Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DE GOIÁSINSTITUTO DE INFORMÁTICA
WALISSON PEREIRA DE SOUSA
Uma Técnica para Ranqueamento deInterpretações SQL Oriundas de
Consultas com Palavras-chave
Goiânia2017

PRPGsistema de bibliotecas ufq
PRORt1TOR'A ot
00UFG
TERMO DE CIÊNCIA E DE AUTORIZAÇÃO PARA DISPONIBILIZAR VERSÕES ELETRÔNICASDE TESES E
DISSERTAÇÕES NA BIBLIOTECA DIGITAL DA UFG
Na qualidade de titular dos direitos de autor, autorizo a Universidade Federal de Goiás (UFG)a disponibilizar, gratuitamente, por meio da Biblioteca Digital de Teses e Dissertações (BDTD/UFG),regulamentada pela Resolução CEPEC no 832/2007, sem ressarcimento dos direitos autorais, deacordo com a Lei no 9610/98, o documento conforme permissões assinaladas abaixo, para fins deleitura, impressão e/ou download, a título de divulgação da produção científica brasileira, a partirdesta data.
1. Identificação do material bibliográfico: [X] Dissertação Tese
2. Identificação da Tese ou Dissertação:
Nome completo do autor: Walisson Pereira de Sousa
Título do trabalho: Uma Técnica para Ranqueamento de Interpretações SQL Oriundas de Consultascom Palavras-chave
3. Informações de acesso ao documento:
Concorda com a liberação total do documento [X] SIM NÃO 1
Havendo concordância com a disponibilização eletrônica, torna-se imprescindível o envio do(s)arquivo(s) em formato digital PDF da tese ou dissertação.
Assinatura do(a) aut€(a
Ciente e de acordo:
Assinatura o(a orientador(a) 2
Data:
1 Neste caso o documento será embargado por até um ano a partir da data de dett•sa. A extensão deste prazo suscita jus-tificativa junto à coordenação do curso. Os dados do documento não serão disponibilizados durante o periodo de embargo.
Casos de embargo:
- Solicitação de registro de patente- Submissão de artigo em revista científica- Publicação como capítulo de livro- Publicação da dissertação/tese em livro
assinatura deve ser escaneada.
Versão atualizada em maio de 2017.

WALISSON PEREIRA DE SOUSA
Uma Técnica para Ranqueamento deInterpretações SQL Oriundas de
Consultas com Palavras-chave
Dissertação apresentada ao Programa de Pós–Graduação doInstituto de Informática da Universidade Federal de Goiás,como requisito parcial para obtenção do título de Mestre emCiência da Computação.
Área de concentração: Ciência da Computação.
Orientador: Prof. Dr. João Carlos da Silva
Goiânia2017

Ficha de identificação da obra elaborada pelo autor, através doPrograma de Geração Automática do Sistema de Bibliotecas da UFG.
CDU 004
Pereira de Sousa, Walisson Uma Técnica para Ranqueamento de Interpretações SQL Oriundasde Consultas com Palavras-chave [manuscrito] / Walisson Pereira deSousa. - 2017. CXXII, 122 f.: il.
Orientador: Prof. Dr. João Carlos da Silva. Dissertação (Mestrado) - Universidade Federal de Goiás, ,Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2017. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas.
1. Consulta a banco de dados. 2. Interpretação de consulta. 3.Banco de dados relacional. I. da Silva, João Carlos, orient. II. Título.


Todos os direitos reservados. É proibida a reprodução total ou parcial dotrabalho sem autorização da universidade, do autor e do orientador(a).
Walisson Pereira de Sousa
Graduou-se em Ciência da Computação na Fundação Unirg, em Gurupi-TO(2011). Após a Graduação, trabalhou como Analista de Suporte Educacio-nal na Fundação Bradesco - Unidade de Formoso do Araguaia-TO, perma-necendo lá por 03 (três) anos. Atualmente é Professor do Instituto Federal deEducação, Ciência e Tecnologia do Tocantins, lotado na cidade de Araguaína-TO.

À minha mãe.

Agradecimentos
Gostaria de agradecer ao Professor Dr. João Carlos que me ouviu, orientou,teve paciência, cuidado e me norteou nesta caminhada. Quero agradecê-lo por todas ascorreções, os conselhos e broncas que me deu. Aprendi muitos nos últimos anos. Aosenhor, meu sincero obrigado.
À minha mãe por todo o apoio que tem me dado, pela formação, pelo caráter,por todos os ensinamentos a mim transmitidos e às minhas irmãs Joyce, Ketlen e Mônicapelo apoio nos momentos difíceis.
Aos colegas de trabalho Charles, Eliakim, Evaldo, Gilvan, Jonathon, José Ro-berto e Júlio, que me ajudaram nessa caminhada. Sem vocês, não conseguiria finalizareste trabalho.
Ao companheiro de mestrado, Audir, pela ajuda com as discussões, com ostestes, com os questionamentos levantados, pela estadia em sua casa, pela companhianos almoços, por toda ajuda que me foi prestada.
Agradeço à Mariana, por sanar todas as dúvidas acerca dos trabalhos desenvol-vidos, por me auxiliar nas etapas do projeto e na implementação do código.
Aos amigos Áurea e Luis pelos momentos inesquecíveis que vivemos no mes-trado, pelos desabafos, pelos grupos de estudos, pelas dificuldades enfrentados juntos.São amigos que levo no coração. Agradeço também aos colegas do laboratório 254 pelosmomentos de descontração e apoio.
Gostaria de agradecer também à Lais e ao Alan, amigos do peito, pelos apurosque passamos, pelas jantas improvisadas, pelas contas que dividimos, por todos osmomentos especiais que passamos juntos.
Aos professores do Instituto de Informática - UFG por todo o conhecimentorepassado. Aos senhores meu mais sincero obrigado.
Quero agradecer à minha amiga Virgínia pelos conselhos, apoio emocional, pelossorrisos e por nossas caminhadas juntos. São pessoas que levo comigo onde for.
Agradecer à Ana Maria, pessoa iluminada, que foi a primeira a me incentivar aparticipar do processo seletivo para ingressar no mestrado. Esse momento em especial eudedico a você, por sempre acreditar em mim.

Ao Instituto Federal do Tocantins - Campus Araguaína pelo apoio financeiro eflexibilização de horário para que eu pudesse assistir às aulas do mestrado e participarde reuniões. Não podendo esquecer de citar o Professor Gildemberg pelo acolhimento,esclarecimento e apoio recebido durante este processo. Meu muito obrigado, Gil.
E agradecer a todos que contribuíram, direta ou indiretamente, à conclusão destetrabalho.
Não se esquecendo de agradecer a Deus por me proporcionar a vivência de tudoisso.

"Quando você fala, apenas está repetindo algo que já sabe. Mas se vocêescutar, talvez aprenda algo novo".
Dalai Lama,.

Resumo
de Sousa, Walisson Pereira. Uma Técnica para Ranqueamento de Interpreta-ções SQL Oriundas de Consultas com Palavras-chave. Goiânia, 2017. 122p.Dissertação de Mestrado. Instituto de Informática, Universidade Federal deGoiás.
Recuperar informações utilizando palavras de uma linguagem natural é uma maneira sim-ples e já consolidada para acessar dados na Web. Seria altamente desejável que um métodosemelhante fosse utilizado para executar consultas em bancos de dados, liberando assimo usuário do aprendizado de uma linguagem de consulta e o conhecimento da estruturado banco de dados a ser consultado. Nesse sentido, um grande esforço de pesquisa vemsendo dedicado pela comunidade de Banco de dados, a fim de desenvolver técnicas deconsultas com palavras-chave mais eficientes para acesso a bancos de dados. No entanto,uma consulta com palavras-chave pode originar uma grande quantidade de interpretaçõesSQL, boa parte delas resultando em dados irrelevantes para a consulta inicial. Este tra-balho realiza um estudo de diferentes técnicas para ranqueamento de interpretações deconsultas e, ao final, propõe uma metodologia de ranqueamento que maximiza a quanti-dade de resultados relevantes para consultas com palavras-chave submetidas a bancos dedados relacionais.
Palavras–chave
Consulta a banco de dados, Interpretação de consulta, Banco de dados Relacio-nal.

Abstract
de Sousa, Walisson Pereira. A Technique for Ranking SQL Interpretationsfrom Keyword Queries. Goiânia, 2017. 122p. MSc. Dissertation. Instituto deInformática, Universidade Federal de Goiás.
Retrieving information using words from a natural language is a simple and alreadyconsolidated way to access data on the Web. It would be highly desirable that a similarmethod could be used to submit queries on databases, thereby freeing the user fromlearning a query language and knowing the searched database structure. In this sense,a great research effort has been dedicated by the database community in order to developmore efficient query keywords techniques for database access. However, a keyword querycan result in a large number of SQL interpretations, most of them irrelevant for the initialquery. This work carry out a study of different query interpretations ranking techniquesand, finally, proposes a ranking methodology that maximizes the amount of relevantresults for keyword queries submitted to relational databases.
Keywords
database query, interpretation of query, relational database

Sumário
Lista de Figuras 12
Lista de Tabelas 13
Lista de Algoritmos 14
1 Introdução 151.1 Contexto e Motivação 151.2 Principais Problemas 171.3 Objetivos 19
1.3.1 Objetivo Geral 191.3.2 Objetivos Específicos 19
1.4 Metodologia 191.5 Organização do Trabalho 20
2 Trabalhos Relacionados 212.1 Características Identificadas 22
2.1.1 Grafo de Dados 222.1.2 Grafo do Esquema 242.1.3 Acesso Prévio aos Dados 252.1.4 Expansão e Limpeza da Consulta 262.1.5 Intervenção do Usuário 272.1.6 Funções de Agregação 282.1.7 Bancos de Dados Utilizados nas Avaliações 292.1.8 Multiplicidade de Bancos de Dados 302.1.9 Técnicas de Ranqueamento 30
2.2 Conclusão 33
3 Técnicas de Ranqueamento de Consultas 353.1 Abordagens Baseadas em Steiner Trees 353.2 Abordagens Baseadas em Candidate Networks 393.3 Abordagens Baseadas no Método Húngaro 42
3.3.1 Definição do Problema 423.3.2 Etapas de Conversão 44
Cálculo dos Pesos Intrínsecos 44Seleção dos Melhores Mapeamentos para Termos de Esquema 45Contextualização e Seleção dos Melhores Mapeamentos para Termos de Valor 46Geração das Configurações 47Geração das Interpretações 47

3.3.3 O Sistema de Ramada et al.[36] 483.3.4 Considerações Finais 49
4 Modelo Proposto para Ranqueamento 514.1 A Proposta 51
4.1.1 Construção do Grafo 524.1.2 Cálculo dos Pesos Intrínsecos 564.1.3 Seleção dos Melhores Mapeamentos para Termos do Esquema 584.1.4 Contextualização e Seleção dos Melhores Mapeamentos para Termos de Valor 584.1.5 Geração das configurações 594.1.6 Ranqueamento 59
Pesos dos Vértices (Vértice) 61Pesos das Arestas (Aresta) 61Pesos dos Vértices e Arestas (VérticeXAresta) 62Peso do Domínio 63
4.1.7 Geração das interpretações 654.1.8 Considerações Finais 65
5 Avaliação 665.1 Métricas 665.2 Bancos de Dados 675.3 Resultados da Avaliação 68
5.3.1 Quantidade de Configurações 705.3.2 TOP-1 Resultados 745.3.3 Reciprocal Rank 755.3.4 Precision 76
5.4 Considerações Finais 77
6 Conclusão 786.1 Contribuições do Estudo 796.2 Limitações da Técnica 806.3 Trabalhos Futuros 80
Referências Bibliográficas 82
A Bancos de Dados Utilizados na Avaliação 86A.1 DBLP 86
A.1.1 Esquema Lógico 86A.1.2 Esquema Físico 87
A.2 IMDb 91A.2.1 Esquema Lógico 91A.2.2 Esquema Físico 91
A.3 Banco de Dados Mondial 96A.3.1 Esquema Lógico 96A.3.2 Esquema Físico 97
B Consultas e Sentidos Pretendidos 119

Lista de Figuras
1.1 Bancos de Dados mais populares[39], acesso em 23 de out de 2017. 161.2 Processo de Tradução 171.3 Banco de dados IMDb [29] 18
3.1 Grafo de Dados do banco de dados IMDB 363.2 Grafo de Dados do banco de dados IMDB com pesos nos vértices 373.3 Grafo com termos da consulta incididos 383.4 Steriner Trees geradas para o exemplo da Tabela 3.1 383.5 grafo do esquema do IMDB (Figura1.3) 403.6 grafo do esquema do IMDB com Informações Identificadas (Figura1.3) 403.7 grafo do esquema do IMDB com Informações Identificadas (Figura1.3) 413.8 Árvores de Junção geradas (exemplo da Tabela 3.3) 413.9 Matriz de pesos sw (cinza claro) e vw (cinza escuro), extraído de [4] 433.10 Etapas de Conversão do Keymantic (inspirado em [4]) 44
4.1 Modificação das Etapas de Conversão (inspirado em [4]) 534.2 Grafo construído com informações do esquema do IMDb 534.3 Grafo do IMDb com Vértices Ponderados 544.4 Grafo do IMDb com Vértices e Arestas Ponderadas 554.5 Grafo do IMDb com Vértices e Arestas Ponderadas 564.6 Grafo com Vértices Incididos 614.7 Grafo com Arestas Incididas 624.8 Grafo com Arestas Incididas 63
5.1 Quantidade média das configurações geradas 705.2 Percentual de TOP-1 resultados relevantes (%) 745.3 Mean Reciprocal Rank 755.4 Precisão Média (Avarage Precision) 76
A.1 DBLP 86A.2 IMDb 91A.3 Banco de Dados Mondial 96

Lista de Tabelas
2.1 Características Identificadas 232.2 Bancos de Dados Utilizados nos Sistemas 292.3 Correlação das Técnicas de Ranqueamento 33
3.1 Exemplo de consulta e sentido pretendido 383.2 Interpretações Geradas 393.3 Exemplo de consulta com palavra-chave 393.4 Interpretações Geradas (exemplo da Tabela 3.3) 423.5 Exemplo de Consulta e Sentido Pretendido 443.6 Matriz de Pesos(SW) 453.7 Matriz de Pesos com Maiores Pontuações Destacadas 463.8 Matriz de Pesos VW 463.9 1ª Configuração da Consulta 473.10 2ª Configuração da Consulta 473.11 Interpretações SQL 48
4.1 Exemplos de Consultas e Sentidos Pretendidos 524.2 Matriz de Pesos sw 584.3 Mapeamento com Melhor Pontuação 584.4 Matriz VW com pesos 594.5 Configuração Gerada 594.6 Configuração após Adição dos Pesos dos Vértices 614.7 Mapeamento após Cálculo dos Pesos 624.8 Configuração e Pontuação (Vértices e Arestas) 634.9 Aplicação do Peso de Domínio 644.10 Consulta e Interpretação Gerada 65
5.1 Características dos bancos de dados utilizados. 685.2 Método Húngaro 695.3 Ponderação por Vértices (Vértice) 715.4 Ponderação por arestas (Aresta) 725.5 Ponderação por Vértices e Arestas (VerticeXAresta) 73
B.1 Consultas e Sentidos Pretendidos - DBLP 120B.2 Consultas e Sentidos Pretendidos - IMDb 121B.3 Consultas e Sentidos Pretendidos - Mondial Database 122

Lista de Algoritmos
4.1 Algoritmo de atribuição dos pesos (SW), retirado de [36] 574.2 Algoritmo de ranqueamento 60

CAPÍTULO 1Introdução
Este capítulo introdutório apresenta o problema abordado neste trabalho, eluci-dando a solução proposta e os desafios enfrentados. Na Seção 1.1 são apresentados o con-texto e a motivação que originaram a ideia central deste trabalho, seguidos da descriçãodo problema na Seção 1.2 e os objetivos na Seção 1.3. A Seção 1.4 descreve a Metodo-logia utilizada para o desenvolvimento deste estudo. A Seção 1.5 apresenta a organizaçãodesta dissertação.
1.1 Contexto e Motivação
Existe uma quantidade imensurável de informação presente em bancos de dadosespalhados pelo globo [15]. Dentre eles, os bancos de dados relacionais se destacampor implementar o modelo mais utilizado. No entanto, para acessá-los são necessáriosconhecimentos acerca de alguma linguagem de consulta; para o modelo relacional, utiliza-se a SQL (Structured Query Language).
O paradigma de consultas com palavras-chave surgiu devido à Internet, para queos usuários não necessitassem memorizar ou manter uma lista dos sites de interesse, e temsido a maneira mais rápida de encontrar as mais variadas informações. Motores de buscacomo o Google1, Bing2 e Yahoo!3 têm facilitado o acesso às mais diversas informaçõespresentes na Web, de maneira simples, apenas fornecendo algumas palavras relacionadasao tema de interesse.
Contudo, as técnicas de consultas com palavras-chave aplicadas à Web nãopodem ser diretamente utilizadas nos bancos de dados relacionais. A normalização dosbancos de dados implica que informações persistam em tabelas distintas, dificultando autilização direta dessas técnicas, como relatado por Agrawal et al. [1].
1https://www.google.com2https://www.bing.com3https://br.search.yahoo.com

1.1 Contexto e Motivação 16
Figura 1.1: Bancos de Dados mais populares[39], acesso em 23de out de 2017.
Além disso, de acordo com Swan [40], os usuários da Internet se sentemimpotentes perante bancos de dados relacionais. O acesso às informações em bancosde dados relacionais é realizado através de uma linguagem de consulta, diferente dalinguagem utilizada no cotidiano. Para isso, sistemas que empregam técnicas utilizadasna Web para acesso a bancos de dados foram propostos com o objetivo de facilitar oacesso aos mais variados tipos de informação.
Como mostrado na Figura 1.1, dos 10 (dez) modelos de banco de dados maisutilizados, o modelo relacional é majoritário[39]. A quantidade de informações presentenesses repositórios e que pode ser disponibilizada ao público geral é imensa. Os sistemasque possibilitam consultas com palavras-chave em bancos de dados relacionais são vistoscomo mais uma maneira de facilitar o acesso às informações, até então, limitadas a umgrupo específico.
Sistemas que permitem usuários leigos submeterem consultas em bancos de da-dos relacionais, sem conhecimento de qualquer linguagem de consulta, têm sido apre-sentados em diversos trabalhos desde a década passada, dentre eles [5], [1], [20], [10],[30], [17], [41], [35], [4], [18], [13], [22], [43] e [36]. Esses trabalhos modelam o bancode dados como um grafo e utilizam principalmente a variação de duas técnicas para oprocesso de ranqueamento das consultas SQL geradas: Candidade Networks e Steinner
Trees. Essas técnicas são discutidas com detalhes no Capítulo 3.A figura 1.2 apresenta, de forma geral, o processo realizado pelos sistemas que
permitem consulta com palavras-chave em bancos de dados relacionais. Nesses sistemas,inicialmente, são selecionados os bancos de dados para que o usuário submeta a consulta.Nessa etapa, são criadas as estruturas que auxiliam no processo de tradução em consultasSQL(criação do grafo do esquema ou dos dados, índices, tabelas ou outras estruturasauxiliares). Em seguida, de acordo com cada sistema, é realizada a separação e expansãodos termos da consulta, mediante técnicas de similaridade e dicionários. Após, é realizadoo mapeamento de cada termo da consulta em detrimento do banco de dados, ou seja, qual

1.2 Principais Problemas 17
Figura 1.2: Processo de Tradução
o papel de cada termo da consulta. Adiante, os termos são agrupados para encontrar ospossíveis cenários formados pelas palavras-chave. O processo de ranqueamento ocorreem seguida, utilizando técnicas que podem variar de acordo com o sistema (utilização degrafos gerados a partir do esquema ou dos dados e outras estruturas). Por fim, é realizadaa geração e submissão das consultas SQL criadas a partir da consulta com palavras-chave.
1.2 Principais Problemas
Uma consulta com palavras-chave consiste em um conjunto (n ≥ 1) de termosseparados por espaço(s) em branco, em que cada termo da consulta expressa algumainformação sobre valores de tuplas, atributos, nome de relações ou operadores. Umdos problemas desta pesquisa é que, durante processo de tradução da consulta, diversasconsultas SQL relacionadas aos termos inseridos pelo usuário poderão emergir, revelando,muitas vezes, consultas que podem não retornar quaisquer resultados ou até mesmoresultados indesejados.
O ranqueamento das interpretações SQL geradas é fundamental para apresen-tação de resultados mais satisfatórios ao usuário. Esse processo se faz necessário paraaproximar o resultado à real intenção do usuário. É importante frisar que geralmente ousuário não conhece a estrutura do banco de dados em que a consulta é submetida.
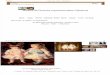
Com isso, existe a necessidade de ranquear essas interpretações, objetivandoencontrar aquelas que mais condizem com a intenção do usuário. Os métodos descritosem [4], [36] e [35] levam em consideração que termos próximos representam informaçõesdo contexto dos dados. Por exemplo, observando a Figura 1.3, na consulta actor george
1.2 Principais Problemas 18
movies (ator george filmes), é entendido que o usuário deseja saber em quais filmes o ator
george atuou.
Figura 1.3: Banco de dados IMDb [29]
Outro problema inerente do processo de tradução de consultas com palavras-chave é a quantidade de interpretações geradas. As técnicas que realizam a traduçãodessas consultas utilizam informações do banco de dados para gerar as consultas SQL,no entanto esse número dificulta a recuperação mais precisa da informação. Para tentarcontornar essa situação é necessário um estudo acerca das características dos sistemasque permitem consultas com palavra-chave, principalmente daquelas que podem impactarna geração e no ranqueamento dessas interpretações. Além disso é preciso indicar quaistécnicas podem ser utilizadas nos sistemas que formulam a consulta SQL somente comos metadados.
O termo ranqueamento expressa "estabelecimento de uma pontuação paraformar uma classificação entre diversos elementos"[16]. Esse termo foi escolhido parautilização neste trabalho em substituição ao termo classificação, pois este último possuimúltiplas interpretações na Língua Portuguesa que fogem ao escopo deste estudo.

1.3 Objetivos 19
1.3 Objetivos
1.3.1 Objetivo Geral
Diante do exposto, de que uma consulta com palavras-chave pode ser interpre-tada para n consultas SQL, o objetivo deste trabalho é propor um método de ranqueamentode interpretações SQL, oriundas de consultas com palavras-chave.
1.3.2 Objetivos Específicos
1. Estudar e conhecer as características mais significativas dos principais sistemas quepermitem a realização de consultas a partir de palavras-chave em bancos de dadosrelacionais;
2. Conhecer o impacto das características no processo de ranqueamento das consultasSQL geradas.
3. Encontrar as técnicas de ranqueamento de consultas que podem ser aplicadas àabordagem adotada pelo sistema descrito em [36], aquela que não utiliza os dadosa priori para a tradução das consultas;
4. Realizar a Implementação das técnicas selecionadas e testar combinações emdiferentes cenários;
5. Avaliar as principais técnicas de ranqueamento de consultas com palavras-chaveselecionadas;
6. Apresentar um método de ranqueamento de consultas que reduza a quantidade deinterpretações geradas durante o processo de tradução da consulta.;
1.4 Metodologia
Este trabalho apresenta metodologia dividida nas seguintes etapas:
• Revisão de Literatura: Esta etapa consiste no primeiro passo do projeto, em queocorreu a realização de uma revisão de literatura das publicações mais relevantespara a extração das características dos sistemas de consulta com palavras-chave.Foram levados em consideração os trabalhos mais significativos que exploramo paradigma de consulta com palavras-chave em bancos de dados relacionais,juntamente com as características que impactam no processo de ranqueamento dasinterpretações geradas. Foram consultadas as bases de dados: Portal de Periódico
da Capes, IEEEXplore, ACM Digital Library, Google Acadêmico e Elsevier.• Estudo das Características Relevantes: nesta etapa, foi feito o levantamento das
principais características de sistemas que permitem consultas com palavras-chave

1.5 Organização do Trabalho 20
em bancos de dados relacionais e um estudo de impacto dessas características noprocesso de ranqueamento.
• Seleção das Técnicas de Ranqueamento: esta etapa visa selecionar os métodosde ranqueamento de consultas para encontrar o(s) que podem ser aplicados nossistemas que não utilizam acesso às instâncias dos bancos de dados para traduzirconsultas com palavras-chave.
• Implementação das Técnicas de Ranqueamento: esta etapa tem por objetivoimplementar as técnicas de ranqueamento selecionadas.
• Formulação dos Testes: nesta etapa foram geradas as consultas com palavras-chave e definidas as possíveis interpretações de cada uma. Devido aos diferentescontextos das bases de dados, foram gerados conjuntos de testes distintos para cadauma delas.
• Avaliação das Técnicas de Ranqueamento: nesta etapa ocorreu a realização dostestes nos bancos de dados escolhidos. Três bancos de dados reais de domíniosdiferentes foram selecionadas para avaliar as técnicas selecionadas.
• Apresentação dos Resultados: nesta etapa são apresentadas a(s) técnica(s) queobtiveram os melhores resultados (dados relevantes), de acordo com cada base dedados.
1.5 Organização do Trabalho
Esta dissertação encontra-se organizada da seguinte maneira: primeiramente,este Capítulo introdutório. No Capítulo 2 são apresentados os trabalhos mais importantesrelacionados ao tema de pesquisa e discorre sobre as características relevantes do siste-mas em questão; o Capítulo 3 apresenta o funcionamento das técnicas de ranqueamentode consultas consideradas relevantes à proposta. A formalização dos modelos de ranque-amento utilizados é apresentada no Capítulo 4. Os testes realizados são apresentados noCapítulo 5. As considerações finais, contribuições e trabalhos futuros são discutidos noCapítulo 6.

CAPÍTULO 2Trabalhos Relacionados
Nos últimos anos, foram escritos diversos trabalhos que discorrem sobre diferen-tes técnicas para composição de consultas SQL a partir de palavras-chave. Esses trabalhospropõem métodos para recuperar informações de bancos de dados relacionais de maneirasimples para o usuário, similarmente como é feito na internet, através de palavras-chave.Em [42] são apresentadas as técnicas que são aplicadas a grafos modelados a partir dastuplas do banco de dados. Chen at al. [8] examinam diferentes aspectos do paradigma deconsulta de palavras-chave aplicados a sistemas que operam sob bases relacionais e XML,em associação com técnicas de Mineração de Dados. O trabalho, além de fornecer umaanálise sobre esse paradigma, apresenta um sistema que utiliza ontologia para expansãodos termos da consulta submetida pelo usuário. Coffman e Weaver[9] realizam a avalia-ção de 7 (sete) técnicas de consulta com palavras-chave, discutindo: número de termos daconsulta, tempos de execução, tempo de resposta, consumo de memória e ameaças paravalidação do método.
Os 14 (quatorze) sistemas elencados nesta pesquisa utilizam, em alguma etapa,grafos para o processo de tradução da consulta, seja a partir das tuplas do banco de dadosou dos metadados. A primeira abordagem necessita da externalização 1 dos dados comoum grafo, no qual cada vértice representa uma tupla e as arestas são atribuídas de acordocom as chaves das relações.
Nos sistemas descritos em [5], [10] e [13], as consultas são construídas deacordo com a incidência dos termos das palavras-chave no grafo. Após a submissão daconsulta, é verificada a existência (ou correlação) dos termos nos vértices dos grafos e,caso ocorra, os vértices são recuperados, juntamente com nós intermediários, formandoSteinner Trees[12]. Este conceito diz respeito a árvores utilizadas para interligar pontosdistintos. Em resolução de consultas por palavras chave em bancos de dados, as Árvoresde Steiner são utilizadas para interligar vértices que possuem correlação ou incidênciamas não existe aresta interligando-os diretamente.
1Copiar as informações do disco rígido para a memória principal

2.1 Características Identificadas 22
Os demais sistemas utilizam o esquema do banco de dados para a modelagemdos grafos: relações são representadas como vértices e as chaves primárias e estrangeirascomo arestas. Uma vantagem em relação à outra abordagem é o menor consumo dememória devido não ser necessário carregar o grafo na memória principal. Foi no SistemaDiscover [20] que ocorreu a formalização de consultas com palavras-chave em bancos dedados relacionais, além de apresentar um algoritmo para ranqueamento das Candidates
Networks (CNs) 2.Bergamaschi et al.[4] pressupõem que nem sempre é possível ter acesso às tuplas
do banco de dados para conversão de consultas com palavras-chave em consultas SQL.Em contrapartida, o processo é realizado utilizando apenas os metadados e um conjuntode técnicas distintas. Esses metadados devem possuir conteúdo relevante e fornecer algumsentido para a consulta. Ex.: na Figura 1.3, o nome da tabela actors possui sentidoexplícito, pois armazena informações de atores.
A tradução de consultas com palavras-chave em consultas SQL é um processoque envolve passos distintos, de acordo com as peculiaridades de cada sistema. Com isso,a próxima seção aborda as características dos principais sistemas que permitem realizarconsultas com palavras-chave em bancos de dados relacionais.
2.1 Características Identificadas
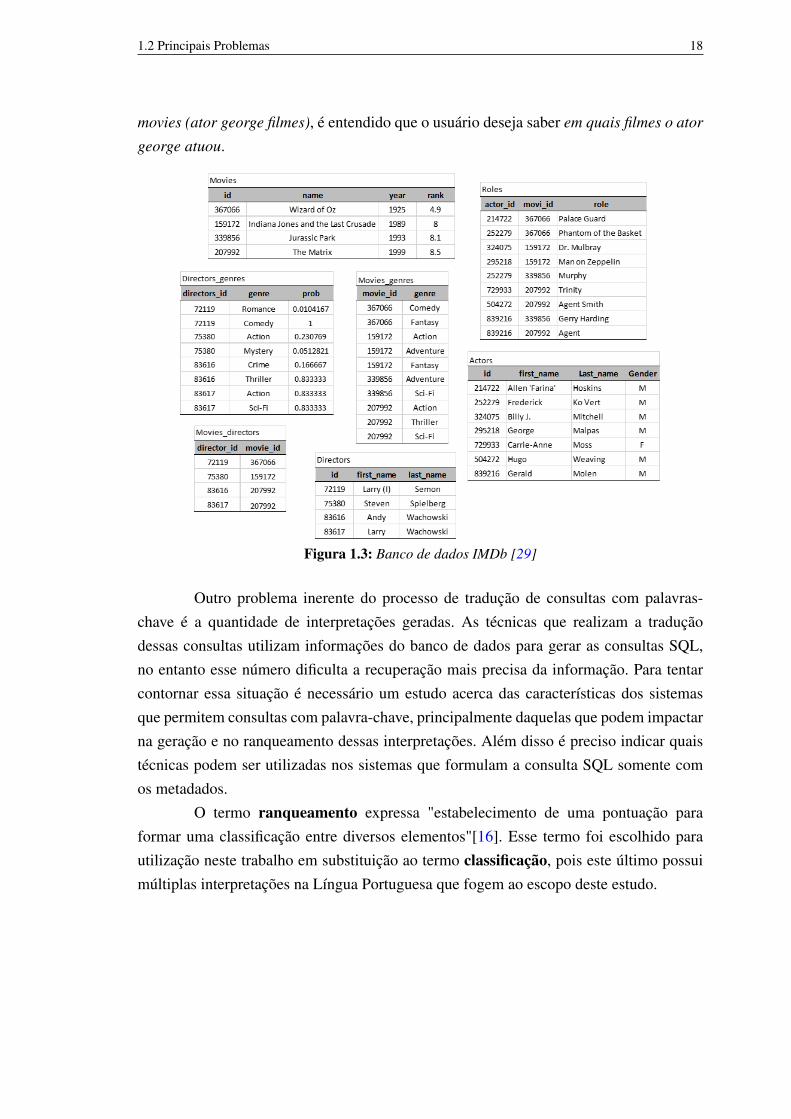
Para a realização deste trabalho, foram selecionados 14 (quatorze) sistemasque possibilitam a submissão de consultas com palavras-chave em bancos de dadosrelacionais, os quais tiveram suas características mais relevantes identificadas, conformemostrado na Tabela 2.1. Essas características podem influenciar diretamente no processode ranqueamento dessas consultas.
As características selecionadas e discutidas são as seguintes: Grafo de Dados,Grafo de Esquema, Acesso Prévio aos Dados, Expansão e Limpeza da Consulta, In-tervenção do Usuário, Multiplicidade de Bancos de Dados, Funções de Agregação,Bancos de Dados e Técnicas de Ranqueamento. Esta seção abordará essas característi-cas e suas peculiaridades.
2.1.1 Grafo de Dados
Os primeiros trabalhos que abordaram consultas com palavras-chave em bancosde dados relacionais sugerem que o banco de dados seja modelado como um grafoG = (V,E), em que cada vértice (v ∈ V ) corresponde a uma tupla (t ∈ T ), conectado a
2Rede que apresenta os possíveis caminhos que os vértices do grafo podem se conectar
2.1 Características Identificadas 23
Tabela 2.1: Características Identificadas
Característica BA
NK
S[5]
DB
Xpl
orer
[1]
DIS
CO
VE
R[2
0]
Din
get
al.[1
0]
Nan
die
Jaga
dish
[30]
Gu
eK
itaga
wa[
17]
SQA
K[4
1]
FRIS
K[3
5]
Key
man
tic[4
]
Ham
met
al.[1
8]
DB
Sem
SXpl
orer
[13]
Mea
nKS
[22]
Exp
ress
Q[4
3]
Ram
ada
etal
.[36]
Acesso Prévio aosDados
X X X X X X X X X X X X
Grafo dos Dados X X XGrafo do Esquema X X X X X X X X X X X XExpansão da Con-sulta
X X X X X X
Proximidade Sintá-tica
X X X X X
Limpeza da consulta X X XDicionário/Ontologia X X X X XIntervenção doUsuário
X X X X X X X
Multiplicidade deBancos de Dados
X X X X X X
Funções de Agrega-ção
X X X
outro vértice por uma aresta (e ∈ E). A conexão entre vértices e arestas é feita de acordocom o relacionamento entre as chaves primária e estrangeira das relações envolvidas. Ostrabalhos [5, 10, 13] seguem essa abordagem para o processamento da consulta.
No sistema BANKS [5, 6] as arestas são ponderadas de acordo com a força entreas relações. Essa força é encontrada de acordo com a quantidade de tuplas conectadasentre duas tabelas. Quanto mais forte for o relacionamento entre as tabelas, menor será opeso da aresta. Para cada aresta do grafo, é criada uma aresta inversa com peso distinto daaresta paralela; a ponderação se estende aos vértices. Inspirada na abordagem PageRank[7], presente no famoso motor de busca Google, BANKS agrega outra característicaimportante: o peso do nó. Dessa maneira, quanto mais conexões um nó possuir, maisprestígio ele terá. Diferente da ponderação da aresta, o peso do nó é dado em função dograu3 do vértice.
O sistema apresentado em [10] modela o banco de dados como um grafo, a partirdas tuplas, de duas maneiras: direcional, quando o sentido do relacionamento entre a
3quantidade de conexões

2.1 Características Identificadas 24
chave primária e estrangeira é relevante; e unidirecional, quando o sentido das chavesé irrelevante. No grafo direcional, existe uma aresta inversa para cada aresta do grafo.A atribuição dos pesos dos vértices e arestas é feita similarmente à utilizada no sistemaBANKS (PageRank [7]) combinada à técnica baseada na autoridade de cada nó, utilizadano sistema ObjectRank [2].
Assim como em [2], Ding et al. [10] exploram a informação semântica do bancode dados para ponderar vértices e arestas. Isso é feito construindo o grafo com anotações,denominado Labeled Graph, a partir das informações extraídas do esquema do banco dedados. Para cada vértice v do grafo G existe uma etiqueta λ(v) que identifica a relação quedeu origem ao vértice em questão. Similarmente, para cada aresta e do grafo G existe umaetiqueta λ(e) informando o relacionamento entre os vértices. Por exemplo: de acordo como esquema presente na Figura 1.3, os vértices gerados a partir das tuplas da relação movies
serão etiquetados com o nome da própria relação (movies). As arestas são etiquetadas deforma a refletir o relacionamento existente entre as tabelas. O relacionamento entre astuplas das tabelas actors e roles é have. Logo, has será a etiqueta da aresta, indicando queactors has roles (atores possuem papéis). Essas informações são utilizadas para verificara relação semântica entre os vértices.
O sistema DBSemSXplorer [13] utiliza abordagem um pouco diferente. Nele,um grafo dos dados é gerado utilizando notação RDF (Resource Description Framework),sendo este um grafo direcional em que vértices e arestas representam informações dastuplas e do esquema. Este modelo utiliza ontologia para representação dos dados, em queé possível determinar a classe em que cada tupla pertence.
2.1.2 Grafo do Esquema
Vários trabalhos foram desenvolvidos com a finalidade de explorar consultasconstituídas de palavras-chave. As primeiras abordagens exigiam a transferência dobanco de dados para a memória RAM, o que foi definido nesses estudos como Grafo
de Dados. As outras abordagens elencadas neste trabalho, e discutidas na Subseçãoanterior, consideram os metadados do banco de dados no processo de ranqueamentodessas consultas. Desse Modo, grafos são modelados a partir do esquema do banco dedados.
Os trabalhos [1], [4],[17], [20],[22], [30], [35], [36] e [41] modelam o esquemado banco de dados como um grafo G = (V,E), nos quais cada vértice v ∈V correspondea uma relação do esquema e o relacionamento entre chaves primária e estrangeira dessasrelações forma as arestas e ∈ E de G.
No entanto, Haam et al. [18] enfatizam que algumas relações são mais impor-tantes que outras, devido principalmente às suas utilizações. Nesse trabalho é utilizado

2.1 Características Identificadas 25
um Grafo de Junção (Join Graph), que pondera a afinidade das relações de acordo coma quantidade de tuplas de uma tabela que se relacionam com tuplas de outras tabela. Opeso de afinidade (Affinity weight), sendo w >= 2, indica o quão próximas as relações sãoumas das outras.
Hristidis et al.[20] propuseram o DISCOVER. Neste sistema existe uma versãonão-dirigida para o grafo dirigido G, identificado como Gµ. O ranqueamento das consultasé realizado pelo caminho mínimo de junções, encontrado a partir dos termos da consultaincidentes no banco de dados. Esse trabalho foi utilizado como base, juntamente com[21], para a construção do sistema descrito em[17], em que os autores propuseram umaferramenta que utiliza o esquema do banco de dados na construção do grafo, definindouma tupla com anotação. Desse modo, o nome da relação é considerado como umdado da tupla. Pesos são atribuídos considerando valores de tupla e metadados, empassos distintos. As funções de ponderação levam em consideração a incidência de cadapalavra-chave nas tuplas e no esquema. As informações de ambos são utilizadas pararanqueamento através da técnica baseada em Candidate Networks.
ExpressQ [43] utiliza o modelo de classificação apresentado por Zeng et al. [44],que distingue as relações em 4 (quatro) categorias: relações objeto, relações de relaciona-mento, relações mistas e relações componente. Na Figura 1.3, as relações objeto são aque-las que são referenciadas por apenas uma relação e que não referenciam qualquer outra,como, por exemplo, movies_genres e directors_genres. As relações de relacionamento sãoaquelas construídas para representar os relacionamentos n : n (roles e movies_directors).As relações componentes são as que representam atributos multivalorados de outra re-lação. Por sua vez, as relações mistas possuem informações tanto de objetos quanto derelacionamentos, ocorrendo nas entidades que possuem associações n : 1. Esse processopermite a captura de informações semânticas utilizadas na construção da consulta. A par-tir dessa classificação, é construído um grafo G = (V,E) unidirecional ORM (Object-
Relationship-Mixed), em que cada vértice v de G corresponde a uma relação. Dois nós u ev são conectados através de uma aresta e (u,v) ∈ E. O vértice leva consigo a classificaçãoda relação que o originou.
2.1.3 Acesso Prévio aos Dados
Nem sempre é possível ter acesso a priori ao banco de dados para a realizaçãoda conversão da consulta de palavras-chave em consulta SQL. Como exemplificado porBergamaschi et al. [4] e Lenzerini [24], sistemas que permitem integração entre bases deinformações e bancos de dados presentes na Web invisível (não indexada pelos motores
de busca) não permitem acesso aos dados para a construção da consulta SQL.Os sistemas BANKS[5], DISCOVER[20], [10], [30] e [43] constroem índices

2.1 Características Identificadas 26
que referenciam tuplas do banco de dados. Por outro lado, os sistemas apresentados em[17] e [13] utilizam índices invertidos que referenciam os termos das tuplas e dos me-tadados. Em [41], índices também são utilizados para retornar o nome da tabela em quea palavra-chave da consulta incide. Por sua vez, a ferramenta discorrida em[35] indexadados e termos do banco de dados utilizando o Apache Lucene (API para indexação dedocumentos). O sistema apresentado em [18] utiliza a ferramenta OracleText para indexa-ção. DBXplorer[1] e MeanKS[22] utilizam tabelas auxiliares para armazenar informaçõesdas tuplas antes do processo de conversão da consulta. MeanKS[22] e [1] fazem uso dafunção de busca nativa do SGBD para encontrar termos do banco de dados relacionadosa termos da consulta.
A necessidade de acesso prévio aos dados para a tradução da consulta podelimitar consideravelmente a aplicabilidade da técnica de consulta com palavras-chave,principalmente nas situações em que não é possível obter acesso direto aos dados paraa formulação das consultas SQL. Keymantic[4] e [36] se destacam dos demais sistemaspor atuarem em ambientes que não fornecem acesso prévio aos dados, uma vez que oprocesso de tradução é feito utilizando-se somente os metadados. No entanto, os nomes derelações e atributos devem ser significativos ao processo de tradução da consulta. Tabelascujos nomes não possuem sentido explícito (Ex.: t1, t2, tab, t) dificultam a realização domapeamento das palavras-chave.
2.1.4 Expansão e Limpeza da Consulta
As características discutidas nesta subseção partem da premissa da expansão,correção ou exclusão de termos da consulta com palavras-chave para a construção daconsulta SQL, feita através de técnicas de verificação sintática e semântica e utilizaçãode dicionários e ontologias. A proximidade sintática trata os possíveis erros de digitaçãocometidos pelo usuário, assim como as derivações das palavras. A utilização de dicio-nários e ontologias permite expandir a consulta baseando-se nos sinônimos dos termos einformações do banco de dados.
O sistema demonstrado em [41] utiliza um algoritmo, aplicado aos termos daconsulta, que calcula a distância sintática entre strings, o que pode ser utilizado paratratar erros de ortografia, cometidos pelo usuário no momento da digitação, e abreviaçõesde palavras. Também é utilizada expansão de termos através de ontologia sinonímiaespecífica (WordNet).
O sistema discorrido em [30], além de Utilizar WordNet, utiliza uma árvore desufixos para expansão dos nomes dos metadados do banco de dados. Baseado em [25],o sistema faz uso de ontologias para verificação da relação semântica entre os termos daconsulta e valores de tuplas/relações. Isso garante, de acordo com os autores, que o usuário

2.1 Características Identificadas 27
não necessite conhecer a estrutura do banco de dados para submissão de consultas. Porexemplo: um sinônimo válido para a relação movies é films
Keymantic[4] e [13] expandem a consulta utilizando WordNet e ontologias,juntamente com um conjunto de técnicas que calcula a similaridade de palavras, dentreelas: Levenshtein, Jaccard e the Hamming.
Os trabalhos [1] e [18] utilizam o comando SQL like para determinados termosno momento da execução da consulta. BANKS[5],[10], DISCOVER[20], [17], [22] e [43]não citam qualquer tipo de técnica similar nos trabalhos. Logo, pressupõe-se que nãoexiste qualquer mecanismo para expansão dos termos da consulta.
Wordnet é também utilizado em [36]. Nesse trabalho, é feita a verificação dosoperadores de agregação, de valores compostos e ordenação. A verificação sintática érealizada através das médias de 3 (três) técnicas: Jaccard, Leveshtein e Cosseno. Ocomando like é utilizado nos termos mapeados como valor de tupla.
O processo de limpeza considera que o usuário pode inserir uma consulta suja,que contenha termos desprezíveis ao processo de interpretação da mesma (preposições,artigos). FRISK[35] apresenta uma abordagem para a limpeza da consulta que divergeda abordagem de eliminação de stopwords, presente em [37]. Para isso, os termos quenão apresentam correlação com informações do esquema/dados ou não possuem papeldefinido são eliminados da consulta.
O processo de limpeza da consulta foi descrito pelos autores em [34], queconsideram tokens como cadeias de caracteres indivisíveis e termos como uma sequênciade tokens. No trabalho, tokens são expandidos para variações próximas ao token original.Esse processo leva em consideração a sinonímia e erros de digitação. Para cada token écriada uma matriz que armazenará as variações sintáticas e sinonímicas desse token, deacordo com a incidência das palavras presentes no banco. Erros de digitação também sãotratados na fase de limpeza da consulta. Por exemplo: movie possui proximidade sintáticacom o nome da tabela movies (Figura 1.3).
2.1.5 Intervenção do Usuário
O sistema BANKS [5] possibilita que o usuário selecione nós relevantes após asubmissão da consulta, nas situações em que um termo da consulta coincida com mais deum vértice, diminuindo resultados não condizentes que a intenção do submissor.
Keymantic [4] oferece, a partir do esquema do banco de dados, uma lista deinterpretações para os termos da consulta informada pelo usuário. No sistema descrito em[30], é possível reeditar a consulta através de indicações feitas pelo sistema. Quando aconsulta possui termos correlativos a informações do banco de dados, é feita a sugestãoao usuário dos termos corretos do banco de dados.

2.1 Características Identificadas 28
O sistema DBXplorer[1] apresenta os caminhos de junção (Join Trees) geradospara que o usuário selecione os que mais lhe agrada. A navegação entre as tabelasretornadas também é possível. Dessa maneira, o usuário pode visualizar todo o conteúdoresidente nas tabelas recuperadas com a consulta.
Tata et al. [41] demonstram que SQAK pode retornar configurações de consultasdiferentes com os mesmos – ou aproximados – scores. Então, o processo é interrompidoe são apresentados os possíveis resultados para que o usuário escolha o mais satisfatório.
MeanKS [22] apresenta ao usuário as possíveis interpretações de cada palavra-chave da consulta para que seja selecionada a mais relevante. Então, é apresentada umalista ranqueada de Redes de Junção Mínima de Tuplas (Minimal Joining Network of
Tuples), para que o usuário selecione a que melhor lhe convém.FRISK [35] é o sistema que permite o usuário participar de quase todas as etapas
do processo de conversão. No primeiro passo, o usuário já intervém, selecionando o bancode dados a ser consultado. Na segunda etapa, o usuário tem a opção de refinar a consultaou continuar o processo automaticamente. Esse refinamento é dado pela possibilidadede combinações diferentes com dados do banco de dados. É nessa etapa que acontecea conversão para operadores de agregação. Após isso, visualmente são apresentados osplanos de junções para que um deles seja selecionado e então tenha sua consulta SQLexecutada.
No sistema [36], o processo de conversão da consulta, após sua submissão,é realizado de forma completamente automatizada, não permitindo ou necessitando daintervenção do usuário nas etapas de tradução.
A possibilidade do usuário intervir nos passos do processo de tradução das con-sultas pode influenciar diretamente na interpretação e, consequentemente, no ranquea-mento. Os sistemas [10], DBSemSXplorer [13], [17], [18], DISCOVER [20] e ExpressQ[43] não fazem menção a qualquer método que permita o usuário intervir nesse processo.
2.1.6 Funções de Agregação
Somente SQAK [41], FRISK [35] e [36] são explícitos sobre o tratamento dasfunções de agregação. Esses sistemas identificam os possíveis termos que representamoperadores de agregação no processo de segmentação da consulta. Um termo, por exem-plo, Media, será convertido para AVG. O sistema descrito em[36], além de permitir opera-dores de agregação, também possibilita o reconhecimento do operador de ordenação SQLorder by.
Bergamaschi et al. [4] pretendem implementar o tratamento de operadores deagregação no Keymantic futuramente. No entanto, não fica explícito se os outros sistemas

2.1 Características Identificadas 29
[1], [5], [10], [13], [17], [18], [20], [22], [30] e [43] realizam o reconhecimento deoperadores de agregação.
2.1.7 Bancos de Dados Utilizados nas Avaliações
A utilização do bancos de dados pode influenciar consideravelmente nos resul-tados da interpretação e ranqueamento da consulta. Para esse tipo de técnica é necessárioque os metadados do banco de dados (nome de relações e atributos) representem a classedos dados que nele é armazenado. Por exemplo, em um banco de dados sobre informaçõesaéreas, a tabela avião deve, logicamente, armazenar dados sobre aeronaves.
O IMDB (Internet Movie Database) banco de dados que armazena informaçõessobre diversos filmes, seriados, documentários, foi utilizado como banco de dados de testenos seguintes trabalhos: [30], [17], [35], [4], [18] e [13]. O Benchmark TPC (Transaction
Processing Performance Council) foi empregado nos sistemas [1], [20], [41], [43] e[22]. DBLP (Digital Bibliography & Library Project) é um repositório de computaçãoda Univesidade de Trier, Alemanha. Essa base foi utilizada para teste nos trabalhos: [5],[10] e [35].
Tabela 2.2: Bancos de Dados Utilizados nos Sistemas
Sistema Bancos de DadosBANKS[5] DBLP, IIT BombayDBXplorer[1] TPC-H, USRDISCOVER[20] TPC-HDing et al.[10] DBLP, Mondial DatabaseNandi e Jagadish[30] IMDBGu e Kitagawa[17] IMDBSQAK[41] Sample University Database ,TPCHFRISK[35] Northwind, IMDB, DBLP,Keymantic[4] University Database, IMDBHamm et al.[18] IMDBDBSemSXplorer[13] IMDBMeanKS [22] TPC-EExpressQ[43] TPC-H, ACMDLRamada et al.[36] Company Database
A ACM Digital Library (ACMDL), plataforma digital de conhecimento cientí-fico, foi utilizada para testes em [43]. O Mondial Dababase (MDB), banco de dados man-tido pela Universidade de Friburgo, Alemanha, que armazena informações geográficassobre a Terra (continentes, países, estados, cidades, rios, lagos), foi utilizado em [10].
Outras bases de dados, menos significativas, foram utilizadas para realização nostestes. Elas estão presentes na Tabela 2.2.

2.1 Características Identificadas 30
2.1.8 Multiplicidade de Bancos de Dados
Consultar informações de diversas bases distintas têm sido um dos tópicos de in-teresse dos pesquisadores da área de Banco Dados. Tecnologias que permitam integraçãode dados deverão emergir a fim de lidar com essa massa crescente de informação [26].Parte dos sistemas mencionados neste trabalho permite que o usuário efetue a consultaem mais de um banco de dados relacional. No entanto, deverão ser utilizadas técnicaspara seleção e ranqueamento dessas bases. Os sistemas abordados neste trabalho, e quepermitem realizar a consulta em mais de um banco de dados de forma automatizada, nãosão claros acerca do processo de ranqueamento.
No DBXplorer [1], após a submissão da consulta, são mostrados os bancos queretornaram resultados relevantes. O usuário deve selecionar o(s) banco(s) de dados aser(em) explorado(s), de acordo com a descrição emitida pelo sistema. FRISK [35] exigeque o usuário selecione o banco de dados, a partir de uma lista, apresentados antes dasubmissão da consulta.
Keymantic [4] possibilita multiplicidade de bancos de dados, mas não fornecemaiores informações sobre como isso é feito. Os sistemas [17] e [41], de acordo com seusautores, prometem futuramente explorar essa característica. Por outro lado, os demaistrabalhos, [5], [10], [13], [18], [20], [22], [30] e [43], não citam a possibilidade deexecução de consultas em mais de um banco de dados.
O sistema desenvolvido por Ramada[36] permite a submissão de consultas compalavras-chave em mais de um banco de dados. Para isso, é realizada a exposição dosmetadados para determinado repositório (no trabalho é utilizada uma tabela de umabase relacional), seguindo o método proposto por Silva et al.[38]. No processo, sãoconsiderados somente 4 (quatro) elementos do modelo. Os elementos dc_title, dc_subject,
dc_description, dc_identifier representam, respectivamente, o título do banco de dados,o assunto, uma breve descrição acerca do banco de dados, o identificador do bancode dados. A seleção e ranqueamento dos bancos de dados relevantes é dada de acordocom a incidência dos termos da consulta nas informações desses descritores. Para isso,cada termo incidido é contabilizado para ranqueamento do banco de dados. A ordemde ranqueamento dos bancos de dados é dada pela quantidade de termos expandidosda consulta incidentes nessas informações. Em suma, quanto mais termos da consultaestiverem presentes na descrição dos bancos de dados, mais relevante o banco de dadosserá para a submissão da consulta em questão.
2.1.9 Técnicas de Ranqueamento
Um consulta formada por palavras-chave submetida pelo usuário, em geral, éinterpretada para mais de uma consulta SQL. Os artigos analisados neste trabalho utilizam

2.1 Características Identificadas 31
técnicas baseadas em Steiner Trees (ST) ou Candidates Networks (CN). Nas abordagensbaseadas em ST, árvores são recuperadas a partir da incidência das palavras-chave nografo modelado através do banco de dados. Essas árvores representam os possíveiscaminhos de junção em que os termos da consulta são mapeados. Desse modo, nósintermediários podem ser recuperados no processo. As técnicas baseadas em CN retornamum grafo das tuplas do banco em que as palavras-chave incidam e possuam caminhos dejunção possíveis.
Os sistemas BANKS[5], [13] e [10] utilizam técnicas baseadas em ST para ran-quear as interpretações geradas. Nesses sistemas, vértices e arestas são ponderadas utili-zando o conceito de proximidade e custo do caminho para o processo de ranqueamento,nomeado Proximity Based Ranking por Bhalotia et al[5] . O sistema descrito em [10]utiliza GST-k (Top-k Group Steiner Tree), que classifica os k-ésimos resultados mais rele-vantes ao usuário, utilizando grafo gerado a partir das tuplas do banco de dados. Para talé empregado um algoritmo de programação dinâmica que encontra as melhores configu-rações de árvores.
Por outro lado, os sistemas apresentados em [1], [20], [30], [17], [41], [35], [18],[22] e [43] utilizam técnicas variadas de acordo com a geração das CNs. Nessa técnica, oesquema do banco de dados é visto como um grafo.
No DBXplorer[1], a tabela símbolo S é consultada para determinar as relações,colunas ou células que contenham pelo menos um dos termos da consulta. Utilizando ografo das relações, Árvores dos Caminhos de Junção (Join Tree Path) são enumeradaspara as possíveis interpretações serem classificadas de acordo com o menor caminho dejunção. As tuplas recuperadas são ordenadas através do número de junções envolvidas nainterpretação. Agrawal et al.[1] acreditam que consultas que envolvem muitas relaçõessão difíceis de compreender.
A técnica utilizada em [20] é similar à de BANKS. No entanto, diversos cami-nhos de junção redundantes podem surgir para uma consulta. DISCOVER[20] efetua aeliminação desses caminhos redundantes, diminuindo a quantidade de interpretações des-prezíveis. Assim, as CNs que contém tuplas que não possuam palavras-chave relacionadase se encontram no fim da cadeia da junção são excluídas.
Em [30], os autores são sucintos acerca do processo de ranqueamento dasinterpretações, realizado através do caminho mínimo de junções, após geradas as CNs.Neste sistema é verificada a distância das palavras-chaves incidentes no grafo construídoa partir do esquema do banco.
MeanKS [22] utiliza a técnica Minimal Joining Network of Tuples (MJNT), tam-bém conhecida como (CNs). O sistema leva em consideração três aspectos: importânciados nós, que pondera vértices de acordo com sua relevância; importância das arestas, queatribui pesos às arestas de acordo com a quantidade de chaves estrangeiras ligadas a outra

2.1 Características Identificadas 32
relação; e abordagem híbrida, que combina as funções de ponderação de nós e arestaspara o ranqueamento da consulta. As consultas são avaliadas e classificadas de acordocom o caminho mínimo de junções e os pesos associados às tuplas das CNs.
No sistema apresentado em [17], as tuplas levam uma informação extra: o nomeda tabela que a mantém. Com isso, caso uma palavra-chave incida em mais de uma tupla,um peso maior será atribuído àquela que possuir o nome da relação e algum dado dessatupla. Atributos e relações possuem pesos e são levados em consideração para o cálculodos pesos atribuídos às tuplas. Então, as CNs são geradas recuperando as tuplas queincidem termos da consulta de palavras-chave. Assim como nos demais trabalhos, tuplasintermediárias, não relacionadas com termos da consulta e que fazem parte do caminho dejunção, também são recuperadas para formar as redes candidatas, classificadas de acordocom o peso das tuplas e com o caminho mínimo.
SQAK [41] define Candidade Interpretation (CI) como o conjunto de possíveisinterpretações geradas a partir de uma consulta com palavras-chave. Uma CI é um con-junto de atributos de um banco de dados com um predicado associado a cada um dessesatributos. Para as interpretações geradas, SQAK utiliza SQN (Simple Query Network), de-finidas como árvores geradas através das CIs. Uma SQN é ponderada, em que o peso érepresentado pela soma de todos os pesos dos nós e arestas. Vértices são ponderados deacordo com a incidência das arestas. Então, a SQN com menor peso é escolhida como amelhor.
Candidate Subspace Generator (CSG) é utilizado no FRISK[35], que consideraas múltiplas incidências de um único termo da consulta nas tuplas do banco. O sistemaapresenta os caminhos de junções gerados (ordenados pela quantidades de junções en-volvendo o caminho) e o usuário deve escolher o que mais lhe agrada. São informadospoucos detalhes acerca do processo de ranqueamento.
Keymantic [4] e [36] não realizam acesso aos dados do banco a priori para aconstrução da consulta. No entanto, Keymantic utiliza os termos do esquema do bancode dados para a construção de um grafo. As arestas ligam dois termos (vértices) quepossam ser relacionados. Utilizando uma busca em largura, são recuperados os caminhosde junção possíveis. O processo favorece os caminhos de menor comprimento. Asconsultas são ranqueadas de acordo com a pontuação obtida nas etapas que antecedemo ranqueamento, juntamente com o caminho mínimo de junções.
A ferramenta de consulta proposta por Haam et al. [18] apresenta Common
Interpretation Tuple Set (CITS), que consiste em uma combinação entre atributos de umarelação e palavras-chave da consulta submetida. As CTISs geradas são ponderadas deacordo com um conjunto de características: o número de palavras-chave que nela incidem,o número de atributos, o número de relações e o peso de afinidade das relações.
Por sua vez, ExpressQ [43] utiliza Centric Distance de um nó a outro para

2.2 Conclusão 33
ranquear as interpretações. O score de cada padrão de consulta gerado é calculado deacordo com a quantidade de nós que envolvem esse padrão. ExpressQ classifica asconsultas considerando a semântica e o relacionamento dos objetos, combinados aonúmero de vértices incidido por palavras-chave no grafo ORM (Object-Role Modeling).
Tabela 2.3: Correlação das Técnicas de Ranqueamento
Sigla Técnica Derivada de Sistemas
ST Steiner Tree - DBSemSXplorer[18]CN Candidate Networks - Nandi e Jagadish[30] e Gu e Kitagawa[17]
PBR Proximity Based Rank ST BANKS[5]JTP Join Tree Path CN DBXplorer[1]MJN Minimum Joining Network CN DISCOVER[20] e MeanKS [22]
GST-k Top-K Group Steiner Trees ST Ding et al.[10]SQN Simple Query Network CN SQAK[41]CSG Candidate Subspace Generator CN FRISK[35]CITS Common Interpretation Tuple Set CN Haam et al.[18]CD Centric Distance CN ExpressQ[43]WM Weight Matrix (Método Húngaro) CN Keymantic[4] e Ramada et al.[36]
Os sistemas discutidos neste trabalho utilizam a variação de duas técnicas paraa tradução da consulta, sendo elas Candidate Networks (CNs) e Steiner Trees (STs),como apresentado na Tabela 2.3. As técnicas diferem principalmente na forma de comoo grafo é construído. As baseadas em STs realizam a materialização do grafo na memóriavolátil do computador (RAM). Por outro lado, as técnicas derivadas de CNs utilizam grafoconstruído com os metadados do banco de dados.
2.2 Conclusão
Neste Capítulo foram apresentadas e discutidas as principais características de 14(quatorze) sistemas que permitem a submissão de consultas em bases de dados relacionaisatravés de palavras-chave. É evidente que essas características impactam no processo deranqueamento das interpretações geradas. Em suma, foi possível concluir que:
• A abordagem baseada nas tuplas pode se tornar cara, dependendo do tamanho dobanco de dados, diante da necessidade de armazenamento do banco de dados comoum grafo na memória principal. Esse processo pode ser dispendioso, de acordocom o tamanho do banco de dados. O IMDB (Internet Movie Database) completopossui aproximadamente 8.3 Gigabytes de informações. A abordagem baseada noesquema reduz consideravelmente o tamanho do grafo, levando vantagem sobre ografo dos dados no quesito consumo de memória RAM;

2.2 Conclusão 34
• Dos sistemas analisados, somente [4] e [36] permitem traduzir a consulta semacessar as instâncias dos bancos de dados. Os demais trabalhos utilizam estruturasexternas (índices, tabelas, arquivos) com informações do banco de dados. Porém,existe a necessidade de uma constante atualização dessas estruturas, uma vez quenovas informações podem ser inseridas na base de dados;
• A utilização de técnicas de expansão e limpeza da consulta pode incrementar otempo de tradução da consulta em determinado sistema. A eliminação de stopwords
pode excluir um termo relevante à consulta. Partindo da premissa que cada palavra-chave desempenha um papel na consulta, em casos ambíguos, palavras-chavepodem ser mapeadas para operadores de agregação, porém podem referenciaralgum dado do banco, perdendo alguma informação relevante ao processo detradução da consulta;
• A intervenção do usuário pode ser útil em casos em que ele possua um conheci-mento mínimo da base de dados que esteja sendo consultada. Em outra situação,apresentar os caminhos de junção pode não fazer sentido para o submissor da con-sulta, caso seja leigo;
• Os sistemas que permitem consultas com palavras-chave em múltiplos banco dedados relacionais necessitam de mecanismos mais eficazes para a seleção dessesbancos de dados. Poucas informações são dadas sobre a escolha do banco de dadosou a ordem para submissão das consultas, com exceção de [36];
• As bases de dados consultadas influenciam na quantidade de interpretações geradas.Quanto maior o banco de dados, em termos de tamanho e quantidade de relações eatributos, maior será o número de interpretações geradas.
A identificação e estudo de cada uma das características elencadas neste trabalhoé parte fundamental para concepção de um sistema que permita acesso a bancos de dadosrelacionais por meio de palavras-chave. Além disso é necessário conhecer o impactodessas características no processo de ranqueamento, pois diversas delas são necessáriaspara o processo de tradução da consulta. Por exemplo: as abordagens baseadas em STs
utilizam um grafo gerado a partir dos dados do banco de dados para a geração dasinterpretações. Por outro lado, as técnicas baseadas em CNs modelam o grafo a partirdo esquema do banco de dados. No entanto, ambas as técnicas utilizam as tuplas para aconstrução das consultas SQL. Os sistemas [4] e [36] divergem dos demais, realizando oranqueamento através da correlação entre palavras-chave e termos do esquema do banco.A quantidade de interpretações geradas a partir das consultas submetidas pode ser maiornesses sistemas, uma vez que o modelo não utiliza os dados do banco de dados na etapade tradução.

CAPÍTULO 3Técnicas de Ranqueamento de Consultas
Este capítulo discute as técnicas de ranqueamento de consultas com palavras-chave em consultas SQL nos sistemas em que este trabalho é baseado.
As abordagens tradicionais, conforme discutido em [3], sofrem com restriçõespara implementação em sistemas reais, como o tempo de carregamento do grafo namemória principal e o fato desses sistemas não poderem atuar em situações em que nãose tem acesso ao conteúdo do banco de dados[6] na fase de interpretação da consulta.No entanto, Alguns sistemas possuem características úteis ao processo de ranqueamento,especialmente BANKS[5], DBXplorer[1] e Discover[20].
Os sistemas que se destacam no processo de tradução da consulta sem a neces-sidade dos dados são Keymantic[3] e o sistema proposto em [36]. Ambos apresentam ummétodo de conversão de consultas com palavras-chave que mais se adéqua ao modelo derecuperação de estudado.
Bergamaschi et al.[3] e Ramada et al. [36] implementaram um método querealiza a tradução das consultas formadas por palavras-chave em consultas SQL utilizandoapenas informações do esquema do banco de dados e métodos de similaridade sintáticae semântica. No modelo utilizado por esses sistemas, a tradução da consulta é realizadasem acesso aos dados do banco de dados.
3.1 Abordagens Baseadas em Steiner Trees
Os sistemas que implementam a técnica Steiner Trees criam um grafo a partir dosdados do banco de dados, como exemplificado na Subseção 2.1.9. O próximo passo para oprocesso de tradução, após a submissão da consulta, é selecionar vértices que contenhamalgum termo da consulta digitada. Um nó é considerado relevante se alguma palavra-chave da consulta, ou parte dela, existe como conteúdo desse vértice. Para cada consulta,será retornada uma lista de vértices que possuem correlação com termos da consulta. Essalista é organizada como árvores (Steiner Trees) formadas por, no mínimo, 1 (um) vértice.
O prestígio do nó (importância) é calculado de acordo com a quantidade deconexões que ele possui. A cada conexão, soma-se um ponto ao prestígio daquele nó.

3.1 Abordagens Baseadas em Steiner Trees 36
Figura 3.1: Grafo de Dados do banco de dados IMDB
Ou seja, quanto maior a quantidade de incidência em determinado nó, este terá maiorprioridade no ranqueamento. De certa maneira, esse processo pode ser influenciado deacordo com as possíveis incidências das palavras-chave. Esse modelo foi proposto devidoacreditar que nós com mais conexões possuem informações mais relevantes, assim comoexemplificado na Figura 3.11. Esse grafo foi criado, a partir do banco de dados daFigura 1.3, para exemplificar o funcionamento das técnicas baseadas em Steiner Trees.Os vértices foram identificados com a primeira letra da tabela pertencente seguido deum número sequencial. Dessa maneira, os vértices da Figura 3.1 m1,m2,m3 pertencemà relação movies. Os outros vértices foram identificados da mesma maneira, a fim defacilitar o reconhecimento desses vértices.
Inicialmente, para calcular o peso do vértice (W (v)) soma-se 1 (um) ponto paracada incidência que o vértice possui. No entanto, a pontuação é normalizada [0-1], atravésda seguinte fórmula:
Wn(v) =W (v)Wmax
,
em que W (v) corresponde ao peso do nó, calculado de acordo com a quantidade deincidências que ele possui e Wmax diz respeito ao peso do vértice com maior pontuação.Também é possível utilizar a fórmula logarítmica em base 2 para cálculo dos pesos:
Wn(v) = log(1+W (v)Wmax
),
1Os vértices foram identificados de acordo com as relações das tabelas: actors (a1, a2, a3), movies(m1,m2)...

3.1 Abordagens Baseadas em Steiner Trees 37
Figura 3.2: Grafo de Dados do banco de dados IMDB com pesosnos vértices
Dessa maneira, o peso do vértice W (v) é somado a 1 e dividido pelo peso do vérticecom maior pontuação Wmax no grafo. Essa abordagem é utilizada para evitar o cálculo devalores excessivamente grandes. Para favorecer nós incidentes e reduzir os efeitos dos nósintermediários, é considerada somente a pontuação dos nós que possuem incidência comtermos da consulta.
O peso da aresta W (e) é calculado em função das relações (R). Cada aresta,inicialmente possui peso = 1; Considerando dois (2) vértices u e v, as tabelas que elespertencem, respectivamente, são R(u) e R(v). O peso normalizado da aresta que interligaesses vértices é calculado utilizando-se a fórmula:
Wn(e) = (1+W (e)
W (e)min),
em que o peso da aresta é dividido pelo menor peso do conjunto de arestas (W (e)min). Opeso global da aresta é calculado com a fórmula:
W (E) =1
(1+∑eW (e)),
.A próxima etapa consiste em combinar os pesos dos vértices e arestas para
encontrar o peso total da árvore, sugerindo novas possibilidades de ranqueamento. Pararecuperar as árvores mais relevantes é utilizado algoritmo que oferece solução heurísticaao calcular e retornar as árvores com melhores resultados, aquelas com maior pontuação,desde que contenham informações relevantes que usuários necessitem recuperar.

3.1 Abordagens Baseadas em Steiner Trees 38
Tabela 3.1: Exemplo de consulta e sentido pretendido
Consulta Sentido Pretendido
movies actor george Informações sobre os filmes que o ator george atuou
A Figura 3.2 apresenta o grafo de dados produzido pelos sistemas baseadosem Steiner Trees. Utilizando a consulta da Tabela 3.1 como exemplo, os nós incidentesretornados, quando conectados, formam Árvores de Steiner.
Figura 3.3: Grafo com termos da consulta incididos
Para o exemplo em questão, são geradas 2 (duas) árvores, em que cada uma delasrepresenta uma resposta à consulta efetuada. A pontuação de cada árvore é calculada deacordo com a pontuação de cada vértice nelas presentes.
Figura 3.4: Steriner Trees geradas para o exemplo da Tabela 3.1
A Figura 3.4 expressa esse comportamento, em que os nós intermediários tam-bém são recuperados. As árvores geradas a e b possuem, respectivamente, pontuação total

3.2 Abordagens Baseadas em Candidate Networks 39
de 1,25 e 0,37. Os vértices destacados em preto são aqueles que possuem correlação comos termos da consulta submetida.
Tabela 3.2: Interpretações Geradas
Árvore Pontuação Interpretação SQL
a 1,25 select* from movies, roles, actors where movies.id=roles.movie_idand roles.actor_id=actors.id and actors.first_name="george"and movies.name="titanic"
b 0,87 select* from movies, roles, actors where movies.id=roles.movie_idand roles.actor_id=actors.id and actors.first_name="george"and movies.name="the beach"
É importante frisar que o exemplo só apresenta um caminho de junção, oque deixa cada árvore com somente uma interpretação possível. Em grafos com maiorquantidade de caminhos, mais interpretações são geradas e ranqueadas de acordo com apontuação de cada árvore. A Tabela 3.2 apresenta as interpretações possíveis para as duasárvores geradas (Figura 3.4).
As arestas também são pontuadas e influenciam no ranqueamento das interpre-tações geradas. Todavia, para o modelo a ser discutido no próximo capítulo, a técnica deponderação de arestas não pode ser aplicada à abordagem que não utiliza acesso aos dadosdo banco de dados para converter consultas com palavras-chave em consultas SQL. Estatécnica está condicionada à necessidade de saber a quantidade de links existentes entre astabelas do banco de dados, as tuplas, e de acordo com as chaves primárias e estrangeiras.Quanto maior quantidade de tuplas conectadas entre duas tabelas, maior será a importân-cia da aresta. No entanto, sem acessar os dados, não é possível saber essa informação.
3.2 Abordagens Baseadas em Candidate Networks
Os sistemas que se enquadram nesta categoria utilizam informações do esquemapara a construção do grafo. Para fins de exemplificação é utilizada a consulta da Tabela3.3.
Tabela 3.3: Exemplo de consulta com palavra-chave
Consulta Sentido Pretendido
movies leonardo dicaprio Filmes nos quais o ator Leonardo Dicaprio participou
A Figura 3.5 apresenta o grafo construído utilizando-se o esquema do banco dedados IMDB. Este grafo é construído utilizando as informações do esquema, em que cada
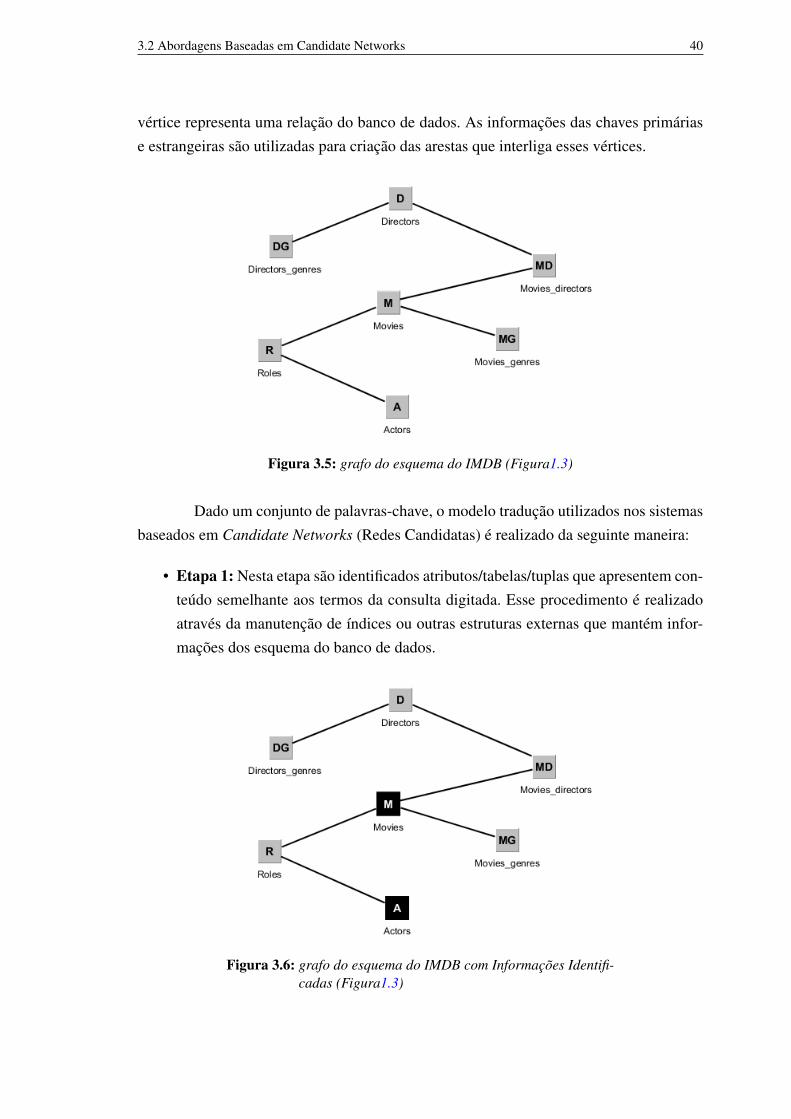
3.2 Abordagens Baseadas em Candidate Networks 40
vértice representa uma relação do banco de dados. As informações das chaves primáriase estrangeiras são utilizadas para criação das arestas que interliga esses vértices.
Figura 3.5: grafo do esquema do IMDB (Figura1.3)
Dado um conjunto de palavras-chave, o modelo tradução utilizados nos sistemasbaseados em Candidate Networks (Redes Candidatas) é realizado da seguinte maneira:
• Etapa 1: Nesta etapa são identificados atributos/tabelas/tuplas que apresentem con-teúdo semelhante aos termos da consulta digitada. Esse procedimento é realizadoatravés da manutenção de índices ou outras estruturas externas que mantém infor-mações dos esquema do banco de dados.
Figura 3.6: grafo do esquema do IMDB com Informações Identifi-cadas (Figura1.3)

3.2 Abordagens Baseadas em Candidate Networks 41
Para o exemplo da Tabela 3.3, tem-se as informações que incidem nos vérticesmovies e actors. Este último foi recuperado porque os termos leonardo dicaprio
remetem a tabela Actors. A Figura 3.6 exibe os nós que serão utilizados nas etapasseguintes.
• Etapa 2: nesta etapa, todos os conjuntos de tabelas no banco de dados que possamconter termos da consulta com palavras-chave são identificados e enumerados. Asjunções de duas tabelas só podem ser realizadas se existirem caminhos possíveisentre elas, ou seja, se possuírem aresta conectando os vértices que as representem.
Figura 3.7: grafo do esquema do IMDB com Informações Identifi-cadas (Figura1.3)
Dessa maneira, como exemplificado pela Figura 3.7, o vértice roles é recuperadotambém é incluído no processo pois interliga os vértices movies e actors, formandoas árvores de junção (Join Trees), também conhecidas como Redes Candidatas.
Figura 3.8: Árvores de Junção geradas (exemplo da Tabela 3.3)
Os vértices não marcados são removidos do grafo deixando apenas os vérticesintermediários, como pode ser conferido na Figura 3.8. Para o exemplo utilizado,

3.3 Abordagens Baseadas no Método Húngaro 42
foram encontradas 3 (três) árvores, uma formada por 3 (três) vértices e duas com 1(um) vértice cada.
• Etapa 3: nesta etapa, para cada árvore enumerada, uma interpretação SQL éconstruída de acordo com as informações dos vértices nela presentes, através darealização da junção com as tabelas intermediárias.
Tabela 3.4: Interpretações Geradas (exemplo da Tabela 3.3)
Árvore Interpretação SQL
a select* from movies where movies. name = ’leonardo’
c select* from actors where actors.first_name=’leonardo’and actors.last_name=’dicaprio’
b select* from movies, roles, actors where movies.id=roles.movie_idand roles.actor_id=actors.id and actors.first_name=’leonardo’and actors.last_name=’dicaprio’
Conforme apresentado pela Tabela 3.4, as interpretações SQL geradas foram ran-queadas de acordo com o comprimento do caminho de junções, tendo prioridadesas interpretações formadas por caminhos de menor comprimento.
As técnicas baseadas em Candidate Networks apresentam uma proposta diferente àapresentada pela abordagem Steiner Tree, principalmente no que diz respeito à forma deconstrução do grafo. Alguns desses modelos permitem a utilização das arestas ponderadase incrementam funções que divergem na forma de como as informações são recuperadas.Na Subseção 2.1.9, essas peculiaridades foram abordadas com detalhes.
3.3 Abordagens Baseadas no Método Húngaro
O método Húngaro foi proposto em [23] e é utilizado amplamente na resoluçãode problemas de otimização combinatória. É um algoritmo que se baseia em matriz(Weight Matrix) para a resolução de problemas. Tendo isso em vista, o algoritmo éempregado nos sistemas de consulta com palavras-chave para encontrar as possíveiscombinações entre termos da consulta e os termos do banco de dados consultado.De maneira simplificada, é gerada uma matriz a cada consulta submetida em que asdimensões dessa matriz é a quantidade de termos da consulta X quantidade de termosdo esquema do banco de dados.
3.3.1 Definição do Problema
A possibilidade de efetuar consultas em bancos de dados relacionais utilizandopalavras-chave tem recebido atenção especial de pesquisadores nas últimas décadas, como

3.3 Abordagens Baseadas no Método Húngaro 43
discutido no Capítulo 2. Seja um banco de dados D um conjunto de tabelas R, uma tabelaé formada por um conjunto de atributos A1..An. O vocabulário de D, descrito como V D,é o conjunto de todos os termos do esquema do banco de dados (nomes de relações,atributos e os respectivos domínios desses atributos). Um termo de banco de dados é ummembro do seu vocabulário. As seguintes definições, descritas em [3], são utilizadas aolongo deste trabalho:
• Termo da consulta: um termo k é uma palavra-chave da consulta. Termos podemser classificados de duas maneiras: termos de esquema (sw), quando possuem cor-relação com qualquer vocábulo de V D, termos de valor (vw), este último podendorepresentar algum valor do banco de dados.
• Consulta com palavras-chave: Uma consulta com palavra-chave q é uma lista determos, em que cada um deles é uma especificação de algum elemento de interesse.
• Mapeamento: Um mapeamento M é o papel que cada termo da consulta compalavra-chave desempenha em cada configuração, ou seja, qual(is) termo(s) dobanco de dados ele possui correlação.
• Configuração: uma configuração C de uma consulta formada por palavras-chaveq sobre um banco de dados D é um conjunto de mapeamentos das palavras-chaveem q para cada termo do banco de dados do vocabulário V D. Uma configuração éconstituída por dois conjuntos de mapeamentos, sendo um vw e um sw.
• Interpretação: uma interpretação é uma consulta SQL gerada após o processo deconversão da consulta com palavras-chave. É necessário elucidar que uma consultacom palavras-chave pode gerar várias interpretações SQL.
• Matriz de Pesos Intrínsecos: matriz utilizada para o cálculo dos pesos SW (termosde esquema), que armazena o valor da correlação entre termos da consulta compalavras-chave e termos do vocabulário do banco de dados, e a matriz VW (termosde valor), responsável por alocar os pesos entre termos que não foram mapeadospara termos de esquema para termos de valor do banco de dados nas configurações.
Figura 3.9: Matriz de pesos sw (cinza claro) e vw (cinza escuro),extraído de [4]
A Figura 3.9 exibe o modelo utilizado para os trabalhos discutidos nesta subseção.Nela é possível verificar que cada palavra-chave da consulta tem sua correlaçãoaveriguada com cada um dos termos de V D.

3.3 Abordagens Baseadas no Método Húngaro 44
3.3.2 Etapas de Conversão
O processo de conversão de consultas com palavras-chave utilizado pelo sistemaKeymantic[4] abrange 5 (cinco) etapas: Cálculo dos Pesos Intrínsecos, Seleção dos Me-lhores Mapeamentos para Termos do Esquema, Contextualização e Seleção dos Me-lhores Mapeamentos para Termos de Valor, Geração das Configurações e Geraçãodas Interpretações, descritas a seguir. A Figura 3.10 apresenta as etapas do processo deconversão do sistema Keymantic.
Figura 3.10: Etapas de Conversão do Keymantic (inspirado em[4])
O exemplo utilizado para apresentar o funcionamento do método pode serconferido na Tabela 3.5.
Tabela 3.5: Exemplo de Consulta e Sentido Pretendido
Consulta Sentido Pretendido
movie titanic actors Informações sobre atores do filme titanic
Cálculo dos Pesos Intrínsecos
Nesta etapa é criada a matriz[m][n] de pesos intrínsecos, na qual m é quantidadede termos da consulta e n é o total de termos do esquema a ser mapeado (nome de tabelas ecolunas); Nesta etapa também verifica-se a correlação sintática de cada palavra-chave paratodos os termos do esquema. Os mapeamentos são criados e pesos (0–100) são atribuídospara cada intersecção da matriz, como exemplificado pela Tabela 3.6.

3.3 Abordagens Baseadas no Método Húngaro 45
Tabela 3.6: Matriz de Pesos(SW)
M M.id M.na MD MD.mo D D.fi MG MG.mo R R.ac R.mo R.ro A A.fi
movie 90 0 0 0 68 0 0 0 68 0 0 68 0 0 0
titanic 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
actors 0 0 0 0 0 0 0 0 0 0 65 0 0 100 0
Esses pesos expressam a correlação entre os termos da consulta e os termos deV D. Keymantic [4] realiza essa atribuição mediante utilização de técnicas de similaridadede strings. De acordo com os autores é utilizado o maior valor encontrado de acordocom as técnicas: Jaccard[31], Hamming[32] e Levenshtein[19], cuja função é verificardeterminar o quão parecidas são duas strings. Os valores retornados por essas métricasvão de 0 a 1, em que 0 expressa que as strings comparadas são totalmente diferentes e 1diz que as duas strings são iguais. Além disse, esse valor é normalizado, multiplicando-opor 100.
Caso um termo seja mapeado com valor 100 significa que houve exatidão nacorrelação com um termo do banco de dados. Um exemplo desse comportamento équando o usuário digita uma consulta como movies name, objetivando saber o título dosfilmes. É atribuído na matriz de pesos SW o valor 100 na intersecção dos termos em queocorra exatidão em função de algum termo de V D.
Para o exemplo discutido (Tabela 3.6), o termo da consulta movie possui pon-tuação 90 para a tabela do banco de dados movies e pontuação 68 para os atributos mo-
vies_directors.movie_id e roles.movie_id. De maneira similar, o termo da consulta actors
é mapeado com pontuação 65 para o atributo roles.actor_id e com pontuação 100 para atabela actors. Isso significa que o termo movie possui 90% de correlação com o nome databela movies. O mesmo ocorre com os outros termos mapeados.
Seleção dos Melhores Mapeamentos para Termos de Esquema
Após o cálculo dos pesos, é feita a seleção dos melhores mapeamentos para ter-mos do esquema. Os mapeamentos que apresentarem as maiores pontuações representamas melhores interpretações da consulta inicial em relação aos metadados do banco de da-dos. Nesta etapa é possível segregar os mapeamentos mais proeminentes. Possivelmenteesses mapeamentos são os que apresentam os melhores resultados. Baseando-se na parteda matriz que pontua os pesos sw, é gerado um conjunto de mapeamentos de palavras-chave para termos de esquema sw. O algoritmo utilizado seleciona os mapeamentos quepossuem maior pontuação, calcula pela soma de todos os pesos atribuídos nos termos daconsulta para determinado mapeamento.
Para a matriz exibida na Tabela 3.7, em destaque, as maiores pontuações são90 pontos para o termo movie e 100 pontos para o termo actors. Em seguida é efetuada
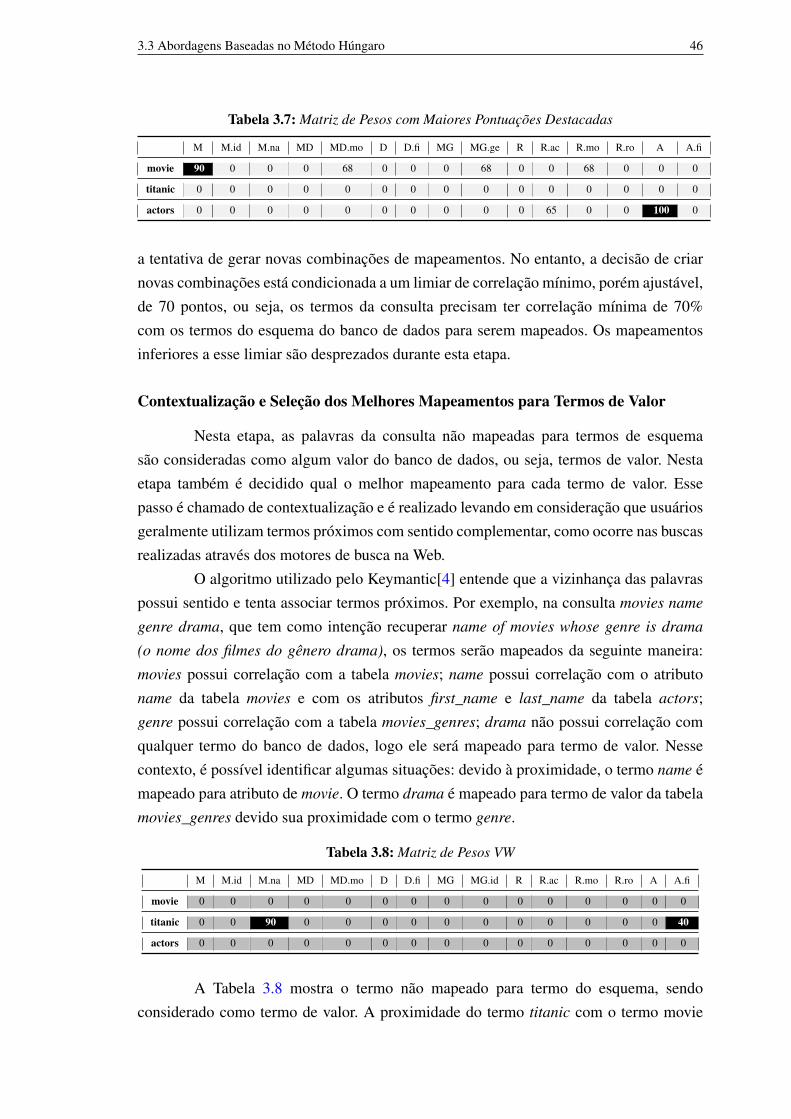
3.3 Abordagens Baseadas no Método Húngaro 46
Tabela 3.7: Matriz de Pesos com Maiores Pontuações Destacadas
M M.id M.na MD MD.mo D D.fi MG MG.ge R R.ac R.mo R.ro A A.fi
movie 90 0 0 0 68 0 0 0 68 0 0 68 0 0 0
titanic 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
actors 0 0 0 0 0 0 0 0 0 0 65 0 0 100 0
a tentativa de gerar novas combinações de mapeamentos. No entanto, a decisão de criarnovas combinações está condicionada a um limiar de correlação mínimo, porém ajustável,de 70 pontos, ou seja, os termos da consulta precisam ter correlação mínima de 70%com os termos do esquema do banco de dados para serem mapeados. Os mapeamentosinferiores a esse limiar são desprezados durante esta etapa.
Contextualização e Seleção dos Melhores Mapeamentos para Termos de Valor
Nesta etapa, as palavras da consulta não mapeadas para termos de esquemasão consideradas como algum valor do banco de dados, ou seja, termos de valor. Nestaetapa também é decidido qual o melhor mapeamento para cada termo de valor. Essepasso é chamado de contextualização e é realizado levando em consideração que usuáriosgeralmente utilizam termos próximos com sentido complementar, como ocorre nas buscasrealizadas através dos motores de busca na Web.
O algoritmo utilizado pelo Keymantic[4] entende que a vizinhança das palavraspossui sentido e tenta associar termos próximos. Por exemplo, na consulta movies name
genre drama, que tem como intenção recuperar name of movies whose genre is drama
(o nome dos filmes do gênero drama), os termos serão mapeados da seguinte maneira:movies possui correlação com a tabela movies; name possui correlação com o atributoname da tabela movies e com os atributos first_name e last_name da tabela actors;genre possui correlação com a tabela movies_genres; drama não possui correlação comqualquer termo do banco de dados, logo ele será mapeado para termo de valor. Nessecontexto, é possível identificar algumas situações: devido à proximidade, o termo name émapeado para atributo de movie. O termo drama é mapeado para termo de valor da tabelamovies_genres devido sua proximidade com o termo genre.
Tabela 3.8: Matriz de Pesos VW
M M.id M.na MD MD.mo D D.fi MG MG.id R R.ac R.mo R.ro A A.fi
movie 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
titanic 0 0 90 0 0 0 0 0 0 0 0 0 0 0 40
actors 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
A Tabela 3.8 mostra o termo não mapeado para termo do esquema, sendoconsiderado como termo de valor. A proximidade do termo titanic com o termo movie
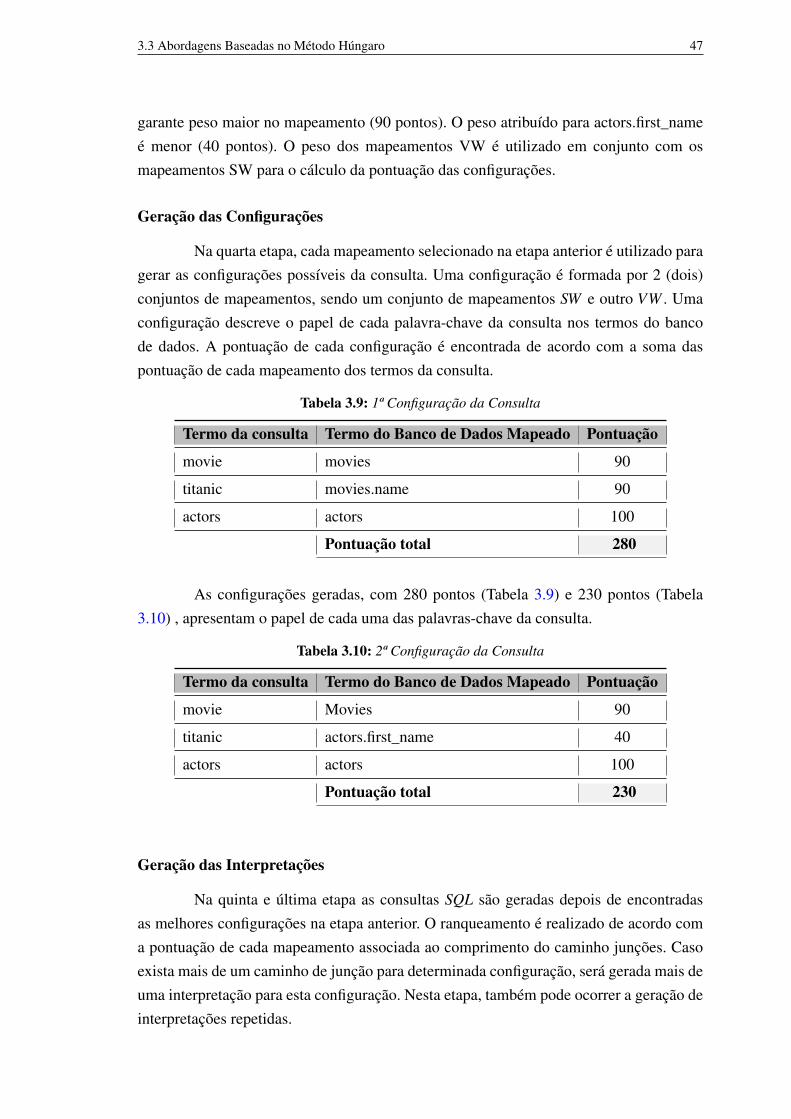
3.3 Abordagens Baseadas no Método Húngaro 47
garante peso maior no mapeamento (90 pontos). O peso atribuído para actors.first_nameé menor (40 pontos). O peso dos mapeamentos VW é utilizado em conjunto com osmapeamentos SW para o cálculo da pontuação das configurações.
Geração das Configurações
Na quarta etapa, cada mapeamento selecionado na etapa anterior é utilizado paragerar as configurações possíveis da consulta. Uma configuração é formada por 2 (dois)conjuntos de mapeamentos, sendo um conjunto de mapeamentos SW e outro VW . Umaconfiguração descreve o papel de cada palavra-chave da consulta nos termos do bancode dados. A pontuação de cada configuração é encontrada de acordo com a soma daspontuação de cada mapeamento dos termos da consulta.
Tabela 3.9: 1ª Configuração da Consulta
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie movies 90
titanic movies.name 90
actors actors 100
Pontuação total 280
As configurações geradas, com 280 pontos (Tabela 3.9) e 230 pontos (Tabela3.10) , apresentam o papel de cada uma das palavras-chave da consulta.
Tabela 3.10: 2ª Configuração da Consulta
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie Movies 90
titanic actors.first_name 40
actors actors 100
Pontuação total 230
Geração das Interpretações
Na quinta e última etapa as consultas SQL são geradas depois de encontradasas melhores configurações na etapa anterior. O ranqueamento é realizado de acordo coma pontuação de cada mapeamento associada ao comprimento do caminho junções. Casoexista mais de um caminho de junção para determinada configuração, será gerada mais deuma interpretação para esta configuração. Nesta etapa, também pode ocorrer a geração deinterpretações repetidas.

3.3 Abordagens Baseadas no Método Húngaro 48
A Tabela 3.11 exibe as interpretações construídas a partir da consulta realizada.Para a geração das interpretações é utilizada uma abordagem que percorre o grafogerado a partir do esquema do banco de dados. Primeiramente, o algoritmo verifica aexistência da correlação dos termos da consulta com as informações grafo. Os vérticesescolhidos são marcado e então realiza-se uma busca em amplitude para encontrarcaminhos que conectam componentes desconectados do grafo. As interpretações sãoapresentadas ordenadamente de acordo com a pontuação da configuração que deu origema essa interpretação e, em seguida, pelo comprimento do caminho de junções.
Tabela 3.11: Interpretações SQL
Consulta com Palavrsa-chave Interpretações Geradas
movie titanic actorsselect* from movies, roles, actors where movies.id=roles.movie_id and roles.actor_id=actors.id andmovies.name=’titanic’
select* from movies, roles, actors where movies.id=roles.movie_id and roles.actor_id=actors.id andactors.first_name=’titanic’
Para o exemplo discorrido na Tabela 3.5, existe apenas um caminho interligandoas configurações apresentadas para a consulta submetida. Nessa situação, para cadaconfiguração existirá somente 1 (uma) interpretação SQL.
3.3.3 O Sistema de Ramada et al.[36]
O Sistema proposto por Ramada et al.[36] foi construído utilizando o métodoproposto pelo sistema Keymantic[3], porém foram adicionadas novas funcionalidadespara o processo de tradução das consultas com palavras-chave em consultas SQL.
Neste sistema, é possível realizar consultas utilizando operadores de agregação.Dessa forma, o sistema extrai da consulta com palavras-chave os termos que possamrepresentar operadores de agregação, logo na primeira etapa do processo. Na última etapado processo de tradução, o termo mapeado como função de agregação é aplicado aotermo de valor mais próximo. Por exemplo, na consulta movie higher rank, que objetivaencontrar informações sobre o filme com maior pontuação, os termos são mapeadosda seguinte maneira: movie é mapeado para a tabela movies; higher é mapeado parao operador SQL de agregação max; rank é mapeado para o atributo rank da tabelamovies. Assim, o operador de agregação será associado ao termo de valor rank, devidoà proximidade dos termos. Uma possível consulta SQL gerada para essa submissão éSELECT MAX(RANK) FROM MOVIES.
A ferramenta também permite a ordenação dos resultados retornados, utilizandoo operador order by. Além disso, melhorias foram feitas tendo como base as técnicas de

3.3 Abordagens Baseadas no Método Húngaro 49
similaridade de strings, utilizando a média dos métodos que calcula distância semânticaentre os termos da consulta e termos do banco de dados. São as métricas de similaridade:Jaccard, Levenshtein e Cosseno.
Neste sistema, a expansão da consulta é realizada utilizando os termos da con-sulta inicial e não as informações do esquema. Este processo é realizado automaticamente,diferentemente do Keymantic[3] que expande os termos do banco e armazena os mesmosem arquivo. Ambas as técnicas classificam as interpretações de acordo com a pontua-ção da configuração em associação com comprimento do caminho de junções. Para estecálculo, Keymantic[3] utiliza um grafo XML, gerado a partir do esquema do banco dedados. O sistema descrito em [36] verifica o tamanho do caminho de junção medianteinformações extraídas do esquema. Além disso, após a submissão da consulta, o sistemaKeymantic[3] necessita que o usuário selecione as configurações criadas. Em seguida,apresenta os caminhos de junção para que o usuário escolha a mais relevante antes daexibição dos resultados.
O sistema desenvolvido por Ramada et al.[36] utiliza o modelo proposto porSilva et al.[38] para a realização de consultas em mais de um banco de dados. Esse modeloé baseado no protocolo OAI-PMH, que possibilita a publicação e compartilhamentode coleções digitais com o objetivo de facilitar a disseminação eficiente de conteúdo,permitindo a interoperabilidade entre os diversos repositórios. Este protocolo utilizao padrão Dublin Core que traz uma série de descritores para o compartilhamento derepositórios. Para o sistema, foram utilizados 23 elementos do modelo. São alguns doselementos: dc_title, dc_subject, dc_description, dc_identifier, respectivamente o título dobanco de dados, o assunto, uma ligeira descrição e o nome do banco de dados criado peloadministrador. A seleção e ranqueamento dos bancos de dados relevantes são realizadosde acordo com a incidência dos termos da consulta nas informações desses descritores.Informações adicionais podem ser consultadas em [38].
Os dois sistemas permitem a realização de consulta por termos compostos, noentanto, Keymantic utiliza aspas entre os termos para agrupá-los e o sistema [36] utilizaapóstrofos. O sistema apresentado em [36] realiza o processo de conversão da consultade maneira automática, diferente do sistema Keymantic, que necessita que o usuárioseleciona uma configuração e uma interpretação para apresentar resultados.
3.3.4 Considerações Finais
Este capítulo apresentou os modelos de tradução e, consequentemente, de ran-queamento utilizadas nos principais sistemas de consulta com palavras-chave em bancosde dados relacionais. Neste Capítulo também foram abordadas as etapas do processo deconversão de consultas de palavras-chave em consultas SQL. As alterações – e incre-

3.3 Abordagens Baseadas no Método Húngaro 50
mentos de funcionalidades – também foram expostos, além de discutir a possibilidade dasubmissão de uma mesma consulta em mais de um banco de dados, apresentando comoo processo é realizado. Os sistemas aqui elencados são utilizados para a realização doprocesso de ranqueamento das consultas de forma combinada. O capítulo seguinte trataacerca do modelo de ranqueamento utilizado no sistema descrito neste trabalho.

CAPÍTULO 4Modelo Proposto para Ranqueamento
O ranqueamento de interpretações de consultas com palavras-chave tem se mos-trado uma maneira desafiadora no sentido de permitir que as diversas interpretações ge-radas sejam ordenadas em função da relevância para o usuário. De acordo com Berga-maschi et al.[4], as técnicas de ranqueamento de consultas são colaborativas, podendo sercombinadas em diferentes cenários para melhora dos resultados. Partindo desta premissa,este Capítulo discorre acerca de uma proposta de combinação de técnicas utilizadas pararanqueamento de interpretações de consultas com palavras-chave sem utilizar as informa-ções armazenadas nos bancos de dados, ou seja, sem acesso direto aos dados na fase detradução da consulta.
O objetivo principal da proposta é o estudo de uma metodologia que produzainterpretações mais próximas à intenção do usuário que submete a consulta, ao mesmotempo que elimine interpretações desnecessárias.
4.1 A Proposta
Conforme discutido nas seções anteriores, os vértices dos grafos, construídosa partir do dos dados, com maior quantidade de conexões costumam apresentar osmelhores resultados das consultas. Esse modelo foi estendido para ser utilizado no métodoproposto. Isso também ocorre com as relações. Aquelas que possuem maior quantidadede conexões representam melhor as possibilidades de consultas de informações. Assim,os atributos relacionados a essas tabelas devem ter certa prioridade no ranqueamento dasinterpretações pretendidas.
Em um banco de dados de filmes, por exemplo o IMDb (Figura 1.3), a tabelamovies é a que possui maior quantidade de relacionamentos. Isso também ocorre com obanco de dados DBLP, que armazena informações acerca de publicações científicas. Nestebanco, a tabela proceeding (trabalhos) é a que apresenta a maior quantidade de conexõescom outras tabelas. Outro ponto em comum observado é que as tabelas com mais atributoscostumam ter mais informações úteis ao usuário, uma vez que uma maior quantidade deatributos possibilita a geração de um maior número de mapeamentos. Esses padrões foram

4.1 A Proposta 52
observados em diversos bancos de dados utilizados nas avaliações dos trabalhos correlatosa este, citados na Subseção 2.1.7.
Tabela 4.1: Exemplos de Consultas e Sentidos Pretendidos
ID Consulta Sentido Pretendido
1 movie titanic actors Informações sobre atores do filme titanic
2 film matrix informações sobre filmes de nome matrix
3 "the beach" informações sobre o filme "the beach"
4 movie name actor nome dos atores dos filmes
Os trabalhos descritos em [1, 20] utilizam um grafo gerado através do esquemado banco de dados para ranqueamento das interpretações construídas. Além disso, essestrabalhos necessitam de estruturas externas ao banco de dados para realizar a conversãoda consulta. O sistema Banks[5] constrói o grafo a partir das tuplas. Neste cenário, o graforeside na memória principal. O sistema Keymantic [4] e o sistema de Ramada et al. [36]realizam a tradução da consulta, exclusivamente, mediante utilização dos metadados dobanco de dados.
O método proposto por este trabalho abrange as características discutidas nessessistemas, utilizando as etapas realizadas pelo Keymantic[4]. Todo o processo de traduçãoe, consequentemente, ranqueamento é explicado utilizando os exemplos apresentados naTabela 4.1. As etapas de conversão são as mesmas descritas na Subseção 3.3.2, com adiçãode duas novas etapas, destacadas em cinza escuro, conforme mostra a Figura 4.1.
Como pode ser visualizado na Figura 4.1, foram adicionadas 2 (duas) novasetapas ao processo: Construção do Grafo e Ranqueamento. Nos trabalhos anteriores[4, 36], o processo de ranqueamento era realizado na etapa de Geração das Configurações(fase 4).
4.1.1 Construção do Grafo
A primeira etapa para o método proposto consiste na construção do grafo a partirde informações do esquema do banco de dados. Logo, cada relação r ∈ R. Cada relação r
do esquema está conectada através das chaves primária e estrangeira a, no mínimo, outrarelação r. Cada atributo a das relações compõe o conjunto de atributos A.
Dessa forma, o banco de de dados é modelado como um grafo G = (v,e) não-dirigido, em que cada relação r equivale a um vértice v ∈V e cada aresta e ∈ E representauma ligação entre os vértices, criada através das chaves primária e estrangeira das relaçõesinterligadas. Cada atributo a das relações também são representados como vértices (v) deG, ligados por uma aresta e ao vértice originado a partir da tabela que determinado atributo
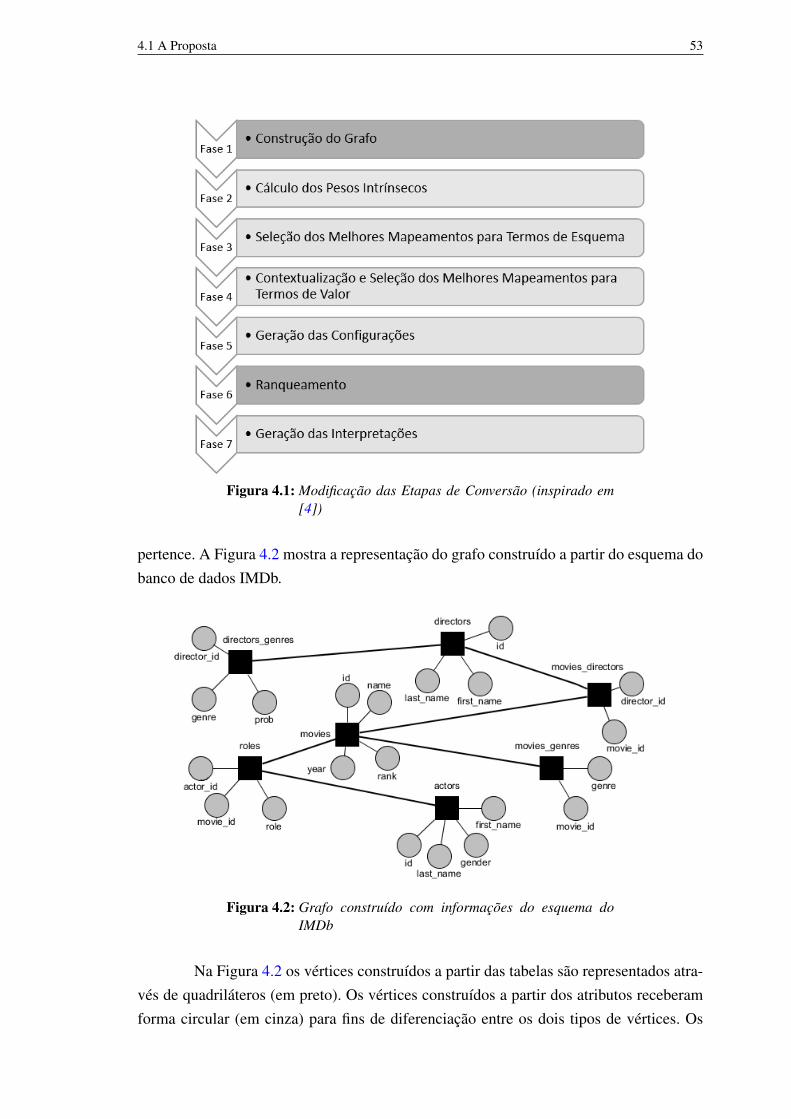
4.1 A Proposta 53
Figura 4.1: Modificação das Etapas de Conversão (inspirado em[4])
pertence. A Figura 4.2 mostra a representação do grafo construído a partir do esquema dobanco de dados IMDb.
Figura 4.2: Grafo construído com informações do esquema doIMDb
Na Figura 4.2 os vértices construídos a partir das tabelas são representados atra-vés de quadriláteros (em preto). Os vértices construídos a partir dos atributos receberamforma circular (em cinza) para fins de diferenciação entre os dois tipos de vértices. Os

4.1 A Proposta 54
vértices são divididos em duas categorias: vértices que representam as relações (vr) e osque representam os atributos (va).
Após a construção do grafo, os vértices gerados a partir das relações têm os pesosatribuídos (w) de acordo com o grau (quantidade de nós conectados a ele), similarmentecomo é realizado nos sistemas [1, 20]. No entanto, a normalização desses pesos (w) érealizada de forma um pouco diferente:
w(vr) = i(vr)∗10
Dessa forma, i(vr) representa a incidência de vértices conectados a um vértice querepresenta uma relação, ou seja, a quantidade de vértices conectados a um vértice vr.
Naturalmente, de acordo com o modelo de ponderação de vértices, o peso dosnós que representam atributos dessas tabelas teriam w(va) = 10, tendo em vista que cadaatributo é ligado apenas a um vértice, ou seja, conectado somente à tabela que ele pertence.Para lidar com essa peculiaridade, foi adotada a seguinte fórmula para pontuá-los:
w(va) =(i(vr)+1)
2∗10
Esse método de pontuação de vértices que representam atributos foi escolhidopara utilização mediante testes realizados. Os atributos que pertencem a relações commais conexões também devem ter certa prioridade no processo de ranqueamento. O grafocom pesos atribuídos ao vértices é mostrado na Figura 4.3.
Figura 4.3: Grafo do IMDb com Vértices Ponderados
Conforme apresentado pela Figura 4.3, os vértices mais expressivos possuemmaior pontuação. O vértice movies (que apresenta informações sobre filmes) possui 70pontos, seguido dos vértices actors (atores), directors (diretores) e roles (papéis) com 50pontos cada. Essa pontuação foi adquirida através da quantidade de vértices adjacentes

4.1 A Proposta 55
multiplicada por 10. Esses vértices representam as informações mais importantes dobanco de dados utilizado como exemplo.
As arestas também recebem pontuação a ser considerada no ranqueamento,sendo atribuída de acordo com a importância de cada uma. O sistema proposto em[22] utiliza o conceito de importância de acordo com a quantidade de chaves primáriasinstanciadas em determinada relação ligadas às chaves estrangeiras da relação conectada.
No modelo de conversão utilizado, os dados não estão disponíveis a priori, oque impede saber essa informação. Tendo isso em vista, neste trabalho, a importância dasarestas é caracterizada pelas tabelas que elas conectam, sendo o peso calculado através damédia dos pesos dos vértices que determinada aresta interliga. Para obtenção do peso decada aresta (w(a)) do grafo é utiliza a seguinte fórmula:
w(a) = n((vr)∗10)− (w(v1)+w(v2))2
sendo n(vr) a quantidade de nós gerados a partir das tabelas, w(v1) e w(v2) os pesos dedois vértices adjacentes que determinada aresta interconecta. Dessa maneira, o peso daaresta é calculado utilizando-se a quantidade total de vértices que representam tabelasmultiplicada por 10 e subtraída a média dos pesos dos dois vértices conectados por essaaresta. A Figura 4.4 ilustra o grafo com os pesos atribuídos às arestas.
Figura 4.4: Grafo do IMDb com Vértices e Arestas Ponderadas
Como apresentado na Figura 4.4, as arestas mais importantes para o bancode dados utilizado como exemplo são as que conectam os vértices movies (filmes) eroles (papéis), com peso igual a 10 e, movies (filmes) e movies_directors (diretores
de filmes) e as arestas entre movies e os vértices gerados de seus atributos, pontuadascom o valor 15. Esses caminhos, de acordo com o modelo de ponderação de arestas,

4.1 A Proposta 56
representam as conexões mais expressivas do grafo. Arestas com menor peso podemimpactar consideravelmente no ranqueamento, uma vez que quanto mais importante fora aresta, menor será o peso atribuído a ela. Dessa forma, o peso da aresta é subtraída dopeso da configuração.
Figura 4.5: Grafo do IMDb com Vértices e Arestas Ponderadas
Além das duas formas de ponderação, outra possibilidade para construção dografo é realizar a atribuição de pesos de forma combinada, conforme apresentado naFigura 4.5. A construção do grafo utilizando as informações do esquema do banco dedados compreende a primeira etapa do processo de tradução – e ranqueamento – dasconsultas com palavras-chave em consulta SQL. Segue-se com o processamento dasetapas seguintes.
4.1.2 Cálculo dos Pesos Intrínsecos
A segunda etapa do processo de conversão realiza o cálculo dos pesos atravésda correlação das palavras-chave da consulta e os termos do banco de dados. O sistemaKeymantic[4] utiliza o maior valor retornado quando comparadas as palavras-chave comos termos do banco de dados. Esses valores são encontrados utilizando as técnicas desimilaridade de strings: Jaccard, Hamming, Levenshtein.
O sistema proposto por Ramada et al. [36] utiliza a média aritmética de três mé-tricas de similaridade de strings (Jaccard, Levenshtein e Cosseno) para calcular a corre-lação dos termos da consulta, conforme pode ser observado no Algoritmo 4.1. Essa abor-dagem é utilizada neste trabalho devido alguns termos apresentarem correlação aceitável(acima do percentual de correlação de 70%), sem realmente estarem correlacionados, umavez que utilizar a média aritmética de 3 (três) métricas reduz essa possibilidade.

4.1 A Proposta 57
Algoritmo 4.1: Algoritmo de atribuição dos pesos (SW), retirado de [36]Input : Q: consulta com palavras-chave, T: termos do esquemaOutput: Matriz de pesos SW
SW ← [0,0,0, ...,0]∑←{Cosseno(w,e),Jaccard(w,e),Levenshtein(w,e)}foreach w ∈ Q do
foreach e ∈ T dosim← 0;media← 0;foreach m ∈ ∑ do
media← media+m(w,e);endmedia← media/3;if media≤ threshold then
S← Synonyms(w);max← 0;foreach s ∈ S do
media← 0;foreach m ∈ ∑ do
media← media+m(s,e);endmedia← media/3;if media > max then
max← media;end
endif media≤ threshold then
sim← 0;else
sim← max;SW [w,e]← sim×100;
endelse
sim← media;SW [w,e]← sim×100;
endend
end

4.1 A Proposta 58
No processo também é realizada a expansão dos termos da consulta, utilizandodicionário Wordnet[28]. Assim, palavras são expandidas para possíveis variações dalíngua. Por exemplo, na consulta 2 (Tabela 4.1) o termo film é expandido para movie,que possui proximidade sintática com o nome da relação movies do banco de dados. Essecomportamento pode ser observado através da Tabela 4.2.
Tabela 4.2: Matriz de Pesos sw
M M.id M.na MD MD.mo D D.fi MG MG.ge R R.ac R.mo R.ro A A.fi
film 90 0 0 0 68 0 0 0 68 0 0 68 0 0 0
matrix 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Após o usuário submeter a consulta, cada termo é classificado com um tipoinicial. No método são utilizados três tipos primitivos: inteiro, real e cadeia de caracteres.Essa classificação é importante para as etapas de mapeamento e contextualização. Nessesentido, os termos de valor marcados como cadeia de caracteres (string) não serãomapeados para atributos inteiros (int) ou reais (float, double). Os termos classificadoscomo inteiros poderão ser mapeados para atributos cadeias de caracteres e inteiros. Ostermos marcados como reais poderão ser mapeados para strings, inteiros e reais. Essainformação é utilizada para dar ênfase a termos mapeados para todos os atributos dedeterminada tabela.
4.1.3 Seleção dos Melhores Mapeamentos para Termos do Esquema
A seleção dos melhores mapeamentos ocorre em função dos pesos atribuídos acada mapeamento. Com segundo exemplo da Tabela 4.1, é possível verificar qual o melhormapeamento para a consulta em questão. Em destaque, na Tabela 4.3, o termo film recebeu90 pontos após calculada a correlação com o termo movies do banco de dados.
Tabela 4.3: Mapeamento com Melhor Pontuação
M M.id M.na MD MD.mo D D.fi MG MG.ge R R.ac R.mo R.ro A A.fi
film 90 0 0 0 68 0 0 0 68 0 0 68 0 0 0
matrix 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4.1.4 Contextualização e Seleção dos Melhores Mapeamentos paraTermos de Valor
Na consulta actor movie name, o termo name será mapeado para atributo demovies devido à proximidade da palavra movie. O mapeamento de name como atributode actor será desprezado, devido distância das duas palavras.
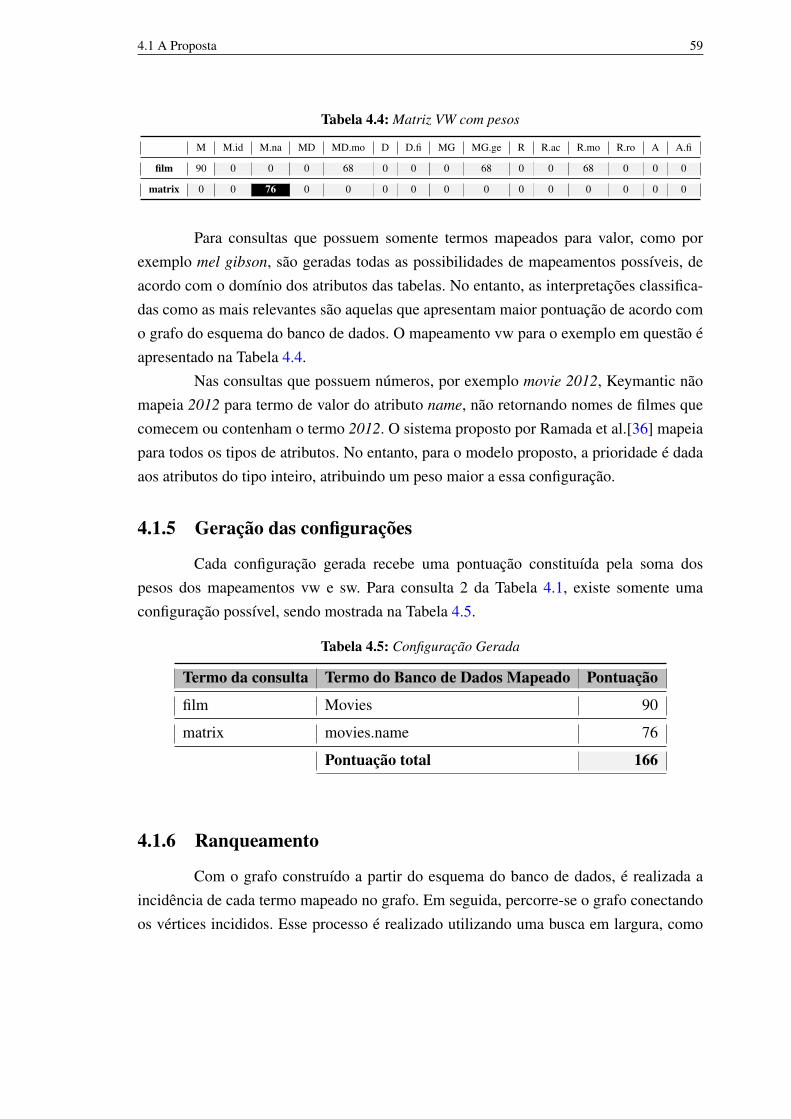
4.1 A Proposta 59
Tabela 4.4: Matriz VW com pesos
M M.id M.na MD MD.mo D D.fi MG MG.ge R R.ac R.mo R.ro A A.fi
film 90 0 0 0 68 0 0 0 68 0 0 68 0 0 0
matrix 0 0 76 0 0 0 0 0 0 0 0 0 0 0 0
Para consultas que possuem somente termos mapeados para valor, como porexemplo mel gibson, são geradas todas as possibilidades de mapeamentos possíveis, deacordo com o domínio dos atributos das tabelas. No entanto, as interpretações classifica-das como as mais relevantes são aquelas que apresentam maior pontuação de acordo como grafo do esquema do banco de dados. O mapeamento vw para o exemplo em questão éapresentado na Tabela 4.4.
Nas consultas que possuem números, por exemplo movie 2012, Keymantic nãomapeia 2012 para termo de valor do atributo name, não retornando nomes de filmes quecomecem ou contenham o termo 2012. O sistema proposto por Ramada et al.[36] mapeiapara todos os tipos de atributos. No entanto, para o modelo proposto, a prioridade é dadaaos atributos do tipo inteiro, atribuindo um peso maior a essa configuração.
4.1.5 Geração das configurações
Cada configuração gerada recebe uma pontuação constituída pela soma dospesos dos mapeamentos vw e sw. Para consulta 2 da Tabela 4.1, existe somente umaconfiguração possível, sendo mostrada na Tabela 4.5.
Tabela 4.5: Configuração Gerada
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
film Movies 90
matrix movies.name 76
Pontuação total 166
4.1.6 Ranqueamento
Com o grafo construído a partir do esquema do banco de dados, é realizada aincidência de cada termo mapeado no grafo. Em seguida, percorre-se o grafo conectandoos vértices incididos. Esse processo é realizado utilizando uma busca em largura, como

4.1 A Proposta 60
pode ser observado no Algoritmo 4.2.Algoritmo 4.2: Algoritmo de ranqueamento
Input : C: conjunto de configurações geradasG: grafo do esquema do banco de dadosvi: vértice inicial
Output: L: Lista ordenada de configurações
F = criarFila(vi);
foreach c ∈C do
foreach M < sw,vw >∈ c doforeach m ∈M < vw,sw > do
while F! = vazia dou← Retira(F);if m correlacionado(u) then
marca(u);endforeach v ad j(u) do
if v ! = visitado thenvisita(v);AdicionaF(v);
endend
endend
endtotal← 0;foreach v marcado do
calcular o total dos pesos de acordo com a técnica (Vértice, Aresta ouVérticeXAresta)
endpontos(c)← total;aplicar peso do domnio(c);
endordenar(C);/* de acordo com a pontuação total da configuração */
Ao final, tem-se um grafo marcado com os vértices que foram incididos compalavras-chave da consulta. Conforme exemplificado na Subseção 4.1.1, pesos são atri-buídos a vértices e arestas, formando assim 3 (três) possibilidades de combinações de

4.1 A Proposta 61
técnicas: Vértices, Arestas e VérticesXArestas.
Pesos dos Vértices (Vértice)
A Figura 4.6 apresenta os vértices incididos de acordo com o mapeamentode cada palavra-chave. O peso dos vértices destacados são adicionados à configuraçãocorrespondente.
Figura 4.6: Grafo com Vértices Incididos
Dessa maneira, a configuração terá pontuação total igual a 276, conforme mos-trado na Tabela
Tabela 4.6: Configuração após Adição dos Pesos dos Vértices
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
film movies 160
matrix movies.name 116
Pontuação total 276
Pesos das Arestas (Aresta)
Devido ao fato de que a importância de uma aresta é definida de acordo com opeso, levando em consideração que quanto menor o peso, maior é a importância da aresta,a pontuação total da configuração terá subtraída o peso da aresta dos respectivos vérticesque ela interliga.

4.1 A Proposta 62
Figura 4.7: Grafo com Arestas Incididas
A Figura 4.7 apresenta a aresta que interconecta os vértices da configuração emquestão. Essa aresta, destacada na figura, possui pontuação igual a 15. Logo, tem-se 15pontos subtraído de cada configuração. Dessa forma, a pontuação total da configuração éde 151, conforme apresentado pela Tabela 4.7.
Tabela 4.7: Mapeamento após Cálculo dos Pesos
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
film movies 90
matrix movies.name 76
Peso da Aresta -15
Pontuação total 151
Pesos dos Vértices e Arestas (VérticeXAresta)
Outra forma de ponderação é utilizar os pesos atribuídos a vértices a arestas dografo. Nesse modelo, o peso dos vértices são somados a cada configuração e o peso daaresta é subtraído de acordo com os vértices interligados por ela, conforme visto na Figura4.8.

4.1 A Proposta 63
Figura 4.8: Grafo com Arestas Incididas
Na Tabela 4.8 é possível visualizar as pontuações dos mapeamentos após calcu-lada a pontuação da configuração.
Tabela 4.8: Configuração e Pontuação (Vértices e Arestas)
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
film movies 160
matrix movies.name 116
Pontuação total 261
Para o exemplo da consulta 2 (Tabela 4.1), é gerada apenas uma configuração,pois existe somente um atributo do tipo string na tabela movies. Em outras situações, casoexista mais de um atributo compatível com o termo inserido, deve-se gerar configuraçõespara todos os atributos de mesmo tipo.
Peso do Domínio
Como cada um dos termos das consultas é classificado com um tipo inicial(inteiro, real ou cadeia de caracteres), a prioridade é que esses termos sejam mapeadospara atributos de tipos similares de acordo com os atributos do banco de dados. Utilizandocomo exemplo a consulta movie 2000, são geradas 4 (quatro) configurações, de acordocom os atributos da tabela: id, rank, name, year. Porém, essas configurações possuem amesma pontuação (130 pontos), sem considerar os pesos do grafo.
O Peso do Domínio foi criado para dar mais importância a configurações quetenham termos mapeados para atributos de tipos compatíveis, conforme discutido na

4.1 A Proposta 64
Subseção 4.1.2. Essa abordagem foi considerada após testes efetuados nos sistemasmostrados em [4, 36], que realizam o mapeamento de termos da consulta identificadoscomo inteiros sem considerar a existência de atributos de mesmo tipo. Para lidar comessa situação, aplica-se 10 pontos aos mapeamentos de atributos do mesmo tipo. Para oexemplo, será atribuído 10 pontos aos atributos id e year. É possível ver pontuação e,consequentemente, a ordem de ranqueamento das configurações na Tabela 4.9.
Tabela 4.9: Aplicação do Peso de Domínio
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie Movies 90
2000 movies.id 50
Pontuação total 140
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie Movies 90
2000 movies.year 50
Pontuação total 140
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie Movies 90
2000 movies.name 40
Pontuação total 130
Termo da consulta Termo do Banco de Dados Mapeado Pontuação
movie Movies 90
2000 movies.rank 40
Pontuação total 130
Sem a atribuição do peso de domínio, as configurações seriam executadas naordem em que os atributos foram especificados ao criar o banco de dados. No modelo deranqueamento utilizado, para os cenários em que são criadas mais de uma configuração,a ordem de criação das possíveis interpretações é realizada de acordo com a pontuação.Ou seja, as configurações que possuem maior pontuação serão processadas primeiro.

4.1 A Proposta 65
4.1.7 Geração das interpretações
Uma Interpretação é uma consulta SQL que responde determinada consulta for-mada por palavras-chave. Para a consulta 2 (Tabela 4.1) existe apenas uma configuraçãogerada. O número de Interpretações geradas está condicionado à quantidade de caminhosde junção existentes que interligam os vértices incididos. Foi gerada apenas uma interpre-tação para a consulta em questão devido a existência de somente um caminho de junçãoque interliga os vértices incididos no grafo. A Tabela 4.10 apresenta a única interpretaçãogerada.
Tabela 4.10: Consulta e Interpretação Gerada
Consulta com Palavras-chave Interpretação Gerada
film matrix select* from movies where movies.name like’%matrix%’
O método proposto visa diminuir a quantidade de configurações geradas duranteo processo de conversão da consulta, pois ao gerar uma quantidade menor de configura-ções, serão geradas também um número menor de interpretações. Após o término destaetapa, as interpretações são executadas no banco de dados utilizado.
4.1.8 Considerações Finais
Devido a possibilidade de associação das técnicas utilizadas para ranqueamentode interpretações de consultas com palavras-chave realizadas em bancos de dados re-lacionais, foram discutidas neste capítulo combinações de técnicas que utilizam grafosconstruídos a partir de informações do esquema do banco de dados. Para isso, no métodoproposto, foi adicionado outro peso a ser utilizado no cálculo das configurações: Peso deDomínio, que dará maior prioridade a mapeamentos de mesmo tipo. O próximo capítuloapresenta a avaliação realizada com as técnicas propostas, utilizando os bancos bancos dedados IMDb, Mondial e DBLP.

CAPÍTULO 5Avaliação
Este capítulo apresenta os resultados da avaliação realizada utilizando as téc-nicas de ranqueamento: Método Húngaro, Vértice, Aresta e VérticeXAresta. Foramutilizados 3 (três) bancos de dados: IMDb, DBLP e Mondial, escolhidos por serem uti-lizados em testes nos trabalhos que abordam consultas com palavras-chave em bancos dedados, conforme mostrado no Capítulo 2. Para cada um deles, foi definido um conjuntode consultas (disponíveis no Apêndice B) compostas por palavras-chave com quantidadesvariadas de termos. A avaliação foi realizada de acordo com as interpretações possíveisde cada consulta, utilizando os modelos vistos em [4], [36], e [35], que baseiam o sentidoda consulta de acordo com a proximidade dos termos.
Os testes da abordagem baseada no Método Húngaro foram realizados atravésda ferramenta desenvolvida na linguagem Java Standard Edition. Esta ferramenta foidisponibilizada pelos criadores em [11]. O sistema foi utilizado sem qualquer modificaçãoem suas configurações padrão.
As demais técnicas (Vértice, Aresta e VérticeXAresta) foram implementadasutilizando a linguagem Java Standard Edition 8 [33]. Para a construção do grafo do bancode dados foi utilizada a ferramenta SchemaCrawler [14]. Essa ferramenta permite obterinformações da estrutura do banco de dados de forma simplificada. Ela foi utilizada para acriação do grafo para o banco de dados escolhido, utilizando as informações do esquema.
Os experimentos foram realizados em um computador Windows 10 64 bits, 4GBRAM, CPU 2GHz.
5.1 Métricas
As métricas escolhidas para a avaliação das técnicas elencadas são comumenteutilizadas em sistemas que realizam recuperação de informações. Além disso, elas tam-bém foram utilizadas para verificar a capacidade dos sistemas em retornar resultados deconsultas com palavras-chave, conforme discutido no Capítulo 2. De acordo com Coff-man e Weaver[9], as técnicas descritas a seguir são utilizadas para aferir a qualidade dosresultados retornados. São elas:

5.2 Bancos de Dados 67
• Quantidade de configurações geradas: quantidade de possibilidades possíveispara cada consulta. Na avaliação, são apresentados os valores médios de cadaconjunto de consultas para cada banco de dados.
• Top-1 resultados relevantes: é o número de consultas para as quais o primeiro re-sultado é relevante, ou seja, se o resultado retornado aparece na primeira colocaçãodentre um conjunto de resultados;
• Reciprocal Rank: avalia a posição do primeiro resultado relevante em relação aotopo do conjunto de resultados, de acordo com a fórmula:
RR =1pi,
em que pi corresponde à posição do resultado relevante retornado a partir de umaconsulta.
• Mean Reciprocal Rank (MRR): a média calculada utilizando valor do Reciprocal
Rank para cada conjunto de consulta, conforme a fórmula:
MRR =∑
Ni=1
1pi
N,
em que N é a quantidade de consultas e pi é a posição em que o resultado corretoda consulta i se encontra dentro do conjunto de resultados retornados.
• Precision: mede a relevância dos n primeiros resultados retornados de uma listaordenada, conforme a fórmula:
P =rn,
em que r corresponde à quantidade de resultados retornados considerados relevan-tes e n diz respeito à quantidade de resultados retornados, relevantes ou não. Amédia dos valores de precisão são também utilizados na avaliação das técnicas.
5.2 Bancos de Dados
Os testes foram realizados em 3 (três) conjuntos de dados amplamente utilizados:DBLP 1, Internet Movie Database (IMDb)2 e Mondial3. Este último é um banco de dadosde informações obtidas de fontes geográficas de dados da Web. O IMDb é um bancode dados popular criado em 1990 por um grupo de fãs de filmes e programas de TV.
1http://dblp.uni-trier.de/2http://www.imdb.com/3http://www.dbis.informatik.uni-goettingen.de/Mondial/

5.3 Resultados da Avaliação 68
Atualmente o IMDb contém mais de 185 milhões de itens de dados, que vão desdefilmes a programas de TV, entretenimento, elenco e membros de equipes. O DBLP éum repositório de publicações científicas, em sua maioria de Ciência da Computação,quem mantém informações de periódicos, conferências e autores. Esta base é mantidapela Universidade de Trier, Alemanha. Os três bancos de dados foram escolhidos paraa realização dos testes porque contém informações reais e pertencem a áreas distintas,sendo essas suficientes para realização dos experimentos.
A Tabela 5.1 fornece estatísticas sobre os bancos de dados utilizados. O Mondialpossui um tamanho menor comparado ao IMDb, porém com um número muito maiorde relações em seu esquema. O IMDb, em contrapartida, possui menor quantidade derelações, no entanto apresenta uma base maior de informações. O DBLP tem certasimilaridade com o IMDb, porém, além de possuir mais informações nele armazenadas,é utilizado para fins distintos.
Tabela 5.1: Características dos bancos de dados utilizados.
Banco de Dados Tamanho (MB) Relações Atributos TuplasMondial 3.2 34 139 21.497IMDb 630.7 7 21 5,674.333DBLP 58 6 22 881.876
Para os experimentos, foram criadas 30 consultas com intuito de recuperarinformações dos bancos de dados em questão. Cada conjunto de consultas foi concebidopara representar informações a serem requisitadas por usuários em mecanismos de buscas.As consultas contém de 1 a 7 termos no Mondial e no DBLP e de 1 a 8 termos no IMDb,estando disponíveis no Apêndice B deste trabalho.
5.3 Resultados da Avaliação
Para cada técnica de ranqueamento foram observados: a quantidade de configu-rações4 (N), quais consultas retornaram resultados relevantes na primeira posição (T1),o Reciprocal Rank (RR) e a Precision(P). As Tabelas5 5.2, 5.3, 5.4 e 5.5 apresentam osvalores resultantes da avaliação realizada. A Tabela 5.2 apresenta os resultados para oMétodo Húngaro. As Tabelas 5.3, 5.4 e 5.5 apresentam, respectivamente, os resultadospara as técnicas Vértice, Aresta e VérticeXAresta.
4uma configuração diz respeito ao papel de cada palavra-chave da consulta, conforme discutido naSubseção 3.3.1
5ID = identificador da consulta (Apêndice B), N = quantidade de configurações geradas, T1 = Top-1resultados, RR = Reciprocal Rank, P = Precision
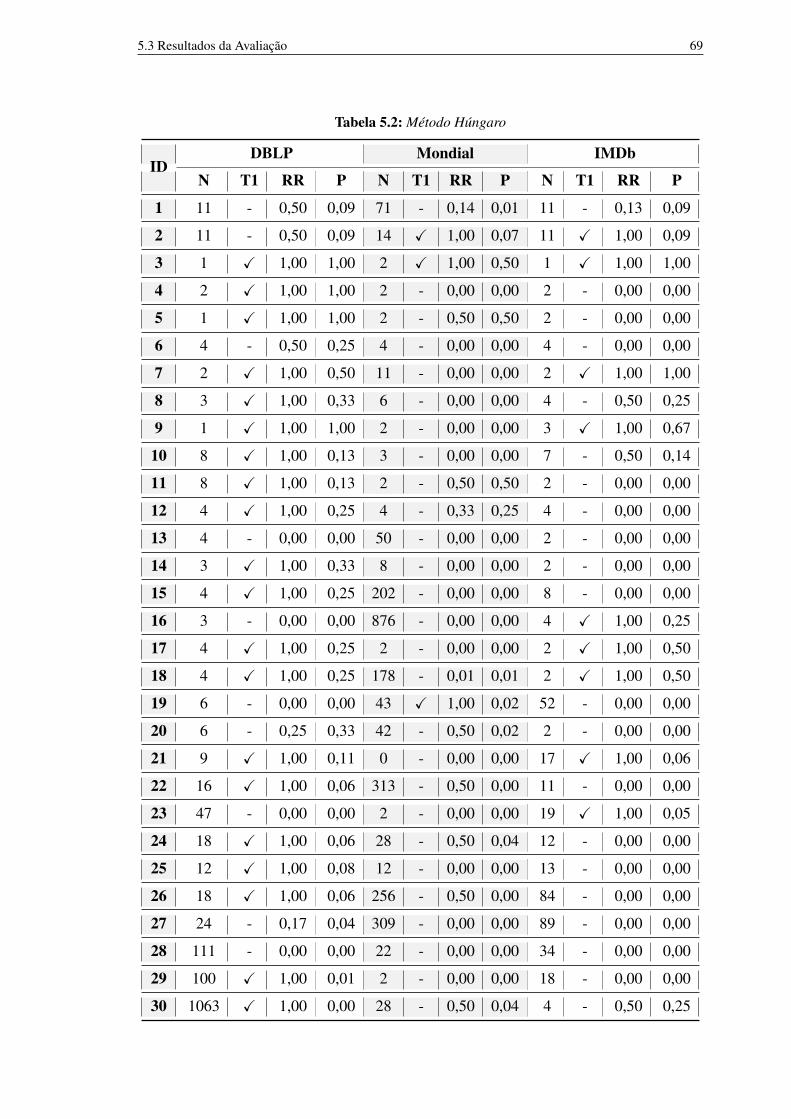
5.3 Resultados da Avaliação 69
Tabela 5.2: Método Húngaro
IDDBLP Mondial IMDb
N T1 RR P N T1 RR P N T1 RR P
1 11 - 0,50 0,09 71 - 0,14 0,01 11 - 0,13 0,09
2 11 - 0,50 0,09 14 X 1,00 0,07 11 X 1,00 0,09
3 1 X 1,00 1,00 2 X 1,00 0,50 1 X 1,00 1,00
4 2 X 1,00 1,00 2 - 0,00 0,00 2 - 0,00 0,00
5 1 X 1,00 1,00 2 - 0,50 0,50 2 - 0,00 0,00
6 4 - 0,50 0,25 4 - 0,00 0,00 4 - 0,00 0,00
7 2 X 1,00 0,50 11 - 0,00 0,00 2 X 1,00 1,00
8 3 X 1,00 0,33 6 - 0,00 0,00 4 - 0,50 0,25
9 1 X 1,00 1,00 2 - 0,00 0,00 3 X 1,00 0,67
10 8 X 1,00 0,13 3 - 0,00 0,00 7 - 0,50 0,14
11 8 X 1,00 0,13 2 - 0,50 0,50 2 - 0,00 0,00
12 4 X 1,00 0,25 4 - 0,33 0,25 4 - 0,00 0,00
13 4 - 0,00 0,00 50 - 0,00 0,00 2 - 0,00 0,00
14 3 X 1,00 0,33 8 - 0,00 0,00 2 - 0,00 0,00
15 4 X 1,00 0,25 202 - 0,00 0,00 8 - 0,00 0,00
16 3 - 0,00 0,00 876 - 0,00 0,00 4 X 1,00 0,25
17 4 X 1,00 0,25 2 - 0,00 0,00 2 X 1,00 0,50
18 4 X 1,00 0,25 178 - 0,01 0,01 2 X 1,00 0,50
19 6 - 0,00 0,00 43 X 1,00 0,02 52 - 0,00 0,00
20 6 - 0,25 0,33 42 - 0,50 0,02 2 - 0,00 0,00
21 9 X 1,00 0,11 0 - 0,00 0,00 17 X 1,00 0,06
22 16 X 1,00 0,06 313 - 0,50 0,00 11 - 0,00 0,00
23 47 - 0,00 0,00 2 - 0,00 0,00 19 X 1,00 0,05
24 18 X 1,00 0,06 28 - 0,50 0,04 12 - 0,00 0,00
25 12 X 1,00 0,08 12 - 0,00 0,00 13 - 0,00 0,00
26 18 X 1,00 0,06 256 - 0,50 0,00 84 - 0,00 0,00
27 24 - 0,17 0,04 309 - 0,00 0,00 89 - 0,00 0,00
28 111 - 0,00 0,00 22 - 0,00 0,00 34 - 0,00 0,00
29 100 X 1,00 0,01 2 - 0,00 0,00 18 - 0,00 0,00
30 1063 X 1,00 0,00 28 - 0,50 0,04 4 - 0,50 0,25
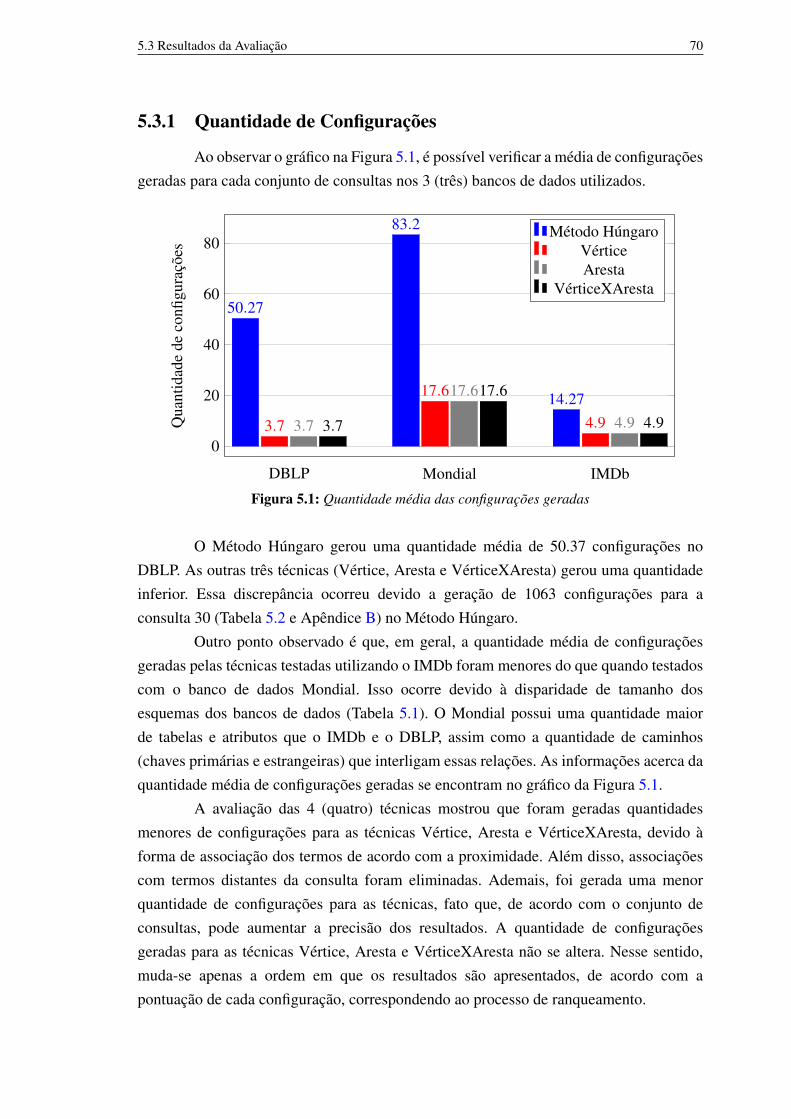
5.3 Resultados da Avaliação 70
5.3.1 Quantidade de Configurações
Ao observar o gráfico na Figura 5.1, é possível verificar a média de configuraçõesgeradas para cada conjunto de consultas nos 3 (três) bancos de dados utilizados.
DBLP Mondial IMDb
0
20
40
60
80
50.27
83.2
14.27
3.7
17.6
4.93.7
17.6
4.93.7
17.6
4.9Qua
ntid
ade
deco
nfigu
raçõ
es
Método HúngaroVérticeAresta
VérticeXAresta
Figura 5.1: Quantidade média das configurações geradas
O Método Húngaro gerou uma quantidade média de 50.37 configurações noDBLP. As outras três técnicas (Vértice, Aresta e VérticeXAresta) gerou uma quantidadeinferior. Essa discrepância ocorreu devido a geração de 1063 configurações para aconsulta 30 (Tabela 5.2 e Apêndice B) no Método Húngaro.
Outro ponto observado é que, em geral, a quantidade média de configuraçõesgeradas pelas técnicas testadas utilizando o IMDb foram menores do que quando testadoscom o banco de dados Mondial. Isso ocorre devido à disparidade de tamanho dosesquemas dos bancos de dados (Tabela 5.1). O Mondial possui uma quantidade maiorde tabelas e atributos que o IMDb e o DBLP, assim como a quantidade de caminhos(chaves primárias e estrangeiras) que interligam essas relações. As informações acerca daquantidade média de configurações geradas se encontram no gráfico da Figura 5.1.
A avaliação das 4 (quatro) técnicas mostrou que foram geradas quantidadesmenores de configurações para as técnicas Vértice, Aresta e VérticeXAresta, devido àforma de associação dos termos de acordo com a proximidade. Além disso, associaçõescom termos distantes da consulta foram eliminadas. Ademais, foi gerada uma menorquantidade de configurações para as técnicas, fato que, de acordo com o conjunto deconsultas, pode aumentar a precisão dos resultados. A quantidade de configuraçõesgeradas para as técnicas Vértice, Aresta e VérticeXAresta não se altera. Nesse sentido,muda-se apenas a ordem em que os resultados são apresentados, de acordo com apontuação de cada configuração, correspondendo ao processo de ranqueamento.
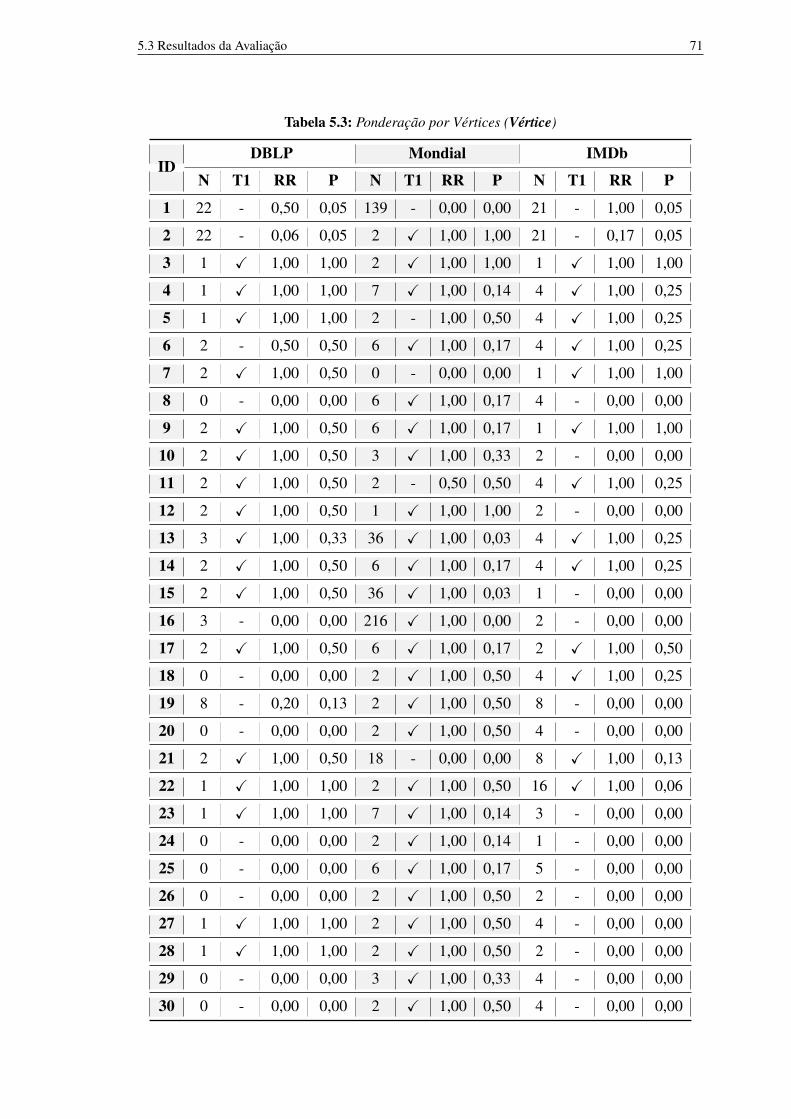
5.3 Resultados da Avaliação 71
Tabela 5.3: Ponderação por Vértices (Vértice)
IDDBLP Mondial IMDb
N T1 RR P N T1 RR P N T1 RR P
1 22 - 0,50 0,05 139 - 0,00 0,00 21 - 1,00 0,05
2 22 - 0,06 0,05 2 X 1,00 1,00 21 - 0,17 0,05
3 1 X 1,00 1,00 2 X 1,00 1,00 1 X 1,00 1,00
4 1 X 1,00 1,00 7 X 1,00 0,14 4 X 1,00 0,25
5 1 X 1,00 1,00 2 - 1,00 0,50 4 X 1,00 0,25
6 2 - 0,50 0,50 6 X 1,00 0,17 4 X 1,00 0,25
7 2 X 1,00 0,50 0 - 0,00 0,00 1 X 1,00 1,00
8 0 - 0,00 0,00 6 X 1,00 0,17 4 - 0,00 0,00
9 2 X 1,00 0,50 6 X 1,00 0,17 1 X 1,00 1,00
10 2 X 1,00 0,50 3 X 1,00 0,33 2 - 0,00 0,00
11 2 X 1,00 0,50 2 - 0,50 0,50 4 X 1,00 0,25
12 2 X 1,00 0,50 1 X 1,00 1,00 2 - 0,00 0,00
13 3 X 1,00 0,33 36 X 1,00 0,03 4 X 1,00 0,25
14 2 X 1,00 0,50 6 X 1,00 0,17 4 X 1,00 0,25
15 2 X 1,00 0,50 36 X 1,00 0,03 1 - 0,00 0,00
16 3 - 0,00 0,00 216 X 1,00 0,00 2 - 0,00 0,00
17 2 X 1,00 0,50 6 X 1,00 0,17 2 X 1,00 0,50
18 0 - 0,00 0,00 2 X 1,00 0,50 4 X 1,00 0,25
19 8 - 0,20 0,13 2 X 1,00 0,50 8 - 0,00 0,00
20 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00
21 2 X 1,00 0,50 18 - 0,00 0,00 8 X 1,00 0,13
22 1 X 1,00 1,00 2 X 1,00 0,50 16 X 1,00 0,06
23 1 X 1,00 1,00 7 X 1,00 0,14 3 - 0,00 0,00
24 0 - 0,00 0,00 2 X 1,00 0,14 1 - 0,00 0,00
25 0 - 0,00 0,00 6 X 1,00 0,17 5 - 0,00 0,00
26 0 - 0,00 0,00 2 X 1,00 0,50 2 - 0,00 0,00
27 1 X 1,00 1,00 2 X 1,00 0,50 4 - 0,00 0,00
28 1 X 1,00 1,00 2 X 1,00 0,50 2 - 0,00 0,00
29 0 - 0,00 0,00 3 X 1,00 0,33 4 - 0,00 0,00
30 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00
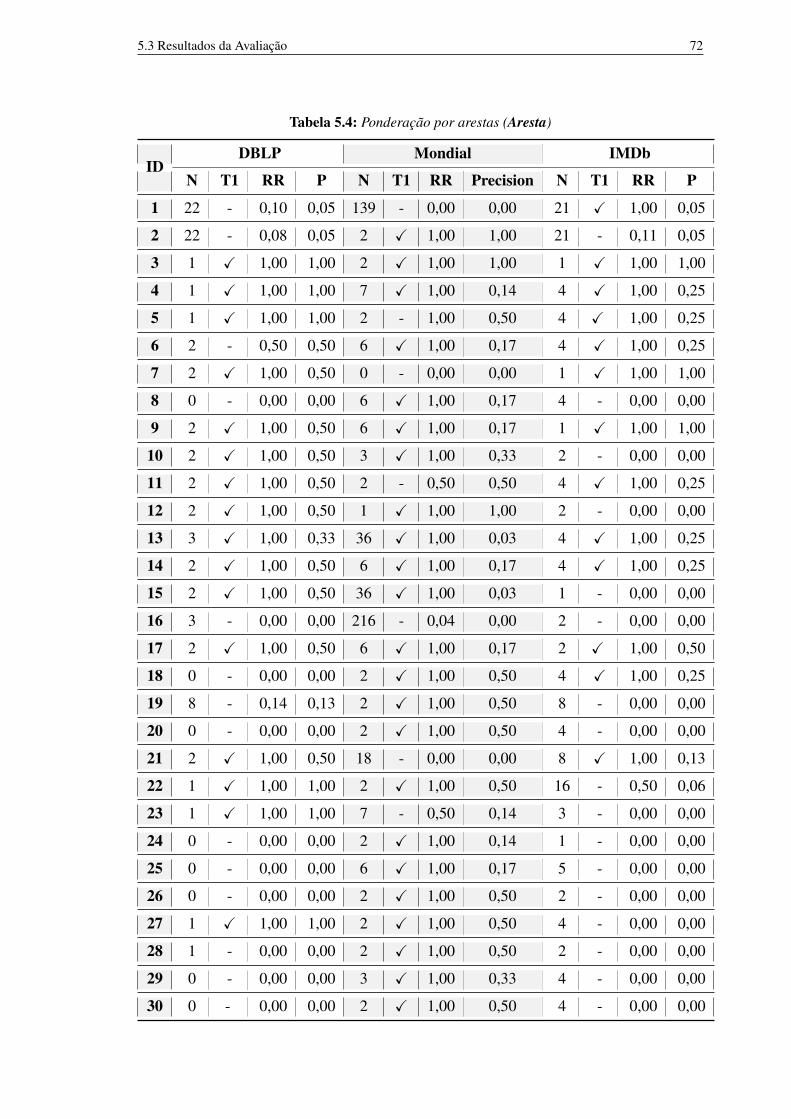
5.3 Resultados da Avaliação 72
Tabela 5.4: Ponderação por arestas (Aresta)
IDDBLP Mondial IMDb
N T1 RR P N T1 RR Precision N T1 RR P
1 22 - 0,10 0,05 139 - 0,00 0,00 21 X 1,00 0,05
2 22 - 0,08 0,05 2 X 1,00 1,00 21 - 0,11 0,05
3 1 X 1,00 1,00 2 X 1,00 1,00 1 X 1,00 1,00
4 1 X 1,00 1,00 7 X 1,00 0,14 4 X 1,00 0,25
5 1 X 1,00 1,00 2 - 1,00 0,50 4 X 1,00 0,25
6 2 - 0,50 0,50 6 X 1,00 0,17 4 X 1,00 0,25
7 2 X 1,00 0,50 0 - 0,00 0,00 1 X 1,00 1,00
8 0 - 0,00 0,00 6 X 1,00 0,17 4 - 0,00 0,00
9 2 X 1,00 0,50 6 X 1,00 0,17 1 X 1,00 1,00
10 2 X 1,00 0,50 3 X 1,00 0,33 2 - 0,00 0,00
11 2 X 1,00 0,50 2 - 0,50 0,50 4 X 1,00 0,25
12 2 X 1,00 0,50 1 X 1,00 1,00 2 - 0,00 0,00
13 3 X 1,00 0,33 36 X 1,00 0,03 4 X 1,00 0,25
14 2 X 1,00 0,50 6 X 1,00 0,17 4 X 1,00 0,25
15 2 X 1,00 0,50 36 X 1,00 0,03 1 - 0,00 0,00
16 3 - 0,00 0,00 216 - 0,04 0,00 2 - 0,00 0,00
17 2 X 1,00 0,50 6 X 1,00 0,17 2 X 1,00 0,50
18 0 - 0,00 0,00 2 X 1,00 0,50 4 X 1,00 0,25
19 8 - 0,14 0,13 2 X 1,00 0,50 8 - 0,00 0,00
20 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00
21 2 X 1,00 0,50 18 - 0,00 0,00 8 X 1,00 0,13
22 1 X 1,00 1,00 2 X 1,00 0,50 16 - 0,50 0,06
23 1 X 1,00 1,00 7 - 0,50 0,14 3 - 0,00 0,00
24 0 - 0,00 0,00 2 X 1,00 0,14 1 - 0,00 0,00
25 0 - 0,00 0,00 6 X 1,00 0,17 5 - 0,00 0,00
26 0 - 0,00 0,00 2 X 1,00 0,50 2 - 0,00 0,00
27 1 X 1,00 1,00 2 X 1,00 0,50 4 - 0,00 0,00
28 1 - 0,00 0,00 2 X 1,00 0,50 2 - 0,00 0,00
29 0 - 0,00 0,00 3 X 1,00 0,33 4 - 0,00 0,00
30 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00

5.3 Resultados da Avaliação 73
Tabela 5.5: Ponderação por Vértices e Arestas (VerticeXAresta)
IDDBLP Mondial IMDb
N T1 RR P N T1 RR Precision N T1 RR P
1 22 - 0,20 0,05 139 - 0,03 0,01 21 - 0,50 0,05
2 22 - 0,25 0,05 2 X 1,00 1,00 21 - 0,17 0,05
3 1 X 1,00 1,00 2 X 1,00 1,00 1 X 0,33 1,00
4 1 X 1,00 1,00 7 X 1,00 0,14 4 X 1,00 0,25
5 1 X 1,00 1,00 2 - 1,00 0,50 4 X 1,00 0,25
6 2 - 0,50 0,50 6 X 1,00 0,17 4 X 1,00 0,25
7 2 X 1,00 0,50 0 - 0,00 0,00 1 X 1,00 1,00
8 0 - 0,00 0,00 6 X 1,00 0,17 4 - 0,00 0,00
9 2 X 1,00 0,50 6 X 1,00 0,17 1 X 1,00 1,00
10 2 X 1,00 0,50 3 X 1,00 0,33 2 - 0,00 0,00
11 2 X 1,00 0,50 2 - 0,50 0,50 4 - 0,33 0,25
12 2 X 1,00 0,50 1 X 1,00 1,00 2 - 0,00 0,00
13 3 X 1,00 0,33 36 X 1,00 0,03 4 X 1,00 0,25
14 2 X 1,00 0,50 6 X 1,00 0,17 4 X 1,00 0,25
15 2 X 1,00 0,50 36 X 1,00 0,03 1 - 0,00 0,00
16 3 - 0,00 0,00 216 X 1,00 0,00 2 - 0,00 0,00
17 2 X 1,00 0,50 6 X 1,00 0,17 2 X 1,00 0,50
18 0 - 0,00 0,00 2 X 1,00 0,50 4 X 1,00 0,25
19 8 - 0,20 0,13 2 X 1,00 0,50 8 - 0,00 0,00
20 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00
21 2 X 1,00 0,50 18 - 0,00 0,00 8 X 1,00 0,13
22 1 X 1,00 1,00 2 X 1,00 0,50 16 X 1,00 0,06
23 1 X 1,00 1,00 7 X 1,00 0,14 3 - 0,00 0,00
24 0 - 0,00 0,00 2 X 1,00 0,14 1 - 0,00 0,00
25 0 - 0,00 0,00 6 X 1,00 0,17 5 - 0,00 0,00
26 0 - 0,00 0,00 2 X 1,00 0,50 2 - 0,00 0,00
27 1 X 1,00 1,00 2 X 1,00 0,50 4 - 0,00 0,00
28 1 X 1,00 1,00 2 X 1,00 0,50 2 - 0,00 0,00
29 0 - 0,00 0,00 3 X 1,00 0,33 4 - 0,00 0,00
30 0 - 0,00 0,00 2 X 1,00 0,50 4 - 0,00 0,00

5.3 Resultados da Avaliação 74
5.3.2 TOP-1 Resultados
Na Figura 5.2, é possível verificar o percentual de consultas que apresentaramresultados relevantes em primeiro lugar. O resultado desta métrica, para os conjuntosde consultas utilizados, demonstra a capacidade das técnicas avaliadas em retornar asinformações solicitadas no topo dentre o conjunto de resultados. Os valores percentuaispodem variar de 0 a 100, em que 100% significa que a técnica retornou informaçõesdesejadas em primeiro lugar para todas as consultas submetidas.
DBLP Mondial IMDb
10
20
30
40
50
60
70
80
66.7
10
30
56.7
76.7
43.346.7
70
36.7
53.3
73.3
40
Perc
entu
alde
TOP-
1R
esul
tado
s(%
)
Método HúngaroVérticeAresta
VérticeXAresta
Figura 5.2: Percentual de TOP-1 resultados relevantes (%)
Do conjunto de consultas executadas, o Método Húngaro obteve melhor resul-tado quando utilizado o banco de dados DBLP, retornando informações relevantes naprimeira colocação em 66.7% das consultas. No banco de dados Mondial, apenas 10%das consultas apresentaram resultados na primeira posição. No IMDb, este método retor-nou resultados no topo em 30% das consultas efetuadas. A técnica Vértice se destacou aoserem submetidas as consultas no banco de dados Mondial, retornando resultados relevan-tes em 76,7% das consutas submetidas. No entanto, exceto no banco de dados Mondial, atécnica Aresta apresentou os piores resultados, apresentando os seguintes valores: 46,7%no banco de dados DBLP, 70% no Mondial e 36,7% no IMDb. A técnica VérticexArestaapresentou resultados um pouco inferiores à técnica Vértice, conseguindo o segundo me-lhor resultado dentre as técnicas avaliadas.
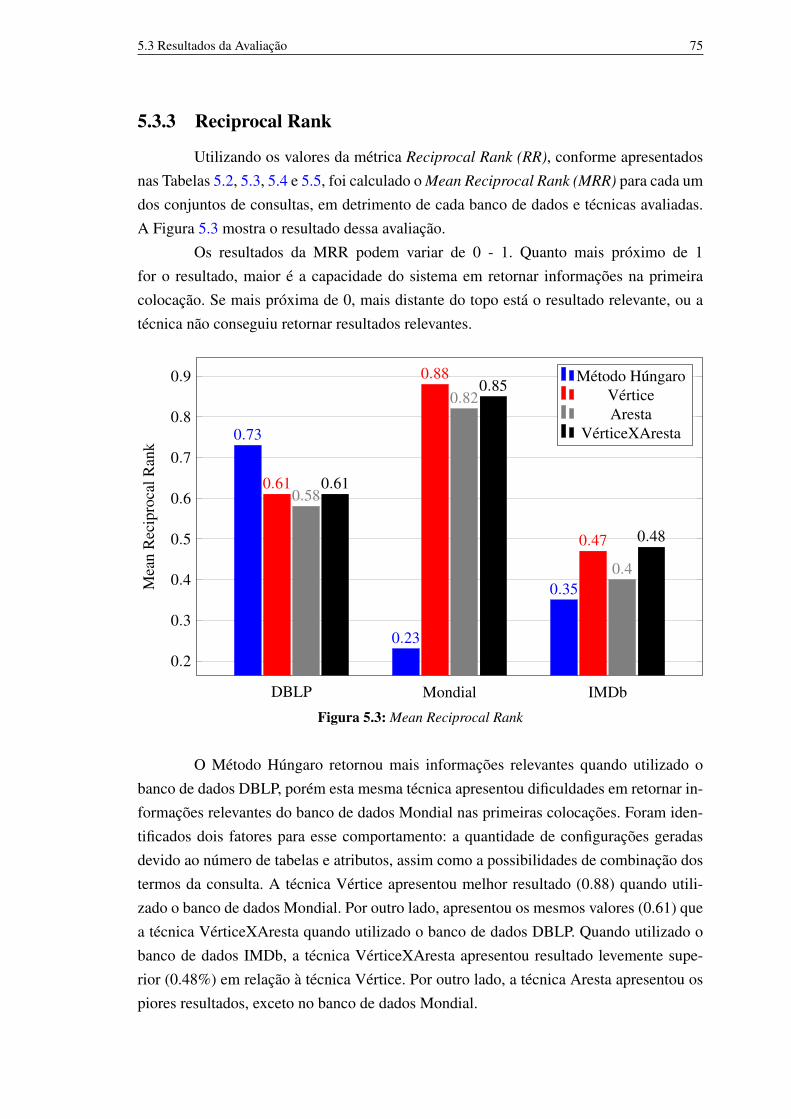
5.3 Resultados da Avaliação 75
5.3.3 Reciprocal Rank
Utilizando os valores da métrica Reciprocal Rank (RR), conforme apresentadosnas Tabelas 5.2, 5.3, 5.4 e 5.5, foi calculado o Mean Reciprocal Rank (MRR) para cada umdos conjuntos de consultas, em detrimento de cada banco de dados e técnicas avaliadas.A Figura 5.3 mostra o resultado dessa avaliação.
Os resultados da MRR podem variar de 0 - 1. Quanto mais próximo de 1for o resultado, maior é a capacidade do sistema em retornar informações na primeiracolocação. Se mais próxima de 0, mais distante do topo está o resultado relevante, ou atécnica não conseguiu retornar resultados relevantes.
DBLP Mondial IMDb
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.73
0.23
0.35
0.61
0.88
0.47
0.58
0.82
0.4
0.61
0.85
0.48
Mea
nR
ecip
roca
lRan
k
Método HúngaroVérticeAresta
VérticeXAresta
Figura 5.3: Mean Reciprocal Rank
O Método Húngaro retornou mais informações relevantes quando utilizado obanco de dados DBLP, porém esta mesma técnica apresentou dificuldades em retornar in-formações relevantes do banco de dados Mondial nas primeiras colocações. Foram iden-tificados dois fatores para esse comportamento: a quantidade de configurações geradasdevido ao número de tabelas e atributos, assim como a possibilidades de combinação dostermos da consulta. A técnica Vértice apresentou melhor resultado (0.88) quando utili-zado o banco de dados Mondial. Por outro lado, apresentou os mesmos valores (0.61) quea técnica VérticeXAresta quando utilizado o banco de dados DBLP. Quando utilizado obanco de dados IMDb, a técnica VérticeXAresta apresentou resultado levemente supe-rior (0.48%) em relação à técnica Vértice. Por outro lado, a técnica Aresta apresentou ospiores resultados, exceto no banco de dados Mondial.

5.3 Resultados da Avaliação 76
5.3.4 Precision
Para o conjunto de consultas efetuadas, utilizando os valores de precisão dasTabelas 5.2, 5.3, 5.4 e 5.5, foi calculada a média da precisão das técnicas avaliadas. Osvalores desta métrica variam de 0 - 1, em que os resultados mais próximos de 1 expressammaior precisão dos resultados. De forma similar, os valores mais próximos de 0 mostramque as técnicas avaliadas foram menos precisas.
DBLP Mondial IMDb
5 ·10−2
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.25
7 ·10−2
0.16
0.42
0.34
0.18
0.38
0.29
0.15
0.41
0.32
0.18
Ava
rage
Prec
isio
n
Método HúngaroVérticeAresta
VérticeXAresta
Figura 5.4: Precisão Média (Avarage Precision)
De acordo com esta métrica, quando são retornados muitos resultados paradeterminada consulta e poucos são relevantes, mais próximo de 0 será o valor de precisão.Quanto mais resultados relevantes forem retornados, mais precisa é a técnica avaliada, ouseja, mais próximo de 1 é o resultado.
Nesta métrica, o método Vértice apresentou melhores resultados nos três bancosde dados avaliados. As outras duas técnicas (Aresta e VérticeXAresta) obtiveram resulta-dos similares à primeira. A técnica baseada no Método Húngaro obteve resultado abaixodo esperado, quando utilizado o banco de dados Mondial e DBLP, mas se assemelha aosdemais quando utilizada com o banco de dados IMDb. Esse comportamento é previsto de-vido à quantidade de configurações retornadas para cada consulta. O Método Húngaro, deacordo com os resultados obtidos nesta avaliação, foi a técnica que mais retornou confi-gurações nos bancos de dados consultados. Esse comportamento faz com que a avaliaçãodessa técnica em relação à métrica Precison seja baixa.

5.4 Considerações Finais 77
5.4 Considerações Finais
Ao identificar as técnicas que podem ser utilizadas para ranqueamento nossistemas de consultas com palavras-chave que não utilizam os dados para a traduçãoda consulta, foi possível utilizá-las em cooperação. A avaliação mostrou que a técnicaVértice apresentou melhores resultados para a maioria dos cenários em que foi executada.Essa técnica utiliza o modelo do Método Húngaro, porém adicionando o grafo doesquema para melhorar o ranqueamento dos resultados. Além disso, reduz a quantidadede configurações geradas em detrimento da proximidade dos termos na consulta.
Foram apresentadas melhorias nos seguintes casos: na consulta "the matrix",que não apresenta qualquer termo correlacionado com o esquema, o Método Húngarocriaria configurações de forma aleatória para cada nome de tabela ou atributo. Com atécnica Vértice, a primeira configuração apresentada é aquela em que o termo da consultaé mapeado para movies, uma vez que este é o vértice mais prestigiado (maior pontuação)do grafo.
Da mesma forma, os atributos das tabelas que possuem mais conexões tambémtem pontuação calculada para favorecê-los. Assim, as consultas que não possuem termosrelacionados a nomes de tabelas serão associados mediante maior pontuação.
Outro ponto em que melhorou a apresentação dos resultados em relação aoMétodo Húngaro foi a atribuição do peso do domínio. Em consultas do tipo movie 2000,os atributos com domínios compatíveis têm pontuação maior. Assim o termo 2000 seráatribuído a atributos do tipo inteiro da tabela movies.

CAPÍTULO 6Conclusão
Para permitir que usuários comuns tenham acesso a informações presentes embancos de dados relacionais, de maneira similar como ocorre na Web, este trabalhopropôs uma técnica para ranqueamento de interpretações de consultas com palavras-chave submetidas em bancos de dados relacionais. O estudo traz uma abordagem mista deranqueamento de interpretações de consultas com palavras-chave em que não se utilizamdos dados para esse processo. Os dados são utilizados apenas no momento da execuçãoda consulta SQL.
Com o objetivo de compreender os fatores que podem impactar no ranqueamentodas interpretações, foi realizada uma revisão de literatura em que foram apresentados osprincipais trabalhos que abordam técnicas de ranqueamento de interpretações de consultascom palavras-chave submetidas em bancos de dados relacionais. Em seguida foramapresentados 14 (quatorze) sistemas e suas características.
Com base nos trabalhos discutidos, foi possível descobrir as características maisrelevantes que influenciam no processo de ranqueamento, além de encontrar as principaistécnicas, a fim de descobrir quais pudessem ser utilizadas para o ranqueamento dasinterpretações sem utilização dos dados dos bancos de dados durante toda a fase demapeamento da consulta.
Ao desenvolver-se a revisão de literatura, foram encontradas apenas duas técni-cas que vão de encontro ao proposto (ambas baseadas no Método Húngaro), no entanto,descobriu-se que as técnicas de ranqueamento podem ser utilizadas em conjunto. Dessamaneira, foram propostas a avaliação de 4 (quatro) técnicas, que neste trabalho foram cha-madas de: Método Húngaro, Vértices, Aresta e VerticeXAresta, sendo estas três últimasimplementadas durante a realização deste trabalho.
As 4 (quatro) técnicas foram testadas utilizando as métricas RR, MRR, Top-1
resultados relevantes, Quantidade de configurações e Precision, escolhidas com base nostrabalhos relacionados. As técnicas foram aplicadas em 3 (três) bancos de dados (DBLP,IMDb e Mondial), sendo elaboradas e submetidas 30 consultas em cada um deles.
Através dos experimentos, ficou evidente que a técnica Vértice apresentou osmelhores resultados na maioria dos cenários. A comparação entre os resultados obtidos

6.1 Contribuições do Estudo 79
com cada técnica, nos 3 (três) bancos de dados testados, evidenciou que a associaçãodos termos mediante proximidade diminuiu a quantidade de configurações geradas paracada consulta. Por outro lado, o peso do domínio favoreceu a interpretação das consultasquando utilizados tipos de dados diferentes de strings. A avaliações realizadas nestetrabalho demonstraram melhorias na correlação entre consulta submetida e resultadosapresentados.
6.1 Contribuições do Estudo
As contribuições trazidas por este estudo são apresentadas a seguir:
• Ranqueamento da Interpretações de acordo com a relevância. Os resultadosretornados são ranqueados através da correlação dos termos da consulta compalavras-chave e os termos do banco de dados, em conjunto com o peso dosvértices do grafo. O usuário almeja que os resultados mais relevantes para a consultasubmetida sejam apresentados em primeiro lugar. Com a técnica de ranqueamentoapresentada neste trabalho (Vértice), os resultados mais relevantes recebem maiorpontuação, ou seja, são considerados mais relevantes.
• Apresentação das principais trabalhos que abordam a tradução e ranquea-mento de consultas com palavras-chave. Este trabalho apresentou as caracterís-ticas que podem influenciar no processo de ranqueamento das interpretações dasconsultas com palavras-chave.
• Combinação de técnicas ranqueamento. As técnicas de consultas com palavra-chave que podem ser utilizadas para ranqueamento de interpretações nos sistemasque não utilizam os dados para a tradução da consulta foram combinadas a avaliadaspara apresentação da melhor técnica.
• Utilização de consultas com palavras-chave para consultas em bancos de da-dos relacionais. Acessar informações de um banco de dados relacional requer co-nhecimento da linguagem SQL. Através de palavras-chave, é possível recuperarinformações de forma simplificada;
• Redução da quantidade de configurações geradas durante o processo de tradu-ção de consultas. Uma configuração representa o papel de cada termo da consultaem função do vocabulário do banco de dados em que as consultas;
Este estudo permite ter uma visão geral dos trabalhos que abordam consultascom palavras-chave em bancos de dados relacionais, apresentando as principais funcio-nalidades dos sistemas.

6.2 Limitações da Técnica 80
6.2 Limitações da Técnica
As técnicas avaliadas possuem limitações que podem dificultar o processo detradução das consultas submetidas. Para a técnica apresentada foram encontradas asseguintes dificuldades:
• mapear termos contendo ponto, vírgula, ponto e vírgula e outros caracteres.Esses caracteres dificulta o mapeamento das palavras-chave em detrimento dasinformações do esquema;
• mapear palavras-chave consideradas pelo algoritmo como termo de valor semque se tenha termos de esquema associados a ele. Por exemplo: na consultaactors titanic, naturalmente o método mapeia o termo de valor titanic como algumdado da tabela actors. Porém, a real intenção da consulta é recuperar informações
sobre atores do filme titanic.• trabalhar com datas. Existem diversas formas de se representar datas. O método
explorado por este trabalho utiliza a língua Inglesa como padrão para consulta,porém ainda podem existir problemas ao se trabalhar com datas. Regiões de mesmalíngua representam datas de forma muito diferentes, inclusive dentro do mesmopaís;
• termos com mais de uma função. Quando um termo da consulta pode representarinformações de esquema, mas também termo de valor. Na consulta film "movie",a intenção é encontrar informações sobre o filme movie, no entanto, movie podeser mapeada para o termo de esquema movies, dificultando a recuperação dainformação desejada.
• expansão dos termos da consulta. As técnicas de expansão utilizadas apresentadificuldades em expandir termos como: title e name. Nesse sentido, os esses termosnão são considerados sinônimos.
• diferenciar pesquisas que utilizam substantivos femininos. Caso o usuário sub-meta a consulta actress "jennifer aniston" (com objetivo de encontrar informa-ções acerca da atriz Jennifer Aniston), o sistema não conseguirá relacionar o termoactress com o nome da tabela actor.
6.3 Trabalhos Futuros
Como trabalhos futuros são apresentados:
• criação de estruturas auxiliares. Essas estruturas serão utilizadas para armazenarinformações acerca de resultados considerados relevantes para melhorar a consultarealizada somente com termos mapeados para valor, ou que não possuam termo de

6.3 Trabalhos Futuros 81
valor sem termo de esquema associado. Além disso, verificar a correlação de paresde palavas-chave, como explorado no trabalho [27].
• processamento da linguagem natural. Expandir o método a fim de permitir arealização de consultas utilizando a linguagem comum ao cotidiano.
• realização de consultas em múltiplos idiomas. A abordagem utilizada para reali-zação deste trabalho realiza a conversão de consultas somente em Língua Inglesa.Versões futuras do protótipo poderão realizar consultas em mais de uma língua.
• criação de uma versão Web do protótipo A versão atual foi desenvolvido emlinguagem Java SE, ou seja, uma aplicação desktop. Ter uma versão Web permitiráque bancos de dados na internet possam ser consultados de qualquer lugar.
• utilização de técnicas de stemming para expansão dos termos. Caso esta técnicaseja empregada, a consulta actress "angelina jolie" pode facilmente retornar asinformações sobre a atriz Angelina Jolie, uma vez que o termo actress pode serextendido para o nome da tabela actor. Essas técnicas podem retirar o reduzir aspalavras-chave ao seu radical comum.
• Utilização de outras técnicas para expansão sinonímia. Ao se descobrir o con-texto em que determinado banco de dados se encontra, a expansão dos termos daconsulta terá maior fidelidade. Para os termos title e name, é possível visualizarque eles são sinônimos no contexto de filmes. Conseguir descobrir o contexto dobanco de dados de forma automatizada garantirá a utilização de sinônimos de formamais assertiva.
• realização de testes com usuários comuns1. Será solicitado que usuários formu-lem consultas com palavras-chave mediante descrição dos bancos de dados apre-sentada. Os testes executados utilizarão as consultas formuladas.
1entende-se usuário comum alguém que utiliza a internet, mas não possui conhecimento de linguagensde consulta e estruturas de bancos de dados

Referências Bibliográficas
[1] AGRAWAL, S. DBXplorer: A System for Keyword-Based Search over Relational
Databases. Icde, p. 5–16, 2002.
[2] BALMIN, A.; VAGELIS, H.; YANNIS, P. ObjectRank : Authority-Based Keyword
Search in Databases. In Proceedings of the Thirtieth international conference on
Very large data bases (VLDB ’04), 30:564 – 575, 2004.
[3] BERGAMASCHI, S.; DOMNORI, E.; GUERRA, F.; TRILLO LADO, R.; VELEGRAKIS, Y.
Keyword search over relational databases: a metadata approach. Proceedings
of the 2011 international conference on Management of data - SIGMOD ’11, p. 565,
2011.
[4] BERGAMASCHI, S.; EMILIA, R.; LADO, R. T. Keymantic : Semantic Keyword-based
Searching in Data Integration Systems. Proceedings of the VLDB Endowment, p.
1637–1640, 2010.
[5] BHALOTIA, G.; HULGERI, A.; NAKHE, C.; CHAKRABARTI, S.; SUDARSHAN, S.
BANKS : Browsing and Keyword Searching in Relational Databases. VLDB ’02:
Proceedings of the 28th International Conference on Very Large Databases, p. 1083
– 1086, 2002.
[6] BHALOTIA, G.; HULGERI, A.; NAKHE, C.; CHAKRABARTI, S.; SUDARSHAN, S.
Keyword searching and browsing in databases using BANKS. Proceedings 18th
International Conference on Data Engineering, p. 431–440, 2002.
[7] BRIN, S.; PAGE, L. Reprint of: The anatomy of a large-scale hypertextual web
search engine. Computer networks, 56(18):3825–3833, 2012.
[8] CHEN, Z.; TORSON, J.; SERVISETTI, S. Reexamining database keyword search:
Beyond performance. In: Innovation in Information & Communication Technology
(ISIICT), 2011 Fourth International Symposium on, p. 94–99. IEEE, 2011.
[9] COFFMAN, J.; WEAVER, A. C. A framework for evaluating database keyword
search strategies. In: Proceedings of the 19th ACM international conference on
Information and knowledge management, p. 729–738. ACM, 2010.

Referências Bibliográficas 83
[10] DING, B.; YU, J. X.; WANG, S.; QIN, L.; ZHANG, X.; LIN, X. Finding top-k min-
cost connected trees in databases. Proceedings - International Conference on
Data Engineering, p. 836–845, 2007.
[11] DOMNORI, E. Keyword based search engine over relational database.
https://sourceforge.net/p/keymantic/wiki/Home/, jan 2017.
[12] DREYFUS, S. E.; WAGNER, R. A. The steiner problem in graphs. Networks,
1(3):195–207, 1971.
[13] FAKHRAEE, S.; FOTOUHI, F. DBSemSXplorer: Semantic-based Keyword Search
System over Relational Databases for Knowledge Discovery. Proceedings of the
Third International Workshop on Keyword Search on Structured Data - KEYS ’12, p.
54–62, 2012.
[14] FATEHI, S. Schemacrawler: Free database schema discovery and comprehen-
sion tool. http://sualeh.github.io/SchemaCrawler/, jan 2017.
[15] FREITAS, R. A. P.; RAMALHO, J. C. Significant properties in the preservation of
relational databases. In: Research and Advanced Technology for Digital Libraries,
14th European Conference, ECDL2010. Springer, 2010.
[16] GEIGER, P. Novíssimo Aulete. Dicionário Contemporâneo da Língua Portu-
guesa. Lexikon, 2011.
[17] GU, J.; KITAGAWA, H. Extending keyword search to metadata on relational
databases. Proceedings - 2008 International Workshop on Information-Explosion
and Next Generation Search, INGS 2008, p. 97–103, 2008.
[18] HAAM, D.; LEE, K. Y.; KIM, M. H. Keyword search on relational databases
using keyword query interpretation. Proceeding - 5th International Conference on
Computer Sciences and Convergence Information Technology, ICCIT 2010, p. 957–
961, 2010.
[19] HEERINGA, W. J. Measuring dialect pronunciation differences using Levensh-
tein distance. PhD thesis, University Library Groningen][Host], 2004.
[20] HRISTIDIS, V.; DISCOVER, Y. P. Discover: Keyword search in relational databa-
ses. In VLDB, pages:670–681, 2002.
[21] HRISTIDIS, V.; GRAVANO, L.; PAPAKONSTANTINOU, Y. Efficient IR-style keyword
search over relational databases. Proceedings of the 29th VLDB Conference, p.
850–861, 2003.

Referências Bibliográficas 84
[22] KARGAR, M.; AN, A.; CERCONE, N.; GODFREY, P.; SZLICHTA, J.; YU, X. MeanKS
: Meaningful Keyword Search in Relational Databases with Complex Schema.
IEEE International Conference on Data Engineering (ICDE), p. 905–908, 2015.
[23] KUHN, H. W.; KUHN, H. W. The Hungarian Method for the Assignment Problem.
p. 29–47, 2010.
[24] LENZERINI, M. Data Integration : A Theoretical Perspective. Proceedings of the
Twenty-first ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database
Systems, p. 233–246, 2002.
[25] LI, Y.; LI, Y.; YU, C.; YU, C.; JAGADISH, H. V.; JAGADISH, H. V. Schema-free
XQuery. Proceedings of the 30th International Conference on Very Large Data
Bases, p. 72–83, 2004.
[26] MCKINSEY & COMPANY. Big data: The next frontier for innovation, competition,
and productivity. McKinsey Global Institute, (June):156, 2011.
[27] MENG, X.; CAO, L.; ZHANG, X.; SHAO, J. Top-k coupled keyword recommen-
dation for relational keyword queries. Knowledge and Information Systems,
50(3):883–916, 2017.
[28] MILLER, G. A. Wordnet: a lexical database for english. Communications of the
ACM, 38(11):39–41, 1995.
[29] MOTL, J.; SCHULTE, O. The ctu prague relational learning repository. arXiv
preprint arXiv:1511.03086, 2015.
[30] NANDI, A.; JAGADISH, H. V. Assisted querying using instant-response interfa-
ces. Sigmod, p. 1156, 2007.
[31] NIWATTANAKUL, S.; SINGTHONGCHAI, J.; NAENUDORN, E.; WANAPU, S. Using of
jaccard coefficient for keywords similarity. In: Proceedings of the International
MultiConference of Engineers and Computer Scientists, volume 1, 2013.
[32] NOROUZI, M.; FLEET, D. J.; SALAKHUTDINOV, R. R. Hamming distance metric
learning. In: Advances in neural information processing systems, p. 1061–1069,
2012.
[33] ORACLE. Java standard edition 8. http://www.oracle.com/technetwork/pt/
java/javase/overview/index.html, aug 2017.
[34] PU, K. Q. Keyword Query Cleaning. p. 909–920, 2008.

Referências Bibliográficas 85
[35] PU, K. Q.; YU, X. Keyword query cleaning. Proceedings of the VLDB Endowment,
1(1):909–920, 2008.
[36] RAMADA, M. S.; DA SILVA, J. C.; DE SÁ LEITAO-JÚNIOR, P. A method for semantic
analysis of keyword-based queries to access information in web databases. In:
Proceedings of the 13th International Conference. IADIS, 2014.
[37] SHEKARPOUR, S.; MARX, E.; NGOMO, A.-C. N. SINA : Semantic Interpretation of
User Queries for Question Answering on Interlinked Data. 2014.
[38] SILVA, J. D.; KOWATA, E.; VINCENZI, A. Extracting and exposing relational
database metadata on the web. In: Proceedings of IADIS International Conference
WWW/Internet, p. 35–42, 2012.
[39] SOLID IT. Db-engines ranking of relational dbms. http://https://db-
engines.com/en/ranking, oct 2017.
[40] SWAN, M. Philosophy of big data: Expanding the human-data relation with
big data science services. In: Big Data Computing Service and Applications
(BigDataService), 2015 IEEE First International Conference on, p. 468–477. IEEE,
2015.
[41] TATA, S.; LOHMAN, G. M. SQAK: Doing More with Keywords. Proceedings of the
2008 ACM SIGMOD international conference on Management of data - SIGMOD ’08,
p. 889, 2008.
[42] YU, J. X.; QIN, L.; CHANG, L. Keyword Search in Relational Databases : A Survey
Schema-Based Keyword Search on Relational Databases. Discover, p. 1–12,
2010.
[43] ZENG, Z.; BAO, Z.; LE, T. N.; LEE, M. L.; LING, W. T. ExpressQ: Identifying
Keyword Context and Search Target in Relational Keyword Queries. Procee-
dings of the 23rd ACM International Conference on Conference on Information and
Knowledge Management - CIKM ’14, p. 31–40, 2014.
[44] ZENG, Z.; BAO, Z.; LEE, M. L.; LING, T. W. A Semantic Approach to Keyword
Search over Relational Databases. In: 32th International Conference, ER, p. 241–
254. 2013.

APÊNDICE ABancos de Dados Utilizados na Avaliação
Foram utilizados 3 (três) bancos de dados na avaliação dos sistemas descritosneste trabalho. A criação dos Esquemas Lógicos apresentados neste apêndice foramgerados através da ferramenta MySQL Workbench, bem como a exportação dos scripts
SQL.
A.1 DBLP
A.1.1 Esquema Lógico
Figura A.1: DBLP

Apêndice A 87
A.1.2 Esquema Físico
CREATE DATABASE ‘dblp‘;
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘inproceeding‘
--
CREATE TABLE ‘inproceeding‘ (
‘InProceedingId‘ int(11) NOT NULL,
‘Title‘ varchar(255) NOT NULL DEFAULT ’’,
‘Pages‘ varchar(15) DEFAULT NULL,
‘Url‘ varchar(255) DEFAULT NULL,
‘ProceedingId‘ int(11) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘author‘
--
CREATE TABLE ‘author‘ (
‘AuthorId‘ int(11) NOT NULL,
‘Name‘ varchar(255) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘proceeding‘
--
CREATE TABLE ‘proceeding‘ (
‘ProceedingId‘ int(11) NOT NULL,
‘Title‘ varchar(255) NOT NULL DEFAULT ’’,
‘EditorId‘ int(11) DEFAULT NULL,
‘PublisherId‘ int(11) DEFAULT NULL,

Apêndice A 88
‘SeriesId‘ int(11) DEFAULT NULL,
‘Year‘ varchar(15) NOT NULL DEFAULT ’’,
‘ISBN‘ varchar(15) DEFAULT NULL,
‘Url‘ varchar(255) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘publisher‘
--
CREATE TABLE ‘publisher‘ (
‘PublisherId‘ int(11) NOT NULL,
‘Name‘ varchar(255) NOT NULL DEFAULT ’’
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘relationauthorinproceeding‘
--
CREATE TABLE ‘relationauthorinproceeding‘ (
‘authorId‘ int(11) NOT NULL DEFAULT ’0’,
‘InProceedingId‘ int(11) NOT NULL DEFAULT ’0’
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘series‘
--
CREATE TABLE ‘series‘ (
‘SeriesId‘ int(11) NOT NULL,
‘Title‘ varchar(255) NOT NULL DEFAULT ’’,
‘Url‘ varchar(255) DEFAULT NULL

Apêndice A 89
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
ALTER TABLE ‘inproceeding‘
ADD PRIMARY KEY (‘InProceedingId‘),
ADD KEY ‘ProceedingId‘ (‘ProceedingId‘);
ALTER TABLE ‘author‘
ADD PRIMARY KEY (‘authorId‘);
ALTER TABLE ‘proceeding‘
ADD PRIMARY KEY (‘ProceedingId‘),
ADD KEY ‘EditorId‘ (‘EditorId‘),
ADD KEY ‘PublisherId‘ (‘PublisherId‘),
ADD KEY ‘SeriesId‘ (‘SeriesId‘);
ALTER TABLE ‘publisher‘
ADD PRIMARY KEY (‘PublisherId‘);
ALTER TABLE ‘relationauthorinproceeding‘
ADD PRIMARY KEY (‘authorId‘,‘InProceedingId‘),
ADD KEY ‘InProceedingId‘ (‘InProceedingId‘);
ALTER TABLE ‘series‘
ADD PRIMARY KEY (‘SeriesId‘);
ALTER TABLE ‘inproceeding‘
MODIFY ‘InProceedingId‘ int(11) NOT NULL AUTO_INCREMENT;
ALTER TABLE ‘author‘
MODIFY ‘authorId‘ int(11) NOT NULL AUTO_INCREMENT;
ALTER TABLE ‘proceeding‘
MODIFY ‘ProceedingId‘ int(11) NOT NULL AUTO_INCREMENT;
ALTER TABLE ‘publisher‘
MODIFY ‘PublisherId‘ int(11) NOT NULL AUTO_INCREMENT;

Apêndice A 90
ALTER TABLE ‘series‘
MODIFY ‘SeriesId‘ int(11) NOT NULL AUTO_INCREMENT;
ALTER TABLE ‘inproceeding‘
ADD CONSTRAINT ‘inproceeding_ibfk_1‘ FOREIGN KEY (‘ProceedingId‘)
REFERENCES ‘proceeding‘ (‘ProceedingId‘);
ALTER TABLE ‘proceeding‘
ADD CONSTRAINT ‘proceeding_ibfk_1‘ FOREIGN KEY (‘SeriesId‘)
REFERENCES ‘series‘ (‘SeriesId‘),
ADD CONSTRAINT ‘proceeding_ibfk_2‘ FOREIGN KEY (‘PublisherId‘)
REFERENCES ‘publisher‘ (‘PublisherId‘),
ADD CONSTRAINT ‘proceeding_ibfk_3‘ FOREIGN KEY (‘EditorId‘)
REFERENCES ‘author‘ (‘authorId‘);
ALTER TABLE ‘relationauthorinproceeding‘
ADD CONSTRAINT ‘relationauthorinproceeding_ibfk_1‘ FOREIGN KEY
(‘authorId‘) REFERENCES ‘author‘ (‘authorId‘),
ADD CONSTRAINT ‘relationauthorinproceeding_ibfk_2‘ FOREIGN KEY
(‘InProceedingId‘) REFERENCES ‘inproceeding‘ (‘InProceedingId‘);
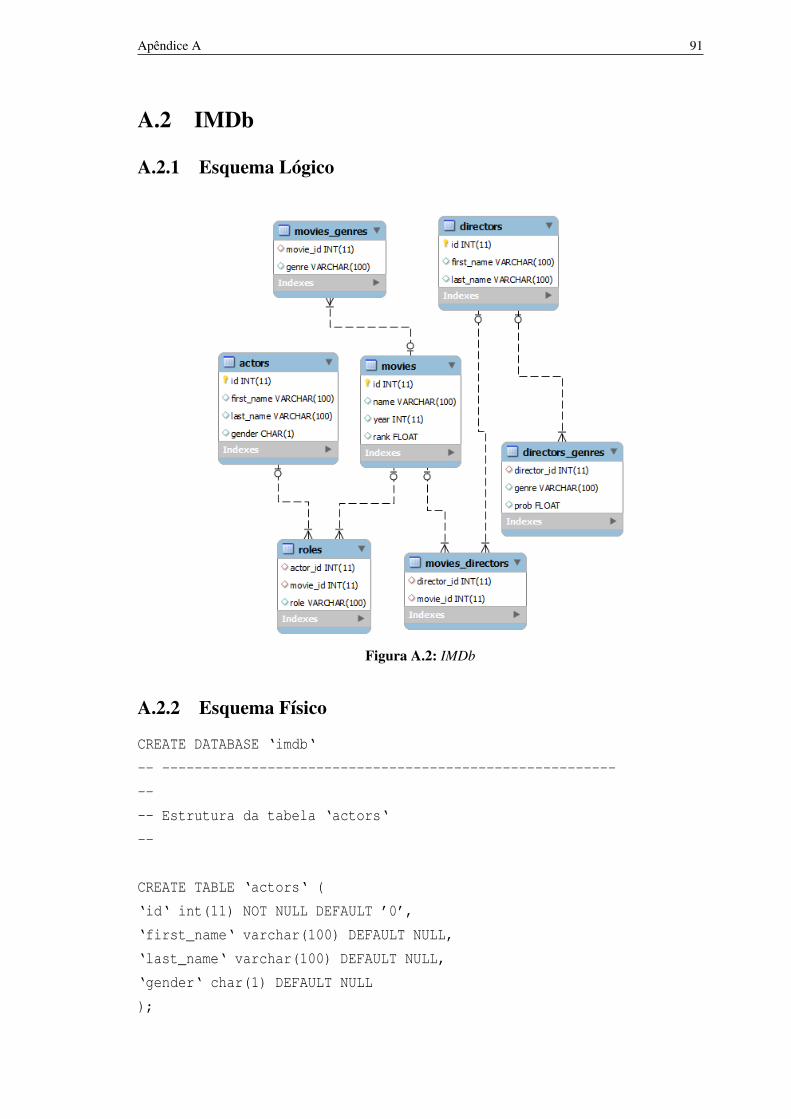
Apêndice A 91
A.2 IMDb
A.2.1 Esquema Lógico
Figura A.2: IMDb
A.2.2 Esquema Físico
CREATE DATABASE ‘imdb‘
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘actors‘
--
CREATE TABLE ‘actors‘ (
‘id‘ int(11) NOT NULL DEFAULT ’0’,
‘first_name‘ varchar(100) DEFAULT NULL,
‘last_name‘ varchar(100) DEFAULT NULL,
‘gender‘ char(1) DEFAULT NULL
);

Apêndice A 92
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘directors‘
--
CREATE TABLE ‘directors‘ (
‘id‘ int(11) NOT NULL DEFAULT ’0’,
‘first_name‘ varchar(100) DEFAULT NULL,
‘last_name‘ varchar(100) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘directors_genres‘
--
CREATE TABLE ‘directors_genres‘ (
‘director_id‘ int(11) DEFAULT NULL,
‘genre‘ varchar(100) DEFAULT NULL,
‘prob‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘movies‘
--
CREATE TABLE ‘movies‘ (
‘id‘ int(11) NOT NULL DEFAULT ’0’,
‘name‘ varchar(100) DEFAULT NULL,
‘year‘ int(11) DEFAULT NULL,
‘rank‘ float DEFAULT NULL
);

Apêndice A 93
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘movies_directors‘
--
CREATE TABLE ‘movies_directors‘ (
‘director_id‘ int(11) DEFAULT NULL,
‘movie_id‘ int(11) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘movies_genres‘
--
CREATE TABLE ‘movies_genres‘ (
‘movie_id‘ int(11) DEFAULT NULL,
‘genre‘ varchar(100) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘roles‘
--
CREATE TABLE ‘roles‘ (
‘actor_id‘ int(11) DEFAULT NULL,
‘movie_id‘ int(11) DEFAULT NULL,
‘role‘ varchar(100) DEFAULT NULL
);
-- --------------------------------------------------------
ALTER TABLE ‘actors‘
ADD PRIMARY KEY (‘id‘),

Apêndice A 94
ADD KEY ‘actors_first_name‘ (‘first_name‘),
ADD KEY ‘actors_last_name‘ (‘last_name‘);
ALTER TABLE ‘directors‘
ADD PRIMARY KEY (‘id‘),
ADD KEY ‘directors_first_name‘ (‘first_name‘),
ADD KEY ‘directors_last_name‘ (‘last_name‘);
ALTER TABLE ‘directors_genres‘
ADD KEY ‘directors_genres_director_id‘ (‘director_id‘);
ALTER TABLE ‘movies‘
ADD PRIMARY KEY (‘id‘),
ADD KEY ‘movies_name‘ (‘name‘);
ALTER TABLE ‘movies_directors‘
ADD KEY ‘movies_directors_director_id‘ (‘director_id‘),
ADD KEY ‘movies_directors_movie_id‘ (‘movie_id‘);
ALTER TABLE ‘movies_genres‘
ADD KEY ‘movies_genres_movie_id‘ (‘movie_id‘);
ALTER TABLE ‘roles‘
ADD KEY ‘roles_actor_id‘ (‘actor_id‘),
ADD KEY ‘roles_movie_id‘ (‘movie_id‘),
ADD KEY ‘roles_role‘ (‘role‘);
ALTER TABLE ‘directors_genres‘
ADD CONSTRAINT ‘directors_genres_ibfk_1‘ FOREIGN KEY (‘director_id‘)
REFERENCES ‘directors‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘movies_directors‘
ADD CONSTRAINT ‘movies_directors_ibfk_1‘ FOREIGN KEY (‘director_id‘)
REFERENCES ‘directors‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘movies_directors_ibfk_2‘ FOREIGN KEY (‘movie_id‘)
REFERENCES ‘movies‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘movies_genres‘

Apêndice A 95
ADD CONSTRAINT ‘movies_genres_ibfk_1‘ FOREIGN KEY (‘movie_id‘)
REFERENCES ‘movies‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘roles‘
ADD CONSTRAINT ‘roles_ibfk_1‘ FOREIGN KEY (‘actor_id‘) REFERENCES
‘actors‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘roles_ibfk_2‘ FOREIGN KEY (‘movie_id‘) REFERENCES
‘movies‘ (‘id‘) ON DELETE CASCADE ON UPDATE CASCADE;
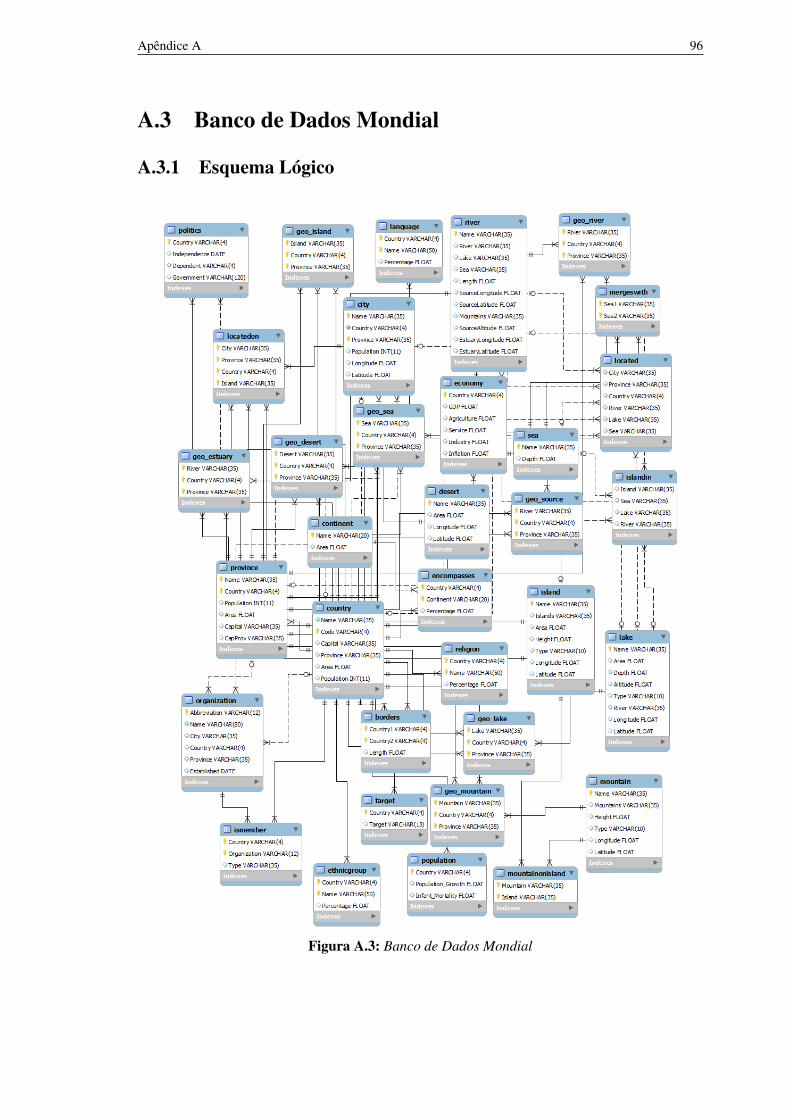
Apêndice A 96
A.3 Banco de Dados Mondial
A.3.1 Esquema Lógico
Figura A.3: Banco de Dados Mondial

Apêndice A 97
A.3.2 Esquema Físico
CREATE DATABASE ‘mondial‘;
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘borders‘
--
CREATE TABLE ‘borders‘ (
‘Country1‘ varchar(4) NOT NULL DEFAULT ’’,
‘Country2‘ varchar(4) NOT NULL DEFAULT ’’,
‘Length‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘city‘
--
CREATE TABLE ‘city‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’,
‘Population‘ int(11) DEFAULT NULL,
‘Longitude‘ float DEFAULT NULL,
‘Latitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘continent‘
--
CREATE TABLE ‘continent‘ (

Apêndice A 98
‘Name‘ varchar(20) NOT NULL DEFAULT ’’,
‘Area‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘country‘
--
CREATE TABLE ‘country‘ (
‘Name‘ varchar(35) NOT NULL,
‘Code‘ varchar(4) NOT NULL DEFAULT ’’,
‘Capital‘ varchar(35) DEFAULT NULL,
‘Province‘ varchar(35) DEFAULT NULL,
‘Area‘ float DEFAULT NULL,
‘Population‘ int(11) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘desert‘
--
CREATE TABLE ‘desert‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Area‘ float DEFAULT NULL,
‘Longitude‘ float DEFAULT NULL,
‘Latitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘economy‘
--

Apêndice A 99
CREATE TABLE ‘economy‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘GDP‘ float DEFAULT NULL,
‘Agriculture‘ float DEFAULT NULL,
‘Service‘ float DEFAULT NULL,
‘Industry‘ float DEFAULT NULL,
‘Inflation‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘encompasses‘
--
CREATE TABLE ‘encompasses‘ (
‘Country‘ varchar(4) NOT NULL,
‘Continent‘ varchar(20) NOT NULL,
‘Percentage‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘ethnicgroup‘
--
CREATE TABLE ‘ethnicgroup‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Name‘ varchar(50) NOT NULL DEFAULT ’’,
‘Percentage‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_desert‘
--

Apêndice A 100
CREATE TABLE ‘geo_desert‘ (
‘Desert‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_estuary‘
--
CREATE TABLE ‘geo_estuary‘ (
‘River‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_island‘
--
CREATE TABLE ‘geo_island‘ (
‘Island‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_lake‘
--
CREATE TABLE ‘geo_lake‘ (

Apêndice A 101
‘Lake‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_mountain‘
--
CREATE TABLE ‘geo_mountain‘ (
‘Mountain‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_river‘
--
CREATE TABLE ‘geo_river‘ (
‘River‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_sea‘
--
CREATE TABLE ‘geo_sea‘ (
‘Sea‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,

Apêndice A 102
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘geo_source‘
--
CREATE TABLE ‘geo_source‘ (
‘River‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘island‘
--
CREATE TABLE ‘island‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Islands‘ varchar(35) DEFAULT NULL,
‘Area‘ float DEFAULT NULL,
‘Height‘ float DEFAULT NULL,
‘Type‘ varchar(10) DEFAULT NULL,
‘Longitude‘ float DEFAULT NULL,
‘Latitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘islandin‘
--
CREATE TABLE ‘islandin‘ (

Apêndice A 103
‘Island‘ varchar(35) DEFAULT NULL,
‘Sea‘ varchar(35) DEFAULT NULL,
‘Lake‘ varchar(35) DEFAULT NULL,
‘River‘ varchar(35) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘ismember‘
--
CREATE TABLE ‘ismember‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Organization‘ varchar(12) NOT NULL DEFAULT ’’,
‘Type‘ varchar(35) DEFAULT ’member’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘lake‘
--
CREATE TABLE ‘lake‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Area‘ float DEFAULT NULL,
‘Depth‘ float DEFAULT NULL,
‘Altitude‘ float DEFAULT NULL,
‘Type‘ varchar(10) DEFAULT NULL,
‘River‘ varchar(35) DEFAULT NULL,
‘Longitude‘ float DEFAULT NULL,
‘Latitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--

Apêndice A 104
-- Estrutura da tabela ‘language‘
--
CREATE TABLE ‘language‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Name‘ varchar(50) NOT NULL DEFAULT ’’,
‘Percentage‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘located‘
--
CREATE TABLE ‘located‘ (
‘City‘ varchar(35) DEFAULT NULL,
‘Province‘ varchar(35) DEFAULT NULL,
‘Country‘ varchar(4) DEFAULT NULL,
‘River‘ varchar(35) DEFAULT NULL,
‘Lake‘ varchar(35) DEFAULT NULL,
‘Sea‘ varchar(35) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘locatedon‘
--
CREATE TABLE ‘locatedon‘ (
‘City‘ varchar(35) NOT NULL DEFAULT ’’,
‘Province‘ varchar(35) NOT NULL DEFAULT ’’,
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Island‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------

Apêndice A 105
--
-- Estrutura da tabela ‘mergeswith‘
--
CREATE TABLE ‘mergeswith‘ (
‘Sea1‘ varchar(35) NOT NULL DEFAULT ’’,
‘Sea2‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘mountain‘
--
CREATE TABLE ‘mountain‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Mountains‘ varchar(35) DEFAULT NULL,
‘Height‘ float DEFAULT NULL,
‘Type‘ varchar(10) DEFAULT NULL,
‘Longitude‘ float DEFAULT NULL,
‘Latitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘mountainonisland‘
--
CREATE TABLE ‘mountainonisland‘ (
‘Mountain‘ varchar(35) NOT NULL DEFAULT ’’,
‘Island‘ varchar(35) NOT NULL DEFAULT ’’
);
-- --------------------------------------------------------

Apêndice A 106
--
-- Estrutura da tabela ‘organization‘
--
CREATE TABLE ‘organization‘ (
‘Abbreviation‘ varchar(12) NOT NULL,
‘Name‘ varchar(80) NOT NULL,
‘City‘ varchar(35) DEFAULT NULL,
‘Country‘ varchar(4) DEFAULT NULL,
‘Province‘ varchar(35) DEFAULT NULL,
‘Established‘ date DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘politics‘
--
CREATE TABLE ‘politics‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Independence‘ date DEFAULT NULL,
‘Dependent‘ varchar(4) DEFAULT NULL,
‘Government‘ varchar(120) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘population‘
--
CREATE TABLE ‘population‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Population_Growth‘ float DEFAULT NULL,
‘Infant_Mortality‘ float DEFAULT NULL
);

Apêndice A 107
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘province‘
--
CREATE TABLE ‘province‘ (
‘Name‘ varchar(35) NOT NULL,
‘Country‘ varchar(4) NOT NULL,
‘Population‘ int(11) DEFAULT NULL,
‘Area‘ float DEFAULT NULL,
‘Capital‘ varchar(35) DEFAULT NULL,
‘CapProv‘ varchar(35) DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘religion‘
--
CREATE TABLE ‘religion‘ (
‘Country‘ varchar(4) NOT NULL DEFAULT ’’,
‘Name‘ varchar(50) NOT NULL DEFAULT ’’,
‘Percentage‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘river‘
--
CREATE TABLE ‘river‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘River‘ varchar(35) DEFAULT NULL,
‘Lake‘ varchar(35) DEFAULT NULL,
‘Sea‘ varchar(35) DEFAULT NULL,

Apêndice A 108
‘Length‘ float DEFAULT NULL,
‘SourceLongitude‘ float DEFAULT NULL,
‘SourceLatitude‘ float DEFAULT NULL,
‘Mountains‘ varchar(35) DEFAULT NULL,
‘SourceAltitude‘ float DEFAULT NULL,
‘EstuaryLongitude‘ float DEFAULT NULL,
‘EstuaryLatitude‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘sea‘
--
CREATE TABLE ‘sea‘ (
‘Name‘ varchar(35) NOT NULL DEFAULT ’’,
‘Depth‘ float DEFAULT NULL
);
-- --------------------------------------------------------
--
-- Estrutura da tabela ‘target‘
--
CREATE TABLE ‘target‘ (
‘Country‘ varchar(4) NOT NULL,
‘Target‘ varchar(13) DEFAULT NULL
);
-- ---------------------------------------------------------
ALTER TABLE ‘borders‘
ADD PRIMARY KEY (‘Country1‘,‘Country2‘),
ADD KEY ‘ix_city_Country2‘ (‘Country2‘),
ADD KEY ‘ix_city_Country1‘ (‘Country1‘);

Apêndice A 109
ALTER TABLE ‘city‘
ADD PRIMARY KEY (‘Name‘,‘Province‘),
ADD KEY ‘ix_city_Country‘ (‘Country‘),
ADD KEY ‘ix_city_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘continent‘
ADD PRIMARY KEY (‘Name‘);
ALTER TABLE ‘country‘
ADD PRIMARY KEY (‘Code‘),
ADD UNIQUE KEY ‘ix_county_Name‘ (‘Name‘);
ALTER TABLE ‘desert‘
ADD PRIMARY KEY (‘Name‘);
ALTER TABLE ‘economy‘
ADD PRIMARY KEY (‘Country‘);
ALTER TABLE ‘encompasses‘
ADD PRIMARY KEY (‘Country‘,‘Continent‘),
ADD KEY ‘ix_encompasses_Continent‘ (‘Continent‘);
ALTER TABLE ‘ethnicgroup‘
ADD PRIMARY KEY (‘Name‘,‘Country‘),
ADD KEY ‘ix_ethnicGroup_Country‘ (‘Country‘);
ALTER TABLE ‘geo_desert‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘Desert‘),
ADD KEY ‘ix_geo_desert_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_desert_Desert‘ (‘Desert‘),
ADD KEY ‘ix_geo_desert_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_estuary‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘River‘),
ADD KEY ‘ix_geo_estuary_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_estuary_River‘ (‘River‘),
ADD KEY ‘ix_geo_estuary_Province‘ (‘Province‘,‘Country‘);

Apêndice A 110
ALTER TABLE ‘geo_island‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘Island‘),
ADD KEY ‘ix_geo_island_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_island_Island‘ (‘Island‘),
ADD KEY ‘ix_geo_island_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_lake‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘Lake‘),
ADD KEY ‘ix_geo_lake_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_lake_Lake‘ (‘Lake‘),
ADD KEY ‘ix_geo_lake_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_mountain‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘Mountain‘),
ADD KEY ‘ix_geo_mountain_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_mountain_Mountain‘ (‘Mountain‘),
ADD KEY ‘ix_geo_mountain_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_river‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘River‘),
ADD KEY ‘ix_geo_river_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_river_River‘ (‘River‘),
ADD KEY ‘ix_geo_river_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_sea‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘Sea‘),
ADD KEY ‘ix_geo_sea_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_sea_Sea‘ (‘Sea‘),
ADD KEY ‘ix_geo_sea_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘geo_source‘
ADD PRIMARY KEY (‘Province‘,‘Country‘,‘River‘),
ADD KEY ‘ix_geo_source_Country‘ (‘Country‘),
ADD KEY ‘ix_geo_source_River‘ (‘River‘),
ADD KEY ‘ix_geo_source_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘island‘
ADD PRIMARY KEY (‘Name‘),

Apêndice A 111
ADD KEY ‘ix_island_Islands‘ (‘Islands‘);
ALTER TABLE ‘islandin‘
ADD KEY ‘ix_islandIn_Lake‘ (‘Lake‘),
ADD KEY ‘ix_islandIn_River‘ (‘River‘),
ADD KEY ‘ix_islandIn_Sea‘ (‘Sea‘),
ADD KEY ‘ix_islandIn_Island‘ (‘Island‘);
ALTER TABLE ‘ismember‘
ADD PRIMARY KEY (‘Country‘,‘Organization‘),
ADD KEY ‘ix_isMember_Organization‘ (‘Organization‘);
ALTER TABLE ‘lake‘
ADD PRIMARY KEY (‘Name‘);
ALTER TABLE ‘language‘
ADD PRIMARY KEY (‘Name‘,‘Country‘),
ADD KEY ‘ix_language_Country‘ (‘Country‘);
ALTER TABLE ‘located‘
ADD KEY ‘ix_located_Country‘ (‘Country‘),
ADD KEY ‘ix_located_River‘ (‘River‘),
ADD KEY ‘ix_located_Lake‘ (‘Lake‘),
ADD KEY ‘ix_located_Sea‘ (‘Sea‘),
ADD KEY ‘ix_located_City‘ (‘City‘,‘Province‘),
ADD KEY ‘ix_located_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘locatedon‘
ADD PRIMARY KEY (‘City‘,‘Province‘,‘Country‘,‘Island‘),
ADD KEY ‘ix_locatedOn_Country‘ (‘Country‘),
ADD KEY ‘ix_locatedOn_Island‘ (‘Island‘),
ADD KEY ‘ix_locatedOn_Province‘ (‘Province‘),
ADD KEY ‘Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘mergeswith‘
ADD PRIMARY KEY (‘Sea1‘,‘Sea2‘),
ADD KEY ‘ix_mergeWith_Sea2‘ (‘Sea2‘);

Apêndice A 112
ALTER TABLE ‘mountain‘
ADD PRIMARY KEY (‘Name‘),
ADD KEY ‘ix_mountain_Mountains‘ (‘Mountains‘);
ALTER TABLE ‘mountainonisland‘
ADD PRIMARY KEY (‘Mountain‘,‘Island‘),
ADD KEY ‘ix_mountainOnIsland_Island‘ (‘Island‘);
ALTER TABLE ‘organization‘
ADD PRIMARY KEY (‘Abbreviation‘),
ADD UNIQUE KEY ‘ix_organization_OrgNameUnique‘ (‘Name‘),
ADD KEY ‘ix_organization_Country‘ (‘Country‘),
ADD KEY ‘ix_organization_City‘ (‘City‘,‘Province‘),
ADD KEY ‘ix_organization_Province‘ (‘Province‘,‘Country‘);
ALTER TABLE ‘politics‘
ADD PRIMARY KEY (‘Country‘),
ADD KEY ‘ix_politics_Dependent‘ (‘Dependent‘);
ALTER TABLE ‘population‘
ADD PRIMARY KEY (‘Country‘);
ALTER TABLE ‘province‘
ADD PRIMARY KEY (‘Name‘,‘Country‘),
ADD KEY ‘ix_province_Country‘ (‘Country‘);
ALTER TABLE ‘religion‘
ADD PRIMARY KEY (‘Name‘,‘Country‘),
ADD KEY ‘ix_religion_Country‘ (‘Country‘);
ALTER TABLE ‘river‘
ADD PRIMARY KEY (‘Name‘),
ADD KEY ‘ix_river_Lake‘ (‘Lake‘),
ADD KEY ‘ix_river_River‘ (‘River‘),
ADD KEY ‘ix_river_Sea‘ (‘Sea‘),
ADD KEY ‘ix_river_Mountains‘ (‘Mountains‘);
ALTER TABLE ‘sea‘

Apêndice A 113
ADD PRIMARY KEY (‘Name‘);
ALTER TABLE ‘target‘
ADD PRIMARY KEY (‘Country‘);
ALTER TABLE ‘borders‘
ADD CONSTRAINT ‘borders_ibfk_1‘ FOREIGN KEY (‘Country1‘) REFERENCES
‘country‘ (‘Code‘),
ADD CONSTRAINT ‘borders_ibfk_2‘ FOREIGN KEY (‘Country2‘) REFERENCES
‘country‘ (‘Code‘);
ALTER TABLE ‘city‘
ADD CONSTRAINT ‘city_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘city_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE;
ALTER TABLE ‘economy‘
ADD CONSTRAINT ‘economy_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘encompasses‘
ADD CONSTRAINT ‘encompasses_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘encompasses_ibfk_2‘ FOREIGN KEY (‘Continent‘) REFERENCES
‘continent‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘ethnicgroup‘
ADD CONSTRAINT ‘ethnicGroup_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_desert‘
ADD CONSTRAINT ‘geo_desert_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_desert_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,

Apêndice A 114
ADD CONSTRAINT ‘geo_desert_ibfk_3‘ FOREIGN KEY (‘Desert‘) REFERENCES
‘desert‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_estuary‘
ADD CONSTRAINT ‘geo_estuary_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_estuary_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_estuary_ibfk_3‘ FOREIGN KEY (‘River‘) REFERENCES
‘river‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_island‘
ADD CONSTRAINT ‘geo_island_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_island_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE ON
UPDATE CASCADE,
ADD CONSTRAINT ‘geo_island_ibfk_3‘ FOREIGN KEY (‘Island‘) REFERENCES
‘island‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_lake‘
ADD CONSTRAINT ‘geo_lake_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_lake_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_lake_ibfk_3‘ FOREIGN KEY (‘Lake‘) REFERENCES
‘lake‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_mountain‘
ADD CONSTRAINT ‘geo_mountain_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_mountain_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_mountain_ibfk_3‘ FOREIGN KEY (‘Mountain‘) REFERENCES
‘mountain‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;

Apêndice A 115
ALTER TABLE ‘geo_river‘
ADD CONSTRAINT ‘geo_river_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_river_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_river_ibfk_3‘ FOREIGN KEY (‘River‘) REFERENCES
‘river‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_sea‘
ADD CONSTRAINT ‘geo_sea_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_sea_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_sea_ibfk_3‘ FOREIGN KEY (‘Sea‘) REFERENCES
‘sea‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘geo_source‘
ADD CONSTRAINT ‘geo_source_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_source_ibfk_2‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘geo_source_ibfk_3‘ FOREIGN KEY (‘River‘) REFERENCES
‘river‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘islandin‘
ADD CONSTRAINT ‘islandIn_ibfk_1‘ FOREIGN KEY (‘Lake‘) REFERENCES
‘lake‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘islandIn_ibfk_2‘ FOREIGN KEY (‘River‘) REFERENCES
‘river‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘islandIn_ibfk_3‘ FOREIGN KEY (‘Sea‘) REFERENCES
‘sea‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘islandIn_ibfk_4‘ FOREIGN KEY (‘Island‘) REFERENCES
‘island‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;

Apêndice A 116
ALTER TABLE ‘ismember‘
ADD CONSTRAINT ‘isMember_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘isMember_ibfk_2‘ FOREIGN KEY (‘Organization‘)
REFERENCES ‘organization‘ (‘Abbreviation‘) ON DELETE CASCADE
ON UPDATE CASCADE;
ALTER TABLE ‘language‘
ADD CONSTRAINT ‘language_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘located‘
ADD CONSTRAINT ‘located_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘located_ibfk_2‘ FOREIGN KEY (‘City‘,‘Province‘)
REFERENCES ‘city‘ (‘Name‘, ‘Province‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘located_ibfk_3‘ FOREIGN KEY (‘River‘) REFERENCES
‘river‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘located_ibfk_4‘ FOREIGN KEY (‘Lake‘) REFERENCES
‘lake‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘located_ibfk_5‘ FOREIGN KEY (‘Sea‘) REFERENCES
‘sea‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘located_ibfk_6‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE;
ALTER TABLE ‘locatedon‘
ADD CONSTRAINT ‘locatedOn_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘locatedOn_ibfk_2‘ FOREIGN KEY (‘Island‘) REFERENCES
‘island‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘locatedOn_ibfk_3‘ FOREIGN KEY (‘City‘,‘Province‘)
REFERENCES ‘city‘ (‘Name‘, ‘Province‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘locatedOn_ibfk_4‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE;

Apêndice A 117
ALTER TABLE ‘mergeswith‘
ADD CONSTRAINT ‘mergesWith_ibfk_1‘ FOREIGN KEY (‘Sea1‘) REFERENCES
‘sea‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘mergesWith_ibfk_2‘ FOREIGN KEY (‘Sea2‘) REFERENCES
‘sea‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘mountainonisland‘
ADD CONSTRAINT ‘mountainOnIsland_ibfk_1‘ FOREIGN KEY (‘Island‘)
REFERENCES ‘island‘ (‘Name‘) ON DELETE CASCADE ON
UPDATE CASCADE,
ADD CONSTRAINT ‘mountainOnIsland_ibfk_2‘ FOREIGN KEY (‘Mountain‘)
REFERENCES ‘mountain‘ (‘Name‘) ON DELETE CASCADE ON
UPDATE CASCADE;
ALTER TABLE ‘organization‘
ADD CONSTRAINT ‘organization_ibfk_1‘ FOREIGN KEY (‘Country‘)
REFERENCES ‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘organization_ibfk_2‘ FOREIGN KEY (‘City‘,‘Province‘)
REFERENCES ‘city‘ (‘Name‘, ‘Province‘) ON DELETE CASCADE
ON UPDATE CASCADE,
ADD CONSTRAINT ‘organization_ibfk_3‘ FOREIGN KEY (‘Province‘,‘Country‘)
REFERENCES ‘province‘ (‘Name‘, ‘Country‘) ON DELETE CASCADE
ON UPDATE CASCADE;
ALTER TABLE ‘politics‘
ADD CONSTRAINT ‘politics_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT ‘politics_ibfk_2‘ FOREIGN KEY (‘Dependent‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘population‘
ADD CONSTRAINT ‘population_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘province‘
ADD CONSTRAINT ‘province_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;

Apêndice A 118
ALTER TABLE ‘religion‘
ADD CONSTRAINT ‘religion_ibfk_1‘ FOREIGN KEY (‘Country‘) REFERENCES
‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘river‘
ADD CONSTRAINT ‘river_ibfk_1‘ FOREIGN KEY (‘Lake‘) REFERENCES
‘lake‘ (‘Name‘) ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE ‘target‘
ADD CONSTRAINT ‘target_Country_fkey‘ FOREIGN KEY (‘Country‘)
REFERENCES ‘country‘ (‘Code‘) ON DELETE CASCADE ON UPDATE CASCADE;

APÊNDICE BConsultas e Sentidos Pretendidos

Apêndice B 120
Tabela B.1: Consultas e Sentidos Pretendidos - DBLP
ID Consulta Sentido Pretendido
1 dblp informações sobre a base dblp
2 springer informações sobre o periófico springer
3 series informação sobre as series das conferências/periódicos
4 title springer informações sobre o periófico springer
5 author morgan informações sobre o autor morgan
6 author inproceeding informações sobre autores e os artigos por eles escritos
7 inproceeding title título dos artigos
8 proceeding title nome das conferências/periódicos
9 publisher name nome dos editores
10 publisher springer informações sobre o editor elsevier
11 series title titulo das series das conferências/periódicos
12 author name jacques informações sobre o autor de nome jacques
13 author id 2 informações sobre autor com id = 2
14 inproceeding year 2012 conferências do ano de 2012
15 author proceeding 2010 informações sobre autores em periódicos no ano de 2010
16 proceeding title year nome e ano dos periódicos/conferências
17 proceeding title database informações sobre periódicos/conferênciasde banco de dados
18 author name bruno informações sobre autor de nome bruno
19 author name proceeding nome dos autores e conferências/periódicos queeles participaram
20 proceeding ISBN title isbn e titulo das conferências/periódicos
21 proceeding year 1992 publisher informações sobre editores das conferências/periódicosdo ano 2000
22 author name series "computer science" nome dos atores que participarem das seriesde ciência da computação
23 author inproceeding publisher name"IEEE Computer Society" informações sobre autores que publicaram artigos
pela editora "IEEE Computer Society"
24 inproceeding title publisher name "AAAI Press" informações sobre artigos publicados pelaeditora "AAAI press"
25 proceeding year 2000 publisher "Oxford University Press" informações sobre as conferências/periódicos quepublicaram artigos pela editora "Oxford University Press"
26 author name inproceeding pages 8 nome dos autores que possuem artigos com 8 páginas
27 author name pierre proceeding year 1998 informações sobre as conferências/periódicos que o autorpierre publicou no ano de 1998
28 series title information proceeding year 2005 informações sobre series com título "information"de conferências/periódicos do ano 2005
29 author name inproceeding title proceeding title publisher nome dos autores, titulos dos artigos publicados poreles nas conferências/periódicos de 2011
30 author name patrick inproceeding title proceedingyear 2011 titulos dos artigos publicados pelo autor patrick nas
conferências/periódicos de 2011

Apêndice B 121
Tabela B.2: Consultas e Sentidos Pretendidos - IMDb
ID Consulta Sentido
1 titanic informações sobre o titanic
2 "beyond titanic" informações sobre o filme beyond titanic
3 movies name nome dos filmes
4 movie titanic informações sobre o filme titanic
5 movie max informações sobre o filme max
6 movie name higher informações sobre o filme higher
7 movies genres drama informações sobre os filmes de gênero drama
8 movie name higher rank o nome do filme com maior rank | O rank do filme de nome higher
9 movies year 2000 higher rank filme lançado no ano 2000 com maior pontuação
10 movie titanic director diretor do filme titanic
11 movie "spider man"genre gêneros cinematográficos que o filme ’spider man’ se enquadra
12 movie titanic actors atores que atuaram no filme titanic
13 actors movie titanic atores que atuaram no filme titanic
14 movie name "independece day"type qual o tipo do filme independence day
15 movie name ’independence day’ genre qual o gênero do filme independency day
16 actors name movie year 2000 nome dos atores que atuaram nos filmes lançados no ano 2000
17 movies name actor tom nome dos filmes que o ator tom cruise atuou
18 actor "jackie chan"movies year 2000 filmes lançados no ano 2000 que o ator jackie chan participou
19 actor "leonardo dicaprio"movies filmes que o ator leonardo dicaprio atuou
20 actor leonardo movies year 2000 filmes lançados no ano 2000 nos quais o ator leonardo participou
21 movie diretor spilberg actor leonardo filmes dirigidos por spilberg nos quais o ator LeonardoDicaprio atuou
22 movies name genre comedy year 1989 nome dos filmes do gênero comédia que foram lançadosno ano de 1989
23 documentary year 2012 documentários que foram lançados no ano de 2012
24 comedy movies actor jim carrey filmes de comédia em que o ator jim carey participou
25 drama movies name actors m year 1995 atores do sexo masculino que atuaram em filmes de dramano ano de 1995
26 quentin tarantino action movies 1998 filmes de ação lançados em 1998 e que foram dirigidospor Quentin Tarantino
27 actors name gender f drama movies year 1990 atrizes que atuaram em filmes de drama no ano de 1990
28 actors name gender f drama genre movies year 1990 atrizes que atuaram em filmes de drama no ano de 1991
29 actors name action movies director quentin nome dos atores que atuaram nos filmes dirigidospelo diretor quentin
30 genres movies name year 1950 gênero e nome dos filmes lançados no ano de 1950

Apêndice B 122
Tabela B.3: Consultas e Sentidos Pretendidos - Mondial Database
ID Consulta Sentido
1 brazil informações acerca do brasil
2 country name nome de todos os países
3 country capital nome de todas as capitais de todos os países
4 country china informações sobre o país de nome china
5 country province informações sobre países e províncias
6 country china province. informações sobre os estados da china
7 country brazil amazonas informações sobre o Estado do Amazonas do País Brasil |informações sobre o rio amazonas do brasil
8 country brazil river informações sobre os rios do brasil
9 country brazil lake informações sobre os lagos do brasil
10 continent america country informações sobre os países do continente americano
11 country province city informações sobre países estados e cidades
12 country province capital informações sobre as capitais dos estados dos países
13 country china province gansu informações sobre a província chinesa de gansu
14 country brasil province capital informações sobre a capital dos estados brasileiros
15 country brasil province pernambuco city recife informações sobre a cidade brasileira recife doestado do pernambuco
16 rivers country name brazil province sergipe informações sobres os rios do estado de Sergipe
17 country "south africa"religion religião(ões) predomintante(s) na África do Sul
18 country name brazil religion percentage Informações sobre os percentuais das religiões do Brasil
19 sea name "indian ocean"slands informações sobre as ilhas do oceano índico
20 province city capital todas as cidades que são capitais de estados
21 country name canada lake informações sobres os lagos canadenses
22 country russia country border informações sobre os países que fazem fronteira com a rússica
23 country name egypt province desert name informações sobre estados do egito que possuem deserto
24 country japan economy agriculture informações econômicas sobre a agricultura japonesa
25 country name japan economy agriculture informações econômicas sobre a agricultura japonesa
26 province "minas gerais"mountains informações sobre as montanhas do estado de Minas Gerais
27 province name "minas gerais"mountains informações sobre as montanhas do estado de Minas Gerais
28 sea name "pacific ocean"river name nome dos rios que desaguam no ocenao pacífico
29 country name chile sea name "pacific ocean"river nomes dos rios chilenos que desaguam no oceano pacífico
30 continent africa country sea nome dos mares que banham o continente africano