Embed Size (px)
Citation preview

Vol. 4, No. 1
Vitória-ES, Brasil – Jan/ Abr2007
pp. 74-95
Recebido em 15/12/2006; revisado em 03/01/2007; aceito em 05/02/2007. Correspondência com autor: * E-mail: [email protected] ** E-mail: [email protected]
Nota do Editor: Este artigo foi aceito por Alexsandro Broedel Lopes.
74
Valor em Risco (VaR) utilizando modelos de previsão de volatilidade: EWMA, GARCH e Volatilidade Estocástica
Fernando Caio Galdi* Universidade de São Paulo
Leonel Molero Pereira**
Universidade de São Paulo
RESUMO: Este artigo explora três modelos utilizados para a estimativa da volatilidade: suavização exponencial – EWMA, volatilidade condicional – GARCH e volatilidade estocástica – VE. A volatilidade estimada por estes modelos pode ser utilizada em uma métrica de risco de mercado denominada Valor em Risco – VaR. A medida do VaR depende da volatilidade, do horizonte de tempo e do intervalo de confiança para os retornos contínuos em análise. Para a avaliação empírica destes modelos utilizamos uma amostra com preços de ações preferenciais da Petrobras para a especificação do GARCH e do modelo de VE. Adicionalmente realizamos testes para se verificar o ajustamento dos modelos à amostra selecionada. Nesse sentido utilizamos o teste de violação dos limites para um VaR de um dia, com intuito de comparar a eficiência dos modelos GARCH, VE e EWMA (sugerido pelo Riskmetrics). Pelos resultados verifica-se que o VaR calculado pelo EWMA sofreu um menor número de violações do que o calculado pelo GARCH e pela VE para uma janela de 1500 observações. Assim, o modelo sugerido pelo Riskmetrics (1999), utilizando a volatilidade calculada através da suavização exponencial, além de ser favorecido pela simplicidade em sua implementação, não forneceu resultados inferiores no teste de violação, comparado a modelos mais sofisticados como o de VE e o GARCH. Palavras Chave: VaR, Volatilidade Estocástica, GARCH, EWMA

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
75
1. INTRODUÇÃO s modelos de volatilidade têm como principal objetivo prover uma métrica que pode ser utilizada na gestão de riscos financeiros, auxílio na seleção de carteiras de ativos e na formação de preços de derivativos. Os modelos de valor em risco – VaR, utilizados na gestão de risco de
instituições financeira, como medida de risco perda financeira para um determinado intervalo confiança e horizonte de tempo, precisam de uma estimativa de volatilidade para a sua elaboração. Os modelos de previsão de volatilidade, como o GARCH e volatilidade estocástica são propostos como alternativa para essa estimativa. Nesse sentido o presente artigo sugere a utilização dos modelos auto-regressivos de heteroscedasticidade condicional e de volatilidade estocástica para a previsão da volatilidade utilizada nas medidas de VaR.
Neste trabalho os modelos são especificados e seus parâmetros estimados utilizando uma longa amostra de retornos contínuos de ações preferenciais de Petrobras. Adicionalmente, realiza uma comparação, através de um teste de violação dos limites de VaR dos modelos obtidos pelo GARCH, pelo modelo de volatilidade estocástica (MVE) e pelo modelo sugerido pelo Riskmetrics (1999) para os retornos marcados a mercado da carteira de ações da Petrobras.
O artigo é organizado em oito seções distintas mais anexos onde a segunda seção apresenta a medida do VaR e a adequação dos modelos de volatilidade a essa medida. A terceira seção introduz os principais conceitos do modelo GARCH. A seção quatro faz uma breve apresentação dos modelos de volatilidade estocástica. Na seção cinco e seis são apresentados os dados utilizados e os modelos de volatilidade são especificados. A sétima seção detalha a realização de um Backtesting para comparar a eficiência dos modelos de previsão de volatilidade utilizados no VaR. A oitava seção apresenta as considerações finais. Os anexos apresentam resultados mais detalhados da estimação de cada modelo. 2. VALOR EM RISCO DE MERCADO (VaR) PARA UMA CARTEIR A
O valor em risco (VaR) tem como finalidade a mensuração de riscos de mercado em termos de volatilidade dos preços dos ativos. O VaR, como definido por Jorion (2001, p.19), sintetiza a maior (ou pior) perda esperada de uma carteira, dentro de determinados períodos de tempo e intervalo de confiança. Formalmente, define-se o VaR para uma posição comprada em um ativo S em um horizonte de tempo j, com probabilidade p, sendo 0<p<1:
p = P(∆Pj ≤VaR) = Fj(VaR) (2.1)
onde ∆Pj representa o ganho ou a perda da posição P, dada por ∆Pj = Pt+j – Pt; Fj(.) é a função de distribuição acumulada (f.d.a) da variável aleatória ∆Pj.
O VaR é dado em unidades monetárias e representa o p-quantil da distribuição Fj(.). Segundo Moretin (2004, p.179) estima-se este quantil a partir da distribuição empírica dos retornos. O VaR calculado em (2.1) tem valor negativo, pois quem tem uma posição comprada sofre perda se ∆Pj<0. A quantia em unidades monetárias no cálculo do VaR é obtida multiplicando o valor da posição financeira pelo VaR do retorno.
O VaR pode ser simplificado, se for possível supor distribuição normal dos retornos contínuos (yt), ou log-retornos, dos ativos que compõem a carteira. Partindo-se das estimativas dos parâmetros da distribuição, como o desvio-padrão dos retornos, pode-se determinar a perda esperada carteira da seguinte maneira:
O
Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
76
( )∫ ∞−=
*ydyyfp , ( )
( )σ
µ
πσ2
* 2
2
1 −−
=y
eyf (2.2)
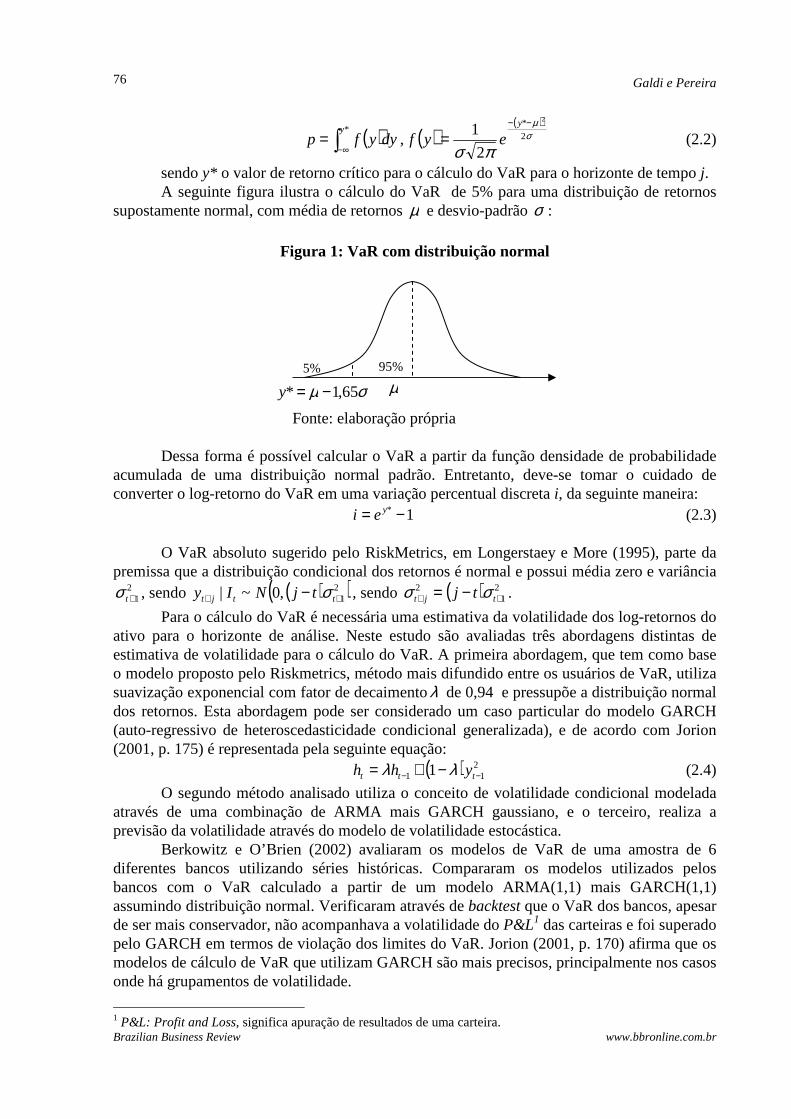
sendo y* o valor de retorno crítico para o cálculo do VaR para o horizonte de tempo j. A seguinte figura ilustra o cálculo do VaR de 5% para uma distribuição de retornos
supostamente normal, com média de retornos µ e desvio-padrão σ :
Figura 1: VaR com distribuição normal
Fonte: elaboração própria
Dessa forma é possível calcular o VaR a partir da função densidade de probabilidade acumulada de uma distribuição normal padrão. Entretanto, deve-se tomar o cuidado de converter o log-retorno do VaR em uma variação percentual discreta i, da seguinte maneira:
1* −= yei (2.3)
O VaR absoluto sugerido pelo RiskMetrics, em Longerstaey e More (1995), parte da premissa que a distribuição condicional dos retornos é normal e possui média zero e variância
21+tσ , sendo ( )( )2
1,0~| ++ − ttjt tjNIy σ , sendo ( ) 21
2++ −= tjt tj σσ .
Para o cálculo do VaR é necessária uma estimativa da volatilidade dos log-retornos do ativo para o horizonte de análise. Neste estudo são avaliadas três abordagens distintas de estimativa de volatilidade para o cálculo do VaR. A primeira abordagem, que tem como base o modelo proposto pelo Riskmetrics, método mais difundido entre os usuários de VaR, utiliza suavização exponencial com fator de decaimentoλ de 0,94 e pressupõe a distribuição normal dos retornos. Esta abordagem pode ser considerado um caso particular do modelo GARCH (auto-regressivo de heteroscedasticidade condicional generalizada), e de acordo com Jorion (2001, p. 175) é representada pela seguinte equação:
( ) 211 1 −− −+= ttt yhh λλ (2.4)
O segundo método analisado utiliza o conceito de volatilidade condicional modelada através de uma combinação de ARMA mais GARCH gaussiano, e o terceiro, realiza a previsão da volatilidade através do modelo de volatilidade estocástica.
Berkowitz e O’Brien (2002) avaliaram os modelos de VaR de uma amostra de 6 diferentes bancos utilizando séries históricas. Compararam os modelos utilizados pelos bancos com o VaR calculado a partir de um modelo ARMA(1,1) mais GARCH(1,1) assumindo distribuição normal. Verificaram através de backtest que o VaR dos bancos, apesar de ser mais conservador, não acompanhava a volatilidade do P&L1 das carteiras e foi superado pelo GARCH em termos de violação dos limites do VaR. Jorion (2001, p. 170) afirma que os modelos de cálculo de VaR que utilizam GARCH são mais precisos, principalmente nos casos onde há grupamentos de volatilidade.
1 P&L: Profit and Loss, significa apuração de resultados de uma carteira.
µ σµ 65,1* −=y
5% 95%

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
77
Neste estudo é utilizado o modelo de volatilidade condicional na forma reduzida para o cálculo do VaR, como foi realizado no trabalho de pesquisa de Berkowitz e O’Brien (2002), originalmente proposto por Zangari (1997). O modelo utilizado será composto por um componente autorregressivo dos retornos, representado por um modelo AR(1)2:
ttt yy εφφ ++= −110 (2.5)
Combinado com um modelo de volatilidade condicional GARCH(1,1)
112
110 −− ++= ttt hh βεαα (2.6)
Para o cálculo do VaR com o modelo de volatilidade condicionada AR(1) mais GARCH(1,1), utiliza-se a média e variância condicionais um passo a frente estimadas através do modelo:
( ) ( )( )1ˆ,1ˆ~| 21 tttt yNIy σ+ (2.7)
Nesse contexto supondo um VaR de 5% de um dia, ( com p = 5%, e z =1,65), ele deve ser calculado da seguinte forma:
( ) ( )1ˆ65,11ˆ 2%5 ttyVaR σ−= (2.8)
Nas seguintes seções são descritos os modelos utilizados para prever a volatilidade utilizada no calculo do VaR. 3. MODELO GARCH
Engle (1982) mostra que é possível modelar simultaneamente a média e a variância de uma série. Para isso lança mão do conceito de variância condicional, que pode ser modelada como um termo autorregressivo:
tqtpttt v+++++= −+−−2
1
2
22
2
110
2 ˆˆˆˆ εαεαεααε L (3.1)
onde tε̂ é o resíduo estimado do modelo yt = a0 + Φ yt-1 + εt e vt é um ruído branco.
A representação da equação acima é a base do modelo auto-regressivo de
heteroscedasticidade condicional (ARCH). Entretanto, em termos de estimação de εt ela não é a mais conveniente, dado que para a realização da estimação conjunta de {yt} e da variância condicional utiliza-se a técnica de máxima verossimilhança. Assim, uma especificação mais adequada é tratar vt como um termo multiplicativo. Logo, a equação pode ser representada da seguinte maneira:
∑=
−+=q
iititt v
1
2
0 ε̂ααε (3.2)
onde α0 e αi são parâmetros constantes tais que α0>0, αi≥0 e 0≤∑αi≤1, para que a
variância dada por ∑=
−=q
ii
10
2 1/ αασ ε, não seja negativa e/ou explosiva.
Bollerslev (1986) expandiu o modelo (3.2) de maneira a permitir que a variância condicional fosse modelada como um processo autorregressivo de média móvel (ARMA). O modelo auto-regressivo de heteroscedasticidade condicional generalizada (GARCH) é “uma generalização do modelo ARCH, no qual a variância condicional de n no instante t depende não somente de perturbações ao quadrado passadas, mas também de variâncias condicionais passadas” (Gujarati, 2005, p.440). A tipificação mais comum é o modelo GARCH(1,1), onde
2 A identificação do modelo ARMA (p,q) utilizado no estudo seguiu a metodologia apresentada por Box Jenkins (1970).

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
78
o primeiro número se refere a defasagem dos termos autorregressivos e o segundo se refere ao número de defasagens no componente de média móvel do modelo. Os modelos GARCH (p,q) são especificados como:
ttt hv=ε (3.3)
onde 12 =vσ e
∑∑=
−=
− ++=p
iiti
q
iitit hh
11
20 βεαα (3.4)
As restrições desse modelo são: α0>0, αi≥0, βi≥0 e 0≤∑αi+∑βi≤1. Interessante notar que os modelos GARCH são heteroscedásticos condicionais, mas
têm uma variância incondicional constante. Para especificação dos modelos GARCH, é necessário que se assuma a distribuição
condicional dos termos de erro εt. A literatura emprega, usualmente, as distribuições: i) Normal, ii) t de Student e/ou iii) distribuição dos erros generalizados. Para uma dada distribuição, estima-se o modelo pelo método de máxima verossimilhança. Por exemplo, para um modelo GARCH (1,1), com T observações, onde se assume a distribuição normal dos termos de erro, tem-se a log-verossimilhança dada por:
∑ −−−−−−=T
tttt hyayhL1
2
10 /)(2
1)log(
2
1)2log(
2
1log φπ (3.5)
No caso da assunção da distribuição t de Student tem-se:
∑
−−−
++−−
+ΓΓ−−= −
T
t
tt
t vh
yayvh
v
vvL
1
2
10
2
2
)2(
)(1log
2
)1(log
2
1
)2/)1((
)2/()2(log
2
1log
φπ (3.6)
onde v é o número de graus de liberdade e Γ(x) é a função Gamma usual, ou seja,
∫∞
−−=Γ0
1)( dyeyx yx .
O presente artigo utiliza as estimações do modelo GARCH considerando os métodos da
máxima verossimilhança baseada na distribuição normal3. 4. MODELO DE VOLATILIDADE ESTOCÁSTICA (MVE)
Segundo Morettin (2004, p.164) “os modelos da família GARCH supõem que a variância
condicional depende dos retornos passados”. O modelo de volatilidade estocástica (MVE), primeiro proposto por Taylor (1986), não faz essa suposição. Este modelo tem como premissa que a volatilidade presente depende de seus valores passados, mas que é independente dos retornos passados. Considerando o preço do ativo financeiro em t (St), o modelo de volatilidade estocástica em tempo discreto, apresentado por Harvey, Ruiz e Shephard (1994), pode ser escrito como:
yt = σt εt, t = 1 ,....., T (4.1) onde yt representa o retorno contínuo do ativo no período t, calculado por yt = ln(St / St-1), e o logσ2 segue um processo AR(1). Assume-se que εt é uma série de termos aleatórios independentes e identicamente distribuídos (iid). Usualmente, εt é especificado para ter uma distribuição padrão, então sua variância, σε
2 é desconhecida. Portanto, para uma distribuição
3 Foram testados, também, os modelos baseados na distribuição t de Student e as diferenças nos resultados encontrados não são significativas.

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
79
normal, σε2 é igual a um, enquanto que, para uma distribuição t, com v graus de liberdade, será
v/(v-2). Seguindo a convenção da literatura, pode-se escrever: yt = σ εt e
0,5ht (4.2)
onde ht é a volatilidade logarítmica em t e σ é um fator escalar constante, por isso não há necessidade de uma constante no termo auto-regressivo estacionário de primeira ordem, conforme a seguinte equação:
ht+1 = Φ ht + ηt , ηt ~iid (0,σ2η), |Φ|< 1 (4.3)
Se εt tem variância finita, a variância de yt é dada por:
( ) ( )222 2heyVar t
σεσσ= (4.4)
onde σh
2 é a variância de ht.
Uma das vantagens do modelo em tempo discreto de volatilidade estocástica é que ele
é análogo aos modelos de tempo contínuo utilizados em artigos de formação de preços de opções, como em Hull e White (1987). As propriedades econométricas básicas dos MVE são discutidas em Taylor (1986, 1994), Shephard (1996), Ghysels, Harvey, e Renault (1996) e Jacquier, Polson, e Rossi (1994). Uma das características chave desse modelo é que ele pode ser linearizado, aplicando-se o logaritmo ao quadrado das observações em (4.2):
log y2t = ht + log εt
2 + log σ 2 (4.5) Posteriormente, o termo( )2log tE ε é somado e subtraído da expressão (4.5), e se chega
a: log y2
t = ht + log εt 2 - E(log εt
2) + log σ 2+ E(log εt 2) (4.6)
A representação dessa expressão pode ser escrita como:
ttt hky ξ++=2log (4.7)
onde к= log σ 2+ ( )2log tE ε e ξt = log εt
2 - ( )2log tE ε .
Conforme apresentado em Harvey, Ruiz e Shephard (1994) a forma de espaço de estado dada pelas equações (4.3) e (4.7) fornecem a base para a estimação dos parâmetros do modelo via a aplicação do filtro de Kalman. Harvey, Ruiz e Shephard (1994) estimaram os parâmetros θ = (Φ, σ2
η) ∈ (-1,1), maximizando seguinte função de quase verossimilhança:
( ) ∑ ∑= =
−−−=n
t
n
ttttQ FvF
nyL
1 1
2
21
log21
2log2
|log πθ (4.8)
onde y = (y1, y2,...), υt é a projeção do erro um passo a frente para o melhor estimador do log y2
t e Ft é o erro quadrático correspondente.
A estimação realizada pelo método de quase máxima verossimilhança é consistente e assintoticamente segue uma distribuição normal. Na próxima seção são detalhadas as características da amostra, com dados de mercado de ações, utilizada para a aplicação dos modelos apresentados. 5. DESCRIÇÃO DOS DADOS
Para a aplicação dos modelos de volatilidade para o cálculo do valor em risco (VaR) foi selecionada a ação preferencial da Petrobrás (Petr4) dada sua alta liquidez e número de

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
80
dias de negociação com uma ampla janela de dados disponível. Os dados são diários (dias úteis) e abrangem o período de 02/01/1995 a 12/01/2006, totalizando 2729 observações.
Alexander (2005, p.90) relata que “no modelo GARCH há uma dicotomia entre se ter dados suficientes para que as estimativas dos parâmetros sejam estáveis, conforme a janela de dados móvel, e dados em excesso, de forma que as previsões não reflitam apropriadamente as condições correntes de mercado”. A amostra selecionada representa uma janela de onze anos para aplicação dos modelos, pois se priorizou a estabilidade dos parâmetros. A figura 2 expressa o comportamento da série de retornos selecionada, destacando eventos que provocaram grupamentos de alta volatilidade.
Figura 2: Retorno Contínuo da Petrobrás PN
-.3
-.2
-.1
.0
.1
.2
.3
500 1000 1500 2000 2500
PETR
Inicialmente foram realizados testes para a identificação da existência ou não de raiz unitária e de heteroscedasticidade condicional na série para a adequada aplicação dos modelos. Pelos testes realizados (Dickey e Fuller aumentado, Phillips e Perron, KPSS e correlograma dos retornos ao quadrado) pode-se dizer que a série é estacionária e heterocedástica, o que a qualifica para a aplicação dos modelos em análise (ver anexo). 6. ESPECIFICAÇÃO DOS MODELOS
Nesta seção são especificados os modelos GARCH e de volatilidade estocástica utilizando a amostra de dados acima mencionada.
A especificação do modelo combinado AR(1) e GARCH (1,1) foi feita com o auxílio do programa EVIEWS. O modelo AR(1) especificado foi:
( )01992,0
132674,0 1 ttt yy ε+= − (6.1)
Os seguintes procedimentos foram seguidos para a estimação do modelo GARCH completo: - O modelo AR(1) foi estimado seguindo o método sugerido por Box e Jenkins (1970);
Crise do México
Crise da Ásia
Eleições
Maxides- valorização
11 de setembro
Crise da Rússia

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
81
- A defasagem do modelo GARCH foi verificada a partir da análise das funções de autocorrelação e autocorrelação parcial dos resíduos quadrados, resultando em um modelo GARCH (1,1) sendo especificado pela sua parcimônia e porque modelos de maior defasagem não apresentaram convergência satisfatória;
- Foi realizado o teste t dos parâmetros estimados, rejeitando-se a hipótese nula de igualdade a zero;
( ) ( ) ( )01115,000813,00000038,0
83784,012972,00000247,0 12
1 −− ++= ttt hh ε (6.2)
- As restrições do modelo foram atendidas, pois as estimativas dos parâmetros são positivas e a soma menor do que 1;
- Verificou-se na função de autocorrelação dos resíduos a inexistência de autocorrelação através do teste Ljung Box;
- Nos testes dos resíduos quadrados verificou-se a existência de autocorrelação (Ljung-Box), e através do teste LM rejeitou-se a hipótese nula de inexistência de autocorrelação nos resíduos quadrados;
- No teste Jarque-Bera de normalidade dos resíduos padronizados, foi possível verificar no histograma que a distribuição dos resíduos é leptocúrtica, rejeitando-se a hipótese de normalidade.
De acordo com os testes, o modelo GARCH (1,1) é adequado para a estimativa da
volatilidade condicional, e será usado para o cálculo do VaR. A figura abaixo contém a previsão estática um passo a frente da variância condicional com base no modelo especificado.
Figura 3:: Previsão um passo a frente da variância condicional
.000
.002
.004
.006
.008
.010
.012
.014
500 1000 1500 2000 2500
Fonte: elaboração própria
A especificação do modelo de volatilidade estocástica (MVE) foi feita com o auxilio do programa STAMP. Na estimação deste modelo, surge um problema de ordem prática, que é a existência de zeros na série de dados. Como os cálculos são realizados em logaritmos, os valores dos retornos não podem ser nulos. A seguinte a transformação sugerida por Breidt e Carriquiry (1994) foi utilizada para contornar o problema:

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
82
)/()log(log 222222
ytyytt csycscsyy +−+≅ , t = 1,2,....,T (6.3)
onde 2
ys é a variância amostral de y e c é um pequeno número (no STAMP é 0,02).
Após a realização da transformação, o modelo é estimado a partir do método de quase
máxima verossimilhança via filtro de Kalman, o que resultou nas seguintes equações:
log y2t = к+ht +ξt � log y2
t = -8,5769 + ht +ξt ht+1 = Φ ht + ηt � ht+1= 0,986323ht + ηt
O modelo convergiu muito fortemente em 14 iterações. O desvio-padrão estimado de ξt é de 1,6888 e o desvio-padrão estimado de ηt é de 0,13382. Importante salientar que o teste de Ljung-Box aplicado aos resíduos estimados pelo modelo sugere a não autocorrelacão. O valor obtido no componente auto-regressivo, de 0,9863 é bastante elevado e sugere que existe uma equivalência de ajustamento entre os modelos GARCH(1,1) e o MVE. A figura 4 apresenta o MVE para os retornos da Petrobras. Pode-se verificar, assim como no caso do modelo GARCH, a existência de agrupamentos de volatilidade expressivos em determinados eventos, entretanto o nível geral de volatilidade do MVE parece ser mais estável.
Figura 4: MVE para os retornos da Petrobras
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
1 114 227 340 453 566 679 792 905 1018 1131 1244 1357 1470 1583 1696 1809 1922 2035 2148 2261 2374 2487 2600 2713
Volatilidade Estocástica Fonte: elaboração própria
Assim, para o caso em análise tanto o modelo GARCH (1,1) quanto o modelo de volatilidade estocástica se mostraram adequados para a estimação do Valor em Risco. Nesse sentido, a próxima seção compara por meio de backtesting o VaR baseado na metodologia do Riskmetrics (1999), que é bastante difundida no mercado, com o VaR baseado nas metodologias GARCH e MVE.

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
83
7. BACKTESTING De acordo com o manual do Riskmetrics (1999), o backtesting compara os resultados
realizados com as medidas geradas pelo modelo, com o intuito de medir a eficácia do modelo utilizado pelas instituições. Um dos métodos usados para avaliar a eficiência de modelos através de teste com realizações passadas é teste de violações dos limites de VaR, pelo o número de excessos fora do intervalo de confiança. O teste utiliza o valor da carteira marcada a mercado, contando o número de vezes que os retornos da carteira excederam o intervalo de confiança estipulado para o VaR. O número de violações pode ser discriminado em: limites superiores, quando o retorno exceder o intervalo de confiança no lado direito da cauda, e limites inferiores, quando o retorno for mais negativo do que o retorno crítico determinado pelo VaR. Neste trabalho aplica-se o teste de violação para limites inferiores, utilizando os retornos marcados a mercado das ações de Petrobras para uma janela de 1500 observações. Desta maneira é possível comparar o comportamento dos modelos GARCH e Riskmetrics quanto a sua eficiência. A figura seguinte mostra os retornos de Petrobras e o VaR calculado pelo modelo Riskmetrics, com volatilidade estimada através de suavização exponencial – EWMA4, com fator de decaimento λ =0,94. É possível perceber que nos momentos de maior volatilidade, os retornos da Petrobras excedem os limites inferiores do VaR.
Figura 5: VaR calculado pelo Riskmetrics/EWMA
-0,25
-0,2
-0,15
-0,1
-0,05
0
0,05
0,1
0,15
0,2
0,25
VaR (EWMA) Petrobras
Fonte: elaboração própria
A figura seguinte apresenta o VaR calculado através do modelo GARCH (1,1) e as violações de limites.
4 EWMA: Exponential Weighted Moving Average.

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
84
Figura 6: VaR calculado pelo GARCH(1,1)
-0,25
-0,2
-0,15
-0,1
-0,05
0
0,05
0,1
0,15
0,2
0,25
VaR (GARCH) Petrobras
Fonte: elaboração própria
A figura 7 apresenta o VaR calculado através do MVE e suas respectivas violações de limites.
Figura 7: VaR calculado pelo MVE
-0,25
-0,2
-0,15
-0,1
-0,05
0
0,05
0,1
0,15
0,2
0,25
VaR (MVE) Petrobras
Fonte: elaboração própria
Os resultados do teste de violação dos limites mostraram que em 4,54% das observações os retornos da Petrobras excederam os limites do VaR calculado com o GARCH, em 3,87% os retornos excederam os limites do VaR calculado com o MVE e somente 3,20% das observações excedeu os limites do VaR calculado pelo EWMA. É importante salientar que esses resultados são indicativos para uma amostra e comparando-os não é possível concluir qual dos modelos é mais eficiente, mas é possível inferir que o VaR calculado pelo EWMA, através do modelo proposto pelo Riskmetrics, sofreu menos violações de limites do que o VaR calculado com a volatilidade prevista pelo GARCH (1,1) e pelo MVE. Entretanto, é importante lembrar que todos os modelos testados permaneceram dentro do nível de significância de 5% utilizado no VaR. 8. CONSIDERAÇÕES FINAIS
Neste artigo foram apresentados 3 modelos utilizados para a estimativa da volatilidade: modelo de suavização exponencial – EWMA, modelo volatilidade condicional – GARCH e o modelo de volatilidade estocástica – MVE. A volatilidade estimada pelos modelos é base para

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
85
o cálculo do VaR que é uma métrica bastante utilizada por instituições financeiras e empresas com exposições para avaliar o risco de perdas prováveis de suas carteiras, ocasionadas pelas variações nos preços dos ativos. A medida do VaR depende da volatilidade, do horizonte de tempo e do intervalo de confiança para os retornos contínuos calculados através das diferenças logarítmicas dos preços dos ativos. Para a avaliação empírica foi utilizada uma amostra com os preços da ação preferencial da Petrobras para a especificação do modelo auto-regressivo de heteroscedasticidade condicional generalizada e de volatilidade estocástica. Tanto o modelo GARCH, quanto o MVE se mostraram adequados para a modelagem da volatilidade. Adicionalmente realizou-se o backtest de violação dos limites para um VaR de 5% calculado um passo a frente, com intuito de comparar a eficiência dos modelos GARCH e MVE com o modelo proposto pelo Riskmetrics, o EWMA. Os resultados dos testes não foram conclusivos, mas verificou-se que o VaR calculado pelo EWMA sofreu um menor número de violações do que o calculado pelo GARCH e pelo MVE, para uma janela de 1500 observações. O modelo sugerido pelo Riskmetrics (1999), que utiliza a volatilidade calculada através da suavização exponencial, além de ser favorecido pela simplicidade em sua implementação, não forneceu resultados inferiores no teste de violação, comparado a modelos mais sofisticados de estimação de volatilidade. Para trabalhos posteriores sugere-se a utilização de carteiras com mais de um ativo, ou a verificação dos modelos para horizontes de projeção maiores do que 1 dia. REFERÊNCIAS ALEXANDER, C. Modelos de Mercado: Um guia para a análise de informações financeiras.
São Paulo: Editora Saraiva, 2005. BOLLERSLEV, T. Generalized autoregressive conditional heteroskedasticity. Journal of
Econometrics 31. 1986, p.307-327. BOX, G.E, JENKINS, G.M. Time series analysis: forecasting and control. San Francisco:
Holden Day, 1970. BREIDT, F.J., CARRIQUIRY, A.L. Improved quasi-maximum likelihood estimation for
stochastic volatility models. In LEE, J.C., Zellner, A. (Eds.), Modeling and prediction: honoring Seymour Geisser, p.228-247. New York: Springer, 1994.
ENDERS, W. Aplied econometric time series. New York: John Wiley & Sons Inc, 2004. ENGLE, R.F. Autoregressive conditional heteroskedasticity with estimates of the variance of
United Kingdom inflation. Econometrica 50. 1982, p.987-1007. GHYSELS, E., HARVEY, A. C., RENAULT, E. Stochastic volatility. In RAO, C. R.,
MADDALA G. S. (Eds.), Statistical methods in finance, p.119-191. Amsterdam: North-Holland, 1996.
GUJARATI, D.N. Econometria básica. São Paulo: Pearson Education do Brasil, 2004. HARVEY, A.C., RUIZ, E., SHEPHARD, N. Multivariate stochastic variance models.
Review of Economic Studies 61. 1994, p.247-264. HULL, J., WHITE, A. The pricing of options on assets with stochastic volatilities. Journal of
Finance 42. 1987, p.281-300. JACQUIER, E., POLSON, N. G., ROSSI, P. E. Bayesian analysis of stochastic volatility
models (with discussion). Journal of Business and Economic Statistics 12. 1994, p.371-417.
JORION, P. Value at Risk. New York: Mcgraw Hill, 2001.

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
86
MORETTIN, P.A., TOLOI, C.M.C. Análise de séries temporais. São Paulo: Editora Edgard Blücher do Brasil, 2004.
MORETTIN, P.A. Econometria Financeira (disponível em www.ime.usp.br/pam). São Paulo, 2004.
RISKMETRICS. Risk management: a practical guide. 1.ed. NewYork: RMG, 1999 SHEPHARD, N. Statistical aspects of ARCH and stochastic volatility. In COX, D. R.,
BARNDORFF-NIELSON, O.E., HINKLEY, D.V. (Eds.), Time series models in econometrics, finance and other fields, p. 1-67. London: Chapman & Hall, 1996.
SPANOS, A. Statistical foundations of econometric models. Cambridge: University Press, 1986.
TAYLOR, S. J. Modelling financial time series. Chichester: John Wiley, 1986. TAYLOR, S. J. Modelling stochastic volatility. Mathematical Finance 4. 1994, p.183-204.

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
87
ANEXOS i) Autocorrelação da série O correlograma dos retornos da ação é apresentado abaixo:
Pela análise da fac e da facp não fica muito claro qual o modelo que o comportamento dessas funções representa. Contudo pode-se perceber uma diminuição significativa tanto na fac quanto na facp na primeira defasagem da série. Nesse contexto são estimados os modelos AR(1), MA(1) e ARMA(1,1) e analisados os respectivos critérios de informação para a seleção do modelo a ser estimado com o GARCH:
Modelo ARMA(1,1) Variable Coefficient Std. Error t-Statistic Prob.
AR(1) -0.058242 0.153047 -0.380551 0.7036 MA(1) 0.179051 0.150903 1.186528 0.2355
R-squared 0.012326 Mean dependent var 0.001218 Adjusted R-squared 0.011964 S.D. dependent var 0.028971 S.E. of regression 0.028797 Akaike info criterion -4.256375 Sum squared resid 2.260544 Schwarz criterion -4.252041 Log likelihood 5807.696 Durbin-Watson stat 2.003717
Inverted AR Roots -.06 Inverted MA Roots -.18

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
88
Modelo AR (1) Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.114847 0.019009 6.041861 0.0000
R-squared 0.011464 Mean dependent var 0.001218 Adjusted R-squared 0.011464 S.D. dependent var 0.028971 S.E. of regression 0.028804 Akaike info criterion -4.256236 Sum squared resid 2.262518 Schwarz criterion -4.254069 Log likelihood 5806.505 Durbin-Watson stat 1.989847
Inverted AR Roots .11
Modelo MA (1)
Variable Coefficient Std. Error t-Statistic Prob.
MA(1) 0.122887 0.019000 6.467663 0.0000
R-squared 0.012546 Mean dependent var 0.001196 Adjusted R-squared 0.012546 S.D. dependent var 0.028988 S.E. of regression 0.028806 Akaike info criterion -4.256124 Sum squared resid 2.263601 Schwarz criterion -4.253957 Log likelihood 5808.481 Durbin-Watson stat 2.004299
Inverted MA Roots -.12
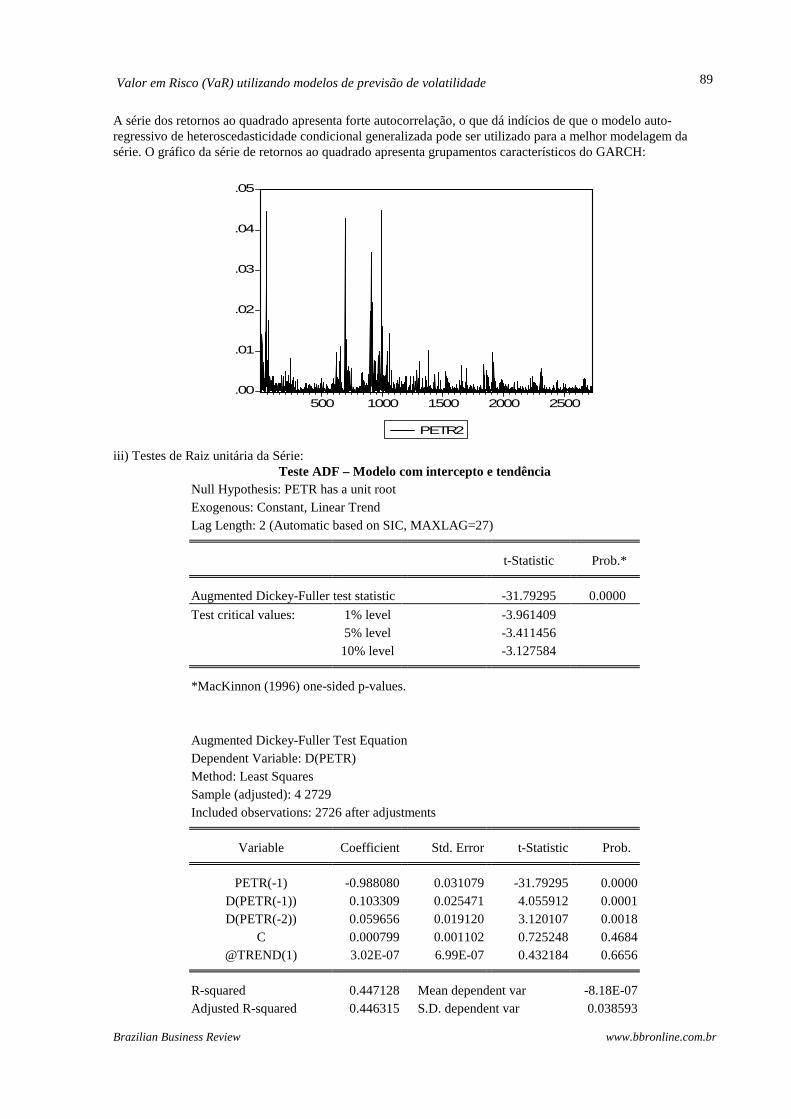
Baseando-se na significância dos coeficientes estimados, bem como nos critérios de informação dos modelos, optou-se por utilizar a especificação AR(1) para a série. ii) Análise da série para a adequação de um modelo GARCH O correlograma dos retornos ao quadrado da ação é apresentado abaixo:
Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
89
A série dos retornos ao quadrado apresenta forte autocorrelação, o que dá indícios de que o modelo auto-regressivo de heteroscedasticidade condicional generalizada pode ser utilizado para a melhor modelagem da série. O gráfico da série de retornos ao quadrado apresenta grupamentos característicos do GARCH:
.00
.01
.02
.03
.04
.05
500 1000 1500 2000 2500
PETR2
iii) Testes de Raiz unitária da Série: Teste ADF – Modelo com intercepto e tendência
Null Hypothesis: PETR has a unit root Exogenous: Constant, Linear Trend Lag Length: 2 (Automatic based on SIC, MAXLAG=27)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -31.79295 0.0000
Test critical values: 1% level -3.961409 5% level -3.411456 10% level -3.127584 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(PETR) Method: Least Squares Sample (adjusted): 4 2729 Included observations: 2726 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. PETR(-1) -0.988080 0.031079 -31.79295 0.0000
D(PETR(-1)) 0.103309 0.025471 4.055912 0.0001 D(PETR(-2)) 0.059656 0.019120 3.120107 0.0018
C 0.000799 0.001102 0.725248 0.4684 @TREND(1) 3.02E-07 6.99E-07 0.432184 0.6656
R-squared 0.447128 Mean dependent var -8.18E-07
Adjusted R-squared 0.446315 S.D. dependent var 0.038593

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
90
S.E. of regression 0.028717 Akaike info criterion -4.260837 Sum squared resid 2.243884 Schwarz criterion -4.249996 Log likelihood 5812.521 F-statistic 550.1436 Durbin-Watson stat 1.999082 Prob(F-statistic) 0.000000
Conclusão: Pelo teste de raiz unitária de Dickey-Fuller aumentado (ADF) não se pode aceitar a hipótese nula de que há uma raiz unitária na série de retornos da ação a 1%, 5% e 10% de significância. As conclusões são as mesmas para o modelo sem intercepto e tendência e com intercepto.
Teste PP – Modelo com intercepto e tendência Null Hypothesis: PETR has a unit root Exogenous: Constant, Linear Trend Bandwidth: 11 (Newey-West using Bartlett kernel)
Adj. t-Stat Prob.* Phillips-Perron test statistic -46.33250 0.0000
Test critical values: 1% level -3.961407 5% level -3.411454 10% level -3.127583 *MacKinnon (1996) one-sided p-values. Residual variance (no correction) 0.000828
HAC corrected variance (Bartlett kernel) 0.000664
Phillips-Perron Test Equation Dependent Variable: D(PETR) Method: Least Squares Sample (adjusted): 2 2729 Included observations: 2728 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. PETR(-1) -0.886767 0.019019 -46.62638 0.0000
C 0.000693 0.001103 0.628217 0.5299 @TREND(1) 2.86E-07 7.00E-07 0.408488 0.6829
R-squared 0.443767 Mean dependent var 2.46E-05
Adjusted R-squared 0.443358 S.D. dependent var 0.038593 S.E. of regression 0.028793 Akaike info criterion -4.256243 Sum squared resid 2.259185 Schwarz criterion -4.249743 Log likelihood 5808.516 F-statistic 1087.012 Durbin-Watson stat 1.989712 Prob(F-statistic) 0.000000
Conclusão: Pelo teste de raiz unitária de Phillips-Perron (PP) não se pode aceitar a hipótese nula de que
há uma raiz unitária na série de retornos da ação a 1%, 5% e 10% de significância. As conclusões são as mesmas para o modelo sem intercepto e tendência e com intercepto. iv) Teste de estacionariedade
Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
91
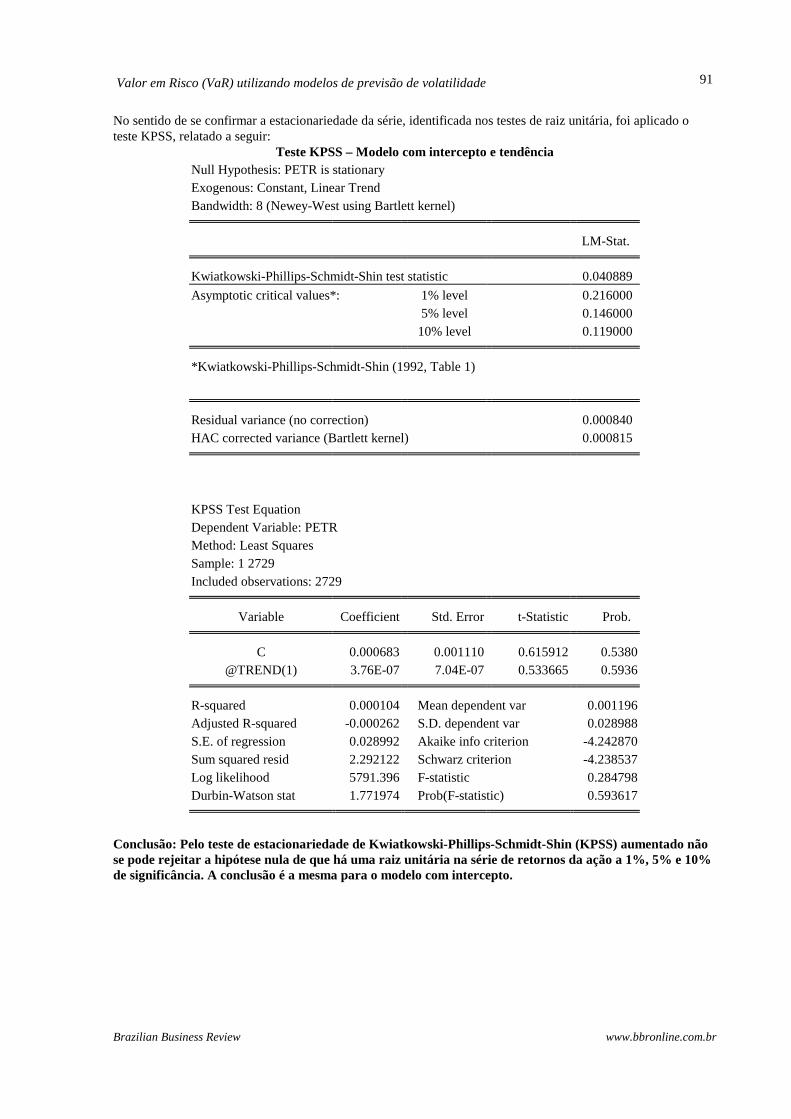
No sentido de se confirmar a estacionariedade da série, identificada nos testes de raiz unitária, foi aplicado o teste KPSS, relatado a seguir:
Teste KPSS – Modelo com intercepto e tendência Null Hypothesis: PETR is stationary Exogenous: Constant, Linear Trend Bandwidth: 8 (Newey-West using Bartlett kernel)
LM-Stat. Kwiatkowski-Phillips-Schmidt-Shin test statistic 0.040889
Asymptotic critical values*: 1% level 0.216000 5% level 0.146000 10% level 0.119000 *Kwiatkowski-Phillips-Schmidt-Shin (1992, Table 1) Residual variance (no correction) 0.000840
HAC corrected variance (Bartlett kernel) 0.000815
KPSS Test Equation Dependent Variable: PETR Method: Least Squares Sample: 1 2729 Included observations: 2729
Variable Coefficient Std. Error t-Statistic Prob. C 0.000683 0.001110 0.615912 0.5380
@TREND(1) 3.76E-07 7.04E-07 0.533665 0.5936 R-squared 0.000104 Mean dependent var 0.001196
Adjusted R-squared -0.000262 S.D. dependent var 0.028988 S.E. of regression 0.028992 Akaike info criterion -4.242870 Sum squared resid 2.292122 Schwarz criterion -4.238537 Log likelihood 5791.396 F-statistic 0.284798 Durbin-Watson stat 1.771974 Prob(F-statistic) 0.593617
Conclusão: Pelo teste de estacionariedade de Kwiatkowski-Phillips-Schmidt-Shin (KPSS) aumentado não se pode rejeitar a hipótese nula de que há uma raiz unitária na série de retornos da ação a 1%, 5% e 10% de significância. A conclusão é a mesma para o modelo com intercepto.
Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
92
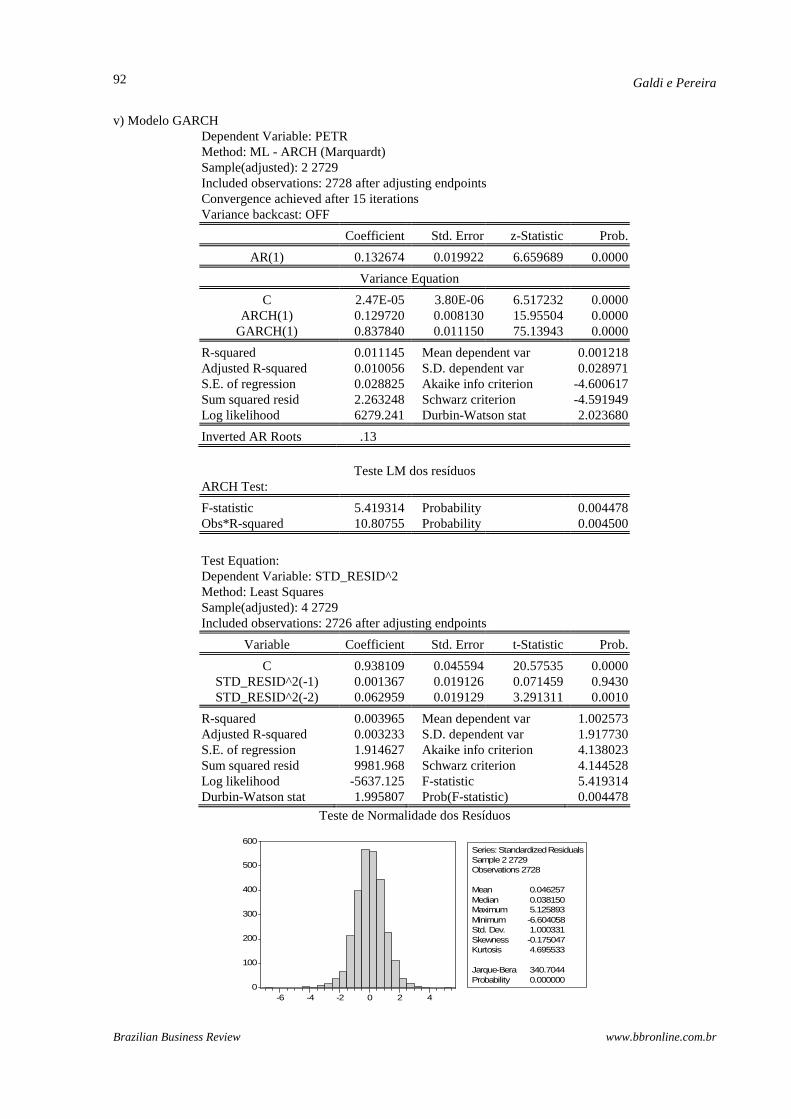
v) Modelo GARCH Dependent Variable: PETR Method: ML - ARCH (Marquardt) Sample(adjusted): 2 2729 Included observations: 2728 after adjusting endpoints Convergence achieved after 15 iterations Variance backcast: OFF
Coefficient Std. Error z-Statistic Prob.
AR(1) 0.132674 0.019922 6.659689 0.0000
Variance Equation
C 2.47E-05 3.80E-06 6.517232 0.0000 ARCH(1) 0.129720 0.008130 15.95504 0.0000
GARCH(1) 0.837840 0.011150 75.13943 0.0000
R-squared 0.011145 Mean dependent var 0.001218 Adjusted R-squared 0.010056 S.D. dependent var 0.028971 S.E. of regression 0.028825 Akaike info criterion -4.600617 Sum squared resid 2.263248 Schwarz criterion -4.591949 Log likelihood 6279.241 Durbin-Watson stat 2.023680
Inverted AR Roots .13
Teste LM dos resíduos
ARCH Test:
F-statistic 5.419314 Probability 0.004478 Obs*R-squared 10.80755 Probability 0.004500
Test Equation: Dependent Variable: STD_RESID^2 Method: Least Squares Sample(adjusted): 4 2729 Included observations: 2726 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
C 0.938109 0.045594 20.57535 0.0000 STD_RESID^2(-1) 0.001367 0.019126 0.071459 0.9430 STD_RESID^2(-2) 0.062959 0.019129 3.291311 0.0010
R-squared 0.003965 Mean dependent var 1.002573 Adjusted R-squared 0.003233 S.D. dependent var 1.917730 S.E. of regression 1.914627 Akaike info criterion 4.138023 Sum squared resid 9981.968 Schwarz criterion 4.144528 Log likelihood -5637.125 F-statistic 5.419314 Durbin-Watson stat 1.995807 Prob(F-statistic) 0.004478
Teste de Normalidade dos Resíduos
0
100
200
300
400
500
600
-6 -4 -2 0 2 4
Series: Standardized ResidualsSample 2 2729Observations 2728
Mean 0.046257Median 0.038150Maximum 5.125893Minimum -6.604058Std. Dev. 1.000331Skewness -0.175047Kurtosis 4.695533
Jarque-Bera 340.7044Probability 0.000000

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
93
vi) Modelo de Volatilidade Estocástica (MVE) Resultados completos: Method of estimation is Maximum likelihood The present sample is: 0 to 2728 MaxLik initialising... it 1 f= -0.61823 e0= 0.00000 step= 1.00000 MaxLik iterating... it 4 f= -0.56087 df= 0.00480 e1= 0.00347 e2= 0.11477 step= 1.00000 it 9 f= -0.55836 df= 0.00009 e1= 0.00021 e2= 0.03684 step= 1.00000 it 14 f= -0.55835 df= 0.00000 e1= 0.00000 e2= 0.00000 step= 0.00010 Equation 1. SVpetr = Level + AR(1) + Irregular Estimation report Model with 3 parameters ( 1 restrictions). Parameter estimation sample is 0. 1 - 2728. 1. (T = 2729). Log-likelihood kernel is -0.5583489. Very strong convergence in 14 iterations. ( likelihood cvg 1.789563e-015 gradient cvg 1.219025e-008 parameter cvg 1.623527e-010 ) Eq 1 : Diagnostic summary report. Estimation sample is 0. 1 - 2728. 1. (T = 2729, n = 2728). Log-Likelihood is -1523.73 (-2 LogL = 3047.47). Prediction error variance is 3.04931 Summary statistics SVpetr Std.Error 1.7462 Normality 114.33 H(909) 0.93420 r( 1) -0.0018508 r(39) 0.011165 DW 1.9980 Q(39,37) 38.960 R^2 0.11195 Eq 1 : Estimated variances of disturbances. Component SVpetr (q-ratio) Irr 2.8520 ( 1.0000) Ar1 0.017907 ( 0.0063) Eq 1 : Estimated standard deviations of disturbances. Component SVpetr (q-ratio) Irr 1.6888 ( 1.0000) Ar1 0.13382 ( 0.0792) Eq 1 : Estimated autoregressive coefficient.

Galdi e Pereira
Brazilian Business Review www.bbronline.com.br
94
The AR(1) rho coefficient is 0.986323. Eq 1 : Estimated coefficients of final state vector. Variable Coefficient R.m.s.e. t-value Lvl -8.5769 0.18600 -46.113 [ 0.0000] Ar1 -0.76884 0.45764 Normality test for Residual SVpetr Sample Size 2728 Mean -0.053013 Std.Devn. 0.998594 Skewness -0.257566 Excess Kurtosis -0.580191 Minimum -3.280796 Maximum 3.113678 Skewness Chi^2(1) 30.163 [0.0000] Kurtosis Chi^2(1) 38.263 [0.0000] Normal-BS Chi^2(2) 68.425 [0.0000] Normal-DH Chi^2(2) 114.33 [0.0000] Goodness-of-fit results for Residual SVpetr Prediction error variance (p.e.v) 3.049310 Prediction error mean deviation (m.d) 2.511845 Ratio p.e.v. / m.d in squares 0.938204 Coefficient of determination R2 0.111953 ... based on differences RD2 0.466639 Information criterion of Akaike AIC 1.117114 ... of Schwartz (Bayes) BIC 1.123613 Serial correlation statistics for Residual SVpetr. Durbin-Watson test is 1.99805. Asymptotic deviation for correlation is 0.019146.

Valor em Risco (VaR) utilizando modelos de previsão de volatilidade
Brazilian Business Review www.bbronline.com.br
95
vii) Rotina de programação em VBA para o cálculo da variância condicional do modelo de decaimento exponencial:
Function ewma(lambida, retornos As Range) i = 1 lambida2 = 1 ewma = 0 Do While lambida2 > 0.00001
ewma = ewma + retornos(i, 1) ^ 2 * lambida2 lambida2 = lambida2 * lambida i = i + 1
Loop ewma = ewma * (1 - lambida)
End Function





























