Embed Size (px)
Citation preview

Paralelização Automática de Código em PlataformasHeterogêneas Modernas
Rogério A. Gonçalves1,2 Alfredo Goldman1
1Laboratório de Sistemas de Software (LSS)Centro de Competência de Software Livre (CCSL)
Instituto de Matemática e Estatística (IME)Universidade de São Paulo (USP)
2Departamento de Computação (DACOM)Universidade Tecnológica Federal do Paraná (UTFPR)
Grupo de Computação de Alto Desempenho e Sistemas Distribuídos
[email protected], {rag,gold}@ime.usp.br
3o Workshop de High Performance ComputingConvênio: USP – Rice University
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 1 / 55

Roteiro
1 Introdução
2 Conceitos
3 Abordagens sobre Paralelização
4 Transformações de Laços
5 Modelo Polyhedral
6 Ferramentas e Exemplos
7 LLVM e Ferramentas
8 Dúvidas
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 2 / 55

Objetivos
Uma visão geral sobre a abordagem de paralelizaçãoautomática.Alguns conceitos sobre o Modelo Polyhedral.Apresentar algumas ferramentas que utilizam essemodelo.Apresentar as ferramentas e projetos LLVM.Exemplos práticos indo do fonte original ao código paraGPU.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 3 / 55

Introdução I
Evolução e heterogeneidade das plataformas dehardware.Dispositivos aceleradores tem sido utilizados nacomposição de supercomputadores.Não há suporte direto à reescrita de aplicaçõesexistentes.Os kits de desenvolvimento ainda não estão maduros osuficiente.Programar novas aplicações ou traduzir aplicações decódigo legado não é uma tarefa trivial.Ponto de vista do software.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 4 / 55

Introdução II
Plataformas vs. Aplicações
No cenário atual é evidente a grande distância entre opotencial de desempenho disponibilizado pelas plataformasmodernas e as aplicações que precisam fazer uso dessepotencial.
Soluções
O ideal é que a ligação entre esses contextos seja feita porferramentas de compilação e ambientes de execução.Fornecendo suporte à execução de aplicações novas e decódigo legado.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 5 / 55

Paralelização de Aplicações I
Existem pelo menos duas formas de se obter aplicaçõesparalelas:
Concepção de aplicações paralelasAdaptar aplicações existentes
Nas duas formas, existe um modelo de programaçãoque fornece suporte à escrita ou adaptação do código, eum modelo de execução que irá executar a versãoparalela do código.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 6 / 55

Paralelização de Aplicações II
No contexto de tradução de código, tem-se pelo menosduas abordagens conhecidas de paralelização que sedistinguem na forma e no momento da intervenção paraparalelização:
Via código fonte: depende da existência do códigofonte (source-to-source).Via código binário: aplica transformações sobre obinário gerado para a execução da aplicação.(Tradução Dinâmica - DBT).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 7 / 55

Aceleração de Aplicações I
A aceleração de aplicações está relacionada com asplataformas modernas.São plataformas heterogêneas, que congregam diversastecnologias e seus elementos de processamento quetrabalham como aceleradores na execução deaplicações.Como exemplos dos dispositivos que atualmentecompõem essas plataformas temos os arranjos decoprocessadores Xeon Phi (Intel), as GPUs (NVidia,AMD) e FPGAS (Xilinx, Altera).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 8 / 55

Aceleração de Aplicações II
O uso de dispositivos aceleradores torna possível adivisão da carga de execução entre um elemento deprocessamento principal e elementos que irão trabalharcomo coprocessadores.Regiões de código paralelizáveis podem sertransformadas em kernels e terem sua execuçãoacelerada em uma GPU. Ex.: Laços.Trabalhos tem proposto modelos para a execução deaplicações combinando dispositivos multicore emultiGPU.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 9 / 55

Abordagens que se destacam
Diretivas de CompilaçãoDiretivas de compilação são usadas para guiar o compilador no processo detradução e paralelização de código.
Paralelização AutomáticaSão usadas técnicas e modelos para detectar automaticamente quaisregiões do código são paralelizáveis.
Nas duas abordagens uma versão paralela do código é gerada para aplataforma alvo.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 10 / 55

Diretivas de Compilação
O código é anotado com diretivas de preprocessamento(#pragma).
Ferramentas que utilizam diretivasO OpenMP (multicore).O hiCUDA (transformar e gerar código para CUDA).O CGCM (otimiza a comunicação e transferências de dados).Os compiladores PGI e o OpenHMPP que implementam o padrãoOpenACC.O accULL é uma implementação do padrão OpenACC com suporte aCUDA e a OpenCL.O OpenMC é uma extensão do OpenMP para suporte a GPU.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 11 / 55

Diretivas de Compilação
Exemplo da diretiva #pragma acc kernels que define uma região decódigo que será transformada em kernels.
1 #pragma acc data copy ( b [ 0 : n∗m] ) c r e a t e ( a [ 0 : n∗m] )2 {3 f o r ( i t e r = 1 ; i t e r <= p ; ++i t e r ) {4 #pragma acc k e r n e l s5 {6 f o r ( i = 1 ; i < n−1; ++i )7 f o r ( j = 1 ; j < m−1; ++j ) {8 /∗ Supr imido . ∗/9 }
10 f o r ( i = 1 ; i < n−1; ++i )11 f o r ( j = 1 ; j < m−1; ++j )12 /∗ Supr imido . ∗/13 }14 }15 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 12 / 55

Paralelização Automática
A ideia é que o código não seja modificado, nemanotado.Regiões paralelizáveis detectadas automaticamente.
Ferramentas da abordagem automáticaPar4All (análise interprocedural)C-to-CUDA
PPCG
KernelGen
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 13 / 55

Transformações de Laços I
Técnicas de otimização de laços são utilizadas porcompiladores há muito tempo.Possibilitam a exploração de processamento paralelo ereduzem o tempo de execução associado aos laços.A análise de dependência deve ser feita sobre todas asiterações do laço.Uma transformação aplicada deve preservar a semânticado código original e a sequência temporal de todas asdependências.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 14 / 55

Transformações de Laços II
Transformações podem ser aplicadas para: analisar,preparar e expor algum paralelismo latente.
Exemplos
loop unrolling, loop interchange, loop skewing, loopreversal, loop blocking e cycle shrinking, loop fusion,peeling e distribuição, entre outras.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 15 / 55

Detecção de Regiões Paralelizáveis I
No processo de paralelização de código é necessáriodetectar as regiões paralelizáveis.Essas regiões são chamadas de Static Control Parts(SCoPs).São partes do código de uma função que podem servistas como uma estrutura de fluxo de controle quecontem apenas laços FOR e IFs.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 16 / 55

Transformações de Laços e Modelo Polyhedral I
O Modelo Polyhedral possui um suporte melhor para arepresentação e análise de código de laços do que aAST.A representação de SCoPs no modelo baseia-se nosconceitos: domínio de iteração, função de scattering efunção de acesso.Encontrando-se um SCoP, a região de código pode serrepresentada no modelo e transformações e otimizaçõespodem ser aplicadas à representação gerada.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 17 / 55

Transformações de Laços e Modelo Polyhedral II
1 f o r ( i =1; i<=n−1; i++) {2 f o r ( j =1; j<=m−1; j++) {3 A[ i ] [ j ] = (A[ i −1] [ j ] + A[ i ] [ j −1] + A[ i +1] [ j ] + A[ i ] [ j +1]) /4 ;4 }5 }
Figura 1: Esquema de acesso e cálculodos elementos
Figura 2: Dependências no uso doselementos
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 18 / 55

Transformações de Laços e Modelo Polyhedral IIIFunção de Scattering : c1 = i + j e c2 = i (novo domíniode iterações).
Figura 3: Domínio de Iteração
DS1 = {(i, j) ∈ Z2|1 ≤ i ≤ n−1∧1 ≤ j ≤ m−1}
Figura 4: Função de ScatteringθS1(i, j) = (i + j, i)θS1(i, j) = (c1, c2)
c1 = i + jc2 = i
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 19 / 55

Transformações de Laços e Modelo Polyhedral IV
Código original e modificado com o CLooG (Skewing):1 f o r ( i =1; i<=n−1; i++) {2 f o r ( j =1; j<=m−1; j++) {3 A[ i ] [ j ] = (A[ i −1][ j ] + A[ i ] [ j −1] + A[ i +1][ j ] + A[ i ] [ j +1]) /4 ; // S14 }5 }
Substituindo as variáveis: i = c2 e j = c1 − i = c1 − c2,tem-se o código final:1 i f ( (m >= 2) && (n >= 2) ) {2 f o r ( c1=2;c1<=n+m−2; c1++) {3 f o r ( c2=max (1 , c1−m+1) ; c2<=min ( c1−1,n−1) ; c2++) {4 A[ c2 ] [ c1−c2 ] = (A[ c2 −1] [ c1−c2 ] + A[ c2 ] [ c1−c2−1] + A[
c2 +1] [ c1−c2 ] + A[ c2 ] [ c1−c2 +1]) /4 ; //S1 ’5 }6 }7 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 20 / 55

Ferramentas que utilizam o Modelo Polyhedral I
São ferramentas que cobrem desde a extração deregiões candidatas à paralelização, passando porbibliotecas que permitem o uso como subprojetos atégeradores de código com base em informações doModelo Polyhedral.Ferramentas que extraem SCoPs: clan e pet.Gerador de Código para C: CLooG.Compiladores como PLuTo e PoCC fazem traduçãosource-to-source de código C e Fortran.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 21 / 55

Ferramentas que utilizam o Modelo Polyhedral II
O C-to-CUDA faz a tradução source-to-source decódigo C para CUDA.
PPCG usa as bibliotecas pet e isl para gerar códigoOpenMP e CUDA.
O PoLLy é um projeto LLVM que implementa o modelopolyhedral para código intermediário (LLVM-IR).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 22 / 55

Por que usar LLVM? I
LLVM (llvm.org) é um projeto que fornece uma infraestrutura para aconstrução de compiladores.
Desenvolvimento: LLVM Team - University of Illinois atUrbana-Champaign.
Licença: University of Illinois/NCSA Open Source License, certificadapela OSI.
Sua organização modular facilita o reuso no desenvolvimento deferramentas de compilação.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 23 / 55

Por que usar LLVM? II
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 24 / 55

Exemplo: LLVM IR ICódigo em C.1 i n t main ( ) {2 i n t a , b , c ;3 a = 5 ;4 b = 2 ;5 c = a + b ;67 i f ( c > 5) {8 c = 2 ∗ c ;9 }
10 e l s e {11 c = 3 ∗ c ;12 }1314 r e t u r n 0 ;15 }
Código em LLVM-IR.1 d e f i n e i32 @main ( ) #0 {2 %1 = a l l o c a i32 , a l i g n 43 %a = a l l o c a i32 , a l i g n 44 %b = a l l o c a i32 , a l i g n 45 %c = a l l o c a i32 , a l i g n 46 s t o r e i32 0 , i32∗ %17 s t o r e i32 5 , i32∗ %a, a l i g n 48 s t o r e i32 2 , i32∗ %b, a l i g n 49 %2 = load i32∗ %a, a l i g n 4
10 %3 = load i32∗ %b, a l i g n 411 %4 = add nsw i32 %2, %312 s t o r e i32 %4, i32∗ %c, a l i g n 413 %5 = load i32∗ %c, a l i g n 414 %6 = icmp sg t i32 %5, 515 br i1 %6, l a b e l %vv , l a b e l %ff1617 vv : ; preds = %018 %7 = load i32∗ %c, a l i g n 419 %8 = mul nsw i32 2 , %720 s t o r e i32 %8, i32∗ %c, a l i g n 421 br l a b e l %fim2223 ff : ; preds = %024 %9 = load i32∗ %c, a l i g n 425 %10 = mul nsw i32 3 , %926 s t o r e i32 %10 , i32∗ %c, a l i g n 427 br l a b e l %fim2829 fim : ; preds = %vv, %ff30 r e t i32 031 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 25 / 55

Exemplo: LLVM IR I
1 d e f i n e i32 @main ( ) #0 {2 %1 = a l l o c a i32 , a l i g n 43 %a = a l l o c a i32 , a l i g n 44 %b = a l l o c a i32 , a l i g n 45 %c = a l l o c a i32 , a l i g n 46 s t o r e i32 0 , i32∗ %17 s t o r e i32 5 , i32∗ %a, a l i g n 48 s t o r e i32 2 , i32∗ %b, a l i g n 49 %2 = load i32∗ %a, a l i g n 4
10 %3 = load i32∗ %b, a l i g n 411 %4 = add nsw i32 %2, %312 s t o r e i32 %4, i32∗ %c, a l i g n 413 %5 = load i32∗ %c, a l i g n 414 %6 = icmp sg t i32 %5, 515 br i1 %6, l a b e l %vv , l a b e l %ff1617 vv : ; preds = %018 %7 = load i32∗ %c, a l i g n 419 %8 = mul nsw i32 2 , %720 s t o r e i32 %8, i32∗ %c, a l i g n 421 br l a b e l %fim2223 ff : ; preds = %024 %9 = load i32∗ %c, a l i g n 425 %10 = mul nsw i32 3 , %926 s t o r e i32 %10 , i32∗ %c, a l i g n 427 br l a b e l %fim2829 fim : ; preds = %vv, %ff30 r e t i32 031 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 26 / 55

Exemplo: LLVM IR ICódigo em C.1 i n t funcA ( i n t x , i n t y ) {2 i n t r e s u l t = x ∗ y ;3 r e t u r n r e s u l t ;4 }56 i n t main ( ) {7 i n t a , b , c ;8 a = 5 ;9 c = funcA ( a , 2) ;
1011 r e t u r n 0 ;12 }
Código em LLVM-IR.1 d e f i n e i32 @funcA ( i32 %x, i32 %y) #0 {2 %1 = a l l o c a i32 , a l i g n 43 %2 = a l l o c a i32 , a l i g n 44 %re su l t = a l l o c a i32 , a l i g n 45 s t o r e i32 %x, i32∗ %1, a l i g n 46 s t o r e i32 %y, i32∗ %2, a l i g n 47 %3 = load i32∗ %1, a l i g n 48 %4 = load i32∗ %2, a l i g n 49 %5 = mul nsw i32 %3, %4
10 s t o r e i32 %5, i32∗ %resu l t , a l i g n 411 %6 = load i32∗ %resu l t , a l i g n 412 r e t i32 %613 }14 d e f i n e i32 @main ( ) #0 {15 %1 = a l l o c a i32 , a l i g n 416 %a = a l l o c a i32 , a l i g n 417 %b = a l l o c a i32 , a l i g n 418 %c = a l l o c a i32 , a l i g n 419 s t o r e i32 0 , i32∗ %120 s t o r e i32 5 , i32∗ %a, a l i g n 421 %2 = load i32∗ %a, a l i g n 422 %3 = c a l l i32 @funcA ( i32 %2, i32 2)23 s t o r e i32 %3, i32∗ %c, a l i g n 424 r e t i32 025 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 27 / 55

Exemplo: LLVM IR ICódigo em C.1 i n t main ( ) {2 i n t i ;3 i n t r e s = 0 ;4 f o r ( i =0; i < 100 ; i++){5 r e s = r e s + i ;6 }78 r e t u r n 0 ;9 }
Código em LLVM-IR.1 d e f i n e i32 @main ( ) #0 {2 %1 = a l l o c a i32 , a l i g n 43 %i = a l l o c a i32 , a l i g n 44 %res = a l l o c a i32 , a l i g n 45 s t o r e i32 0 , i32∗ %16 s t o r e i32 0 , i32∗ %res , a l i g n 47 s t o r e i32 0 , i32∗ %i , a l i g n 48 br l a b e l %29
10 ; < label >:2 ; preds = %9, %011 %3 = load i32∗ %i , a l i g n 412 %4 = icmp s l t i32 %3, 10013 br i1 %4, l a b e l %5, l a b e l %121415 ; < label >:5 ; preds = %216 %6 = load i32∗ %res , a l i g n 417 %7 = load i32∗ %i , a l i g n 418 %8 = add nsw i32 %6, %719 s t o r e i32 %8, i32∗ %res , a l i g n 420 br l a b e l %92122 ; < label >:9 ; preds = %523 %10 = load i32∗ %i , a l i g n 424 %11 = add nsw i32 %10 , 125 s t o r e i32 %11 , i32∗ %i , a l i g n 426 br l a b e l %22728 ; < label >:12 ; preds = %229 r e t i32 030 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 28 / 55

Exemplo: LLVM IR I
1 d e f i n e i32 @main ( ) #0 {2 %1 = a l l o c a i32 , a l i g n 43 %i = a l l o c a i32 , a l i g n 44 %res = a l l o c a i32 , a l i g n 45 s t o r e i32 0 , i32∗ %16 s t o r e i32 0 , i32∗ %res , a l i g n 47 s t o r e i32 0 , i32∗ %i , a l i g n 48 br l a b e l %29
10 ; < label >:2 ; preds = %9, %011 %3 = load i32∗ %i , a l i g n 412 %4 = icmp s l t i32 %3, 10013 br i1 %4, l a b e l %5, l a b e l %121415 ; < label >:5 ; preds = %216 %6 = load i32∗ %res , a l i g n 417 %7 = load i32∗ %i , a l i g n 418 %8 = add nsw i32 %6, %719 s t o r e i32 %8, i32∗ %res , a l i g n 420 br l a b e l %92122 ; < label >:9 ; preds = %523 %10 = load i32∗ %i , a l i g n 424 %11 = add nsw i32 %10 , 125 s t o r e i32 %11 , i32∗ %i , a l i g n 426 br l a b e l %22728 ; < label >:12 ; preds = %229 r e t i32 030 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 29 / 55

Ferramentas LLVM
Projetos como o DragonEgg, PoLLy e NVPTXpossibilitam que regiões paralelizáveis sejam traduzidaspara kernels que possam ter sua execução lançada emGPUs.DragonEgg: Plugin para GCC que traduz códigointermediário (GIMPLE) para a representaçãointermediária do LLVM (LLVM-IR).PoLLy: Implementação do Modelo Polyhedral paraLLVM.NVPTX: Backend do LLVM para gerar código PTX(intermediário das GPUs da NVIDIA).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 30 / 55

PoLLy I
Aplica otimizações e transformações sobre o códigointermediário LLVM-IR.Da mesma forma que outras ferramentas, o PoLLytrabalha com (SCoPs).O PoLLy implementa um conjunto de passos quedetectam e traduzem essas partes do código para arepresentação do modelo polyhedral para que possamser aplicadas análises e transformações, e o códigoLLVM-IR otimizado gerado.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 31 / 55

Gerando Código para GPU
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 32 / 55

Exemplo Soma de Vetores I
Código do exemplo soma de vetores:
1 i n t main ( ) {2 i n t i ;3 /∗ I n i c i a l i z a c a o dos v e t o r e s . ∗/4 i n i t_ a r r a y ( ) ;5
6 /∗ Ca l c u l o . ∗/7 f o r ( i = 0 ; i < N; i++) {8 h_c [ i ] = h_a [ i ] + h_b [ i ] ;9 }
10
11 /∗ Resu l t ado s . ∗/12 p r i n t_a r r a y ( ) ;13 che ck_re su l t ( ) ;14
15 r e t u r n 0 ;16 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 33 / 55

Exemplo Soma de Vetores II
Código LLVM-IR equivalente gerado:1 @h_a = common g l o b a l [1024 x float ] zeroinitializer , a l i g n 162 @h_b = common g l o b a l [1024 x float ] zeroinitializer , a l i g n 163 @h_c = common g l o b a l [1024 x float ] zeroinitializer , a l i g n 164 d e f i n e void @init_array ( ) #0 {5 }6 d e f i n e void @print_array ( ) #0 {7 }8 d e f i n e void @check_result ( ) #0 {9 }
10 d e f i n e i32 @main ( ) #0 {11 %1 = a l l o c a i32 , a l i g n 412 %i = a l l o c a i32 , a l i g n 413 s t o r e i32 0 , i32∗ %114 c a l l void @init_array ( )15 s t o r e i32 0 , i32∗ %i , a l i g n 416 br l a b e l %21718 ; <label >:2 ; preds = %18, %019 %3 = load i32∗ %i , a l i g n 420 %4 = icmp s l t i32 %3, 102421 br i1 %4, l a b e l %5, l a b e l %21
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 34 / 55

Exemplo Soma de Vetores III
2223 ; < l a b e l >:5 ; preds = %224 %6 = load i32∗ %i , a l i g n 425 %7 = s e x t i32 %6 to i6426 %8 = ge t e l emen t p t r inbounds [1024 x float ]∗ @h_a , i32 0 , ←↩
i64 %727 %9 = load float∗ %8, a l i g n 428 %10 = load i32∗ %i , a l i g n 429 %11 = s e x t i32 %10 to i6430 %12 = ge t e l emen t p t r inbounds [1024 x float ]∗ @h_b , i32 0 , ←↩
i64 %1131 %13 = load float∗ %12 , a l i g n 432 %14 = fadd float %9, %1333 %15 = load i32∗ %i , a l i g n 434 %16 = s e x t i32 %15 to i6435 %17 = ge t e l emen t p t r inbounds [1024 x float ]∗ @h_c , i32 0 , ←↩
i64 %1636 s t o r e float %14 , float∗ %17 , a l i g n 437 br l a b e l %18
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 35 / 55

Exemplo Soma de Vetores IV
38 ; < l a b e l >:18 ; preds = %539 %19 = load i32∗ %i , a l i g n 440 %20 = add nsw i32 %19 , 141 s t o r e i32 %20 , i32∗ %i , a l i g n 442 br l a b e l %24344 ; <label >:21 ; preds = %245 c a l l void @print_array ( )46 c a l l void @check_result ( )47 r e t i32 048 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 36 / 55

Exemplo Soma de Vetores V
O CFG do laço de repetição contido na função main:
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 37 / 55

Exemplo Soma de Vetores VI
Laço em destaque como SCoP detectado pelo PoLLy:
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 38 / 55

Exemplo Soma de Vetores VII
O PoLLy detecta as SCoPs do código que serãotraduzidas para a representação polyhedral.O PoLLy pode ser usado para separar o código emblocos independentes.
Visualização do código com blocos independentes queforam separados pelo PoLLy.O SCoP continua sendo o mesmo, porém foi alteradointernamente, com a recuperação dos ponteiros paraelementos dos arranjos sendo feita no início do corpodo laço.
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 39 / 55

Exemplo Soma de Vetores VIII
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 40 / 55

Exemplo da Estrutura de um kernel para GPU
Kernel para a soma de vetores:
1 __global__ vo i d vecAdd ( f l o a t ∗ A, f l o a t ∗ B, f l o a t ∗ C, i n t n ) {2 i n t i d = blockDim . x ∗ b l o c k I d x . x + th r e a d I d x . x ;3 i f ( i d < n ) {4 C[ i d ] = A[ i d ] + B[ i d ] ;5 }6 }78 i n t main ( ) {9 /∗ . . . ∗/
10 i n t t h r e ad sPe rB l o ck = 256 ;11 i n t b l o c k sPe rG r i d =(N + th r ead sPe rB l o ck − 1) /
th r e ad sPe rB l o ck ;12 vecAdd<<<b lock sPe rG r i d , th r eadsPe rB lock >>>(d_A, d_B, d_C, N) ;13 /∗ . . . ∗/14 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 41 / 55

Mapeamento de identificadores no LLVM-IR
O NVPTX fornece declarações de funções que recuperam os identificadores:
CUDA Significado LLVM-IR para o NVPTX
threadIdx.x Id da Thread na dim. x declare i32 @llvm.nvvm.read.ptx.sreg.tid.x()
threadIdx.y Id da Thread na dim. y declare i32 @llvm.nvvm.read.ptx.sreg.tid.y()
threadIdx.z Id da Thread na dim. z declare i32 @llvm.nvvm.read.ptx.sreg.tid.z()
blockIdx.x Id do Bloco na dim. x declare i32 @llvm.nvvm.read.ptx.sreg.ctaid.x()
blockIdx.y Id do Bloco na dim. y declare i32 @llvm.nvvm.read.ptx.sreg.ctaid.y()
blockIdx.z Id do Bloco na dim. z declare i32 @llvm.nvvm.read.ptx.sreg.ctaid.z()
blockDim.x Dimensão x do Bloco declare i32 @llvm.nvvm.read.ptx.sreg.ntid.x()
blockDim.y Dimensão y do Bloco declare i32 @llvm.nvvm.read.ptx.sreg.ntid.y()
blockDim.z Dimensão z do Bloco declare i32 @llvm.nvvm.read.ptx.sreg.ntid.z()
gridDim.x Dimensão x do Grid declare i32 @llvm.nvvm.read.ptx.sreg.nctaid.x()
gridDim.y Dimensão y do Grid declare i32 @llvm.nvvm.read.ptx.sreg.nctaid.y()
gridDim.z Dimensão z do Grid declare i32 @llvm.nvvm.read.ptx.sreg.nctaid.z()
warp size Tamanho do warp declare i32 @llvm.nvvm.read.ptx.sreg.warpsize()
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 42 / 55

Transformação para Kernels I
Funções de módulos LLVM-IR podem ser transformados em kernels.
Para exemplificar a transformação de funções para a estrutura dekernels, consideremos o exemplo soma de vetores. Tanto o CFG dafunção principal (main), quanto a função sum_vectors().
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 43 / 55

Transformação para Kernels II
A correspondência entre os trechos de código LLVM-IR original e oformato para o NVPTX. Transformação da função sum_vectors parakernel :
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 44 / 55

Transformação para Kernels III
Sequência de passos necessários para gerar, carregar o código dokernel e efetuar transferências:
1 vo i d sum_vectors ( ) {2 /∗ Gerando o PTX. ∗/3 cha r ∗ptx = generatePTX ( l l , s i z e ) ;4 /∗ Cr iando um con t ex to . ∗/5 cuCtxCreate (&cudaContext , 0 , cudaDev ice ) ;6 /∗ Carregando o modulo . ∗/7 cuModuleLoadDataEx(&cudaModule , ptx , 0 , 0 , 0) ;8 /∗ Recuperando a funcao k e r n e l . ∗/9 cuModuleGetFunct ion (&ke r n e l Func t i o n , cudaModule , " sum_kernel " ) ;
10 /∗ Tran s f e r i n d o os dados para a memoria do d i s p o s i t i v o . ∗/11 cuMemcpyHtoD( devBuf ferA , &hostA [ 0 ] , s i z e o f ( f l o a t )∗N) ;12 cuMemcpyHtoD( devBuf ferB , &hostB [ 0 ] , s i z e o f ( f l o a t )∗N) ;13 /∗ De f i n i c a o das d imensoes do a r r a n j o de t h r e ad s . ∗/14 c a l c u l a t eD imen s i o n s (&b lockS i zeX , &b lockS i zeY , &b lockS i zeZ , &g r i dS i z eX , &
g r i dS i z eY , &g r i d S i z eZ ) ;15 /∗ Parametros da funcao k e r n e l . ∗/16 vo i d ∗ ke rne lPa rams [ ] = { &devBuf ferA , &devBuf ferB , &devBuf f e rC } ;17 /∗ Lancando a execucao do k e r n e l . ∗/18 cuLaunchKerne l ( k e r n e l Func t i o n , g r i dS i z eX , g r i dS i z eY , g r i dS i z eZ , b lockS i zeX
, b lockS i zeY , b l ockS i z eZ , 0 , NULL , kerne lParams , NULL) ;19 /∗ Recuperando o r e s u l t a d o . ∗/20 cuMemcpyDtoH(&hostC [ 0 ] , devBuf fe rC , s i z e o f ( f l o a t )∗N) ;21 r e t u r n 0 ;22 }
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 45 / 55

Sequência de Passos para os Próximos Exemplos I
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 46 / 55

Exemplo: vectorAdd (Soma de Vetores)
1 f l o a t h_a [N ] ;2 f l o a t h_b [N ] ;3 f l o a t h_c [N ] ;45 i n t main ( ) {6 i n t i ;7 /∗ I n i c i a l i z a c a o dos v e t o r e s . ∗/8 i n i t_ a r r a y ( ) ;9
10 /∗ Ca l c u l o . ∗/11 f o r ( i = 0 ; i < N; i++) {12 h_c [ i ] = h_a [ i ] + h_b [ i ] ;13 }1415 /∗ Resu l t ado s . ∗/16 p r i n t_a r r a y ( ) ;17 che ck_re su l t ( ) ;1819 r e t u r n 0 ;20 }
Código em C.Transformada em LLVM-IR. (Fase 1)SCoP detectado pelo PoLLy (Fases 2, 3 e 4).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 47 / 55

Exemplo: vectorAdd (Soma de Vetores)
1 f l o a t h_a [N ] ;2 f l o a t h_b [N ] ;3 f l o a t h_c [N ] ;45 i n t main ( ) {6 i n t i ;7 /∗ I n i c i a l i z a c a o dos v e t o r e s . ∗/8 i n i t_ a r r a y ( ) ;9
10 /∗ Ca l c u l o . ∗/11 f o r ( i = 0 ; i < N; i++) {12 h_c [ i ] = h_a [ i ] + h_b [ i ] ;13 }1415 /∗ Resu l t ado s . ∗/16 p r i n t_a r r a y ( ) ;17 che ck_re su l t ( ) ;1819 r e t u r n 0 ;20 }
Código em C.Transformada em LLVM-IR. (Fase 1)SCoP detectado pelo PoLLy (Fases 2, 3 e 4).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 47 / 55

Transformação para vectoradd-kernel
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 48 / 55

Código para o vectoradd-kernel
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 49 / 55

Código PTX para o vectoradd-kernel
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 50 / 55

Exemplo: sincos (Cálculo de Seno e Cosseno)
1 s u b r o u t i n e s i n c o s_ f un c t i o n ( nx , ny ,nz , x , y , xy )
23 i m p l i c i t none45 i n t e g e r , i n t e n t ( i n ou t ) : : nx , ny ,
nz6 r e a l , i n t e n t ( i n ) : : x ( nx , ny , nz ) ,
y ( nx , ny , nz )7 r e a l , i n t e n t ( i n ou t ) : : xy ( nx , ny ,
nz )89 i n t e g e r : : i , j , k
1011 do k = 1 , nz12 do j = 1 , ny13 do i = 1 , nx14 xy ( i , j , k ) = s i n ( x ( i , j , k ) )
+ cos ( y ( i , j , k ) )15 enddo16 enddo17 enddo1819 end s u b r o u t i n e s i n c o s_ f un c t i o n
Rotina em Fortran + Código Principal em C.Transformada em LLVM-IR. (Fase 1)SCoP detectado pelo PoLLy (Fases 2, 3 e 4).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 51 / 55
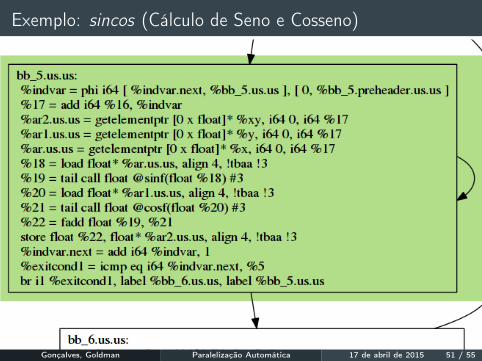
Exemplo: sincos (Cálculo de Seno e Cosseno)
1 s u b r o u t i n e s i n c o s_ f un c t i o n ( nx , ny ,nz , x , y , xy )
23 i m p l i c i t none45 i n t e g e r , i n t e n t ( i n ou t ) : : nx , ny ,
nz6 r e a l , i n t e n t ( i n ) : : x ( nx , ny , nz ) ,
y ( nx , ny , nz )7 r e a l , i n t e n t ( i n ou t ) : : xy ( nx , ny ,
nz )89 i n t e g e r : : i , j , k
1011 do k = 1 , nz12 do j = 1 , ny13 do i = 1 , nx14 xy ( i , j , k ) = s i n ( x ( i , j , k ) )
+ cos ( y ( i , j , k ) )15 enddo16 enddo17 enddo1819 end s u b r o u t i n e s i n c o s_ f un c t i o n
Rotina em Fortran + Código Principal em C.Transformada em LLVM-IR. (Fase 1)SCoP detectado pelo PoLLy (Fases 2, 3 e 4).
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 51 / 55

Transformação para sincos-kernel
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 52 / 55

Código para o sincos-kernel
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 53 / 55

Referências e Links
D. F. Bacon, S. L. Graham, O. J. Sharp, Oliver, and J. Sharp,“Compiler Transformations for High-Performance Computing,” ACMComput. Surv., vol. 26, no. 4, pp. 345–420, Nov. 1994.M. Benabderrahmane, L.-N. Pouchet, A. Cohen, and C. Bastoul, “ThePolyhedral Model is More Widely Applicable Than You Think,” inProceedings of the 19th Joint European Conference on Theory andPractice of Software, International Conference on CompilerConstruction, 2010, pp. 283–303.LLVM: http://llvm.org
PoLLy: htpp://polly.llvm.org
NVPTX: http://llvm.org/docs/NVPTXUsage.html
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 54 / 55

Contatos
Rogério A. Gonçalves:[email protected], [email protected] Goldman:[email protected]
Gonçalves, Goldman Paralelização Automática 17 de abril de 2015 55 / 55





























