Embed Size (px)
Citation preview

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
XXXVII SBPO -
XXXVII Simpósio Brasileiro de Pesquisa Operacional: 27-30/setembro/2005, Gramado/RS
MINICURSO
UMA INTRODUÇÃO À TEORIA DA AMOSTRAGEM COM
APLICAÇÕES EM PESQUISAS ELEITORAIS
Gutemberg Hespanha Brasil Antonio Fernando Pêgo e Silva
Departamento de Estatística -UFES/ES
“CADA ELEIÇÃO É UMA ELEIÇÃO”.
“CADA ELEIÇÃO TEM UMA HISTÓRIA DIFERENTE DAS OUTRAS”.
Motes Consagrados nas Eleições

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2633
XXXVII SBPO - XXXVII Simpósio Brasileiro de Pesquisa Operacional: 27-30/setembro/2005, Gramado/RS
UMA INTRODUÇÃO À TEORIA DA AMOSTRAGEM COMAPLICAÇÕES EM PESQUISAS ELEITORAIS
Gutemberg Hespanha Brasil
Antonio Fernando Pêgo e Silva Departamento de Estatística (UFES/ES)
RESUMO
O mini-curso está organizado em duas partes. A primeira descreve o básico da teoria estatística da amostragem, com todas as deduções e exemplos: conceitos básicos e definições, por que e como coletar amostras, a amostragem probabilística, a amostragem aleatória simples e a amostragem aleatória estratificada e outros tipos de desenho amostral usados em pesquisas de opinião. Expõe-se também um desenho diferente dos tradicionais, que supõem que o voto esteja relacionado fortemente a características da população tais como distribuições etárias, de renda e sexo. A “metodologia bayesiana” procura selecionar aqueles locais que sejam mais representativos do comportamento político da população. Identificam-se os locais (municípios, áreas, bairros e/ou agregações de bairros, etc) mais representativos da população votante, no sentido de que o comportamento do voto assumido pelos eleitores destes locais, seja o mais similar possível ao comportamento da população de toda a área considerada, adotando-se como critério uma medida de divergência, e construindo-se uma "hierarquia de similitudes", para selecionar os locais "mais representativos" da área em estudo. A segunda parte apresenta como a teoria se aplica em pesquisas eleitorais. Simplificadamente, uma pesquisa eleitoral nada mais é do que uma tentativa de avaliar, através de um procedimento amostral, as intenções de voto do eleitorado em uma dado momento do processo de decisão de voto do eleitor, até a sua cristalização, isto é, até a sua decisão definitiva. Uma pesquisa pode ser considerada como uma fotografia instantânea da realidade; a teoria da amostragem é a técnica estatística desenvolvida para tratar apropriadamente do problema da seleção das amostras. Assim, descrevem-se: as metodologias das pesquisas eleitorais, erros em pesquisas eleitorais, e alguns exemplos de pesquisas eleitorais realizadas nos níveis municipal e estadual. PALAVRAS CHAVES: Amostragem. Pesquisa de Opinião. Metodologias Clássica e Bayesiana. Previsão Eleitoral. Campanhas Políticas. Medidas de Informação.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2634
SUMÁRIO INTRODUÇÃO GERAL 4 PARTE 1 INTRODUÇÃO À TEORIA DA AMOSTRAGEM 5 1. Introdução à Teoria da Amostragem “Clássica” 51.1 Introdução 51.2. Conceitos Básicos e Definições 61.3. Por que Coletar Amostras? 91.4. Como Devemos Amostrar? 111.5. Amostragem Probabilística 131.5.1. Amostragem Aleatória Simples 161.5.2. Amostragem Aleatória Estratificada 402. Metodologia “Bayesiana” para Pesquisas Eleitorais 732.1. Introdução 732.2. Procedimento para Seleção de Locais 732.3. Análise Bayesiana do Modelo 77 PARTE 2 – APLICAÇÕES EM PESQUISAS ELEITORAIS 87 3. Metodologias das Pesquisas Eleitorais 883.1. O que Significa uma Pesquisa de Opinião Pública Eleitoral? 883.2. Pesquisas de Opinião Pública (opinion pools) 883.3. Desenho da Amostra 893.4. Desenho Amostral: Metodologia “Clássica” 903.5. Desenho Amostral: Metodologia “Bayesiana” 913.6. Questionários e Planejamento de Pesquisas Eleitorais 914. Erros em Pesquisas Eleitorais 934.1. Introdução e Exemplos 934.2. Questões Influentes nos Levantamentos Estatísticos Amostrais 954.3. Erros em Pesquisas por Amostragem 954.4. Aprendendo com os Erros em Pesquisas Eleitorais 974.5. Comentários: Indecisos e Pesquisas Eleitorais 1085. Pesquisas eleitorais: Metodologias Clássica e Bayesiana 1095.1. Estudos de Caso no Estado do Espírito Santo 1095.2. Metodologia Bayesiana: Eleições de 1990 - Governo e Senado do ES 1155.3. Monitoramento de Eleições Municipais no Município de Guarapari/ES- 124 1992 – Metodologias “Clássica e Bayesiana” 5.4. Eleições Municipais no Município da Serra/ES, 1996, Metodologias 130 “Clássica e Bayesiana” 5.5. Pesquisa Eleitoral no Espírito Santo, setembro/2001 1385.6. Análise dos Resultados da Eleição 2002, Governo ES, via Metodologia Bayesiana
142
6. Comentários e Discussão 1477. Referências 150

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2635
INTRODUÇÃO GERAL Para o senso comum, o uso da terminologia “pesquisas estatísticas” está frequentemente associado a pesquisas de opinião pública utilizando métodos estatísticos. Mais especificamente, refere-se ao uso de amostras selecionadas objetivando a realização de inferências sobre alguma população. Em períodos eleitorais essa associação é mais evidente. É o que tentamos apresentar neste trabalho. Simplificadamente, uma pesquisa eleitoral nada mais é do que uma tentativa de avaliar, através de um procedimento amostral, as intenções de voto do eleitorado em uma dado momento do processo de decisão de voto do eleitor, até a sua cristalização, isto é, até a sua decisão definitiva. Desse modo, uma pesquisa retrata apenas a realidade instantânea, relativa ao momento da pesquisa. Deve, em princípio, ser utilizada com cautela como uma previsão do resultado final da eleição, pois o processo de cristalização do voto até o dia das eleições está sempre sujeito a perturbações de todo tipo, seja pelo próprio movimento sócio-econômico, seja pelas agressões entre os diversos candidatos participantes. Outro ponto importante é que as pesquisas não são apenas úteis para indicar "quem está na frente", as informações geradas por uma boa pesquisa podem servir para direcionar todas as estratégias do candidato na campanha. Como vimos, uma pesquisa pode ser considerada como uma fotografia instantânea da realidade; a teoria da amostragem é a técnica estatística desenvolvida para tratar apropriadamente do problema da seleção das amostras. A teoria da amostragem e a história das sondagens de opinião em diversos países do mundo demonstram que, através de um procedimento amostral bem planejado, e bem executado, é realmente possível fazer inferências bastante precisas a respeito de um universo com muitos eleitores a partir de apenas algumas entrevistas. A economia de tempo e recursos é o que viabiliza a utilização das pesquisas eleitorais que, se bem conduzidas tecnicamente, podem levar a resultados sem prejuízos excessivos em termos de nitidez. Organização O mini-curso está organizado em duas partes. A primeira descreve o básico da teoria estatística da amostragem: conceitos básicos e definições, por que e como coletar amostras, a amostragem probabilística, a amostragem aleatória simples e por fim a amostragem aleatória estratificada; enfim o ferramental fundamental da amostragem “clássica”. Além disso, descreve sucintamente uma outra metodologia de amostragem que usa argumentos bayesianos. A segunda apresenta como a teoria se aplica a pesquisas eleitorais: as metodologias das pesquisas eleitorais, os erros em pesquisas eleitorais, e algumas pesquisas eleitorais no Estado do Espírito Santo. Na seção final alguns comentários sintéticos são feitos à guisa de conclusão.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2636
PARTE 1 – INTRODUÇÃO À TEORIA DA AMOSTRAGEM 1. INTRODUÇÃO À TEORIA DA AMOSTRAGEM “CLÁSSICA” 1.1. INTRODUÇÃO A amostragem científica vem sendo utilizada com sucesso desde meados do século XX. Algumas obras importantes geraram luz sobre novos conceitos e problemas surgidos gerando uma sólida teoria. Algumas delas são: Hansen, Hurwitz and Madow (1953), Deming (1960), Kish (1965), Moser and Kalton (1971), Raj (1972), Cochran (1977). Um livro bastante acessível é Barnett (1991), “Sample Survey: Principles and Methods”, que apresenta além da teoria estatística um capítulo sobre como executar um levantamento amostral. Bolfarine e Bussab (1994) é uma referência em língua portuguesa (recentemente publicado como livro). Na parte 1 deste trabalho, procuramos apresentar alguns dos principais conceitos utilizados na teoria da amostragem, os princípios básicos, e várias demonstrações detalhadas, usualmente não encontradas em livros texto. O capítulo 1, especificamente, trata da amostragem mais frequentemente aplicada pelas empresas e institutos de pesquisa de opinião. No capítulo 2 apresentamos uma abordagem alternativa que vem sendo aplicada em pesquisas eleitorais.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2637
1.2. CONCEITOS BÁSICOS E DEFINIÇÕES Sampling Suvey: Levantamento por Amostragem População Alvo (“Target Population”) É a população finita total sobre a qual desejamos informações. Exemplo: todos os jovens de 16 anos do ES. População em Estudo É o conjunto finito básico de indivíduos que pretendemos estudar. Exemplo: todos os jovens de 16 anos cujo endereço pertence às áreas urbanas dos municípios do ES, ou de qualquer outro estado brasileiro, onde se esteja fazendo o levantamento por amostragem. A população em estudo pode ser mais reduzida ou mais fácil de acessar, população esta, cujas propriedades esperamos poder explicar (ou extrapolar) para a população alvo. Característica Populacional É o aspecto da população que desejamos medir. Por exemplo, a proporção de jovens de 16 anos de idade que exercerá o seu direito de voto nas próximas eleições. Esta característica expressa alguma agregação da população em relação a como esta varia de um indivíduo para outro. Cada indivíduo contribui com sua parcela (um número de descrição qualitativa) para alguma medida de interesse (intenção de votar nas eleições, etc.). Como isso pode variar de indivíduo para indivíduo, nós usamos o termo variável de interesse. A característica populacional, também conhecida como parâmetro populacional, geralmente será um total, uma média ou uma proporção desta variável (medida) sobre a população. Unidades Amostrais
As unidades amostrais, em grande parte dos levantamentos, são representadas pelos próprios indivíduos, nestes casos são geralmente chamadas de unidades elementares. Em algumas situações, mesmo que nosso interesse se recaia sobre os indivíduos, não podemos selecionar estes indivíduos de uma forma tão trivial (talvez não haja uma lista a qual recorrermos). Nesses casos, as unidades amostrais podem ser as famílias, em outros as escolas, os locais de trabalho, etc. dependendo do tipo de levantamento. No caso dos jovens de 16 anos de idade, poderíamos acessá-los, principalmente nas escolas, mas não exclusivamente, incluindo-se os locais de trabalho, as suas residências, etc.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2638
Assim, os membros potenciais da amostra, as unidades amostrais, podem ter formas diferentes. A escolha deve ser feita no início do levantamento, já que pode afetar a operacionalização dos métodos amostrais. Alguns são mais adequados a determinados tipos de seleção que outros. Por exemplo, suponha que desejemos conduzir um levantamento sobre os gastos familiares em alguma cidade. Embora os “indivíduos” em nossa população em estudo sejam “famílias”, algumas definições convencionais de família devem ser adotadas. Do mesmo modo, não há nenhum meio trivial ou fácil de acessarmos tais unidades familiares naturalmente. “As famílias não estão disponíveis nas ruas para serem entrevistadas”. Logo, o endereço vem a ser a unidade amostral, mesmo que a população de endereços não seja de interesse principal. Quadro ou Grade ou Moldura Amostral (desenho ou Plano)
Assim, a fonte de nossa amostra é o conjunto das unidades amostrais. Esta é chamada de grade amostral ou moldura de amostragem, que é simplesmente a fonte ou lista de onde será selecionada a amostra. Algumas vezes as unidades amostrais podem ser os indivíduos membros da população (em) estudo. Muitas vezes não o será e o quadro amostral é a subdivisão mais grosseira da população estudada, com cada unidade amostral contendo um conjunto distinto de membros da população. Lista
Para se usar o quadro amostral como matéria prima da qual retiraremos nossa amostra, devemos estar aptos a identificar as unidades amostrais. Realmente, o quadro ou moldura amostral é escolhido tendo isto em mente. Uma lista de melhor qualidade, contendo todas as unidades amostrais, pode existir, tal como, a lista de endereços da cidade, ou a dos alunos matriculados em uma Universidade, onde queremos estudar os hábitos de leitura, uso de computadores, etc. De posse de tal lista é particularmente fácil escolher a amostra. Mas se nenhuma lista adequada é acessível para consulta, devemos pelo menos obter ou montar uma lista conceitual. Por exemplo: em um estudo de hábitos de leitura e uso de computador pelos alunos de uma região, podemos não possuir a lista de toso os estudantes, no entanto podemos ter acesso a uma lista de escolas e posteriormente das séries/cursos que funcionam em cada escola. Esta lista pode ser suficiente para gerar a informação que queremos obter e conseguir acessar os estudantes para o nosso levantamento. Tais distinções são importantes para implementação de levantamentos por amostragem. Alguns problemas que necessitam de algum refinamento dizem respeito à: (i) Escolha de unidades amostrais onde haja várias alternativas existem; (ii) Discrepância entre o ideal de uma população alvo e a realidade de uma grade
amostral acessível; (iii) Listagens incompletas ou impossíveis de serem obtidas;

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2639
(iv) Implementação de levantamentos por amostragem, sua organização e administração envolve um complexo conjunto de problemas de planejamento, custeio e treinamento.
Posteriormente discutiremos os seguintes problemas: (a) Se existem diferentes tipos de indivíduos, nossa amostra deveria refletir essas
diferenças de alguma maneira balanceada, já que esses indivíduos poderiam possuir problemas de naturezas diferentes. Há situações em que se procura balancear a amostra através de cotas preestabelecidas (tipo uma “maquete” da formação sócio-econômica populacional) e procedimentos de estratificação, respeitando-se os pesos dos estratos populacionais.
(b) Não-respostas nas pesquisas podem contaminar os resultados do levantamento,
o que também pode acontecer com o entendimento inadequado, por parte dos respondentes, ao entrevistador ou ao questionário. Nestes casos, um treinamento adequado e conduzido de forma a reduzir as diferenças, na maneira de perguntar e na forma de conduzir a entrevista, entre os entrevistadores, seria útil e poderia reduzir de forma substancial o problema de questões em branco e de respostas sem sentido ou mal entendimento das questões.
A redução dessas dificuldades deve ser buscada em dois níveis: (a) Procedimento Pragmático: Esse nível de procedimento é tipicamente não estatístico. Há situações, tais como a escolha das unidades amostrais, administração do levantamento, desenho do próprio questionário, treinamento adequado dos entrevistadores, que requerem experiência em uma série de áreas/assuntos ou situações aplicadas. O conhecimento adequado da área de aplicação do levantamento/pesquisa (medicina, agricultura, área social, etc.) deve ser combinado a estudos ou integração com psicólogos ou especialistas em “design” de questionários ou procedimentos de testes psicológicos, de sociólogos ou outros especialistas no assunto, para avaliar a relevância da base dados disponibilizadas, para a escolha da moldura/grade amostral, e talvez haja necessidade de um especialista em computação para a obtenção de processo automatizado de produção dos dados resultantes. Hoje estamos cada vez mais envolvidos em grupos multidisciplinares, onde a formação da equipe passa, necessariamente, por essa variedade de habilidades. Na maioria das vezes, devemos depender do bom senso ou da experiência dos organizadores de uma pesquisa, no sentido de que explorem as circunstâncias locais e apreendam a realidade. Preliminarmente, estudos pilotos podem auxiliar na execução do levantamento principal. (b) Estatístico: Em contraste aos referidos problemas práticos, não estatísticos, temos aqueles relativos à Estatística, como representatividade de um levantamento, sua validade, a escolha de procedimentos de amostragem adequados, métodos de estimação de características da população (e as propriedades desses estimadores) e interpretação

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2640
e legitimidade dos resultados, todos dependem de forma vital de um entendimento e aplicação apropriados das idéias estatísticas. Uma sólida base estatística no desenho de uma pesquisa por amostragem é de extrema importância; dificuldades “práticas” de implementação podem reduzir sua efetivação e devem, portanto, ser resolvidos tão cedo quanto possível. Por outro lado, um levantamento que não apresenta tais problemas “práticos” também não estará apto a ser completamente executado se sua base estatística é inadequada. Nesse caso, ele se torna sem valor se não respeita as considerações do desenho estatístico, além de tornar impossível interpretar ou medir a precisão dos resultados. O estudo das teorias e metodologias estatísticas apropriadas é o tema desse curso. 1.3. PORQUÊ COLETAR AMOSTRAS ? Nosso objetivo é extrapolar resultados acerca de uma população a qual estamos interessados em estudar alguma característica de nosso interesse, população esta constituída de um número finito de indivíduos, em que para cada um deles alguma medida Y é observável. Queremos caracterizar a população por algum parâmetro ou informação de tal medida – talvez sua média, ou valor total, ou proporção. Então, por quê não observar todos os indivíduos na população e determinar a resposta ‘exata’? Em alguns casos, onde a população é pequena e fácil de acessar, esta seria uma solução bastante razoável. Se quisermos determinar a nota média de uma turma de amostragem, “não é concebível” coletar uma amostra dos alunos e tentar fazer uma inferência sobre a nota média de toda a turma, a menos que essas pessoas não possam mais ser acessadas como um todo e seja necessário algum tipo de amostra. Nesse caso, no entanto, é mais razoável uma inspeção completa. De modo inverso, em populações maiores poderíamos fazer uma inspeção completa, desde que haja importância social e/ou política para justificar esta grande despesa. Isto se dá, por exemplo, no caso dos Censos, os quais procuram entrevistar todas as famílias existentes no país. Mesmo os censos, já começam a incorporar uma parcela de amostragem probabilística, onde são feitos estudos mais específicos. Mais comumente, faz sentido, por uma série de razões, restringirmos nosso estudo da população a uma amostra de “alguns” de seus membros e usar a informação obtida deste modo para inferir as características da população como um todo. Quais seriam essas razões? CUSTOS Normalmente, haverá um limite de nossos recursos, em termos de dinheiro disponível ou esforço, que poderemos aplicar. Este é o principal obstáculo à uma

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2641
enumeração completa da população. Há também a necessidade de contrabalançar precisão e custos. Inspeções rápidas e superficiais de um grande número de indivíduos (possivelmente, mesmo toda a população) podem fornecer, em vista das imprecisões de medição, informações menos precisas que aquelas obtidas através de uma inspeção mais cuidadosa de alguma amostra menor, mas criteriosamente escolhida. Os fatores de custos diferentes são também relevantes. Em amostragem dos jovens de 16 anos de idade, poderíamos ter uma conduta de entrevistas diretas com aqueles em algum grupo (por exemplo, aqueles estiverem hospitalizados), mas enviar cartas ou questionários através dos Correios para aqueles em outro grupo (por exemplo, aqueles que estiverem temporariamente fora do ES ou área). Os custos unitários de amostragem nesses dois diferentes “estratos” serão, provavelmente, bem diferentes e o “desenho amostral” que escolhermos empregar deve refletir esta diferença, talvez devêssemos tomar uma amostra relativamente menor daqueles hospitalizados do que daqueles que estão fora de casa, ou podemos amostrar primeiro um grupo por “conglomerado” (todos aqueles em um hospital, em particular) para controlar os custos de contrato e viagens. UTILIDADE
Em alguns casos nossas unidades amostrais podem ser destruídas no processo de amostragem. Aqui o estudo completo da população é inadequado ou inaplicável (ou mesmo inútil), mesmo se pudermos fazê-lo. Muitas vezes não há ganhos substanciais em conhecermos “tudo” sobre determinada população se ela não vai mais existir para a exploração e explicação do nosso conhecimento. Assim, um fabricante de lâmpadas ou fósforos não irá testar o tempo de vida de cada lâmpada, ou acender todos os fósforos, para demonstrar a qualidade de seu produto. Depois de tais testes não haveria mais nada para vender e ele, muito provavelmente, estaria falido. ACESSIBILIDADE
Freqüentemente há diferentes facilidades de acesso para diferentes unidades amostrais. Algumas podem até mesmo não ser observáveis como um todo. Outras vezes, podemos ser obrigados a aceitar ou coletar apenas uma única amostra da população. Por exemplo: observações históricas (séries temporais) podem estar incompletas – dados de temperaturas ou chuvas armazenados por um determinado período de interesse, podem ter sido coletados esporadicamente; opiniões sobre alguma questão contemporânea (momento histórico) polêmica podem ter sido recolhidas de forma incompleta e agora não há como reconstituir as circunstâncias da época para um estudo mais completo.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2642
1.4. COMO DEVEMOS AMOSTRAR? Esta é, obviamente, a principal questão a ser respondida. Sua resolução exigirá uma formalização mais acentuada do problema de amostragem de populações finitas, e dos objetivos de um levantamento por amostragem. De forma mais intuitiva, o objetivo geral deve ser o de retirar uma amostra que é uma “representação honesta” da população e que nos leve à estimativa da característica populacional com tanto maior “precisão” ou “exatidão” quanto possamos esperar para o custo ou esforço que estamos dispostos a empreender. Vários métodos pragmáticos de amostragem ou de apelo intuitivo foram desenvolvidos ao longo dos anos, e são amplamente empregados. Tais métodos “ad hoc” incluem os seguintes. AMOSTRAGEM POR ACESSIBILIDADE
Com o estímulo principal da conveniência administrativa, uma amostra é escolhida com a única preocupação de facilidade de acesso. “Tomaremos as observações mais fáceis de serem obtidas”. Evidentemente, algumas armadilhas causadas pela falta de representatividade parecem óbvias. Nos casos de amostragem por fluxo, por exemplo, apesar da grande operacionalidade, dependendo da qualidade do planejamento de amostragem, pode-se facilmente gerar uma amostra com distorções grosseiras em relação à população que se pretende fazer as extrapolações. Basta não observar adequadamente as divisões territoriais de uma cidade, que os problemas provavelmente aparecerão. Mesmo havendo controle do perfil populacional, as particularidades e problemas regionais devem ser observados e podem ser importantes, dependendo dos objetivos do levantamento. É necessário garantir uma adequada cobertura espacial da região ou cidade em estudo. Outros casos, dizem respeito a uma má administração do levantamento, não observar características de comportamento das pessoas, como os horários que se encontram disponíveis para entrevistas (horários durante o dia, nos dias de semana, por exemplo, privilegiam mais a estudantes, aposentados e desempregados), pode levar a inevitáveis defeitos ou falhas nos resultados de tais pesquisas, como ferramentas de se entender a população. Em outras situações, mesmo que o problema não seja tão óbvio, os erros podem ser igualmente sérios. AMOSTRAGEM INTENCIONAL
Na amostragem intencional, o experimentador, reconhecendo que a população pode bem conter diferentes tipos de indivíduos, com diferentes medidas de facilidade de acesso, exerce uma escolha deliberada e subjetiva em retirar aquela que ele julga ser uma amostra “representativa”. Os resultados de tal procedimento de amostragem “podem” ser muito bons, se a intuição e julgamento do experimentador são válidos, e deve-se até reconhecer que alguns levantamentos podem empregar este princípio em “algum grau”. A amostragem intencional visa a diminuição “antecipada” de fontes de distorções; mas haverá sempre o risco de permanecerem distorções devido à julgamentos

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2643
pessoais, de perda de informação sobre certos aspectos ou características importantes (até mesmo cruciais) na estrutura da população. OBS.: Na verdade, tais conhecimentos do experimentador e procedimentos relacionados, poderiam ser agregados e serem levados em consideração na hora do planejamento de amostragem, cuidados com detalhes que poderiam passar despercebidos, como informações sobre características regionais, mesmo geográficas, aglomerados urbanos que surgiram recentemente, etc, sem que isso signifique em intervir deliberadamente na escolha da amostra. AMOSTRAGEM POR COTAS OU QUOTAS
Na amostragem por cotas, o que se deseja é obter uma amostra mais “próxima” possível da população. É como se estivéssemos interessados em “fazer uma maquete” do perfil populacional. Este perfil está sendo simbolizado em termos das variáveis populacionais de interesse, as quais queremos “controlar” (controlar, no sentido administrativo). Desse modo, pode-se estar interessado em traçar percentuais de sexo, faixa etária, escolaridade, perfil sócio-econômico, etc., de modo que a amostra tenha um perfil o mais “fiel” possível do perfil populacional. Por exemplo, em uma pesquisa eleitoral no estado do Espírito Santo, pode-se desenhar a amostra por microrregiões ou mesorregiões homogêneas. Essa homogeneidade pode ser definida por proximidade geográfica e características sócio-econômicas. No entanto, esse controle de cotas, acaba por introduzir um elemento não probabilístico na amostragem, na medida em que, a partir de determinado momento, os entrevistadores poderão estar à procura de um indivíduo com um perfil predeterminado para conclusão da sua “tarefa” do dia. De todo modo, para dar um exemplo, pode-se utilizar a idéia da pesquisa eleitoral no ES, com o controle de cotas sexo por município.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2644
Assim, poderíamos escolher os indivíduos segundo o critério a seguir:
Resumo da População dos Municípios da Grande Vitória
Municípios Homens % Mulheres % Total %
Vitória 86.319 22,67 101.706 24,41 188.025 23,58%
Vila Velha 97.327 25,56 109.278 26,23 206.605 25,91%
Serra 85.736 22,51 88.899 21,34 174.635 21,90%
Cariacica 96.290 25,28 101.365 24,33 197.655 24,79%
Viana 15.169 3,98 15.389 3,69 30.558 3,83%
Total 380.841 416.637 797.478 100,00%
% 47,76% 52,24% Fonte: IBGE – Censo 2000. Hoje a Grande Vitória engloba mais municípios. Com 16 anos ou mais.
Assim, preestabelecemos os percentuais de homens e mulheres que devem fazer parte da amostra, percentuais especificados para cada município. O mesmo poderia ser estabelecido para faixa etária, escolaridade, etc ou todos eles ao mesmo tempo, o que é o caso mais comum. O uso combinado de amostragem probabilística e controle de cotas é bastante difundido nas pesquisas de opinião e nas pesquisas eleitorais, em toda parte. Suas vantagens e desvantagens já foram bastante discutidas e continuam a ser alvo de estudos por pesquisadores da área. Por causa da necessidade de um componente aleatório no nosso processo de seleção da amostra, com a intenção de fazermos extrapolações para a população e podermos comparar as “qualidades das estimativas” do ponto de vista probabilístico, é que precisamos definir um novo procedimento, chamado amostragem probabilística. 1.5. A AMOSTRAGEM PROBABILÍSTICA Suponha que, em nosso objetivo de estudar uma população alvo, resolvemos o modo de escolha das unidades amostrais apropriadas e da grade de amostragem que a inclui. Suponha que o quadro de amostragem representa a população finita acessível, e que as unidades amostrais são os indivíduos membros de tal população. Mas, nós nos referimos apenas à “população” e seus “membros” ou “indivíduos”. Nosso interesse se concentra em relação aos valores tomados (ou assumidos) por alguma variável, Y, para os diferentes membros da população, e sobre medidas

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2645
agregadoras (parâmetros) desta variável sobre toda a população. Assim, se há N membros, podemos representá-los por Y1, Y2,..., YN, esses sendo os valores de Y apresentados (tomados ou assumidos) pelos diferentes membros. Estamos interessados em características populacionais definidas com respeito à Y. As mais comuns são:
(i) O total populacional, ∑=
=N
jjT YY
1.
(ii) A média populacional, NYY
NY T
N
jj == ∑
=1
1 .
(iii) A proporção, P, de membros da população que pertencem à alguma categoria de classificação para a medida Y.
O objetivo da pesquisa por amostragem será estimar uma ou mais características da população através da informação contida em uma amostra de n ( )Nn ≤ membros da população. Suponha que os valores de Y para a amostra são nyyy ..., , , 21 , onde cada yi é um dos valores Yj de Y, na população como um todo. Nem todos os Yj’s são necessariamente diferentes; o mesmo acontece com os yi’s. Desse modo pode-se resumir a terminologia da seguinte forma: POPULAÇÃO: N Tamanho Populacional
TY Total Populacional Y Média Populacional P Proporção Populacional R Razão Populacional
AMOSTRA:
n Tamanho Amostral
Ty Total Amostral y Média Amostral p Proporção Amostral r Razão ou Íncice Amostral PROPRIEDADES DOS ESTIMADORES Nas descrições das propriedades seguintes, consideramos que temos uma população, a qual possui um parâmetro θ que se deseja estimar. Para tal, lançamos mão de um levantamento por amostragem o qual nos fornecerá as estatísticas necessárias para o processo de estimação do parâmetro de interesse, θ .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2646
É de interesse dos pesquisadores que os estimadores obtidos, que são as estatísticas obtidas, possuam propriedades “qualitativas” para que possamos considerá-los “bons estimadores”, do ponto de vista estatístico. Algumas das propriedades mais desejáveis são: 1. Não-tendenciosidade
Se a estatística ( )nyyygT ,...,, 21= (função dos valores amostrais) é um estimador de θ , de modo que ( ) θ=TE , então diz-se que T é não-viesado ou não-tendencioso para θ (ou mesmo, não-viciado). 2. Erro Quadrático Médio e Viés
( ) ( )2θ−= TETEQM
( ) ( ) ( )[ ]2θ−+−= TETETETEQM
( )[ ] ( )[ ] ( )[ ] ( )[ ]{ }22 ..2 θθ −+−−+−= TETETETTETE ( )[ ] ( )[ ] ( )[ ]{ } ( )[ ]22 ..2 θθ −+−−+−= TEETETETETETE ( ) ( )[ ]2θ−+= TEETV
( ) ( )[ ]2θ−+= TETV . Então, o erro quadrático médio pode ser representado por:
( ) ( ) ( )TBTVTEQM 2+= . Onde, ( ) ( )[ ]θ−= TETB é o viés (ou tendência) de T como estimador de θ . Se T é um estimador não-viesado (ou não-tendencioso), teremos que ( ) θ=TE , ( ) 0=TB e, portanto, ( ) ( )TVTEQM = .
3. Eficiência Se temos dois estimadores, 1T e 2T , que são estimadores não-viesados de θ , então se ( ) ( )21 TVTV ≤ , diz-se que 1T é mais eficiente do que 2T . Então, medimos eficiência através da variância dos estimadores, quanto menor for a variância mais eficiente será o estimador, em relação ao seu concorrente. 1.5.1. AMOSTRAGEM ALEATÓRIA SIMPLES

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2647
Suponha que temos uma população representada por NYYY ,...,, 21 . Coletamos uma amostra aleatória simples (através de sorteio, por exemplo) de n elementos (n<N), dentre os N elementos populacionais. Assim, teremos nyyy ,...,, 21 representando a amostra aleatória simples selecionada. Se os elementos são selecionados com ou sem reposição, então teremos o seguinte.
Com reposição: N N N ... N 1 2 3 n
Serão, então, nN maneiras de escolhermos n indivíduos (elementos) dentre os N existentes.
Sem reposição: N N-1 N-2 ... N-(n-1) 1 2 3 n
Serão, então, ( )!!nN
N−
maneiras de escolhermos n indivíduos (elementos) dentre os
N existentes. Teremos ainda o seguinte:
( ) ( ) ( ) ( ) ( )( )
!!
11....
21.
11.1,...,,,. ... .,.. 1321213121 N
nNnNNNN
yyyyyPyyyPyyPyP nn−
=−−−−
=−
Mas como esses mesmos elementos poderiam ter sido escolhidos em quaisquer dessas n posições, que mesmo assim teríamos o mesmo conjunto escolhido, teremos:
( ) ( )nN
n CNnNnyyyyP 1
!!!,...,,, 321 =
−= .
Queremos utilizar a estatística y (obtida através da amostra aleatória simples selecionada) para estima Y , a média populacional.
Quais serão as propriedades de y como estimador de Y , onde ∑=
=n
iiy
ny
1
1 é a
média da amostra aleatória simples e ∑=
=N
jjY
NY
1
1 é a média populacional ?
1) ( ) ?=yE
Temos que:
( ) ( ) ( )∑ ∑∑∑= ===
⎥⎦
⎤⎢⎣
⎡===⎟⎟
⎠
⎞⎜⎜⎝
⎛=
n
i
N
jjij
n
ii
n
ii YyPY
nyE
ny
nEyE
1 111
111 .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2648
Mas, ( ) ( )( )
( )NN
nNnN
NYyP ji1
!!
!!1
=−
×−−
== . Para cada posição i (ou i-ésima escolha)
desejamos apenas o elemento j da população para ocupá-la. Então,
( ) ∑∑ ∑== =
==⎥⎦
⎤⎢⎣
⎡=
n
i
n
i
N
jj YY
nNY
nyE
11 1
111 .
Portanto, y é estimador não-viesado (ou não-tendencioso) de Y .
2) ( ) ?=yVar
( ) ( ) ( )⎥⎦
⎤⎢⎣
⎡+=⎟⎟
⎠
⎞⎜⎜⎝
⎛= ∑∑∑∑
= <==
n
i
n
jiji
n
ii
n
ii yyCovyVar
ny
nVaryVar
112
1,211 .
Mas, ( ) ( ) ( ) ( ) 2222 YyEyEyEyVar iiii −=−= e ( ) ( )N
YYyPYyEN
jjji
N
jji
11
2
1
22 ∑∑==
=== .
Assim, ( ) ∑=
−=N
jji YY
NyVar
1
221 .
Portanto,
( ) ( )2
1NSNyVar i −= (1.1)
onde ( )∑=
−−
=N
jj YY
NS
1
22
11 é a variância populacional.
Por outro lado,
( ) ( ) ( ) ( )jijiji yEyEyyEyyCov ., −= .
( ) ( ) 2, YyyEyyCov jiji −= .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2649
Mas, ( ) ( ) ( ) ( )∑∑∑∑ =======
r ssjsjrisr
r ssjrisrji YyPYyYyPYYYyYyPYYyyE .|,
( ) ∑∑ −=
r ssrji NN
YYyyE 11
1
( ) ( )∑∑−=
r ssrji YY
NNyyE
12 , para jisr ≠< e .
Além disso, ∑∑∑∑==
−⎟⎟⎠
⎞⎜⎜⎝
⎛=
N
kk
N
kk
r ssr YYYY
1
22
12 .
Assim, podemos escrever:
( ) ( )2
1
22
111, YYY
NNyyCov
N
kk
N
kkji −
⎥⎥⎦
⎤
⎢⎢⎣
⎡−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= ∑∑==
.
( ) ( ) ( )⎥⎥⎦
⎤
⎢⎢⎣
⎡−−−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= ∑∑==
2
1
22
11
11, YNNYY
NNyyCov
N
kk
N
kkji
( ) ( ) ⎥⎥⎦
⎤
⎢⎢⎣
⎡+−−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= ∑∑==
222
1
22
111, YNYNYY
NNyyCov
N
kk
N
kkji
( ) ( ) ⎥⎦
⎤⎢⎣
⎡+−−
−= ∑
=
222
1
222
11, YNYNYYN
NNyyCov
N
kkji
( ) ( ) ( ) ⎥⎦
⎤⎢⎣
⎡−
−−
=⎥⎦
⎤⎢⎣
⎡+−
−= ∑∑
==
2
1
22
1
2
11
11, YNY
NNYNY
NNyyCov
N
kk
N
kkji
( ) 22
1
2 11
11, SN
YNYNN
yyCovN
kkji
−=⎥
⎦
⎤⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−
−−
= ∑=
.
( ) jiNSyyCov ji ≠
−= ,,
2
(1.2)
onde 2S é a variância populacional.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2650
Desse modo,
( ) ( ) ( )⎥⎦
⎤⎢⎣
⎡+=⎟⎟
⎠
⎞⎜⎜⎝
⎛= ∑∑∑∑
= <==
n
i
n
jiji
n
ii
n
ii yyCovyVar
ny
nVaryVar
112
1,211 .
( ) ( ) ⎥⎦
⎤⎢⎣
⎡ −+−= ∑∑∑
= <=
n
i
n
ji
n
i NS
NSN
nyVar
1
2
1
2
2 211 .
( ) ⎥⎦
⎤⎢⎣
⎡−−= ∑∑
= <
n
i
n
jiNS
NnS
NnNS
nyVar
1
222
2 121 .
Como ( )2
111
−=∑∑
= <
nnn
i
n
ji, temos que:
( ) ( )⎥⎦
⎤⎢⎣
⎡ −−−=
21.21 222
2
nnNS
NnS
NnNS
nyVar .
( ) ⎥⎦
⎤⎢⎣
⎡+−−=
NnS
NSn
NnS
NnNS
nyVar
22
221 22222
2 .
( ) ⎥⎦
⎤⎢⎣
⎡−=
NSn
NnNS
nyVar
222
2
1 .
( ) ⎥⎦⎤
⎢⎣⎡ −=
Nn
nnSyVar 12
2
.
( ) ( )n
SfyVar2
1−= (1.3)
onde Nnf = é a fração amostral ou de amostragem.
Se Nn → , teremos 1→f e ( ) 0→yVar , o que significa dizer que estaremos “amostrando” toda a população.
Se ∞→N , teremos 0→f e ( )n
SyVar2
→ , que é a variância da média amostral
obtida através da amostragem com reposição ou de população infinita.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2651
Se escrevermos ∑=
=n
iii ywy
1
* . , onde iw é o peso da i-ésima observação e 11
=∑=
n
iiw ,
teremos o seguinte:
( ) ( ) ( )∑ ∑∑∑= >=
+=⎟⎟⎠
⎞⎜⎜⎝
⎛=
n
i i ijjijiii
n
iii yyCovwwyVarwywVaryVar
1
2
1
* ,2.. .
( ) ( )∑ ∑∑= >
⎟⎟⎠
⎞⎜⎜⎝
⎛ −+
−=
n
i i ijjii N
SwwSN
NwyVar1
222* 21. .
( ) ( ) ∑ ∑∑= >
⎟⎟⎠
⎞⎜⎜⎝
⎛ −+
−=
n
i i ijjii ww
NSwS
NNyVar
1
222* 21 .
( ) ( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−−= ∑ ∑∑
= >
n
i i ijjii wwwN
NSyVar
1
22
* 21 .
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−−= ∑ ∑∑∑
= >=
n
i i ijji
n
iii wwwwN
NSyVar
1 1
222
* 2 .
( )⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−= ∑ ∑
= =
n
i
n
iii wwN
NSyVar
1
2
1
22
* .
( ) ⎥⎦
⎤⎢⎣
⎡−= ∑
=
n
iiwN
NSyVar
1
22
* 1 .
( ) ⎥⎦
⎤⎢⎣
⎡−= ∑
=
n
ii N
wSyVar1
22* 1 .
Desse modo, queremos que ∑=
n
iiw
1
2 seja mínimo, já que as outras quantidades
envolvidas na expressão são constantes.
Note que ∑−
=
−=1
11
n
iin ww . Então queremos minimizar ∑ ∑∑
−
=
−
==
=⎟⎟⎠
⎞⎜⎜⎝
⎛−+=
1
1
21
1
2
1
2 1n
i
n
iii
n
ii Qwww .
Logo, ( )11221
1−⎟
⎠
⎞⎜⎝
⎛−+=
∂∂ ∑
−
=
n
iii
i
wwwQ .
Igualando a expressão anterior a zero, obtemos:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2652
in
wwwwwiwww i
n
iinn
n
iii ∀=⇒====⇒∀=⎟⎟⎠
⎞⎜⎜⎝
⎛−= ∑∑
=
−
=
11 e ... 11
21
1
1.
Portanto, tomando pesos iguais à n1 , minimizamos a variância do estimador da
média populacional Y . Ou seja, nenhum outro tipo de ponderação forneceria uma variância menor. Como a variância do estimador da média populacional depende da variância populacional 2S , pode acontecer de não termos acesso antecipado a essa quantidade, talvez por falta de pesquisas anteriores sobre a população alvo. Nesse caso, podemos estimar a variância populacional através da variância amostral, representada por:
( )2
1
2
11 ∑
=
−−
=n
ii yy
ns
Vamos verificar se esse estimador é não-viesado ou não-tendencioso.
( ) ( ) ( ) ( )⎥⎦
⎤⎢⎣
⎡−
−=⎥
⎦
⎤⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡−
−= ∑∑∑
===
2
1
22
1
22
1
2
11
11
11 ynEyE
nyny
nEyy
nEsE
n
ii
n
ii
n
ii
( ) ( )⎥⎥⎦
⎤
⎢⎢⎣
⎡−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= ∑ ∑= =
2
1 1
22 11
1 ynEN
Yn
sEn
i
N
jj .
Temos que: ( ) ( ) ( ) ( )[ ]222
1 yEyEn
SfyVar −=−=
Então: ( ) ( ) ( )[ ] ( ) 22
22
2 11 Yn
SfyEn
SfyE +−=+−= .
Assim,
( ) ( )⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+−−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= ∑ ∑= =
22
1 1
22 111
1 Yn
SfnN
Yn
sEn
i
N
jj .
( ) ( ) ⎥⎦
⎤⎢⎣
⎡−−−
−= ∑
=
22
1
22 111
1 SfYnN
Ynn
sEN
jj .
( ) ( )⎥⎥⎦
⎤
⎢⎢⎣
⎡−−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
−= ∑
=
22
1
22 111
1 SfYYN
nn
sEN
jj .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2653
( ) ( )⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−
−= ∑
=
22
1
22 111
1 SfYNYN
nn
sEN
jj .
( ) ( )[ ] ( )⎭⎬⎫
⎩⎨⎧ −−−
−= 222 11
11 SfSN
Nn
nsE .
( )⎭⎬⎫
⎩⎨⎧ +−−
−= 22222
11 S
NnSS
NnNS
Nn
nsE , já que
Nnf = .
( ) ( )222
11 SnS
nsE −
−= .
( ) ( ) 22 11
1 Snn
sE −−
= .
( ) 22 SsE = .
Portanto, 2s é estimador não-tendencioso da variância populacional 2S . Se a variável de nosso interesse (aquela que está sendo medida na pesquisa) tem distribuição Normal, teremos então que o estimador, y , da média populacional, Y , também terá distribuição Normal.
Isto é: ( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−
nSfYNy
2
1,~ .
Então, através da distribuição de probabilidade do estimador, podemos encontrar intervalos de confiança para a média populacional desconhecida. Pode-se escrever:
( ) ( )n
fSzyYn
fSzy −+≤≤
−−
11
22αα (1.4)
. Quando 2S não for conhecido, o que parece ser a regra em situações práticas, podemos usar em seu lugar o seu estimador, 2s . Nesse caso, teremos:
( ) ( )n
fstyYn
fsty −+≤≤
−−
11
22αα (1.5)
Agora, uma nova questão se apresenta. Qual deve ser o tamanho da amostra a ser selecionada para estimarmos a média populacional?

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2654
Essa pergunta pode ser remodelada de modo a introduzirmos metas a serem estabelecidas de forma a garantirmos certos graus de precisão para a estimativa a ser encontrada. Desse modo, pode-se perguntar: qual deve ser o tamanho amostral necessário para obtermos uma estimativa com um determinado nível de “confiança” e uma determinada “margem de erro” preestabelecidos. Se y é o estimador de Y , pode-se definir precisão em termos da diferença entre os valores de y e Y . Além disso, pode-se definir confiança em termos da “crença” que temos de que essa precisão seja atingida. Essa crença pode ser medida em termos de probabilidade. Então, traduzindo em linguagem estatística/probabilística, o que temos é o seguinte: ( ) α≤>− dYyP ou ( ) α−>≤− 1dYyP .
Nas expressões anteriores, d é a precisão ou margem de erro e ( )α−1 expressa o grau de confiança. Como, em quase todas as pesquisas de opinião, por exemplo, podemos supor que a média amostral segue uma distribuição aproximadamente Normal, por termos
“tamanhos amostrais razoavelmente grandes”, com média Y e variância ( )n
Sf2
1− ,
podemos reescrever as expressões do modo seguinte. ( ) α≤>− dYyP .
( ) ( )α≤
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−
>
−
−
nSf
d
nSf
YyP
22
11.
Então através da padronização da distribuição Normal, podemos obter o valor tabelado αz que determina tal probabilidade (ou confiança). Assim temos:
( )n
Sf
dz2
1−≤α
( )( )
nSf
dz 2
22
1−≤⇔ α ( ) 2
22
1αz
dn
Sf ≤−⇔ 2
22
1αz
dn
SNn
≤⎟⎠⎞
⎜⎝⎛ −⇔ 2
222
αzd
NS
nS
≤⎟⎟⎠
⎞⎜⎜⎝
⎛−⇔

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2655
NS
zd
nS 2
2
22
+≤⇔α
2
2
2
2 11SN
Szd
n ⎟⎟⎠
⎞⎜⎜⎝
⎛+≤⇔
α
212
2
2
SNS
zdn
−
⎟⎟⎠
⎞⎜⎜⎝
⎛+≥⇔
α
.
Portanto, o tamanho amostral que permite garantir as quantidades prescritas para erro e confiança será:
12
2
22
−
⎟⎟⎠
⎞⎜⎜⎝
⎛+≥
NS
zdSnα
.
Uma outra maneira de expressar o tamanho amostral, necessário para a margem de erro e o nível de confiança desejados, é:
NS
zd
nS 2
2
22
+≤α
NzS
dn
1122
2
+≤⇔α
NzS
dn
1122
2
+≤⇔α
NzS
dn
1.
12
+⎟⎟⎠
⎞⎜⎜⎝
⎛≤⇔
α
NzSdN
n11
.1
2
⎥⎥⎦
⎤
⎢⎢⎣
⎡+⎟⎟
⎠
⎞⎜⎜⎝
⎛≤⇔
α
NzSdNn
12
1.
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡+⎟⎟
⎠
⎞⎜⎜⎝
⎛≥⇔
α
Portanto,
12
..1.
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+≥
αzSdNNn é uma forma alternativa, mas equivalente.
De modo equivalente, poderíamos fixar 2
2
αzdV = e prescrever que a variância do
estimador não deve ultrapassar esse valor. Assim,
( ) VyVar ≤ ( ) Vn
Sf ≤−⇔2
1 Vn
SNn
≤⎟⎠⎞
⎜⎝⎛ −⇔
2
1 VSNn
≤⎟⎠⎞
⎜⎝⎛ −⇔ 211 2
11SV
Nn≤⎟
⎠⎞
⎜⎝⎛ −⇔
2
11SV
Nn+≤⇔ 2
11SV
Nn+≤⇔ ⎥⎦
⎤⎢⎣⎡ +≤⇔ N
SV
Nn 2111 1
21−
⎥⎦⎤
⎢⎣⎡ +≥⇔ N
SVNn .
Portanto, para um V prefixado, temos 1
21−
⎥⎦⎤
⎢⎣⎡ +≥ N
SVNn .
Ou ainda,

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2656
VSNn
≤⎟⎠⎞
⎜⎝⎛ −⇔ 211 111 2
≤⎟⎠⎞
⎜⎝⎛ −⇔
VS
Nn
NVS
VS
n
22
11+≤×⇔ ⎥
⎦
⎤⎢⎣
⎡+≤⇔
NVS
SV
n
2
2 11
122
.1
−
⎥⎦
⎤⎢⎣
⎡+≥
NVS
VSn . (1.6)
Todas as expressões são equivalentes, mas apresentam formas diferentes de preestabelecer erro e confiança e verificar o valor do tamanho amostral n. Se for razoável supor que a distribuição da média da amostra aleatória simples tem distribuição aproximadamente Normal, pode-se obter intervalos de confiança para a média populacional. Então,
( ) ( )n
fSzyYn
fSzy −+≤≤
−−
1..1.. αα (1.7)
é o intervalo com ( ) %1001 ×−α de confiança para a verdadeira média populacional Y . Se não conhecermos o valor da variância populacional, como deve ser a maioria dos casos práticos, pode-se estimá-la através dos dados amostrais, utilizando-se a
variância amostral, ( )∑=
−−
=n
ii yy
ns
1
22
11 , a qual é um estimador não-tendencioso de
2S . Neste caso, como já é conhecido dos resultados de inferência estatística, temos que:
( ) ( )1~1
−−
−nt
nf
s
Yy.
Onde ( )1−nt significa distribuição t de Student com (n-1) graus de liberdade. NOTA: A distribuição t de Sudent com k graus de liberdade é resultado da razão entre uma distribuição Normal Padrão e a raiz quadrada de uma distribuição Qui-

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2657
quadrado com k graus de liberdade dividida por seus graus de liberdade, isto é ( )
k
Ntk
k 2
1,0χ
= .
EXEMPLO: (Exercício 2.1, Vic Barnett - 1991) Duas amostras aleatórias simples independentes de tamanhos 200 e 400 foram escolhidas uma após a outra (sem reposição) de uma população de 2.400 estudantes em uma escola. A cada estudante foi perguntado sobre a distância (em milhas) da escola até onde ele ou ela moram. As médias e variâncias amostrais são:
2001 =n 14,51 =y 87,321 =s
4502 =n 90,42 =y 02,422 =s
Calcule um intervalo de 99% de confiança para a distância média da escola até onde os estudantes residem. ▼Trata-se, então, de duas amostras independentes de duas populações, de homens e mulheres, da mesma escola, e queremos obter o intervalo para a média da população total ou conjunta, isto é, [ ] ?%99; =YIC
21
2211
21
21
nnynyn
nnyy
ny
y iii
++
=+
+== ∑∑∑
( ) ( ) ( ) 2
112
111
2112
1 .11
snyyn
yys i
i −=−⇒−
−= ∑∑
( ) ( ) ( ) 2
222
222
2222
2 .11
snyyn
yys i
i −=−⇒−
−= ∑∑
Além disso, podemos representar a variância geral como uma combinação das variâncias das duas amostras, do seguinte modo:
( ) ( )2
.1.1
21
222
2112
−+−+−
=nn
snsns
Pelos dados da amostra, obtém-se os valores anteriores como sendo: 97,4=y ,
97,32 =s e 99,1=s . Desse modo, temos que:
( )[ ] ( ) ( )⎥⎦
⎤⎢⎣
⎡ −+
−−=−
nfsty
nfstyYIC 1;1%100.1;
22ααα

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2658
[ ]⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −×+⎟
⎠⎞
⎜⎝⎛ −×−=
6501
2400650199,157,297,4;
6501
2400650199,157,297,4%99; YIC
[ ] [ ]1712,097,4;1712,097,4%99; +−=YIC .▲
EXEMPLO: (2.5, Cochran) Em um estudo sobre o possível uso da amostragem para diminuir o trabalho de conferência de um almoxarifado, foi feita a contagem do valor dos artigos contidos em cada uma das 36 prateleiras da sala. Os valores, em dólares inteiros (com aproximação para + ou para –, conforme a fração seja maior ou menor que 0,5), foram os seguintes:
29 38 42 44 45 47 51 53 53 54 56 56 56 58 58 59 60 6060 60 61 61 61 62 64 65 65 67 67 68 69 71 74 77 82 85
A estimativa a ser feita, mediante amostragem, deve ser correta dentro de um limite de 200 dólares, admitindo-se 1 estimativa errada em cada 20. Um assessor sugeriu que uma amostra acidental simples de 12 prateleiras satisfará as condições. Você concorda?
∑ = 138.2y 682.1312 =∑ y ▼Temos que 36=N , e 12=n é suficiente? A média e o desvio-padrão populacionais são, respectivamente,
59,459,38889 ≅=Y e 6,1111,59871 ≅=S . Se fixarmos 05,0=α e o desvio (tolerância) em 200=d , podemos escrever:
12
12
2
6,1196,1200
36113611
−
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛
×+×=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
×+×≥
Szd
NNn
α
[ ] 1149,2136 −+≥n
43,11≥n
12=n .
Logo 12=n é suficiente.
( ) ( ) 98,436,1112
123636 22 ≅×⎟⎠⎞
⎜⎝⎛ −
×=×⎟⎠⎞
⎜⎝⎛ −
×= Sn
nNNyVar T .▲

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2659
Total Populacional ( )TY Temos que: YNYT ×= . O estimador não-tendencioso de TY é yNyT ×= , já que:
( ) ( ) ( ) TT
T YNYNYNyENyNEyE =×=×==×= . .
( ) TT YyE = .
i) Esperança para verificar se é não tendencioso; ii) Variância, para verificar se é eficiente.
Temos que a variância de Ty pode ser obtida por:
( ) ( ) ( )yVarNyNVaryVar T2. ==
( )n
SfN2
2 1−=
n
SNnN
22 1 ⎟
⎠⎞
⎜⎝⎛ −=
22
.S
nNnNN ⎟⎠⎞
⎜⎝⎛ −
=
( ) 2SnNnN
−=
21 SnNN ⎟
⎠⎞
⎜⎝⎛ −=
( ) 21 SnNNyVar T ⎟
⎠⎞
⎜⎝⎛ −= (1.8)
Como encontrar ou escolher o valor de n? Se temos que [ ] α≤>− dYyP TT , então pode-se escrever:
( )n
fSNdz
−≤
122α

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2660
( )αz
dn
fSN≤
−⇒
122
( ) 222 1
⎟⎟⎠
⎞⎜⎜⎝
⎛≤
−⇒
αzd
nfSN
22222
⎟⎟⎠
⎞⎜⎜⎝
⎛≤−⇒
αzd
nfSN
nSN
22222
⎟⎟⎠
⎞⎜⎜⎝
⎛≤−⇒
αzd
Nn
nSN
nSN
2
222
. ⎟⎟⎠
⎞⎜⎜⎝
⎛+≤⇒
αzdSN
nSN
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+≤⇒
22
22 .11αz
dSNSNn
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+≤⇒
2
2 .111
αzSd
NNn
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+≤⇒
2
.1111
αzSd
NNn
12
.11
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+≥
αzSd
NNn (1.9)
Precisamos, agora, estabelecer um intervalo de confiança. A partir do intervalo para a média populacional, estabelecemos o intervalo para TY .
IC para Y : ( ) ( )n
fSzyYn
fSzy −+≤≤
−−
11
22αα .
Multiplicando-se por N, teremos:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2661
( ) ( )n
fSNzyNYNn
fSNzyN −+≤≤
−−
1...1..22αα
( ) ( )
nfSNzyY
nfSNzy TTT
−+≤≤
−−
1.1.22αα (1.10)
EXEMPLO: (Exercício 2.3, Vic Barnett - 1991) Em uma biblioteca os livros são dispostos em 130 estantes de tamanhos semelhantes. Os números de livros em 15 estantes. Foram achados os números de livros em 15 estantes escolhidas ao acaso, a saber: 28 23 25 33 31 18 22 29 30 22 26 20 21 28 25 Calcule o número total, TY , de livros na biblioteca, e calcule o intervalo com 95% de confiança para TY . Suponha que a estimativa resultante não é precisa o suficiente; queremos estar 95% certos de que a estimativa de TY , obtida através de uma amostra aleatória simples, esteja num intervalo de 100 (livros) do verdadeiro valor. Quantas estantes deveriam ser incluídas na amostra? ▼O tamanho populacional é estantes 300=N e o tamanho amostral é
estantes 15=n . a) ?=Ty e [ ] ?%95; =TYIC Temos, dos dados amostrais, que:
4,25== ∑ny
y i e ( ) 4,41
1 2 =−−
= ∑ yyn
s i .
A estimativa do total populacional será obtida por:
yNyT .= ⇒ 33024,25130 =×=Ty livros.
( )[ ] ( )⎥⎦
⎤⎢⎣
⎡ −××±=×−
nfsNzyYIC TT
1%1001;2αα
( )[ ]⎥⎥⎦
⎤
⎢⎢⎣
⎡×⎟⎠⎞
⎜⎝⎛ −×××±=×−
151
1301514,413096,13302%1001; αTYIC
( )[ ] [ ]2733302%1001; ±=×−αTYIC
b) ?=n

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2662
[ ] 05,0100 ≤>− TYyP
12
2
10011
−
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
×+≥⇒
szNNn
α
12
4,455,2100
13011130
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛
×+≥⇒ n
69,80≥⇒ n
81=n
Se 96,1
2
=αz , teríamos um tamanho amostral de 64=n .
Logo, seriam incluídas na amostra 49 estantes.▲ EXEMPLO: (Exercício 2.4, Cochran) Uma amostra acidental simples de 30 domicílios foi selecionada em uma zona urbana que contém 14.848 domicílios. O número de pessoas em cada um dos domicílios que integram a amostra é o seguinte:
5, 6, 3, 3, 2, 3, 3, 3, 4, 4, 3, 2, 7, 4, 3, 5, 4, 4, 3, 3, 4, 3, 3, 1, 2, 4, 3, 4, 2, 4. Estimar o número total de pessoas que vivem na zona e calcular a probabilidade de que essa estimativa esteja dentro do limite de %10± do valor real. ▼O tamanho populacional é de 848.14=N domicílios e o tamanho amostral é de
300=n domicílios. Temos que, 47,3=y , 224,1=s e queremos obter o total, ?=Ty
51.47351473,0747,3848.14 ≅=×=×= yNyT pessoas. Queremos que a estimativa obedeça a seguinte condição: estar dentro do limite de
%10± do valor real . E queremos calcular a seguinte probabilidade [ ] ?1,0 =≤− TTT YYyP
[ ]( ) ( ) ( ) ⎥
⎥⎦
⎤
⎢⎢⎣
⎡ ×≤=
⎥⎥⎦
⎤
⎢⎢⎣
⎡ ×≤
−=×≤−
T
T
T
T
T
TTTTT yVar
YZP
yVarY
yVarYy
PYYyP1,01,01,0
Mas, ( ) 21 SnNNyVarV T ⎟
⎠⎞
⎜⎝⎛ −×==

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2663
e ,2810.993.549499,1130848.14848.141ˆ 2 =×⎟
⎠⎞
⎜⎝⎛ −=⎟
⎠⎞
⎜⎝⎛ −×= s
nNNV
3.315,65ˆ =V .
Desse modo, a probabilidade desejada pode ser obtida por:
( ) ⎥⎦⎤
⎢⎣⎡ ×
≤=⎥⎥⎦
⎤
⎢⎢⎣
⎡≤
3.315,6551.4731,01,0 ZP
yVarYZP
T
T
[ ] [ ] [ ]55,10255,155,11,552427 ≤≤×=≤≤−=≤= ZPZPZP = 0,8788643943,02 =× .▲ Proporção Populacional ( )P
Suponha que NiX i ,...,2,1 eldesfavoráv se,0
favorável se,1=∀
⎩⎨⎧
=
com ( ) PXP i == 1 e ( ) QPXP i =−== 10 , Ni ,...,2,1=∀ . Então, pode-se escrever:
XXN
PN
jj == ∑
=1
1 , onde NXXX ,...,, 21 representa a população.
xxn
pn
ii == ∑
=1
1 , onde nxxx ,...,, 21 representa a amostra.
Então o estimador não tendencioso de P é xp = .
( ) ( ) ( )∑∑==
=⎟⎟⎠
⎞⎜⎜⎝
⎛==
n
ii
n
ixE
nx
nEpExE
11
11
( )[ ] ∑∑==
=+−=n
i
n
iP
nPP
n 11
1.11.01

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2664
PPnn
== ..1 .
( ) ( ) PpExE ==
Para obtermos a variância de p, pode-se proceder do modo seguinte.
( ) ( )∑∑==
=⎟⎟⎠
⎞⎜⎜⎝
⎛=
n
ii
n
ii xVar
nx
nVarpVar
12
1
11
( ) ( ) ( ) ( )[ ]∑=
−+−−=n
iPPPP
n 1
222 1101
( ) ( ) ( ) ( )[ ]PPnPPnn
222 1101
−+−−=
( ) ( ) ( ) ( )[ ]PPPPn
22 1101−+−−=
( ) ( )[ ]211 PPPnP
−+−=
( ) ( )[ ]PP
nPP
−+−
= 11
( )
nPP −
=1
Portanto,
( ) ( )n
PPpVar −=
1 (1.11)
Para amostragem sem reposição, temos que:
( ) ( )n
SfpVar21−
= .
( )2
1
2
11 ∑
=
−−
=N
jj PX
NS
( )∑=
+−−
=N
jjj PPXX
NS
1
222 21
1

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2665
⎟⎟⎠
⎞⎜⎜⎝
⎛+−
−= ∑ ∑
= =
N
j
N
jjj PNXPX
NS
1
2
1
22 .21
1
⎟⎟⎠
⎞⎜⎜⎝
⎛+−
−= ∑
=
N
jj PNPNPX
NS
1
222 ....21
1
⎟⎟⎠
⎞⎜⎜⎝
⎛−
−= ∑
=
N
jj PNX
NS
1
222 .1
1
( )22 ..1
1 PNPNN
S −−
=
( )
11.2
−−
=N
PPNS (1.12)
Obs.: PNXXN
j
N
jjj .
1 1
2 ==∑ ∑= =
, já que os valores de jX são 0 ou 1.
Substituindo-se 2S na expressão da variância, obtem-se:
( ) ( ) ( ) ( )( )nN
PPNfn
SfpVar.1
1.112
−−
−=−=
( ) ( )( )
( )( )nN
PPNN
nNnNPPN
NnpVar
.11.
.11.1
−−
⎟⎠⎞
⎜⎝⎛ −
=−−
⎟⎠⎞
⎜⎝⎛ −=
( ) ( ) ( )( )nN
PPnNpVar.11.
−−−
= (1.13)
Como encontrar ou escolher o valor de n? Novamente, se temos a exigência de que [ ] α≤>− dPpP , então pode-se escrever:
( ) ( )( )
( ) ( )( )
α≤
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−−−
>
−−−
−
nNPPnN
d
nNPPnN
PpP
.11.
.11.
.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2666
Utilizado-se a aproximação normal, a qual é razoável em pesquisas de opinião, já que temos amostras grandes, teremos:
( ) ( )( )
αz
nNPPnN
d≥
−−−
.11.
( ) ( )
( )nNPPnN
zd
.11.
−−−
≥⇒α
( ) ( )
( )nNPPnN
zd
.11.
2
−−−
≥⎟⎟⎠
⎞⎜⎜⎝
⎛⇒
α
( )( ) ⎟
⎠⎞
⎜⎝⎛ −
−−
≥⎟⎟⎠
⎞⎜⎜⎝
⎛⇒ 1
11
2
nN
NPP
zd
α
( )( ) ⎟
⎠⎞
⎜⎝⎛ −≥⎟⎟
⎠
⎞⎜⎜⎝
⎛−−
⇒ 11
12
nN
zd
PPN
α
( )( ) n
Nzd
PPN
≥+⎟⎟⎠
⎞⎜⎜⎝
⎛−−
⇒ 11
12
α
( )( ) nz
dPP
NN
111
112
≥⎥⎥⎦
⎤
⎢⎢⎣
⎡+⎟⎟
⎠
⎞⎜⎜⎝
⎛−−
⇒α
( )( )
12
111
−
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−−
+×≥αz
dPP
NNn (1.14)
Outra maneira de representar o valor de n:
( )2
⎟⎟⎠
⎞⎜⎜⎝
⎛≤
αzdpVar e com
2
⎟⎟⎠
⎞⎜⎜⎝
⎛=
αzdV ,
( ) VpVar ≤ ( ) ( )( ) V
nNPPnN
≤−
−−⇒
.11. ( )
( ) VN
PPnN
≤−−
⎟⎠⎞
⎜⎝⎛ −⇒
111

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2667
( )( )PP
VNnN
−−
+≤⇒1
11
( )
( )⎥⎦⎤
⎢⎣
⎡−
−+≤⇒
PNPVN
Nn 1111
⎥⎦⎤
⎢⎣⎡ −+≤⇒
NPQV
NPQNV
Nn11
⎥⎦⎤
⎢⎣⎡ −+≤⇒
NPQV
PQV
Nn11
⎥⎦⎤
⎢⎣⎡ −+≤⇒
NVNPQ
PQV
n111
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+≤⇒ 1111
VPQ
NPQV
n
1
111−
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+×≥
VPQ
NVPQn (1.15)
Se tomarmos V
PQn =0 como uma estimativa inicial para o tamanho amostral,
teremos:
( )1
00 111−
⎥⎦⎤
⎢⎣⎡ −+×≥ n
Nnn (1.16)
como sendo o tamanho total da amostra a ser escolhida. Quando não se conhece a variância populacional, e também os valores de P e Q, pode-se proceder determinando-se um tamanho provisório ou inicial, para obter uma estimativa de do valor de P e depois recalcular o tamanho amostral necessário para o nível de confiança, a margem de erro e a variância estimada, completando-se a amostra com os “indivíduos” restantes. Um outro procedimento seria maximizar a variância populacional, para o caso de estimarmos o valor de P. Nesse caso, sabe-se que a distribuição binomial tem a sua variância maximizada quando os valores de P e Q são iguais à 0,5. Assim, teríamos
( ) .25,01 =−= PPPQ Nessa situação teremos um tamanho amostral também maximizado, de forma que o erro prescrito será provavelmente menor.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2668
Além disso, numa amostragem sem reposição, se não conhecemos a variância populacional poderíamos utilizar seu estimador não-tendencioso: a variância amostral.
Então, ( )∑=
−−
=n
ii xx
ns
1
22
11 .
Qual seria, então, o estimador não-tendencioso da ( )pVar ?
( ) ( ) ( ) ( )1112
−−=−=
nnnpqf
nsfpVar .
( ) ( )( )pqnN
nNpVar1−
−= (1.17)
EXEMPLO: (Exercício 3.6, Cochran) Escolheu-se uma amostra acidental simples de 290 domicílios, de uma área urbana que contém 14.828 domicílios. A cada família perguntou-se se era proprietária da casa onde morava ou se a alugava, e se tinha um banheiro no interior da casa para seu uso exclusivo. Os resultados foram os seguintes:
Moram em casas próprias:
147 famílias
Moram em casas alugadas:
143 famílias
Têm banheiro: Casas próprias 141 famílias Casas alugadas 109 famílias
Não têm banheiro: Casas próprias 6 famílias Casas alugadas 34 famílias
(a) Para as famílias que moram em casas alugadas, estime a percentagem, em toda
a área, das que têm banheiro para uso exclusivo e determine o erro-padrão de sua estimativa;
(b) Estime o número total de famílias que moram em casas alugadas na área e não têm banheiro para uso exclusivo, e ache o erro-padrão de sua estimativa.
▼Então, temos que 828.14=N e 290=n . (a) i) Moram em casa alugada: 143; ii) Tem banheiro: 109 Se p é a percentagem de pessoas que moram em casas alugadas e têm banheiro
particular, então 762,0143109
==p , ou seja %2,76=p .
A estimativa do erro-padrão é dada por:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2669
( ) ( )( )
( )( )1143828.14
238,0762,0143828.141
ˆ−×××−
=−
−==
nNpqnNpVarV
036,00,035565ˆ ≅=V , ou seja, %6,3ˆ =V .
Assim, ( )%6,32,76 ±=p . (b) i) Moram em casas alugadas: 143; ii) Não têm banheiro privado: 34. Se representarmos, 1Ty : número total de pessoas que moram em casa alugada, teremos que:
312.77311,738290143828.141 ≅=×=Ty pessoas.
Se denotarmos, p : percentagem de famílias que moram em casas alugadas e não têm banheiro privativo, então obteremos:
238,014334
==p , ou seja, %8,23=p .
Seja 2Ty : número total de famílias que moram em casa alugada e que não têm banheiro. Então,
738.11.738,45514334
29014314.8282 ≅=⎟
⎠⎞
⎜⎝⎛×⎟
⎠⎞
⎜⎝⎛×=Ty .
( ) 762,0238,01143312.7312.71ˆ 2
2 ××⎟⎠⎞
⎜⎝⎛ −×=×⎟
⎠⎞
⎜⎝⎛ −×== s
nNNyVarV T
258257,8371ˆ ≅=V
e 258738.12 ±=Ty famílias.▲ EXEMPLO: (Exercício 4.1, Cochran) Em um distrito que contem 4.000 casas, deve-se estimar o número de casas habitadas pelos proprietários, com um erro padrão não superior a 2%, e a percentagem de casas onde existem dois automóveis, com erro-padrão não superior a 1%. (Os números 2 e 1% são os valores absolutos e não os coeficientes de variação.) Supõe-se que a verdadeira percentagem de casas habitadas pelos proprietários esteja entre 45 e 65%, e a de casas com dois automóveis entre 5 e 10%. Qual a grandeza da amostra necessária ao atendimento dos dois objetivos? ▼Temos que 000.4=N residências e 65,045,0 ≤≤ P é a proporção de residências habitadas.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2670
Então para um erro-padrão dentro das especificações, ( ) 02,02 ≤ps , teremos:
( ) ( ) 02,0102,02
2 ≤−⇒≤n
Sfps .
( ) ( ) ( )1
222
02,002,01−
⎥⎦⎤
⎢⎣⎡ +
××≥⇒≤−⇒
NQPQPn
nSf .
Com 5,0==QP , tem-se que:
( )1
202,0000.4
5,05,05,05,0−
⎥⎦⎤
⎢⎣⎡ +
××≥n
54,540≥⇒ n ou 541≅n .
Para o caso de estimar as residências com dois automóveis, temos que
10,005,0 ≤≤ P e especifica-se ( ) 01,02 ≤ps .
Então, do mesmo modo que antes, ( )1
201,0000.4
9,01,09,01,0−
⎥⎦⎤
⎢⎣⎡ +
×××≥n e obtém-se que
69,734≥⇒ n ou 735=n . Portanto, o tamanho amostral que satisfaz as duas exigências é 735=n residências.▲

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2671
1.5.2. AMOSTRAGEM ALEATÓRIA ESTRATIFICADA Um exemplo do uso “bem difundido” da amostragem estratifica, é o caso das pesquisas de opinião, em geral, e das pesquisas eleitorais, em particular. Nessas situações, existem razões para se supor que haja sempre algum tipo de característica mais acentuada em uma determinada região, que agregue mais os comportamentos e opiniões dos indivíduos, do que em outra mais distante geograficamente. No quadro a seguir, apresenta-se a divisão do Estado do Espírito Santo em regiões e microrregiões, de acordo com as suas proximidades geográficas. Essas regiões e microrregiões, podem ser consideradas estratos, onde faríamos a divisão ou repartição da amostra, a ser entrevistada. REGIÕES MICRORREGIÕES POPULAÇÃO (%) Região 1
Micro Vitória 44,04Região 2
Micro Guarapari 5,23 Micro Itapemirim 1,24
Região 3 Micro Afonso Cláudio 3,72 Micro Sta. Teresa 2,89
Região 4 Micro Alegre 5,02 Micro Cach. Itapemirim 10,21
Região 5 Micro São Mateus 5,20 Micro Linhares 8,24
Região 6 Micro B. S. Francisco 2,84 Micro N. Venécia 3,79 Micro Colatina 6,10 Micro Montanha 1,47
Fonte: IBGE – Censo 2000.
Observe-se que, na representação anterior há duas maneiras diferentes, mas não excludentes, de considerar a estratificação do ES, uma representada pelas regiões e outra, pelas microrregiões. Na verdade são subdivisões complementares. Suponha, então, que a população seja dividida, ou subdividida, em subpopulações consideradas “homogêneas” sob algum critério, tipo sócio-econômico, regional, ou outro critério.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2672
Por exemplo, poderíamos ter a seguinte divisão:
N
Subpopulação 1 2 3 ... k
Tamanho 1N 2N 3N kN
Média 1Y 2Y 3Y ... kY
Variância 21S 2
2S 23S ... 2
kS
Proporção 1P 2P 3P ... kP
Total 1TY 2TY 3TY ... TkY
Temos que, ∑=
=k
jjNN
1 é o tamanho populacional.
Novamente, podemos estar interessados em estimar a média populacional Y . Se representarmos os pesos das subpopulações por iW , pode-se dizer que a média populacional será um combinação das médias das subpopulações, que chamaremos de estratos. Desse modo, teremos:
i
k
ii
N
ji
k
iij YWYN
NY
NY ∑∑ ∑
== =
===11 1
11 ,
onde kjNN
W jj ,...,2,1, == , são chamados pesos das k subpopulações ou estratos.
Para obtermos uma representação para a variância em termos das variâncias dos estratos, pode-se proceder do modo seguinte.
( )∑=
−−
=N
jj YY
NS
1
22
11
( )∑ ∑= =
⎥⎦
⎤⎢⎣
⎡−
−=
k
i
N
jij
i
YYN
S1 1
22
11
( )∑ ∑= =
⎥⎦
⎤⎢⎣
⎡−+−
−=
k
i
N
jiiij
i
YYYYN
S1 1
22
11

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2673
( ) ( )( ) ( )∑ ∑∑ ∑= == =
⎥⎦
⎤⎢⎣
⎡−+−−+−
−=
k
i
N
ji
N
j
N
jiiijiij
ii i
YYYYYYYYN
S1 1
2
1 1
22 21
1
Mas,
( )( ) ( ) ( ) ( ) ( )( ) 02222111
=−−=⎟⎟⎠
⎞⎜⎜⎝
⎛−−=−−=−− ∑∑∑
===iiiii
N
jiiiji
N
jiiji
N
jiiij YNYNYYYNYYYYYYYYYYY
iii
Então,
( ) ( )∑ ∑∑= ==
⎥⎦
⎤⎢⎣
⎡−+−
−=
k
i
N
ji
N
jiij
ii
YYYYN
S1 1
2
1
22
11 .
Além disso, temos que ( ) ( ) 2
1
2 1 ii
N
jiij SNYY
i
−=−∑=
e ( ) ( )21
2 YYNYY ii
N
ji
i
−=−∑=
.
Assim,
( ) ( )[ ]∑=
−+−−
=k
iiiii YYNSN
NS
1
222 11
1, (1.18)
onde ( )∑=
−−
=iN
jiij
ii YY
NS
1
22
11 .
Vamos, então, selecionar uma amostra aleatória estratificada de tamanho n, com
1n elementos ou indivíduos do primeiro estrato, com 2n elementos do segundo
estrato, ...., com kn elementos do estrato k. Sendo que ∑=
=k
iinn
1 é o tamanho total
da amostra a ser selecionada. Simbolicamente, temos a seguinte representação:
iniii yyyy ,...,,, 321 , para ki ,...,3,.2,1= . Ou ainda,
kknkkknn yyyyyyyyyyyy ,...,,,,...,,...,,,,,...,,, 32122322211131211 21.
Além disso, teremos também as médias e variâncias amostrais:
kyyyy ,...,,, 321 e 223
22
21 ,...,,, kssss ,
onde ∑=
=in
jij
ii y
ny
1
1 e ( )∑=
−−
=in
jiij
ii yy
ns
1
22
11 .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2674
O estimador da média populacional é então:
∑∑==
==k
ii
ik
iiiest y
NNyWy
11.
Um outro estimador da média populacional poderia ser representado por:
∑∑==
==k
ii
ik
iiiest y
nn
yWy11
** .
Quando acontece de termos a igualdade nn
NN ii = , teremos o que se chama de
“alocação proporcional”.
A fração amostral em cada estrato será kiNnf
i
ii ,...,2,1, == .
De modo semelhante ao que foi feito para amostra aleatória simples, vamos estudar as propriedades dos estimadores, no caso de amostra aleatória estratificada. Temos que:
( ) ( ) YYWyEWyWEyEk
iii
k
iii
k
iiiest ===⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑∑∑
=== 111.
Observe-se que ( ) YyE i = , pois a amostragem é aleatória simples dentro de cada estrato e já vimos que a média amostral é um estimador não-tendencioso da média populacional, no caso, média da subpopulação. Portanto, ( ) YyE est = e a não-tendenciosidade está demonstrada. Para a obtenção da variância, procede-se do seguinte modo:
( ) ( ) ( )∑∑∑===
−==⎟⎟⎠
⎞⎜⎜⎝
⎛=
k
i i
iii
k
iii
k
iiiest n
SfWyVarWyWVaryVar1
22
1
2
11 .
Obs.: A igualdade vale, supondo-se que as médias nos estratos não são correlacionadas entre si. Por outro lado,
( ) ( ) YYnnYWyEWyWEyE
k
ii
ik
iii
k
iii
k
iiiest ∑∑∑∑
====
≠===⎟⎟⎠
⎞⎜⎜⎝
⎛=
11
*
1
*
1
** em geral.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2675
Temos que ( ) YyE est =* , se nn
NN ii = , isto é, no caso de “alocação proporcional”,
quando selecionamos os tamanhos amostrais proporcionalmente aos tamanhos da subpopulações.
Quando Nn
Nn
nn
NN
i
iii =⇒= ⇒ nNNn i
i .⎟⎠
⎞⎜⎝
⎛= .
Alguns casos especiais de alocações e as expressões para a variância do estimador da média:
a) Fração amostral desprezível
Nesse caso teremos,
( ) ∑=
=k
i i
iiest n
SWyVar1
22 . (1.19)
b) Alocação Proporcional
( ) ( )i
ik
iiest n
SfWyVar2
1
2 1∑=
−=
( ) ( )nW
SfWyVari
ik
iiest
2
1
2 1∑=
−=
( ) ( )n
SfWyVar ik
iiest
2
11∑
=
−=
( ) ( ) 2
1
1i
k
iiest SW
nfyVar ∑
=
−= , (1.20)
onde Nnf = .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2676
c) Variâncias Iguais nos Estratos e Alocação Proporcional:
( ) ( ) 2
1
1i
k
iiest SW
nfyVar ∑
=
−= , onde 22
wi SS = (variância constante nos estratos).
( ) ( ) 2
1
1w
k
iiest SW
nfyVar ∑
=
−=
( ) ( ) ∑=
−=
k
ii
west W
nSfyVar
1
21
Mas, ∑∑==
==k
i
ik
ii N
NW11
1.
Então,
( ) ( ) 21west S
nfyVar −
= (1.21)
Total Populacional ( )TY Temos que YNYT ×= . O estimador não-tendencioso de TY é:
∑=
==k
iiiestT yWNyNy
1.
∑=
=k
ii
iT y
NNNy
1
∑=
=k
iiiT yNy
1 (1.22)
Além disso, a variância do estimador é:
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑
=
k
iiiT yNVaryVar
1
( ) ( )∑=
=k
iiiT yVarNyVar
1
2.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2677
( ) ( )∑=
−=k
i i
iiiT n
SfNyVar1
22 1.
( ) ( )∑=
−=k
iii
i
iT Sf
nNyVar
1
22
.1. (1.23)
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑
=
k
iiiT yNEyE
1
( ) ( )∑=
=k
iiiT yENyE
1
( ) ∑=
=k
iiiT YNyE
1.
( ) ∑∑
=
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=k
i i
N
jij
iT N
YNyE
i
1
1
( ) ∑∑= =
=k
i
N
jijT
i
YyE1 1
( ) ∑=
=k
iiTT YyE
1
( ) TT YyE = .
Se a variância populacional, em cada estrato, é desconhecida, precisamos estimá-la. Os estimadores dos valores de kiSi ,...,2,1,2 = , são dados por:
( )∑=
−−
=in
jiij
ii yy
ns
1
22
11 .
( ) ( )∑=
−=k
i i
iiiest n
sfWys1
222 1

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2678
( ) ∑=
⎟⎟⎠
⎞⎜⎜⎝
⎛−=
k
i i
i
i
iiest n
sNn
NNys
1
2
2
22 1
( ) ( )∑=
−=k
i i
iii
iest n
snNNNys
1
2
22 (1.24)
Para a igualdade das variâncias dos estratos, utiliza-se o estimador 2
WS .
Usa-se ( )2
1 1
2 1 ∑∑= =
•−−
=k
i
n
jiijW
i
yykN
s como estimador de 2WS .
Então, o estimador da variância de esty será:
( ) ( )∑ −=
i
iiiWest n
nNNNsys 2
22 . (1.25)
No caso de alocação proporcional, teremos:
( )n
sNnys W
est
22 1 ⎟
⎠⎞
⎜⎝⎛ −= . (1.26)
Intervalos de Confiança para Y : ( ) ( )⎟⎟⎠
⎞⎜⎜⎝
⎛+≤≤− estestestest yszyYyszy 2
2
2
2αα
Proporção ( )P
∑=
=N
jjX
NP
1
1 ,
onde ⎩⎨⎧
=contrário caso,0
Aticacaracterís a ocorrer se,1jX
O estimador geral da proporção é dado por:
∑=
∑= ⎟
⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛∑=
==k
i
k
i
in
j jxiniWipiWestp
1 1 1
1 ,
onde ip é o estimador da proporção iP , via amostra aleatória simples, dentro do estrato i.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2679
Queremos estudar as propriedades do estimador da proporção, via amostra aleatória estratificada. Assim, para o caso do valor esperado, temos:
( ) ( )∑ ∑∑= ==
===⎟⎟⎠
⎞⎜⎜⎝
⎛=
k
ii
k
iiii
k
iiiest PPWpEWpWEpE
1 11.
Então, estp é estimador não-tendencioso ou não-viesado de P. Observe que ( ) ii PpE = , pois ip é o estimador obtido via amostra aleatória simples dentro de cada estrato ou subpopulação, e que já demonstrou-se ser não-viesado. Para a variância de estp pode-se proceder do modo seguinte.
( ) ( )∑=
=k
iiiest pVarWpVar
1
2
( ) ( )( )∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=
k
i ii
iiiiiest nN
QPnNWpVar1
2
1
( ) ( ) ( )( )∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛−
−−=
k
i ii
iiiiiest nN
PPnNWpVar1
2
11
. (1.27)
Pode-se também representar P como: ∑∑= =
=k
i
N
j i
ji
NX
NP
1 1
1 .
Quando não se conhece os valores dos sPi ' , pode-se usar os valores dos seus estimadores amostrais, spi ' , e então:
( ) ( ) ( )∑= −
−−=
k
i i
iiiiest n
ppfWps1
22
111
. (1.28)
Comparação entre os Estimadores: Nesse ponto, surge a necessidade de uma comparação entre os estimadores da média populacional, via amostra aleatória simples e via amostra aleatória estratificada, ambos estimadores não-tendenciosos ou não-viesados da média Y da população. Como os dois estimadores são não-viciados, como demonstrado, vamos comparar as suas performances através da comparação de suas variâncias.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2680
Então, podemos tomar a diferença entre as variâncias dos dois estimadores, como segue:
( ) ( )
( ) ( )⎪⎪⎩
⎪⎪⎨
⎧
−=
−=
∑=
k
ii
iest S
NN
nfyVar
nSfyVar
1
2
2
1
1
( ) ( ) ( ) ( )∑=
−−−=−
k
ii
iest S
NN
nf
nSfyVaryVar
1
22 11 (estratificação com alocação
proporcional)
( ) ( ) ( )⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=− ∑
=
k
ii
iest S
NNS
nfyVaryVar
1
221 .
Substituindo-se a expressão de 2S , teremos:
( ) ( ) ( ) ( ) ( )[ ]⎭⎬⎫
⎩⎨⎧
−−+−−
−=− ∑∑
==
2
11
2211
11i
k
i
ik
iiiiiest S
NNYYNSN
NnfyVaryVar .
Se NN
NN
NN iii ≅
−≅
−−
111 , pode-se escrever:
( ) ( ) ( ) ( )[ ]⎭⎬⎫
⎩⎨⎧
−−+−
=− ∑=
k
iiii
iest SYYS
NN
nfyVaryVar
1
2221 .
( ) ( ) ( ) ( )∑=
−−
=−k
ii
iest YY
NN
nfyVaryVar
1
21 .
( ) ( ) ( ) ( )∑=
≥−−
=−k
iiiest YYW
nfyVaryVar
1
2 01 .
A expressão anterior representa a variância entre os estratos. Observe-se que a expressão
( ) ( ) ( ) ( ) ( )[ ]⎭⎬⎫
⎩⎨⎧
−−+−−
−=− ∑∑
==
2
11
2211
11i
k
i
ik
iiiiiest S
NNYYNSN
NnfyVaryVar ,
pode ser reescrita como
( ) ( ) ( )( ) ( ) ( ) 01
11 2
11
2≥
⎭⎬⎫
⎩⎨⎧
−−−−
−=− ∑∑
==i
k
ii
k
iiiest SNN
NYYN
NnfyVaryVar ,

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2681
já que ( ) ( )( )∑∑ ∑∑
== ==⎥⎦
⎤⎢⎣
⎡−
−−−−=⎟
⎠
⎞⎜⎝
⎛−−
−−=−−− k
ii
iik
i
k
ii
iii
k
i
ii
i SNN
NNNNSNN
NNS
NNS
NN
1
2
1 1
22
1
2
111
11
11
( )( )( )
22
11 ii
iiii S
NNNNS
NNNNNNNN
−−
=−
+−−= .
Observe que a primeira parcela dentro das chaves representa a variabilidade entre os estratos e a segunda parcela representa a variabilidade dentro dos estratos. Desse modo podemos dizer que: “a estratificação é recomendável, principalmente, quando a variância entre os estratos é maior do que a variância dentro dos estratos”. Nesse caso, o estimador obtido através da amostra estratificada é mais eficiente do que o estimador obtido através da amostra aleatória simples. Para se encontrar o valor do tamanho amostral em cada estrato, pode-se proceder do seguite modo:
nNNn i
i ×= (alocação proporcional).
Verifiquemos, agora, a incorporação de um elemento de penalidade para o nosso modelo de repartição da amostra entre os estratos. O objetivo é introduzir um raciocínio de “otimização” ou de “busca do ótimo” para a repartição da amostra entre os vários estratos, contemplando aspectos além do tamanho dos estratos. Custos de Amostragem: Representemos por 0C e iC , o custo básico (inerente à todas amostragens) e o custo de seleção do i-ésimo estrato. Desse modo, pode-se representar o custo total de amostragem por:
∑=
+=k
iiiT CnCC
10 .
Pode-se proceder de algumas maneiras diferentes: 1. Pode-se querer minimizar a variância do estimador para um custo total fixo. Nesse caso, queremos escolher knnn ,...,, 21 , de modo a minimizar a ( )estyVar . Sabe-se que, para o caso de amostragem aleatória estratificada, a variância é dada por
( ) ( )∑=
−=k
i i
iiiest n
SfWyVar1
22 1 ou por ( ) ∑ ∑
= =
−=k
i
k
iii
i
iiest SW
NnSWyVar
1 1
22
2 .1 ,

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2682
sujeitos à restrição de que o custo total seja igual a ∑=
+=k
iiiT CnCC
10 .
Estamos diante de diferentes custos de amostragem para os diferentes estratos. Pode-se utiliza multiplicadores de Lagrange na tarefa de otimização desejada: minimizar a variância do estimador sujeito às restrições nos custos. Assim,
( ) kiCnyVarnn
L k
iiiest
ii
,...,2,1,1
=⎥⎦
⎤⎢⎣
⎡+
∂∂
=∂∂ ∑
=
λ .
kiCnSWNn
SWnn
L k
iii
k
i
k
iii
i
ii
ii
,...,2,1,.111 1
22
2 =⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛+⎟⎟
⎠
⎞⎜⎜⎝
⎛−
∂∂
=∂∂ ∑∑ ∑
== =
λ .
.,...,2,1,2
22
kiCn
SWnL
ii
ii
i
=+−=∂∂ λ
.,...,2,1,2
22
kiCn
SWi
i
ii ==⇒ λ
⇒ kiCSWn
i
iii ,...,2,1,
222 ==
λ.
⇒ kiCSWn
i
iii ,...,2,1, ==λ . (*)
Multiplicando a expressão anterior por iC em ambos os lados, obtém-se:
kiCSWCn iiiii ,...,2,1, ==λ . Somando-se para os k estratos:
∑∑==
=k
iiii
k
iii CSWCn
11λ .
⇒ ∑∑==
=k
iiii
k
iii CSWCn
11λ
⇒ ( ) ∑=
=−k
iiiiT CSWCC
10λ

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2683
⇒ ( )0
1
CC
CSW
T
k
iiii
−=∑=λ (**).
Substituindo-se (**) em (*), temos:
( )
ki
CC
CSWC
SWn
T
k
iiii
i
iii ,...,2,1,
0
1
=
−×
=
∑=
.
( )
( )ki
CSW
CSWCCn k
iiii
iiiTi ,...,2,1,
1
0 =−
=
∑=
. (1.29)
A expressão mostra que o valor de in é inversamente proporcional ao custo em cada estrato e diretamente proporcional à variância de cada estrato. Assim, para encontrarmos o tamanho da amostra de cada estrato por “alocação ótima”, ou otimizada, para um custo total fixo, utilizamos a fórmula de in anterior. Para determinarmos o tamanho total da amostra, podemos proceder do modo seguinte.
∑=
=k
iinn
1
( )( )
∑∑=
=
×
−=
k
ik
iiiii
Tii
CSWC
CCSWn
1
1
0
( )
( )∑
∑
=
=
−= k
iiii
k
iiiiT
CSW
CSWCCn
1
10
, (1.30)
já que a parte do denominador dentro da soma é constante para a segunda soma. Se considerássemos o custo de amostragem constante em todos os estratos, teríamos:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2684
∑=
+=n
iiT CnCC
10
⇒ ∑=
+=n
iiT nCCC
10
⇒ nCCCT += 0
CCC
n T 0−= (1.31)
Substituindo-se esse resultado a fórmula de in , teremos:
( )ki
CSWC
SWCCn k
iiiii
iiTi ,...,2,1,
1
0 =×
−=
∑=
.
⇒( )
kiCSWC
SWCCn k
iii
iiTi ,...,2,1,
1
0 =×
−=
∑=
.
⇒( )
kiSWC
SWCCn k
iii
iiTi ,...,2,1,
1
0 =×
−=
∑=
.
⇒( )
kiSW
SWC
CCn k
iii
iiTi ,...,2,1,
1
0 =×−
=
∑=
.
kiSW
SWnn k
iii
iii ,...,2,1,
1
=×=
∑=
. (1.32)
Esse tipo de alocação é denominado Alocação de Neyman, isto é, alocação com custo fixo para cada estrato e minimizando a variância. Qual seria, então, a variância do estimador da média para esse tipo de alocação (alocação de Neyman)?
( ) ∑∑==
−=k
iii
k
i i
iiest SW
NnSWyVar
1
2
1
22 1 .
Substituindo-se o valor de in na expressão anterior e com alguma álgebra, obtemos:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2685
( ) ∑∑
∑==
=
−=k
iii
k
ik
iii
ii
iiest SW
N
SW
SnWSWyVar
1
2
1
1
22 1
⇒ ( ) ∑∑
∑=
=
=
−=k
iii
ii
k
iiik
iiiest SW
NSnW
SWSWyVar
1
21
1
22 1 .
⇒ ( ) ∑∑∑===
−=k
iii
k
iii
k
i
iiest SW
NSW
nSWyVar
1
2
11
1 .
( ) ∑∑==
−⎟⎟⎠
⎞⎜⎜⎝
⎛=
k
iii
k
iiiest SW
NSW
nyVar
1
22
1
11. (1.33)
2. Pode-se querer minimizar o custo do processo de estimação para uma variância
fixa. Pode-se, por exemplo, fixar ( ) VyVar est = , onde o valor de V pode ser escolhido
como 2
⎟⎟⎠
⎞⎜⎜⎝
⎛=
αzdV .
Nesse caso pode-se escrever:
( ) VSWN
SWn
yVark
iii
k
iiiest =−⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑∑
== 1
22
1
11 .
Agora, seguindo o mesmo raciocínio de antes, queremos encontrar in , para uma variância preestabelecida, de forma a minimizar o custo de amostragem. Vimos, quando da expressão do lagrangiano, que em (*) tínhamos:
kiCSW
ni
iii ,...,2,1, ==λ .
Então, queremos encontrar h de modo que o valor i
iii C
SWhn ×= seja substituído na
expressão da variância a ser fixada.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2686
Assim,
( ) VSWNn
SWyVark
iii
k
i i
iiest =−= ∑∑
== 1
2
1
22 1
⇒ ∑∑==
−×
=k
iii
k
i
i
ii
ii SWN
CSWh
SWV1
2
1
22 1
⇒ ∑∑==
−×
=k
iii
k
i ii
iii SWNSWh
CSWV
1
2
1
22 1
⇒ ∑∑==
−=k
iii
k
i
iii SWNh
CSWV
1
2
1
1
⇒ ∑∑==
=+k
iiii
k
iii CSW
hSW
NV
11
2 11
⇒ ∑∑==
÷+=k
iiii
k
iii CSWSW
NV
h 11
211
∑
∑
=
=
+=⇒ k
iii
k
iiii
SWN
V
CSWh
1
2
1
1.
Então, para uma variância fixa, minimiza-se o custo de amostragem ao se escolher os tamanhos amostrais nos estratos do seguinte modo:
kiCSW
SWN
V
CSWn
i
iik
iii
k
iiii
i ,...,2,1,1
1
2
1 =×⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
+=
∑
∑
=
= . (1.34)
Para encontrarmos o tamanho amostral total, basta somar os valores de in em todos os estratos.
∑=
=k
iinn
1

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2687
∑∑
∑=
=
= ×⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
+=
k
i i
iik
iii
k
iiii
CSW
SWN
V
CSWn
1
1
2
1
1
∑∑
∑=
=
=
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
+=
k
i i
iik
iii
k
iiii
CSW
SWN
V
CSWn
1
1
2
1
1. (1.35)
Se considerarmos os custos constantes em todos os estratos, teremos:
∑
∑
=
=
+
⎟⎟⎠
⎞⎜⎜⎝
⎛
= k
iii
k
iii
SWN
V
SWn
1
2
2
1
1 (1.36)
Além disso, poderíamos considerar, na alocação de Neyman, as variâncias constantes em cada estrato. Nesse caso, teríamos a seguinte repartição da amostra:
nSW
SWn k
iwi
wii ×=
∑=1
,
onde iSS iw ∀= ,22 .
⇒ nWS
SWn k
iiw
wii ×=
∑=1
⇒ nW
Wn k
ii
ii ×=
∑=1
⇒ nWn ii ×= (Alocação Proporcional),
já que ∑∑==
===k
i
ik
ii N
NNNW
111.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2688
Estas flexibilizações acabam por implicar em um procedimento de alocação das fatias de amostragem em cada estrato, proporcionalmente ao tamanho do estrato. Pela simplicidade do procedimento ele deveria ser adotado sempre que forem razoáveis tais suposições ou flexibilizações. 3. Pode-se querer o tamanho amostral necessário para fornecer uma variância
especificada com determinados pesos amostrais.
Queremos que ( ) α≤>− dYyP est com 2
⎟⎟⎠
⎞⎜⎜⎝
⎛=
αzdV .
Além disso, temos que:
( ) VSWNn
SWyVark
iii
k
i i
iiest =−= ∑∑
== 1
2
1
22 1
⇒
∑
∑
=
=
+= k
iii
k
iiii
SWN
V
wSWn
1
2
1
22
1
( )
∑
∑
=
=
+= k
iii
k
iiii
SWN
V
wSWn
1
2
1
22
1 (1.37)
Desse modo, como uma primeira aproximação para o tamanho amostral poderíamos tomar
⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑
=
k
iiii wSW
Vn
1
220
1 ,
ou, mais precisamente, pode-se escrever
∑=
+= k
iiiSW
NV
nn
1
2
0
11
⇒1
1
20
11−
=⎟⎟⎠
⎞⎜⎜⎝
⎛+= ∑
k
iiiSW
NVnn
Nos casos especiais de alocação proporcional e alocação de Neyman, teremos:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2689
⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑
=
k
iiiSW
Vn
1
20
1 e 1
00 1
−
⎟⎠
⎞⎜⎝
⎛ +=Nn
nn ;
2
10
1⎟⎟⎠
⎞⎜⎜⎝
⎛= ∑
=
k
iiiSW
Vn e
1
1
20
11−
=⎟⎟⎠
⎞⎜⎜⎝
⎛+= ∑
k
iiiSW
NVnn , respectivamente.
Nesse momento cabe uma comparação entre alocação proporcional e alocação ótima. Sejam:
pV : variância do estimador da média, obtido através da alocação proporcional;
NV : variância do estimador da média, obtido através da alocação de Neyman.
( ) ∑∑ ∑== =
+⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=−
k
iii
k
i
k
iiiiiNp SW
NSW
nSW
nfVV
1
2
1
2
1
2 111
∑∑∑∑====
+⎟⎟⎠
⎞⎜⎜⎝
⎛−−=−
k
iii
k
iii
k
iii
k
iiiNp SW
NSW
nSW
nNnSW
nVV
1
22
11
2
1
2 111
Se representarmos ∑=
=k
iiiSWS
1, poderemos escrever:
⎟⎟⎠
⎞⎜⎜⎝
⎛−=−=− ∑∑
==
2
1
22
1
2 111 SSWn
Sn
SWn
VVk
iii
k
iiiNp
( )21
1 SSWn
VV i
k
iiNp −=− ∑
=
⇒ ( ) 01 2
1≥−=− ∑
=
SSWn
VV i
k
iiNp
⇒ Np VV ≥ Portanto, o estimador fornecido pela alocação de Neyman é mais eficiente do que o fornecido pela alocação proporcional. Observe-se que nas contas anteriores, tivemos a seguinte igualdade:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2690
( )21
2
1
2 11 SSWn
SSWn
VV i
k
ii
k
iiiNp −=⎟⎟
⎠
⎞⎜⎜⎝
⎛−=− ∑∑
==
.
Esta expressão é válida porque:
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛+−=− ∑ ∑∑∑
= ===
k
i
k
iiii
k
iiii
k
ii SWSSWSW
nSSW
n 1 1
2
1
22
1211
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛+−=− ∑ ∑∑∑
= ===
k
i
k
iiii
k
iiii
k
ii WSSWSSW
nSSW
n 1 1
2
1
22
1211
Como 11
=∑=
k
iiW e ∑
=
=k
iiiSWS
1, tem-se que:
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛+−=− ∑∑
==
22
1
22
1211 SSSW
nSSW
n
k
iiii
k
ii
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−=− ∑∑
==
2
1
22
1
11 SSWn
SSWn
k
iiii
k
ii ,
o que completa a demonstração. Proporção ( )P
Temos que: ∑=
=k
iiiest pWp
1, onde .,...,2,1,1
1kix
np
in
jj
ii == ∑
=
Pelos mesmos motivos, já discutidos anteriormente, esse estimador é não-tendencioso, isto é, ( ) PpE est = , já visto anteriormente. A variância populacional em cada estrato, pode ser representada por:
( )iii
ii PP
NNS −⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= 11
2 .
Temos então que a variância do estimador da proporção pode ser obtida de modo semelhante ao procedimento adotado para a média amostral, como aconteceu o caso de amostragem aleatória simples. As diferenças dizem respeito ao fato de que, agora, a variância vai depender dos sPi ' . A variância, então, será:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2691
( ) ( ) ( )∑∑==
−⎟⎟⎠
⎞⎜⎜⎝
⎛−−
==k
iii
i
ii
i
ik
iiiest PP
NnN
nWpVarWpVar
1
2
1
2 11
, (1.38)
também já demonstrado anteriormente.
Se todos os sNi ' são grandes, pode-se trocar ⎟⎟⎠
⎞⎜⎜⎝
⎛−−
1i
ii
NnN por ( )if−1 .
Teremos diferentes formas para a variância do estimador da proporção, dependendo do tipo de alocação que será utilizada. No caso de alocação proporcional, tem-se:
( ) ( ) ( )∑=
−−
−=
k
iii
i
iest PP
NW
nnNpVar
1
2
11
( ) ( )∑=
−−
=k
iiiiest PPW
nfpVar
111 ,
já que quando iN é grande, ii NN ≈−1 . Se adotarmos essa aproximação, podemos obter os tamanhos amostrais dos estratos, para a alocação de Neyman, como segue. • Ignorando-se os custos de amostragem, temos:
( )
( )n
PPW
PPWn k
iiii
iiii ×
−
−=
∑=1
1
1.
• Custo total fixo:
∑=
+=k
iii nccC
10 .
( ) ( )
( )∑=
−
−−= k
iiii
iiiii
cPPW
cPPWcCn
1
0
1
1.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2692
Quando ( ) kiPPN
NS iii
ii ,...,2,1,1
12 =−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= for desconhecida, utilizamos o seu
estimador ( ) kippn
ns iii
ii ,...,2,1,1
12 =−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
= .
Obs.: Para se verificar que a variância populacional tem realmente a forma descrita, pode-se proceder do modo seguinte.
⎩⎨⎧
= Aocorre n~ se 0,
Aocorre se ,1ijX
Temos que : ( )∑ −−
=22
11
iiji
i YYN
S ,
onde kiPXN
Y i
N
jij
ii
i
,...,2,1,11
=== ∑=
.
Então:
( )∑=
−−
=iN
jiij
ii PY
NS
1
22
11
( )∑=
+−−
=iN
jiiijij
ii PPYY
NS
1
222 21
1
⎥⎦
⎤⎢⎣
⎡+−
−= ∑∑
==
2
11
22 21
1ii
N
jiji
N
jij
ii PNYPY
NS
ii
⎥⎦
⎤⎢⎣
⎡+−
−= ∑∑
==
2
11
2 21
1ii
N
jiji
N
jij
ii PNYPY
NS
ii
, já que 1 ou 0=ijY .
[ ]22 21
1iiiiiii
ii PNPNPPN
NS +−
−=
[ ]22
11
iiiii
i PNPNN
S −−
=
( )iii
ii PP
NNS −−
= 11
2 .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2693
Comparação entre Amostra Aleatória Simples e Estratificada com Alocação de Neyman Cabe também fazer uma comparação entre os estimadores da média populacional, obtidos através de amostragem aleatória simples e da amostragem estratificada com alocação otimizada. Como anteriormente, as performances serão comparadas através das variâncias dos estimadores, já que ambos são não-viesados. Temos que:
( ) ( )n
SfyVar2
1−= e ( ) ∑∑==
−⎟⎟⎠
⎞⎜⎜⎝
⎛=
k
iii
k
iiiest SW
NSW
nyVar
1
22
1
11 , para a variância dos
estimadores das amostras aleatórias, simples e estratificada, respectivamente.
( ) ( ) ( ) ∑∑==
+⎟⎟⎠
⎞⎜⎜⎝
⎛−−=−
k
iii
k
iiiest SW
NSW
nnSfyVaryVar
1
22
1
2 111 .
Sendo 22
1SSW
k
iii =⎟⎟⎠
⎞⎜⎜⎝
⎛∑=
, tem-se que:
( ) ( ) ( ) ∑=
+−−=−k
iiiest SW
NnS
nSfyVaryVar
1
222 11 .
( ) ( ) ∑=
+−⎟⎠⎞
⎜⎝⎛ −
=−k
iiiest SW
NnS
nS
NnNyVaryVar
1
222 1 .
( ) ( ) ∑=
+−⎟⎠⎞
⎜⎝⎛ −=−
k
iiiest SW
NnSS
NnyVaryVar
1
22
2 111 .
Como já visto, pode-se representar a variância populacional como
( ) ( )[ ]∑=
−+−−
=k
iiiii YYNSN
NS
1
222 11
1 .
Assim,
( ) ( ) ( ) ( )[ ] ∑∑==
+−−+−−
⎟⎠⎞
⎜⎝⎛ −=−
k
iii
k
iiiiiest SW
NnSYYNSN
NNnyVaryVar
1
22
1
22 111
111 .
Se, além disso, considerarmos que as populações dos estratos são grandes o
bastante para podermos considerar NN
NN
NN iii ≈
−≈
−−
111 , pode-se escrever:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2694
( ) ( ) ( ) ∑∑==
+−⎥⎦
⎤⎢⎣
⎡ −−
+−−
⎟⎠⎞
⎜⎝⎛ −=−
k
iii
k
ii
ii
iest SW
NnSYY
NNS
NN
NnyVaryVar
1
22
1
22 111
111 .
( ) ( ) ( )[ ] ∑∑==
+−−+⎟⎠⎞
⎜⎝⎛ −=−
k
iii
k
iiiiiest SW
NnSYYWSW
NnyVaryVar
1
22
1
22 111 .
( ) ( ) ( ) ∑∑∑∑====
+−−⎟⎠⎞
⎜⎝⎛ −+−=−
k
iii
k
iii
k
iii
k
iiiest SW
NnSYYW
NnSW
NSW
nyVaryVar
1
22
1
2
1
2
1
2 11111 .
( ) ( ) ( )n
SYYWNn
SWn
yVaryVark
iii
k
iiiest
2
1
2
1
2 111−−⎟
⎠⎞
⎜⎝⎛ −+=− ∑∑
==
.
( ) ( ) ( ) ( )∑∑==
−⎟⎠⎞
⎜⎝⎛ −+−=−
k
iii
k
iiiest YYW
NnSSW
nyVaryVar
1
2
1
22 111
( ) ( ) ( ) ( ) 01111
2
1
2≥−⎟
⎠⎞
⎜⎝⎛ −+−=− ∑∑
==
k
iii
k
iiiest YYW
NnSSW
nyVaryVar ,
pois, como visto anteriormente ( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−=− ∑∑
==
2
1
22
1
11 SSWn
SSWn
k
iiii
k
ii .
Desse modo, a alocação ótima (Neyman) tem estimador mais eficiente do que o estimador obtido através de amostragem aleatória simples. No caso de se estar estimando o tamanho populacional, pode-se determinar o tamanho amostral como segue.
( ) ( ) ( )estestT yVarNyNVaryVar 2. == .
( ) VSWN
SWn
NyVark
iii
k
iiiT =
⎥⎥⎦
⎤
⎢⎢⎣
⎡−⎟⎟
⎠
⎞⎜⎜⎝
⎛= ∑∑
== 1
22
1
2 11 .
⇒ VSWNNSW
nN k
iii
k
iii =
⎥⎥⎦
⎤
⎢⎢⎣
⎡−⎟⎟
⎠
⎞⎜⎜⎝
⎛ ∑∑== 1
222
1
2
.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2695
⇒ ∑∑==
+=⎟⎟⎠
⎞⎜⎜⎝
⎛ k
iii
k
iii SWNVSW
nN
1
22
1
2
.
⇒ 2
1
2
1
2
1
⎟⎟⎠
⎞⎜⎜⎝
⎛
+=
∑
∑
=
=
k
iii
k
iii
SWN
SWNV
n.
⇒
∑
∑
=
=
+
⎟⎟⎠
⎞⎜⎜⎝
⎛
= k
iii
k
iii
SWNV
SWNn
1
2
2
1
2
.
⇒
∑
∑
=
=
+
⎟⎟⎠
⎞⎜⎜⎝
⎛
= k
iii
k
iii
SNNNV
SNNNn
1
2
2
1
22
.
Portanto,
∑
∑
=
=
+
⎟⎟⎠
⎞⎜⎜⎝
⎛
= k
iii
k
iii
SNV
SNn
1
2
2
1 , (1.39)
é o tamanho amostral desejado.
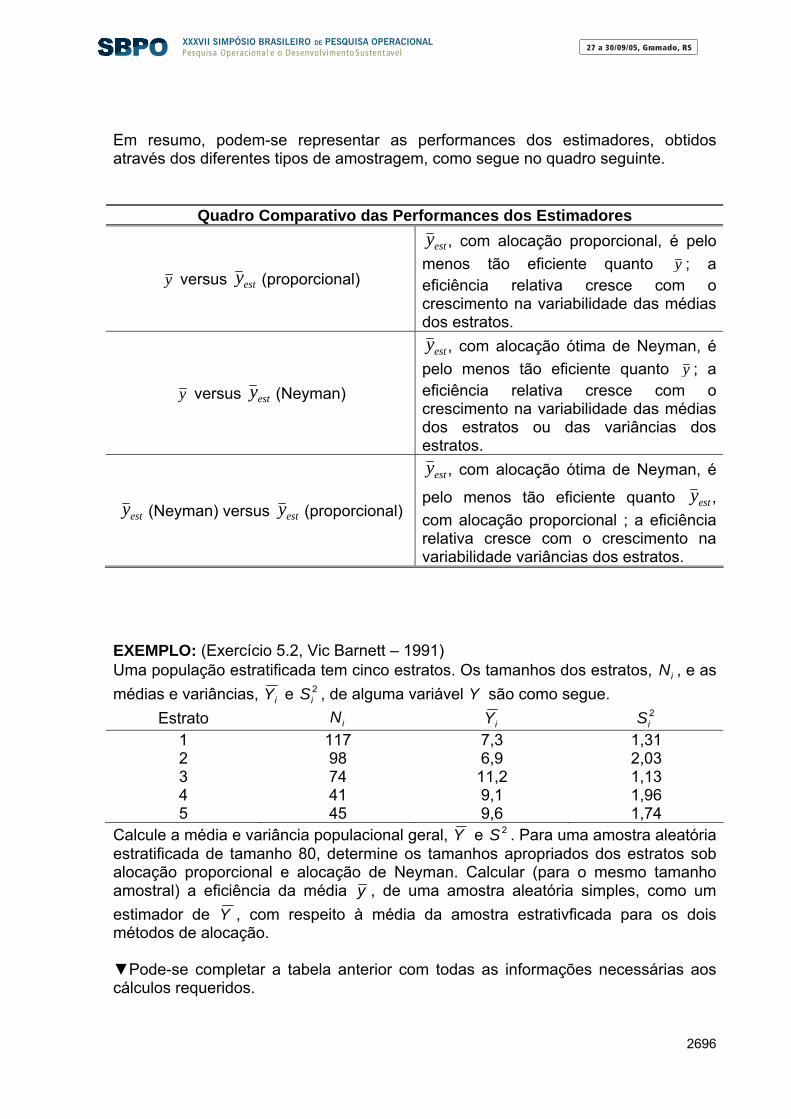
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2696
Em resumo, podem-se representar as performances dos estimadores, obtidos através dos diferentes tipos de amostragem, como segue no quadro seguinte.
Quadro Comparativo das Performances dos Estimadores
y versus esty (proporcional)
esty , com alocação proporcional, é pelo menos tão eficiente quanto y ; a eficiência relativa cresce com o crescimento na variabilidade das médias dos estratos.
y versus esty (Neyman)
esty , com alocação ótima de Neyman, é pelo menos tão eficiente quanto y ; a eficiência relativa cresce com o crescimento na variabilidade das médias dos estratos ou das variâncias dos estratos.
esty (Neyman) versus esty (proporcional)
esty , com alocação ótima de Neyman, é
pelo menos tão eficiente quanto esty , com alocação proporcional ; a eficiência relativa cresce com o crescimento na variabilidade variâncias dos estratos.
EXEMPLO: (Exercício 5.2, Vic Barnett – 1991) Uma população estratificada tem cinco estratos. Os tamanhos dos estratos, iN , e as médias e variâncias, iY e 2
iS , de alguma variável Y são como segue. Estrato iN iY 2
iS 1 117 7,3 1,31 2 98 6,9 2,03 3 74 11,2 1,13 4 41 9,1 1,96 5 45 9,6 1,74
Calcule a média e variância populacional geral, Y e 2S . Para uma amostra aleatória estratificada de tamanho 80, determine os tamanhos apropriados dos estratos sob alocação proporcional e alocação de Neyman. Calcular (para o mesmo tamanho amostral) a eficiência da média y , de uma amostra aleatória simples, como um estimador de Y , com respeito à média da amostra estrativficada para os dois métodos de alocação. ▼Pode-se completar a tabela anterior com todas as informações necessárias aos cálculos requeridos.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2697
Estrato iN iY 2iS iS ii SN ×
1 117 7,3 1,31 1,145 133,913 2 98 6,9 2,03 1,425 139,629 3 74 11,2 1,13 1,063 78,663 4 41 9,1 1,96 1,400 57,400 5 45 9,6 1,74 1,319 59,359
Total 375 468,963 Temos que:
• ∑=
×=k
iii YWY
1, 5,4,3,2,1=i
• ( ) ( ) ⎥⎦
⎤⎢⎣
⎡−×+×−
− ∑ ∑=
k
iiiii YYNSN
NS
1
222 11
1
Então,
44,86,9375451,9
375412,11
375749,6
375963,7
375117
=×+×+×+×+×=Y
( ) ( )[ ]60,7717,98564,57231,77151,4876,5678,482,49196,91151,96374
12 +++++++++=S
Logo, 4,312 =S e 2,08=S . Para uma amostra de tamanho 80=n , teremos as seguintes repartições: (i) Os valores de in através de alocação proporcional podem ser obtidos por
meio da expressão: nNNn i
i ×⎟⎠
⎞⎜⎝
⎛= .
Assim,
2580375117
1 =×=n , 2120,98037598
2 ≅=×=n , 1615,88037574
3 ≅=×=n ,
98,78037541
4 ≅=×=n e 109,68037545
5 ≅=×=n .
Neste caso, o tamanho da amostra será 81. Caso se decida por manter o tamanho amostral em 80 “elementos”, deve-se escolher de onde será retirado o excedente. Pode ser, por exemplo, no último estrato. Mas, neste caso, esta decisão não está levando qualquer caráter de “otimização”.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2698
(ii) Os valores de in , através da alocação de Neyman, podem ser obtidos por
meio da expressão: nSN
SNnSW
SWn k
iii
iik
iii
iii ×
×
×=×
×
×=
∑∑== 11
.
Assim,
238,2280468,963133,913
1 ≅=×=n , 248,2380468,963139,629
2 ≅=×=n ,
134,1380468,96378,663
3 ≅=×=n , 108,980468,96357,400
4 ≅=×=n
e 101,1080468,96359,359
5 ≅=×=n .
(iii) Por último, temos que fazer uma avaliação das performances dos
estimadores, com respeito à suas eficiências, em relação à média aleatória simples.
Vamos comparar as variâncias, ( )yVar , ( )PestyVar e ( )NestyVar .
( ) 0,04238280
4,313758011
2
=×⎟⎠⎞
⎜⎝⎛ −=×⎟
⎠⎞
⎜⎝⎛ −=
nS
NnyVar ;
( ) 0,01558980
1,5853073758011
2
=×⎟⎠⎞
⎜⎝⎛ −=
××⎟⎠⎞
⎜⎝⎛ −=
∑n
SW
NnyVar
k
iii
Pest ;
( ) 0,0114051,585307375
11,25056980111 2
2
=×−×=××−⎟⎟⎠
⎞⎜⎜⎝
⎛××= ∑∑
k
iii
k
iiiNest SW
NSW
nyVar
. Como era de se esperar, o estimador “ótimo” de Neyman tem a menor variância entre todos os três estimadores, seguido pela amostragem estratificada com alocação proporcional e, por último, o estimador obtido via amostragem aleatória simples. ▲

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2699
EXEMPLO: (5.3, Cochran) Os dados da tabela abaixo mostram a estratificação de todas as fazendas de um Condado, de acordo com o tamanho das fazendas e o número médio de acres plantados co milho nas fazendas de cada estrato.
Tamanho das Fazendas
(acres)
Número de Fazendas
hN
Média de Acres com Milho
Y
Desvio-Padrão hS
00─40 394 5,4 8,3 40─ 80 461 16,3 13,3 81─120 391 24,3 15,1
121─160 334 34,5 19,8 161─200 169 42,1 24,5 201─240 113 50,1 26,0
241 148 63,8 35,2 Tamanho ou Média 2.010 26,3 Para uma amostra de 100 fazendas, calcule o tamanho da amostra de cada estrato com (a) repartição proporcional; (b) repartição ótima. Compare a precisão desses processos com a da amostragem aleatória simples. ▼Pode-se resumir as quantidades necessárias aos cálculos na seguinte tabela: Estrato iN iY iS 2
iS iW ii SW × 2ii SW ×
1 394 5,4 8,3 68,890 0,196 1,627 13,5042 461 16,3 13,3 176,890 0,229 3,050 40,5703 391 24,3 15,1 228,010 0,195 2,937 44,3544 334 34,5 19,8 392,040 0,166 3,290 65,1455 169 42,1 24,5 600,250 0,084 2,060 50,4696 113 50,1 26,0 676,000 0,056 1,462 38,0047 148 63,8 35,2 1239,040 0,074 2,592 91,233
Geral 2.010 26,3 1,000 17,018 343,279 (i) Para calcularmos os valores de in por alocação proporcional, utiliza-se a expressão:
nWnNNn i
ii ×=×⎟
⎠
⎞⎜⎝
⎛= .
Assim, os tamanhos amostrais, determinados por alocação proporcional, são:
2019,6100196,01 ≅=×=n 2322,9100229,02 ≅=×=n
194,19100194,03 ≅=×=n 176,16100166,04 ≅=×=n
84,8100084,05 ≅=×=n 66,5100056,06 ≅=×=n

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2700
73,7100074,07 ≅=×=n (ii) Para a determinação dos valores de in , através da alocação ótima de Neyman,
utiliza-se a expressão nSW
SWn k
iii
iii ×
×
×=
∑=1
.
Desse modo, obtemos a seguinte repartição “ótima”:
101000,09560110017,0181,627
1 ≅×=×=n
181000,17924210017,0183,050
2 ≅×=×=n
171000,172610017,0182,937
3 ≅×=×=n
191000,19332910017,0183,290
4 ≅×=×=n
121000,12104310017,0182,060
5 ≅×=×=n
91000,08588910017,0181,462
6 ≅×=×=n
151000,15229710017,0182,592
7 ≅×=×=n
(iii) Queremos comparar a “precisão” dessas repartições com a da amostragem aleatória simples. As expressões das variâncias dos estimadores, podem ser representadas por:
( )n
SNnyVar
2
1 ×⎟⎠⎞
⎜⎝⎛ −= para a amostra aleatória simples;
( )n
SW
NnyVar
k
iii
Pest
∑ ××⎟⎠⎞
⎜⎝⎛ −=
2
1 para a alocação proporcional;
( ) ∑∑ ××−⎟⎟⎠
⎞⎜⎜⎝
⎛××=
k
iii
k
iiiNest SW
NSW
nyVar 2
211 para a alocação ótima de Neyman.
Além disso, temos que:
( ) ( )[ ]∑=
−+−−
=k
iiiii YYNSN
NS
1
222 11
1 .

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2701
As parcelas da expressão anterior, são dadas por:
( )∑=
=−k
iii SN
1
2 686.609,271 e ( ) 556.547,181
2=−∑
=
k
iii YYN .
Assim,
( ) 618,79556.547,18-686.609,27009.212 =×=S ;
( ) 5,88007912
=×⎟⎠⎞
⎜⎝⎛ −=
nS
NnyVar ;
( ) 3,2449241
2
=×
×⎟⎠⎞
⎜⎝⎛ −=
∑n
SW
NnyVar
k
iii
Pest ;
( ) 2,7254611 22
=××−⎟⎟⎠
⎞⎜⎜⎝
⎛××= ∑∑
k
iii
k
iiiNest SW
NSW
nyVar .
Precisão: Se RP é a razão de precisão, podemos escrever:
%181%100244924,3880079,5
≅×=PRP e %216%10072546,2
880079,5≅×=NRP . ▲
EXEMPLO: (5.14, Cochran) Em uma empresa, 62% dos empregados são homens, especializados ou não, 31% são mulheres que trabalham nos escritórios, e 7% exercem funções de supervisão. Através de uma amostra de 400 empregados, a empresa deseja estimar a proporção de empregados que se utilizam de certas instalações recreativas. As conjecturas preliminares são de que as instalações são utilizadas por 40 a 50% dos homens, 20 a 30% das mulheres, e 5 a 10% dos supervisores. (a) Como você repartiria a amostra entre os três grupos? (b) Se as proporções reais de usuários fossem, respectivamente, 48, 21 e 4%, qual seria o erro-padrão da proporção estimada,
estp ? (c) Qual seria o erro-padrão de p para uma amostra acidental simples com 000.4=n ?
▼Temos que %62=HP , %31=MP e %7=SP . Além disso, 400=n . As instalações são utilizadas por:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2702
%50%40 ≤≤ HP , %30%20 ≤≤ MP e %10%5 ≤≤ SP .
(a) Considerando-se o percentual médio, para cada intervalo fornecido, escolhemos
os seguintes percentuais: 45,01 =P , 25,02 =P e 075,03 =P . Observe que
•== PNNW i
i .
Estrato ( )iii PPS −= 1 ii SW ×
1 0,4975 0,30845 2 0,4330 0,13423 3 0,2634 0,01844
Total 0,46112 (i) in por alocação de Neyman
nSW
SWn k
iii
iii ×
×
×=
∑=1
2681 =n 1162 =n 163 =n
(ii) in por alocação proporcional
nPnWnNN
n ii
i ×=×=×⎟⎠⎞
⎜⎝⎛= • .
24840062,01 =×=n 12440031,02 =×=n 2840007,03 =×=n
(b) Segue que as proporções reais de usuários são:
48,01 =P , 21,02 =P e 04,03 =P .
( ) ?min =estpVar
( )minestpVar
( )∑=
⎟⎟⎠
⎞⎜⎜⎝
⎛−×
−=
k
i i
i
i
iii
Nn
nPPW
1
2
11
( ) ( ) ( )16
96,004,007,0116
79,021,031,0268
52,048,062,0 222 ××+
××+
××=
00001176,0000137,0000358,0 ++=
00050676,0=

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2703
Na expressão anterior, considerou-se 0≅i
i
Nn .
( ) 0225,0min =⇒ estpVar .
(c) 48,01 =P , 21,02 =P e 04,03 =P .
( ) ?=pVar
Temos que ( ) ( )( ) ( )ii
k
ii PPW
nnPQ
NnNpVar −=×
−−
= ∑=
111 1
2 .
Se considerarmos QPS ×=2 e ( )( ) 1
1≈
−−
NnN , então podemos escrever:
( ) ( )ii
k
ii PPW
npVar −= ∑
=
111
2 .
Logo,
( ) ( ) ( ) ( )400
96,004,007,079,021,031,052,048,062,0 222 ×+×+×=pVar
( ) 00058081,0=pVar
( ) 00241,0=pVar . ▲

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2704
2. Metodologia “Bayesiana” para Pesquisas Eleitorais 2.1. Introdução O modelo Bayesiano para previsão de resultados eleitorais propostos por Bernardo (1984) utiliza um desenho amostral diferente dos comumente adotados. Através da medida de divergência de Kullback-Leibler, Kullback & Leibler (1951) e Kullback (1968), selecionam-se os locais de votação (municípios, zonas eleitorais, etc) mais representativos do comportamento político da população sendo considerada (país, estado, município, etc). Uma vez identificados estes locais, uma amostra aleatória de mesma dimensão de eleitores é selecionada em cada uma deles. Diversas aplicações bem sucedidas e alguns desenvolvimentos vêm ocorrendo desde então. Algumas referências são: Brasil, Migon & Souza (1986); Migon, Souza, Brasil & Sant'Anna (1986); Mendonça & Migon (1987), Souza & Brasil (1989), Brasil, Pego e Silva e Macedo (1996) e outras. Deve-se destacar que a metodologia também pode ser adotada em outras situações, via uso de outros vetores de dados representativos de uma dada região e suas áreas componentes; no entanto a aplicação mais freqüente é nas pesquisas eleitorais. Neste trabalho apresenta-se uma descrição dessa metodologia detalhando o procedimento heurístico para a seleção do número de locais a serem pesquisados, desenvolvido em Brasil e Pego e Silva (1994), e alguns exercícios comparativos onde se pode observar o seu desempenho. 2.2. Procedimento para seleção de locais 2.2.1. Seleção dos locais mais representativos O universo eleitoral não é homogêneo. Encontra-se disperso desigualmente pelo espaço geográfico. As metodologias de pesquisa amostral procuram alguma forma de caracterizar a variabilidade da população. Diferentemente dos métodos tradicionais de planejamento amostral, que supõem que o voto esteja relacionado fortemente a características da população tais como distribuições etárias, de renda e sexo, a metodologia proposta por Bernardo (1984), procura selecionar aqueles locais que sejam mais representativos do comportamento político da população. Uma vez identificados esses locais, uma amostra aleatória de mesma dimensão de eleitores é selecionada em cada um deles. O método está fundamentado em uma abordagem bayesiana, Lindley (1971,1978), e foi aplicado na monitoração das eleições na Espanha em 1982. A seleção dos locais das entrevistas não é feita aleatoriamente, mas segue um critério estatístico de minimização da medida de divergência entre o comportamento eleitoral dos locais e aquele verificado no universo eleitoral considerado.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2705
Assim, deve-se identificar os locais (Zonas Eleitorais, Municípios, bairros, etc) mais representativos da população votante, no sentido de que o comportamento do voto assumido pelos eleitores destes locais, seja o mais similar possível ao comportamento da população como um todo (o estado, o município, etc). Isso porque alguns locais podem ter gerado um resultado similar ao de toda a região. Necessita-se, portanto, de uma medida de distância (ou de discriminação) entre as correspondentes distribuições de probabilidade: a de toda a região e a de cada um dos locais. Observe-se que o método trata a heterogeneidade do universo mediante a utilização de uma medida de proximidade, ou seja, permite identificar e selecionar aqueles locais que mais se aproximam do comportamento de toda população de eleitores. Nas aplicações da parte 2 serão considerados vários exemplos: (i) os locais serão identificados com os municípios e a região será o estado em questão; (ii) os locais serão agregações de bairros e a região um município. A seleção dos locais mais similares é feita com base nos resultados da eleição imediatamente anterior. Aplica-se, então, um critério de minimização das "distâncias" entre esses locais e o universo eleitoral; a partir daí podemos construir uma "hierarquia de similitudes", para selecionar os locais "mais representativos" do universo considerado. O critério adotado é a medida de divergência direta de Kullback-Leibler. Observe-se que esta medida de divergência é coerente com a abordagem Bayesiana, Aitchinson (1975). No Apêndice ao capítulo 2, apresenta-se uma breve descrição da medida divergência de Kullback-Leibler. Assume-se implicitamente que existe alguma estabilidade temporal no comportamento eleitoral, pelo menos de uma eleição para a eleição seguinte. Convém ressaltar que o critério adotado elimina as áreas atípicas a serem pesquisadas. A medida de divergência direta D[Q,P], D[.] ≥ 0, proposta por Kullback-Leibler reflete a perda esperada entre a utilização de uma distribuição aproximada Q e a distribuição verdadeira P, ocorrendo D[Q,P] = 0 apenas quando as distribuições Q e P são iguais. Assim, a medida de divergência resulta em um valor igual a zero apenas quando as distribuições P e Q são iguais. Logo, quanto mais afastadas de zero forem as medidas Di, menos similares serão os locais. No caso de distribuições discretas, o caso em questão, a medida de Kullback-Leibler procura discriminar entre duas distribuições de probabilidade multinomiais, uma relativa à toda região considerada (resultado global) e tantas outras quantos forem os locais que configuram a região; equação (2.1). Se P for a distribuição global (uma distribuição multinomal), e Q for a distribuição de cada local a considerado na comparação (também uma distribuição multinomial), então a medida de Kullback-Leibler, Di, pode ser determinada como:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2706
Distribuição verdadeira: P = (p1, ..., pm) , pi ≥ 0 Distribuição aproximada: Q = (q1, ..., qm) , qi ≥ 0
D Q P p Logpqi i
i
ii
m
[ , ] .=⎡
⎣⎢
⎤
⎦⎥ ≥
=∑ 0
1 (2.1)
Logo, quanto mais afastadas de zero forem as medidas Di, menos similares serão os locais. Quanto menor for a medida Di, mais representativo será o local i (zona eleitoral, município, etc), ou seja, é mais similar à região como um todo, no sentido descrito anteriormente. Adota-se a suposição de que esses "locais representativos" de toda a região permanecem os mesmos de uma eleição para a seguinte. No apêndice ao capítulo 2 apresentam-se os argumentos para a determinação do estimador bayesiano, $θ ij, da probabilidade de um eleitor do i-ésimo local, i.e., com características similares às daqueles que vivem na região abrangida pelo local i votar no j-ésimo candidato (ou partido). Este estimador é:
(2.2) m.,,,,1,2,=j ,2/)1m(n
2/1nˆi
ijij ++
+=θ
Quando aplicado ao presente caso, a medida de Divergência de Kullback-Leibler fica:
D Ln i ki jj
mj
ij
=⎛
⎝⎜
⎞
⎠⎟ =
=∑θ
θθ1
1 2. $ , ,..., . (2.3)
onde: nij - número de votos para o candidato (ou partido) j no local i (Zona Eleitoral - ZE, município, etc) na eleição anterior; N - total de votos; m - número de candidatos (ou partidos) existentes;
n ni ijj
m
==∑
1 - número de votos no local i (ZE ou município);
θ j iji
k
n N==∑ /
1- proporção de votos obtidos pelo candidato j (na área total) na eleição
imediatamente anterior; j = 1, 2,...m. Através do uso de 2.3 podemos ordenar os locais de acordo com a similitude, i.e. do mais similar ao menos similar à toda região sendo estudada. Quanto menor for a medida Di, mais representativo será o local i (ZE, município, etc), ou seja, é mais similar à região como um todo, no sentido de que os eleitores do local i têm um comportamento assumido de voto, similar a toda a região.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2707
Lembramos ainda que é adotada a suposição de que esses "locais representativos" de toda a região permanecem os mesmos de uma eleição para a seguinte. Nas aplicações da parte 2 verifica-se empiricamente essa suposição nos pleitos de 1982 a 2002 no Estado do Espírito Santo. 2.2.2. Um procedimento para a seleção do número de locais Através do uso de (2.3) podemos ordenar os locais em ordem de similitude, i.e. do mais similar ao menos similar a toda região sendo estudada. Restam ainda algumas decisões: (i) quantos locais "mais similares" selecionar? E, (ii) quantas entrevistas realizar em cada local? Quanto ao número de locais similares a serem selecionados para pesquisa (intenção de voto, "boca de urna", projeção final dos resultados após a apuração dos primeiros votos), adotamos um procedimento heurístico bastante simples; Brasil & Pêgo e Silva (1991). A medida de divergência, dada por (2.3), resulta em um valor igual a zero apenas quando as distribuições P e Q são iguais. Assim, quanto mais afastadas de zero forem as medidas Di, menos similares serão os locais. Suponha que o primeiro local mais representativo, com medida D1, seja "razoavelmente" similar ao todo. Nesse caso, se calcularmos o Erro Quadrático Médio (EQM) dessa distribuição com relação à distribuição global, essa quantidade será pequena. Obtemos então, o EQM1. Suponha que tomemos médias (“moveis”) sucessivas, θ ij , entre as distribuições dos locais subseqüentemente similares e realizemos a mesma comparação via EQM, obtendo-se o EQM2 , EQM3 , etc. Teremos então, para i = 1, 2,...,k e j = 1,2,..., m:
∑=
=i
1lljijˆ.
i1 θθ (2.4)
( )2m
1jijji .
m1EQM ∑
=
−= θθ (2.5)
Intuitivamente é de se esperar que, enquanto estivermos combinando locais realmente similares, o gráfico EQM versus o número de municípios apresente um comportamento estável ou declinante. De outro lado, quando introduzirmos na média, municípios pouco similares, é de se esperar que o EQM apresente comportamento crescente. Desse modo, analisando-se o gráfico mencionado, poderíamos realizar uma escolha do número de locais de modo a que não sejam tão poucos a ponto de termos graus de liberdade insuficientes e nem tantos que tornem a pesquisa muito dispendiosa em termos de custos. Ou seja, deveríamos selecionar o número de locais no entorno do menor EQM. Nas aplicações da parte 2 utilizamos este procedimento para selecionar o número de locais.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2708
Cabem alguns comentários adicionais. Na composição da amostra é importante a decisão entre o número de locais similares escolhidos e o número de eleitores a entrevistar em cada local. Esta decisão resulta em um compromisso entre custo e precisão. Além do mais, como argumentam Mendonça & Migon (1987), considerando-se que os eleitores em cada local selecionado devem apresentar um comportamento heterogêneo para representar o universo, é razoável ter-se "uma maior fração amostral nesse estágio (eleitores), comparativamente à fração amostral do primeiro estágio (locais)". Por exemplo, Bernardo (1984), menciona que selecionou uma amostra aleatória de 50 eleitores em cada uma das 20 áreas mais representativas da província de Valencia na Espanha (aproximadamente 1.800.000 eleitores em 1982), sendo que estes números foram obtidos através de simulações com os resultados da eleição imediatamente anterior. O procedimento decorrente do uso das equações (2.4) e (2.5), e os resultados de diversas aplicações, sugerem que seja utilizado o procedimento proposto para a seleção do número de locais, mas pouco pode ser dito quanto à quantidade de eleitores a serem entrevistados (no caso de pesquisa de intenção de voto), exceto que deve ser maior do que o número de locais. Um outro ponto importante diz respeito à magnitude da medida de divergência: quanto mais próximo de zero, melhor. No entanto, pode ocorrer que o local mais similar ao todo, possua uma medida de divergência que indique que a similaridade “não é tão boa”. 2.3 – Análise Bayesiana do Modelo Descrevemos sucintamente nesta seção o modelo bayesiano para análise dos resultados, como proposto em Bernardo (1984); outras referências são Mendonça & Migon (1987) e Souza & Brasil (1989), sendo que estes últimos apresentam uma descrição detalhada do algoritmo. Algumas definições necessárias: θij : probabilidade de um eleitor do local de votação i votar no candidato j; θij > 0, e θ ijj
m==∑ 11 , i = 1,2,...,k e j = 1,2,...,m;
k : é o número de locais existentes; ni : tamanho da amostra no local i; ni = [ni1 + ni2 + ... + nim ]; N : matriz de dimensão k x m, cujo elemento (i,j) é nij ; Xij : variável aleatória contínua representando os "log-odds" (razão de chances) associados a θij , ou seja:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2709
X Logijij
ij=
−
⎡
⎣⎢
⎤
⎦⎥ ∈ℜ
θθ1
, X ij (2.6)
Na análise bayesiana assume-se que o vetor aleatório, ni = [ni1 + ni2 + ... + nim], tem distribuição multinomial com parâmetros θij : θi = [θi1 , θi2 , ... , θim ]. Assim, o modelo observacional é:
[ni1 , ni2 , ... , nim ] ∼ Multinomial (θi) (2.7)
[ni1 , ni2 , ... , nim ] ∝=∏θ i
n
i
mi
1
Do ponto de vista bayesiano necessitamos especificar uma distribuição a priori para os θij's. Para simplificação do trabalho operacional podemos utilizar uma priori não-informativa, como descrito no Apêndice ao capítulo. A distribuição Dirichlet é a priori natural para um modelo observacional multinomial. A priori não-informativa fica: [θi1 ,θi2 ,...,θim ] ∏
=
−∝m
1i
21iθ . (2.8)
Daí, a distribuição a posteriori fica:
[θi1 , θi2 , ... , θim ] ∼ Dirichlet (N + 1/2). (2.9)
i.e., uma distribuição Dirichlet com parâmetros (nij + 1/2), j = 1, 2,..., m. O estimador de Bayes para a proporção de eleitores, $θ ij , é dado pela média da posteriori:
$ [ ]//
θ θij ijij
iE N
nn m
= | =+
+
1 22
(2.10)
Podemos fazer uma mudança de escala, e obter os valores Xij na escala da razão de chances(“log-odds”), correspondente ao vetor ni = [ni1 + ni2 + ... + nim]
X Logn
n n mijij
i ij=
−
− + −
⎡
⎣⎢
⎤
⎦⎥
1 21 2
/( ) /
. (2.11)
Note que os Xij's realmente descrevem, para a amostra observada, a força do candidato j no local i. A vantagem de usar (2.11) consiste no fato dos Xij's serem números reais, o que flexibiliza na escolha do modelo para os percentuais de cada candidato em toda a região considerada.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2710
Duas suposições razoáveis precisam ser feitas para completar a análise coerentemente ao plano amostral da seção 2.2: (i) o vetor de "log-odds" a posteriori, Xi , tem distribuição normal multivariada com vetor de médias μi ∈ ℜm e matriz de precisão constante H0 ∈ ℜm x m
[xi | μi , H0 ] ∼ NM[μi , H0 ] (2.12) A suposição será verdadeira se o tamanho da amostra ni, em cada local, for o mesmo, e se, para todo i, θij ≅ θi ; j = 1, 2, ..., m. Isso é razoável uma vez que os locais selecionados são os mais similares à região como um todo. (ii) o vetor de médias μi = [μi1, μi2 , ... , μim] é aproximadamente normal em cada local de votação com média comum δ ∈ ℜm, e matriz de precisão comum H1 ∈ ℜm x m :
[μi | δ , H1 ] ∼ NM[δ , H1 ]. (2.13) O vetor de médias δ (na escala da razão de chances) contém as quantidades de interesse, i.e., o vetor de preferências de votos para cada candidato em toda a região. As suposições (i) e (ii) definem um modelo hierárquico como em Lindley & Smith (1972). Combinando (2.12) e (2.13), temos a distribuição conjunta dos vetores Xi e μi, para cada local de votação
P[Xi , μi | δ , H0 , H1 ] ∼ P[Xi | μi , H0 ].P[μi | δ, H1 ]. (2.14) Considerando-se que “t” é o número de locais escolhidos no plano amostral, pode-se determinar a distribuição de Xi (centrada no vetor de interesse δ), integrando-se fora o parâmetro incômodo (nuisance) μi, na distribuição conjunta P[xi , μi | δ , H0 , H1]. Obtemos:
[Xi | δ , H0 , H1 ] ∼ NM[δ , H0.( H0 + H1)-1.H1] (2.15)
Onde o vetor Xi tem dimensão m, com média δ = [δ1, δ2,..., δm], descrevendo o comportamento eleitoral global da região e tem matriz de precisão desconhecida: H = H0 (H0 + H1 )-1 H1] ∈ Rmxm. A prova utiliza resultados encontrados em Lindley & Smith (1972) e Smith (1973). Prova: Seja t o número de locais escolhidos, então a densidade conjunta da amostra é:
i=∏
1
t
P[Xi , μi | δ , H0 , H1 ] = P[X1 , X2 , ..., Xt , μ1 , μ2 , ..., μt | δ , H0 , H1 ].

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2711
Para encontrar a distribuição de [X1, X2, ..., Xt] integra-se a probabilidade encontrada com relação a cada μi . Utilizando-se resultados de lindley & smith (1972), temos:
P[X1 , X2 , ..., Xt | δ , H0 , H1 ] = ... [ | , ]. [ | , ] ...∫ ∏∫=
NM X H NM H d di ii
t
i i mμ μ δ μ μ01
1 1
= NM X H NM H di i ii
t
i[ | , ] [ , ]μ μ μ01
1∫∏=
= i=∏
1
t
NM [(Xi | δ ) , H0.( H0 + H1)-1.H1]
Para encontrar a média e a matriz de precisão da distribuição de cada Xi, temos:
[ ]E X E E Xi i i[ ] ( | )= =μ δ
[ ] [ ] [ ]V X E V X V E X E H V H Hi i i i i i[ ] ( | ) ( | ) [ ] [ ]= + = + = +− − −μ μ μ0
10
11
1
Logo, visto que a precisão de Xi = 1/[ ]H H0
11
1− −+ , a matriz de precisão H fica: H H H H H= + −
0 0 11
1( ) . . [Xi] ∼ NM[δ , H] Isso implica que, cada vetor Xi é uma amostra aleatória de uma normal multivariada com vetor de médias δ e matriz de precisão constante H. ♦ Desse modo, o modelo proposto tem dois conjuntos de parâmetros desconhecidos: o vetor de médias δ e a matriz de precisão H. Uma estimativa de δ pode ser obtida através de outra análise bayesiana: uma distribuição para o vetor δ e o estimador de Bayes. Adotando-se uma distribuição a priori não-informativa para δ e H,
P H Hm
[ , ]( )
δ ∝−
+12 , (2.16)
determina-se uma distribuição a posteriori para δ como:
P P X H P Hi[ | ] [ | , ]. [ , ]δ δ δDADOS ∝ . (2.17) A distribuição a posteriori de referência, P[δ|DADOS], é uma distribuição T multivariada, com (t - m) graus de liberdade; Bernardo (1979):
[ ]P S X X T t[ | ] ( )( )
/δ δ δDADOS ∝ + − −
− 2 (2.18)
Onde X = [ X X X m1 2, ,..., ]é a média amostral dos "log-odds", e,

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2712
∑=
=t
1iijj X
t1X , j = 1, 2, ... , m (2.19)
S = { sij } ; s X X X X tlk il li
t
ik k= − −=∑ ( )( ) /
1 ; l, k=1, 2,..., t. (2.20)
Logo, a média da distribuição [δ|DADOS] é E[δ|DADOS] = X com matriz de dispersão igual a S/(t-m). Os intervalos de probabilidade a posteriori dos componentes do vetor δ podem ser obtidos a partir das distribuições marginais de (2.18). Temos:
P X hs
t mj jjjδ αα∈ ±−
⎧⎨⎩
⎫⎬⎭
⎡
⎣⎢⎢
⎤
⎦⎥⎥= −.
( )( )1 (2.21)
Onde hα é o quantil (1 - α/2) da distribuição T normalizada com (t - m) graus de liberdade. Como os δj's estão na escala da razão de chances, utiliza-se a transformação inversa para obter o estimador desejado:
)]X(EXP1[)X(EXP
ˆj
jj +=ψ , j = 1, 2, ..., m. (2.22)
onde jψ̂ representa a proporção de votos a ser obtida pelo candidato j em toda a região considerada. Os intervalos de credibilidade de (1-α)% podem ser determinados diretamente das distribuições marginais T de Student com (t - m) graus de liberdade, similarmente a (2.22). Observe-se que os intervalos de credibilidade dependerão do número de graus de liberdade, e da dispersão Sij, i.e., da dispersão dos Xij entre os locais escolhidos; quanto menor a dispersão, mais estreitos serão os intervalos. Em resumo: Os argumentos utilizados no desenvolvimento da análise bayesiana adotam: (i) Priori não-informativa via regra de Jeffreys, Box & Tiao (1973); (ii) Mudança de escala nos “log-odds” associados a θij, obtendo-se um vetor de “log-odds” X, suposto pertencer a uma distribuição normal multivariada; (iii) As suposições anteriores são verdadeiras apenas se o tamanho da amostra selecionada em cada local, ni , for o mesmo e, se puder-se identificar θIJ ≈ θJ , j = 1, 2, ..., m. tudo isso conduz a um modelo hierárquico como em Lindley & Smith (1972);

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2713
(iv) O número de locais escolhidos no plano amostral deve ser fixado, para completar a análise, e obter as estimativas pontuais θj , e sua dispersão; (v) Os intervalos de credibilidade dependem do número de graus de liberdade (que são função de: número de candidatos, número de locais selecionados) e da dispersão entre os locais escolhidos. (vi) O modelo pressupõe que os “t”, (t << k) locais escolhidos e, onde ocorreriam as “n” entrevistas, sejam realmente similares. Observe-se que, se o tamanho da amostra global for igual a “N”, a amostra em cada uma dos locais terá dimensão n = N/t.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2714
Apêndice 2.1. Análise Bayesiana do Modelo Multinomial - Dirichlet Neste apêndice apresentamos a análise bayesiana do modelo Multinomial-Dirichlet; Box & Tiao (1973) e Berger (1985). Distribuição Multinomial - é uma generalização da distribuição binomial. Considere a situação onde se tem k eventos mutuamente exclusivos, A1, A2,..., Ak, consistindo uma partição do espaço amostral, ou seja, tem-se k resultados possíveis em cada ensaio, ao invés de apenas dois. Suponha que o experimento seja repetido n vezes. Seja ni o número de vezes que o evento Ai ocorre nas n repetições do experimento e pi a probabilidade de ocorrência de Ai. Temos então:
n1 , n2 , ... , nk nnk
ii =∑
=1
p1 , p2 , ... , pk 11
=∑=
k
iip pi > 0
∏=
==k
1i i
nin
kn2
n1
k21ik21 !n
p!np...p.p.!n!...n!.n
!n]n,p|n,...,n,n[Pi
k11
n ,...,1 ,0ni = ; i = 1,2,...,k
E[ni ] = npi ; V[ni ] = npi(1 - pi), i = 1, 2, ..., k.
Cov[ni ,nj] = -npipj , i = 1, 2, ..., k e i ≠ j. As variáveis ni 's são dependentes e, usualmente estabelece-se o valor de uma
delas como: ni0 = (1 - ∑−
=
1
1
k
iin ); o mesmo para pi0 = (1 - ∑
−
=
1
1
k
iip ).
Distribuição Dirichlet - é uma generalização da distribuição Beta. Considere a família de distribuições de Dirichlet (P|α) ~ D(α) com parâmetros α=[α1,α2,...,αk], αi >
0 e P = [p1 , p2 ,...,pk , 0< pi ≤1, com 1pk
1ii =∑
=
. Definindo-se o parâmetro
complementar como ∑=
=k
1ii0 αα , a função de densidade Dirichlet fica:
)1(i
k1i
ik
1i
0 ip.)(
)(]|P[P −=
=
ΠΓΠ
Γ= α
ααα
;0iii /]p[E ααμ == ; )1.(
).(]p[V0
20
ii0i +
−=
ααααα
)1.(.
]p,p[COV0
20
jiji +
−=αααα , i = 1, 2,..., k.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2715
A distribuição de Dirichlet é (k-1) dimensional devido à restrição nos pi’s. No cálculo das Esperanças Matemáticas com relação a essa densidade, deve-se substituir pk
por (1-∑−
=
1
1
k
iip ) e integrar sobre p1, ..., pk-1. A distribuição marginal de qualquer pi é
uma Dirichlet de dimensão unitária, ou seja, uma distribuição Beta. Modelo Multinomial-Dirichlet - se o modelo observacional segue uma multinomial com parâmetro P = (p1 , ...,pk), a distribuição Dirichlet é a priori natural, assim como no modelo univariado Bernoulli-Beta. Modelo Observacional - a verossimilhança de uma a.a.(k) de uma distribuição Multinomial é:
i
nik
ik np
nnnPi
11 !],...,[ == Π
ini
ki p1 =∝ Π ,
1nn
k
ii =∑
= ∑
−
=
1
1
k
iip = 1, pi > 0.
Distribuição a priori para P: P ~ D(α) )1(
ik
1ii
k1i
0k1
ip.)(
)(]|p,...,p[P −=
=
ΠΓΠ
Γ= α
ααα
)1(1 −
=∝ i
iki p αΠ
com
pi ≥ 0, αi > 0, ∑=
=k
1ii0 αα , ∑
−
=
1
1
k
iip = 1, I =1, 2,..., k.
Distribuição a posteriori para P: seja a amostra observada N = [n1 , ..., nk].
∫=
Pd]P[P].P|N[P]P[P].P|N[P]N|P[P
]P[P].P|N[P ∝ )1(
ik
1ini
k1i
ii p.p −== ΠΠ∝ α
11 −+
=∝ iini
ki p αΠ
Comparando-se com uma Dirichlet, verifica-se que a distribuição a posteriori também é da mesma família, logo:
(P|N) ~ D(α + N); ou seja, uma Dirichlet com parâmetros (αi + ni) i = 1, 2, ..., k. Modelo Multinomial-Dirichlet utilizando uma Priori Não-Informativa (de referência): Adotando-se a Regra de Jeffreys (ver Box & Tiao, 1973 - pag. 55), pode-se calcular uma priori não-informativa para os parâmetros da Multinomial

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2716
P[P] ∝ [p1 , p2 , ..., pk ]-1/2.
A posteriori para (P) é calculada do mesmo modo: “verossimilhança X priori”: )1(
ik
1ini
k1i
ii p.p]N|PP[ −== ΠΠ∝ α
1ni
k1i
iip]N|PP[ −+=Π∝ α .
Logo, a distribuição a posteriori de referência é também uma Dirichlet: (P|N) ~ D(α + N), ou seja, uma Dirichlet com parâmetros αi = (ni + 1/2), i = 1, 2, ..., k. Daí, o Valor Esperado de cada pi dado os dados, N, é:
2kn21n
)21n(21n]N|p[E i
k
1i i
ii +
+=
+
+=∑ =
;
visto que n = (n1 + n2 + ... + nk). Apêndice 2.2. A Medida de Divergência de Kullback-Leibler A medida de divergência de Kullback-Leibler está diretamente relacionada ao conceito de "informação" e este, ao de entropia. Neste apêndice faz-se uma breve descrição destes conceitos relacionados. Algumas referências são: Berger (1985), Kendall (1973), Kulback & Leibler (1951) e Kullback (1968). Clausius em 1854 introduziu o conceito de entropia, hoje conhecido como segunda lei da termodinâmica. Em 1877 Boltzman fez a ligação entre o conceito termodinâmico de entropia e o conceito estatístico de desordem. Hartley em 1928 introduziu os fundamentos matemáticos da "teoria da informação" em sistemas de comunicações. O livro "The Mathematical Theory of Comunications" de Shannon & Weaver, publicado em 1949, define informação como uma "propriedade estatística de um conjunto de mensagens possíveis, não de uma mensagem individual". A ligação completa entre a teoria estatística e a teoria da informação foi apresentada por Kullback & Leibler (1951) e Kullback (1968). Observe-se que a medida de divergência de Kulback-Leibler é coerente com os argumentos Bayesianos; Aitchinson (1975). A entropia de uma distribuição P, H(P), é uma medida da incerteza associada a essa distribuição de probabilidade. Assim, se Y tem distribuição contínua p(Y|θ), a entropia, H[.], é dada por:

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2717
[ ] ∫∞
∞−
−=−= dy)|Y(p].|Y(p[Ln)}|Y(p{LnE)]|Y(p[H θθθθ
No caso discreto, onde temos resultados possíveis Y1, Y2,..., Yn com probabilidades
p1, p2,..., pn , com pi ≥ 0 e 1pk
1ii =∑
=
, temos:
[ ] ∑=
−=−=n
1iiii )p(Ln.p}p{LnE)]|Y(p[H θ
se pi = 0, então pi.Ln(pi ) = 0. A informação é exatamente o negativo a entropia. Assim, a informação sobre p(Y|θ), I[.], é:
[ ] ∫∞
∞−
== dy)|Y(p].|Y(p[Ln)}|Y(p{LnE)]|Y(p[Ip θθθθ .
Enquanto a entropia é uma medida de desorganização, a informação é uma medida de organização de um grupo de mensagens. Vale a esse respeito o comentário de Norbert Wiener: "quanto mais provável é uma mensagem, menos informação ela propicia". Considere agora a classe de modelos paramétricos: y ∈ Y, θ ∈ Θ e p(Y|θ) uma função densidade sobre y. Suponha que x seja um conjunto de dados disponíveis descrevendo uma classe de medidas similarmente parametrizadas. Quer-se verificar o ajuste de q(Y|x) sobre p(Y|θ). Necessita-se então de uma medida global de divergência de q(Y|x), da verdadeira densidade p(Y|θ). A medida de divergência direta proposta por Kullback-Leibler para problemas de estimação é dada por:
dy)|Y(p.)x|Y(q)|Y(pLn)]x|Y(q),|Y(p[D
Yθθθ ∫ ⎥
⎦
⎤⎢⎣
⎡= ,
Onde: D[.] ≥ 0 e, D[.] = 0 apenas quando q(Y|x) = p(Y|θ). A medida reflete a perda esperada entre a utilização de uma distribuição aproximada Q e a distribuição verdadeira P:
)}]x|Y(q{Ln[E)}]|Y(p{Ln[E x)]|q(Y ,|D[p(Y pp −= θθ .
No caso discreto, se a distribuição verdadeira é P = [p1, p2,..., pm], pi ≥ 0 e 1pk
1ii =∑
=
; e,
Q = [q1 , q2 ,..., qm], qi ≥ 0 e 1qk
1ii =∑
=
, é a distribuição aproximada, a medida de
divergência fica:
][ .0)]Q(Ln[E)]P(Ln[EqpLn.pP,QD
m
1i i
ii ≥−=⎢
⎣
⎡⎥⎦
⎤= ∑
=

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2718
PARTE 2 – APLICAÇÕES EM PESQUISAS ELEITORAIS 3. Metodologias das Pesquisas Eleitorais 3.1. O que Significa uma Pesquisa de Opinião Pública Eleitoral? 3.2. Pesquisas de Opinião Pública (opinion pools) 3.3. Desenho da Amostra 3.4. Desenho Amostral: Metodologia “Clássica” 3.5. Desenho Amostral: Metodologia “Bayesiana” 3.6. Questionários e Planejamento de Pesquisas Eleitorais 4. Erros em Pesquisas Eleitorais 4.1. Introdução e Exemplos 4.2. Questões Influentes nos Levantamentos Estatísticos Amostrais 4.3. Erros em Pesquisas por Amostragem 4.4. Aprendendo com os Erros em Pesquisas Eleitorais 4.5. Comentários: Indecisos e Pesquisas Eleitorais 5. Pesquisas eleitorais: Metodologias Clássica e Bayesiana 5.1. Estudos de Caso no Estado do Espírito Santo 5.2. Metodologia Bayesiana: Eleições de 1990 - Governo e Senado do ES 5.3. Monitoramento de Eleições Municipais no Município de Guarapari/ES – 1992 – Metodologias “Clássica e Bayesiana” 5.4. Eleições Municipais no Município da Serra/ES – 1996 – Metodologias “Clássica e Bayesiana” 5.5. Pesquisa Eleitoral no Espírito Santo, setembro/2001 5.6. Análise dos Resultados da Eleição 2002, Governo ES, via Metodologia Bayesiana 6. Comentários e Discussão 7. Referências
“A informação de que você dispõe não é a informação que você deseja.
A informação que você deseja não é a informação que você necessita. A informação que você necessita não é a informação que você consegue obter. A informação que você consegue obter custa mais do que você deseja pagar.”
Citado em Bernstein (1996), Against the Gods (Desafio aos Deuses)

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2719
3. Metodologias das Pesquisas Eleitorais 3.1.O que significa uma pesquisa de opinião pública eleitoral? Uma pesquisa eleitoral representa, modernamente, a mais apropriada tentativa de conhecer as diferentes percepções e expectativas da população com o universo da política. Simplificadamente, uma pesquisa nada mais é do que uma tentativa de avaliar, através de um procedimento amostral, as intenções de voto do eleitorado em uma dado momento do processo de decisão de voto do eleitor, até a sua cristalização, isto é, até a sua decisão definitiva. A importância deste instrumento, enquanto base para um processo de gerenciamento e monitoramento de uma campanha eleitoral significa, na prática, uma indiscutível vantagem política, pois permite a captação de informações fundamentais a respeito do interessado, de outros candidatos e dos anseios e expectativas da população. Uma pesquisa retrata apenas a realidade instantânea, relativa ao momento da pesquisa. Deve, em princípio, ser utilizada com cautela como uma previsão do resultado final da eleição, pois o processo de cristalização do voto até o dia das eleições está sempre sujeito a perturbações de todo tipo, seja pelo próprio movimento sócio-econômico, seja pelo embate entre os diversos candidatos participantes, ou outros motivos. Outro ponto importante é que as pesquisas não são apenas úteis para indicar "quem está na frente", as informações geradas por uma boa pesquisa podem servir para direcionar todas as estratégias do candidato na campanha. 3.2. Pesquisas de opinião pública (opinion pools) Até 1932 as pesquisas de opinião eram um processo informal (não-científicas). Alguns conceitos estatísticos importantes só vieram à luz nos anos 1930 a 1950. Por exemplo: Testes de Hipóteses Estatísticas (Neyman), 1933; Amostragem Probabilística (Neyman), 1934; Intervalos de Confiança (Neyman), 1934; o primeiro livro de Planejamento de Experimentos (Fisher), 1935; e o primeiro livro sobre Amostragem (Hanson, Hurwicz & Madow) em 1953; ver por exemplo, Haak (1979), Stigler (1996) e Fienberg (1992). De outro lado, uma nova técnica de amostragem foi introduzida por George Gallup em 1932 e aplicada com sucesso nas pesquisas de opinião pré eleitorais no estado de Iowa (EUA): a amostragem por quotas. Haak (1979) considera esta, a primeira pesquisa eleitoral moderna. As pesquisas previram corretamente o resultado. O método de amostragem por cotas é hoje extensivamente utilizado com sucesso em vários países. Nesse procedimento, a população a ser pesquisada é dividida em

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2720
subgrupos (estratos) de acordo com as necessidades do levantamento. Por exemplo: estratifica-se por região geográfica e controlam-se as quotas de idade, sexo e classificação sócio-econômica. Um pressuposto subjacente a esses métodos de pesquisa de opinião pública eleitoral é que o universo eleitoral não é homogêneo e encontra-se disperso desigualmente pelo espaço geográfico. Por outro lado, a suposição de que o voto esteja relacionado com, distribuições etárias, sexo e classe sócio-econômica, também é uma alguma forma de caracterizar a variabilidade da população, e acessá-la para realização das entrevistas. As opções de possibilidade de pesquisa em uma época eleitoral vão desde as pesquisas (pré eleitorais) periódicas de intenção de voto, com ou sem monitoração da campanha, às pesquisas de “boca de urna” e de primeiros votos apurados. Em qualquer caso deseja-se prever acertadamente o resultado final. A introdução das urnas eletrônicas no processo de votação, com um rápido processamento dos resultados, eliminou um pouco do glamour das pesquisas pós-votação. 3.3. Desenho da Amostra A parte 1 desse trabalho apresentou detalhadamente a teoria estatística que sustenta a amostragem. Apenas a amostragem probabilística, e algumas variações, têm suporte teórico. O desenho amostral compreendendo, desde o dimensionamento da amostra, e toda a sucessão de escolhas até a seleção do indivíduo a ser entrevistado, constitui-se em um plano amostral completo. O desenho da amostra pode ser convenientemente considerado em quatro itens: População: deve-se definir tão aproximadamente quanto possível a população a ser coberta pela investigação. Isso deve ser feito por áreas de interesse demográfico e geográfico e outras características profissionais ou técnicas. Os grupos etários também precisam ser definidos. Nas pesquisas eleitorais atuais, de acordo com o código eleitoral brasileiro, o universo considerado compreende todos os indivíduos aptos a votar, i.e., com idade igual ou superior a 16 anos, cadastrado nos TRE’s. Deve-se observar que o voto não é obrigatório para os eleitores de 16 a 17 anos e acima de 70 anos de idade. Método: deve-se decidir se é viável um censo completo ou se basta uma amostra. Esta decisão será afetada por vários condicionantes: tempo, recursos financeiros, urgência, disponibilidade de pessoal. Se decidir por amostra deve-se usar técnicas de amostragem aleatória (ou probabilística). Número de Estágios: deve-se definir o número de estágios de amostragem. A maioria das amostras aleatórias adota necessariamente alguma forma de amostragem em estágios múltiplos em conseqüência das limitações práticas das pesquisas, quais sejam, custo, gerenciamento, tempo, etc. Em cada dois ou mais estágios sucessivos tira-se uma amostra por seleção aleatória (casual), estratificada ou não, até que se cheque às unidades amostrais finais.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2721
Estratificação da População: Deve-se estratificar ou dividir a população a ser levantada em grupos identificados como relevantes (e presumivelmente homogêneos). A estratificação é um importante conceito estatístico e deve ser amplamente utilizada tanto em amostragem probabilística quanto em amostragem por quotas. O exemplo 3.1 ilustra dois desenhos amostrais. Exemplo 3.1: Desenho amostral e estágios Desenho amostral em quatro estágios: Estágio 1 – Município (áreas urbana e rural) Estágio 2 – Distrito eleitoral (ou bairro) Estágio 3 – Setor censitário e Unidades habitacionais (domicílios) Estágio 4 – Indivíduos Desenho amostral em três estágios: Estágio 1 – Localização geográfica: Áreas/Regiões de um Município Estágio 2 – Pontos de Fluxos Estágio 3 – Seleção dos indivíduos de acordo com um controle de quotas ♦ As amostras devem ser estratificadas por fração de amostragem uniforme, onde para cada estrato é alocado o mesmo rateio, digamos, 10% (observe-se que nesse caso a tem-se a mesma proporção da composição do universo); ou por fração de amostragem variável. Nesse caso, são extraídas amostras de diferentes proporções em cada estrato. Na amostragem com fração de amostragem variável, o usual é se determinar os tamanhos dos estratos de acordo com sua participação na população total (a rigor dever-se-ia observar a homogeneidade de cada estrato, representada por sua variância). 3.4. Desenho Amostral: Metodologia “Clássica” Na parte 1 apresentou-se a amostragem "clássica" usualmente adotada, a qual suficientemente é bem conhecida; ver, por exemplo, Raj (1972), Cochran (1977), Deming (1960), Kish (1965). A disponibilidade de informações e o custo, constituem-se em dois fatores que levam à predileção pelo uso da amostragem por cotas nas pesquisas eleitorais. Por exemplo, não se tem disponível um cadastro dos eleitores (com sua localização e outros dados); nem todos os domicílios possuem telefone fixo, o que também impossibilita uma pesquisa via telefone.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2722
Desse modo, uma vez definida a abrangência da pesquisa (país, estado, município), usualmente adota-se uma amostragem aleatória estratificada por regiões (áreas) com algum tipo de controle de quotas (exemplo: sexo, faixa etária, classificação sócio-econômica, escolaridade). Podem ser utilizados os dados censitários (com eventuais atualizações das PNAD’s) ou do Tribunal Superior Eleitoral (TSE e TRE’s). A amostra deve ser dimensionada utilizando-se as relações usuais para levantamentos dessa natureza adotando-se um intervalo de confiança (usualmente) de 95%, como descrito na parte 1. 3.5. Desenho Amostral: Metodologia “Bayesiana” No capítulo 2 da parte 1, também descreveu-se uma metodologia alternativa para pesquisas eleitorais. Diferentemente dos desenhos tradicionais de planejamento amostral, que supõem que o voto esteja relacionado fortemente a características da população tais como distribuições etárias, de renda e sexo, a metodologia proposta por Bernardo (1984), procura selecionar aqueles locais que sejam mais representativos do comportamento político da população. Identificam-se os locais (municípios, áreas, bairros e/ou agregações de bairros, etc) mais representativos da população votante, no sentido de que o comportamento do voto assumido pelos eleitores destes locais, seja o mais similar possível ao comportamento da população de toda a área considerada, adotando-se como critério a medida de divergência direta de Kullback-Leibler, para selecionar os locais "mais representativos" do município, e, construindo-se uma "hierarquia de similitudes". Uma vez identificados esses locais, uma amostra aleatória de mesma dimensão de eleitores é selecionada em cada um deles. 3.6. Questionários e Planejamento de Pesquisas Eleitorais No planejamento das pesquisas políticas são utilizados dois tipos e pesquisas: quantitativas e qualitativas. Neste trabalho estamos discutindo apenas as pesquisas quantitativas. Ressalte-se que essas pesquisas são complementares. As pesquisas qualitativas não são inferenciais, tendo apenas caráter exploratório, lidando com aspectos subjetivos, captando motivações e atitudes do eleitorado, muitas vezes contribuindo para a elaboração do questionário da pesquisa quantitativa; Rita (2002), Nunes (2002). Os questionários para uma pesquisa eleitoral dependem fundamentalmente dos objetivos da pesquisa e da localização temporal da mesma, relativamente à data da eleição. Assim, numa pesquisa realizada um ano antes do pleito os conjuntos de questões podem ser bastante diferentes de uma realizada nos trinta dias anteriores. Os questionários são estruturados em blocos ou módulos constituídos de baterias de perguntas objetivando captar diferentes percepções do eleitorado. Apenas o

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2723
módulo/bloco contendo as perguntas identificatórias (perfil do entrevistado), e que definem o plano amostral, devem estar presentes em toda pesquisa eleitoral. Desse modo, em uma campanha eleitoral o planejamento das pesquisas políticas pode se dividido em pelo menos três fases: (i) mapeamento do eleitorado em termos sociais e políticos; (ii) posicionamento do candidato/partido e seus concorrentes e (iii) acompanhamento/monitoramento da campanha. O questionário é estruturado de acordo com essas fases. Usualmente em uma pesquisa de intenção de voto com o intuito de monitorar a campanha de algum candidato, são avaliados os seguintes grupos de questões: (1) perfil sócio-econômico do entrevistado (sexo, faixa etária, classe social, renda, etc); (2) perfil político (simpatia por partidos, voto na ultima eleição, avaliação das administrações, etc); (3) atitudes e preferências políticas (voto espontâneo, voto estimulado, avaliação dos índices de rejeição dos candidatos, avaliação das preferências por chapas simuladas, principais lideranças políticas, etc.) e, (4) avaliação dos temas julgados mais importantes pelos eleitores (medição do alcance da publicidade, penetração da mensagem eleitoral, etc).

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2724
4. Erros em Pesquisas Eleitorais 4.1. Introdução e Exemplos Na realização de uma pesquisa eleitoral um dos principais componentes é o procedimento de dimensionamento e determinação da amostra. Esse componente é diretamente estatístico, técnico, e foi descrito na parte 1. No entanto, muitas outras questões necessitam ser adequadamente tratadas para se ter uma pesquisa confiável (sample survey ou opinion poll). São questões envolvendo a elaboração do questionário, o modo da entrevista, o trabalho de campo e até mesmo a análise dos resultados. Todas essas coisas constituem fontes de variação erro. Como já descrito, mesmo se a amostra representar razoavelmente a população, existe uma variação natural entre os valores populacionais procurados (por exemplo, a intenção de voto dos eleitores). Essa variação natural chamada frequentemente de “variação amostral’ ou “erro amostral” estará sempre presente. Assim toda pesquisa por amostragem e em especial as eleitorais têm associados um erro da estimativa obtida e uma variância. De outro lado, é reconhecido que as pesquisas eleitorais provêm uma das poucas oportunidades para se avaliar a performance dos levantamentos amostrais através de critérios objetivos, uma vez que se pode confrontar a evolução dos resultados das pesquisas de opinião pré-eleitorais, com o resultado final do voto cristalizado nas urnas pelo eleitorado. Daí a importância da avaliação dos resultados das pesquisas eleitorais, seus erros e acertos. Neste capítulo apresentamos alguns exemplos no sentido de ilustrar alguns erros e como, possivelmente, evitá-los, e, também, servir de orientação para a interpretação dos resultados dessas pesquisas por parte dos eleitores. Dois exemplos de grandes erros em previsão eleitoral nos Estados Unidos, são consagrados exemplificados, recorrentemente, na literatura especializada; Haak (1979). Exemplo 4.1: Pesquisas pré-eleitorais de 1936 – eleições presidenciais nos EUA A revista Literacy Digest utilizou durante os 20 anos precedendo 1936, com sucesso, o procedimento de enviar (correio) 20 milhões de cédulas a possíveis eleitores selecionados através de listas disponíveis. Obtinha-se um retorno aproximado de 3 milhões (15%) de cédulas. Nas eleições de 1936, a revista enviou 10 milhões de cédulas, obtendo um retorno de 2,3 milhões: 23% de respondentes e 77% de não-respondentes. Na mesma ocasião foi divulgada uma pesquisa nacional de G. Gallup (com três mil entrevistas). Os resultados estão na tabela 3.1. Como se observa, apesar da amostra da revistas ser extraordinariamente grande, o erro foi substancial.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2725
Tabela: 4.1 – Pesquisas Pré-eleitorais nos EUA, 1936 Gallup Digest Real Franklin D. Roosevelt 57,7% 43% 62,5% Alfred E. Landon 42,3% 57% 37,5%
Fonte: Quais foram as principais razões do erro? Em primeiro lugar, foi uma pesquisa com respostas voluntárias, com as cédulas enviadas pelo correio. Além disso, os bancos de dados disponíveis para a seleção dos nomes e endereços, incluíam números de nomes através de listas telefônicas das principais cidades dos EUA. A lista só incluía habitantes urbanos suficientemente ricos para terem telefone (na época), excluindo praticamente a população rural. Finalmente, o tempo decorrido entre o envio das cédulas e a obtenção das respostas foi grande, o que impossibilitou a visualização de quaisquer tendências de voto. O que se aprende com esse exemplo é que a amostra não precisa ser muito grande, tem que ser não tendenciosa. Essa tendenciosidade encontrou-se principalmente nas listas utilizadas, que não refletiam apropriadamente o eleitorado, e no viés de não-respostas, produzindo uma amostragem não proporcional. ♦ Exemplo 4.2: Pesquisas pré-eleitorais de 1948 – eleições presidenciais nos EUA Um sumário dos resultados das pesquisas realizadas por três institutos e o voto oficial, encontra-se na tabela 3.2. Todas as pesquisas erraram as previsões. Este foi um grande desastre em pesquisas eleitorais que, na ocasião, gerou descrédito nas pesquisas por amostragem. O “Social Science Research Council” do governo americano procurou averiguar as causas do fracasso do “método de amostragem”; Haak (1979), Souza (1990). Tabela 4.2 - Pesquisas Pré-eleitorais nos EUA, 1948
Dewey Truman Outros Data Pesquisa Inst. Gallup 49,5 44,5 6,0 2 semanas antes Inst. Crossley 49,9 44,8 5,3 2 semanas antes Inst. Roper 52,2 37,1 10,7 2 semanas antes Resultado Oficial 45,1 49,5 5,4 02/11/1948
Fonte: As principais razões para a falha nas pesquisa foram: (i) falta de aleatorização na escolha das unidades amostrais (eleitores) para compor a amostra, no plano de amostragem por quotas adotado; (ii) ) não-representatividade adequada do perfil

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2726
populacional na amostra. Constatou-se que o perfil educacional das amostras diferiu daquele da população votante; (iii) falhas das pesquisas em detectar mudanças nas intenções de voto durante os últimos estágios da campanha [os indecisos]. A população que interessa, é aquela que vota no dia da eleição. Quanto mais próximo do dia da eleição for realizada a pesquisa, mais provável representar

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2727
a população que irá realmente votar. Nesse pleito de 1948 os institutos fizeram a última pesquisa de vinte a vinte e cinco dias antes da realização das eleições, não sendo verificada a “tendência histórica” dos resultados. Existem aqueles eleitores que decidem de "última hora". Nessas pesquisas 15% dos eleitores ainda indecisos nas pesquisas, decidiram o voto nas 2 últimas semanas; Haak (1979). [Observe-se que nos EUA o voto é facultativo. O comparecimento dos inscritos tem ficado entre 50-70%]. ♦ 4.2. Questões Influentes nos Levantamentos Estatísticos Amostrais De maneira geral, são oito as principais fontes de erro nas pesquisas por amostragem: (1) Fonte dos dados (2) A população [informações sobre a população] (3) A taxa de respostas (4) O método de contato [entrevista direta, telefone, etc] (5) O momento da pesquisa [ocasião da realização] (6) A redação das questões [pode haver indução nas respostas] (7) O tamanho da amostra [sample size] (8) O procedimento amostral [sampling procedure] Desse modo na realização de uma pesquisa esses elementos devem ser balanceados e devidamente controlados para o sucesso levantamento amostral. Várias referências especializadas tratam detalhadamente do assunto: Hoinville, Jowell et al (1978), Moser and Kalton (1971) e Barnett (1991). Essa última referência apresenta um bom resumo sobre a condução de um “sample survey”. 4.3. Erros em pesquisas por amostragem Diversas classificações e tipologias dos erros em amostragem podem ser encontradas em Cochran (1977), Bussab (1991) e Barnett (1991). A Variabilidade natural na População é uma característica inevitável e não deveria ser observada como erro; isso porque sempre vai existir variabilidade entre as unidades amostrais. Como está-se investigando apenas uma amostra e não toda a população, sempre vai existir erro amostral (esse erro é “técnico”). Esse é o erro amostral [exemplo: 3% / Intervalo de confiança: Ex: 95%]. Existe também confiança no Sistema de Referência (Frame) utilizado para definir a população. No entanto podem ocorrem erros no gerenciamento do processo de obtenção da amostra no sentido de atender as exigências estabelecidas no “plano/desenho amostral”. Uma classificação dos erros baseada em Barnett (1991), encontra-se na tabela 4.3.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2728
Tabela 4.3 : Uma Classificação dos Erros de amostragem Tipo de Erro Forma Específico Variação Amostral
Erro amostral
Sistema de Referência Aspectos “técnicos” (varia-bilidade intrínseca, etc)
Não-Observacional
• Erro de Não-Inclusão • Erro de Não-Resposta
• Erro de Cobertura
Observacional
• Erro de resposta • Erro de mensuração
Erro na entrevista Erro nas questões Erro de registro Erro de codificação Erro de Processamento • Medição não-acurada • Erro intrínseco
Fonte: Adaptado de Barnett (1991) Os erros de cobertura e de não-resposta são não-observacionais, i.e. os erros decorrem exatamente da não observação. Erros de Cobertura (Cobertura incompleta) – quando existe a possibilidade que alguns membros ou grupos da população não serem incluídos na amostra. Exemplos: (i) algumas pesquisas por telefone, onde, para o objetivo desejado, nem todos os domicílios possuam telefone; (ii) pesquisas com entrevista em pontos de fluxo, onde alguns segmentos circulem pelos pontos com probabilidade muito baixa. Erros de Não-Resposta – Os indivíduos são selecionados, mas não querem responder a algumas questões. O indivíduo selecionado se recusa a responder à pesquisa (pode ser devido ao método de entrevista, pode ser que a questão não seja relevante para esse indivíduo, etc). Nos erros observacionais os indivíduos são escolhidos para a amostra mas algumas observações estão faltando. Exemplos: (i) questões enganosas ou incorretamente expressas podem conduzir a respostas incorretas; (ii) uma resposta correta pode ser registrada incorretamente; (iii) uma resposta correta pode ser codificada erroneamente ou digitada com erro na base de dados, etc..

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2729
4.4. Aprendendo com os Erros em Pesquisas Eleitorais Exemplo 4.3 – Eleições municipais, Rio de Janeiro - 03/10/1992 - primeiro turno A tabela 4.4 apresenta os resultados de uma pesquisa de boca de urna realizada pelo Ibope, com 2.700 entrevistas. O resultado é instrutivo por vários motivos, inclusive por que, a ocorrência de erros em pesquisas de boca de urna, realizando-se as entrevistas após o eleitor depositar seu voto na urna, tem, aparentemente, menor probabilidade de erro. Tabela 4.4: Eleições Municipais RJ – 1992 - boca de urna e resultado final CANDIDATO BOCA DE URNA
IBOPE – 2700 ENTREVISTAS (%)
RESULTADO SOBRE O (%) DE
VOTANTES
RESULTADO SOBRE O (%) TOTAL DE
ELEITORES BENEDITA 30,0 25,02 23,02 CESAR MAIA 15,8 16,55 14,37 CIDINHA 18,0 14,00 12,15 OUTROS 36,2 23,54 16,40 BRANCOS 11,90 10,33 NULOS 12,14 10,53 ABSTENÇÃO ------ ------- 13,20 TOTAL 100,0 100,00 100,00 Fonte: Jornal do Brasil, 03/10/1992. Comentários: Observam-se dois tipos de erro: (i) Erro do segundo colocado (a pesquisa de boca de urna indicava como vitoriosos no primeiro turno: Benedita e Cidinha); (ii) Erro nas magnitudes (as diferenças entre os valores finais – TRE – e os da pesquisa foram maiores que o erro amostral, determinado pelo tamanho da amostra, cerca de 2%). Nas pesquisas de boca de urna os resultados são usualmente interpretados e/ou comparados com o percentual de votantes (o universo considerado reduz-se usualmente àqueles eleitores que efetivamente compareceram às urnas). Nas pesquisas pré-eleitorais os resultados, porque o universo inclui todos os eleitores, pois ainda não se sabe o percentual daqueles que não irão comparecer às urnas (abstenção), são relativos ao total de eleitores (inclui os indecisos, votos em branco e votos nulos). No entanto, todas as duas possibilidades devem ser consideradas nas avaliações dos erros: percentual com relação ao total de eleitores e com relação aos votantes.
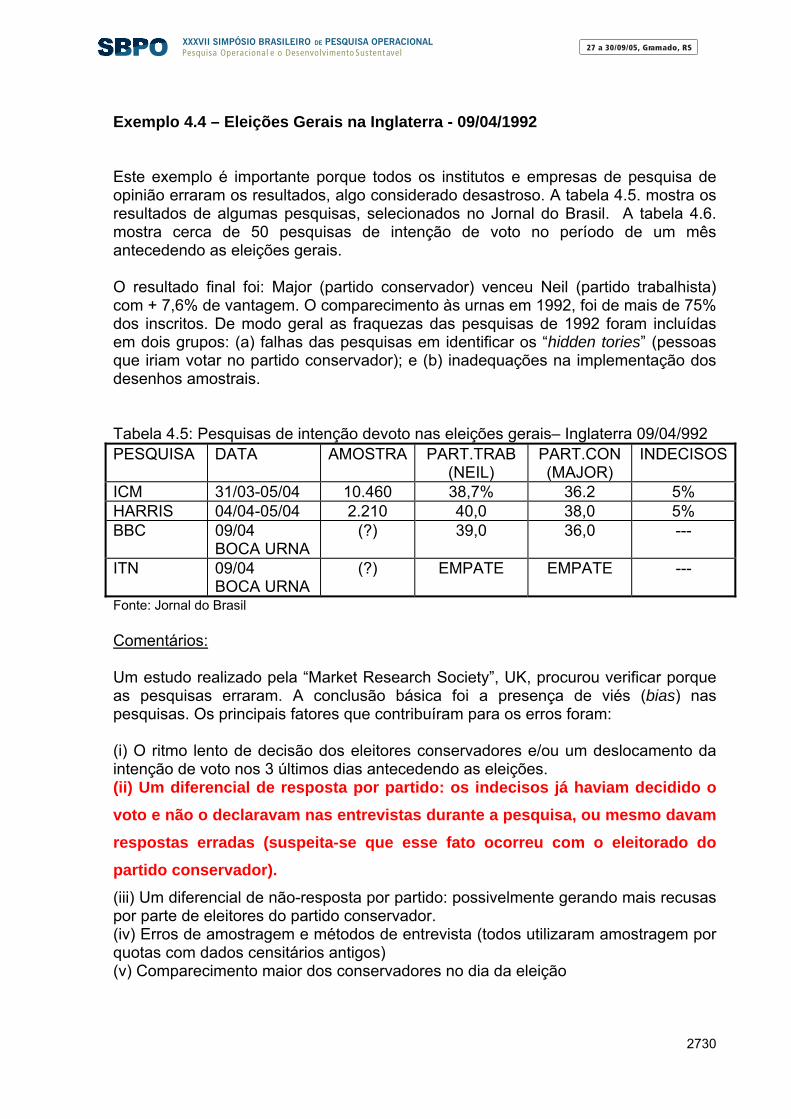
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2730
Exemplo 4.4 – Eleições Gerais na Inglaterra - 09/04/1992 Este exemplo é importante porque todos os institutos e empresas de pesquisa de opinião erraram os resultados, algo considerado desastroso. A tabela 4.5. mostra os resultados de algumas pesquisas, selecionados no Jornal do Brasil. A tabela 4.6. mostra cerca de 50 pesquisas de intenção de voto no período de um mês antecedendo as eleições gerais. O resultado final foi: Major (partido conservador) venceu Neil (partido trabalhista) com + 7,6% de vantagem. O comparecimento às urnas em 1992, foi de mais de 75% dos inscritos. De modo geral as fraquezas das pesquisas de 1992 foram incluídas em dois grupos: (a) falhas das pesquisas em identificar os “hidden tories” (pessoas que iriam votar no partido conservador); e (b) inadequações na implementação dos desenhos amostrais. Tabela 4.5: Pesquisas de intenção devoto nas eleições gerais– Inglaterra 09/04/992 PESQUISA DATA AMOSTRA PART.TRAB
(NEIL) PART.CON (MAJOR)
INDECISOS
ICM 31/03-05/04 10.460 38,7% 36.2 5% HARRIS 04/04-05/04 2.210 40,0 38,0 5% BBC 09/04
BOCA URNA (?) 39,0 36,0 ---
ITN 09/04 BOCA URNA
(?) EMPATE EMPATE ---
Fonte: Jornal do Brasil Comentários: Um estudo realizado pela “Market Research Society”, UK, procurou verificar porque as pesquisas erraram. A conclusão básica foi a presença de viés (bias) nas pesquisas. Os principais fatores que contribuíram para os erros foram: (i) O ritmo lento de decisão dos eleitores conservadores e/ou um deslocamento da intenção de voto nos 3 últimos dias antecedendo as eleições. (ii) Um diferencial de resposta por partido: os indecisos já haviam decidido o voto e não o declaravam nas entrevistas durante a pesquisa, ou mesmo davam respostas erradas (suspeita-se que esse fato ocorreu com o eleitorado do partido conservador). (iii) Um diferencial de não-resposta por partido: possivelmente gerando mais recusas por parte de eleitores do partido conservador. (iv) Erros de amostragem e métodos de entrevista (todos utilizaram amostragem por quotas com dados censitários antigos) (v) Comparecimento maior dos conservadores no dia da eleição
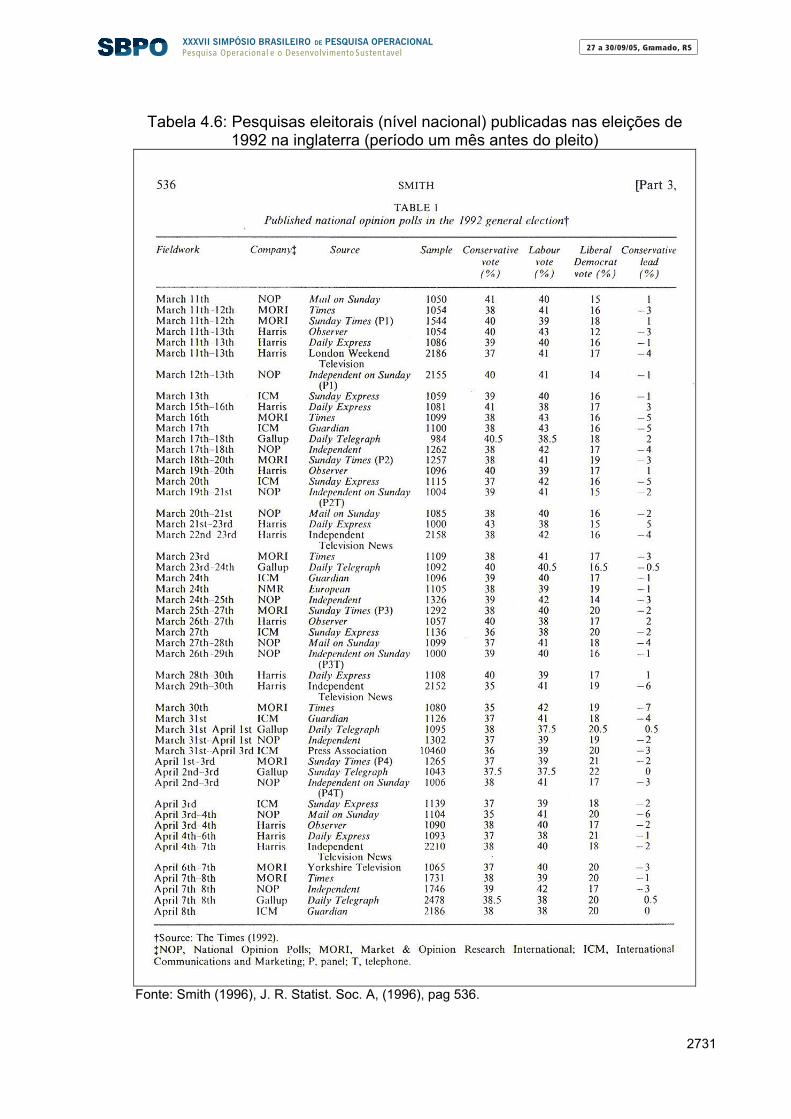
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2731
Tabela 4.6: Pesquisas eleitorais (nível nacional) publicadas nas eleições de 1992 na inglaterra (período um mês antes do pleito)
Fonte: Smith (1996), J. R. Statist. Soc. A, (1996), pag 536.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2732
Observando-se a tabela 4.6 nota-se que as empresas/institutos de pesquisa de opinião realizaram pesquisas até no dia anterior às eleições. A diferença do percentual de votos de Major (conservador) para Neil (trabalhador) variou de –7 a +5 pontos; média de –1,5 pontos (última coluna da tabela). No entanto não se pode atribuir todo o erro ao método de amostragem por quotas. A figura 4.1 mostra o registro histórico dos resultados das pesquisas de opinião na Inglaterra (1964 - 1987) – onde foram realizadas simultaneamente, pesquisa via amostragem aleatória e por quotas. Observa-se que a amostragem aleatória nem sempre produz melhores resultados (exemplo: 1966 e 1974). Desde 1979 utilizam-se, apenas por razões de custo, amostras por quotas. Em 1997, houve um retorno ao uso de amostras aleatórias. Figura 4.1: Registro histórico dos resultados das pesquisas de opinião na Inglaterra
(1964 - 1987) – onde pesquisa via amostragem aleatória e por quotas foram realizadas simultaneamente
Fonte: Smith (1996), J. R. Statist. Soc. A, (1996), pag 536.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2733
Exemplo 4.5 – Eleições Majoritárias no Espírito Santo – Governador 1998 As tabelas 4.7a a 4.7d apresentam os resultados divulgados na mídia impressa de várias pesquisas realizadas de 16 de julho a 4 de outubro de 1998 no estado do Espírito Santo. São mostrados os resultados para Governador: voto estimulado e espontâneo. Desta eleição até o presente uma grande quantidade de empresas passou a realizar pesquisas de opinião até com metodologias alternativas (o que é saudável). Além disso, também existem as pesquisas quantitativas e qualitativas para planejamento das campanhas, que não são divulgadas. Comentários:
• Um aspecto importante diz respeito à divulgação dos resultados das pesquisas, no sentido de melhor informar o eleitor e a sociedade. Além das características do plano amostral utilizado, método de coleta dos dados (entrevista), erro amostral, tamanho da amostra, e perfil dos entrevistados, também devem ser corretamente apresentados: voto espontâneo e estimulado e não agregar os votos brancos, nulos e indecisos. Restringiu-se no exemplo apenas às informações mostradas nos veículos de divulgação.
• Nota-se que algumas informações básicas nem sempre são divulgadas.
• Confrontando-se os resultados em datas próximas nota-se que nem sempre
estão dentro das margens de erro indicadas.
• Apenas quando as pesquisas realizadas se aproximam da data da eleição, os resultados começam a ser divulgados em termos dos votos válidos (excluindo-se brancos, nulos e indecisos). As empresas divulgaram resultados sobre o total de votantes até o dia 29/09 (a eleição foi dia 4 de outubro). Nesta eleição a abstenção foi de 21,81% do eleitorado, e os brancos e nulos totalizaram 16,58%. Mesmo usando os votos válidos, ambas as empresas erraram o percentual do segundo colocado (diferença maior que o erro amostral). Observe-se que, corretamente, o IBOPE divulgou o resultado nas duas bases (votantes e total de eleitores), indicando o percentual de indecisos praticamente a um dia do pleito.
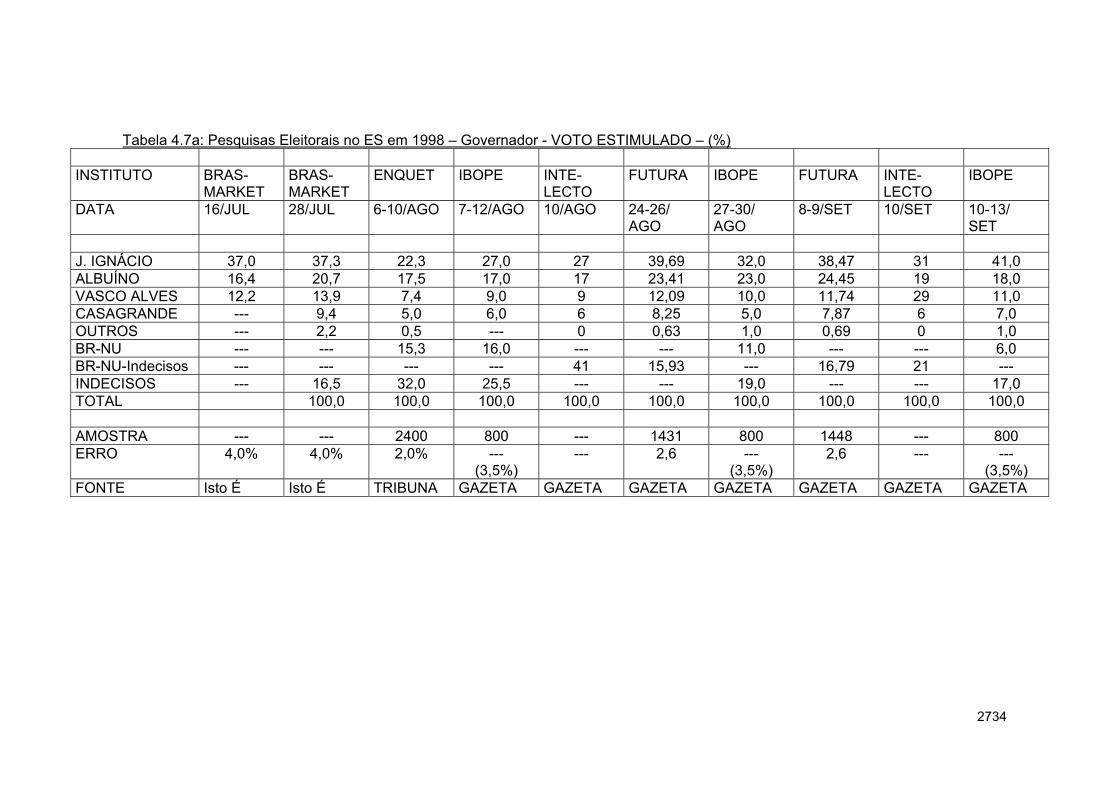
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2734
Tabela 4.7a: Pesquisas Eleitorais no ES em 1998 – Governador - VOTO ESTIMULADO – (%)
INSTITUTO BRAS-
MARKET BRAS-MARKET
ENQUET IBOPE INTE-LECTO
FUTURA IBOPE FUTURA INTE-LECTO
IBOPE
DATA 16/JUL 28/JUL 6-10/AGO 7-12/AGO 10/AGO 24-26/ AGO
27-30/ AGO
8-9/SET 10/SET 10-13/ SET
J. IGNÁCIO 37,0 37,3 22,3 27,0 27 39,69 32,0 38,47 31 41,0 ALBUÍNO 16,4 20,7 17,5 17,0 17 23,41 23,0 24,45 19 18,0 VASCO ALVES 12,2 13,9 7,4 9,0 9 12,09 10,0 11,74 29 11,0 CASAGRANDE --- 9,4 5,0 6,0 6 8,25 5,0 7,87 6 7,0 OUTROS --- 2,2 0,5 --- 0 0,63 1,0 0,69 0 1,0 BR-NU --- --- 15,3 16,0 --- --- 11,0 --- --- 6,0 BR-NU-Indecisos --- --- --- --- 41 15,93 --- 16,79 21 --- INDECISOS --- 16,5 32,0 25,5 --- --- 19,0 --- --- 17,0 TOTAL 100,0 100,0 100,0 100,0 100,0 100,0 100,0 100,0 100,0 AMOSTRA --- --- 2400 800 --- 1431 800 1448 --- 800 ERRO 4,0% 4,0% 2,0% ---
(3,5%) --- 2,6 ---
(3,5%) 2,6 --- ---
(3,5%) FONTE Isto É Isto É TRIBUNA GAZETA GAZETA GAZETA GAZETA GAZETA GAZETA GAZETA
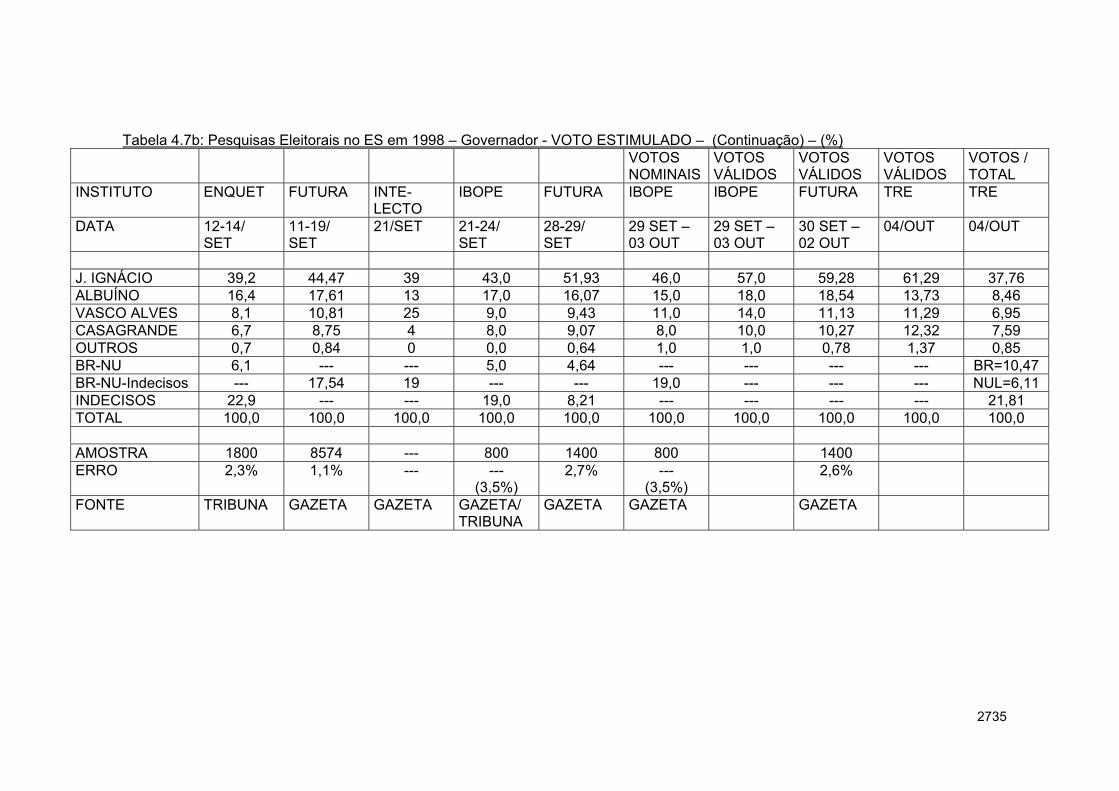
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2735
Tabela 4.7b: Pesquisas Eleitorais no ES em 1998 – Governador - VOTO ESTIMULADO – (Continuação) – (%)
VOTOS NOMINAIS
VOTOS VÁLIDOS
VOTOS VÁLIDOS
VOTOS VÁLIDOS
VOTOS / TOTAL
INSTITUTO ENQUET FUTURA INTE-LECTO
IBOPE FUTURA IBOPE IBOPE FUTURA TRE TRE
DATA 12-14/ SET
11-19/ SET
21/SET 21-24/ SET
28-29/ SET
29 SET – 03 OUT
29 SET – 03 OUT
30 SET – 02 OUT
04/OUT 04/OUT
J. IGNÁCIO 39,2 44,47 39 43,0 51,93 46,0 57,0 59,28 61,29 37,76 ALBUÍNO 16,4 17,61 13 17,0 16,07 15,0 18,0 18,54 13,73 8,46 VASCO ALVES 8,1 10,81 25 9,0 9,43 11,0 14,0 11,13 11,29 6,95 CASAGRANDE 6,7 8,75 4 8,0 9,07 8,0 10,0 10,27 12,32 7,59 OUTROS 0,7 0,84 0 0,0 0,64 1,0 1,0 0,78 1,37 0,85 BR-NU 6,1 --- --- 5,0 4,64 --- --- --- --- BR=10,47 BR-NU-Indecisos --- 17,54 19 --- --- 19,0 --- --- --- NUL=6,11 INDECISOS 22,9 --- --- 19,0 8,21 --- --- --- --- 21,81 TOTAL 100,0 100,0 100,0 100,0 100,0 100,0 100,0 100,0 100,0 100,0 AMOSTRA 1800 8574 --- 800 1400 800 1400 ERRO 2,3% 1,1% --- ---
(3,5%) 2,7% ---
(3,5%) 2,6%
FONTE TRIBUNA GAZETA GAZETA GAZETA/ TRIBUNA
GAZETA GAZETA GAZETA
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2736
Tabela 4.7c: Pesquisas Eleitorais no ES em 1998 – Governador – VOTO ESPONTÂNEO – (%)
INSTITUTO BRAS-
MARKET BRAS-MARKET
ENQUET IBOPE INTE-LECTO
FUTURA IBOPE FUTURA INTE-LECTO
IBOPE
DATA 16/JUL 28/JUL 6-10/AGO 7-12/AGO 10/AGO 24-26/ AGO
27-30/ AGO
8-9/SET 10/SET 10-13/ SET
J. IGNÁCIO 13,1 7,0 21,73 18,0 28,38 27,0 ALBUÍNO 9,8 7,0 16,49 12,0 17,13 12,0 VASCO ALVES 3,5 3,0 5,66 4,0 7,25 7,0 CASAGRANDE 2,5 2,0 3,91 2,0 4,70 4,0 OUTROS 0,1 2,0 3,70 1,0 2,97 1,0 BR-NU 11,6 10,0 --- 10,0 --- 6,0 BR-NU-Indecisos --- --- 46,06 --- 33,43 --- INDECISOS 59,4 70,0 --- 54,0 --- 44,0 TOTAL 100,0 100,0 100,0 100,0 100,0 100,0 AMOSTRA --- --- 2400 800 --- 1431 800 1448 --- 800 ERRO 4,0% 4,0% 2,0% ---
(3,5%) --- 2,6 ---
(3,5%) 2,6 --- ---
(3,5%) FONTE Isto É Isto É TRIBUNA GAZETA GAZETA GAZETA GAZETA GAZETA GAZETA GAZETA
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2737
Tabela 4.7d: Pesquisas Eleitorais no ES em 1998 – Governador – VOTO ESPONTÂNEO – (Continuação) – (%)
VOTOS NOMINAIS
VOTOS VÁLIDOS
VOTOS VÁLIDOS
VOTOS VÁLIDOS
VOTOS / TOTAL
INSTITUTO ENQUET FUTURA INTE-LECTO
IBOPE FUTURA IBOPE IBOPE FUTURA TRE TRE
DATA 12-14/ SET
11-19/ SET
21/SET 21-24/ SET
28-29/ SET
29 SET – 03 OUT
29 SET – 03 OUT
30 SET – 02 OUT
04/OUT 04/OUT
J. IGNÁCIO 29,4 28,57 32,0 38,93 61,29 37,76 ALBUÍNO 10,9 12,13 11,0 12,00 13,73 8,46 VASCO ALVES 4,2 6,27 5,0 5,86 11,29 6,95 CASAGRANDE 4,9 4,67 5,0 5,50 12,32 7,59 OUTROS 0,6 0,36 0,0 1,94 1,37 0,85 BR-NU 4,6 --- 4,0 5,43 --- BR=10,47 BR-NU-Indecisos --- 44,07 --- --- --- NUL=6,11 INDECISOS 45,4 --- 43,0 30,36 --- 21,81 TOTAL 100,0 100,0 100,0 100,0 100,0 100,0 AMOSTRA 1800 8574 --- 800 1400 800 1400 ERRO 2,3% 1,1% --- ---
(3,5%) 2,7% ---
(3,5%) 2,6%
FONTE TRIBUNA GAZETA GAZETA GAZETA/ TRIBUNA
GAZETA GAZETA GAZETA

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
Exemplo 4.6 – Eleições Presidenciais 2002; Análise de Figueiredo (2002) Figueiredo (2002b) analisa os erros e acertos nas pesquisas de intenção de voto para Presidente da República realizadas em 2002. Como já mencionado as pesquisas de intenção de voto constituem oportunidade rara de avaliar os institutos e empresas de pesquisa de opinião (e indiretamente suas metodologias). O que se espera é que as estimativas amostrais de intenção de voto, conduzindo a valores dos votos estimados e a conseqüente posição dos concorrentes na disputa, fiquem o mais próximo possível do resultado final. Fica claro que as estimativas devem ser confrontadas com as margens de erro adotadas nos levantamentos e definidas a priori. Além disso, não existe uma única maneira de fazer as comparações visto que as diferenças entre o resultado final e as estimativas de voto devem ser computadas para todos os candidatos. Segundo Figueiredo (2002b), os métodos mais eficientes de avaliação dos resultados são: (i) “método 1” – média das diferenças absolutas entre a intenção de voto declarada e votos apurados oficialmente; (ii) “método 2” – média das diferenças absolutas entre intenção de voto estimada e votos válidos oficiais (nesse caso excluem-se aqueles que não citam candidatos, indicam voto branco ou nulo). A tabela 4.8 mostra os resultados da última pesquisa de intenção de voto divulgadas pelos institutos Datafolha, Ibope, Vox Populi e CNT/Sensus, antes das eleições de 2002, avaliadas pelos dois “métodos”, e o resultado final do TSE.
Tabela 4.8: Intenção de voto total e válidos e resultado oficial – Eleição Presidencial primeiro turno, 2002 (%)
Datafolha 05/out
IBOPE 5/out
Vox Populi 4/out
Sensus 29/set
TSE (resultado do 1º Turno)
Eleição presidencial 1º turno 2002 (em %)
Total Válidos Total Válidos Total Válidos Total Válidos Total Válidos Lula 45 48 45 50 43 48 40,6 46,2 41,6 46,44 Serra 19 21 20 22 19 21 18,8 21,4 20,8 23,2 Garotinho 17 19 15 17 15 17 15,1 17,2 16 17,87 Ciro Gomes 11 12 9 10 13 14 12,7 14,5 10,8 11,97 José Maria 1 1 1 1 0 0 0,5 0,6 0,4 0,47 Rui Costa 0 0 0 0 0 0 0,2 0,2 0,04 0,05 Brancos/ Nulos/ Indecisos 6 * 10 * 10 * 12,3 * 10,4 * Número de Entrevistas 12.554 3.000 2.501 2.000 Margem de Erro (+/-) 2,00% 1,80% 2,00% 3,00% Número de Cidades 419 203 155 195 Fonte: Últimas Pesquisas divulgadas ; ver sites: Datafolha, Ibope, Vox Populi e CNT/Sensus, relatórios e tabelas especiais e TSE A tabela 4.9 mostra o desempenho dos institutos no primeiro turno. Observa-se que, em média, os institutos foram bem sucedidos, ficando todas as médias das diferenças absolutas abaixo do erro amostral. No entanto, pontualmente existem alguns erros que superam o erro amostral; por exemplo no caso do Ibope, o percentual de votos válidos para o candidato Lula (50% e 46,4%).
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2739
Tabela 4.9: Diferenças e Média das Diferenças absolutas entre intenção de votos totais e estimados e resultado oficial – Eleição Presidencial 2002, 1o Turno (%)
Datafolha 05/out
IBOPE 5/out
Vox Populi 4/out
Sensus 29/set
Diferença (estimativa - oficial)
Diferença (estimativa - oficial)
Diferença (estimativa - oficial) Diferença (estimativa - oficial)
Método 1 Método 2 Método 1 Método 2 Método 1 Método 2 Método 1 Método 2
Eleição - 1º turno 2002 (em %)
Total Válidos Total Válidos Total Válidos Total Válidos
Lula 3,4 1,56 3,4 3,56 1,4 1,56 -1,0 -0,24 Serra -1,8 -2,2 -0,8 -1,2 -1,8 -2,2 -2,0 -1,8 Garotinho 1,0 1,13 -1,0 -0,87 -1,0 -0,87 -0,9 -0,67 Ciro Gomes 0,2 0,03 -1,8 -1,97 2,2 2,03 1,9 2,53 José Maria 0,6 0,53 0,6 0,53 -0,4 -0,47 0,1 0,13 Rui Costa -0,04 -0,05 -0,04 -0,05 -0,04 -0,05 0,16 0,15 Brancos/ Nulos/ Indecisos -4,4 * -0,4 * -0,6 * 1,9 * Média das diferenças abs. 1,63 0,92 1,15 1,36 1,03 1,2 1,14 0,92 Margem de Erro (+/-) 2,0% 1,8% 2,0% 3,0% Fonte: Últimas Pesquisas divulgadas ; ver sites: Datafolha, Ibope, Vox Populi e CNT/Sensus, relatórios e tabelas especiais e TSE

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2740
4.5. Comentários: Indecisos e Pesquisas Eleitorais As eleições de 1998 e 2002 em todo o Brasil mostraram que os indecisos devem ser considerados. O que se observou em alguns estados foi que a distribuição do voto dos indecisos não foi idêntica àquela apresentada pelos que já haviam manifestado a sua intenção de voto durante a campanha. Este é um ponto importante, pois, esta suposição sempre esteve implícita nas pesquisas eleitorais. Isso significa que não se pode deixar de considerar uma expectativa de votos brancos, nulos bem como a abstenção propriamente dita no dia da votação. Esse problema pode ser resolvido de várias maneiras. De outro lado, o processo de decisão do voto vem apresentando similaridades: uma parte do eleitorado, cerca de 25-30%, os eleitores de voto cristalizado, decide imediatamente o seu voto. Um eleitorado flutuante que são aqueles que ficam à espera de informações sobre os candidatos para se transformarem em eleitores de voto cristalizado e os eleitores retardatários que só se definem de 15 a 7 dias das eleições, às vezes até na véspera ou mesmo no dia das eleições. Estes representam de 15% a 20% dos eleitores incluindo brancos e nulos; Icaza-Sanches (). Em 2002, quinze dias antes das eleições, entre 40% e 50% dos eleitores ainda não haviam decidido em quem votar para deputado. Nota-se que o eleitor está cada vez mais independente na decisão do seu voto. Muitos eleitores não “votam casado” em um mesmo partido e nem numa mesma coligação. Nem mesmo são fiéis ao que se denomina “esquerda” e “direita”. Além disso, está demorando um pouco mais para decidir o seu voto. As pesquisas indicam isso.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2741
5. Pesquisas eleitorais: Metodologias Clássica e Bayesiana 5.1. Estudos de Caso no Estado do Espírito Santo (ES) O Sistema de Referência Na elaboração do desenho amostral algumas variáveis devem ser consideradas sendo as mais importantes: (i) o erro amostral desejado (exatidão); (ii) a disponibilidade de dados e os elementos necessários à confecção do plano, i.e. o sistema de referência; e, (iii) a quantidade de recursos disponíveis para a realização da pesquisa. Em muitas situações a variedade de desenhos que se pode propor, mesmo com essas três restrições é muito grande. Como os exemplos reais ocorrem no estado do Espírito Santo é de vital importância a apresentação de alguns dados pertinentes. É bastante interessante o agrupamento dos municípios em Microrregiões e estas em Mesorregiões. No Brasil, este trabalho é realizado pelo IBGE. Os municípios pertencentes a essas Microrregiões possuem certas semelhanças quanto aos seus aspectos físicos (por exemplo, relevo e clima) e sócio-econômicos. Segundo a distribuição do IBGE para o ano 2000, o estado do Espirito Santo está dividido em 4 mesorregiões (Noroeste Espírito-Santense, Litoral Norte Espírito-Santense, Central Espírito-Santense e Sul Espírito-Santense) e 13 microrregiões geográficas, contendo um total de 77 municípios. Os dados populacionais estão na tabela 5.1 e a figura 5.1 mostra as treze microrregiões do ES. A figura 5.3 mostra a distribuição da população do ES por microrrregião. Observe-se que esta não é a única classificação possível e/ou existente. Consiste em uma maneira de estruturar o espaço geográfico do Estado em unidades que possam ser observadas em suas especificidades, ou uma simples estratificação. Na verdade, nos exemplos das seções seguintes, esta estratificação é adotada apenas parcialmente. A figura 5.2 ilustra uma outra estratificação para o ES, que consiste numa agregação em seis grandes regiões. Tabela 5.1: Divisão do ES em municípios por meso e microrregiões - Censo 2000 Mesorregião Microrregião Municípios População %
1 – Barra de São Francisco 4 86.328 2,792 – Nova Venécia 6 115.028 3,72
1 – Noroeste Espirito Santense
3 – Colatina 6 185.221 5,994 – Montanha 4 50.766 1,645 – São Mateus 4 157.868 5,10
2 – Litoral Norte Espirito Santense
6 – Linhares 7 249.960 8,087 – Afonso Cláudio 7 124.531 4,038 – Santa Teresa 6 98.083 3,179 – Vitória 5 1.336.521 43,21
3 – Central Espirito Santense
10 – Guarapari 6 158.680 5,134 – Sul Espirito Santense 11 – Alegre 9 152.320 4,92
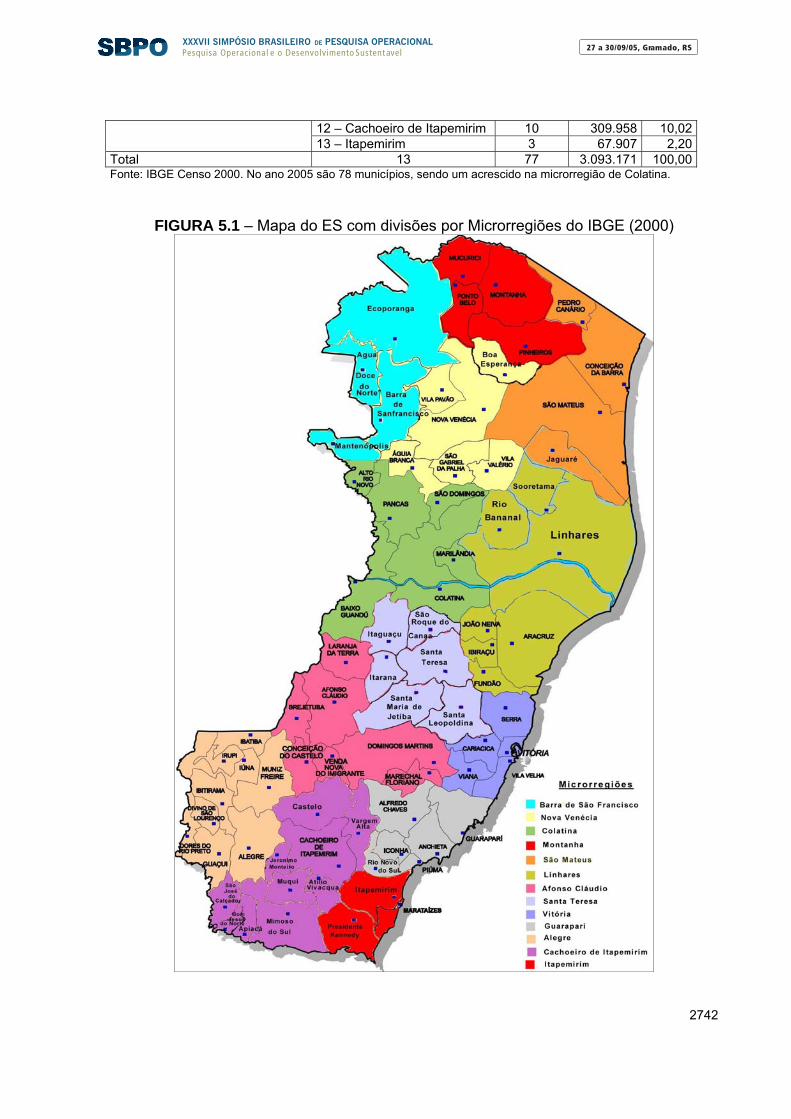
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2742
12 – Cachoeiro de Itapemirim 10 309.958 10,02 13 – Itapemirim 3 67.907 2,20
Total 13 77 3.093.171 100,00Fonte: IBGE Censo 2000. No ano 2005 são 78 municípios, sendo um acrescido na microrregião de Colatina.
FIGURA 5.1 – Mapa do ES com divisões por Microrregiões do IBGE (2000)

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2743
Figura 5.2. Grandes Regiões do Espírito Santo
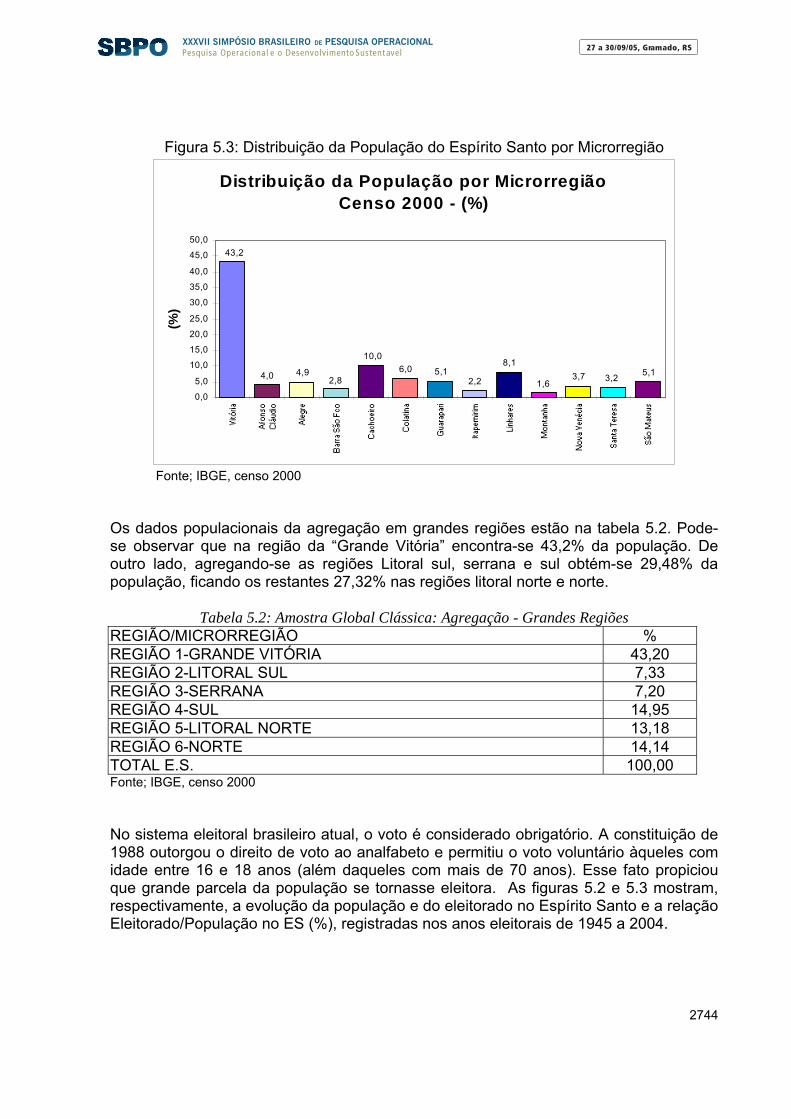
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2744
Figura 5.3: Distribuição da População do Espírito Santo por Microrregião
Distribuição da População por Microrregião Censo 2000 - (%)
5,13,23,71,6
8,1
2,25,16,0
2,84,94,0
10,0
43,2
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
40,0
45,0
50,0
(%)
Fonte; IBGE, censo 2000 Os dados populacionais da agregação em grandes regiões estão na tabela 5.2. Pode-se observar que na região da “Grande Vitória” encontra-se 43,2% da população. De outro lado, agregando-se as regiões Litoral sul, serrana e sul obtém-se 29,48% da população, ficando os restantes 27,32% nas regiões litoral norte e norte.
Tabela 5.2: Amostra Global Clássica: Agregação - Grandes Regiões REGIÃO/MICRORREGIÃO % REGIÃO 1-GRANDE VITÓRIA 43,20 REGIÃO 2-LITORAL SUL 7,33 REGIÃO 3-SERRANA 7,20 REGIÃO 4-SUL 14,95 REGIÃO 5-LITORAL NORTE 13,18 REGIÃO 6-NORTE 14,14 TOTAL E.S. 100,00 Fonte; IBGE, censo 2000 No sistema eleitoral brasileiro atual, o voto é considerado obrigatório. A constituição de 1988 outorgou o direito de voto ao analfabeto e permitiu o voto voluntário àqueles com idade entre 16 e 18 anos (além daqueles com mais de 70 anos). Esse fato propiciou que grande parcela da população se tornasse eleitora. As figuras 5.2 e 5.3 mostram, respectivamente, a evolução da população e do eleitorado no Espírito Santo e a relação Eleitorado/População no ES (%), registradas nos anos eleitorais de 1945 a 2004.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2745
Figura 5.3: Evolução da População e do Eleitorado no Espírito Santo
Evolução da População e do Eleitorado ES
3.352.024
1.700.000
1.403.0001.242.000
964.000912.000
957.000
803.000
2.743.000
1.599.0001.803.000
2.145.000
2.499.103
2.334.5462.635.307
2.895.547
3.201.722
2.236.1762.146.425
377.884
577.474307.009
122.281
180.607261.969
233.053
494.947727.735 971.658
1.159.546
1.710.729
1.423.2111.407.759
1.916.899
0
500.000
1.000.000
1.500.000
2.000.000
2.500.000
3.000.000
3.500.000
4.000.000
1945 1950 1954 1958 1962 1966 1970 1974 1978 1982 1986 1989 1990 1994 1998 2002 2004
PopulaçãoEleitorado
Fonte; IBGE, censo 2000; TSE
Figura 5.4: Evolução da relação Eleitorado/População no ES (%)
ELEITORADO / POPULAÇÃO - ES (%)
45,30
54,01
66,7167,04
40,36
49,67
56,33
66,2062,37
30,95
15,2318,87
28,7224,7224,18
26,93
33,97
0,00
10,00
20,00
30,00
40,00
50,00
60,00
70,00
80,00
1945 1947 1950 1954 1958 1962 1966 1970 1974 1978 1982 1986 1990 1994 1998 2002 2004
(%)
Eleit/Pop
Fonte; IBGE, censo 2000; TSE
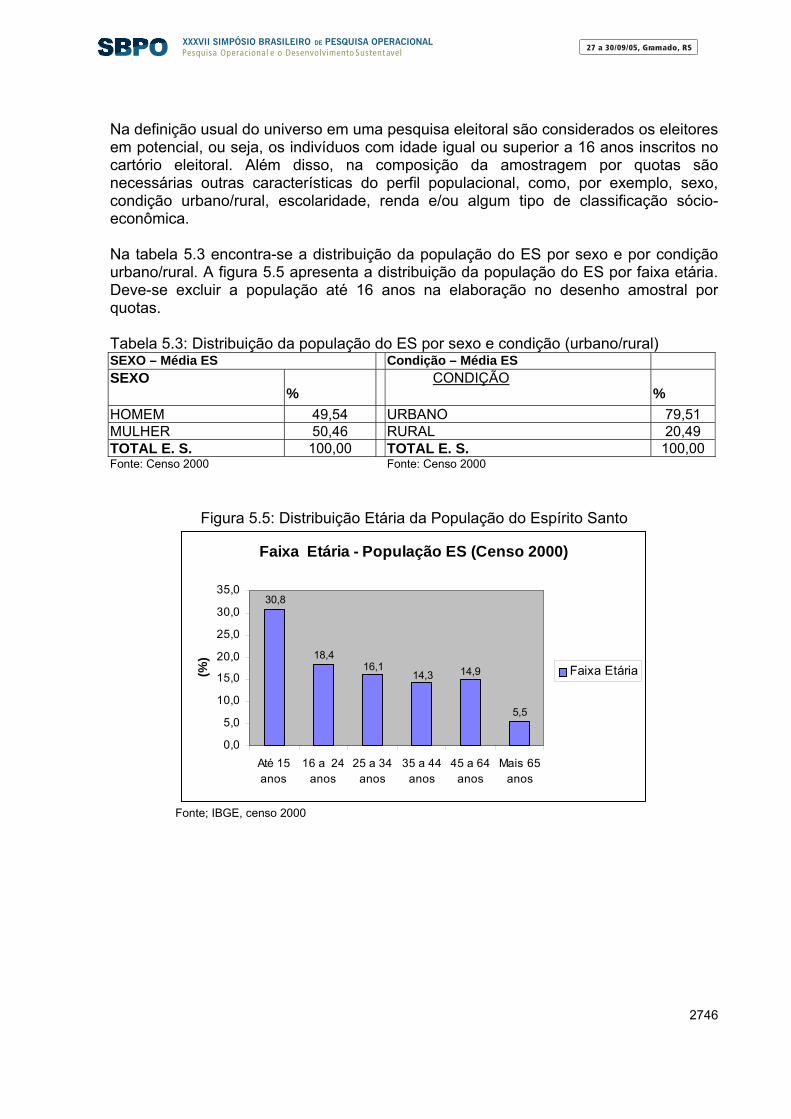
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2746
Na definição usual do universo em uma pesquisa eleitoral são considerados os eleitores em potencial, ou seja, os indivíduos com idade igual ou superior a 16 anos inscritos no cartório eleitoral. Além disso, na composição da amostragem por quotas são necessárias outras características do perfil populacional, como, por exemplo, sexo, condição urbano/rural, escolaridade, renda e/ou algum tipo de classificação sócio-econômica. Na tabela 5.3 encontra-se a distribuição da população do ES por sexo e por condição urbano/rural. A figura 5.5 apresenta a distribuição da população do ES por faixa etária. Deve-se excluir a população até 16 anos na elaboração no desenho amostral por quotas.
Tabela 5.3: Distribuição da população do ES por sexo e condição (urbano/rural) SEXO – Média ES Condição – Média ES SEXO
% CONDIÇÃO
% HOMEM 49,54 URBANO 79,51 MULHER 50,46 RURAL 20,49 TOTAL E. S. 100,00 TOTAL E. S. 100,00 Fonte: Censo 2000 Fonte: Censo 2000
Figura 5.5: Distribuição Etária da População do Espírito Santo
Faixa Etária - População ES (Censo 2000)
5,5
14,914,316,1
18,4
30,8
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
Até 15anos
16 a 24anos
25 a 34anos
35 a 44anos
45 a 64anos
Mais 65anos
(%)
Faixa Etária
Fonte; IBGE, censo 2000

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2747
5.2. Metodologia Bayesiana: Eleições de 1990 - Governo e Senado do ES Nas eleições majoritárias no ES em 1990, a emissora de TV, TV Gazeta ES, realizou uma apuração paralela do resultado. Os resultados eram enviados dos locais de contagem em todo o estado, via telefone, para uma central de apuração. Surgiu então a oportunidade de utilizar a metodologia bayesiana com os resultados dos primeiros votos apurados, mas considerando-se a seleção dos locais mais similares. Para isso, fez-se uma análise dos locais mais representativos desde 1982 e determinou-se a projeção dos resultados finais com os primeiros votos apurados. A aplicação foi descrita em Brasil e Pego e Silva (1994). 5.2.1. A Seleção dos Locais mais Representativos Nas eleições de 1990 - Governo, Senado e Câmara Federal - o Estado do Espírito Santo estava dividido em 67 municípios e 48 Zonas Eleitorais (ZE's), sendo que uma ZE podia abranger mais de um município. Optou-se por trabalhar com a unidade básica município. Cada município possui um número variado de seções (ou urnas) contendo, em média, aproximadamente 270 eleitores. O total de eleitores em todo o estado em 15/11/90 era de 1.423.211. O número de eleitores varia bastante por município; por exemplo, o município de Vitória (a capital do Estado) possuía 160.803 eleitores em 1990, enquanto que o município com menor eleitorado era Divino de São Lourenço com 2.836 eleitores. Utilizando o esquema descrito no capítulo 2, ordenamos os locais segundo a medida de divergência de Kullback-Leibler para os anos eleitorais de 1982, 1986 e 1990 onde houve eleições ao governo estadual e para 1989 onde tivemos a eleição presidencial. Para a aplicação da metodologia adotou-se o resultado de 1986 para governador. Os resultados estão na Tabela 5.4. No vetor de resultados finais utilizamos o percentual obtido por cada candidato bem como votos brancos e nulos. Os resultados ficaram praticamente inalterados quando introduzimos as abstenções. (A ordenação de 1990 foi obtida após o término das eleições). A Tabela 5.4 foi construída do seguinte modo. Os 25 municípios mais similares ao todo (estado), segundo os resultados de cada ano eleitoral, foram ordenados em ordem decrescente de similitude. Assim, o primeiro município possui maior similaridade de comportamento eleitoral com relação ao estado como um todo. O ano de 1986, por ser o mais central foi tomado como referência. Observe-se que na coluna referente a 1986 temos a ordenação 1 a 25; a seguir, para os outros anos verificou-se quais posições estes municípios ocuparam. Se o município selecionado pela ordenação não figura entre um dos 25 de 1986, fica identificado com um X. Desse modo, por exemplo, o município de número 6, foi o 60 mais similar em 1986, ficou em 230 em 1982, em 110 em 1989 e em 140 em 1990. De outro lado, o município número 2, praticamente não alterou sua posição ao longo da década.
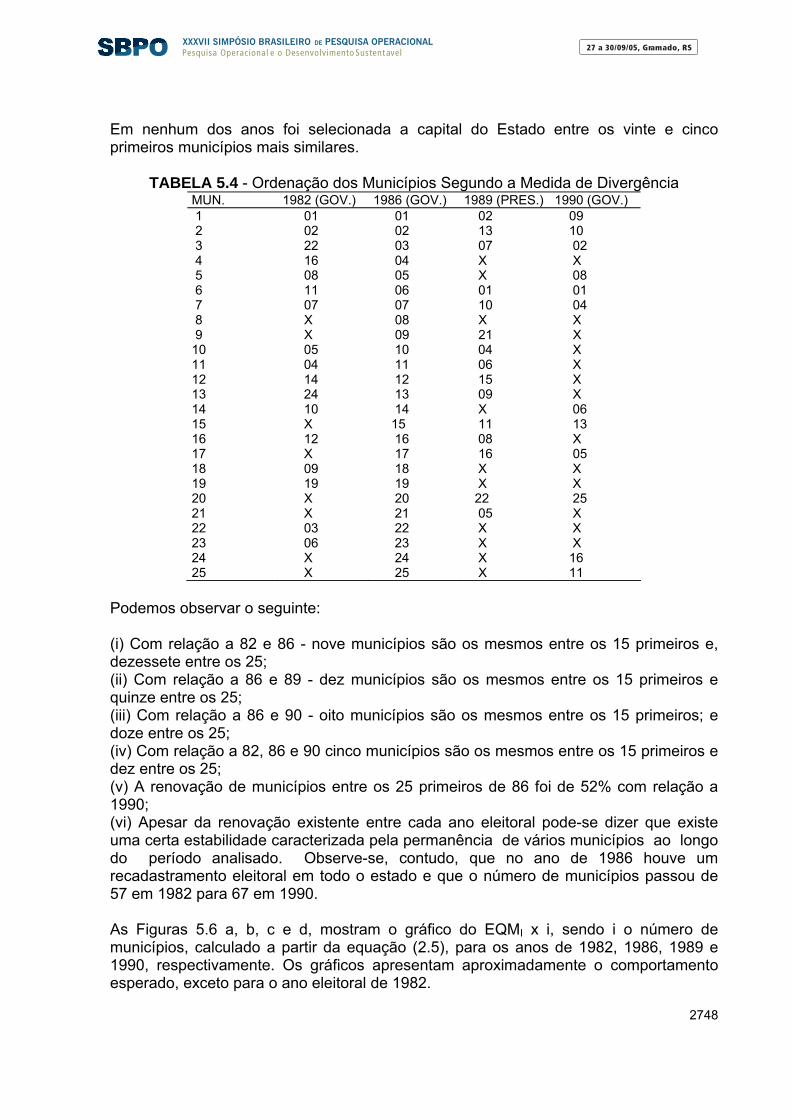
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2748
Em nenhum dos anos foi selecionada a capital do Estado entre os vinte e cinco primeiros municípios mais similares.
TABELA 5.4 - Ordenação dos Municípios Segundo a Medida de Divergência MUN. 1982 (GOV.) 1986 (GOV.) 1989 (PRES.) 1990 (GOV.) 1 01 01 02 09 2 02 02 13 10 3 22 03 07 02 4 16 04 X X 5 08 05 X 08 6 11 06 01 01 7 07 07 10 04 8 X 08 X X 9 X 09 21 X 10 05 10 04 X 11 04 11 06 X 12 14 12 15 X 13 24 13 09 X 14 10 14 X 06 15 X 15 11 13 16 12 16 08 X 17 X 17 16 05 18 09 18 X X 19 19 19 X X 20 X 20 22 25 21 X 21 05 X 22 03 22 X X 23 06 23 X X 24 X 24 X 16 25 X 25 X 11
Podemos observar o seguinte: (i) Com relação a 82 e 86 - nove municípios são os mesmos entre os 15 primeiros e, dezessete entre os 25; (ii) Com relação a 86 e 89 - dez municípios são os mesmos entre os 15 primeiros e quinze entre os 25; (iii) Com relação a 86 e 90 - oito municípios são os mesmos entre os 15 primeiros; e doze entre os 25; (iv) Com relação a 82, 86 e 90 cinco municípios são os mesmos entre os 15 primeiros e dez entre os 25; (v) A renovação de municípios entre os 25 primeiros de 86 foi de 52% com relação a 1990; (vi) Apesar da renovação existente entre cada ano eleitoral pode-se dizer que existe uma certa estabilidade caracterizada pela permanência de vários municípios ao longo do período analisado. Observe-se, contudo, que no ano de 1986 houve um recadastramento eleitoral em todo o estado e que o número de municípios passou de 57 em 1982 para 67 em 1990. As Figuras 5.6 a, b, c e d, mostram o gráfico do EQMI x i, sendo i o número de municípios, calculado a partir da equação (2.5), para os anos de 1982, 1986, 1989 e 1990, respectivamente. Os gráficos apresentam aproximadamente o comportamento esperado, exceto para o ano eleitoral de 1982.
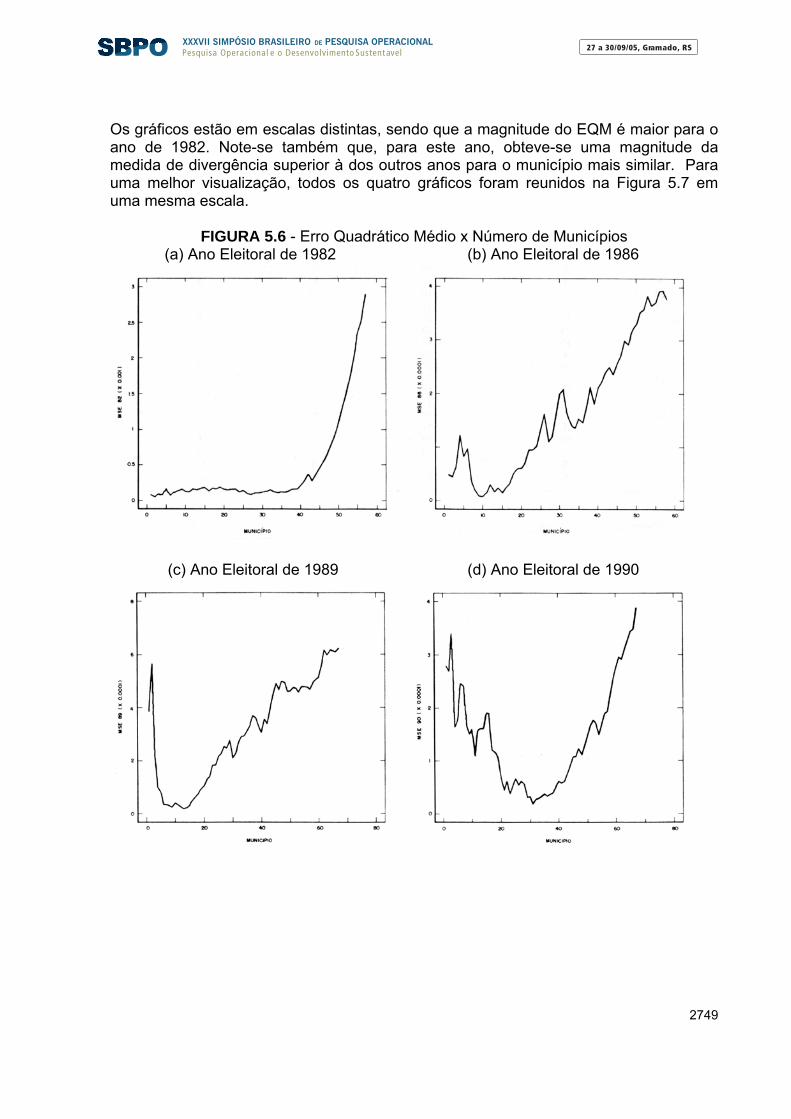
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2749
Os gráficos estão em escalas distintas, sendo que a magnitude do EQM é maior para o ano de 1982. Note-se também que, para este ano, obteve-se uma magnitude da medida de divergência superior à dos outros anos para o município mais similar. Para uma melhor visualização, todos os quatro gráficos foram reunidos na Figura 5.7 em uma mesma escala.
FIGURA 5.6 - Erro Quadrático Médio x Número de Municípios (a) Ano Eleitoral de 1982 (b) Ano Eleitoral de 1986
(c) Ano Eleitoral de 1989 (d) Ano Eleitoral de 1990
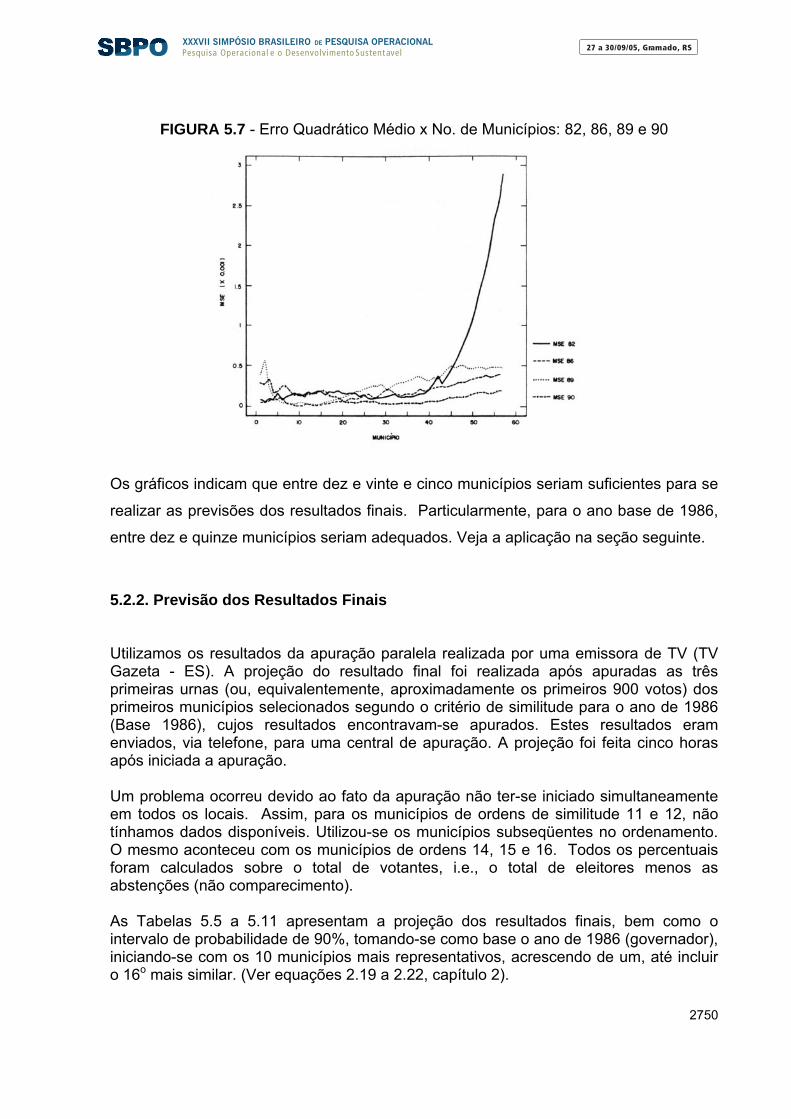
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2750
FIGURA 5.7 - Erro Quadrático Médio x No. de Municípios: 82, 86, 89 e 90
Os gráficos indicam que entre dez e vinte e cinco municípios seriam suficientes para se
realizar as previsões dos resultados finais. Particularmente, para o ano base de 1986,
entre dez e quinze municípios seriam adequados. Veja a aplicação na seção seguinte.
5.2.2. Previsão dos Resultados Finais Utilizamos os resultados da apuração paralela realizada por uma emissora de TV (TV Gazeta - ES). A projeção do resultado final foi realizada após apuradas as três primeiras urnas (ou, equivalentemente, aproximadamente os primeiros 900 votos) dos primeiros municípios selecionados segundo o critério de similitude para o ano de 1986 (Base 1986), cujos resultados encontravam-se apurados. Estes resultados eram enviados, via telefone, para uma central de apuração. A projeção foi feita cinco horas após iniciada a apuração. Um problema ocorreu devido ao fato da apuração não ter-se iniciado simultaneamente em todos os locais. Assim, para os municípios de ordens de similitude 11 e 12, não tínhamos dados disponíveis. Utilizou-se os municípios subseqüentes no ordenamento. O mesmo aconteceu com os municípios de ordens 14, 15 e 16. Todos os percentuais foram calculados sobre o total de votantes, i.e., o total de eleitores menos as abstenções (não comparecimento). As Tabelas 5.5 a 5.11 apresentam a projeção dos resultados finais, bem como o intervalo de probabilidade de 90%, tomando-se como base o ano de 1986 (governador), iniciando-se com os 10 municípios mais representativos, acrescendo de um, até incluir o 16o mais similar. (Ver equações 2.19 a 2.22, capítulo 2).
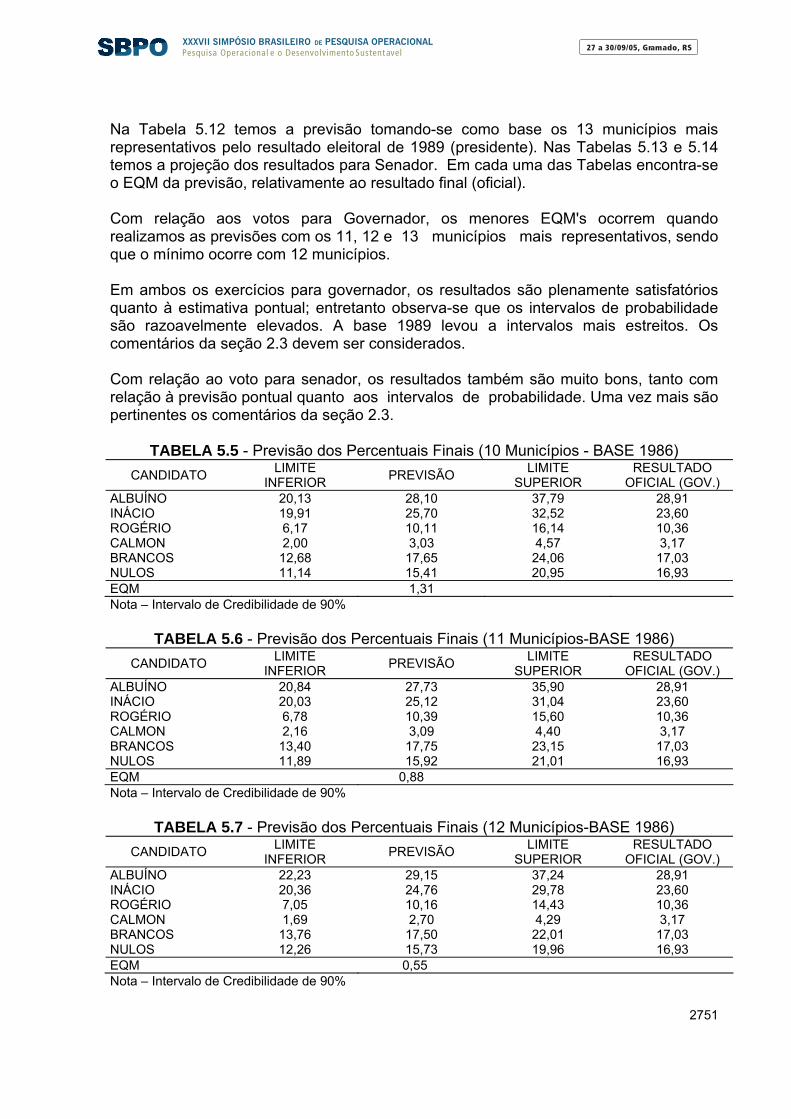
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2751
Na Tabela 5.12 temos a previsão tomando-se como base os 13 municípios mais representativos pelo resultado eleitoral de 1989 (presidente). Nas Tabelas 5.13 e 5.14 temos a projeção dos resultados para Senador. Em cada uma das Tabelas encontra-se o EQM da previsão, relativamente ao resultado final (oficial). Com relação aos votos para Governador, os menores EQM's ocorrem quando realizamos as previsões com os 11, 12 e 13 municípios mais representativos, sendo que o mínimo ocorre com 12 municípios. Em ambos os exercícios para governador, os resultados são plenamente satisfatórios quanto à estimativa pontual; entretanto observa-se que os intervalos de probabilidade são razoavelmente elevados. A base 1989 levou a intervalos mais estreitos. Os comentários da seção 2.3 devem ser considerados. Com relação ao voto para senador, os resultados também são muito bons, tanto com relação à previsão pontual quanto aos intervalos de probabilidade. Uma vez mais são pertinentes os comentários da seção 2.3.
TABELA 5.5 - Previsão dos Percentuais Finais (10 Municípios - BASE 1986)
CANDIDATO LIMITE INFERIOR PREVISÃO LIMITE
SUPERIOR RESULTADO
OFICIAL (GOV.) ALBUÍNO 20,13 28,10 37,79 28,91 INÁCIO 19,91 25,70 32,52 23,60 ROGÉRIO 6,17 10,11 16,14 10,36 CALMON 2,00 3,03 4,57 3,17 BRANCOS 12,68 17,65 24,06 17,03 NULOS 11,14 15,41 20,95 16,93 EQM 1,31 Nota – Intervalo de Credibilidade de 90%
TABELA 5.6 - Previsão dos Percentuais Finais (11 Municípios-BASE 1986) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 20,84 27,73 35,90 28,91 INÁCIO 20,03 25,12 31,04 23,60 ROGÉRIO 6,78 10,39 15,60 10,36 CALMON 2,16 3,09 4,40 3,17 BRANCOS 13,40 17,75 23,15 17,03 NULOS 11,89 15,92 21,01 16,93 EQM 0,88 Nota – Intervalo de Credibilidade de 90%
TABELA 5.7 - Previsão dos Percentuais Finais (12 Municípios-BASE 1986) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 22,23 29,15 37,24 28,91 INÁCIO 20,36 24,76 29,78 23,60 ROGÉRIO 7,05 10,16 14,43 10,36 CALMON 1,69 2,70 4,29 3,17 BRANCOS 13,76 17,50 22,01 17,03 NULOS 12,26 15,73 19,96 16,93 EQM 0,55 Nota – Intervalo de Credibilidade de 90%

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2752
TABELA 5.8 - Previsão dos Percentuais Finais (13 Municípios-BASE 1986) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 23,51 30,06 37,58 28,91 INÁCIO 20,04 24,09 28,68 23,60 ROGÉRIO 7,48 10,27 13,94 10,36 CALMON 1,84 2,78 4,19 3,17 BRANCOS 13,95 17,24 21,13 17,03 NULOS 12,52 15,55 19,17 16,93 EQM 0,61 Nota – Intervalo de Credibilidade de 90%
TABELA 5.9 - Previsão dos Percentuais Finais (14 Municípios-BASE 1986) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 24,03 30,28 37,41 28,91 INÁCIO 20,52 25,27 30,72 23,60 ROGÉRIO 7,49 10,13 13,57 10,36 CALMON 1,63 2,56 3,99 3,17 BRANCOS 13,64 16,85 20,64 17,03 NULOS 11,76 14,91 18,73 16,93 EQM 1,53 Nota – Intervalo de Credibilidade de 90%
TABELA 5.10 - Previsão dos Percentuais Finais (15 Municípios-Base 1986) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 24,32 29,69 35,72 28,91 INÁCIO 21,40 25,51 30,13 23,60 ROGÉRIO 7,94 10,25 13,14 10,36 CALMON 1,73 2,52 3,67 3,17 BRANCOS 14,31 17,20 20,53 17,03 NULOS 12,14 14,82 17,98 16,93 EQM 1,53 Nota – Intervalo de Credibilidade de 90% TABELA 5.11 - Previsão dos Percentuais Finais (16 Municípios-BASE 1986)
CANDIDATO LIMITE INFERIOR PREVISÃO LIMITE
SUPERIOR RESULTADO
OFICIAL (GOV.) ALBUÍNO 24,72 29,62 35,06 28,91 INÁCIO 21,61 25,35 29,52 23,60 ROGÉRIO 8,15 10,27 12,87 10,36 CALMON 1,70 2,42 3,44 3,17 BRANCOS 14,51 17,14 20,15 17,03 NULOS 12,57 15,19 18,25 16,93 EQM 1,20 Nota – Intervalo de Credibilidade de 90%
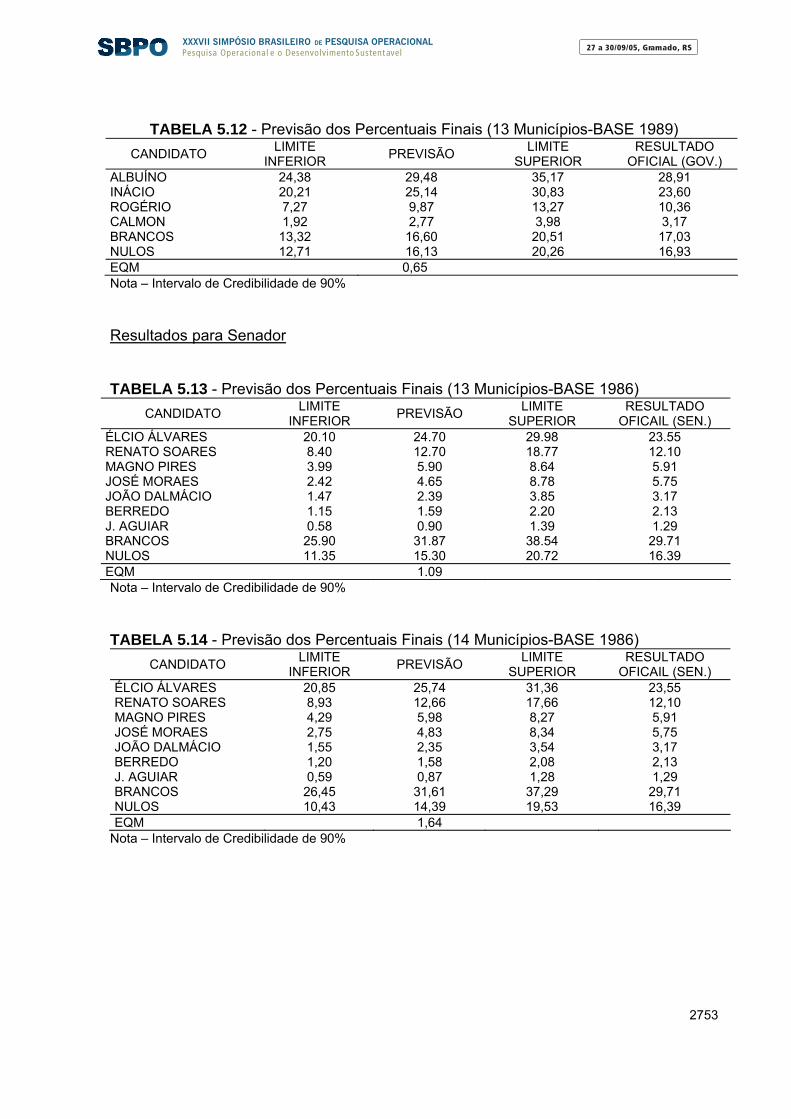
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2753
TABELA 5.12 - Previsão dos Percentuais Finais (13 Municípios-BASE 1989) CANDIDATO LIMITE
INFERIOR PREVISÃO LIMITE SUPERIOR
RESULTADO OFICIAL (GOV.)
ALBUÍNO 24,38 29,48 35,17 28,91 INÁCIO 20,21 25,14 30,83 23,60 ROGÉRIO 7,27 9,87 13,27 10,36 CALMON 1,92 2,77 3,98 3,17 BRANCOS 13,32 16,60 20,51 17,03 NULOS 12,71 16,13 20,26 16,93 EQM 0,65 Nota – Intervalo de Credibilidade de 90% Resultados para Senador TABELA 5.13 - Previsão dos Percentuais Finais (13 Municípios-BASE 1986)
CANDIDATO LIMITE INFERIOR PREVISÃO LIMITE
SUPERIOR RESULTADO
OFICAIL (SEN.) ÉLCIO ÁLVARES 20.10 24.70 29.98 23.55 RENATO SOARES 8.40 12.70 18.77 12.10 MAGNO PIRES 3.99 5.90 8.64 5.91 JOSÉ MORAES 2.42 4.65 8.78 5.75 JOÃO DALMÁCIO 1.47 2.39 3.85 3.17 BERREDO 1.15 1.59 2.20 2.13 J. AGUIAR 0.58 0.90 1.39 1.29 BRANCOS 25.90 31.87 38.54 29.71 NULOS 11.35 15.30 20.72 16.39 EQM 1.09 Nota – Intervalo de Credibilidade de 90% TABELA 5.14 - Previsão dos Percentuais Finais (14 Municípios-BASE 1986)
CANDIDATO LIMITE INFERIOR PREVISÃO LIMITE
SUPERIOR RESULTADO
OFICAIL (SEN.) ÉLCIO ÁLVARES 20,85 25,74 31,36 23,55 RENATO SOARES 8,93 12,66 17,66 12,10 MAGNO PIRES 4,29 5,98 8,27 5,91 JOSÉ MORAES 2,75 4,83 8,34 5,75 JOÃO DALMÁCIO 1,55 2,35 3,54 3,17 BERREDO 1,20 1,58 2,08 2,13 J. AGUIAR 0,59 0,87 1,28 1,29 BRANCOS 26,45 31,61 37,29 29,71 NULOS 10,43 14,39 19,53 16,39 EQM 1,64
Nota – Intervalo de Credibilidade de 90%

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2754
5.2.3. Considerações Finais ao Estudo de Caso 5.2 Neste exercício adotou-se a metodologia descrita no capítulo 2 para elaboração de um plano amostral baseado na seleção dos "locais de votação mais representativos" de uma região estudada, como proposto por Bernardo (1984). Introduziu-se também um procedimento heurístico para a escolha do número de locais a serem pesquisados, e realizou-se uma aplicação completa, incluindo a previsão dos resultados finais, a partir dos primeiros votos apurados. Os resultados preditivos foram satisfatórios em termos de previsão pontual. Quanto à estabilidade do comportamento eleitoral, relativamente aos locais escolhidos através da medida de divergência de Kullback-Leibler, pode-se verificar que existe estabilidade no período estudado (1982-1990) pelo menos no sentido de que vários municípios permanecem os mesmos entre os 25 primeiros ordenados decrescentemente segundo a medida utilizada. Isso tudo a despeito de ter havido um recadastramento eleitoral no ano de 1986, que causou algum tipo de reordenação na distribuição do eleitorado no estado e, da criação de dez novos municípios no período. A hipótese de “exchangeability” pertinente à análise bayesiana funcionou razoavelmente bem. Observe-se que o número médio de votos existentes em cada uma das três primeiras urnas foi de aproximadamente 300. Estas três primeiras urnas poderiam ser quaisquer dentro dos municípios selecionados; além disso, deveriam apresentar a variabilidade existente em todo o município. O procedimento sugerido para a escolha do número de locais parece adequado e funcionou muito bem na aplicação particular. Pode-se dizer que existe uma certa "robustez" em toda a metodologia visto que, mesmo não se respeitando inteiramente a ordem de similitude dos locais a partir do 110, em virtude da indisponibilidade de dados, os resultados ainda continuaram razoáveis. Observe-se, contudo, que, na aplicação, os dez municípios mais similares tiveram dados disponíveis. No apêndice a esta seção, pode-se verificar que o total de votos nas seções de cada um dos municípios selecionados variou de 611 a 1294, violando a condição de que deveriam ser aproximadamente os mesmos. No entanto, mesmo assim os resultados foram satisfatórios. Quanto aos aspectos preditivos, em termos globais, os resultados foram plenamente
satisfatórios, o que se comprova pela pequena magnitude do erro quadrático médio nas
Tabelas 5.6 a 5.14. A estimativa pontual foi muito boa em todos os casos, apresentando
apenas altos intervalos de probabilidade o que deveu-se principalmente à dispersão
dos resultados em cada local selecionado.
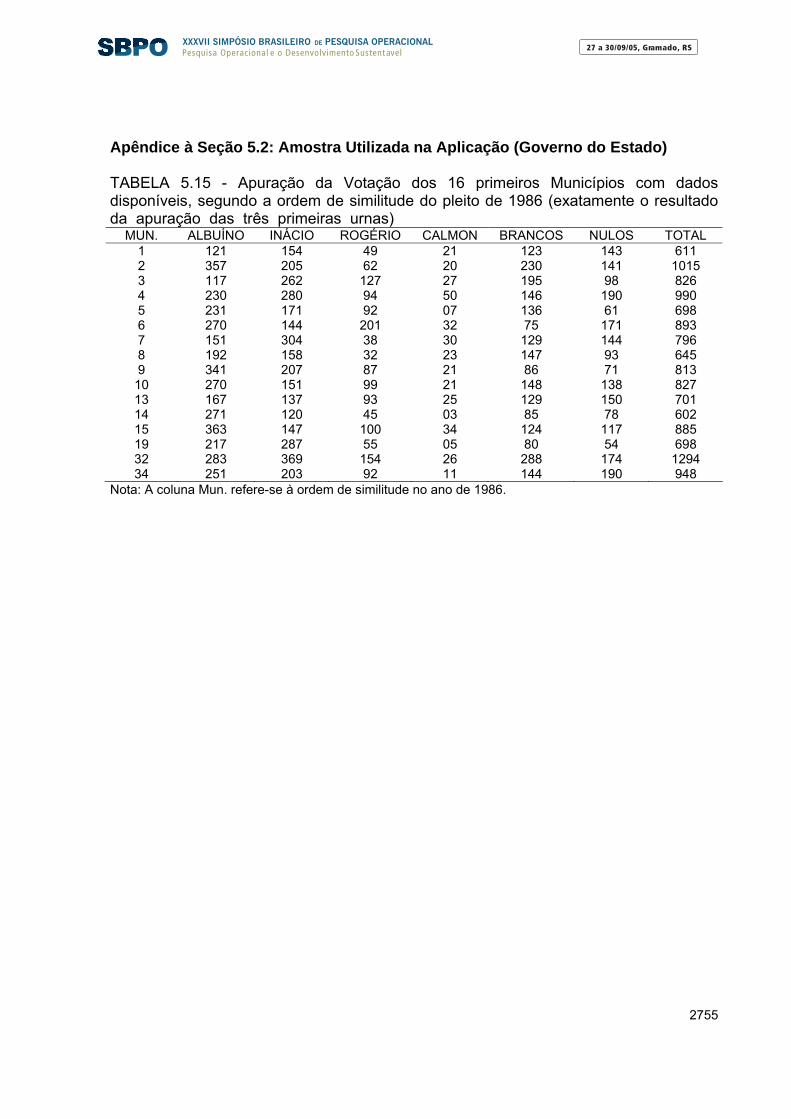
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2755
Apêndice à Seção 5.2: Amostra Utilizada na Aplicação (Governo do Estado) TABELA 5.15 - Apuração da Votação dos 16 primeiros Municípios com dados disponíveis, segundo a ordem de similitude do pleito de 1986 (exatamente o resultado da apuração das três primeiras urnas)
MUN. ALBUÍNO INÁCIO ROGÉRIO CALMON BRANCOS NULOS TOTAL 1 121 154 49 21 123 143 611 2 357 205 62 20 230 141 1015 3 117 262 127 27 195 98 826 4 230 280 94 50 146 190 990 5 231 171 92 07 136 61 698 6 270 144 201 32 75 171 893 7 151 304 38 30 129 144 796 8 192 158 32 23 147 93 645 9 341 207 87 21 86 71 813 10 270 151 99 21 148 138 827 13 167 137 93 25 129 150 701 14 271 120 45 03 85 78 602 15 363 147 100 34 124 117 885 19 217 287 55 05 80 54 698 32 283 369 154 26 288 174 1294 34 251 203 92 11 144 190 948
Nota: A coluna Mun. refere-se à ordem de similitude no ano de 1986.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2756
5.3. Monitoramento de Eleições Municipais no Município de Guarapari/ES – 1992 – Metodologias “Clássica e Bayesiana” Usualmente em uma pesquisa eleitoral, são avaliados os seguintes grupos de questões: (1) perfil sócio-econômico do entrevistado (sexo, faixa etária, classe social, renda, etc); (2) perfil político (simpatia por partidos, voto na ultima eleição, avaliação das administrações, etc); (3) atitudes e preferências políticas (voto espontâneo, voto estimulado, avaliação dos índices de rejeição dos candidatos, avaliação das preferências por chapas simuladas, principais lideranças políticas, etc) e, (4) avaliação dos temas julgados mais importantes pelos eleitores (medição do alcance da publicidade, penetração da mensagem eleitoral, etc). Neste monitoramento eleitoral, realizado através de cinco pesquisas de opinião, todas estas questões e outras mais, foram avaliadas, o que propiciou um bom direcionamento da campanha por parte dos estrategistas de marketing. Do ponto de vista da amostragem estatística utilizamos os dois desenhos amostrais de natureza bastante distinta descritos no capítulo 2. Com o desenho da amostragem bayesiana pode-se fazer uma checagem propiciando maior confiabilidade nos resultados da pesquisa. Brasil, Macedo, Pego e Silva e Dos Anjos (1993). 5.3.1. Os Desenhos Amostrais A amostragem "clássica" adotada foi suficientemente descrita no capítulo 1; ver por exemplo, Raj (1972), Cochran (1977), Barnett (1991). Apresentamos aqui apenas uma breve descrição do procedimento adotado. De acordo com os dados censitários disponíveis (Censo-1991), a população residente no município de Guarapari era de 61.597 habitantes, sendo 39.794 eleitores, segundo o Tribunal Regional Eleitoral. Para a amostragem clássica, o município foi dividido em 11 áreas, sendo 10 urbanas perfazendo 86,3% do eleitorado e, uma interiorana, com 13,7% do eleitorado, predominantemente rural. Adotou-se uma amostragem aleatória estratificada por microrregiões (áreas) com controle de quotas, abrangendo sexo, faixa etária e classificação sócio-econômica (critério ABA-ABIPEME). Observe-se que essas microrregiões de Guarapari são compostas por bairros geograficamente próximos, e possuem, aparentemente, uma razoável homogeneidade quanto à população residente. A amostra foi dimensionada utilizando-se as relações usuais adotando-se um intervalo de confiança de 95%. Os pesos de cada microrregião foram estabelecidos segundo o peso eleitoral correspondente, utilizando-se para isso os dados do cadastro eleitoral do TRE. Todas as Microrregiões (áreas) foram consideradas como auto-representativas, i.e., com probabilidade igual a 1 de pertencerem à amostra (na microrregião Interior, de difícil acesso, as entrevistas foram concentradas em cinco locais). Desse modo a amostra foi dimensionada para um total de 590 entrevistas conduzindo a um erro amostral de 4,0%.
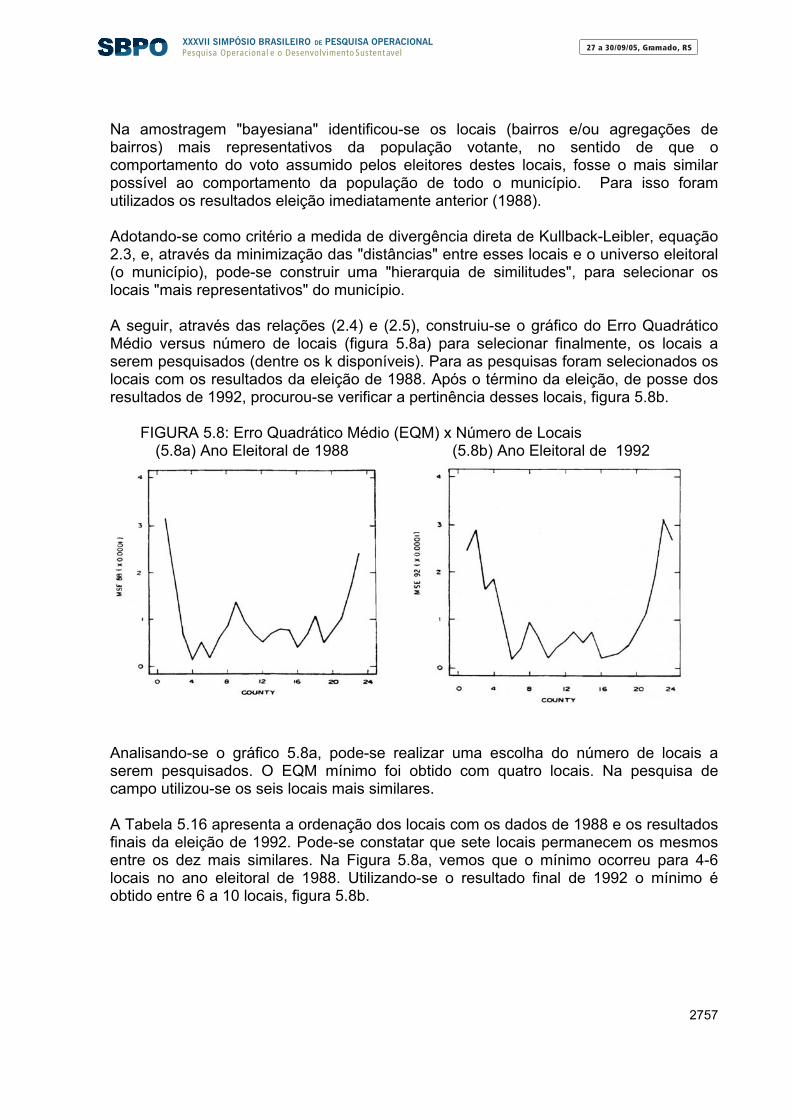
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2757
Na amostragem "bayesiana" identificou-se os locais (bairros e/ou agregações de bairros) mais representativos da população votante, no sentido de que o comportamento do voto assumido pelos eleitores destes locais, fosse o mais similar possível ao comportamento da população de todo o município. Para isso foram utilizados os resultados eleição imediatamente anterior (1988). Adotando-se como critério a medida de divergência direta de Kullback-Leibler, equação 2.3, e, através da minimização das "distâncias" entre esses locais e o universo eleitoral (o município), pode-se construir uma "hierarquia de similitudes", para selecionar os locais "mais representativos" do município. A seguir, através das relações (2.4) e (2.5), construiu-se o gráfico do Erro Quadrático Médio versus número de locais (figura 5.8a) para selecionar finalmente, os locais a serem pesquisados (dentre os k disponíveis). Para as pesquisas foram selecionados os locais com os resultados da eleição de 1988. Após o término da eleição, de posse dos resultados de 1992, procurou-se verificar a pertinência desses locais, figura 5.8b. FIGURA 5.8: Erro Quadrático Médio (EQM) x Número de Locais
(5.8a) Ano Eleitoral de 1988 (5.8b) Ano Eleitoral de 1992
Analisando-se o gráfico 5.8a, pode-se realizar uma escolha do número de locais a serem pesquisados. O EQM mínimo foi obtido com quatro locais. Na pesquisa de campo utilizou-se os seis locais mais similares. A Tabela 5.16 apresenta a ordenação dos locais com os dados de 1988 e os resultados finais da eleição de 1992. Pode-se constatar que sete locais permanecem os mesmos entre os dez mais similares. Na Figura 5.8a, vemos que o mínimo ocorreu para 4-6 locais no ano eleitoral de 1988. Utilizando-se o resultado final de 1992 o mínimo é obtido entre 6 a 10 locais, figura 5.8b.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2758
Desse modo, para o município de Guarapari optou-se por realizar, por razões de custo, aproximadamente 40 entrevistas nos seis locais mais similares, totalizando uma amostra de 240 indivíduos. Para a pesquisa de "boca-de-urna" a amostra foi de aproximadamente 50 entrevistas em cada um dos seis locais. Observe-se que foram selecionados os locais de acordo com o resultado de 1988 (Figura 5.8a). TABELA 5.16 – Ordenação dos Locais Segundo a Medida de Divergência
LOCAL 1988 1992 1 1 4 2 2 X 3 3 X 4 4 10 5 5 8 6 6 2 7 7 1 8 9 7 9 9 X 10 10 3
5.3.2. Monitoramento: Resultados das Pesquisas A Tabela 5.17 sintetiza as pesquisas realizadas com as duas metodologias expostas. As datas de realização das pesquisas foram decididas pelo cliente. As Figuras 5.9 e 5.10 apresentam a evolução do voto ao longo do período monitorado, menção espontânea e estimulada (por cédula eleitoral), respectivamente; contém também o percentual de indecisos. TABELA 5.17: Pesquisas Realizadas – Datas e Tamanhos Amostrais
METODOLOGIA SET./1991 MAR./1992 AG./1992 SET./1992 OUT./1992 BOCA-URNA
CLÁSSICA 520 592 593 593 ------- BAYESIANA ----- ------ 266 236 311 Os gráficos não incluem votos brancos e nulos e outros candidatos com baixa intenção
de voto, ou mesmo em evidência em diferentes pontos da campanha. Observa-se o
decréscimo do percentual de indecisos ao longo do período de um ano, até as eleições
em 03/10/1992. Figuras contendo o percentual de "outros candidatos" (não
apresentadas) podem ilustrar acontecimentos e atitudes tomadas ao longo da
campanha. Por exemplo, o acentuado decréscimo do percentual de "outros candidatos"
da pesquisa de setembro/91 para março/92, deve-se ao fato de a pesquisa ter
indicado que um dos candidatos deveria abrir mão da candidatura em favor da
candidata que consagrou-se vencedora no pleito de 03 de outubro de 1992. A
transferência do voto detectada em uma pesquisa foi confirmada na seguinte.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2759
FIGURA 5.9 – Evolução da Intenção de Voto - Espontâneo (Incluindo Indecisos)
Evolução da Intenção de VotoGuarapari - 1992 - Espontâneo
31,0
34,7
44,4
5,07,1
34,5
2,0 2,0
10,57,3
23,4
46,0
39,9
16,214,3
6,4
36,0 35,0
30,5
0,0
10,0
20,0
30,0
40,0
50,0
set/91 mar/92 ago/92 set/92 Out - 92 (TRE)
(%)
MorenaPaulo B.Hugo B.Indecisos
FIGURA 5.10: Evolução da Intenção de Voto – Estimulado (Incluindo indecisos)
Evolução da Intenção de VotoGuarapari - 1992 - Estimulado
37,0
44,4
34,5
15,0
50,950,5
48,5
7,0
19,417,7
10,5
4,0 3,57,38,3
12,810,514,5
9,4
0,0
10,0
20,0
30,0
40,0
50,0
60,0
set/91 mar/92 ago/92 set/92 Out - 92 (TRE)
MorenaPaulo B.Hugo B.Indecisos
Base: Total de eleitores
A Tabela 5.18 apresenta resultados típicos da comparação das duas metodologias, caso de Tabelas de frequências globais, para as pesquisas realizadas em setembro/92. Os resultados são aproximados, a despeito dos tamanhos das amostras utilizados (bem menor no caso bayesiano); ver a tabela 5.17. As Tabelas 5.19 e 5.20 apresentam alguns resultados de cruzamentos entre variáveis. Outras tabelas cruzadas de características globais de toda a região sendo pesquisada, não apresentadas, também são similares. Observe que no procedimento bayesiano não existe controle de cotas, e o perfil de classe e outras variáveis não precisa necessariamente aproximar o da população.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2760
TABELA 5.18 – Comparação de Resultados das Duas Metodologias – Tabelas de Freqüência (Setembro/1992)
CANDIDATO
CANDIDATO DE PREFERÊNCIA (RESPOSTA ESTIMULADA)
CLÁSSICA BAYESIANA
REJEIÇÃO DO VOTO (RESPOSTA ESTIMULADA)
CLÁSSICA BAYESIANA OLGA V. 0,8 0,8 10,8 16,5 PAULO B. 19,4 23,3 16,4 17,8 HUGO B. 8,3 7,6 14,5 13,1 D. GOTARDO 2,7 2,5 7,1 4,7 MORENA 50,9 52,1 13,0 16,5 BRANCO/NULO 7,5 5,5 5,9 3,8 NÃO SABE/NR 10,4 8,2 33,2 27,5 TOTAL 100,0 100,0 100,0 100.0 Um resultado bastante interessante foi com relação à questão: "Qual o seu candidato a vereador?" Parece anti-intuitivo que as preferências dos eleitores fiquem sequer parecidas relativamente aos dois procedimentos amostrais. No entanto, não foi esse o caso. Na pesquisa de agosto de 1992, por exemplo, dentre os 12 candidatos a vereador mais mencionados em ambas as pesquisas, nove foram coincidentes.
TABELA 5.19: Candidato de Preferência (Espontâneo) X Classe Social Amostra Clássica - (Setembro/1992)
COL PCT CANDIDATO AB C DE ROW
TOTAL OLGA 0.0 0.0 1.1 0.7 PAULO B. 16.1 12.3 17.9 16.2 HUGO B. 3.4 7.1 6.8 6.4 D. GOTARDO 2.3 1.3 2.0 1.9 MORENA 57.5 56.1 38.7 46.0 BRANCO-NULO 9.1 9.1 2.8 5.4 NÃO SABE/NR 11.5 14.2 30.5 23.4 COLUMN TOTAL
14.7
26.1
59.2
100.0
TABELA 5.20: Candidato de Preferência (Espontâneo) X Classe Social
Amostra Bayesiana - (Setembro/1992) COL PCT CANDIDATO AB C DE ROW
TOTAL OLGA 0.0 0.0 2.1 1.3 PAULO B. 27.8 20.0 15.7 18.6 HUGO B. 5.6 6.7 7.1 6.8 D. GOTARDO 1.7 1.4 1.3 MORENA 47.2 51.7 42.1 45.3 BRANCO-NULO 8.3 6.7 1.4 3.8 NÃO SABE/NR 11.1 13.3 30.0 22.9 COLUMN TOTAL
15.3
25.4
59.3
100.0
Resta apresentar a pesquisa de "boca-de-urna" realizada via metodologia bayesiana. Aproximadamente cinqüenta entrevistas foram efetivadas em cada um dos seis locais similares. As entrevistas ocorreram no período de 08 às 10 horas da manhã. Um controle de quotas pouco rigoroso foi realizado (sexo e idade). Observou-se, contudo, um alto índice de não-respostas (16.7%), i.e. de indivíduos

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2761
que não declaravam ao pesquisador o seu voto após depositá-lo na urna. A solução adotada foi a substituição do entrevistado. A Tabela 5.21 mostra os resultados. TABELA 5.20: Previsão dos Resultados Finais – Pesquisa de Boca-de-Urna CANDIDATO OLGA V. PAULO B. HUGO B. GOTARDO MORENA BR/NU TOT. BOCA DE URNA 1.0 36.5 6.8 2.9 49.2 3.6 100.0 RESULTADO 0.9 34.5 7.3 3.7 44.4 9.2 100.0 OBS: Percentuais calculados sobre o total de votantes O intervalo de probabilidade de 90% para a candidata vencedora ficou em: (38,03 – 60,41), o qual e bastante amplo; mas é devido ao fato do exíguo número de graus de liberdade decorrente do pequeno número de locais selecionados. Ver os comentários apresentados em Brasil & Pego e Silva (1993). 5.3.2. Discussão do Estudo de Caso 5.3 Nesta aplicação foram adotadas duas metodologias com características distintas e que encerram um alto grau de completitude, pelo menos no sentido de servir aos propósitos descritos na introdução ao exercício. A metodologia bayesiana apresentou resultados bastante similares à metodologia clássica, a despeito do tamanho da amostra pesquisada ser bem menor. Isso comprova que esta metodologia é muito boa quanto se trata de captar características globais de toda a região sendo pesquisada, no caso, o município. Quando houver interesse em atuar em áreas específicas, por exemplo, a metodologia clássica parece ser mais adequada. Analisando-se as Figuras 5.9 e 5.10 e, considerando-se que houve um processo de
"impeachment" presidencial próximo a data das eleições, observa-se claramente a
necessidade de estender-se o período de acompanhamento das pesquisas até pelo
menos uma semana antes do pleito, dada a volatilidade de uma parcela do
eleitorado.
A pesquisa de "boca-de-urna" conduzida de acordo com a metodologia bayesiana apresentou resultados satisfatórios, na medida em que acertou a ordem e a magnitude do percentual de votos de todos os candidatos. Entretanto, acreditamos que os resultados poderiam ter sido melhores caso o período das entrevistas fosse ampliado e se houvesse um tratamento adequado (algo muito difícil) das não-respostas que ocorreram em número excessivo. Apesar do método adotar a hipótese de permutabilidade (exchangeability) entre as diversas seções e entre os indivíduos de cada seção, um controle de quotas parece ter contribuído para a qualidade dos resultados. Existe um compromisso entre o número de locais selecionados e o número de candidatos disputando o pleito, pois isso influi na determinação dos graus de liberdade e, consequentemente, nos intervalos de probabilidade. Desse modo, o número de locais a serem pesquisados também deve ser controlado pela quantidade de candidatos disputando o pleito, para garantir os graus de liberdade necessários à determinação dos intervalos de probabilidade para as previsões.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2762
5.4. Eleições Municipais no Município da Serra/ES – 1996 – Metodologias “Clássica e Bayesiana” Neste exercício apresentam-se os resultados do monitoramento de uma campanha no município da Serra na região metropolitana de Vitória, ES. Foram realizadas várias pesquisas eleitorais durante os quatro meses que antecederam as eleições municipais para Prefeito da Serra-ES, em 03/10/96. Como se observa na Tabela 5.21, a metodologia bayesiana foi utilizada apenas para monitorar a intenção de voto, considerando seu custo ser substancialmente reduzido. Tabela 5.21: Pesquisas Realizadas–Datas e Tamanhos Amostrais – Serra/ES- 1996
PESQUISAS 26-28/Julho/96 17/ Agosto/96 30-31/Agosto/96 21/Setembro/96 03/Outubro/96 Clássica (705) -------------- Clássica (704) ----------- Eleições
Bayesiana (218) Bayesiana (241) -------------- Bayesiana (240) (...) Tamanho da amostra entre parênteses. Em abril de 1996 a população do município era de 266.851 habitantes e 141.000 eleitores. Outras características demográficas também foram usadas para implementar o plano amostral, através do controle de cotas. Observe-se que as duas pesquisas Bayesianas, de menor custo, foram utilizadas apenas para monitoramento da campanha. Nas pesquisas “clássicas”, optou-se por trabalhar com amostragem aleatória estratificada por áreas constituídas por agregações de bairros geograficamente próximos. Isto também facilita o planejamento da campanha. Por exemplo, na pesquisa realizada em 26-28 de julho de 1996, via amostragem “clássica”, a estratificação adotada está na Tabela 5.22. O município foi dividido em onze áreas. A área “rural” foi excluída do levantamento, sendo a pesquisa realizada nas 10 áreas urbanas. Cada uma das dez áreas foi constituída por bairros geograficamente contíguos. Exemplificando, a área “Centro/Sede” foi composta pelos bairros: Centro/sede, Jardim da Serra,São Judas Tadeu, Santo Antônio, Cascata, Jardim Bela Vista, São Domingos, Jardim Primavera e Jardim Guanabara. De modo geral, dentro de cada área, a amostra foi dimensionada de acordo com o peso populacional. Como mencionado, para fins da estratificação o município foi dividido em 10 áreas. A amostra foi dimensionada adotando-se um intervalo de confiança de 95%. Os pesos de cada uma das 10 áreas foram estabelecidos segundo o peso populacional correspondente. Todas as áreas foram consideradas como autorepresentativas, i.e., com probabilidade 1 de pertencer à amostra. Observe-se que, agregadamente, o plano amostral é similar se utilizarmos o peso eleitoral. Desse modo, a amostra realizada foi de 705 eleitores conduzindo a um erro amostral máximo de 3,7%. Em resumo, isso significa que, se tomássemos 100 amostras com a mesma metodologia, em 95 delas os resultados estariam dentro da

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2763
margem de erro prevista de mais ou menos 3,7%, considerando-se como universo o município da Serra. As inferências por área devem ser consideradas apenas informativamente, uma vez que o erro amostral aumenta consideravelmente (da ordem do dobro do erro para o universo considerado: o município). TABELA 5.22: Resumo - áreas e participação populacional – Serra 1996 V1 ÁREAS/BAIRROS % 01 CENTRO/SEDE 6,88 02 VISTA DA SERRA 9,29 03 CIVIT (SERRA DOURADA) 12,98 04 BARCELONA 14,41 05 LARANJEIRAS 6,55 06 JOSÉ DE ANCHIETA 7,72 07 CARAPINA 16,28 08 SÃO DIOGO 5,60 09 FEU ROSA 9,95 10 LITORAL 10,34 TOTAL 100,00 Para a utilização da metodologia bayesiana, a seleção dos locais mais similares foi realizada segundo o resultado do pleito de 1992. Na eleição de 1992 pode-se agregar os resultados em 52 locais, identificados aproximadamente como bairros. O vetor de resultados incluiu os votos dos quatro candidatos, mais votos brancos e nulos, formando uma distribuição multinomial com 6 probabilidades. Esses resultados estão na Tabela 5.23. Através do uso da medida de divergência de Kullback-Liebler, determinou-se a medida de divergência para cada local de votação. Na tabela 5.24 os locais encontram-se ordenados segundo a similitude, do mais ao menos similar (a todo o município). Observe-se que os valores da magnitude das medidas de divergência são muito próximos de zero. (Em que grau os locais podem ser considerados realmente similares, é um outro tópico que merece mais pesquisas). A seguir procurou-se determinar o número de municípios a serem pesquisados, via o procedimento heurístico definido na seção 2.3. O resultado pode ser visualizado na figura 5.11. O valor mínimo ocorreu para os dois primeiros locais e, o segundo menor valor, para seis locais. Optou-se por utilizar os seis primeiros locais, para garantir mais graus de liberdade. Finalmente, na Tabela 5.25, vemos os resultados percentuais por local de votação e ordem de similitude.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2764
Tabela 5.23: Resultados da eleição de1992, Serra/ES, por local de votação (Entrada do programa para seleção de locais) ELEICAO MUNICIPAL SERRA 92 - RESULTADO 6 52 PENHAFR VIDIGAL MOTTA BRICE BRANCOS NULOS CENTRO 2546 931 3856 836 736 561 S.DOMINGOS 369 114 444 40 79 43 J.B.VISTA 489 359 742 374 417 370 VIS.SERRA 1178 308 1145 406 507 324 S.J.TADEU 124 33 131 24 26 16 SAOMARCOS 491 177 878 203 179 124 CASCATA 160 28 342 78 56 32 N.SENHORA 111 45 231 49 49 26 CAMP.SERRA 369 305 255 52 186 83 NV.CARAPINA 464 341 877 395 324 254 BARROBRANCO 282 144 664 212 239 86 CALABOUCO 540 305 736 370 274 193 MATASERRA 290 483 766 384 183 166 PORTOCANOA 243 224 598 342 144 107 SERRADOUR-I 170 130 619 168 130 122 SERRADOUR-II 430 205 953 258 206 166 SERRADOUR-III 226 174 553 200 141 111 BARCELONA-I 288 255 1166 371 179 231 BARCELONA-II 229 207 892 298 159 138 TAQUARA-I 252 185 387 171 170 92 TAQUARA-II 268 194 321 165 184 127 CHICO-CITY 383 123 712 197 165 125 PQ.RES.LAR. 400 525 0 931 350 338 LAR.VELHA 176 74 318 91 85 58 JOSEANCHI. 1371 816 1678 738 703 454 CONCHEIRAS 747 317 896 204 381 218 SOSSEGO 946 145 743 140 390 260 J.LIMOEIRO 320 375 486 288 190 131 SAODIOGO 254 214 482 456 155 136 SAOGERALDO 221 89 157 74 61 49 ANDRECARL. 479 424 1195 419 263 295 CARAPINA 806 246 578 347 335 181 BOAVISTA 493 106 610 179 255 158 T.CARAPINA 1147 447 1053 715 406 366 B.DEFATIMA 601 676 1492 691 291 397 EURICOSALES 188 233 560 405 154 118 N.HORIZONTE 392 187 535 177 270 139 FEUROSA-I 1850 389 1763 338 531 447 CARAPEBUS 55 97 138 88 46 21 BICANGA 52 6 38 7 11 14 MANGUINHOS 173 157 449 100 73 52 J.ATLANTICO 325 1407 1018 239 318 247 JACARAIPE 245 631 695 196 130 113 NOVAALMEIDA 1464 507 2081 488 580 295 PUTIRI 40 7 51 3 15 6 CALOGI 92 7 93 9 54 22 CAMARACLUB 101 156 48 13 28 25 C.HELIOFERR. 14 11 30 18 9 11 VALPARAISO 135 110 476 395 65 108 CHAC.PARREI. 305 159 503 152 117 104 JARDIMTROP. 202 114 289 59 100 78 PLA.SERRANO 110 19 51 17 41 27

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2765
Tabela 5.24: Resultados da eleição de1992, Serra/ES, Medidas de divergência por local
de votação MEDIDAS DE DIVERGENCIA CALABOUCO(EL DOURADO) 0.004529469 CHAC.PARREI. 0.005528682 JOSEANCHI. 0.005679335 TAQUARA-I 0.007970175 NV.CARAPINA 0.010642888 LAR.VELHA 0.013417012 N.HORIZONTE 0.016037205 SERRADOUR-III 0.016099324 ANDRECARL. 0.020346700 SERRADOUR-II 0.021412388 JARDIMTROP. 0.022097136 TAQUARA-II 0.023558144 NOVAALMEIDA 0.025958959 CONCHEIRAS 0.026403824 T.CARAPINA 0.027532474 CHICO-CITY 0.028864520 SAOMARCOS 0.029112454 CENTRO 0.030571328 J.LIMOEIRO 0.033281060 BARROBRANCO 0.034092432 VIS.SERRA 0.034145034 J.B.VISTA 0.034979144 B.DEFATIMA 0.035813022 N.SENHORA 0.036772477 PORTOCANOA 0.038345695 MANGUINHOS 0.039535343 C.HELIOFERR. 0.041465663 SAOGERALDO 0.042103326 BOAVISTA 0.047266452 CARAPINA 0.047704681 SERRADOUR-I 0.054528782 MATASERRA 0.055878876 BARCELONA-II 0.062663319 SAODIOGO 0.067043127 FEUROSA-I 0.069760372 S.J.TADEU 0.070915136 BARCELONA-I 0.071927062 EURICOSALES 0.075867579 CARAPEBUS 0.076190638 CASCATA 0.103877591 SOSSEGO 0.119136696 JACARAIPE 0.120104310 S.DOMINGOS 0.120771073 BICANGA 0.138674841 CAMP.SERRA 0.142353870 VALPARAISO 0.150480531 PLA.SERRANO 0.152951846 PUTIRI 0.162056019 J.ATLANTICO 0.213537960 CALOGI 0.225788505 CAMARACLUB 0.330578805 PQ.RES.LAR. 2.316926929

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2766
Tabela 5.25: Resultados da eleição de1992, Serra/ES, por local de votação e ordem de similitude (%)
TRE/92 21,8% 12,8% 35,6% 12,3% 10,1% 7,5% Local PENHAFR VIDIGAL MOTTA BRICE BRANCOS NULOS CALABOUCO 0.223 0.126 0.304 0.153 0.113 0.080 CHAC.PARREI. 0.227 0.119 0.375 0.114 0.087 0.078 JOSEANCHI. 0.238 0.142 0.291 0.128 0.122 0.079 TAQUARA-I 0.200 0.147 0.307 0.136 0.135 0.073 NV.CARAPINA 0.175 0.128 0.330 0.149 0.122 0.096 LAR.VELHA 0.219 0.092 0.395 0.114 0.106 0.073 N.HORIZONTE 0.230 0.110 0.314 0.104 0.159 0.082 SERRADOUR-III 0.161 0.124 0.393 0.142 0.100 0.079 ANDRECARL. 0.156 0.138 0.388 0.136 0.086 0.096 SERRADOUR-II 0.194 0.093 0.429 0.116 0.093 0.075 JARDIMTROP. 0.240 0.135 0.342 0.070 0.119 0.093 TAQUARA-II 0.213 0.154 0.255 0.131 0.146 0.101 NOVAALMEIDA 0.270 0.094 0.384 0.090 0.107 0.055 CONCHEIRAS 0.270 0.115 0.324 0.074 0.138 0.079 T.CARAPINA 0.277 0.108 0.255 0.173 0.098 0.089 CHICO-CITY 0.224 0.072 0.417 0.116 0.097 0.073 SAOMARCOS 0.239 0.086 0.427 0.099 0.087 0.061 CENTRO 0.269 0.098 0.407 0.088 0.078 0.059 J.LIMOEIRO 0.179 0.209 0.271 0.161 0.106 0.073 BARROBRANCO 0.173 0.089 0.408 0.130 0.147 0.053 VIS.SERRA 0.304 0.080 0.296 0.105 0.131 0.084 J.B.VISTA 0.178 0.131 0.270 0.136 0.152 0.135 B.DEFATIMA 0.145 0.163 0.360 0.167 0.070 0.096 N.SENHORA 0.217 0.088 0.450 0.096 0.096 0.052 PORTOCANOA 0.147 0.135 0.360 0.206 0.087 0.065 MANGUINHOS 0.172 0.156 0.446 0.100 0.073 0.052 C.HELIOFERR. 0.150 0.119 0.316 0.192 0.098 0.119 SAOGERALDO 0.338 0.137 0.241 0.114 0.094 0.076 BOAVISTA 0.273 0.059 0.338 0.099 0.142 0.088 CARAPINA 0.323 0.099 0.232 0.139 0.134 0.073 SERRADOUR-I 0.127 0.097 0.461 0.126 0.097 0.091 MATASERRA 0.128 0.212 0.337 0.169 0.081 0.073 BARCELONA-II 0.119 0.108 0.463 0.155 0.083 0.072 SAODIOGO 0.150 0.126 0.284 0.268 0.091 0.080 FEUROSA-I 0.348 0.073 0.331 0.064 0.100 0.084 S.J.TADEU 0.348 0.094 0.368 0.069 0.074 0.046 BARCELONA-I 0.116 0.102 0.468 0.149 0.072 0.093 EURICOSALES 0.113 0.141 0.337 0.244 0.093 0.071 CARAPEBUS 0.124 0.217 0.309 0.197 0.104 0.048 CASCATA 0.229 0.041 0.490 0.112 0.081 0.046 SOSSEGO 0.360 0.055 0.283 0.053 0.149 0.099 JACARAIPE 0.122 0.314 0.345 0.098 0.065 0.056 S.DOMINGOS 0.338 0.105 0.407 0.037 0.073 0.040 BICANGA 0.399 0.049 0.293 0.057 0.087 0.110 CAMP.SERRA 0.295 0.244 0.204 0.042 0.149 0.067 VALPARAISO 0.105 0.085 0.369 0.306 0.051 0.084 PLA.SERRANO 0.412 0.073 0.192 0.065 0.155 0.102 PUTIRI 0.323 0.060 0.410 0.028 0.124 0.052 J.ATLANTICO 0.091 0.396 0.286 0.067 0.090 0.070 CALOGI 0.330 0.027 0.333 0.034 0.194 0.080 CAMARACLUB 0.271 0.418 0.130 0.036 0.076 0.068 PQ.RES.LAR. 0.157 0.206 0.000 0.366 0.138 0.133

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2767
Figura 5.11: Erro Quadrático Médio (EQM) x Número de Locais, Serra/ES, 1992
0 10 20 30 40 50 60
MUNICIPIOS
0
0.5
1
1.5
2
2.5
3
PSER
RA
92.E
QM
EDIO
(X 1E-4)MUNICIPIOS X EQM
Em resumo: (i) Em 26-28/julho de 1996 foram realizadas pesquisas com as duas metodologias; (ii) Na pesquisa com amostragem clássica a amostra foi de 705 eleitores. A amostra foi estratificada por áreas e foi realizado um controle de cotas; (iii) Na pesquisa com amostragem bayesiana a amostra foi de 218 eleitores. O seguinte roteiro foi adotado na seleção dos indivíduos nos locais similares: (a) os entrevistados devem necessariamente ser moradores do local; (b) os indivíduos devem ser entrevistados ao acaso (nunca entrevistar duas pessoas juntas); (c) metade de cada sexo; e, (d) metade abaixo de 35 anos, metade acima de 35 anos. Observe-se que é um plano bastante flexível. As tabelas 5.26 e 5.27 apresentam dois resultados comparativos. Uma vez mais a pesquisa via amostragem bayesiana consegue captar apropriadamente os resultados globais de toda a região sendo pesquisada (no caso o município).

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2768
Tabela 5.26: Comparação Intenção e Rejeição do Voto: “Clássico / Bayesiano” - Voto Espontâneo e Estimulado, Pesquisas Realizadas em 26-28/julho de 1996
INTENÇÃO DE VOTO REJEIÇÃO DE VOTO CANDIDATO ESPONTÂNEO ESTIMULADO ESPONTÂNEO ESTIMULADOJOÃO MIGUEL
5,2 / 4,6 13,2 / 11,5 4,5 / 3,7 13,3 / 13,3
SÉRGIO VIDIGAL
23,3 / 18,8 42,0 / 42,7 1,6 / 0,5 5,4 / 4,6
GILSON GOMES
4,7 / 3,2 13,0 / 10,6 3,4 / 0,9 8,2 / 7,8
OUTROS 6,7 / 10,6 15,0 / 15,1 16,7 / 19,3 25,8 / 26,6 NS-NR 60,1 / 62,8 16,7 / 20,2 73,8 / 75,7 47,2 / 47,7 OBS: “Clássico/Bayesiano” – primeiro resultado pesquisa “Clássica”; segundo resultado “bayesiana”.
Tabela 5.27: Comparação: “Clássico / Bayesiano” – Certeza da Intenção de Voto, Pesquisas Realizadas em 26-28/julho de 1996
CLÁSSICA BAYESIANA Value Label Frequency Percent Frequency Percent Seu voto esta decidido 300 42.6 92 42.2 e dificilmente mudará Pode ser que mude de 201 28.5 54 24.8 idéia, por várias razões Existe uma grande chance 70 9.9 25 11.5 de mudar de idéia NS-NR 134 19.0 47 21.6 ------- ------- ------- ------- Total 705 100.0 218 100.0
Finalmente, na Tabela 5.27 encontra-se o resultado final das eleições e na Figura 5.12 a evolução da intenção de voto captada pelas quatro pesquisas e o resultado final. A aplicação consistiu em um exercício conjunto da utilização das metodologias clássica e bayesiana: foram realizadas pesquisas em dois períodos (26-27 de julho e 30-31 de agosto), segundos as duas metodologias e, quando o objetivo era apenas o monitoramento, realizou-se a pesquisa com a metodologia bayesiana, com uma amostra menor. Observa-se que a pesquisa bayesiana acompanha muito bem as tendências de evolução do voto ao longo do período de campanha, a despeito dos pequenos tamanhos amostrais.
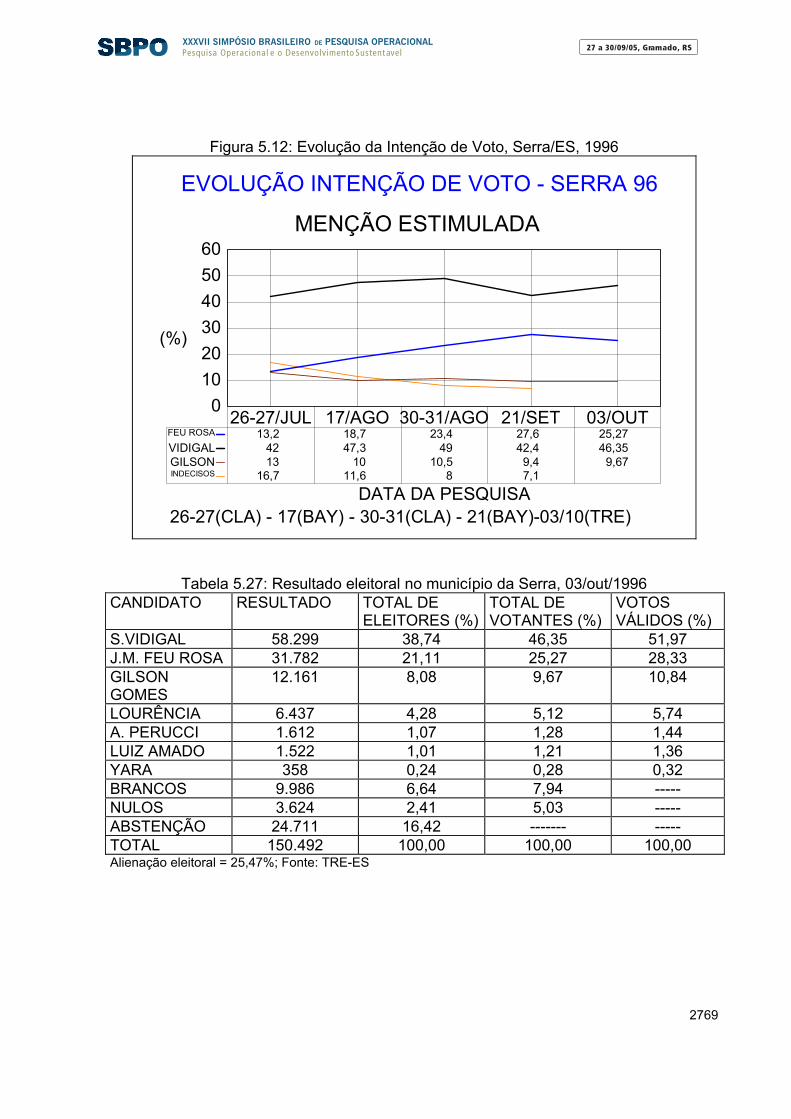
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2769
Figura 5.12: Evolução da Intenção de Voto, Serra/ES, 1996
EVOLUÇÃO INTENÇÃO DE VOTO - SERRA 96
MENÇÃO ESTIMULADA
26-27(CLA) - 17(BAY) - 30-31(CLA) - 21(BAY)-03/10(TRE)
26-27/JUL 17/AGO 30-31/AGO 21/SET 03/OUT
DATA DA PESQUISA
0102030405060
(%)
FEU ROSA 13,2 18,7 23,4 27,6 25,27VIDIGAL 42 47,3 49 42,4 46,35GILSON 13 10 10,5 9,4 9,67INDECISOS 16,7 11,6 8 7,1
Tabela 5.27: Resultado eleitoral no município da Serra, 03/out/1996 CANDIDATO RESULTADO TOTAL DE
ELEITORES (%)TOTAL DE VOTANTES (%)
VOTOS VÁLIDOS (%)
S.VIDIGAL 58.299 38,74 46,35 51,97 J.M. FEU ROSA 31.782 21,11 25,27 28,33 GILSON GOMES
12.161 8,08 9,67 10,84
LOURÊNCIA 6.437 4,28 5,12 5,74 A. PERUCCI 1.612 1,07 1,28 1,44 LUIZ AMADO 1.522 1,01 1,21 1,36 YARA 358 0,24 0,28 0,32 BRANCOS 9.986 6,64 7,94 ----- NULOS 3.624 2,41 5,03 ----- ABSTENÇÃO 24.711 16,42 ------- ----- TOTAL 150.492 100,00 100,00 100,00 Alienação eleitoral = 25,47%; Fonte: TRE-ES

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2770
5.5. Pesquisa Eleitoral no Espírito Santo, setembro/2001 Esta foi uma pesquisa prospectiva objetivando avaliar as chances de um determinado pré-candidato a deputado federal no pleito do ano 2002 no ES. A pesquisa foi realizada com as metodologias “Clássica” e “Bayesiana”. A metodologia bayesiana foi usada apenas para checagem da pesquisa “clássica”, que propicia também uma visão regional. O objetivo desta apresentação é ilustrar a teoria. Na pesquisa “clássica” adotou-se uma amostragem aleatória estratificada por regiões constituídas de microrregiões e municípios. O Estado do Espírito Santo foi dividido em seis grandes regiões e estas, subdivididas de acordo com as 13 microrregiões do IBGE, como nas Figuras 5.1 e 5.2 e Tabela 5.2. Na seleção dos municípios para realização das entrevistas procurou-se incluir aqueles “mais similares”. A amostra foi dimensionada com 1216 entrevistas a eleitores conduzindo a um erro amostral máximo de 2,8%, para um intervalo de confiança de 95%. Para seleção dos indivíduos em cada microrregião foi utilizado um controle de quotas. Resumo: amostragem aleatória estratificada por região geográfica, com controle de cotas (sexo, faixa etária, classificação econômica). Critérios de Estratificação: Grandes Regiões/Microrregiões/Municípios/Indivíduos. As entrevistas foram domiciliares, com o entrevistado selecionado de acordo com as cotas. As Tabelas 5.28 a 5.33 exibem alguns resultados usualmente obtidos em pesquisa similares.
Tabela 5.28: Pesquisa ES, 09/2001, Amostra por Região V1-Região
525 43,2 43,2 43,2
92 7,6 7,6 50,7
87 7,2 7,2 57,9
181 14,9 14,9 72,8
161 13,2 13,2 86,0
170 14,0 14,0 100,0
1216 100,0 100,0
Grande Vitória
Litoral Sul
Serrana
Sul
Litoral Norte
Norte
Total
ValidFrequency Percent Valid Percent
CumulativePercent

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2771
Tabela 5.29: Pesquisa ES, 09/2001, Momento da Escolha Deputado
V29-Momento da Escolha Cand. Dep. Federal em 1998
271 22,3 23,5 23,5
225 18,5 19,5 43,0
190 15,6 16,5 59,4
180 14,8 15,6 75,0
175 14,4 15,2 90,2
113 9,3 9,8 100,0
1154 94,9 100,0
62 5,1
1216 100,0
Uma semana a um mês antes
Cerca de três meses antes
Não Votou ou Votou nulo ouem branco
Entre seis meses e um anoantes
No dia da eleição
Um pouco antes de votar
Total
Valid
NS-NRMissing
Total
Frequency Percent Valid PercentCumulative
Percent
Tabela 5.30: Pesquisa ES, 09/2001, Voto presidente em 2002 V20-Voto Presidente-Estimulado
408 33,6 37,3 37,3
158 13,0 14,4 51,7
124 10,2 11,3 63,0
122 10,0 11,1 74,2
88 7,2 8,0 82,2
82 6,7 7,5 89,7
38 3,1 3,5 93,2
36 3,0 3,3 96,4
23 1,9 2,1 98,5
13 1,1 1,2 99,7
3 ,2 ,3 100,0
1095 90,0 100,0
121 10,0
1216 100,0
Lula
Nenhum deles
Ciro Gomes
Roseana Sarney
Garotinho
Itamar Franco
José Serra
Não vai votar-Branco-Nulo
Enéas
Outro candidato
Tasso Jereissati
Total
Valid
NS-NRMissing
Total
Frequency Percent Valid PercentCumulative
Percent

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2772
Tabela 5.31: Pesquisa ES, 09/2001, Voto Governador em 2002
V21-Voto Governador-Estimulado
270 22,2 25,1 25,1
200 16,4 18,6 43,7
173 14,2 16,1 59,8
135 11,1 12,6 72,4
119 9,8 11,1 83,4
75 6,2 7,0 90,4
44 3,6 4,1 94,5
38 3,1 3,5 98,0
21 1,7 2,0 100,0
1075 88,4 100,0
141 11,6
1216 100,0
Paulo Hartung
Max Mauro
Gerson Camata
Nenhum deles
Sérgio Vidigal
José Ignácio
João Coser
Não vai votar-Branco-Nulo
Outro candidato
Total
Valid
NS-NRMissing
Total
Frequency Percent Valid PercentCumulative
Percent
Tabela 5.32: Pesquisa ES, 09/2001, Voto Deputado Federal – Estimulado por cartão
V24-Voto Deputado Federal-Estimulado
228 18,8 22,8 22,8
177 14,6 17,7 40,5
135 11,1 13,5 53,9
134 11,0 13,4 67,3
79 6,5 7,9 75,2
77 6,3 7,7 82,9
55 4,5 5,5 88,4
44 3,6 4,4 92,8
37 3,0 3,7 96,5
22 1,8 2,2 98,7
13 1,1 1,3 100,0
1001 82,3 100,0
215 17,7
1216 100,0
Um Novo
Rita Camata
Max Mauro
Magno Malta
Nilton Baiano
Ricardo Ferraço
José Carlos Elias
José Carlos da Fonseca Jr
João Coser
João Miguel Feu Rosa
Marcus Vicente
Total
Valid
NS-NRMissing
Total
Frequency Percent Valid PercentCumulative
Percent

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2773
Tabela 5.33: Pesquisa ES, 09/2001, Preferência Partidária
V35-Partido político de preferência-Espontâneo
580 47,7 50,4 50,4
234 19,2 20,3 70,8
156 12,8 13,6 84,3
47 3,9 4,1 88,4
46 3,8 4,0 92,4
25 2,1 2,2 94,6
18 1,5 1,6 96,2
9 ,7 ,8 97,0
8 ,7 ,7 97,7
7 ,6 ,6 98,3
6 ,5 ,5 98,8
4 ,3 ,3 99,1
2 ,2 ,2 99,3
2 ,2 ,2 99,5
2 ,2 ,2 99,7
2 ,2 ,2 99,8
1 ,1 ,1 99,9
1 ,1 ,1 100,0
1150 94,6 100,0
66 5,4
1216 100,0
Nenhum
PT
PMDB
PFL
PSDB
Não acredita em política
PDT
PSB
PTB
PPS
Vota no candidato
PL
Pc do B
PV
PMN
PPB
PRONA-Partido do Enéas
Qualquer um, exceto PT
Total
Valid
NS-NRMissing
Total
Frequency Percent Valid PercentCumulative
Percent

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2774
5.6. Análise dos Resultados da Eleição 2002, Governo ES, via Metodologia Bayesiana Na tabela 5.34 estão os resultados finais da eleição para Governador do estado do Espírito Santo assim discriminados: (i) votos válidos; (ii) votos apurados (incluindo brancos e nulos) e, (iii) votos totais (que refletem todos os eleitores aptos a votar). Tabela 5.34: Resultado Global das Eleições de 2002 ao Governo do ES
Candidato nº Partido Votos % votos válidos
% votos totais
PAULO HARTUNG 40 PSB 820.949 53,97 38,25 MAX MAURO 14 PTB 631.326 41,50 29,41 HAROLDO SANTOS FILHO 25 PFL 31.104 2,04 1,45 PAULO RUY 45 PSDB 22.987 1,51 1,07 SÔNIA SANTOS 29 PCO 6.099 0,40 0,28 SILVIO FELINTO 16 PSTU 5.648 0,37 0,26 WALTER MACIEL 19 PTN 3.138 0,21 0,15 Total de votos válidos 1.521.251 100,00 Brancos 78.873 3,67 Nulos 167.925 7,82 Total de votos apurados 1.768.049 Abstenção 378.376 17,63 Total de eleitores 2.146.425 100,00 Neste exemplo foi feito o seguinte exercício: (i) Com o resultado final de eleição de 2002, exibido na tabela 5.35, utilizou-se a medida de divergência de Kullback-liebler,
∑=
≥⎥⎦
⎤⎢⎣
⎡=
m
i i
iii q
pLogpPQD1
0.],[ ,
para hierarquizar os resultados de cada município (uma distribuição multinomial) com relação ao verificado no estado como um todo. Este procedimento hierarquizou todos os 78 municípios em uma ordem de similitude, relativamente ao resultado de todo o estado, como mostrado na figura 5.13. Nesta, o município de ordem 1 apresentou o resultado mais próximo, de acordo com a medida de Kullback-liebler, do resultado de todo o estado. Equivalentemente, o município de ordem 78 é o mais divergente. (ii) A seguir, com o procedimento heurístico: ( )
2
11
.1ˆ.1 ∑∑==
−==m
jijji
i
lljij m
EQMi
θθθθ , determinou-
se a quantidade de municípios para obtenção aproximada do resultado global; Figura 5.14. Constatou-se que com os nove municípios (menor EQM médio) mais similares consegue-se estimar o resultado global (o estado) satisfatoriamente.
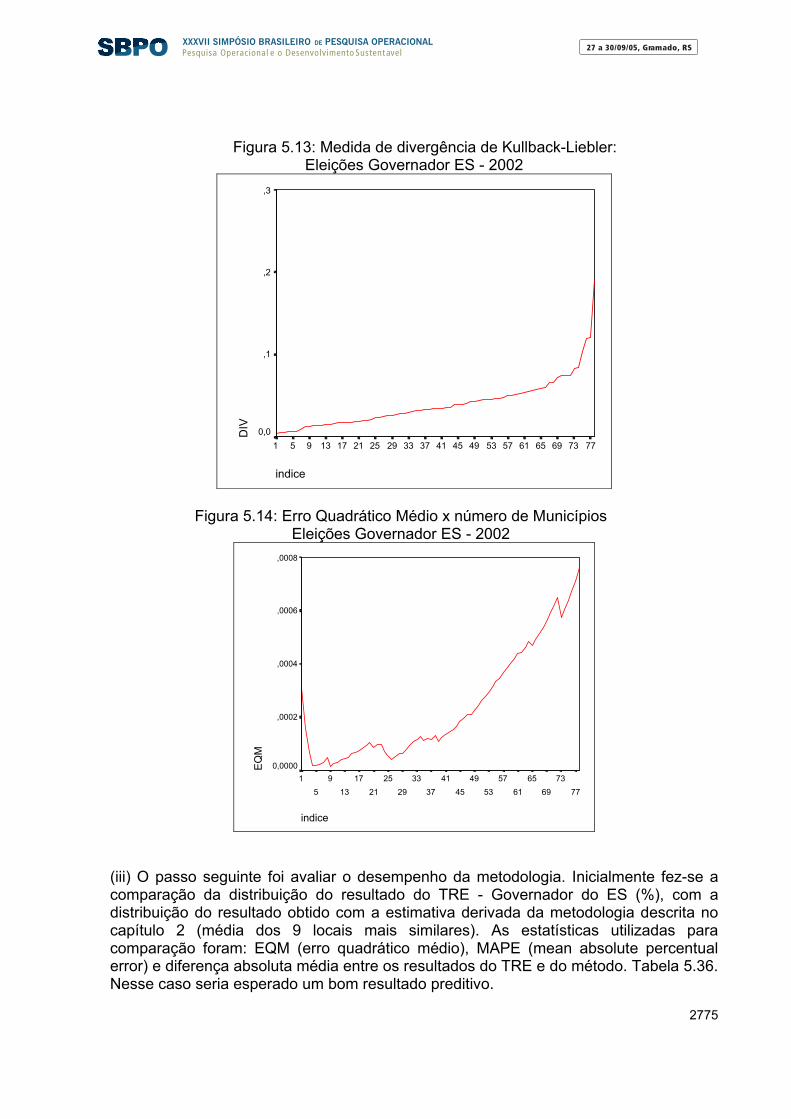
27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2775
Figura 5.13: Medida de divergência de Kullback-Liebler:
Eleições Governador ES - 2002
indice
7773696561575349454137332925211713951
DIV
,3
,2
,1
0,0
Figura 5.14: Erro Quadrático Médio x número de Municípios Eleições Governador ES - 2002
indice
7773
6965
6157
5349
4541
3733
2925
2117
139
51
EQ
M
,0008
,0006
,0004
,0002
0,0000
(iii) O passo seguinte foi avaliar o desempenho da metodologia. Inicialmente fez-se a comparação da distribuição do resultado do TRE - Governador do ES (%), com a distribuição do resultado obtido com a estimativa derivada da metodologia descrita no capítulo 2 (média dos 9 locais mais similares). As estatísticas utilizadas para comparação foram: EQM (erro quadrático médio), MAPE (mean absolute percentual error) e diferença absoluta média entre os resultados do TRE e do método. Tabela 5.36. Nesse caso seria esperado um bom resultado preditivo.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2776
Tabela 5.35: Resultado Governo/ES (2002) por Município – (municípios selecionados)
Max Hartung Silvio Haroldo Ruy Outros Brancos Nulos AfonsoClaudio 5.471 8761 26 157 443 32 912 2111 AguaDocedoNor 2.763 2989 34 40 155 13 409 1354 AguiaBranca 1.793 2389 4 39 80 18 243 792 Alegre 4.559 9417 45 370 414 98 905 2849 AlfredoChaves 2.301 4750 17 54 217 21 550 894 AltoRioNovo 753 2466 3 29 150 9 201 726 Anchieta 4.382 5866 19 148 225 33 791 1345 Apiaca 1.093 2444 5 40 99 4 174 635 Aracruz 18.821 14289 71 545 394 114 1369 3494 AtilioVivacqua 1.569 3430 6 84 96 12 194 742 BaixoGuandu 6.423 7301 51 314 382 73 814 2503 BarradeSaoFra 8.699 7505 56 233 283 57 1020 3066 BoaEsperanca 2.687 3557 14 115 164 14 407 1121 BomJesusdoNor 1.216 3584 20 19 86 6 305 653 Brejetuba 2.042 2094 2 15 184 5 248 887 CachoeirodeItapemirim 32.542 44096 259 1813 806 582 5162 6976 Cariacica 71.809 63197 894 3638 1548 1216 5641 12294 Castelo 6.122 9501 48 604 331 45 1335 2427 Colatina 14.097 38352 144 1031 678 238 3215 5274 ConceicaodaBarra 4.238 5137 24 133 221 53 774 2211 ConceicaodoCast 1.597 3476 12 96 190 15 492 1105 DivinodeSaoLour 674 1458 3 33 92 12 139 423 DomingosMartins 4.145 10395 49 187 452 35 1187 1773 DoresdoRioPreto 647 2060 5 88 78 10 227 593 Ecoporanga 3.618 6374 18 166 273 37 647 1891 Fundão 3.263 3500 20 106 104 31 379 896 GovernadorLnd 1.306 3463 3 78 107 9 312 641 Guacui 3.428 8132 33 210 331 51 766 1900 Guarapari 16.636 25526 145 920 673 193 2492 4226 Ibatiba 2.250 6292 17 86 339 13 409 1271 Ibiracu 2.086 3483 11 625 102 17 375 933 Iúna 3.709 8591 18 192 354 30 748 1920 Montanha 3.136 3898 14 132 157 28 447 1678 Mucurici 1.105 1525 4 47 81 11 107 549 MunizFreire 2.815 5118 12 118 310 16 571 1476 SantaLeopoldina 1.440 4347 10 83 143 17 363 848 SantaMariadeJet 4.812 8746 8 103 326 21 701 1616 SantaTeresa 2.873 8401 42 127 311 27 734 1590 SaoMateus 13.595 24739 88 432 371 137 1568 4720 Serra 69.304 67163 694 3280 1297 1321 6190 13852 Sooretama 1.630 5855 11 78 177 30 629 1461 VargemAlta 2.723 5256 13 52 181 19 618 915 VendaNova 2.268 5012 20 110 204 24 634 1263 Viana 15.608 12851 111 602 328 214 1587 2659 VilaPavao 1.783 2287 22 18 62 12 277 624 VilaValerio 2.968 3161 2 34 92 6 251 1012 VilaVelha 108.630 64025 844 4542 1484 1733 6137 11020 Vitória 63.102 102129 995 4469 1814 1441 5710 10281 Estado - ES 631.326 820.949 5.648 31.104 22.987 9.237 78.873 167.925

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2777
(iii - continuação) As estatísticas adotadas foram:
∑=
−=8
1
2)ˆ(81
iiiEQM θθ ; ∑
=
−=
8
1i i
iiˆ
81MAPE
θθθ
; ∑=
−=8
1iiiˆ
81Abs.Dif θθ
Onde:
iθ é o Resultado Final (TRE) do Candidato i;
iθ̂ é o Resultado Estimado (previsto) para o Candidato i, através dos k=9 municípios, incluídos na base similar .
Tabela 5.36: Comparação do Resultado do TRE com o resultado obtido com a estimativa da metodologia (média dos 9 locais mais similares) na Eleição 2002 para
Governador do ES (%) Max Hartung Silvio Haroldo Ruy Outros Brancos NulosResultado médio com os 9 Municípios mais similares - 2002
35,14
46,24
0,27
1,53
1,24
0,46
5,29
9,87
Resultado TRE 35,71 46,43 0,32 1,76 1,30 0,52 4,46 9,50 MAPE=2,73% 1,58 0,40 16,52 12,84 4,28 12,80 18,56 3,88 Dif. Absoluta Média = 0,47 0,56 0,19 0,05 0,23 0,06 0,07 0,83 0,37 Observe-se que se tem uma distribuição (multinomial) com um vetor de oito parâmetros: os percentuais obtidos por cada candidato e de votos brancos e nulos. Como esperado, uma vez que os 9 municípios selecionados foram derivados da própria eleição de 2002, os resultados são excelentes. Isso significa que esses nove municípios mais similares são bons preditores do comportamento eleitoral do estado. (iv) A comparação do desempenho apresentada na Tabela 5.37 é mais audaciosa. Verificou-se os nove municípios que permaneceram mais frequentemente como os mais similares ao (resultado do) ES nos anos eleitorais de 1982 a 1998. A Tabela 5.38 mostra a distribuição dos resultados nos municípios, no ano 2002. Na primeira coluna da tabela encontra-se a ordem de similitude desses municípios na eleição de 2002. Os quatro últimos municípios foram, na verdade, dessimilares. Assim mesmo, realizou-se as comparações da tabela 5.37. Pelos critérios usados, o desempenho da metodologia foi bom, comprovando a sua “robustez”.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2778
Tabela 5.37: Comparação do resultado do TRE com o resultado obtido com a estimativa da metodologia (média dos 9 locais mais similares), mas considerando-se os
municípios mais “estáveis” desde 1982, na Eleição 2002 para Governador/ES(%) Max Hartung Silvio Haroldo Ruy Outros Brancos NulosResultado médio com os 9 Municípios mais “estáveis”
37,61
43,68
0,28
2,40
1,17
0,47
4,81
9,61
Resultado TRE 35,71 46,43 0,32 1,76 1,30 0,52 4,46 9,50 MAPE= 3,26% 5,33 5,93 13,04 36,42 10,27 10,68 7,85 1,19 Dif. Absoluta Média = 1,01 1,90 2,75 0,04 0,64 0,13 0,05 0,35 0,11 Tabela 5.38: Distribuição Percentual dos Resultado nos municípios mais “estáveis” no
período 1982-1998, no resultado de 2002 Ordem dos Municípios “estáveis” no resultado de 2002
Max Hartung Silvio Haroldo Ruy Outros Brancos Nulos
Mun 1 0,327 0,502 0,003 0,018 0,013 0,004 0,049 0,083Mun 2 0,353 0,478 0,003 0,020 0,009 0,006 0,056 0,076Mun 3 0,343 0,453 0,002 0,013 0,013 0,004 0,056 0,117Mun 5 0,393 0,422 0,002 0,013 0,013 0,004 0,046 0,108Mun 7 0,307 0,483 0,002 0,015 0,014 0,005 0,060 0,115
Mun 25 0,460 0,378 0,003 0,018 0,01 0,006 0,047 0,078Mun 39 0,481 0,365 0,002 0,014 0,01 0,003 0,035 0,089Mun 62 0,273 0,456 0,002 0,082 0,013 0,002 0,049 0,122Mun 24 0,448 0,394 0,006 0,023 0,01 0,008 0,035 0,077
média base estável 0,376 0,437 0,003 0,024 0,012 0,005 0,048 0,096TRE 0,357 0,464 0,003 0,018 0,013 0,005 0,045 0,095

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2779
6. Comentários e Discussão Na parte 1 descrevemos duas metodologias amostrais que podem ser adotadas para realizar sondagens amostrais e, particularmente, pesquisa eleitorais. A lógica dos dois desenhos descritos nos capítulos 1 e 2 é distinta, e, cada um, tem suas vantagens e desvantagens. Nas aplicações do capítulo 5 procuramos acentuar essas características. As metodologias podem ser utilizadas comparativamente para checagem dos resultados. É salutar para o processo democrático que venham a público pesquisas de opinião que adotem metodologias distintas. No caso da metodologia bayesiana, os exemplos mostram que a seleção dos locais mais similares é de fundamental importância para um bom funcionamento da metodologia. Quanto menor for a medida Di, dada por (2.3) , mais representativo será o local i, ou seja, é mais similar à região como um todo. O que ocorre é que a magnitude de Di deve ser considerada visto que, o primeiro local mais similar na "hierarquia de similitudes", pode indicar uma grande divergência entre as distribuições de probabilidade subjacentes e uma alta heterogeneidade entre os locais "mais representativos" do universo considerado. Um outro fator de grande importância para aplicações de sucesso da metodologia, é a observação do ponto de corte obtido através dos argumentos heurísticos apresentados. O número de locais, em torno do EQM mínimo, indica que os locais adicionalmente considerados aumentam a divergência entre as distribuições de modo mais substancial, implicando em incluir locais com alta heterogeneidade em relação ao todo considerado. As aplicações apresentadas neste trabalho corroboram essas observações. Existe um compromisso entre o número de locais selecionados e o número de candidatos disputando o pleito, pois isso influi na determinação dos graus de liberdade e, consequentemente, nos intervalos de probabilidade. Desse modo, o número de locais a serem pesquisados também deve ser controlado vis a vis a quantidade de candidatos disputando o pleito, para garantir os graus de liberdade necessários à determinação dos intervalos de probabilidade para as previsões. Na parte 2 apresentamos as principais fontes de erro em pesquisa eleitorais, ilustrando com casos reais, alguns erros verificados em pesquisas realizadas com a metodologia “clássica”. Nossa experiência indica que, com um planejamento apropriado, pode-se realizar, a um custo adicional reduzido, as duas metodologias de pesquisa; o que possibilita uma maior confiabilidade e credibilidade dos resultados. Seguem-se algumas reflexões sobre as últimas eleições especialmente as eleições municipais de 2000 e 2004.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2780
(i) O eleitor está resolvendo votar conscientemente e com maior independência. O eleitor está demorando mais a decidir o seu voto, esperou verem confirmadas a suas opiniões sobre os candidatos e, eventualmente, mudou o seu voto durante a campanha, alterando o padrão de cristalização do voto verificado em outros pleitos anteriores. (ii) Os comentários já exaustivamente veiculados por todos os analistas de que o eleitor valorizou a quem cuidou bem da sua localidade, da sua cidade, ou que apresentou mais perspectivas de fazê-lo mais adequadamente, com ética e eficiência administrativa, aparentemente foi levado em consideração. (iii) O percentual de indecisos, no voto estimulado, ainda estava no nível dos 10% na última semana antes das eleições, em alguns municípios (2000). (iv) Muitos eleitores não ficaram satisfeitos diante das alternativas de candidatos às quais estava solicitado a escolher. O espectro de escolhas apresentado não era adequado à sua representação. Por isso ele mudou muito de opinião durante a campanha, ou demorou mais até ter a sua escolha definitiva. “O grau de certeza da intenção e voto” diminuiu em alguns casos, ao invés de aumentar, à medida que se aproximava a data das eleições. (v) O Eleitor foi assediado por inúmeros grupos de pesquisa, que semanalmente percorriam os bairros, criteriosamente ou não, ao mesmo tempo que foi bombardeado por grande quantidade de resultados de pesquisas, muitas vezes desconexos. (vi) A divulgação dos resultados apenas como os votos válidos reforça o fato de que o que vale é o voto atribuído a candidatos e, no final, alguém deverá ser eleito. Até as eleições de 1996, o voto em branco era considerado como válido para as os cargos legislativos (deputado e vereador). O voto válido significa que só serão contabilizados para o cômputo final, os votos em candidatos. O não comparecimento às urnas significa, de certo modo, que o eleitor concorda com o resultado que vem sendo esboçado pelas pesquisas. (vii) Voto indeciso, abstenção, e resultado sobre os votos válidos e sobre os votos totais. A verdadeira dimensão dos resultados só é percebida quando visualisamos os votos totais e, os resultados sobressaem de outro modo. Os votos indecisos devem ser observados, principalmente no que diz respeito à divulgação das pesquisas eleitorais. Finalizando, quais as garantias de confiabilidade de uma autêntica pesquisa eleitoral quantitativa? Diríamos que todos os aspectos devem ser considerados: (i) A garantia de definição adequada de um eficiente plano amostral (na metodologia “clássica”, um plano amostral consiste na seleção adequada de um subconjunto representativo da população alvo a ser pesquisada, assim como na delimitação, no caso da amostragem estratificada, dos estratos e na observação de características

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2781
tais como sexo, idade e classe social, fundamentais para um controle de qualidade de uma pesquisa. Na metodologia “bayesiana” consiste na escolha adequada do número de locais e do compromisso com o número de eleitores a serem entrevistados em cada local). (ii) O uso de um questionário com perguntas testadas, padronizadas e eficazes na aplicação. Isto significa a utilização de questionário que já tenha sido testado eficazmente em diversos tipos de situações idênticas ou semelhantes. (iii) Na utilização de programa computacional adequado para análise dos dados. (iv) No treinamento apropriado da equipe de apoio (entrevistadores de campo e codificadores). A equipe de apoio deve ser levada a um treinamento regular e sistemático da utilização do questionário, principalmente no que se refere ao monitoramento do plano amostral, e na observância das características do eleitorado (EX: sexo, idade, classe social e local de moradia). Por outro lado, argumenta Chico Santa Rita (Batalhas Eleitorais, 2001): Deve-se utilizar adequadamente as pesquisa qualitativas e quantitativas. “Não adianta ter uma boa pesquisa nas mãos de quem não sabe ler e interpretar”. “Também não adianta ter uma pesquisa sem credibilidade”, sem metodologia.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2782
7. Referências AITCHINSON, J. (1975), Goodness of Prediction Fit, Biometrika, 62, 3, 547-554. ALMEIDA, Alberto Carlos (2002), Como são feitas as pesquisas eleitorais e de opinião, Editora FGV, Rio de Janeiro. BARNETT, Vic (1991), Sample Survey: Principles and Methods, Edward Arnold, London, U.K. BERGER, J. O. (1985), Statistical Decision Theory and Bayesian Analysis, 2nd Ed., Springer-Verlag. BERNARDO, J. M. (1979), Reference Posterior Distribution for Bayesian Inference (With discussion), J. Royal Stat. Soc., B, 41, 113-147. BERNARDO, J. M. (1984), Monitoring the 1982 Spanish Socialist Victory: A Bayesian analysis, J. Amer. Statist. Assoc., 79, 387, 510-515. BOLFARINE, H. e BUSSAB, W. O. (1994), Elementos de Amostragem, Minicurso do 11o SINAPE, 24-29 de julho de 1994, Belo Horizonte, MG. BOX, G. E. P. & TIAO, G. C. (1973), Bayesian Inference in Statistical Analysis, Reading, Mass., Addison-Wesley. BRASIL, G. H., MIGON, H. S. & SOUZA, R. C. (1986), Relatório Sobre Pesquisas Eleitorais no Estado do Rio de Janeiro utilizando a Metodologia Bayesiana, [Texto não publicado]. BRASIL, G.H., MACEDO, J.W.F., PÊGO E SILVA, A. F. e DOS ANJOS, E. E. , "Monitoramento de Eleições Municipais no ES - Amostragem Clássica e Bayesiana", Anais do XXV SBPO, pag 277-282, Campinas, SP, Novembro/1993. BRASIL, Gutemberg H. & PÊGO E SILVA, Antonio Fernando (1991), Pesquisas Eleitorais: Algumas Considerações Sobre a Metodologia Bayesiana para Pesquisas Eleitorais com Aplicação às Eleições de 1990 no Estado do Espirito Santo, Revista Brasileira de Estatística, Vol 52, No 197/198, 69-92, 1991. (Publicado em 1994). BRASIL, G. H., PÊGO E SILVA, A. F. e MACEDO, J. W. F. (1996), “Considerations upon the Bayesian Model for Electoral Polls with Applications to the Elections in Brazil and a Comparison with the Classical Model”, Estadística, Vol 48, Números 150-151, 81-114, 1996, (Publicado em Junho/1998). BRASIL, Gutemberg H. e DOXSEY, Jaime, R. (1994), As Pesquisas de Opinião, in Ex Libris: a opinião da UFES em A Gazeta, compilação e organização de D. Protti e H. Pessali, Vitória, UFES-Rede Gazeta, 1994. BUSSAB, Wilton de O. e MORETTIN, P.A. (2002), Estatística Básica, 5a Edição, Editora Saraiva. BUSSAB, Wilton de O. (1991), Erros em Levantamentos e experimentação, Seminário apresentado no XX Encontro Regional da Associação Brasileira de Estatística - ABE, Abril/1991, Vitória – ES, manuscrito, 12 páginas. COCHRAN W. G. (1977), Sampling Techniques, 3rd edition, Wiley. DEMING, E. W. (1960), Samplig Design in Business Research, Wiley, New York. Fienberg, Stephen E. (1992). “A Brief History of Statistics in Three and One-half Chapters: A Review Essay.” Statistical Science, 7, 208–225. FIGUEIREDO, Rubens (2002a), (organizador), Marketing Político e Persuasão Eleitoral, 2a edição, Fundação Konrad Adenauer, Rio de Janeiro.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2783
FIGUEIREDO, Rubens (2002b), Erros e Acertos nas Pesquisas Eleitorais, Jornal Folha de São Paulo, 09/11/2002, página A7. GRANDI, R., MARINS, A. e FALCÃO, E. (organizadores), (1992), Voto é Marketing...O Resto é Política, Edições Loyola, São Paulo. HAAK, Dennis G. (1979), Statistical Literacy: A Guide to Interpretation, Duxbury Press, California, USA. HANSEN, M. H., HURWITZ, W. N. and MADOW, W. G. (1953), Sample Survey Methods and Theory, John Wiley, New York, Vols I and II. HOINVILLE, G. JOWELL, R. et al (1978), Survey Research Practice, Heinemann, London. KENDALL, M. G. (1973), Entropy, Probability and Information, Int. Stat. Rev., Vol 41, No 1, 59-68. KISH, L. (1965), Survey Sampling, John Wiley, New York. KULLBACK, S. and LEIBLER, R. A. (1951), On Information and Sufficiency, Ann. Math. Statist., 22, 525-540. KULLBACK, S. (1968), Information Theory and Statistics, New York, Dover Press. LINDLEY, D.V. (1971), Bayesian Statistics - A Review, SIAM, Philadelphia, Second printing 1978. LINDLEY, D. V. & SMITH, A. F. M. (1972), Bayes Estimates for the Linear Model, J. Royal Stat. Soc., B, 34, 1-42. LINDLEY, D.V. (1978), The Bayesian Approach, Scand. J. Sttatist., 5, 1-26. MENDONÇA, Isabel G. S. Furtado de & MIGON, Helio S. (1987), Pesquisa Eleitoral: Uma Analise Bayesiana, R. Bras. Estat., Rio de Janeiro, V. 48, No 89/190, 25-34. MIGON, H. S.,BRASIL, G. H., SOUZA, R. C. & SANT'ANNA, A. P. (1986), Relatório Sobre Pesquisas Eleitorais no Estado do Rio de Janeiro utilizando a Metodologia Bayesiana, [Texto não publicado]. MOSER, C. A, and Kalton, G. (1971), Survey methods in Social Investigation, 2nd Ed., Heinemann, London. NUNES, M. C. (2002), O papel das Pesquisas, In FIGUEIREDO, Rubens (organizador), 2002, Marketing Político e Persuasão Eleitoral, 2a edição, Fundação Konrad Adenauer, Rio de Janeiro. O’MUIRCHEARTAIGH, Colm and LYNN, Peter (1977), Editorial: The 1997 UK Pre-election Polls, J. R. Statist. Soc. A.,160, part 3, pp. 381-388. RAJ, D. (1972), The Design of Sample Surveys, McGraw Hill. RITA, Chico Santa (2002), Batalhas Eleitorais: 25 anos de Marketing Político, 3a edição, Geração Editorial, São Paulo. SANCHEZ, Homero Icaza , SMITH, A. F. M. (1973), A General Bayesian Linear Model, J. R. S. S., Series B, 35 (1), 67-73. SMITH, T. M. F. (1996), Public Opinion Polls; the UK General Election, 1992, J. R. Statist. Soc. A.,159, part 3, pp. 535-545. SOUZA, R. C. & BRASIL, G. H. (1989), A Bayesian model to Forecast an Election Outcome: An Application to the Brazilian States Elections of 1986, Estadistica, 41, 136, 13-30.

27 a 30/09/05, Gramado, RSPesquisa Operacional e o Desenvolvimento Sustentável
2784
SOUZA, Jorge de (1990), Pesquisa Eleitoral - Críticas e Técnicas, Gráfica do Senado Federal, Brasília, 1990. STIGLER, S. M. (1996), The history of statistics in 1933, Statistical Science, Vol 11, No 3, 244-252, 1996. THIOLLENT, Michel (1989), Pesquisa Eleitorais em debate na imprensa, Cortez Editora, São Paulo, 1989.





























