Embed Size (px)
Citation preview

Universidade Federal do ABC (1/108)Web Mining
Web Mining
Cleonice Caro, David Quadro e Leonardo Villani

Universidade Federal do ABC (2/108)Web Mining
Agenda
Introdução
Mineração de Dados e Web Semântica
Algoritmo PageRank
Estado da Arte
Referências

Universidade Federal do ABC (3/108)Web Mining
Web Mining
Fonte: http://memagazine.asme.org/articles/2008
/november/Web_Mining_Innovation.cfm

Universidade Federal do ABC (4/108)Web Mining
Introdução
Introdução a Web Mining
O que é Web Mining?
Coleta de Dados
Categorias de dados
Estrutura da Web Mining

Universidade Federal do ABC (5/108)Web Mining
Introdução a Web Mining
Devido grande quantidade de informação disponível na Internet, a Web é um campo fértil para a pesquisa de mineração de dados
Podemos entender Web Mining como uma extensão de Data Mining aplicado a dados da Internet
A pesquisa em Web Mining envolve diversos campos de pesquisa em computação tais como: bancos de dados, recuperação de informação e inteligência artificial (aprendizado de máquina e linguagem natural)

Universidade Federal do ABC (6/108)Web Mining
O que é Web Mining?
Web Mining é o uso de técnicas de data mining para descobrir e extrair automaticamente informações relevantes dos documentos e serviços ligados a Internet;
De forma geral, Web Mining pode ser conceituada como a descoberta e análise inteligente de informações úteis da Web;

Universidade Federal do ABC (7/108)Web Mining
Coleta de Dados
Na mineração de dados na Web, os dados podem ser coletados:
– Do lado do servidor;
– No lado do cliente;
– No proxy dos servidores.
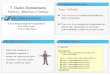
Universidade Federal do ABC (8/108)Web Mining
Modelo de Web Mining

Universidade Federal do ABC (9/108)Web Mining
Coleta de Dados
Do lado do servidor
– O arquivo de log de um servidor Web constitui-se em uma fonte importantíssima de informações para a realização de mineração do uso da Web.
– Isto pode ser explicado pelo fato destes arquivos apresentarem registros da navegação dos visitantes do site.
– Entretanto, os dados do uso do site armazenados por arquivos de log podem não ser inteiramente confiáveis, por exemplo, as views de páginas - número de vezes que a página foi requisitada, e não recarregada ou atualizada, não são gravadas no arquivo de log do servidor

Universidade Federal do ABC (10/108)Web Mining
Coleta de Dados
No lado do cliente
– Esta coleta de informações pode ser implementada usando programas remotos como os implementados com a linguagem baseada em objetos – javascript ou com os applets da linguagem orientada a objetos – Java;
– O uso do javascript aparentemente é uma melhor solução pelo fato de sua interpretação exigir menor tempo, porém as implementações não capturaram todos os clicks que o usuário realiza;

Universidade Federal do ABC (11/108)Web Mining
Coleta de Dados
No proxy dos servidores
– O proxy Web atua em um nível intermediário entre o Browser do cliente e do servidor Web;
– O proxy pode ser utilizado para diminuir o tempo de carga das páginas Web;
– A atividade final do proxy é garantir que as páginas mais requisitadas estejam disponíveis para facilitar no momento de cópia, proporcionando que a realização desta atividade seja feita de forma mais rápida;
– Através deste tipo de informação é possível identificar as páginas mais requisitadas por um grupo de usuários anônimos;

Universidade Federal do ABC (12/108)Web Mining
Categorias de dados
Conteúdo
Estrutura
Uso
Perfil do usuário

Universidade Federal do ABC (13/108)Web Mining
Categorias de dados
Conteúdo
– Constituem-se nos dados reais das páginas Web, isto é, a página projetada para atender ao usuário. Esta geralmente constitui-se de textos e gráficos.
Estrutura
– Dados os quais descrevem a organização dos conteúdos. A estrutura interna das páginas inclui o conjunto de tags HTML ou XML. A principal estrutura de informação entre páginas se constitui nos hiperlinks que conectam uma página a outra.

Universidade Federal do ABC (14/108)Web Mining
Categorias de dados
Uso
– Dados que descrevem os padrões de uso de páginas Web, como o endereço IP, páginas acessadas e a data e hora de acesso
Perfil do usuário
– Constitui-se em dados que fornecem informações sobre usuários de um site Web
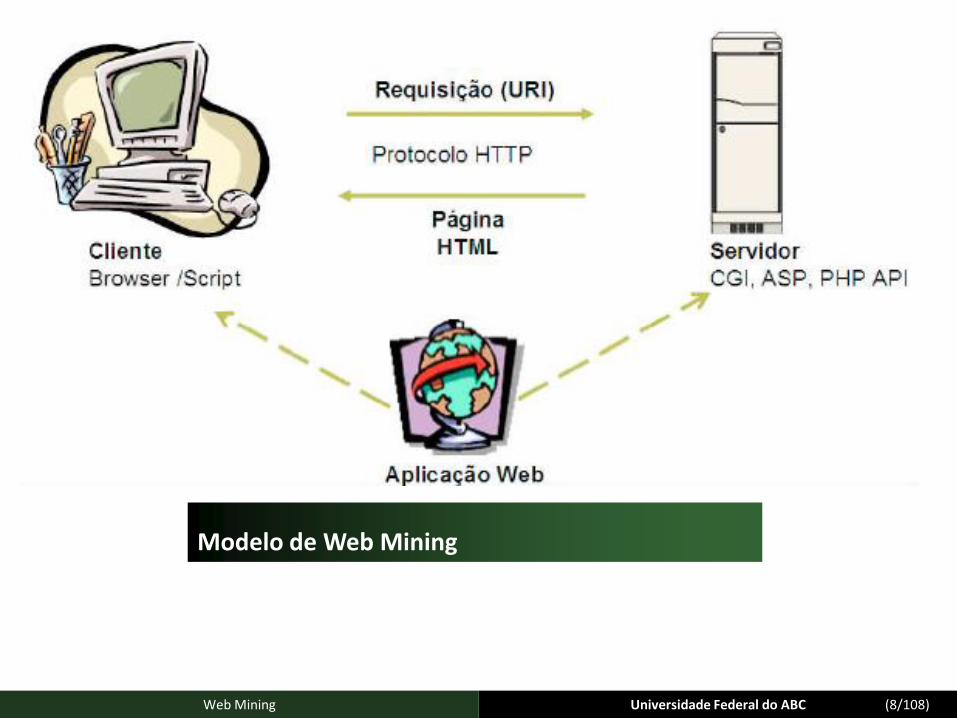
Universidade Federal do ABC (15/108)Web Mining
Estrutura da Web Mining

Universidade Federal do ABC (16/108)Web Mining
Categorias em que se divide a mineração na Web
Tipos de buscas:
– Informação contida dentro dos documentos da Web (mineração de conteúdo ou Web ContentMining);
– Informação contida entre os documentos da Web (mineração de estrutura ou Web StructureMining);
– Informação contida na utilização ou interação com a Web (mineração de uso Web Log Mining);
– Clustering;

Universidade Federal do ABC (17/108)Web Mining
Busca de documentos ou mineração de conteúdo
É o processo de extração de informações úteis sobre o conteúdo, dados e documentos da Web
– Consiste em se encontrar sites Web contendo documentos especificados por palavras-chave;
– Mineração em Banco de Dados Web;
– Mineração de conteúdo envolve a utilização de técnicas de Recuperação de Informação.

Universidade Federal do ABC (18/108)Web Mining
Busca de conteúdos em sites Web por palavras-chave
Os dados que compõem o conteúdo da Web consistem de dados não-estruturados do tipo textos, de dados semi-estruturados do tipo documentos HTML e dados estruturados tais como dados contidos em bancos de dados acessados pelas páginas;
A pesquisa que consiste em aplicar técnicas de mineração para descobrir conhecimento escondido em textos é chamada Text Mining, e é uma sub área de Mineração do Conteúdo da Web.

Universidade Federal do ABC (19/108)Web Mining
Mineração em Banco de Dados Web
O objetivo do Banco de Dados é modelar os dados da Web e integrá-los de forma a permitir consultas mais sofisticadas, do que simplesmente consultas baseadas em palavras-chave ;
Isto é possível descobrindo-se os esquemas dos documentos na Web e construindo Web Warehouses ;
A pesquisa nesta área lida sobretudo com dados semi-estruturados (XML);
Dados semi-estruturados se referem a dados que possuem alguma estrutura mas não esquemas rígidos como é o caso dos bancos de dados.

Universidade Federal do ABC (20/108)Web Mining
Recuperação de Informação.
Auxilia o usuário no processo de busca ou filtragem de informação;
É o processo que realiza os principais mecanismos de busca na Internet ao procurar atender da melhor maneira possível as solicitações feitas por usuários através de palavras-chave.

Universidade Federal do ABC (21/108)Web Mining
Seleção e pré-processamento da informação ou mineração de estrutura
É o processo de inferir conhecimento através da topologia, organização e estrutura de links da Web entre referências de páginas
– Consiste em selecionar e pre-processarautomaticamente informações obtidas na Internet;
– O pré-processamento envolve qualquer tipo de transformação da informação obtida na busca, como por exemplo, poda de textos, transformação da representação da informação em outros formalismos;

Universidade Federal do ABC (22/108)Web Mining
Generalização ou mineração de uso
É o processo de extração de padrões de navegação interessantes dos registros de acesso Web
– Consiste em descobrir automaticamente padrões gerais em sites Web ou entre vários sites Web;
– Utiliza dados secundários derivados da interação do usuário com a Web;
– Esta tarefa envolve a utilização de técnicas de inteligência artificial e de mineração de dados.

Universidade Federal do ABC (23/108)Web Mining
Generalização ou mineração de uso
Dados secundários incluem:
– Registros de log de servidores de acesso a Web -Web Log Mining
– Registros de log de servidores proxy, perfis de usuários
– Transações do usuário
– Consultas do usuário
– Dados de arquivos “Bookmarks” ou Favoritos

Universidade Federal do ABC (24/108)Web Mining
Clustering
É uma técnica de Data Mining para fazer agrupamentos automáticos de dados segundo seu grau de semelhança
– O critério de semelhança faz parte da definição do problema.
– É o processo inverso da classificação, pois parte de uma situação em que não existem classes, somente elementos de um universo (não se sabe quais são as classes, nem quantas, muito menos as características de cada uma).
– A partir dos elementos, as técnicas de clustering são responsáveis por definir as classes e enquadrar os elementos

Universidade Federal do ABC (25/108)Web Mining
Clustering
O objetivo então é identificar automaticamente grupos de afinidades, avaliando a similaridade entre os elementos e colocando os mais semelhantes no mesmo grupo e os menos semelhantes em grupos diferentes;
Em geral, a avaliação de similaridade entre os elementos é feita através de uma função de similaridade, analisando as características que representam os elementos.

Universidade Federal do ABC (26/108)Web Mining
Mineração de Dados e Web Semântica
Evolução da Web;
Características propostas para a Web Semântica;
Objetivos da Web Semântica;
Funcionamento da Web Semântica;

Universidade Federal do ABC (27/108)Web Mining
Mineração de Dados e Web Semântica
A Web 3.0 é considerada como um grande conjunto de dados estruturados em que a semântica aplicada a eles, permite que etapas da mineração, como o pré-processamento e a extração de conhecimento, possam se tornar mais simples e eficientes;
Prevê a criação de mecanismos de busca da informação, que oferecem conhecimento customizado, de acordo com as necessidades da corporação.

Universidade Federal do ABC (28/108)Web Mining
Evolução da Web
Web 1.0 - repositório de informações universais e páginas estáticas
Web 2.0 - Os sites começam a ser focados como serviço e permitem maior interatividade para os usuários
Web 3.0 - Permite a recuperação e organização do conhecimento por seres humanos e máquinas

Universidade Federal do ABC (29/108)Web Mining
Web 3.0

Universidade Federal do ABC (30/108)Web Mining
Web 3.0
A Web 3.0 preconiza a mudança de World WideWeb (rede mundial) para World Wide Database (base de dados mundial) com o uso de ontologias.
Organiza e agrupa a informação por temas, assuntos e interesses previamente determinados, expressos na ontologia.
Busca estruturar o conteúdo disponível, dentro dos conceitos de compreensão das máquinas e semântica das redes

Universidade Federal do ABC (31/108)Web Mining
Web Semântica
A Web Semântica é uma iniciativa relativamente recente, inspirada por Tim Berners-Lee, que propõe o avanço da Web conhecida para que a mesma se torne um sistema distribuído de representação e processamento do conhecimento.
O objetivo da Web Semântica não é somente permitir acesso a informação da Web em si através de sistemas de busca, mas também permitir o uso integrado de documentos na Web.

Universidade Federal do ABC (32/108)Web Mining
Características propostas para a Web Semântica são:
Formato padronizado: A Web Semântica propõe padrões para uma linguagem descritiva de metadados uniforme, que além de servir como base para troca de dados, suporta representação do conhecimento em vários níveis.
Por exemplo, texto pode ser anotado com uma representação formal que explicita conhecimento sobre o texto.
O mesmo pode ser feito com imagens e possivelmente áudio e vídeo.

Universidade Federal do ABC (33/108)Web Mining
Características propostas para a Web Semântica são:
Vocabulário e conhecimento padronizados: a Web Semântica encoraja e facilita a formulação de vocabulários e conhecimentos compartilhados na forma de ontologias, que podem ser disponibilizadas para modelagem de novos domínios e atividades.
Com isto uma grande quantidade de conhecimento pode ser estruturada, formalizada e representada para possibilitar a automação do acesso e uso.

Universidade Federal do ABC (34/108)Web Mining
Características propostas para a Web Semântica são:
Serviços compartilhados: além das estruturas estáticas, serviços na Web - os já conhecidos web services, podem ser usados para composição de aplicações que podem estar localizadas em sistemas diferentes, programados em linguagens diferentes e com acesso a dados especializados, usando a Internet para comunicação entre os módulos dos sistemas

Universidade Federal do ABC (35/108)Web Mining
Objetivos da Web Semântica
O formato padrão de dados , a popularidade dos documentos com metadados (anotações) sobre conteúdo e a ambição para formalização em grande escala do conhecimento propostos pela Web Semântica causa duas conseqüências para a área de mineração de dados da Web:
A primeira é que a disponibilidade de informação melhor estruturada permitirá o uso mais amplo de métodos existentes de mineração de dados, já que muitos dos algoritmos poderão ser usados com apenas pequenas modificações

Universidade Federal do ABC (36/108)Web Mining
Objetivos da Web Semântica
A segunda conseqüência é a possibilidade de uso do conhecimento formalizado através das ontologias.
A ontologia descreve os conceitos das fontes de dados, que podem ser documentos, planilhas, banco de dados, entre outros.
O termo original é a palavra aristotélica “categoria”, que pode ser usada para a classificação de informações.
A combinação destas duas características possibilita o aprendizado onde o conhecimento é adquirido a partir dos dados já anotados e pode ser usado para mais anotações e enriquecimento do conhecimento.

Universidade Federal do ABC (37/108)Web Mining
Objetivos da Web Semântica
Para realizar o objetivo da Web Semântica é necessário, primeiramente, que novos objetos na Web sejam anotados usando os padrões de formato, conhecimento e vocabulário para metadados.
Mais complicada será a tarefa de converter a vasta quantidade de objetos já existentes para uso com as ferramentas da Web Semântica.
Algumas abordagens para automação desta tarefa envolvem a anotação e classificação de acordo com ontologias pré-existentes e até mesmo a reorganização de ontologias existentes.

Universidade Federal do ABC (38/108)Web Mining
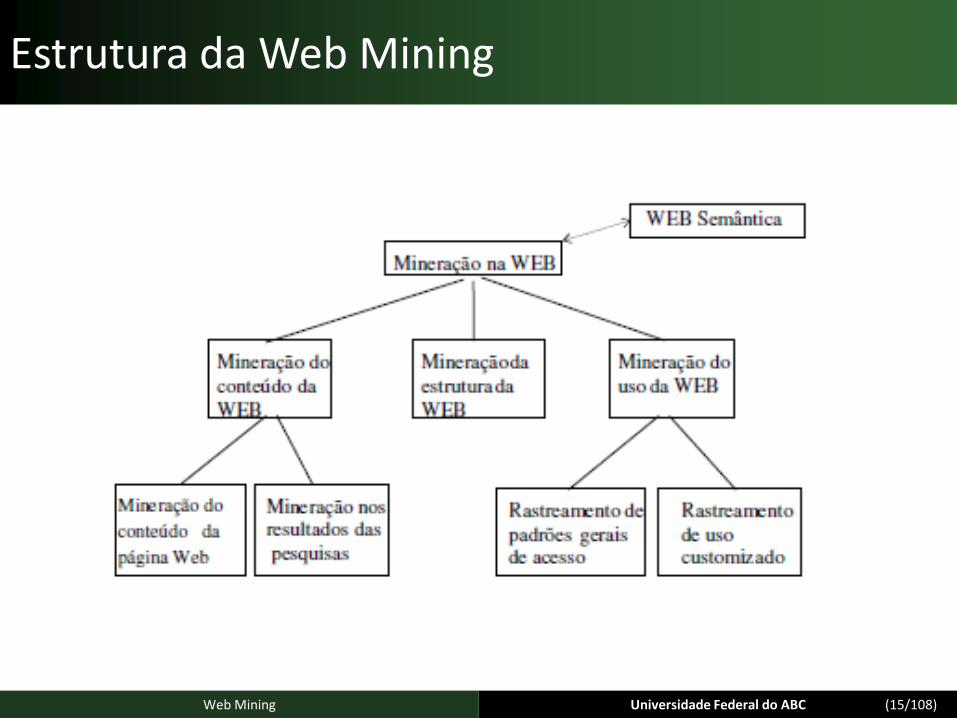
Funcionamento da Web Semântica
Camada Esquema
– Responsável por estruturar os dados e definir seu significado para que possa elaborar um raciocínio lógico
Camada Ontologia
– Responsável por definir relações entre os dados.
– Neste nível se dá o entendimento comum e compartilhado de um domínio.
– Na prática, a camada ontologia serve de vocabulário consistente para a troca de informações entre aplicações

Universidade Federal do ABC (39/108)Web Mining
Funcionamento da Web Semântica
Camada Lógica
– Responsável por definir mecanismos para fazer inferência sobre os dados.
– Composta por um conjunto de regras de inferência que os agentes poderão utilizar para relacionar e processar informações.
Universidade Federal do ABC (40/108)Web Mining
Funcionamento da Web Semântica

Universidade Federal do ABC (41/108)Web Mining
Algoritmo PageRank
PageRank é um algoritmo de mineração de estruturas na Web, implementado pelos criadores do Google, e é uma forma de ordenar páginas encontradas por relevância.

Universidade Federal do ABC (42/108)Web Mining
Algoritmo PageRank

Universidade Federal do ABC (43/108)Web Mining
Algoritmo PageRank
Segundo o próprio Lawrence Page: "The web creates new challenges for information retrieval. The amount of information on the web is growing rapidly, as well as the number of new users inexperienced in the art of web research. People are likely to surf the web using its link graph, often starting with high quality human maintained indices such as Yahoo! or with search engines.“

Universidade Federal do ABC (44/108)Web Mining
Algoritmo PageRank
Segundo ALTMAN e TENNENHOLTZ: "The ranking of agents based on other agents' input is fundamental to e-commerce and multi-agent systems Moreover, the ranking of agents based on other agents' input have become a central ingredient of a variety of Internet sites, where perhaps the most famous examples are Google's PageRank algorithm and ebay's reputation system"

Universidade Federal do ABC (45/108)Web Mining
Algoritmo PageRank
E continuando sua observação: "PageRank is probably the most popular page ranking procedure, it may be interesting to attempt and provide axiomatization for other page ranking procedures, such as Hubs and Authorities [6]. Once such axiomatization is found the di erent axiomatic systems can be compared as a basis for rigorous evaluation."

Universidade Federal do ABC (46/108)Web Mining
Algoritmo PageRank
Outro Estudo baseado no PR, KURLAND e LEE definem sua pesquisa: "Inspired by the PageRank and HITS (hubs and authorities) algorithms for Web search, we propose a structural re-ranking approach to ad hoc information retrieval: we reorder the documents in an initially retrieved set by exploiting asymmetric relationships between them."

Universidade Federal do ABC (47/108)Web Mining
Algoritmo PageRank
KURLAND E LEE, concluem: "Based on our results, we believe that exploring other methods for combining statistical language models and explicitly graph-based techniques is a fruitful line for future research."

Universidade Federal do ABC (48/108)Web Mining
Algoritmo PageRank
RAMANATHAN define que "Language modeling is the task of estimating the probability distribution of linguistic units such as words, sentences, queries, utterances, or even complete documents. The probability distribution itself is referred to as a language model. Language models have been used in a variety of NLP tasks including speech recognition, document classification, optical character recognition, and statistical machine translation."

Universidade Federal do ABC (49/108)Web Mining
Como tudo começou...
Desenvolvido inicialmente por Larry Page (1998) com a posterior colaboração de Sergey Brin, fundadores do Google, PageRank (representado por PR) foi a base para o surgimento do algoritmo do Google.
O nome PageRank é então uma alusão a seu criador (Larry Page) e ao fato de ser uma nota dada pelo Google às páginas (page, em inglês) indexadas em seus servidores.
PR é uma das centenas de variáveis utilizadas pelo Google para definir quem aparece primeiro nos resultados naturais de busca.
O sistema do PageRank já foi copiado por seus concorrente, mas o Google faz constantemente melhorias no algoritimodo PageRank garantindo a dianteira

Universidade Federal do ABC (50/108)Web Mining
Porém, este método de classificação não e novo.
Olhando a história..
Encontramos Jon Kleinberg, que criou HITS (Hypertext InducedTopic Search), alguns anos antes Page e Brin.
Na verdade, os fundadores do Google, citou a criação do PageRank. Este algoritmo foi muito importante antes do ponto-boom COM, antes de o Google tornou-se um sucesso.
Indo mais para trás, encontramos o trabalho de Gabriel Pinski Narine Francis, que, como PageRank ou algoritmo HITS, desenvolveram uma maneira de classificar as publicações por quantas vezes ele foi citado em outras publicações. Interativa foi a teoria de classificação.
Já em 1965, Charles H Hubblell desenvolveu algoritmos deste tipo.

Universidade Federal do ABC (51/108)Web Mining
Em 1941
Descobriu-se um algoritmo deste tipo remonta a 1941, desenvolvido por Wassily Leontief, economista da Universidade Harvard.
Este trabalho lhe rendeu o Prêmio Nobel de Economia em 1973.

Universidade Federal do ABC (52/108)Web Mining
Algoritmo PageRank
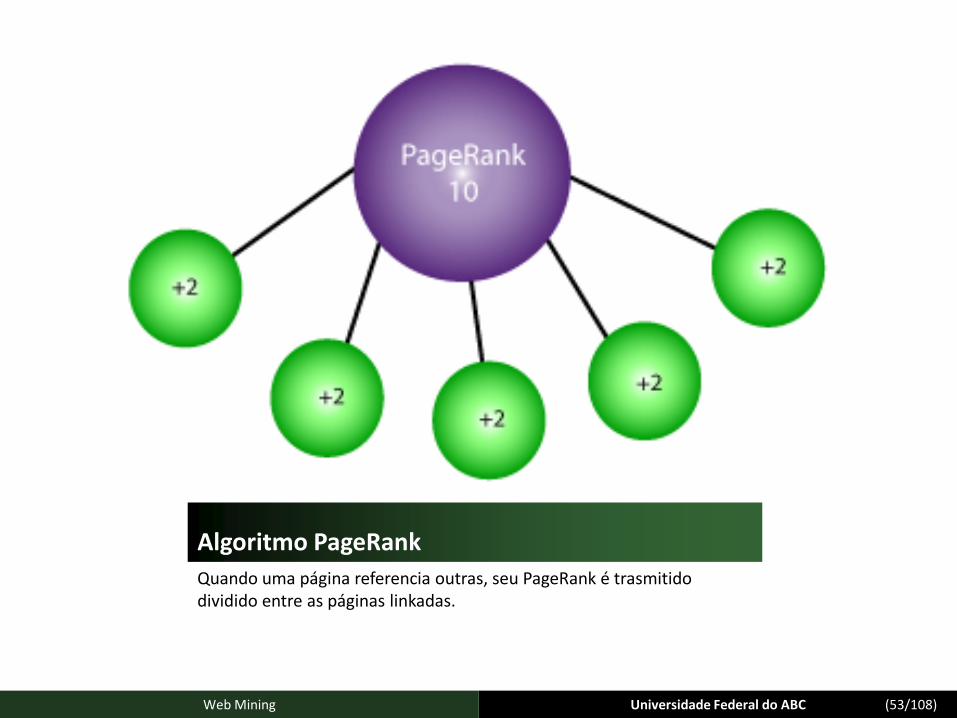
Este algoritmo basicamente avalia páginas baseado na quantidade de ligações a ela feitas por outras páginas consideradas importantes.
Usa a estrutura dos grafos correspondente à ligações de e para uma página para ter uma métrica de importância da página.
Universidade Federal do ABC (53/108)Web Mining
Algoritmo PageRank
Quando uma página referencia outras, seu PageRank é trasmitido dividido entre as páginas linkadas.

Universidade Federal do ABC (54/108)Web Mining
Coração do Google
É o algoritmo que determina se um site aparece em primeiro lugar, segundo, terceiro e assim por diante.
A ideia básica do Google é ser um sistema que possa classificar todas as páginas existentes na web e assim trazer como resultado, ao se pesquisar uma palavra-chave, o que seria o resultado mais relevante segundo uma série de cálculos e fatores.

Universidade Federal do ABC (55/108)Web Mining
Quantidade x Qualidade
O conceito básico do PageRank é o mesmo de artigos acadêmicos:
– Ele considera que cada link que uma página recebe (ou dá) é um voto de qualidade, assim como nos meios acadêmicos a relevância de um profissional se dá pelo número de vezes e por quem ele foi citado.
– Portanto, não conta somente a quantidade de links mas também – e sobretudo – a sua qualidade.
– Considerando que o site A tenha dez links de páginas de baixa relevância, enquanto B recebe apenas um link de uma página muito relevante; esta última, segundo o PageRank, será muito mais importante do que a outra

Universidade Federal do ABC (56/108)Web Mining
Como funciona?
A web funciona através de hiperlinks. Se a página A linkapara a página B, então a página B recebeu um voto.
Mas o peso do voto depende do PageRank da página A.
Para cada página, o Google atribui um PageRank com o valor numérico de 1 a 10 sendo 10 o mais importante.
Páginas mais populares recebem um alto PageRank. Páginas como a NASA, a W3.org, a Microsoft tem o PageRank 10.
Se uma destas páginas linkar para o seu site, é como se ela votasse ao seu favor, aumentando o valor do seu PageRank.
Universidade Federal do ABC (57/108)Web Mining
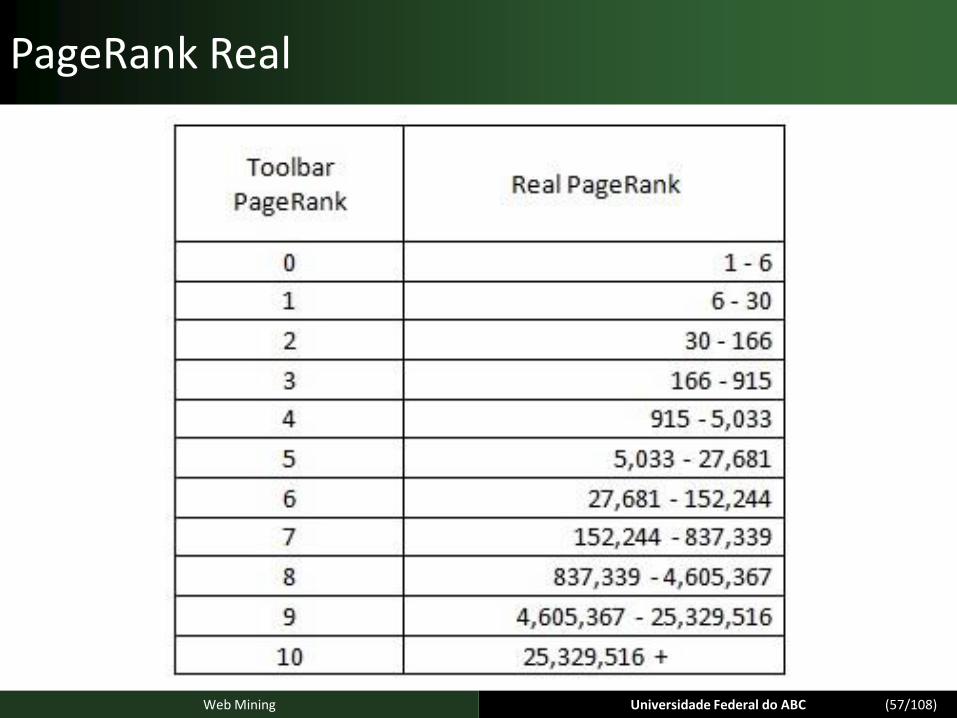
PageRank Real

Universidade Federal do ABC (58/108)Web Mining
PageRank Real
É importante notar é que, quanto mais alto for o Toolbar PageRank, mais difícil será alcançar o próximo valor.
Pular de PageRank 1 para 2 é muito mais fácil do que pular de PageRank 5 para 6.

Universidade Federal do ABC (59/108)Web Mining
Links como votos
Base: Utilizar os links como votos, atribuindo uma determinada valorização a um link proveniente da página A e outro tipo de valorização ao link da página B.

Universidade Federal do ABC (60/108)Web Mining
PageRank
Vários sites com PageRank 1 linkando para um site tem um peso menor que um link de PageRank 10.
O algoritmo do PageRank atualmente tem diversos outros detalhes que causam variação na pontuação, com a intensão de corrigir distorções que podem acontecer

Universidade Federal do ABC (61/108)Web Mining
Como melhorar minha posição no PR
Portanto para que as páginas do um site tenham um alto PR é necessário obter links de web sites relevantes para o seu seguimento apontando para o seu web site.

Universidade Federal do ABC (62/108)Web Mining
Formula original
A fórmula abaixo é o algoritmo PageRank inicial que pode ser encontrado no protótipo original:

Universidade Federal do ABC (63/108)Web Mining
Onde
PR(A) é o PageRank da página A.
d é um fator de amortecimento, que tem um valor entre 0 e 1.
PR(i) são os valores de PageRank que tem cada uma das páginas i ligando para A.
C(i) é o número total de links externos na página i (seja ou não A).

Universidade Federal do ABC (64/108)Web Mining
Algoritmo Recursivo
Como podemos ver é um algoritmo recursivo, porque a mudança do PR de uma página afeta os PR dos outros links , e mudança do esta no de outra e assim sucessivamente pode afetar o retorno à página inicial.
Aqui o efeito “Googledance” que ocorre quando o Google atualiza o PR e outros sistemas de classificação que utilizam, porque o PageRank não é a única forma de classificar usando a busca no Google.

Universidade Federal do ABC (65/108)Web Mining
Descobrindo o conteúdo da internet
Os robots começam seu trabalho em uma determinada página. Armazenam o seu conteúdo e mapeiam todos os links existentes nela;
Em seguida, priorizam cada um desses links e começam a seguí-los, armazenando o conteúdo encontrado e mapeando os links encontrados, e assim sucessivamente (recursivamente).
Universidade Federal do ABC (66/108)Web Mining
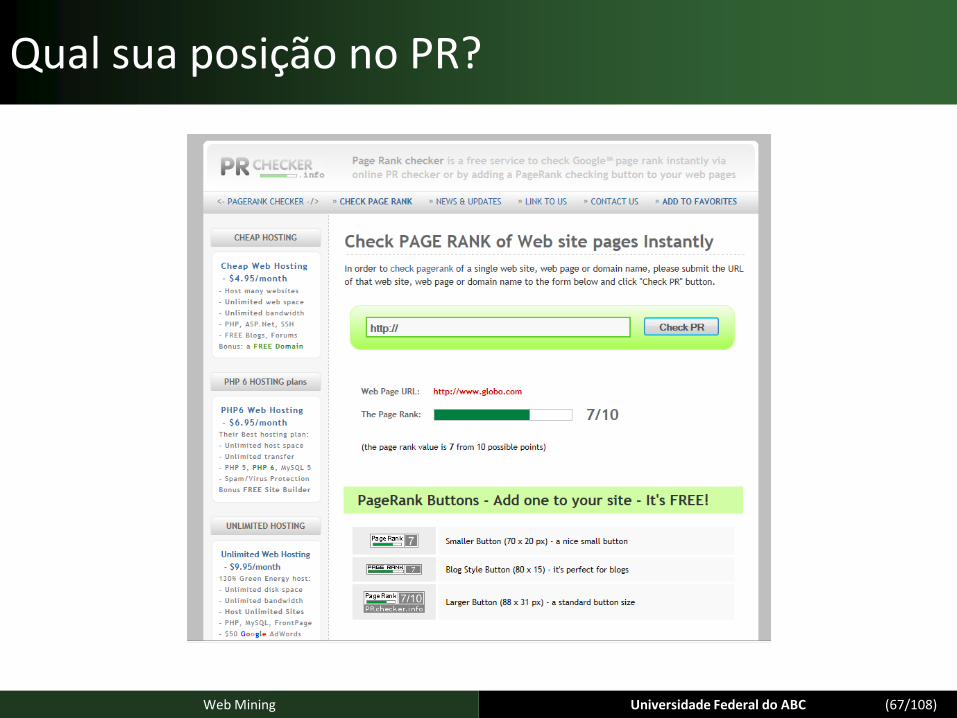
Qual sua posição no PR?
Universidade Federal do ABC (67/108)Web Mining
Qual sua posição no PR?
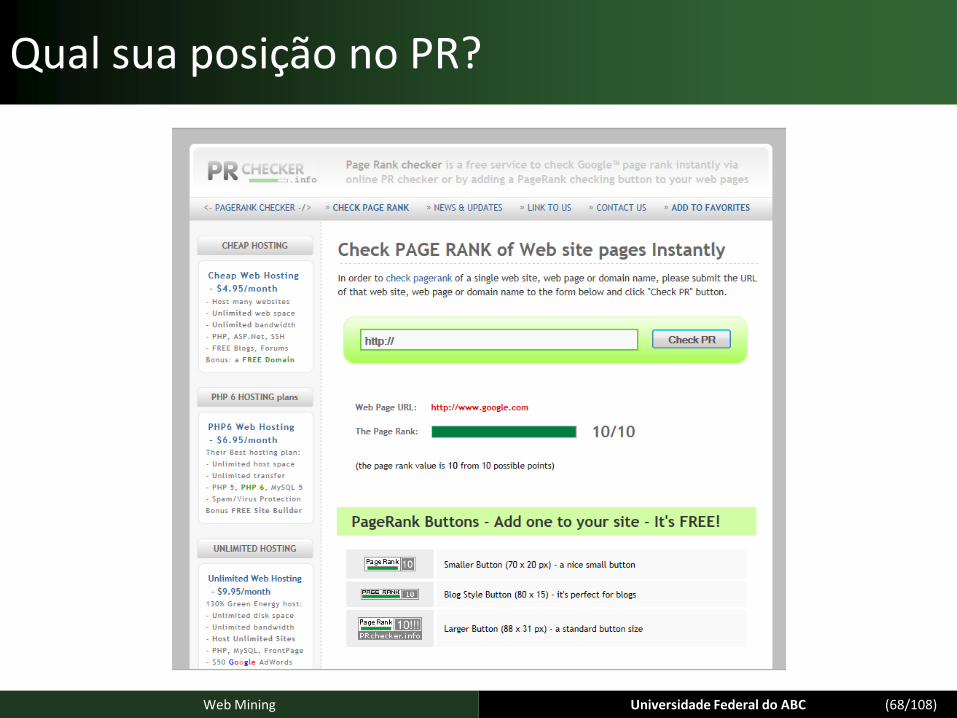
Universidade Federal do ABC (68/108)Web Mining
Qual sua posição no PR?

Universidade Federal do ABC (69/108)Web Mining
Qual sua posição no PR?

Universidade Federal do ABC (70/108)Web Mining
Escondendo seu Site do PageRank
Diversas pessoas acham que o Google controla a web e todos os sites que ela contém, mas isso não é verdade;
Os sites nos resultados de pesquisa do Google são controlados pelos webmasters desses sites.

Universidade Federal do ABC (71/108)Web Mining
Escondendo seu Site do PageRank
Pode-se remover o conteúdo (incluindo um snippet, título, conteúdo da página ou todo um URL ou site) dos resultados de pesquisa;
Pode-se indicar que o Google não deve rastrear ou indexar a página;
Há vários requisitos dependendo do tipo de conteúdo que você deseja remover.

Universidade Federal do ABC (72/108)Web Mining
Escondendo seu Site do PageRank
Após a realização dessas alterações e após o Google ter rastreado o site novamente, o conteúdo deverá sair naturalmente do índice do Google

Universidade Federal do ABC (73/108)Web Mining
Escondendo seu Site do PageRank
Outra técnica interessante é o uso do robots.txtpara impedir que o Google rastreie a página;
Em geral, mesmo se um URL for rejeitado pelo robots.txt, ainda poderemos indexar a página se encontrarmos seu URL em outro site;
No entanto, o Google não indexará a página se ela estiver bloqueada no arquivo robots.txt e houver um pedido de remoção para a página.

Universidade Federal do ABC (74/108)Web Mining
Escondendo seu Site do PageRank
No arquivo Robots.txt, inclua estas cláusulas:
User-agent: Googlebot
Disallow: /
Estas cláusulas informa ao Googlebot para não indexar nenhuma das páginas do site.

Universidade Federal do ABC (75/108)Web Mining
Search Engine Optimization (SEO)
Também conhecido como Otimização de Mecanismos de Busca;
Otimização de Sites é o conjunto de estratégias com o objetivo de potencializar e melhorar o posicionamento de um site nas páginas de resultados naturais nos sites de busca:
– SEO de White Hat
– SEO de Black Hat

Universidade Federal do ABC (76/108)Web Mining
Estado da arte
KddCup
– Competição anual de Descoberta de Conhecimento e Mineração de Dados realizada pela ACM SIGKDD;
WebKdd
– Workshop do KddCup específico para Descoberta do conhecimento e mineração de dados na Web;
SnaKdd
– Workshop do KddCup específico para Mineração e Análise de Redes Sociais;

Universidade Federal do ABC (77/108)Web Mining
Aprendizagem de preferências de perfis de novos usuários em Sistemas de Recomendação
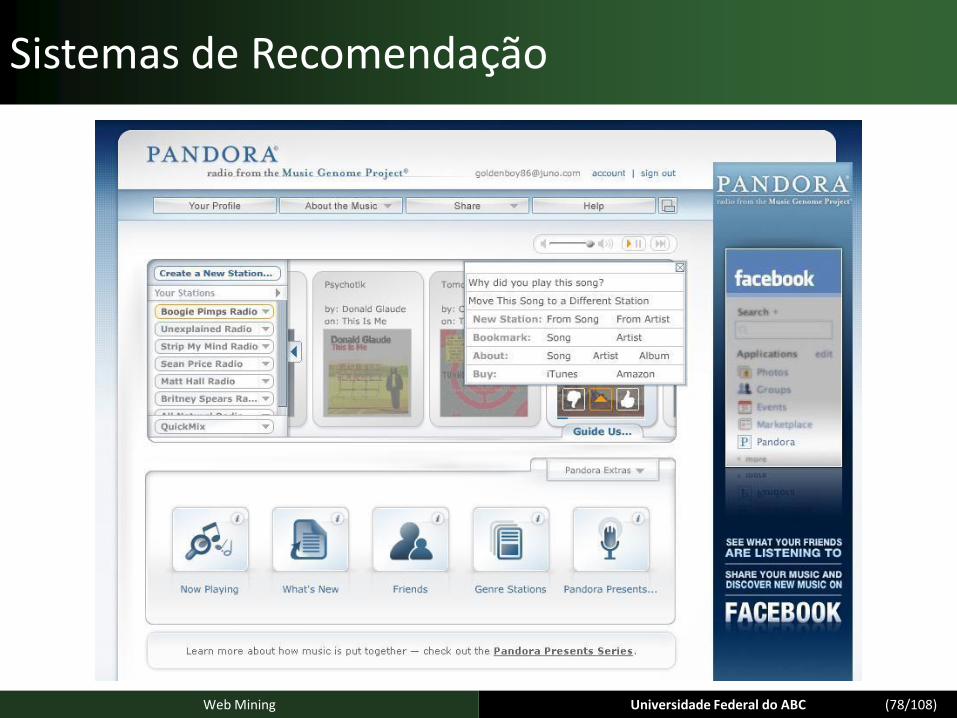
Universidade Federal do ABC (78/108)Web Mining
Sistemas de Recomendação
Universidade Federal do ABC (79/108)Web Mining
Sistemas de Recomendação

Universidade Federal do ABC (80/108)Web Mining
Qual a tecnologia utilizada por eles para tornar isso possível?
Filtragem colaborativa é a melhor tecnologia conhecida para sistemas de recomendação

Universidade Federal do ABC (81/108)Web Mining
Problemas
Carregamento inicial
Novos itens
Novos usuários

Universidade Federal do ABC (82/108)Web Mining
Como resolver?

Universidade Federal do ABC (83/108)Web Mining
Como resolver?

Universidade Federal do ABC (84/108)Web Mining
Métodos para descoberta do conhecimento
Métodos implícitos;
Métodos explícitos;

Universidade Federal do ABC (85/108)Web Mining
Outras formas de classificar
Olhar quem está no controle:
– Controlado pelo usuário;
– Controlado pelo sistema;
– Iniciativa mista.

Universidade Federal do ABC (86/108)Web Mining
Controlado pelo usuário
Vantagens
Desvatangens
– Podem não ser capazes de encontrar itens que expressam bem sua preferência.

Universidade Federal do ABC (87/108)Web Mining
Critérios desejáveis
Minimizar o esforço do usuário

Universidade Federal do ABC (88/108)Web Mining
Critérios desejáveis
Maximizar a precisão da recomendação
Universidade Federal do ABC (89/108)Web Mining
Estudo de caso

Universidade Federal do ABC (90/108)Web Mining
Objetivo
Definir qual é a melhor métrica para seleção de itens que melhor expressem as preferências do novo usuário;

Universidade Federal do ABC (91/108)Web Mining
Tipos de medidas para selecionar itens
Popularidade
Entropia
– Entropia0
– HELF
IGCN

Universidade Federal do ABC (92/108)Web Mining
Popularidade
Freqüência com que usuários avaliam o item;
Vantagem:
– Muitas pessoas são suscetíveis a taxa de itens de popularidades;
– Fácil e barato calcular
Desvantagem:
– Dependendo da distribuição da classificação, um item popular pode não ser informativo;
– Itens populares armazenam ainda mais avaliações;
– Itens impopulares podem ser difíceis de serem recomendados;
Universidade Federal do ABC (93/108)Web Mining
Popularidade

Universidade Federal do ABC (94/108)Web Mining
Entropia
Representa a dispersão de opiniões de usuários sobre o item;
Exemplo:
– Se 2.000 pessoas avaliam um item;
– E suas opiniões ficam distribuídas da seguinte forma: 400/2000, 400/2000, 400/2000, 400/2000, 400/2000 (correspondente a uma escala de classificação de 1,2,3,4,5);
– O item teria uma pontuação máxima de entropia;

Universidade Federal do ABC (95/108)Web Mining
Falem bem ou falem mau mas falem de mim!
Lema da Entropia

Universidade Federal do ABC (96/108)Web Mining
Entropia0
A maioria dos itens podem não receber as avaliações de todos os membros;
Trata a falta de avaliações em uma categoria separada;
Uma categoria(0) com os itens que não tiveram classificação;
Quanto menor a freqüência do item nesta categoria mais popular ele é;

Universidade Federal do ABC (97/108)Web Mining
HELF
Harmonic mean of Entropy and Logarithm of Frequency;
Pontuação de entropia
x
Freqüência de classificação

Universidade Federal do ABC (98/108)Web Mining
HELF
Aumenta a chance dos membros estarem familiarizados com o item;
Opiniões do usuário sobre o item possuem uma alta variabilidade;

Universidade Federal do ABC (99/108)Web Mining
IGCN
Baseado no conceito da filtragem colaborativa;
Encontrar seu verdadeiro vizinho que pensa igual;
Utiliza algoritmo de agrupamento para estipular uma vizinhança (grupos de usuários que pensam iguais);

Universidade Federal do ABC (100/108)Web Mining
IGCN
Utiliza algoritmo de árvores de decisão;
Nós folhas são os rótulos das respectivas vizinhanças formadas;
Nó raiz, o novo usuário;
Nó internos são os testes que leva o usuário a sua respectiva vizinhança;

Universidade Federal do ABC (101/108)Web Mining
Experimento off-line
11.000 usuários
9.000 filmes
3 milhões de classificações
– Escala de 0,5 a 5 estrelas

Universidade Federal do ABC (102/108)Web Mining
Experimento on-line
Foram criadas quatro formas de inscrição;
Eram escolhidos randomicamente para cada novo usuário;
Cada processo utilizou uma das métricas mencionadas para:
– Disponibilizar os filmes para o usuário classificar;
– Recomendar os filmes para o usuário.
Universidade Federal do ABC (103/108)Web Mining
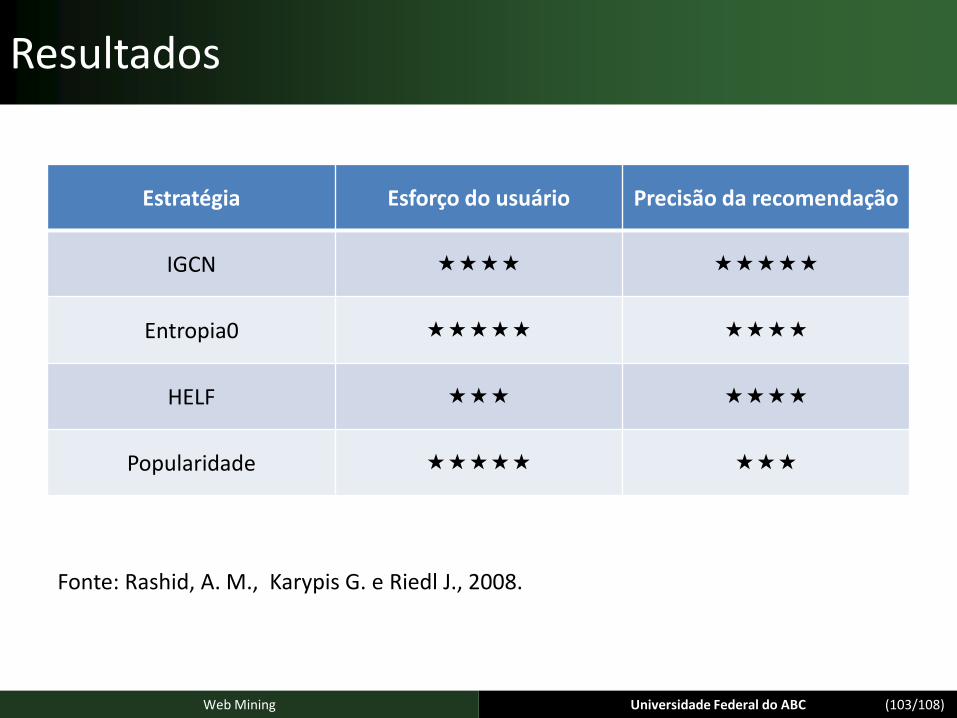
Resultados
Estratégia Esforço do usuário Precisão da recomendação
IGCN
Entropia0
HELF
Popularidade
Fonte: Rashid, A. M., Karypis G. e Riedl J., 2008.

Universidade Federal do ABC (104/108)Web Mining
Trabalhos futuros
Limitação da abordagem em conjunto de dados esparsos
– Cenário comum em comércio eletrônico;
A aprendizagem do perfil de usuário pode ser uma atividade contínua, pois as preferências do usuário podem mudar ao longo do tempo;

Universidade Federal do ABC (105/108)Web Mining
Trabalhos futuros
Preferências antigas devem ser descartadas ou mais peso deve ser dado às preferências recente.
O problema de atualização de perfil por avaliação de idade é interessante para direcionar trabalhos futuros;

Universidade Federal do ABC (106/108)Web Mining
Referências
Mineração na Web. Marinho, L. B. ; Girardi, R. Disponível em: http://portal.sbc.org.br/index.php?language=1&subject=101&content=magazine&id=8&option=abstract&sid=13&aid=33
Notas de Aula – Curso de Data Mining . Amo, Sandra. Disponível em: http://pt.scribd.com/doc/52799786/Definicao-Web-Mining
Notas de Aula – Pinheiro, J.M.S. Disponível em: www.projetoderedes.com.br
Conceitos de Mineração de Dados na Web. Santos, R. Disponível em: http://www.lac.inpe.br/~rafael.santos/Docs/WebMedia/2009/webmedia2009.pdf
Web intelligence – inteligência artificial para Descoberta de conhecimento na web . Loh, S. Garin, R. S. Disponível em: http://inforede.net/Technical/Business/IT/Web%20Inteligence.pdf
Learning Preferences of New Users in Recommender Systems: An Information Theoretic Approach. Rashid, A. M., Karypis G. e Riedl J., SIGKDD Explorations, 2008.

Universidade Federal do ABC (107/108)Web Mining
Referências
ALTMAN, Alon; TENNENHOLTZ, Moche. Ranking Systems: The PageRank Axioms. Faculty of Industrial Engineering and Management Technion. Israel Institute of Technology. 2005.
BRIN, Sergey; PAGE, Lawrence. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Computer Science Department, Stanford University, Stanford, CA 94305, USA. 1998.
KURLAND, Oren. LEE, Lillian. PageRank without hyperlinks: Structural re-ranking using links induced by language models. Computer Science Department, Cornell University, Ithaca NY 14853, U.S.A.
LIU, Tina. ANALYZING THE IMPORTANCE OF GROUP STRUCTURE IN THE GOOGLE PAGERANK ALGORITHM. A Thesis Submitted to the Graduate.
Faculty of Rensselaer Polytechnic Institute in Partial Fulfillment of the Requirements for the Degree of MASTER OF COMPUTER SCIENCE.
RAMANATHAN, Ananthakrishnan. Language Modeling for Information Retrieval. Annual Progress Seminar Report. Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Department of Computer Science and Engineering. Indian Institute of Technology, Bombay. Mumbai.

Universidade Federal do ABC (108/108)Web Mining
Artigo para resumir
WebKDD 2008: 10 years of knowledge discovery on the web post-workshop report.
– Olfa Nasraoui, Myra Spiliopoulou, Osmar R. Zaïane, Jaideep Srivastava, and Bamshad Mobasher. 2008.
– SIGKDD Explor. Newsl. 10, 2 (December 2008), 78-83. DOI=10.1145/1540276.1540299
– http://doi.acm.org/10.1145/1540276.1540299