Embed Size (px)
Citation preview

Fundamentos de Estatística
Universidade Tecnológica Federal do ParanáPrograma de Pós-Graduação em Engenharia Mecânica - PPGEM
Profa Daniele Toniolo Dias F. Rosawww. fotoacustica.fis.ufba.br/daniele/

O Método de Engenharia e o
Pensamento Estatístico
• Um engenheiro é alguém que resolve problemas de interesse da sociedade, pela aplicação eficiente de princípios estatísticos.
• Os engenheiros o realizam seja pelo refinamento de um produto ou processo já existente, seja pela um produto ou processo já existente, seja pela elaboração do projeto de um novo produto ou processo que atenda às necessidades dos consumidores.
• O método de engenharia ou científico é a abordagem para formular e resolver esses problemas.

• Note que o método de engenharia caracteriza uma • Note que o método de engenharia caracteriza uma
forte relação recíproca entre o problema, os fatores
que podem influenciar sua solução, um modelo do
fenômeno e a experiência para verificar a adequação
do modelo e da solução proposta para o problema.
• O quadrado pontilhado indica que vários ciclos ou
interações dessas etapas podem ser requeridos para
obter a solução final.

Variáveis aleatórias contínuas
• Em medidas, os dados podem ser influenciados por pequenas variações de temperatura, pressão, vibração, entre outras variáveis não controladas.
• Uma peça tirada da produção, a qual possui uma medida muito precisa sempre possui dispersão em medida muito precisa sempre possui dispersão em torno da mesma.
• É comum modelar a faixa de valores possíveis dentro de um intervalo.

O Método científico e a Estatística
• A estatística lida com a coleta, a apresentação, a análise e o uso dos dados para tomar decisões, resolver problemas e planejar produtos e processos.
• Especificamente, técnicas estatísticas podem ser uma ajuda poderosa no planejamento de novos produtos e ajuda poderosa no planejamento de novos produtos e sistemas, melhorando os projetos existentes e planejando, desenvolvendo e melhorando as pesquisas futuras.
• Métodos estatísticos são usados para nos ajudar a entender a variabilidade de um sistema.

Fontes potenciais de variabilidade
• Exemplo 1: O consumo de um carro não é dependentes da distância registrada apenas. Depende de fatores como tipo de estrada, condições do carro, tipo de gasolina, etc.
• Exemplo 2: Um engenheiro está projetando um • Exemplo 2: Um engenheiro está projetando um conector de náilon para aplicação automotiva. A parede deste conector está condicionada a força de remoção do conector. O primeiro protótipo foi feito e as seguintes forças de remoção são medidas: 12,6; 12,9; 13,4; 12,3 ;13,6; 13,5; 12,6; 13,1 N.

Análise descritiva e exploratória de
dados
• Os dados devem ser cuidadosamente coletados (observados), devidamente (observados), devidamente conhecidos e utilizados para analisar e interpretar a sua variabilidade de forma a possibilitar uma correta resposta à hipótese em estudo.

Conceitos básicos em Estatística
• INFORMAÇÃO NUMÉRICA: um conjunto de dados estatísticos consiste de uma ou mais medidas, escores ou valores observados (coletados) de certo número de indivíduos, objetos, ensaios, experimentos, etc.
• ASPECTO BÁSICO DA INFORMAÇÃO: A análise • ASPECTO BÁSICO DA INFORMAÇÃO: A análise estatística de um conjunto de dados só faz sentido quando existir “variabilidade” nos valores observados, ou seja, os valores devem apresentar diferenças nas diferentes unidades de observação utilizadas. A não existência de variabilidade entre os valores observados torna desnecessária a utilização de qualquer método estatístico.

• POPULAÇÃO: Conjunto de indivíduos ou objetos os quais o pesquisador tem interesse, que apresentam relevância para a investigação de hipótese em estudo. Podemos ainda dizer que a população é formada por todos os valores possíveis de serem observados numa dada situação. No caso de estudos experimentais, o alvo é sempre uma dada população. A resposta para a alvo é sempre uma dada população. A resposta para a hipótese de interesse é dada por uma conclusão a respeito da população em estudo.
• Uma população pode ser investigada a partir da observação de seus elementos através de duas diferentes formas: Censo ou Amostra.

• CENSO: Denominamos de censo aquelas situações onde a investigação é realizada a partir da observação de todos os elementos de uma população. Esse tipo de observação somente é possível em populações finitas.
• AMOSTRA: Na grande maioria das vezes (quase sempre!) não é possível observar todos os elementos de uma população, porém é possível observar-se uma parte desta população. O conjunto de elementos parte desta população. O conjunto de elementos efetivamente observado é denominado amostra. Podemos então dizer que uma amostra é todo e qualquer subconjunto necessariamente finito da população.
• Para que a amostra seja uma representação realista, não tendenciosa, da população, é necessário que seus elementos sejam escolhidos de forma rigorosamente aleatória.

• Amostra Aleatória: Amostra de N valores ou
indivíduos (unidades experimentais) obtidos
de tal forma que todos os possíveis de tal forma que todos os possíveis
elementos da população tenham a mesma
“chance” de participar na amostra.

Coletando dados na Engenharia• Nos estudos observacionais os dados são obtidos à
medida que se tornam disponíveis. O engenheiro observa o processo ou população, perturbando-o tão pouco quanto possível, e registra as grandezas de interesse.
• Por exemplo: um pesquisador avalia o desempenho de • Por exemplo: um pesquisador avalia o desempenho de um processo de fabricação de componentes plásticos através da injeção em molde. Pode-se observar o processo, selecionar componentes à medida que são fabricados e medir importantes características de interesse (espessura da parede, o encolhimento ou a resistência da peça). Ou também registrar as variáveis de processo (temperatura do molde, o conteúdo de umidade da matéria-prima e o tempo do ciclo.

• Nos experimentos planejados, o engenheiro faz variações propositais nas variáveis controláveis de alguns sistemas ou processos, observa os dados de saída do sistema resultante e, então, faz uma inferência ou decisão sobre as variáveis que são responsáveis pelas mudanças observadas no desempenho de saída.
• Por Exemplo: mudança na espessura da parede do • Por Exemplo: mudança na espessura da parede do conector de náilon (ex. em variabilidade) com objetivo de descobrir se uma força de remoção maior poderia ser ou não obtida.
• Experimentos planejados com princípios básicos, tais como, aleatorização, são necessários para estabelecer as relações de causa e efeito.

• O planejamento de experimentos tem um papel muito importante no projeto e desenvolvimento de engenharia e na melhoria dos processos de fabricação.
• Geralmente, quando produtos e processos são planejados e desenvolvidos com experimentos planejados, eles têm melhor desempenho, mais alta confiabilidade e menores custos globais. confiabilidade e menores custos globais.
• Experimentos planejados também desempenham um papel crucial na redução do tempo de condução de um projeto de engenharia e do desenvolvimento de atividades.

• INFERÊNCIA ESTATÍSTICA: Embora seja observada “apenas” uma amostra, o objetivo de qualquer estudo é estabelecer conclusões com respeito à população de interesse. A metodologia utilizada para se fazer a passagem dos resultados obtidos na amostra para conclusões populacionais é chamada “inferência estatística”.estatística”.
A inferência estatística pode ser definida em duas etapas:
• Estimação: Obter informação sobre uma característica populacional;
• Teste de Hipóteses: Utilização da informação amostral para responder as hipóteses de interesse no estudo.

• ANÁLISE ESTATÍSTICA:
• O processo de organização, processamento, sumarização e retirada de conclusões sobre um determinado conjunto de dados (amostra) é chamado de análise estatística. As hipóteses chamado de análise estatística. As hipóteses (questões de interesse) daqueles que realizam o estudo indicam o tipo de dado que precisa der obtido e consequentemente a inferência a ser realizada.

Resumo e análise estatística de dados

Organização, sumarização e
representação de dados
• A organização, sumarização e apresentação dos dados observados são essenciais para um bom julgamento estatístico, dado que permitem que sejam estatístico, dado que permitem que sejam identificadas características importantes da amostra e ainda mais, indicar modelos que podem ser mais adequados para verificação da hipótese em estudo.

Tipos de Variáveis
• VARIÁVEIS CATEGÓRICAS: Denominamos variáveis categóricas aquelas medidas (características) observadas na amostra que apenas identificam a unidade de observação. Em outras palavras, uma variável categórica identifica um atributo, classe, qualidade,..., da unidade de observação. Exemplo: Sexo, Grau de escolaridade, tipo de solo, fornecedor, Sexo, Grau de escolaridade, tipo de solo, fornecedor, etc.
• VARIÁVEIS QUANTITATIVAS: Denominamos de variáveis quantitativas aquelas medidas (características) observadas na amostra que estabelecem uma informação resultante de uma contagem ou de uma mensuração feita na unidade experimental.

Classificação das variáveis

Apresentação dos Dados
• A apresentação de informações contidas num conjunto de dados pode ser feita de várias formas. O objetivo de uma apresentação dos dados é organizar os valores observados de forma a obter o máximo de informação. Os procedimentos usuais de apresentação de dados são tabelas e gráficos.
• Consideremos o seguinte experimento: Uma indústria química formula um experimento para verificar se um novo método de fabricação de um produto químico é superior a um método tradicional de fabricação. Um experimento foi realizado obtendo-se dados de produção industrial dos métodos A (Tradicional) e B (Novo Método), cujos resultados estão apresentados na Tabela seguinte:

Dados de produção industrial
* *** **
*Variável categórica nominal **Variável quantitativa contínua

• A apresentação usual dos dados observados é feita através de uma tabela de distribuição de frequências, onde são apresentados os valores observados, a frequência com que cada valor foi observado, o percentual que este número de frequência representa em relação ao total de observação, bem como os respectivos valores acumulados.
Distribuição de Frequência da Variável Método de Distribuição de Frequência da Variável Método de
Produção Industrial.

Distribuição de
Frequência da
Variável Produção
Industrial
Notação:
fi = frequência do i-ésimo valor
pi = frequência percentual do i-ésimo valor
⇒
pi = frequência percentual do i-ésimo valor
⇒ pi = fi / n
n = tamanho da amostra (número de
unidades observadas)
Fi = frequência acumulada até o i-ésimo
valor, ou seja, número de observações até
o i-ésimo valor ⇒
Pi = frequência percentual acumulada até
o i-ésimo valor, ou seja, percentual de
observações até
o i-ésimo valor ⇒
∑=
=i
aai fF
1
∑=
=i
aai pP
1

• Problema:
• No caso das variáveis quantitativas, como no exemplo acima, podemos ter que a variável assume um grande número de valores todos (ou a grande maioria) com baixas frequências, logo a distribuição de frequências baixas frequências, logo a distribuição de frequências se torna grande sem uma maior contribuição para a interpretação dos dados.
• Nessas situações, recomenda-se a categorização da variável através do estabelecimento de intervalos de acordo com os objetivos do estudo.

Distribuição de Frequência da Variável Produção
Industrial Categorizada.
• No exemplo:
Sugestão Usual:
Os intervalos gerados pela categorização devem ter o mesmo
comprimento e/ou aproximadamente mesmas frequências.

• Qualquer conjunto de dados fica mais fácil de analisar se for representado graficamente. No gráfico tradicional para uma distribuição de frequências, cada intervalo é representado por um retângulo, cuja base coincide com a largura do próprio intervalo e cuja área é idêntica, ou proporcional, a sua frequência.é idêntica, ou proporcional, a sua frequência.
• A figura geométrica obtida é chamada de histograma.
• A área total do histograma é igual a um, quando a área de cada retângulo for igual à frequência do intervalo correspondente.

Histograma da produção industrial categorizada
10
20
30
40
50
60
70 _
Freq
uênc
ia (%
)
x
_x+s
_x-s
_x
_x-2s_x-2s _
x+2s
• Para facilitar a comparação com os dados da tabela, a altura de cada retângulo, e não a sua área, é igual à frequência do intervalo.
• Isto não alteram o aspecto geral do histograma, já que as bases dos retângulos são todas iguais.
74 76 78 80 82 84 86 88 90 92 94 960
Produção
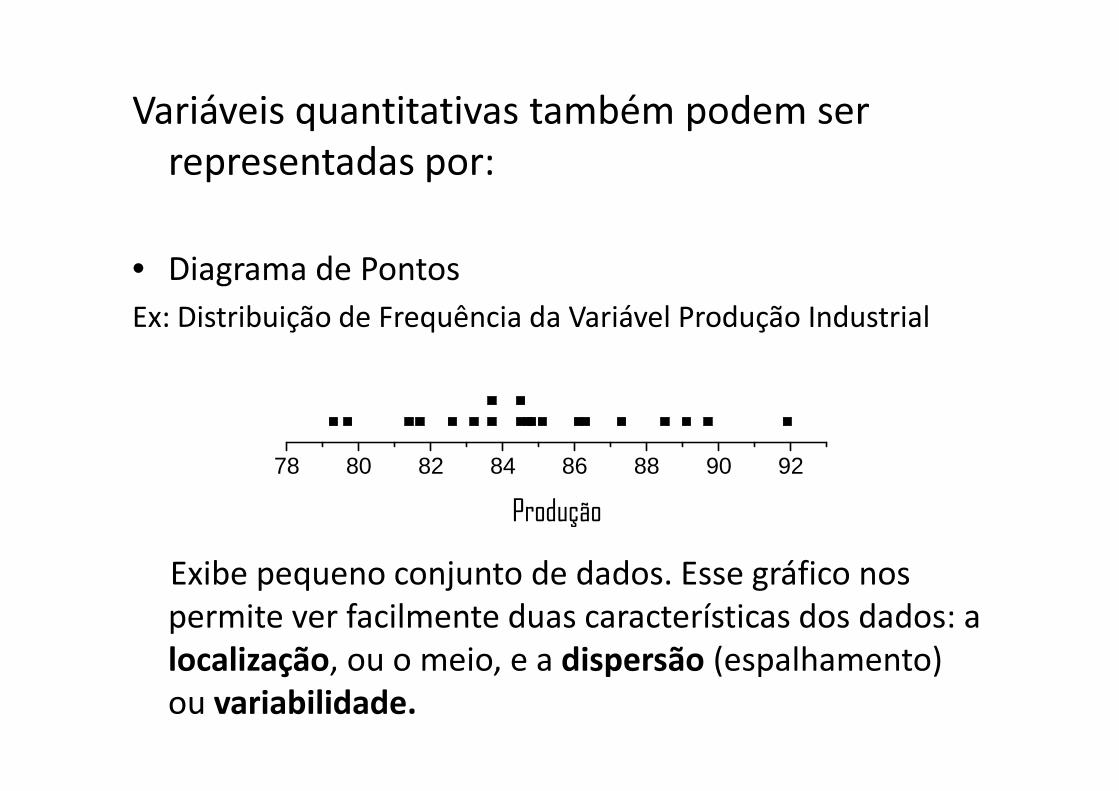
Variáveis quantitativas também podem ser
representadas por:
• Diagrama de Pontos
Ex: Distribuição de Frequência da Variável Produção Industrial
Exibe pequeno conjunto de dados. Esse gráfico nos permite ver facilmente duas características dos dados: a localização, ou o meio, e a dispersão (espalhamento) ou variabilidade.
78 80 82 84 86 88 90 92
Produção

• Ramos e Folhas
– Utilização: Conjunto pequeno de dados
– Vantagem: Visualização completa das obs.
– Construção: Cada obs. dividida em duas partes:
Ramos Folhas
79
81
82
83
84
3 7
4 7
6
2 7 7
5 5 7 8dividida em duas partes:
Ramos e Folhas
Ex: Distribuição de Frequência da Variável Produção Industrial
Unidade das Folhas=0,1
84
85
86
87
88
89
91
5 5 7 8
1
1 3
3
5
1 7
9

Variáveis qualitativas podem ser representadas por:
• Gráfico em Barras
• Gráfico de Setores (Gráfico “Pizza”)
• Gráfico em Retângulo

Sumarização dos Dados
• A distribuição de frequências além de apresentar os dados observados, também pode ser considerada uma sumarização de dados. Porém, na maioria dos casos, é desejado obter valores que possam representar cada uma das variáveis em estudo. uma das variáveis em estudo.
• Esses valores devem ser medidas que, sob algum ponto de vista sejam representativos dos dados observados. As medidas usualmente utilizadas se referem a locação e dispersão dos dados.

• A média aritmética de um conjunto de dados,
que é uma medida da sua localização, ou
tendência central, é simplesmente a soma de
todos os valores, dividida pelo número total de
elementos no conjunto.
Média:Populacional: ∑=
Nj
N
yµPopulacional:
yi= i-ésimo valorN= número total de valores na população
Amostral:
xi= i-ésimo valorn= número total de valores na amostra
∑=j N1
∑=
=n
i
i
n
xx
1

• Para obter a medida do espalhamento das observações em torno da média, que é o desvio padrão, primeiro calculamos a diferença, ou desvio, de cada valor individual em relação a média amostral:
• Em seguida somamos os quadrados de todos os desvios e dividimos o total por n-1. O resultado dessas
xxd ii −=
desvios e dividimos o total por n-1. O resultado dessas operações é a variância amostral (s2) do conjunto de observações:
( )11
)( 1
2
1
2
2
−
−=
−==
∑∑==
n
xx
n
d
sxV
n
ii
n
ii
Por que (n-1)?
Quando dividimos por n-1 temos que S2 é um estimador não viciado, importante propriedade
da inferência estatística:
Se a amostra é grande, os valores obtidos dividindo por n ou n-1 são praticamente iguais.

• Enquanto a média tem as mesmas unidades que as observações originais, as unidades da variância são, pela própria definição, o quadrado das unidades de partida. Para que as medidas de dispersão e de posição tenham as mesmas unidades, costumamos substituir a variância pela sua raiz quadrada, que é chamada de desvio padrão amostral:
• O desvio padrão geralmente é usado para definir intervalos em torno da média.
2)( sxVs ==
σO desvio padrão populacional é representado pela letra grega:

• Calcule a média e o desvio padrão para a
distribuição de frequência da variável
Exercício
distribuição de frequência da variável
produção industrial.

Distribuição Normal
• Modelo mais utilizado para distribuição de uma variável aleatória.
• Teorema central do limite faz com que a forma seja um sino simétrico. De forma que o Ponto central (máximo), representa a média.
• Em uma medida, quando os desvios são decorrentes de • Em uma medida, quando os desvios são decorrentes de variáveis independentes podemos usar o modelo para tirar conclusões aproximadas em em relação à média.
• Exemplo: o desvio (ou erro) no comprimento de uma peça usinada é dependente de variações na temperatura e na umidade, vibrações, variações no ângulo de corte, desgaste da ferramenta de corte, desgaste no mancal, variação na velocidade, entre outras.

• A distribuição normal é uma distribuição contínua, ou seja, a variável pode assumir qualquer valor dentro de um intervalo pré-definido (qq valor real).
• Uma distribuição contínua da variável x é definida pela sua densidade de probabilidade f(x):
( )dxedxxf
x2
2
2
2
1)( σ
µ
πσ
−−
=
f(x)= densidade de probabilidade da variável aleatória x
µ= média populacional
σ2= variância populacional
• Para indicar que uma variável aleatória x se distribui normalmente, com µ e σ2, usaremos que x≈N(µ ,σ2) , onde o sinal ≈ lê-se “distribui-se de acordo com”.
2πσ

• Distribuição de frequências de uma variável aleatória
2
2
2
1)(
x
exf−
=π
• Distribuição de frequências de uma variável aleatória normal padrão x≈N(0,1). Note que x é o afastamento em relação média, em número de desvios padrão.
• A probabilidade de que a<x<b é igual:
=Probabilidade de que o valor da variável aleatória de densidade de probabilidade f(x) seja observado no intervalo [a,b]
( ) ( ) ∫=≤≤=<<b
a
dxxfbxaPbxaP )(

• Na prática podemos consultar na tabela a seguir os valores das integrais para vários intervalos de uma variável z≈N(0,1) para obter as probabilidades correspondentes a quaisquer limites.
2
2
2
1)(
x
exf−
=π
( ) ( )
( ) ( )%73,999973,0)(33
%26,686826,0)(
3
3
==+<<−
==+<<−
∫
∫
+
−
+
−
σµ
σµ
σµ
σµ
σµσµ
σµσµ
dxxfxP
dxxfxP
correspondentes a quaisquer limites.
• Padronização: Padronizar uma variável aleatória x (µ,σ2) é construir a partir dela uma nova variável aleatória z, cujos valores são obtidos subtraindo-se de cada valor de x a média populacional e dividindo-se o resultado pelo desvio padrão:
σµ−= x
zx= variável aleatória com distribuição N(µ,σ2)
z= variável aleatória com distribuição N(0,1)

• O valor numérico de z representa o
afastamento do valor de x em relação à média
populacional µ, medindo em desvios padrão,
ou seja: x=µ+zσ
Exercício
• Padronize a variável aleatória produção e
fazendo z=-2 encontre o valor de x que está a
dois desvios padrão abaixo da média (compare
com o gráfico de histograma)
Exercício

Tabela de Probabilidades
Associadas à área da Cauda
Direita da Distribuição Normal
Padronizada
Valor de z até a segunda casa
Valor de z até a primeira casa decimal
Ex: z=1,96 →0,0250 fração da área
total sob a curva que está a direita.
Por simetria:
95% restantes estão entre z=-1,96 e
z=1,96.

• Aceitando o modelo normal como uma representação adequada da distribuição populacional da produção industrial, use a tabela acima, juntamente com os valores dos parâmetros amostrais para responder:
• Qual a probabilidade de utilizando um método ao acaso os dados de produção industrial ficarem entre 83 e 87?
Exercício
os dados de produção industrial ficarem entre 83 e 87?
• Faça um esboço da área correspondente a esta probabilidade.
Obs: não esquecer que a resposta se baseia na validade de duas
suposições: a de que a distribuição dos dados de produção
industrial é normal e a de que os parâmetros populacionais são
iguais aos valores amostrais.

Por que a distribuição normal é importante?
• Mesmo que a população de interesse não se distribua normalmente, as técnicas podem ser usadas, porque continuam aproximadamente válidas.
• Essa robustez vem do teorema do limite central:
Se a flutuação total numa certa variável aleatória for o resultado da soma das flutuações de muitas variáveis independentes e de importância mais ou menos igual, a sua distribuição tenderá para a normalidade, não importa qual seja a natureza das distribuições das variáveis individuais.

Como calcular um intervalo de confiança para
a média
• O principal motivo para querermos um modelo é a perspectiva de usá-lo para fazer inferências sobre os parâmetros populacionais.
• Supondo que apenas um dado da produção industrial tenha sido coletado e este seja 79,3 (o primeiro valor). O que esse valor nos permite dize a respeito da O que esse valor nos permite dize a respeito da produção industrial média populacional µ?
• Aceitando o modelo normal, podemos dizer que temos 95% de confiança na dupla desigualdade
• Tomando a desigualdade da esquerda e somando 1,96σ aos dois lados temos:
σµσµ 96,13,7996,1 +<<−

• Subtraindo 1,96σ da desigualdade da direita, temos:
• Combinando as duas temos um intervalo de 95% de confiança para a média populacional:
• Supondo que σ=3,28 (na verdade um valor amostral)
σµ 96,13,79 +<
µσ <− 96,13,79
σµσ 96,13,7996,13,79 +<<−• Supondo que σ=3,28 (na verdade um valor amostral)
determinamos numericamente os limites desse intervalo:
E ainda há 5% de probabilidade de estarmos enganados.73,8587,72 << µ
σµσ zxzx ii +<<−
Intervalo de confiança para a média populacional, a partir de uma
observação:
xi= uma observação, z= ponto da distribuição N(0,1) no nível desejado

• Em pesquisas que envolvem a consideração de duas ou mais variáveis, estas são estudadas também simultaneamente,procurando-se uma possível correlação entre elas, isto é, quer-se saber se as alterações sofridas por uma das variáveis são
Covariância e Correlação
alterações sofridas por uma das variáveis são acompanhadas por alterações nas outras.
• Quando existirem duas séries de dados, existirão várias medidas estatísticas que podem ser usadas para capturar como as duas séries se movem juntas através do tempo.

• As duas mais largamente usadas são a correlação e a covariância. Para duas séries de dados, X (X1, X2,.) e Y(Y1,Y2... ), a covariância fornece uma medida não padronizada do grau no qual elas se movem juntas, e é estimada tomando o produto dos desvios da média para cada variável em cada período.
( )( )n1
• O sinal na covariância indica o tipo de relação que as
duas variáveis têm. Um sinal positivo indica que elas
movem juntas e um negativo que elas movem em
direções opostas.
( )( )∑=
−−−
=n
iii yyxx
nyxCov
11
1),(

• Enquanto a covariância cresce com o poder do relacionamento, ainda é relativamente difícil fazer julgamentos sobre o poder do relacionamento entre as duas variáveis observando apenas a covariância, pois ela não é padronizada.
• A correlação é a medida padronizada da relação entre duas variáveis. Ela pode ser calculada da covariância:
• A correlação nunca pode ser maior do que 1 ou menor do que -1. Uma correlação próxima a zero indica que as duas variáveis não estão relacionadas (são estatisticamente independentes).
∑=
−
−−
=n
i y
i
x
i
s
yy
s
xx
nyxr
11
1),(

• Uma correlação positiva indica que as duas variáveis movem juntas, e a relação é forte quanto mais a correlação se aproxima de um.
• Uma correlação negativa indica que as duas variáveis movem-se em direções opostas, e que a relação também fica mais forte quanto mais próxima de -1 a correlação ficar. correlação ficar.
• Duas variáveis que estão perfeitamente correlacionadas positivamente (r=1) movem-se essencialmente em perfeita proporção na mesma direção, enquanto dois conjuntos que estão perfeitamente correlacionados negativamente movem-se em perfeita proporção em direções opostas.

• Uma regressão simples é uma extensão do conceito
correlação/covariância. Ela tenta explicar uma
variável, a qual é chamada variável dependente,
usando a outra variável, chamada variável
independente.
• Se as duas variáveis são plotadas uma contra a outra
num gráfico de espalhamento, com Y no eixo vertical
e X no eixo horizontal, a regressão tenta ajustar uma e X no eixo horizontal, a regressão tenta ajustar uma
linha reta através dos pontos, de tal modo que
minimiza a soma dos desvios quadrados dos pontos
da linha.
• Quando tal linha é ajustada, dois parâmetros
emergem - um é o ponto em que a linha corta o
eixo Y, chamado de intercepção da regressão, e o
outro é a inclinação da linha de regressão.

• Relação linear entre duas variáveis, acrescida de um erro aleatório, a linearidade do conjunto de pontos está perturbada por uma certa dispersão.

• A inclinação (b) da regressão mede a direção e a magnitude da relação.
• Quando as duas variáveis estão correlacionadas positivamente, a inclinação também será positiva, enquanto quando as duas variáveis estão correlacionadas negativamente, a inclinação será negativa.
• A magnitude da inclinação da regressão pode ser lida como segue: para cada acréscimo unitário na variável como segue: para cada acréscimo unitário na variável (X), a variável dependente mudará por b (inclinação). A ligação estreita entre a inclinação da regressão e a correlação/covariância não seria surpreendente desde que a inclinação for estimada usando a covariância:
( )xV
yxCovbinclinação
),(==

• A intercepção (a) da regressão pode ser lida de várias maneiras. Uma interpretação diz que ela é o valor que Y terá quando X é zero.
• Uma outra é mais direta, e está baseada em como ela é calculada: na diferença entre o valor médio de Y, e o valor ajustado da inclinação de X.
µµ −==
• Os parâmetros da regressão são sempre estimados com algum ruído, parcialmente porque o dado é medido com erro e porque os estimamos de amostra de dados. Este ruído é capturado numa dupla de estatísticas.
)(int xy baercepção µµ −==

• Um é o R2 da regressão, que mede a proporção da variabilidade em Y que é explicada por X. É uma função direta da correlação entre as variáveis
• Um valor de R2 muito próximo de 1 indica uma forte relação entre as duas variáveis, apesar de a relação poder ser positiva ou negativa.
( )22 , yxrR =
poder ser positiva ou negativa.
• Uma outra medida do ruído numa regressão é o erro padrão, que mede o "espalhamento" ao redor de cada um dos dois parâmetros estimados - a intercepção e a inclinação. Cada parâmetro tem um erro padrão associado, que é calculado dos dados:

Erro Padrão da Intercepção =
Erro Padrão da Inclinação=

Combinações lineares de variáveis
aleatórias





























