrada de tamanho 10% do registro• Número de páginas no hash será: 0,1B/0,67 = 0,15B

UFU/FACOM/BCC GBD2 Página:.58
Comparação de Desempenho de ArquivosArquivo Heap + Hash
• Varredura(Scan)
(
Varrer o hash não é viável, pois seria necessário varrer os buckets e mais um IO no arquivo de dados para cada entrada i.e., Custo IO > BR
Então, varrer o heapTempo = B (D + RC)Custo IOs = B

UFU/FACOM/BCC GBD2 Página:.59
Comparação de Desempenho de ArquivosArquivo Heap + Hash
• BuscaIgual (predicado k = valor) Calcular a função hash (H) Ler o bucket (sem overflow) (D) Varrer em média metade do bucket para localizar a
entrada (C 3,35R) Ler página no arquivo de dados (D) Processar o registro (C) Tempo = H + D + 3.35RC + D + C
= H + 2D + C(3,35R + 1) Custo IO = 2

UFU/FACOM/BCC GBD2 Página:.60
Comparação de Desempenho de ArquivosArquivo Heap + Hash
• BuscaFaixa(intervalo) Ler todos os buckets do hash e realizar um IO para cada
entrada do intervalo ou fazer uso do heap Vamos comparar o número de IO de duas alternativas
Varrer o Hash e ler heap direto: (0,15B + R #pgm)Varrer o Heap: B
Logo se #pgm < (0,85B/R) será viável o uso do hash, caso contrário, ou quando não se conhece a estatística, usa-se o heap, i.e.:Tempo = B(D + RC)Custo IO = B

UFU/FACOM/BCC GBD2 Página:.61
Comparação de Desempenho de ArquivosArquivo Heap + Hash
• Inserção Calcular a função hash (H) Ler o bucket (sem overflow)(D) Ler página no arquivo de dados (D) Inserir registro no final da página (C) Inserir entrada no final do bucket (C) Reescrever o bucket e a páginia de dados(2D) Tempo = H +2D + 2C + 2D = H + 4D + 2C Custo IO = 4

UFU/FACOM/BCC GBD2 Página:.62
Comparação de Desempenho de ArquivosArquivo Heap + Hash
• Remoção Calcular a função hash (tempo = H) Ler o bucket (D) Ler página no arquivo de dados(D) Localizar e remover entrada no bucket (3,35RC) Localizar e remover registro na página (2C) Regravar o bucket e a páginia de dados (2D) Tempo = H +2D + 3,35RC + 2C + 2D
= H + 4D + C(3,35R + 2) Custo IO = 4

UFU/FACOM/BCC GBD2 Página:.63
Comparação de Desempenho de Arquivos
TEMPO VARREDURA BUSCAIGUAL BUSCAFAIXA INSERÇÃO REMOÇÃO
HEAP 2D + C
SORTED
HASH FILE H + D + 0,4RC C + 2D + H
BTREE FILE
BTREE INDEX
HASH INDEX H + 4D + 2C
B (D + RC) O,5B (D + RC) B (D + RC) BuscaIgual +
D + C
B (D + RC)(D+2C)log2B +
C log2R
BuscaIgual + D# pgm +
RC(# pgm + 0,5)
BuscaIgual + B(D+C)
BuscaIgual + B(D+C)
1,25B (D + 0,8RC)1,25B (D +
0,8RC)BuscaIgual +
0,4RC + D
B (1,5D + RC)
logF1.5B (D + Clog2(F-1)) +
Clog20,67R
BuscaIgual + 1,5#pgm (D +
0,67RC)BuscaIgual +
D + 2CBuscaIgual +
D + 2C
B (D + RC)
logF0,15B (D + Clog2(F-1)) +
Clog26,7R + D + R
BuscaIgual + 0,15D#pgm +
R#pgm(D + 2C)
BuscaIgual + 2D + 3C
BuscaIgual + 2D + 3C
B (D + RC)H + 2D + C(3,35R
+ 1) B (D + RC)H + 4D +
C(3,35R+1)

UFU/FACOM/BCC GBD2 Página:.64
Comparação de Desempenho de Arquivos
IO V A R R E D U R AB U S C A IG U A L B US C A F A IX AIN S E RÇ Ã O RE M O Ç Ã OHE A P B 0 , 5 B B 2 0 , 5 B + 1S O R TE D B HA S H F IL E 1 , 2 5 B 1 1 ,2 5 B 2 2
B TR E E F IL E 1 , 5 B
B TR E E IN D E X B HA S H IN D E X B 2 B 4 4
l o g2B l o g2B + # p g mB + l o g2B B + l o g2B
l o gF1 , 5 B l o gF1 ,5 B +
1 , 5 # p g m 1 +
l o gF1 ,5 B 1 +
l o gF1 , 5 B
1 + l o gF0 , 1 5B1 + l o gF0 ,1 5 B + # p g m ( 0 , 1 5 + R )
3 + l o gF0 ,1 5B
3 + l o gF0 , 1 5B

UFU/FACOM/BCC GBD2 Página:.65
Organização de ArquivosConsiderações finais• Uso em ajuste(tunning) de SBD • Geram impactos positivos e negativos na carga de
trabalho do SGBD• Analisar frequencia de operações• Sobrecarga de espaço em disco• Hash tem melhor desempenho em busca com predicado
de igualdade• Árvore B+ tem melhor desempenho em busca por
intervalo • Algumas consultas podem ser avaliadas usando somente
o índice, por exemplo: employee(eid, dno, age, hobby, sal) SELECT avg(sal) FROM employee

UFU/FACOM/BCC GBD2 Página:.66
Organização de ArquivosConsiderações finais – Alguns exemplos de uso de índices
agrupados, usando o esquema employee(eid, dno, age, hobby, sal)

UFU/FACOM/BCC GBD2 Página:.67
Organização de ArquivosConsiderações finais – Alguns exemplos de uso de índices
agrupados

UFU/FACOM/BCC GBD2 Página:.68
Organização de ArquivosConsiderações finais • Chaves compostas em caso de Árvores B+ podem usar
prefixo como chave

UFU/FACOM/BCC GBD2 Página:.69
Organização de ArquivosConsiderações finais • Especificação de índices no SQL 99
CREATE INDEX IndAgeGrau ON EstudantesWITH STRUCTURE = BTREE,KEY = (Idade, Média)

UFU/FACOM/BCC GBD2 Página:.70
Organização de Arquivos
Exercícios

UFU/FACOM/BCC GBD2 Página:.71
Fim - Organização de Arquivos
Fim - Organização de Arquivos







![Banco de Dados Distribuídos - facom.ufu.brilmerio/sbd/sbd5aSqlDDLparte1.pdf · [ TEMPLATE [=] modelo ] [ ENCODING [=] codificação ] [ TABLESPACE [=] tablespace ] ] ... Exclui uma](https://img.document.onl/doc/110x75/5c4a45fc93f3c3521c5a471a/banco-de-dados-distribuidos-facomufubr-ilmeriosbd-template-modelo.jpg)






