Embed Size (px)
Citation preview

6º Fórum Internacional de Software Livre
Alta Disponibilidade na Prática utilizando servidores Linux
- Tito Lívio Castro- Edison Pignaton de Freitas- Jorgito Matiuzzi Stochero

Roteiro
Introdução Tolerância a falhas Metodologia de projeto de sistemas
tolerantes a falhas Estudo de Caso Implementação Demonstração

Introdução
Disponibilidade de um sistema computacional é a probabilidade de que este sistema esteja funcionando e pronto para uso
Classes– Disponibilidade Básica (99% a 99,9%)– Alta Disponibilidade (99,99% a 99,999%)– Disponibilidade Contínua (99,999...%)

Introdução
Alta Disponibilidade é uma sub-área da Tolerância a Falhas que visa manter a disponibilidade dos serviços prestados por um sistema computacional– redundância de hardware– reconfiguração de software– Vários computadores juntos agindo como um só,
cada um monitorando os outros e assumindo seus serviços caso perceba que algum deles falhou

Conceitos básicos
Falha– Origem do problema– Ex. :um bloco de código inconsistente
Erro– Consequência da falha, gerando comportamento não
desejado do sistema– Ex. : buffer overflow
Defeito– Resultado aparente do comportamento indevido– Ex. Crash devido ao buffer overflow

Conceitos básicos
Failover– Uma máquina assume os serviços de outra, quando esta
última falha– Automático ou manual (pode ou não ser transparente)
Failback– Processo inverso do failover, executado quando o
servidor que apresentou falha é recolocado em sv

Tolerância a Falhas
Como conseguir ???– Redundância– Monitoração– Reação imediata

Metodologia de Projeto
Definição de objetivos– Custo, desempenho, confiabilidade
Limitação de escopo– Tipo de falhas consideradas, que partes do
sistema serão tolerantes a falhas Definição de níveis de tratamento Definição da reconfiguração e reparos Projeto dos mecanismos de tratamento Identificação do hard core Avaliação do resultado

Estudo de Caso
Servidor de Arquivos e Autenticação 600 estações de trabalho Ambiente heterogêneo Necessidade de alta disponibilidade

Estudo de Caso
Requisitos– Custo: baixo– Desempenho: tempo de acesso aos arquivos no
servidor próximo ao tempo de acesso de arquivos locais
– Confiabilidade: o sistema não deve sair do ar em horários de expediente normal (acima de 99%)

Estudo de Caso
Escopo– Falhas consideradas
Degradação de hardware Falhas de software
– Partes tolerantes Acesso, edição e armazenamento de arquivos Sistema de autenticação

Estudo de Caso
Níveis de Tratamento– Falhas consideradas em nível de componentes
individuais (LDAP, samba, hw, etc)– Erros serão considerados do tipo paradas imprevistas
(crash)– Defeitos: não acesso aos dados e impossibilidade de
autenticação Mecanismos de Tratamento
– Detecção de erros durante a operação do sistema– Recuperação através do mascaramento do defeito para o
usuário

Estudo de Caso
Recuperação e reparos– Replicação da base de usuários– Recovery da base de usuários– Replicação dos dados– Acesso aos dados replicados
Projeto dos mecanismos de tratamento– Detecção: técnica de heartbeat (heartbeat)– Tratamento: mascaramento (heartbeat/drbd/slurp)

Estudo de Caso
Solução para Replicação - RAID Nível 1– Escrita nos discos “D” de dados é replicada nos
discos “D´” -> Esquema de Espelhamento
D D´
b
a a´
b´
Variantes:- Hw: componentes prontos
unidos por barramentos (somente um nível possível de falha)
- Sw: controle por sincronização (baixo custo e maior flexibilidade)
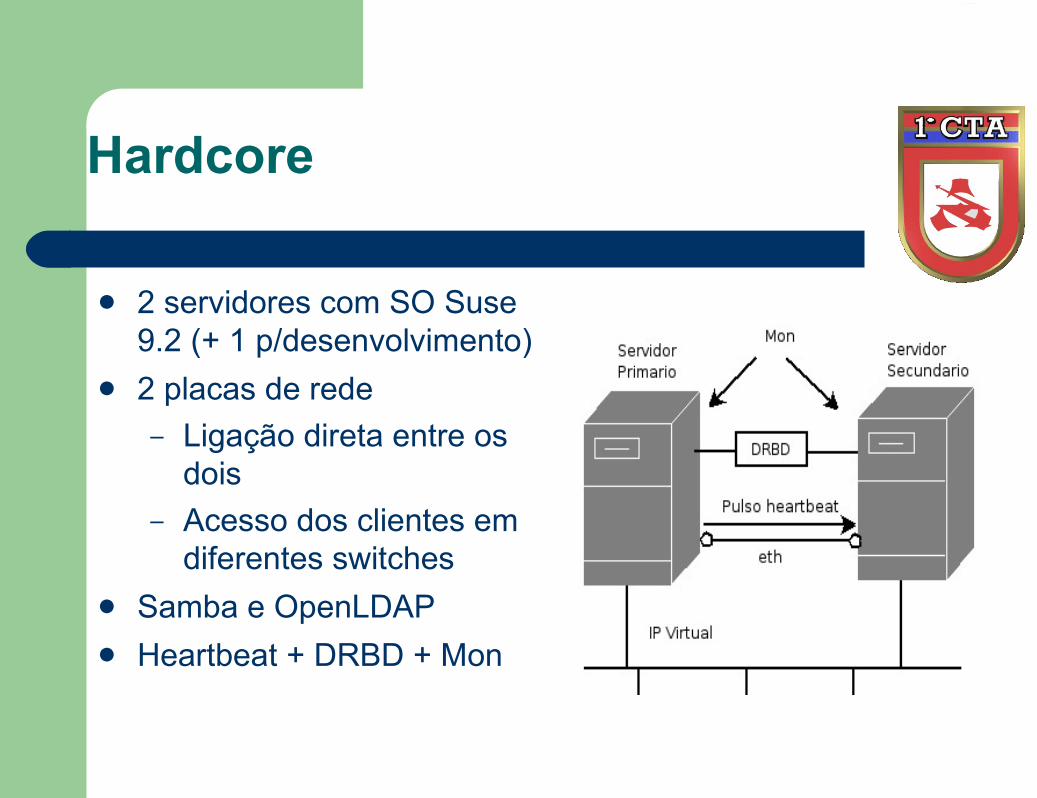
Hardcore
2 servidores com SO Suse 9.2 (+ 1 p/desenvolvimento)
2 placas de rede– Ligação direta entre os
dois– Acesso dos clientes em
diferentes switches Samba e OpenLDAP Heartbeat + DRBD + Mon

Hardcore
SERVIÇOS Samba (versão 3.0.9-2.1) OpenLDAP (versão 2.2.15-5.1) Apache (versão 2.0.50-7.3)
ALTA DISPONIBILIDADE DRBD -Duplicated Redundant Block Device – (versão
0.7.10 - http://oss.linbit.com/drbd) Heartbeat (versão 1.2.3-3.1) Mon (versão 0.99.2-354)

DRBD
Replicação de disco através da rede Driver de bloco para o kernel que cria um dispositivo
de bloco virtual (disco real local + conexão de rede)

HeartBeat
Monitoração dos nodos do cluster Coordena as ações de failover e failback Solução de reativação automática de serviços são
baseadas neste pacote

Mon
Monitoração Periódica dos Serviços (rápida e ágil) Pode enviar alertas por e-mail, pagers, celulares e
logs. Conceitos principais
– Máquinas (hostgroup) + Serviços + Monitores + Alertas
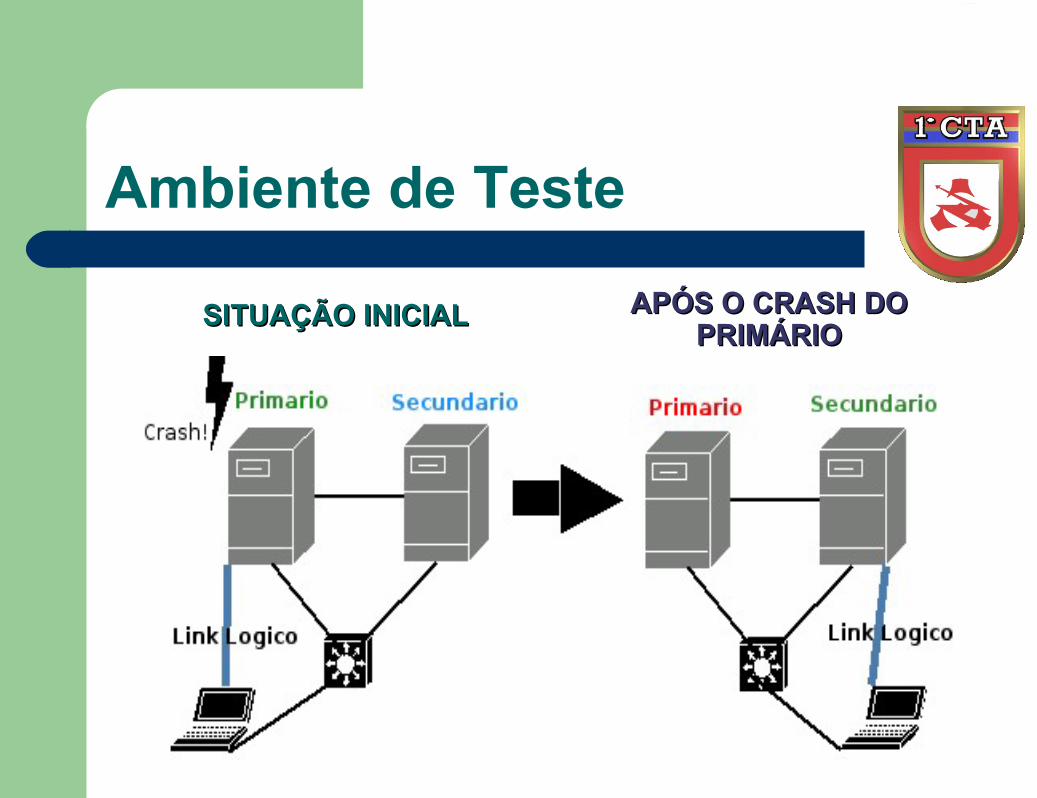
Ambiente de Teste
SITUAÇÃO INICIALSITUAÇÃO INICIAL APÓS O CRASH DO APÓS O CRASH DO PRIMÁRIOPRIMÁRIO

DEMONSTRAÇÃO
• Configuração dos serviços
• Teste da alta disponibilidade

Demonstração





























