
Uma abordagem para a escolha do melhorMétodo de Seleção de Instâncias usando
meta-aprendizagem
Por
Shayane de Oliveira Moura
Dissertação de Mestrado
Universidade Federal de Pernambuco
www.cin.ufpe.br/~posgraduacao
Recife, 2015

Universidade Federal de PernambucoCentro de InformáticaPós-graduação em Ciência da Computação
Shayane de Oliveira Moura
Uma abordagem para a escolha do melhor Método deSeleção de Instâncias usando meta-aprendizagem
Este trabalho foi apresentado à Pós-graduação em Ci-
ência da Computação do Centro de Informática da
Universidade Federal de Pernambuco como requisito
parcial para obtenção do grau de Mestre em Ciência
da Computação.
Orientador: George Darmiton da Cunha Cavalcanti
Recife, 2015

Catalogação na fonte
Bibliotecária Jane Souto Maior, CRB4-571
M929a Moura, Shayane de Oliveira Uma abordagem para a escolha do melhor método de seleção
de instâncias usando meta-aprendizagem / Shayane de Oliveira Moura. – Recife: O Autor, 2015.
107 f.: il., fig., tab. Orientador: George Darmiton da Cunha Cavalcanti. Dissertação (Mestrado) – Universidade Federal de
Pernambuco. CIn, Ciência da computação, 2015. Inclui referências.
1. Inteligência artificial. 2. Aprendizagem de máquinas. I. Cavalcanti, George Darmiton da Cunha (orientador). II. Título. 006.3 CDD (23. ed.) UFPE- MEI 2015-162

Dissertação de Mestrado apresentada por Shayane de Oliveira Moura à Pós-Graduação
em Ciência da Computação do Centro de Informática da Universidade Federal de Per-
nambuco, sob o título Uma abordagem para a escolha do melhor Método de Seleção
de Instâncias usando meta-aprendizagem, orientada pelo Prof. George Darmiton
da Cunha Cavalcanti e aprovada pela Banca Examinadora formada pelos professores:
———————————————————————–
Prof. Cleber Zanchettin
Centro de Informática/UFPE
———————————————————————–
Profa. Rita Maria da Silva Julia
Faculdade de Computação / UFU
———————————————————————–
Prof. George Darmiton da Cunha Cavalcanti
Centro de Informática/UFPE
Visto e permitida a impressão.
Recife, 21 de agosto de 2014
—————————————————————————————
Profa. Edna Natividade da Silva Barros
Vice-Coordenador da Pós-Graduação em Ciência da Computação do
Centro de Informática da Universidade Federal de Pernambuco.

Dedico:
À minha mãe, Maria Eunice de Oliveira Moura;
Às minhas irmãs: Charmenha (In memoriam),
Charmile, Charlene e Charline;
Ao meu pai, João Antonio de Moura.
Aos meus sobrinhos: Shayná, Sabrina, Cauã, Lucas e
Laura.
Às minhas tias, às minhas primas, às minhas
Oliveiras!

Agradecimentos
À Deus, pelo desafio da vida, pelo dom de aprender, pelas vitórias já alcançadas e
por me permitir crescer todos os dias.
À UFPE e aos seus professores, pela oportunidade e por todo o aprendizado profis-
sional e pessoal adquirido ao longo desses anos.
Em especial ao professor George Darmiton. Conhecer e trabalhar com você é um
prazer. Com muita competência, sabe ser exigente na medida certa, instigar a busca
por conhecimentos e direcionar bem os seus alunos. É paciente, bem humorado,
cordial, ético, você é exemplar, professor!
Aos professores Cleber Zanchettin e Rita Silva Julia, pela participação na banca de
avaliação deste trabalho e pelas ótimas contribuições fornecidas.
Ao IF Sertão - PE, Campus Ouricuri e a todos os profissionais dessa instituição da
qual tenho orgulho em fazer parte. Obrigada pelo apoio à minha qualificação e ao
apoio financeiro. Espero saber compensar o incentivo!
Ao professor Ágio Felipe, pelo incentivo para eu fazer esse mestrado. Tenho grande
admiração por você como pessoa e como professor.
À Marcelo Bassani e a Halisson Alberdan, pela parceria na realização de todos os
experimentos, pelos ensinamentos que tanto me ajudaram e pela amizade construída.
A participação de vocês foi essencial neste trabalho.
Aos colegas de disciplina, de noites em claro para fazer listas e projetos, aos amigos
que sem os quais esse mestrado não teria sido tão divertido: Leandro Henrique
Espíndola, Davi Hirafuji, Halisson Alberdan e Marcelo Bassani.
À Lorena Brizza e a Crislene Paixão, por todas as broncas, as brincadeiras, a amizade
sincera e por me permitir ter mais um lar, ganhei mais uma família, como as outras
adquiridas onde a vida já me levou e que eu guardo com tanto amor!
Aos meus amigos de sempre, àqueles que fazem eu me sentir segura, que estão
sempre comigo para o que der e vier e que me fazem acreditar que conseguirei tudo:
Iulanda Nascimento, Sherly Gabriela, Tamiris Santos, família Gama, Enilce Lima,
Marla Maria Ms, Elizângela Sousa, Karine Vasconcelos, Nadjane Lopes, Joselha Mateus,
Raquel Brígido, Lyrane Brito, Sâmmia Alcântara, Débora Farias, Ana Marina Lemos, ...
enfim, que esses representem todos os amigos que sabem que meu amor é recíproco.
Ao mestrado, não apenas pelo crescimento, como também, pelos amigos que me
trouxe: além de todos os já agradecidos acima, Luma Seixa, Alysson Bispo, Francisco
Kbça, Peter Keays, Elizane Moraes, Renata da Hora, Leonardo Dorneles, Alysson José,
Jesús Pavón, Ammis Sánchez, Jean Teixeira, Maria Clara Bezerra, Anderson Elias,
George Gomes, porteiros do INOCOOP...
Ao mestrado. Obrigada mestrado, por me fazer conhecer Antonio Jorge Fontenele
Neto, que durante esse percurso foi Jorge, Antonio, Tonho, Neto e agora é meu Tonho!

Ao meu Tonho pelo mestrado! Em qual segundo desse período não estivemos
juntos? O nosso Recife! Quantas ideias, angústias, alegrias, tarefas, desafios, experi-
ências novas, momentos incríveis nós compartilhamos! Meu Tonho, muito obrigada
principalmente nesta etapa final, por ter acompanhado a minha rotina, pela força,
pelo amor, por trabalharmos juntos e conseguirmos tantas coisas. Você é sensacional!
Obrigada mestrado e Recife por fazer essa amizade se tornar um amor tão especial!
Amo você, Tonho!
Por fim, à família Oliveira! Como é maravilhoso fazer parte de vocês! Como é
bom saber que vocês são o meu maior exemplo de amor, honestidade, amizade,
compreensão, união, luta e vitória. Mãe, Charmenha (In memoriam), Charmile,
Charlene, Charline e pai, obrigada por ajudarem a me construir, vocês me ensinam
todo dia a ter coragem, fé e amor.

Repito por pura alegria de viver:
a salvação é pelo risco, sem o qual a vida não vale a pena!
—CLARICE LISPECTOR

Resumo
Os sistemas de Descoberta de Conhecimentos em Bases de Dados (mais conheci-
dos como sistemas KDD) e métodos de Aprendizagem de Máquinas preveem situações,
agrupam e reconhecem padrões, entre outras tarefas que são demandas de um mundo
no qual a maioria dos serviços está sendo oferecido por meio virtual. Apesar dessas
aplicações se preocuparem em gerar informações de fácil interpretação, rápidas e
confiáveis, as extensas bases de dados utilizadas dificultam o alcance de precisão
unida a um baixo custo computacional. Para resolver esse problema, as bases de
dados podem ser reduzidas com o objetivo de diminuir o tempo de processamento e
facilitar o seu armazenamento, bem como, guardar apenas informações suficientes e
relevantes para a extração do conhecimento. Nesse contexto, Métodos de Seleção de
Instâncias (MSIs) têm sido propostos para reduzir e filtrar as bases de dados, selecio-
nando ou criando novas instâncias que melhor as descrevam. Todavia, aqui se aplica
o Teorema do No Free Lunch, ou seja, a performance dos MSIs varia conforme a base e
nenhum dos métodos sempre sobrepõe seu desempenho aos demais. Por isso, esta
dissertação propõe uma arquitetura para selecionar o “melhor” MSI para uma dada
base de dados (mais adequado em relação à precisão), chamada Meta-CISM (Meta-
learning for Choosing Instance Selection Method). Estratégias de meta-aprendizagem
são utilizadas para treinar um meta-classificador que aprende sobre o relacionamento
entre a taxa de acerto de MSIs e a estrutura das bases. O Meta-CISM utiliza ainda
reamostragem e métodos de seleção de atributos para melhorar o desempenho do
meta-classificador. A proposta foi avaliada com os MSIs: C-pruner, DROP3, IB3, ICF e
ENN-CNN. Os métodos de reamostragem utilizados foram: Bagging e Combination
(método proposto neste trabalho). Foram utilizados como métodos de seleção de
atributos: Relief-F, CFS, Chi Square Feature Evaluation e Consistency-Based Subset
Evaluation. Cinco classificadores contribuíram para rotular as meta-instâncias: C4.5,
PART, MLP-BP, SMO e KNN. Uma MLP-BP treinou o meta-classificador. Os experi-
mentos foram realizados com dezesseis bases de dados públicas. O método proposto
(Meta-CISM) foi melhor que todos os MSIs estudados, na maioria dos experimentos
realizados. Visto que eficientemente seleciona um dos três melhores MSIs em mais de
85% dos casos, a abordagem é adequada para ser automaticamente utilizada na fase
de pré-processamento das base de dados.
Palavras-chave: Aprendizagem de Máquinas. Mineração de Dados. Meta-aprendizagem.
Métodos de Seleção de Instâncias (MSI). Meta-CISM.

Abstract
The systems for Knowledge Discovery in Databases (better known as KDD systems)
and Machine Learning methods predict situations, recognize and group (cluster) pat-
terns, among other tasks that are demands of a world in which the most of the services
is being offered by virtual ways. Although these applications are concerned in gene-
rate fast, reliable and easy to interpret information, extensive databases used for such
applications make difficult achieving accuracy with a low computational cost. To solve
this problem, the databases can be reduced aiming to decrease the processing time
and facilitating its storage, as well as, to save only sufficient and relevant information
for the knowledge extraction. In this context, Instances Selection Methods (ISMs) have
been proposed to reduce and filter databases, selecting or creating new instances that
best describe them. Nevertheless, No Free Lunch Theorem is applied, that is, the ISMs
performance varies according to the base and none of the methods always overco-
mes their performance over others. Therefore, this work proposes an architecture to
select the "best"ISM for a given database (best suited in relation to accuracy), called
Meta-CISM (Meta-learning for Choosing Instance Selection Method). Meta-learning
strategies are used to train a meta-classifier that learns about the relationship between
the accuracy rate of ISMs and the bases structures. The Meta-CISM still uses resam-
pling and feature selection methods to improve the meta-classifier performance. The
proposal was evaluated with the ISMs: C-pruner, DROP3, IB3, ICF and ENN-CNN.
Resampling methods used were: Bagging and Combination (method proposed in this
work). The Feature Selection Methods used were: Relief-F, CFS, Chi Square Feature
Evaluation e Consistency-Based Subset Evaluation. Five classifiers contributed to label
the meta-instances: C4.5, PART, MLP-BP, SMO e KNN. The meta-classifier was trained
by a MLP-BP. Experiments were carried with sixteen public databases. The proposed
method (Meta-CISM) was better than all ISMs studied in the most of the experiments
performed. Since that efficiently selects one of the three best ISMs in more than 85%
of cases, the approach is suitable to be automatically used in the pre-processing of the
databases.
Keywords: Machine Learning. Data Mining. Meta-learning. Instance Selection
Method (ISM). Meta-CISM

Lista de Figuras
2.1 Estrutura de uma árvore de decisões. A partir do melhor atributo, os
dados são divididos, um novo atributo é escolhido, até que um critério de
parada seja satisfeito e as classes estejam representadas nas folhas. . . . . . 30
2.2 Classificação de uma instância desconhecida com KNN. O conjunto T é
usado para classificar uma instância desconhecida x, com a classe c1 ou c2,
por voto majoritário. Para k = 3, a instância é classificada como pertencente
à classe c2. Para k = 5, a instância é classificada com a classe c1. E para k = 7,
a instância é novamente classificada como pertencente à classe c2. Isso
mostra a influência da escolha do valor de k no algoritmo KNN. . . . . . . . 32
2.3 Neurônio Artificial. O Combinador linear (∑
) faz a soma ponderada dos
sinais de entrada do neurônio ( f1, f2, . . . , fn), multiplicados pelos seus
respectivos pesos (w1, w2, . . . , wn), com o Limiar de ativação (θ). Caso
o potencial de ativação (u), resultado do somatório, seja positivo, produz
um potencial excitatório, caso negativo, produz um potencial inibitório. O
potencial de ativação é limitado pela função de ativação (g ) para gerar a
saída do neurônio (y). Fonte: Adaptado de SILVA; SPATTI; FLAUZINO (2010) 33
2.4 Multilayer Perceptron - MLP. Possui uma camada de entrada LE com
N1, . . . , Np neurônios correspondentes às variáveis de entrada de cada
exemplo a ser mostrado para a rede. Em seguida, as camadas escondi-
das L1, . . . ,L j podem ter quantidades de neurônios diferentes(Nq , Nr
), a
depender da topologia escolhida para a rede. E a última camada é a ca-
mada de saída LS que tem um neurônio para cada saída possível da MLP
(N1, . . . , Ns). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.5 Exemplo de como PART constrói uma árvore de decisões parcial. Está-
gio 1 - um teste divide as instâncias em nós (em cinza porque não foram
expandidos ainda). Estágio 2 - O nó 3 com menor entropia é expandido.
Estágio 3 - o nó com menor entropia é uma folha (preto), então começa
o retrocesso a partir da expansão do nó 5. Estágio 4 - a expansão do nó
5 gera apenas folhas, desse modo, inicia-se a poda da árvore. O nó 5 e o
nó 3 viram folhas. Estágio 5 - continua o retrocesso e o próximo nó com
menor entropia é o 4, que é expandido em folhas, mas não obedece à regra
de substituição da subárvore. A construção da árvore de decisões parcial
encerra com 3 folhas em 5 estágios. Fonte: FRANK; WITTEN (1998) . . . . 38
2.6 Separação de duas classes com hiperplanos. Uma base de dados com
classes linearmente separáveis tem suas classes facilmente distintas com
várias possibilidades de hiperplanos. . . . . . . . . . . . . . . . . . . . . . . . . 40

2.7 Hiperplano aleatório separativo de duas classes. Um hiperplano esco-
lhido aleatoriamente pode errar ao classificar novos exemplos. . . . . . . . 40
2.8 Hiperplano a partir de uma SVM. Um hiperplano escolhido por uma SVM
procura estar equidistante das classes e possuir a maior margem possível
(mg ), diminuindo a possibilidade de erro de classificação. . . . . . . . . . . 41
2.9 Mudança de dimensão e separação linear de conjuntos não linearmente
separáveis. As figuras a) e c) representam os conjuntos em suas dimensões
originais de classes não-linearmente separáveis, unidimensional e bidi-
mensional, respectivamente. Em em b) e d) a mudança de dimensão de
a) e c) para 2 dimensões e 3 dimensões, respectivamente, torna possível a
separação linear de suas classes. . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.10 Restrições dos multiplicadores de Lagrange. As restrições de desigual-
dade fazem os multiplicadores pertencerem a uma caixa. Enquanto a res-
trição de igualdade linear faz pertencerem a uma linha diagonal. Portanto,
um passo do SMO deve encontrar um ponto ótimo da função objetivo
sobre um segmento de linha diagonal. Fonte: PLATT (1999) . . . . . . . . . 47
2.11 Base de dados antes e depois da aplicação de um MSI. Antes de aplicar
um método de seleção de instâncias (MSI), a base pode ter ruídos, instân-
cias irrelevantes e não distinguir bem as classes, após a aplicação de um
MSI a base tende a se tornar mais sucinta e ao mesmo tempo mais eficiente. 57
2.12 Modelo do processo de seleção de características com validação. Inici-
almente, os subconjuntos são gerados e em seguida avaliados, até que
obedeçam o critério de parada e sigam para validação. Fonte: DASH; LIU
(1997) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
3.1 Processo de construção da Meta-base e treinamento do meta-classificador.
Cada base de dados é submetida à fase de reamostragem para aumentar
o número de bases de dados disponíveis. Cada nova base de dados passa
pelos processos de Extração de características e Anotação para tornar-se
uma meta-instância. A meta-base resultante pode ser reduzida pelo pro-
cesso de Seleção de Características. Em seguida, é usada para treinar o
meta-classificador F. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3.2 Módulo de Anotação. Cada base de dados Γi j é reduzida por N diferentes
MSIs e as precisões das bases de dados resultantes Ωl são calculadas como
a média dos M classificadores cm. O rótulo é o MSI com a maior média de
precisão. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87

3.3 Avaliação do Meta-classificador. Cada base de dados de teste tem suas
meta-características extraídas. A quantidade de meta-características pode
ser reduzida se o módulo de seleção de atributos for utilizado. Finalmente,
são submetidas ao meta-classificador treinado F para obter o MSI mais
adequado para a base de dados de entrada ∆. . . . . . . . . . . . . . . . . . . 88
4.1 Parâmetro K para KNN. Taxas de acerto com barras de erro para cada
meta-base em relação a cada valor de K. . . . . . . . . . . . . . . . . . . . . . . 92
4.2 Camadas escondidas para MLP-BP (meta-base mbBagging ). Com a meta-
base mbBagging, é exibida a influência da quantidade neurônios em uma
camada escondida sobre a taxa de acerto, a partir das possíveis variações
de taxa de aprendizado e momento. . . . . . . . . . . . . . . . . . . . . . . . . 93
4.3 Camadas escondidas para MLP-BP (meta-base mbCombination). Com
a meta-base mbCombination, é exibida a influência da quantidade neurô-
nios em uma camada escondida sobre a taxa de acerto, a partir das possí-
veis variações de taxa de aprendizado e momento. . . . . . . . . . . . . . . . 94
4.4 Camadas escondidas para MLP-BP (meta-base mbBaggingCombination).
Com a meta-base mbBaggingCombination, é exibida a influência da quan-
tidade de neurônios em uma camada escondida sobre a taxa de acerto, a
partir das possíveis variações de taxa de aprendizado e momento. . . . . . 95
4.5 Taxa de aprendizado e momento para MLP-BP. Taxas de acerto individu-
ais e média das taxas de acerto de todas as meta-bases, por combinação de
taxa de aprendizado com momento, para indicação da combinação mais
adequada a ser utilizada na MLP-BP. . . . . . . . . . . . . . . . . . . . . . . . . 96
4.6 Avaliação de meta-classificadores. Taxas de acerto dos meta-classificadores:
KNN, MLP-PB, PART e C4.5 sobre as meta-bases: mbBagging, mbCombina-
tion e mbBaggingCombination . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.7 Algoritmos de busca para Consistency-based Subset Evaluation. Taxas
de acerto do meta-classificador MLP-BP para as meta-bases: mbBagging,
mbCombination e mbBaggingCombination, aplicadas ao método de sele-
ção de atributos Consistency-based Subset Evaluation com os algoritmos
de busca: Best First Search e Genetic Search. . . . . . . . . . . . . . . . . . . . 98
4.8 Algoritmos de busca para Correlation-based Feature Selection - CFS. Ta-
xas de acerto do meta-classificador MLP-BP para as meta-bases: mbBag-
ging, mbCombination e mbBaggingCombination, aplicadas ao método
de seleção de atributos Correlation-based Feature Selection - CFS com os
algoritmos de busca: Best First Search e Genetic Search. . . . . . . . . . . . . 99

4.9 Taxas de acerto relativas às variações do número de atributos no ran-
king para Chi Square Feature Evaluation. Taxas de acerto do meta-classificador
MLP-BP para as meta-bases: mbBagging, mbCombination e mbBagging-
Combination, aplicadas ao método de seleção de atributos Chi Square
Feature Evaluation com variação do número de atributos no ranking de 1
a 30. Os pontos em destaque correspondem às quantidades de atributos
escolhidas para cada meta-base. . . . . . . . . . . . . . . . . . . . . . . . . . . 100
4.10 Taxas de acerto relativas às variações do número de atributos no ran-
king para Relief - F . Taxas de acerto do meta-classificador MLP-BP para as
meta-bases: mbBagging, mbCombination e mbBaggingCombination, apli-
cadas ao método de seleção de atributos Relief - F com variação do número
de atributos no ranking de 1 a 30. Os pontos em destaque correspondem
às quantidades de atributos escolhidas para cada meta-base. . . . . . . . . 100
4.11 Histograma das meta-caracteríticas selecionadas pelos Métodos de Se-
leção de Atributos. Frequência de escolha de cada meta-característica
(no range de 0 a 12), considerando a soma dos resultados de cada meta-
base (mbBagging, mbCombination e mbBaggingCombination) submetida
a todos os Métodos de Seleção de Atributos (Consistency-based Subset Eva-
luation com Best First Search, Correlation-based Feature Selection - CFS
com Genetic Search, Chi Square Feature Evaluation e Relief - F ) . . . . . . . 101
4.12 Taxas de acerto alcançadas com o uso de métodos de seleção de atribu-
tos sobre a meta-base mbBagging . Resultado dos classificadores sobre
a meta-base mbBagging quando submetida aos quatro métodos de sele-
ção de atributos (Consistency-based Subset Evaluation, Correlation-based
Feature Selection - CFS, Chi Square Feature Evaluation e Relief - F ). . . . . . 103
4.13 Taxas de acerto alcançadas com o uso de métodos de seleção de atribu-
tos sobre a meta-base mbCombination. Resultado dos classificadores so-
bre a meta-base mbCombination quando submetida aos quatro métodos
de seleção de atributos (Consistency-based Subset Evaluation, Correlation-
based Feature Selection - CFS, Chi Square Feature Evaluation e Relief - F ). . 104
4.14 Taxas de acerto alcançadas com o uso de métodos de seleção de atribu-
tos sobre a meta-base mbBaggingCombination. Resultado dos classifi-
cadores sobre a meta-base mbBaggingCombination) quando submetida
aos quatro métodos de seleção de atributos (Consistency-based Subset
Evaluation, Correlation-based Feature Selection - CFS, Chi Square Feature
Evaluation e Relief - F ). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104

4.15 Desempenho de Meta-CISM sem seleção de atributos para a meta-base
mbBagging. O gráfico apresenta as médias dos resultados de precisão
dos MSIs estudados e de Meta-CISM para as bases de dados geradas por
Bagging, separadas por classificador. . . . . . . . . . . . . . . . . . . . . . . . . 106
4.16 Desempenho de Meta-CISM sem seleção de atributos para a meta-base
mbCombination. O gráfico apresenta as médias dos resultados de precisão
dos MSIs estudados e de Meta-CISM para as bases de dados geradas por
Combination, separadas por classificador. . . . . . . . . . . . . . . . . . . . . 107
4.17 Desempenho de Meta-CISM sem seleção de atributos para a meta-base
mbBaggingCombination. O gráfico apresenta as médias dos resultados de
precisão dos MSIs estudados e de Meta-CISM para para as bases de dados
geradas por Bagging e Combination juntas, separadas por classificador. . . 107
4.18 Taxas de ranking de Meta-CISM sem seleção de atributos para a meta-
base mbBagging. Os MSIs foram ordenados em ranking pela média das
precisões dos classificadores para cada base, a fim de mostrar com que
frequência o Meta-CISM escolhe os melhores MSIs. O gráfico apresenta o
ranking das bases correspondentes à meta-base mbBagging. . . . . . . . . 110
4.19 Taxas de ranking de Meta-CISM sem seleção de atributos para a meta-
base mbCombination. Os MSIs foram ordenados em ranking pela média
das precisões dos classificadores para cada base, a fim de mostrar com que
frequência o Meta-CISM escolhe os melhores MSIs. O gráfico apresenta o
ranking das bases correspondentes à meta-base mbCombination. . . . . . 111
4.20 Taxas de ranking do Meta-CISM sem seleção de atributos para a meta-
base mbBaggingCombination. Os MSIs foram ordenados em ranking pela
média das precisões dos classificadores para cada base, a fim de mostrar
com que frequência o Meta-CISM escolhe os melhores MSIs. O gráfico
apresenta o ranking das bases correspondentes à meta-base mbBagging-
Combination. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4.21 Desempenho do Meta-CISM com seleção de atributos para a meta-base
mbBagging. O gráfico apresenta a média dos resultados de precisão do
Meta-CISM com e sem o módulo de seleção de atributos, separadas por
classificador, para as bases de dados geradas por Bagging. . . . . . . . . . . 113
4.22 Desempenho do Meta-CISM com seleção de atributos para a meta-base
mbCombination. O gráfico apresenta a média dos resultados de precisão
do Meta-CISM com e sem o módulo de seleção de atributos, separadas por
classificador, para as bases de dados geradas por Combination. . . . . . . . 114

4.23 Desempenho do Meta-CISM com seleção de atributos para a meta-base
mbBaggingCombination. O gráfico apresenta a média dos resultados de
precisão do Meta-CISM com e sem o módulo de seleção de atributos,
separadas por classificador, para as bases de dados geradas por mbBag-
gingCombination. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114

Lista de Tabelas
2.1 Características dos métodos de seleção de atributos utilizados . . . . . . . . 72
3.1 Medidas de caracterização dos dados . . . . . . . . . . . . . . . . . . . . . . . 86
4.1 Informações das bases de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.2 Quantidade de neurônios para primeira camada escondida de uma MLP-BP 93
4.3 Atributos selecionados por cada Método de Seleção de Atributos . . . . . . 102
4.4 Médias de precisão para cada MSI avaliados por cinco classificadores
(meta-base mbBagging ). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.5 Médias de precisão para cada MSI avaliados por cinco classificadores
(meta-base mbCombination). . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.6 Médias de precisão para cada MSI avaliados por cinco classificadores
(meta-base mbBaggingCombination). . . . . . . . . . . . . . . . . . . . . . . 106
4.7 Teste de Friedman para os resultados do Meta-CISM e demais MSIs estuda-
dos, aplicados às meta-bases mbBagging, mbCombination e mbBagging-
Combination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.8 Teste de Wilcoxon comparando Meta-CISM × MSIs . . . . . . . . . . . . . . . 109
4.9 Teste de Holm-Bonferroni comparando Meta-CISM × MSIs . . . . . . . . . 110
4.10 Comparação das médias de precisão do Meta-CISM com e sem o módulo
de seleção de atributos (meta-base mbBagging ). . . . . . . . . . . . . . . . . 112
4.11 Comparação das médias de precisão do Meta-CISM com e sem o módulo
de seleção de atributos (meta-base mbCombination). . . . . . . . . . . . . . 112
4.12 Comparação das médias de precisão do Meta-CISM com e sem o módulo
de seleção de atributos (meta-base mbBaggingCombination). . . . . . . . 113
4.13 Teste de Friedman para os resultados do Meta-CISM com a aplicação de
Métodos de Seleção de Atributos nas meta-bases mbBagging, mbCombina-
tion e mbBaggingCombination. . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.14 Redução do tempo para o cálculo das meta-características com o uso do
Módulo de Seleção de Atributos . . . . . . . . . . . . . . . . . . . . . . . . . . . 116

Lista de Acrônimos
AM Aprendizagem de Máquina
CFS Consistency-based Subset Evaluation
CNN Condensed Nearest Neighbor
DM Data Mining
DROP3 Decremental Reduction Optimization Procedure 3
ENN Edited Nearest Neighbor
HVDM Heterogeneous Value Difference Metric
IB3 Instance Based 3
ICF Iterative Caise Filtering
KBIS Knowledge-base IS
KDD Knowledge Discovery in Databases
KKT Condições Karush-Kuhn-Tucker
KNN K Nearest Neighbors
META-CISM Meta-learning for Choosing Instance Selection Method
MLP-BP Multilayer Perceptron com Backpropagation
MSA Método de Seleção de Atributos
MSI Método de Seleção de Instâncias
RNA Rede Neural Artificial
SA Sistemas de Aprendizagem
SMO Sequential Minimal Optimization
SVM Support Vector Machine

Sumário
1 Introdução 20
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.2 Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.3 Estrutura do documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2 Conceitos básicos 25
2.1 Aprendizagem de máquinas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.2 Classificação de Padrões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2.1 C4.5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2.2 K - Nearest Neighbor (KNN) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.2.3 Multilayer Perceptron - MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.2.4 PART . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.2.5 Sequential Minimal Optimization (SMO) . . . . . . . . . . . . . . . . . . . . 39
2.3 Meta-aprendizagem e caracterização de dados . . . . . . . . . . . . . . . . 50
2.4 Métodos de seleção de instâncias . . . . . . . . . . . . . . . . . . . . . . . . 56
2.4.1 ENN-CNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
2.4.2 Instance Based 3 - IB3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
2.4.3 Decremental Reduction Optimization Procedure 3 - DROP3 . . . . . . . . 63
2.4.4 Iterative Caise Filtering - ICF . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.4.5 C-pruner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
2.5 Métodos de seleção de atributos . . . . . . . . . . . . . . . . . . . . . . . . . 69
2.5.1 Consistency-based Subset Evaluation . . . . . . . . . . . . . . . . . . . . . . 72
2.5.2 Correlation-based Feature Selection - CFS . . . . . . . . . . . . . . . . . . . 73
2.5.3 Chi Square Feature Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 74
2.5.4 Relief - F . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.6 Métodos de reamostragem . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
2.6.1 Bagging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
2.7 Trabalhos relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
3 Meta-CISM
Meta-learning for Choosing Instance Selection Method 79
3.1 Geração do meta-classificador F . . . . . . . . . . . . . . . . . . . . . . . . 80
3.1.1 Reamostragem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.1.1.1 Proposta de reamostragem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3.1.2 Geração de meta-instância . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.1.3 Seleção de atributos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
3.1.4 Treinamento do meta-classificador . . . . . . . . . . . . . . . . . . . . . . . . 88

3.2 Avaliação do meta-classificador F . . . . . . . . . . . . . . . . . . . . . . . . 88
4 Estudo Experimental 89
4.1 Bases de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.2 Configurações para o Módulo de Anotação . . . . . . . . . . . . . . . . . . 91
4.3 Meta-classificadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.3.1 Configuração de parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.3.1.1 Parâmetros para KNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.3.1.2 Parâmetros para MLP-BP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.3.2 Avaliação dos meta-classificadores . . . . . . . . . . . . . . . . . . . . . . . . 96
4.4 Métodos de seleção de atributos . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.4.1 Configuração de parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.4.2 Avaliação dos métodos de seleção de atributos . . . . . . . . . . . . . . . . . 103
4.5 Avaliação do Meta-CISM sem seleção de atributos . . . . . . . . . . . . . . 105
4.6 Avaliação do Meta-CISM com seleção de atributos . . . . . . . . . . . . . . 112
4.7 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
5 Conclusões 119
5.1 Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
5.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
Referências 122

202020
1Introdução
1.1 Motivação
Ao abrirmos e-mails, redes sociais ou quando apenas nos conectamos à internet,
recebemos, adicionalmente, recomendações de leituras, compras, pessoas a curtir,
jogos e muitas outras propostas que nos impressionam porque, na maioria das vezes,
tais recomendações são exatamente o que nos interessa. O sistema parece nos conhe-
cer. E de fato, ele nos conhece. A cada clique, geramos informações que são guardadas
e analisadas para gerar o nosso perfil. Entregamos informações suficientes para traçar
um perfil do que nós somos de acordo com o foco do sistema, seja comportamento,
gostos, consumo, etc.
Outra situação curiosa envolve organizações que precisam analisar as tendências
políticas, sociais e econômicas. Por exemplo, empresas que precisam tomar decisões
de negócios, avaliar clientes ou procurar possíveis clientes. Essas empresas usam a tec-
nologia para identificar os padrões de consumo, analisam os perfis, procuram padrões
e tendências a partir de dados de outras empresas, dados históricos, econômicos e
resultados anteriores de suas próprias ações. Sistemas de segurança também estão
aliados à tecnologia para guardar informações, dar permissões, auxiliar investigações,
como no caso do uso de câmeras para reconhecer pessoas e observar situações sus-
peitas. Na medicina, investigações sobre doenças, com o uso da teconologia para
analisar sintomas, também têm trazido grandes avanços ao setor.
Essas situações são algumas de muitas que têm em comum a formação de grandes
bases de dados e o uso dessas em Processos de Descoberta de Conhecimento em
Bases de Dados, em inglês, Knowledge Discovery in Databases - KDD. Um campo
multidisciplinar que envolve: aprendizado de máquinas, reconhecimento de padrões,
banco de dados, estatística, sistemas especialistas, entre outros. Os processos KDD
estão em evidência pela vasta aplicação em um mundo no qual a maioria dos serviços
está sendo oferecido com facilidade, conforto e segurança, por meio virtual. Assim, a

1.1. MOTIVAÇÃO 21
abundância de dados disponíveis e as informações que estes dados podem fornecer
não podem deixar de ser aproveitadas. Bases de dados são formadas e submetidas aos
processos KDD para extração do conhecimento implícito nos dados, úteis à descoberta
de padrões e tomadas de decisões. Um processo KDD possui etapas interligadas
que podem ocorrer em um ciclo iterativo: consolidação dos dados, seleção e pré-
processamento, mineração de dados (Data Mining ) e interpretação.
Mineração de dados é uma etapa normalmente confundida com o processo com-
pleto de KDD. No entanto, essa etapa corresponde à aplicação de uma técnica (geral-
mente de aprendizagem de máquinas) que descobrirá padrões nos dados. O tempo
de processamento e a precisão dos resultados da Mineração de dados são os fatores
mais importantes para a obtenção de bons resultados do processo KDD. Tempo e
precisão estão diretamente ligados à qualidade dos dados trazidos pela etapa anterior:
seleção e pré-processamento. Na etapa de seleção e pré-processamento, os dados são
submetidos a técnicas capazes de melhorar o subconjunto de exemplos e transformar
os dados para adequá-los ao processo de mineração a ser utilizado. Apesar de outros
contextos de aprendizagem de máquinas também disporem de grandes bases de da-
dos para tratamento, processos KDD têm sido os maiores impulsores dessas extensas
bases e da necessidade de pré-processamento delas.
Diante dessa necessidade de pré-processamento de bases de dados, surgem os
Métodos de Seleção de Instâncias (MSIs). Um Método de Seleção de Instância (MSI)
é um algoritmo de pré-processamento que busca eliminar nos dados disponíveis,
instâncias redundantes, irrelevantes e ruidosas que não ajudam ou até prejudicam o
resultado final do processo no qual serviu como pré-processamento. A redução de
uma base com um MSI pode melhorar os resultados do processo completo, reduzir o
custo computacional e reduzir a necessidade de armazenamento da base de dados.
O uso de Métodos de Seleção de Instâncias pode focar em um de dois objetivos
principais:
• manter ou melhorar a precisão final, reduzindo a base de dados o máximo
possível;
• ou, reduzir a base de dados o máximo possível, mesmo que haja uma perda
tolerável de precisão;
Mais de cem MSIs têm sido propostos nas últimas décadas GARCÍA; LUENGO;
HERRERA (2015). O problema é que cada um trata os dados de maneira diferente, e
desse modo, têm resultados finais com desempenhos diferentes. Alguns conseguem
lidar melhor com bases que possuem valores faltantes, outros com bases ruidosas,
outros apenas com duas classes, outros não são bons com atributos categóricos, ou a
distribuição espacial e estatística dos dados influencia no desempenho. E assim, a
composição da base que o algoritmo precisa reduzir influencia, tanto no resultado

1.1. MOTIVAÇÃO 22
de precisão, quanto de redução. Portanto, a performance dos MSIs varia de acordo
com as bases de dados nas quais eles são aplicados. Peculiaridades destas bases criam
ambientes que são mais adequados a alguns métodos que outros. Os trabalhos de
REINARTZ (2002), KIM; OOMMEN (2003a) e CZARNOWSKI; JEDRZEJOWICZ (2006)
corroboram que a falta de um MSI que constantemente se sobreponha aos demais,
direciona pesquisas recentes à busca de formas para definir o MSI mais adequado
para cada base de dados.
Neste trabalho, levamos em conta a precisão após a aplicação do MSI e deixamos a
análise de redução das bases de dados fora do escopo. Considerando que um algo-
ritmo de seleção de instâncias será aplicado, utilizamos MSIs de abordagens distintas,
como ENN-CNN que é uma junção do algoritmo de condensação e incremental Con-
densed Nearest Neighbor - CNN (HART, 1968) com o algoritmo de edição e decremental
Edited Nearest Neighbor - ENN (WILSON, 1972), proposto por CAISES et al. (2011). E
além desse, utilizamos métodos híbridos (em relação à condensação e edição) que se
diferenciam na direção de pesquisa: Instance Based 3 - IB3 (AHA; KIBLER; ALBERT,
1991), com direção de pesquisa incremental; C-pruner (ZHAO et al., 2003) e Decremen-
tal Reduction Optimization Procedure 3 - DROP3 (WILSON; MARTINEZ, 2000), os dois
com direção de pesquisa decremental; e Iterative Caise Filtering - ICF (BRIGHTON;
MELLISH, 2002), com direção de pesquisa em lote.
Investigamos qual dos MSIs utilizados fornece a melhor precisão. Por conseguinte,
propomos uma arquitetura para escolher o “melhor” método de seleção de instâncias
para uma nova base de dados, o Meta-CISM (Meta-learning for Choosing Instance
Selection Method).
A arquitetura proposta é baseada em meta-aprendizagem. Modelos comuns de
aprendizagem estruturam características de um problema real em forma de bases
de dados e a partir dessas aprendem o comportamento do sistema que as gerou.
Com o aprendizado, são capazes de prever os resultados do sistema em novas bases
representantes de outros problemas semelhantes. Esse é um sitema de aprendizagem
(SA). Meta-aprendizagem é o aprendizado sobre os sistemas de aprendizagem, na
qual várias bases dos SAs são estudadas.
Ao invés de modelar os problemas reais para uma base de dados, cada base que
serviu de entrada para um SA, é modelada para ser uma meta-instância de uma meta-
base a ser utilizada em outro sistema de aprendizagem. Características da estrutura
da base são extraídas para a geração de meta-características ou meta-atributos. A
denominação meta-aprendizagem se dá à aprendizagem sobre a meta-base formada.
Usando meta-aprendizagem, a arquitetura proposta aprende como os MSIs se
comportam dependendo da estrutura da base que lhe é aplicada. Para cada base de
treinamento, é obtida a indicação do MSI com “melhor” desempenho em precisão.
O sistema de meta-aprendizagem avalia a relação entre as características da base

1.2. OBJETIVO 23
(meta-características) e o MSI que tem melhor desempenho para ela (meta-classe),
identificando relações de dependência. Com o aprendizado dessa dependência entre a
estrutura da base e o MSI que “melhor” lida com ela, o sistema de meta-aprendizagem
pode prever para novas bases aquele MSI que terá a melhor precisão.
Propomos uma arquitetura que usa reamostragem na fase inicial para aumen-
tar a quantidade de bases a serem estudados e assim obter melhor generalização.
Estruturamos o sistema de meta-aprendizagem com uma fase de extração das meta-
características e outra para a obtenção das meta-classes. Verificamos as melho-
res meta-características a serem usadas no treinamento com um módulo de sele-
ção de atributos. Treinamos o meta-classificador e obtemos uma função de um
meta-classificador treinado. Indicamos ainda as etapas para o uso e teste do meta-
classificador treinado. Finalmente, analisamos os resultados dos experimentos reali-
zados e verificamos se Meta-CISM é uma boa opção para a fase de pré-processamento
de dados.
1.2 Objetivo
Esta dissertação busca contribuir com as pesquisas relacionadas ao uso de meta-
aprendizagem para a escolha de Métodos de Seleção de Instâncias (MSIs). Para este
fim, sugere uma arquitetura para a escolha automática de um MSI adequado para
uma dada base de dados, de forma a obter a melhor precisão possível. Junto a essa
arquitetura, propõe-se a apresentar os conceitos envolvidos em processos de meta-
aprendizagem e em seleção de instâncias, assim como, investigar a inclusão de outros
métodos de aprendizagem de máquinas no processo.
Mais especificamente, objetiva:
• Sugerir a arquitetura: Meta-CISM (Meta-learning for Choosing Instance Selection
Method).
• Utilizar meta-aprendizagem como meio para indicação do MSI mais apropriado
dada uma nova base de dados.
• Incluir métodos de Reamostragem para diminuir a dependência do método
proposto às grandes quantidades de bases disponíveis para treino.
• Avaliar meta-características e a utilização de Métodos de Seleção de Atributos
(MSAs) na arquitetura proposta.

1.3. ESTRUTURA DO DOCUMENTO 24
1.3 Estrutura do documento
Este documento tem a seguinte estrutura:
Capítulo 1 - Contextualiza os Métodos de Seleção de Instâncias e explica a neces-
sidade de uma abordagem para a escolha do “melhor” método a ser
aplicado. Além disso, define os objetivos do estudo e descreve a estrutura
deste documento.
Capítulo 2 - As técnicas utilizadas nos experimentos são explanadas e são apresenta-
das as premissas para entendimento da arquitetura proposta.
Capítulo 3 - A arquitetura Meta-CISM (Meta-learning for Choosing Instance Selection
Method) é apresentada.
Capítulo 4 - Os experimentos realizados são relatados e seus resultados são avaliados.
Capítulo 5 - Mostra as contribuições que este trabalho fornece às pesquisas envolvi-
das em Métodos de Seleção de Instâncias e em meta-aprendizagem. São
apresentadas as conclusões extraídas dos estudos realizados associados
aos resultados obtidos com os experimentos da arquiterura proposta. In-
dicações para pesquisas complementares também estão presentes neste
capítulo.

252525
2Conceitos básicos
Este capítulo traz uma revisão dos conceitos básicos e das principais contribuições
da literatura necessárias ao estudo proposto. Inicialmente, a Aprendizagem de Má-
quinas é apresentada na Seção 2.1. Em seguida, a Seção 2.2 especifica o estudo para
a aprendizagem supervisionada e mostra os algoritmos de classificação escolhidos.
A Seção 2.3 fornece os conceitos de meta-aprendizagem e detalha as medidas de
caracterização de dados utilizadas. A Seção 2.4 discorre sobre os métodos de seleção
de instâncias existentes e o porquê dos escolhidos para experimentação. Na Seção 2.5,
os métodos de seleção de atributos utilizados são apresentados. A Seção 2.6 define
reamostragem e explica o método Bagging executado. Enfim, a Seção 2.7 mostra
como pesquisadores vêm trabalhando na área e qual a inovação deste trabalho.
2.1 Aprendizagem de máquinas
Entre seres vivos, relacionamos a inteligência com a capacidade dos indivíduos
de aprender. Não obstante, em Inteligência Artificial, essa capacidade também tem
grande relevância e é estudada pela subárea chamada de Aprendizagem de Máquinas
(AM) (MICHALSKI, 1986).
Programadores não são capazes de prever todas as situações possíveis ou as mu-
danças ocorridas com o passar do tempo, e muitas vezes não sabem encontrar a
solução de um problema diretamente. Nesse sentido, a Aprendizagem de Máquinas é
o caminho para que os algoritmos criados sejam os próprios responsáveis por encon-
trar soluções, adaptar-se e melhorar seus desempenhos com experiências anteriores.
O objetivo da AM é criar algoritmos capazes de generalizar comportamentos para
que os sistemas saibam agir em novas situações, de acordo com um conhecimento
adquirido de forma automática.
Os conceitos abaixo são premissas para entender o funcionamento de algoritmos
de aprendizagem de máquinas:

2.1. APRENDIZAGEM DE MÁQUINAS 26
Preditor, indutor ou hipótese - é o nome dado ao algoritmo de aprendizagem de
máquinas tanto no momento da aprendizagem quanto após, na fase de utilização do
conhecimento aprendido (essa última fase é mais característica para a denominação
hipótese).
Atributos, características ou descritores - são informações extraídas de ocorrências
conhecidas do evento a ser aprendido. Cada atributo é uma característica particular
do problema. Podem ser quantitativos (grandezas numéricas, normalmente, resultan-
tes de medições) ou qualitativos (apresentam maior nível de abstração e podem ser
categóricos ou simbólicos).
Instância - é o conjunto dos atributos extraídos de cada ocorrência conhecida do
problema. Uma instância é a representação completa de um evento ocorrido.
Base de dados ou conjunto de dados - é a coleção de instâncias que servirá de base
para o algoritmo de aprendizagem entender o comportamento anterior dos eventos e
generalizar para eventos futuros.
Treinamento - o algoritmo de aprendizagem, em muitos casos, processa a base de
dados (ou parte dela) para aprender e gerar um indutor pronto para reconhecer dados
desconhecidos.
Teste - após o treinamento, instâncias de teste (podendo ser parte da base original)
são submetidas ao indutor e é verificado se esse consegue identificar a classe correta
de cada uma. Esse procedimento ajuda a analisar se o indutor conseguiu generalizar
bem.
Valores faltantes - são valores ausentes em atributos de algumas instâncias da base
de dados, normalmente ocasionados por problemas na fase de extração de caracterís-
ticas.
Ruídos - instâncias com erros e não representativas do problema, existentes por
causa de erros na fase de extração dos atributos ou rotulação da instância.
Valores atípicos (outliers) - valores que não são ruídos, ou seja, realmente represen-
tam o problema, mas, têm valores fora do padrão da classe.
Bias ou viés - como várias hipóteses podem ser capazes de modelar o conceito,

2.1. APRENDIZAGEM DE MÁQUINAS 27
é necessário que o processo tenha um critério de preferência de uma em relação a
outra, o que denominamos de bias.
Variância - mede o quanto o indutor se modifica ao ser treinado com diferentes
conjuntos de treinamento.
Estabilidade - o indutor é estável se sua variância é baixa, ou seja, não sofre muita
mudança na hipótese gerada se o conjunto de treinamento for alterado.
Sobreajustamento (overfitting) - após o treinamento o indutor não consegue ge-
neralizar bem e tem aprendizado muito específico para o conjunto de treinamento.
Engana com um bom desempenho no treino, mas depois demonstra maus resultados
no teste. Pode ser devido à base de dados ou às configurações de treinamento do
indutor.
Subajustamento (underfitting) - o desempenho é ruim tanto no treinamento
quanto no teste. Esse problema é ocasionado por causa de um conjunto de trei-
namento pequeno, pouco descritivo ou pela configuração do indutor a ser treinado.
A partir dessas premissas, são apresentadas as quatro formas para realizar a apren-
dizagem de máquinas (NORVIG; RUSSELL, 2014). Cada uma se modela para resolver
problemas diferentes.
1 - Apredizagem supervisionada: a base de dados submetida ao algoritmo possui
instâncias com um atributo especial, chamado de classe ou rótulo. Após aprender
as relações atributos-classes, o preditor se torna capaz de reconhecer a classe
de novas instâncias. Com a aprendizagem supervisionada é possível resolver
problemas de Classificação (quando o número de classes é limitado) e Regressão
(quando as classes são valores contínuos e, portanto, não têm quantidade defi-
nida).
2 - Apredizagem não-supervisionada: essa forma de aprendizagem não tem classes
predefinidas para os problemas de entrada. Assim, o algoritmo de aprendizagem
analisa como as instâncias descritoras dos problemas podem se agrupar a partir
das relações entre seus atributos. Resolvem problemas de agrupamentos, também
chamados de clusterização.
3 - Apredizagem semi-supervisionada: também utilizada em problemas de Classi-
ficação e Regressão, essa forma de aprendizagem conta com alguns exemplos

2.1. APRENDIZAGEM DE MÁQUINAS 28
rotulados e outros não, e faz inferências sobre as classes de algumas instâncias não
rotuladas para utilizá-las no treinamento do preditor e melhorar seu desempenho.
4 - Apredizagem por esforço: utilizada para tomada de decisões instantâneas. En-
quanto é operado, o algoritmo de aprendizagem realiza ações e tem a resposta se
agiu corretamente ou não. A cada resposta correta o preditor recebe um bônus
para seguir na mesma direção, enquanto decisões erradas trazem penalidades
para ajustar as decisões tomadas.
As características dos diversos tipos de algoritmos de aprendizagem de máquinas
permitem também classificá-los segundo paradigmas e modos de aprendizagem.
Quanto aos paradigmas, temos:
• Simbólico: representado principalmente por árvores e regras de decisões, esse
paradigma analisa exemplos e contra-exemplos de um conceito e constrói uma
estrutura simbólica de representação para esse conceito.
• Estatístico: um modelo estatístico é utilizado para encontrar a hipótese que
melhor representa os parâmetros do conceito induzido. Tal modelo pode ser
paramétrico (quando fazem suposição sobre a distribuição dos dados) ou não-
paramétricos (quando não fazem suposição sobre a distribuição dos dados). Os
algoritmos Baysianos fazem parte desse paradigma.
• Baseado em exemplos: supõe que instâncias da mesma classe sejam parecidas,
assim, novas instâncias são classificadas ou agrupadas de acordo com a sua
similaridade com instâncias conhecidas. O K Nearest Neighbors - KNN (COVER;
HART, 1967) é um dos principais representantes desse paradigma.
• Conexionistas: utiliza redes neurais artificiais (RNAs). Uma RNA é um modelo
computacional inspirado no sistema nervoso humano que com unidades sim-
ples de processamento interconectadas, realizam processamentos complexos
com boa performance. Exemplos de algoritmos de classificação conexionis-
tas são: Multilayer Perceptron com Backpropagation - MLP-BP (RUMELHART;
HINTON; WILLIAMS, 1986) e Self-Organizing Map - SOM (KOHONEN, 1998).
• Evolutivo: inspirado na teoria da evolução das espécies de Charles Darwing
em que apenas os mais adaptados sobrevivem, o paradigma evolucionista usa
populações de soluções que competem até que seja encontrada uma solução
ótima. OlexGA (PIETRAMALA et al., 2008) é um algoritmo evolutivo popular para
classificação de documentos.

2.2. CLASSIFICAÇÃO DE PADRÕES 29
Quanto ao modo, podemos classificar algoritmos de aprendizagem de máquinas
como incrementais ou não-incrementais. Os algoritmos incrementais atualizam a
resposta do indutor a cada novo exemplo submetido, enquanto, os não-incrementais
necessitam que toda a base de dados seja novamente submetida a cada novo exemplo.
A próxima seção discorre sobre classificação de padrões, o ramo da aprendiza-
gem supervisionada estudado nesta dissertação. Do mesmo modo, apresenta os
classificadores utilizados, de diversos paradigmas e modos de aprendizagem.
2.2 Classificação de Padrões
Em Aprendizagem de Máquinas, Reconhecimento de Padrões é o ramo que procura
replicar a capacidade humana de agrupar objetos e situações em categorias, de acordo
com as características comuns que apresentam (padrão).
Reconhecer padrões consiste em utilizar um algoritmo que extrapole o conheci-
mento fornecido por dados extraídos dos problemas, e desse modo, tenha a capaci-
dade de atribuí-los corretamente aos grupos aos quais pertencem. Sendo, principal-
mente, capaz de modelar um conceito geral desses padrões para agrupar corretamente
exemplos nunca vistos pelo processo de reconhecimento. Quando esse processo é
realizado com aprendizagem supervisionada, é chamado de Classificação.
A classificação de um padrão ocorre após o treinamento de um algoritmo classi-
ficador que é responsável por descobrir os padrões dos grupos e criar uma função
preditora ou hipótese capaz de reconhecer novas entradas.
Este trabalho utiliza algoritmos de classificação para rotular meta-instâncias e para
treinar o meta-classificador. Os classificadores utilizados pertencem a paradigmas de
aprendizado diferentes e são descritos nas seções a seguir.
2.2.1 C4.5
C4.5 (QUINLAN, 1993) é uma árvore de decisão proposta para melhorar o algoritmo
ID3 (QUINLAN, 1986). Uma Árvore de Decisão é uma técnica de aprendizagem
supervisionada, não incremental e de paradigma simbólico. Usa a estratégia “dividir
para conquistar”, ou seja, o problema é dividido em subproblemas mais simples
até que a complexidade de interpretação seja mínima. Inicialmente, um atributo é
escolhido para ser a raiz. Dessa raiz, os dados são divididos a partir de seus valores
em nós. A cada nó, um novo atributo é escolhido para dividir os dados, até que todos
os exemplos divididos pertençam a uma mesma classe, gerando folhas. Uma grande
vantagem de árvores de decisões é a geração de regras de decisões que facilitam a
classificação de instâncias desconhecidas. A Figura 2.1 mostra a estrutura de uma

2.2. CLASSIFICAÇÃO DE PADRÕES 30
árvore de decisão.
Figura 2.1: Estrutura de uma árvore de decisões. A partir do melhor atributo,os dados são divididos, um novo atributo é escolhido, até que um critério de
parada seja satisfeito e as classes estejam representadas nas folhas.
O C4.5 escolhe os melhores atributos com a medida de Razão de Ganho, segundo
(QUINLAN, 1986), melhor que a medida Ganho de Informação, usada por ID3, em
termos de precisão e complexidade. A Razão de Ganho é calculada para a escolha do
melhor atributo pela divisão entre o Ganho de Informação e a Entropia do atributo.
Outras melhoras do C4.5 em relação ao ID3, foram:
• tratar atributos tanto contínuos quanto discretos - para atributos contínuos, cria
um limite e divide os exemplos entre os que estão acima do limite e aqueles que
são inferiores ou iguais a esse limite.
• ignorar os valores faltantes dos atributos - nesse caso, não calula entropia nem
ganho de informação para os valores faltantes.
• tratar o sobreajustamento com um método de pós poda - elimina folhas que
possuem maior erro que o nó de origem, fazendo o nó virar a folha.
2.2.2 K - Nearest Neighbor (KNN)
O algoritmo de classificação de padrões K - Nearest Neighbor (KNN) é um dos mais
simples da literatura. Ele faz parte do grupo de técnicas de aprendizado baseado em
instâncias e usa da proximidade espacial dos exemplos para inferir suas classes.
O uso de KNN não exige um treinamento prévio do algoritmo. Dado um conjunto
de treinamento T = x1, x2, . . . , xN com classes conhecidas C = c1,c2, . . . ,cM e uma

2.2. CLASSIFICAÇÃO DE PADRÕES 31
instância nova a ser classificada x, o algoritmo calcula a distância entre a instância
desconhecida x e as demais instâncias do conjunto de treinamento T . Em seguida,
ordena as distâncias encontradas em ordem crescente. Os k vizinhos mais próximos
são aqueles que estão menos distantes de x. O elemento k representa a quantidade de
vizinhos considerados para a verificação da classe pertencente à maioria dos vizinhos
de x. Este processo de identificar a classe predominante entre os vizinhos de uma
instância é denominado voto majoritário. Através do voto majoritário, o exemplo x é
classificado com a classe da maioria dos seus vizinhos.
A Figura 2.2 mostra um modelo de classificação com KNN e a influência do valor
de k na classificação de novas instâncias. O conjunto T é usado para classificar a
instância desconhecida x. Dada a configuração espacial dos exemplos de treinamento,
valores diferentes de k classificam o novo exemplo com classes diferentes. Para os
valores k = 3 e k = 7, a instância é classificada como pertencente à classe c2. Já para
k = 5, a classe c1 é atribuída à nova instância. Esse fato mostra que apesar do usuário
ser o responsável por definir a métrica para o cálculo de distâncias e o número k para
a quantidade de vizinhos mais próximos a serem analisados, alguns cuidados devem
ser adotados na implementação do KNN, a fim de alcançar uma boa classificação:
• A métrica de distância escolhida deve ser capaz de lidar com o tipo de informação
presente na base de dados e nos exemplos que podem surgir para classificação
(ex.: atributos categóricos).
• A normalização dos dados permite cálculos de distâncias mais justos para os
valores dos atributos, não permitindo que um atributo domine o resultado.
• O valor de k deve ser sempre ímpar para não gerar empate no voto dos vizinhos
para a classe.
• Um valor de k muito pequeno torna a classificação sensível a ruídos, porém, um
k muito grande pode incluir vizinhos de outra classe.
A presença de ruídos ou atributos irrelevantes pode afetar bastante o resultado
do KNN. Além disso, esse algoritmo se torna computacionalmente custoso quando o
tamanho da base de dados é muito grande, devido ao cálculo de distância efetuado
para cada exemplo de treinamento. Entretanto, a facilidade de implementação, a
flexibilidade e os ótimos resultados apresentados, fazem o KNN ser um dos mais
utilizados em experimentos de classificação (WU et al., 2008).

2.2. CLASSIFICAÇÃO DE PADRÕES 32
Figura 2.2: Classificação de uma instância desconhecida com KNN. Oconjunto T é usado para classificar uma instância desconhecida x, com a classe
c1 ou c2, por voto majoritário. Para k = 3, a instância é classificada comopertencente à classe c2. Para k = 5, a instância é classificada com a classe c1. Epara k = 7, a instância é novamente classificada como pertencente à classe c2.
Isso mostra a influência da escolha do valor de k no algoritmo KNN.
.
2.2.3 Multilayer Perceptron - MLP
O cérebro humano processa informações a partir da ativação de uma série de
neurônios biológicos, interagindo em uma rede neural com uma intercomunicação
(sinapses) entre seus níveis de ativação. As Redes Neurais Artificiais (RNAs) se inspi-
ram no sistema neurológico humano para resolver problemas conforme o cérebro.
Assim, neurônios artificiais são modelos computacionais dos neurônios biológicos
e suas interconexões em rede (sinapses artificiais) permitem o processamento de
informações para resolução de tarefas complexas (ALMEIDA, 1995).
O primeiro neurônio artificial foi modelado matematicamente por MCCULLOCH;
PITTS (1943). A Figura 2.3 apresenta o neurônio artificial composto pelos seguintes
elementos (SILVA; SPATTI; FLAUZINO, 2010):
a) Sinais de entrada f1, f2, . . . , fn: sinais dos quais o conhecimento deve ser extraído,
normalmente normalizados para melhorar o desempenho da rede. Neste trabalho,
são os atributos das instâncias.

2.2. CLASSIFICAÇÃO DE PADRÕES 33
b) Pesos sinápticos w1, w2, . . . , wn: valores que indicam a relevância de cada atributo
para o neurônio.
c) Limiar de ativação θ: é uma variável que indica como a soma das variáveis de
entrada afetará a saída do neurônio. É considerado negativo para fazer subtração
no somatório do Combinador linear.
d) Combinador linear ∑
: produz o potencial de ação que pode gerar disparos positi-
vos ou negativos para outros neurônios. Soma as entradas multiplicadas por seus
pesos e subtrai o limiar de ativação.
e) Potencial de ativação u: é o resultado do Combinador linear. Quando positivo,
gera um potencial excitatório, quando negativo, produz um potencial inibitório.
f) Função de ativação g : limita o valor de saída do neurônio para valores aceitáveis.
g) Sinal de saída y: valor de resposta do neurônio, o qual pode ser utilizado pelos
neurônios a ele interconectados na rede.
Figura 2.3: Neurônio Artificial. O Combinador linear (∑
) faz a somaponderada dos sinais de entrada do neurônio ( f1, f2, . . . , fn), multiplicadospelos seus respectivos pesos (w1, w2, . . . , wn), com o Limiar de ativação (θ).Caso o potencial de ativação (u), resultado do somatório, seja positivo, produz
um potencial excitatório, caso negativo, produz um potencial inibitório. Opotencial de ativação é limitado pela função de ativação (g ) para gerar a saída
do neurônio (y). Fonte: Adaptado de SILVA; SPATTI; FLAUZINO (2010)
As funções de ativação dos neurônios podem ser:
Função Degrau: g (u) assume 1, se u ≥ 0 ou 0, se u < 0.
Função Degrau Bipolar ou Função Sinal: g (u) assume 1, se u > 0; 0, se u = 0; ou −1,
se u < 0.

2.2. CLASSIFICAÇÃO DE PADRÕES 34
Função Rampa Simétrica: considerando um intervalo limite [−a, a], g (u) assume a,
se u > a; u, se −a ≤ u ≤ a; ou −a, se u < a.
Função Logística: valores reais entre zeros e uns, pela equação 2.1, na qual β é uma
constante real associada ao nível de inclinação da função logística frente ao seu ponto
de inflexão:
g (u) = 1
1+e−βu
2.1
Função Tangente Hiperbólica: assume valores entre −1e1, a partir da equação 2.2,
e neste caso, β está associada ao nível de inclinação da função tangente hiperbólica
frente ao seu ponto de inflexão.
g (u) = 1−e−βu
1+e−βu
2.2
Função Gaussiana: a saída do neurônio tem valores de potenciais de ativação u
posicionados a uma mesma distância da sua média. Obedece a equação 2.3, na qual c
define a média e σ é o desvio padrão da função gaussiana.
g (u) = e− (u−c)2
2σ2 2.3
Função Linear ou identidade: valores idênticos ao potencial de ativação, ou seja,
g (u) = u.
Algumas estruturas precisam ser definidas para a construção e utilização de uma
rede neural. As RNAs possuem basicamente três partes: camada de entrada (neurônios
que recebem os dados de entrada); camadas intermediárias, escondidas ou ocultas
(neurônios responsáveis por extrair o conhecimento); e camada de saída (responsá-
veis por organizar e entregar a saída da rede neural). A arquitetura de uma rede se
caracteriza pelo arranjo entre neurônios e como interagem durante o processamento.
São exemplos de arquiteturas: redes diretas (feedforward) de camadas simples, re-
des diretas de camadas múltiplas, redes recorrentes e redes reticuladas. Definindo a
arquitetura, a quantidade de camadas, número de neurônios nas camadas e outras
composições estruturais, tem-se a topologia da rede.
Um algoritmo de treinamento é utilizado para ajustar os pesos e os limiares de
ativação dos neurônios, a fim de adquirir conhecimento sobre o problema e produzir
saídas próximas aos valores desejados. No processo de treinamento, todos os exem-
plos devem ser apresentados à rede mais de uma vez, denominando-se época cada
apresentação completa da base de dados. Os ajustes nos pesos e limiares ocorrem em
lote de padrões (após cada época) ou padrão-por-padrão (ajustando a cada padrão

2.2. CLASSIFICAÇÃO DE PADRÕES 35
apresentado). O processo de treinamento pode ocorrer de forma supervisionada,
não-supervisionada ou com reforço.
O Perceptron é a rede neural artificial de configuração mais simples. Ele consiste
de uma camada neural com apenas um neurônio nessa camada. Foi proposto por
ROSENBLATT (1958) para identificar padrões geométricos, como letras e números.
Uma vez que trabalha com um neurônio, o funcionamento da rede Perceptron é
idêntico ao funcionamento de um neurônio artificial, mostrado acima, e a formulação
matemática para seu processamento interno é dada pelas equações 2.4 (na qual
i = 1, . . . ,n é o conjunto dos dados de entradas de um exemplo) e 2.5.
u =n∑
i=1wi . fi −θ
2.4
y = g (u) 2.5
A função de ativação para o Perceptron pode ser a Função Degrau ou Degrau Bi-
polar. O processo de treinamento é supervisionado e o algoritmo de aprendizagem é
a Regra de Hebb (DONALD, 1949), que incrementa pesos e limiares quando a saída
é condizente com a desejada (potencial de ativação excitatório) e decrementa (po-
tencial de ativação inibitório) quando a saída da rede é diferente da saída desejada.
As equações 2.6 e 2.7 mostram como os pesos e limiares são ajustados. Para essas
equações, têm-se:
• wi , o peso para a i-ésima entrada da rede neural;
• η, a taxa de aprendizagem, que define a velocidade de aprendizagem até a
estabilidade das respostas da rede;
• x(k), a k-ésima amostra de treinamento;
• sd (k), a saída desejada para a k-ésima amostra de treinamento;
• θ, o limiar de ativação;
• y , o valor da saída produzida pelo Perceptron.
w atuali = w anter i or
i +η.(d (k) − y
).x(k)
2.6
θatual = θanter i or +η.(d (k) − y
).x(k)
2.7
Todavia, o Perceptron é restrito por resolver apenas problemas linearmente se-
paráveis. Nesse contexto, essa rede neural artificial perdeu o foco de estudos, e a

2.2. CLASSIFICAÇÃO DE PADRÕES 36
sua popularização só voltou com o surgimento do algoritmo Backpropagation de
RUMELHART; HINTON; WILLIAMS (1986). O Backpropagation permitiu o uso de
redes com mais de uma camada, as redes neurais Perceptron Multicamadas (PMC)
ou Multilayer Perceptron (MLP). As MLPs suprem a necessidade de classificação de
dados não linearmente separáveis.
A Figura 2.4 mostra a estrutura das MLPs. Na primeira camada, a camada de
entrada (LE ), o número de neurônios N1, . . . , Np corresponde às variáveis de entrada
de cada exemplo a ser mostrado para a rede. A quantidade de camadas escondidas
L1, . . . ,L j é definida a partir do projeto da rede, bem como a quantidade de neurônios
em cada camada escondida(Nq , Nr
). A última camada de uma rede neural artificial
é a camada de saída (LS), que tem um neurônio para cada saída possível da MLP
(N1, . . . , Ns).
Figura 2.4: Multilayer Perceptron - MLP. Possui uma camada de entrada LE
com N1, . . . , Np neurônios correspondentes às variáveis de entrada de cadaexemplo a ser mostrado para a rede. Em seguida, as camadas escondidas
L1, . . . ,L j podem ter quantidades de neurônios diferentes(Nq , Nr
), a depender
da topologia escolhida para a rede. E a última camada é a camada de saída LS
que tem um neurônio para cada saída possível da MLP (N1, . . . , Ns).
A rede neural MLP tem arquitetura feedforward de camadas múltiplas, as fun-
ções de ativação podem ser Função Logística ou Função Tangente Hiperbólica e tem
aprendizado supervisionado. O algoritmo utilizado para seu treinamento é o Back-
propagation, que faz parte dos algoritmos supervisionados (possuem a orientação da
saída desejada) e estáticos (não alteram a estrutura da rede) das redes multicamadas.
Com o Backpropagation, o treinamento ocorre em duas fases:
1ª Fase - Forward (para frente) - o padrão é apresentado e as saídas dos neurônios
são transmitidas até a última camada para gerar a saída final.
2ª Fase - Backward (para trás) - o erro é calculado na última camada a partir da
comparação da saída da rede com a saída desejada e os pesos e limiares são

2.2. CLASSIFICAÇÃO DE PADRÕES 37
corrigidos da saída até a entrada até que seja atingido o erro mínimo aceitável
ou a a quantidade de épocas especificadas como limite da rede).
2.2.4 PART
O algoritmo de regras de aprendizado PART, proposto por FRANK; WITTEN (1998),
combina estratégias da árvore de decisões C4.5 de QUINLAN (1993) (descrita na Seção
Seção 2.2.1) e estratégias das regras de aprendizado RIPPER de COHEN (1995). O
objetivo dessa combinação é diminuir a complexidade presente nos dois métodos,
por não usar, como esses, a fase de otimização global. Além disso, se propõe a eliminar
o problema de sobrepoda1 de RIPPER, diminiur o tempo de execução, o tamanho e
a redundância do conjunto de regras e a restrição aos testes atributo-valor de uma
árvore de decisões, como ocorre em C4.5. A ideia principal de PART é inferir regras
utilizando a técnica dividir-para-conquistar junto a geração repetida de árvores de
decisões parciais.
Com o uso da técnica dividir-para-conquistar, PART constrói uma regra por vez e
remove as instâncias cobertas por ela. Assim, segue criando recursivamente regras
para as instâncias restantes até que não sobrem instâncias no conjunto de treinamento.
A diferença para RIPPER consiste em como essas regras são criadas. Nesse ponto,
entram as árvores de decisões parciais similares a C4.5. Para cada regra, uma árvore é
construída e podada para o conjunto de instâncias correntes. Dessa árvore de decisões,
a folha que cobrir o maior número de exemplos vira uma regra e a árvore é descartada.
O fato de recriar árvores de decisões a cada nova regra é o responsável por evitar a
sobrepoda.
PART não gera árvores completas a cada regra, gera árvores parciais. O algoritmo
faz um teste para dividir os exemplos em subconjuntos e toma decisões da mesma
maneira que C4.5. Com o propósito de criar as menores árvores possíveis, e em con-
sequência, gerar regras mais gerais, a decisão de expansão dos subconjuntos se dá a
partir daquele que apresentar a menor entropia média. A Figura 2.5 de FRANK; WIT-
TEN (1998) mostra um exemplo de como uma árvore de decisões parcial é construída,
passo a passo:
1Também chamado de generalização apressada e ocorre quando o algoritmo não atinge o conheci-mento necessário, ou seja, não faz boa generalização do problema.

2.2. CLASSIFICAÇÃO DE PADRÕES 38
Figura 2.5: Exemplo de como PART constrói uma árvore de decisões parcial.Estágio 1 - um teste divide as instâncias em nós (em cinza porque não foram
expandidos ainda). Estágio 2 - O nó 3 com menor entropia é expandido.Estágio 3 - o nó com menor entropia é uma folha (preto), então começa o
retrocesso a partir da expansão do nó 5. Estágio 4 - a expansão do nó 5 geraapenas folhas, desse modo, inicia-se a poda da árvore. O nó 5 e o nó 3 viram
folhas. Estágio 5 - continua o retrocesso e o próximo nó com menor entropia é o4, que é expandido em folhas, mas não obedece à regra de substituição da
subárvore. A construção da árvore de decisões parcial encerra com 3 folhas em5 estágios. Fonte: FRANK; WITTEN (1998)
Estágio 1 - Um teste para os exemplos correntes os divide em subconjuntos ainda
não expandidos. Nós não expandidos são representados pela cor cinza.
Estágio 2 - Verifica-se que o nó 3 apresenta a menor entropia. Este nó é expandido e
gera uma folha, ou seja, todos os exemplos pertencentes à mesma classe
(representada pela cor preta) e outro nó.
Estágio 3 - Após a expansão do nó 3, o nó com menor entropia é aquele que já re-
presenta uma folha. Assim, começa um processo de retrocesso e o nó 5 é
expandido, gerando duas folhas.
Estágio 4 - Não há mais como expandir após o nó 5, visto que este possui como filhos,
duas folhas. Dessa forma, o processo de poda é iniciado, conforme a
poda de C4.5, por substituição de subárvore. O erro das folhas do nó 5 é
analisado e aceito para ser substituído por uma folha. A mesma análise é

2.2. CLASSIFICAÇÃO DE PADRÕES 39
feita para o nó 3 quando o nó 5 vira uma folha e a substituição da subárvore
também é aceita, vista no estágio 4.
Estágio 5 - O retrocesso continua e o próximo nó com menor entropia ainda não
expandido é o 4. O nó quatro é expandido para duas folhas, mas no
processo de poda, não tem a sua subárvore aceita para ser substituída
por uma folha. Por isso, a construção da árvore de decisões termina, não
necessitando expandir o nó 1. A árvore termina com três folhas em 5
estágios.
Uma vez criada uma árvore de decisões parcial, uma única regra é estraída da folha
que cobrir o maior número de instâncias. Como dito anteriormente, essas instâncias
são removidas do conjunto de treino e uma nova árvore é construída para extrair
uma nova regra com as instâncias restantes. O conjunto de regras está completo
quando não restar mais instâncias a serem cobertas por regras advindas das árvores
de decisões parciais.
FRANK; WITTEN (1998) afirma que PART opera eficientemente sem a necessidade
de otimização global e sabe lidar com conjuntos de dados patológicos (com ruídos ou
valores faltantes). Além disso, tem precisão similar a C4.5 e melhor que RIPPER.
2.2.5 Sequential Minimal Optimization (SMO)
Sequential Minimal Optimization - SMO é um algoritmo de treinamento para Má-
quinas de Vetores Suporte (Support Vector Machines - SVM ). Contudo, para entender
SMO é necessário entender, primeiramente, o que é uma SVM.
Support Vector Machine - SVM
SVM é uma técnica de aprendizagem de máquinas fundamentada em Teoria da
Aprendizagem Estatística e em Otimização Matemática. Proposta inicialmente por
BOSER; GUYON; VAPNIK (1992) e melhorada por CORTES; VAPNIK (1995), a técnica
busca encontrar um hiperplano de separação dos dados de forma que possuam a
maior margem de segurança possível, ou seja, a máxima distância entre os vetores
suportes.
Em conjuntos de dados com classes linearmente separáveis, a distinção das classes
pode acontecer com diferentes hiperplanos de separação. A Figura 2.6 mostra um
exemplo de duas classes e como vários hiperplanos podem ser eficientes na separação
de seus elementos.

2.2. CLASSIFICAÇÃO DE PADRÕES 40
Figura 2.6: Separação de duas classes com hiperplanos. Uma base de dadoscom classes linearmente separáveis tem suas classes facilmente distintas com
várias possibilidades de hiperplanos.
Entretanto, mesmo escolhendo um hiperplano que atenda ao objetivo de distinção
dos exemplos disponíveis, não é possível garantir que um exemplo novo se encaixe do
lado do hiperplano que represente a sua classe (Figura 2.7).
Figura 2.7: Hiperplano aleatório separativo de duas classes. Um hiperplanoescolhido aleatoriamente pode errar ao classificar novos exemplos.
O risco de erro é diminuído com a escolha de um hiperplano que tenha como
critério a maior margem de separação das classes e, consequentemente, o menor erro
de classificação. Esse é o trabalho de uma SVM. Ela cria vetores suporte a partir dos
elementos mais próximos de classes diferentes, para fazer um hiperplano equidistante
entre essas classes e que maximize a margem de separação, conforme a Figura 2.8.
Funções de Langrange são utilizadas para garantir essa maximização, enquanto algo-
ritmos de otimização quadrática, caso do SMO, encontram o hiperplano ótimo.

2.2. CLASSIFICAÇÃO DE PADRÕES 41
Figura 2.8: Hiperplano a partir de uma SVM. Um hiperplano escolhido poruma SVM procura estar equidistante das classes e possuir a maior margem
possível (mg ), diminuindo a possibilidade de erro de classificação.
A separação de problemas lineares por uma SVM pode ser definida pelo hiperplano
de separação representado pela Equação 2.8, em que w é o vetor normal para o
hiperplano e x é o vetor do exemplo de entrada. É necessário encontrar o hiperplano
de separação em f (x) = 0 e encontrar os vetores suportes, sobre os planos f (x) =+1
para a classe y =+1 e f (x) =−1 para a classe y =−1, conforme as Equações 2.9 e 2.10.
f (x) = w.x +b 2.8
f1(x) = w.x +b =+1 2.9
f2(x) = w.x +b =−1 2.10
Considerando que a distância entre um ponto em duas dimensões (x0, y0) e uma
linha (Ax +B y +C = 0) é dada pela Equação 2.11, é possível formular a margem de
separação das classes, usando a distância entre o ponto extremo de uma classe e o
vetor da reta de separação do hiperplano w , conforme a Equação 2.12.
di st = Ax0 +B y0 +CpA2 +B 2
2.11
mg = |w.x +b|‖w‖ = 1
‖w‖ 2.12
Assim, a margem de separação de uma classe a outra ( f1(x) para f2(x)), mostrada
na Figura 2.7, é dada pela Equação 2.13.
2mg = 2
‖w‖ 2.13

2.2. CLASSIFICAÇÃO DE PADRÕES 42
Sabendo que um hiperplano ótimo é aquele que tem a maior margem entre seus
vetores suportes, a determinação desse hiperplano deve maximizar 2mg . Equivalente
a minimizar ‖w‖ = w T w , não deixando pontos entre f1(x) e f2(x), ou seja, sujeito a :
w xi +b ≥+1, se a classe yi =+1 e w xi +b ≤−1, se a classe yi =−1. Essas duas condições
juntas podem ser expressas por:
yi (w.xi +b) ≥ 1 2.14
O problema de otimização pode ser expresso pela Equação 2.15. Essa equação re-
presenta um problema de Programação Quadrática (problema PQ), dado que a função
objetivo quadrática está sujeita a um conjunto de restrições lineares. Considera-se xi
o i-ésimo exemplo de treino e yi a classe correta da SVM para o i-ésimo exemplo de
treino xi . Os valores de yi podem ser +1 para exemplos do hiperplano superior ou −1
para aqueles pertencentes ao hiperplano inferior.
mi nw,b
1
2w T w sujeito a yi (w.xi +b) ≥ 1, ∀xi
2.15
Problemas de extremos (mínimos e máximos), sujeitos a restrições de igualdade,
podem ser resolvidos com Multiplicadores de Lagrange. Multiplicadores de Lagrange
combinam a função objetivo e as restrições em uma função, resolvendo a função
objetivo com um conjunto de multiplicadores αi .
Para um problema definido por F (x) como função objetivo e gi (x) = 0 (com i =1, . . . , N) como restrições, chama-se Lagrangiano à Função ou Função de Lagrange, a
Equação 2.16.
L(x, ?) = F (x)+N∑
i=1αi gi (x)
2.16
Desse modo, introduzindo um multiplicador de Lagrange αi para cada exemplo de
treino (α1, . . . ,αn ≥ 0), tem-se:
L(w,b,α) ≡ 1
2w T w −
N∑i=1
αi yi (w.xi +b)+N∑
i=1αi
2.17
Dentro de uma forma dual, ao invés de minimizar L(w,b,α) com respeito a w ,
podemos resolver a maximização de L(w,b,α) com respeito a α, sujeito às restrições
de que o gradiente de L(w,b,α) para as variáveis primárias w e b sejam nulos e α≥ 0
(Equações 2.18 e 2.19).
∂L
∂w= 0 ∴ w =
N∑i=1
αi yi xi
2.18

2.2. CLASSIFICAÇÃO DE PADRÕES 43
∂L
∂b= 0 ∴
N∑i=1
αi yi = 0 2.19
Resolvendo as Equações 2.18 e 2.19, as variáveis primal w e b são eliminadas com
a substituição desses resultados em L(w,b,α) (Equação 2.20).
LD ≡N∑
i=1αi − 1
2
∑i , jαiα j yi y j xi x j
2.20
Na Equação 2.20, o vetor xi é o vetor de entrada e x j é o padrão de entrada perten-
cente ao j-ésimo exemplo. Maximizando LD com respeito a α, o hiperplano ótimo é
obtido com w da Equação 2.18 e com b, calculado pela Equação 2.21.
b = 1−w.x(s), sendo x(s) um vetor suporte no hiperplano superior. 2.21
Todavia, uma SVM que resolve apenas problemas linearmente separáveis se torna
muito restrita. A maioria dos problemas reais se caracteriza por pertencer a classes não
linearmente separáveis. Para problemas não lineares, as máquinas de vetores suporte
mapeam o espaço original dos dados para um espaço não-linear de maior dimensão e
criam o hiperplano no qual os exemplos sejam linearmente separáveis. A Figura 2.9
mostra como é possível fazer essa separação num espaço de maior dimensão. Em
a) um conjunto unidimensional possui exemplos de duas classes que não podem
ser separados por uma reta. Ao aplicar uma determinada função Φ(x) sobre esses
exemplos, o resultado bidimensional possibilita a criação de uma reta de separação
entre suas classes. Do mesmo modo, em b) um conjunto bidimensional não tem
suas classes linearmente separáveis e com a aplicação de uma função Φ(x), é possível
identificar um hiperplano que as separem linearmente em terceira dimensão.

2.2. CLASSIFICAÇÃO DE PADRÕES 44
Figura 2.9: Mudança de dimensão e separação linear de conjuntos nãolinearmente separáveis. As figuras a) e c) representam os conjuntos em suasdimensões originais de classes não-linearmente separáveis, unidimensional ebidimensional, respectivamente. Em em b) e d) a mudança de dimensão de a) ec) para 2 dimensões e 3 dimensões, respectivamente, torna possível a separação
linear de suas classes.
A Função de Lagrange utilizando o mapeamento da função Φ(x) para um espaço
de alta dimensão, seria:
LD ≡N∑
i=1αi − 1
2
∑i , jαiα j yi y jΦ(xi )Φ(x j )
2.22
Entretanto, encontrar e executar a função Φ(x) que mapeie o espaço de caracterís-
ticas de um conjunto de dados para outro que o torne linearmente separável, pode
ser computacionalmente custoso e inviável. As funções de mapeamento utilizadas
por SVMs são funções especiais, chamadas de Funções de Kernel (Equação 2.23).
Com uma Função de Kernel é possível mapear os pontos de um conjunto implicita-
mente, sem definir o mapeamento de Φ(x), ao calcular o produto escalar dos vetores
de características em outro espaço.
k(xi , x j ) =Φ(xi ).Φ(x j ) 2.23
Exemplos de Funções de Kernel utilizadas em SVMs são:
• Kernel Polinomial, com p sendo o grau do polinômio:
K (xi , x j ) = (xi x j +1)p 2.24

2.2. CLASSIFICAÇÃO DE PADRÕES 45
• Kernel RBF (Radius Basis Function), sendo γ a largura da função de base radial
gaussiana:
K (xi , x j ) = e−γ‖xi x j‖2 2.25
• Kernel Sigmoidal, no qual o parâmetro k pode ser visto como um parâmetro de
escala dos dados de entrada e θ como um parâmetro que controla o desloca-
mento limite de mapeamento:
K (xi , x j ) = t anh (kxT xi +θ) 2.26
Usando uma Função de Kernel K (xi , x j ), o Lagrangiano à Função fica:
LD ≡N∑
i=1αi − 1
2
∑i , jαiα j yi y j K (xi , x j )
2.27
Outro parâmetro importante das SVMs é o parâmetro C , pois, ele flexibiliza as mar-
gens para erros pequenos, diminuindo a sensibilidade de SVMs a ruídos ou separação
imperfeita. Com C , entre f1(x) e f2(x) (hiperplanos de margens superior e inferior,
respectivamente) podem existir alguns exemplos que não fazem parte dos vetores
suporte. A penalidade aplicada por causa dos exemplos que atravessam as margens é
dada pela introdução de ξi ≥ 0, ∀i (Equações 2.29 e 2.29).
w.xi +b ≥+1−ξi para yi =+1 2.28
w.xi +b ≤−1+ξi para yi =−1 2.29
À função objetivo do problema de otimização também é adicionado um termo de
penalidade, conforme a Equação 2.30.
mi ni mi zarw,b,ξ
1
2w T w +C
N∑i=1
ξi
2.30
sujeito a yi (w.xi +b)+ξi −1 ≥ 0, 1 ≤ i ≤ N
ξi ≥ 0, 1 ≤ i ≤ N
Com esse problema em sua forma dual, a Função de Lagrange permanece inal-
tareda, exceto às restrições, visto que os multiplicadores αi , agora são limitados por
C (Equação 2.31).
maxi mi zeα
LD ≡N∑
i=1αi − 1
2
∑i , jαiα j yi y j K (xi , x j )
2.31

2.2. CLASSIFICAÇÃO DE PADRÕES 46
sujeito a:
0 ≤αi ≤C , ∀i ;∑i αi yi = 0
A fim de fazer o problema de Programação Quadrática ser positivamente definido,
o Kernel deve obedecer condições de Karush-Kuhn-Tucker(KKT) (KUHN, 2014). Es-
sas condições são suficientes e necessárias para encontrar um ponto ótimo de um
problema de Programação Quadrática definido positivo. Para o problema de PQ em
questão ser resolvido para todo i , as condições KKT são:
αi = 0 ⇔ yi f (xi ) ≥ 1,
0 <αi <C ⇔ yi f (xi ) = 1, 2.32
αi =C ⇔ yi f (xi ) ≤ 1.
Sendo f (xi ) a saída da SVM para o i-ésimo exemplo de treino e as condições KKT
avaliadas exemplo por exemplo.
Sequential Minimal Optimization - SMO
A partir da definição de Support Vector Machines (SVMs), entende-se por Sequential
Minimal Optimization - SMO, um algoritmo que implementa a SVM e encontra seus
vetores suportes resolvendo dois multiplicadores de Lagrange a cada passo.
O diferencial de SMO para outros algoritmos de SVMs está em resolver o problema
de Programação Quadrátiva sem usar métodos numéricos e sem usar grande espaço
para armazenamento de uma matriz. O método decompõe o problema em subproble-
mas e busca resolver o menor problema de otimização possível. Visto que uma das
restrições de uma SVM está em obedecer a uma igualdade linear∑
i αi yi = 0, o menor
problema de otimização possível é a otimização conjunta de dois multiplicadores de
Lagrange αi e esses podem ser resolvidos analiticamente (PLATT, 1999). Para manter
a condição de igualdade linear verdadeira, quando um multiplicador é atualizado, o
outro deve ser ajustado, conforme a Equação 2.34.
∑i∈A
αi yi =∑j∈B
α j y j
2.33
SMO consiste em três passos a cada iteração: a escolha de dois multiplicadores de
Lagrange para resolver, através de buscas heurísticas; a busca pelos valores ótimos
dos multiplicadores escolhidos, com um método analítico; e a atualização dos valores
ótimos da SVM.
Os multiplicadores de Lagrange de cada iteração devem obedecer a Equação 2.34,
a fim de não violar a condição∑
i αi yi = 0.

2.2. CLASSIFICAÇÃO DE PADRÕES 47
αnovo1 y1 +αnovo
2 y2 = const ante =αanter i or1 y1 +αanter i or
2 y2
2.34
Conforme mostra a Figura 2.10 de PLATT (1999), valores novos são viáveis para a
resolução do problema se respeitarem as retrições: 0 ≤α1 , α2 ≥C .
Figura 2.10: Restrições dos multiplicadores de Lagrange. As restrições dedesigualdade fazem os multiplicadores pertencerem a uma caixa. Enquanto arestrição de igualdade linear faz pertencerem a uma linha diagonal. Portanto,
um passo do SMO deve encontrar um ponto ótimo da função objetivo sobre umsegmento de linha diagonal. Fonte: PLATT (1999)
.
No primeiro passo do algoritmo SMO, o valor de αnovo2 é encontrado e atualizado
para a obtenção de αnovo1 . Para α2, tem-se a restrição:
L ≤αnovo2 ≤ H
2.35
Considerando que αnovoi é o novo multiplicador de Lagrange do exemplo xi e
αanter i ori é o valor anterior do multiplicador, tem-se:
se y1 6= y2
L = max(0,αanter i or
2 −αanter i or1
)H = mi n
(C ,C +αanter i or
2 −αanter i or1
)se y1 = y2
L = max(0,αanter i or
2 +αanter i or1 −C
)H = mi n
(C ,αanter i or
2 +αanter i or1
)A função atual é a função em xi determinada pelos valores dos multiplicadores de
Lagrange e por b no estágio atual da aprendizagem, dada por:
f (xi ) =l∑
j=1α j y j K (x j , xi )+b
2.36
A distância do ponto xi ao hiperplano atual, dado pela atualização dos multiplica-

2.2. CLASSIFICAÇÃO DE PADRÕES 48
dores de Lagrange, equivale a Ei . Ei é o erro do i-ésimo exemplo de treino, ou seja, à
diferença entre f (xi ) e a classe yi pertencente ao ponto xi (Equação 2.37).
Ei = f (xi )− yi =[
l∑j=1
α j y j K (x j , xi )+b
]− yi
2.37
A Equação 2.38 expressa a quantidade adicional exigida, dada pela segunda de-
rivada da função objetivo ao longo da linha diagonal. Nessa equação, x1 e x2 são os
pontos associados a α1 e α2, respectivamente.
η= K (x1, x1)+K (x2, x2)−2K (x1, x2) = ‖Φ(x1)−Φ(x2)‖2 2.38
Existindo um αaux , limitado por L ≤ αaux ≤ H , dado pela Equação 2.39, o valor
máximo da função objetivo é dado pela Equação 2.40.
αaux2 =αanter i or
2 + y2(E1 −E2)
η
2.39
αnovo2 =
H se αaux
2 ≥ H ;
αaux2 se L <αaux
2 < H ;
L se αaux2 ≤ L
2.40
Após encontrar o valor de αnovo2 , é possível encontrar o valor de αnovo
1 , com a
Equação 2.41.
αnovo1 =αanter i or
1 + y1 y2
(αanter i or
2 −αnovo2
) 2.41
Uma heurística diferente é utilizada para cada um dos dois multiplicadores de
Lagrange a serem escolhidos nas iterações. Na escolha de α2, o ponto x2 é escolhido
entre os exemplos que violam as condições KKT (Equação 2.32). O algoritmo primeiro
encontra no conjunto de treinamento, todos os pontos que violam as condições KKT
e faz um subconjunto desses, como pontos elegíveis para otimização. Em seguida,
percorre todo o subconjunto criado e faz os seguintes testes (considerando um nível
de tolerância tol): E2.y2 < −tol e α2 < C ou E2.y2 > tol e α2 > 0. Quando o algoritmo
encontra um exemplo que satisfaz esses testes, seleciona-o para otimizar.
Na segunda heurística, o ponto x1 deve ser escolhido com o intuito de ser atu-
alizado junto a x2, e assim, causar um grande acréscimo da função objetivo. Para
encontrar x1, o algoritmo SMO maximiza o valor dado por |E1 −E2|. Se E1 é positivo, o
x1 com menor erro E2 é o escolhido. Se E1 é negativo, o x1 com maior erro E2 é selecio-
nado para otimização. Caso o x1 escolhido não forneça um acréscimo significante na
função objetivo, o SMO analisa todos os pontos x1 fora das bordas, ou seja, 0 <α<C . E
se mesmo nos pontos fora da borda, o ponto adequado não for encontrado, a procura

2.2. CLASSIFICAÇÃO DE PADRÕES 49
por esse é feita em todo o conjunto de treinamento.
Após conseguir um acréscimo de valores na função objetivo com o uso dos pontos
x1 e x2, a heurística escolhe novos pontos e termina o processo quando todos os pontos
do conjunto de treinamento atendem às condições de KKT. A fim de reduzir contas
adicionais, uma lista com os erros de todos os pontos de treinamento é mantida na
memória.
A solução proposta pelo algoritmo SMO obedece a restrição αi[
yi (w.xi +b)−1]= 0
para i = 1,2, . . . , l , ou seja, αi[
yi f (xi )−1] = 0. Correspondente à Equação 2.32, vista
anteriormente:
αi = 0 ⇔ yi f (xi ) ≥ 1,
0 <αi <C ⇔ yi f (xi ) = 1,
αi =C ⇔ yi f (xi ) ≤ 1.
Logo, SMO satisfaz as condições de complementariedade de Karush-Kuhn-Tucker
e classifica com a máxima margem entre os conjuntos.
O valor de b, do vetor w e dos erros Ei são calculados separadamente, ao fim
de cada iteração, quando as condições KKT são atendidas pelos pontos x1 e x2. A
atualização dos valores se dá sempre utilizando o valor atual e o valor anterior, com a
função f (xi ) (Equação 2.36).
Para o exemplo x1, o valor de b1 deve forçar a saída da SVM para y1 quando a
entrada for o exemplo x1, dado por:
b1 =−[
E1 + y1
(αnovo
1 −αanter i or1
)K (x1, x1)+ y2
(αnovo
2 −αanter i or2
)K (x1, x2)+banter i or
] 2.42
Para o exemplo x2, o valor de b2 deve forçar a saída da SVM para y2 quando a
entrada for o exemplo x2, dado por:
b1 =−[
E2 + y1
(αnovo
1 −αanter i or1
)K (x1, x2)+ y2
(αnovo
2 −αanter i or2
)K (x2, x2)+banter i or
] 2.43
Para valores de b1 = b2, o novo valor de b é bnovo = b1 = b2. Caso contrário, o
intervalo entre b1 e b2 possui todos os limiares que são consistentes com as condições
de KKT. Portanto, o SMO escolhe o limiar que está no meio do intervalo, ou seja:
bnovo = b1 +b2
2
2.44
Em conjuntos de dados linearmente separáveis, o valor do vetor w pode ser atuali-

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 50
zado por:
bnovo = w anter i or + y1
(αnovo
1 −αanter i or1
)x1 + y2
(αnovo
2 −αanter i or2
)x2
2.45
A cada iteração, os erros Ei são atualizados por:
E novoi = E anter i or
i + y1
(αnovo
1 −αanter i or1
)K (x1, xi )+
2.46
+y2
(αnovo
2 −αanter i or2
)K (x2, xi )+bnovobanter i or
Denomina-se g ap a diferença entre a função objetivo atual e a função objetivo
anterior. A atualização da função objetivo também pode ser feita usando o g ap da
seguinte forma:
g ap =(αnovo
1 −αanter i or1
)+
(αnovo
2 −αanter i or2
)+
2.47
−[
2∑j=1
l∑i=1
yi y j
(αnovo
j −αanter i orj
)K (x j , xi )
]i 6=1i 6=2
+
− 1
2y2
1
(αnovo
1 −αanter i or1
)K (x1, x1)− 1
2y2
2
(αnovo
2 −αanter i or2
)K (x2, x2)+
− y1 y2
[αnovo
1 αnovo2 −αanter i or
1 αanter i or2
]K (x1, x2)
Mesmo contendo mais subproblemas a serem resolvidos no processo, cada sub-
problema do SMO é resolvido rapidamente. Além disso, esse algoritmo foi escolhido
por representar a ideia original de SVM, atuando com um processo relativamente
simples.
2.3 Meta-aprendizagem e caracterização de dados
Bastante difundido entre pesquisadores, o teorema do "No Free Lunch" (WOLPERT;
MACREADY, 1997) se aplica a algoritmos de aprendizagem de máquinas, visto que
nenhum algoritmo consegue obter sempre as melhores performances em todas as
situações. Algumas saídas têm sido propostas para lidar com esse problema, como
combinação de classificadores, aprendizagem ativa e meta-aprendizagem.
Dando foco em meta-aprendizagem, BRAZDIL et al. (2008) afirma que deve ser
possível aprender sobre o próprio processo de aprendizagem, e ainda, que um sistema
poderia aprender a lucrar com a experiência anterior para gerar conhecimento adicio-
nal e simplificar a seleção automática de modelos eficientes que resumem os dados.
Meta-aprendizagem também foi definida por SMITH-MILES (2008) como exploração

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 51
do conhecimento sobre a performance de algoritmos para melhorar essa performance
ou selecionar algoritmos de aprendizagem.
As principais diferenças entre o aprendizado básico e o aprendizado em nível meta
estão no escopo e em como acumula experiência. O escopo do aprendizado básico é
uma tarefa específica, a experiência é acumulada a partir de situações do problema
sobre suas saídas. Já no meta-aprendizado, o escopo está definido por várias tarefas e
guarda experiências sobre como as saídas estudadas se comportaram em cada tarefa.
Para recomendação de algoritmos, a comunidade acadêmica considera que é
possível modelar as características dos problemas para relacionar ao desempenho
desses algoritmos, analisando como uma situação clara de aprendizagem. Assim,
meta-aprendizagem, ou um aprendizado sobre a aprendizagem, tem sido campo de
grandes pesquisas e ótimos resultados, como em NAKHAEIZADEH (1993), GIRAUD-
CARRIER et al. (2002), LEYVA et al. (2014) e OLIVEIRA MOURA et al. (2014a).
Os conceitos de meta-aprendizagem apresentados a seguir, são importantes para
a compreensão da proposta do nosso trabalho.
• Meta-características: são medidas extraídas das bases de dados com a expecta-
tiva de que forneçam informações relevantes para determinar o comportamento
dessas bases em relação aos métodos estudados.
• Meta-instâncias: são formadas pelas meta-características extraídas das bases
de dados de amostra, utilizadas como atributos e rotuladas pela informação da
saída desejada para cada base, a partir de conhecimentos a priori do problema
ou resultados experimentais.
• Meta-base: é construída com as meta-instâncias criadas contendo informações
de todas as amostras de bases.
Um dos principais requisitos para aplicação de meta-aprendizagem é caracterizar
bases de dados através de medidas. Caracterizar dados em tarefas de classificação de
padrões é extrair medidas e informações dos dados que possam revelar padrões de
comportamento entre eles, associados às saídas desejadas. As meta-características,
seguem a mesma ideia da caracterização de dados comuns, sendo nesse caso, inferidas
de bases de dados ao invés de dados brutos e associadas ao desempenho de algoritmos
como saídas.
Muitas medidas de caracterização de dados têm sido propostas para diversas
tarefas de meta-aprendizagem (LEYVA et al., 2014). Para algoritmos de seleção de
instâncias, entre os autores que definiram medidas de caracterização de dados para
gerar atributos de meta-bases, destacamos e apresentamos a diante, as medidas
sugeridas por SOTOCA; MOLLINEDA; SANCHEZ (2006), por CAISES et al. (2011) e

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 52
por LEYVA et al. (2014), por terem sido utilizadas pela maioria dos estudos propostos
recentemente.
As medidas de CAISES et al. (2011), estão relacionadas ao conceito de conjunto
local. O conjunto local de uma instância é formado pela maior hiperesfera possível de
instâncias da mesma classe, de acordo com suas distâncias ao vizinho mais próximo.
Algumas das medidas de CAISES et al. (2011) foram desmembradas e suas partes foram
utilizadas em nosso trabalho como medidas individuas, porque várias distâncias intra-
locais foram nulas e impediam o cálculo de algumas divisões. Uma breve descrição
das medidas de CAISES et al. (2011) é apresentada a seguir:
• Pontos isolados são o número de pontos que são mais próximos a instâncias de
outras classes (inimigas) que a instâncias pertencentes a sua própria classe.
• Cardinalidade média de conjuntos locais mostra instâncias de bordas e se as
bordas das classes são regulares ou irregulares.
• Dispersão intergrupos (DP1 e DP2) determina o grau de proximidade entre gru-
pos. Ao invés de usarmos DP1 e DP2, usamos as suas partes, que são: distância
intergrupos, distância intragrupos, gruposNE e diâmetro do grupo.
• Nível de ruído informa o nível de ruído a partir das instânicas excluídas pela
execução do ENN.
• Desbalanceamento é o grau de disparidade do número de instâncias por classes.
• Número de atributos nominais é usado para escolher MSIs que trabalham com
atributos nominais e eliminar aqueles que possuem performance baixa na pre-
sença desses atributos.
• Número de classes influencia na performance de classificadores e na complexi-
dade dos algoritmos de treino.
• Regiões fornece informações sobre a distribuição dos dados.
Já SOTOCA; MOLLINEDA; SANCHEZ (2006) faz uma revisão das medidas de com-
plexidade existentes na literatura e discute como aplicá-las em meta-aprendizagem
no domínio de classificação de padrões. Essas medidas também são eficientes quando
aplicadas em métodos de seleção de instâncias, conforme mostrado por LEYVA; GON-
ZALEZ; PEREZ (2015) e MOLLINEDA; SÁNCHEZ; SOTOCA (2005). Geralmente, são
agrupadas nas categorias: estatísticas, separabilidade de classes, geometria e densi-
dade e, sobreposição.
Dentre as medidas estatísticas, usamos:

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 53
• medidas de informações simples, pela contagem no conjunto completo de
instâncias de cada base: número de instâncias, número de atributos, número de
classes, atributos numéricos, atributos binários, atributos nominais. Também
utilizadas em CAISES et al. (2011)
• medidas de informações proporcionais, pela proporção de valores de cada tipo
em relação ao número completo de instâncias da base de dados: proporção de
atributos numéricos, proporção de atributos binários, proporção de atributos
nominais.
• Entropia mede a quantidade de informação presente na base de dados para
identificar uma instância pertencente a uma classe ci do conjunto de C classes.
O valor de entropia da base H (Γ) em relação às classes, pode ser calculado com
a Equação 2.48, na qual p (ci ) é a probabilidade a priori da classe ci , ou seja, é a
frequência da classe na base de dados.
H (Γ) =−C∑
i=1p (ci ) log2
(p (ci )
) 2.48
Como medidas de sobreposição, usamos Raio discrimintante de Fisher (F1) e
Volume da região de sobreposição (F2), estas medidas inicialmente foram propostas
para problemas de duas classes, mas ganharam generalização para mais classes em
MOLLINEDA; SÁNCHEZ; SOTOCA (2005).
• F1 generalizada para várias classes consistem em:
F 1g en =
C∑i=1
ni .δ(m,mi )
C∑i=1
ni∑j=1
δ(xij ,mi )
2.49
Para F1, é necessário calcular previamente, o número de exemplos por cada
classe, aqui representado por ni , a média da base de dados completa m, a média
por classe mi , δ equivale a uma medida de distância e xij é o exemplo j da classe
i.
• Em F2, a generalização segue:
F 2g en = ∑ci ,c j
∏k
mi nmaxk −maxmi nk
maxmaxk −mi nmi nk
2.50

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 54
Nesta medida, considera-se: k = 1, . . . ,d para um problema com d atributos, ou
d dimensional. Então, deve-se calcular um vetor com os atributos máximos
ou mínimos de cada classe e em seguida fazer as comparações entre classes,
conforme abaixo:
mi nmaxk = mi nmax( fk ,ci ),max( fk ,c j )
maxmi nk = maxmi n( fk ,ci ),mi n( fk ,c j )
maxmaxk = mi nmax( fk ,ci ),max( fk ,c j )
mi nmi nk = maxmi n( fk ,ci ),mi n( fk ,c j )
O resultado do produto dos atributos do vetor resultante é somado a cada itera-
ção de comparação entre classes.
As medidas de separabilidade de classes utilizadas foram:
• Frações de pontos sobre as bordas (N1)
É construída uma árvore geradora mínima, em inglês Minimum Spanning Tree
(MST), em que todos as instâncias da base de dados são consideradas pontos e
conectadas ao seu vizinho mais próximo. A quantidade de pontos conectados
ao seu inimigo mais próximo, ou seja, conectado a uma classe diferente, é
considerada a quantidade de pontos de borda. A medida N1 equivale à fração
dos pontos de borda sobre o número total de pontos (instâncias) da base de
dados.
• Raio de distância média entre classes dos vizinhos (N2)
Verifica o quanto os dados são discrinantes, com a comparação da dispersão
inter-classes com a separabilidade intra-classes. Quanto menor o valor da me-
dida, mais discriminantes são os dados.
N 2 =
n∑i=1
δ(N1 = (xi ), xi )
n∑i=1
δ(N1 6= (xi ), xi )
2.51
δ indica o cálculo da distância entre a instância em questão e N1 = (xi ) que é o
vizinho mais próximo dentro da mesma classe ou N1 6= (xi ) que é o vizinho mais
próximo de outra classe (inimigo mais próximo).

2.3. META-APRENDIZAGEM E CARACTERIZAÇÃO DE DADOS 55
• Estimação da taxa de erro (N3)
N3 corresponde à taxa de erro obtida pela aplicação do método Leaving-one-out.
Leaving-one-out pertence ao grupo de algoritmos de avaliação de classificadores
por validação cruzada. Considere o método de validação cruzada k-fold, em
que o conjunto de treinamento original é dividido em k subconjuntos e em k
execuções cada subconjunto é usado como teste, enquanto os demais fazem
o treino do classificador. O resultado da avaliação é a média dos k resultados
de testes. Leaving-one-out é equivalente a aplicação de k-fold com k igual ao
número total de exemplos de treino, ou seja, um exemplo vai para teste e os
demais para treino a cada execução.
Medidas de geometria e densidade:
• ε-Vizinhança (T1)
Enquanto N1 indica as formas geométricas das classes a partir do lado externo,
através das bordas, T1 começa de dentro das classes para indicar tais formas.
Cada instância de treino é tida como centro de uma bola que vai crescendo o
máximo possível com a inclusão de instâncias de mesma classe, até encontrar
uma instância inimiga (de outra classe). Após a criação de todas as bolas, aquelas
completamente dentro de outras são consideradas redundantes e são removidas.
Finalmente, o número de bolas equivale à quantidade necessária para cobrir
todas as classes. T1 é o número de bolas normalizado pelo número de instâncias
da base de dados.
• Média do número de pontos por dimensão (T2)
Descreve a densidade da distribuição espacial dos exemplos, apenas dividindo o
número de instâncias da base de dados n pelo número de atributos d .
T 2 = n
d
2.52
• Densidade D1
A densidade é definida como a média do número de instância pelo volume da
base de dados. O volume corresponde ao produto dos tamanhos dos ranges dos
atributos dessa base de dados. Assim, D1 é definida por:
D1 = n
vol
2.53

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 56
Em que n é o número de instâncias e vol o volume da base.
• Volume da vizinhança local (D2)
Nessa medida, o volume é dado pela equação:
Vi =d∏
h=1(max( fh , Nk (xi ))−mi n( fh , Nk (xi )))
2.54
Nk (xi ) são os k vizinhos mais próximos da instância xi . Assim, calcula-se o valor
máximo e mínimo de cada atributo fh entre esses vizinhos e o volume de cada
instância se dá pela equação 2.54. A medida D2 é o valor médio de Vi por n
instâncias de treino, conforme a equação 2.55
D2 = 1
n
n∑i=1
Vi
2.55
• Densidade da classe em região de sobreposição (D3)
Para computar D3, encontramos os k vizinhos mais próximos de cada instância
i e verificamos se a maioria desses vizinhos pertence a classes diferentes da ins-
tância em questão. Quando sim, consideramos que essa instância está em região
de sobreposição e acrescentamos em D3. MOLLINEDA; SÁNCHEZ; SOTOCA
(2005) propôs D3 porque as regiões de sobreposição têm grande influência nos
erros dos classificadores. Levando em conta tal importância, calculamos D3
com 3 e 5 vizinhos e normalizamos o valor pelo número de instâncias da base
de dados para minimizar a dispersão dos valores na meta-base. Quando D3 é
calculada com apenas um vizinho, produz os mesmos valores que N3, ou seja,
indica a taxa de erro pelo método leaving-one-out.
2.4 Métodos de seleção de instâncias
Em tarefas de classificação, os principais problemas em relação às bases de dados
são: ruídos (instâncias com informações erradas), informações irrelevantes, necessi-
dade de grande espaço para armazenamento, e execução do algoritmo intratável ou
muito lento devido ao tamanho da base de dados. Métodos de seleção de instâncias
(MSIs) são algoritmos que se propõem a mitigar esses problemas. MSIs reduzem as ba-
ses de dados, criando um subconjunto de instâncias que melhor descrevem as classes,
com dois objetivos: reduzir o custo computacional e melhorar as taxas de acerto dos

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 57
processos de classificação. O dois objetivos podem ser atingidos simultaneamente,
no entanto, quando o custo computacional é a meta principal, são aceitas pequenas
perdas nas taxas de acerto de classificação para aumento na redução da base de dados.
A Figura 2.11 mostra como a utilização de um MSI pode beneficar uma base de dados
e discriminar melhor suas classes.
Figura 2.11: Base de dados antes e depois da aplicação de um MSI. Antes deaplicar um método de seleção de instâncias (MSI), a base pode ter ruídos,
instâncias irrelevantes e não distinguir bem as classes, após a aplicação de umMSI a base tende a se tornar mais sucinta e ao mesmo tempo mais eficiente.
Neste trabalho, assumimos que seleção de instâncias corresponde à busca, em
todo o vetor de espaço, daquelas instâncias que melhor descrevem as classes das bases
de dados. Logo, são entendidos como MSIs, tanto métodos que criam instâncias novas
para representar a base de dados (também chamados de geração de protótipos), como
métodos que selecionam a partir das instâncias já disponíveis (seleção de protótipos).
Desde 1968, quando o primeiro MSI foi criado, Condensed Nearest Neighbor -
CNN (HART, 1968), quase cem outros métodos foram sugeridos por muitos autores.
GARCÍA; LUENGO; HERRERA (2015) apresentam uma taxonomia com esses MSIs,
mostrando a distinção entre eles de acordo com suas abordagens em relação à:
• tipo de seleção: métodos de condensação, edição e híbridos;
• direção de pesquisa: incremental, decremental, em lote, misto e fixo;
• avaliação da pesquisa: filtro e wrapper ;
• outras propriedades: representação, função de distância e votação.
Dentro da família de condensação, CNN ainda é o mais usado em trabalhos re-
centes. Ele tem direção de pesquisa incremental, normalmente, alcança boas taxas
de redução e é muito sensível a ruídos por causa da inclusão das instâncias clas-
sificadas erroneamente. Muitos métodos foram criados baseados no CNN com a
pretenção de melhorar esse algoritmo. No entanto, as mudanças propostas são mais
complexas, necessitam de elevado tempo para processamento e continuam sensíveis

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 58
a ruídos. Outros métodos desta família são: Reduced Nearest Neighbor - RNN (decre-
mental) (GATES, 1972), Selective Nearest Neighbor - SNN (decremental) (RITTER et al.,
1975), Minimal Consistent Set - MCS (decremental) (DASARATHY, 1994) and Patterns
by Ordered Projection - POP (batch) (RIQUELME; AGUILAR-RUIZ; TORO, 2003).
O método decremental Edited Nearest Neighbor - ENN (WILSON, 1972) pertence à
família dos métodos de edição. Ele remove as instâncias que têm classes diferentes
de seus vizinhos. ENN é normalmente usado apenas como filtro de ruídos, devido a
sua baixa taxa de redução. Métodos que tentaram melhorar o ENN como Repeated
ENN - RENN (decremental) e All-KNN (em lote) (TOMEK, 1976) aumentaram a com-
plexidade, o custo computacional e não obtiveram boas taxas de redução. Então, foi
adotada a combinação proposta por CAISES et al. (2011) combinando ENN com CNN,
visto que possuem resultados complementares. A (Seção 2.4.1) detalha os métodos e a
combinação utilizada.
A maioria dos métodos propostos atualmente é da família de métodos híbridos.
Esses métodos tentam combinar as vantagens das abordagens de condensação e
edição para construir métodos que alcancem boas taxas de redução, sem perdas
relevantes em suas precisões e com baixo custo computacional. Por esses motivos,
essa família possui uma maior importância e, portanto, foram utilizados quatro mé-
todos híbridos. Eles diferem na direção de pesquisa: o método incremental Instance
Based 3 - IB3 (AHA; KIBLER; ALBERT, 1991) (Seção 2.4.2); os métodos decremen-
tais e filtros de avaliação de pesquisa: Decremental Reduction Optimization Proce-
dure 3 - DROP3 (WILSON; MARTINEZ, 2000) (Seção 2.4.3) e C-pruner (ZHAO et al.,
2003) (Seção 2.4.5); e o método de processamento em lote Iterative Caise Filtering -
ICF (BRIGHTON; MELLISH, 2002) (Seção 2.4.4).
Estratégias de geração de protótipos e meta-heurísticas têm a grande vantagem
de explorar um largo espaço de soluções, no entanto, o alto custo computacional
dessas técnicas as colocam em desvantagem no uso prático comparadas às demais
abordagens. Exemplos de métodos baseados em geração de protótipos são: Prototype
nearest neighbor (PNN) (CHANG, 1974), Hybrid LVQ3 algorithm (HYB) (KIM; OOM-
MEN, 2003b) e Differential evolution (DE) (TRIGUERO; GARCÍA; HERRERA, 2011).
Já Explore (CAMERON-JONES, 1995), Cooperative coevolutionary instance selection
(CoCoIS) (GARCÍA-PEDRAJAS; DEL CASTILLO; ORTIZ-BOYER, 2010) e Tabu search
(ZhangTS) (ZHANG; SUN, 2002) são MSIs que abordam meta-heurística.
Além da popularidade dos métodos mencionados, em JANKOWSKI; GROCHOWSKI
(2004) uma comparação entre algoritmos de seleção de instâncias mostra a perfor-
mance relevante dos métodos escolhidos. Entre os métodos IB’s, IB3 tem o melhor
resultado. E em relação a métodos DROP’s, DROP3 tem boas saídas com baixo custo.
Os outros métodos têm performance semelhante àqueles do grupo a que pertencem,
mas diferem conforme explicado anteriormente. Baseados nessa análise, foram es-

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 59
colhidos MSIs que possuem abordagens distintas, a saber: ENN-CNN, IB3, DROP3,
C-pruner e ICF. As seções seguintes detalham os métodos utilizados.
2.4.1 ENN-CNN
A combinação do uso de Condensed Nearest Neighbor - CNN (HART, 1968) com
Edited Nearest Neighbor - ENN (WILSON, 1972) proposta por CAISES et al. (2011),
consiste simplesmente em executar ENN como um filtro e em seguida CNN.
O método CNN possui dois passos. No primeiro passo, uma instância de cada
classe é selecionada aleatoriamente para formar uma nova base de dados. No segundo,
esta nova base de dados é usada para treinar um classificador que classifica todas
as instâncias da base de dados original. As instâncias classificadas erroneamente
são incluídas na nova base de dados a fim de garantir que instâncias desconhecidas
e similares àquelas classificadas erroneamente serão corretamente classificadas. O
Algoritmo 2.1 apresenta um pseudo-código para CNN.

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 60
Algoritmo 2.1 Condensed Nearest Neighbor - CNNEntrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: K . número de vizinhos considerados na classificação com KNN
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
Etapa 1 - Seleção aleatória de instâncias de cada classe
1: S =;2: para i ← 1 até n faça
3: Escolha aleatória de tu ∈C (i ),
4: S ← S ∪ tu . tu , a instância da classe, é adicionada ao subconjunto S
5: fim para
Etapa 2 - Inclusão de instâncias erroneamente classificadas
6: para j ← 1 até u faça
7: se K N N (T ( j ),S) 6=C (T ( j )) então . Classifica a instância T ( j ) com o
classificador K N N em relação ao subconjunto S e verifica se a predição da classe
foi errada
8: S ← S ∪T ( j ) . T ( j ), a instância erroneamente classificada, é adicionada ao
subconjunto S
9: fim se
10: fim para
ENN é bastante simples. Ele tenta preservar as instâncias não pertencentes às
bordas das classes e assim, aumentar a margem de separação entre elas. Para tanto,
elimina as instâncias erroneamente classificadas, decrementando a base de dados
original. Seu pseudo-código é apresentado no Algoritmo 2.2.

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 61
Algoritmo 2.2 Edited Nearest Neighbor - ENNEntrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: K . número de vizinhos considerados na classificação com KNN
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
1: S ← T
2: para j ← 1 até u faça
3: se K N N (T ( j ),T ) 6=C (T ( j )) então . Classifica a instância T ( j ) com o
classificador K N N e verifica se a predição da classe foi errada
4: S ← S −S( j ) . S( j ), a instância erroneamente classificada, é retirada do
subconjunto S
5: fim se
6: fim para
2.4.2 Instance Based 3 - IB3
No método Instance Based 3 - IB3 (AHA; KIBLER; ALBERT, 1991), o mais recente
dos métodos IB’s, uma nova base de dados é criada com as instâncias da base de dados
original cujas instâncias aceitáveis mais próximas têm classes diferentes das instâncias
que estão sendo adicionadas. A aceitabilidade de instâncias é baseada em intervalo
de confiança e precisão de classificação. O pseudo-código de IB3 é apresentado no
Algoritmo 2.3.

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 62
Algoritmo 2.3 Instance Based 3 - IB3Entrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
1: S =;2: para j ← 1 até u faça
3: y ← Acei t abi l i d ade(T ( j ),S) . Instância aceitável mais próxima de T ( j ) em S.
Caso não exista, uma instância aleatória de S é atribuída
4: se C (T ( j )) 6=C (y) então . Caso T ( j ) não classifique y corretamente, y é
inserida em S
5: S ← S ∪T ( j ) . A instância erroneamente classificada por T ( j ), é inserida no
subconjunto S
6: fim se
7: Atualize o registro de classificação de y
8: para l ← 1 até r faça
9: se d(T ( j ),S(l )) ≤ d(T ( j ), y) então . Caso a distância entre T ( j ) e S(l ) seja
menor ou igual à distância entre T ( j ) e y , atualizar o registro de classificação de
S(l )
10: Atualize o registro de classificação de S(l )
11: se registro de l é significativamente pobre então
12: S ← S −S(l )
13: fim se
14: fim se
15: fim para
16: fim para
17: para j ← 1 até r faça
18: se S( j ) não é aceitável então
19: S ← S −S( j )
20: fim se
21: fim para
Aceitabilidade é uma função na qual se a precisão em classificação de uma instân-
cia for significativamente superior à frequência da sua classe, ela será mantida, senão
será eliminada. Para diminuir a sensibilidade com bases desbalanceadas, IB3 nor-
maliza a aceitação de cada instância em relação à frequência das classes. A Equação

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 63
2.56 apresenta o cálculo dos limites de intervalo de confiança utilizados em IB3.Para
a precisão de um exemplo em S, tem-se: n o número de tentativas de classificação
da instância, p a precisão nas tentativas de classificação e z o nível de confiança. Já
para a frequência da classe, considera-se: n o número de instâncias já processadas,
p a proporção de instâncias processadas que pertencem a essa classe e z o nível de
confiança.
p + z2/2n ± z√
p(1−p)n + z2
4n2
1+ z2/n
2.56
2.4.3 Decremental Reduction Optimization Procedure 3 - DROP3
Decremental Reduction Optimization Procedure 3 - DROP3 é um de cinco métodos
propostos por WILSON; MARTINEZ (2000). O algoritmo executa primeiramente o
algoritmo ENN. Depois, ordena as instâncias de acordo com suas distâncias para
a instância mais próxima que possui classe diferente. Em seguida, DROP3 remove
toda instância do conjunto que não altera a classificação do conjunto das instâncias
associadas. Instâncias associadas são aquelas que possuem ti como vizinho mais
próximo, formando o conjunto A(ti ). As instâncias de A(ti ) possuem com relação a ti .

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 64
Algoritmo 2.4 Decremental Reduction Optimization Procedure 3 - DROP3Entrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: K . número de vizinhos considerados na classificação com KNN
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
1: S ← T
2: para i ← 1 até r faça
3: N (Si ) ← [K +1] N N (S(i ),S) . Inicializa o conjunto N (Si ) de K +1 vizinhos mais
próximos de S(i )
4: para j ← 1 até nx faça
5: A(Si ( j )) ← A(Si ( j ))∪ S(i ) . Adiciona N (Si ) ao conjunto de associados de
seus vizinhos
6: fim para
7: fim para
8: para l ← 1 até r faça
9: se C (S(l )) 6=C (K N N (S(l ),T ) então
10: S ← S −S(l )
11: fim se
12: fim para
13: S ← or denaçãoi ni m(S) . Ordena S em ordem decrescente de distância ao inimigo
mais próximo
14: para q ← 1 até r faça
15: com ← número de associados de S(q) corretamente classificados com S(q)
como vizinho.
16: sem ← número de associados de S(q) corretamente classificados sem S(q)
como vizinho.
17: se com − sem ≤ 0 então
18: S ← S −S(q)
19: para a ← 1 até nx faça
20: N (A(Si (a))) ← N (A(Si (a)))− A(Si (a))
21: Adicione em N (A(Si (a))) no novo vizinho mais próximo de A(Si (a)) em
S.
22: fim para
23: fim se
24: fim para

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 65
2.4.4 Iterative Caise Filtering - ICF
O objetivo de Iterative Caise Filtering - ICF (BRIGHTON; MELLISH, 2002) é remover
instâncias dos centros das classes e reter as instâncias das bordas das classes. O ICF
usa o método ENN como um filtro de ruído no seu pré-processamento. Logo após,
as instâncias são removidas usando os conceitos de: conjunto local, acessibilidade e
cobertura. A saber:
• Conjunto local: o conjunto local de uma instância x, L(x) é aquele que contém,
dentro da maior esfera possível centrada em x, todas as instâncias da mesma
classe de x.
• Acessibilidade (x) = x ′ ∈ T : x ′ ∈ L(x) : é quantidade de exemplos no conjunto
local de x.
• Cobertura (x) = x ′ ∈ T : x ∈ L(x ′) : é quantidade de conjuntos locais diferentes nos
quais x está presente.
A instância x é removida se a sua Acessibilidade é maior que sua Cobertura. O
Algoritmo 2.5 mostra o pseudo-código de ICF.

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 66
Algoritmo 2.5 Iterative Caise Filtering - ICFEntrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: K . número de vizinhos considerados na classificação com KNN
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
1: S ← T
2: para l ← 1 até r faça
3: se C (S(l )) 6=C (K N N (S(l ),T ) então
4: S ← S −S(l )
5: fim se
6: fim para
7: enquanto S é atual i zado faça
8: para i ← 1 até r faça
9: Calcule Acessi bi l i d ade(S(i ))
10: Calcule Cober tur a(S(i ))
11: fim para
12: para q ← 1 até r faça
13: se Acessi bi l i d ade(S(q)) >Cober tur a(S(q)) então
14: S ← S −S(q)
15: fim se
16: fim para
17: fim enquanto
2.4.5 C-pruner
O método C-pruner (ZHAO et al., 2003) também usa os conceitos de acessibilidade
e cobertura, descritos na Seção 2.4.4. Porém, sua cobertura considera apenas as
instâncias da mesma classe. Estes dois conceitos são usados para determinar se uma
instância é ruidosa, supérflua ou crítica, conforme segue:
• Instância Supérflua: é a instância x que pode ser classificada corretamente pelas
instâncias da Acessi bi l i d ade(x). Diz-se que x é implicada pela Acessi bi l i d ade(x).
• Instância Crítica: duas condições podem tornar uma instância crítica. Na pri-
meira, se pelo menos uma instância xi pertencente à Cober tur a(x), não é im-
plicada pela Acessi bi l i d ade(xi ), a instância x é crítica. A outra é que após a

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 67
deleção de x, se pelo menos uma instância xi pertencente á Cober tur a(x), não é
implicada pela Acessi bi l i d ade(xi ), essa instância x também é crítica.
• Instância Ruidosa: Se uma instância x não é supérflua e a Acessi bi l i d ade(x) >Cober tur a(x), então x é uma instância ruidosa.
As instâncias críticas afetam a classificação de outras instâncias, por isso, são
as únicas retidas na base de dados final. As instâncias ruidosas e supérfluas são
removidas, segundo as regras:
Regra 1 - Para ser podada, ou seja, eliminada, uma instância x deve ser uma instância
ruidosa ou uma instância supéflua, mas não crítica.
Regra 2 - A ordem de remoção de duas instâncias xi e x j deve ser guiadas pelas
condições:
* Obs.:
* H −K N N (x) é o número de instâncias pertencentes à mesma classe de
x em K N N (x)
* D −N E(x) é a distância da instância x ao seu inimigo mais próximo, ou
sej, à instância de classe distinta da classe de x.
• Se H −K N N (xi ) > H −K N N (x j ), então, xi é removido primeiro.
• Se H −K N N (xi ) = H −K N N (x j ) e D −N E(xi ) > D −N E(x j ), então, x j é
removido primeiro.
• Se H −K N N (xi ) = H −K N N (x j ) e D − N E(xi ) = D − N E(x j ), então, a
ordem de remoção é escolhida aleatoriamente.
O Algoritmo 2.6 contém o pseudo-código de C-pruner.

2.4. MÉTODOS DE SELEÇÃO DE INSTÂNCIAS 68
Algoritmo 2.6 C-prunerEntrada: T = t1, . . . , tu . conjunto de instâncias originais da base de dados
Entrada: C = c1, . . . ,cn . classes da base de dados
Entrada: K . número de vizinhos considerados na classificação com KNN
Entrada: di st . distância considerada na classificação com KNN
Saída: S = s1, ..., sr . conjunto de instâncias selecionadas
1: S ← T
2: para l ← 1 até r faça
3: Calcule Acessi bi l i d ade(S(l ))
4: Calcule Cober tur a(S(l ))
5: fim para
6: para i ← 1 até r faça
7: se S(i ) é uma Instância Ruído então
8: S ← S −S(i )
9: para todo S(i )i ∈Cober tur a(S(i )) faça
10: Acessi bi l i d ade(S(i )i ) ← Acessi bi l i d ade(S(i )i )−S(i )
11: Atualiza Acessi bi l i d ade(S(i )i )
12: fim para
13: para todo S(i ) j ∈ Acessi bi l i d ade(S(i )) faça
14: Cober tur a(S(i ) j ) ←Cober tur a(S(i ) j )−S(i )
15: fim para
16: fim se
17: fim para
18: Ordena S conforme a Regra 2.
19: para q ← 1 até r faça
20: se S(q) satisfaz a Regra 1 então
21: S ← S −S(q)
22: para todo S(q)p ∈Cober tur a(S(q)) faça
23: Acessi bi l i d ade(S(q)p ) ← Acessi bi l i d ade(S(q)p )−S(q)
24: Atualiza Acessi bi l i d ade(S(q)p )
25: fim para
26: fim se
27: fim para

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 69
2.5 Métodos de seleção de atributos
O desempenho de um classificador depende da interação entre o número de
instâncias, número de atributos da base de dados e a complexidade desses dados.
Espera-se que um elevado número de instâncias ou atributos ajude o algoritmo de
classificação a entender a relação entre os dados de entrada e a saída. No entanto,
essa não é uma realidade sempre válida.
Como visto na Seção 2.4, uma base de dados deve ter instâncias batantes para que
as classes tenham representatividade e possam ser reconhecidas. Por outro lado, deve
ser considerado que se estiverem apenas representando ruídos ou redundâncias, as
instâncias afetarão negativamente na precisão e no custo computacional.
Da mesma forma, os atributos trazem a preocupação de como sua quantidade
afeta o desempenho da classificação e o custo computacional. A quantidade de atri-
butos é a dimensão da base de dados. O aumento dessa dimensionalidade traz um
aumento exponencial da complexidade do problema. Essa é uma situação conhecida
como Maldição da Dimensionalidade. Como consequência da Maldição da Dimen-
sionalidade, quando o número de instâncias para treino é relativamente pequeno em
relação aos atributos, a precisão do classificador é afetada. Isso se dá pelo fato de que
tantos atributos podem não ter informações relevantes e não ter representação sufici-
ente para que o classificador descubra os seus padrões. VALIANT (1984) afirma que
o número de instâncias necessárias para um bom resultado de classificação, cresce
exponencialmente com o número de atributos.
Um caminho para fugir da Maldição de Dimensionalidade é reduzir a dimensiona-
lidade das bases de dados. Podemos citar como vantagens desse processo:
• a melhora da eficácia, quando os atributos, ainda que condizentes com o nú-
mero de instâncias, não contribuem para o processo de classificação. Visto que
suas informações são irrelevantes, ou seja, não são descritivos do problema,
ou, porque são altamente correlacionados a outros atributos e assim possuem
informações redundantes.
• melhora na eficiência computacional, reduzindo a complexidade e tempo de
execução dos algoritmos.
• redução do tamanho necessário para a base de dados, relativo à quantidade de
instâncias.
• redução do espaço para armazenamento da base de dados.
• simplificação do modelo e interpretação dos dados.
• facilitação da visualização dos dados.

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 70
A redução de dimensionalidade pode ser feita de duas maneiras: criação de novos
atributos com a transformação dos originais ou seleção de atributos. Posto que
podemos avaliar as meta-características geradas na arquitetura proposta a fim de
melhorar os resultados e tornar o processo mais rápido, sugerimos o uso de seleção
de atributos como um módulo do Meta-CISM.
Selecionar atributos significa reduzir o número de características extraídas do
problema para uma quantidade capaz de melhorar o desempenho da classificação,
seja em tempo computacional, em precisão ou ambos simultaneamente. Para sugerir
um subconjundo de características, esses métodos utilizam estratégias para decidir
como os atributos serão combinados e qual o critério para a avaliação da qualidade
das possíveis combinações.
Geralmente, os métodos de seleção de atributos são categorizados como: Filtro,
Wrapper ou Embarcado. Na categoria Filtro, estão os algoritmos que trabalham no pré-
processamento e, independente de algoritmos de aprendizagem, avaliam a relevância
dos subconjuntos de atributos. Os algoritmos do tipo Wrapper, por sua vez, utilizam
o algoritmo de aprendizagem para avaliar o processo de seleção. E na categoria
Embarcados, estão os algoritmos de aprendizagem que possuem o seletor de atributos
intrínseco e realiza a seleção de subconjuntos como parte de seu processo.
Os métodos do tipo filtro têm destaque porque são menos custosos computacio-
nalmente e podem ser associados a diferentes algoritmos de aprendizagem. O ponto
fundamental desses métodos é a maneira como avaliam a relevância dos atributos.
A relevância de um atributo pode ser definida por um critério de qualidade, depen-
dente da natureza do problema e dos atributos envolvidos. Medidas de avaliação
encontradas na literatura são:
• Consistência: redução do conjunto de atributos mantendo a consistência original
• Dependência: correlação entre atributos e classe.
• Distância: discriminação entre atributos.
• Divergência: distância probabilística ou divergência entre as densidades de
probabilidade condicional das classes.
• Informação / Incerteza: ganho de informação com adição ou remoção de um
atributo;
Em relação às saídas, exitem duas abordagens de seleção de atributos: ranking
e seleção de subconjunto. Outras nomeações encontradas são, respecitivamente:
Contínua e Binária; non-ranker e ranker ; e univariado e multivariado. Os métodos de
seleção do tipo ranking ordenam os atributos de acordo com sua importância indivi-
dual, dando pesos de relevância para cada atributo. Já os métodos do tipo seleção de

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 71
subconjunto definem para cada atributo d se esse estará no subconjunto ou não, a
partir da avaliação dos subconjuntos possíveis, que corresponde a 2d possibilidades.
(MOLINA; BELANCHE; NEBOT, 2002)
O uso das médidas de avaliação é suficiente para os métodos de ranking e os
tornam muito mais simples que a seleção de subconjunto, porém, despreza a corre-
lação e redundância entre atributos. Portanto, os dn primeiro atributos relevantes
individualmente podem não fazer parte do melhor subconjunto e não ser relevantes
numa combinação. Já para os métodos de seleção de subconjuntos, avaliar todos os
subconjuntos possíveis de atributos pode ser uma tarefa inviável. Logo, esses métodos
necessitam fazer uma busca heurística, na qual alguns subconjuntos são analisados
até que um critério de parada seja satisfeito. Para tanto, além da medida de avaliação,
essa busca precisa definir:
1 - A direção da pesquisa (ponto inicial da busca):
• Para trás - inicia com todos os atributos e remove um atributo por vez;
• Para frente - inicia sem atributos e inclui um atributo por vez;
• Bidirecional - a busca começa em qualquer ponto e atributos podem ser
adicionados e removidos;
• Ponderada - todos os atributos estão presentes nas iterações, porém, rece-
bem pesos diferentes em cada uma;
• Aleatória - ponto de partida da busca e atributos a serem removidos ou
adicionados são decididos de forma aleatória;
2 - Procedimento para efetuar a busca, ex.:
• Backward Elimination
• Forward Selection
• Random Search
• Best First
• Genetic Search
3 - Estratégia de busca:
• Exaustiva - busca exaustiva para encontrar o subconjunto de características
que atenda o critério de avaliação.
• Sequencial - o atributos são adicionados ou removidos um a um até que não
haja melhora na qualidade da solução.
• Aleatória - os conjuntos escolhidos são completamente aleatórios.

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 72
4 - Critério de parada, ex.:
• Número máximo de iterações
• Valor da medida de avaliação obtida
DASH; LIU (1997) apresentam uma visão geral do processo de seleção de subcon-
juntos na Figura 2.12
Figura 2.12: Modelo do processo de seleção de características com validação.Inicialmente, os subconjuntos são gerados e em seguida avaliados, até que
obedeçam o critério de parada e sigam para validação. Fonte: DASH; LIU (1997)
Escolhemos avaliar os métodos da categoria filtro e dentre eles, variar os tipos de
abordagens e medidas de avaliação, conforme a Tabela 2.1. Os algoritmos de seleção
de subconjuntos escolhidos têm direção de pesquisa para frente e utilizam a estratégia
de busca exaustiva. A escolha do procedimento de busca será avaliada na Seção 4.4.
Tabela 2.1: Características dos métodos de seleção de atributos utilizados
Abordagem Método de Seleção de AtributosMedida deAvaliação
Seleção desubconjunto
Consistency-Based Subset Evaluation Consistência
Correlation-based Feature Selection - CFS Dependência
RankingChi Square Feature Evaluation Distância
Relief - F Dependência
Apresentamos a seguir, a descrições individuais de cada método de seleção de
atributos estudado com seus respectivos algoritmos.
2.5.1 Consistency-based Subset Evaluation
O método de seleção de atributos Consistency-Based Subset Evaluation, proposto
por (LIU; SETIONO, 1996), inicia seu processo com um conjunto vazio de atributos

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 73
e faz uma busca exaustiva com um procedimento de busca pré-definido. A cada
subconjunto de atributos criado, as instâncias de treinamento são projetadas sobre
esse subconjunto e a consitência dos seus valores é avaliada em relação às classes.
O critério de parada é encontrar o menor subconjunto com consistência igual à do
conjunto completo de atributos.
A formula de consistencia utilizada é:
Consi stenc y(S) = 1−∑J
i=0 |Di |− |Mi |n
2.57
Considere S um subconjunto de atributos, J é o número de combinações distintas
de valores de atributos para S, |Di | é o número de ocorrências da i-ésima combinação
dos atributos, |Mi | é a cardinalidade da classe majoritária para a i-ésima combinação
dos atributos e n é o número total de instâncias na base de dados.
A busca desse método tem direção de pesquisa para frente, produzindo uma lista
de atributos, classificadas de acordo com sua contribuição global para a consistência
do conjunto de atributos.
2.5.2 Correlation-based Feature Selection - CFS
Correlation-based Feature Selection - CFS (HALL, 1998) procura subconjuntos
que contêm atributos que são altamente correlacionadas com a classe e têm baixa
correlação uns com os outros. Inicia sem atributos e com o procedimento de busca
escolhido, faz uma busca exautiva pelo subconjunto que na adição de outros atributos,
não aumenta o mérito já encontrado.
CFS calcula uma matriz de correlação entre: atributo-classe e entre atributo-
atributo. O grau de correlação entre atributos ( fi e f j ) é calculado usando entropia H
na seguinte fórmula:
U(
fi , f j)= 2×
[H
(fi
)+H(
f j)−H
(fi , f j
)H
(fi
)+H(
f j) ] 2.58
Logo após calcular a matrix de correlação, CFS segue com a medida de avaliação:
Mér i to (S) = d × rac√d +d (d −1)raa
2.59
Na Equação 2.59, temos:
Mér i to (S) - mérito de um subconjunto de atributos S ⊂ D contendo d atributos;
rac - é a média da correlação entre atributos e a classe;
raa - é a média da correlação entre atributos com outros atributos;

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 74
O poder preditivo do conjunto de atributos avaliado é indicado pelo numerador,
enquanto o denominador indica o quão redundantes são os atributos.
2.5.3 Chi Square Feature Evaluation
O teste estatístico Chi Square é utilizado para seleção de atributos com a medição
do grau de independência entre cada atributo e a classe (FRANK et al., 2005). As
hipóteses desse teste são:
• H0: não há correlação entre os atributos (são independentes);
• H1: há correlação entre os atributos (um influencia no outro).
O teste é calculado pela Equação 2.61, que deve ser precedida pelo cálculo da
frequência esperada Ei j (Equação 2.60) para todas as combinações possíveis dos
valores do atributo F com cada classe C .
Ei j =q fi ×qc j
n
2.60
No cálculo de Ei j , temos:
• q fi é a quantidade de instâncias que possui o valor fi , sendo i petencente ao
conjunto T do número de possíveis valores para o atributo F (i ∈ T |T = 1 É i É t )
• qc j é a quantidade de instâncias da classe c j , sendo j pertencente às classes
possíveis da base de dados ( j ∈C |C = 1 É i ÉC ).
• e n é o número de instâncias da base de dados.
Além de Ei j , o cálculo do teste Chi Square Feature Evaluation (Equação 2.61) possui
Oi j como a razão entre a quantidade de instâncias que possuem o valor fi e a classe
c j , simultaneamente, sobre o número total de instâncias da base de dados n.
X 2 =t∑
i=1
C∑j=1
Oi j −Ei j
Ei j
2.61
A hipótese nula (H0) é rejeitada ao ultrapassar um limiar tabelado pelo teste esta-
tístico Chi Square, a partir dos graus de liberdade calculados pela Equação 2.62.
g l = (T −1)∗ (C −1) 2.62
Como faz o cálculo dos atributos individualmente, Chi Square Feature Evaluation
gera um ranking dos atributos, no qual quanto maior for o X 2 calculado, maior
correlação o atributo tem com o atributo classe, e assim, melhor é a sua classificação
no ranking.

2.5. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 75
2.5.4 Relief - F
Espera-se que instâncias da mesma classe tenham atributos com valores próximos,
enquanto instâncias de classes diferentes tenham maior distinção entre seus valores.
Baseados nessa ideia, KIRA; RENDELL (1992) construiram o algoritmo Relief que
atribui pesos para indicar a relevância de cada atributo e os ordena em ranking de
acordo com o atendimento a esses critérios. Inicialmente, o algoritmo seleciona,
aleatoriamente, uma instância da base de dados. Para essa instância, são procurados
o vizinho mais próximo da mesma classe (nearest hit) e o vizinho mais próximo de
outra classe (nearest miss). A instância selecionada é então comparada com seus
vizinhos e tem o peso dos seus atributos iniciados em zero e atualizados pela equação:
Wx =Wx − di f f (X ,R,nH)2
a+ di f f (X ,R,nM)2
a
2.63
Para a Equação 2.63, considere:
• Wx é o peso do atributo x;
• R é uma instância escolhida aleatoriamente;
• nH é o vizinho mais próximo da mesma classe (nearest hit);
• nM é o vizinho mais próximo de uma classe diferente (nearest miss).
• a é o número de instâncias amostradas aleatoriamente;
• A função di f f calcula a diferença entre duas instâncias para um dado atributo.
O processo é realizado com uma quantidade escolhida pelo usuário de a instâncias
amostradas aleatoriamente.
Relief - F é uma melhoria proposta por KONONENKO (1994) para o algoritmo
Relief de KIRA; RENDELL (1992). O problema encontrado por KONONENKO (1994)
em Relief foi não atender a mais de duas classes. Assim, propuseram Relief - F que
com os mesmos princípios de Relief atribui pesos de relevância aos atributos, porém,
trata de múltiplas classes com a ponderação das diferenças entre a instância analisada
e k vizinhos de cada classe distinta e da mesma classe, utilizando a probabilidade a
priori P de cada classe. Essa mudança ainda ajuda a suavizar a influência dos ruídos
no processo de Relief.
A equação para Relief - F é:
Wx =Wx −
k∑j=1
di f f(X ,R,nH j
)2
a ×k+
∑C 6=cl ass(R)
[P (C )
P (cl ass(R))
k∑j=1
di f f(X ,R,nM j
)2
]a ×k
2.64

2.6. MÉTODOS DE REAMOSTRAGEM 76
Ao final, cada peso dos atributos reflete a sua capacidade de distinguir valores
entre as classes.
2.6 Métodos de reamostragem
Métodos de reamostragem são técnicas que manipulam um conjunto de dados
para a obtenção de uma quantidade maior de novos conjuntos. Em Reconhecimento
de Padrões, esses métodos estão vinculados a comitês de classificadores. São utili-
zados para gerar diversidade e diminuir a correlação entre classificadores treinados
com as diferentes amostras geradas no processo de reamostragem. A resposta de um
comitê é uma combinação dos resultados obtidos pelos classificadores treinados.
Neste trabalho, não estamos interessados em comitês de classificadores, mas,
no processo de geração de novas bases de dados a partir de uma única, da qual
amostras são selecionadas obedecendo os critérios do método de reamostragem.
O objetivo é gerar mais representatividade dos dados. As manipulações da base
de dados podem ser realizadas com mudanças nos atributos ou instâncias e com
subamostragem (quando a base reamostrada é produto da redução da base original)
ou sobreamostragem (quando dados artificiais são gerados para fazer a reamostragem).
Além disso, os métodos podem usar reposição ou não reposição de dados que já foram
utilizados em uma nova base, para a criação de outra. O método de reamostragem
utilizado nos experimentos da arquitetura proposta foi o Bagging de BREIMAN (1996),
descrito a seguir.
2.6.1 Bagging
Também conhecido como Bootstrap Aggregating, Bagging é um método de reamos-
tragem bastante simples e intuitivo. Dado um conjunto de treinamento T = x1, . . . , xn
com N instâncias, o algoritmo cria subconjuntos de N ′ < N instâncias selecionadas
aleatoriamente do conjunto original, com reposição da instância selecionada a cada
inclusão em uma nova base.
O Algoritmo 2.7 apresenta o pseudo-código de Bagging apenas na fase de reamos-
tragem, excluindo a classificação como comitê.

2.7. TRABALHOS RELACIONADOS 77
Algoritmo 2.7 Pseudo-código: BaggingEntrada: T = x1, . . . , xn . conjunto de N instâncias originais da base de dados
Entrada: P . Porcentagem de seleção de instâncias da base de dados T
Entrada: Q . Quantidade de novas bases a serem criadas
Saída: S = s1, ..., si . conjunto de instâncias selecionadas
1: I = P ×N . Cálculo da quantidade de instâncias a serem selecionadas
2: para q ← 1 até Q faça
3: para i ← 1 até I faça
4: Escolha aleatória de x j ∈ T
5: S ← S ∪x j
6: fim para
7: fim para
2.7 Trabalhos relacionados
Pesquisas sobre meta-aprendizagem para a escolha de Métodos de Seleção de
Instâncias (MSIs) são recentes. Estudos iniciais focaram na criação de medidas de
caracterização de dados e na investigação da relação entre essas medidas e a per-
formance de MSIs. MOLLINEDA; SÁNCHEZ; SOTOCA (2005) usaram medidas de
caracterização de dados para predizer se a aplicação de um MSI é adequada ou não,
dado um problema. Iniciando a utilização de meta-aprendizagem, SOTOCA; MOL-
LINEDA; SANCHEZ (2006) revisaram algumas medidas de caracterização de dados
e indicaram possíveis aplicações da abordagem, sugerindo o uso para Métodos de
Seleção de Instâncias. SMITH-MILES; ISLAM (2010) adotaram meta-aprendizagem
para verificar a relação entre o sucesso de um MSI, características dos dados e métodos
de aprendizagem de máquinas.
A seleção do melhor MSI para uma base de dados foi estudada por CAISES et al.
(2011). Eles propuseram o método Selective Combination for Instance Selection (SCIS)
para determinar o mais adequado MSI a ser aplicado às bases de dados de entrada.
O SCIS usa regras empíricas construídas com base em medidas de caracterização
de bases de dados. Embora esse estudo tenha obtido bons resultados, o processo é
limitado. Considerando que são feitas por humanos, regras empíricas são limitadas
ao tamanho da amostra, esforço do especialista e duração da análise, que afetam
diretamente a eficácia e eficiência do processo.
Mais recentemente, LEYVA; GONZáLEZ; PéREZ (2013) afirmaram que faltam, no

2.7. TRABALHOS RELACIONADOS 78
campo relacionado a escolha de MSIs por meio de meta-aprendizagem, propostas
direcionadas a uma abordagem integral, além da necessidade de estabelecer diretrizes
para o desenvolvimento de sistemas capazes de explorar seus benefícios. Com este
propósito, no mesmo artigo, lançaram um framework e o sistema Knowledge-base IS
(KBIS) que foi mais profundamente estudado em LEYVA et al. (2014). O sistema KBIS
faz um balanceamento entre precisão e redução, possilibitando flexibilização para
um ou para o outro através do parâmetro b, escolhido pelo usuário. Utiliza regressão
linear para predizer a performance de redução à parte de precisão, ao invés de indicar
o melhor desempenho entre candidatos. Após o cálculo do balanceamento, verifica
o MSI que o maximiza e aplica esse à base de dados. A modularidade de preditores
permite que algoritmos de seleção de instâncias sejam adicionados sem a necessidade
de retreino para todo o processo. O trabalho, no entanto, utilizou poucas medidas
de caracterização de dados e o sistema KBIS apresentou algumas desvantagens por
ser dependente do classificador utilizado para a criação das meta-instâncias e ser
dependente da quantidade de meta-instâncias para treino.
Nossa proposta com Meta-CISM é estudar classificação ao invés de regressão,
com o intuito de indicar o melhor MSI entre os candidatos para uma base de dados.
Buscamos generalização na criação de meta-instâncias com o uso da média de preci-
são de classificadores pertencentes a abordagens diferentes. Além disso, utilizamos
reamostragem para ter uma boa representatividade no treino do meta-classificador.

797979
3Meta-CISM
Meta-learning for Choosing Instance
Selection Method
Este capítulo descreve o método proposto: Meta-CISM (Meta-learning for Choo-
sing Instance Selection Method), que tem o objetivo de escolher o “melhor” Método de
Seleção de Instâncias (MSI) para um dado problema (tarefa). O método foi desenvol-
vido para lidar com problemas de classificação supervisionada, ou seja, as instâncias
dessas tarefas são definidas por um vetor de características e por uma classe. O con-
junto de todas as instâncias de cada tarefa é denominado base de dados. Sendo um
problema representado por uma base de dados, cada instância do método proposto
(Meta-CISM), denominada meta-instância, é representada por um vetor de caracte-
rísticas e uma classe extraídos dessa base de dados. O conjunto de meta-instâncias
forma a meta-base.
O método é composto por duas partes: Geração do meta-classificador e Avaliação
do meta-classificador. Para a geração do meta-classificador (Seção 3.1), cada base
de dados passa por um processo de reamostragem, a fim de aumentar a quantidade
de bases, e assim, o tamanho da meta-base de treinamento, visto que cada base de
dados gera apenas uma meta-instância. Em seguida, as bases de dados resultantes são
usadas para produzir meta-instâncias. Essa atividade é realizada pelos módulos de
Extração de Características e de Anotação. Todas as meta-instâncias geradas formam
a meta-base que pode ser submetida ao Módulo de Seleção de Atributos, definido
na Seção 3.1.3. Finalmente, o meta-classificador é treinado para gerar a função
capaz de indicar o “melhor” MSI para novas bases de dados, na Seção 3.1.4. O meta-
classificador é avaliado usando uma base de dados de teste, conforme descrito na
Seção 3.2.

3.1. GERAÇÃO DO META-CLASSIFICADOR F 80
3.1 Geração do meta-classificador F
O objetivo da Geração do meta-classificador F é obter uma função destinada a
escolher entre vários MSIs, aquele mais adequado para uma base de dados (Figura 3.1).
Para um bom desempenho no treinamento desse meta-classificador, é necessário
compor uma meta-base com informações relevantes sobre como a estrutura da base
dados pode influenciar na performance dos MSIs.
A construção da meta-base é composta por duas fases: Reamostragem (Seção 3.1.1)
e Geração de meta-instância (Seção 3.1.2). Uma vez que a meta-base foi construída, é
possível treinar o meta-classificador F. No entanto, visando melhorar a taxa de acerto
desse meta-classificador F e reduzir o custo computacional, os melhores atributos da
meta-base são selecionados pelo módulo de Seleção de atributos.
3.1.1 Reamostragem
Dado que meta-aprendizagem pode ser definida como aprender sobre o próprio
processo de aprendizagem, o processo de classificação na meta-aprendizagem tam-
bém necessita de uma base de dados, denominada meta-base. Cada meta-instância
dessa meta-base tem seu vetor de características e classe extraídos de uma base de
dados que representa uma tarefa específica. Assim, cada base de dados Γi gera apenas
uma meta-instância.
O tamanho da meta-base deve ser diretamente relacionado à quantidade de MSIs a
serem usados, visto que ela deve ter meta-instâncias suficientes para representar cada
MSI. Esse tamanho também deve ter uma boa proporção em relação à quantidade
de meta-atributos para fugir da maldição da dimensionalidade, além de estar direta-
mente relacionado ao classificador a ser usado no treino do meta-classificador. Alguns
classificadores como MLP têm melhor desempenho com a utilização de grandes
quantidades de instâncias durante a aprendizagem.
Para aumentar o número de bases de dados disponíveis e, portanto, aumentar a
quantidade de meta-instâncias para o treinamento do meta-classificador, a primeira
fase para a construção da meta-base é a reamostragem. Nessa fase, um método de
reamostragem cria novas bases de dados Γi j a partir das originais Γi , usando variações,
com reposição ou sem reposição, das instâncias ou atributos da base de dados Γi .
O método de reamostragem a ser utilizado deve garantir a diversidade entre as
bases de dados a serem geradas. É importante analisar como o método faz a reamos-
tragem (por características ou por instâncias) e se a quantidade necessária de novas
bases relacionada à quantidade de instâncias ou de características da base de dados
original não gerará bases redundantes. Entre os métodos da literatura, podemos citar
o Bagging (BREIMAN, 1996) e Random Subspace (HO, 1998).

3.1. GERAÇÃO DO META-CLASSIFICADOR F 81
Figura 3.1: Processo de construção da Meta-base e treinamento dometa-classificador. Cada base de dados é submetida à fase de reamostragempara aumentar o número de bases de dados disponíveis. Cada nova base dedados passa pelos processos de Extração de características e Anotação para
tornar-se uma meta-instância. A meta-base resultante pode ser reduzida peloprocesso de Seleção de Características. Em seguida, é usada para treinar o
meta-classificador F.

3.1. GERAÇÃO DO META-CLASSIFICADOR F 82
O Bagging, por exemplo, gera bases Γi j com a criação de subconjuntos aleatórios
das instâncias da base de dados Γi , com reposição das instâncias a cada nova base
criada. Esse método foi escolhido como base para os experimentos devido à sua
popularidade e simplicidade de implementação.
Outros testes foram realizados com Random Subspace. Porém, como esse método
faz a reamostragem aleatória das características de uma base de dados, a necessidade
de criação de novas bases a partir de outras que continham poucos atributos resultou
na criação de muitas bases iguais e por isso seus experimentos não foram levados
adiante.
Com o intuito de criar a maior quantidade de bases, com a maior diversidade
possível, através da manipulação dos seus atributos, criamos um novo método de rea-
mostragem, chamado Combination. Na próxima seção (Seção 3.1.1.1), apresentamos
e exemplificamos o uso do método.
3.1.1.1 Proposta de reamostragem
Neste trabalho, propomos uma reamostragem que combina os atributos de uma
base de dados, denominada Combination. A técnica utiliza análise combinatória,
fazendo combinação simples dos atributos de uma base de dados para formar sub-
bases com atributos diferentes ou em quantidades diferentes, mantendo o mesmo
número de instâncias da base a partir da qual foi derivada. A quantidade de bases que
podem ser geradas depende da quantidade de atributos da base de dados original,
obedecendo a Equação 3.1.
k =d∑
p=1
d !
p !(d −p)!
3.1
Considere d o número de características da base de dados original e p, variando
p = 1, . . . ,d , a quantidade de características das novas bases na realização da combina-
ção. Para cada quantidade de características p, uma certa quantidade de combinações
k ′ podem ser feitas, gerando novas bases. Logo, cada base de dados Γi pode gerar um
número k de novas bases Γi j , com j = 1,2, . . . ,k. Isso corresponde à soma das quanti-
dades de combinações k ′ possíveis com cada variação do número de características
p.
Para facilitar a compreensão do que foi explanado sobre Combination, considere
uma base de dados Γi com um conjunto de atributos A = a1, a2, a3. Conforme descrito
no método, d é a quantidade de atributos da base de dados, neste caso, do conjunto
A, d = 3. O valor de p faz todas as variações possíveis da quantidade de atributos
existentes em A, para gerar os atributos das novas bases Γi j . Ou seja, p terá os valores
p = 1,2 e 3 e as k novas bases Γi j (com j = 1,2, . . . ,k) terão 1,2 ou 3 atributos. Pela

3.1. GERAÇÃO DO META-CLASSIFICADOR F 83
Equação 3.1, temos:
• Quando p = 1, serão geradas 3 novas bases de dados.
k1 = 3!
1!(3−1)!= 6
2= 3
3.2
• Para p = 2, mais 3 novas bases de dados serão geradas.
k2 = 3!
2!(3−2)!= 6
2= 3
3.3
• E finalmente, quando p = 3, mais 1 nova base de dados será gerada.
k3 = 3!
3!(3−3)!= 6
6= 1
3.4
Ao total, o número de novas bases Γi j geradas será k = k1 +k2 +k3 = 7. Equivalente
ao somatório das quantidades de bases geradas com ps diferentes.
k =3∑
p=1
3!
p !(3−p)!= 7
3.5
Dependendo da quantidade de bases de dados novas Γi j desejadas para cada base
Γi , o valor de d pode ser considerado pequeno e a quantidade de novas bases Γi j
também será pequena. Por outro lado, se d for considerado grande, não será possível
utilizar todas as bases Γi j geradas. Nesse caso, sugerimos fazer uma compensação,
utilizando todas as bases Γi j geradas por aquelas Γi que contêm poucas características
(d pequeno) e escolhendo aleatoriamente bases Γi j geradas por bases de dados Γi
que contêm muitas características (d grande), até completar a quantidade de bases
desejadas no fim da fase de reamostragem.
O pseudo-código para o método de reamostragem Combination é apresentado a
seguir, no Algoritmo 3.1.

3.1. GERAÇÃO DO META-CLASSIFICADOR F 84
Algoritmo 3.1 Método de Reamostragem CombinationEntrada: Γi . Base de dados a ser reamostrada
Entrada: A = a1, . . . , ad . Conjunto de atributos da base de dados Γi
Saída: Bases de dados Γi j , com j = 1,2, . . . ,k . Bases geradas após a reamostragem
1: para p ← 1 até d faça
2: kp ← d !p !(d−p)! . Verifica quantas combinações de atributos são possíveis para
cada variação de p
3: para j ← 1 até kp faça
4: A1 ← combinação j com kp atributos de A. . Seleção de atributos de A, de
acordo com a combinação j
5: Γi j ← Γi (A1) . Criação da nova base Γi j a partir da base original Γi e a
seleção de atributos A1
6: fim para
7: fim para
3.1.2 Geração de meta-instância
Na fase de Geração de meta-instância, após a reamostragem, cada base de dados
Γi j passa pelo processo de Extração de características, com o propósito de gerar
descritores da meta-instância; e pelo processo de Anotação, para gerar o rótulo dessa
meta-instância.
O módulo de Extração de características extrai medidas de caracterização de
dados de cada base de dados Γi j , gerando descritores da meta-instância. Esses descri-
tores têm como objetivos extrair informações sobre a estrutura das bases de dados e
extrair informações que influenciem na performance dos MSIs para o treinamento do
meta-classificador.
Diversos trabalhos, como os de SOTOCA; MOLLINEDA; SANCHEZ (2006), CAI-
SES et al. (2011) e LEYVA et al. (2014), sugerem meta-características que podem ser
utilizadas nesse módulo. A Tabela 3.1 mostra as meta-características extraídas nos
experimentos deste trabalho, descritas na Seção 2.3. A coluna Tipo classifica as medi-
das de acordo com a informação geral que extrai dos dados; a coluna Medida indica
o nome da medida de caracterização de dados; e as colunas Numéricos e Categóri-
cos informam se a medida consegue ser extraída a partir de valores numéricos ou
categóricos, respectivamente.
A classe da meta-instância é dada pelo Módulo de Anotação. Esse módulo é
responsável por rotular a meta-instância com a referência do “melhor” MSI, podendo
levar em consideração a precisão de classificação, a redução, o custo computacional ou

3.1. GERAÇÃO DO META-CLASSIFICADOR F 85
uma combinação desses. Neste trabalho, o “melhor” MSI é aquele que alcançar a maior
média de precisão de classificação para cada base de dados Γi j . A precisão média para
cada MSI é calculada da seguinte forma: (1) a base de dados Γi j é reduzida usando N
diferentes MSIs e (2) os novos conjuntos de instâncias gerados Ωi (i = 1,2, . . . , N) são
submetidos a M classificadores (c1,c2, . . . ,cM ) para obter suas precisões de classificação.
Depois de obtidas as médias dessas precisões, o MSI com maior média é representado
por uma classe (MSI1, MSI2, . . . , MSIn) para rótular a meta-instância. Esse processo é
ilustrado na Figura 3.2. Para minimizar a influência dos classificadores sobre a decisão
do “melhor” MSI, os classificadores envolvidos devem ser diversos e usar diferentes
abordagens de aprendizado.

3.1. GERAÇÃO DO META-CLASSIFICADOR F 86
Tabela 3.1: Medidas de caracterização dos dados
Tipo Medida Numéricos Categóricos
Estatística
Número de instâncias Sim Sim
Número de atributos Sim Sim
Número de classes Sim Sim
Atributos numéricos Sim Sim
Atributos binários Sim Sim
Atributos nominais Sim Sim
Proporção de atributos numéricos Sim Sim
Proporção de atributos binários Sim Sim
Proporção de atributos nominais Sim Sim
Nível de ruído Sim Sim
Desbalanceamento Sim Sim
Entropia Sim Sim
Baseada em
conjunto local
Pontos isolados Sim Sim
Número de regiões Sim Sim
Distância intergrupos Sim Sim
Distância intragrupos Sim Sim
Distância gruposNE Sim Sim
Diâmetro do grupo Sim Sim
LscAvgNorm Sim Sim
Separabilidade
de classes
N1 Sim Sim
N2 Sim Sim
N3 Sim Sim
Geometria e
densidade
T1 Sim Sim
T2 Sim Sim
D1 Sim Sim
D2 Sim Não
D3_K3 Sim Sim
D3_K5 Sim Sim
SobreposiçãoF1 Sim Não
F2 Sim Não

3.1. GERAÇÃO DO META-CLASSIFICADOR F 87
Figura 3.2: Módulo de Anotação. Cada base de dados Γi j é reduzida por Ndiferentes MSIs e as precisões das bases de dados resultantes Ωl são calculadascomo a média dos M classificadores cm . O rótulo é o MSI com a maior média de
precisão.
3.1.3 Seleção de atributos
Posto que dentre as meta-características geradas pelo processo de Extração de
características, algumas podem ser irrelevantes ou podem prejudicar a performance
do meta-classificador, o desempenho de treinamento do meta-classificador pode ser
favorecido com o uso de um método de seleção de atributos.
Portanto, o Módulo de Seleção de Atributos tem o objetivo de formar uma nova
meta-base com meta-características selecionadas de tal maneira que a performance
de classificação dessa nova meta-base seja melhor ou igual à performance de classifi-
cação da meta-base com todas as meta-características originais.
No Meta-CISM, esse módulo é opcional, dado que as meta-características do
processo de Extração de características podem ser poucas, suficientes ou consideradas
importantes para o treinamento do meta-classificador.

3.2. AVALIAÇÃO DO META-CLASSIFICADOR F 88
3.1.4 Treinamento do meta-classificador
Com a meta-base construída, o treinamento do meta-classificador é realizado com
um algoritmo de classificação que aprenderá a relação entre os atributos (descritores
representantes das bases de dados) e as classes (rótulos representantes dos “melhores”
MSI para a cada base), gerando uma função do meta-classificador treinado F, capaz
de definir o “melhor” MSI para novas bases.
3.2 Avaliação do meta-classificador F
Com o meta-classificador treinado, a operação e teste desse é feita através da
Avaliação do meta-classificador F. Bases de dados de teste ∆ têm suas medidas de
caracterização extraídas. Em seguida, essas meta-características podem ser reduzidas
por um método de seleção de atributos. Finalmente, são submetidas à função F do
meta-classificador treinado. E essa função F é a responsável por indicar o “melhor”
MSI para a base de dados de entrada.
Figura 3.3: Avaliação do Meta-classificador. Cada base de dados de teste temsuas meta-características extraídas. A quantidade de meta-características podeser reduzida se o módulo de seleção de atributos for utilizado. Finalmente, sãosubmetidas ao meta-classificador treinado F para obter o MSI mais adequado
para a base de dados de entrada ∆.

898989
4Estudo Experimental
Neste capítulo são apresentados os detalhes de como os experimentos foram reali-
zados e os resultados obtidos para validação do método proposto: Meta-CISM (Meta-
learing for Choosing Instance Selection Method). O método Meta-CISM é avaliado com
e sem o módulo de seleção de atributos para três meta-bases: mbBagging, para essa
meta-base, o método Bagging foi utilizado na fase de reamostragem; mbCombination,
gerada com o método de reamostragem Combination; e mbBaggingCombination, que
é uma meta-base construída com a união das outras duas meta-bases mencionadas.
A Seção 4.1 mostra a estrutura das bases de dados, a metodologia para os métodos
de reamostragem e sumariza as medidas de caracterização das bases. A Seção 4.2
apresenta os métodos de seleção de instâncias e classificadores utilizados para a cons-
trução das meta-bases. Na Seção 4.3 são descritos os experimentos para a escolha do
classificador aplicado como meta-classificador. Estão presentes nessa seção, inicial-
mente, a descrição dos estudos realizados para escolher valores para os parâmetros
necessários ao KNN e à MLP-BP. Em seguida, a seção apresenta uma análise de todos
os classificadores selecionados, com o propósito de escolher o mais adequado para
uso como meta-classificador. A Seção 4.4 discorre sobre os métodos de seleção de
atributos e as configurações utilizadas para esses. Além disso, essa seção relata uma
análise sobre os métodos de seleção de atributos a serem utilizados na avaliação do
método Meta-CISM. Os resultados da versão de Meta-CISM sem seleção de atribu-
tos são mostrados na Seção 4.5 e a validação da inclusão do Módulo de Seleção de
Atributos é avaliada na Seção 4.6. A Seção 4.7 sumariza os resultados obtidos.
As medidas de caracterização dos dados foram implementadas usando o software
Matlab 2012b. Os experimentos para redução da base de dados e classificação no Mó-
dulo de Anotação foram executados no Keel Tool 2.0. E os procedimentos de seleção
de atributos e classificação no treinamento do meta-classificador foram realizados no
software Weka 3.6.10.
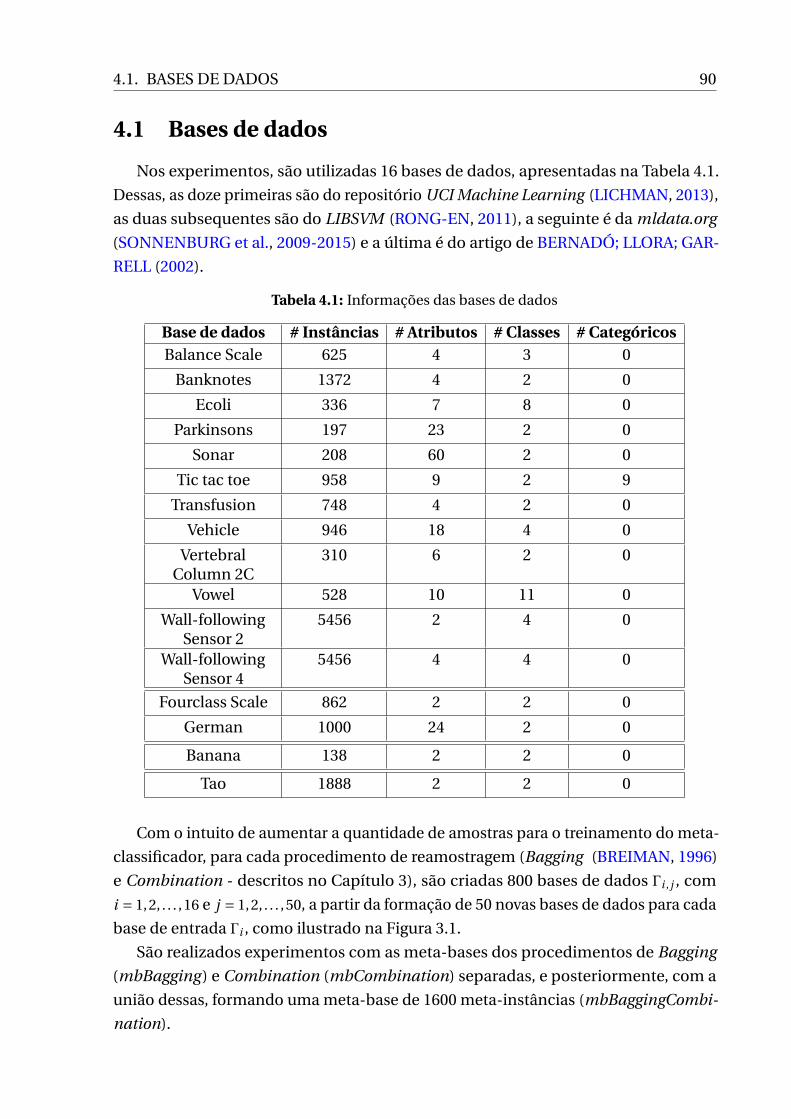
4.1. BASES DE DADOS 90
4.1 Bases de dados
Nos experimentos, são utilizadas 16 bases de dados, apresentadas na Tabela 4.1.
Dessas, as doze primeiras são do repositório UCI Machine Learning (LICHMAN, 2013),
as duas subsequentes são do LIBSVM (RONG-EN, 2011), a seguinte é da mldata.org
(SONNENBURG et al., 2009-2015) e a última é do artigo de BERNADÓ; LLORA; GAR-
RELL (2002).
Tabela 4.1: Informações das bases de dados
Base de dados # Instâncias # Atributos # Classes # CategóricosBalance Scale 625 4 3 0
Banknotes 1372 4 2 0
Ecoli 336 7 8 0
Parkinsons 197 23 2 0
Sonar 208 60 2 0
Tic tac toe 958 9 2 9
Transfusion 748 4 2 0
Vehicle 946 18 4 0
VertebralColumn 2C
310 6 2 0
Vowel 528 10 11 0
Wall-followingSensor 2
5456 2 4 0
Wall-followingSensor 4
5456 4 4 0
Fourclass Scale 862 2 2 0
German 1000 24 2 0
Banana 138 2 2 0
Tao 1888 2 2 0
Com o intuito de aumentar a quantidade de amostras para o treinamento do meta-
classificador, para cada procedimento de reamostragem (Bagging (BREIMAN, 1996)
e Combination - descritos no Capítulo 3), são criadas 800 bases de dados Γi , j , com
i = 1,2, . . . ,16 e j = 1,2, . . . ,50, a partir da formação de 50 novas bases de dados para cada
base de entrada Γi , como ilustrado na Figura 3.1.
São realizados experimentos com as meta-bases dos procedimentos de Bagging
(mbBagging ) e Combination (mbCombination) separadas, e posteriormente, com a
união dessas, formando uma meta-base de 1600 meta-instâncias (mbBaggingCombi-
nation).

4.2. CONFIGURAÇÕES PARA O MÓDULO DE ANOTAÇÃO 91
O Módulo de Extração de Características extrai trinta medidas de caracterização
de dados sobre as bases, descritas no Capítulo 2. A Tabela 3.1 mostra tais medidas
organizadas por tipo e a indicação dos tipos de dados com os quais trabalham.
4.2 Configurações para o Módulo de Anotação
Para o Módulo de Anotação, foram usados cinco MSIs (MSI1, MSI2, . . . , MSI5) de
abordagens distintas e com performance relevante em trabalhos publicados, conforme
abordado no Capítulo 2. São eles: C-pruner (ZHAO et al., 2003), DROP3 (WILSON;
MARTINEZ, 2000), IB3 (AHA; KIBLER; ALBERT, 1991), ICF (BRIGHTON; MELLISH,
2002) e ENN-CNN (CAISES et al., 2011).
Quanto aos classificadores, também foram escolhidos cinco representantes de
diferentes abordagens: C4.5 (árvore de decisão) (QUINLAN, 1993), K Nearest Neigh-
bors - KNN (lazy learning ) (COVER; HART, 1967), Sequential Minimal Optimization
- SMO (máquina de vetores de suporte) (PLATT, 1999), Multilayer Perceptron com
Backpropagation - MLP-BP (rede neural) (RUMELHART; HINTON; WILLIAMS, 1986)
e PART (Crisp rule) (FRANK; WITTEN, 1998). Os parâmetros desses classificadores
seguiram os valores padrões do software. E todos utilizaram o método de validação
cruzada k-fold, com k = 10.
Para os cálculos de distâncias, usamos Heterogeneous Value Difference Metric -
HVDM (WILSON; MARTINEZ, 1997) porque é uma medida de distância heterogênea,
ou seja, consegue trabalhar tanto com atributos numéricos como categóricos.
4.3 Meta-classificadores
Qualquer algoritmo de classificação supervisionada poderia ser utilizado para o
treinamento do meta-classificador. Neste trabalho, analisamos as saídas de 4 classifi-
cadores, também utilizados para geração das precisões médias dos MSIs: C4.5 (QUIN-
LAN, 1993), K Nearest Neighbors - KNN (COVER; HART, 1967), Multilayer Percep-
tron com Backpropagation - MLP-BP (RUMELHART; HINTON; WILLIAMS, 1986) e
PART (FRANK; WITTEN, 1998).
4.3.1 Configuração de parâmetros
Os parâmetros dos classificadores KNN e MLP-BP podem variar em diversos valo-
res. As Subseções 4.3.1.1 e 4.3.1.2, mostram estudos para indicar a melhor configura-
ção desses classificadores para serem utilizados como meta-classificadores. Nesses
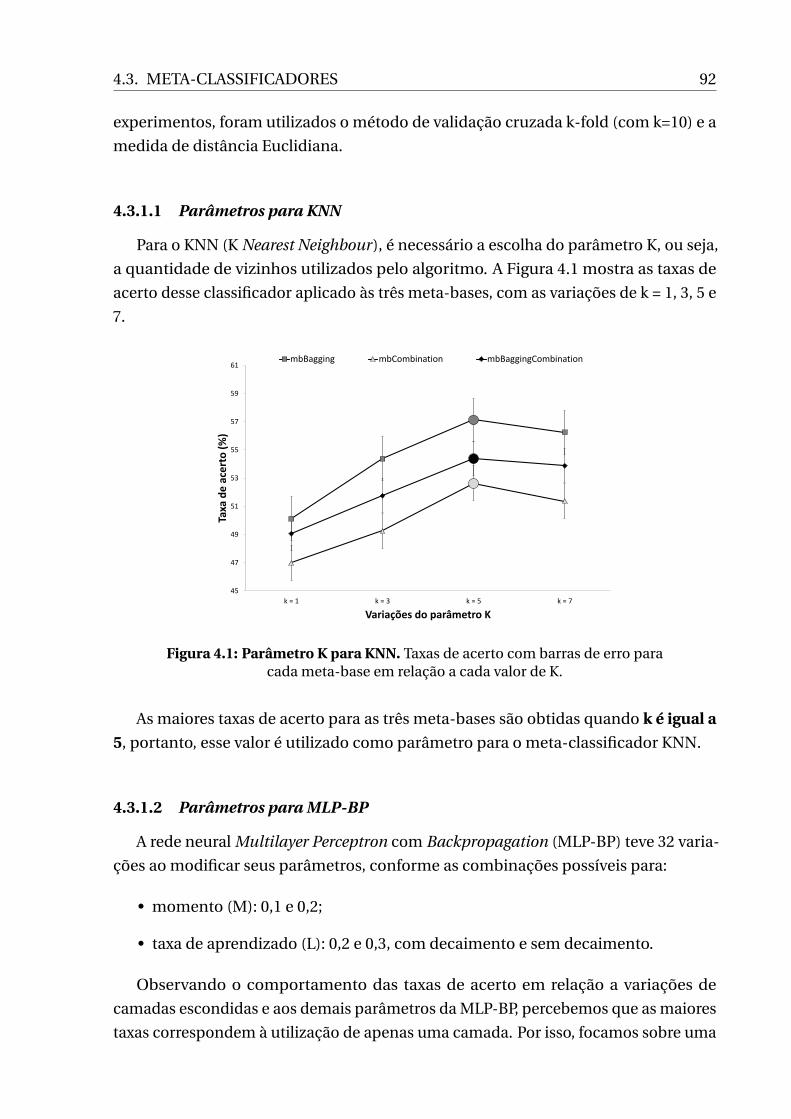
4.3. META-CLASSIFICADORES 92
experimentos, foram utilizados o método de validação cruzada k-fold (com k=10) e a
medida de distância Euclidiana.
4.3.1.1 Parâmetros para KNN
Para o KNN (K Nearest Neighbour), é necessário a escolha do parâmetro K, ou seja,
a quantidade de vizinhos utilizados pelo algoritmo. A Figura 4.1 mostra as taxas de
acerto desse classificador aplicado às três meta-bases, com as variações de k = 1, 3, 5 e
7.
45
47
49
51
53
55
57
59
61
k = 1 k = 3 k = 5 k = 7
Taxa
de
ace
rto
(%
)
Variações do parâmetro K
mbBagging mbCombination mbBaggingCombination
Figura 4.1: Parâmetro K para KNN. Taxas de acerto com barras de erro paracada meta-base em relação a cada valor de K.
As maiores taxas de acerto para as três meta-bases são obtidas quando k é igual a
5, portanto, esse valor é utilizado como parâmetro para o meta-classificador KNN.
4.3.1.2 Parâmetros para MLP-BP
A rede neural Multilayer Perceptron com Backpropagation (MLP-BP) teve 32 varia-
ções ao modificar seus parâmetros, conforme as combinações possíveis para:
• momento (M): 0,1 e 0,2;
• taxa de aprendizado (L): 0,2 e 0,3, com decaimento e sem decaimento.
Observando o comportamento das taxas de acerto em relação a variações de
camadas escondidas e aos demais parâmetros da MLP-BP, percebemos que as maiores
taxas correspondem à utilização de apenas uma camada. Por isso, focamos sobre uma

4.3. META-CLASSIFICADORES 93
camada escondida para a investigação da quantidade de neurônios a ser utilizado, de
acordo com a Tabela 4.2.
Tabela 4.2: Quantidade de neurônios para primeira camada escondida de umaMLP-BP
Símbolo Representação #Neurônios
cl #classes 5
at #atributos 30
ac #atributos + #classes 35
ac_avg (#atributos + #classes)/2 17
As Figuras 4.2, 4.3 e 4.4 mostram que dentre as três meta-bases, duas (mbBagging
e mbCombination) alcançam as maiores taxas de acerto com "cl", equivalente a 5
neurônios correspondentes ao número de classes do problema. Verifica-se ainda que
mbCombination e mbBaggingCombination não tiveram suas classificações benefiadas
com a utilização de decaimento da taxa de aprendizado.
55
56
57
58
59
60
L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3 L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3
M = 0,1 M = 0,1 M = 0,1 M = 0,1 M = 0,2 M = 0,2 M = 0,2 M = 0,2
Taxa
de
ace
rto
(%
)
Parâmetros: momento (M) e taxa de aprendizado (L)
cl at ac ac_avg
Figura 4.2: Camadas escondidas para MLP-BP (meta-base mbBagging ).Com a meta-base mbBagging, é exibida a influência da quantidade neurônios
em uma camada escondida sobre a taxa de acerto, a partir das possíveisvariações de taxa de aprendizado e momento.

4.3. META-CLASSIFICADORES 94
49
50
51
52
53
54
55
56
L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3 L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3
M = 0,1 M = 0,1 M = 0,1 M = 0,1 M = 0,2 M = 0,2 M = 0,2 M = 0,2
Taxa
de
ace
rto
(%
)
Parâmetros: momento (M) e taxa de aprendizado (L)
cl at ac ac_avg
Figura 4.3: Camadas escondidas para MLP-BP (meta-base mbCombination).Com a meta-base mbCombination, é exibida a influência da quantidadeneurônios em uma camada escondida sobre a taxa de acerto, a partir das
possíveis variações de taxa de aprendizado e momento.

4.3. META-CLASSIFICADORES 95
49
50
51
52
53
54
55
56
57
L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3 L = 0,2 Com decaimento
L = 0,2 L = 0,3 Com decaimento
L = 0,3
M = 0,1 M = 0,1 M = 0,1 M = 0,1 M = 0,2 M = 0,2 M = 0,2 M = 0,2
Taxa
de
ace
rto
(%
)
Parâmetros: momento (M) e taxa de aprendizado (L)
cl at ac ac_avg
Figura 4.4: Camadas escondidas para MLP-BP (meta-basembBaggingCombination). Com a meta-base mbBaggingCombination, é
exibida a influência da quantidade de neurônios em uma camada escondidasobre a taxa de acerto, a partir das possíveis variações de taxa de aprendizado e
momento.

4.3. META-CLASSIFICADORES 96
Por fim, a Figura 4.5 apresenta, para as três meta-bases, a relação entre a taxa
de acerto e as combinações de momento e taxa de aprendizado sem decaimento,
utilizando uma camada escondida com 5 neurônios. Apesar da melhor taxa de acerto
para a meta-base mbBagging ser equivalente a M = 0,2 e L = 0,3, as demais bases não
acompanham esse desempenho. Observa-se, no entanto, boas taxas de acerto para as
três meta-bases quando M = 0,2 e L = 0,2, correlato à melhor média de taxa de acerto
entre essas meta-bases, para cada par de parâmetros.
46
48
50
52
54
56
58
60
62
mbBagging mbCombination mbBaggingCombination Médias
Taxa
de
ace
rto
(%
)
Meta-bases
(M = 0,1 L = 0,2) (M = 0,1 L = 0,3) (M = 0,2 L = 0,2) (M = 0,2 L = 0,3)
Figura 4.5: Taxa de aprendizado e momento para MLP-BP. Taxas de acertoindividuais e média das taxas de acerto de todas as meta-bases, por
combinação de taxa de aprendizado com momento, para indicação dacombinação mais adequada a ser utilizada na MLP-BP.
Logo, são escolhidos como parâmetros para o meta-classificador baseado na rede
neural MLP com Backpropagation: uma camada escondida com 5 neurônios, taxa
de aprendizado L = 0,2 sem decaimento e momento M = 0,2. A função de transfe-
rência utilizada foi a tangente hiperbólica e o treinamento ocorreu com validação
cruzada k-fold, com k = 10.
4.3.2 Avaliação dos meta-classificadores
O algoritmo de classificação utilizado como meta-classificador afeta diretamente
o desempenho do método Meta-CISM. Por isso, a escolha desse é feita a partir da
avaliação de quatro classificadores bem conhecidos na literatura: K Nearest Neigh-
bors - KNN (COVER; HART, 1967), Multilayer Perceptron com Backpropagation - MLP-

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 97
BP (RUMELHART; HINTON; WILLIAMS, 1986), C4.5 (QUINLAN, 1993) e PART (FRANK;
WITTEN, 1998). Os dois primeiros adotam os parâmetros estabelecidos na Seção 4.3.
A Figura 4.6 mostra as taxas de acerto desses classificadores aplicados às meta-
bases mbBagging, mbCombination e mbBaggingCombination. Notamos nesses re-
sultados que a rede neural MLP-BP obteve as maiores taxas de acerto para as três
meta-bases e, portanto, é escolhida como meta-classificador para os experimentos de
validação do método Meta-CISM.
50
51
52
53
54
55
56
57
58
59
mbBagging mbCombination mbBaggingCombination
Taxa
de
ace
rto
(%
)
Meta-bases
C4.5 KNN MLP PART
Figura 4.6: Avaliação de meta-classificadores. Taxas de acerto dosmeta-classificadores: KNN, MLP-PB, PART e C4.5 sobre as meta-bases:
mbBagging, mbCombination e mbBaggingCombination.
4.4 Métodos de seleção de atributos
Antes de submetidas ao meta-classificador, as meta-bases podem passar por um
método de seleção de atributos, a fim de diminuir o custo computacional e melhorar
a precisão na classificação.
Neste trabalho, os métodos para seleção de atributos se diferenciam, inicialmente,
pelo uso de algoritmos de busca para a escolha do melhor subconjunto de atributos
ou pelo uso de ranking de uma quantidade determinada de atributos para a base de
dados final.

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 98
4.4.1 Configuração de parâmetros
Dos métodos estudados, dois utilizam algoritmos de busca: Consistency-Based
Subset Evaluation (LIU; SETIONO, 1996) e Correlation-based Feature Selection - CFS
(HALL, 1998), ambos variando os algoritmos de busca entre Genetic Search e Best First
Search. Os outros dois ordenam os atributos, criando rankings com a variação de 1 a
30 atributos selecionados para a base final: Chi Square Feature Evaluation (FRANK
et al., 2005) e Relief - F (KONONENKO, 1994).
Avaliando os algoritmos de busca Genetic Search e Best First Search para o método
de seleção de atributos Consistency-based Subset Evaluation aplicado às meta-bases
estudadas, notamos, na Figura 4.7, que quando Best First Search é utilizado, o meta-
classificador alcança melhor desempenho.
45
47
49
51
53
55
57
59
mbBagging mbCombination mbBaggingCombination
Taxa
de
ace
rto
(%
)
Meta-bases
Best First Search Genetic Search
Figura 4.7: Algoritmos de busca para Consistency-based Subset Evaluation.Taxas de acerto do meta-classificador MLP-BP para as meta-bases: mbBagging,mbCombination e mbBaggingCombination, aplicadas ao método de seleção deatributos Consistency-based Subset Evaluation com os algoritmos de busca: Best
First Search e Genetic Search.
No caso de Correlation-based Feature Selection - CFS, a Figura 4.8 mostra que
Genetic Search obtém melhores taxas de acerto para as meta-bases.
Para os métodos que fazem ranking dos atributos de uma base de dados, podendo
avaliar desde um até todos os atributos disponíveis, as meta-bases mostram melhor
desempenho com quantidades diferentes de atributos. A análise e escolha para cada
uma é feita considerando que, quando as taxas de acerto são muito próximas, quanto
menor for a quantidade de atributos, menor será o custo computacional.

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 99
52
53
54
55
56
57
58
mbBagging mbCombination mbBaggingCombination
Taxa
de
ace
rto
(%
)
Meta-bases
Best First Search Genetic Search
Figura 4.8: Algoritmos de busca para Correlation-based Feature Selection -CFS. Taxas de acerto do meta-classificador MLP-BP para as meta-bases:
mbBagging, mbCombination e mbBaggingCombination, aplicadas ao métodode seleção de atributos Correlation-based Feature Selection - CFS com os
algoritmos de busca: Best First Search e Genetic Search.
Assim, usando Chi Square Feature Evaluation (FRANK et al., 2005), a Figura 4.9
mostra que a meta-base mbBagging tem as melhores taxas de acerto com diferença
irrelevante para 10 e 14 atributos no ranking. Logo, mbBagging é analisada com o
ranking de 10 atributos. A meta-base mbCombination também é avaliada com 10
atributos no ranking , tendo em vista que além de apresentar pouca diferença para
o melhor resultado equivalente a 26 atributos, traz uma redução do custo compu-
tacional. A meta-base mbBaggingCombination demonstra maior establidade para
a relação de quantidade de atributos e taxa de acerto. No entanto, ainda tomando
por base a menor quantidade de atributos para redução do custo computacional, a
meta-base mbBaggingCombination é avaliada com 6 atributos no ranking .
A mesma lógica é aplicada para o Relief - F (KONONENKO, 1994), mostrado na
Figura 4.10. A meta-base mbBagging utiliza nos experimentos 6 atributos no ran-
king , por ser correspondente à segunda melhor taxa de acerto com menor quantidade
de atributos. A meta-base mbCombination segue e usa o segundo melhor resultado
com o ranking de 16 atributos. Já mbBaggingCombination, apesar de ter as me-
lhores taxas com 23 e 27 atributos, usa 10 atributos no ranking para melhor custo
computacional sem muita perda em precisão.
Os atributos selecionados por Consistency-based Subset Evaluation com Best First
Search, Correlation-based Feature Selection - CFS com Genetic Search, Chi Square
Feature Evaluation e Relief - F podem ser visto na Tabela 4.3. Um histograma da
frequência de escolha desses atributos pelos métodos de seleção de atributos é apre-
sentado na Figura 4.11.

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 100
47
49
51
53
55
57
59
61
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Taxa
de
ace
rto
(%
)
Número de atributos no ranking
mbBagging mbCombinaton mbBaggingCombination
Figura 4.9: Taxas de acerto relativas às variações do número de atributos noranking para Chi Square Feature Evaluation. Taxas de acerto do
meta-classificador MLP-BP para as meta-bases: mbBagging, mbCombination embBaggingCombination, aplicadas ao método de seleção de atributos Chi
Square Feature Evaluation com variação do número de atributos no ranking de1 a 30. Os pontos em destaque correspondem às quantidades de atributos
escolhidas para cada meta-base.
35
40
45
50
55
60
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Taxa
de
ace
rto
(%
)
Número de atributos no ranking
mbBagging mbCombination mbBaggingCombination
Figura 4.10: Taxas de acerto relativas às variações do número de atributosno ranking para Relief - F . Taxas de acerto do meta-classificador MLP-BP para
as meta-bases: mbBagging, mbCombination e mbBaggingCombination,aplicadas ao método de seleção de atributos Relief - F com variação do número
de atributos no ranking de 1 a 30. Os pontos em destaque correspondem àsquantidades de atributos escolhidas para cada meta-base.

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 101
0
1
2
3
4
5
6
7
8
9
10
11
12
Frequência
Me
did
as
Figu
ra4.
11:H
isto
gram
ad
asm
eta-
cara
cter
ític
asse
leci
on
adas
pel
os
Mét
od
os
de
Sele
ção
de
Atr
ibu
tos.
Freq
uên
cia
de
esco
lha
de
cad
am
eta-
cara
cter
ísti
ca(n
ora
nge
de
0a
12),
con
sid
eran
do
aso
ma
dos
resu
ltad
osd
eca
da
met
a-b
ase
(mbB
aggi
ng,
mbC
ombi
nat
ion
em
bBag
gin
gCom
bin
atio
n)
sub
met
ida
ato
do
so
sM
éto
do
sd
eSe
leçã
od
eA
trib
uto
s(C
onsi
sten
cy-b
ased
Subs
etE
valu
atio
nco
mB
estF
irst
Sear
ch,C
orre
lati
on-b
ased
Feat
ure
Sele
ctio
n-
CF
Sco
mG
enet
icSe
arch
,Ch
iSqu
are
Feat
ure
Eva
luat
ion
eR
elie
f-F
).

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 102
Tabela 4.3: Atributos selecionados por cada Método de Seleção de Atributos
Consistency - Consistency-based Subset Evaluation com Best First Search
CFS - Correlation-based Feature Selection com Genetic Search
Chi Square - Chi Square Feature Evaluation
B - mbBagging C - mbCombination BC - mbBaggingCombination
Consistency CFS Chi Square Relief - F
MEDIDA B C BC B C BC B C BC B C BCAtributos binários X XAtributos categóricos XAtributos numéricos X X X X XD1 X X X X X X XD2 X X X XD3_K3 X X X X X X XD3_K5 X X X X X X X XDesbalanceamento X X X X X XDiâmetro do grupo X X X X X X XDistância gruposNE X X X X X X X X XDistância intergrupos X X X X X X X X X X XDistância intragrupos X X X X X X X X X XEntropia X X X X X X X X X X XF1 X X XF2 X X X XLscAvgNorm X X X X X X XN1N2 X X X X X X XN3 X X X X X XNível de ruído X X X X XNúmero de atributos X X XNúmero de classes X X XNúmero de instâncias X X X X X XNúmero de regiões X X X X X X XPontos isolados X X X X XProporção de atribu-tos binários
X
Proporção de atribu-tos categóricos
X X
Proporção de atribu-tos numéricos
X X
T1 X X X X X XT2 X X X X

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 103
4.4.2 Avaliação dos métodos de seleção de atributos
Foram analisados quatro métodos de seleção de atributos, conforme estudo da
seção anterior: Consistency-based Subset Evaluation (LIU; SETIONO, 1996) com Best
First ; Correlation-based Feature Selection - CFS (HALL, 1998) com Genetic Search; Chi
Square Feature Evaluation (FRANK et al., 2005) com 10 atributos para mbBagging e
mbCombination e 6 atributos para mbBaggingCombination; e Relief - F (KIRA; REN-
DELL, 1992) com 6, 16 e 10 atributos para as meta-bases mbBagging, mbCombination
e mbBaggingCombination, respectivamente. As Figuras 4.12, 4.13 e 4.14 mostram as
taxas de acerto de diferentes classificadores para as meta-bases mbBagging, mbCombi-
nation e mbBaggingCombination, respectivamente, quando submetidas aos métodos
de seleção de atributos estudados. Nessas figuras, verifica-se que todos os métodos de
seleção de atributos levam os classificadores a desempenhos muito próximos, mesmo
alterando as meta-bases. A realização do teste estatístico de Friedman comprova
que não há diferenças estatísticas entre eles (p-value = 0,9893). Assim, realizamos a
análise dos resultados do Meta-CISM, com todos os MSAs aplicados separadamente
nas meta-bases para comparar com os resultados do método proposto utilizando as
meta-bases sem a aplicação de métodos de seleção de atributos.
Figura 4.12: Taxas de acerto alcançadas com o uso de métodos de seleção deatributos sobre a meta-base mbBagging . Resultado dos classificadores sobrea meta-base mbBagging quando submetida aos quatro métodos de seleção de
atributos (Consistency-based Subset Evaluation, Correlation-based FeatureSelection - CFS, Chi Square Feature Evaluation e Relief - F ).

4.4. MÉTODOS DE SELEÇÃO DE ATRIBUTOS 104
Figura 4.13: Taxas de acerto alcançadas com o uso de métodos de seleção deatributos sobre a meta-base mbCombination. Resultado dos classificadores
sobre a meta-base mbCombination quando submetida aos quatro métodos deseleção de atributos (Consistency-based Subset Evaluation, Correlation-based
Feature Selection - CFS, Chi Square Feature Evaluation e Relief - F ).
Figura 4.14: Taxas de acerto alcançadas com o uso de métodos de seleção deatributos sobre a meta-base mbBaggingCombination. Resultado dos
classificadores sobre a meta-base mbBaggingCombination) quando submetidaaos quatro métodos de seleção de atributos (Consistency-based Subset
Evaluation, Correlation-based Feature Selection - CFS, Chi Square FeatureEvaluation e Relief - F ).

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 105
4.5 Avaliação do Meta-CISM sem seleção de atributos
O meta-classificador sugere o “melhor” MSI em termos de classificação para cada
meta-instância correspondente a uma base de dados. Assim, para avaliar os resultados
desse meta-classificador, cada base Γi , j foi reduzida pelo MSI indicado e se tornou
uma base Γ(i , j )R . Em seguida, cada Γ(i , j )R foi submetida aos mesmos classificadores do
Módulo de Anotação (C4.5, KNN, MLP-BP, Part e SMO, utilizando validação cruzada
k-fold, com k = 10), obtendo a taxa de acerto para cada classificador. O desempenho
do método Meta-CISM foi calculado pela média das taxas de acerto de cada clas-
sificador aplicado a todas as bases Γ(i , j )R , separadas de acordo com sua meta-base
correspondente.
Com o intuito de comparar os resultados de Meta-CISM com os resultados indi-
viduais dos MSIs, as bases de dados Γi , j foram reduzidas com cada MSI e seguiram
os demais procedimentos de classificação e médias de taxa de acerto descritos no
parágrafo anterior. Nesse caso, os resultados são as médias das taxas de acerto de cada
classificador para cada MSI aplicado às bases, separadas por meta-base correspon-
dente.
As Tabelas 4.4, 4.5 e 4.6 e as Figuras 4.15, 4.16 e 4.17 mostram, para cada meta-base,
o desempenho de Meta-CISM comparado com o desempenho alcançado pelos demais
MSIs, separados por classificador. Os valores em destaque nas tabelas, correspondem
às maiores taxas de acerto para cada classificador. Percebemos que em todas as
situações o método proposto está no topo, sozinho ou com outros métodos.
Tabela 4.4: Médias de precisão para cada MSI avaliados por cincoclassificadores (meta-base mbBagging ).
KNN C4.5 SMO PART MLP
C-pruner 73,73% (0,16) 71,31% (0,17) 66,46% (0,18) 58,02% (0,17) 58,12% (0,17)
DROP3 77,64% (0,12) 71,52% (0,11) 62,45% (0,20) 57,51% (0,17) 55,39% (0,18)
ENN-CNN 79,91% (0,11) 73,18% (0,12) 63,62% (0,20) 60,25% (0,18) 57,53% (0,18)
IB3 78,55% (0,14) 69,29% (0,18) 64,46% (0,21) 59,99% (0,19) 54,13% (0,19
ICF 71,58% (0,17) 71,72% (0,11) 69,06% (0,18) 60,24% (0,17) 57,49% (0,18)
Meta-CISM 79,92% (0,11) 76,82% (0,11) 69,62% (0,18) 62,52% (0,18) 60,05% (0,19)
Tabela 4.5: Médias de precisão para cada MSI avaliados por cincoclassificadores (meta-base mbCombination).
KNN C4.5 SMO PART MLP
C-pruner 59,44% (0,16) 59,12% (0,17) 51,36% (0,21) 52,82% (0,20) 49,11% (0,18)
DROP3 64,80% (0,1)4 64,36% (0,09) 50,03% (0,21) 50,86% (0,19) 47,91% (0,18)
ENN-CNN 64,18% (0,12) 65,01% (0,11) 51,70% (0,20) 52,69% (0,20) 49,51% (0,19)
IB3 65,92% (0,09) 62,78% (0,14) 51,86% (0,21) 52,00% (0,21) 47,58% (0,18)
ICF 65,10% (0,14) 68,17% (0,09) 53,23% (0,20) 53,61% (0,20) 49,88% (0,18)
Meta-CISM 67,57% (0,13) 67,98% (0,10) 53,60% (0,20) 54,03% (0,20) 50,60% (0,18)

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 106
Tabela 4.6: Médias de precisão para cada MSI avaliados por cincoclassificadores (meta-base mbBaggingCombination).
KNN C4.5 SMO PART MLP
C-pruner 66,58% (0,18) 65,22% (0,62) 58,91% (0,46) 55,42% (0,54) 53,62% (0,64)DROP3 71,22% (0,52) 67,94% (0,55) 56,24% (0,46) 54,19% (0,44) 51,65% (0,58)
ENN-CNN 72,05% (0,50) 69,09% (0,57) 57,66% (0,46) 56,47% (0,50) 53,52% (0,59)IB3 72,23% (0,59) 66,03% (0,48) 58,16% (0,46) 56,00% (0,47) 50,85% (0,56)ICF 68,34% (0,56) 69,94% (0,56) 61,15% (0,46) 56,92% (0,50) 53,68% (0,64)
Meta-CISM 73,99% (0,63) 72,40% (0,62) 61,08% (0,46) 56,42% (0,54) 55,17% (0,64)
Figura 4.15: Desempenho de Meta-CISM sem seleção de atributos para ameta-base mbBagging. O gráfico apresenta as médias dos resultados de
precisão dos MSIs estudados e de Meta-CISM para as bases de dados geradaspor Bagging, separadas por classificador.

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 107
Figura 4.16: Desempenho de Meta-CISM sem seleção de atributos para ameta-base mbCombination. O gráfico apresenta as médias dos resultados deprecisão dos MSIs estudados e de Meta-CISM para as bases de dados geradas
por Combination, separadas por classificador.
Figura 4.17: Desempenho de Meta-CISM sem seleção de atributos para ameta-base mbBaggingCombination. O gráfico apresenta as médias dos
resultados de precisão dos MSIs estudados e de Meta-CISM para para as basesde dados geradas por Bagging e Combination juntas, separadas por
classificador.

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 108
Escolhemos o teste estatístico não-paramétrico de Friedman para analisar se exis-
tem diferenças estatísticas entre o Meta-CISM e os demais MSIs. Com o uso dos valores
das Tabelas 4.4, 4.5 e 4.6, obtivemos os resultados do teste para as meta-bases mb-
Bagging, mbCombination e bmBaggingCombination, respecitvamente. A Tabela 4.7
exibe a média de ranks de cada método, o p-value e a estatística de teste para cada
meta-base.
Em H0 (hipótese nula) verificamos se as médias de classificação de Meta-CISM e
dos MSIs são iguais para os resultados dos classificadores. Em H1 (hipótese alternativa)
verificamos se essas médias são estatisticamente diferentes. Friedman é calculado
de acordo com a distribuição Qui-quadrado. Temos para os seis métodos, 5 graus de
liberdade. De acordo com a tabela Qui-quadrado de valores críticos, para um nível de
significância α= 5%, a estatística de teste não deve ultrapassar 9,236. Já para α= 10% o
valor crítico é 11,071. O p-value indica o quanto os dados estão compatíveis com o
que diz a hipótese nula e deve ser maior que o nível de significância esperado para
não rejeitar H0. Em nossos experimentos, constatamos a um nível de significância
α= 5% que H0 deve ser rejeitada, visto que na Tabela 4.7 as estatísticas de teste e os
p-values obtidos para os MSIs nas aplicações das bases mbBagging, mbCombination
e mbBaggingCombination foram maiores que os limites citados acima. Diante desses
resultados, temos fortes evidências para afirmar que Meta-CISM e os MSIs possuem
diferenças estatísticas.
Tabela 4.7: Teste de Friedman para os resultados do Meta-CISM e demais MSIsestudados, aplicados às meta-bases mbBagging, mbCombination e
mbBaggingCombination
Friedman de acordo com a distribuição Chi-Quadrado, com 5 graus de liberdade
e valores críticos: 9,236 para α= 5% e 11,070 para α= 10% .
H0 As médias de classificação dos métodos são iguais.
H1 As médias de classificação dos métodos são diferentes.
Rejeitar a hipótese nula quando P-VALUE<α (nível de significância).
mbBagging mbCombination mbBaggingCombination
CPRUNER
RA
NK
S
4 4,8 4,6
DROP3 5 5 5
ENNCNN 2,8 3,8 3,4
IB3 4,6 4,2 4,2
ICF 3,6 2 2,2
META-CISM 1 1,2 1,6
Estatística de Teste 14,942857 17,228571 13,228571
P-VALUE 0,010609 0,004086 0,021328
A fim de verificar se o método proposto é responsável por diferenças significantes
em relação a cada um dos MSIs estudados, foram executados os testes: Wilcoxon
signed-ranks test com 90% e 95% de nível de confiança e o teste de múltiplas compa-

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 109
rações Holm–Bonferroni com 95% de confiança. Os resultados do teste de Wilcoxon
são apresentados na Tabela 4.8. Essa tabela possui os valores da soma dos rankings
positivos, equivalentes ao método proposto, uma vez que é uma comparação do
Meta - CISM com cada um dos MSIs; a soma dos rankings negativos, correspondentes
à soma dos rankings do método em comparação; e os p-values para cada meta-base.
O teste de Wilcoxon indica que o método proposto é superior à maioria dos méto-
dos estudados com 90% de confiança. O Meta-CISM se mostra melhor que todos os
MSIs para a meta-base mbBagging. Para a meta-base mbBaggingCombination, apenas
sobre ICF não alcança o melhor resultado. Já com a meta-base mbCombination, não
alcança diferenças estatísticas sobre ENNCNN e ICF. Com 95% de confiança, não
mostrou diferenças significativas sobre quaisquer MSIs.
Fazendo comparações com os p-values gerados com o teste de Holm-Bonferroni,
presentes na 4.9, vimos que: para as meta-bases mbBagging e mbCombination, o
Meta-CISM consegue, com nível de significância de 5%, melhores resultados que
C-pruner, DROP3, IB3 e ICF, enquanto é estatisticamente igual a ENN-CNN; para a
meta-base mbBaggingCombination, com a mesma significância, Meta-CISM é su-
perior a C-pruner, DROP3 e IB3 e possui igualdade estatística em relação a ICF e
ENN-CNN.
Tabela 4.8: Teste de Wilcoxon comparando Meta-CISM × MSIs
R+ soma dos rankings de Meta-CISM.
R- soma dos rankings do método em comparação.
H0 As médias de classificação dos métodos são iguais.
H1 A média de classificação do Meta-CISM é maior que a média do método em comparação.
Rejeitar a hipótese nula quando P-VALUE<α (nível de significância).
α= 5% e α= 10%
META-CISM × mbBagging mbCombination mbBaggingCombination
CPRUNER
R+ 15 15 15
R- 0 0 0
P-VALUE 0,0625 0,0625 0,0625
DROP3
R+ 15 15 15
R- 0 0 0
P-VALUE 0,0625 0,0625 0,0625
ENNCNN
R+ 15 15 14
R- 0 0 1
P-VALUE 0,0625 0,0625 0,125
IB3
R+ 15 15 15
R- 0 0 0
P-VALUE 0,0625 0,0625 0,0625
ICF
R+ 15 14 12
R- 0 1 3
P-VALUE 0,0625 0,125 ≥ 2

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 110
Tabela 4.9: Teste de Holm-Bonferroni comparando Meta-CISM × MSIs
H0 As médias de classificação dos métodos são iguais.H1 A média de classificação do Meta-CISM é maior que a média do método em comparação.
Rejeitar a hipótese nula quando P-VALUE<α (nível de significância).α= 5% e α= 10%
META-CISM P-VALUES
× mbBagging mbCombination mbBaggingCombination
CPRUNER 0,01123 0,002346 0,01123DROP3 0,000723 0,00132 0,004059
ENNCNN 0,12819 0,027992 0,12819IB3 0,002346 0,01123 0,027992
ICF 0,027992 0,498962 0,61209
Outra análise possível é a verificação das escolhas de Meta-CISM, atestando com
que frequência o meta-classificador escolhe o 1º, 2º, 3º, 4º ou o 5º melhor MSI para
cada base de dados (Figuras 4.18, 4.19 e 4.20). Esse diagnóstico é possível a partir do
cálculo da média das precisões dos classificadores para cada base aplicada aos MSIs,
atribuindo uma posição (1º, 2º, 3º, 4º ou 5º) para cada MSI.
O metódo escolhe um dos três melhores MSIs para mais de 85% das bases de
todos os casos. Com a meta-base mbBagging, o Meta-CISM mostrou alta precisão nos
resultados, uma vez que 98,13% das bases tiveram indicação do MSI mais adequado a
ser aplicado. Em mbCombination, 86,5% dos casos têm um dos três melhores MSIs
indicados. E em mbBaggingCombination um dos três melhores MSIs é sugerido para
88,44% das bases.
0
10
20
30
40
50
60
70
80
90
100
1º 2º 3º 4º 5º 6º
Fre
qu
ên
cia
(%)
Ranking de escolhas
Figura 4.18: Taxas de ranking de Meta-CISM sem seleção de atributos para ameta-base mbBagging. Os MSIs foram ordenados em ranking pela média das
precisões dos classificadores para cada base, a fim de mostrar com quefrequência o Meta-CISM escolhe os melhores MSIs. O gráfico apresenta o
ranking das bases correspondentes à meta-base mbBagging.

4.5. AVALIAÇÃO DO META-CISM SEM SELEÇÃO DE ATRIBUTOS 111
0
10
20
30
40
50
60
1º 2º 3º 4º 5º 6º
Fre
qu
ên
cia
(%)
Ranking de escolhas
Figura 4.19: Taxas de ranking de Meta-CISM sem seleção de atributos para ameta-base mbCombination. Os MSIs foram ordenados em ranking pela média
das precisões dos classificadores para cada base, a fim de mostrar com quefrequência o Meta-CISM escolhe os melhores MSIs. O gráfico apresenta o
ranking das bases correspondentes à meta-base mbCombination.
0
10
20
30
40
50
60
1º 2º 3º 4º 5º 6º
Fre
qu
ên
cia
(%)
Ranking de escolhas
Figura 4.20: Taxas de ranking do Meta-CISM sem seleção de atributos para ameta-base mbBaggingCombination. Os MSIs foram ordenados em rankingpela média das precisões dos classificadores para cada base, a fim de mostrar
com que frequência o Meta-CISM escolhe os melhores MSIs. O gráficoapresenta o ranking das bases correspondentes à meta-base
mbBaggingCombination.
O método Meta-CISM é validado pelo desempenho satisfatório nos resultados
apresentados, considerando as boas escolhas e o alcance de taxas de acerto iguais ou
superiores aos demais métodos estudados.

4.6. AVALIAÇÃO DO META-CISM COM SELEÇÃO DE ATRIBUTOS 112
4.6 Avaliação do Meta-CISM com seleção de atributos
Um avanço do Meta-CISM pode ser atingido com a inclusão do Módulo de Seleção
de Atributos. Se um subconjunto das meta-características atuar com desempenho
semelhante ou até melhor que o conjunto completo dessas meta-características, a
redução do custo computacional e a melhora no processo de meta-aprendizagem
compensará a inclusão desse módulo.
Tendo em vista os resultados já apresentados para o método proposto sem o Mó-
dulo de Seleção de Atributos, as Tabelas 4.10, 4.11 e 4.12 e as Figuras 4.21, 4.22 e
4.23 apontam como esse módulo influencia nos resultados. Tanto as figuras como
as tabelas, mostram uma comparação das taxas de acerto do método Meta-CISM
sem a seleção de atributos e com quatro algoritmos diferentes de seleção de atribu-
tos, a saber: Consistency-based Subset Evaluation (LIU; SETIONO, 1996) com Best
First ; Correlation-based Feature Selection - CFS (HALL, 1998) com Genetic Search; Chi
Square Feature Evaluation (FRANK et al., 2005) com 10 atributos para mbBagging e
mbCombination e 6 atributos para mbBaggingCombination; e Relief - F (KIRA; REN-
DELL, 1992) com 6, 16 e 10 atributos para as bases mbBagging, mbCombination e
mbBaggingCombination, respectivamente.
Tabela 4.10: Comparação das médias de precisão do Meta-CISM com e sem omódulo de seleção de atributos (meta-base mbBagging ).
KNN C4.5 SMO PART MLP
Sem seleção de atributos 79,92% (0,11) 76,82% (0,11) 69,62% (0,18) 62,52% (0,18) 60,05% (0,19)
CFS 79,17% (0,11) 76,92% (0,11) 69,41% (0,18) 59,69% (0,18) 59,50% (0,19)
Chi Squared 79,55% (0,11) 76,82% (0,11) 68,90% (0,19) 60,55% (0,18) 58,91% (0,19)
Consistency 79,41% (0,11) 76,65% (0,11) 68,94% (0,19) 60,89% (0,18) 59,11% (0,19)
Relief - F 79,43% (0,12) 77,15% (0,11) 68,60% (0,19) 60,76% (0,18) 58,89% (0,19)
Tabela 4.11: Comparação das médias de precisão do Meta-CISM com e sem omódulo de seleção de atributos (meta-base mbCombination).
KNN C4.5 SMO PART MLP
Sem seleção de atributos 67,57% (0,13) 67,98% (0,10) 53,60% (0,20) 54,03% (0,20) 50,60% (0,18)
CFS 67,91% (0,13) 68,74% (0,09) 53,86% (0,20) 54,26% (0,20) 49,84% (0,18)
Chi Squared 67,72% (0,13) 68,59% (0,11) 53,51% (0,21) 53,73% (0,20) 49,93% (0,19)
Consistency 68,60% (0,12) 68,32% (0,10) 53,30% (0,21) 53,77% (0,20) 50,15% (0,18)
Relief - F 68,28% (0,18) 68,67% (0,18) 53,61% (0,18) 53,95% (0,18) 50,11% (0,18)

4.6. AVALIAÇÃO DO META-CISM COM SELEÇÃO DE ATRIBUTOS 113
Tabela 4.12: Comparação das médias de precisão do Meta-CISM com e sem omódulo de seleção de atributos (meta-base mbBaggingCombination).
KNN C4.5 SMO PART MLP
Sem seleção de atributos 73,99% (0,13) 72,40% (0,11) 61,08% (0,21) 56,42% (0,19) 55,17% (0,19)CFS 73,87% (0,13) 72,72% (0,11) 60,77% (0,21) 56,86% (0,19) 54,13% (0,19)
Chi Squared 73,37% (0,14) 72,81% (0,11) 60,73% (0,21) 57,24% (0,19) 54,77% (0,19)Consistency 74,01% (0,13) 72,66% (0,11) 60,88% (0,21) 56,78% (0,19) 54,61% (0,20)
Relief - F 74,20% (0,13) 73,08% (0,11) 60,48% (0,21) 56,60% (0,19) 54,36% (0,19)
Figura 4.21: Desempenho do Meta-CISM com seleção de atributos para ameta-base mbBagging. O gráfico apresenta a média dos resultados de precisão
do Meta-CISM com e sem o módulo de seleção de atributos, separadas porclassificador, para as bases de dados geradas por Bagging.

4.6. AVALIAÇÃO DO META-CISM COM SELEÇÃO DE ATRIBUTOS 114
Figura 4.22: Desempenho do Meta-CISM com seleção de atributos para ameta-base mbCombination. O gráfico apresenta a média dos resultados de
precisão do Meta-CISM com e sem o módulo de seleção de atributos, separadaspor classificador, para as bases de dados geradas por Combination.
Figura 4.23: Desempenho do Meta-CISM com seleção de atributos para ameta-base mbBaggingCombination. O gráfico apresenta a média dos
resultados de precisão do Meta-CISM com e sem o módulo de seleção deatributos, separadas por classificador, para as bases de dados geradas por
mbBaggingCombination.
Visualmente e estatisticamente, não são encontradas diferenças significativas nas
taxas de acerto para as meta-bases estudadas. Com os valores das Tabelas 4.10, 4.11
e 4.12, realizamos o teste estatístico não-paramétrico de Friedman para analisar se
existem diferenças estatísticas nos resultados antes e após a aplicação de diferentes

4.6. AVALIAÇÃO DO META-CISM COM SELEÇÃO DE ATRIBUTOS 115
MSAs. Para a hipótese nula (H0) definimos que há igualdade nas médias de classifi-
cação do Meta-CISM com e sem a aplicação dos métodos de seleção de atributos. E
para a hipótese alternativa (H1) investigamos se essas médias são estatisticamente
diferentes.
A Tabela 4.13 contém os resultados do Teste de Friedam realizado e, nesse caso,
para a análise de 5 configurações, temos 4 graus de liberdade com os seguintes valores
críticos: 7,779 para α= 5% e 9,488 para α= 10%. Com níveis de significância α= 5% e
α= 10%, aceitamos H0, em razão dos p-values obtidos para as avaliações do uso de
MSAs aplicados às meta-bases de mbBagging, mbCombination e mbBaggingCombina-
tion, serem maiores que α. Os valores das estatísticas de teste menores que os valores
críticos, mostrados nessa tabela, ratificam que os dados condizem com a afirmação da
hipótese nula, ou seja, os resultados do teste de Friedman informam que os métodos
possuem resultados estatisticamente iguais.
Tabela 4.13: Teste de Friedman para os resultados do Meta-CISM com aaplicação de Métodos de Seleção de Atributos nas meta-bases mbBagging,
mbCombination e mbBaggingCombination.
Friedman de acordo com a distribuição Chi-Quadrado, com 4 graus de liberdade
e valores críticos: 7,779 para α= 5% e 9,488 para α= 10% .
H0 As médias de classificação dos métodos são iguais.
H1 As médias de classificação dos métodos são diferentes.
Rejeitar a hipótese nula quando P-VALUE<α (nível de significância).
mbBagging mbCombination mbBaggingCombination
Sem SA
RA
NK
S
1,6 3 3,2
CFS 3,2 3,4 2,2
Chi Squared 3,4 2,8 4
Consistency 3,4 2,8 3,2
Relief 3,4 3 2,4
Estatística de Teste 4,96 0,48 4,16
P-VALUE 0,291426 0,975419. 0,384785
Embora as taxas de acerto não tenham melhorado com o uso do Módulo de Seleção
de Atributos, o Meta-CISM manteve sua precisão. A Tabela 4.14 mostra a soma dos
tempos para calcular cada medida de caracterização de dados e a redução provocada
pelo uso de métodos de seleção de atributos em quatro das dezesseis bases de dados
estudadas. A redução do número de meta-características, por exemplo, de trinta para
seis em mbBagging aplicado a Correlation-based Feature Selection com Genetic Search
- CFS e a Relief - F, provoca uma queda considerável no custo computacional. E dado o
alcance de até 80% de redução no tempo para o cálculo, podemos validar o uso desse
módulo como contribuição ao Meta-CISM.

4.6.AV
ALIA
ÇÃ
OD
OM
ETA
-CISM
CO
MSE
LEÇ
ÃO
DE
ATR
IBU
TO
S116
Tabela 4.14: Redução do tempo para o cálculo das meta-características com ouso do Módulo de Seleção de Atributos
B - mbBagging C - mbCombination BC - mbBaggingCombination
BANANA VERTEBRAL COLUMN 2C PARKINSONS SONAR
TEMPO TOTAL (s) 91,8984 (6,1780) 2035,1122 (40,4292) 2154,8370 (45,3762) 6919,0297 (98,8893)
TEMPO REDUZIDO (s) % TEMPO REDUZIDO (s) % TEMPO REDUZIDO (s) % TEMPO REDUZIDO (s) %
Consistency-basedSubset Evaluation com
Best First Search
B 85,7180 (5,7665) 7% 1898,8272 (37,7354) 7% 2010,0810 (42,3315) 7% 6454,3057 (92,2977) 7%C 85,8114 (5,7668) 7% 1899,7507 (37,7361) 7% 2011,6261 (42,3546) 7% 6458,8425 (92,3021) 7%
BC 85,8113 (5,7668) 7% 1899,7504 (37,7362) 7% 2011,6251 (42,3546) 7% 6458,8404 (92,30221) 7%
Correlation-basedFeature Selection comGenetic Search - CFS
B 30,6116 (2,0610) 67% 677,9219 (13,4774) 67% 716,9750 (15,1165) 67% 2302,2557 (32,9493) 67%C 49,2094 (3,2982) 46% 1087,2170 (21,5722) 47% 1151,5968 (24,2137) 47% 3697,1323 (52,7750) 47%
BC 61,3181 (4,1200) 33% 1356,9938 (26,9572) 33% 1436,8534 (30,2396) 33% 4613,0981 (65,9432) 33%
Chi Square FeatureEvaluation
B 30,8416 (2,0631) 60% 680,0594 (13,4892) 60% 720,1017 (15,1232) 60% 2311,4542 (33,0057) 60%C 36,8169 (2,4752) 66% 814,0149 (16,1790) 67% 860,7637 (18,1403) 67% 2763,4056 (39,5447) 67%
BC 24,5986 (1,6515) 73% 543,0176 (10,7895) 73% 573,9693 (12,0948) 73% 1842,3299 (26,3657) 73%
Relief - FB 18,5162 (1,2357) 80% 408,1523 (8,0914) 80% 433,1214 (9,0817) 80% 1389,7978 (19,8214) 80%C 55,0111 (3,7080) 40% 1219,7754 (24,2571) 40% 1290,3608 (27,2075) 40% 4143,9302 (59,3062) 40%
BC 42,8026 (2,8829) 53% 948,5754 (18,8636) 53% 1003,5829 (21,1669) 53% 3222,2262 (46,1219) 53%

4.7. CONSIDERAÇÕES FINAIS 117
4.7 Considerações Finais
Os extensos experimentos apresentados nas seções anteriores, propiciam obser-
vações adicionais dos resultados, além das análises realizadas para a verificação dos
objetivos pretendidos neste trabalho.
Iniciando com os processos de reamostragem, a meta-base mbBagging demonstra
ter a melhor estrutura. Pois nos experimentos, desde aqueles executados para a confi-
guração de parâmetros do KNN, MLP-BP e Métodos de Seleção de Atributos (MSAs)
até os resultados do método proposto, as maiores taxas de acerto são obtidas por
essa meta-base. Além disso, todos os MSAs escolheram as menores quantidades de
meta-características para ela. A meta-base mbCombination ficou com a pior posição,
dado que os MSAs lhe atribuem as maiores quantidades de meta-características e
essa meta-base está, na maioria das vezes, relacionada às menores precisões. Já a
meta-base mbBaggingCombination apresentou as menores variações de respostas
para os diferentes experimentos realizados.
Os resultados que se referem às meta-bases, indicam que o processo de reamostra-
gem Combination, neste estudo, não apresentou os melhores resultados possíveis. É
provável que um dos motivos dessas respostas esteja no processo de atribuição dos
atributos às novas bases de dados, visto que o método Combination inicia criando
bases de apenas um atributo. Assim, pode não gerar bases com boa representatividade
do problema, principalmente, quando a base de origem possue uma grande dimensão
de atributos. A ordem de geração das bases do método deve ser reavaliada.
Nos estudos sobre parâmetros para o KNN, podemos destacar o comportamento
das precisões das meta-bases com a variação dos k-vizinhos mais próximos. Notamos
que um número k muito pequeno, não gera as melhores respostas, a classificação é
afetada pela proximidade entre as classes. No entanto, o acréscimo de k só melhora as
taxas de acerto até um certo nível (k = 5, o valor escolhido). A frente desse, as taxas
começam a cair, o raio de vizinhos acaba atingindo as fronteiras das classes.
Já nos parâmetros da MLP-BP, vimos que poucos neurônios são suficientes para
uma boa generalização da rede. As melhores respostas foram obtidas com as menores
quantidades de neurônios (nesse caso, cl = 5 neurônios e ac_av g = 17 neurônios).
Observamos ainda, que o decaimento da taxa de aprendizagem não contribuiu para
os melhores resultados.
A rede neural MLP-BP foi a melhor opção como meta-classificador. Todavia, forne-
ceu as piores precisões entre os classificadores utilizados nas bases de dados submeti-
das às aplicações dos MSIs para a avaliação do Meta-CISM. Nessas avaliações o KNN
foi o melhor classificador.
Os métodos de seleção de atributos não ofereceram aumento das precisões quando
aplicados nas meta-bases: mbBagging, mbCombination e mbBaggingCombination.

4.7. CONSIDERAÇÕES FINAIS 118
Entretanto, conseguiram reduzi-las consideravelmente. Todas essas meta-bases foram
construídas com trinta meta-características. As maiores reduções foram produzidas
pelos métodos Relief-F e CFS com Genetic Search. Pois, diminuiram a meta-base
mbBagging para seis meta-características e o tempo de processamento em 80% e
67% do tempo total, respectivamente. O MSA que fez as maiores reduções globais
foi o Chi Square Feature Evaluation, considerando reduções das três meta-bases. Já
Consistency-based Subset Evaluation foi o MSA que reteve mais meta-características
nas meta-bases.
Uma investigação geral sobre as meta-características escolhidas pelos MSAs estu-
dados, revela, conforme a Figura 4.11, que com um range de 0 a 12 chances, Entropia e
Distância Intergrupos foram as meta-características mais selecionadas para continuar
na meta-base. Em seguida, estão entre as mais escolhidas, as meta-características: Dis-
tância Intragrupos e Distância GruposNE. Isso sugere que essas meta-características
são relevantes para o uso na escolha de MSIs com meta-aprendizagem. Quinze meta-
características foram escolhidas com uma frequência maior que 50% das chances,
ou seja, seis vezes ou mais. E outras quinze meta-características foram selecionadas
menos de seis vezes. A meta-característica que demonstrou ter menor influência
nas meta-bases foi N 1, já que não foi escolhida por nenhum MSA e possuia a menor
divergência entre seus valores nas meta-bases. Também foram pouco influentes,
meta-características que informam estruturas simples das bases, como: Atributos
binários, Proporção de atributos binários, Atributos nominais, Proporção de atributos
nominais e Proporção de atributos numéricos.
Quanto aos objetivos principais desta dissertação, constatamos que foram atendi-
dos, uma vez que o método proposto (Meta-CISM) obteve respostas bastante satis-
fatórias em relação aos demais MSIs. A precisão atingida pela arquitetura proposta
esteve entre as melhores taxas de acerto em todos os resultados mostrados. O uso
de meta-aprendizagem permitiu ao Meta-CISM escolher os “melhores” MSIs em
85% dos casos (referente à precisão) para serem aplicados nas bases de dados (Figu-
ras 4.18, 4.18 e 4.20). Os processos de reamostragem possibilitaram o treinamento
de uma MLP com apenas dezesseis bases adquiridas de repositórios (Tabela 4.1). O
Módulo de Seleção de Atributos contribuiu para a redução do custo computacional
(Seção 4.6). Em suma, os estudos realizados contribuem para pesquisas sobre o uso
de meta-aprendizagem para a escolha de métodos de seleção de instâncias.

119119119
5Conclusões
Esta dissertação propôs a arquitetura Meta-CISM (Meta-learing for Choosing Ins-
tance Selection Method) para selecionar o “melhor” Método de Seleção de Instâncias
(MSI) dada uma base de dados, baseada em meta-aprendizagem.
Dezesseis bases de dados foram reamostradas e utilizadas na construção da meta-
base. Trinta medidas de caracterização de dados foram extraídas dessas bases rea-
mostradas e usadas como descritores. Após a aplicação dos MSIs em cada base de
dados, a maior precisão da média de cinco classificadores foi usada para determi-
nar o “melhor” MSI para ser rótulo de uma meta-instância. Os descritores e rótulos
compõem as meta-instâncias integrantes da meta-base que foi usada para treinar um
meta-classificador responsável por selecionar o “melhor” MSI para novas bases. A
inclusão do Módulo de Seleção de Atributos também foi estudada para verificar os
benefícios trazidos ao Meta-CISM.
Este capítulo apresenta as principais contribuições desta dissertação na Seção 5.1.
A Seção 5.2 indica como aprofundar a pesquisa e aperfeiçoar o método proposto.
5.1 Contribuições
A principal contribuição deste trabalho é a proposta do Meta-CISM (Meta-learing
for Choosing Instance Selection Method). Um método que seleciona automaticamente
o “melhor” MSI para uma base de dados, e além disso, preocupa-se em:
• se adequar à realidade da baixa disponibilidade de bases de dados para a geração
das meta-instâncias da meta-base de treino, ao incluir o Módulo de Reamostra-
gem;
• ser imparcial ao tipo de classificador utilizado para rotulação das meta-instâncias,
utilizando a média de vários tipos de algoritmos de classificação;
• propiciar o uso de vários classificadores e métodos de seleção de atributos;

5.1. CONTRIBUIÇÕES 120
• e melhorar o custo computacional do processo, através do Módulo de Seleção
de Atributos.
Outra importante contribuição é a formulação do método de reamostragem Combi-
nation. Esse método permite criar novas bases de dados com a garantia da diversidade
entre elas, porque sempre varia ou na quantidade de atributos ou em quais atributos
serão escolhidos para as novas bases. Apesar dessa importante aptidão, Combination
precisa de ajustes, visto que a meta-base mbCombination, gerada por esse processo
de reamostragem, obteve os resultados menos satisfatórios.
Os experimentos realizados contribuem para ratificar a eficiência do uso de meta-
aprendizagem com Métodos de Seleção de Instâncias. Os resultados obtidos mostram
que, na maioria das vezes, o Meta-CISM estatisticamente se sobrepõe a todos os MSIs
estudados (C-pruner, DROP3, IB3, ICF e ENN-CNN). Logo, a abordagem é adequada
para ser usada automaticamente na fase de pré-processamento das bases de dados,
visto que eficientemente seleciona um dos três melhores MSIs em mais de 85% dos
casos.
O uso do Módulo de Seleção de Atributos se mostra relevante, devido à redução
do custo computacional e à permanência dos valores de taxas de acerto. Qualquer
um dos métodos de seleção de atributos estudados poderia ser escolhido para a
aplicação nesse módulo, pois, atingiram resultados estatisticamente iguais e não
resultaram na melhora das taxas de acerto. Todavia, os métodos Correlation-based
Feature Selection com Genetic Search - CFS e Relief - F foram os que mais reduziram
as meta-características e assim, os que mais diminuiram a complexidade das meta-
bases (reduzindo a dimensão) e o tempo de processamento. A pesquisa indica que a
melhor configuração para o uso de cada um deles é: Best First Search para Consistency-
based Subset Evaluation; no caso de Correlation-based Feature Selection - CFS, Genetic
Search; em Chi Square Feature Evaluation, o ranking de 10 atributos para a meta-base
mbBagging ; também 10 atributos para a meta-base mbCombination e para a meta-
base mbBaggingCombination, 6 atributos no ranking ; para o Relief - F, 6 atributos
no ranking para a meta-base mbBagging, a meta-base mbCombination ficou com o
ranking de 16 atributos; e mbBaggingCombination com 10 atributos no ranking.
Quanto ao meta-classificador, a pesquisa aponta que dentre os quatro classificado-
res analisados (C4.5, KNN, MLP-BP e PART), a rede neural MLP-BP é a melhor opção
para classificação das meta-bases.
A meta-base mbBagging gerada pelo procedimento de reamostragem Bagging,
atingiu os melhores resultados com e sem o Módulo de Seleção de Atributos. Em
seguida, a meta-base mbBaggingCombination foi quem alcançou as melhores taxas,
com 1600 meta-instâncias, das quais 800 derivam do procedimento de Bagging e 800
derivam do procedimento de Combination. Por último, ficou a meta-base mbCombi-
nation gerada apenas pelo processo de Combination. Este resultado pode indicar que

5.2. TRABALHOS FUTUROS 121
os atributos selecionados na reamostragem Combination não foram suficientes ou os
mais representativos do problema.
Parte dos resultados desta pesquisa foi divulgada nos artigos: Chossing Instance
Selection Method using meta-learning (OLIVEIRA MOURA et al., 2014a) e Uma abor-
dagem para a escolha do melhor método de seleção de instâncias usando meta-
aprendizagem (OLIVEIRA MOURA et al., 2014b), publicados nos anais dos eventos
SMC 2014 e ENIAC 2014, respectivamente.
5.2 Trabalhos Futuros
Trabalhos futuros incluem:
• verificar o comportamento do Meta-CISM com outra configuração, alterando
os procedimentos de reamostragem, os métodos de seleção de instâncias, os
classificadores e aumentando o número de meta-características;
• considerar a porcentagem de redução para cada MSI no módulo de Anotação,
seus relacionamentos com a precisão e verificar detalhadamente o custo com-
putacional do método;
• analisar mais profundamente o método Combination e verificar possíveis me-
lhorias.

122122122Referências
AHA, D. W.; KIBLER, D.; ALBERT, M. K. Instance-based learning algorithms. Machinelearning, [S.l.], v.6, n.1, p.37–66, 1991.
ALMEIDA, M. A. F. Introdução ao Estudo das Redes Neurais Artificiais. [S.l.]: UFSC,1995.
BERNADÓ, E.; LLORA, X.; GARRELL, J. M. XCS and GALE: a comparative study of twolearning classifier systems on data mining. In: Advances in learning classifiersystems. [S.l.]: Springer, 2002. p.115–132.
BOSER, B. E.; GUYON, I. M.; VAPNIK, V. N. A training algorithm for optimal marginclassifiers. In: COMPUTATIONAL LEARNING THEORY, 1992. Anais. . . [S.l.: s.n.], 1992.p.144–152.
BRAZDIL, P.; CARRIER, C. G.; SOARES, C.; VILALTA, R. Metalearning: applications todata mining. 1.ed. [S.l.]: Springer Science & Business Media, 2008.
BREIMAN, L. Bagging predictors. Machine learning, [S.l.], v.24, n.2, p.123–140, 1996.
BRIGHTON, H.; MELLISH, C. Advances in instance selection for instance-basedlearning algorithms. Data mining and knowledge discovery, [S.l.], v.6, n.2, p.153–172,2002.
CAISES, Y.; GONZáLEZ, A.; LEYVA, E.; PéREZ, R. Combining instance selectionmethods based on data characterization: an approach to increase their effectiveness.Information Sciences, [S.l.], v.181, n.20, p.4780–4798, 2011.
CAMERON-JONES, R. Instance selection by encoding length heuristic with randommutation hill climbing. In: AUSTRALIAN JOINT CONFERENCE ON ARTIFICIALINTELLIGENCE, 1995. Anais. . . [S.l.: s.n.], 1995. p.99–106.
CHANG, C.-L. Finding prototypes for nearest neighbor classifiers. IEEE Transactionson Computers, [S.l.], v.100, n.11, p.1179–1184, 1974.
COHEN, W. W. Fast effective rule induction. In: INTERNATIONAL CONFERENCE ONMACHINE LEARNING, 1995. Anais. . . [S.l.: s.n.], 1995. p.115–123.
CORTES, C.; VAPNIK, V. Support-vector networks. Machine learning, [S.l.], v.20, n.3,p.273–297, 1995.
COVER, T.; HART, P. Nearest neighbor pattern classification. IEEE Transactions onInformation Theory, [S.l.], v.13, n.1, p.21–27, 1967.
CZARNOWSKI, I.; JEDRZEJOWICZ, P. Instance reduction approach to machinelearning and multi-database mining. Annales UMCS Sectio AI Informatica, [S.l.], v.4,n.1, p.60–71, 2006.
DASARATHY, B. Minimal consistent set (MCS) identification for optimal nearestneighbor decision systems design. IEEE Transactions on Systems, Man andCybernetics, [S.l.], v.24, n.3, p.511–517, 1994.

REFERÊNCIAS 123
DASH, M.; LIU, H. Feature Selection for Classification. Intelligent Data Analysis,[S.l.], v.1, p.131–156, 1997.
DONALD, H. The organization of behavior: a neuropsychological theory. [S.l.]: NewYork: Wiley, 1949.
FRANK, E.; HALL, M.; HOLMES, G.; KIRKBY, R.; PFAHRINGER, B.; WITTEN, I. H.;TRIGG, L. Weka. In: Data Mining and Knowledge Discovery Handbook. [S.l.]:Springer, 2005. p.1305–1314.
FRANK, E.; WITTEN, I. H. Generating Accurate Rule Sets Without GlobalOptimization. [S.l.]: University of Waikato: Department of Computer Science, 1998.144–151p.
GARCÍA-PEDRAJAS, N.; DEL CASTILLO, J. A. R.; ORTIZ-BOYER, D. A cooperativecoevolutionary algorithm for instance selection for instance-based learning. MachineLearning, [S.l.], v.78, n.3, p.381–420, 2010.
GARCÍA, S.; LUENGO, J.; HERRERA, F. Data Preprocessing in Data Mining. [S.l.]:New York: Springer, 2015.
GATES, G. The reduced nearest neighbor rule. IEEE Transactions on InformationTheory, [S.l.], v.18, n.3, p.431–433, 1972.
GIRAUD-CARRIER, C.; FLACH, P.; PENG, Y.; FARRAND, J.; BENSUSAN, H. METAL: ameta-learning assistant for providing user support in machine learning and datamining. 2002.
HALL, M. A. Correlation-based Feature Subset Selection for Machine Learning.1998. Tese (Doutorado em Ciência da Computação) — University of Waikato,Hamilton, New Zealand.
HART, P. The condensed nearest neighbor rule. IEEE Transactions on InformationTheory, [S.l.], v.14, n.3, p.515–516, 1968.
HO, T. K. The random subspace method for constructing decision forests. IEEETransactions on Pattern Analysis and Machine Intelligence, [S.l.], v.20, n.8,p.832–844, 1998.
JANKOWSKI, N.; GROCHOWSKI, M. Comparison of Instances Seletion Algorithms I.Algorithms Survey. In: RUTKOWSKI, L.; SIEKMANN, J.; TADEUSIEWICZ, R.; ZADEH,L. (Ed.). Artificial Intelligence and Soft Computing - ICAISC 2004. [S.l.]: SpringerBerlin Heidelberg, 2004. p.598–603. (Lecture Notes in Computer Science, v.3070).
KIM, S.-W.; OOMMEN, B. J. A brief taxonomy and ranking of creative prototypereduction schemes. Pattern Analysis & Applications, [S.l.], v.6, n.3, p.232–244, 2003.
KIM, S.-W.; OOMMEN, B. J. Enhancing prototype reduction schemes with LVQ3-typealgorithms. Pattern Recognition, [S.l.], v.36, n.5, p.1083–1093, 2003.
KIRA, K.; RENDELL, L. A. A practical approach to feature selection. In:INTERNATIONAL WORKSHOP ON MACHINE LEARNING, 1992. Anais. . . [S.l.: s.n.],1992. p.249–256.

REFERÊNCIAS 124
KOHONEN, T. The self-organizing map. Neurocomputing, [S.l.], v.21, n.1, p.1–6, 1998.
KONONENKO, I. Estimating attributes: analysis and extensions of relief. In:MACHINE LEARNING, 1994. Anais. . . [S.l.: s.n.], 1994. p.171–182.
KUHN, H. W. Nonlinear programming: a historical view. In: Traces and Emergenceof Nonlinear Programming. [S.l.]: Springer, 2014. p.393–414.
LEYVA, E.; CAISES, Y.; GONZÁLEZ, A.; PÉREZ, R. On the use of meta-learning forinstance selection: an architecture and an experimental study. Information Sciences,[S.l.], v.266, p.16–30, 2014.
LEYVA, E.; GONZáLEZ, A.; PéREZ, R. Knowledge-based instance selection: acompromise between efficiency and versatility. Knowledge-Based Systems, [S.l.],v.47, p.65–76, 2013.
LEYVA, E.; GONZALEZ, A.; PEREZ, R. A Set of Complexity Measures Designed forApplying Meta-Learning to Instance Selection. IEEE Transactions on Knowledge andData Engineering, [S.l.], v.27, n.2, p.354–367, Feb 2015.
LICHMAN, M. UCI Machine Learning Repository. 2013.
LIU, H.; SETIONO, R. A probabilistic approach to feature selection - A filter solution.In: INTERNATIONAL CONFERENCE ON MACHINE LEARNING, 13., 1996. Anais. . .[S.l.: s.n.], 1996. p.319–327.
MCCULLOCH, W. S.; PITTS, W. A logical calculus of the ideas immanent in nervousactivity. The bulletin of mathematical biophysics, [S.l.], v.5, n.4, p.115–133, 1943.
MICHALSKI, R. S. Understanding the nature of learning: issues and researchdirections. Machine learning: An artificial intelligence approach, [S.l.], v.2, p.3–25,1986.
MOLINA, L.; BELANCHE, L.; NEBOT, A. Feature selection algorithms: a survey andexperimental evaluation. In: IEEE INTERNATIONAL CONFERENCE ON DATAMINING, 2002. Anais. . . [S.l.: s.n.], 2002. p.306–313.
MOLLINEDA, R. A.; SÁNCHEZ, J. S.; SOTOCA, J. M. Data characterization for effectiveprototype selection. In: Pattern Recognition and Image Analysis. [S.l.]: Springer,2005. p.27–34.
NAKHAEIZADEH, G. Project statlog: comparative testing and evaluation of statisticaland logical learning algorithms for large-scale applications in classification,prediction and control. 1993.
NORVIG, P.; RUSSELL, S. Inteligência Artificial, 3ª Edição. [S.l.]: Elsevier Brasil, 2014.v.1.
OLIVEIRA MOURA, S. de; FREITAS, M. Bassani de; CARDOSO, H.; CAVALCANTI, G.Choosing instance selection method using meta-learning. In: IEEE INTERNATIONALCONFERENCE ON SYSTEMS, MAN AND CYBERNETICS, 2014. Anais. . . [S.l.: s.n.],2014. p.2003–2007.

REFERÊNCIAS 125
OLIVEIRA MOURA, S. de; FREITAS, M. Bassani de; CARDOSO, H.; CAVALCANTI, G.Uma abordagem para a escolha do melhor método de seleção de instâncias usandometa-aprendizagem. In: ENCONTRO NACIONAL DE INTELIGêNCIA ARTIFICIAL ECOMPUTACIONAL, 2014. Anais. . . [S.l.: s.n.], 2014.
PIETRAMALA, A.; POLICICCHIO, V. L.; RULLO, P.; SIDHU, I. A genetic algorithm fortext classification rule induction. In: Machine Learning and Knowledge Discovery inDatabases. [S.l.]: Springer, 2008. p.188–203.
PLATT, J. C. Fast training of support vector machines using sequential minimaloptimization. Advances in kernel methods—support vector learning, [S.l.], v.3,1999.
QUINLAN, J. R. Induction of decision trees. Machine learning, [S.l.], v.1, n.1, p.81–106,1986.
QUINLAN, J. R. C4.5: programs for machine learning. [S.l.]: Morgan kaufmann, 1993.v.1.
REINARTZ, T. A unifying view on instance selection. Data Mining and KnowledgeDiscovery, [S.l.], v.6, n.2, p.191–210, 2002.
RIQUELME, J. C.; AGUILAR-RUIZ, J. S.; TORO, M. Finding representative patternswith ordered projections. Pattern Recognition, [S.l.], v.36, n.4, p.1009–1018, 2003.
RITTER, G.; WOODRUFF, H.; LOWRY, S.; ISENHOUR, T. An algorithm for a selectivenearest neighbor decision rule. IEEE Transactions on Information Theory, [S.l.],v.21, n.6, p.665–669, 1975.
RONG-EN, F. LIBSVM Data: classification, regression, and multi-label. Acessado em:02 de agosto de 2015, http://www.csie.ntu.edu.tw/ cjlin/libsvmtools/datasets.
ROSENBLATT, F. The perceptron: a probabilistic model for information storage andorganization in the brain. Psychological review, [S.l.], v.65, n.6, p.386, 1958.
RUMELHART, D.; HINTON, G.; WILLIAMS, R. Learning internal representation byback propagation. Parallel distributed processing: exploration in themicrostructure of cognition, [S.l.], v.1, 1986.
SILVA, I. N. da; SPATTI, D. H.; FLAUZINO, R. A. Redes Neurais Artificiais paraengenharia e ciências aplicadas curso prático. Artliber, [S.l.], 2010.
SMITH-MILES, K. A. Cross-disciplinary perspectives on meta-learning for algorithmselection. ACM Computing Surveys (CSUR), [S.l.], v.41, n.1, p.6, 2008.
SMITH-MILES, K.; ISLAM, R. Meta-learning for data summarization based oninstance selection method. In: IEEE CONGRESS ON EVOLUTIONARYCOMPUTATION, 2010. Anais. . . [S.l.: s.n.], 2010. p.1–8.
SONNENBURG, S.; ONG, C. S.; HENSCHEL, S.; BRAUN, M. L.; HOYER, P. O. MachineLearning Data Set Repository (2011). Acessado em: 02 de agosto de 2013.

REFERÊNCIAS 126
SOTOCA, J.; MOLLINEDA, R.; SANCHEZ, J. A meta-learning framework for patternclassification by means of data complexity measures. Inteligencia Artificial, [S.l.],v.10, n.29, p.31–38, 2006.
TOMEK, I. An Experiment with the Edited Nearest-Neighbor Rule. IEEE Transactionson Systems, Man and Cybernetics, [S.l.], n.6, p.448–452, 1976.
TRIGUERO, I.; GARCÍA, S.; HERRERA, F. Differential evolution for optimizing thepositioning of prototypes in nearest neighbor classification. Pattern Recognition,[S.l.], v.44, n.4, p.901–916, 2011.
VALIANT, L. G. A theory of the learnable. Communications of the ACM, [S.l.], v.27,n.11, p.1134–1142, 1984.
WILSON, D. L. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data.IEEE Transactions on Systems, Man and Cybernetics, [S.l.], v.SMC-2, n.3, p.408–421,1972.
WILSON, D. R.; MARTINEZ, T. R. Improved heterogeneous distance functions.Journal of Artificial Intelligence Research, [S.l.], p.1–34, 1997.
WILSON, D. R.; MARTINEZ, T. R. Reduction techniques for instance-based learningalgorithms. Machine learning, [S.l.], v.38, n.3, p.257–286, 2000.
WOLPERT, D. H.; MACREADY, W. G. No free lunch theorems for optimization. IEEETransactions on Evolutionary Computation, [S.l.], v.1, n.1, p.67–82, 1997.
WU, X.; KUMAR, V.; QUINLAN, J. R.; GHOSH, J.; YANG, Q.; MOTODA, H.;MCLACHLAN, G. J.; NG, A.; LIU, B.; PHILIP, S. Y. et al. Top 10 algorithms in datamining. Knowledge and Information Systems, [S.l.], v.14, n.1, p.1–37, 2008.
ZHANG, H.; SUN, G. Optimal reference subset selection for nearest neighborclassification by tabu search. Pattern Recognition, [S.l.], v.35, n.7, p.1481–1490, 2002.
ZHAO, K.-P.; ZHOU, S.-G.; GUAN, J.-H.; ZHOU, A.-Y. C-pruner: an improved instancepruning algorithm. In: INTERNATIONAL CONFERENCE ON MACHINE LEARNINGAND CYBERNETICS, 2003. Anais. . . [S.l.: s.n.], 2003. v.1, p.94–99.
Recommended

















