Embed Size (px)
Citation preview

Cassandra Thrift e CQL
KEEPCALM
AND
COME TO THEDARK SIDE

Thrift API
Primeira API para comunicação com o Cassandra
Mostrava vários detalhes internos do Cassandra, deixando os comandos verborrágicos e perigosos
Interface difícil de se trabalhar
Muitas transformações devem ser feitas via código

Thrift API

Thrift API
COMO RAIOS EU FAÇO UMA PESQUISA NISSO????

Thrift API
Por impossibilidade de se usar o CQL quando começamos a trabalhar com o Cassandra escolhemos um cliente chamado Astyanax porém a complexidade era alta, daí tivemos que criar uma camada de abstração, surgiu o Cassandree.
O uso do Cassandree no Adsever está no nosso log de impressão e controle de cliques através do Tracker e Batches

Thrift API

Thrift API

CQL API
Evolução para uma API mais robusta
CQL3 (Cassandra Query Language) foi criada para abstrair a complexidade do Cassandra e permitir que sua utilização seja muito mais simples, poderosa e segura.
Até a versão 1.1.X do Cassandra, o CQL3 ainda era beta, com a versão 1.2.X ele se tornou estável e passou a ser chamado em muitos lugares apenas por CQL.
Sintaxe semelhante ao SQL para facilitar aprendizado

CQL API

CQL API

CQL API
Quando atualizamos o Cassandra para a versão 1.2.1 estávamos prontos para usar o CQL 3 e o cluster já estava estabilizado
Utilizamos o cliente Datastax Java Driver para conexão. Esse cliente se assemelha em muito a JDBC, isso facilita muito
Utilizamos o Java Driver dentro do Dashboard para armazenamento do histórico de ofertas e como base de dados principal

CQL API

CQL API

CQL API

CQL API
CREATE KEYSPACE demodb WITH REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor': 3};
CREATE TABLE users (
user_name varchar,
password varchar,
gender varchar,
session_token varchar,
state varchar,
birth_year bigint,
PRIMARY KEY (user_name));
INSERT INTO emp (empID, deptID, first_name, last_name) VALUES (104, 15, 'jane', 'smith');
SELECT * FROM emp WHERE empID IN (130,104) ORDER BY deptID DESC;

Os detalhes maléficos do Cassandra
Collections Columns
TTL
UUID
Indexes
Compound Keys

Collections Columns
O cassandra é schemaless, ou seja, coluna existe ou não, pra mim tanto faz
Mas no CQL é necessário uma formalidade nas colunas para que eu consiga fazer buscas.

Collections Columns
CREATE TABLE conta_oferta (campanha int,categoria int,loja bigint,ofertas map<timestamp,bigint>,PRIMARY KEY ((campanha,categoria), loja) );
O CQL trás um novo tipo de coluna, a coluna de coleção.
Existem 3 tipos de coleções permitidas: SetListMap
campanha | categoria | loja | ofertas----------+-----------+------+--------------------------------------------------------------
6637 | 6424 | 50 | {2013-08-27 02:00:00-0300: 30, 2013-08-27 03:00:00-0300: 50}

Collections Columns
Uma collection column permite guardar valores dinâmicos, traduzindo a forma schemaless do cassandra para um mundo mais schemafull
Cada item de uma collection column pode ter um TTL específico

TTL
Cada coluna na CF pode ter uma data para expirar ou um Time To Live próprio. Assim mantemos sempre dados válidos no servidor, não há a necessidade de criar rotinas complexas de expurgo ou pedir para a Infra apagar os destinations =P
No Dashboard cada item da coluna de ofertas tem um TTL de 30 dias

UUID Em uma base relacional o ID pode ser um número
inteiro com incremento continuo já que a base fica em apenas em um computador
Já que o Cassandra é clusterizado, para evitar choque de ids é necessário uma estratégia mais avançada e para isso é usado o UUID (universallyunique id). Esse id é tem o formato hexadecimal e é criado baseado na hora e em outros fatores, como MAC address
Exemplo: ff63a295-e425-4773-9358-dd717039c1c2
No Java:java.util.UUID.randomUUID();

Índices
A busca no cassandra é feita apenas por chaves, nunca por colunas
Para fazer buscas por colunas é necessário transformá-las em chaves, ou seja, criar índices
CREATE TABLE users ( userID uuid, frame text, lname text, state text, zipint, PRIMARY KEY (userID, zip) );
CREATE INDEX users_state ON users (state)

Chaves
As chaves em uma CF servem para separar os dados entre os nós, ordená-los e buscá-los.
Buscas devem ser feitas respeitando as chaves e suas prioridades
Buscas devem ser da “esquerda para a direita”

ChavesCREATE TABLE calendario (
dia int, mes int, ano int, compromisso text, PRIMARY KEY (dia,mes,ano) );
INSERT INTO calendario (dia,mes,ano,compromisso) VALUES(27,08,2013,'preparando apresentacao');
SELECT * FROM calendario WHERE dia = 27;
dia | mes | ano | compromisso-----+-----+------+-----------------27 | 8 | 2013 | preparando aula

ChavesSELECT * FROM calendario WHERE mes = 8;
Bad Request: Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING
Ordem: dia > mês > ano
Uma Clustering Key não pode ser usada sem sua Partition Key

Chaves
Partition Key Chave responsável por espalhar os dados entre os nós do cluster É a linha da Colum Family
Clustering Key Ordena os dados dentro de cada
separação feita pela Partition Key É o prefixo das colunas
Compound Key Uma chave composta pela
Partition Key e Clustering Key
CREATE TABLE calendario ( dia int, mes int, ano int, compromisso text, PRIMARY KEY (dia,mes,ano) );
Partition Key
Clustering Key
Compound Key

Chaves
RowKey: 27=> (column=8:2013:, value=, timestamp=1377636632488000)=> (column=8:2013:compromisso,
value=707265706172616e646f2061756c61, timestamp=1377636632488000)

Chaves
Mas por que isso existe?
Para garantir performance. Sem isso o Cassandra deve buscar a informação em todos os nós do
cluster
ALLOW FILTERING Caso performance não seja o meu problema, eu posso avisar o
Cassandra disso através da sintax ALLOW FILTERING
SELECT * FROM calendario WHERE mes = 8 ALLOW FILTERING;
dia | mes | ano | compromisso-----+-----+------+-----------------27 | 8 | 2013 | preparando aula

Lógica para busca
1) O campo a ser procurado deve ser um índice
1) A ordem dos índices deve ser respeitada
1)Pense na Query antes de criar sua CF
1)Use ao máximo chaves naturais
1)Pense na query antes!
1)Lembre-se que em 95% o seu sistema usará as mesmas queries, então pense antes na query

Normalização
Facilita a atualização de dados
Permite que eu contenha apenas informações consistentes, sem campos NULL
Permite informações em lista (com ajuda de uma tabela de relacionamento), como por exemplo, múltiplos telefones

Normalização
Criação mais coerente de queries complexas
Os publishers beta testers, com campanhas ativas, da categoria moda, que sejam do signo de Virgem e com ascendente em Áries

Novo paradigma
Mas por que devemos usar apenas esse tipo de paradigma?
Quanto de meta informação nós precisamos para guardar informações normalizadas?
Quantas primary keys com auto increment (chaves não naturais), quantas foreign keys, quantas tabelas de relacionamentos precisamos para normalizar as informações?

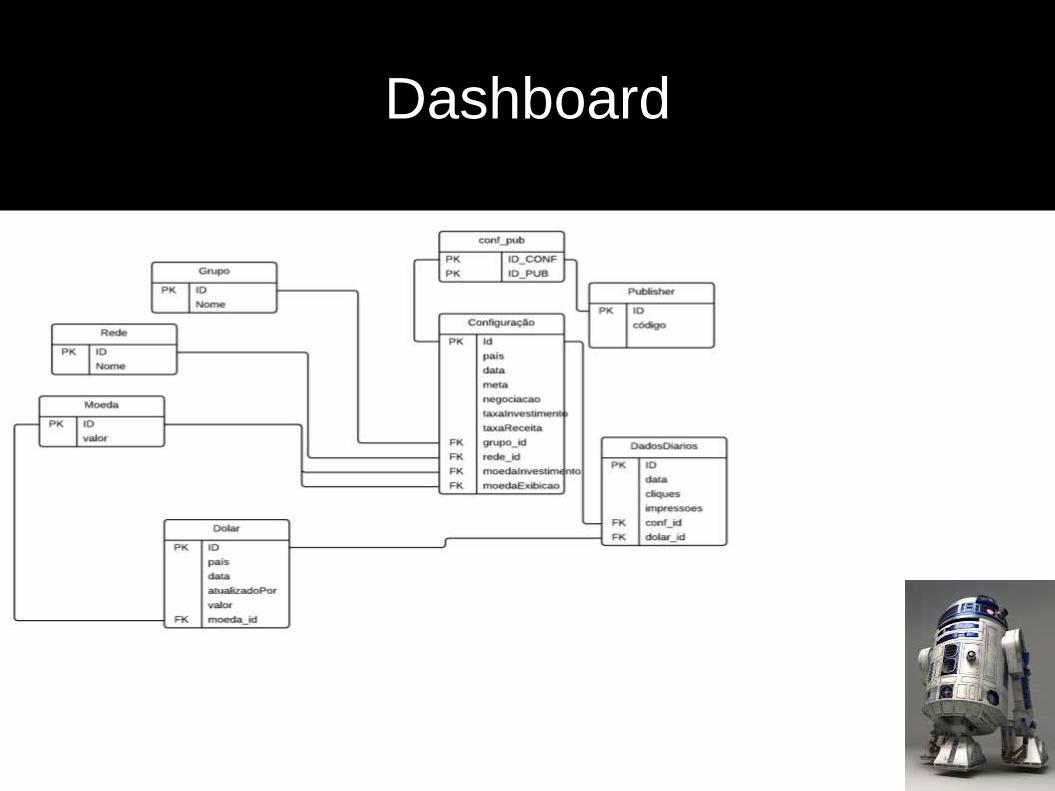
Dashboard
O Dashboard em 99% do tempo procura informações, por que eu quero facilidade para atualizar uma informação se isso vai prejudicar minha busca?
Por que eu não posso ter um campo nulo? Para economizar espaço? Mas e as chavesprimarias e estrangeiras que eu vou precisar, para ter essa economia?
Quantas vezes eu vou precisar saber sobre os publishers de Virgem com ascendente em Áries?
Dashboard

Dashboard

Dashboard

OBRIGADO!