Embed Size (px)
Citation preview

www
Utilização de Redes Neuronais Artificiais para a Modelação da Degradação de Sistemas de Distribuição de Água
José Pedro Gamito de Saldanha Calado Matos
Dissertação
Presidente: Prof. António Pinheiro
Orientador: Prof. António Jorge Monteiro
Vogais: Prof. António Bento Franco
Prof. Joaquim Luís Dias
Utilização de Redes Neuronais Artificiais para a Modelação da Degradação de Sistemas de Distribuição de Água
José Pedro Gamito de Saldanha Calado Matos
Dissertação para obtenção do Grau de Mestre em
Engenharia Civil
Jurí
Prof. António Pinheiro
Prof. António Jorge Monteiro
Prof. António Bento Franco
Prof. Joaquim Luís Dias
Novembro 2008
Utilização de Redes Neuronais Artificiais para a Modelação da Degradação de Sistemas de Distribuição de Água
José Pedro Gamito de Saldanha Calado Matos
para obtenção do Grau de Mestre em


i
Agradecimentos
A realização deste trabalho foi apenas possível graças à disponibilidade, ao apoio, à dedicação, à
amizade e, por vezes, à paciência de muitas pessoas. A todas elas expresso o meu sincero
agradecimento.
Em especial, é imprescindível agradecer:
Ao Professor António Jorge Monteiro, orientador científico desta dissertação, pelas ideias com que
soube sempre enriquecer o trabalho e pela confiança, consideração e disponibilidade ímpares que
demonstrou.
À EPAL, cujo apoio foi fundamental para a concretização do trabalho, não só através dos dados
disponibilizados, mas também da atenção e do tempo dos seus colaboradores.
Ao Doutor Andrew Donnely e a todo o Grupo de Monitorização e Controlo, pela consideração e
empenho demonstrados na fase inicial do trabalho.
Ao Engenheiro Sérgio Rodrigues, pelos experientes conselhos e pelo interesse revelado.
Ao Professor Miguel Ayala Botto, que prescindiu do seu tempo para encaminhar o meu estudo das
redes neuronais artificiais.
Ao meu pai, cuja exigência me motivou a ir mais além e cujos sábios conselhos me ajudaram a,
inúmeras vezes, aperfeiçoar o trabalho.
À minha mãe, que com o seu carinho e preocupação me acompanhou constantemente.
Aos meus colegas de trabalho, tanto, na Hidra, como, posteriormente, na AGS, que me apoiaram
da melhor forma possível.
E, finalmente, à Natércia, que esteve sempre comigo, de alma e coração, e sem a qual teria sido
impossível levar a cabo esta empresa.
Obrigado, ainda, a todos aqueles que não tive a clarividência de nomear, mas contribuíram
positivamente para este projecto.


iii
Resumo
Nos últimos anos, tem-se verificado, por parte das entidades gestoras de sistemas de
abastecimento de água, um aumento da preocupação com o desempenho das infra-estruturas e,
particularmente, com os níveis de perdas.
Um dos desafios que se apresentam a estas entidades é a definição de estratégias de intervenção
optimizadas a longo prazo, objectivo para o qual é importante produzir boas estimativas do
desempenho futuro dos sistemas.
Como forma de responder a esse desafio, analisou-se, neste trabalho, a adequação da aplicação
de modelos baseados em redes neuronais artificiais a esta problemática, tendo-se desenvolvido
uma metodologia para a aplicação tais modelos à da degradação de sistemas de distribuição de
água.
Como caso de estudo, a metodologia foi aplicada, com bons resultados, à rede de distribuição de
água da Cidade de Lisboa, cujos dados, fornecidos pela EPAL contêm informação referente a
mais de 1 400 km de tubagens.
Apesar de se terem verificado algumas limitações aos modelos de degradação baseados em
redes neuronais artificiais, conclui-se que o seu desempenho é bastante bom em previsões de
médio e curto prazo.
Considera-se que este é um tema de investigação promissor, fornecendo uma boa base para o
desenvolvimento de um modelo económico-financeiro que, aplicado conjuntamente com o modelo
de degradação, permita, de forma integrada, optimizar as estratégias de intervenção nos
sistemas.
Palavras-chave: degradação de sistemas de distribuição; distribuição de água;
gestão de activos; perceptrão multicamada; redes neuronais artificiais; roturas.


v
Abstract
In the past few years there has been a tendency among water services companies to acknowledge
the performance of their infrastructures as a main concern, particularly, in what concerns water
losses.
One of the challenges these companies face relies on the definition of intervention strategies in the
long run, a goal that in order to be fulfilled requires good projections of the systems future
performance.
As an answer to this challenge, this work sought to analyze the potential of artificial neural
networks based applications to this problem. As a result, a methodology has been developed to
guide the usage of such applications to model the degradation of water distribution systems.
As a case study, the methodology has been applied, with good results, to the city of Lisbon water
distribution network, whose data, given by EPAL, contains information relative to more than
1 400 km of mains.
Although some limitations have been identified in artificial neural networks based degradation
models, their performance has proven to be rather good in the short and medium term.
Overall, this investigation theme is considered promising, providing a strong base for the
development of a financial-economical model, which applied with the degradation model, may be
capable of providing an integrated approach for optimizing intervention strategies in water
distribution systems.
Keywords: artificial neural networks; infrastructure asset management; multilayer
perception ; ruptures; water distribution systems; water distribution systems degradation.


vii
Índice do texto
1. INTRODUÇÃO ........................................................................................................................... 1
1.1 ENQUADRAMENTO ................................................................................................................. 1
1.2 OBJECTIVOS .......................................................................................................................... 1
1.3 DESCRIÇÃO SUMÁRIA DO ESTUDO ........................................................................................... 3
2. A EVOLUÇÃO DO ABASTECIMENTO DE ÁGUA EM PORTUGAL ....................................... 5
2.1 ASPECTOS HISTÓRICOS GERAIS .............................................................................................. 5
2.2 A CIDADE DE LISBOA .............................................................................................................. 5
2.3 SITUAÇÃO ACTUAL E PERSPECTIVAS FUTURAS EM PORTUGAL. ................................................. 6
3. A AVALIAÇÃO DE ROTURAS EM SISTEMAS DE ABASTECIMENTO DE ÁGUA..............11
3.1 O DESAFIO DO CONTROLO DE PERDAS ..................................................................................11
3.2 CAMPOS DE ACÇÃO NA REDUÇÃO DE PERDAS ........................................................................14
3.3 ÁREAS DE INTERESSE PRIORITÁRIO NA REDUÇÃO DE PERDAS .................................................15
3.4 ENQUADRAMENTO DO PRESENTE TRABALHO .........................................................................16
3.5 CAMPOS DE APLICAÇÃO – GESTÃO ESTRATÉGICA DE ACTIVOS E IDENTIFICAÇÃO DE ZONAS DE
INTERVENÇÃO PRIORITÁRIA ..............................................................................................................18
3.6 PERSPECTIVAS E DESAFIOS ..................................................................................................19
4. REDES NEURONAIS ARTIFICIAIS E ALGORITMOS GENÉTICOS .....................................21
4.1 ASPECTOS GERAIS ...............................................................................................................21
4.2 RAZÕES DA APLICAÇÃO ........................................................................................................21
4.2.1 Redes neuronais artificiais ........................................................................................21
4.2.2 Algoritmos genéticos .................................................................................................23
4.3 EVOLUÇÃO HISTÓRICA ..........................................................................................................24
4.3.1 Redes neuronais artificiais ........................................................................................24
4.3.2 Algoritmos genéticos .................................................................................................25
4.4 PRINCÍPIOS E DESCRIÇÃO DAS REDES NEURONAIS ARTIFICIAIS ................................................26
4.4.1 Princípios de funcionamento e convenções ..............................................................26
4.4.2 Paralelismo com os sistemas biológicos ...................................................................31
4.4.3 Modelos de redes neuronais artificiais ......................................................................33
4.4.4 Treino do PMC ..........................................................................................................39

viii
5. METODOLOGIA PROPOSTA PARA A MODELAÇÃO DA DEGRADAÇÃO DE CONDUTAS
DE ÁGUA ..........................................................................................................................................47
5.1 INTRODUÇÃO .......................................................................................................................47
5.2 SELECÇÃO E TRATAMENTO DE INFORMAÇÃO ..........................................................................47
5.2.1 Análise dos dados e definição de objectivos ............................................................47
5.2.2 Preparação dos dados ..............................................................................................48
5.3 PROCEDIMENTOS DE MODELAÇÃO.........................................................................................49
5.3.1 Considerações prévias ..............................................................................................49
5.3.2 Definição da arquitectura da rede .............................................................................49
5.3.3 Escolha do algoritmo de treino ..................................................................................55
5.3.4 Escolha da dimensão dos grupos de validação e teste ............................................56
5.4 VALIDAÇÃO DOS RESULTADOS ..............................................................................................56
5.5 OUTRAS FERRAMENTAS DESENVOLVIDAS ..............................................................................57
5.6 SÍNTESE DO MÉTODO ...........................................................................................................59
6. CASO DE ESTUDO – A REDE DE DISTRIBUIÇÃO DE ÁGUA DA CIDADE DE LISBOA ...61
6.1 INTRODUÇÃO .......................................................................................................................61
6.2 DADOS DISPONIBILIZADOS ....................................................................................................63
6.2.1 Considerações gerais ................................................................................................63
6.2.2 Dados de tubagens ...................................................................................................64
6.2.3 Dados de ordens de trabalhos ..................................................................................66
6.2.4 Considerações adicionais .........................................................................................67
6.3 CARACTERIZAÇÃO E ANÁLISE PRELIMINAR DO SISTEMA ESTUDADO ..........................................67
6.3.1 A rede de abastecimento ..........................................................................................67
6.3.2 Registos de roturas ...................................................................................................75
6.4 PREPARAÇÃO DO MODELO DE DEGRADAÇÃO DA REDE DE ABASTECIMENTO .............................80
6.4.1 Considerações prévias ..............................................................................................80
6.4.2 Preparação dos dados ..............................................................................................81
6.4.3 Definição da arquitectura da rede .............................................................................82
6.4.4 Selecção do algoritmo de treino ................................................................................90
6.4.5 Treino da rede ...........................................................................................................92
6.4.6 Validação ...................................................................................................................95

ix
6.5 ANÁLISE DOS RESULTADOS ..................................................................................................97
6.6 CONSIDERAÇÕES ADICIONAIS SOBRE AS VARIÁVEIS EXPLICATIVAS ........................................102
6.7 A DISPERSÃO DO FENÓMENO ..............................................................................................103
7. NOTAS CONCLUSIVAS E RECOMENDAÇÕES PARA ESTUDOS SUBSEQUENTES .....107
8. REFERÊNCIAS BIBLIOGRÁFICAS ......................................................................................110
ANEXO I – TEOREMA DA APROXIMAÇÃO UNIVERSAL ................................................................ I
ANEXO II – DEMONSTRAÇÃO DO ALGORITMO DA RETROPROPAGAÇÃO DOS ERROS ...... III
ANEXO III – EXEMPLOS DE DIFERENTES PMC TREINADOS ................................................... VII
ANEXO IV – COMPARAÇÃO DE DIFERENTES ALGORITMOS DE TREINO .............................. IX
ANEXO V – SISTEMA DA EPAL ..................................................................................................... XI
ANEXO VI – DADOS DE TUBAGENS – DISTRIBUIÇÃO ............................................................. XIII
ANEXO VII – DADOS DE TUBAGENS – ADUÇÃO ....................................................................... XV
ANEXO VIII – DADOS DE ORDENS DE TRABALHOS (OT) ...................................................... XVII
ANEXO IX – EXTENSÃO DA REDE POR FREGUESIA ............................................................... XXI
ANEXO X – ÍNDICE MENSAL DE ROTURAS ............................................................................. XXIII
ANEXO XI – ÍNDICE MÉDIO ANUAL DE ROTURAS POR FREGUESIA................................... XXV
ANEXO XII – RESULTADOS DOS TESTES EFECTUADOS PARA DEFINIR A ARQUITECTURA
DO PMC ...................................................................................................................................... XXVII
ANEXO XIII – EQM VERSUS CORRELAÇÃO PARA VÁRIAS TOPOLOGIAS DE PMCS....... XXIX
ANEXO XIV – CÓDIGO DA APLICAÇÃO DE AG DESENVOLVIDA PARA DETERMINAÇÃO DA
TOPOLOGIA ÓPTIMA DO PMC ................................................................................................. XXXI
ANEXO XV – PARÂMETROS UTILIZADOS NO AG UTILIZADO PARA DETERMINAÇÃO DA
TOPOLOGIA ÓPTIMA DO PMC ............................................................................................... XXXIX
ANEXO XVI – RESULTADOS DA COMPARAÇÃO DE ALGORITMOS DE TREINO .................. XLI
ANEXO XVII – RELAÇÃO ENTRE DIÂMETROS E ÍNDICE OT/(100KM.ANO) NO CONJUNTO
DE DADOS E NA RNA ................................................................................................................. XLIII
ANEXO XVIII – PROCESSO DE GERAÇÃO DE PADRÕES FICTÍCIOS PARA ANÁLISE DE
RESULTADOS ...............................................................................................................................XLV
ANEXO XIX – RELAÇÃO ENTRE IDADE, ÍNDICE OT/(100KM.ANO) PRÉVIAS E ÍNDICE DE
OT/(100KM.ANO) APREENDIDA PELA RNA TREINADA .........................................................XLIX

x
Índice de quadros e figuras do texto
QUADRO 3.1 – BALANÇO HÍDRICO EM SISTEMAS DE ABASTECIMENTO DE ÁGUA. ADAPTADO DE ALEGRE ET
AL, 2006. ................................................................................................................................... 14
QUADRO 3.2 – BALANÇO HÍDRICO EM SISTEMAS DE ABASTECIMENTO DE ÁGUA. ADAPTADO DE ALEGRE ET
AL, 2004. ÁREAS DE APLICAÇÃO DO PRESENTE ESTUDO. .............................................................. 17
QUADRO 3.3 – VARIÁVEIS RELACIONADAS COM O APARECIMENTO DE ROTURAS EM SISTEMAS DE
DISTRIBUIÇÃO DE ÁGUA............................................................................................................... 17
QUADRO 6.1 – EFEITO DA SUBSTITUIÇÃO DE REDE NAS ROTURAS, RECLAMAÇÕES E PERDA EM LISBOA.
ADAPTADO DE LUÍS, 2008. ......................................................................................................... 61
QUADRO 6.2 – REGISTO DA PRIMEIRA FILTRAGEM APLICADA AOS DADOS DAS TUBAGENS DE DISTRIBUIÇÃO.
................................................................................................................................................. 65
QUADRO 6.3 – REGISTO DA SEGUNDA FILTRAGEM APLICADA AOS DADOS DAS TUBAGENS DE DISTRIBUIÇÃO.
................................................................................................................................................. 65
QUADRO 6.4 – DATAS ADMITIDAS NO ESTUDO PARA O INÍCIO E O FIM DA APLICAÇÃO DE MATERIAIS. ......... 65
QUADRO 6.5 – REGISTO DA PRIMEIRA FILTRAGEM APLICADA AOS DADOS DAS TUBAGENS DE ADUÇÃO...... 66
QUADRO 6.6 – REGISTO DA SEGUNDA FILTRAGEM APLICADA AOS DADOS DAS TUBAGENS DE ADUÇÃO. .... 66
QUADRO 6.7 – REGISTO DA FILTRAGEM APLICADA AOS DADOS DE OT. .................................................. 67
QUADRO 6.8 – REGISTO DA VALIDAÇÃO EFECTUADA AOS DADOS DE OT. ............................................... 67
QUADRO 6.9 – AVALIAÇÃO DA IMPORTÂNCIA DOS VÁRIOS PARÂMETROS PARA O MODELO. ...................... 83
QUADRO 6.10 – ANÁLISE À SENSIBILIDADE DE CADA PARÂMETRO NO RESULTADO DA SIMULAÇÃO DA REDE
NET20X1_5. ............................................................................................................................ 103
FIGURA 2.1 – AQUEDUTO DAS ÁGUAS LIVRES, LISBOA............................................................................ 6
FIGURA 2.2 – POPULAÇÃO SERVIDA POR SISTEMA PÚBLICO DE DISTRIBUIÇÃO DE ÁGUA, POR CONCELHO, EM
2002 (ESQUERDA) E 2006 (DIREITA). ADAPTADO DE INSAAR, 2008. ............................................. 7
FIGURA 2.3 – PRESENÇA DA ADP EM PORTUGAL – SISTEMAS DE ABASTECIMENTO E DRENAGEM.
ADAPTADO DE ADP, 2008. ........................................................................................................... 8
FIGURA 2.4 – POPULAÇÃO ABRANGIDA PELAS DIFERENTES MODELOS DE GESTÃO DO SERVIÇO DE
ABASTECIMENTO PÚBLICO DE ÁGUA EM “BAIXA”. ADAPTADO DE IRAR, 2006.................................... 8
FIGURA 3.1 – MOTIVOS AMBIENTAIS E DE ESCASSEZ APRESENTADOS EM 2006 PARA JUSTIFICAR A
ADOPÇÃO DE MEDIDAS EM SERVIÇOS DE ABASTECIMENTO DE ÁGUA. ADAPTADO DE INSAAR, 2008.
................................................................................................................................................. 11
FIGURA 3.2 – TARIFA MÉDIA DE ABASTECIMENTO [€/M3] POR CONCELHO, EM 2004, PARA UM CONSUMO
ANUAL DE 120 M3. ADAPTADO DE IRAR, 2006. ............................................................................ 12

xi
FIGURA 3.3 – MEDIDAS ADOPTADAS EM 2006 POR MOTIVOS AMBIENTAIS E DE ESCASSEZ EM SERVIÇOS DE
ABASTECIMENTO DE ÁGUA. ADAPTADO DE INSAAR, 2008. .......................................................... 13
FIGURA 3.4 – INVESTIMENTO REALIZADO (EXCEPTO EM BARRAGENS). ABASTECIMENTO DE ÁGUA –
CONTINENTE – 1987 A 2006. ADAPTADO DE INSAAR, 2008. ...................................................... 14
FIGURA 4.1 – APLICAÇÃO DE DIFERENTES MÉTODOS DEPENDENDO DA DISPONIBILIDADE DE DADOS E
CONHECIMENTO (TEORIA). ADAPTADO DE (KASABOV, 1996). ........................................................ 23
FIGURA 4.2 – ILUSTRAÇÃO DE UM PERCEPTÃO MULTICAMADA. .............................................................. 27
FIGURA 4.3 – MODELO DE UM NÓ DE UMA RNA. ................................................................................... 28
FIGURA 4.4 – CONVENÇÕES ADOPTADAS PARA DESCREVER AS REDES (EXEMPLO DE UM PMC). ............. 29
FIGURA 4.5 – DIAGRAMA DE UM NEURÓNIO (FONTE: WIKIPEDIA, POR MARIANA RUIZ VILLARREAL) .......... 31
FIGURA 4.6 – CONTRASTE ENTRE REDES NEURONAIS ARTIFICIAIS E BIOLÓGICAS. À ESQUERDA, UM
PORMENOR MICROSCÓPICO DO SISTEMA NERVOSO DE UM RATO E, À DIREITA, UMA RNA UTILIZADA
NO JET PROPULSION LABORATORY, NASA. ................................................................................ 33
FIGURA 4.7 – REPRESENTAÇÃO ESQUEMÁTICA DO PERCEPTRÃO. .......................................................... 33
FIGURA 4.8 – SEPARAÇÃO LINEAR DE CLASSES. ................................................................................... 35
FIGURA 4.9 – ESQUEMA DAS LIGAÇÕES E ELEMENTOS PRESENTES NUM PMC. ...................................... 37
FIGURA 4.10 – ILSTRAÇÃO DE UM PMC APÓS A FASE DE TREINO, COM PESOS SINÁPTICOS POSITIVOS
EVIDENCIADOS A AZUL E PESOS SINÁPTICOS NEGATIVOS MARCADOS A VERMELHO. A COLORAÇÃO
NOS NÓS REPRESENTA O VALOR DA CONSTANTE ASSOCIADA. ....................................................... 38
FIGURA 4.11 – FUNÇÃO DE ACTIVAÇÃO LINEAR. ................................................................................... 40
FIGURA 4.12 – FUNÇÃO DE ACTIVAÇÃO SIGMOIDAL. .............................................................................. 40
FIGURA 4.13 – FUNÇÃO DE ACTIVAÇÃO TANGENTE HIPERBÓLICA. .......................................................... 40
FIGURA 4.14 – FUNÇÃO DE ACTIVAÇÃO ARCO-TANGENTE. ..................................................................... 41
FIGURA 4.15 – PROCESSO DE TREINO EM QUE A REDE PERDEU A CAPACIDADE DE GENERALIZAÇÃO. ....... 44
FIGURA 5.1 – EQM MÉDIO APÓS VALIDAÇÃO CRUZADA PARA PMC DE UMA E DUAS CAMADAS, COM
INTERVALOS DE CONFIANÇA DE 95% OBTIDOS RECORRENDO À DISTRIBUIÇÃO DE T-STUDENT......... 54
FIGURA 5.2 – MODO DE TREINO E SIMULAÇÃO DA FERRAMENTA DE TESTE DE REDES E SEPARADOR DE
OPÇÕES. .................................................................................................................................... 58
FIGURA 5.3 – OPERAÇÃO DO MODO DE TESTE, QUE POSSIBILITA A IMPORTAÇÃO DE VALORES DE EQM,
CORRELAÇÃO E TEMPO DE TREINO PARA O EXCEL EM TREINOS SEGUIDOS, PERMITINDO OBTER
AMOSTRAGENS ESTATÍSTICAS DA CAPACIDADE DE CADA REDE. ..................................................... 59
FIGURA 5.4 – FLUXOGRAMA REPRESENTATIVO DO MÉTODO PROPOSTO. ................................................ 60
FIGURA 6.1 – DIAGRAMA ALTIMÉTRICO DA REDE DE ABASTECIMENTO DE ÁGUA DE LISBOA. ADAPTADO DE
FRANCO, 2006. ......................................................................................................................... 62

xii
FIGURA 6.2 – ESQUEMA DA REDE DE DISTRIBUIÇÃO DE ÁGUA DE LISBOA. ............................................... 62
FIGURA 6.3 – REDE DE DISTRIBUIÇÃO DE ÁGUA, POR ZONA ALTIMÉTRICA , NA CIDADE DE LISBOA.
ADAPTADO DE LUÍS, 2004. ......................................................................................................... 63
FIGURA 6.4 – COMPOSIÇÃO, POR EXTENSÃO DE MATERIAL, DA REDE DE DISTRIBUIÇÃO. .......................... 68
FIGURA 6.5 – COMPOSIÇÃO, POR EXTENSÃO DE MATERIAL, DA REDE DE ADUÇÃO. .................................. 69
FIGURA 6.6 – IDADE DA REDE. CURVA DE EXTENSÃO ACUMULADA DE ACORDO COM O ANO DE INSTALAÇÃO
PARA A REDE DE DISTRIBUIÇÃO. .................................................................................................. 69
FIGURA 6.7 – IDADE DA REDE. CURVA DE EXTENSÃO ACUMULADA DE ACORDO COM O ANO DE INSTALAÇÃO
PARA A REDE DE ADUÇÃO. .......................................................................................................... 70
FIGURA 6.8 – CARACTERIZAÇÃO DA REDE DE DISTRIBUIÇÃO POR ANO DE INSTALAÇÃO E MATERIAL
(CONSIDERANDO FF, FC, FFD E PEAD). .................................................................................... 71
FIGURA 6.9 – EVOLUÇÃO DA EXTENSÃO DA REDE, A PARTIR DA INFORMAÇÃO DISPONÍVEL, NO PERÍODO EM
ANÁLISE. .................................................................................................................................... 72
FIGURA 6.10 – DISPOSIÇÃO DA REDE DE DISTRIBUIÇÃO POR DIÂMETRO DAS TUBAGENS. ......................... 73
FIGURA 6.11 – DISPOSIÇÃO DA REDE DE ADUÇÃO POR DIÂMETRO DAS TUBAGENS. ................................. 73
FIGURA 6.12 – CARACTERIZAÇÃO DA REDE DE DISTRIBUIÇÃO POR ANO DE INSTALAÇÃO E DIÂMETRO
(CONSIDERANDO FF, FC, FFD E PEAD). .................................................................................... 74
FIGURA 6.13 – DISPOSIÇÃO DA REDE DE DISTRIBUIÇÃO POR SUBSISTEMAS. ........................................... 74
FIGURA 6.14 – DISPOSIÇÃO DA REDE DE ADUÇÃO POR SUBSISTEMAS. ................................................... 75
FIGURA 6.15 – REGISTO DO ÍNDICE DE ROTURAS PARA OS ANOS EM ANÁLISE. ........................................ 75
FIGURA 6.16 – REGISTO DO ÍNDICE DE ROTURAS MÉDIO POR MATERIAL. ................................................ 76
FIGURA 6.17 – REGISTO DO ÍNDICE DE ROTURAS MENSAL MÉDIO PARA OS ANOS EM ANÁLISE. ................. 76
FIGURA 6.18 – ÍNDICE DE ROTURAS MENSAL MÉDIO PARA OS ANOS EM ANÁLISE, OBTIDO PARA CADA UMA
DAS CAUSAS REGISTADAS. .......................................................................................................... 77
FIGURA 6.19 – ÍNDICE DE ROTURAS MENSAL MÉDIO PARA OS ANOS EM ANÁLISE, OBTIDO PARA CADA UM
DOS MATERIAIS ESTUDADOS [ROT/(100 KM.ANO)]. ........................................................................ 78
FIGURA 6.20 – DISTRIBUIÇÃO PERCENTUAL ACUMULADA DAS CAUSAS DE INTERVENÇÃO EM ROTURAS, POR
TIPO DE MATERIAL. ..................................................................................................................... 78
FIGURA 6.21 – ÍNDICE DE ROTURAS PARA OS PRINCIPAIS SUBSISTEMAS DA REDE. .................................. 79
FIGURA 6.22 – NÚMERO DE ROTURAS ANUAL, EM TUBAGENS VALIDADAS, PARA AS DIVISÕES OCIDENTAL E
ORIENTAL. ................................................................................................................................. 80
FIGURA 6.23 – ESQUEMAS DOS PMC TREINADOS PARA 6 VARIÁVEIS. .................................................... 83
FIGURA 6.24 – ESQUEMAS DOS PMC TREINADOS PARA 5 VARIÁVEIS. .................................................... 83

xiii
FIGURA 6.25 – EQM MÉDIO, APÓS VALIDAÇÃO K-FOLD, PARA PMC DE UMA E DUAS CAMADAS, COM
INTERVALOS DE CONFIANÇA DE 95% OBTIDOS RECORRENDO À DISTRIBUIÇÃO DE T-STUDENT
(NÚMERO DE LIGAÇÕES SINÁPTICAS; 90% DOS TESTES). .............................................................. 85
FIGURA 6.26 – EQM MÉDIO, APÓS VALIDAÇÃO K-FOLD, PARA PMC DE UMA E DUAS CAMADAS, COM
INTERVALOS DE CONFIANÇA DE 95% OBTIDOS RECORRENDO À DISTRIBUIÇÃO DE T-STUDENT
(NÚMERO DE NÓS; 90% DOS TESTES). ......................................................................................... 85
FIGURA 6.27 – CORRELAÇÃO MÉDIA, APÓS VALIDAÇÃO K-FOLD, PARA PMC DE UMA E DUAS CAMADAS,
COM INTERVALOS DE CONFIANÇA DE 95% OBTIDOS RECORRENDO À DISTRIBUIÇÃO DE T-STUDENT. 86
FIGURA 6.28 – TEMPO DE TREINO MÉDIO, APÓS VALIDAÇÃO K-FOLD, PARA PMC DE UMA E DUAS CAMADAS,
COM INTERVALOS DE CONFIANÇA DE 95% OBTIDOS RECORRENDO À DISTRIBUIÇÃO DE T-STUDENT. 86
FIGURA 6.29 – CONSTITUIÇÃO DO CROMOSSOMA DO AG UTILIZADO PARA DETERMINAR A MELHOR
TOPOLOGIA DE PMC. ................................................................................................................. 87
FIGURA 6.30 – RESULTADO DO CRUZAMENTO DE DOIS PMC (PMC 1 E PMC 2) NO ÂMBITO DA APLICAÇÃO
DE AG DESENVOLVIDA (NÚMERO DE NÓS NAS CAMADAS OCULTAS). .............................................. 89
FIGURA 6.31 – RESULTADO DO EQM DE TREINO ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS ALGORITMOS DE
TREINO, PARA A REDE NET20X1_5, COM VALIDAÇÃO K-FOLD, DE SUBCONJUNTOS DE VALIDAÇÃO A
CONTABILIZAR 20% DO TOTAL DE DADOS. .................................................................................... 91
FIGURA 6.32 – RESULTADO DA CORRELAÇÃO DE TREINO ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS ALGORITMOS
DE TREINO, PARA A REDE NET20X1_5, COM VALIDAÇÃO K-FOLD, DE SUBCONJUNTOS DE VALIDAÇÃO A
CONTABILIZAR 20% DO TOTAL DE DADOS. .................................................................................... 91
FIGURA 6.33 – RESULTADO DO TEMPO MÉDIO DE TREINO ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS ALGORITMOS
DE TREINO, PARA A REDE NET20X1_5, COM VALIDAÇÃO K-FOLD, DE SUBCONJUNTOS DE VALIDAÇÃO A
CONTABILIZAR 20% DO TOTAL DE DADOS. .................................................................................... 92
FIGURA 6.34 – RESULTADO DA SIMULAÇÃO DO ÍNDICE OT/(100KM.ANO) PARA O CONJUNTO DE TUBAGENS
VALIDADO, NUM GRÁFICO COM A IDADE DOS ELEMENTOS DE TUBAGEM EM ABCISSA E O ÍNDICE
OT/(100KM.ANO) MÉDIO PARA TUBAGENS DE DETERMINADA IDADE EM ORDENADA. ....................... 94
FIGURA 6.35 – REPRESENTAÇÃO DA RNA ESCOLHIDA. A COR AZUL DENOTA PESOS SINÁPTICOS POSITIVOS
E A COR VERMELHA NEGATIVOS, SENDO A INTENSIDADE DAS CORES PROPORCIONAL AO MÓDULO DO
VALOR. ...................................................................................................................................... 94
FIGURA 6.36 – CORRESPONDÊNCIA ENTRE OS DADOS E AS PREVISÕES DA REDE ESCOLHIDA. ÍNDICE DE
OT/100KM/ANO EM ORDEM À IDADE DAS TUBAGENS, POR MATERIAL. ............................................ 95
FIGURA 6.37 – CORRESPONDÊNCIA ENTRE OS DADOS E AS PREVISÕES DA REDE ESCOLHIDA. ÍNDICE DE
OT/100KM/ANO EM ORDEM À IDADE DAS TUBAGENS, POR MATERIAL. ............................................ 96
FIGURA 6.38 – CORRESPONDÊNCIA ENTRE OS DADOS E AS PREVISÕES DA REDE ESCOLHIDA. ÍNDICE DE
OT/100KM/ANO EM ORDEM AO DIÂMETRO NOMINAL DAS TUBAGENS. ............................................. 96

xiv
FIGURA 6.39 – CORRESPONDÊNCIA ENTRE OS DADOS E AS PREVISÕES DA REDE ESCOLHIDA. ÍNDICE DE
OT/100KM/ANO EM ORDEM AO SUBSISTEMA DE ABASTECIMENTO. ................................................. 97
FIGURA 6.40 – RELAÇÃO ENTRE ÍNDICES DE ROTURA PRÉVIOS (OT/(100KM.ANO) PRÉVIAS) E PREVISTOS
(OT/(100KM.ANO)). ................................................................................................................... 98
FIGURA 6.41 – RESULTADO DA SIMULAÇÃO DO ÍNDICE OT/(100KM.ANO), NUM GRÁFICO COM A IDADE DOS
ELEMENTOS DE TUBAGEM EM ABCISSA E O ÍNDICE OT/(100KM.ANO) MÉDIO EM ORDENADA............. 99
FIGURA 6.42 – RESULTADO DA SIMULAÇÃO DO ÍNDICE OT/(100KM.ANO), NUM GRÁFICO COM A IDADE DOS
ELEMENTOS DE TUBAGEM EM ABCISSA E O ÍNDICE OT/(100KM.ANO) MÉDIO PARA TUBAGENS DE
DETERMINADA IDADE EM ORDENADA. POR MATERIAL; COM 37,5 OT/(100KM.ANO) PRÉVIAS. ........ 100
FIGURA 6.43 – RESULTADO DA SIMULAÇÃO DO ÍNDICE OT/(100KM.ANO), NUM GRÁFICO COM A IDADE DOS
ELEMENTOS DE TUBAGEM EM ABCISSA E O ÍNDICE OT/(100KM.ANO) MÉDIO PARA TUBAGENS DE
DETERMINADA IDADE EM ORDENADA. POR MATERIAL; COM 550 OT/(100KM.ANO) PRÉVIAS. ......... 101
FIGURA 6.44 – RELAÇÃO ENTRE OBSERVAÇÕES E PREVISÕES DE OT/(100KM.ANO) MÉDIAS PARA AS
CLASSES DE DIÂMETRO NOMINAL (37,5 OT(100KM.ANO) PRÉVIAS). ............................................ 101
FIGURA 6.45 – RELAÇÃO ENTRE OBSERVAÇÕES E PREVISÕES DE OT/(100KM.ANO) MÉDIAS NOS
SUBSISTEMAS DE DISTRIBUIÇÃO (37,5 OT(100KM.ANO) PRÉVIAS). .............................................. 102
FIGURA 6.46 – DISTRIBUIÇÃO DO NÚMERO DE ROTURAS NUM ÚNICO TECHO DE TUBAGEM, PARA A REDE DE
DISTRIBUIÇÃO DA ÁGUA DE LISBOA (ESCALA LOGARÍTMICA). ........................................................ 104
Índice de quadros e figuras do anexo
QUADRO A1 – CAMPOS DE DADOS DE TUBAGENS DE DISTRIBUIÇÃO. ...................................................... XIII
QUADRO A2 – CAMPOS DE DADOS DE TUBAGENS DE ADUÇÃO. .............................................................. XV
QUADRO A3 – CAMPOS DE DADOS DAS ORDENS DE TRABALHOS. ........................................................ XVII
QUADRO A4 – REGISTO DO NÚMERO DE RESULTADOS ADMITIDOS COMO VÁLIDOS EM CADA CAMPO DE
DADOS, PARA AS OT. ............................................................................................................... XVIII
QUADRO A5 – REGISTO DAS OPÇÕES TOMADAS PARA VALIDAÇÃO DOS DADOS DE OT. .......................... XIX
QUADRO A 6 – RESULTADOS DO EQM, OBTIDOS EM REDES COM UMA CAMADA OCULTA (90% DOS DADOS).
.............................................................................................................................................. XXVII
QUADRO A 7 – RESULTADOS DE CORRELAÇÃO, OBTIDOS EM REDES COM UMA CAMADA OCULTA (100%
DOS DADOS). .......................................................................................................................... XXVII
QUADRO A 8 – RESULTADOS DE TEMPOS DE TREINO, OBTIDOS EM REDES COM UMA CAMADA OCULTA
(100% DOS DADOS). ............................................................................................................... XXVII
QUADRO A 9 – RESULTADOS DO EQM, OBTIDOS EM REDES COM DUAS CAMADAS OCULTAS (90% DOS
DADOS). ................................................................................................................................ XXVIII

xv
QUADRO A 10 – RESULTADOS DE CORRELAÇÃO, OBTIDOS EM REDES COM DUAS CAMADAS OCULTAS
(100% DOS DADOS). .............................................................................................................. XXVIII
QUADRO A 11 – RESULTADOS DE TEMPOS DE TREINO [S], OBTIDOS EM REDES COM DUAS CAMADAS
OCULTAS (100% DOS DADOS). ................................................................................................ XXVIII
QUADRO A 12 – SÍNTESE DOS PARÂMETROS UTILIZADOS NO AG. ..................................................... XXXIX
QUADRO A 13 – RESULTADOS DO EQM OBTIDOS ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS ALGORITMOS DE
TREINO, PARA A REDE NET20X1_5 (100% DOS DADOS). .............................................................. XLI
QUADRO A 14 – RESULTADOS DA CORRELAÇÃO OBTIDOS ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS ALGORITMOS
DE TREINO, PARA A REDE NET20X1_5 (100% DOS DADOS). .......................................................... XLI
QUADRO A 15 – RESULTADOS TEMPO DE TREINO [S] OBTIDOS ATRAVÉS DA UTILIZAÇÃO DE VÁRIOS
ALGORITMOS DE TREINO, PARA A REDE NET20X1_5 (100% DOS DADOS). ..................................... XLI
QUADRO A 16 – PONTOS AMOSTRAIS ADMITIDOS PARA O PARÂMETRO SUBSISTEMA DE DISTRIBUIÇÃO... XLV
QUADRO A 17 – PONTOS AMOSTRAIS ADMITIDOS PARA O PARÂMETRO MATERIAL. ................................ XLVI
QUADRO A 18 – PONTOS AMOSTRAIS ADMITIDOS PARA O PARÂMETRO IDADE DA TUBAGEM. .................. XLVI
QUADRO A 19 – PONTOS AMOSTRAIS ADMITIDOS PARA O PARÂMETRO DIÂMETRO NOMINAL. ................ XLVII
QUADRO A 20 – PONTOS AMOSTRAIS ADMITIDOS PARA O PARÂMETRO OT/(100KM.ANO) PRÉVIAS. ...... XLVII
FIGURA A 1 – REPRESENTAÇÃO DE UM PMC TREINADO SEM CAMADA OCULTA....................................... VII
FIGURA A 2 – REPRESENTAÇÃO DE UM PMC TREINADO COM UMA CAMADA OCULTA DE 20 NÓS. ............. VII
FIGURA A 3 – REPRESENTAÇÃO DE UM PMC TREINADO COM UMA CAMADA OCULTA DE 40 NÓS. ............. VII
FIGURA A 4 – COMPARAÇÃO ENTRE DIFERENTES ALGORITMOS DE TREINO PARA O CASO DE ESTUDO. ...... IX
FIGURA A 5 – SISTEMA DA EPAL. ADAPTADO DE FRANCO, 2006. .......................................................... XI
FIGURA A6 – EXTENSÃO DA REDE POR FREGUESIA .............................................................................. XXI
FIGURA A7 – ÍNDICES MÉDIOS MENSAIS DE ROTURAS. ......................................................................... XXIII
FIGURA A8 – ÍNDICE MENSAL MÉDIO DE ROTURAS COM DESVIO-PADRÃO. ............................................. XXIII
FIGURA A9 – ÍNDICES MÉDIOS ANUAIS DE ROTURAS POR FREGUESIA. .................................................. XXV
FIGURA A 10 – EQM VERSUS CORRELAÇÃO PARA VÁRIAS TOPOLOGIAS DE PMC ................................ XXIX
FIGURA A 11 – DIÂMETRO NOMINAL VERSUS OT/(100KM.ANO), PARA A RNA TREINADA E PARA O
CONJUNTO DE DADOS. .............................................................................................................. XLIII
FIGURA A 12 – RELAÇÃO ENTRE IDADE, ÍNDICE OT/(100KM.ANO) PRÉVIAS E ÍNDICE DE OT/(100KM.ANO)
APREENDIDA PELA RNA TREINADA. ........................................................................................... XLIX


xvii
Lista de abreviações
AG Algoritmos genéticos
EPAL Empresa Portuguesa de Águas de Livres
EQM Erro quadrático médio
FC Fibrocimento
FF Ferro fundido (cinzento)
FFD Ferro fundido dúctil
GA Gestão de activos
INAG Instituto Nacional da Água
INSAAR Inventário Nacional de Sistemas de Abastecimento de Água e de Águas Residuais
IRAR Instituto Regulador de Águas e Resíduos
NASA North American Space Agency
OT Ordem de trabalho
PEAASAR Plano Estratégico de Abastecimento de Água e Saneamento de Águas Residuais
PEAD Polietileno de alta densidade
PMC Perceptrão multicamada
RBR Rede de base radial
RNA Rede neuronal artificial
SIG Sistema de informação geográfica
ZMC Zona de medição e controlo


1
1. Introdução
1.1 Enquadramento Nos últimos anos, a importância dada aos recursos naturais e à sua adequada utilização tem
aumentado, a par de uma maior compreensão e aceitação de conceitos como o desenvolvimento
sustentável e a necessidade de internalização de custos, outrora considerados marginais.
Embora esta tendência se verifique na quase totalidade dos domínios de acção humana, o
abastecimento de água constitui uma actividade em que a sustentabilidade assume importância
especial, dado o seu carácter vital para a sobrevivência.
Com o aumento da população nos aglomerados urbanos, muitas vezes acompanhado por um
aumento dos consumos, a pressão exercida sobre os aquíferos e outras origens de água potável
tem vindo a crescer, por vezes causando efeitos negativos persistentes nas zonas de
exploração.
Por outro lado, tem-se assistido a uma maior responsabilização das entidades gestoras pelos
constrangimentos causados pelo mau desempenho das infra-estruturas. Numa óptica de
internalização de custos sociais, não será totalmente inesperado que as entidades gestoras
possam ter que responder financeiramente pela ocupação da via pública ou por falhas ou
interrupções de abastecimento.
Estas razões, incluindo também recentes desenvolvimentos tecnológicos, têm levado as
entidades gestoras de sistemas de abastecimento de água a investir em programas de controlo e
redução de perdas, renovação das redes e, em geral, no melhoramento do desempenho das
infra-estruturas. No entanto, embora estas medidas melhorem o desempenho dos sistemas, por
vezes de forma significativa, não correspondem, necessariamente, a um procedimento de
exploração óptimo, sustentável a longo prazo. As, tecnologias de telemetria e telegestão, a
utilização de materiais mais duráveis, métodos construtivos mais eficientes, sistemas de
informação mais potentes e ferramentas de cálculo superiores constituem instrumentos da maior
importância mas, em regra, não permitem inferir directamente a evolução temporal do
comportamento dos sistemas nem definir estratégias de actuação.
É numa óptica de contribuição para uma base fiável de previsão dos desempenhos dos sistemas
de abastecimento de água que é desenvolvido o presente trabalho.
1.2 Objectivos No passado, face à falta de informação detalhada sobre o comportamento de cada tubagem e
enfrentando-se grandes dificuldades para relacionar perdas com partes localizadas dos sistemas
de abastecimento, utilizaram-se frequentemente métodos estatísticos e a experiência dos

2
responsáveis para definir as zonas em que seria mais proveitoso proceder a campanhas de
renovação das redes.
Presentemente, podem ser implementados instrumentos que, para além de permitirem analisar o
estado actual dos sistemas, facilitam a tarefa do decisor. Como exemplo deste tipo de
instrumentos, podem ser referidas as zonas de medição e controlo (ZMC) que permitem, numa
área limitada da rede, efectuar balanços hídricos de forma simples e controlar, em tempo real, o
estado do sistema, pelo que se revelam bastante superiores, do ponto de vista de resultados, às
abordagens tradicionais.
Independentemente da mais-valia que constituem estas inovações, continuam a existir
dificuldades associadas ao estabelecimento de estratégias de ampliação de redes ou à definição
de taxas de renovação anual. Assim, os objectivos do presente estudo podem ser sintetizados
nos seguintes quatro aspectos principais:
1. A análise da adequação da aplicação de redes neuronais artificiais à modelação da
degradação de sistemas de abastecimento de água;
2. O estabelecimento de um método coerente para aplicação das redes neuronais artificiais
a sistemas com características gerais análogas às do presente caso de estudo;
3. O estudo e percepção das principais variáveis responsáveis pela degradação das redes
de distribuição de água, estabelecendo uma hierarquização entre estas;
4. A elaboração de um modelo de simulação da degradação da rede, orientado para apoiar
decisões das entidades gestoras.
No que se refere ao primeiro aspecto, pretende-se fornecer, neste documento, uma base para a
compreensão e utilização de Redes Neuronais Artificiais (RNA), discutindo-se a diversidade, as
propriedades e as aplicações destes modelos e analisando as mais-valias e possibilidades que a
sua aplicação poderá trazer em termos de previsão de fugas de água.
Não obstante as RNA serem modelos de grande potencialidade, a profusão das variantes
possíveis leva a que o utilizador acabe normalmente por recorrer a regras heurísticas baseadas
em experiências obtidas a partir de casos específicos, podendo adoptar-se um modelo que não
se adapte perfeitamente ao problema em questão. Assim, procurou-se identificar e justificar as
opções tomadas na construção das redes neuronais artificiais, aplicando e desenvolvendo
metodologias de optimização, pesquisando caminho para estudos futuros e cumprindo o
segundo objectivo deste trabalho.
O terceiro aspecto referido tem aplicação mais orientada para o planeamento. Devido à carência
de dados ou, simplesmente, à carência de ferramentas adequadas ao seu tratamento,
desconhece-se, em profundidade, qual a relação entre o número de roturas registado nas
tubagens e as variáveis com ele relacionadas. Sabe-se, por exemplo, que a tendência geral dos
sistemas de abastecimento é que a probabilidade de roturas cresça com a idade das tubagens e
que o material tenha bastante influência no comportamento do sistema. No entanto, devido à

3
quantidade de variáveis intervenientes, a análise estatística tradicional resulta num grau de
complexidade excessivo, sendo ainda que, por vezes, se define o próprio comportamento do
sistema antes do estudo (quando, por exemplo, se define que a lei que rege a variação das
roturas com a idade é exponencial) imputando-se, desde logo, possíveis limitações ao modelo.
1.3 Descrição sumária do estudo Desde 2001, a Empresa Portuguesa de Águas de Lisboa (EPAL) implementou um sistema de
informação geográfica (SIG) para a gestão da rede, sendo este trabalho baseado na extensa
matriz de dados acumulada até ao início de 2008.
Focando-se em particular no sistema de abastecimento da cidade de Lisboa, actualmente com
cerca de 1 400 km de tubagens em funcionamento, o presente estudo incidiu nas tubagens com
diâmetro nominal até 315 mm.
Com a grande quantidade de dados disponível, treinaram-se vários modelos de redes neuronais
artificiais (RNA ou artificial neural networks (ANN), segundo a designação anglo-saxónica),
pretendendo simular o comportamento da rede de abastecimento da cidade de Lisboa.
Não obstante os modelos conexionistas, como as RNA, serem poderosos, para obter um modelo
fiável e robusto, e dado que as RNA são um tema que se reveste de alguma complexidade,
foram desenvolvidos vários mecanismos de análise e melhoramento dos resultados. Seguiu-se
esta óptica, recorrendo à optimização dos modelos aplicando algoritmos genéticos (AG).
Tendo-se treinado modelos com qualidade, adequados aos dados disponíveis e com boa
capacidade de generalização, procedeu-se à análise e interpretação dos resultados obtidos
seguindo-se, posteriormente, a aplicação dos modelos à previsão da degradação da rede no
futuro, em função do estado actual e diversos parâmetros normalmente fixados pela entidade
gestora.
Para o desenvolvimento dos cálculos deste trabalho utilizaram-se unicamente os programas
Microsoft Excel™ e Matlab™ (com Neural Network Toolbox™ e Genetic Algoríthms Toolbox™).
A programação foi executada, tanto em Visual Basic for Applications (VBA), como no ambiente
do Matlab™, incluindo várias ferramentas que promovem o interface entre os vários programas.
Pretendeu-se, assim, compilar uma série de ferramentas e procedimentos, que aplicadas numa
ordem lógica facilitassem e estruturassem o tratamento de dados e o treino de RNA,
inclusivamente aplicando AG, não só para problemas semelhantes aos tratados, mas cobrindo
um âmbito mais geral. Em síntese, pretende-se que o trabalho exigido ao utilizador se concentre
nas áreas que mais interessam: o tratamento e preparação dos dados e a análise de resultados.
No capítulo 2 são introduzidos conceitos sobre as RNA e os AG, justificando-se a utilização
destas ferramentas. Inclui-se, também, a apresentação de aspectos da evolução histórica,
sobretudo das RNA, uma vez que o seu peso neste trabalho o justifica.

4
No capítulo 3 é levada a cabo uma síntese da actividade de avaliação de roturas em sistemas de
abastecimento de água, incluindo referências às metodologias seguidas e tendências actuais.
Após a introdução às RNA e aos AG feita no capítulo 3, o capítulo 4 é dedicado a uma descrição
mais prática dos problemas identificados, das soluções encontradas e das metodologias
propostas de utilização destas ferramentas, em problemas semelhantes aos estudados.
O caso de estudo da rede de distribuição de Lisboa é apresentado no capítulo 5. No mesmo
capítulo são analisados os dados disponibilizados pela EPAL, caracterizando-se o sistema e
procedendo-se uma análise preliminar do respectivo comportamento. Seguidamente, é descrita a
preparação do modelo de degradação da rede de distribuição, tanto na vertente do
comportamento médio, como na da distribuição probabilística do fenómeno. A análise dos
resultados obtidos é então explanada, terminando-se o capítulo com algumas considerações
sobre as variáveis explicativas.
Finalmente, no capítulo 6, são apresentadas conclusões do trabalho e desenvolvidas
recomendações para eventuais estudos subsequentes.

5
2. A evolução do abastecimento de água em Portugal
2.1 Aspectos históricos gerais Enquanto elemento essencial para a vida, a água determinou desde o início da civilização, a
localização e o desenvolvimento de importantes aglomerados populacionais.
Por exemplo, o sistema de abastecimento a Roma incluía onze aquedutos principais, construídos
entre 312 A.C. (AquaAppia) e 226 D.C. (Aqua Alexandrina), tendo o maior destes aquedutos
(Anio Novus) cerca de 95 km. Na era imperial, quando se pensa que a população de Roma era
superior a 1 milhão de habitantes, estima-se que o sistema pudesse abastecer a cidade com
mais de 1 m3/dia por habitante (Inf08). Em Roma estavam também generalizados os sistemas de
água canalizada em chumbo, de onde deriva o termo britânico para canalização, plumbing (de
chumbo, plumb).
Nos séculos mais recentes, nomeadamente a partir da era industrial, os sistemas existentes,
maioritariamente com escoamento em superfície livre, foram sendo substituídos por sistemas em
pressão. Em Portugal, esta revolução teve lugar no séc. XIX, com a introdução dos sistemas de
adução e distribuição de água domiciliária construídos com tubagens de ferro fundido
funcionando sob pressão (Matos, 2000).
No séc. XX assistiu-se à continuação da evolução dos sistemas de distribuição de água em
diversos campos. Foram aplicados novos materiais, tais como o fibrocimento, o ferro fundido
dúctil, o aço, o betão e os plásticos, foi generalizada a preocupação com a qualidade da água e
foi ampliado a grande parte da população o acesso a sistemas públicos de abastecimento.
No início do séc. XXI, enquanto se estendem os predicados de ampliação dos sistemas do
séc. XX e tendo sido ultrapassados os problemas críticos de carência de água, assiste-se a um
aumento substancial da preocupação com a qualidade e com o uso eficiente da água, conceitos
cada vez mais profundamente enraizados na sociedade.
2.2 A cidade de Lisboa O abastecimento de água na cidade de Lisboa foi, até ao séc. XVIII, levado a cabo
principalmente por bicas e nascentes, sem um sistema de distribuição estruturado. O Aqueduto
das Águas Livres, construído durante o reinado de D. João V e progressivamente reforçado e
ampliado até ao séc. XIX veio alterar este panorama. Esta infra-estrutura, pensada desde 1728,
foi mandada construir em 1731 por proposta de Cláudio Gorgel do Amaral (Palácio Galveias,
1990) para solucionar o problema de falta de água em Lisboa (Figura 2.1).

6
Figura 2.1 – Aqueduto das Águas Livres, Lisboa.
Foi a partir da construção do aqueduto e de toda a infra-estrutura de apoio que evoluiu o sistema
de abastecimento de Lisboa. Em 2 de Abril de 1868, o abastecimento de água a Lisboa foi
concessionado à CAL, Companhia das Águas de Lisboa (EPAL, 2004) e, em meados do século
passado, depois de um período de carência de água nos anos 20, Lisboa já era abastecida
através do aqueduto, do canal do Alviela (1880) e do canal do Tejo (1940). O crescimento da
capital continuava a impor à CAL o planeamento e execução de obras e infra-estruturas. Assim,
nos anos 50 e 60, as origens de água foram melhoradas e reforçadas para saturar as infra-
estruturas de adução existentes (Quintela, et al., 2004).
A 30 de Outubro de 1974 terminava o longo período de concessão à CAL, tendo a gestão do
sistema de abastecimento da cidade passado para a responsabilidade da EPAL, Empresa
Pública de Águas de Lisboa, cuja designação se alterou em 1981 para Empresa Pública das
Águas Livres e, finalmente, para Empresa Portuguesa das Águas Livres, S.A., em 1991 (EPAL,
2004).
Em 4 de Junho de 1987 foi concluído o sistema de Castelo do Bode, pondo fim a novo período
de carência durante os anos 80, quando a população da cidade chegou a mais de 900 000
habitantes. Esta infra-estrutura, considerada a principal componente do sistema de
abastecimento da EPAL, foi ampliada em 1996 e tem uma capacidade de produção na ordem
dos 625 000 m3/dia, assegurando sem problemas a demanda, não só da capital, mas de
dezenas de concelhos (EPAL, 2004).
Actualmente, a rede de distribuição de Lisboa, sectorizada em 5 patamares de pressão
principais, tem cerca de 1 400 km de tubagens, um total de 15 reservatórios e 9 estações
elevatórias, responsáveis pelo abastecimento a 93 000 ramais de ligação predial distribuídos
numa área de 83 km2 (EPAL, 2004).
2.3 Situação actual e perspectivas futuras em Portugal. A situação precisa do abastecimento de água em Portugal é difícil de aferir, no entanto,
iniciativas como o INSAAR (Inventário Nacional de Sistemas de Abastecimento de Água e de
Águas Residuais), levado a cabo pelo INAG (Instituto Nacional da Água), ou a informação

7
disponibilizada pelo IRAR (Instituto Regulador de Águas e Resíduos), permitem ter uma
panorâmica geral da evolução do país.
No último meio século, a expansão das redes de distribuição pública foi notável e, em 2006,
cerca de 91% da população em Portugal Continental era já coberta (INSAAR, 2008), como se
pode observar através Figura 2.2.
Figura 2.2 – População servida por sistema público de distribuição de água, por concelho,
em 2002 (esquerda) e 2006 (direita). Adaptado de INSAAR, 2008.
Até 1993, a responsabilidade da exploração dos serviços de água e de águas residuais era um
exclusivo da administração local (municípios). O Decreto-Lei nº. 372/93, de 5 de Novembro, veio
permitir o acesso de capitais privados ao sector (Marques, 2006), tendo sido nesse mesmo ano
formada a empresa AdP (Águas de Portugal), que tem, tal como se pode observar na Figura 2.3,
presença em grande parte do território nacional.
Com a abertura do mercado, os modelos de gestão do abastecimento em baixa multiplicaram-se
(Figura 2.4), tendo o IRAR sido criado em 1997 para suprir as necessidades de regulação no
sector. No abastecimento em alta, esta reforma teve ainda profundas implicações a vários níveis,
designadamente, na beneficiação e na construção de infra-estruturas, na melhoria da qualidade
geral da água e, consequentemente, no aumento substancial dos custos por m3, que se verificou
em muitos sistemas.

8
Figura 2.3 – Presença da AdP em Portugal – Sistemas de abastecimento e drenagem.
Adaptado de AdP, 2008.
Figura 2.4 – População abrangida pelas diferentes modelos de gestão do serviço de
abastecimento público de água em “baixa”. Adaptado de IRAR, 2006.

9
Com o PEAASAR II (segunda versão do Plano Estratégico de Abastecimento de Água e
Saneamento de Águas Residuais, de 2007 a 2013), definem-se as linhas orientadoras para o
sector da água até 2013. Embora este documento tenha sido bastante criticado por alguns
grupos de opinião, contém aquelas que serão as premissas do futuro próximo, designadamente
(Ministério do Ambiente, do Ordenamento do Território e do Desenvolvimento Regional, 2006):
• A universalidade, a continuidade e a qualidade do serviço;
• A sustentabilidade do sector; e
• A protecção dos valores ambientais.
Estas premissas serão suportadas nos seguintes objectivos operacionais:
• Servir cerca de 95% da população total do País com sistemas públicos de
abastecimento de água;
• Servir cerca de 90% da população total do País com sistemas públicos de saneamento
de águas residuais urbanas, sendo que em cada sistema integrado o nível de
atendimento desejável deve ser de, pelo menos, 70% da população abrangida;
• Garantir a recuperação integral dos custos incorridos dos serviços;
• Contribuir para a dinamização do tecido empresarial privado nacional e local; e
• Cumprir os objectivos decorrentes do normativo nacional e comunitário de protecção do
ambiente e saúde pública.


11
3. A avaliação de roturas em sistemas de abastecimento de água
3.1 O desafio do controlo de perdas Face às alterações verificadas nos últimos anos tanto na gestão do sector das águas, como na
percepção social do custo da água, as perdas assumem uma relevância maior que nunca, pelo
que cada vez mais as entidades gestoras investem no seu controlo e diminuição. Vários factores
podem contribuir para esta posição, no entanto, daqueles que se poderiam referir, destacam-se
os seguintes:
• O custo elevado de produção e/ou aquisição da água;
• A escassez dos recursos hídricos, que se reflecte em questões de quantidade e
qualidade da água captada;
• A taxa de recursos hídricos;
• A pressão social no sentido da sustentabilidade e uso racional dos recursos;
• Requisitos legais.
Na Figura 3.1 apresenta-se um gráfico, compilado no âmbito do INSAAR, que ilustra algumas
preocupações de entidades gestoras (EG) em Portugal.
Figura 3.1 – Motivos ambientais e de escassez apresentados em 2006 para justificar a
adopção de medidas em serviços de abastecimento de água. Adaptado de INSAAR, 2008.

12
Por um lado, as políticas definidas pelo Governo as orientações do Regulador (IRAR) exigem
cada vez mais e melhor serviço de abastecimento de água, designadamente, através de critérios
mais exigentes de qualidade da água e de serviço, que acarretam custos adicionais que só
parcialmente poderão ser compensados por ganhos de eficiência. Por outro, para garantir a
qualidade da água e a continuidade do serviço, muitos dos sistemas de abastecimento em
“baixa” tiveram que aderir a sistemas em “alta”, cuja respectiva sustentabilidade económica exige
elevadas tarifas para aquisição de água em “alta”, que passaram a constituir uma parcela muito
significativa dos custos da actividade, quando comparada com aquela que constituíam os custos
de utilização de captações próprias.O reforço na competitividade no sector, também fomentada
pelos PEAASAR, contribui, por sua vez, para que as entidades gestoras privadas reduzam as
margens de lucro. De facto, a revisão das tarifas praticadas que está a ter lugar terá que ser
continuada no futuro, designadamente convergindo para uma situação em que a tarifa assegure
a integral cobertura dos custos de produção e tenha em conta custos de escassez e ambientais
(Serra, 2006). O aumento das tarifas de água praticadas em “alta”, que subiu em média mais de
20% nos últimos quatro anos, assim como os dados disponibilizados pelo IRAR (ver Figura 3.2),
mostram que o processo de revisão dos tarifários está longe de estabilizar.
Figura 3.2 – Tarifa média de abastecimento [€/m3] por concelho, em 2004, para um
consumo anual de 120 m3. Adaptado de IRAR, 2006.

13
À medida que a tensão sobre os recursos hídricos aumenta devido a múltiplos factores, as
entidades gestoras podem ser obrigadas a actuar não apenas por razões económicas, mas para
assegurar níveis adequados de serviço às populações, sendo a redução de perdas uma das
medidas preferidas (Figura 3.3) e, possivelmente, uma das mais sustentáveis a médio prazo.
Paralelamente, medidas de controlo de perdas, no sentido lato, podem ser adoptadas por razões
da própria imagem e consciência ambiental da entidade gestora e/ou por imposição regulatória.
Figura 3.3 – Medidas adoptadas em 2006 por motivos ambientais e de escassez em
serviços de abastecimento de água. Adaptado de INSAAR, 2008.
Finalmente, é comummente reconhecido que as perdas estão relacionadas com a degradação
dos sistemas. Assim, no futuro, não só é de esperar um aumento da pressão económica, social,
ambiental e legislativa sobre as entidades gestoras, mas os próprios sistemas, na sua maior
parte com idade inferior a meio século, terão tendência para se apresentarem cada vez mais
degradados, exigindo mais intervenções de beneficiação e reparação. Na Figura 3.4 ilustra-se a
evidência deste fenómeno, na medida em que o investimento no abastecimento de água está
bastante concentrado no passado recente e, portanto, a maior parte dos sistemas ainda não
atingiu pontos críticos de degradação.

14
Figura 3.4 – Investimento realizado (excepto em barragens). Abastecimento de água –
Continente – 1987 a 2006. Adaptado de INSAAR, 2008.
3.2 Campos de acção na redução de perdas As perdas, definidas como a diferença entre a água entrada no sistema e o consumo autorizado
(Alegre, et al., 2004), podem ser devidas a várias causas, como se pode observar através do
esquema do balanço hídrico num sistema de abastecimento apresentado no Quadro 3.1.
Quadro 3.1 – Balanço hídrico em sistemas de abastecimento de água. Adaptado de Alegre et al, 2006.
Água entrada no sistema
Consumo autorizado
Consumo autorizado facturado
Consumo facturado medido (incluindo água exportada Água facturada
Consumo facturado não medido
Consumo autorizado não
facturado
Consumo não facturado medido
Água não facturada (Perdas Comerciais)
Consumo não facturado não medido
Perdas de água
Perdas aparentes Uso não autorizado
Erros de medição
Perdas reais
Fugas nas condutas de adução e /ou distribuição
Fugas e extravasamentos nos reservatórios de adução e /ou
distribuição
Fugas nos ramais (a montante do ponto de medição)
Para interpretar correctamente este quadro é conveniente definir os conceitos de perdas reais e
aparentes. Assim, segundo Alegre et al., 2004:

15
• Perdas reais correspondem a perdas físicas de água do sistema em pressão, até ao
contador do cliente, durante o período de referência. O volume de perdas através de
todos os tipos de fissuras, roturas e extravasamentos depende da frequência, do caudal
e da duração média de cada fuga.
• O conceito de perdas aparentes contabiliza todos os tipos de imprecisões associadas às
medições da água produzida e da água consumida, e ainda o consumo não-autorizado
(por furto ou uso ilícito).
De acordo com estas definições fica claro que o volume efectivo de perdas totais (diferentes das
perdas comerciais, uma vez que não incluem nenhuma parcela de consumos autorizados) deve
ser encarado em dois planos bastante diferentes. Apesar de, para as entidades gestoras, fazer
sentido reduzir, tanto perdas reais, como perdas comerciais, as estratégias para o conseguir são,
regra geral, independentes.
As perdas comerciais são vulgarmente controladas através da expansão, substituição e
calibração dos parques de contadores e da monitorização de caudais para procura de
consumidores ilícitos. As perdas reais são perdas “físicas”, podendo ocorrer por todo o sistema
de abastecimento, desde a captação até ao utilizador final. Na generalidade dos sistemas, é nas
condutas de distribuição e nos ramais que os volumes perdidos são maiores, tanto devido à
extensão como à dificuldade de monitorização destas infra-estruturas.
Na prevenção das perdas reais seguem-se metodologias activas e metodologias reactivas. As
metodologias reactivas respondem a fugas na rede, incidindo na sua detecção e correcção,
podendo ter resultados bastante rápidos, pelo que são naturalmente apelativas para as entidades
gestoras. As metodologias activas prevêem uma actuação orientada para a prevenção das
roturas ao nível do planeamento e da renovação das infra-estruturas, sendo tradicionalmente
levadas a cabo em períodos alargados.
A primeira metodologia baseia-se na detecção de pontos de perda existentes nas redes,
designadamente roturas, sendo apoiada em várias tecnologias tais como a monitorização de
caudais em tempo real em ZMC (Zonas de Medição e Controlo) e equipamentos de detecção
activa de fugas como pré-localizadores, correladores acústicos e geófonos. A segunda
metodologia actua numa vertente de prevenção das fugas antes de estas terem lugar e engloba
a substituição de tubagens degradadas e o controlo de pressão nas redes.
3.3 Áreas de interesse prioritário na redução de perdas Tal como foi referido no ponto anterior, as perdas podem ser aparentes ou reais. No campo das
perdas aparentes, especialmente quando se trata de usos ilícitos ou roubos, a entidade gestora
só pode ir até certo ponto, sendo um processo difícil e moroso, na prática inviável de realizar,
procurar todos os pontos de consumo não autorizado. Uma tecnologia que poderá contribuir para
a diminuição deste problema é a telemedição de caudais junto dos pontos de consumo, que
apesar de hoje ser uma tecnologia cara, poderá ser mais acessível no futuro.

16
As perdas reais, representando vulgarmente a maior fatia das perdas em termos de volume, são
um tema mais promissor. Por um lado, a evolução de tecnologias para acções reactivas tem sido
uma constante, sendo que os equipamentos utilizados para detecção activa de fugas são cada
vez mais acessíveis, eficazes e de fácil utilização. Da mesma forma, também ferramentas da
maior utilidade, tais como sistemas com caudalímetros ligados por via remota a centrais de
monitorização e controlo são mais fiáveis e baratos. O recurso a ferramentas de modelação em
conjunto com equipamentos que possibilitem o controlo de pressões sem afectar a qualidade de
serviço é outra abordagem a ter em conta. Não obstante, como se refere no primeiro capítulo,
embora os efeitos da degradação das redes possam ser mitigados, não podem ser impedidos e,
como tal, mais tarde ou mais cedo, faz sentido do ponto de vista económico, social e ambiental
proceder à renovação das infra-estruturas mais degradadas.
Em virtude das avultadas somas envolvidas na renovação das redes de distribuição, este é um
processo que merece grande planeamento e reflexão, o que por muitas vezes não acontece.
Sendo um fenómeno que se estende no tempo, muitas vezes não é percepcionado pelos
decisores quão importante é a delineação adequada da estratégia de renovação. O IRAR indica
1,0 a 2,0% ao ano como intervalo de referência para a taxa de reabilitação das condutas
correspondente a um bom desempenho (IRAR, 2006), no entanto, a taxa optimizada poderá não
se situar neste intervalo, dependendo do caso específico, e continuam por definir quais os
critérios para a selecção das tubagens a beneficiar. Esta problemática, tema central da Gestão
de Activos (GA, também designada gestão patrimonial de infra-estruturas), tem sido alvo de
interesse por parte da comunidade científica, de que são exemplo os casos do projecto
comunitário CARE-W (Computer Aided REhabilitation of Water Networks) ou a plataforma
WSSTP (Water Supply and Sanitation Technology Platform).
3.4 Enquadramento do presente trabalho Este trabalho, cujo objectivo passa por relacionar algumas variáveis explicativas com a
degradação dos sistemas de distribuição, pode auxiliar a tarefa de diagnóstico de áreas para
implementação de estratégias reactivas quando a medição directa não é possível e, para além
disso, prever o desempenho futuro da rede, auxiliando o planeamento de intervenções activas.
Numa perspectiva mais geral, regista-se que um enquadramento adequado deste fenómeno
constitui uma ferramenta bastante útil no âmbito da GA, permitindo prever níveis de serviço,
avaliar riscos e fazer projecções de custos futuros de forma acessível, fiável e, sobretudo,
próxima da realidade.
Fugas e roturas são duas faces da degradação dos sistemas de distribuição de água e, embora
estejam intrinsecamente relacionadas, não correspondem ao mesmo fenómeno. Não obstante,
ao aumento da magnitude e do número das roturas corresponde normalmente um aumento das
fugas, pelo que ambas constituem bons indicadores do estado de conservação dos sistemas de
distribuição. Como tal, entende-se que o esforço que se desenvolve para a modelação de roturas
se poderá reflectir directamente na redução dos volumes de fugas.

17
Quanto ao balanço hídrico, a metodologia desenvolvida para modelação de fugas em condutas
de distribuição pode ser aplicada sem alterações substanciais à modelação das fugas nas
condutas de adução e nos ramais (Quadro 3.2).
Quadro 3.2 – Balanço hídrico em sistemas de abastecimento de água. Adaptado de Alegre
et al, 2004. Áreas de aplicação do presente estudo.
Água entrada no sistema
Consumo autorizado
Consumo autorizado facturado
Consumo facturado medido (incluindo água exportada Água facturada
Consumo facturado não medido
Consumo autorizado não
facturado
Consumo não facturado medido
Água não facturada (Perdas Comerciais)
Consumo não facturado não medido
Perdas de água
Perdas aparentes Uso não autorizado
Erros de medição
Perdas reais
Fugas nas condutas de adução e /ou distribuição
Fugas e extravasamentos nos reservatórios de adução e /ou
distribuição
Fugas nos ramais (a montante do ponto de medição)
As variáveis que normalmente se considera terem influência no fenómeno das roturas são
múltiplas e de naturezas diferentes. Podem ser relacionadas com a tubagem utilizada, com a
instalação e a concepção dos sistemas, com a operação e, finalmente, podem corresponder a
variáveis externas e de mais difícil controlo. No Quadro 3.3 faz-se uma síntese das variáveis
mais importantes.
Quadro 3.3 – Variáveis relacionadas com o aparecimento de roturas em sistemas de distribuição de água.
Tubagem Instalação Operação Externas
Idade Material
Classe de pressão Diâmetro Extensão
Qualidade de execução da obra
Número de acessórios
Número de ramais
Pressão média Variações de pressão
Turbulência e velocidade média do escoamento
Tipo de solo Propriedades
bioquímicas da água Nível freático
Temperatura média Variações térmicas
Cargas externas Acidentes naturais
Acidentes provocados
Muitas das ferramentas utilizadas para fazer este tipo de análise são criticadas por demasiada
complexidade e dificuldades de implementação em situações práticas. Por necessitar de dados
de que as entidades gestoras não dispõem e limitando a análise a determinado conjunto de

18
variáveis explicativas, o processo de GA acaba muitas vezes por não ser levado do início ao fim
sem uma componente empírica demasiado “pesada”. Assim, é importante que o método
proposto seja versátil, permitindo a obtenção de resultados aceitáveis com diferentes conjuntos
de variáveis.
Neste sentido, o presente trabalho explora a utilização das RNA para o modelação da
degradação dos sistemas de distribuição devido à facilidade de implementação, à robustez e à
plasticidade desta ferramenta computacional.
3.5 Campos de aplicação – Gestão estratégica de activos e identificação de zonas de intervenção prioritária
Como já foi referido, antevêem-se duas aplicações potenciais para a metodologia utilizada no
presente estudo. Um será a integração em modelos de GA, o outro1 a selecção de zonas das
redes em que são mais produtivas intervenções imediatas, tanto ao nível de beneficiação, como
ao nível de detecção activa de fugas.
Segundo Alegre, 2007, a GA pode ser definida como:
Gestão patrimonial de infra-estruturas2 é o conjunto da estratégia da organização e das
actividades e das práticas sistemáticas e coordenadas correspondentes, através das quais a
organização gere as suas infra-estruturas de modo racional, garantindo o equilíbrio entre o
desempenho, o custo e o risco que lhes estão associados durante o ciclo de vida dos activos que
a compõem.
Este equilíbrio requer a existência de competências em três pilares fundamentais: gestão,
engenharia e informação.
A gestão patrimonial de infra-estruturas deve ser planeada a um nível estratégico, a um nível
táctico e a um nível operacional.
Desta definição resulta que a GA, aplicada ao sector do abastecimento de água, é um campo
vasto, que explícita ou implicitamente engloba quase na totalidade as várias vertentes da
actividade. Assim, estabelecer um programa de GA é bastante complexo, mas uma vez que,
para que esse programa tenha efeitos positivos, a actuação da entidade competente deve
manter-se coerente no médio e longo prazo, é crítico que, de início, os problemas sejam
correctamente definidos e as estratégias bem delineadas. Caso isso não aconteça, poderá
1 Embora as intervenções imediatas, de um nível táctico, também possam ser inseridas no âmbito da GA, aqui optou-se por as destacar, pois são frequentemente levadas a cabo mesmo na ausência de um programa de GA. 2 Neste documento utilizam-se os termos GA (Gestão de Activos) e gestão patrimonial de infra-estruturas como sinónimos. Não obstante se utilize principalmente o termo GA, neste caso específico optou-se pela designação alternativa porque a autora da citação defende essa terminologia.

19
suceder que, vítima de mudanças de rumo recorrentes, o programa de GA seja descaracterizado
e os resultados operacionais se fiquem aquém dos esperados.
Nesse sentido, embora seja recomendado que uma organização não espere por ter informação
credível sobre todos os aspectos envolvidos para pôr em prática uma abordagem de GA (Alegre,
2007), é aconselhável que, tão cedo quanto possível, essa abordagem evolua.
A gestão, e especialmente gestão a médio e longo prazo, como deverá necessariamente ser a
gestão de infra-estruturas cujos componentes principais têm uma vida útil de 50 ou 100 anos,
exige planeamento e, consequentemente, projecção do futuro. O processo de projecção pode ser
mais ou menos detalhado, tendo ambas as abordagens vantagens e inconvenientes. Uma
projecção pouco detalhada, geralmente apoiada na experiência e no bom senso dos decisores,
apresenta geralmente resultados aceitáveis, embora limitados. Pelo outro lado, uma projecção
muito detalhada pode ser difícil e cara de conseguir, podendo, no entanto, dar resultados com
grande fiabilidade quando adequadamente aplicada.
A utilização das RNA visa atingir um equilíbrio adequado na projecção da evolução das redes,
sendo o número e o tipo de parâmetros facilmente alterado sem ser necessário modificar a
estrutura do modelo, de acordo com a informação disponível.
Uma implementação correcta de um modelo de RNA pode contribuir para a avaliação de riscos,
para a determinação da manutenção necessária e para a determinação das prioridades de
reabilitação, respondendo paralelamente a algumas questões-chave da GA em sistemas de
abastecimento:
• Em que circunstâncias ocorrem falhas?
• Qual a probabilidade de falha?
Para além desta utilização, de um nível estratégico, pode considerar-se a utilização ao nível mais
táctico, de selecção das zonas das redes em que são mais produtivas intervenções imediatas,
quer ao nível de beneficiação, quer ao nível de detecção activa de fugas. Este tipo de decisão,
apoiada na análise indirecta da rede (por via das RNA), fará mais sentido quando equipamentos
de medição de caudais forem poucos ou inexistentes, pese o facto de que, tendo o fenómeno
das roturas uma forte componente aleatória, medições actuais podem não ser representativas de
comportamentos futuros.
3.6 Perspectivas e desafios Sendo o abastecimento de água um sector com grandes desafios de mudança, pensa-se, pelas
razões já expostas, que o combate às perdas será, cada vez mais, uma preocupação das
entidades gestoras. Dado que este combate é levado a cabo em várias frentes, estratégicas
tácticas e operacionais, é possível vislumbrar várias linhas de investigação com grande potencial.
Uma vez que a detecção activa de fugas é um campo bastante técnico, em que as evoluções se
prendem principalmente com melhorias no equipamento disponível, o contributo que um

20
engenheiro civil pode dar para novos desenvolvimentos é algo limitado. Por outro lado, no campo
das medidas activas de planeamento estratégico e táctico, o conhecimento da engenharia civil
pode ser aproveitado com grande utilidade.
Nos encontros nacionais da especialidade, destacam-se comunicações com ênfase em
campanhas de detecção activa de fugas, regulação de pressões na rede como medida de
redução de perdas (Araujo, et al., 2006) (Dias, et al., 2006) (Gomes, et al., 2008) e aplicação de
modelos de GA, tais como o CARE-W ou o modelo integrado da EPAL (Alegre, et al., 2004)
(Marques, et al., 2004) (Franco, et al., 2008) (Luís, et al., 2004). Em plataformas internacionais,
tais como a WSSTP, dá-se bastante relevância à GA, sendo analisados variados vectores de
melhoria, incluindo as ferramentas de análise e tratamento de dados (Water Supply and
Sanitation Technology Platform, 2008).
Em Alegre, 2007, é apresentada uma lista extensa de áreas de estudo relacionadas com a GA,
sendo, para cada área, classificado o grau de conhecimento actualmente detido e a relevância
para o LNEC (Laboratório Nacional de Engenharia Civil). Nesta lista destacam-se vários temas
com interesse para investigação. De entre estes, o desenvolvimento de ferramentas de previsão
do desempenho (“Develop predictive tools for performance prediction”) aparece como tendo a
maior relevância no panorama nacional.
Modelos integrados desenvolvidos no passado, de que é exemplo o CARE-W, apresentam
algumas lacunas. No caso da análise da degradação dos sistemas efectuada segundo a
metodologia do CARE-W, o número de parâmetros a introduzir no modelo é limitado, sendo que
grande parte destes são indispensáveis, o que inviabiliza a utilização de todas as potencialidades
do modelo por parte de entidades gestoras que não disponham de informação adequada. Por
outro lado, a análise estatística que é feita baseia-se num modelo de regressão de Poisson, o
que constitui uma assumpção a priori que não corresponde necessariamente à realidade.
Paralelamente, a ferramenta desenvolvida é apenas aplicável a redes de distribuição de águas,
não sendo fácil ao utilizador final utilizar a mesma metodologia para drenagem, por exemplo.
Alternativas à análise estatística, tais como algoritmos genéticos ou a lógica difusa, apresentam
frequentemente bons resultados. No entanto, não sendo modelos de aproximação de funções
per si, acabam por necessitar de um trabalho de preparação exigente, tanto em tempo como em
conhecimentos técnicos.
Não sofrendo estas limitações, pensa-se que o potencial de modelos baseados em RNA, do
género do desenvolvido no presente trabalho é vasto, podendo estes contribuir grandemente
para a melhoria das metodologias de GA.

21
4. Redes neuronais artificiais e algoritmos genéticos
4.1 Aspectos gerais As Redes Neuronais Artificiais, ou RNA, também designadas Redes Neuronais, Modelos
Conexionistas, Processadores Distribuídos em Paralelo ou Neurocomputadores, surgiram em
1943, pelo trabalho de McCulloch e Pitts (Lingireddy, et al., 2005), inspiradas no funcionamento
do cérebro humano. Hoje constituem uma área de interesse da Inteligência Artificial, a par de
métodos como os Algorítmos Genéticos (AG), a Lógica Difusa, Sistemas Simbólicos e outros.
Em linhas gerais, as RNA são modelos computacionais inspirados na biologia, constituídos por
unidades de processamento (nós ou neurónios), ligações entre estas, algoritmos de treino e
algoritmos de activação (Kasabov, 1996).
De acordo com (Haykin, 1999), as RNA podem ser definidas da seguinte forma:
Uma rede neuronal artificial é um processador massivamente distribuído em paralelo constituído
por unidades de processamento simples, que tem a propensão natural para armazenar
conhecimento experimental e torná-lo disponível para ser utilizado. Assemelha-se ao cérebro em
dois aspectos:
1. O conhecimento é adquirido pela rede a partir do meio envolvente através de um
processo de aprendizagem;
2. As intensidades das ligações entre neurónios, conhecidas como pesos sinápticos, são
usadas para armazenar o conhecimento adquirido.
Os AG são um tipo de ferramenta computacional inspirada na selecção natural e na genética.
Sendo quase universais enquanto ferramentas de optimização, oferecem sobre outros métodos a
vantagem de permitirem a análise simultânea de vários vectores durante o processo de busca de
solução óptima. Esta classe de algoritmos de optimização também se destaca pela utilização de
regras probabilísticas, em detrimento de regras determinísticas, o que assegura a robustez da
metodologia (Lingireddy, et al., 2005).
4.2 Razões da aplicação
4.2.1 Redes neuronais artificiais
A degradação dos sistemas de distribuição de água é um fenómeno complexo, em que intervêm
muitas variáveis e cujas inter-relações não são conhecidas em profundidade. Os modelos de
métodos estatísticos, tradicionalmente usados para o estudar, para além de complexos, não têm
atingido o grau de precisão e generalização que seria desejável para a implementação em

22
sistemas de apoio à decisão. Assim, justifica-se a necessidade de procurar novas ferramentas
que possibilitem o estudo integrado e mais eficiente deste problema.
As RNA têm vindo a ser desenvolvidas e aplicadas nos mais diversos campos da ciência para
responder a desafios tão distintos como o processamento de linguagem e imagens, o
reconhecimento de padrões, a classificação de dados, aproximação de funções, optimização,
predição, planeamento, monitorização, diagnóstico e controlo. No que toca à engenharia
hidráulica, as RNA estão também bastante difundidas, tendo sido empregues na previsão de
hidrogramas de cheia, (Pasculescu, 2004), na modelação da qualidade da água (Lingireddy, et
al., 2005) e modelação da degradação estrutural de sistemas de distribuição de água (Jafar, et
al., 2006).
As razões da crescente utilização das RNA em todos estes campos prendem-se, sem dúvida,
com os benefícios que lhes estão associados:
• Aprendizagem – Uma RNA pode ser iniciada “sem conhecimento” e treinada com um
dado conjunto de exemplos (inputs e outputs, no caso de treino supervisionado ou
apenas inputs, no caso de treino não supervisionado); através do treino, as intensidades
das ligações entre neurónios alteram-se de tal forma que a rede aprende a produzir o
resultado desejado para os dados introduzidos;
• Generalização – Se um novo conjunto de dados diferir dos exemplos conhecidos for
introduzido na rede, esta produz o melhor resultado possível com base nos exemplos
usados;
• Paralelismo massivo potencial – No decurso do processamento da informação, vários
neurónios “disparam” simultaneamente;
• Robustez – Se alguns neurónios “falharem”, o sistema pode ainda ter um bom
desempenho;
• Correspondência parcial – Na maior parte dos casos uma correspondência total ao casos
.de exemplo não é necessária.
Estes benefícios, na prática traduzem-se em que as RNA consigam encontrar boas soluções
mesmo com dados sujeitos a ruído, falhas, informações imprecisas ou corrompidas (Kasabov,
1996).
Não obstante os benefícios da aplicação das RNA sejam interessantes, é importante manter
presente que outros métodos também apresentam vantagens e cada um tem uma área de
aplicação preferencial. Na Figura 4.1 apresenta-se um esquema que racionaliza a adopção de
vários métodos de acordo com o conhecimento teórico dos problemas e a quantidade de dados
disponíveis.
Face à quantidade de dados que pode ser armazenada, hoje em dia, graças à evolução dos
Sistemas de Informação Geográfica, ou SIG, entende-se que as RNA podem ser aplicadas com
bastante sucesso à modelação da degradação de sistemas de distribuição de água. Porém,

23
também o poderão ser os métodos estatísticos. Face a estes, as RNA apresentam uma
vantagem substancial que reside no facto de ser desnecessário conhecer qual a relação
funcional entre as variáveis que regem o fenómeno a modelar3 (Lingireddy, et al., 2005) e
(Kasabov, 1996).
Figura 4.1 – Aplicação de diferentes métodos dependendo da disponibilidade de dados e
conhecimento (teoria). Adaptado de (Kasabov, 1996).
4.2.2 Algoritmos genéticos
Vários autores referem as complementaridades entre os AG e as RNA (Mitchell, 1999)
(Lingireddy, et al., 2005). No presente estudo optou-se por introduzir os AG, não como
alternativa, mas como complemento às RNA, procurando optimizar o seu funcionamento,
designadamente ao nível do treino.
Uma vez que os AG, ao contrário das RNA, permitem o processamento de vários vectores de
solução em paralelo, efectuam uma busca bastante mais transversal ao espaço de soluções e,
dessa forma, permitem ultrapassar algumas limitações dos métodos de treino normalmente
associados às RNA. Por outro lado, o carácter geral dos AG permite que sejam utilizados para
orientar a definição da arquitectura das RNA, um processo que normalmente é realizado através
de um procedimento de tentativa e erro.
3 Em alternativa a modelos de regressão convencionais poderão também ser aplicados modelos estatísticos não paramétricos que, tal como as RNA, não implicam o conhecimento prévio de relações funcionais.

24
4.3 Evolução histórica
4.3.1 Redes neuronais artificiais
Pode dizer-se que a história das RNA começou em 1943, pelo trabalho de McCulloch e Pitts, que
conceberam neurónios artificiais como modelos simplificados de neurónios biológicos, tendo
deduzido que, com um número suficiente de unidades, pesos sinápticos correctamente ajustados
e a operar em paralelo, a sua concepção teria capacidade para aproximar qualquer função. No
entanto, o modelo desenvolvido carecia da habilidade de aprender. Em 1949, surgia o livro A
organização do comportamento, em que Donald Hebb estabeleceu o seu famoso postulado em
que afirma que a eficiência de uma sinapse variável entre dois neurónios é aumentada pela
activação repetida de um pelo outro através dessa sinapse. Este resultado, tendo constituído a
primeira tentativa de apresentar uma regra explícita de modificação sináptica, foi bastante
importante nos desenvolvimentos subsequentes das RNA4.
Na sequência da crescente actividade científica em torno desta nova disciplina, Rosenblatt
concebeu o perceptrão, um filtro linear com capacidade de adaptação. Tal como foi estabelecido
no teorema da convergência do perceptrão, esta rede tem a capacidade de encontrar sempre
solução, num número de passos finito, desde que os dados correspondessem a um conjunto
linearmente separável. Mais tarde, Widrow e Hoff, desenvolveram um algoritmo de treino
baseado no erro quadrático médio (EQM) que implementaram na Adaline (Adaptative Linear
Element). Dois anos depois, era proposta por Widrow a Madaline (Multiple-adaline), uma das
primeiras redes neuronais com vários componentes adaptáveis que tinha a capacidade de
aprender. Em 1963, a utilização de estruturas com vários elementos foi reforçada por Winograd e
Cowan, que demonstraram em que medida um número elevado de elementos pode representar
colectivamente um conceito único, com um aumento correspondente de robustez e paralelismo.
Na sequencia destes sucessos, durante a década de sessenta, o progresso das RNA parecia
nada menos que auspicioso e o seu campo de aplicação virtualmente ilimitado. No entanto, em
1969, Minsky e Papert demonstraram matematicamente que há limites fundamentais nas
operações que perceptrões de camada única podem executar e declararam que não havia
razões para assumir que qualquer desses limites pudesse vir a ser ultrapassado na versão
multilinear. Para além disso, as redes multilineares tinham alguns problemas próprios, como o
problema da atribuição de crédito5, abordado por Minsky em 1961.
Assim, durante a década de 70, o estudo e desenvolvimento das RNA foi posto de lado por
muitos investigadores e, não obstante a maior parte dos conceitos e ideias necessários para
4 Em 1956, inspirados neste postulado, Rochester, Holland, Haibt e Duda acabaram por concluir que a inibição é também necessária. 5 “Credit Assignment Problem for Reinforcement Learning Systems”. Face ao elevado número de variáveis, torna-se complicado quantificar a contribuição que cada neurónio que tem para o resultado final. Neste sentido, é difícil seleccionar eficientemente que ligações modificar e em que medida o fazer.

25
ultrapassar os problemas levantados na década de 60 já tivesse sido desenvolvida, as soluções
tardaram em aparecer devido a dificuldades na experimentação e ao efeito desencorajador que
teve a constatação de severas limitações nas redes neuronais, após um período de tão profícuo
desenvolvimento.
No decorrer deste hiato, vários trabalhos contribuíram para o avanço e, finalmente, o “renascer”
das RNA. Destacam-se os mapas topológicos de von der Malsburg (1973), A ART (Adaptive
resonance Theory) de Gossberg (1980), os mapas de Kohonen (1982), a máquina de Boltzmann,
por Ackley, Hinton e Sejnowski (1985) e, especialmente, as redes de Hopfield (1980) que,
embora não constituam modelos realistas dos sistemas neurobiológicos, vieram despertar
implicações profundas na compreensão das RNA (Haykin, 1999). Por outro lado, a utilização de
redes neuronais de camadas múltiplas (perceptrões multicamada ou PMC), implementando
funções de activação não lineares (por exemplo sigmóides ou logísticas, introduzidas em 1967
por Cohen), o modelo aditivo de Grossberg (1967/68) e Amari (1972) e, finalmente, o algoritmo
de retropropagação, publicado em 1986 por Rumelhart, Hinton e Williams6 permitiu ultrapassar
as limitações assinaladas por Minsky.
Apesar dos PMC serem, ainda hoje, a RNA mais utilizada devido à sua eficiência e concepção
simples, a partir da década de oitenta grandes progressos têm sido feitos no campo da
inteligência artificial e, em particular, das RNA. Em 1988 Broomhead e Lowe introduziram as
RBR (Redes de base radial ou, em inglês, Radial Basis Functions), que constituem uma
alternativa aos PMC e, no início dos anos noventa, Vapnik e diversos colaboradores inventaram
as máquinas de apoio vectorial.
4.3.2 Algoritmos genéticos
Pode dizer-se que o desenvolvimento dos algoritmos genéticos teve início das décadas de 50 e
60, quando os processos evolutivos que se verificam na natureza serviram de inspiração à
criação de métodos de optimização.
Apesar de se terem desenvolvido vários trabalhos baseados nas teorias evolutivas a partir de
1954, foi só com as estratégias evolutivas, implementadas por Rechenberg (1965, 1973) para
optimizar parâmetros de mecanismos como aerofólios7, que a evolução artificial ganhou
notoriedade.
Fogel, Owens e Walsh (1966), desenvolveram uma abordagem alternativa conhecida como
programação evolucionária, em que soluções candidatas para determinadas tarefas são
6 Não obstante a importantíssima contribuição de Rumelhart, Hinton e Williamns, a autoria do algoritmo deve ser partilhada com Werbos (1974), Bryson e Ho (1969), Parker (1985) e LeCun (1985) (Haykin, 1999). 7 Um aerofólio (ou fólio) é uma secção bidimensional, projectada para provocar variação na direcção da velocidade de um fluido. No caso de Rechenberg, a asa de um avião.

26
representadas como máquinas de estados finitos que evoluem através de mutações e processos
de selecção das que demonstram maior aptidão.
Os Algoritmos Genéticos, AG, propriamente ditos foram concebidos por John Holland na
Universidade do Michigan nas décadas de 60 e 70. Ao contrário das estratégias evolutivas e da
programação evolucionária, os AG não foram desenvolvidos para encontrar soluções para
problemas reais, mas como um método formal para estudar os fenómenos da adaptação e tentar
reproduzi-los em sistemas informáticos. O trabalho de Holland, que se destacou dos anteriores
por incorporar, não só a mutação, mas também o cruzamento entre indivíduos e a inversão8, foi,
para além disso, o primeiro a ser enquadrado numa base teórica firme.
Com o desenvolvimento das várias teorias evolutivas, motivado pela capacidade que
demonstram como ferramentas de optimização e o aumento dramático da capacidade do
hardware disponível, as diferenças entre as estratégias evolutivas, a programação evolucionária,
e os AG foram-se esbatendo e, actualmente, é comum designar a generalidade das teorias
evolutivas por Algoritmos Genéticos.
4.4 Princípios e descrição das redes neuronais artificiais
4.4.1 Princípios de funcionamento e convenções
As RNA são processadores paralelos constituídos por unidades de processamento denominadas
neurónios ou nós, ligações entre estes, constantes (bias), funções de aptidão (fitness functions) e
algoritmos de treino. Na prática, as RNA são redes de nós e respectivas ligações, que
armazenam informação de forma implícita na topologia e nos pesos das ligações e têm a
capacidade de se ajustar.
Dependendo da sua configuração, as RNA podem ter a capacidade de aproximar funções
dinâmicas, reconhecendo tanto padrões espaciais (feed-forward nets) como espaciais e
temporais (redes recorrentes ou feedback nets), aprender sem qualquer tipo de supervisão (por
exemplo, mapas auto-organizáveis), ou funcionar como aproximadores universais (PMC e RBF).
Uma vez definida a topologia (numero de camadas e distribuição de nós e ligações), uma matriz
de dados (ℝ�) é utilizada para treinar a RNA. No caso de o treino ser supervisionado, os pesos
das ligações da rede são alterados no sentido de minorar a diferença entre os outputs da rede e
os alvos (ℝ�) através de um algoritmo de treino. Para modificar uma rede previamente treinada
podem ser utilizados algoritmos de adaptação, bastante semelhantes às de treino.
Na Figura 4.2 ilustra-se um exemplo de uma RNA simples – PMC, ℝ� → ℝ. Como se pode
observar para o caso do PMC, as RNA são constituídas por uma camada de inputs que tem a
8 Baseada na inversão cromossómica; processo pelo qual um segmento de um cromossoma se “desliga” e sofre uma inversão de 180º antes de se voltar a “ligar” à cadeia.

27
dimensão do vector de dados e cujos nós, na prática, assumem os valores desses dados.
Seguem-se as camadas ocultas (hidden layers), denominadas assim porque os seus nós não
têm contacto directo com o “exterior”. Finalmente, após determinado número de camadas
ocultas, coloca-se a camada de outputs. Os valores dos nós desta última camada são a resposta
da RNA aos dados introduzidos.
Figura 4.2 – Ilustração de um perceptão multicamada.
As ligações têm como única propriedade o seu “peso”, o qual é multiplicado pelo nível de
activação do nó a montante para produzir a contribuição para o nó a jusante. No caso de o peso
ser um valor positivo, a ligação é denominada excitatória, sendo, no caso oposto, considerada
inibitória. Apesar de tal não estar representado na Figura 4.2, é comum ligar um nó fictício com
nível da activação sempre igual a um a cada nó da rede (exceptuando os da camada de inputs).
Na prática, estes nós adicionais funcionam como constantes, pois os pesos das suas ligações
são também sujeitos ao processo de treino.
O nó é a unidade base de uma RNA. Como tal, é necessário conhece-lo para compreender o
funcionamento da totalidade da rede. Na Figura 4.3 sintetiza-se o funcionamento de um nó
genérico em que fi, fa, e fo correspondem às funções de transformação que podem ocorrer no
interior. O nó apresentado recebe ligações de três nós a montante e está ligado a três nós para
jusante.

28
Figura 4.3 – Modelo de um nó de uma RNA.
Tal como referido anteriormente, as operações que se realizam dentro do nó de uma RNA
podem ser três:
• Função de input (fi) – No caso mais comum corresponde ao somatório dos inputs num
único valor real, mas outras concepções, tais como o piatório, também podem ser
aplicadas;
• Função de activação (fa) – Esta função faz corresponder o resultado da função de inputs
a um nível de activação do nó, variando normalmente entre -1 e 1 ou entre 0 e 1;
• Função de output (fo) – Aplica-se a função de output para produzir um sinal a partir do
nível de activação do nó. Na maioria dos casos esta função não é utilizada, pois o que é
transmitido é simplesmente o nível de activação.
Para clarificar as análises feitas, é conveniente estabelecer algumas convenções.
Nomeadamente, é necessário identificar o significado dos índices aplicados a nós, constantes e
ligações. Na Figura 4.4 criou-se um esquema ilustrativo para o caso do PMC, escolhido por ser a
rede eleita para este trabalho e devido ao seu carácter simples.

29
Figura 4.4 – Convenções adoptadas para descrever as redes (exemplo de um PMC).
A rede apresentada tem uma camada de inputs com 3 nós, ��, a que se segue uma camada
oculta, j, e uma camada de output, j+1. Ao contrário dos nós da camada de inputs, os nós das
camadas seguintes são identificados através de dois índices ���, o superior indicando a
designação da camada em que se inserem e o inferior indicando a ordem do nó. As ligações, por
seu turno, têm que ser identificadas através de três índices, �� , em que o índice superior se
refere à camada para que se dirigem e os índices inferiores à ordem do nó de partida e do nó de
chegada, respectivamente. Finalmente, as constantes, ���, por se associarem individualmente a
cada nó (excluindo os de input), são identificadas tal como estes.
Tendo em consideração que a RNA pode ter um número arbitrário de camadas, que cada
camada pode ter um número arbitrário de nós e que as ligações são feitas num único sentido,
esta convenção retrata bem um PMC. Caso se queira alargar estas convenções para outras
redes podem utilizar-se os mesmos princípios mas adicionando mais um índice para identificar
ligações pois, no caso geral, estas podem existir no interior da mesma camada, para uma
camada “anterior” ou qualquer outra. Nas restantes representações, omitem-se as setas
indicadoras da direcção do fluxo, admitindo-se que este se processa da camada de inputs para a
camada de outputs, tal como se omite a representação das constantes.
O treino é porventura o tópico mais complexo da utilização das RNA. Apesar desta complexidade
variar bastante de acordo com o tipo de rede e também, em alguma medida, com o problema em
estudo, utilizar o processo de treino adequado pode fazer grande diferença nos resultados finais.
Embora nalguns modelos de redes, tais como o Perceptrão e a generalidade dos filtros lineares,
o processo de treino seja relativamente directo uma vez que os parâmetros dos algoritmos de

30
treino são poucos, em grande parte das concepções de redes e especialmente nas não lineares,
os processos de treino são mais complexos.
Quanto ao modo de treino, as RNA dividem-se, como já referido, em supervisionadas e não
supervisionadas, referindo-se este termo à necessidade de registos de valores reais. É na
primeira categoria que se insere o PMC, objecto deste trabalho. No caso particular desta rede, o
processo de minimização do erro mais utilizado é a retropropagação (e respectivas adaptações).
A retropropagação pode ser aplicada de duas formas, a determinística (batch learning) e a
estocástica (incremental learning). Para clarificar estes conceitos é conveniente introduzir as
noções de padrão de treino e de época. Para este efeito, atenda-se a que as RNA são, no fundo,
funções ℝ� → ℝ�, ou seja, introduzindo-se na rede um vector � = ��� … ���, esta produz um
vector � = ��� … ���. Seja o objectivo classificar os vectores ou aproximar uma função, o
treino por supervisão consiste em fornecer à rede uma série de � padrões (�) e respectivas
observações (�), a partir dos quais a rede se ajusta para diminuir uma determinada função de
custo [1].
���� ⋯ ���⋮ ⋱ ⋮��� ⋯ ���� ��� �� �!"#$$$$$$$$% & ��� ⋯ ���⋮ ⋱ ⋮��� ⋯ ���' ≈ & )�� ⋯ )��⋮ ⋱ ⋮)�� ⋯ )��' [1]
No caso do modo estocástico, fornece-se à rede um padrão, comparando-se o resultado obtido
com o resultado desejado. De acordo com a função custo, os pesos da rede são reajustados no
sentido da diminuição do erro. Seguidamente, apresenta-se o próximo padrão à rede, repetindo-
se o processo.
Na generalidade dos casos, o número de padrões que constituem o grupo de treino é limitado,
pelo que é comum apresente o grupo de treino à rede mais de uma vez para que a rede se
adapte convenientemente. A uma passagem de todos os vectores do grupo de treino dá-se o
nome de época. O modo determinístico consiste em apresentar uma época de padrões à rede
promovendo-se apenas alterações nos pesos sinápticos entre épocas a partir do erro global
calculado ao invés de o fazer entre padrões.
Independentemente do modo de treino, existem limitações na retropropagação, pelo que devem
ser seguidas “boas práticas” para obter resultados consistentes e suficientemente aproximados
da solução ideal.
Seguidamente aborda-se o paralelismo com o funcionamento dos sistemas neuronais biológicos
e descrevem-se vários modelos de RNA, partindo dos mais simples para os mais complexos de
forma a possibilitar ao leitor uma melhor compreensão do tema.

31
4.4.2 Paralelismo com os sistemas biológicos
As RNA não são apenas uma ferramenta inspirada num modelo natural, são, para além disso,
uma ferramenta orientada para auxiliar o estudo do cérebro ao nível subsimbólico. Assim, esta é
uma temática pluridisciplinar, em que psicólogos, neurologistas, matemáticos, informáticos e
engenheiros tomam parte activa. Neste enquadramento, pensa-se que conhecer, ainda que
superficialmente, a relação de paralelismo entre as redes neuronais artificiais e biológicas é uma
valência importante para o utilizador das RNA.
Os neurónios, tal como estabeleceu Santiago Ramón y Cajal, são as células que constituem a
unidade base do sistema nervoso. São compostos pelo corpo celular (ou soma), árvore
dendrítica e axónio. Na Figura 4.5 apresenta-se o diagrama completo de um neurónio9.
Figura 4.5 – Diagrama de um neurónio (fonte: Wikipedia, por Mariana Ruiz Villarreal)
O sistema nervoso humano é composto por cerca de dez mil milhões de neurónios, podendo
cada neurónio estabelecer ligações sinápticas com cerca de 10 000 outras células (Haykin,
1999).
9 Note-se que existem tipos diferentes de neurónios. Não obstante, o diagrama contém as características gerais destas células.

32
No caso mais comum, os estímulos nervosos são recebidos através das dendritres e do corpo
celular, enquanto a emissão de sinais é predominantemente feita através dos axónios. Uma vez
que cada neurónio é envolvido por uma membrana que o isola dos restantes, a comunicação
processa-se por via eléctrica e por via química por intermédio de substâncias denominadas
neurotransmissores. Face ao estímulo, a membrana polarizada no neurónio pode propagar sinais
eléctricos que resultam na segregação dos neurotransmissores, que atravessam a ligação
sináptica e se ligam à célula seguinte da cadeia.
Quando, em 1943, McCulloch e Pitts conceberam o seu modelo computacional e lançaram as
fundações das RNA pretendiam construir um modelo digital do neurónio biológico. Na primeira
vaga de interesse pelas RNA, os resultados obtidos, não só por McCulloch e Pitts, mas também
por outros cientistas, acompanhados por progressos na área da neurologia, estimularam a
percepção das RNA como objectos de estudo para compreensão do sistema nervoso.
Paralelamente, alguns pioneiros no desenvolvimento da inteligência artificial depositaram
esperanças nas RNA, razões pelas quais a biologia acabou por ter uma grande influência no seu
desenvolvimento. Só posteriormente, quando se comprovou o interesse prático destes modelos
para a resolução de problemas concretos, se vislumbraram aplicações à engenharia.
Assim, as RNA retêm muitas características dos sistemas biológicos. Tal como nestes, o
processamento de informação é conseguido através de múltiplas unidades básicas funcionando
em paralelo, cada unidade recebendo e efectuando várias ligações, com as unidades de
processamento a realizar apenas operações simples, armazenando o “conhecimento” na
estrutura da própria rede e os processos de reforço e inibição do “peso” das ligações a obedecer
a lógicas semelhantes.
Apesar das RNA demonstrarem potencialidades interessantes, o sistema nervoso é uma rede de
complexidade admirável, incomparavelmente superior às RNA modernas sob todos os pontos de
vista. As construções mentais derivam do processamento de informação a vários níveis, desde
interacções moleculares até circuitos inter-regionais e ao próprio sistema nervoso central. Tal
como os neurónios artificiais são básicos quando comparados com os biológicos, também as
RNA são básicas quando comparadas com os circuitos locais encontrados no cérebro (Haykin,
1999). Na Figura 4.6 são apreciáveis as diferenças.

33
Figura 4.6 – Contraste entre redes neuronais artificiais e biológicas. À esquerda, um
pormenor microscópico do sistema nervoso de um rato e, à direita, uma RNA utilizada no
Jet Propulsion Laboratory, NASA.
4.4.3 Modelos de redes neuronais artificiais
Perceptrão
O perceptrão é a forma mais simples de RNA utilizada para a classificação de padrões
considerados linearmente separáveis (padrões que residem em lados opostos de um hiperplano)
(Haykin, 1999).
Esta RNA, apresentada na Figura 4.7, é constituída por um único nó com pesos sinápticos (ou
ligações) e constantes ajustáveis. A computação do valor introduzido no nó de output é realizada
multiplicado o valor de cada input, ��, pelo peso da respectiva ligação ao nó de output, ��� , o que
resulta na expressão [2], em que ν representa o valor do campo local induzido (número real que
é transformado em ���). O esquema do nó utilizado por Rosenblatt foi o proposto por McCulloch e
Pitts.
Figura 4.7 – Representação esquemática do perceptrão.

34
*�� = , � ����-� ∙ �� [2]
Devido às propriedade do perceptrão, o resultado fornecido pela rede, y, é binário, assumindo o
valor +1 ou -1 consoante o valor do campo local induzido seja superior ou inferior a zero.
O algoritmo de convergência desenvolvido para o perceptrão é do tipo supervisionado, ou seja,
para efectuar o treino é necessário deter a classificação desejada para cada um vectores que
fazem parte dos dados. Assumindo [3] e [4], em que que ��� representa a constante, podem
utilizar-se operações matriciais para calcular o campo local induzido [5] na iteração i.
/0123 = �1, ��123, �6123, … , ��123�78 = ����, ��� , 6�� , … , ��� �7 9 [3]
0 = �0113, 0123, … , 01;3� [4]
*��123 = 870123 [5]
Se as classes forem linearmente separáveis, existe um conjunto de pesos 8 com o qual *�� é
positivo para todos os conjuntos 0123 pertencentes a uma das classes e negativo no caso
contrário.
As operações são efectuadas a cada vector introduzido na rede. Deste modo, caso 0123 seja
correctamente classificado, 812 + 13 = 8123, ou seja, não há alterações nos pesos sinápticos.
Se o vector não for classificado com sucesso, os pesos são actualizados de acordo com a regra
[6]:
/812 + 13 = 8123 − >1230123 ?@ 871230123 > 0 @ 0123 ∈ DE)??@ F812 + 13 = 8123 + >1230123 ?@ 871230123 ≤ 0 @ 0123 ∈ DE)??@ H9 [6]
Em que > representa o parâmetro da taxa de aprendizagem.
Pelo teorema da convergência do perceptrão, Rosenblatt estabeleceu que caso os padrões
utilizados no treino do perceptão pertençam a duas classes linearmente separáveis, o algoritmo
do perceptrão converge a posiciona a superfície de decisão no hiperplano entre essas classes.
Mais tarde, provou-se que aumentando o número de nós, aumenta também o número de classes
que o perceptrão permite separar (Haykin, 1999).
Não obstante tenha constituído uma importante inovação, o perceptrão apresenta limitações
associadas ao comportamento linear, as limitações que Minsky e Pappert formalizaram em 1969.
Na Figura 4.8 ilustra-se este aspecto.

35
Figura 4.8 – Separação linear de classes.
O perceptrão foi paradigmático e é interessante na introdução a redes mais complexas, em
particular ao PMC que, como o nome indica, é nele inspirado.
Filtros lineares adaptativos
Os filtros lineares adaptativos surgem como redes que, tal como o perceptrão, separam
linearmente classes. São também interessantes pois, tendo estruturas semelhantes à do
perceptrão, incorporam algoritmos de treino e conceitos que são adoptados no PMC.
As principais necessidades que levaram ao desenvolvimento dos filtros lineares adaptativos
foram a dificuldade que o perceptrão apresentava na adaptação contínua (por exemplo a um
sinal) e a imposição de que as classes fossem totalmente separáveis. De facto, a estrutura geral
dos filtros lineares é semelhante à do perceptrão, registando-se as principais diferenças ao nível
dos nós de output e do processo de treino.
A operação destas RNA pode ser sintetizada da seguinte forma (Haykin, 1999)10:
1. Processo de filtragem, que envolve a computação de dois sinais:
a. Um output, representado por I�, que é produzido em resposta aos J elementos
do padrão11 0123, designadamente ��123, �6123, … , ��123.
b. Um sinal de erro, representado por @123r, que é obtido comparando o output I��123
com o correspondente output �123, produzido pelo sistema desconhecido. De
facto, �123 actua como uma resposta desejada ou um sinal alvo.
2. Processo adaptativo, que envolve o ajustamento automático dos pesos sinápticos da
rede em concordância com o sinal de erro @123.
A diferença ao nível do nó reside no facto deste ter um comportamento linear, pois o valor que
devolve é igual ao do campo local induzido [7].
10 A demonstração é feita, sem perda de generalidade, para o caso de um neurónio único na camada de output. 11 No original utiliza-se o termo vector de estímulo. No entanto, entendeu-se que a utilização do termo padrão, na medida em que é unificadora, é preferível no presente contexto.

36
I�� = *�� = , � ����-� ∙ �� [7]
Ao nível do treino as alterações são mais profundas, designadamente devido à quantificação do
erro [8]. Com este passo, a adaptação da rede assemelha-se a um processo de optimização.
Assim sendo, passa a ser possível aplicar métodos como o do gradiente, de Newton ou de
Gauss-Newton.
@123 = �123 − I123 [8]
Neste contexto surgiu o algoritmo dos mínimos quadrados. Neste processo, define-se uma
função custo [9], que é minimizada durante o treino. Derivando a equação da função custo em
ordem aos pesos sinápticos, 8, é possível obter uma estimativa do gradiente (em [10]) que se
utiliza para formular a equação de actualização da rede [11].
K183 = 12 @6123 [9]
LMNOK183123O8123 = @123 O@123O8
@123 = �123 − 0781239 P OK183O8 = −078123 [10]
812 + 13 = 8123 + >0123@123 [11]
Nesta fórmula, > representa a taxa de aprendizagem.
Uma vez que o método se baseia numa estimativa do gradiente, a trajectória que percorre o
vector 8 é aleatória, o que representa um inconveniente face ao método do gradiente. No
entanto, não requer o conhecimento prévio da estatística do problema e é aplicável a várias
tipologias de RNA (Haykin, 1999).
Face ao perceptrão, este algoritmo é inovador na medida em que incorpora uma função de custo
baseada no erro, utilizando um nó linear. Para além disto, a computação é executada em
contínuo, após cada padrão.
Perceptrão multicamada
A retropropagação aplicada ao perceptrão multicamada (PMC), desenvolvida por Rumelhart
(1986), veio resolver o problema da atribuição de crédito que descredibilizou as RNA nas
décadas de setenta e oitenta.

37
Um PMC é uma rede neuronal do tipo feed-forward, constituída por uma camada de input, um
número arbitrário de camadas ocultas e uma camada de output, organizadas sequencialmente,
em que cada nó está ligado a todos os neurónios da camada seguinte. Na Figura 4.9 apresenta-
se um esquema de um PMC com uma camada oculta.
Figura 4.9 – Esquema das ligações e elementos presentes num PMC.
Como já referido, os PMC são úteis por constituírem aproximadores universais, tendo o potencial
para aproximar qualquer função contínua com nível de erro abaixo de qualquer superior a 0, tal
como é estabelecido pelo teorema do aproximador universal (Anexo I). Não obstante, a prática
demonstra que tal resultado não é muitas vezes aplicável, uma vez que a quantidade de nós e
dados necessária para o atingir aumenta consideravelmente com a complexidade da função e a
diminuição do erro.
Embora sendo um aproximador universal bastante aquém dessa definição na implementação a
problemas reais, o PMC apresenta vantagens em relação a soluções de aproximação
tradicionais (polinomiais ou trigonométricas), pois a degradação da qualidade da aproximação
com o aumento de dimensões do problema é bastante menor (Haykin, 1999).
A complexidade que os PMC podem adquirir é substancial e as operações que ocorrem no
interior da rede praticamente imperscrutáveis, pelo que o treino, assumindo o papel de pedra de
toque no sucesso da aplicação destas redes, deve seguir procedimentos que evitem, tanto
quanto possível, problemas na solução final. A título de exemplo ilustra-se na Figura 4.10 um
PMC treinado, com pesos sinápticos positivos evidenciados a azul e pesos sinápticos negativos
a vermelho, cujas cores são tanto mais fortes quanto maior a intensidade da ligação. As cores
nos nós dizem respeito ao valor do sinal das constantes a eles associadas, sendo a simbologia
idêntica.

38
Figura 4.10 – Ilstração de um PMC após a fase de treino, com pesos sinápticos positivos
evidenciados a azul e pesos sinápticos negativos marcados a vermelho. A coloração nos
nós representa o valor da constante associada.
Como tal, e uma vez que o PMC é a rede eleita para este trabalho, dedica-se o ponto 4.4.4 ao
seu treino.
Sobre outros modelos
À parte das redes feed-forward apresentadas, existem muitas outras concepções de RNA. Umas
têm mais interesse teórico, pois representam conceitos inteiramente novos, outras têm interesse
prático em várias aplicações.
Modelos como as máquinas de Boltzmann ou as redes de Hopfield constituíram marcos
importantes na área das RNA e são exemplos do primeiro grupo. As primeiras destacam-se por
implementarem nós estocásticos. As segundas são redes recursivas, em que cada nó é ligado a
todos os restantes e a convergência é atingida quando os sinais de activação tendem para um
estado de equilíbrio, correspondente a um estado de energia mínima.
Em aplicações práticas, estas redes são, na generalidade dos casos, suplantadas por
concepções alternativas. Estas concepções, em que se incluem, naturalmente, os filtros lineares
e o PMC, contêm um grupo mais vasto de RNA.
Em particular, as Redes de Base Radial (RBR), partilham com os PMC o título de aproximadores
universais. Havendo diferenças marcantes ao nível da arquitectura destas redes e do processo
de treino, na prática os modelos destacam-se pois os PMC constituem aproximações globais,
enquanto as RBR constituem aproximações locais da função alvo, o que significa que o PMC
poderá requerer um menor número de parâmetros que a RBR para o mesmo grau de
aproximação (Haykin, 1999).

39
A introdução de ligações recorrentes numa RNA pode conferir-lhe a capacidade de
reconhecimento de padrões temporais, para além do reconhecimento de padrões espaciais
realizado pelas redes feed-forward. Assim, este tipo de modelos pode ser aplicado na modelação
de sistemas dinâmicos, em que o estado do sistema depende dos estados anteriores, o que é
uma potencialidade significativa em campos como a robótica, ou a composição de música.
Exemplos destas redes são as redes de Elmann (Pasculescu, 2004), ou as Long Short-Term
Memory Networks (Schmidhuber, 2008). No entanto, segundo Kasabov, 1994, tal capacidade é
conseguida à custa de perda de capacidade no processo de treino em relação às redes feed-
forward, resultado da complexidade superior da rede, pelo que só se deverá optar por este tipo
de solução quando o problema o exigir.
Um tipo de redes inteiramente diferente são os mapas auto-organizáveis que, como o nome
indica, organizam os pesos sinápticos de forma a classificar os padrões introduzidos de acordo
com características distintivas. Estas redes têm a particularidade de não necessitarem de “alvos”.
Estes modelos são aplicados, por exemplo, para descobrir características desconhecidas em
conjuntos de dados.
4.4.4 Treino do PMC
Introdução
Por ser a RNA eleita para este trabalho, o PMC deve ser analisado em pormenor. Neste ponto
faz-se essa análise. Identificam-se as principais funções de activação utilizadas, apresenta-se a
formulação teórica do algoritmo da retropropagação, abordam-se os temas da generalização e
da validação cruzada.
Funções de activação
As funções de activação a introduzir nos nós de um PMC devem ser contínuas e diferenciáveis
para que se consiga aplicar o algoritmo da retropropagação. Por outro lado, pelo menos algumas
devem ser não-lineares, ou a rede será incapaz de aproximar funções não-lineares, como alertou
Minsky (1969).
As funções de activação mais importantes e normalmente referidas na bibliografia são quatro:
• a linear, ilustrada na Figura 4.11 e representada pela equação [12];
• a sigmoidal ou logística, ilustrada na Figura 4.12 e representada pela equação [13];
• a tangente hiperbólica, ilustrada na Figura 4.13 e representada pela equação [14];
• a arco-tangente, ilustrada na Figura 4.14 e representada pela equação [15].

40
Figura 4.11 – Função de activação linear.
Q1R3 = R [12]
Figura 4.12 – Função de activação sigmoidal.
Q1R3 = 11 + @ST [13]
Figura 4.13 – Função de activação tangente hiperbólica.
Q1R3 = 2 ∙ 11 + @ST − 1 [14]

41
Figura 4.14 – Função de activação arco-tangente.
Q1R3 = 2U ∙ arctan [U2 ∙ R\ [15]
Não sendo necessário que entre camadas as funções de activação sejam idênticas, é prática
corrente que todos os nós da mesma camada partilhem a mesma função de activação. Assim, os
PMC incluem normalmente funções de activação não lineares nas camadas ocultas, do tipo
sigmoidal ou tangente hiperbólica, sendo que na camada de output é comum adoptar também a
função de activação linear que, ao contrário das restantes não converge assimptoticamente e,
como tal, não limita os resultados possíveis.
No presente caso de estudo optou-se por utilizar apenas funções de activação não-lineares, do
tipo tangente hiperbólica nas camadas ocultas e sigmoidal na camada de outputs. Procedeu-se
desta forma porque, enquanto a função tangente hiperbólica tem um espaço de soluções definido
entre -1 e 1, a função sigmoidal está limitada a resultados entre 0 e 1, pelo que proporciona
resultados da rede sempre positivos como faz sentido quando se trata de probabilidade de
roturas. Não obstante, por ser assimptoticamente convergente para 1, a função sigmoidal
apresenta também um inconveniente quando é utilizada na camada de output. Como os valores
introduzidos na RNA são normalizados, há que voltar dar escala aos outputs no final do treino.
Ora, se a normalização dos resultados utilizados para treino foi de 0 para o menor e de 1 para o
maior, uma vez que os resultados gerados são assimptoticamente convergentes para 1, a RNA
nunca terá capacidade para prever valores superiores aos registados no grupo de treino. Por
forma a contornar este problema, a normalização dos dados foi feita ente 0 e 0.8, proporcionando
à rede a capacidade para prever resultados cerca de 20% superiores aos disponíveis.
A retropropagação
O algoritmo da retropropagação, pela importância que assumiu e continua a assumir no campo
das RNA, merece atenção detalhada. É utilizado para actualizar pesos sinápticos no interior dos
PMC e, sendo bastante semelhante ao método dos mínimos quadrados, apresenta como
principal inovação a capacidade de generalizar a imputação de erros em redes de camadas
múltiplas.

42
A demonstração seguinte é baseada em Haykin (1999). Será primeiro descrito o método para
actualização de pesos sinápticos em ligações a nós da camada de ouput. Estes são diferentes
dos restantes uma vez que o erro pode ser aferido directamente através de [16]:
@�123 = ��123 − I�123 [16]
Em que:
expoente ] indica a camada de output; � representa um nó específico da camada 123 representa o padrão ou a época de cálculo, conforme o treino seja estocástico ou
determinístico; @ é o sinal de erro; � é o objectivo do cálculo; I representa o sinal no nó. No caso da camada de output, a resposta da rede ao padrão.
Uma vez que cada camada pode ter mais que um nó, a energia instantânea de erro, K123, não é
definida por [16], mas por [17], expressão em que se somam os erros de todos os nós da
camada de output. Desta grandeza, normalizada para a totalidade do grupo de treino, resulta o
erro instantâneo médio, K�é_123, definido por [18], em que ` é o número total de padrões de
teste.
K123 = 12 ,a@�b6123� [17]
K�é_ = 1̀ , K123c�-� [18]
Conforme o modo de treino seja estocástico ou determinístico, o erro instantâneo a considerar
será K123 ou K�é_ . No Anexo II apresenta-se o algoritmo da retropropagação, deduzido para o
primeiro caso, sem perda de generalidade.
Como se pode inferir através da demonstração apresentada no Anexo II, a retropropagação é um
algoritmo que funciona em duas fases.
• Na primeira, o padrão é apresentado à rede e o “sinal” é propagado para jusante, sendo
no fim deste processo calculada a energia instantânea de erro.
• Na segunda, em que a rede é actualizada, é calculado o gradiente local dos nós de
output e são adaptados os pesos sinápticos das respectivas ligações. Seguidamente
são calculados gradientes locais e actualizados pesos sinápticos para montante até se
atingir a camada de input.

43
Quando o processo de adaptação acaba, é apresentado um novo padrão à rede, continuando-se
o processo até que K atinja o valor desejado ou se interrompa o treino por outro motivo.
Como se referiu anteriormente, este processo pode ser executado, de forma semelhante, no
treino determinístico, substituindo-se para o efeito K por K�é_ . Todavia, ao invés de se efectuar a
retropropagação entre padrões, apenas se efectuam alterações aos pesos sinápticos entre
épocas (apresentação de todos os padrões de treino à rede).
Na sua concepção original, este algoritmo baseia-se no método do gradiente, no entanto, tal
como acontece no caso dos filtros lineares, é possível modificar o método para utilizar métodos
mais sofisticados, tais como métodos quasi-Newton ou métodos conjugados. Em particular
aponta-se o método de Levenberg-Marquardt, com o qual se obtém resultados bastante bons em
redes de tamanho pequeno e médio, tanto ao nível do erro instantâneo final, como ao nível de
tempos de treino.
Várias modificações, tais como a introdução de um parâmetro de inércia, e parâmetros de
aprendizagem variáveis têm sido desenvolvidos para melhorar o desempenho da
retropropagação. No entanto, como se verá, o método de Levenberg-Marquardt em particular,
sendo mais sofisticado que os métodos de gradiente por utilizar a segunda derivada, provou ser
bastante superior no caso em estudo, tal como em outros casos citados na bibliografia, pelo que
referências a estes parâmetros, não obstante sejam conceptualmente interessantes, têm pouco
interesse prático e não serão desenvolvidas.
Generalização
A generalização é uma competência essencial das RNA. Segundo Haykin (1999), um PMC
generaliza bem quando o mapeamento de inputs e outputs realizado é correcto (ou praticamente
correcto) para dados de teste, nunca utilizados na criação ou no treino da rede.
Devido à capacidade dos PMC, quando o número de nós é elevado, dispõe-se de capacidade
para “armazenar” informação relativa a muitos aspectos do grupo de treino. Ora, se o número de
nós não se ajustar à quantidade de padrões disponibilizada e a complexidade da função que se
pretende mapear, há o risco de a rede assimilar ruído, ajustando-se bastante bem aos padrões
de treino, mas degradando previsões para padrões não conhecidos, mesmo quando apenas
ligeiramente diferentes dos utilizados no treino (Haykin, 1999). Quando isto acontece diz-se que
a rede está sobretreinada.
Ao utilizar RNA, garantir que o ponto em que as redes ficam sobretreinadas é evitado é essencial
para que os resultados tenham fiabilidade. A título de exemplo, ilustra-se na Figura 4.15, um
caso em que o erro quadrático médio do grupo de teste se degrada grandemente enquanto o do
grupo de treino diminui à medida que o processo de retropropagação de desenvolve.

44
Figura 4.15 – Processo de treino em que a rede perdeu a capacidade de generalização.
Para evitar que isto aconteça, existem várias abordagens. Uma, proposta por Poggio e Girosi
(1990) citados em Haykin (1999), recomenda que se utilize a função mais suavizada que
aproxime os dados de treino, o que se traduz por redes simples, com “poucos” nós. Também
segundo Haykin (1999), este ponto é apoiado por Wieland e Leighton (1987).
A generalização depende essencialmente de três factores:
• o tamanho e a representatividade do grupo de treino;
• a arquitectura da rede;
• a complexidade do problema, ou seja, da função a aproximar.
Uma vez que em problemas análogos ao tratado neste trabalho, o primeiro e o terceiro pontos
não variam, resta actuar sobre a arquitectura da rede, ou seja, sobre o número de nós e a sua
distribuição. Embora existam algumas fórmulas teóricas, que indicam o número mínimo de
padrões de treino a fornecer a uma RNA para que uma boa generalização seja assegurada,
verifica-se que acabam por ser bastante pessimistas e apontam para valores bastante elevados.
No que à aproximação de funções diz respeito, o teorema do aproximador universal (Anexo I)
fornece uma base teórica para a pretensão de que os PMCs podem aproximar quaisquer funções
contínuas. No entanto, o número de nós e, consequentemente, o número de padrões disponíveis
para treino necessários não é facilmente definido, pelo que a arquitectura da rede tem de
balançar duas tendências opostas:
• Por um lado, deve existir um número mínimo de nós para que a função seja
convenientemente aproximada.

45
• Por outro, um número demasiado elevado de nós pode levar à degradação da
capacidade de generalização.
Em termos práticos, é comum experimentar várias redes, analisando a capacidade de
generalização com o objectivo de seleccionar a melhor arquitectura. Tal pode ser feito pelo
método da validação cruzada.
Alternativamente, pode iniciar-se o treino com uma arquitectura relativamente complexa,
eliminando posteriormente as ligações com pesos sinápticos mais “fracos” que, potencialmente,
armazenam bastante ruído.
Validação cruzada
A validação cruzada (cross-validation) é um processo pelo qual o conjunto de dados é dividido
em vários conjuntos, uns actuando directamente no treino da rede e outros sendo utilizados para
avaliar a capacidade de generalização, cuja utilização é facilitada no modo de treino
determinístico. Para a implementar, o conjunto de dados é dividido aleatoriamente em três
subconjuntos: treino, validação e teste.
Neste contexto, o conjunto de treino é utilizado para estimar os parâmetros livres da rede (pesos
sinápticos), sendo o grupo de validação utilizado para averiguar a capacidade de generalização,
uma vez que não intervém directamente no treino, o que possibilita a escolha da melhor
arquitectura. O grupo de teste é incluído como garante de que a rede escolhida não ficou
sobretreinada também para os padrões do grupo de validação.
Numa variante da validação cruzada, a paragem antecipada (early stopping) adopta-se um
processo pelo qual o treino é interrompido quando a capacidade de generalização se começa a
degradar. Nesta modalidade, adoptada no presente trabalho, o conjunto de dados é também
dividido em subconjuntos de treino, validação e teste. No entanto, ao contrário do que acontece
na concepção original da validação cruzada, o erro vai sendo estimado também para o
subconjunto de validação, sendo processo de treino terminado quando esse erro começar a
aumentar. O subconjunto de teste, não intervindo directa ou indirectamente no treino, serve, mais
uma vez, de garante dos resultados obtidos.
Segundo Haykin (1999), com base em resultados obtidos por Kearns (1996), a percentagem do
conjunto de dados a adoptar para subconjunto de validação deve variar com a relação entre a
complexidade da função a aproximar e o número de padrões disponível. No entanto, o mesmo
autor sugere que 20% é um valor que funciona uma vasta gama de casos.
Outras variantes são mencionadas na bibliografia (Haykin, 1999), (Lingireddy, et al., 2005).
Designadamente os métodos designados na terminologia anglo-saxónica por K-fold cross-
validation (validação cruzada K-fold) e leave one out cross-validation. O primeiro consiste em
dividir o conjunto de dados em K subconjuntos, repetindo-se o treino com paragem antecipada K
vezes. Em cada uma destas, o subconjunto de validação é composto por um dos K fragmentos
do conjunto de dados, sendo que o subconjunto de treino é constituído pelos restantes K – 1. O

46
erro de treino considerado é a média dos K erros calculados. No segundo método, bastante
semelhante, apenas um padrão é deixado à parte em cada processo de treino, ou seja, K é igual
ao número de padrões de dados.
Embora repetir o treino para todos os padrões disponíveis possa constituir um processo
extremamente moroso, a validação cruzada K-fold, é interessante em termos práticos, pois
assegura que, mesmo que um dos subconjuntos de validação seja constituído em grande parte
por padrões contidos no conjunto de treino, o erro médio estimado para a rede não é
subestimado.

47
5. Metodologia proposta para a modelação da degradação de condutas de água
5.1 Introdução Os fenómenos que levam à degradação das condutas de água são numerosos e difíceis de
quantificar. Assim, apesar de na prática se comprovarem relações entre o número de roturas e
diversos parâmetros, é delicado quantificar com a precisão desejável a influência que cada um
destes parâmetros tem no cômputo final das roturas. Esta dificuldade está essencialmente
associada a dois factores: a ocorrência de roturas é um fenómeno com uma forte componente
aleatória e, num sistema real de distribuição de água, é comum a conjugação de múltiplos
factores que podem influenciar a probabilidade de ocorrência de roturas.
Enquanto a primeira dificuldade à análise, a componente aleatória, pode ser ultrapassada
através do estudo de um número conveniente de dados, a sobreposição de variáveis requer uma
abordagem diferente, uma vez que é difícil obter, em quantidade, dados que contenham
informação relativa a todas as variáveis que seria desejável analisar. Sabendo que, quanto mais
variáveis se incluem, de mais casos se necessita para obter resultados com nível de confiança
aceitável, há que escolher a priori quais os parâmetros mais importantes. Por outro lado, as
relações entre parâmetros podem não ser lineares e as distribuições estatísticas são muitas
vezes desconhecidas, pelo que, mesmo num cenário de abundância de dados, os processos de
tratamento e análise dos dados não são triviais.
Como já foi referido, as RNA, surgem como ferramentas com potencial de aplicação em
problemas desta natureza devido a diversos factores. Não obstante, são ferramentas que surgem
em diversas concepções e requerem a definição de vários parâmetros da sua arquitectura e
processo de treino.
O presente trabalho tem intuito de, com base nas RNA, ultrapassar as dificuldades apontadas,
não só para o caso da degradação de condutas de água, mas também em problemas análogos.
Pretende-se desenvolver um modelo que, de forma estruturada e lógica, permita definir e treinar
redes neuronais adequadas à resolução de problemas reais.
5.2 Selecção e tratamento de informação
5.2.1 Análise dos dados e definição de objectivos
A selecção e o tratamento de informação são a base de qualquer aplicação de redes neuronais.
Embora esteja provado pelo teorema da aproximação universal que os Perceptrões Multicamada
(PMC) podem aproximar, a qualquer grau, qualquer função contínua (Kasabov, 1996), na prática
verifica-se que o processo de preparação dos dados é crucial para o sucesso da aplicação

48
(Lingireddy, et al., 2005). Assim, a primeira fase da metodologia proposta prevê uma análise
criteriosa dos dados disponíveis, identificando-se claramente quais os objectivos a alcançar.
Em função dos dados disponíveis e dos objectivos taçados, deverá ser examinada a adequação
e aplicabilidade das RNA ao problema. Caso estas sejam aplicáveis com vantagens sobre outros
métodos, deverá proceder-se à escolha de um grupo relativamente reduzido de RNA que tenham
potencial para o caso em análise.
No vasto campo de aplicação das RNA enquadram-se, como já foi exposto, muitos tipos de rede.
Assim, como regra geral, desaconselha-se uma abordagem que implique a experimentação de
redes diversas sem uma séria análise prévia, propondo-se, pelo contrário, que se estudem em
pormenor as redes que, à partida, têm mais afinidade com o problema, investindo no
melhoramento do seu desempenho.
Seguindo este raciocínio e no âmbito deste trabalho, analisaram-se em maior profundidade os
PMC, visto serem o tipo de rede mais utilizado, terem uma concepção simples e serem
adequados à captação dos parâmetros estatísticos de conjuntos de dados (Kasabov, 1996), tal
como é necessário para a modelação da degradação das condutas de água.
Paralelamente, a selecção das variáveis mais importantes para a caracterização do fenómeno
deve ter em conta que, quanto maior o número de variáveis e mais complexas as suas relações,
de mais dados necessitará a RNA escolhida para ser correctamente treinada.
5.2.2 Preparação dos dados
Uma vez escolhidas as variáveis, é boa prática preparar os dados utilizados no treino das redes
para que o treino da rede neuronal seja mais eficiente (Lingireddy, et al., 2005).
Uma etapa em que se sintetizem as variáveis a partir de conhecimentos já adquiridos, tornando
mais explícita a informação que contêm é, quando possível, bastante produtiva. Outras
operações podem ser aplicadas com sucesso, tais como a adimensionalização, a logaritmização
ou a utilização de médias móveis.
A experiência tem demonstrado que a filtração do ruído da amostra e normalização dos dados
(geométrica ou logarítmica) são medidas que beneficiam a qualidade final da rede neuronal, não
devendo ser esquecidas.
No âmbito deste trabalho propõe-se as seguintes medidas:
• No caso de variáveis não numéricas (tais como o material da tubagem, por exemplo),
cada classe deverá ser convertida num número real, sendo os intervalos entre classes
iguais. Para melhorar o desempenho da RNA, se for possível, a ordem deverá
corresponder à relação com os resultados. Utilizando de novo o exemplo do material da
tubagem, poder-se-ia atribuir o número 1 ao ferro fundido dúctil, o número 2 ao
polietileno de alta densidade, o número 3 ao ferro fundido e o número 4 ao fibrocimento,
por ordem crescente de roturas registadas.

49
• Para cada variável, os dados devem ser normalizados. No caso desenvolvido, uma vez
que é utilizada uma função de activação assimptótica (como se verá), a normalização
das ordens de trabalhos por 100 km por ano foi feita ente 0 e 0,8 por forma a ficar
assegurada a capacidade de generalização da RNA.
• Dividir trechos de tubagem com comprimentos elevados em trechos mais pequenos com
características idênticas. É importante proceder deste modo porque a RNA capta
informação dando a cada padrão a mesma importância, o que não se adequa ao
problema em estudo, em que elementos de maior comprimento são mais significativos
para a análise. No âmbito deste trabalho recomenda-se a divisão em trechos de
aproximadamente 50 m. Registos com menos de 25 m de comprimento são ignorados e
registos com mais de 75 são divididos em duas ou mais parcelas.
5.3 Procedimentos de modelação
5.3.1 Considerações prévias
As RNA, são versáteis, podendo ser utilizadas para um vasto conjunto de aplicações. No
entanto, esta versatilidade é conseguida através da plasticidade das próprias redes. Assim,
escolher a rede certa para o problema em mãos pode tornar-se um desafio.
Face a esta dificuldade, alguns utilizadores acabam por considerar um grupo vasto de redes e
algoritmos de treino e proceder à comparação entre estes, seleccionando o melhor. Outra
abordagem corrente é fazer certas escolhas empíricas baseadas em trabalhos precedentes.
Apesar da segunda abordagem ser frequentemente utilizada, uma vez que corresponde a um
atalho tentador, os resultados obtidos por essa via poderão não ser os melhores. De facto, em
casos de aplicações de RNA, constata-se que diferentes autores propõem frequentemente a
adopção de medidas distintas e por vezes contraditórias, isto porque cada problema induz
comportamentos específicos nas RNA, por vezes inesperados face a referências passadas.
Deste modo, pensa-se que é produtivo investir numa comparação de soluções sólida, mesmo
que esse procedimento demore algum tempo12.
No caso do PMC e redes afins, estas escolhas podem consistir na utilização de uma ou mais
camadas ocultas, ou na adopção de um algoritmo de treino específico.
5.3.2 Definição da arquitectura da rede
Embora se pretenda introduzir alguma ordem na tomada de decisões sobre a constituição das
RNA, na realidade estes modelos funcionam como um conjunto completo. Assim, propõe-se que
12 Principalmente tempo computacional, uma vez que os processos de treino podem ser algo demorados.

50
as decisões com mais impacto sobre o desempenho da rede sejam definidas inicialmente,
caminhando-se progressivamente para as opções menos decisivas.
Como será intuitivo, tomam-se os aspectos estruturais como os mais importantes, pelo que as
primeiras características da rede a definir devem ser o número de inputs, o número de outputs, o
tipo de ligações entre nós, o número de camadas ocultas, o número de nós e as funções de
transferência a utilizar.
Inputs e outputs
A escolha do número de inputs deve obedecer às considerações tecidas no ponto 5.3.1, mas
está essencialmente condicionada pela especificidade do problema que se pretende resolver, tal
como acontece com o número de outputs.
Quando os fenómenos em estudo são razoavelmente conhecidos, o número de inputs é fixo. No
entanto, com o aumento de dimensões o treino torna-se mais exigente, sendo necessários cada
vez mais padrões de dados.
No caso da degradação de redes de distribuição de água, os parâmetros que é possível
considerar são muitos (uma síntese é feita no Quadro 3.3). Contudo, na prática não é viável
armazenar dados relativos a todos estes parâmetros, pelo que o grupo a considerar é restrito.
Dependendo do número de dados disponível, a viabilidade de inserção de mais parâmetros no
modelo varia. Diversos trabalhos têm sido desenvolvidos no sentido de quantificar o número de
dados necessário para obter resultados com margens de erro definidas em problemas de
dimensão conhecida, no entanto, tais estudos não são facilmente aplicáveis ao caso da
degradação de tubagens devido a dois factores principais: na sua maior parte dizem respeito a
problemas de classificação de padrões e não de aproximação de funções e, na generalidade,
pecam por ser excessivamente conservativos, indicando quantidades de dados bastante
superiores às que se verifica serem necessárias para obter bons resultados em casos práticos
(Haykin, 1999).
Assim, propõe-se que a determinação do número óptimo de inputs seja feita em dois passos:
1. Treinar um PMC muito simples, sem camada oculta, com a totalidade dos inputs
disponíveis. Avaliando-se seguidamente o módulo do peso das ligações sinápticas à
camada de output. Os parâmetros que apresentarem as ligações mais fortes são mais
importantes, enquanto aqueles que gerarem os pesos sinápticos mais ténues poderão
ser retirados do modelo;
2. Executar o treino (com validação cruzada) para um PMC de características que se
estima assemelharem-se às finais, reduzindo progressivamente o número de inputs.
Utilizar demasiados parâmetros pode levar ao sobretreino da rede. Desta forma, quando
a rede perde demasiado rápido a capacidade de generalização, produzindo piores
resultados nos subconjuntos de validação, o treino é interrompido antes de se atingir o

51
estado óptimo. Assim, quando o desempenho da rede atingir o melhor valor, dever-se-á
ter atingido o ponto ideal de variáveis de input face ao número de dados disponível.
Para execução do segundo passo, a RNA poderá ter a seguinte configuração:
• PMC com uma camada oculta de 20 a 30 nós;
• Funções de activação não-lineares na camada oculta e funções de activação lineares na
camada de output;
• Subconjuntos de validação e teste correspondentes, cada um, a 20% do total de dados;
• Treino efectuado utilizando a retropropagação modificada com o algoritmo de
Levenberg-Marquardt.
Tendo-se utilizado o programa Matlab para executar as operações com RNA e AG, notou-se
alguma dificuldade na avaliação das redes treinadas, uma vez que os pesos sinápticos são
armazenados em “estruturas” com uma ou mais matrizes. Assim desenvolveu-se uma ferramenta
que possibilita a observação dos PMC treinados em AutoCAD, numa representação gráfica cujas
cores indicam os valores de pesos sinápticos. Com esta ferramenta, o passo 1 para a
determinação do número óptimo de inputs fica facilitado.
Partindo da premissa de que, com o aumento de dimensão do PMC, será atingido um ponto
óptimo e, a partir desse ponto, haverá ligações sinápticas supérfluas, analisando graficamente as
redes é possível observar o ponto em que se começa a registar um número crescente de
ligações com pesos sinápticos de módulo reduzido.
No Anexo III apresentam-se graficamente três redes: uma rede sem camada oculta, uma rede
com 20 nós na camada oculta e, finalmente, uma rede com 40 nós na camada oculta.
Tipo de ligações entre nós
O tipo de ligações entre nós é geralmente associado ao tipo da rede escolhida, numa rede do
tipo PMC, as ligações são integrais entre camadas adjacentes, pelo que a questão não se
coloca. No entanto, alguns autores argumentam que os resultados obtidos com redes que
contenham conjuntos agregados (clusters) de nós especializados, com capacidade de assimilar
melhor características particulares do espaço de dados, são superiores aos obtidos com recurso
a redes feed-forward integralmente conectadas.
Neste trabalho, considerou-se que a construção de conjuntos agregados não traria benefícios
que compensassem o acréscimo de complexidade que daí adviria.

52
Funções de activação
Normalmente, num PMC, as funções de activação são escolhidas para cada uma das camadas
ocultas13 e para a camada de output. Estando provado que, se todas as funções forem lineares,
o PMC não tem capacidade de reproduzir funções não lineares (Haykin, 1999), recomenda-se
que sejam sempre incluídas funções de activação não lineares.
A opção mais comum parece ser a adopção de funções não lineares, do tipo sigmoidal, tangente
hiperbólica e arco tangente, nas camadas ocultas e, na camada de output, funções lineares. Esta
escolha permite que a rede seja não linear e possibilite uma generalização alargada a resultados
fora do intervalo do conjunto de dados original14. Por outro lado, em alguns problemas, não faz
sentido que se obtenham valores negativos. Quando é este o caso, podem seguir-se três
alternativas:
• Utilizar funções de activação lineares e igualar quaisquer valores negativos a 0;
• Utilizar funções de activação lineares modificadas, que tenham como mínimo o valor 0;
• Utilizar a função de activação sigmoidal, sempre positiva.
A primeira alternativa tem o inconveniente de obrigar à introdução do passo de transformar
valores negativos em zero em todas as aplicações do modelo. Já a segunda é de difícil
aplicação, já que a retropropagação implica que as funções de activação sejam contínuas. A
terceira opção apresenta o inconveniente de limitar o espaço de resultados ao do intervalo de
dados original.
Neste trabalho foi adoptada a terceira alternativa, não só pela mais fácil aplicação mas também
porque a introdução de funções de activação não lineares na última camada poderá contribuir
para a apreensão de características adicionais contidas no conjunto de dados. Para contornar a
limitação apontada a este procedimento, a normalização dos dados foi efectuada de forma que
ao valor máximo contido no conjunto correspondesse o valor 0.8, ao invés do valor 1,
reservando-se desta forma um intervalo de 20% para extrapolação.
Número de nós
Conceptualmente, quanto mais neurónios tem uma RNA, mais potencial tem para apreender a
informação contida nos dados, incluído ruído. A escolha do número de neurónios ideal depende
intrinsecamente do problema a resolver.
Redes com um número reduzido de ligações são treinadas rapidamente, generalizam com bons
resultados (comparativamente aos resultados obtidos para o conjunto de treino) e captam as
13 Na realidade, as funções de transferência poderiam ser especificadas para cada neurónio, independentemente da camada. No entanto, as vantagens dessa abordagem são difíceis de avaliar e a resposta da rede mais difícil de estudar. 14 A função de activação linear é a única, do grupo apresentado, que não converge assimptoticamente.

53
características essenciais dos dados. Com o aumento de ligações, os processos de treino ficam
mais “pesados”, sendo que número de operações necessárias por época cresce
exponencialmente (Lingireddy, et al., 2005). Para além disso, a facilidade com que ocorrem
casos de sobretreino (overfitting) aumenta.
Não havendo uma regra empírica que “acerte” na previsão do número ideal de nós para um
PMC, a melhor alternativa é proceder à experimentação com diversos números, por forma a
obter uma amostra com significado estatístico e, a partir dos resultados, escolher o número de
nós adequado. Neste procedimento, recomenda-se a utilização da validação cruzada ou K-fold e
a retropropagação modificada com o algoritmo de Levenberg-Marquardt.
Adoptando esta metodologia há que ter em atenção dois aspectos importantes. Por um lado,
verificou-se que durante o treino um número reduzido de casos não chega a convergir, gerando
Erros Quadráticos Médios (EQM) elevados relativamente aos de redes que atingem um nível
aceitável de treino. Isto faz com que a média dos resultados fique excessivamente afectada, pelo
que se propõe a utilização do conjunto dos melhores 90% dos resultados.
Por outro lado, notou-se que a variância dos resultados obtidos aumenta em função do número
de nós15, pelo que, quanto maior a rede, de mais treinos se precisará para obter uma estimativa
aceitável da média do EQM. Assim, preconiza-se a aplicação da distribuição de t-Student16 para
gerar intervalos de confiança que permitam a comparação dos valores. Nota-se que, na
generalidade dos problemas, para amostras com mais de 40 treinos se poderá utilizar a
distribuição normal (Montgomery, et al., 2003).
Na Figura 5.1 ilustra-se um exemplo deste procedimento, em que foram testadas redes com uma
e duas camadas e um total de nós na camada oculta variável entre 0 e 40.
15 Este efeito deve-se, possivelmente, à maior instabilidade causada pelo ruído, que leva a que o treino seja interrompido devido ao aumento do erro no subconjunto de validação. 16 A utilização desta distribuição baseia-se no resultado do Teorema do Limite Central, que estabelece que, quando uma experiência aleatória é repetida, a variável aleatória que representa o resultado médio (ou total) das repetições tende para ter uma distribuição normal quando o número de repetições é grande (Montgomery, et al., 2003). Quando o número de repetições é limitado, a distribuição de t-Student é mais adequada.

54
Figura 5.1 – EQM médio após validação cruzada para PMC de uma e duas camadas, com
intervalos de confiança de 95% obtidos recorrendo à distribuição de t-Student.
Número de camadas ocultas
O número de camadas ocultas pode ser optimizado por intermédio de algumas considerações
teóricas. Segundo (Kasabov, 1996), a capacidade de aproximação de uma RNA é função do
número de ligações entre nós no seu interior. Assim, fará sentido aumentar o número de nós
numa única camada oculta para obter redes mais complexas e potentes mas, a partir de certo
ponto, verifica-se que é mais eficiente distribuir esse número por várias camadas ocultas, tanto
ao nível da capacidade final da rede, como ao nível do tempo de treino.
Com o objectivo de quantificar com precisão a partir de que ponto seria conveniente aumentar o
número de camadas ocultas, deduziu-se uma expressão que indica, para uma rede PMC
genérica, a partir de que número de nós fará sentido optar por duas camadas ocultas17.
O número de ligações num PMC com uma camada oculta pode ser obtido através de [19].
d ∙ �̀ + �̀ ∙ e [19]
Em que,
d – representa o número de nós de input;
�̀ – representa o número de nós na camada oculta;
17 Assumindo que a capacidade da rede é proporcional ao número de ligações entre nós e que todas as ligações apresentam o mesmo potencial. Na dedução seguinte não se consideram as ligações correspondentes a constantes nos nós. Estas ligações, no entanto, têm pouco peso, uma vez que a sua contabilização corresponde apenas à soma do número de nós, sendo independente do número de camadas.
7.70E-04
8.20E-04
8.70E-04
9.20E-04
9.70E-04
1.02E-03
0 5 10 15 20 25 30 35 40 45
EQM
Número de nós na rede
1 camada
2 camadas

55
e – representa o número de nós de output.
Generalizando para J camadas ocultas resulta a expressão [20]:
d ∙ �̀ + , �̀ ∙ �̀f��S��-� + �̀ ∙ e [20]
Para duas ou mais camadas ocultas, o número de ligações passa a variar com a distribuição dos
nós. Não obstante, particularizando para J = 2, é possível determinar a dimensão óptima da cada
camada aplicando a mudança de variável �̀ = `` − 6̀ à expressão anterior, obtendo-se [21].
Derivando em ordem a 6̀ e igualando a 0 tem-se a equação desejada, [22].
d ∙ 1`` − 6̀3 + 1`` − 6̀3 ∙ 6̀ + 6̀ ∙ e [21]
�� 6̀ �d ∙ 1`` − 6̀3 + 1`` − 6̀3 ∙ 6̀ + 6̀ ∙ e� = 0 P
P 6̀ = `` + e − d2
[22]
Igualando o número de ligações com uma e duas camadas ocultas, para o mesmo número de
nós, ``, e aplicando a equação [22], obtém-se [23].
1`` + d − e36 − 4`` ∙ d = 0 [23]
De acordo com a dedução, quando o número de nós é suficiente para que o primeiro membro da
equação anterior seja superior a 0, é vantajoso distribuir esses nós por mais de uma camada
intermédia.
Tendo-se efectuado simulações com recurso a Algoritmos Genéticos (AG), cujo cromossoma
reproduzia a constituição de PMC com distribuições arbitrárias dos nós por até 4 camadas
ocultas, verificou-se que as arquitecturas para que tendiam as simulações eram bastante
semelhantes às obtidas através da aplicação das fórmulas anteriores. Esta experiência é tratada
com algum pormenor no capítulo referente ao caso de estudo.
5.3.3 Escolha do algoritmo de treino
A escolha do algoritmo de treino depende do problema em estudo e da quantidade de dados,
sendo difícil generalizar quaisquer recomendações.
Para o treino de PMC é normalmente utilizada a retropropagação, no entanto, não na forma
original (gradiente), mas principalmente em versões modificadas. Como regra geral, quando a
dimensão das redes é bastante grande, os métodos de gradiente modificados são mais

56
utilizados, pois minimizam o tempo de treino. Contudo, para as aplicações na degradação de
sistemas de distribuição, as redes não devem atingir tais dimensões, pelo que algoritmos de
segunda ordem, do tipo conjugado ou Gauss-Newton são preferíveis. Destes, destaca-se o de
Levenberg-Marquardt, que, para o caso de estudo, revelou ser superior aos restantes algoritmos
a todos os níveis (desempenho da rede final, tempo de treino e correlação entre previsões e
dados) excepto, porventura, na quantidade de memória volátil (random access memory ou RAM)
exigida no processo de cálculo. Com base nestes resultados e em outros casos de estudo
apresentados na literatura (Demuth, et al., 2008), pensa-se que será pertinente afirmar que, em
problemas semelhantes ao estudado, a opção por este tipo de treino levará a resultados bastante
bons.
No Anexo IV apresenta-se uma comparação dos vários algoritmos disponíveis no software
utilizado (Matlab Neural Networks Toolbox 4), EQM versus correlação. Para efectuar os treinos
foi utilizada validação cruzada com conjuntos de validação de dimensão igual a 20% do total de
dados disponíveis, seleccionados aleatoriamente.
5.3.4 Escolha da dimensão dos grupos de validação e teste
A escolha da dimensão dos grupos de validação e teste, para implementação da validação
cruzada ou K-fold é também dependente do problema em estudo. Como já referido no capítulo 4,
com base em resultados obtidos por Kearns (1996), a percentagem do conjunto de dados a
adoptar para subconjunto de validação deve variar com a relação entre a complexidade da
função a aproximar e o número de padrões disponível.
Este autor afirma que, após dado número de padrões de treino, a dimensão dos grupos de
validação e teste deixa de ter grande influência no resultado final, sugerindo que 20% é um valor
que funciona numa vasta gama de casos.
Assim, quando os dados disponíveis forem bastantes – e devem sê-lo para que se considere um
número adequado de variáveis e a RNA tenha bom desempenho – propõe-se a utilização de
subconjuntos de validação e teste com cerca de 20% do total de padrões de dados disponíveis.
5.4 Validação dos resultados Admitindo que as RNA são aplicáveis ao problema em estudo, que os dados são suficientes e
que os procedimentos utilizados treinam um PMC adequado, em princípio, serão produzidos
resultados aceitáveis. Há, no entanto, que proceder à validação dos mesmos, não no sentido de
EQM ou correlação, pois essa é uma etapa do treino, mas aplicando espírito crítico aos
resultados obtidos.
Uma vez que as RNA são modelos “cinzentos” em que os cálculos a ocorrer no interior do
modelo são difíceis de acompanhar, um procedimento para verificar a qualidade dos resultados
obtidos passa por analisar pontos amostrais do espaço de resultados. No entanto, identificou-se

57
um factor que dificulta este tipo de análise: o espaço de input é um hipercubo com número de
dimensões variável (cinco no caso de estudo – idade, material, diâmetro, subsistemas e
OT/(100km.ano) prévias18), o que faz com que a divisão dos resultados observados, por um
número de pontos amostrais finito, não seja directa.
Para obviar esta dificuldade, foi criada uma ferramenta que selecciona pontos pré-definidos de
cada uma das variáveis consideradas, criando padrões de dados correspondentes à totalidade
das combinações possíveis. Simulando estes padrões na RNA treinada, é possível observar na
totalidade a correspondência entre os espaços de inputs e outputs. Por forma possibilitar a
comparação entre os resultados reais e os previstos, a ferramenta contabiliza a totalidade de
comprimento de rede de distribuição que tem as características de cada um dos padrões
gerados, e calculando o resultado esperado de acordo com a média ponderada dos valores
reais.
Finalmente, notou-se que pode existir um EQM mínimo teórico inerente ao próprio conjunto de
dados, que pode ser superior a zero e constitui o limite do treino das RNAs. O facto que está
subjacente a este efeito é que podem existir dois trechos de tubagem com características
exactamente idênticas (diâmetro, material, idade, subsistema e OT/(100km.ano) prévias) e
registos de OT/(100km.ano) diferentes. No sentido de aferir este valor, foi construída uma função
em VBA com o objectivo de calcular o EQM mínimo inerente ao conjunto de dados.
A operação desta função implica a catalogação de todos os padrões distintos contidos nos dados
e a determinação da média de OT/(100km.ano) para cada um. Seguidamente, é calculado o
EQM entre os dados e o conjunto de padrões gerado.
5.5 Outras ferramentas desenvolvidas Para além da programação desenvolvida para criar representações gráficas dos PMC e para a
utilização de AG, que voltará a ser referida no âmbito do caso de estudo, foram desenvolvidas
ferramentas para facilitar e automatizar a execução do trabalho. Estas ferramentas incluem:
• Módulo para separar os padrões de dados aleatoriamente, dividindo-os, caso desejado,
em elementos com comprimento aproximado de um valor especificado;
• Módulo para preencher a folha de cálculo com valores calculados a partir de fórmulas
especificadas apenas numa linha. Este módulo provou ser essencial, pois o cálculo
repetido de fórmulas em folhas de cálculo com extensões que chegam a 600 000 linhas
induziu no Microsoft Excel erros demasiado frequentes e ficheiros com tamanhos
incomportáveis;
18 Ordens de trabalhos por 100 km por ano registadas entre 2002 e 2004. Para alvos foram adoptados os valores registados de 2005 a 2007, daí a nomenclatura “prévias” para identificar o primeiro conjunto. No capítulo referente ao caso de estudo o significado destas variáveis é aprofundado.

58
• Módulo para teste, treino e simulação de RNA, que faz o interface entre o Microsoft Excel
e o Matlab.
Esta ferramenta permite a simulação de RNA, disponibilizando um leque variado de
opções permitem praticamente dispensar a utilização directa do programa Matlab.
Utilizando-a, a exportação de resultados para o Excel é automática, sendo possível,
inclusivamente, fazer simulações de matrizes de dimensões superiores às suportadas
pelo Matlab (o que, de facto, foi necessário). Na Figura 5.2 é ilustrado o interface do
modo de treino e simulação. A Figura 5.3 reporta-se ao funcionamento em modo de
teste.
• Módulo para geração de padrões representativos do espaço de soluções da RNA
utilizado para validação dos resultados.
Figura 5.2 – Modo de treino e simulação da ferramenta de teste de redes e separador de
opções.

59
Figura 5.3 – Operação do modo de teste, que possibilita a importação de valores de EQM,
correlação e tempo de treino para o Excel em treinos seguidos, permitindo obter
amostragens estatísticas da capacidade de cada rede.
5.6 Síntese do método Apesar de se terem ordenado as várias fases do método por forma a torná-lo o mais directo
possível, o processo de escolha e treino das RNA deveria ser iterativo.
Na Figura 5.4 apresenta-se um fluxograma que pretende clarificar a metodologia proposta. As
actividades principais são realçadas a azul, os vários passos compreendidos na definição da
arquitectura da rede são apresentados a preto e, finalmente, a avaliação do desempenho da rede
está destacada a vermelho, pois deverá ser uma constante durante o treino.

60
Figura 5.4 – Fluxograma representativo do método proposto.
Análise dos dados e
definição de objectivos
Preparação dos dados
Definição da arquitectura
da rede
Escolha de inputs e outputs
Escolha do tipo de ligações entre nós
Escolha de funções de activação
Escolha do número de nós
Escolha do número de camadas
Escolha do algoritmo de
treino
Escolha da dimensão dos
grupos de validação e teste
Validação dos resultados
Avaliação do desempenho da rede

61
6. Caso de estudo – A rede de distribuição de água da cidade de Lisboa
6.1 Introdução O caso de estudo consiste na modelação da degradação das condutas do sistema de
distribuição de água de Lisboa com base em dados disponibilizados pela EPAL, referentes ao
período compreendido entre 24 de Janeiro de 2002 e 28 de Agosto de 2007.
Fazem parte do objecto de estudo todas as tubagens afectas a distribuição (em oposição a
adução), com diâmetros inferiores a 315 mm. Por motivos práticos relacionados com o treino das
RNA o estudo restringiu-se a tubagens de Ferro Fundido cinzento (FF), Fibrocimento (FC), Ferro
Fundido Dúctil (FFD) e Polietileno de Alta Densidade (PEAD), os materiais com maior presença
na rede.
O sistema de abastecimento de Lisboa foi já introduzido no capítulo 2, no entanto, complementa-
se essa informação com elementos gráficos e alguns números mais relevantes.
No Anexo V é ilustrado o sistema da EPAL, incluindo as infra-estruturas principais. A rede de
distribuição é alimentada preferencialmente pelo Aqueduto Tejo, à cota 17,0 m, pelo Aqueduto
Alviela, à cota 27,7 m, e pelo Adutor de Vila Franca de Xira – Telheiras, à cota 126,0 m (Luís, et
al., 2004).
A partir dos pontos de chegada, a água é elevada e a sua distribuição é feita por zonas
altimétricas independentes que abastecem a rede em patamares de 30 m cada, que se
desenvolvem entre as cotas 0 e 150 m (Luís, et al., 2004).
Na Figura 6.1 apresenta-se o diagrama altimétrico da rede, onde são identificados os principais
subsistemas. . A rede de distribuição de Lisboa é esquematizada na Figura 6.2. Na Figura 6.3 é
ilustrada a rede de distribuição de água, por zona altimétrica
Até 2002, o índice de roturas por 100 km por ano chegou a 112,0, para o FC, e 143,4, para o FF.
(Luís, et al., 2008). Desde 2002, tem vindo a ser desenvolvido um programa de renovação da
rede de distribuição de Lisboa, complementado com a sectorização da rede em zonas de
medição e controlo, investimento na detecção de fugas e medidas de controlo de fraudes e
contadores. Os resultados têm sido expressivos, e apresentam-se, para a totalidade da rede, no
Quadro 6.1.
Quadro 6.1 – Efeito da substituição de rede nas roturas, reclamações e perda em Lisboa. Adaptado de Luís, 2008.
2002 2003 2004 2005 2006 2007Substituição da rede (km) 54.1 74.4 56.1 85.3 65.2 20.2
Média de roturas (rot./(100km.ano)) 92 64 51 48 43 44
Reclamações de abastecimento 20 048 20 286 17 045 17 462 13 042 11 205
Volume anual de perdas (x106 m3) 32.0 30.5 30.4 26.9 23.4 19.4

62
Figura 6.1 – Diagrama altimétrico da rede de abastecimento de água de Lisboa. Adaptado de Franco, 2006.
Seguidamente descreve-se o processo de tratamento e análise de dados, bem como a aplicação
da metodologia proposta no capítulo 1. Procede-se também à análise das RNA treinadas e à
utilização dos resultados obtidos para estimativa da distribuição de roturas na rede.
Figura 6.2 – Esquema da rede de distribuição de água de Lisboa.

63
Figura 6.3 – Rede de distribuição de água, por zona altimétrica , na cidade de Lisboa.
Adaptado de Luís, 2004.
6.2 Dados disponibilizados
6.2.1 Considerações gerais
Os dados utilizados no presente estudo foram obtidos a partir de informação armazenada na
base de dados do SIG da EPAL, o G-Interaqua. Podem identificar-se duas matrizes principais,
uma referente às tubagens que constituem o sistema e outra correspondente às ordens de
trabalhos (OT), ou seja, intervenções registadas.
Presentemente, a base de dados utilizada pela EPAL foi adoptada por outras entidades gestoras,
sendo que cada uma tem as suas necessidades previstas no interface do G-Interaqua. Desta
forma, analisando as tabelas de dados, é possível encontrar campos que, para a EPAL, são
redundantes e outros que não são sequer utilizados. Isto contribui para que a informação “bruta”
seja, não só mais difícil de analisar, como imprópria para aplicar directamente no treino de RNA.
Nos pontos seguintes indicam-se os procedimentos utilizados no tratamento da informação,
filtrando campos irrelevantes com demasiadas falhas de registo ou, simplesmente, fora do âmbito
do estudo.
Tendo em conta a utilização que se pretende dar aos dados, assim como a sua quantidade,
adoptou-se um critério que privilegia a qualidade da informação. Neste sentido, face a campos
com informação em falta, optou-se por descartar o registo da entidade de forma a não introduzir

64
desvios no modelo. Por outro lado, dado que esta filtragem não segue nenhuma regra
discriminatória, sendo apenas regida pela qualidade da informação, não se espera que a
omissão de registos se traduza em enviesamento da amostra.
Seguidamente enumeram-se os campos de dados disponíveis, sendo analisada tanto a validade
como a relevância da informação para efeitos do presente estudo. Descrevem-se, igualmente, os
critérios adoptados.
6.2.2 Dados de tubagens
A informação referente a tubagens disponível é dividida em dois grupos, de acordo com a função
cumprida pelo trecho considerado no sistema: distribuição ou adução. Não obstante, o conjunto
de informações registadas para estes tipos de entidades é bastante semelhante.
Tubagens de distribuição
O Anexo VI indica quais os campos que contêm a totalidade da informação disponibilizada sobre
tubagens usadas na distribuição. Destes, alguns destacam-se como bastante relevantes para o
estudo das roturas, outros, apesar de poderem não ser directamente relacionados com esta
temática, são úteis na validação da informação.
De um universo de 1 271 km de rede distribuídos por 33 763 registos removeram-se tubagens
cuja informação, nos campos chave, se apresentava incompleta. Neste sentido foram
executadas duas filtragens, seguidas por uma etapa de validação.
O Quadro 6.2 reporta-se à primeira etapa da filtragem, em que foi descartada 16,1% da extensão
de rede disponível. Na segunda filtragem, foram removidos os registos que não correspondiam a
tubagens com diâmetros iguais ou inferiores a 315 mm ou cujo material não se inseria no grupo
dos quatro materiais com maior presença na rede (FF, FC, FFD e PEAD). No Quadro 6.3 é
apresentado o balanço deste processo, no final do qual resta 81,4% do comprimento inicial da
rede.
Findo este processo, notou-se que algumas tubagens apresentavam relações entre ano de
instalação e material incoerentes (por exemplo, um troço em PEAD com data de instalação de
1937). Analisando a rede, foram aferidas as datas em que seria mais provável o início e o
término da aplicação de cada um dos materiais e, estando estas disponíveis, foi possível efectuar
a validação de cada registo. O Quadro 6.4 traduz o critério adoptado, tendo-se assinalado 6,1 km
de rede com inválidos.
Concluído o processo, classificaram-se 26 970 registos como válidos, correspondendo a 1 029
km de rede, ou seja, 81% da extensão inicial.

65
Quadro 6.2 – Registo da primeira filtragem aplicada aos dados das tubagens de
distribuição.
Quadro 6.3 – Registo da segunda filtragem aplicada aos dados das tubagens de
distribuição.
Quadro 6.4 – Datas admitidas no estudo para o início e o fim da aplicação de materiais.
Tubagens de adução
Os dados referentes a tubagens utilizadas na adução são registados de forma muito semelhante
à dos dados das tubagens da distribuição. No Quadro A2 Anexo VII são descritos os campos em
que se sintetiza a informação disponível para estes elementos.
Uma vez que as tubagens afectas à distribuição perfazem um grupo bastante maior (mais de 5
vezes superior) que as que cumprem funções de adução, a filtragem aplicada aos dados seguiu
os critérios estabelecidos para as primeiras que, por serem mais numerosas, devem ter um peso
acrescido do estudo.
No Quadro 6.5 podem observar-se os resultados do primeiro passo da filtragem, que excluiu os
registos cuja informação, nos campos chave, se apresentava incompleta. Nesta etapa, dos 2 272
registos iniciais, totalizando 232 km de tubagem, foi excluída uma parte significativa, cerca de
56,5%, restando 1 196 registos totalizando 101 km de condutas.
No segundo passo de filtração, excluíram-se diâmetros superiores a 315 mm e materiais não
pertencentes ao grupo seleccionado para estudo (FF, FC, FFD e PEAD). Essencialmente devido
a uma parte significativa destas tubagens apresentar diâmetros superiores aos estudados mas
também porque, na adução, o material mais utilizado é o betão armado (cerca de 47,1% da
extensão total da rede, contra apenas 0,3% na distribuição), os registos utilizáveis ficaram
Designação Número de registos Comprimento total
Código universal 33 763 1 271 268
Ano de instalação 30 404 1 202 378
Comprimento (m) 30 401 1 202 378
Diâmetro (mm) 30 103 1 201 373
Estado de ciclo de vida 29 828 1 193 033
Material 29 808 1 192 880
Freguesia 27 210 1 073 388
Subsistema 27 205 1 073 361
Observações 27 167 1 071 535
Função 27 014 1 066 113
Designação Número de registos Comprimento total
Código universal 27 014 1 066 113
Diâmetro (mm) 26 418 1 041 526
Material 26 299 1 035 434
FC FF PEAD FFD
Ano Inicial 1950 1933 1999 1977
Ano final 1995 1981 - -

66
reduzidos a apenas 102, que totalizam pouco mais de 5 km de rede (2,3% da extensão inicial),
tal como se pode observar a partir do Quadro 6.6.
Ponderando que, ao incluir a adução no estudo, seriam apenas adicionados 5 km de rede aos
1 029 km obtidos através da análise de tubagens de distribuição e sabendo que existem
diferenças inerentes à função que desempenham os dois tipos de tubagem, concluiu-se que
seria mais adequado limitar o estudo ao maior grupo.
Quadro 6.5 – Registo da primeira filtragem aplicada aos dados das tubagens de adução.
Quadro 6.6 – Registo da segunda filtragem aplicada aos dados das tubagens de adução.
6.2.3 Dados de ordens de trabalhos
Os dados registados para as ordens de trabalhos, ou OT, contêm mais informação que os seus
congéneres referentes às tubagens. Parte desta informação não é aplicável ao estudo, pelo que
é necessário clarificar quais os campos classificados como relevantes. No Quadro A3 do Anexo
VIII são descritos os campos, dos quais aparecem destacados os de maior relevância.
Tal como para as tubagens, foi necessário filtrar os dados previamente à sua utilização no treino
das RNA. Uma vez que as OT são registadas para quaisquer intervenções na rede da EPAL, e
não só para roturas ocorridas em tubagens, deve-se, para além de excluir registos com
informações incompletas, eliminar as OT que não correspondem a roturas na rede principal ou
cujas causas sejam provocadas. Este passo é sintetizado no Quadro 6.7, em que se indicam os
campos que foram analisados, assim como o número de registos remanescentes após a
filtragem. No Anexo VIII são igualmente descritos os critérios adoptados.
O processo de validação que se seguiu, resumido no Quadro 6.8, limitou as OT que passaram na
primeira triagem àquelas que estavam associadas a tubagens identificadas, também elas, como
válidas. Todavia, à semelhança do que aconteceu para a informação de tubagens, também se
notaram nas OT inconsistências, nomeadamente encontrando-se registos com datas
Designação Número de registos Comprimento total
Código universal 2 272 232 234
Ano de instalação 1 858 168 455
Comprimento (m) 1 858 168 455
Diâmetro (mm) 1 716 166 888
Estado de ciclo de vida 1 497 132 104
Material 1 486 131 724
Subsistema 1 472 130 937
Observações 1 440 128 208
Regime de escoamento 1 215 104 478
Tipo de assentamento 1 200 101 114
Tipo de secção 1 196 101 098
Designação Número de registos Comprimento total
Código universal 1 196 101 098
Diâmetro (mm) 112 5 846
Material 102 5 382

67
precedentes ao ano de instalação da tubagem. Desta forma, também estes registos foram
eliminados.
Na sequência deste processo, do universo de 4 735 registos, foram assinalados como válidos
para o presente estudo 1 763, cerca de 37,2% do total.
Quadro 6.7 – Registo da filtragem aplicada aos dados de OT.
Quadro 6.8 – Registo da validação efectuada aos dados de OT.
6.2.4 Considerações adicionais
Os dados disponibilizados pela EPAL são muitos e correspondentes a uma rede de dimensão
apreciável, todavia, embora a lista de campos, tanto em tubagens como em OT, seja extensa,
não contém informação suficiente para equacionar a totalidade dos parâmetros que podem
influenciar roturas em sistemas de abastecimento de água (indicados no Quadro 3.3).
De facto, verifica-se que a ausência de campos com informação sobre a classe de pressão das
tubagens, o número de ramais associados ou a exposição da tubagem a cargas excepcionais
(tais como vias de tráfego intenso), para designar apenas alguns, limita a qualidade dos modelos
desenvolvidos.
6.3 Caracterização e análise preliminar do sistema estudado
6.3.1 A rede de abastecimento
Acompanhando a filtragem dos dados, foi indispensável proceder à análise e à caracterização da
rede de abastecimento. Não só porque é conveniente conhecer os dados a usar, mas porque, no
Designação Número de registos
Código universal 4 735
Causa de intervenção 4 453
Comunicado por 4 453
Data da comunicação 4 150
Natureza da intervenção 4 115
Tipo de intervenção 3 940
Tipo de trabalho executado 3 493
Localização 3 399
Localização da intervenção 3 396
Proprietário do local de intervenção 3 350
Responsabilidade 3 280
Observações de abertura 3 256
Observações de execução 3 253
Observações de inspecção 3 246
Designação Número de registos
Filtragem1 OT 3 246
Tubagens válidas 2 059
OT mais recente que a instalação da tubagem 1 763
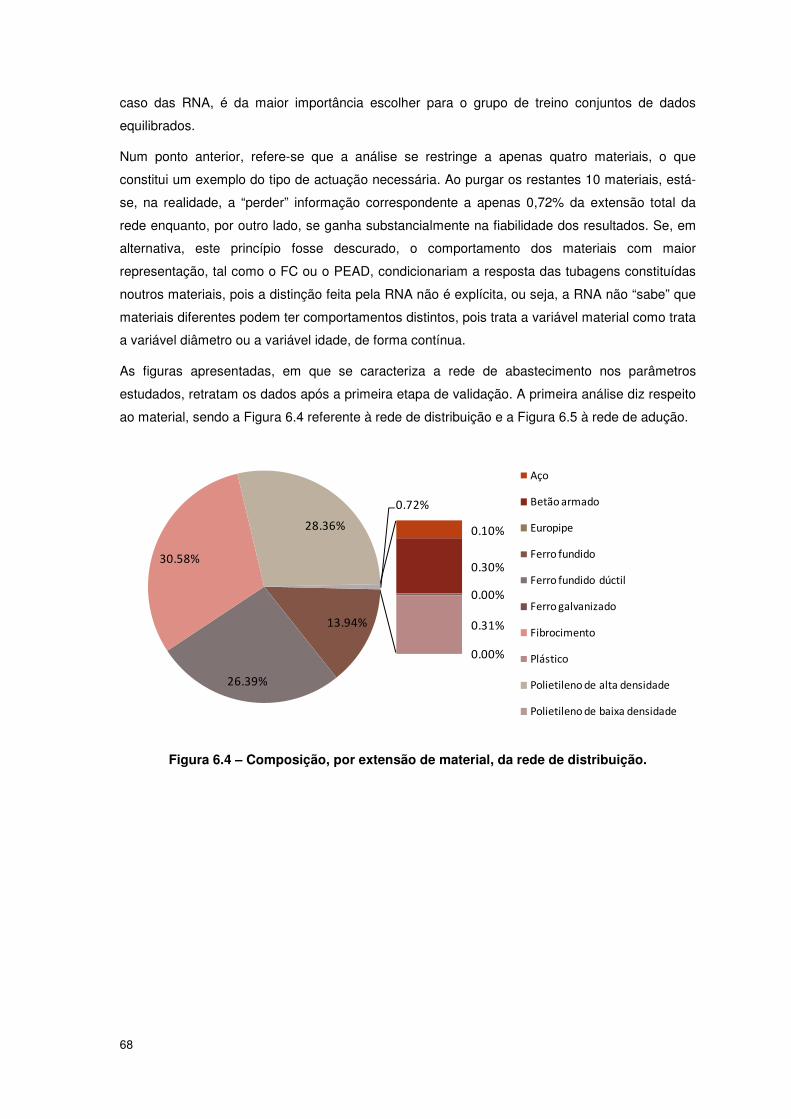
68
caso das RNA, é da maior importância escolher para o grupo de treino conjuntos de dados
equilibrados.
Num ponto anterior, refere-se que a análise se restringe a apenas quatro materiais, o que
constitui um exemplo do tipo de actuação necessária. Ao purgar os restantes 10 materiais, está-
se, na realidade, a “perder” informação correspondente a apenas 0,72% da extensão total da
rede enquanto, por outro lado, se ganha substancialmente na fiabilidade dos resultados. Se, em
alternativa, este princípio fosse descurado, o comportamento dos materiais com maior
representação, tal como o FC ou o PEAD, condicionariam a resposta das tubagens constituídas
noutros materiais, pois a distinção feita pela RNA não é explícita, ou seja, a RNA não “sabe” que
materiais diferentes podem ter comportamentos distintos, pois trata a variável material como trata
a variável diâmetro ou a variável idade, de forma contínua.
As figuras apresentadas, em que se caracteriza a rede de abastecimento nos parâmetros
estudados, retratam os dados após a primeira etapa de validação. A primeira análise diz respeito
ao material, sendo a Figura 6.4 referente à rede de distribuição e a Figura 6.5 à rede de adução.
Figura 6.4 – Composição, por extensão de material, da rede de distribuição.
0.10%
0.30%
0.00%
13.94%
26.39%
30.58%
0.31%
28.36%
0.00%
0.72%
Aço
Betão armado
Europipe
Ferro fundido
Ferro fundido dúctil
Ferro galvanizado
Fibrocimento
Plástico
Polietileno de alta densidade
Polietileno de baixa densidade

69
Figura 6.5 – Composição, por extensão de material, da rede de adução.
Como se pode observar, as composições de ambos os sistemas são bastante distintas,
nomeadamente nas percentagens de tubagens em betão armado e PEAD.
Outro gráfico relevante é aquele que ilustra a idade da rede. Para este efeito, optou-se por uma
curva de extensão acumulada. Na Figura 6.6, para a distribuição, tal como na Figura 6.7, para a
adução, as abcissas correspondem ao ano de instalação das tubagens e as ordenadas à
extensão acumulada das tubagens instaladas até um dado ano.
Figura 6.6 – Idade da rede. Curva de extensão acumulada de acordo com o ano de
instalação para a rede de distribuição.
1.16%
47.13%
0.97%0.26%
32.01%
14.30%
1.56%
2.60%
0.01%
6.56%
Aço
Betão armado
Betão Armado (Rocla)
Europipe
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Poliester reforçado a fibra de vidro
Polietileno de alta densidade
-
200
400
600
800
1 000
1 200
1920 1930 1940 1950 1960 1970 1980 1990 2000 2010
Ex
ten
são
da
re
de
cu
jo a
no
de
inst
ala
ção
é
igu
al
ou
in
feri
or
[km
]
Ano de instalação

70
Figura 6.7 – Idade da rede. Curva de extensão acumulada de acordo com o ano de
instalação para a rede de adução.
Observando a Figura 6.6, nota-se claramente o efeito da campanha de renovação da rede posta
em prática em 2002 pela EPAL, uma vez que a curva, sensivelmente a partir desse ano,
aumenta bastante de declive. A partir da Figura 6.7, tem-se a percepção que os investimentos na
adução não têm sido tão relevantes, depreendendo-se até uma redução da taxa de instalação
face ao período anterior a 1985.
Um dos objectivos deste trabalho é que, com o auxílio das RNA, se consigam captar as relações,
por vezes complexas, que existem entre os vários parâmetros estudados. Por outras palavras,
não se procura obter a relação funcional entre a idade e o número de roturas, ou entre o
diâmetro e o número de roturas, mas relações que integrem a informação contida nos vários
parâmetros. Pretende-se, por exemplo, que o modelo seja sensível a ocorrências tais como o
aumento da correlação entre o diâmetro e a probabilidade de roturas com a idade, para tubagens
de um material específico. Assim, é útil conhecer a rede, não somente numa perspectiva
unidimensional, observando cada parâmetro de cada vez, mas também bidimensional. Neste
sentido, apresenta-se, na Figura 6.8, um gráfico que ilustra a composição da rede de distribuição
por idade e material.
-
20
40
60
80
100
120
1920 1930 1940 1950 1960 1970 1980 1990 2000 2010
Ex
ten
são
da
re
de
cu
jo a
no
de
inst
ala
ção
é
igu
al
ou
in
feri
ror
[km
]
Ano de instalação

71
Figura 6.8 – Caracterização da rede de distribuição por ano de instalação e material
(considerando FF, FC, FFD e PEAD).
Mais uma vez, é evidenciado o elevado investimento na renovação da rede efectuado desde
2002. No entanto, deve ter-se em conta que, uma vez que fica indisponível a maior parte da
informação referente às tubagens desactivadas ou substituídas, a renovação da rede contribui
não só para o aumento da extensão dos novos materiais, mas também para o decréscimo da
extensão dos antigos. Com esta observação, pretende-se salientar que as quantidades
apresentadas no gráfico não correspondem à totalidade das tubagens instaladas em cada ano,
mas apenas às que, até à data da obtenção da informação, se mantinham na rede.
Para clarificar este aspecto, recorre-se à Figura 6.9, que apresenta a evolução das extensões
das tubagens de cada material na rede, do início de 2002 até Agosto de 2007. Enquanto para o
FFD e, em especial, o PEAD, se verifica um aumento de extensão na rede a partir de 2002, as
extensões de FF e FC mantêm-se constantes. Esta observação, tal como se pode depreender,
não corresponde exactamente à realidade, pois a extensão total da rede de distribuição não
aumentou apreciavelmente nos últimos anos e têm sido substituídas extensões significativas dos
materiais mais antigos.
Na informação referente às tubagens são registados campos de ano de instalação e de estado
de ciclo de vida, não é registado, porém, o ano de desactivação ou substituição. Assim, não
obstante se consiga seguir com exactidão o aumento da extensão de qualquer material, não se
-
10
20
30
40
50
60
70
80
90
100
19
26
19
34
19
40
19
46
19
52
19
58
19
64
19
70
19
76
19
82
19
88
19
94
20
00
20
06
Exte
nsã
o n
a re
de
[km
]
Ano de instalação
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Polietileno de alta densidade

72
consegue distribuir a diminuição no tempo da extensão dos materiais que estão a ser postos fora
de serviço.
Os cálculos efectuados, nomeadamente valores de roturas por comprimento e por ano, são
afectados por esta limitação. Para cada período, as operações efectuadas deveriam dizer
respeito à extensão da rede à data, mas tal não é possível pois a informação sobre as tubagens
substituídas e desactivadas é perdida. Assim, como o índice de roturas por comprimento por ano,
para os períodos passados, só pode ser obtido a partir dos dados registados nas tubagens ainda
em operação, é provável que seja estimado por defeito, pois são as tubagens com pior
desempenho as mais substituídas.
Figura 6.9 – Evolução da extensão da rede, a partir da informação disponível, no período
em análise.
Outro parâmetro do modelo é o diâmetro da tubagem, proporcional ao perímetro e, como tal,
relacionável com área em que podem ocorrer roturas. Na Figura 6.10 pode observar-se a
presença de cada classe de diâmetro na rede de distribuição, sendo a Figura 6.11 referente às
tubagens de adução.
0
1
1
2
2
3
3
4
2002 2003 2004 2005 2006 2007
Ex
ten
são
da
re
de
[1
00
km
]
Ano
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Polietileno de alta densidade

73
Figura 6.10 – Disposição da rede de distribuição por diâmetro das tubagens.
Figura 6.11 – Disposição da rede de adução por diâmetro das tubagens.
Tal como para o ano de instalação e o material, também para o diâmetro se efectuou uma
análise bidimensional da rede de distribuição. A partir da Figura 6.12, que se reporta a essa
mesma análise, pode concluir-se que não existem variações extremas de material para material,
no que respeita à disposição dos diâmetros.
Não obstante, para o PEAD e o FFD, algumas classes assumirem relevância face às restantes,
pode considerar-se que as tubagens do grupo de materiais seleccionados para treino das RNA
apresentam uma boa representatividade de diâmetros até aos 315 mm.
-
50
100
150
200
250
25
38
40
50
60
63
76
80
90
10
0
10
2
10
8
11
0
12
5
13
0
15
0
16
0
18
0
20
0
22
0
22
5
25
0
30
0
31
5
35
0
40
0
45
0
50
0
60
0
75
0
80
0
Ex
ten
são
na
re
de
[k
m]
Diâmetro [mm]
-
5
10
15
20
25
30
50
80
10
0
20
0
30
0
35
0
40
0
50
0
56
0
60
0
70
0
75
0
80
0
82
0
10
00
12
00
12
50
15
00
Ex
ten
são
na
re
de
[k
m]
Diâmtro [mm]

74
Figura 6.12 – Caracterização da rede de distribuição por ano de instalação e diâmetro
(considerando FF, FC, FFD e PEAD).
Quanto à disposição da rede por subsistema, apresentam-se, na Figura 6.13 e na Figura 6.14,
gráficos ilustrativos, respectivamente para a distribuição e a adução.
Figura 6.13 – Disposição da rede de distribuição por subsistemas.
-
50
100
150
200
Ext
en
são
na
re
de
[k
m]
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Polietileno de alta densidade
47.85%
1.37%17.59%
0.01%
17.39%
1.17%
0.02%
9.46%
3.99%
1.15%
3.72%
Zona Alta
Zona Alta Redutora
Zona Baixa
Zona Baixa Redutora
Zona Média
Zona Sobrepressora
Zona Superior
Zona Superior Charneca
Zona Superior do Monsanto
Zona Superior Redutora

75
Figura 6.14 – Disposição da rede de adução por subsistemas.
Uma análise semelhante é apresentada, para a rede de distribuição, ao nível da freguesia. No
entanto, devido ao elevado número de freguesias e, como se verá, à menor relevância no
resultado final do modelo, opta-se por remeter para o Anexo IX esta informação.
6.3.2 Registos de roturas
Os registos de roturas validados foram, tal como as tubagens, analisados sob vários prismas. A
primeira análise efectuada foi ao índice anual de roturas por 100 km por ano, entre os anos de
2002 e 2007, apresentada na Figura 6.15.
Figura 6.15 – Registo do índice de roturas para os anos em análise.
38.46%
33.78%
16.51%
6.82%
4.43%
Zona Alta
Zona Baixa
Zona Média
Zona Superior Charneca
Zona Superior do Monsanto
25.57
45.83
37.3639.70
37.40
27.87
0
5
10
15
20
25
30
35
40
45
50
2002 2003 2004 2005 2006 2007
Ro
tura
s/(1
00
km
.an
o)
Ano

76
Para estimar correctamente os índices foi tido em conta o efeito de perda do “histórico de
tubagens”, referido no ponto anterior, e valores obtidos para 2002 e 2007, em que os dados não
respeitam à totalidade do ano, foram corrigidos para, proporcionalmente, corresponderem a um
ano de registos. Este cuidado foi aplicado às restantes análises efectuadas.
Da mesma forma, apresenta-se, na Figura 6.16, o índice médio de OT/(100km.ano) por cada um
dos materiais analisados.
Figura 6.16 – Registo do índice de roturas médio por material.
O índice médio mensal de roturas por 100 km por ano foi igualmente calculado, apresentando-se
o gráfico resultante na Figura 6.17. Observando este gráfico foi possível notar que as médias
mensais de roturas apresentavam um padrão inesperado, com roturas a crescer nos meses de
verão, até Setembro, e um pico nos meses de Janeiro e Dezembro.
Figura 6.17 – Registo do índice de roturas mensal médio para os anos em análise.
56.63
7.74
62.38
10.26
0
10
20
30
40
50
60
70
OT
/(1
00
km
.an
o)
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Polietileno de alta densidade
42.58
30.3428.54
33.0334.47
36.58 37.2939.59 40.46
37.41
29.69
44.12
0
5
10
15
20
25
30
35
40
45
50
Jan Fev Mar Abr Mai Jun Jul Ago Set Out Nov Dez
Ro
tura
s/(1
00
km
.an
o)
me
nsa
is m
éd
ias
Mês

77
No Anexo X é apresentado o histograma do índice médio mensal de roturas para todos os meses
do período estudado, sendo também apresentado o gráfico da Figura 6.17 com indicação do
desvio-padrão. Embora o período analisado seja insuficiente para demonstrar estatisticamente
que há influência sazonal no número de roturas, procuraram-se mais evidências que
suportassem ou refutassem esta hipótese.
Com este intuito, analisou-se a distribuição anual do tipo de roturas e das roturas em cada tipo
de material. Na Figura 6.18 apresenta-se o índice de roturas mensal médio de acordo com o tipo
de rotura, notando-se que os tipos de avarias mais comuns, tubo rachado e tubo seccionado,
apresentam a mesma tendência sazonal. As roturas do tipo “tubo rachado” são mais comuns nos
meses quentes e, pelo contrário, roturas do tipo “tubo seccionado” são mais concentradas nos
meses de Dezembro, Janeiro e Fevereiro.
Figura 6.18 – Índice de roturas mensal médio para os anos em análise, obtido para cada
uma das causas registadas.
Na Figura 6.19, que se reporta ao índice de roturas mensais médias por material da tubagem,
verifica-se um efeito semelhante. Tubagens em FF apresentam, em média, mais tendência para
romper nos meses de Dezembro, Janeiro e Fevereiro, enquanto para as tubagens de FC a
tendência é oposta, sendo apreciável uma preponderância de roturas em meses mais quentes
(Agosto apresenta o máximo).
0
5
10
15
20
25Jan
Fev
Mar
Abr
Mai
Jun
Jul
Ago
Set
Out
Nov
Dez
Tubo rachado
Tubo furado
Tubo seccionado
Avaria de juntas
Uniões desvedadas

78
Figura 6.19 – Índice de roturas mensal médio para os anos em análise, obtido para cada
um dos materiais estudados [rot/(100 km.ano)].
Completando a análise, foram estimados os tipos de rotura por material tal como se apresenta na
Figura 6.20. Tal como esperado a partir dos gráficos anteriores, o FF apresenta uma
percentagem superior de roturas devido a tubos seccionados, enquanto nas tubagens em FC
não se passa o mesmo, sendo os casos de tubos rachados mais de 70% do total.
Figura 6.20 – Distribuição percentual acumulada das causas de intervenção em roturas,
por tipo de material.
0
20
40
60
80
100
120Jan
Fev
Mar
Abr
Mai
Jun
Jul
Ago
Set
Out
Nov
Dez
Ferro fundido
Ferro fundido dúctil
Fibrocimento
Polietileno de alta densidade
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Ferro fundido Ferro fundido dúctil
Fibrocimento Polietileno de alta densidade
Dis
trib
uiç
ão
pe
rce
ntu
al
acu
mu
lad
a
do
tip
o d
e r
otu
ras
Material
Uniões desvedadas
Avaria de juntas
Tubo seccionado
Tubo furado
Tubo rachado
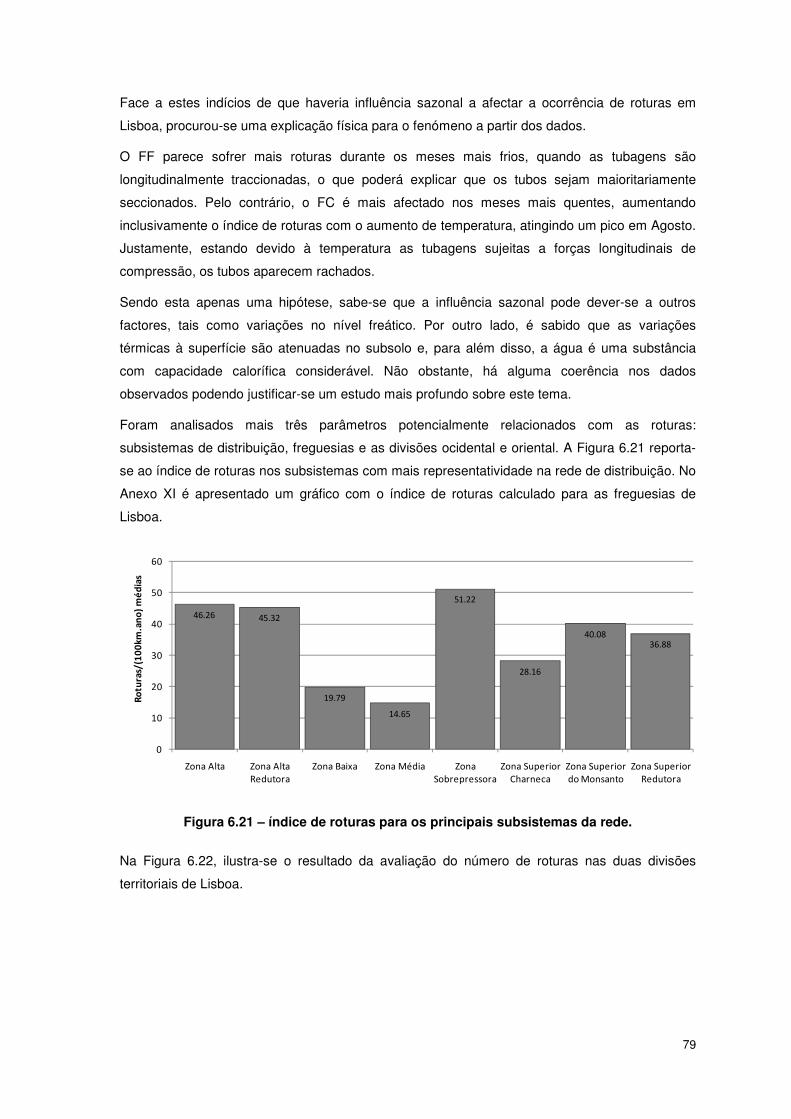
79
Face a estes indícios de que haveria influência sazonal a afectar a ocorrência de roturas em
Lisboa, procurou-se uma explicação física para o fenómeno a partir dos dados.
O FF parece sofrer mais roturas durante os meses mais frios, quando as tubagens são
longitudinalmente traccionadas, o que poderá explicar que os tubos sejam maioritariamente
seccionados. Pelo contrário, o FC é mais afectado nos meses mais quentes, aumentando
inclusivamente o índice de roturas com o aumento de temperatura, atingindo um pico em Agosto.
Justamente, estando devido à temperatura as tubagens sujeitas a forças longitudinais de
compressão, os tubos aparecem rachados.
Sendo esta apenas uma hipótese, sabe-se que a influência sazonal pode dever-se a outros
factores, tais como variações no nível freático. Por outro lado, é sabido que as variações
térmicas à superfície são atenuadas no subsolo e, para além disso, a água é uma substância
com capacidade calorífica considerável. Não obstante, há alguma coerência nos dados
observados podendo justificar-se um estudo mais profundo sobre este tema.
Foram analisados mais três parâmetros potencialmente relacionados com as roturas:
subsistemas de distribuição, freguesias e as divisões ocidental e oriental. A Figura 6.21 reporta-
se ao índice de roturas nos subsistemas com mais representatividade na rede de distribuição. No
Anexo XI é apresentado um gráfico com o índice de roturas calculado para as freguesias de
Lisboa.
Figura 6.21 – índice de roturas para os principais subsistemas da rede.
Na Figura 6.22, ilustra-se o resultado da avaliação do número de roturas nas duas divisões
territoriais de Lisboa.
46.26 45.32
19.79
14.65
51.22
28.16
40.0836.88
0
10
20
30
40
50
60
Zona Alta Zona Alta Redutora
Zona Baixa Zona Média Zona Sobrepressora
Zona Superior Charneca
Zona Superior do Monsanto
Zona Superior Redutora
Ro
tura
s/(1
00
km
.an
o)
mé
dia
s

80
Figura 6.22 – Número de roturas anual, em tubagens validadas, para as divisões ocidental
e oriental.
Finalmente, estudou-se qual a relação que teria o histórico de roturas nas roturas futuras. Com
este objectivo dividiram-se os dados de acordo com dois períodos, de 2002 a 2004 e de 2005 a
2007. Em cada período contabilizou-se o número de elementos com, pelo menos, uma rotura
registada.
De um total de 26 070 elementos de tubagem validados, 669 (2,57%) apresentaram roturas no
período entre 2002 e 2004 e 706 (2,71%) apresentaram roturas no período entre 2005 e 2007.
Destes, 160 (0,61%) apresentaram roturas tanto no primeiro como no segundo período.
Calculando a probabilidade condicionada resulta que, em tubagens que apresentaram uma ou
mais roturas no primeiro período, a probabilidade de se registar uma ou mais roturas no segundo
período não é 2,71%, mas 23,9% (160/669). Isto significa que, no período de 2005 a 2007, a
probabilidade de rotura das tubagens que sofreram roturas de 2002 a 2004 é 8,83 vezes superior
à das restantes.
6.4 Preparação do modelo de degradação da rede de abastecimento
6.4.1 Considerações prévias
O estudo da degradação do sistema de distribuição de água de Lisboa pode ser encarado como
um problema de aproximação de uma função ℝ� → ℝ, em que J é o número de variáveis
explicativas considerado. Desta forma, podem aplicar-se RNA, particularmente do tipo PMC ou
RBR. Destas, escolheu-se o PMC pelas razões expostas nos capítulos anteriores.
0
50
100
150
200
250
2002 2003 2004 2005 2006 2007
Nú
me
ro d
e r
otu
ras
em
tu
ba
ge
ns
va
lid
ad
as
Ano
Ocidental Oriental

81
Todas as redes PMC são designadas de acordo com a forma netAxBxC_D_E;
A indica o número de nós na primeira camada oculta;
B, caso exista, indica o número de nós na segunda camada oculta;
C, representa o número de nós na camada de output (no presente trabalho assume sempre o
valor 1);
D representa o número de inputs considerado;
E, caso exista, fornece informação adicional (é utilizado o sufixo lin quando a função de
activação na última camada é linear.
6.4.2 Preparação dos dados
Os dados seleccionados utilizados para o treino das redes, foram:
• Comprimento;
• Material;
• Idade (em 2008);
• Diâmetro;
• Subsistema;
• Freguesia;
• OT/(100km.ano) prévias (registos de 2002 a 2004);
• OT/(100km.ano) (registos de 2005 a 2007).
Destes, definiu-se que o índice OT/(100km.ano) registado entre 2005 e 2007, doravante
denominado simplesmente índice OT/(100km.ano), seria utilizado como alvo, enquanto as
restantes variáveis poderiam fazer parte dos padrões de treino. O padrão corresponde a um
vector em que o valor de cada entrada corresponde a uma variável. O conjunto de todos os
padrões define a matriz utilizada no treino.
Antes de iniciar o processo executaram-se ainda alguns passos. O primeiro consistiu na “mistura”
aleatória dos vários padrões, para não se enviesar o treino19.
Seguidamente, uma vez que cada padrão tem peso idêntico para a RNA, optou-se por dividir
padrões correspondentes a elementos de tubagem extensos em vários padrões mais pequenos,
por forma a que todos os padrões apresentados correspondessem a trechos de tubagem com
comprimento semelhante.
19 Esta medida é apenas relevante no modo de treino estocástico, não utilizado, porém, mesmo no modo determinístico pode ter interesse, uma vez que facilita a definição de subconjuntos de validação e teste.

82
Considerando-se que a extensão óptima seria a de 50 m, padrões de elementos com
comprimento inferior a metade desse valor foram retirados, enquanto padrões com mais de 75 m
foram divididos em dois, padrões com mais de 125 m, divididos em três e assim sucessivamente.
Idealmente, seria desejável utilizar a totalidade dos dados, no entanto, 1 029 km de rede
validados implicariam mais de um milhão de padrões, o que tornaria extremamente pesada
qualquer tentativa de treino de PMC. Por outro lado, não sendo um valor muito diferente da
média dos registos (39,5 m), o valor adoptado garante que se analisam 903 km de rede (87,7%
do total). Finalmente, foram executados testes com comprimentos de 10 e 20 m, não sendo os
resultados preliminares bastante parecidos.
Após a separação em padrões com representatividade semelhante, os dados não numéricos
foram convertidos em valores reais, com cada classe igualmente distanciada. Sendo cada
variável normalizada entre 0 e 1 entre a totalidade dos dados. Exceptuam-se os índices de
roturas, em que a normalização foi feita entre 0 e 0,8 prevendo a utilização da função de
activação sigmoidal no nó final da rede.
6.4.3 Definição da arquitectura da rede
Escolha de inputs
Com base na metodologia proposta, foram analisados vários conjuntos de parâmetros. O
comprimento do elemento, não estando relacionado com o comprimento físico dos trechos de
tubagem, não foi contabilizado em nenhum.
No Quadro 6.9 resumem-se os resultados obtidos. Na análise efectuada através de redes de
pequena dimensão (T1 a T13), pode depreender-se que os parâmetros mais importantes são,
por ordem decrescente: OT/(100km.ano) prévias, idade, material, subsistema e diâmetro.
O que se percepciona dos esquemas das redes treinadas é coerente com a informação obtida
através de EQM e correlação. As OT/(100km.ano) prévias têm muita importância, seguidas pela
idade. Com menos importância aparecem o diâmetro, o subsistema, o material e a freguesia.
Através da análise do comportamento de redes de maior dimensão (net20x1), pode observar-se
que a introdução de dados relativos à freguesia perturba o modelo, sendo que através da
utilização de diâmetros, idades, materiais, subsistemas e OT/(100.ano) prévias a qualidade da
aproximação é maximizada, tanto a nível de EQM como de correlação.
Embora estes resultados sejam inesperados no que toca ao material, pode encontrar-se uma
explicação para o reduzido peso deste parâmetro na Figura 6.8, onde se pode ver que cada
material tem uma época de aplicação bem marcada e sobreposições são raras. Assim, a RNA
evidencia dificuldade em separar claramente qual a influência do material e da idade.
Atendendo aos resultados obtidos, optou-se por utilizar padrões de 5 variáveis, deixando de fora
apenas a freguesia.

83
Quadro 6.9 – Avaliação da importância dos vários parâmetros para o modelo.
A partir dos esquemas as redes de menor dimensão (net0x1_6 e nt0x1_5),
net0x1_6_lin net0x1_6
Figura 6.23 – Esquemas dos PMC treinados para 6 variáveis.
net0x1_5_lin net0x1_5
Figura 6.24 – Esquemas dos PMC treinados para 5 variáveis.
Teste Diâmetro Idade Material Subsistema FreguesiaOT/
(100km.ano)PMC EQM Correlação
T1 net0x1_6_lin 8.89E-04 30.0%
T2 net0x1_6 8.99E-04 28.4%
T3 net0x1_5_lin 8.90E-04 30.0%
T4 net0x1_5 9.00E-04 28.3%
T5 net0x1_3_lin 8.91E-04 29.8%
T6 net0x1_3 9.15E-04 25.8%
T7 net0x1_3_lin 9.47E-04 17.8%
T8 net0x1_3 9.53E-04 15.9%
T9 net0x1_1_lin 9.75E-04 4.9%
T10 net0x1_1_lin 9.48E-04 17.4%
T11 net0x1_1_lin 9.58E-04 14.3%
T12 net0x1_1_lin 9.69E-04 9.2%
T13 net0x1_1_lin 9.07E-04 26.9%
T14* net20x1_6 8.84E-04 39.7%
T15* net20x1_5 8.64E-04 42.7%
T15* net20x1_5_lin 9.13E-04 39.1%
T16* net20x1_3 9.62E-04 33.0%
*Valores obtidos a partir da média de 10 treinos em que foi aplicada validação K-fold com cada um dos
subconjuntos de validação e teste a contabilizar 20% dos dados
Incluído
Não incluído
Freguesia
OT/(100km.ano) prévias
Subsistema
Material
Idade
Diâmetro
Freguesia
OT/(100km.ano) prévias
Subsistema
Material
Idade
Diâmetro
OT/(100km.ano) prévias
Subsistema
Material
Idade
Diâmetro
OT/(100km.ano) prévias
Subsistema
Material
Idade
Diâmetro

84
Escolha das funções de activação
As funções de activação na camada oculta devem ser não lineares para que o PMC tenha
capacidade de aproximar funções também não lineares, como é o caso. Sendo que é possível
aplicar qualquer função diferenciável a monotonamente crescente, há um grupo de funções que
se destaca, sendo adoptado na maioria dos trabalhos com PMC. Este grupo é composto pelas
funções tangente hiperbólica, sigmoidal e arco-tangente.
O software utilizado não disponibiliza de origem a função de activação arco-tangente e, sendo
esta bastante semelhante à função tangente hiperbólica, optou-se por não desenvolver uma
rotina para a incluir como opção no processo de retropropagação.
Face à função sigmoidal, a função tangente hiperbólica é preferível, pois não é estritamente
positiva (Veelenturf, 1995). Deste modo, a função de activação nos nós das camadas ocultas foi
sempre a tangente hiperbólica.
Na camada de output é comum a utilização de funções de activação lineares. No entanto, pelas
razões já expostas e face aos resultados obtidos, optou-se por utilizar a função sigmoidal.
Escolha do número de camadas e nós
A escolha do número óptimo de camadas e nós é porventura a parte mais importante da
definição da arquitectura do PMC. A escolha de poucos nós pode produzir resultados
insatisfatórios pela simplicidade da aproximação, enquanto a escolha de muitos nós pode
resultar numa aproximação excelente no treino e aproximações totalmente desadequadas na
validação.
Na realidade, embora se fale correntemente no número de nós, o parâmetro mais importante
consiste no número de ligações sinápticas entre estes (Kasabov, 1996), sendo que a relação
entre as grandezas varia com o número de camadas adoptado.
A determinação do número de nós e camadas contemplou dois procedimentos distintos. Por um
lado, procedeu-se experimentação de redes com diferentes topologias, com recurso a validação
K-fold e utilizando a retropropagação modificada com o algoritmo de Levenberg-Marquardt. Por
outro, foi preparada uma simulação de AG que, no fundo, automatiza e orienta a
experimentação.
Os resultados do processo de experimentação de várias topologias de PMC incluindo EQM,
correlação e tempo de treino, são apresentados da Figura 6.25 à Figura 6.28, em ordem ao
número de ligações sinápticas e ao número de nós. Tabelas, contendo os resultados obtidos,
assim como informação adicional, são apresentadas Anexo XII Note-se que, quanto ao EQM,
tanto as figuras como os quadros do anexo contêm valores referentes ao grupo de melhores
resultados (90% do total), pelas razões apresentadas no capítulo 1.

85
Figura 6.25 – EQM médio, após validação K-fold, para PMC de uma e duas camadas, com
intervalos de confiança de 95% obtidos recorrendo à distribuição de t-Student (número de
ligações sinápticas; 90% dos testes).
Figura 6.26 – EQM médio, após validação K-fold, para PMC de uma e duas camadas, com
intervalos de confiança de 95% obtidos recorrendo à distribuição de t-Student (número de
nós; 90% dos testes).
7.70E-04
8.20E-04
8.70E-04
9.20E-04
9.70E-04
1.02E-03
0 100 200 300 400 500 600
EQ
M
Número de ligações sinápticas na rede
1 camada
2 camadas
7.70E-04
8.20E-04
8.70E-04
9.20E-04
9.70E-04
1.02E-03
0 5 10 15 20 25 30 35 40 45
EQ
M
Número de nós na rede
1 camada
2 camadas

86
Figura 6.27 – Correlação média, após validação K-fold, para PMC de uma e duas camadas,
com intervalos de confiança de 95% obtidos recorrendo à distribuição de t-Student.
Figura 6.28 – Tempo de treino médio, após validação K-fold, para PMC de uma e duas
camadas, com intervalos de confiança de 95% obtidos recorrendo à distribuição de t-
Student.
Analisando os elementos obtidos, nota-se que a correlação é semelhante para todas as
topologias a partir de 10 nós na camada oculta, no entanto, ao nível de EQM (o parâmetro mais
importante), notam-se diferenças mais substanciais. Embora não seja a rede que alcançou o
melhor desempenho (net19x16x1_5), a rede net20x1_5 apresenta, em média, os melhores
resultados em relação ao EQM, sendo que, no que diz respeito à correlação, não se afasta
demasiado da rede com o melhor resultado (net17x13x1_5), razões pelas quais se admitiu ser a
que melhores condições tem para prever a degradação da rede de distribuição de Lisboa.
Num gráfico que relaciona o EQM e a correlação, remetido para o Anexo XIII, pode ver-se que a
relação entre as duas grandezas é, no espaço de resultados, aproximadamente linear para cada
topologia de rede, mas há uma tendência de translação da correlação entre redes.
Quanto ao número de camadas, o que se verifica é que as redes com duas camadas apresentam
os melhores resultados (em absoluto) porém, na média, o desempenho não é tão bom. Pensa-se
que os bons desempenhos se devem à maior capacidade que têm estas redes (em virtude do
maior número de ligações sinápticas), por outro lado, em média, os resultados não reflectem
esse aspecto, provavelmente devido à paragem antecipada do treino em virtude da degradação
do desempenho para o subconjunto de validação.
0%
10%
20%
30%
40%
50%
0 100 200 300 400 500 600
Co
rre
laçã
o
Número de ligações sinápticas na rede
1 camada
2 camadas
0%
10%
20%
30%
40%
50%
0 10 20 30 40 50
Co
rre
laçã
o
Número de nós na rede
1 camada
2 camadas
0
50
100
150
200
250
300
350
400
0 100 200 300 400 500 600
Tem
po
mé
dio
de
tre
ino
[s]
Número de ligações sinápticas na rede
1 camada
2 camadas
0
50
100
150
200
250
300
350
400
0 10 20 30 40 50
Tem
po
mé
dio
de
tre
ino
[s]
Número de nós na rede
1 camada
2 camadas

87
Quanto à relação do desempenho da rede (baseado no EQM) com o índice OT/(100km.ano),
verifica-se que, na média, a rede net20x1_5 tem um erro médio (8.53x10-04) equivalente a +-
122,4 OT/(100km.ano) o que, à primeira vista, é alarmante. No entanto, utilizando a função
criada para determinar o EQM mínimo intrínseco à amostra, foi possível aferir que esse valor
(5,62x10-4) corresponde a +- 99,3 OT/(100km.ano).
Uma vez que a média de OT/(100km.ano), para as tubagens que constituem dados, é de 32,7,
tanto o EQM mínimo como o EQM médio do PMC escolhido parecem excessivos. No entanto, é
importante lembrar que o índice é calculado para cada elemento de tubagem individualmente.
Por exemplo, um elemento com 50 m de comprimento que registe duas roturas por ano, terá um
índice de 4000 OT/(100km.ano). Se esta for um elemento, por exemplo, em FFD, esperar-se-ia
um valor muito inferior, na ordem de 7 ou 8. Assim, por cada tubagem que apresenta roturas, o
desempenho da rede de acordo com o EQM é fortemente afectado, o que explica valores tão
elevados. Não obstante, no treino das redes, como se verá, tal efeito não constitui um problema.
Os AG foram utilizados, como já referido, para automatizar o processo de procura da melhor
topologia para a RNA. Fazendo-o seguindo princípios da evolução natural, partiam de uma
população de topologias de RNA (cromossomas) variadas, geradas aleatoriamente, por meio de
operações de mutação e cruzamento de indivíduos na procura da topologia com melhores
desempenhos.
A aplicação desenvolvida incorpora o treino de RNA, com validação cruzada, no AG, sendo o
desempenho médio das redes o parâmetro de comparação dos cromossomas. O cromossoma
adoptado incorpora toda a informação necessária à definição de PMC. Sendo limitado, por
razões práticas, a redes com quatro camadas ocultas, a estrutura do cromossoma apresenta-se
na Figura 6.29.
Número de
camadas ocultas
Número total
de nós
Nós na 1ª
camada oculta
Nós na 2ª
camada oculta
Nós na 3ª
camada oculta
Nós na 4ª
camada oculta
Figura 6.29 – Constituição do cromossoma do AG utilizado para determinar a melhor topologia de PMC.
Na implementação deste AG surgiram algumas dificuldades. A primeira resulta de não se poder
cruzar informação de dois cromossomas distintos com facilidade, pois os “valores” do
cromossoma não são independentes entre si (o número de nós nas camadas ocultas tem que ser
igual ao número total de nós e só podem haver nós em camadas que “existam” de acordo com a
primeiro valor do vector). Seguidamente sintetiza-se o processo utilizado para solucionar este
problema, ilustrando-se, na Figura 6.30, um exemplo.

88
Como cruzar informação entre dois PMCs (PMC 1 e PMC 2) distintos?
PMC 1 4 10 4 2 2 2
PMC 2 2 20 15 5 0 0
Número de camadas ocultas
Número total de nós
Número de nós em cada camada
231
3 15
2 13
Valores médios para número de camadas ocultas e número de nós.
A que se adicionam valores aleatórios segundo uma distribuição normal com a média obtida e desvio padrão escolhido no início do processo.
e1 2
+ componentealeatória
Adimensionalização PMC 1 0.4 0.2 0.2 0.2
PMC 2 0.75 0.25 0 0
Soma 0.575 0.225 0.1 0.1
Dimensionalização
2 13 9 4
2 13 10 3
Componente aleatória
A introdução de componente aleatória, tal como nos passos 1 e 2, é feita de acordo com a distribuição normal. A média é igual ao resultado da dimensionalização da soma da distribuição de nós pelas camadas de PMC 1 e PMC 2 e o desvio-padrão é escolhido no início do processo.
O processo de dimensionalização deve redistribuir os restos da operação por forma a que o número de nós e camadas seja respeitado.
A obtenção da distribuição de nós pelas camadas ocultas é feita em quatro passos:
3
+ componentealeatória

89
Figura 6.30 – Resultado do cruzamento de dois PMC (PMC 1 e PMC 2) no âmbito da
aplicação de AG desenvolvida (número de nós nas camadas ocultas).
A segunda dificuldade, surge pelo facto de se estar a executar um programa dentro de outro,
tornando-se a simulação muito lenta20.
Uma terceira dificuldade, mais determinante, surge devido ao facto de o treino dos PMC ser um
processo intrinsecamente estocástico (não em função do modo de treino, que é determinístico,
mas em função do estado inicial das redes21, que é aleatório, e do processo de selecção dos
subconjuntos de validação, também aleatório). Uma vez que o resultado, para dada topologia de
rede, não é sempre igual, o AG oscila indefinidamente, pois uma rede que tem melhor
desempenho numa época pode não ter na seguinte.
Há várias formas de lidar com este aspecto. A mais simples será efectuar apenas um treino para
cada rede e utilizar o valor obtido nas épocas seguintes. Este procedimento, no entanto, não é
adequado, pois pode levar à adopção de topologias inadequadas, uma vez que um treino não é
amostra suficiente. Outra hipótese, a formalmente mais adequada, consiste em, em cada época,
realizar um número de treinos com significado estatístico suficiente para comparar valores
médios. Esta alternativa, porém, não é exequível, uma vez que elevaria o tempo de computação
para valores demasiado altos.
Propôs-se então uma solução de compromisso. Nesta solução prevê-se que cada cromossoma
seja treinado, em cada época em que esteja presente, determinado número de vezes (por
exemplo, 10 vezes), armazenando-se a média de EQM obtida e o número de treinos
acumulados. A partir da época em que o número de treinos acumulado excede um valor limite
20 Para redes com 40 nós pode exceder os 2 dois dias de computação num computador Intel Core 2 Duo com 2,00 GHz e 2 GB de RAM. 21 Para iniciar o processo de retropropagação é necessário arbitrar valores para as ligações sinápticas da RNA.
0
2
4
6
8
10
12
14
1 2 3 4
Nú
me
ro d
e n
ós
Identificação da camada oculta
PMC 1
PMC 2
PMC final

90
(por exemplo, 40 treinos), tendo-se já compilado uma amostra razoável, o PMC passa a ser
treinado uma única vez por época, poupando tempo computacional. Desta forma, investe-se na
avaliação mais precisa das topologias que apresentam os melhores resultados.
Para implementar este tipo de rotina, é necessário armazenar, no mínimo, valores médios e o
número total de testes. No entanto, para todas as combinações de topologias (incluindo número
total de nós variável22) é fácil constatar que a matriz necessária facilmente toma dimensões
apreciáveis, excedendo a capacidade do Matlab.
Assim, reduziu-se o âmbito do AG à determinação da topologia óptima com número de nós fixo a
priori, ou seja, à determinação do número de camadas ocultas e da distribuição de nós entre
estas.
Os resultados obtidos vieram confirmar a adequação das equações [22] e [23] quanto à
estimativa de distribuição de nós por camadas ocultas.
No Anexo XIV é apresentado o código desenvolvido, em Matlab, no âmbito do AG. Os
parâmetros utilizados são sintetizados no Anexo XV.
6.4.4 Selecção do algoritmo de treino
A selecção do algoritmo de treino passou, tal como é proposto no capítulo 1, pela
experimentação dos vários algoritmos disponibilizados na Neural Networks Toolbox do Matlab23.
O processo de treino utilizado apoia-se no módulo para teste, treino e simulação de RNA
desenvolvido. Com esta ferramenta foi possível treinar uma rede repetidas vezes, recorrendo à
validação K-fold, sendo que, em cada ciclo de treino (treino de todos os algoritmos), o estado
inicial da rede e os subgrupos de validação são estritamente iguais, tornando-se possível a
comparação objectiva dos algoritmos.
A informação devolvida pela ferramenta, a cada ciclo e para cada algoritmo, inclui o EQM, a
correlação e o tempo de treino.
Os testes foram efectuados para a rede net20x1_5, anteriormente seleccionada como a rede
com mais potencial para a modelação da degradação do sistema de distribuição de água de
Lisboa. Da Figura 6.31 à Figura 6.33 são apresentados os resultados obtidos, incluindo barras de
erro indicadoras do desvio-padrão de cada amostra. Em todos os testes, o subconjunto de
validação foi composto por 20% dos dados.
Analisando os resultados obtidos, é patente que a retropropagação de Levenberg-Marquardt
(trainlm) se destaca, tanto a nível de EQM, bastante abaixo de qualquer um dos restantes
algoritmos, mas também a nível da correlação, cuja média é a única a exceder os 40%.
22 Dentro de um intervalo previamente definido. 23 Uma lista das abreviaturas dos algoritmos de treino é apresentada no Anexo IV.
91
Apenas em tempo de treino este algoritmo é superado, pela retropropagação resiliente (trainrp),
no entanto, para efeitos do presente estudo, o tempo de treino tem uma importância mínima, pelo
que se considera que a suposição inicial de que o retropropagação modificada com o algoritmo
de Levenberg-Marquardt é válida e, portanto, a rede net20x1_5 é, de facto, a mais adequada
para levar a cabo a modelação pretendida neste trabalho.
No Anexo IV é apresentado um gráfico de EQM versus correlação, ilustrativo do desempenho
atingido através de cada um dos diferentes algoritmos.
Figura 6.31 – Resultado do EQM de treino através da utilização de vários algoritmos de
treino, para a rede net20x1_5, com validação K-fold, de subconjuntos de validação a
contabilizar 20% do total de dados.
Figura 6.32 – Resultado da correlação de treino através da utilização de vários algoritmos
de treino, para a rede net20x1_5, com validação K-fold, de subconjuntos de validação a
contabilizar 20% do total de dados.
8.00E-04
8.50E-04
9.00E-04
9.50E-04
1.00E-03
1.05E-03
traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
EQ
M
Algoritmo de treino
0%
10%
20%
30%
40%
50%
60%
traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
Co
rre
laçã
o
Algoritmo de treino

92
Figura 6.33 – Resultado do tempo médio de treino através da utilização de vários
algoritmos de treino, para a rede net20x1_5, com validação K-fold, de subconjuntos de
validação a contabilizar 20% do total de dados.
6.4.5 Treino da rede
Uma vez definida a arquitectura do PMC, o treino da rede definitiva aparece como uma etapa
trivial, pois já foram executadas dezenas (no presente caso centenas) de treinos. No entanto,
algumas considerações adicionais justificam-se.
Na metodologia anterior deu-se primazia à validação K-fold, no entanto, neste tipo de treino, a
rede é treinada para cada uma das combinações de subconjuntos de treino e validação à vez,
até que a totalidade dos dados tenha pertencido ao subgrupo de validação. Deste modo, o EQM
pode ser obtido sem dificuldade, porém, uma vez que a rede é inicializada para cada combinação
de subconjuntos (os pesos sinápticos são gerados aleatoriamente), na prática são treinadas não
uma, mas K redes, não resultando uma rede “treinada” do processo.
Alguns problemas que podem ser resolvidos com recurso a RNA necessitam de uma grande
eficiência por parte das redes, ou seja, o treino tem que produzir bons resultados num espaço de
tempo curto e, nesse sentido, a validação K-fold é bastante interessante.
Neste trabalho procura-se modelar a degradação de sistemas de distribuição de água, pelo que é
mais importante que a rede tenha o melhor desempenho possível do que o tempo que demora a
ser treinada ou quantos treinos são necessários até se obter uma rede que seja satisfatória24.
Assim, talvez a validação K-fold não seja a melhor opção.
24 Como se pode observar através dos resultados anteriormente expostos, o processo de treino (até com validação K-fold) está sujeito alguma aleatoriedade, podendo até não convergir para um EQM minimamente
0
50
100
150
200
250
300
traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
Te
mp
o d
e t
rein
o [
s]
Algoritmo de treino

93
A validação cruzada, é também concebida para assegurar boas capacidades de generalização,
no entanto, ao contrário da validação K-fold, a cada processo de treino corresponde uma única
rede “treinada”. A desvantagem deste método é que o treino fica mais sensível à componente
estocástica do treino que advém do estado inicial do PMC e da selecção dos subgrupos de
treino, validação e teste.
Assim, corre-se o risco de que um bom desempenho através de validação cruzada se deva ao
facto de os padrões de dados contidos no subconjunto de validação serem muito semelhantes
aos contidos no subconjunto de treino e não à capacidade da rede propriamente dita. Foi
exactamente devido a este facto que o processo de escolha da rede adequada (net20x1_5) foi
exigente.
Uma vez se tomaram as precauções necessárias para que a rede a treinar tenha a capacidade
de fazer boas generalizações, o processo que se propõe para treino da rede definitiva consiste
na execução de vários treinos da rede net20x1_5, recorrendo a validação cruzada, sendo
guardada a matriz de pesos sinápticos correspondente ao melhor desempenho (menor EQM).
Para levar a cabo este tipo de treino recorreu-se, mais uma vez, ao módulo para teste, treino e
simulação de RNA, que permite executar um número arbitrário de treinos, sendo “guardada” a
matriz de pesos que os melhores resultados produziu.
A rede definitiva foi obtida através do teste de 50 PMC com a arquitectura adoptada, tendo sido o
EQM final de (8.33x10-4), correspondente a 120,97 OT/(100km.ano), um resultado 48,2%
superior ao do EQM mínimo intrínseco do conjunto de dados.
Na Figura 6.34 apresenta-se um gráfico particularmente elucidativo da adequação das RNA para
o efeito pretendido neste trabalho, com a idade das tubagens25 em abcissas e o índice médio de
OT/(100km.ano) para as tubagens de determinada idade. Na Figura 6.35 ilustra-se uma
representação gráfica da RNA escolhida.
Note-se como o resultado da simulação se ajusta aos dados que, ademais, não apresentam uma
evolução exponencial do índice de roturas em função da idade, como seria de esperar, mas uma
relação funcional mais complexa, em virtude da grande campanha de renovação da rede levada
a cabo em Lisboa desde 2002.
aceitável. Assim, é concebível que o treino seja repetido algumas vezes até que uma rede com desempenho acima da média seja produzida. 25 Idades relativas ao ano de 2008.

94
Figura 6.34 – Resultado da simulação do índice OT/(100km.ano) para o conjunto de
tubagens validado, num gráfico com a idade dos elementos de tubagem em abcissa e o
índice OT/(100km.ano) médio para tubagens de determinada idade em ordenada.
Figura 6.35 – Representação da RNA escolhida. A cor azul denota pesos sinápticos
positivos e a cor vermelha negativos, sendo a intensidade das cores proporcional ao
módulo do valor.
0
50
100
150
200
250
300
350
400
0 10 20 30 40 50 60 70 80
OT
/(1
00
km
.an
o)
Idade da tubagem
Dados
net20x1_5

95
6.4.6 Validação
A validação dos dados foi efectuada, tal como referido no capítulo 1, recorrendo à analise gráfica
dos resultados obtidos através da simulação de OT/(100km.ano) para os elementos validados da
rede de distribuição de Lisboa.
O gráfico mais expressivo é, porventura, aquele a que se reporta a Figura 6.34 (acima). No
entanto, a análise deve ser, como já foi referido, multidimensional. Assim, complementou-se este
elemento com os gráficos apresentados na Figura 6.36, que fazem uma análise semelhante, por
material da tubagem, e com o gráfico de OT(100km.ano) acumuladas com a idade das tubagens
(Figura 6.37).
Seguidamente, faz-se a análise das simulações da rede na óptica dos diâmetros (Figura 6.38) e
dos subsistemas (Figura 6.39). Para o Anexo XVII remete-se a relação entre diâmetros e
materiais.
Figura 6.36 – Correspondência entre os dados e as previsões da rede escolhida. Índice de
OT/100km/ano em ordem à idade das tubagens, por material.
0
20
40
60
80
100
120
140
160
180
0 10 20 30 40 50 60 70 80
OT/
(10
0k
m.a
no
)
Idade
FF
FF sim.
0
50
100
150
200
250
300
350
400
0 10 20 30 40 50 60 70 80
OT/
(10
0k
m.a
no
)
Idade
FC
FC sim.
0
10
20
30
40
50
60
70
80
0 10 20 30 40 50 60 70 80
OT/
(10
0k
m.a
no
)
Idade
FFD
FFD sim.
0
2
4
6
8
10
12
14
0 10 20 30 40 50 60 70 80
OT/
(10
0k
m.a
no
)
Idade
PEAD
PEAD sim.
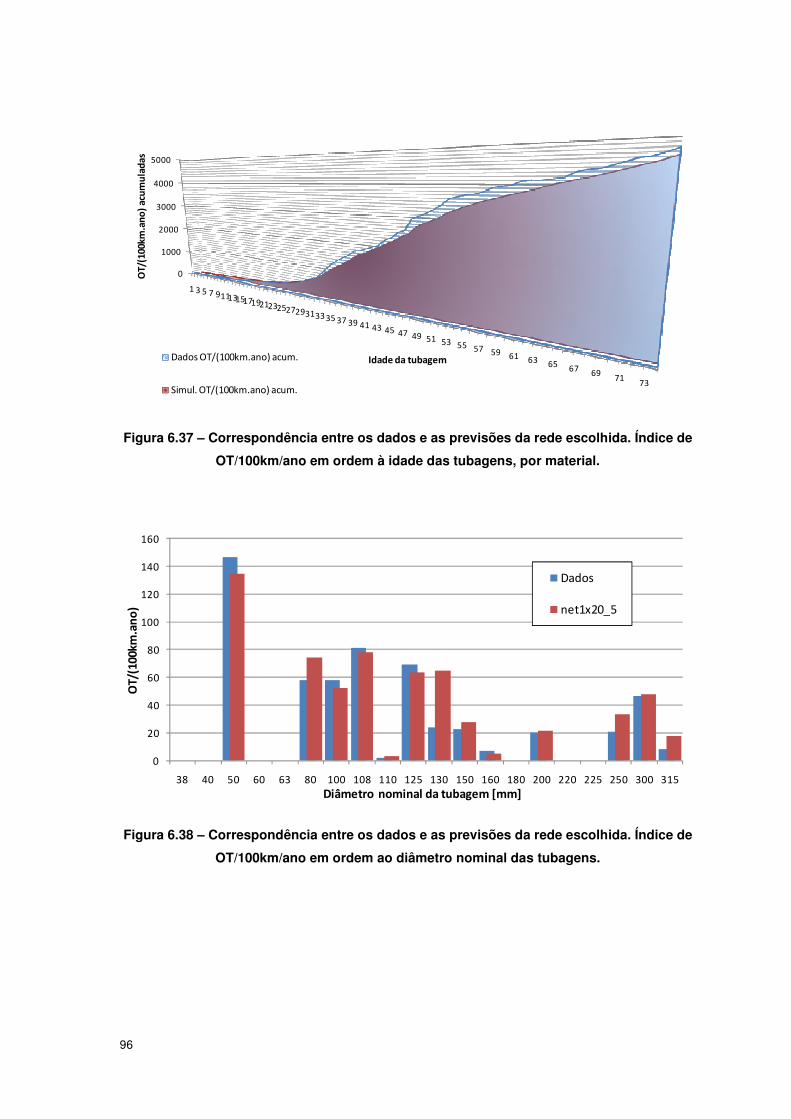
96
Figura 6.37 – Correspondência entre os dados e as previsões da rede escolhida. Índice de
OT/100km/ano em ordem à idade das tubagens, por material.
Figura 6.38 – Correspondência entre os dados e as previsões da rede escolhida. Índice de
OT/100km/ano em ordem ao diâmetro nominal das tubagens.
0
1000
2000
3000
4000
5000
1 3 5 7 911131517192123252729313335 37 39 41 43 45 47 49 51 53 55 57 59 61 63 65 67 6971
73
OT
/(1
00
km
.an
o)
acu
mu
lad
as
Idade da tubagemDados OT/(100km.ano) acum.
Simul. OT/(100km.ano) acum.
0
20
40
60
80
100
120
140
160
38 40 50 60 63 80 100 108 110 125 130 150 160 180 200 220 225 250 300 315
OT
/(1
00
km
.an
o)
Diâmetro nominal da tubagem [mm]
Dados
net1x20_5

97
Figura 6.39 – Correspondência entre os dados e as previsões da rede escolhida. Índice de
OT/100km/ano em ordem ao subsistema de abastecimento.
Como se pode observar através dos elementos obtidos, o PMC net20x1_5, treinado pela
metodologia proposta, parece adequar-se bem à simulação da degradação da rede de
distribuição de água de Lisboa, até ao nível de diâmetros e subsistemas, variáveis que
apresentam uma relação relativamente fraca com as roturas. Note-se que os dados utilizados
nos elementos gráficos compreendem a totalidade das tubagens validadas (subconjuntos de
treino, validação e teste).
A validação poderia ser levada a cabo apenas com dados do subconjunto de teste, o único que
não intervém, directa ou indirectamente, no treino. No entanto, tal procedimento não traria
grandes ganhos, uma vez os processos de determinação da arquitectura da rede e,
posteriormente, de treino, tiveram em consideração a importância de os conjuntos de treino,
validação e teste originarem desempenhos semelhantes.
Assim, conclui-se que, na vizinhança dos dados disponíveis, a rede net20x1_5 tem um bom
desempenho. No entanto, tal pode não ser verdade para todo espaço de padrões possível (por
exemplo, tubagens em PEAD com mais de 30 anos, ou FF recentemente instalado).
6.5 Análise dos resultados Para analisar os resultados para a totalidade dos padrões concebíveis, recorreu-se a um módulo
em VBA, descrito sumáriamente no capítulo 1, que gera pontos amostrais do espaço de
resultados. Dado que o espaço de padrões possíveis é um hipercubo com 5 dimensões
(diâmetro, material, idade, subsistema e OT/(100km.ano) prévias), o processo é
computacionalmente exigente e, para se obter uma amostra representativa, facilmente se têm de
considerar mais de 300 000 combinações de padrões.
0 10 20 30 40 50 60
Zona Sobrepressora
Zona Alta
Zona Alta Redutora
Zona Superior do Monsanto
Zona Superior Redutora
Zona Superior Charneca
Zona Baixa
Zona Média
Zona Baixa Redutora
Zona Superior
OT/(100km.ano)
Su
bsi
ste
ma
de
dis
trib
uiç
ão
net20x1_5
Dados

98
Os padrões fictícios gerados são, então, simulados na RNA treinada, obtendo-se como resultado
uma amostra homogénea do espaço de resultados. No Anexo VIII explica-se em maior detalhe o
processo e indicam-se quais os pontos amostrais seleccionados para o caso do presente estudo.
Passando aos resultados, devem ser interpretados da seguinte forma:
• A informação correspondente aos dados é composta por valores reais, contidos nos
dados da fornecidos pela EPAL.
• A informação simulada corresponde a uma fatia homogénea do espaço de resultados,
transversal aos parâmetros que se analisam em cada gráfico. Assim, num gráfico de
idade versus OT(100km.ano), está na realidade a reflectir-se a resposta média da rede
para pontos com essas características, mas com diâmetros variáveis, OT/(100km.ano)
prévias variáveis, materiais variáveis e subsistemas variáveis.
Embora analisar informação relativa ao “diâmetro médio” ou ao “subsistema médio” não
tenha implicações demasiado grandes nas respostas da RNA, o parâmetro
OT/(100km.ano) prévias tem. Assim, os gráficos seguintes, à excepção do primeiro, são
referentes a um índice de OT/(100km.ano) prévias específico.
• Tal como as previsões, os dados são influenciados por este efeito, em que parâmetros
que não são incluídos no gráfico exercem influência no resultado do mesmo. Ao
comparar previsões e dados há que ter este factor em conta.
A Figura 6.40 reporta-se à relação entre índices de rotura prévios e índices de rotura registados
(dados) ou simulados (rede net20x1_5). Como se pode observar, a relação é aproximadamente
linear, mas valores muito elevados tendem à redução no futuro.
Figura 6.40 – Relação entre índices de rotura prévios (OT/(100km.ano) prévias) e previstos
(OT/(100km.ano)).
0
500
1000
1500
2000
2500
3000
0 500 1000 1500 2000 2500 3000 3500 4000
OT
/(1
00
km
.an
o)
OT/(100km.ano) prévias
Dados
net20x1_5

99
Na Figura 6.41 ilustra-se a resposta da RNA face à idade da tubagem, para diferentes casos de
OT(100km.ano) prévias. Comparando os gráficos com o da Figura 6.34, nota-se imediatamente a
influência do efeito relatado anteriormente. Se com caracetrísticas idênticas às da rede existente
os resultados se assemelham aos reais, com a média homogénea de pontos amostrais obtém-se
uma curva bastante suave. Note-se, igualmente, a influência do parâmetreo OT/(100km.ano).
Caso de 0 OT/(100km.ano) prévias Caso de 37,5 OT/(100km.ano) prévias
Caso de 850 OT/(100km.ano) prévias Caso de 2750 OT/(100km.ano) prévias
Figura 6.41 – Resultado da simulação do índice OT/(100km.ano), num gráfico com a idade
dos elementos de tubagem em abcissa e o índice OT/(100km.ano) médio em ordenada.
Nas duas figuras seguintes, é feita uma análise equivalente, discretizada por material.
Observando os resultados obtidos pode antever-se aquela que é possivelmente a maior limitação
do modelo. Os materiais têm um comportamento bastante diferente do que é esperado, e
verificado, na realidade, especialmente para idades de tubagem não presentes na rede.
Este efeito deve-se ao facto de que, para cada um dos materiais, não existem dados em todo o
intervalo de idades considerado, o que leva o PMC a reduzir a inportância do material como
parâmetro (note-se o fraco peso sináptico das ligações a partir do nó de input do material, no
caso dos PMC sem camada oculta).
Particularmente, note-se o mau resultado obtido para o FFD. Tendo o menor valor de índice de
roturas para idades reduzidas da tubagem, passa ao pior para tubagens mais velhas. A função
que descreve este comportamento faz lembrar a função de activação utilizada, a tangente
0
50
100
150
200
250
300
0 20 40 60 80 100
OT/
(10
0k
m.a
no
)
Idade da tubagem
Dados
net20x1_5
0
50
100
150
200
250
300
0 20 40 60 80 100
OT/
(10
0k
m.a
no
)
Idade da tubagem
Dados
net20x1_5
0
100
200
300
400
500
600
0 20 40 60 80 100
OT/
(10
0k
m.a
no
)
Idade da tubagem
Dados
net20x1_5
0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100
OT/
(10
0k
m.a
no
)
Idade da tubagem
Dados
net20x1_5

100
hiperbólica. Desta forma, pensa-se que o modelo desenvolvido, embora tendo um ajuste
bastante bom à rede real, não pode ser aplicado com sucesso a redes muito diferentes. De facto,
as RNA (em particular o PMC) não têm, tal como se vê, uma capacidade de generalização que
permita este tipo de utilização.
Há, no entanto, procedimentos, não adoptados no âmbito deste trabalho, que podem melhorar os
resultados, designadamente treinar o RNA com um conjunto de dados fictício, correspondente ao
comportamento esperado, numa etapa anterior ao treino definitivo, com dados reais.
Não obstante, pensa-se que a utilização do presente modelo numa projecção de 5 a 10 anos não
incorre num erro substancial devido a este efeito.
Figura 6.42 – Resultado da simulação do índice OT/(100km.ano), num gráfico com a idade
dos elementos de tubagem em abcissa e o índice OT/(100km.ano) médio para tubagens de
determinada idade em ordenada. Por material; com 37,5 OT/(100km.ano) prévias.
A relação de diâmetros nominais e índice OT(100km.ano) previsto é apresentada na Figura 6.44,
sendo que a Figura 6.45 se reporta a uma análise semelhante, por subsistema de distribuição.
Da análise destes elementos nota-se que a resposta média da rede é bastante suave, como
esperado.
Embora, no que se refere ao diâmetro, os resultados sejam razoavelmente ajustados, para os
subsistemas nota-se uma desadequação grande, porventura devido à composição das tubagens
existentes nos mesmos, que não sendo homogénea como a dos pontos amostrais simulados,
interfere na análise. Não obstante, será de reconsiderar a inclusão do subsistema como
parâmetro em modelos futuros.
0
50
100
150
200
250
300
350
400
0 10 20 30 40 50 60 70 80 90
OT
/(1
00
km
.an
o)
Idade da tubagem
FF FC
PEAD FFD
FF sim. FC sim.
PEAD sim. FFD sim.

101
No caso do diâmetro, sendo os intervalos considerados para o diâmetro bastante “largos”, é
possível a distribuição dos dados tenha sido repartida desigualmente, contribuindo para o
agravamento da interferência observada.
Figura 6.43 – Resultado da simulação do índice OT/(100km.ano), num gráfico com a idade
dos elementos de tubagem em abcissa e o índice OT/(100km.ano) médio para tubagens de
determinada idade em ordenada. Por material; com 550 OT/(100km.ano) prévias.
Figura 6.44 – Relação entre observações e previsões de OT/(100km.ano) médias para as
classes de diâmetro nominal (37,5 OT(100km.ano) prévias).
0
100
200
300
400
500
600
700
800
0 10 20 30 40 50 60 70 80 90
OT
/(1
00
km
.an
o)
Idade da tubagem
FF FC
PEAD FFD
FF sim. FC sim.
PEAD sim. FFD sim.
0
20
40
60
80
100
120
25 75 125 175 225 282.5
OT
/(1
00
km
.an
o)
Classe de diâmetro nomial [mm]
Dados
net20x1_5

102
Figura 6.45 – Relação entre observações e previsões de OT/(100km.ano) médias nos
subsistemas de distribuição (37,5 OT(100km.ano) prévias).
No Anexo XIX figura um gráfico tri-dimensional que pretende ilustrar a relação entre Idade,
OT/(100km.ano) prévias e OT/(100km.ano). Da sua análise, é possível verificar que, para
efectuar previsões, a rede treinada se baseia sobretudo na idade da tubagem quando o índice de
OT/(100km.ano) prévias é baixo, sendo que, quando este valor aumenta, ganha uma relevância
muito grande.
6.6 Considerações adicionais sobre as variáveis explicativas Das variáveis explicativas estudadas, pensa-se que a que mais influência tem é o número prévio
roturas, que como resultado da análise directa dos dados, quer a partir da análise do
comportamento dos PMC treinados.
Seguidamente, destaca-se a idade, que pode ser facilmente correlacionada com as roturas, o
que é também observado no comportamento dos PMC treinados.
O material, cuja influência não foi inteiramente captada pela rede net20x1_5, é totalmente
indissociável do desempenho das redes de distribuição de água. Embora do ponto de vista
matemático fique “obscurecido” pela idade das condutas, como foi já referido, pensa-se que será
o terceiro parâmetro de maior importância.
O diâmetro aparece como o quarto parâmetro quanto à influência no número de roturas. E, a
partir da Figura 6.38, nota-se uma clara diminuição do índice de roturas com o aumento do
diâmetro. De facto, este resultado não seria o inicialmente esperado, pois com o aumento de
diâmetro aumenta também o perímetro da tubagem e, consequentemente, a área em que podem
haver falhas no material. Hipóteses que explicam este comportamento podem residir num maior
0 25 50 75 100 125 150
Zona Sobrepressora
Zona Alta
Zona Alta Redutora
Zona Superior do …
Zona Superior Redutora
Zona Superior Charneca
Zona Baixa
Zona Média
Zona Baixa Redutora
Zona Superior
OT/(100km.ano)
Su
bsi
ste
ma
de
dis
trib
uiç
ão

103
cuidado na colocação de condutas de maior diâmetro, ou até na menor sujeição a flutuações de
pressão provocadas por sobpressoras em edifícios.
Finalmente, o subsistema de distribuição revelou-se a variável que menos influência tem no
número de roturas. Essencialmente, a sua inclusão pretendeu, na medida do possível, incluir
implicitamente no modelo condições de exploração, características geotécnicas do solo e outras
variáveis que não é fácil contabilizar directamente. Da análise dos resultados pode constatar-se
que, caso esse objectivo tenha sido cumprido, foi-o tenuemente. Tal como já foi referido, a
inclusão deste parâmetro em trabalhos subsequentes merece reconsideração.
Um procedimento descrito em Lingireddy, et al., 2005, propõe que, para aferir a importância de
um parâmetro, o mesmo deverá ser substituido pelo valor médio da amostra em todos os
padrões de dados, sendo, seguidamente, efectuada a simulação dos novos padrões, na RNA
(previamente treinada). O cálculo do erro entre previsões e dados será indicativo dessa
importância.
Tendo-se levado a cabo este procedimento para os padrões considerados no presente estudo,
foi elaborado o Quadro 6.10, em que se apresentam os resultados obtidos ao substituir um
parâmetro pelo seu valor médio na totalidade dos padrões de dados. Tal como se pode avaliar,
os resultados obtidos corroboram inteiramente a análise efectuada.
Quadro 6.10 – Análise à sensibilidade de cada parâmetro no resultado da simulação da rede net20x1_5.
6.7 A dispersão do fenómeno A grande parte do estudo desenvolvido foi orientada para obter um modelo, baseado em RNA,
que tenha capacidade de prever o índice de roturas em elementos de tubagem do sistema de
distribuição de água de Lisboa. No entanto, o índice corresponde à média do número de roturas
esperado, não contendo qualquer tipo informação quanto à dispersão inerente à ocorrência de
roturas.
No âmbito da GA, particularmente em modelos de simulação da rede, é interessante contabilizar
a dispersão, pois a partir desta pode ser compreendido qual o risco que corre a entidade gestora
de que num dado ano, por obra do acaso, o número de roturas seja superior ao esperado.
Desta forma, com base nos valores médios estimados pela rede net20x1_5, foi aplicada a
distribuição estatística de Poisson, comparando os resultados obtidos, elemento a elemento de
tubagem, com os que, de facto, ocorreram de 2002 a 2007 na rede de distribuição de água
cidade de Lisboa.
Parâmetro em "falta" Diâmetro Idade Material Subsistema OT/(100km.ano)
EQM 8.66E-04 9.18E-04 8.90E-04 8.59E-04 9.21E-04
Correlação 34.0% 28.1% 32.5% 35.0% 25.2%
EQM/EQM mínimo 154.03% 163.44% 158.35% 152.92% 163.81%

104
Escolheu-se esta distribuição por dois motivos. O primeiro diz respeito à própria definição da
distribuição de Poisson, aplicável a fenómenos em que o número médio de falhas é
independente das falhas que já ocorreram26, podendo ser utilizada em fenómenos espaciais e/ou
temporais, como é o caso. O segundo, motivo prende-se à simplicidade desta distribuição, em
que o único parâmetro é a média, justamente o resultado produzido pela RNA treinada.
Para cada elemento de tubagem foi estimado o índice médio de roturas, por 100 km, por ano.
Seguidamente, com base na distribuição de Poisson, foi calculada a probabilidade do elemento
apresentar de 1 a 13 roturas no período que vai de 2005 a 2007.
Somando as probabilidades de ocorrer determinado número de roturas em cada um dos
elementos considerados, obteve-se a previsão do número total de elementos de tubagem com
esse registo. Comparando os resultados estimados com aqueles que foram registados em
Lisboa, foi elaborada a Figura 6.46.
Figura 6.46 – Distribuição do número de roturas num único techo de tubagem, para a rede
de distribuição da água de Lisboa (escala logarítmica).
Como se pode observar, apesar de o fenómeno apresentar, tal como esperado, uma dispersão
superior à da distribuição de Poisson, a estimativa obtida é muito próxima da realidade. Note-se
26 O que constitui uma hipótese razoável num sistema de distribuição de água, pois uma rotura, localizada no espaço, deixa a maior parte do sistema intacto.
Na prática, por diversas razões, sabe-se que não é assim, devido a flutuações de pressão na conduta, tensões induzidas durante a reparação e ainda outros factores. Não obstante, a hipótese admitida é, como se infere a partir dos resultados obtidos, próxima da realidade.
0.1
1
10
100
1000
10000
100000
0 1 2 3 4 5 6 7 8 9 10 11 12 13
Nú
me
ro d
e t
rech
os
de
tu
ba
ge
m c
om
x r
otu
ras
Número de roturas no trecho de tubagem, no período em análise
Somatório dos casos registados
Somatório das ocorrências previstas

105
que, em virtude do gráfico estar reproduzido em escala logarítmica, erros pequenos (à direita)
são ampliados.
No cômputo dos 26 070 elementos, que contabilizaram 1 082 roturas no período estudado, a
previsão obtida através da aplicação de RNA e distribuição de Poisson subestimou o número de
roturas total em cerca de 12,5%, possivelmente devido à menor dispersão da distribuição
utilizada.
Não obstante, a correlação entre valores reais e estimados é de 100,0%, se considerados os
trechos de tubagem que contabilizam 0 roturas, e de 96,3% se se contabilizarem somente
trechos com uma ou mais roturas. Quanto ao parâmetro r2, estes valores são de 100,0 e 92,7%.


107
7. Notas conclusivas e recomendações para estudos subsequentes A modelação da degradação dos sistemas de distribuição de água é uma temática com interesse
em vários planos, sendo desejável económica, social e ambientalmente. É, no entanto, um
fenómeno complexo, em que se deparam ao investigador problemas nem sempre fáceis de
ultrapassar. Neste trabalho, explorou-se a aplicação de redes neuronais artificiais, do tipo
perceptrão multicamada, para efeitos da degradação de redes de distribuição de água.
Em virtude de várias razões conjunturais, assiste-se a um esforço, por parte das entidades
gestoras de sistemas de abastecimento de água portuguesas, no sentido da melhoria do
desempenho das suas infra-estruturas. Neste sentido, o combate às perdas tem vindo a ganhar
cada vez mais importância no panorama nacional.
Sendo uma actividade desenvolvida em várias frentes, a redução de perdas assenta em meios
reactivos, tais como equipamento de detecção de fugas ou de telemetria, e meios activos, de que
são exemplo a reabilitação e renovação das redes. Ao contrário dos meios reactivos, que actuam
no imediato, com o objectivo de reduzir perdas existentes, os meios activos actuam num plano
preventivo, demorando períodos mais alargados até surtir efeito.
Face aos avultados investimentos inerentes à reabilitação ou à renovação das infra-estruturas de
abastecimento de água, as opções tomadas devem ser criteriosamente ponderadas, sob
diversos pontos de vista, sendo essa uma das matérias da gestão de activos.
Não sendo o desempenho da generalidade dos processos de modelação da degradação dos
sistemas de distribuição de água, desenvolvidos até à data, plenamente satisfatório, com este
trabalho pretendeu-se explorar algumas potencialidades inerentes às redes neuronais artificiais
e, possivelmente, contribuir para a evolução deste tema em Portugal.
No presente trabalho, foi desenvolvida uma metodologia para levar a cabo a criação de modelos
de degradação de sistemas de distribuição de água baseados no perceptrão multicamada (tipo
de rede neuronal artificial). Da experiência adquirida, importa salientar algumas vantagens, e
também inconvenientes, da utilização de redes neuronais artificiais para o efeito pretendido. No
primeiro grupo destacam-se os seguintes aspectos:
• a conceptualização acessível do processo;
• a qualidade das previsões conseguidas, superior à alcançada por via de regressão estatística;
• o impacto, relativamente reduzido, das parametrizações na qualidade final das previsões;
• a boa capacidade de adaptação do modelo a novos dados;
• a facilidade de integração de novas variáveis no modelo;
• a generalidade da metodologia que, uma vez dominada, pode ser utilizada para fins bastante diversificados, com resultados interessantes.

108
No segundo grupo, é necessário referir que:
• o treino inicial das redes neuronais artificiais pode ser um processo moroso e necessita de alguma experiência por parte de quem o executa;
• os cálculos efectuados internamente são complexos, pelo que os modelos baseados em redes neuronais artificiais são mais orientados para obter resultados do que contribuir para a compreensão teórica dos fenómenos;
• ao contrário do que alguns autores defendem, as redes neuronais artificiais têm uma capacidade de generalização limitada e, para definir os intervalos em que são válidas, é necessário um extensivo trabalho de análise de resultados.
A metodologia desenvolvida foi aplicada ao sistema de distribuição de água da cidade de Lisboa,
para diâmetros nominais de tubagem inferiores a 315 mm. Os dados foram fornecidos pela
EPAL, e são referentes ao período de 24 de Janeiro de 2002 a 28 de Agosto de 2007.
Numa etapa de análise prévia dos dados foi possível verificar a importância do histórico de
roturas. Constatou-se, por exemplo, que, em média, uma conduta que tenha tido, pelo menos,
uma rotura num intervalo de três anos, tem uma probabilidade de apresentar roturas, nos três
anos seguintes, mais de oito vezes superior à observada nas restantes condutas do sistema.
Para além deste aspecto, foram procuradas explicações para a sazonalidade da ocorrência de
roturas que, aparentemente, se faz sentir no sistema de distribuição de água de Lisboa. Da
análise efectuada, concluiu-se que as variações de temperatura podem ter alguma influência no
fenómeno.
Das variáveis consideradas pertinentes para a modelação da degradação de sistemas de
distribuição de água foram, no âmbito do caso de estudo, testadas seis. A partir do estudo
efectuado foi possível ordenar, por ordem de importância, a relação entre cada variável e o
fenómeno das roturas. De acordo com os resultados obtidos, a variável que mais influência teve
foi o número prévio de roturas registado, sendo seguido pela idade das tubagens. Com um grau
de importância um pouco menor, foram identificados o material e o diâmetro nominal das
tubagens. O subsistema de distribuição e a freguesia provaram ter uma relação reduzida com o
número de roturas.
Não tendo sido possível, naturalmente, estudar todas as variáveis explicativas, pensa-se que
pode ser interessante, no futuro, aplicar a metodologia incorporando elementos adicionais como,
por exemplo, o índice de ramais por metro linear de conduta, o tipo de solo, a classe de pressão
da conduta e a proximidade de vias de tráfego intenso.
Como complemento às redes neuronais artificiais, foram explorados algoritmos genéticos com o
objectivo de definir parâmetros do modelo, não se tendo verificado ganhos significativos de
produtividade.
Da análise dos resultados obtidos para o caso de estudo, conclui-se que a metodologia proposta
permitiu obter um bom ajustamento aos dados reais, para o período compreendido entre 2005 e
2007. Não obstante, observou-se que as previsões obtidas com recurso à rede neuronal artificial

109
treinada não são fiáveis em condições muito diferentes daquelas que, actualmente, caracterizam
o sistema de distribuição de água de Lisboa, razão pela qual não se propõe a utilização do
modelo para previsões superiores a 10 anos.
Embora a rede neuronal desenvolvida se tenha provado inadequada para a modelação do
fenómeno das roturas a longo prazo, os resultados obtidos para o curto prazo são bastante bons.
Neste sentido, o estudo de um modelo híbrido, apoiado em sistemas de lógica difusa ou análises
estatísticas, para efectuar estimativas a longo prazo, e redes neuronais para efectuar estimativas
a curto prazo, parece promissor. Com efeito, numa óptica económico-financeira, devido à taxa de
actualização do capital, os primeiros anos da análise são os que mais importância têm e, por
essa razão, é significativa a relevância que assume a estimativa das roturas nos períodos
iniciais.
Com vista à elaboração de um modelo de simulação da degradação de sistemas de distribuição
de água, não apenas baseado em valores médios, mas incluindo a dispersão do fenómeno,
testou-se a adequação da distribuição de Poisson. Embora os resultados obtidos tenham sido
encorajadores, constatou-se que a ocorrência de roturas não é independente no número de
roturas precedente e, como tal, a distribuição real do fenómeno tem maior dispersão que a que
resulta da distribuição de Poisson.
Em síntese, crê-se que a utilização de redes neuronais artificiais para modelação da degradação
de sistemas de distribuição de água constitui uma temática promissora. De facto, face ao
aumento da preocupação das entidades gestoras com o desempenho das infra-estruturas,
haverá cada vez mais dados disponíveis para o treino de modelos baseados em redes neuronais
artificiais e, consequentemente, o desempenho destes modelos terá tendência a melhorar no
futuro.
Como trabalho a desenvolver, recomenda-se a inclusão, no modelo proposto nesta dissertação,
de dados relativos a tubagens de policloreto de vinilo (PVC), muito comuns em grande parte das
cidades em Portugal. Recomenda-se, igualmente, a comparação dos resultados obtidos através
da metodologia proposta com outros métodos, designadamente de regressão estatística.
Finalmente, encara-se como uma ampliação do presente trabalho a concepção de um modelo
económico-financeiro que, aplicado conjuntamente com o modelo de degradação, permita, de
forma integrada, optimizar as estratégias de intervenção nos sistemas.
Como nota final, considera-se justo fazer uma apreciação muito positiva do desempenho das
infra-estruturas de distribuição geridas pela EPAL e, especialmente, das estratégias de
intervenção que conduziram às campanhas de renovação que a Empresa tem levado a cabo
desde 2002.

110
8. Referências bibliográficas
Inforoma. [Online] [Citação: 29 de 08 de 2008.]
http://www.inforoma.it/feature.php?lookup=aqueduct.
Alegre, H., 2007. Gestão Patrimonial de Infra-Estruturas de Abastecimento de Água e de
Drenagem e Tratamento de Águas Residuais. Lisboa : Laboratório Nacional de Engenharia Civil,
2007.
Alegre, H.; Duarte, P.; Volta, M., 2004. Resultados do Projecto Europeu CARE-W para Apoio à
Reabilitação de Redes de Água. Faro : APESB, 11º ENaSB, 2004.
Alegre, H., et al., 2004. Indicadores de Desempenho para Serviços de Abastecimento de Água.
Lisboa : Laboratório Nacional de Engenharia Civil, 2004. ISBN 1 900222 27 2.
Araujo, L. S.; Ramos, H. M., 2006. Utilização Optimizada de Válvulas Redutoras de Pressão em
Redes de Distribuição de Água. Figueira da Foz : XII SILUBESA, 2006.
Demuth, H.; Beale, M.; Hagan, M., 2008. Neural Network Toolbox 6. Natick, Massachusetts :
The MathWorks, Inc., 2008.
Dias, N.; Covas, D.; Ramos, H., 2006. Melhoria do Desempenho Técnico de Sistemas de
Distribuição de Água Através do Controlo da Pressão. Figueira da Foz : XII SILUBESA, 2006.
EPAL, 2008. EPAL. [Online] 2008. [Citação: 27 de 8 de 2008.] www.epal.pt/epal/.
EPAL. 2004. A EPAL. Lisboa : Empresa Portuguesa de Águas Livres, S.A., 2004.
Franco, A. B., 2006. Combate às Perdas e Renovação da Rede, Imperativos de Melhoria do
Desempenho Energético-Ambiental da Rede de Distribuição de Lisboa. Curso de Formação -
Planeamento Urbano e Reabilitação Urbana na Dimensão do Desempenho Energético-Ambiental
da Cidade. Lisboa : Lisboa E-Nova, 2006.
Franco, A. B.; Luís, A. M.; Donnelly, A., 2008. De uma Extensiva, Embora Fragmentada, Busca
por um Aumento de Eficiência, ao Desenvolvimento de um Modelo Integrado de Gestão de
Activos - O Caso da EPAL. Cascais : APRH, 9º Congresso da Água, 2008.
Gomes, R.; Marques, A. S.; Sousa, J. ,2008. Estimativa dos Benefícios Resultantes da
Implementação do Controlo de Pressão em Sistemas de Distribuição de Água. Cascais : APRH,
9º Congresso da Água, 2008.
Haykin, S., 1999. Neural Networks - A Comprehensive Foundation. Singapura : Pearson
Education, 1999. ISBN 81-7808-300-0.
INSAAR, 2004. INSAAR. INAG. [Online] FCT, UNL, 2004. [Citação: 10 de 08 de 2008.]
http://insaar.inag.pt.

111
INAG. 2008. Relatório do estado - Abastecimento de Água e Saneamento de Águas Residuais -
Sistemas Públicos Urbanos - Campanha INSAAR 2006. s.l. : INAG, 2008.
IRAR, 2006. Relatório Anual do Sector de Águas e Resíduos em Portugal (2006). Lisboa :
Instituto Regulador de Águas e Resíduos, 2006. ISBN 978-989-95392-3-5.
Jafar, R.; et al., 2006. Use of the artificial neural networks (ANN) for modeling the structural
degradation in water distribution systems. Lille : International Water Association, 2006.
Kasabov, N. K., 1996. Foundations of Neural Networks, Fuzzy Systems, and Knowledge
Engineering. Massachusetts : MIT Press, 1996. ISBN 0-262-11212-4.
Lingireddy, S.; Brion, G. M., 2005. Artificial Neural Networks in Water Supply Engineering.
Reston, Virginia : ASCE, 2005. ISBN 0-7844-0765-7.
Luís, A. A.; et al., 2004. Análise da Estratégia de Investimento na Rede de Distribuição de
Lisboa. Faro : APESB, 11º ENaSB, 2004.
Luis, A. A. A.; et al., 2004. Renovação da Rede de Distribuição de Água de Lisboa - As Causas
e os Efeitos na Redução de Perdas. Faro : APESB, 11º ENaSB, 2004.
Luís, A. A. A.; Figueira, J. F. C.; Santos, M. A. C. S. S., 2008. Renovação da Rede de
Distribuição de Água de Lisboa - Efeitos na Redução de Perdas e Melhoria da Qualidade do
Serviço. Cascais : APRH, 9º Congresso da Água, 2008.
Marques, J.; et al., 2004. Aplicação do CARE-W aos SMAS de Oeiras e Amadora. Faro :
APESB, 11º ENaSB, 2004.
Marques, R. C., 2006. A Concessão dos Sistemas Municipais de Abastecimento de Água e de
Águas Residuais. Um Balanço da Primeira Década. Paço de Arcos : Associação Portuguesa dos
Recursos Hídricos, 2006.
Matos, J. S., 2000. Saneamento Ambiental II. Lisboa : Instituto Superior Técnico, 2000.
Ministério do Ambiente, do Ordenamento do Território e do Desenvolvimento Regional.
2006. Plano Estratégico de Abastecimento de Água e Saneamento de Águas Residuais (2007-
2013). Lisboa : Diário da República, 2006.
Mitchell, M., 1999. An Introduction to Genetic Algorithms. Cambridge, Massachusetts : MIT
Press, 1999. ISBN 0-262-13316-4(HB).
Montgomery, D. C.; Runger, G. C., 2003. Applied Statistics and Probability for Engineers. New
York : John Wiley & Sons, Inc., 2003. ISBN 0-471-20454-4.
Palácio Galveias, 1990. D. João V e o Abastecimento de Água a Lisboa. Lisboa : Câmara
Municipal de Lisboa, Pelouro da Cultura - Museu da Cidade, 1990.
Pasculescu, C. V., 2004. Modeling in urban hydrology and hydraulics using artificial neural
networks. Lisbon : Instituto Superior Técnico, 2004.

112
Quintela, A. C.; Portela, M. M., 2004. Alberto Abecassis Manzanares e a Engenharia Hidráulica
em Portugal. Lisboa : IST, Departamento de Engenharia Civil e Arquitectura, 2004.
Schmidhuber, J., 2008. Jürgen Schmidhuber's Home Page. IDSIA (Istituto Dalle Molle di Studi
sull'Intelligenza Artificiale). [Online] 25 de Ago de 2008. [Citação: 7 de Set de 2008.]
http://www.idsia.ch/~juergen/.
Serra, P., 2006. PEAASAR 2007-2013. Lisboa : 8º Congresso da Água, APRH, 2006.
Veelenturf, L. P. J., 1995. Analysis and Applications of Artificial Neural Networks. Hertfordshire :
Prentice Hall International (UK) Limited, 1995. ISBN 0-13-489832-X (hbk).
Water Supply and Sanitation Technology Platform, 2008. WSSTP - Urban Pilot Theme 2:
Project Proposals - Asset Management for Sustainable Urban Water. 2008.

Anexos


Anexos i
Anexo I – Teorema da aproximação universal
O teorema da aproximação universal estabelece que um PMC com uma camada oculta tem a
capacidade para aproximar, com qualquer erro desejado, qualquer função contínua.
Segundo Haykin, 1999:
Seja h1∙3 uma função não constante, estritamente crescente e contínua. Seja d�i um hipercubo
unitário com jk dimensões·. O espaço das funções contínuas em d�i é designado Dad�ib.
Então, dada qualquer função Q ∋ Dad�ib e m > 0, existe um inteiro n e conjuntos de constantes
reais o�, �� e p��, em que 2 = 1, … , j� @ ; = 1, … , jk, tais que podemos definir
qaR�, … , R�i b = , o��r�-� h s, p��R� +�i
�-� ��t [24]
Como uma aproximação da função Q1∙3; ou seja,
uqaR�, … , R�i b − QaR�, … , R�i bu < m [25]
Para todos os R�, R6, … , R�i, pertencentes ao padrão de dados.


Anexos iii
Anexo II – Demonstração do algoritmo da retropropagação dos erros
Tendo como objectivo a minimização de K (energia instantânea de erro) por via da alteração dos
parâmetros livres do PMC, os pesos sinápticos a retropropagação recorre ao método do
gradiente para ajustar o PMC no decorrer de várias iterações. Como tal, é através da derivação
de K em ordem ao peso sináptico p que se quantifica a alteração a fazer, ∆p. No entanto, é
importante definir previamente algumas grandezas. A primeira, o campo local induzido, é definida
por [26]:
*�123 = , p�� 123 ∙ I�S�123� [26]
Sendo que: I�S� representa o sinal de activação do nó j, da camada ] − 1; p�� representa o peso sináptico da ligação entre o nó j, da camada ] − 1 e o nó �, da
camada ]; *� representa o campo local induzido do nó �.
A grandeza seguinte, o sinal de activação, é definida através de [27]:
I�123 = fay*�123z [27]
Sendo que: I� representa o sinal de activação do nó �, da camada ]; fa representa a função de activação.
Assim, estão definidas as grandezas necessárias para prosseguir a dedução do algoritmo da
retropopagação. Na expressão [28] racionaliza-se a derivada da energia instantânea de erro em
varias derivadas parciais, que uma fez definidas, permitem o cálculo.
OK123Op�� 123 = OK123O@�123 O@�123OI�123 OI�123O*�123 O*�123Op�� 123 [28]
A primeira derivada parcial do membro direito da equação [28] é, atendendo a [17], definida por
[29] e igual ao erro no nó �.
OK123O@�123 = @�123 [29]

iv Anexos
A segunda derivada parcial – do erro em ordem ao sinal de activação – é dada por [30], resultado
que resulta directamente de [16].
A derivada do sinal de activação em ordem ao campo local induzido é equivalente à derivada da
função de activação [27].
OI�123O*�123 = Ofay*�123zO*�123 = fa′y*�123z [31]
Em que ′ evidencia que se trata de uma derivada em função do argumento.
Finalmente, a partir de [26] constata-se que da última derivada parcial da equação [28] assume o
valor do sinal de activação do nó j, presente na camada ] − 1 e ponto de origem da ligação
sináptica que se pretende actualizar, tal como se indica em [32].
O*�123Op�� 123 = I�S�123 [32]
Introduzindo as equações [29], [30], [31] e [32] em [28], obtém-se a expressão da derivada da
energia instantânea de erro em função do peso sináptico:
OK123Op�� 123 = −@�123 ∙ fa′y*�123z ∙ I�S�123 [33]
Assim, aplicando o método do gradiente, obtém-se na expressão [34], uma forma de actualizar o
peso sináptico da ligação entre os nós ��S� e ��. Esta expressão é normalmente designada por
regra delta.
∆p�� 123 = −> OK123Op�� 123 = > ∙ |� ∙ I�S�123 [34]
Nesta expressão introduzem-se as seguintes grandezas: |� representa o gradiente local da energia instantânea de erro e é definido por [35]; > é o parâmetro de aprendizagem, que controla o passo de actualização. Quanto maior for
mais rápida será a actualização de pesos sinápticos podendo, no entanto, a convergência
não ser alcançada devido a instabilidade no cálculo.
O@�123OI�123 = −1 [30]

Anexos v
|�123 = − OK123O*�123 = −@�123 ∙ fa′y*�123z [35]
A demonstração anterior pouco mais é do que uma generalização do método dos erros
quadráticos mínimos para uma camada de output com vários nós. No entanto, a pedra de toque
da retropropagação consiste em definir a actualização de pesos sinápticos de ligações para e
entre camadas ocultas. De facto, enquanto na camada de output se pode dispor directamente de
uma medição objectiva do erro, nas camadas ocultas tal não é verdade e, desta forma, o
gradiente local não pode ser obtido através da equação [35].
Para evidenciar que as fórmulas seguintes dizem respeito à actualização de pesos sinápticos de
ligações para camadas ocultas e não para a camada de output, utiliza-se o expoente ; para
identificar a camada e o índice j para identificar o nó.
A equação [36] fornece uma definição alternativa do gradiente local.
|�� 123 = − OK123O*�� 123 = − OK123OI�� 123 ∙ fa′y*�� 123z [36]
Recordando [16] e diferenciando [17] em ordem a I�� obtém-se a equação [37]. Desenvolvendo-
a, pode apresentar-se a igualdade sob a forma utilizada em [38].
OK123OI�� 123 = , @�123 O@�123OI�� 123� [37]
Para obter a expressão de cálculo do gradiente local, voltam a utilizar-se as expressões [16], [26]
e [27], referentes ao erro, ao campo local induzido e ao sinal de activação do nó � (camada de
output). A partir destas, é possível obter [39] e [40] e, assim, explicitar [38] na forma apresentada
em [41].
O@�123O*�123 = −fa′y*�123z [39]
O*�123OI�� 123 = p�� 123 [40]
OK123OI�� 123 = , @�123 O@�123O*�123 O*�123OI�� 123� [38]

vi Anexos
OK123OI�� 123 = − , @�123 ∙ fa′�*� 123� ∙ p�� 123 [41]
Atendendo à definição do gradiente local para nós da camada de output presente em [35] resulta
a equação [42].
OK123OI�� 123 = − , |�123 ∙ p�� 123 [42]
Introduzindo [42] em [36] obtém-se em [43] a expressão para o gradiente local num nó da
camada oculta, ;, também designada fórmula da retropropagação.
|�� 123 = fa′y*�� 123z ∙ , |�123 ∙ p�� 123 [43]
Uma vez definido o gradiente local, é possível aplicar a regra delta para actualizar o peso
sináptico da ligação desejada. Dado que a igualdade [43] pode ser generalizada para duas
camadas consecutivas, não sendo necessariamente a segunda de output, é possível actualizar
todos os pesos sinápticos do PMC deste modo.

Anexos vii
Anexo III – Exemplos de diferentes PMC treinados
Nos exemplos seguintes ilustram-se PMC treinados com dados do caso de estudo e seguindo a
metodologia proposta.
Ligações azuis evidenciam pesos sinápticos positivos e ligações vermelhas pesos sinápticos
negativos. O valor da constante, ilustrado no nó, segue a mesma terminologia. Entre cada
camada os pesos sinápticos são normalizados, sendo a que a cor mais intensa é atribuída
àquele que apresenta o maior módulo. Procede-se do mesmo modo relativamente às constantes.
Figura A 1 – Representação de um PMC treinado sem camada oculta.
Figura A 2 – Representação de um PMC treinado com uma camada oculta de 20 nós.
Figura A 3 – Representação de um PMC treinado com uma camada oculta de 40 nós.


Anexos ix
Anexo IV – Comparação de diferentes algoritmos de treino
Abreviações dos algoritmos de treino:
trainbfg BFGS quasi-Newton
backpropagation
trainoss One step secant backpropagation
trainlm Levenberg-Marquardt
backpropagation
traingdx Gradient descent with momentum
and adaptative learning rate
backpropagation
trainrp Resilient backpropagation
traincgp Conjugate gradient backpropagation
with Polak-Ribiere updates
traincgb Conjugate gradient backpropagation
with Powel-Beale restarts
trainscg Scaled conjugate gradient
backpropagation
Figura A 4 – Comparação entre diferentes algoritmos de treino para o caso de estudo.
0%
5%
10%
15%
20%
25%
30%
35%
40%
45%
50%
7.00E-04 7.50E-04 8.00E-04 8.50E-04 9.00E-04 9.50E-04 1.00E-03 1.05E-03 1.10E-03 1.15E-03 1.20E-03
Co
rre
laçã
o
EQM
trainbfg trainoss trainlm
traingdx trainrp traincgp
traincgb trainscg


Anexos xi
Anexo V – Sistema da EPAL
Figura A 5 – Sistema da EPAL. Adaptado de Franco, 2006.


Anexos xiii
Anexo VI – Dados de tubagens – Distribuição
Quadro A1 – Campos de dados de tubagens de distribuição.
Designação Descrição Observações
Dados gerais
Código universal Identificação da tubagem no sistema Irrelevante para o estudo
Ano de instalação Ano de instalação da tubagem
Ano limite inferiorData mínima de instalação (caso se desconheça a data
exacta)
Ano limite superiorData máxima de instalação (caso se desconheça a data
exacta)
Comprimento (m) Comprimento do trecho
Diâmetro (mm) Diâmetro da tubagem [mm]
Estado de ciclo de vida Classificação do estado de operacionalidade da tubagem
Estado operacionalClassificação do estado "actual" do funcionamento da
tubagem - Falta informação -
Material Material de que é composta a tubagem
Responsável pela execução Entidade responsável pela execução da obra de instalação Campo incompleto
Entidade promotora Entidade responsável pela tubagem
Localização
Arruamento Arruamento em que o trecho está inserido Irrelevante para o estudo
Carta Militar Quadrícula da carta militar em que o trecho está inserido Irrelevante para o estudo
Freguesia Freguesia em que a tubagem se insere
Sistema - Sem informação - Sempre 'Distribuição'
Subsistema Subsistema da rede em a que está ligada a tubagem
Outras informações
Classe - Sem informação -
Código da entidade Identificação secundária da entidade no sistema Irrelevante para o estudo
Código da entidade pai - Sem informação -
Entidade agregadora - águas - Sem informação -
Data de actualização (aaaa-
mm-dd)Data de actualização da informação da tubagem Irrelevante para o estudo
Fonte de informação Fonte da informação introduzida no sistema Irrelevante para o estudo
Obs. sobre fonte de
informação - Observações - Irrelevante para o estudo
Observações - Observações - Campo incompleto
Utilizador Utilizador que introduziu a informação no sistema Irrelevante para o estudo
Informação específica para distribuição
Código patrimonial - Sem informação -
FunçãoFunção da tubagem (semelhante ao campo 'Estado de ciclo
de vida')
Localização - Observações - Campo incompleto
Modelação matemática Se a tubagem está incluída na modelação matemática Irrelevante para o estudo
Tipo de junta Informação sobre a aplicação de juntas automáticas Campo incompleto
Campos cujo número de
entradas não justifica a
inclusão no estudo


Anexos xv
Anexo VII – Dados de tubagens – Adução
Quadro A2 – Campos de dados de tubagens de adução.
Designação Descrição Observações
Dados gerais
Código universal Identificação da tubagem no sistema Irrelevante para o estudo
Ano de instalação Ano de instalação da tubagem
Ano limite inferiorData mínima de instalação (caso se desconheça a data
exacta)
Ano limite superiorData máxima de instalação (caso se desconheça a data
exacta)
Comprimento (m) Comprimento do trecho
Diâmetro (mm) Diâmetro da tubagem [mm]
Estado de ciclo de vida Classificação do estado de operacionalidade da tubagem
Estado operacional - Falta informação -
Material Material de que é composta a tubagem
Responsável pela execução Entidade responsável pela execução da obra de instalação Campo incompleto
Entidade promotora Entidade responsável pela tubagem
Localização
Arruamento Arruamento em que o trecho está inserido Irrelevante para o estudo
Carta Militar Quadrícula da carta militar em que o trecho está inserido Irrelevante para o estudo
Freguesia Freguesia em que a tubagem se insere
Sistema - Sem informação - Sempre 'Distribuição'
Subsistema Subsistema da rede em a que está ligada a tubagem
Outras informações
Classe - Sem informação -
Código da entidade Identificação secundária da entidade no sistema Irrelevante para o estudo
Código da entidade pai - Sem informação -
Entidade agregadora - águas - Sem informação -
Data de actualização (aaaa-
mm-dd)Data de actualização da informação da tubagem Irrelevante para o estudo
Fonte de informação Fonte da informação introduzida no sistema Irrelevante para o estudo
Obs. sobre fonte de
informação - Observações - Irrelevante para o estudo
Observações - Observações - Campo incompleto
Utilizador Utilizador que introduziu a informação no sistema Irrelevante para o estudo
Informação específica para adução
Altura (mm) - Sem informação -
Área da secção (m2) - Falta informação - Informação redundante
Capacidade de transporte
(m3)
- Falta informação -
Declive (%) - Sem informação -
Designação de adutor Designação do sistema adutor em que a tubagem se insere
Dimensão da secção (mm) Dimensão da secção (diâmetro para secções circulares) Campo incompleto
Regime de escoamento Regime do escoamento (pressão ou superfície livre)
Tipo de assentamento Tipo de assentamento utilizado no trecho de tubagem Campo incompleto
Tipo de secção Forma da secção
Campos cujo número de
entradas não justifica a
inclusão no estudo


Anexos xvii
Anexo VIII – Dados de ordens de trabalhos (OT)
Quadro A3 – Campos de dados das ordens de trabalhos.
Designação Descrição Observações
Dados gerais
Código universal Identificação da OT no sistema Irrelevante para o estudo
Base de trabalho Classificação em troço de tubagem ou adutor
Causa de intervenção Causa da intervenção
Comunicado por Entidade que comunicou o problema
Data da comunicação Data em que foi comunicado o problema (no caso de não se
Hora da comunicação
Natureza da intervenção Razão da intervenção - caracterização do problema Campo incompleto
Tipo de intervenção Intervenção programada ou não
Tipo de trabalho executado Tipo de trabalho executado na tubagem Campo incompleto
Localização
Arruamento Arruamento em que a OT é programada Irrelevante para o estudo
Carta Militar Quadrícula da carta militar em que a OT foi assinalada Irrelevante para o estudo
Coordenada M Coordenada M em que foi assinalada a OT no SIG Irrelevante para o estudo
Coordenada P Coordenada P em que foi assinalada a OT no SIG Irrelevante para o estudo
Divisão Divisão Oriental ou Ocidental Campo incompleto
Freguesia Freguesia em que a OT é programada
Localização - Observações -
Localização da intervençãoLocalização da intervenção (faixa de rodagem, edifício,
passeio, etc…)Campo incompleto
SistemaSistema em que foi programada a OT (adução ou
distribuição)
Subsistema Sub-sistema em que foi programada a OT
Informações sobre a OT
Corte de abastecimento Ocorrência de corte de abastecimento Campo incompleto
Danos particulares Danos a particulares Campo incompleto
Desinfecção da rede Necessidade de desinfecção da rede Irrelevante para o estudo
Infiltração Ocorrência de infiltrações Campo incompleto
OT da rede recente Sim / Não Campo incompleto
Pavimento danificado Sim / Não Campo incompleto
Perda de água - Sem informação - Campo incompleto
Perigo de contaminação Sim / Não Campo incompleto
Ramal fechado Necessidade de fechar ramais
Suspensão da rede Necessidade de suspensão da rede Irrelevante para o estudo
Tratamento da OT
Código de OT Identificação secundária da entidade no sistema Irrelevante para o estudo
Comunicação nº Número da comunicação Campo incompleto
Data de actualização (aaaa-
mm-dd)Data de actualização da OT Irrelevante para o estudo
Equipa Equipa responsável pela OT Irrelevante para o estudo
Equipa de execução
Estado da OTEstado registado da OT no sistema (executado, fechado ou
histórico)Irrelevante para o estudo
Utilizador Utilizador que introduziu a informação no sistema Irrelevante para o estudo
Proprietário do local de
intervenção
Entidade responsável pelo terreno em que se programou a
OT
Responsabilidade Responsabilidade pela OT Campo incompleto

xviii Anexos
Quadro A3 – Campos de dados das ordens de trabalhos (Cont.).
Quadro A4 – Registo do número de resultados admitidos como válidos em cada campo de
dados, para as OT.
Designação Descrição Observações
Datas
Data de abertura Data de abertura da OT Irrelevante para o estudo
Hora de abertura
Data de fecho (aaaa-mm-dd) Data de fecho da OT (estado da OT) Irrelevante para o estudo
Hora de fecho
Início de inspecção (data) Data de início de inspecção Irrelevante para o estudo
Início de inspecção (hora)
Fim de inspecção (data) Data de fim de inspecção Campo incompleto
Fim de inspecção (hora)
Início previsto de execução
(data)Data de início previsto de execução Irrelevante para o estudo
Início previsto de execução
(hora)
Fim previsto de execução
(data)Fim previsto para a execução da OT Campo incompleto
Fim previsto de execução
(hora)
Estado da previsão de
execuçãoEstado de previsão de execução da OT Irrelevante para o estudo
Data de início de execução
(aaaa-mm-dd)Data de início de execução Irrelevante para o estudo
Hora de início de execução
Data de fim de execução
(aaaa-mm-dd)Data de fim de execução Irrelevante para o estudo
Hora de fim de execução
Informações adicionais
Classe - Sem informação -
Endereço - Observações -
Estado de transmissão 0, 1 ou 2 Irrelevante para o estudo
Local de inspecção - Observações -
Nº da entidade - Sem informação -
Número de polícia - Observações -
Observações de abertura - Observações -
Observações de execução - Observações -
Observações de inspecção - Observações -
Campo Registos válidos Registos não válidos
Causa de intervenção 4 453 282
Comunicado por 4 735 0
Natureza da intervenção 4 691 44
Tipo de intervenção 4 535 200
Tipo de trabalho executado 4 144 591
Localização da intervenção 4 713 22
Proprietário do local de intervenção 4 607 128
Responsabilidade 4 311 424

Anexos xix
Quadro A5 – Registo das opções tomadas para validação dos dados de OT.
Os quadros anteriores (Quadro A4 e Quadro A5) pretendem clarificar o processo de validação
das OT, apresentando os resultados obtidos nos campos que se considerou conterem a
informação mais sensível no que respeita à adequação dos dados ao presente estudo. No
Quadro A5 ilustra-se, para cada um dos parâmetros, a lista das classificações possíveis,
realçando-se a vermelho aquelas que condicionaram a informação quanto à inclusão no modelo
proposto.
Paralelamente, um outro campo, designado Localização, não é incluído no Quadro A5 devido ao
extenso número de classificações que pode conter. Não obstante, foi igualmente analisado,
procedendo-se da mesma forma que nos restantes, ou seja, optando-se por invalidar os dados
que não correspondiam ao tipo desejado – de roturas em condutas de distribuição.
Causa de intervenção Registos Comunicado por Registos
-- Não conhecido -- 638 Particular 3529Acidental 3495 -- Não conhecido -- 462
Indeterminado 312 Câmara Municipal de Lisboa 94
Provocada 266 MCT 246
Tratamento em curso 16 ASL 70
Assentamento de terreno 5 DTF / Vigilante 96Defeito de montagem 3 Regimento Sapadores Bombeiros 145
Polícia Segurança Pública 93
Natureza da intervenção Registos Tipo de intervenção Registos
-- Não conhecido -- 981 -- Não conhecido -- 573
Avaria de órgão 44 Não programada 3962
Tubo rachado 1640 Programada 200
Tubo furado 265Tubo seccionado 728
Avaria de juntas 1065
Uniões desvedadas 12
Tipo de trabalho executado Registos Localização da intervenção Registos
Reparação 4140 -- Não conhecido -- 2779
Reparações diversas 4 Faixa de rodagem 468
Outros (registos excluídos) 591 Passeio 1466
Edifício 22
Proprietário do local de intervenção Registos Responsabilidade Registos
-- Não conhecido -- 1398 -- Não conhecido -- 148
APL - Porto de Lisboa 315 Câmara Municipal de Lisboa 25Recintos EPAL 41 Emp. Portuguesa das Águas Livres SA 4311
Terrenos particulares 38 Particular 247
Via pública 2815 R. S. Bombeiros 4
Zona de obras 128


Anexos xxi
Anexo IX – Extensão da rede por freguesia
Figura A6 – Extensão da rede por freguesia
- 20 40 60 80 100
Ajuda
Alcantara
Alto do Pina
Alvalade
Ameixoeira
Anjos
Beato
Benfica
Campo Grande
Campolide
Carnide
Castelo
Charneca
Coracao de Jesus
Encarnacao
Graca
Lapa
Lumiar
Madalena
Martires
Marvila
Merces
Nossa Senhora de Fatima
Pena
Penha de Franca
Prazeres
Sacramento
Santa Catarina
Santa Engracia
Santa Isabel
Santa Justa
Santa Maria de Belem
Santa Maria dos Olivais
Santiago
Santo Condestavel
Santo Estevao
Santos-o-Velho
Sao Cristovao e Sao Lourenco
Sao Domingos de Benfica
Sao Francisco Xavier
Sao Joao
Sao Joao de Brito
Sao Joao de Deus
Sao Jorge de Arroios
Sao Jose
Sao Mamede
Sao Miguel
Sao Nicolau
Sao Paulo
Sao Sebastiao da Pedreira
Sao Vicente de Fora
Se
Socorro
Extenção da rede [km]


Anexos xxiii
Anexo X – Índice mensal de roturas
Figura A7 – Índices médios mensais de roturas.
Figura A8 – Índice mensal médio de roturas com desvio-padrão.
0
10
20
30
40
50
60
70
80
Jan-
02Fe
v-02
Mar
-02
Abr
-02
Ma
i-02
Jun-
02Ju
l-02
Ago
-02
Set-
02O
ut-0
2N
ov-0
2D
ez-0
2Ja
n-03
Fev-
03M
ar-0
3A
br-0
3M
ai-
03Ju
n-03
Jul-
03A
go-0
3Se
t-03
Out
-03
Nov
-03
Dez
-03
Jan-
04Fe
v-04
Mar
-04
Abr
-04
Ma
i-04
Jun-
04Ju
l-04
Ago
-04
Set-
04O
ut-0
4N
ov-0
4D
ez-0
4Ja
n-05
Fev-
05M
ar-0
5A
br-0
5M
ai-
05Ju
n-05
Jul-
05A
go-0
5Se
t-05
Out
-05
Nov
-05
Dez
-05
Jan-
06Fe
v-06
Mar
-06
Abr
-06
Ma
i-06
Jun-
06Ju
l-06
Ago
-06
Set-
06O
ut-0
6N
ov-0
6D
ez-0
6Ja
n-07
Fev-
07M
ar-0
7A
br-0
7M
ai-
07Ju
n-07
Jul-
07A
go-0
7
Ro
tura
s/(1
00
km
.an
o)
Mês
42.58
30.34 28.5433.03 34.47 36.58 37.29 39.59 40.46
37.41
29.69
44.12
0
10
20
30
40
50
60
70
Jan Fev Mar Abr Mai Jun Jul Ago Set Out Nov Dez
Ro
tura
s/(1
00
km
.an
o)
me
nsa
is
mé
dia
s
Mês


Anexos xxv
Anexo XI – Índice médio anual de roturas por freguesia
Figura A9 – Índices médios anuais de roturas por freguesia.
0
20
40
60
80
100
120
Ajuda Alcantara Alto do Pina Alvalade
Ameixoeira Anjos Beato Benfica
Campo Grande Campolide Carnide Coracao de Jesus
Lapa Lumiar Marvila Merces
Nossa Senhora de Fatima Pena Penha de Franca Prazeres
Santa Isabel Santa Maria de Belem Santa Maria dos Olivais Santo Condestavel
Sao Domingos de Benfica Sao Francisco Xavier Sao Joao Sao Joao de Brito
Sao Joao de Deus Sao Jorge de Arroios Sao Mamede Sao Paulo


Anexos xxvii
Anexo XII – Resultados dos testes efectuados para definir a arquitectura do PMC
Quadro A 6 – Resultados do EQM, obtidos em redes com uma camada oculta (90% dos dados).
Quadro A 7 – Resultados de correlação, obtidos em redes com uma camada oculta (100% dos dados).
Quadro A 8 – Resultados de tempos de treino, obtidos em redes com uma camada oculta (100% dos dados).
EQM (90%)Rede net1_5 net5x1_5 net10x1_5 net15x1_5 net20x1_5 net25x1_5 net30x1_5 net35x1_5 net40x1_5
Mínimo 9.83E-04 9.02E-04 8.80E-04 8.04E-04 8.03E-04 8.39E-04 8.48E-04 8.08E-04 8.50E-04Máximo 9.84E-04 9.34E-04 9.28E-04 8.81E-04 8.43E-04 9.24E-04 8.66E-04 8.88E-04 9.73E-04
Média 9.84E-04 9.18E-04 9.09E-04 8.44E-04 8.28E-04 8.65E-04 8.58E-04 8.48E-04 8.91E-04Desvio-padrão 3.63E-08 8.80E-06 1.09E-05 2.62E-05 9.95E-06 2.08E-05 6.25E-06 1.94E-05 3.77E-05
Amostra (90% total) 45 45 66 54 21 28 12 25 12Nós camadas ocultas 0 5 10 15 20 25 30 35 40
Número de ligações 6 36 71 106 141 176 211 246 281
Correlação (100%)Rede net1_5 net5x1_5 net10x1_5 net15x1_5 net20x1_5 net25x1_5 net30x1_5 net35x1_5 net40x1_5
Mínimo 27.2% 30.2% 31.5% 11.5% 31.1% 30.6% 24.5% 11.6% 8.0%Máximo 27.2% 42.0% 46.0% 45.3% 45.6% 45.4% 45.8% 47.0% 46.2%
Média 27.2% 39.5% 42.3% 38.9% 41.6% 40.8% 43.2% 39.7% 39.4%Desvio-padrão 0.0% 2.4% 2.8% 7.2% 2.6% 4.4% 5.4% 7.4% 12.0%
Amostra (90% total) 50 50 74 61 24 32 14 28 14Nós camadas ocultas 0 5 10 15 20 25 30 35 40
Número de ligações 6 36 71 106 141 176 211 246 281
Tempo de treino (100%)Rede net1_5 net5x1_5 net10x1_5 net15x1_5 net20x1_5 net25x1_5 net30x1_5 net35x1_5 net40x1_5
Mínimo 4.16 10.27 15.21 17.95 37.55 37.22 69.35 71.33 85.80Máximo 8.75 29.12 34.85 57.18 64.09 89.99 109.48 148.06 268.79
Média 6.02 16.86 24.37 35.05 50.17 59.53 90.55 106.65 184.03Desvio-padrão 0.52 3.58 4.17 7.49 7.19 13.27 12.98 20.25 54.56
Amostra (90% total) 50 50 74 61 24 32 14 28 14Nós camadas ocultas 0 5 10 15 20 25 30 35 40
Número de ligações 6 36 71 106 141 176 211 246 281

xxviii Anexos
Quadro A 9 – Resultados do EQM, obtidos em redes com duas camadas ocultas (90% dos dados).
Quadro A 10 – Resultados de correlação, obtidos em redes com duas camadas ocultas (100% dos dados).
Quadro A 11 – Resultados de tempos de treino [s], obtidos em redes com duas camadas ocultas (100% dos dados).
Todos os testes foram efectuados recorrendo à validação K-fold, com subconjunto de validação a totalizar 20% do total de dados. O treino foi efectuado com
a retropropagação modificada com o algoritmo de Levenberg-Marquardt (modo determinístico).
EQM (90%)Rede net7x3x1_5 net9x6x1_5 net12x8x1_5 net14x11x1_5 net17x13x1_5 net19x16x1_5 net22x18x1_5
Mínimo 8.53E-04 8.44E-04 8.60E-04 8.24E-04 8.34E-04 7.87E-04 8.65E-04Máximo 9.32E-04 8.84E-04 9.29E-04 9.37E-04 8.83E-04 9.42E-04 9.20E-04
Média 8.99E-04 8.60E-04 8.92E-04 9.08E-04 8.59E-04 8.69E-04 8.83E-04Desvio-padrão 2.44E-05 1.10E-05 1.66E-05 2.34E-05 1.27E-05 3.21E-05 1.79E-05
Amostra (90% total) 23 22 34 28 20 21 8Nós camadas ocultas 10 15 20 25 30 35 40
Número de ligações 70 121 185 261 350 451 565
Correlação (100%)Rede net7x3x1_5 net9x6x1_5 net12x8x1_5 net14x11x1_5 net17x13x1_5 net19x16x1_5 net22x18x1_5
Mínimo 26.5% 29.9% 31.5% 31.6% 34.6% 21.2% 17.7%Máximo 45.6% 45.1% 45.9% 46.5% 47.7% 51.4% 45.1%
Média 38.8% 42.3% 41.1% 42.5% 43.5% 41.5% 38.8%Desvio-padrão 4.7% 3.2% 3.2% 3.4% 3.0% 6.8% 8.5%
Amostra (90% total) 26 25 38 32 23 24 9Nós camadas ocultas 10 15 20 25 30 35 40
Número de ligações 70 121 185 261 350 451 565
Tempo de treino (100%)Rede net7x3x1_5 net9x6x1_5 net12x8x1_5 net14x11x1_5 net17x13x1_5 net19x16x1_5 net22x18x1_5
Mínimo 25.75 27.63 45.63 72.99 104.50 152.29 228.17Máximo 55.77 59.17 108.86 146.82 195.95 382.48 606.75
Média 35.87 37.58 70.96 96.37 151.38 256.12 378.60Desvio-padrão 6.95 6.57 12.36 16.37 24.65 68.10 142.42
Amostra (90% total) 26 25 38 32 23 24 9Nós camadas ocultas 10 15 20 25 30 35 40
Número de ligações 70 121 185 261 350 451 565

Anexos xxix
Anexo XIII – EQM versus correlação para várias topologias de PMCs
Figura A 10 – EQM versus correlação para várias topologias de PMC
20.0%
25.0%
30.0%
35.0%
40.0%
45.0%
50.0%
7.50E-04 8.00E-04 8.50E-04 9.00E-04 9.50E-04 1.00E-03 1.05E-03
Co
rre
laçã
o
EQM
net1_5
net5x1_5
net10x1_5
net15x1_5
net20x1_5
net25x1_5
net30x1_5
net35x1_5
net40x1_5
net7x3x1_5
net9x6x1_5
net12x8x1_5
net14x11x1_5
net17x13x1_5
net19x16x1_5
net22x18x1_5


Anexos xxxi
Anexo XIV – Código da aplicação de AG desenvolvida para determinação da topologia óptima do PMC
Para execução deste código foi utilizada a Genetic Algorithms Toolbox do Matlab, pelo que o
código que se segue não corresponde a um AG completo, mas apenas às funções
personalizadas que foi preciso criar para adaptar a toolbox às necessidades do presente
problema
• Função para geração da população inicial;
• Função para mutação dos cromossomas;
• Função para cruzamento dos cromossomas;
• Função cálculo de desempenhos.
Função para geração da população
inicial
function Population = GA_CreNet(GenomeLength, FitnessFcn, options)
%Número de nós total global NN; NN = [5 10]+ [-0.4999 0.4999]; global VARNN VARNN = NN(2)/10; %Número de nós por camada [min máx] global NNeur NNeur= [5 10] + [-0.4999 0.4999]; global VARNNEUR VARNNEUR = NNeur(2)/8; %Número de camadas ocultas global NLay NLay = [1 3] + [-0.4999 0.4999]; global VARLAY VARLAY = 1; %Probabilidade de mutação no número de
camadas global ProbMLn ProbMLn = 0.50; %Probabilidade de mutação no número de nós global ProbMNn ProbMNn = 0.80; %Probabilidade de mutação em cada camada global ProbMLv ProbMLv = 0.75;
%Probabilidade de obtenção de valores intermédios - cruzamento
global PIntr PIntr = 0.33; %Variáveis para a função objectivo global Show Show = inf; global Epochs Epochs = 100; global Repeat Repeat = 10; global Train_fctn Train_fctn = 'trainlm'; global MemRed MemRed = 1; global Parcial Parcial = .8; global ALTERNATIVO ALTERNATIVO = 1; global MgERRO; MgERRO = 0.000003; global Dimmax; Dimmax = 40; global MATRIZ
MATRIZ=zeros(HipContador(round(NN(2)),round(NLay(2))),3);
%Estado da simulaçao global ESTADO ESTADO = [options.PopulationSize 1 0]; popsize = options.PopulationSize;

xxxii Anexos
Pop1 = zeros(popsize,GenomeLength); rand('state',sum(100*clock)); for a=1:popsize Pop1(a,1) = round(NLay(1) + (NLay(2)-
NLay(1))* rand); Pop1(a,2) = round(NN(1) + (NN(2)-NN(1))*
rand); for b=3:GenomeLength Pop1(a,b) = rand; end end for a=1:popsize aux = 0; aux1 = 0; restos = zeros(Pop1(a,1),2); soma = sum(Pop1(a,3:Pop1(a,1)+2)); for b=3:Pop1(a,1)+2 %escala aux = max(1,floor(Pop1(a,b) / soma *
Pop1(a,2))); restos(b-2,1) = (Pop1(a,b) / soma *
Pop1(a,2))-aux; restos(b-2,2) = b; Pop1(a,b) = aux; aux1 = aux1 + aux; end if aux1 ~= Pop1(a,2) %redistribuição dos
restos aux2 = sortrows(restos); b = (Pop1(a,2)-aux1); while b > 0 Pop1(a,aux2(Pop1(a,1)+1-b,2)) =
Pop1(a,aux2(Pop1(a,1)+1-b,2)) + 1; b= b-1; end c=0; while b < 0 c = max(b,c); while
or(aux2(c+2,1)<=0,Pop1(a,aux2(c+2,2))==1)
c = c+1; while aux2(c+2,2)==0; c=c+1 ; end end Pop1(a,aux2(c+2,2)) =
Pop1(a,aux2(c+2,2)) - 1; b= b+1; end end end for a=1:popsize for b=Pop1(a,1)+3:NLay(2)+2 Pop1(a,b)=0;
end end Pop = round(Pop1) Population = Pop; function Cont = HipContador(NN,NLay) % Forma a matriz de armazenamento dos
resultados vector = zeros(NLay,1); vector(1) = 1; vector(NLay) = -1; a=NLay; b=0; c=0; while vector(1)<= NN vector(NLay) = vector(NLay)+1; for b=NLay:-1:2 if vector(b) > NN vector(b:NLay)=0; vector(b-1)=vector(b-1)+1; end end if sum(vector(1:NLay))==NN b = 0; for a=1:NLay if vector(a) == 0 b=sum(vector(a:NLay)); a = NLay+1; end end if b == 0 c=c+1; end end end Cont = c;
Função para mutação de
cromossomas
function mutationChildren = GA_MutaNet(parents, options, nvars, FitnessFcn, state, thisScore, thisPopulation)
%Probabilidade de mutação no número de
camadas global ProbMLn %Probabilidade de mutação no número de nós global ProbMNn

Anexos xxxiii
%Probabilidade de mutação em cada camada global ProbMLv %Número de nós total global NN global VARNN %Número de nós por camada [min máx] global NNeur global VARNNEUR %Número de camadas ocultas global NLay global VARLAY disp (' --- Mutaçao ---'); parents [a b] = size(thisPopulation); GenLenght = b; [a b] = size(parents); ParentN = b; MutC1= zeros(ParentN,GenLenght); for a=1:ParentN %Construçao do vector de
mutações a partir a populaçao base MutC1(a,1:GenLenght) =
thisPopulation(parents(a),1:GenLenght); end rand('state',sum(100*clock)); for a=1:ParentN rede =
thisPopulation(parents(a),1:GenLenght); for b=3:GenLenght %normalizar os valores rede(b) = rede(b)/rede(2); end aux = rede(1); %número de camadas
prévias if rand <= ProbMLn %Mutaçao no número
de camadas rede(1) =
round(max(NLay(1),min(NLay(2),rede(1) + sqrt(VARLAY)*randn ))); %Altera-se uma camada de cada vez %NLay(1) + (NLay(2)-NLay(1))* rand);
end if rand <= ProbMNn %Alterações no número
total de nós rede(2) =
round(max(NN(1),min(NN(2),rede(2)+sqrt(VARNN)*randn)));
end if aux ~= rede(1) %para não haverem layers
com peso 0 no meio... for b=aux+2:rede(1)+2 rede(b) = rede(b) +
sqrt(VARNNEUR)/NNeur(2)*randn; %A variancia também é normalizada
end end for b=3:GenLenght %Alterações no tamanho
das camadas if rand <= ProbMLv rede(b) = rede(b) +
sqrt(VARNNEUR)/NNeur(2)*randn; %A variância também é normalizada
end end aux = 0; aux1 = 0; restos = zeros(rede(1),2); soma = sum(rede(3:rede(1)+2)); for b=3:rede(1)+2 %escala aux = max(1,floor(rede(b) / soma *
rede(2))); restos(b-2,1) = (rede(b) / soma * rede(2))-
aux; restos(b-2,2) = b; rede(b) = aux; aux1 = aux1 + aux; end if aux1 ~= rede(2) %redistribuição dos
restos aux2 = sortrows(restos); b = (rede(2)-aux1); while b > 0 rede(aux2(rede(1)+1-b,2)) =
rede(aux2(rede(1)+1-b,2)) + 1; b= b-1; end c=0; while b < 0 c = max(b,c); while
or(aux2(c+2,1)<=0,rede(aux2(c+2,2))==1)
c = c+1; while aux2(c+2,2)==0; c=c+1 ; end end rede(aux2(c+2,2)) = rede(aux2(c+2,2)) -
1; b= b+1; end end for b=(rede(1)+3):round(NLay(2)+2) rede(b)=0; end
MutC1(a,1:GenLenght)=round(rede(1:GenLenght));

xxxiv Anexos
for b=3:GenLenght %Para não aparecerem
mais nós por camada que os máximos if MutC1(a,b)>NNeur(2) MutC1(a,b)=NNeur(2); MutC1(a,2)=
sum(MutC1(a,3:GenLenght)); end end for b=MutC1(a,1)+3:GenLenght %Para as
camadas não usadas ficarem sempre 0 MutC1(a,b)=0; end end newpop = thisPopulation; for a=1:ParentN newpop(parents(a),1:GenLenght) =
MutC1(a,1:GenLenght); end round(MutC1) mutationChildren = round(MutC1);
Função para cruzamento de
cromossomas
function xoverKids = GA_xoverNet(parents, options, nvars, FitnessFcn, unused, thisPopulation)
thisPopulation disp (' --- Crossover ---'); parents %Estado global ESTADO ESTADO(2) = 1; ESTADO(3) = ESTADO(3) +1; global PIntr global NNeur global NLay GenLenght = nvars; [a b] = size(parents); ParentN = b; rand('state',sum(100*clock)); xoverC1= zeros(ParentN/2,GenLenght); for a=1:2:ParentN-1 %Número de camadas de cada pai - ordena
por numero de camadas
aux = sortrows([thisPopulation(parents(a),1) parents(a);thisPopulation(parents(a+1),1) parents(a+1)]);
%[Nlayers Pai %Nlayers Pai]; %Normalização dos pais thisPopulation(parents(a),3:GenLenght) =
thisPopulation(parents(a),3:GenLenght)/thisPopulation(parents(a),2);
thisPopulation(parents(a+1),3:GenLenght) = thisPopulation(parents(a+1),3:GenLenght)/thisPopulation(parents(a+1),2);
%Fazer o cruzamento for b=2:GenLenght %aux(1,1) if rand <= PIntr NMin =
min(thisPopulation(aux(1,2),b),thisPopulation(aux(2,2),b));
NMax = max(thisPopulation(aux(1,2),b),thisPopulation(aux(2,2),b));
xoverC1((a+1)/2,b) = NMin + (NMax-NMin)*rand;
else if rand<=0.5 xoverC1((a+1)/2,b)=
thisPopulation(aux(1,2),b); else xoverC1((a+1)/2,b)=
thisPopulation(aux(2,2),b); end end end if rand <= PIntr %Para o novo número de
camadas auxNC = round(aux(1,1)-
0.4999+(aux(2,1)+0.4999-(aux(1,1)-0.4999))*rand);
else if rand<=0.5 auxNC = aux(1,1); else auxNC = aux(2,1); end end xoverC1((a+1)/2,1)=auxNC; %Digita o
numero de camadas xoverC1((a+1)/2,2) =
round(xoverC1((a+1)/2,2)); %Faz o arredondamento do número de NN (já escolhido)
for b=aux(1,1)+1:auxNC %novas camadas xoverC1((a+1)/2,b+2)=
thisPopulation(aux(2,2),b+2); end

Anexos xxxv
aux = 0; aux1 = 0; restos = zeros(xoverC1((a+1)/2,1),2); soma =
sum(xoverC1((a+1)/2,3:xoverC1((a+1)/2,1)+2));
for b=3:xoverC1((a+1)/2,1)+2 %escala aux = max(1,floor(xoverC1((a+1)/2,b) /
soma * xoverC1((a+1)/2,2))); restos(b-2,1) = (xoverC1((a+1)/2,b) /
soma * xoverC1((a+1)/2,2))-aux; restos(b-2,2) = b; xoverC1((a+1)/2,b) = aux; aux1 = aux1 + aux; end if aux1 ~= xoverC1((a+1)/2,2)
%redistribuição dos restos aux2 = sortrows(restos); b = (xoverC1((a+1)/2,2)-aux1); while b > 0
xoverC1((a+1)/2,aux2(xoverC1((a+1)/2,1)+1-b,2)) = xoverC1((a+1)/2,aux2(xoverC1((a+1)/2,1)+1-b,2)) + 1;
b= b-1; end c=0; while b < 0 c = max(b,c); while
or(aux2(c+2,1)<=0,xoverC1((a+1)/2,aux2(c+2,2))==1)
c = c+1; while aux2(c+2,2)==0; c=c+1 ; end end xoverC1((a+1)/2,aux2(c+2,2)) =
xoverC1((a+1)/2,aux2(c+2,2)) - 1; b= b+1; end end for
b=(xoverC1((a+1)/2,1)+3):round(NLay(2)+2)
xoverC1((a+1)/2,b)=0; end end xoverC1 = round(xoverC1); for a=1:ParentN/2 for b=3:GenLenght %Para não aparecerem
mais nós por camada que os máximos
if xoverC1(a,b)>NNeur(2) xoverC1(a,b)=NNeur(2); xoverC1(a,2)=
sum(xoverC1(a,3:GenLenght)); end end end xoverKids = xoverC1
Função cálculo de desempenhos
function y = GAtoolNetComp(Vector) %Para comparar redes de tipologias diferentes %Variáveis global Show global Epochs global Repeat global Parcial global Train_fctn global MemRed global ALTERNATIVO global MgERRO global MATRIZ global NN global NLay global Dimmax %Dados dados = [0 1;0 1;0 1;0 1;0 1]; %Número de camadas ocultas NLays=Vector(1); %Dimensão das camadas ocultas; NNeu = zeros(1,1+NLays); for a=1:NLays NNeu(1,a) = Vector(a+1); end NNeu(1,NLays+1) = 1; %Funçoes de activação aux = 'tansig'; transf = cell(1,NLays+1); for a=1:NLays transf{1,a} = aux; end transf{1,NLays+1}= 'logsig'; net =
newelm(dados,NNeu,transf,Train_fctn,'learngdm','mse');
net.trainParam.show = Show; net.trainParam.epochs = Epochs; if Train_fctn == 'trainlm' net.trainParam.mem_reduc = MemRed; end

xxxvi Anexos
%inicializar a rede net.initFcn = 'initlay'; for a=1:NLays + 1 %Layers net.layers{a}.initFcn = 'initwb'; for b=1:NLays+1%NNeu(a) net.layerWeights{a,b}.initFcn = 'rands'; end end Dinp = net.numinputs; %Inputs e constantes for a=1:NLays+1 for b=1:Dinp net.inputWeights{a,b}.initFcn= 'rands'; end net.biases{a}.initFcn = 'rands'; end if net.numLayers-2 == -1 net.numLayers-2 end Vector %Análise de resultados prévios Id =
Numero(Vector,round(NN(2)),round(NLay(2)));
%Execuçao do código das ANN if Id ~= 0 if MATRIZ(Id,1) <= Dimmax perfact =
performanceNetC(net,evalin('base','dados'),evalin('base','alvos'),struct ('P',evalin('base','d_valida'), 'T', evalin('base','a_valida')), struct ('P',evalin('base','d_teste'), 'T', evalin('base','a_teste')),1)
%Preenchimento da matriz de resultados MATRIZ(Id,2)=
(MATRIZ(Id,2)*MATRIZ(Id,1)+perfact*Repeat*Parcial)/(MATRIZ(Id,1)+Repeat*Parcial);
MATRIZ(Id,1)= MATRIZ(Id,1)+Repeat*Parcial;
else perfact =
performanceNetC(net,evalin('base','dados'),evalin('base','alvos'),struct ('P',evalin('base','d_valida'), 'T', evalin('base','a_valida')), struct ('P',evalin('base','d_teste'), 'T', evalin('base','a_teste')),0)
MATRIZ(Id,2)= (MATRIZ(Id,2)*MATRIZ(Id,1)+perfact)/(MATRIZ(Id,1)+1);
MATRIZ(Id,1)= MATRIZ(Id,1)+1; end
result= MATRIZ(Id,2); disp(strcat('Fitness: ',num2str(result),'
(',num2str(MATRIZ(Id,1)),')')); else result = 1; end y = result; function
y=performanceNetC(rede,dados,alvos,valida,teste,grupo)
%Variáveis global Repeat global ESTADO global Parcial repeats = Repeat; parcials = Parcial; if grupo == 0 repeats=1; parcials=1; end rand('state',sum(100*clock)); [r c]=size(alvos); aux = 0; resultad = zeros(repeats); for a = 1:repeats
disp(strcat(num2str(ESTADO(2)),'/',num2str(ESTADO(1)*Repeat),', ',num2str(ESTADO(3)),'ª geração'));
disp(strcat(num2str(a),'/',num2str(repeats))); %Estado de progresso
if grupo == 0 ESTADO(2) = ESTADO(2)+Repeat; else ESTADO(2) = ESTADO(2)+1; end rede= init(rede); %Fazer a simulaçao [redeaux,tr] =
train(rede,dados,alvos,[],[],valida,teste); [r c]=size(tr.perf); resultad(a) = tr.perf(c); end auxvect = sortrows(resultad);

Anexos xxxvii
aux = sum(auxvect(1:max(round(repeats*parcials),1)));
%disp('Fitness ='); %disp(aux/max(round(repeats*parcials),1)); y = aux/max(round(repeats*parcials),1); function Numer =
Numero(Cromossoma,NN,NLay) vector = zeros(NLay,1); vector(1) = 1; vector(NLay) = -1; a=NLay; b=0; c=0; nume=0; while vector(1)<= NN vector(NLay) = vector(NLay)+1; for b=NLay:-1:2 if vector(b) > NN vector(b:NLay)=0; vector(b-1)=vector(b-1)+1; end end if sum(vector(1:NLay))==NN b = 0; for a=1:NLay if vector(a) == 0 b=sum(vector(a:NLay)); a = NLay+1; end end if b == 0 c=c+1; if Cromossoma(3:NLay+2)==
transpose(vector) nume = c; end end end end Numer = nume;


Anexos xxxix
Anexo XV – Parâmetros utilizados no AG utilizado para determinação da topologia óptima do PMC
Quadro A 12 – Síntese dos parâmetros utilizados no AG.
Parâmetros da população
Número de variáveis no cromossoma 6 Tipo da população Números inteiros
Dimensão da população (número de indivíduos) 20 Ordenação dos resultados
Diferenciação do desempenho “fitness scaling” Ordenação simples (Rank)
Função de selecção Uniforme estocástica Opções de reprodução
Indivíduos de elite 0
Percentagem de cruzamento 70%
Percentagem de mutação 30% Funções externas utilizadas (ver Anexo XIV)
Função de geração da população inicial @GA_CreNet
Função de cruzamento @GA_xoverNet Função de mutação @GA_MutaNet
Função de desempenho @GAtoolNetComp Número total de nós no PMC
Intervalo do número total de nós no PMC Variável
Variância no número total de nós no PMC 1/10 do número máximo Número de nós por camada
Intervalo do número de nós por camada Variável
Variância do número de nós por camada 1/8 do número máximo Número de camadas ocultas
Intervalo do número camadas ocultas [1 4]
Variância do número camadas ocultas 1 Probabilidades de mutação (apenas cromossomas seleccionados para mutação)
Probabilidade de mutação do número de camadas ocultas 50%
Probabilidade de mutação no número total de nós 80%
Probabilidade de mutação do número de nós em cada camada oculta
75%
Probabilidades de cruzamento (apenas cromossomas seleccionados para cruzamento)
Probabilidade de obtenção de valores intermédios no cruzamento (em oposição a obter valores de um ou outro dos cromossomas “pai”)
33%
Parâmetros para treino dos PMC
Número máximo de épocas de treino do PMC 100 Algoritmo de treino do PMC Retropropagação de Levenberg-Marquardt
(trainlm) Repetições do treino do PMC por época do AG 10
Purga dos piores resultados obtidos no treino do PMC 20%
Dimensão do subconjunto de validação 20% Número de dados a partir dos quais se efectua apenas um treino do PMC por época
40


Anexos xli
Anexo XVI – Resultados da comparação de algoritmos de treino
A comparação seguinte foi levada a cabo para a rede net20x1_5 (escolhida como a mais
adequada para modelação da degradação das redes de distribuição de água). Os grupos de
validação e teste correspondem, cada um, a 20% do total de dados.
Note-se que estes algoritmos correspondem todos a modificações da retropropagação de
Rumelhart, não alterando a essência da propagação dos erros, mas apenas a forma de
computação da correcção do peso sináptico de cada ligação.
Dos algoritmos testados os mais importantes são porventura o traingdx, por ser o mais próximo
da concepção de Rumelhart, e os trainlm (Levenberg-Marquardt) e trainrp (retropropagação
resiliente), devido aos bons resultados obtidos. A lista completa das abreviaturas utilizadas
encontra-se no Anexo IV.
Quadro A 13 – Resultados do EQM obtidos através da utilização de vários algoritmos de
treino, para a rede net20x1_5 (100% dos dados).
Quadro A 14 – Resultados da correlação obtidos através da utilização de vários algoritmos
de treino, para a rede net20x1_5 (100% dos dados).
Quadro A 15 – Resultados tempo de treino [s] obtidos através da utilização de vários
algoritmos de treino, para a rede net20x1_5 (100% dos dados).
EQM (100%)Algoritmo traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
Mínimo 9.24E-04 8.95E-04 9.00E-04 8.90E-04 9.03E-04 9.32E-04 1.01E-03 8.12E-04Máximo 9.74E-04 9.47E-04 9.42E-04 9.33E-04 1.08E-03 1.02E-03 1.05E-03 1.06E-03
Média 9.52E-04 9.15E-04 9.15E-04 9.06E-04 9.23E-04 9.84E-04 1.03E-03 8.54E-04Desvio-padrão 1.18E-05 1.25E-05 1.04E-05 8.94E-06 3.36E-05 2.39E-05 8.68E-06 4.56E-05Amostra (total) 50 50 50 50 50 50 50 50
Correlação (100%)Algoritmo traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
Mínimo 3.8% 28.8% 23.6% 25.3% 5.0% 9.5% -3.5% 8.0%Máximo 33.4% 37.1% 35.8% 35.8% 36.6% 31.6% 17.2% 46.6%
Média 26.4% 34.3% 31.0% 32.2% 33.6% 20.6% 9.8% 41.5%Desvio-padrão 5.0% 1.9% 2.5% 2.5% 5.3% 5.0% 5.1% 7.2%Amostra (total) 50 50 50 50 50 50 50 50
Tempo de treino (100%)Algoritmo traingdx trainrp traincgp traincgb trainscg trainbfg trainoss trainlm
Mínimo 219.8 24.5 30.2 36.8 3.9 24.7 20.8 21.5Máximo 284.3 58.3 67.2 66.2 82.9 77.2 143.8 85.2
Média 248.0 38.3 46.9 50.3 65.2 50.5 50.2 44.6Desvio-padrão 15.4 7.8 7.4 5.8 14.9 10.6 26.4 9.7Amostra (total) 50 50 50 50 50 50 50 50


Anexos xliii
Anexo XVII – Relação entre diâmetros e índice OT/(100km.ano) no conjunto de dados e na RNA
Figura A 11 – Diâmetro nominal versus OT/(100km.ano), para a RNA treinada e para o conjunto de dados.
0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200 250 300 350
OT
/(1
00
km
.an
o)
Diâmetro nominal da tubagem [mm]
FF
FC
PEAD
FFD
FF sim.
FC sim.
PEAD sim.
FFD sim.


Anexos xlv
Anexo XVIII – Processo de geração de padrões fictícios para análise de resultados
O módulo para geração de padrões fictícios pretende dar uma amostra de todo o hipercubo dos
dados para que a RNA pode, hipoteticamente, vir a ter que fazer previsões. Para este efeito, há
que definir, por parâmetro, quantos e quais os pontos amostrais a considerar. No caso de os
parâmetros corresponderem a variáveis discretas, essa tarefa é directa, no caso de variáveis
contínuas há que definir o intervalo em torno de cada ponto amostral.
Para além de gerar padrões com todas as combinações dos pontos amostrais escolhidos, este
módulo calcula o indicador OT/(100km.ano) real que corresponde a cada padrão fictício. Uma
vez que alguns parâmetros podem ser contínuos, a correspondência é feita de acordo com o
intervalo definido, havendo um “vizinhança” em que registos de padrões reais, semelhantes ao
fictício, são contabilizados.
Posteriormente, a matriz dos padrões fictícios é normalizada e simulada na RNA, obtendo-se um
vector com a as previsões para o índice OT(100km.ano). Os valores normalizados são, portanto
valores representativos dos vários parâmetros em cada um dos padrões. Do Quadro A 17 ao
Quadro A 20 são definidos os pontos amostrais seleccionados para cada um dos parâmetros.
Quadro A 16 – Pontos amostrais admitidos para o parâmetro subsistema de distribuição.
Subsistema de distribuição
Classe
Valor
representativo
Zona Sobrepressora 1
Zona Alta 2
Zona Alta Redutora 3
Zona Superior do Monsanto 4
Zona Superior Redutora 5
-- Não conhecido -- 6
Zona Superior Charneca 7
Zona Baixa 8
Zona Média 9
Zona Baixa Redutora 10
Zona Superior 11

xlvi Anexos
Quadro A 17 – Pontos amostrais admitidos para o parâmetro material.
Quadro A 18 – Pontos amostrais admitidos para o parâmetro idade da tubagem.
Material
Classe
Valor
representativo
FF 1
FC 2
PEAD 3
FFD 4
Idade da tubagem [anos]
Valor
mínimo
Valor
máximo
Valor
representativo
Valor
mínimo
Valor
máximo
Valor
representativo
0 2 1 50 52 51
2 4 3 52 54 53
4 6 5 54 56 55
6 8 7 56 58 57
8 10 9 58 60 59
10 12 11 60 62 61
12 14 13 62 64 63
14 16 15 64 66 65
16 18 17 66 68 67
18 20 19 68 70 69
20 22 21 70 72 71
22 24 23 72 74 73
24 26 25 74 76 75
26 28 27 76 78 77
28 30 29 78 80 79
30 32 31 80 82 81
32 34 33 82 84 83
34 36 35 84 86 85
36 38 37 86 88 87
38 40 39 88 90 89
40 42 41 90 92 91
42 44 43 92 94 93
44 46 45 94 96 95
46 48 47 96 98 97
48 50 49 98 100 99

Anexos xlvii
Quadro A 19 – Pontos amostrais admitidos para o parâmetro diâmetro nominal.
Quadro A 20 – Pontos amostrais admitidos para o parâmetro OT/(100km.ano) prévias.
Diâmetro nominal [mm]
Valor
mínimo
Valor
máximo
Valor
representativo
0 50 25
50 100 75
100 150 125
150 200 175
200 250 225
250 315 283
OT/(100km.ano) prévias
Valor
mínimo
Valor
máximo
Valor
representativo
Valor
mínimo
Valor
máximo
Valor
representativo
0 0 0.0 200 250 225.0
0 5 2.5 250 300 275.0
5 10 7.5 300 400 350.0
10 15 12.5 400 500 450.0
15 20 17.5 500 600 550.0
20 25 22.5 600 700 650.0
25 30 27.5 700 800 750.0
30 35 32.5 800 900 850.0
35 40 37.5 900 1 000 950.0
40 45 42.5 1 000 1 500 1 250.0
45 50 47.5 1 500 2 000 1 750.0
50 60 55.0 2 000 2 500 2 250.0
60 70 65.0 2 500 3 000 2 750.0
70 80 75.0 3 000 3 500 3 250.0
80 90 85.0 3 500 4 000 3 750.0
90 100 95.0 4 000 5 000 4 500.0
100 150 125.0 5 000 6 000 5 500.0
150 200 175.0 6 000 7 000 6 500.0


Anexos xlix
Anexo XIX – Relação entre idade, índice OT/(100km.ano) prévias e índice de OT/(100km.ano) apreendida pela RNA treinada
Figura A 12 – Relação entre idade, índice OT/(100km.ano) prévias e índice de OT/(100km.ano) apreendida pela RNA treinada.
0 13
28
43
65
95 225 45
0 750
1250 27
50 4500
0
500
1000
1500
2000
2500
3000
3500
1
13
25
37
49
61
73
85
97 OT/(100km.ano) prévias
OT
/(1
00
km
.an
o)
Idade da tubagem
3000-3500
2500-3000
2000-2500
1500-2000
1000-1500
500-1000
0-500