Embed Size (px)
Citation preview

1
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL PROGRAMA DE PÓS-GRADUAÇÃO EM LETRAS
EDITAL DOCFIX-FAPERGS 2012
TÍTULO DO PROJETO Recuperação da informação em representação do conhecimento em bases de
textos científicos de Linguística e de Medicina: padrões e processamento automático da linguagem
GRANDE ÁREA DO CONHECIMENTO
Linguística/Linguística Aplicada/ Linguística Computacional
COORDENADOR DO SUBPROJETO Profa. Dra. Maria José Bocorny Finatto (PPG - Letras, UFRGS)
A – IDENTIFICAÇÃO E OBJETIVOS Responsável: Profa. Dra. Maria José Bocorny Finatto, docente e orientadora do PPG-Letras -UFRGS, CNPq (bolsista PQ). Linhas de Pesquisa em que atua: Lexicografia e Terminologia: Relações Textuais (linha institucional do PPG-Letras-UFRGS)/Linguística de Corpus/Processamento da Linguagem Natural/Estudos de Linguagens Especializadas/Estudos da Tradução Técnica/ Formação de Tradutores/Ensino de Línguas. Área de Concentração em que atua: Estudos da Linguagem/Linguística Aplicada/Terminologia/ Linguística de Corpus/ Processamento de Linguagem Natural/Estudos de Linguagens Especializadas/Estudos da Tradução/Formação de Tradutores. Colaboradores:
Dra. Lucelene Lopes (doutora em PLN pela PUCRS) Prof. Dr. Valdir do Nascimento Flores (linguista, consultor, docente do PPG-
UFRGS) Prof. Dr. Danilo Blank (médico, consultor, professor da Faculdade de Medicina da
UFRGS) Bolsista Pós-Doutoranda: Alena Ciulla (doutora em Linguística pela Universidade Federal do Ceará/ Universidade de Nancy) Natureza do Subprojeto A pesquisa aqui proposta é interdisciplinar, pois integra dois grandes campos de conhecimento, de um lado, os Estudos da Linguagem; de outro, a Ciência da Computação. Nesses campos, destaca, respectivamente, os Estudos sobre Textos

2
Especializados/Terminologia e o Processamento da Linguagem Natural (PLN)/Recuperação da Informação. O ponto de chegada do estudo proposto será a melhoria das técnicas de Recuperação de Informação e da representação de conhecimento mediante o emprego de técnicas e de ferramentas PLN, associadas a recursos e conhecimentos dos estudos linguísticos sobre Terminologia, Linguística de Corpus, Linguística das Linguagens Especializadas e Tradução de textos técnico-científicos. A proposta de pesquisa envolve o reconhecimento de padrões de uso da linguagem em textos especializados das áreas de conhecimento desenhadas, grosso modo, pela Linguística e pela Medicina, com foco específico para duas subáreas ou domínios: a) da Linguística Saussuriana; b) das Pneumopatias Ocupacionais. Os domínios específicos alvo do projeto, abordados via corpora1 reunidos, serão a Linguística Saussuriana e a área de conhecimento denominada Pneumopatias Ocupacionais. O primeiro se insere no âmbito das Ciências Humanas e Sociais e a segundo no âmbito das Ciências da Saúde. Reitera-se que esse reconhecimento será feito tanto do ponto de vista linguístico-discursivo, quanto do ponto de vista matemático-computacional, tendo em vista a melhoria de desempenho de recursos computacionais para recuperação e categorização de informação científica nessas subáreas, podendo ser estendido para outras. Objetivo Geral No âmbito de um estudo avançado, que associa Estudos da Linguagem/Linguística Aplicada e Ciência da Computação/Linguística Computacional (VIEIRA, LIMA, 2001; VIEIRA, 2002), pretende-se pesquisar a conformação das Linguagens Especializadas/Textos Técnico-científicos, relacionando-se Estudos do Texto e do Discurso (com ênfase para a escrita científica em português), Terminologia (KRIEGER, FINATTO, 2004) e Linguística de Corpus (BERBER SARDINHA, 2004). Partindo-se desse bloco de inter-relações, avança-se rumo às metodologias de Processamento da Linguagem Natural (PLN) e de Recuperação da Informação em Linguística Computacional para subsidiar diferentes frentes de investigação que lidam com a linguagem científica escrita (ensino, descrição linguística, representação do conhecimento). Nesse quadro, busca-se tratar do reconhecimento e do processamento da linguagem escrita utilizada em diferentes domínios específicos do conhecimento, visando-se qualificar a arquitetura de sistemas para recuperação e representação facilitada da informação textual explicitada. Em que pese a delimitação necessária de temas e de domínios científicos, aqui restritos a dois, pela experiência prévia dos envolvidos no projeto com o tratamento da linguagem e das terminologias (de áreas como Pediatria, Física, Química e Ciência da Computação), será necessário contrastar os corpora de Linguística Saussuriana e de Pneumopatias Ocupacionais com textos de outras áreas do conhecimento, incluindo textos extraídos de jornais e revistas, que representam a linguagem não especializada, com vistas a identificar padrões próprios de cada âmbito de conhecimento e padrões genéricos da comunicação científica em seus diferentes cenários.
1 Corpora, plural de corpus, significa, no sentido da Linguística de Corpus (cf. apresentada no Brasil por BERBER SARDINHA, 2004) uma coleção de textos em formato digital, criteriosamente organizada, passível de ser explorada com apoio computacional, com vistas à descrição da linguagem e da informação
neles presentes.

3
Objetivos Específicos Como o objetivo mais amplo deste projeto envolve a realização de estudos sobre a área de recuperação automatizada de informações e representação do conhecimento com aporte linguístico, colocam-se alguns objetivos específicos:
O primeiro objetivo envolve reunir corpora representativos (cf. BIBER, 1993 e 1998) nos dois domínios selecionados: Linguística Saussuriana e Pneumopatias Ocupacionais.
No segmento a, planejamos reunir diferentes versões da obra CURSO DE LINGUÍSTICA GERAL (CLG), publicação fundamental da Linguística Moderna (SAUSSURE, 1970). O CLG é um livro organizado por colegas de Saussure a partir de notas de seus alunos, publicado originalmente em francês em 1915. As diferentes versões a reunir, considerando-se textos em formato digital ou para esse formato transpostos, são, inicialmente, o original em francês e as diferentes traduções para o português do Brasil e para o inglês. O CLG é a obra mais importante associada a Saussure. Entretanto, por ser uma publicação póstuma, produzida a partir de notas de aula de seus alunos, tornou-se centro de toda uma série de polêmicas, especialmente sobre deficiências na continuidade no texto e até algumas contradições (conforme CULLER, 1979 e CARVALHO, 1976). No Brasil, contamos com uma tradução bastante prestigiada e utilizada do CLG, produzida nos anos 70, a qual já mereceria hoje uma revisão. Por esses motivos, além de outros, apontados de longa data em um volume considerável de reflexões e de críticas sobre o que está posto no CLG (ou sobre o que está posto no CLG em contraponto com o colocado em obras que dele tratam, como se vê em HENGE, 2008), torna-se ainda mais importante poder reunir esse corpus e explorá-lo. No segmento b, já contamos com um corpus em português reunido pelo projeto Pneumopatias Ocupacionais (www.ufrgs.br/textecc) o qual compreende um Glossário Experimental e uma criteriosa seleção de textos acadêmicos, artigos de periódicos e de trabalhos em eventos que abarcam documentos produzidos até o ano de 2012.
O segundo objetivo específico é identificar de técnicas e métodos de PLN/ Linguística Computacional capazes de proporcionar uma EXTRAÇÃO AUTOMÁTICA de informações relevantes de textos agrupados nesses dois domínios de conhecimento.
Esses grupos de textos (o texto do CLG e uma base de textos sobre Pneumopatias Ocupacionais), reunidos em amostras que ultrapassam 1 milhão de palavras, são os corpora antes referidos. Em seguida da etapa de extração, trabalha-se também buscando técnicas e métodos para a ESTRUTURAÇÃO DA INFORMAÇÃO oriunda dos corpora em formatos que viabilizem o estudo linguístico dos vocabulários empregados, das terminologias e das estruturas frasais recorrentes. Entende-se por extração e estruturação de informações de corpora de domínio atividades que podem ser exemplificadas como:
1. Tratamento do corpus com técnicas de Linguística de Corpus, de Terminologia e de estatística lexical: reconhecimento amostral de macro e microestrutura textuais;

4
2. Identificação dos textos por tipos e temas predominantes; 3. Verificação de padrões de frases; 4. Etiquetagem de termos (palavras e multipalavras – construções e
expressões ); 5. Obtenção de listas de termos/expressões por diversos tipos de
frequências; 6. Obtenção de palavras-chave (termos relevantes); 7. Identificação de termos recorrentes correspondentes a conteúdo nocional
relevante ou com valor terminológico específico; 8. Organização visual de termos relevantes sob a forma de nuvens de
conceitos (tag clouds); 9. Organização hierárquica taxonômica e não-taxonômica dos termos
relevantes (hierarquia de conceitos).
O terceiro objetivo envolve proporcionar um incremento para formação interdisciplinar de futuros linguistas/profissionais de Letras e de cientistas da computação, de modo que saibam cooperar em prol da obtenção de avanços no tratamento da informação científica escrita em português do Brasil.
Nesse terceiro objetivo, prevemos o trabalho de orientação e de coorientação de estudantes de graduação das duas áreas de conhecimento, incluindo a formação de mestres. Prevê-se também o oferecimento de disciplinas regulares e de cursos livres junto ao PPG-Letras da UFRGS, considerando algumas iniciativas entre este PPG e os grupos de PLN da Faculdade de Informática da PUCRS e do Instituto de Informática da UFRGS. B – RELEVÂNCIA DO PROJETO E CONTRIBUIÇÃO PARA A LINHA DE PESQUISA DO PPG LETRAS DA UFRGS Esta proposta de investigação se insere na linha de pesquisa do PPG-Letras-UFRGS intitulada Terminologia e Lexicografia: Relações Textuais, na especialidade Teorias Linguísticas do Léxico. Nessa especialidade, estuda-se, entre outros tópicos, a comunicação científico-técnica em suas diferentes apresentações, com ênfase para o vocabulário e as terminologias em diferentes cenários comunicativos e textuais. A produção dessa linha de pesquisa tem sido constante, embora pudesse obter maior visibilidade perante outras áreas de conhecimento, especialmente as áreas de conhecimento que têm suas linguagens, textos, terminologias e traduções estudadas, e que poderiam aproveitar esses resultados para diferentes fins. Cada vez mais, esse tipo de estudo, qual seja, o estudo das linguagens técnico-científicas, necessita de apoio informatizado, visto que o tratamento do dado linguístico, cada vez mais abundante e disponível on-line, precisa fazer frente a grandes volumes e de variedades de textos. Nesse sentido, sobretudo desde o avanço das metodologias e princípios da Linguística de Corpus entre pesquisadores brasileiros (BERBER SARDINHA, 2004), passamos a utilizar computadores para nos auxiliar na sistematização da descrição linguística dos textos técnico-científicos, construindo grandes corpora, acervos textuais em formato digital, que são explorados e descritos, extensivamente, com apoio de softwares e ferramentas informatizadas diversas.

5
Entretanto, pesquisadores linguistas, como geralmente não têm formação em Computação ou muita experiência no tratamento matemático-computacional da linguagem em grandes volumes de dados, muitas vezes empregam recursos pouco rentáveis em termos de desempenho. Em geral, não conseguem construir ou propor, de um modo objetivo e exequível, sistemas adequados para os seus propósitos de estudo de modo a obter resultados em larga escala (considerando um enfoque extensivo dos fenômenos da linguagem escrita). Carecemos, assim, nas diferentes subáreas dos Estudos da Linguagem, de uma maior cooperação com profissionais dedicados, desde longa data, ao tratamento computacional de dados linguísticos, mono ou multilíngue. É uma realidade esse microcenário da pesquisa linguística brasileira, carente de reconhecimento social e ainda muito ilhada em si mesma frente à necessidade de diálogo com diferentes áreas de conhecimento. Esse isolamento torna, infelizmente, ainda bastante corriqueira uma sinonímia, equivocada, entre Gramática Tradicional Normativa e Linguística, sobretudo em veículos de comunicação de massa. Ainda que limitada a uma dada área de conhecimento, a cooperação qualificada com a Ciência da Computação, aqui proposta, tem grande potencial para fazer frente a esse problema. Nesse sentido, alheios aos problemas “internos” dos Estudos da Linguagem no cenário brasileiro e face à profusão e à dispersão da informação científica, sobretudo na internet, profissionais da Ciência da Computação/PLN têm buscado, com pouco ou quase nenhum apoio de linguistas (DIAS-DA-SILVA et al., 2007) metodologias e instrumentos para a sua filtragem, seleção e recomendação. Afinal, nos dias de hoje, feliz e infelizmente, tornou-se extremamente volumosa quantidade de informação escrita disponível nas diversas áreas do conhecimento (ORASAN, 2001), inclusive sob a forma de artigos científicos, revistas especializadas e também livros que qualquer pessoa pode acessar facilmente on-line. Em função dessa abundância de dados, há necessidade do pesquisador, ou do estudante de uma dada área de conhecimento, selecionar criteriosamente seus materiais. E, mesmo que se tenha um recorte temático de busca de informação bem definido, será importante contar com sistemas que organizem e categorizem o todo da informação obtida. Nesse sentido, metodologias para filtragem e categorização de informação dispersa, disponíveis em diversos formatos, vêm sendo estudadas há bastante tempo em Linguística Computacional/PLN, como atesta, por exemplo, a obra de quase 500 páginas Advances in Automatic Text Sumarization de Mani e Maybury, 2ª ed. de 2001 (MANI, MAYBURY, 2001). Entretanto, a maior ou menor eficiência dos sistemas “buscadores” disponíveis na internet mostra que há ainda muito a melhorar em ferramentas como, por exemplo, o Google Acadêmico. Todavia, entre a comunidade internacional que pesquisa sobre PLN, há ainda poucos estudos dirigidos à recuperação da informação a partir de fontes científicas escritas com o português do Brasil. Esse pouco se dimensiona frente ao grande volume de estudos e de ferramentas que já se produziram para o inglês ou outras línguas (NUNES, OLIVEIRA, ALUÍSIO, RINO; SILVA, 2005, p.34). Um trabalho importante, em PLN, que tenta identificar traços do texto científico em português com vistas ao seu tratamento computacional é, por exemplo, Uma Revisão Bibliográfica sobre a Estruturação de Textos Científicos em Português (FELTRIM, ALUÍSIO, NUNES, 2000). Ainda assim, os trabalhos feitos na área de PLN, embora muito meritórios, necessitam de um maior e melhor aporte linguístico, advindo de pesquisadores que estudam a Linguagem e a Comunicação no cenário científico. Afinal, no contexto dos Estudos da Linguagem, bastante já se tem escrito sobre o texto científico escrito em português (ou para ele traduzido), quer no âmbito dos estudos de Terminologia, de Gêneros Textuais

6
ou na grande área dos estudos do Texto e do Discurso. Por outro lado, no contexto dos Grandes Desafios da Pesquisa em Computação no Brasil (LIMA, NUNES, VIEIRA, 2007), reconhece-se o desafio do Processamento da Linguagem Natural (PLN) que contemple o português, e, no cenário internacional das pesquisas em computação, o processamento da língua natural faz parte da agenda de pesquisa das mais importantes universidades e centros de pesquisa. No Brasil, temos a iniciativa PORSIMPLES, por exemplo, junto ao Núcleo Interinstitucional de Linguística Computacional da USP (NILC), que visa reconhecer padrões para simplificação da informação textual para atender a usuários com capacidade limitadas de compreensão de leitura (ver artigos de MARGARIDO, PARDO e ALUÍSIO (2008) disponíveis eletronicamente em http://caravelas.icmc.usp.br/wiki/index.php/Publications). Apesar do tanto produzido a respeito, ainda carecemos de confrontos entre o que oferecem diferentes metodologias automáticas de identificação de informação relevante em áreas científicas, as especificidades comunicativas e textuais da língua portuguesa e as necessidades de diferentes usuários brasileiros. Tratar o conhecimento gerado sob a forma de texto científico, com apoio dessas metodologias, visa reapresentar o conteúdo do texto sob a forma de extratos de informação mais relevante ou sob a forma de representações ou esquemas de nódulos conceituais. Com elas, pretende-se que tanto o acesso de leigos quanto a tomada de decisão por parte de pesquisadores e de gestores, em meio à profusão de informação dispersa, sejam mais facilitados. Para esse intento, acreditamos, a integração entre o linguista e o cientista da computação será muito importante. Relevância dos domínios em foco: Saussure e a Pneumopatias Ocupacionais No que tange à escolha dos domínios a tratar neste projeto de pesquisa, que serão representados por corpora especialmente selecionados, representativos dos conhecimentos científicos em Linguística Saussuriana e em Pneumopatias Ocupacionais, vale ainda justificar a relevância de ambos e do tratamento de seus textos para o cenário da produção científica do Brasil. No próximo ano, em 2013, comemora-se o centenário da morte de Ferdinand de Saussure (Genebra, 1857-1913), considerado o fundador da Linguística Moderna. Seu pensamento e seus escritos (incluindo, sobretudo, o CLG), são basilares para os Estudos da Linguagem em nível mundial e são também relevantes para outras áreas do conhecimento direta ou indiretamente conexas – como, por exemplo, Fonoaudiologia, Psicologia, Filosofia da Linguagem e Antropologia. Dada a efeméride em 2013 – devem tornar-se foco das maiores atenções e revisões, o que colocará em evidência também a pesquisa linguística brasileira em meio ao cenário mundial. Nessa situação de especial visibilidade e interesse, recrudescerão as necessidades de informação, por parte de leigos e de semileigos, sobre que temos disponível em português do Brasil sobre a figura e sobre a herança de Ferdinand de Saussure. Embora Saussure seja um nome associado a diversos pontos de informação dispersa, sobretudo em sites na internet – incluindo desde acervos de bibliotecas acadêmicas até redes de relacionamento como Facebook e Orkut, falta-nos uma base ou ponto de informação organizados, que organizem sua trajetória e que inter-relacione suas obras ou escritos. Isso sem contar a indicação da produção bibliográfica em português do Brasil associada à sua figura/obra/pensamentos, em livros mais antigos e ou mais recentes, tais como as publicações do tipo manual ou livro introdutório como, por exemplo, “Para

7
compreender Saussure” (CARVALHO, 1976) ou “Compreender Saussure a partir dos manuscritos” (DEPECKER, 2011), entre tantos outros. O material a ser organizado poderia inclusive ser de interesse de grupos ou de associações de pesquisadores brasileiros, constituindo um corpus tal como se vê no site do Institut de Linguistique Française (ILF) - http://www.ilf.cnrs.fr/spip.php%3Frubrique1.html. Quanto à área das Pneumopatias Ocupacionais, cujo conhecimento e acesso é questão de Saúde Pública, embora haja grande a importância do tema e do seu conhecimento por parte de trabalhadores e de agentes de saúde, parece haver muito mais informação organizada e categorizada disponível em inglês do que em português. Publicações como o SUPLEMENTO - Doenças Respiratórias Ambientais e Ocupacionais, do Jornal Brasileiro de Pneumologia - publicação oficial da Sociedade Brasileira de Pneumologia e Tisiologia (J. Bras. Pneumol. v. 32, suplemento 2, p.S19-S134, Maio 2006) ainda parecem ser “ilhas” importantes em meio a várias fontes de dispersão de informação sobre doenças respiratórias associadas a determinados tipos de trabalho ou ocupação. A esse respeito, vale salientar o projeto, em andamento pela proponente deste projeto, de um Glossário Experimental da terminologia associada a esse tema, disponível em www.ufrgs.br/textecc. Para esse trabalho, ainda são encontradas várias dificuldades, embora já contemos com um bom corpus e com apoio de colegas médicos e da área de PLN. Associado a esse Glossário, vemos uma hierarquia de conceitos (hierarquia sintagmas relevantes num dado corpus) gerada pela ferramenta ExATOlp (LOPES, VIEIRA, FERNANDES, COUTO, 2012). Essa iniciativa pode ser considerada um bom subsídio e um antecedente importante para a pesquisa aqui proposta. Em síntese, além da importância das áreas de conhecimento a serem tratadas como objeto de estudo neste projeto, Linguística/Saussure e Medicina/Pneumopatias Ocupacionais, vale dizer que, para as Teorias Linguísticas do Léxico, Terminologia e Estudos do Texto, a aproximação com a Ciência da Computação em geral e com o PLN em específico tende a nos inserir, enquanto linguistas, no panorama da pesquisa nacional em melhores condições de visibilidade e de reconhecimento. No âmbito da linha de pesquisa do PPG-Letras da UFRGS, cria-se uma nova opção de formação e de conhecimento, visto que a cooperação com o profissional de Informática só tende a qualificar o trabalho do linguista (e vice-versa), sobretudo no que diz respeito aos resultados mais aplicados e práticos da pesquisa sobre linguagens e textos especializados.
C – MATERIAIS E METODOLOGIA A SER EMPREGADA Considerando os primeiros resultados do projeto Glossário Experimental de Pneumopatias Ocupacionais (www.ufrgs.br/textecc), pretende-se utilizar as ferramentas computacionais desenvolvidas na tese recentemente defendida por Lucelene Lopes (LOPES, 2012) para extração de termos relevantes de corpora em língua portuguesa e para a estruturação desses termos em nuvens e hierarquias de conceitos. A utilização dessas ferramentas incorporadas no software ExATOlp (LOPES, VIEIRA, FERNANDES, COUTO, 2012) representa o estado da arte em extração de informação de corpora em língua portuguesa, tendo inclusive algumas técnicas aplicáveis a outras línguas (LOPES, FERNANDES, VIEIRA, 2012).

8
Nesse sentido, pretende-se inicialmente desenvolver casos de estudo para corpora em português buscando a definição de um processo genérico que possa ser aplicado a qualquer outro corpus de domínio. No entanto, pretende-se, no decorrer do projeto, ampliar as técnicas utilizadas para processar igualmente textos escritos em outras línguas, como por exemplo, os corpora de Saussure, especialmente a obra CLG, Curso de Linguística Geral, que possuem versões em diferentes idiomas feitas a partir do original em francês. Como consequência de seus objetivos práticos, irá compor esse projeto de pesquisa o desenvolvimento e adaptação das ferramentas existentes, notadamente o ExATOlp, para automatizar todos os processos que serão propostos durante esse trabalho de pesquisa. Dessa forma, não somente busca-se definir teoricamente o processo de extração e organização de informações a partir de corpora, mas disponibilizar ferramentas computacionais que permitem a utilização ampla do processo proposto para pesquisadores de qualquer área do conhecimento. Os materiais textuais a serem empregados, considerando-se apenas os mais nucleares, correspondem aos corpora dos textos de Saussure (especialmente o CLG, original em francês e traduções para o português do Brasil e o inglês) e aos corpora iniciais e ampliados da temática Pneumopatias Ocupacionais do Glossário Experimental de Pneumopatias Ocupacionais (687 textos/documentos caracterizados em MARCOLIN, EVERS, FINATTO, GOLDNADEL, 2010 e mais cerca de novos 200 documentos reunidos em 2012). Desses dois blocos de materiais, temos um que foi inicialmente explorado com uma ferramenta de PLN e outro que é completamente novo.
D – POTENCIAL DO SUBPROJETO PARA O DESENVOLVIMENTO CIENTIFICO, TECNOLOGICO E DE INOVACAO DO RS Os aspectos mais relevantes deste subprojeto, no que diz respeito ao mérito científico e potencial para desenvolvimento tecnológico e de inovação local, situam-se na fértil área do processamento computacional de linguagens naturais/PLN. Esse campo é indicado como uma das áreas de pesquisa prioritárias na Ciência da Computação (LIMA, NUNES, VIEIRA, 2007). Como já mencionado, o desenvolvimento científico dessa área sofre com o fato de que é necessário a cooperação entre cientistas de formação distinta. Cientistas da Computação e da Linguística devem trabalhar de forma integrada para trazer a correta percepção dos fenômenos da linguagem em uso para ferramentas automatizadas de extração de informação (LEITE, RINO, PARDO, NUNES, 2007). Infelizmente, o número de linguistas com formação ou experiência para atuar em projetos desse tipo é muito escasso, principalmente o do tipo de linguista que mais interessa, o que consegue articular a dimensão do vocabulário/texto/corpus/discurso e níveis de análise da língua à arquitetura e ao funcionamento de sistemas. Pois, tal como vemos em Nunes, Oliveira, Aluísio, Rino e Silva (2005, p.35),
“formalizar conhecimento lingüístico para ser processado pelo computador exige, por sua complexidade e riqueza, a delimitação dos fenômenos lingüísticos a serem tratados, a qual nem sempre é aceita por significativa parte dos lingüistas. Isso tem afastado esses profissionais da área de PLN e, com, isso, a construção adequada de recursos continua limitada.”

9
O desenvolvimento tecnológico aportado por esse subprojeto fica claro quando se observa que os objetivos incluem, além do estudo de padrões de uso da linguagem de diversos corpora específicos, a materialização de ferramentas computacionais que possam automatizar a geração de recursos linguísticos extraídos dos corpora de interesse. Dessa forma, resulta desse subprojeto não apenas estudos aprofundados sobre a linguagem e a informação de diferentes corpora de domínio, mas também os meios computacionais para desenvolver estudos semelhantes no futuro. Esse produto por si só justifica a realização desse subprojeto que pode estabelecer uma ponte de integração durável entre aos Estudos da Linguagem e a Computação. Ademais, este subprojeto pretende catalisar a cooperação e ampliar cooperações existentes entre o grupo de pesquisa no Instituto de Letras da UFRGS com diversos pesquisadores afinados com a Ciência da Computação e estudos da Linguagem com apoio computacional e Linguística de Corpus, a saber:
Profa. Dra. Sandra Aluísio do NILC/USP; Profa. Dra. Renata Vieira da PUC-RS; Prof. Dr. Tony Berber Sardinha da PUC-SP; Profa. Dra. Aline Villavicencio da UFRGS (Instituto de Informática).
O potencial de inovação deste subprojeto fica claro quando se observa a existência de diversas empresas dedicadas ao tema do PLN já atuando no Rio Grande do Sul (tais como as empresas PLUGAR, AI-ENGINEERS, INTEXT MINING e ACXIOM), sem que nenhuma possua recursos tecnológicos tão avançados como as ferramentas computacionais de extração e estruturação de informações a partir de corpora, notadamente o software ExATOlp (LOPES, VIEIRA, FERNANDES, COUTO, 2012). Assim, é possível imaginar cooperações dos envolvidos neste subprojeto com as empresas já atuantes no RS, mas até a criação de empresas do tipo startups dedicadas a temas específicos relacionados ao foco central da recuperação e categorização da informação dispersa na web. Contribuição para a formação de recursos humanos Sob um ponto de vista acadêmico, a realização de deste subprojeto pode contribuir claramente para a formação de recursos humanos em nível de pós-graduação. Isso se dá ao agregarem-se um pesquisador com doutorado recente na área de PLN (o bolsista solicitado) e seus recentes parceiros de pesquisa e grupo atual de linguistas composto por uma docente pesquisadora (proponente deste projeto), seus colegas docentes de linha de pesquisa e orientandos da proponente junto ao PPG-Letras da UFRGS, incluindo orientandos de Iniciação Científica. Esse incremento de grupo permitirá a formação de um número maior de doutorandos, mestrandos e bolsistas de Iniciação Científica por atividades de coorientação, salientando-se que estão previstas algumas atividades de ensino para o bolsista recém-doutor, em parceria com a pesquisadora proponente. No entanto, o maior ganho esperado se traduz no aumento da qualificação dos alunos formados junto ao PPG-Letras-UFRGS, pois o aumento de poder computacional deve alavancar muito a qualidade dos trabalhos realizados que se ocupam de produzir descrições sobre os textos e linguagens técnico-científicos, considerando-se, especialmente, a necessidade de se tratar com grandes volumes de dados de uma maneira que seja eficiente e racional. Espera-se, especificamente, que muito do tempo investido em trabalho atualmente feito de forma manual, especialmente no que se refere à seleção e validação

10
da informação mais relevante extraída de corpora científicos, seja drasticamente reduzido pela inclusão de ferramentas computacionais mais eficientes. Adicionalmente, ao reduzir-se a quantidade de trabalho manual a ser desenvolvido, espera-se ganhar não somente tempo, mas qualidade no produto final, pois tornam-se automatizadas várias das atividades repetitivas mais vulneráveis ao erro humano, condição natural à manipulação de grandes quantidades de dados por leitura humana, ao mesmo tempo que há mais conforto para a realização do trabalho humano, que contará com uma pré-filtragem eficiente de dados a serem considerados e examinados. De um ponto de vista estritamente numérico/quantitativo, pretende-se também aumentar a capacidade de absorção anual média de alunos nos grupo de pesquisa integrados pela proponente deste subprojeto, com a captação de mais 1 doutorando a cada dois anos, 1 mestrando e 2 novos bolsistas de IC, os quais podem ser coorientados pelo recém-doutor, bolsista solicitado neste subprojeto. Esse aumento na formação de recursos humanos, conjugado com a maior experiência com ferramentas computacionais, vai perfeitamente ao encontro da necessidade expressa anteriormente de formar linguistas capazes de articular a dimensão do vocabulário/texto/corpus/discurso e níveis de análise da língua à arquitetura e ao funcionamento de sistemas computacionais. E – INTERACAO COM EMPRESAS Este subprojeto por sua própria natureza apresenta um grande potencial para repasse tecnológico. Esse potencial se justifica tanto por lidar com técnicas e métodos que representam o estado da arte na extração e estruturação de informações a partir de corpora, quanto por situar-se em uma área de grande aplicabilidade nos dias atuais. O advento da internet e sua ampla utilização torna extremamente fácil a obtenção de volumes enormes de textos, que são a forma mais abundante de informação disponível (MAEDCHE, STAAB, 2001). Porém, conforme dito anteriormente, extrair informações relevantes dessa quantidade enorme de dados é um desafio quase que impossível para usuários humanos. Dessa forma, um número muito grande de empresas, e mesmo usuários individuais, busca formas automáticas de extrair e estruturar informações. Esse tipo de demanda tem fomentado a criação de empresas especializadas nesse tipo de recuperação de informações. Apenas para citar casos específicos, aqui no Rio Grande do Sul, temos as empresas:
PLUGAR (www.plugar.com.br) que atua na recuperação de diversos tipos de informação oriunda de bases textuais;
AI-ENGINNERS (www.ai-engineers.com) que atua na área específica da recuperação de informações emocionais (reações de clientes e público em geral) a partir de textos publicados em redes sociais;
INTEXT MINING (www.intext.com.br) que provê ferramentas especializadas na recuperação de conhecimento;
ACXIOM (www.acxiom.com.br) que desenvolve e fornece soluções de PLN específicas para empresas;
Essas empresas são candidatas naturais à formação de parcerias de pesquisa e de repasse tecnológico com os envolvidos neste subprojeto. Soma-se a essas prováveis parcerias a possibilidade de criação de empresas incubadas com os alunos vinculados ao subprojeto, pois, conforme já mencionado, a área

11
de processamento de linguagem natural devidamente enriquecida com uma forte base linguística e terminológica torna-se uma vantagem tecnológica clara frente às opções atualmente disponíveis no mercado. Adicionalmente, cita-se como exemplo a empresa AI-ENGINEERS que é uma empresa incubada oriunda do grupo de PLN do Instituto de Informática da UFRGS. Dessa forma, é possível imaginar que a disponibilização de técnicas e de métodos avançados através de uma ferramenta de software automatizada contribua para a criação de novas empresas de forte viés tecnológico ou que reforce as já existentes. F – ESTIMATIVA DA PORCENTAGEM DE APLICABILIDADE DO PROJETO Dado o caráter deste projeto, estima-se que tenha cerca de 70% de aplicação prática imediata, especialmente no que se refere à representação da informação dos corpora reunidos.
G – DO PRINCIPAL COLABORADOR EXTERNO Ainda que essa demanda seja feita de forma genérica, este projeto foi arquitetado tendo-se em vista a participação da Dra. Lucelene Lopes, recentemente titulada pelo Programa de Pós-Graduação em Ciência da Computação da PUC-RS. Adicionalmente, fez parte do trabalho de tese da Dra. Lucelene Lopes (LOPES, 2012) a proposta de diversas técnicas linguísticas e estatísticas voltadas à extração de termos relevantes de corpora de domínio, bem como da geração automática de recursos linguísticos (listas de termos, concordanciadores, nuvens e hierarquias de conceitos) através da ferramenta de software ExATOlp. Dentre as publicações relevantes da Dra. Lucelene no tema deste projeto salientam-se as seguintes:
Lucelene Lopes, Renata Vieira, Maria J. Finatto, Adriano Zanette, Daniel Martins, e Luis Carlos Ribeiro Jr., Automatic extraction of composite terms for construction of ontologies: an experiment in the health care area, RECIIS, 3 (2009), pp. 72–84.
Lucelene Lopes, Paulo Fernandes, Renata Vieira, e Guilherme Fedrizzi, ExATO lp – An Automatic Tool for Term Extraction from Portuguese Language Corpora, in Proceedings of the 4th Language & Technology Conference: Human Language Techno- logies as a Challenge for Computer Science and Linguistics (LTC’09), Poznan, Poland, November 2009, Faculty of Mathematics and Computer Science of Adam Mickiewicz University, Adam Mickiewicz University, pp. 427–431.
Lucelene Lopes, Paulo Fernandes, Renata Vieira, Guilherme Fedrizzi, e Daniel Martins, Exatolp - a tool for domain relevant terms extraction, in PROPOR 2010 – International Conference on Computational Processing of Portuguese Language, 2010.
Lucelene Lopes, Leandro H. Oliveira, e Renata Vieira, Portuguese term ex- traction methods: Comparing linguistic and statistical approaches, in PROPOR 2010 – International Conference on Computational Processing of Portuguese Language, 2010.
Lucelene Lopes e Renata Vieira, Building Domain Specific Corpora in Portuguese Language, Tech. Report TR 062, Pontifícia Universidade Católica do Rio Grande do Sul (PUCRS), Porto Alegre, Brazil, Dezembro 2010.

12
Lucelene Lopes e Renata Vieira, Processamento de linguagem natural e o tratamento computacional de linguagens científicas, in Linguagens Especializadas em Corpora: modos de dizer e interfaces de pesquisa, Cristina Lopes Perna, Heloísa Koch Delgado, e Maria José Finatto, eds., EDIPUCRS, Porto Alegre, Brazil, 2010, pp. 183–201.
Lucelene Lopes, Renata Vieira, Maria José Finatto, e Daniel Martins, Extracting compound terms from domain corpora, Journal of the Brazilian Computer Society, 16 (2010), pp. 247–259. 10.1007/s13173-010-0020-4.
Lucelene Lopes, Renata Vieira, e Daniel Martins, Hierarquias de conceitos extraídas automaticamente de corpus de domínio específico - um experimento sobre um corpus de pediatria, in XII Congresso Brasileiro de Informática em Saúde (CBIS), Sociedade Brasileira de Informática em Saúde, 2010, pp. 1–6.
Lucelene Lopes e Renata Vieira, Improving quality of portuguese term extraction, in PROPOR 2012 – International Conference on Computational Processing of Portuguese Language, 2012.
Lucelene Lopes, Paulo Fernandes, Renata Vieira, e Gabriel Couto, ExATOlp: extraction of language resources from Portuguese corpora, in PROPOR 2012 – International Conference on Computational Processing of Portuguese Language, 2012.
Lucelene Lopes, Paulo Fernandes, e Renata Vieira, Domain Term Relevance Through tf-dcf, in ICAI’2012 – International Conference on Artificial Inteligence, 2012.
H – DADOS DO BOLSISTA DOCFIX
Alena Ciulla e Silva é graduada em Letras pela Universidade Federal do Rio Grande do Sul (UFRGS), com habilitação em tradução do francês para o português. Em seu mestrado pela Universidade Federal do Ceará (UFC), iniciou seus estudos em Referenciação sob a tutela de Mônica Magalhães Cavalcante, da UFC, e produziu uma dissertação sobre processos dêiticos e anafóricos. No doutorado, sua tese foi sobre os processos referenciais e suas funções no discurso, em especial o literário, sob a orientação de Mônica Magalhães Cavalcante, da UFC, e de Denis Apothéloz, da Universidade de Nancy 2, França, onde realizou um estágio de março a dezembro de 2006, como bolsista da CAPES. Já lecionou língua portuguesa e inglês instrumental nas Faculdades Christus, Fanor e nos cursos do Magister (UFC), atuando também como tradutora freelancer. Após o estágio de doutorado na França, morou na Suíça, onde engajou-se em estudos de Linguística Computacional e, em 2010, trabalhou como assistente de pesquisa pós-doutoranda no projeto Text+Berg na construção de um tradutor automático de francês/alemão com base em corpus paralelo, no Instituto de Linguística Computacional na Universidade de Zurique. I – ATIVIDADES E CRONOGRAMA FÍSICO-FINANCEIRO A parte FINANCEIRA deste projeto, de modo geral, apoia-se na sustentação financeira da proponente enquanto docente e pesquisa do PPG-LETRAS da UFRGS e da sua atuação como pesquisadora junto ao CNPq. Entretanto, o financiamento deste subprojeto está totalmente relacionado à concessão de UMA BOLSA para remuneração das atividades do recém-doutor indicado, especialista em PLN, nos termos do Edital FAPERGS DOCFIX.

13
As atividades previstas neste subprojeto se dividem em cinco eixos de trabalho que possuem sobreposições. Os eixos são:
Construção de corpora de interesse; Desenvolvimento e adaptação de técnicas e métodos de extração de informação; Desenvolvimento e adaptação de técnicas e métodos de estruturação de
conhecimento; Experimentação sobre os corpora de interesse; Atividades genéricas de desenvolvimento de soluções computacionais.
Dentro do eixo de construção de corpora de interesse (eixo A), serão realizadas tarefas para compor os dois novos corpora de interesse já citados, sendo um acervo de textos de Linguística de Saussure, e outro um acervo da área médica sobre Pneumopatias Ocupacionais. Adicionalmente, serão associados ao conjunto de dados a serem tratados neste projeto outros corpora já existentes e disponíveis nas áreas de Pediatria, Computação, Geologia, Literatura, Física e Química em uso pelos grupos de pesquisa da proponente desta pesquisa. No eixo de desenvolvimento e adaptação de técnicas e métodos de extração (eixo B), será dada continuidade a trabalhos desenvolvidos na tese de Lucelene Lopes (LOPES, 2012) que envolvem a detecção, refinamento e escolha de termos relevantes baseado na extração de sintagmas nominais (LOPES, VIEIRA, 2012). Dessa forma, as tarefas irão centrar-se na adaptação das técnicas e métodos existentes, mas também no desenvolvimento de novas técnicas e métodos que permitam identificar contextos de utilização dos sintagmas nominais extraídos de forma a acrescentar informação para as manipulações futuras. Especificamente, pretende-se aprimorar a detecção de contextos relacionados a sintagmas verbais e utilização de adjetivos. No eixo de desenvolvimento e adaptação de técnicas e métodos de estruturação de conhecimento (eixo C), será feito também um trabalho de continuidade à tese de Lucelene Lopes, que já propõe a geração de nuvens e de conceitos (LOPES, VIEIRA, FERNANDES, COUTO, 2012). Especificamente, pretende-se agregar novas informações a esses formatos de expressão (nuvens e hierarquias), que possam ser refinados segundo as novas informações contextuais que se pretende disponibilizar com as atividades do eixo anterior. Pretende-se, ainda, estudar e propor novas formas de estruturação com vistas a uma análise de sentimentos, ou seja, detecção de opiniões expressas nos textos sobre os conceitos extraídos. Esse novo tipo de análise será possível principalmente devido à detecção de adjetivos. O eixo de experimentações sobre os corpora de interesse (eixo D) terá tanto a finalidade de servir de prova de conceitos das técnicas e dos métodos propostos, quanto à finalidade de permitir um estudo aprofundado das áreas dos corpora serem criados, especialmente o corpus de Saussure. Nessas atividades, será particularmente interesse a intervenção de especialistas nas áreas específicas em foco (linguistas e médicos, consultores). Finalmente, as atividades genéricas de desenvolvimento de soluções computacionais (eixo E) dizem respeito à automatização dos processos utilizados nas atividades do eixo anterior através da proposta de novas ferramentas computacionais e/ou adaptação das ferramentas existentes. As tarefas propostas para o primeiro eixo são:
A1: Estudo e apropriação de corpora já construídos anteriormente pelo grupo de

14
pesquisa e seus parceiros; A2: Construção de um corpus com textos traduzidos para o Português do
linguista Ferdinand de Saussure; A3: Construção de um corpus com textos médicos sobre pneumopatias; A4: Construção de um corpus análogo ao corpus construído na tarefa A2, porém
com os textos originais em Francês.
As tarefas propostas para o segundo eixo são: B1: Estudo e apropriação das técnicas de extração de conhecimento já existentes
nos trabalhos de LOPES e VIEIRA (2012); B2: Proposta de aprimoramentos para detectar sintagmas verbais; B3: Proposta de aprimoramentos para detectar sintagmas adjetivais e locuções
adjetivas; B4: Adaptação das técnicas e métodos de extração existentes para o Português
para tratamento de Francês. As tarefas propostas para o terceiro eixo são:
C1: Estudo e apropriação das técnicas de estruturação de termos já existentes nos trabalhos de LOPES, VIEIRA, FERNANDES, COUTO (2012);
C2: Proposta de aprimoramentos para gerar nuvens de conceitos levando em consideração contextos verbais e adjetivais;
C3: Proposta de aprimoramentos para gerar hierarquias de conceitos levando em consideração contextos verbais e adjetivais;
C4: Proposta de novos métodos e técnicas de estruturação de conhecimento visando à análise de sentimentos.
As tarefas propostas para o quarto eixo são:
D1: Experimentos com os corpora já construídos anteriormente pelo grupo de pesquisa e seus parceiros;
D2: Experimentos com um corpus com textos traduzidos para o Português do linguista Ferdinand de Saussure;
D3: Experimentos com um corpus com textos médicos sobre pneumopatias; D4: Experimentos com o corpus de Saussure com os textos originais em Francês.
As tarefas propostas para o quinto eixo são:
E1: Estudo e apropriação das funcionalidades da versão atual da ferramenta ExATOlp;
E2: Desenvolvimento de software que implemente as extensões propostas nas tarefas B2 e B3;
E3: Desenvolvimento de software que implemente as extensões propostas nas tarefas C2 e C3;
E4: Desenvolvimento de software que implemente as extensões propostas na tarefa C4;
E5: Desenvolvimento de software que implemente as extensões propostas na tarefa B4.
A disposição das tarefas propostas ao longo do tempo está descrita no cronograma a seguir que representa em cada coluna um dos 8 semestres que
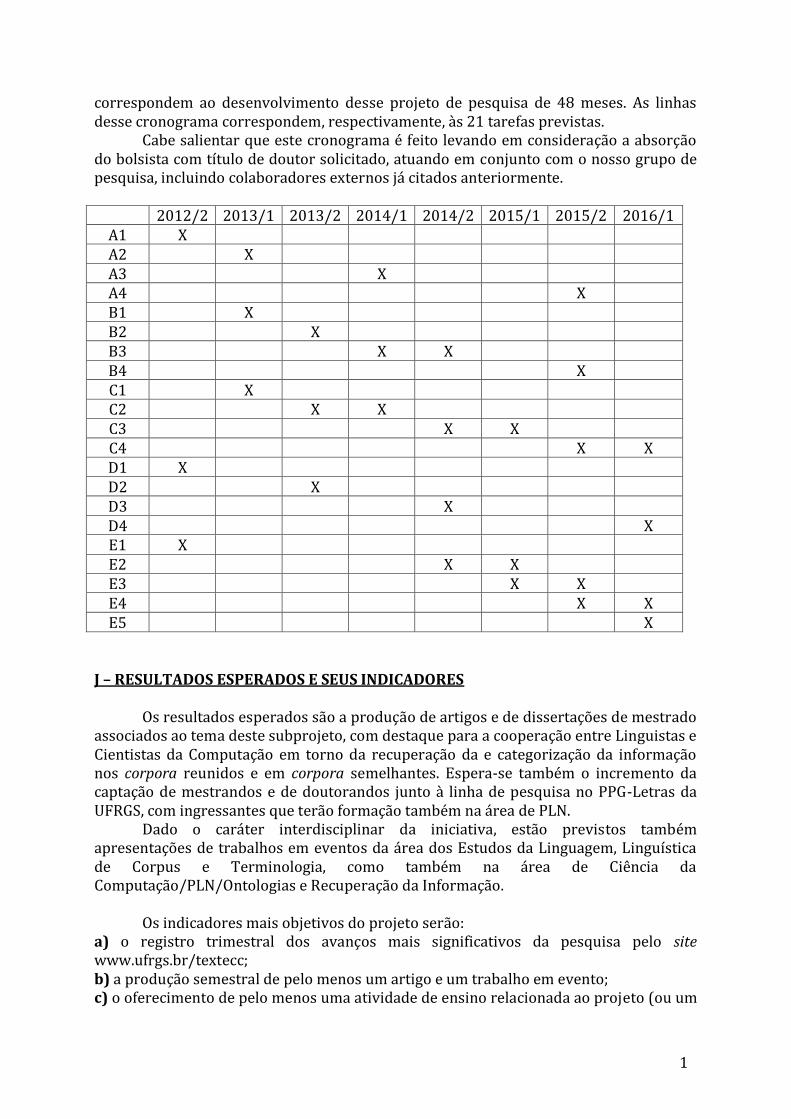
15
correspondem ao desenvolvimento desse projeto de pesquisa de 48 meses. As linhas desse cronograma correspondem, respectivamente, às 21 tarefas previstas. Cabe salientar que este cronograma é feito levando em consideração a absorção do bolsista com título de doutor solicitado, atuando em conjunto com o nosso grupo de pesquisa, incluindo colaboradores externos já citados anteriormente.
2012/2 2013/1 2013/2 2014/1 2014/2 2015/1 2015/2 2016/1 A1 X A2 X A3 X A4 X B1 X B2 X B3 X X B4 X C1 X C2 X X C3 X X C4 X X D1 X D2 X D3 X D4 X E1 X E2 X X E3 X X E4 X X E5 X
J – RESULTADOS ESPERADOS E SEUS INDICADORES Os resultados esperados são a produção de artigos e de dissertações de mestrado associados ao tema deste subprojeto, com destaque para a cooperação entre Linguistas e Cientistas da Computação em torno da recuperação da e categorização da informação nos corpora reunidos e em corpora semelhantes. Espera-se também o incremento da captação de mestrandos e de doutorandos junto à linha de pesquisa no PPG-Letras da UFRGS, com ingressantes que terão formação também na área de PLN. Dado o caráter interdisciplinar da iniciativa, estão previstos também apresentações de trabalhos em eventos da área dos Estudos da Linguagem, Linguística de Corpus e Terminologia, como também na área de Ciência da Computação/PLN/Ontologias e Recuperação da Informação. Os indicadores mais objetivos do projeto serão: a) o registro trimestral dos avanços mais significativos da pesquisa pelo site www.ufrgs.br/textecc; b) a produção semestral de pelo menos um artigo e um trabalho em evento; c) o oferecimento de pelo menos uma atividade de ensino relacionada ao projeto (ou um

16
curso livre, ou workshop ou disciplina de curta duração e menor carga horária junto ao PPG-Letras da UFRGS); d) incremento do número de participantes de Iniciação Científica junto aos grupos de pesquisa integrados pela proponente do projeto, oriundos de cursos de graduação em Ciência de Computação e de graduação em Letras. BIBLIOGRAFIA CITADA BERBER SARDINHA, Tony. (2004) Linguística de Corpus. Barueri: Manole. BIBER, Douglas. (1993) Representativeness in Corpus Design. Literary and Linguistic Computing, Vol. 8, No. 4, pp. 243- 257. BIBER, Douglas. (1998) Corpus Linguistics: Investigating language Structure and Use. Cambridge, UK: Cambridge University Press. 301 p. CARVALHO, Castelar de (1976). Para compreender Saussure. Rio de Janeiro: Vozes. CULLER, Jonathan (1979). As ideias de Saussure. São Paulo: Cultrix. DEPECKER, Loic. (2011) Compreender Saussure a partir dos manuscritos, Rio de Janeiro: Vozes. DIAS-DA-SILVA , B.C.; MONTILHA, G.; RINO, L.H.M.; SPECIA, L.; NUNES, M.G.V.; OLIVEIRA Jr., O.N.; MARTINS, R.T.; PARDO, T.A.S. (2007). Introdução ao Processamento das Línguas Naturais e Algumas Aplicações. Série de Relatórios do NILC. NILC-TR-07-10. São Carlos-SP, Agosto, 121p. pdf. FELTRIM, V.D.; ALUÍSIO, S.M.; NUNES, M.G.V. (2000). Uma Revisão Bibliográfica sobre a Estruturação de Textos Científicos em Português. Relatório Técnico, Série Computação, n.120, ICMC-USP, São Carlos. HENGE, Gláucia da Silva. Obras introdutórias à leitura de Saussure: o que falam e como falam do CLG? Cadernos de Letras da UFF – Dossiê: Patrimônio cultural e latinidade, no 35, p. 117-135, 2008 KRIEGER, Maria da Graça; FINATTO, Maria José B. Introdução à Terminologia: Teoria & Prática. São Paulo: Contexto, 2004. LEITE, D.S., RINO, L.H.M., PARDO, T.A.S., NUNES, M.G.V. (2007) Extractive Automatic Summarization: Doesmore linguistic knowledge make a difference? In C. Biemann, I. Matveeva, R. Mihalcea, and D. Radev. (eds.), Proceedings of the HLT/NAACL Workshop onTextGraphs-2: Graph-Based Algorithms for Natural Language Processing, pp.17-24. LIMA, V.L.S.; NUNES, M.G.V.; VIEIRA, R. (2007) Desafios do Processamento de Línguas Naturais. In: SEMISH – Seminário Integrado de Software e Hardware, 2007, Rio de Janeiro. Anais do XXVI Congresso da Sociedade Brasileira de Computação. SBC. pp. 2202-2216. LOPES, L.; VIEIRA, R; FINATTO, M.J.; ZANETTE, A.; MARTINS, D.; RIBEIRO JR., L.C. (2009) Automatic extraction of composite terms for construction of ontologies: an experiment in the health care area, RECIIS, 3, pp. 72–84. LOPES, L; FERNANDES, P.; VIEIRA, R.; FEDRIZZI, G. (2009) ExATO lp – An Automatic Tool for

17
Term Extraction from Portuguese Language Corpora, In Proceedings of the 4th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (LTC’09), Poznan, Poland, Faculty of Mathematics and Computer Science of Adam Mickiewicz University, pp. 427–431. LOPES, L.; VIEIRA, R. (2010) Building Domain Specific Corpora in Portuguese Language, Tech. Report TR 062, Programa de Pós-Graduação em Ciência da Computação (PPGCC), Pontifícia Universidade Católica do Rio Grande do Sul (PUCRS), Porto Alegre, Brazil. LOPES, L.; VIEIRA, R; FINATTO, M.J.; MARTINS, D. (2010) Extracting compound terms from domain corpora, Journal of the Brazilian Computer Society, 16, pp. 247–259. LOPES, L. (2012) Extração automática de conceitos a partir de textos em língua portuguesa. Tese de Doutorado, Programa de Pós-Graduação em Ciência da Computação (PPGCC), Pontifícia Universidade Católica do Rio Grande do Sul (PUCRS), p. 156. LOPES, L.; VIEIRA, R. (2012) Improving quality of portuguese term extraction, In PROPOR 2012 – International Conference on Computational Processing of Portuguese Language. LOPES, L.; VIEIRA, R.; FERNANDES, P.; COUTO, G. (2012) ExATOlp: extraction of language resources from Portuguese corpora, In PROPOR 2012 – International Conference on Computational Processing of Portuguese Language. LOPES, L.; FERNANDES, P.; VIEIRA, R. (2012) Domain Term Relevance Through tf-dcf, In ICAI’2012 – International Conference on Artificial Inteligence, WORLDCOMP, Las Vegas, USA. MAEDCHE, A.; STAAB, S. (2001) Learning ontologies for the semantic web, in SemWeb, 2001. MARCOLIN, P.; EVERS, A.; FINATTO, M. J. B.; GOLDNADEL, M. (2010) Pneumomatologias: formação em Terminologia em curso de Tradução no Brasil. In: Actas do XII Simposio Iberoamericano de Terminologia. RITerm 2010, 2012. Buenos Aires: Editorial Colegios de Traductores Publicos de la Ciudad de Buenos Aires, 2012. p. 254-278. MARGARIDO, P.R.A.; PARDO; T.A.S.; ALUÍSIO. S.M. (2008). Sumarização Automática para Simplificação de Textos: Experimentos e Lições Aprendidas. Publicado nos Proceedings do IHC – UAI 2008. NUNES, M.G.V.; OLIVEIRA JÙNIOR, O.N. ALUISIO, S.M.; RINO, L.H.M; SILVA, B.C.D. (2005) Desafios da construção de recursos lingüísticos para o processamento do português do Brasil. In: BERBER SARDINHA, Tony (org). A língua portuguesa no computador. Campinas-SP: Mercado de Letras/São Paulo: FAPESP. Coleção As Faces da Lingüística Aplicada. pp. 33-70. ORASAN, C. (2001). Patterns in scientific abstracts. In: Proceedings of Corpus Linguistics, 2001 Conference, Lancaster University, Lancaster, UK, pp. 433 – 443. SAUSSURE, F. de. (1970) Curso de Linguística Geral. São Paulo: Cultrix.
VIEIRA, Renata; LIMA, Vera Lúcia Strube de . ERI/Lingüística computacional: princípios e aplicações. In: Luciana Porcher Nedel. (Org.). IX Escola Regional de Informática – 2001 (ERI2001). 1 ed. Porto Alegre: SBC- Regional Sul, 2001, v. 1, p. 27-58. VIEIRA, Renata. Linguística computacional: fazendo uso do conhecimento da língua. Entrelinhas (UNISINOS.Online), São Leopoldo, v. 2, n. 4, p. 20-25, 2002.

18
Porto Alegre, 27 de junho de 2012.
Coordenador do Subprojeto:
Profa. Dra. Maria José Bocorny Finatto
Coordenador do PPG-Letras da UFRGS
Prof. Dr. Valdir do Nascimento Flores





























